Содержание
- Cuneiform не могу записать изображение windows 10
- Не могу записать изображение cuneiform
- Как отсканировать документ на компьютер и как распознать текст.
- Как отсканировать документ на компьютер и как его распознать?
Cuneiform не могу записать изображение windows 10
Сообщения: 1
Благодарности:
Скажите, пож, вы под какой ОС ставили драйвера сканера?
У меня тоже появляются два twain-сканера Xerox WorkCenter PE16e и Xerox WorkCenter PE16e USB, но в отличие от вашего случая, ни один не хочет работать ни с одним софтом, чтобы ни делал и сколько бы не переставлял драйверы.
ОС 2003 R2.
На ХР драйверы встают нормально и сканер работает.
Кстати, файла face.ini не нашел. Это чьето ПО созадет его?
И, кстати, ставил драйвера Samsung от МФУ-близнеца. Драйвера одни и те же
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 195
Благодарности: 6
сейчас стоит:
c:temp полный доступ
c:winsystem32spool полный доступ
c:Documents and Settingsuser полный дступ
все остальное только чтениевыполнение
Сообщения: 195
Благодарности: 6
все это было проделано.
1 пункт как то, по моему, не очень уместно просто потому что через ж. меня не устравиает такой вариант. (про сохранение паролей не знал. спасибо)
2 разрешения даны. утильками от systernals насобирал логов (по 10 тыс строк в каждом. в том числе и при админских правах и без оных).
3 и это проделывал. не помогло. привело только к ошибке новой. «Failed to update the system registry.»
решение было найдено, и порядок действий такой:
1. даем пользователю права админа.
2. ставим CuneiForm.
3. запускаем его 1 раз.
4. добавляем ращрешения к следующим веткам реестра:
Источник
Не могу записать изображение cuneiform
На демонёнке та же проблема, но с распознаванием у него не лучшая ситуация.  Просто реальной альтернативы ей я не знаю.
Просто реальной альтернативы ей я не знаю.
Решение стандартных проблем с Cuneiform 12
Описание ошибки:
Ошибка передачи данных.
Причина в особенностях работы TWAIN драйверов сканера, в CuneiForm используются 2 режима передачи memory-buffered (режим по умолчанию) и memory-native. Раньше драйвера сканера не всегда реализовали оба, или один из них был не очень стабилен. Была ситуация когда это зависело и от производителя, и от версии драйвера. Сейчас у производителей промышленных сканеров (Fujitsu, Kodak и др.) поддерживаются все режимы, а у остальных производителей видимо ситуация с режимами передачи иногда остается нестабильной.
Лекарство:
Необходимо отредактировать файл face.ini, который находится в директории windows. Находим в файле ключ TWAIN_TransferMode и делаем его равным memory-native. То есть должно быть TWAIN_TransferMode=memory-native
Проблема с установкой в Windows Vista:
Лекарство:
Проблему можно решить отредактировав файл «CuneiForm v12 Master.msi» (который распаковывается в TEMP директории после запуска setup.exe). Редактируется файл при помощи Orca (из Windows SDK ) (1,62 МБ). Открываем файл «CuneiForm v12 Master.msi» при помощи Orca, находим строчку «LaunchCondition» и удаляем имеющуюся там запись, щелкнув правой кнопкой мышки и нажав «Drop Row». Сохраняем файл. И всё отлично устанавливается и в Висте.
Проблемы работы с правами пользователя:
Не запускается с правами пользователя.
Решение:
1. Переустановить программу.
2. Необходимо дать пользователям полные права доступа к ветке HKEY_CLASSES_ROOTCuneiformFace.DocumentCLSID и на соответствующую этому CLSID ( ). (скопировать ваш CLSID из данного раздела и найти его далее в реестре)
3. В каталоге установленной программы дать пользователям права на создание файлов, а СОЗДАТЕЛЮ-ВЛАДЕЛЬЦУ на их изменение и удаление.(или просто дать полный доступ на папку данному пользователю)
Я сумел скомпилировать под Windows CuneiForm-Linux v1.0.0 http://launchpad.net/cuneiform-linux
Посредством компилятора MS VC++ 6.0.
Все подробности тут:
Подскажите, из командной строки работать умеет?
Ура! Сообщество бесплатных программ пополнилось, наконец-таки, софтиной, которая может распознавать отсканированный текст на русском языке. Может, где-то за бугром и есть бесплатные программы, которые могут распознать латиницу, но с кириллицей такого не было. А флагман русскоязычного OCR (оптического распознавания текста) оставался платный FineReader (сейчас у компании ABBYY версия FineReader 9.0, которые наши доблестные пираты, наконец-то взломали). В славные 90-е годы у FineReader был более-менее сносный конкурент CuneiForm, но через какое-то время этот продукт от Cognitive Technologies завис на версии 2000 года. Я даже думал, что CuneiForm спекся, однако.
однако в декабре 2007 г. руководство Cognitive Technologies решилось передать CuneiForm в Open Sourse. Правда пока CuneiForm вышел под грифом Freeware, версия у продукта 12. Дистрибутив CuneiForm 12 размещён на DVD диске к февральскому номеру «Hard’n’soft».
Вчера я устанавливал этот продукт на свой комп и был расстроен, все попытки отсканировать любой текст заканчивались провалом, то есть вылазило окошко «Ошибка при передачи данных«. Ну думаю, фигня это, а не софт и думал было удалить прогу, а дистрибутив стереть с жёсткого диска.
но передумал. А сегодня ко мне пришла идея, что если невозможно отсканировать текст через CuneiForm напрямую, то можно это сделать через другую программу, то есть затем открыть изображение. Через что-же отсканировать? — подумал я. Ведь если сканировать через платные графические программы (Photoshop или ACDSee), то смысл от бесплатности CuneiForm улетучивается.
В моем арсенале бесплатных графических программ есть GIMP 2.4.2, XnView 1.92 и IrfanView 4.10. Я начал с последней и сохранил полученное изображение в формате tiff (другие, вроде bmp или jpg в данном случае не подойдут). На выходе получился файл ScanImage001 размером 412 Кб. Сразу скажу, что для испытания я использовал страницу 13 из учебника «Философия» под ред. В.Д.Губина (М., 2004). После распознавания в полученном тексте было несколько ошибок (а где их не бывает, в том же FineReader они имеются).
Затем я отсканировал тот же текст через GIMP. Попутно отмечу, что прога по времени достаточно загружалась (ещё бы, это же не вьювер, а полноценный графический пакет). Файл Без имени на выходе оказался тяжёлым 3,37 Мб, но зато качество распознавания его в CuneiForm было чуть получше.
Чемпионом же тестирования оказался XnView, давший на выходе файл scan 1 размером 422 Кб, который CuneiForm распознал лучше остальных.
Итак, для начала неплохо. Надеюсь, что новые версии CuneiForm позволят обходиться без вспомогательных программ.
Поживём-увидим.
Поступила задача наладить автоматическое распознание текста с фотографий, т.е. пользователь при загрузке фотогографии на сервер, получает еще и распознанный с нее текст. Сказано — сделано. Было найдено хорошее бесплатное консольное решение — cuneiform. Никсовая версия лежит здесь: https://launchpad.net/cuneiform-linux.
Итак, установка. В Убунте кстати доступна версия 0.7 из репозитариев. Версия 0.9 является последней на данный момент.
Дополнительный аргумент «-DCMAKE_INSTALL_PREFIX=/your/dir» установит cuneiform в нужную директорию.
Запускать можно со следующими аргрументами:
-l
Указывает язык документа. Из возможных: eng(по умолчанию) ger fra rus swe spa ita ruseng ukr srp hrv pol dan por dut cze rum hun bul slo lav lit est tur.
-o
Сохраняет в файл.
-f
Формат полученного текста. Из поддерживаемых: text(по умолчанию), html, rtf, smarttext(plain text with TeX paragraphs), hocr(hOCR HTML format), native(Cuneiform 2000 format)
—dotmatrix
Оптимизация работы скрипта под изображение, распечатанное с помощью матричного принтера.
—fax
Оптимизация работы скрипта под изображение, распечатанное с помощью факса.
—singlecolumn
Отключает анализ страницы и подразумевает, что у нас изображение состоит из одной колонки текста.
Далее захотелось уже графический интерфейс под бытовые нужды. Есть 2 штуки на выбор — это YAGF и Cuneiform-Qt:


Источник
Как отсканировать документ на компьютер и как распознать текст.

Вопрос, как сканировать и распознать текст, был актуален всегда. Одно время казалось, что эпоха сканеров ушла. А ведь и правда, зачем, например, сканировать несколько часов, а то и дней, какую-либо книжку или доклад, если все уже давным-давно выложено в интернете в формате pdf или еще лучше в wordовском. Скачал, открыл и не паришься.
Однако последнее время, все чаще ко мне стали обращаться с вопросом, мол, «купил сканер, какой программой лучше отсканировать и распознать текст». У меня уже был урок о программе для распознавания текста со сканера. Но там был приведен пример на платной программе. И я решил поискать бесплатный аналог, и нашел.
Эта программа называется CuneiForm и скачать её можете отсюда. Перемотайте в самый низ страницы и там будут ссылки, нажмите на ту, которая подчеркнута, на рисунке ниже, красным.

После чего запустите скачанный файл. Если выскочит окно, показанное на рисунке ниже, нажмите запустить.

Установка будет обычная без всяких наворотов, я вообще просто нажимал далее и все установилось.
Дальше будут выскакивать различные советы, хотите посмотрите их, но я просто нажал закрыть. Программа на русском и, честно говоря, тут можно ничего и не объяснять, но я все-таки покажу на примере как с ней работать.
Для начала расскажу вам, что за кнопки расположены на главной панели, в программе CuneiForm.

Кнопка №1, «мастер распознования», является как бы кнопкой «все и сразу», т.е. когда вы вставляете в сканер текст и нажимаете на эту кнопку, то она сразу и сканирует, после распознает, а в конце еще и сохраняет получившийся документ. Это очень удобно, когда сканируешь большие объемы информации, например, когда нужно «отсканить» целую книжку.
Кнопка №2, служит для того, чтобы просто отсканировать то что «вставлено» в сканер. Что такое сканирование – это, грубо говоря, фотографирование того что «вставлено» в сканер. В итоге вы получаете просто изображение с фотографированным текстом. Эта кнопка удобна тогда, когда вам не нужно распознавать текст.
Кнопка №3, позволяет провести разметку документа, например, если вам его нужно разделить на области.
Кнопка №4, это кнопка распознования. Ну, например эта кнопка вам нужна для того, если кто-то по почте прислал отсканированный текст и вам его надо распознать.
Кнопка №5, эта кнопка для сохранения ваших «творений».
Кнопка №6, рабочая область. Именно тут вы будите видеть то, что происходит в программе.
Кнопка №7, окно для увеличения того, что есть на рабочей области.
С программой мы познакомились, теперь пора узнать как она работает.
Как отсканировать документ на компьютер и как его распознать?
Нажмите на кнопку №1, и перед вами откроется такое окно.

Выбираем пункт «Отсканировать» и нажимаем далее.

На этом шаге задаются параметры для сканирования и формат листа сканирования. Настройте как вам надо, или если хотите, как показано на рисунке выше. Нажимаем далее.

Здесь идет настройка яркости, контраста и т.п. Это может улучшить качество сканированного документа, в случае если сам документ очень плохого качества. Если документ нормального качества, то просто нажмите далее.

Программа запустила сканер и начала сканировать документ. После окончания выдастся окно, в котором будет спрашиваться, что делать дальше.

Нажмем «Распознать прямо сейчас» и далее.

Теперь выберем язык, который был на отсканированном документе и символ, который будет отображаться вместо нераспознанных букв. Нажимаем далее.

Здесь одет выбор характеристик текста, для лучшего распознания. Программа спрашивает его вид и стиль. Выберите то, что показано на рисунке, и нажмите далее. А вообще потом чем чаще вы будете экспериментировать, тем проще будете подбирать этот самый стиль.

На данном шаге просто отметьте все галочки и нажмите далее. После чего пойдет процесс распознавания.
После того, как он закончиться, в «рабочей области» программы автоматически открывается приложение Microsoft Office Word для дальнейшего редактирования и сохранения, а в «окне увеличения» оригинал документа.

Если файл документа распознан не корректно (не все картинки или текст распознаны правильно) и вручную исправлять долго, можно подправить его благодаря специальным панелям. Для этого нужно нажать на кнопку «разметка» и откроется окно разметки.

В котором, зелёным блоком выделяются картинки, а синим текст. Изменить масштаб для удобства редактирования блоков можно на верхней панели, на рисунке выше, отмечено зелёной чертой.
Удалить не корректные блоки можно с помощью нажатия правой кнопки мышки при наведённом курсоре.
Панели для нанесения блоков (указанны на рис выше):
1. Выделить текстовый блок;
2. Выделить таблицу;
3. Выделить картинку;
4. Добавить прямоугольник к блоку;
5. Вырезать прямоугольник из блока.
После того как всё было подправлено нажать на иконку «распознавание» и окно приобретёт вид как показано на предыдущем рисунке.
Главные преимущества программы:
Вот в принципе и все. Как вы видите все на русском языке и никаких сложностей возникнуть не должно.
Источник
Adblock
detector
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Бесплатная программа для автоматического распознавания отсканированного текста. Вид у программы не карамельный, но дело своё она знает.
Компьютер уже уверенно вошел в жизнь рядового гражданина. Когда надо получить сравнительно небольшой объем печатной информации, проще всего набрать этот текст вручную при помощи текстового редактора.
Однако иногда надо «переписать» целую книгу. В таких случаях рациональнее всего использовать сканер. Но сам по себе сканер делает только фотокопию текста, которую никак нельзя редактировать. Для того, чтобы изменить информацию на полученном изображении следует провести распознавание документа.
Бесспорным лидером в этом деле является система OCR (англ. optical character recognition — оптическое распознавание текста) от Abbyy — FineReader. Но стоит она довольно дорого и не каждый может позволить себе иметь в своем арсенале такой инструмент. Сегодня мы познакомимся с бесплатной альтернативой Файн Ридера — программой CuneiForm
. Приведу сравнительную таблицу возможностей обеих пакетов:
Сравнение распознавалки текста CuneiForm с платным аналогом FineReader
Как видим, если хочется бесплатно распознавать текст, придется кое в чем уступить. Первое, с чем придется смириться — неумение CuneiForm работать с некоторыми сканерами (в особенности сканерами МФУ). Поэтому придется сканировать документ при помощи стандартных функций Windows. Второе — надо следить за разрешением сканирования.
Это связано с тем, что CuneiForm не может обрабатывать большие файлы (свыше 100 Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато качество распознавания текста в программе намного выше, чем у платного конкурента, а поэтому оптимальным вариантом параметров скана будет 200 dpi (можно и больше, но тогда есть вероятность, что программа просто зависнет).
Количество языков тоже невелико, но основные есть. Более того, хоть комбинировать языки и нельзя, зато в CuneiForm есть смешанный англо-русский режим распознавания! На этом минусы заканчиваются:). Можно начинать установку.
Установка CuneiForm
Здесь сложностей нет, поскольку Вам поможет инсталлятор. Просто запускайте установочный файл и следуйте инструкциям. После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.

Интерфейс программы
Интерфейс CuneiForm намного проще, чем у Fine Reader, и почти не требует настройки. Программой можно полностью управлять благодаря кнопкам на панели инструментов. Рассмотрим их более детально:

Программа может работать в режиме мастера, который активируется первой кнопкой. Но если CuneiForm не поддерживает Ваш сканер, то от этого режима стоит отказаться. Следующая кнопка запускает процесс сканирования (опять же, если есть поддержка сканера). На этой и следующих кнопках Вы можете заметить небольшие стрелочки. Нажав на них, мы получим доступ к некоторым дополнительным функциям.
Работа с CuneiForm
Теперь давайте опробуем CuneiForm на практике. Если программа поддерживает Ваш сканер, то первой кнопкой, которую следует нажать, будет «Получить изображение». Если же такой возможности нет, то откроем уже готовый скан (поддерживаются форматы JPG, GIF, BMP, PNG (не всегда корректно), а также TIF (в полной мере)).

Теперь следует произвести разметку. Она помогает определить блоки, из которых состоит страница. Поддерживается распознавание блоков в виде текста (синяя рамка), рисунков (зеленая рамка) или таблиц (оранжевая рамка) (автоматическую разметку можно доработать вручную, используя контекстное меню блока).

Когда текст обозначен, самое время провести его распознавание. Для этого нажимаем следующую кнопку. По окончании процесса распознавания в рабочем окне отобразится текст, который можно редактировать в небольшом встроенном текстовом редакторе похожем на Microsoft Word. При этом Вы сразу сможете увидеть те слова, в которых программа «не уверена» (голубая подсветка) и в которых есть ошибка (сомнительная буква — розовая).

И, наконец, после успешного редактирования можно сохранить результат нашей работы. Кликаем последнюю кнопку на панели инструментов и сохраняем текст как RTF, HTML или TXT-файл.

Если же Вы желаете большего, то, нажав на стрелочку сбоку, Вы сможете выбрать опции экспорта в одну из предложенных программ (Microsoft Word, Excel или Евфрат).

Посмотрите на предыдущий скриншот. Наверняка вы обратили внимание, что в дополнительных меню кнопок, начиная с «Разметки» и заканчивая «Сохранением», есть в конце пункт «Автомат». Активирование этой опции освобождает Вас от нажатия выбранной кнопки. То есть можно автоматизировать процесс обработки скана до того, что Вы будете лишь открывать новый документ. Все остальное CuneiForm сделает сама!
Общие настройки CuneiForm
Программа изначально настроена самым оптимальным образом, но если Вы что-то захотите изменить, просто зайдите в меню «Файл» и выберите опцию «Общие параметры». Это может пригодиться для смены языка и некоторых других параметров распознавания, форматирования и сканирования текстов.

Пакетное распознавание
На этом можно было бы и закончить, если бы в пакет CuneiForm не входила еще одна утилитка. Откройте «Пуск» снова и в папке с программой обнаружите еще одно приложение — «Пакетное распознавание». Представьте, что Вы отсканировали целую книгу! и теперь надо ее распознать!!! Если открывать каждый файл-скан по отдельности на это уйдет уйма времени, пакетный же режим представляет возможность указать нужные файлы, а об остальном программа позаботится сама.

Для начала нужно создать новый пакет файлов. Нажимаем соответствующую кнопку и следуем подсказкам запустившегося мастера:


По окончании распознавания Вы сможете увидеть в основном окне все распознанные документы. Если распознавание прошло успешно, то в левой боковой панели Вы обнаружите активными только два списка: «Исходные» и «Обработанные». Если же будут файлы, которые не удалось распознать, их мы найдем в разделе «Ошибки».

Выводы
Потенциал у CuneiForm явно хороший, однако разработка ведется довольно медленно. Несмотря на открытый исходный код, компания Cognitive, видимо, очень требовательна к разработчикам, раз прогресс так долго не появляется. Остается только надеяться, что дело сдвинется с мертвой точки и программа станет еще лучше, а пока довольствуемся малым. Но такое ли уж оно и малое… Выбор за Вами!
подпишитесь на новые видеоуроки!
Недавно занялся поиском бесплатных приложений для распознавания отсканированного текста, или как их еще называют программы OCR. Желание платить за популярного монстра ABBYY FineReader, совсем не было, но как оказалось, предлагают очень мало вариантов программ такого плана для бесплатного использования. Первый попавшийся вариант оказался , пожалуй, одна из самых популярных программ для Windows, но в своем нынешнем виде не дружит с русским языком. Один из читателей блога, предложил попробовать труды отечественных разработчиков .

Процедура установки стандартная, перечень из нескольких стандартных вопросов, где самое запоминающееся это лицензионное соглашения и выбор папки, куда будут инсталлирована программа. Несколько секунд ожидания и все готово к работе. Ничего лишнего не устанавливается и дополнительно программные компоненты тоже не придется скачивать и устанавливать.
Запустив программу, получаем стандартный для OCR интерфейс, меню из нескольких пунктов, большие кнопки для доступа к основным функциям и основное окно разбито на две части для изображения и готового текста которые распознали.
Самая первая кнопка в панели инструментов, где нарисованная волшебная палочка, это мастер, запустив которые пройдем все этапы, начиная от сканирования и заканчивая готовым текстом пригодным для редактирования, которые заботливо будет предлагать выбрать нужные настройки. Получатся этакий полуавтоматический режим, делам только общие настройки, не вникая в нюансы.
Можно пойти по более сложному пути, пройдясь ручками по каждому пункту отдельно, зато сможете сделать кучу дополнительных правок и тонких настроек, которые позволят получить более качественный конечный результат.
С помощью кнопки, где нарисован сканер, можем отсканировать нужный документ или загрузить готовую картинку. После чего получим панель с инструментами с помощью, которой можем подкорректировать изображение, повернуть его и выбрать область для распознавания.
Кнопочка с циркулем, позволяет сделать разметку страницы, выделяя колонки, изображения и блоки с текстом. Все блоки, которые будут найдены, можно редактировать, передвигая их и изменяя размеры с помощью мыши. Поводите курсором около синих линий и увидите, как он будут менять свою форму, дальше, думаю, сами разберетесь.
Ионкой с очками, распознаем непосредственно текст, в подготовленных областях. После того как текст будет готов, щелкните по любой букве и увидите тот участок рисунка картинки, на котором она была найдена.
Кнопка с самолетиком предназначена для сохранения распознанного текста в файлы или в Word Excel, почему опять этот стандартный набор непонятно, ведь есть еще куча замечательных текстовых редакторов.
В зависимости от того на каком этапе будете находиться панель инструментов будет менять свое содержимое, предлагая нужные на конкретном этапе инструменты.
Теперь перейдем к печальному на Windows 7 отказался работать со сканером, программа его видела, сканер даже начинал гудеть, и на мониторе бежала пунктирная линия свидетельствующая что идет передача данных, а в конце выбрасывала ошибку. Все пляски с бубном и чтения форумов не дало положительных результатов. В том числе редактирование файла «Face.INI», где по рекомендации было исправлено «TWAIN_TransferMode=memory-buffered» на TWAIN_TransferMode=memory-native». В итоге пришлось делать обходной маневр, сканировать текст стандартными средствами Windows, а в CuneiForm подсовывать готовую картинку.
Еще плохо, что не поддерживаются pdf фалы самой программой. Приходится прибегать к обходным маневрам, использовать сторонние программы чтоб из pdf документов делать картинки, а потом задействовать OCR. Но опять из-за низкого разрешения картинок, качество распознавания текста очень низкое, поэтому потом приходится много чего исправлять руками.
Чуть не забыл, первый запуск на Windows Vista и 7 лучше делать от имени администратора, иначе программа впадет в транс на несколько минут, не подавая признаков жизни.
Программа действительно работает со всеми основными языками, их около 20 штуку включая русском, английском, украинском, немецком, французском, испанском, итальянском и смешанном русско-английском.
CuneiForm оставила двоякое впечатление, вроде работает, но не полностью, скорей всего из-за того что работу на программой прекратили в 2007 году, а после открытия исходных кодов команда которая могла дальше развивать проект так и не собралась. Приятно, что понимает русский язык, но придется немного приноровиться, пока научитесь подбирать нормальные параметры для сканирования, чтоб результаты распознавания удовлетворяли. Сейчас нахожусь именно на этом этапе.
В нынешнем виде не могу рекомендовать для использования обычным пользователям. Кто рискнул попробовать CuneiForm, морально подготовитесь, что с первого раза хороших результатов не получится, и решение возникших проблем придется искать самим.
Работает в 32-х и 64-х битных операционных системах. Интерфейс полностью на русском языке, и похоже других вариантов не предлагается.
Страница для бесплатного скачивания CuneiForm http://www.cuneiform.ru/downloads/index.html
Последняя версия на момент написания CuneiForm V12
Размер программы: архив 33,3Мб
Совместимость: Windows Vista и 7, Windows Xp
Распознавание текста – очень удобная возможность. Вам больше не надо перепечатывать большие объемы из книг и статей. Для учителей, студентов и научных работников такие программные приложения – настоящий подарок. Рассмотрим разные приложения и определим, какая программа для распознавания текста с картинки – лучшая.
Как это работает
Оптическое распознавание текста (OCR — Optical Character Recognition) – это возможность преобразовать текст из графического вида (фото, скан, pdf) в обычный формат. Преобразованный текст можно редактировать.
Любая растровая картинка состоит из точек. Программное обеспечение для распознавания выделяет на картинке буквы и переводит их в текст. Происходит анализ структуры документа. Выделяются текстовые блоки. Затем строятся линии, которые делятся на слова, а далее на символы. Каждый символ сравнивается с шаблонами. После чего строятся гипотезы, что это за символ. Исходя их них, ПО анализирует разные варианты разбиения строк на слова, а слова на символы. Количество таких гипотез огромно. В конец концов программа принимает решение и выдает текст.
Обзор программного обеспечения
Условно все приложения можно разделить на три категории:
- Платные.
- Бесплатные.
- Онлайн сервисы.
Рассмотрим несколько вариантов из каждого раздела.
Платные и бесплатные программы
OCR CuneiForm
Бесплатная программа для распознавания сканированного текста, которую можно скачать здесь.
Приложение было разработано в 1993 году в компании Cognitive Technologies. Одной из главных особенностей ее на тот момент была возможность опознавания смеси русского и английского языков. В 2009 году была добавлена ветка, которая позволяет распознавать смесь других языков. Программный продукт поставлялся со сканерами и МФУ от ведущих производителей: Hewlet-Pachard, Epson, Xerox и т.д. Последняя версия вышла в 2009 году.
После скачивания и установки пробуем распознать текст. Для примера возьмем эту статью.
Интерфейс программы прост, меню на русском.

Нажимаем значок папки и грузим картинку. Нажимаем кнопку распознавания.

Результат не впечатляет. Разноцветный текст не распознан.

Не смотря на заявленное использование разных словарей, английский тоже распознался плохо.

В общем, идеальное фото можно перевести в символы, но чем ниже качество исходной картинки, тем ниже оно и у результата.
Надо заметить, это единственная русифицированная программа распознавания текста при сканировании, которую удалось скачать бесплатно легальным образом. Все остальные в лучшем случае имеют пробный бесплатный период.
RiDoc
Программа для распознавания текста с фото или со сканера с бесплатным периодом в 30 дней. Скачать можно здесь.
Приложение обладает неплохим функционалом и доступным интерфейсом. Для загрузки картинки нажимаем кнопку «Открыть».

Далее кнопку «Распознать».

В итоге получаем готовый результат. Его можно открыть в Word или OpenOffice.

Вот результат.

Тоже не идеально, но намного больше, чем в предыдущем случае.
Также можно наложить водяной знак или склеить несколько картинок.
ReadIris
Платный программный продукт с пробной версией, рассчитанной на 100 страниц или 10 дней. Скачать программу для сканера для распознавания текста с официального сайта можно тут.
Разработчик – бельгийская компания IRIS, созданная в 1986 году. Основная специализация — технологии и продукты для интеллектуального распознавания документов.
Программа преобразует картинку, файл PDF или отсканированный документ в полностью редактируемый текстовый файл. Извлекает текст из ваших документов, сохраняя при этом макет исходного файла. Имеет следующие возможности:
- конвертировать файлы Word, Excel и PowerPoint в индексированные PDF-файлы;
- конвертация документов с помощью контекстного меню;
- индикатор качества для импортируемых документов;
- автоматическое обнаружение сканеров;
- модуль коррекции перспективы.
Интерфейс программы русифицирован (указывается при установке) и достаточно прост.

Нажимаем кнопку «Из файла» и выбираем нашу картинку. Программа автоматически разделила ее на два блока.

Для распознавания нажмите кнопку «Открыть» и укажите путь для картинки. Формат указывается строкой выше.

Результат превзошел все ожидания. Даже начертание сохранилось.

Можно отправить документ по почте или в облако. Для этого следует щелкнуть по списку сверху и выбрать. По умолчанию сохраняется в файл.

Стоит эта программа около 6000 руб.
ABBYY FineReader
Самая известная и раскрученная программа. Скачать пробную версию можно здесь.
Платная стоит 6990 р. Российская разработка 1993 года, до сих пор считается одной из лучших в мире. Основные возможности:
- Распознавание таблиц и графиков, математических формул.
- Просмотр и навигация pdf.
- Создание и прямое редактирование pdf.
- Работа с цифровой подписью.
- Сравнение документов.
- Добавление комментариев.
Программа обладает множеством возможностей. Интерфейс русифицирован и доступен.

После нажатия кнопки «Открыть» и выбора картинки, начинается автоматическое его деление на блоки.

Для начала процесса нажмите соответствующую кнопку.

Дальше осталось выбрать, в каком формате сохранять и указать папку, в которую следует сохранить документ.

Откроем результат. Как видите, распознавание прошло идеально.

Еще раз сравним с ReadIris.

Первый вариант (Finereader) выполнен безупречно. Поэтому, пожалуй, пальму первенства отдаем этой программе. По цене они сопоставимы, так что разница в 600-700 рублей особой роли не играет.
Распознавание текста по фото онлайн
IMGonline
Онлайн сервис обработки картинок. На сайте представлены инструменты:
- Сжатие и изменение размера картинки
- Обрезка, кадрирование
- Обработка встроенных метаданных
- Эффекты
- Улучшения
- Определение палитры цветов картинки
- Получение фона
- Определение процента похожести и пр.
Удобный сайт, который дает множество возможностей обработки картинки. Интерфейс прост и понятен.

Предлагает две программы. Сравним. Загрузим файл и нажмем кнопку «ОК».

Дальше нажимаем на ссылку.

Результат не радует.

Пробуем вторую программу.

Тоже сомнительно.

Выставим дополнительный язык.

Проверяем результат.
Немного лучше, но до совершенства далеко.
img2txt
Программа для распознавания текста с фото онлайн, сканирования не допускает.
Сайт функционирует с 2014 года. Других сервисов, кроме текущего, разработчики не планируют.

Выберите файл и нажмите «Загрузить». Затем следует нажать «Начать распознавание».
Результат тоже далек от совершенства.

Сonvertio
Достаточно большой платный портал, на котором вы можете воспользоваться следующими возможностями:
- Конвертация видео, аудио, картинок.
- Преобразование PDF в Word, Excel, PowerPoint.
- Разделение PDF.
- Сжатие PDF, PNG и пр.
Принцип работы абсолютно аналогичен, но настроек больше. Картинки можно перетягивать.

Можно указать несколько языков и тип документа, куда сохраняется результат.

Незарегистрированным пользователям доступны только 10 страниц для распознавания.
После нажатия на каптчу, выберите «Преобразовать».

Нажмите скачать.

Результат превзошел все ожидания.

Оказывается, и у простых сервисов онлайн есть возможность качественного распознавания. Так что Convertio объявляется однозначным победителем в этой номинации. Но, как и любой отличный продукт, он платен.
Итак, мы рассмотрели различные инструменты распознавания текста. Выяснилось, что бесплатные могут помочь, но качество остается не на высоте. Так что, если вам постоянно требуется переводить текст из печатного вида в электронный, придется раскошелиться.
Отличного Вам дня!
Название программы
: OCR CuneiForm
Версия
: 12
Размер
: 33,4 Мб
Язык
: несколько языков в т.ч. русский
Тип программы
: распознавание текста
Лицензия
: свободная с открытым кодом
Описание программы
OCR CuneiForm может распознавать любые полиграфические, машинописные гарнитуры всех начертаний и шрифты, получаемые с принтеров за исключением декоративных и рукописных. В систему встроены специальные алгоритмы для распознавания текста с матричного принтера, плохих ксерокопий факсов и машинописи.
OCR CuneiForm это:
- высокое качество распознавания;
- высокая скорость работы;
- распознавание текстов на русском, английском, смешанном русско-английском, украинском, немецком, французском, испанском, итальянском, шведском и других (всего более 20);
- работа в режиме автофрагментации для поиска текстовых блоков, таблиц и изображений, а также мощное средство ручной и полуавтоматической фрагментации;
- распознавание таблиц любой структуры и сложности, в том числе и без отображения линий табличной сетки;
- автоматическое сохранение иллюстраций (черно-белых и цветных) и таблиц в получаемом на выходе документе;
- полное сохранение топологии страницы;
- поддержка пакетного режима сканирования и распознавания;
- простота использования и интуитивный интерфейс, встроенные помощники по работе с программой;
- встроенный текстовый редактор для работы с распознанным текстом;
- совмещенный показ изображений и результатов распознавания.
В системе используется целый ряд уникальных технологий, среди которых адаптивное распознавание, нейронные сети, когнитивный анализ альтернатив распознавания и другие.
Вопросы и ответы по программе
Что такое CuneiForm?
CuneiForm — это система оптического распознавания крупнейшего российского разработчика программного обеспечения Cognitive Technologies, которая обеспечивает быстрое и высококачественное преобразование бумажных документов и электронных графических файлов, получаемых, например, со сканера или факса, в редактируемый текст для последующей работы с ним в текстовых редакторах.
Для кого предназначена OCR CuneiForm?
Система распознавания текстов CuneiForm предназначена для всех, кому приходится вводить в компьютер факсы, книги, газеты, машинописные страницы, тексты договоров и т.д. Для работы с системой достаточно положить страницу с текстом в сканер, нажать кнопку, и через несколько секунд Вы получите готовый результат в многофункциональном текстовом редакторе.
Какие шрифты распознает OCR CuneiForm, требуется ли обучение?
CuneiForm — шрифтонезависимая (OmniFont) система. Алгоритмы, заложенные в CuneiForm, исходят из правил написания букв, из их топологии, и не требуют задания каких-либо эталонов, или обучения.
В системе используется технология интеллектуального самообучения на базе адаптивного распознавания символов.
Распознаются любые печатные шрифты — книги, газеты, журналы, распечатки с лазерных и матричных принтеров, тексты с пишущих машинок и т.п.
Не распознается рукописный текст и декоративные шрифты (готический, стилизованный под рукописный).
В CuneiForm существуют специальные настройки для распознавания текстов с матричного принтера и факсов 200×100 dpi.
Чем OCR CuneiForm отличается от других подобных программ?
- качеством распознавания;
- высокой скоростью работы;
- использованием уникальных технологий, таких как адаптивное распознавание, нейронные сети, когнитивный анализ альтернатив распознавания и других;
- простой использования и интуитивным интерфейсом;
- функциональным наполнением, наличием многих дополнительных возможностей.
Поддерживает ли OCR CuneiForm работу с таблицами?
Да. Программа автоматически находит в тексте таблицы различной структуры, в том числе без линий разграфки. Встроенный редактор поддерживает редактирование таблиц (можно уменьшать/увеличивать, удалять/создавать колонки и т.д.)
Как OCR CuneiForm отнесется к картинкам в тексте?
Как пожелаете. Может просто проигнорировать их присутствие, а может сохранить в выходном документе в черно-белом, сером или цветном виде, в зависимости от вашего желания.
Ссылки для загрузки
- Скачать установочную версию с depositfiles.
Информация взята с официального сайта программы
Ура! Сообщество бесплатных программ пополнилось, наконец-таки, софтиной, которая может распознавать отсканированный текст на русском языке. Может, где-то за бугром и есть бесплатные программы, которые могут распознать латиницу, но с кириллицей такого не было. А флагман русскоязычного OCR (оптического распознавания текста) оставался платный FineReader
(сейчас у компании ABBYY
версия FineReader 9.0
, которые наши доблестные пираты, наконец-то взломали). В славные 90-е годы у FineReader был более-менее сносный конкурент CuneiForm
, но через какое-то время этот продукт от Cognitive Technologies
завис на версии 2000 года. Я даже думал, что CuneiForm спекся, однако,…
однако в декабре 2007 г. руководство Cognitive Technologies решилось передать CuneiForm в Open Sourse
. Правда пока CuneiForm вышел под грифом Freeware
, версия у продукта 12. Дистрибутив CuneiForm 12 размещён на DVD диске к февральскому номеру «Hard»n»soft».
Вчера я устанавливал этот продукт на свой комп и был расстроен, все попытки отсканировать любой текст заканчивались провалом, то есть вылазило окошко «Ошибка при передачи данных
«. Ну думаю, фигня это, а не софт и думал было удалить прогу, а дистрибутив стереть с жёсткого диска…
но передумал. А сегодня ко мне пришла идея, что если невозможно отсканировать текст через CuneiForm напрямую, то можно это сделать через другую программу, то есть затем открыть изображение. Через что-же отсканировать? — подумал я. Ведь если сканировать через платные графические программы (Photoshop или ACDSee), то смысл от бесплатности CuneiForm улетучивается.
В моем арсенале бесплатных графических программ есть GIMP 2.4.2
, XnView 1.92
и IrfanView 4.10.
Я начал с последней и сохранил полученное изображение в формате tiff
(другие, вроде bmp или jpg в данном случае не подойдут). На выходе получился файл ScanImage001 размером 412 Кб. Сразу скажу, что для испытания я использовал страницу 13 из учебника «Философия» под ред. В.Д.Губина (М., 2004). После распознавания в полученном тексте было несколько ошибок (а где их не бывает, в том же FineReader они имеются).
Затем я отсканировал тот же текст через GIMP. Попутно отмечу, что прога по времени достаточно загружалась (ещё бы, это же не вьювер, а полноценный графический пакет). Файл Без имени на выходе оказался тяжёлым 3,37 Мб, но зато качество распознавания его в CuneiForm было чуть получше.
Чемпионом же тестирования оказался XnView, давший на выходе файл scan 1 размером 422 Кб, который CuneiForm распознал лучше остальных.
Итак, для начала неплохо. Надеюсь, что новые версии CuneiForm позволят обходиться без вспомогательных программ.
Поживём-увидим.
← Вернуться в раздел «Программы»
Подскажите, из командной строки работать умеет?
Автор: vovabmz
Дата сообщения: 06.05.2010 16:19
Ребята, как программа? Стоит качать?
Автор: SergeyZX
Дата сообщения: 06.05.2010 19:22
Если нужно распознавать текст, а платить не хочется, то эта программа, вроде, лучшая. Только не ясна ситуация с ее дальнейшим развитием. В Linux у меня заработала только в консольном режиме, в Win нормально работает.
Автор: Victor_VG
Дата сообщения: 06.05.2010 20:10
SergeyZX
На демонёнке та же проблема, но с распознаванием у него не лучшая ситуация. Просто реальной альтернативы ей я не знаю.
Автор: cirusnsk
Дата сообщения: 14.09.2010 09:58
Решение стандартных проблем с Cuneiform 12
Описание ошибки:
Ошибка передачи данных.
Причина в особенностях работы TWAIN драйверов сканера, в CuneiForm используются 2 режима передачи memory-buffered (режим по умолчанию) и memory-native. Раньше драйвера сканера не всегда реализовали оба, или один из них был не очень стабилен. Была ситуация когда это зависело и от производителя, и от версии драйвера. Сейчас у производителей промышленных сканеров (Fujitsu, Kodak и др.) поддерживаются все режимы, а у остальных производителей видимо ситуация с режимами передачи иногда остается нестабильной.
Лекарство:
Необходимо отредактировать файл face.ini, который находится в директории windows. Находим в файле ключ TWAIN_TransferMode и делаем его равным memory-native. То есть должно быть TWAIN_TransferMode=memory-native
Проблема с установкой в Windows Vista:
Лекарство:
Проблему можно решить отредактировав файл «CuneiForm v12 Master.msi» (который распаковывается в TEMP директории после запуска setup.exe). Редактируется файл при помощи Orca (из Windows SDK ) (1,62 МБ). Открываем файл «CuneiForm v12 Master.msi» при помощи Orca, находим строчку «LaunchCondition» и удаляем имеющуюся там запись, щелкнув правой кнопкой мышки и нажав «Drop Row». Сохраняем файл. И всё отлично устанавливается и в Висте.
Проблемы работы с правами пользователя:
Не запускается с правами пользователя.
Решение:
1. Переустановить программу.
2. Необходимо дать пользователям полные права доступа к ветке HKEY_CLASSES_ROOTCuneiformFace.DocumentCLSID и на соответствующую этому CLSID ({5D1A…}). (скопировать ваш CLSID из данного раздела и найти его далее в реестре)
3. В каталоге установленной программы дать пользователям права на создание файлов, а СОЗДАТЕЛЮ-ВЛАДЕЛЬЦУ на их изменение и удаление.(или просто дать полный доступ на папку данному пользователю)
Автор: monday2000
Дата сообщения: 04.11.2010 20:46
Я сумел скомпилировать под Windows CuneiForm-Linux v1.0.0 http://launchpad.net/cuneiform-linux
Посредством компилятора MS VC++ 6.0.
Все подробности тут:
http://www.djvu-scan.ru/forum/index.php?topic=115.0
Добавлено:
Цитата:
Подскажите, из командной строки работать умеет?
Эта версия именно из командной строки работает.
Автор: DoXeR
Дата сообщения: 04.12.2010 18:03
программа фигня полная у меня крякозябры распознает..
Автор: alex_party
Дата сообщения: 26.01.2011 11:17
Пробовал работать в сабже, ОС: Win7, аппарат: Xerox Phaser 3100MFP XPS, с ним почему-то некорректно работает, сканирует, механика сканера проходит, все действия делает, но окончательное изображение не выводит в программу, только при просмотре, неудобно конечно. Ладно, это можно обойти: сканировать стандартной программой Семерки, а изображение выданное помещать в сабж, только вот распознает он конечно похуже *Fine Reader’a*. Но основной камень преткновения в другом, не хочет программа вообще открывать *PDF* документы ( . Посмотрел версию для печати, там 1 раз всего упоминается, что не открывает. Так что… действительно ни как в ней нельзя с *PDF* документами работать… без вариантов вообще?
Автор: Engaged Clown
Дата сообщения: 19.04.2011 22:09
Автор: opt_step
Дата сообщения: 08.08.2011 09:59
шапку подрехтовал
Автор: Uraanfgh56
Дата сообщения: 09.02.2012 18:13
Как обстоят дела с распознованием рукописного текста ?
Автор: Artyk
Дата сообщения: 11.02.2012 15:28
Если вылазит ошибка «не могу записать изображение» после окончания сканирования, то
Есть 2 версии Cuneiform:
1) CuneiForm OpenOCR (версия продукта 01.08.1006);
2) CuneiForm v12 Master (версия 12.07.1206).
При установке поз 1. возникали те же проблемы — «не могу записать изображение».
Последовательная установка поз.2 без удаления поз.1 приводила к вылету,
к невозможности производить операции в обоих программах.
Снес все, почистил реестр. Установил только поз.2 — все заработало.
Взято отсюда
http://openocr.org/forum/viewtopic.php?f=3&t=2915
из поста от rods_alex
За что ему БОЛЬШОЕ ЧЕЛОВЕЧЕСКОЕ СПАСИБО!!!
P.S. Наверное можно уже и в шапку инфу поместить — насобиралось уже ответов на проблемные вопросы.
Автор: goblin63
Дата сообщения: 29.04.2012 10:27
Вышла уже 1.1.0, а из командной строки так и не работает распознание таблиц, и сохранение их в dbf.
Автор: SergeyZX
Дата сообщения: 27.05.2012 13:41
Добрый день! Я так понял, под Linux давно вышла обновленная версия, работающая из командной строки. А никто не пробовал сделать какие-то библиотеки этой версии, чтобы их вставить в версию под Win? Или там все очень глубоко зашито и просто так не обновить?
Автор: j52
Дата сообщения: 27.05.2012 16:28
SergeyZX
Цитата:
А никто не пробовал сделать какие-то библиотеки этой версии, чтобы их вставить в версию под Win?
А если прочитать хотя-бы предыдущую страницу
темы…
Автор: adasiko
Дата сообщения: 07.10.2012 16:54
Почему сабж ни в какую не хочет распознавать этот документ http://habrastorage.org/storage2/73e/e44/6ed/73ee446ed12516507e54ef366a7a2312.png? только «unit 6» получается и всё, уж что не делал: из консоли запускал, выделял области чтоб полегче, но все равно — на выходе ноль…
Автор: Oblako217
Дата сообщения: 22.01.2013 14:58
Недавно скачала Cuneiform v12, извлекла. Установила, стала открывать, не получается — выходит окошко с надписью InstallShield. Там написано что-то про параметры командной строки. Уже долго бьюсь, очень нужна эта программа, но никак не открывается. Помогите, объясните, что не так я делаю.
Автор: zhe_zho
Дата сообщения: 23.01.2013 02:22
Цитата:
выходит окошко с надписью InstallShield. Там написано что-то про параметры командной строки.
Лучше поконкретней, и/или снимок экрана.
Автор: chymax3m
Дата сообщения: 14.04.2013 14:58
Скажите, а может ктото собрать YAGF (графическую оболочку для cuneiform) под Windows?
Автор: Start
Дата сообщения: 09.08.2014 09:03
Форум не открывается с 07-08-2014.
Надеюсь это решится.
Там много полезного.
http://openocr.org/forum/
Автор: Start
Дата сообщения: 22.12.2014 18:36
Автор: Alex_Piggy
Дата сообщения: 23.12.2014 14:50
Доброе время, Start
Посмотрел. Это не reg4, а reg5 с измененной шапкой. Reg4 и Reg5 немного отличаются в передаче hex. Reg5 — hex в unicode. То есть «data»=»abc» в reg4 может выглядеть как
«data»=hex(2):61,62,63
а в reg5 это будет
«data»=hex(2):61,00,62,00,63,00
Убрал лишние нули. На живых системах не запускал. Пожалуйста, запускайте осторожно. Теоретически может работать и на Win98 и на WinXP
1.reg — убраны нули, 2.reg — hex переведен в текст. *.bat — файлы, которыми были полученны соответствующие reg.
zip-архив
Автор: Start
Дата сообщения: 23.12.2014 20:26
Alex_Piggy Спасибо.
Проверил, 1.reg и 2.reg работают хорошо и на Win98, и на WinXP.
Из кода ещё нужно лишние ключи убрать (если таковые найдутся).
2.reg — редактировать не получатся, в AkelPad вместо символов квадратики, блокнот не может сохранить в нужном формате.
1.reg редактируется блокнотом, после чего он остаётся работоспособным. буду его использовать.
Ещё есть код для удаления (восстановления) ключей реестра. Он был получен при установке CuneiForm v12 Master на чистую WinXP вместе с ключами для работы программы.
С кодом удаления (восстановления) замечена проблема — перестаёт работать программа Oracle VM VirtualBox, (где-то я про это читал). Видимо у них есть общие ключи.
Сырой файл реестра для удаления (восстановления):
http://download.files.namba.net/files/66928601
Автор: Alex_Piggy
Дата сообщения: 23.12.2014 21:52
Start
Как именно перестает работать? Какие сообщения выводятся? Вполне может быть. Достаточно удаления библиотек в system32 из списка расшаренных и ветки «HKEY_LOCAL_MACHINESOFTWAREClassesMSComDlg.CommonDialog» …
Какой программой Вы смотрели изменения? Попробуйте systracer или regshot.
Я сейчас не могу поставить виртуалку. Может через пару дней…
Автор: Start
Дата сообщения: 23.12.2014 23:10
Пишет, что:
Не удалось создать COM-объект VirtualBox.
Работа приложения будет завершена.
Детали:
Код ошибки метода:
E_NOINTERFACE (0x80004002)
Для создания файлов реестра использовал systracer
Делал много снимков (копировал виртуальные машины для чистой установки), пока файлы реестра не получились одинаковыми.
Там ещё дело в том, что в реестр программы CuneiForm v12 Master добавлено куча хлама (реестр портфеля например). Изначально программу не предполагали делать бесплатной и возможно, как у нас бывает, чтобы сложнее было разобраться в реестр добавили всякого лишнего.
Автор: Alex_Piggy
Дата сообщения: 24.12.2014 07:48
Доброе время, Start
Зашел с другой стороны. Запустил setup, нашел темп в который распаковалось, распаковал Фаром msi, все библиотеки для system32 скопировал в Cuneiform и запустил батник
Код:
cd /d «%~dp0»
regsvr32 /s Apuma.dll
regsvr32 /s Layout2.ocx
regsvr32 /s comdlg32.ocx
regsvr32 /s EditCtl.ocx
Автор: Start
Дата сообщения: 24.12.2014 08:57
Цитата:
скопировал в Cuneiform и запустил батник
Это интересно, но у меня не запустилось.
Win98 батник не понимает.
В WinXP пишет, что:
Невозможно загрузить сервер распознавания. Проверьте правильность установки программы.
Может быть нужно регистрировать больше файлов.
Цитата:
нашел темп в который распаковалось
Я тоже так распаковывал, (для справки) там есть ещё файлы 12 штук с длинными названиями и без расширения:
Global_…………………_006097C4DE24
они от Виндовс, при установки они переименовываются (как должны быть, в основном там .DLL) и копируются в system32, если они более новые.
Но эти файлы в Виндовс есть и они не нужны даже в Win98, всё работает без них.
Цитата:
Как полностью проверить работаспособность Cuneiform?
Если запустилось без ошибок, обычно всё работает.
Автор: Alex_Piggy
Дата сообщения: 24.12.2014 16:05
Start
В чистой WinXP после указанных манипуляций Face.exe запускается. Распознавание не пробовал. Для полной очистки — надо убрать несколько веток, характерных для CuneiForm
Код: [no]
[-HKEY_CLASSES_ROOTAppIDFace.EXE]
[-HKEY_CLASSES_ROOTAppID{4B006AA2-DB0B-11D3-9FA8-005004570953}]
[-HKEY_CLASSES_ROOTCLSID{4B006AA4-DB0B-11D3-9FA8-005004570953}]
[-HKEY_CLASSES_ROOTCLSID{5D1A5D06-7F90-11D2-9B06-000000000000}]
[-HKEY_CLASSES_ROOTCognitive.Cuneiform]
[-HKEY_CLASSES_ROOTCognitive.Cuneiform.1]
[-HKEY_CLASSES_ROOTCuneiformFace.Document]
[/no]
Автор: Start
Дата сообщения: 24.12.2014 19:53
Цитата:
Для полной очистки — надо убрать несколько веток, характерных для CuneiForm
Создал файлик, применил.
До применения файла эти ветви были, после удалились, но программа удачно запустилась. Наверное это не все ветви.
Автор: Alex_Piggy
Дата сообщения: 24.12.2014 22:25
Start
Это ветки, которые создаются при запуске Face.exe
Две свежеустановленные Win98 — одна в VirtualPC2007, вторая — в QEMU 2.1.2 — библиотека APuma.dll не регистрируется, Ваш файл не запускается (в VirtualPC BSOD, в QEMU — просто ошибка инициализации Apuma). Образы скинуть? На какой системе Вы пробовали (живая или виртуалка, свежая или нет)? Скачаю — попробую на Win98IF, но он отличается сильно.
На рабочем столе bat ярлыки создавать нельзя. Можно VBS. Или что нужно?
Если интересует, попробую собрать из исходников под Win98. Но нужно ли?
Страницы: 12345
Предыдущая тема: Посоветуйте софт для работы с аудио коллекцией
Форум Ru-Board.club — поднят 15-09-2016 числа. Цель — сохранить наследие старого Ru-Board, истории становления российского интернета. Сделано для людей.
Содержание
- Cuneiform не могу записать изображение windows 10
- Как распознать текст на Windows 10 с помощью CuneiForm
- Cuneiform не могу записать изображение windows 10
- 3- Настройка Windows для исправления критических ошибок cuneiform.exe:
- Как вы поступите с файлом cuneiform.exe?
- Некоторые сообщения об ошибках, которые вы можете получить в связи с cuneiform.exe файлом
- CUNEIFORM.EXE
- процессов:
Cuneiform не могу записать изображение windows 10
Сообщения: 1
Благодарности:
Скажите, пож, вы под какой ОС ставили драйвера сканера?
У меня тоже появляются два twain-сканера Xerox WorkCenter PE16e и Xerox WorkCenter PE16e USB, но в отличие от вашего случая, ни один не хочет работать ни с одним софтом, чтобы ни делал и сколько бы не переставлял драйверы.
ОС 2003 R2.
На ХР драйверы встают нормально и сканер работает.
Кстати, файла face.ini не нашел. Это чьето ПО созадет его?
И, кстати, ставил драйвера Samsung от МФУ-близнеца. Драйвера одни и те же
Последний раз редактировалось alxwp, 06-08-2008 в 15:33 .
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 195
Благодарности: 6
Никак не могу застаивть его работать под ограниченой учеткой. под админом идет — под пользователем не хочет. говорит «не удалось загрузить ядро распознавания». куда и какие нужно дать разрешения пользователю?
сейчас стоит:
c:temp полный доступ
c:winsystem32spool полный доступ
c:Documents and Settingsuser полный дступ
все остальное только чтениевыполнение
| Конфигурация компьютера | |
| Материнская плата: Gigabyte GA-EP45-DS3L | |
| HDD: ST3500410AS, 500 Gb, SATA | |
| Звук: Realtek ALC888 @ Intel 82801JB ICH10 — High Definition Audio Controller | |
| CD/DVD: PHILIPS SPD2514T | |
| ОС: Windows Corporate, x86 | |
- Категория:Офис
- Операционная система: Windows 10
- Русский язык: Есть
- Лицензия: Бесплатно
- Загрузок: 5689
Скачать CuneiForm бесплатно
Скачать CuneiForm для Windows 10 стоит тем пользователям, кто хочет распознать напечатанный текст. CuneiForm – это одна из лучших программ для распознавания текста, которую вы можете скачать бесплатно. По своим возможностям утилита вплотную приблизилась к возможностям платных утилит, таких как, например, Finereader и т.д. А по некоторым параметрам эта бесплатная утилита даже превосходит платные аналоги, поэтому вы можете смело выбрать этот софт, если вы хотите распознать текст.
Как распознать текст на Windows 10 с помощью CuneiForm
Чтобы распознать текст вам даже не нужен сканер, как многие считают. Достаточно уже готового изображения с текстом, а также надежной программы. CuneiForm – это и есть та самая надежная и бесплатная программа для распознавания текстов на Windows 10. С помощью этой утилиты вы сможете распознать тексты на различных языках, в том числе и на русском, и на английском. Функционал программы может быть расширен, если вы установите в нее новые языковые модули. В этом случае вы сможете распознать и другие иностранные языки. Такая модульная система позволяет усовершенствовать CuneiForm до той версии, которая полностью вас удовлетворит. Но это не единственные плюсы CuneiForm, есть и другие, например:
- Программа сохраняет исходное форматирование текста;
- CuneiForm позволяет отсканировать даже рукописный текст;
- Вы можете установить дополнительные языки;
Если вы сканируете журнал или газету, то вероятно, что вы захотите сохранить исходное форматирование текста. Это означает, что все заголовки, списки и другое оформление, останется на своих местах. Это делает чтение текста в будущем намного удобнее, чем просто голый текст. Перед тем, как сохранить текст, вы можете отредактировать его. Это позволит вам убрать из текста ошибки еще до того, как вы получите итоговый документ. По сравнению с некоторыми аналогами, ошибок в тексте, который был создан с помощью CuneiForm, намного меньше.
Если вы хотите отсканировать не книгу, и даже не журнал, а рукописный текст, то вам точно нужно скачать CuneiForm для Windows 10. Эта утилита идеально работает даже со самым сложным подчерком. И если мы сравним эту утилиту, и ее аналоги, то окажется, что эта бесплатная программа превосходит платные аналоги. После распознавания рукописного текста вы сможете оформить текст так, как будто он был написан от руки, но при этом это будет печатный текст. А с тем учетом, что CuneiForm работает с 20+ языками, то вы сможете использовать программу для любых задач.
Cuneiform не могу записать изображение windows 10
Сообщения: 1
Благодарности:
Скажите, пож, вы под какой ОС ставили драйвера сканера?
У меня тоже появляются два twain-сканера Xerox WorkCenter PE16e и Xerox WorkCenter PE16e USB, но в отличие от вашего случая, ни один не хочет работать ни с одним софтом, чтобы ни делал и сколько бы не переставлял драйверы.
ОС 2003 R2.
На ХР драйверы встают нормально и сканер работает.
Кстати, файла face.ini не нашел. Это чьето ПО созадет его?
И, кстати, ставил драйвера Samsung от МФУ-близнеца. Драйвера одни и те же
Последний раз редактировалось alxwp, 06-08-2008 в 15:33 .
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 195
Благодарности: 6
Никак не могу застаивть его работать под ограниченой учеткой. под админом идет — под пользователем не хочет. говорит «не удалось загрузить ядро распознавания». куда и какие нужно дать разрешения пользователю?
сейчас стоит:
c:temp полный доступ
c:winsystem32spool полный доступ
c:Documents and Settingsuser полный дступ
все остальное только чтениевыполнение
| Конфигурация компьютера | |
| Материнская плата: Gigabyte GA-EP45-DS3L | |
| HDD: ST3500410AS, 500 Gb, SATA | |
| Звук: Realtek ALC888 @ Intel 82801JB ICH10 — High Definition Audio Controller | |
| CD/DVD: PHILIPS SPD2514T | |
| ОС: Windows Corporate, x86 | |

3- Настройка Windows для исправления критических ошибок cuneiform.exe:

- Нажмите правой кнопкой мыши на «Мой компьютер» на рабочем столе и выберите пункт «Свойства».
- В меню слева выберите » Advanced system settings».
- В разделе «Быстродействие» нажмите на кнопку «Параметры».
- Нажмите на вкладку «data Execution prevention».
- Выберите опцию » Turn on DEP for all programs and services . » .
- Нажмите на кнопку «add» и выберите файл cuneiform.exe, а затем нажмите на кнопку «open».
- Нажмите на кнопку «ok» и перезагрузите свой компьютер.
Всего голосов ( 31 ), 17 говорят, что не будут удалять, а 14 говорят, что удалят его с компьютера.
Как вы поступите с файлом cuneiform.exe?
Некоторые сообщения об ошибках, которые вы можете получить в связи с cuneiform.exe файлом
(cuneiform.exe) столкнулся с проблемой и должен быть закрыт. Просим прощения за неудобство.
(cuneiform.exe) перестал работать.
cuneiform.exe. Эта программа не отвечает.
(cuneiform.exe) — Ошибка приложения: the instruction at 0xXXXXXX referenced memory error, the memory could not be read. Нажмитие OK, чтобы завершить программу.
(cuneiform.exe) не является ошибкой действительного windows-приложения.
(cuneiform.exe) отсутствует или не обнаружен.
CUNEIFORM.EXE
Проверьте процессы, запущенные на вашем ПК, используя базу данных онлайн-безопасности. Можно использовать любой тип сканирования для проверки вашего ПК на вирусы, трояны, шпионские и другие вредоносные программы.
процессов:
Cookies help us deliver our services. By using our services, you agree to our use of cookies.
Adblock
detector
Запустите программу и кликните по иконке «Мастер распознавания».
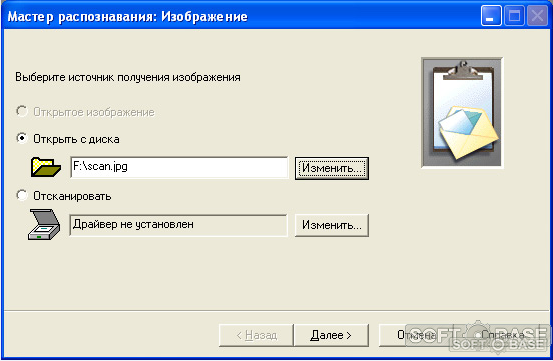
Вам будет предложено воспользоваться сканером для сканирования и передачи полученного изображения в программу, либо открыть изображение с диска.
В нашем примере рассмотрим второй вариант.
1. Отмечаем пункт «Открыть с диска» и кнопкой «Изменить» указываем путь к файлу изображения на диске — кнопка «Далее».
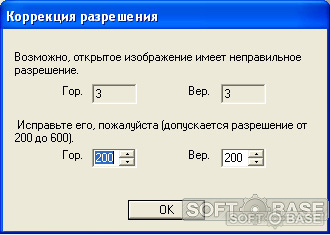
2. Если изображение имеет разрешение более 600 пикселей, откроется окно с сообщением о превышении максимального размера.
Впишите реальный размер, либо оставьте предложенный и жмите «Ок».
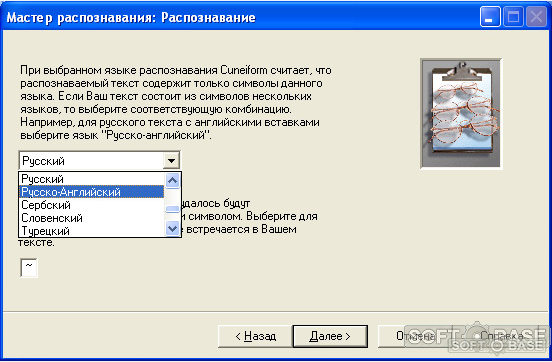
3. «Мастер распознавания». Здесь из списка выбираем язык либо их комбинацию, которые присутствуют на изображении — после чего снова кликаем «Далее».
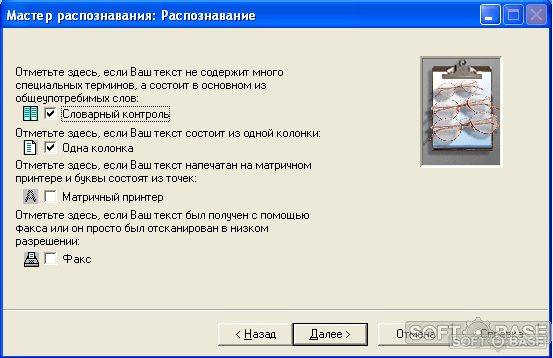
4. С следующем окне советуем отметить:
- «Словарный контроль», если текст не содержит общий терминов.Это повысит качество распознавания.
- «Одна колонка» — отметьте если на изображении текст представлен в виде одной колонки.
- «Матричный принтер» — отметьте, если изображение низкого качества.
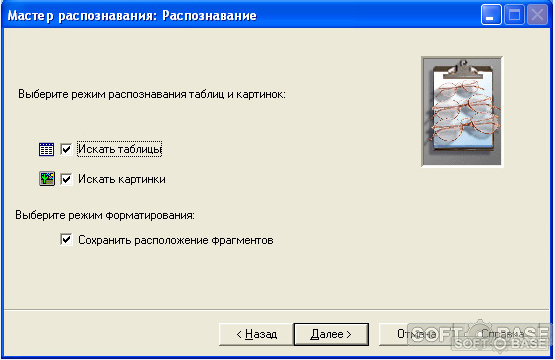
5. «Режим распознавания таблиц и картинок»:
- «Искать таблицы» — отмечайте при наличии таблиц на изображении.
- «Искать картинки» — при наличии картинок, которые останутся в тексте.
- «Сохранить расположение фрагментов» — оставить текущее расположения различных элементов оформления текста — таблиц, изображений и заголовков — на листе.
В окне экспорта, будет предложено сохранить распознанный документ в один из доступных форматов.
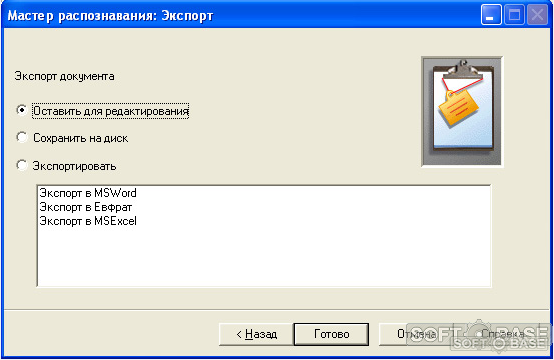
В большинстве случаев довольно удобно сразу сделать экспорт в Word и затем уже выполнять форматирование текста и перетягивание элементов оформления.
При наличии большого количества ошибок в распознанном документе, используйте ручное редактирование, когда в верхней части окна отображается исходный результат, а в нижней окно исходного документа, для облегчения сравнения результата с исходным изображением.
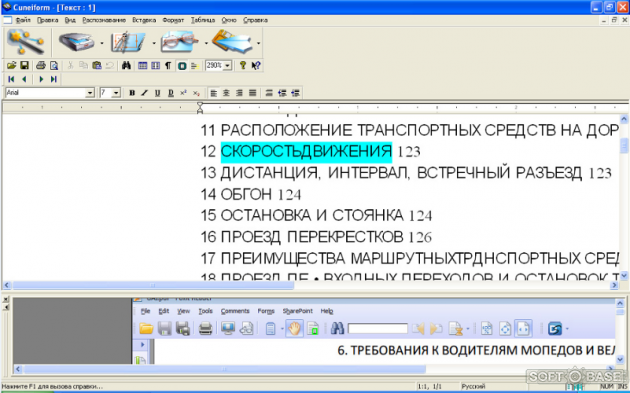
Примечание: слова с возможными ошибками выделены зеленым цветом, что облегчает их поиск и исправление.
-
Выпуски
-
Группы
-
Подборки
-
Все вместе -
Автомобили -
Бизнес и карьера -
Дом и семья -
Мир женщины -
Hi-Tech -
Компьютеры и интернет -
Культура, стиль жизни -
Новости и СМИ -
Общество -
Прогноз погоды -
Спорт -
Страны и регионы -
Туризм -
Экономика и финансы -
Email-маркетинг -
Поиск авиабилетов
Программы, помогающие думать, сочинять, фантазировать
565
![]()
| Открытая группа |
|
11993 участника |
Важные темы:
- Авторам тем. Что делать, если тема не публикуется
(7) - Открыть неведомое в Интернете? — Есть хороший приём…
(2) - Гипертекстовые машины развития мысли
(14) - Тренинг двухполушарного мышления
(6) - Нам 10 лет! Получи бонус от TurboBit!
- Рассылки, за которыми следит группа:
- Усилители интеллекта: теории, эксперименты, технологии
- Концепции и программы прикладного мышления
Активные участники:
Последние откомментированные темы:
-
Мой детектив в 67 томах (2020-2022) FB2
(2)
,
30.01.2022
-
Убираем водяной знак с видео и фотографий
(1)
,
06.09.2021
-
Факты о биткойнах: 8 удивительных фактов, о которых вы не знали
(3)
,
16.07.2021
-
Сергей Лукьяненко — Сборник произведений — 303 книги (FB2)
(1)
,
31.05.2021
-
Как построить дом / How to Build a House (2002) PDF
(1)
,
26.05.2021
-
Разговорный английский на все 100%. Английский для иммигрантов и путешественников (Видеокурс)
(1)
,
14.04.2021
-
Анальные Свингер Игры Порнозвезд / Anal Swinging Pornstar Games (2015) WEBRip
(1)
,
14.04.2021
-
Информационное поле земли.
(1)
,
09.04.2021
20230204144854
Реклама
- Темы
- Галерея
- Файлы
- Поиск по группе

Вступите в группу, и вы сможете просматривать изображения в полном размере

|
Это интересно 0 |
||||