Содержание
- Кодировка в csv-файле
- Решение
- type of encoding to read csv files in pandas
- 2 Answers 2
- UnicodeDecodeError when reading CSV file in Pandas with Python
- 23 Answers 23
- Pandas read_csv() tricks you should know to speed up your data analysis
- Some of the most helpful Pandas tricks to speed up your data analysis
- 1. Dealing with different character encodings
- 2. Dealing with headers
- No headers
- Consider different row as headers
- 3. Dealing with columns
- 4. Parsing date columns
- UnicodeDecodeError при чтении CSV-файла в панд с Python
- 4 ответов:
Кодировка в csv-файле
Помощь в написании контрольных, курсовых и дипломных работ здесь.
CSV Кодировка (Python3)
import requests from bs4 import BeautifulSoup import csv def get_html(url): r =.
Фильтрация строк в csv файле
Прошу помощи в реализации нужно удалить строки из csv содержащие определенные слова пробовал при.
Среднее значение столбца в csv файле
всем привет, пожалуйста помогите с этой задачей. не могу понять эти задачи csv. Дано: Загрузите.
Слетела кодировка в файле
Писал диплом, залагал комп, перегрузил винду открываю основную копию файла слетела кодировка.
Вложения
 |
output.zip (511 байт, 6 просмотров) |
Решение
Добавлено через 7 минут
C трех попыток угадал 🙂
Неверное кодирование windows-1251 в windows-1252.
Админ написал, про кодировку: в полях varchar кодировка cp1251
А как правильно перекодировать? что то не получается.
Добавлено через 23 минуты
Ошибка:
UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x90 in position 63: character maps to
Добавлено через 6 минут
Ну если файл был записан на диск в неверной кодировке, значит его сначала нужно исправить и только потом пользоваться.
Добавлено через 2 минуты
Перекодировать файл можно и в обычном текстовом редакторе, только нужно понимать разницу между перекодировать файл и переоткрытьперечитать в другой кодировке и не перепутать последовательность этих операций: сначала перекодировать, затем перечитать
Я в двух текстовых редакторах легко это сделал: в Akelpad и SynWrite.
Вот я в этом пока не очень, если можете подсказать как это сделать буду признателен, сто то не получается, с оракла получилось исправить кодировку а тут нет((
Добавлено через 1 час 23 минуты
Пока не нашел ничего лучше, чем перекодировать каждый столбец:
Я же вам показал как за одну операцию перекодировать сразу весь файл.
Как его сразу создать с вменяемой кодировкой я не могу сказать, ничего не зная о том в какой кодировке выгружаются у вас данные из БД.
Добавлено через 9 минут
P.S. Можете попробовать сохранить файл в windows-1251:
Админам на заметку:
Чой-та за фигня творится c сохранением постов?
Добавлено через 11 минут
Ну и заодно попросить показать, что выдает команда: SHOW VARIABLES LIKE ‘character%’;
Импорт в csv и кодировка
Здаравствуйте. Создаю скриптом csv файл в кодировке UTF-8. Данные содержат символы.
 Кодировка CSV файла
Кодировка CSV файла
Доброго времени суток! Образовалась такая проблема: при создании сайта на php (задание такое.
Русская кодировка в текстовом csv
пытаюсь выводить текстовые данные в файл, но они же из обычных textbox и если их потом открыть как.
Источник
type of encoding to read csv files in pandas
2 Answers 2
Or iterate over several formats in a try/except statement:

A CSV file is a text file. If it contains only ASCII characters, no problem nowadays, most encodings can correctly handle plain ASCII characters. The problem arises with non ASCII characters. Exemple
| character | Latin1 code | cp850 code | UTF-8 codes |
|---|---|---|---|
| é | ‘xe9’ | ‘x82’ | ‘xc3xa9’ |
| è | ‘xe8’ | ‘x8a’ | ‘xc3xa8’ |
| ö | ‘xf6’ | ‘x94’ | ‘xc3xb6’ |
As you spoke of CP1252, it is a Windows variant of Latin1, but it does not share the property of being able to decode any byte.
The common way is to ask people sending you CSV file to use the same encoding and try to decode with that encoding. Then you have two workarounds for badly encoded files. First is the one proposed by CygnusX: try a sequence of encodings terminated with Latin1, for example encodings = [«utf-8-sig», «utf-8», «cp1252», «latin1»] (BTW Latin1 is an alias for ISO-8859-1 so no need to test both).
The second one is to open the file with errors=’replace’ : any offending byte will be replaced with a replacement character. At least all ASCII characters will be correct:
Источник
UnicodeDecodeError when reading CSV file in Pandas with Python
I’m running a program which is processing 30,000 similar files. A random number of them are stopping and producing this error.
The source/creation of these files all come from the same place. What’s the best way to correct this to proceed with the import?

23 Answers 23
You can also use one of several alias options like ‘latin’ instead of ‘ISO-8859-1’ (see python docs, also for numerous other encodings you may encounter).
Simplest of all Solutions:
Then, you can read your file as usual:
and the other different encoding types are:

Pandas allows to specify encoding, but does not allow to ignore errors not to automatically replace the offending bytes. So there is no one size fits all method but different ways depending on the actual use case.
You know the encoding, and there is no encoding error in the file. Great: you have just to specify the encoding:
You do not want to be bothered with encoding questions, and only want that damn file to load, no matter if some text fields contain garbage. Ok, you only have to use Latin1 encoding because it accept any possible byte as input (and convert it to the unicode character of same code):
You know that most of the file is written with a specific encoding, but it also contains encoding errors. A real world example is an UTF8 file that has been edited with a non utf8 editor and which contains some lines with a different encoding. Pandas has no provision for a special error processing, but Python open function has (assuming Python3), and read_csv accepts a file like object. Typical errors parameter to use here are ‘ignore’ which just suppresses the offending bytes or (IMHO better) ‘backslashreplace’ which replaces the offending bytes by their Python’s backslashed escape sequence:

after executing this code you will find encoding of ‘filename.csv’ then execute code as following

This is a more general script approach for the stated question.
One starts with all the standard encodings available for the python version (in this case 3.7 python 3.7 standard encodings). A usable python list of the standard encodings for the different python version is provided here: Helpful Stack overflow answer
Trying each encoding on a small chunk of the data; only printing the working encoding. The output is directly obvious. This output also addresses the problem that an encoding like ‘latin1’ that runs through with ought any error, does not necessarily produce the wanted outcome.
In case of the question, I would try this approach specific for problematic CSV file and then maybe try to use the found working encoding for all others.
In my case, a file has USC-2 LE BOM encoding, according to Notepad++. It is encoding=»utf_16_le» for python.
Hope, it helps to find an answer a bit faster for someone.

Try changing the encoding. In my case, encoding = «utf-16» worked.

Try specifying the engine=’python’. It worked for me but I’m still trying to figure out why.
In my case this worked for python 2.7:
And for python 3, only:
This will help. Worked for me. Also, make sure you’re using the correct delimiter and column names.
You can start with loading just 1000 rows to load the file quickly.

Struggled with this a while and thought I’d post on this question as it’s the first search result. Adding the encoding=»iso-8859-1″ tag to pandas read_csv didn’t work, nor did any other encoding, kept giving a UnicodeDecodeError.

Fortunately, there are a few solutions.
Option 1, fix the exporting. Be sure to use UTF-8 encoding.
Option 3: solution is my preferred solution personally. Read the file using vanilla Python.
Hope this helps people encountering this issue for the first time.
Источник
Pandas read_csv() tricks you should know to speed up your data analysis
Some of the most helpful Pandas tricks to speed up your data analysis

Aug 21, 2020 · 7 min read

Importing data is the first step in any data science project. Often, you’ll work with data in CSV files and run into problems at the very beginning. In this article, you’ll see how to use the Pandas read_csv() function to deal with the following common problems.
Please check out my Github repo for the source code.
1. Dealing with different character encodings
Character encodings are specific sets of rules for mapping from raw binary byte strings to characters that make up the human-readable text [1]. Python has built-in support for a list of standard encodings.
Character e n coding mismatches are less common today as UTF-8 is the standard text encoding in most of the programming languages including Python. However, it is definitely still a problem if you are trying to read a file with a different encoding than the one it was originally written. You are most likely to end up with something like below or DecodeError when that happens:

The Pandas read_csv() function has an argument call encoding that allows you to specify an encoding to use when reading a file.
Let’s take a look at an example below:
Then, you should get an UnicodeDecodeError when trying to read the file with the default utf8 encoding.

In order to read it correctly, you should pass the encoding that the file was written.

Headers refer to the column names. For some datasets, the headers may be completely missing, or you might want to consider a different row as headers. The read_csv() function has an argument called header that allows you to specify the headers to use.
If your CSV file does not have headers, then you need to set the argument header to None and the Pandas will generate some integer values as headers
For example to import data_2_no_headers.csv

Let’s take a look at data_2.csv
3. Dealing with columns
When your input dataset contains a large number of columns, and you want to load a subset of those columns into a DataFrame, then usecols will be very useful.
Performance-wise, it is better because instead of loading an entire DataFrame into memory and then deleting the spare columns, we can select the columns we need while loading the dataset.
Let’s use the same dataset data_2.csv and select the product and cost columns.

We can also pass the column index to usecols :
4. Parsing date columns
Date columns are represented as objects by default when loading data from a CSV file.
To read the date column correctly, we can use the argument parse_dates to specify a list of date columns.
To specify a custom column name instead of the auto-generated year_month_day, we can pass a dictionary instead.
If your date column is in a different format, then you can customize a date parser and pass it to the argument date_parser :
For more about parsing date columns, please check out this article
Источник
UnicodeDecodeError при чтении CSV-файла в панд с Python
Я запускаю программу, которая обрабатывает 30 000 подобных файлов. Случайное число из них останавливаются и производят эту ошибку.
источник / создание этих файлов все приходят из одного и того же места. Каков наилучший способ исправить это, чтобы продолжить импорт?
4 ответов:
самое простое из всех решений:
затем вы можете прочитать файл как обычно:
редактировать 1:
Если есть много файлов, то вы можете пропустить возвышенный шаг.
просто прочитайте файл с помощью
и другие различные типы кодирования:
Pandas позволяет указать кодировку, но не позволяет игнорировать ошибки, чтобы автоматически не заменять нарушающие байты. Так что нет один размер подходит всем метод, но разными способами в зависимости от фактического использования.
вы знаете кодировку, и в файле нет ошибки кодирования. Отлично: вам нужно просто указать кодировку:
вы не хотите, чтобы вас беспокоили вопросы кодирования, и только хочу, чтобы этот проклятый файл загружался, независимо от того, содержат ли некоторые текстовые поля мусор. Хорошо, вы только должны использовать Latin1 кодировка, потому что она принимает любой возможный байт в качестве входного (и преобразует его в символ Юникода того же кода):
вы знаете, что большая часть файла записывается в определенной кодировке, но он также содержит ошибки кодирования. Примером реального мира является файл UTF8, который был отредактирован с помощью редактора, отличного от utf8, и который содержит некоторые строки с другая кодировка. Панды не имеет никакого положения для специальной обработки ошибок, но Python open функция имеет (предполагая Python3), и read_csv принимает файл как объект. Типичные ошибки параметр для использования здесь ‘ignore’ который просто подавляет оскорбительные байты или (ИМХО лучше) ‘backslashreplace’ который заменяет оскорбительные байты их Python с обратной косой чертой escape-последовательности:
боролся с этим некоторое время и думал, что я отправлю на этот вопрос, так как это первый результат поиска. Добавление тега encoding=’iso-8859-1″ в pandas read_csv не работало, как и любая другая кодировка, продолжало давать UnicodeDecodeError.
Источник
Learn how to use Pandas to convert a dataframe to a CSV file, using the .to_csv() method, which helps export Pandas to CSV files. You’ll learn how to work with different parameters that allow you to include or exclude an index, change the seperators and encoding, work with missing data, limit columns, and how to compress.
CSVs, short for comma separated values, are highly useful formats that store data in delimited text file (typically separated by commas), that place records on separate rows. They are often used in many applications because of their interchangeability, which allows you to move data between different proprietary formats with ease.
Knowing how to work with CSV files in Python and Pandas will give you a leg up in terms of getting started!
The Quick Answer: Use the .to_csv() Function
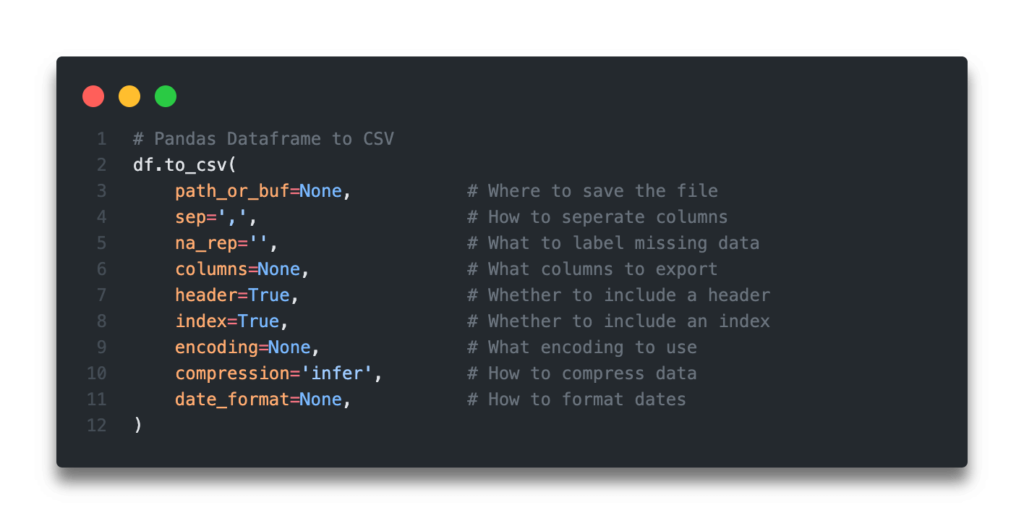
A Quick Summary
The table below summarizes the key parameters and their scenarios of the Pandas .to_csv() method. Click on a parameter in the table to go to the detailed section below.
| Parameter | When to Use It | An Example |
|---|---|---|
index = |
Write with or without and index | df.to_csv(..., index = False) |
columns = |
Write only a subset of columns to CSV | df.to_csv(..., columns = ['col1', 'col2']) |
sep = |
Change the type of separator to use | df.to_csv(..., sep = 't') |
na_rep = |
How to change how missing data are saved | df.to_csv(..., na_rep = 'N/A') |
header = |
Whether to include a header or not | df.to_csv(..., header = False) |
encoding = |
Change the encoding type used | df.to_csv(..., encoding = 'utf-8') |
compression = |
Whether to compress the data or not | df.to_csv(..., compression = True) |
date_format = |
Specify the format for datetime values |
df.to_csv(..., date_format = '%Y-%m-%d') |
What are CSV Files?
Comma-separated value files, or CSV files, are text files often used to represent tabular data. Data are commonly separated by commas, giving them their name. While data attributes are separated by commas, records tend to be separated by new lines.
CSV files are light-weight and tend to be relatively platform agnostic. Because of this, they are often used to transfer data between different systems.
A CSV file will often store the headers of a table in the first row. Many programs will know to interpret a first row as the header row.
Let’s take a look at how a CSV file may store data:
Name,Year,Sales
Nik,2020,1000
Nik,2021,2300
Jane,2020,1900
Jane,2021,3400If we were to convert this to a table, it would look like this:
| Name | Year | Sales |
|---|---|---|
| Nik | 2020 | 1000 |
| Nik | 2021 | 2300 |
| Jane | 2020 | 1900 |
| Jane | 2021 | 3400 |
Let’s now dive into how to load a sample Pandas dataframe which you’ll use throughout this tutorial to export your data.
Loading a Sample Dataframe
If you want to follow along with this tutorial, feel free to load the dataframe provided below. The dataframe will have three columns and only four records, to keep things lightweight and easy to use.
# Loading a Sample Dataframe
import pandas as pd
df = pd.DataFrame.from_dict(
{ 'Name': ['Nik', 'Nik', 'Jane', 'Jane'],
'Year': [2020, 2021, 2020, 2021],
'Sales': [1000, 2300, 1900, 3400],
}
)
print(df)
# Returns:
# Name Year Sales
# 0 Nik 2020 1000
# 1 Nik 2021 2300
# 2 Jane 2020 1900
# 3 Jane 2021 3400Now that you have a dataframe to work with, let’s learn how to use Pandas to export a dataframe to a CSV file.
In order to use Pandas to export a dataframe to a CSV file, you can use the aptly-named dataframe method, .to_csv(). The only required argument of the method is the path_or_buf = parameter, which specifies where the file should be saved.
The argument can take either:
- A relative filename, which will save the file as a CSV file in the current working directory, or
- A full file path, which will save the file as a CSV in the location specified
Let’s see what this looks in our Pandas code:
# Export a Pandas Dataframe to CSV
# Relative File Path
df.to_csv('datagy.csv')
# Fixed File Path
df.to_csv('/Users/datagy/datagy.csv')In the next section, you’ll learn how to remove an index from your Pandas dataframe when exporting to a CSV file.
Exporting Pandas to CSV Without Index
By default, Pandas will include a dataframe index when you export it to a CSV file using the .to_csv() method. If you don’t want to include an index, simply change the index = False parameter.
Let’s see how we can do this:
# Export a Pandas Dataframe to CSV without an Index
# Without the index
df.to_csv('datagy.csv', index = False)
# With the Index
df.to_csv('datagy.csv')Doing so can be quite helpful when your index is meaningless. However, think carefully about this if you are using the index to store meaningful information, such as time series data.
The default parameter for this is True. Because of this, if you do want to include the index, you can simply leave the argument alone.
Working with Columns When Exporting Pandas to CSV
When you export your data, you may be cognizant of the size of your data. One of the ways that you can reduce the size of the exported CSV file is to limit the number of columns that you export.
You can specify which columns to include in your export using the columns = argument, which accepts a list of columns that you want to include. Any columns not included in the list will not be included in the export.
Let’s see how we can use the columns = parameter to specify a smaller subset of columns to export:
# Export a Pandas Dataframe to CSV with only some columns
# Only certain columns
df.to_csv('datagy.csv', columns=['Name', 'Year'])
# All columns
df.to_csv('datagy.csv')Want to learn more about calculating the square root in Python? Check out my tutorial here, which will teach you different ways of calculating the square root, both without Python functions and with the help of functions.
Changing the Separator When Exporting Pandas to CSV
While comma-separated value files get their names by virtue of being separated by commas, CSV files can also be delimited by other characters. For example, a common separator is the tab value, which can be represented programatically by t.
Let’s see how we can use the sep= argument to change our separator in Pandas:
# Export a Pandas Dataframe to CSV with a different delimiter
# Specific delimiter
df.to_csv('datagy.csv', sep='t')
# Comma delimiter
df.to_csv('datagy.csv')In the next section, you’ll learn how to label missing data when exporting a dataframe to CSV.
Working with Missing Data When Exporting Pandas to CSV
By default, CSV files will not include any information about missing data. They will actually, simply, not show any value at all.
If, however, you want to display a different value, such as N/A for all your missing values, you can do this using the na_rep = argument. The default argument for this is an empty string, but it accepts any type of string.
Let’s load in the string 'N/A' to make it clear that the data is actually missing:
# Export a Pandas Dataframe to CSV With Missing Data
# Different Missing Identifier
df.to_csv('datagy.csv', na_rep='N/A')
# Blank String for Missing Data
df.to_csv('datagy.csv')Removing Header When Exporting Pandas to CSV
There may be times in your data science journey where you find yourself needing to export a dataset from Pandas without a header. This can be particularly true when exporting large datasets that will need to be appended together afterwards.
Pandas makes it easy to export a dataframe to a CSV file without the header.
This is done using the header = argument, which accepts a boolean value. By default, it uses the value of True, meaning that the header is included.
Let’s see how we can modify this behaviour in Pandas:
# Export a Pandas Dataframe Without a Header
# Without Header
df.to_csv('datagy.csv', header=False)
# With Header
df.to_csv('datagy.csv')Pandas to CSV with Different Encodings
When you’re working with string data, you’ll often find yourself needing to encode data. This is less common when you’re working with numerical or encoded data only, but strings will often require a little bit extra instruction on how they are to be interpreted.
The default type of encoding is utf-8, which is an incredibly common encoding format.
Let’s see how we can export a Pandas dataframe to CSV using the latin1 encoding:
# Export a Pandas Dataframe With Encodings
# With latin1 Encoding
df.to_csv('datagy.csv', encoding='latin1')
# With utf-8 Encoding
df.to_csv('datagy.csv')Compress Data When Exporting Pandas to CSV
When you’re working with large datasets that are meant for long-term storage, it can be helpful to compress the dataset, especially when saving it to a CSV format.
When we compress a dataset, the file size becomes smaller. However, the time that it takes Pandas to export to CSV also increases. Similarly, the time that Pandas will take to read the CSV file into a dataframe increases. This is because the compression step takes longer than simply exporting.
However, there are many use cases when compression is a helpful tool, especially when archiving data for long-term storage, or when data isn’t used frequently.
Let’s see how we can use this boolean argument to compress our data:
# Export a Pandas Dataframe With Compression
# With gzip Compression
df.to_csv('datagy.csv', compression='gzip')
# Without Compression
df.to_csv('datagy.csv')Check out some other Python tutorials on datagy, including our complete guide to styling Pandas and our comprehensive overview of Pivot Tables in Pandas!
Specify Date Format When Exporting Pandas to CSV
Pandas makes working with date time formats quite easy. However, the databases that you’re moving data between may have specific formats for dates that need to be followed.
Thankfully, Pandas makes this process quite easy, by using the date_format = argument. The argument accepts a string that allows us to specify how dates should be formatted in the exported CSV.
To learn more about Python date formats, check out my tutorial that will teach you to convert strings to date times.
Let’s see how we can apply a YYYY-MM-DD format to our dates when exporting a Pandas dataframe to CSV:
# Export a Pandas Dataframe With Date Format Specified
# With YYYY-MM-DD Format
df.to_csv('datagy.csv', date_format='%Y-%m-%d')
# Without specified date format
df.to_csv('datagy.csv')Want to learn more about Python f-strings? Check out my in-depth tutorial, which includes a step-by-step video to master Python f-strings!
Conclusion
In this tutorial, you learned how to use Pandas to export your dataframes to CSV files. You learned how to make excellent use of the Pandas .to_csv() function, along with how to use its many parameters to customize how your data as exported. Some of the key ones you learned to use are the index=, which includes or excludes an index, and the encoding= parameter, which specifies the encoding you wish to use.
To learn more about the Pandas .to_csv() method, check out the official documentation here.
Code Sample, a copy-pastable example if possible
import pandas cyrillic_filename = "./файл_1.csv" # 'c' engine fails: df = pandas.read_csv(cyrillic_filename, engine="c", encoding="cp1251") --------------------------------------------------------------------------- OSError Traceback (most recent call last) <ipython-input-18-9cb08141730c> in <module>() 2 3 cyrillic_filename = "./файл_1.csv" ----> 4 df = pandas.read_csv(cyrillic_filename , engine="c", encoding="cp1251") d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, skip_footer, doublequote, delim_whitespace, as_recarray, compact_ints, use_unsigned, low_memory, buffer_lines, memory_map, float_precision) 653 skip_blank_lines=skip_blank_lines) 654 --> 655 return _read(filepath_or_buffer, kwds) 656 657 parser_f.__name__ = name d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in _read(filepath_or_buffer, kwds) 403 404 # Create the parser. --> 405 parser = TextFileReader(filepath_or_buffer, **kwds) 406 407 if chunksize or iterator: d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in __init__(self, f, engine, **kwds) 762 self.options['has_index_names'] = kwds['has_index_names'] 763 --> 764 self._make_engine(self.engine) 765 766 def close(self): d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in _make_engine(self, engine) 983 def _make_engine(self, engine='c'): 984 if engine == 'c': --> 985 self._engine = CParserWrapper(self.f, **self.options) 986 else: 987 if engine == 'python': d:_devservicesprotocol_sortvenvlibsite-packagespandasioparsers.py in __init__(self, src, **kwds) 1603 kwds['allow_leading_cols'] = self.index_col is not False 1604 -> 1605 self._reader = parsers.TextReader(src, **kwds) 1606 1607 # XXX pandas_libsparsers.pyx in pandas._libs.parsers.TextReader.__cinit__ (pandas_libsparsers.c:4209)() pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source (pandas_libsparsers.c:8895)() OSError: Initializing from file failed # 'python' engine work: df = pandas.read_csv(cyrillic_filename, engine="python", encoding="cp1251") df.size >>172440 # 'c' engine works if filename can be encoded to utf-8 latin_filename = "./file_1.csv" df = pandas.read_csv(latin_filename, engine="c", encoding="cp1251") df.size >>172440
Problem description
The ‘c’ engine should read the files with non-UTF-8 filenames
Expected Output
File content readed into dataframe
Output of pd.show_versions()
INSTALLED VERSIONS
commit: None
python: 3.6.1.final.0
python-bits: 32
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 42 Stepping 7, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
LOCALE: None.None
pandas: 0.20.3
pytest: None
pip: 9.0.1
setuptools: 28.8.0
Cython: None
numpy: 1.13.2
scipy: 0.19.1
xarray: None
IPython: 6.2.1
sphinx: None
patsy: None
dateutil: 2.6.1
pytz: 2017.2
blosc: None
bottleneck: None
tables: None
numexpr: None
feather: None
matplotlib: None
openpyxl: 2.4.8
xlrd: None
xlwt: None
xlsxwriter: None
lxml: 4.0.0
bs4: None
html5lib: 1.0b10
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: 2.9.6
s3fs: None
pandas_gbq: None
pandas_datareader: None
None

![]()
So we’ve all gotten that error, you download a CSV from the web or get emailed it from your manager, who wants analysis done ASAP, and you find a card in your Kanban labelled URGENT AFF,so you open up VSCode, import Pandas and then type the following: pd.read_csv('some_important_file.csv').
Now, instead of the actual import happening, you get the following, near un-interpretable stacktrace:

What does that even mean?! And what the heck is utf-8. As a brief primer/crash course, your computer (like all computers), stores everything as bits (or series of ones and zeros). Now, in order to represent human-readable things (think letters) from ones and zeros, the Internet Assigned Numbers Authority came together and came up with the ASCII mappings. These basically map bytes (binary bits) to codes (in base-10, so numbers) which represent various characters. For example, 00111111 is the binary for 063 which is the code for ?.
These letters then come together to form words which form sentences. The number of unique characters that ASCII can handle is limited by the number of unique bytes (combinations of 1 and 0) available. However, to summarize: using 8 bits allows for 256 unique characters which is NO where close in handling every single character from every single language. This is where Unicode comes in; unicode assigns a «code points» in hexadecimal to each character. For example U+1F602 maps to 😂. This way, there are potentially millions of combinations, and is far broader than the original ASCII.
UTF-8
UTF-8 translates Unicode characters to a unique binary string, and vice versa. However, UTF-8, as its name suggests, uses an 8-bit word (similar to ASCII), to save memory. This is similar to a technique known as Huffman Coding which represents the most-used characters or tokens as the shortest words. This is intuitive in the sense that, we can afford to assign tokens used the least to larger bytes, as they are less likely to be sent together. If every character would be sent in 4 bytes instead, every text file you have would take up four times the space.
Caveat
However, this also means that the number of characters encoded by specifically UTF-8, is limited (just like ASCII). There are other UTFs (such as 16), however, this raises a key limitation, especially in the field of data science: sometimes we either don’t need the non-UTF characters or can’t process them, or we need to save on space. Therefore, here are three ways I handle non-UTF-8 characters for reading into a Pandas dataframe:
Find the correct Encoding Using Python
Pandas, by default, assumes utf-8 encoding every time you do pandas.read_csv, and it can feel like staring into a crystal ball trying to figure out the correct encoding. Your first bet is to use vanilla Python:
with open('file_name.csv') as f:
print(f)
Enter fullscreen mode
Exit fullscreen mode
Most of the time, the output resembles the following:
<_io.TextIOWrapper name='file_name.csv' mode='r' encoding='utf16'>
Enter fullscreen mode
Exit fullscreen mode
.
If that fails, we can move onto the second option
Find Using Python Chardet
chardet is a library for decoding characters, once installed you can use the following to determine encoding:
import chardet
with open('file_name.csv') as f:
chardet.detect(f)
Enter fullscreen mode
Exit fullscreen mode
The output should resemble the following:
{'encoding': 'EUC-JP', 'confidence': 0.99}
Enter fullscreen mode
Exit fullscreen mode
Finally
The last option is using the Linux CLI (fine, I lied when I said three methods using Pandas)
iconv -f utf-8 -t utf-8 -c filepath -o CLEAN_FILE
Enter fullscreen mode
Exit fullscreen mode
- The first
utf-8afterfdefined what we think the original file format is -
tis the target file format we wish to convert to (in this caseutf-8) -
cskips ivalid sequences -
ooutputs the fixed file to an actual filepath (instead of the terminal)
Now that you have your encoding, you can go on to read your CSV file successfully by specifying it in your read_csv command such as here:
pd.read_csv("some_csv.txt", encoding="not utf-8")
Enter fullscreen mode
Exit fullscreen mode
- path_or_buf :str, объект пути, файлоподобный объект или None, по умолчанию None
-
Строка,объект пути (реализующий os.PathLike[str])или файлоподобный объект,реализующий функцию write().Если None,результат возвращается в виде строки.Если передан недвоичный объект файла,его следует открыть с помощью функцииnewline=’’, отключение универсальных символов новой строки. Если передан объект двоичного файла,modeможет потребоваться‘b’.
Изменения в версии 1.2.0:Введена поддержка объектов бинарных файлов.
- sep :str, по умолчанию ‘,’
-
Строка длиной 1.Разделитель полей для выходного файла.
- na_rep :str, по умолчанию »
-
Пропущенное представление данных.
- float_format :str, Callable, по умолчанию None
-
Строка форматирования для чисел с плавающей запятой.Если задана Callable,она имеет приоритет над другими параметрами форматирования чисел,например десятичным.
- columns:sequence, optional
-
Колонки писать.
- заголовок : bool или список str, по умолчанию True
-
Выпишите названия столбцов.Если список строк задан,то предполагается,что это псевдонимы для названий колонок.
- index : bool, по умолчанию True
-
Напишите имена строк (индекс).
- index_label : str или sequence, или False, по умолчанию None
-
Метка столбца для индексного столбца (столбцов)по желанию.Если задано None,иheaderandindexимеют значение True,то используются имена индексов.Если объект использует MultiIndex,то должна быть указана последовательность.Если False,то не печатайте поля для имен индексов.Используйте index_label=False для упрощения импорта в R.
- режим :str, по умолчанию ‘w’
-
Режим записи Python. Доступные режимы записи такие же, как и в
open(). - encoding:str, optional
-
Строка,представляющая кодировку,которую следует использовать в выходном файле,по умолчанию ‘utf-8’.encodingне поддерживается,еслиpath_or_bufявляется недвоичным файловым объектом.
- сжатие : str или dict, по умолчанию ‘infer’
-
Для оперативного сжатия выходных данных. Если ‘infer’ и ‘path_or_buf’ аналогичны пути, то обнаружите сжатие из следующих расширений: ‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’ , ‘.tar.gz’, ‘.tar.xz’ или ‘.tar.bz2’ (в противном случае без сжатия). Установите
Noneдля отсутствия сжатия. Также может быть dict с ключом'method'установленным на один из {'zip','gzip','bz2','zstd','tar'} и другие пары ключ-значение пересылаются вzipfile.ZipFile,gzip.GzipFile,bz2.BZ2File,zstandard.ZstdCompressorилиtarfile.TarFile, соответственно. Например, для более быстрого сжатия и создания воспроизводимого gzip-архива можно передать следующее:compression={'method': 'gzip', 'compresslevel': 1, 'mtime': 1}.Новое в версии 1.5.0:Добавлена поддержка.tarfiles.
Изменено в версии 1.0.0:Теперь может быть диктой с ключом ‘method’ в качестве режима сжатия и другими записями в качестве дополнительных опций сжатия,если режим сжатия-‘zip’.
Изменено в версии 1.1.0:Передача параметров сжатия в качестве ключей в dict поддерживается для режимов сжатия ‘gzip’,’bz2′,’zstd’ и ‘zip’.
Изменено в версии 1.2.0:Поддерживается сжатие для объектов двоичных файлов.
Изменено в версии 1.2.0:Предыдущие версии пересылали записи dict для ‘gzip’ вgzip.openinstead ofgzip.GzipFileчто не позволило установитьmtime.
- цитирование : необязательная константа из модуля csv
-
По умолчанию установлено значение csv.QUOTE_MINIMAL.Если вы установилиfloat_formatто float преобразуются в строки и,таким образом,csv.QUOTE_NONNUMERIC будет рассматривать их как нечисловые.
- кавычка :str, по умолчанию ‘»‘
-
Строка длиной 1.Символ,используемый для цитирования полей.
- lineterminator:str, optional
-
Символ новой строки или последовательность символов для использования в выходном файле.По умолчаниюos.linesep,что зависит от ОС,в которой вызывается этот метод (‘n’ для linux,’rn’ для Windows,т.е.).
Изменен в версии 1.5.0:Ранее был line_terminator,изменен для согласованности с read_csv и модулем ‘csv’ стандартной библиотеки.
- chunksize : int или None
-
Ряды писать за раз.
- date_format : str, по умолчанию Нет
-
Строка формата для объектов даты.
- двойные кавычки : bool, по умолчанию True
-
Контрольное цитированиеquotecharвнутри поля.
- escapechar : str, по умолчанию Нет
-
Строка длиной 1.Символ,используемый для экранированияsepandquotecharwhen appropriate.
- десятичная :str, по умолчанию ‘.’
-
Символ,признанный десятичным разделителем.Например,используйте ‘,’ для европейских данных.
- ошибки :str, по умолчанию «строгие»
-
Задает способ обработки ошибок кодирования и декодирования. Полный список опций см. В аргументе ошибок для
open().Новинка в версии 1.1.0.
- storage_options:dict, optional
-
Дополнительные параметры, которые имеют смысл для конкретного подключения к хранилищу, например хост, порт, имя пользователя, пароль и т. д. Для URL-адресов HTTP(S) пары ключ-значение перенаправляются в
urllib.request.Requestв качестве параметров заголовка. Для других URL-адресов (например, начинающихся с «s3://» и «gcs://») пары «ключ-значение» перенаправляются вfsspec.open. Дополнительные сведения см.fsspecиurllib, а дополнительные примеры вариантов хранения см . здесь .Новое в версии 1.2.0.