Продолжаем раскапывать новые фичи Windows Server 2012. Сегодня речь пойдет о технологии дедупликации данных (data deduplication). В общем случае дедупликация — это поиск и удаление дублирующихся данных. Найденные копии данных удаляются и заменяются ссылками на оригинал, что позволяет хранить только уникальный контент и высвобождает дисковое пространство. Цель дедупликации заключается в том, чтобы разместить большее количество данных на меньшем пространстве.
Описание
Дедупликация бывает разная — на уровне файлов, блоков данных и даже на битовом уровне. В Windows Server 2012 используется блочная дедупликация. Файлы разбиваются на небольшие блоки различного размера (32–128 КБ), определяются дублирующие блоки и сохраняется одна копия каждого блока. Избыточные копии блока заменяются ссылками на эту единственную копию. Блоки организуются в файлы-контейнеры, которые могут сжиматься для дальнейшей оптимизации использования пространства, и помещаются в хранилище блоков.
Для примера предположим, у нас есть два файла — File1 и File2. В исходном состоянии они содержат метаданные (имя файла, аттрибуты и т.п.) и сами данные.

После дедупликации данные из File1 и File2 удаляются и заменяются заглушками, указывающими на соответствующие блоки данных, хранящиеся в общем хранилище блоков. Так как блоки A, B и C одинаковы для обоих файлов, они хранятся в единственной копии, что снижает объем дискового пространства, необходимый для хранения обоих файлов.
Во время доступа к одному из файлов соответствующие блоки собираются вместе. При этом пользователь или приложение работают с файлом как и раньше, не подозревая о том, что файл был подвергнут преобразованиям. Это позволяет применять дедупликацию, не беспокоясь о ее влиянии на поведение приложений или доступ пользователей к файлу.

Таким образом, после включения дедупликации тома и оптимизации данных том содержит:
• Оптимизированные файлы (файлы точек повторного анализа) которые содержат указатели на соответствующие блоки данных в хранилище блоков, необходимые для построения исходного файла;
• Хранилище блоков (данные оптимизированных файлов);
• Неоптимизированные файлы (т. е. пропущенные файлы, например файлы состояния системы, зашифрованные файлы, файлы с дополнительными атрибутами или файлы размером менее 32 КБ);
Планирование
Дедупликация может значительно снизить потребляемое дисковое пространство (на 50-90% и более), но только при правильном планировании. Поэтому при выборе объекта для дедупликации следует учитывать некоторые моменты.
Тип данных
Эффективность дедупликации очень сильно зависит от типа данных. Так мультимедийные файлы (фотографии, музыка, видео) практически не содержат повторяющихся данных, поэтому их дедупликация не даст большой экономии. В то же время файлы виртуальных машин (VHD) замечательно дедуплицируются и на них экономия может составлять до 95 %. По этой причине перед включением дедупликации рекомендуется выполнить предварительную оценку данных на предмет дедуплицируемости 🙂
Частота изменения файлов
Файлы, которые часто изменяются и к которым часто обращаются пользователи или приложения, не очень подходят для дедупликации. Постоянный доступ к данным и их изменение скорее всего сведут на нет все результаты дедупликации и могут просто не дать дедупликации возможности обработать файлы. Проще говоря, для дедупликации хорошо подойдут данные, которые часто читают, но редко изменяют.
Загруженность сервера
Во время дедупликации выполняется чтение, обработка и запись большого объема данных. Этот процесс потребляет ресурсы сервера, что необходимо учитывать при планировании развертывания. Как правило, сервера имеют периоды высокой и низкой активности. Большую часть дедупликации можно выполнить, когда ресурсы доступны. Постоянно высоконагруженные сервера не рекомендуется использовать для дедупликации.
Не рекомендуется выполнять дедупликацию файлов, которые открыты, постоянно изменяются в течение продолжительного периода времени либо имеют высокие требования ввода/вывода, например файлы работающих виртуальных машин, динамических баз данных SQL или активных сеансов VDI. Дело в том, что при дедупликации не выполняется обработка файлов, открытых постоянно в монопольном режиме для записи. Это значит, что дедупликация не будет проведена до тех пор, пока файл не будет закрыт. Только тогда задание оптимизации выполнит попытку обработать файл, отвечающий выбранным параметрам политики дедупликации.
В принципе дедупликацию можно настроить на обработку постоянно изменяющихся файлов. Но в этом случае возможна ситуация, когда процесс оптимизации не сможет получить доступ к этим файлам и пропустит их обработку. Не стоит тратить ресурсы сервера на дедупликацию файлов, в которые постоянно записываются новые данные.
Приведу рекомендации Microsoft. Для дедупликации:
Не рекомендуется
- Сервера Hyper-V;
- VHD-файлы запущенных виртуальных машин;
- Службы WSUS;
- Сервера SQL и Exchange;
- Любые файлы, размер которых равен или больше 1 Тб.
Рекомендуется:
- Файловые ресурсы общего доступа (общие папки, профили и домашние папки пользователей, прочие файлопомойки);
- Развертывание программных продуктов (бинарники, образа дисков и обновления ПО);
- Библиотеки виртуализации (VHD-диски);
- Тома архивов SQL и Exchange.
Надо сказать, что рекомендации Microsoft часто противоречат друг другу, поэтому не стоит их безоговорочно принимать на веру. В любом случае перед включением дедупликации необходим тщательный анализ.
Для определения ожидаемой экономии в результате включения дедупликации можно использовать средство оценки дедупликации Ddpeval.exe. После установки компонента дедупликации утилита Ddpeval.exe автоматически устанавливается в папку WindowsSystem32. Кстати, ее можно просто скопировать из любой установки Windows Server 2012 и запустить в системах Windows 7, Windows 8 или Windows Server 2008 R2.
Синтаксис у программы проще некуда, пишем Ddpeval.exe и указываем путь. В качестве пути можно указать локальный диск, папку или сетевую шару:
Ddpeval.exe E:
Ddpeval E:Test
Ddpeval.exe \ServerShare
Программа выдаст ожидаемый размер экономии дискового пространства, после чего уже можно принимать решение — включать дедупликацию или нет.

Системные требования
Дедупликация предъявляет к системе некоторые требования.
Тома
• Тома, предназначенные для дедупликации не должны быть системными или загрузочными. Дедупликация не поддерживается для томов операционной системы;
• Тома могут быть разбиты под MBR или GPT и отформатированы в NTFS. Новая отказоустойчивая файловая система ReFS не поддерживается;
• Тома могут находиться на локальных дисках либо в общедоступном хранилище (SAS, iSCSI или Fibre Channel);
• Windows должна видеть тома как несъемные диски. Сетевые диски и съемные носители не поддерживаются;
• Нельзя включать дедупликацию для общих томов кластера (Claster Shared Volume, CSV). Если дедуплицированный том преобразовать в CSV, то доступ к данным останется, но задания дедупликации не смогут отработать;
Аппаратные ресурсы
• Оборудование серверов должно отвечать минимальным требованиям Windows Server 2012. Функция дедупликации разработана для поддержки минимальных конфигураций, таких как система с одним процессором, 4 ГБ ОЗУ и одним жестким диском SATA;
• Сервер должен иметь одно процессорное ядро и 350 МБ свободной памяти для выполнения задания дедупликации на одном томе, при этом будет обрабатываться около 1,5 ТБ данных в день. Если планируется поддерживать дедупликацию в нескольких томах на одном сервере, необходимо соответствующим образом увеличить производительность системы, чтобы гарантировать, что она сможет обрабатывать данные.
• Функция дедупликации поддерживает одновременную обработку до 90 томов, однако при дедупликации одновременно может обрабатываться один том на физическое процессорное ядро плюс один. Применение технологии Hyper-Threading не влияет на этот процесс, поскольку для обработки тома можно использовать только физические ядра. К примеру сервер с 16 процессорными ядрами и 90 томами будет обрабатывать по 17 томов одновременно, пока не обработает все 90 томов;
• К виртуальным серверам применяются те же правила, что и к физическому оборудованию в отношении ресурсов сервера.
Общие требования
• Наличие свободного места на диске. При отсутствии дискового пространства на дедуплицированном томе некоторые приложения не смогут получить доступ к данным и будут завершены с ошибкой. Необходимо сохранять, по крайней мере, один гигабайт свободного места на дедуплицированном томе;
• Жесткие квоты. При использовании FSRM (File System Resource Managet) не поддерживается установка жестких квот на объем тома. Когда для тома установлены жесткие квоты, фактический объем свободного места на томе и ограниченное квотами пространство отличается, что может привести к неудаче процесса дедупликации. Все другие FSRM-квоты, в том числе мягкие квоты на объем тома и квоты на подпапки, будут нормально работать при дедупликации;
• Файлы с дополнительными атрибутами, зашифрованные файлы, файлы размером меньше 32 КБ и файлы точек повторного анализа при дедупликации не обрабатываются.
Установка и настройка
Для включения дедупликации можно воспользоваться диспетчером сервера (Server Manager). Запускаем его и открываем пункт «Add roles and features».

В ролях сервера отмечаем пункт «Data Deduplication», соглашаемся на установку необходимых компонентов и жмем Install.

Затем все в том же Server Manager идем в «File and Storage Services» -> «Volumes» и выбираем диск, который планируется оптимизировать. Напоминаю, что дедупликацию можно включить для логического диска, или тома (Volume). Кликаем на выбраном томе и в контекстном меню выбираем пункт «Configure Data Deduplication».

В открывшемся окне включаем дедупликацию для выбранного тома. Также можно произвести некоторые настройки:
• Указать количество дней, прошедших с последнего изменения файла, после которых файл можно оптимизировать. Как я уже говорил, для дедупликации лучше подходят редко изменяемые файлы, поэтому период по умолчанию составляет 5 дней. Для часто изменяющихся файлов период можно уменьшить до 1-2 дней, а если задать значение 0, дедупликация будет выполняться для всех файлов вне зависимости от их срока существования.
• Исключить из процесса дедупликации отдельные файлы (по расширениям) или целые папки. Кстати, Microsoft почему то не рекомендует этого делать.

Нажав на кнопку «Set Deduplication Shedule» мы попадаем в окно настройки расписания запуска оптимизации. По умолчанию файлы обрабатываются внутри активного тома один раз в час в режиме фоновой (background) оптимизации. Дополнительно можем включить производительную (throughput) оптимизацию и настроить для нее основное и дополнительное расписание. Например, можно запланировать производительную оптимизацию на часы минимальной активности сервера.

Из консоли PowerShel можно сделать все то же самое (и даже больше) гораздо быстрее. Установка фичи:
Install-WindowsFeature -Name FS-Data-Deduplication
Включение дедупликации c дефолтными настройками на выбраном томе:
Enable-DedupVolume -Volume E:

Для настройки есть командлет Set-DedupVolume. С его помощью можно настроить гораздо больше параметров, чем из графического интерфейса:
-MinimumFileSize — минимальный размер файла (в байтах) для дедупликации. По умолчанию составляет 32 КБ. Уменьшить это значение нельзя, но можно увеличить.
-NoCompress — указывает, надо ли сжимать данные после дедупликации ($True — не сжимать, $False — сжимать). Сжатие освобождает дисковое пространство, но задействует дополнительные ресурсы процессора. По умолчанию сжатие включено.
-NoCompressionFileType — указываем типы файлов, которые не надо сжимать. Это значит, что файлы будут дедуплицированы, но не сжаты, например потому что их формат уже предполагает сжатие. По умолчанию в эту группу включены все аудио, видео файлы, изображения, архивные файлы и файлы MS Office нового формата (.docx, .xlsx и т.д.).
-ChunkRedundancyThreshold — если я правильно понял, то он указывает количество ссылок на блок данных в активной зоне, при котором этот блок необходимо продублировать. По умолчанию этот параметр равен 100, при его уменьшении количество дублирующих блоков увеличиться и соответственно понизится эффективность дедупликации. В общем, лучше не трогать.
Для примера выставим минимальный возраст файлов 2 дня, минимальный размер 64КБ и отключим сжатие на диске E командой:
Set-DedupVolume -Volume E: -MinimumFileAgeDays 2 -MinimumFileSize 65536
-NoCompress $true

Задания дедупликации
Дедупликация включает в себя три функции, которые выполняются в виде запланированных заданий — оптимизация, очистка данных и сбор мусора.
Фоновая оптимизация (Background Optimization) — режим по умолчанию. В этом режиме процесс оптимизации файлов запускается в фоновом режиме с регулярностью раз в 1 час. Процесс работает с низким приоритетом, потребляя не более 25% системной памяти. Подобный режим запуска позволяет максимально экономить ресурсы сервера и выполнять оптимизацию только при отсутствии нагрузки. Если ресурсы для выполнения задания оптимизации окажутся недоступны без влияния на рабочую нагрузку сервера, то задание будет остановлено.
Производительная оптимизация (Throughput Optimization) — может использоваться дополнительно, вместе с фоновой. Производительная оптимизация запускается ежедневно в указанное время, с нормальным приоритетом и отрабатывает вне зависимости от того, есть ли у сервера свободные ресурсы или нет. Можно запланировать ее на часы низкой активности сервера для ускорения процесса оптимизации.

Очистка данных (Scrubbing) — встроенная функция целостности данных, выполняющая проверку контрольных сумм и согласованности метаданных. Также имеется встроенная избыточность для критических метаданных и наиболее популярных блоков данных. Когда выполняется доступ к данным или обработка данных в заданиях, эта функция обнаруживает повреждения и регистрирует их в журнале. Очистка используется для анализа повреждения хранилища блоков и, по возможности, для выполнения восстановления.

Для восстановления поврежденных данных можно использовать три источника:
1) Дедупликация создает резервные копии популярных блоков. Популярность определяется количеством ссылок на них в области, которую называют активной зоной. Если рабочая копия повреждена, средство дедупликации будет использовать резервную;
2) При использовании дисков в зеркальной конфигурации дедупликация может использовать зеркальный образ избыточного блока для обслуживания операций ввода-вывода и устранения повреждения;
3) Если обрабатывается файл с поврежденным блоком, то поврежденный блок исключается и для устранения повреждения используется новый входящий блок.
Очистка целостности данных проводится еженедельно, при этом инициируется задание, которое пытается выполнить восстановление всех повреждений, занесенных во внутренний журнал повреждений дедупликации во время операций ввода-вывода с файлами дедупликации. По необходимости очистку можно запустить вручную командой PowerShell:
Start-DedupJob E: –Type Scrubbing
Чтобы проверить целостность всех дедуплицированных данных в томе, используйте параметр -full. Этот параметр, называемый также глубокой очисткой, задает очистку всего набора дедуплицированных данных и поиск всех повреждений, приводящих к отказам в доступе к данным.
Сбор мусора (Garbage Collection) — обработка удаленных или измененных данных, т.е. удаление все блоков данных, на которые больше нет ссылок. Когда оптимизированный файл удаляется или переписывается новыми данными, старые данные в хранилище блоков не удаляются немедленно. Задания сбора мусора обрабатывают ранее удаленное или перезаписанное содержимое, чтобы освободить место на диске.

Операция сбора мусора также выполняется еженедельно. Она удаляет блоки, на которые нет ссылок, и сжимает контейнеры, содержащие более 5 % данных, на которые нет ссылок. Во время каждой десятой сборки мусора используется параметр /Full, который запускает задание по освобождению всего доступного пространства и максимально сжимает весь контейнер. Процесс сбора мусора связан с интенсивной обработкой данных, поэтому его надо либо запланировать на нерабочие часы, либо запускать вручную и отслеживать нагрузку. Сделать это можно командой:
Start-DedupJob E: –Type GarbageCollection
А если добавить ключ –full, то задание будет сжимать все контейнеры максимально возможным образом.
Задания дедупликации можно настроить в Server Manager (только оптимизацию), с помощью командлета Set-DedupShedule или в планировщике заданий, в разделе MicrosoftWindowsDeduplication. Кстати, дедупликация поддерживает только планирование недельных заданий. Если требуется создать расписание на любой другой временной период, то используйте планировщик заданий Windows. Имейте в виду, что вы не сможете просматривать расписания пользовательских заданий, созданных или измененных в планировщике заданий, с помощью командлета Get-DedupSchedule.

В принципе настройки расписания по умолчанию должны удовлетворять большинство конфигураций сервера. Однако в определенных ситуациях может потребоваться ускорение дедупликации. Например, при большом объеме входящих данных для ускорения процесса стоит добавить дополнительные задания оптимизации. Или если данные быстро удаляются и требуется возвращать свободный объем максимально оперативно, то необходимо добавить дополнительные задания сбора мусора.
Мониторинг результатов
Основные результаты дедупликации для конкретного тома можно увидеть, открыв его свойства в Server Manager. Здесь показано общее количество сэкономленного пространства и процент оптимизации. Как видите, в моем случае сжатие 76%, а экономия составила почти 32ГБ. Очень неплохо.

Несколько больше информации выдаст команда Get-DedupVolume E: | fl

Посмотреть, когда и с каким результатом прошла последняя оптимизация можно командой:
Get-DedupStatus -Volume E: | fl

Ну и подробные данные (размер хранилища блоков, средний размер блока и т.п.) покажет командлет Get-DedupMetadata.

На этом пожалуй закончу обзор. Все, что в него не уместилось можно посмотреть на Technet, лучше в оригинале (перевод ужасный). В качестве заключения скажу, что на мой взгляд дедупликация — фича интересная, но довольно неоднозначная и требующая правильного подхода и планирования.
Disk / Data Deduplication is a feature new to Windows in Server 2012 and has recently been improved in Server 2012 R2. Data Deduplication is based on the idea that if you have multiple copies of the same file you can only actually write one to disk and then just provide pointers to the copy.
Contents
- Install and enable Data Deduplication in GUI
- Enable Data Deduplication with Powershell
- Author
- Recent Posts

Jim Jones has been a SysAdmin for 15 years and is currently working as a Sr. Network Administrator in West Virginia, USA. Honored to be elected a vExpert and Veeam Vanguard, Jim can be found on Twitter @k00laidIT and at his personal site, koolaid.info.
Server 2012 takes that idea one step further to be able to recognize duplication down to the level of chunks of files (32–128 KB). Further with Windows Server 2012 R2 they have improved the performance of deduplicated volumes to allow them to be a repository for Hyper-V VHDs.
So where does this really help? The use case for this technology is obviously fileservers, specifically those that have large files that aren’t modified very often. In my case, my two biggest usages are for Veeam backup files of my virtual machines and the images within the document retention system. According to Microsoft you can expect to see space savings up to 95% on virtual hard drives, 80 on ISOs and other deployment software and 50% on basic user documents. If you have a mix of all of the above the process can save you between 50-60% of the actual data size.
Install and enable Data Deduplication in GUI
Getting started with Windows Server 2012 R2 disk deduplication is not hard but it does require a few steps. To make this easy here’s a quick run down.
- Enable the Data Deduplication Role under File and Storage Services> File and iSCSI Services.

- Enable Deduplication on a volume under Server Manager > Volumes by right clicking on the volume and choosing “Configure Data Deduplication…”

- Configure the basic settings for the volume in the window that pops up. You can mess with these depending on your particular need, but I recommend not setting the “Deduplicate files older than…” setting any lower than the default of three days. More than that can have a negative impact on your I/O load.

- Finally you can modify the schedule in which deduplication occurs. By default Windows will just allow it to run at low priority and pause when the server is busy. In our environment backups are typically done by midnight so I allow it to run at normal priority between 12 AM and 6 AM in addition to the default.





After you set Data Deduplication up you can easily monitor how it’s doing, although I would probably give it at least a day to process on a mature file server before expecting to see real results. Graphically you can look at the properties either of the volume or any folder contained with it to see how it’s doing by comparing Size versus Size on disk. Know that that will reflect not only deduplication but also any compression you may have turned on as well. As you can see from the screenshot, the results can be rather staggering.

Verfiy Data Deduplication
Further you run Get-DedupeStatus as Administrator from the PowerShell prompt to see the output of just what Data Deduplication is doing for you.
Enable Data Deduplication with Powershell
So you want to do this in a few places at once? The good news is all the configuration above can be done via PowerShell if you would like to script it. The commands below will enable the role, configure Data Deduplication on a mythical volume F:, and configure the Minimum File Age to 5 days. There are other settings possible but these should get you going for most uses.
Import-Module ServerManager Add-WindowsFeature -name FS-Data-Deduplication Import-Module Deduplication Enable-DedupVolume F: Set-Dedupvolume F: -MinimumFileAgeDays 5
For more information regarding when and where to use Data Deduplication Technet has a pretty good read on the subject.
Дата: 03.06.2016 Автор Admin
В данной статье я расскажу как легко и быстро можно настроить дедупликацию через Powershell.
1) Устанавливаем роль дедупликации.
|
Import-Module ServerManager Add-WindowsFeature -name FS-Data-Deduplication Import-Module Deduplication |
2) Включаем дедупликацию. В данном случае на диске E
|
Enable-DedupVolume E: -UsageType Default |
Если вы планируете дедуплицировать хранилище дисков виртуальных машин Hyper-v, используйте следующую команду:
|
Enable-DedupVolume E: -UsageType HyperV |
3) Задаем минимальное количество дней, после которых выполняется дедупликация файлов
|
Set-Dedupvolume E: -MinimumFileAgeDays 20 |
Если необходимо дедупликацировать файлы сразу и вам необходима максимальная дедупликация установите значение 0
4) Добавляем каталог, который не нужно дедупликацировать (если необходимо)
|
Set-DedupVolume –Volume «E:» -ExcludeFolder «E:temp» |
5) Устанавливаем минимальный размер файла
|
Set-DedupVolume –Volume «E:» -MinimumFileSize «32768» |
6) Отключаем дедупликацию используемых файлов
|
Set-DedupVolume –Volume «E:» -OptimizeInUseFiles:$False Set-DedupVolume –Volume «E:» -OptimizePartialFiles:$False |
Для просмотра текущих запущенных заданий дедупликации выполните команду:
Для просмотра существующих заданий используйте команду:
Если вы хотите добавить новое задание используйте команду — New-DedupSchedule
Ниже пример как добавить задание оптимизации:
|
New-DedupSchedule –Name «ThroughputOptimization» –Type Optimization –Days on,Tues,Wed,Thurs,Fri,Sunday –Start 00:00 –DurationHours 8 -Priority Normal |
Теперь разберем этот пример
–Name — имя нового задания
–Type тип задания (Optimization/GarbageCollection/Scrubbing)
Scrubbing — восстановление поврежденных данных
GarbageCollection — сборка мусора (высвобождение места)
Optimization — дедупликация и сжатие данных
–Days дни в которые задание должно запускаться
—Start в какое время
–DurationHours сколько часов может выполняться задание
—Priority приоритет
Для просмотра текущего статуса дедупликации используйте команду:
Вывод будет таким:
Enabled UsageType SavedSpace SavingsRate Volume
——- ——— ———- ———— ——
True Default 76.94 GB 66 % E:
В моем случае дедупликация превратила 65 GB в 354MB.
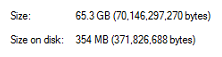
Это очень эффективно! Удачной настройки! =)
Related posts: