Оперативная память (ОЗУ) является тем компонентом персональных компьютеров, важность которого, при современной архитектуре вычислительных систем, сложно переоценить, и без которого работа их (в силу архитектурных особенностей) не представляется возможной. Было бы интересно посмотреть, как именно ОС управляет доступной ей памятью? Как она распределяет её между загруженными приложениями? Как происходит организация (создание) в памяти нового процесса, как код программы получает управление и как процессу выделяется дополнительная память по запросу, в случае, когда выделенная изначально память заканчивается? Как организовано адресное пространство процесса? Подобные вопросы возникали и продолжают возникать у многих довольно часто, но далеко не на все из них находятся вразумительные ответы.
Поскольку круг вопросов, касающихся оперативной памяти настолько велик, что не может быть освещен в одной статье, здесь мы коснемся лишь части огромного механизма управления памяти в ОС Microsoft Windows, а именно изучим адресное пространство процесса, увидим, что же размещается [системой] в пространстве памяти, выделяемой процессу.
Память (общее определение) — физическое устройство или среда для хранения данных, используемая в вычислениях в течении определенного времени.
Код приложений (программ), исполняемый в произвольный момент времени на процессоре, оперирует данными. Данные, которые в текущий момент необходимы коду для выполнения, должны быть размещены в физической (оперативной) памяти или регистрах общего назначения. Если данные размещены в памяти, то их положение нужно каким-либо образом определить — проще всего сделать это при помощи некоего числа (порядкового номера), называемым адресом [в массиве]. Иными словами, оперативную память легче всего себе представить в виде массива байт. Чтобы обратиться к конкретному байту данных (массива), или адресовать его, логично было бы использовать порядковый номер. Подобным образом можно поступить со всеми байтами, пронумеровав их целыми положительными числами, установив ноль за начало отсчёта. Индекс байта в этом огромном массиве и будет его адресом.
Адресация на уровне процессора
В первых микропроцессорах компании Intel (архитектуры x86) был доступен единственный режим работы процессора, впоследствии названный реальным режимом. Адресация памяти в процессорах того времени была достаточно простой и носила название сегментной. Суть её заключалась в том, что ячейка памяти адресовалась при помощи двух составляющих: сегмент : смещение (сегмент — область адресного пространства фиксированного размера, смещение — адрес ячейки памяти относительно начала сегмента). Специфика архитектуры упомянутых [первых] микропроцессоров накладывала ограничения на размер физического адресного пространства (16 килобайт, 64 килобайта, 1 мегабайт…), и память, доступная программно, была не более размера оперативной (физически установленной) памяти компьютера. Это было просто, логично и понятно. Тем не менее, описанная архитектура имела ряд недостатков, к тому же в индустрии появились тенденции дальнейшего развития:
- Была актуальна проблема согласования выделения памяти различным приложениям. Размещение кода/данных приложений в едином для всех программ пространстве памяти требовало от операционной системы (а иногда и от самой программы) сложного механизма постоянного отслеживания занятого пространства.
- Наметился переход к многозадачным операционным системам, в которых большое количество задач должно было выполняться [псевдо]параллельно, что затрудняло использование общего пространства памяти.
- В условиях множества одновременно выполняющихся задач встала проблема безопасности, необходимости ограничения доступа к «чужим» процессам в памяти.
Эти, а так же некоторые другие, проблемы явились отправной точкой для работы над усовершенствованием, в следствии чего в процессоре 80286 появился защищенный режим и концепция сегментной адресации памяти была значительно расширена для обеспечения новых требований. Например в защищенном режиме сегменты могли располагаться (начинаться) в памяти в произвольном месте (база), иметь нефиксированный размер (лимит), уровни доступа, типы содержимого и прочее. И наконец, по прошествии некоторого времени была создана новая архитектура, получившая название IA-32, в которой были введены несколько новых моделей организации оперативной памяти:
- Базовая плоская модель (basic flat model) — наиболее простая модель памяти [системы], операционная система и приложения получают в своё распоряжение непрерывное, не сегментированное адресное пространство.
- Защищенная плоская модель (protected flat model) — более сложная модель памяти [системы], может применяться страничный механизм изоляции пользовательского/системного кода/данных, описываются четыре сегмента: кода/данных (для уровня привилегий 3, пользовательский уровень) и кода/данных (для уровня привелегий 0, ядро).
- Мульти-сегментная модель (multi-segment Model) — самая сложная модель памяти [системы], предоставляется аппаратная защита кода, данных, программ и задач. Каждой программе (или задаче) назначаются их собственные таблицы [сегментных] дескрипторов и собственные сегменты.
И главным завоеванием защищенного режима явилось появление механизма страничной организации/адресации памяти.
Страничная организация памяти это альтернативный тип управления памятью, разработанный для обеспечения организации виртуального адресного пространства (виртуальной памяти) в многозадачных операционных системах. В отличие от сегментной адресации, которая делила адресное пространство на сегменты определенной длины, страничная адресация делит пространство на множество страниц равного размера. Изменения коснулись и принципов адресации: если в реальном режиме работы процессора пара сегментный_регистр : смещение могла адресовать ячейку памяти, то в защищенном режиме сегмент был заменен на селектор, который содержал индекс в таблице дескрипторов и биты вида таблицы дескрипторов + биты привилегий.
Механизм трансляции адресов (преобразование адреса)
Поскольку одним из нововведений защищенного режима было создание виртуальной адресации, потребовались механизм трансляции виртуальных адресов в физические, а так же механизм трансляции страниц. Именно благодаря трансляции операционная система имеет возможность создавать для каждого процесса иллюзию полноразмерного обособленного адресного пространства и обеспечивать защиту собственного ядра [от пользовательских процессов]. Адрес, по которому код программы (процесса) пытается обратиться к данным (где-то в оперативной памяти), изначально закодирован в исполняемой инструкции (пример фрагмента кода):
|
. . . cmp [edi+ecx*4+4], esi . . . |
..и проходит через некоторое количество преобразований, начиная от декодирования инструкции процессором и заканчивая выставлением адреса на шину. Давайте посмотрим, какие же этапы проходит преобразование адреса:
- Эффективный адрес — адрес, задаваемый в аргументах машинной инструкции при помощи регистров, смещений, коэффициентов. Фактически эффективный адрес представляет собой смещение от начала сегмента (базы). Как раз для нашего примера (выше): эффективный адрес = EDI + ECX * 4 + 4;
- Логический адрес – адрес, представляющий собой пару
селектор: смещение. Традиционно селектор (левая часть) располагается в сегментном регистре, смещение (правая часть) в регистре общего назначения или указывается непосредственно, для нашего примера это:DS:[EDI+ECX*4+4]. Как мы видим, часто сегментный регистр (левая часть) не указывается (выбирается неявно). Фактически с логическими адресами и имеет дело программист в своих программах; - Линейный адрес — это 32-/64-разрядный адрес, получаемый путем использования селектора (содержащегося в левой части виртуального адреса, в сегментном регистре, для нашего примера задан неявно, в
DS) в качестве индекса в таблице дескрипторов (для вычисления базы сегмента) и добавления к ней смещения (правая часть виртуального адреса, в нашем случае значение, вычисляемое на основе выражения EDI+ECX*4+4). Линейный адрес = база сегмента + эффективный адрес. - Гостевой физический адрес — при использовании аппаратной виртуализации. В случае, когда в системе работают виртуальные машины, физические адреса (получаемые в каждой из них), необходимо транслировать ещё раз.
- Физический адрес — это финальная часть преобразований адреса внутри процессора. Физический адрес:
- (для сегментной адресации) полностью совпадает с линейным адресом;
- (для сегментно-страничной адресации) получается путем преобразования трех частей значения линейного адреса на основании: каталога страниц, таблицы страниц и смещения внутри страницы;
И наконец этот получившийся физический адрес выставляется на адресную шину процессора; может как совпадать с адресом ячейки оперативной памяти, так и не совпадать с ним;
Отсюда следует, что существуют логическое, линейное и физическое адресные пространства, которые активно взаимодействуют между собой, и на совокупности которых основана адресация в современных операционных системах. Фактически, процесс преобразования адресов, используемых программистом в своей программе в адрес физической ячейки оперативной памяти, является цепочкой преобразований от первого пункта к последнему и именуется трансляцией адресов (прозрачное преобразование одного вида адреса в другой).
Механизм трансляции страниц (страничное преобразование)
Алгоритмы преобразования линейного адреса в физический (этапы 3 → 5) варьируются в зависимости от множества причин (состояния определенных регистров). В некоторых режимах линейный адрес делится на несколько частей, при этом каждая часть является индексом в специализированной системной таблице (все они расположены в памяти), а число и размер описанных таблиц различаются в зависимости от режима работы процессора. Запись в таблице первого уровня представляет собой адрес начала таблицы следующего уровня, а для последнего уровня — информация о физическом адресе страницы в памяти и её свойствах. Иначе говоря:
Страничная память — способ организации виртуальной памяти, при котором виртуальные адреса отображаются на физические постранично.
Соответственно, на данном этапе, мы уже имеем дело уже с разбиением адресного пространства на страницы (определенного размера) или со страничной организацией памяти. Иными словами, мы имеем дело с виртуальной памятью. Процессор как бы делит линейное адресное пространство на блоки (страницы) фиксированного размера (в зависимости от установок — 4Кб, 2Мб, 4Мб), которые уже могут отображаются в физической памяти или на жестком диске. И вот тут стоит обратить внимание на один крайне важный аппаратный механизм:
В произвольный момент времени та или иная страница может «находиться» (быть сопоставлена) в физической памяти, а может и не находиться в ней.
Иными словами, преобразование линейного адреса в физический может закончиться неудачей, если:
- страницы в данный момент нет в физической памяти;
- таблицы не содержат необходимых данных;
- недостаточно прав доступа;
Во всех этих случаях возникает аппаратное событие — так называемое исключение Page Fault (#PF), которое предписывает обработчику исключения произвести дополнительные действия по устранению возникшей проблемы: подгрузить (отсутствующую) страницу с диска (либо скинуть (ненужную) страницу на диск). Как только страница была подгружена, то выполнение прерванного кода продолжится с инструкции, которая вызвала #PF. Именно механизм страничной адресации (преобразования) и позволяет операционной системе организовать виртуальное адресное пространство, о котором речь пойдет далее. К сожалению, подробное описание механизмов преобразования адресов и типов адресации выходит за рамки данной статьи, далее мы переходим к «программному» уровню, то есть непосредственно к механизмам операционной системы.
Адресация на уровне ОС
Сами понимаете, что было бы не совсем корректно называть излагаемое в данной главе некоей «программной» частью адресации в операционной системе, поскольку:
Механизмы, используемые операционными системами, имеют аппаратную поддержку на уровне процессора.
..поэтому операционная система Windows эксплуатирует особенности той архитектуры, на которой она в данный момент функционирует (выполняется) и всего-лишь использует аппаратные механизмы [процессора]. Становится очевидным, что если Windows исполняется на станциях, построенных на базе процессоров архитектуры IA-32, то используется защищенный режим работы процессора. Версии операционной системы Windows для архитектуры IA-32, пользуются механизмом сегментации защищенного режима лишь в минимальном объёме:
- используются всего два уровня привилегий: 0 и 3;
- и из всех доступных способов организации памяти используется защищенная плоская модель со страничной адресацией (protected flat model);
Защищенная плоская модель в Windows имеет свои особенности: память представляется программе [задаче] в виде единого непрерывного адресного пространства (линейное адресное пространство). Код, данные и стек — всё содержатся в этом адресном пространстве, то есть объединены в один физический сегмент.
Есть соглашение, что все селекторы для процесса идентичны, это значит что адресация внутри процесса фактически базируется на смещении (а селекторы сегментов остаются неизменными). Исходя из этого, если каждый процесс [в системе] использует собственное адресное пространство линейным способом, то есть адресация базируется (фактически) на смещении, селекторы сегментов остаются неизменными, то сегментные регистры не нужны и их можно «опустить», «упразднить». На основе плоской модели памяти базируется часто упоминаемый в литературе механизм виртуальной памяти.
Виртуальная память – стратегия организации памяти [операционной системой], основанная на идее создания единого виртуального адресного [псевдо]пространства, состоящего из физической памяти (ОЗУ) и дисковой памяти (жесткий/твердотельный диск).
Возникает вопрос: почему это пространство называется виртуальным? А потому что виртуальный адрес может и не присутствовать в физической памяти, все механизмы [защищенного режима] созданы лишь для имитации (создания иллюзии для программы) его существования, ведь используются селекторы:смещения (которые могут ссылаться на любой адрес) совместно со страничным преобразованием (страницы могут быть сопоставлены с физической памятью, а могут и не быть), то есть все сущности по сути эфемерны, пользователь не знает как и где они размещены!!
Размерность адресных пространств
Не случайно во множественном числе, поскольку и эта тема несет в себе огромное количество неопределенностей и неточностей. Выше мы говорили о том, что существуют логическое, линейное и физическое адресные пространства в архитектуре процессора.
Физическое адресное пространство
Итак, размерность физического (процессорного) адресного пространства зависит от особенностей аппаратной архитектуры:
- 32-бита: используются 32-битные указатели (размерность 4 байта), и размер адресного пространства равен 232 = 4294967296 байт (4 гигабайта, Гб). Шестнадцатеричное представление диапазона: 00000000 — FFFFFFFF.
- 64-бита: используются 64-битные указатели (размерность 8 байт) и размер адресного пространства процесса равен 264 = 18446744073709551616 байт (16 экзабайт, Эб. ~17 миллиардов гигабайт). Шестнадцатеричное представление диапазона: 0000000000000000 — FFFFFFFFFFFFFFFF.
| Разрядность (битность) приложения | Разрядность указателя | Размер адресного пространства [процесса] | Адреса диапазона (шестнадцатеричные) |
|---|---|---|---|
| 32 бита | 32 бита (4 байта) | 232 (4294967296 байт = 4 гигабайта) | 00000000 — FFFFFFFF |
| 64 бита | 64 бита (8 байт) | 264 (18446744073709551616 байт = ~17 миллиардов гигабайт = 16 экзабайт) | 0000000000000000 — FFFFFFFFFFFFFFFF |
Но это, опять же, теоретическая адресация на основе разрядности.
Линейное адресное пространство
Линейное адресное пространство процесса теоретически могло бы быть идентично физическому адресному пространству, но на практике вступают в действие ограничения операционной системы, которые зависят от: версии операционной системы, [определенных] настроек (флагов) операционной системы и приложений, типа запуска: 32-битное приложение на 32-битной ОС, 32-битное приложение на 64-битной ОС, 64-битное на 64-битной ОС.
- 32-бита: размер линейного адресного пространства процесса равен 4Гб, верхние 2Гб (или 1Гб, в зависимости от флагов) из которых защищены на уровне страниц. Поэтому для пользовательского приложения в 32-битной ОС определен лимит в 2Гб (или 3, в зависимости от флагов), за пределы которого процесс выбраться не может (без использования специализированных технологий вида AWE).
- 64-бита: размер линейного адресного пространства процесса равен 16Тб или 256Тб, из которых (верхняя) часть защищена на уровне страниц. Поэтому 32/64-битному пользовательским приложениям может быть определен лимит в 2Гб, 4Гб, 8Тб и 128Тб (в зависимости от разрядности/версии/флагов).
Виртуальные адреса используются приложениями, однако сама операционная система (равно как и процессор) не способна по этим виртуальным адресам непосредственно обращаться к данным, потому как виртуальные адреса не являются адресами физического устройства хранения информации (ОЗУ/ДИСК), другими словами физически по этим адресам информация не хранится.
Для того, чтобы код, располагающийся по виртуальным адресам можно было выполнить, эти адреса должны быть отображены на физические адреса, по которым действительно могут храниться код и данные. Это особенности аппаратной архитектуры x86 (проще: так устроен центральный процессор).
Или, если выразиться иначе, выполняемый код или используемые данные должны находиться в физической памяти, только в этом случае они будут выполнены/обработаны процессором.
Еще раз: код и данные, которые в данный момент обрабатываются/исполняются, физически располагаются в ОЗУ.
Использование страничной организации операционной системой
Получается интересная ситуация: с одной стороны, для каждого процесса в операционной системе Windows выделяется адресное пространство, которое фактически эквивалентно размерности теоретического адресного пространства; с другой стороны размер физически установленной оперативной памяти (ОЗУ) компьютера может быть в разы меньше суммы всех адресных пространств процессов, исполняемых в данный момент в системе. Как нам в подобной ситуации обеспечить нормальное функционирование операционной системы? А очень просто, поскольку:
- виртуальные адреса суть иллюзия, они могут не ссылаться на физическую память;
- [в подавляющем большинстве случаев] процесс не использует всё виртуальное адресное пространство, отведенное для него; то есть адресное пространство процесса не обязательно заполнено [под завязку] данными;
- общие для всех процессов данные могут разделяться множеством процессов (экономия оперативной памяти);
- не обязательно код и данные всех процессов [постоянно] держать в ОЗУ (экономия оперативной памяти);
И в обеспечении всех этих механизмов нам на помощь приходит страничная организация (о которой говорилось выше): она позволяет операционной системе прозрачно (незаметно) для пользователя/приложения выполнять ряд очень нужных системе манипуляций:
- подгружать/выгружать неиспользуемые страницы с/на носитель информации (жесткий диск: HDD, SSD);
- проецировать общие страницы [общих ключевых библиотек] в несколько адресных пространств одновременно;
Страницы, которые в определенный промежуток времени не используются, из ОЗУ переносятся (перепроецируются) на любой физический носитель, установленный в системе — в файл (файл подкачки, страничный файл, page file, swap-файл, «своп») либо [в некоторых ОС] в область подкачки (специализированный раздел).
Сопоставлением (отображением) виртуальных адресов на физические адреса ОЗУ или файла подкачки занимается так называемый диспетчер виртуальной памяти (VMM, Virtual Memory Manager).
Диспетчер виртуальной памяти (Virtual memory manager, Kernel-mode memory manager) — модуль ядра ОС Windows, предназначающийся для организации подсистемы виртуальной памяти: создания таблицы адресов для процессов, организации общего доступа к памяти, осуществления защиты на уровне страниц, поддержки возможность отображения файлов на память, распределения физической памяти между процессами, организации выгрузки/загрузки страниц между физической памятью и файлом подкачки, обеспечения всех процессов достаточным для функционирования объемом физической памяти.
Упрощенная схема процесса «отображения» выглядит следующим образом:

Схема действительно упрощена, поскольку на деле в процессе сопоставления участвует множество структур: таблица указателей на каталог страниц, каталог страниц, таблица страниц. Как видно из нашего рисунка, виртуальные адреса могут проецироваться на физическую намять, файл подкачки или любой файл, располагающийся в файловой системе. На основе приведенной схемы мы может сделать довольно-таки важный вывод:
Виртуальное адресное пространство создается для каждого процесса, работающего в операционной в системе и напрямую не связано с адресацией физической памяти (ОЗУ).
и теперь вы, надеюсь, понимаете, что:
Виртуальный адрес может быть просто не сопоставлен с физической памятью!!
Получается, что у виртуальных страниц адреса одни, аппаратные страницы выделяются по мере необходимости из имеющихся в наличии свободных страниц физической памяти, и, понятное дело, что физические адреса будут случайными и, в большинстве случаев, не будут совпадать с виртуальными. Напомню, что синхронизация между виртуальными и физическими страницами памяти обеспечивается аппаратно (на уровне процессора), называется страничным преобразованием и была нами описана выше. Наиболее значимые особенности виртуальной памяти таковы:
- Виртуальная память, доступная программе, напрямую не связана с физической памятью.
- Каждая программа работает в своей виртуальном адресном пространстве. Размер этого пространства может быть больше размера фактически установленной в машине оперативной памяти.
- Адресное пространство [каждого] процесса (программы), исполняющегося в ОС, изолировано [от подобных адресных пространств других процессов].
Когда какая-либо программа обращается к своим данным, которые [в этот момент] отсутствуют в ОЗУ, то функция обработчика страничного нарушения диспетчера виртуальной памяти производит следующие манипуляции:
- сохраняет в стек адрес инструкции, следующей за инструкцией, вызвавшей #PF;
- производит поиск свободной (незанятой) физической страницы;
- создает новый элемент в таблице страниц;
- подгружает недостающие данные из файла подкачки в ОЗУ;
- производит проецирование виртуальной страницы на физическую;
- производит восстановление адреса из стека и выполняет «перезапуск» инструкции (следующей за той, на которой было прервано выполнение);
Все эти процессы происходят на уровне ядра операционной системы, поэтому они «прозрачны» или «неразличимы» для пользовательского приложения (а программисту, в реалиях высокоуровневого программирования, зачастую и вовсе не интересны).
Теперь несколько слов об изоляции или закрытости [адресного пространства] процесса. Виртуальное пространство [каждого] процесса изолировано, или, можно сказать по-другому — процессы отделены друг от друга в своем собственном виртуальном адресном пространстве. Поэтому любой поток в рамках некоего процесса получает доступ только лишь к той памяти, которая принадлежит родительскому процессу. Наглядно, изолированность выражается в том, что некая программа A в своем адресном пространстве может хранить запись данных по условному адресу 12345678h, и в то же время у программы B по абсолютно тому же адресу 12345678h (но уже в его собственном адресном пространстве) могут находиться совершенно другие данные. Изолированность, к тому же подразумевает, что код одной программы (если быть точным, то потока в рамках процесса) не может получить доступ к памяти другой программы (без дополнительных манипуляций). Достоинства виртуальной памяти:
- Упрощается программирование. Программисту больше не нужно учитывать ограниченность памяти, или согласовывать использование памяти с другими приложениями.
- Повышается безопасность. Адресное пространство процесса изолировано.
- Однородность массива. Адресное пространство линейно.
[пример] Виртуальное адресное пространство процесса
Я думаю, после некоторого количества теоретических выкладок, самое время перейти ближе к рассмотрению основной темы статьи. Напомню, что мы будем исследовать структуру памяти 32-битного процесса Windows. Для исследования памяти процесса нам потребуется специализированное программное средство, которое поможет нам увидеть адресное пространство процесса в деталях. Использовать мы будем утилиту VMMap от Марка Руссиновича, отличное приложение, которое выводит подробную информацию по использованию памяти в рамках того или иного процесса. Однако, не обошлось, что называется, и без ложки дегтя. Бытует мнение, что данное ПО отражает карту процесса не достаточно подробно, игнорируя кое-какие структуры памяти, однако, как отправная точка для понимания принципов размещения объектов в памяти вполне нас устроит.
Для практического эксперимента я буду использовать самописный модуль test2.exe, написанный на ассемблере, код которого предельно прост, отображает всего-лишь некоторые оконные элементы и выводит информационное окно перед выходом. В модуле используются (импортируются) функции SetFocus, SendMessageA, MessageBoxA, CreateWindowExA, DefWindowProcA, DispatchMessageA, ExitProcess, GetMessageA, GetModuleHandleA, LoadCursorA, LoadIconA, PostQuitMessage, RegisterClassA, ShowWindow, TranslateMessage, UpdateWindow из библиотек user32.dll и kernel32.dll. Итак, запускаем на исполнение тестовый файл test2.exe а затем, пока приложение исполняется, загружаем программу VMMap, указывая ей открыть наш целевой процесс. Вот что мы наблюдаем:

Поскольку информации довольно много, к карте процесса потребуется небольшое пояснение. И хотя это и не статья, описывающая функционал утилиты VMMap, однако мы должны осветить некоторые ключевые моменты, потому как без знаний о заголовках столбцов и видах типов регионов мы в изучении далеко не продвинемся.
| Наименование столбца | Описание |
|---|---|
| Address | Стартовый адрес региона в виртуальном пространстве процесса. Шестнадцатеричное представление. |
| Type | Тип региона (см. таблицу далее). |
| Size | Полный размер выделенной области. Отражает максимальный размер физической памяти, которая необходима для хранения региона. Так же включает зарезервированные области. |
| Committed | Количество памяти региона, которое «отдано», «передано» или «зафиксировано» — то есть эта память уже связана с ОЗУ, страничным файлом [подкачки], или с отображенным файлом (mapped file) [на диске]. |
| Private | Часть всей памяти, выделенной для региона, которая приватна, то есть принадлежит исключительно процессу-владельцу и не может быть разделена с другими процессами. |
| Total WS | Общее количество физической памяти, выделенной для региона (ОЗУ + файл подкачки). |
| Private WS | Приватная часть физической памяти [региона/файла]. Принадлежит исключительно владельцу и не может быть разделена (использована совместно) с другими процессами. |
| Shareable WS | Общедоступная часть физической памяти [региона/файла]. Может быть использована совместно другими процессами, которым так же необходим данный регион (файл). |
| Shared WS | Общедоступная часть физической памяти [региона/файла]. Уже используется совместно с другими процессами. |
| Locked WS | Часть физической памяти [региона/файла], которая гарантированно находится в ОЗУ и не вызывает ошибок страниц (необходимость подгрузки из файла подкачки), когда к ней пытаются получить доступ. |
| Blocks | Количество выделенных в регионе блоков памяти. Блок — неразрывная группа страниц с идентичными атрибутами защиты, сопоставленная с одним регионом физической памяти. Если Вы посмотрите внимательно то заметите, что значения параметра «Blocks», отличные от нуля, встречаются в регионах, которые разбиты на несколько частей (подрегионы, блоки). Обычно имеется несколько подрегионов: основной регион + резервные. |
| Protection | Типы операций, которые могут быть применены к региону. Для регионов, которые подразделяются на подблоки (+), колонка указывает общую (сводную) информацию по типам защиты в подблоках. В случае применения к региону неразрешенного типа операций, возникает «Ошибка доступа». Ошибка доступа происходит в случаях: когда происходит попытка запустить код из региона, который не помечен как исполняемый (если DEP включена), или при попытке записи в регион, который не помечен как предназначенный для записи или для «копирования-при-записи» (copy-on-write), или в случае попытки доступа к региону, который маркирован как «нет доступа» или просто зарезервирован, но не подтвержден. Атрибуты защиты присваиваются регионам виртуальной памяти на основе атрибутов сопоставленных регионов физической памяти. |
| Details | Дополнительная информация по региону. Тут могут отображаться: путь файла бэкапа, идентификатор кучи (для региона heap), идентификатор потока (для стека), указатель на .NET-домен и прочее. |
WS (Working Set) — так называемый рабочий набор, то есть множество (массив) страниц физической памяти (ОЗУ), уже выделенных для процесса и использующихся для фактического хранения кода/данных. Когда требуется доступ к каким-либо адресам виртуальной памяти, фактически с этими адресами должна быть связана физическая память (потому что операции чтения/записи/выполнения могут производиться только с физической памятью). Поэтому, когда с данными адресами будет сопоставлена физическая память, она добавляется как раз к рабочему набору процесса (working set).
Ну и необходимо описать все виды типов (type) регионов. Типы регионов у можно наблюдать на карте процесса в столбце Type:
| Тип региона | Описание |
|---|---|
| Free | Диапазон виртуальных адресов не сопоставленных с физической памятью. Это память, которая еще не занята. Регион или часть региона доступны для резервирования (выделения). |
| Shareable | Регион, который может быть разделен с другими процессами и забекаплен в физической памяти либо файле подкачки. Подобные регионы обычно содержат данные, которые разделены между процессами, то есть используются несколькими программами, через общие, специально оформленные, секции DLL или другие объекты. |
| Private Data | Частные данные. Это регион, выделенный через функцию VirtualAlloc. Эта часть памяти не управляется менеджером кучи (Heap Manager), функциями .NET и не выделяется стеку. Обычно содержит данные приложения, которые используются только нашей программой и не доступны другим процессам. Так же содержит локальные структуры процесса/потока, такие как PEB или TEB. Типичная «память программы». Регион сопоставлен со страничным файлом. |
| Unusable | Виртуальная память, которая не может быть использована из-за фрагментации. Это осколки, которые уже закреплены за регионом. Гранулярность выделения памяти в Windows — регионы по 64Кб. Когда Вы пытаетесь выделить память с помощью функции VirtualAlloc и запрашиваете, к примеру 8 килобайт, VirtualAlloc возвращает адрес региона в 64 килобайта. Оставшиеся 56Кб помечаются как неиспользуемые (unusable). Обратите внимание на то, что области Unusable «следуют» в карте за не кратными 64Кб регионами, на самом же деле, это всего-лишь память, которая входит в регион (принадлежит региону-владельцу), но на данный момент не используется. |
| Image | Регион сопоставлен с образом исполняемого EXE- или DLL-файла, проецируемого в память. Это именно тот регион, куда загружается образ пользовательского приложения со всеми его секциями (в нашем случае test2.exe). |
| Image (ASLR) | Образы системных библиотек, загружаемые с использованием механизма безопасности ОС под названием ASLR (Address Space Layout Randomization). ASLR — рандомизация расположения в адресном пространстве процесса таких структур как: образ исполняемого файла, подгружаемая библиотека, куча и стек. Вкратце, ОС игнорирует предпочитаемый базовый адрес загрузки, который задан в заголовке PE и загружает библиотеку в адрес по выбору «менеджера загрузки». Для поддержки ASLR, библиотека должна быть скомпилирована со специализированной опцией, либо без неё, когда используется принудительная рандомизация (ForceASLR). Таким образом, усиливается безопасность процесса и исключаются конфликты базовых адресов образов [подгружаемых модулей]. Применяется начиная с Windows Vista. Технология так же известна под псевдонимом Rebasing. |
| Thread Stack | Стек. Регион сопоставлен со стеком потока. Каждый поток имеет свой собственный стек, соответственно под каждый поток выделяется регион для хранения его собственного стека. Когда в процессе создается новый поток, система резервирует регион адресного пространства для стека потока. Для чего обычно используется стек? Ну как и все стеки, стек потока предназначается для хранения локальных переменных, содержимого регистров и адресов возврата из функций. |
| Mapped File | Проецируемые файлы. Это немного не то же, что «проецирование» образа самой программы и необходимых библиотек. Все отображаемые в адресное пространство процесса файлы могут быть трех видов: самой программой, библиотеками, и рабочими объектами. Проецируемые (mapped) файлы это и есть вот эти самые рабочие объекты, которые может создавать и использовать код программы. Обычно это файлы, которые содержат какие-либо требующиеся приложению данные и с которыми приложение работает напрямую. Проецирование файлов — наиболее удобный способ обработки внешних данных, поскольку данные из файла становятся доступны непосредственно в адресном пространстве процесса (регион памяти сопоставлен с файлом или частью файла), а на самом деле они размещаются на диске. Таким образом программе файл доступен в виде большого массива, нет необходимости писать собственный код загрузки файла в память, на лицо экономия на операциях ввода-вывода и операциях с блоками памяти. ОС делает всё это прозрачно для разработчика, собственными механизмами, получается для кода область проецируемых файлов — это обычная память. Проецируемые файлы предназначены для операций с файлами из кода основной программы, ведь рано или поздно подобные операции с файлами приходится использовать практически во всех проектах, и зачастую это влечет за собой большое количество дополнительной работы, поскольку пользовательское приложение должно уметь работать с файлами: открывать, считывать и закрывать файлы, переписывать фрагменты файла в буфер и оттуда в другую область файла. В Windows все подобные проблемы решаются как раз при помощи проецируемых в память файлов (memory-mapped files). Проецируемый в память файл может иметь имя и быть разделяемым, то есть совместно использоваться несколькими приложениями. Работа с проецируемыми файлами в пользовательском режиме обеспечивается функциями CreateFileMapping и MapViewOfFile. |
| Heap (Private Data) | Куча. Это регион зарезервированного адресного пространства процесса, предназначенный для динамического распределения небольших областей памяти. Представляет из себя закрытую область памяти, которая управляется так называемым «Менеджером кучи» (Heap Manager). Данные в этой области хранятся «в куче» (или «свалены в кучу»), то есть друг за другом, разнородные, без какой-либо систематизации. Смысл кучи сводится к обработке множества запросов на создание/уничтожение множества мелких объектов (блоков памяти). Куча используется различными функциями WinAPI, вызываемыми кодом Вашего приложения, либо функциями самого приложения, для выделения различных временных буферов хранения строк, переменных, структур, объектов. Память в куче выделяется участками (индексами), которые имеют фиксированный размер (8 байт). |
Как Вы видите из карты процесса, всё адресное пространство процесса разбито на множество неких зон различного назначения, называемых регионами. Регионов в адресном пространстве достаточно много. Однако, для начала, давайте посмотрим на «общее» разбиение адресного пространства процесса, дабы возникло понимание, как что и где может размещаться. Разбиение адресного пространства в определенной степени зависит от версии ядра Windows.
Общая концепция разбиения виртуального адресного пространства 32-битных программ:
| Начало | Конец | Размер | Описание |
|---|---|---|---|
| 00000000 | 0000FFFF | 64Кб | Область нулевых указателей. Зарезервировано. Данная область всегда маркируется как свободная (Free). Попытка доступа к памяти по этим адресам вызывает генерацию исключения нарушения доступа STATUS_ACCESS_VIOLATION. Область применяется для выявления программистами некорректных, нулевых указателей, тем самым позволяя выявлять некорректно работающий код. Если по каким-то причинам (напр.: возврат значения функцией) переменная или регистр вдруг принимает нулевое (неинициализированное) значение, то дальнейшая попытка обращения к памяти (запись/чтение) с использованием данной переменной/регистра приведет к генерации исключения (напр.: mov eax, dword ptr [esi], где ESI=0). |
| 00010000 | 7FFEFFFF | 2Гб (3Гб) | Пользовательский режим (User mode). Пользовательская часть кода и данных. В это пространство загружается пользовательское приложение, с разбивкой по секциям. Отображаются все проецируемые в память файлы, доступные данному процессу. В этом пространстве создаются пользовательская часть стеков потоков приложения. Тут присутствуют основные системные библиотеки ntdll.dll, kernel32.dll, user32.dll, gdi32.dll. |
| 7FFF0000 | 7FFFFFFF | 64Кб | Область некорректных указателей. Зарезервировано. Данная область всегда маркируется как свободная (Free). Попытка доступа к памяти по этим адресам вызывает генерацию исключения нарушения доступа STATUS_ACCESS_VIOLATION. Хотя эта область формально и относится к области памяти пользовательского режима, она является «пограничной», то есть имеется риск при операциях с большими блоками памяти выйти за границы пользовательского режима и перезаписать данные режима ядра, поэтому Microsoft предпочла заблокировать доступ к данной области. Область применяется для выявления некорректных (вышедших за пределы пользовательской памяти) указателей (переменные/регистры) в коде (например: mov eax, dword ptr [esi], где ESI=значение, входящее в диапазон 7FFF0000-7FFFFFFF). |
| 80000000 | FFFFFFFF | 2Гб (1Гб) | Режим ядра (Kernel mode). Код и данные модулей ядра, код драйверов устройств, код низкоуровневого управления потоками, памятью, файловой системой, сетевой подсистемой. Размещается кеш буферов ввода/вывода, области памяти, не сбрасываемые в файл подкачки. Таблицы, используемые для контроля страниц памяти процесса (PTE?). В этом пространстве создаются ядерная часть стеков для каждого потока в каждом процессе. Пространство недоступно из пользовательского режима, и попытка обращения из кода режима пользователя приведет к исключению нарушения доступа. Пространство «общее», то есть идентично (одинаково) для всех процессов системы. |
Ну, регионы мы бегло рассмотрели, давайте разберемся, как же происходит построение адресного пространства для конкретного процесса? Ведь должен существовать в системе механизм выделения и заполнения регионов. Все начинается с того, что пользователь либо некий код инициируют выполнение исполняемого модуля (программы). Одни из примеров подобного действия может быть двойной щелчок в проводнике по имени исполняемого файла. В этом случае код инициирующего выполнение потока вызывает функцию CreateProcess либо родственную из набора функций, предназначающихся для создания нового процесса. Какие же действия выполняет ядро после вызова данной функции:
- Находит исполняемый файл (.exe), указанный в параметре функции CreateProcess. В случае каких проблем просто возвращает управление со статусом false.
- Создает новый объект ядра «процесс».
- Создает адресное пространство процесса.
- Во вновь созданном адресном пространстве резервирует регион (набор страниц). Размер региона выбирается с расчетом, чтобы в него мог уместиться исполняемый .exe-файл. Загрузчик образа смотрит на параметр заголовка .exe-файла, который указывает желательное расположение (адрес) этого региона. По-умолчанию =
00400000, однако может быть изменен при компиляции. - Отмечает, что физическая память, связанная с зарезервированным регионом это сам .exe-файл на диске.
- После окончания процесс проекции .exe-файла на адресное пространство процесса, система анализирует секцию import directory table, в которой представлен список DLL-библиотек (которые содержат функции необходимые коду исполняемого файла) и список самих функций.
- Для каждой найденной DLL-библиотеки производится «отображение», то есть вызывается функция LoadLibrary, которая выполняет следующие действия:
- Резервирует регион в адресном пространстве процесса. Размер выбирается таковым, чтобы в регион мог поместиться загружаемый DLL-файл. Желаемый адрес загрузки DLL указывается в заголовке. Если размер региона по желаемому адрес меньше размера загружаемого DLL, либо регион занят, ядро пытается найти другой регион.
- Отмечает, что физическая память, связанная с зарезервированным регионом это DLL-файл на диске.
- Производится настройка образа библиотеки, сопоставление функций. Результатом этого является заполненная таблица (массив) адресов импортируемых функций, чтобы в процессе работы код обращается к своему массиву для определения точки входа в необходимую функцию.
Очевидно, что в момент создания процесса, адресное пространство практически все свободно (незарезервировано). Поэтому, для того, что бы воспользоваться какой-либо частью адресного пространства, надо эту самую часть для начала выделить (зарезервировать) посредством специализированных функций.
Резервирование (reserving) — операция выделения региона (выделения блока памяти по те или иные нужды).
Резервирование региона происходит вместе с выравниванием начала региона с учетом так называемой гранулярности (зависит от процессора, 64Кб). При резервировании обеспечивается дополнительно еще и кратность размера региона размеру страницы (зависит от процессора, 4Кб), поэтому если вы пытаетесь зарезервировать регион некратной величины, система округлит значение до ближайшей большей кратной величины.
Страница (page) — минимальная единица [объема памяти], используемая системой при управлении памятью (как мы и писали выше).
Размещение в адресном пространстве структур и библиотек
Далее по тексту я буду приводить описание непосредственно регионов памяти, делая цветовую маркировку для удобства сопоставления типа региона фактически размещаемым данным.
| Адрес | Модуль | Описание | ||||||
|---|---|---|---|---|---|---|---|---|
| 00040000 | apisetschema.dll | Предназначена для организации и разделения на уровни выполнения огромного количества функций базовых DLL системы. Подобная технология была названа «Наборами API» (API Sets), появилась в Windows 7 и предназначалась для группировки всех [многочисленных] функций в 34 различных типа и уровня выполнения, с целью предотвратить циклические зависимости между модулями и минимизировать проблемы с производительностью, которые обусловлены обеспечением зависимости новых DLL от набора Win32 API в адресном пространстве процесса. Перенаправляет вызовы, адресованные базовым DLL к их новым копиям, разделенным на уровни. | ||||||
| 00050000 | Стек потока | [64-битный] стек потока. | ||||||
| 00090000 | Стек потока. | Одномерный массив элементов с упорядоченными адресами (организованный по принципу «последний пришел — первым ушел» (LIFO)), предназначенный для хранения небольших объемов данных фиксированного размера (слово/двойное слово/четверное слово): стековых фреймов, передаваемых в функцию аргументов, локальных переменных функций, временно сохраняемых значений регистров. Для каждого потока выделяется собственный (отдельный) стек. Каждый раз при создании нового потока в контексте процесса, система резервирует регион адресного пространства для стека потока и передает данному региону определенный объем [физической] памяти. Для стека система резервирует 1024Кб (1Мб) адресного пространства и передает ему всего две страницы (2х8Кб?) памяти. Но перед фактическим выполнением потока система устанавливает указатель стека на конец верхней страницы региона стека, это именно та страница, с которой поток начнет использовать свой стек. Вторая страница сверху называется сторожевой (guard page). Как только активная страница «переполняется», поток вынужден обратиться к следующей (сторожевой) странице. В этом случае система уведомляется о данном факте и передает память еще одной странице, расположенной непосредственно за сторожевой. После чего флаг PAGE_GUARD переходит к странице, которой только что была передана память. Благодаря описанному механизму объем памяти стека увеличивается исключительно по мере необходимости. | ||||||
| 00280000 | msctf.dll.mui | Файл локализации библиотеки msctf.dll, описанной ниже. В общем смысле представляет собой переведенные на русский язык текстовые строки/константы, используемые библиотекой. | ||||||
| 00400000 | test2.exe | Собственно образ нашей программы. Отображается в виртуальном адресном пространстве благодаря системному механизму проецирования файлов. Исполняемый .exe-файл проецируется на адресное пространство программы по определенным адресам и становится его частью. Проецирование состоит в том, что данные [из файла] не копируются в память, а как бы связываются с данными на физическом носителе, то есть любое обращение к памяти по этим адресам инициирует чтение данных с диска, память как бы «читается» из файла на диске. Виртуальный адрес 00400000 является «предпочитаемой базой образа» (Image base), константой, которую можно изменять при компиляции. По традиции, никто этим не заморачивается, и, в большинстве случаев, данный адрес актуален для подавляющего большинства программ (но встречаются и исключения).
Не путайте «базу образа» (image base) с «точкой входа» (entry point). Вторая представляет из себя адрес, с которого начинается исполнение кода программы. Обычно лежит по некоторому смещению относительно «базы образа». Образ исполняемого файла (test2.exe) содержит в себе секции. Данный факт можно подтвердить, раскрыв (+) содержимое образа. Объясняется это тем, что exe-файл состоит из множества частей: непосредственно секция кода, секция данных, секция ресурсов, констант. Все эти секции загрузчик размещает по собственным областям памяти и назначает различные атрибуты доступа. |
||||||
| 00410000 | locale.nls | NLS предоставляет поддержку местной раскладки клавиатуры и шрифтов. NLS позволяет приложениям устанавливать локаль для пользователя и получать (отображать) местные значения времени, даты, и других величин, отображаемых в формате региональных настроек. | ||||||
| 01F80000 | SoftDefault.nls | |||||||
| 02250000 | StaticCache.dat | |||||||
| 735A0000 | uxtheme.dll | Тема оформления. Функционал библиотеки позволяет менять визуальное представление интерфейса (вид многочисленных элементов управления) программ без необходимости менять базовый (в ядре) функционал операционной системы. | ||||||
| 73A30000 | comctl.dll | Библиотека реализует готовые элементы управления (контролы), которые используются в графическом интерфейсе. | ||||||
| 74B20000 | dwmapi.dll | Интерфейс диспетчера окон рабочего стола (DWM, Desktop Windows Manager). DWM — графический интерфейс рабочего стола, использующийся в Windows Aero. Управляет объединением различных выполняющихся и визулизируемых окон с рабочим столом. В своей программе я никаких специфических функций Windows Aero не использую, но, могу предположить, что образ библиотеки dwmapi.dll отображается на адресное пространство процесса по причине включенного на уровне системы интерфейса Aero. | ||||||
| 751F0000 75250000 752D0000 | wow64win.dll wow64.dll wow64cpu.dll | В адресном пространстве процесса по данным адресам находятся библиотеки DLL пользовательского режима, отвечающие за работу подсистемы Wow64. Они появились в нашем адресном пространстве не случайно, поскольку, напомню, что наш 32-разрядный процесс test2.exe запущен в 64-разрядной ОС Windows 7 Professional.
Wow64 (Windows 32-bit on Windows 64-bit) — эмуляция Win32 приложений на 64-разрядной ОС Windows. Представляет из себя программную среду, позволяющую исполнять 32-разрядные приложения на 64-разрядной версии Windows. Механизм используется в 64-разрядных версиях Windows в виде набора библиотек DLL пользовательского режима. Помимо данных библиотек в 64-разрядной версии ОС присутствует поддержка со стороны ядра (изменение контекста). Перехватывает системные вызовы 32-битных версий ntdll.dll и user32.dll, поступающих от 32-битных приложений и транслирует их в 64-битные вызовы ядра. С помощью Wow64 создаются 32-разрядные версии структур данных для процесса, например
|
||||||
| 75500000 | msctf.dll | Библиотека расширяет функционал, предоставляемый службами Microsoft для работы с текстом (Microsoft Text Services). Среди функций библиотеки имеются функции усовершенствованной текстовой обработки и ввода текста. Функционал библиотеки msctf.dll предоставляет двунаправленный обмен между приложением и службами работы с текстом. Предоставляет поддержку различных языков. | ||||||
| 75810000 | msvcrt.dll | Microsoft Visual C++ Runtime. Библиотека времени выполнения языка C, обеспечивающая вспомогательные функций для работы с памятью, устройствами ввода/вывода, математическими функциями. Довольно много прототипов функций, используемых в языках C/C++ содержится в данной библиотеке. | ||||||
| 758C0000 | gdi32.dll | Одна из четырех основных библиотек поддержки Win32 API. Часть интерфейса графического устройства (GDI, Graphics Device Interface) или интерфейса между приложениями и графическими драйверами видеокарты, работающая в режиме пользователя. Содержит функции и методы для представления графических объектов и вывода их на устройство отображения, отвечает за отрисовку линий, кривых, обработку палитры и управление шрифтами, можно сказать полностью отвечает на графику. Приложения посылают запросы коду GDI, работающему в режиме пользователя, который пересылает их GDI режима ядра, а тот уже перенаправляет данные запросы драйверам графического адаптера. Моя программа [напрямую] не импортирует функции из gdi32.dll напрямую, однако библиотека проецируется в адресное пространство любого процесса, использующего оконный интерфейс. | ||||||
| 75A80000 | advapi32.dll | Одна из четырех основных библиотек поддержки Win32 API. Содержит большое количество часто востребованных функций: работа с реестром, сервисами, выключение (перезагрузка) ПК, и прч. В системе присутствует огромное количество библиотек, которые статически слинкованы с библиотекой advapi32.dll. Поэтому, без проецирования её в адресное пространство процесса никак не обойтись. | ||||||
| 76С00000 | kernel32.dll | Одна из четырех основных библиотек поддержки Win32 API. В библиотеке содержатся основные подпрограммы для поддержки работы подсистемы Win32. Много ключевых процедур и функций, которые используются в пользовательских программах, содержатся в библиотеке kernel32.dll. Это работа с процессами (GetModuleHandle, GetProcAddress, ExitProcess), вводом-выводом, памятью, синхронизацией. Ранее kernel32.dll загружался во всех контекстах процесса по одному и тому же адресу. Теперь, думаю именно из-за ASLR, в адресному пространстве каждого процесса он загружается по разным адресам? Большинство экспортируемых библиотекой kernel32.dll функций используют «родной» API ядра напрямую. | ||||||
| 77070000 | user32.dll | Одна из четырех основных библиотек поддержки Win32 API. Эта библиотека проецируется практически в каждый процесс Win32. Библиотека содержит часто используемые функции для обработки сообщений, меню, взаимодействия. Напомню, что в моей программе используются такие функции как: SetFocus, SendMessage, MessageBox, CreateWindowEx, DefWindowProcA, DispatchMessageA, GetMessageA, LoadCursorA, LoadIconA, PostQuitMessage, RegisterClassA, ShowWindow, TranslateMessage, UpdateWindow. Все эти функции предоставляются системной библиотекой user32.dll, поэтому без проецирования её в адресное пространство моего процесса моя программа (test2.exe) работать не будет. | ||||||
| 771F0000 | kernelbase.dll | Результат технологии разделения на уровни выполнения базовых функций DLL. Содержит так называемые низкоуровневые функции, которые ранее помещались в библиотеках kernel32.dll и advapi32.dll. Теперь код направляет запросы к этой библиотеке низкоуровневых функций, вместо того, чтобы, как раньше, выполнять их напрямую. | ||||||
| 77C00000 | ntdll.dll | Библиотека, обеспечивающая «родной» интерфейс (Native API) функций ядра как для приложений раннего этапа загрузки ОС, так и для функций интерфейса WinAPI. Все функции подсистемы Win32 можно разделить на две части: функции, требующие перехода в режим ядра и функции не требующие перехода в режим ядра. Для обработки API-функций пользовательского режима, которые требуют перехода в режим ядра и существует библиотека ntdll.dll. По своей структуре ntdll.dll представляет собой обычную библиотеку пользовательского режима, представляющую собой своеобразный «мост» (переходник) между функциями библиотек пользовательского режима и кодом, который реализует соответствующий функционал в ядре. Пользовательский режим (user mode) и режим ядра (kernel mode) существенно отличаются в реализации, однако пользовательский режим должен максимально сохранять совместимость с привычными (старыми) форматами входных/выходных данных функций, в то время как режим ядра может потребовать существенного видоизменения кода от версии Windows к версии. С этой точки зрения, ntdll.dll играет роль интерфейса совместимости, именно благодаря ему разработчики Microsoft могут свободно менять [при выпуске новых версий/пакетов обновлений Windows] внутреннюю реализацию функций в ядре, сохраняя, при этом, формат параметров функций пользовательского режима. Можно сказать, что Native API создан с единственной целью — вызывать функции ядра, код которого располагается в нулевом кольце защиты. Большинство точек входа в Native API являются «заглушками», которые передают параметры и управление коду режима ядра. | ||||||
| 77DE0000 | ntdll.dll | То же самое, что и описанный ntdll.dll, только для 32-битного процесса. | ||||||
| 7EFDB000 | TEB |
Блок переменных окружения потока (Thread Environment Block). Структура данных, размещаемая в адресном пространстве процесса, которая содержит информацию о конкретном потоке в пределах основного (текущего) процесса (в нашем случае — test2.exe). Каждый поток имеет свой TEB. Заполняется через функцию MmCreateTeb и заполняется загрузчиком потока. Создается, контролируется и разрушается исключительно самой ОС. Подобные регионы создаются и уничтожаются по мере появления/уничтожения потоков в процессе. Wow64 процессы имеют два TEB для каждого потока? | ||||||
| 7EFDE000 | PEB |
Блок переменных окружения процесса (Process Environment Block). Структура данных, размещенная в адресном пространстве процесса, которая содержит информацию о загруженных модулях (LDR_DATA), окружении, базовой информации и другие данные, которые требуются для нормального функционирования процесса. Создается через функцию MmCreatePeb и заполняется загрузчиком процесса на этапе создания адресного пространства процесса. PEB создается, контролируется и уничтожается исключительно самой ОС. Wow64 процессы имеют два PEB для каждого процесса? | ||||||
| 80000000 | Ядро | Память выше данного значения принадлежит ядру. В этой области памяти находятся модули ядра, объекты ядра и пользовательские объекты, доступные всем процессам — проекции системных файлов. Но это все уже тема отдельной статьи. |
Выводы
К каким выводам можно придти после изучения адресного пространства процесса? Первый состоит в том, что понятие «памяти» для пользовательских программ это достаточно условное обозначение, поскольку регионы адресного пространства могут по разному отображаться на различные объекты операционной системы. Второй состоит в том, что адресное пространство процесса это огромный линейный массив байтов, в котором хранится всё, с чем непосредственно работает процесс (программа). Массив этот виртуален, не ограничен физической памятью, уникален для каждого приложения и обладает достаточной размерностью, дабы программист не задумывался о его ограничениях. Механизм создания адресного пространства процесса достаточно сложен, и в статье удалось рассмотреть лишь малую часть его логики. В добавок, мы вовсе не касались 64-битных реалий, грозно смотрящих на нас из недалекого будущего  но, пожалуй это тема отдельной статьи.
но, пожалуй это тема отдельной статьи.
Методы
распределения памяти, при которых задаче
уже может не предоставляться сплошная
(непрерывная) область памяти, называют
разрывными.
Идея выделять память задаче не одной
сплошной областью, а фрагментами,
позволяет уменьшить фрагментацию
памяти, однако этот подход требует для
своей реализации больше ресурсов, он
намного сложнее. Если задать адрес
начала текущего фрагмента программы и
величину смещения относительно этого
начального адреса, то можно указать
необходимую нам переменную или команду.
Таким образом, виртуальный адрес можно
представить состоящим из двух полей.
Первое поле будет указывать на ту часть
программы, к которой обращается процессор,
для определения местоположения этой
части в памяти, а второе поле виртуального
адреса позволит найти нужную нам ячейку
относительно найденного базового
адреса. Программист может либо
самостоятельно разбивать программу на
фрагменты, либо можно автоматизировать
эту задачу, возложив ее на систему
программирования.
Сегментный способ
организации виртуальной памяти
Первым
среди разрывных методов распределения
памяти был сегментный.
Для этого метода программу необходимо
разбивать на части и уже каждой такой
части выделять физическую память.
Естественным способом разбиения
программы на части является разбиение
ее на логические элементы – так называемые
сегменты.
В принципе, каждый программный модуль
(или их совокупность, если это необходимо)
может быть воспринят как отдельный
сегмент, и вся программа тогда будет
представлять собой множество сегментов.
Каждый сегмент размещается в памяти
как до определенной степени самостоятельная
единица. Логически обращение к элементам
программы в этом случае будет состоять
из имени сегмента и смещения относительно
начала этого сегмента. Физически имя
(или порядковый номер) сегмента будет
соответствовать некоторому адресу, с
которого этот сегмент начинается при
его размещении в памяти, и смещение
должно прибавляться к этому базовому
адресу.
Преобразование
имени сегмента в его порядковый номер
осуществит система программирования.
Для каждого сегмента система
программирования указывает его объем.
Он должен быть известен операционной
системе, чтобы она могла выделять ему
необходимый объем памяти. Операционная
система будет размещать сегменты в
памяти и для каждого сегмента она должна
вести учет местонахождения этого
сегмента. Вся информация о текущем
размещении сегментов задачи в памяти
обычно сводится в таблицу
сегментов,
чаще такую таблицу называют
таблицей дескрипторов сегментов задачи.
Каждая задача имеет свою таблицу
сегментов.
Таким
образом, виртуальный адрес для этого
способа будет состоять из двух полей –
номера сегмента и смещения относительно
начала сегмента. Соответствующая
иллюстрация приведена на рис. 20 для
случая обращения к ячейке, виртуальный
адрес которой равен сегменту с номером
11 со смещением от начала этого сегмента,
равным 612. Как видно на рисунке, операционная
система разместила данный сегмент в
памяти, начиная с ячейки с номером 19700.

Рис.
20. Сегментный способ организации
виртуальной памяти (числа шестнадцатеричные)
Итак,
каждый сегмент, размещаемый в памяти,
имеет соответствующую информационную
структуру, часто называемую дескриптором
сегмента.
Именно операционная система строит для
каждого исполняемого процесса
соответствующую таблицу дескрипторов
сегментов, и при размещении каждого из
сегментов в оперативной или внешней
памяти отмечает в дескрипторе текущее
местоположение сегмента. Если сегмент
задачи в данный момент находится в
оперативной памяти, то об этом делается
пометка в дескрипторе. Как правило, для
этого используется бит
присутствия
Р
(от слова «present»). В этом случае в поле
адреса диспетчер памяти записывает
адрес физической памяти, с которого
сегмент начинается, а в поле длины
сегмента (limit) указывается количество
адресуемых ячеек памяти. Это поле
используется не только для того, чтобы
размещать сегменты без наложения друг
на друга, но и для того, чтобы контролировать,
не обращается ли код исполняющейся
задачи за пределы текущего сегмента. В
случае превышения длины сегмента
вследствие ошибок программирования
можно говорить о нарушении адресации
и с помощью введения специальных
аппаратных средств генерировать сигналы
прерывания, которые позволят фиксировать
(обнаруживать) такого рода ошибки.
Если
бит присутствия в дескрипторе указывает,
что сегмент находится не в оперативной,
а во внешней памяти (например, на жестком
диске), то названные поля адреса и длины
используются для указания адреса
сегмента в координатах внешней памяти.
Помимо
информации о местоположении сегмента,
в дескрипторе сегмента, как правило,
содержатся данные о его типе (сегмент
кода или сегмент данных), правах доступа
к этому сегменту (можно или нельзя его
модифицировать, предоставлять другой
задаче), отметка об обращениях к данному
сегменту (информация о том, как часто
или как давно этот сегмент используется
или не используется, на основании которой
можно принять решение о том, чтобы
предоставить место, занимаемое текущим
сегментом, другому сегменту).
При
передаче управления следующей задаче
операционная система должна занести в
соответствующий регистр (на рис. 20 –
регистр таблицы сегментов) адрес таблицы
дескрипторов сегментов этой задачи.
Сама таблица дескрипторов сегментов,
в свою очередь, также представляет собой
системный сегмент данных, который
обрабатывается диспетчером памяти
операционной системы.
При
таком подходе появляется возможность
размещать в оперативной памяти не все
сегменты задачи, а только задействованные
в данный момент. Благодаря этому, с одной
стороны, общий объем виртуального
адресного пространства задачи может
превосходить объем физической памяти
компьютера, на котором эта задача будет
выполняться. С другой стороны, даже если
потребности в памяти не превосходят
имеющуюся физическую память, можно
размещать в памяти больше задач, поскольку
любой задаче, как правило, все ее сегменты
единовременно не нужны. А увеличение
коэффициента
мультипрограммирования,
как известно, позволяет увеличить
загрузку системы и более эффективно
использовать ресурсы вычислительной
системы. Очевидно, однако, что увеличивать
количество задач можно только до
определенного предела, ибо если в памяти
не будет хватать места для часто
используемых сегментов, то производительность
системы резко упадет. Ведь сегмент,
находящийся вне оперативной памяти,
для участия в вычислениях должен быть
перемещен в оперативную память. При
этом если в памяти есть свободное
пространство, то необходимо всего лишь
найти нужный сегмент во внешней памяти
и загрузить его в оперативную память.
А если свободного места нет, придется
принять решение — на место какого из
присутствующих сегментов будет
загружаться требуемый. Перемещение
сегментов из оперативной памяти на
жесткий диск и обратно часто называют
свопингом
сегментов.
Итак,
если требуемого сегмента в оперативной
памяти нет, то возникает прерывание, и
управление через диспетчер памяти
передается программе загрузки сегмента.
Пока происходит поиск сегмента во
внешней памяти и загрузка его в
оперативную, диспетчер памяти определяет
подходящее для сегмента место. Возможно,
что свободного места нет, и тогда
принимается решение о выгрузке
какого-нибудь сегмента и выполняется
его перемещение во внешнюю память. Если
при этом еще остается время, то процессор
передается другой готовой к выполнению
задаче. После загрузки необходимого
сегмента процессор вновь передается
задаче, вызвавшей прерывание из-за
отсутствия сегмента. Всякий раз при
считывании сегмента в оперативную
память в таблице дескрипторов сегментов
необходимо установить адрес начала
сегмента и признак присутствия сегмента.
При
поиске свободного места используется
одна из вышеперечисленных дисциплин
работы диспетчера памяти (применяются
правила «первого подходящего» и «самого
неподходящего» фрагментов). Если
свободного фрагмента памяти достаточного
объема нет, но, тем не менее, сумма этих
свободных фрагментов превышает требования
по памяти для нового сегмента, то в
принципе может быть применено «уплотнение
памяти». В идеальном случае размер
сегмента должен быть достаточно малым,
чтобы его можно было разместить в
случайно освобождающихся фрагментах
оперативной памяти, но достаточно
большим, чтобы содержать логически
законченную часть программы с тем, чтобы
минимизировать межсегментные обращения.
Для
решения проблемы замещения (определения
того сегмента, который должен быть либо
перемещен во внешнюю память, либо просто
замещен новым) используются следующие
дисциплины (их называют «дисциплинами
замещения»):
– правило
FIFO (First In First Out — первый пришедший первым
и выбывает);
– правило
LRU (Least Recently Used — дольше других
неиспользуемый);
– правило
LFU (Least Frequently Used — реже других используемый);
– случайный
(random) выбор сегмента.
Первая
и последняя дисциплины являются самыми
простыми в реализации, но они не учитывают,
насколько часто используется тот или
иной сегмент, и, следовательно, диспетчер
памяти может выгрузить или расформировать
тот сегмент, к которому в самом ближайшем
будущем будет обращение. Безусловно,
достоверной информация о том, какой из
сегментов потребуется в ближайшем
будущем, в общем случае быть не может,
но вероятность ошибки для этих дисциплин
многократно выше, чем у второй и третьей,
в которых учитывается информация об
использовании сегментов.
В
алгоритме FIFO с каждым сегментом
связывается очередность его размещения
в памяти. Для замещения выбирается
сегмент, первым попавший в память. Каждый
вновь размещаемый в памяти сегмент
добавляется в хвост этой очереди.
Алгоритм учитывает только время
нахождения сегмента в памяти, но не
учитывает фактическое использование
сегментов. Например, первые загруженные
сегменты программы могут содержать
переменные, требующиеся на протяжении
всей ее работы. Это приводит к немедленному
возвращению к только что замещенному
сегменту.
Для
реализации дисциплин LRU и LFU необходимо,
чтобы процессор имел дополнительные
аппаратные средства. Минимальные
требования — достаточно, чтобы при
обращении к дескриптору сегмента для
получения физического адреса, с которого
сегмент начинает располагаться в памяти,
соответствующий бит
обращения
менял свое значение (скажем, с нулевого,
которое устанавливает операционная
система, в единичное). Тогда диспетчер
памяти может время от времени просматривать
таблицы дескрипторов исполняющихся
задач и собирать для соответствующей
обработки статистическую информацию
об обращениях к сегментам. В результате
можно составить список, упорядоченный
либо по длительности простоя (для
дисциплины LRU), либо по частоте использования
(для дисциплины LFU).
Более подробно
алгоритмы замещения рассмотрены ниже
в подразделе, посвященном страничному
способу организации виртуальной памяти.
Важнейшей
проблемой, которая возникает при
организации мультипрограммного режима,
является защита памяти. Для того чтобы
выполняющиеся приложения не смогли
испортить саму операционную систему и
другие вычислительные процессы,
необходимо, чтобы доступ к таблицам
сегментов с целью их модификации был
обеспечен только для кода самой ОС. Для
этого код операционной системы должен
выполняться в некотором привилегированном
режиме, из которого можно осуществлять
манипуляции дескрипторами сегментов,
тогда как выход за пределы сегмента в
обычной прикладной программе должен
вызывать прерывание по защите памяти.
Каждая прикладная задача должна иметь
возможность обращаться только к
собственным и к общим сегментам.
При
сегментном способе организации
виртуальной памяти появляется несколько
интересных возможностей.
Во-первых,
при загрузке программы на исполнение
можно размещать ее в памяти не целиком,
а «по мере необходимости». Действительно,
поскольку в подавляющем большинстве
случаев алгоритм, по которому работает
код программы, является разветвленным,
а не линейным, то в зависимости от
исходных данных некоторые части
программы, расположенные в самостоятельных
сегментах, могут быть не задействованы;
значит, их можно и не загружать в
оперативную память.
Во-вторых,
некоторые программные модули могут
быть разделяемыми. Поскольку эти
программные модуля являются сегментами,
относительно легко организовать доступ
к таким общим сегментам. Сегмент с
разделяемым кодом располагается в
памяти в единственном экземпляре, а в
нескольких таблицах дескрипторов
сегментов исполняющихся задач будут
находиться указатели на такие разделяемые
сегменты.
Однако
у сегментного способа распределения
памяти есть и недостатки. Прежде всего
(см. рис. 20), для доступа к искомой ячейке
памяти приходится тратить много времени.
Сначала необходимо найти и прочитать
дескриптор сегмента, а уже потом,
используя полученные данные о
местонахождении нужного сегмента,
вычислить конечный физический адрес.
Для того чтобы уменьшить эти потери,
используется кэширование – те дескрипторы,
которые используются в данный момент,
могут быть размещены в сверхоперативной
памяти (специальных регистрах, размещаемых
в процессоре).
Несмотря
на то, что рассмотренный способ
распределения памяти приводит к
существенно меньшей фрагментации
памяти, нежели способы с неразрывным
распределением, фрагментация остается.
Кроме того, много памяти и процессорного
времени теряется на размещение и
обработку дескрипторных таблиц. Ведь
на каждую задачу необходимо иметь свою
таблицу дескрипторов сегментов. А при
определении физических адресов приходится
выполнять операции сложения, что требует
дополнительных затрат времени.
Поэтому
следующим способом разрывного размещения
задач в памяти стал способ, при котором
все фрагменты задачи имеют одинаковую
длину, причем эта длина должна быть
кратна степени двойки, чтобы операции
сложения можно было заменить операциями
конкатенации (слияния). Это – страничный
способ организации виртуальной памяти.
Примером
использования сегментного способа
организации виртуальной памяти является
операционная система OS/2 первого
поколения, которая была создана для
персональных компьютеров на базе
процессора i80286. В этой операционной
системе в полной мере использованы
аппаратные средства микропроцессора,
который специально проектировался для
поддержки сегментного способа
распределения памяти.
OS/2
v.1 поддерживала распределение памяти,
при котором выделялись сегменты программы
и сегменты данных. Система позволяла
работать как с именованными, так и с
неименованными сегментами. Имена
разделяемых сегментов данных имели ту
же форму, что и имена файлов. Процессы
получали доступ к именованным разделяемым
сегментам, используя их имена в специальных
системных вызовах. Операционная система
OS/2 v.1 допускала разделение программных
сегментов приложений и подсистем, а
также глобальных сегментов данных
подсистем. Вообще, вся концепция системы
OS/2 была построена на понятии разделения
памяти: процессы почти всегда разделяют
сегменты с другими процессами. В этом
состояло существенное отличие системы
OS/2 от систем типа UNIX, которые обычно
разделяют только реентерабельные
программные модули между процессами.
Сегменты,
которые активно не использовались,
могли выгружаться на жесткий диск.
Система восстанавливала их, когда в
этом возникала необходимость. Так как
все области памяти, используемые
сегментом, должны были быть непрерывными,
OS/2 перемещала в основной памяти сегменты
таким образом, чтобы максимизировать
объем свободной физической памяти.
Такое переразмещение сегментов называется
уплотнением памяти (компрессией).
Программные сегменты не выгружались,
поскольку они могли просто перезагружаться
с исходных дисков. Области в младших
адресах физической памяти, которые
использовались для запуска DOS-программ
и кода самой OS/2, в компрессии не
участвовали. Кроме того, система или
прикладная программа могла временно
фиксировать сегмент в памяти с тем,
чтобы гарантировать наличие буфера
ввода-вывода в физической памяти до тех
пор, пока операция ввода-вывода не
завершится.
Если
в результате компрессии памяти не
удавалось создать необходимое свободное
пространство, то супервизор выполнял
операции фонового плана для перекачки
достаточного количества сегментов из
физической памяти, чтобы дать возможность
завершиться исходному запросу.
Механизм
перекачки сегментов использовал файловую
систему для выгрузки данных из физической
памяти и обратно. Ввиду того что перекачка
и компрессия влияли на производительность
системы в целом, пользователь мог
сконфигурировать систему так, чтобы
эти функции не выполнялись. Было
организовано в OS/2 и динамическое
присоединение обслуживающих программ.
Программы OS/2 используют команды
удаленного вызова. Ссылки, генерируемые
этими вызовами, определяются в момент
загрузки самой программы или ее сегментов.
Такое отсроченное определение ссылок
называется динамическим присоединением.
Загрузочный формат модуля OS/2 представляет
собой расширение формата загрузочного
модуля DOS. Он был расширен, чтобы
поддерживать необходимое окружение
для свопинга сегментов с динамическим
присоединением. Динамическое присоединение
уменьшает объем памяти для программ в
OS/2, одновременно делая возможными
перемещения подсистем и обслуживающих
программ без необходимости повторного
редактирования адресных ссылок к
прикладным программам.
Страничный способ
организации виртуальной памяти
Как
уже упоминалось, при страничном способе
организации виртуальной памяти все
фрагменты программы, на которые она
разбивается (за исключением последней
ее части), получаются одинаковыми.
Одинаковыми полагаются и единицы памяти,
которые предоставляются для размещения
фрагментов программы. Эти одинаковые
части называют страницами
и говорят, что оперативная память
разбивается на физические страницы, а
программа – на виртуальные страницы.
Часть виртуальных страниц задачи
размещается в оперативной памяти, а
часть – во внешней. Обычно место во
внешней памяти, в качестве которой в
абсолютном большинстве случаев выступают
накопители на магнитных дисках (поскольку
они относятся к быстродействующим
устройствам с прямым доступом), называют
файлом подкачки
или страничным
файлом (paging
file). Иногда этот файл называют swap-файлом,
тем самым подчеркивая, что записи этого
файла – страницы – замещают друг друга
в оперативной памяти. В некоторых
операционных системах выгруженные
страницы располагаются не в файле, а в
специальном разделе дискового пространства
(в Unix-системах, например, для этих целей
выделяется специальный раздел, но кроме
него могут быть использованы и файлы,
выполняющие те, же функции, если объёма
раздела недостаточно).
Разбиение
всей оперативной памяти на страницы
одинаковой величины, причем кратной
степени двойки, приводит к тому, что
вместо одномерного адресного пространства
памяти можно говорить о двухмерном.
Первая координата адресного пространства
– это номер страницы, вторая координата
– номер ячейки внутри выбранной страницы
(его называют индексом). Таким образом,
физический адрес определяется парой
(Pp,
i), а виртуальный адрес – парой (Рv,
i), где Рv
– номер виртуальной страницы, Pp
– номер физической страницы, i – индекс
ячейки внутри страницы. Количество
битов, отводимое под индекс, определяет
размер страницы, а количество битов,
отводимое под номер виртуальной страницы,
– объем потенциально доступной для
программы виртуальной памяти. Отображение,
осуществляемое системой во время
исполнения, сводится к отображению Рv
в Pp
и приписыванию к полученному значению
битов адреса, задаваемых величиной i.
При этом нет необходимости ограничивать
число виртуальных страниц числом
физических, то есть не поместившиеся
страницы можно размещать во внешней
памяти, которая в данном случае служит
расширением оперативной.
Для
отображения виртуального адресного
пространства задачи на физическую
память, как и в случае сегментного
способа организации, для каждой задачи
необходимо иметь таблицу
страниц (таблицу дескрипторов страниц)
для трансляции адресных пространств.
Для описания каждой страницы диспетчер
памяти операционной системы заводит
соответствующий дескриптор, который
отличается от дескриптора сегмента
прежде всего тем, что в нем нет поля
длины – ведь все страницы имеют одинаковый
размер. По номеру виртуальной страницы
в таблице дескрипторов страниц текущей
задачи находится соответствующий
элемент (дескриптор). Если бит присутствия
имеет единичное значение, значит данная
страница размещена в оперативной, а не
во внешней памяти, и мы в дескрипторе
имеем номер физической страницы,
отведенной под данную виртуальную. Если
же бит присутствия равен нулю, то в
дескрипторе мы будем иметь адрес
виртуальной страницы, расположенной
во внешней памяти. Таким образом и
осуществляется трансляция виртуального
адресного пространства на физическую
память. Этот механизм трансляции
иллюстрирует рис. 21.
Защита страничной
памяти, как и в случае сегментного
механизма, основана на контроле уровня
доступа к каждой странице. Как правило,
возможны следующие уровни доступа:
– только
чтение;
– чтение
и запись;
– только
выполнение.
Каждая
страница снабжается соответствующим
кодом уровня доступа. При трансформации
логического адреса в физический
сравнивается значение кода разрешенного
уровня доступа с фактически требуемым.
При их несовпадении работа программы
прерывается.
При
обращении к виртуальной странице, не
оказавшейся в данный момент в оперативной
памяти, возникает прерывание, и управление
передается диспетчеру памяти, который
должен найти свободное место. Обычно
предоставляется первая же свободная
страница. Если свободной физической
страницы нет, то диспетчер памяти по
одной из вышеупомянутых дисциплин
замещения (LRU, LFU, FIFO, случайный доступ)
определит страницу, подлежащую
расформированию или сохранению во
внешней памяти. На ее месте он разместит
новую виртуальную страницу, к которой
было обращение из задачи, но которой не
оказалось в оперативной памяти.

Рис.
21. Страничный способ организации
виртуальной памяти (числа шестнадцатеричные)
Для
решения проблемы замещения могут быть
использованы биты обращения и изменения
(модификации). Большинство компьютеров
с виртуальной памятью поддерживают два
статусных бита, связанных с каждой
страницей. Бит R (Referenced – обращения)
устанавливается всякий раз, когда
происходит
обращение
к странице (чтение или запись). Бит М
(Modified – изменение) устанавливается,
когда страница записывается (то есть
изменяется). Биты содержатся в каждом
элементе таблицы страниц. Важно
реализовать обновление этих битов при
каждом обращении к памяти, поэтому
необходимо, чтобы они задавались
аппаратно. Если однажды бит был установлен
в 1, то он остается равным 1 до тех пор,
пока операционная система программно
не вернет его в состояние 0. Если данные
биты поддерживаются, то они являются
частью дескриптора страницы (на рис. 21
не показаны).
Биты
R и M могут использоваться для построения
простого алгоритма замещения страниц
NRU (не использовавшаяся в последнее
время страница), описанного ниже.
Когда
процесс запускается, оба страничных
бита для всех его страниц операционной
системой установлены на 0. Периодически
(например, при каждом прерывании по
таймеру) бит R очищается, чтобы отличить
страницы, к которым давно не происходило
обращения, от тех, на которые были ссылки.
Когда
возникает страничное прерывание,
операционная система проверяет все
страницы и делит их на четыре категории
на основании текущих значений битов R
и M:
Класс 0: не было
обращений и изменений.
Класс 1: не было
обращений, страница изменена.
Класс 2: было
обращение, страница не изменена.
Класс 3: произошло
и обращение, и изменение.
Хотя
класс 1 на первый взгляд кажется
невозможным, такое случается, когда у
страницы из класса 3 бит R сбрасывается
во время прерывания по таймеру. Прерывания
по таймеру не стирают бит М, потому что
эта информация необходима для того,
чтобы знать, нужно ли переписывать
страницу на диске или нет. Поэтому если
бит R устанавливается на ноль, а М остается
нетронутым, страница попадает в класс
1.
Алгоритм
NRU удаляет страницу с помощью случайного
поиска в непустом классе с наименьшим
номером. В этом алгоритме подразумевается,
что лучше выгрузить измененную страницу,
к которой не было обращений, по крайней
мере, в течение одного тика системных
часов, чем стереть часто используемую
страницу. Привлекательность алгоритма
NRU заключается в том, что он легок для
понимания, умеренно сложен в реализации
и дает производительность, которая,
конечно, не оптимальна, но может вполне
оказаться достаточной.
Для
повышения эффективности алгоритма
FIFO, изложенного в подразделе «Сегментный
способ организации виртуальной памяти»
могут быть использованы алгоритмы
«Вторая попытка» и «Часы», которые
являются переработанными вариантами
этого алгоритма. Алгоритм «вторая
попытка» позволяет избежать проблемы
вытеснения из памяти часто используемых
страниц. У самой старейшей страницы
изучается бит R. Если он равен 0, страница
не только находится в памяти долго, она
вдобавок еще и не используется, поэтому
немедленно заменяется новой. Если же
бит R равен 1, то ему присваивается
значение 0, страница переносится в конец
списка, а время ее загрузки обновляется,
то есть считается, что страница только
что попала в память. Затем процедура
продолжается. Хотя алгоритм «вторая
попытка» является корректным, он слишком
неэффективен, потому что постоянно
передвигает страницы по списку. Поэтому
лучше хранить все страничные блоки в
кольцевом списке в форме часов. Стрелка
указывает на старейшую страницу. Когда
происходит страничное прерывание,
проверяется та страница, на которую
направлена стрелка. Если ее бит R равен
0, страница выгружается, на ее место в
круг встает новая страница, а стрелка
сдвигается вперед на одну позицию. Если
бит R равен 1, то он сбрасывается, а стрелка
перемещается к следующей странице. Этот
процесс повторяется до тех пор, пока не
находится та страница, у которой бит R
= 0. Неудивительно, что этот алгоритм
называется «часы». Он отличается от
алгоритма «вторая попытка» только своей
реализацией.
Для
реализации алгоритма LFU (редко используемая
страница) с каждой страницей связывается
счетчик, устанавливаемый операционной
системой в 0 при загрузке страницы в
память. Во время каждого прерывания по
таймеру ОС просматривает все дескрипторы
страниц и для каждой страницы прибавляет
к значению счетчика значение бита
обращения R,
после чего сбрасывает бит R
в 0. При страничном прерывании для
замещения выбирается страница с
наименьшим значением счетчика.
Недостатком
представленного выше метода является
то, что он «никогда ничего не забывает»,
т.е. активно использовавшаяся ранее
страница продолжает иметь большое
значение счетчика и после того, как
перестала использоваться.. Небольшая
доработка алгоритма снимает указанную
проблему. Этот алгоритм известен под
названием «старение» (aging). Изменение
состоит из двух частей. Во-первых, каждый
счетчик сдвигается вправо на один разряд
перед прибавлением бита R. Во-вторых,
бит R добавляется в крайний слева, а не
в крайний справа бит счетчика. Когда
происходит страничное прерывание,
удаляется та страница, чей счетчик имеет
наименьшую величину. Ясно, что счетчик
страницы, к которой не было обращений,
скажем, за четыре тика, будет начинаться
с четырех нулей и, таким образом, иметь
более низкое значение, чем счетчик
страницы, на которую не ссылались в
течение только трех тиков часов.
Подробнее
с алгоритмами замещения страниц можно
ознакомиться в разделе «Алгоритмы
замещения страниц» главы «Управление
памятью» книги «Современные операционные
системы» Э. Таненбаума.
Е
4 байта
сли объем физической памяти небольшой
и даже часто требуемые страницы не
удается разместить в оперативной памяти,
возникает так называемая «пробуксовка».
Другими словами, пробуксовка
– это ситуация, при которой загрузка
нужной страницы вызывает перемещение
во внешнюю память той страницы, с которой
мы тоже активно работаем. Очевидно, что
это очень плохое явление. Чтобы его не
допускать, желательно увеличить объем
оперативной памяти (сейчас это просто,
поскольку стоимость модуля оперативной
памяти многократно снизилась), уменьшить
количество параллельно выполняемых
задач или прибегнуть к более эффективным
дисциплинам замещения.
Для
абсолютного большинства современных
операционных систем характерна дисциплина
замещения страниц LRU как самая эффективная.
Так, именно эта дисциплина используется
в OS/2 и в Linux. Однако в операционных
системах Windows NT/2000/XP разработчики, желая
сделать их максимально независимыми
от аппаратных возможностей процессора,
отказались от этой дисциплины и применили
правило FIFO. А для того, чтобы хоть как-то
компенсировать неэффективность правила
FIFO, была введена «буферизация» тех
страниц, которые должны быть записаны
в файл подкачки на диск (в системе Windows
NT файл с выгруженными виртуальными
страницами носит название PageFile.sys) или
просто расформированы. Принцип буферизации
прост. Прежде чем замещаемая страница
действительно окажется во внешней
памяти или просто расформированной,
она помечается как кандидат на выгрузку.
Если в следующий раз произойдет обращение
к странице, находящейся в таком «буфере»,
то страница никуда не выгружается и
уходит в конец списка FIFO. В противном
случае страница действительно выгружается,
а на ее место в «буфер» попадает следующий
«кандидат». Величина такого «буфера»
не может быть большой, поэтому эффективность
страничной реализации памяти в Windows
NT/2000/XP, намного ниже, чем в других
операционных системах, и явление
пробуксовки начинается даже при
существенно большем объеме оперативной
памяти.
Как
и в случае с сегментным способом
организации виртуальной памяти,
страничный механизм приводит к тому,
что без специальных аппаратных средств
он существенно замедляет работу
вычислительной системы. Поэтому обычно
используется кэширование страничных
дескрипторов. Наиболее эффективным
механизмом кэширования является
ассоциативный кэш. Именно такой
ассоциативный кэш и создан в 32-разрядных
микропроцессорах i80x86. Начиная с i80386,
который поддерживает страничный способ
распределения памяти, в этих микропроцессорах
имеется кэш на 32 страничных дескриптора.
Поскольку размер страницы в этих
микропроцессорах равен 4 Кбайт, возможно
быстрое обращение к памяти размером
128 Кбайт.
Основным
достоинством страничного способа
распределения памяти является минимальная
фрагментация. Поскольку на каждую задачу
может приходиться по одной незаполненной
странице, очевидно, что память можно
использовать достаточно эффективно.
Другим очевидным преимуществом
страничного способа по сравнению с
сегментным является ускорение
преобразовании виртуального адреса в
физический за счет замены операции
суммирования на конкатенацию.
Этот
метод организации виртуальной памяти
был бы одним из самых лучших, если бы не
два следующих обстоятельства.
Первое
– это то, что страничная трансляция
виртуальной памяти требует существенных
накладных расходов. В самом деле, таблицы
страниц нужно тоже размещать в памяти.
Кроме того, эти таблицы нужно обрабатывать;
именно с ними работает диспетчер памяти.
Второй
существенный недостаток страничной
адресации заключается в том, что программы
разбиваются на страницы случайно, без
учета логических взаимосвязей, имеющихся
в коде. Это приводит к тому, что
межстраничные переходы, как правило,
осуществляются чаще, нежели межсегментные,
и к тому, что становится трудно организовать
разделение программных модулей между
выполняющимися процессами.
Для
того чтобы избежать второго недостатка,
постаравшись сохранить достоинства
страничного способа распределения
памяти, был предложен еще один способ
– сегментно-страничный. Правда, за счет
увеличения накладных расходов на его
реализацию.
Способы подкачки
страниц
В
простейшей схеме страничной подкачки
в момент запуска процессов нужные им
страницы отсутствуют в памяти. Как
только центральный процессор пытается
выбрать первую команду, он получает
страничное прерывание, побуждающее
операционную систему перенести в память
страницу, содержащую первую инструкцию.
Обычно следом быстро происходят
страничные прерывания для глобальных
переменных и стека. Через некоторое
время в памяти скапливается большинство
необходимых процессу страниц, и он
приступает к работе с относительно
небольшим количеством ошибок из-за
отсутствия страниц. Этот метод называется
подкачкой
страниц по запросу
(demand paging), потому что страницы загружаются
в память по требованию, а не заранее.
Конечно,
достаточно легко написать тестовую
программу, систематически читающую все
страницы в огромном адресном пространстве,
вызывая так много страничных прерываний,
что будет не хватать памяти для их
обработки. К счастью, большинство
процессов не работают таким образом.
Они характеризуются локальностью
обращений, означающей, что во время
выполнения любой фразы процесс обращается
только к сравнительно небольшой части
своих страниц. Каждый проход многоходового
компилятора, например, обращается только
к части от общего количества страниц,
и каждый раз к другой части.
В
ряде операционных систем с пакетным
режимом работы для борьбы с пробуксовкой
используется метод «рабочего набора».
Рабочий
набор
— это множество «активных» страниц
задачи за некоторый интервал Т, то есть
тех страниц, к которым было обращение
за этот интервал времени. Реально
количество активных страниц задачи (за
интервал Т) все время изменяется, и это
естественно, но, тем не менее, для каждой
задачи можно определить среднее
количество ее активных страниц. Это
количество и есть рабочий набор задачи.
Наблюдения за исполнением множества
различных программ показали, что даже
если интервал Т равен времени выполнения
всей работы, то размер рабочего набора
часто существенно меньше, чем общее
число страниц программы. Таким образом,
если операционная система может
определить рабочие наборы исполняющихся
задач, то для предотвращения пробуксовки
достаточно планировать на выполнение
только такое количество задач, чтобы
сумма их рабочих наборов не превышала
возможности системы.
Если
рабочий набор целиком находится в
памяти, процесс будет работать, не
вызывая большого количества ошибок, до
тех пор пока он не перейдет к другой
фазе выполнения (то есть к следующему
проходу компилятора). Если доступная
память слишком мала для того, чтобы
содержать полный рабочий набор, процесс
вызовет много страничных прерываний и
будет работать медленнее, так как
выполнение инструкции занимает несколько
наносекунд, а чтение страницы с диска
обычно требует 10 мс.
Многие
системы со страничной организацией
пытаются отслеживать рабочий набор
каждого процесса и обеспечивают его
нахождение в памяти до его запуска.
Такой подход носит название модели
рабочего набора. Он разработан для того,
чтобы значительно снизить процент
страничных прерываний. Загрузка страниц
перед тем, как разрешить процессу
работать, также называется опережающей
подкачкой страниц
(pre-paging). Следует заметить, что рабочий
набор изменяется с течением времени.
Чтобы
реализовать модель рабочего набора,
необходимо, чтобы операционная система
отслеживала, какие страницы в нем
находятся. Наличие этой информации
также немедленно приводит к возможному
алгоритму замещения страниц: когда
происходит страничное прерывание,
ищется и выгружается страница, не
находящаяся в рабочем наборе. Для
реализации такого алгоритма нужен
точный метод определения того, какая
страница находится в рабочем наборе, а
какая в него не включена в любой заданный
момент времени.
Применяемый
в большинстве случаев подход заключается
в использовании времени выполнения
программы. Рабочий набор определяется
как множество страниц, использовавшихся
в течение последних, например, 100 мс
времени выполнения. Заметим, что для
каждого процесса считается только его
собственное время работы. Таким образом,
если процесс стартовал во время Т и
занял процессор на 40 мс за реальное
время Т+100 мс, для определения рабочего
набора его время равно 40 мс. Время работы
процессора, которое фактически использовал
процесс с момента запуска, часто
называется текущим
виртуальным временем.
При таком приближении рабочий набор
процесса – это множество страниц, к
которому он обращался за последние τ
секунд виртуального времени.
Рассмотрим
алгоритм замещения страниц, основанный
на рабочем наборе. Его базовая идея
заключается в том, чтобы найти страницу,
не включенную в рабочий набор, и выгрузить
ее. На рис. 22 изображена часть таблицы
страниц.
Поскольку
в качестве кандидатов на удаление
рассматриваются только те страницы,
которые в настоящее время находятся в
памяти, отсутствующие в памяти страницы
этим алгоритмом игнорируются. Каждая
запись содержит (по крайней мере) два
элемента информации: приближенное
время, в которое страница использовалась
в последний раз, и бит R (обращения).
Алгоритм
работает следующим образом. Предполагается,
что аппаратное обеспечение устанавливает
биты R и M, как было описано выше.
Предполагается также, что периодическое
прерывание по таймеру вызывает запуск
программы, очищающей бит R при каждом
тике часов. При каждом страничном
прерывании исследуется таблица страниц
и ищется страница, подходящая для
удаления из памяти.

Рис.22.
Алгоритм «рабочий набор» (числа
шестнадцатеричные)
В
процессе обработки каждой записи
проверяется бит R. Если он равен 1, текущее
виртуальное время записывается в поле
«Время последнего использования» (Time
of last use) в таблице страниц, указывая, что
страница использовалась в тот момент,
когда произошло прерывание.
Если
бит R равен 0, это означает, что к странице
не было обращений в течение последнего
тика часов, и она может быть кандидатом
на удаление. Чтобы понять, нужно ли ее
выгружать, вычисляется ее возраст, то
есть текущее виртуальное время минус
ее время последнего использования, и
сравнивается с τ. Если возраст больше
величины τ, это означает, что страница
более не находится в рабочем наборе.
Она стирается, а на ее место загружается
новая страница. Однако сканирование
таблицы продолжается, обновляя остальные
записи.
Если
же бит R равен 0, но возраст страницы
меньше или равен времени τ, это значит,
что страница до сих пор находится в
рабочем наборе. Она временно обходится,
но страница с наибольшим возрастом
запоминается. Если проверена вся таблица,
а кандидат на удаление не найден, это
означает, что все страницы входят в
рабочий набор. В этом случае, если были
найдены одна или больше страниц с битом
R = 0, удаляется та из них, которая имеет
наибольший возраст. В худшем случае ко
всем страницам произошло обращение за
время текущего такта часов (и, следовательно,
все они имеют бит R = 1), тогда для удаления
случайным образом выбирается одна из
них, причем желательно чистая, если
такая страница существует.
Исходный
алгоритм «рабочий набор» громоздок,
так как при каждом страничном прерывании
следует проверять таблицу страниц до
тех пор, пока не определится местоположение
подходящего кандидата. Усовершенствованный
алгоритм, основанный на часовом алгоритме,
но также использующий информацию
рабочего набора, называется WSClock.
Благодаря простоте реализации и хорошей
производительности этот алгоритм широко
используется на практике. Для него
необходима структура данных в виде
кольцевого списка страничных блоков,
как в алгоритме «часы». Каждая запись,
кроме бита R (показан) и бита M (не показан),
содержит поле «время последнего
использования» из базового алгоритма
«рабочий набор».
Как
и в случае алгоритма «часы», при каждом
страничном прерывании первой проверяется
та страница, на которую указывает
стрелка. Если бит R равен 1, это значит,
что страница использовалась в течение
последнего такта часов, поэтому она не
является идеальным кандидатом на
удаление. Тогда бит R устанавливается
на 0, стрелка передвигается на следующую
страницу и для нее повторяется алгоритм.
Если
страница, на которую указывает стрелка,
имеет бит R=0, то возможны два варианта.
Если возраст страницы больше величины
τ и страница — чистая, то она не входит
в рабочий набор и на диске есть ее
действительная копия. Тогда в данный
страничный блок просто загружается
новая страница. Если, напротив, страница
«грязная», ее нельзя немедленно стереть,
так как на диске нет ее последней копии.
Чтобы избежать переключения процессов,
запись на диск включается в график
планирования, но стрелка сдвигается на
позицию, и алгоритм продолжает работу
со следующей страницей. Несмотря на то
что «грязная» страница может быть
старше, чистая находится ближе в ряду
страниц, которые можно использовать
немедленно.
Сегментно-страничный
способ организации
виртуальной
памяти
Как
и в сегментном способе распределения
памяти, программа разбивается на
логически законченные части – сегменты
– и виртуальный адрес содержит указание
на номер соответствующего сегмента.
Вторая
составляющая виртуального адреса –
смещение относительно начала сегмента
– в свою очередь может быть представлено
состоящим из двух полей: виртуальной
страницы и индекса. Другими словами,
получается, что виртуальный адрес теперь
состоит из трех компонентов: сегмента,
страницы и индекса. Получение физического
адреса и извлечение из памяти необходимого
элемента для этого способа иллюстрирует
рис. 23.
Из
рисунка сразу видно, что этот способ
организации виртуальной памяти вносит
еще большую задержку доступа к памяти.
Необходимо сначала вычислить адрес
дескриптора сегмента и прочитать его,
затем определить адрес элемента таблицы
страниц этого сегмента и извлечь из
памяти необходимый элемент и уже только
после этого можно к номеру физической
страницы приписать номер ячейки в
странице (индекс). Задержка доступа к
искомой ячейке получается, по крайней
мере, в три раза больше, чем при простой
прямой адресации. Чтобы избежать этой
неприятности, вводится кэширование,
причем кэш, как правило, строится по
ассоциативному принципу. Другими
словами, просмотры двух таблиц в памяти
могут быть заменены одним обращением
к ассоциативной памяти.

Рис.
23. Сегментно-страничный способ организации
виртуальной
памяти
Принцип
действия ассоциативного запоминающего
устройства предполагает, что каждой
ячейке памяти такого устройства ставится
в соответствие ячейка, в которой
записывается некий ключ (признак, адрес),
позволяющий однозначно идентифицировать
содержимое ячейки памяти. Сопутствующую
ячейку с информацией, позволяющей
идентифицировать основные данные,
обычно называют полем
тега.
Просмотр полей тега всех ячеек
ассоциативного устройства памяти
осуществляется одновременно, то есть
в каждой ячейке тега есть необходимая
логика, позволяющая посредством побитовой
конъюнкции найти данные по их признаку
за одно обращение к памяти (если они
там, конечно, присутствуют). Часто поле
тегов называют аргументом, а поле с
данными – функцией. В данном случае в
качестве аргумента при доступе к
ассоциативной памяти выступают номер
сегмента и номер виртуальной страницы,
а в качестве функции от этих аргументов
получается номер физической страницы.
Остается приписать номер ячейки в
странице к полученному номеру, и получить
адрес искомой команды или операнда.
Следует
оценить достоинства сегментно-страничного
способа. Разбиение программы на сегменты
позволяет размещать сегменты в памяти
целиком. Сегменты разбиты на страницы,
все страницы сегмента загружаются в
память. Это позволяет сократить число
обращений к отсутствующим страницам,
поскольку вероятность выхода за пределы
сегмента меньше вероятности выхода за
пределы страницы. Страницы исполняемого
сегмента находятся в памяти, но при этом
они могут находиться не рядом друг с
другом, а «россыпью», поскольку диспетчер
памяти манипулирует страницами. Наличие
сегментов облегчает разделение
программных модулей между параллельными
процессами. Возможна и динамическая
компоновка задачи. А выделение памяти
страницами позволяет минимизировать
фрагментацию.
Однако
поскольку этот способ распределения
памяти требует очень значительных
затрат вычислительных ресурсов и его
не так просто реализовать, используется
он редко, причем в дорогих мощных
вычислительных системах. Возможность
реализовать сегментно-страничное
распределение памяти заложена и в
семейство микропроцессоров i80x86, однако
вследствие слабой аппаратной поддержки,
трудностей при создании систем
программирования и операционной системы
практически в персональных компьютерах
эта возможность не используется.
Управление памятью ОС
Типы адресов
Три типа адресов:
-
Символьные — присваивает пользователь при написании программы на алгоритмичеком языке программирования либо ассемблере. К ним относятся имена переменных, имена функций и меток.
-
Виртуальные — вырабатывает транслятор, переводящий программу на машинный язык. Т.к. во время трансляции чаще всего неизвестно в какую область оперативной памяти будет загружена программа, то транслятор присваивает переменным и функциям виртуальные адреса (условные адреса), считая по умолчанию, что программа будет размещена с нулевого адреса.
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. У каждого процесса собственное виртуальное адресное пространство, которое ограничено разрядностью архитектуры компьютера.
-
Физические — соответствует номерам ячеек оперативной памяти в которые действительно загружены данные.
В некоторых случаях (в специализированных системах), когда заранее точно известно в какой области оперативной памяти будет выполняться программа, транслятор выдает исполняемый код сразу в физических адресах.
Существует два способа преобразования виртуальных адресов в физические:
-
Перемещающий загрузчик
0 0E 1C ------------------------- | | a | | b | | - виртуальные адреса в программе ------------------------- ------------------------------------------ | | | a | | b | | | - оперативная память ------------------------------------------ 0 038A 038A+ 038A+ 0E 0CПеремещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти в который предстоит загружать программы и информация, предоставленная транслятором об адресно-зависимых константах программы выполняет загрузку программы в память, совмещая ее с заменой виртуальных адресов физическими.
-
Динамическое преобразование
0 0E 1C ------------------------- | | a | | b | | - виртуальные адреса в программе ------------------------- ------------------------------------------ | | | a | | b | | | - оперативная память ------------------------------------------ 0 038AПрограмма загружается в оперативную память в неизменном виде в виртуальных адресах. Во время выполнения программы при каждом обращении к оперативной памяти происходит преобразование виртуального адреса в физический. Метод позволяет перемещать программу в оперативной памяти, в то же время расход на перерасчет виртуальных адресов в физические растет.
Понятие виртуальной памяти
Механизмы виртуальной памяти:
-
Overlay. Программист при написании программы с помощью транслятора разбивал процесс на части, называемые оверлеями (overlays), указывал порядок вызова оверлея и параметры, необходимые для передачи из одного оверлея в другой.
-
Swapping. Процесс переноса задачи целиком из оперативной памяти на жесткий диск и обратно.
-
Виртуальная память — совокупность программно-апаратных средств позволяющих пользователю писать программы, размер которых превосходит имеющуюся оперативную память. Для этого она решает следующие задачи:
- Размещает данные в запоминающих устройствах различного типа.
- Перемещает по мере необходимости данные между запоминающими устройствами разного типа
- Преобразует виртуальные адреса в физические (процессор)
Классификация методов управления памятью
-
###Без использования внешней памяти
-
####С фиксированными разделами
Вся оперативная память делится на разделы фиксированного размера в момент установки ОС либо ее загрузки. В один раздел может быть загружен только один процесс
-------------- ----- | ОС | 1 | 2 | ... | n | - оперативная память, n разделов = n процессов -------------- -----Процесс, запущенный на выполнение добавляется в очередь процессов, которая может быть общей или персональной для каждого раздела памяти. Для преобразования виртуальных адресов в физический используется перемещающий загрузчик, потому что процесс загружался в память один раз (и навсегда (: )
Недостатки:
- Жесткость: сколько разделов — столько процессов (не больше)
- Процесс, не помещающийся ни в одном из разделов не может быть выполнен
- Неэффективное использование: процесс не занимает память на 100%
Преимущества:
- Простота реализации
-
####С динамическими разделами
------------------- | ОС | | - оперативная память в момент загрузки ОС ------------------- ------------------ --------- | ОС | П1 | П2 | ... | Пn | - оперативная память в момент выполнения процессов (у каждого процесса свой объем памяти) ------------------ --------- ---------------------- --------------- | ОС | П1 |\| П2 | ... |\\| Пn | - оперативная память после некоторого времени выполнения процессов, ---------------------- --------------- фрагментированные области - |\|После загрузки ОС вся память является свободной (не разбитой на разделы). Каждому вновь поступившему на выполнение процессу выделяется столько памяти, сколько ему необходимо.
Недостатки:
- Фрагментация — наличие большого числа несмежных участков памяти маленького размера.
Преимущества:
- Количество одновременно запущенных процессов зависит от общего количества памяти и размера памяти процессов (увеличивается уровень мультипрограммирования)
Задачи, которые выполняет ОС в данном методе:
- Ведение таблиц свободных и занятых областей памяти
- При поступлении нового процесса анализ требований к оперативной памяти, выбор свободного раздела, загрузка в раздел процесса и корректировка таблиц свободных и занятых областей.
- (При завершении процесса) Корректировка таблиц свободных и занятых областей
-
####С перемещающими разделами
В начале работает также как и метод с динамическими разделами. В определенное время (по расписанию или при нехватке памяти) происходит дефрагментация разделов — сдвиг занятых разделов в сторону старших или младших адресов.
-
-
###С использованием внешней памяти
-
####Страничное распределение памяти
Страница — непрерывная последовательность адресов, лежащая в заданном диапазоне фиксированного размера равного степени двойки. Размер страница выбирается из размера имеющейся оперативной памяти и типа операционной системы. Процесс делится на страницы в момент запуска на выполнение и создается служебная структура называемая таблица страниц процесса. Для каждого процесса существует своя таблица страниц.
При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные — на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. Страницы не загруженные в память могут находится в файле подкачки или в исходном исполняемом файле. Таблица страниц содержит следующую служебную информациюо страницах процесса: номер виртуальной страницы, номер физической страницы, признак присутствия в оперативной памяти, права доступа к странице, признак чтения/записи страницы, признак выгружаемости страницы, признак модификации.
При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данные виртуальной страницы находятся в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же виртуальная страница в данный момент выгружена на диск, то происходит страничное прерывание, выполняющийся процесс приостанавливается и активизируется другой процесс. Программа обработки страничного проерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка происходит немедленно; если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти.
Критерии выбора страниц для выгрузки:
- Дольше всего неиспользовавшая страница
- Первая попавшаяся страница
- Страница к которой в последнее время было меньше всего обращений
В некоторых системах используется понятие рабочего множества страниц — страницы, которые чаще всего используются в процессе. После того, как выбрана страница, которая должна покинуть оперативную память, анализируется признак модификации: если вытесняемая страница с момента загрузки была модифицирована, то ее новая версия переносится на диск; если же нет, то содержимое может быть просто уничтожено.
Виртуальный адрес ------------- - | P | S | ------ | ------------- | | | | | | Таблица | | страниц | | ------------- | | ------------- | | ------------- | - | P | N | - | ------------- | | ------------- | | | | ------------------- | | Физический | | адрес | | ------------- | - | N | S | ------ ------------- P - номер виртуальной страницы N - номер физической страницы S - cмещение в пределах виртуальной страницыПри каждом обращении к виртуаьной памяти аппаратными средствами выполняется следующее действие: на основании начального адреса таблицы страниц, номера виртуальной страницы, длины записи в таблице страниц определяется адрес нужной записи в таблице, извлекается адрес физической страницы, к этому номеру присоединяется смещение.
На производительность системы со страничной организацией памяти влияет страничное прерывание.
Преимущества:
- Самое быстрое преобразование виртуального адреса в физический.
- Отсутствие фрагментации
Недостатки:
- Неэффективное использование памяти — чем больше процессор, тем больше неиспользуемых страниц.
- В одной странице хранятся и данные, и код программы
-
####Сегментное распределение памяти
Сегмент — непрерывная последовательность адресов, лежащих в заданном диапазоне переменного размера. Разбиение процесса на сегменты происходит в момент трансляции программы в машинный код.
Виды сегментов: сегмент кода, сегмент данных, сегмент стека.
Разбиение процесса на смысловые части — сегменты — позволяет дифференцировать права доступа к сегментам путем ограничения инструкций процессора, возможных для работы с данным сегментом. Сегмент кода, содрежащий какую-либо функцию может быть доступен различным процессам. При запуске процесса на выполнение ОС создает специальную информационную структуру, которая называется таблица сегментов, которая содержит описание всех сегментов текущего процесса: номер сегмента, физический адрес начала сегмента, предел (размер) сегмента, тип сегмента, признак присутствия сегмента, признак модификации, права доступа к сегменту, чтение/запись сегмента. Часть сегментов загружается в оперативную память, а часть остается на диске. при каждом обращении к оперативной памяти происходит обращение к таблице сегментов для преобразования виртуального адреса в физический. Если сегмент не загружен в память, то происходит сегментное прерывание — процесс приостанавливается и запускается другой процесс.

Каждый процесс имеет доступ к двум таблицам сегмента: LDT — локальная дескрипторная таблица, содержащая описание сегментов текущего процесса; GDT — глобальная дескрипторная таблица, содержащая описание сегментов ядра ОС. На основании номер виртуального адреса находится запись в таблице сегментов и из нее извлекается физический адрес начала сегмента, к которому прибавляется смещение — получается физический адрес.
Преимущества:
- Дифференцированные права доступа к сегментам
- Один и тот же сегмент кода может быть использован различными процессами
Недостатки:
- Медленное преобразование адреса по сравнению со страничным
- Появляется фрагментация памяти
-
####Сегментно-страничное распределение памяти
При странично-сегментной организации памяти процесс делится на сегменты в момент трансляции(все теже 3 вида сегментов), сегмент делится на страницы в момент запуска процесса на выполнение.
При сегментно-страничной организации памяти, создается 2 информационные структуры:
1) Таблица сегментов
2) Таблица страниц сегмента.Загрузка процесса выполняется постранично.
ВА — виртуальный адрес
| N | P | S |
|
|
| ——
|….|
——
| N |
——
|….|
——Виртуальный адрес при сегментно-страничной организации памяти состоит из 3х частей:
1) Номер сегмента
2) Номер виртуальной страницы
3) S — Смещение внутри виртуальной страницыПри каждом обращении к памяти аппаратными средствами выполняется:
1) В таблице сегментов находится нужная запись. В которой хранится:
* Тип сегмента
* Права доступа сегмента
* И физический адрес таблицы страниц сегмента2) Из записи извлекается физический адрес таблицы страниц, в которой находится соответсвие между виртуальной и физической страницей, кроме этих 2х полей присутсвует еще: * Признак присутвия * Признак модификации 3) Использую номер физической страницы, к операции конкатенации добавлятся смещение внутри страницы, получается физический адрес.(!) В данном методе отсутвует сегментное прерывание.
Недостатки:
1) Самое медленное преобразование виртуального адреса в физический.
2) Неэффективное использование памяти в последних страницах сегмента.Преимущесва обьединяют все преимущества страничных и сегментного способа организации памяти.
Вывод:
Все современные процессоры используют только странично-сегментную организацию памяти.
-

*** Принцип кеширования данных
Кеш - это способ организации совместного функционирования двух типов запоминающих устройств, который позволяет Уменьшить среднее время доступа за счет динамического копирования наиболее часто используемой информации.
| ------ /
| | РП | |
| ---------------- | время
| | СВЗУ | | доступа
$ | ———————— |
| | ОП | |
| ——————————— |
| | ДУ | |
. ———————————
/
РП - Регистры Процессора
СВЗУ - СверхОперативное Запоминающее Устройство
ОП - Оперативная Память
ДУ - Дисковое Устройство
--------- < Медленный канал передачи данных > ---------
| ЦП | =========================================== | ОП |
--------- > < ---------
/
|
|
|
/
---------
| СОЗУ |
---------
*Это частный случай использования кеш-памяти для уменьшения среднего времени доступа к данным, хранящимся в оперативной памяти
Если наша оперативная память адресованная, то кеш память *не адресуемма*, поэтому в кеш памяти хранится следущая информационная структура:
-----------------------------------------------------------------------------------------------
|Физический Адрес| Данные | Доп. Информация|
| Пр. Мод. | ПО |
|:---------------|:-------|:---------|:----|
Каждый запрос к оперативной памяти выполняется по следущему алгоритму:
1) проРассматривается содержимое кеш памяти с целью определения, не находятся там ли нужные нам данные
2) Если данные обнаружены, то они считываются и передаются в процессор(признак обращения изменяется)
3) Если нужных данных - нет, то они вместе со своим адресом копируются из оперативной памяти в кеш-память. Если в кеш памяти нет свободного места, то выбираются данные к которым в последний период было меньше всего обращений(для вытеснения)
4) Если вытесняемые данные были модифицированы, то они переписываются в оперативную память, если не были модифицированы, то кеш-память помечается как свободная.
5) На практике, в кеш-память вмещается не один элемент данных, а блок связанных адресов.
6) Для определения вероятности кеширования данных используется 2 принципа:
1) Принцип пространственной локальности
Если произошло обращение, по некоторому адресу, то с высокой степени вероятности в ближайщее время произойдет обращение к соседним адресам
2) Временная локальность
Если произошло обращение по некоторому адресу, то следующее обращение по этому же адресу произойдет в ближайщее время.
Аннотация: Виртуальная память. Реализация виртуальной памяти в Windows. Структура виртуального адресного пространства. Выделение памяти процессам. Дескрипторы виртуальных адресов. Трансляция адресов. Ошибки страниц. Пределы памяти.
Виртуальная память
Всем процессам в операционной системе Windows предоставляется важнейший ресурс – виртуальная память (virtual memory). Все данные, с которыми процессы непосредственно работают, хранятся именно в виртуальной памяти.
Название «виртуальная» произошло из-за того что процессу неизвестно реальное (физическое) расположение памяти – она может находиться как в оперативной памяти (ОЗУ), так и на диске. Операционная система предоставляет процессу виртуальное адресное пространство (ВАП, virtual address space) определенного размера и процесс может работать с ячейками памяти по любым виртуальным адресам этого пространства, не «задумываясь» о том, где реально хранятся данные.
Размер виртуальной памяти теоретически ограничивается разрядностью операционной системы. На практике в конкретной реализации операционной системы устанавливаются ограничения ниже теоретического предела. Например, для 32-разрядных систем (x86), которые используют для адресации 32 разрядные регистры и переменные, теоретический максимум составляет 4 ГБ (232 байт = 4 294 967 296 байт = 4 ГБ). Однако для процессов доступна только половина этой памяти – 2 ГБ, другая половина отдается системным компонентам. В 64 разрядных системах (x64) теоретический предел равен 16 экзабайт (264 байт = 16 777 216 ТБ = 16 ЭБ). При этом процессам выделяется 8 ТБ, ещё столько же отдается системе, остальное адресное пространство в нынешних версиях Windows не используется.
Введение виртуальной памяти, во-первых, позволяет прикладным программистам не заниматься сложными вопросами реального размещения данных в памяти, во-вторых, дает возможность операционной системе запускать несколько процессов одновременно, поскольку вместо дорогого ограниченного ресурса – оперативной памяти, используется дешевая и большая по емкости внешняя память.
Реализация виртуальной памяти в Windows
Схема реализации виртуальной памяти в 32-разрядной операционной системе Windows представлена на рис.11.1. Как уже отмечалось, процессу предоставляется виртуальное адресное пространство размером 4 ГБ, из которых 2 ГБ, расположенных по младшим адресам (0000 0000 – 7FFF FFFF), процесс может использовать по своему усмотрению (пользовательское ВАП), а оставшиеся два гигабайта (8000 0000 – FFFF FFFF) выделяются под системные структуры данных и компоненты (системное ВАП)1Специальный ключ /3GB в файле boot.ini увеличивает пользовательское ВАП до 3 ГБ, соответственно, уменьшая системное ВАП до 1 ГБ. Начиная с Windows Vista вместо файла boot.ini используется утилита BCDEDIT. Чтобы увеличить пользовательское ВАП, нужно выполнить следующую команду: bcdedit /Set IncreaseUserVa 3072. При этом, чтобы приложение могло использовать увеличенное ВАП, оно должно компилироваться с ключом /LARGEADDRESSAWARE.. Отметим, что каждый процесс имеет свое собственное пользовательское ВАП, а системное ВАП для всех процессов одно и то же.

Рис.
11.1.
Реализация виртуальной памяти в 32-разрядных Windows
Виртуальная память делится на блоки одинакового размера – виртуальные страницы. В Windows страницы бывают большие (x86 – 4 МБ, x64 – 2 МБ) и малые (4 КБ). Физическая память (ОЗУ) также делится на страницы точно такого же размера, как и виртуальная память. Общее количество малых виртуальных страниц процесса в 32 разрядных системах равно 1 048 576 (4 ГБ / 4 КБ = 1 048 576).
Обычно процессы задействуют не весь объем виртуальной памяти, а только небольшую его часть. Соответственно, не имеет смысла (и, часто, возможности) выделять страницу в физической памяти для каждой виртуальной страницы всех процессов. Вместо этого в ОЗУ (говорят, «резидентно») находится ограниченное количество страниц, которые непосредственно необходимы процессу. Такое подмножество виртуальных страниц процесса, расположенных в физической памяти, называется рабочим набором процесса (working set).
Те виртуальные страницы, которые пока не требуются процессу, операционная система может выгрузить на диск, в специальный файл, называемый файлом подкачки (page file).
Каким образом процесс узнает, где в данный момент находится требуемая страница? Для этого служат специальные структуры данных – таблицы страниц (page table).
Структура виртуального адресного пространства
Рассмотрим, из каких элементов состоит виртуальное адресное пространство процесса в 32 разрядных Windows (рис.11.2).
В пользовательском ВАП располагаются исполняемый образ процесса, динамически подключаемые библиотеки (DLL, dynamic-link library), куча процесса и стеки потоков.
При запуске программы создается процесс (см. лекцию 6 «Процессы и потоки»), при этом в память загружаются код и данные программы (исполняемый образ, executable image), а также необходимые программе динамически подключаемые библиотеки (DLL). Формируется куча (heap) – область, в которой процесс может выделять память динамическим структурам данных (т. е. структурам, размер которых заранее неизвестен, а определяется в ходе выполнения программы). По умолчанию размер кучи составляет 1 МБ, но при компиляции приложения или в ходе выполнения процесса может быть изменен. Кроме того, каждому потоку предоставляется стек (stack) для хранения локальных переменных и параметров функций, также по умолчанию размером 1 МБ.
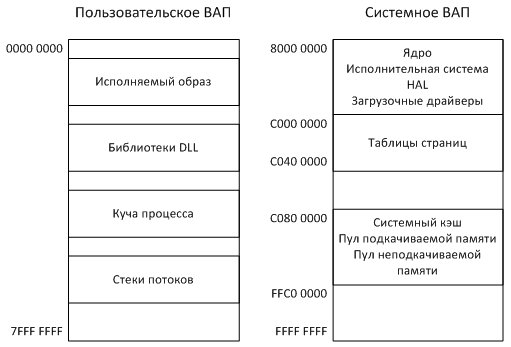
Рис.
11.2.
Структура виртуального адресного пространства
В системном ВАП расположены:
- образы ядра (ntoskrnl.exe), исполнительной системы, HAL (hal.dll), драйверов устройств, требуемых при загрузке системы;
- таблицы страниц процесса;
- системный кэш;
- пул подкачиваемой памяти (paged pool) – системная куча подкачиваемой памяти;
- пул подкачиваемой памяти (nonpaged pool) – системная куча неподкачиваемой памяти;
- другие элементы (см. [5]).
Переменные, в которых хранятся границы разделов в системном ВАП, приведены в [5, стр. 442]. Вычисляются эти переменные в функции MmInitSystem (файл basentosmmmminit.c, строка 373), отвечающей за инициализацию подсистемы памяти. В файле basentosmmi386mi386.h приведена структура ВАП и определены константы, связанные с управлением памятью (например, стартовый адрес системного кэша MM_SYSTEM_CACHE_START, строка 199).
Выделение памяти процессам
Существует несколько способов выделения виртуальной памяти процессам при помощи Windows API2См. обзор в MSDN «Comparing Memory Allocation Methods» (http://msdn.microsoft.com/en-us/library/windows/desktop/aa366533(v=vs.85).aspx).. Рассмотрим два основных способа – с помощью функции VirtualAlloc и с использованием кучи.
1. WinAPI функция VirtualAlloc позволяет резервировать и передавать виртуальную память процессу. При резервировании запрошенный диапазон виртуального адресного пространства закрепляется за процессом (при условии наличия достаточного количества свободных страниц в пользовательском ВАП), соответствующие виртуальные страницы становятся зарезервированными (reserved), но доступа к этой памяти у процесса нет – при попытке чтения или записи возникнет исключение. Чтобы получить доступ, процесс должен передать память зарезервированным страницам, которые в этом случае становятся переданными (commit).
Отметим, что резервируются участки виртуальной памяти по адресам, кратным значению константы гранулярности выделения памяти MM_ALLOCATION_GRANULARITY (файл basentosincmm.h, строка 54). Это значение равно 64 КБ. Кроме того, размер резервируемой области должен быть кратен размеру страницы (4 КБ).
WinAPI функция VirtualAlloc для выделения памяти использует функцию ядра NtAllocateVirtualMemory (файл basentosmmallocvm.c, строка 173).
2. Для более гибкого распределения памяти существует куча процесса, которая управляется диспетчером кучи (heap manager). Кучу используют WinAPI функция HeapAlloc, а также оператор языка C malloc и оператор C++ new. Диспетчер кучи предоставляет возможность процессу выделять память с гранулярностью 8 байтов (в 32-разрядных системах), а для обслуживания этих запросов использует те же функции ядра, что и VirtualAlloc.
Дескрипторы виртуальных адресов
Для хранения информации о зарезервированных страницах памяти используются дескрипторы виртуальных адресов (Virtual Address Descriptors, VAD). Каждый дескриптор содержит данные об одной зарезервированной области памяти и описывается структурой MMVAD (файл basentosmmmi.h, строка 3976).
Границы области определяются двумя полями – StartingVpn (начальный VPN) и EndingVpn (конечный VPN). VPN (Virtual Page Number) – это номер виртуальной страницы; страницы просто нумеруются, начиная с нулевой. Если размер страницы 4 КБ (212 байт), то VPN получается из виртуального адреса начала страницы отбрасыванием младших 12 бит (или 3 шестнадцатеричных цифр). Например, если виртуальная страница начинается с адреса 0x340000, то VPN такой страницы равен 0x340.
Дескрипторы виртуальных адресов для каждого процесса организованы в сбалансированное двоичное АВЛ дерево3АВЛ дерево – структура данных для организации эффективного поиска; двоичное дерево, сбалансированное по высоте. Названо в честь разработчиков – советских ученых Г. М. Адельсон Вельского и Е. М. Ландиса. (AVL tree). Для этого в структуре MMVAD имеются поля указатели на левого и правого потомков: LeftChild и RightChild.
Для хранения информации о состоянии области памяти, за которую отвечает дескриптор, в структуре MMVAD содержится поле флагов VadFlags.