Обновлено 29.07.2019

Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов на просторах рунета Pyatilistnik.org. Продолжаем с вами усовершенствовать свои навыки и знания в сфере системного администрирования. В предыдущей статье мы с вами разобрали основные понятия DNS сервера и его компонентов. Сегодня мы более подробно разберем, одну из его полезнейших вещей, которую очень часто используют, например на RDS фермах, или различных балансировщиках. Речь пойдет про функционал DNS Round Robin, рассмотрим его настройку и его применение.
Теория
Статья описывает одну из технологий балансировки нагрузки, которая может быть реализована средствами DNS. Для перевода имени хоста в IP-адрес клиент DNS направляет серверу DNS рекурсивный запрос (т.е. запрос, на который сервер DNS возвращает клиенту либо ответ с IP адресом, либо ответ с ошибкой).
В подавляющем большинстве случаев в зонах DNS содержится только один IP адрес, соответствующий тому или иному имени хоста. А какой IP адрес будет возвращать клиенту сервер DNS, если зона содержит несколько записей типа A для одного и того же имени? Ответ простой: сервер DNS всегда возвращает клиенту все IP адреса, соответствующие запрашиваемому имени. А дальше клиент пытается связаться с первым IP адресом в списке и, если он не будет найден, делает попытку связаться со вторым адресом и т.д.
Предположим, у меня есть несколько зеркальных веб-сайтов по имени www.gorbunov.pro, расположенных на разных площадках и имеющих IP адреса 20.0.0.1, 30.0.0.1 и 40.0.0.1.
В ответ на рекурсивный запрос клиента об имени www.gorbunov.pro сервер DNS вернет клиенту весь набор записей из зоны:
www.gorbunov.pro 20.0.0.1
www.gorbunov.pro 30.0.0.1
www.gorbunov.pro 40.0.0.1
Поскольку адрес 20.0.0.1 идет первым в списке, клиент всегда будет пытаться связаться именно с сайтом по адресу 20.0.0.1. Получается, что сайты 30.0.0.1 и 40.0.0.1 используются только как пассивный резерв. До тех пор, пока «жив» сайт по адресу 20.0.0.1, сайты 30.0.0.1 и 40.0.0.1 не получат от клиента ни одного запроса.
Как сделать, чтобы запросы “доставались” всем хостам? Ответ простой: настроить на сервере DNS функцию Round robin.
При включенной функции Round robin сервер DNS постоянно «перемешивает» ответы клиентам, поэтому на первый запрос клиента DNS об имени www.gorbunov.pro сервер DNS вернет ответ
www.gorbunov.pro 20.0.0.1
www.gorbunov.pro 30.0.0.1
www.gorbunov.pro 40.0.0.1
На второй запрос от клиента или от другого сервера DNS будет возвращен ответ
www.gorbunov.pro 30.0.0.1
www.gorbunov.pro 40.0.0.1
www.gorbunov.pro 20.0.0.1
На третий запрос будет ответ
www.gorbunov.pro 40.0.0.1
www.gorbunov.pro 20.0.0.1
www.gorbunov.pro 30.0.0.1
В результате мы получаем динамическую балансировку запросов клиентов между несколькими хостами.
Практика
____________________________________________________________________________________
Проверка работы DNS Round robin
В Windows Server опция Enable round robin включена по умолчанию. Достаточно в консоли DNS Manager открыть свойства DNS сервера и посмотреть вкладку Advanced.
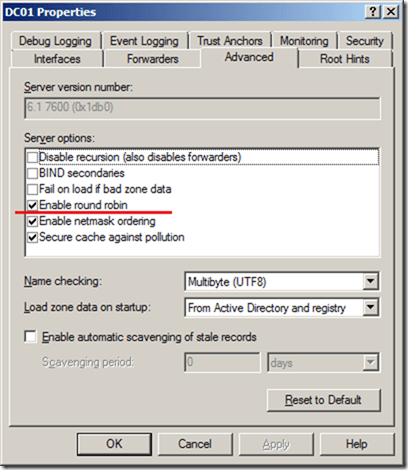
Что такое DNS Round robin и как он работает-01
Для практической проверки функционала DNS Round robin создаем зону gorbunov.pro и добавляем в нее три записи для хоста www.
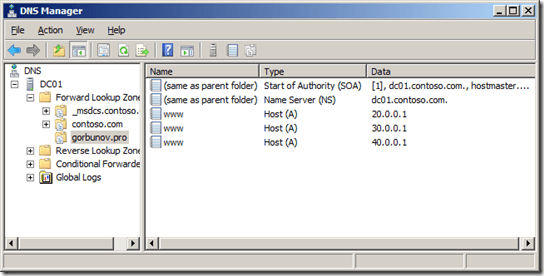
Что такое DNS Round robin и как он работает-02
Если вы попробуете теперь “попинговать” хост www.gorbunov.pro, то с удивлением обнаружите, что клиент все время отправляет пакеты на адрес 20.0.0.1 (выделено красным). Понятно, что ответа от хоста нет, но и DNS Round robin не работает!
C:>ping www.gorbunov.pro
Pinging www.gorbunov.pro [20.0.0.1] with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 20.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
C:>ping www.gorbunov.pro
Pinging www.gorbunov.pro [20.0.0.1] with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 20.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
C:>
Анализ кэша DNS на стороне клиента дает следующий результат:
C:>ipconfig /displaydns
Windows IP Configuration
www.gorbunov.pro
—————————————-
Record Name . . . . . : www.gorbunov.pro
Record Type . . . . . : 1
Time To Live . . . . : 3567
Data Length . . . . . : 4
Section . . . . . . . : Answer
A (Host) Record . . . : 20.0.0.1
Record Name . . . . . : www.gorbunov.pro
Record Type . . . . . : 1
Time To Live . . . . : 3567
Data Length . . . . . : 4
Section . . . . . . . : Answer
A (Host) Record . . . : 30.0.0.1
Record Name . . . . . : www.gorbunov.pro
Record Type . . . . . : 1
Time To Live . . . . : 3567
Data Length . . . . . : 4
Section . . . . . . . : Answer
A (Host) Record . . . : 40.0.0.1
C:>
Теперь становится понятно, почему мы “пингуем” один и тот же хост 20.0.0.1. Сервер DNS возвращает клиенту все записи из зоны с указанием времени кэширования, равным по умолчанию 1 часу (или 3600 секундам). Поэтому до истечения времени кэширования (TTL – Time To Live) клиент больше не направляет к серверу DNS никаких новых запросов.
Сброс кэша командой ipconfig / flushdns и новая команда
ping www.gorbunov.pro приводят, наконец к желаемому результату.C:>ipconfig /flushdns
Windows IP Configuration
Successfully flushed the DNS Resolver Cache.
C:>ping www.gorbunov.pro –n 1
Pinging www.gorbunov.pro [30.0.0.1] with 32 bytes of data:
Request timed out.
Теперь ясно, что для правильной работы DNS Round robin потребуется изменение параметров кэширования, чтобы клиенты постоянно получали обновленный список с “перемешанными” записями.
Настройка времени кэширования ответов DNS
Возможные варианты:
постоянный сброс кэша на стороне клиента (плохой вариант);
установка времени кэширования, равное нулю, в свойствах зоны (плохой вариант, поскольку влияет на всю зону);
установка индивидуального времени кэширования на отдельных записях (хороший вариант).
Для настройки индивидуального времени кэширования в консоли DNS Manager требуется сначала включить режим View –> Advanced. Затем последовательно открываем свойства записей (в нашем примере это три записи www) и ставим время кэширования, равное нулю.
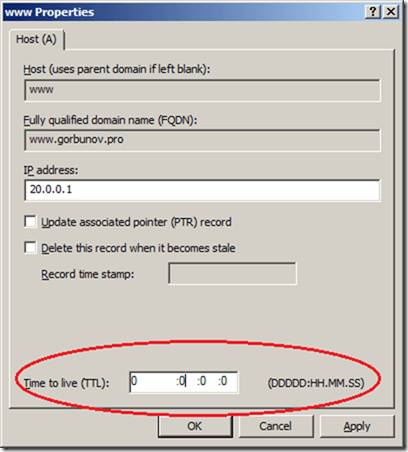
Что такое DNS Round robin и как он работает-03
Проверка работы дает в конце концов желаемый результат!
C:>ping www.gorbunov.pro –n 1
Pinging www.gorbunov.pro [20.0.0.1] with 32 bytes of data:
Request timed out.
Ping statistics for 20.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
C:>ping www.gorbunov.pro –n 1
Pinging www.gorbunov.pro [30.0.0.1] with 32 bytes of data:
Request timed out.
Ping statistics for 30.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
C:>ping www.gorbunov.pro –n 1
Pinging www.gorbunov.pro [40.0.0.1] with 32 bytes of data:
Request timed out.
Ping statistics for 40.0.0.1:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
Файл зоны на сервере DNS при этом будет выглядеть так:
;
; Database file gorbunov.pro.dns for gorbunov.pro zone.
; Zone version: 7
;
@ IN SOA dc01.contoso.com. hostmaster.contoso.com. (
7 ; serial number
900 ; refresh
600 ; retry
86400 ; expire
3600 ) ; default TTL
www 0 A 20.0.0.1
0 A 30.0.0.1
0 A 40.0.0.1
Добавления нуля в записи типа A можно сделать и вручную непосредственно в файле зоны.
- Исключения
В настройках сервера DNS по умолчанию включена и опция Enable netmask ordering. Смысл опции заключаются в том, что при наличии нескольких IP адресов для одного и того же имени хоста сервер DNS анализирует из какой сети пришел запрос от клиента. Если IP сеть клиента совпадает с номером сети одного из IP адресов хоста, то такой IP всегда возвращается первым. Проще говоря, если в нашем примере клиент с адресом 30.67.98.123 будет запрашивать имя www.gorbunov.pro, то ему всегда первым в списке будет возвращаться адрес 30.0.0.1. В серверах Windows опция Enable netmask ordering перебивает опцию Enable round robin. Т.е. клиентам DNS первым всегда возвращается адрес ближайшего хоста, даже несмотря на правильно настроенную функцию DNS Round robin.
- Выводы
Технология DNS Round robin часто применяется для динамической балансировки нагрузки между зеркальными хостами. Она значительно проще в реализации, чем вариант настройки для тех же целей кластера NLB. При настройке DNS Round robin на серверах Windows не забывайте, что настройки по умолчанию для сервера DNS не позволяют в полной мере реализовать балансировку запросов и требуется ручная конфигурация сервера.
Привет.
DNS – важная инфраструктурная служба. Настолько, что в предыдущей статье на тему безопасности DNS использовалась специальная иллюстрация:
В принципе, мало что изменилось – поэтому в данной, обновлённой версии статьи про безопасность DNS в Windows Server, я расскажу про то же самое, но уже детальнее. Будет рассматриваться Windows Server 2012 R2 и Windows Server 2016 – оба со всеми обновлениями на апрель 2016 года, для тюнинга будет использоваться ATcmd, в общем – работы много.
Безопасность и тюнинг DNS в Windows Server 2012 R2 и 2016
- Механизм SocketPool – защищаемся от предсказуемости DNS-порта
- Secure cache against pollution – защищаемся от отравления DNS-кэша
- Блокируем раннее обновление кэша – Cache Locking
- Привязка DNS-сервера к сетевым интерфейсам
- Удалённое управление DNS-сервером
- Настраиваем Global Query Block List
- Отключение обработки рекурсивных запросов
- Ограничение времени кэширования записей
- Отключаем AXFR / IXFR трансфер у зон, интегрированных в Active Directory
- Ограничение числа Resource Record’ов (RR) в ответе DNS-сервера
- Настройка BIND secondaries
- Настройка тайм-аута AXFR / IXFR трансфера
- Настройка времени блокировки AXFR / IXFR трансфера
- Фильтрация Name checking
- Механизм Aging/Scavenging в DNS
- Работа Round Robin и Netmask Ordering
- Блокировка динамической регистрации по типу RR
- Настройка EDNS0 в Windows Server 2012 R2
- Настройка DNS-форвардеров в Windows Server
- Ускоряем загрузку DNS-зон в Windows Server 2012 R2 и старше
Начнём.
Механизм SocketPool – защищаемся от предсказуемости DNS-порта
SocketPool появился как способ противодействия описанной в KB 953230 уязвимости, называемой иногда “Kaminsky bug”. Суть достаточно проста. В версиях Microsoft DNS до NT 6.1 для отправки данных DNS-сервера стартово инициализировался один сокет, от которого шло взаимодействие (в частности – ответы на UDP-запросы клиентов). Один сокет = разовая инициализация = одинаковый случайный ID транзакции. Это позволяло проводить атаку на перебор вариантов ID и с определённой вероятностью отравить кэш DNS-сервера путём отправки ему “заранее” неправильного ответа на предсказуемый запрос. А после, соответственно, DNS-сервер отдавал бы клиентам неправильную информацию из своего кэша, таким образом перенаправляя трафик туда, куда надо нарушителю.
Бороться с этим было решено достаточно просто – выделяя под нужды DNS-сервера пул сокетов, и отправляя ответы со случайного из них. Плюс, для каждой DNS-транзакции стал генериться уникальный ID, что дополнительно усложнило задачу отравления кэша, сделав её, при корректном применении всех защитных мер, осуществимой лишь теоретически.
Настройка SocketPool
По умолчанию пул равен 2.500 сокетам (притом, замечу, под пул выделяется одинаковое число и IPv4-портов, и IPv6 – т.е. в сумме по умолчанию зарезервированно 5 тысяч портов), но если ваш DNS-сервер обрабатывает запросы от внешних клиентов – увеличьте пул до 10К (если попробовать больше, выдаст DNS_ERROR_DWORD_VALUE_TOO_LARGE с кодом 9567). В случае, если DNS-сервер локальный – допустим, это DNS-сервер контроллера домена, и к нему обращаются клиенты из внутренней сети – стандартных 2.500 сокетов хватит.
Команда для задания количества сокетов, которые под себя “застолбит” сервис DNS:
Посмотреть текущую ситуацию с выделенными для SocketPool сокетам также можно в сводной информации по расширенным настройкам DNS server’а:
Как видно, параметр этот не одинок – продолжим про остальные.
Возможные проблемы, связанные с SocketPool, и настройка исключений
Возможные проблемы связаны с тем, что DNS Server застолбит под себя много UDP-сокетов, и различное ПО может от этого не иметь возможность сделать то же самое. Известный пример – это WDS (Windows Deployment Services). Эта служба резервирует для себя диапазон портов с 64.000 по 65.000, и в случае, когда DNS Server заберёт нужное число под SocketPool, могут возникнуть проблемы из-за наложения диапазонов DNS и WDS. Они решаемы, благодаря тому, что в WDS, который в Windows Server 2012 R2, встроен механизм динамического выбора портов. Включается он достаточно просто:
Замечу, что данный случай, когда существует штатный способ обойти ситуацию – единичная редкость. Вообще, так как механизм SocketPool резервирует под себя непрерывный блок UDP-портов, находящихся в верхней четверти всего доступного диапазона – т.е. с 49К и до 64К (это лишь 16К портов), то немудрено, что блок в 10К будет занимать много места и, возможно, конфликтовать с другими сервисами на том же хосте. Поэтому есть механизм, который позволяет исключить один или более диапазонов из SocketPool. Это делается специальной настройкой – штатного интерфейса у неё нет, поэтому выглядеть, например, исключение из пула портов диапазона 62000-63000, будет так:
Дополнительной и достаточно хитрой проблемой будет сценарий “Мы когда-то обновлялись с Windows Server 2003”. В этом случае в реестре может остаться технический параметр сетевого стека, актуальный до-NT-6.0 – т.н. MaxUserPort. Данный параметр ограничивает сверху диапазон выдаваемых приложению портов. То есть, если этот параметр есть, Windows Server 2012 R2 поменяет логику выдачи портов для DNS-сервера с “выдавать из диапазона 49K – 64K” на устаревший “выдавать с 1024 порта по MaxUserPort”. Поэтому для нормальной работы этот параметр надо, в случае его присутствия, удалить, он от устаревшей версии Windows Server и сейчас не нужен:
Суммаризируем советы по этому масштабному пункту:
- Выставляем SocketPool везде в 2.500 – за исключением тех DNS-серверов, которые опубликованы в Интернет. У них – 10.000.
- Заранее отключаем устаревшее управление диапазоном выделяемых портов, которое MaxUserPort. Оно нам сейчас только мешает и всё путает.
- В случае острой необходимости используем исключения из диапазона SocketPool, чтобы не конфликтовать с другими сервисами, которые тоже хотят зарезервировать для себя ‘слушающие ‘UDP-порты.
Теперь двигаемся дальше.
Secure cache against pollution – защищаемся от отравления DNS-кэша
Идея этой настройки, появившейся ещё в Windows NT 4.0, и включенной по умолчанию с Windows Server 2003, проста. Она состоит в том, чтобы читать из ответа DNS-сервера только запрашиваемые ранее сведения, и игнорировать остальные. Рассмотрим пример.
Допустим, на DNS-сервер пришёл запрос от клиента – “хочу A-запись с именем msdn.microsoft.com”. DNS-сервер посмотрел в зонах, расположеных на нём – не нашёл. Потом посмотрел у себя в кэше – тоже нет. ОК, на DNS-сервере включена рекурсия. Он запрашивает другой сервер (например, DNS провайдера или какой-нибудь публичный) и ждёт ответ. И сервер присылает ему ответ – вида “msdn.microsoft.com доступен по адресу 1.2.3.4”. Но иногда сервер хочет помочь – вдруг следующим запросом Вы захотите microsoft.com? И он присылает не только msdn.microsoft.com, но и ту информацию, которую он выяснил попутно – адрес microsoft.com. По умолчанию ответ обрабатывается и добавляется в кэш, т.к. предполагается, что сервер хороший, и присылает только полезную и нужную информацию.
Но жизнь жёстче.
Поэтому надо включать параметр secure cache against pollution, чтобы исключить даже теоретическую возможность получения недостоверной информации из DNS-ответа.
Проще всего сделать это через консоль управления сервером – открыть Properties, вкладку Advanced и установить нужное значение.
Блокируем раннее обновление кэша – Cache Locking
Механизм Cache Locking появился в Windows Server 2008 R2 и, по сути, является дополнительной мерой безопасности для защиты от “Kaminsky bug”. Работает Cache Locking просто – на какое-то время запрещает обновление успешно закэшированных записей. Параметр задаётся в процентах – допустим, если установить его в 50, то в случае, если Ваш сервер закэширует какую-нибудь запись, TTL которой равен 6 часам, все попытки обновить её на протяжении первых 3х часов будут игнорироваться. Установка параметра в 100, как понятно, приведёт к блокировке всех запросов на обновление имеющихся в кэше записей. Это – рекомендованное значение данного параметра, т.к. обычно Вы запрашиваете какую-то DNS-запись, сервер узнаёт про неё информацию и кэширует – перезапись “на лету”, пока не истекло время кэширования, не предполагается.
Настраиваем данный параметр:
Напомню, что после смены этого параметра, как и подавляющего большинства других параметров уровня сервера, необходимо перезапустить службу DNS Server.
Привязка DNS-сервера к сетевым интерфейсам
По умолчанию DNS-сервер слушает трафик и реагирует на запросы со всех интерфейсов. Это включает в себя все IPv4-адреса и все IPv6 (как unicast’ы, так и link local’ы). Да и при добавлении нового интерфейса он будет сразу же использоваться службой DNS. Имеет смысл из соображений предсказуемости переключить эту настройку на явное указание адресов, на которых DNS-сервер будет принимать трафик. Например, если в инфраструктуре не используется IPv6, а DNS Server настроен “по умолчанию”, и на его интерфейсах включен сетевой компонент IPv6, он (DNS Server) будет обрабатывать запросы, пришедшие на адрес link local (вида fe80::идентификатор хоста), что является в указанной ситуации не нужным и не должно, согласно принципу Уильяма Оккама, существовать. Также не очевидно, что в случае установки нового сетевого соединения с хоста, на котором запущена служба DNS Server, подразумевается, что надо сразу же начать обрабатывать запросы клиентов, пришедшие на новопоявившийся интерфейс.
Как настраивается привязка DNS-сервера к сетевым интерфейсам
Необходимо зайти в настройки DNS Server, выбрать Properties и на вкладке Interfaces в явном виде выбрать только те адреса, на которые нужно принимать dns-запросы. Вот так:
Удалённое управление DNS-сервером
DNS-сервером можно управлять дистанционно через три технологически различных способа – это прямое подключение по TCP/IP (в данном случае, по сути, обычно и называемое RPC), отправка команд через Named Pipes и локальный вызов процедур (LPC). Имеются в виду, безусловно, способы подключения именно к службе и COM-объектам DNS-сервера, а не к хосту, на котором эта служба запущена. Так вот, если ваш DNS-сервер администрируется не всеми из них – а так обычно и бывает – то лишние надо выключать. Если это, допустим, опубликованный наружу DNS-сервер, который установлен на отдельной виртуальной машине, и управление осуществляется путём подключения администратора по RDP, то ничего, кроме LPC (чтобы MMC-консоль работала) серверу не нужно. Если это инфраструктурная виртуалка, к которой подключаются удалённой оснасткой, то ей надо только RPC поверх TCP/IP, никакие named pipes ей не нужны. Данная настройка (для случая с LPC) будет выглядеть так, иные варианты делаются по аналогии:
Настраиваем Global Query Block List
Глобальный блок-лист имён – достаточно интересная штука. Необходимость его использования вызвана тем, что в случае использования хостами динамической регистрации DNS-имён возможна ситуация, когда злонамеренный участник зарегистрирует well-known имя, которое используется сетевой службой (например, wpad или isatap). Имя другого компьютера или сервера ему зарегистрировать, в случае существования оных и включённого механизма secure updates, не дадут, а вот wpad допустим – пожалуйста, ведь сервера с таким именем нет, это служебный идентификатор. А после – данный компьютер будет отвечать на запросы пытающихся автоконфигурироваться клиентов вида “а дайте мне настройки” по адресу “http://wpad.имя_домена/wpad.dat”, отдавая им то, что посчитает нужным. Это неправильно. Ну и второй вариант злонамеренного использования – удалённый пользователь может получить информацию об инфраструктурных сервисах, запросив эти технические resource record’ы. Соответственно, GQBL нужен для того, чтобы отсечь эти возможности.
Как этот механизм будет работать? Рассмотрим вариант для наличия в GQBL стандартного имени wpad.
При добавлении имени в GQBL будут игнорироваться запросы для всех типов записей (это важно – не только A и AAAA, а всех) для всех зон, для которых данный сервер является authoritative. То есть, допустим, если на сервере есть зоны domain.local и _msdcs.domain.local, то запросы wpad._msdcs.domain.local и wpad.domain.local, несмотря на фактическое наличие/отсутствие данной записи, будут возвращать ответ, что запись не найдена.
Замечу, что если что – это можно обойти, если создать зону с именем wpad.domain.local и в ней – пустую запись нужного типа. В именах зон проверка не происходит. Уязвимостью это не является, т.к. удалённо динамически зарегистрировать зону нельзя.
Запросы для других зон (не находящихся на сервере) под это подпадать не будут (т.е. wpad.externaldomain.ru под этот механизм не подпадёт).
Интересным является также момент про то, как данный механизм работает с логами. При первой блокировке в журнал пишется событие, где написано, что запрос от такого-то клиента заблокирован по причине нахождения искомого в GQBL. После запись уже не ведётся. Это не баг, а защита от простейшей атаки – переполнения журнала путём отправки огромного количества запросов на предсказуемо блокируемый FQDN. После перезапуска сервера счётчик сбросится на нуль и опять – первая блокировка будет записана в журнал, далее – нет.
Теперь настройка.
Настройка Global Query Block List на Windows Server 2012 R2
Включить этот фильтр на уровне сервера просто:
Задать содержимое – тоже несложно. Можно задать весь лист целиком, редактировать каждую запись отдельно – увы, только через реестр:
Отключение обработки рекурсивных запросов
Данная опция нужна только в одном сценарии – когда ваш DNS-сервер нужен исключительно для разрешения имён в тех зонах, которые на нём расположены, и не обслуживает произвольные запросы клиентов. Это, говоря проще, выделенная машина – например, для поддержки интернет-доменов предприятия, или в случае делегирования провайдером reverse lookup’ов (см. Создание обратной зоны с нестандартной маской).
В упомянутых случаях DNS-сервер должен отвечать исключительно на один тип вопросов – про те зоны, которые ему явно известны и локально находятся. Абстрактные же запросы вида “а поищи-ка мне вот такое вот имя” не нужны и приводят к потенциальной DoS-атаке.
Отключение рекурсии выглядит так:
Как понятно из названия, вместе с ней отключаются и форвардеры – это логично, т.к. серверу без рекурсии форвардеры не нужны – он принципиально не обрабатывает запросы, для которых может понадобиться запрос какого-либо другого сервера.
Ограничение времени кэширования записей
Записи, которые DNS-сервер получил от других DNS-серверов, не только передаются запрашивающим клиентам, но и кэшируются на сервере. Время кэширования указано в самой записи – у неё есть личный TTL.
В ряде случаев имеет смысл сделать работу более динамичной и ускорить актуализацию записей, установив максимальный TTL для всех RR’ов на сервере. Простой пример – некто установил огромный TTL (например, 42 дня), а по факту запись иногда меняется. В этом случае пока запись не устареет в кэше, ваш DNS-сервер будет давать неверный/устаревший ответ. Проще указать некую верхнюю границу – допустим, сутки – и записи с любыми TTL не будут храниться в кэше дольше этого срока, и сервер будет их запрашивать. Ничтожный рост трафика (один доп.пакет в день) гораздо лучше, чем, допустим, три недели испытывать проблемы с электронной почтой, потому что кто-то обновил MX, но забыл, что TTL выставлен огромный, поэтому изменение по факту применится очень нескоро. Этому, кстати, способствует тот момент, что в интерфейсе Microsoft DNS Server изменение TTL у DNS-записи доступно только в расширенном режиме работы. Вот как окно редактирования DNS-записи выглядит обычно:
А вот как в случае, когда в меню View включён пункт Advanced:
Не забывайте про то, что нужно выставлять разумные TTL у записей. Ну а теперь как ограничить максимальный срок жизни записи в кэше DNS-сервера:
86400 – это секунд в сутках, как понятно.
Не менее важным параметром является ограничение времени кэширования негативного ответа. Суть достаточно проста – в случае, если в качестве ответа на запрос пришёл отказ, ваш DNS-сервер запоминает это, чтобы при повторных запросах каждый раз не повторять обращение – ну, экономит силы. Нет смысла раз в секунду по-честному бегать и проверять, не появилась ли запись, если удалённый сервер сообщил, что её нет.
Однако на практике данный параметр желательно настроить на какой-то небольшой интервал времени – чтобы с одной стороны, часто запрашивающий клиент не мог перегрузить DNS-сервер, а с другой, при появлении запрашиваемой записи на удалённом сервере мы бы могли про это узнать в разумное время.
Я поставлю время кэширования негативного ответа в 5 минут:
Отключаем AXFR/IXFR трансфер у зон, интегрированных в Active Directory
В том случае, если все сервера, на которых находится определённая зона, расположены на контроллерах Active Directory, то наличие возможности трансфера зоны стандартным способом – AXFR / IXFR запросом по TCP 53 является уязвимостью, так как может помочь потенциальному злоумышленнику узнать дополнительные сведения об инфраструктуре. Притом достаточно простым способом – например, подключившись при помощи nslookup и выполнив команду ls. Нормальная же репликация зоны происходит через механизмы LDAP-репликации Active Directory.
Отключаем просто – открываем свойства (Properties) у нужной DNS-зоны, выбираем вкладку Zone Transfers:
Это надо сделать не только у зон, интегрированных в Active Directory, но и у всех копий зоны, находящихся на secondary-серверах, с которых не забирают копию другие secondary-сервера.
Ограничение числа Resource Record’ов (RR) в ответе DNS-сервера
Данная настройка позволит обойти одну редкую, но неприятную проблему, связанную с разным поведением DNS-клиентов. Суть проста – в случае, когда в ответ надо добавить много записей, и, несмотря на EDNS0 и прочие ухищрения, они не влезают, у ответа ставится бит “неполный” – т.н. “truncation bit”. По идее, после получения ответа с таким битом, запрашивающий должен насторожиться и переспросить повторно, но уже по TCP (не забывайте, DNS-сервер умеет отвечать на запросы не только по UDP), чтобы получить не-урезанный ответ. Однако так поступают не все клиенты. Более того, высока вероятность того, что где-то в цепочке передачи рекурсивного запроса кто-то один не будет поддерживать запросы/ответы по TCP, поэтому информация просто потеряется – грубо говоря, клиент, получив не полный ответ, а урезанный, запросит иным способом, а в ответ – тишина, в результате клиент может решить, что имя просто не разрешилось полноценно.
Чтобы минимизировать вероятность этой ситуации, нужно сделать ряд шагов.
Первым делом – разберитесь с максимальным размером UDP-ответа. Чем лучше разберётесь – тем ниже вероятность возникновения упомянутой ситуации.
Вторым – проверьте, все ли ваши DNS-сервера отвечают по TCP. Для этого в ATcmd есть встроенный тест – команда test dns ports, которой надо лишь указать имя домена (например, локального домена Active Directory) – она найдёт все NS-сервера за этот домен, и попробует запросить у каждого и UDP- и TCP-вариант ответа. Обеспечение возможности клиентов посылать вашим DNS-серверам запросы через TCP – это тот минимум, который вы можете сделать, т.к. не можете влиять на все DNS-сервера в рекурсивной цепочке. Примитивный подход “DNS работает только через UDP, через TCP только трансфер зон, поэтому TCP за исключением трансфера надо блочить на firewall’е” не работает – вы решите массу проблем и уберёте непонятные сбои, если клиенты смогут нормально переспрашивать DNS-сервер по TCP.
А теперь можно и ограничить число RR в DNS-ответе. Я поставлю 28 (это максимальное ограничение).
Это обозначает то, что я уверен, что у меня нет ни одной записи, которая разрешается сразу в более чем 28 ответов, но если таковые есть (допустим, чужие, после рекурсивного запроса) – клиенту будет возвращаться не “сколько влезло плюс пометка, что влезло не всё”, а только 28 лучших. Сценарий с возвратом большого числа записей возможен, в принципе, в паре основных случаев – когда запрашивается разрешение имени какого-то высоконагруженного ресурса (в ответе пачка A и AAAA), или когда во внутренней сети запрашивается Active Directory-специфичная корневая или SRV запись (допустим, за корень домена в DNS регистрируются все DC – поэтому в больших доменах очевидна ситуация, когда ответ на вопрос “а кто у нас хост за domain.local” возвращает опять же большую пачку A- и AAAA-записей). В этом случае нужно оперировать настройками сервера по части приоритета выдачи только нужных ответов, а не всех, и максимально избегать линейного решения ситуации “вот тебе в ответ на запрос 250 A-ответов про все DC в домене, делай что хочешь”.
Настройка BIND secondaries
По сути, этот параметр делает одну-единственную вещь – запрещает при стандартном трансфере зоны с текущего DNS-сервера передавать несколько записей одной операцией, чем замедляет трансфер. Поддержка функционала передачи нескольких записей есть в BIND уже достаточно давно, с версии 4.9.4, поэтому на данный момент включение данной опции не имеет смысла и лишь замедлит трансфер DNS-зон.
Для настройки этой опции нужно выбрать свойства (Properties) у сервера DNS, там – вкладку Advanced, а после выбрать соответствующий параметр:
Настройка тайм-аута AXFR / IXFR трансфера
По умолчанию трансфер DNS-зоны считается несостоявшимся, если тайм-аут со стороны отвечающего сервера превысил 30 секунд бездействия. Этот параметр можно и нужно править – например, снизить до 15 секунд, чтобы раньше “отсекать” ситуации, когда сервер не осуществляет трансфер, а просто подключился и сидит. Хорошие DNS-серверы так себя не ведут, действуют быстро и закрывают TCP-сессию тоже оперативно. Правим:
Настройка времени блокировки AXFR / IXFR трансфера
Одной из загадок в поведении Microsoft DNS Server, обнаруживаемой в начале использования, является то, что после удачной передачи зоны с одного сервера на другой, и быстрого рефреша консоли нажатием F5, вылезает ошибка “Всё, трансфер зоны сломался”. В самом деле, чему там ломаться-то в такой ситуации?
Ломаться действительно нечему – просто срабатывает механизм защиты primary DNS от перегрузки. Логика следующая:
- Допустим, что у нас есть DNS-зона, которая расположена на 1 primary DNS-серверах и на 100 secondary. Притом все secondary обновляют её исключительно с primary, т.е. никакой иерархии secondary нет.
- Один из secondary начинает скачивать зону. Пока он это делает, в эту же зону хочет записаться dynamic update какой-либо записи. Допускать этого нельзя, поэтому на зону на время трансфера накладывается write lock.
- Зона успешно передана – write lock снят, записи в зону произведены, и primary уведомляет всех secondary (через механизм DNS Notify), что есть изменения. Все они приходят качать зону, она опять блокируется от записей.
Такие “качели” приводят к тому, что зона непрерывно крутится в цикле “накопить пачку отложенных записей – массово раздать зону”. По сути, ради каждого единичного обновления все сервера подрываются полностью передавать зону (мы ж не уверены, что у всех есть IXFR). Вот для блокировки этого и нужен данный параметр. Время блокировки считается просто – количество секунд, по факту потраченное на последний успешный трансфер зоны (параметр хранится для каждой DNS-зоны на DNS-сервере отдельно), домножается на коэффициент, и результирующее число – это тот интервал, когда все запросы на трансфер будут безусловно отвергаться (в логах у secondary вы увидите событие 6525, “primary server refuses zone transfer”). Если этот параметр установить явно в нуль, то механизм полностью выключится – вы можете сделать так в случае, если подобная защита не нужна (малое число DNS-серверов), тогда ваша зона будет актуализироваться максимально быстро. Я просто уменьшу данный параметр с 10 (значение по умолчанию) до 3 раз – т.е. если зона передаётся за 3 секунды, следующие 9 секунд все запросы на трансфер будут отклоняться.
Фильтрация Name checking
Настройка Name Checking на уровне DNS Server’а указывает на то, по каким критериям будут фильтроваться имена в запросах. То есть в случае, если имя в запросе подпадает под выбранную логику проверки – запрос обрабатывается, если нет – то считается ошибочным и отбрасывается. Вариантов настройки будет четыре:
Вариант Strict RFC (ANSI)
В запрашиваемых именах могут быть только символы, которые указаны в RFC 952 и RFC 1123. Т.е. подмножество семибитовых ASCII-символов, case insensitive, по сути – только английские буквы, цифры и минус/тире/дефис.
Вариант Non RFC (ANSI)
Strict RFC плюс подчёркивание.
Вариант Multibyte (UTF8)
Имена могут быть в Unicode (RFC 2181).
Вариант All Names
Фильтрация не производится, сервер пытается обработать все полученные строки.
Что выбрать? Тут всё достаточно сложно. Ситуаций много. Например, если ваш DNS-сервер держит исключительно внешние зоны, в которых нет хостов с именами, использующими символы национальных алфавитов, и предназначен он лишь для этой задачи (т.е. на нём нет рекурсии), то имеет смысл использовать Non RFC. Для обычного сервера, который кэширует запросы клиентов, подойдёт Multibyte. Отключать фильтрацию целиком нецелесообразно.
Фильтрация по размеру FQDN – каждый компонент не более 63 байт и все в сумме – не более 255 – всегда сохраняется и не редактируема.
Наглядный пример – то, что на картинке, может быть только на сервере, который настроен не на Strict RFC / Non RFC:
Если у данного сервера поменять настройку на Strict RFC и сделать на зоне Reload, то запись тихо пропадёт – сервер проигнорирует её при загрузке. А если после вернуть настройки на All Names и опять сделать Reload – запись опять появится.
Как настраивается фильтрация Name Checking в Windows Server 2008 R2 DNS
Для настройки этой опции нужно выбрать свойства (Properties) у сервера DNS, и там – вкладку Advanced, а после выбрать необходимый режим.
Механизм Aging/Scavenging в DNS
Динамически добавленные в DNS-зону записи не умеют пропадать сами. Это не баг, это так положено. В WINS (который NBNS) (не к ночи он будет помянут) этот механизм был штатным, а вот в DNS – увы. Поэтому фирма Microsoft добавила данный механизм в свою реализацию DNS Server. Как он будет работать?
У каждой динамически зарегистрированной записи будет указываться time stamp – время последнего успешного изменения этой записи. После, на протяжении no-refresh time (по умолчанию – 7 дней), все обновления этой записи будут игнорироваться. В оригинале, когда этот механизм был в WINS, это было нужно, чтобы информация о записи “расползлась” по инфраструктуре, сейчас делается с другими целями. Когда no-refresh time закончится, у записи начинает бежать обратный отсчёт – refresh-time. Это время, в течении которого запись должна обновиться. Если она не обновится за это время (по умолчанию – тоже 7 дней), то она является кандидатом на удаление. И вот тут-то, если на уровне сервера включен механизм Scavenging of stale records, такие записи будут удаляться. Делается это раз в сутки (если включен автоматический режим), либо вручную.
Этот механизм полезен, т.к. при должной настройке будет эффективно удалять ненужные DNS-записи, например, переименованных или удалённых из домена рабочих станций.
Не забывайте, что механизм включается и на уровне сервера, и на уровне зоны. Чтобы механизм функционировал, необходимо включить его и там и там. Т.е. и зона должна одобрять идею автоматической очистки, и конкретный сервер знать, что периодически надо удалять записи, не обновлённые уже X дней.
Включать данный механизм полезно ещё по одной причине. Мало того, что он будет удалять устаревшие записи. Он ещё будет, вводя no-refresh interval, уменьшать трафик репликации Active Directory. Т.е. если за время no-refresh interval придёт запрос на динамическое обновление записи, и в нём не будет ничего нового, кроме продления срока жизни, то без механизма aging/scavenging этот запрос будет отработан и в зону будет произведена запись (бессмысленная), что вызовет репликацию раздела Active Directory, в котором находится эта запись. А в случае, если механизм будет включен, сервер посмотрит, и если запрос не будет содержать никакой новой информации (ну, например, машину просто перезагрузили – она ту же A-запись пытается зарегистрировать, по сути – просто сбросить time stamp), он будет проигнорирован. Это никак не повлияет на качество работы DNS, а вот новую репликацию не инициирует. Профит!
Как включается Aging/Scavenging в Microsoft Windows Server 2008 R2 DNS
Первое – включаем на уровне сервера. Этот пункт находится в настройках сервера (Properties), вкладке Advanced, снизу. Время, задаваемое там – это критерий очистки. Т.е. раз в сутки сервер, на котором это включено, будет находить все динамически зарегистрированные записи, которые не обновлялись указанное в настройках время, и удалять их. Можно указать этот параметр достаточно большим – я указываю 30 дней, если рабочая станция месяц не обновляла свою запись – наверное, смысла жить в DNS ей больше нет. Вернётся – заново зарегистрирует.
Второе – включаем на уровне зоны. Задаём no-refresh и refresh интервалы. Обычно стандартное время менять не нужно. В общем, всё.
Работа Round Robin и Netmask Ordering
Оба данных механизма, в общем, преследуют предсказуемую цель – улучшить жизнь DNS-клиента, выдавая ему заранее перетасованные и (желательно) только лучшие RR-записи в ответ на запрос, на который надо вернуть большое подмножество ответов. Поэтому по умолчанию оба этих параметра включены:
Как будет вести себя DNS-сервер в зависимости от их настроек:
- Если оба параметра выключены, то клиенту в ответ на запрос возвращается всегда одинаковый комплект A- и AAAA-записей, порядок их не меняется.
- Если включен только Netmask Ordering, то из списка всех A- и AAAA-записей хоста будут выбраны те, у кого первые N бит совпадают с source address клиентского запроса, и эти записи будут помещены в верх списка по критерию “чем больше бит совпало, тем лучше”. Обратите внимание на то, что source address – это, в случае рекурсии, всё время одинаковый адрес вашего DNS-сервера, который форвардит запросы наружу, поэтому фактически Netmask Ordering нужен только на сервере, к которому напрямую подключаются клиенты, и хорошо подходит, допустим, для задачи “дай список DC за домен”, где клиент и DC в региональном филиале скорее всего будут в одном сегменте сети.
- Если включен только Round Robin, то A- и AAAA-записи в ответе перемешиваются каждый раз, благодаря чему простые реализации DNS client’ов, которые берут первый попавшийся ответ, математически ровно распределяют попытки подключения между хостами.
- Ну а если включены оба режима, то вначале отработает Netmask Ordering, а не подпавшие под него записи будут перетасованы Round Robin’ом.
Данные параметры полезные и выключать их особо не требуется – вреда от них нет.
В случае же, если вам нужно исключить какой-либо тип RR из ротации round robin – т.е. надо, чтобы записи именно этого типа отдавались клиенту вот именно в одном и том же порядке всегда – то есть специальная команда:
Посмотреть исключённые в данный момент типы записей можно как обычно, командой show dnsserver.
Блокировка динамической регистрации по типу RR
В зонах, где разрешена динамическая регистрация, возможно указание того, какие именно типы записей можно обновлять динамически, а какие – нет. Это логично – разрешая динамическое обновление зоны (что безопасное, что обычное), администратор обычно подразумевает, что туда могут регистрироваться новые хосты. А вот что можно удалённо записать произвольную SOA, NS, или сделать NS-делегирование – это, в общем, неправильно.
Для управления этим есть параметр updatetypes, текущие настройки его можно посмотреть той же командой show dnsserver:
Задавать его придётся битовой маской, где каждый бит – это разрешение или запрет для динамической регистрации определённого типа RR. В одном DWORD собраны настройки и для всех зон, поддерживающих только безопасные обновления, и для всех зон, поддерживающих обычные динамические обновления:
Практический пример применения этого параметра – допустим, у вас есть домен Active Directory с названием kontora.local. Вы хотите, чтобы все сетевые принтеры в фирме были подключены не по IP-адресам, а по DNS-именам. Принтеры умеют, получив новый адрес от DHCP, динамически зарегистрироваться в DNS – но не умеют делать это безопасно, т.к. не имеют учётной записи в Active Directory. Ради принтеров ослаблять безопасность основной DNS-зоны домена – неправильно. Можно сделать субдомен prn.kontora.local и сказать принтерам регистрироваться в нём. Но тогда неплохо бы подстраховаться, чтобы они регистрировали именно A-записи, а вот например NS чисто технически обновить было бы нельзя (чтобы не было атаки на добавление rogue-DNS, в котором под A-записями принтеров будут скрываться узлы, которые будут делать что-то нехорошее).
Настройка EDNS0 в Windows Server 2012 R2
Данный блок настроек, из-за своей неочевидности и необходимости подробно разобрать лежащие в их основе технологии, вынесен в отдельную статью на нашей Knowledge Base – https://www.atraining.ru/edns0-windows-server/. Относится он скорее к тюнингу, чем к безопасности, но это никак не снижает его нужности.
Настройка DNS-форвардеров в Windows Server
Стандартное окно, где можно добавить форвардеры – очень простое.
В случае работы с conditional forwarders, которые появились с Windows Server 2003, вам разве что добавляется возможность повлиять на тайм-аут запроса – мол, если за это время DNS-сервер не ответит, запрос считается пропавшим без вести.
Но на самом деле возможностей настройки – гораздо больше.
Командлет Set-DnsServerRecursion поможет настроить более тонкую обработку рекурсии. Какие у него будут параметры?
Параметр -SecureResponse
Данный параметр очень ценный – он будет указывать, проверять ли ответ удалённого сервера на возможность cache pollution. То есть, допустим сценарий – вы сделали conditional forwarder, который говорит, чтобы все запросы вида *.atraining.ru перенаправлялись на адрес 178.159.49.230. Обычно подобные conditional forwarder’ы используются как обеспечение разрешения партнёрских внутренних DNS-зон в рамках forest trust – поэтому простой вопрос – а есть ли смысл, чтобы хост 178.159.49.230 передавал информацию дальше, если не найдёт у себя? По идее нет – вы указываете DNS-серверы партнёра, которые являются authoritative за его зону. Вот, используя этот параметр, можно указать – как в данном случае будет вести себя ваш сервер, получив ответ – поверит в любом случае или удостоверится, что присылающий сервер является авторитативным за зону, из которой пришёл ответ.
Параметр -Timeout
Стандартный тайм-аут ответа удалённого сервера – 15 секунд. Вы можете повлиять на этот параметр – увеличив его (тогда далёкие сервера будут успевать отвечать), или уменьшив (тогда нерабочий сервер будет определяться быстрее).
Параметр -AdditionalTimeout
Это – плюсик к предыдущему параметру, показывающий, что если в запросе будет бит рекурсии, то надо дополнительно подождать – ведь удалённый сервер может куда-то сбегать и спросить. Стандартно это дополнительные 4 секунды, как у гранаты Ф1 (хотя сейчас они от 3.2 секунд бывают, так что DNS server чуток тормознее). Если настраиваете региональный DNS-сервер, который пробрасывает запросы по VPN до центрального офиса – возможно, надо увеличить данный параметр, это положительно повлияет на уменьшение false negative в кэше сервера.
Параметр -RetryInterval
Это то время, через которое DNS-сервер попробует заново отправить запрос, после того, как прошёл тайм-аут по предыдущему. По умолчанию – три секунды. Не ставьте меньше, если не уверены, что всё работает просто идеально и очень быстро – вначале разберитесь с предыдущими параметрами, цель – не ускорить запросы (вы их не ускорите, они вами только отправляются и принимается результат), а снизить частоту сбоев из-за раннего тайм-аута.
Ускоряем загрузку DNS-зон в Windows Server 2012 R2 и старше
Hotfix 3038024 приносит новую функциональность в DNS server в Windows Server 2012 R2 и старше. Заключается она в альтернативном механизме подгрузки зон и решении проблем с “зависшим” форвардером (это когда DNS server при наличии более одного форвардера почему-то после тайм-аута первого не пробует второй). Ключевое – действует этот метод только для серверов, которые подгружают зоны из файлов, а не из Active Directory – т.е. данный приём нужен только для проксирующих и держащих внешние зоны DNS-серверов.
До установки 3038024 обязательно установите апрельский update rollup. Microsoft пишет, что хотфикс меняет загрузку зон только в случае, если DNS-сервер стартует с параметром “Load zone data on startup: From registry” (это когда BootMethod будет равен 2), по факту же работает всегда – поэтому, кстати, этот хотфикс добавлен в Windows Server 2016 сразу же, как часть функционала.
В общем, пока всё.
Заключение
Надеюсь, что данная статья поможет Вам корректно и эффективно настроить сервис DNS в инфраструктуре предприятия. Ну, а про DNSSEC (как и ранее про EDNS0) – напишем отдельно. Удач!
Возможно, вам будет также интересно почитать другие статьи про DNS на нашей Knowledge Base
Consider the following multiple A records for a DNS record proxy.mydomain.com:
- proxy.mydomain.com IN A 192.168.10.5
- proxy.mydomain.com IN A 10.136.53.5
- proxy.mydomain.com IN A 10.136.52.5
- proxy.mydomain.com IN A 10.136.33.5
- proxy.mydomain.com IN A 192.168.15.5
These records are defined on a DNS server. When a client queries the DNS server for the address to proxy.mydomain.com, the DNS server returns all the addresses above. However, the order of answers returned keeps varying. The first client asking for answers could get them in the following order for instance:
- proxy.mydomain.com IN A 192.168.10.5
- proxy.mydomain.com IN A 10.136.53.5
- proxy.mydomain.com IN A 10.136.52.5
- proxy.mydomain.com IN A 10.136.33.5
- proxy.mydomain.com IN A 192.168.15.5
The second client could get them in the following order:
- proxy.mydomain.com IN A 10.136.53.5
- proxy.mydomain.com IN A 10.136.52.5
- proxy.mydomain.com IN A 10.136.33.5
- proxy.mydomain.com IN A 192.168.15.5
- proxy.mydomain.com IN A 192.168.10.5
The third client could get:
- proxy.mydomain.com IN A 10.136.52.5
- proxy.mydomain.com IN A 10.136.33.5
- proxy.mydomain.com IN A 192.168.15.5
- proxy.mydomain.com IN A 192.168.10.5
- proxy.mydomain.com IN A 10.136.53.5
This is called round-robin. Basically it rotates between the various IP addresses. All IP addresses are offered as answers, but the order is rotated so that as long as clients choose the first answer in the list every client chooses a different IP address.
Notice I said clients choose the first answer in the list. This needn’t always be the case though. When I said clients above, I meant the client computer that is querying the DNS server for an answer. But that’s not really who’s querying the server. Instead, an application on the client (e.g. Chrome, Internet Explorer) or the client OS itself is the one looking for an answer. These ask the DNS resolver which is usually a part of the OS for an answer, and it’s the resolver that actually queries the server and gets the list of answers above.
The DNS resolver can then return the list as it is to the requesting application, or it can apply a re-ordering of its own. For instance, if the client is from the 192.168.10.0 network, the resolver may re-order the answers such that the 192.168.10.5 answer is always first. This is called Subnet prioritization. Basically, the resolver prioritizes answers that are from the same subnet as the client. The idea being that client applications would prefer reaching out to a server in their same subnet (it’s closer to them, no need to go over the WAN link for instance) than one on a different subnet.
Subnet prioritization can be disabled on the resolver side by adding a registry key PrioritizeRecordData (link) with value 0 (REG_DWORD) at HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesDnsCacheParameters. By default this key does not exist and has a default value of 1 (subnet prioritization enabled).
Subnet prioritization can also be set on the server side so it orders the responses based on the client network. This is controlled by the registry key LocalNetPriority (link) under HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesDNSParameters on the DNS server. By default this is 0, so the server doesn’t do any subnet prioritization. Change this to 1 and the server will order its responses according to the client subnet.
By default the server also does round-robin for the results it returns. This can be turned off via the DNS Management tool (under server properties > advanced tab). If round-robin is off the server returns records in the order they were added.
More on subnet prioritization at this link.
That’s is not the end though. 
Consider a server who has round-robin and subnet prioritization enabled. Now consider the DNS records from above:
- proxy.mydomain.com IN A 192.168.10.5
- proxy.mydomain.com IN A 10.136.53.5
- proxy.mydomain.com IN A 10.136.52.5
- proxy.mydomain.com IN A 10.136.33.5
- proxy.mydomain.com IN A 192.168.15.5
The first and last records are from class C networks. The other three are from Class A networks. In reality though thanks to CIDR these are all class C addresses.
Now say there’s a client with IP address 10.136.50.2/24 asking the server for answers. On the face of it the client network does not match any of the answer record networks so the server will simply return answers as per round-robin, without any re-ordering. But in reality though the client 10.136.50.2/24 is in the same network as 10.136.52.5/24 and both are part of a larger 10.136.48.0/20 network that’s simply been broken into multiple /24 networks (to denote clients, servers, etc). What can we do so the server correctly identifies the proxy record for this client?
This is where the LocalNetPriorityNetMask registry key under HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesDNSParameters on the DNS server comes into play. This key – which does not exist by default – tells the server what subnet mask to assume when it’s trying to subnet prioritize. By default the server assumes a /24 subnet, but by tweaking this key we can tell the server to use a different subnet in its calculations and thus correctly return an answer.
The LocalNetPriorityNetMask key takes a REG_DWORD value in a hex format. Check out this KB article for more info, but a quick run through:
A netmask can be written as xxx.xxx.xxx.xxx. 4 pairs of numbers. The LocalNetPriorityNetMask key is of format 0xaabbccdd – again, 4 pairs of hex numbers. This is a mask that’s applied on the mask of 255.255.255.255 so to calculate this number you subtract the mask you want from 255.255.255.255 and convert the resulting numbers into hex.
For example: you want a /8 netmask. That is 255.0.0.0. Subtracting this from 255.255.255.255 leaves you with 0.255.255.255.255. What’s that in hex? 00ffffff. So LocalNetPriorityNetMask will be 0x00ffffff. Easy?
So in the example above I want a /20 netmask. That is, I am telling the server to assume the clients and the record IPs it has to be in a /20 network, so subnet prioritize accordingly. A /20 netmask is 255.255.240.0. Subtract from 255.255.255.255 to get 0.0.15.255. Which in hex is 00000fff (15 decimal is F hex). So all I have to do is put this value as LocalNetPriorityNetMask on the DNS server, restart the service, and now the server will correctly return subnet prioritized answers for my /20 network.
Update: Some more links as I did some more reading on this topic later.
- Ace Fekay’s post – a must read!
- A subnet calculator (also gives you the wildcard, which you can use for calculating the
LocalNetPriorityNetMaskkey) - I am not very clear on what happens if you disable
RoundRobinbut there are multiple entries from the same subnet. What order are they returned in? Here’s a link to theRoundRobinsetting, doesn’t explain much but just linking it in case it helps in the future. - More as a note to myself (and any others if they wonder the same) – the subnet mask you specify is applied on the client. That is to say if you client has an IP address of say 10.136.20.10, by default the DNS server will assume a subnet mask of /24 (Class C is the default) and assume the client is in a 10.136.20.0/24 network. So any records from that range are prioritized. If you want to include other records, you specify a larger subnet mask. Thus, for example, if you specify a /20 then the client is assumed to have an IP address 10.136.20.10/20, so its network range is considered to be 10.136.16.1 – 10.136.31.254 (don’t wrack your brain – use the subnet calculator for this). So any record in this range is prioritized over records not in this range.
- The Windows calculator can be used to find the
LocalNetPriorityNetMaskkey value. Say you want a subnet mask of /19. The subnet calculator will tell you this has a wildcard of 0.0.31.255 – i.e. 00011111.11111111. Put this (13 1’s) into the Windows calculator to get the hex value 3FFF.
Introduction
In this post, I’ll provide a background on DNS round robin to load balance Exchange 2013 or Exchange 2016 CAS services.
Once done, I’ll demonstrate how this can be set up and then we’ll do a quick test.
Background
DNS Round Robin is where you have multiple A records for the same host name but different IPs for each record. For example:
mail.litwareinc.com IN A 10.2.0.21
mail.litwareinc.com IN A 10.2.0.22
When a client attempts to resolve the name mail.litwareinc.com, it will receive a response from the DNS server that includes two A records. Some clients can select an IP to connect to and then connect to the next IP in the list if that IP is not providing the expected service. Internet Explorer and some other Web Browsers can do this, in addition to Outlook.
DNS Round Robin is fully supported as a CAS service load balancing method for Exchange 2013 and Exchange 2016. For Exchange 2010 it is supported for some CAS protocols.
Session affinity in Exchange 2013 and 2016
Round Robin DNS is quite basic. It does not maintain session affinity which means that the client may not continue to connect to the same CAS server for the duration of the session. For Exchange 2010, this was a problem because of the processing that was done on the CAS server. In Exchange 2013 and 2016, the CAS services no longer require session affinity and basically act as a proxy to proxy the traffic through to the mailbox server where the mailbox database for that mailbox is active.
Advantages of DNS Round Robin for CAS load balancing
The advantages of using DNS round robin over a hardware load balancer are below:
- Cost, well actually it’s free.
- Quick and easy to set up as we’ll see later.
- Simple – you no longer need to know anything about load balancing solutions such as Kemp, Loadbalancer.org or F5. In fact, this is how Microsoft load balance connections to their Office 365 datacenter pairs.
Disadvantages of DNS Round Robin for CAS load balancing
Right, this is where we should pay attention as there are significant disadvantages:
- No health monitoring – DNS Round Robin is done entirely at the DNS level which is separate from Exchange. For this reason, an Exchange server failure will not stop that IP being passed on to clients for them to connect to until an administrator removes the A record from DNS. The failover happens at the client level as when it fails to connect to an IP, it’ll connect to the next IP.
- No load monitoring – for the same reason as above, DNS is unaware if one of your Exchange servers has an extremely high load or other issue causing a performance impact on the server.
- No ‘weighting’ – with DNS round robin, you cannot specify that 70% of connections are handled by one server with more compute resources whereas the other server handles only the remaining 30%. DNS round robin gives equal weight to each server. For example, if you have two servers, they will be load balanced 50:50 and this cannot be changed.
- No active/passive load balancing – for the same reason as above, you cannot have an active/passive setup. Each server has handles the same load.
- No reporting or logging – some load balancers provide failover reporting and almost all provide logging. This can be helpful if you repeatedly have failovers and you’d like to troubleshoot in more detail.
- Stopping a server is not instant – if you find that an Exchange server is still accepting client connections but has a problem and you need to remove it from the load balancer, you need to remove the A record associated with the server. The time this takes will depend on the Time To Live for the A record and it certainly won’t be instant as when you force stop a server in a hardware load balancer.
How to set up CAS DNS Round Robin Load Balancing
In this demo, I have two Exchange 2016 servers which are configured in a DAG. This provides high availability for the mailbox role. Instructions on how to set up an Exchange 2016 DAG can be found here. The servers and their IPs are below:
- LITEX01: 10.2.0.21
- LITEX02: 10.2.0.22
Users will connect to OWA, ActiveSync, Outlook Anywhere and all other services using the name mail.litwareinc.com. For autodiscover they will connect to autodiscover.litwareinc.com.
First we need to configure the virtual directories on both our Exchange 2016 servers to use these names. For instructions on how to do this, see here. This ensures that any autodiscover response directs clients to one of the hostnames that we’ll configure DNS round robin for and that no clients will connect to the server hostname itself and therefore not be load balanced.
Our next step is to create the required A records:
mail.litwareinc.com IN A 10.2.0.21
mail.litwareinc.com IN A 10.2.0.22
autodiscover.litwareinc.com IN A 10.2.0.21
autodiscover.litwareinc.com IN A 10.2.0.22
Below you can see a screenshot of how these records look on one of my domain controllers:

We can confirm that DNS round robin is in fact working by doing an nslookup for these names from one of our client machines. We’ll run the commands below:
nslookup
mail.litwareinc.com
autodiscover.litwareinc.com

Above we can see that the DNS answer includes both IPs for each response. If you look carefully, you’ll see that the same IP is not provided for each record – it’s random.
That’s it for internal DNS round robin load balancing setup.
For the external connections, create two NAT rules for your Exchange 2016 servers and open 443 from the internet to each server. Each server needs its own public IP.
Next, create two A records in your public DNS zone which resolve to your public IPs. Below are the DNS records that are created on my isolated ‘virtual’ internet:
mail.litwareinc.com IN A 95.59.2.21
mail.litwareinc.com IN A 95.59.2.22
autodiscover.litwareinc.com IN A 95.59.2.21
autodiscover.litwareinc.com IN A 95.59.2.22
I’ve put a computer on the virtual network and repeated the nslookup commands:
nslookup
mail.litwareinc.com
autodiscover.litwareinc.com

Testing CAS load balancing using DNS round robin
To do a quick test, I’m using Outlook 2016 in cached mode and have used autodiscover to create the Outlook profile.
If we display the Connection Status window, we can confirm that we are indeed connecting to the correct hostname – mail.litwareinc.com:

This however does not tell us which CAS server we are connected to. To do this, I’m using Resource Monitor to show the TCP connections for the Outlook.exe process.

Above we can see that Outlook is connected to 10.2.0.22 which is LITEX02. To simulate a failure of LITEX02, I’ve force powered off the virtual machine which would be the equivalent to a sudden total failure of the server.

Above we can see that Outlook connections to LITEX02, (10.2.0.22) are failing and showing up as greyed out.

Above shows more connections failing but now we’re starting to see new connections to 10.2.0.21 which is LITEX01.

Now we can see that all connections to LITEX02 have ended and been replaced with connections to LITEX01 and our failover is complete. From the point of view of Outlook, nothing was noticed. Outlook was responsive throughout the failover and in fact did not disconnect.
Conclusion
In this post we’ve gone through a bit of the background on DNS load balancing in Exchange 2016 and I’ve demonstrated how to set up DNS round robin to load balance your CAS services.
In the next post I’ll do further demonstrations with Outlook in online mode and we’ll also test out OWA and simulated partial CAS failures (e.g. single virtual directory failures).
– December 4, 2008Posted in: Networking, Operating Systems
A round robin lets you load balance by pointing the same host name to multiple servers in DNS. As long as round robin service is enabled in the DNS server, incoming requests will be spread among the servers.
Following is the short version of how to do this. For a more comprehensive look at this, see Rodney Buikes excellent article on the subject.
- In the DNS Mgmt application on your DNS server, right click the server name in the tree in the left pane, select Properties, select the Advanced tab, ensure that ‘Enable round robin’ is selected.
- Add HOST(A) records in the appropriate forward lookup zone, pointing to the servers to be covered.
- If you want a little poor-man’s fault tolerance, ensure that the TTL of each record is set to a short period of time, i.e. 15 seconds. This ensures that if one of the servers fails, repeated attempts to connect will soon hit another server.

About Editor
 Опубликовано: 08.07.2020
Опубликовано: 08.07.2020
Используемые термины: Remote Desktop Gateway, Active Directory, Терминальный сервер.
В данном руководстве мы рассмотрим развертывание роли шлюза удаленных рабочих столов (Remote Desktop Gateway или RDG) на отдельном сервере с Windows Server 2019. Действия будут аналогичны для Windows Server 2012 и 2016 (даже, в основных моментах, 2008 R2). Предполагается, что в нашей инфраструктуре уже имеются:
1. Служба каталогов Active Directory — настроено по инструкции Как установить роль контроллера домена на Windows Server.
2. Два терминальных сервера — настроено по инструкции Установка и настройка терминального сервера на Windows Server.
Пошагово, мы выполним следующие действия:
Установка серверной роли
Настройка шлюза
Создание групп в AD
Создание политик RDG
Привязка сертификата
Настройка клиента для подключения
Remoteapp через Gateway
DNS round robin
Часто встречаемые ошибки
Установка роли
Открываем Диспетчер серверов:

Переходим в Управление — Добавить роли и компоненты:

При появлении окна приветствия нажимаем Далее (при желании, можно поставить галочку Пропускать эту страницу по умолчанию):

На страницы выбора типа установки оставляем выбор на Установка ролей или компонентов:

Выбираем целевой сервер — если установка выполняется на сервере локально, то мы должны увидеть один сервер для выбора:

Ставим галочку Службы удаленных рабочих столов:

Дополнительные компоненты нам не нужны:

… просто нажимаем Далее.
На странице служб удаленных рабочих столов идем дальше:

Выбираем конкретные роли — нам нужен Шлюз удаленных рабочих столов. После установки галочки появится предупреждение о необходимости поставить дополнительные пакеты — кликаем по Добавить компоненты:

Откроется окно для настроек политик:

… нажимаем Далее.
Откроется окно роли IIS:

… также нажимаем Далее.
При выборе служб ролей веб-сервера ничего не меняем:

… и идем дальше.
В последнем окне ставим галочку Автоматический перезапуск конечного сервера, если требуется:

Нажимаем Установить:

Дожидаемся окончания установки роли:

Сервер может уйти в перезагрузку.
Настройка RDG
Для настройки Microsoft Remote Desktop Gateway мы создадим группу компьютеров в Active Directory, настроим политику для RDG и создадим сертификат.
Создание групп для терминальных серверов
Политика ресурсов позволит задать нам конкретные серверы, на которые терминальный шлюз позволит нам подключаться. Для этого мы откроем консоль Active Directory — Users and computers (Пользователи и компьютеры Active Directory) и создаем группу:

* в данном примере мы создаем группу All terminals в организационном юните Servers Group. Это группа безопасности (Security), локальная в домене (Domain local).
Добавим в нашу группу терминальные серверы:

* в данном примере у нас используются два сервера — Terminal-1 и Terminal-2.
Закрываем консоль Active Directory — Users and computers.
Настройка политик
Для предоставления доступа к нашим терминальным серверам, создадим политики для подключений и ресурсов.
В диспетчере сервера переходим в Средства — Remote Desktop Services — Диспетчер шлюза удаленных рабочих столов:

Раскрываем сервер — кликаем правой кнопкой по Политики — выбираем Создание новых политик безопасности:

Устанавливаем переключатель в положении Создать политику авторизации подключений к удаленным рабочим столам и авторизации ресурсов удаленных рабочих столов (рекомендуется):

Даем название политике:

Задаем параметры авторизации:

* мы указали, что пользователи должны подтверждать право вводом пароля, также мы указали, что для применения политики они должны принадлежать группе Domain Users.
В следующем окне есть возможность настроить ограничения использования удаленного рабочего стола. При желании, можно их настроить:

* в нашем случае ограничений нет. При необходимости, устанавливаем переключатель в положение Отключить перенаправление для следующих типов клиентских устройств и оставляем галочки пункты для ограничений.
Далее настраиваем временные ограничения использования удаленного подключения. Если в этом есть необходимость, оставляем галочки в состоянии Включить и указываем количество минут, по прошествии которых сеанс будет отключен:

В следующем окне мы увидим вне введенные настройки:

Идем далее.
Откроется страница создания политики для авторизации ресурса — задаем для нее название:

Указываем группу пользователей, для которой будет применяться политика:

* как и при создании первой политики, мы добавили группу Domain Users.
Теперь выбираем группу ресурсов, на которую будет разрешен доступ со шлюза терминалов:

* мы выбрали группу, созданную нами ранее в AD.
Указываем разрешенный для подключения порт или диапазон портов:

* в данном примере мы разрешим подключение по порту 3389, который используется по умолчанию для RDP.
Нажимаем Готово:

Политики будут созданы.
Настройка сертификата
Для работы системы нам необходим сертификат, который можно купить или получить бесплатно от Let’s Encrypt. Однако, с некоторыми неудобствами, будет работать и самоподписанный. Мы рассмотрим вариант настройки с ним.
Запускаем «Диспетчер шлюза удаленных рабочих столов» — кликаем правой кнопкой по названию нашего сервера — выбираем Свойства:

Переходим на вкладку Сертификат SSL:

Выбираем вариант Создать сомозаверяющий сертификат и кликаем по Создать и импортировать сертификат:

Задаем или оставляем имя для сертификата — нажимаем OK:

Мы увидим информацию о создании сертификата:

Консоль диспетчера шлюза перестанет показывать ошибки и предупреждения:

Сервер готов к работе.
Подключение к серверу терминалов через шлюз
Выполним первое подключение с использованием шлюза. В качестве клиентской операционной системы могут использоваться Windows, Linux, Mac OS. Рассмотрим пример на Windows 10.
Запускаем «Подключение к удаленному рабочему столу» (приложение можно найти в Пуск или ввести команду mstsc). На вкладке Общие вводим локальное имя конечного сервера, к которому мы хотим подключиться:

* в нашем случае мы будем подключаться к серверу terminal-1.dmosk.local.
Переходим на вкладку Дополнительно и кликаем по Параметры:

Переключаем параметр приложения в положение Использовать следующие параметры сервера шлюза удаленных рабочих столов и указываем внешнее имя сервера:

* важно указать именно имя сервера, а не IP-адрес. В моем примере имя сервера rdp.dmosk.local (данное имя не является правильным внешним, но это только пример).
Кликаем Подключить:

Если мы используем самозаверенный сертификат, приложение выдаст ошибку. Кликаем по Просмотреть сертификат:

Переходим на вкладку Состав и кликаем Копировать в файл:

Указываем путь для выгрузки файла:

Открываем папку, куда сохранили сертификат. Кликаем по сохраненному файлу правой кнопкой и выбираем Установить сертификат:

Выбираем Локальный компьютер — Далее:

В качестве размещения сертификата выбираем Доверенные корневые центры сертификации:

Импортируем сертификат.
После снова пробуем подключиться к удаленному рабочему столу через шлюз:
Система запросит логин и пароль для подключения (возможно, дважды) — вводим данные для учетной записи с правами на подключение (на основе настройки политики RDG).
Настройка Remoteapp через Gateway
Предположим, у нас есть опубликованное приложение Remoteapp и мы хотим подключаться к терминальному серверу через настроенный шлюз. Для этого открываем rdp-файл приложения на редактирование (например, блокнотом) и вносим в него изменения:
…
gatewayhostname:s:rdg.dmosk.local
gatewayusagemethod:i:1
…
* где:
- gatewayhostname:s:rdg.dmosk.local — добавленная строка. Настройка говорит, что если при подключении к серверу нужно использовать шлюз, то это должен быт rdg.dmosk.local.
- gatewayusagemethod:i:1 — отредактированная строка. Указывает, что необходимо использовать шлюз.
Пробуем подключиться.
Несколько терминальных серверов и dns round robin
При наличие нескольких серверов терминалов, мы можем создать несколько записей в DNS, чтобы получать по round robin разные серверы:

Однако, при попытке подключиться к незарегистрированному серверу мы увидим ошибку:

Для решения переходим в настройку шлюза — кликаем правой кнопкой по Политики авторизации ресурсов и выбираем Управление локальными группами компьютеров:

Выбираем нужную группу компьютеров и нажимаем Свойства:

* в моем случае это была единственная группа, созданная по умолчанию.
На вкладке Сетевые ресурсы добавляем имя, созданное в DNS:

Теперь подключение будет выполняться без ошибок.
Возможные ошибки
При подключении мы можем столкнуть со следующими ошибками.
1. Учетная запись пользователя не указана в списке разрешений шлюза удаленных рабочих столов.
Причиной является отсутствие пользователя, под которым идет подключение к шлюзу, в группе, которой разрешено использование политики. Для решения проблемы проверяем настройки политики — группы пользователей, которым разрешено использование политики и к каким ресурсам разрешено подключение. В итоге, наш пользователь должен быть в нужной группе, а терминальный сервер, к которому идет подключение должен быть указан в соответствующей группе ресурсов.
2. Возможно, удаленный компьютер указан в формате NetBIOS (например, computer1), но шлюз удаленных рабочих столов ожидает полное доменное имя или IP-адрес (например, computer1.fabrikam.com или 157.60.0.1).
Обращение к терминальному серверу выполняется по незарегистрированному имени. Необходимо проверить настройку в клиенте подключения или зарегистрировать ресурс, как мы это делали при настройке нескольких терминальных серверов.
3. Сертификат шлюза удаленных рабочих столов просрочен или отозван.
В данном случае нужно проверить, какой сертификат привязан к RDG. Также нужно убедиться, что привязанный сертификат, на самом деле, не просрочен или отозван. В крайнем случае, можно заново создать сертификат.
So, what is Round Robin?
It’s a method of load balancing that enables you to spread the network load between servers on your network.
For example, let’s say I have three WEB servers hosting the same content with three A host records.
All with the same name of SA but with different IP addresses.
The goal is to load balance between these three servers to help share the network load.
That’s exactly what Round Robin will do. I’ve created another record called a CNAME record. This record maps the alias name in this case, www to the true name sa.serveracademy.
From our DNS server. We can check the status of Round Robin and Netmask Ordering from Server Manager.
Let’s go ahead and open server manager, click tools, and DNS manager, from our server right click then click properties, then click Advanced.
And you can see that round robin and netmask ordering are both checked and enabled by default.
- Now I’ll show you how round robin works
- The 1st client will get the 1st address, then the second address, then the third address. The second client will get the 2nd address first, the third address 2nd, and the 1st address third. Then the third client will get the 3rd address first the 1st address second, and the 2nd address third and down the line.
The 4th client would get the 1st address again then back and forth and back and forth.
- So, the advantage of Round Robin is to ensure that there is load balancing anytime duplicate names are found with different IP addresses in the DNS environment.
- We can test Round Robin by opening a DOS prompt in administrator mode and typing nslookup, then pressing return. This puts nslookup in interactive mode.
- Now type www.serveracademy
- if you recall that is our CNAME record and press return
- Now press the up arrow key and press return.
Each time you press the up arrow key, and press return
your reloading the CNAME record, and you getting different results.
You can see that the WEB server IP addresses are rotating, and that round-robin is working as it should.
- But one of the disadvantages of Round Robin is that the DNS server never goes out to see if one of the servers is down.
So, if, for example, SA1 is down that means that 33% or more of my clients will attempt to connect and fail.
- So, this is not hardware load balancing,
- But it is there and provides this basic functionality.
Configuring Netmask Ordering
- One way you can enhance DNS Round Robin is by enabling NetMask Ordering
- So, what is Netmask Ordering?
Let’s go back to our example, Let’s say we have created one more webserver, an A record with a name of SA with an address of 10.0.1.10.
If we have one client on the 192.168.0 subnet, it will get the normal rotation of 1,2,3,4
Then the next client that shows up from the 192.168.0 subnet might get 2,3,1,4.
But if we have two more clients connect and their client IP address is on the 10.0.1.0 subnet, the SA4 server will always be the most preferred server.
Anything in this subnet will always be on top of the list.
But these two clients on the 192.168.0 subnet will never get the address for SA4 at the top because they belong on the wrong subnet.
For those two clients, 10.0.1.10 will always be the least preferred IP address.

Server Academy Members Only
Want to access this lesson? Just sign up for a free Server Academy account and you’ll be on your way. Already have an account? Click the Sign Up Free button to get started..