17 декабря 2021
4 417
0
Время чтения ≈ 17 минут

Содержание:
- Что такое контейнеризация и почему она важна
- Что такое Docker
- Что такое Kubernetes
- Проблема оркестрации контейнеров
- В чем разница Kubernetes и Docker Swarm
- Заключение
Говоря о технологии виртуализации вообще и контейнеризацию в частности, невозможно обойти вниманием два ключевых для этого направления инструмента — Docker и Kubernetes. Ведь они не только крайне популярны, но и напрямую связаны друг с другом по функционалу — позволяют создавать и обслуживать среды для запуска контейнеризованных приложений.
В этой статье разберём базовые различия между Kubernetes и Docker, основные области их применения, а также некоторые проблемы, связанные с этими технологиями, например вопрос мониторинга. Но сначала немного погрузимся в теорию.
Почему контейнеризация важна
Что такое контейнер приложения
Контейнеризация (контейнерная виртуализация) — это метод виртуализации, при котором единое «пользовательское пространство» в ядре операционной системы разделяется на несколько независимых логических разделов. Один экземпляр такого раздела называется контейнером или зоной. В каждом контейнере можно запускать одно приложение, изолированное от остальной системы.
Контейнер функционирует как экземпляр исполняемого ПО, где двоичный код приложения соседствует со всеми необходимыми для его запуска компонентами — от конфигурационных файлов до среды исполнения. Каждое приложение в контейнере получает свою собственную частную сеть и виртуальную файловую систему, которая не используется совместно с другими контейнерами или хостом.
Чем отличается контейнеризация от виртуализации
По своему функционалу и назначению контейнеры приложений похожи на виртуальные машины (VM), которые действуют на основе аппаратной виртуализации. Однако, не следует напрямую отождествлять понятия «контейнеризация» и «аппаратная виртуализация». Это отдельные технологии виртуализации, которые решают схожие задачи разными способами.
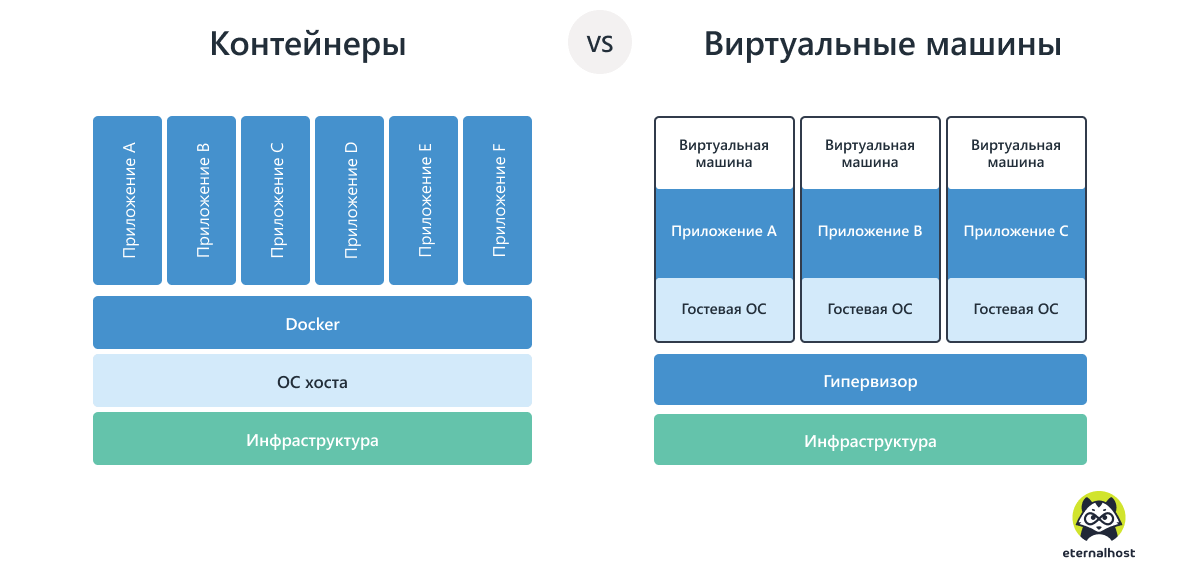
Виртуальная машина — это полноценная операционная система внутри другой ОС, с собственным ядром и другими изолированными ресурсами. Контейнер — не готовый «компьютер», а лишь изолированный механизм для запуска одного приложения.
В отличие от аппаратной виртуализации, контейнеризация обеспечивает разделение ресурсов не на аппаратном уровне, а на базе ядра операционной системы. Контейнеры более легковесны, менее требовательны и полностью зависимы от «материнской» ОС, чем VM.
Зачем нужна контейнеризация
Контейнеры решают критически важную проблему переносимости кода. Они сводят на нет возможные противоречия между собственной локальной средой разработки и производственной средой приложения.
Упаковка в контейнеры позволяя отделить код от базовой инфраструктуры, в которой он работает. В производственной среде этот контейнер можно запускать на любом компьютере, на котором есть платформа контейнеризации. В продакшене код будет работать также хорошо, как и на машине программиста.
Преимущества контейнеризации
- Контейнеризация стала ключевым техническим компонентом для обеспечения непрерывного развертывания и уменьшения жизненного цикла инновации продукта. Благодаря тому, что предприятия разбивают монолитную архитектуру своих производств на гибкие контейнерные микросервисы, время вывода на рынок начинает отсчитываться не в месяцах, а в днях.
- Упрощение конфигурирования приложений. Стандартный контейнер Docker универсален. Упакованное в него приложение может работать без дополнительных настроек где угодно — на персональном компьютере (ПК, Mac, Linux), в облаке, на локальных серверах и даже на пограничных устройствах.
- Контейнерная технология крайне эффективна как средство повышения эффективности разработки. Небольшие группы могут разрабатывать и упаковывать свои приложения на локальных устройствах (например, ноутбуках), а затем развертывать его в практически любой тестовой или производственной среде. Время и усилия, сэкономленные при тестировании и развертывании, кардинально меняют правила игры во всем процессе автоматизации производства.
- Контейнеры легко воспроизвести, поэтому их удобно использовать для автоматического масштабирования приложений. Такой подход дает возможность легко подстраиваться под требования быстро растущего и меняющегося пользовательского трафика.
Практические примеры использования контейнеров

- Создание производственного кластера. Если перед DevOps стоит задача развёртывания надёжной и легко масштабируемой системы для автоматизированного управления контейнерным кластером, то он скорее всего не будет делать это вручную. К услугам специалиста ряд готовых решений на основе Docker и Kubernetes. Например, коммерческая платформа OpenShift от компании Red Hat и ее бесплатная опенсорсная версия OKD.
- Перенос кластерной инфраструктуры в облако. Миграция сервисов компании на облачную, мультиоблачную или гибридную платформу не только открывает новые возможности для развития, но и сулит ряд сложностей, связанных с совместимостью. Чтобы с легкостью переносить инфраструктуру между собственными сервисами и облаками различных производителей, компании используют такие удобные инструменты управления комбинированными средами, как Rancher.
- Платформа для машинного обучения. Контейнерные кластеры, оркестрируемые Kubernetes, прекрасно подходят для упрощенного развертывания систем ML. Примером реализации такой технологии служит специализированный сервис Kubeflow.
- Бессерверная вычислительная платформа. Благодаря системе оркестрации контейнеров Kubernetes и фреймворку для построения шаблонов бессерверных приложений Kubeless, каждый разработчик сможет создать собственную serverless инфраструктуру в любой среде.
Подобно тому, как название фирмы Xerox стало нарицательным именем для всех копировальных аппаратов или копий бумажных документов, а поисковик Google обогатил интернет-словарь глаголом «гуглить», Docker стал синонимом работы с контейнерами.
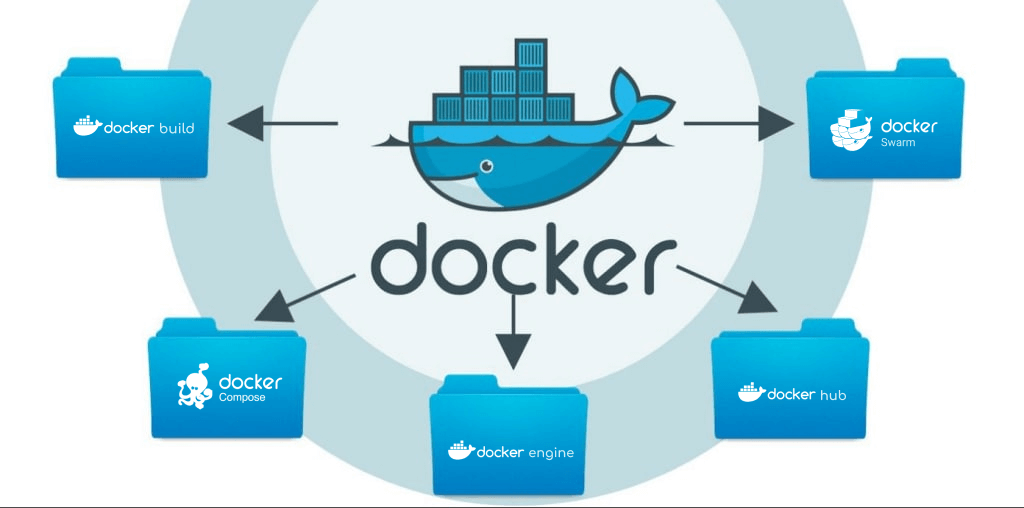
Однако Docker — больше, чем сами контейнеры. Это обширный набор инструментов для разработчиков, позволяющий создавать, публиковать, запускать и управлять контейнерными приложениями.
Для чего нужен Docker
Создание образов
Docker Build создает базовый образ контейнера, который включает все необходимое для запуска приложения — его код, двоичные файлы, сценарии, зависимости, конфигурацию, переменные среды и другое. Для определения и запуска многоконтейнерных приложений применяется инструмент Docker Compose.
Docker Build и Docker Compose тесно интегрированы с репозиториями кода (GitHub), а также с инструментами конвейера непрерывной интеграции и непрерывного развертывания — CI/CD (например, Jenkins).
Совместное использование образов
Docker Hub — служба реестра Docker, применяемая для поиска образов контейнеров, а также предоставления ограниченного (для разработчиков) или общего доступа к этим образам. Docker Hub по функциональности похож на GitHub.
Запуск контейнеров
Среда выполнения контейнеров Docker Engine работает практически на любой платформе — компьютерах Mac и Windows, серверах Linux и Windows, в облаке и на пограничных устройствах.
Docker Engine функционирует как обертка над движком containerd — исполняемой средой для запуска контейнеров с открытым исходным кодом, поддерживаемой независимым проектом Cloud Native Computing Foundation (DNCF).
Встроенная оркестрация контейнеров
Встроенный инструмент Docker Swarm управляет кластером модулей Docker или «роем» (от англ. swarm). Обычно такой кластер создается на разных нодах. Функционал Docker Swarm напрямую пересекается с Kubernetes.
Подробнее об устройстве и работе с Docker можно узнать из нашей статьи «Что такое Docker».
Что такое Kubernetes
Kubernetes (K8s) — портативная платформа оркестрации контейнеров с открытым исходным кодом. Этот инструмент используется для автоматизации развертывания контейнерных приложений на разных хостах, а также планового масштабирования и управления ими.
С помощью K8s можно не отвлекаться на обслуживание отдельной виртуальной или физической машины с развернутыми контейнерами, а управлять целым их кластером. В рамках кластера K8s можно планово запускать контейнеры (Docker, containerd и CRI-O), опираясь на объем имеющихся вычислительных мощностей и индивидуальные ресурсные потребности каждого контейнера.
Платформу Kubernetes выбирают 88% организаций, использующих контейнеризацию в производстве. Первоначально разработанный Google, теперь он доступен во многих дистрибутивах и широко поддерживается всеми поставщиками общедоступных облачных услуг. Собственный управляемый сервис Kubernetes есть у Amazon (Elastic Kubernetes Service), Microsoft (Azure Kubernetes Service) и Google (Kubernetes).
Включена K8s и во многие популярные дистрибутивы, включая Red Hat OpenShift, Rancher / SUSE, VMWare Tanzu и IBM Cloud. Такая широкая поддержка позволяет Kubernetes избежать привязки к конкретным производителям софта. Это дает использующим ее DevOps-инжинерам больше возможностей сосредоточиться на собственном продукте.
Как работает Kubernetes
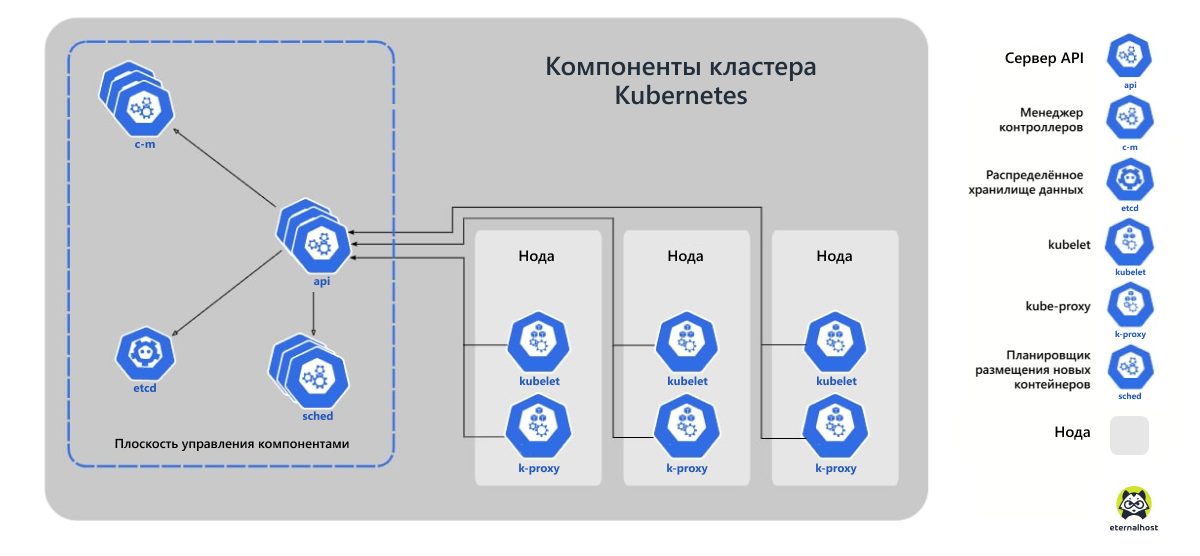
Контейнеры в Kubernetes объединяются в логические объекты под названием поды (pods) — наборы из одной или более базовых единиц, готовых к развертыванию на нодах («узлах» физических или виртуальных машин).
Настройка и управление подами осуществляется с помощью трех базовых агентов или утилит: kubectl, kubelet и kubeadm. Помимо основного управляющего агента kubelet, на каждом «узле» работает сетевой прокси kube-proxy, который настраивает правила сети.
Жизненным циклом подов можно легко управлять и масштабировать их до нужного состояния. За счет этого обеспечивается высокий уровень контроля за стабильностью и качеством работы развернутых приложений.
Для чего нужен Kubernetes
- Управление контейнерами на нескольких хостах одновременно.
- Оптимизация ресурсов используемого оборудования.
- Автоматическое развертывание и обновления приложений.
- Подключение и добавление хранилищ для запуска приложений с отслеживанием состояния.
- Масштабирование контейнерных приложений и их ресурсов на лету.
- Декларативное управление службами, что гарантирует полный контроль над развернутыми приложениями.
- Автоматический контроль работоспособность и восстановление приложений с помощью функций автозапуска, автозамены, авторепликации и автомасштабирования.
Взаимодействие Kubernetes и Docker
Долгое время средой выполнения контейнеров используемой Kubernetes по умолчанию был Docker. Но Docker никогда не предназначался для работы внутри Kubernetes.
По этой причине, разработчики Kubernetes реализовали собственное API — Container Runtime Interface (CRI). Этот интерфейс позволяет выбирать между различными средами выполнения контейнеров, делая платформу более гибкой и менее зависимой от Docker.
Однако, подобное изменение создало новую трудность для команды Kubernetes, поскольку Docker не поддерживает CRI. Поэтому вместе с собственным API, в Kubernetes был внедрен «адаптер» под названием Dockershim. Он переводит команды CRI на «язык» платформы Docker.
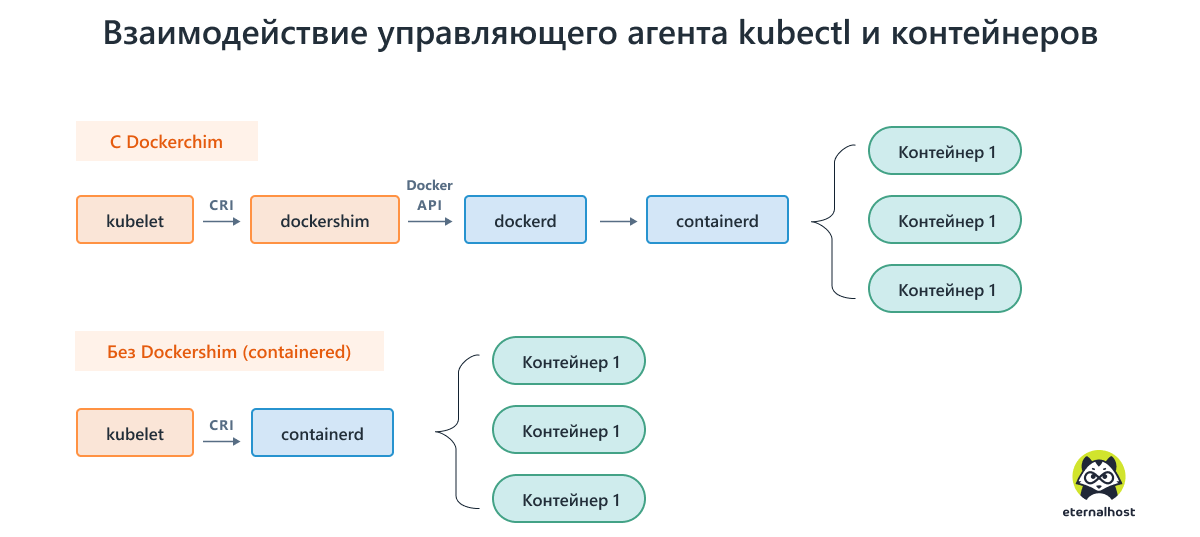
Сегодня прямая привязка Kubernetes к Docker осталась в прошлом. в 2021 компания официально заявила об отказе от ориентации на Docker — пост в официальном блоге получил говорящий заголовок «Без паники». Приоритет получили альтернативные среды выполнения контейнеров — containerd и CRI-O. Более того, начиная с релиза K8s 1.24, Docker (Dockershim) будет официально исключён из кодовой базы Kubernetes, хотя поддержка в более старых версиях останется.
Подробнее о теории и практике работы с Kubernetes можно узнать из отдельной статьи «Kubernetes для чайников».
Проблема оркестрации контейнеров
Главной точкой пересечения для Kubernetes и Docker является оркестрация (или оркестровка) контейнерных кластеров. Хотя Docker Swarm также является инструментом оркестрации, Kubernetes де-факто стал ведущим стандартом оркестровки контейнеров из-за его большей гибкости и возможностей масштабирования.
Хотя у Docker Swarm и Kubernetes оркестрация контейнеров организована немного по-разному, но они сталкиваются с одними и теми же проблемами. Современное приложение может состоять из десятков или сотен контейнерных микросервисов, которые должны бесперебойно работать вместе. Они размещаются на нескольких хост-машинах, называемых нодами («узлами»), которые могут быть соединены в один кластер.
Если рассмотреть схему взаимодействия контейнеров и нод, станет очевидно, что для координации такой распределенной системы необходим ряд специальных инструментов — платформ оркестровки. Системы оркестрации контейнеров часто сравнивают с дирижером, который искусно направляет отдельные инструменты оркестра для совместного исполнения сложных симфонических партий.
Задачи платформ оркестрации контейнеров
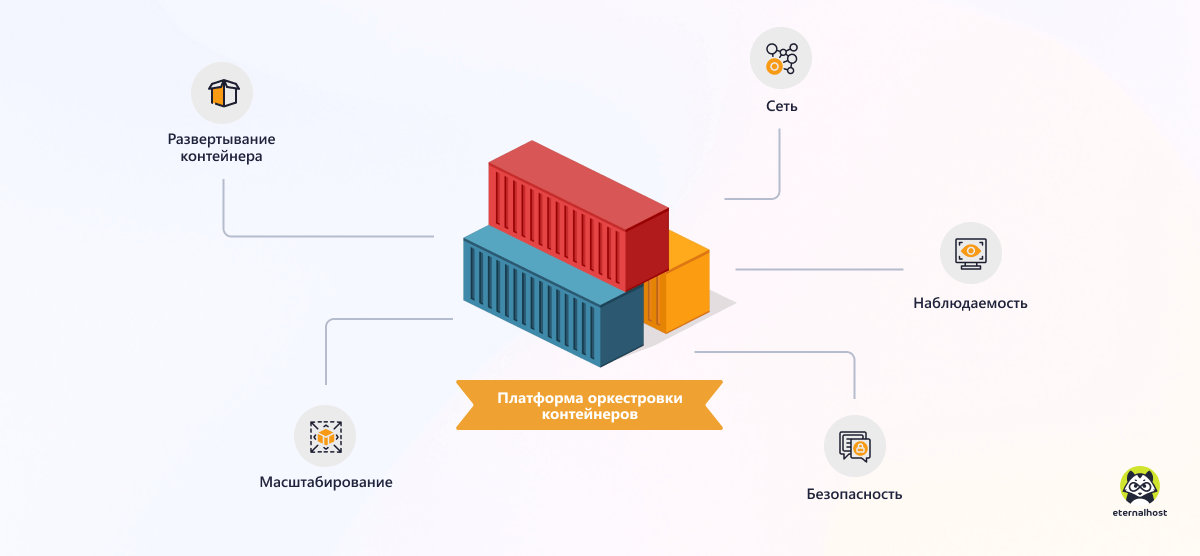
Развертывание контейнера
Платформа оркестрации способна не только получить образ контейнера из репозитория и развернуть его на ноде. Она обеспечивает автоматическое воссоздание отказавших экземпляров, их последовательное развертывание, во избежание простоя конечных пользователей, а также управление всем жизненным циклом контейнера.
Масштабирование
Это одна из самых важных задач платформы оркестровки. «Планировщик» (scheduler) главной ноды определяет размещение новых контейнеров, чтобы вычислительные ресурсы использовались наиболее эффективно. Контейнеры можно реплицировать или удалять «на лету», чтобы соответствовать изменяющемуся пользовательскому трафику.
Сеть
Контейнерные сервисы должны легко находить друг друга и обмениваться данными безопасным образом. Учитывая динамический характер контейнеров, это довольно сложно осуществить. Кроме того, некоторые службы (например, интерфейс) должны быть постоянно доступны конечным пользователям, а для распределения трафика между несколькими нодами требуется балансировщик нагрузки.
Наблюдаемость
Платформа оркестрации должна предоставлять данные о своих внутренних состояниях и действиях в форме журналов, событий, показателей или трассировки транзакций. Это позволяет операторам правильно оценить состояние и поведение контейнерной инфраструктуры, а также приложений, работающих в ней.
Безопасность
Платформа оркестрации имеет различные встроенные инструменты для предотвращения уязвимостей — безопасные конвейеры развертывания контейнеров, зашифрованный сетевой трафик, хранилища секретов и многое другое. Однако одних этих механизмов недостаточно для создания надежного контура безопасности. Необходим комплексный подход по модели DevSecOps.
Рассмотрев теоретические основы, можно подробнее рассмотреть различия между Kubernetes и Docker.
В чем разница Kubernetes и Docker Swarm
И Docker Swarm, и Kubernetes — это платформы для оркестрации контейнеров производственного уровня, но у каждой из них есть свои сильные стороны.
Платформа Docker Swarm
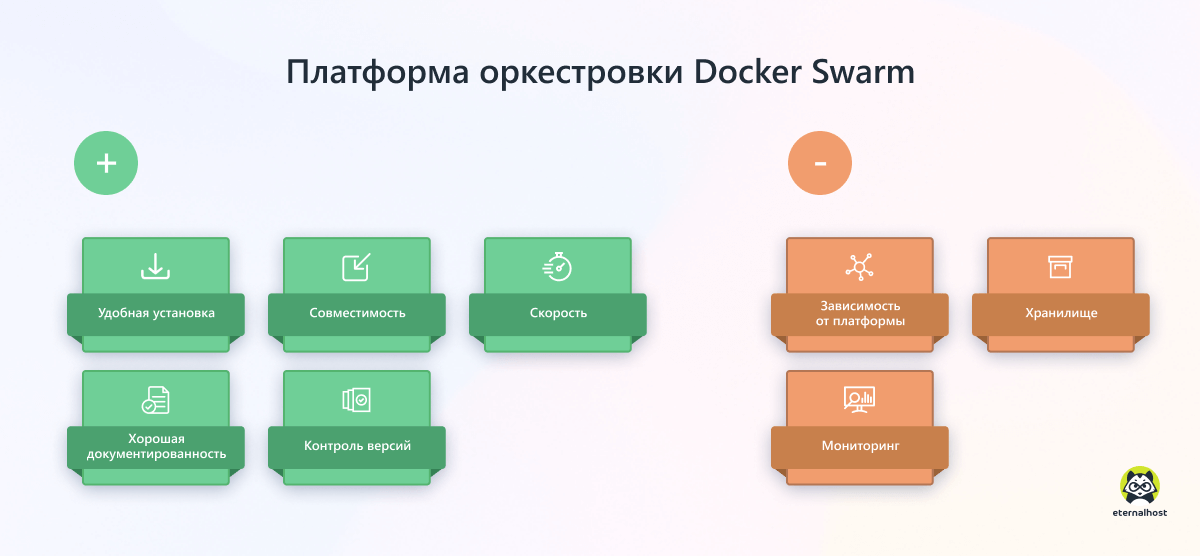
Встроенная утилита Docker Swarm (Docker in swarm mode, «Docker в режиме роя») — самый простой в развертывании и управлении оркестратор. Это хороший выбор для организации, которая только начинает использовать контейнеры в производстве.
Swarm надежно покрывает 80% всех возможных сценариев оркестровки контейнеров. При этом его инструментарий примерно в 5 раз легче освоить, чем Kubernetes.
Swarm легко интегрируется с остальной частью набора инструментов Docker, например с Docker Compose и Docker CLI. Это обеспечивает привычный пользовательский интерфейс с плавной кривой обучения. Для контейнеров Docker Swarm считается более безопасным и простым в устранении неполадок, чем Kubernetes.
Плюсы Docker Swarm
- Удобная установка. Для работы Docker Swarm использует тот же интерфейс командной строки, что и Docker. Это упрощает настройку и дальнейшую работу пользователей. Ведь им нужно изучить только один набор инструментов для создания сред и конфигураций.
- Совместимость. Docker Swarm работает поверх Docker и идеально совместим с другими инструментами этой экосистемы. Пользователи работают с одним и тем же интерфейсом командной строки Docker, который обеспечивает простую в использовании структуру команд.
- Скорость. Docker Swarm предоставляет динамичную среду, которая позволяет приложениям быстро запускаться в виртуальном пространстве.
- Хорошая документированность. Docker постоянно обновляет свою документацию, чтобы давать пользователям самую последнюю информацию по изменениям в своей экосистеме.
- Контроль версий. Пользователи могут легко отслеживать текущие версии docker-контейнера, чтобы контролировать расхождения с предыдущими версиями.
Минусы Docker Swarm
- Зависимость от платформы. Docker Swarm поддерживает несколько операционных систем, но только на базе Linux.
- Хранилище. В Docker нет встроенной реализации хранилища, поэтому Docker Swarm — не самое простое решение для подключения контейнеров к хранилищу.
- Мониторинг. В Docker Swarm нет встроенных инструментов расширенного мониторинга, позволяющих собрать больше данных в режиме реального времени.
Платформа Kubernetes
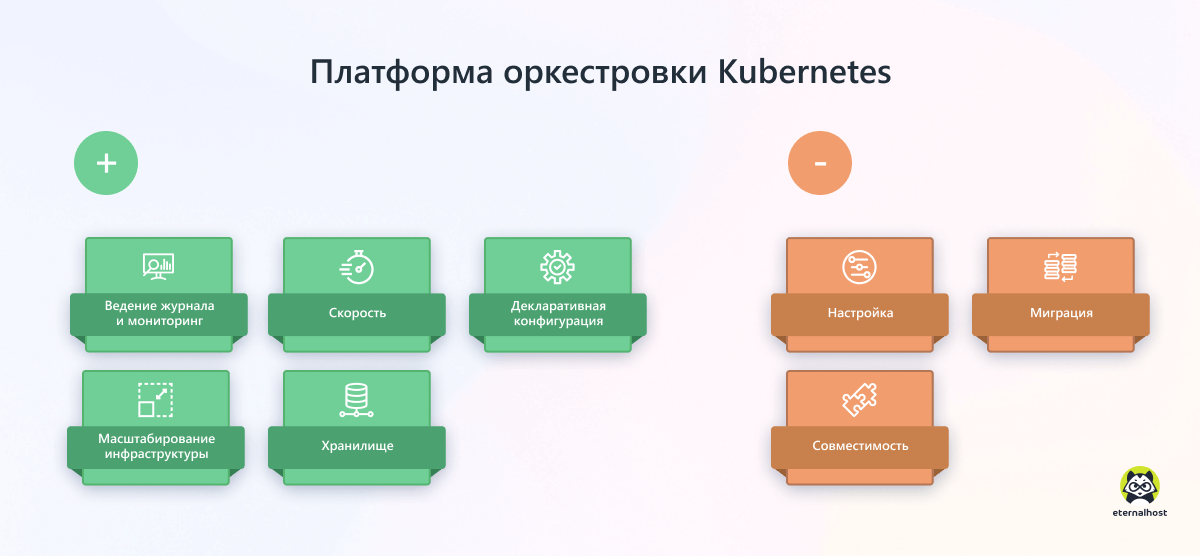
Главные «козыри» платформы оркестрации Kubernetes — почти безграничная масштабируемость, гибкая настраиваемость и богатая технологическая экосистема, включающая множество фреймворков с открытым исходным кодом для мониторинга, управления и безопасности.
Плюсы Kubernetes
- Ведение журнала и мониторинг. Поддержка нескольких вариантов ведения журнала и мониторинга при развертывании служб в кластере.
- Скорость. Kubernetes способен обновлять приложения в непрерывном режиме, добиваясь стабильного аптайма и отсутствия простоев.
- Декларативная конфигурация системы. Декларативный подход позволяет разработчику сообщить API-серверу о необходимом ему состоянии системы, а распределение ресурсов, организацию процессов и другие детали реализации берет на себя kubectl.
- Масштабирование инфраструктуры. Из-за неизменной и декларативной природы Kubernetes систему легко расширять с помощью методов горизонтального, автоматического и ручного масштабирования, а также применения контроллера репликаций.
- Хранилище. Kubernetes обменивается данными между контейнерами, надежно сохраняя данные на удаленном хранилище, пока пользователь не решит их удалить.
Минусы Kubernetes
- Настройка. Kubernetes использует разные настройки для каждой операционной системы, что усложняет процесс.
- Миграция. Если приложение уже кластеризовано или не имеет состояния, попытка миграции в Kubernetes приведет к сбою настройки подов и необходимости переработки конфигурации.
- Совместимость. Kubernetes несовместим с существующими инструментами Docker CLI и Compose.
Kubernetes vs Docker Swarm
| Kubernetes | Docker Swarm |
| Комплексная установка. | Облегченная установка поверх Docker. |
| Более сложный — длительный процесс обучения, но более мощный инструмент. | Легкий и простой в освоении, но с ограниченной функциональностью. |
| Поддерживает автоматическое масштабирование. | Масштабирование в ручном режиме. |
| Встроенный мониторинг. | Требуются сторонние инструменты для мониторинга. |
| Ручная настройка балансировщика нагрузки. | Автоматическая балансировка нагрузки. |
| Необходим отдельный инструмент CLI. | Интегрирован с Docker CLI. |
Заключение
Kubernetes и Docker — технологии контейнеризации с разными сферами применения, которые успешно работают как по отдельности, так и вместе. Первый инструмент служит для определения и запуска контейнеров, а второй — это система оркестрации, которая представляет и управляет контейнерами в веб-приложении.
Возможность создание контейнеров — это главное, чем Docker отличается от Kubernetes. Сам Kubernetes не создает контейнеры, а полагается на готовый способ их реализации, такой как Docker или containerd.
Docker целесообразно применять для разработки программного обеспечения. Это включает настройку, создание и распространение контейнеров, с использованием конвейеров CI / CD и DockerHub в качестве реестра образов.
Kubernetes хорошо показывает себя в операциях с кластерами контейнеров, решая проблемы автоматизации развертывания, работы в сети, масштабирования и мониторинга. Хотя Docker Swarm является альтернативой в этой области, Kubernetes — лучший выбор при оркестровке больших распределенных приложений с сотнями подключенных микросервисов, включая базы данных, секреты и внешние зависимости.
Чтобы использовать возможности контейнеризации на 100%, Docker и Kubernetes нужна подходящая рабочая среда. Правильное решение — VPS от Eternalhost. Мощные виртуальные сервера с возможностью быстрого масштабирования ресурсов!
Оцените материал:
[Всего голосов: 0 Средний: 0/5]
OpenShift – это платформа RedHat для облачной разработки как услуга ( PaaS ). Он использует Kubernetes в качестве оркестровки контейнеров (так что вы можете использовать OpenShift в качестве реализации Kubernetes ), но предоставляя некоторые функции, пропущенные в Kubernates, такие как автоматизация процесса сборки контейнеров, управление работоспособностью, хранение динамических ресурсов или многопользовательская поддержка, чтобы привести некоторые из них.
В этом посте я собираюсь объяснить, как вы можете развернуть образ Docker из Docker Hub в экземпляр OpenShift .
Важно отметить, что OpenShift предлагает другие способы создания и развертывания контейнера в его инфраструктуре, о чем вы можете прочитать на https://docs.openshift.com/enterprise/3.2/dev_guide/builds.html, но, как читалось в предыдущем В этом случае я собираюсь показать вам, как развернуть уже созданные образы Docker из Docker Hub .
Первое, что нужно сделать, это создать учетную запись в OpenShift Online . Это бесплатно и ради этого поста достаточно. Конечно, вы можете использовать любой другой подход OpenShift, например, OpenShift Origin .
После этого вам необходимо войти в кластер OpenShift . В случае OpenShift Online с использованием токена предоставляется:
|
1 |
|
Затем вам нужно создать новый проект внутри OpenShift .
Вы можете понимать проект как пространство имен Kubernetes с дополнительными функциями.
Затем давайте создадим новое приложение в предыдущем проекте на основе образа Docker, опубликованного в Docker Hub . Этот пример представляет собой приложение VertX, где вы можете получить преступления от нескольких вымышленных злодеев от Лекса Лютора до Гру.
|
1 |
|
В этом случае новое приложение под названием преступления создается на основе изображения lordofthejars / crime: 1.0 . После выполнения предыдущей команды создается новый модуль с предыдущим образом + служба + контроллер репликации.
После этого нам нужно создать маршрут, чтобы сервис был доступен для публичного интернета.
|
1 |
|
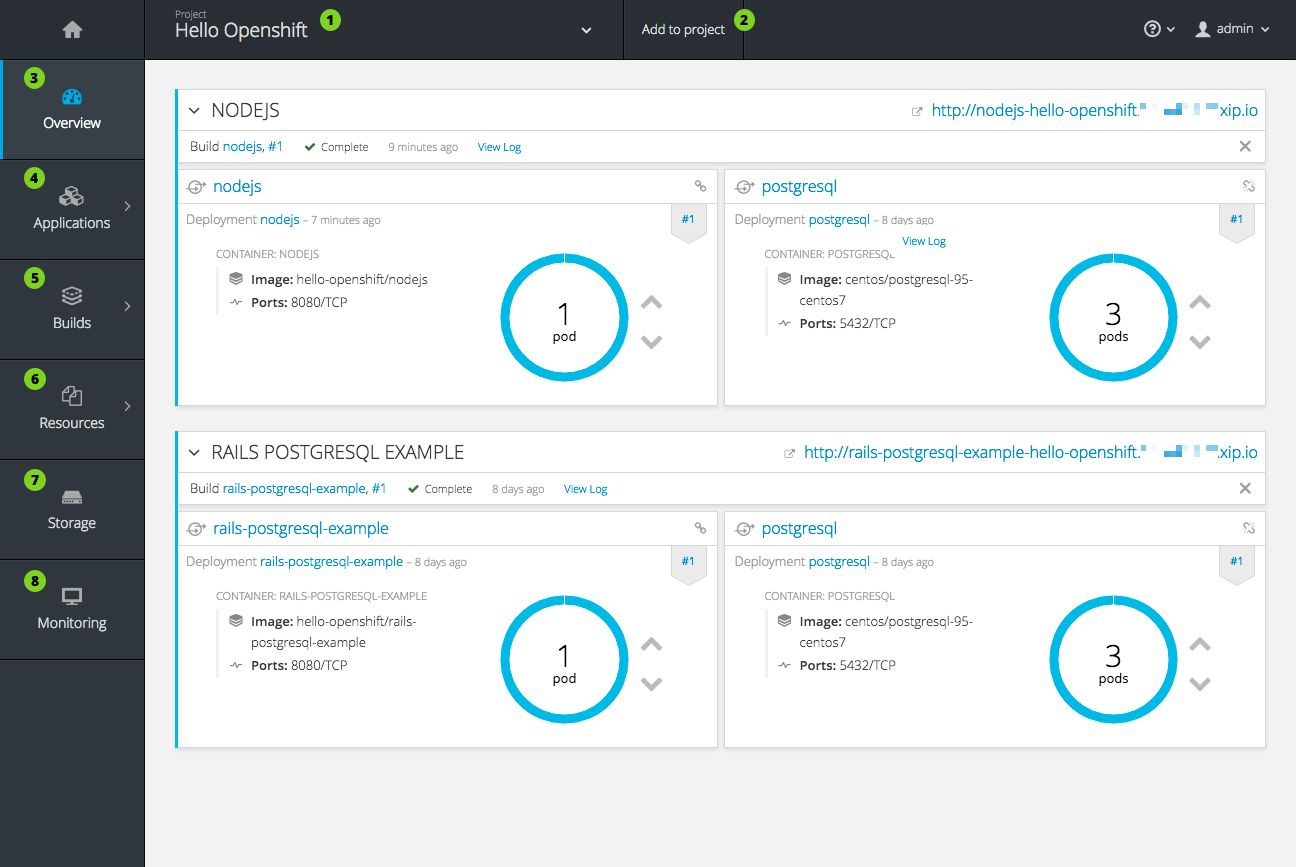
Последний шаг – просто получить версию сервиса из браузера, в моем случае это было: http://crimeswelcome-villains.1d35.starter-us-east-1.openshiftapps.com/version уведомление о том, что вам нужно изменить публичный хост с тем, который сгенерирован вашим маршрутизатором, а затем добавьте версию . Вы можете найти общедоступный URL-адрес, перейдя на панель инструментов OpenShift , в верхней части определения модулей.
Хорошо, теперь вы получите версию 1.0, которую мы развернули. Теперь предположим, что вы хотите выполнить обновление до следующей версии службы, до версии 1.1, поэтому вам нужно выполнить следующие команды для развертывания следующей версии контейнера службы преступлений, который помещается в Docker Hub .
|
1 |
|
С помощью предыдущей команды вы конфигурируете внутренний реестр OpenShift Docker, выпуская следующий образ Docker .
Затем давайте подготовим приложение, чтобы при применении следующей команды развертывания развертывался новый образ:
|
1 |
|
И, наконец, вы можете выполнить развертывание приложения, используя:
|
1 |
|
Через несколько секунд вы снова можете перейти по адресу http://crimeswelcome-villains.1d35.starter-us-east-1.openshiftapps.com/version (конечно, смените хост с вашим хостом), и вы получите следующую версию: 1.1.
Наконец, что происходит, если эта новая версия содержит ошибку, и вы хотите сделать откат развертывания до предыдущей версии? Просто запустите следующую команду:
И предыдущая версия будет развернута снова, поэтому через несколько секунд вы можете снова перейти к / version и снова увидите версию 1.0.
Наконец, если вы хотите удалить приложение для запуска чистого кластера:
Как видите, развертывание образов контейнера из Docker Hub в OpenShift действительно легко. Обратите внимание, что существуют другие способы развертывания нашего приложения в OpenShift ( https://docs.openshift.com/enterprise/3.2/dev_guide/builds.html ), в этом посте я только что показал вам один.
Команды: https://gist.github.com/lordofthejars/9fb5f08e47775a185a9b1f80f4af7aff
Install Docker
Following Kubernetes’s recommendation, we are choosing docker-1.12.6 as our container.
# yum install docker-1.13.1
Copy the Registry’s certs to docker cert folder. Do the step for all of the nodes.
This step is not required, just only for your existing private docker registry.
# scp -r ca.crt sokm1:/etc/docker/certs.d/
Add proxy settings for Docker. As Kubernetes’s images from Google are needed, so proxy is required.
Create a file called /etc/systemd/system/docker.service.d/http-proxy.conf that adds the HTTP_PROXY environment variable.
Or, if you are behind an HTTPS proxy server, create a file called /etc/systemd/system/docker.service.d/https-proxy.conf that adds the HTTPS_PROXY environment variable.
# mkdir -p /etc/systemd/system/docker.service.d/
# vi /etc/systemd/system/docker.service.d/http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://196.168.0.127:8118/" "NO_PROXY=localhost,127.0.0.1,180.169.188.90,hub.docker.gemii.cc,192.168.0.169"
#
# vi /etc/systemd/system/docker.service.d/https-proxy.conf
[Service]
Environment="HTTP_PROXY=http://192.168.0.127:8118/" "NO_PROXY=localhost,127.0.0.1,180.169.188.90,hub.docker.gemii.cc,192.168.0.169"
Configure Docker storage
Here we created a disk /dev/sdb already.
# cat <<EOF > /etc/sysconfig/docker-storage-setup
STORAGE_DRIVER=overlay2
DEVS=/dev/sdb
CONTAINER_ROOT_LV_NAME=docker-lv
CONTAINER_ROOT_LV_SIZE=100%FREE
CONTAINER_ROOT_LV_MOUNT_PATH=/var/lib/docker
VG=docker-vg
EOF
# docker-storage-setup
INFO: Device node /dev/sdb1 exists.
Physical volume "/dev/sdb1" successfully created.
Volume group "docker-vg" successfully created
#
Verify the configuration. You should have a dm.thinpooldev value in the /etc/sysconfig/docker-storage file and a docker-pool logical volume:
# cat /etc/sysconfig/docker-storage
DOCKER_STORAGE_OPTIONS="--storage-driver devicemapper --storage-opt dm.fs=xfs --storage-opt dm.thinpooldev=/dev/mapper/docker--vg-docker--pool --storage-opt dm.use_deferred_removal=true --storage-opt dm.use_deferred_deletion=true "
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home cl -wi-ao---- <141.12g
root cl -wi-ao---- 50.00g
swap cl -wi-a----- <7.88g
docker-pool docker-vg twi-a-t--- 39.79g 0.00 0.05
Recreate Docker Storage
If you delete the docker lib files, you may encounter this issue when you try to re-start the docker.
# systemctl stop docker
# rm -rf /var/lib/docker/*
# systemctl restart docker
# systemctl status docker.service
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/docker.service.d
└─http-proxy.conf, https-proxy.conf
Active: failed (Result: exit-code) since Fri 2018-02-09 21:51:53 EST; 3min 41s ago
Docs: http://docs.docker.com
Process: 1909 ExecStart=/usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current $OPTIONS $DOCKER_STORAGE_OPTIONS $DOCKER_NETWORK_OPTIONS $ADD_REGISTRY $BLOCK_REGISTRY $INSECURE_REGISTRY $REGISTRIES (code=exited, status=1/FAILURE)
Main PID: 1909 (code=exited, status=1/FAILURE)
Feb 09 21:51:52 oskw1 systemd[1]: Starting Docker Application Container Engine...
Feb 09 21:51:52 oskw1 dockerd-current[1909]: time="2018-02-09T21:51:52.716637492-05:00" level=info msg="libcontainerd: new containerd process, pid: 1916"
Feb 09 21:51:53 oskw1 dockerd-current[1909]: time="2018-02-09T21:51:53.750274954-05:00" level=fatal msg="Error starting daemon: error initializing graphdriver: devmapper: Unable to take ownership of thin-pool (docker...used data blocks"
Feb 09 21:51:53 oskw1 systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE
Feb 09 21:51:53 oskw1 systemd[1]: Failed to start Docker Application Container Engine.
Feb 09 21:51:53 oskw1 systemd[1]: Unit docker.service entered failed state.
Feb 09 21:51:53 oskw1 systemd[1]: docker.service failed.
Hint: Some lines were ellipsized, use -l to show in full.
So may need to Recreate the storage.
Delete the LV and PV firstly.
# lvremove docker-lv
# vgremove docker-vg
# pvs
# fdisk -l /dev/sdb
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000626bf
Device Boot Start End Blocks Id System
/dev/sdb1 2048 209715199 104856576 8e Linux LVM
sdb1 partition exists, so we need to delete it.
# fdisk -l /dev/sdb
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000626bf
Device Boot Start End Blocks Id System
/dev/sdb1 2048 209715199 104856576 8e Linux LVM
[[email protected] docker]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
g create a new empty GPT partition table
G create an IRIX (SGI) partition table
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help): p
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000626bf
Device Boot Start End Blocks Id System
/dev/sdb1 2048 209715199 104856576 8e Linux LVM
Command (m for help): d
Selected partition 1
Partition 1 is deleted
Command (m for help): v
Remaining 209715199 unallocated 512-byte sectors
Command (m for help): p
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000626bf
Device Boot Start End Blocks Id System
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
Then try to recreate the docker storage, we still failed. so need to erase the dos.
# docker-storage-setup
WARNING: Device for PV c1fD2e-ke13-OXvg-XPLO-SJ1f-a2RV-UwdTTO not found or rejected by a filter.
ERROR: Found dos signature on device /dev/sdb at offset 0x1fe. Wipe signatures using wipefs or use WIPE_SIGNATURES=true and retry.
#
# wipefs /dev/sdb
offset type
----------------------------------------------------------------
0x1fe dos [partition table]
#
# wipefs --all --force /dev/sdb
/dev/sdb: 2 bytes were erased at offset 0x000001fe (dos): 55 aa
/dev/sdb: calling ioclt to re-read partition table: Success
# wipefs /dev/sdb
#
# docker-storage-setup --reset
# docker-storage-setup
INFO: Device node /dev/sdb1 exists.
Physical volume "/dev/sdb1" successfully created.
Volume group "docker-vg" successfully created
Using default stripesize 64.00 KiB.
Rounding up size to full physical extent 104.00 MiB
Thin pool volume with chunk size 512.00 KiB can address at most 126.50 TiB of data.
Logical volume "docker-pool" created.
Logical volume docker-vg/docker-pool changed.
# systemctl start docker
#
Check Docker Status
[[email protected] ~]# docker info
Containers: 15
Running: 15
Paused: 0
Stopped: 0
Images: 10
Server Version: 1.13.1
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: systemd
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Swarm: inactive
Runtimes: runc docker-runc
Default Runtime: docker-runc
Init Binary: docker-init
containerd version: (expected: aa8187dbd3b7ad67d8e5e3a15115d3eef43a7ed1)
runc version: N/A (expected: 9df8b306d01f59d3a8029be411de015b7304dd8f)
init version: N/A (expected: 949e6facb77383876aeff8a6944dde66b3089574)
Security Options:
seccomp
WARNING: You're not using the default seccomp profile
Profile: /etc/docker/seccomp.json
selinux
Kernel Version: 4.15.1-1.el7.elrepo.x86_64
Operating System: CentOS Linux 7 (Core)
OSType: linux
Architecture: x86_64
Number of Docker Hooks: 3
CPUs: 4
Total Memory: 15.67 GiB
Name: oskm1.os.gemii.tech
ID: ZNMN:H5NQ:LKFW:W4EM:PDWJ:RJGS:NVV5:NTU3:QRSB:FJOY:V2D7:J4T2
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Http Proxy: http://192.168.0.127:8118/
Https Proxy: http://192.168.0.127:8118/
No Proxy: localhost,127.0.0.1,180.169.188.90,hub.docker.gemii.cc,192.168.0.169
Registry: https://index.docker.io/v1/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
Registries: docker.io (secure)
EDIT 2022: By now, there are obviously dozens of way to provision k8s, unlike 2015 when we started using it. kubeadm, microk8s, k3s, kube-spray, etc.
My advice: (If your cluster can’t fit on your workstation/laptop,) Rent a Hetzner server for 40 euro a month, and run WSL2 if on Windows.
Set up k8s cluster on the remote machine (with any of the above, I prefer microk8s these days). Set up Docker and Telepresence on your local Linux/Mac/WSL2 env. Install kubectl and connect it to the remote cluster.
Telepresence will let you replace a remote pod with a local docker pod, with access to local files (hopefully the same git repo that’s used to build the pod you’re developing/replacing), and possibly nodemon (or other language-specific auto-source-code-reload system).
Write bash functions. I cannot stress this enough, this will save you hundreds of hours of time. If replacing the pod and starting to develop isn’t one line / two words, then you’re doing it not-well-enough.
2016 answer below:
Another great starting point is this Vagrant setup, esp. if your host OS is Windows. The obvious advantages being
- quick and painless setup
- easy to destroy / recreate the machine
- implicit limit on resources
- ability to test horizontal scaling by creating multiple nodes
The disadvantages — you need lot of RAM, and VirtualBox is VirtualBox… for better or worse.
A mixed advantage / disadvantage is mapping files through NFS. In our setup, we created two sets of RC definitions — one that just download a docker image of our application servers; the other with 7 extra lines that set up file mapping from HostOS -> Vagrant -> VirtualBox -> CoreOS -> Kubernetes pod; overwriting the source code from the Docker image.
The downside of this is NFS file cache — with it, it’s problematic, without it, it’s problematically slow. Even setting mount_options: 'nolock,vers=3,udp,noac' doesn’t get rid of caching problems completely, but it works most of the time. Some Gulp tasks ran in a container can take 5 minutes when they take 8 seconds on host OS. A good compromise seems to be mount_options: 'nolock,vers=3,udp,ac,hard,noatime,nodiratime,acregmin=2,acdirmin=5,acregmax=15,acdirmax=15'.
As for automatic code reload, that’s language specific, but we’re happy with Django’s devserver for Python, and Nodemon for Node.js. For frontend projects, you can of course do a lot with something like gulp+browserSync+watch, but for many developers it’s not difficult to serve from Apache and just do traditional hard refresh.
We keep 4 sets of yaml files for Kubernetes. Dev, «devstable», stage, prod. The differences between those are
- env variables explicitly setting the environment (dev/stage/prod)
- number of replicas
- devstable, stage, prod uses docker images
- dev uses docker images, and maps NFS folder with source code over them.
It’s very useful to create a lot of bash aliases and autocomplete — I can just type rec users and it will do kubectl delete -f ... ; kubectl create -f .... If I want the whole set up started, I type recfo, and it recreates a dozen services, pulling the latest docker images, importing the latest db dump from Staging env and cleaning up old Docker files to save space.
OpenWhisk Deployment on Kubernetes

Apache OpenWhisk is an open source, distributed Serverless platform
that executes functions (fx) in response to events at any scale. The
OpenWhisk platform supports a programming model in which developers
write functional logic (called Actions), in any supported programming
language, that can be dynamically scheduled and run in response to
associated events (via Triggers) from external sources (Feeds) or from
HTTP requests.
This repository supports deploying OpenWhisk to Kubernetes and OpenShift.
It contains a Helm chart that can be used to deploy the core
OpenWhisk platform and optionally some of its Event Providers
to both single-node and multi-node Kubernetes and OpenShift clusters.
Table of Contents
- Prerequisites: Kubernetes and Helm
- Deploying OpenWhisk
- Administering OpenWhisk
- Development and Testing OpenWhisk on Kubernetes
- Cleanup
- Issues
Prerequisites: Kubernetes and Helm
Kubernetes is a container orchestration
platform that automates the deployment, scaling, and management of
containerized applications. Helm is a package
manager for Kubernetes that simplifies the management of Kubernetes
applications. You do not need to have detailed knowledge of either Kubernetes or
Helm to use this project, but you may find it useful to review their
basic documentation to become familiar with their key concepts and terminology.
Kubernetes
Your first step is to create a Kubernetes cluster that is capable of
supporting an OpenWhisk deployment. Although there are some technical
requirements that the Kubernetes
cluster must satisfy, any of the options described below is
acceptable.
Simple Docker-based options
The simplest way to get a small Kubernetes cluster suitable for
development and testing is to use one of the Docker-in-Docker
approaches for running Kubernetes directly on top of Docker on your
development machine. Configuring Docker with 4GB of memory and
2 virtual CPUs is sufficient for the default settings of OpenWhisk.
Depending on your host operating system, we recommend the following:
- MacOS: Use the built-in Kubernetes support in Docker for Mac
version 18.06 or later. Please follow our
setup instructions to initially create
your cluster. - Linux: Use kind.
Please follow our setup instructions
to initially create your cluster. - Windows: Use the built-in Kubernetes support in Docker for Windows
version 18.06 or later. Please follow our
setup instructions to initially create
your cluster.
Using a Kubernetes cluster from a cloud provider
You can also provision a Kubernetes cluster from a cloud provider,
subject to the cluster meeting the technical
requirements. You will need at least
1 worker node with 4GB of memory and 2 virtual CPUs to deploy the default
configuration of OpenWhisk. You can deploy to significantly larger clusters
by scaling up the replica count of the various components and labeling multiple
nodes as invoker nodes. We have
detailed documentation on using Kubernetes clusters from the following
major cloud providers:
- IBM (IKS)
- Google (GKE)
- Amazon (EKS)
We would welcome contributions of documentation for Azure (AKS) and any other public cloud providers.
Using OpenShift
You will need at least 1 worker node with 4GB of memory and 2 virtual
CPUs to deploy the default configuration of OpenWhisk. You can deploy
to significantly larger clusters by scaling up the replica count of
the various components and labeling multiple nodes as invoker nodes.
For more detailed documentation, see:
- OpenShift 4
Using a Kubernetes cluster you built yourself
If you are comfortable with building your own Kubernetes clusters and
deploying services with ingresses to them, you should also
be able to deploy OpenWhisk to a do-it-yourself cluster. Make sure
your cluster meets the technical requirements.
You will need at least 1 worker node with 4GB of memory and 2 virtual CPUs to deploy
the default configuration of OpenWhisk. You can deploy to
significantly larger clusters by scaling up the replica count of the
various components and labeling multiple nodes as invoker nodes.
Additional more detailed instructions:
- Some general comments.
- Using kubeadm on Ubuntu 18.04.
Helm
Helm is a tool to simplify the
deployment and management of applications on Kubernetes clusters.
The OpenWhisk Helm chart requires Helm 3.
Our automated testing currently uses Helm v3.2.4
Follow the Helm install instructions
for your platform to install Helm v3.0.1 or newer.
Deploying OpenWhisk
Now that you have your Kubernetes cluster and have installed
the Helm 3 CLI, you are ready to deploy OpenWhisk.
Overview
You will use Helm to deploy OpenWhisk to your Kubernetes cluster.
There are four deployment steps that are described in more
detail below in the rest of this section.
- Initial cluster setup. If you have provisioned a
multi-node cluster, you should label the worker nodes
to indicate their intended usage by OpenWhisk. - Customize the deployment. You will
create amycluster.yamlthat specifies key facts about your
Kubernetes cluster and the OpenWhisk configuration you wish to
deploy. Predefinedmycluster.yamlfiles for common flavors
of Kubernetes clusters are provided in the deploy
directory. - Deploy OpenWhisk with Helm. You will use Helm and
mycluster.yamlto deploy OpenWhisk to your Kubernetes cluster. - Configure the
wskCLI. You need to
tell thewskCLI how to connect to your OpenWhisk deployment.
Initial setup
Single Worker Node Clusters
If your cluster has a single worker node, then you should
configure OpenWhisk without node affinity. This is done by adding
the following lines to your mycluster.yaml
affinity:
enabled: false
toleration:
enabled: false
invoker:
options: "-Dwhisk.kubernetes.user-pod-node-affinity.enabled=false"
Multi Worker Node Clusters
If you are deploying OpenWhisk to a cluster with multiple worker
nodes, we recommend using node affinity to segregate the compute nodes
used for the OpenWhisk control plane from those used to execute user
functions. Do this by labeling each node with
openwhisk-role=invoker. In the default configuration, which uses the
KubernetesContainerFactory, the node labels are used in conjunction
with Pod affinities to inform the Kubernetes scheduler how to place
work so that user actions will not interfere with the OpenWhisk
control plane. When using the non-default DockerContainerFactory,
OpenWhisk assumes it has exclusive use of these invoker nodes and will
schedule work on them directly, completely bypassing the Kubernetes
scheduler. For each node
<INVOKER_NODE_NAME> you want to be an invoker, execute
kubectl label node <INVOKER_NODE_NAME> openwhisk-role=invoker
If you are targeting OpenShift, use the command
oc label node <INVOKER_NODE_NAME> openwhisk-role=invoker
For more precise control of the placement of the rest of OpenWhisk’s
pods on a multi-node cluster, you can optionally label additional
non-invoker worker nodes. Use the label openwhisk-role=core
to indicate nodes which should run the OpenWhisk control plane
(the controller, kafka, zookeeeper, and couchdb pods).
If you have dedicated Ingress nodes, label them with
openwhisk-role=edge. Finally, if you want to run the OpenWhisk
Event Providers on specific nodes, label those nodes with
openwhisk-role=provider.
If the Kubernetes cluster does not allow you to assign a label to a
node, or you cannot use the affinity attribute, you use the yaml
snippet shown above in the single worker node configuration to disable
the use of affinities by OpenWhisk.
Customize the Deployment
You will need a mycluster.yaml file to record key aspects of your
Kubernetes cluster that are needed to configure the deployment of
OpenWhisk to your cluster. For details, see the documentation
appropriate to your Kubernetes cluster:
- Docker for Mac
- Docker for Windows
- kind
- IBM Cloud Kubernetes Service (IKS)
- Google (GKE)
- Amazon (EKS)
- OpenShift
Default/template mycluster.yaml for various types of Kubernetes clusets
can be found in subdirectories of deploy.
Beyond the basic Kubernetes cluster specific configuration information,
the mycluster.yaml file can also be used
to customize your OpenWhisk deployment by enabling optional features
and controlling the replication factor of the various microservices
that make up the OpenWhisk implementation. See the configuration
choices documentation for a
discussion of the primary options.
Deploy With Helm
For simplicity, in this README, we have used owdev as the release name and
openwhisk as the namespace into which the Chart’s resources will be deployed.
You can use a different name and/or namespace simply by changing the commands
used below.
NOTE: The commands below assume Helm v3.2.0 or higher. Verify your local Helm version with the command helm version.
Deploying Released Charts from Helm Repository
The OpenWhisk project maintains a Helm repository at https://openwhisk.apache.org/charts.
You may install officially released versions of OpenWhisk from this repository:
helm repo add openwhisk https://openwhisk.apache.org/charts
helm repo update
helm install owdev openwhisk/openwhisk -n openwhisk --create-namespace -f mycluster.yaml
Deploying from Git
To deploy directly from sources, either download the
latest source release or
git clone https://github.com/apache/openwhisk-deploy-kube.git and use the Helm chart
from the helm/openwhisk folder of the source tree.
helm install owdev ./helm/openwhisk -n openwhisk --create-namespace -f mycluster.yaml
Checking status
You can use the command helm status owdev -n openwhisk to get a summary
of the various Kubernetes artifacts that make up your OpenWhisk
deployment. Once the pod name containing the word install-packages is in the Completed state,
your OpenWhisk deployment is ready to be used.
NOTE: You can check the status of the pod by running the following command kubectl get pods -n openwhisk --watch.
Configure the wsk CLI
Configure the OpenWhisk CLI, wsk, by setting the auth and apihost
properties (if you don’t already have the wsk cli, follow the
instructions here
to get it). Replace whisk.ingress.apiHostName and whisk.ingress.apiHostPort
with the actual values from your mycluster.yaml.
wsk property set --apihost <whisk.ingress.apiHostName>:<whisk.ingress.apiHostPort> wsk property set --auth 23bc46b1-71f6-4ed5-8c54-816aa4f8c502:123zO3xZCLrMN6v2BKK1dXYFpXlPkccOFqm12CdAsMgRU4VrNZ9lyGVCGuMDGIwP
Configuring the CLI for Kubernetes on Docker for Mac and Windows
The docker0 network interface does not exist in the Docker for Mac/Windows
host environment. Instead, exposed NodePorts are forwarded from localhost
to the appropriate containers. This means that you will use localhost
instead of whisk.ingress.apiHostName when configuring
the wsk cli and replace whisk.ingress.apiHostPort
with the actual values from your mycluster.yaml.
wsk property set --apihost localhost:<whisk.ingress.apiHostPort> wsk property set --auth 23bc46b1-71f6-4ed5-8c54-816aa4f8c502:123zO3xZCLrMN6v2BKK1dXYFpXlPkccOFqm12CdAsMgRU4VrNZ9lyGVCGuMDGIwP
Verify your OpenWhisk Deployment
Your OpenWhisk installation should now be usable. You can test it by following
these instructions
to define and invoke a sample OpenWhisk action in your favorite programming language.
You can also issue the command helm test owdev -n openwhisk to run the basic
verification test suite included in the OpenWhisk Helm chart.
Note: if you installed self-signed certificates, which is the default
for the OpenWhisk Helm chart, you will need to use wsk -i to
suppress certificate checking. This works around cannot validate certificate errors from the wsk CLI.
If your deployment is not working, check our
troubleshooting guide for ideas.
Scale-up your OpenWhisk Deployment
Using defaults, your deployment is configured to provide a bare-minimum working platform for testing and exploration. For your specialized workloads, you can scale-up your openwhisk deployment by defining your deployment configurations in your mycluster.yaml which overrides the defaults in helm/openwhisk/values.yaml. Some important parameters to consider (for other parameters, check helm/openwhisk/values.yaml and configurationChoices):
actionsInvokesPerminute: limits the maximum number of invocations per minute.actionsInvokesConcurrent: limits the maximum concurrent invocations.containerPool: total memory available perinvokerinstance.Invokeruses this memory to create containers for user-actions. The concurrency-limit (actions running in parallel) will depend upon the total memory configured forcontainerPooland memory allocated per action (default:256mb per container).
For more information about increasing concurrency-limit, check scaling-up your deployment.
Administering OpenWhisk
Wskadmin is the tool to perform various administrative operations against an OpenWhisk deployment.
Since wskadmin requires credentials for direct access to the database (that is not normally accessible to the outside), it is deployed in a pod inside Kubernetes that is configured with the proper parameters. You can run wskadmin with kubectl. You need to use the <namespace> and the deployment <name> that you configured with --namespace and --name when deploying.
You can then invoke wskadmin with:
kubectl -n <namespace> -ti exec <name>-wskadmin -- wskadmin <parameters>
For example, is your deployment name is owdev and the namespace is openwhisk you can list users in the guest namespace with:
$ kubectl -n openwhisk -ti exec owdev-wskadmin -- wskadmin user list guest
23bc46b1-71f6-4ed5-8c54-816aa4f8c502:123zO3xZCLrMN6v2BKK1dXYFpXlPkccOFqm12CdAsMgRU4VrNZ9lyGVCGuMDGIwP
Check here for details about the available commands.
Development and Testing OpenWhisk on Kubernetes
This section outlines how common OpenWhisk development tasks are
supported when OpenWhisk is deployed on Kubernetes using Helm.
Running OpenWhisk test cases
Some key differences in a Kubernetes-based deployment of OpenWhisk are
that deploying the system does not generate a whisk.properties file and
that the various internal microservices (invoker, controller,
etc.) are not directly accessible from the outside of the Kubernetes cluster.
Therefore, although you can run full system tests against a
Kubernetes-based deployment by giving some extra command line
arguments, any unit tests that assume direct access to one of the internal
microservices will fail. First clone the core OpenWhisk repository
locally and set $OPENWHISK_HOME to its top-level directory. Then, the
system tests can be executed in a
batch-style as shown below, where WHISK_SERVER and WHISK_AUTH are
replaced by the values returned by wsk property get --apihost and
wsk property get --auth respectively.
cd $OPENWHISK_HOME ./gradlew :tests:testSystemKCF -Dwhisk.auth=$WHISK_AUTH -Dwhisk.server=https://$WHISK_SERVER -Dopenwhisk.home=`pwd`
You can also launch the system tests as JUnit test from an IDE by
adding the same system properties to the JVM command line used to
launch the tests:
-Dwhisk.auth=$WHISK_AUTH -Dwhisk.server=https://$WHISK_SERVER -Dopenwhisk.home=`pwd`
NOTE: You need to install JDK 8 in order to run these tests.
Deploying a locally built docker image.
If you are using Kubernetes in Docker, it is
straightforward to deploy local images by adding a stanza to your
mycluster.yaml. For example, to use a locally built controller image,
just add the stanza below to your mycluster.yaml to override the default
behavior of pulling a stable openwhisk/controller image from Docker Hub.
controller: imageName: "whisk/controller" imageTag: "latest"
Selectively redeploying using a locally built docker image
You can use the helm upgrade command to selectively redeploy one or
more OpenWhisk components. Continuing the example above, if you make
additional changes to the controller source code and want to just
redeploy it without redeploying the entire OpenWhisk system you can do
the following:
If you are using a multi-node Kubernetes cluster you will need to
repeat the following steps on all nodes that may run the controller
component.
The first step is to rebuild the docker image:
# Execute this command in your openwhisk directory
bin/wskdev controller -b
Note that the wskdev flags -x and -d are not compatible
with the Kubernetes deployment of OpenWhisk.
Alternatively, you can build all of the OpenWhisk docker components:
# Execute this command in your openwhisk directory
./gradlew distDocker
After building the new docker image(s), tag the new image:
# Tag the docker image you seek to redeploy
docker tag whisk/controller whisk/controller:v2
Then, edit your mycluster.yaml to contain:
controller: imageName: "whisk/controller" imageTag: "v2"
Redeploy with Helm by executing this command in your
openwhisk-deploy-kube directory:
helm upgrade owdev ./helm/openwhisk -n openwhisk -f mycluster.yaml
Deploying Lean Openwhisk version.
To have a lean setup (no Kafka, Zookeeper and no Invokers as separate entities):
Cleanup
Use the following command to remove all the deployed OpenWhisk components:
helm uninstall owdev -n openwhisk
By default, helm uninstall removes the history of previous deployments.
If you want to keep the history, add the command line flag --keep-history.
Issues
If your OpenWhisk deployment is not working, check our
troubleshooting guide for ideas.
Report bugs, ask questions and request features here on GitHub.
You can also join our slack channel and chat with developers. To get access to our slack channel, request an invite here.