This command almost gives me what I want :-
echo "\123.123.123.123path11 - path2path3 path4path5" | sed 's_\_/_g' | sed 's_ _\ _g'
/123.123.123.123/path1/1 - path2/path3 path4/path5
But as one can see, its lost the ‘//’ at the beginning!
ie, desired outout :-
//123.123.123.123/path1/1 - path2/path3 path4/path5
What am I missing?
Edit: After not testing the basics of echo (many thanks to all who pointed that out). I should of also been more clear on the end-game of this question.
I want to use this in a script, and define the windows path at the top.
How can I echo the path to a tmp file for sed?
This obviously wont work :-
WIN_PATH="\123.123.123.123path11 - path2path3 path4path5"
UNIX_PATH=`echo $WIN_PATH | sed 's_\_/_g' | sed 's_ _\ _g'`
![]()
jww
94.9k88 gold badges395 silver badges860 bronze badges
asked Apr 12, 2011 at 8:48
![]()
Ian VaughanIan Vaughan
19.6k13 gold badges57 silver badges74 bronze badges
3
Use single quotes instead of double quotes in echo — as it is the shell interprets your two backslashes as an escape sequence for :
$ echo '\123.123.123.123path11 - path2path3 path4path5' | sed 's_\_/_g' | sed 's_ _\ _g'
//123.123.123.123/path1/1 - path2/path3 path4/path5
Using single quotes suppresses shell expansions (e.g. variables) and disables most escape sequences.
answered Apr 12, 2011 at 8:54
![]()
Your problem is that in \ is already the escape secuence for so you have already lost one of the on the echo.
You can try just :
echo "\123.123.123.123path11 - path2path3 path4path5"
to see it.
You have to escape those to make it work i.e.:
echo "\\123.123.123.123path11 - path2path3 path4path5" | sed 's_\_/_g' | sed 's_ _\ _g'
//123.123.123.123/path1/1 - path2/path3 path4/path5
answered Apr 12, 2011 at 8:54
![]()
pconcepcionpconcepcion
5,5515 gold badges35 silver badges53 bronze badges
Bash uses the (backslash) as an escape. It isn’t being munched by sed, but by bash before passing the string to echo. Try:
echo "\123"
You’ll get:
123
To solve your problem, put your text into a file, and read it from there to avoid shell escaping:
$ cat >file
\123.123.123.123path11 - path2path3 path4path5
$ cat file | sed 's_\_/_g' | sed 's_ _\ _g'
//123.123.123.123/path1/1 - path2/path3 path4/path5
answered Apr 12, 2011 at 8:55
![]()
odrmodrm
5,0911 gold badge18 silver badges13 bronze badges
1
if you want to do that, use single quotes so that the slash does not get interpreted.
echo '\123.123.123.123path11 - path2path3 path4path5'
answered Apr 12, 2011 at 8:56
![]()
kurumikurumi
24.9k4 gold badges44 silver badges51 bronze badges
0
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.
Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.

Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
$ sed options file
По умолчанию sed применяет указанные при вызове правила, выраженные в виде набора команд, к STDIN. Это позволяет передавать данные непосредственно sed.
Например, так:
$ echo "This is a test" | sed 's/test/another test/'Вот что получится при выполнении этой команды.

Простой пример вызова sed
В данном случае sed заменяет слово «test» в строке, переданной для обработки, словами «another test». Для оформления правила обработки текста, заключённого в кавычки, используются прямые слэши. В нашем случае применена команда вида s/pattern1/pattern2/. Буква «s» — это сокращение слова «substitute», то есть — перед нами команда замены. Sed, выполняя эту команду, просмотрит переданный текст и заменит найденные в нём фрагменты (о том — какие именно, поговорим ниже), соответствующие pattern1, на pattern2.
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:
$ sed 's/test/another test' ./myfile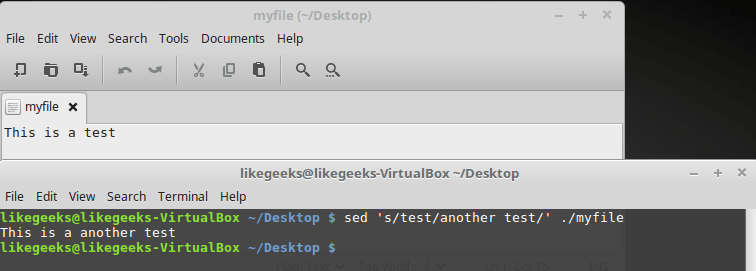
Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Sed не меняет данные в обрабатываемом файле. Редактор читает файл, обрабатывает прочитанное, и отправляет то, что получилось, в STDOUT. Для того, чтобы убедиться в том, что исходный файл не изменился, достаточно, после того, как он был передан sed, открыть его. При необходимости вывод sed можно перенаправить в файл, возможно — перезаписать старый файл. Если вы знакомы с одним из предыдущих материалов этой серии, где речь идёт о перенаправлении потоков ввода и вывода, вы вполне сможете это сделать.
Выполнение наборов команд при вызове sed
Для выполнения нескольких действий с данными, используйте ключ -e при вызове sed. Например, вот как организовать замену двух фрагментов текста:
$ sed -e 's/This/That/; s/test/another test/' ./myfile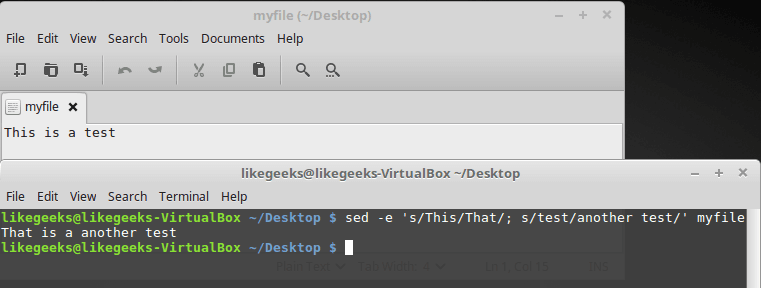
Использование ключа -e при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела.
Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
$ sed -e '
> s/This/That/
> s/test/another test/' ./myfileВот что получится после того, как команда, представленная в таком виде, будет выполнена.
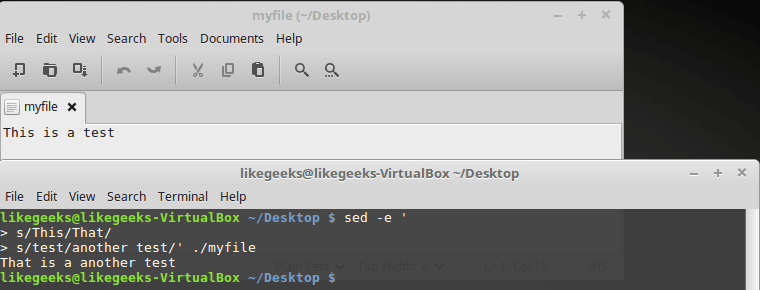
Другой способ работы с sed
Чтение команд из файла
Если имеется множество команд sed, с помощью которых надо обработать текст, обычно удобнее всего предварительно записать их в файл. Для того, чтобы указать sed файл, содержащий команды, используют ключ -f:
Вот содержимое файла mycommands:
s/This/That/
s/test/another test/Вызовем sed, передав редактору файл с командами и файл для обработки:
$ sed -f mycommands myfileРезультат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.
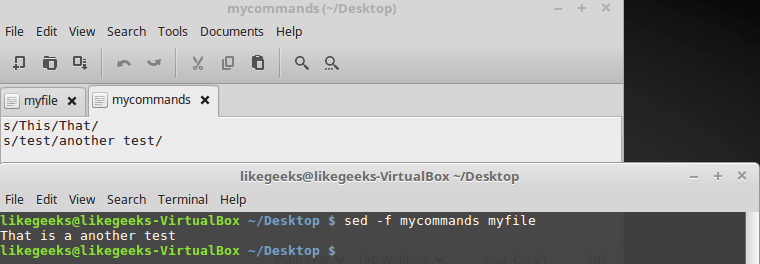
Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
$ sed 's/test/another test/' myfileВот что содержится в файле, и что будет получено после его обработки sed.
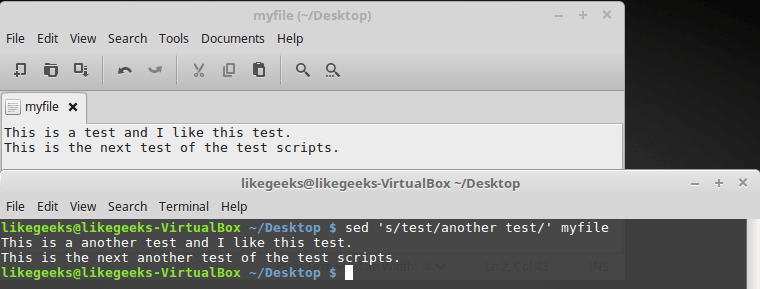
Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
s/pattern/replacement/flagsВыполнение этой команды можно модифицировать несколькими способами.
- При передаче номера учитывается порядковый номер вхождения шаблона в строку, заменено будет именно это вхождение.
- Флаг
gуказывает на то, что нужно обработать все вхождения шаблона, имеющиеся в строке. - Флаг
pуказывает на то, что нужно вывести содержимое исходной строки. - Флаг вида
w fileуказывает команде на то, что нужно записать результаты обработки текста в файл.
Рассмотрим использование первого варианта команды замены, с указанием позиции заменяемого вхождения искомого фрагмента:
$ sed 's/test/another test/2' myfile
Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g:
$ sed 's/test/another test/g' myfileКак видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.

Глобальная замена
Флаг команды замены p позволяет выводить строки, в которых найдены совпадения, при этом ключ -n, указанный при вызове sed, подавляет обычный вывод:
$ sed -n 's/test/another test/p' myfileКак результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.
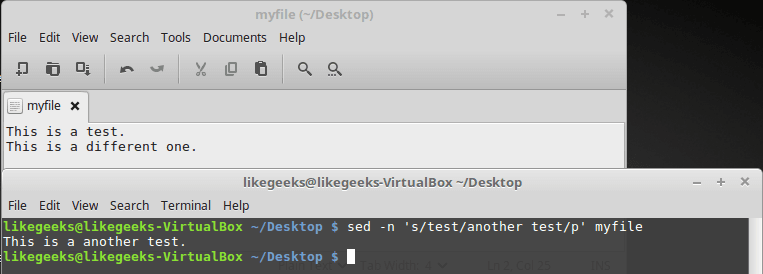
Использование флага команды замены p
Воспользуемся флагом w, который позволяет сохранить результаты обработки текста в файл:
$ sed 's/test/another test/w output' myfile
Сохранение результатов обработки текста в файл
Хорошо видно, что в ходе работы команды данные выводятся в STDOUT, при этом обработанные строки записываются в файл, имя которого указано после w.
Символы-разделители
Представьте, что нужно заменить /bin/bash на /bin/csh в файле /etc/passwd. Задача не такая уж и сложная:
$ sed 's//bin/bash//bin/csh/' /etc/passwdОднако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s:
$ sed 's!/bin/bash!/bin/csh!' /etc/passwdВ данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
- Задать ограничение на номера обрабатываемых строк.
- Указать фильтр, соответствующие которому строки нужно обработать.
Рассмотрим первый подход. Тут допустимо два варианта. Первый, рассмотренный ниже, предусматривает указание номера одной строки, которую нужно обработать:
$ sed '2s/test/another test/' myfile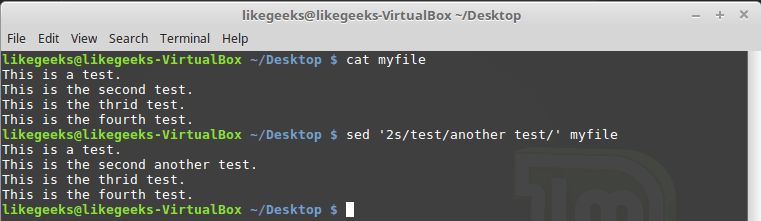
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
$ sed '2,3s/test/another test/' myfile
Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
$ sed '2,$s/test/another test/' myfile
Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
$ sed '/likegeeks/s/bash/csh/' /etc/passwd
По аналогии с тем, что было рассмотрено выше, шаблон передаётся перед именем команды s.

Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Утилита sed годится не только для замены одних последовательностей символов в строках на другие. С её помощью, а именно, используя команду d, можно удалять строки из текстового потока.
Вызов команды выглядит так:
$ sed '3d' myfileМы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.
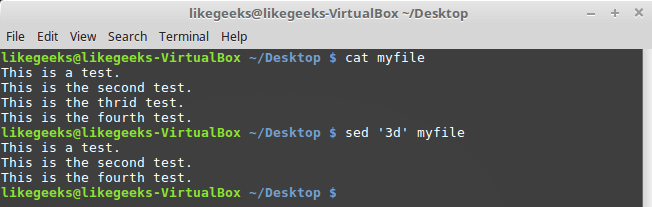
Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:
$ sed '2,3d' myfile
Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:
$ sed '3,$d' myfile
Удаление строк до конца файла
Строки можно удалять и по шаблону:
$ sed '/test/d' myfile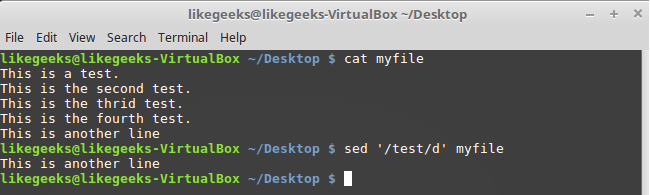
Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:
$ sed '/second/,/fourth/d' myfile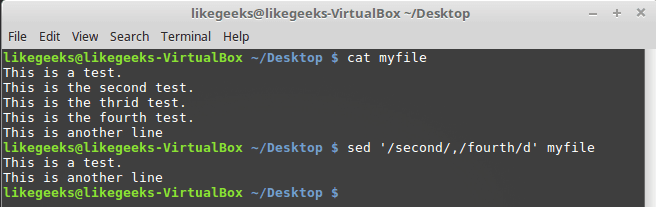
Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a:
- Команда
iдобавляет новую строку перед заданной. - Команда
aдобавляет новую строку после заданной.
Рассмотрим пример использования команды i:
$ echo "Another test" | sed 'iFirst test '
Команда i
Теперь взглянем на команду a:
$ echo "Another test" | sed 'aFirst test '
Команда a
Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Тут нам поможет указание номера опорной строки в потоке, или шаблона. Учтите, что адресация строк в виде диапазона тут не подойдёт. Вызовем команду i, указав номер строки, перед которой надо вставить новую строку:
$ sed '2iThis is the inserted line.' myfile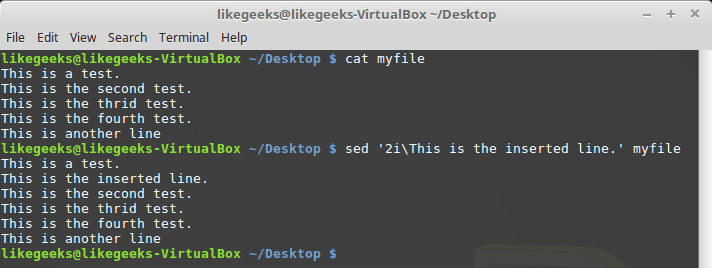
Команда i с указанием номера опорной строки
Проделаем то же самое с командой a:
$ sed '2aThis is the appended line.' myfile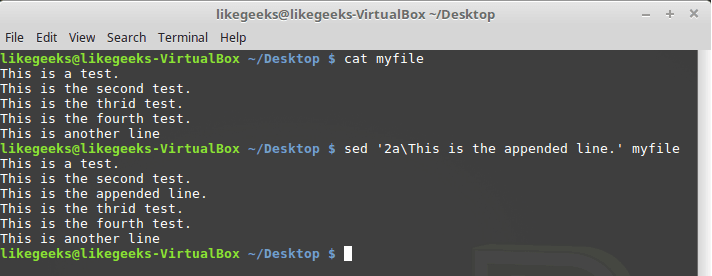
Команда a с указанием номера опорной строки
Обратите внимание на разницу в работе команд i и a. Первая вставляет новую строку до указанной, вторая — после.
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:
$ sed '3cThis is a modified line.' myfile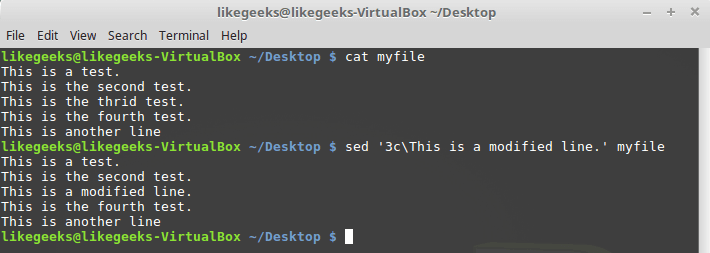
Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:
$ sed '/This is/c This is a changed line of text.' myfile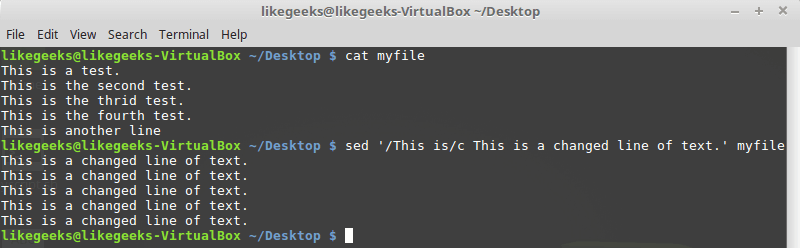
Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:
$ sed 'y/123/567/' myfile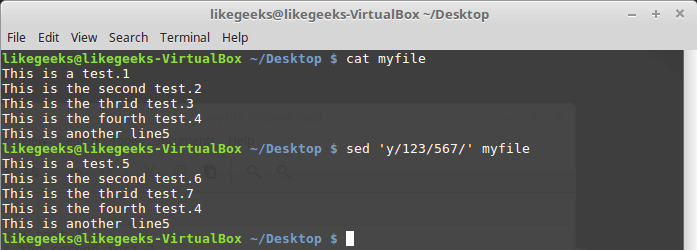
Замена символов
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Если вызвать sed, использовав команду =, утилита выведет номера строк в потоке данных:
$ sed '=' myfile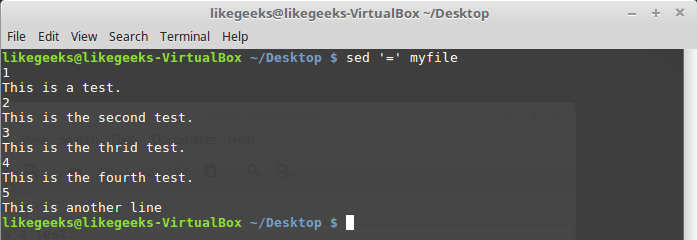
Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Если передать этой команде шаблон и воспользоваться ключом sed -n, выведены будут только номера строк, соответствующих шаблону:
$ sed -n '/test/=' myfile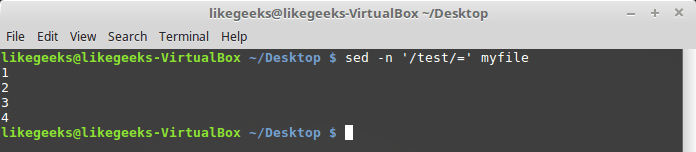
Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Выше мы рассматривали приёмы вставки данных в поток, указывая то, что надо вставить, прямо при вызове sed. В качестве источника данных можно воспользоваться и файлом. Для этого служит команда r, которая позволяет вставлять в поток данные из указанного файла. При её вызове можно указать номер строки, после которой надо вставить содержимое файла, или шаблон.
Рассмотрим пример:
$ sed '3r newfile' myfile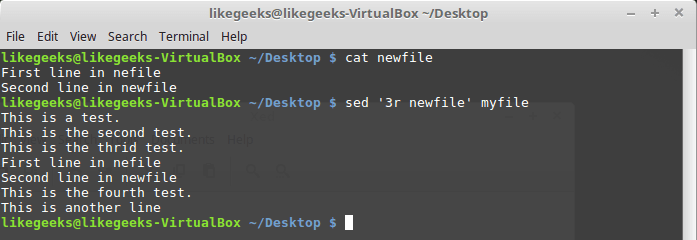
Вставка в поток содержимого файла
Тут содержимое файла newfile было вставлено после третьей строки файла myfile.
Вот что произойдёт, если применить при вызове команды r шаблон:
$ sed '/test/r newfile' myfile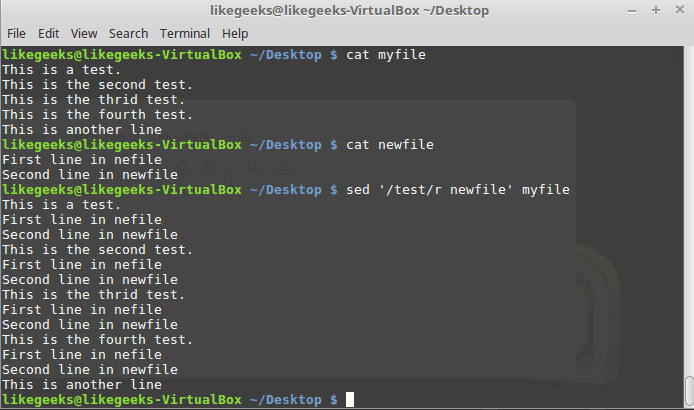
Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Представим себе такую задачу. Есть файл, в котором имеется некая последовательность символов, сама по себе бессмысленная, которую надо заменить на данные, взятые из другого файла. А именно, пусть это будет файл newfile, в котором роль указателя места заполнения играет последовательность символов DATA. Данные, которые нужно подставить вместо DATA, хранятся в файле data.
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:
$ Sed '/DATA>/ {
r newfile
d}' myfile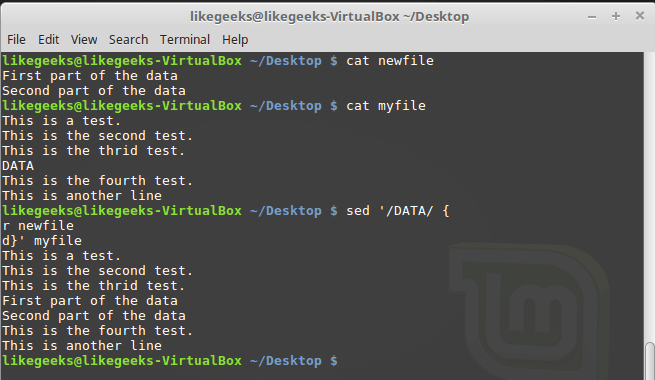
Замена указателя места заполнения на реальные данные
Как видите, вместо заполнителя DATA sed добавил в выходной поток две строки из файла data.
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Уважаемые читатели! А вы пользуетесь sed в повседневной работе? Если да — поделитесь пожалуйста опытом.
To explain the problem you’re seeing, it’s happening in the second sed command:
sed -e 's///\/g'
make uses as a special character that can be used to escape %, so \ is an escape sequence that translates to (a single backslash.)
Other than two backslashes in a row or when followed by %, the backslash is preserved verbatim, so / is kept as / and won’t cause any problems (that’s why only this place caused trouble.)
So the sed command that actually gets executed is:
sed -e 's////g'
It’s easier to see how this command is incomplete if you use a different delimiter, such as #:
sed -e 's#/#/g'
First off, the ending delimiter (in this case #) is missing. Furthermore, the replacement is getting a / and not a as intended.
You can fix it by adding an extra backslash (or two will also work):
sed -e 's///\/g'
But this might look quite odd to someone reading that code, so I’d recommend adding a comment to explain what is going on.
Another good idea would be to double every backslash, to make it clear that make is using one level of them as escape sequences:
sed -e 's/\//\\/g'
Ugh, still pretty awful… Using a delimiter other than # might help a little bit, but probably not that much:
sed -e 's#/#\\#g'
For the specific case you’re using sed here, which is to convert a Cygwin path to a Windows path, you can actually use cygpath --windows, as pointed out by @HaiVu in comments.
http://www.user.su/Массовое_переименование_в_консоли
меняем .bak на .kab
rename ‘s/.bak$/.kab/’ *.bak
делаем все буквы маленькими
rename ‘y/A-Z/a-z/’ *
http://habrahabr.ru/post/55121/
Замена текста в файлах
Чтобы заменить в текстовом файле все вхождения последовательности символов “windows” на “linux” написать в консоли:
sed -i s/windows/linux/g /адрес/имя_файла
Если надо заменить текст не в одном файле, то есть несколько способов. Для того, чтобы заменить текст «Windows» на «Linux» во всех файлах в текущей директории, название которой начинается с «test», введите в консоли:
perl -i -pe ‘s/Windows/Linux/;’ test*
Чтобы провести ту же операцию во всех поддиректориях:
find. -name ‘*.txt’ -print | xargs perl -pi -e’s/Windows/Linux/ig’ *.txt
Или вы хотите сделать то же самое для на обычных файлов со множеством переносов строк и странных символов (файл — в другой кодировке):
find -type f -name ‘*.txt’ -print0 | xargs —null perl -pi -e ‘s/Windows/Linux/’
http://compiling.ru/solutions/massovoe-pereimenovanie-fajlov-v-bash/
Удаление или замена пробелов в имени файла
Пробелы в имени файла – это не самая хорошая идея. Если вам нужно удалить пробелы в именах всех файлов в текущем каталоге, то для этого вы можете использовать следующую команду:
ls | grep » » | while read -r f; do mv -i «$f» `echo $f | tr -d ‘ ‘`; done
В случае, если вам нужно заменить пробел в имени фала на подчеркивание (или любой другой символ), то используйте следующую команду:
ls | grep » » | while read -r f; do mv «$f» `echo $f | tr ‘ ‘ ‘_’`; done
Как это работает? ls и grep будут циклично обрабатывать все файлы в текущем рабочем каталоге, содержащие пробел в имени. В теле цикла, мы затем выполним команду mv, преобразуя месторасположения файла с помощью команды tr. Удостоверьтесь, что, при использовании команды mv, параметр -i включен, чтобы избежать случайной перезаписи файлов.
Преобразование имен фалов из нижнего регистра в верхний:
Эта команда преобразует имена всех файлов в текущем каталоге из нижнего регистра в верхний. Удостоверьтесь, что, при использовании команды mv, параметр -i включен, чтобы избежать случайной перезаписи некоторых файлов. Для командной строки Linux имена “File” и “file” – это разные файлы. Если вы преобразуете с помощью mv “file” в “FILE”, то вы перезапишете существующий “FILE”.
for i in $( ls | grep [a-z] ); do mv -i $i `echo $i | tr ‘a-z’ ‘A-Z’`; done
Преобразование имен фалов из верхнего регистра в нижний:
Эта команда преобразует имена всех файлов в текущем каталоге из верхнего регистра в нижний. Удостоверьтесь, что, при использовании команды mv, параметр -i включен, чтобы избежать случайной перезаписи некоторых файлов. Для командной строки Linux имена “File” и “file” – это разные файлы. Если вы преобразуете с помощью mv “FILE” в “file”, то вы перезапишете существующий “file”.
for i in $( ls | grep [A-Z] ); do mv -i $i `echo $i | tr ‘A-Z’ ‘a-z’`; done
http://epol.su/linux/item/краткий-справочник-по-массовому-переименовыванию-файлов.html
$ rename ‘s/.c.orig$/.c/’ *.c # переименовать все *.c.orig в *.c
$ rename ‘y/A-Z/a-z/’ *.JPG # имена фотографий маленькими буквами
$ rename ‘s/U/u/g’ *.JPG # тоже самое
$ rename ‘$_=lc’ * # тоже самое, но для всех файлов
$ rename ‘s/deftones-//’ *.mp3 # убрать префис ‘deftones-‘ у *.mp3
$ rename ‘s/^/jerk-/’ *.swf # добавить префикс ‘jerk-‘ у *.swf
$ rename ‘s/ /_/g’ * # пробелы в именах файлах заменить на ‘_’
# перевести в большой регистр часть имени файла
$ rename -v ‘s/sd.*ed/U$&E/’ House.M.D.s0*
House.M.D.s03e04.rus.avi renamed as House.M.D.S03E04.rus.avi
House.M.D.s03e05.rus.avi renamed as House.M.D.S03E05.rus.avi
House.M.D.s03e06.rus.avi renamed as House.M.D.S03E06.rus.avi
House.M.D.s03e07.rus.avi renamed as House.M.D.S03E07.rus.avi
http://wiki.dieg.info/doku.php/faq
Поиск и замена текста в нескольких файлах:
Чтобы заменить foo на bar в нескольких файлах, выполните следующую команду Perl:
> perl -pi~ -e ‘s/foo/bar/’ [files]
Оригинальные файлы при этом будут сохраны с именами filename~.
# perl -pi~ -e ‘s/ua.archive.ubuntu.com/mirror.yandex.ru/’ /etc/apt/sources.list
replace, входит в состав MySQL (т.е. должен быть установлен MySQL Server). В приведенном примере, в файле config.inc.php заменяются ВСЕ вхождения слова change-this-to-your.domain.tld на yourdomain.com
> replace «change-this-to-your.domain.tld» «yourdomain.com» — config.inc.php
В файле collabnet_subversion_httpd.conf заменить на строку collabnet_subversion_httpd.conf. Используются утилиты sed:
> sed -i -e ‘s/ServerName 10.1.7.1:9876/ServerName 10.1.7.2:9876/’ ./collabnet_subversion_httpd.conf
http://zenux.ru/articles/23/
переименовывает все файлы в текущем каталоге, заменяя пробелы на символы подчеркивания «_»:
$ find . -type f | while read i; do mv «$i» «$(echo «$i» | tr ‘ ‘ _)»; done
Is there some way to run a command (such as ICMP message or another protocol), get a response from a remote machine (not on my own private local network) and analyze the message to find some evidence that this machine is running a Windows or a Linux operating system?
![]()
asked Feb 24, 2012 at 13:58
![]()
3
It isn’t definitive but nmap will do this with the command nmap -O -v (see docs for more details) If you’re running windows or want a gui, look at zenmap
answered Feb 24, 2012 at 14:06
![]()
Journeyman Geek♦Journeyman Geek
125k51 gold badges252 silver badges418 bronze badges
2
If you’re on an IPv4 network, just use ping. If the response has a TTL of 128, the target is probably running Windows. If the TTL is 64, the target is probably running some variant of Unix.
answered Feb 28, 2012 at 2:50
![]()
Harry JohnstonHarry Johnston
5,6647 gold badges30 silver badges55 bronze badges
5
: Presumes ping service enabled on Windows local and remote hosts
:
del _IX.txt, Windows.txt
ping -n 1 [computername|ipaddress] | findstr /i /c:"Reply" > ttl.txt
for /f "tokens=1-9* delims=:=< " %%a in (ttl.txt) do (
if %%i leq 130 (
if %%i geq 100 (
echo Windows & rem or echo %%c >> Windows.txt
) else (
if %%i equ 64 (
echo *IX & rem or echo %%c >> _IX.txt
)
)
)
)
answered Nov 9, 2012 at 1:10
![]()
1
One way to go is to use NMap. From the response, it can guess the remote OS.
![]()
Diogo
29.9k65 gold badges148 silver badges221 bronze badges
answered Feb 24, 2012 at 14:03
![]()
ApacheApache
15.9k23 gold badges99 silver badges150 bronze badges
0
Package: xprobe ‘OR’ xprobe2
Description: Remote OS identification
Xprobe2 allows you to determine what operating system is running on a remote
host. It sends several packets to a host and analyses the returned answers.
Xprobe2’s functionality is comparable to the OS fingerprinting feature in nmap.
Example:
$ sudo apt-get install xprobe
$ sudo xprobe2 -T21-23,80,53,110 ###.###.###.###
answered Feb 24, 2012 at 16:16
![]()
taotao
1,4158 silver badges11 bronze badges
Old post but thought I would add to this too, if the device is SNMP enabled you can also query for the sysDescr which will tell you the OS it is using.
Download a MIB browser, a good one that I use is here: http://www.ireasoning.com/downloadmibbrowserfree.php. You basically give it the IP address of the device and do a walk operation.
![]()
fixer1234
26.8k61 gold badges72 silver badges115 bronze badges
answered Jul 22, 2015 at 8:05
![]()
2
Following the suggestion of Johnathon64, you could use SNMP to query directly on the server
— assuming the remote server itself is configured to use SNMP. You could launch a command-line query such as the one below to do it:
snmpget -v1 -c public <RemoteServerIP> sysDescr.0 | sed -n 's/.*STRING: //p' | tr -d "
Explaining the command itself:
snmpgetwill query the object sysDescr, which contains the object’s default name.- The following
sedwill exclude the beginning output, which only contains the polled OID and the beginning of the string. - The last command,
tr, will exclude any double-quotes, usually found in the SNMP query.
The last two commands are only for formatting the output — if you don’t need them, may use the very first command to extract the complete output.
![]()
zx485
2,17011 gold badges16 silver badges23 bronze badges
answered Mar 10, 2020 at 16:50
![]()
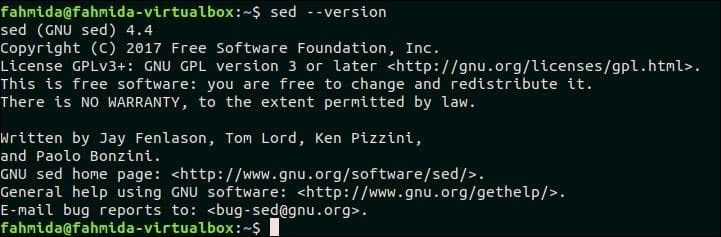
`sed` — полезная функция обработки текста в GNU / Linux. Полная форма sed — это Stream Editor. Многие типы простых и сложных задач обработки текста могут быть легко решены с помощью команды `sed`. Любую конкретную строку в тексте или файле можно искать, заменять и удалять, используя регулярное выражение с командой `sed. Но эта команда временно выполняет все типы модификации, и исходное содержимое файла по умолчанию не изменяется. При необходимости пользователь может сохранить измененный контент в другом файле. Основное использование команды `sed` объясняется в этом руководстве на 50 уникальных примерах. Перед тем, как начать это руководство, вы должны проверить установленную версию `sed` в вашей операционной системе, выполнив следующую команду. Учебник разработан на основе GNU sed. Таким образом, эта версия `sed` потребуется для практики примеров, показанных в этом руководстве.
$ sed—версия
Следующий вывод показывает, что в системе установлен GNU Sed версии 4.4.
Синтаксис:
sed[опции]… [сценарий][файл]
Если в команде `sed` имя файла не указано, сценарий будет работать со стандартными входными данными. Скрипт `sed` может выполняться без каких-либо опций.
Содержание:
- Простая подстановка текста с помощью «sed»
- Заменить все экземпляры текста в определенной строке файла с помощью опции «g»
- Заменить только второе совпадение в каждой строке
- Заменить только последнее совпадение в каждой строке
- Заменить первое совпадение в файле новым текстом
- Заменить последнее совпадение в файле новым текстом
- Экранирование обратной косой черты в командах замены для управления поиском и заменой путей к файлам
- Замените полный путь всех файлов только именем файла без каталога
- Заменить текст, но только если в строке найден другой текст
- Заменить текст, но только если какой-либо другой текст не найден в строке
- Добавьте строку до и после соответствующего шаблона с помощью ‘1’
- Удалить совпадающие строки
- Удалить совпадающую строку и 2 строки после совпадающей строки
- Удалить все пробелы в конце строки текста
- Удалите все строки, которые совпадают два раза в строке
- Удалите все строки с единственным пробелом
- Удалить все непечатаемые символы
- Если в строке есть совпадение, добавьте что-нибудь в конец строки
- Если есть совпадение в строке, вставьте строку перед совпадением
- Если есть совпадение в строке, вставьте строку после совпадения
- Если совпадений нет, добавьте что-нибудь в конец строки
- Если совпадений нет, удалите строку
- Дублировать совпадающий текст после добавления пробела после текста
- Заменить одну из строк в списке новой строкой
- Замените совпавшую строку строкой, содержащей символы новой строки
- Удалите символы новой строки из файла и вставьте запятую в конце каждой строки
- Удалите запятые и добавьте новые строки, чтобы разделить текст на несколько строк
- Найти совпадение без учета регистра и удалить строку
- Найдите совпадение без учета регистра и замените его новым текстом
- Найдите совпадение без учета регистра и замените его заглавными буквами одного и того же текста
- Найдите совпадение без учета регистра и замените его строчными буквами одного и того же текста
- Заменить все прописные буквы в тексте строчными
- Найдите число в строке и добавьте символ валюты после числа
- Добавляйте запятые к числам, которые содержат более 3 цифр
- Заменить символы табуляции на 4 пробела
- Замените 4 последовательных символа пробела на символ табуляции
- Обрезать все строки до первых 80 символов
- Найдите строковое регулярное выражение и добавьте после него некоторый стандартный текст
- Найдите строковое регулярное выражение и вторую копию найденной строки после него
- Запуск многострочных сценариев `sed` из файла
- Сопоставьте многострочный шаблон и замените новым многострочным текстом
- Заменить порядок двух слов, соответствующих шаблону
- Используйте несколько команд sed из командной строки
- Объедините sed с другими командами
- Вставить пустую строку в файл
- Удалите все буквенно-цифровые символы из каждой строки файла.
- Используйте «&» для соответствия строке
- Сменить пару слов
- Делайте первый символ каждого слова заглавным
- Печатать номера строк файла
1. Простая подстановка текста с помощью «sed»
Любая конкретная часть текста может быть найдена и заменена с помощью поиска и замены шаблона с помощью команды `sed`. В следующем примере «s» обозначает задачу поиска и замены. Слово «Bash» будет искать в тексте «Язык сценариев Bash», и если это слово существует в тексте, оно будет заменено словом «Perl».
$ эхо«Язык сценариев Bash»|sed‘s / Bash / Perl /’
Выход:
Слово «Баш» присутствует в тексте. Таким образом, на выходе получается «Perl Scripting Language».

Команда `sed` также может использоваться для замены любой части содержимого файла. Создайте текстовый файл с именем weekday.txt со следующим содержанием.
weekday.txt
понедельник
вторник
среда
четверг
Пятница
Суббота
Воскресенье
Следующая команда выполнит поиск и заменит текст «Воскресенье» на текст «Воскресенье — выходной».
$ Кот weekday.txt
$ sed‘s / воскресенье / воскресенье — выходной /’ weekday.txt
Выход:
«Воскресенье» существует в файле weekday.txt, и это слово заменяется текстом «Воскресенье — выходной» после выполнения указанной выше команды «sed».

Наверх
2. Заменить все экземпляры текста в определенной строке файла с помощью опции «g»
Параметр ‘g’ используется в команде `sed` для замены всех вхождений совпадающего шаблона. Создайте текстовый файл с именем python.txt со следующим содержанием, чтобы узнать об использовании опции «g». Этот файл содержит слово. «Python» многократно.
python.txt
Python — очень популярный язык.
Python прост в использовании. Python легко изучить.
Python — кроссплатформенный язык
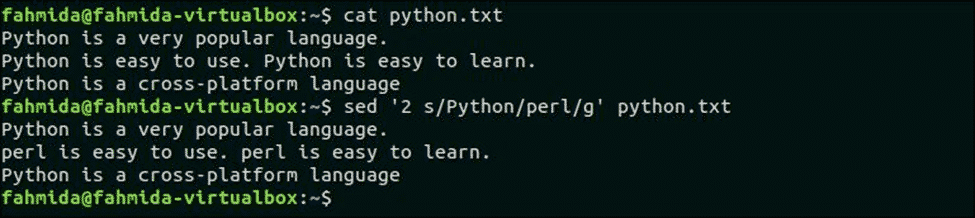
Следующая команда заменит все вхождения ‘Python’Во второй строке файла, python.txt. Здесь, «Python» встречается два раза во второй строке.
$ cat python.текст
$ sed ‘2 s / Python / perl / g’ питон.текст
Выход:
Следующий вывод появится после запуска скрипта. Здесь «Python» во второй строке заменяется на «Perl».
Наверх
3. Заменить только второе совпадение в каждой строке
Если какое-либо слово встречается в файле несколько раз, то конкретное вхождение слова в каждой строке можно заменить с помощью команды `sed` с номером вхождения. Следующая команда `sed` заменит второе вхождение шаблона поиска в каждой строке файла, python.txt.
$ sed ‘s / Python / perl / g2’ питон.текст
Выход:
Следующий вывод появится после выполнения указанной выше команды. Здесь поисковый текст «Python ’ появляется два раза только во второй строке и заменяется текстом ‘Perl‘.
Наверх
4. Заменить только последнее совпадение в каждой строке
Создайте текстовый файл с именем lang.txt со следующим содержанием.
lang.txt
Язык программирования Bash. Язык программирования Python. Язык программирования Perl.
Язык гипертекстовой разметки.
Расширяемый язык разметки.
$ sed‘s / (. * ) Programming / 1Scripting /’ lang.txt

Наверх
5. Заменить первое совпадение в файле новым текстом
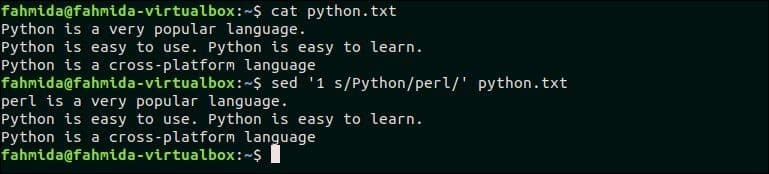
Следующая команда заменит только первое совпадение поискового шаблона ‘Python‘По тексту, ‘Perl‘. Здесь, ‘1’ используется для сопоставления с первым вхождением шаблона.
$ cat python.текст
$ sed ‘1 s / Python / perl /’ питон.текст
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Здесь. первое вхождение «Python» в первой строке заменяется на «perl».
Наверх
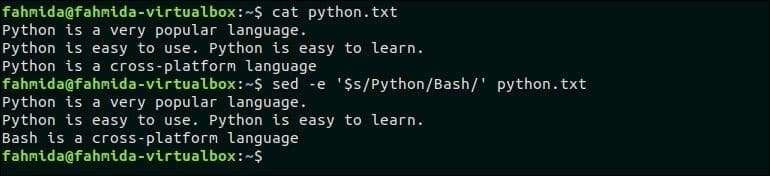
6. Заменить последнее совпадение в файле новым текстом
Следующая команда заменит последнее вхождение шаблона поиска, ‘Python‘По тексту, «Баш». Здесь, ‘$’ символ используется для соответствия последнему вхождению шаблона.
$ cat python.текст
$ sed -e ‘$ s / Python / Bash /’ питон.текст
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
7. Экранирование обратной косой черты в командах замены для управления поиском и заменой путей к файлам
Необходимо избегать обратной косой черты в пути к файлу для поиска и замены. Следующая команда `sed` добавит обратную косую черту () в путь к файлу.
$ эхо/дом/убунту/код/Perl/add.pl |sed‘s; /; \ /; g’
Выход:
Путь к файлу, ‘/Home/ubuntu/code/perl/add.pl’ предоставляется в качестве входных данных в команде `sed`, и следующий результат появится после выполнения указанной выше команды.

Наверх
8. Замените полный путь всех файлов только именем файла без каталога
Имя файла можно очень легко получить из пути к файлу, используя `basename` команда. Команда `sed` также может использоваться для получения имени файла из пути к файлу. Следующая команда получит имя файла только из пути к файлу, указанного командой `echo`.
$ эхо«/home/ubuntu/temp/myfile.txt»|sed‘s /.*///’
Выход:
Следующий вывод появится после выполнения указанной выше команды. Здесь имя файла «myfile.txt ’ печатается как вывод.

Наверх
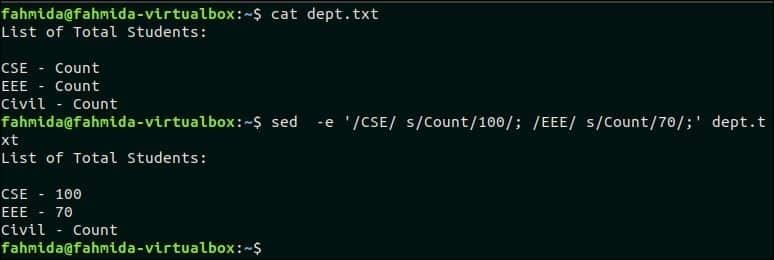
9. Заменить текст, но только если в строке найден другой текст
Создайте файл с именем ‘dept.txt ’ со следующим содержимым, чтобы заменить любой текст на другой текст.
dept.txt
Список общего количества студентов:
CSE — Count
EEE — Count
Гражданский — Граф
В следующей команде `sed` используются две команды замены. Здесь текст «Считать‘Будет заменен на 100 в строке, содержащей текст, ‘CSE‘И текст‘Считать’ будет заменен на 70 в строке, содержащей шаблон поиска, ‘EEE ’.
$ Кот dept.txt
$ sed-e‘/ CSE / s / Count / 100 /; / EEE / s / Count / 70 /; ‘ dept.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
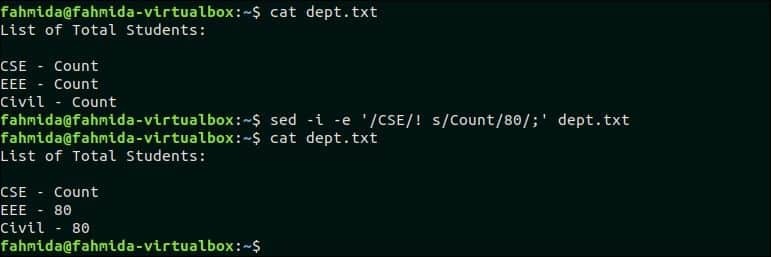
10. Заменить текст, но только если какой-либо другой текст не найден в строке
Следующая команда `sed` заменит значение« Count »в строке, не содержащей текста,« CSE ». dept.txt файл содержит две строки, которые не содержат текста «CSE». Так что ‘Считать‘Текст будет заменен на 80 в двух строках.
$ Кот dept.txt
$ sed-я-e‘/ CSE /! s / Count / 80 /; ‘ dept.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
11. Добавьте строку до и после соответствующего шаблона, используя « 1»
Последовательность совпадающих шаблонов команды `sed` обозначается« 1 »,« 2 »и так далее. Следующая команда `sed` выполнит поиск по шаблону« Bash », и если шаблон совпадает, то к нему будет обращаться« 1 »в части заменяющего текста. Здесь текст «Bash» ищется во входном тексте, и один текст добавляется перед, а другой текст добавляется после « 1».
$ эхо«Баш язык»|sed‘s / (Bash ) / Изучите 1 программирование /’
Выход:
Следующий вывод появится после выполнения указанной выше команды. Здесь, ‘Учить’ текст добавлен перед «Баш» и ‘программирование‘Текст добавляется после’Баш.

Наверх
12. Удалить совпадающие строки
‘D’ опция используется в команде `sed` для удаления любой строки из файла. Создайте файл с именем os.txt и добавьте следующий контент, чтобы проверить функцию ‘D’ вариант.
кошка os.txt
Окна
Linux
Android
Операционные системы
Следующая команда `sed` удалит эти строки из os.txt файл, содержащий текст «OS».
$ Кот os.txt
$ sed‘/ OS / d’ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.

Наверх
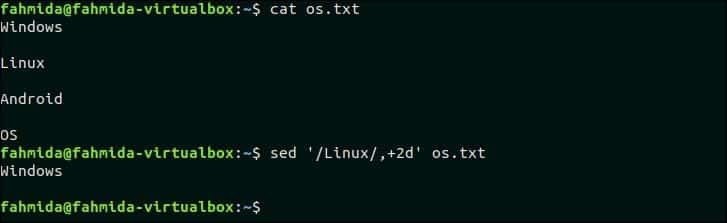
13. Удалить совпадающую строку и 2 строки после совпадающей строки
Следующая команда удалит три строки из файла os.txt если узор, ‘Linux ’ найден. os.txt содержит текст, ‘Linux‘Во второй строке. Итак, эта строка и следующие две строки будут удалены.
$ sed‘/ Linux /, + 2d’ os.txt
Выход:
Следующий вывод появится после выполнения указанной выше команды.
Наверх
14. Удалить все пробелы в конце строки текста
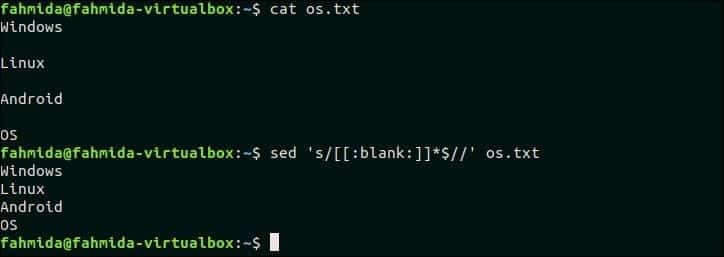
С использованием [:пустой:] Класс может использоваться для удаления пробелов и табуляции из текста или содержимого любого файла. Следующая команда удалит пробелы в конце каждой строки файла, os.txt.
$ Кот os.txt
$ sed‘s / [[: blank:]] * $ //’ os.txt
Выход:
os.txt содержит пустые строки после каждой строки, которые удаляются указанной выше командой `sed`.
Наверх
15. Удалите все строки, которые совпадают два раза в строке
Создайте текстовый файл с именем, input.txt со следующим содержимым и дважды удалите те строки файла, которые содержат шаблон поиска.
input.txt
PHP — это язык сценариев на стороне сервера.
PHP — это язык с открытым исходным кодом, и PHP чувствителен к регистру.
PHP не зависит от платформы.
Текст «PHP» содержится два раза во второй строке файла, input.txt. В этом примере используются две команды `sed` для удаления тех строк, которые содержат шаблон‘php‘ два раза. Первая команда `sed` заменит второе вхождение« php »в каждой строке на«дл‘И отправьте вывод во вторую команду` sed` в качестве ввода. Вторая команда `sed` удалит те строки, которые содержат текст,‘дл‘.
$ Кот input.txt
$ sed‘s / php / dl / i2; t’ input.txt |sed‘/ дл / д’
Выход:
input.txt файл имеет две строки, которые содержат шаблон, ‘Php’ два раза. Таким образом, после выполнения вышеуказанных команд появится следующий вывод.

Наверх
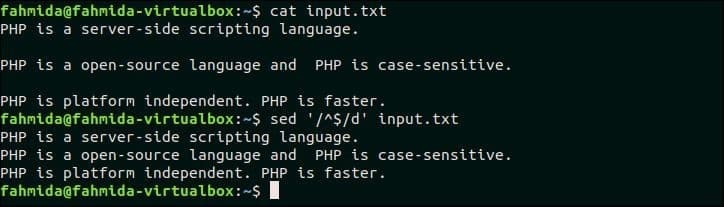
16. Удалите все строки, в которых есть только пробел
Выберите любой файл, содержащий пустые строки в содержимом, чтобы протестировать этот пример. input.txt Файл, созданный в предыдущем примере, содержит две пустые строки, которые можно удалить с помощью следующей команды `sed`. Здесь ‘^ $’ используется для поиска пустых строк в файле, input.txt.
$ Кот input.txt
$ sed‘/ ^ $ / д’ input.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
17. Удалить все непечатаемые символы
Непечатаемые символы можно удалить из любого текста, заменив непечатаемые символы на них. В этом примере используется класс [: print:] для определения непечатаемых символов. « T» — это непечатаемый символ, и его нельзя проанализировать напрямую с помощью команды `echo`. Для этого символ « t» назначается в переменной $ tab, которая используется в команде `echo`. Вывод команды `echo` отправляется в команде` sed`, которая удаляет символ ‘ t’ из вывода.
$ вкладка=$‘ т’
$ эхо«Привет$ tabWorld«
$ эхо«Привет$ tabWorld«|sed‘s / [^ [: print:]] // g’
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Первая команда `echo ‘напечатает вывод с пробелом табуляции, а команда` sed` напечатает вывод после удаления пробела табуляции.

Наверх
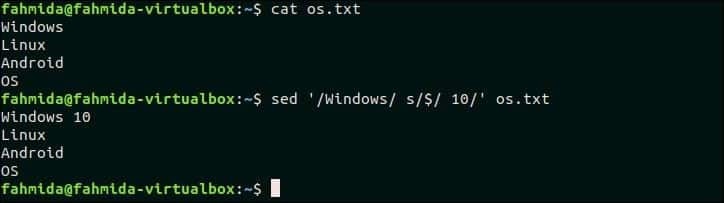
18. Если в строке есть совпадение, добавьте что-нибудь в конец строки
Следующая команда добавит «10» в конец строки, содержащей текст «Windows» в os.txt файл.
$ Кот os.txt
$ sed‘/ Windows / s / $ / 10 /’ os.txt
Выход:
После выполнения команды появится следующий вывод.
Наверх
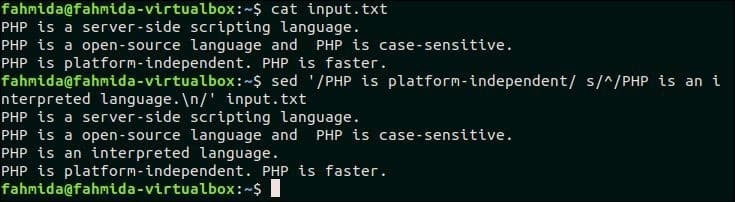
19. Если в строке есть совпадение, вставьте строку перед текстом
Следующая команда `sed` будет искать текст,‘PHP не зависит от платформы » в input.txt созданный ранее файл. Если файл содержит этот текст в какой-либо строке, то «PHP — это интерпретируемый язык » будет вставлен перед этой строкой.
$ Кот input.txt
$ sed‘/ PHP не зависит от платформы / s / ^ / PHP — это интерпретируемый язык. N /’ input.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
20. Если в строке есть совпадение, вставьте строку после этой строки
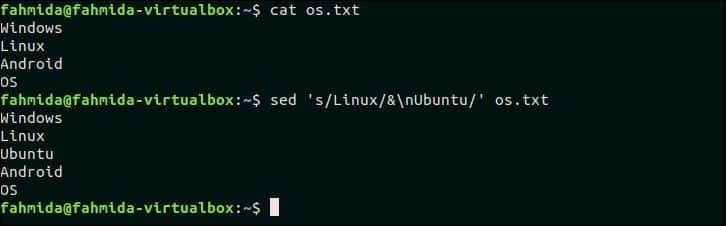
Следующая команда `sed` будет искать текст,‘Linux ’ в файле os.txt и если текст существует в какой-либо строке, то новый текст, ‘Ubuntu‘Будет вставлен после этой строки.
$ Кот os.txt
$ sed‘s / Linux / & nUbuntu /’ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
21. Если совпадений нет, добавьте что-нибудь в конец строки
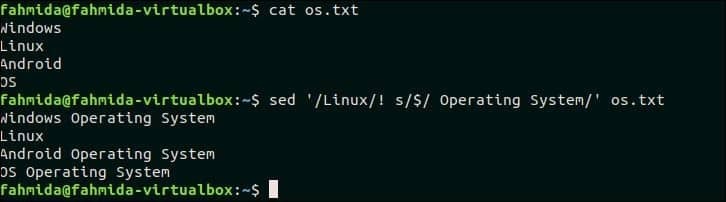
Следующая команда `sed` будет искать эти строки в os.txt который не содержит текста, «Linux» и добавьте текст «Операционная система‘В конце каждой строки. Здесь, ‘$Символ ‘используется для обозначения строки, в которую будет добавлен новый текст.
$ Кот os.txt
$ sed‘/ Linux /! S / $ / Операционная система / ‘ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. В файле os.txt есть три строки, которые не содержат текста «Linux» и нового текста, добавленного в конце этих строк.
Наверх
22. Если совпадений нет, удалите строку
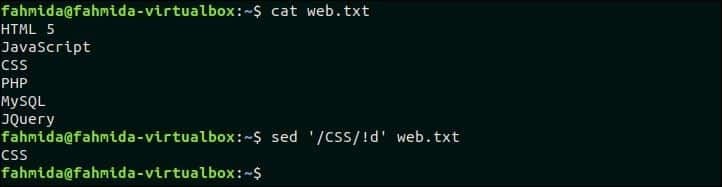
Создайте файл с именем web.txt и добавьте следующее содержимое и удалите строки, не содержащие соответствующий шаблон. web.txt HTML 5JavaScriptCSSPHPMySQLJQuery Следующая команда `sed` будет искать и удалять те строки, которые не содержат текста,« CSS ». $ cat web.txt $ sed ‘/ CSS /! d’ web.txt Выход: Следующий вывод появится после выполнения вышеуказанных команд. В файле есть одна строка, содержащая текст «CSE». Итак, вывод содержит всего одну строку.
Наверх
23. Дублировать совпадающий текст после добавления пробела после текста
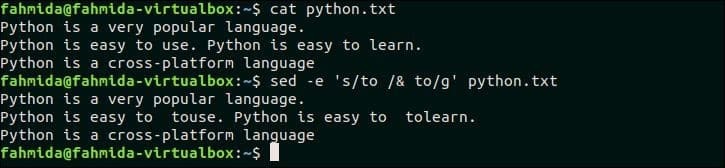
Следующая команда `sed` будет искать слово‘ to ’в файле, python.txt и если слово существует, то то же слово будет вставлено после поискового слова путем добавления пробела. Здесь, ‘&’ символ используется для добавления повторяющегося текста.
$ Кот python.txt
$ sed-e‘s / to / & to / g’ python.txt
Выход:
Следующий вывод появится после выполнения команд. Здесь слово «to» ищется в файле, python.txt и это слово существует во второй строке этого файла. Так, ‘к’С пробелом добавляется после совпадающего текста.
Наверх
24. Заменить один список строк новой строкой
Вы должны создать два файла списка для тестирования этого примера. Создайте текстовый файл с именем list1.txt и добавьте следующий контент.
cat list1.txt
1001 => Джафар Али
1023 => Нир Хоссейн
1067 => Джон Мишель
Создайте текстовый файл с именем list2.txt и добавьте следующий контент.
$ cat list2.txt
1001 CSE GPA-3.63
1002 CSE GPA-3.24
1023 CSE GPA-3.11
1067 CSE GPA-3.84
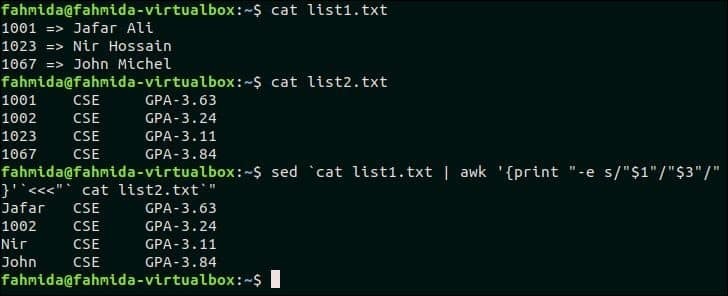
Следующая команда `sed` сопоставит первый столбец двух текстовых файлов, показанных выше, и заменит соответствующий текст значением третьего столбца файла. list1.txt.
$ Кот list1.txt
$ Кот list2.txt
$ sed`Кот list1.txt |awk‘{print «-e s /» $ 1 «/» $ 3 «/»}’`<<<«`cat list2.txt`«
Выход:
1001, 1023 и 1067 из list1.txt файл соответствует трем данным list2.txt файла, и эти значения заменяются соответствующими именами третьего столбца list1.txt.
Наверх
25. Замените совпавшую строку строкой, содержащей символы новой строки
Следующая команда будет принимать входные данные от команды `echo` и искать слово, «Python» в тексте. Если слово существует в тексте, то новый текст, «Добавленный текст» будет вставлен с новой строкой. $ echo «Bash Perl Python Java PHP ASP» | sed ‘s / Python / Добавленный текст n /’ Выход: Следующий вывод появится после выполнения указанной выше команды.

Наверх
26. Удалите символы новой строки из файла и вставьте запятую в конце каждой строки
Следующая команда `sed` заменит каждую новую строку запятой в файле os.txt. Здесь, -z опция используется для разделения строки символом NULL.
$ sed-z‘s / n /, / g’ os.txt
Выход:
Следующий вывод появится после выполнения указанной выше команды.
Наверх
27. Удалите запятые и добавьте новую строку, чтобы разделить текст на несколько строк.
Следующая команда `sed` примет разделенную запятыми строку из команды` echo` в качестве входных данных и заменит запятую на новую строку.
$ эхо«Каниз Фатема, 30-е, партия»|sed«s /, / п/g»
Выход:
Следующий вывод появится после выполнения указанной выше команды. Входной текст содержит три данных, разделенных запятыми, которые заменяются символом новой строки и печатаются в три строки.

Наверх
28. Найти совпадение без учета регистра и удалить строку
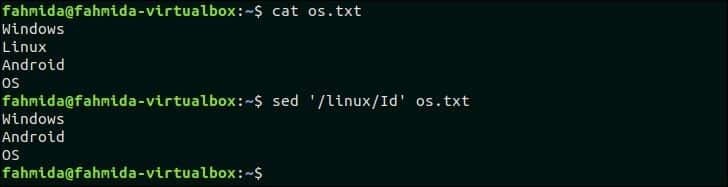
‘I’ используется в команде `sed` для совпадения без учета регистра, что указывает на игнорирование регистра. Следующая команда `sed` будет искать строку, содержащую слово, ‘Linux‘И удалите строку из os.txt файл.
$ Кот os.txt
$ sed‘/ linux / Id’ os.txt
Выход:
Следующий вывод появится после выполнения указанной выше команды. os.txt содержит слово «Linux», совпадающее с шаблоном, «linux» для поиска без учета регистра и удаляется.
Наверх
29. Найдите совпадение без учета регистра и замените его новым текстом
Следующая команда `sed` будет принимать входные данные от команды` echo` и заменять слово «bash» словом «PHP».
$ эхо«Мне нравится программировать на bash»|sed‘s / Bash / PHP / i’
Выход:
Следующий вывод появится после выполнения указанной выше команды. Здесь слово «Bash» соответствует слову «bash» для поиска без учета регистра и заменено словом «PHP».

Наверх
30. Найдите совпадение без учета регистра и замените его заглавными буквами одного и того же текста
‘ U’ используется в `sed` для преобразования любого текста в прописные буквы. Следующая команда `sed` будет искать слово, ‘Linux‘ в os.txt файл, и если слово существует, оно заменит слово заглавными буквами.
$ Кот os.txt
$ sed‘s / (Linux ) / U 1 / Ig’ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Слово «Linux» в файле os.txt заменяется словом «LINUX».

Наверх
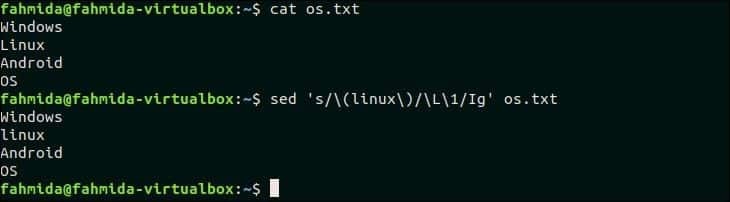
31. Найдите совпадение без учета регистра и замените его строчными буквами одного и того же текста
‘ L’ используется в `sed` для преобразования любого текста в строчные буквы. Следующая команда `sed` будет искать слово, «Linux» в os.txt файл и замените слово строчными буквами.
$ Кот os.txt
$ sed‘s / (Linux ) / L 1 / Ig’ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Слово «Linux» здесь заменено словом «linux».
Наверх
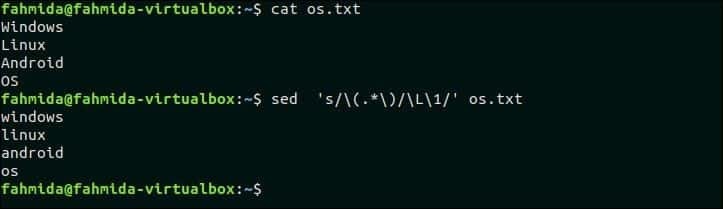
32. Замените все прописные символы текста строчными
Следующая команда `sed` будет искать все символы верхнего регистра в os.txt файл и замените символы строчными буквами с помощью ‘ L’.
$ Кот os.txt
$ sed‘s / (. * ) / L 1 /’ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
33. Найдите число в строке и добавьте любой символ валюты перед номер
Создайте файл с именем items.txt со следующим содержанием.
items.txt
HDD 100
Монитор 80
Мышь 10
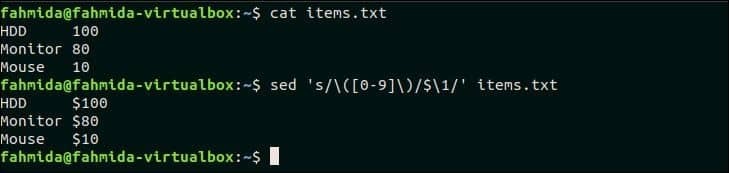
Следующая команда `sed` будет искать число в каждой строке items.txt файла и добавьте символ валюты «$» перед каждым числом.
$ Кот items.txt
$ sed‘s / ([0-9] ) / $ 1 / g’ items.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Здесь перед номером каждой строки добавляется символ «$».
Наверх
34. Добавляйте запятые к числам, которые содержат более 3 цифр
Следующая команда `sed` будет принимать число в качестве входных данных из команды` echo` и добавлять запятую после каждой группы из трех цифр, считая справа. Здесь «: a» обозначает метку, а «ta» используется для повторения процесса группировки.
$ эхо«5098673»|sed-e: а -e‘s / (. * [0-9] ) ([0-9] {3 } ) / 1, 2 /; ta’
Выход:
Число 5098673 дается в команде `echo`, а команда` sed` генерирует число 5 098 673, добавляя запятую после каждой группы из трех цифр.

Наверх
35. Заменяет символ табуляции на 4 пробела
Следующая команда `sed` заменит каждый символ табуляции ( t) четырьмя пробелами. Символ «$» используется в команде `sed` для соответствия символу табуляции, а символ« g »используется для замены всех символов табуляции.
$ эхо-e«1 т2 т3″|sed $‘s / t / / g’
Выход:
Следующий вывод появится после выполнения указанной выше команды.

Наверх
36. Заменяет 4 последовательных символа пробела на символ табуляции
Следующая команда заменит 4 последовательных символа символом табуляции ( t).
$ эхо-e«1 2»|sed $‘s / / t / g’
Выход:
Следующий вывод появится после выполнения указанной выше команды.

Наверх
37. Обрезать все строки до первых 80 символов
Создайте текстовый файл с именем in.txt который содержит строки более 80 символов для проверки этого примера.
in.txt
PHP — это язык сценариев на стороне сервера.
PHP — это язык с открытым исходным кодом, и PHP чувствителен к регистру. PHP не зависит от платформы.
Следующая команда `sed` обрезает каждую строку in.txt файл на 80 символов.
$ Кот in.txt
$ sed‘s / (^. {1,80 } ). * / 1 /’ in.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Вторая строка файла in.txt содержит более 80 символов, и при выводе эта строка обрезается.

Наверх
38. Найдите строковое регулярное выражение и добавьте после него некоторый стандартный текст
Следующая команда `sed` будет искать текст,‘Привет‘Во вводимом тексте и добавьте текст‘ Джон‘После этого текста.
$ эхо«Здравствуйте, как поживаете?»|sed‘s / (привет ) / 1 Джон /’
Выход:
Следующий вывод появится после выполнения указанной выше команды.

Наверх
39. Найдите строковое регулярное выражение и добавьте текст после второго совпадения в каждой строке
Следующая команда `sed` будет искать текст,‘PHP‘В каждой строке input.txt и замените второе совпадение в каждой строке текстом, «Новый текст добавлен».
$ Кот input.txt
$ sed‘s / (PHP ) / 1 (добавлен новый текст) / 2’ input.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. Текст поиска, ‘PHP’Дважды появляется во второй и третьей строках input.txt файл. Итак, текст «Добавлен новый текст’Вставляется во вторую и третью строки.

Наверх
40. Запуск многострочных сценариев `sed` из файла
В файле можно хранить несколько сценариев sed, и все сценарии можно выполнять вместе, запустив команду sed. Создайте файл с именем ‘Sedcmd‘И добавьте следующее содержание. Здесь в файл добавлены два сценария `sed`. Один скрипт заменит текст ‘PHP‘ по ‘ASP«Другой сценарий заменит текст»,независимый‘По тексту‘зависимый‘.
sedcmd
s/PHP/ASP/
s/независимый/зависимый/
Следующая команда `sed` заменит весь« PHP »и« независимый »текст на« ASP »и« зависимый ». Здесь опция «-f» используется в команде «sed» для выполнения сценария «sed» из файла.
$ Кот sedcmd
$ sed-f sedcmd input.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.

Наверх
41. Сопоставьте многострочный шаблон и замените новым многострочным текстом
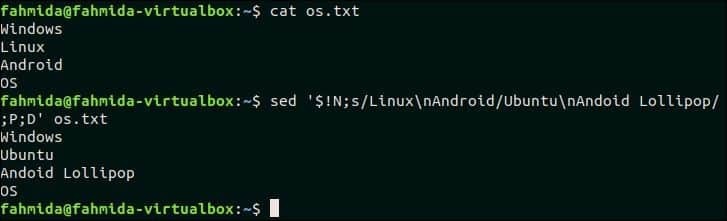
Следующая команда `sed` будет искать многострочный текст, ‘Linux nAndroid’ и если шаблон совпадает, то совпадающие строки будут заменены многострочным текстом, ‘Ubuntu nAndroid Lollipop‘. Здесь P и D используются для многострочной обработки.
$ Кот os.txt
$ sed‘$! N; s / Linux nAndoid / Ubuntu nAndoid Lollipop /; P; D ‘ os.txt
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
42. Замена порядка двух слов в тексте, соответствующих шаблону
Следующая команда `sed` будет вводить два слова из команды` echo` и менять порядок этих слов.
$ эхо«Perl Python»|sed-e‘s / ([^] * ) * ([^] * ) / 2 1 /’
Выход:
Следующий вывод появится после выполнения указанной выше команды.

Наверх
43. Выполнение нескольких команд `sed` из командной строки
Параметр ‘-e’ используется в команде `sed` для запуска нескольких скриптов` sed` из командной строки. Следующая команда `sed` принимает текст в качестве входных данных из команды` echo` и заменяет ‘Ubuntu‘ по ‘Кубунту‘ и ‘Centos‘ по ‘Fedora‘.
$ эхо«Ubuntu Centos Debian»|sed-es / Ubuntu / Kubuntu /; s / Centos / Fedora / ‘
Выход:
Следующий вывод появится после выполнения указанной выше команды. Здесь «Ubuntu» и «Centos» заменены на «Kubuntu» и «Fedora».

Наверх
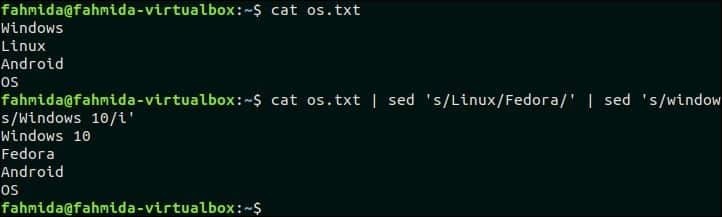
44. Комбинируйте `sed` с другими командами
Следующая команда объединит команду `sed` с командой` cat`. Первая команда `sed` будет принимать входные данные от os.txt файл и отправьте вывод команды второй команде `sed` после замены текста ‘Linux’ на ‘Fedora’. Вторая команда `sed` заменит текст« Windows »на« Windows 10 ».
$ Кот os.txt |sed‘s / Linux / Fedora /’|sed‘s / windows / Windows 10 / i’
Выход:
Следующий вывод появится после выполнения указанной выше команды.
Наверх
45. Вставить пустую строку в файл
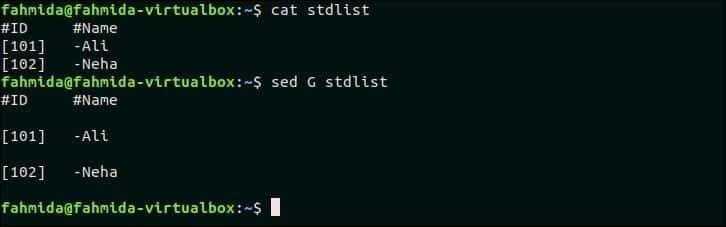
Создайте файл с именем stdlist со следующим содержанием.
stdlist
#ID # Имя
[101]-Али
[102]-Неха
Опция «G» используется для вставки пустой строки в файл. Следующая команда `sed` вставит пустые строки после каждой строки stdlist файл.
$ Кот stdlist
$ sed G stdlist
Выход:
Следующий вывод появится после выполнения вышеуказанных команд. После каждой строки файла вставляется пустая строка.
Наверх
46. Замените все буквенно-цифровые символы пробелом в каждой строке файла.
Следующая команда заменит все буквенно-цифровые символы пробелом в stdlist файл.
$ Кот stdlist
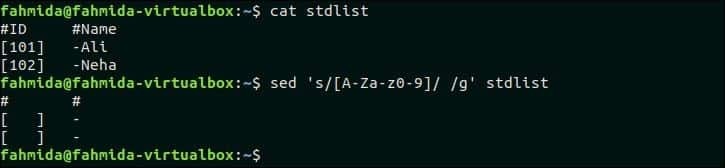
$ sed‘s / [A-Za-z0-9] // g’ stdlist
Выход:
Следующий вывод появится после выполнения вышеуказанных команд.
Наверх
47. Используйте «&» для печати совпадающей строки
Следующая команда выполнит поиск слова, начинающегося с «L», и заменит текст, добавив «Соответствующая строка —‘С совпадающим словом, используя символ‘ & ’. Здесь «p» используется для печати измененного текста.
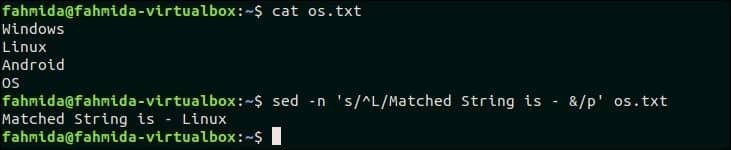
$ sed-n‘s / ^ L / Соответствующая строка — & / p’ os.txt
Выход:
Следующий вывод появится после выполнения указанной выше команды.
Наверх
48. Переключить пару слов в файле
Создайте текстовый файл с именем course.txt со следующим содержимым, содержащим пару слов в каждой строке.
course.txt
PHP ASP
MySQL Oracle
CodeIgniter Laravel
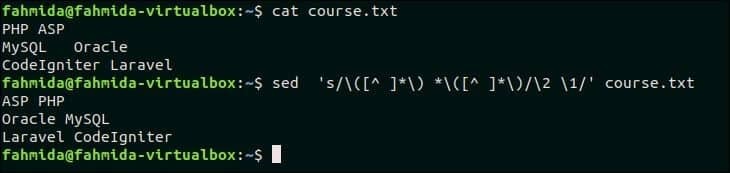
Следующая команда переключит пару слов в каждой строке файла, course.txt.
$ sed‘s / ([^] * ) * ([^] * ) / 2 1 /’ course.txt
Выход:
Следующий вывод появится после переключения пары слов в каждой строке.
Наверх
49. Делайте первый символ каждого слова заглавным
Следующая команда `sed` берет вводимый текст из команды` echo` и преобразует первый символ каждого слова в заглавную букву.
$ эхо«Мне нравится программировать на bash»|sed‘s / ([a-z] ) ([a-zA-Z0-9] * ) / u 1 2 / g’
Выход:
Следующий вывод появится после выполнения указанной выше команды. Текст ввода «Мне нравится программирование на bash» печатается как «Мне нравится программирование на Bash» после заглавной буквы в первом слове.

Наверх
50. Печатать номера строк файла
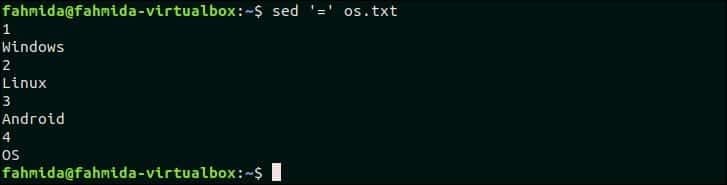
Символ ‘=’ используется командой `sed` для вывода номера строки перед каждой строкой файла. Следующая команда распечатает содержимое os.txt файл с номером строки.
$ sed‘=’ os.txt
Выход:
Следующий вывод появится после выполнения указанной выше команды. Есть четыре строки в os.txt файл. Итак, номер строки печатается перед каждой строкой файла.
Наверх
Вывод:
Различные варианты использования команды `sed` объясняются в этом руководстве на очень простых примерах. Вывод всех упомянутых здесь сценариев `sed` генерируется временно, а содержимое исходного файла остается неизменным. Но если вы хотите, вы можете изменить исходный файл, используя опцию –i или –in-place команды `sed. Если вы новый пользователь Linux и хотите изучить основные способы использования команды `sed` для выполнения различных типов задач манипуляции строками, то это руководство поможет вам. Надеюсь, после прочтения этого руководства любой пользователь получит ясное представление о функциях команды `sed`.
Часто задаваемые вопросы
Для чего используется команда sed?
Команда sed может использоваться по-разному. При этом в основном используется для замены слов в файле или поиска и замены.
Самое замечательное в sed то, что вы можете искать слово в файле и заменять его, но вам даже не нужно открывать файл — sed просто сделает все за вас!
Кроме того, его можно использовать для удаления. Все, что вам нужно сделать, это ввести слово, которое вы хотите найти, заменить или удалить, в sed, и оно появится. для вас — затем вы можете заменить это слово или удалить все следы слова из своего файл.
sed — фантастический инструмент, позволяющий заменять такие вещи, как IP-адреса, и все, что очень важно, что вы иначе не хотели бы помещать в файл. sed должен знать любой инженер-программист!
Что такое S и G в команде sed?
Проще говоря, функция S, которую можно использовать в sed, просто означает «подстановка». После ввода S вы можете заменить или заменить все, что хотите — просто набрав S, вы замените только первое вхождение слова в строке.
Следовательно, если у вас есть предложение или строка, в которых он упоминается более одного раза, функция S не идеальна, поскольку она заменит только первое вхождение. Вы можете указать шаблон, чтобы S также заменял слова каждые два вхождения.
Указание G в конце команды sed произведет глобальную замену (это то, что означает G). Имея это в виду, если вы укажете G, он заменит каждое вхождение слова, которое вы выбрали, а не только первое вхождение, которое делает S.
Как запустить сценарий sed?
Вы можете запустить sed-скрипт разными способами, но наиболее распространенный из них — в командной строке. Здесь вы можете просто указать sed и файл, для которого вы хотите использовать команду.
Это позволяет вам использовать sed для этого файла, что позволяет вам находить, удалять и заменять по мере необходимости.
Вы также можете использовать его в сценарии оболочки, и таким образом вы можете передать все, что хотите, сценарию, и он запустит для вас команду поиска и замены. Это полезно, если вы не хотите указывать особо конфиденциальные данные внутри скрипта, поэтому вместо этого вы можете передать их как переменную.
Имейте в виду, что это, конечно, доступно только в Linux, поэтому вам нужно будет убедиться, что у вас есть командная строка Linux, чтобы запустить свой сценарий sed.