Операционная система Windows 10 является одной из самых сложных и запутанных для начинающих пользователей. Прямо «из коробки» она просто работает, но если требуется настроить ее каким-то особым образом, то это может повлечь за собой множество проблем. Оказывается, что во всех компьютерах и прочих устройства, работающих на базе последней сборки этой ОС, есть скрытая от посторонних глаз настройках, которая значительно повышает скорость работы всей системы.
После обновления до Windows 10 Fall Creators Update (1709) все владельцы компьютеров и планшетов должны были заметить, что система стала работать ощутимо медленнее. Особенно сильно это заметно на компьютерах с обычными жесткими дисками (HDD) и слабеньким процессором. Сначала многие подумали, что дело в неправильно работающих драйверах видеокарты, которые после установки апдейта начали работать некорректно, однако эта гипотеза была очень быстро опровергнута.

Пользователи выяснили, что даже самые крутые 3D-игры на максимальных настройках не тормозят, тогда как многие системные программы в Windows 10 очень сильно «тупят». Наиболее сильно это заметно при работе с приложением «Проводник», который позволяет работать с файлами. Зачастую некоторые папки открываются по одной минуте, от чего многие пользователи в бешенстве.

Оказалось, что Microsoft добавила во все компьютеры на базе Windows 10 новую разработку под названием Control Flow Guard. Это своего рода специальная защита, направленная на борьбы с уязвимостями, связанными с повреждениями памяти. Защита защитой, но она в несколько раз снижает скорость работы всей операционной системы, причем отключить ее, на первый взгляд, невозможно.

К счастью, была обнаружена скрытая настройка, которая значительно повышает скорость работы всех компьютеров на Windows 10. Для этого необходимо запустить «Защитник Windows», а затем перейти в раздел «Управление приложениями и браузеров». Потребуется открыть подраздел «Параметры защиты от эксплойт», после чего отключить защиту CFG (Control Flow Guard). Чтобы все начало работать потребуется перезагрузить компьютер.

После выполнения этих действий и перезагрузки компьютера, он начнет работать в разы быстрее, поскольку фирменная система защиты Control Flow Guard перестанет использоваться. Зачем Microsoft принудительно включала эту настройку для всех – неизвестно, однако на форумах компании уже имеются десятки тысяч отзывов от пользователей, которые жалуются на медленную работу операционной системы Windows 10 из-за такого нововведения.
Встроенная функция безопасности Windows 10 – Control Flow Guard (CFG) предназначена для борьбы с уязвимостями повреждения памяти. Control Flow Guard помогает предотвратить повреждение памяти, что очень помогает предотвратить атаки вымогателей. Возможности сервера ограничены тем, что необходимо в этот момент времени, чтобы уменьшить поверхность атаки. Защита от эксплойтов является частью функции защиты от эксплойтов в Защитнике Windows. CFG является частью этой функции.
Содержание
- Контроль Flow Guard в Windows 10
- 1] Что такое Control Flow Guard и как он работает
- 2] Как Control Flow Guard влияет на производительность браузера
- 3] Как отключить Control Flow Guard в Windows 10
Контроль Flow Guard в Windows 10
Давайте немного углубимся в функцию Control Flow Guard в Windows 10 и ответим на несколько вопросов, таких как:
- Что такое Control Flow Guard и как он работает?
- Как Control Flow Guard влияет на производительность браузера?
- Как отключить Control Flow Guard?
1] Что такое Control Flow Guard и как он работает
Control Flow Guard – это функция, которая усложняет эксплойтам выполнение произвольного кода из-за уязвимостей, таких как переполнение буфера. Как мы знаем, уязвимости программного обеспечения часто эксплуатируются путем предоставления маловероятных, необычных или экстремальных данных работающей программе. Например, злоумышленник может воспользоваться уязвимостью, связанной с переполнением буфера, предоставляя программе больше входных данных, чем ожидалось, тем самым превышая область, зарезервированную программой для хранения ответа. Эта схема может повредить соседнюю память, которая может содержать указатель на функцию. Когда программа вызывает эту функцию, она может перейти в непредусмотренное место, указанное злоумышленником.
Чтобы избежать таких случаев, мощная комбинация поддержки компиляции и времени выполнения от Control Flow Guard реализует целостность потока управления, которая жестко ограничивает места, где могут выполняться инструкции косвенного вызова. Он также определяет набор функций в приложении, которые могут быть потенциальными целями для косвенных вызовов. Таким образом, Control Flow Guard добавляет дополнительные проверки безопасности, которые могут обнаружить попытки взлома исходного кода.
Когда проверка CFG не выполняется во время выполнения, Windows немедленно завершает работу программы, тем самым устраняя любую уязвимость, которая пытается косвенно вызвать неверный адрес.
2] Как Control Flow Guard влияет на производительность браузера
Сообщается, что эта функция вызывает проблемы с производительностью браузеров на базе Chromium. Все основные браузеры, такие как Google Chrome, Microsoft Edge browser, Vivaldi и многие другие, похоже, пострадали от этого. Эта проблема обнаружилась, когда разработчики Vivaldi запустили модульные тесты Chromium в Windows 7 и обнаружили, что они работают быстрее, чем в самой последней версии Windows 10.
Менеджер команды ядра Windows признал проблему и сказал, что они создали исправление, которое будет выпущено через пару недель.
3] Как отключить Control Flow Guard в Windows 10
Если вы хотите отключить эту функцию, следуйте этой процедуре.

Нажмите Пуск и найдите Безопасность Windows .
Выберите «Безопасность Windows» на левой панели раздела « Обновление и безопасность » в настройках Защитника Windows.

Выберите « Управление приложениями и браузером » и прокрутите вниз, чтобы найти « Настройки защиты от эксплойтов ». Выберите его и выберите Control Flow Guard ’.
Нажмите стрелку раскрывающегося списка и выберите «Выключить по умолчанию».
Надеюсь, это поможет.

Компания Microsoft не оставляет попыток победить в бесконечной войне с эксплоитописателями, раз за разом реализуя новые техники по защите приложений. На сей раз разработчики операционной системы Windows подошли к решению данного вопроса более фундаментально, переведя свой взгляд на корень проблемы. Работа почти каждого эксплоита так или иначе нацелена на перехват потока исполнения приложения, следовательно, не помешало бы «научить» приложения следить за этим моментом.
Концепия Control Flow Integrity (целостность потока исполнения) была описана еще в 2005 году. И вот, 10 лет спустя, разработчики из компании Microsoft представили свою неполную реализацию данного концепта — Control Flow Guard.
Что такое Control Flow Guard
Control Flow Guard (Guard CF, CFG) — относительно новый механизм защиты Windows (exploit mitigation), нацеленный на то, чтобы усложнить процесс эксплуатации бинарных уязвимостей в пользовательских приложениях и приложениях режима ядра. Работа данного механизма заключается в валидации неявных вызовов (indirect calls), предотвращающей перехват потока исполнения злоумышленником (например, посредством перезаписи таблицы виртуальных функций). В сочетании с предыдущими механизмами защиты (SafeSEH, ASLR, DEP и т.д.) являет собой дополнительную головную боль для создателей эксплоитов.
Данная секьюрити фича доступна пользователям ОС Microsoft Windows 8.1 (Update 3, KB3000850) и Windows 10.
Компиляция программ с поддержкой CFG доступна в Microsoft Visual Studio 2015 (как включить?).
Аналогичная реализация механизма защиты на основе концепции Control Flow Integrity для ОС семейства Linux имеется в расширении PaX.
Как работает Control Flow Guard
Рассмотрим принцип работы CFG в пользовательском режиме. Данный механизм имеет два основных компонента: битовую карту адресов (управляется ядром) и процедуру проверки указателя вызываемой функции (используется пользовательскими приложениями).
Вся служебная информация CFG заносится в IMAGE_LOAD_CONFIG_DIRECTORY исполняемого файла во время компиляции:

GuardCFCheckFunctionPointer— указатель на процедуру проверкиGuardCFFunctionTable— таблица валидных адресов функций (используется ядром для инициализации битовой карты)GuardCFFunctionCount— количество функций в таблицеGuardFlags— флаги
В заголовок IMAGE_NT_HEADERS.OptionalHeader.DllCharacteristics заносится флаг IMAGE_DLLCHARACTERISTICS_GUARD_CF, показывающий, что данный исполняемый файл поддерживает механизм CFG.
Всю служебную информацию можно посмотреть при помощи инструмента dumpbin.exe из Microsoft Visual Studio 2015 (Microsoft Visual Studio 14.0VCbindumpbin.exe), запустив его с ключом /loadconfig.
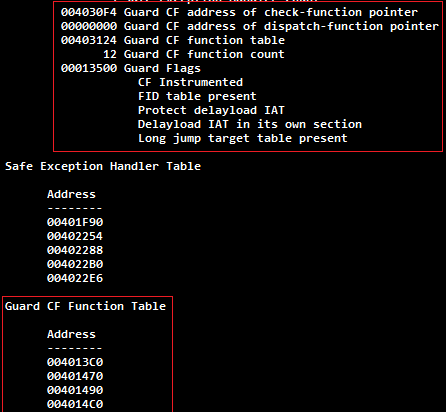
GuardFlags
Заголовочный файл winnt.h для Windows 10 (1511) содержит следующие флаги CFG (последний является маской, а не флагом):
IMAGE_GUARD_CF_INSTRUMENTED(0x00000100) — Модуль производит проверки потока исполнения при поддержке системыIMAGE_GUARD_CFW_INSTRUMENTED(0x00000200) — Модуль производит проверки целостности потока исполнения и записиIMAGE_GUARD_CF_FUNCTION_TABLE_PRESENT(0x00000400) — Модуль содержит таблицу валидных функцийIMAGE_GUARD_SECURITY_COOKIE_UNUSED(0x00000800) — Модуль не использует security cookie (/GS)IMAGE_GUARD_PROTECT_DELAYLOAD_IAT(0x00001000) — Модуль поддерживает Delay Load Import Table, доступную только для чтенияIMAGE_GUARD_DELAYLOAD_IAT_IN_ITS_OWN_SECTION(0x00002000) — Delay Load Import Table находится в своей собственной.didatсекцииIMAGE_GUARD_CF_FUNCTION_TABLE_SIZE_MASK(0xF0000000) — Шаг одного элемента таблицы валидных функций Guard CF кодируются в данных битах (дополнительное количество байтов для каждого элемента)
Стоит отметить, что это неполный список существующих флагов. Наиболее полный список можно получить из внутренностей файла link.exe (компоновщик):

Также стоит обратить внимание на присутствие некоторых интересных флагов, официальной информации о которых нет. Разработчики Microsoft, по всей видимости, тестируют дополнительный механизм CFG для проверки адреса записи (IMAGE_GUARD_CFW_INSTRUMENTED).
Битовая карта
Во время загрузки ОС ядром (функция nt!MiInitializeCfg) создается битовая карта nt!MiCfgBitMapSection, которая является общей (shared) секцией для всех процессов. При запуске процесса, поддерживающего CFG, происходит отображение (mapping) битовой карты в адресное пространство процесса. После чего адрес и размер битовой карты заносятся в структуру ntdll!LdrSystemDllInitBlock.
Сопоставлением адресов функций с битами в битовой карте занимается загрузчик исполняемых файлов (функция nt!MiParseImageCfgBits). Каждый бит в битовой карте отвечает за 8 байт пользовательского адресного пространства процесса. Адреса начала всех валидных функций соотносятся с единичным битом по соответствующему смещению в битовой карте, а всё остальное — 0.

Процедура проверки указателя вызываемой функции
Каждый неявный вызов в программе на этапе компиляции обрамляется проверкой адреса вызываемой функции. Адрес процедуры проверки устанавливает загрузчик исполняемых файлов, поскольку изначально установлен адрес пустой процедуры, тем самым сохраняя обратную совместимость.
Для наглядности посмотрим на один и тот же код, скомпилированный без CFG и с ним.
Оригинальный код на C++:
class CSomeClass
{
public:
virtual void doSomething()
{
std::cout << "hello";
}
};
int main()
{
CSomeClass *someClass = new CSomeClass();
someClass->doSomething();
return 0;
}ASM листинг (вырезка):
mov eax, [ecx] ; EAX = CSomeClass::vftable
call dword ptr [eax] ; [EAX] = CSomeClass::doSomething()С ключом компиляции /guard:cf :
mov eax, [edi] ; EAX = CSomeClass::vftable
mov esi, [eax] ; ESI = CSomeClass::doSomething()
mov ecx, esi
call ds:___guard_check_icall_fptr ; checks that ECX is valid function pointer
mov ecx, edi
call esiВ первом случае код подвержен атаке с использованием техники подмены таблицы виртуальных функций. Если атакующий при эксплуатации уязвимости способен перезаписать данные объекта, то он может подменить таблицу виртуальных функций таким образом, что вызов функции someClass->doSomething() приведет к выполнению контролируемого атакующим кода, тем самым перехватив поток исполнения приложения.
В случае же использования Control Flow Guard, адрес вызываемой функции предварительно будет сверен с битовой картой. Если соответствующий бит будет равен нулю, произойдет программное исключение.
При запуске данного приложения на ОС, которые поддерживают механизм Guard CF, загрузчик исполняемых файлов построит битовую карту и перенаправит адрес проверяющей процедуры на функциюntdll!LdrpValidateUserCallTarget.
Данная функция в ОС Windows 10 (build 1511) реализована следующим образом:
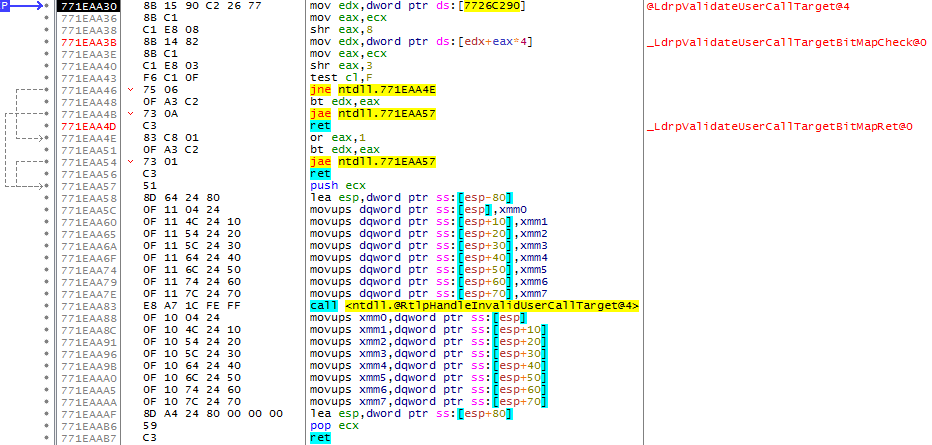
Изучим алгоритм данной функции на примере входного адреса 0x0B3385B0.
B3385B016 = 10110011001110000101101100002
Проверяемый адрес данная функция получает через регистр ecx. В регистр edx заносится адрес битовой карты. В моем случае битовая карта расположилась по адресу 0x01430000.
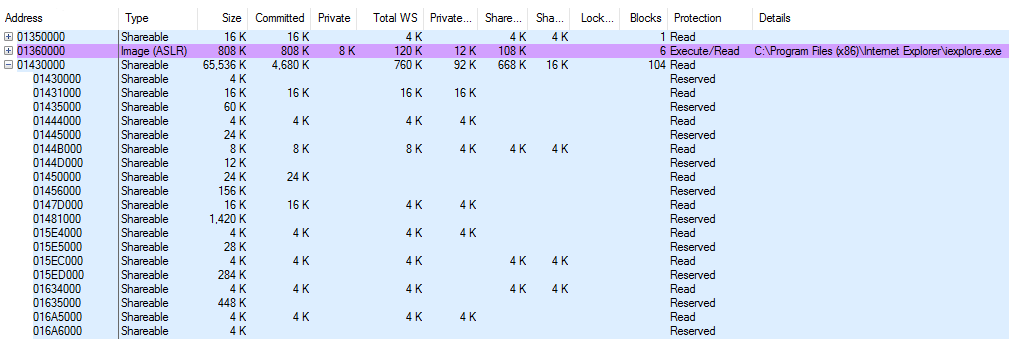
Три байта (24 бита) старшего порядка (подчеркнуты) адреса соответствуют смещению в битовой карте. В данном случае смещение будет равно 0xB3385. Единица измерения битовой карты равна 4 байтам (32 бита), поэтому для получения нужной ячейки необходимо вычислить базовый адрес карты + смещение * 4. Для данного примера получаем 0x01430000 + 0xB3385 * 4 = 0x16FCE14. Значение ячейки битовой карты записывается в регистр edx.
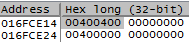
Целевую ячейку получили, теперь требуется определить номер интересующего нас бита. Номером является значение следующих 5 бит адреса (выделены жирным). Но нужно учитывать, что если проверяемый адрес не выравнен по границе 16 байт (address & 0xf != 0), то использоваться будет нечетный бит (offset | 0x1). В данном случае адрес выравнен и номер бита будет равен 101102 = 2210.
Теперь остается только проверить значение бита, проведя bit test. Инструкция bt проверяет значение бита первого регистра, порядковый номер которого берется из 5 младших бит (по модулю 32) второго регистра. В случае, если бит равен 1, будет выставлен Carry Flag (CF) и программа продолжит свое выполнение в обычном режиме. 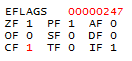
В ином случае будет вызвана функция ntdll!RtlpHandleInvalidUserCallTarget и работа программы завершится 29-ым прерыванием с параметром 0xA на стеке, что означает nt!_KiRaiseSecurityCheckFailure(FAST_FAIL_GUARD_ICALL_CHECK_FAILURE).
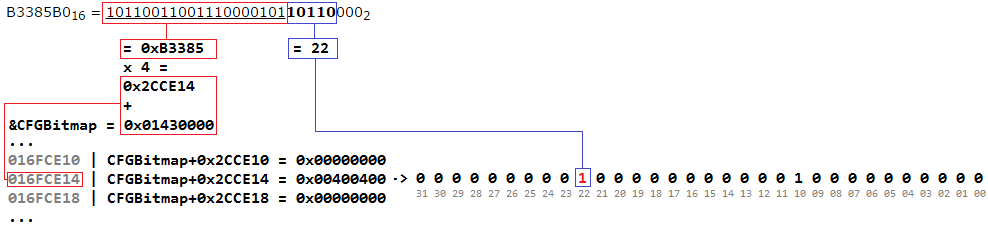
Проверив 22-ой бит, можно убедиться, что адрес вызываемой функции является валидным.
Реализация данного алгоритма на Python выглядит следующим образом:
def calculate_bitmap_offset(addr):
offset = (addr >> 8) * 4
bit = (addr >> 3) % 32
aligned = (addr & 0xF == 0)
if not aligned:
bit = bit | 1
print "addr = 0x%08x, offset = 0x%x, bit index = %u, aligned? %s" % (addr, offset, bit, "yes" if aligned else "no")
calculate_bitmap_offset(0x0B3385B0)Результат работы скрипта:
addr = 0x0b3385b0, offset = 0x2cce14, bit index = 22, aligned? yesИсключения
Не во всех случаях вызов невалидной функции будет заканчиваться 29-ым прерыванием. В функции ntdll!RtlpHandleInvalidUserCallTarget происходят следующие проверки:
- Включен ли DEP для текущего процесса
- Имеет ли целевой адрес необходимые права (
PAGE_EXECUTE_WRITECOPY | PAGE_EXECUTE_READWRITE | PAGE_EXECUTE_READ | PAGE_EXECUTE) - Разрешены ли «suppressed» вызовы —
ntdll!RtlGuardAllowSuppressedCalls - Является ли целевой адрес «suppressed» —
ntdll!RtlpGuardIsSuppressedAddress
Псевдокод данной функции выглядит следующим образом:
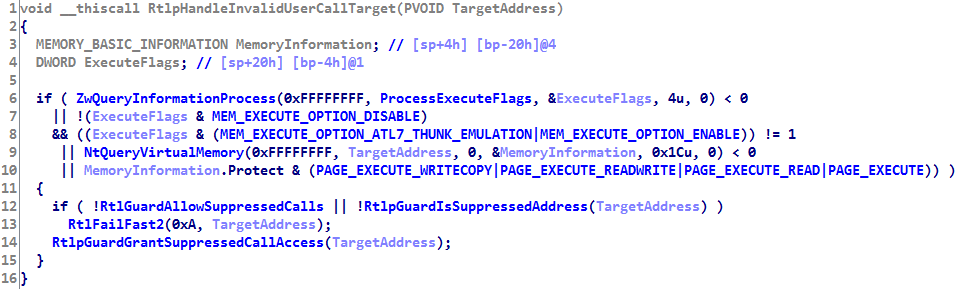
Официальная информация про «suppressed» вызовы отсутствует. Можно лишь сказать, что данные вызовы требуют поддержку компилятора — должна быть установлена маска IMAGE_GUARD_CF_FUNCTION_TABLE_SIZE_MASK во флагах GuardFlags и компилятор должен сгенерировать расширенную таблицу. В байтах, соответствующих данной маске, хранится значение дополнительного размера для элементов таблицы GuardCFFunctionTable. Если адрес функции является «suppressed», то байт, следующий за адресом, должен быть равен единице.
Разрешить «suppressed» вызовы можно, например, с помощью ветки реестра HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionImage File Execution Options, установив параметр CFGOptions для требуемого приложения в значение 1.
Слабые места Control Flow Guard
Как и любой другой защитный механизм, CFG имеет некоторые слабые места:
-
Выключенный DEP процесса влечет за собой потерю смысла проверок CFG, поскольку функция
ntdll!RtlpHandleInvalidUserCallTargetв таком случае будет всегда разрешать исполнение невалидного адреса. -
Адрес битовой карты хранится по фиксированному адресу и может быть легко вычислен из пользовательского режима. Пользователю запрещено модифицировать данные в битовой карте, но эксплоитописатели так или иначе найдут способ обойти это ограничение.
-
Если исполняемый файл не скомпилирован с поддержкой CFG, то поддержка CFG в подгружаемых им модулей теряет смысл. Битовая карта и адрес процедуры проверки заполняются только при условии, что исполняемый файл поддерживает механизм CFG, поэтому проверки внутри кода модулей будут являться простыми заглушками.
-
CFG зависит от процесса компиляции, поэтому модули сторонних разработчиков и даже старые модули Microsoft являются уязвимым местом в защищаемом CFG исполняемом файле. Поскольку битовая карта составляется по таблице адресов валидных функций, которая генерируется компилятором, весь код модуля без поддержки CFG будет помечен в битовой карте валидным адресатом.
-
За каждые 8 байт адресного пространства отвечает 1 бит, но, на самом деле, 1 выравненный адрес соотносится с одним четным битом, при этом следующий нечетный бит соотносится сразу с 15 байтами адресного пространства. Убедиться в этом можно, запустив приведенный выше Python скрипт в цикле и проанализировав результат:
addr = 0x08f38480, offset = 0x23ce10, bit index = 16, aligned? yes addr = 0x08f38481, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38482, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38483, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38484, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38485, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38486, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38487, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38488, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38489, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f3848a, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f3848b, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f3848c, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f3848d, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f3848e, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f3848f, offset = 0x23ce10, bit index = 17, aligned? no addr = 0x08f38490, offset = 0x23ce10, bit index = 18, aligned? yes addr = 0x08f38491, offset = 0x23ce10, bit index = 19, aligned? no addr = 0x08f38492, offset = 0x23ce10, bit index = 19, aligned? no addr = 0x08f38493, offset = 0x23ce10, bit index = 19, aligned? no addr = 0x08f38494, offset = 0x23ce10, bit index = 19, aligned? no ...Из этого следует, что у атакующего есть возможность вызвать недоверенную функцию в непосредственной близости от доверенной функции, при условии, что последняя не выравнена.
-
Динамически генерируемые функции (например, JIT-функции) требуют особого внимания от разработчиков, поскольку необходимо обеспечить проверки неявных вызовов на стадии генерирования функций. В добавок к этому, необходимо учитывать, что стандартное поведение функций
ntdll!NtAllocVirtualMemoryиntdll!NtProtectVirtualMemoryзаключается в проставлении единичного бита для всего региона памяти в битовой карте Control Flow Guard, если память становится исполняемой (PAGE_EXECUTE_*). -
CFG не способен предотвратить перехват потока исполнения при модификации атакующим адреса возврата функции.
- Вызовы библиотечных функций (например, WinAPI) с точки зрения CFG являются валидными, но атакующему предстоит решить задачу наполнения стека/регистров необходимыми параметрами.
Реализация обхода Control Flow Guard на примере Adobe Flash Player
Начиная с Windows 8 плагин Adobe Flash Player интегрирован в Internet Explorer, а с Windows 8.1 (Update 3) он поставляется с поддержкой CFG. Существует несколько реализаций обхода Control Flow Guard в эксплоитах под Adobe Flash Player, некоторые из которых актуальны и по сей день.
Обход при помощи динамического кода
В Adobe Flash Player активно используется JIT-компиляция, которая позволяет избегать выполнения такой ресурсоемкой операции, как интерпретация ActionScript кода. Но, как было сказано ранее, динамически генерируемые функции требуют дополнительного внимания со стороны разработчиков. Два метода обхода, описанные ниже, являются следствием упущения разработчиков в отношении работы с выделением памяти.
Отсутствие проверок неявных вызовов в динамическом коде
Данный метод был предложен и реализован исследователем Francisco Falcón из Core Security в своем анализе эксплоита для уязвимости CVE-2015-0311. Оригинальная статья довольно хорошо и подробно описывает процесс реализации обхода. Суть метода заключается в модификации внутренней таблицы виртуальных функций определенного ActionScript класса. После чего один из методов данного класса должен быть вызван из тела динамически сгенерированной функции. Для данной цели хорошо подходит класс ByteArray.
Структура объекта ByteArray:

По смещению $+8 находится указатель на объект класса VTable:
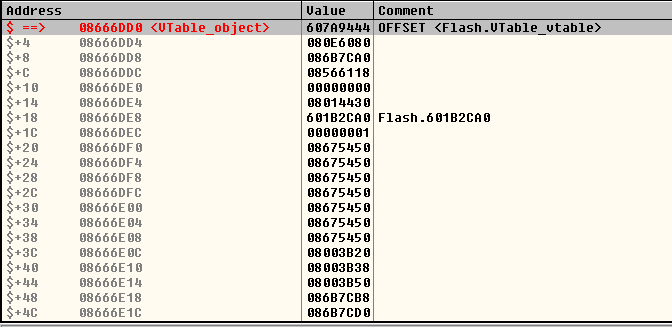
Класс VTable является внутренним представлением виртуальной таблицы функций (то есть не той, которую генерирует C++) для классов ActionScript.
Объект данного класса содержит в себе указатели на объекты класса MethodEnv:

Данный класс представляет собой описание метода ActionScript и содержит указатель на тело функции в памяти по смещению $+4.
В объекте VTable по смещению $+D4 находится описание метода ByteArray::toString(). Имея возможность произвольно читать и писать в память, атакующий способен изменить указатель функции на тело функции (MethodEnv + 4) и благополучно перехватить поток исполнения приложения, выполнив ByteArray::toString().
Такое становится возможным по причине того, что метод данного класса будет вызываться из JIT-кода:
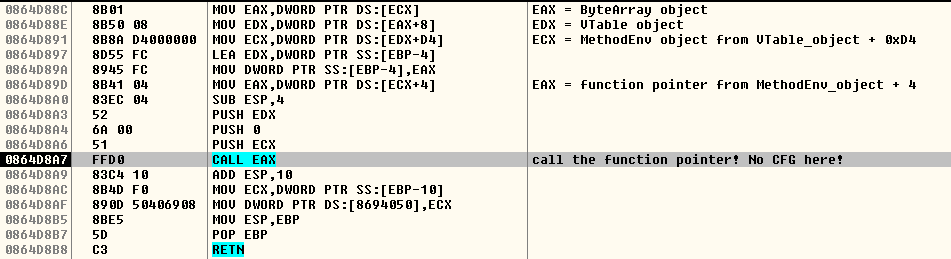
Как видно на скриншоте выше, неявный вызов происходит без предварительной проверки вызываемого адреса, поскольку данная функция была сгенерирована динамически.
Данный метод обхода CFG был исправлен с выходом Adobe Flash Player версии 18.0.0.160 (KB3065820, Июнь 2015). Исправление заключается в следующем: если JIT-функция содержит неявный вызов, то JIT-компилятор вставит вызов процедуры проверки непосредственно перед неявным вызовом.
Любой адрес в пределах тела динамической функции является валидным
Предыдущий метод обхода был возможен из-за недочета в функции, которая производит неявный вызов. А данный метод возможен из-за недочета в функции, которую неявно вызывют.
Исследователи Юрий Дроздов и Людмила Дроздова из Center of Vulnerability Research представили данный метод обхода CFG на конференции Defcon Russia (Санкт-Петербург, 2015) (презентация, статья). Их метод основан на том факте, что при выделении исполняемой памяти ядро выставляет единичный бит в битовой карте CFG для всей выделенной памяти. Посмотрим, к чему может привести такое поведение.
Предположим, что существует некая JIT-функция по адресу 0x69BC9080, в теле которой находится следующий код:
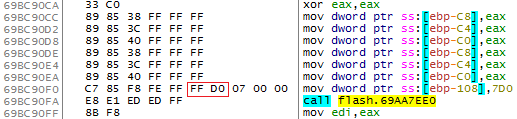
Что именно делает эта функция, нас не интересует, нужно лишь обратить внимание на 2 байта FF D0 инструкции по адресу 0x69BC90F0. Что будет, если начало функции вдруг сдвинется в середину данной инструкции? Вот что:

FF D0 — не что иное, как call eax! Вот так безобидная на первый взгляд функция превратилась в прекрасную цель для атакующего — неявный вызов без проверки Control Flow Guard. Нужно лишь разобраться с двумя вопросами: как добиться нужной последовательности байтов и как записать в регистр необходимый адрес.
Сгенерировать необходимую последовательность можно, просто экспериментируя с ActionScript-кодом. Стоит лишь учитывать тот факт, что Nanojit (JIT-компилятор AVM) обфусцирует генерируемый код, поэтому легкого пути не будет. Посмотрим, во что превратит Nanojit данную функцию:
public static function useless_func():uint
{
return 0xD5EC;
}Результат:

Совсем не то, что мы ожидали. Опытным путем можно прийти, например, к такому варианту кода:
public static function useless_func():void
{
useless_func2(0x11, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26);
}
public static function useless_func2(arg1:uint, arg2:uint, arg3:uint, a, b, c, d, e, f, g, h, i, j, k, l, m, n, p, q, r, s, t, u, v, w, x, y, z):void
{
}Тело первой функции будет содержать следующие инструкции:

Интересующие нас байты FF 11 являются инструкцией call [ecx]:

Неявный вызов получили, теперь нужно занести в регистр ecx контролируемый адрес. Выясним, что хранится в данном регистре в момент вызова функции useless_func().
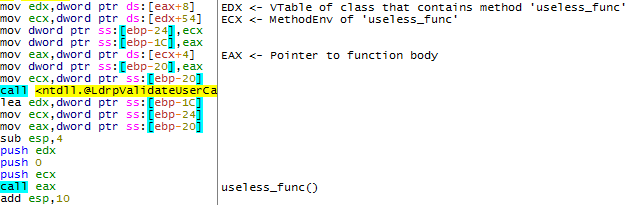
В момент вызова функции, в регистре ecx находится объект класса MethodEnv. Первый DWORD данного класса является указателем на виртуальную таблицу функций (ту, которую генерирует компилятор C++). Эта таблица в момент вызова метода useless_func() не используется, поэтому ничего не мешает атакующему непосредственно перед вызовом метода заменить указатель на свой.
Реализация данного алгоритма будет следующей:
var class_addr:uint = read_addr(UselessClass);
var vtable:uint = read_dword(class_addr + 8);
var methodenv:uint = read_dword(vtable + 0x54); // $+54 = useless_func
var func_ptr:uint = read_dword(methodenv + 4);
write_dword(methodenv + 4, func_ptr + offset_to_call_ecx);
write_dword(methodenv, rop_gadget); // ecx <- pointer to rop gadgets
UselessClass.useless_func(); // call [ecx]Таким образом, нам удалось перехватить поток исполнения приложения и перейти, в данном случае, к выполнению ROP-гаджета.
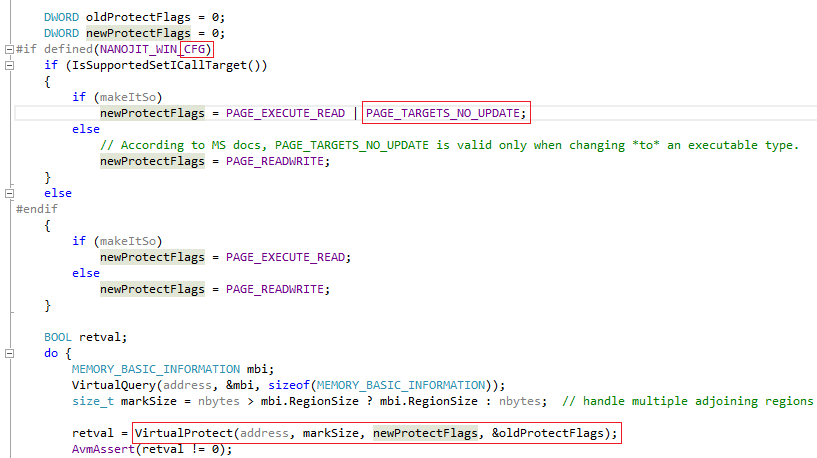
Этот метод обхода CFG был исправлен в версии 18.0.0.194 (KB3074219, Июнь 2015). Исправление заключается в использовании нового флага
PAGE_TARGETS_INVALID/PAGE_TARGETS_NO_UPDATE (0x40000000) для функций VirtualAlloc и VirtualProtect в связке с новой функцией WinAPI — SetProcessValidCallTargets.
Флаг PAGE_TARGETS_INVALID при выделении исполняемой памяти выставляет нулевой бит для всего участка памяти, а флаг PAGE_TARGETS_NO_UPDATE при изменении типа памяти на исполняемую предотвращает изменение битовой карты для целевого участка памяти.
Данное исправление можно наблюдать в функции AVMPI_makeCodeMemoryExecutable в исходном коде ядра AVM (AVMPI/MMgcPortWin.cpp):
Вызов функции SetProcessValidCallTargets реализован в AVMPI_makeTargetValid (AVMPI/MMgcPortWin.cpp):
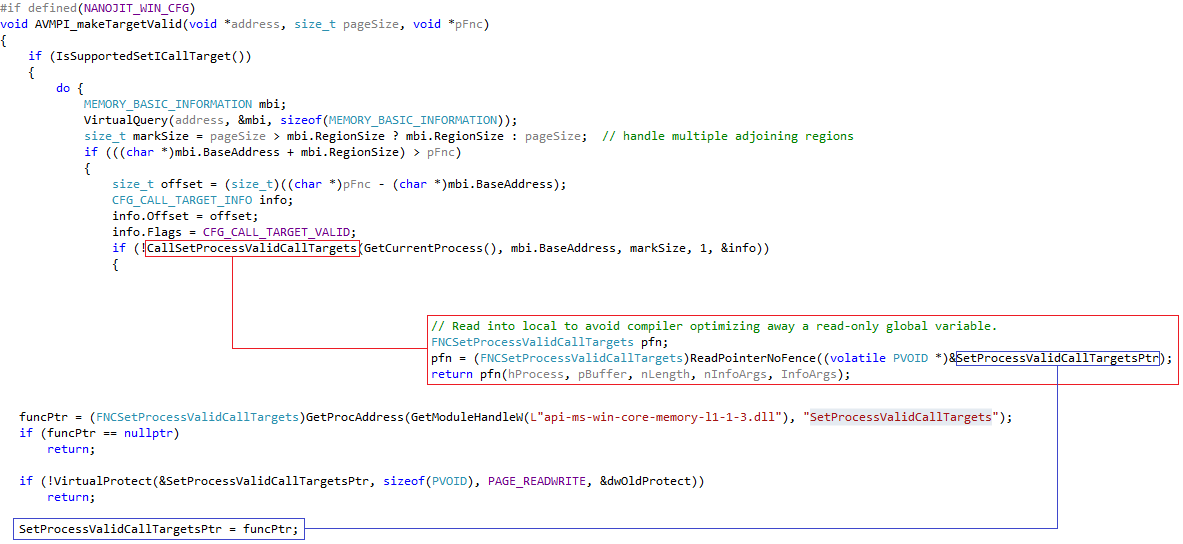
Из этого можно сделать вывод, что правильная последовательность действий при размещении в памяти динамически генерируемого кода в условиях работы CFG должна быть следующей:
VirtualAlloc(PAGE_READWRITE)- Запись кода в выделенный участок
VirtualProtect(PAGE_EXECUTE_READ |PAGE_TARGETS_NO_UPDATE)SetProcessValidCallTargets()
И, конечно же, не стоит забывать про неявные вызовы внутри динамического кода.
Обход при помощи функций WinAPI
Проверка Control Flow Guard заключается в валидации вызываемого адреса, но валидными адресами являются не только начала пользовательских функций. Все функции WinAPI, как и любые другие функции из таблицы импорта, являются валидными адресатами для неявного вызова. Атакующему ничего не мешает перевести поток исполнения напрямую в библиотечную функцию, минуя тем самым выполнение шеллкода (shellcode) или ROP-гаджетов. Хорошим кандидатом для такой цели является WinAPI функция kernel32!WinExec.
Данная идея впервые была озвучена исследователем Yuki Chen из Qihoo 360 Vulcan Team на конференции SyScan (Сингапур, 2015) в презентации, посвященной эксплуатации уязвимости в Internet Explorer 11 с обходом новых механизмов защиты. Также на конференции BlackHat (США, 2015) исследователь Francisco Falcón описал реализацию данного метода применительно к Adobe Flash Player.
В своей реализации Francisco Falcón оперировал методом toString() объекта класса Vector, но мы попробуем реализовать данный метод, пользуясь наработками из предыдущего.
Основная сложность данного метода заключается в том, чтобы передать параметры WinExec через стек. Данная функция, согласно справке, принимает 2 параметра: LPCSTR lpCmdLine и UINT uCmdShow.
lpCmdLine— указатель на строку, которую нужно выполнить (должна заканчиваться нулевым байтом).uCmdShow— режим отображения запускаемого приложения.
Обратимся к скриншоту из предыдущего метода:
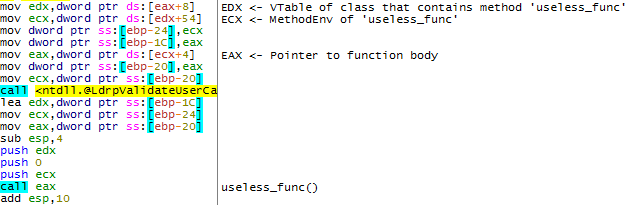
В момент вызова нашей функции на стеке оказывается 3 параметра. Третий параметр нас не интересует. Со вторым все отлично, поскольку 0 = SW_HIDE (приложение запустится скрыто). Первым параметром является указатель на объект MethodEnv.

Как мы уже выяснили ранее, первые 4 байта данного объекта являются указателем на виртуальную таблицу функций, и в момент вызова ActionScript-метода она никак не задействуется. Следующие 4 байта указывают на тело функции, и именно их нужно изменить на указатель функции WinExec.
Поскольку порча указателя на тело функции не приведет ни к чему хорошему, в нашем распоряжении имеется лишь первые 4 байта. В данный размер можно, например, уместить строку cmd (командная строка Windows). Данной командой, конечно, не добиться полной компрометации системы, но для демонстрации подойдет.
Модифицируем алгоритм из предыдущего метода и получим следующий код:
var class_addr:uint = read_addr(UselessClass);
var vtable:uint = read_dword(class_addr + 8);
var methodenv:uint = read_dword(vtable + 0x50); // $+50 = useless_func
var winexec:uint = get_proc_addr("kernel32.dll", "WinExec");
write_dword(methodenv + 4, winexec); // useless_func() --> WinExec()
write_dword(methodenv, 0x00646d63); // '', 'd', 'm', 'c'
UselessClass.useless_func();Поиск WinAPI функции в условиях современных Flash-эксплоитов является тривиальной задачей. Данную реализацию мы опустим, но с ней можно всегда ознакомиться, изучив пакет Flash Exploiter из фреймворка Metasploit.
Выполнив приведенный выше алгоритм при эксплуатации уязвимости, можно убедиться в работоспособности данного метода:

Данная реализация, несмотря на свою работоспособность и лаконичность, представляет малый интерес для атакующего, поскольку дает небольшой спектр возможностей.
Образец для подражания
Все современные Flash-эксплоиты так или иначе используют метод запуска полезной нагрузки (payload) из утекших исходников эксплоитов компании HackingTeam. Автором данного метода является Виталий Торопов. Его метод основан на вызове WinAPI функции kernel32!VirtualProtect, благодаря чему достигается обход всех механизмов защиты и, в том числе, Control Flow Guard.
Целью данного метода является метод apply() класса Function (core/FunctionClass.cpp)
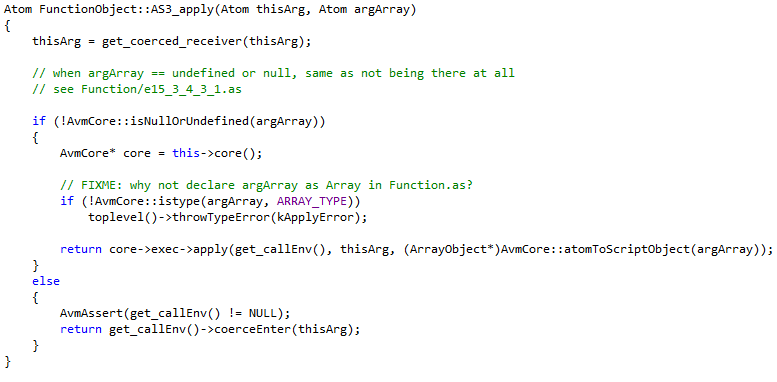
В исходном коде данного метода происходит нативный вызов core->exec->apply(get_callEnv(), thisArg, (ArrayObject*)AvmCore::atomToScriptObject(argArray));, который можно перехватить, оперируя объектами ActionScript.
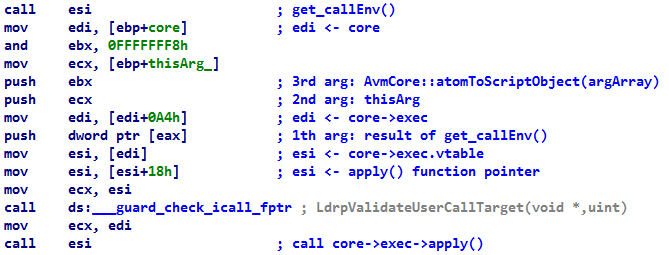
Подробное описание данного метода требует отдельной статьи, но с реализацией можно ознакомиться на GitHub. Также есть хороший материал с разбором данного метода в условиях 64-битного Flash в блоге Metasploit.
Другие работы по обходу Control Flow Guard
В данной статье были рассмотрены методы обхода CFG при эксплуатации уязвимостей Adobe Flash Player. Но мир не крутится вокруг Flash, поэтому рекомендуем ознакомиться со следующими исследованиями, в которых затрагивается вопрос обхода Control Flow Guard в Internet Explorer 11.
- Zhang Yunhai @ Black Hat 2015
Перезапись read-only указателя___guard_check_icall_fptrиспользуяCustomHeap::HeapбиблиотекиJscript9. - Yuki Chen @ SyScan 2015
Вызов WinAPI функцииkernel32!LoadLibraryA - Rafal Wojtczuk & Jared DeMott @ DerbyCon 2015 (video), заметка в блоге Bromium Labs
Интересное исследование, в котором представлена новая техника — «десинхронизация стека» (stack desync). Данная техника основана на том, что Control Flow Guard не способен контролировать валидность адреса возврата функции. Модификация адреса возврата достигается за счет вызова функции с несоответствующим соглашением о вызове (calling convention).
Заключение
Несмотря на свои недостатки, Control Flow Guard при должном внимании со стороны разработчиков является хорошим дополнением в арсенале борцов с эксплоитами в среде ОС Windows. Компании Microsoft удалось, пусть и не полностью, реализовать концепцию Control Flow Integrity, минимально повлияв на производительность приложений, и сохранив обратную совместимость. Данный механизм еще не достиг предела своих возможностей, и разработчики из Microsoft наверняка в ближайшем будущем смогут усилить защиту приложений.
Хочется надеяться, что все разработчики приложений задумаются над современной защитой от эксплуатации уязвимостей и добавят в свои продукты поддержку CFG.
Подобные механизмы защиты появляются и на уровне железа. Компания Intel, например, выпустила спецификацию их новой технологии, нацеленную на противодействие ROP-атакам — CET (Control-flow Enforcement Technology) (статья на хабре). В добавок к лучшей производительности, CET избавлен от многих недостатков Control Flow Guard.
Источники
Jack Tang, Trend Micro Threat Solution Team. Exploring Control Flow Guard in Windows 10.
mj0011, Qihoo 360 Vulcan Team. Windows 10 Control Flow Guard Internals.
Source code for the Actionscript virtual machine, GitHub.
Francisco Falcon, Core Security. Exploiting Adobe Flash Player in the era of Control Flow Guard.
 Flow Control — опция необходима для защиты от переполнения буфера, включать необходимо при большом входящем трафике.
Flow Control — опция необходима для защиты от переполнения буфера, включать необходимо при большом входящем трафике.
Включать или нет: только если наблюдаются странности в работе сети при большом количестве входящего трафика (обычно для игр включать ненужно).
Эта настройка предназначена для ситуаций, когда входящего трафика так много, что может произойти ошибка переполнения буфера, при котором оборудование отправляет команду паузы, после которой повторил отправку данных спустя некоторое время. Если подобную команду не послать — будет перегрузка, часть данных может потеряться, в итоге могут быть например глюки в игре. Также стоит понимать, что из-за команды паузы — увеличится значение пинга.
Функция полезна, когда происходит загрузка большого количества данных, например торренты. Игры обычно не имеют настолько активный трафик.
Функция например присутствует в сетевом адаптере D-Link DFE-550TX.
Flow Control включать стоит, когда наблюдаются непонятные задержки, обрывы, пропадания, лаги, тормоза при просмотре онлайн-видео. Также эту опцию включают при соединении разноскоростного оборудования или разноскоростных сетей, образно говоря, чтобы скоростная сеть не забила трафиком порт менеескоростной.
Опция сетевого адаптера Realtek:

Однако также спокойно может встречаться и в адаптерах других производителей, например Intel, Atheros.
Кстати открыть диспетчер устройств можно простым способом — зажмите Win + R, появится окошко Выполнить, вставьте команду devmgmt.msc и нажмите ОК.
Надеюсь данная информация оказалась полезной.
На главную!
22.08.2021
![]() В этой статье будут рассмотрены настройки сетевой платы, которые теоретически могут снизить высокий пинг в игре, победить лаги и как то повлиять на fps. Из первой части мы поняли, что динамичные многопользовательские онлайн игры используют протокол UDP, поэтому при ее настройке будем это учитывать. Обращаю внимание, что так сбить высокий пинг и убрать лаги получится, если у вас слабый компьютер и «хорошая» сетевуха или наоборот. Играясь с этими параметрами, нужно пробовать переложить нагрузку на то железо, которое у вас не испытывает проблем с производительностью. И итогом всей этой битвы и мучений, может быть станет выигрыш в несколько миллисекунд.
В этой статье будут рассмотрены настройки сетевой платы, которые теоретически могут снизить высокий пинг в игре, победить лаги и как то повлиять на fps. Из первой части мы поняли, что динамичные многопользовательские онлайн игры используют протокол UDP, поэтому при ее настройке будем это учитывать. Обращаю внимание, что так сбить высокий пинг и убрать лаги получится, если у вас слабый компьютер и «хорошая» сетевуха или наоборот. Играясь с этими параметрами, нужно пробовать переложить нагрузку на то железо, которое у вас не испытывает проблем с производительностью. И итогом всей этой битвы и мучений, может быть станет выигрыш в несколько миллисекунд.
Почему пинг высокий и как его понизить?
В первой части (из серии статей) мы пробовали победить высокую сетевую задержку с помощью настройки MTU. В этой рассмотрим и узнаем, какие настройки сетевой платы пригодятся любителям игр.
 Jumbo Frame — Jumbo Packet — Большой кадр:
Jumbo Frame — Jumbo Packet — Большой кадр:
Использование этого параметра, наверно только гипотетически поможет снизить пинг в играх и наверно какая то выгода будет во время долгих массовых сражений и осад, когда в одну секунду генерируется очень приличное количество трафика. Дело в том, что использование больших кадров должно быть настроено у всех участников взаимодействия, как у клиента и сервера, так и транзитных узлов. Но за пределами вашего провайдера (да и у самого провайдера) mtu всегда примерно равен 1,5 кб плюсминус десятки байтов. Если использовать его в локальных сетях (где можно точно проконтролировать эту настройку у всех), то там пинг зачастую и так достаточно низкий.
В чем плюс? Если использовать 9 кб у всех участников, вместо 1,5 кб, то для обсчета одного кадра потребуется в 6 раз реже задействовать процессор. Что должно лучше сказаться на прибавке фпс.
В чем минус? Если использовать его только на клиенте, при отсылке на остальных узлах пакет будет фрагментирован, в лучшем случаем на 6 частей, а при mtu <1500 может и на более. Которые в итоге будут переданы на каждый последующий узел, и где он должен попасть на сервер без потерь и корректно собран в один целый. В век высоких технологий, сбор и разбиение проходят быстро, но тем не менее, не всегда возможно предсказать насколько будет загружено оборудование обрабатывающее эти фрагменты. И эта фрагментация и загрузка транзитных узлов и может привести к росту пинга.
Значение: Выкл.
Checksum Offload — IPv4 Checksum Offload — Контрольная сумма разгрузки IPv4:
Если ваш адаптер имеет такую функцию, то включите ее. Это позволит освободить центральный процессор от расчета и проверки контрольных сумм для отправляемых и принимаемых пакетов. Что должно положительно сказаться на фпс в игре. Но бывают и обратные случаи, когда отключение это функции позволяет улучшить пинг и снизить лаги. Так что, попробуйте поиграться с этим параметром, при наличии лагом и скачущего пинга.
Значение: Вкл для Tx и Rx
Speed & Duplex — Link Speed/Duplex Mode — Скорость и дуплекс
Тут нужно проверить, что у вас стоит 101001 Гб дуплекс. При использовании режима полудуплекс, пинг становится выше.
Можете в этом убедиться, переключив режимы и пингануть любой сервер.
Значение: Дуплексный режим
Flow Control — Управление потоком
Данная настройка призвана решать проблему, когда входящий трафик приходит с такой скоростью, что создает угрозу переполнения буфера на сетевом оборудовании и тогда источнику отправляется команда, чтобы он выждал паузу и снова повторил отправку данных, через какой-то промежуток времени. Если же такой команды не послать, то из-за перегрузки часть данных просто потеряется, т.е. в игре это гарантированный лаг. Вроде бы хорошая и правильная и нужная функция, но только для тех кто скачивает большие объемы. В играх как правило трафик приходит не в таком интенсивном режиме. Если же кадр паузы будет послан, то одномоментно увеличится пинг. Т.е. если у вас в играх частые лаги и высокая сетевая задержка, попробуйте поиграться с этим параметром.
Значение: Выключить
Transmit Buffers — Буферы передачи / Receive Buffers — Буферы приема
Зачастую буфер приема имеет в настройках больший размер, так как трафика мы скачиваем больше, чем отдаем. Здесь главное придерживаться правила, что буфер приема минимум должен быть равен 100*mtu. Если mtu=1500 байт, то размер буфера должен быть не меньше 147 кб. Если будет меньше, то в массовых событиях в игре, с генерацией большого количества трафика, возможна потеря пакетов. Прямого влияние на пинг, данные настройки не оказывают. Скорее это касается лагов. Так что убедитесь, что данные параметры выставлены по умолчанию и не имеют слишком малого размера.
Для буфера передачи вполне подойдет заводское значение. Вряд ли на клиенте в игре можно на генерировать столько трафика, чтобы пакеты при этом не поместились в буфер.
TCP/UDP Checksum Offload IPv4/IPv6 — Контрольная сумма разгрузки TCP/UDP IPv4/IPv6
Чтобы узнать, дошел ли пакет до адресата целый и без ошибок, для проверки на другой стороне в него добавляют контрольную сумму, которая рассчитывается на основании данных пакета. Если у вас имеется данная функция в настройке, попробуйте ее включить для обоих типов трафика. Таким образом все вычисления будет проводить не процессор, а сетевой адаптер, что в итоге должно положительно сказаться на фпс в игре.
Значение: Rx & Tx Включить
Interrupt Moderation — Модерация прерывания
При получении одного пакета, сетевой адаптер вызывает прерывание. Когда идет интенсивный обмен трафиком такие прерывания создают нагрузку на процессор. И чтобы снизить ее, придумали накапливать события в течении какого-то времени и после этого вызывать прерывание (IRQ). Таким образом реже задействуя процессор. У такого способа есть свои плюсы, описанный ранее и так же можно сказать, что вся прелесть этой функции раскрывается для тех, кто много качает.
Из минусов, чтобы пакет был обработан, он ожидает, пока отработает таймер. Это то и добавляет пинга в игре.
Значение: Выключить
 Receive Side Scaling — RSS — Получение бокового масштабирования
Receive Side Scaling — RSS — Получение бокового масштабирования
Это интересный и нужный механизм для обладателей многоядерных процессоров. При включении его, пакеты делятся по потокам и каждый поток может обрабатывать отдельный процессор. Т.е. задействуются все ядра, что должно положительно сказаться на производительности в целом и на пинге в частности. Если эта функция выключена, весь трафик обрабатывается одним ядром.
Но все эти преимущества будут, если драйвер написан без ошибок. Иначе, бывают случаи, когда после включения начинаются проблемы и деградация производительности. Если вы впервые включаете его, внимательно понаблюдайте за сетью какое-то время.
Значение: Включить
Large Send Offload IPv4/IPv6 — Giant Send Offload — Разгрузка при большой отправке IPv4/IPv6
Фрагментацией пакетов данных при отправке будет заниматься сетевой адаптер, а не программное обеспечение. В идеале аппаратное фрагментирование проходит быстрее, меньше задействуется процессор, что в итоге для любителей игр должно положительно сказаться на пинге и фпс.
Есть еще настройка Large Send Offload v2, она выполняет ту же функцию, только для пакетов покрупнее. Иногда ее включение плохо влияет на производительность сети.
Значение: Включить
И в заключении коротко про пинг и представленные настройки
Некоторые параметры у разных производителей называются по-разному. Если вы у себя их не нашли, значит производитель не предусмотрел их настройку.
Вы должны понимать, что рекомендуемые здесь значения ориентированы на снижение пинга. Поэтому для любителей торрентов, данные параметры могут негативно сказаться на производительности и вызвать повышенную нагрузку на систему.
Все манипуляции с настройками сетевого адаптера обязательно проводите поэтапно. Не стоит все увиденое применять на практике сразу и одномоментно. На разных сетевых платах, эти настройки могут показать разное поведение.
Так же конечный результат зависит и от прямоты рук программистов, которые писали драйвера.
Надеюсь эта статья открыла что то новое для вас и помогла, хоть чуть-чуть, снизить высокий пинг в любимой игре.
Продолжение тут: третья и четвертая части
- Информация о материале
- Опубликовано: 01.09.2016 г.

Совершенно случайно наткнулся на статью о системе защиты Control Flow Guard, которая появилась в Windows 10 и Windows 8.1 Update 3 после одного из обновлений. Оказывается это технология сильно тормозит работу компьютера, особенно это ощущается на ПК без SSD диска.
Вот как было у меня:
Пользовался ноутбуком на Windows 8, скорость работы и всё остальное меня вполне устраивало. Но потом вышла Windows 10 и компьютер постоянно начал предлагать обновится. Я с этим делом не торопился и решил, что буду переходить на десятку намного позже, чтобы разработчики исправили баги, так присущие их продуктам, особенно «сырым».
Обновился до Windows 10 в один из последних дней возможного бесплатного перехода на новую операционную систему и сразу заметил как упала скорость работы по сравнению с восьмеркой. Возможности откатить на Windows 8 уже не было. Пришлось «наслаждаться» тем что имеем.
И вот спустя почти год я вдруг узнал, что есть такая программа как Control Flow Guard и она всему виной. Как говорится — «Лучше поздно, чем никогда!».
Это система защиты персонального компьютера от атак, которые направлены на повреждение памяти. Стал разбираться и оказалось, данная технология непосредственна связана с Защитником Windows. Получается большое количество людей, которые используют другие антивирусы и у которых стандартный виндосовский защитник отключен не используют эту технологию защиты. Ну и славно. Значит не так она и важна.
В любом случае интересно провести эксперимент и сравнить скорость загрузки и работы ноутбука с CFG и без неё. Сказано — сделано!
Как отключить Control Flow Guard в Windows 10
У кого стоит Windows 8, думаю, по аналогии не составит труда разобраться ведь отключается CFG в защитнике виндоус. Для наглядности прилагаю скриншот ниже.
- Заходим в Защитник Windows.
- Переходим на вкладку «Управление приложениями и браузером».
- Находим там защиту потока управления и в выпадающем списке ставим значение «Выкл, по умолчанию».
- Перезагружаем компьютер и наслаждаемся более быстрой загрузкой.
Встроенная функция безопасности Windows 10 — Control Flow Guard (CFG) предназначена для борьбы с уязвимостями, связанными с повреждением памяти. Control Flow Guard помогает предотвратить повреждение памяти, что очень полезно для предотвращения атак программ-вымогателей. Возможности сервера ограничены тем, что необходимо в данный момент, чтобы уменьшить поверхность атаки. Защита от эксплойтов является частью функции Exploit Guard в Защитнике Windows. CFG является частью этой функции.
Давайте углубимся в функцию Control Flow Guard в Windows 10 и ответим на несколько вопросов, например:
- Что такое Control Flow Guard и как он работает?
- Как Control Flow Guard влияет на производительность браузера?
- Как отключить Control Flow Guard?
1]Что такое Control Flow Guard и как он работает
Control Flow Guard — это функция, которая затрудняет выполнение эксплойтами произвольного кода из-за уязвимостей, таких как переполнение буфера. Как мы знаем, уязвимости программного обеспечения часто используются для передачи маловероятных, необычных или экстремальных данных в работающую программу. Например, злоумышленник может воспользоваться уязвимостью переполнения буфера, предоставив программе больше входных данных, чем ожидалось, тем самым переполнив область, зарезервированную программой для хранения ответа. Эта схема, возможно, повреждает соседнюю память, которая может содержать указатель на функцию. Когда программа вызывает эту функцию, она может перейти в непредусмотренное место, указанное злоумышленником.
Чтобы избежать таких случаев, мощная комбинация поддержки компиляции и времени выполнения от Control Flow Guard реализует целостность потока управления, которая жестко ограничивает места, где могут выполняться инструкции косвенного вызова. Он также определяет набор функций в приложении, которые могут быть потенциальными целями для косвенных вызовов. Таким образом, Control Flow Guard вставляет дополнительные проверки безопасности, которые могут обнаруживать попытки взлома исходного кода.
Когда проверка CFG завершается неудачно во время выполнения, Windows немедленно завершает работу программы, тем самым нарушая работу любого эксплойта, который пытается косвенно вызвать недопустимый адрес.
2]Как Control Flow Guard влияет на производительность браузера
Сообщается, что эта функция вызывает проблемы с производительностью браузеров на основе Chromium. Похоже, он затронул все основные браузеры, такие как Google Chrome, Microsoft Edge, Vivaldi и многие другие. Проблема обнаружилась, когда разработчики Vivaldi запустили модульные тесты Chromium в Windows 7 и обнаружили, что они работают быстрее, чем в самой последней версии Windows 10.
Менеджер группы ядра Windows признал проблему и сказал, что они создали исправление, которое будет отправлено через пару недель.
3]Как отключить Control Flow Guard в Windows 10
Если вы хотите отключить эту функцию, выполните следующую процедуру.
Нажмите «Пуск» и найдите Безопасность Windows.
Выберите Безопасность Windows на левой панели «Обновление и безопасность‘в настройках Защитника Windows.
Выбирать ‘Управление приложениями и браузером‘и прокрутите вниз, чтобы найти’Настройки защиты от эксплойтов‘. Выделите его и выберите ‘Защита потока управления‘.
Нажмите стрелку раскрывающегося списка и выберите вариант «Выкл. По умолчанию».
Надеюсь, это поможет.
.
Привет.
Это – вторая часть статьи. Поэтому всё, что относится к первой, относится и к этой. В этой, правда, будет больше настроек сетевых адаптеров, но не суть. Не буду повторяться, разве что в плане диспозиции.
Диспозиция
Я предполагаю, что Вы, товарищ читатель, знаете на приемлемом уровне протокол TCP, да и вообще протоколы сетевого и транспортного уровней. Ну и канального тоже. Чем лучше знаете – тем больше КПД будет от прочтения данной статьи.
Речь будет идти про настройку для ядра NT 6.1 (Windows 7 и Windows Server 2008 R2). Всякие исторические ссылки будут, но сами настройки и команды будут применимы к указанным ОС, если явно не указано иное.
В тексте будут упоминаться ключи реестра. Некоторые из упоминаемых ключей будут отсутствовать в официальной документации. Это не страшно, но перед любой серьёзной модификацией рабочей системы лучше фиксировать то, что Вы с ней делаете, и всегда иметь возможность удалённого доступа, не зависящую от состояния сетевого интерфейса (например KVM).
Содержание (то, что зачёркнуто, было в первой части статьи)
Работаем с RSS
Работаем с CTCP
Работаем с NetDMA
Работаем с DCA
Работаем с ECN
Работаем с TCP Timestamps
Работаем с WSH
Работаем с MPP
- Работаем с управлением RWND (autotuninglevel)
- Работаем с Checksum offload IPv4/IPv6/UDP/TCP
- Работаем с Flow Control
- Работаем с Jumbo Frame
- Работаем с AIFS (Adaptive Inter-frame Spacing)
- Работаем с Header Data Split
- Работаем с Dead Gateway Detection
Работаем с управлением RWND (autotuninglevel)
Данный параметр тесно связан с описаным ранее параметром WSH – Window Scale Heuristic. Говоря проще, включение WSH – это автоматическая установка данного параметра, а если хотите поставить его вручную – выключайте WSH.
Параметр определяет логику управление размером окна приёма – rwnd – для TCP-соединений. Если Вы вспомните, то размер этого окна указывается в поле заголовка TCP, которое называется window size и имеет размер 16 бит, что ограничивает окно 2^16 байтами (65536). Этого может быть мало для текущих высокоскоростных соединений (в сценариях вида “с одного сервера по IPv6 TCPv6-сессии и десятигигабитной сети копируем виртуалку” – совсем тоскливо), поэтому придуман RFC 1323, где описывается обходной способ. Почему мало? Потому что настройка этого окна по умолчанию такова:
- Для сетей со скоростью менее 1 мегабита – 8 КБ (если точнее, 6 раз по стандартному MSS – 1460 байт)
- Для сетей со скоростью 100 Мбит и менее, но более 1 Мбит – 17 КБ (12 раз по стандартному MSS – 1460 байт)
- Для сетей со скоростью выше 100 Мбит – 64 КБ (максимальное значение без поддержки RFC 1323)
Способ обхода, предлагаемый в RFC 1323, прост и красив. Два хоста, ставящих TCP-сессию, согласовывают друг с другом параметр, который является количеством бит, на которые будет сдвинуто значение поля windows size. То есть, если они согласуют этот параметр равный 2, то оба из них будут читать это поле сдвинутым “влево” на 2 бита, что даст увеличение параметра в 2^2=4 раза. И, допустим, значение этого поля в 64К превратится в 256К. Если согласуют 5 – то поле будет сдвинуто “влево” на 5 бит, и 64К превратится в 2МБ. Максимальный поддерживаемый Windows порог этого значения (scaling) – 14, что даёт максимальный размер окна в 1ГБ.
Как настраивается RWND в Windows
Существующие варианты настройки этого параметра таковы:
netsh int tcp set global autotuninglevel=disabled– фиксируем значение по умолчанию (для гигабитного линка это будет 64K), множитель – нуль. Это поможет, если промежуточные узлы (например, старое сетевое оборудование) не понимает, что значение окна TCP – это не поле window size, а оно, модифицированное с учётом множителя scaling.netsh int tcp set global autotuninglevel=normal– оставляем автонастройку, значение множителя – не более 8.netsh int tcp set global autotuninglevel=highlyrestricted– оставляем автонастройку, значение множителя – не более 2.netsh int tcp set global autotuninglevel=restricted– оставляем автонастройку, значение множителя – не более 4.netsh int tcp set global autotuninglevel=experimental– оставляем автонастройку, значение множителя – до 14.
Ещё раз – если Вы включите WSH, он сам будет подбирать “максимальный” множитель, на котором достигается оптимальное качество соединения. Подумайте перед тем, как править этот параметр вручную.
Работаем с Checksum offload IPv4/IPv6/UDP/TCP
Данная пачка технологий крайне проста. Эти настройки снимают с CPU задачи проверки целостности полученых данных, которые (задачи, а не данные) являются крайне затратными. То есть, если Вы получили UDP-датаграмму, Вам, по сути, надо проверить CRC у ethernet-кадра, у IP-пакета, и у UDP-датаграммы. Всё это будет сопровождаться последовательным чтением данных из оперативной памяти. Если скорость интерфейса большая и трафика много – ну, Вы понимаете, что эти, казалось бы, простейшие операции, просто будут занимать ощутимое время у достаточно ценного CPU, плюс гонять данные по шине. Поэтому разгрузки чексумм – самые простые и эффективно влияющие на производительность технологии. Чуть подробнее про каждую из них:
IPv4 checksum offload
Сетевой адаптер самостоятельно считает контрольную сумму у принятого IPv4 пакета, и, в случае, если она не сходится, дропит пакет.
Бывает продвинутая версия этой технологии, когда адаптер умеет сам проставлять чексумму отправляемого пакета. Тогда ОС должна знать про поддержку этой технологии, и ставить в поле контрольной суммы нуль, показывая этим, чтобы адаптер выставлял параметр сам. В случае chimney, это делается автоматически. В других – зависит от сетевого адаптера и драйвера.
IPv6 checksum offload
Учитывая, что в заголовке IPv6 нет поля checksum, под данной технологией обычно имеется в виду “считать чексумму у субпротоколов IPv6, например, у ICMPv6”. У IPv4 это тоже подразумевается, если что, только у IPv4 субпротоколов, подпадающих под это, два – ICMP и IGMP.
UDPv4/v6 checksum offload
Реализуется раздельно для приёма и передачи (Tx и Rx), соответственно, считает чексуммы для UDP-датаграмм.
TCPv4/v6 checksum offload
Реализуется раздельно для приёма и передачи (Tx и Rx), соответственно, считает чексуммы для TCP-сегментов. Есть тонкость – в TCPv6 чексумма считается по иной логике, нежели в UDP.
Общие сведения для всех технологий этого семейства
Помните, что все они, по сути, делятся на 2 части – обработка на адаптере принимаемых данных (легко и не требует взаимодействия с ОС) и обработка адаптером отправляемых данных (труднее и требует уведомления ОС – чтобы ОС сама не считала то, что будет посчитано после). Внимательно изучайте документацию к сетевым адаптерам, возможности их драйверов и возможности ОС.
Ещё есть заблуждение, гласящее примерно следующее “в виртуалках всё это не нужно, ведь это все равно работает на виртуальных сетевухах, значит, считается на CPU!”. Это не так – у хороших сетевых адаптеров с поддержкой VMq этот функционал реализуется раздельно для каждого виртуального комплекта буферов отправки и приёма, и в случае, если виртуальная система “заказывает” этот функционал через драйвер, то он включается на уровне сетевого адаптера.
Как включить IP,UDP,TCP checksum offload в Windows
Включается в свойствах сетевого адаптера. Операционная система с данными технологиями взаимодействует через минипорт, читая настройки и учитывая их в случае формирования пакетов/датаграмм/сегментов для отправки. Так как по уму это всё реализовано в NDIS 6.1, то надо хотя бы Windows Server 2008.
Работаем с Flow Control
Вы наверняка видели в настройках сетевых адаптеров данный параметр. Он есть практически на всех, поскольку технология данная (официально называемая 802.3x) достаточно простая и древняя. Но это никак не отменяет её эффективность.
Суть технологии проста – существует множество ситуаций, когда приём кадра L2 нежелателен (заполнен буфер приёма, перегружена шина данных, загружен порт получателя). В этом случае без управления потоком кадр придётся просто отбросить (обычный tail-drop). Это повлечёт за собой последующее обнаружение потери пакета, который был в кадре, и долгие выяснения на уровне протоколов более высоких уровней (того же TCP), что и как произошло. Иными словами, потеря 1.5КБ кадра превратится в каскад проблем, согласований и выяснений, на которые будет затрачено много времени и куда как больше трафика, чем если бы потери удалось избежать.
А избежать её просто – надо отправить сигнальный кадр с названием PAUSE – попросить партнёра “притормозить на чуток”. Соответственно, надо, чтобы устройство умело и обрабатывать такие кадры, и отправлять их. Кадр устроен просто – это 802.3 с вложением с кодом 0x0001, отправляемое на мультикастовый адрес 01-80-C2-00-00-01, внутри которого – предлагаемое время паузы.
Включайте поддержку этой технологии всегда, когда это возможно – в таком случае в моменты пиковой нагрузки сетевая подсистема будет вести себя более грамотно, сокращая время перегрузки за счёт интеллектуального управления загрузкой канала.
Как включить Flow control в Windows
Включается в свойствах сетевого адаптера. Операционная система с данной технологией не взаимодействует. Не забудьте про full duplex.
Работаем с Jumbo Frame
Исторически размер данных кадра протокола Ethernet – это 1.5КБ, что в сумме со стандартным заголовком составляет 1518 байт, а в случае транкинга 802.1Q – 1522 байт. Соответственно, этот размер оставался, а скорости росли – 10 Мбит, 100 Мбит, 1 Гбит. Скорость в 100 раз выросла – а размер кадра остался. Непорядок. Ведь это обозначает, что процессор в 100 раз чаще “дёргают” по поводу получения нового кадра, что объём служебных данных также остался прежним. Совсем непорядок.
Идея jumbo frame достаточно проста – увеличить максимальный размер кадра. Это повлечёт огромное количество плюсов:
- Улучшится соотношение служебных и “боевых” данных – ведь вместо, допустим, 4х IP-пакетов можно отправить один.
- Уменьшится число переключений контекста – можно будет реже инициировать функцию “пришёл новый кадр”.
- Можно соответствующим образом увеличить размеры PDU верхних уровней – пакета IP, датаграммы UDP, сегмента TCP – и получить соответствующие преимущества.
Данная технология реализуема только на интерфейсах со скоростями 1 гбит и выше. Если Вы включите jumbo frames на уровне сетевого адаптера, а после согласуете скорость в 100 мбит, то данная настройка не будет иметь смысла.
Для увеличения максимального размера кадра есть достаточно технологических возможностей – например, длина кадра хранится в поле размером в 2 байта, поэтому менять формат кадра 802.3 не нужно – место есть. Ограничением является логика подсчёта CRC, которая становится не очень эффективна при размерах >12К, но это тоже решаемо.
Самый простой способ – выставить у адаптера данный параметр в 9014 байт. Это является тем, что сейчас “по умолчанию” называется jumbo frame и шире всего поддерживается.
Есть ли у данной технологии минусы? Есть. Первый – в случае потери кадра из-за обнаружения сбоя в CRC Вы потеряете в 6 раз больше данных. Второй – появляется больше сценариев, когда будет фрагментация сегментов TCP-сессий. Вообще, в реальности эта технология очень эффективна в сценарии “большие потоки не-realtime данных в локальной сети”, учитывайте это. Копирование файла с файл-сервера – это целевой сценарий, разговор по скайпу – нет. Замечу также, что протокол IPv6 более предпочтителен в комбинации с Jumbo frame.
Как включить Jumbo frame в Windows
Включается в свойствах сетевого адаптера (естественно, только гигабитного). Операционная система с данной технологией не взаимодействует, автоматически запрашивая у сетевой подсистемы MTU канального уровня.
Работаем с AIFS (Adaptive Inter-frame Spacing)
Данная технология предназначена для оптимизации работы на half-duplex сетях со скоростями 10/100 мегабит, и, в общем-то, сейчас не особо нужна. Суть её проста – в реальной жизни, при последовательной передаче нескольких ethernet-кадров одним хостом, между ними есть паузы – чтобы и другие хосты могли “влезть” и передать свои данные, и чтобы работал механизм обнаружения коллизий (который CSMA/CD). Иначе, если бы кадры передавались “вплотную”, хост, копирующий по медленной сети большой поток данных, монополизировал бы всю сеть для себя. В случае же full-duplex данная мера уже не сильно интересна, потому что ситуации “из N хостов одновременно может передавать только один” нет. Помните, что включая данную технологию, Вы позволяете адаптеру уменьшать межкадровое расстояние ниже минимума, что приведёт к чуть более эффективному использованию канала, но в случае коллизии Вы получите проблему – “погибнет” не только один кадр, но и соседний (а то и несколько).
Данные паузы называются или interframe gap, или interframe spacing. Минимальное штатное значение этого параметра – 96 бит. AIFS уменьшает это значение до:
- 47 бит в случае канала 10/100 МБит.
- 64 бит в случае канала 1 ГБит.
- 40 бит в случае канала 10 ГБит.
Как понятно, чисто технически уменьшать это значение до чисел менее 32 бит (размер jam) совсем неправильно, поэтому можно считать 32 бита технологическим минимумом IFS.
Процесс, который состоит в приёме потока кадров с одним IFS и отправкой с другим IFS, иногда называется IFG Shrinking.
В общем, говоря проще – негативные эффекты этой технологии есть, но они будут только на 10/100 Мбит сетях в режиме half-duplex, т.к. связаны с более сложным сценарием обработки коллизий. В остальном у технологии есть плюс, Вы получите небольшой выигрыш в части эффективности загрузки канала в сценарии “плотный поток от одного хоста”.
Да, не забудьте, что коммутатор должен “понимать” ситуацию, когда кадры идут плотным (и более плотным, чем обычно) потоком.
Как включить Adaptive Inter-frame Spacing в Windows
Включается в свойствах сетевого адаптера. Операционная система с данной технологией не взаимодействует.
Работаем с Header Data Split
Фича достаточно интересна и анонсирована только в NDIS 6.1. Суть такова – допустим, что у Вас нет Chimney Offload и Вы обрабатываете заголовки программно. К Вам приходят кадры протокола Ethernet, а в них, как обычно – различные вложения протоколов верхних уровней – IP,UDP,TCP,ICMP и так далее. Вы проверяете CRC у кадра, добавляете кадр в буфер, а после – идёт специфичная для протокола обработка (выясняется протокол сетевого уровня, выясняется содержимое заголовка и предпринимаются соответствующие действия). Всё логично.
Но вот есть одна проблема. Смотрите. Если Вы приняли, допустим, сегмент TCP-сессии, обладающий 10К данных, то, по сути, последовательность действий будет такая (вкратце):
- Сетевая карта: Обработать заголовок 802.3; раз там 0x0800 (код протокола IPv4), то скопировать весь пакет и отдать наверх на обработку. Ведь в данные нам лезть незачем – не наша задача, отдадим выше.
- Минипорт: Прочитать заголовок IP, понять, что он нормальный, найти код вложения (раз TCP – то 6) и скопировать дальше. Данные-то не нам не нужны – это не наша задача, отдадим выше.
- NDIS: Ага, это кусок TCP-сессии номер X – сейчас изучим его и посмотрим, как и что там сделано
Заметили проблему? Она проста. Каждый слой читает свой заголовок, который исчисляется в байтах, а тащит ради этого путём копирования весь пакет.
Технология Header-Data Split адресно решает этот вопрос – заголовки пакетов и данные хранятся отдельно. Т.е. когда при приёме кадра в нём обнаруживается “расщепимое в принципе” содержимое, то оно разделяется на части – в нашем примере заголовки IP+TCP будут в одном буфере, а данные – в другом. Это сэкономит трафик копирования, притом очень ощутимо – как минимум на порядки (сравните размеры заголовков IP, который максимум 60 байт, и размер среднего пакета). Технология крайне полезна.
Как включить Header-Data Split в Windows
Включится оно само, как только сетевой драйвер отдаст минипорту флаг о поддержке данной технологии. Можно выключить вручную, отдав NDIS_HD_SPLIT_COMBINE_ALL_HEADERS через WMI на данный сетевой адаптер – тогда минипорт будет “соединять” головы и жо не-головы пакетов перед отправкой их на NDIS. Это может помочь в ситуациях, когда адаптер некорректно “расщепляет” сетевой трафик, что будет хорошо заметно (например, ничего не будет работать, потому что TCP-заголовки не будут обрабатываться корректно). В общем и целом – включайте на уровне сетевого адаптера, и начиная с Windows Server 2008 SP2 всё дальнейшее будет уже не Вашей заботой.
Работаем с Dead Gateway Detection
Данный механизм – один из самых смутных. Я лично слышал вариантов 5 его работы, все из которых были неправильными. Давайте разберёмся.
Первое – для функционирования этого механизма надо иметь хотя бы 2 шлюза по умолчанию. Не маршрутов, вручную добавленых в таблицу маршрутизации через route add например, а два и более шлюза.
Второе – этот механизм работает не на уровне IP, а на уровне TCP. Т.е. по сути, это обнаружение повторяющихся ошибок при попытке передать TCP-данные, и после этого – команда всему IP-стеку сменить шлюз на другой.
Как же будет работать этот механизм? Логика достаточно проста. Стартовые условия – механизм включен и параметр TcpMaxDataRetransmissions настроен по-умолчанию, то есть равен 5. Допустим, что у нас на данный момент есть 10 tcp-подключений.
- На каждое подключение создаётся т.н. RCE – route cache entry – строчка в кэше маршрутов, которая говорит что-то вида такого “все соединения с IP-адреса X на IP-адрес Y ходят через шлюз Z, пересчитывать постоянно это не нужно, потому что полностью обрабатывать таблицу маршрутизации ради 1го пакета – уныло и долго. Ну, этакий Microsoft’овский свичинг L3 типа CEF.

- Соединение N1 отправляет очередной сегмент TCP-сессии. В ответ – тишина. Помер.
- Соединение N1 отправляет тот же сегмент TCP-сессии, уже имея запись, что 1 раз это не получилось. В ответ – опять тишина. Нет ACK’а. И этот сегмент стал героем.
- Соединение N1 нервничает и отправляет тот же сегмент TCP-сессии. ACK’а нет. Соединение понимает, что так жить нельзя и делает простой вывод – произошло уже 3 сбоя отправки, что больше, чем половина значения
TcpMaxDataRetransmissions, которое у нас 5. Соединение объявляет шлюз нерабочим и заказывает смену шлюза. - ОС выбирает следующий по приоритету шлюз, обрабатывает маршрут и генерит новую RCE-запись.
- Счётчик ошибок сбрасывается на нуль, и всё заново – злополучный сегмент соединения N1 опять пробуют отправить.

Когда такое происходит для более чем 25% соединений (у нас их 10, значит, когда такое случится с 3 из них), то IP-стек меняет шлюз по-умолчанию. Уже не для конкретного TCP-соединения, а просто – для всей системы. Счётчик количества “сбойных” соединений сбрасывается на нуль и всё готово к продолжению.
Как настроить Dead Gateway Detection в Windows
Для настройки данного параметра нужно управлять тремя значениями в реестре, находящимися в ключе:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesTcpipParameters
Все они имеют тип 32bit DWORD и следующую логику настройки:
TcpMaxDataRetransmissions– Количество повторных передач TCP-сегментов. От этого числа берётся критерий “Более половины”.TcpMaxConnectRetransmissions– То же самое, но для повторных попыток подключения, а не передачи сегментов данных.EnableDeadGWDetect– Включён ли вообще алгоритм обнаружения “мёртвого” шлюза. Единица – включён, нуль – отключен.
Вместо заключения
Сетевых настроек – много. Знать их необходимо, чтобы не делать лишнюю работу, не ставить лишний софт, который кричит об “уникальных возможностях”, которые, на самом деле, встроены в операционную систему, не разрабатывать дурацкие архитектурные решения, базирующиеся на незнании матчасти архитектором, и в силу множества других причин. В конце концов, это интересно.
Если как-нибудь дойдут руки – будет новая часть статьи.
После обновления до Windows 10 Fall Creators Update (1709) Проводник может очень медленно работать, а файлы в папках подгружаются поэтапно. Виновата новая защита Control Flow Guard, которую Microsoft может включить. Эта функция безопасности платформы, которая была создана для борьбы с уязвимостями, связанными с повреждением памяти.
![]()
Установив жесткие ограничения на то, где приложения могут выполняться, Control Flow Guard может значительно затруднять выполнение эксплойтами произвольного кода с помощью таких уязвимостей, как переполнение буфера. Но на некоторых устройствах она может серьезно снижать скорость работы Проводника в Windows 10.
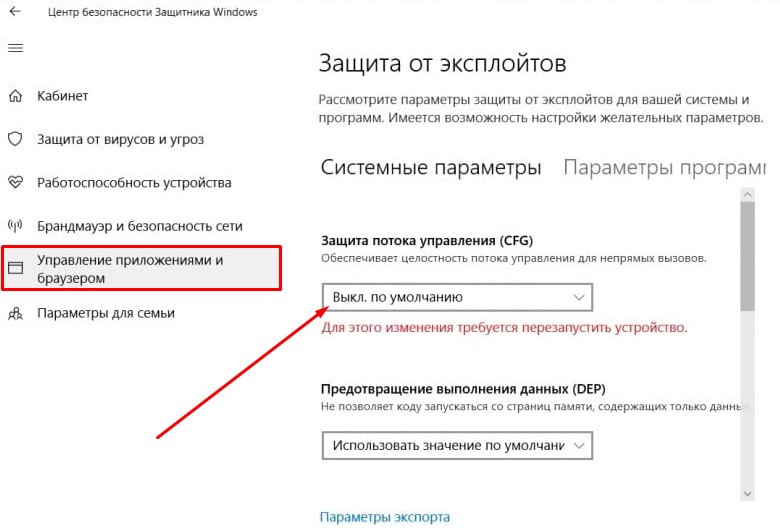
Как отключить Control Flow Guard в Windows 10
1. Откройте Пуск и наберите Центр безопасности Защитник Windows.
2. Зайдите: Управление приложениями и браузером > Параметры защиты от эксплойтов >
3. В Использовать строгий CFG установите Выкл. по умолчанию:

4. Перезагрузите компьютер.
Проводник снова должен начать работать быстро.