Часть 2
Что такое Git и зачем он нужен?
Git — это консольная утилита, для отслеживания и ведения истории изменения файлов, в вашем проекте. Чаще всего его используют для кода, но можно и для других файлов. Например, для картинок — полезно для дизайнеров.
С помощью Git-a вы можете откатить свой проект до более старой версии, сравнивать, анализировать или сливать свои изменения в репозиторий.
Репозиторием называют хранилище вашего кода и историю его изменений. Git работает локально и все ваши репозитории хранятся в определенных папках на жестком диске.
Так же ваши репозитории можно хранить и в интернете. Обычно для этого используют три сервиса:
-
GitHub
-
Bitbucket
-
GitLab
Каждая точка сохранения вашего проекта носит название коммит (commit). У каждого commit-a есть hash (уникальный id) и комментарий. Из таких commit-ов собирается ветка. Ветка — это история изменений. У каждой ветки есть свое название. Репозиторий может содержать в себе несколько веток, которые создаются из других веток или вливаются в них.
Как работает
Если посмотреть на картинку, то становиться чуть проще с пониманием. Каждый кружок, это commit. Стрелочки показывают направление, из какого commit сделан следующий. Например C3 сделан из С2 и т. д. Все эти commit находятся в ветке под названием main. Это основная ветка, чаще всего ее называют master . Прямоугольник main* показывает в каком commit мы сейчас находимся, проще говоря указатель.

В итоге получается очень простой граф, состоящий из одной ветки (main) и четырех commit. Все это может превратиться в более сложный граф, состоящий из нескольких веток, которые сливаются в одну.

Об этом мы поговорим в следующих статьях. Для начала разберем работу с одной веткой.
Установка
Основой интерфейс для работы с Git-ом является консоль/терминал. Это не совсем удобно, тем более для новичков, поэтому предлагаю поставить дополнительную программу с графическим интерфейсом (кнопками, графиками и т.д.). О них я расскажу чуть позже.
Но для начала, все же установим сам Git.
-
Windows. Проходим по этой ссылке, выбираем под вашу ОС (32 или 64 битную), скачиваем и устанавливаем.
-
Для Mac OS. Открываем терминал и пишем:
#Если установлен Homebrew
brew install git
#Если нет, то вводим эту команду.
git --version
#После этого появится окно, где предложит установить Command Line Tools (CLT).
#Соглашаемся и ждем установки. Вместе с CLT установиться и git-
Linux. Открываем терминал и вводим следующую команду.
# Debian или Ubuntu
sudo apt install git
# CentOS
sudo yum install gitНастройка
Вы установили себе Git и можете им пользоваться. Давайте теперь его настроим, чтобы когда вы создавали commit, указывался автор, кто его создал.
Открываем терминал (Linux и MacOS) или консоль (Windows) и вводим следующие команды.
#Установим имя для вашего пользователя
#Вместо <ваше_имя> можно ввести, например, Grisha_Popov
#Кавычки оставляем
git config --global user.name "<ваше_имя>"
#Теперь установим email. Принцип тот же.
git config --global user.email "<адрес_почты@email.com>"Создание репозитория
Теперь вы готовы к работе с Git локально на компьютере.
Создадим наш первый репозиторий. Для этого пройдите в папку вашего проекта.
#Для Linux и MacOS путь может выглядеть так /Users/UserName/Desktop/MyProject
#Для Windows например С://MyProject
cd <путь_к_вашему_проекту>
#Инициализация/создание репозитория
git initТеперь Git отслеживает изменения файлов вашего проекта. Но, так как вы только создали репозиторий в нем нет вашего кода. Для этого необходимо создать commit.
#Добавим все файлы проекта в нам будующий commit
git add .
#Или так
git add --all
#Если хотим добавить конкретный файл то можно так
git add <имя_файла>
#Теперь создаем commit. Обязательно указываем комментарий.
#И не забываем про кавычки
git commit -m "<комментарий>"Отлично. Вы создали свой первый репозиторий и заполнили его первым commit.
Процесс работы с Git
Не стоит после каждого изменения файла делать commit. Чаще всего их создают, когда:
-
Создан новый функционал
-
Добавлен новый блок на верстке
-
Исправлены ошибки по коду
-
Вы завершили рабочий день и хотите сохранить код
Это поможет держать вашу ветки в чистоте и порядке. Тем самым, вы будете видеть историю изменений по каждому нововведению в вашем проекте, а не по каждому файлу.
Визуальный интерфейс
Как я и говорил ранее, существуют дополнительные программы для облегчения использования Git. Некоторые текстовые редакторы или полноценные среды разработки уже включают в себя вспомогательный интерфейс для работы с ним.
Но существуют и отдельные программы по работе с Git. Могу посоветовать эти:
-
GitHub Desktop
-
Sourcetree
-
GitKraken
Я не буду рассказывать как они работают. Предлагаю разобраться с этим самостоятельно.
Создаем свой первый проект и выкладываем на GitHub
Давайте разберемся как это сделать, с помощью среды разработки Visual Studio Code (VS Code).
Перед началом предлагаю зарегистрироваться на GitHub.
Создайте папку, где будет храниться ваш проект. Если такая папка уже есть, то создавать новую не надо.
После открываем VS Code .

-
Установите себе дополнительно анализаторы кода для JavaScript и PHP
-
Откройте вашу папку, которую создали ранее
После этого у вас появится вот такой интерфейс
-
Здесь будут располагаться все файлы вашего проекта
-
Здесь можно работать с Git-ом
-
Кнопка для создания нового файла
-
Кнопка для создания новой папки
Если ваш проект пустой, как у меня, то создайте новый файл и назовите его
index.html. После этого откроется окно редактирование этого файла. Напишите в нем!и нажмите кнопкуTab. Автоматически должен сгенерироваться скелет пустой HTML страницы. Не забудьте нажатьctrl+sчтобы файл сохранился.
Давайте теперь перейдем во вкладу для работы с Git-ом.
Откроется вот такое окно:
-
Кнопка для публикации нашего проекта на GitHub
-
После нажатия на кнопку
1, появится всплывающее окно. Нужно выбрать второй вариант или там где присутствует фраза...public repository
Если вы хотите создать локальный репозиторий и опубликовать код в другой сервис, то необходимо нажать на кнопку
Initialize Repository. После этого, вручную выбрать сервис куда публиковать.
После того, как выбрали «Опубликовать на GitHub публичный репозиторий» (пункт 2), программа предложит вам выбрать файлы, которые будут входить в первый commit. Проставляем галочки у всех файлов, если не проставлены и жмем ОК . Вас перекинет на сайт GitHub, где нужно будет подтвердить вход в аккаунт.
Вы создали и опубликовали репозиторий на GitHub.
Теперь сделаем изменения в коде и попробуем их снова опубликовать. Перейдите во вкладку с файлами, отредактируйте какой-нибудь файл, не забудьте нажать crtl+s (Windows) или cmd+s (MacOS), чтобы сохранить файл. Вернитесь обратно во вкладу управления Git.
Если посмотреть на значок вкладки Git, то можно увидеть цифру 1 в синем кружке. Она означает, сколько файлов у нас изменено и незакоммичено. Давайте его закоммитим и опубликуем:
-
Кнопка для просмотра изменений в файле. Необязательно нажимать, указал для справки
-
Добавляем наш файл для будущего commit
-
Пишем комментарий
-
Создаем commit
-
Отправляем наш commit в GitHub
Поздравляю, вы научились создавать commit и отправлять его в GitHub!
Итог
Это первая вводная статья по утилите Git. Здесь мы рассмотрели:
-
Как его устанавливать
-
Как его настраивать
-
Как инициализировать репозиторий и создать commit через консоль
-
Как на примере VS Code, опубликовать свой код на GitHub
Забегая вперед, советую вам погуглить, как работают следующие команды:
git help # справка по всем командам
git clone
git status
git branch
git checkout
git merge
git remote
git fetch
git push
git pull
P.S. Для облегчения обучения, оставлю вам ссылку на бесплатный тренажер по Git.
https://learngitbranching.js.org/
В телеграмм канале Step by Step , я публикую еще больше материала и провожу обучающие стримы, для всех желающих.
Что такое Git?
Что же такое Git, если говорить коротко?
Очень важно понять эту часть материала, потому что если вы поймёте, что такое Git и основы того, как он работает, тогда, возможно, вам будет гораздо проще его использовать.
Пока вы изучаете Git, попробуйте забыть всё, что вы знаете о других СКВ, таких как Subversion и Perforce.
Это позволит вам избежать определённых проблем при использовании инструмента.
Git хранит и использует информацию совсем иначе по сравнению с другими системами, даже несмотря на то, что интерфейс пользователя достаточно похож, и понимание этих различий поможет вам избежать путаницы во время использования.
Снимки, а не различия
Основное отличие Git от любой другой СКВ (включая Subversion и её собратьев) — это подход к работе со своими данными.
Концептуально, большинство других систем хранят информацию в виде списка изменений в файлах.
Эти системы (CVS, Subversion, Perforce, Bazaar и т. д.) представляют хранимую информацию в виде набора файлов и изменений, сделанных в каждом файле, по времени (обычно это называют контролем версий, основанным на различиях).
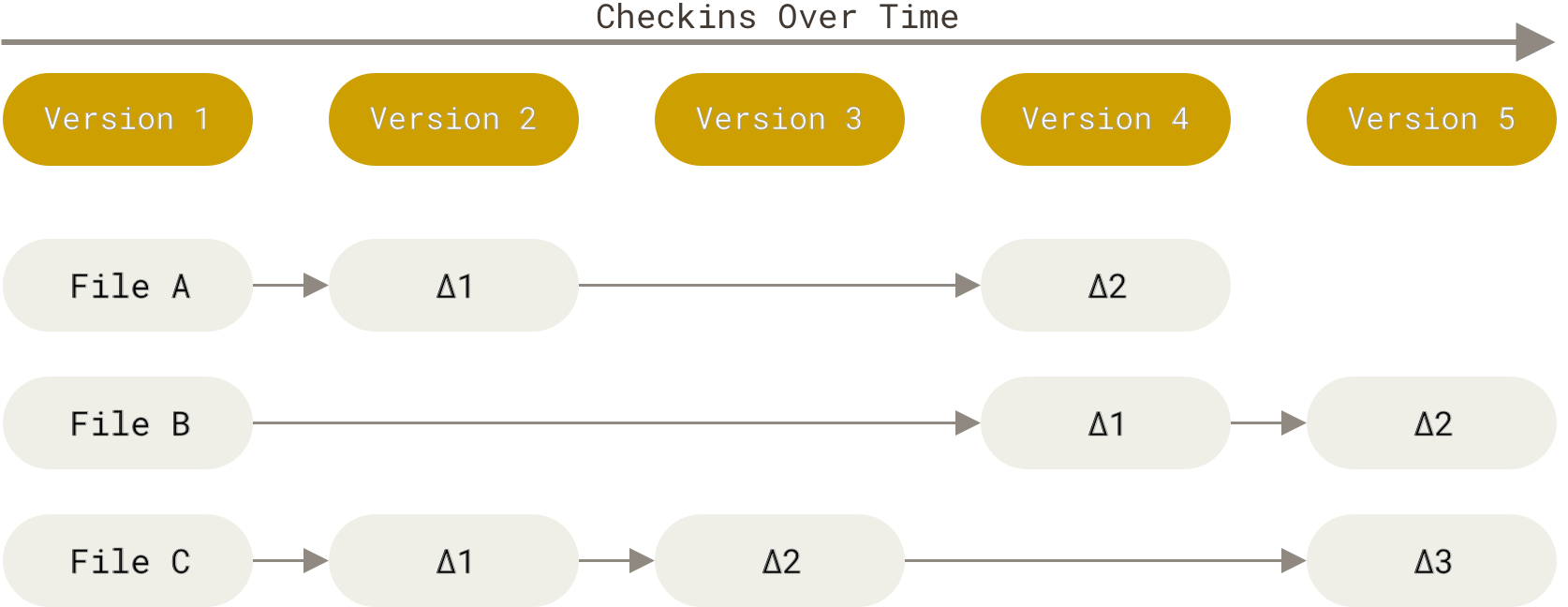
Рисунок 4. Хранение данных как набора изменений относительно первоначальной версии каждого из файлов
Git не хранит и не обрабатывает данные таким способом.
Вместо этого, подход Git к хранению данных больше похож на набор снимков миниатюрной файловой системы.
Каждый раз, когда вы делаете коммит, то есть сохраняете состояние своего проекта в Git, система запоминает, как выглядит каждый файл в этот момент, и сохраняет ссылку на этот снимок.
Для увеличения эффективности, если файлы не были изменены, Git не запоминает эти файлы вновь, а только создаёт ссылку на предыдущую версию идентичного файла, который уже сохранён.
Git представляет свои данные как, скажем, поток снимков.
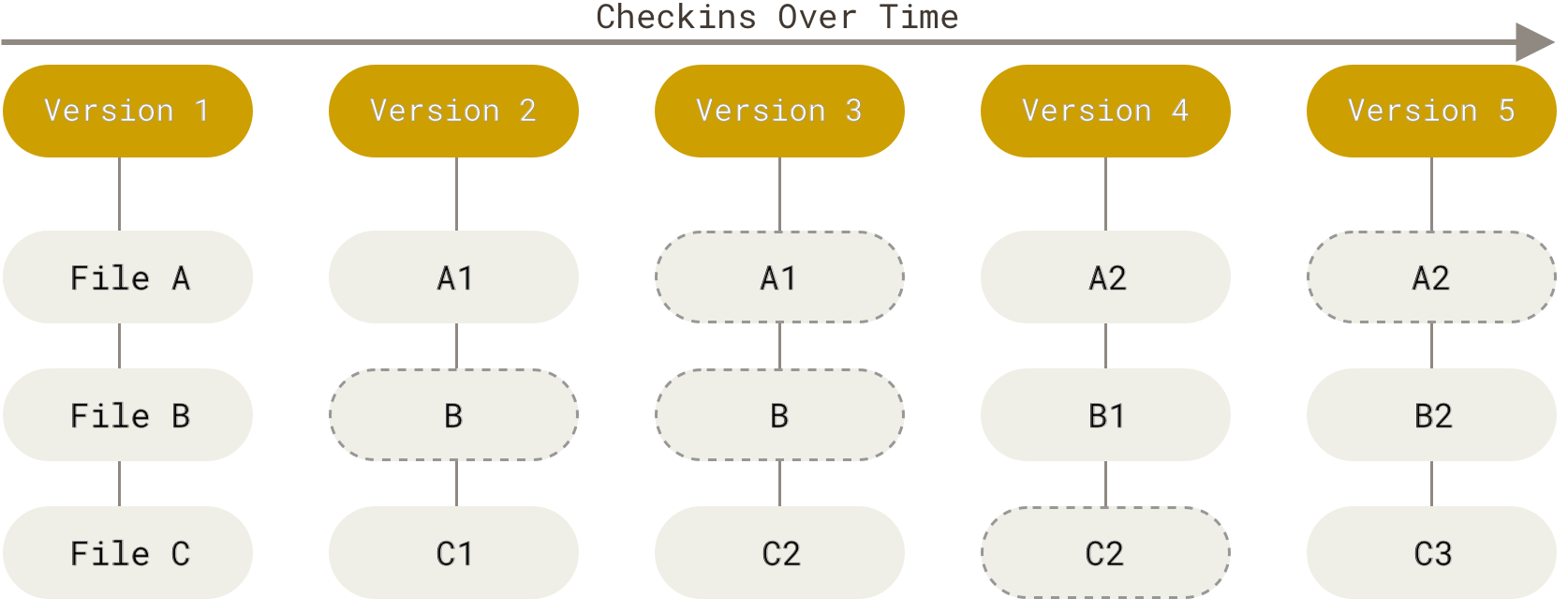
Рисунок 5. Хранение данных как снимков проекта во времени
Это очень важное отличие между Git и почти любой другой СКВ.
Git переосмысливает практически все аспекты контроля версий, которые были скопированы из предыдущего поколения большинством других систем.
Это делает Git больше похожим на миниатюрную файловую систему с удивительно мощными утилитами, надстроенными над ней, нежели просто на СКВ.
Когда мы будем рассматривать управление ветками в главе Ветвление в Git, мы увидим, какие преимущества вносит такой подход к работе с данными в Git.
Почти все операции выполняются локально
Для работы большинства операций в Git достаточно локальных файлов и ресурсов — в основном, системе не нужна никакая информация с других компьютеров в вашей сети.
Если вы привыкли к ЦСКВ, где большинство операций страдают от задержек из-за работы с сетью, то этот аспект Git заставит вас думать, что боги скорости наделили Git несказанной мощью.
Так как вся история проекта хранится прямо на вашем локальном диске, большинство операций кажутся чуть ли не мгновенными.
Для примера, чтобы посмотреть историю проекта, Git не нужно соединяться с сервером для её получения и отображения — система просто считывает данные напрямую из локальной базы данных.
Это означает, что вы увидите историю проекта практически моментально.
Если вам необходимо посмотреть изменения, сделанные между текущей версией файла и версией, созданной месяц назад, Git может найти файл месячной давности и локально вычислить изменения, вместо того, чтобы запрашивать удалённый сервер выполнить эту операцию, либо вместо получения старой версии файла с сервера и выполнения операции локально.
Это также означает, что есть лишь небольшое количество действий, которые вы не сможете выполнить, если вы находитесь оффлайн или не имеете доступа к VPN в данный момент.
Если вы в самолёте или в поезде и хотите немного поработать, вы сможете создавать коммиты без каких-либо проблем (в вашу локальную копию, помните?): когда будет возможность подключиться к сети, все изменения можно будет синхронизировать.
Если вы ушли домой и не можете подключиться через VPN, вы всё равно сможете работать.
Добиться такого же поведения во многих других системах либо очень сложно, либо вовсе невозможно.
В Perforce, для примера, если вы не подключены к серверу, вам не удастся сделать многого; в Subversion и CVS вы можете редактировать файлы, но вы не сможете сохранить изменения в базу данных (потому что вы не подключены к БД).
Всё это может показаться не таким уж и значимым, но вы удивитесь, какое большое значение это может иметь.
Целостность Git
В Git для всего вычисляется хеш-сумма, и только потом происходит сохранение.
В дальнейшем обращение к сохранённым объектам происходит по этой хеш-сумме.
Это значит, что невозможно изменить содержимое файла или каталога так, чтобы Git не узнал об этом.
Данная функциональность встроена в Git на низком уровне и является неотъемлемой частью его философии.
Вы не потеряете информацию во время её передачи и не получите повреждённый файл без ведома Git.
Механизм, которым пользуется Git при вычислении хеш-сумм, называется SHA-1 хеш.
Это строка длиной в 40 шестнадцатеричных символов (0-9 и a-f), она вычисляется на основе содержимого файла или структуры каталога.
SHA-1 хеш выглядит примерно так:
24b9da6552252987aa493b52f8696cd6d3b00373Вы будете постоянно встречать хеши в Git, потому что он использует их повсеместно.
На самом деле, Git сохраняет все объекты в свою базу данных не по имени, а по хеш-сумме содержимого объекта.
Git обычно только добавляет данные
Когда вы производите какие-либо действия в Git, практически все из них только добавляют новые данные в базу Git.
Очень сложно заставить систему удалить данные либо сделать что-то, что нельзя впоследствии отменить.
Как и в любой другой СКВ, вы можете потерять или испортить свои изменения, пока они не зафиксированы, но после того, как вы зафиксируете снимок в Git, будет очень сложно что-либо потерять, особенно, если вы регулярно синхронизируете свою базу с другим репозиторием.
Всё это превращает использование Git в одно удовольствие, потому что мы знаем, что можем экспериментировать, не боясь серьёзных проблем.
Для более глубокого понимания того, как Git хранит свои данные и как вы можете восстановить данные, которые кажутся утерянными, см. Операции отмены.
Три состояния
Теперь слушайте внимательно.
Это самая важная вещь, которую нужно запомнить о Git, если вы хотите, чтобы остаток процесса обучения прошёл гладко.
У Git есть три основных состояния, в которых могут находиться ваши файлы: изменён (modified), индексирован (staged) и зафиксирован (committed):
-
К изменённым относятся файлы, которые поменялись, но ещё не были зафиксированы.
-
Индексированный — это изменённый файл в его текущей версии, отмеченный для включения в следующий коммит.
-
Зафиксированный значит, что файл уже сохранён в вашей локальной базе.
Мы подошли к трём основным секциям проекта Git: рабочая копия (working tree), область индексирования (staging area) и каталог Git (Git directory).

Рисунок 6. Рабочая копия, область индексирования и каталог Git
Рабочая копия является снимком одной версии проекта.
Эти файлы извлекаются из сжатой базы данных в каталоге Git и помещаются на диск, для того чтобы их можно было использовать или редактировать.
Область индексирования — это файл, обычно находящийся в каталоге Git, в нём содержится информация о том, что попадёт в следующий коммит.
Её техническое название на языке Git — «индекс», но фраза «область индексирования» также работает.
Каталог Git — это то место, где Git хранит метаданные и базу объектов вашего проекта.
Это самая важная часть Git и это та часть, которая копируется при клонировании репозитория с другого компьютера.
Базовый подход в работе с Git выглядит так:
-
Изменяете файлы вашей рабочей копии.
-
Выборочно добавляете в индекс только те изменения, которые должны попасть в следующий коммит, добавляя тем самым снимки только этих изменений в индекс.
-
Когда вы делаете коммит, используются файлы из индекса как есть, и этот снимок сохраняется в ваш каталог Git.
Если определённая версия файла есть в каталоге Git, эта версия считается зафиксированной (committed).
Если файл был изменён и добавлен в индекс, значит, он индексирован (staged).
И если файл был изменён с момента последнего распаковывания из репозитория, но не был добавлен в индекс, он считается изменённым (modified).
В главе Основы Git вы узнаете больше об этих состояниях и какую пользу вы можете извлечь из них или как полностью пропустить часть с индексом.
Введение
Git — один из видов систем контроля версий (или СКВ). Такие системы записывают изменения в набор файлов, а позже позволяют вернуться к определенной версии.
Вам может пригодиться СКВ, если вы, например, программист, системный администратор, дизайнер (или в целом работаете с массивом изменяющихся файлов) и хотите сохранить каждую версию проекта. Вы сможете вернуться к любому из сохраненных состояний, просмотреть изменения и увидеть их авторов. Так гораздо проще исправлять возникающие проблемы.
В целом СКВ можно разделить таким образом:
- Локальные — все файлы хранятся только в вашей операционной системе, например, разложены по папкам с версиями.
- Централизованные — проект хранится на сервере, а ваша рабочая версия включает только текущий набор файлов.
- Распределенные — копии проекта (и вся информация о версиях) располагаются не только на сервере, но и на нескольких клиентских машинах, чтобы обеспечить устойчивость к отказу сервера.
Очевидно, что Git — не единственная система контроля версий, однако по многим параметрам самая удобная и популярная на сегодняшний день. Благодаря распределенной структуре репозитории Git хранятся на всех клиентских компьютерах, что защищает от потерь данных и позволяет полноценно управлять версиями проекта оффлайн.
Главная отличительная черта Git состоит в подходе к обработке данных. Каждый раз при сохранении данных проекта (коммите) система фиксирует состояние файла (делает снимок) и создает ссылку на этот снимок. Последующие изменения отражаются через ссылки на более ранние версии файла. Нет необходимости снова сохранять файл целиком. К тому же, основываясь на контрольных hash-суммах, система снимков обеспечивает целостность всей истории изменений. На практике это означает, что невозможно (либо крайне трудно) полностью удалить данные из рабочего каталога и утратить к ним любой доступ. В большинстве случаев данные можно восстановить из ранней версии проекта.
Таким образом, систему контроля версий в Git проще всего представлять как поток снимков (сохраненных состояний проекта).
У проектных файлов в Git есть 3 базовых состояния
- Измененные (modified) — файлы в процессе рабочего редактирования.
- Индексированные (staged) — та часть измененных файлов, которая уже подготовлена к фиксации после редактирования.
- Зафиксированные (committed) — файлы, уже сохраненные в локальном репозитории.
У Git есть рабочий каталог, где хранятся метаданные и локальная база рабочего проекта. Именно эта часть копируется, когда вы клонируете проект (репозиторий) с сервера.
Чаще всего работа с Git устроена примерно так:
- Вы вносите правки в файлы рабочей копии проекта.
- Индексируете их, подготавливая к коммиту (здесь Git создает снимки новых правок).
- Делаете коммит, и индексированные правки наконец сохраняются в вашем каталоге Git.
Установка Git
Создать свой проект и начать пользоваться Git в нем достаточно просто. Мы будем рассматривать работу в командной строке терминала, потому что там реализован полный набор команд. Вероятно, в будущем вам будет проще воспользоваться встроенными инструментами в крупном приложении (например, в Visual Studio, если вы программист).
Однако командная строка все равно удобна для тонкой настройки и «нестандартных» действий, поэтому полезно представлять себе, как управлять проектом через нее.
Сначала потребуется установить Git на свой компьютер.
Установка в Linux
Для дистрибутивов, похожих на Fedora, RHEL или CentOS, выполните команду dnf:
> sudo dnf install git-all
На Ubuntu и других Debian-подобных систем введите apt:
> sudo apt install git
Более подробные сведения можно получить по ссылке: https://git-scm.com/download/linux.
Установка на Mac
Один из способов установки — воспользоваться Xcode Command Line Tools. В терминале нужно ввести:
> git --version
И следовать дальнейшим инструкциям.
Если вы пользуетесь Homebrew, запустите команду:
$ brew install git
Подробности доступны по ссылке: https://git-scm.com/download/mac.
Установка в Windows
Новейшая сборка доступна на официальном сайте Git по ссылке: https://git-scm.com/download/win (загрузка запустится автоматически).
Настройка Git
Настроить рабочую среду нужно только один раз — после обновлений параметры не сбросятся. Если понадобится, в любое время можно изменить ваши настройки.
Самый удобный способ изменения конфигурации — встроенная утилита git config. Настройки Git имеют три уровня:
- Параметры из файла [path]/etc/gitconfig (системные) могут работать для всех пользователей системы и репозиториев. Они редактируются командой git config —system.
- Параметры из файла ~/.gitconfig или ~/.config/git/config (глобальные) применяются к одному пользователю, если запустить команду git config —global.
- Локальные параметры из файла config в рабочем каталоге .git/config сохраняют только для выбранного репозитория. Ему соответствует команда git config —local.
Если запускать git config без параметров, будет использоваться локальный уровень, никакие из более глобальных настроек не изменятся.
Всю используемую конфигурацию можно просмотреть так:
> git config --list --show-origin
Представимся Git, чтобы в рабочих коммитах сохранялось ваше авторство:
> git config --global user.name "Danil Z"
> git config --global user.email danilz@danilz.com
Также можно выбрать и текстовый редактор, введя команду git config —global core.editor. Например, чтобы выбрать Emacs, выполните:
> git config --global core.editor emacs
В Windows нужно указывать полный путь к файлу. К примеру, для установки Notepad++ нужно запустить подобную команду:
> git config --global core.editor "'C:/Program Files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin"
Стоит отметить, что на практике текстовый редактор в Git может и не пригодиться, особенно если вы активно используете стороннее ПО — например, в Visual Studio все текстовые заметки для Git можно писать в отдельном окне. Текстовые редакторы в командной строке отличаются своеобразным управлением, которое потребует от вас отдельного изучения.
Общий список текущих настроек просматривается с помощью команды git config —list. Проверить, что записано в любой из доступных настроек, можно командой с ключом git config <key>:
> git config user.email
Выбор ветки по умолчанию
Итак, наконец можно создать репозиторий в выбранном каталоге командой git init. Основная ветка автоматически будет названа master. Изменить это (в нашем случае задав ветку main) можно так:
> git config --global init.defaultBranch main
Работа в репозитории
Как правило, есть два варианта начать работу с репозиторием Git:
- Можно выбрать локальный каталог и создать новый репозиторий в нем.
- Можно клонировать существующий репозиторий с локального компьютера или сервера. Обычно проекты клонируются именно с сервера.
Если у вас на компьютере уже есть рабочий проект, но еще не назначен контроль версий, то нужно сначала перейти в каталог проекта.
Linux:
> cd /home/user/SomeConsoleApp
macOS:
> cd /Users/user/SomeConsoleApp
Windows:
> cd C:/Users/user/SomeConsoleApp
Инициализируем репозиторий:
> git init
Команда создаст каталог с именем .git, в котором будут храниться структурные файлы репозитория.
И, наконец, нужно добавить под контроль версий все существующие файлы командой git add . (точка в конце важна!). Можно добавлять и по одному файлу, с помощью git add <имя файла>.
Заодно создадим начальный коммит командой git commit:
> git add readme.md
> git commit -m 'Initial project version'
Команду git add можно гибко настраивать с помощью дополнительных параметров (флагов), которые подробно описаны в официальной документации: https://git-scm.com/docs/git-add. К примеру, команда git add —force добавит даже игнорируемые файлы, а git add —update позволит обновить отслеживаемые файлы.
В этом репозитории вы можете продолжать работать и дальше, со временем обновляя его и отправляя рабочие версии на сервер.
Клонирование существующего репозитория
Когда вы работаете в команде, разрабатываемые проекты часто размещают на сервере. Это один из самых распространенных сценариев. Вам нужно получить копию проекта последней версии на свой компьютер, чтобы далее вносить в него свой вклад.
В качестве примера мы будем рассматривать проект, который создадим на ресурсе https://github.com/ . После регистрации на сайте и подтверждения по e-mail нужно создать новый репозиторий, как показано на скриншотах.


Видно, что можно выбрать тип репозитория:
- публичный (public) – доступ открыт для любого пользователя, однако права на редактирование выдает владелец проекта;
- приватный/скрытый (private) — проект виден только владельцу, другие участники добавляются вручную.
Для нашего примера создадим приватный репозиторий под названием SomeConsoleApp и будем работать с ним далее.
Самые удобные способы клонирования проекта — через протоколы HTTP и SSH, прочесть обо всех более развёрнуто можно по ссылке: https://git-scm.com/book/en/v2/Git-on-the-Server-The-Protocols.
Для наших целей воспользуемся протоколом https и следующей командой:
> git clone https://github.com/DanZDev2/SomeConsoleApp SomeConsoleApp
На вашем компьютере в каталоге, куда вы перешли в командной строке, должен появиться каталог SomeConsoleApp, внутри него — каталог .git и все скачанные файлы репозитория последней версии.
После получения проекта обычно начинается более рутинный рабочий процесс — правки, добавление функционала и т. д. Далее в какой-то момент вы захотите сохранить прогресс в новой версии проекта.
Правила и периодичность обновления могут быть почти любыми, но хорошим тоном обычно считается сохранять рабочую (или промежуточно завершенную) версию. Важное требование для команд разработчиков — возможность сборки проекта, иначе другие участники команды будут вынуждены тратить время на борьбу с ошибками компиляции.
Сохранение снимков и просмотр статуса проекта
Как упоминалось ранее, часть файлов в рабочем каталоге может и не находиться под контролем версий. За отслеживаемыми файлами «наблюдает» Git, они были как минимум в прошлом снимке состояния проекта. Неотслеживаемыми могут быть, например, вспомогательные файлы в рабочем проекте, если они не зафиксированы в прошлой версии проекта и не готовы к коммиту. Их можно выделить в отдельную категорию для Git, о чем будет рассказано далее.
Сразу после клонирования все файлы проекта будут отслеживаемыми. Отредактировав их и привнеся что-то новое, вы индексируете (stage) и фиксируете (commit) правки, и так для каждой версии проекта.
При этом нужно внимательно следить, чтобы вспомогательные файлы, особенно объемные, оставались вне контроля версий. Если по недосмотру добавить их в коммит и отправить на сервер — вероятнее всего, ваши правки придется частично откатывать.
Проверить состояние файлов в рабочем каталоге можно командой git status. После клонирования консоль выведет примерно такую информацию:
On branch master
Your branch is up to date with ‘origin/master’.
nothing to commit, working tree clean
Теперь отредактируем файлы (в этом примере было консольное демо-приложение, созданное с помощью Visual Studio) и сравним статус:
>git status
On branch master
Your branch is up to date with ‘origin/master’.
Untracked files:
(use “git add <file>...” to include in what will be committed)
Program.cs
SomeConsoleApp.csproj
SomeConsoleApp.sln
nothing added to commit but untracked files present (use “git add” to track)
Теперь зафиксируем изменения. В коммит войдут только те файлы, которые вы изменили и добавили командой git add. Остальные будут лишь дополнительными файлами в каталоге проекта.
Стандартный способ — команда git commit, которую мы уже видели раньше. Без дополнительных аргументов она откроет встроенный текстовый редактор, поэтому для простоты рекомендуется добавить аргумент -m и вписать комментарий в кавычках:
> git commit -m "Task 2: basic project template added"
Для удаления ненужных файлов из репозитория можно использовать команду git rm <file-name>. Файл также пропадет из рабочего каталога. Выполнить коммит необходимо и в этом случае; до тех пор структура проекта не изменится.
Файл .gitignore
Как упоминалось ранее, в рабочий каталог могут попадать файлы, которые вам бы не хотелось отправлять на сервер. Это и документы с вашими экспериментами или образцами, и автоматически генерируемые части проекта, актуальные только на вашем компьютере. Git может полностью игнорировать их, если создать в рабочем каталоге файл с названием .gitignore и внести в него все имена ненужных файлов и папок.
Открывать файл можно в любом текстовом редакторе. Обычно удобнее не перечислять абсолютно все имена (которые к тому же всегда известны), а воспользоваться подобными инструкциями:
/bin
/obj
*.pdb
*.exe
Если прописать такое содержимое файла .gitignore, то репозиторий git будет полностью игнорировать папки /bin и /obj, а также любые файлы с расширениями .pdb и .exe, хранящиеся в вашем рабочем каталоге.
Рекомендуется создавать .gitignore до первой отправки вашего проекта в удаленный репозиторий, чтобы на сервер не попало никаких лишних файлов и каталогов. Разумеется, важно проверить, чтобы в .gitignore не были упомянуты критичные для проекта файлы, иначе у других участников команды возникнут проблемы после следующего обновления.
Управление удаленными репозиториями
Просмотреть список текущих онлайн-репозиториев можно командой git remote. Добавить другие — с помощью команды git remote add <shortname> <url>, например:
>git remote add myDemo https://github.com/DanZDev2/DemoApp
>git remote
myDemo
origin
Отправка изменений в удаленный репозиторий (Push)
На вашем компьютере есть проект со внесенными изменениями, но вы хотите поделиться новой версией со всей командой.
Команда для отправки изменений на сервер такова: git push <remote-name> <branch-name>. Если ваша ветка называется master, то команда для отправки коммитов станет такой:
> git push origin master
Она сработает, если у вас есть права на запись на том сервере, откуда вы клонировали проект. Также предполагается, что другие участники команды за это время не обновляли репозиторий.
Следует к тому же помнить, что в разработке для промежуточных правок часто используется не главная ветка (master), а одна из параллельных (например, Dev). Работая в команде, этому обязательно нужно уделять пристальное внимание.
Получение изменений из репозитория (Pull)
Самый простой и быстрый способ получить изменения с сервера — выполнить команду git pull, которая извлечет (fetch) данные с сервера и попытается встроить/объединить (merge) их с вашей локальной версией проекта.
На этом этапе могут возникать конфликты версий, когда несколько человек поработали над одними и теми же файлами в проекте и сохранили свои изменения. Избежать этого можно, если изолировать части проекта, поручив работу над одной частью только одному человеку. Разумеется, на практике это не всегда выполнимо, поэтому в Git есть инструменты для разрешения конфликтов версий. Они будут рассмотрены далее.
Создание веток и переключение между ними
Создадим две дополнительные ветки Dev и Test (например, одна может пригодиться для процесса разработки, а другая — для запуска в тестирование). Введем команду git branch <branch-name> дважды с разными аргументами:
>git branch Dev
>git branch Test
Ветки созданы, но мы по-прежнему работаем в master. Для переключения на другую нужно выполнить git checkout <branch-name>:
>git checkout Dev
Switched to branch ‘Dev’
Your branch is up to date with ‘origin/Dev’.
Внесем некоторые изменения в файл README.md и зафиксируем их, чтобы они отразились в ветке Dev:
>git add .
>git commit -m “dev readme changed”
[Dev #####] dev readme changed
1 file changed, 2 insertions(+)
Если теперь отправить их на сервер, то можно убедиться в появившемся отличии веток:


Для переключения обратно на ветку master нужно снова ввести команду git checkout master. Она не изменялась, а значит, после редактирования проекта ветки разойдутся. Это нормальная ситуация для проектов в Git. Важно только понимать, для каких целей используется каждая из веток, и не забывать вовремя переключаться между ними.
Слияние веток (merge)
Работа над проектами часто ведется в несколько этапов, им могут соответствовать ветки (в нашем примере Dev → Test → master). Отдельные ветки могут создаваться для срочного исправления багов, быстрого добавления временных функций, для делегирования части работы другому отделу и т. д. Предположим, что нужно применить изменения из ветки Dev, внеся их в master. Перейдем в master и выполним команду git merge <source-branch>:
>git merge Dev
Updating #####..#####
Fast-forward
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
Изменения успешно перенесены. В наших упрощенных условиях команда завершилась без ошибок, не найдя конфликтов в файлах. Если же над общими участками какого-либо файла успели поработать несколько человек, с этим нужно разбираться вручную. При возникновении ошибок Git помечает общие части файлов из разных веток и сообщает о конфликте.
Для разрешения конфликтов есть консольная утилита git mergetool. Однако если файл проекта объемный, а общих частей много, пользоваться ей не слишком удобно. Общая рекомендация для таких случаев — пользоваться сторонними инструментами, как и в случае с текстовым редактором для Git.
Когда спорные участки всех файлов приведены к итоговому состоянию, нужно повторить стандартную процедуру: создать коммит и отправить их командой push в нужную ветку в репозитории.
Дальнейшая работа с проектом из репозитория Git, как правило, повторяется по алгоритму:
- pull (забрать изменения с сервера);
- внести правки, добавить что-то важное в проекте;
add (добавить изменённые файлы к коммиту); - commit (сохранить состояние проекта с комментариями);
- push (отправить изменения на сервер).
- merge (при необходимости внедрить изменения из другой ветки проекта).
Заключение
Мы рассмотрели, как устанавливать и настраивать Git в различных ОС, создавать новые и клонировать существующие репозитории, получать и отправлять новые версии проекта, а также ознакомились с базовыми концепциями ведения веток.
Этой информации обычно хватает для повседневных задач, связанных с хранением рабочих проектов.
В последние годы популярность git демонстрирует взрывной рост. Эта система контроля версий используется различными проектами с открытым исходным кодом.
Новичков часто пугает большое количество замысловатых команд и сложных аргументов. Но для начала все они и не нужны. Можно начать с изучения наиболее часто используемых команд, и после этого постепенно расширять свои знания. Именно так мы и поступим в этой статье. Поехали!
Основы
Git — это набор консольных утилит, которые отслеживают и фиксируют изменения в файлах (чаще всего речь идет об исходном коде программ, но вы можете использовать его для любых файлов на ваш вкус). Изначально Git был создан Линусом Торвальдсом при разработке ядра Linux. Однако инструмент так понравился разработчикам, что в последствии, он получил широкое распространение и его стали использовать в других проектах. С его помощью вы можете сравнивать, анализировать, редактировать, сливать изменения и возвращаться назад к последнему сохранению. Этот процесс называется контролем версий.
Для чего он нужен? Ну во-первых, чтобы отследить изменения, произошедшие с проектом, со временем. Проще говоря, мы можем посмотреть как менялись файлы программы, на всех этапах разработки и при необходимости вернуться назад и что-то отредактировать. Часто бывают ситуации, когда, во вполне себе работающий код, вам нужно внести определенные правки или улучшить какой-то функционал, по желанию заказчика. Однако после внедрения нововведений, вы с ужасом понимаете, что все сломалось. У вас начинается судорожно дергаться глаз, а в воздухе повисает немой вопрос: “Что делать?” Без системы контроля версий, вам надо было бы долго напряженно просматривать код, чтобы понять как было до того, как все перестало работать. С Гитом же, все что нужно сделать — это откатиться на коммит назад.
Во-вторых он чрезвычайно полезен при одновременной работе нескольких специалистов, над одним проектом. Без Гита случится коллапс, когда разработчики, скопировав весь код из главной папки и сделав с ним задуманное, попытаются одновременно вернуть весь код обратно.
Git является распределенным, то есть не зависит от одного центрального сервера, на котором хранятся файлы. Вместо этого он работает полностью локально, сохраняя данные в директориях на жестком диске, которые называются репозиторием. Тем не менее, вы можете хранить копию репозитория онлайн, это сильно облегчает работу над одним проектом для нескольких людей. Для этого используются сайты вроде github и bitbucket.
Установка
Установить git на свою машину очень просто:
- Linux — нужно просто открыть терминал и установить приложение при помощи пакетного менеджера вашего дистрибутива. Для Ubuntu команда будет выглядеть следующим образом:
sudo apt-get install git
- Windows — мы рекомендуем git for windows, так как он содержит и клиент с графическим интерфейсом, и эмулятор bash.
- OS X — проще всего воспользоваться homebrew. После его установки запустите в терминале:
brew install git
Если вы новичок, клиент с графическим интерфейсом(например GitHub Desktop и Sourcetree) будет полезен, но, тем не менее, знать команды очень важно.
Настройка
Итак, мы установили git, теперь нужно добавить немного настроек. Есть довольно много опций, с которыми можно играть, но мы настроим самые важные: наше имя пользователя и адрес электронной почты. Откройте терминал и запустите команды:
git config --global user.name "My Name" git config --global user.email myEmail@example.com
Теперь каждое наше действие будет отмечено именем и почтой. Таким образом, пользователи всегда будут в курсе, кто отвечает за какие изменения — это вносит порядок.
Git хранит весь пакет конфигураций в файле .gitconfig, находящемся в вашем локальном каталоге. Чтобы сделать эти настройки глобальными, то есть применимыми ко всем проектам, необходимо добавить флаг –global. Если вы этого не сделаете, они будут распространяться только на текущий репозиторий.
Для того, чтобы посмотреть все настройки системы, используйте команду:
git config --list
Для удобства и легкости зрительного восприятия, некоторые группы команд в Гит можно выделить цветом, для этого нужно прописать в консоли:
git config --global color.ui true git config --global color.status auto git config --global color.branch auto
Если вы не до конца настроили систему для работы, в начале своего пути — не беда. Git всегда подскажет разработчику, если тот запутался, например:
- Команда git —help — выводит общую документацию по git
- Если введем git log —help — он предоставит нам документацию по какой-то определенной команде (в данном случае это — log)
- Если вы вдруг сделали опечатку — система подскажет вам нужную команду
- После выполнения любой команды — отчитается о том, что вы натворили
- Также Гит прогнозирует дальнейшие варианты развития событий и всегда направит разработчика, не знающего, куда двигаться дальше
Тут стоит отметить, что подсказывать система будет на английском, но не волнуйтесь, со временем вы изучите несложный алгоритм ее работы и будете разговаривать с ней на одном языке.
Создание нового репозитория
Как мы отметили ранее, git хранит свои файлы и историю прямо в папке проекта. Чтобы создать новый репозиторий, нам нужно открыть терминал, зайти в папку нашего проекта и выполнить команду init. Это включит приложение в этой конкретной папке и создаст скрытую директорию .git, где будет храниться история репозитория и настройки.
Создайте на рабочем столе папку под названием git_exercise. Для этого в окне терминала введите:
$ mkdir Desktop/git_exercise/ $ cd Desktop/git_exercise/ $ git init
Командная строка должна вернуть что-то вроде:
Initialized empty Git repository in /home/user/Desktop/git_exercise/.git/
Это значит, что наш репозиторий был успешно создан, но пока что пуст. Теперь создайте текстовый файл под названием hello.txt и сохраните его в директории git_exercise.
Определение состояния
status — это еще одна важнейшая команда, которая показывает информацию о текущем состоянии репозитория: актуальна ли информация на нём, нет ли чего-то нового, что поменялось, и так далее. Запуск git status на нашем свежесозданном репозитории должен выдать:
$ git status On branch master Initial commit Untracked files: (use "git add ..." to include in what will be committed) hello.txt
Сообщение говорит о том, что файл hello.txt неотслеживаемый. Это значит, что файл новый и система еще не знает, нужно ли следить за изменениями в файле или его можно просто игнорировать. Для того, чтобы начать отслеживать новый файл, нужно его специальным образом объявить.
Подготовка файлов
В git есть концепция области подготовленных файлов. Можно представить ее как холст, на который наносят изменения, которые нужны в коммите. Сперва он пустой, но затем мы добавляем на него файлы (или части файлов, или даже одиночные строчки) командой add и, наконец, коммитим все нужное в репозиторий (создаем слепок нужного нам состояния) командой commit.
В нашем случае у нас только один файл, так что добавим его:
$ git add hello.txt
Если нам нужно добавить все, что находится в директории, мы можем использовать
$ git add -A
Проверим статус снова, на этот раз мы должны получить другой ответ:
$ git status On branch master Initial commit Changes to be committed: (use "git rm --cached ..." to unstage) new file: hello.txt
Файл готов к коммиту. Сообщение о состоянии также говорит нам о том, какие изменения относительно файла были проведены в области подготовки — в данном случае это новый файл, но файлы могут быть модифицированы или удалены.
Фиксация изменений
Как сделать коммит
Представим, что нам нужно добавить пару новых блоков в html-разметку (index.html) и стилизовать их в файле style.css. Для сохранения изменений, их необходимо закоммитить. Но сначала, мы должны обозначить эти файлы для Гита, при помощи команды git add, добавляющей (или подготавливающей) их к коммиту. Добавлять их можно по отдельности:
git add index.html
git add css/style.css
или вместе — всё сразу:
git add .
Конечно добавлять всё сразу удобнее, чем прописывать каждую позицию отдельно. Однако, тут надо быть внимательным, чтобы не добавить по ошибке ненужные элементы. Если же такое произошло изъять оттуда ошибочный файл можно при помощи команды
git reset:
git reset css/style.css
Теперь создадим непосредственно сам коммит
git commit -m 'Add some code'
Флажок -m задаст commit message — комментарий разработчика. Он необходим для описания закоммиченных изменений. И здесь работает золотое правило всех комментариев в коде: «Максимально ясно, просто и содержательно обозначь написанное!»
Как посмотреть коммиты
Для просмотра все выполненных фиксаций можно воспользоваться историей коммитов. Она содержит сведения о каждом проведенном коммите проекта. Запросить ее можно при помощи команды:
git log
В ней содержится вся информация о каждом отдельном коммите, с указанием его хэша, автора, списка изменений и даты, когда они были сделаны. Отследить интересующие вас операции в списке изменений, можно по хэшу коммита, при помощи команды git show :
git show hash_commit
Ну а если вдруг нам нужно переделать commit message и внести туда новый комментарий, можно написать следующую конструкцию:
git commit --amend -m 'Новый комментарий'
В данном случае сообщение последнего коммита перезапишется. Но злоупотреблять этим не стоит, поскольку эта операция опасная и лучше ее делать до отправки коммита на сервер.
Удаленные репозитории
Сейчас наш коммит является локальным — существует только в директории .git на нашей файловой системе. Несмотря на то, что сам по себе локальный репозиторий полезен, в большинстве случаев мы хотим поделиться нашей работой или доставить код на сервер, где он будет выполняться.
1. Что такое удаленный репозиторий
Репозиторий, хранящийся в облаке, на стороннем сервисе, специально созданном для работы с git имеет ряд преимуществ. Во-первых — это своего рода резервная копия вашего проекта, предоставляющая возможность безболезненной работы в команде. А еще в таком репозитории можно пользоваться дополнительными возможностями хостинга. К примеру -визуализацией истории или возможностью разрабатывать вашу программу непосредственно в веб-интерфейсе.
Клонирование
Клонирование — это когда вы копируете удаленный репозиторий к себе на локальный ПК. Это то, с чего обычно начинается любой проект. При этом вы переносите себе все файлы и папки проекта, а также всю его историю с момента его создания. Чтобы склонировать проект, сперва, необходимо узнать где он расположен и скопировать ссылку на него. В нашем руководстве мы будем использовать адрес https://github.com/tutorialzine/awesome-project, но вам посоветуем, попробовать создать свой репозиторий в GitHub, BitBucket или любом другом сервисе:
git clone https://github.com/tutorialzine/awesome-project
При клонировании в текущий каталог, там будет создана папка, в которую поместятся все проектные файлы и скрытая директория .git, с самим репозиторием, или с необходимой информацией о нем. В такой ситуации, для клонируемого репозитория, по умолчанию, будет создана папка с одноименным названием, но его можно залить и в другую директорию, например:
git clone https://github.com/tutorialzine/awesome-project new-folder
2. Подключение к удаленному репозиторию
Чтобы загрузить что-нибудь в удаленный репозиторий, сначала нужно к нему подключиться. Регистрация и установка может занять время, но все подобные сервисы предоставляют хорошую документацию.
Чтобы связать наш локальный репозиторий с репозиторием на GitHub, выполним следующую команду в терминале. Обратите внимание, что нужно обязательно изменить URI репозитория на свой.
# This is only an example. Replace the URI with your own repository address.
$ git remote add origin https://github.com/tutorialzine/awesome-project.git
Проект может иметь несколько удаленных репозиториев одновременно. Чтобы их различать, мы дадим им разные имена. Обычно главный репозиторий называется origin.
3. Отправка изменений на сервер
Сейчас самое время переслать наш локальный коммит на сервер. Этот процесс происходит каждый раз, когда мы хотим обновить данные в удаленном репозитории.
Команда, предназначенная для этого — push. Она принимает два параметра: имя удаленного репозитория (мы назвали наш origin) и ветку, в которую необходимо внести изменения (master — это ветка по умолчанию для всех репозиториев).
$ git push origin master Counting objects: 3, done. Writing objects: 100% (3/3), 212 bytes | 0 bytes/s, done. Total 3 (delta 0), reused 0 (delta 0) To https://github.com/tutorialzine/awesome-project.git * [new branch] master -> master
Эта команда немного похожа на git fetch, с той лишь разницей, что при помощи fetch мы импортируем коммиты в локальную ветку, а применив push, мы экспортируем их из локальной в удаленную. Если вам необходимо настроить удаленную ветку используйте git remote. Однако пушить надо осторожно, ведь рассматриваемая команда перезаписывает безвозвратно все изменения. В большинстве случаев, ее используют, чтобы опубликовать выгружаемые локальные изменения в центральный репозиторий. А еще ее применяют для того, чтобы поделиться, внесенными в локальный репозиторий, нововведениями, с коллегами или другими удаленными участниками разработки проекта. Подытожив сказанное, можно назвать git push — командой выгрузки, а git pull и git fetch — командами загрузки или скачивания. После того как вы успешно запушили измененные данные, их необходимо внедрить или интегрировать, при помощи команды слияния git merge.
В зависимости от сервиса, который вы используете, вам может потребоваться аутентифицироваться, чтобы изменения отправились. Если все сделано правильно, то когда вы посмотрите в удаленный репозиторий при помощи браузера, вы увидите файл hello.txt
4. Запрос изменений с сервера
Если вы сделали изменения в вашем удаленном репозитории, другие пользователи могут скачать изменения при помощи команды pull.
$ git pull origin master From https://github.com/tutorialzine/awesome-project * branch master -> FETCH_HEAD Already up-to-date.
Так как новых коммитов с тех пор, как мы склонировали себе проект, не было, никаких изменений доступных для скачивания нет.
Как удалить локальный репозиторий
Вам не понравился один из ваших локальных Git-репозиториев и вы хотите стереть его со своей машины. Для этого вам всего лишь надо удалить скрытую папку «.git» в корневом каталоге репозитория. Сделать это можно 3 способами:
- Проще всего вручную удалить эту папку «.git» в корневом каталоге «Git Local Warehouse».
- Также удалить, не устраивающий вас, репозиторий можно на github. Открываете нужный вам объект и переходите в пункт меню Настройки. Там, прокрутив ползунок вниз, вы попадете в зону опасности, где один из пунктов будет называться «удаление этого хранилища».
- Последний метод удаления локального хранилища через командную строку, для этого в терминале необходимо ввести следующую команду:
cd repository-path/ rm -r .git
Ветвление
Во время разработки новой функциональности считается хорошей практикой работать с копией оригинального проекта, которую называют веткой. Ветви имеют свою собственную историю и изолированные друг от друга изменения до тех пор, пока вы не решаете слить изменения вместе. Это происходит по набору причин:
- Уже рабочая, стабильная версия кода сохраняется.
- Различные новые функции могут разрабатываться параллельно разными программистами.
- Разработчики могут работать с собственными ветками без риска, что кодовая база поменяется из-за чужих изменений.
- В случае сомнений, различные реализации одной и той же идеи могут быть разработаны в разных ветках и затем сравниваться.
1. Создание новой ветки
Основная ветка в каждом репозитории называется master. Чтобы создать еще одну ветку, используем команду branch <name>
$ git branch amazing_new_feature
Это создаст новую ветку, пока что точную копию ветки master.
2. Переключение между ветками
Сейчас, если мы запустим branch, мы увидим две доступные опции:
$ git branch amazing_new_feature * master
master — это активная ветка, она помечена звездочкой. Но мы хотим работать с нашей “новой потрясающей фичей”, так что нам понадобится переключиться на другую ветку. Для этого воспользуемся командой checkout, она принимает один параметр — имя ветки, на которую необходимо переключиться.
$ git checkout amazing_new_feature
В Git ветка — это отдельная линия разработки. Git checkout позволяет нам переключаться как между удаленными, так и меду локальными ветками. Это один из способов получить доступ к работе коллеги или соавтора, обеспечивающий более высокую продуктивность совместной работы. Однако тут надо помнить, что пока вы не закомитили изменения, вы не сможете переключиться на другую ветку. В такой ситуации нужно либо сделать коммит, либо отложить его, при помощи команды git stash, добавляющей текущие незакоммиченные изменения в стек изменений и сбрасывающей рабочую копию до HEAD’а репозитория.
3. Слияние веток
Наша “потрясающая новая фича” будет еще одним текстовым файлом под названием feature.txt. Мы создадим его, добавим и закоммитим:
$ git add feature.txt $ git commit -m "New feature complete.”
Изменения завершены, теперь мы можем переключиться обратно на ветку master.
$ git checkout master
Теперь, если мы откроем наш проект в файловом менеджере, мы не увидим файла feature.txt, потому что мы переключились обратно на ветку master, в которой такого файла не существует. Чтобы он появился, нужно воспользоваться merge для объединения веток (применения изменений из ветки amazing_new_feature к основной версии проекта).
$ git merge amazing_new_feature
Теперь ветка master актуальна. Ветка amazing_new_feature больше не нужна, и ее можно удалить.
$ git branch -d awesome_new_feature
Если хотите создать копию удаленного репозитория — используйте git clone. Однако если вам нужна только определенная его ветка, а не все хранилище — после git clone выполните следующую команду в соответствующем репозитории:
git checkout -b <имя ветки> origin/<имя ветки>
После этого, новая ветка создается на машине автоматически.
Бывают ситуации, когда после слива каких-то изменений из рабочей ветки в исходную версию проекта, ее, по правилам хорошего тона, необходимо удалить, чтобы она более не мешалась в вашем коде. Но как это сделать?
Для локально расположенных веток существует команда:
git branch -d local_branch_name
где флажок -d являющийся опцией команды git branch — это сокращенная версия ключевого слова —delete, предназначенного для удаления ветки, а local_branch_name – название ненужной нам ветки.
Однако тут есть нюанс: удалить текущую ветку, в которую вы, в данный момент просматриваете — нельзя. Если же вы все-таки попытаетесь это сделать, система отругает вас и выдаст ошибку с таким содержанием:
Error: Cannot delete branch local_branch_name checked out at название_директории
Так что при удалении ветвей, обязательно переключитесь на другой branch.
Дополнительно
В последней части этого руководства мы расскажем о некоторых дополнительных трюках, которые могут вам помочь.
1. Отслеживание изменений, сделанных в коммитах
У каждого коммита есть свой уникальный идентификатор в виде строки цифр и букв. Чтобы просмотреть список всех коммитов и их идентификаторов, можно использовать команду log:
$ git log commit ba25c0ff30e1b2f0259157b42b9f8f5d174d80d7 Author: Tutorialzine Date: Mon May 30 17:15:28 2016 +0300 New feature complete commit b10cc1238e355c02a044ef9f9860811ff605c9b4 Author: Tutorialzine Date: Mon May 30 16:30:04 2016 +0300 Added content to hello.txt commit 09bd8cc171d7084e78e4d118a2346b7487dca059 Author: Tutorialzine Date: Sat May 28 17:52:14 2016 +0300 Initial commit
Как вы можете заметить, идентификаторы довольно длинные, но для работы с ними не обязательно копировать их целиком — первых нескольких символов будет вполне достаточно. Чтобы посмотреть, что нового появилось в коммите, мы можем воспользоваться командой show [commit]
$ git show b10cc123 commit b10cc1238e355c02a044ef9f9860811ff605c9b4 Author: Tutorialzine Date: Mon May 30 16:30:04 2016 +0300 Added content to hello.txt diff --git a/hello.txt b/hello.txt index e69de29..b546a21 100644 --- a/hello.txt +++ b/hello.txt @@ -0,0 +1 @@ +Nice weather today, isn't it?
Чтобы увидеть разницу между двумя коммитами, используется команда diff (с указанием промежутка между коммитами):
$ git diff 09bd8cc..ba25c0ff diff --git a/feature.txt b/feature.txt new file mode 100644 index 0000000..e69de29 diff --git a/hello.txt b/hello.txt index e69de29..b546a21 100644 --- a/hello.txt +++ b/hello.txt @@ -0,0 +1 @@ +Nice weather today, isn't it?
Мы сравнили первый коммит с последним, чтобы увидеть все изменения, которые были когда-либо сделаны. Обычно проще использовать git difftool, так как эта команда запускает графический клиент, в котором наглядно сопоставляет все изменения.
2. Возвращение файла к предыдущему состоянию
Гит позволяет вернуть выбранный файл к состоянию на момент определенного коммита. Это делается уже знакомой нам командой checkout, которую мы ранее использовали для переключения между ветками. Но она также может быть использована для переключения между коммитами (это довольно распространенная ситуация для Гита — использование одной команды для различных, на первый взгляд, слабо связанных задач).
В следующем примере мы возьмем файл hello.txt и откатим все изменения, совершенные над ним к первому коммиту. Чтобы сделать это, мы подставим в команду идентификатор нужного коммита, а также путь до файла:
$ git checkout 09bd8cc1 hello.txt
3. Исправление коммита
Если вы опечатались в комментарии или забыли добавить файл и заметили это сразу после того, как закоммитили изменения, вы легко можете это поправить при помощи commit —amend. Эта команда добавит все из последнего коммита в область подготовленных файлов и попытается сделать новый коммит. Это дает вам возможность поправить комментарий или добавить недостающие файлы в область подготовленных файлов.
Для более сложных исправлений, например, не в последнем коммите или если вы успели отправить изменения на сервер, нужно использовать revert. Эта команда создаст коммит, отменяющий изменения, совершенные в коммите с заданным идентификатором.
Самый последний коммит может быть доступен по алиасу HEAD:
$ git revert HEAD
Для остальных будем использовать идентификаторы:
$ git revert b10cc123
При отмене старых коммитов нужно быть готовым к тому, что возникнут конфликты. Такое случается, если файл был изменен еще одним, более новым коммитом. И теперь git не может найти строчки, состояние которых нужно откатить, так как они больше не существуют.
4. Разрешение конфликтов при слиянии
Помимо сценария, описанного в предыдущем пункте, конфликты регулярно возникают при слиянии ветвей или при отправке чужого кода. Иногда конфликты исправляются автоматически, но обычно с этим приходится разбираться вручную — решать, какой код остается, а какой нужно удалить.
Давайте посмотрим на примеры, где мы попытаемся слить две ветки под названием john_branch и tim_branch. И Тим, и Джон правят один и тот же файл: функцию, которая отображает элементы массива.
Джон использует цикл:
// Use a for loop to console.log contents.
for(var i=0; i<arr.length; i++) {
console.log(arr[i]);
}
Тим предпочитает forEach:
// Use forEach to console.log contents.
arr.forEach(function(item) {
console.log(item);
});
Они оба коммитят свой код в соответствующую ветку. Теперь, если они попытаются слить две ветки, они получат сообщение об ошибке:
$ git merge tim_branch Auto-merging print_array.js CONFLICT (content): Merge conflict in print_array.js Automatic merge failed; fix conflicts and then commit the result.
Система не смогла разрешить конфликт автоматически, значит, это придется сделать разработчикам. Приложение отметило строки, содержащие конфликт:
<<<<<<< HEAD // Use a for loop to console.log contents. for(var i=0; i<arr.length; i++) { console.log(arr[i]); } ======= // Use forEach to console.log contents. arr.forEach(function(item) { console.log(item); }); >>>>>>> Tim's commit.
Над разделителем ======= мы видим последний (HEAD) коммит, а под ним — конфликтующий. Таким образом, мы можем увидеть, чем они отличаются и решать, какая версия лучше. Или вовсе написать новую. В этой ситуации мы так и поступим, перепишем все, удалив разделители, и дадим git понять, что закончили.
// Not using for loop or forEach. // Use Array.toString() to console.log contents. console.log(arr.toString());
Когда все готово, нужно закоммитить изменения, чтобы закончить процесс:
$ git add -A $ git commit -m "Array printing conflict resolved."
Как вы можете заметить, процесс довольно утомительный и может быть очень сложным в больших проектах. Многие разработчики предпочитают использовать для разрешения конфликтов клиенты с графическим интерфейсом. (Для запуска нужно набрать git mergetool).
5. Настройка .gitignore
В большинстве проектов есть файлы или целые директории, в которые мы не хотим (и, скорее всего, не захотим) коммитить. Мы можем удостовериться, что они случайно не попадут в git add -A при помощи файла .gitignore
- Создайте вручную файл под названием .gitignore и сохраните его в директорию проекта.
- Внутри файла перечислите названия файлов/папок, которые нужно игнорировать, каждый с новой строки.
- Файл .gitignore должен быть добавлен, закоммичен и отправлен на сервер, как любой другой файл в проекте.
Вот хорошие примеры файлов, которые нужно игнорировать:
- Логи
- Артефакты систем сборки
- Папки node_modules в проектах node.js
- Папки, созданные IDE, например, Netbeans или IntelliJ
- Разнообразные заметки разработчика.
Файл .gitignore, исключающий все перечисленное выше, будет выглядеть так:
*.log build/ node_modules/ .idea/ my_notes.txt
Символ слэша в конце некоторых линий означает директорию (и тот факт, что мы рекурсивно игнорируем все ее содержимое). Звездочка, как обычно, означает шаблон.
Git bash и git.io
Руководствуясь часто встречающимися, при изучении системы, вопросами новичков, разберем еще несколько непонятных словосочетаний.
- Git Bash(Bourne Again Shell) — это приложение, являющееся эмулятором командной строки и предоставляющее, операционной системе, некоторые распространенные утилиты bash и собственно саму систему Git. Это терминал, используемый для взаимодействия с персональным компьютером, посредством письменных команд.
- URL-адреса хранилищ на Гитхабе могут быть довольно длинными, из-за больших имен репозиториев и файлов. Работать с такими ссылками очень не удобно. Поэтому сайт github.io создал git.io — неплохой сервис по преобразованию этих длинных и беспорядочных URL-адресов в более короткие и понятные. Сайт был создан в 2011 году и вплоть до недавнего времени отлично справлялся со своими обязанностями. Однако в начале этого года компания Гитхаб, из-за участившихся попыток хакеров использовать сайт в злонамеренных целях, остановила работу сервиса, а чем известила пользователей в своем блоге. Разработчики популярного ресурса рекомендуют пользоваться другими URL-cutter’ами, пока работа сервиса не будет налажена.
Заключение.
Вот и все! Наше руководство окончено. Мы очень старались собрать всю самую важную информацию и изложить ее как можно более сжато и кратко.
Git довольно сложен, и в нем есть еще много функций и трюков. Если вы хотите с ними познакомиться, вот некоторые ресурсы, которые мы рекомендуем:
- Официальная документация, включающая книгу и видеоуроки – тут.
- “Getting git right” – Коллекция руководств и статей от Atlassian – тут.
- Список клиентов с графическим интерфейсом – тут.
- Онлайн утилита для генерации .gitignore файлов – тут.
Оригинал статьи доступен на сайте http://tutorialzine.com
Другие статьи по теме
10 полезных Git команд, которые облегчат работу
Шпаргалка по Git, в которой представлены основные команды
Git — абсолютный лидер по популярности среди современных систем управления версиями. Это развитый проект с активной поддержкой и открытым исходным кодом. Система Git была изначально разработана в 2005 году Линусом Торвальдсом — создателем ядра операционной системы Linux. Git применяется для управления версиями в рамках колоссального количества проектов по разработке ПО, как коммерческих, так и с открытым исходным кодом. Система используется множеством профессиональных разработчиков программного обеспечения. Она превосходно работает под управлением различных операционных систем и может применяться со множеством интегрированных сред разработки (IDE).
Git — система управления версиями с распределенной архитектурой. В отличие от некогда популярных систем вроде CVS и Subversion (SVN), где полная история версий проекта доступна лишь в одном месте, в Git каждая рабочая копия кода сама по себе является репозиторием. Это позволяет всем разработчикам хранить историю изменений в полном объеме.
Разработка в Git ориентирована на обеспечение высокой производительности, безопасности и гибкости распределенной системы.
Производительность
Git показывает очень высокую производительность в сравнении со множеством альтернатив. Это возможно благодаря оптимизации процедур фиксации коммитов, создания веток, слияния и сравнения предыдущих версий. Алгоритмы Git разработаны с учетом глубокого знания атрибутов, характерных для реальных деревьев файлов исходного кода, а также типичной динамики их изменений и последовательностей доступа.
Некоторые системы управления версиями руководствуются именами файлов при работе с деревом файлов и ведении истории версий. Вместо обработки названий система Git анализирует содержимое. Это важно, поскольку файлы исходного кода часто переименовывают, разделяют и меняют местами. Объектные файлы репозитория Git формируются с помощью дельта‑кодирования (фиксации отличий содержимого) и компрессии. Кроме того, такие файлы в чистом виде хранят объекты с содержимым каталога и метаданными версий.
Вместе с тем распределенная архитектура системы сама по себе обеспечивает существенный прирост производительности.
Рассмотрим пример: разработчик Элис меняет исходный код. Она добавляет функцию для будущей версии 2.0, после чего делает коммит и сопровождает изменения описанием. Затем она разрабатывает другую функцию и делает еще один коммит. Разумеется, эти изменения сохраняются в истории в виде отдельных рабочих элементов. Затем Элис переключается на ветку, соответствующую версии 1.3 того же ПО — так она сможет исправить баг, затрагивающий эту конкретную версию. Это нужно, чтобы команда Элис могла выпустить версию 1.3.1 с исправлениями до завершения работы над версией 2.0. Затем Элис вернется к ветке для версии 2.0 и продолжит работу над соответствующими функциями. Все перечисленные действия можно выполнить без доступа к сети, поэтому система Git отличается быстротой и надежностью, даже если работать в самолете. Когда Элис будет готова отправить все внесенные изменения в удаленный репозиторий, ей останется лишь выполнить команду push.
Безопасность
При разработке в Git прежде всего обеспечивается целостность исходного кода под управлением системы. Содержимое файлов, а также объекты репозитория, фиксирующие взаимосвязи между файлами, каталогами, версиями, тегами и коммитами, защищены при помощи криптографически стойкого алгоритма хеширования SHA1. Он защищает код и историю изменений от случайных и злонамеренных модификаций, а также позволяет проследить историю в полном объеме.
Использование Git гарантирует подлинность истории изменений исходного кода.
В некоторых других системах управления версиями отсутствует защита от тайного внесения изменений. Это может стать серьезной угрозой информационной безопасности в любой организации, занимающейся разработкой ПО.
Гибкость
Гибкость — одна из основных характеристик Git. Она проявляется в поддержке различных нелинейных циклов разработки, эффективности использования с малыми и крупными проектами, а также совместимости со многими системами и протоколами.
В отличие от SVN, система Git рассчитана прежде всего на создание веток и использование тегов. Поэтому процедуры с участием веток и тегов (например, объединение и возврат к предыдущей версии) сохраняются в истории изменений. Не все системы управления версиями обладают настолько широкими возможностями отслеживания.
Контроль версий с помощью Git
Git — это лучшее решение для большинства команд разработки ПО. Разумеется, оценку следует проводить с учетом конкретных требований. Мы лишь хотим перечислить основные причины, по которым команды предпочитают использовать Git.
Превосходные характеристики
Функциональность, производительность, безопасность и гибкость Git удовлетворяют требованиям большинства команд и разработчиков. Эти качества системы подробно описаны выше. При сравнении системы с большинством альтернатив многие команды приходят к выводу, что Git обладает значительными преимуществами.
Git — признанный стандарт
Git является самым популярным инструментом своего класса и поэтому привлекателен по ряду причин. В Atlassian управление исходным кодом проектов практически всегда осуществляется в Git.
Великое множество профессиональных разработчиков уже получили опыт использования Git, а выпускники высших учебных заведений зачастую знакомы только с этой системой. В некоторых организациях работникам требуется обучение при переходе на Git с других систем управления версиями, однако многие разработчики (как штатные, так будущие сотрудники) уже обладают необходимыми знаниями.
Однако привлекательность Git обусловлена не только высокой популярностью среди разработчиков. В системе также предусмотрена интеграция различных инструментов и сервисов, включая интегрированные среды разработки и собственные инструменты Atlassian. В число последних входит настольный клиент для распределенных систем управления версиями Sourcetree, система отслеживания задач и проектов Jira, а также сервис размещения кода Bitbucket.
Начинающим разработчикам, которые хотят приобрести ценные навыки работы с инструментами разработки ПО, следует изучить Git как одну из систем управления версиями.
Git — это качественный проект с открытым кодом
Проект Git имеет открытый исходный код, а также активно поддерживается и непрерывно развивается уже более 10 лет. Кураторы проекта продемонстрировали взвешенный и продуманный подход к выполнению требований пользователей, регулярно выпуская релизы для повышения удобства и расширения функциональных возможностей системы. Качество ПО с открытым исходным кодом легко проверяется, и многие организации всецело доверяют таким продуктам.
Вокруг Git сформировалось многочисленное сообщество пользователей, а сам проект получает активную поддержку со стороны сообщества. Система обладает подробной и качественной документацией: всем желающим в числе прочего доступны книги, учебные руководства, специализированные веб‑сайты, подкасты и обучающие видеоролики.
Git — это система с открытым исходным кодом, поэтому разработчики‑любители могут пользоваться ей совершенно бесплатно. В сфере разработки ПО с открытым исходным кодом Git определенно выступает главным преемником успешных систем управления версиями предыдущих поколений, таких как SVN и CVS.
Критика Git
Git нередко критикуют за сложность освоения: одни термины могут быть незнакомы новичкам, а другие — иметь иное значение. Так, понятие revert (возврат к предыдущей версии) в Git имеет другой смысл, нежели в SVN и CVS. Тем не менее Git — очень мощная система, предлагающая пользователям широкие возможности. Их изучение займет какое‑то время, однако усвоенные навыки помогут участникам команды работать намного быстрее.
Команды, перешедшие на Git с нераспределенной системы управления версиями, могут захотеть и дальше пользоваться центральным репозиторием. Несмотря на распределенную архитектуру, Git допускает возможность создания классического репозитория, где сохраняются все изменения проекта. При этом в Git продуктивность разработчиков не зависит от доступности и производительности «центрального» сервера. Каждому пользователю доступна полная копия репозитория, в которой он может просматривать всю историю проекта даже в периоды отсутствия соединения с сетью и перебоев в системе. Распределенная архитектура и гибкость Git позволяют участникам проекта работать в удобном ритме и пользоваться уникальными преимуществами, о которых они могли не подозревать раньше.
Теперь вы разобрались в основах управления версиями, получили представление о Git и узнали, почему командам разработки ПО стоит пользоваться этой системой. Теперь можно перейти к изучению преимуществ, которые Git может предоставить в масштабах организации.
#статьи
- 14 янв 2021
-

11
Команды разработчиков пользуются системой контроля версий. Чаще всего это Git. Разбираемся, что это значит, зачем нужно и как устроено.
vlada_maestro / shutterstock

Автор статей о программировании. Изучает Python, разбирает сложные термины и объясняет их на пальцах новичкам. Если что-то непонятно — возможно, вы ещё не прочли его следующую публикацию.
Git — это система для управления версиями исходного кода программ. В статье мы познакомимся с её основными возможностями, покажем отличие от GitHub и объясним, зачем Git новичку. Ещё вы узнаете, с чего начать обучение и почему не стоит тратить время на альтернативные программы.
Представьте ситуацию: геймер доходит до финала, проигрывает и возвращается к началу уровня — попадает в ближайшую контрольную точку игры, где разработчики разрешили сохраниться. Если мы уберём контрольные точки, после каждого проигрыша придётся начинать игру заново.
В программировании за сохранение кода в контрольных точках отвечает система контроля версий — специальная технология, которую можно подключить к любому проекту. Система контроля версий страхует от ошибок и возвращает код в то состояние, когда всё работало.
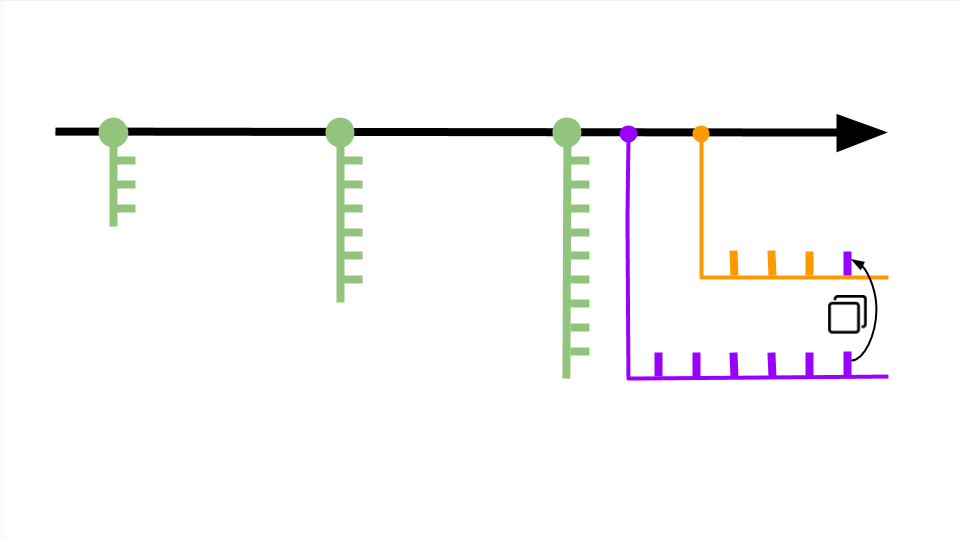
Контрольные точки называются коммитами. Один коммит — это пакет изменений, хранящий информацию с добавленными, отредактированными или удалёнными файлами кода. В один коммит принято добавлять не более десяти изменений — так получается длинная история версий, которая позволяет в случае ошибки откатиться с минимальной потерей работоспособного кода.
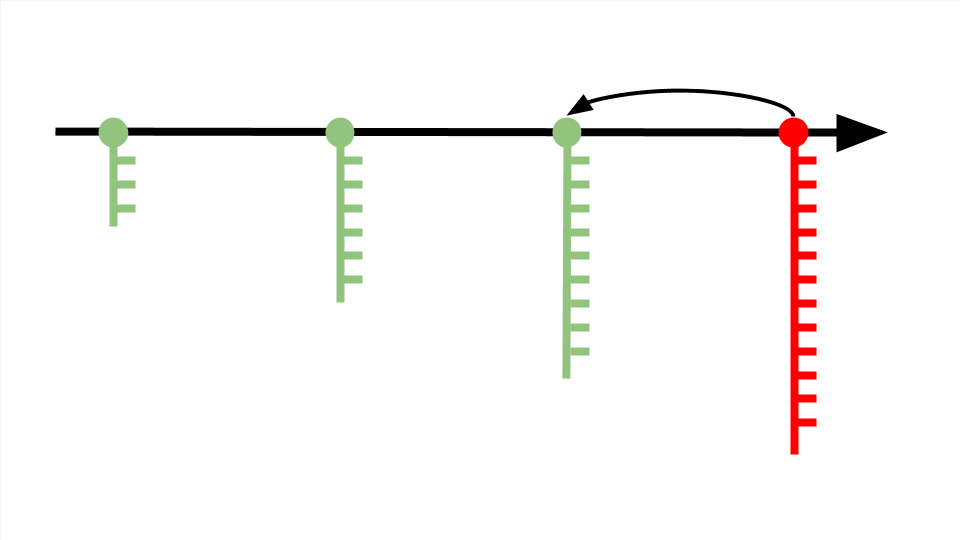
Коммиты располагаются на master-ветке — основной версии проекта, которая после завершения работы превратится в продукт.
Система контроля версий позволяет создавать ответвления от master-ветки и экспериментировать с проектом, не мешая другим участника команды.
Возьмём предыдущую схему, где мы обнаружили ошибку и откатились на один коммит назад. Чтобы поправить код, создадим несколько дополнительных веток и в каждой протестируем разные варианты решения проблемы. Когда решение найдено, ветку с правильным кодом переносим в master-ветку и сохраняем коммит. Лишние ветки оставляем или удаляем, поскольку они не влияют на проект и скрыты от других разработчиков — это ваш личный черновик.
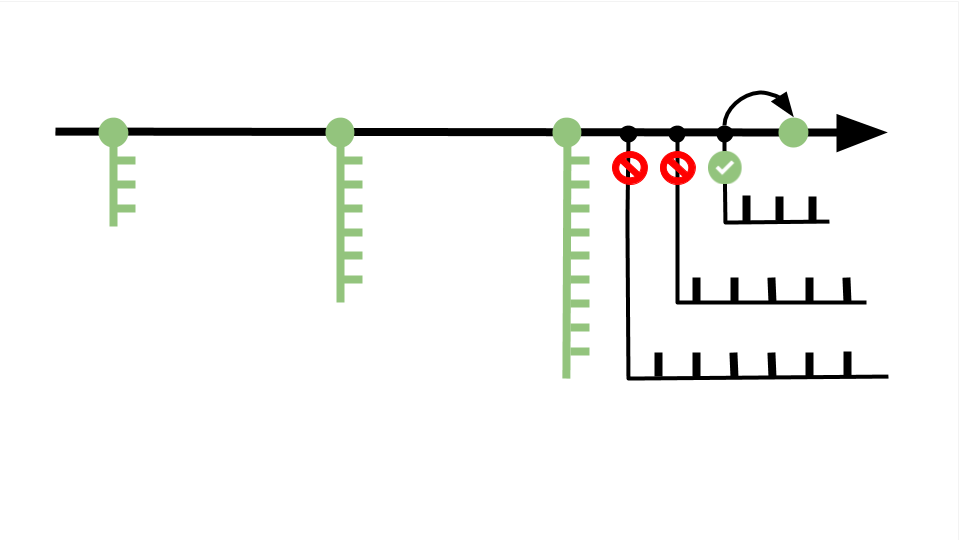
Часто бывает так: разработчики отделяются от master-ветки и работают над частью проекта самостоятельно — например, чтобы протестировать дополнительные функции. Но не могут продолжить, пока кто-то из команды не допишет код.
Система контроля версий позволяет не ждать обновления master-ветки и разрешает всем участникам команды свободно перемещаться между ветками других разработчиков для копирования нужных фрагментов кода.
Бывают и обратные ситуации, когда несколько разработчиков одновременно дописывают код, заливают его в master-ветку и сталкиваются с конфликтом — один файл получает несколько несогласованных изменений. В этом случае Git попробует автоматически исправить ошибки. Если не получится, разработчики это увидят и смогут поправить код вручную.
Системы контроля версий бывают локальными, централизованными или распределёнными.
- Локальная система хранит файлы на одном устройстве, централизованная использует общий сервер, а распределённая — общее облачное хранилище и локальные устройства участников команды. В локальной системе удобно работать с большими проектами, но сложно взаимодействовать с удалённой командой.
- В централизованной системе налажена удалённая работа, но всё привязано к одному серверу. Любой сбой или взлом может повредить файлы проекта.
- В распределённой системе налажена удалённая работа. Если с файлами основного репозитория что-то случится — проект легко восстановить из копии любого участника команды.
Из-за удобства и гибкости распределённая система версий Git считается современным форматом. Это стандарт для большинства ИТ-команд.
Git — это программа, которую нужно установить и подключить к проекту для управления системой контроля версий. GitHub — это сайт-хранилище для историй версий проектов: вы подключаете Git, регистрируетесь на GitHub, создаёте онлайн-репозиторий и переносите файлы с Git на GitHub.
Git — это самая популярная система контроля версий, а GitHub — онлайн-хранилище кода. Git и GitHub настроены на взаимодействие и поэтому часто используются как единый механизм работы с проектом.
Если нужно, Git можно заменить альтернативной программой контроля версий, а GitHub — другим онлайн-хранилищем кода. Большинству работодателей это не нужно, поскольку знакомство с другими сервисами отнимает время и неудобно многим разработчикам.
Git используется в большинстве компаний, где над проектом работает хотя бы два разработчика:
- Новый человек приходит в компанию и клонирует репозиторий проекта на ПК.
- Получает задачу, создаёт новую ветку и пишет код.
- Когда всё готово — отправляет запрос на добавление кода в master-ветку.
- Другие разработчики смотрят код, оставляют комментарии и указывают на ошибки.
- Новичок дорабатывает код, обновляет master-ветку и переходит к следующей задаче.
Это общая схема того, как проходит командная работа в проекте. В ней не учтены правила использования Git, которые каждая команда пишет под себя. Например, у каждой команды свой порядок проверки кода и свои критерии его готовности для добавления в master-ветку.
Знание Git и знание правил использования Git в команде — это два разных навыка, которые можно сравнить с умением ездить на автомобиле и знанием правил дорожного движения. Если умеете управлять автомобилем — вам проще сконцентрироваться и быстро выучить правила. С Git аналогичная ситуация: если вы умеете управлять системой контроля версий, то можете сразу влиться в проект, не отвлекаться на второстепенные вещи и сосредоточиться на качестве кода.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Школа дронов для всех
Учим программировать беспилотники и управлять ими.
Узнать больше

A command-line session showing repository creation, addition of a file, and remote synchronization |
|
| Original author(s) | Linus Torvalds[1] |
|---|---|
| Developer(s) | Junio Hamano and others[2] |
| Initial release | 7 April 2005; 17 years ago |
| Stable release |
2.39.1[3] |
| Repository |
|
| Written in | Primarily in C, with GUI and programming scripts written in Shell script, Perl, Tcl and Python[4][5] |
| Operating system | POSIX (Linux, macOS, Solaris, AIX), Windows |
| Available in | English |
| Type | Version control |
| License | GPL-2.0-only[i][7] |
| Website | git-scm.com |
Git ()[8] is a distributed version control system that tracks changes in any set of computer files, usually used for coordinating work among programmers collaboratively developing source code during software development. Its goals include speed, data integrity, and support for distributed, non-linear workflows (thousands of parallel branches running on different systems).[9][10][11]
Git was originally authored by Linus Torvalds in 2005 for development of the Linux kernel, with other kernel developers contributing to its initial development.[12] Since 2005, Junio Hamano has been the core maintainer. As with most other distributed version control systems, and unlike most client–server systems, every Git directory on every computer is a full-fledged repository with complete history and full version-tracking abilities, independent of network access or a central server.[13] Git is free and open-source software distributed under the GPL-2.0-only license.
History[edit]
Git development began in April 2005, after many developers of the Linux kernel gave up access to BitKeeper, a proprietary source-control management (SCM) system that they had been using to maintain the project since 2002.[14][15] The copyright holder of BitKeeper, Larry McVoy, had withdrawn free use of the product after claiming that Andrew Tridgell had created SourcePuller by reverse engineering the BitKeeper protocols.[16] The same incident also spurred the creation of another version-control system, Mercurial.
Linus Torvalds wanted a distributed system that he could use like BitKeeper, but none of the available free systems met his needs. Torvalds cited an example of a source-control management system needing 30 seconds to apply a patch and update all associated metadata, and noted that this would not scale to the needs of Linux kernel development, where synchronizing with fellow maintainers could require 250 such actions at once. For his design criterion, he specified that patching should take no more than three seconds, and added three more goals:[9]
- Take Concurrent Versions System (CVS) as an example of what not to do; if in doubt, make the exact opposite decision.[11]
- Support a distributed, BitKeeper-like workflow.[11]
- Include very strong safeguards against corruption, either accidental or malicious.[10]
These criteria eliminated every version-control system in use at the time, so immediately after the 2.6.12-rc2 Linux kernel development release, Torvalds set out to write his own.[11]
The development of Git began on 3 April 2005.[17] Torvalds announced the project on 6 April and became self-hosting the next day.[17][18] The first merge of multiple branches took place on 18 April.[19] Torvalds achieved his performance goals; on 29 April, the nascent Git was benchmarked recording patches to the Linux kernel tree at the rate of 6.7 patches per second.[20] On 16 June, Git managed the kernel 2.6.12 release.[21]
Torvalds turned over maintenance on 26 July 2005 to Junio Hamano, a major contributor to the project.[22] Hamano was responsible for the 1.0 release on 21 December 2005.[23]
Naming[edit]
Torvalds sarcastically quipped about the name git (which means «unpleasant person» in British English slang): «I’m an egotistical bastard, and I name all my projects after myself. First ‘Linux’, now ‘git’.»[24][25] The man page describes Git as «the stupid content tracker».[26] The read-me file of the source code elaborates further:[27]
«git» can mean anything, depending on your mood.
- Random three-letter combination that is pronounceable, and not actually used by any common UNIX command. The fact that it is a mispronunciation of «get» may or may not be relevant.
- Stupid. Contemptible and despicable. Simple. Take your pick from the dictionary of slang.
- «Global information tracker»: you’re in a good mood, and it actually works for you. Angels sing, and a light suddenly fills the room.
- «Goddamn idiotic truckload of sh*t»: when it breaks.
The source code for Git refers to the program as, «the information manager from hell.»
Releases[edit]
List of Git releases:[28]
| Version | Original release date | Latest (patch) version | Release date (of the patch) | Notable changes |
|---|---|---|---|---|
| 0.99 | 2005-07-11 | 0.99.9n | 2005-12-15 | |
| 1.0 | 2005-12-21 | 1.0.13 | 2006-01-27 | |
| 1.1 | 2006-01-08 | 1.1.6 | 2006-01-30 | |
| 1.2 | 2006-02-12 | 1.2.6 | 2006-04-08 | |
| 1.3 | 2006-04-18 | 1.3.3 | 2006-05-16 | |
| 1.4 | 2006-06-10 | 1.4.4.5 | 2008-07-16 | |
| 1.5 | 2007-02-14 | 1.5.6.6 | 2008-12-17 | |
| 1.6 | 2008-08-17 | 1.6.6.3 | 2010-12-15 | |
| 1.7 | 2010-02-13 | 1.7.12.4 | 2012-10-17 | |
| 1.8 | 2012-10-21 | 1.8.5.6 | 2014-12-17 | |
| 1.9 | 2014-02-14 | 1.9.5 | 2014-12-17 | |
| 2.0 | 2014-05-28 | 2.0.5 | 2014-12-17 | |
| 2.1 | 2014-08-16 | 2.1.4 | 2014-12-17 | |
| 2.2 | 2014-11-26 | 2.2.3 | 2015-09-04 | |
| 2.3 | 2015-02-05 | 2.3.10 | 2015-09-29 | |
| 2.4 | 2015-04-30 | 2.4.12 | 2017-05-05 | |
| 2.5 | 2015-07-27 | 2.5.6 | 2017-05-05 | |
| 2.6 | 2015-09-28 | 2.6.7 | 2017-05-05 | |
| 2.7 | 2015-10-04 | 2.7.6 | 2017-07-30 | |
| 2.8 | 2016-03-28 | 2.8.6 | 2017-07-30 | |
| 2.9 | 2016-06-13 | 2.9.5 | 2017-07-30 | |
| 2.10 | 2016-09-02 | 2.10.5 | 2017-09-22 | |
| 2.11 | 2016-11-29 | 2.11.4 | 2017-09-22 | |
| 2.12 | 2017-02-24 | 2.12.5 | 2017-09-22 | |
| 2.13 | 2017-05-10 | 2.13.7 | 2018-05-22 | |
| 2.14 | 2017-08-04 | 2.14.6 | 2019-12-07 | |
| 2.15 | 2017-10-30 | 2.15.4 | 2019-12-07 | |
| 2.16 | 2018-01-17 | 2.16.6 | 2019-12-07 | |
| 2.17 | 2018-04-02 | 2.17.6 | 2021-03-09 | |
| 2.18 | 2018-06-21 | 2.18.5 | 2021-03-09 | |
| 2.19 | 2018-09-10 | 2.19.6 | 2021-03-09 | |
| 2.20 | 2018-12-09 | 2.20.5 | 2021-03-09 | |
| 2.21 | 2019-02-24 | 2.21.4 | 2021-03-09 | |
| 2.22 | 2019-06-07 | 2.22.5 | 2021-03-09 | |
| 2.23 | 2019-08-16 | 2.23.4 | 2021-03-09 | |
| 2.24 | 2019-11-04 | 2.24.4 | 2021-03-09 | |
| 2.25 | 2020-01-13 | 2.25.5 | 2021-03-09 | Sparse checkout management made easy[29] |
| 2.26 | 2020-03-22 | 2.26.3 | 2021-03-09 |
[30] |
| 2.27 | 2020-06-01 | 2.27.1 | 2021-03-09 | |
| 2.28 | 2020-07-27 | 2.28.1 | 2021-03-09 |
[31] |
| 2.29 | 2020-10-19 | 2.29.3 | 2021-03-09 |
[32] |
| 2.30 | 2020-12-27 | 2.30.7 | 2022-12-13 |
[33] |
| 2.31 | 2021-03-15 | 2.31.6 | 2023-01-17 |
[34][35] |
| 2.32 | 2021-06-06 | 2.32.5 | 2023-01-17 | |
| 2.33 | 2021-08-16 | 2.33.6 | 2023-01-17 | |
| 2.34 | 2021-11-15 | 2.34.6 | 2023-01-17 | |
| 2.35 | 2022-01-25 | 2.35.6 | 2023-01-17 | |
| 2.36 | 2022-04-18 | 2.36.4 | 2023-01-17 | |
| 2.37 | 2022-06-27 | 2.37.5 | 2023-01-17 | |
| 2.38 | 2022-10-02 | 2.38.3 | 2023-01-17 | |
| 2.39 | 2022-12-12 | 2.39.1 | 2023-01-17 | |
|
Legend: Old version Older version, still maintained Latest version
|
||||
| Sources:[36][37] |
Design
Git’s design was inspired by BitKeeper and Monotone.[38][39] Git was originally designed as a low-level version-control system engine, on top of which others could write front ends, such as Cogito or StGIT.[39] The core Git project has since become a complete version-control system that is usable directly.[40] While strongly influenced by BitKeeper, Torvalds deliberately avoided conventional approaches, leading to a unique design.[41]
Characteristics[edit]
Git’s design is a synthesis of Torvalds’s experience with Linux in maintaining a large distributed development project, along with his intimate knowledge of file-system performance gained from the same project and the urgent need to produce a working system in short order. These influences led to the following implementation choices:[42]
- Strong support for non-linear development
- Git supports rapid branching and merging, and includes specific tools for visualizing and navigating a non-linear development history. In Git, a core assumption is that a change will be merged more often than it is written, as it is passed around to various reviewers. In Git, branches are very lightweight: a branch is only a reference to one commit. With its parental commits, the full branch structure can be constructed.[improper synthesis?]
- Distributed development
- Like Darcs, BitKeeper, Mercurial, Bazaar, and Monotone, Git gives each developer a local copy of the full development history, and changes are copied from one such repository to another. These changes are imported as added development branches and can be merged in the same way as a locally developed branch.[43]
- Compatibility with existing systems and protocols
- Repositories can be published via Hypertext Transfer Protocol Secure (HTTPS), Hypertext Transfer Protocol (HTTP), File Transfer Protocol (FTP), or a Git protocol over either a plain socket or Secure Shell (ssh). Git also has a CVS server emulation, which enables the use of existing CVS clients and IDE plugins to access Git repositories. Subversion repositories can be used directly with git-svn.[44]
- Efficient handling of large projects
- Torvalds has described Git as being very fast and scalable,[45] and performance tests done by Mozilla[46] showed that it was an order of magnitude faster diffing large repositories than Mercurial and GNU Bazaar; fetching version history from a locally stored repository can be one hundred times faster than fetching it from the remote server.[47]
- Cryptographic authentication of history
- The Git history is stored in such a way that the ID of a particular version (a commit in Git terms) depends upon the complete development history leading up to that commit. Once it is published, it is not possible to change the old versions without it being noticed. The structure is similar to a Merkle tree, but with added data at the nodes and leaves.[48] (Mercurial and Monotone also have this property.)
- Toolkit-based design
- Git was designed as a set of programs written in C and several shell scripts that provide wrappers around those programs.[49] Although most of those scripts have since been rewritten in C for speed and portability, the design remains, and it is easy to chain the components together.[50]
- Pluggable merge strategies
- As part of its toolkit design, Git has a well-defined model of an incomplete merge, and it has multiple algorithms for completing it, culminating in telling the user that it is unable to complete the merge automatically and that manual editing is needed.[51]
- Garbage accumulates until collected
- Aborting operations or backing out changes will leave useless dangling objects in the database. These are generally a small fraction of the continuously growing history of wanted objects. Git will automatically perform garbage collection when enough loose objects have been created in the repository. Garbage collection can be called explicitly using
git gc.[52] - Periodic explicit object packing
- Git stores each newly created object as a separate file. Although individually compressed, this takes up a great deal of space and is inefficient. This is solved by the use of packs that store a large number of objects delta-compressed among themselves in one file (or network byte stream) called a packfile. Packs are compressed using the heuristic that files with the same name are probably similar, without depending on this for correctness. A corresponding index file is created for each packfile, telling the offset of each object in the packfile. Newly created objects (with newly added history) are still stored as single objects, and periodic repacking is needed to maintain space efficiency. The process of packing the repository can be very computationally costly. By allowing objects to exist in the repository in a loose but quickly generated format, Git allows the costly pack operation to be deferred until later, when time matters less, e.g., the end of a workday. Git does periodic repacking automatically, but manual repacking is also possible with the
git gccommand. For data integrity, both the packfile and its index have an SHA-1 checksum inside, and the file name of the packfile also contains an SHA-1 checksum. To check the integrity of a repository, run thegit fsckcommand.[53]
Another property of Git is that it snapshots directory trees of files. The earliest systems for tracking versions of source code, Source Code Control System (SCCS) and Revision Control System (RCS), worked on individual files and emphasized the space savings to be gained from interleaved deltas (SCCS) or delta encoding (RCS) the (mostly similar) versions. Later revision-control systems maintained this notion of a file having an identity across multiple revisions of a project. However, Torvalds rejected this concept.[54] Consequently, Git does not explicitly record file revision relationships at any level below the source-code tree.
These implicit revision relationships have some significant consequences:
- It is slightly more costly to examine the change history of one file than the whole project.[55] To obtain a history of changes affecting a given file, Git must walk the global history and then determine whether each change modified that file. This method of examining history does, however, let Git produce with equal efficiency a single history showing the changes to an arbitrary set of files. For example, a subdirectory of the source tree plus an associated global header file is a very common case.
- Renames are handled implicitly rather than explicitly. A common complaint with CVS is that it uses the name of a file to identify its revision history, so moving or renaming a file is not possible without either interrupting its history or renaming the history and thereby making the history inaccurate. Most post-CVS revision-control systems solve this by giving a file a unique long-lived name (analogous to an inode number) that survives renaming. Git does not record such an identifier, and this is claimed as an advantage.[56][57] Source code files are sometimes split or merged, or simply renamed,[58] and recording this as a simple rename would freeze an inaccurate description of what happened in the (immutable) history. Git addresses the issue by detecting renames while browsing the history of snapshots rather than recording it when making the snapshot.[59] (Briefly, given a file in revision N, a file of the same name in revision N − 1 is its default ancestor. However, when there is no like-named file in revision N − 1, Git searches for a file that existed only in revision N − 1 and is very similar to the new file.) However, it does require more CPU-intensive work every time the history is reviewed, and several options to adjust the heuristics are available. This mechanism does not always work; sometimes a file that is renamed with changes in the same commit is read as a deletion of the old file and the creation of a new file. Developers can work around this limitation by committing the rename and the changes separately.
Git implements several merging strategies; a non-default strategy can be selected at merge time:[60]
- resolve: the traditional three-way merge algorithm.
- recursive: This is the default when pulling or merging one branch, and is a variant of the three-way merge algorithm.
When there are more than one common ancestors that can be used for a three-way merge, it creates a merged tree of the common ancestors and uses that as the reference tree for the three-way merge. This has been reported to result in fewer merge conflicts without causing mis-merges by tests done on prior merge commits taken from Linux 2.6 kernel development history. Also, this can detect and handle merges involving renames.
— Linus Torvalds[61]
- octopus: This is the default when merging more than two heads.
Data structures[edit]
Git’s primitives are not inherently a source-code management system. Torvalds explains:[62]
In many ways you can just see git as a filesystem—it’s content-addressable, and it has a notion of versioning, but I really designed it coming at the problem from the viewpoint of a filesystem person (hey, kernels is what I do), and I actually have absolutely zero interest in creating a traditional SCM system.
From this initial design approach, Git has developed the full set of features expected of a traditional SCM,[40] with features mostly being created as needed, then refined and extended over time.

Some data flows and storage levels in the Git revision control system
Git has two data structures: a mutable index (also called stage or cache) that caches information about the working directory and the next revision to be committed; and an immutable, append-only object database.
The index serves as a connection point between the object database and the working tree.
The object database contains five types of objects:[63][53]
- A blob (binary large object) is the content of a file. Blobs have no proper file name, time stamps, or other metadata (A blob’s name internally is a hash of its content.[64]). In git each blob is a version of a file, it holds the file’s data.
- A tree object is the equivalent of a directory. It contains a list of file names, each with some type bits and a reference to a blob or tree object that is that file, symbolic link, or directory’s contents. These objects are a snapshot of the source tree. (In whole, this comprises a Merkle tree, meaning that only a single hash for the root tree is sufficient and actually used in commits to precisely pinpoint to the exact state of whole tree structures of any number of sub-directories and files.)
- A commit object links tree objects together into history. It contains the name of a tree object (of the top-level source directory), a timestamp, a log message, and the names of zero or more parent commit objects.
- A tag object is a container that contains a reference to another object and can hold added meta-data related to another object. Most commonly, it is used to store a digital signature of a commit object corresponding to a particular release of the data being tracked by Git.
- A packfile object collects various other objects into a zlib-compressed bundle for compactness and ease of transport over network protocols.
Each object is identified by a SHA-1 hash of its contents. Git computes the hash and uses this value for the object’s name. The object is put into a directory matching the first two characters of its hash. The rest of the hash is used as the file name for that object.
Git stores each revision of a file as a unique blob. The relationships between the blobs can be found through examining the tree and commit objects. Newly added objects are stored in their entirety using zlib compression. This can consume a large amount of disk space quickly, so objects can be combined into packs, which use delta compression to save space, storing blobs as their changes relative to other blobs.
Additionally, git stores labels called refs (short for references) to indicate the locations of various commits. They are stored in the reference database and are respectively:[65]
- Heads (branches): Named references that are advanced automatically to the new commit when a commit is made on top of them.
- HEAD: A reserved head that will be compared against the working tree to create a commit.
- Tags: Like branch references but fixed to a particular commit. Used to label important points in history.
References[edit]
Every object in the Git database that is not referred to may be cleaned up by using a garbage collection command or automatically. An object may be referenced by another object or an explicit reference. Git knows different types of references. The commands to create, move, and delete references vary. git show-ref lists all references. Some types are:
- heads: refers to an object locally,
- remotes: refers to an object which exists in a remote repository,
- stash: refers to an object not yet committed,
- meta: e.g. a configuration in a bare repository, user rights; the refs/meta/config namespace was introduced retrospectively, gets used by Gerrit,[66]
- tags: see above.
Implementations[edit]

gitg is a graphical front-end using GTK+.
Git (the main implementation in C) is primarily developed on Linux, although it also supports most major operating systems, including the BSDs (DragonFly BSD, FreeBSD, NetBSD, and OpenBSD), Solaris, macOS, and Windows.[67][68]
The first Windows port of Git was primarily a Linux-emulation framework that hosts the Linux version. Installing Git under Windows creates a similarly named Program Files directory containing the Mingw-w64 port of the GNU Compiler Collection, Perl 5, MSYS2 (itself a fork of Cygwin, a Unix-like emulation environment for Windows) and various other Windows ports or emulations of Linux utilities and libraries. Currently, native Windows builds of Git are distributed as 32- and 64-bit installers.[69] The git official website currently maintains a build of Git for Windows, still using the MSYS2 environment.[70]
The JGit implementation of Git is a pure Java software library, designed to be embedded in any Java application. JGit is used in the Gerrit code-review tool, and in EGit, a Git client for the Eclipse IDE.[71]
Go-git is an open-source implementation of Git written in pure Go.[72] It is currently used for backing projects as a SQL interface for Git code repositories[73] and providing encryption for Git.[74]
The Dulwich implementation of Git is a pure Python software component for Python 2.7, 3.4 and 3.5.[75]
The libgit2 implementation of Git is an ANSI C software library with no other dependencies, which can be built on multiple platforms, including Windows, Linux, macOS, and BSD.[76] It has bindings for many programming languages, including Ruby, Python, and Haskell.[77][78][79]
JS-Git is a JavaScript implementation of a subset of Git.[80]
Git server[edit]

Screenshot of Gitweb interface showing a commit diff
As Git is a distributed version control system, it could be used as a server out of the box. It’s shipped with a built-in command git daemon which starts a simple TCP server running on the GIT protocol.[81] Dedicated Git HTTP servers help (amongst other features) by adding access control, displaying the contents of a Git repository via the web interfaces, and managing multiple repositories. Already existing Git repositories can be cloned and shared to be used by others as a centralized repo. It can also be accessed via remote shell just by having the Git software installed and allowing a user to log in.[82] Git servers typically listen on TCP port 9418.[83]
Open source[edit]
- Hosting the Git server using the Git Binary.[84]
- Gerrit, a Git server configurable to support code reviews and provide access via ssh, an integrated Apache MINA or OpenSSH, or an integrated Jetty web server. Gerrit provides integration for LDAP, Active Directory, OpenID, OAuth, Kerberos/GSSAPI, X509 https client certificates. With Gerrit 3.0 all configurations will be stored as Git repositories, and no database is required to run. Gerrit has a pull-request feature implemented in its core but lacks a GUI for it.
- Phabricator, a spin-off from Facebook. As Facebook primarily uses Mercurial, Git support is not as prominent.[85]
- RhodeCode Community Edition (CE), supporting Git, Mercurial and Subversion with an AGPLv3 license.
- Kallithea, supporting both Git and Mercurial, developed in Python with GPL license.
- External projects like gitolite,[86] which provide scripts on top of Git software to provide fine-grained access control.
- There are several other FLOSS solutions for self-hosting, including Gogs[87] and Gitea, a fork of Gogs, both developed in Go language with MIT license.
Git server as a service[edit]
There are many offerings of Git repositories as a service. The most popular are GitHub, SourceForge, Bitbucket and GitLab.[88][89][90][91][92]
Adoption[edit]
The Eclipse Foundation reported in its annual community survey that as of May 2014, Git is now the most widely used source-code management tool, with 42.9% of professional software developers reporting that they use Git as their primary source-control system[93] compared with 36.3% in 2013, 32% in 2012; or for Git responses excluding use of GitHub: 33.3% in 2014, 30.3% in 2013, 27.6% in 2012 and 12.8% in 2011.[94] Open-source directory Black Duck Open Hub reports a similar uptake among open-source projects.[95]
Stack Overflow has included version control in their annual developer survey[96] in 2015 (16,694 responses),[97] 2017 (30,730 responses),[98] 2018 (74,298 responses)[99] and 2022 (71,379 reponses).[100] Git was the overwhelming favorite of responding developers in these surveys, reporting as high as 93.9% in 2022.
Version control systems used by responding developers:
| Name | 2015 | 2017 | 2018 | 2022 |
|---|---|---|---|---|
| Git | 69.3% | 69.2% | 87.2% | 93.9% |
| Subversion | 36.9% | 9.1% | 16.1% | 5.2% |
| TFVC | 12.2% | 7.3% | 10.9% | [ii] |
| Mercurial | 7.9% | 1.9% | 3.6% | 1.1% |
| CVS | 4.2% | [ii] | [ii] | [ii] |
| Perforce | 3.3% | [ii] | [ii] | [ii] |
| VSS | [ii] | 0.6% | [ii] | [ii] |
| ClearCase | [ii] | 0.4% | [ii] | [ii] |
| Zip file backups | [ii] | 2.0% | 7.9% | [ii] |
| Raw network sharing | [ii] | 1.7% | 7.9% | [ii] |
| Other | 5.8% | 3.0% | [ii] | [ii] |
| None | 9.3% | 4.8% | 4.8% | 4.3% |
The UK IT jobs website itjobswatch.co.uk reports that as of late September 2016, 29.27% of UK permanent software development job openings have cited Git,[101] ahead of 12.17% for Microsoft Team Foundation Server,[102] 10.60% for Subversion,[103] 1.30% for Mercurial,[104] and 0.48% for Visual SourceSafe.[105]
Extensions[edit]
There are many Git extensions, like Git LFS, which started as an extension to Git in the GitHub community and is now widely used by other repositories. Extensions are usually independently developed and maintained by different people, but at some point in the future, a widely used extension can be merged with Git.
Other open-source Git extensions include:
- git-annex, a distributed file synchronization system based on Git
- git-flow, a set of Git extensions to provide high-level repository operations for Vincent Driessen’s branching model
- git-machete, a repository organizer & tool for automating rebase/merge/pull/push operations
Microsoft developed the Virtual File System for Git (VFS for Git; formerly Git Virtual File System or GVFS) extension to handle the size of the Windows source-code tree as part of their 2017 migration from Perforce. VFS for Git allows cloned repositories to use placeholders whose contents are downloaded only once a file is accessed.[106]
Conventions[edit]
Git does not impose many restrictions on how it should be used, but some conventions are adopted in order to organize histories, especially those which require the cooperation of many contributors.
- The master branch is created by default with git init [107] and is often used as the branch that other changes are merged into.[108] Correspondingly, the default name of the upstream remote is origin and so the name of the default remote branch is origin/master. The use of master as the default branch name is not universally true. Repositories created in GitHub and GitLab will initialize with a main branch instead of master. [109] [110]
- Pushed commits should usually not be overwritten, but should rather be reverted[111] (a commit is made on top which reverses the changes to an earlier commit). This prevents shared new commits based on shared commits from being invalid because the commit on which they are based does not exist in the remote. If the commits contain sensitive information, they should be removed, which involves a more complex procedure to rewrite history.
- The git-flow[112] workflow and naming conventions are often adopted to distinguish feature specific unstable histories (feature/*), unstable shared histories (develop), production ready histories (main), and emergency patches to released products (hotfix).
- Pull requests are not a feature of git, but are commonly provided by git cloud services. A pull request is a request by one user to merge a branch of their repository fork into another repository sharing the same history (called the upstream remote).[113] The underlying function of a pull request is no different than that of an administrator of a repository pulling changes from another remote (the repository that is the source of the pull request). However, the pull request itself is a ticket managed by the hosting server which initiates scripts to perform these actions; it is not a feature of git SCM.
Security[edit]
Git does not provide access-control mechanisms, but was designed for operation with other tools that specialize in access control.[114]
On 17 December 2014, an exploit was found affecting the Windows and macOS versions of the Git client. An attacker could perform arbitrary code execution on a target computer with Git installed by creating a malicious Git tree (directory) named .git (a directory in Git repositories that stores all the data of the repository) in a different case (such as .GIT or .Git, needed because Git does not allow the all-lowercase version of .git to be created manually) with malicious files in the .git/hooks subdirectory (a folder with executable files that Git runs) on a repository that the attacker made or on a repository that the attacker can modify. If a Windows or Mac user pulls (downloads) a version of the repository with the malicious directory, then switches to that directory, the .git directory will be overwritten (due to the case-insensitive trait of the Windows and Mac filesystems) and the malicious executable files in .git/hooks may be run, which results in the attacker’s commands being executed. An attacker could also modify the .git/config configuration file, which allows the attacker to create malicious Git aliases (aliases for Git commands or external commands) or modify extant aliases to execute malicious commands when run. The vulnerability was patched in version 2.2.1 of Git, released on 17 December 2014, and announced the next day.[115][116]
Git version 2.6.1, released on 29 September 2015, contained a patch for a security vulnerability (CVE-2015–7545)[117] that allowed arbitrary code execution.[118] The vulnerability was exploitable if an attacker could convince a victim to clone a specific URL, as the arbitrary commands were embedded in the URL itself.[119] An attacker could use the exploit via a man-in-the-middle attack if the connection was unencrypted,[119] as they could redirect the user to a URL of their choice. Recursive clones were also vulnerable since they allowed the controller of a repository to specify arbitrary URLs via the gitmodules file.[119]
Git uses SHA-1 hashes internally. Linus Torvalds has responded that the hash was mostly to guard against accidental corruption, and the security a cryptographically secure hash gives was just an accidental side effect, with the main security being signing elsewhere.[120][121] Since a demonstration of the SHAttered attack against git in 2017, git was modified to use a SHA-1 variant resistant to this attack. A plan for hash function transition is being written since February 2020.[122]
Trademark[edit]
«Git» is a registered word trademark of Software Freedom Conservancy under US500000085961336 since 2015-02-03.
See also[edit]
- Comparison of version-control software
- Comparison of source-code-hosting facilities
- List of version-control software
Notes[edit]
- ^ GPL-2.0-only since 2005-04-11. Some parts under compatible licenses such as LGPLv2.1.[6]
- ^ a b c d e f g h i j k l m n o p q r s Not listed as an option in this survey
References[edit]
- ^ «Initial revision of «git», the information manager from hell». GitHub. 8 April 2005. Archived from the original on 16 November 2015. Retrieved 20 December 2015.
- ^ «Commit Graph». GitHub. 8 June 2016. Archived from the original on 20 January 2016. Retrieved 19 December 2015.
- ^ «[ANNOUNCE] Git 2.39.1 and others». 17 January 2023. Retrieved 17 January 2023.
- ^ «Git website». Archived from the original on 9 June 2022. Retrieved 9 June 2022.
- ^ «Git Source Code Mirror». GitHub. Archived from the original on 3 June 2022. Retrieved 9 June 2022.
- ^ «Git’s LGPL license at github.com». GitHub. 20 May 2011. Archived from the original on 11 April 2016. Retrieved 12 October 2014.
- ^ «Git’s GPL license at github.com». GitHub. 18 January 2010. Archived from the original on 11 April 2016. Retrieved 12 October 2014.
- ^ «Tech Talk: Linus Torvalds on git (at 00:01:30)». Archived from the original on 20 December 2015. Retrieved 20 July 2014 – via YouTube.
- ^ a b Torvalds, Linus (7 April 2005). «Re: Kernel SCM saga.» linux-kernel (Mailing list). Archived from the original on 1 July 2019. Retrieved 3 February 2017. «So I’m writing some scripts to try to track things a whole lot faster.»
- ^ a b Torvalds, Linus (10 June 2007). «Re: fatal: serious inflate inconsistency». git (Mailing list).
- ^ a b c d Linus Torvalds (3 May 2007). Google tech talk: Linus Torvalds on git. Event occurs at 02:30. Archived from the original on 28 May 2007. Retrieved 16 May 2007.
- ^ «A Short History of Git». Pro Git (2nd ed.). Apress. 2014. Archived from the original on 25 December 2015. Retrieved 26 December 2015.
- ^ Chacon, Scott (24 December 2014). Pro Git (2nd ed.). New York, NY: Apress. pp. 29–30. ISBN 978-1-4842-0077-3. Archived from the original on 25 December 2015.
- ^ Brown, Zack (27 July 2018). «A Git Origin Story». Linux Journal. Linux Journal. Archived from the original on 13 April 2020. Retrieved 28 May 2020.
- ^ BitKeeper and Linux: The end of the road? Archived 8 June 2017 at the Wayback Machine
- ^ McAllister, Neil (2 May 2005). «Linus Torvalds’ BitKeeper blunder». InfoWorld. Archived from the original on 26 August 2015. Retrieved 8 September 2015.
- ^ a b Torvalds, Linus (27 February 2007). «Re: Trivia: When did git self-host?». git (Mailing list).
- ^ Torvalds, Linus (6 April 2005). «Kernel SCM saga.» linux-kernel (Mailing list).
- ^ Torvalds, Linus (17 April 2005). «First ever real kernel git merge!». git (Mailing list).
- ^ Mackall, Matt (29 April 2005). «Mercurial 0.4b vs git patchbomb benchmark». git (Mailing list).
- ^ Torvalds, Linus (17 June 2005). «Linux 2.6.12». git-commits-head (Mailing list).
- ^ Torvalds, Linus (27 July 2005). «Meet the new maintainer…» git (Mailing list).
- ^ Hamano, Junio C. (21 December 2005). «Announce: Git 1.0.0». git (Mailing list).
- ^ «GitFaq: Why the ‘Git’ name?». Git.or.cz. Archived from the original on 23 July 2012. Retrieved 14 July 2012.
- ^ «After controversy, Torvalds begins work on ‘git’«. PC World. 14 July 2012. Archived from the original on 1 February 2011.
Torvalds seemed aware that his decision to drop BitKeeper would also be controversial. When asked why he called the new software, ‘git’, British slang meaning ‘a rotten person’, he said. ‘I’m an egotistical bastard, so I name all my projects after myself. First Linux, now git.’
- ^ «git(1) Manual Page». Archived from the original on 21 June 2012. Retrieved 21 July 2012.
- ^ «Initial revision of ‘git’, the information manager from hell · git/git@e83c516». GitHub. Archived from the original on 8 October 2017. Retrieved 21 January 2016.
- ^ «Tags». GitHub. Archived from the original on 29 September 2021. Retrieved 28 January 2022.
- ^ «Highlights from Git 2.25». The GitHub Blog. 13 January 2020. Archived from the original on 22 March 2021. Retrieved 27 November 2020.
A sparse checkout is nothing more than a list of file path patterns that Git should attempt to populate in your working copy when checking out the contents of your repository. Effectively, it works like a .gitignore, except it acts on the contents of your working copy, rather than on your index.
- ^ «Highlights from Git 2.26». The GitHub Blog. 22 March 2020. Archived from the original on 22 March 2021. Retrieved 25 November 2020.
You may remember when Git introduced a new version of its network fetch protocol way back in 2018. That protocol is now used by default in 2.26, so let’s refresh ourselves on what that means. The biggest problem with the old protocol is that the server would immediately list all of the branches, tags, and other references in the repository before the client had a chance to send anything. For some repositories, this could mean sending megabytes of extra data, when the client really only wanted to know about the master branch. The new protocol starts with the client request and provides a way for the client to tell the server which references it’s interested in. Fetching a single branch will only ask about that branch, while most clones will only ask about branches and tags. This might seem like everything, but server repositories may store other references (such as the head of every pull request opened in the repository since its creation). Now, fetches from large repositories improve in speed, especially when the fetch itself is small, which makes the cost of the initial reference advertisement more expensive relatively speaking. And the best part is that you won’t need to do anything! Due to some clever design, any client that speaks the new protocol can work seamlessly with both old and new servers, falling back to the original protocol if the server doesn’t support it. The only reason for the delay between introducing the protocol and making it the default was to let early adopters discover any bugs.
- ^ «Highlights from Git 2.28». The GitHub Blog. 27 July 2020. Archived from the original on 22 March 2021. Retrieved 25 November 2020.
- ^ «Highlights from Git 2.29». The GitHub Blog. 19 October 2020. Archived from the original on 22 March 2021. Retrieved 25 November 2020.
- ^ «Git 2.30 Release Notes». Git Downloads. 27 December 2020. Archived from the original on 22 March 2021. Retrieved 27 December 2020.
- ^ «Git 2.31 Release Notes». Git Downloads. 3 April 2021. Retrieved 3 April 2021.
{{cite web}}: CS1 maint: url-status (link) - ^ «Highlights from Git 2.31». The GitHub Blog. 15 March 2021. Retrieved 2 July 2021.
- ^ «git/git». GitHub. Archived from the original on 8 February 2017. Retrieved 1 December 2011.
- ^ Hamano, Junio (21 November 2007). «How to maintain Git». GitHub. Archived from the original on 22 March 2021. Retrieved 1 August 2020.
- ^ Torvalds, Linus (5 May 2006). «Re: [ANNOUNCE] Git wiki». linux-kernel (Mailing list). «Some historical background» on Git’s predecessors
- ^ a b Torvalds, Linus (8 April 2005). «Re: Kernel SCM saga». linux-kernel (Mailing list). Archived from the original on 22 March 2021. Retrieved 20 February 2008.
- ^ a b Torvalds, Linus (23 March 2006). «Re: Errors GITtifying GCC and Binutils». git (Mailing list). Archived from the original on 22 March 2021. Retrieved 3 February 2017.
- ^ Torvalds, Linus (20 October 2006). «Re: VCS comparison table». git (Mailing list). Archived from the original on 22 March 2021. Retrieved 3 February 2017. A discussion of Git vs. BitKeeper.
- ^ «Git – A Short History of Git». git-scm.com. Archived from the original on 22 March 2021. Retrieved 15 June 2020.
- ^ «Git – Distributed Workflows». git-scm.com. Archived from the original on 22 October 2014. Retrieved 15 June 2020.
- ^ Gunjal, Siddhesh (19 July 2019). «What is Version Control Tool? Explore Git and GitHub». Medium. Retrieved 25 October 2020.
- ^ Torvalds, Linus (19 October 2006). «Re: VCS comparison table». git (Mailing list).
- ^ Jst’s Blog on Mozillazine «bzr/hg/git performance». Archived from the original on 29 May 2010. Retrieved 12 February 2015.
- ^ Dreier, Roland (13 November 2006). «Oh what a relief it is». Archived from the original on 16 January 2009., observing that «git log» is 100x faster than «svn log» because the latter must contact a remote server.
- ^ «Trust». Git Concepts. Git User’s Manual. 18 October 2006. Archived from the original on 22 February 2017.
- ^ Torvalds, Linus. «Re: VCS comparison table». git (Mailing list). Retrieved 10 April 2009., describing Git’s script-oriented design
- ^ iabervon (22 December 2005). «Git rocks!». Archived from the original on 14 September 2016., praising Git’s scriptability.
- ^ «Git – Git SCM Wiki». git.wiki.kernel.org. Retrieved 25 October 2020.
- ^ «Git User’s Manual». 10 March 2020. Archived from the original on 10 May 2020.
- ^ a b «Git – Packfiles». git-scm.com.
- ^ Torvalds, Linus (10 April 2005). «Re: more git updates.» linux-kernel (Mailing list).
- ^ Haible, Bruno (11 February 2007). «how to speed up ‘git log’?». git (Mailing list).
- ^ Torvalds, Linus (1 March 2006). «Re: impure renames / history tracking». git (Mailing list).
- ^ Hamano, Junio C. (24 March 2006). «Re: Errors GITtifying GCC and Binutils». git (Mailing list).
- ^ Hamano, Junio C. (23 March 2006). «Re: Errors GITtifying GCC and Binutils». git (Mailing list).
- ^ Torvalds, Linus (28 November 2006). «Re: git and bzr». git (Mailing list)., on using
git-blameto show code moved between source files. - ^ Torvalds, Linus (18 July 2007). «git-merge(1)». Archived from the original on 16 July 2016.
- ^ Torvalds, Linus (18 July 2007). «CrissCrossMerge». Archived from the original on 13 January 2006.
- ^ Torvalds, Linus (10 April 2005). «Re: more git updates…» linux-kernel (Mailing list).
- ^ «Git – Git Objects». git-scm.com.
- ^ Some of git internals
- ^ «Git – Git References». git-scm.com.
- ^ «Project Configuration File Format». Gerrit Code Review. Archived from the original on 3 December 2020. Retrieved 2 February 2020.
- ^ «downloads». Archived from the original on 8 May 2012. Retrieved 14 May 2012.
- ^ «git package versions – Repology». Archived from the original on 19 January 2022. Retrieved 30 November 2021.
- ^ «msysGit». GitHub. Archived from the original on 10 October 2016. Retrieved 20 September 2016.
- ^ «Git – Downloading Package». git-scm.com. (source code)
- ^ «JGit». Archived from the original on 31 August 2012. Retrieved 24 August 2012.
- ^ «Git – go-git». git-scm.com. Retrieved 19 April 2019.
- ^ «SQL interface to Git repositories, written in Go.», github.com, retrieved 19 April 2019
- ^ «Keybase launches encrypted git». keybase.io. Retrieved 19 April 2019.
- ^ «Dulwich». Archived from the original on 29 May 2012. Retrieved 27 August 2012.
- ^ «libgit2». GitHub. Archived from the original on 11 April 2016. Retrieved 24 August 2012.
- ^ «rugged». GitHub. Archived from the original on 24 July 2013. Retrieved 24 August 2012.
- ^ «pygit2». GitHub. Archived from the original on 5 August 2015. Retrieved 24 August 2012.
- ^ «hlibgit2». Archived from the original on 25 May 2013. Retrieved 30 April 2013.
- ^ «js-git: a JavaScript implementation of Git». GitHub. Archived from the original on 7 August 2013. Retrieved 13 August 2013.
- ^ «Git – Git Daemon». git-scm.com. Retrieved 10 July 2019.
- ^ 4.4 Git on the Server – Setting Up the Server Archived 22 October 2014 at the Wayback Machine, Pro Git.
- ^ «1.4 Getting Started – Installing Git». git-scm.com. Archived from the original on 2 November 2013. Retrieved 1 November 2013.
- ^ Chacon, Scott; Straub, Ben (2014). «Git on the Server – Setting Up the Server». Pro Git (2nd ed.). Apress. ISBN 978-1484200773.
- ^ Diffusion User Guide: Repository Hosting Archived 20 September 2020 at the Wayback Machine.
- ^ «Gitolite: Hosting Git Repositories».
- ^ «Gogs: A painless self-hosted Git service».
- ^ Krill, Paul (28 September 2016). «Enterprise repo wars: GitHub vs. GitLab vs. Bitbucket». InfoWorld. Retrieved 2 February 2020.
- ^ «github.com Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 31 March 2013. Retrieved 2 February 2020.
- ^ «sourceforge.net Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 20 October 2020. Retrieved 2 February 2020.
- ^ «bitbucket.org Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 23 June 2017. Retrieved 2 February 2020.
- ^ «gitlab.com Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 30 November 2017. Retrieved 2 February 2020.
- ^ «Eclipse Community Survey 2014 results | Ian Skerrett». Ianskerrett.wordpress.com. 23 June 2014. Archived from the original on 25 June 2014. Retrieved 23 June 2014.
- ^ «Results of Eclipse Community Survey 2012». eclipse.org. Archived from the original on 11 April 2016.
- ^ «Compare Repositories – Open Hub». Archived from the original on 7 September 2014.
- ^ «Stack Overflow Annual Developer Survey». Stack Exchange, Inc. Retrieved 9 January 2020.
Stack Overflow’s annual Developer Survey is the largest and most comprehensive survey of people who code around the world. Each year, we field a survey covering everything from developers’ favorite technologies to their job preferences. This year marks the ninth year we’ve published our annual Developer Survey results, and nearly 90,000 developers took the 20-minute survey earlier this year.
- ^ «Stack Overflow Developer Survey 2015». Stack Overflow. Archived from the original on 4 May 2019. Retrieved 29 May 2019.
- ^ «Stack Overflow Developer Survey 2017». Stack Overflow. Archived from the original on 29 May 2019. Retrieved 29 May 2019.
- ^ «Stack Overflow Developer Survey 2018». Stack Overflow. Archived from the original on 30 May 2019. Retrieved 29 May 2019.
- ^ «Stack Overflow Developer Survey 2022». Stack Overflow. Retrieved 4 August 2022.
- ^ «Git (software) Jobs, Average Salary for Git Distributed Version Control System Skills». Itjobswatch.co.uk. Archived from the original on 8 October 2016. Retrieved 30 September 2016.
- ^ «Team Foundation Server Jobs, Average Salary for Microsoft Team Foundation Server (TFS) Skills». Itjobswatch.co.uk. Archived from the original on 29 October 2016. Retrieved 30 September 2016.
- ^ «Subversion Jobs, Average Salary for Apache Subversion (SVN) Skills». Itjobswatch.co.uk. Archived from the original on 25 October 2016. Retrieved 30 September 2016.
- ^ «Mercurial Jobs, Average Salary for Mercurial Skills». Itjobswatch.co.uk. Archived from the original on 23 September 2016. Retrieved 30 September 2016.
- ^ «VSS/SourceSafe Jobs, Average Salary for Microsoft Visual SourceSafe (VSS) Skills». Itjobswatch.co.uk. Archived from the original on 29 October 2016. Retrieved 30 September 2016.
- ^ «Windows switch to Git almost complete: 8,500 commits and 1,760 builds each day». Ars Technica. 24 May 2017. Archived from the original on 24 May 2017. Retrieved 24 May 2017.
- ^ «git-init». Git. Archived from the original on 15 March 2022.
- ^ «Git – Branches in a Nutshell». git-scm.com. Archived from the original on 20 December 2020. Retrieved 15 June 2020.
The «master» branch in Git is not a special branch. It is exactly like any other branch. The only reason nearly every repository has one is that the git init command creates it by default and most people don’t bother to change it.
- ^ github/renaming, GitHub, 4 December 2020, retrieved 4 December 2020
- ^ Default branch name for new repositories now main, GitLab, 22 June 2021, retrieved 22 June 2021
- ^ «Git Revert | Atlassian Git Tutorial». Atlassian.
Reverting has two important advantages over resetting. First, it doesn’t change the project history, which makes it a «safe» operation for commits that have already been published to a shared repository.
- ^ «Gitflow Workflow | Atlassian Git Tutorial». Atlassian. Retrieved 15 June 2020.
- ^ «Forking Workflow | Atlassian Git Tutorial». Atlassian. Retrieved 15 June 2020.
- ^ «Git repository access control». Archived from the original on 14 September 2016. Retrieved 6 September 2016.
- ^ Pettersen, Tim (20 December 2014). «Securing your Git server against CVE-2014-9390». Archived from the original on 24 December 2014. Retrieved 22 December 2014.
- ^ Hamano, J. C. (18 December 2014). «[Announce] Git v2.2.1 (and updates to older maintenance tracks)». Newsgroup: gmane.linux.kernel. Archived from the original on 19 December 2014. Retrieved 22 December 2014.
- ^ «CVE-2015-7545». 15 December 2015. Archived from the original on 26 December 2015. Retrieved 26 December 2015.
- ^ «Git 2.6.1». GitHub. 29 September 2015. Archived from the original on 11 April 2016. Retrieved 26 December 2015.
- ^ a b c Blake Burkhart; et al. (5 October 2015). «Re: CVE Request: git». Archived from the original on 27 December 2015. Retrieved 26 December 2015.
- ^ «hash – How safe are signed git tags? Only as safe as SHA-1 or somehow safer?». Information Security Stack Exchange. 22 September 2014. Archived from the original on 24 June 2016.
- ^ «Why does Git use a cryptographic hash function?». Stack Overflow. 1 March 2015. Archived from the original on 1 July 2016.
- ^ «Git – hash-function-transition Documentation». git-scm.com.
External links[edit]
![]()
Wikimedia Commons has media related to Git.
![]()
Wikibooks has a book on the topic of: Git
- Official website

- Git at Open Hub
|
A command-line session showing repository creation, addition of a file, and remote synchronization |
|
| Original author(s) | Linus Torvalds[1] |
|---|---|
| Developer(s) | Junio Hamano and others[2] |
| Initial release | 7 April 2005; 17 years ago |
| Stable release |
2.39.1[3] |
| Repository |
|
| Written in | Primarily in C, with GUI and programming scripts written in Shell script, Perl, Tcl and Python[4][5] |
| Operating system | POSIX (Linux, macOS, Solaris, AIX), Windows |
| Available in | English |
| Type | Version control |
| License | GPL-2.0-only[i][7] |
| Website | git-scm.com |
Git ()[8] is a distributed version control system that tracks changes in any set of computer files, usually used for coordinating work among programmers collaboratively developing source code during software development. Its goals include speed, data integrity, and support for distributed, non-linear workflows (thousands of parallel branches running on different systems).[9][10][11]
Git was originally authored by Linus Torvalds in 2005 for development of the Linux kernel, with other kernel developers contributing to its initial development.[12] Since 2005, Junio Hamano has been the core maintainer. As with most other distributed version control systems, and unlike most client–server systems, every Git directory on every computer is a full-fledged repository with complete history and full version-tracking abilities, independent of network access or a central server.[13] Git is free and open-source software distributed under the GPL-2.0-only license.
History[edit]
Git development began in April 2005, after many developers of the Linux kernel gave up access to BitKeeper, a proprietary source-control management (SCM) system that they had been using to maintain the project since 2002.[14][15] The copyright holder of BitKeeper, Larry McVoy, had withdrawn free use of the product after claiming that Andrew Tridgell had created SourcePuller by reverse engineering the BitKeeper protocols.[16] The same incident also spurred the creation of another version-control system, Mercurial.
Linus Torvalds wanted a distributed system that he could use like BitKeeper, but none of the available free systems met his needs. Torvalds cited an example of a source-control management system needing 30 seconds to apply a patch and update all associated metadata, and noted that this would not scale to the needs of Linux kernel development, where synchronizing with fellow maintainers could require 250 such actions at once. For his design criterion, he specified that patching should take no more than three seconds, and added three more goals:[9]
- Take Concurrent Versions System (CVS) as an example of what not to do; if in doubt, make the exact opposite decision.[11]
- Support a distributed, BitKeeper-like workflow.[11]
- Include very strong safeguards against corruption, either accidental or malicious.[10]
These criteria eliminated every version-control system in use at the time, so immediately after the 2.6.12-rc2 Linux kernel development release, Torvalds set out to write his own.[11]
The development of Git began on 3 April 2005.[17] Torvalds announced the project on 6 April and became self-hosting the next day.[17][18] The first merge of multiple branches took place on 18 April.[19] Torvalds achieved his performance goals; on 29 April, the nascent Git was benchmarked recording patches to the Linux kernel tree at the rate of 6.7 patches per second.[20] On 16 June, Git managed the kernel 2.6.12 release.[21]
Torvalds turned over maintenance on 26 July 2005 to Junio Hamano, a major contributor to the project.[22] Hamano was responsible for the 1.0 release on 21 December 2005.[23]
Naming[edit]
Torvalds sarcastically quipped about the name git (which means «unpleasant person» in British English slang): «I’m an egotistical bastard, and I name all my projects after myself. First ‘Linux’, now ‘git’.»[24][25] The man page describes Git as «the stupid content tracker».[26] The read-me file of the source code elaborates further:[27]
«git» can mean anything, depending on your mood.
- Random three-letter combination that is pronounceable, and not actually used by any common UNIX command. The fact that it is a mispronunciation of «get» may or may not be relevant.
- Stupid. Contemptible and despicable. Simple. Take your pick from the dictionary of slang.
- «Global information tracker»: you’re in a good mood, and it actually works for you. Angels sing, and a light suddenly fills the room.
- «Goddamn idiotic truckload of sh*t»: when it breaks.
The source code for Git refers to the program as, «the information manager from hell.»
Releases[edit]
List of Git releases:[28]
| Version | Original release date | Latest (patch) version | Release date (of the patch) | Notable changes |
|---|---|---|---|---|
| 0.99 | 2005-07-11 | 0.99.9n | 2005-12-15 | |
| 1.0 | 2005-12-21 | 1.0.13 | 2006-01-27 | |
| 1.1 | 2006-01-08 | 1.1.6 | 2006-01-30 | |
| 1.2 | 2006-02-12 | 1.2.6 | 2006-04-08 | |
| 1.3 | 2006-04-18 | 1.3.3 | 2006-05-16 | |
| 1.4 | 2006-06-10 | 1.4.4.5 | 2008-07-16 | |
| 1.5 | 2007-02-14 | 1.5.6.6 | 2008-12-17 | |
| 1.6 | 2008-08-17 | 1.6.6.3 | 2010-12-15 | |
| 1.7 | 2010-02-13 | 1.7.12.4 | 2012-10-17 | |
| 1.8 | 2012-10-21 | 1.8.5.6 | 2014-12-17 | |
| 1.9 | 2014-02-14 | 1.9.5 | 2014-12-17 | |
| 2.0 | 2014-05-28 | 2.0.5 | 2014-12-17 | |
| 2.1 | 2014-08-16 | 2.1.4 | 2014-12-17 | |
| 2.2 | 2014-11-26 | 2.2.3 | 2015-09-04 | |
| 2.3 | 2015-02-05 | 2.3.10 | 2015-09-29 | |
| 2.4 | 2015-04-30 | 2.4.12 | 2017-05-05 | |
| 2.5 | 2015-07-27 | 2.5.6 | 2017-05-05 | |
| 2.6 | 2015-09-28 | 2.6.7 | 2017-05-05 | |
| 2.7 | 2015-10-04 | 2.7.6 | 2017-07-30 | |
| 2.8 | 2016-03-28 | 2.8.6 | 2017-07-30 | |
| 2.9 | 2016-06-13 | 2.9.5 | 2017-07-30 | |
| 2.10 | 2016-09-02 | 2.10.5 | 2017-09-22 | |
| 2.11 | 2016-11-29 | 2.11.4 | 2017-09-22 | |
| 2.12 | 2017-02-24 | 2.12.5 | 2017-09-22 | |
| 2.13 | 2017-05-10 | 2.13.7 | 2018-05-22 | |
| 2.14 | 2017-08-04 | 2.14.6 | 2019-12-07 | |
| 2.15 | 2017-10-30 | 2.15.4 | 2019-12-07 | |
| 2.16 | 2018-01-17 | 2.16.6 | 2019-12-07 | |
| 2.17 | 2018-04-02 | 2.17.6 | 2021-03-09 | |
| 2.18 | 2018-06-21 | 2.18.5 | 2021-03-09 | |
| 2.19 | 2018-09-10 | 2.19.6 | 2021-03-09 | |
| 2.20 | 2018-12-09 | 2.20.5 | 2021-03-09 | |
| 2.21 | 2019-02-24 | 2.21.4 | 2021-03-09 | |
| 2.22 | 2019-06-07 | 2.22.5 | 2021-03-09 | |
| 2.23 | 2019-08-16 | 2.23.4 | 2021-03-09 | |
| 2.24 | 2019-11-04 | 2.24.4 | 2021-03-09 | |
| 2.25 | 2020-01-13 | 2.25.5 | 2021-03-09 | Sparse checkout management made easy[29] |
| 2.26 | 2020-03-22 | 2.26.3 | 2021-03-09 |
[30] |
| 2.27 | 2020-06-01 | 2.27.1 | 2021-03-09 | |
| 2.28 | 2020-07-27 | 2.28.1 | 2021-03-09 |
[31] |
| 2.29 | 2020-10-19 | 2.29.3 | 2021-03-09 |
[32] |
| 2.30 | 2020-12-27 | 2.30.7 | 2022-12-13 |
[33] |
| 2.31 | 2021-03-15 | 2.31.6 | 2023-01-17 |
[34][35] |
| 2.32 | 2021-06-06 | 2.32.5 | 2023-01-17 | |
| 2.33 | 2021-08-16 | 2.33.6 | 2023-01-17 | |
| 2.34 | 2021-11-15 | 2.34.6 | 2023-01-17 | |
| 2.35 | 2022-01-25 | 2.35.6 | 2023-01-17 | |
| 2.36 | 2022-04-18 | 2.36.4 | 2023-01-17 | |
| 2.37 | 2022-06-27 | 2.37.5 | 2023-01-17 | |
| 2.38 | 2022-10-02 | 2.38.3 | 2023-01-17 | |
| 2.39 | 2022-12-12 | 2.39.1 | 2023-01-17 | |
|
Legend: Old version Older version, still maintained Latest version
|
||||
| Sources:[36][37] |
Design
Git’s design was inspired by BitKeeper and Monotone.[38][39] Git was originally designed as a low-level version-control system engine, on top of which others could write front ends, such as Cogito or StGIT.[39] The core Git project has since become a complete version-control system that is usable directly.[40] While strongly influenced by BitKeeper, Torvalds deliberately avoided conventional approaches, leading to a unique design.[41]
Characteristics[edit]
Git’s design is a synthesis of Torvalds’s experience with Linux in maintaining a large distributed development project, along with his intimate knowledge of file-system performance gained from the same project and the urgent need to produce a working system in short order. These influences led to the following implementation choices:[42]
- Strong support for non-linear development
- Git supports rapid branching and merging, and includes specific tools for visualizing and navigating a non-linear development history. In Git, a core assumption is that a change will be merged more often than it is written, as it is passed around to various reviewers. In Git, branches are very lightweight: a branch is only a reference to one commit. With its parental commits, the full branch structure can be constructed.[improper synthesis?]
- Distributed development
- Like Darcs, BitKeeper, Mercurial, Bazaar, and Monotone, Git gives each developer a local copy of the full development history, and changes are copied from one such repository to another. These changes are imported as added development branches and can be merged in the same way as a locally developed branch.[43]
- Compatibility with existing systems and protocols
- Repositories can be published via Hypertext Transfer Protocol Secure (HTTPS), Hypertext Transfer Protocol (HTTP), File Transfer Protocol (FTP), or a Git protocol over either a plain socket or Secure Shell (ssh). Git also has a CVS server emulation, which enables the use of existing CVS clients and IDE plugins to access Git repositories. Subversion repositories can be used directly with git-svn.[44]
- Efficient handling of large projects
- Torvalds has described Git as being very fast and scalable,[45] and performance tests done by Mozilla[46] showed that it was an order of magnitude faster diffing large repositories than Mercurial and GNU Bazaar; fetching version history from a locally stored repository can be one hundred times faster than fetching it from the remote server.[47]
- Cryptographic authentication of history
- The Git history is stored in such a way that the ID of a particular version (a commit in Git terms) depends upon the complete development history leading up to that commit. Once it is published, it is not possible to change the old versions without it being noticed. The structure is similar to a Merkle tree, but with added data at the nodes and leaves.[48] (Mercurial and Monotone also have this property.)
- Toolkit-based design
- Git was designed as a set of programs written in C and several shell scripts that provide wrappers around those programs.[49] Although most of those scripts have since been rewritten in C for speed and portability, the design remains, and it is easy to chain the components together.[50]
- Pluggable merge strategies
- As part of its toolkit design, Git has a well-defined model of an incomplete merge, and it has multiple algorithms for completing it, culminating in telling the user that it is unable to complete the merge automatically and that manual editing is needed.[51]
- Garbage accumulates until collected
- Aborting operations or backing out changes will leave useless dangling objects in the database. These are generally a small fraction of the continuously growing history of wanted objects. Git will automatically perform garbage collection when enough loose objects have been created in the repository. Garbage collection can be called explicitly using
git gc.[52] - Periodic explicit object packing
- Git stores each newly created object as a separate file. Although individually compressed, this takes up a great deal of space and is inefficient. This is solved by the use of packs that store a large number of objects delta-compressed among themselves in one file (or network byte stream) called a packfile. Packs are compressed using the heuristic that files with the same name are probably similar, without depending on this for correctness. A corresponding index file is created for each packfile, telling the offset of each object in the packfile. Newly created objects (with newly added history) are still stored as single objects, and periodic repacking is needed to maintain space efficiency. The process of packing the repository can be very computationally costly. By allowing objects to exist in the repository in a loose but quickly generated format, Git allows the costly pack operation to be deferred until later, when time matters less, e.g., the end of a workday. Git does periodic repacking automatically, but manual repacking is also possible with the
git gccommand. For data integrity, both the packfile and its index have an SHA-1 checksum inside, and the file name of the packfile also contains an SHA-1 checksum. To check the integrity of a repository, run thegit fsckcommand.[53]
Another property of Git is that it snapshots directory trees of files. The earliest systems for tracking versions of source code, Source Code Control System (SCCS) and Revision Control System (RCS), worked on individual files and emphasized the space savings to be gained from interleaved deltas (SCCS) or delta encoding (RCS) the (mostly similar) versions. Later revision-control systems maintained this notion of a file having an identity across multiple revisions of a project. However, Torvalds rejected this concept.[54] Consequently, Git does not explicitly record file revision relationships at any level below the source-code tree.
These implicit revision relationships have some significant consequences:
- It is slightly more costly to examine the change history of one file than the whole project.[55] To obtain a history of changes affecting a given file, Git must walk the global history and then determine whether each change modified that file. This method of examining history does, however, let Git produce with equal efficiency a single history showing the changes to an arbitrary set of files. For example, a subdirectory of the source tree plus an associated global header file is a very common case.
- Renames are handled implicitly rather than explicitly. A common complaint with CVS is that it uses the name of a file to identify its revision history, so moving or renaming a file is not possible without either interrupting its history or renaming the history and thereby making the history inaccurate. Most post-CVS revision-control systems solve this by giving a file a unique long-lived name (analogous to an inode number) that survives renaming. Git does not record such an identifier, and this is claimed as an advantage.[56][57] Source code files are sometimes split or merged, or simply renamed,[58] and recording this as a simple rename would freeze an inaccurate description of what happened in the (immutable) history. Git addresses the issue by detecting renames while browsing the history of snapshots rather than recording it when making the snapshot.[59] (Briefly, given a file in revision N, a file of the same name in revision N − 1 is its default ancestor. However, when there is no like-named file in revision N − 1, Git searches for a file that existed only in revision N − 1 and is very similar to the new file.) However, it does require more CPU-intensive work every time the history is reviewed, and several options to adjust the heuristics are available. This mechanism does not always work; sometimes a file that is renamed with changes in the same commit is read as a deletion of the old file and the creation of a new file. Developers can work around this limitation by committing the rename and the changes separately.
Git implements several merging strategies; a non-default strategy can be selected at merge time:[60]
- resolve: the traditional three-way merge algorithm.
- recursive: This is the default when pulling or merging one branch, and is a variant of the three-way merge algorithm.
When there are more than one common ancestors that can be used for a three-way merge, it creates a merged tree of the common ancestors and uses that as the reference tree for the three-way merge. This has been reported to result in fewer merge conflicts without causing mis-merges by tests done on prior merge commits taken from Linux 2.6 kernel development history. Also, this can detect and handle merges involving renames.
— Linus Torvalds[61]
- octopus: This is the default when merging more than two heads.
Data structures[edit]
Git’s primitives are not inherently a source-code management system. Torvalds explains:[62]
In many ways you can just see git as a filesystem—it’s content-addressable, and it has a notion of versioning, but I really designed it coming at the problem from the viewpoint of a filesystem person (hey, kernels is what I do), and I actually have absolutely zero interest in creating a traditional SCM system.
From this initial design approach, Git has developed the full set of features expected of a traditional SCM,[40] with features mostly being created as needed, then refined and extended over time.
Some data flows and storage levels in the Git revision control system
Git has two data structures: a mutable index (also called stage or cache) that caches information about the working directory and the next revision to be committed; and an immutable, append-only object database.
The index serves as a connection point between the object database and the working tree.
The object database contains five types of objects:[63][53]
- A blob (binary large object) is the content of a file. Blobs have no proper file name, time stamps, or other metadata (A blob’s name internally is a hash of its content.[64]). In git each blob is a version of a file, it holds the file’s data.
- A tree object is the equivalent of a directory. It contains a list of file names, each with some type bits and a reference to a blob or tree object that is that file, symbolic link, or directory’s contents. These objects are a snapshot of the source tree. (In whole, this comprises a Merkle tree, meaning that only a single hash for the root tree is sufficient and actually used in commits to precisely pinpoint to the exact state of whole tree structures of any number of sub-directories and files.)
- A commit object links tree objects together into history. It contains the name of a tree object (of the top-level source directory), a timestamp, a log message, and the names of zero or more parent commit objects.
- A tag object is a container that contains a reference to another object and can hold added meta-data related to another object. Most commonly, it is used to store a digital signature of a commit object corresponding to a particular release of the data being tracked by Git.
- A packfile object collects various other objects into a zlib-compressed bundle for compactness and ease of transport over network protocols.
Each object is identified by a SHA-1 hash of its contents. Git computes the hash and uses this value for the object’s name. The object is put into a directory matching the first two characters of its hash. The rest of the hash is used as the file name for that object.
Git stores each revision of a file as a unique blob. The relationships between the blobs can be found through examining the tree and commit objects. Newly added objects are stored in their entirety using zlib compression. This can consume a large amount of disk space quickly, so objects can be combined into packs, which use delta compression to save space, storing blobs as their changes relative to other blobs.
Additionally, git stores labels called refs (short for references) to indicate the locations of various commits. They are stored in the reference database and are respectively:[65]
- Heads (branches): Named references that are advanced automatically to the new commit when a commit is made on top of them.
- HEAD: A reserved head that will be compared against the working tree to create a commit.
- Tags: Like branch references but fixed to a particular commit. Used to label important points in history.
References[edit]
Every object in the Git database that is not referred to may be cleaned up by using a garbage collection command or automatically. An object may be referenced by another object or an explicit reference. Git knows different types of references. The commands to create, move, and delete references vary. git show-ref lists all references. Some types are:
- heads: refers to an object locally,
- remotes: refers to an object which exists in a remote repository,
- stash: refers to an object not yet committed,
- meta: e.g. a configuration in a bare repository, user rights; the refs/meta/config namespace was introduced retrospectively, gets used by Gerrit,[66]
- tags: see above.
Implementations[edit]
gitg is a graphical front-end using GTK+.
Git (the main implementation in C) is primarily developed on Linux, although it also supports most major operating systems, including the BSDs (DragonFly BSD, FreeBSD, NetBSD, and OpenBSD), Solaris, macOS, and Windows.[67][68]
The first Windows port of Git was primarily a Linux-emulation framework that hosts the Linux version. Installing Git under Windows creates a similarly named Program Files directory containing the Mingw-w64 port of the GNU Compiler Collection, Perl 5, MSYS2 (itself a fork of Cygwin, a Unix-like emulation environment for Windows) and various other Windows ports or emulations of Linux utilities and libraries. Currently, native Windows builds of Git are distributed as 32- and 64-bit installers.[69] The git official website currently maintains a build of Git for Windows, still using the MSYS2 environment.[70]
The JGit implementation of Git is a pure Java software library, designed to be embedded in any Java application. JGit is used in the Gerrit code-review tool, and in EGit, a Git client for the Eclipse IDE.[71]
Go-git is an open-source implementation of Git written in pure Go.[72] It is currently used for backing projects as a SQL interface for Git code repositories[73] and providing encryption for Git.[74]
The Dulwich implementation of Git is a pure Python software component for Python 2.7, 3.4 and 3.5.[75]
The libgit2 implementation of Git is an ANSI C software library with no other dependencies, which can be built on multiple platforms, including Windows, Linux, macOS, and BSD.[76] It has bindings for many programming languages, including Ruby, Python, and Haskell.[77][78][79]
JS-Git is a JavaScript implementation of a subset of Git.[80]
Git server[edit]
Screenshot of Gitweb interface showing a commit diff
As Git is a distributed version control system, it could be used as a server out of the box. It’s shipped with a built-in command git daemon which starts a simple TCP server running on the GIT protocol.[81] Dedicated Git HTTP servers help (amongst other features) by adding access control, displaying the contents of a Git repository via the web interfaces, and managing multiple repositories. Already existing Git repositories can be cloned and shared to be used by others as a centralized repo. It can also be accessed via remote shell just by having the Git software installed and allowing a user to log in.[82] Git servers typically listen on TCP port 9418.[83]
Open source[edit]
- Hosting the Git server using the Git Binary.[84]
- Gerrit, a Git server configurable to support code reviews and provide access via ssh, an integrated Apache MINA or OpenSSH, or an integrated Jetty web server. Gerrit provides integration for LDAP, Active Directory, OpenID, OAuth, Kerberos/GSSAPI, X509 https client certificates. With Gerrit 3.0 all configurations will be stored as Git repositories, and no database is required to run. Gerrit has a pull-request feature implemented in its core but lacks a GUI for it.
- Phabricator, a spin-off from Facebook. As Facebook primarily uses Mercurial, Git support is not as prominent.[85]
- RhodeCode Community Edition (CE), supporting Git, Mercurial and Subversion with an AGPLv3 license.
- Kallithea, supporting both Git and Mercurial, developed in Python with GPL license.
- External projects like gitolite,[86] which provide scripts on top of Git software to provide fine-grained access control.
- There are several other FLOSS solutions for self-hosting, including Gogs[87] and Gitea, a fork of Gogs, both developed in Go language with MIT license.
Git server as a service[edit]
There are many offerings of Git repositories as a service. The most popular are GitHub, SourceForge, Bitbucket and GitLab.[88][89][90][91][92]
Adoption[edit]
The Eclipse Foundation reported in its annual community survey that as of May 2014, Git is now the most widely used source-code management tool, with 42.9% of professional software developers reporting that they use Git as their primary source-control system[93] compared with 36.3% in 2013, 32% in 2012; or for Git responses excluding use of GitHub: 33.3% in 2014, 30.3% in 2013, 27.6% in 2012 and 12.8% in 2011.[94] Open-source directory Black Duck Open Hub reports a similar uptake among open-source projects.[95]
Stack Overflow has included version control in their annual developer survey[96] in 2015 (16,694 responses),[97] 2017 (30,730 responses),[98] 2018 (74,298 responses)[99] and 2022 (71,379 reponses).[100] Git was the overwhelming favorite of responding developers in these surveys, reporting as high as 93.9% in 2022.
Version control systems used by responding developers:
| Name | 2015 | 2017 | 2018 | 2022 |
|---|---|---|---|---|
| Git | 69.3% | 69.2% | 87.2% | 93.9% |
| Subversion | 36.9% | 9.1% | 16.1% | 5.2% |
| TFVC | 12.2% | 7.3% | 10.9% | [ii] |
| Mercurial | 7.9% | 1.9% | 3.6% | 1.1% |
| CVS | 4.2% | [ii] | [ii] | [ii] |
| Perforce | 3.3% | [ii] | [ii] | [ii] |
| VSS | [ii] | 0.6% | [ii] | [ii] |
| ClearCase | [ii] | 0.4% | [ii] | [ii] |
| Zip file backups | [ii] | 2.0% | 7.9% | [ii] |
| Raw network sharing | [ii] | 1.7% | 7.9% | [ii] |
| Other | 5.8% | 3.0% | [ii] | [ii] |
| None | 9.3% | 4.8% | 4.8% | 4.3% |
The UK IT jobs website itjobswatch.co.uk reports that as of late September 2016, 29.27% of UK permanent software development job openings have cited Git,[101] ahead of 12.17% for Microsoft Team Foundation Server,[102] 10.60% for Subversion,[103] 1.30% for Mercurial,[104] and 0.48% for Visual SourceSafe.[105]
Extensions[edit]
There are many Git extensions, like Git LFS, which started as an extension to Git in the GitHub community and is now widely used by other repositories. Extensions are usually independently developed and maintained by different people, but at some point in the future, a widely used extension can be merged with Git.
Other open-source Git extensions include:
- git-annex, a distributed file synchronization system based on Git
- git-flow, a set of Git extensions to provide high-level repository operations for Vincent Driessen’s branching model
- git-machete, a repository organizer & tool for automating rebase/merge/pull/push operations
Microsoft developed the Virtual File System for Git (VFS for Git; formerly Git Virtual File System or GVFS) extension to handle the size of the Windows source-code tree as part of their 2017 migration from Perforce. VFS for Git allows cloned repositories to use placeholders whose contents are downloaded only once a file is accessed.[106]
Conventions[edit]
Git does not impose many restrictions on how it should be used, but some conventions are adopted in order to organize histories, especially those which require the cooperation of many contributors.
- The master branch is created by default with git init [107] and is often used as the branch that other changes are merged into.[108] Correspondingly, the default name of the upstream remote is origin and so the name of the default remote branch is origin/master. The use of master as the default branch name is not universally true. Repositories created in GitHub and GitLab will initialize with a main branch instead of master. [109] [110]
- Pushed commits should usually not be overwritten, but should rather be reverted[111] (a commit is made on top which reverses the changes to an earlier commit). This prevents shared new commits based on shared commits from being invalid because the commit on which they are based does not exist in the remote. If the commits contain sensitive information, they should be removed, which involves a more complex procedure to rewrite history.
- The git-flow[112] workflow and naming conventions are often adopted to distinguish feature specific unstable histories (feature/*), unstable shared histories (develop), production ready histories (main), and emergency patches to released products (hotfix).
- Pull requests are not a feature of git, but are commonly provided by git cloud services. A pull request is a request by one user to merge a branch of their repository fork into another repository sharing the same history (called the upstream remote).[113] The underlying function of a pull request is no different than that of an administrator of a repository pulling changes from another remote (the repository that is the source of the pull request). However, the pull request itself is a ticket managed by the hosting server which initiates scripts to perform these actions; it is not a feature of git SCM.
Security[edit]
Git does not provide access-control mechanisms, but was designed for operation with other tools that specialize in access control.[114]
On 17 December 2014, an exploit was found affecting the Windows and macOS versions of the Git client. An attacker could perform arbitrary code execution on a target computer with Git installed by creating a malicious Git tree (directory) named .git (a directory in Git repositories that stores all the data of the repository) in a different case (such as .GIT or .Git, needed because Git does not allow the all-lowercase version of .git to be created manually) with malicious files in the .git/hooks subdirectory (a folder with executable files that Git runs) on a repository that the attacker made or on a repository that the attacker can modify. If a Windows or Mac user pulls (downloads) a version of the repository with the malicious directory, then switches to that directory, the .git directory will be overwritten (due to the case-insensitive trait of the Windows and Mac filesystems) and the malicious executable files in .git/hooks may be run, which results in the attacker’s commands being executed. An attacker could also modify the .git/config configuration file, which allows the attacker to create malicious Git aliases (aliases for Git commands or external commands) or modify extant aliases to execute malicious commands when run. The vulnerability was patched in version 2.2.1 of Git, released on 17 December 2014, and announced the next day.[115][116]
Git version 2.6.1, released on 29 September 2015, contained a patch for a security vulnerability (CVE-2015–7545)[117] that allowed arbitrary code execution.[118] The vulnerability was exploitable if an attacker could convince a victim to clone a specific URL, as the arbitrary commands were embedded in the URL itself.[119] An attacker could use the exploit via a man-in-the-middle attack if the connection was unencrypted,[119] as they could redirect the user to a URL of their choice. Recursive clones were also vulnerable since they allowed the controller of a repository to specify arbitrary URLs via the gitmodules file.[119]
Git uses SHA-1 hashes internally. Linus Torvalds has responded that the hash was mostly to guard against accidental corruption, and the security a cryptographically secure hash gives was just an accidental side effect, with the main security being signing elsewhere.[120][121] Since a demonstration of the SHAttered attack against git in 2017, git was modified to use a SHA-1 variant resistant to this attack. A plan for hash function transition is being written since February 2020.[122]
Trademark[edit]
«Git» is a registered word trademark of Software Freedom Conservancy under US500000085961336 since 2015-02-03.
See also[edit]
- Comparison of version-control software
- Comparison of source-code-hosting facilities
- List of version-control software
Notes[edit]
- ^ GPL-2.0-only since 2005-04-11. Some parts under compatible licenses such as LGPLv2.1.[6]
- ^ a b c d e f g h i j k l m n o p q r s Not listed as an option in this survey
References[edit]
- ^ «Initial revision of «git», the information manager from hell». GitHub. 8 April 2005. Archived from the original on 16 November 2015. Retrieved 20 December 2015.
- ^ «Commit Graph». GitHub. 8 June 2016. Archived from the original on 20 January 2016. Retrieved 19 December 2015.
- ^ «[ANNOUNCE] Git 2.39.1 and others». 17 January 2023. Retrieved 17 January 2023.
- ^ «Git website». Archived from the original on 9 June 2022. Retrieved 9 June 2022.
- ^ «Git Source Code Mirror». GitHub. Archived from the original on 3 June 2022. Retrieved 9 June 2022.
- ^ «Git’s LGPL license at github.com». GitHub. 20 May 2011. Archived from the original on 11 April 2016. Retrieved 12 October 2014.
- ^ «Git’s GPL license at github.com». GitHub. 18 January 2010. Archived from the original on 11 April 2016. Retrieved 12 October 2014.
- ^ «Tech Talk: Linus Torvalds on git (at 00:01:30)». Archived from the original on 20 December 2015. Retrieved 20 July 2014 – via YouTube.
- ^ a b Torvalds, Linus (7 April 2005). «Re: Kernel SCM saga.» linux-kernel (Mailing list). Archived from the original on 1 July 2019. Retrieved 3 February 2017. «So I’m writing some scripts to try to track things a whole lot faster.»
- ^ a b Torvalds, Linus (10 June 2007). «Re: fatal: serious inflate inconsistency». git (Mailing list).
- ^ a b c d Linus Torvalds (3 May 2007). Google tech talk: Linus Torvalds on git. Event occurs at 02:30. Archived from the original on 28 May 2007. Retrieved 16 May 2007.
- ^ «A Short History of Git». Pro Git (2nd ed.). Apress. 2014. Archived from the original on 25 December 2015. Retrieved 26 December 2015.
- ^ Chacon, Scott (24 December 2014). Pro Git (2nd ed.). New York, NY: Apress. pp. 29–30. ISBN 978-1-4842-0077-3. Archived from the original on 25 December 2015.
- ^ Brown, Zack (27 July 2018). «A Git Origin Story». Linux Journal. Linux Journal. Archived from the original on 13 April 2020. Retrieved 28 May 2020.
- ^ BitKeeper and Linux: The end of the road? Archived 8 June 2017 at the Wayback Machine
- ^ McAllister, Neil (2 May 2005). «Linus Torvalds’ BitKeeper blunder». InfoWorld. Archived from the original on 26 August 2015. Retrieved 8 September 2015.
- ^ a b Torvalds, Linus (27 February 2007). «Re: Trivia: When did git self-host?». git (Mailing list).
- ^ Torvalds, Linus (6 April 2005). «Kernel SCM saga.» linux-kernel (Mailing list).
- ^ Torvalds, Linus (17 April 2005). «First ever real kernel git merge!». git (Mailing list).
- ^ Mackall, Matt (29 April 2005). «Mercurial 0.4b vs git patchbomb benchmark». git (Mailing list).
- ^ Torvalds, Linus (17 June 2005). «Linux 2.6.12». git-commits-head (Mailing list).
- ^ Torvalds, Linus (27 July 2005). «Meet the new maintainer…» git (Mailing list).
- ^ Hamano, Junio C. (21 December 2005). «Announce: Git 1.0.0». git (Mailing list).
- ^ «GitFaq: Why the ‘Git’ name?». Git.or.cz. Archived from the original on 23 July 2012. Retrieved 14 July 2012.
- ^ «After controversy, Torvalds begins work on ‘git’«. PC World. 14 July 2012. Archived from the original on 1 February 2011.
Torvalds seemed aware that his decision to drop BitKeeper would also be controversial. When asked why he called the new software, ‘git’, British slang meaning ‘a rotten person’, he said. ‘I’m an egotistical bastard, so I name all my projects after myself. First Linux, now git.’
- ^ «git(1) Manual Page». Archived from the original on 21 June 2012. Retrieved 21 July 2012.
- ^ «Initial revision of ‘git’, the information manager from hell · git/git@e83c516». GitHub. Archived from the original on 8 October 2017. Retrieved 21 January 2016.
- ^ «Tags». GitHub. Archived from the original on 29 September 2021. Retrieved 28 January 2022.
- ^ «Highlights from Git 2.25». The GitHub Blog. 13 January 2020. Archived from the original on 22 March 2021. Retrieved 27 November 2020.
A sparse checkout is nothing more than a list of file path patterns that Git should attempt to populate in your working copy when checking out the contents of your repository. Effectively, it works like a .gitignore, except it acts on the contents of your working copy, rather than on your index.
- ^ «Highlights from Git 2.26». The GitHub Blog. 22 March 2020. Archived from the original on 22 March 2021. Retrieved 25 November 2020.
You may remember when Git introduced a new version of its network fetch protocol way back in 2018. That protocol is now used by default in 2.26, so let’s refresh ourselves on what that means. The biggest problem with the old protocol is that the server would immediately list all of the branches, tags, and other references in the repository before the client had a chance to send anything. For some repositories, this could mean sending megabytes of extra data, when the client really only wanted to know about the master branch. The new protocol starts with the client request and provides a way for the client to tell the server which references it’s interested in. Fetching a single branch will only ask about that branch, while most clones will only ask about branches and tags. This might seem like everything, but server repositories may store other references (such as the head of every pull request opened in the repository since its creation). Now, fetches from large repositories improve in speed, especially when the fetch itself is small, which makes the cost of the initial reference advertisement more expensive relatively speaking. And the best part is that you won’t need to do anything! Due to some clever design, any client that speaks the new protocol can work seamlessly with both old and new servers, falling back to the original protocol if the server doesn’t support it. The only reason for the delay between introducing the protocol and making it the default was to let early adopters discover any bugs.
- ^ «Highlights from Git 2.28». The GitHub Blog. 27 July 2020. Archived from the original on 22 March 2021. Retrieved 25 November 2020.
- ^ «Highlights from Git 2.29». The GitHub Blog. 19 October 2020. Archived from the original on 22 March 2021. Retrieved 25 November 2020.
- ^ «Git 2.30 Release Notes». Git Downloads. 27 December 2020. Archived from the original on 22 March 2021. Retrieved 27 December 2020.
- ^ «Git 2.31 Release Notes». Git Downloads. 3 April 2021. Retrieved 3 April 2021.
{{cite web}}: CS1 maint: url-status (link) - ^ «Highlights from Git 2.31». The GitHub Blog. 15 March 2021. Retrieved 2 July 2021.
- ^ «git/git». GitHub. Archived from the original on 8 February 2017. Retrieved 1 December 2011.
- ^ Hamano, Junio (21 November 2007). «How to maintain Git». GitHub. Archived from the original on 22 March 2021. Retrieved 1 August 2020.
- ^ Torvalds, Linus (5 May 2006). «Re: [ANNOUNCE] Git wiki». linux-kernel (Mailing list). «Some historical background» on Git’s predecessors
- ^ a b Torvalds, Linus (8 April 2005). «Re: Kernel SCM saga». linux-kernel (Mailing list). Archived from the original on 22 March 2021. Retrieved 20 February 2008.
- ^ a b Torvalds, Linus (23 March 2006). «Re: Errors GITtifying GCC and Binutils». git (Mailing list). Archived from the original on 22 March 2021. Retrieved 3 February 2017.
- ^ Torvalds, Linus (20 October 2006). «Re: VCS comparison table». git (Mailing list). Archived from the original on 22 March 2021. Retrieved 3 February 2017. A discussion of Git vs. BitKeeper.
- ^ «Git – A Short History of Git». git-scm.com. Archived from the original on 22 March 2021. Retrieved 15 June 2020.
- ^ «Git – Distributed Workflows». git-scm.com. Archived from the original on 22 October 2014. Retrieved 15 June 2020.
- ^ Gunjal, Siddhesh (19 July 2019). «What is Version Control Tool? Explore Git and GitHub». Medium. Retrieved 25 October 2020.
- ^ Torvalds, Linus (19 October 2006). «Re: VCS comparison table». git (Mailing list).
- ^ Jst’s Blog on Mozillazine «bzr/hg/git performance». Archived from the original on 29 May 2010. Retrieved 12 February 2015.
- ^ Dreier, Roland (13 November 2006). «Oh what a relief it is». Archived from the original on 16 January 2009., observing that «git log» is 100x faster than «svn log» because the latter must contact a remote server.
- ^ «Trust». Git Concepts. Git User’s Manual. 18 October 2006. Archived from the original on 22 February 2017.
- ^ Torvalds, Linus. «Re: VCS comparison table». git (Mailing list). Retrieved 10 April 2009., describing Git’s script-oriented design
- ^ iabervon (22 December 2005). «Git rocks!». Archived from the original on 14 September 2016., praising Git’s scriptability.
- ^ «Git – Git SCM Wiki». git.wiki.kernel.org. Retrieved 25 October 2020.
- ^ «Git User’s Manual». 10 March 2020. Archived from the original on 10 May 2020.
- ^ a b «Git – Packfiles». git-scm.com.
- ^ Torvalds, Linus (10 April 2005). «Re: more git updates.» linux-kernel (Mailing list).
- ^ Haible, Bruno (11 February 2007). «how to speed up ‘git log’?». git (Mailing list).
- ^ Torvalds, Linus (1 March 2006). «Re: impure renames / history tracking». git (Mailing list).
- ^ Hamano, Junio C. (24 March 2006). «Re: Errors GITtifying GCC and Binutils». git (Mailing list).
- ^ Hamano, Junio C. (23 March 2006). «Re: Errors GITtifying GCC and Binutils». git (Mailing list).
- ^ Torvalds, Linus (28 November 2006). «Re: git and bzr». git (Mailing list)., on using
git-blameto show code moved between source files. - ^ Torvalds, Linus (18 July 2007). «git-merge(1)». Archived from the original on 16 July 2016.
- ^ Torvalds, Linus (18 July 2007). «CrissCrossMerge». Archived from the original on 13 January 2006.
- ^ Torvalds, Linus (10 April 2005). «Re: more git updates…» linux-kernel (Mailing list).
- ^ «Git – Git Objects». git-scm.com.
- ^ Some of git internals
- ^ «Git – Git References». git-scm.com.
- ^ «Project Configuration File Format». Gerrit Code Review. Archived from the original on 3 December 2020. Retrieved 2 February 2020.
- ^ «downloads». Archived from the original on 8 May 2012. Retrieved 14 May 2012.
- ^ «git package versions – Repology». Archived from the original on 19 January 2022. Retrieved 30 November 2021.
- ^ «msysGit». GitHub. Archived from the original on 10 October 2016. Retrieved 20 September 2016.
- ^ «Git – Downloading Package». git-scm.com. (source code)
- ^ «JGit». Archived from the original on 31 August 2012. Retrieved 24 August 2012.
- ^ «Git – go-git». git-scm.com. Retrieved 19 April 2019.
- ^ «SQL interface to Git repositories, written in Go.», github.com, retrieved 19 April 2019
- ^ «Keybase launches encrypted git». keybase.io. Retrieved 19 April 2019.
- ^ «Dulwich». Archived from the original on 29 May 2012. Retrieved 27 August 2012.
- ^ «libgit2». GitHub. Archived from the original on 11 April 2016. Retrieved 24 August 2012.
- ^ «rugged». GitHub. Archived from the original on 24 July 2013. Retrieved 24 August 2012.
- ^ «pygit2». GitHub. Archived from the original on 5 August 2015. Retrieved 24 August 2012.
- ^ «hlibgit2». Archived from the original on 25 May 2013. Retrieved 30 April 2013.
- ^ «js-git: a JavaScript implementation of Git». GitHub. Archived from the original on 7 August 2013. Retrieved 13 August 2013.
- ^ «Git – Git Daemon». git-scm.com. Retrieved 10 July 2019.
- ^ 4.4 Git on the Server – Setting Up the Server Archived 22 October 2014 at the Wayback Machine, Pro Git.
- ^ «1.4 Getting Started – Installing Git». git-scm.com. Archived from the original on 2 November 2013. Retrieved 1 November 2013.
- ^ Chacon, Scott; Straub, Ben (2014). «Git on the Server – Setting Up the Server». Pro Git (2nd ed.). Apress. ISBN 978-1484200773.
- ^ Diffusion User Guide: Repository Hosting Archived 20 September 2020 at the Wayback Machine.
- ^ «Gitolite: Hosting Git Repositories».
- ^ «Gogs: A painless self-hosted Git service».
- ^ Krill, Paul (28 September 2016). «Enterprise repo wars: GitHub vs. GitLab vs. Bitbucket». InfoWorld. Retrieved 2 February 2020.
- ^ «github.com Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 31 March 2013. Retrieved 2 February 2020.
- ^ «sourceforge.net Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 20 October 2020. Retrieved 2 February 2020.
- ^ «bitbucket.org Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 23 June 2017. Retrieved 2 February 2020.
- ^ «gitlab.com Competitive Analysis, Marketing Mix and Traffic». Alexa. Archived from the original on 30 November 2017. Retrieved 2 February 2020.
- ^ «Eclipse Community Survey 2014 results | Ian Skerrett». Ianskerrett.wordpress.com. 23 June 2014. Archived from the original on 25 June 2014. Retrieved 23 June 2014.
- ^ «Results of Eclipse Community Survey 2012». eclipse.org. Archived from the original on 11 April 2016.
- ^ «Compare Repositories – Open Hub». Archived from the original on 7 September 2014.
- ^ «Stack Overflow Annual Developer Survey». Stack Exchange, Inc. Retrieved 9 January 2020.
Stack Overflow’s annual Developer Survey is the largest and most comprehensive survey of people who code around the world. Each year, we field a survey covering everything from developers’ favorite technologies to their job preferences. This year marks the ninth year we’ve published our annual Developer Survey results, and nearly 90,000 developers took the 20-minute survey earlier this year.
- ^ «Stack Overflow Developer Survey 2015». Stack Overflow. Archived from the original on 4 May 2019. Retrieved 29 May 2019.
- ^ «Stack Overflow Developer Survey 2017». Stack Overflow. Archived from the original on 29 May 2019. Retrieved 29 May 2019.
- ^ «Stack Overflow Developer Survey 2018». Stack Overflow. Archived from the original on 30 May 2019. Retrieved 29 May 2019.
- ^ «Stack Overflow Developer Survey 2022». Stack Overflow. Retrieved 4 August 2022.
- ^ «Git (software) Jobs, Average Salary for Git Distributed Version Control System Skills». Itjobswatch.co.uk. Archived from the original on 8 October 2016. Retrieved 30 September 2016.
- ^ «Team Foundation Server Jobs, Average Salary for Microsoft Team Foundation Server (TFS) Skills». Itjobswatch.co.uk. Archived from the original on 29 October 2016. Retrieved 30 September 2016.
- ^ «Subversion Jobs, Average Salary for Apache Subversion (SVN) Skills». Itjobswatch.co.uk. Archived from the original on 25 October 2016. Retrieved 30 September 2016.
- ^ «Mercurial Jobs, Average Salary for Mercurial Skills». Itjobswatch.co.uk. Archived from the original on 23 September 2016. Retrieved 30 September 2016.
- ^ «VSS/SourceSafe Jobs, Average Salary for Microsoft Visual SourceSafe (VSS) Skills». Itjobswatch.co.uk. Archived from the original on 29 October 2016. Retrieved 30 September 2016.
- ^ «Windows switch to Git almost complete: 8,500 commits and 1,760 builds each day». Ars Technica. 24 May 2017. Archived from the original on 24 May 2017. Retrieved 24 May 2017.
- ^ «git-init». Git. Archived from the original on 15 March 2022.
- ^ «Git – Branches in a Nutshell». git-scm.com. Archived from the original on 20 December 2020. Retrieved 15 June 2020.
The «master» branch in Git is not a special branch. It is exactly like any other branch. The only reason nearly every repository has one is that the git init command creates it by default and most people don’t bother to change it.
- ^ github/renaming, GitHub, 4 December 2020, retrieved 4 December 2020
- ^ Default branch name for new repositories now main, GitLab, 22 June 2021, retrieved 22 June 2021
- ^ «Git Revert | Atlassian Git Tutorial». Atlassian.
Reverting has two important advantages over resetting. First, it doesn’t change the project history, which makes it a «safe» operation for commits that have already been published to a shared repository.
- ^ «Gitflow Workflow | Atlassian Git Tutorial». Atlassian. Retrieved 15 June 2020.
- ^ «Forking Workflow | Atlassian Git Tutorial». Atlassian. Retrieved 15 June 2020.
- ^ «Git repository access control». Archived from the original on 14 September 2016. Retrieved 6 September 2016.
- ^ Pettersen, Tim (20 December 2014). «Securing your Git server against CVE-2014-9390». Archived from the original on 24 December 2014. Retrieved 22 December 2014.
- ^ Hamano, J. C. (18 December 2014). «[Announce] Git v2.2.1 (and updates to older maintenance tracks)». Newsgroup: gmane.linux.kernel. Archived from the original on 19 December 2014. Retrieved 22 December 2014.
- ^ «CVE-2015-7545». 15 December 2015. Archived from the original on 26 December 2015. Retrieved 26 December 2015.
- ^ «Git 2.6.1». GitHub. 29 September 2015. Archived from the original on 11 April 2016. Retrieved 26 December 2015.
- ^ a b c Blake Burkhart; et al. (5 October 2015). «Re: CVE Request: git». Archived from the original on 27 December 2015. Retrieved 26 December 2015.
- ^ «hash – How safe are signed git tags? Only as safe as SHA-1 or somehow safer?». Information Security Stack Exchange. 22 September 2014. Archived from the original on 24 June 2016.
- ^ «Why does Git use a cryptographic hash function?». Stack Overflow. 1 March 2015. Archived from the original on 1 July 2016.
- ^ «Git – hash-function-transition Documentation». git-scm.com.
External links[edit]
![]()
Wikimedia Commons has media related to Git.
![]()
Wikibooks has a book on the topic of: Git
- Official website
- Git at Open Hub