Problem
You attempt to use the Exchange Admin Center (EAC) to activate a mailbox database in a DAG cluster but noticed that one of the nodes fails with the error:
Mailbox G to L
An Active Manager operation failed. Error: The database action failed. Error: An error occurred while trying to validate the specified database copy for possible activation. Error:
exchdr01:
Server ‘exchdr01.contoso.com’ is not up according to the Windows Failover Cluster service.
[Database: Mailbox G to L, Server: exchprod01.contoso.com]
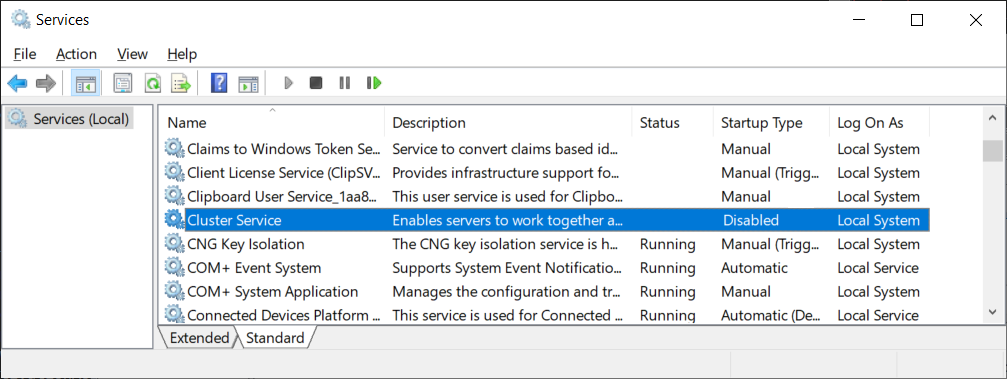
You log onto the server exhibiting this problem and notice that the services console indicate the Cluster Service is Disabled and not started.
Solution
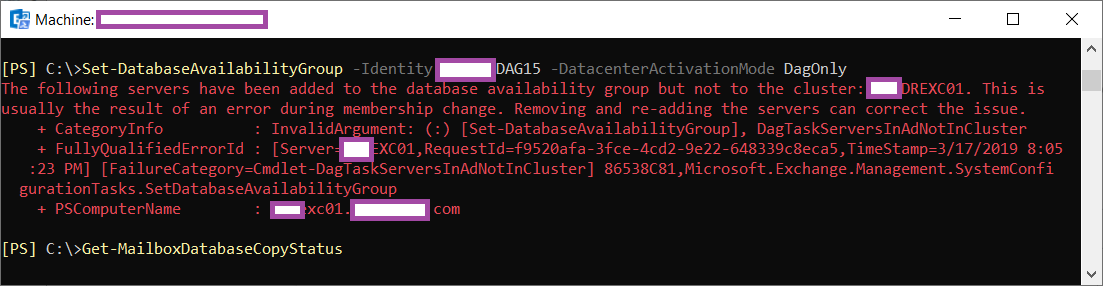
This error through me off for a bit of time as the node was added to the cluster for a few days and the process did not throw any errors. It was not until I decided to make modifications to the DAG configuration when I received the following error message that made me realize the node wasn’t added to the DAG properly:
[PS] C:>Set-DatabaseAvailabilityGroup -Identity DAG15 -DatacenterActivationMode DagOnly
The following servers have been added to the database availability group but not to the cluster: drexch01. This is
usually the result of an error during membership change. Removing and re-adding the servers can correct the issue.
+ CategoryInfo : InvalidArgument: (:) [Set-DatabaseAvailabilityGroup], DagTaskServersInAdNotInCluster
+ FullyQualifiedErrorId : [Server=exchprod01,RequestId=f9520afa-3fce-4cd2-9e22-648339c8eca5,TimeStamp=3/17/2019 8:05
:23 PM] [FailureCategory=Cmdlet-DagTaskServersInAdNotInCluster] 86538C81,Microsoft.Exchange.Management.SystemConfi
gurationTasks.SetDatabaseAvailabilityGroup
+ PSComputerName : exchprod01.contoso.com
[PS] C:>
Simply removing the mailbox database copies on the problematic node, remove the node from the DAG and re-adding it corrected the problem of the cluster service as well as database activation.
- Remove From My Forums
-
Question
-
I have two Exchange 2010 Servers. Each runs the CAS, Hub and Database Roles. I have one server set as the primary. The second server is in a remote office. Whenever the backup runs on the Primary server the Active Database switches to the secondary
Exchange server. I’ve been unable to figure out what this keeps happening or a way of preventing it. I’d like to disable the database from automatically going active on the second server. Does anyone know of a way to do that?
Answers
-
-
Marked as answer by
Sunday, February 26, 2012 4:07 PM
-
Marked as answer by
I’ve been banging my head against the wall a bit here on an issue.
I have a set of Exchange 2019 servers I’m trying to add to a DAG of existing Exchange 2019 servers.
They’re split in to two sites within AD, and they’re also physically in two locations.
There’s a firewall in between them, but we’ve opened up all the ports for this to work properly. That we can tell, based on hits on the firewall.
The issue is that when we use the ECP to add a server at the second site in to the DAG, the UI says it worked just fine, but when you go to the server itself, it’s all failed.
The Cluster Service service installs, but is disabled and fails to start.
Test-replication health shows:
Server Check Result Error
<Redacted> ReplayService Passed <Redacted> ActiveManager FAILED Active Manager is in an unknown state on server ‘<Redacted>’. Basic database administrative operations such as mounting or dismounting and the ability to have failovers or switchovers is not available. Review the event logs for more details. Error: Unable to access cluster root key (Error: An error occurred while attempting a cluster operation. Error: Cluster API failed: «OpenCluster(null) failed with 0x6d9. Error: There are no more endpoints available from the endpoint mapper»)
<Redacted> TasksRpcListener Passed <Redacted> TcpListener Passed <Redacted> ServerLocatorService Passed <Redacted> DatabaseRedundancy FAILED There were database redundancy check failures for database ‘<Redacted>’ that may be lowering its redundancy and putting the database at risk of data loss. Redundancy Count: 0. Expected Redundancy Count: 2. Detailed error(s):
<Redacted>:
The active database copy '<Redacted>' is dismounted with an error that would
prevent it from mounting. Error: Failed to determine the mount status of the active database copy.
<Redacted> DatabaseAvailability FAILED Failures: There were database availability check failures for database ‘<Redacted>’ that may be lowering its availability. Availability Count: 0. Expected Availability Count: 2. Detailed error(s):
<Redacted>:
Server '<Redacted>' is not up according to the Windows Failover Cluster service.
There were database availability check failures for database '<Redacted>' that may be lowering its availability.
Availability Count: 1. Expected Availability Count: 2. Detailed error(s):
<Redacted>:
Server '<Redacted>' is not up according to the Windows Failover Cluster service.
<Redacted>:
Server '<Redacted>' is not up according to the Windows Failover Cluster service.
<Redacted> DBCopySuspended Passed <Redacted> DBCopyFailed Passed <Redacted> DBInitializing Passed <Redacted> DBDisconnected Passed <Redacted> DBLogCopyKeepingUp Passed <Redacted> DBLogReplayKeepingUp PassedServer Check Result Error
<Redacted> ReplayService Passed <Redacted> ActiveManager FAILED Active Manager is in an unknown state on server ‘<Redacted>’. Basic database administrative operations such as mounting or dismounting and the ability to have failovers or switchovers is not available. Review the event logs for more details. Error: Unable to access cluster root key (Error: An error occurred while attempting a cluster operation. Error: Cluster API failed: «OpenCluster(null) failed with 0x6d9. Error: There are no more endpoints available from the endpoint mapper»)
<Redacted> TasksRpcListener Passed <Redacted> TcpListener Passed <Redacted> ServerLocatorService Passed <Redacted> DatabaseRedundancy FAILED There were database redundancy check failures for database ‘<Redacted>’ that may be lowering its redundancy and putting the database at risk of data loss. Redundancy Count: 0. Expected Redundancy Count: 2. Detailed error(s):
<Redacted>:
The active database copy '<Redacted>' is dismounted with an error that would
prevent it from mounting. Error: Failed to determine the mount status of the active database copy.
<Redacted> DatabaseAvailability FAILED Failures: There were database availability check failures for database ‘<Redacted>’ that may be lowering its availability. Availability Count: 0. Expected Availability Count: 2. Detailed error(s):
<Redacted>:
Server '<Redacted>' is not up according to the Windows Failover Cluster service.
There were database availability check failures for database '<Redacted>' that may be lowering its availability.
Availability Count: 1. Expected Availability Count: 2. Detailed error(s):
<Redacted>:
Server '<Redacted>' is not up according to the Windows Failover Cluster service.
<Redacted>:
Server '<Redacted>' is not up according to the Windows Failover Cluster service.
<Redacted> DBCopySuspended Passed <Redacted> DBCopyFailed Passed <Redacted> DBInitializing Passed <Redacted> DBDisconnected Passed <Redacted> DBLogCopyKeepingUp Passed <Redacted> DBLogReplayKeepingUp Passed
On a functioning server I can do get-clusternode and it shows the existing servers in the DAG, and going get-databaseavailabilitygroup shows the misbehaving servers in the DAG.
So, for all intents and purposes, it should be working, but it’s failing.
Google shows other folks with a simlar issue, but no solutions.
Today on my own companies network 4Logic IT Solutions we had an issue when trying to activate a database copy inside a database availability group (DAG) cluster.
When attempting to move the active mailbox database to another node using Exchange Management Console (EMC) or Exchange Management Shell (EMS) the following error was experianced.
———————————————————
Microsoft Exchange Error
———————————————————
Cannot activate database copy ‘Activate Database Copy…’.
Activate Database Copy…
Failed
Error:
An Active Manager operation failed. Error The database action failed. Error: An error occurred while trying to validate the specified database copy for possible activation. Error: Server ‘QV1-EXC1.4logic.lan’ is not up according to the Windows Failover Cluster service.. [Database: QV1-EXC1-Database-01, Server: OP-SRV1.4logic.lan]
An Active Manager operation failed. Error An error occurred while trying to validate the specified database copy for possible activation. Error: Server ‘QV1-EXC1.4logic.lan’ is not up according to the Windows Failover Cluster service.

The error stated that Windows cluster services reported the node as being down. So I fired up Failover Cluster Management MMC snapin to investigate further. The following errors were being generated:
File share witness resource ‘File Share Witness (\qv1-utl1.4logic.lanDAG01.4logic.lan)’ failed to arbitrate for the file share ‘\qv1-utl1.4logic.lanDAG01.4logic.lan’. Please ensure that file share ‘\qv1-utl1.4logic.lanDAG01.4logic.lan’ exists and is accessible by the cluster.

Node ‘QV1-EXC1’ failed to form a cluster. This was because the witness was not accessible. Please ensure that the witness resource is online and available.

I went over to my server hosting the File Witness Share QV1-UTL1.4logic.lan. DAG01$ was the only trusted object added to the Share permissions. I added Exchange Trusted Subsystem and my Administrator account (for testing purposes) to the Share Permissions.

I then restarted the Cluster Services service on QV1-EXC1. After the permission change the cluster service came online again.

Problem: After a server reboot an Exchange DAG member is down, the Cluster Service Fails to start.
Unable to start the cluster service it terminates with the Event ID 7024
«The Cluster Service terminated with service-specific error cannot create a file when that file already exists.»
Error Messages in Event Log:
Service Control Manager Event ID 7001
The Cluster Service service depends on the Csv File System Driver service which failed to start because of the following error:
The system cannot find the file specified.
Service Control Manager Event ID 7000
The Csv File System Driver service failed to start due to the following error:
The system cannot find the file specified.
MSExchangeRepl Event ID 4113
Database redundancy health check failed.
Database copy: DB_NAME
Redundancy count: 1
Error: Passive copy ‘DB_NAMEEXCH_SERVER’ is not UP according to clustering.
MSExchangeRepl Event ID 2060
The Microsoft Exchange Replication service encountered a transient error while attempting to start a replication instance for DB_NAMEEXCH_SERVER. The copy will be set to failed. Error: The NetworkManager has not yet been initialized. Check the event logs to determine the cause.
Solution:
Check Device Manager and the Microsoft Failover Cluster Virtual Adapter has a yellow exclamation mark (this is netft.sys)
“This device is not working properly because Windows cannot load the drivers required for this device. (Code 31)”
Need to remove the «Microsoft Failover Cluster Virtual Adapter» and reinstall it using the following steps:
1. From Device Manager/Network adapters, click on View—>Show hidden devices and then uninstall «Microsoft Failover Cluster Virtual Adapter»
2. Reboot the server for changes to take effect
3. After reboot Open Device Manager/Network adapters
4. From Action Menu Select “Add Legacy Hardware” and then click Next
5. Select “Install the Hardware that I manually selected from a list (Advanced)” and click Next
6. Select “Network Adapters” and then click Next
7. Select “Microsoft” From the left pane and select “Microsoft Failover Cluster Virtual Adapter” from the right list
8. Once the Adapter is added successfully you be able to start the cluster service successfully and let the DAG sync up the queue log files.
NOTE: If you reboot your server and issue comes back follow the same steps but disable IPv6 on the network adapters since it is not required when Exchange is not on a Domain Controller.
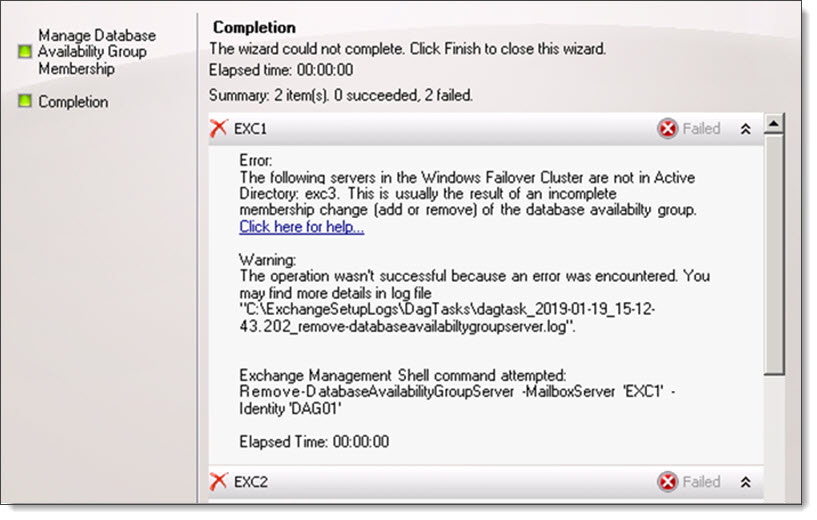
The following servers in the Windows Failover Cluster are not in Active Directory: <server name>. This is usually the result of an incomplete membership change (add or remove) of the database availability group.
I ran into this error recently while trying to remove two Exchange 2010 members from a database availability group (DAG).
The error stated that a member of the DAG, a server named EXC3, did not exist in Active Directory. This was odd because queries to the Exchange 2010 management tools only returned two Exchange servers–EXC1 and EXC2.
We further confirmed that there was no computer account for EXC3 in Active Directory Users and Computers. We did, however, see remanents of EXC3 in ADSI Edit.
Talking with our customer we discovered that there had been a third Exchange server, named EXC3, that had crashed and was never recovered.
To verify the status of all nodes in your database availability group, open PowerShell and import the Windows Failover Clustering cmdlets with Import-Module.
C:> Import-Module FailoverClusters
Next, run the Get-ClusterNode cmdlet. This will retrieve the status of all our nodes.
C:> Get-ClusterNodeName State
---- -----
EXC1 Up
EXC2 Up
EXC3 Down
In the example above, we can see EXC1 and EXC2 are operational, whereas EXC3 is offline.
Because EXC3 no longer exists (and the fact we plan to collapse the entire DAG anyway) we can forcibly evict the failed node. To do this issue the following command.
C:> Get-ClusterNode -Name "EXC3" | Remove-ClusterNodeRemove-ClusterNode
Are you sure you want to evict node EXC3
[Y] Yes [N] No [S] Suspend [?] Help (default is "Y"): Y
You will be prompted to confirm. Press enter to accept the default action of “Yes”.
If we repeat the first Get-ClusterNode command we will only have the two operation cluster nodes remaining.
C:> Get-ClusterNodeName State
---- -----
EXC1 Up
EXC2 Up
With no more failed nodes we can remove the two operational nodes using either the Exchange 2010 management console or PowerShell.

Have you run into this error while add or remove members to a DAG? What did you do to fix it? Drop a comment below or join the conversation on Twitter


Gareth is an Microsoft MVP specializing in Exchange and Office 365. Gareth also contributes to the Office 365 for IT Pros book, which is updated monthly with new content. Find Gareth on LinkedIn, Twitter, or, Facebook.
Reader Interactions
| title | description | ms.date | author | ms.author | ms.topic |
|---|---|---|---|---|---|
|
Troubleshooting cluster issue with Event ID 1135 |
Describes how to troubleshoot the Cluster Service Startup issue with Event ID 1135. |
10/21/2021 |
Deland-Han |
delhan |
troubleshooting |
Troubleshooting cluster issue with Event ID 1135
Applies to: Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, versions 21H2 and 20H2
[!div class=»nextstepaction»]
Try our Virtual Agent — It can help you quickly identify and fix common Active Directory replication issues.
This article helps you diagnose and resolve Event ID 1135, which may be logged during the startup of the Cluster service in Failover Clustering environment.
Start Page
Event ID 1135 indicates that one or more Cluster nodes were removed from the active failover cluster membership. It may be accompanied by the following symptoms:
- Cluster Failovernodes being removed from active Failover Cluster membership:
Having a problem with nodes being removed from active Failover Cluster membership - Event ID 1069
Event ID 1069 — Clustered Service or Application Availability - Event ID 1177 for Quorum loss
Event ID 1177 — Quorum and Connectivity Needed for Quorum - Event ID 1006 for Cluster service halted:
Event ID 1006 — Cluster Service Startup
A validation and the network tests would be recommended as one of the initial troubleshooting steps to ensure there are no configuration issues that might be a cause for problems.
Check if installed the recommended hot fixes
The Cluster service is the essential software component that controls all aspects of failover cluster operation and manages the cluster configuration database. If you see the event ID 1135, Microsoft recommends you to install the fixes mentioned in the below KB articles and reboot all the nodes of the cluster, then observe if issue reoccurs.
- Hotfix for Windows Server 2012 R2
- Hotfix for Windows Server 2012
- Hotfix for Windows Server 2008 R2
Check if the cluster service running on all the nodes
Follow the following command according to your Windows operation system to validate that cluster service is continuously running and available.
For Windows Server 2008 R2 cluster
From an elevated cmd prompt, run: cluster.exe node /stat
For Windows Server 2012 and Windows Server 2012 R2 cluster
Run the following PowerShell command: Get-ClusterResource
Is the cluster service continuously running and available on all the nodes?
Several scenarios of Event ID 1135
We want you to take a closer look on at the System Event logs on all the nodes of your cluster. Review the Event ID 1135 that you are seeing on the nodes and copy all the instances of this event. This will make it convenient for you to look at them and review.
Event ID 1135 Cluster node ' **NODE A** ' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
There are three typical scenarios:
Scenario A
You are looking at all the Events and all the nodes in the cluster are indicating that NODE A had lost communication.


It could be possible that when you are seeing the system logs on NODE A, it has events for all the remaining nodes in the cluster.
Solution
This quite suggests that at the time of issue, either due to network congestion or otherwise the communication to the NODE A was lost.
You should review and validate the Network configuration and communication issues. Remember to look for issues pertaining to Node A.
Scenario B
You are looking at the Events on the nodes and let us say that your cluster is dispersed across two sites. NODE A, NODE B, and NODE C at Site 1 and NODE D & NODE E at Site 2.

On Nodes A,B, and C, you see that the events that are logged are for connectivity to Nodes D & E. Similarly, when you see the events on Nodes D & E, the events suggest that we lost communication with A, B, and C.

Solution
If you see similar activity, it is indicative that there was a communication failure, over the link that connects these sites. We would recommend that you review the connection across the sites, if this is over a WAN connection, we would suggest that you verify with your ISP about the connectivity.
Scenario C
You are looking at the Events on the nodes and you see that the names of the nodes do not tally out with any particular pattern. Let us say that your cluster is dispersed across two sites. NODE A, NODE B and NODE C at Site 1 and NODE D & NODE E at Site 2.
- On Node A: You see events for Nodes B, D, E.
- On Node B: You see events for Nodes C, D, E.
- On Node C: You see events for Nodes A, B, E.
- On Node D: You see events for Nodes A, C, E.
- On Node E: You see events for Nodes B, C, D.
- Or any other combinations.

Solution
Such events are possible when the network channels between the nodes are choked and the cluster communication messages are not reaching in a timely manner, making the cluster to feel that the communication between the nodes is lost resulting in the removal of nodes from the cluster membership.
Review Cluster Networks
We would recommend that you review your Cluster Networks by checking the following three options one by one to continue this troubleshooting guide.
Check for Antivirus Exclusion
Exclude the following file system locations from virus scanning on a server that is running Cluster Services:
-
The path of the FileShare Witness
-
The %Systemroot%Cluster folder
Configure the real-time scanning component within your antivirus software to exclude the following directories and files:
-
Default virtual machine configuration directory (C:ProgramDataMicrosoftWindowsHyper-V)
-
Custom virtual machine configuration directories
-
Default virtual hard disk drive directory (C:UsersPublicDocumentsHyper-VVirtual Hard Disks)
-
Custom virtual hard disk drive directories
-
Custom replication data directories, if you are using Hyper-V Replica
-
Snapshot directories
-
mms.exe
[!NOTE]
This file may have to be configured as a process exclusion within the antivirus software. -
Vmwp.exe
[!NOTE]
This file may have to be configured as a process exclusion within the antivirus software.
Additionally, when you use Live Migration together with Cluster Shared Volumes, exclude the CSV path C:Clusterstorage and all its subdirectories. If you are troubleshooting failover issues or general problems with Cluster services and antivirus software is installed, temporarily uninstall the antivirus software or check with the manufacturer of the software to determine whether the antivirus software works with Cluster services. Just disabling the antivirus software is insufficient in most cases. Even if you disable the antivirus software, the filter driver is still loaded when you restart the computer.
Check for Network Port Configuration in Firewall
The Cluster service controls server cluster operations and manages the cluster database. A cluster is a collection of independent computers that act as a single computer. Managers, programmers, and users see the cluster as a single system. The software distributes data among the nodes of the cluster. If a node fails, other nodes provide the services and data that were formerly provided by the missing node. When a node is added or repaired, the cluster software migrates some data to that node.
System service name: ClusSvc
| Application | Protocol | Ports |
|---|---|---|
| Cluster Service | UDP | 3343 |
| Cluster Service | TCP | 3343 (This port is required during a node join operation.) |
| RPC | TCP | 135 |
| Cluster Admin | UDP | 137 |
| Kerberos | UDP/TCP | 464* |
| SMB | TCP | 445 |
| Randomly allocated high UDP ports** | UDP | Random port number between 1024 and 65535 Random port number between 49152 and 65535*** |
[!NOTE]
Additionally, for successful validation on Windows Failover Clusters on Windows Server 2008 and above, allow inbound and outbound traffic for ICMP4, ICMP6.
-
For more information, see Creating a Windows Server 2012 Failover Cluster Fails with Error 0xc000005e.
-
For more information about how to customize these ports, see Service overview and network port requirements for Windows in the «References» section.
This is the range in Windows Server 2012, Windows 8, Windows Server 2008 R2, Windows 7, Windows Server 2008, and Windows Vista.
Besides, run the following command to check for Network Port Configuration in Firewall. For example: This command helps determine port 3343 availableopen used for Failover Cluster:
netsh advfirewall firewall show rule name="Failover Clusters (UDP-In)" verbose
Run the Cluster Validation report for any errors or warnings
The cluster validation tool runs a suite of tests to verify that your hardware and settings are compatible with failover clustering.
Follow these instructions:
-
Run the Cluster Validation report for any errors or warnings. For more information, see Understanding Cluster Validation Tests: Network

-
Verify for warnings and errors for Networks. For more information, see Understanding Cluster Validation Tests: Network.



Check the List Network Binding Order
This test lists the order in which networks are bound to the adapters on each node.
The Adapters and Bindings tab lists the connections in the order in which the connections are accessed by network services. The order of these connections reflects the order in which generic TCP/IP calls/packets are sent on to the wire.
Follow the below steps to change the binding order of network adapters:
-
Click Start, click Run, type
ncpa.cpl, and then click OK. You can see the available connections in the LAN and High-Speed Internet section of the Network Connections window. -
On the Advanced menu, click Advanced Settings, and then click the Adapters and Bindings tab.
-
In the Connections area, select the connection that you want to move higher in the list. Use the arrow buttons to move the connection. As a general rule, the card that talks to the network (domain connectivity, routing to other networks, etc. should be the first bound (top of the list) card.
Cluster nodes are multi-homed systems. Network priority affects DNS Client for outbound network connectivity. Network adapters used for client communication should be at the top in the binding order. Non-routed networks can be placed at lower priority. In Windows Server 2012 and Windows Server2012 R2, the Cluster Network Driver (NETFT.SYS) adapter is automatically placed at the bottom in the binding order list.
Check the Validate Network Communication
Latency on your network could also cause this to happen. The packets may not be lost between the nodes, but they may not get to the nodes fast enough before the timeout period expires.
This test validates that tested servers can communicate with acceptable latency on all networks.
For example: Under Validate Network Communication, you may see the following messages for network latency issues:
Succeeded in pinging network interface node003.contoso.com IP Address 192.168.0.2 from network interface node004.contoso.com IP Address 192.168.0.3 with maximum delay 500 after 1 attempt(s). Either address 10.0.0.96 is not reachable from 192.168.0.2 or **the ping latency is greater than the maximum allowed 2000 ms** This may be expected, since network interfaces node003.contoso.com - Heartbeat Network and node004.contoso.com - Production Network are on different cluster networks Either address 192.168.0.2 is not reachable from 10.0.0.96 or **the ping latency is greater than the maximum allowed 2000 ms** This may be expected, since network interfaces node004.contoso.com - Production Network and node003.contoso.com - Heartbeat Network for MSCS are on different cluster networks
For multi-site cluster, you may increase the time-out values. For more information, see Configure Heartbeat and DNS Settings in a Multi-Site Failover Cluster.
Check with ISP for any WAN connectivity issues.
Check if you encounter any of the following issues.
Network packets lost between nodes
-
Check Packet loss using Performance
If the packet is lost on the wire somewhere between the nodes, then the heartbeats will fail. We can easily find out if this is a problem by using Performance Monitor to look at the «Network InterfacePackets Received Discarded» counter. Once you have added this counter, look at the Average, Minimum, and Maximum numbers and if they are any value higher than zero, then the receive buffer needs to be adjusted up for the adapter.
If you are experiencing network packet lost on VMware virtualization platform, see the «Cluster installed in the VMware virtualization platform» section.
-
Upgrade the NIC drivers
This issue can occurs due to outdated NIC driversIntegration Components (IC)VmTools or faulty NIC adapters.
If there are network packets lost between nodes on Physical machines, please have your network adapter driver updates. Old or out-of-date network card drivers and/or firmware.
At times, a simple misconfiguration of the network card or switch can also cause loss of heartbeats.

Cluster installed in the VMware virtualization platform
Verify VMware adapter issues in case of VMware environment.
This issue may occur if the packets are dropped during high traffic bursts. Ensure that there is no traffic filtering occurring (for example, with a mail filter). After eliminating this possibility, gradually increase the number of buffers in the guest operating system and verify.
To reduce burst traffic drops, follow these steps:
- Open Run box by using Windows Key + R.
- Type
devmgmt.mscand press Enter. - Expand Network adapters
- Right-click vmxnet3 and click Properties.
- Click the Advanced tab.
- Click Small Rx Buffers and increase the value. The default value is 512 and the maximum is 8192.
- Click Rx Ring #1 Size and increase the value. The default value is 1024 and the maximum is 4096.
Check the following URLs to verify VMware adapter issues in case of VMware environment:
-
Nodes being removed from Failover Cluster membership on VMware ESX?.
-
Large packet loss at the guest operating system level on the VMXNET3 vNIC in ESXi
Notice any Network congestion
Network congestion can also cause network connectivity issues.
Verify your network is configured as per MS and vendor recommendations, see Configuring Windows Failover Cluster Networks.
Check the network configuration
If it still does not work, please check if you have seen partitioned network in cluster GUI or you have NIC teaming enabled on the heartbeat NIC.
If you see partitioned network in cluster GUI, see «Partitioned» Cluster Networks to troubleshoot the issue.
If you have NIC teaming enabled on the heartbeat NIC, check Teaming software functionality as per teaming vendor’s recommendation.
Upgrade the NIC drivers
This issue can occurs due to outdated NIC drivers or faulty NIC adapters.
If there are network packets lost between nodes on Physical machines, have your network adapter driver updates. Old or out-of-date network card drivers and/or firmware.
At times, a simple misconfiguration of the network card or switch can also cause loss of heartbeats.
Check the network configuration
If it still does not work, check whether you have seen partitioned network in cluster GUI or you have NIC teaming enabled on the heartbeat NIC.
Unable to Remove Failed Server from DAG in Exchange Server 2010
When an Exchange Server 2010 Mailbox server that is a member of a Database Availability Group has failed, part of the recovery process is to remove it from DAG membership.
In some scenarios this process may result in an error “A quorum of cluster nodes was not present to form a cluster“. The full error text is below.
[PS] C:>Remove-DatabaseAvailabilityGroupServer -Identity DAG -MailboxServer EX2
Confirm
Are you sure you want to perform this action?
Removing Mailbox server "EX2" from database availability group "dag".
[Y] Yes [A] Yes to All [N] No [L] No to All [?] Help (default is "Y"): y
WARNING: The operation wasn't successful because an error was encountered. You may find more details in log file
"C:ExchangeSetupLogsDagTasksdagtask_2010-11-25_03-48-09.814_remove-databaseavailabiltygroupserver.log".
There was a problem changing the quorum model for database availability group dag. Error: An Active Manager operation f
ailed. Error: An error occurred while attempting a cluster operation. Error: Cluster API '"SetClusterQuorumResource() f
ailed with 0x1725. Error: A quorum of cluster nodes was not present to form a cluster"' failed..
+ CategoryInfo : InvalidArgument: (:) [Remove-DatabaseAvailabilityGroupServer], DagTaskProblemChangingQuo
rumException
+ FullyQualifiedErrorId : 80D96894,Microsoft.Exchange.Management.SystemConfigurationTasks.RemoveDatabaseAvailabili
tyGroupServer
To resolve this issue use the -ConfigurationOnly switch instead to remove the failed Mailbox server from the Exchange 2010 DAG. In this example server EX2 is being removed.
[PS] C:>Remove-DatabaseAvailabilityGroupServer -Identity DAG -MailboxServer EX2 -ConfigurationOnly
Next, evict the failed node from the Windows Failover Cluster.
Note: you need to import the Failover Cluster module into your Exchange Management Shell session to perform this task.
[PS] C:>Import-Module FailoverClusters [PS] C:>Get-ClusterNode EX2 | Remove-ClusterNode -Force
The failed server has now been removed from the Exchange 2010 DAG and the Windows Failover Cluster.
[adrotate banner=”49″]
About the Author
Paul is a former Microsoft MVP for Office Apps and Services. He works as a consultant, writer, and trainer specializing in Office 365 and Exchange Server. Paul no longer writes for Practical365.com.