 Дедупликация Windows — отличная технология, которая позволяет гораздо более оптимально использовать дисковое пространство и существенно сократить затраты на хранение данных. Но существуют сценарии, при которых использование дедупликации является нежелательным, например, хранилище виртуальных машин и в случае вынужденного включения дедупликации на таких томах, от нее следует отказаться при первой возможности. Однако этот процесс имеет свои особенности, которые мы подробно разберем в данной статье.
Дедупликация Windows — отличная технология, которая позволяет гораздо более оптимально использовать дисковое пространство и существенно сократить затраты на хранение данных. Но существуют сценарии, при которых использование дедупликации является нежелательным, например, хранилище виртуальных машин и в случае вынужденного включения дедупликации на таких томах, от нее следует отказаться при первой возможности. Однако этот процесс имеет свои особенности, которые мы подробно разберем в данной статье.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Вопреки традициям начнем с короткого практического вступления. После апгрейда дисковой подсистемы в нашей виртуальной лаборатории мы решили отключить дедупликацию и восстановить дедуплицированные данные. Общий объем данных на томе составлял 2,9 ТБ, в сжатом виде он занимал 1,2 ТБ, а емкость дискового массива равнялась 3,63 ТБ. Вроде бы все в порядке и проблем возникнуть не должно, места для восстановленных данных хватает с запасом. Ну тогда запускаем!
Через какое-то время мы с некоторым удивлением наблюдали следующую картину:
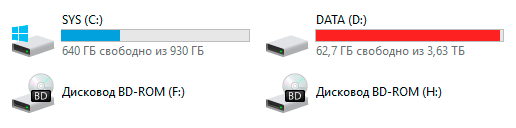 Первая мысль — что вообще происходит?! Как такое может быть?! Некоторые, слабые духом администраторы могут в такой момент удариться в панику и начать предпринимать необдуманные действия, последствия которых могут быть самыми разными по силе деструктивного воздействия.
Первая мысль — что вообще происходит?! Как такое может быть?! Некоторые, слабые духом администраторы могут в такой момент удариться в панику и начать предпринимать необдуманные действия, последствия которых могут быть самыми разными по силе деструктивного воздействия.
Но не будем спешить, а прежде всего разберемся в сути происходящих процессов. Начнем с дедупликации, что происходит во время оптимизации данных? Давайте посмотрим на схему ниже:
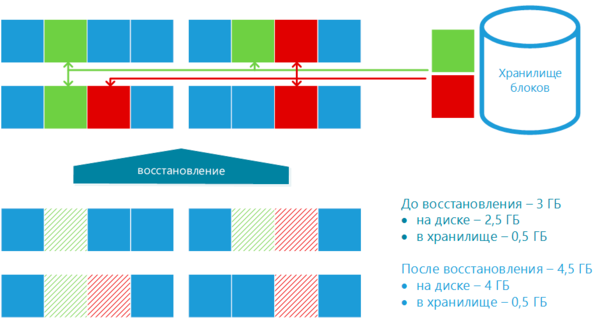
 Уникальные данные обозначены синим цветом, а одинаковые блоки зеленым и красным. В процессе дедупликации такие блоки копируются в специальное хранилище и в таблице файлов (MFT) ссылки на них заменяются ссылками на блок хранилища. Оптимизированные блоки могут быть сразу очищены, безо всякого опасения потери данных, тем самым достигается выигрыш в дисковом пространстве.
Уникальные данные обозначены синим цветом, а одинаковые блоки зеленым и красным. В процессе дедупликации такие блоки копируются в специальное хранилище и в таблице файлов (MFT) ссылки на них заменяются ссылками на блок хранилища. Оптимизированные блоки могут быть сразу очищены, безо всякого опасения потери данных, тем самым достигается выигрыш в дисковом пространстве.
В нашем примере степень дедупликации составила 25%, при этом объем данных на диске уменьшился с 4 ГБ до 2,5 ГБ, но еще 0,5 ГБ оказалось помещено в хранилище.
А теперь рассмотрим обратный процесс.
 При восстановлении дедуплицированных данных система последовательно находит блоки, имеющие ссылку на хранилище, извлекает из хранилища нужные данные и записывает их на диск для каждого файла отдельно, заменяя в MFT ссылки на хранилище ссылками на реальные данные. Но блоки их хранилища удалять нельзя, так как они могут быть использованы во множестве иных мест. Процесс удаления неиспользуемых блоков хранилища (уборка мусора) будет запущен после процесса восстановления.
При восстановлении дедуплицированных данных система последовательно находит блоки, имеющие ссылку на хранилище, извлекает из хранилища нужные данные и записывает их на диск для каждого файла отдельно, заменяя в MFT ссылки на хранилище ссылками на реальные данные. Но блоки их хранилища удалять нельзя, так как они могут быть использованы во множестве иных мест. Процесс удаления неиспользуемых блоков хранилища (уборка мусора) будет запущен после процесса восстановления.
Таким образом для успешного восстановления нам нужно иметь запас свободного пространства равный размеру данных + размеру хранилища! Размер хранилища в свою очередь зависит от разнородности данных, чем более разнообразные данные хранятся на томе, тем большее количество блоков будет находиться в хранилище и может оказаться так, что свободного места на томе для одновременного расположения восстановленных данных и хранилища не хватит.
Что делать в таком случае? Остановить процесс восстановления и принудительно выполнить уборку мусора. Обычно администраторы нервно реагируют на прерывание процессов обработки данных, но в данном случае бояться нечего.
Целостность данных обеспечивается на уровне файловой системы NTFS, блок может быть или восстановлен, тогда ссылка в MFT будет указывать на блок данных, либо дедуплицирован — ссылка указывает на хранилище. Даже если произойдет аварийное завершение работы, то NTFS при загрузке изучит журнал и зафиксирует завершенные транзакции и откатит незавершенные.
Давайте посмотрим еще на одну схему:
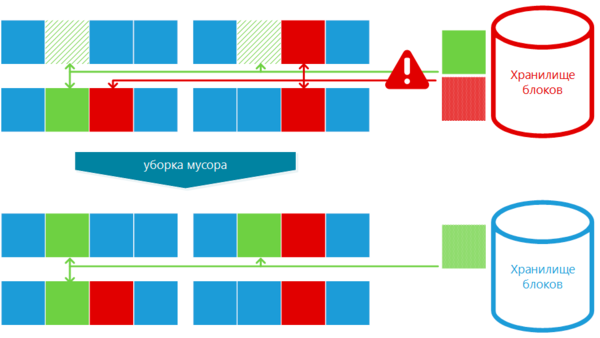
В процессе восстановления система успела восстановить два нижних файла и частично один верхний, но затем да диске закончилось свободное место. Останавливаем восстановление и запускаем уборку мусора. Сборщик мусора произведет анализ и выяснит, что на красный блок хранилища ссылок в MFT нет и его можно удалить. Таким образом часть места будет освобождена и процесс восстановления можно будет продолжить.
Как оценить размер необходимого свободного пространства? Достаточно просто, сначала откройте свойства диска, затем выделите все пользовательские данные и оцените их размер.
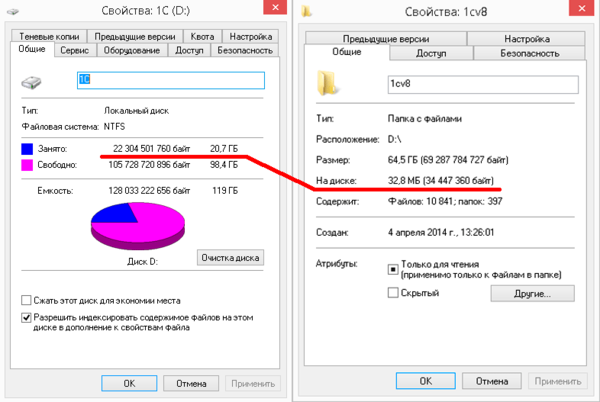 Как видим размер оптимизированных данных 20,7 ГБ, полный размер 64,5 ГБ из них на диске 32,8 МБ. Что это значит? А это означает, что остальной объем данных расположен в хранилище. Так как размером в 38 МБ можно пренебречь, то мы имеем размер хранилища в 20,7 ГБ, поэтому для успешного восстановления данных нам потребуется 85,2 ГБ.
Как видим размер оптимизированных данных 20,7 ГБ, полный размер 64,5 ГБ из них на диске 32,8 МБ. Что это значит? А это означает, что остальной объем данных расположен в хранилище. Так как размером в 38 МБ можно пренебречь, то мы имеем размер хранилища в 20,7 ГБ, поэтому для успешного восстановления данных нам потребуется 85,2 ГБ.
Теперь, когда вы владеете теорией, можно переходить к практике. Прежде всего отключите все регламентные задания, связанные с дедупликацией, не удаляйте, а именно отключите.
 Затем откроем консоль PowerShell с правами администратора и запустим процесс восстановления данных:
Затем откроем консоль PowerShell с правами администратора и запустим процесс восстановления данных:
Start-DedupJob -Volume D: -Type UnoptimizationЕсли свободного места для завершения операции нам не хватает, то остановим операцию:
Stop-DedupJob -Volume D:Так как данная операция автоматически выключает дедупликацию для тома снова включим ее:
Enable-DedupVolume -Volume D:И запустим уборку мусора:
Start-DedupJob -Volume D: -Type GarbageCollectionПо окончании данного процессора снова можно запустить процесс восстановления данных. Для контроля выполняемых процессов используйте команду:
Get-DedupJobОднако имейте в виду, что большую часть времени индикатор выполнения находится на нулевом значении, а потом быстро пробегает до 100%, косвенно оценить выполнение задания можно по дисковой активности системы. Скорость восстановления несколько выше скорости дедупликации, но все равно ниже скорости обычного копирования данных. Поэтому если есть возможность скопировать данные, отформатировать том и вернуть их назад — так и следует поступить, будет гораздо быстрее.
Можно ли работать с данными во время процесса восстановления? Да, можно, но придется мириться с некоторым снижением производительности дисковой подсистемы. Как показывает наш опыт, критического падения производительности не происходит, мы даже смогли запустить несколько виртуальных машин и работать с ними, не испытывая сильного дискомфорта.
После того, как все операции будут завершены еще раз проверьте состояние дедупликации командой:
Get-DedupVolumeДедупликация тома должна быть выключена (False в колонке Enabled), если это не так, то выполните:
Disable-DedupVolume -Volume D:Как видим, располагая знаниями о происходящих процессах, мы можем успешно выполнить операцию отключения дедупликации и восстановления данных без нервных срывов, простоев и судорожных действий сомнительного содержания, хотя в самом начале ситуация представлялась нестандартной и непонятной.
Поэтому мы в очередной раз выразим свое твердое мнение, что системный администратор должен в обязательном порядке владеть необходимым минимумом знаний о применяемых им в работе технологиях.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Продолжаем раскапывать новые фичи Windows Server 2012. Сегодня речь пойдет о технологии дедупликации данных (data deduplication). В общем случае дедупликация — это поиск и удаление дублирующихся данных. Найденные копии данных удаляются и заменяются ссылками на оригинал, что позволяет хранить только уникальный контент и высвобождает дисковое пространство. Цель дедупликации заключается в том, чтобы разместить большее количество данных на меньшем пространстве.
Описание
Дедупликация бывает разная — на уровне файлов, блоков данных и даже на битовом уровне. В Windows Server 2012 используется блочная дедупликация. Файлы разбиваются на небольшие блоки различного размера (32–128 КБ), определяются дублирующие блоки и сохраняется одна копия каждого блока. Избыточные копии блока заменяются ссылками на эту единственную копию. Блоки организуются в файлы-контейнеры, которые могут сжиматься для дальнейшей оптимизации использования пространства, и помещаются в хранилище блоков.
Для примера предположим, у нас есть два файла — File1 и File2. В исходном состоянии они содержат метаданные (имя файла, аттрибуты и т.п.) и сами данные.

После дедупликации данные из File1 и File2 удаляются и заменяются заглушками, указывающими на соответствующие блоки данных, хранящиеся в общем хранилище блоков. Так как блоки A, B и C одинаковы для обоих файлов, они хранятся в единственной копии, что снижает объем дискового пространства, необходимый для хранения обоих файлов.
Во время доступа к одному из файлов соответствующие блоки собираются вместе. При этом пользователь или приложение работают с файлом как и раньше, не подозревая о том, что файл был подвергнут преобразованиям. Это позволяет применять дедупликацию, не беспокоясь о ее влиянии на поведение приложений или доступ пользователей к файлу.

Таким образом, после включения дедупликации тома и оптимизации данных том содержит:
• Оптимизированные файлы (файлы точек повторного анализа) которые содержат указатели на соответствующие блоки данных в хранилище блоков, необходимые для построения исходного файла;
• Хранилище блоков (данные оптимизированных файлов);
• Неоптимизированные файлы (т. е. пропущенные файлы, например файлы состояния системы, зашифрованные файлы, файлы с дополнительными атрибутами или файлы размером менее 32 КБ);
Планирование
Дедупликация может значительно снизить потребляемое дисковое пространство (на 50-90% и более), но только при правильном планировании. Поэтому при выборе объекта для дедупликации следует учитывать некоторые моменты.
Тип данных
Эффективность дедупликации очень сильно зависит от типа данных. Так мультимедийные файлы (фотографии, музыка, видео) практически не содержат повторяющихся данных, поэтому их дедупликация не даст большой экономии. В то же время файлы виртуальных машин (VHD) замечательно дедуплицируются и на них экономия может составлять до 95 %. По этой причине перед включением дедупликации рекомендуется выполнить предварительную оценку данных на предмет дедуплицируемости 🙂
Частота изменения файлов
Файлы, которые часто изменяются и к которым часто обращаются пользователи или приложения, не очень подходят для дедупликации. Постоянный доступ к данным и их изменение скорее всего сведут на нет все результаты дедупликации и могут просто не дать дедупликации возможности обработать файлы. Проще говоря, для дедупликации хорошо подойдут данные, которые часто читают, но редко изменяют.
Загруженность сервера
Во время дедупликации выполняется чтение, обработка и запись большого объема данных. Этот процесс потребляет ресурсы сервера, что необходимо учитывать при планировании развертывания. Как правило, сервера имеют периоды высокой и низкой активности. Большую часть дедупликации можно выполнить, когда ресурсы доступны. Постоянно высоконагруженные сервера не рекомендуется использовать для дедупликации.
Не рекомендуется выполнять дедупликацию файлов, которые открыты, постоянно изменяются в течение продолжительного периода времени либо имеют высокие требования ввода/вывода, например файлы работающих виртуальных машин, динамических баз данных SQL или активных сеансов VDI. Дело в том, что при дедупликации не выполняется обработка файлов, открытых постоянно в монопольном режиме для записи. Это значит, что дедупликация не будет проведена до тех пор, пока файл не будет закрыт. Только тогда задание оптимизации выполнит попытку обработать файл, отвечающий выбранным параметрам политики дедупликации.
В принципе дедупликацию можно настроить на обработку постоянно изменяющихся файлов. Но в этом случае возможна ситуация, когда процесс оптимизации не сможет получить доступ к этим файлам и пропустит их обработку. Не стоит тратить ресурсы сервера на дедупликацию файлов, в которые постоянно записываются новые данные.
Приведу рекомендации Microsoft. Для дедупликации:
Не рекомендуется
- Сервера Hyper-V;
- VHD-файлы запущенных виртуальных машин;
- Службы WSUS;
- Сервера SQL и Exchange;
- Любые файлы, размер которых равен или больше 1 Тб.
Рекомендуется:
- Файловые ресурсы общего доступа (общие папки, профили и домашние папки пользователей, прочие файлопомойки);
- Развертывание программных продуктов (бинарники, образа дисков и обновления ПО);
- Библиотеки виртуализации (VHD-диски);
- Тома архивов SQL и Exchange.
Надо сказать, что рекомендации Microsoft часто противоречат друг другу, поэтому не стоит их безоговорочно принимать на веру. В любом случае перед включением дедупликации необходим тщательный анализ.
Для определения ожидаемой экономии в результате включения дедупликации можно использовать средство оценки дедупликации Ddpeval.exe. После установки компонента дедупликации утилита Ddpeval.exe автоматически устанавливается в папку WindowsSystem32. Кстати, ее можно просто скопировать из любой установки Windows Server 2012 и запустить в системах Windows 7, Windows 8 или Windows Server 2008 R2.
Синтаксис у программы проще некуда, пишем Ddpeval.exe и указываем путь. В качестве пути можно указать локальный диск, папку или сетевую шару:
Ddpeval.exe E:
Ddpeval E:Test
Ddpeval.exe ServerShare
Программа выдаст ожидаемый размер экономии дискового пространства, после чего уже можно принимать решение — включать дедупликацию или нет.

Системные требования
Дедупликация предъявляет к системе некоторые требования.
Тома
• Тома, предназначенные для дедупликации не должны быть системными или загрузочными. Дедупликация не поддерживается для томов операционной системы;
• Тома могут быть разбиты под MBR или GPT и отформатированы в NTFS. Новая отказоустойчивая файловая система ReFS не поддерживается;
• Тома могут находиться на локальных дисках либо в общедоступном хранилище (SAS, iSCSI или Fibre Channel);
• Windows должна видеть тома как несъемные диски. Сетевые диски и съемные носители не поддерживаются;
• Нельзя включать дедупликацию для общих томов кластера (Claster Shared Volume, CSV). Если дедуплицированный том преобразовать в CSV, то доступ к данным останется, но задания дедупликации не смогут отработать;
Аппаратные ресурсы
• Оборудование серверов должно отвечать минимальным требованиям Windows Server 2012. Функция дедупликации разработана для поддержки минимальных конфигураций, таких как система с одним процессором, 4 ГБ ОЗУ и одним жестким диском SATA;
• Сервер должен иметь одно процессорное ядро и 350 МБ свободной памяти для выполнения задания дедупликации на одном томе, при этом будет обрабатываться около 1,5 ТБ данных в день. Если планируется поддерживать дедупликацию в нескольких томах на одном сервере, необходимо соответствующим образом увеличить производительность системы, чтобы гарантировать, что она сможет обрабатывать данные.
• Функция дедупликации поддерживает одновременную обработку до 90 томов, однако при дедупликации одновременно может обрабатываться один том на физическое процессорное ядро плюс один. Применение технологии Hyper-Threading не влияет на этот процесс, поскольку для обработки тома можно использовать только физические ядра. К примеру сервер с 16 процессорными ядрами и 90 томами будет обрабатывать по 17 томов одновременно, пока не обработает все 90 томов;
• К виртуальным серверам применяются те же правила, что и к физическому оборудованию в отношении ресурсов сервера.
Общие требования
• Наличие свободного места на диске. При отсутствии дискового пространства на дедуплицированном томе некоторые приложения не смогут получить доступ к данным и будут завершены с ошибкой. Необходимо сохранять, по крайней мере, один гигабайт свободного места на дедуплицированном томе;
• Жесткие квоты. При использовании FSRM (File System Resource Managet) не поддерживается установка жестких квот на объем тома. Когда для тома установлены жесткие квоты, фактический объем свободного места на томе и ограниченное квотами пространство отличается, что может привести к неудаче процесса дедупликации. Все другие FSRM-квоты, в том числе мягкие квоты на объем тома и квоты на подпапки, будут нормально работать при дедупликации;
• Файлы с дополнительными атрибутами, зашифрованные файлы, файлы размером меньше 32 КБ и файлы точек повторного анализа при дедупликации не обрабатываются.
Установка и настройка
Для включения дедупликации можно воспользоваться диспетчером сервера (Server Manager). Запускаем его и открываем пункт «Add roles and features».

В ролях сервера отмечаем пункт «Data Deduplication», соглашаемся на установку необходимых компонентов и жмем Install.

Затем все в том же Server Manager идем в «File and Storage Services» -> «Volumes» и выбираем диск, который планируется оптимизировать. Напоминаю, что дедупликацию можно включить для логического диска, или тома (Volume). Кликаем на выбраном томе и в контекстном меню выбираем пункт «Configure Data Deduplication».

В открывшемся окне включаем дедупликацию для выбранного тома. Также можно произвести некоторые настройки:
• Указать количество дней, прошедших с последнего изменения файла, после которых файл можно оптимизировать. Как я уже говорил, для дедупликации лучше подходят редко изменяемые файлы, поэтому период по умолчанию составляет 5 дней. Для часто изменяющихся файлов период можно уменьшить до 1-2 дней, а если задать значение 0, дедупликация будет выполняться для всех файлов вне зависимости от их срока существования.
• Исключить из процесса дедупликации отдельные файлы (по расширениям) или целые папки. Кстати, Microsoft почему то не рекомендует этого делать.

Нажав на кнопку «Set Deduplication Shedule» мы попадаем в окно настройки расписания запуска оптимизации. По умолчанию файлы обрабатываются внутри активного тома один раз в час в режиме фоновой (background) оптимизации. Дополнительно можем включить производительную (throughput) оптимизацию и настроить для нее основное и дополнительное расписание. Например, можно запланировать производительную оптимизацию на часы минимальной активности сервера.

Из консоли PowerShel можно сделать все то же самое (и даже больше) гораздо быстрее. Установка фичи:
Install-WindowsFeature -Name FS-Data-Deduplication
Включение дедупликации c дефолтными настройками на выбраном томе:
Enable-DedupVolume -Volume E:

Для настройки есть командлет Set-DedupVolume. С его помощью можно настроить гораздо больше параметров, чем из графического интерфейса:
-MinimumFileSize — минимальный размер файла (в байтах) для дедупликации. По умолчанию составляет 32 КБ. Уменьшить это значение нельзя, но можно увеличить.
-NoCompress — указывает, надо ли сжимать данные после дедупликации ($True — не сжимать, $False — сжимать). Сжатие освобождает дисковое пространство, но задействует дополнительные ресурсы процессора. По умолчанию сжатие включено.
-NoCompressionFileType — указываем типы файлов, которые не надо сжимать. Это значит, что файлы будут дедуплицированы, но не сжаты, например потому что их формат уже предполагает сжатие. По умолчанию в эту группу включены все аудио, видео файлы, изображения, архивные файлы и файлы MS Office нового формата (.docx, .xlsx и т.д.).
-ChunkRedundancyThreshold — если я правильно понял, то он указывает количество ссылок на блок данных в активной зоне, при котором этот блок необходимо продублировать. По умолчанию этот параметр равен 100, при его уменьшении количество дублирующих блоков увеличиться и соответственно понизится эффективность дедупликации. В общем, лучше не трогать.
Для примера выставим минимальный возраст файлов 2 дня, минимальный размер 64КБ и отключим сжатие на диске E командой:
Set-DedupVolume -Volume E: -MinimumFileAgeDays 2 -MinimumFileSize 65536
-NoCompress $true

Задания дедупликации
Дедупликация включает в себя три функции, которые выполняются в виде запланированных заданий — оптимизация, очистка данных и сбор мусора.
Фоновая оптимизация (Background Optimization) — режим по умолчанию. В этом режиме процесс оптимизации файлов запускается в фоновом режиме с регулярностью раз в 1 час. Процесс работает с низким приоритетом, потребляя не более 25% системной памяти. Подобный режим запуска позволяет максимально экономить ресурсы сервера и выполнять оптимизацию только при отсутствии нагрузки. Если ресурсы для выполнения задания оптимизации окажутся недоступны без влияния на рабочую нагрузку сервера, то задание будет остановлено.
Производительная оптимизация (Throughput Optimization) — может использоваться дополнительно, вместе с фоновой. Производительная оптимизация запускается ежедневно в указанное время, с нормальным приоритетом и отрабатывает вне зависимости от того, есть ли у сервера свободные ресурсы или нет. Можно запланировать ее на часы низкой активности сервера для ускорения процесса оптимизации.

Очистка данных (Scrubbing) — встроенная функция целостности данных, выполняющая проверку контрольных сумм и согласованности метаданных. Также имеется встроенная избыточность для критических метаданных и наиболее популярных блоков данных. Когда выполняется доступ к данным или обработка данных в заданиях, эта функция обнаруживает повреждения и регистрирует их в журнале. Очистка используется для анализа повреждения хранилища блоков и, по возможности, для выполнения восстановления.

Для восстановления поврежденных данных можно использовать три источника:
1) Дедупликация создает резервные копии популярных блоков. Популярность определяется количеством ссылок на них в области, которую называют активной зоной. Если рабочая копия повреждена, средство дедупликации будет использовать резервную;
2) При использовании дисков в зеркальной конфигурации дедупликация может использовать зеркальный образ избыточного блока для обслуживания операций ввода-вывода и устранения повреждения;
3) Если обрабатывается файл с поврежденным блоком, то поврежденный блок исключается и для устранения повреждения используется новый входящий блок.
Очистка целостности данных проводится еженедельно, при этом инициируется задание, которое пытается выполнить восстановление всех повреждений, занесенных во внутренний журнал повреждений дедупликации во время операций ввода-вывода с файлами дедупликации. По необходимости очистку можно запустить вручную командой PowerShell:
Start-DedupJob E: –Type Scrubbing
Чтобы проверить целостность всех дедуплицированных данных в томе, используйте параметр -full. Этот параметр, называемый также глубокой очисткой, задает очистку всего набора дедуплицированных данных и поиск всех повреждений, приводящих к отказам в доступе к данным.
Сбор мусора (Garbage Collection) — обработка удаленных или измененных данных, т.е. удаление все блоков данных, на которые больше нет ссылок. Когда оптимизированный файл удаляется или переписывается новыми данными, старые данные в хранилище блоков не удаляются немедленно. Задания сбора мусора обрабатывают ранее удаленное или перезаписанное содержимое, чтобы освободить место на диске.

Операция сбора мусора также выполняется еженедельно. Она удаляет блоки, на которые нет ссылок, и сжимает контейнеры, содержащие более 5 % данных, на которые нет ссылок. Во время каждой десятой сборки мусора используется параметр /Full, который запускает задание по освобождению всего доступного пространства и максимально сжимает весь контейнер. Процесс сбора мусора связан с интенсивной обработкой данных, поэтому его надо либо запланировать на нерабочие часы, либо запускать вручную и отслеживать нагрузку. Сделать это можно командой:
Start-DedupJob E: –Type GarbageCollection
А если добавить ключ –full, то задание будет сжимать все контейнеры максимально возможным образом.
Задания дедупликации можно настроить в Server Manager (только оптимизацию), с помощью командлета Set-DedupShedule или в планировщике заданий, в разделе MicrosoftWindowsDeduplication. Кстати, дедупликация поддерживает только планирование недельных заданий. Если требуется создать расписание на любой другой временной период, то используйте планировщик заданий Windows. Имейте в виду, что вы не сможете просматривать расписания пользовательских заданий, созданных или измененных в планировщике заданий, с помощью командлета Get-DedupSchedule.

В принципе настройки расписания по умолчанию должны удовлетворять большинство конфигураций сервера. Однако в определенных ситуациях может потребоваться ускорение дедупликации. Например, при большом объеме входящих данных для ускорения процесса стоит добавить дополнительные задания оптимизации. Или если данные быстро удаляются и требуется возвращать свободный объем максимально оперативно, то необходимо добавить дополнительные задания сбора мусора.
Мониторинг результатов
Основные результаты дедупликации для конкретного тома можно увидеть, открыв его свойства в Server Manager. Здесь показано общее количество сэкономленного пространства и процент оптимизации. Как видите, в моем случае сжатие 76%, а экономия составила почти 32ГБ. Очень неплохо.

Несколько больше информации выдаст команда Get-DedupVolume E: | fl

Посмотреть, когда и с каким результатом прошла последняя оптимизация можно командой:
Get-DedupStatus -Volume E: | fl

Ну и подробные данные (размер хранилища блоков, средний размер блока и т.п.) покажет командлет Get-DedupMetadata.

На этом пожалуй закончу обзор. Все, что в него не уместилось можно посмотреть на Technet, лучше в оригинале (перевод ужасный). В качестве заключения скажу, что на мой взгляд дедупликация — фича интересная, но довольно неоднозначная и требующая правильного подхода и планирования.
В Windows Server 2012 появилась новая функция Data Deduplication (Дедупликация данных). Что же такое дедубликация? Дедупликация данных в общем случае – это процедура поиска и удаления дублирующих данных на носителе информации без ущерба для целостности информации. Цель дудупликации – хранить информацию в небольших блоках (32-128 Кб), выявлять одинаковые (дублирующие блоки) и сохранять только одну копию для каждого блока, а блоки-дубликаты заменять ссылками на единственную копию.
Ранее для организации дедупликации приходилось использовать сторонние продукты (существуют как аппаратные решение по дедупликации на уровне дисковых массивов, так и программные на уровне файлов). Стоимость подобных решений была достаточно высока, ведь они в первую очередь ориентированы на богатых корпоративных заказчиков. Теперь эта функция абсолютно бесплатно доступна всем пользователям a Windows Server 2012.
Есть небольшой хак, позволяющий включить дедупликацию и в клиентских ОС (Windows 8 и Windows 8.1).
В Windows Server 2012 функция дедупликация реализована в виде двух компонентов:
- Драйвера–фильтра, который контролирует функции ввода/вывода
- Службы дедупликации – контролирует три операции («Сборка мусора», «Оптимизация» и «Очистка»).
Указанные компоненты отвечают за поиск совпадающих данных, организации их хранения в единственном числе и корректное предоставление к ним доступа.
Ранее дедупликация в продуктах Microsoft встречалась в почтовом сервер Exchange 200/2003/2007 – в компоненте Single Instance Storage (на сервере в ящике одного из адресатов хранится только один экземпляр сообщения, а остальные адресаты получают просто ссылку на него).
Дедупликация данных в Windows Server 2012 выполняется в фоновом режиме и по-умолчанию запускается каждый час. Процесс запускается при низкой нагрузке на сервер и не снижает общую производительность сервера. Также по-умолчанию дедупликации подвергаются файлы, к которым не было доступа более 30 дней. Кроме того, процедура не осуществляется для следующих типов файлов:: aac, aif, aiff, asf, asx, au, avi, flac, jpeg, m3u, mid, midi, mov, mp1, mp2, mp3, mp4, mpa, mpe, mpeg, mpeg2, mpeg3, mpg, ogg, qt, qtw, ram, rm, rmi, rmvb, snd, swf, vob, wav, wax, wma, wmv, wvx, accdb, accde, accdr, accdt, docm, docx, dotm, dotx, pptm, potm, potx, ppam, ppsx, pptx, sldx, sldm, thmx, xlsx, xlsm, xltx, xltm, xlsb, xlam, xll, ace, arc, arj, bhx, b2, cab, gz, gzip, hpk, hqx, jar, lha, lzh, lzx, pak, pit, rar, sea, sit, sqz, tgz, uu, uue, z, zip, zoo.
Функционал управления дедупликацей доступен из графического интерфейса и через PowerShell. Рассмотрим оба варианта.
Windows Server 2012 Data Deduplication GUI
Чтобы включить дедупликацию данных нужно установить компонент Data Deduplicaion роли File and Storage Services. Сделать это можно из консоли Server Manahger.

После окончания установки компонента откройте консоль Server manager -> File and Storage Servcies -> Volumes –> и щелкните правой кнопкой по разделу, для которого хотите включить дедупликацию и выберите Configure Data Deduplication.

В следующем окне поставьте галочку на пункт “Enable data deduplication”. Здесь же можно указать каталоги, которые не нужно дедуплицировать и настройки планировщика дедупликации.
Текущий уровень дедупликации будет отображаться в столбце Deduplication Rate (обновится через несколько часов).
Для анализа использования дискового пространства и возможной экономии от включения дедупликаций для данного тома, разработана утилита DDPEVAL.exe. Оценить, сколько же дискового пространства получится сэкономить после включении Data deduplication, можно с помощью следующей команды (учтите, для больших томов она может создать существенную нагрузку на CPU)
c:windowssystem32ddpeval.exe e:
В моем случае экономия составила бы порядка 57%.
Дедупликация с Powershell
Процессом дедупликации можно управлять и из Powershell. Для этого нужно установить функцию Data-Deduplicationс помощью команд:
Import-Module ServerManager
Add-WindowsFeature -name FS-Data-Deduplication
Import-Module Deduplication
После того, как функция дедупликации включена, ее нужно сконфигурировать. Чтобы включить дедуплликацию для диска D:, выполним команду:
Enable-DedupVolume D:

По-умолчаию дедупликации подвергаются файлы, к которым не было доступа (Last Access)более 30 дней. Это значение можно изменить, например, на 2 дня, для этого выполните команду:
Set-DedupVolume D: -MinimumFileAgeDays 2
Обычно процесс дедупликации запускается планировщиком Windows, но его можно запустить и вручную:
Start-DedupJob D: –Type Optimization
Текущую статистику можно посмотреть с помощью команды:
Get-DedupStatus

Со списком текущих заданий можно познакомится с помощью команды:
Get-DedupJob
Все результаты работы для тома можно отобразить командой PoSH:
Get-DedupMetadata -Volume D:
И, наконец, полностью отменить дедупликацию для тома можно командой:
Start-DedupJob -Volume D: -Type Unoptimization
На скриншоте ниже видно, что после включения дедупликации на диске E: (для теста я сложил на него 4 одинаковых ISO с Windows 8), размер занятого места на диске уменьшился с 12 Гб до 3Гб. 
Служба дедупликации хранит свою базу и дедуплицированные чанки в каталоге System Volume Information. Поэтому ни в коем случае не стоит вручную вмешиваться в его структуру.
Рекомендации по использованию технологии Data Deduplication в Windows Server 2012
Microsoft опубликовала следующие результаты исследования эффективности при дудупликации различных типов данных.
| Типы данных | Возможная экономия места |
| Общие данные | 50-60% |
| Документы | 30-50% |
| Библиотека приложений | 70-80% |
| Библиотека VHD(X) | 80-95% |
Основные особенности Data Deduplication в Windows Server 2012:
- Работает только на NTFS томах и не подерживает файловую систему ReFS
- Не поддерживается для загрузочных и системных томов
- Не работает со сжатыми и шифрованными файлами NTFS
- Поддерживает кеширование и BITS
- Не поддерживает файлы меньше 32KB
- Не настраивается через групповые политики
- Не поддерживает Cluster Shared Volumes
- Дедупликация – процесс не мгновенный и требует определённого времени
| external help file | Module Name | online version | schema |
|---|---|---|---|
|
Dedup_Cmdlets.xml |
Deduplication |
https://learn.microsoft.com/powershell/module/deduplication/disable-dedupvolume?view=windowsserver2012-ps&wt.mc_id=ps-gethelp |
2.0.0 |
SYNOPSIS
Disables data deduplication activity on one or more volumes.
SYNTAX
Disable-DedupVolume [-Volume] <String[]> [-DataAccess] [-CimSession <CimSession[]>] [-ThrottleLimit <Int32>]
[-AsJob] [<CommonParameters>]
DESCRIPTION
The Disable-DedupVolume cmdlet disables further data deduplication activity on one or more volumes.
After you disable data deduplication, the volume remains in a deduplicated state and the existing deduplicated data is accessible.
The server stops running data deduplication jobs for the volume and new data is not deduplicated.
To undo data deduplication on a volume, use the Start-DedupJob cmdlet and specify Unoptimization for the Type parameter.
After you disable data deduplication on a volume, you can perform all read-only deduplication cmdlet operations on the volume.
For example, you can use the Get-DedupStatus cmdlet to get deduplication status for a volume that has data deduplication metadata.
After you disable data deduplication on a volume, you cannot use the data deduplication job-related cmdlets and the Update-DedupStatus cmdlet to perform operations on the volume.
For example, you cannot use Start-DedupJob to start a data deduplication job for a volume on which you have disabled data deduplication.
EXAMPLES
Example 1: Disable data deduplication on volumes
PS C:> Disable-DedupVolume -Volume "D:","E:","F:","G:"
This command disables data deduplication for volumes D:, E:, F:, and G:.
Example 2: Disable data deduplication on a volume by using a GUID
PS C:>Disable-DedupVolume -Volume "\?Volume{26a21bda-a627-11d7-9931-806e6f6e6963}"
This command disables data deduplication for the volume that has the GUID 26a21bda-a627-11d7-9931-806e6f6e6963.
Example 3: Suspend I/O activity for a specified volume
PS C:> Disable-DedupVolume -Volume "X:" -DataAccess
This command suspends I/O activity for data deduplication on the specified volume.
Effectively, this command causes the data deduplication file system mini-filter to detach from the specified volume.
After this command completes, I/O to data deduplication files fails with an ERROR_INVALID_FUNCTION error until either the Enable-DedupVolume -DataAccess command runs, or the server restarts.
PARAMETERS
-AsJob
Runs the cmdlet as a background job. Use this parameter to run commands that take a long time to complete.
The cmdlet immediately returns an object that represents the job and then displays the command prompt.
You can continue to work in the session while the job completes.
To manage the job, use the *-Job cmdlets.
To get the job results, use the Receive-Job cmdlet.
For more information about Windows PowerShell background jobs, see about_Jobs.
Type: SwitchParameter Parameter Sets: (All) Aliases: Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-CimSession
Runs the cmdlet in a remote session or on a remote computer.
Enter a computer name or a session object, such as the output of a New-CimSession or Get-CimSession cmdlet.
The default is the current session on the local computer.
Type: CimSession[] Parameter Sets: (All) Aliases: Session Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-DataAccess
Indicates that data access to deduplicated files on the volume is disabled.
Type: SwitchParameter Parameter Sets: (All) Aliases: Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-ThrottleLimit
Specifies the maximum number of concurrent operations that can be established to run the cmdlet.
If this parameter is omitted or a value of 0 is entered, then Windows PowerShell® calculates an optimum throttle limit for the cmdlet based on the number of CIM cmdlets that are running on the computer.
The throttle limit applies only to the current cmdlet, not to the session or to the computer.
Type: Int32 Parameter Sets: (All) Aliases: Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-Volume
Specifies an array of system volumes for which to disable data deduplication.
Specify one or more volume IDs, drive letters, or volume GUID paths.
For drive letters, use the format D:.
For volume GUID paths, use the format \\?Volume{{GUID}}.
Separate multiple volumes with a comma.
Type: String[] Parameter Sets: (All) Aliases: Path,Name,DeviceId Required: True Position: 1 Default value: None Accept pipeline input: True (ByPropertyName) Accept wildcard characters: False
CommonParameters
This cmdlet supports the common parameters: -Debug, -ErrorAction, -ErrorVariable, -InformationAction, -InformationVariable, -OutVariable, -OutBuffer, -PipelineVariable, -Verbose, -WarningAction, and -WarningVariable. For more information, see about_CommonParameters.
INPUTS
System.String[]
OUTPUTS
Microsoft.Management.Infrastructure.CimInstance#
The Microsoft.Management.Infrastructure.CimInstance object is a wrapper class that displays Windows Management Instrumentation (WMI) objects.
The path after the pound sign (#) provides the namespace and class name for the underlying WMI object.
NOTES
RELATED LINKS
Enable-DedupVolume
Get-DedupVolume
Set-DedupVolume
Update-DedupStatus
| external help file | Module Name | online version | schema |
|---|---|---|---|
|
Dedup_Cmdlets.xml |
Deduplication |
https://learn.microsoft.com/powershell/module/deduplication/disable-dedupvolume?view=windowsserver2012-ps&wt.mc_id=ps-gethelp |
2.0.0 |
SYNOPSIS
Disables data deduplication activity on one or more volumes.
SYNTAX
Disable-DedupVolume [-Volume] <String[]> [-DataAccess] [-CimSession <CimSession[]>] [-ThrottleLimit <Int32>]
[-AsJob] [<CommonParameters>]
DESCRIPTION
The Disable-DedupVolume cmdlet disables further data deduplication activity on one or more volumes.
After you disable data deduplication, the volume remains in a deduplicated state and the existing deduplicated data is accessible.
The server stops running data deduplication jobs for the volume and new data is not deduplicated.
To undo data deduplication on a volume, use the Start-DedupJob cmdlet and specify Unoptimization for the Type parameter.
After you disable data deduplication on a volume, you can perform all read-only deduplication cmdlet operations on the volume.
For example, you can use the Get-DedupStatus cmdlet to get deduplication status for a volume that has data deduplication metadata.
After you disable data deduplication on a volume, you cannot use the data deduplication job-related cmdlets and the Update-DedupStatus cmdlet to perform operations on the volume.
For example, you cannot use Start-DedupJob to start a data deduplication job for a volume on which you have disabled data deduplication.
EXAMPLES
Example 1: Disable data deduplication on volumes
PS C:> Disable-DedupVolume -Volume "D:","E:","F:","G:"
This command disables data deduplication for volumes D:, E:, F:, and G:.
Example 2: Disable data deduplication on a volume by using a GUID
PS C:>Disable-DedupVolume -Volume "\?Volume{26a21bda-a627-11d7-9931-806e6f6e6963}"
This command disables data deduplication for the volume that has the GUID 26a21bda-a627-11d7-9931-806e6f6e6963.
Example 3: Suspend I/O activity for a specified volume
PS C:> Disable-DedupVolume -Volume "X:" -DataAccess
This command suspends I/O activity for data deduplication on the specified volume.
Effectively, this command causes the data deduplication file system mini-filter to detach from the specified volume.
After this command completes, I/O to data deduplication files fails with an ERROR_INVALID_FUNCTION error until either the Enable-DedupVolume -DataAccess command runs, or the server restarts.
PARAMETERS
-AsJob
Runs the cmdlet as a background job. Use this parameter to run commands that take a long time to complete.
The cmdlet immediately returns an object that represents the job and then displays the command prompt.
You can continue to work in the session while the job completes.
To manage the job, use the *-Job cmdlets.
To get the job results, use the Receive-Job cmdlet.
For more information about Windows PowerShell background jobs, see about_Jobs.
Type: SwitchParameter Parameter Sets: (All) Aliases: Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-CimSession
Runs the cmdlet in a remote session or on a remote computer.
Enter a computer name or a session object, such as the output of a New-CimSession or Get-CimSession cmdlet.
The default is the current session on the local computer.
Type: CimSession[] Parameter Sets: (All) Aliases: Session Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-DataAccess
Indicates that data access to deduplicated files on the volume is disabled.
Type: SwitchParameter Parameter Sets: (All) Aliases: Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-ThrottleLimit
Specifies the maximum number of concurrent operations that can be established to run the cmdlet.
If this parameter is omitted or a value of 0 is entered, then Windows PowerShell® calculates an optimum throttle limit for the cmdlet based on the number of CIM cmdlets that are running on the computer.
The throttle limit applies only to the current cmdlet, not to the session or to the computer.
Type: Int32 Parameter Sets: (All) Aliases: Required: False Position: Named Default value: None Accept pipeline input: False Accept wildcard characters: False
-Volume
Specifies an array of system volumes for which to disable data deduplication.
Specify one or more volume IDs, drive letters, or volume GUID paths.
For drive letters, use the format D:.
For volume GUID paths, use the format \\?Volume{{GUID}}.
Separate multiple volumes with a comma.
Type: String[] Parameter Sets: (All) Aliases: Path,Name,DeviceId Required: True Position: 1 Default value: None Accept pipeline input: True (ByPropertyName) Accept wildcard characters: False
CommonParameters
This cmdlet supports the common parameters: -Debug, -ErrorAction, -ErrorVariable, -InformationAction, -InformationVariable, -OutVariable, -OutBuffer, -PipelineVariable, -Verbose, -WarningAction, and -WarningVariable. For more information, see about_CommonParameters.
INPUTS
System.String[]
OUTPUTS
Microsoft.Management.Infrastructure.CimInstance#
The Microsoft.Management.Infrastructure.CimInstance object is a wrapper class that displays Windows Management Instrumentation (WMI) objects.
The path after the pound sign (#) provides the namespace and class name for the underlying WMI object.
NOTES
RELATED LINKS
Enable-DedupVolume
Get-DedupVolume
Set-DedupVolume
Update-DedupStatus
- Remove From My Forums
-
Question
-
Hi all.
I have a 2 node cluster 2012 R2 on which «Data Deduplication» was activated on several volumes (3PAr). I want to completely delete this feature. I have already rehydrated all the volumes with cmdlet
Start Dedupjob -volume XXXX -Type -Unoptimization
Now, I have just this configuration using Get-DedupSchedule
Enabled Type StartTime Days Name
——- —- ——— —- —-
False Optimization BackgroundOptimization
True GarbageCollection 2:45 AM Saturday WeeklyGarbageCollection
True Scrubbing 3:45 AM Saturday WeeklyScrubbingGet-DedupStatus output gives me now nothing..
Using perfmon, I see that there is still activity during the week on ddpsvc service. This activity is not negligible.
I can stop the service itself, and may be put it in disabled state. Anyway, I want to remove completely this service.
Is there a way to remove the deduplication feature ? The Checkbox is grayed out on Server Manager when I try to remove it..
Thanks.
Patrick.
Answers
-
Hi Patrick,
Thanks for your post.
If you disable Data DeDuplication via the GUI or Powershell, it does not actually undo the work it has done. Worse, if you have disabled, you also cannot run a garbage cleanup command (which cleans up the data created by the deduplication technology).
So, its important that you leave Data Deduplication enabled, but EXCLUDE
the entire drive first.You may refer to the thread discussed before.
Disable Deduplication on Windows 2012
https://social.technet.microsoft.com/forums/windowsserver/en-US/482949ba-ecbe-4017-92d1-ccbd71888d80/disable-deduplication-on-windows-2012
Besides, you could refer to the articles below.
https://support.software.dell.com/ja-jp/appassure/kb/125890
Please Note: Since the web site is not hosted by Microsoft, the link may change without notice. Microsoft does not guarantee the accuracy of this information.
Best Regards,
Mary Dong
Please remember to mark the replies as answers if they help and unmark them if they provide no help. If you have feedback for TechNet Subscriber Support, contact tnmff@microsoft.com.
-
Proposed as answer by
Tuesday, February 9, 2016 1:41 AM
-
Marked as answer by
Mary Dong
Monday, February 15, 2016 1:42 AM
-
Proposed as answer by

Update – 11/11/2020: I’ve added a link here to Microsoft’s updated Server 2016 documentation that details deduplication – Understanding Data Deduplication
I just thought I’d post about this, as it’s something I’ve come up against recently, how to disable deduplication on a volume on Server 2012, 2012 R2 or 2016 and inflate the data back to it’s original form. In this example, the volume in question is E:
So let’s start with step one;
DO NOT DISABLE DEDUPLICATION ON THE VOLUME
If you disable dedup on the volume first, you simply stop new data being processed, rather than rehydrating your already deduplicated data.
So with that in mind the, step two would be to run the following command in PowerShell;
Start-DedupJob -Type Unoptimization -Volume E: -Full
When that job has completed, which you can check with the Get-DedupJob
command, you’ll then find that deduplication has been disabled on the disk. Since there’s still the garbage collection job to run, we need to rather counter-intuitively turn dedup back on for the volume with the following command Enable-DedupVolume -Volume E:
Once this is done, the next step is to run the following command to start your garbage collection on the volume;
Start-DedupJob -Type GarbageCollection -Volume E: -Full
Finally, after that, the final step is to turn off dedup on the volume with the following command;
Disable-DedupVolume -Volume E:
And that should save you any unnecessary drama.
Note
When all this is done, the volume will still show in some places like server manager sat at 0% deduplication rate, which is fine, as we’ve turned it off. I would guess this is just a bug, but it seems once a volume has been touched by the deduplication processes, it never goes back to a blank value for dedup rate.