 PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Существуют разные рекомендации по оптимизации PostgreSQL для совместной работы с 1С, мы будем опираться на официальные рекомендации, изложенные на ИТС, также можно использовать онлайн-калькулятор для быстрого расчета некоторых параметров. Если данные калькулятора и рекомендации 1С будут расходиться — то предпочтение будет отдано рекомендациям 1С.
Для тестирования мы использовали систему:
- CPU — Core i5-4670 — 3.4/3.8 ГГц
- RAM — 32 ГБ DDR3
- Системный диск — SSD WD Green 120 ГБ
- Диск для данных — 2 х SSD Samsung 860 EVO 250 ГБ — RAID1
- СУБД — PostgresPro 11.6
- Платформа — 8.3.16.1148
- ОС — Debian 10 x64
Прежде всего выполним тестирование с параметрами по умолчанию:
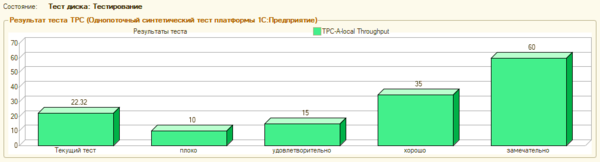 Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Перейдем к оптимизации. Все изменения следует вносить в файл postgesql.conf, который располагается в Linuх для сборки от 1С по пути /etc/postgres/1x/main, а для сборки от PostgresPro в /var/lib/pgpro/1c-1x/data. В Windows данный файл располагается в каталоге данных, по умолчанию это C:Program FilesPostgreSQL 1C1хdata. Все параметры указаны в порядке их следования в конфигурационном файла.
Одним из основных параметров, используемых при расчетах, является объем оперативной памяти. При этом следует использовать то значение, которое вы готовы выделить серверу СУБД, за вычетом ОЗУ используемой ОС и другими службами, скажем, сервером 1С. В нашем случае будет использоваться значение в 24 ГБ.
Затем рассчитаем значения отдельных параметров с помощью калькулятора, для чего укажем ОС и версию Postgres, тип накопителя, количество доступной памяти и количество ядер процессора. В поле DB Type указываем Data Warehouses, количество соединений можем проигнорировать, так как вычисляемый результат будет значительно расходиться с рекомендациями 1С.
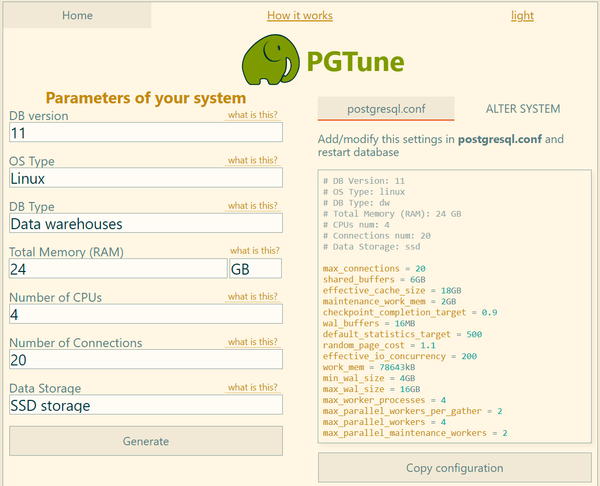 Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
max_connections = 500..1000Максимальное число соединений, 1С рекомендует указанные выше значения, мы установили 1000.
shared_buffers = RAM/4Объем памяти для совместного кеша страниц, разделяется между всеми процессами Postgres, рекомендуемое значение — четверть доступного объема памяти, в нашем случае 6 ГБ.
temp_buffers = 256MBВерхний лимит для временных таблиц в каждой сессии, рекомендуется фиксированное значение.
work_mem = RAM/32..64Указывает объем памяти, который может быть использован для запроса прежде, чем будут задействованы временные файлы на диске. Применяется для каждого соединения и каждой операции, поэтому итоговый объем используемой памяти может существенно превосходить указанное значение. Это один из тех параметров, вычисляемое значение которого калькулятором существенно отличается от рекомендаций 1С. Для объема памяти в 24 ГБ рекомендуемыми значениями будут 375 — 750 МБ, мы выбрали 512 МБ.
maintenance_work_mem = RAM/16..32 или work_mem * 4Объем памяти для обслуживающих задач (автовакуум, реиндексация и т.д.), указываем рекомендованный калькулятором объем, в нашем случае 2 ГБ.
max_files_per_process = 1000Максимальное количество открытых файлов на один процесс, в сборке от PostgresPro для Linux это значение по умолчанию.
bgwriter_delay = 20ms
bgwriter_lru_maxpages = 400
bgwriter_lru_multiplier = 4.0Параметры процесса фоновой записи, который отвечает за синхронизацию страниц в shared_buffers с диском.
effective_io_concurrency = 2 для RAID, 200 для SSD, 500..1000 для NVMeДопустимое число одновременных операций ввода/вывода. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 200, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно.
Важно! Параметр effective_io_concurrency настраивается только в среде Linux, в Windows системах его значение должно быть равно нулю.
max_worker_processes = 4
max_parallel_workers_per_gather = 2
max_parallel_workers = 4
max_parallel_maintenance_workers = 2Настройки фоновых рабочих процессов, выбираются исходя из количества процессорных ядер, берем значения из калькулятора. Выше указаны настройки для четырехъядерного СРU.
fsync = onЗаставляет сервер добиваться физической записи изменений на диск. Выключение данной опции хотя и позволяет повысить производительность, но значительно увеличивает риск неисправимой порчи данных при внезапном выключении питания.
synchronous_commit = offАльтернатива отключению fsync, позволяет серверу не ждать сохранения данных на диске, прежде чем сообщить клиенту об успешном завершении операции. Позволяет достаточно безопасно повысить производительность работы. В случае внезапного выключения питания могут быть потеряны несколько последних транзакций, но сама база останется в рабочем состоянии, также, как и при штатной отмене потерянных транзакций.
wal_buffers = 16MBЗадает размер буферов журнала предзаписи (WAL, он же журнал транзакций), если оставить эту настройку без изменений, то сервер будет автоматически устанавливать это значение в 1/32 от shared_buffers, но не менее 64 КБ и не более размера одного сегмента WAL в 16 МБ.
commit_delay = 1000
commit_siblings = 5Указывает задержку в мс перед записью транзакций на диск при числе открытых транзакций, указанных во второй опции. Имеет смысл при количестве транзакций более 1000 в секунду, на меньших значениях эффекта не имеет.
min_wal_size = 512MB..4G
max_wal_size = 2..4 * min_wal_sizeМинимальный и максимальный размер файлов журнала предзаписи. Указываем значения из калькулятора, в нашем случае это 4 ГБ и 16 ГБ.
checkpoint_completion_target = 0.5..0.9Скорость записи изменений на диск, рассчитывается как время между точками сохранения транзакций (чекпойнты) умноженное на данный показатель, позволяет растянуть процесс записи по времени и тем самым снизить одномоментную нагрузку на диски. В нашем случае использовано рекомендованное калькулятором максимальное значение 0,9.
seq_page_cost = 1.0Стоимость последовательного чтения с диска, является относительным числом, вокруг которого определяются все остальные переменные стоимости, данное значение является значением по умолчанию.
random_page_cost = 1.5..2.0 для RAID, 1.1..1.3 для SSDСтоимость случайного чтения с диска, чем ниже это число, тем более вероятно использование сканирования по индексу, нежели полное считывание таблицы, однако не следует указывать слишком низких, не соответствующих реальной производительности дисковой подсистемы, значений, иначе вы можете получить обратный эффект, когда производительность упрется в медленный случайный доступ.
Так как это относительные значения, но не имеет смысла устанавливать random_page_cost ниже seq_page_cost, однако при применении производительных SSD имеет смысл понизить стоимость обоих значений, чтобы повысить приоритет дисковых операций по отношению к процессорным.
Для производительных SSD можно использовать значения:
seq_page_cost = 0.5
random_page_cost = 0.5А для NVme:
seq_page_cost = 0.1
random_page_cost = 0.1Но еще раз напомним, данные значения не являются панацеей и должны устанавливаться осмысленно, с реальным пониманием производительности дисковой подсистемы сервера, бездумное копирование настроек способно привести к обратному эффекту.
effective_cache_size = RAM - shared_buffersОпределяет эффективный размер кеша, который может использоваться при одном запросе. Этот параметр не влияет на размер выделяемой памяти, не резервирует ее, а служит для ориентировочной оценки доступного размера кеша планировщиком запросов. Чем он выше, тем большая вероятность использования сканирования по индексу, а не последовательного сканирования. При расчете следует использовать выделенный серверу объем RAM, а не полный объем ОЗУ. В нашем случае это 18 ГБ.
autovacuum = onВключение автовакуума, это очень важный для производительности базы параметр. Не отключайте его!
autovacuum_max_workers = NCores/4..2 но не меньше 4Количество рабочих процессов автовакуума, рассчитывается по числу процессорных ядер, не менее 4, в нашем случае 4.
autovacuum_naptime = 20sВремя сна процессов автовакуума, большое значение будет приводить к неэффективно работе, слишком малое только повысит нагрузку без видимого эффекта.
row_security = offОтключает политику защиты на уровне строк, данная опция не используется платформой и ее отключение дает некоторое повышение производительности.
max_locks_per_transaction = 256 Максимальное количество блокировок в одной транзакции, рекомендация от 1С.
escape_string_warning = off
standard_conforming_strings = offДанные опции специфичны для 1С и регулируют использование символа для экранирования.
Сохраним файл конфигурации и перезапустим PostgreSQL, в Linux это можно выполнить командами:
pg-setup service stop
pg-setup service start
В Windows штатными средствами операционной системы, либо скриптами из поставки сборки PostgreSQL:
 После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
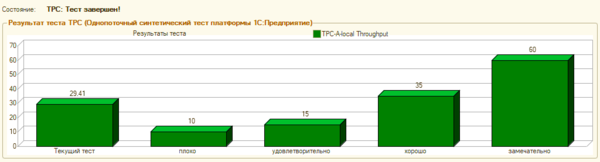 Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Указанные выше настройки и параметры являются базовым набором для оптимизации PostgreSQL при совместной работе с 1С:Предприятие и доступны даже начинающим администраторам. Для выполнения этих действий не требуется глубокого понимания работы СУБД, достаточно просто правильно рассчитать ряд значений. Данные рекомендации основаны на официальных и рекомендуются в качестве базовой настройки сервера СУБД сразу после инсталляции.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
В этой статье я покажу параметры, на которые следует обратить внимание, когда происходит оптимизация PostgreSQL для 1С.
Введение
Для оптимизации PostgreSLQ нужно отредактировать некоторые параметры его работы. Редактировать можно основной конфиг (postgresql.conf), который для 14 версии находится в этом каталоге – /etc/postgresql/14/main/. Хотя в некоторых случаях конфиг может быть и в другом месте.
Но мне кажется, лучше создать новый конфиг в каталоге /etc/postgresql/14/main/conf.d/. Этот конфиг можете назвать как угодно, но расширение файла должно быть .conf, например my-pg.conf. В этом случае основной конфиг не будет изменяться, но параметры указанные в файле my-pg.conf будут приоритетнее. И в случае чего, вы можете просто очистить my-pg.conf и вернуть настройки по умолчанию.
В этой статье будет показана оптимизация PostgreSQL для его работы с базами 1С. Я постараюсь не просто написать параметры и их значения, а объяснить, для чего я правлю тот или иной параметр.
Потребления памяти
Здесь мы настроим потребление памяти сервером PostgreSQL. Основной особенностью его работы с памятью является то, что вся работа с базами и таблицами ведётся в специальном буфере (shared_buffers). Для этого PostgreSQL при старте выделяет себе shared_buffers. Но таблички загружаются в shared_buffers не просто так, они туда попадают только если они требуются для работы. То есть нужна для работы какая-та табличка, PostgreSQL ищет её в shared_buffers, если не найдет то начинает искать её на диске.
Всякие временные таблички, которые любит создавать 1С хранятся в другой области памяти – temp_buffers. А раз 1С их любит создавать, то нужно и под это выделить побольше памяти.
Процессы, которые работают с данными, например выполняют какие-то запросы, потребляют память под названием work_mem. При этом, такие процессы, запрашивая данные из shared_buffers, а обрабатывают их в work_mem.
Но есть в PostgreSQL и служебные процессы, которые для своих операций выделяют себе maintenance_work_mem.
shared_buffers
Для начала нам нужно выделить память для хранения данных (баз и их табличек). Это делается с помощью параметра shared_buffers.
Я полагаю что нет смысла задавать shared_buffers намного больше чем размер всех баз, но некоторый запас всё же стоит оставить. Но это только, если у вас много физической памяти и вы можете сделать такой запас. Во многих статьях пишут, что нужно установить этот параметр в 15% – 40% от всей доступной памяти.
Как вариант, задайте этот параметр побольше (40%), затем пусть база поработает. После чего, с помощью команды free, посмотрите сколько сейчас занято памяти в shared. Если занято намного меньше, чем вы задали в параметре, то можете уменьшить значение этого параметра. Поставьте значение в 1,5 – 2 раза больше, чем сейчас занимает shared.
Представим, что у вас доступно 30GB памяти, а базы будут занимать 5GB. Тогда под shared_buffers можно выделить 8GB (shared_buffers = 8192MB). Хоть 40% от 30GB – это 12GB, но так как базы данных у нас занимают всего 5GB, то я выделяю чуть меньше.
А если базы данных вырастут до 20GB, а количество памяти останется 30GB, тогда уж можно выделить 12GB. При этом все базы данных в память у нас уже не поместятся. Но самые часто используемые данные будут находится в оперативной памяти.
temp_buffers
Временные буферы нужны для временных объектов, в основном для временных таблиц. Этот параметр задаёт лимит для временных буферов в каждой сессии. Так как 1С любит создавать временные таблицы, рекомендуется увеличить значение этого параметра, например до 256: temp_buffers = 256MB.
work_mem
Максимальный лимит памяти, который выделяется для обработки запросов. То есть, каждый запрос сможет получить этот объём памяти. Для 1С, мне кажется, должно хватить 512MB (если столько есть физически на каждое соединение). То есть: work_mem = 512MB.
Если для запроса не хватит work_mem памяти, то запрос будет использовать временные файлы на диске, поэтому стоит следить за их количеством. Это можно делать с помощью следующего запроса:
# select sum(temp_files) as temp_files, pg_size_pretty(sum(temp_bytes)) as temp_size from pg_stat_database;
temp_files | temp_size
------------+-----------
0 | 0 bytes
(1 строка)
Если временных файлов нет, значит всё хорошо.
Есть формула по которой можно вычислить максимальное значение для work_mem: (вся память – shared_bufer) / максимальное_количество_соединений.
С помощью такого запроса можно узнать количество соединений в данный момент:
SELECT COUNT(*) as connections,
backend_type
FROM pg_stat_activity
where state = 'active' OR state = 'idle'
GROUP BY backend_type
ORDER BY connections DESC;
Представим ситуацию, у вас 30GB всего памяти, на shared_bufer выделили 8GB. Вычислили, что соединений в процессе работы максимально было 15. Значит высчитываем (30 –  / 15 = 1,46GB. Это довольно много, поэтому можем уменьшить и указать – work_mem = 512MB.
/ 15 = 1,46GB. Это довольно много, поэтому можем уменьшить и указать – work_mem = 512MB.
Затем понаблюдаем, не растёт ли количество временных файлов. Если не растёт, то всё хорошо. А если растёт, то можно немного увеличить значение, но не делать его больше чем 1,46GB.
maintenance_work_mem
В PostgreSQL одни процессы выполняют запросы клиентов, а другие обслуживают базу данных. Например, выполняют VACUUM и ANALYZE. Параметр maintenance_work_mem как раз задаёт максимальный объём памяти для операций обслуживания.
Так как служебные операции обычно не выполняются параллельно, то можем указать здесь немного больше чем в work_mem. Например, в два раза больше – maintenance_work_mem = 1024MB.
Эффективность планирования
Когда мы пишем запрос на SQL, мы говорим что хотим получить, а не как это сделать. За то “как это сделать” отвечает планировщик основываясь на статистике. Статистика включает в себя: сколько у нас таблиц, сколько в них строчек, сколько они занимают страниц, как распределены данные в столбцах и тому подобное. Планировщик решает с каких таблиц начать выполнение запроса, какие условия и в каком порядке применять и так далее. Планировщик подготавливает план выполнения.
Также, при планировании запроса, сервер должен определить, какие таблицы нужно сканировать целиком (предпочтительно, если таблица находится на диске), а в каких использовать сканирование по индексу (предпочтительно, если таблица находится в оперативной памяти).
effective_cache_size
Этот параметр влияет на планировщик запросов, а не ограничивает дисковый кэш. Чем выше, тем больше вероятность, что будет применяться сканирование по индексу. Чем ниже, тем более вероятно, что будет выбрано последовательное сканирование.
В общем, если памяти у вас хватает, то задавать это значение нужно побольше. Вы как бы говорите серверу, у меня много памяти, и таблички скорее всего уже загружены в память. Это приведёт к применению сканированию по индексу для каждого запроса.
Считается что нужно выделять от 50% до 75% доступной памяти. Допустим у вас на сервере 30GB, тогда делаем – effective_cache_size = 15GB.
random_page_cost
Как я уже писал, PostgreSQL при построении плана запроса может выбрать либо последовательное сканирование всей таблицы, либо рандомное сканирование по индексу. Если seek time дисковой подсистемы большое, то дешевле использовать последовательное сканирование. А если маленькое, то лучше использовать сканирование по индексу. Грубо говоря, если у вас диск очень быстрый, то даже с него лучше выполнять сканирование по индексу.
Seek Time – время позиционирования на нужную дорожку. На SSD дисках нет механического позиционирования, поэтому Seek Time маленькое.
Сам сервер Postgres не знает, какая у нас дисковая подсистема. И с помощью этого параметра мы ему об этом сообщаем. Установите random_page_cost:
- 4.0 – для HDD;
- 1.5-2.0 – для RAID из HDD;
- 1.1 – 1.3 – для SSD;
- 0.1 – для NVMe.
Например – random_page_cost = 1.2.
Автоматический VACUUM
В PostgreSQL, когда данные изменяются (UPDATE), или удаляются (DELETE), это не приводит к изменению старых версий изменяемых или удаляемых строк. Версия строки не должна удаляться до тех пор, пока она остаётся потенциально видимой для других транзакций. Однако, в конце концов, устаревшая или удалённая версия строки оказывается не нужна ни одной из транзакций. В этот момент такие строки можно удалить физически с помощью команды VACUUM.
autovacuum
А чтобы удаление старых и не нужных строк происходило автоматически, нужно включить – autovacuum = on.
autovacuum_max_workers
Если включен autovacuum, то процессов автоматической очистки может быть запущено не больше чем указано в этом параметре, например autovacuum_max_workers = 4.
Многие советуют устанавливать значение этого параметра не меньше 4. Но если у вас много ядер, то можете указать значение, рассчитанное по формуле “количество ядер / 4“.
autovacuum_naptime
Этот параметр задаёт задержку между запусками процессов автоочистки для отдельной базы данных. Он связан с параметром autovacuum_max_workers.
Объясню как этот работает. Допустим у вас 4 базы данных. И вы установили autovacuum_max_workers = 4 и autovacuum_naptime = 20s. Процесс автоматической очистки будет работать следующем образом. Просыпаются 4 процесса автоматической очистки и одновременно обрабатывают 4 базы. Через 20 секунд это повторяется.
Или другой пример. У вас 20 баз данных, а настройки такие же. Просыпаются 4 процесса автоматической очистки и чистят 4 базы. Через 20 секунд просыпаются ещё 4 процесса автоматической очистки и чистятся другие 4 базы. И так далее.
То есть, если у вас много баз данных, и позволяет количество ядер, то лучше увеличить значение autovacuum_max_workers.
Если задать слишком большое значение autovacuum_naptime, то таблицы не будут успевать очищаться. Это приведёт к распуханию базы данных. А если задать слишком маленькое значение, то базы данных будут слишком часто проверятся на необходимость в чистке.
Для 1С рекомендуют установить значение в 20 секунд: autovacuum_naptime = 20s.
Определить раздутые таблицы в базе поможет этот скрипт. Он перечисляет раздутые таблицы и оценивает объемы раздувания. Вы можете вручную очистить эти таблицы с помощью запросов: VACUUM ANALYZE <имя таблицы>; или VACUUM FULL <имя таблицы>;.
Процесс фоновой записи
В PostgreSQL есть специальный процесс фоновой записи. Этот процесс отвечает за сброс грязных буферов из shared_buffer на диск. Когда количество shared_buffer уже недостаточно, данный процесс записывает изменённые страницы на диск, освобождая память. Это снижает вероятность того, что процессы, выполняющие запросы пользователей, не смогут найти чистые буферы и им придётся сбрасывать грязные буферы самостоятельно.
bgwriter_delay
Но процесс фоновой записи увеличивает общую нагрузку на диск, так как он может записывать неоднократно изменяемую страницу несколько раз, тогда как её можно было бы записать всего один раз (при checkpoint).
Этот параметр задаёт задержку между раундами активности фоновой записи. Во время раунда этот процесс осуществляет запись некоторого количества грязных буферов на диск. Затем он засыпает на время bgwriter_delay, и всё повторяется снова.
Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс. А слишком маленькое значение будет грузить процессор, так как постоянно будет запускаться процесс фоновой записи.
По умолчанию этот параметр установлен в 200ms, рекомендуется уменьшить это значение, например до: bgwriter_delay = 20ms.
bgwriter_lru_multiplier
Число записываемых грязных буферов на диск данных процессом фоновой записи может быть больше чем в предыдущий раз в указанное количество раз. Другими словами, bgwriter_lru_multiplier это множитель. Средняя недавняя потребность умножается на bgwriter_lru_multiplier и предполагается что именно столько данных потребуется записать. Увеличение этого множителя больше 1 даёт некоторую страховку от резких скачков потребностей. По умолчанию равен 2.0.
Рекомендуется указать значение 4.0 – bgwriter_lru_multiplier = 4.0. При этом число сбрасываемых буферов ограничено следующем параметром.
bgwriter_lru_maxpages
Максимальное число буферов, которое сможет записать процесс фоновой записи за раунд. При нулевом значении фоновая запись отключается.
Рекомендуется установить 400 – bgwriter_lru_maxpages = 400.
Надёжность и скорость работы
Здесь мы рассмотрим параметры, которые отвечают за надёжность хранения баз. Можно пожертвовать некоторой надёжностью, и увеличить скорость работы. Но не стоит переусердствовать, ведь в случае сбоя можно остаться вообще без данных.
full_page_writes
Здесь нужно разобраться как PostgreSQL сбрасывает странички на диск и восстанавливает базу в случае сбоя. SQL сервер изменяя каждую страничку данных, предварительно пишет о запланированном изменении в журнале предварительной записи (WAL). И периодически выполняет контрольные точки (checkpoint), то есть сбрасывает изменённые странички на диск.
При восстановлении базы, PostgreSQL смотрит журнал WAL с последней контрольной точки и проделывает работы по восстановлению. Но чтобы восстановление прошло, нужно полагаться на уже записанные данные.
Если параметр full_page_writes включен, то при каждой контрольной точке, записываются изменённые странички (8KB) целиком в журнал wall. Вот на эти странички (гарантированно исправные) и будет полагаться PostgreSQL при востановлении.
То есть, когда параметр включен, гарантировано восстановление базы после сбоя. А когда выключен, есть шанс базу не восстановить.
Иногда можно выключить этот параметр, чтобы уменьшить нагрузку на сервер. Во первых современные файловые системы также имеют свой журнал. А во вторых, для восстановления работы с базой можно полагаться на реплики, ведь переключение на реплику может быть выполнено быстрее, чем перезагрузка основного сервера и автоматическое восстановление базы.
Кстати, на файловой системе ZFS также рекомендуют этот параметр выключать – ссылка. Это связано с тем, что ZFS всегда записывает полные блоки и вы можете отключить запись полных страниц в PostgreSQL. Ещё, про этот параметр можете почитать здесь.
Я бы рекомендовал задать параметр full_page_writes = off, настроить репликацию кластера на резервный сервер и периодически делать резервные копии.
synchronous_commit
Определяет, после завершения какого уровня обработки WAL сервер будет сообщать об успешном выполнении операции.
Если параметр включен (on) – происходит ожидании локального сброса WAL на диск и только после этого операция фиксируется. А если параметр выключен (off) – возрастает производительность сервера, при этом гарантирована целостность базы. Но вы можете потерять несколько последних транзакций при сбое.
Так как этот параметр может значительно увеличить производительность и не сильно влияет на безопасность, то рекомендуется выключать фиксацию транзакций: synchronous_commit = off.
Этот параметр может принимать и другие значения, но я их не буду рассматривать.
ssl
Сервер PostgreSQL можно запустить с включённым механизмом SSL. Но если сервер баз данных защищен другими способами, то можно выключить шифрование, уменьшив нагрузку на процессор. Чтобы выключить механизм SSL установите: ssl = off.
fsync
Если этот параметр включен, сервер старается добиться, чтобы изменения были записаны на диск физически, выполняя системные вызовы fsync() или другими подобными методами.
Хотя отключение fsync даёт выигрыш в скорости, это может привести к неисправимой порче данных в случае сбоя системы.
Во многих случаях отключение synchronous_commit может дать больший выигрыш в скорости, чем отключение fsync, при этом не добавляя риски повреждения данных. Поэтому не рекомендуется выключать этот параметр: fsync = on.
Нагрузка на диск
checkpoint_timeout
Чтобы изменения в базе данных не потерялись, Postgres периодически сбрасывает изменённые данные на диск. Такой сброс называется контрольной точкой (checkpoint).
Такой сброс по умолчанию выполняется раз в 5 минут, я думаю не следует менять это значение – checkpoint_timeout = 5min.
checkpoint_completion_target
Этот параметр задает долю от общего времени между контрольными точками. Например, контрольные точки происходят раз в 5 минут. А для параметра checkpoint_completion_target мы установим значение 0,9. Это будет означать что контрольные точки будут происходить раз в 5 минут, а сам процесс сброса данных на диск будет происходить 5*0,9 = 4,5 минуты. Остальные 30 секунд останутся для запаса, например для завершения контрольной точки.
Значение этого параметра не рекомендуется изменять. Если задать его слишком маленьким, то в момент контрольной точки будет слишком сильная нагрузка на диск. А если указать 1, то контрольные точки не будут успевать завершаться. А значение 0,9 позволяет сделать нагрузку на диск более плавной и оставляет некоторое время на завершение контрольной точки – checkpoint_completion_target = 0,9.
effective_io_concurrency
Параметр задаёт допустимое число параллельных операций ввода/вывода. Чем больше это число, тем больше операций ввода/вывода будет пытаться выполнить параллельно PostgreSQL в отдельном сеансе. Допустимые значения лежат в интервале от 1 до 1000, а нулевое значение отключает асинхронные запросы ввода/вывода.
Для RAID массивов, можно увеличить на количество дисков. Для RAID5 следует исключить 1 диск. Если диск не нагружен, то можно увеличить. Для SSD диска можно указать несколько сотен, например: effective_io_concurrency = 200.
Предупреждение! В Windows системах этот параметр должен равняться нулю.
Выделение памяти под WAL
Журнал предварительной записи (WAL), в основном нужен для надёжности и способности восстановить базы в случае сбоя. Но он занимает место на диске. Здесь я рассмотрю параметры для настойки размера WAL.
min_wal_size
Этот параметр ограничивает размер WAL снизу. Этим самым мы резервируем некоторое место для WAL, чтобы справиться с резкими скачками его использования.
Рекомендуется увеличить значение этого параметра, например – min_wal_size = 1G. Вообще выделите столько места, сколько не жалко.
А чтобы узнать сколько сейчас занимает WAL, выполните:
$ du -sh /var/lib/postgresql/14/main/pg_wal/ 2,1G /var/lib/postgresql/14/main/pg_wal/
max_wal_size
Максимальный размер, до которого может вырастать WAL. Если мы приближаемся к этому порогу, то будет выполнена дополнительная контрольная точка и старые (не нужные) записи из WAL будут удалены. Размер WAL может превышать max_wal_size при особых обстоятельствах, например при большой нагрузке.
Уменьшение этого параметра сделает более частыми контрольные точки, при этом возрастёт нагрузка. Но зато восстановления баз данных в случае сбоя будет происходить быстрее. Увеличение этого параметра может привести к увеличению времени, которое потребуется для восстановления после сбоя.
Можно выставить – max_wal_size = 4G.
Также можете установить параметр checkpoint_warning = 3min. Тогда, если контрольные точки будут случаться чаще 3 минут, то вы увидите записи об этом в журнале с рекомендацией увеличить max_wal_size.
wal_keep_size
Задаёт минимальный объём прошлых сегментов журнала WAL, который будет сохраняться, чтобы ведомый сервер мог выбрать их при потоковой репликации. Если ведомый сервер, подключённый к передающему, отстаёт больше чем на wal_keep_size то репликация может сломаться.
Если у вас используется репликация на ведомый сервер, то задайте этот параметр немного меньше чем max_wal_size, например wal_keep_size = 3G.
row_security
Этот параметр определяет, должна ли выдаваться ошибка при применении политик защиты строк. Политика защиты строк может сделать так, чтобы одним пользователям разрешалось читать определённые строки, а другим не разрешалось.
Для 1С можно отключить этот параметр, так как политика защиты строк здесь не используется: row_security = off.
standard_conforming_strings
Этот параметр определяет, будет ли обратная косая черта в обычных строковых константах восприниматься буквально, как того требует стандарт SQL.
Для 1С нужно разрешить использовать символ “” для экранирования, поэтому указываем: standard_conforming_strings = off.
escape_string_warning
Предыдущим параметром мы разрешили использовать символ “” для экранирования. А с помощью этого параметра нужно выключить предупреждения об использовании этого символа: escape_string_warning = off.
Различные ограничения
max_files_per_process
Задаёт максимальное число файлов, которые могут быть одновременно открыты каждым серверным подпроцессом. По умолчанию 1 процесс может открыть 1000 файлов. Можно это значение не изменять: max_files_per_process = 1000.
max_locks_per_transaction
Этот параметр управляет средним числом блокировок объектов, выделяемым для каждой транзакции. Значение по умолчанию – 64. Но его можно увеличить, если запросы обращаются ко множеству различных таблиц в одной транзакции.
Для 1С это значение нужно увеличивать, хотя бы до 256: max_locks_per_transaction = 256.
max_connections
Определяет максимальное число одновременных подключений к серверу.
Для 1С можно задать от 500 до 1000, например max_connections = 500.
Логирование
Здесь будут рассмотрены параметры логирования, которые можно изменить для уменьшения логирования и уменьшения нагрузки на сервер. Но совсем логирование всё таки лучше не выключать.
log_min_messages
Минимальный уровень сообщений. Совсем логи отключать не стоит, но и слишком частая запись создаст дополнительную нагрузку. Я бы рекомендовал установить этому параметру значение FATAL. В этом случае сервер будет сообщать об ошибке, из-за которой прерваны все сессии или текущая сессия. Или можно установить уровень LOG – в этом случае в лог будет записываться информация, полезная для администратора, например о выполнении контрольных точек.
log_min_messages = log
log_min_error_statement
Этим параметром определяется, если SQL-оператор завершается ошибкой, то он будет, или не будет записан в лог.
Здесь уровень можно оставить по умолчанию – ERROR. В этом случае вы будите видеть ошибки, которые привели к прерыванию сессий (PANIC, FATAL), если различные служебные процессы завершились с ошибками (LOG), и ошибки текущих команд (ERROR).
log_min_error_statement = error
log_min_duration_statement
Записывает в журнал продолжительность выполнения всех команд, время работы которых не меньше указанного. Например, при значении 250ms в журнал сервера будут записаны все команды, выполняющиеся 250 миллисекунд и дольше. При нулевом значении записывается продолжительность выполнения всех команд. Со значением -1 запись полностью отключается.
Можем указать log_min_duration_statement = 10000, тогда в лог будут сохраняться запросы, которые выполнялись более 10 секунд.
Ссылки на используемую информацию
Для написания этой статьи я использовал свой опыт настройки сервера PostgreSQL и пробежался по подобным статьям. Ну и конечно использовал документацию. Вот основные ссылки:
- Документация от postgrespro.ru
- Настройка Postgres Pro для решений 1С
- Настройка PostgreSQL для работы в связке с 1С на infostart.ru
- Тюнинг базы Postgres от highload.today
- Лучшие практики по настройке PostgreSQL от gilev.ru
- Оптимизация производительности PostgreSQL для работы с 1С:Предприятие от interface31.ru
- Настройки PostgreSQL для работы с 1С:Предприятием взятые с сайта ИТС – its.1c.ru
- Ускорение работы 1С с postgresql и диагностика проблем производительности
А если хотите разобраться как работает PostgreSQL, можете почитать этот цикл статей.
Сводка

Имя статьи
Оптимизация PostgreSQL для 1С
Описание
В этой статье я покажу параметры, на которые следует обратить внимание, когда происходит оптимизация PostgreSQL для 1С
По умолчанию PostgreSQL настроен таким образом, чтобы расходовать минимальное количество ресурсов для работы с небольшими базами до 4 Gb на не очень производительных серверах. То есть, если дело касается систем посерьезней, то вы столкнетесь с большими потерями производительности базы данных лишь потому, что дефолтные настройки могут в корне не соответствовать производительности вашего северного оборудования. Настройки выделения ресурсов оперативной памяти RAM для работы PostgreSQL хранятся в файле postgresql.conf.
Доступен как из папки, куда установлен PostgreSQL / Data, так и из pgAdmin:

В общем на начальном этапе при возникновении трудностей и замедления работы БД, заметной для глаз пользователей достаточно увеличить три параметра:
shared_buffers
Это размер памяти, разделяемой между процессами PostgreSQL, отвечающими за выполнения активных операций. Максимально-допустимое значение этого параметра – 25% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 64-128 Mb (8192-16384).
temp_buffers
Это размер буфера под временные объекты (временные таблицы). Среднее значение 2-4% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 32-64 Mb.
work_mem
Это размер памяти, используемый для сортировки и кэширования таблиц.
При 1-2 Gb RAM на сервере, рекомендуемое значение 32-64 Mb.
Для вступления новых значений в силу, потребуется перезапуск службы, поэтому лучше делать во вне рабочее время.
Еще два важных параметра это maintenance_work_mem (для операций VACUUM, CREATE INDEX и других) и max_stack_depth
Примеры оптимальных настроек:
Hardware:
- CPU: E3-1240 v3 @ 3.40GHz
- RAM: 32Gb 1600Mhz
- Диски: Plextor M6Pro
postgresql.conf:
- shared_buffers = 8GB
- work_mem = 128MB
- maintenance_work_mem = 2GB
- fsync = on
- synchronous_commit = off
- wal_sync_method = fdatasync
- checkpoint_segments = 64
- seq_page_cost = 1.0
- random_page_cost = 6.0
- cpu_tuple_cost = 0.01
- cpu_index_tuple_cost = 0.0005
- cpu_operator_cost = 0.0025
- effective_cache_size = 24GB
Вариант настроек от pgtune:

Полезные запросы:
Блокировки БД по пользователям
Код SQL
select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename; Вывести все таблицы, размером больше 10 Мб
Код SQL
SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size
from pg_tables
where tableName not like ‘sql_%’ and pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) like ‘%MB%’; Определение размеров таблиц в базе данных PostgreSQL
Код SQL
SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size
from pg_tables
where tableName not like ‘sql_%’
order by size; Пользователи блокирующие конкретную таблицу
Код SQL
select a.usename, t.relname, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid inner join pg_stat_all_tables t on t.relid=l.relation where t.relname = ‘tablename’; Код SQL
select relation::regclass, mode, a.usename, granted, pid from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not mode = ‘AccessShareLock’ and relation is not null; Запросы с эксклюзивными блокировками
Код SQL
select a.usename, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where mode ilike ‘%exclusive%’; Количество блокировок по пользователям
Код SQL
select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename; Количество подключений по пользователям
Код SQL
select count(usename), usename from pg_stat_activity group by usename order by count(usename) desc; 
На данный момент производительность PostgreSQL в связке с сервером 1С:Предприятия в сравнении с тем же MS SQL оставляет желать лучшего. Эта статья продолжение попыток добиться достойной производительности на PostgreSQL. Хотя на данный момент у меня не получилось добиться производительности сопоставимой MS SQL, но думаю в недалеком будущем эта проблема будет решена.
Далее в статье перечислены основные параметы и особенности, на которые следует обратить внимание при оптимизации PostgreSQL.
Основные параметры PostgreSQL.
shared_buffers
Объём совместно используемой памяти, выделяемой PostgreSQL для кэширования данных, определяется числом страниц shared_buffers по 8 килобайт каждая. Следует учитывать, что операционная система сама кэширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память. Размер shared_buffers зависит от многих факторов, для начала можно принять следующие значения:
- 8–16 Мб – Обычный настольный компьютер с 512 Мб и небольшой базой данных,
- 80–160 Мб – Небольшой сервер, предназначенный для обслуживания базы данных с объёмом оперативной памяти 1 Гб и базой данных около 10 Гб,
- 400 Мб – Сервер с несколькими процессорами, с объёмом памяти в 8 Гб и базой данных занимающей свыше 100 Гб обслуживающий несколько сотен активных соединений одновременно.
work_mem
Под каждый запрос выделяется ограниченный объём памяти. Этот объём используется для сортировки, объединения и других подобных операций. При превышении этого объёма сервер начинает использовать временные файлы на диске, что может существенно снизить производительность. Оценить необходимое значение для work_mem можно разделив объём доступной памяти (физическая память минус объём занятый под другие программы и под совместно используемые страницы shared_buffers) на максимальное число одновременно используемых активных соединений.
maintenance_work_mem
Эта память используется для выполнения операций по сбору статистики ANALYZE, сборке мусора VACUUM, создания индексов CREATE INDEX и добавления внешних ключей. Размер памяти выделяемой под эти операции должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size
PostgreSQL в своих планах опирается на кэширование файлов, осуществляемое операционной системой. Этот параметр соответствует максимальному размеру объекта, который может поместиться в системный кэш. Это значение используется только для оценки. effective_cache_size можно установить в ½ — 2/3 от объёма имеющейся в наличии оперативной памяти, если вся она отдана в распоряжение PostgreSQL.
ВНИМАНИЕ! Следующие параметры могут существенно увеличить производительность работы PostgreSQL. Однако их рекомендуется использовать только если имеются надежные ИБП и программное обеспечение, завершающее работу системы при низком заряде батарей.
fsync
Данный параметр отвечает за сброс данных из кэша на диск при завершении транзакций. Если установить в этом параметре значение off, то данные не будут записываться на дисковые накопители сразу после завершения операций. Это может существенно повысить скорость операций insert и update, но есть риск повредить базу, если произойдет сбой (неожиданное отключение питания, сбой ОС, сбой дисковой подсистемы).
Отрицательное влияние включенного fsync можно уменьшить отключив его и положившись на надежность вашего оборудования. Или правильно подобрав параметр wal_sync_method — метод, который используется для принудительной записи данных на диск.
Возможные значения:
- open_datasync – запись данных методом
open()с параметромO_DSYNC, - fdatasync – вызов метода
fdatasync()после каждогоcommit, - fsync_writethrough – вызывать
fsync()после каждогоcommitигнорирую параллельные процессы, - fsync – вызов
fsync()после каждогоcommit, - open_sync – запись данных методом
open()с параметромO_SYNC.
ПРИМЕЧАНИЕ! Не все методы доступны на определенных платформах. Выбор метода зависит от операционной системы под управлением, которой работает PostgreSQL.
В состав PostgreSQL входит утилита pg_test_fsync, с помощью которой можно определить оптимальное значение параметра wal_sync_method.
Она выполняет серию дисковых тестов с использованием различных методов синхронизации. В результате этого теста получаются оценки производительности дисковой системы, по которым можно определить оптимальный метод синхронизации для данной операционной системы.
Я решил провести вышеуказанный тест на своем рабочем компьютере, имеющем следующие характеристики:
- CPU: Intel Core i3-3220 @ 3.30GHz x 2
- RAM: 4GB
- HDD: Seagate ST3320418AS 320GB
Тест на Windows:
- ОС: Windows 7 Максимальная x64
- ФС: NTFS
- СУБД: PostgreSQL 9.4.2-1.1C x64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
По результатам теста мы видим, что для Windows оптимальным решением будет использование open_datasync.
Тест на Linux:
- ОС: Debian 8.6 Jessie
- Ядро: x86_64 Linux 3.16.0-4-amd64
- ФС: ext4
- СУБД: PostgreSQL 9.4.2-1.1C amd64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
По результатам теста мы видим, что наилучшую скорость выдают методы fdatasync и open_datasync. Так же можно заметить, что на же оборудовании Linux выдал скорость записи почти в половину больше, чем на Windows.
Следует учитывать, что в данных тестах использовалась дисковая система, состоящая из одного диска. При использовании RAID массива с большим количеством дисков картина может быть другой.
wal_buffers
Количество памяти используемое в SHARED MEMORY для ведения транзакционных логов. При доступной памяти 1-4 Гб рекомендуется устанавливать 256-1024 Кб. Этот параметр стоит увеличивать в системах с большим количеством модификаций таблиц базы данных.
checkpoint_segments
Oпределяет количество сегментов (каждый по 16 МБ) лога транзакций между контрольными точками. Для баз данных с множеством модифицирующих данные транзакций рекомендуется увеличение этого параметра. Критерием достаточности количества сегментов является отсутствие в логе предупреждений (warning) о том, что контрольные точки происходят слишком часто.
full_page_writes
Включение этого параметра гарантирует корректное восстановление, ценой увеличения записываемых данных в журнал транзакций. Отключение этого параметра ускоряет работу, но может привести к повреждению базы данных в случае системного сбоя или отключения питания.
synchronous_commit
Включает/выключает синхронную запись в лог-файлы после каждой транзакции. Включение синхронной записи защищает от возможной потери данных. Но, накладывает ограничение на пропускную способность сервера. Вы можете отключить синхронную запись, если вам необходимо обеспечить более высокую производительность по количеству транзакций. А потенциально низкая возможность потери небольшого количества изменений при крахе системы не критична. Для отключения синхронной записи установите значение off в этом параметре.
Еще одним способом увеличения производительности работы PostgreSQL является перенос журнала транзакций (pg_xlog) на другой диск. Выделение для журнала транзакций отдельного дискового ресурса позволяет получить получить при этом существенный выигрыш в производительности 10%-12% для нагруженных OLTP систем.
В Linux это делается с помощью создания символьной ссылки на новое положение каталога с журналом транзакций.
В Windows можно использовать для этих целей утилиту Junction. Для этого надо:
- Остановить PostgreSQL.
- Сделать бэкап
C:Program FilesPostgreSQLX.X.Xdatapg_xlog. - Скопировать
C:Program FilesPostgreSQLX.X.Xdatapg_xlogвD:pg_xlogи удалитьC:Program FilesPostgreSQLX.X.Xdatapg_xlog. - Распаковать программу Junction в
C:Program FilesPostgreSQLX.X.Xdata. - Открыть окно CMD, перейти в
C:Program FilesPostgreSQLX.X.Xdataи выполнитьjunction -s pg_xlog D:pg_xlog. - Установить права на папку
D:pg_xlogпользователю postgres. - Запустить PostgreSQL.
ГдеX.X.X— версия используемой PostgreSQL.
Особенности и ограничения в 1С:Предприятие при работе с PostgreSQL.
Использование конструкции ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ.
В СУБД PostgreSQL реализована только частичная поддержка FULL OUTER JOIN (ERROR: “FULL JOIN is only supported with mergejoinable join conditions”). Для реализации полной поддержки FULL OUTER JOIN при работе 1С:Предприятия 8 с PostgreSQL подобный запрос трансформируется в другую форму с эквивалентным результатом, однако эффективность использования конструкции ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ снижается.
В связи с этим не рекомендуется использовать ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ при работе с PostgreSQL. В большинстве случаев без использования этой конструкции можно обойтись, переписав исходный запрос.
Оптимизация использования виртуальной таблицы СрезПоследних при работе с PostgreSQL.
Проблема: При работе с PostgreSQL использование соединения с виртуальной таблицей СрезПоследних может приводить к существенному снижению производительности. Из-за ошибки оптимизатора может быть выбран неоптимальный план выполнения запроса.
Решение: Если в запросе используется соединение с виртуальной таблицей языка запросов 1С:Предприятия СрезПоследних и запрос работает с неудовлетворительной производительностью, то рекомендуется вынести обращение к виртуальной таблице в отдельный запрос с сохранением результатов во временной таблице.
Решение проблемы с зависанием PostgreSQL.
При выполнения некоторых регламентных операций (Закрытие месяца, Расчет себестоимости и т.п.), где используются сложные запросы с большим количеством соединений больших таблиц, возможно существенное увеличение времени выполнения операции. В основном, эти проблемы связаны с работой оптимизатора PostgreSQL и отсутствием актуальной статистики по таблицам, участвующим в запросе.
Варианты решения проблемы:
- Увеличить количество записей, просматриваемых при сборе статистики по таблицам. Большие значения могут повысить время выполнения команды
ANALYZE, но улучшат построение плана запроса:- Файл postgresql.conf —
default_statistics_target = 1000 -10000.
- Файл postgresql.conf —
- Отключение оптимизатору возможности использования
NESTED LOOPпри выборе плана выполнения запроса в конфигурации PostgreSQL:- Файл postgresql.conf —
enable_nestloop = off. - Отрицательным эффектом этого способа является возможное замедление некоторых запросов, поскольку при их выполении будут использоваться другие, более затратные, методы соединения (
HASH JOIN).
- Файл postgresql.conf —
- Отключение оптимизатору возможности изменения порядка соединений таблиц в запросе:
- Файл postgresql.conf —
join_collapse_limit=1. - Следует использовать этот метод, если вы уверены в правильности порядка соединений таблиц в проблемном запросе.
- Файл postgresql.conf —
- Изменение параметров настройки оптимизатора:
- Файл postgresql.conf:
seq_page_cost = 0.1random_page_cost = 0.4cpu_operator_cost = 0.00025
- Файл postgresql.conf:
- Использование версии PostgreSQL 9.1.2-1.1.C и выше, в которой реализован независимый от
AUTOVACUUMсбор статистики, на основе информации об изменении данных в таблице. По умолчанию включен сбор статистики только для временных таблиц и во многих ситуациях этого достаточно. При возникновении проблем с производительностью выполнения регламентных операций, можно включить сбор статистики для всех или отдельных проблемных таблиц изменив значение параметра конфигурации PostgreSQL (файл postgresql.conf)online_analyze.table_type = "temporary"наonline_analyze.table_type = "all".
После изменения этих параметров, следует оценить возможное влияние этих изменений на работу системы и выбрать наиболее приемлимый вариант для ваших задач.
Послесловие.
Ко всему вышеперечисленному можно так же добавить:
- Необходимость использования управляемых блокировок при разработке прикладного решения. Если же у вас типовая конфигурация, то по возможности ее так же необходимо переводить на управляемые блокировки.
- Рекомендацию реализовать для PostgreSQL кэширование на SSD-накопитель. Сделать это можно с помощью Flashcache или Bcache. Подробнее вопрос организации системы кэширования я рассмотрю в другой статье.
- Довольно удобный веб-сервис для начальной настройки PostgreSQL. Его порекомендовал мне товарищ Vasiliy P. Melnik. Несмотря на то, что интерфейс на английском, он простой и интуитивно понятный. Думаю каждый желающий сможет с ним разобраться.
Статья обновлена 8 октября 2016 года. Добавлены сравнительные тесты
03:07 18.03.2020
Оптимизация производительности PostgreSQL для работы с 1С:Предприятие
PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
Существуют разные рекомендации по оптимизации PostgreSQL для совместной работы с 1С, мы будем опираться на официальные рекомендации, изложенные на ИТС, также можно использовать онлайн-калькулятор для быстрого расчета некоторых параметров. Если данные калькулятора и рекомендации 1С будут расходиться — то предпочтение будет отдано рекомендациям 1С.
Для тестирования мы использовали систему:
- CPU — Core i5-4670 — 3.4/3.8 ГГц
- RAM — 32 ГБ DDR3
- Системный диск — SSD WD Green 120 ГБ
- Диск для данных — 2 х SSD Samsung 860 EVO 250 ГБ — RAID1
- СУБД — PostgresPro 11.6
- Платформа — 8.3.16.1148
- ОС — Debian 10 x64
Прежде всего выполним тестирование с параметрами по умолчанию:
Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Перейдем к оптимизации. Все изменения следует вносить в файл postgesql.conf, который располагается в Linuх для сборки от 1С по пути /etc/postgres/1x/main, а для сборки от PostgresPro в /var/lib/pgpro/1c-1x/data. В Windows данный файл располагается в каталоге данных, по умолчанию это C:Program FilesPostgreSQL 1C1хdata. Все параметры указаны в порядке их следования в конфигурационном файла.
Одним из основных параметров, используемых при расчетах, является объем оперативной памяти. При этом следует использовать то значение, которое вы готовы выделить серверу СУБД, за вычетом ОЗУ используемой ОС и другими службами, скажем, сервером 1С. В нашем случае будет использоваться значение в 24 ГБ.
Затем рассчитаем значения отдельных параметров с помощью калькулятора, для чего укажем ОС и версию Postgres, тип накопителя, количество доступной памяти и количество ядер процессора. В поле DB Type указываем Data Warehouses, количество соединений можем проигнорировать, так как вычисляемый результат будет значительно расходиться с рекомендациями 1С.
Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
max_connections = 500..1000Максимальное число соединений, 1С рекомендует указанные выше значения, мы установили 1000.
shared_buffers = RAM/4Объем памяти для совместного кеша страниц, разделяется между всеми процессами Postgres, рекомендуемое значение — четверть доступного объема памяти, в нашем случае 6 ГБ.
temp_buffers = 256MBВерхний лимит для временных таблиц в каждой сессии, рекомендуется фиксированное значение.
work_mem = RAM/32..64Указывает объем памяти, который может быть использован для запроса прежде, чем будут задействованы временные файлы на диске. Применяется для каждого соединения и каждой операции, поэтому итоговый объем используемой памяти может существенно превосходить указанное значение. Это один из тех параметров, вычисляемое значение которого калькулятором существенно отличается от рекомендаций 1С. Для объема памяти в 24 ГБ рекомендуемыми значениями будут 375 — 750 МБ, мы выбрали 512 МБ.
maintenance_work_mem = RAM/16..32 или work_mem * 4Объем памяти для обслуживающих задач (автовакуум, реиндексация и т.д.), указываем рекомендованный калькулятором объем, в нашем случае 2 ГБ.
max_files_per_process = 1000Максимальное количество открытых файлов на один процесс, в сборке от PostgresPro для Linux это значение по умолчанию.
bgwriter_delay = 20ms
bgwriter_lru_maxpages = 400
bgwriter_lru_multiplier = 4.0Параметры процесса фоновой записи, который отвечает за синхронизацию страниц в shared_buffers с диском.
effective_io_concurrency = 2 для RAID, 200 для SSD, 500..1000 для NVMeДопустимое число одновременных операций ввода/вывода. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 200, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно.
Важно! Параметр effective_io_concurrency настраивается только в среде Linux, в Windows системах его значение должно быть равно нулю.
max_worker_processes = 4
max_parallel_workers_per_gather = 2
max_parallel_workers = 4
max_parallel_maintenance_workers = 2Настройки фоновых рабочих процессов, выбираются исходя из количества процессорных ядер, берем значения из калькулятора. Выше указаны настройки для четырехъядерного СРU.
fsync = onЗаставляет сервер добиваться физической записи изменений на диск. Выключение данной опции хотя и позволяет повысить производительность, но значительно увеличивает риск неисправимой порчи данных при внезапном выключении питания.
synchronous_commit = offАльтернатива отключению fsync, позволяет серверу не ждать сохранения данных на диске, прежде чем сообщить клиенту об успешном завершении операции. Позволяет достаточно безопасно повысить производительность работы. В случае внезапного выключения питания могут быть потеряны несколько последних транзакций, но сама база останется в рабочем состоянии, также, как и при штатной отмене потерянных транзакций.
wal_buffers = 16MBЗадает размер буферов журнала предзаписи (WAL, он же журнал транзакций), если оставить эту настройку без изменений, то сервер будет автоматически устанавливать это значение в 1/32 от shared_buffers, но не менее 64 КБ и не более размера одного сегмента WAL в 16 МБ.
commit_delay = 1000
commit_siblings = 5Указывает задержку в мс перед записью транзакций на диск при числе открытых транзакций, указанных во второй опции. Имеет смысл при количестве транзакций более 1000 в секунду, на меньших значениях эффекта не имеет.
min_wal_size = 512MB..4G
max_wal_size = 2..4 * min_wal_sizeМинимальный и максимальный размер файлов журнала предзаписи. Указываем значения из калькулятора, в нашем случае это 4 ГБ и 16 ГБ.
checkpoint_completion_target = 0.5..0.9Скорость записи изменений на диск, рассчитывается как время между точками сохранения транзакций (чекпойнты) умноженное на данный показатель, позволяет растянуть процесс записи по времени и тем самым снизить одномоментную нагрузку на диски. В нашем случае использовано рекомендованное калькулятором максимальное значение 0,9.
seq_page_cost = 1.0Стоимость последовательного чтения с диска, является относительным числом, вокруг которого определяются все остальные переменные стоимости, данное значение является значением по умолчанию.
random_page_cost = 1.5..2.0 для RAID, 1.1..1.3 для SSDСтоимость случайного чтения с диска, чем ниже это число, тем более вероятно использование сканирования по индексу, нежели полное считывание таблицы, однако не следует указывать слишком низких, не соответствующих реальной производительности дисковой подсистемы, значений, иначе вы можете получить обратный эффект, когда производительность упрется в медленный случайный доступ.
Так как это относительные значения, но не имеет смысла устанавливать random_page_cost ниже seq_page_cost, однако при применении производительных SSD имеет смысл понизить стоимость обоих значений, чтобы повысить приоритет дисковых операций по отношению к процессорным.
Для производительных SSD можно использовать значения:
seq_page_cost = 0.5
random_page_cost = 0.5А для NVme:
seq_page_cost = 0.1
random_page_cost = 0.1Но еще раз напомним, данные значения не являются панацеей и должны устанавливаться осмысленно, с реальным пониманием производительности дисковой подсистемы сервера, бездумное копирование настроек способно привести к обратному эффекту.
effective_cache_size = RAM - shared_buffersОпределяет эффективный размер кеша, который может использоваться при одном запросе. Этот параметр не влияет на размер выделяемой памяти, не резервирует ее, а служит для ориентировочной оценки доступного размера кеша планировщиком запросов. Чем он выше, тем большая вероятность использования сканирования по индексу, а не последовательного сканирования. При расчете следует использовать выделенный серверу объем RAM, а не полный объем ОЗУ. В нашем случае это 18 ГБ.
autovacuum = onВключение автовакуума, это очень важный для производительности базы параметр. Не отключайте его!
autovacuum_max_workers = NCores/4..2 но не меньше 4Количество рабочих процессов автовакуума, рассчитывается по числу процессорных ядер, не менее 4, в нашем случае 4.
autovacuum_naptime = 20sВремя сна процессов автовакуума, большое значение будет приводить к неэффективно работе, слишком малое только повысит нагрузку без видимого эффекта.
row_security = offОтключает политику защиты на уровне строк, данная опция не используется платформой и ее отключение дает некоторое повышение производительности.
max_locks_per_transaction = 256 Максимальное количество блокировок в одной транзакции, рекомендация от 1С.
escape_string_warning = off
standard_conforming_strings = offДанные опции специфичны для 1С и регулируют использование символа для экранирования.
Сохраним файл конфигурации и перезапустим PostgreSQL, в Linux это можно выполнить командами:
pg-setup service stop
pg-setup service start
В Windows штатными средствами операционной системы, либо скриптами из поставки сборки PostgreSQL:
После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Указанные выше настройки и параметры являются базовым набором для оптимизации PostgreSQL при совместной работе с 1С:Предприятие и доступны даже начинающим администраторам. Для выполнения этих действий не требуется глубокого понимания работы СУБД, достаточно просто правильно рассчитать ряд значений. Данные рекомендации основаны на официальных и рекомендуются в качестве базовой настройки сервера СУБД сразу после инсталляции.
read more at Записки IT специалиста
Существуют разные рекомендации по оптимизации PostgreSQL для совместной работы с 1С, мы будем опираться на официальные рекомендации, изложенные на ИТС, также можно использовать онлайн-калькулятор для быстрого расчета некоторых параметров. Если данные калькулятора и рекомендации 1С будут расходиться — то предпочтение будет отдано рекомендациям 1С.
Для тестирования мы использовали систему:
- CPU — Core i5-4670 — 3.4/3.8 ГГц
- RAM — 32 ГБ DDR3
- Системный диск — SSD WD Green 120 ГБ
- Диск для данных — 2 х SSD Samsung 860 EVO 250 ГБ — RAID1
- СУБД — PostgresPro 11.6
- Платформа — 8.3.16.1148
- ОС — Debian 10 x64
Прежде всего выполним тестирование с параметрами по умолчанию:
Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Перейдем к оптимизации. Все изменения следует вносить в файл postgesql.conf, который располагается в Linuх для сборки от 1С по пути /etc/postgres/1x/main, а для сборки от PostgresPro в /var/lib/pgpro/1c-1x/data. В Windows данный файл располагается в каталоге данных, по умолчанию это C:Program FilesPostgreSQL 1C1хdata. Все параметры указаны в порядке их следования в конфигурационном файла.
Одним из основных параметров, используемых при расчетах, является объем оперативной памяти. При этом следует использовать то значение, которое вы готовы выделить серверу СУБД, за вычетом ОЗУ используемой ОС и другими службами, скажем, сервером 1С. В нашем случае будет использоваться значение в 24 ГБ.
Затем рассчитаем значения отдельных параметров с помощью калькулятора, для чего укажем ОС и версию Postgres, тип накопителя, количество доступной памяти и количество ядер процессора. В поле DB Type указываем Data Warehouses, количество соединений можем проигнорировать, так как вычисляемый результат будет значительно расходиться с рекомендациями 1С.
Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
max_connections = 500..1000Максимальное число соединений, 1С рекомендует указанные выше значения, мы установили 1000.
shared_buffers = RAM/4Объем памяти для совместного кеша страниц, разделяется между всеми процессами Postgres, рекомендуемое значение — четверть доступного объема памяти, в нашем случае 6 ГБ.
temp_buffers = 256MBВерхний лимит для временных таблиц в каждой сессии, рекомендуется фиксированное значение.
work_mem = RAM/32..64Указывает объем памяти, который может быть использован для запроса прежде, чем будут задействованы временные файлы на диске. Применяется для каждого соединения и каждой операции, поэтому итоговый объем используемой памяти может существенно превосходить указанное значение. Это один из тех параметров, вычисляемое значение которого калькулятором существенно отличается от рекомендаций 1С. Для объема памяти в 24 ГБ рекомендуемыми значениями будут 375 — 750 МБ, мы выбрали 512 МБ.
maintenance_work_mem = RAM/16..32 или work_mem * 4Объем памяти для обслуживающих задач (автовакуум, реиндексация и т.д.), указываем рекомендованный калькулятором объем, в нашем случае 2 ГБ.
max_files_per_process = 1000Максимальное количество открытых файлов на один процесс, в сборке от PostgresPro для Linux это значение по умолчанию.
bgwriter_delay = 20ms
bgwriter_lru_maxpages = 400
bgwriter_lru_multiplier = 4.0Параметры процесса фоновой записи, который отвечает за синхронизацию страниц в shared_buffers с диском.
effective_io_concurrency = 2 для RAID, 200 для SSD, 500..1000 для NVMeДопустимое число одновременных операций ввода/вывода. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 200, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно.
Важно! Параметр effective_io_concurrency настраивается только в среде Linux, в Windows системах его значение должно быть равно нулю.
max_worker_processes = 4
max_parallel_workers_per_gather = 2
max_parallel_workers = 4
max_parallel_maintenance_workers = 2Настройки фоновых рабочих процессов, выбираются исходя из количества процессорных ядер, берем значения из калькулятора. Выше указаны настройки для четырехъядерного СРU.
fsync = onЗаставляет сервер добиваться физической записи изменений на диск. Выключение данной опции хотя и позволяет повысить производительность, но значительно увеличивает риск неисправимой порчи данных при внезапном выключении питания.
synchronous_commit = offАльтернатива отключению fsync, позволяет серверу не ждать сохранения данных на диске, прежде чем сообщить клиенту об успешном завершении операции. Позволяет достаточно безопасно повысить производительность работы. В случае внезапного выключения питания могут быть потеряны несколько последних транзакций, но сама база останется в рабочем состоянии, также, как и при штатной отмене потерянных транзакций.
wal_buffers = 16MBЗадает размер буферов журнала предзаписи (WAL, он же журнал транзакций), если оставить эту настройку без изменений, то сервер будет автоматически устанавливать это значение в 1/32 от shared_buffers, но не менее 64 КБ и не более размера одного сегмента WAL в 16 МБ.
commit_delay = 1000
commit_siblings = 5Указывает задержку в мс перед записью транзакций на диск при числе открытых транзакций, указанных во второй опции. Имеет смысл при количестве транзакций более 1000 в секунду, на меньших значениях эффекта не имеет.
min_wal_size = 512MB..4G
max_wal_size = 2..4 * min_wal_sizeМинимальный и максимальный размер файлов журнала предзаписи. Указываем значения из калькулятора, в нашем случае это 4 ГБ и 16 ГБ.
checkpoint_completion_target = 0.5..0.9Скорость записи изменений на диск, рассчитывается как время между точками сохранения транзакций (чекпойнты) умноженное на данный показатель, позволяет растянуть процесс записи по времени и тем самым снизить одномоментную нагрузку на диски. В нашем случае использовано рекомендованное калькулятором максимальное значение 0,9.
seq_page_cost = 1.0Стоимость последовательного чтения с диска, является относительным числом, вокруг которого определяются все остальные переменные стоимости, данное значение является значением по умолчанию.
random_page_cost = 1.5..2.0 для RAID, 1.1..1.3 для SSDСтоимость случайного чтения с диска, чем ниже это число, тем более вероятно использование сканирования по индексу, нежели полное считывание таблицы, однако не следует указывать слишком низких, не соответствующих реальной производительности дисковой подсистемы, значений, иначе вы можете получить обратный эффект, когда производительность упрется в медленный случайный доступ.
Так как это относительные значения, но не имеет смысла устанавливать random_page_cost ниже seq_page_cost, однако при применении производительных SSD имеет смысл понизить стоимость обоих значений, чтобы повысить приоритет дисковых операций по отношению к процессорным.
Для производительных SSD можно использовать значения:
seq_page_cost = 0.5
random_page_cost = 0.5А для NVme:
seq_page_cost = 0.1
random_page_cost = 0.1Но еще раз напомним, данные значения не являются панацеей и должны устанавливаться осмысленно, с реальным пониманием производительности дисковой подсистемы сервера, бездумное копирование настроек способно привести к обратному эффекту.
effective_cache_size = RAM - shared_buffersОпределяет эффективный размер кеша, который может использоваться при одном запросе. Этот параметр не влияет на размер выделяемой памяти, не резервирует ее, а служит для ориентировочной оценки доступного размера кеша планировщиком запросов. Чем он выше, тем большая вероятность использования сканирования по индексу, а не последовательного сканирования. При расчете следует использовать выделенный серверу объем RAM, а не полный объем ОЗУ. В нашем случае это 18 ГБ.
autovacuum = onВключение автовакуума, это очень важный для производительности базы параметр. Не отключайте его!
autovacuum_max_workers = NCores/4..2 но не меньше 4Количество рабочих процессов автовакуума, рассчитывается по числу процессорных ядер, не менее 4, в нашем случае 4.
autovacuum_naptime = 20sВремя сна процессов автовакуума, большое значение будет приводить к неэффективно работе, слишком малое только повысит нагрузку без видимого эффекта.
row_security = offОтключает политику защиты на уровне строк, данная опция не используется платформой и ее отключение дает некоторое повышение производительности.
max_locks_per_transaction = 256 Максимальное количество блокировок в одной транзакции, рекомендация от 1С.
escape_string_warning = off
standard_conforming_strings = offДанные опции специфичны для 1С и регулируют использование символа для экранирования.
Сохраним файл конфигурации и перезапустим PostgreSQL, в Linux это можно выполнить командами:
pg-setup service stop
pg-setup service start
В Windows штатными средствами операционной системы, либо скриптами из поставки сборки PostgreSQL:
После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Указанные выше настройки и параметры являются базовым набором для оптимизации PostgreSQL при совместной работе с 1С:Предприятие и доступны даже начинающим администраторам. Для выполнения этих действий не требуется глубокого понимания работы СУБД, достаточно просто правильно рассчитать ряд значений. Данные рекомендации основаны на официальных и рекомендуются в качестве базовой настройки сервера СУБД сразу после инсталляции.
источник: https://interface31.ru/tech_it/2020/03/optimizaciya-proizvoditel-nosti-p…