Project description
Beautiful Soup is a library that makes it easy to scrape information
from web pages. It sits atop an HTML or XML parser, providing Pythonic
idioms for iterating, searching, and modifying the parse tree.
Quick start
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<p>Some<b>bad<i>HTML")
>>> print(soup.prettify())
<html>
<body>
<p>
Some
<b>
bad
<i>
HTML
</i>
</b>
</p>
</body>
</html>
>>> soup.find(text="bad")
'bad'
>>> soup.i
<i>HTML</i>
#
>>> soup = BeautifulSoup("<tag1>Some<tag2/>bad<tag3>XML", "xml")
#
>>> print(soup.prettify())
<?xml version="1.0" encoding="utf-8"?>
<tag1>
Some
<tag2/>
bad
<tag3>
XML
</tag3>
</tag1>
To go beyond the basics, comprehensive documentation is available.
Links
- Homepage
- Documentation
- Discussion group
- Development
- Bug tracker
- Complete changelog
Note on Python 2 sunsetting
Beautiful Soup’s support for Python 2 was discontinued on December 31,
2020: one year after the sunset date for Python 2 itself. From this
point onward, new Beautiful Soup development will exclusively target
Python 3. The final release of Beautiful Soup 4 to support Python 2
was 4.9.3.
Supporting the project
If you use Beautiful Soup as part of your professional work, please consider a
Tidelift subscription.
This will support many of the free software projects your organization
depends on, not just Beautiful Soup.
If you use Beautiful Soup for personal projects, the best way to say
thank you is to read
Tool Safety, a zine I
wrote about what Beautiful Soup has taught me about software
development.
Building the documentation
The bs4/doc/ directory contains full documentation in Sphinx
format. Run make html in that directory to create HTML
documentation.
Running the unit tests
Beautiful Soup supports unit test discovery using Pytest:
$ pytest
Download files
Download the file for your platform. If you’re not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution

Beautiful Soup — это
библиотека Python для извлечения данных из файлов HTML и XML. Она работает
с вашим любимым парсером, чтобы дать вам естественные способы навигации,
поиска и изменения дерева разбора. Она обычно экономит программистам
часы и дни работы.
Эти инструкции иллюстрируют все основные функции Beautiful Soup 4
на примерах. Я покажу вам, для чего нужна библиотека, как она работает,
как ее использовать, как заставить ее делать то, что вы хотите, и что нужно делать, когда она
не оправдывает ваши ожидания.
Примеры в этой документации работают одинаково на Python 2.7
и Python 3.2.
Возможно, вы ищете документацию для Beautiful Soup 3.
Если это так, имейте в виду, что Beautiful Soup 3 больше не
развивается, и что поддержка этой версии будет прекращена
31 декабря 2020 года или немногим позже. Если вы хотите узнать о различиях между Beautiful Soup 3
и Beautiful Soup 4, читайте раздел Перенос кода на BS4.
Эта документация переведена на другие языки
пользователями Beautiful Soup:
- 这篇文档当然还有中文版.
- このページは日本語で利用できます(外部リンク)
- 이 문서는 한국어 번역도 가능합니다.
- Este documento também está disponível em Português do Brasil.
Быстрый старт¶
Вот HTML-документ, который я буду использовать в качестве примера в этой
документации. Это фрагмент из «Алисы в стране чудес»:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
Прогон документа через Beautiful Soup дает нам
объект BeautifulSoup, который представляет документ в виде
вложенной структуры данных:
from bs4 import BeautifulSoup soup = BeautifulSoup (html_doc, 'html.parser') print(soup.prettify()) # <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p class="title"> # <b> # The Dormouse's story # </b> # </p> # <p class="story"> # Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1"> # Elsie # </a> # , # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> # and # <a class="sister" href="http://example.com/tillie" id="link3"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p class="story"> # ... # </p> # </body> # </html>
Вот несколько простых способов навигации по этой структуре данных:
soup.title # <title>The Dormouse's story</title> soup.title.name # u'title' soup.title.string # u'The Dormouse's story' soup.title.parent.name # u'head' soup.p # <p class="title"><b>The Dormouse's story</b></p> soup.p['class'] # u'title' soup.a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find(id="link3") # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
Одна из распространенных задач — извлечь все URL-адреса, найденные на странице в тегах <a>:
for link in soup.find_all('a'): print(link.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
Другая распространенная задача — извлечь весь текст со страницы:
print(soup.get_text()) # The Dormouse's story # # The Dormouse's story # # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # # ...
Это похоже на то, что вам нужно? Если да, продолжайте читать.
Установка Beautiful Soup¶
Если вы используете последнюю версию Debian или Ubuntu Linux, вы можете
установить Beautiful Soup с помощью системы управления пакетами:
$ apt-get install python-bs4 (для Python 2)
$ apt-get install python3-bs4 (для Python 3)
Beautiful Soup 4 публикуется через PyPi, поэтому, если вы не можете установить библиотеку
с помощью системы управления пакетами, можно установить с помощью easy_install или
pip. Пакет называется beautifulsoup4. Один и тот же пакет
работает как на Python 2, так и на Python 3. Убедитесь, что вы используете версию
pip или easy_install, предназначенную для вашей версии Python (их можно назвать
pip3 и easy_install3 соответственно, если вы используете Python 3).
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
(BeautifulSoup — это, скорее всего, не тот пакет, который вам нужен. Это
предыдущий основной релиз, Beautiful Soup 3. Многие программы используют
BS3, так что он все еще доступен, но если вы пишете новый код,
нужно установить beautifulsoup4.)
Если у вас не установлены easy_install или pip, вы можете
скачать архив с исходным кодом Beautiful Soup 4 и
установить его с помощью setup.py.
$ python setup.py install
Если ничего не помогает, лицензия на Beautiful Soup позволяет
упаковать библиотеку целиком вместе с вашим приложением. Вы можете скачать
tar-архив, скопировать из него в кодовую базу вашего приложения каталог bs4
и использовать Beautiful Soup, не устанавливая его вообще.
Я использую Python 2.7 и Python 3.2 для разработки Beautiful Soup, но библиотека
должна работать и с более поздними версиями Python.
Проблемы после установки¶
Beautiful Soup упакован как код Python 2. Когда вы устанавливаете его для
использования с Python 3, он автоматически конвертируется в код Python 3. Если
вы не устанавливаете библиотеку в виде пакета, код не будет сконвертирован. Были
также сообщения об установке неправильной версии на компьютерах с
Windows.
Если выводится сообщение ImportError “No module named HTMLParser”, ваша
проблема в том, что вы используете версию кода на Python 2, работая на
Python 3.
Если выводится сообщение ImportError “No module named html.parser”, ваша
проблема в том, что вы используете версию кода на Python 3, работая на
Python 2.
В обоих случаях лучше всего полностью удалить Beautiful
Soup с вашей системы (включая любой каталог, созданный
при распаковке tar-архива) и запустить установку еще раз.
Если выводится сообщение SyntaxError “Invalid syntax” в строке
ROOT_TAG_NAME = u'[document]', вам нужно конвертировать код из Python 2
в Python 3. Вы можете установить пакет:
$ python3 setup.py install
или запустить вручную Python-скрипт 2to3
в каталоге bs4:
$ 2to3-3.2 -w bs4
Установка парсера¶
Beautiful Soup поддерживает парсер HTML, включенный в стандартную библиотеку Python,
а также ряд сторонних парсеров на Python.
Одним из них является парсер lxml. В зависимости от ваших настроек,
вы можете установить lxml с помощью одной из следующих команд:
$ apt-get install python-lxml
$ easy_install lxml
$ pip install lxml
Другая альтернатива — написанный исключительно на Python парсер html5lib, который разбирает HTML таким же образом,
как это делает веб-браузер. В зависимости от ваших настроек, вы можете установить html5lib
с помощью одной из этих команд:
$ apt-get install python-html5lib
$ easy_install html5lib
$ pip install html5lib
Эта таблица суммирует преимущества и недостатки каждого парсера:
| Парсер | Типичное использование | Преимущества | Недостатки |
| html.parser от Python | BeautifulSoup(markup, "html.parser") |
|
|
| HTML-парсер в lxml | BeautifulSoup(markup, "lxml") |
|
|
| XML-парсер в lxml | BeautifulSoup(markup, "lxml-xml")BeautifulSoup(markup, "xml") |
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
Я рекомендую по возможности установить и использовать lxml для быстродействия. Если вы
используете версию Python 2 более раннюю, чем 2.7.3, или версию Python 3
более раннюю, чем 3.2.2, необходимо установить lxml или
html5lib, потому что встроенный в Python парсер HTML просто недостаточно хорош в старых
версиях.
Обратите внимание, что если документ невалиден, различные парсеры будут генерировать
дерево Beautiful Soup для этого документа по-разному. Ищите подробности в разделе Различия
между парсерами.
Приготовление супа¶
Чтобы разобрать документ, передайте его в
конструктор BeautifulSoup. Вы можете передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup with open("index.html") as fp: soup = BeautifulSoup(fp) soup = BeautifulSoup("<html>data</html>")
Первым делом документ конвертируется в Unicode, а HTML-мнемоники
конвертируются в символы Unicode:
BeautifulSoup("Sacré bleu!")
<html><head></head><body>Sacré bleu!</body></html>
Затем Beautiful Soup анализирует документ, используя лучший из доступных
парсеров. Библиотека будет использовать HTML-парсер, если вы явно не укажете,
что нужно использовать XML-парсер. (См. Разбор XML.)
Виды объектов¶
Beautiful Soup превращает сложный HTML-документ в сложное дерево
объектов Python. Однако вам придется иметь дело только с четырьмя
видами объектов: Tag, NavigableString, BeautifulSoup
и Comment.
Tag¶
Объект Tag соответствует тегу XML или HTML в исходном документе:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') tag = soup.b type(tag) # <class 'bs4.element.Tag'>
У объекта Tag (далее «тег») много атрибутов и методов, и я расскажу о большинстве из них
в разделах Навигация по дереву и Поиск по дереву. На данный момент наиболее
важными особенностями тега являются его имя и атрибуты.
Имя¶
У каждого тега есть имя, доступное как .name:
Если вы измените имя тега, это изменение будет отражено в любой HTML-
разметке, созданной Beautiful Soup:
tag.name = "blockquote" tag # <blockquote class="boldest">Extremely bold</blockquote>
Атрибуты¶
У тега может быть любое количество атрибутов. Тег <b имеет атрибут “id”, значение которого равно
id = "boldest">
“boldest”. Вы можете получить доступ к атрибутам тега, обращаясь с тегом как
со словарем:
Вы можете получить доступ к этому словарю напрямую как к .attrs:
tag.attrs # {u'id': 'boldest'}
Вы можете добавлять, удалять и изменять атрибуты тега. Опять же, это
делается путем обращения с тегом как со словарем:
tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # <b another-attribute="1" id="verybold"></b> del tag['id'] del tag['another-attribute'] tag # <b></b> tag['id'] # KeyError: 'id' print(tag.get('id')) # None
Многозначные атрибуты¶
В HTML 4 определено несколько атрибутов, которые могут иметь множество значений. В HTML 5
пара таких атрибутов удалена, но определено еще несколько. Самый распространённый из
многозначных атрибутов — это class (т. е. тег может иметь более
одного класса CSS). Среди прочих rel, rev, accept-charset,
headers и accesskey. Beautiful Soup представляет значение(я)
многозначного атрибута в виде списка:
css_soup = BeautifulSoup('<p class="body"></p>') css_soup.p['class'] # ["body"] css_soup = BeautifulSoup('<p class="body strikeout"></p>') css_soup.p['class'] # ["body", "strikeout"]
Если атрибут выглядит так, будто он имеет более одного значения, но это не
многозначный атрибут, определенный какой-либо версией HTML-
стандарта, Beautiful Soup оставит атрибут как есть:
id_soup = BeautifulSoup('<p id="my id"></p>') id_soup.p['id'] # 'my id'
Когда вы преобразовываете тег обратно в строку, несколько значений атрибута
объединяются:
rel_soup = BeautifulSoup('<p>Back to the <a rel="index">homepage</a></p>') rel_soup.a['rel'] # ['index'] rel_soup.a['rel'] = ['index', 'contents'] print(rel_soup.p) # <p>Back to the <a rel="index contents">homepage</a></p>
Вы можете отключить объединение, передав multi_valued_attributes = None в качестве
именованного аргумента в конструктор BeautifulSoup:
no_list_soup = BeautifulSoup('<p class="body strikeout"></p>', 'html', multi_valued_attributes=None) no_list_soup.p['class'] # u'body strikeout'
Вы можете использовать get_attribute_list, того чтобы получить значение в виде списка,
независимо от того, является ли атрибут многозначным или нет:
id_soup.p.get_attribute_list('id') # ["my id"]
Если вы разбираете документ как XML, многозначных атрибутов не будет:
xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml') xml_soup.p['class'] # u'body strikeout'
Опять же, вы можете поменять настройку, используя аргумент multi_valued_attributes:
class_is_multi= { '*' : 'class'} xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml', multi_valued_attributes=class_is_multi) xml_soup.p['class'] # [u'body', u'strikeout']
Вряд ли вам это пригодится, но если все-таки будет нужно, руководствуйтесь значениями
по умолчанию. Они реализуют правила, описанные в спецификации HTML:
from bs4.builder import builder_registry builder_registry.lookup('html').DEFAULT_CDATA_LIST_ATTRIBUTES
NavigableString¶
Строка соответствует фрагменту текста в теге. Beautiful Soup
использует класс NavigableString для хранения этих фрагментов текста:
tag.string # u'Extremely bold' type(tag.string) # <class 'bs4.element.NavigableString'>
NavigableString похожа на строку Unicode в Python, не считая того,
что она также поддерживает некоторые функции, описанные в
разделах Навигация по дереву и Поиск по дереву. Вы можете конвертировать
NavigableString в строку Unicode с помощью unicode():
unicode_string = unicode(tag.string) unicode_string # u'Extremely bold' type(unicode_string) # <type 'unicode'>
Вы не можете редактировать строку непосредственно, но вы можете заменить одну строку
другой, используя replace_with():
tag.string.replace_with("No longer bold") tag # <blockquote>No longer bold</blockquote>
NavigableString поддерживает большинство функций, описанных в
разделах Навигация по дереву и Поиск по дереву, но
не все. В частности, поскольку строка не может ничего содержать (в том смысле,
в котором тег может содержать строку или другой тег), строки не поддерживают
атрибуты .contents и .string или метод find().
Если вы хотите использовать NavigableString вне Beautiful Soup,
вам нужно вызвать метод unicode(), чтобы превратить ее в обычную для Python
строку Unicode. Если вы этого не сделаете, ваша строка будет тащить за собой
ссылку на все дерево разбора Beautiful Soup, даже когда вы
закончите использовать Beautiful Soup. Это большой расход памяти.
BeautifulSoup¶
Объект BeautifulSoup представляет разобранный документ как единое
целое. В большинстве случаев вы можете рассматривать его как объект
Tag. Это означает, что он поддерживает большинство методов, описанных
в разделах Навигация по дереву и Поиск по дереву.
Вы также можете передать объект BeautifulSoup в один из методов,
перечисленных в разделе Изменение дерева, по аналогии с передачей объекта Tag. Это
позволяет вам делать такие вещи, как объединение двух разобранных документов:
doc = BeautifulSoup("<document><content/>INSERT FOOTER HERE</document", "xml") footer = BeautifulSoup("<footer>Here's the footer</footer>", "xml") doc.find(text="INSERT FOOTER HERE").replace_with(footer) # u'INSERT FOOTER HERE' print(doc) # <?xml version="1.0" encoding="utf-8"?> # <document><content/><footer>Here's the footer</footer></document>
Поскольку объект BeautifulSoup не соответствует действительному
HTML- или XML-тегу, у него нет имени и атрибутов. Однако иногда
бывает полезно взглянуть на .name объекта BeautifulSoup, поэтому ему было присвоено специальное «имя»
.name “[document]”:
soup.name # u'[document]'
Комментарии и другие специфичные строки¶
Tag, NavigableString и BeautifulSoup охватывают почти
все, с чем вы столкнётесь в файле HTML или XML, но осталось
ещё немного. Пожалуй, единственное, о чем стоит волноваться,
это комментарий:
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>" soup = BeautifulSoup(markup) comment = soup.b.string type(comment) # <class 'bs4.element.Comment'>
Объект Comment — это просто особый тип NavigableString:
comment # u'Hey, buddy. Want to buy a used parser'
Но когда он появляется как часть HTML-документа, Comment
отображается со специальным форматированием:
print(soup.b.prettify()) # <b> # <!--Hey, buddy. Want to buy a used parser?--> # </b>
Beautiful Soup определяет классы для всего, что может появиться в
XML-документе: CData, ProcessingInstruction,
Declaration и Doctype. Как и Comment, эти классы
являются подклассами NavigableString, которые добавляют что-то еще к
строке. Вот пример, который заменяет комментарий блоком
CDATA:
from bs4 import CData cdata = CData("A CDATA block") comment.replace_with(cdata) print(soup.b.prettify()) # <b> # <![CDATA[A CDATA block]]> # </b>
Навигация по дереву¶
Вернемся к HTML-документу с фрагментом из «Алисы в стране чудес»:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup (html_doc, 'html.parser')
Я буду использовать его в качестве примера, чтобы показать, как перейти от одной части
документа к другой.
Проход сверху вниз¶
Теги могут содержать строки и другие теги. Эти элементы являются
дочерними (children) для тега. Beautiful Soup предоставляет множество различных атрибутов для
навигации и перебора дочерних элементов.
Обратите внимание, что строки Beautiful Soup не поддерживают ни один из этих
атрибутов, потому что строка не может иметь дочерних элементов.
Навигация с использованием имен тегов¶
Самый простой способ навигации по дереву разбора — это указать имя
тега, который вам нужен. Если вы хотите получить тег <head>, просто напишите soup.head:
soup.head # <head><title>The Dormouse's story</title></head> soup.title # <title>The Dormouse's story</title>
Вы можете повторять этот трюк многократно, чтобы подробнее рассмотреть определенную часть
дерева разбора. Следующий код извлекает первый тег <b> внутри тега <body>:
soup.body.b # <b>The Dormouse's story</b>
Использование имени тега в качестве атрибута даст вам только первый тег с таким
именем:
soup.a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
Если вам нужно получить все теги <a> или что-нибудь более сложное,
чем первый тег с определенным именем, вам нужно использовать один из
методов, описанных в разделе Поиск по дереву, такой как find_all():
soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
.contents и .children¶
Дочерние элементы доступны в списке под названием .contents:
head_tag = soup.head head_tag # <head><title>The Dormouse's story</title></head> head_tag.contents [<title>The Dormouse's story</title>] title_tag = head_tag.contents[0] title_tag # <title>The Dormouse's story</title> title_tag.contents # [u'The Dormouse's story']
Сам объект BeautifulSoup имеет дочерние элементы. В этом случае
тег <html> является дочерним для объекта BeautifulSoup:
len(soup.contents) # 1 soup.contents[0].name # u'html'
У строки нет .contents, потому что она не может содержать
ничего:
text = title_tag.contents[0] text.contents # AttributeError: У объекта 'NavigableString' нет атрибута 'contents'
Вместо того, чтобы получать дочерние элементы в виде списка, вы можете перебирать их
с помощью генератора .children:
for child in title_tag.children: print(child) # The Dormouse's story
.descendants¶
Атрибуты .contents и .children применяются только в отношении
непосредственных дочерних элементов тега. Например, тег <head> имеет только один непосредственный
дочерний тег <title>:
head_tag.contents # [<title>The Dormouse's story</title>]
Но у самого тега <title> есть дочерний элемент: строка “The Dormouse’s
story”. В некотором смысле эта строка также является дочерним элементом
тега <head>. Атрибут .descendants позволяет перебирать все
дочерние элементы тега рекурсивно: его непосредственные дочерние элементы, дочерние элементы
дочерних элементов и так далее:
for child in head_tag.descendants: print(child) # <title>The Dormouse's story</title> # The Dormouse's story
У тега <head> есть только один дочерний элемент, но при этом у него два потомка:
тег <title> и его дочерний элемент. У объекта BeautifulSoup
только один прямой дочерний элемент (тег <html>), зато множество
потомков:
len(list(soup.children)) # 1 len(list(soup.descendants)) # 25
.string¶
Если у тега есть только один дочерний элемент, и это NavigableString,
его можно получить через .string:
title_tag.string # u'The Dormouse's story'
Если единственным дочерним элементом тега является другой тег, и у этого другого тега есть строка
.string, то считается, что родительский тег содержит ту же строку
.string, что и дочерний тег:
head_tag.contents # [<title>The Dormouse's story</title>] head_tag.string # u'The Dormouse's story'
Если тег содержит больше чем один элемент, то становится неясным, какая из строк
.string относится и к родительскому тегу, поэтому .string родительского тега имеет значение
None:
print(soup.html.string) # None
.strings и .stripped_strings¶
Если внутри тега есть более одного элемента, вы все равно можете посмотреть только на
строки. Используйте генератор .strings:
for string in soup.strings: print(repr(string)) # u"The Dormouse's story" # u'nn' # u"The Dormouse's story" # u'nn' # u'Once upon a time there were three little sisters; and their names weren' # u'Elsie' # u',n' # u'Lacie' # u' andn' # u'Tillie' # u';nand they lived at the bottom of a well.' # u'nn' # u'...' # u'n'
В этих строках много лишних пробелов, которые вы можете
удалить, используя генератор .stripped_strings:
for string in soup.stripped_strings: print(repr(string)) # u"The Dormouse's story" # u"The Dormouse's story" # u'Once upon a time there were three little sisters; and their names were' # u'Elsie' # u',' # u'Lacie' # u'and' # u'Tillie' # u';nand they lived at the bottom of a well.' # u'...'
Здесь строки, состоящие исключительно из пробелов, игнорируются, а
пробелы в начале и конце строк удаляются.
Проход снизу вверх¶
В продолжение аналогии с «семейным деревом», каждый тег и каждая строка имеет
родителя (parent): тег, который его содержит.
.parent¶
Вы можете получить доступ к родительскому элементу с помощью атрибута .parent. В
примере документа с фрагментом из «Алисы в стране чудес» тег <head> является родительским
для тега <title>:
title_tag = soup.title title_tag # <title>The Dormouse's story</title> title_tag.parent # <head><title>The Dormouse's story</title></head>
Строка заголовка сама имеет родителя: тег <title>, содержащий
ее:
title_tag.string.parent # <title>The Dormouse's story</title>
Родительским элементом тега верхнего уровня, такого как <html>, является сам объект
BeautifulSoup:
html_tag = soup.html type(html_tag.parent) # <class 'bs4.BeautifulSoup'>
И .parent объекта BeautifulSoup определяется как None:
print(soup.parent) # None
.parents¶
Вы можете перебрать всех родителей элемента с помощью
.parents. В следующем примере .parents используется для перемещения от тега <a>,
закопанного глубоко внутри документа, до самого верха документа:
link = soup.a link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> for parent in link.parents: if parent is None: print(parent) else: print(parent.name) # p # body # html # [document] # None
Перемещение вбок¶
Рассмотрим простой документ:
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>") print(sibling_soup.prettify()) # <html> # <body> # <a> # <b> # text1 # </b> # <c> # text2 # </c> # </a> # </body> # </html>
Тег <b> и тег <c> находятся на одном уровне: они оба непосредственные
дочерние элементы одного и того же тега. Мы называем их одноуровневые. Когда документ
красиво отформатирован, одноуровневые элементы выводятся с одинаковым отступом. Вы
также можете использовать это отношение в написанном вами коде.
.next_sibling и .previous_sibling¶
Вы можете использовать .next_sibling и .previous_sibling для навигации
между элементами страницы, которые находятся на одном уровне дерева разбора:
sibling_soup.b.next_sibling # <c>text2</c> sibling_soup.c.previous_sibling # <b>text1</b>
У тега <b> есть .next_sibling, но нет .previous_sibling,
потому что нет ничего до тега <b> на том же уровне
дерева. По той же причине у тега <c> есть .previous_sibling,
но нет .next_sibling:
print(sibling_soup.b.previous_sibling) # None print(sibling_soup.c.next_sibling) # None
Строки “text1” и “text2” не являются одноуровневыми, потому что они не
имеют общего родителя:
sibling_soup.b.string # u'text1' print(sibling_soup.b.string.next_sibling) # None
В реальных документах .next_sibling или .previous_sibling
тега обычно будет строкой, содержащей пробелы. Возвращаясь к
фрагменту из «Алисы в стране чудес»:
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
Вы можете подумать, что .next_sibling первого тега <a>
должен быть второй тег <a>. Но на самом деле это строка: запятая и
перевод строки, отделяющий первый тег <a> от второго:
link = soup.a link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> link.next_sibling # u',n'
Второй тег <a> на самом деле является .next_sibling запятой
link.next_sibling.next_sibling # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
.next_siblings и .previous_siblings¶
Вы можете перебрать одноуровневые элементы данного тега с помощью .next_siblings или
.previous_siblings:
for sibling in soup.a.next_siblings: print(repr(sibling)) # u',n' # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> # u' andn' # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> # u'; and they lived at the bottom of a well.' # None for sibling in soup.find(id="link3").previous_siblings: print(repr(sibling)) # ' andn' # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> # u',n' # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> # u'Once upon a time there were three little sisters; and their names weren' # None
Проход вперед и назад¶
Взгляните на начало фрагмента из «Алисы в стране чудес»:
<html><head><title>The Dormouse's story</title></head> <p class="title"><b>The Dormouse's story</b></p>
HTML-парсер берет эту строку символов и превращает ее в
серию событий: “открыть тег <html>”, “открыть тег <head>”, “открыть
тег <html>”, “добавить строку”, “закрыть тег <title>”, “открыть
тег <p>” и так далее. Beautiful Soup предлагает инструменты для реконструирование
первоначального разбора документа.
.next_element и .previous_element¶
Атрибут .next_element строки или тега указывает на то,
что было разобрано непосредственно после него. Это могло бы быть тем же, что и
.next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a> в фрагменте из «Алисы в стране чудес». Его
.next_sibling является строкой: конец предложения, которое было
прервано началом тега <a>:
last_a_tag = soup.find("a", id="link3") last_a_tag # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> last_a_tag.next_sibling # '; and they lived at the bottom of a well.'
Но .next_element этого тега <a> — это то, что было разобрано
сразу после тега <a>, не остальная часть этого предложения:
это слово “Tillie”:
last_a_tag.next_element # u'Tillie'
Это потому, что в оригинальной разметке слово «Tillie» появилось
перед точкой с запятой. Парсер обнаружил тег <a>, затем
слово «Tillie», затем закрывающий тег </a>, затем точку с запятой и оставшуюся
часть предложения. Точка с запятой находится на том же уровне, что и тег <a>, но
слово «Tillie» встретилось первым.
Атрибут .previous_element является полной противоположностью
.next_element. Он указывает на элемент, который был встречен при разборе
непосредственно перед текущим:
last_a_tag.previous_element # u' andn' last_a_tag.previous_element.next_element # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
.next_elements и .previous_elements¶
Вы уже должны были уловить идею. Вы можете использовать их для перемещения
вперед или назад по документу, в том порядке, в каком он был разобран парсером:
for element in last_a_tag.next_elements: print(repr(element)) # u'Tillie' # u';nand they lived at the bottom of a well.' # u'nn' # <p class="story">...</p> # u'...' # u'n' # None
Поиск по дереву¶
Beautiful Soup определяет множество методов поиска по дереву разбора,
но они все очень похожи. Я буду долго объяснять, как работают
два самых популярных метода: find() и find_all(). Прочие
методы принимают практически те же самые аргументы, поэтому я расскажу
о них вкратце.
И опять, я буду использовать фрагмент из «Алисы в стране чудес» в качестве примера:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup (html_doc, 'html.parser')
Передав фильтр в аргумент типа find_all(), вы можете
углубиться в интересующие вас части документа.
Виды фильтров¶
Прежде чем подробно рассказывать о find_all() и подобных методах, я
хочу показать примеры различных фильтров, которые вы можете передать в эти
методы. Эти фильтры появляются снова и снова в
поисковом API. Вы можете использовать их для фильтрации по имени тега,
по его атрибутам, по тексту строки или по некоторой их
комбинации.
Строка¶
Самый простой фильтр — это строка. Передайте строку в метод поиска, и
Beautiful Soup выполнит поиск соответствия этой строке. Следующий
код находит все теги <b> в документе:
soup.find_all('b') # [<b>The Dormouse's story</b>]
Если вы передадите байтовую строку, Beautiful Soup будет считать, что строка
кодируется в UTF-8. Вы можете избежать этого, передав вместо нее строку Unicode.
Регулярное выражение¶
Если вы передадите объект с регулярным выражением, Beautiful Soup отфильтрует результаты
в соответствии с этим регулярным выражением, используя его метод search(). Следующий код
находит все теги, имена которых начинаются с буквы “b”; в нашем
случае это теги <body> и <b>:
import re for tag in soup.find_all(re.compile("^b")): print(tag.name) # body # b
Этот код находит все теги, имена которых содержат букву “t”:
for tag in soup.find_all(re.compile("t")): print(tag.name) # html # title
Список¶
Если вы передадите список, Beautiful Soup разрешит совпадение строк
с любым элементом из этого списка. Следующий код находит все теги <a>
и все теги <b>:
soup.find_all(["a", "b"]) # [<b>The Dormouse's story</b>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
True¶
Значение True подходит везде, где возможно.. Следующий код находит все
теги в документе, но не текстовые строки:
for tag in soup.find_all(True): print(tag.name) # html # head # title # body # p # b # p # a # a # a # p
Функция¶
Если ничто из перечисленного вам не подходит, определите функцию, которая
принимает элемент в качестве единственного аргумента. Функция должна вернуть
True, если аргумент подходит, и False, если нет.
Вот функция, которая возвращает True, если в теге определен атрибут “class”,
но не определен атрибут “id”:
def has_class_but_no_id(tag): return tag.has_attr('class') and not tag.has_attr('id')
Передайте эту функцию в find_all(), и вы получите все
теги <p>:
soup.find_all(has_class_but_no_id) # [<p class="title"><b>The Dormouse's story</b></p>, # <p class="story">Once upon a time there were...</p>, # <p class="story">...</p>]
Эта функция выбирает только теги <p>. Она не выбирает теги <a>,
поскольку в них определены и атрибут “class” , и атрибут “id”. Она не выбирает
теги вроде <html> и <title>, потому что в них не определен атрибут
“class”.
Если вы передаете функцию для фильтрации по определенному атрибуту, такому как
href, аргументом, переданным в функцию, будет
значение атрибута, а не весь тег. Вот функция, которая находит все теги a,
у которых атрибут href не соответствует регулярному выражению:
def not_lacie(href): return href and not re.compile("lacie").search(href) soup.find_all(href=not_lacie) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Функция может быть настолько сложной, насколько вам нужно. Вот
функция, которая возвращает True, если тег окружен строковыми
объектами:
from bs4 import NavigableString def surrounded_by_strings(tag): return (isinstance(tag.next_element, NavigableString) and isinstance(tag.previous_element, NavigableString)) for tag in soup.find_all(surrounded_by_strings): print tag.name # p # a # a # a # p
Теперь мы готовы подробно рассмотреть методы поиска.
find_all()¶
Сигнатура: find_all(name, attrs, recursive, string, limit, **kwargs)
Метод find_all() просматривает потомков тега и
извлекает всех потомков, которые соответствую вашим фильтрам. Я привел несколько
примеров в разделе Виды фильтров, а вот еще несколько:
soup.find_all("title") # [<title>The Dormouse's story</title>] soup.find_all("p", "title") # [<p class="title"><b>The Dormouse's story</b></p>] soup.find_all("a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find_all(id="link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] import re soup.find(string=re.compile("sisters")) # u'Once upon a time there were three little sisters; and their names weren'
Кое-что из этого нам уже знакомо, но есть и новое. Что означает
передача значения для string или id? Почему
find_all ("p", "title") находит тег <p> с CSS-классом “title”?
Давайте посмотрим на аргументы find_all().
Аргумент name¶
Передайте значение для аргумента name, и вы скажете Beautiful Soup
рассматривать только теги с определенными именами. Текстовые строки будут игнорироваться, так же как и
теги, имена которых не соответствуют заданным.
Вот простейший пример использования:
soup.find_all("title") # [<title>The Dormouse's story</title>]
В разделе Виды фильтров говорилось, что значением name может быть
строка, регулярное выражение, список, функция или
True.
Именованные аргументы¶
Любой нераспознанный аргумент будет превращен в фильтр
по атрибуту тега. Если вы передаете значение для аргумента с именем id,
Beautiful Soup будет фильтровать по атрибуту “id” каждого тега:
soup.find_all(id='link2') # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Если вы передадите значение для href, Beautiful Soup отфильтрует
по атрибуту “href” каждого тега:
soup.find_all(href=re.compile("elsie")) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
Для фильтрации по атрибуту может использоваться строка, регулярное
выражение, список, функция или значение True.
Следующий код находит все теги, атрибут id которых имеет значение,
независимо от того, что это за значение:
soup.find_all(id=True) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Вы можете отфильтровать несколько атрибутов одновременно, передав более одного
именованного аргумента:
soup.find_all(href=re.compile("elsie"), id='link1') # [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]
Некоторые атрибуты, такие как атрибуты data-* в HTML 5, имеют имена, которые
нельзя использовать в качестве имен именованных аргументов:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>') data_soup.find_all(data-foo="value") # SyntaxError: keyword can't be an expression
Вы можете использовать эти атрибуты в поиске, поместив их в
словарь и передав словарь в find_all() как
аргумент attrs:
data_soup.find_all(attrs={"data-foo": "value"}) # [<div data-foo="value">foo!</div>]
Нельзя использовать именованный аргумент для поиска в HTML по элементу “name”,
потому что Beautiful Soup использует аргумент name для имени
самого тега. Вместо этого вы можете передать элемент “name” вместе с его значением в
составе аргумента attrs:
name_soup = BeautifulSoup('<input name="email"/>') name_soup.find_all(name="email") # [] name_soup.find_all(attrs={"name": "email"}) # [<input name="email"/>]
Поиск по классу CSS¶
Очень удобно искать тег с определенным классом CSS, но
имя атрибута CSS, “class”, является зарезервированным словом в
Python. Использование class в качестве именованного аргумента приведет к синтаксической
ошибке. Начиная с Beautiful Soup 4.1.2, вы можете выполнять поиск по классу CSS, используя
именованный аргумент class_:
soup.find_all("a", class_="sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Как и с любым именованным аргументом, вы можете передать в качестве значения class_ строку, регулярное
выражение, функцию или True:
soup.find_all(class_=re.compile("itl")) # [<p class="title"><b>The Dormouse's story</b></p>] def has_six_characters(css_class): return css_class is not None and len(css_class) == 6 soup.find_all(class_=has_six_characters) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Помните, что один тег может иметь несколько значений
для атрибута “class”. Когда вы ищете тег, который
соответствует определенному классу CSS, вы ищете соответствие любому из его
классов CSS:
css_soup = BeautifulSoup('<p class="body strikeout"></p>') css_soup.find_all("p", class_="strikeout") # [<p class="body strikeout"></p>] css_soup.find_all("p", class_="body") # [<p class="body strikeout"></p>]
Можно искать точное строковое значение атрибута class:
css_soup.find_all("p", class_="body strikeout") # [<p class="body strikeout"></p>]
Но поиск вариантов строкового значения не сработает:
css_soup.find_all("p", class_="strikeout body") # []
Если вы хотите искать теги, которые соответствуют двум или более классам CSS,
следует использовать селектор CSS:
css_soup.select("p.strikeout.body") # [<p class="body strikeout"></p>]
В старых версиях Beautiful Soup, в которых нет ярлыка class_
можно использовать трюк с аргументом attrs, упомянутый выше. Создайте
словарь, значение которого для “class” является строкой (или регулярным
выражением, или чем угодно еще), которую вы хотите найти:
soup.find_all("a", attrs={"class": "sister"}) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Аргумент string¶
С помощью string вы можете искать строки вместо тегов. Как и в случае с
name и именованными аргументами, передаваться может строка,
регулярное выражение, список, функция или значения True.
Вот несколько примеров:
soup.find_all(string="Elsie") # [u'Elsie'] soup.find_all(string=["Tillie", "Elsie", "Lacie"]) # [u'Elsie', u'Lacie', u'Tillie'] soup.find_all(string=re.compile("Dormouse")) [u"The Dormouse's story", u"The Dormouse's story"] def is_the_only_string_within_a_tag(s): """Return True if this string is the only child of its parent tag.""" return (s == s.parent.string) soup.find_all(string=is_the_only_string_within_a_tag) # [u"The Dormouse's story", u"The Dormouse's story", u'Elsie', u'Lacie', u'Tillie', u'...']
Хотя значение типа string предназначено для поиска строк, вы можете комбинировать его с
аргументами, которые находят теги: Beautiful Soup найдет все теги, в которых
.string соответствует вашему значению для string. Следующий код находит все теги <a>,
у которых .string равно “Elsie”:
soup.find_all("a", string="Elsie") # [<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>]
Аргумент string — это новое в Beautiful Soup 4.4.0. В ранних
версиях он назывался text:
soup.find_all("a", text="Elsie") # [<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>]
Аргумент limit¶
find_all() возвращает все теги и строки, которые соответствуют вашим
фильтрам. Это может занять некоторое время, если документ большой. Если вам не
нужны все результаты, вы можете указать их предельное число — limit. Это
работает так же, как ключевое слово LIMIT в SQL. Оно говорит Beautiful Soup
прекратить собирать результаты после того, как их найдено определенное количество.
В фрагменте из «Алисы в стране чудес» есть три ссылки, но следующий код
находит только первые две:
soup.find_all("a", limit=2) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Аргумент recursive¶
Если вы вызовете mytag.find_all(), Beautiful Soup проверит всех
потомков mytag: его дочерние элементы, дочерние элементы дочерних элементов, и
так далее. Если вы хотите, чтобы Beautiful Soup рассматривал только непосредственных потомков (дочерние элементы),
вы можете передать recursive = False. Оцените разницу:
soup.html.find_all("title") # [<title>The Dormouse's story</title>] soup.html.find_all("title", recursive=False) # []
Вот эта часть документа:
<html> <head> <title> The Dormouse's story </title> </head> ...
Тег <title> находится под тегом <html>, но не непосредственно
под тегом <html>: на пути встречается тег <head>. Beautiful Soup
находит тег <title>, когда разрешено просматривать всех потомков
тега <html>, но когда recursive=False ограничивает поиск
только непосредстввенно дочерними элементами, Beautiful Soup ничего не находит.
Beautiful Soup предлагает множество методов поиска по дереву (они рассмотрены ниже),
и они в основном принимают те же аргументы, что и find_all(): name,
attrs, string, limit и именованные аргументы. Но
с аргументом recursive все иначе: find_all() и find() —
это единственные методы, которые его поддерживают. От передачи recursive=False в
метод типа find_parents() не очень много пользы.
Вызов тега похож на вызов find_all()¶
Поскольку find_all() является самым популярным методом в Beautiful
Soup API, вы можете использовать сокращенную запись. Если относиться к
объекту BeautifulSoup или объекту Tag так, будто это
функция, то это похоже на вызов find_all()
с этим объектом. Эти две строки кода эквивалентны:
soup.find_all("a") soup("a")
Эти две строки также эквивалентны:
soup.title.find_all(string=True) soup.title(string=True)
find()¶
Сигнатура: find(name, attrs, recursive, string, **kwargs)
Метод find_all() сканирует весь документ в поиске
всех результатов, но иногда вам нужен только один. Если вы знаете,
что в документе есть только один тег <body>, нет смысла сканировать
весь документ в поиске остальных. Вместо того, чтобы передавать limit=1
каждый раз, когда вы вызываете find_all(), используйте
метод find(). Эти две строки кода эквивалентны:
soup.find_all('title', limit=1) # [<title>The Dormouse's story</title>] soup.find('title') # <title>The Dormouse's story</title>
Разница лишь в том, что find_all() возвращает список, содержащий
единственный результат, а find() возвращает только сам результат.
Если find_all() не может ничего найти, он возвращает пустой список. Если
find() не может ничего найти, он возвращает None:
print(soup.find("nosuchtag")) # None
Помните трюк с soup.head.title из раздела
Навигация с использованием имен тегов? Этот трюк работает на основе неоднократного вызова find():
soup.head.title # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title>
find_parents() и find_parent()¶
Сигнатура: find_parents(name, attrs, string, limit, **kwargs)
Сигнатура: find_parent(name, attrs, string, **kwargs)
Я долго объяснял, как работают find_all() и
find(). Beautiful Soup API определяет десяток других методов для
поиска по дереву, но пусть вас это не пугает. Пять из этих методов
в целом похожи на find_all(), а другие пять в целом
похожи на find(). Единственное различие в том, по каким частям
дерева они ищут.
Сначала давайте рассмотрим find_parents() и
find_parent(). Помните, что find_all() и find() прорабатывают
дерево сверху вниз, просматривая теги и их потомков. find_parents() и find_parent()
делают наоборот: они идут снизу вверх, рассматривая
родительские элементы тега или строки. Давайте испытаем их, начав со строки,
закопанной глубоко в фрагменте из «Алисы в стране чудес»:
a_string = soup.find(string="Lacie") a_string # u'Lacie' a_string.find_parents("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] a_string.find_parent("p") # <p class="story">Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; # and they lived at the bottom of a well.</p> a_string.find_parents("p", class_="title") # []
Один из трех тегов <a> является прямым родителем искомой строки,
так что наш поиск находит его. Один из трех тегов <p> является
непрямым родителем строки, и наш поиск тоже его
находит. Где-то в документе есть тег <p> с классом CSS “title”,
но он не является родительским для строки, так что мы не можем найти
его с помощью find_parents().
Вы могли заметить связь между find_parent(),
find_parents() и атрибутами .parent и .parents,
упомянутыми ранее. Связь очень сильная. Эти методы поиска
на самом деле используют .parents, чтобы перебрать все родительские элементы и проверить
каждый из них на соответствие заданному фильтру.
find_next_siblings() и find_next_sibling()¶
Сигнатура: find_next_siblings(name, attrs, string, limit, **kwargs)
Сигнатура: find_next_sibling(name, attrs, string, **kwargs)
Эти методы используют .next_siblings для
перебора одноуровневых элементов для данного элемента в дереве. Метод
find_next_siblings() возвращает все подходящие одноуровневые элементы,
а find_next_sibling() возвращает только первый из них:
first_link = soup.a first_link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> first_link.find_next_siblings("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] first_story_paragraph = soup.find("p", "story") first_story_paragraph.find_next_sibling("p") # <p class="story">...</p>
find_previous_siblings() и find_previous_sibling()¶
Сигнатура: find_previous_siblings(name, attrs, string, limit, **kwargs)
Сигнатура: find_previous_sibling(name, attrs, string, **kwargs)
Эти методы используют .previous_siblings для перебора тех одноуровневых элементов,
которые предшествуют данному элементу в дереве разбора. Метод find_previous_siblings()
возвращает все подходящие одноуровневые элементы,, а
а find_next_sibling() только первый из них:
last_link = soup.find("a", id="link3") last_link # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> last_link.find_previous_siblings("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] first_story_paragraph = soup.find("p", "story") first_story_paragraph.find_previous_sibling("p") # <p class="title"><b>The Dormouse's story</b></p>
find_all_next() и find_next()¶
Сигнатура: find_all_next(name, attrs, string, limit, **kwargs)
Сигнатура: find_next(name, attrs, string, **kwargs)
Эти методы используют .next_elements для
перебора любых тегов и строк, которые встречаются в документе после
элемента. Метод find_all_next() возвращает все совпадения, а
find_next() только первое:
first_link = soup.a first_link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> first_link.find_all_next(string=True) # [u'Elsie', u',n', u'Lacie', u' andn', u'Tillie', # u';nand they lived at the bottom of a well.', u'nn', u'...', u'n'] first_link.find_next("p") # <p class="story">...</p>
В первом примере нашлась строка “Elsie”, хотя она
содержится в теге <a>, с которого мы начали. Во втором примере
нашелся последний тег <p>, хотя он находится
в другой части дерева, чем тег <a>, с которого мы начали. Для этих
методов имеет значение только то, что элемент соответствует фильтру и
появляется в документе позже, чем тот элемент, с которого начали поиск.
find_all_previous() и find_previous()¶
Сигнатура: find_all_previous(name, attrs, string, limit, **kwargs)
Сигнатура: find_previous(name, attrs, string, **kwargs)
Эти методы используют .previous_elements для
перебора любых тегов и строк, которые встречаются в документе до
элемента. Метод find_all_previous() возвращает все совпадения, а
find_previous() только первое:
first_link = soup.a first_link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> first_link.find_all_previous("p") # [<p class="story">Once upon a time there were three little sisters; ...</p>, # <p class="title"><b>The Dormouse's story</b></p>] first_link.find_previous("title") # <title>The Dormouse's story</title>
Вызов find_all_previous ("p") нашел первый абзац в
документе (тот, который с class = "title"), но он также находит
второй абзац, а именно тег <p>, содержащий тег <a>, с которого мы
начали. Это не так уж удивительно: мы смотрим на все теги,
которые появляются в документе раньше, чем тот, с которого мы начали. Тег
<p>, содержащий тег <a>, должен был появиться до тега <a>, который
в нем содержится.
Селекторы CSS¶
Начиная с версии 4.7.0, Beautiful Soup поддерживает большинство селекторов CSS4 благодаря
проекту SoupSieve. Если вы установили Beautiful Soup через pip, одновременно должен был установиться SoupSieve,
так что вам больше ничего не нужно делать.
В BeautifulSoup есть метод .select(), который использует SoupSieve, чтобы
запустить селектор CSS и вернуть все
подходящие элементы. Tag имеет похожий метод, который запускает селектор CSS
в отношении содержимого одного тега.
(В более ранних версиях Beautiful Soup тоже есть метод .select(),
но поддерживаются только наиболее часто используемые селекторы CSS.)
В документации SoupSieve перечислены все
селекторы CSS, которые поддерживаются на данный момент, но вот некоторые из основных:
Вы можете найти теги:
soup.select("title") # [<title>The Dormouse's story</title>] soup.select("p:nth-of-type(3)") # [<p class="story">...</p>]
Найти теги под другими тегами:
soup.select("body a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("html head title") # [<title>The Dormouse's story</title>]
Найти теги непосредственно под другими тегами:
soup.select("head > title") # [<title>The Dormouse's story</title>] soup.select("p > a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("p > a:nth-of-type(2)") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] soup.select("p > #link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select("body > a") # []
Найти одноуровневые элементы тега:
soup.select("#link1 ~ .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("#link1 + .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Найти теги по классу CSS:
soup.select(".sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("[class~=sister]") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Найти теги по ID:
soup.select("#link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select("a#link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Найти теги, которые соответствуют любому селектору из списка:
soup.select("#link1,#link2") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Проверка на наличие атрибута:
soup.select('a[href]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Найти теги по значению атрибута:
soup.select('a[href="http://example.com/elsie"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select('a[href^="http://example.com/"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select('a[href$="tillie"]') # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select('a[href*=".com/el"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
Есть также метод select_one(), который находит только
первый тег, соответствующий селектору:
soup.select_one(".sister") # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
Если вы разобрали XML, в котором определены пространства имен, вы можете использовать их в
селекторах CSS:
from bs4 import BeautifulSoup xml = """<tag xmlns:ns1="http://namespace1/" xmlns:ns2="http://namespace2/"> <ns1:child>I'm in namespace 1</ns1:child> <ns2:child>I'm in namespace 2</ns2:child> </tag> """ soup = BeautifulSoup(xml, "xml") soup.select("child") # [<ns1:child>I'm in namespace 1</ns1:child>, <ns2:child>I'm in namespace 2</ns2:child>] soup.select("ns1|child", namespaces=namespaces) # [<ns1:child>I'm in namespace 1</ns1:child>]
При обработке селектора CSS, который использует пространства имен, Beautiful Soup
использует сокращения пространства имен, найденные при разборе
документа. Вы можете заменить сокращения своими собственными, передав словарь
сокращений:
namespaces = dict(first="http://namespace1/", second="http://namespace2/") soup.select("second|child", namespaces=namespaces) # [<ns1:child>I'm in namespace 2</ns1:child>]
Все эти селекторы CSS удобны для тех, кто уже
знаком с синтаксисом селекторов CSS. Вы можете сделать все это с помощью
Beautiful Soup API. И если CSS селекторы — это все, что вам нужно, вам следует
использовать парсер lxml: так будет намного быстрее. Но вы можете
комбинировать селекторы CSS с Beautiful Soup API.
Изменение дерева¶
Основная сила Beautiful Soup в поиске по дереву разбора, но вы
также можете изменить дерево и записать свои изменения в виде нового HTML или
XML-документа.
Изменение имен тегов и атрибутов¶
Я говорил об этом раньше, в разделе Атрибуты, но это стоит повторить. Вы
можете переименовать тег, изменить значения его атрибутов, добавить новые
атрибуты и удалить атрибуты:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') tag = soup.b tag.name = "blockquote" tag['class'] = 'verybold' tag['id'] = 1 tag # <blockquote class="verybold" id="1">Extremely bold</blockquote> del tag['class'] del tag['id'] tag # <blockquote>Extremely bold</blockquote>
Изменение .string¶
Если вы замените значение атрибута .string новой строкой, содержимое тега будет
заменено на эту строку:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) tag = soup.a tag.string = "New link text." tag # <a href="http://example.com/">New link text.</a>
Будьте осторожны: если тег содержит другие теги, они и все их
содержимое будет уничтожено.
append()¶
Вы можете добавить содержимое тега с помощью Tag.append(). Это работает
точно так же, как .append() для списка в Python:
soup = BeautifulSoup("<a>Foo</a>") soup.a.append("Bar") soup # <html><head></head><body><a>FooBar</a></body></html> soup.a.contents # [u'Foo', u'Bar']
extend()¶
Начиная с версии Beautiful Soup 4.7.0, Tag также поддерживает метод
.extend(), который работает так же, как вызов .extend() для
списка в Python:
soup = BeautifulSoup("<a>Soup</a>") soup.a.extend(["'s", " ", "on"]) soup # <html><head></head><body><a>Soup's on</a></body></html> soup.a.contents # [u'Soup', u''s', u' ', u'on']
NavigableString() и .new_tag()¶
Если вам нужно добавить строку в документ, нет проблем — вы можете передать
строку Python в append() или вызвать
конструктор NavigableString:
soup = BeautifulSoup("<b></b>") tag = soup.b tag.append("Hello") new_string = NavigableString(" there") tag.append(new_string) tag # <b>Hello there.</b> tag.contents # [u'Hello', u' there']
Если вы хотите создать комментарий или другой подкласс
NavigableString, просто вызовите конструктор:
from bs4 import Comment new_comment = Comment("Nice to see you.") tag.append(new_comment) tag # <b>Hello there<!--Nice to see you.--></b> tag.contents # [u'Hello', u' there', u'Nice to see you.']
(Это новая функция в Beautiful Soup 4.4.0.)
Что делать, если вам нужно создать совершенно новый тег? Наилучшим решением будет
вызвать фабричный метод BeautifulSoup.new_tag():
soup = BeautifulSoup("<b></b>") original_tag = soup.b new_tag = soup.new_tag("a", href="http://www.example.com") original_tag.append(new_tag) original_tag # <b><a href="http://www.example.com"></a></b> new_tag.string = "Link text." original_tag # <b><a href="http://www.example.com">Link text.</a></b>
Нужен только первый аргумент, имя тега.
insert()¶
Tag.insert() похож на Tag.append(), за исключением того, что новый элемент
не обязательно добавляется в конец родительского
.contents. Он добавится в любое место, номер которого
вы укажете. Это работает в точности как .insert() в списке Python:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) tag = soup.a tag.insert(1, "but did not endorse ") tag # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a> tag.contents # [u'I linked to ', u'but did not endorse', <i>example.com</i>]
insert_before() и insert_after()¶
Метод insert_before() вставляет теги или строки непосредственно
перед чем-то в дереве разбора:
soup = BeautifulSoup("<b>stop</b>") tag = soup.new_tag("i") tag.string = "Don't" soup.b.string.insert_before(tag) soup.b # <b><i>Don't</i>stop</b>
Метод insert_after() вставляет теги или строки непосредственно
после чего-то в дереве разбора:
div = soup.new_tag('div') div.string = 'ever' soup.b.i.insert_after(" you ", div) soup.b # <b><i>Don't</i> you <div>ever</div> stop</b> soup.b.contents # [<i>Don't</i>, u' you', <div>ever</div>, u'stop']
clear()¶
Tag.clear() удаляет содержимое тега:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) tag = soup.a tag.clear() tag # <a href="http://example.com/"></a>
decompose()¶
Tag.decompose() удаляет тег из дерева, а затем полностью
уничтожает его вместе с его содержимым:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) a_tag = soup.a soup.i.decompose() a_tag # <a href="http://example.com/">I linked to</a>
replace_with()¶
PageElement.extract() удаляет тег или строку из дерева
и заменяет его тегом или строкой по вашему выбору:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) a_tag = soup.a new_tag = soup.new_tag("b") new_tag.string = "example.net" a_tag.i.replace_with(new_tag) a_tag # <a href="http://example.com/">I linked to <b>example.net</b></a>
replace_with() возвращает тег или строку, которые были заменены, так что
вы можете изучить его или добавить его обратно в другую часть дерева.
wrap()¶
PageElement.wrap() обертывает элемент в указанный вами тег. Он
возвращает новую обертку:
soup = BeautifulSoup("<p>I wish I was bold.</p>") soup.p.string.wrap(soup.new_tag("b")) # <b>I wish I was bold.</b> soup.p.wrap(soup.new_tag("div") # <div><p><b>I wish I was bold.</b></p></div>
Это новый метод в Beautiful Soup 4.0.5.
unwrap()¶
Tag.unwrap() — это противоположность wrap(). Он заменяет весь тег на
его содержимое. Этим методом удобно очищать разметку:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) a_tag = soup.a a_tag.i.unwrap() a_tag # <a href="http://example.com/">I linked to example.com</a>
Как и replace_with(), unwrap() возвращает тег,
который был заменен.
smooth()¶
После вызова ряда методов, которые изменяют дерево разбора, у вас может оказаться несколько объектов NavigableString подряд. У Beautiful Soup с этим нет проблем, но поскольку такое не случается со свежеразобранным документом, вам может показаться неожиданным следующее поведение:
soup = BeautifulSoup("<p>A one</p>") soup.p.append(", a two") soup.p.contents # [u'A one', u', a two'] print(soup.p.encode()) # <p>A one, a two</p> print(soup.p.prettify()) # <p> # A one # , a two # </p>
Вы можете вызвать Tag.smooth(), чтобы очистить дерево разбора путем объединения смежных строк:
soup.smooth() soup.p.contents # [u'A one, a two'] print(soup.p.prettify()) # <p> # A one, a two # </p>
smooth() — это новый метод в Beautiful Soup 4.8.0.
Вывод¶
Красивое форматирование¶
Метод prettify() превратит дерево разбора Beautiful Soup в
красиво отформатированную строку Unicode, где каждый
тег и каждая строка выводятся на отдельной строчке:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup) soup.prettify() # '<html>n <head>n </head>n <body>n <a href="http://example.com/">n...' print(soup.prettify()) # <html> # <head> # </head> # <body> # <a href="http://example.com/"> # I linked to # <i> # example.com # </i> # </a> # </body> # </html>
Вы можете вызвать prettify() для объекта BeautifulSoup верхнего уровня
или для любого из его объектов Tag:
print(soup.a.prettify()) # <a href="http://example.com/"> # I linked to # <i> # example.com # </i> # </a>
Без красивого форматирования¶
Если вам нужна просто строка, без особого форматирования, вы можете вызвать
unicode() или str() для объекта BeautifulSoup или объекта Tag
внутри:
str(soup) # '<html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>' unicode(soup.a) # u'<a href="http://example.com/">I linked to <i>example.com</i></a>'
Функция str() возвращает строку, кодированную в UTF-8. Для получения более подробной информации см.
Кодировки.
Вы также можете вызвать encode() для получения байтовой строки, и decode(),
чтобы получить Unicode.
Средства форматирования вывода¶
Если вы дадите Beautiful Soup документ, который содержит HTML-мнемоники, такие как
“&lquot;”, они будут преобразованы в символы Unicode:
soup = BeautifulSoup("“Dammit!” he said.") unicode(soup) # u'<html><head></head><body>u201cDammit!u201d he said.</body></html>'
Если затем преобразовать документ в строку, символы Unicode
будет кодироваться как UTF-8. Вы не получите обратно HTML-мнемоники:
str(soup) # '<html><head></head><body>xe2x80x9cDammit!xe2x80x9d he said.</body></html>'
По умолчанию единственные символы, которые экранируются при выводе — это чистые
амперсанды и угловые скобки. Они превращаются в «&», «<»
и “>”, чтобы Beautiful Soup случайно не сгенерировал
невалидный HTML или XML:
soup = BeautifulSoup("<p>The law firm of Dewey, Cheatem, & Howe</p>") soup.p # <p>The law firm of Dewey, Cheatem, & Howe</p> soup = BeautifulSoup('<a href="http://example.com/?foo=val1&bar=val2">A link</a>') soup.a # <a href="http://example.com/?foo=val1&bar=val2">A link</a>
Вы можете изменить это поведение, указав для
аргумента formatter одно из значений: prettify(), encode() или
decode(). Beautiful Soup распознает пять возможных значений
formatter.
Значение по умолчанию — formatter="minimal". Строки будут обрабатываться
ровно настолько, чтобы Beautiful Soup генерировал валидный HTML / XML:
french = "<p>Il a dit <<Sacré bleu!>></p>" soup = BeautifulSoup(french) print(soup.prettify(formatter="minimal")) # <html> # <body> # <p> # Il a dit <<Sacré bleu!>> # </p> # </body> # </html>
Если вы передадите formatter = "html", Beautiful Soup преобразует
символы Unicode в HTML-мнемоники, когда это возможно:
print(soup.prettify(formatter="html")) # <html> # <body> # <p> # Il a dit <<Sacré bleu!>> # </p> # </body> # </html>
Если вы передаете formatter="html5", это то же самое, что
formatter="html", только Beautiful Soup будет
пропускать закрывающую косую черту в пустых тегах HTML, таких как “br”:
soup = BeautifulSoup("<br>") print(soup.encode(formatter="html")) # <html><body><br/></body></html> print(soup.encode(formatter="html5")) # <html><body><br></body></html>
Если вы передадите formatter=None, Beautiful Soup вообще не будет менять
строки на выходе. Это самый быстрый вариант, но он может привести
к тому, что Beautiful Soup будет генерировать невалидный HTML / XML:
print(soup.prettify(formatter=None)) # <html> # <body> # <p> # Il a dit <<Sacré bleu!>> # </p> # </body> # </html> link_soup = BeautifulSoup('<a href="http://example.com/?foo=val1&bar=val2">A link</a>') print(link_soup.a.encode(formatter=None)) # <a href="http://example.com/?foo=val1&bar=val2">A link</a>
Если вам нужен более сложный контроль над выводом, вы можете
использовать класс Formatter из Beautiful Soup. Вот как можно
преобразовать строки в верхний регистр, независимо от того, находятся ли они в текстовом узле или в
значении атрибута:
from bs4.formatter import HTMLFormatter def uppercase(str): return str.upper() formatter = HTMLFormatter(uppercase) print(soup.prettify(formatter=formatter)) # <html> # <body> # <p> # IL A DIT <<SACRÉ BLEU!>> # </p> # </body> # </html> print(link_soup.a.prettify(formatter=formatter)) # <a href="HTTP://EXAMPLE.COM/?FOO=VAL1&BAR=VAL2"> # A LINK # </a>
Подклассы HTMLFormatter или XMLFormatter дают еще
больший контроль над выводом. Например, Beautiful Soup сортирует
атрибуты в каждом теге по умолчанию:
attr_soup = BeautifulSoup(b'<p z="1" m="2" a="3"></p>') print(attr_soup.p.encode()) # <p a="3" m="2" z="1"></p>
Чтобы выключить сортировку по умолчанию, вы можете создать подкласс на основе метода Formatter.attributes(),
который контролирует, какие атрибуты выводятся и в каком
порядке. Эта реализация также отфильтровывает атрибут с именем “m”,
где бы он ни появился:
class UnsortedAttributes(HTMLFormatter): def attributes(self, tag): for k, v in tag.attrs.items(): if k == 'm': continue yield k, v print(attr_soup.p.encode(formatter=UnsortedAttributes())) # <p z="1" a="3"></p>
Последнее предостережение: если вы создаете объект CData, текст внутри
этого объекта всегда представлен как есть, без какого-либо
форматирования. Beautiful Soup вызовет вашу функцию для замены мнемоник,
на тот случай, если вы написали функцию, которая подсчитывает
все строки в документе или что-то еще, но он будет игнорировать
возвращаемое значение:
from bs4.element import CData soup = BeautifulSoup("<a></a>") soup.a.string = CData("one < three") print(soup.a.prettify(formatter="xml")) # <a> # <![CDATA[one < three]]> # </a>
get_text()¶
Если вам нужна только текстовая часть документа или тега, вы можете использовать
метод get_text(). Он возвращает весь текст документа или
тега в виде единственной строки Unicode:
markup = '<a href="http://example.com/">nI linked to <i>example.com</i>n</a>' soup = BeautifulSoup(markup) soup.get_text() u'nI linked to example.comn' soup.i.get_text() u'example.com'
Вы можете указать строку, которая будет использоваться для объединения текстовых фрагментов
в единую строку:
# soup.get_text("|") u'nI linked to |example.com|n'
Вы можете сказать Beautiful Soup удалять пробелы в начале и
конце каждого текстового фрагмента:
# soup.get_text("|", strip=True) u'I linked to|example.com'
Но в этом случае вы можете предпочесть использовать генератор .stripped_strings
и затем обработать текст самостоятельно:
[text for text in soup.stripped_strings] # [u'I linked to', u'example.com']
Указание парсера¶
Если вам нужно просто разобрать HTML, вы можете скинуть разметку в
конструктор BeautifulSoup, и, скорее всего, все будет в порядке. Beautiful
Soup подберет для вас парсер и проанализирует данные. Но есть
несколько дополнительных аргументов, которые вы можете передать конструктору, чтобы изменить
используемый парсер.
Первым аргументом конструктора BeautifulSou является строка или
открытый дескриптор файла — сама разметка, которую вы хотите разобрать. Второй аргумент — это
как вы хотите, чтобы разметка была разобрана.
Если вы ничего не укажете, будет использован лучший HTML-парсер из тех,
которые установлены. Beautiful Soup оценивает парсер lxml как лучший, за ним идет
html5lib, затем встроенный парсер Python. Вы можете переопределить используемый парсер,
указав что-то из следующего:
- Какой тип разметки вы хотите разобрать. В данный момент поддерживаются:
“html”, “xml” и “html5”. - Имя библиотеки парсера, которую вы хотите использовать. В данный момент поддерживаются
“lxml”, “html5lib” и “html.parser” (встроенный в Python
парсер HTML).
В разделе Установка парсера вы найдете сравнительную таблицу поддерживаемых парсеров.
Если у вас не установлен соответствующий парсер, Beautiful Soup
проигнорирует ваш запрос и выберет другой парсер. На текущий момент единственный
поддерживаемый парсер XML — это lxml. Если у вас не установлен lxml, запрос на
парсер XML ничего не даст, и запрос “lxml” тоже
не сработает.
Различия между парсерами¶
Beautiful Soup представляет один интерфейс для разных
парсеров, но парсеры неодинаковы. Разные парсеры создадут
различные деревья разбора из одного и того же документа. Самые большие различия будут
между парсерами HTML и парсерами XML. Вот короткий
документ, разобранный как HTML:
BeautifulSoup("<a><b /></a>") # <html><head></head><body><a><b></b></a></body></html>
Поскольку пустой тег <b /> не является валидным кодом HTML, парсер превращает его в
пару тегов <b></b>.
Вот тот же документ, который разобран как XML (для его запуска нужно, чтобы был
установлен lxml). Обратите внимание, что пустой тег <b /> остается, и
что в документ добавляется объявление XML вместо
тега <html>:
BeautifulSoup("<a><b /></a>", "xml") # <?xml version="1.0" encoding="utf-8"?> # <a><b/></a>
Есть также различия между парсерами HTML. Если вы даете Beautiful
Soup идеально оформленный документ HTML, эти различия не будут
иметь значения. Один парсер будет быстрее другого, но все они будут давать
структуру данных, которая выглядит точно так же, как оригинальный
документ HTML.
Но если документ оформлен неидеально, различные парсеры
дадут разные результаты. Вот короткий невалидный документ, разобранный с помощью
HTML-парсера lxml. Обратите внимание, что висячий тег </p> просто
игнорируется:
BeautifulSoup("<a></p>", "lxml") # <html><body><a></a></body></html>
Вот тот же документ, разобранный с помощью html5lib:
BeautifulSoup("<a></p>", "html5lib") # <html><head></head><body><a><p></p></a></body></html>
Вместо того, чтобы игнорировать висячий тег </p>, html5lib добавляет
открывающй тег <p>. Этот парсер также добавляет пустой тег <head> в
документ.
Вот тот же документ, разобранный с помощью встроенного в Python
парсера HTML:
BeautifulSoup("<a></p>", "html.parser") # <a></a>
Как и html5lib, этот парсер игнорирует закрывающий тег </p>. В отличие от
html5lib, этот парсер не делает попытки создать правильно оформленный HTML-
документ, добавив тег <body>. В отличие от lxml, он даже не
добавляет тег <html>.
Поскольку документ <a></p> невалиден, ни один из этих способов
нельзя назвать “правильным”. Парсер html5lib использует способы,
которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход
самый “правильный”, но правомерно использовать любой из трех методов.
Различия между парсерами могут повлиять на ваш скрипт. Если вы планируете
распространять ваш скрипт или запускать его на нескольких
машинах, вам нужно указать парсер в
конструкторе BeautifulSoup. Это уменьшит вероятность того, что ваши пользователи при разборе
документа получат результат, отличный от вашего.
Кодировки¶
Любой документ HTML или XML написан в определенной кодировке, такой как ASCII
или UTF-8. Но когда вы загрузите этот документ в Beautiful Soup, вы
обнаружите, что он был преобразован в Unicode:
markup = "<h1>Sacrxc3xa9 bleu!</h1>" soup = BeautifulSoup(markup) soup.h1 # <h1>Sacré bleu!</h1> soup.h1.string # u'Sacrxe9 bleu!'
Это не волшебство. (Хотя это было бы здорово, конечно.) Beautiful Soup использует
подбиблиотеку под названием Unicode, Dammit для определения кодировки документа
и преобразования ее в Unicode. Кодировка, которая была автоматически определена, содержится в значении
атрибута .original_encoding объекта BeautifulSoup:
soup.original_encoding 'utf-8'
Unicode, Dammit чаще всего угадывает правильно, но иногда
делает ошибки. Иногда он угадывает правильно только после
побайтового поиска по документу, что занимает очень много времени. Если
вы вдруг уже знаете кодировку документа, вы можете избежать
ошибок и задержек, передав кодировку конструктору BeautifulSoup
как аргумент from_encoding.
Вот документ, написанный на ISO-8859-8. Документ настолько короткий, что
Unicode, Dammit не может разобраться и неправильно идентифицирует кодировку как
ISO-8859-7:
markup = b"<h1>xedxe5xecxf9</h1>" soup = BeautifulSoup(markup) soup.h1 <h1>νεμω</h1> soup.original_encoding 'ISO-8859-7'
Мы можем все исправить, передав правильный from_encoding:
soup = BeautifulSoup(markup, from_encoding="iso-8859-8") soup.h1 <h1>םולש</h1> soup.original_encoding 'iso8859-8'
Если вы не знаете правильную кодировку, но видите, что
Unicode, Dammit определяет ее неправильно, вы можете передать ошибочные варианты в
exclude_encodings:
soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"]) soup.h1 <h1>םולש</h1> soup.original_encoding 'WINDOWS-1255'
Windows-1255 не на 100% подходит, но это совместимое
надмножество ISO-8859-8, так что догадка почти верна. (exclude_encodings
— это новая функция в Beautiful Soup 4.4.0.)
В редких случаях (обычно когда документ UTF-8 содержит текст в
совершенно другой кодировке) единственным способом получить Unicode может оказаться
замена некоторых символов специальным символом Unicode
“REPLACEMENT CHARACTER” (U+FFFD, �). Если Unicode, Dammit приходится это сделать,
он установит атрибут .contains_replacement_characters
в True для объектов UnicodeDammit или BeautifulSoup. Это
даст понять, что представление в виде Unicode не является точным
представление оригинала, и что некоторые данные потерялись. Если документ
содержит �, но .contains_replacement_characters равен False,
вы будете знать, что � был в тексте изначально (как в этом
параграфе), а не служит заменой отсутствующим данным.
Кодировка вывода¶
Когда вы пишете документ из Beautiful Soup, вы получаете документ в UTF-8,
даже если он изначально не был в UTF-8. Вот
документ в кодировке Latin-1:
markup = b''' <html> <head> <meta content="text/html; charset=ISO-Latin-1" http-equiv="Content-type" /> </head> <body> <p>Sacrxe9 bleu!</p> </body> </html> ''' soup = BeautifulSoup(markup) print(soup.prettify()) # <html> # <head> # <meta content="text/html; charset=utf-8" http-equiv="Content-type" /> # </head> # <body> # <p> # Sacré bleu! # </p> # </body> # </html>
Обратите внимание, что тег <meta> был переписан, чтобы отразить тот факт, что
теперь документ кодируется в UTF-8.
Если вы не хотите кодировку UTF-8, вы можете передать другую в prettify():
print(soup.prettify("latin-1")) # <html> # <head> # <meta content="text/html; charset=latin-1" http-equiv="Content-type" /> # ...
Вы также можете вызвать encode() для объекта BeautifulSoup или любого
элемента в супе, как если бы это была строка Python:
soup.p.encode("latin-1") # '<p>Sacrxe9 bleu!</p>' soup.p.encode("utf-8") # '<p>Sacrxc3xa9 bleu!</p>'
Любые символы, которые не могут быть представлены в выбранной вами кодировке, будут
преобразованы в числовые коды мнемоник XML. Вот документ,
который включает в себя Unicode-символ SNOWMAN (снеговик):
markup = u"<b>N{SNOWMAN}</b>" snowman_soup = BeautifulSoup(markup) tag = snowman_soup.b
Символ SNOWMAN может быть частью документа UTF-8 (он выглядит
так: ☃), но в ISO-Latin-1 или
ASCII нет представления для этого символа, поэтому для этих кодировок он конвертируется в “☃”:
print(tag.encode(“utf-8”))
# <b>☃</b>print tag.encode(“latin-1”)
# <b>☃</b>print tag.encode(“ascii”)
# <b>☃</b>
Unicode, Dammit¶
Вы можете использовать Unicode, Dammit без Beautiful Soup. Он полезен в тех случаях.
когда у вас есть данные в неизвестной кодировке, и вы просто хотите, чтобы они
преобразовались в Unicode:
from bs4 import UnicodeDammit dammit = UnicodeDammit("Sacrxc3xa9 bleu!") print(dammit.unicode_markup) # Sacré bleu! dammit.original_encoding # 'utf-8'
Догадки Unicode, Dammit станут намного точнее, если вы установите
библиотеки Python chardet или cchardet. Чем больше данных вы
даете Unicode, Dammit, тем точнее он определит кодировку. Если у вас есть
собственные предположения относительно возможных кодировок, вы можете передать
их в виде списка:
dammit = UnicodeDammit("Sacrxe9 bleu!", ["latin-1", "iso-8859-1"]) print(dammit.unicode_markup) # Sacré bleu! dammit.original_encoding # 'latin-1'
В Unicode, Dammit есть две специальные функции, которые Beautiful Soup не
использует.
Парные кавычки¶
Вы можете использовать Unicode, Dammit, чтобы конвертировать парные кавычки (Microsoft smart quotes) в
мнемоники HTML или XML:
markup = b"<p>I just x93lovex94 Microsoft Wordx92s smart quotes</p>" UnicodeDammit(markup, ["windows-1252"], smart_quotes_to="html").unicode_markup # u'<p>I just “love” Microsoft Word’s smart quotes</p>' UnicodeDammit(markup, ["windows-1252"], smart_quotes_to="xml").unicode_markup # u'<p>I just “love” Microsoft Word’s smart quotes</p>'
Вы также можете конвертировать парные кавычки в обычные кавычки ASCII:
UnicodeDammit(markup, ["windows-1252"], smart_quotes_to="ascii").unicode_markup # u'<p>I just "love" Microsoft Word's smart quotes</p>'
Надеюсь, вы найдете эту функцию полезной, но Beautiful Soup не
использует ее. Beautiful Soup по умолчанию
конвертирует парные кавычки в символы Unicode, как и
все остальное:
UnicodeDammit(markup, ["windows-1252"]).unicode_markup # u'<p>I just u201cloveu201d Microsoft Wordu2019s smart quotes</p>'
Несогласованные кодировки¶
Иногда документ кодирован в основном в UTF-8, но содержит символы Windows-1252,
такие как, опять-таки, парные кавычки. Такое бывает,
когда веб-сайт содержит данные из нескольких источников. Вы можете использовать
UnicodeDammit.detwingle(), чтобы превратить такой документ в чистый
UTF-8. Вот простой пример:
snowmen = (u"N{SNOWMAN}" * 3) quote = (u"N{LEFT DOUBLE QUOTATION MARK}I like snowmen!N{RIGHT DOUBLE QUOTATION MARK}") doc = snowmen.encode("utf8") + quote.encode("windows_1252")
В этом документе бардак. Снеговики в UTF-8, а парные кавычки
в Windows-1252. Можно отображать или снеговиков, или кавычки, но не
то и другое одновременно:
print(doc) # ☃☃☃�I like snowmen!� print(doc.decode("windows-1252")) # ☃☃☃“I like snowmen!”
Декодирование документа как UTF-8 вызывает UnicodeDecodeError, а
декодирование его как Windows-1252 выдаст тарабарщину. К счастью,
UnicodeDammit.detwingle() преобразует строку в чистый UTF-8,
позволяя затем декодировать его в Unicode и отображать снеговиков и кавычки
одновременно:
new_doc = UnicodeDammit.detwingle(doc) print(new_doc.decode("utf8")) # ☃☃☃“I like snowmen!”
UnicodeDammit.detwingle() знает только, как обрабатывать Windows-1252,
встроенный в UTF-8 (и наоборот, мне кажется), но это наиболее
общий случай.
Обратите внимание, что нужно вызывать UnicodeDammit.detwingle() для ваших данных
перед передачей в конструктор BeautifulSoup или
UnicodeDammit. Beautiful Soup предполагает, что документ имеет единую
кодировку, какой бы она ни была. Если вы передадите ему документ, который
содержит как UTF-8, так и Windows-1252, скорее всего, он решит, что весь
документ кодируется в Windows-1252, и это будет выглядеть как
☃☃☃“I like snowmen!”.
UnicodeDammit.detwingle() — это новое в Beautiful Soup 4.1.0.
Нумерация строк¶
Парсеры html.parser и html5lib могут отслеживать, где в
исходном документе был найден каждый тег. Вы можете получить доступ к этой
информации через Tag.sourceline (номер строки) и Tag.sourcepos
(позиция начального тега в строке):
markup = "<pn>Paragraph 1</p>n <p>Paragraph 2</p>" soup = BeautifulSoup(markup, 'html.parser') for tag in soup.find_all('p'): print(tag.sourceline, tag.sourcepos, tag.string) # (1, 0, u'Paragraph 1') # (2, 3, u'Paragraph 2')
Обратите внимание, что два парсера понимают
sourceline и sourcepos немного по-разному. Для html.parser эти числа
представляет позицию начального знака “<”. Для html5lib
эти числа представляют позицию конечного знака “>”:
soup = BeautifulSoup(markup, 'html5lib') for tag in soup.find_all('p'): print(tag.sourceline, tag.sourcepos, tag.string) # (2, 1, u'Paragraph 1') # (3, 7, u'Paragraph 2')
Вы можете отключить эту функцию, передав store_line_numbers = False
в конструктор BeautifulSoup:
markup = "<pn>Paragraph 1</p>n <p>Paragraph 2</p>" soup = BeautifulSoup(markup, 'html.parser', store_line_numbers=False) soup.p.sourceline # None
Эта функция является новой в 4.8.1, и парсеры, основанные на lxml, не
поддерживают ее.
Проверка объектов на равенство¶
Beautiful Soup считает, что два объекта NavigableString или Tag
равны, если они представлены в одинаковой разметке HTML или XML. В этом
примере два тега <b> рассматриваются как равные, даже если они находятся
в разных частях дерева объекта, потому что они оба выглядят как
<b>pizza</b>:
markup = "<p>I want <b>pizza</b> and more <b>pizza</b>!</p>" soup = BeautifulSoup(markup, 'html.parser') first_b, second_b = soup.find_all('b') print first_b == second_b # True print first_b.previous_element == second_b.previous_element # False
Если вы хотите выяснить, указывают ли две переменные на один и тот же
объект, используйте is:
print first_b is second_b # False
Копирование объектов Beautiful Soup¶
Вы можете использовать copy.copy() для создания копии любого Tag или
NavigableString:
import copy p_copy = copy.copy(soup.p) print p_copy # <p>I want <b>pizza</b> and more <b>pizza</b>!</p>
Копия считается равной оригиналу, так как у нее
такая же разметка, что и у оригинала, но это другой объект:
print soup.p == p_copy # True print soup.p is p_copy # False
Единственная настоящая разница в том, что копия полностью отделена от
исходного дерева объекта Beautiful Soup, как если бы в отношении нее вызвали
метод extract():
print p_copy.parent # None
Это потому, что два разных объекта Tag не могут занимать одно и то же
пространство в одно и то же время.
Разбор части документа¶
Допустим, вы хотите использовать Beautiful Soup, чтобы посмотреть на
теги <a> в документе. Было бы бесполезной тратой времени и памяти разобирать весь документ и
затем снова проходить по нему в поисках тегов <a>. Намного быстрее
изначательно игнорировать все, что не является тегом <a>. Класс
SoupStrainer позволяет выбрать, какие части входящего
документ разбирать. Вы просто создаете SoupStrainer и передаете его в
конструктор BeautifulSoup в качестве аргумента parse_only.
(Обратите внимание, что эта функция не будет работать, если вы используете парсер html5lib.
Если вы используете html5lib, будет разобран весь документ, независимо
от обстоятельств. Это потому что html5lib постоянно переставляет части дерева разбора
в процессе работы, и если какая-то часть документа не
попала в дерево разбора, все рухнет. Чтобы избежать путаницы, в
примерах ниже я принудительно использую встроенный в Python
парсер HTML.)
SoupStrainer¶
Класс SoupStrainer принимает те же аргументы, что и типичный
метод из раздела Поиск по дереву: name, attrs, string и **kwargs. Вот
три объекта SoupStrainer:
from bs4 import SoupStrainer only_a_tags = SoupStrainer("a") only_tags_with_id_link2 = SoupStrainer(id="link2") def is_short_string(string): return len(string) < 10 only_short_strings = SoupStrainer(string=is_short_string)
Вернемся к фрагменту из «Алисы в стране чудес»
и увидим, как выглядит документ, когда он разобран с этими
тремя объектами SoupStrainer:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ print(BeautifulSoup(html_doc, "html.parser", parse_only=only_a_tags).prettify()) # <a class="sister" href="http://example.com/elsie" id="link1"> # Elsie # </a> # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> # <a class="sister" href="http://example.com/tillie" id="link3"> # Tillie # </a> print(BeautifulSoup(html_doc, "html.parser", parse_only=only_tags_with_id_link2).prettify()) # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> print(BeautifulSoup(html_doc, "html.parser", parse_only=only_short_strings).prettify()) # Elsie # , # Lacie # and # Tillie # ... #
Вы также можете передать SoupStrainer в любой из методов. описанных в разделе
Поиск по дереву. Может, это не безумно полезно, но я
решил упомянуть:
soup = BeautifulSoup(html_doc) soup.find_all(only_short_strings) # [u'nn', u'nn', u'Elsie', u',n', u'Lacie', u' andn', u'Tillie', # u'nn', u'...', u'n']
Устранение неисправностей¶
diagnose()¶
Если у вас возникли проблемы с пониманием того, что Beautiful Soup делает с
документом, передайте документ в функцию Diagnose(). (Новое в
Beautiful Soup 4.2.0.) Beautiful Soup выведет отчет, показывающий,
как разные парсеры обрабатывают документ, и сообщит вам, если
отсутствует парсер, который Beautiful Soup мог бы использовать:
from bs4.diagnose import diagnose with open("bad.html") as fp: data = fp.read() diagnose(data) # Diagnostic running on Beautiful Soup 4.2.0 # Python version 2.7.3 (default, Aug 1 2012, 05:16:07) # I noticed that html5lib is not installed. Installing it may help. # Found lxml version 2.3.2.0 # # Trying to parse your data with html.parser # Here's what html.parser did with the document: # ...
Простой взгляд на вывод diagnose() может показать, как решить
проблему. Если это и не поможет, вы можете скопировать вывод Diagnose(), когда
обратитесь за помощью.
Ошибки при разборе документа¶
Существует два вида ошибок разбора. Есть сбои,
когда вы подаете документ в Beautiful Soup, и это поднимает
исключение, обычно HTMLParser.HTMLParseError. И есть
неожиданное поведение, когда дерево разбора Beautiful Soup сильно
отличается от документа, использованного для создания дерева.
Практически никогда источником этих проблемы не бывает Beautiful
Soup. Это не потому, что Beautiful Soup так прекрасно
написан. Это потому, что Beautiful Soup не содержит
кода, который бы разбирал документ. Beautiful Soup опирается на внешние парсеры. Если один парсер
не подходит для разбора документа, лучшим решением будет попробовать
другой парсер. В разделе Установка парсера вы найдете больше информации
и таблицу сравнения парсеров.
Наиболее распространенные ошибки разбора — это HTMLParser.HTMLParseError: и
malformed start tagHTMLParser.HTMLParseError: bad end. Они оба генерируются встроенным в Python парсером HTML,
tag
и решением будет установить lxml или
html5lib.
Наиболее распространенный тип неожиданного поведения — когда вы не можете найти
тег, который точно есть в документе. Вы видели его на входе, но
find_all() возвращает [], или find() возвращает None. Это
еще одна распространенная проблема со встроенным в Python парсером HTML, который
иногда пропускает теги, которые он не понимает. Опять же, решение заключается в
установке lxml или html5lib.
Проблемы несоответствия версий¶
SyntaxError: Invalid syntax(в строкеROOT_TAG_NAME =) — вызвано запуском версии Beautiful Soup на Python 2
u'[document]'
под Python 3 без конвертации кода.ImportError: No module named HTMLParser— вызвано запуском
версия Beautiful Soup на Python 3 под Python 2.ImportError: No module named html.parser— вызвано запуском
версия Beautiful Soup на Python 2 под Python 3.ImportError: No module named BeautifulSoup— вызвано запуском
кода Beautiful Soup 3 в системе, где BS3
не установлен. Или код писали на Beautiful Soup 4, не зная, что
имя пакета сменилось наbs4.ImportError: No module named bs4— вызвано запуском
кода Beautiful Soup 4 в системе, где BS4 не установлен.
Разбор XML¶
По умолчанию Beautiful Soup разбирает документы как HTML. Чтобы разобрать
документ в виде XML, передайте “xml” в качестве второго аргумента
в конструктор BeautifulSoup:
soup = BeautifulSoup(markup, "xml")
Вам также нужно будет установить lxml.
Другие проблемы с парсерами¶
- Если ваш скрипт работает на одном компьютере, но не работает на другом, или работает в одной
виртуальной среде, но не в другой, или работает вне виртуальной
среды, но не внутри нее, это, вероятно, потому что в двух
средах разные библиотеки парсеров. Например,
вы могли разработать скрипт на компьютере с установленным lxml,
а затем попытались запустить его на компьютере, где установлен только
html5lib. Читайте в разделе Различия между парсерами, почему это
важно, и исправляйте проблемы, указывая конкретную библиотеку парсера
в конструктореBeautifulSoup. - Поскольку HTML-теги и атрибуты нечувствительны к регистру, все три HTML-
парсера конвертируют имена тегов и атрибутов в нижний регистр. Таким образом,
разметка <TAG></TAG> преобразуется в <tag></tag>. Если вы хотите
сохранить смешанный или верхний регистр тегов и атрибутов, вам нужно
разобрать документ как XML.
Прочие ошибки¶
UnicodeEncodeError: 'charmap' codec can't encode character(или практически любая другая ошибка
u'xfoo' in position bar
UnicodeEncodeError) — это не проблема с Beautiful Soup.
Эта проблема проявляется в основном в двух ситуациях. Во-первых, когда вы пытаетесь
вывести символ Unicode, который ваша консоль не может отобразить, потому что не знает, как.
(Смотрите эту страницу в Python вики.) Во-вторых, когда
вы пишете в файл и передаете символ Unicode, который
не поддерживается вашей кодировкой по умолчанию. В этом случае самым простым
решением будет явное кодирование строки Unicode в UTF-8 с помощью
u.encode("utf8").KeyError: [attr]— вызывается при обращении кtag['attr'], когда
в искомом теге не определен атрибутattr. Наиболее
типичны ошибкиKeyError: 'href'иKeyError:. Используйте
'class'tag.get('attr'), если вы не уверены, чтоattr
определен — так же, как если бы вы работали со словарем Python.AttributeError: 'ResultSet' object has no attribute 'foo'— это
обычно происходит тогда, когда вы ожидаете, чтоfind_all()вернет
один тег или строку. Ноfind_all()возвращает список тегов
и строк в объектеResultSet. Вам нужно перебрать
список и поискать.fooв каждом из элементов. Или, если вам действительно
нужен только один результат, используйтеfind()вместо
find_all().AttributeError: 'NoneType' object has no attribute 'foo'— это
обычно происходит, когда вы вызываетеfind()и затем пытаетесь
получить доступ к атрибуту.foo. Но в вашем случае
find()не нашел ничего, поэтому вернулNoneвместо
того, чтобы вернуть тег или строку. Вам нужно выяснить, почему
find()ничего не возвращает.
Повышение производительности¶
Beautiful Soup никогда не будет таким же быстрым, как парсеры, на основе которых он
работает. Если время отклика критично, если вы платите за компьютерное время
по часам, или если есть какая-то другая причина, почему компьютерное время
важнее программистского, стоит забыть о Beautiful Soup
и работать непосредственно с lxml.
Тем не менее, есть вещи, которые вы можете сделать, чтобы ускорить Beautiful Soup. Если
вы не используете lxml в качестве основного парсера, самое время
начать. Beautiful Soup разбирает документы
значительно быстрее с lxml, чем с html.parser или html5lib.
Вы можете значительно ускорить распознавание кодировок, установив
библиотеку cchardet.
Разбор части документа не сэкономит много времени в процессе разбора,
но может сэкономить много памяти, что сделает
поиск по документу намного быстрее.
Beautiful Soup 3¶
Beautiful Soup 3 — предыдущая версия, и она больше
активно не развивается. На текущий момент Beautiful Soup 3 поставляется со всеми основными
дистрибутивами Linux:
$ apt-get install python-beautifulsoup
Он также публикуется через PyPi как BeautifulSoup:
$ easy_install BeautifulSoup
$ pip install BeautifulSoup
Вы можете скачать tar-архив Beautiful Soup 3.2.0.
Если вы запустили easy_install beautifulsoup или easy_install, но ваш код не работает, значит, вы ошибочно установили Beautiful
BeautifulSoup
Soup 3. Вам нужно запустить easy_install beautifulsoup4.
Архивная документация для Beautiful Soup 3 доступна онлайн.
Перенос кода на BS4¶
Большая часть кода, написанного для Beautiful Soup 3, будет работать и в Beautiful
Soup 4 с одной простой заменой. Все, что вам нужно сделать, это изменить
имя пакета c BeautifulSoup на bs4. Так что это:
from BeautifulSoup import BeautifulSoup
становится этим:
from bs4 import BeautifulSoup
- Если выводится сообщение
ImportError“No module named BeautifulSoup”, ваша
проблема в том, что вы пытаетесь запустить код Beautiful Soup 3, в то время как
у вас установлен Beautiful Soup 4. - Если выводится сообщение
ImportError“No module named bs4”, ваша проблема
в том, что вы пытаетесь запустить код Beautiful Soup 4, в то время как
у вас установлен Beautiful Soup 3.
Хотя BS4 в основном обратно совместим с BS3, большинство
методов BS3 устарели и получили новые имена, чтобы соответствовать PEP 8. Некоторые
из переименований и изменений нарушают обратную совместимость.
Вот что нужно знать, чтобы перейти с BS3 на BS4:
Вам нужен парсер¶
Beautiful Soup 3 использовал модуль Python SGMLParser, который теперь
устарел и был удален в Python 3.0. Beautiful Soup 4 по умолчанию использует
html.parser, но вы можете подключить lxml или html5lib
вместо него. Вы найдете таблицу сравнения парсеров в разделе Установка парсера.
Поскольку html.parser — это не то же, что SGMLParser, вы
можете обнаружить, что Beautiful Soup 4 дает другое дерево разбора, чем
Beautiful Soup 3. Если вы замените html.parser
на lxml или html5lib, может оказаться, что дерево разбора опять
изменилось. Если такое случится, вам придется обновить код,
чтобы разобраться с новым деревом.
Имена методов¶
renderContents->encode_contentsreplaceWith->replace_withreplaceWithChildren->unwrapfindAll->find_allfindAllNext->find_all_nextfindAllPrevious->find_all_previousfindNext->find_nextfindNextSibling->find_next_siblingfindNextSiblings->find_next_siblingsfindParent->find_parentfindParents->find_parentsfindPrevious->find_previousfindPreviousSibling->find_previous_siblingfindPreviousSiblings->find_previous_siblingsgetText->get_textnextSibling->next_siblingpreviousSibling->previous_sibling
Некоторые аргументы конструктора Beautiful Soup были переименованы по
той же причине:
BeautifulSoup(parseOnlyThese=...)->BeautifulSoup(parse_only=...)BeautifulSoup(fromEncoding=...)->BeautifulSoup(from_encoding=...)
Я переименовал один метод для совместимости с Python 3:
Tag.has_key()->Tag.has_attr()
Я переименовал один атрибут, чтобы использовать более точную терминологию:
Tag.isSelfClosing->Tag.is_empty_element
Я переименовал три атрибута, чтобы избежать использования зарезервированных слов
в Python. В отличие от других, эти изменения не являются обратно
совместимыми. Если вы использовали эти атрибуты в BS3, ваш код не сработает
на BS4, пока вы их не измените.
UnicodeDammit.unicode->UnicodeDammit.unicode_markupTag.next->Tag.next_elementTag.previous->Tag.previous_element
Генераторы¶
Я дал генераторам PEP 8-совместимые имена и преобразовал их в
свойства:
childGenerator()->childrennextGenerator()->next_elementsnextSiblingGenerator()->next_siblingspreviousGenerator()->previous_elementspreviousSiblingGenerator()->previous_siblingsrecursiveChildGenerator()->descendantsparentGenerator()->parents
Так что вместо этого:
for parent in tag.parentGenerator(): ...
Вы можете написать это:
for parent in tag.parents: ...
(Хотя старый код тоже будет работать.)
Некоторые генераторы выдавали None после их завершения и
останавливались. Это была ошибка. Теперь генераторы просто останавливаются.
Добавились два генератора: .strings и
.stripped_strings.
.strings выдает
объекты NavigableString, а .stripped_strings выдает строки Python,
у которых удалены пробелы.
XML¶
Больше нет класса BeautifulStoneSoup для разбора XML. Чтобы
разобрать XML, нужно передать “xml” в качестве второго аргумента
в конструктор BeautifulSoup. По той же причине
конструктор BeautifulSoup больше не распознает
аргумент isHTML.
Улучшена обработка пустых тегов
XML. Ранее при разборе XML нужно было явно указать,
какие теги считать пустыми элементами. Аргумент SelfClosingTags
больше не распознается. Вместо этого
Beautiful Soup считает пустым элементом любой тег без содержимого. Если
вы добавляете в тег дочерний элемент, тег больше не считается
пустым элементом.
Мнемоники¶
Входящие мнемоники HTML или XML всегда преобразуются в
соответствующие символы Unicode. В Beautiful Soup 3 было несколько
перекрывающих друг друга способов взаимодействия с мнемониками. Эти способы
удалены. Конструктор BeautifulSoup больше не распознает
аргументы smartQuotesTo и convertEntities. (В Unicode,
Dammit все еще присутствует smart_quotes_to, но по умолчанию парные кавычки
преобразуются в Unicode). Константы HTML_ENTITIES,
XML_ENTITIES и XHTML_ENTITIES были удалены, так как они
служили для настройки функции, которой больше нет (преобразование отдельных мнемоник в
символы Unicode).
Если вы хотите на выходе преобразовать символы Unicode обратно в мнемоники HTML,
а не превращать Unicode в символы UTF-8, вам нужно
использовать средства форматирования вывода.
Прочее¶
Tag.string теперь работает рекурсивно. Если тег А
содержит только тег B и ничего больше, тогда значение A.string будет таким же, как
B.string. (Раньше это был None.)
Многозначные атрибуты, такие как class, теперь в качестве значений имеют списки строк,
а не строки. Это может повлиять на поиск
по классу CSS.
Если вы передадите в один из методов find* одновременно string и
специфичный для тега аргумент, такой как name, Beautiful Soup будет
искать теги, которые, во-первых, соответствуют специфичным для тега критериям, и, во-вторых, имеют
Tag.string, соответствующий заданному вами значению string. Beautiful Soup не найдет сами строки. Ранее
Beautiful Soup игнорировал аргументы, специфичные для тегов, и искал
строки.
Конструктор BeautifulSoup больше не распознает
аргумент markupMassage. Теперь это задача парсера —
обрабатывать разметку правильно.
Редко используемые альтернативные классы парсеров, такие как
ICantBelieveItsBeautifulSoup и BeautifulSOAP,
удалены. Теперь парсер решает, что делать с неоднозначной
разметкой.
Метод prettify() теперь возвращает строку Unicode, а не байтовую строку.
Перевод документации¶
Переводы документации Beautiful Soup очень
приветствуются. Перевод должен быть лицензирован по лицензии MIT,
так же, как сам Beautiful Soup и англоязычная документация к нему.
Есть два способа передать ваш перевод:
- Создайте ветку репозитория Beautiful Soup, добавьте свой
перевод и предложите слияние с основной веткой — так же,
как вы предложили бы изменения исходного кода. - Отправьте в дискуссионную группу Beautiful Soup
сообщение со ссылкой на
ваш перевод, или приложите перевод к сообщению.
Используйте существующие переводы документации на китайский или португальский в качестве образца. В
частности, переводите исходный файл doc/source/index.rst вместо
того, чтобы переводить HTML-версию документации. Это позволяет
публиковать документацию в разных форматах, не
только в HTML.

Beautiful Soup — это
библиотека Python для извлечения данных из файлов HTML и XML. Она работает
с вашим любимым парсером, чтобы дать вам естественные способы навигации,
поиска и изменения дерева разбора. Она обычно экономит программистам
часы и дни работы.
Эти инструкции иллюстрируют все основные функции Beautiful Soup 4
на примерах. Я покажу вам, для чего нужна библиотека, как она работает,
как ее использовать, как заставить ее делать то, что вы хотите, и что нужно делать, когда она
не оправдывает ваши ожидания.
Эта документация относится к Beautiful Soup версии 4.11.0. Примеры в
документации приведены для Python 3.8.
Возможно, вы ищете документацию для Beautiful Soup 3.
Если это так, имейте в виду, что Beautiful Soup 3 больше не
развивается, и что поддержка этой версии прекращена
31 декабря 2020 года. Если вы хотите узнать о различиях между Beautiful Soup 3
и Beautiful Soup 4, читайте раздел Перенос кода на BS4.
Эта документация переведена на другие языки
пользователями Beautiful Soup:
-
这篇文档当然还有中文版.
-
このページは日本語で利用できます(外部リンク)
-
이 문서는 한국어 번역도 가능합니다.
-
Este documento também está disponível em Português do Brasil.
Техническая поддержка¶
Если у вас есть вопросы о Beautiful Soup или возникли проблемы,
отправьте сообщение в дискуссионную группу. Если
ваша проблема связана с разбором HTML-документа, не забудьте упомянуть,
что говорит о нем
функция diagnose().
Быстрый старт¶
Вот HTML-документ, который я буду использовать в качестве примера в этой
документации. Это фрагмент из «Алисы в стране чудес»:
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
Прогон документа через Beautiful Soup дает нам
объект BeautifulSoup, который представляет документ в виде
вложенной структуры данных:
from bs4 import BeautifulSoup soup = BeautifulSoup (html_doc, 'html.parser') print(soup.prettify()) # <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p class="title"> # <b> # The Dormouse's story # </b> # </p> # <p class="story"> # Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1"> # Elsie # </a> # , # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> # and # <a class="sister" href="http://example.com/tillie" id="link3"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p class="story"> # ... # </p> # </body> # </html>
Вот несколько простых способов навигации по этой структуре данных:
soup.title # <title>The Dormouse's story</title> soup.title.name # u'title' soup.title.string # u'The Dormouse's story' soup.title.parent.name # u'head' soup.p # <p class="title"><b>The Dormouse's story</b></p> soup.p['class'] # u'title' soup.a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find(id="link3") # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
Одна из распространенных задач — извлечь все URL-адреса, найденные на странице в тегах <a>:
for link in soup.find_all('a'): print(link.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
Другая распространенная задача — извлечь весь текст со страницы:
print(soup.get_text()) # The Dormouse's story # # The Dormouse's story # # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # # ...
Это похоже на то, что вам нужно? Если да, продолжайте читать.
Установка Beautiful Soup¶
Если вы используете последнюю версию Debian или Ubuntu Linux, вы можете
установить Beautiful Soup с помощью системы управления пакетами:
$ apt-get install python3-bs4
Beautiful Soup 4 публикуется через PyPi, поэтому, если вы не можете установить библиотеку
с помощью системы управления пакетами, можно установить с помощью easy_install или
pip. Пакет называется beautifulsoup4. Убедитесь, что вы
используете версию pip или easy_install, предназначенную для вашей версии Python
(они могут называться pip3 и easy_install3 соответственно).
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
(BeautifulSoup — это не тот пакет, который вам нужен. Это
предыдущий основной релиз, Beautiful Soup 3. Многие программы используют
BS3, так что он все еще доступен, но если вы пишете новый код,
нужно установить beautifulsoup4.)
Если у вас не установлены easy_install или pip, вы можете
скачать архив с исходным кодом Beautiful Soup 4 и
установить его с помощью setup.py.
$ python setup.py install
Если ничего не помогает, лицензия на Beautiful Soup позволяет
упаковать библиотеку целиком вместе с вашим приложением. Вы можете скачать
tar-архив, скопировать из него в кодовую базу вашего приложения каталог bs4
и использовать Beautiful Soup, не устанавливая его вообще.
Я использую Python 3.8 для разработки , но библиотека должна работать
и с более поздними версиями Python.
Установка парсера¶
Beautiful Soup поддерживает парсер HTML, включенный в стандартную библиотеку Python,
а также ряд сторонних парсеров на Python.
Одним из них является парсер lxml. В зависимости от ваших настроек,
вы можете установить lxml с помощью одной из следующих команд:
$ apt-get install python-lxml
$ easy_install lxml
$ pip install lxml
Другая альтернатива — написанный исключительно на Python парсер html5lib, который разбирает HTML таким же образом,
как это делает веб-браузер. В зависимости от ваших настроек, вы можете установить html5lib
с помощью одной из этих команд:
$ apt-get install python-html5lib
$ easy_install html5lib
$ pip install html5lib
Эта таблица суммирует преимущества и недостатки каждого парсера:
|
Парсер |
Типичное использование |
Преимущества |
Недостатки |
|
html.parser от Python |
|
|
|
|
HTML-парсер в lxml |
|
|
|
|
XML-парсер в lxml |
|
|
|
|
html5lib |
|
|
|
Я рекомендую по возможности установить и использовать lxml для быстродействия. Если вы
используете очень старую версию Python — более ранню, чем 3.2.2 –
необходимо установить lxml или html5lib, потому что встроенный в Python
парсер HTML просто недостаточно хорош в старых версиях.
Обратите внимание, что если документ невалиден, различные парсеры будут генерировать
дерево Beautiful Soup для этого документа по-разному. Ищите подробности в разделе Различия
между парсерами.
Приготовление супа¶
Чтобы разобрать документ, передайте его в
конструктор BeautifulSoup. Вы можете передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup with open("index.html") as fp: soup = BeautifulSoup(fp, 'html.parser') soup = BeautifulSoup("<html>a web page</html>", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники
конвертируются в символы Unicode:
print(BeautifulSoup("<html><head></head><body>Sacré bleu!</body></html>", "html.parser")) # <html><head></head><body>Sacré bleu!</body></html>
Затем Beautiful Soup анализирует документ, используя лучший из доступных
парсеров. Библиотека будет использовать HTML-парсер, если вы явно не укажете,
что нужно использовать XML-парсер. (См. Разбор XML.)
Виды объектов¶
Beautiful Soup превращает сложный HTML-документ в сложное дерево
объектов Python. Однако вам придется иметь дело только с четырьмя
видами объектов: Tag, NavigableString, BeautifulSoup
и Comment.
Tag¶
Объект Tag соответствует тегу XML или HTML в исходном документе:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'html.parser') tag = soup.b type(tag) # <class 'bs4.element.Tag'>
У объекта Tag (далее «тег») много атрибутов и методов, и я расскажу о большинстве из них
в разделах Навигация по дереву и Поиск по дереву. На данный момент наиболее
важными особенностями тега являются его имя и атрибуты.
Имя¶
У каждого тега есть имя, доступное как .name:
Если вы измените имя тега, это изменение будет отражено в любой HTML-
разметке, созданной Beautiful Soup:
tag.name = "blockquote" tag # <blockquote class="boldest">Extremely bold</blockquote>
Атрибуты¶
У тега может быть любое количество атрибутов. Тег <b имеет атрибут «id», значение которого равно
id = "boldest">
«boldest». Вы можете получить доступ к атрибутам тега, обращаясь с тегом как
со словарем:
tag = BeautifulSoup('<b id="boldest">bold</b>', 'html.parser').b tag['id'] # 'boldest'
Вы можете получить доступ к этому словарю напрямую как к .attrs:
tag.attrs # {'id': 'boldest'}
Вы можете добавлять, удалять и изменять атрибуты тега. Опять же, это
делается путем обращения с тегом как со словарем:
tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # <b another-attribute="1" id="verybold"></b> del tag['id'] del tag['another-attribute'] tag # <b>bold</b> tag['id'] # KeyError: 'id' tag.get('id') # None
Многозначные атрибуты¶
В HTML 4 определено несколько атрибутов, которые могут иметь множество значений. В HTML 5
пара таких атрибутов удалена, но определено еще несколько. Самый распространённый из
многозначных атрибутов — это class (т. е. тег может иметь более
одного класса CSS). Среди прочих rel, rev, accept-charset,
headers и accesskey. Beautiful Soup представляет значение(я)
многозначного атрибута в виде списка:
css_soup = BeautifulSoup('<p class="body"></p>', 'html.parser') css_soup.p['class'] # ['body'] css_soup = BeautifulSoup('<p class="body strikeout"></p>', 'html.parser') css_soup.p['class'] # ['body', 'strikeout']
Если атрибут выглядит так, будто он имеет более одного значения, но это не
многозначный атрибут, определенный какой-либо версией HTML-
стандарта, Beautiful Soup оставит атрибут как есть:
id_soup = BeautifulSoup('<p id="my id"></p>', 'html.parser') id_soup.p['id'] # 'my id'
Когда вы преобразовываете тег обратно в строку, несколько значений атрибута
объединяются:
rel_soup = BeautifulSoup('<p>Back to the <a rel="index">homepage</a></p>', 'html.parser') rel_soup.a['rel'] # ['index'] rel_soup.a['rel'] = ['index', 'contents'] print(rel_soup.p) # <p>Back to the <a rel="index contents">homepage</a></p>
Вы можете отключить объединение, передав multi_valued_attributes = None в качестве
именованного аргумента в конструктор BeautifulSoup:
no_list_soup = BeautifulSoup('<p class="body strikeout"></p>', 'html.parser', multi_valued_attributes=None) no_list_soup.p['class'] # 'body strikeout'
Вы можете использовать get_attribute_list, чтобы получить значение в виде списка,
независимо от того, является ли атрибут многозначным или нет:
id_soup.p.get_attribute_list('id') # ["my id"]
Если вы разбираете документ как XML, многозначных атрибутов не будет:
xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml') xml_soup.p['class'] # 'body strikeout'
Опять же, вы можете поменять настройку, используя аргумент multi_valued_attributes:
class_is_multi= { '*' : 'class'} xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml', multi_valued_attributes=class_is_multi) xml_soup.p['class'] # ['body', 'strikeout']
Вряд ли вам это пригодится, но если все-таки будет нужно, руководствуйтесь значениями
по умолчанию. Они реализуют правила, описанные в спецификации HTML:
from bs4.builder import builder_registry builder_registry.lookup('html').DEFAULT_CDATA_LIST_ATTRIBUTES
NavigableString¶
Строка соответствует фрагменту текста в теге. Beautiful Soup
использует класс NavigableString для хранения этих фрагментов текста:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'html.parser') tag = soup.b tag.string # 'Extremely bold' type(tag.string) # <class 'bs4.element.NavigableString'>
NavigableString похожа на строку Unicode в Python, не считая того,
что она также поддерживает некоторые функции, описанные в
разделах Навигация по дереву и Поиск по дереву. Вы можете конвертировать
NavigableString в строку Unicode с помощью str:
unicode_string = str(tag.string) unicode_string # 'Extremely bold' type(unicode_string) # <type 'str'>
Вы не можете редактировать строку непосредственно, но вы можете заменить одну строку
другой, используя replace_with():
tag.string.replace_with("No longer bold") tag # <b class="boldest">No longer bold</b>
NavigableString поддерживает большинство функций, описанных в
разделах Навигация по дереву и Поиск по дереву, но
не все. В частности, поскольку строка не может ничего содержать (в том смысле,
в котором тег может содержать строку или другой тег), строки не поддерживают
атрибуты .contents и .string или метод find().
Если вы хотите использовать NavigableString вне Beautiful Soup,
вам нужно вызвать метод unicode(), чтобы превратить ее в обычную для Python
строку Unicode. Если вы этого не сделаете, ваша строка будет тащить за собой
ссылку на все дерево разбора Beautiful Soup, даже когда вы
закончите использовать Beautiful Soup. Это большой расход памяти.
BeautifulSoup¶
Объект BeautifulSoup представляет разобранный документ как единое
целое. В большинстве случаев вы можете рассматривать его как объект
Tag. Это означает, что он поддерживает большинство методов, описанных
в разделах Навигация по дереву и Поиск по дереву.
Вы также можете передать объект BeautifulSoup в один из методов,
перечисленных в разделе Изменение дерева, по аналогии с передачей объекта Tag. Это
позволяет вам делать такие вещи, как объединение двух разобранных документов:
doc = BeautifulSoup("<document><content/>INSERT FOOTER HERE</document", "xml") footer = BeautifulSoup("<footer>Here's the footer</footer>", "xml") doc.find(text="INSERT FOOTER HERE").replace_with(footer) # 'INSERT FOOTER HERE' print(doc) # <?xml version="1.0" encoding="utf-8"?> # <document><content/><footer>Here's the footer</footer></document>
Поскольку объект BeautifulSoup не соответствует действительному
HTML- или XML-тегу, у него нет имени и атрибутов. Однако иногда
бывает полезно взглянуть на .name объекта BeautifulSoup, поэтому ему было присвоено специальное «имя»
.name «[document]»:
Комментарии и другие специфичные строки¶
Tag, NavigableString и BeautifulSoup охватывают почти
все, с чем вы столкнётесь в файле HTML или XML, но осталось
ещё немного. Пожалуй, единственное, с чем вам придется столкнуться,
это комментарий:
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string type(comment) # <class 'bs4.element.Comment'>
Объект Comment — это просто особый тип NavigableString:
comment # 'Hey, buddy. Want to buy a used parser'
Но когда он появляется как часть HTML-документа, Comment
отображается со специальным форматированием:
print(soup.b.prettify()) # <b> # <!--Hey, buddy. Want to buy a used parser?--> # </b>
В Beautiful Soup также определены классы Stylesheet, Script
и TemplateString для встроенных таблиц стилей CSS (любые строки
внутри тега <style>), встроенного Javascript (любые строки
в теге <script>) и шаблонов HTML (любые строки в
теге <template>). Эти классы работают точно так же, как
NavigableString; их единственная цель — облегчить извлечение
основной части страницы, игнорируя строки, которые представляют
что-то еще. (Эти классы являются новыми в Beautiful Soup 4.9.0, и
парсер html5lib их не использует.)
Beautiful Soup определяет классы для всего, что может появиться в
XML-документе: CData, ProcessingInstruction,
Declaration и Doctype. Как и Comment, эти классы
являются подклассами NavigableString, которые добавляют что-то еще к
строке. Вот пример, который заменяет комментарий блоком
CDATA:
from bs4 import CData cdata = CData("A CDATA block") comment.replace_with(cdata) print(soup.b.prettify()) # <b> # <![CDATA[A CDATA block]]> # </b>
Навигация по дереву¶
Вернемся к HTML-документу с фрагментом из «Алисы в стране чудес»:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup (html_doc, 'html.parser')
Я буду использовать его в качестве примера, чтобы показать, как перейти от одной части
документа к другой.
Проход сверху вниз¶
Теги могут содержать строки и другие теги. Эти элементы являются
дочерними (children) для тега. Beautiful Soup предоставляет множество различных атрибутов для
навигации и перебора дочерних элементов.
Обратите внимание, что строки Beautiful Soup не поддерживают ни один из этих
атрибутов, потому что строка не может иметь дочерних элементов.
Навигация с использованием имен тегов¶
Самый простой способ навигации по дереву разбора — это указать имя
тега, который вам нужен. Если вы хотите получить тег <head>, просто напишите soup.head:
soup.head # <head><title>The Dormouse's story</title></head> soup.title # <title>The Dormouse's story</title>
Вы можете повторять этот трюк многократно, чтобы подробнее рассмотреть определенную часть
дерева разбора. Следующий код извлекает первый тег <b> внутри тега <body>:
soup.body.b # <b>The Dormouse's story</b>
Использование имени тега в качестве атрибута даст вам только первый тег с таким
именем:
soup.a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
Если вам нужно получить все теги <a> или что-нибудь более сложное,
чем первый тег с определенным именем, вам нужно использовать один из
методов, описанных в разделе Поиск по дереву, такой как find_all():
soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
.contents и .children¶
Дочерние элементы доступны в списке под названием .contents:
head_tag = soup.head head_tag # <head><title>The Dormouse's story</title></head> head_tag.contents # [<title>The Dormouse's story</title>] title_tag = head_tag.contents[0] title_tag # <title>The Dormouse's story</title> title_tag.contents # ['The Dormouse's story']
Сам объект BeautifulSoup имеет дочерние элементы. В этом случае
тег <html> является дочерним для объекта BeautifulSoup:
len(soup.contents) # 1 soup.contents[0].name # 'html'
У строки нет .contents, потому что она не может содержать
ничего:
text = title_tag.contents[0] text.contents # AttributeError: У объекта 'NavigableString' нет атрибута 'contents'
Вместо того, чтобы получать дочерние элементы в виде списка, вы можете перебирать их
с помощью генератора .children:
for child in title_tag.children: print(child) # The Dormouse's story
Если вы хотите изменить дочерние элементы тега, используйте методы, описанные в разделе
Изменение дерева. Не изменяйте список .contents
напрямую: это может привести к неуловимым проблемам, которые трудно
обнаружить.
.descendants¶
Атрибуты .contents и .children применяются только в отношении
непосредственных дочерних элементов тега. Например, тег <head> имеет только один непосредственный
дочерний тег <title>:
head_tag.contents # [<title>The Dormouse's story</title>]
Но у самого тега <title> есть дочерний элемент: строка «The Dormouse’s
story». В некотором смысле эта строка также является дочерним элементом
тега <head>. Атрибут .descendants позволяет перебирать все
дочерние элементы тега рекурсивно: его непосредственные дочерние элементы, дочерние элементы
дочерних элементов и так далее:
for child in head_tag.descendants: print(child) # <title>The Dormouse's story</title> # The Dormouse's story
У тега <head> есть только один дочерний элемент, но при этом у него два потомка:
тег <title> и его дочерний элемент. У объекта BeautifulSoup
только один прямой дочерний элемент (тег <html>), зато множество
потомков:
len(list(soup.children)) # 1 len(list(soup.descendants)) # 26
.string¶
Если у тега есть только один дочерний элемент, и это NavigableString,
его можно получить через .string:
title_tag.string # 'The Dormouse's story'
Если единственным дочерним элементом тега является другой тег, и у этого другого тега есть строка
.string, то считается, что родительский тег содержит ту же строку
.string, что и дочерний тег:
head_tag.contents # [<title>The Dormouse's story</title>] head_tag.string # 'The Dormouse's story'
Если тег содержит больше чем один элемент, то становится неясным, какая из строк
.string относится и к родительскому тегу, поэтому .string родительского тега имеет значение
None:
print(soup.html.string) # None
.strings и .stripped_strings¶
Если внутри тега есть более одного элемента, вы все равно можете посмотреть только на
строки. Используйте генератор .strings:
for string in soup.strings: print(repr(string)) 'n' # "The Dormouse's story" # 'n' # 'n' # "The Dormouse's story" # 'n' # 'Once upon a time there were three little sisters; and their names weren' # 'Elsie' # ',n' # 'Lacie' # ' andn' # 'Tillie' # ';nand they lived at the bottom of a well.' # 'n' # '...' # 'n'
В этих строках много лишних пробелов, которые вы можете
удалить, используя генератор .stripped_strings:
for string in soup.stripped_strings: print(repr(string)) # "The Dormouse's story" # "The Dormouse's story" # 'Once upon a time there were three little sisters; and their names were' # 'Elsie' # ',' # 'Lacie' # 'and' # 'Tillie' # ';n and they lived at the bottom of a well.' # '...'
Здесь строки, состоящие исключительно из пробелов, игнорируются, а
пробелы в начале и конце строк удаляются.
Проход снизу вверх¶
В продолжение аналогии с «семейным деревом», каждый тег и каждая строка имеет
родителя (parent): тег, который его содержит.
.parent¶
Вы можете получить доступ к родительскому элементу с помощью атрибута .parent. В
примере документа с фрагментом из «Алисы в стране чудес» тег <head> является родительским
для тега <title>:
title_tag = soup.title title_tag # <title>The Dormouse's story</title> title_tag.parent # <head><title>The Dormouse's story</title></head>
Строка заголовка сама имеет родителя: тег <title>, содержащий
ее:
title_tag.string.parent # <title>The Dormouse's story</title>
Родительским элементом тега верхнего уровня, такого как <html>, является сам объект
BeautifulSoup:
html_tag = soup.html type(html_tag.parent) # <class 'bs4.BeautifulSoup'>
И .parent объекта BeautifulSoup определяется как None:
print(soup.parent) # None
.parents¶
Вы можете перебрать всех родителей элемента с помощью
.parents. В следующем примере .parents используется для перемещения от тега <a>,
закопанного глубоко внутри документа, до самого верха документа:
link = soup.a link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> for parent in link.parents: print(parent.name) # p # body # html # [document]
Перемещение вбок¶
Рассмотрим простой документ:
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></a>", 'html.parser') print(sibling_soup.prettify()) # <a> # <b> # text1 # </b> # <c> # text2 # </c> # </a>
Тег <b> и тег <c> находятся на одном уровне: они оба непосредственные
дочерние элементы одного и того же тега. Мы называем их одноуровневые. Когда документ
красиво отформатирован, одноуровневые элементы выводятся с одинаковым отступом. Вы
также можете использовать это отношение в написанном вами коде.
.next_sibling и .previous_sibling¶
Вы можете использовать .next_sibling и .previous_sibling для навигации
между элементами страницы, которые находятся на одном уровне дерева разбора:
sibling_soup.b.next_sibling # <c>text2</c> sibling_soup.c.previous_sibling # <b>text1</b>
У тега <b> есть .next_sibling, но нет .previous_sibling,
потому что нет ничего до тега <b> на том же уровне
дерева. По той же причине у тега <c> есть .previous_sibling,
но нет .next_sibling:
print(sibling_soup.b.previous_sibling) # None print(sibling_soup.c.next_sibling) # None
Строки «text1» и «text2» не являются одноуровневыми, потому что они не
имеют общего родителя:
sibling_soup.b.string # 'text1' print(sibling_soup.b.string.next_sibling) # None
В реальных документах .next_sibling или .previous_sibling
тега обычно будет строкой, содержащей пробелы. Возвращаясь к
фрагменту из «Алисы в стране чудес»:
# <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a> # <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> # <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
Вы можете подумать, что .next_sibling первого тега <a>
должен быть второй тег <a>. Но на самом деле это строка: запятая и
перевод строки, отделяющий первый тег <a> от второго:
link = soup.a link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> link.next_sibling # ',n '
Второй тег <a> на самом деле является .next_sibling запятой
link.next_sibling.next_sibling # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
.next_siblings и .previous_siblings¶
Вы можете перебрать одноуровневые элементы данного тега с помощью .next_siblings или
.previous_siblings:
for sibling in soup.a.next_siblings: print(repr(sibling)) # ',n' # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> # ' andn' # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> # '; and they lived at the bottom of a well.' for sibling in soup.find(id="link3").previous_siblings: print(repr(sibling)) # ' andn' # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> # ',n' # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> # 'Once upon a time there were three little sisters; and their names weren'
Проход вперед и назад¶
Взгляните на начало фрагмента из «Алисы в стране чудес»:
# <html><head><title>The Dormouse's story</title></head> # <p class="title"><b>The Dormouse's story</b></p>
HTML-парсер берет эту строку символов и превращает ее в
серию событий: «открыть тег <html>», «открыть тег <head>», «открыть
тег <html>», «добавить строку», «закрыть тег <title>», «открыть
тег <p>» и так далее. Beautiful Soup предлагает инструменты для реконструирование
первоначального разбора документа.
.next_element и .previous_element¶
Атрибут .next_element строки или тега указывает на то,
что было разобрано непосредственно после него. Это могло бы быть тем же, что и
.next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a> в фрагменте из «Алисы в стране чудес». Его
.next_sibling является строкой: конец предложения, которое было
прервано началом тега <a>:
last_a_tag = soup.find("a", id="link3") last_a_tag # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> last_a_tag.next_sibling # ';nand they lived at the bottom of a well.'
Но .next_element этого тега <a> — это то, что было разобрано
сразу после тега <a>, не остальная часть этого предложения:
это слово «Tillie»:
last_a_tag.next_element # 'Tillie'
Это потому, что в оригинальной разметке слово «Tillie» появилось
перед точкой с запятой. Парсер обнаружил тег <a>, затем
слово «Tillie», затем закрывающий тег </a>, затем точку с запятой и оставшуюся
часть предложения. Точка с запятой находится на том же уровне, что и тег <a>, но
слово «Tillie» встретилось первым.
Атрибут .previous_element является полной противоположностью
.next_element. Он указывает на элемент, который был встречен при разборе
непосредственно перед текущим:
last_a_tag.previous_element # ' andn' last_a_tag.previous_element.next_element # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
.next_elements и .previous_elements¶
Вы уже должны были уловить идею. Вы можете использовать их для перемещения
вперед или назад по документу, в том порядке, в каком он был разобран парсером:
for element in last_a_tag.next_elements: print(repr(element)) # 'Tillie' # ';nand they lived at the bottom of a well.' # 'n' # <p class="story">...</p> # '...' # 'n'
Поиск по дереву¶
Beautiful Soup определяет множество методов поиска по дереву разбора,
но они все очень похожи. Я буду долго объяснять, как работают
два самых популярных метода: find() и find_all(). Прочие
методы принимают практически те же самые аргументы, поэтому я расскажу
о них вкратце.
И опять, я буду использовать фрагмент из «Алисы в стране чудес» в качестве примера:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup (html_doc, 'html.parser')
Передав фильтр в аргумент типа find_all(), вы можете
углубиться в интересующие вас части документа.
Виды фильтров¶
Прежде чем подробно рассказывать о find_all() и подобных методах, я
хочу показать примеры различных фильтров, которые вы можете передать в эти
методы. Эти фильтры появляются снова и снова в
поисковом API. Вы можете использовать их для фильтрации по имени тега,
по его атрибутам, по тексту строки или по некоторой их
комбинации.
Строка¶
Самый простой фильтр — это строка. Передайте строку в метод поиска, и
Beautiful Soup выполнит поиск соответствия этой строке. Следующий
код находит все теги <b> в документе:
soup.find_all('b') # [<b>The Dormouse's story</b>]
Если вы передадите байтовую строку, Beautiful Soup будет считать, что строка
кодируется в UTF-8. Вы можете избежать этого, передав вместо нее строку Unicode.
Регулярное выражение¶
Если вы передадите объект с регулярным выражением, Beautiful Soup отфильтрует результаты
в соответствии с этим регулярным выражением, используя его метод search(). Следующий код
находит все теги, имена которых начинаются с буквы «b»; в нашем
случае это теги <body> и <b>:
import re for tag in soup.find_all(re.compile("^b")): print(tag.name) # body # b
Этот код находит все теги, имена которых содержат букву «t»:
for tag in soup.find_all(re.compile("t")): print(tag.name) # html # title
Список¶
Если вы передадите список, Beautiful Soup разрешит совпадение строк
с любым элементом из этого списка. Следующий код находит все теги <a>
и все теги <b>:
soup.find_all(["a", "b"]) # [<b>The Dormouse's story</b>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
True¶
Значение True подходит везде, где возможно.. Следующий код находит все
теги в документе, но не текстовые строки:
for tag in soup.find_all(True): print(tag.name) # html # head # title # body # p # b # p # a # a # a # p
Функция¶
Если ничто из перечисленного вам не подходит, определите функцию, которая
принимает элемент в качестве единственного аргумента. Функция должна вернуть
True, если аргумент подходит, и False, если нет.
Вот функция, которая возвращает True, если в теге определен атрибут «class»,
но не определен атрибут «id»:
def has_class_but_no_id(tag): return tag.has_attr('class') and not tag.has_attr('id')
Передайте эту функцию в find_all(), и вы получите все
теги <p>:
soup.find_all(has_class_but_no_id) # [<p class="title"><b>The Dormouse's story</b></p>, # <p class="story">Once upon a time there were…bottom of a well.</p>, # <p class="story">...</p>]
Эта функция выбирает только теги <p>. Она не выбирает теги <a>,
поскольку в них определены и атрибут «class» , и атрибут «id». Она не выбирает
теги вроде <html> и <title>, потому что в них не определен атрибут
«class».
Если вы передаете функцию для фильтрации по определенному атрибуту, такому как
href, аргументом, переданным в функцию, будет
значение атрибута, а не весь тег. Вот функция, которая находит все теги a,
у которых атрибут href не соответствует регулярному выражению:
import re def not_lacie(href): return href and not re.compile("lacie").search(href) soup.find_all(href=not_lacie) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Функция может быть настолько сложной, насколько вам нужно. Вот
функция, которая возвращает True, если тег окружен строковыми
объектами:
from bs4 import NavigableString def surrounded_by_strings(tag): return (isinstance(tag.next_element, NavigableString) and isinstance(tag.previous_element, NavigableString)) for tag in soup.find_all(surrounded_by_strings): print(tag.name) # body # p # a # a # a # p
Теперь мы готовы подробно рассмотреть методы поиска.
find_all()¶
Сигнатура метода: find_all(name, attrs, recursive, string, limit, **kwargs)
Метод find_all() просматривает потомков тега и
извлекает всех потомков, которые соответствую вашим фильтрам. Я привел несколько
примеров в разделе Виды фильтров, а вот еще несколько:
soup.find_all("title") # [<title>The Dormouse's story</title>] soup.find_all("p", "title") # [<p class="title"><b>The Dormouse's story</b></p>] soup.find_all("a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find_all(id="link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] import re soup.find(string=re.compile("sisters")) # 'Once upon a time there were three little sisters; and their names weren'
Кое-что из этого нам уже знакомо, но есть и новое. Что означает
передача значения для string или id? Почему
find_all ("p", "title") находит тег <p> с CSS-классом «title»?
Давайте посмотрим на аргументы find_all().
Аргумент name¶
Передайте значение для аргумента name, и вы скажете Beautiful Soup
рассматривать только теги с определенными именами. Текстовые строки будут игнорироваться, так же как и
теги, имена которых не соответствуют заданным.
Вот простейший пример использования:
soup.find_all("title") # [<title>The Dormouse's story</title>]
В разделе Виды фильтров говорилось, что значением name может быть
строка, регулярное выражение, список, функция или
True.
Именованные аргументы¶
Любой нераспознанный аргумент будет превращен в фильтр
по атрибуту тега. Если вы передаете значение для аргумента с именем id,
Beautiful Soup будет фильтровать по атрибуту «id» каждого тега:
soup.find_all(id='link2') # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Если вы передадите значение для href, Beautiful Soup отфильтрует
по атрибуту «href» каждого тега:
soup.find_all(href=re.compile("elsie")) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
Для фильтрации по атрибуту может использоваться строка, регулярное
выражение, список, функция или значение True.
Следующий код находит все теги, атрибут id которых имеет значение,
независимо от того, что это за значение:
soup.find_all(id=True) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Вы можете отфильтровать несколько атрибутов одновременно, передав более одного
именованного аргумента:
soup.find_all(href=re.compile("elsie"), id='link1') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
Некоторые атрибуты, такие как атрибуты data-* в HTML 5, имеют имена, которые
нельзя использовать в качестве имен именованных аргументов:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>', 'html.parser') data_soup.find_all(data-foo="value") # SyntaxError: keyword can't be an expression
Вы можете использовать эти атрибуты в поиске, поместив их в
словарь и передав словарь в find_all() как
аргумент attrs:
data_soup.find_all(attrs={"data-foo": "value"}) # [<div data-foo="value">foo!</div>]
Нельзя использовать именованный аргумент для поиска в HTML по элементу «name»,
потому что Beautiful Soup использует аргумент name для имени
самого тега. Вместо этого вы можете передать элемент «name» вместе с его значением в
составе аргумента attrs:
name_soup = BeautifulSoup('<input name="email"/>', 'html.parser') name_soup.find_all(name="email") # [] name_soup.find_all(attrs={"name": "email"}) # [<input name="email"/>]
Поиск по классу CSS¶
Очень удобно искать тег с определенным классом CSS, но
имя атрибута CSS, «class», является зарезервированным словом в
Python. Использование class в качестве именованного аргумента приведет к синтаксической
ошибке. Начиная с Beautiful Soup 4.1.2, вы можете выполнять поиск по классу CSS, используя
именованный аргумент class_:
soup.find_all("a", class_="sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Как и с любым именованным аргументом, вы можете передать в качестве значения class_ строку, регулярное
выражение, функцию или True:
soup.find_all(class_=re.compile("itl")) # [<p class="title"><b>The Dormouse's story</b></p>] def has_six_characters(css_class): return css_class is not None and len(css_class) == 6 soup.find_all(class_=has_six_characters) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Помните, что один тег может иметь несколько значений
для атрибута «class». Когда вы ищете тег, который
соответствует определенному классу CSS, вы ищете соответствие любому из его
классов CSS:
css_soup = BeautifulSoup('<p class="body strikeout"></p>', 'html.parser') css_soup.find_all("p", class_="strikeout") # [<p class="body strikeout"></p>] css_soup.find_all("p", class_="body") # [<p class="body strikeout"></p>]
Можно искать точное строковое значение атрибута class:
css_soup.find_all("p", class_="body strikeout") # [<p class="body strikeout"></p>]
Но поиск вариантов строкового значения не сработает:
css_soup.find_all("p", class_="strikeout body") # []
Если вы хотите искать теги, которые соответствуют двум или более классам CSS,
следует использовать селектор CSS:
css_soup.select("p.strikeout.body") # [<p class="body strikeout"></p>]
В старых версиях Beautiful Soup, в которых нет ярлыка class_
можно использовать трюк с аргументом attrs, упомянутый выше. Создайте
словарь, значение которого для «class» является строкой (или регулярным
выражением, или чем угодно еще), которую вы хотите найти:
soup.find_all("a", attrs={"class": "sister"}) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Аргумент string¶
С помощью string вы можете искать строки вместо тегов. Как и в случае с
name и именованными аргументами, передаваться может строка,
регулярное выражение, список, функция или значения True.
Вот несколько примеров:
soup.find_all(string="Elsie") # ['Elsie'] soup.find_all(string=["Tillie", "Elsie", "Lacie"]) # ['Elsie', 'Lacie', 'Tillie'] soup.find_all(string=re.compile("Dormouse")) # ["The Dormouse's story", "The Dormouse's story"] def is_the_only_string_within_a_tag(s): """Return True if this string is the only child of its parent tag.""" return (s == s.parent.string) soup.find_all(string=is_the_only_string_within_a_tag) # ["The Dormouse's story", "The Dormouse's story", 'Elsie', 'Lacie', 'Tillie', '...']
Хотя значение типа string предназначено для поиска строк, вы можете комбинировать его с
аргументами, которые находят теги: Beautiful Soup найдет все теги, в которых
.string соответствует вашему значению для string. Следующий код находит все теги <a>,
у которых .string равно «Elsie»:
soup.find_all("a", string="Elsie") # [<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>]
Аргумент string — это новое в Beautiful Soup 4.4.0. В ранних
версиях он назывался text:
soup.find_all("a", text="Elsie") # [<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>]
Аргумент limit¶
find_all() возвращает все теги и строки, которые соответствуют вашим
фильтрам. Это может занять некоторое время, если документ большой. Если вам не
нужны все результаты, вы можете указать их предельное число — limit. Это
работает так же, как ключевое слово LIMIT в SQL. Оно говорит Beautiful Soup
прекратить собирать результаты после того, как их найдено определенное количество.
В фрагменте из «Алисы в стране чудес» есть три ссылки, но следующий код
находит только первые две:
soup.find_all("a", limit=2) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Аргумент recursive¶
Если вы вызовете mytag.find_all(), Beautiful Soup проверит всех
потомков mytag: его дочерние элементы, дочерние элементы дочерних элементов, и
так далее. Если вы хотите, чтобы Beautiful Soup рассматривал только непосредственных потомков (дочерние элементы),
вы можете передать recursive = False. Оцените разницу:
soup.html.find_all("title") # [<title>The Dormouse's story</title>] soup.html.find_all("title", recursive=False) # []
Вот эта часть документа:
<html> <head> <title> The Dormouse's story </title> </head> ...
Тег <title> находится под тегом <html>, но не непосредственно
под тегом <html>: на пути встречается тег <head>. Beautiful Soup
находит тег <title>, когда разрешено просматривать всех потомков
тега <html>, но когда recursive=False ограничивает поиск
только непосредстввенно дочерними элементами, Beautiful Soup ничего не находит.
Beautiful Soup предлагает множество методов поиска по дереву (они рассмотрены ниже),
и они в основном принимают те же аргументы, что и find_all(): name,
attrs, string, limit и именованные аргументы. Но
с аргументом recursive все иначе: find_all() и find() —
это единственные методы, которые его поддерживают. От передачи recursive=False в
метод типа find_parents() не очень много пользы.
Вызов тега похож на вызов find_all()¶
Поскольку find_all() является самым популярным методом в Beautiful
Soup API, вы можете использовать сокращенную запись. Если относиться к
объекту BeautifulSoup или объекту Tag так, будто это
функция, то это похоже на вызов find_all()
с этим объектом. Эти две строки кода эквивалентны:
soup.find_all("a") soup("a")
Эти две строки также эквивалентны:
soup.title.find_all(string=True) soup.title(string=True)
find()¶
Сигнатура метода: find(name, attrs, recursive, string, **kwargs)
Метод find_all() сканирует весь документ в поиске
всех результатов, но иногда вам нужен только один. Если вы знаете,
что в документе есть только один тег <body>, нет смысла сканировать
весь документ в поиске остальных. Вместо того, чтобы передавать limit=1
каждый раз, когда вы вызываете find_all(), используйте
метод find(). Эти две строки кода эквивалентны:
soup.find_all('title', limit=1) # [<title>The Dormouse's story</title>] soup.find('title') # <title>The Dormouse's story</title>
Разница лишь в том, что find_all() возвращает список, содержащий
единственный результат, а find() возвращает только сам результат.
Если find_all() не может ничего найти, он возвращает пустой список. Если
find() не может ничего найти, он возвращает None:
print(soup.find("nosuchtag")) # None
Помните трюк с soup.head.title из раздела
Навигация с использованием имен тегов? Этот трюк работает на основе неоднократного вызова find():
soup.head.title # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title>
find_parents() и find_parent()¶
Сигнатура метода: find_parents(name, attrs, string, limit, **kwargs)
Сигнатура метода: find_parent(name, attrs, string, **kwargs)
Я долго объяснял, как работают find_all() и
find(). Beautiful Soup API определяет десяток других методов для
поиска по дереву, но пусть вас это не пугает. Пять из этих методов
в целом похожи на find_all(), а другие пять в целом
похожи на find(). Единственное различие в том, по каким частям
дерева они ищут.
Сначала давайте рассмотрим find_parents() и
find_parent(). Помните, что find_all() и find() прорабатывают
дерево сверху вниз, просматривая теги и их потомков. find_parents() и find_parent()
делают наоборот: они идут снизу вверх, рассматривая
родительские элементы тега или строки. Давайте испытаем их, начав со строки,
закопанной глубоко в фрагменте из «Алисы в стране чудес»:
a_string = soup.find(string="Lacie") a_string # 'Lacie' a_string.find_parents("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] a_string.find_parent("p") # <p class="story">Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; # and they lived at the bottom of a well.</p> a_string.find_parents("p", class_="title") # []
Один из трех тегов <a> является прямым родителем искомой строки,
так что наш поиск находит его. Один из трех тегов <p> является
непрямым родителем строки, и наш поиск тоже его
находит. Где-то в документе есть тег <p> с классом CSS «title»,
но он не является родительским для строки, так что мы не можем найти
его с помощью find_parents().
Вы могли заметить связь между find_parent(),
find_parents() и атрибутами .parent и .parents,
упомянутыми ранее. Связь очень сильная. Эти методы поиска
на самом деле используют .parents, чтобы перебрать все родительские элементы и проверить
каждый из них на соответствие заданному фильтру.
find_next_siblings() и find_next_sibling()¶
Сигнатура метода: find_next_siblings(name, attrs, string, limit, **kwargs)
Сигнатура метода: find_next_sibling(name, attrs, string, **kwargs)
Эти методы используют .next_siblings для
перебора одноуровневых элементов для данного элемента в дереве. Метод
find_next_siblings() возвращает все подходящие одноуровневые элементы,
а find_next_sibling() возвращает только первый из них:
first_link = soup.a first_link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> first_link.find_next_siblings("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] first_story_paragraph = soup.find("p", "story") first_story_paragraph.find_next_sibling("p") # <p class="story">...</p>
find_previous_siblings() и find_previous_sibling()¶
Сигнатура метода: find_previous_siblings(name, attrs, string, limit, **kwargs)
Сигнатура метода: find_previous_sibling(name, attrs, string, **kwargs)
Эти методы используют .previous_siblings для перебора тех одноуровневых элементов,
которые предшествуют данному элементу в дереве разбора. Метод find_previous_siblings()
возвращает все подходящие одноуровневые элементы,, а
а find_next_sibling() только первый из них:
last_link = soup.find("a", id="link3") last_link # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> last_link.find_previous_siblings("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] first_story_paragraph = soup.find("p", "story") first_story_paragraph.find_previous_sibling("p") # <p class="title"><b>The Dormouse's story</b></p>
find_all_next() и find_next()¶
Сигнатура метода: find_all_next(name, attrs, string, limit, **kwargs)
Сигнатура метода: find_next(name, attrs, string, **kwargs)
Эти методы используют .next_elements для
перебора любых тегов и строк, которые встречаются в документе после
элемента. Метод find_all_next() возвращает все совпадения, а
find_next() только первое:
first_link = soup.a first_link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> first_link.find_all_next(string=True) # ['Elsie', ',n', 'Lacie', ' andn', 'Tillie', # ';nand they lived at the bottom of a well.', 'n', '...', 'n'] first_link.find_next("p") # <p class="story">...</p>
В первом примере нашлась строка «Elsie», хотя она
содержится в теге <a>, с которого мы начали. Во втором примере
нашелся последний тег <p>, хотя он находится
в другой части дерева, чем тег <a>, с которого мы начали. Для этих
методов имеет значение только то, что элемент соответствует фильтру и
появляется в документе позже, чем тот элемент, с которого начали поиск.
find_all_previous() и find_previous()¶
Сигнатура метода: find_all_previous(name, attrs, string, limit, **kwargs)
Сигнатура метода: find_previous(name, attrs, string, **kwargs)
Эти методы используют .previous_elements для
перебора любых тегов и строк, которые встречаются в документе до
элемента. Метод find_all_previous() возвращает все совпадения, а
find_previous() только первое:
first_link = soup.a first_link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> first_link.find_all_previous("p") # [<p class="story">Once upon a time there were three little sisters; ...</p>, # <p class="title"><b>The Dormouse's story</b></p>] first_link.find_previous("title") # <title>The Dormouse's story</title>
Вызов find_all_previous ("p") нашел первый абзац в
документе (тот, который с class = "title"), но он также находит
второй абзац, а именно тег <p>, содержащий тег <a>, с которого мы
начали. Это не так уж удивительно: мы смотрим на все теги,
которые появляются в документе раньше, чем тот, с которого мы начали. Тег
<p>, содержащий тег <a>, должен был появиться до тега <a>, который
в нем содержится.
Селекторы CSS¶
В BeautifulSoup есть метод .select(), который использует SoupSieve , чтобы запустить селектор CSS
и вернуть все подходящие
элементы. В Tag есть похожий метод, который запускает селектор CSS
в отношении содержимого одного тега.
(Интеграция SoupSieve была добавлена в Beautiful Soup 4.7.0. В более ранних
версиях также есть метод .select(), но поддерживаются только самые
часто используемые селекторы CSS. Если вы установили Beautiful
Soup через pip, одновременно должен был установиться SoupSieve, так что
ничего больше вам делать не нужно.)
В документации SoupSieve перечислены все
селекторы CSS, которые поддерживаются на данный момент, но вот некоторые из основных:
Вы можете найти теги:
soup.select("title") # [<title>The Dormouse's story</title>] soup.select("p:nth-of-type(3)") # [<p class="story">...</p>]
Найти теги под другими тегами:
soup.select("body a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("html head title") # [<title>The Dormouse's story</title>]
Найти теги непосредственно под другими тегами:
soup.select("head > title") # [<title>The Dormouse's story</title>] soup.select("p > a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("p > a:nth-of-type(2)") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] soup.select("p > #link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select("body > a") # []
Найти одноуровневые элементы тега:
soup.select("#link1 ~ .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("#link1 + .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Найти теги по классу CSS:
soup.select(".sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("[class~=sister]") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Найти теги по ID:
soup.select("#link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select("a#link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Найти теги, которые соответствуют любому селектору из списка:
soup.select("#link1,#link2") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Проверка на наличие атрибута:
soup.select('a[href]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Найти теги по значению атрибута:
soup.select('a[href="http://example.com/elsie"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select('a[href^="http://example.com/"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select('a[href$="tillie"]') # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select('a[href*=".com/el"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
Есть также метод select_one(), который находит только
первый тег, соответствующий селектору:
soup.select_one(".sister") # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
Если вы разобрали XML, в котором определены пространства имен, вы можете использовать их в
селекторах CSS:
from bs4 import BeautifulSoup xml = """<tag xmlns:ns1="http://namespace1/" xmlns:ns2="http://namespace2/"> <ns1:child>I'm in namespace 1</ns1:child> <ns2:child>I'm in namespace 2</ns2:child> </tag> """ soup = BeautifulSoup(xml, "xml") soup.select("child") # [<ns1:child>I'm in namespace 1</ns1:child>, <ns2:child>I'm in namespace 2</ns2:child>] soup.select("ns1|child") # [<ns1:child>I'm in namespace 1</ns1:child>]
При обработке селектора CSS, который использует пространства имен, Beautiful Soup
всегда пытается использовать префиксы пространства имен, которые имеют смысл в зависимости от того, что
он увидел при разборе документа. Вы всегда можете предоставить свой
словарь сокращений:
namespaces = dict(first="http://namespace1/", second="http://namespace2/") soup.select("second|child", namespaces=namespaces) # [<ns1:child>I'm in namespace 2</ns1:child>]
Все эти селекторы CSS удобны для тех, кто уже
знаком с синтаксисом селекторов CSS. Вы можете сделать все это с помощью
Beautiful Soup API. И если CSS селекторы — это все, что вам нужно, вам следует
использовать парсер lxml: так будет намного быстрее. Но вы можете
комбинировать селекторы CSS с Beautiful Soup API.
Изменение дерева¶
Основная сила Beautiful Soup в поиске по дереву разбора, но вы
также можете изменить дерево и записать свои изменения в виде нового HTML или
XML-документа.
Изменение имен тегов и атрибутов¶
Я говорил об этом раньше, в разделе Атрибуты, но это стоит повторить. Вы
можете переименовать тег, изменить значения его атрибутов, добавить новые
атрибуты и удалить атрибуты:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'html.parser') tag = soup.b tag.name = "blockquote" tag['class'] = 'verybold' tag['id'] = 1 tag # <blockquote class="verybold" id="1">Extremely bold</blockquote> del tag['class'] del tag['id'] tag # <blockquote>Extremely bold</blockquote>
Изменение .string¶
Если вы замените значение атрибута .string новой строкой, содержимое тега будет
заменено на эту строку:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.a tag.string = "New link text." tag # <a href="http://example.com/">New link text.</a>
Будьте осторожны: если тег содержит другие теги, они и все их
содержимое будет уничтожено.
append()¶
Вы можете добавить содержимое тега с помощью Tag.append(). Это работает
точно так же, как .append() для списка в Python:
soup = BeautifulSoup("<a>Foo</a>", 'html.parser') soup.a.append("Bar") soup # <a>FooBar</a> soup.a.contents # ['Foo', 'Bar']
extend()¶
Начиная с версии Beautiful Soup 4.7.0, Tag также поддерживает метод
.extend(), который добавляет каждый элемент списка в Tag
по порядку:
soup = BeautifulSoup("<a>Soup</a>", 'html.parser') soup.a.extend(["'s", " ", "on"]) soup # <a>Soup's on</a> soup.a.contents # ['Soup', ''s', ' ', 'on']
NavigableString() и .new_tag()¶
Если вам нужно добавить строку в документ, нет проблем — вы можете передать
строку Python в append() или вызвать
конструктор NavigableString:
soup = BeautifulSoup("<b></b>", 'html.parser') tag = soup.b tag.append("Hello") new_string = NavigableString(" there") tag.append(new_string) tag # <b>Hello there.</b> tag.contents # ['Hello', ' there']
Если вы хотите создать комментарий или другой подкласс
NavigableString, просто вызовите конструктор:
from bs4 import Comment new_comment = Comment("Nice to see you.") tag.append(new_comment) tag # <b>Hello there<!--Nice to see you.--></b> tag.contents # ['Hello', ' there', 'Nice to see you.']
(Это новая функция в Beautiful Soup 4.4.0.)
Что делать, если вам нужно создать совершенно новый тег? Наилучшим решением будет
вызвать фабричный метод BeautifulSoup.new_tag():
soup = BeautifulSoup("<b></b>", 'html.parser') original_tag = soup.b new_tag = soup.new_tag("a", href="http://www.example.com") original_tag.append(new_tag) original_tag # <b><a href="http://www.example.com"></a></b> new_tag.string = "Link text." original_tag # <b><a href="http://www.example.com">Link text.</a></b>
Нужен только первый аргумент, имя тега.
insert()¶
Tag.insert() похож на Tag.append(), за исключением того, что новый элемент
не обязательно добавляется в конец родительского
.contents. Он добавится в любое место, номер которого
вы укажете. Это работает в точности как .insert() в списке Python:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.a tag.insert(1, "but did not endorse ") tag # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a> tag.contents # ['I linked to ', 'but did not endorse', <i>example.com</i>]
insert_before() и insert_after()¶
Метод insert_before() вставляет теги или строки непосредственно
перед чем-то в дереве разбора:
soup = BeautifulSoup("<b>leave</b>", 'html.parser') tag = soup.new_tag("i") tag.string = "Don't" soup.b.string.insert_before(tag) soup.b # <b><i>Don't</i>leave</b>
Метод insert_after() вставляет теги или строки непосредственно
после чего-то в дереве разбора:
div = soup.new_tag('div') div.string = 'ever' soup.b.i.insert_after(" you ", div) soup.b # <b><i>Don't</i> you <div>ever</div> leave</b> soup.b.contents # [<i>Don't</i>, ' you', <div>ever</div>, 'leave']
clear()¶
Tag.clear() удаляет содержимое тега:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.a tag.clear() tag # <a href="http://example.com/"></a>
decompose()¶
Tag.decompose() удаляет тег из дерева, а затем полностью
уничтожает его вместе с его содержимым:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') a_tag = soup.a i_tag = soup.i i_tag.decompose() a_tag # <a href="http://example.com/">I linked to</a>
Поведение уничтоженного Tag или NavigableString не
определено, и вам не следует его использовать. Если вы не уверены,
было ли что-то уничтожено, вы можете проверить по его
свойству decomposed (новое в Beautiful Soup 4.9.0):
i_tag.decomposed # True a_tag.decomposed # False
replace_with()¶
PageElement.extract() удаляет тег или строку из дерева
и заменяет его одним или несколькими тегами либо строками по вашему выбору:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') a_tag = soup.a new_tag = soup.new_tag("b") new_tag.string = "example.com" a_tag.i.replace_with(new_tag) a_tag # <a href="http://example.com/">I linked to <b>example.com</b></a> bold_tag = soup.new_tag("b") bold_tag.string = "example" i_tag = soup.new_tag("i") i_tag.string = "net" a_tag.b.replace_with(bold_tag, ".", i_tag) a_tag # <a href="http://example.com/">I linked to <b>example</b>.<i>net</i></a>
replace_with() возвращает тег или строку, которые были заменены, так что
вы можете изучить его или добавить его обратно в другую часть дерева.
Возможность передавать несколько аргументов в replace_with() является новой
в Beautiful Soup 4.10.0.
wrap()¶
PageElement.wrap() обертывает элемент в указанный вами тег. Он
возвращает новую обертку:
soup = BeautifulSoup("<p>I wish I was bold.</p>", 'html.parser') soup.p.string.wrap(soup.new_tag("b")) # <b>I wish I was bold.</b> soup.p.wrap(soup.new_tag("div")) # <div><p><b>I wish I was bold.</b></p></div>
Это новый метод в Beautiful Soup 4.0.5.
unwrap()¶
Tag.unwrap() — это противоположность wrap(). Он заменяет весь тег на
его содержимое. Этим методом удобно очищать разметку:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') a_tag = soup.a a_tag.i.unwrap() a_tag # <a href="http://example.com/">I linked to example.com</a>
Как и replace_with(), unwrap() возвращает тег,
который был заменен.
smooth()¶
После вызова ряда методов, которые изменяют дерево разбора, у вас может оказаться несколько объектов NavigableString подряд. У Beautiful Soup с этим нет проблем, но поскольку такое не случается со свежеразобранным документом, вам может показаться неожиданным следующее поведение:
soup = BeautifulSoup("<p>A one</p>", 'html.parser') soup.p.append(", a two") soup.p.contents # ['A one', ', a two'] print(soup.p.encode()) # b'<p>A one, a two</p>' print(soup.p.prettify()) # <p> # A one # , a two # </p>
Вы можете вызвать Tag.smooth(), чтобы очистить дерево разбора путем объединения смежных строк:
soup.smooth() soup.p.contents # ['A one, a two'] print(soup.p.prettify()) # <p> # A one, a two # </p>
Это новый метод в Beautiful Soup 4.8.0.
Вывод¶
Красивое форматирование¶
Метод prettify() превратит дерево разбора Beautiful Soup в
красиво отформатированную строку Unicode, где каждый
тег и каждая строка выводятся на отдельной строчке:
markup = '<html><head><body><a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, 'html.parser') soup.prettify() # '<html>n <head>n </head>n <body>n <a href="http://example.com/">n...' print(soup.prettify()) # <html> # <head> # </head> # <body> # <a href="http://example.com/"> # I linked to # <i> # example.com # </i> # </a> # </body> # </html>
Вы можете вызвать prettify() для объекта BeautifulSoup верхнего уровня
или для любого из его объектов Tag:
print(soup.a.prettify()) # <a href="http://example.com/"> # I linked to # <i> # example.com # </i> # </a>
Добавляя переводы строк (n), метод prettify()
изменяет значение документа HTML и не должен использоваться для
переформатирования. Цель prettify() — помочь вам визуально
понять структуру документов, с которыми вы работаете.
Без красивого форматирования¶
Если вам нужна просто строка, без особого форматирования, вы можете вызвать
str() для объекта BeautifulSoup или для объекта Tag внутри него:
str(soup) # '<html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>' str(soup.a) # '<a href="http://example.com/">I linked to <i>example.com</i></a>'
Функция str() возвращает строку, кодированную в UTF-8. Для получения более подробной информации см.
Кодировки.
Вы также можете вызвать encode() для получения байтовой строки, и decode(),
чтобы получить Unicode.
Средства форматирования вывода¶
Если вы дадите Beautiful Soup документ, который содержит HTML-мнемоники, такие как
«&lquot;», они будут преобразованы в символы Unicode:
soup = BeautifulSoup("“Dammit!” he said.", 'html.parser') str(soup) # '“Dammit!†he said.'
Если затем преобразовать документ в байтовую строку, символы Unicode
будут кодироваться как UTF-8. Вы не получите обратно HTML-мнемоники:
soup.encode("utf8") # b'xe2x80x9cDammit!xe2x80x9d he said.'
По умолчанию единственные символы, которые экранируются при выводе — это чистые
амперсанды и угловые скобки. Они превращаются в «&», «<»
и «>», чтобы Beautiful Soup случайно не сгенерировал
невалидный HTML или XML:
soup = BeautifulSoup("<p>The law firm of Dewey, Cheatem, & Howe</p>", 'html.parser') soup.p # <p>The law firm of Dewey, Cheatem, & Howe</p> soup = BeautifulSoup('<a href="http://example.com/?foo=val1&bar=val2">A link</a>', 'html.parser') soup.a # <a href="http://example.com/?foo=val1&bar=val2">A link</a>
Вы можете изменить это поведение, указав для
аргумента formatter одно из значений: prettify(), encode() или
decode(). Beautiful Soup распознает пять возможных значений
formatter.
Значение по умолчанию — formatter="minimal". Строки будут обрабатываться
ровно настолько, чтобы Beautiful Soup генерировал валидный HTML / XML:
french = "<p>Il a dit <<Sacré bleu!>></p>" soup = BeautifulSoup(french, 'html.parser') print(soup.prettify(formatter="minimal")) # <p> # Il a dit <<Sacré bleu!>> # </p>
Если вы передадите formatter = "html", Beautiful Soup преобразует
символы Unicode в HTML-мнемоники, когда это возможно:
print(soup.prettify(formatter="html")) # <p> # Il a dit <<Sacré bleu!>> # </p>
Если вы передаете formatter="html5", это то же самое, что
formatter="html", только Beautiful Soup будет
пропускать закрывающую косую черту в пустых тегах HTML, таких как «br»:
br = BeautifulSoup("<br>", 'html.parser').br print(br.encode(formatter="html")) # b'<br/>' print(br.encode(formatter="html5")) # b'<br>'
Кроме того, любые атрибуты, значения которых являются пустой строкой
станут логическими атрибутами в стиле HTML:
option = BeautifulSoup('<option selected=""></option>').option print(option.encode(formatter="html")) # b'<option selected=""></option>' print(option.encode(formatter="html5")) # b'<option selected></option>'
(Это новое поведение в Beautiful Soup 4.10.0.)
Если вы передадите formatter=None, Beautiful Soup вообще не будет менять
строки на выходе. Это самый быстрый вариант, но он может привести
к тому, что Beautiful Soup будет генерировать невалидный HTML / XML:
print(soup.prettify(formatter=None)) # <p> # Il a dit <<Sacré bleu!>> # </p> link_soup = BeautifulSoup('<a href="http://example.com/?foo=val1&bar=val2">A link</a>', 'html.parser') print(link_soup.a.encode(formatter=None)) # b'<a href="http://example.com/?foo=val1&bar=val2">A link</a>'
Если вам нужен более сложный контроль над выводом, вы можете
использовать класс Formatter из Beautiful Soup. Вот как можно
преобразовать строки в верхний регистр, независимо от того, находятся ли они в текстовом узле или в
значении атрибута:
from bs4.formatter import HTMLFormatter def uppercase(str): return str.upper() formatter = HTMLFormatter(uppercase) print(soup.prettify(formatter=formatter)) # <p> # IL A DIT <<SACRÉ BLEU!>> # </p> print(link_soup.a.prettify(formatter=formatter)) # <a href="HTTP://EXAMPLE.COM/?FOO=VAL1&BAR=VAL2"> # A LINK # </a>
Так можно увеличить отступ при красивом форматировании:
formatter = HTMLFormatter(indent=8) print(link_soup.a.prettify(formatter=formatter)) # <a href="http://example.com/?foo=val1&bar=val2"> # A link # </a>
Подклассы HTMLFormatter или XMLFormatter дают еще
больший контроль над выводом. Например, Beautiful Soup сортирует
атрибуты в каждом теге по умолчанию:
attr_soup = BeautifulSoup(b'<p z="1" m="2" a="3"></p>', 'html.parser') print(attr_soup.p.encode()) # <p a="3" m="2" z="1"></p>
Чтобы выключить сортировку по умолчанию, вы можете создать подкласс на основе метода Formatter.attributes(),
который контролирует, какие атрибуты выводятся и в каком
порядке. Эта реализация также отфильтровывает атрибут с именем «m»,
где бы он ни появился:
class UnsortedAttributes(HTMLFormatter): def attributes(self, tag): for k, v in tag.attrs.items(): if k == 'm': continue yield k, v print(attr_soup.p.encode(formatter=UnsortedAttributes())) # <p z="1" a="3"></p>
Последнее предостережение: если вы создаете объект CData, текст внутри
этого объекта всегда представлен как есть, без какого-либо
форматирования. Beautiful Soup вызовет вашу функцию для замены мнемоник,
на тот случай, если вы написали функцию, которая подсчитывает
все строки в документе или что-то еще, но он будет игнорировать
возвращаемое значение:
from bs4.element import CData soup = BeautifulSoup("<a></a>", 'html.parser') soup.a.string = CData("one < three") print(soup.a.prettify(formatter="html")) # <a> # <![CDATA[one < three]]> # </a>
get_text()¶
Если вам нужен только человекочитаемый текст внутри документа или тега, используйте
метод get_text(). Он возвращает весь текст документа или
тега в виде единственной строки Unicode:
markup = '<a href="http://example.com/">nI linked to <i>example.com</i>n</a>' soup = BeautifulSoup(markup, 'html.parser') soup.get_text() 'nI linked to example.comn' soup.i.get_text() 'example.com'
Вы можете указать строку, которая будет использоваться для объединения текстовых фрагментов
в единую строку:
# soup.get_text("|") 'nI linked to |example.com|n'
Вы можете сказать Beautiful Soup удалять пробелы в начале и
конце каждого текстового фрагмента:
# soup.get_text("|", strip=True) 'I linked to|example.com'
Но в этом случае вы можете предпочесть использовать генератор .stripped_strings
и затем обработать текст самостоятельно:
[text for text in soup.stripped_strings] # ['I linked to', 'example.com']
Начиная с версии Beautiful Soup 4.9.0, в которой используются парсеры lxml или html.parser
содержание тегов <script>, <style> и <template>
обычно не считается „текстом“, так как эти теги не являются частью
воспринимаемого человеком содержания страницы.
Начиная с Beautiful Soup версии 4.10.0, вы можете вызывать get_text(),
.strings или .stripped_strings в объекте NavigableString. Это
вернет либо сам объект, либо ничего, поэтому единственный случай, когда стоит это делать —
это когда вы перебираете смешанный список (mixed list).
Указание парсера¶
Если вам нужно просто разобрать HTML, вы можете скинуть разметку в
конструктор BeautifulSoup, и, скорее всего, все будет в порядке. Beautiful
Soup подберет для вас парсер и проанализирует данные. Но есть
несколько дополнительных аргументов, которые вы можете передать конструктору, чтобы изменить
используемый парсер.
Первым аргументом конструктора BeautifulSou является строка или
открытый дескриптор файла — сама разметка, которую вы хотите разобрать. Второй аргумент — это
как вы хотите, чтобы разметка была разобрана.
Если вы ничего не укажете, будет использован лучший HTML-парсер из тех,
которые установлены. Beautiful Soup оценивает парсер lxml как лучший, за ним идет
html5lib, затем встроенный парсер Python. Вы можете переопределить используемый парсер,
указав что-то из следующего:
-
Какой тип разметки вы хотите разобрать. В данный момент поддерживаются:
«html», «xml» и «html5». -
Имя библиотеки парсера, которую вы хотите использовать. В данный момент поддерживаются
«lxml», «html5lib» и «html.parser» (встроенный в Python
парсер HTML).
В разделе Установка парсера вы найдете сравнительную таблицу поддерживаемых парсеров.
Если у вас не установлен соответствующий парсер, Beautiful Soup
проигнорирует ваш запрос и выберет другой парсер. На текущий момент единственный
поддерживаемый парсер XML — это lxml. Если у вас не установлен lxml, запрос на
парсер XML ничего не даст, и запрос «lxml» тоже
не сработает.
Различия между парсерами¶
Beautiful Soup представляет один интерфейс для разных
парсеров, но парсеры неодинаковы. Разные парсеры создадут
различные деревья разбора из одного и того же документа. Самые большие различия будут
между парсерами HTML и парсерами XML. Вот короткий
документ, разобранный как HTML встроенным в Python парсером:
BeautifulSoup("<a><b/></a>", "html.parser") # <a><b></b></a>
Поскольку одиночный тег <b/> не является валидным кодом HTML, парсер преобразует его в
пару тегов <b></b>.
Вот тот же документ, который разобран как XML (для его запуска нужно, чтобы был
установлен lxml). Обратите внимание, что одиночный тег <b/> остается, и
что в документ добавляется объявление XML вместо
тега <html>:
print(BeautifulSoup("<a><b/></a>", "xml")) # <?xml version="1.0" encoding="utf-8"?> # <a><b/></a>
Есть также различия между парсерами HTML. Если вы даете Beautiful
Soup идеально оформленный документ HTML, эти различия не будут
иметь значения. Один парсер будет быстрее другого, но все они будут давать
структуру данных, которая выглядит точно так же, как оригинальный
документ HTML.
Но если документ оформлен неидеально, различные парсеры
дадут разные результаты. Вот короткий невалидный документ, разобранный с помощью
HTML-парсера lxml. Обратите внимание, что тег <a> заключен в теги <body> и
<html>, а висячий тег </p> просто игнорируется:
BeautifulSoup("<a></p>", "lxml") # <html><body><a></a></body></html>
Вот тот же документ, разобранный с помощью html5lib:
BeautifulSoup("<a></p>", "html5lib") # <html><head></head><body><a><p></p></a></body></html>
Вместо того, чтобы игнорировать висячий тег </p>, html5lib добавляет
открывающй тег <p>. html5lib также добавляет пустой тег <head>; lxml этого не
сделал.
Вот тот же документ, разобранный с помощью встроенного в Python
парсера HTML:
BeautifulSoup("<a></p>", "html.parser") # <a></a>
Как и lxml, этот парсер игнорирует закрывающий тег </p>. В отличие от
html5lib, этот парсер не делает попытки создать
правильно оформленный HTML-документ, добавив теги <html> или <body>.
Поскольку документ <a></p> невалиден, ни один из этих способов
нельзя назвать „правильным“. Парсер html5lib использует способы,
которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход
самый „правильный“, но правомерно использовать любой из трех методов.
Различия между парсерами могут повлиять на ваш скрипт. Если вы планируете
распространять ваш скрипт или запускать его на нескольких
машинах, вам нужно указать парсер в
конструкторе BeautifulSoup. Это уменьшит вероятность того, что ваши пользователи при разборе
документа получат результат, отличный от вашего.
Кодировки¶
Любой документ HTML или XML написан в определенной кодировке, такой как ASCII
или UTF-8. Но когда вы загрузите этот документ в Beautiful Soup, вы
обнаружите, что он был преобразован в Unicode:
markup = "<h1>Sacrxc3xa9 bleu!</h1>" soup = BeautifulSoup(markup, 'html.parser') soup.h1 # <h1>Sacré bleu!</h1> soup.h1.string # 'Sacrxe9 bleu!'
Это не волшебство. (Хотя это было бы здорово, конечно.) Beautiful Soup использует
подбиблиотеку под названием Unicode, Dammit для определения кодировки документа
и преобразования ее в Unicode. Кодировка, которая была автоматически определена, содержится в значении
атрибута .original_encoding объекта BeautifulSoup:
soup.original_encoding 'utf-8'
Unicode, Dammit чаще всего угадывает правильно, но иногда
делает ошибки. Иногда он угадывает правильно только после
побайтового поиска по документу, что занимает очень много времени. Если
вы вдруг уже знаете кодировку документа, вы можете избежать
ошибок и задержек, передав кодировку конструктору BeautifulSoup
как аргумент from_encoding.
Вот документ, написанный на ISO-8859-8. Документ настолько короткий, что
Unicode, Dammit не может разобраться и неправильно идентифицирует кодировку как
ISO-8859-7:
markup = b"<h1>xedxe5xecxf9</h1>" soup = BeautifulSoup(markup, 'html.parser') print(soup.h1) # <h1>νεμω</h1> print(soup.original_encoding) # iso-8859-7
Мы можем все исправить, передав правильный from_encoding:
soup = BeautifulSoup(markup, 'html.parser', from_encoding="iso-8859-8") print(soup.h1) # <h1>×ולש</h1> print(soup.original_encoding) # iso8859-8
Если вы не знаете правильную кодировку, но видите, что
Unicode, Dammit определяет ее неправильно, вы можете передать ошибочные варианты в
exclude_encodings:
soup = BeautifulSoup(markup, 'html.parser', exclude_encodings=["iso-8859-7"]) print(soup.h1) # <h1>×ולש</h1> print(soup.original_encoding) # WINDOWS-1255
Windows-1255 не на 100% подходит, но это совместимое
надмножество ISO-8859-8, так что догадка почти верна. (exclude_encodings
— это новая функция в Beautiful Soup 4.4.0.)
В редких случаях (обычно когда документ UTF-8 содержит текст в
совершенно другой кодировке) единственным способом получить Unicode может оказаться
замена некоторых символов специальным символом Unicode
«REPLACEMENT CHARACTER» (U+FFFD, �). Если Unicode, Dammit приходится это сделать,
он установит атрибут .contains_replacement_characters
в True для объектов UnicodeDammit или BeautifulSoup. Это
даст понять, что представление в виде Unicode не является точным
представление оригинала, и что некоторые данные потерялись. Если документ
содержит �, но .contains_replacement_characters равен False,
вы будете знать, что � был в тексте изначально (как в этом
параграфе), а не служит заменой отсутствующим данным.
Кодировка вывода¶
Когда вы пишете документ из Beautiful Soup, вы получаете документ в UTF-8,
даже если он изначально не был в UTF-8. Вот
документ в кодировке Latin-1:
markup = b''' <html> <head> <meta content="text/html; charset=ISO-Latin-1" http-equiv="Content-type" /> </head> <body> <p>Sacrxe9 bleu!</p> </body> </html> ''' soup = BeautifulSoup(markup, 'html.parser') print(soup.prettify()) # <html> # <head> # <meta content="text/html; charset=utf-8" http-equiv="Content-type" /> # </head> # <body> # <p> # Sacré bleu! # </p> # </body> # </html>
Обратите внимание, что тег <meta> был переписан, чтобы отразить тот факт, что
теперь документ кодируется в UTF-8.
Если вы не хотите кодировку UTF-8, вы можете передать другую в prettify():
print(soup.prettify("latin-1")) # <html> # <head> # <meta content="text/html; charset=latin-1" http-equiv="Content-type" /> # ...
Вы также можете вызвать encode() для объекта BeautifulSoup или любого
элемента в супе, как если бы это была строка Python:
soup.p.encode("latin-1") # b'<p>Sacrxe9 bleu!</p>' soup.p.encode("utf-8") # b'<p>Sacrxc3xa9 bleu!</p>'
Любые символы, которые не могут быть представлены в выбранной вами кодировке, будут
преобразованы в числовые коды мнемоник XML. Вот документ,
который включает в себя Unicode-символ SNOWMAN (снеговик):
markup = u"<b>N{SNOWMAN}</b>" snowman_soup = BeautifulSoup(markup, 'html.parser') tag = snowman_soup.b
Символ SNOWMAN может быть частью документа UTF-8 (он выглядит
так: ☃), но в ISO-Latin-1 или
ASCII нет представления для этого символа, поэтому для этих кодировок он конвертируется в «☃»:
print(tag.encode("utf-8")) # b'<b>xe2x98x83</b>' print(tag.encode("latin-1")) # b'<b>☃</b>' print(tag.encode("ascii")) # b'<b>☃</b>'
Unicode, Dammit¶
Вы можете использовать Unicode, Dammit без Beautiful Soup. Он полезен в тех случаях.
когда у вас есть данные в неизвестной кодировке, и вы просто хотите, чтобы они
преобразовались в Unicode:
from bs4 import UnicodeDammit dammit = UnicodeDammit("Sacrxc3xa9 bleu!") print(dammit.unicode_markup) # Sacré bleu! dammit.original_encoding # 'utf-8'
Догадки Unicode, Dammit станут намного точнее, если вы установите
библиотеки Python charset-normalizer, chardet или
cchardet. Чем больше данных вы даете Unicode, Dammit, тем
точнее он определит кодировку. Если у вас есть собственные предположения относительно
возможных кодировок, вы можете передать
их в виде списка:
dammit = UnicodeDammit("Sacrxe9 bleu!", ["latin-1", "iso-8859-1"]) print(dammit.unicode_markup) # Sacré bleu! dammit.original_encoding # 'latin-1'
В Unicode, Dammit есть две специальные функции, которые Beautiful Soup не
использует.
Парные кавычки¶
Вы можете использовать Unicode, Dammit, чтобы конвертировать парные кавычки (Microsoft smart quotes) в
мнемоники HTML или XML:
markup = b"<p>I just x93lovex94 Microsoft Wordx92s smart quotes</p>" UnicodeDammit(markup, ["windows-1252"], smart_quotes_to="html").unicode_markup # '<p>I just “love” Microsoft Word’s smart quotes</p>' UnicodeDammit(markup, ["windows-1252"], smart_quotes_to="xml").unicode_markup # '<p>I just “love” Microsoft Word’s smart quotes</p>'
Вы также можете конвертировать парные кавычки в обычные кавычки ASCII:
UnicodeDammit(markup, ["windows-1252"], smart_quotes_to="ascii").unicode_markup # '<p>I just "love" Microsoft Word's smart quotes</p>'
Надеюсь, вы найдете эту функцию полезной, но Beautiful Soup не
использует ее. Beautiful Soup по умолчанию
конвертирует парные кавычки в символы Unicode, как и
все остальное:
UnicodeDammit(markup, ["windows-1252"]).unicode_markup # '<p>I just “love†Microsoft Word’s smart quotes</p>'
Несогласованные кодировки¶
Иногда документ кодирован в основном в UTF-8, но содержит символы Windows-1252,
такие как, опять-таки, парные кавычки. Такое бывает,
когда веб-сайт содержит данные из нескольких источников. Вы можете использовать
UnicodeDammit.detwingle(), чтобы превратить такой документ в чистый
UTF-8. Вот простой пример:
snowmen = (u"N{SNOWMAN}" * 3) quote = (u"N{LEFT DOUBLE QUOTATION MARK}I like snowmen!N{RIGHT DOUBLE QUOTATION MARK}") doc = snowmen.encode("utf8") + quote.encode("windows_1252")
В этом документе бардак. Снеговики в UTF-8, а парные кавычки
в Windows-1252. Можно отображать или снеговиков, или кавычки, но не
то и другое одновременно:
print(doc) # ☃☃☃�I like snowmen!� print(doc.decode("windows-1252")) # ☃☃☃“I like snowmen!”
Декодирование документа как UTF-8 вызывает UnicodeDecodeError, а
декодирование его как Windows-1252 выдаст тарабарщину. К счастью,
UnicodeDammit.detwingle() преобразует строку в чистый UTF-8,
позволяя затем декодировать его в Unicode и отображать снеговиков и кавычки
одновременно:
new_doc = UnicodeDammit.detwingle(doc) print(new_doc.decode("utf8")) # ☃☃☃“I like snowmen!”
UnicodeDammit.detwingle() знает только, как обрабатывать Windows-1252,
встроенный в UTF-8 (и наоборот, мне кажется), но это наиболее
общий случай.
Обратите внимание, что нужно вызывать UnicodeDammit.detwingle() для ваших данных
перед передачей в конструктор BeautifulSoup или
UnicodeDammit. Beautiful Soup предполагает, что документ имеет единую
кодировку, какой бы она ни была. Если вы передадите ему документ, который
содержит как UTF-8, так и Windows-1252, скорее всего, он решит, что весь
документ кодируется в Windows-1252, и это будет выглядеть как
☃☃☃“I like snowmen!”.
UnicodeDammit.detwingle() — это новое в Beautiful Soup 4.1.0.
Нумерация строк¶
Парсеры html.parser и html5lib могут отслеживать, где в
исходном документе был найден каждый тег. Вы можете получить доступ к этой
информации через Tag.sourceline (номер строки) и Tag.sourcepos
(позиция начального тега в строке):
markup = "<pn>Paragraph 1</p>n <p>Paragraph 2</p>" soup = BeautifulSoup(markup, 'html.parser') for tag in soup.find_all('p'): print(repr((tag.sourceline, tag.sourcepos, tag.string))) # (1, 0, 'Paragraph 1') # (3, 4, 'Paragraph 2')
Обратите внимание, что два парсера понимают
sourceline и sourcepos немного по-разному. Для html.parser эти числа
представляет позицию начального знака «<». Для html5lib
эти числа представляют позицию конечного знака «>»:
soup = BeautifulSoup(markup, 'html5lib') for tag in soup.find_all('p'): print(repr((tag.sourceline, tag.sourcepos, tag.string))) # (2, 0, 'Paragraph 1') # (3, 6, 'Paragraph 2')
Вы можете отключить эту функцию, передав store_line_numbers = False
в конструктор BeautifulSoup:
markup = "<pn>Paragraph 1</p>n <p>Paragraph 2</p>" soup = BeautifulSoup(markup, 'html.parser', store_line_numbers=False) print(soup.p.sourceline) # None
Эта функция является новой в 4.8.1, и парсеры, основанные на lxml, не
поддерживают ее.
Проверка объектов на равенство¶
Beautiful Soup считает, что два объекта NavigableString или Tag
равны, если они представлены в одинаковой разметке HTML или XML. В этом
примере два тега <b> рассматриваются как равные, даже если они находятся
в разных частях дерева объекта, потому что они оба выглядят как
<b>pizza</b>:
markup = "<p>I want <b>pizza</b> and more <b>pizza</b>!</p>" soup = BeautifulSoup(markup, 'html.parser') first_b, second_b = soup.find_all('b') print(first_b == second_b) # True print(first_b.previous_element == second_b.previous_element) # False
Если вы хотите выяснить, указывают ли две переменные на один и тот же
объект, используйте is:
print(first_b is second_b) # False
Копирование объектов Beautiful Soup¶
Вы можете использовать copy.copy() для создания копии любого Tag или
NavigableString:
import copy p_copy = copy.copy(soup.p) print(p_copy) # <p>I want <b>pizza</b> and more <b>pizza</b>!</p>
Копия считается равной оригиналу, так как у нее
такая же разметка, что и у оригинала, но это другой объект:
print(soup.p == p_copy) # True print(soup.p is p_copy) # False
Единственная настоящая разница в том, что копия полностью отделена от
исходного дерева объекта Beautiful Soup, как если бы в отношении нее вызвали
метод extract():
print(p_copy.parent) # None
Это потому, что два разных объекта Tag не могут занимать одно и то же
пространство в одно и то же время.
Расширенная настройка парсера¶
Beautiful Soup предлагает несколько способов настроить то, как парсер
обрабатывает входящий HTML и XML. Этот раздел охватывает наиболее часто
используемые методы настройки.
Разбор части документа¶
Допустим, вы хотите использовать Beautiful Soup, чтобы посмотреть на
теги <a> в документе. Было бы бесполезной тратой времени и памяти разобирать весь документ и
затем снова проходить по нему в поисках тегов <a>. Намного быстрее
изначательно игнорировать все, что не является тегом <a>. Класс
SoupStrainer позволяет выбрать, какие части входящего
документ разбирать. Вы просто создаете SoupStrainer и передаете его в
конструктор BeautifulSoup в качестве аргумента parse_only.
(Обратите внимание, что эта функция не будет работать, если вы используете парсер html5lib.
Если вы используете html5lib, будет разобран весь документ, независимо
от обстоятельств. Это потому что html5lib постоянно переставляет части дерева разбора
в процессе работы, и если какая-то часть документа не
попала в дерево разбора, все рухнет. Чтобы избежать путаницы, в
примерах ниже я принудительно использую встроенный в Python
парсер HTML.)
SoupStrainer¶
Класс SoupStrainer принимает те же аргументы, что и типичный
метод из раздела Поиск по дереву: name, attrs, string и **kwargs. Вот
три объекта SoupStrainer:
from bs4 import SoupStrainer only_a_tags = SoupStrainer("a") only_tags_with_id_link2 = SoupStrainer(id="link2") def is_short_string(string): return string is not None and len(string) < 10 only_short_strings = SoupStrainer(string=is_short_string)
Вернемся к фрагменту из «Алисы в стране чудес»
и увидим, как выглядит документ, когда он разобран с этими
тремя объектами SoupStrainer:
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ print(BeautifulSoup(html_doc, "html.parser", parse_only=only_a_tags).prettify()) # <a class="sister" href="http://example.com/elsie" id="link1"> # Elsie # </a> # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> # <a class="sister" href="http://example.com/tillie" id="link3"> # Tillie # </a> print(BeautifulSoup(html_doc, "html.parser", parse_only=only_tags_with_id_link2).prettify()) # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> print(BeautifulSoup(html_doc, "html.parser", parse_only=only_short_strings).prettify()) # Elsie # , # Lacie # and # Tillie # ... #
Вы также можете передать SoupStrainer в любой из методов. описанных в разделе
Поиск по дереву. Может, это не безумно полезно, но я
решил упомянуть:
soup = BeautifulSoup(html_doc, 'html.parser') soup.find_all(only_short_strings) # ['nn', 'nn', 'Elsie', ',n', 'Lacie', ' andn', 'Tillie', # 'nn', '...', 'n']
Настройка многозначных атрибутов¶
В документе HTML атрибуту вроде class присваивается список
значений, а атрибуту вроде id присваивается одно значение, потому что
спецификация HTML трактует эти атрибуты по-разному:
markup = '<a class="cls1 cls2" id="id1 id2">' soup = BeautifulSoup(markup, 'html.parser') soup.a['class'] # ['cls1', 'cls2'] soup.a['id'] # 'id1 id2'
Вы можете отключить многозначные атрибуты, передав
multi_valued_attributes=None. Все атрибуты получат
единственное значение:
soup = BeautifulSoup(markup, 'html.parser', multi_valued_attributes=None) soup.a['class'] # 'cls1 cls2' soup.a['id'] # 'id1 id2'
Вы можете слегка изменить это поведение, передав
в multi_valued_attributes словарь. Если вам это нужно, взгляните на
HTMLTreeBuilder.DEFAULT_CDATA_LIST_ATTRIBUTES, чтобы увидеть
конфигурацию Beautiful Soup, которая используется по умолчанию и которая основана на
спецификации HTML.
(Это новая функция в Beautiful Soup 4.8.0.)
Обработка дублирующих атрибутов¶
С парсером html.parser вы можете использовать
в конструкторе аргумент on_duplicate_attribute. С помощью этого аргумента можно указать
Beautiful Soup, что следует делать с тегом, в котором более одного раза определен один и тот же
атрибут:
markup = '<a href="http://url1/" href="http://url2/">'
Поведение по умолчанию — использовать последнее найденное в теге значение:
soup = BeautifulSoup(markup, 'html.parser') soup.a['href'] # http://url2/ soup = BeautifulSoup(markup, 'html.parser', on_duplicate_attribute='replace') soup.a['href'] # http://url2/
С помощью on_duplicate_attribute = 'ignore' вы можете указать Beautiful Soup
использовать первое найденное значение и игнорировать остальные:
soup = BeautifulSoup(markup, 'html.parser', on_duplicate_attribute='ignore') soup.a['href'] # http://url1/
(lxml и html5lib всегда делают это именно так; их поведение нельзя
изменить изнутри Beautiful Soup.)
Если вам нужно больше, вы можете передать функцию, которая вызывается для каждого дублирующего значения:
def accumulate(attributes_so_far, key, value): if not isinstance(attributes_so_far[key], list): attributes_so_far[key] = [attributes_so_far[key]] attributes_so_far[key].append(value) soup = BeautifulSoup(markup, 'html.parser', on_duplicate_attribute=accumulate) soup.a['href'] # ["http://url1/", "http://url2/"]
(Это новая функция в Beautiful Soup 4.9.1.)
Создание пользовательских подклассов¶
Когда парсер сообщает Beautiful Soup о теге или строке, Beautiful
Soup создает экземпляр объекта Tag или NavigableString, чтобы
поместить туда эту информацию. Вместо этого поведения по умолчанию вы можете
указать Beautiful Soup создавать экземпляр подклассов для Tag или
NavigableString. Для этих подклассов вы определяете нужное вам поведение:
from bs4 import Tag, NavigableString class MyTag(Tag): pass class MyString(NavigableString): pass markup = "<div>some text</div>" soup = BeautifulSoup(markup, 'html.parser') isinstance(soup.div, MyTag) # False isinstance(soup.div.string, MyString) # False my_classes = { Tag: MyTag, NavigableString: MyString } soup = BeautifulSoup(markup, 'html.parser', element_classes=my_classes) isinstance(soup.div, MyTag) # True isinstance(soup.div.string, MyString) # True
Это может быть полезно при включении Beautiful Soup в тестовый
фреймворк.
(Это новая функция в Beautiful Soup 4.8.1.)
Устранение неисправностей¶
diagnose()¶
Если у вас возникли проблемы с пониманием того, что Beautiful Soup делает с
документом, передайте документ в функцию Diagnose(). (Новое в
Beautiful Soup 4.2.0.) Beautiful Soup выведет отчет, показывающий,
как разные парсеры обрабатывают документ, и сообщит вам, если
отсутствует парсер, который Beautiful Soup мог бы использовать:
from bs4.diagnose import diagnose with open("bad.html") as fp: data = fp.read() diagnose(data) # Diagnostic running on Beautiful Soup 4.2.0 # Python version 2.7.3 (default, Aug 1 2012, 05:16:07) # I noticed that html5lib is not installed. Installing it may help. # Found lxml version 2.3.2.0 # # Trying to parse your data with html.parser # Here's what html.parser did with the document: # ...
Простой взгляд на вывод diagnose() может показать, как решить
проблему. Если это и не поможет, вы можете скопировать вывод Diagnose(), когда
обратитесь за помощью.
Ошибки при разборе документа¶
Существует два вида ошибок разбора. Есть сбои,
когда вы подаете документ в Beautiful Soup, и это поднимает
исключение, обычно HTMLParser.HTMLParseError. И есть
неожиданное поведение, когда дерево разбора Beautiful Soup сильно
отличается от документа, использованного для создания дерева.
Практически никогда источником этих проблемы не бывает Beautiful
Soup. Это не потому, что Beautiful Soup так прекрасно
написан. Это потому, что Beautiful Soup не содержит
кода, который бы разбирал документ. Beautiful Soup опирается на внешние парсеры. Если один парсер
не подходит для разбора документа, лучшим решением будет попробовать
другой парсер. В разделе Установка парсера вы найдете больше информации
и таблицу сравнения парсеров.
Наиболее распространенные ошибки разбора — это HTMLParser.HTMLParseError: и
malformed start tagHTMLParser.HTMLParseError: bad end. Они оба генерируются встроенным в Python парсером HTML,
tag
и решением будет установить lxml или
html5lib.
Наиболее распространенный тип неожиданного поведения — когда вы не можете найти
тег, который точно есть в документе. Вы видели его на входе, но
find_all() возвращает [], или find() возвращает None. Это
еще одна распространенная проблема со встроенным в Python парсером HTML, который
иногда пропускает теги, которые он не понимает. Опять же, решение заключается в
установке lxml или html5lib.
Проблемы несоответствия версий¶
-
SyntaxError: Invalid syntax(в строкеROOT_TAG_NAME =) — вызвано запуском устаревшей версии Beautiful Soup на Python 2
'[document]'
под Python 3 без конвертации кода. -
ImportError: No module named HTMLParser— вызвано запуском
устаревшей версии Beautiful Soup на Python 2 под Python 3. -
ImportError: No module named html.parser— вызвано запуском
версии Beautiful Soup на Python 3 под Python 2. -
ImportError: No module named BeautifulSoup— вызвано запуском
кода Beautiful Soup 3 в системе, где BS3
не установлен. Или код писали на Beautiful Soup 4, не зная, что
имя пакета сменилось наbs4. -
ImportError: No module named bs4— вызвано запуском
кода Beautiful Soup 4 в системе, где BS4 не установлен.
Разбор XML¶
По умолчанию Beautiful Soup разбирает документы как HTML. Чтобы разобрать
документ в виде XML, передайте «xml» в качестве второго аргумента
в конструктор BeautifulSoup:
soup = BeautifulSoup(markup, "xml")
Вам также нужно будет установить lxml.
Другие проблемы с парсерами¶
-
Если ваш скрипт работает на одном компьютере, но не работает на другом, или работает в одной
виртуальной среде, но не в другой, или работает вне виртуальной
среды, но не внутри нее, это, вероятно, потому что в двух
средах разные библиотеки парсеров. Например,
вы могли разработать скрипт на компьютере с установленным lxml,
а затем попытались запустить его на компьютере, где установлен только
html5lib. Читайте в разделе Различия между парсерами, почему это
важно, и исправляйте проблемы, указывая конкретную библиотеку парсера
в конструктореBeautifulSoup. -
Поскольку HTML-теги и атрибуты нечувствительны к регистру, все три HTML-
парсера конвертируют имена тегов и атрибутов в нижний регистр. Таким образом,
разметка <TAG></TAG> преобразуется в <tag></tag>. Если вы хотите
сохранить смешанный или верхний регистр тегов и атрибутов, вам нужно
разобрать документ как XML.
Прочие ошибки¶
-
UnicodeEncodeError: 'charmap' codec can't encode character(или практически любая другая ошибка
'xfoo' in position bar
UnicodeEncodeError). Эта проблема проявляется в основном в двух ситуациях.
Во-первых, когда вы пытаетесь вывести символ Unicode,
который ваша консоль не может отобразить, потому что не знает, как. (Смотрите эту страницу
в Python вики.)
Во-вторых, когда вы пишете в файл и передаете символ Unicode, который
не поддерживается вашей кодировкой по умолчанию.
В этом случае самым простым решением будет явное кодирование строки Unicode в UTF-8
с помощьюu.encode("utf8"). -
KeyError: [attr]— вызывается при обращении кtag['attr'], когда
в искомом теге не определен атрибутattr. Наиболее
типичны ошибкиKeyError: 'href'иKeyError: 'class'.
Используйтеtag.get('attr'), если вы не уверены, чтоattr
определен — так же, как если бы вы работали со словарем Python. -
AttributeError: 'ResultSet' object has no attribute 'foo'— это
обычно происходит тогда, когда вы ожидаете, чтоfind_all()вернет
один тег или строку. Ноfind_all()возвращает список тегов
и строк в объектеResultSet. Вам нужно перебрать
список и поискать.fooв каждом из элементов. Или, если вам действительно
нужен только один результат, используйтеfind()вместо
find_all(). -
AttributeError: 'NoneType' object has no attribute 'foo'— это
обычно происходит, когда вы вызываетеfind()и затем пытаетесь
получить доступ к атрибуту.foo. Но в вашем случае
find()не нашел ничего, поэтому вернулNoneвместо
того, чтобы вернуть тег или строку. Вам нужно выяснить, почему
find()ничего не возвращает. -
AttributeError: 'NavigableString' object has no attribute— Обычно это происходит, потому что вы обрабатываете строку так,
'foo'
будто это тег. Вы можете проходить по списку, предполагая,
что он не содержит ничего, кроме тегов, хотя на самом деле он содержит как теги, так и
строки.
Повышение производительности¶
Beautiful Soup никогда не будет таким же быстрым, как парсеры, на основе которых он
работает. Если время отклика критично, если вы платите за компьютерное время
по часам, или если есть какая-то другая причина, почему компьютерное время
важнее программистского, стоит забыть о Beautiful Soup
и работать непосредственно с lxml.
Тем не менее, есть вещи, которые вы можете сделать, чтобы ускорить Beautiful Soup. Если
вы не используете lxml в качестве основного парсера, самое время
начать. Beautiful Soup разбирает документы
значительно быстрее с lxml, чем с html.parser или html5lib.
Вы можете значительно ускорить распознавание кодировок, установив
библиотеку cchardet.
Разбор части документа не сэкономит много времени в процессе разбора,
но может сэкономить много памяти, что сделает
поиск по документу намного быстрее.
Перевод документации¶
Переводы документации Beautiful Soup очень
приветствуются. Перевод должен быть лицензирован по лицензии MIT,
так же, как сам Beautiful Soup и англоязычная документация к нему.
Есть два способа передать ваш перевод:
-
Создайте ветку репозитория Beautiful Soup, добавьте свой
перевод и предложите слияние с основной веткой — так же,
как вы предложили бы изменения исходного кода. -
Отправьте в дискуссионную группу Beautiful Soup
сообщение со ссылкой на ваш перевод, или приложите перевод к сообщению.
Используйте существующие переводы документации на китайский или португальский в качестве образца. В
частности, переводите исходный файл doc/source/index.rst вместо
того, чтобы переводить HTML-версию документации. Это позволяет
публиковать документацию в разных форматах, не
только в HTML.
Beautiful Soup 3¶
Beautiful Soup 3 — предыдущая версия, и она больше
активно не развивается. На текущий момент Beautiful Soup 3 поставляется со всеми основными
дистрибутивами Linux:
$ apt-get install python-beautifulsoup
Он также публикуется через PyPi как BeautifulSoup:
$ easy_install BeautifulSoup
$ pip install BeautifulSoup
Вы можете скачать tar-архив Beautiful Soup 3.2.0.
Если вы запустили easy_install beautifulsoup или easy_install, но ваш код не работает, значит, вы ошибочно установили Beautiful
BeautifulSoup
Soup 3. Вам нужно запустить easy_install beautifulsoup4.
Архивная документация для Beautiful Soup 3 доступна онлайн.
Перенос кода на BS4¶
Большая часть кода, написанного для Beautiful Soup 3, будет работать и в Beautiful
Soup 4 с одной простой заменой. Все, что вам нужно сделать, это изменить
имя пакета c BeautifulSoup на bs4. Так что это:
from BeautifulSoup import BeautifulSoup
становится этим:
from bs4 import BeautifulSoup
-
Если выводится сообщение
ImportError«No module named BeautifulSoup», ваша
проблема в том, что вы пытаетесь запустить код Beautiful Soup 3, в то время как
у вас установлен Beautiful Soup 4. -
Если выводится сообщение
ImportError«No module named bs4», ваша проблема
в том, что вы пытаетесь запустить код Beautiful Soup 4, в то время как
у вас установлен Beautiful Soup 3.
Хотя BS4 в основном обратно совместим с BS3, большинство
методов BS3 устарели и получили новые имена, чтобы соответствовать PEP 8. Некоторые
из переименований и изменений нарушают обратную совместимость.
Вот что нужно знать, чтобы перейти с BS3 на BS4:
Вам нужен парсер¶
Beautiful Soup 3 использовал модуль Python SGMLParser, который теперь
устарел и был удален в Python 3.0. Beautiful Soup 4 по умолчанию использует
html.parser, но вы можете подключить lxml или html5lib
вместо него. Вы найдете таблицу сравнения парсеров в разделе Установка парсера.
Поскольку html.parser — это не то же, что SGMLParser, вы
можете обнаружить, что Beautiful Soup 4 дает другое дерево разбора, чем
Beautiful Soup 3. Если вы замените html.parser
на lxml или html5lib, может оказаться, что дерево разбора опять
изменилось. Если такое случится, вам придется обновить код,
чтобы разобраться с новым деревом.
Имена методов¶
-
renderContents->encode_contents -
replaceWith->replace_with -
replaceWithChildren->unwrap -
findAll->find_all -
findAllNext->find_all_next -
findAllPrevious->find_all_previous -
findNext->find_next -
findNextSibling->find_next_sibling -
findNextSiblings->find_next_siblings -
findParent->find_parent -
findParents->find_parents -
findPrevious->find_previous -
findPreviousSibling->find_previous_sibling -
findPreviousSiblings->find_previous_siblings -
getText->get_text -
nextSibling->next_sibling -
previousSibling->previous_sibling
Некоторые аргументы конструктора Beautiful Soup были переименованы по
той же причине:
-
BeautifulSoup(parseOnlyThese=...)->BeautifulSoup(parse_only=...) -
BeautifulSoup(fromEncoding=...)->BeautifulSoup(from_encoding=...)
Я переименовал один метод для совместимости с Python 3:
-
Tag.has_key()->Tag.has_attr()
Я переименовал один атрибут, чтобы использовать более точную терминологию:
-
Tag.isSelfClosing->Tag.is_empty_element
Я переименовал три атрибута, чтобы избежать использования зарезервированных слов
в Python. В отличие от других, эти изменения не являются обратно
совместимыми. Если вы использовали эти атрибуты в BS3, ваш код не сработает
на BS4, пока вы их не измените.
-
UnicodeDammit.unicode->UnicodeDammit.unicode_markup -
Tag.next->Tag.next_element -
Tag.previous->Tag.previous_element
Следующие методы остались от API Beautiful Soup 2; они
устарели с 2006 года, и их не следует использоваться вовсе:
-
Tag.fetchNextSiblings -
Tag.fetchPreviousSiblings -
Tag.fetchPrevious -
Tag.fetchPreviousSiblings -
Tag.fetchParents -
Tag.findChild -
Tag.findChildren
Генераторы¶
Я дал генераторам PEP 8-совместимые имена и преобразовал их в
свойства:
-
childGenerator()->children -
nextGenerator()->next_elements -
nextSiblingGenerator()->next_siblings -
previousGenerator()->previous_elements -
previousSiblingGenerator()->previous_siblings -
recursiveChildGenerator()->descendants -
parentGenerator()->parents
Так что вместо этого:
for parent in tag.parentGenerator(): ...
Вы можете написать это:
for parent in tag.parents: ...
(Хотя старый код тоже будет работать.)
Некоторые генераторы выдавали None после их завершения и
останавливались. Это была ошибка. Теперь генераторы просто останавливаются.
Добавились два генератора: .strings и
.stripped_strings. .strings выдает
объекты NavigableString, а .stripped_strings выдает строки Python,
у которых удалены пробелы.
XML¶
Больше нет класса BeautifulStoneSoup для разбора XML. Чтобы
разобрать XML, нужно передать «xml» в качестве второго аргумента
в конструктор BeautifulSoup. По той же причине
конструктор BeautifulSoup больше не распознает
аргумент isHTML.
Улучшена обработка пустых тегов
XML. Ранее при разборе XML нужно было явно указать,
какие теги считать пустыми элементами. Аргумент SelfClosingTags
больше не распознается. Вместо этого
Beautiful Soup считает пустым элементом любой тег без содержимого. Если
вы добавляете в тег дочерний элемент, тег больше не считается
пустым элементом.
Мнемоники¶
Входящие мнемоники HTML или XML всегда преобразуются в
соответствующие символы Unicode. В Beautiful Soup 3 было несколько
перекрывающих друг друга способов взаимодействия с мнемониками. Эти способы
удалены. Конструктор BeautifulSoup больше не распознает
аргументы smartQuotesTo и convertEntities. (В Unicode,
Dammit все еще присутствует smart_quotes_to, но по умолчанию парные кавычки
преобразуются в Unicode). Константы HTML_ENTITIES,
XML_ENTITIES и XHTML_ENTITIES были удалены, так как они
служили для настройки функции, которой больше нет (преобразование отдельных мнемоник в
символы Unicode).
Если вы хотите на выходе преобразовать символы Unicode обратно в мнемоники HTML,
а не превращать Unicode в символы UTF-8, вам нужно
использовать средства форматирования вывода.
Прочее¶
Tag.string теперь работает рекурсивно. Если тег А
содержит только тег B и ничего больше, тогда значение A.string будет таким же, как
B.string. (Раньше это был None.)
Многозначные атрибуты, такие как class, теперь в качестве значений имеют списки строк,
а не строки. Это может повлиять на поиск
по классу CSS.
Объекты Tag теперь реализуют метод __hash__, так что два
объекта Tag считаются равными, если они генерируют одинаковую
разметку. Это может изменить поведение вашего скрипта, если вы поместите объект Tag
в словарь (dictionary) или множество (set).
Если вы передадите в один из методов find* одновременно string и
специфичный для тега аргумент, такой как name, Beautiful Soup будет
искать теги, которые, во-первых, соответствуют специфичным для тега критериям, и, во-вторых, имеют
Tag.string, соответствующий заданному вами значению string. Beautiful Soup не найдет сами строки. Ранее
Beautiful Soup игнорировал аргументы, специфичные для тегов, и искал
строки.
Конструктор BeautifulSoup больше не распознает
аргумент markupMassage. Теперь это задача парсера —
обрабатывать разметку правильно.
Редко используемые альтернативные классы парсеров, такие как
ICantBelieveItsBeautifulSoup и BeautifulSOAP,
удалены. Теперь парсер решает, что делать с неоднозначной
разметкой.
Метод prettify() теперь возвращает строку Unicode, а не байтовую строку.
Improve Article
Save Article
Improve Article
Save Article
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work. The latest Version of Beautifulsoup is v4.9.3 as of now.
Prerequisites
- Python
- Pip
How to install Beautifulsoup?
To install Beautifulsoup on Windows, Linux, or any operating system, one would need pip package. To check how to install pip on your operating system, check out – PIP Installation – Windows || Linux.
Now, run a simple command,
pip install beautifulsoup4
Wait and relax, Beautifulsoup would be installed shortly.
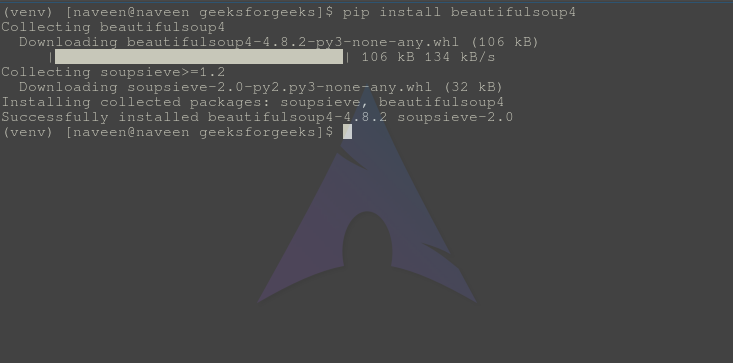
Install Beautifulsoup4 using Source code
One can install beautifulsoup, using source code directly, install beautifulsoup tarball from here – download the Beautiful Soup 4 source tarball
after downloading cd into the directory and run,
Python setup.py install
Verifying Installation
To check whether the installation is complete or not, let’s try implementing it using python
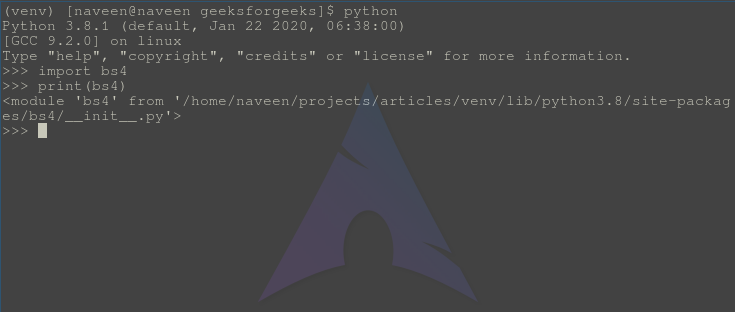
Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml, html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль beautifulsoup4 (VirtualEnv):~$ python3 -m pip install -U beautifulsoup4
Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер
lxml. - Парсер
html5lib. - Встроенный в Python парсер
html.parser.
- Парсер
- Основные приемы работы с BeautifulSoup4.
- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: <a></p>.
Парсер lxml.
- Для запуска примера, необходимо установить модуль
lxml. - Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup("<a></p>", "lxml") # <html><body><a></a></body></html>
Обратите внимание, что тег <a> заключен в теги <body> и <html>, а висячий тег </p> просто игнорируется.
Парсер html5lib.
- Для запуска примера, необходимо установить модуль
html5lib. - Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup("<a></p>", "html5lib") # <html><head></head><body><a><p></p></a></body></html>
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег </p>, и к тому же добавляет открывающий тег <p>. Также html5lib добавляет пустой тег <head> (lxml этого не сделал).
Встроенный в Python парсер html.parser.
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как
lxml. - Более строгий, чем
html5lib.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup("<a></p>", 'html.parser') # <a></a>
Как и lxml, встроенный в Python парсер игнорирует закрывающий тег </p>. В отличие от html5lib, этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги <html> или <body>.
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup(). Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup # передаем объект открытого файла with open("index.html") as fp: soup = BeautifulSoup(fp, 'html.parser') # передаем строку soup = BeautifulSoup("<html>a web page</html>", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = "<html><head></head><body>Sacré bleu!</body></html>" >>> parse = BeautifulSoup(html, 'html.parser') >>> print(parse) # <html><head></head><body>Sacré bleu!</body></html>
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p>"""
Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.prettify()) # <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p class="title"> # <b> # The Dormouse's story # </b> # </p> # <p class="story"> # Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1"> # Elsie # </a> # , # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> # and # <a class="sister" href="http://example.com/tillie" id="link3"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p class="story"> # ... # </p> # </body> # </html>
Навигация по структуре HTML-документа:
# извлечение тега `title` >>> soup.title # <title>The Dormouse's story</title> # извлечение имя тега >>> soup.title.name # 'title' # извлечение текста тега >>> soup.title.string # 'The Dormouse's story' # извлечение первого тега `<p>` >>> soup.p # <p class="title"><b>The Dormouse's story</b></p> # извлечение второго тега `<p>` и # представление его содержимого списком >>> soup.find_all('p')[1].contents # ['Once upon a time there were three little sisters; and their names weren', # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # ',n', # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # ' andn', # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, # ';nand they lived at the bottom of a well.'] # выдаст то же самое, только в виде генератора >>> soup.find_all('p')[1].strings # <generator object Tag._all_strings at 0x7ffa2eb43ac0>
Перемещаться по одному уровню можно при помощи атрибутов .previous_sibling и .next_sibling. Например, в представленном выше HTML, теги <a> обернуты в тег <p> — следовательно они находятся на одном уровне.
>>> first_a = soup.a >>> first_a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> >>> first_a.previous_sibling # 'Once upon a time there were three little sisters; and their names weren' >>> next = first_a.next_sibling >>> next # ',n' >>> next.next_sibling # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings.
for sibling in soup.a.next_siblings: print(repr(sibling)) # ',n' # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> # ' andn' # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> # '; and they lived at the bottom of a well.' for sibling in soup.find(id="link3").previous_siblings: print(repr(sibling)) # ' andn' # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> # ',n' # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> # 'Once upon a time there were three little sisters; and their names weren'
Атрибут .next_element строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и .next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a>, его .next_sibling является строкой: конец предложения, которое было прервано началом тега <a>:
last_a = soup.find("a", id="link3") last_a # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> last_a.next_sibling # ';nand they lived at the bottom of a well.'
Однако .next_element этого тега <a> — это то, что было разобрано сразу после тега <a> — это слово Tillie, а не остальная часть предложения.
last_a_tag.next_element # 'Tillie'
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег <a>, затем слово Tillie, затем закрывающий тег </a>, затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег <a>, но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element. Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
last_a_tag.previous_element # ' andn' last_a_tag.previous_element.next_element # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
for element in last_a_tag.next_elements: print(repr(element)) # 'Tillie' # ';nand they lived at the bottom of a well.' # 'n' # <p class="story">...</p> # '...' # 'n'
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах <a>:
>>> for a in soup.find_all('a'): ... print(a.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
# Весь текст HTML-страницы с разделителями `n` >>> soup.get_text('n', strip='True') # "The Dormouse's storynThe Dormouse's storyn # Once upon a time there were three little sisters; and their names weren # Elsien,nLacienandnTillien;nand they lived at the bottom of a well.n..." # а можно создать список строк, а потом форматировать как надо >>> [text for text in soup.stripped_strings] # ["The Dormouse's story", # "The Dormouse's story", # 'Once upon a time there were three little sisters; and their names were', # 'Elsie', # ',', # 'Lacie', # 'and', # 'Tillie', # ';nand they lived at the bottom of a well.', # '...']
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup.find(), а всех совпавших элементов — BeautifulSoup.find_all().
# ищет все теги `<title>` >>> soup.find_all("title") # [<title>The Dormouse's story</title>] # ищет все теги `<a>` и все теги `<b>` >>> soup.find_all(["a", "b"]) # [<b>The Dormouse's story</b>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] # ищет все теги `<p>` с CSS классом "title" >>> soup.find_all("p", "title") # [<p class="title"><b>The Dormouse's story</b></p>] # ищет все теги с CSS классом, в именах которых встречается "itl" soup.find_all(class_=re.compile("itl")) # [<p class="title"><b>The Dormouse's story</b></p>] # ищет все теги с id="link2" >>> soup.find_all(id="link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] # ищет все теги `<a>`, содержащие указанные атрибуты >>> soup.find_all('a', attrs={'class': 'sister', 'id': 'link1'}) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] # ищет текст внутри всех тегов, который содержит 'sisters' >>> import re >>> soup.find(string=re.compile("sisters")) # 'Once upon a time there were three little sisters; and their names weren' # ищет все теги, имена которых начинаются на букву 'b' for tag in soup.find_all(re.compile("^b")): print(tag.name) # body # b # ищет все теги в документе, но не текстовые строки for tag in soup.find_all(True): print(tag.name) # html # head # title # body # p # b # p # a # a # a # p
Поиск тегов при помощи CSS селекторов:
>>> soup.select("title") # [<title>The Dormouse's story</title>] >>> soup.select("p:nth-of-type(3)") # [<p class="story">...</p>]
Поиск тега под другими тегами:
>>> soup.select("body a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] >>> soup.select("html head title") # [<title>The Dormouse's story</title>]
Поиск тега непосредственно под другими тегами:
>>> soup.select("head > title") # [<title>The Dormouse's story</title>] >>> soup.select("p > a:nth-of-type(2)") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] >>> soup.select("p > #link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
Поиск одноуровневых элементов:
# поиск всех `.sister` в которых нет `#link1` >>> soup.select("#link1 ~ .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] # поиск всех `.sister` в которых есть `#link1` >>> soup.select("#link1 + .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] # поиск всех `<a>` у которых есть сосед `<p>`
Поиск тега по классу CSS:
>>> soup.select(".sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Поиск тега по ID:
>>> soup.select("#link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] >>> soup.select("a#link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого <ul> будут являться три тега <li> и тег <ul> со всеми вложенными тегами.
, что все переводы строк n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r'>s+<', '><', html.replace('n', ''))
html = """ <div> <ul> <li>текст 1</li> <li>текст 2</li> <ul> <li>текст 2-1</li> <li>текст 2-2</li> </ul> <li>текст 3</li> </ul> </div> """ >>> from bs4 import BeautifulSoup >>> root = BeautifulSoup(html, 'html.parser') # найдем в дереве первый тег `<ul>` >>> first_ul = root.ul # извлекаем список непосредственных дочерних элементов # переводы строк `n` и пробелы между тегами так же # распознаются как дочерние элементы >>> first_ul.contents # ['n', <li>текст 1</li>, 'n', <li>текст 2</li>, 'n', <ul> # <li>текст 2-1</li> # <li>текст 2-2</li> # </ul>, 'n', <li>текст 3</li>, 'n'] # убираем переводы строк `n` как из списка, так и из тегов # лучше конечно сразу убрать переводы строк из исходного HTML >>> [str(i).replace('n', '') for i in first_ul.contents if str(i) != 'n'] # ['<li>текст 1</li>', # '<li>текст 2</li>', # '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>', # '<li>текст 3</li>'] # то же самое, что и `first_ul.contents` # только в виде итератора >>> first_ul.children # <list_iterator object at 0x7ffa2eb52460>
Извлечение ВСЕХ дочерних элементов. Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
>>> import re # сразу уберем переводы строк из исходного HTML >>> html = re.sub(r'>s+<', '><', html.replace('n', '')) >>> root = BeautifulSoup(html, 'html.parser') # найдем в дереве первый тег `<ul>` >>> first_ul = root.ul # извлекаем список ВСЕХ дочерних элементов >>> list(first_ul.descendants) # [<li>текст 1</li>, # 'текст 1', # <li>текст 2</li>, # 'текст 2', # <ul><li>текст 2-1</li><li>текст 2-2</li></ul>, # <li>текст 2-1</li>, # 'текст 2-1', # <li>текст 2-2</li>, # 'текст 2-2', # <li>текст 3</li>, # 'текст 3']
, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут .strings или генератор .stripped_strings.
Генератор .stripped_strings дополнительно удаляет все переводы строк n и пробелы между тегами в исходном HTML-документе.
>>> list(first_ul.strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3'] >>> first_ul.stripped_strings # <generator object Tag.stripped_strings at 0x7ffa2eb43ac0> >>> list(first_ul.stripped_strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3']
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent.
html = """ <div> <ul> <li>текст 1</li> <li>текст 2</li> <ul> <li>текст 2-1</li> <li>текст 2-2</li> </ul> <li>текст 3</li> </ul> </div> """ >>> from bs4 import BeautifulSoup >>> import re # сразу уберем переводы строк и пробелы # между тегами из исходного HTML >>> html = re.sub(r'>s+<', '><', html.replace('n', '')) >>> root = BeautifulSoup(html, 'html.parser') # найдем теги `<li>` вложенные во второй `<ul>`, # используя CSS селекторы >>> child_ul = root.select('ul > ul > li') >>> child_ul # [<li>текст 2-1</li>, <li>текст 2-2</li>] # получаем доступ к родителю >>> child_li[0].parent # <ul><li>текст 2-1</li><li>текст 2-2</li></ul> # доступ к родителю родителя >>> child_li[0].parent.parent.contents [<li>текст 1</li>, <li>текст 2</li>, <ul><li>текст 2-1</li><li>текст 2-2</li></ul>, <li>текст 3</li>]
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents.
>>> child_li[0] # <li>текст 2-1</li> >>> [parent.name for parent in child_li[0].parents] # ['ul', 'ul', 'div', '[document]']
Изменение имен тегов HTML-документа:
>>> soup = BeautifulSoup('<p><b class="boldest">Extremely bold</b></p>', 'html.parser') >>> tag = soup.b # присваиваем новое имя тегу >>> tag.name = "blockquote" >>> tag # <blockquote class="boldest">Extremely bold</blockquote> >>> soup # <p><blockquote class="boldest">Extremely bold</blockquote></p>
Изменение HTML-тега <p> на тег <div>:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html.parser') >>> soup.p.name = 'div' >>> soup # <div><b>Extremely bold</b></div>
Добавление новых тегов в HTML-документ.
Добавление нового тега в дерево HTML:
>>> soup = BeautifulSoup("<p><b></b></p>", 'html.parser') >>> original_tag = soup.b # создание нового тега `<a>` >>> new_tag = soup.new_tag("a", href="http://example.com") # строка нового тега `<a>` >>> new_tag.string = "Link text" # добавление тега `<a>` внутрь `<b>` >>> original_tag.append(new_tag) >>> original_tag # <b><a href="http://example.com">Link text.</a></b> >>> soup # <p><b><a href="http://example.com">Link text</a></b></p>
Добавление новых тегов до/после определенного тега или внутрь тега.
>>> soup = BeautifulSoup("<p><b>leave</b></p>", 'html.parser') >>> tag = soup.new_tag("i", id='new') >>> tag.string = "Don't" # добавление нового тега <i> до тега <b> >>> soup.b.insert_before(tag) >>> soup.b # <p><i>Don't</i><b>leave</b></p> # добавление нового тега <i> после тега <b> >>> soup.b.insert_after(tag) >>> soup # <p><b>leave</b><i>Don't</i></p> # добавление нового тега <i> внутрь тега <b> >>> soup.b.string.insert_before(tag) >>> soup.b # <p><b><i>Don't</i>leave</b></p>
Удаление и замена тегов в HTML-документе.
Удаляем тег или строку из дерева HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example.com</i></a>' >>> soup = BeautifulSoup(html, 'html.parser') >>> a_tag = soup.a # удаляем HTML-тег `<i>` с сохранением # в переменной `i_tag` >>> i_tag = soup.i.extract() # смотрим что получилось >>> a_tag # <a href="http://example.com/">I linked to</a> >>> i_tag # <i>example.com</i>
Заменяем тег и/или строку в дереве HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example</i></a>' >>> soup = BeautifulSoup(html, 'html.parser') >>> a_tag = soup.a # создаем новый HTML тег >>> new_tag = soup.new_tag("b") >>> new_tag.string = "sample" # производим замену тега `<i>` внутри тега `<a>` >>> a_tag.i.replace_with(new_tag) >>> a_tag # <a href="http://example.com/">I linked to <b>sample</b></a>
Изменение атрибутов тегов HTML-документа.
У тега может быть любое количество атрибутов. Тег <b id = "boldest"> имеет атрибут id, значение которого равно boldest. Доступ к атрибутам тега можно получить, обращаясь с тегом как со словарем:
>>> soup = BeautifulSoup('<p><b id="boldest">bolder</b></p>', 'html.parser') >>> tag = soup.b >>> tag['id'] # 'boldest' # доступ к словарю с атрибутами >>> tag.attrs # {'id': 'boldest'}
Можно добавлять и изменять атрибуты тега.
# изменяем `id` >>> tag['id'] = 'bold' # добавляем несколько значений в `class` >>> tag['class'] = ['new', 'bold'] # или >>> tag['class'] = 'new bold' >>> tag # <b class="new bold" id="bold">bolder</b>
А так же производить их удаление.
>>> del tag['id'] >>> del tag['class'] >>> tag # <b>bolder</b> >>> tag.get('id') # None
Данная инструкция по BeautifulSoup является вводным руководством по использованию библиотеки BeautifulSoup Python. В примерах показано использование тегов, модификация документа и перебор его элементов, а также парсинг веб-страниц.
Содержание статьи
- BeautifulSoup на примерах
- Установка BeautifulSoup в Python
- Пример HTML-кода страницы
- BeautifulSoup простой пример парсинга HTML
- BeautifulSoup теги, атрибуты name и text
- BeautifulSoap перебираем HTML теги
- BeautifulSoup атрибут children
- BeautifulSoup атрибут descendants
- BeautifulSoup и веб-скрапинг HTML
- BeautifulSoup метод prettify()
- BeautifulSoup метод find(), поиск элементов по id
- BeautifulSoup метод find_all() поиск всех тегов в HTML
- BeautifulSoup методы select() и select_one() CSS селекторы
- BeautifulSoup метод append() добавление нового HTML-тега
- BeautifulSoup метод insert() вставка HTML-тега
- BeautifulSoup метод replace_with() замена текста в теге
- BeautifulSoup метод decompose() удаление HTML-тега
BeautifulSoup является библиотекой Python для парсинга HTML и XML документов. Часто используется для скрапинга веб-страниц. BeautifulSoup позволяет трансформировать сложный HTML-документ в сложное древо различных объектов Python. Это могут быть теги, навигация или комментарии.
Установка BeautifulSoup в Python
Для установки необходимых модулей используется команда pip3.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Для начала требуется установить lxml модуль, который используется в BeautifulSoup.
BeautifulSoup устанавливается при помощи использования указанной выше команды.
Пример HTML-кода страницы
В последующих примерах будет использован данный HTML-файл:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
<!DOCTYPE html> <html> <head> <title>Header</title> <meta charset=«utf-8»> </head> <body> <h2>Operating systems</h2> <ul id=«mylist» style=«width:150px»> <li>Solaris</li> <li>FreeBSD</li> <li>Debian</li> <li>NetBSD</li> <li>Windows</li> </ul> <p> FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms. </p> <p> Debian is a Unix-like computer operating system that is composed entirely of free software. </p> </body> </html> |
BeautifulSoup простой пример парсинга HTML
В первом примере будет использован BeautifulSoup модуль для получения трех тегов.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) print(soup.h2) print(soup.head) print(soup.li) |
Код в данном примере позволяет вывести HTML-код трех тегов.
|
from bs4 import BeautifulSoup |
Здесь производится импорт класса BeautifulSoup из модуля bs4. Таким образом, BeautifulSoup является главным рабочим классом.
|
with open(«index.html», «r») as f: contents = f.read() |
Открывается файл index.html и производится чтение его содержимого при помощи метода read().
|
soup = BeautifulSoup(contents, ‘lxml’) |
Создается объект BeautifulSoup. Данные передаются конструктору. Вторая опция уточняет объект парсинга.
|
print(soup.h2) print(soup.head) |
Далее выводится HTML-код следующих двух тегов: h2 и head.
В примере много раз используются элементы li, однако выводится только первый из них.
|
$ ./simple.py <h2>Operating systems</h2> <head> <title>Header</title> <meta charset=«utf-8»/> </head> <li>Solaris</li> |
Это результат вывода.
BeautifulSoup теги, атрибуты name и text
Атрибут name указывает на название тега, а атрибут text указывает на его содержимое.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) print(«HTML: {0}, name: {1}, text: {2}».format(soup.h2, soup.h2.name, soup.h2.text)) |
Код в примере позволяет вывести HTML-код, название и текст h2 тега.
|
$ ./tags_names.py HTML: <h2>Operating systems</h2>, name: h2, text: Operating systems |
Это результат вывода.
Метод recursiveChildGenerator() позволяет перебрать содержимое HTML-документа.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) for child in soup.recursiveChildGenerator(): if child.name: print(child.name) |
Данный пример позволяет перебрать содержимое HTML-документа и вывести названия всех его тегов.
|
$ ./traverse_tree.py html head title meta body h2 ul li li li li li p p |
Данные теги являются частью рассматриваемого HTML-документа.
BeautifulSoup атрибут children
При помощи атрибута children можно вывести все дочерние теги.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) root = soup.html root_childs = [e.name for e in root.children if e.name is not None] print(root_childs) |
В данном примере извлекаются дочерние элементы html тега, после чего они помещаются в список Python и выводятся в консоль. Так как атрибут children также убирает пробелы между тегами, необходимо добавить условие, которое позволяет выбирать только названия тегов.
|
$ ./get_children.py [‘head’, ‘body’] |
Следовательно, у тегов html есть два дочерних элемента: head и body.
BeautifulSoup атрибут descendants
При помощи атрибута descendants можно получить список всех потомков (дочерних элементов всех уровней) рассматриваемого тега.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) root = soup.body root_childs = [e.name for e in root.descendants if e.name is not None] print(root_childs) |
Данный пример позволяет найти всех потомков главного тега body.
|
$ ./get_descendants.py [‘h2’, ‘ul’, ‘li’, ‘li’, ‘li’, ‘li’, ‘li’, ‘p’, ‘p’] |
Перечисленные выше теги являются потомками главного тега body.
BeautifulSoup и веб-скрапинг HTML
Requests является простой HTTP библиотекой в Python. Она позволяет использовать разнообразные методы для получения доступа к веб-ресурсам при помощи HTTP.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup import requests as req resp = req.get(«http://www.something.com») soup = BeautifulSoup(resp.text, ‘lxml’) print(soup.title) print(soup.title.text) print(soup.title.parent) |
Данный пример извлекает название рассматриваемой веб-страницы. Здесь также выводится имя ее родителя.
|
resp = req.get(«http://www.something.com») soup = BeautifulSoup(resp.text, ‘lxml’) |
Здесь мы получаем информацию о веб-странице.
|
print(soup.title) print(soup.title.text) print(soup.title.parent) |
Код выше помогает вывести HTML-код заголовка, его текст, а также HTML-код его родителя.
|
$ ./scraping.py <title>Something.</title> Something. <head><title>Something.</title></head> |
Это результат вывода.
BeautifulSoup метод prettify()
При помощи метода prettify() можно добиться того, чтобы HTML-код выглядел аккуратнее.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup import requests as req resp = req.get(«http://www.something.com») soup = BeautifulSoup(resp.text, ‘lxml’) print(soup.prettify()) |
Таким образом, мы оптимизируем HTML-код простой веб-страницы.
|
$ ./prettify.py <html> <head> <title> Something. </title> </head> <body> Something. </body> </html> |
Это результат вывода.
BeautifulSoup метод find(), поиск элементов по id
При помощи метода find() можно найти элементы страницы, используя различные опорные параметры, id в том числе.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) #print(soup.find(«ul», attrs={ «id» : «mylist»})) print(soup.find(«ul», id=«mylist»)) |
Код в примере находит тег ul, у которого id mylist. Строка в комментарии является альтернативным способом выполнить то же самое задание.
BeautifulSoup метод find_all() поиск всех тегов в HTML
При помощи метода find_all() можно найти все элементы, которые соответствуют заданным критериям.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) for tag in soup.find_all(«li»): print(«{0}: {1}».format(tag.name, tag.text)) |
Код в примере позволяет найти и вывести на экран все li теги.
|
$ ./find_all.py li: Solaris li: FreeBSD li: Debian li: NetBSD |
Это результат вывода.
Метод find_all() также при поиске использует список из названий тегов.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) tags = soup.find_all([‘h2’, ‘p’]) for tag in tags: print(» «.join(tag.text.split())) |
В данном примере показано, как найти все h2 и p элементы, после чего вывести их содержимое на экран.
Метод find_all() также может использовать функцию, которая определяет, какие элементы должны быть выведены.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/python3 from bs4 import BeautifulSoup def myfun(tag): return tag.is_empty_element with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) tags = soup.find_all(myfun) print(tags) |
Данный пример выводит пустые элементы.
|
$ ./find_by_fun.py [<meta charset=«utf-8»/>] |
Единственным пустым элементом в документе является meta.
Также можно найти запрашиваемые элементы, используя регулярные выражения.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/python3 import re from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) strings = soup.find_all(string=re.compile(‘BSD’)) for txt in strings: print(» «.join(txt.split())) |
В данном примере выводится содержимое элементов, в которых есть строка с символами ‘BSD’.
|
$ ./regex.py FreeBSD NetBSD FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms. |
Это результат вывода.
BeautifulSoup методы select() и select_one() CSS селекторы
При помощи методов select() и select_one() для нахождения запрашиваемых элементов можно использовать некоторые CSS селекторы.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) print(soup.select(«li:nth-of-type(3)»)) |
В данном примере используется CSS селектор, который выводит на экран HTML-код третьего по счету элемента li.
|
$ ./select_nth_tag.py <li>Debian</li> |
Данный элемент li является третьим в списке.
В CSS символ # используется для выбора тегов по их id-атрибутам.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) print(soup.select_one(«#mylist»)) |
В данном примере выводятся элементы, которых есть id под названием mylist.
BeautifulSoup метод append() добавление нового HTML-тега
Метод append() добавляет в рассматриваемый HTML-документ новый тег.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) newtag = soup.new_tag(‘li’) newtag.string=‘OpenBSD’ ultag = soup.ul ultag.append(newtag) print(ultag.prettify()) |
В примере выше показано, как в HTML-документ добавить новый тег li.
|
newtag = soup.new_tag(‘li’) newtag.string=‘OpenBSD’ |
Для начала, требуется создать новый тег при помощи метода new_tag().
Далее создается сноска на тег ul.
Затем созданный ранее тег li добавляется к тегу ul.
Таким образом, тег ul выводится аккуратно отформатированным.
BeautifulSoup метод insert() вставка HTML-тега
Метод insert() позволяет вставить тег в определенно выбранное место.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) newtag = soup.new_tag(‘li’) newtag.string=‘OpenBSD’ ultag = soup.ul ultag.insert(2, newtag) print(ultag.prettify()) |
В примере показано, как поставить тег li на третью позицию в выбранном ul теге.
BeautifulSoup метод replace_with() замена текста в теге
Метод replace_with() заменяет содержимое выбранного элемента.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) tag = soup.find(text=«Windows») tag.replace_with(«OpenBSD») print(soup.ul.prettify()) |
В примере показано, как при помощи метода find() найти определенный элемент, а затем, используя метод replace_with(), заменить его содержимое.
BeautifulSoup метод decompose() удаление HTML-тега
Метод decompose() удаляет определенный тег из структуры документа и уничтожает его.
|
#!/usr/bin/python3 from bs4 import BeautifulSoup with open(«index.html», «r») as f: contents = f.read() soup = BeautifulSoup(contents, ‘lxml’) ptag2 = soup.select_one(«p:nth-of-type(2)») ptag2.decompose() print(soup.body.prettify()) |
В данном примере показано, как удалить второй элемент p в документе.
В данном руководстве было показано, как использовать библиотеку BeautifulSoup в Python.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
If you’re using a recent version of Debian or Ubuntu Linux, you can
install Beautiful Soup with the system package manager:
$ apt-get install python-bs4
Beautiful Soup 4 is published through PyPi, so if you can’t install it
with the system packager, you can install it with easy_install or
pip. The package name is beautifulsoup4, and the same package
works on Python 2 and Python 3.
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
(The BeautifulSoup package is probably not what you want. That’s
the previous major release, Beautiful Soup 3.
Lots of software uses
BS3, so it’s still available, but if you’re writing new code you
should install beautifulsoup4.)
If you don’t have easy_install or pip installed, you can
download the Beautiful Soup 4 source tarball and
install it with setup.py.
$ python setup.py install
If all else fails, the license for Beautiful Soup allows you to
package the entire library with your application. You can download the
tarball, copy its bs4 directory into your application’s codebase,
and use Beautiful Soup without installing it at all.
I use Python 2.7 and Python 3.2 to develop Beautiful Soup, but it
should work with other recent versions.
2.1. Problems after installation¶
Beautiful Soup is packaged as Python 2 code. When you install it for
use with Python 3, it’s automatically converted to Python 3 code. If
you don’t install the package, the code won’t be converted. There have
also been reports on Windows machines of the wrong version being
installed.
If you get the ImportError “No module named HTMLParser”, your
problem is that you’re running the Python 2 version of the code under
Python 3.
If you get the ImportError “No module named html.parser”, your
problem is that you’re running the Python 3 version of the code under
Python 2.
In both cases, your best bet is to completely remove the Beautiful
Soup installation from your system (including any directory created
when you unzipped the tarball) and try the installation again.
If you get the SyntaxError “Invalid syntax” on the line
ROOT_TAG_NAME = u'[document]', you need to convert the Python 2
code to Python 3. You can do this either by installing the package:
$ python3 setup.py install
or by manually running Python’s 2to3 conversion script on the
bs4 directory:
$ 2to3-3.2 -w bs4
2.2. Installing a parser¶
Beautiful Soup supports the HTML parser included in Python’s standard
library, but it also supports a number of third-party Python parsers.
One is the lxml parser. Depending on your setup,
you might install lxml with one of these commands:
$ apt-get install python-lxml
$ easy_install lxml
$ pip install lxml
Another alternative is the pure-Python html5lib parser, which parses HTML the way a
web browser does. Depending on your setup, you might install html5lib
with one of these commands:
$ apt-get install python-html5lib
$ easy_install html5lib
$ pip install html5lib
This table summarizes the advantages and disadvantages of each parser library:
| Parser | Typical usage | Advantages | Disadvantages |
| Python’s html.parser | BeautifulSoup(markup, "html.parser") |
|
|
| lxml’s HTML parser | BeautifulSoup(markup, "lxml") |
|
|
| lxml’s XML parser | BeautifulSoup(markup, ["lxml", "xml"])BeautifulSoup(markup, "xml") |
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
If you can, I recommend you install and use lxml for speed. If you’re
using a version of Python 2 earlier than 2.7.3, or a version of Python
3 earlier than 3.2.2, it’s essential that you install lxml or
html5lib–Python’s built-in HTML parser is just not very good in older
versions.
Note that if a document is invalid, different parsers will generate
different Beautiful Soup trees for it. See Differences between parsers for details.
Install beautifulsoup python 3 windows, linux and Ubuntu. In the tutorial we will learn the installation of the beautifulsoup in python. The python programming language will support the third party module as beautiful soup. The module developer should be well prepared and the installer should be executable. The debian is based on the operating system and said as platform specific installer. The library makes easy to scrape off the information from web pages. Also sits at the top and provides pythonic idioms for searching, iterating and modifying.
Pip install BeautifulSoup
Installing Beautiful Soup in Windows:-
We make use of python packages available from the website and use the setup.py to install beautiful soup.
Verifying Python path in Windows:-
The python.exe is not added to environment by default in windows.
So to check from the windows command line prompt we type python.
The command will work without errors and python is added in the environment within the installed directory.
For the python 2.x it has c:python2x and python 3.x we have c:python3x
For adding path in windows machine we have to,
Right-click on MY Computer<properties<environment variables<system variable<path variable and add section to path variable.
C:pythonXY for example C:Python 27
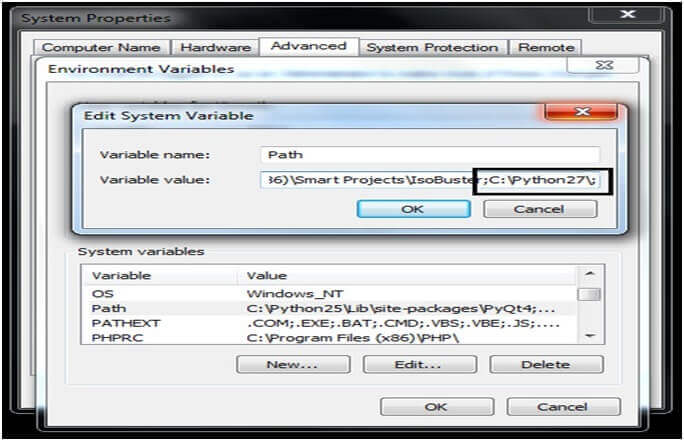
Install beautifulsoup python 3 windows
Install beautiful soup 4 with python 2.7 on windows 10:-
We can add system variable by,
- Click on Properties of My Computer.
- Choose Advanced System Settings
- Then click on Advanced Tab
- After that click on Environment Variables
- Then System Variables >>> select the variable path.
- Click to edit and then add the following lines at the end of it
- C:python27;c:Python27scripts
You do this once only.
- Then restart windows.
- Install the beautifulsoup4
- Then open cmd and type,
pip install beautifulsoup4
easy_install beautifulsoup4
or
easy_install beautifulsoup
Then add the Python path in Windows and next process after Python path is ready we follow the steps for installing Beautiful Soup on a Windows machine.
2) Installation on Ubuntu:-
If pip is not installed does it now:-
apt-get update
apt-get-y install python pip
3) Install beautifulsoup 4 with pip:-
Pip install beautifulsoup4
It will also support python 2 and 3 version.
Installation on Windows with Pip:-
install pip to download python packages faster and easier from the command line.
Then open command prompt as,
Download get-pip, py then open CMD and cd to folder downloaded and run it.
Cd C:UsersAttilaDesktopFolder
Python get-pip.py
Then the pip is installed on your system and tests it by checking versions as,
Pip-V
Install beautiful soup with pip
Pip install beautifulsoup4
Easy install and pip are the tools used for managing and installing Python packages.
Anyone of them can be used to install Beautiful Soup.
Copy
Studo pip install beautifulsoup4
5) Installation on Windows without pip:-
Install the beautifulsoup without pip on windows,
- Firstly download the latest package for extracting.
- Then Open CMD and cd to the folder from which you have extracted.
Cd:C:UsersAttilaDesktopFolderbeautifulsoup4-4.1.0
Here open cmd and type,
Pip install beautifulsoup4
I would like to install Beautiful Soup 4 but I can’t install Beautiful Soup by copying the file into the site-packages directory.
Firstly we have to install pip and then run some commands from the command prompt.
Python-m pip
After getting Usage and Commands instructions you have to install and if python is not found it needs to be added to the path.
So you can run the same command from the installation directory of python.
Python-m pip install Beautifilsoup4
Easy_install beautiful soup4 or
Easy_install beautiful soup
To install easy_install
The python programming g will support modules such as beautiful soup.
We expect the module developer and prepare an installer.
6) Installing Beautiful Soup in Linux:-
Installing Beautiful Soup is simple and straightforward in Linux machines. For versions like Ubuntu and Debian the beautifulsoup is available as package.
The package is installed using the system package manager.
There are three ways to install Beautiful Soup in Linux machines:-
Using the package manager
Using easy_install
Using pip
7) Installing Beautiful Soup using the package manager:-
Linux machines come with a package manager to install various packages.
The default package manager is based on the apt-get and we will use the apt-get.
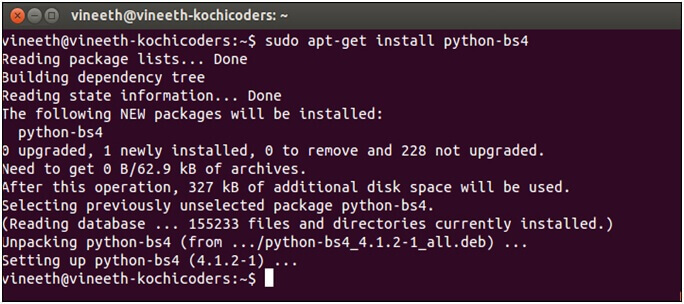
 Installing Beautiful Soup using easy_install:-
Installing Beautiful Soup using easy_install:-
 Installing Beautiful Soup using easy_install:-
Installing Beautiful Soup using easy_install:-This tool will install the package from Python Package Index (PyPI) and type the command as,
Copy
Sudo easy_install beautifulsoup4
Active network connection is important to install the beautifulsoup in Linux.
The setup.py script come with python package downloaded from the pypi.pythopn.org.
9) Installing Beautiful Soup using setup.py:-
Install Python packages using the script that come with every Python package and downloaded it from the Python package index.
Unzip to folder
Then open up command line prompt and navigate to the unzipped folder as
Cd BeautifulSoup
Python setup.install
The python setup.py install is installed on the system.
- Need pip use by downloading and running python setup.py from a directory.
- Easy_install beautifulsoup4
Or easy_install beautifulSoup
- Use http://pypi.python.org/pypi/setuptools
- Install the pip by the get-pip method and downloading it then we will save it.
- Then add system by,
- Clicking properties of my computer
- Choose the advanced system setting
- Then click advanced tab
- Then enviourement variables
- From the system variables,>>select path
Open cmd and type
Pip install beautifulsoup4
Checking way is python-m pip
If we get usage and command instruction then you have installed beautiful soup on system.
Python-m pip install beautifulsoup4
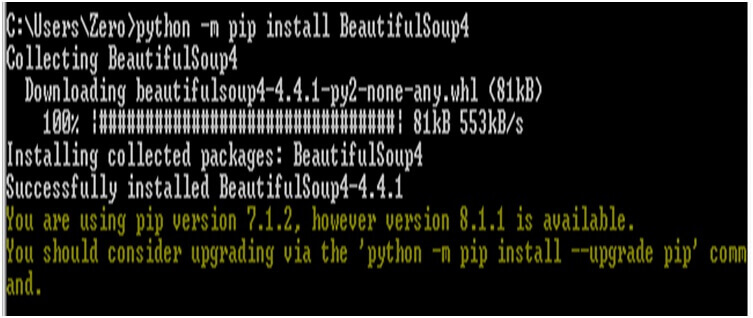
As BeautifulSoup is not a standard python library, we need to install it first. We are going to install the BeautifulSoup 4 library (also known as BS4), which is the latest one.
To isolate our working environment so as not to disturb the existing setup, let us first create a virtual environment.
Creating a virtual environment (optional)
A virtual environment allows us to create an isolated working copy of python for a specific project without affecting the outside setup.
Best way to install any python package machine is using pip, however, if pip is not installed already (you can check it using – “pip –version” in your command or shell prompt), you can install by giving below command −
Linux environment
$sudo apt-get install python-pip
Windows environment
To install pip in windows, do the following −
-
Download the get-pip.py from https://bootstrap.pypa.io/get-pip.py or from the github to your computer.
-
Open the command prompt and navigate to the folder containing get-pip.py file.
-
Run the following command −
>python get-pip.py
That’s it, pip is now installed in your windows machine.
You can verify your pip installed by running below command −
>pip --version pip 19.2.3 from c:usersyadurappdatalocalprogramspythonpython37libsite-packagespip (python 3.7)
Installing virtual environment
Run the below command in your command prompt −
>pip install virtualenv
After running, you will see the below screenshot −

Below command will create a virtual environment (“myEnv”) in your current directory −
>virtualenv myEnv
Screenshot

To activate your virtual environment, run the following command −
>myEnvScriptsactivate

In the above screenshot, you can see we have “myEnv” as prefix which tells us that we are under virtual environment “myEnv”.
To come out of virtual environment, run deactivate.
(myEnv) C:Usersyadur>deactivate C:Usersyadur>
As our virtual environment is ready, now let us install beautifulsoup.
Installing BeautifulSoup
As BeautifulSoup is not a standard library, we need to install it. We are going to use the BeautifulSoup 4 package (known as bs4).
Linux Machine
To install bs4 on Debian or Ubuntu linux using system package manager, run the below command −
$sudo apt-get install python-bs4 (for python 2.x) $sudo apt-get install python3-bs4 (for python 3.x)
You can install bs4 using easy_install or pip (in case you find problem in installing using system packager).
$easy_install beautifulsoup4 $pip install beautifulsoup4
(You may need to use easy_install3 or pip3 respectively if you’re using python3)
Windows Machine
To install beautifulsoup4 in windows is very simple, especially if you have pip already installed.
>pip install beautifulsoup4
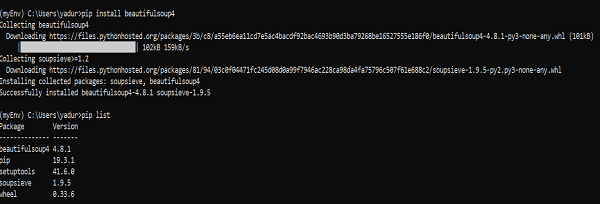
So now beautifulsoup4 is installed in our machine. Let us talk about some problems encountered after installation.
Problems after installation
On windows machine you might encounter, wrong version being installed error mainly through −
-
error: ImportError “No module named HTMLParser”, then you must be running python 2 version of the code under Python 3.
-
error: ImportError “No module named html.parser” error, then you must be running Python 3 version of the code under Python 2.
Best way to get out of above two situations is to re-install the BeautifulSoup again, completely removing existing installation.
If you get the SyntaxError “Invalid syntax” on the line ROOT_TAG_NAME = u’[document]’, then you need to convert the python 2 code to python 3, just by either installing the package −
$ python3 setup.py install
or by manually running python’s 2 to 3 conversion script on the bs4 directory −
$ 2to3-3.2 -w bs4
Installing a Parser
By default, Beautiful Soup supports the HTML parser included in Python’s standard library, however it also supports many external third party python parsers like lxml parser or html5lib parser.
To install lxml or html5lib parser, use the command −
Linux Machine
$apt-get install python-lxml $apt-get insall python-html5lib
Windows Machine
$pip install lxml $pip install html5lib
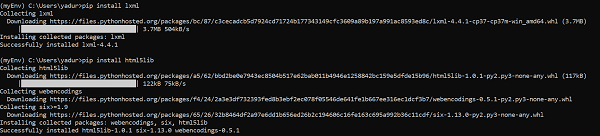
Generally, users use lxml for speed and it is recommended to use lxml or html5lib parser if you are using older version of python 2 (before 2.7.3 version) or python 3 (before 3.2.2) as python’s built-in HTML parser is not very good in handling older version.
Running Beautiful Soup
It is time to test our Beautiful Soup package in one of the html pages (taking web page – https://www.tutorialspoint.com/index.htm, you can choose any-other web page you want) and extract some information from it.
In the below code, we are trying to extract the title from the webpage −
from bs4 import BeautifulSoup import requests url = "https://www.tutorialspoint.com/index.htm" req = requests.get(url) soup = BeautifulSoup(req.text, "html.parser") print(soup.title)
Output
<title>H2O, Colab, Theano, Flutter, KNime, Mean.js, Weka, Solidity, Org.Json, AWS QuickSight, JSON.Simple, Jackson Annotations, Passay, Boon, MuleSoft, Nagios, Matplotlib, Java NIO, PyTorch, SLF4J, Parallax Scrolling, Java Cryptography</title>
One common task is to extract all the URLs within a webpage. For that we just need to add the below line of code −
for link in soup.find_all('a'):
print(link.get('href'))
Output
https://www.tutorialspoint.com/index.htm https://www.tutorialspoint.com/about/about_careers.htm https://www.tutorialspoint.com/questions/index.php https://www.tutorialspoint.com/online_dev_tools.htm https://www.tutorialspoint.com/codingground.htm https://www.tutorialspoint.com/current_affairs.htm https://www.tutorialspoint.com/upsc_ias_exams.htm https://www.tutorialspoint.com/tutor_connect/index.php https://www.tutorialspoint.com/whiteboard.htm https://www.tutorialspoint.com/netmeeting.php https://www.tutorialspoint.com/index.htm https://www.tutorialspoint.com/tutorialslibrary.htm https://www.tutorialspoint.com/videotutorials/index.php https://store.tutorialspoint.com https://www.tutorialspoint.com/gate_exams_tutorials.htm https://www.tutorialspoint.com/html_online_training/index.asp https://www.tutorialspoint.com/css_online_training/index.asp https://www.tutorialspoint.com/3d_animation_online_training/index.asp https://www.tutorialspoint.com/swift_4_online_training/index.asp https://www.tutorialspoint.com/blockchain_online_training/index.asp https://www.tutorialspoint.com/reactjs_online_training/index.asp https://www.tutorix.com https://www.tutorialspoint.com/videotutorials/top-courses.php https://www.tutorialspoint.com/the_full_stack_web_development/index.asp …. …. https://www.tutorialspoint.com/online_dev_tools.htm https://www.tutorialspoint.com/free_web_graphics.htm https://www.tutorialspoint.com/online_file_conversion.htm https://www.tutorialspoint.com/netmeeting.php https://www.tutorialspoint.com/free_online_whiteboard.htm http://www.tutorialspoint.com https://www.facebook.com/tutorialspointindia https://plus.google.com/u/0/+tutorialspoint Tweets by tutorialspoint http://www.linkedin.com/company/tutorialspoint https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg https://www.tutorialspoint.com/index.htm /about/about_privacy.htm#cookies /about/faq.htm /about/about_helping.htm /about/contact_us.htm
Similarly, we can extract useful information using beautifulsoup4.
Now let us understand more about “soup” in above example.