
This part of the documentation covers the installation of Requests.
The first step to using any software package is getting it properly installed.
$ pipenv install requests¶
To install Requests, simply run this simple command in your terminal of choice:
$ pipenv install requests
If you don’t have pipenv installed (tisk tisk!), head over to the Pipenv website for installation instructions. Or, if you prefer to just use pip and don’t have it installed,
this Python installation guide
can guide you through the process.
Get the Source Code¶
Requests is actively developed on GitHub, where the code is
always available.
You can either clone the public repository:
$ git clone git://github.com/requests/requests.git
Or, download the tarball:
$ curl -OL https://github.com/requests/requests/tarball/master # optionally, zipball is also available (for Windows users).
Once you have a copy of the source, you can embed it in your own Python
package, or install it into your site-packages easily:
$ cd requests $ pip install .
Requests is a simple, yet elegant, HTTP library.
>>> import requests >>> r = requests.get('https://httpbin.org/basic-auth/user/pass', auth=('user', 'pass')) >>> r.status_code 200 >>> r.headers['content-type'] 'application/json; charset=utf8' >>> r.encoding 'utf-8' >>> r.text '{"authenticated": true, ...' >>> r.json() {'authenticated': True, ...}
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your PUT & POST data — but nowadays, just use the json method!
Requests is one of the most downloaded Python packages today, pulling in around 30M downloads / week— according to GitHub, Requests is currently depended upon by 1,000,000+ repositories. You may certainly put your trust in this code.

Installing Requests and Supported Versions
Requests is available on PyPI:
$ python -m pip install requests
Requests officially supports Python 3.7+.
Supported Features & Best–Practices
Requests is ready for the demands of building robust and reliable HTTP–speaking applications, for the needs of today.
- Keep-Alive & Connection Pooling
- International Domains and URLs
- Sessions with Cookie Persistence
- Browser-style TLS/SSL Verification
- Basic & Digest Authentication
- Familiar
dict–like Cookies - Automatic Content Decompression and Decoding
- Multi-part File Uploads
- SOCKS Proxy Support
- Connection Timeouts
- Streaming Downloads
- Automatic honoring of
.netrc - Chunked HTTP Requests
API Reference and User Guide available on Read the Docs
Cloning the repository
When cloning the Requests repository, you may need to add the -c fetch.fsck.badTimezone=ignore flag to avoid an error about a bad commit (see
this issue for more background):
git clone -c fetch.fsck.badTimezone=ignore https://github.com/psf/requests.git
You can also apply this setting to your global Git config:
git config --global fetch.fsck.badTimezone ignore
Requests — это модуль для языка Python, который используют для упрощения работы с HTTP-запросами. Он удобнее и проще встроенного Urllib настолько, что даже в документации Python рекомендовано использовать Requests.
Установка библиотеки Requests
Самый простой вариант установки сторонних пакетов в Python — использовать pip — систему управления пакетами. Обычно pip предустанавливается вместе с интерпретатором. Если его нет — можно скачать. Для этого нужно ввести в командную строку:
Linux / MacOS
python -m ensurepip --upgrade
Windows
py -m ensurepip --upgrade
Когда pip установлен, для установки модуля Requests нужно ввести команду:
pip install requests
Как настроить библиотеку Requests. Библиотека не требует дополнительной настройки — ею можно сразу же пользоваться.
Начало работы. Давайте рассмотрим пример простейшего запроса в модуле Requests:
import requests # делаем запрос на чтение страницы https://sky.pro/media/
response = requests.get('https://sky.pro/media/')
print(response.ok) # проверяем успешен ли запрос?
print(response.text) # выводим полученный ответ на экран
А вот как сделать то же самое, но при помощи встроенной библиотеки Urllib:
from urllib.request import urlopen
# открываем запрос на чтение страницы http://sky.pro/media
with urlopen('http://sky.pro/media') as response:
response_status = response.status # сохраняем статус запроса в переменную
html = response.read() # вычитываем ответ в переменную
print(response_status == 200) # проверяем успешен ли запрос
print(html.decode()) # выводим полученный ответ на экран
Модуль Requests в Python упрощает и автоматизирует многие действия, которые в стандартной библиотеке надо делать самостоятельно. Именно за это её любят и используют многие разработчики.
Давайте разберёмся, как работать с Requests, и из чего состоят HTTP-запросы.
Методы HTTP-запросов
HTTP — это протокол передачи информации в интернете. Он описывает правила и формат общения между двумя сторонами. Например, как браузеру описать запрос, а серверу — сформировать ответ. HTTP — это текстовый протокол, поэтому его может прочитать и человек.
Давайте разберем простейший запрос:
GET /media/ HTTP/1.1 Host: sky.pro
Первая строка формирует запрос: мы говорим серверу, что хотим прочитать (GET) ресурс по адресу /media/. В конце указывается версия протокола: HTTP/1.1.
Начиная со второй строки передается дополнительная информация, которая называется заголовками. Она опциональная — кроме заголовка Host. Он указывает домен, на котором находится запрашиваемый ресурс.
HTTP-ответ выглядит аналогично:
HTTP/1.1 200 OK Content-Type: text/html <тело ответа>
В первой строке указывается версия протокола и код ответа — статус, который описывает результат запроса. В следующих строках, так же, как и в запросе, перечисляются заголовки. В данном случае сервер говорит, что в ответе находится HTML-страница (Content-Type: text/html).
И в самом конце находится тело ответа: файл, HTML-страница или ничего. Браузер отрисовывает тело ответа — это уже то, что видит человек, когда загружает страницу.
Методы HTTP-запросов нужны, чтобы объяснить серверу, какое действие мы хотим совершить над ресурсом. Ресурс — это цель HTTP-запроса. Это может быть документ, фотография или просто веб-страница.
Разберем на примерах распространённые методы — в чём их суть и чем они отличаются. Важно: ниже разбираются механизмы работы каждого метода в том виде, в котором они описаны в спецификации. На практике поведение может отличаться, но такое встречается нечасто.
OPTIONS
Метод OPTIONS нужен, чтобы спросить сервер о том, какие методы поддерживает ресурс. Он редко используется напрямую, обычно вызывается браузером автоматически. Поддерживается не всеми сайтами/ресурсами. Пример:
HTTP-ответ выглядит аналогично:
import requests
response = requests.options('https://httpbin.org')
print(response.text) # будет пустым
print(response.headers['Allow']) # 'HEAD, GET, OPTIONS'
GET
GET — самый распространённый HTTP-метод. Его используют для чтения интернет-ресурса. Браузер отправляет метод GET, когда мы открываем какой-либо сайт. Пример:
import requests
response = requests.get('https://httpbin.org/get')
print(response.text)
POST
Метод POST используют для отправки на сервер данных, которые передаются в теле запроса. Для этого при вызове requests.post() надо указать аргумент data, который принимает на вход словарь, список кортежей, байты или файл.
Если для передачи данных используется формат JSON, вместо data можно указать json. Это просто удобная конвенция, которая правильно формирует отправляемый запрос. Пример:
import requests
data_response = requests.post('https://httpbin.org/post', data={'foo': 'bar'})
print(data_response.text) # переданные данные находятся по ключу form
json_response = requests.post('https://httpbin.org/post', json={'foo': 'bar'})
print(data_response.text) # ключ form пустой, теперь данные лежат в json
HEAD
Этот метод очень похож на GET — с той лишь разницей, что HEAD возвращает пустое тело ответа. Он нужен, когда нужно посмотреть только на заголовки, не загружая ответ целиком.
Например, мы хотим иметь свежую версию PDF-файла с расписанием автобусов. Файл хранится на каком-то сайте и периодически обновляется. Вместо того, чтобы каждый раз скачивать и сверять файл вручную, можно использовать метод HEAD. Он поможет быстро проверить дату изменения файла по заголовкам ответа.
import requests
response = requests.get('https://httpbin.org/head')
print(response.text) # ответ будет пустым
print(response.headers)
PUT
Метод PUT очень похож на POST — с той разницей, что несколько последовательных вызовов PUT должны приводить к одному и тому же результату.
POST этого не гарантирует и может привести к неожиданным результатам, например к дублированию созданной сущности.
import requests
response = requests.put('https://httpbin.org/put', data={'foo': 'bar'})
print(response.text)
PATCH
PATCH аналогичен методу POST, но с двумя отличиями: он используется для частичных изменений ресурса и его нельзя использовать в HTML-формах.
В теле запроса передается набор модификаций, которые надо применить.
import requests
response = requests.patch('https://httpbin.org/patch', data={'foo': 'bar'})
print(response.text)
DELETE
Метод используется для удаления ресурса. Поддерживает передачу данных, однако не требует её: тело запроса может быть пустым.
Как и PUT, последовательный вызов DELETE должен приводить к одному и тому же результату.
import requests
response = requests.delete('https://httpbin.org/delete')
print(response.text)
HTTP-коды состояний
Каждый ответ HTTP-запроса обязательно имеет код состояния — трехзначное число, которое как-то характеризует полученный результат. По этому коду можно понять, всё ли успешно отработало, и если произошла ошибка, то почему.
Всего выделяют пять групп кодов состояний:
1хх-коды.
К этой группе относятся информационные коды состояний. Они сообщают клиенту о промежуточном статусе запроса и не являются финальным результатом.
Их немного, и останавливаться на них мы не будем, потому что они встречаются нечасто.
2хх-коды.
Коды из этой группы означают, что запрос принят и обработан сервером без ошибок:
- 200 OK — запрос выполнен успешно. Чаще всего встречается именно это число.
- 201 Created — в результате запроса был создан новый ресурс. Как правило, этим кодом отвечают на POST- и иногда PUT-запросы.
- 202 Accepted — запрос принят, но ещё не выполнен. Используется, когда по какой-то причине сервер не может выполнить его сразу. Например, если обработку делает какой-то сторонний процесс, который выполняется раз в день.
- 204 No Content — указывает, что тело ответа пустое, но заголовки могут содержать полезную информацию. Не используется с методом HEAD, поскольку ответ на него всегда должен быть пустым.
3хх-коды.
Это группа кодов перенаправления. Это значит, что клиенту нужно сделать какое-то действие, чтобы запрос продолжил выполняться:
- 301 Moved Permanently — URL запрашиваемого ресурса изменился, новый URL содержится в ответе.
- 302 Found — аналогичен предыдущему коду. Отличие в том, что URL изменился временно. При этом статусе состояния поисковые системы не будут менять ссылку в своей поисковой выдаче на новую.
- 304 Not Modified — означает, что содержимое ресурса было закешировано, его содержимое не поменялось и запрос можно не продолжать.
4хх-коды.
Это коды ошибок, которые допустил клиент при формировании запроса:
- 400 Bad Request — запрос сформирован с ошибкой, поэтому сервер не может его обработать. Причин может быть много, но чаще всего ошибку надо искать в теле запроса.
- 401 Unauthorized — для продолжения необходимо залогиниться.
- 403 Forbidden — пользователь залогинен, но у него нет прав для доступа к ресурсу.
- 404 Not Found — всем известный код: страница не найдена. Некоторые сайты могут возвращать 404 вместо 403, чтобы скрыть информацию от неавторизованных пользователей.
- 405 Method Not Allowed — данный ресурс не поддерживает метод запроса. Например, так бывает, если разработчик хочет отправить PUT-запрос на ресурс, который его не поддерживает.
- 429 Too Many Requests — означает, что сработал защитный механизм: он ограничивает слишком частые запросы от одного пользователя. Таким образом защищаются от DDoS- или brute-force-атак.
5хх-коды.
Это ошибки, которые возникли на сервере во время выполнения запроса:
- 500 Internal Server Error — на сервере произошла неожиданная ошибка. Как правило, происходит из-за того, что в коде сервера возникает исключение.
- 502 Bad Gateway — возникает, если на сервере используется обратный прокси, который не смог достучаться до приложения.
- 503 Service Unavailable — сервер пока не готов обработать запрос. В ответе также может содержаться информация о том, когда сервис станет доступен.
- 504 Gateway Timeout — эта ошибка означает, что обратный прокси не смог получить ответ за отведенное время (обычно — 60 секунд).
Заголовки, текст ответа и файлы Cookie
Теперь рассмотрим, как работать с запросами и ответами в Requests. Чтобы увидеть результат HTTP-запроса, можно использовать один из трех способов.
Выбор способа зависит от того, какие данные мы получили. В непонятной ситуации можно использовать атрибут text, который возвращает содержимое в виде строки:
import requests
response = requests.get('https://httpbin.org/get')
print(response.text)
Если заранее известно, что ответ будет в формате JSON, можно использовать одноименный атрибут, который автоматически распарсит ответ и вернет его в виде словаря:
json_response = response.json() print(json_response)
Обратите внимание, как изменится вывод функции print().
Наконец, если ответом на запрос является файл, стоит использовать атрибут content, который возвращает байты:
import requests
response = requests.get('https://httpbin.org/image/jpeg')
print(response.content)
Попробуйте вывести на экран response.text для предыдущего запроса и сравните результат.
Заголовок — это дополнительная информация, которой обмениваются клиент и сервер. В заголовках могут содержаться: размер ответа (Content-Length), формат передаваемых данных (Content-Type) или информация о клиенте (User-Agent).
Полный список очень длинный, знать их все необязательно, а часть и вовсе подставляется автоматом. Например, модуль Requests зачастую сам проставляет Content-Type — формат передаваемых данных.
Заголовок состоит из названия и значения, которые разделяются двоеточием, поэтому удобнее всего передавать их в виде словаря. Рассмотрим на примере, как это работает:
import requests
response = requests.get('https://httpbin.org/image', headers={'Accept': 'image/jpeg'})
print(response.headers)
Здесь мы передали заголовок, который указывает, в каком формате мы хотим получить изображение. Попробуйте поменять значение на image/png и посмотрите, как изменится ответ.
Так же можно посмотреть и на заголовки запроса:
print(response.request.headers)
Обратите внимание, что Requests сам подставил информацию о клиенте — User-Agent.
Cookie (куки) — это информация, которую сервер отправляет браузеру для хранения. Они позволяют зафиксировать некоторое состояние. Например, в куки может храниться информация о том, что пользователь уже залогинен. Она хранится в браузере и передается на сервер при каждом запросе, поэтому нам не нужно каждый раз проходить авторизацию заново.
Работать с куками в модуле Requests очень просто:
import requests
response = requests.get('https://httpbin.org/cookies', cookies={'foo': 'bar'})
print(response.text)
Посмотреть, какие куки пришли от сервера, можно при помощи атрибута cookies объекта Response:
print(response.cookies)
Как отправлять запросы при помощи Python Requests
Рассмотрим несколько частых примеров использования модуля Requests, чтобы понять, как отправлять запросы.
Скачивание файлов
import requests
response = requests.get('https://www.python.org/static/img/python-logo.png')
with open('python_logo.png', 'wb') as image:
image.write(response.content)
Выше описан не самый эффективный способ скачивания файлов. Если файл окажется большого размера, код выше загрузит результат целиком в оперативную память. В лучшем случае программа упадет с ошибкой, в худшем — всё намертво зависнет.
Вот как это можно исправить:
import requests
response = requests.get('https://www.python.org/static/img/python-logo@2x.png', stream=True)
with open('python_logo.png', 'wb') as image:
for chunk in response.iter_content(chunk_size=1024):
image.write(chunk)
В этом варианте мы используем параметр stream=True, который открывает соединение, но не скачивает содержимое. Затем мы задаем размер чанка — кусочка информации, который будет скачиваться за одну итерацию цикла, и делаем его равным 1 Кб (1024 байт). Модуль Requests сам закрывает соединение после прочтения последнего чанка.
Чтобы заранее узнать размер файла, можно воспользоваться методом HEAD. Эта информация передается в заголовке ‘Content-Length’ и исчисляется в байтах.
import requests
head_response = requests.head('https://www.python.org/static/img/python-logo@2x.png')
image_size = int(head_response.headers['Content-Length'])
print('Размер загружаемого файла: {0} кб'.format(image_size / 1024))
Авторизация на сайте
Рассмотрим два способа авторизации, которые встречаются чаще всего: Basic Auth и Bearer Auth. В обоих случаях механизм очень похожий — запрос должен передать заголовок ‘Authorization’ с каким-то значением. Для Basic Auth — это логин и пароль, закодированные в base64, для Bearer — токен, который мы получили на сайте заранее.
Для базовой авторизации у модуля Requests есть очень удобный параметр auth=, который делает всю работу за нас:
import requests
response = requests.get('https://httpbin.org/basic-auth/foo/bar')
print(response.status_code) # 401
response = requests.get('https://httpbin.org/basic-auth/foo/bar', auth=('foo', 'bar'))
print(response.status_code) # 200
print(response.request.headers[‘Authorization’]) # 'Basic Zm9vOmJhcg=='
Обратите внимание, что модуль Requests сам добавил заголовок Authorization и подставил туда закодированные логин и пароль.
Для Bearer Auth нам придется добавлять его самостоятельно:
import requests
response = requests.get('https://httpbin.org/bearer')
print(response.status_code) # 401
headers = {'Authorization': 'Bearer some_token'}
response = requests.get('https://httpbin.org/bearer', headers=headers)
print(response.status_code) # 200
У каждого API своя спецификация — вместо Bearer может быть Token или что-то другое. Поэтому важно внимательно читать документацию сервиса.
Мультискачивание
Напишем код, который умеет скачивать сразу несколько файлов. Для этого вынесем работу с модулем Requests в отдельную функцию и параметризируем место сохранения файла.
Не забывайте про сохранение файла по чанкам, чтобы крупные файлы не загружались в память целиком.
import requests
def download_file(url, save_path):
response = requests.get(url, stream=True)
with open(save_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=1024):
file.write(chunk)
download_list = [
'https://cdn.pixabay.com/photo/2022/04/10/19/33/house-7124141_1280.jpg',
'https://cdn.pixabay.com/photo/2022/08/05/18/50/houseplant-7367379_1280.jpg',
'https://cdn.pixabay.com/photo/2022/06/09/04/53/ride-7251713_1280.png',
]
for url in download_list:
save_path = url.split('/')[-1]
download_file(url, save_path)
Заключение
Модуль Requests — мощный инструмент, с которым разработчик может сделать сложный HTTP-запрос всего в пару строк. У него интуитивно понятный интерфейс, поэтому он так популярен в сообществе Python.
С помощью модуля реквест можно выполнить множество функций: от авторизации на сайте до скачивания нескольких файлов одновременно.

Requests — это элегантная и простая HTTP-библиотека для Python, созданная для людей. Одна из самых известных библиотек для python, используемых разработчиками по всему миру. Эта статья посвящена тому, как можно установить библиотеку python в Windows/ Linux/ macOS и т.д.
Установка
Windows
Для установки запросов в Windows потребуется Python (желательно последней версии), поэтому, если у вас не установлен python, перейдите к – Как загрузить и установить последнюю версию Python в Windows. Теперь откройте командную строку из окна и выполните следующую команду:
python -m pip install requestsБум..!! Теперь все готово, библиотека запросов успешно загружена.
Linux
Для установки запросов в Linux потребуется Python (предпочтительно последней версии) и последняя версия pip, поэтому, если у вас не установлен python, перейдите к – Как загрузить и установить последнюю версию Python в Linux. Чтобы установить pip в linux – Как установить PIP в Linux?.
pip install requestsmacOS
Для установки запросов на Mac потребуется Python (предпочтительно последней версии) и pip последней версии, поэтому, если у вас не установлен python, перейдите к – Как загрузить и установить последнюю версию Python на mac«. Для установки pip mac Os
sudo easy_install pip sudo pip install --upgrade pip Теперь для установки запросов:
pip install requestsАльтернативный общий метод
Последний способ установки запросов в любой операционной системе-захватить базовые файлы и установить запросы вручную, и запросы активно разрабатываются на GitHub, где код всегда доступен. Для кода – посетите здесь.
Вы можете либо клонировать общедоступный репозиторий:
git clone git://github.com/psf/requests.gitИли скачайте tarball:
curl -OL https://github.com/psf/requests/tarball/master
# optionally, zipball is also available (for Windows users).Как только у вас появится копия исходного кода, вы сможете легко встроить его в свой собственный пакет Python или установить в пакеты вашего сайта:
cd requests
pip installДля документации библиотеки запросов – посетите здесь
Библиотека Requests:
эффективные и простые
HTTP-запросы в Python


![]()
Модуль Requests предоставляет возможность управления HTTP-запросами при помощи языка Python. Инструментарий библиотеки широкий и рассчитан на все случаи взаимодействия с web-приложениями. Код, написанный с применением Requests, не является громоздким, легко читается, а функции и методы наглядно настраиваются под специфические нужды.
Несмотря на то, что в Python встроен модуль urllib3, обладающий сходным функционалом, практически все применяют Requests, что свидетельствует о его удобстве и простоте.
1. Основные возможности библиотеки Requests
Модуль разработан с учетом потребностей современных web-разработчиков и актуальных технологий. Многие операции автоматизированы, а ручные настройки сведены к минимуму.
Для понимания инструментария библиотеки перечислим ее основные возможности:
– поддержка постоянного HTTP-соединения и его повторное использование;
– применение международных и национальных доменов;
– использование Cookie: передача и получение значений в формате ключ: значение;
– автоматическое декодирование контента;
– SSL верификация;
– аутентификация пользователей на большинстве ресурсов с сохранением;
– поддержка proxy при необходимости;
– загрузка и выгрузка файлов;
– стриминговые загрузки и фрагментированные запросы;
– задержки соединений;
– передача требуемых заголовков на web-ресурсы и др.
В целом, практически любая задача, которая возникает у разработчика, нашла свое отражение в коде библиотеки. Важно понимать, что Requests не предназначен для парсинга ответа сервера (для этого применяют другие модули, например, Beautiful Soup).
2. Первичная настройка и начало работы
Первым делом установим библиотеку в требуемую папку (через консоль).
pip install requests # Для Windows
pip3 install requests # Для Linux, MacOSЭта команда установит Requests и дополнительные зависимые модули.
Полезно знать
Согласно рекомендациям официальной документации Python можно применять и другой способ установки библиотек, который позволяет контролировать версию языка, запускать библиотеку напрямую из консоли.
Консоль/Терминал — Примеры альтернативной установки
python -m pip install requests # Установит библиотеку для последней версии Python
python3.7 -m pip install requests # Requests для Python 3.7Чтобы проверить, что все прошло успешно, сделаем простой GET запрос на сайт https://github.com.
Пример – Интерактивный режим
>>> import requests
>>> response = requests.get('https://github.com')
>>> response
<Response [200]>Никаких ошибок не получено, следовательно, запрос прошел успешно. Ответ от сервера сохраняем в объект response. В нем содержится вся необходимая информация для анализа, которую нам предоставил сервис. Рассмотрим основные атрибуты данного объекта (в примерах ниже часть ответов сервера будет вырезана, чтобы не загромождать пространство).
Пример – Интерактивный режим
>>> dir(response)
[…, 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_permanent_redirect', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'next', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url']К любому из этих атрибутов можно обратиться, чтобы получить более детальную информацию.
1. Атрибут ‘headers’
Пример – Интерактивный режим
>>> response.headers
{'Server': 'GitHub.com', 'Date': 'Fri, 05 Mar 2021 09:47:19 GMT', 'Content-Type': 'text/html; charset=utf-8', …}Свойство позволяет просмотреть заголовки ответа сервера: его тип, дату обращения, формат содержимого, кодировку и др.
2. Атрибуты: ‘status_code’, ‘ok’
Пример – Интерактивный режим
>>> response.status_code
200
>>> response.ok
TrueКод статуса 200 говорит о том, что запрашиваемый сайт обнаружен, и мы от него получили успешный ответ.
Важно знать
Коды HTTP-ответов показывают успешность выполнения запросов к серверу. Их группируют по 5 классам:
– информационного характера (100-199) – разного рода подсказки, призывы к продолжению промежуточных действий
– успешные (200-299) – запрос обработан, ответ получен, содержимого нет, но присланы заголовки и т.п.
– коды перенаправления (300-399) – пользователь перенаправляется по другой ссылке
– ошибки на стороне клиента (400-499) – пользователь не авторизован, нет такой страницы, запрещен доступ и др.
– ошибки на сервере (500-599) – сервис не доступен по каким-либо причинам, метод запроса им не поддерживается.
Благодаря возможности проверять статус ответа, мы можем по-разному реагировать исходя из этого. Свойство ok более общее. Удобно, когда нужно убедиться, что все хорошо (под этим понимаются ответы с кодами от 200 до 399).
3. Атрибуты: ‘url’, ‘request’
Пример – Интерактивный режим
>>> response.request
<PreparedRequest [GET]>
>>> response.url
'https://github.com/'Приведенные свойства предоставляют информацию о методе запроса (GET, POST и др.) и запрашиваемой ссылке со всеми дополнительными параметрами.
4. Атрибуты: ‘text’, ‘content’, ‘json’
Пример – Интерактивный режим
>>> response.text
'nnnnn<!DOCTYPE html>n<html lang="en" class="html-fluid">n <head>n <meta charset="utf-8">n <link rel="dns-prefetch" href="https://github.githubassets.com">n <link rel="dns-prefetch" href="https://user-images.githubusercontent.com/">…
>>> response.content
b'nnnnn<!DOCTYPE html>n<html lang="en" class="html-fluid">n <head>n <meta charset="utf-8">n <link rel="dns-prefetch" href="https://github.githubassets.com">n <link rel="dns-prefetch" href="https://avatars.githubusercontent.com">…
>>> response.json()
Error…Свойство text показывает тело ответа сервера в текстовом формате (актуально для html-страниц), content – результат в виде байтов (удобно при скачивании графической, аудио- или видеоинформации), метод json() приводит содержимое ответа к обычному словарю (если данные к нему приводимы, в противном случае будет ошибка, как в примере; актуально для API-запросов).
3. Разные типы HTTP-запросов
Для получения содержимого web-страницы используется метод GET, работу которого мы показали выше. Библиотека Requests позволяет обращаться к сервисам с помощью других запросов, если они разрешены на сервере. Чтобы полноценно продемонстрировать его работу, разработчики библиотеки создали специальный сайт https://httpbin.org/, на котором можно их опробовать.

1. Метод OPTIONS
С помощью данного метода мы увидим принимаемые ресурсом или конкретным его разделом HTTP-запросы (просмотр опций включен не у всех ресурсов).
Пример – Интерактивный режим
>>> response = requests.options('https://httpbin.org/')
>>> response.headers['Access-Control-Allow-Methods']
GET, POST, PUT, DELETE, PATCH, OPTIONSКак видим, на сайте имеется возможность протестировать практически все виды HTTP-запросов.
2. Метод GET
У GET-запросов могут присутствовать параметры, которыми легко управлять. Например: https://site.ru/?text=python&lang=ru (ищем сайты про Python на русском языке на некоем условном поисковике). Для этого есть именованный аргумент params. Предположим, требуется 11 страница в категории автомобили.
Пример – Интерактивный режим
>>> get_params = {'page': 11, 'product': 'car'}
>>> response = requests.get('https://httpbin.org/', params=get_params)
>>> response.url
'https://httpbin.org/?page=11&product=car'Ссылка успешно сформирована и передана на сервис.
3. Метод POST
Для отправки данных (например, форм) применяют метод POST библиотеки Requests. В аргументе data указываются все требуемые поля. Ответом будет json-объект с переданными данными, а также ряд иных сведений (заголовки, ip-адрес, ссылка).
Пример – Интерактивный режим
>>> post_params = {'user': 'admin', 'password': 'admin_pass1'}
>>> response = requests.post('https://httpbin.org/post', data=post_params)
>>> response.json()['form']
{'password': 'admin_pass1', 'user': 'admin'}4. Метод HEAD
Аналогичен запросу GET по своей сути, но может служить предварительным тестом ресурса, с которого планируется скачивать файл большого размера. Если заголовки получены, то все хорошо и можно приступать к загрузке.
Пример – Интерактивный режим
>>> response = requests.head('https://httpbin.org/')
>>> response.headers
{'Date': 'Sat, 06 Mar 2021 11:40:49 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Content-Length': '9593', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}5. Метод PUT
Представленный метод является идемпотентным. Это значит, что повторная отправка идентичных данных никак не повлияет на работу ресурса. Если использовать метод POST, то возможны ошибки.
Пример – Интерактивный режим
>>> put_params = {'user': 'admin', 'password': 'admin_pass1'}
>>> response = requests.put('https://httpbin.org/put', data=put_params)
>>> response.status_code
200
>>> response = requests.put('https://httpbin.org/', data=put_params)
>>> response.status_code
405В первом случае запрос отработал удачно (о чем говорит код 200), тогда как во втором – нет (405 код – неразрешенный метод по указанному адресу).
6. Метод PATCH
Предполагает частичное обновление данных на сервере.
Пример – Интерактивный режим
>>> patch_params = {'user': 'new_admin', 'password': 'new_pass'}
>>> response = requests.patch('https://httpbin.org/patch', data=patch_params)
>>> response.status_code
200Чаще всего применяется для изменения содержимого конфигурационных файлов (например, вы поменяли токен для доступа к API).
7. Метод DELETE
Когда требуется удаление некоего ресурса.
Пример – Интерактивный режим
>>> del_params = {"name": "Николай", "job": "Повар"}
>>> response = requests.delete('https://httpbin.org/delete', data=del_params)
>>> response.json()['form']
{'job': 'Повар', 'name': 'Николай'}Читайте также
4. Практика: скачивание файлов
Предположим, перед нами стала задача скачать картинку с определенного сайта и сохранить ее к себе. Проще, конечно, это сделать руками, но когда у вас будет список из хотя бы 100 фотографий, проблема автоматизации будет очевидной. Продемонстрируем 2 способа применения библиотеки Requests для загрузки фото.
Способ 1 – Единовременная загрузка изображения
import requests
response = requests.get('https://www.hdwallpapers.in/download/colorful_glowing_shape_lines_4k_8k_hd_abstract-HD.jpg')
with open('img.jpg', 'wb') as picture:
picture.write(response.content)
Скачивание изображения с помощью библиотеки requests
Фото специально выбрано большого размера для теста. Минус первого способа таков: если на сервере произойдет ошибка во время скачивания, то все что вы делали, потеряется. Более того, сам файл займет солидную часть в памяти (а если это фильм на 50 Гб?). Достаточно неудобно.
Способ 2 – Запись файла частями
import requests
response = requests.get('https://www.hdwallpapers.in/download/colorful_glowing_shape_lines_4k_8k_hd_abstract-HD.jpg',
stream=True)
with open('img.jpg', 'wb') as picture:
for chunk in response.iter_content(chunk_size=10000):
if chunk:
picture.write(chunk)
Во-первых, мы добавили параметр stream=True к методу get() . Это гарантирует постепенную загрузку фотографии, что не позволит переполнять память. Метод iter_content() скачивает картинку частями (в нашем случае – по 10 Кб). Таким образом, мы «дописываем» изображение новыми кусками на каждой итерации, а если связь с сервером будет потеряна, то на ПК останется хотя бы часть фото.
Читайте также
5. Практика: авторизация на сайте
Так как на большинстве сайтов авторизация является защищенной и сложной, использовать модуль Requests не всегда получится. В некоторых случаях потребуется ключ для API того или иного ресурса.
Рассмотрим https://api.github.com, который разрешает аутентификацию через токен. Его можно получить на сайте в настройках вашего персонального профиля:

Страница получения токена GitHub
API может помочь в получении информации о пользователе, его репозиториях, подписчиках. Более того, не можно создавать новые файлы и репозитории, модифицировать имеющиеся. Чтобы ознакомиться со всеми возможностями, необходимо изучить документацию.
Пример логина и токена GitHub
Логин: smartiqa-user
Токен: 3b7cbc8bbe0c7866ccd003c1ba21add68f6ddb31Пример – Интерактивный режим
>>> import requests
>>> response = requests.get('https://api.github.com/user', auth=('smartiqa-user', '3b7cbc8bbe0c7866ccd003c1ba21add68f6ddb31'))
>>> response.json()
{'login': 'smartiqa-user', 'id': 713123083, …'type': 'User', 'site_admin': False, 'name': 'Smartiqa Programming and QA', 'company': None, 'blog': '', 'location': 'Russia'}Часть информации вырезана, для краткости. В ответе мы получим такие данные: логин, имя, данные об аккаунте, аватарке, подписчиках, правах, времени создания и т.п.
Если обратиться по другой ссылке (например, посмотреть все репозитории пользователя), API предоставит следующие сведения:
Пример – Интерактивный режим
>>> response = requests.get('https://api.github.com/user/repos', auth=('smartiqa-user', '3b7cbc8bbe0c7866ccd003c1ba21add68f6ddb31'))
>>> response.json()
[{'id': 281217463, 'node_id': 'MDEwOlJlcG9zaXRvcnkyODEyMTc0NjM=', 'name': 'blog', 'full_name': 'smartiqaorg/blog', 'private': True, 'owner': {'login': 'smartiqaorg', 'id': 44243438, 'node_id': 'MDEyOk9yZ2FuaXphdGlvbjQ0MjQzNDM4', 'avatar_url': 'https://avatars.githubusercontent.com/u/44243438?v=4',
...
'archived': False, 'disabled': False, 'open_issues_count': 0, 'license': None, 'forks': 0, 'open_issues': 0, 'watchers': 0, 'default_branch': 'main', 'permissions': {'admin': True, 'push': True, 'pull': True}}]
Ответ занимает несколько страниц (здесь приводится только часть, так как он большой по объему), если у вас имеется хотя бы 2-3 репозитория: названия, ссылки, комментарии и исправления, обновление, структура и т.п.
6. Практика: Сессии и прокси
Сайты, особенно высоконагруженные, не очень любят видеть на своих страницах роботов (если они не одобрены, для чего часто внедряют API). Те, кто сталкивался с парсингом ресурсов, могли не раз убедиться, что со временем сервисы закрывают доступ по вашему IP или на основании пересылаемых модулем Requests данных. В каждом случае решение проблемы индивидуально. Однако имеются базовые приемы, снижающие вероятность блокировки работы вашего скрипта.
Сделаем стандартный запрос на главную страницу сайта https://www.python.org.
Пример – Интерактивный режим
>>> import requests
>>> response = requests.get('https://www.python.org/')
>>> response.request.headers
{'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}Строка response.request.headers отображает отправляемые нами заголовки на сайт. В качестве юзер-агента указана библиотека requests, что не очень хорошо, так как любой нормальный сервис вас сразу же забанит при частых запросах. Его стоит поменять на реальный, как у «живого» человека.
Пример – Интерактивный режим
>>> import requests
>>> user_agent = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.72 Safari/537.36'}
>>> response = requests.get('https://www.python.org/', headers=user_agent)
>>> response.request.headers
{'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}Как видим, сервер теперь думает, что мы вошли через браузер Chrome, например. Это не гарантирует отсутствие блокировки, но уменьшает ее шансы.
На практике можно дополнительно пользоваться сессией и прокси-серверами:
- Сессии помогают сайту «запоминать» нас (со всеми параметрами), чтобы при каждом новом обращении к нему (отдельным страницам) не отправлять все заголовки заново, с нуля.
- Прокси подменяют наш IP-адрес на другой, который пока что не находится в «черном списке». Следует понимать, что их использование не всегда имеет негативный оттенок. В частности, они могут ускорять маршрутизацию к ресурсам (которые находятся на другом конце планеты), обходить блокировку отдельных провайдеров или стран (когда требуется посетить ресурс, недоступный через ваш IP).

Схема работы прокси-сервера
В коде ниже ответы сервиса изменены в целях безопасности (на своем ПК вы увидите реальные значения).
Пример – Интерактивный режим
>>> import requests
>>> user_agent = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.72 Safari/537.36'}
>>> proxy = {'http': 'http://185.253.98.21:3128',
'https': 'http://185.253.98.21:3128'}
>>> response = requests.get('https://ramziv.com/ip')
>>> response.text
29.174.182.126
>>> session = requests.Session()
>>> session.proxies.update(proxy)
>>> session.headers.update(user_agent)
>>> response = session.get('https://ramziv.com/ip')
>>> response.text
185.253.98.21
На странице https://ramziv.com/ip можно выяснить свой IP-адрес. В первом случае мы его не меняли (отобразился реальный), а потом с помощью сессий, прокси и заголовков мы подменили свои данные.
Читайте также
7. Практика: Мультискачивание и редиректы
Ниже представлен код, позволяющий загружать любое количество картинок с учетом редиректов сайта. Воспользуемся сайтом https://picsum.photos/, который генерирует случайные изображения. Напишем функцию, чтобы скачивать требуемое количество файлов размером 200×200. Применим сессии и подмену юзер-агента.
Пример – Интерактивный режим
import requests
user_agent = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.72 Safari/537.36'}
session = requests.Session()
session.headers.update(user_agent)
def pics_downloader (num_of_pics):
for num in range(num_of_pics):
response = session.get('https://picsum.photos/200', allow_redirects=True, stream=True)
with open(f'{num}.jpg', 'wb') as picture:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
picture.write(chunk)
print(f'Скачано {num + 1} фото из {num_of_pics}')
pics_downloader(20)Параметр allow_redirects по умолчанию включен (приведен для наглядности). Передав значение в функцию, мы скачаем требуемое количество картинок.
Таким образом, библиотека Requests не зря является одной из самых скачиваемых. Ее функционал огромен, а использование достаточно простое. Можно легко автоматизировать рутинные задачи для работы с web-сервисами, которые сэкономят массу времени.
Как вам материал?


Читайте также
Для начала давайте разберемся, что же вообще такое библиотека Requests.
Requests — это HTTP-библиотека, написанная на Python (под лицензией Apache2). Она спроектирована для взаимодействия людей с эим языком. Это означает, что вам не нужно вручную добавлять строки запроса в URL-адреса или заносить данные в форму для POST-запроса. Если это кажется вам бессмысленным, не волнуйтесь. В нужное время все прояснится.
Что же делает библиотека Requests?
Библиотека Requests дает вам возможность посылать HTTP/1.1-запросы, используя Python. С ее помощью вы можете добавлять контент, например заголовки, формы, многокомпонентные файлы и параметры, используя только простые библиотеки Python. Также вы можете получать доступ к таким данным.
В программировании библиотека — это набор или, точнее сказать, предварительно настроенный набор подпрограмм, функций и операций, которые в дальнейшем может использовать ваша программа. Эти элементы часто называют модулями, которые хранятся в объектном формате.
Библиотеки очень важны, потому что вы можете загрузить модуль и использовать все, что он предлагает, без явной связи с вашей программой. Они действительно автономны, так что вы можете создавать свои собственные программы с ними, и все же они остаются отделенными от ваших программ.
Таким образом, о модулях можно думать как о неких шаблонах кода.
Повторимся еще раз, Requests — это библиотека языка Python.
Как установить Requests
Сразу сообщим вам хорошую новость: существует множество способов для установки Requests. С полным списком можно ознакомиться в официальной документации библиотеки Requests.
Вы можете использовать pip, easy_install или tarball.
Если вам нужен исходный код, вы можете найти его на GitHub.
Мы для установки библиотеки воспользуемся менеджером pip.
В интерпретаторе Python введите следующую команду:
pip install requests
Импортирование модуля Requests
Для работы с библиотекой Requests в Python вам необходимо импортировать соответствующий модуль. Вы можете это сделать, просто поместив следующий код в начало вашей программы:
import requests
Разумеется, предварительно этот модуль должен быть установлен и доступен для интерпретатора.
Делаем запрос
Когда вы пингуете веб-сайт или портал для получения информации, то это как раз и называется созданием запроса.
Для получения веб-страницы вам нужно написать что-то в таком духе:
r = requests.get(‘https://github.com/timeline.json’)
Работаем с кодом ответа
Перед тем как вы будете что-то делать с веб-сайтом или URL, хорошей идеей будет проверить код ответа, который вернул вам сервер. Это можно сделать следующим образом:
r = requests.get('https://github.com/timeline.json')
r.status_code
>>200
r.status_code == requests.codes.ok
>>> True
requests.codes['temporary_redirect']
>>> 307
requests.codes.teapot
>>> 418
requests.codes['o/']
>>> 200
Получаем содержимое страницы
После того как сервер вам ответил, вы можете получить нужный вам контент. Это также делается при помощи функции get библиотеки Requests.
import requests
r = requests.get('https://github.com/timeline.json')
print(r.text)
# Библиотека Requests также имеет встроенный JSON-декодер на
# тот случай, если вам понадобятся данные JSON
import requests
r = requests.get('https://github.com/timeline.json')
print(r.json)
Работаем с заголовками
Используя словари Python, вы можете просмотреть заголовки ответа сервера. Особенностью работы библиотеки Requests является то, что для получения доступа к заголовкам вы можете использовать в ключах словаря как заглавные, так и строчные буквы.
Если вызываемого заголовка нет, будет возвращено значение None.
r.headers
{
'status': '200 OK',
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json; charset=utf-8'
}
r.headers['Content-Type']
>>>'application/json; charset=utf-8'
r.headers.get('content-type')
>>>'application/json; charset=utf-8'
r.headers['X-Random']
>>>None
# Получаем заголовки данного URL
resp = requests.head("http://www.google.com")
print resp.status_code, resp.text, resp.headers
Кодирование
Библиотека Requests автоматически декодирует любой контент, извлеченный из сервера. Хотя большинство наборов символов Unicode в любом случае легко декодируются.
Когда вы делаете запрос к серверу, библиотека Requests делает обоснованное предположение о кодировке ответа. Это делается на основании заголовков HTTP. Предполагаемая кодировка будет использоваться при доступе к файлу r.text.
С помощью этого файла вы можете определить, какую кодировку использует библиотека Requests, и при необходимости изменить ее. Это возможно благодаря атрибуту r.encoding, который вы найдете в файле.
Когда вы измените значение кодировки, в дальнейшем библиотека Requests при вызове вами r.text будет использовать новый тип кодировки.
print(r.encoding) >> utf-8 >>> r.encoding = ‘ISO-8859-1’
Пользовательские заголовки
Если вы хотите добавить пользовательские заголовки в HTTP-запрос, вы должны передать их через словарь в параметр заголовков.
import json
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
headers = {'content-type': 'application/json'}
r = requests.post(url, data=json.dumps(payload), headers=headers)
Переадресация и история
Библиотека Requests автоматически поддерживает переадресацию при выполнении команд GET и OPTION.
Например, GitHub из соображений безопасности автотоматически переадресует все HTTP-запросы на HTTPS.
Вы можете отслеживать статус переадресации при помощи метода history, который реализован для объекта response.
r = requests.get('http://github.com')
r.url
>>> 'https://github.com/'
r.status_code
>>> 200
r.history
>>> []
Осуществление POST-запроса HTTP
Также с помощью библиотеки Requests вы можете работать и с POST-запросами:
r = requests.post(http://httpbin.org/post)
Но вы также можете выполнять и другие HTTP-запросы, такие как PUT, DELETE, HEAD, и OPTIONS.
r = requests.put("http://httpbin.org/put")
r = requests.delete("http://httpbin.org/delete")
r = requests.head("http://httpbin.org/get")
r = requests.options("http://httpbin.org/get")
При помощи этих методов можно сделать массу разных вещей. Например, при помощи следующего кода вы можете создать репозиторий GitHub:
import requests, json
github_url = "https://api.github.com/user/repos"
data = json.dumps({'name':'test', 'description':'some test repo'})
r = requests.post(github_url, data, auth=('user', '*****'))
print r.json
Ошибки и исключения
Есть ряд ошибок и исколючений, с которыми вам надо ознакомиться при использовании библиотеки Requests.
- При проблемах с сетью, например с
DNS, или отказе соединения, библиотека Requests вызовет исключениеConnectionError. - При недопустимом ответе HTTP библиотека Requests вызвоет исключение
HTTPError, но это довольно редкий случай. - Если время запроса истекло, возникнет исключение
Timeout. - Когда при запросе будет превышено заранее заданное количество переадресаций, возникнет исключение
TooManyRedirects.
Все исключения, вызываемые библиотекой Requests, наследуются от объекта requests.exceptions.RequestException.
Дополнительные материалы
Более подробно про билиотеку Requests вы можете почитать, пройдя по следующим ссылкам:
- http://docs.python-requests.org/en/latest/api/
- http://pypi.python.org/pypi/requests
- http://docs.python-requests.org/en/latest/user/quickstart/
- http://isbullsh.it/2012/06/Rest-api-in-python/#requests
Библиотека requests является стандартным инструментом для составления HTTP-запросов в Python. Простой и аккуратный API значительно облегчает трудоемкий процесс создания запросов. Таким образом, можно сосредоточиться на взаимодействии со службами и использовании данных в приложении.
Содержание статьи
- Python установка библиотеки requests
- Python библиотека Requests метод GET
- Объект Response получение ответа на запрос в Python
- HTTP коды состояний
- Получить содержимое страницы в Requests
- HTTP заголовки в Requests
- Python Requests параметры запроса
- Настройка HTTP заголовка запроса (headers)
- Примеры HTTP методов в Requests
- Python Requests тело сообщения
- Python Requests анализ запроса
- Python Requests аутентификация HTTP AUTH
- Python Requests проверка SSL сертификата
- Python Requests производительность приложений
- Объект Session в Requests
- HTTPAdapter — Максимальное количество повторов запроса в Requests
В данной статье представлены наиболее полезные особенности requests. Показано, как изменить и приспособить requests к различным ситуациям, с которыми программисты сталкиваются чаще всего. Здесь также даются советы по эффективному использованию requests и предотвращению влияния сторонних служб, которые могут сильно замедлить работу используемого приложения. Мы использовали библиотек requests в уроке по парсингу html через библиотеку BeautifulSoup.
Ключевые аспекты инструкции:
- Создание запросов при помощи самых популярных HTTP методов;
- Редактирование заголовков запросов и данных при помощи строки запроса и содержимого сообщения;
- Анализ данных запросов и откликов;
- Создание авторизированных запросов;
- Настройка запросов для предотвращения сбоев и замедления работы приложения.
В статье собран оптимальный набор информации, необходимый для понимания данных примеров и особенностей их использования. Информация представлена в доступной в форме. Тем не менее, стоит иметь в виду, что для оптимального разбора инструкции потребуются хотя бы базовые знания HTTP.
Далее будут показаны наиболее эффективные методы использования requests в разрабатываемом приложении.
Python установка библиотеки requests
Для начала работы потребуется установить библиотеку requests. Для этого используется следующая команда.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Тем, кто для работы с пакетами Python, использует виртуальную среду Pipenv, необходимо использовать немного другую команду.
|
$ pipenv install requests |
Сразу после установки requests можно полноценно использовать в приложении. Импорт requests производится следующим образом.
Таким образом, все подготовительные этапы для последующего использования requests завершены. Начинать изучение requests лучше всего с того, как сделать запрос GET.
Python библиотека Requests метод GET
Такие HTTP методы, как GET и POST, определяют, какие действия будут выполнены при создании HTTP запроса. Помимо GET и POST для этой задачи могут быть использованы некоторые другие методы. Далее они также будут описаны в руководстве.
GET является одним из самых популярных HTTP методов. Метод GET указывает на то, что происходит попытка извлечь данные из определенного ресурса. Для того, чтобы выполнить запрос GET, используется requests.get().
Для проверки работы команды будет выполнен запрос GET в отношении Root REST API на GitHub. Для указанного ниже URL вызывается метод get().
|
requests.get(‘https://api.github.com’) <Response [200]> |
Если никакие python ошибки не возникло, вас можно поздравить – первый запрос успешно выполнен. Далее будет рассмотрен ответ на данный запрос, который можно получить при помощи объекта Response.
Объект Response получение ответа на запрос в Python
Response представляет собой довольно мощный объект для анализа результатов запроса. В качестве примера будет использован предыдущий запрос, только на этот раз результат будет представлен в виде переменной. Таким образом, получится лучше изучить его атрибуты и особенности использования.
|
response = requests.get(‘https://api.github.com’) |
В данном примере при помощи get() захватывается определенное значение, что является частью объекта Response, и помещается в переменную под названием response. Теперь можно использовать переменную response для того, чтобы изучить данные, которые были получены в результате запроса GET.
HTTP коды состояний
Самыми первыми данными, которые будут получены через Response, будут коды состояния. Коды состояния сообщают о статусе запроса.
Например, статус 200 OK значит, что запрос успешно выполнен. А вот статус 404 NOT FOUND говорит о том, что запрашиваемый ресурс не был найден. Существует множество других статусных кодов, которые могут сообщить важную информацию, связанную с запросом.
Используя .status_code, можно увидеть код состояния, который возвращается с сервера.
|
>>> response.status_code 200 |
.status_code вернул значение 200. Это значит, что запрос был выполнен успешно, а сервер ответил, отобразив запрашиваемую информацию.
В некоторых случаях необходимо использовать полученную информацию для написания программного кода.
|
if response.status_code == 200: print(‘Success!’) elif response.status_code == 404: print(‘Not Found.’) |
В таком случае, если с сервера будет получен код состояния 200, тогда программа выведет значение Success!. Однако, если от сервера поступит код 404, тогда программа выведет значение Not Found.
requests может значительно упростить весь процесс. Если использовать Response в условных конструкциях, то при получении кода состояния в промежутке от 200 до 400, будет выведено значение True. В противном случае отобразится значение False.
Последний пример можно упростить при помощи использования оператора if.
|
if response: print(‘Success!’) else: print(‘An error has occurred.’) |
Стоит иметь в виду, что данный способ не проверяет, имеет ли статусный код точное значение 200. Причина заключается в том, что другие коды в промежутке от 200 до 400, например, 204 NO CONTENT и 304 NOT MODIFIED, также считаются успешными в случае, если они могут предоставить действительный ответ.
К примеру, код состояния 204 говорит о том, что ответ успешно получен, однако в полученном объекте нет содержимого. Можно сказать, что для оптимально эффективного использования способа необходимо убедиться, что начальный запрос был успешно выполнен. Требуется изучить код состояния и в случае необходимости произвести необходимые поправки, которые будут зависеть от значения полученного кода.
Допустим, если при использовании оператора if вы не хотите проверять код состояния, можно расширить диапазон исключений для неудачных результатов запроса. Это можно сделать при помощи использования .raise_for_status().
|
import requests from requests.exceptions import HTTPError for url in [‘https://api.github.com’, ‘https://api.github.com/invalid’]: try: response = requests.get(url) # если ответ успешен, исключения задействованы не будут response.raise_for_status() except HTTPError as http_err: print(f‘HTTP error occurred: {http_err}’) # Python 3.6 except Exception as err: print(f‘Other error occurred: {err}’) # Python 3.6 else: print(‘Success!’) |
В случае вызова исключений через .raise_for_status() к некоторым кодам состояния применяется HTTPError. Когда код состояния показывает, что запрос успешно выполнен, программа продолжает работу без применения политики исключений.
На заметку. Для более продуктивной работы в Python 3.6 будет не лишним изучить f-строки. Не стоит пренебрегать ими, так как это отличный способ упростить форматирование строк.
Анализ способов использования кодов состояния, полученных с сервера, является неплохим стартом для изучения requests. Тем не менее, при создании запроса GET, значение кода состояния является не самой важной информацией, которую хочет получить программист. Обычно запрос производится для извлечения более содержательной информации. В дальнейшем будет показано, как добраться до актуальных данных, которые сервер высылает отправителю в ответ на запрос.
Зачастую ответ на запрос GET содержит весьма ценную информацию. Она находится в теле сообщения и называется пейлоад (payload). Используя атрибуты и методы библиотеки Response, можно получить пейлоад в различных форматах.
Для того, чтобы получить содержимое запроса в байтах, необходимо использовать .content.
|
>>> response = requests.get(‘https://api.github.com’) >>> response.content b‘{«current_user_url»:»https://api.github.com/user»,»current_user_authorizations_html_url»:»https://github.com/settings/connections/applications{/client_id}»,»authorizations_url»:»https://api.github.com/authorizations»,»code_search_url»:»https://api.github.com/search/code?q={query}{&page,per_page,sort,order}»,»commit_search_url»:»https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}»,»emails_url»:»https://api.github.com/user/emails»,»emojis_url»:»https://api.github.com/emojis»,»events_url»:»https://api.github.com/events»,»feeds_url»:»https://api.github.com/feeds»,»followers_url»:»https://api.github.com/user/followers»,»following_url»:»https://api.github.com/user/following{/target}»,»gists_url»:»https://api.github.com/gists{/gist_id}»,»hub_url»:»https://api.github.com/hub»,»issue_search_url»:»https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}»,»issues_url»:»https://api.github.com/issues»,»keys_url»:»https://api.github.com/user/keys»,»notifications_url»:»https://api.github.com/notifications»,»organization_repositories_url»:»https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}»,»organization_url»:»https://api.github.com/orgs/{org}»,»public_gists_url»:»https://api.github.com/gists/public»,»rate_limit_url»:»https://api.github.com/rate_limit»,»repository_url»:»https://api.github.com/repos/{owner}/{repo}»,»repository_search_url»:»https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}»,»current_user_repositories_url»:»https://api.github.com/user/repos{?type,page,per_page,sort}»,»starred_url»:»https://api.github.com/user/starred{/owner}{/repo}»,»starred_gists_url»:»https://api.github.com/gists/starred»,»team_url»:»https://api.github.com/teams»,»user_url»:»https://api.github.com/users/{user}»,»user_organizations_url»:»https://api.github.com/user/orgs»,»user_repositories_url»:»https://api.github.com/users/{user}/repos{?type,page,per_page,sort}»,»user_search_url»:»https://api.github.com/search/users?q={query}{&page,per_page,sort,order}»}’ |
Использование .content обеспечивает доступ к чистым байтам ответного пейлоада, то есть к любым данным в теле запроса. Однако, зачастую требуется конвертировать полученную информацию в строку в кодировке UTF-8. response делает это при помощи .text.
|
>>> response.text ‘{«current_user_url»:»https://api.github.com/user»,»current_user_authorizations_html_url»:»https://github.com/settings/connections/applications{/client_id}»,»authorizations_url»:»https://api.github.com/authorizations»,»code_search_url»:»https://api.github.com/search/code?q={query}{&page,per_page,sort,order}»,»commit_search_url»:»https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}»,»emails_url»:»https://api.github.com/user/emails»,»emojis_url»:»https://api.github.com/emojis»,»events_url»:»https://api.github.com/events»,»feeds_url»:»https://api.github.com/feeds»,»followers_url»:»https://api.github.com/user/followers»,»following_url»:»https://api.github.com/user/following{/target}»,»gists_url»:»https://api.github.com/gists{/gist_id}»,»hub_url»:»https://api.github.com/hub»,»issue_search_url»:»https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}»,»issues_url»:»https://api.github.com/issues»,»keys_url»:»https://api.github.com/user/keys»,»notifications_url»:»https://api.github.com/notifications»,»organization_repositories_url»:»https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}»,»organization_url»:»https://api.github.com/orgs/{org}»,»public_gists_url»:»https://api.github.com/gists/public»,»rate_limit_url»:»https://api.github.com/rate_limit»,»repository_url»:»https://api.github.com/repos/{owner}/{repo}»,»repository_search_url»:»https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}»,»current_user_repositories_url»:»https://api.github.com/user/repos{?type,page,per_page,sort}»,»starred_url»:»https://api.github.com/user/starred{/owner}{/repo}»,»starred_gists_url»:»https://api.github.com/gists/starred»,»team_url»:»https://api.github.com/teams»,»user_url»:»https://api.github.com/users/{user}»,»user_organizations_url»:»https://api.github.com/user/orgs»,»user_repositories_url»:»https://api.github.com/users/{user}/repos{?type,page,per_page,sort}»,»user_search_url»:»https://api.github.com/search/users?q={query}{&page,per_page,sort,order}»}’ |
Декодирование байтов в строку требует наличия определенной модели кодировки. По умолчанию requests попытается узнать текущую кодировку, ориентируясь по заголовкам HTTP. Указать необходимую кодировку можно при помощи добавления .encoding перед .text.
|
>>> response.encoding = ‘utf-8’ # Optional: requests infers this internally >>> response.text ‘{«current_user_url»:»https://api.github.com/user»,»current_user_authorizations_html_url»:»https://github.com/settings/connections/applications{/client_id}»,»authorizations_url»:»https://api.github.com/authorizations»,»code_search_url»:»https://api.github.com/search/code?q={query}{&page,per_page,sort,order}»,»commit_search_url»:»https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}»,»emails_url»:»https://api.github.com/user/emails»,»emojis_url»:»https://api.github.com/emojis»,»events_url»:»https://api.github.com/events»,»feeds_url»:»https://api.github.com/feeds»,»followers_url»:»https://api.github.com/user/followers»,»following_url»:»https://api.github.com/user/following{/target}»,»gists_url»:»https://api.github.com/gists{/gist_id}»,»hub_url»:»https://api.github.com/hub»,»issue_search_url»:»https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}»,»issues_url»:»https://api.github.com/issues»,»keys_url»:»https://api.github.com/user/keys»,»notifications_url»:»https://api.github.com/notifications»,»organization_repositories_url»:»https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}»,»organization_url»:»https://api.github.com/orgs/{org}»,»public_gists_url»:»https://api.github.com/gists/public»,»rate_limit_url»:»https://api.github.com/rate_limit»,»repository_url»:»https://api.github.com/repos/{owner}/{repo}»,»repository_search_url»:»https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}»,»current_user_repositories_url»:»https://api.github.com/user/repos{?type,page,per_page,sort}»,»starred_url»:»https://api.github.com/user/starred{/owner}{/repo}»,»starred_gists_url»:»https://api.github.com/gists/starred»,»team_url»:»https://api.github.com/teams»,»user_url»:»https://api.github.com/users/{user}»,»user_organizations_url»:»https://api.github.com/user/orgs»,»user_repositories_url»:»https://api.github.com/users/{user}/repos{?type,page,per_page,sort}»,»user_search_url»:»https://api.github.com/search/users?q={query}{&page,per_page,sort,order}»}’ |
Если присмотреться к ответу, можно заметить, что его содержимое является сериализированным JSON контентом. Воспользовавшись словарем, можно взять полученные из .text строки str и провести с ними обратную сериализацию при помощи использования json.loads(). Есть и более простой способ, который требует применения .json().
|
>>> response.json() {‘current_user_url’: ‘https://api.github.com/user’, ‘current_user_authorizations_html_url’: ‘https://github.com/settings/connections/applications{/client_id}’, ‘authorizations_url’: ‘https://api.github.com/authorizations’, ‘code_search_url’: ‘https://api.github.com/search/code?q={query}{&page,per_page,sort,order}’, ‘commit_search_url’: ‘https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}’, ’emails_url’: ‘https://api.github.com/user/emails’, ’emojis_url’: ‘https://api.github.com/emojis’, ‘events_url’: ‘https://api.github.com/events’, ‘feeds_url’: ‘https://api.github.com/feeds’, ‘followers_url’: ‘https://api.github.com/user/followers’, ‘following_url’: ‘https://api.github.com/user/following{/target}’, ‘gists_url’: ‘https://api.github.com/gists{/gist_id}’, ‘hub_url’: ‘https://api.github.com/hub’, ‘issue_search_url’: ‘https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}’, ‘issues_url’: ‘https://api.github.com/issues’, ‘keys_url’: ‘https://api.github.com/user/keys’, ‘notifications_url’: ‘https://api.github.com/notifications’, ‘organization_repositories_url’: ‘https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}’, ‘organization_url’: ‘https://api.github.com/orgs/{org}’, ‘public_gists_url’: ‘https://api.github.com/gists/public’, ‘rate_limit_url’: ‘https://api.github.com/rate_limit’, ‘repository_url’: ‘https://api.github.com/repos/{owner}/{repo}’, ‘repository_search_url’: ‘https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}’, ‘current_user_repositories_url’: ‘https://api.github.com/user/repos{?type,page,per_page,sort}’, ‘starred_url’: ‘https://api.github.com/user/starred{/owner}{/repo}’, ‘starred_gists_url’: ‘https://api.github.com/gists/starred’, ‘team_url’: ‘https://api.github.com/teams’, ‘user_url’: ‘https://api.github.com/users/{user}’, ‘user_organizations_url’: ‘https://api.github.com/user/orgs’, ‘user_repositories_url’: ‘https://api.github.com/users/{user}/repos{?type,page,per_page,sort}’, ‘user_search_url’: ‘https://api.github.com/search/users?q={query}{&page,per_page,sort,order}’} |
Тип полученного значения из .json(), является словарем. Это значит, что доступ к его содержимому можно получить по ключу.
Коды состояния и тело сообщения предоставляют огромный диапазон возможностей. Однако, для их оптимального использования требуется изучить метаданные и заголовки HTTP.
HTTP заголовки ответов на запрос могут предоставить определенную полезную информацию. Это может быть тип содержимого ответного пейлоада, а также ограничение по времени для кеширования ответа. Для просмотра HTTP заголовков загляните в атрибут .headers.
|
>>> response.headers {‘Server’: ‘GitHub.com’, ‘Date’: ‘Mon, 10 Dec 2018 17:49:54 GMT’, ‘Content-Type’: ‘application/json; charset=utf-8’, ‘Transfer-Encoding’: ‘chunked’, ‘Status’: ‘200 OK’, ‘X-RateLimit-Limit’: ’60’, ‘X-RateLimit-Remaining’: ’59’, ‘X-RateLimit-Reset’: ‘1544467794’, ‘Cache-Control’: ‘public, max-age=60, s-maxage=60’, ‘Vary’: ‘Accept’, ‘ETag’: ‘W/»7dc470913f1fe9bb6c7355b50a0737bc»‘, ‘X-GitHub-Media-Type’: ‘github.v3; format=json’, ‘Access-Control-Expose-Headers’: ‘ETag, Link, Location, Retry-After, X-GitHub-OTP, X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset, X-OAuth-Scopes, X-Accepted-OAuth-Scopes, X-Poll-Interval, X-GitHub-Media-Type’, ‘Access-Control-Allow-Origin’: ‘*’, ‘Strict-Transport-Security’: ‘max-age=31536000; includeSubdomains; preload’, ‘X-Frame-Options’: ‘deny’, ‘X-Content-Type-Options’: ‘nosniff’, ‘X-XSS-Protection’: ‘1; mode=block’, ‘Referrer-Policy’: ‘origin-when-cross-origin, strict-origin-when-cross-origin’, ‘Content-Security-Policy’: «default-src ‘none'», ‘Content-Encoding’: ‘gzip’, ‘X-GitHub-Request-Id’: ‘E439:4581:CF2351:1CA3E06:5C0EA741’} |
.headers возвращает словарь, что позволяет получить доступ к значению заголовка HTTP по ключу. Например, для просмотра типа содержимого ответного пейлоада, требуется использовать Content-Type.
|
>>> response.headers[‘Content-Type’] ‘application/json; charset=utf-8’ |
У объектов словарей в качестве заголовков есть своим особенности. Специфика HTTP предполагает, что заголовки не чувствительны к регистру. Это значит, что при получении доступа к заголовкам можно не беспокоится о том, использованы строчным или прописные буквы.
|
>>> response.headers[‘content-type’] ‘application/json; charset=utf-8’ |
При использовании ключей 'content-type' и 'Content-Type' результат будет получен один и тот же.
Это была основная информация, требуемая для работы с Response. Были задействованы главные атрибуты и методы, а также представлены примеры их использования. В дальнейшем будет показано, как изменится ответ после настройки запроса GET.
Python Requests параметры запроса
Наиболее простым способом настроить запрос GET является передача значений через параметры строки запроса в URL. При использовании метода get(), данные передаются в params. Например, для того, чтобы посмотреть на библиотеку requests можно использовать Search API на GitHub.
|
import requests # Поиск местонахождения для запросов на GitHub response = requests.get( ‘https://api.github.com/search/repositories’, params={‘q’: ‘requests+language:python’}, ) # Анализ некоторых атрибутов местонахождения запросов json_response = response.json() repository = json_response[‘items’][0] print(f‘Repository name: {repository[«name»]}’) # Python 3.6+ print(f‘Repository description: {repository[«description»]}’) # Python 3.6+ |
Передавая словарь {'q': 'requests+language:python'} в параметр params, который является частью .get(), можно изменить ответ, что был получен при использовании Search API.
Можно передать параметры в get() в форме словаря, как было показано выше. Также можно использовать список кортежей.
|
>>> requests.get( ... ‘https://api.github.com/search/repositories’, ... params=[(‘q’, ‘requests+language:python’)], ... ) <Response [200]> |
Также можно передать значение в байтах.
|
>>> requests.get( ... ‘https://api.github.com/search/repositories’, ... params=b‘q=requests+language:python’, ... ) <Response [200]> |
Строки запроса полезны для уточнения параметров в запросах GET. Также можно настроить запросы при помощи добавления или изменения заголовков отправленных сообщений.
Для изменения HTTP заголовка требуется передать словарь данного HTTP заголовка в get() при помощи использования параметра headers. Например, можно изменить предыдущий поисковой запрос, подсветив совпадения в результате. Для этого в заголовке Accept медиа тип уточняется при помощи text-match.
|
import requests response = requests.get( ‘https://api.github.com/search/repositories’, params={‘q’: ‘requests+language:python’}, headers={‘Accept’: ‘application/vnd.github.v3.text-match+json’}, ) # просмотр нового массива `text-matches` с предоставленными данными # о поиске в пределах результатов json_response = response.json() repository = json_response[‘items’][0] print(f‘Text matches: {repository[«text_matches»]}’) |
Заголовок Accept сообщает серверу о типах контента, который можно использовать в рассматриваемом приложении. Здесь подразумевается, что все совпадения будут подсвечены, для чего в заголовке используется значение application/vnd.github.v3.text-match+json. Это уникальный заголовок Accept для GitHub. В данном случае содержимое представлено в специальном JSON формате.
Перед более глубоким изучением способов редактирования запросов, будет не лишним остановиться на некоторых других методах HTTP.
Примеры HTTP методов в Requests
Помимо GET, большой популярностью пользуются такие методы, как POST, PUT, DELETE, HEAD, PATCH и OPTIONS. Для каждого из этих методов существует своя сигнатура, которая очень похожа на метод get().
|
>>> requests.post(‘https://httpbin.org/post’, data={‘key’:‘value’}) >>> requests.put(‘https://httpbin.org/put’, data={‘key’:‘value’}) >>> requests.delete(‘https://httpbin.org/delete’) >>> requests.head(‘https://httpbin.org/get’) >>> requests.patch(‘https://httpbin.org/patch’, data={‘key’:‘value’}) >>> requests.options(‘https://httpbin.org/get’) |
Каждая функция создает запрос к httpbin сервису, используя при этом ответный HTTP метод. Результат каждого метода можно изучить способом, который был использован в предыдущих примерах.
|
>>> response = requests.head(‘https://httpbin.org/get’) >>> response.headers[‘Content-Type’] ‘application/json’ >>> response = requests.delete(‘https://httpbin.org/delete’) >>> json_response = response.json() >>> json_response[‘args’] {} |
При использовании каждого из данных методов в Response могут быть возвращены заголовки, тело запроса, коды состояния и многие другие аспекты. Методы POST, PUT и PATCH в дальнейшем будут описаны более подробно.
Python Requests тело сообщения
В соответствии со спецификацией HTTP запросы POST, PUT и PATCH передают информацию через тело сообщения, а не через параметры строки запроса. Используя requests, можно передать данные в параметр data.
В свою очередь data использует словарь, список кортежей, байтов или объект файла. Это особенно важно, так как может возникнуть необходимость адаптации отправляемых с запросом данных в соответствии с определенными параметрами сервера.
К примеру, если тип содержимого запроса application/x-www-form-urlencoded, можно отправить данные формы в виде словаря.
|
>>> requests.post(‘https://httpbin.org/post’, data={‘key’:‘value’}) <Response [200]> |
Ту же самую информацию также можно отправить в виде списка кортежей.
|
>>> requests.post(‘https://httpbin.org/post’, data=[(‘key’, ‘value’)]) <Response [200]> |
В том случае, если требуется отравить данные JSON, можно использовать параметр json. При передачи данных JSON через json, requests произведет сериализацию данных и добавит правильный Content-Type заголовок.
Стоит взять на заметку сайт httpbin.org. Это чрезвычайно полезный ресурс, созданный человеком, который внедрил использование requests – Кеннетом Рейтцом. Данный сервис предназначен для тестовых запросов. Здесь можно составить пробный запрос и получить ответ с требуемой информацией. В качестве примера рассмотрим базовый запрос с использованием POST.
|
>>> response = requests.post(‘https://httpbin.org/post’, json={‘key’:‘value’}) >>> json_response = response.json() >>> json_response[‘data’] ‘{«key»: «value»}’ >>> json_response[‘headers’][‘Content-Type’] ‘application/json’ |
Здесь видно, что сервер получил данные и HTTP заголовки, отправленные вместе с запросом. requests также предоставляет информацию в форме PreparedRequest.
Python Requests анализ запроса
При составлении запроса стоит иметь в виду, что перед его фактической отправкой на целевой сервер библиотека requests выполняет определенную подготовку. Подготовка запроса включает в себя такие вещи, как проверка заголовков и сериализация содержимого JSON.
Если открыть .request, можно просмотреть PreparedRequest.
|
>>> response = requests.post(‘https://httpbin.org/post’, json={‘key’:‘value’}) >>> response.request.headers[‘Content-Type’] ‘application/json’ >>> response.request.url ‘https://httpbin.org/post’ >>> response.request.body b‘{«key»: «value»}’ |
Проверка PreparedRequest открывает доступ ко всей информации о выполняемом запросе. Это может быть пейлоад, URL, заголовки, аутентификация и многое другое.
У всех описанных ранее типов запросов была одна общая черта – они представляли собой неаутентифицированные запросы к публичным API. Однако, подобающее большинство служб, с которыми может столкнуться пользователь, запрашивают аутентификацию.
Python Requests аутентификация HTTP AUTH
Аутентификация помогает сервису понять, кто вы. Как правило, вы предоставляете свои учетные данные на сервер, передавая данные через заголовок Authorization или пользовательский заголовок, определенной службы. Все функции запроса, которые вы видели до этого момента, предоставляют параметр с именем auth, который позволяет вам передавать свои учетные данные.
Одним из примеров API, который требует аутентификации, является Authenticated User API на GitHub. Это конечная точка веб-сервиса, которая предоставляет информацию о профиле аутентифицированного пользователя. Чтобы отправить запрос API-интерфейсу аутентифицированного пользователя, вы можете передать свое имя пользователя и пароль на GitHub через кортеж в get().
|
>>> from getpass import getpass >>> requests.get(‘https://api.github.com/user’, auth=(‘username’, getpass())) <Response [200]> |
Запрос выполнен успешно, если учетные данные, которые вы передали в кортеже auth, действительны. Если вы попытаетесь сделать этот запрос без учетных данных, вы увидите, что код состояния 401 Unauthorized.
|
>>> requests.get(‘https://api.github.com/user’) <Response [401]> |
Когда вы передаете имя пользователя и пароль в кортеже параметру auth, вы используете учетные данные при помощи базовой схемы аутентификации HTTP.
Таким образом, вы можете создать тот же запрос, передав подробные учетные данные базовой аутентификации, используя HTTPBasicAuth.
|
>>> from requests.auth import HTTPBasicAuth >>> from getpass import getpass >>> requests.get( ... ‘https://api.github.com/user’, ... auth=HTTPBasicAuth(‘username’, getpass()) ... ) <Response [200]> |
Хотя вам не нужно явно указывать обычную аутентификацию, может потребоваться аутентификация с использованием другого метода. requests предоставляет другие методы аутентификации, например, HTTPDigestAuth и HTTPProxyAuth.
Вы даже можете предоставить свой собственный механизм аутентификации. Для этого необходимо сначала создать подкласс AuthBase. Затем происходит имплементация __call__().
|
import requests from requests.auth import AuthBase class TokenAuth(AuthBase): «»»Implements a custom authentication scheme.»»» def __init__(self, token): self.token = token def __call__(self, r): «»»Attach an API token to a custom auth header.»»» r.headers[‘X-TokenAuth’] = f‘{self.token}’ # Python 3.6+ return r requests.get(‘https://httpbin.org/get’, auth=TokenAuth(‘12345abcde-token’)) |
Здесь пользовательский механизм TokenAuth получает специальный токен. Затем этот токен включается заголовок X-TokenAuth запроса.
Плохие механизмы аутентификации могут привести к уязвимостям безопасности, поэтому, если службе по какой-то причине не нужен настраиваемый механизм аутентификации, вы всегда можете использовать проверенную схему аутентификации, такую как Basic или OAuth.
Пока вы думаете о безопасности, давайте рассмотрим использование requests в SSL сертификатах.
Python Requests проверка SSL сертификата
Всякий раз, когда данные, которые вы пытаетесь отправить или получить, являются конфиденциальными, безопасность важна. Вы общаетесь с защищенными сайтами через HTTP, устанавливая зашифрованное соединение с использованием SSL, что означает, что проверка SSL сертификата целевого сервера имеет решающее значение.
Хорошей новостью является то, что requests по умолчанию все делает сам. Однако в некоторых случаях необходимо внести определенные поправки.
Если требуется отключить проверку SSL-сертификата, параметру verify функции запроса можно присвоить значение False.
|
>>> requests.get(‘https://api.github.com’, verify=False) InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced—usage.html#ssl-warnings InsecureRequestWarning) <Response [200]> |
В случае небезопасного запроса requests предупреждает о возможности потери информации и просит сохранить данные или отказаться от запроса.
Примечание. Для предоставления сертификатов
requestsиспользует пакет, который вызываетсяcertifi. Это дает понятьrequests, каким ответам можно доверять. Поэтому вам следует часто обновлятьcertifi, чтобы обеспечить максимальную безопасность ваших соединений.
Python Requests производительность приложений
При использовании requests, особенно в среде приложений, важно учитывать влияние на производительность. Такие функции, как контроль таймаута, сеансы и ограничения повторных попыток, могут помочь обеспечить бесперебойную работу приложения.
Таймауты
Когда вы отправляете встроенный запрос во внешнюю службу, вашей системе нужно будет дождаться ответа, прежде чем двигаться дальше. Если ваше приложение слишком долго ожидает ответа, запросы к службе могут быть сохранены, пользовательский интерфейс может пострадать или фоновые задания могут зависнуть.
По умолчанию в requests на ответ время не ограничено, и весь процесс может занять значительный промежуток. По этой причине вы всегда должны указывать время ожидания, чтобы такого не происходило. Чтобы установить время ожидания запроса, используйте параметр timeout. timeout может быть целым числом или числом с плавающей точкой, представляющим количество секунд ожидания ответа до истечения времени ожидания.
|
>>> requests.get(‘https://api.github.com’, timeout=1) <Response [200]> >>> requests.get(‘https://api.github.com’, timeout=3.05) <Response [200]> |
В первом примере запрос истекает через 1 секунду. Во втором примере запрос истекает через 3,05 секунды.
Вы также можете передать кортеж. Это – таймаут соединения (время, за которое клиент может установить соединение с сервером), а второй – таймаут чтения (время ожидания ответа, как только ваш клиент установил соединение):
|
>>> requests.get(‘https://api.github.com’, timeout=(2, 5)) <Response [200]> |
Если запрос устанавливает соединение в течение 2 секунд и получает данные в течение 5 секунд после установления соединения, то ответ будет возвращен, как это было раньше. Если время ожидания истекло, функция вызовет исключение Timeout.
|
import requests from requests.exceptions import Timeout try: response = requests.get(‘https://api.github.com’, timeout=1) except Timeout: print(‘The request timed out’) else: print(‘The request did not time out’) |
Ваша программа может поймать исключение Timeout и ответить соответственно.
Объект Session в Requests
До сих пор вы имели дело с requests API высокого уровня, такими как get() и post(). Эти функции являются абстракцией того, что происходит, когда вы делаете свои запросы. Они скрывают детали реализации, такие как управление соединениями, так что вам не нужно о них беспокоиться.
Под этими абстракциями находится класс под названием Session. Если вам необходимо настроить контроль над выполнением запросов или повысить производительность ваших запросов, вам может потребоваться использовать Session напрямую.
Сессии используются для сохранения параметров в запросах.
Например, если вы хотите использовать одну и ту же аутентификацию для нескольких запросов, вы можете использовать сеанс:
|
import requests from getpass import getpass # используя менеджер контента, можно убедиться, что ресурсы, применимые # во время сессии будут свободны после использования with requests.Session() as session: session.auth = (‘username’, getpass()) # Instead of requests.get(), you’ll use session.get() response = session.get(‘https://api.github.com/user’) # здесь можно изучить ответ print(response.headers) print(response.json()) |
Каждый раз, когда вы делаете запрос session, после того как он был инициализирован с учетными данными аутентификации, учетные данные будут сохраняться.
Первичная оптимизация производительности сеансов происходит в форме постоянных соединений. Когда ваше приложение устанавливает соединение с сервером с помощью Session, оно сохраняет это соединение в пуле соединений. Когда ваше приложение снова хочет подключиться к тому же серверу, оно будет использовать соединение из пула, а не устанавливать новое.
HTTPAdapter — Максимальное количество повторов запроса в Requests
В случае сбоя запроса возникает необходимость сделать повторный запрос. Однако requests не будет делать это самостоятельно. Для применения функции повторного запроса требуется реализовать собственный транспортный адаптер.
Транспортные адаптеры позволяют определить набор конфигураций для каждой службы, с которой вы взаимодействуете. Предположим, вы хотите, чтобы все запросы к https://api.github.com были повторены три раза, прежде чем, наконец, появится ConnectionError. Для этого нужно построить транспортный адаптер, установить его параметр max_retries и подключить его к существующему объекту Session.
|
import requests from requests.adapters import HTTPAdapter from requests.exceptions import ConnectionError github_adapter = HTTPAdapter(max_retries=3) session = requests.Session() # использование `github_adapter` для всех запросов, которые начинаются с указанным URL session.mount(‘https://api.github.com’, github_adapter) try: session.get(‘https://api.github.com’) except ConnectionError as ce: print(ce) |
При установке HTTPAdapter, github_adapter к session, session будет придерживаться своей конфигурации для каждого запроса к https://api.github.com.
Таймауты, транспортные адаптеры и сессии предназначены для обеспечения эффективности используемого кода и стабильности приложения.
Заключение
Изучение библиотеки Python requests является очень трудоемким процессом.
После разбора данных в статье примеров можно научиться тому, как:
- Создавать запросы, используя различные методы HTTP –
GET,POSTиPUT; - Настраивать свои запросы, изменив заголовки, аутентификацию, строки запросов и тела сообщений;
- Проверять данные, которые были отправлены на сервер, а также те данные, которые сервер отправил обратно;
- Работать с проверкой SSL сертификата;
- Эффективно использовать
requests,max_retries,timeout,Sessionsи транспортные адаптеры.
Грамотное использование requests позволит наиболее эффективно настроить разрабатываемые приложения, исследуя широкий спектр веб-сервисов и данных, опубликованных на них.
- Данная статья является переводом статьи: Python’s Requests Library (Guide)
- Изображение статьи принадлежит сайту © RealPython

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
Requests
Requests is a simple, yet elegant, HTTP library.
>>> import requests >>> r = requests.get('https://httpbin.org/basic-auth/user/pass', auth=('user', 'pass')) >>> r.status_code 200 >>> r.headers['content-type'] 'application/json; charset=utf8' >>> r.encoding 'utf-8' >>> r.text '{"authenticated": true, ...' >>> r.json() {'authenticated': True, ...}
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your PUT & POST data — but nowadays, just use the json method!
Requests is one of the most downloaded Python packages today, pulling in around 30M downloads / week— according to GitHub, Requests is currently depended upon by 1,000,000+ repositories. You may certainly put your trust in this code.
Installing Requests and Supported Versions
Requests is available on PyPI:
$ python -m pip install requests
Requests officially supports Python 3.7+.
Supported Features & Best–Practices
Requests is ready for the demands of building robust and reliable HTTP–speaking applications, for the needs of today.
- Keep-Alive & Connection Pooling
- International Domains and URLs
- Sessions with Cookie Persistence
- Browser-style TLS/SSL Verification
- Basic & Digest Authentication
- Familiar
dict–like Cookies - Automatic Content Decompression and Decoding
- Multi-part File Uploads
- SOCKS Proxy Support
- Connection Timeouts
- Streaming Downloads
- Automatic honoring of
.netrc - Chunked HTTP Requests
API Reference and User Guide available on Read the Docs
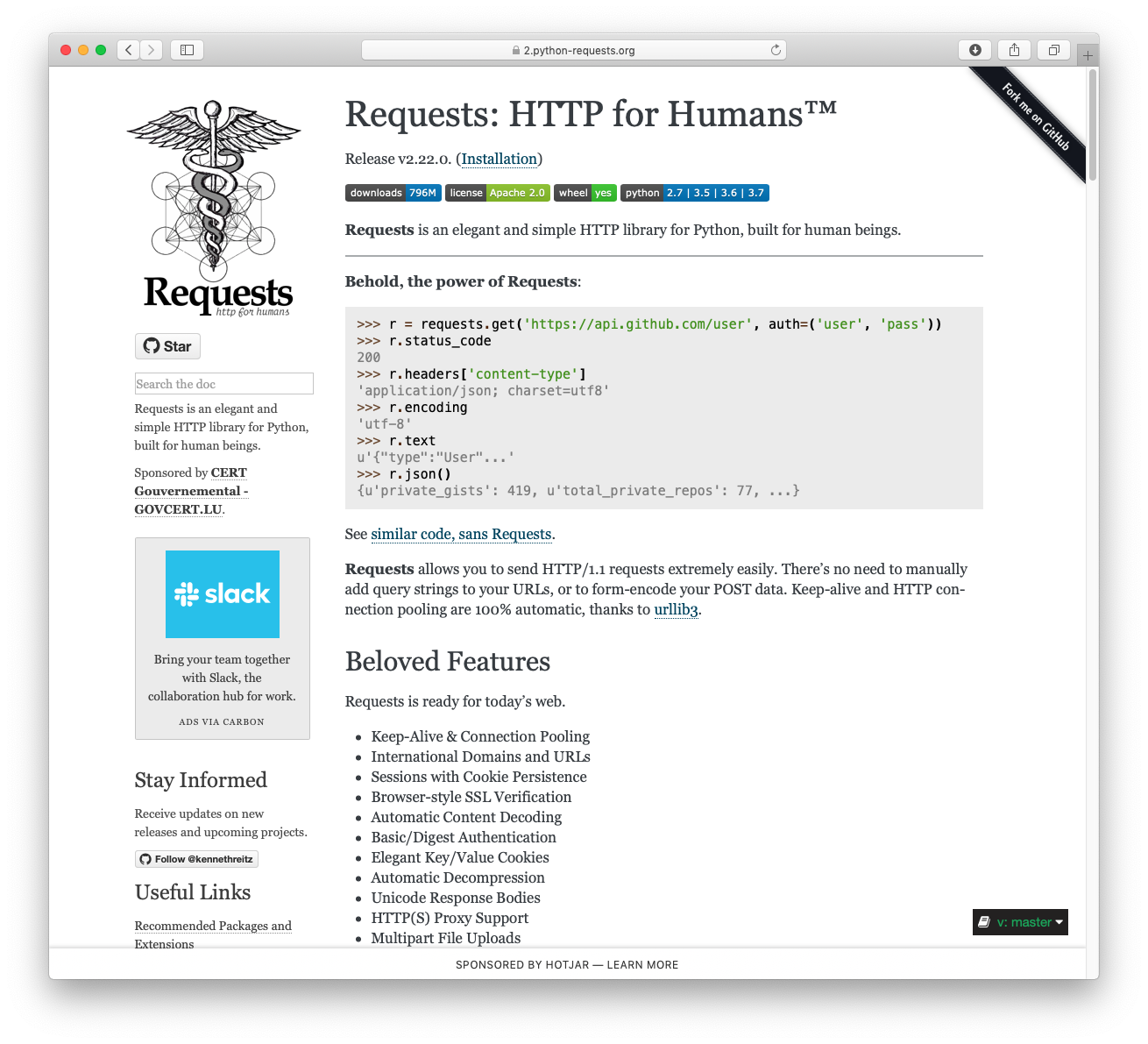
Cloning the repository
When cloning the Requests repository, you may need to add the -c fetch.fsck.badTimezone=ignore flag to avoid an error about a bad commit (see
this issue for more background):
git clone -c fetch.fsck.badTimezone=ignore https://github.com/psf/requests.git
You can also apply this setting to your global Git config:
git config --global fetch.fsck.badTimezone ignore


-
Главная
-
Инструкции
-
Python
-
Введение в работу с библиотекой Requests в Python
Requests — это одна из библиотек, которая поможет вам подружить ваш локальный скрипт с веб-ресурсами и глобальной сетью. Requests предоставляет разработчику обширный пул функций для работы со всеми видами HTTP-запросов. Благодаря этой библиотеке вы сможете получить прогноз погоду, перевести текст, скачать фильм или фото без использования браузера внутри скрипта.
В этом материале вы найдете вводную информацию по этой библиотеке, которой будет достаточно для её использования в ваших скриптах.
В рамках всего материала речь будет идти про работу в IDE Pycharm.
Библиотека Requests в Python является сторонней, поэтому перед началом работы её необходимо установить. Создаем проект и открываем терминал. В Python установка библиотеки Requests осуществляется следующей командой:
pip3 install requestsЕсли вы используете виртуальную среду Pipenv, то установка библиотеки Requests в Python 3 производится другой командой:
pipenv install requestsПосле исполнения этих команд начнется загрузка модуля. С помощью команды pip freeze можем узнать, какие модули были установлены:
PS C:UsersTimewebPycharmProjectsRequestTimeweb> pip3 freezecertifi==2022.9.24
charset-normalizer==2.1.1
idna==3.4
requests==2.28.1
urllib3==1.26.12
Расскажем, какие функции выполняют эти модули:
- certifi — пакет сертификатов для обеспечения безопасного соединения;
- charset-normalizer — библиотека, которая автоматически распознает тексты неизвестной кодировки. Полезный модуль, поскольку не все сайты и сервисы работают на распространенной UTF-8;
- idna — библиотека для поддержки интернационализированных доменных имен в приложениях;
- requests — собственно, сам модуль request;
- urllib3 — модуль, включающий в себя функции и классы для работы с URL-адресами;
Первые запросы
В этой части статьи мы напишем код для получения информации с ресурсов и узнаем основные составляющие библиотеки Request. В дальнейшем мы более детально разберем все аспекты.
Работа с библиотекой Requests в Python начинается с импорта:
import requestОбратимся к сайту google.com:
import requests as rqresponse = rq.get('https://google.com')
print(response)
Вывод:
<Response [200]>Здесь мы используем HTTP-запрос GET. Его работа аналогична переходу на сайт по URL в браузере. Далее мы подробнее разберем его.
В ответ мы получили объект Response. У него огромное количество различных свойств, которые мы также разберем дальше. При выводе этого объекта мы получаем код 200 — он означает, что запрос выполнен успешно. Если мы обратимся к несуществующему разделу на сайте google.com, то получим ответ об его отсутствии:
import requests as rqresponse = rq.get('https://google.com/timeweb')
print(response)
Вывод:
<Response [404]>Теперь разберем, какие вообще существуют запросы и как с ними работать.
HTTP-запросы
Основным запросом к сервисам и сайтам является GET. Он позволяет просматривать содержимое ресурса без его изменения. Однако для полноценной работы с ресурсами в сети может понадобится ряд других запросов. Некоторые из них могут не поддерживаться со стороны того или иного сервера. Вот 7 запросов, которые поддерживает библиотека Request:
- GET
- POST
- OPTIONS
- HEAD
- PUT
- PATCH
- DELETE
Для тестирования библиотеки создатели спроектировали сайт https://httpbin.org, с помощью которого вы можете попрактиковаться.
GET
GET передает информацию сайту прямо в заголовке. Поэтому его стоит использовать в случаях, когда передаваемая информация не является чем-то ценным: например, поиск некоторой страницы в интернет-магазине. Его не стоит использовать для передачи паролей, банковский карт и подобных данных.
Для передачи данных серверу к его URL-адресу добавляется знак ?, затем идут сами данные. Выглядит это следующим образом:
https://serverurl.ru/get?param1=value1¶m2=value2где:
- https://serverurl.ru/get — это URL;
- param1=value1¶m2=value2 — параметры. Если параметров несколько, то они отделяются амперсандом «&».
В Request GET имеет следующий синтаксис:
request.get( 'URL-адрес', {key: value}, различные аргументы)где:
- URL-адрес — адрес ресурса;
- {key: value} — параметры. Метод самостоятельно включит их в запрос. Необязательный аргумент метода;
- Различные аргументы — необязательные аргументы. Например, время таймаута.
Опробуем его на практике:
import requests as rqGetParams = {'param1': 'value1', 'param2': 'value2'}
response = rq.get('https://google.com', GetParams)
print(response.url)
Вывод:
https://www.google.com/?param1=value1¶m2=value2POST
POST используется для отправки данных на сайт в теле запроса. Тело запроса — это данные, передающиеся при совершении запроса к ресурсу. Эта информация не размещается в заголовке и подходят для передачи конфиденциальных данных.
В Request POST имеет следующий синтаксис:
request.post('URL-адрес', {key: value}, различные аргументы}где
- URL-адрес — адрес ресурса;
- {key: value} — параметры. Метод самостоятельно включит их в тело запроса. Необязательный аргумент метода;
- Различные аргументы — необязательные аргументы. Например, время таймаута.
Если не указать параметры, то GET и POST запросы вернут одинаковый результат для одного URL. Посмотрим, как работает это на практике:
import requests as rqPostParams = {'param1': 'value1', 'param2': 'value2'}
response = rq.post('https://httpbin.org/post', PostParams, timeout=2)
print(response.json()['form'])
Вывод:
{'param1': 'value1', 'param2': 'value2'}С помощью метода json() мы получили тело запроса из response. К слову, если бы мы совершили аналогичный запрос к google.com, то получили бы ошибку:
import requests as rqPostParams = {'param1': 'value1', 'param2': 'value2'}
response = rq.post('https://google.com', PostParams, timeout=2)
print(response)
Вывод:
<Response [405]>Ошибка 405 (Method Not Allowed) означает, что ресурс не поддерживает такой запрос.
Для того, чтобы узнать какие запросы поддерживает ресурс необходимо использовать OPTIONS.
OPTIONS
С помощью OPTIONS мы можем узнать, какие запросы не будут заблокированы ресурсом.
Синтаксис OPTIONS:
request.option('URL-адрес', необязательные аргументы)Отправим OPTIONS-запрос к google.com и узнаем, какие запросы он поддерживает:
import requests as rqresponse = rq.options('https://google.com', timeout=2)
print(response.headers['Allow'])
Вывод:
GET, HEADHEAD
В ответ на HEAD сервер вернет HTTP заголовки. Этот запрос выполняется, когда нужно получить не содержимое файла, а другие данные. Также HEAD может выполнять тестовые функции.
Синтаксис:
request.head('URL-адрес', различные аргументы)где
- URL-адрес — адрес ресурса;
- Различные аргументы — необязательные аргументы. Например, время таймаута.
Применим его к google.com:
import requests as rqresponse = rq.head('https://google.com', timeout=2)
print(response.headers)
В выводе мы получили большое количество заголовков.
PUT
PUT создает новый объект или заменяет существующий. Он похож на метод POST, но отличается идемпотентностью. Это означает, что при повторных выполнениях PUT с аналогичными данными результат не изменится.
Для лучшего понимания представим базу данных с паролями и логинами. Допустим пользователь хочет поменять пароль. При использовании метода POST он добавит новую запись со своим идентификатором, в данном случае логином (при отсутствии других программных проверок). При использовании PUT он обновит текущий.
Синтаксис:
request.put('URL-адрес', {key: value}, различные аргументы)где:
- URL-адрес — адрес ресурса;
- {key: value} — параметры. Метод самостоятельно включит их в тело запроса.
- Различные аргументы — необязательные аргументы. Например, время таймаута.
Применим его к httpbin:
import requests as rqPutParams = {'param1': 'value2', 'param2': 'value2'}
response = rq.put('https://httpbin.org/put', data=PutParams, timeout=2)
print(response.status_code)
Вывод:
200PATCH
С помощью PATCH осуществляется частичное обновление данных на ресурсе (например, смена токена). Синтаксис следующий:
request.patch ('URL-адрес', {key: value}, различные аргументы)где:
- URL-адрес — адрес ресурса;
- {key: value} — параметры. Метод самостоятельно включит их в тело запроса.
- Различные аргументы — необязательные аргументы. Например, время таймаута.
Применим его httpbin:
import requests as rqPatchParams = {'param1': 'value2', 'param2': 'value2'}
response = rq.patch('https://httpbin.org/patch', data=PatchParams, timeout=2)
print(response.status_code)
Вывод:
200DELETE
Используется для удаления некого объекта на ресурсе. Синтаксис:
requests.delete('URL-адрес', {key: value})где:
- URL-адрес — адрес ресурса;
- {key: value} — параметры (данные, которые необходимо удалить). Метод самостоятельно включит их в тело запроса.
Применение:
import requests as rqDelParams = {'param1': 'value2', 'param2': 'value2'}
response = rq.delete('https://httpbin.org/delete', data=DelParams, timeout=2)
print(response.status_code)
Вывод:
200Объект Response
Как было показано в примерах, объект Response обладает большим количеством методов и свойств. Ниже вы найдете их с кратким описанием:
- apparent_encoding — кодировка, распознанная charset-normalizer;
- close() — закрывает соединение с сервером;
- content — вывод полученных данных в байтах;
- cookies — вывод куки;
- elapsed — вывод времени;
- encoding — выбор кодировки для декодирования;
- headers — вывод заголовков ресурса;
- history — вывод переадресации;
- is_permanent_redirect — определение постоянных редиректов;
- is_redirect — определение наличия редиректа;
- iter_content() — возврат данных по частям;
- iter_lines() — возврат данных построчно;
- json() — возврат данных в формате JSON;
- links — возврат ссылок в заголовках ответа;
- next — возврат PreparedRequest;
- ok — True при удачном соединении, False при неудачном;
- raise_for_status() — вызов исключения HTTPError;
- reason — вывод текстового представления объекта;
- request — возврат результат PreparedRequest;
- status_code — код ответа;
- text — вывод ответа в юникоде;
- url — вывод URL.
Заключение
В рамках этого материала мы рассмотрели основные элементы библиотеки Requests. Если вы хотите узнать о ней больше, то официальная документация библиотеки Requests Python даст вам необходимые ответы. А для тестирования своих скриптов можно использовать облачные серверы от timeweb.cloud.