Since both pip nor python commands are not installed along Python in Windows, you will need to use the Windows alternative py, which is included by default when you installed Python. Then you have the option to specify a general or specific version number after the py command.
C:> py -m pip install pandas %= one of Python on the system =%
C:> py -2 -m pip install pandas %= one of Python 2 on the system =%
C:> py -2.7 -m pip install pandas %= only for Python 2.7 =%
C:> py -3 -m pip install pandas %= one of Python 3 on the system =%
C:> py -3.6 -m pip install pandas %= only for Python 3.6 =%
Alternatively, in order to get pip to work without py -m part, you will need to add pip to the PATH environment variable.
C:> setx PATH "%PATH%;C:<pathtopythonfolder>Scripts"
Now you can run the following command as expected.
C:> pip install pandas
Troubleshooting:
Problem:
connection error: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed
Solution:
This is caused by your SSL certificate is unable to verify the host server. You can add pypi.python.org to the trusted host or specify an alternative SSL certificate. For more information, please see this post. (Thanks to Anuj Varshney for suggesting this)
C:> py -m pip install --trusted-host pypi.python.org pip pandas
Problem:
PermissionError: [WinError 5] Access is denied
Solution:
This is a caused by when you don’t permission to modify the Python site-package folders. You can avoid this with one of the following methods:
-
Run Windows Command Prompt as administrator (thanks to DataGirl’s suggestion) by:
 + R to open run
+ R to open run - type in
cmd.exein the search box - CTRL + SHIFT + ENTER
- An alternative method for step 1-3 would be to manually locate cmd.exe, right click, then click Run as Administrator.
-
Run pip in user mode by adding
--useroption when installing with pip. Which typically install the package to the local %APPDATA% Python folder.
 + R to open run
+ R to open run C:> py -m pip install --user pandas
- Create a virtual environment.
C:> py -m venv c:pathtonewvenv
C:> <pathtothenewvenv>Scriptsactivate.bat
Pandas in Python is a package that is written for data analysis and manipulation. Pandas offer various operations and data structures to perform numerical data manipulations and time series. Pandas is an open-source library that is built over Numpy libraries. Pandas library is known for its high productivity and high performance. Pandas is popular because it makes importing and analyzing data much easier.
Pandas programs can be written on any plain text editor like notepad, notepad++, or anything of that sort and saved with a .py extension. To begin with, writing Pandas Codes and performing various intriguing and useful operations, one must have Python installed on their System. This can be done by following the step by step instructions provided below:
What if Python already exists? Let’s check
To check if your device is pre-installed with Python or not, just go to the Command line(search for cmd in the Run dialog( + R).
Now run the following command:
python --version
If Python is already installed, it will generate a message with the Python version available.
To install Python, please visit: How to Install Python on Windows or Linux?
Downloading and Installing Pandas
Pandas can be installed in multiple ways on Windows and on Linux. Various different ways are listed below:
Windows
Python Pandas can be installed on Windows in two ways:
- Using pip
- Using Anaconda
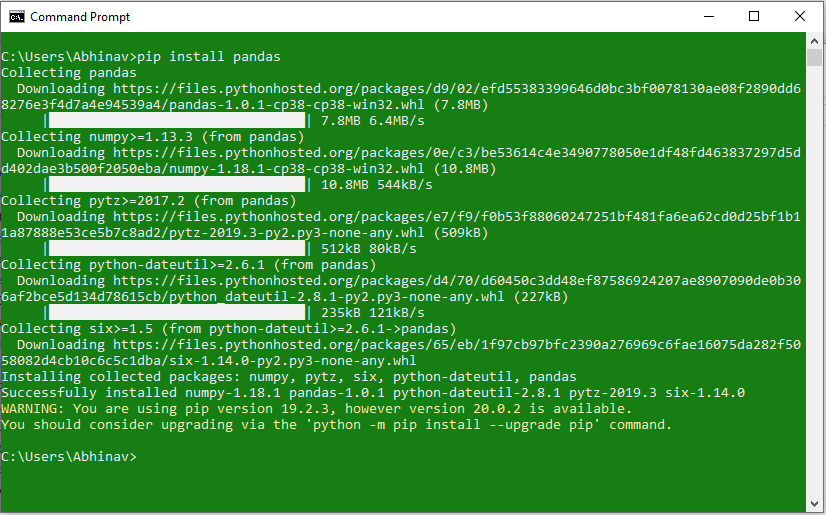
Install Pandas using pip
PIP is a package management system used to install and manage software packages/libraries written in Python. These files are stored in a large “on-line repository” termed as Python Package Index (PyPI).
Pandas can be installed using PIP by the use of the following command:
pip install pandas
Install Pandas using Anaconda
Anaconda is open-source software that contains Jupyter, spyder, etc that are used for large data processing, data analytics, heavy scientific computing. If your system is not pre-equipped with Anaconda Navigator, you can learn how to install Anaconda Navigator on Windows or Linux?
Steps to Install Pandas using Anaconda Navigator:
Step 1: Search for Anaconda Navigator in Start Menu and open it.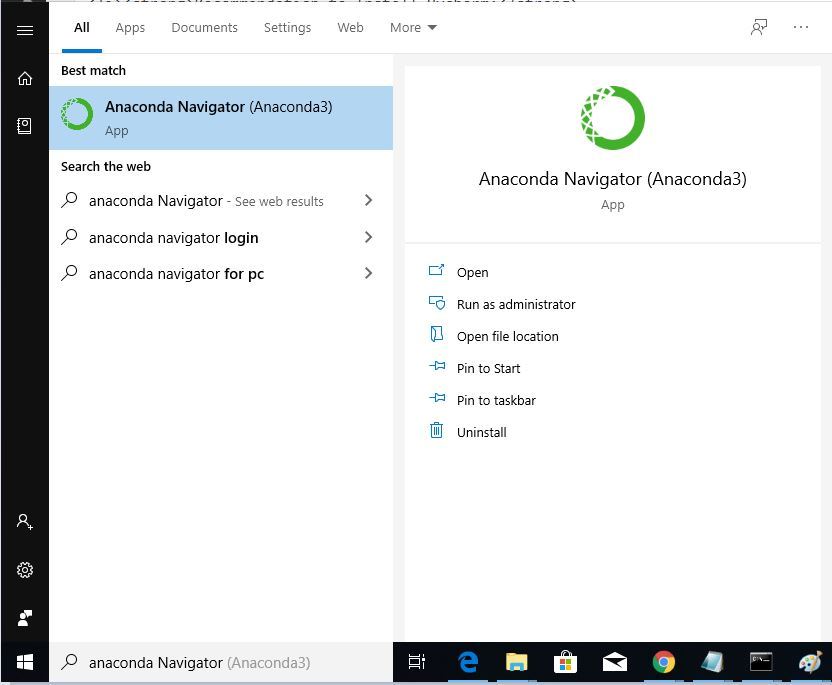
Step 2: Click on the Environment tab and then click on the create button to create a new Pandas Environment.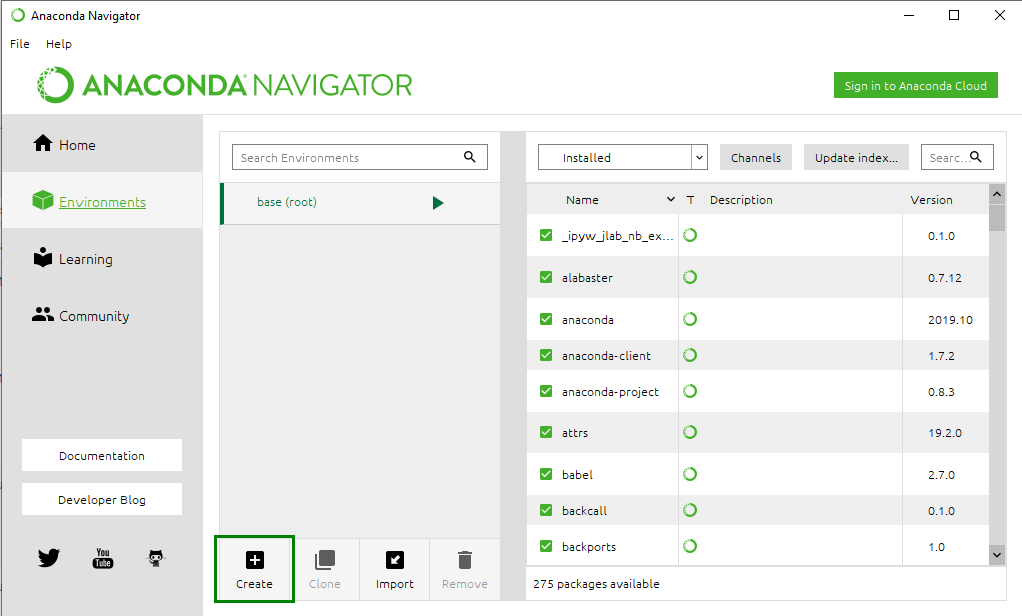
Step 3: Give a name to your Environment, e.g. Pandas and then choose a python version to run in the environment. Now click on the Create button to create Pandas Environment.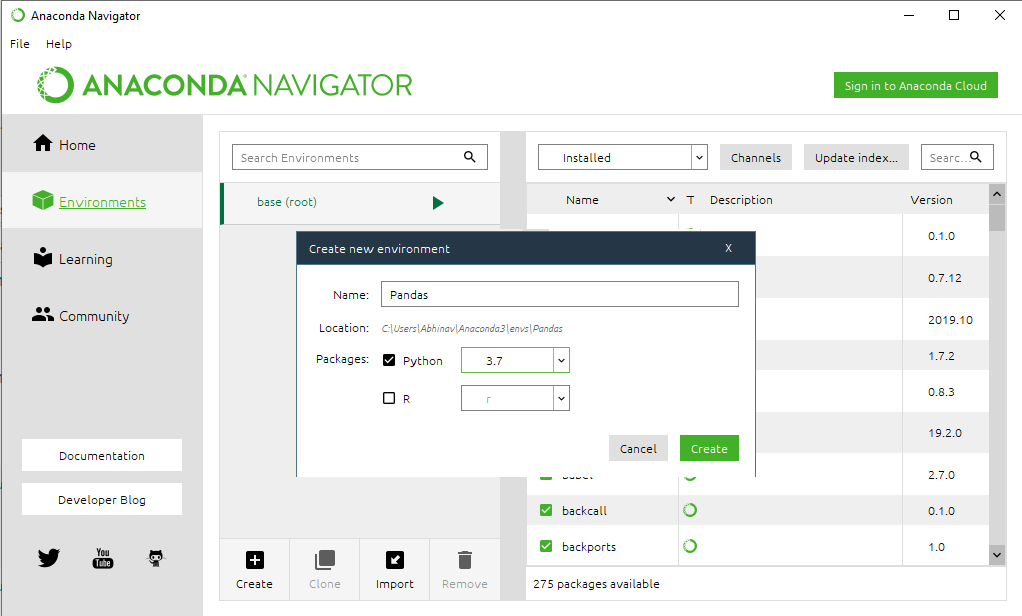
Step 4: Now click on the Pandas Environment created to activate it.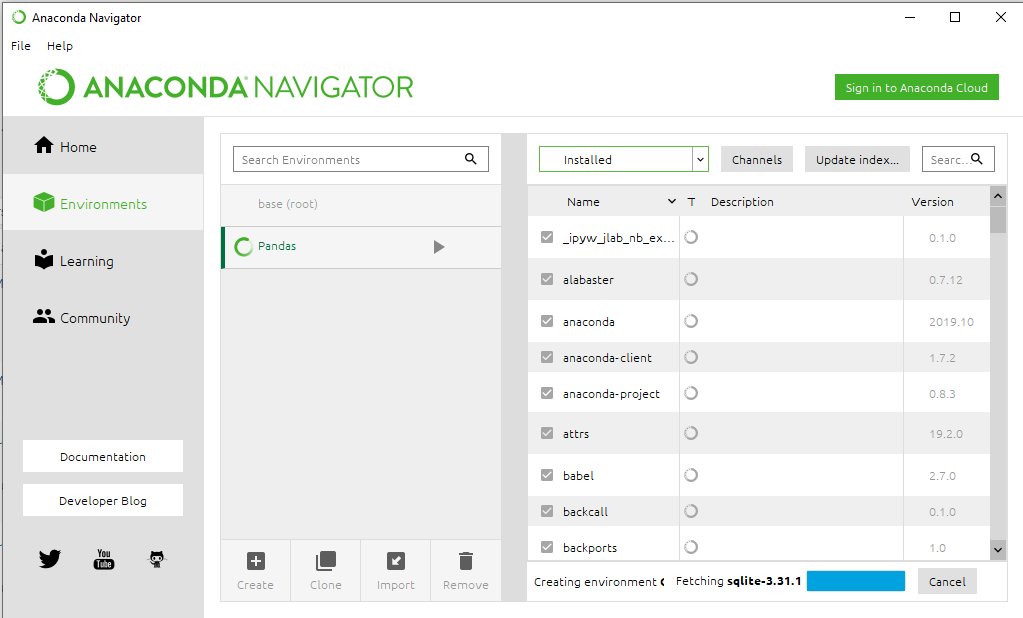
Step 5: In the list above package names, select All to filter all the packages.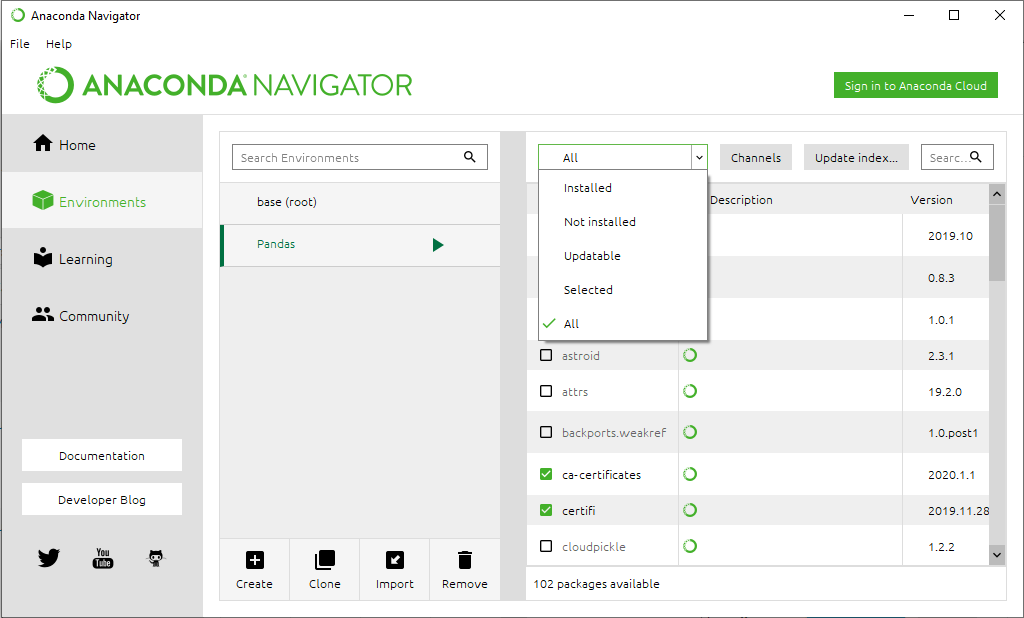
Step 6: Now in the Search Bar, look for ‘Pandas‘. Select the Pandas package for Installation.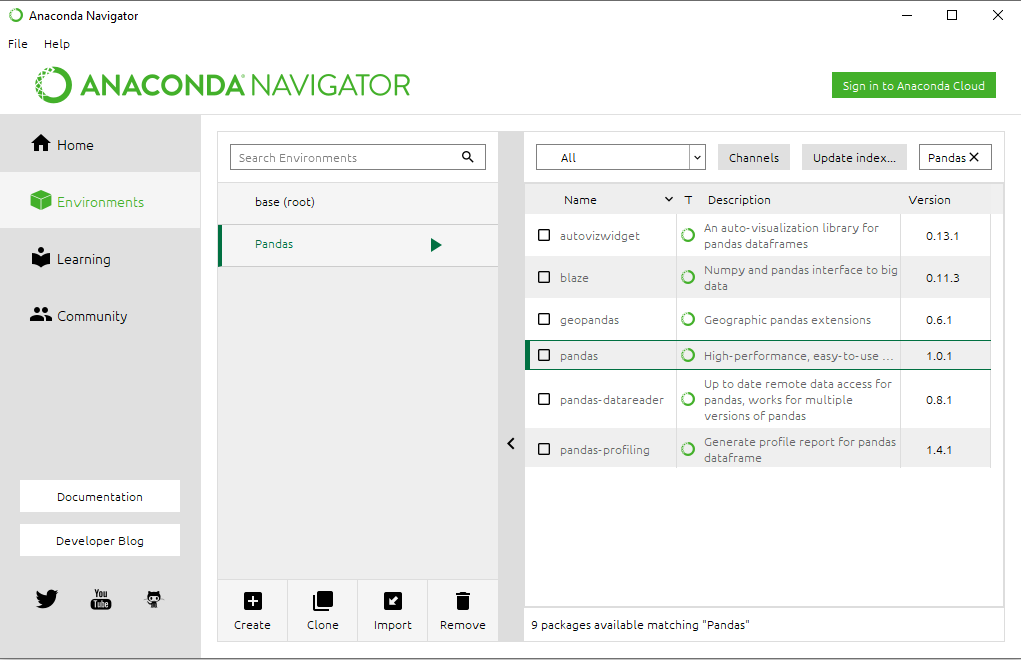
Step 7: Now Right Click on the checkbox given before the name of the package and then go to ‘Mark for specific version installation‘. Now select the version that you want to install.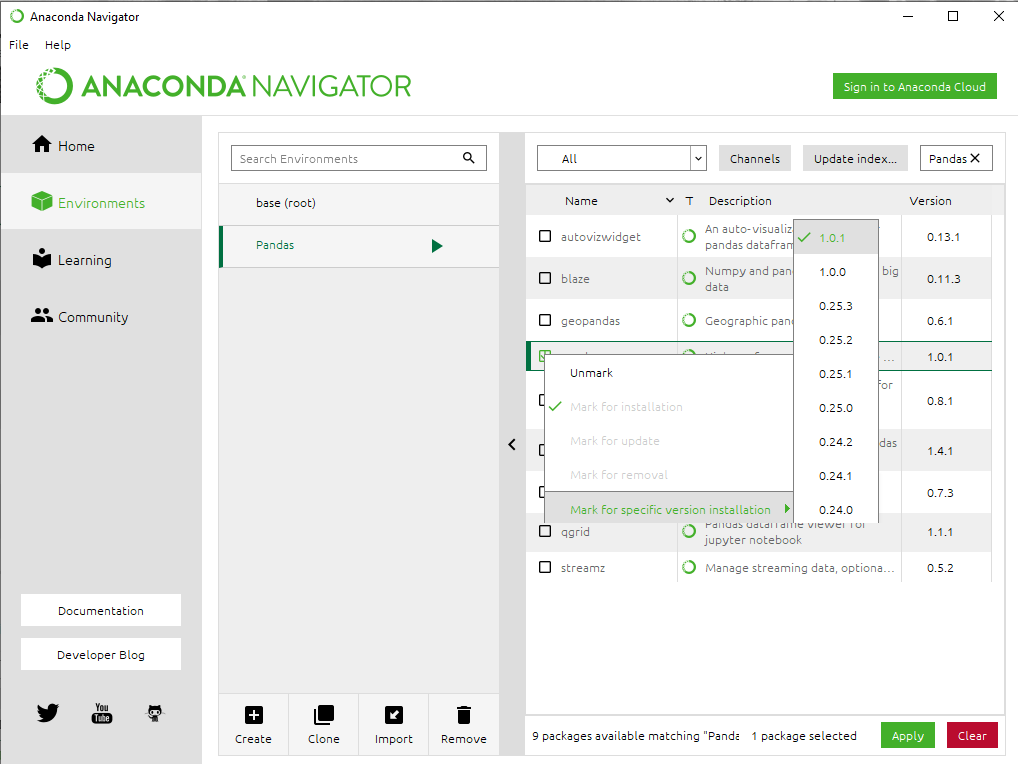
Step 8: Click on the Apply button to install the Pandas Package.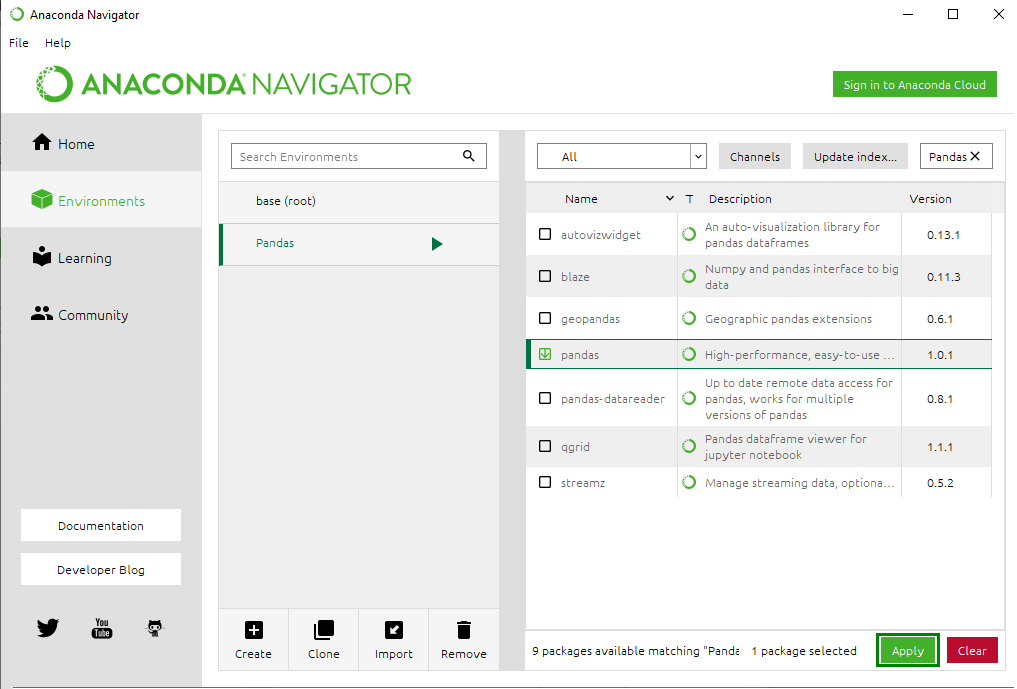
Step 9: Finish the Installation process by clicking on the Apply button.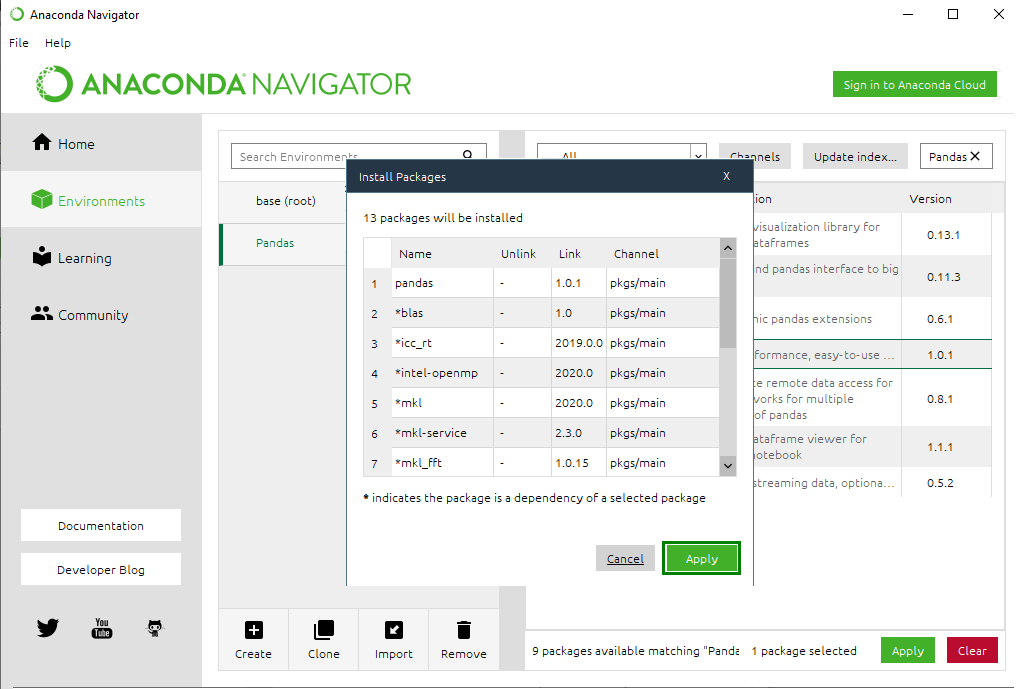
Step 10: Now to open the Pandas Environment, click on the Green Arrow on the right of package name and select the Console with which you want to begin your Pandas programming.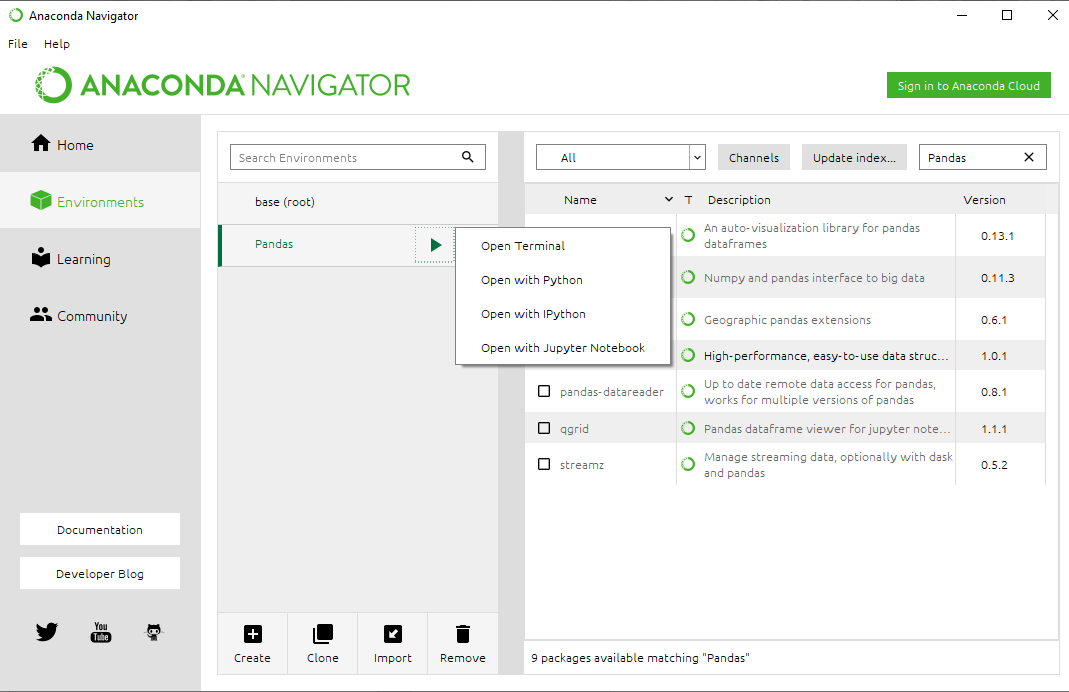
Pandas Terminal Window:
Linux
To install Pandas on Linux, just type the following command in the Terminal Window and press Enter. Linux will automatically download and install the packages and files required to run Pandas Environment in Python:
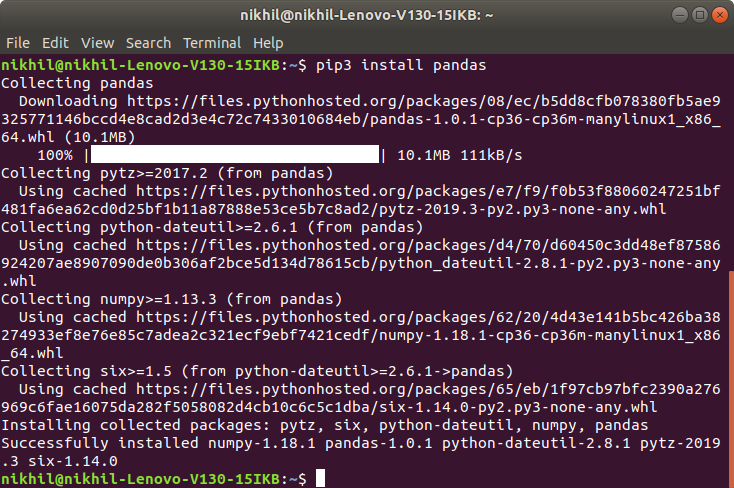
pip3 install pandas
Pandas in Python is a package that is written for data analysis and manipulation. Pandas offer various operations and data structures to perform numerical data manipulations and time series. Pandas is an open-source library that is built over Numpy libraries. Pandas library is known for its high productivity and high performance. Pandas is popular because it makes importing and analyzing data much easier.
Pandas programs can be written on any plain text editor like notepad, notepad++, or anything of that sort and saved with a .py extension. To begin with, writing Pandas Codes and performing various intriguing and useful operations, one must have Python installed on their System. This can be done by following the step by step instructions provided below:
What if Python already exists? Let’s check
To check if your device is pre-installed with Python or not, just go to the Command line(search for cmd in the Run dialog( + R).
Now run the following command:
python --version
If Python is already installed, it will generate a message with the Python version available.
To install Python, please visit: How to Install Python on Windows or Linux?
Downloading and Installing Pandas
Pandas can be installed in multiple ways on Windows and on Linux. Various different ways are listed below:
Windows
Python Pandas can be installed on Windows in two ways:
- Using pip
- Using Anaconda
Install Pandas using pip
PIP is a package management system used to install and manage software packages/libraries written in Python. These files are stored in a large “on-line repository” termed as Python Package Index (PyPI).
Pandas can be installed using PIP by the use of the following command:
pip install pandas
Install Pandas using Anaconda
Anaconda is open-source software that contains Jupyter, spyder, etc that are used for large data processing, data analytics, heavy scientific computing. If your system is not pre-equipped with Anaconda Navigator, you can learn how to install Anaconda Navigator on Windows or Linux?
Steps to Install Pandas using Anaconda Navigator:
Step 1: Search for Anaconda Navigator in Start Menu and open it.
Step 2: Click on the Environment tab and then click on the create button to create a new Pandas Environment.
Step 3: Give a name to your Environment, e.g. Pandas and then choose a python version to run in the environment. Now click on the Create button to create Pandas Environment.
Step 4: Now click on the Pandas Environment created to activate it.
Step 5: In the list above package names, select All to filter all the packages.
Step 6: Now in the Search Bar, look for ‘Pandas‘. Select the Pandas package for Installation.
Step 7: Now Right Click on the checkbox given before the name of the package and then go to ‘Mark for specific version installation‘. Now select the version that you want to install.
Step 8: Click on the Apply button to install the Pandas Package.
Step 9: Finish the Installation process by clicking on the Apply button.
Step 10: Now to open the Pandas Environment, click on the Green Arrow on the right of package name and select the Console with which you want to begin your Pandas programming.
Pandas Terminal Window:
Linux
To install Pandas on Linux, just type the following command in the Terminal Window and press Enter. Linux will automatically download and install the packages and files required to run Pandas Environment in Python:
pip3 install pandas
{{ header }}
Installation
The easiest way to install pandas is to install it
as part of the Anaconda distribution, a
cross platform distribution for data analysis and scientific computing.
This is the recommended installation method for most users.
Instructions for installing from source,
PyPI, ActivePython, various Linux distributions, or a
development version are also provided.
Python version support
Officially Python 3.8, 3.9, 3.10 and 3.11.
Installing pandas
Installing with Anaconda
Installing pandas and the rest of the NumPy and
SciPy stack can be a little
difficult for inexperienced users.
The simplest way to install not only pandas, but Python and the most popular
packages that make up the SciPy stack
(IPython, NumPy,
Matplotlib, …) is with
Anaconda, a cross-platform
(Linux, macOS, Windows) Python distribution for data analytics and
scientific computing.
After running the installer, the user will have access to pandas and the
rest of the SciPy stack without needing to install
anything else, and without needing to wait for any software to be compiled.
Installation instructions for Anaconda
can be found here.
A full list of the packages available as part of the
Anaconda distribution
can be found here.
Another advantage to installing Anaconda is that you don’t need
admin rights to install it. Anaconda can install in the user’s home directory,
which makes it trivial to delete Anaconda if you decide (just delete
that folder).
Installing with Miniconda
The previous section outlined how to get pandas installed as part of the
Anaconda distribution.
However this approach means you will install well over one hundred packages
and involves downloading the installer which is a few hundred megabytes in size.
If you want to have more control on which packages, or have a limited internet
bandwidth, then installing pandas with
Miniconda may be a better solution.
Conda is the package manager that the
Anaconda distribution is built upon.
It is a package manager that is both cross-platform and language agnostic
(it can play a similar role to a pip and virtualenv combination).
Miniconda allows you to create a
minimal self contained Python installation, and then use the
Conda command to install additional packages.
First you will need Conda to be installed and
downloading and running the Miniconda
will do this for you. The installer
can be found here
The next step is to create a new conda environment. A conda environment is like a
virtualenv that allows you to specify a specific version of Python and set of libraries.
Run the following commands from a terminal window:
conda create -n name_of_my_env python
This will create a minimal environment with only Python installed in it.
To put your self inside this environment run:
source activate name_of_my_env
On Windows the command is:
activate name_of_my_env
The final step required is to install pandas. This can be done with the
following command:
conda install pandas
To install a specific pandas version:
conda install pandas=0.20.3
To install other packages, IPython for example:
conda install ipython
To install the full Anaconda
distribution:
conda install anaconda
If you need packages that are available to pip but not conda, then
install pip, and then use pip to install those packages:
conda install pip pip install django
Installing from PyPI
pandas can be installed via pip from
PyPI.
Note
You must have pip>=19.3 to install from PyPI.
pip install pandas
pandas can also be installed with sets of optional dependencies to enable certain functionality. For example,
to install pandas with the optional dependencies to read Excel files.
pip install "pandas[excel]"
The full list of extras that can be installed can be found in the :ref:`dependency section.<install.optional_dependencies>`
Installing with ActivePython
Installation instructions for
ActivePython can be found
here. Versions
2.7, 3.5 and 3.6 include pandas.
Installing using your Linux distribution’s package manager.
The commands in this table will install pandas for Python 3 from your distribution.
| Distribution | Status | Download / Repository Link | Install method |
|---|---|---|---|
| Debian | stable | official Debian repository | sudo apt-get install python3-pandas |
| Debian & Ubuntu | unstable (latest packages) | NeuroDebian | sudo apt-get install python3-pandas |
| Ubuntu | stable | official Ubuntu repository | sudo apt-get install python3-pandas |
| OpenSuse | stable | OpenSuse Repository | zypper in python3-pandas |
| Fedora | stable | official Fedora repository | dnf install python3-pandas |
| Centos/RHEL | stable | EPEL repository | yum install python3-pandas |
However, the packages in the linux package managers are often a few versions behind, so
to get the newest version of pandas, it’s recommended to install using the pip or conda
methods described above.
Handling ImportErrors
If you encounter an ImportError, it usually means that Python couldn’t find pandas in the list of available
libraries. Python internally has a list of directories it searches through, to find packages. You can
obtain these directories with:
import sys sys.path
One way you could be encountering this error is if you have multiple Python installations on your system
and you don’t have pandas installed in the Python installation you’re currently using.
In Linux/Mac you can run which python on your terminal and it will tell you which Python installation you’re
using. If it’s something like «/usr/bin/python», you’re using the Python from the system, which is not recommended.
It is highly recommended to use conda, for quick installation and for package and dependency updates.
You can find simple installation instructions for pandas in this document: installation instructions </getting_started.html>.
Installing from source
See the :ref:`contributing guide <contributing>` for complete instructions on building from the git source tree. Further, see :ref:`creating a development environment <contributing_environment>` if you wish to create a pandas development environment.
Installing the development version of pandas
Installing a nightly build is the quickest way to:
- Try a new feature that will be shipped in the next release (that is, a feature from a pull-request that was recently merged to the main branch).
- Check whether a bug you encountered has been fixed since the last release.
You can install the nightly build of pandas using the scipy-wheels-nightly index from the PyPI registry of anaconda.org with the following command:
pip install --pre --extra-index https://pypi.anaconda.org/scipy-wheels-nightly/simple pandas
Note that first uninstalling pandas might be required to be able to install nightly builds:
pip uninstall pandas -y
Running the test suite
pandas is equipped with an exhaustive set of unit tests, covering about 97% of
the code base as of this writing. To run it on your machine to verify that
everything is working (and that you have all of the dependencies, soft and hard,
installed), make sure you have pytest >= 7.0 and Hypothesis >= 6.34.2, then run:
>>> pd.test() running: pytest --skip-slow --skip-network --skip-db /home/user/anaconda3/lib/python3.9/site-packages/pandas ============================= test session starts ============================== platform linux -- Python 3.9.7, pytest-6.2.5, py-1.11.0, pluggy-1.0.0 rootdir: /home/user plugins: dash-1.19.0, anyio-3.5.0, hypothesis-6.29.3 collected 154975 items / 4 skipped / 154971 selected ........................................................................ [ 0%] ........................................................................ [ 99%] ....................................... [100%] ==================================== ERRORS ==================================== =================================== FAILURES =================================== =============================== warnings summary =============================== =========================== short test summary info ============================ = 1 failed, 146194 passed, 7402 skipped, 1367 xfailed, 5 xpassed, 197 warnings, 10 errors in 1090.16s (0:18:10) =
This is just an example of what information is shown. You might see a slightly different result as what is shown above.
Dependencies
Required dependencies
pandas requires the following dependencies.
| Package | Minimum supported version |
|---|---|
| NumPy | 1.20.3 |
| python-dateutil | 2.8.2 |
| pytz | 2020.1 |
Optional dependencies
pandas has many optional dependencies that are only used for specific methods.
For example, :func:`pandas.read_hdf` requires the pytables package, while
:meth:`DataFrame.to_markdown` requires the tabulate package. If the
optional dependency is not installed, pandas will raise an ImportError when
the method requiring that dependency is called.
If using pip, optional pandas dependencies can be installed or managed in a file (e.g. requirements.txt or pyproject.toml)
as optional extras (e.g.,«pandas[performance, aws]>=1.5.0«). All optional dependencies can be installed with pandas[all],
and specific sets of dependencies are listed in the sections below.
Performance dependencies (recommended)
Note
You are highly encouraged to install these libraries, as they provide speed improvements, especially
when working with large data sets.
Installable with pip install "pandas[performance]"
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| numexpr | 2.7.3 | performance | Accelerates certain numerical operations by using uses multiple cores as well as smart chunking and caching to achieve large speedups |
| bottleneck | 1.3.2 | performance | Accelerates certain types of nan by using specialized cython routines to achieve large speedup. |
| numba | 0.53.1 | performance | Alternative execution engine for operations that accept engine="numba" using a JIT compiler that translates Python functions to optimized machine code using the LLVM compiler. |
Timezones
Installable with pip install "pandas[timezone]"
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| tzdata | 2022.1(pypi)/ 2022a(for system tzdata) |
timezone |
Allows the use of If you would like to keep your system tzdata version updated, |
Visualization
Installable with pip install "pandas[plot, output_formatting]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| matplotlib | 3.6.1 | plot | Plotting library |
| Jinja2 | 3.0.0 | output_formatting | Conditional formatting with DataFrame.style |
| tabulate | 0.8.9 | output_formatting | Printing in Markdown-friendly format (see tabulate) |
Computation
Installable with pip install "pandas[computation]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| SciPy | 1.7.1 | computation | Miscellaneous statistical functions |
| xarray | 0.21.0 | computation | pandas-like API for N-dimensional data |
Excel files
Installable with pip install "pandas[excel]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| xlrd | 2.0.1 | excel | Reading Excel |
| xlsxwriter | 1.4.3 | excel | Writing Excel |
| openpyxl | 3.0.7 | excel | Reading / writing for xlsx files |
| pyxlsb | 1.0.8 | excel | Reading for xlsb files |
HTML
Installable with pip install "pandas[html]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| BeautifulSoup4 | 4.9.3 | html | HTML parser for read_html |
| html5lib | 1.1 | html | HTML parser for read_html |
| lxml | 4.6.3 | html | HTML parser for read_html |
One of the following combinations of libraries is needed to use the
top-level :func:`~pandas.read_html` function:
- BeautifulSoup4 and html5lib
- BeautifulSoup4 and lxml
- BeautifulSoup4 and html5lib and lxml
- Only lxml, although see :ref:`HTML Table Parsing <io.html.gotchas>`
for reasons as to why you should probably not take this approach.
Warning
- if you install BeautifulSoup4 you must install either
lxml or html5lib or both.
:func:`~pandas.read_html` will not work with only
BeautifulSoup4 installed. - You are highly encouraged to read :ref:`HTML Table Parsing gotchas <io.html.gotchas>`.
It explains issues surrounding the installation and
usage of the above three libraries.
XML
Installable with pip install "pandas[xml]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| lxml | 4.6.3 | xml | XML parser for read_xml and tree builder for to_xml |
SQL databases
Installable with pip install "pandas[postgresql, mysql, sql-other]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| SQLAlchemy | 1.4.16 | postgresql, mysql, sql-other |
SQL support for databases other than sqlite |
| psycopg2 | 2.8.6 | postgresql | PostgreSQL engine for sqlalchemy |
| pymysql | 1.0.2 | mysql | MySQL engine for sqlalchemy |
Other data sources
Installable with pip install "pandas[hdf5, parquet, feather, spss, excel]"
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| PyTables | 3.6.1 | hdf5 | HDF5-based reading / writing |
| blosc | 1.21.0 | hdf5 | Compression for HDF5; only available on conda |
| zlib | hdf5 | Compression for HDF5 | |
| fastparquet | 0.6.3 |
|
Parquet reading / writing (pyarrow is default) |
| pyarrow | 7.0.0 | parquet, feather | Parquet, ORC, and feather reading / writing |
| pyreadstat | 1.1.2 | spss | SPSS files (.sav) reading |
| odfpy | 1.4.1 | excel | Open document format (.odf, .ods, .odt) reading / writing |
Warning
-
If you want to use :func:`~pandas.read_orc`, it is highly recommended to install pyarrow using conda.
The following is a summary of the environment in which :func:`~pandas.read_orc` can work.System
Conda
PyPI
Linux
Successful
Failed
macOS
Successful
Failed
Windows
Failed
Failed
Access data in the cloud
Installable with pip install "pandas[fss, aws, gcp]"
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| fsspec | 2021.7.0 | fss, gcp, aws | Handling files aside from simple local and HTTP (required dependency of s3fs, gcsfs). |
| gcsfs | 2021.7.0 | gcp | Google Cloud Storage access |
| pandas-gbq | 0.15.0 | gcp | Google Big Query access |
| s3fs | 2021.08.0 | aws | Amazon S3 access |
Clipboard
Installable with pip install "pandas[clipboard]".
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| PyQt4/PyQt5 | 5.15.1 | clipboard | Clipboard I/O |
| qtpy | 2.2.0 | clipboard | Clipboard I/O |
Note
Depending on operating system, system-level packages may need to installed.
For clipboard to operate on Linux one of the CLI tools xclip or xsel must be installed on your system.
Compression
Installable with pip install "pandas[compression]"
| Dependency | Minimum Version | pip extra | Notes |
|---|---|---|---|
| brotli | 0.7.0 | compression | Brotli compression |
| python-snappy | 0.6.0 | compression | Snappy compression |
| Zstandard | 0.15.2 | compression | Zstandard compression |
Установка¶
Проще всего установить pandas в составе Anaconda — кроссплатформенного дистрибутива для анализа данных и научных вычислений. Это рекомендуемый метод установки для большинства пользователей.
Здесь вы также найдете инструкции по установке из исходников, с помощью PyPI, ActivePython, различных дистрибутивов Linux и версию для разработки.
Поддержка версий Python¶
Официально поддерживается Python 3.8, 3.9 и 3.10.
Установка с помощью Anaconda¶
Установка pandas и остальной части стека NumPy и SciPy может быть немного сложной для неопытных пользователей.
Проще всего установить не только pandas, но и Python и самые популярные пакеты, составляющие стек SciPy (IPython , NumPy, Matplotlib и так далее) с использованием Anaconda — кроссплатформенного (Linux, macOS, Windows) дистрибутива Python для анализа данных и научных вычислений.
После запуска установщика пользователь получит доступ к pandas и остальной части стека SciPy без необходимости устанавливать что-либо еще и без необходимости ждать, пока какое-либо программное обеспечение будет скомпилировано.
Инструкции по установке Anaconda можно найти здесь.
Полный список пакетов, доступных в составе дистрибутива Anaconda, можно найти здесь.
Еще одним преимуществом установки Anaconda является то, что вам не нужны права администратора для ее установки. Anaconda может быть установлена в домашнем каталоге пользователя, что упрощает удаление Anaconda в случае необходимости (просто удалите эту папку).
Установка с помощью Miniconda¶
В предыдущем разделе было описано, как установить pandas в составе дистрибутива Anaconda. Однако этот подход означает, что вы установите более сотни пакетов и предполагает загрузку установщика, размер которого составляет несколько сотен мегабайт.
Если вы хотите иметь больший контроль над пакетами или пропускная способность интернета у вас ограничена, то установка pandas с помощью Miniconda может вам подойти лучше.
Conda — это менеджер пакетов, на котором построен дистрибутив Anaconda. Это менеджер пакетов, который является одновременно кроссплатформенным и независимым от языка (он похож на комбинацию pip и virtualenv).
Miniconda позволяет вам создать минимальную автономную установку Python, а затем использовать команды Conda для установки дополнительных пакетов (см. краткое руководство по Miniconda на русском).
Сначала вам нужно установить Conda, и загрузка и запуск Miniconda решит эту задачу. Установщик можно найти здесь.
Следующим шагом является создание новой среды conda. Виртуальная среда conda похожа на ту, которая создается virtualenv, она позволяет указать конкретную версию Python и набор библиотек. Запустите следующие команды из окна терминала:
conda create -n name_of_my_env python
Это создаст минимальную среду, в которой будет установлен только Python. Чтобы активировать эту среду, запустите:
source activate name_of_my_env
В Windows команда следующая:
Последним шагом необходимо установить pandas. Это можно сделать с помощью следующей команды:
Установить определенную версию pandas:
conda install pandas=0.20.3
Установить другие пакеты, например, IPython:
Установить полный дистрибутив Anaconda:
Если вам нужны пакеты, доступные для pip, но не для conda, установите pip, а затем используйте pip для установки этих пакетов:
conda install pip pip install django
Установка из PyPI¶
pandas можно установить через pip из PyPI.
Примечание
У вас должен быть pip>=19.3 для установки из PyPI.
Установка с ActivePython¶
Инструкции по установке ActivePython можно найти здесь. Версии 2.7, 3.5 и 3.6 включают pandas.
Установка с помощью менеджера пакетов вашего дистрибутива Linux.¶
Команды в этой таблице установят pandas для Python 3 из вашего дистрибутива.
|
Дистрибутив |
Статус |
Ссылка на скачивание / репозиторий |
Команда для установки |
|---|---|---|---|
|
Debian |
стабильный |
Официальный репозиторий Debian |
|
|
Debian & Ubuntu |
нестабильный (последние пакеты) |
NeuroDebian |
|
|
Ubuntu |
стабильный |
Официальный репозиторий Ubuntu |
|
|
OpenSuse |
стабильный |
Репозиторий OpenSuse |
|
|
Fedora |
стабильный |
Официальный репозиторий Fedora |
|
|
Centos/RHEL |
стабильный |
Репозиторий EPEL |
|
Однако пакеты в менеджерах пакетов linux часто отстают на несколько версий, поэтому, чтобы получить новейшую версию pandas, рекомендуется устанавливать ее с помощью команд pip или conda, описанных выше.
Обработка ошибок импорта¶
Если вы столкнулись с ошибкой ImportError, это обычно означает, что Python не смог найти pandas в списке доступных библиотек. Внутри Python есть список каталогов, в которых он ищет пакеты. Вы можете получить список этих каталогов с помощью команды:
Одна из возможных причин ошибки — это если Python в системе установлен более одного раза, и pandas не установлен в том Python, который вы используете на текущий момент. В Linux/Mac вы можете запустить what python на своем терминале, и он сообщит вам, какой Python вы используете. Если это что-то вроде «/usr/bin/python», вы используете Python из системы, что не рекомендуется.
Настоятельно рекомендуется использовать conda для быстрой установки и обновления пакетов и зависимостей. Вы можете найти простые инструкции по установке pandas в этом документе.
Установка из исходников¶
Полные инструкции по сборке из исходного дерева git см. в Contributing guide. Если вы хотите создать среду разработки pandas, смотрите Creating a development environment.
Запуск набора тестов¶
pandas оснащен исчерпывающим набором модульных тестов, покрывающих около 97% кодовой базы на момент написания этой статьи. Чтобы запустить его на своем компьютере и удостовериться, что все работает (и что у вас установлены все зависимости, программные и аппаратные), убедитесь, что у вас есть pytest >= 6.0 и Hypothesis >= 3.58, затем запустите:
>>> pd.test() running: pytest --skip-slow --skip-network C:UsersTPAnaconda3envspy36libsite-packagespandas ============================= test session starts ============================= platform win32 -- Python 3.6.2, pytest-3.6.0, py-1.4.34, pluggy-0.4.0 rootdir: C:UsersTPDocumentsPythonpandasdevpandas, inifile: setup.cfg collected 12145 items / 3 skipped ..................................................................S...... ........S................................................................ ......................................................................... ==================== 12130 passed, 12 skipped in 368.339 seconds =====================
Зависимости¶
|
Пакет |
Минимальная поддерживаемая версия |
|---|---|
|
NumPy |
1.18.5 |
|
python-dateutil |
2.8.1 |
|
pytz |
2020.1 |
Рекомендуемые зависимости¶
-
numexpr: для ускорения некоторых числовых операций. numexpr использует несколько ядер, а также интеллектуальное разбиение на фрагменты и кэширование для достижения значительного ускорения. Установленная версия должна быть 2.7.1 или выше.
-
bottleneck: для ускорения определенных типов оценок
nan. bottleneck использует специализированные подпрограммы cython для достижения больших ускорений. Установленная версия должна быть 1.3.1 или выше.
Примечание
Настоятельно рекомендуется установить эти библиотеки, поскольку они обеспечивают повышение скорости, особенно при работе с большими наборами данных.
Дополнительные зависимости¶
pandas имеет множество необязательных зависимостей, которые используются только для определенных методов. Например, для pandas.read_hdf() требуется пакет pytables, а для DataFrame.to_markdown() – пакет tabulate. Если необязательная зависимость не установлена, pandas выведет ImportError при вызове метода, требующего этой зависимости.
Визуализация¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
matplotlib |
3.3.2 |
Библиотека графиков |
|
Jinja2 |
2.11 |
Условное форматирование с DataFrame.style |
|
tabulate |
0.8.7 |
Печать в формате, дружественном к Markdown (см. tabulate) |
Вычисления¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
SciPy |
1.14.1 |
Дополнительные статистические функции |
|
numba |
0.50.1 |
Альтернативный механизм выполнения операций прокатки (см. Enhancing performance) |
|
xarray |
0.15.1 |
pandas-подобный API для N-мерных данных |
Файлы Excel¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
XLRD |
2.0.1 |
Чтение Excel |
|
xlwt |
1.3.0 |
Запись Excel |
|
xlsxwriter |
1.2.2 |
Запись Excel |
|
openpyxl |
3.0.3 |
Чтение и запись файлов xlsx |
|
pyxlsb |
1.0.6 |
Чтение файлов xlsb |
HTML¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
BeautifulSoup4 |
4.8.2 |
Парсер HTML для read_html |
|
html5lib |
1.1 |
Парсер HTML для read_html |
|
lxml |
4.5.0 |
Парсер HTML для read_html |
Для использования функции верхнего уровня read_html() необходима одна из следующих комбинаций библиотек:
-
BeautifulSoup4 и html5lib
-
BeautifulSoup4 и lxml
-
BeautifulSoup4 и html5lib и lxml
-
Только lxml, хотя в HTML Table Parsing Gotchas объясняется, почему вам, вероятно, не следует использовать этот подход.
Предупреждение
-
Если вы устанавливаете BeautifulSoup4, вы должны установить либо lxml, либо html5lib, либо оба.
read_html()не работает, если установлен только BeautifulSoup4 (см. подробнее о парсерах в документации BeautifulSoup на русском). -
Настоятельно рекомендуется прочитать HTML Table Parsing Gotchas. Там объясняются проблемы, связанные с установкой и использованием трех вышеуказанных библиотек.
XML¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
lxml |
4.5.0 |
Анализатор XML для read_xml и построитель дерева для to_xml |
Базы данных SQL¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
SQLAlchemy |
1.4.0 |
Поддержка SQL для баз данных, отличных от sqlite |
|
psycopg2 |
2.8.4 |
Движок PostgreSQL для sqlalchemy |
|
pymysql |
0.10.1 |
Движок MySQL для sqlalchemy |
Другие источники данных¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
PyTables |
3.6.1 |
Чтение и запись на основе HDF5 |
|
blosc |
1.20.1 |
Сжатие для HDF5 |
|
zlib |
Сжатие для HDF5 |
|
|
fastparquet |
0.4.0 |
Чтение и запись parquet |
|
pyarrow |
1.0.1 |
Чтение и запись parquet, ORC и feather |
|
pyreadstat |
1.1.0 |
Чтение файлов SPSS (.sav) |
Предупреждение
-
Если вы хотите использовать
read_orc(), настоятельно рекомендуется установить pyarrow с помощью conda. Ниже приводится краткое описание среды, в которой может работатьread_orc().Система
Conda
PyPI
Linux
Успешно
Ошибка (pyarrow == 3.0 Успешно)
macOS
Успешно
Не удалось
Windows
Не удалось
Не удалось
Доступ к данным в облаке¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
fsspec |
0.7.4 |
Обработка файлов помимо простых локальных и HTTP |
|
gcsfs |
0.6.0 |
Доступ к облачному хранилищу Google |
|
pandas-gbq |
0.14.0 |
Доступ к Google Big Query |
|
s3fs |
0.4.0 |
Доступ к Amazon S3 |
Буфер обмена¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
PyQt4/PyQt5 |
Ввод и вывод буфера обмена |
|
|
qtpy |
Ввод и вывод буфера обмена |
|
|
xclip |
Ввод и вывод буфера обмена в Linux |
|
|
xsel |
Ввод и вывод буфера обмена в Linux |
Сжатие¶
|
Зависимость |
Минимальная версия |
Примечания |
|---|---|---|
|
Zstandard |
Сжатие Zstandard |
pip install pandas
The Python pandas library is among the top 100 Python libraries, with more than 81,118,623 downloads. This article will show you everything you need to get this installed in your Python environment.
- Library Link
How to Install pandas on Windows?
- Type
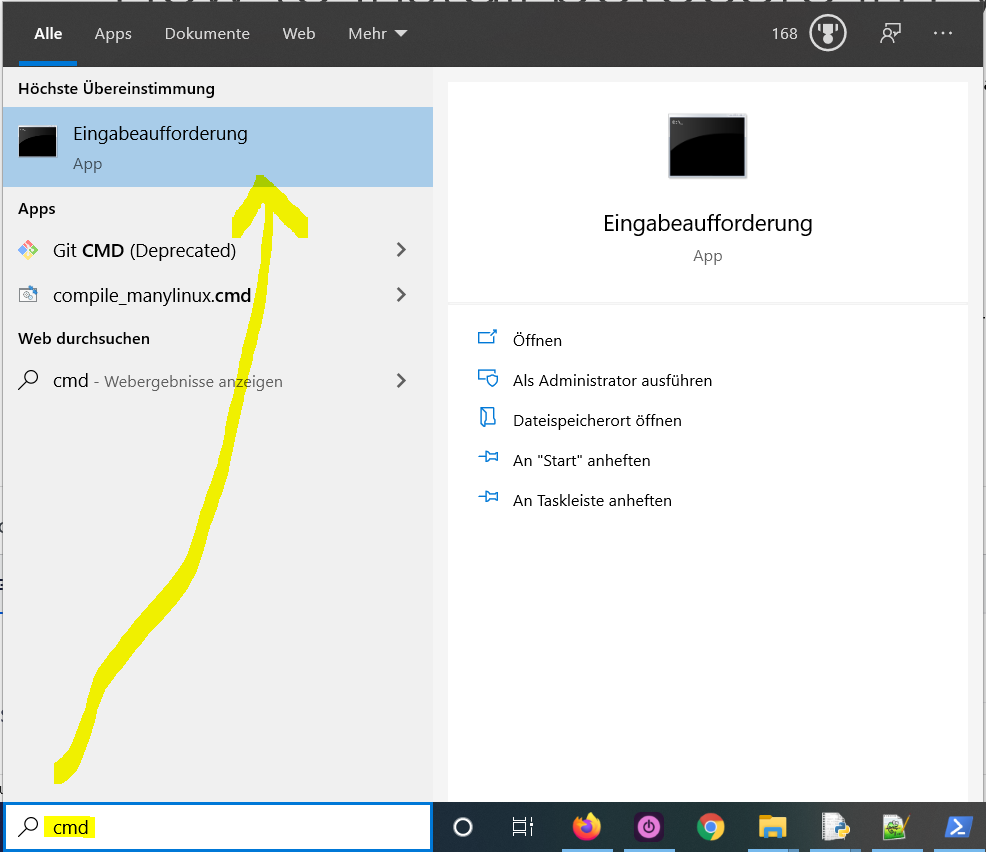
"cmd"in the search bar and hitEnterto open the command line. - Type “
pip install pandas” (without quotes) in the command line and hitEnteragain. This installs pandas for your default Python installation. - The previous command may not work if you have both Python versions 2 and 3 on your computer. In this case, try
"pip3 install pandas"or “python -m pip install pandas“. - Wait for the installation to terminate successfully. It is now installed on your Windows machine.
Here’s how to open the command line on a (German) Windows machine:
First, try the following command to install pandas on your system:
pip install pandas
Second, if this leads to an error message, try this command to install pandas on your system:
pip3 install pandas
Third, if both do not work, use the following long-form command:
python -m pip install pandas
The difference between pip and pip3 is that pip3 is an updated version of pip for Python version 3. Depending on what’s first in the PATH variable, pip will refer to your Python 2 or Python 3 installation—and you cannot know which without checking the environment variables. To resolve this uncertainty, you can use pip3, which will always refer to your default Python 3 installation.
How to Install pandas on Linux?
You can install pandas on Linux in four steps:
- Open your Linux terminal or shell
- Type “
pip install pandas” (without quotes), hit Enter. - If it doesn’t work, try
"pip3 install pandas"or “python -m pip install pandas“. - Wait for the installation to terminate successfully.
The package is now installed on your Linux operating system.
How to Install pandas on macOS?
Similarly, you can install pandas on macOS in four steps:
- Open your macOS terminal.
- Type “
pip install pandas” without quotes and hitEnter. - If it doesn’t work, try
"pip3 install pandas"or “python -m pip install pandas“. - Wait for the installation to terminate successfully.
The package is now installed on your macOS.
Given a PyCharm project. How to install the pandas library in your project within a virtual environment or globally? Here’s a solution that always works:
- Open
File > Settings > Projectfrom the PyCharm menu. - Select your current project.
- Click the
Python Interpretertab within your project tab. - Click the small
+symbol to add a new library to the project. - Now type in the library to be installed, in your example
"pandas"without quotes, and clickInstall Package. - Wait for the installation to terminate and close all pop-ups.
Here’s the general package installation process as a short animated video—it works analogously for pandas if you type in “pandas” in the search field instead:
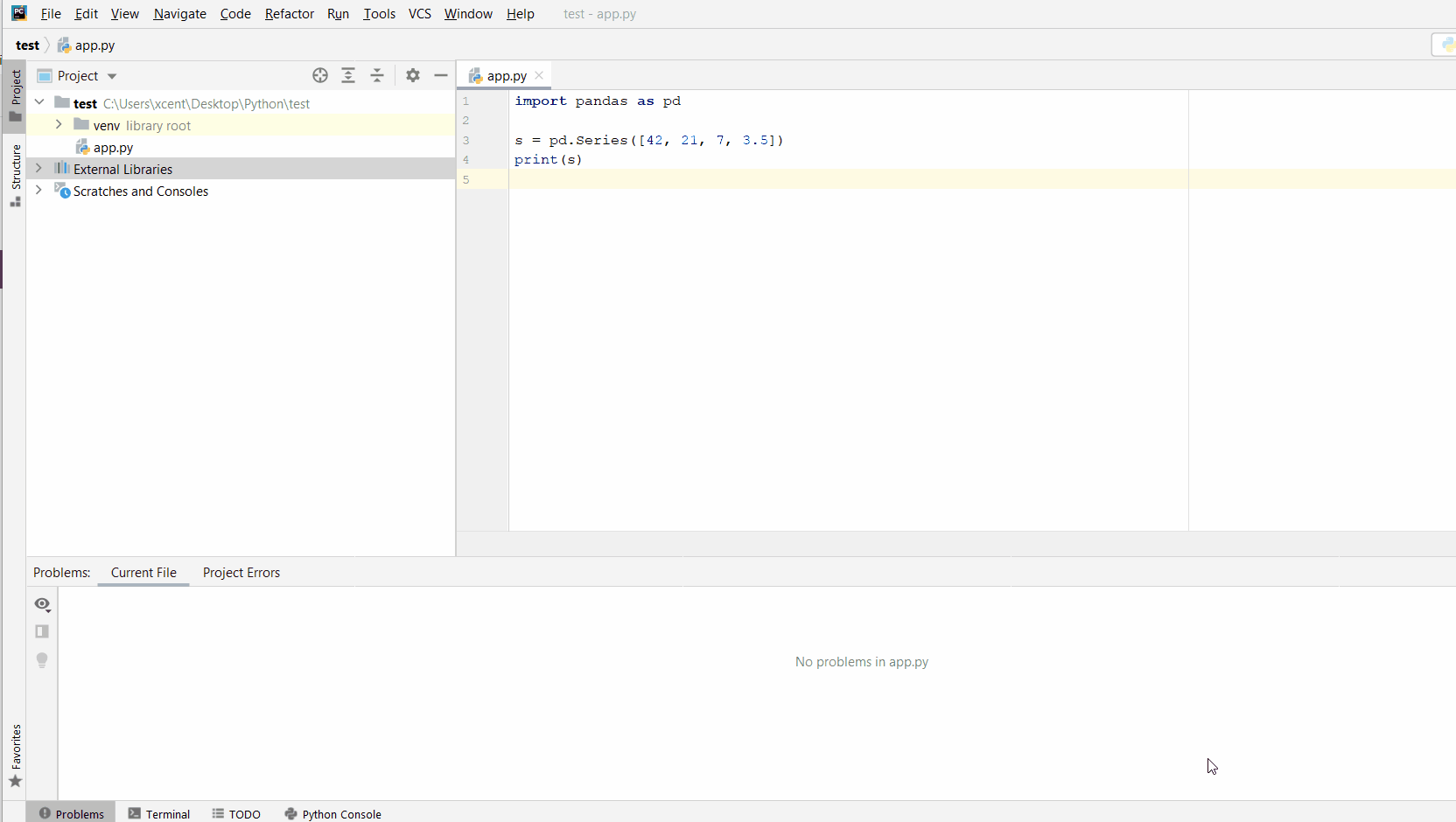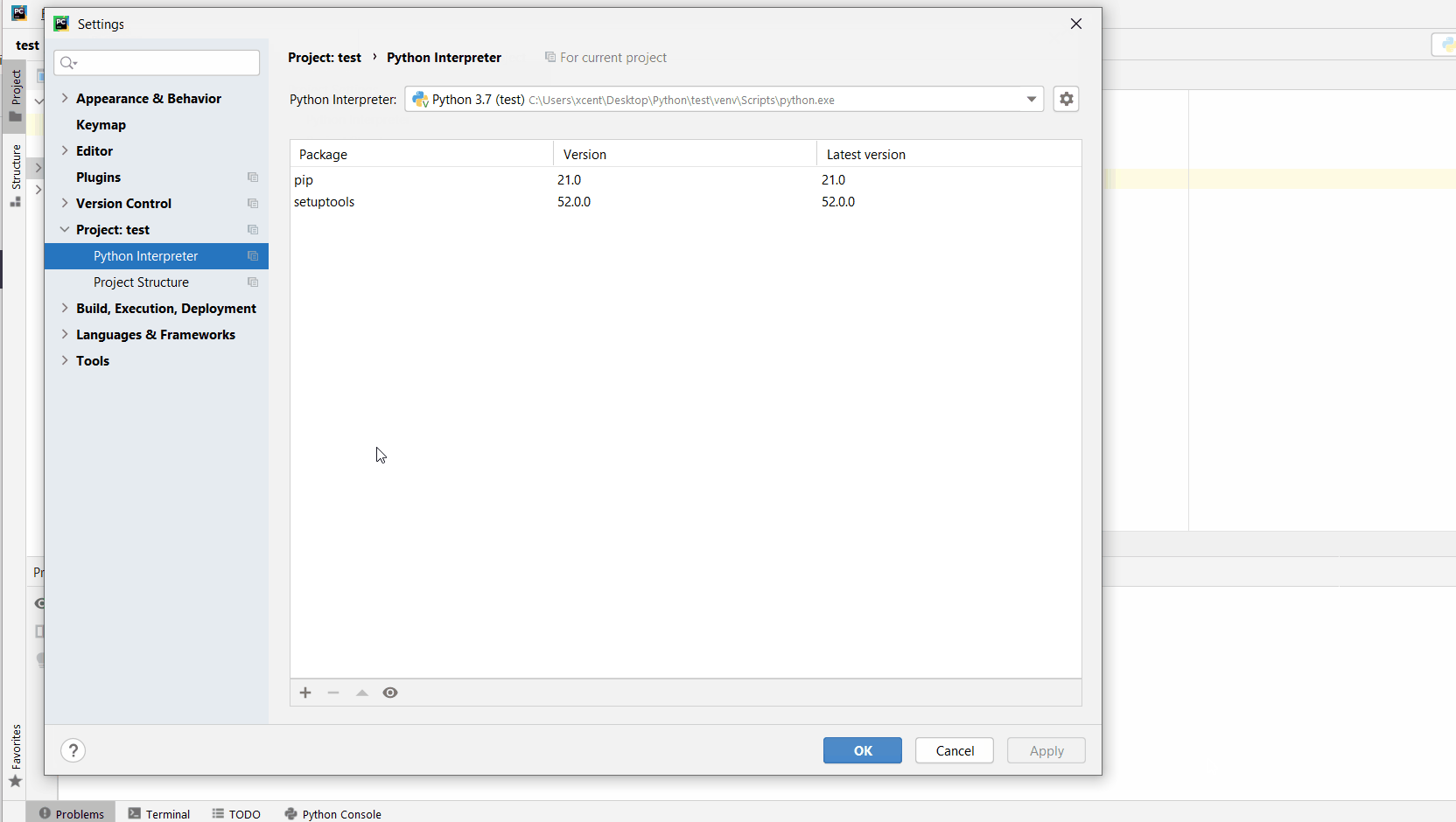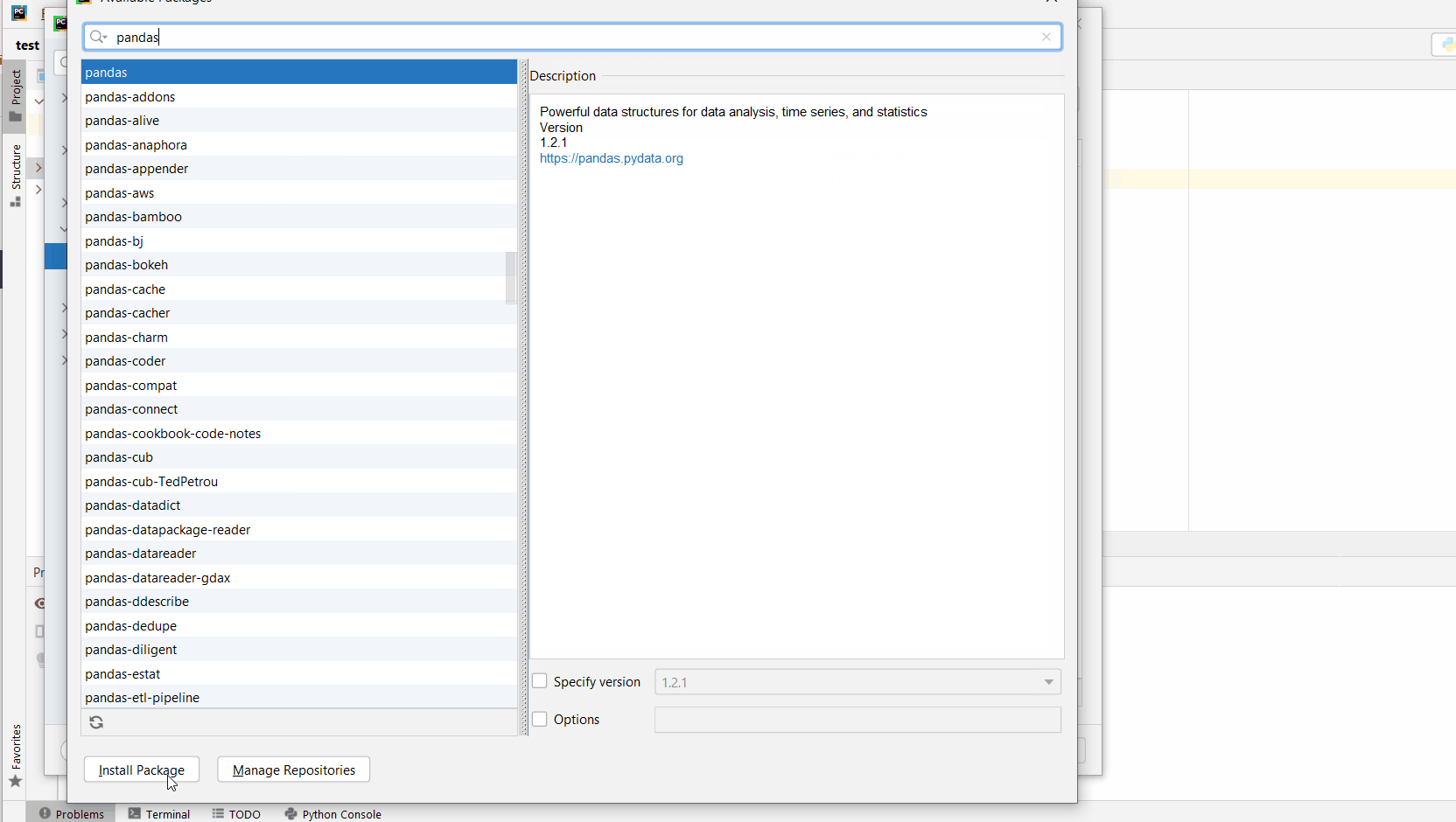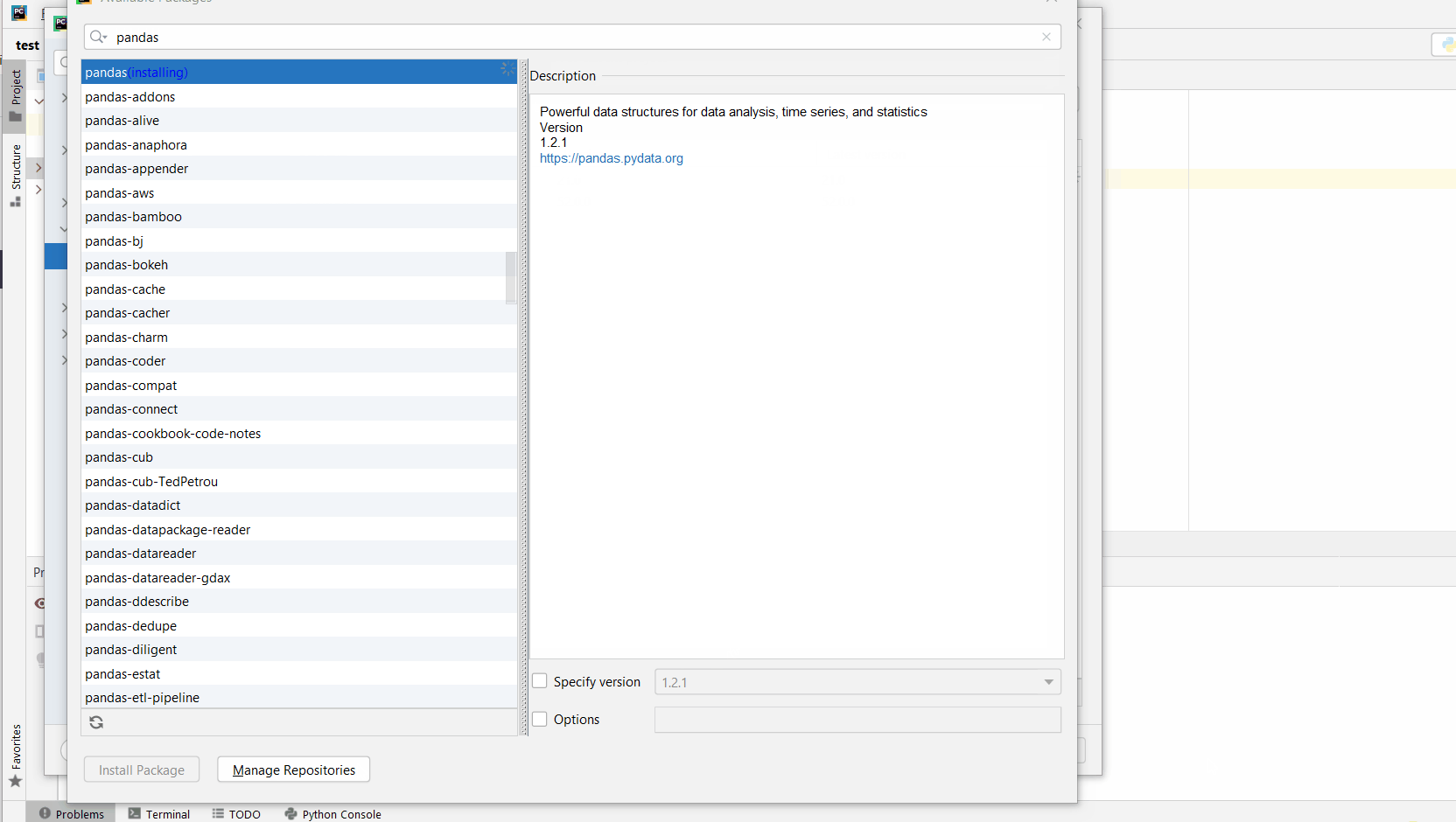
Make sure to select only “pandas” because there may be other packages that are not required but also contain the same term (false positives):
How to Install pandas in a Jupyter Notebook?
To install any package in a Jupyter notebook, you can prefix the !pip install my_package statement with the exclamation mark "!". This works for the pandas library too:
!pip install my_package
This automatically installs the pandas library when the cell is first executed.
How to Resolve ModuleNotFoundError: No module named ‘pandas’?
Say you try to import the pandas package into your Python script without installing it first:
import pandas # ... ModuleNotFoundError: No module named 'pandas'
Because you haven’t installed the package, Python raises a ModuleNotFoundError: No module named 'pandas'.
To fix the error, install the pandas library using “pip install pandas” or “pip3 install pandas” in your operating system’s shell or terminal first.
See above for the different ways to install pandas in your environment.
Improve Your Python Skills
If you want to keep improving your Python skills and learn about new and exciting technologies such as Blockchain development, machine learning, and data science, check out the Finxter free email academy with cheat sheets, regular tutorials, and programming puzzles.
Join us, it’s fun! 🙂
Programmer Humor – Blockchain

While working as a researcher in distributed systems, Dr. Christian Mayer found his love for teaching computer science students.
To help students reach higher levels of Python success, he founded the programming education website Finxter.com. He’s author of the popular programming book Python One-Liners (NoStarch 2020), coauthor of the Coffee Break Python series of self-published books, computer science enthusiast, freelancer, and owner of one of the top 10 largest Python blogs worldwide.
His passions are writing, reading, and coding. But his greatest passion is to serve aspiring coders through Finxter and help them to boost their skills. You can join his free email academy here.