Перевод
Ссылка на автора

Последние несколько месяцев я работал над проектом Data Science, который обрабатывает огромный набор данных, и стало необходимым использовать распределенную среду, предоставляемую Apache PySpark.
Я много боролся при установке PySpark на Windows 10. Поэтому я решил написать этот блог, чтобы помочь любому легко установить и использовать Apache PySpark на компьютере с Windows 10.
1. Шаг 1
PySpark требует Java версии 7 или новее и Python версии 2.6 или новее. Давайте сначала проверим, установлены ли они, или установим их и убедимся, что PySpark может работать с этими двумя компонентами.
Установка Java
Проверьте, установлена ли на вашем компьютере Java версии 7 или новее. Для этого выполните следующую команду в командной строке.

Если Java установлена и настроена для работы из командной строки, выполнение вышеуказанной команды должно вывести информацию о версии Java на консоль. Иначе, если вы получите сообщение, подобное:
«Java» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл.
тогда вы должны установить Java.
а) Для этого скачайте Java из Скачать бесплатное программное обеспечение Java
б) Получить Windows x64 (например, jre-8u92-windows-x64.exe), если вы не используете 32-разрядную версию Windows, в этом случае вам нужно получитьWindows x86 Offlineверсия.
в) Запустите установщик.
d) После завершения установки закройте текущую командную строку, если она уже была открыта, снова откройте ее и проверьте, можете ли вы успешно запуститьJava — версиякоманда.
2. Шаг 2
питон
Python используется многими другими программными инструментами. Поэтому вполне возможно, что требуемая версия (в нашем случае версия 2.6 или более поздняя) уже доступна на вашем компьютере. Чтобы проверить, доступен ли Python и найти его версию, откройте командную строку и введите командуPython — версия
Если Python установлен и настроен для работы из командной строки, при выполнении вышеуказанной команды информация о версии Python должна выводиться на консоль. Например, я получил следующий вывод на моем ноутбуке:
C: Users uug20> python —version
Python 3.7.3
Вместо этого, если вы получите сообщение, как
«Python» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл ».
Это означает, что вам нужно установить Python. Для этого
а) Перейти к питону скачать стр.
б) НажмитеПоследний выпуск Python 2ссылка.
c) Загрузите установочный файл MSI для Windows x86–64. Если вы используете 32-разрядную версию Windows, загрузите установочный файл MSI для Windows x86.
г) Когда вы запускаете установщик, наНастроить Pythonраздел, убедитесь, что опцияДобавить python.exe в путьвыбран. Если этот параметр не выбран, некоторые утилиты PySpark, такие как pyspark и spark-submit, могут не работать.
e) После завершения установки закройте командную строку, если она уже была открыта, снова откройте ее и проверьте, можете ли вы успешно запуститьPython — версиякоманда.
3. Шаг 3
Установка Apache Spark
а) Перейти к искре скачать стр.
б) Выберите последнюю стабильную версию Spark.
с)Выберите тип упаковки: sвыберите версию, предварительно созданную для последней версии Hadoop, такую какПредварительно построен для Hadoop 2.6,
г)Выберите тип загрузки:ВыбратьПрямое скачивание,
д) Нажмите на ссылку рядом сСкачать Sparkзагрузить заархивированный tar-файл, заканчивающийся расширением .tgz, такой как spark-1.6.2-bin-hadoop2.6.tgz.
f) Для установки Apache Spark вам не нужно запускать какой-либо установщик. Извлеките файлы из загруженного tar-файла в любую папку по вашему выбору, используя 7Zip инструмент / другие инструменты для разархивирования.
Убедитесь, что путь к папке и имя папки, содержащей файлы Spark, не содержат пробелов.
Я создал папку с именем spark на моем диске D и распаковал заархивированный tar-файл в папку с именем spark-2.4.3-bin-hadoop2.7. Таким образом, все файлы Spark находятся в папке с именем D: spark spark-2.4.3-bin-hadoop2.7. Давайте назовем эту папку SPARK_HOME в этом посте.
Чтобы проверить успешность установки, откройте командную строку, перейдите в каталог SPARK_HOME и введите bin pyspark. Это должно запустить оболочку PySpark, которую можно использовать для интерактивной работы со Spark.
Последнее сообщение содержит подсказку о том, как работать со Spark в оболочке PySpark с использованием имен sc или sqlContext. Например, при вводе sc.version в оболочке должна появиться версия Spark. Вы можете выйти из оболочки PySpark так же, как вы выходите из любой оболочки Python — набрав exit ().
Оболочка PySpark выводит несколько сообщений при выходе. Поэтому вам нужно нажать Enter, чтобы вернуться в командную строку.
4. Шаг 4
Настройка установки Spark
Первоначально, когда вы запускаете оболочку PySpark, она выдает много сообщений типа INFO, ERROR и WARN. Давайте посмотрим, как удалить эти сообщения.
Установка Spark в Windows по умолчанию не включает утилиту winutils.exe, которая используется Spark. Если вы не укажете своей установке Spark, где искать winutils.exe, вы увидите сообщения об ошибках при запуске оболочки PySpark, такие как
«ОШИБКА Shell: не удалось найти двоичный файл winutils в двоичном пути hadoop java.io.IOException: не удалось найти исполняемый файл null bin winutils.exe в двоичных файлах Hadoop».
Это сообщение об ошибке не препятствует запуску оболочки PySpark. Однако если вы попытаетесь запустить автономный скрипт Python с помощью утилиты bin spark-submit, вы получите ошибку. Например, попробуйте запустить скрипт wordcount.py из папки примеров в командной строке, когда вы находитесь в каталоге SPARK_HOME.
«Bin spark-submit examples src main python wordcount.py README.md»
Установка winutils
Давайте загрузим winutils.exe и сконфигурируем нашу установку Spark, чтобы найти winutils.exe.
a) Создайте папку hadoop bin внутри папки SPARK_HOME.
б) Скачать winutils.exe для версии hadoop, для которой была создана ваша установка Spark. В моем случае версия hadoop была 2.6.0. Так что я загруженное winutils.exe для hadoop 2.6.0 и скопировал его в папку hadoop bin в папке SPARK_HOME.
c) Создайте системную переменную среды в Windows с именем SPARK_HOME, которая указывает путь к папке SPARK_HOME.
d) Создайте в Windows другую переменную системной среды с именем HADOOP_HOME, которая указывает на папку hadoop внутри папки SPARK_HOME.
Поскольку папка hadoop находится внутри папки SPARK_HOME, лучше создать переменную среды HADOOP_HOME, используя значение% SPARK_HOME% hadoop. Таким образом, вам не нужно менять HADOOP_HOME, если SPARK_HOME обновлен.
Если вы теперь запустите сценарий bin pyspark из командной строки Windows, сообщения об ошибках, связанные с winutils.exe, должны исчезнуть.
5. Шаг 5
Настройка уровня журнала для Spark
Каждый раз при запуске или выходе из оболочки PySpark или при запуске утилиты spark-submit остается много дополнительных сообщений INFO. Итак, давайте внесем еще одно изменение в нашу установку Spark, чтобы в консоль записывались только предупреждения и сообщения об ошибках. Для этого:
a) Скопируйте файл log4j.properties.template в папку SPARK_HOME conf как файл log4j.properties в папке SPARK_HOME conf.
b) Установите для свойства log4j.rootCategory значение WARN, console.
c) Сохраните файл log4j.properties.
Теперь любые информационные сообщения не будут записываться на консоль.
Резюме
Чтобы работать с PySpark, запустите командную строку и перейдите в каталог SPARK_HOME.
а) Чтобы запустить оболочку PySpark, запустите утилиту bin pyspark. Когда вы окажетесь в оболочке PySpark, используйте имена sc и sqlContext и введите exit (), чтобы вернуться в командную строку.
б) Чтобы запустить автономный скрипт Python, запустите утилиту bin spark-submit и укажите путь к вашему скрипту Python, а также любые аргументы, которые нужны вашему скрипту Python, в командной строке. Например, чтобы запустить скрипт wordcount.py из каталога examples в папке SPARK_HOME, вы можете выполнить следующую команду:
«bin spark-submit examples src main python wordcount.py README.md«
6. Шаг 6
Важно: я столкнулся с проблемой при установке
После завершения процедуры установки на моем компьютере с Windows 10 я получал следующее сообщение об ошибке.
Файл «C: Users uug20 Anaconda3 lib site-packages zmq backend cython __ init__.py», строка 6, вот . import (константы, ошибка, сообщение, контекст, ImportError: сбой загрузки DLL: указанный модуль не найден.
Решение:
Я просто разобрался, как это исправить!
В моем случае я не знал, что мне нужно добавить ТРИ пути, связанные с миникондами, в переменную окружения PATH.
C: Users uug20 Anaconda3
C: Users uug20 Anaconda3 Scripts
C: Users uug20 Anaconda3 Library bin
После этого я не получил никаких сообщений об ошибках, и pyspark начал работать правильно и открыл записную книжку Jupyter после ввода pyspark в командной строке.
Надеюсь, это работает и для вас!
Содержание
- Install PySpark to run in Jupyter Notebook on Windows
- Spark — 2.3.2, Hadoop — 2.7, Python 3.6, Windows 10
- Apache Spark and PySpark
- PySpark Installation and setup
- 1. Install Java 8
- Check if JAVA is installed
- 2. Download and Install Spark
- 3. Download and setup winutils.exe
- 4. Check PySpark installation
- 5. PySpark with Jupyter notebook
- More about Spark
- Scalability
- Speed
- Getting Started with PySpark on Windows
- Installing Prerequisites
- Python
- Installing Apache Spark
- Configuring the Spark Installation
- Installing winutils
- Configuring the log level for Spark
- Summary
- References
- How to Install Apache Spark on Windows 10
- Install Apache Spark on Windows
- Step 1: Install Java 8
- Step 2: Install Python
- Step 3: Download Apache Spark
- Step 4: Verify Spark Software File
- Step 5: Install Apache Spark
- Step 6: Add winutils.exe File
- Step 7: Configure Environment Variables
- Step 8: Launch Spark
- Test Spark
- Установка Apache PySpark в Windows 10
- 1. Шаг 1
Install PySpark to run in Jupyter Notebook on Windows
Spark — 2.3.2, Hadoop — 2.7, Python 3.6, Windows 10

Jan 20, 2019 · 5 min read
When you need to scale up your machine learning abilities, you will need a distributed computation. PySpark interface to Spark is a good option. Here is a simple guide, on installation of Apache Spark with PySpark, alongside your anaconda, on your windows machine.

Apache Spark and PySpark
Apache Spark is an analytics engine and parallel computation framework with Scala, Python and R interfaces. Spark can load data directly from disk, memory and other data storage technologies such as Amazon S3, Hadoop Distributed File System (HDFS), HBase, Cassandra and others.
PySpark Installation and setup
If you find the right guide, it can be a quick and painless installation. But since its fast evolving infrastructure, methods and versions are dynamic, and a lot of outdated and confusing materials out there.
Most issues caused from improperly set environment variables, so be accurate about it and recheck. Another set of problems come from winutils.exe file,which an hadoop component for Windows OS. It is used for running shell commands, and accessing local files. I stole a trick from this article, that solved issues with file.
1. Install Java 8
Before you can start with spark and hadoop, you need to make sure you have java 8 installed, or to install it.
Check if JAVA is installed
You Should get something like:
Check the setup for environment variables: JAVA_HOME and PATH, as described below.
Go to Java’s official download website, accept Oracle license and download Java JDK 8, suitable to your system.

Run the executable, and JAVA by default will be installed in:
Add the following environment variable:
Add to PATH variable the following directory:
2. Download and Install Spark

Extract the file to your chosen directory (7z can open tgz). In my case, it was C:spark. There is another compressed directory in the tar, extract it (into here) as well.
Setup the environment variables
Add the following path to PATH environment variable:
3. Download and setup winutils.exe
Save winutils.exe in to bin directory of your spark installation, SPARK_HOMEbin directory. In my case: C:sparkspark-2.3.2-bin-hadoop2.7bin. Now the trick. It’s not a must, things did not work well for me without it.
The output is something of the sort:
4. Check PySpark installation
In your anaconda prompt,or any python supporting cmd, type pyspark, to enter pyspark shell. To be prepared, best to check it in the python environment from which you run jupyter notebook. You supposed to see the following:

Run the following commands, the output should be [1,4,9,16].
To exit pyspark shell, type Ctrl-z and enter. Or the python command exit()
5. PySpark with Jupyter notebook
Install conda findspark, to access spark instance from jupyter notebook. Check current installation in Anaconda cloud. In time of writing:
Open your python jupyter notebook, and write inside:
Last line will output SPARK_HOME path. It’s just for test, you can delete it.
Run the same test example as in pyspark shell:
In the end, stop the session
Installation and setup is done. Next article, let’s start discussing how to run and develop machine learning models.
More about Spark
Scalability
Spark Runs Everywhere. Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud, against diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
You can deploy Spark on a cluster if you’d like to run it in a distributed mode. You can also run locally on a multicore machine without any setup.
Speed
Unlike Hadoop spark maintains the intermediate results in memory rather than writing every intermediate output to disk. This hugely cuts down the execution time of the operation, resulting in faster execution of task, as more as 100X time a standard MapReduce job. Apache Spark can also hold data onto the disk. When data crosses the threshold of the memory storage it is spilled to the disk. This way spark acts as an extension of MapReduce. Explanation from here.
Источник
Getting Started with PySpark on Windows
I decided to teach myself how to work with big data and came across Apache Spark. While I had heard of Apache Hadoop, to use Hadoop for working with big data, I had to write code in Java which I was not really looking forward to as I love to write code in Python. Spark supports a Python programming API called PySpark that is actively maintained and was enough to convince me to start learning PySpark for working with big data.
In this post, I describe how I got started with PySpark on Windows. My laptop is running Windows 10. So the screenshots are specific to Windows 10. I am also assuming that you are comfortable working with the Command Prompt on Windows. You do not have to be an expert, but you need to know how to start a Command Prompt and run commands such as those that help you move around your computer’s file system. In case you need a refresher, a quick introduction might be handy.
Often times, many open source projects do not have good Windows support. So I had to first figure out if Spark and PySpark would work well on Windows. The official Spark documentation does mention about supporting Windows.
Installing Prerequisites
PySpark requires Java version 7 or later and Python version 2.6 or later. Let’s first check if they are already installed or install them and make sure that PySpark can work with these two components.
Java is used by many other software. So it is quite possible that a required version (in our case version 7 or later) is already available on your computer. To check if Java is available and find it’s version, open a Command Prompt and type the following command.
If Java is installed and configured to work from a Command Prompt, running the above command should print the information about the Java version to the console. For example, I got the following output on my laptop.
Instead if you get a message like
It means you need to install Java. To do so,
Go to the Java download page. In case the download link has changed, search for Java SE Runtime Environment on the internet and you should be able to find the download page.
Click the Download button beneath JRE
Accept the license agreement and download the latest version of Java SE Runtime Environment installer. I suggest getting the exe for Windows x64 (such as jre-8u92-windows-x64.exe ) unless you are using a 32 bit version of Windows in which case you need to get the Windows x86 Offline version.
Python
Python is used by many other software. So it is quite possible that a required version (in our case version 2.6 or later) is already available on your computer. To check if Python is available and find it’s version, open a Command Prompt and type the following command.
If Python is installed and configured to work from a Command Prompt, running the above command should print the information about the Python version to the console. For example, I got the following output on my laptop.
Instead if you get a message like
It means you need to install Python. To do so,
Go to the Python download page.
Click the Latest Python 2 Release link.
Download the Windows x86-64 MSI installer file. If you are using a 32 bit version of Windows download the Windows x86 MSI installer file.
When you run the installer, on the Customize Python section, make sure that the option Add python.exe to Path is selected. If this option is not selected, some of the PySpark utilities such as pyspark and spark-submit might not work.

Installing Apache Spark
Go to the Spark download page.
For Choose a Spark release, select the latest stable release of Spark.
For Choose a package type, select a version that is pre-built for the latest version of Hadoop such as Pre-built for Hadoop 2.6.
For Choose a download type, select Direct Download.
In order to install Apache Spark, there is no need to run any installer. You can extract the files from the downloaded tarball in any folder of your choice using the 7Zip tool.
Make sure that the folder path and the folder name containing Spark files do not contain any spaces.
The PySpark shell outputs a few messages on exit. So you need to hit enter to get back to the Command Prompt.
Configuring the Spark Installation
This error message does not prevent the PySpark shell from starting. However if you try to run a standalone Python script using the binspark-submit utility, you will get an error. For example, try running the wordcount.py script from the examples folder in the Command Prompt when you are in the SPARK_HOME directory.
which produces the following error that also points to missing winutils.exe
Installing winutils
Create a hadoopbin folder inside the SPARK_HOME folder.
Download the winutils.exe for the version of hadoop against which your Spark installation was built for. In my case the hadoop version was 2.6.0. So I downloaded the winutils.exe for hadoop 2.6.0 and copied it to the hadoopbin folder in the SPARK_HOME folder.
Create a system environment variable in Windows called SPARK_HOME that points to the SPARK_HOME folder path. Search the internet in case you need a refresher on how to create environment variables in your version of Windows such as articles like these.
Create another system environment variable in Windows called HADOOP_HOME that points to the hadoop folder inside the SPARK_HOME folder.
If you now run the binpyspark script from a Windows Command Prompt, the error messages related to winutils.exe should be gone. For example, I got the following messages after running the binpyspark utility after configuring winutils
The binspark-submit utility can also be successfully used to run wordcount.py script.
Configuring the log level for Spark
There are still a lot of extra INFO messages in the console everytime you start or exit from a PySpark shell or run the spark-submit utility. So let’s make one more change to our Spark installation so that only warning and error messages are written to the console. In order to do this
Copy the log4j.properties.template file in the SPARK_HOMEconf folder as log4j.properties file in the SPARK_HOMEconf folder.
Set the log4j.rootCategory property value to WARN, console
Save the log4j.properties file.
Summary
In order to work with PySpark, start a Windows Command Prompt and change into your SPARK_HOME directory.
To start a PySpark shell, run the binpyspark utility. Once your are in the PySpark shell use the sc and sqlContext names and type exit() to return back to the Command Prompt.
To run a standalone Python script, run the binspark-submit utility and specify the path of your Python script as well as any arguments your Python script needs in the Command Prompt. For example, to run the wordcount.py script from examples directory in your SPARK_HOME folder, you can run the following command
binspark-submit examplessrcmainpythonwordcount.py README.md
References
I used the following references to gather information about this post.
Downloading Spark and Getting Started (chapter 2) from O’Reilly’s Learning Spark book.
Any suggestions or feedback? Leave your comments below.
Источник
How to Install Apache Spark on Windows 10
Home » DevOps and Development » How to Install Apache Spark on Windows 10
Apache Spark is an open-source framework that processes large volumes of stream data from multiple sources. Spark is used in distributed computing with machine learning applications, data analytics, and graph-parallel processing.
This guide will show you how to install Apache Spark on Windows 10 and test the installation.

Install Apache Spark on Windows
Installing Apache Spark on Windows 10 may seem complicated to novice users, but this simple tutorial will have you up and running. If you already have Java 8 and Python 3 installed, you can skip the first two steps.
Step 1: Install Java 8
Apache Spark requires Java 8. You can check to see if Java is installed using the command prompt.
Open the command line by clicking Start > type cmd > click Command Prompt.
Type the following command in the command prompt:
If Java is installed, it will respond with the following output:

Your version may be different. The second digit is the Java version – in this case, Java 8.
If you don’t have Java installed:
1. Open a browser window, and navigate to https://java.com/en/download/.

2. Click the Java Download button and save the file to a location of your choice.
3. Once the download finishes double-click the file to install Java.
Note: At the time this article was written, the latest Java version is 1.8.0_251. Installing a later version will still work. This process only needs the Java Runtime Environment (JRE) – the full Development Kit (JDK) is not required. The download link to JDK is https://www.oracle.com/java/technologies/javase-downloads.html.
Step 2: Install Python
1. To install the Python package manager, navigate to https://www.python.org/ in your web browser.
2. Mouse over the Download menu option and click Python 3.8.3. 3.8.3 is the latest version at the time of writing the article.
3. Once the download finishes, run the file.

4. Near the bottom of the first setup dialog box, check off Add Python 3.8 to PATH. Leave the other box checked.
5. Next, click Customize installation.

6. You can leave all boxes checked at this step, or you can uncheck the options you do not want.
7. Click Next.
8. Select the box Install for all users and leave other boxes as they are.
9. Under Customize install location, click Browse and navigate to the C drive. Add a new folder and name it Python.
10. Select that folder and click OK.

11. Click Install, and let the installation complete.
12. When the installation completes, click the Disable path length limit option at the bottom and then click Close.
13. If you have a command prompt open, restart it. Verify the installation by checking the version of Python:
Note: For detailed instructions on how to install Python 3 on Windows or how to troubleshoot potential issues, refer to our Install Python 3 on Windows guide.
Step 3: Download Apache Spark
2. Under the Download Apache Spark heading, there are two drop-down menus. Use the current non-preview version.
3. Click the spark-2.4.5-bin-hadoop2.7.tgz link.

4. A page with a list of mirrors loads where you can see different servers to download from. Pick any from the list and save the file to your Downloads folder.
Step 4: Verify Spark Software File
1. Verify the integrity of your download by checking the checksum of the file. This ensures you are working with unaltered, uncorrupted software.
2. Navigate back to the Spark Download page and open the Checksum link, preferably in a new tab.
3. Next, open a command line and enter the following command:

5. Compare the code to the one you opened in a new browser tab. If they match, your download file is uncorrupted.
Step 5: Install Apache Spark
Installing Apache Spark involves extracting the downloaded file to the desired location.
1. Create a new folder named Spark in the root of your C: drive. From a command line, enter the following:
2. In Explorer, locate the Spark file you downloaded.
3. Right-click the file and extract it to C:Spark using the tool you have on your system (e.g., 7-Zip).
4. Now, your C:Spark folder has a new folder spark-2.4.5-bin-hadoop2.7 with the necessary files inside.
Step 6: Add winutils.exe File
Download the winutils.exe file for the underlying Hadoop version for the Spark installation you downloaded.
1. Navigate to this URL https://github.com/cdarlint/winutils and inside the bin folder, locate winutils.exe, and click it.

2. Find the Download button on the right side to download the file.
3. Now, create new folders Hadoop and bin on C: using Windows Explorer or the Command Prompt.
4. Copy the winutils.exe file from the Downloads folder to C:hadoopbin.
Step 7: Configure Environment Variables
Configuring environment variables in Windows adds the Spark and Hadoop locations to your system PATH. It allows you to run the Spark shell directly from a command prompt window.
1. Click Start and type environment.
2. Select the result labeled Edit the system environment variables.
3. A System Properties dialog box appears. In the lower-right corner, click Environment Variables and then click New in the next window.

4. For Variable Name type SPARK_HOME.
5. For Variable Value type C:Sparkspark-2.4.5-bin-hadoop2.7 and click OK. If you changed the folder path, use that one instead.

6. In the top box, click the Path entry, then click Edit. Be careful with editing the system path. Avoid deleting any entries already on the list.

7. You should see a box with entries on the left. On the right, click New.
8. The system highlights a new line. Enter the path to the Spark folder C:Sparkspark-2.4.5-bin-hadoop2.7bin. We recommend using %SPARK_HOME%bin to avoid possible issues with the path.

9. Repeat this process for Hadoop and Java.
10. Click OK to close all open windows.
Note: Star by restarting the Command Prompt to apply changes. If that doesn’t work, you will need to reboot the system.
Step 8: Launch Spark
1. Open a new command-prompt window using the right-click and Run as administrator:
2. To start Spark, enter:
If you set the environment path correctly, you can type spark-shell to launch Spark.
3. The system should display several lines indicating the status of the application. You may get a Java pop-up. Select Allow access to continue.
Finally, the Spark logo appears, and the prompt displays the Scala shell.

4., Open a web browser and navigate to http://localhost:4040/.
5. You can replace localhost with the name of your system.
6. You should see an Apache Spark shell Web UI. The example below shows the Executors page.

7. To exit Spark and close the Scala shell, press ctrl-d in the command-prompt window.
Note: If you installed Python, you can run Spark using Python with this command:
Test Spark
In this example, we will launch the Spark shell and use Scala to read the contents of a file. You can use an existing file, such as the README file in the Spark directory, or you can create your own. We created pnaptest with some text.
1. Open a command-prompt window and navigate to the folder with the file you want to use and launch the Spark shell.
2. First, state a variable to use in the Spark context with the name of the file. Remember to add the file extension if there is any.
3. The output shows an RDD is created. Then, we can view the file contents by using this command to call an action:

This command instructs Spark to print 11 lines from the file you specified. To perform an action on this file (value x), add another value y, and do a map transformation.
4. For example, you can print the characters in reverse with this command:
5. The system creates a child RDD in relation to the first one. Then, specify how many lines you want to print from the value y:

The output prints 11 lines of the pnaptest file in the reverse order.
You should now have a working installation of Apache Spark on Windows 10 with all dependencies installed. Get started running an instance of Spark in your Windows environment.
Our suggestion is to also learn more about what Spark DataFrame is, the features, and how to use Spark DataFrame when collecting data.
Источник
Установка Apache PySpark в Windows 10
Дата публикации Aug 30, 2019

Последние несколько месяцев я работал над проектом Data Science, который обрабатывает огромный набор данных, и стало необходимым использовать распределенную среду, предоставляемую Apache PySpark.
Я много боролся при установке PySpark на Windows 10. Поэтому я решил написать этот блог, чтобы помочь любому легко установить и использовать Apache PySpark на компьютере с Windows 10.
1. Шаг 1
PySpark требует Java версии 7 или новее и Python версии 2.6 или новее. Давайте сначала проверим, установлены ли они, или установим их и убедимся, что PySpark может работать с этими двумя компонентами.
Установка Java
Проверьте, установлена ли на вашем компьютере Java версии 7 или новее. Для этого выполните следующую команду в командной строке.

Если Java установлена и настроена для работы из командной строки, выполнение вышеуказанной команды должно вывести информацию о версии Java на консоль. Иначе, если вы получите сообщение, подобное:
«Java» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл.
тогда вы должны установить Java.
б) Получить Windows x64 (например, jre-8u92-windows-x64.exe), если вы не используете 32-разрядную версию Windows, в этом случае вам нужно получитьWindows x86 Offlineверсия.
в) Запустите установщик.
2. Шаг 2
питон
Если Python установлен и настроен для работы из командной строки, при выполнении вышеуказанной команды информация о версии Python должна выводиться на консоль. Например, я получил следующий вывод на моем ноутбуке:
Вместо этого, если вы получите сообщение, как
«Python» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл ».
Это означает, что вам нужно установить Python. Для этого
а) Перейти к питонускачатьстр.
б) НажмитеПоследний выпуск Python 2ссылка.
c) Загрузите установочный файл MSI для Windows x86–64. Если вы используете 32-разрядную версию Windows, загрузите установочный файл MSI для Windows x86.
г) Когда вы запускаете установщик, наНастроить Pythonраздел, убедитесь, что опцияДобавить python.exe в путьвыбран. Если этот параметр не выбран, некоторые утилиты PySpark, такие как pyspark и spark-submit, могут не работать.
3. Шаг 3
Установка Apache Spark
а) Перейти к искрескачатьстр.
б) Выберите последнюю стабильную версию Spark.
с)Выберите тип упаковки: sвыберите версию, предварительно созданную для последней версии Hadoop, такую какПредварительно построен для Hadoop 2.6,
г)Выберите тип загрузки:ВыбратьПрямое скачивание,
f) Для установки Apache Spark вам не нужно запускать какой-либо установщик. Извлеките файлы из загруженного tar-файла в любую папку по вашему выбору, используя7Zipинструмент / другие инструменты для разархивирования.
Убедитесь, что путь к папке и имя папки, содержащей файлы Spark, не содержат пробелов.
Я создал папку с именем spark на моем диске D и распаковал заархивированный tar-файл в папку с именем spark-2.4.3-bin-hadoop2.7. Таким образом, все файлы Spark находятся в папке с именем D: spark spark-2.4.3-bin-hadoop2.7. Давайте назовем эту папку SPARK_HOME в этом посте.
Чтобы проверить успешность установки, откройте командную строку, перейдите в каталог SPARK_HOME и введите bin pyspark. Это должно запустить оболочку PySpark, которую можно использовать для интерактивной работы со Spark.
Оболочка PySpark выводит несколько сообщений при выходе. Поэтому вам нужно нажать Enter, чтобы вернуться в командную строку.
4. Шаг 4
Настройка установки Spark
Первоначально, когда вы запускаете оболочку PySpark, она выдает много сообщений типа INFO, ERROR и WARN. Давайте посмотрим, как удалить эти сообщения.
Установка Spark в Windows по умолчанию не включает утилиту winutils.exe, которая используется Spark. Если вы не укажете своей установке Spark, где искать winutils.exe, вы увидите сообщения об ошибках при запуске оболочки PySpark, такие как
«ОШИБКА Shell: не удалось найти двоичный файл winutils в двоичном пути hadoop java.io.IOException: не удалось найти исполняемый файл null bin winutils.exe в двоичных файлах Hadoop».
Это сообщение об ошибке не препятствует запуску оболочки PySpark. Однако если вы попытаетесь запустить автономный скрипт Python с помощью утилиты bin spark-submit, вы получите ошибку. Например, попробуйте запустить скрипт wordcount.py из папки примеров в командной строке, когда вы находитесь в каталоге SPARK_HOME.
«Bin spark-submit examples src main python wordcount.py README.md»
Установка winutils
Давайте загрузим winutils.exe и сконфигурируем нашу установку Spark, чтобы найти winutils.exe.
a) Создайте папку hadoop bin внутри папки SPARK_HOME.
б) Скачатьwinutils.exeдля версии hadoop, для которой была создана ваша установка Spark. В моем случае версия hadoop была 2.6.0. Так что язагруженноеwinutils.exe для hadoop 2.6.0 и скопировал его в папку hadoop bin в папке SPARK_HOME.
c) Создайте системную переменную среды в Windows с именем SPARK_HOME, которая указывает путь к папке SPARK_HOME.
d) Создайте в Windows другую переменную системной среды с именем HADOOP_HOME, которая указывает на папку hadoop внутри папки SPARK_HOME.
Поскольку папка hadoop находится внутри папки SPARK_HOME, лучше создать переменную среды HADOOP_HOME, используя значение% SPARK_HOME% hadoop. Таким образом, вам не нужно менять HADOOP_HOME, если SPARK_HOME обновлен.
Если вы теперь запустите сценарий bin pyspark из командной строки Windows, сообщения об ошибках, связанные с winutils.exe, должны исчезнуть.
5. Шаг 5
Настройка уровня журнала для Spark
Каждый раз при запуске или выходе из оболочки PySpark или при запуске утилиты spark-submit остается много дополнительных сообщений INFO. Итак, давайте внесем еще одно изменение в нашу установку Spark, чтобы в консоль записывались только предупреждения и сообщения об ошибках. Для этого:
a) Скопируйте файл log4j.properties.template в папку SPARK_HOME conf как файл log4j.properties в папке SPARK_HOME conf.
b) Установите для свойства log4j.rootCategory значение WARN, console.
c) Сохраните файл log4j.properties.
Теперь любые информационные сообщения не будут записываться на консоль.
Резюме
Чтобы работать с PySpark, запустите командную строку и перейдите в каталог SPARK_HOME.
а) Чтобы запустить оболочку PySpark, запустите утилиту bin pyspark. Когда вы окажетесь в оболочке PySpark, используйте имена sc и sqlContext и введите exit (), чтобы вернуться в командную строку.
б) Чтобы запустить автономный скрипт Python, запустите утилиту bin spark-submit и укажите путь к вашему скрипту Python, а также любые аргументы, которые нужны вашему скрипту Python, в командной строке. Например, чтобы запустить скрипт wordcount.py из каталога examples в папке SPARK_HOME, вы можете выполнить следующую команду:
«bin spark-submit examples src main python wordcount.py README.md«
6. Шаг 6
Важно: я столкнулся с проблемой при установке
После завершения процедуры установки на моем компьютере с Windows 10 я получал следующее сообщение об ошибке.
Решение:
Я просто разобрался, как это исправить!
В моем случае я не знал, что мне нужно добавить ТРИ пути, связанные с миникондами, в переменную окружения PATH.
C: Users uug20 Anaconda3
C: Users uug20 Anaconda3 Scripts
C: Users uug20 Anaconda3 Library bin
После этого я не получил никаких сообщений об ошибках, и pyspark начал работать правильно и открыл записную книжку Jupyter после ввода pyspark в командной строке.
Источник
Время прочтения: 9 мин.
Мы говорим Big Data, подразумеваем — Apache Spark. Сейчас это, пожалуй, самый мощный и модный фреймворк для распределённой обработки больших данных в задачах Data Science, поэтому для всех аналитиков как никогда важна задача изучения Spark и получения практических навыков работы с ним. Однако привычная среда обитания Spark — это, как правило, серверные кластеры промышленного масштаба под управлением Linux, что, несомненно, слегка усложняет работу с ним в уютных домашних условиях. Но нет ничего невозможного. В этой статье мы научимся ставить PySpark на локальную машину c ОС Windows и использовать его (на примере задачи векторизации и сравнения текстов алгоритмом Word2Vec, входящим в библиотеку mllib).
- Установка Spark на ОС Windows
Шаг 1. Установка Java JDK
Так как Spark в основе своей работает на Java-машине, то нужно иметь установленную в системе Java JDK. Для этого посмотрите в «Программах и компонентах», есть ли в списке установленных программ строка «Java(TM) SE Development Kit 8.x.x.», а на диске C папка «C:Program FilesJavajdk-8.x.x» (в обоих случаях версия должна быть 8 или больше). Если нет, переходите по адресу, нажимайте ссылку «JDK download». На странице скачивания загружайте исполняемый файл с описанием «Windows x64 Installer» и устанавливайте его.
Шаг 2. Установка Apache Spark
Для скачивания Spark перейдите по адресу:

По умолчанию в строке «1. Choose a Spark release» будет стоять последняя рабочая версия Spark (на сегодняшний день это 3.1.2, соответственно, дальше по тексту все названия папок и файлов будут с этим номером).
В строке «2. Choose a package type» выберите «Pre-built for Apache Hadoop 2.7». Затем в строке «3. Download Spark» щёлкните по ссылке «spark-3.1.2-bin-hadoop2.7.tgz» и скачайте файл с дистрибутивом Spark.
Внутри скачанного архива находится папка «spark-3.1.2-bin-hadoop2.7». Распакуйте её, например, WinRAR-ом (или любым другим архиватором, умеющим в zip). Создайте на диске C папку «С:spark» и скопируйте в неё распакованную папку «spark-3.1.2-bin-hadoop2.7».

Шаг 3. Установка утилиты winutils.exe
Так как Spark разрабатывался для работы в среде Hadoop, то специально для Windows энтузиасты сделали его сборку, которая позволяет Spark-у работать на Windows-машине как на одиночном Hadoop-кластере. Для работы в среде Hadoop 2.7 скачайте файл «winutils.exe» по ссылке и положите его в папку «С:sparkspark-3.1.2-bin-hadoop2.7bin».
Шаг 4. Создание папки c:tmphive
Создать папку «С:tmphive» нужно для того, чтобы Spark не падал с ошибкой об отсутствии Hadoop Hive. То есть, у нас-то он отсутствует в любом случае, но ошибок об этом возникать не будет. Для корректной работы перейдите в папку «С:sparkspark-3.1.2-bin-hadoop2.7bin» и выполните в командной строке:
winutils.exe chmod -R 777 C:tmphivewinutils.exe ls -F C:tmphive
Шаг 5. Изменение переменных окружения
Далее нужно создать переменные окружения пользователя, необходимые для корректной работы Spark…
SPARK_HOME = C:Sparkspark-3.1.2-bin-hadoop2.7
HADOOP_HOME = C:Sparkspark-3.1.2-bin-hadoop2.7
JAVA_HOME = C:Program filesJavajdk-x.x.x
…и добавить в переменную PATH пути:
C:Sparkspark-3.1.2-bin-hadoop2.7
C:Program filesJavajdk-x.x.x
Внимание! Имена путей нужно указывать точно такие же, как и у вас в системе!
После этого перезагрузите компьютер.
Шаг 6. Установка PySpark
Для работы со Spark в Python нужно установить PySpark:
pip install pyspark
Шаг 7. Устранение неочевидных подводных камней
Из линуксовой природы Python-а, Spark-а и PySpark-а вытекает одна особенность (которая, впрочем, может проявиться не у всех). При установке Python 3.x на Linux в системе создаётся так называемая «жёсткая ссылка» с именем «python3», указывающая на исполняемый модуль Python вне зависимости от того, куда он установлен. Таким образом, если выполнить в командной строке Linux команду «python3», то в любом случае запустится интерпретатор Python версии 3.xx.
Неожиданно выяснилось, что при работе в Windows PySpark пытается внутри себя запустить интерпретатор Python как раз по имени «python3», что вызывает ошибку выполнения скрипта, т.к. данный исполняемый модуль не может быть найден в системе. Для устранения этой проблемы необходимо скопировать исполняемый модуль python.exe, установленный в системе, в ту же самую папку установки, но только с именем python3.exe.
В случае, если вы работаете с Jupyter Notebook (или с другим инструментом) , запускаемым из пакета Anaconda нужно скопировать файл С:ProgramDataAnaconda3python.exe. Если вы работаете в PyCharm или другом отдельно стоящем инструменте, то скопируйте python.exe файл (или делайте это в той папке, куда была выполнена локальная установка Python)
Шаг 8. Запуск Spark в коде Python
Запустим Jupyter Notebook, создадим новый ноутбук и выполним следующий код:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
conf = SparkConf()
conf.setMaster("local").setAppName('My app')
sc = SparkContext.getOrCreate(conf=conf)
spark = SparkSession(sc)
print('Запущен Spark версии', spark.version)
Если всё было выполнено правильно, то создастся Spark-сессия и появится сообщение:
Запущен Spark версии 3.1.2
Также по адресу запустится web-сервер с панелью управления нашим свежеиспечённым Saprk-кластером, состоящим из одной ноды:

Поздравляю, у вас всё получилось, вы великолепны. А теперь попробуем на практическом примере обработать с помощью Spark данные, хранящиеся на диске Windows-машины.
- Работа с Word2Vec из пакета MlLib PySpark
Для примера возьмём случай из жизни.
В ходе проверки для установления того факта, что разные документы могут принадлежать одному клиенту, понадобилось сравнить адреса, указанные в этих документах. Разумеется, адреса могли быть записаны в произвольной форме, с ошибками, мусорными и незначащими словами и символами, и т.д., и т.п.
Например, если в разных документах указаны адреса «Город Подольск Московской области» и «Москва обл. гподолск» — то, скорее всего, это один и тот же адрес, а если «Город Подольск Московской области» и «Город Пинск Брестской области» — то это явно разные адреса, несмотря на одинаковую форму записи. Кроме того, если адрес совпадал по нескольким компонентам (например, область и район, или город и улица), но не совпадал по другим компонентам, то это также было признаком того, что, возможно, это один и тот же адрес, просто некорректно указанный.
Для сравнения таких адресов было решено использовать очистку строк от мусора и незначащих фрагментов, токенизацию (разбиение на отдельные значащие компоненты, в нашем случае – на одиночные слова) и, самое главное — представление токенизированных строк в виде числовых векторов с последующим сравнением косинусного расстояния между ними.
Векторизацию строк выполняли старым добрым методом Word2Vec. Реализация этого метода, как и многих других, встроена в PySpark в библиотеку mllib, и, так же, как и у многих других, не представляет никаких трудностей для практического использования в коде Python.
Итак, just do it.
Сначала положим в рабочий каталог csv-файл, содержащий набор строк с адресами, подлежащими сравнению (для служебных целей добавим столбец, содержащий единицы).
Файл «spark_test_data.csv»:
a;id
1;пос. Пригородный обл.Воронежская калачеевский, р-н
1;респ. Мордовия, Саранская обл ленинскиЙ р, с.петровка
1;калач п.пригородный
1;Мордовия, р/н.Саранский пос. Рабочий
Далее напишем следующий код в Jupyter Notebook (в дополнение к коду инициализации spark-сессии, который был приведён выше).
from pyspark.sql.functions import udf
from pyspark.sql.types import ArrayType, StringType
from pyspark.ml.feature import Word2Vec
from scipy.spatial.distance import cosine
import pyspark.sql.functions as F
Загрузим данные, создадим датафрейм, покажем его состав и структуру.
data = spark.read.load('documents/spark_test_data.csv', format = 'csv', sep = ';', inferSchema = 'true', header = 'true')
data.show(truncate = False)
data.printSchema()

Далее объявим UDF-функцию токенизации строковых полей. Предварительно удаляем мусорные знаки препинания и сокращённые наименования типов населённых пунктов, разбиваем на слова по пробелам, оставляем элементы с длиной больше одного символа, на выходе получаем отсортированный по алфавиту список с элементами поля — отдельными словами.
def splitter(inStr):
if inStr is None:
inStr = 'пустой адрес'
splt = sorted(inStr.lower()
.replace('гор.', ' ')
.replace('край', ' ')
.replace('края', ' ')
.replace('кв.', ' ')
.replace('"', ' ')
.replace('\', ' ')
.replace('/', ' ')
.replace('*', ' ')
.replace('_', ' ')
.replace('.', ' ')
.replace(',', ' ')
.replace('-', ' ')
.replace('?', ' ')
.replace('пос', ' ')
.replace('пгт', ' ')
.replace('аул', ' ')
.replace('район', ' ')
.replace('село', ' ')
.replace('област', ' ')
.replace('обл', ' ')
.replace('республик', ' ')
.replace('респ', ' ')
.split(' '))
res = [x for x in splt if len(x) > 1]
if len(res) == 0:
return ['пустой адрес']
return res
tokenizer_udf = udf(lambda x: splitter(x), ArrayType(StringType()))
Объявим UDF-функцию вычисления косинусного расстояния между векторами в полях датафрейма:
cosine_udf = udf(lambda x, y: abs(float(1 - cosine(x, y))))Преобразуем исходный датафрейм: токенизируем поле с адресами и свяжем каждую запись с каждой, чтобы показать, как будет меняться сходство между разными адресами.
df = data
df = df.select('a', 'id', tokenizer_udf('id').alias('tok_id'))
df = df.join(df.select('a', F.col('tok_id').alias('tok_id2')), on = 'a', how = 'fullouter')
df.select('tok_id', 'tok_id2').show(truncate = False)

Как мы видим токенизатор очистил адреса от мусора и разбил на значащие элементы (названия элементов адреса – области, района, города и т.д.). Теперь векторизуем и сравним смежные поля с токенизированными адресами в преобразованном датафрейме и посмотрим, насколько Word2Vec справится с возложенной на него задачей.
Выполняем векторизацию, устанавливаем число размерностей в пространстве векторизации vectorSize = 100, минимальное число включений токена в словарь модели minCoiunt = 5:
word2Vec = Word2Vec(vectorSize = 100, minCount = 5, inputCol = 'tok_id', outputCol = 'vec_id')
model = word2Vec.fit(df)
df = model.transform(df)
df.select('tok_id', 'vec_id').distinct().show()
word2Vec = Word2Vec(vectorSize = 100, minCount = 5, inputCol = 'tok_id2', outputCol = 'vec_id2')
model = word2Vec.fit(df)
df = model.transform(df)
Получаем на выходе следующую модель векторизации (вектора показаны не полностью, не все 100 элементов, т.к. тогда они бы просто не влезли в текст статьи):

Вычисляем косинусное расстояние между векторами и записываем результат сравнения в новый столбец:
df = df.withColumn('similarity', cosine_udf('vec_id', 'vec_id2'))
df.select('tok_id', 'tok_id2', 'similarity').orderBy(F.col('similarity').desc()).show(truncate = False)
Получаем на выходе следующий результат:

Как видим, модель прекрасно справилась со своей задачей — мало того, что сходство между одинаковыми адресами было рассчитано как 100% (что очевидно), но и адреса с элементами из одной области и района тоже были отнесены к весьма схожим. А вот сходство между адресами, которые вообще не содержат отдельных похожих элементов, упало ниже 13%.
В самом конце не забудем выключить нашу spark-сессию, чтобы освободить ресурсы кластера для других пользователей (на самом деле других пользователей на нашей машине, конечно же, нет, но правила хорошего тона диктуют выполнять данную процедуру каждый раз при завершении расчётов, что является весьма полезной привычкой при работе на кластерах общего пользования):
sc.stop()Итак, мы научились запускать Spark на Windows и использовать в практических целях модель Word2Vec, встроенную в Spark, что может весьма облегчить практику изучения этого инструмента и использования его для работы с текстами, содержащимися в хранилищах больших данных.
In this article, I will explain how to install and run PySpark on windows and also explain how to start a history server and monitor your jobs using Web UI.
Related:
- PySpark Install on Mac OS
- Apache Spark Installation on Windows
PySpark is a Spark library written in Python to run Python applications using Apache Spark capabilities. so there is no PySpark library to download. All you need is Spark.
Follow the below steps to Install PySpark on Windows.
Install Python or Anaconda distribution
Download and install either Python from Python.org or Anaconda distribution which includes Python, Spyder IDE, and Jupyter notebook. I would recommend using Anaconda as it’s popular and used by the Machine Learning & Data science community.
Follow Install PySpark using Anaconda & run Jupyter notebook
Install Java 8
To run the PySpark application, you would need Java 8 or a later version hence download the Java version from Oracle and install it on your system.
Post-installation set JAVA_HOME and PATH variable.
JAVA_HOME = C:Program FilesJavajdk1.8.0_201
PATH = %PATH%;C:Program FilesJavajdk1.8.0_201bin
PySpark is a Spark library written in Python to run Python applications using Apache Spark capabilities. so there is no PySpark library to download. All you need is Spark; follow the below steps to install PySpark on windows.
1. On Spark Download page, select the link “Download Spark (point 3)” to download. If you wanted to use a different version of Spark & Hadoop, select the one you wanted from drop-downs, and the link on point 3 changes to the selected version and provides you with an updated link to download.

2. After download, untar the binary using 7zip and copy the underlying folder spark-3.0.0-bin-hadoop2.7 to c:apps
3. Now set the following environment variables.
SPARK_HOME = C:appsspark-3.0.0-bin-hadoop2.7
HADOOP_HOME = C:appsspark-3.0.0-bin-hadoop2.7
PATH=%PATH%;C:appsspark-3.0.0-bin-hadoop2.7bin
Install winutils.exe on Windows
Download winutils.exe file from winutils, and copy it to %SPARK_HOME%bin folder. Winutils are different for each Hadoop version hence download the right version from https://github.com/steveloughran/winutils
PySpark shell
Now open the command prompt and type pyspark command to run the PySpark shell. You should see something like this below.

Spark-shell also creates a Spark context web UI and by default, it can access from http://localhost:4041.
Web UI
Apache Spark provides a suite of Web UIs (Jobs, Stages, Tasks, Storage, Environment, Executors, and SQL) to monitor the status of your Spark application.

History Server
History servers, keep a log of all PySpark applications you submit by spark-submit, pyspark shell. before you start, first you need to set the below config on spark-defaults.conf
spark.eventLog.enabled true
spark.history.fs.logDirectory file:///c:/logs/path
Now, start the history server on Linux or Mac by running.
$SPARK_HOME/sbin/start-history-server.sh
If you are running PySpark on windows, you can start the history server by starting the below command.
$SPARK_HOME/bin/spark-class.cmd org.apache.spark.deploy.history.HistoryServer
By default, History server listens at 18080 port and you can access it from the browser using http://localhost:18080/

By clicking on each App ID, you will get the details of the application in PySpark web UI.
Conclusion
In summary, you have learned how to install PySpark on windows and run sample statements in spark-shell
If you have any issues, setting up, please message me in the comments section, I will try to respond with the solution.
Happy Learning !!
Related Articles
- Install PySpark in Jupyter on Mac using Homebrew
- Install PySpark in Anaconda & Jupyter Notebook
- How to Install PySpark on Mac (in 2022)
- Dynamic way of doing ETL through Pyspark
- How to Find PySpark Version?
- PySpark Shell Command Usage with Examples
- Pyspark: Exception: Java gateway process exited before sending the driver its port number
Использование pyspark в python — это не просто вопрос импорта пакета pyspark. Вам необходимо создать среду Spark из разных сред, прежде чем вы сможете использовать pyspark в Python.
Среда, необходимая для создания pyspark:
python3, jdk, spark, Scala, Hadoop (необязательно)
1. Загрузите и настройте переменные среды
1.1 jdk
ссылка для скачивания:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Откройте переменные среды в Windows:
Создайте JAVA_HOME: C: Program Files Java jdk1.8.0_181
Создать CLASSPATH:.;% JAVA_HOME% lib;% JAVA_HOME% lib tools.jar
Добавьте в путь:% JAVA_HOME% bin;
Проверьте успешность установки: откройте командную строку cmd и введите java -version
1.2 Scala
ссылка для скачивания:https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.msi
установить после загрузки
Создайте SCALA_HOME: C: Program Files (x86) scala
Добавление пути:;% SCALA_HOME% bin;% JAVA_HOME% bin ;;% HADOOP_HOME% bin
Проверьте, прошла ли установка успешно: откройте командную строку cmd и введите scala -version
1.3 spark
ссылка для скачивания:http://mirror.bit.edu.cn/apache/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
Вы также можете загрузить указанную версию:http://spark.apache.org/downloads.html

После загрузки разархивируйте его и поместите в любой каталог, но в имени каталога не должно быть пробелов.
Переменные среды:
Создайте SPARK_HOME: D: spark-2.2.0-bin-hadoop2.7
Добавление пути:% SPARK_HOME% bin
Проверьте, прошла ли установка успешно: откройте командную строку cmd и введите spark-shell
Spark-shell сообщила об ошибке: ошибка не найдена: значение sqlContext. ссылка:https://www.liyang.site/2017/04/19/20170419-spark-error-01/
или в пути есть пробелы.
1.4 Hadoop
Если вам нужно получить данные из hdfs, вам следует сначала установить hadoop. Чтобы узнать о взаимосвязи между Spark и Hadoop, вы можете перейти в этот блог:Заменит ли Spark Hadoop?
ссылка для скачивания:
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz

Разархивируйте его в указанный каталог.
Переменные среды:
Создать HADOOP_HOME: D: hadoop-2.7.7
Добавление пути:% HADOOP_HOME% bin
Проверьте, прошла ли установка успешно: откройте командную строку cmd и введите hadoop
Во время тестирования HADoop было сообщено об ошибке: Ошибка: JAVA_HOME установлен неправильно. Ссылка: https://blog.csdn.net/qq_24125575/article/details/76186309
1.5 pyspark
Чтобы установить pyspark под python, вы можете перейти на официальный сайт, чтобы загрузить pyspark и затем установить его. Избегайте тайм-аута
ссылка для скачивания:https://pypi.tuna.tsinghua.edu.cn/packages/9a/5a/271c416c1c2185b6cb0151b29a91fff6fcaed80173c8584ff6d20e46b465/pyspark-2.4.5.tar.gz
После загрузки используйте для установки pip install pyspark-2.4.5.tar.gz.
Во-вторых, проверьте, прошла ли установка успешно
Проверьте, завершена ли вся среда:
Создайте новый файл py и включите следующий тестовый код:
```python
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
counts = words.count()
print("Number of elements in RDD -> %i" % counts)
Если вам не по себе:
from pyspark import SparkContext
from pyspark import SparkConf
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc=SparkContext.getOrCreate(conf)
rdd=sc.parallelize([1,2,3,4,5])
rdd1=rdd.map(lambda r:r+10)
print(rdd1.collect())
попробуй снова.
Примечание. Рекомендуется добавить эти две строки кода перед кодом, чтобы автоматически найти место установки Spark, которое добавляется вверху файла py.
import findspark
findspark.init()
Introduction
Apache Spark is an open-source framework that processes large volumes of stream data from multiple sources. Spark is used in distributed computing with machine learning applications, data analytics, and graph-parallel processing.
This guide will show you how to install Apache Spark on Windows 10 and test the installation.

Prerequisites
- A system running Windows 10
- A user account with administrator privileges (required to install software, modify file permissions, and modify system PATH)
- Command Prompt or Powershell
- A tool to extract .tar files, such as 7-Zip
Installing Apache Spark on Windows 10 may seem complicated to novice users, but this simple tutorial will have you up and running. If you already have Java 8 and Python 3 installed, you can skip the first two steps.
Step 1: Install Java 8
Apache Spark requires Java 8. You can check to see if Java is installed using the command prompt.
Open the command line by clicking Start > type cmd > click Command Prompt.
Type the following command in the command prompt:
java -versionIf Java is installed, it will respond with the following output:
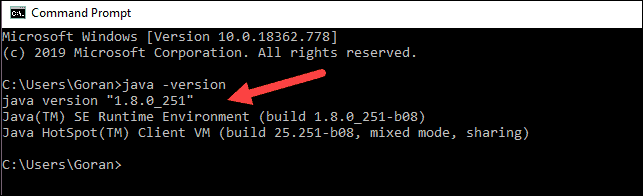
Your version may be different. The second digit is the Java version – in this case, Java 8.
If you don’t have Java installed:
1. Open a browser window, and navigate to https://java.com/en/download/.
2. Click the Java Download button and save the file to a location of your choice.
3. Once the download finishes double-click the file to install Java.
Note: At the time this article was written, the latest Java version is 1.8.0_251. Installing a later version will still work. This process only needs the Java Runtime Environment (JRE) – the full Development Kit (JDK) is not required. The download link to JDK is https://www.oracle.com/java/technologies/javase-downloads.html.
Step 2: Install Python
1. To install the Python package manager, navigate to https://www.python.org/ in your web browser.
2. Mouse over the Download menu option and click Python 3.8.3. 3.8.3 is the latest version at the time of writing the article.
3. Once the download finishes, run the file.
4. Near the bottom of the first setup dialog box, check off Add Python 3.8 to PATH. Leave the other box checked.
5. Next, click Customize installation.
6. You can leave all boxes checked at this step, or you can uncheck the options you do not want.
7. Click Next.
8. Select the box Install for all users and leave other boxes as they are.
9. Under Customize install location, click Browse and navigate to the C drive. Add a new folder and name it Python.
10. Select that folder and click OK.
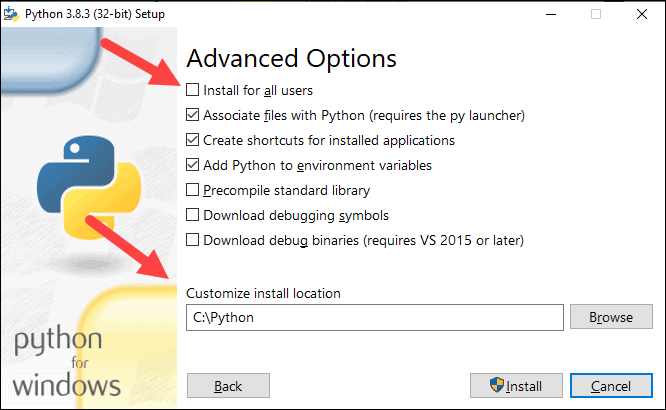
11. Click Install, and let the installation complete.
12. When the installation completes, click the Disable path length limit option at the bottom and then click Close.
13. If you have a command prompt open, restart it. Verify the installation by checking the version of Python:
python --versionThe output should print Python 3.8.3.
Note: For detailed instructions on how to install Python 3 on Windows or how to troubleshoot potential issues, refer to our Install Python 3 on Windows guide.
Step 3: Download Apache Spark
1. Open a browser and navigate to https://spark.apache.org/downloads.html.
2. Under the Download Apache Spark heading, there are two drop-down menus. Use the current non-preview version.
- In our case, in Choose a Spark release drop-down menu select 2.4.5 (Feb 05 2020).
- In the second drop-down Choose a package type, leave the selection Pre-built for Apache Hadoop 2.7.
3. Click the spark-2.4.5-bin-hadoop2.7.tgz link.
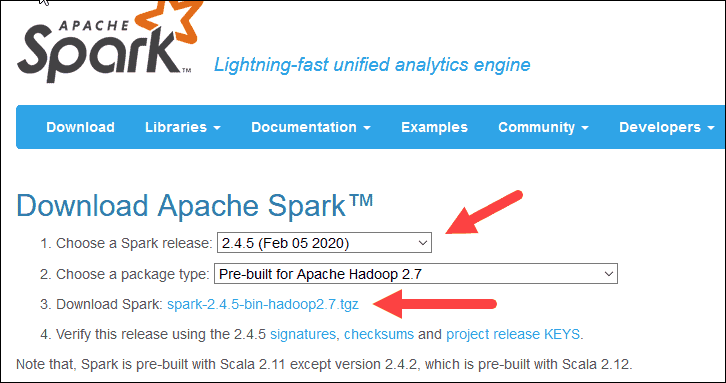
4. A page with a list of mirrors loads where you can see different servers to download from. Pick any from the list and save the file to your Downloads folder.
Step 4: Verify Spark Software File
1. Verify the integrity of your download by checking the checksum of the file. This ensures you are working with unaltered, uncorrupted software.
2. Navigate back to the Spark Download page and open the Checksum link, preferably in a new tab.
3. Next, open a command line and enter the following command:
certutil -hashfile c:usersusernameDownloadsspark-2.4.5-bin-hadoop2.7.tgz SHA5124. Change the username to your username. The system displays a long alphanumeric code, along with the message Certutil: -hashfile completed successfully.
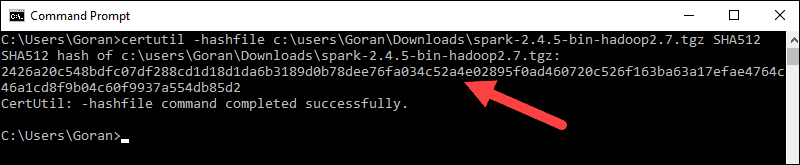
5. Compare the code to the one you opened in a new browser tab. If they match, your download file is uncorrupted.
Step 5: Install Apache Spark
Installing Apache Spark involves extracting the downloaded file to the desired location.
1. Create a new folder named Spark in the root of your C: drive. From a command line, enter the following:
cd
mkdir Spark2. In Explorer, locate the Spark file you downloaded.
3. Right-click the file and extract it to C:Spark using the tool you have on your system (e.g., 7-Zip).
4. Now, your C:Spark folder has a new folder spark-2.4.5-bin-hadoop2.7 with the necessary files inside.
Step 6: Add winutils.exe File
Download the winutils.exe file for the underlying Hadoop version for the Spark installation you downloaded.
1. Navigate to this URL https://github.com/cdarlint/winutils and inside the bin folder, locate winutils.exe, and click it.
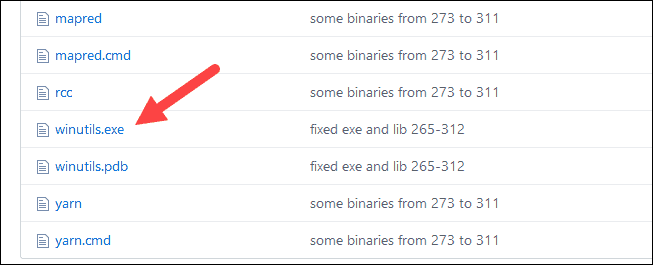
2. Find the Download button on the right side to download the file.
3. Now, create new folders Hadoop and bin on C: using Windows Explorer or the Command Prompt.
4. Copy the winutils.exe file from the Downloads folder to C:hadoopbin.
Step 7: Configure Environment Variables
Configuring environment variables in Windows adds the Spark and Hadoop locations to your system PATH. It allows you to run the Spark shell directly from a command prompt window.
1. Click Start and type environment.
2. Select the result labeled Edit the system environment variables.
3. A System Properties dialog box appears. In the lower-right corner, click Environment Variables and then click New in the next window.
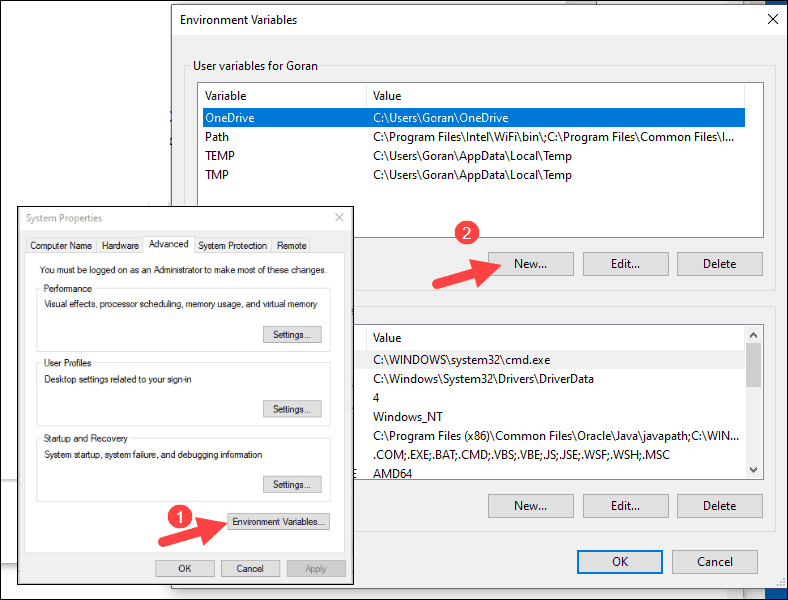
4. For Variable Name type SPARK_HOME.
5. For Variable Value type C:Sparkspark-2.4.5-bin-hadoop2.7 and click OK. If you changed the folder path, use that one instead.
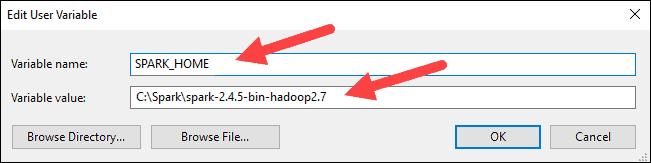
6. In the top box, click the Path entry, then click Edit. Be careful with editing the system path. Avoid deleting any entries already on the list.
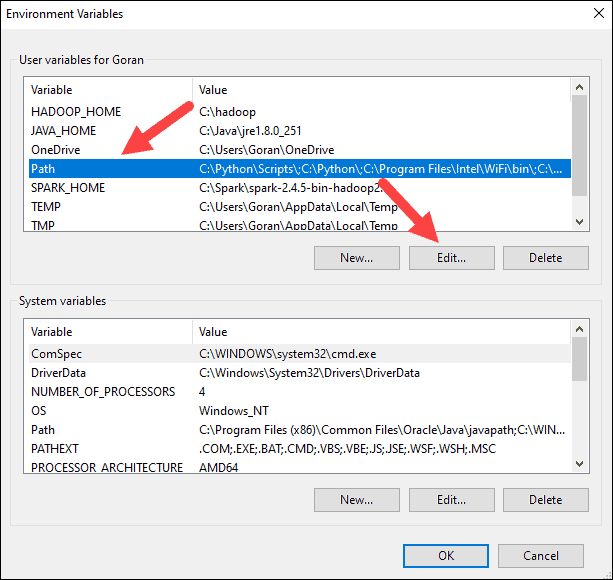
7. You should see a box with entries on the left. On the right, click New.
8. The system highlights a new line. Enter the path to the Spark folder C:Sparkspark-2.4.5-bin-hadoop2.7bin. We recommend using %SPARK_HOME%bin to avoid possible issues with the path.
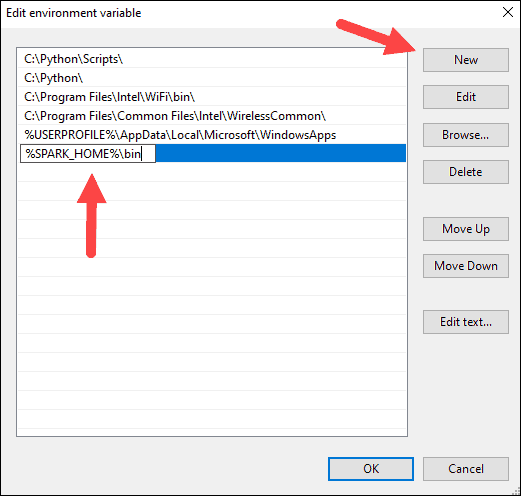
9. Repeat this process for Hadoop and Java.
- For Hadoop, the variable name is HADOOP_HOME and for the value use the path of the folder you created earlier: C:hadoop. Add C:hadoopbin to the Path variable field, but we recommend using %HADOOP_HOME%bin.
- For Java, the variable name is JAVA_HOME and for the value use the path to your Java JDK directory (in our case it’s C:Program FilesJavajdk1.8.0_251).
10. Click OK to close all open windows.
Note: Star by restarting the Command Prompt to apply changes. If that doesn’t work, you will need to reboot the system.
Step 8: Launch Spark
1. Open a new command-prompt window using the right-click and Run as administrator:
2. To start Spark, enter:
C:Sparkspark-2.4.5-bin-hadoop2.7binspark-shellIf you set the environment path correctly, you can type spark-shell to launch Spark.
3. The system should display several lines indicating the status of the application. You may get a Java pop-up. Select Allow access to continue.
Finally, the Spark logo appears, and the prompt displays the Scala shell.
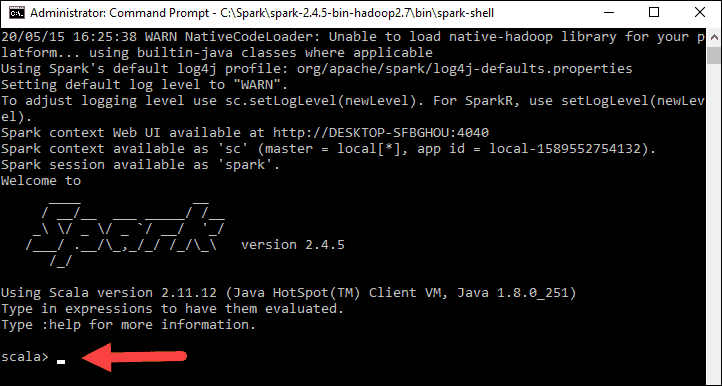
4., Open a web browser and navigate to http://localhost:4040/.
5. You can replace localhost with the name of your system.
6. You should see an Apache Spark shell Web UI. The example below shows the Executors page.
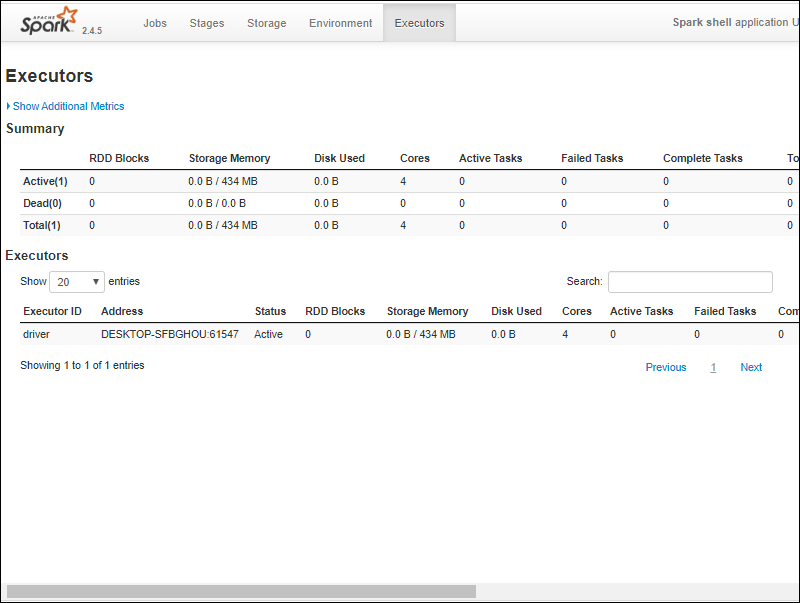
7. To exit Spark and close the Scala shell, press ctrl-d in the command-prompt window.
Note: If you installed Python, you can run Spark using Python with this command:
pysparkExit using quit().
Test Spark
In this example, we will launch the Spark shell and use Scala to read the contents of a file. You can use an existing file, such as the README file in the Spark directory, or you can create your own. We created pnaptest with some text.
1. Open a command-prompt window and navigate to the folder with the file you want to use and launch the Spark shell.
2. First, state a variable to use in the Spark context with the name of the file. Remember to add the file extension if there is any.
val x =sc.textFile("pnaptest")3. The output shows an RDD is created. Then, we can view the file contents by using this command to call an action:
x.take(11).foreach(println)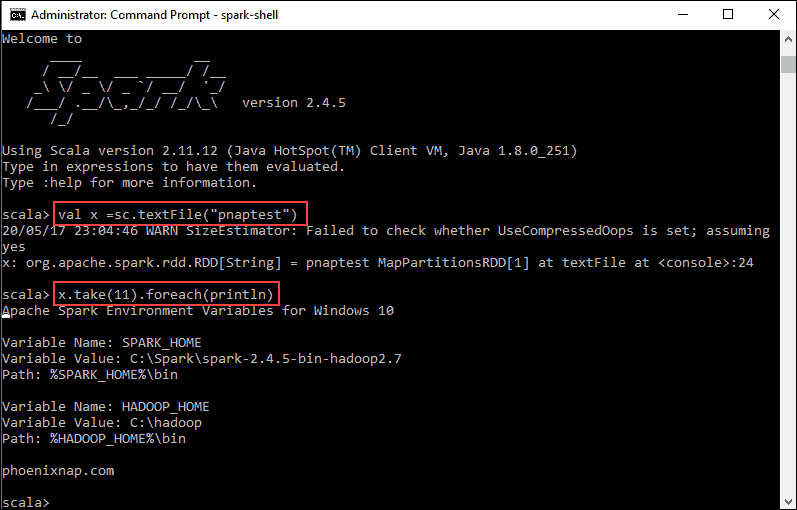
This command instructs Spark to print 11 lines from the file you specified. To perform an action on this file (value x), add another value y, and do a map transformation.
4. For example, you can print the characters in reverse with this command:
val y = x.map(_.reverse)5. The system creates a child RDD in relation to the first one. Then, specify how many lines you want to print from the value y:
y.take(11).foreach(println)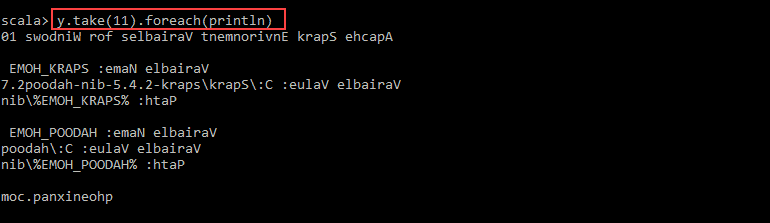
The output prints 11 lines of the pnaptest file in the reverse order.
When done, exit the shell using ctrl-d.
Conclusion
You should now have a working installation of Apache Spark on Windows 10 with all dependencies installed. Get started running an instance of Spark in your Windows environment.
Our suggestion is to also learn more about what Spark DataFrame is, the features, and how to use Spark DataFrame when collecting data.
Время прочтения
16 мин
Просмотры 3.6K

Данная статья обобщает базовые шаги по установке и началу работы с PySpark Structured Streaming при участии брокера сообщений Kafka. Предполагается, что читатель уже знаком с языком программирования Python и сервисом Kafka.
При помощи PySpark Structured Streaming можно быстро разрабатывать масштабируемые сервисы обработки данных в реальном времени. Такой подход позволяет в короткие сроки сделать выгодное предложение клиенту, вовремя заметить аномалию в системе или же отображать актуальные данные. Масштабируемость обеспечивается фреймворком Spark. Модуль Structured Streaming позволяет разрабатывать программы обработки данных в реальном времени, используя синтаксис SQL.
Здесь будут рассмотрены только самые простые примеры работы с Kafka посредством PySpark: чтение/запись в Kafka, а также разбор и сохранение поступающих сообщений в формате JSON и AVRO. Для подробного ознакомления можно прочитать статьи на официальном сайте:
-
Spark Structured Streaming
-
Spark Structured Streaming Kafka Integration
Требования к окружению
Все примеры были отлажены на подсистеме Ubuntu 20.04, Python 3.10.1, Spark 3.2.1, Kafka 3, OpenJDK 11.0.11 (необходима для работы Spark).
1.1) Подготовка виртуальной среды
Создаём пустую директорию с названием проекта, где инициализируем виртуальную среду (команда в терминале):
python -m venv .venvАктивируем в терминале при помощи следующей команды (из директории, где была создана виртуальная среда):
source .venv/bin/activateУстанавливаем PySpark:
pip install wheel pysparkЧтобы проверить, что всё установилось корректно, можно запустить интерпретатор PySpark:
pysparkДолжен запуститься интерпретатор Python, где доступен Spark.

1.2) Запуск сервиса Kafka
Для примера Kafka будет запущена локально. Это можно сделать, выполнив действия из официальной инструкции. Если умеете пользоваться Docker, то можно запустить её при помощи данного docker-compose или же использовать любой удобный для вас образ.
2) Чтение сообщений из топика Kafka
Создаём любой файл *.py. Для примера это будет example1.py.
Для работы со Spark необходимо инициализировать объект SparkSession:
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName('quickstart-streaming-kafka')
.getOrCreate())
spark.sparkContext.setLogLevel('WARN')При инициализации SparkSession вы можете указывать различные имена в методе appName(), которые позволяют позже опознавать свои приложения (например, при мониторинге всех запущенных приложений Spark на кластере).
Последняя строка опциональна, она влияет на вывод логов работы Spark. Установив значение «WARN», не будут выводиться информационные логи.
Укажем источник данных – топик Kafka:
source = (spark
.readStream
.format('kafka')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('subscribe', 'input00')
.load())Используя объект SparkSession, можно указывать источник данных, благодаря чему получим объект DataFrame, который и будет представлять получаемые данные. Источники в Spark делятся на два типа:
-
batch – разовая работа, когда вам заранее известен объём данных (для этого используется свойство
readуSparkSession); -
stream – потоковая работа, когда приложение запущено и обрабатывает поступающие данные (для этого используется свойство
readStream) в реальном времени. В данном режиме Spark с некоторой периодичностью формирует batch из поступающих данных.
Чтобы считывать из Kafka, необходимо в формате format() передать строку «kafka«. Список обязательных опций при работе с данным форматом:
-
kafka.bootstrap.servers – адрес сервера брокера (можно несколько – через запятую внутри строки);
-
subscribe – топик, откуда будут считываться новые сообщения (можно несколько – через запятую внутри строки).
Посмотрим схему получаемых сообщений, используя метод printSchema() у получившегося DataFrame:
source.printSchema()Вывод в терминале:
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)Краткая информация по каждому полю:
-
key – ключ, который используется в Kafka для определения партиции, в которую должно было попасть сообщение;
-
value – непосредственно сами данные, которые необходимо обрабатывать;
-
topic – название топика, откуда было получено сообщение (источники в Spark позволяют подписываться сразу на несколько топиков, их можно идентифицировать по данному полю);
-
partition и offset – партиция и смещение служат указателем, где именно в топике хранится сообщение;
-
timestamp и timestampType – информация о времени, когда поступило сообщение в топик.
Можно заметить, что поля «key» и «value» имеют двоичный формат. И если поступит сообщение со значением «Hello, World!«, то оно будет представлено массивом байтов:
-------------------------------------------
Batch: 1
-------------------------------------------
+----+--------------------+-------+---------+------+--------------------+-------------+
| key| value| topic|partition|offset| timestamp|timestampType|
+----+--------------------+-------+---------+------+--------------------+-------------+
|[30]|[48 65 6C 6C 6F 2...|input00| 0| 3|2022-03-11 08:28:...| 0|
+----+--------------------+-------+---------+------+--------------------+-------------+В Spark можно выполнять выборку с применением различных выражений, например, приведение типов. Используя метод selectExpr(), где можно указать выводимые поля в DataFrame, выведем и преобразуем поле «value» к строке, а также выведем «offset«:
df = (source
.selectExpr('CAST(value AS STRING)', 'offset'))Напишем простой вывод данных из источника в консоль:
console = (df
.writeStream
.format('console'))У любого DataFrame можно вызвать свойство writeStream, после чего указать формат вывода. В нашем случае это вывод в консоль (полный список поддерживаемых форматов доступен в документации). Таким образом, получится объект DataStreamWriter, который осталось только запустить:
console.start().awaitTermination()Метод start() запускает поток на выполнение. Но для того, чтобы программа не остановилась, необходимо поставить её в ожидание. Это можно сделать методом awaitTermination(), который будет ожидать, пока поток не будет терминирован.
Посмотрим на вывод, записав сообщение «Hello, World!» в топик «input00«:
-------------------------------------------
Batch: 1
-------------------------------------------
+-------------+------+
| value|offset|
+-------------+------+
|Hello, World!| 5|
+-------------+------+Готово! Теперь мы можем читать сообщения из Kafka.
Полный код примера
def main():
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName('streaming-kafka')
.getOrCreate())
spark.sparkContext.setLogLevel('WARN')
source = (spark
.readStream
.format('kafka')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('subscribe', 'input00,input01')
.load())
source.printSchema()
df = (source
.selectExpr('CAST(value AS STRING)', 'offset'))
console = (df
.writeStream
.format('console')
.queryName('console output'))
console.start().awaitTermination()
if __name__ == '__main__':
main()3) Запуск скрипта
Для запуска Spark приложений используется spark-submit. Чтобы взаимодействовать с Kafka, необходимо добавить зависимость «spark-sql-kafka-0-10_2.12» (актуальная версия для Spark 3.2.1 на момент написания статьи) к аргументу «—packages» (если есть доступ к сети Интернет или пакет уже имеется в кэше) или «—jars» (если имеется локально на запускаемой машине, необходимо указать путь).
spark-submit принимает множество параметров, о которых можно прочитать в документации. Эта утилита доступна в виртуальной среде Python, где был установлен пакет PySpark, поэтому её можно запускать данной командой в терминале при активированной виртуальной среде (должна быть установлена Java):
spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1 example1.py4) Пишем в топик Kafka
Вывод в топик Kafka написать не многим сложнее, чем вывод в консоль.
Дополняя предыдущий пример, напишем ещё один выход для df:
query = (df
.writeStream
.format('kafka')
.queryName('kafka-output')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('topic', 'output00')
.option('checkpointLocation', './.local/checkpoint'))Для вывода в Kafka необходимо в метод format() записать «kafka» и указать в опциях:
-
kafka.bootstrap.servers – адрес брокер сервера (можно несколько – через запятую внутри строки);
-
topic – в какой топик записывать данные (только один);
-
checkpointLocation – указать директорию, где будут записываться/читаться чекпоинты. Чекпоинты сохраняют указатель на месте, где остановилась обработка источника, что может пригодиться при перезапуске программы (продолжит с того места, где остановился). Настраивается на
DataStreamWriter. Более подробно про чекпоинты можно прочитать в документации.
Ещё добавочно здесь появилась строка с методом queryName(). Это необязательно, но так как у нас появился второй поток в одной программе, следует их все проименовать, чтобы различать при мониторинге. Запустим оба потока:
console.start()
query.start().awaitTermination()Вывод:
-------------------------------------------
Batch: 1
-------------------------------------------
+-------------------+------+
| value|offset|
+-------------------+------+
|Hello, second sink!| 0|
+-------------------+------+Сообщение в топик Kafka также записан:

ВАЖНО: у выходного DataFrame обязательно должно быть поле «value«, иначе программа упадёт с ошибкой. Именно это поле и будет записано в «value» сообщения для Kafka. Поле «key» может отсутствовать в DataFrame.
Благодаря тому, что у каждого потока есть свое название, мы можем их с лёгкостью отличать в Spark Web-UI, который запускается параллельно с развёртыванием Spark приложения (по умолчанию доступно по localhost:4040).


Отлично, теперь мы можем записывать новые сообщения в топик Kafka!
Полный код примера
def main():
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName('streaming-kafka')
.getOrCreate())
spark.sparkContext.setLogLevel('WARN')
source = (spark
.readStream
.format('kafka')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('subscribe', 'input00')
.load())
df = (source
.selectExpr('CAST(value AS STRING)', 'offset'))
console = (df
.writeStream
.format('console')
.queryName('console-output'))
query = (df
.writeStream
.format('kafka')
.queryName('kafka-output')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('topic', 'output00')
.option('checkpointLocation', './.local/checkpoint'))
console.start()
query.start().awaitTermination()
if __name__ == '__main__':
main()5) Сообщение в формате JSON
Передавая данные, мы всегда ждём чего-то большего, чем просто одну строку. Для этого можно использовать текстовые форматы данных, например, JSON. Spark имеет функции, которые могут преобразовать строку в struct, то есть в структуру данных.
Будем обрабатывать следующую структуру данных:
{
"name": String,
"age": Int
}Заводим источник source, который вычитывает сообщения из топика Kafka, при этом поле «value» приводим к типу String (как описано в разделе 2).
В Spark есть функция from_json(), которая может приводить поле из строки к структуре. При этом ей необходимо передать схему сообщения, которая может быть типа DataType, а также String. Воспользуемся первым вариантом:
from pyspark.sql import types as t
schema = t.StructType(
[
t.StructField('name', t.StringType(), True),
t.StructField('age', t.IntegerType(), True),
],
)Все типы можно найти в пакете pyspark.sql.types. Комбинируя таким образом типы данных, можно описывать необходимую схему.
Теперь нужно применить функцию from_json() к полю, которое содержит строку с JSON:
from pyspark.sql import functions as f
df = (df
.select(f.from_json('value', schema).alias('data')))
print("df schema")
df.printSchema()Вывод схемы:
df schema
root
|-- data: struct (nullable = true)
| |-- name: string (nullable = true)
| |-- age: integer (nullable = true)Первым аргументом функции from_json() было передано название поля, вторым аргументом – схема данных. Метод alias() изменяет название получившегося поля (аналогично слову AS в SQL).
Добавим немного логики: будем фильтровать по полю «age«, что больше или равно 18 при помощи метода where(). Так как при парсинге мы получаем структуру, то при обращении к конкретному полю структуры необходимо обращаться через точку («data.age«):
df = df.where(df['data.age'] >= 18)Структуру можно легко развернуть при помощи метода select():
console = df.select('data.*')
print("console schema")
console.printSchema()Вывод схемы:
console schema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)Не стоит переживать по поводу строк с выводом в консоль, как print() и printSchema(), так как в сам запрос обработки Spark они не попадут, выполнятся только в момент инициализации запроса (то есть при поступлении новых данных эти выводы отрабатываться не будут).
Добавим вывод в консоль:
console = (console
.writeStream
.format('console')
.queryName('console-output'))Для сохранения данных в Kafka, подготовим также JSON. Для этого в Spark есть функция to_json(), принимающая ColumnOrName, где можно указать поле, которое содержит структуру:
df = df.withColumn('value', f.to_json('data'))
query = (df
.writeStream
.format('kafka')
.queryName('kafka-output')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('topic', 'output00')
.option('checkpointLocation', './.local/checkpoint'))Готово!
Полный код примера
def main():
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
from schema_example3 import schema
spark = (SparkSession
.builder
.appName('streaming-kafka')
.getOrCreate())
spark.sparkContext.setLogLevel('WARN')
source = (spark
.readStream
.format('kafka')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('subscribe', 'input00')
.load())
df = (source
.selectExpr('CAST(value AS STRING)', 'offset'))
df = (df
.select(f.from_json('value', schema).alias('data')))
print("df schema")
df.printSchema()
df = df.where(df['data.age'] >= 18)
console = df.select('data.*')
print("console schema")
console.printSchema()
console = (console
.writeStream
.format('console')
.queryName('console-output'))
df = df.withColumn('value', f.to_json('data'))
query = (df
.writeStream
.format('kafka')
.queryName('kafka-output')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('topic', 'output00')
.option('checkpointLocation', './.local/checkpoint'))
console.start()
query.start().awaitTermination()
if __name__ == '__main__':
main()Схема данных:
from pyspark.sql import types as t
schema = t.StructType(
[
t.StructField('name', t.StringType(), True),
t.StructField('age', t.IntegerType(), True),
],
)Запишем три JSON строки в топик «input00«:
{"name":"Ivan","age":15}
{"name":"Vladimir","age":33}
{"name":"Dmitry","age":24}Из них только две записи проходят условие фильтрации. Вывод в консоле:
+--------+---+
| name|age|
+--------+---+
|Vladimir| 33|
| Dmitry| 24|
+--------+---+Состояние топика «output00«:

6) Сообщение в формате AVRO
Работа с AVRO не входит в основной модуль работы со Spark. Для этого необходимо, как и с Kafka, подтягивать дополнительный пакет при запуске приложения:
spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1,org.apache.spark:spark-avro_2.12:3.2.1 example4.pyДля сериализации и десериализации сообщений формата AVRO в Spark есть две функции: to_avro() и from_avro(), которые хранятся в модуле pyspark.sql.avro:
from pyspark.sql.avro import functions as faПереведём структуру данных из прошлого примера в формат AVRO и сохраним как файл *.avsc:
{
"type": "record",
"name": "Person",
"namespace": "example",
"fields": [
{"name": "name","type": ["string", "null"]},
{"name": "age","type": ["long", "null"]}
]
}Для метода from_avro() необходимо передать колонку и схему в формате строки. Получить схему можно обычным способом из файла:
schema = open('schema_example4.avsc', 'r').read()Относительно примера с JSON остаётся только заменить функцию десериализации колонки, где хранится сообщение (в отличии от JSON, AVRO хранится в двоичном формате, а значит нам не нужно изначально приводить колонку «value» к строковому типу):
df = (source
.select(fa.from_avro('value', schema).alias('data')))На выходе to_avro() указывать схему опционально. Но лучше всё же её указать, иначе могут возникнуть проблемы при десериализации (например, если порядок колонок был нарушен):
df = df.withColumn('value', fa.to_avro('data', schema))Таким образом, мы можем сериализовать и десериализовать сообщения в формате AVRO.
Полный код примера
def main():
from pyspark.sql import SparkSession
from pyspark.sql.avro import functions as fa
schema = open('schema_example4.avsc', 'r').read()
spark = (SparkSession
.builder
.appName('streaming-kafka')
.getOrCreate())
spark.sparkContext.setLogLevel('WARN')
source = (spark
.readStream
.format('kafka')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('subscribe', 'input00')
.load())
df = (source
.select(fa.from_avro('value', schema).alias('data')))
print("df schema")
df.printSchema()
df = df.where(df['data.age'] >= 18)
console = df.select('data.*')
print("console schema")
console.printSchema()
console = (console
.writeStream
.format('console')
.queryName('console-output'))
df = df.withColumn('value', fa.to_avro('data', schema))
query = (df
.writeStream
.format('kafka')
.queryName('kafka-output')
.option('kafka.bootstrap.servers', 'localhost:9092')
.option('topic', 'output00')
.option('checkpointLocation', './.local/checkpoint'))
console.start()
query.start().awaitTermination()
if __name__ == '__main__':
main()Схема данных в формате AVRO:
{
"type": "record",
"name": "Person",
"namespace": "com.neoflex.example",
"fields": [
{"name": "name","type": ["string", "null"]},
{"name": "age","type": ["long", "null"]}
]
}Для публикации сообщений в формате AVRO в Kafka был написан и приложен к примерам Producer. Все примеры из статьи доступны в репозитории.
Заключение
Цель статьи – научиться писать простейшие процессы потоковой обработки с применением фреймворка PySpark, взаимодействовать с Kafka и читать/писать сообщения в форматах JSON и AVRO. Spark позволяет использовать синтаксис SQL, благодаря чему программы получаются удобочитаемы за счёт отсутствия необходимости изучать синтаксис очередного фреймворка, ведь SQL достаточно широко известен.
Таким образом, используя брокер сообщения Kafka и PySpark Structured Streaming, вы сможете описывать свои системы обработки данных любой сложности и масштабируемости.
Автор статьи: Дмитрий Жданов, специалист бизнес-направления Fast Data компании Neoflex.