Python 2 предварительно установлен на Mac и большинстве дистрибутивов Linux. Для новых Python проектов рекомендуется Python 3, который был впервые выпущен в 2008 году.
Инструкции по установке Python в Windows
Загрузите последнюю версию программы установки и запустите ее.
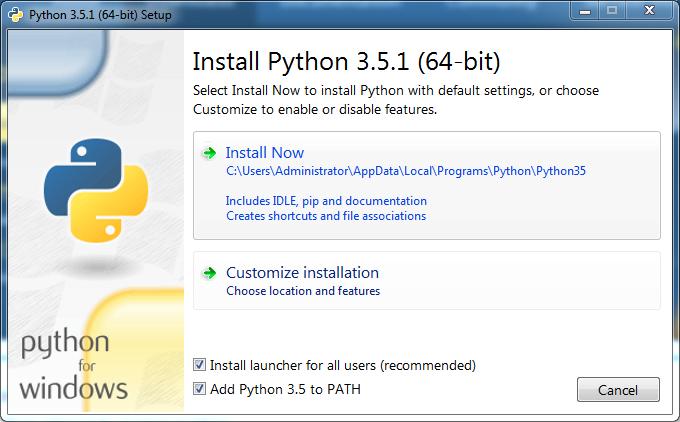
Для удобства используйте все параметры по умолчанию, кроме «Add python.exe to Path».
Установка Python на Mac
Установите Selenium-WebDriver для Python
PIP — это менеджер пакетов для Python. PIP поставляется с установщиком Python, Выполните следующую команду для обновления до последней версии PIP.
|
python —m pip install —upgrade pip |
Установка Selenium-WebDriver для Python
Выполняем в терминал Windows, Linux или Mac
Результат
|
Collecting selenium Downloading selenium—3.0.2—py2.py3—none—any.whl (915kB) 100% |################################| 921kB 525kB/s Installing collected packages: selenium Successfully installed selenium—3.0.2 |
Установка драйвера
Каждый браузер имеет свой собственный драйвер для Selenium. Мы подготовили нужную информацию для установки драйверов для каждого браузера.
Время прочтения
5 мин
Просмотры 403K
Туториал
Из песочницы
Перевод
Представляю перевод неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
Предисловие от автора статьи
Selenium WebDriver – это программная библиотека для управления браузерами. WebDriver представляет собой драйверы для различных браузеров и клиентские библиотеки на разных языках программирования, предназначенные для управления этими драйверами.
По сути своей использование такого веб-драйвера сводится к созданию бота, выполняющего всю ручную работу с браузером автоматизированно.
Библиотеки WebDriver доступны на языках Java, .Net (C#), Python, Ruby, JavaScript, драйверы реализованы для браузеров Firefox, InternetExplorer, Safari, Andriod, iOS (а также Chrome и Opera).
Сфера применения
Чаще всего Selenium WebDriver используется для тестирования функционала веб-сайтов/веб-ориентированных приложений. Автоматизированное тестирование удобно, потому что позволяет многократно запускать повторяющиеся тесты. Регрессионное тестирование, то есть, проверка, что старый код не перестал работать правильно после внесения новых изменений, является типичным примером, когда необходима автоматизация. WebDriver предоставляет все необходимые методы, обеспечивает высокую скорость теста и гарантирует корректность проверки (поскольку человеский фактор исключен). В официальной документации Selenium приводятся следующие плюсы автоматизированного тестирования веб-приложений:
- возможность проводить чаще регрессионное тестирование;
- быстрое предоставление разработчикам отчета о состоянии продукта;
- получение потенциально бесконечного числа прогонов тестов;
- обеспечение поддержки Agile и экстремальным методам разработки;
- сохранение строгой документации тестов;
- обнаружение ошибок, которые были пропущены на стадии ручного тестирования.
Функционал WebDriver позволяет использовать его не только для тестирования, но и для администрирования веб-сервисов, сократив до возможного предела количество действий, производимых вручную. Selenium WebDriver становится незаменимым помощником в случаях, когда, к примеру, ядро сайта устарело и требует от модераторов большого количества телодвижений для реализации маленьких фич (например, загрузки галереи фото).
Также одной из незаменимых особенностей Selenium WebDriver является ожидание загрузки страницы. Сюда можно отнести случаи, когда парсинг данных на странице невозможен из-за страниц перенаправления или ожидания, содержащих примерно такой текст: «Подождите, страница загружается». Такие страницы, само собой разумеется, не является целью парсинга, однако обойти их часто не представляется возможным. Естественно, без Selenium WebDriver. Selenium WebDriver позволяет в таких случаях «ожидать», как ожидал бы человек, пока на странице, к примеру, не появится элемент с необходимым именем.
Еще один плюс Selenium заключен в том, что действия веб-драйвера видимы визуально и требуют минимального времени нахождения на странице, это позволяет с удобством демонстрировать функционал сайта, когда необходима презентация сервиса.
Некоторые проблемы WebDriver (из сети и личного опыта):
- бывает, что поведение отличается в разных браузерах;
- иногда возникают сложности с поиском элементов (XPath и другие методы иногда просто не работают, хотя должны);
- необъяснимые падения драйвера прямо посреди теста;
- взаимодействие возможно только с первой вкладкой браузера, драйвер позволяет открывать новые вкладки и новые окна, но не позволяет в них работать;
- необходимо четко продумывать архитектуру теста, часто использовать assert или ожидания, чтобы тест умел «думать», когда делать и когда нет.
Подробнее о проекте Selenium и серии их ПО можно прочитать здесь, либо в официальной документации или ее переводе.
Содержание:
1. Установка
2. Первые Шаги
3. Навигация
4. Поиск Элементов
5. Ожидания
6. Объекты Страницы
7. WebDriver API
8. Приложение: Часто Задаваемые Вопросы
1. Установка
1.1. Введение
Привязка Selenium к Python предоставляет собой простой API [Интерфейс программирования приложений (англ. Application Programming Interface) — Прим. пер.] для написания тестов функциональности/тестов соответствия требованиям с использованием веб-драйвера Selenium WebDriver. С помощью Selenium Python API вы можете интуитивно просто получить доступ ко всему функционалу Selenium WebDriver.
Привязка Python-Selenium предоставляет удобный API для доступа к таким веб-драйверам Selenium как Firefox, Ie, Chrome, Remote и других. На данный момент поддерживаются версии Python 2.7, 3.2, 3.3 и 3.4.
В данной документации рассмотрен Selenium 2 WebDriver API. Selenium 1 / Selenium RC API в ней не охвачены.
1.2. Загрузка Selenium для Python
Вы можете загрузить привязку Selenium к Python со страницы пакета selenium на PyPI. Однако, лучшим способом будет использование модуля pip. Python 3.4 содержит pip в стандартной библиотеке. Используя pip, вы можете установить selenium следующей командой:
pip install selenium
Для создания изолированной среды Python вы можете использовать virtualenv. Также библиотека Python 3.4 содержит модуль pyvenv, который практически аналогичен virtualenv.
1.3. Подробная инструкция для пользователей Windows
Примечание
Для данной инсталляции вам необходим доступ к сети Интернет.
1. Установите Python 3.4 через файл MSI, доступный на странице загрузок сайта python.org.
2. Запустите командную строку через программу cmd.exe и запустите команду pip установки selenium, как показано ниже.
C:Python34Scriptspip.exe install selenium
Теперь вы можете запускать свои тестовые скрипты, используя Python. К примеру, если вы создали скрипт на основе Selenium и сохранили его в C:my_selenium_script.py, то вы можете запустить его следующей командой:
C:Python34python.exe C:my_selenium_script.py
1.4. Загрузка Selenium server
Примечание
Selenium server необходим в случаях, когда вы хотите использовать remote WebDriver [удаленный — Прим. пер.]. За дополнительной информацией обращайтесь к разделу Использование Selenium с remote WebDriver. Если вы только начинаете изучать Selenium, вы можете пропустить этот раздел и продолжить изучение со следующей главы.
Selenium server написан на языке Java. Для его запуска рекомендована среда Java Runtime Environment (JRE) версии 1.6 или выше.
Вы можете скачать Selenium server 2.x на странице загрузок сайта selenium. Имя файла должно выглядеть примерно таким образом: selenium-server-standalone-2.x.x.jar. Вы всегда можете загрузить последнюю версию Selenium server 2.x.
Если Java Runtime Environment (JRE) не установлена в вашей системе, вы можете скачать JRE с сайта Oracle. Если вы используете системы GNU/Linux и имеете права root [права администратора — Прим. пер.], вы так же можете установить JRE, используя инструкции вашей системы.
Если команда java доступна в PATH (переменная окружения), вы можете запустить Selenium server используя следующую команду:
java -jar selenium-server-standalone-2.x.x.jar
Замените 2.x.x актуальной версией Selenium server, скачанной вами с сайта.
Если JRE установлена под пользователем, не обладающим правами root и/или если она недоступна в переменной окружения PATH, вы можете ввести относительный или полный путь до файла java. Аналогично, вы можете дополнить имя jar-файла Selenium server до относительного или полного пути. После этого команда будет выглядеть так:
/путь/до/java -jar /путь/до/selenium-server-standalone-2.x.x.jar
Перейти к следующей главе
Supported Python Versions¶
- Python 3.7+
Installing¶
If you have pip on your system, you can simply install or upgrade the Python bindings:
Alternately, you can download the source distribution from PyPI (e.g. selenium-4.8.0.tar.gz), unarchive it, and run:
Note: You may want to consider using virtualenv to create isolated Python environments.
Example 0:¶
- open a new Firefox browser
- load the page at the given URL
from selenium import webdriver browser = webdriver.Firefox() browser.get('http://selenium.dev/')
Example 1:¶
- open a new Firefox browser
- load the Yahoo homepage
- search for “seleniumhq”
- close the browser
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys browser = webdriver.Firefox() browser.get('http://www.yahoo.com') assert 'Yahoo' in browser.title elem = browser.find_element(By.NAME, 'p') # Find the search box elem.send_keys('seleniumhq' + Keys.RETURN) browser.quit()
Example 2:¶
Selenium WebDriver is often used as a basis for testing web applications. Here is a simple example using Python’s standard unittest library:
import unittest from selenium import webdriver class GoogleTestCase(unittest.TestCase): def setUp(self): self.browser = webdriver.Firefox() self.addCleanup(self.browser.quit) def test_page_title(self): self.browser.get('http://www.google.com') self.assertIn('Google', self.browser.title) if __name__ == '__main__': unittest.main(verbosity=2)
Selenium Server (optional)¶
For normal WebDriver scripts (non-Remote), the Java server is not needed.
However, to use Selenium Webdriver Remote or the legacy Selenium API (Selenium-RC), you need to also run the Selenium server. The server requires a Java Runtime Environment (JRE).
Download the server separately, from: https://www.selenium.dev/downloads/
Run the server from the command line:
java -jar selenium-server-4.6.0.jar
Then run your Python client scripts.
Contributing¶
- Create a branch for your work
- Ensure tox is installed (using a virtualenv is recommended)
- python3.7 -m venv .venv && . .venv/bin/activate && pip install tox
- After making changes, before committing execute tox -e linting
- If tox exits 0, commit and push otherwise fix the newly introduced breakages.
- flake8 requires manual fixes
- black will often rewrite the breakages automatically, however the files are unstaged and should staged again.
- isort will often rewrite the breakages automatically, however the files are unstaged and should staged again.
Introduction
Python language bindings for Selenium WebDriver.
The selenium package is used to automate web browser interaction from Python.
Several browsers/drivers are supported (Firefox, Chrome, Internet Explorer), as well as the Remote protocol.
Supported Python Versions
-
Python 3.7+
Installing
If you have pip on your system, you can simply install or upgrade the Python bindings:
pip install -U selenium
Alternately, you can download the source distribution from PyPI (e.g. selenium-4.8.0.tar.gz), unarchive it, and run:
python setup.py install
Note: You may want to consider using virtualenv to create isolated Python environments.
Drivers
Selenium requires a driver to interface with the chosen browser. Firefox,
for example, requires geckodriver, which needs to be installed before the below examples can be run. Make sure it’s in your PATH, e. g., place it in /usr/bin or /usr/local/bin.
Failure to observe this step will give you an error selenium.common.exceptions.WebDriverException: Message: ‘geckodriver’ executable needs to be in PATH.
Other supported browsers will have their own drivers available. Links to some of the more popular browser drivers follow.
Example 0:
-
open a new Firefox browser
-
load the page at the given URL
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://selenium.dev/')Example 1:
-
open a new Firefox browser
-
load the Yahoo homepage
-
search for “seleniumhq”
-
close the browser
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.yahoo.com')
assert 'Yahoo' in browser.title
elem = browser.find_element(By.NAME, 'p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN)
browser.quit()Example 2:
Selenium WebDriver is often used as a basis for testing web applications. Here is a simple example using Python’s standard unittest library:
import unittest
from selenium import webdriver
class GoogleTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def test_page_title(self):
self.browser.get('http://www.google.com')
self.assertIn('Google', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)Selenium Server (optional)
For normal WebDriver scripts (non-Remote), the Java server is not needed.
However, to use Selenium Webdriver Remote or the legacy Selenium API (Selenium-RC), you need to also run the Selenium server. The server requires a Java Runtime Environment (JRE).
Download the server separately, from: https://www.selenium.dev/downloads/
Run the server from the command line:
java -jar selenium-server-4.6.0.jar
Then run your Python client scripts.
Use The Source Luke!
View source code online:
Contributing
Create a branch for your work
Ensure tox is installed (using a virtualenv is recommended)
python3.7 -m venv .venv && . .venv/bin/activate && pip install tox
After making changes, before committing execute tox -e linting
If tox exits 0, commit and push otherwise fix the newly introduced breakages.
flake8 requires manual fixes
black will often rewrite the breakages automatically, however the files are unstaged and should staged again.
isort will often rewrite the breakages automatically, however the files are unstaged and should staged again.
Selenium Scripts are built to do some tedious tasks which can be automated using headless web browsers.
For example, Searching for some Questions on Different Search engines and storing results in a file by visiting each link. This task can take a long for a normal human being but with the help of selenium scripts one can easily do it
Now, Some of You may be wondering what is headless web browsers. It’s nothing but a browser that can be controlled using these selenium scripts for automation(web tasks). Selenium Scripts can be programmed using various languages such as JavaScript, Java, Python, etc.
How to Use selenium with Python and Linux Environment.
Python should already be installed. It can be 2.* or 3.* version.
Steps:
- Installing Selenium
- Installing Webdrivers (headless)
- Creating Simple Code
Installing Selenium
Whatever Operating System You are Using Python command is Same for Installing Selenium Library.
First Method
Open Terminal/Cmd and Write Command as written Below
python -m pip install selenium
Second Method
Alternatively, you can download the source distribution here, unarchive it, and run the command below:
python setup.py install
Installing Webdrivers
One Can Install Firefox, Chromium, PhantomJs(Deprecated Now), etc.
- for using Firefox you may need to install GeckoDriver
- for using Chrome you may need to install Chromium
In this article, Firefox is used so One can Follow the Below Steps to Install:-
Steps for Linux:-
1. Go to the geckodriver releases page. Find the latest version of the driver for your platform and download it.
For example:
wget https://github.com/mozilla/geckodriver/releases/download/v0.24.0/geckodriver-v0.24.0-linux64.tar.gz
2. Extract the file with:
tar -xvzf geckodriver*
3. Make it executable:
chmod +x geckodriver
4. Move Files to usr/local/bin
sudo mv geckodriver /usr/local/bin/
Steps for Windows:-
1. Same as Step 1 in Linux Download the GeckoDriver
2. Extract it using WinRar or any application you may have.
3. Add it to Path using Command Prompt
setx path "%path%;GeckoDriver Path"
For Example:-
setx path "%path%;c:/user/eliote/Desktop/geckodriver-v0.26.0-win64/geckodriver.exe"
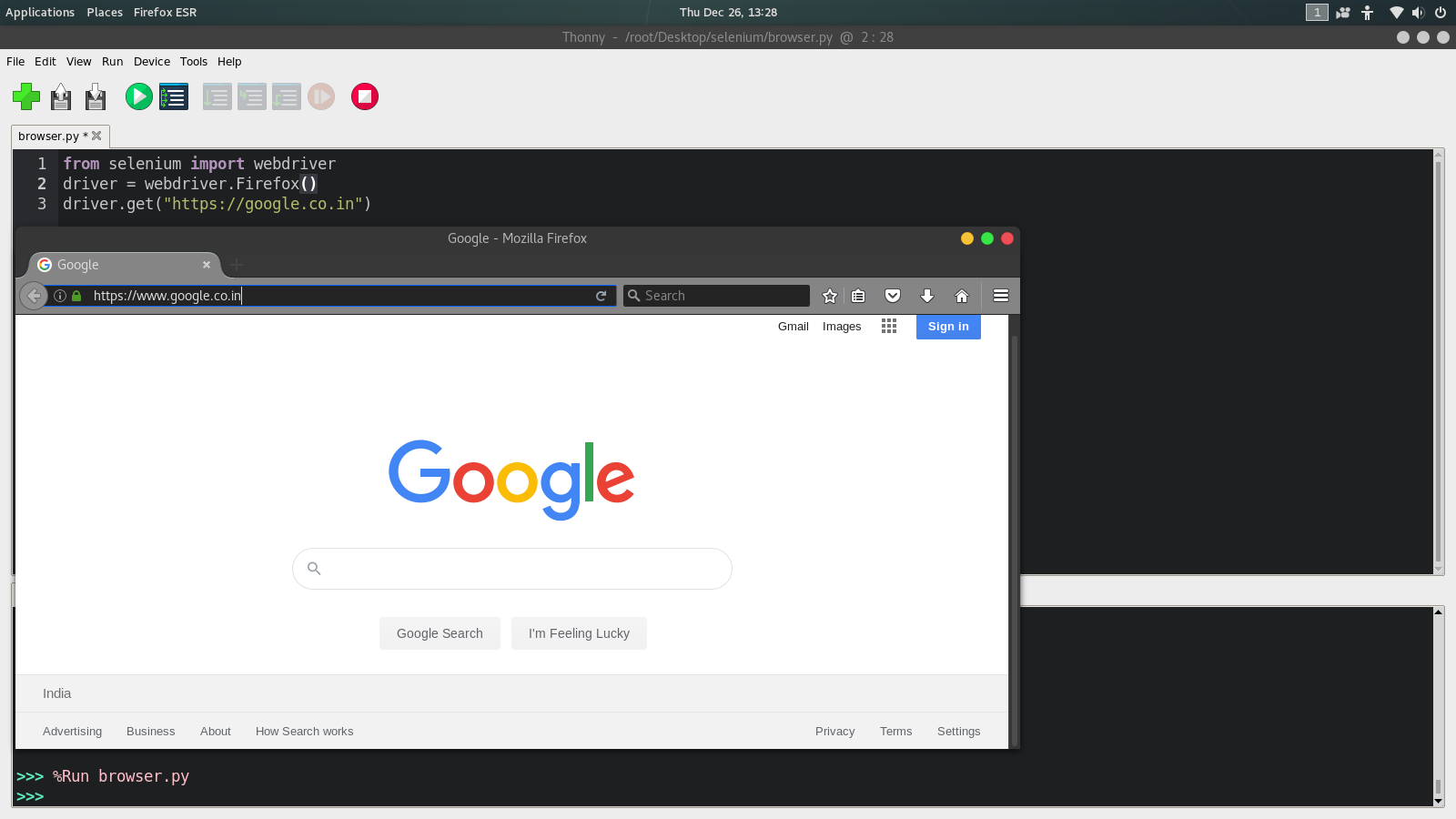
Creating Simple Code
Python3
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://google.co.in")
Output:
Selenium Scripts are built to do some tedious tasks which can be automated using headless web browsers.
For example, Searching for some Questions on Different Search engines and storing results in a file by visiting each link. This task can take a long for a normal human being but with the help of selenium scripts one can easily do it
Now, Some of You may be wondering what is headless web browsers. It’s nothing but a browser that can be controlled using these selenium scripts for automation(web tasks). Selenium Scripts can be programmed using various languages such as JavaScript, Java, Python, etc.
How to Use selenium with Python and Linux Environment.
Python should already be installed. It can be 2.* or 3.* version.
Steps:
- Installing Selenium
- Installing Webdrivers (headless)
- Creating Simple Code
Installing Selenium
Whatever Operating System You are Using Python command is Same for Installing Selenium Library.
First Method
Open Terminal/Cmd and Write Command as written Below
python -m pip install selenium
Second Method
Alternatively, you can download the source distribution here, unarchive it, and run the command below:
python setup.py install
Installing Webdrivers
One Can Install Firefox, Chromium, PhantomJs(Deprecated Now), etc.
- for using Firefox you may need to install GeckoDriver
- for using Chrome you may need to install Chromium
In this article, Firefox is used so One can Follow the Below Steps to Install:-
Steps for Linux:-
1. Go to the geckodriver releases page. Find the latest version of the driver for your platform and download it.
For example:
wget https://github.com/mozilla/geckodriver/releases/download/v0.24.0/geckodriver-v0.24.0-linux64.tar.gz
2. Extract the file with:
tar -xvzf geckodriver*
3. Make it executable:
chmod +x geckodriver
4. Move Files to usr/local/bin
sudo mv geckodriver /usr/local/bin/
Steps for Windows:-
1. Same as Step 1 in Linux Download the GeckoDriver
2. Extract it using WinRar or any application you may have.
3. Add it to Path using Command Prompt
setx path "%path%;GeckoDriver Path"
For Example:-
setx path "%path%;c:/user/eliote/Desktop/geckodriver-v0.26.0-win64/geckodriver.exe"
Creating Simple Code
Python3
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://google.co.in")
Output:
Selenium’s Python Module is built to perform automated testing with Python. Selenium Python bindings provides a simple API to write functional/acceptance tests using Selenium WebDriver. Through Selenium Python API you can access all functionalities of Selenium WebDriver in an intuitive way. To check more details about Selenium visit – Selenium Basics – Components, Features, Uses and Limitations.
Selenium Python Introduction
Selenium Python bindings provide a convenient API to access Selenium WebDrivers like Firefox, Ie, Chrome, Remote etc. Selenium released it’s latest version 4.5.0. The current supported Python versions are 3.7 and above.
- Open Source and Portable – Selenium is an open source and portable Web testing Framework.
- Combination of tool and DSL – Selenium is combination of tools and DSL (Domain Specific Language) in order to carry out various types of tests.
- Easier to understand and implement – Selenium commands are categorized in terms of different classes which make it easier to understand and implement.
- Reduce test execution time – Selenium supports parallel test execution that reduce the time taken in executing parallel tests.
- Lesser resources required – Selenium requires lesser resources when compared to its competitors like UFT, RFT, etc.
- Supports Multiple Operating Systems – Android, iOS, Windows, Linux, Mac, Solaris.
- Supports Multiple Browsers – Google Chrome, Mozilla Firefox, Internet Explorer, Edge, Opera, Safari, etc.
- Parallel Test Execution – It also supports parallel test execution which reduces time and increases the efficiency of tests.
Selenium Python Installation
For any operating system selenium can be installed after you have installed python on your operating system. If not, checkout – Download and Install Python 3 Latest Version
First Method
Open Terminal/Cmd and Write Command as written Below
python -m pip install selenium
Second Method
Alternatively, you can download the source distribution here, unarchive it, and run the command below:
python setup.py install
Installing Webdrivers
One Can Install Firefox, Chromium, PhantomJs(Deprecated Now), etc.
- for using Firefox you may need to install GeckoDriver
- for using Chrome you may need to install Chromium
In this article, Firefox is used so One can Follow the Below Steps to Install:-
Steps for Linux:-
1. Go to the geckodriver releases page. Find the latest version of the driver for your platform and download it.
For example:
wget https://github.com/mozilla/geckodriver/releases/download/v0.24.0/geckodriver-v0.24.0-linux64.tar.gz
2. Extract the file with:
tar -xvzf geckodriver*
3. Make it executable:
chmod +x geckodriver
4. Move Files to usr/local/bin
sudo mv geckodriver /usr/local/bin/
Steps for Windows:-
1. Same as Step 1 in Linux Download the GeckoDriver
2. Extract it using WinRar or any application you may have.
3. Add it to Path using Command Prompt
setx path "%path%;GeckoDriver Path"
For Example:-
setx path "%path%;c:/user/eliote/Desktop/geckodriver-v0.26.0-win64/geckodriver.exe"
Creating Simple Code
Python3
Output:
В данной статье вы изучите продвинутую технику веб-автоматизации в Python. Мы используем Selenium с браузером без графического интерфейса, экспортируем отобранные данные в CSV файлы и завернем ваш отобранный код в класс Python.
Содержание
- Мотивация: отслеживаем музыкальные привычки
- Установка и Настройка Selenium
- Пробный запуск браузера в режиме Headless
- Веб-парсинг в Python
- Расширяем потенциал
- Исследуем каталог
- Создание класса
- Собираем структурированные данные
- Что дальше и чему мы научились?
1. Мотивация: отслеживаем музыкальные привычки
Предположим, что вы время от времени слушаете музыку на bandcamp.com или soundcloud и вам хочется вспомнить название песни, которую вы услышали несколько месяцев назад.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Конечно, вы можете покопаться в истории вашего браузера и проверить каждую песню, но это весьма болезненная затея… Все, что вы помните, это то, что вы услышали песню несколько месяцев назад и она в жанре электроника.
«Было бы классно», думаете вы «Если бы у меня запись моей истории прослушиваний. Я мог бы просто взглянуть на электронную музыку, которую я слушал пару месяцев назад и найти эту песню!»
Сегодня мы создадим простой класс Python под названием BandLeader, который подключается к bandcamp.com, стримит музыку из раздела «Найденное» на главной странице, и отслеживает вашу историю прослушиваний.
История прослушиваний будет сохранена на диске в CSV файле. Далее, вы можете в любой момент просматривать CSV файл в вашей любимой программе для работы с таблицами, или даже в Python.
Если у вас есть опыт в веб-парсинга в Python, то вы знакомы с созданием HTTP запросами и использованием API Python для навигации в DOM. Сегодня мы затронем все эти пункты, за одним исключением.
Сегодня вы используете браузер в режиме без графического интерфейса (режим «командной строки») для выполнения запросов HTTP.
Консольный браузер – это обычный веб браузер, который работает без видимого пользовательского интерфейса. Как вы могли догадаться, он может делать больше, чем выполнять запросы: проводить рендер HTML (правда, вы этого не будете видеть), хранить информацию о сессии, даже проводить асинхронные сетевые связи на коде JavaScript.
Если вы хотите автоматизировать современную сеть, консольные браузеры – неотъемлемая часть.
Бесплатный бонус: Скачайте основу проекта Python+Selenium с полным исходным кодом, который вы можете использовать как основу для вашего веб-парсинга в Python и автоматических приложениях.
Первый шаг, перед тем как написать первую строчку кода – это установка Selenium с поддержкой WebDriver для вашего любимого браузера. Далее в статье мы будем работать с Firefox Selenium, но Chrome также будет отлично.
- Установка драйвера geckodriver для Firefox Selenium
- Установка драйвера chromedriver для Chrome Selenium
По выше указанным ссылкам имеется полное описание процесса установки драйверов для Selenium.
Далее, нужно установить Selenium при помощи pip, или как вам удобнее. Если вы создали виртуальное пространство для этого проекта, просто введите:
|
sudo pip install selenium |
[Если у вас будут вопросы в ходе изучения данной статьи, полный код можно найти на GitHub.]
Время для пробного запуска.
3. Пробный запуск браузера
Чтобы убедиться, что все работает, попробуйте выполнить простой поиск в интернете через DuckDuckGo. Используйте свой предпочитаемый интерпретатор Python и введите:
|
from selenium.webdriver import Firefox from selenium.webdriver.firefox.options import Options opts = Options() opts.set_headless() assert opts.headless # без графического интерфейса. browser = Firefox(options=opts) browser.get(‘https://duckduckgo.com’) |
Таким образом, вы только что создали Firefox в режиме консольного приложения (без головы т.е. без графического интерфейса), направленный на https://duckduckgo.com. Вы создали экземпляр «Options» и применили его для активации мода headless в конструкторе Firefox. Это похоже на введение команды firefox – headless в командной строке.
4. Веб-парсинг в Python
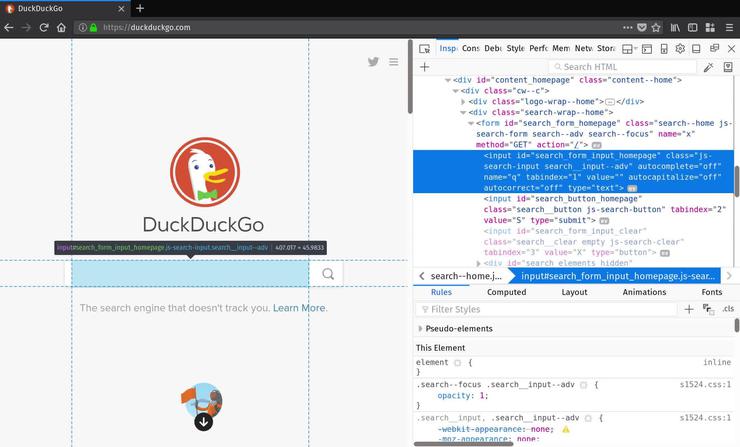
Теперь, когда страница загружена, вы можете запросить DOM при помощи методов, определенных в вашем созданном объекте браузера.
Но откуда мы знаем, что запрашивать? Лучший способ – это открыть ваш веб браузер и использовать его инструменты разработки для исследования содержимого страницы. Сейчас вы можете получить форму поиска для отправки запроса, чтобы выполнить запрос. Проверив главную страницу DuckDuckGo, вы увидите, что элемент поисковой формы<input> имеет атрибут ID «search_form_input_homepage«. Вот, что вам нужно:
|
search_form = browser.find_element_by_id(‘search_form_input_homepage’) search_form.send_keys(‘real python’) search_form.submit() |
Вы найдете поисковую форму, используя метод send_keys для заполнения, затем метод submit для выполнения поиска для «Real Python». Вы можете проверить результат:
|
results = browser.find_elements_by_class_name(‘result’) print(results[0].text) |
Результат:
|
Real Python — Real Python Get Real Python and get your hands dirty quickly so you spend more time making real applications. Real Python teaches Python and web development from the ground up ... https://realpython.com |
Похоже, все работает. Чтобы избежать появления невидимых экземпляров браузера, нужно закрыть объект браузера перед окончанием сессии в Python:
5. Расширяем потенциал
Вы удостоверились в том, что можете управлять браузером в режиме headless (без головы т.е. без графического интерфейса), используя Python, теперь перейдем к практике.
- Вам нужно включать музыку;
- Вам нужно искать и просматривать музыку;
- Вам нужна информация о проигрываемой музыке.
Для начала, отправимся на https://bandcamp.com и покопаемся в инструментах разработки вашего браузера. Вы увидите большую и яркую кнопку воспроизведения внизу экрана с HTML атрибутом class, который содержит значение «playbutton«. Проверим, как это работает:
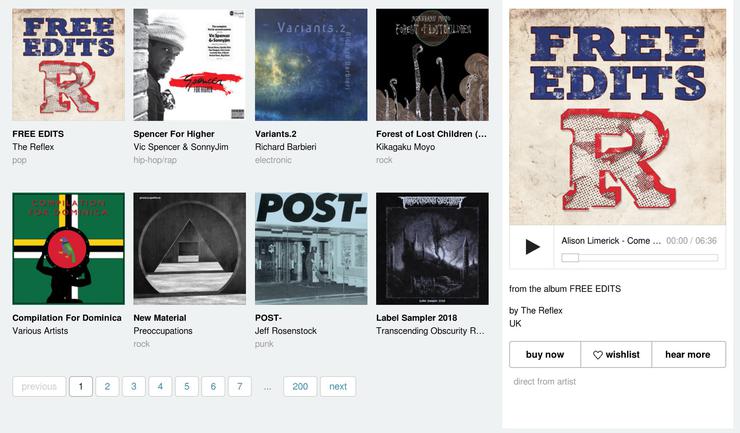
|
opts = Option() opts.set_headless() browser = Firefox(options=opts) browser.get(‘https://bandcamp.com’) browser.find_element_by_class(‘playbutton’).click() |
Вы должны слышать музыку! Запустите трек и оставьте его, вернитесь обратно в веб браузер. Рядом с кнопкой воспроизведения находится окно поиска. Еще раз, нужно проверить эту секцию. Вы найдете, что каждый видимый и доступный трек имеет значение класса «discover-item«, а каждый объект кликабельный. В Python, проверка выполняется следующим образом:
|
tracks = browser.find_elements_by_class_name(‘discover-item’) len(tracks) # 8 tracks[3].click() |
Следующий трек должен воспроизвестись. Это первый шаг в исследовании bandcamp при помощи Python! Вы уделите несколько минут, переключая разные треки в пространстве Python, но скромная библиотека из 8 песен может быстро надоесть.
6. Изучаем каталог
Вернувшись в свой браузер, вы увидите кнопку для изучения всех треков, связанных с окном поиска bandcamp. Сейчас все должно выглядеть знакомым: каждая кнопка имеет значение класса»item-page«. Последняя кнопка — “далее” показывает следующие восемь композиций в каталоге. Нужно выполнить следующее:
|
next_button = [e for e in browser.find_elements_by_class_name(‘item-page’) if e.text.lower().find(‘next’) > —1] next_button.click() |
Отлично! Теперь, может вам захочется просмотреть новые треки, и вы подумаете «Я просто перепишу переменные моих треков, так же, как я делал это минуту назад». Но здесь мы с вами столкнемся с хитростями.
Во первых, bandcamp разработали свой сайт так, чтобы пользователям было удобно им пользоваться, а не для скриптов Python для доступа к программному обеспечению. Вызывая next_button.click(), реальный веб браузер отвечает, выполняя какой-нибудь код JavaScript. Если вы попробуете сделать это в своем браузере, то увидите, что некоторое время уходит на эффект анимации каталога песен при прокрутке. Если вы попробуете переписать переменные композиций перед окончанием анимации, то можете получить не все треки, или получить те, которые вам не нужны.
Решение? Вы можете просто заснуть на секунду, или, если вы проделываете работу в оболочке Python, вы, вероятно, даже не заметите этого – в конце концов, на набор данных также уходит время.
Еще один небольшой момент, который можно обнаружить только путем проб и ошибок. Попробуйте запустить такой же код еще раз:
|
tracks = browser.find_elements_by_class_name(‘discover-item’) assert(len(tracks) == 8) # AssertionError |
Вы обнаружите кое-что странное. len(tracks) не равен 8, даже если пачка состоит из восьми треков. Углубившись, вы обнаружите, что ваш список состоит из треков, которые были показаны ранее. Чтобы получить треки, которые будут видны в браузере, нужно сделать небольшую фильтрацию результатов.
Попробовав несколько вариантов, вы решите оставить трек, только если его координата х на странице попадают в определенные рамки содержимого элемента. Контейнер каталога имеет значение класса «discover-results«. Выполним следующее:
|
discover_section = self.browser.find_element_by_class_name(‘discover-results’) left_x = discover_section.location[‘x’] right_x = left_x + discover_section.size[‘width’] discover_items = browser.find_element_by_class_name(‘discover_items’) tracks = [t for t in discover_items if t.location[‘x’] >= left_x and t.location[‘x’] < right_x] assert len(tracks) == 8 |
7. Создание класса
Если вас утомляет переписывать одни и те же команды снова и снова в пространстве Python, вам нужно выгрузить часть из них в модуль. Простейший класс для вашей работы с bandcamp должен выполнять следующие задачи:
- Инициализация headless браузера и выполнить направление на bandcamp;
- Хранение списка доступных треков;
- Поддержка поиска треков;
- Воспроизведение, пауза, переключение треков;
Четыре в одном. Вот простой код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
from selenium.webdriver import Firefox from selenium.webdriver.firefox.options import Options from time import sleep, ctime from collections import namedtuple from threading import Thread from os.path import isfile import csv BANDCAMP_FRONTPAGE=‘https://bandcamp.com/’ class BandLeader(): def __init__(self): # Инициализация браузера. opts = Options() opts.set_headless() self.browser = Firefox(options=opts) self.browser.get(BANDCAMP_FRONTPAGE) # Список треков. self._current_track_number = 1 self.track_list = [] self.tracks() def tracks(self): »’ Запрос страницы для получения списка доступных треков »’ # Режим сна, пока браузер обрабатывает и выполняет все анимации sleep(1) # Получаем хранилище для списка видимых треков. discover_section = self.browser.find_element_by_class_name(‘discover-results’) left_x = discover_section.location[‘x’] right_x = left_x + discover_section.size[‘width’] # Фильтруем объекты в списке, чтобы получить только те, которые мы можем включать. discover_items = self.browser.find_elements_by_class_name(‘discover-item’) self.track_list = [t for t in discover_items if t.location[‘x’] >= left_x and t.location[‘x’] < right_x] # Вывод доступных треков на экран. for (i,track) in enumerate(self.track_list): print(‘[{}]’.format(i+1)) lines = track.text.split(‘n’) print(‘Album : {}’.format(lines[0])) print(‘Artist : {}’.format(lines[1])) if len(lines) > 2: print(‘Genre : {}’.format(lines[2])) def catalogue_pages(self): »’ Вывод доступных в настоящее время страниц в каталоге. »’ print(‘PAGES’) for e in self.browser.find_elements_by_class_name(‘item-page’): print(e.text) print(») def more_tracks(self,page=‘next’): »’ Продвижение каталога, обновление списка композиций, мы можем передать число для продвижения любых доступных страниц. »’ next_btn = [e for e in self.browser.find_elements_by_class_name(‘item-page’) if e.text.lower().strip() == str(page)] if next_btn: next_btn[0].click() self.tracks() def play(self,track=None): »’ Запускаем трек. Если не указан номер трека, запустится выбранная только что композиция »’ if track is None: self.browser.find_element_by_class_name(‘playbutton’).click() elif type(track) is int and track <= len(self.track_list) and track >= 1: self._current_track_number = track self.track_list[self._current_track_number — 1].click() def play_next(self): »’ Воспроизводится следующий доступный трек »’ if self._current_track_number < len(self.track_list): self.play(self._current_track_number+1) else: self.more_tracks() self.play(1) def pause(self): »’ Пауза воспроизведения. »’ self.play() |
Весьма удобно. Вы можете импортировать этот код в ваше пространство Python и запустить bandcamp! Но постойте, разве мы не затеяли это все потому, что нам нужно собирать информацию о вашей истории прослушиваний?
8. Собираем структурированные данные
Наша последняя с вами задача, это отслеживать прослушанные вами треки. Как нам это сделать? Что буквально означает слушать что-либо? Если вы пролистываете каталог, переключая треки спустя пару секунд, это считается за прослушивание песни? Скорее всего, нет. Нам нужно включить фактор длительности прослушивания в сбор данных.
Сейчас нам нужно:
- Собрать структурированную информацию о воспроизводимых композициях;
- Хранить базу данных треков;
- Сохранить и восстановить эту базу данных на диск и из диска.
Используем namedtuple для сортировки отслеживаемой вами информации. Кортежи с названиями хороши для показа связки атрибутов без привязки к ним. Это немного похоже на запись базы данных.
|
TrackRec = namedtuple(‘TrackRec’, [ ‘title’, ‘artist’, ‘artist_url’, ‘album’, ‘album_url’, ‘timestamp’ # When you played it ]) |
Чтобы собрать эту информацию, добавьте метод в класс BandLeader. Проверка при помощи инструментов разработки браузера откроет необходимые элементы HTML и атрибуты для выбора всей необходимой информации. Кстати, вам понадобится только информация о недавно прослушанных треках, если в это время музыка воспроизводилась. К счастью, страница плеера добавляет класс «playing» к кнопке воспроизведения, когда музыка играет, и убирает его, когда воспроизведение прекращается. Держа в голове данные нюансы, нужно прописать несколько методов:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def is_playing(self): »’ Выдает True, если трек воспроизводится в данный момент. »’ playbtn = self.browser.find_element_by_class_name(‘playbutton’) return playbtn.get_attribute(‘class’).find(‘playing’) > —1 def currently_playing(self): »’ Возвращает запись воспроизводимого в данный момент трека или None, если ничего не воспроизводится. »’ try: if self.is_playing(): title = self.browser.find_element_by_class_name(‘title’).text album_detail = self.browser.find_element_by_css_selector(‘.detail-album > a’) album_title = album_detail.text album_url = album_detail.get_attribute(‘href’).split(‘?’)[0] artist_detail = self.browser.find_element_by_css_selector(‘.detail-artist > a’) artist = artist_detail.text artist_url = artist_detail.get_attribute(‘href’).split(‘?’)[0] return TrackRec(title, artist, artist_url, album_title, album_url, ctime()) except Exception as e: print(‘there was an error: {}’.format(e)) return None |
Для точного измерения, можно также модифицировать метод play для продолжения отслеживания играющего в данный момент трека:
|
def play(self, track=None): »’ Запуск трека. Если номер композиции не поддерживается, воспроизведется предыдущий трек. »’ if track is None: self.browser.find_element_by_class_name(‘playbutton’).click() elif type(track) is int and track <= len(self.track_list) and track >= 1: self._current_track_number = track self.track_list[self._current_track_number — 1].click() sleep(0.5) if self.is_playing(): self._current_track_record = self.currently_playing() |
Далее, нам нужно создать какую-либо базу данных. Хотя она может плохо масштабироваться при больших объемах, в простом списке все должно пройти хорошо.
Добавляем строку:
В методе инициализации класса BandCamp __init__ . Так как нам нужно дать возможность тому, чтобы прошло определенное время перед входом в объект TrackRec в базе данных, мы используем инструменты threading нашего Python, для запуска отдельных процессов, которые поддерживают базу данных в фоновом режиме.
Мы привяжем метод _maintain() к экземплярам BandLeader, которые запустят раздельный поток. Новый метод будет периодически проверять значение self._current_track_record и добавлять его в базу данных, если это новый трек.
Мы запустим поток, когда класс станет подтвержденным, путем добавления кода в __init__.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# Новый init. def __init__(self): # Инициализация браузера. opts = Options() opts.set_headless() self.browser = Firefox(options=opts) self.browser.get(BANDCAMP_FRONTPAGE) # Состояние списка треков. self._current_track_number = 1 self.track_list = [] self.tracks() # Состояние базы данных. self.database = [] self._current_track_record = None # Поток поддержки базы данных. self.thread = Thread(target=self._maintain) self.thread.daemon = True # Закрывает поток вместе с основным процессом. self.thread.start() self.tracks() def _maintain(self): while True: self._update_db() sleep(20) # Проверка каждые 20 секунд. def _update_db(self): try: check = (self._current_track_record is not None and (len(self.database) == 0 or self.database[—1] != self._current_track_record) and self.is_playing()) if check: self.database.append(self._current_track_record) except Exception as e: print(‘error while updating the db: {}’.format(e) |
Если вы никогда не работали с мультипоточным программированием в Python, вы должны с этим ознакомиться! Для нашей нынешней цели, вы можете представить потоки как цикл, который возвращает фоновый режим основного процесса Python (тот, с которым вы напрямую взаимодействуете). Каждые двадцать секунд цикл выполняет небольшую проверку, чтобы увидеть, нужно ли обновить базу данных. Если нужно, он добавляет новую запись. Вполне себе круто.
Самым последним будет сохранение базы данных и восстановление из сохраненных состояний. Используя модуль csv, вы гарантированно будете хранить свою базу данных в очень портативном формате, кроме этого, базу данных можно будет использовать, даже если вы покинете ваш чудесный класс BandLeader 
Метод __init__ снова нужно изменить, на этот раз, для принятия пути файла, в котором вы хотите сохранить базу данных. Вам может понадобиться загрузить эту базу данных, если она доступна, и периодически её сохранять, когда она будет обновлена. Обновления выглядят следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
def __init__(self,csvpath=None): self.database_path=csvpath self.database = [] # Загрузка базы данных из диска, если возможно. if isfile(self.database_path): with open(self.database_path, newline=») as dbfile: dbreader = csv.reader(dbfile) next(dbreader) self.database = [TrackRec._make(rec) for rec in dbreader] # … остальная часть метода __init__ остается неизменной … # Новый метод save_db. def save_db(self): with open(self.database_path,‘w’,newline=») as dbfile: dbwriter = csv.writer(dbfile) dbwriter.writerow(list(TrackRec._fields)) for entry in self.database: dbwriter.writerow(list(entry)) # Наконец, добавляем вызов save_db в метод поддержи вашей базы данных. def _update_db(self): try: check = (self._current_track_record is not None and self._current_track_record is not None and (len(self.database) == 0 or self.database[—1] != self._current_track_record) and self.is_playing()) if check: self.database.append(self._current_track_record) self.save_db() except Exception as e: print(‘error while updating the db: {}’.format(e) |
Ву а ля! Вы можете слушать музыку и хранить запись прослушанных треков. Великолепно.
Кое-что интересное показанном выше коде: использование namedtuple действительно начинает окупаться. При конвертации из формата CSV , вы получаете возможность упорядочивать строки в файле CSV для заполнения строк в объектах TrackRec. Также вы можете создать заглавную строку файла CSV, ссылаясь на атрибут TrackRec._fields. Это одна из причин, по которой использование кортежа имеет смысл во время работы со столбчатыми данными.
Что дальше и чему мы научились?
С этого момента вы умеете делать намного больше! Вот несколько идей, навскидку, которые можно реализовать при помощи суперсилы связки Python + Selenium:
- Вы можете расширить класс BandLeader для навигации по страницам альбомов и воспроизводить найденные в них треки;
- Вы можете создать плейлист на основании своих любимых и наиболее часто прослушиваемых композиций;
- Возможно, вы захотите добавить функцию автоматического воспроизведения;
- Может быть, вам захочется запросить песни по дате, названию или артисту и составить таким образом плейлист.
Здесь вы можете скачать основы проектов «Python + Selenium» со всеми исходными кодами, которые вы можете использовать как фундамент для веб-парсинга и автоматизации приложений.
Вы узнали, что Python может делать то же самое, что и веб-браузер, и даже больше. Вы можете легко прописывать скрипты для контроля экземпляров виртуального браузера, работающего в облаке, создавать ботов, которые могут взаимодействовать с реальными пользователями, или просто заполняют формы! Развивайтесь и автоматизируйте!

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
In this post, we are going to learn How to Install selenium on Windows Python. The prerequisite to install the selenium on the window is python, So we will install python step by step, later install selenium and work with how to automate web browsers on Windows with python.
- How to open chrome browser in selenium Python
- How to open Edge browser in selenium Python
- How to open Firefox browser in selenium Python
- How to install selenium in VSCode
The prerequisite is to install Python on Windows First
The prerequisite to installing a selenium web driver is Python. To download and install python will follow the below steps.
- Download the latest version of Python from the official page python. The python executable file will download on our operating system. click on executable and the python installation landing page will open then click install.
- Check “Add Python 3.10 to PATH” and click install.

- Once the installation is complete, this window will pop-up to show the installation is successful.

- Now, We can verify python is installed using the below command. To open a command prompt go to the window search bar and type ‘Run’.In the run bar type ‘cmd’
2. Install selenium on window with Python
To install selenium on the window with python, We have to make sure python is already installed, else follow the above mention step to install Python., then open the command prompt and run the below command to install selenium.
Sometimes the above command throw error in this case we can use pip with the -m flag. The -m flag stands for the module that is used to specify the module.
python -m pip install selenium
To update the existing version of selenium, we can use the below command
Once the installation of the selenium library is complete. We can verify the selenium version by using the below command.
Output
Name: selenium Version: 4.1.0 Summary: Home-page: https://www.selenium.dev Author: Author-email: License: Apache 2.0 Location: c:usersAdminappdatalocalprogramspythonpython310libsite-packages Requires: urllib3, trio-websocket, trio Required-by:
3. How to automate web browser on windows using Selenium
To make work selenium driver with web automation, we have to download a browser driver that can work with the browser of our choice.
| Browers Drivers | Link to download | |
| ChromeDriver | https://chromedriver.chromium.org/downloads | |
| Internet Explorer | https://www.selenium.dev/documentation/ie_driver_server/ | |
| Microsoft Edge | https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ | |
| Firefox | https://github.com/mozilla/geckodriver/releases | |
| Opera | https://github.com/operasoftware/operachromiumdriver/releases |
3.1 How to open Chrome Browser in Selenium Python
- Download chromedriver from the link in the table.
- unzip and copy chromedriver.exe to the python script directory location.
- The path of the python script directory for us is” C:UsersAdminAppDataLocal Programs Python Python310Scripts”. It can be different depending on what location we have chosen while installing python.
- Run the below code to automatically open the chrome web browers.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.google.com")
print(driver.title)
driver.quit()
3.2 How to open Microsft Edge browser in selenium Python
- Download the Microsfoftedge driver from the link in the table.
- unzip and copy msedgedriver.exe to the python script directory location.
- The path of the python script directory for Us is” C:UsersAdminAppDataLocal Programs Python Python310Scripts”. It can be different depending on what location we have chosen while installing python.
- Run the below code to automatically open the Microsft Edgebrowser.
from selenium import webdriver
driverEdge = webdriver.Edge()
driverEdge.get('https://bing.com')
driverEdge.quit()
3.3 How to open Firefox browser in selenium Python
- Download Firefoxdriver from the link in the table. .
- unzip and copy geckodriver.exe to the python script directory location.
- The path of the python script directory for Us is” C:UsersAdminAppDataLocal Programs Python Python310Scripts”. It can be different depending on what location we have chosen while installing python.
- Run the below code to automatically open the Firefox web browser.
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('https://bing.com')
driverEdge.quit()
Summary
in this post, we have learned how to Install selenium on Windows Python and web drivers setup step by step with examples.