Возможность дедупликации данных впервые появилась в Windows Server 2012. С тех пор прошло много времени и в Windows Server 2016 включена уже третья версия дедупликации, переработанная и улучшенная. О том, что именно умеет новая дедупликация и чем она отличается от предыдущих реализаций, а также об особенностях ее настройки и работы и пойдет речь в этой и последующих статьях.
Начнем с изменений. Итак
Что нового
Первое и наиболее важное изменение в работе дедупликации Windows Server 2016 — это введение многопоточности.
Многопоточность
В Windows Server 2012 R2 дедупликация работает в однопоточном режиме и может задействовать не более 1 процессорного ядра на один том. Это серьезно ограничивает производительность, а для обхода этого ограничения необходимо разбивать диски на несколько томов меньшего размера. При этом максимальный размер тома не должен быть больше 10Тб.
В Windows Server 2016 движок дедупликации переработан и задание дедупликации может работать в многопоточном режиме, используя для каждого тома сразу несколько вычислительных потоков и очередей вводавывода. Изменения эти наглядно проиллюстрированы на картинке ниже, честно позаимствованной 🙂 на технете.

На картинке все выглядит красиво и убедительно, а как обстоит дело на практике? Чтобы убедиться в том, что многопоточность действительно работает, я провел небольшой эксперимент. Для эксперимента я взял сервер с двумя 6-ядерными процессорами, что при включенном HyperThreading дает нам 24 логических процессора. На сервере была установлена Windows Server 2012 R2 и включена дедупликация для одного тома.
Я запустил на сервере процедуру оптимизации, замерил производительность и выяснил, что процесс дедупликации (fsdmhost.exe) использует максимум 4% мощности процессора, что примерно соответствует 1 логическому ядру.
![]()
Затем операционная система на сервере была проапгрейжена на Windows Server 2016, после чего я повторно замерил производительность. И как видите, после апгрейда дедупликация уже не ограничена одним ядром и может использовать больше 4% процессорной мощности сервера.
![]()
Внедрение многопоточности и другие изменения в движке повлияли на ограничения по размеру томов и файлов. Поскольку многопоточность увеличивает производительность дедупликации и снимает необходимость в разбиении диска на несколько томов, в Windows Server 2016 для дедупликации можно использовать тома до 64Тб. Также увеличен максимальный размер файла, теперь поддерживается дедупликация файлов размером до 1Тб.
Ну и изменения помельче.
Поддержка виртуализованных приложений резервного копирования
В Windows Server 2012 был всего один тип дедупликации, предназначенный в основном для обычных файловых серверов. Дедупликация таких нагрузок, как постоянно работающие виртуальные сервера, не поддерживалась, поскольку дедупликация не умела работать с открытыми файлами.
В Windows Server 2012 R2 дедупликация научилась использовать VSS, соответственно стала поддерживаться дедупликация виртуальных серверов. Для таких нагрузок появился отдельный тип дедупликации.
В Windows Server 2016 добавился еще один, третий тип дедупликации, предназначенный специально для виртуализованных серверов резервного копирования (напр. DPM). Надо сказать, что такой вариант был и раньше, однако в связи со специфическими нагрузками настройки дедупликации требовалось подбирать вручную. В Windows Server 2016 для таких нагрузок добавлен отдельный тип дедупликации, уже включающий в себя необходимые настройки.
Поддержка Nano Server
Nano Server — это вариант развертывания операционной системы Windows Server 2016 с минимальным количеством устанавливаемых компонентов. Nano Server полностью поддерживает дедупликацию.
Поддержка последовательного обновления кластера
Последовательное обновление кластера (Cluster OS Rolling Upgrade) — это новая функция Windows Server 2016, с помощью которой можно последовательно проапгрейдить операционную систему на каждом узле кластера с Server 2012 R2 до Server 2016, при этом не останавливая работу кластера. Это возможно благодаря специальному смешанному режиму работы кластера, когда в кластере одновременно могут работать узлы Windows Server 2012 R2 и Windows Server 2016.
Смешанный режим означает, что одни и те-же данные могут находиться на узлах с разными версиями дедупликации. Дедупликация Windows Server 2016 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в течение всего процесса обновления кластера.
Установка и включение дедупликации
Первое, что нужно сделать для включения дедупликации — это установить соответствующую роль сервера. Можно из оснастки «Server Manager» запустить мастер и добавить роль файлового сервера с компонентом «Data Deduplication».

Либо из PowerShell выполнить команду:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Включение и настройка дедупликации
После добавления компонента надо включить дедупликацию для конкретного тома (или нескольких томов). Сделать это можно двумя разными способами — из графической оснастки либо с помощью PowerShell.
Для настройки из GUI открываем «Server Manager», переходим в раздел «File and storage services» — «Volumes», встаем на нужный том, кликаем по нему правой клавишей мыши и в открывшемся меню выбираем пункт «Configure Data Deduplication».

Затем выбираем необходимый тип дедупликации и жмем «Apply». Дополнительно можно указать типы файлов, которые не должны подвергаться дедупликации, а также исключить из дедупликации определенные директории.

Следующее, что необходимо сделать после включения — это настроить расписание, по которому будут отрабатывать задания дедупликации, поэтому дальше жмем на кнопку «Set Deduplication Schedule».
По умолчанию включена фоновая оптимизация (background optimization), а также можно настроить два дополнительных задания принудительной оптимизации (throughput optimization). Настроек здесь немного — можно только выбрать дни недели, задать время запуска и продолжительность работы.

Гораздо больше возможностей для настройки предоставляет PowerShell. Для включения дедупликации используем такую команду:
Enable-DedupVolume -Name D: -UsageType HyperV
После включения просмотрим имеющиеся задания дедупликации:
Get-DedupSchedule
Как видите, здесь картина несколько иная. Так кроме фоновой оптимизации имеется задание приоритетной оптимизации (PriorityOptimization), а также задания сборки мусора (GarbageCollection) и очистки (Scrubbing). Все эти задания не видны из графической оснастки.

Кроме этого, PowerShell позволяет более тонко настроить параметры выполнения задания. Для примера создадим новое задание оптимизации. Задание должно запускаться в 8 утра с понедельника по пятницу и работать 12 часов, с нормальным приоритетом, использовать не более 50% оперативной памяти и 100% процессорной мощности:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 12 -Start (Get-Date ″12/8/2016 8:00 PM″) -Memory 50 -Cores 100 -Priority Normal
Примечание. В принципе заданию можно дать любое имя. Но если создать задание с именем ThroughputOptimization, то оно будет отображаться и в графической оснастке.
Затем произведем еще несколько изменений. Во первых сменим время и параметры запуска задания сбора мусора:
Set-DedupSchedule -Name WeeklyGarbageCollection -DurationHours 12 -Start (Get-Date ″12/8/2016 8:00 PM″) -Memory 50 -Cores 100 -Priority Normal -Full $true
Перенесем на воскресенье задание очистки:
Set-DedupSchedule -Name WeeklyScrubbing -Days Sunday -DurationHours 12 -Start (Get-Date ″12/8/2016 8:00 PM″) -Memory 50 -Cores 100 -Priority Normal
И отключим приоритетную оптимизацию:
Set-DedupSchedule -Name PriorityOptimization -Enabled $false

Ручной запуск дедупликации
При необходимости задание дедупликации можно запустить вручную. Для примера запустим полную оптимизацию тома D с максимальным приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -Full

Отследить запущенные задания дедупликации можно с помощью команды Get-DedupJob. Обратите внимание, что одновременно отрабатывает только одна задача, а остальные стоят в очереди и ждут ее завершения. Если текущая задача не завершится в ближайшее время, то задания в очереди отменятся и очередь будет очищена. Об этом необходимо помнить при составлении расписания, так как если различные задачи пересекаются между собой, то некоторые из них не смогут вовремя отработать.

Просмотр состояния дедупликации
Данные о состоянии дедупликации для тома можно посмотреть командой:
Get-DedupVolume -Volume D: | fl
Так мы можем посмотреть основные параметры тома — полный объем, свободное место, уровень сжатия и т.д.

А проверить состояние заданий дедупликации можно такой командой:
Get-DedupStatus -Volume D: | fl
Эта команда кроме всего прочего покажет, когда и с каким результатом были завершены задания дедупликации. В случае проблем с дедупликацией эту информацию можно использовать для диагностики.

Выключение дедупликации
Отключить дедупликацию для тома можно либо из графической оснастки, убрав соответствующую галочку, либо с помощью PowerShell. Например:
Disable-DedupVolume -Name D:

Выключение дедупликации для тома отменяет все запланированные задания, а также запрещает запуск любых задач дедупликации, кроме read-only операций (команды типа Get) и раздедупликации (unoptimization). При этом сами данные остаются в том же состоянии, в котором они были до выключения дедупликации, просто новые данные перестают дедуплицироваться.
После выключения дедупликации доступ к данным остается и с ними можно работать так же, как и раньше. Это поведение можно изменить, воспользовавшись ключом DataAccess, например:
Disable-DedupVolume -Name D: -DataAccess
Эта команда удаляет драйвер-фильтр файловой системы для указанного тома, тем самым останавливая все операции ввода-вывода для дедуплицированных файлов. Соответственно при попытке обращения к файлам вы получите отказ в доступе. Вернуть доступ можно командой Enable-DedupVolume с ключом DataAccess.

Ну и если необходимо полностью убрать дедупликацию и вернуть данные к исходному состоянию, то можно воспользоваться процедурой раздедупликации. Например следующей командой запустим раздедупликацию для тома D с максимально-возможной скоростью:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full

Обратите внимание, что для раздедупликации потребуется дополнительное дисковое пространство. Если свободного места на томе недостаточно, то процедура завершится ошибкой. В этом случае можно воспользоваться альтернативным способом — просто скопировать данные на другой том. При копировании данные автоматически разжимаются, опять же можно раздедуплицировать не сразу весь том, а скопировать данные по частям.
На этом пока закончим. А в следующей части более подробно разберем настройки дедупликации и рассмотрим некоторые особенности ее работы.
Data Deduplication (дедупликация данных) — это возможность уменьшать пространства за счет удаления одной части дублирующих данных. Впервые Microsoft выпустила такую возможность в Windows Server 2012 и технически она менялась вплоть до самой последней версии сервера 2019. Технология дедупликации реализована у множества брендов в том числе: HP, CISCO, IBM и VmWare.
Для чего нужна и как работает дедупликация
Если взять обычный файловый или бэкап сервер, то мы увидим большой объем полностью или частично дублирующих файлов. На файловых серверах это полные копии данных, которые хранят разные пользователи, а на бэкап серверах — это минимум файлы с ОС. С определенным интервалом происходит процесс сканирования блоков с данными в 32-128 Кб и проверка уникальности. Такие блоки так же называются чанками (chunk/куски) и это важно запомнить, так как это название вы будете видеть в Powershell. При нахождении одинаковых чанков они оба будут удалены и заменен ссылкой на уникальный чанк помещенный в специальное место. Такие ссылки будут помещены в папку System Volume Information, а блоки, с уникальными данными, в контейнеры. Все такие данные, в Windows Server, имеют возможность восстановления в случае критических повреждений.
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
- Оптимизированные файлы, состоящие из ссылок на уникальные чанки;
- Чанки, организованные в контейнеры, которые сжимаются и помещаются в хранилище;
- Не оптимизированные файлы.
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:


Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
- файловая система только NTFS;
- поддержка томов до 10 Тб;
- не рекомендуется использовать с файлами объем которых достигает 1 Тб;
- 2012 не поддерживает VSS (не может работать с открытыми файлами) с 2012 r2 эта поддержка появилась;
- один режим работы.
Windows Server 2016
- файловая система только NTFS;
- поддержка томов до 64 Тб;
- дедупликация работает с первым 1 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- возможность доступна в Nano Server.
Windows Server 2019
- файловая система NTFS или ReFS;
- поддержка томов до 64 Тб;
- работа с первыми 4 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- интеграция с BranchCache;
- возможность доступна в Nano Server.
Процесс дедупликации происходит по расписанию, а не «на лету», и из-за этого есть общие рекомендации по размеру разделов. Если разделы будут больше описанных выше, то скорость работы сканирования может быть меньше чем обновление этих файлов. В версии 2016 в процесс дедупликации была добавлена парализация, что позволило увеличить скорость и общий объем работы для работы этой роли:

Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная — вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные — все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет — они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:

Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):

На этапе выбора ролей сервера, во вкладе «Файловые службы и службы хранилища» и «Файловые службы и службы iSCSI» выбираем «Дедупликация данных»:

Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:

Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:

Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:
- Документы пользователей — экономия 30-50%
- Установочные файлы — экономия 70-80%
- Файлы виртуализации — экономия 80-95%
- Файловые хранилища — экономия 50-60%

Для оценки места я поместил 3 одинаковых установочных архива с Exchange 2013 общим объемом 6 Гб на диск Е.
Открываем Powershell/CMD и пишем команду, которая имеет следующий синтаксис:
DDPEval.exe <раздел>
DDPEval.exe <раздел><папка>
# Пример
DDPEval.exe E:Folder1
По каким-то причинам у меня определилась Windows 10, хотя я использую Windows Server 2019
Как можно увидеть — экономия на полностью идентичных файлах в 69 % или 4.27 Gb.
Я удалил файлы с Exchange и поместил 3 разных образа Linux (Ubuntu, Debian, Centos):


Экономия в 2%.
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:

Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:

Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:

По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:

Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации. Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) — включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) — расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) — расписание аналогично предыдущему. Можно настроить на вечернее время.

На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Install-WindowsFeature -Name "FS-Data-Deduplication" -ComputerName "Имя компьютера" -IncludeAllSubFeature -IncludeManagementToolsСледующим способом мы увидим все команды модуля дедупликации:
Get-Command -Module Deduplication
Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
- HyperV;
- Backup;
- Default (файловый сервер, устанавливается по умолчанию).
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:
Enable-DedupVolume -Volume 'E:','D:' -UsageType 'Default'
В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить ‘E:’ на ‘E:’:
No MSFT_DedupVolume objects found with property ‘Volume’ equal to ‘E:’
Так мы узнаем на каких томах настроена дедупликация:
Get-DedupVolume
Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
- ExcludeFolder — ограничения на папки, например ‘E:Folder1’,’E:Folder2»
- ExcludeFileType — ограничения по расширениям, например ‘txt’,’jpg’;
- MinimumFileAgeDays — минимальный возраст файла в днях, который будет оптимизироваться.
Следующий пример установит эти настройки и вернет их:
Set-DedupVolume `
-Volume 'E:' `
-ExcludeFolder 'E:folder_exclude' `
-ExcludeFileType 'txt','rar' `
-MinimumFileAgeDays 15
Get-DedupVolume | Select *
По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Set-DedupVolume `
-Volume 'E:' `
-MinimumFileSize 1GB
Get-DedupVolume | Select *
Есть еще несколько параметров, которые устанавливаются:
- ChunkRedundancyThreshold — устанавливает порог ссылок после которого будет создан еще один идентичный чанк. По умолчанию равен 100. С помощью этого параметра увеличивается избыточность. Проявляется она в более быстром и гарантированном (в случае повреждения) доступе файла. Не рекомендуется менять;
- InputOutputScale — установка значения I/O для распараллеливания процесса от 0 до 36. По умолчанию значение рассчитывается само;
- NoCompress — значению в $True или $False устанавливающая будет ли происходить сжатие;
- NoCompressionFileType — расширение файлов к которым не будет применяться сжатие;
- OptimizeInUseFiles — будут ли оптимизированы открытые файлы, например подключенные файлы VHDx;
- OptimizePartialFiles — если $True — будет работать блочная дедупликация. В ином случае будет работать файловая дедупликация;
- Verify — добавляет еще одну проверку идентичности чанков. Они будут сравниваться побайтно. Не могу сказать о ситуациях, где это могло бы пригодиться.
Для отключения используется следующая команда:
Disable-DedupVolume -Volume 'E:'
Отключенная дедупликация не конвертирует файлы в их исходное состояние. В примере выше у нас просто не будут оптимизироваться новые файлы и выполнятся задачи. Если к команде добавить параметр -DataAccess, то мы отключим доступ к файлам прошедшим через процесс дедупликации. О том как отменить дедупликацию полностью — будет рассказано далее.
Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
- Оптимизация (Optimization) — разбиение данных на блоки, их сравнение, сжатие и помещение в хранилище System Volume Information. По умолчанию происходит раз в час;
- Сбор мусора (GarbageCollection) — удаление устаревших фрагментов (например восстановление тех данных у которых нет дубликатов). По умолчанию происходит каждую субботу;
- Проверка целостности (Scrubbing) — обнаружение повреждений в хранилище блоков и их восстановление. По умолчанию происходит каждую субботу;
- Отмена оптимизации (Unoptimization)— отмена или отключение оптимизации на томе. Выполняется по требованию.
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:

Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:
Get-DedupSchedule
Задания никогда не выполняются одновременно — только в процессе очереди.
Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:
Set-DedupSchedule `
-Name 'WeeklyGarbageCollection' `
-Type 'GarbageCollection' `
-Enabled $True `
-StopWhenSystemBusy $True `
-Days 'Friday' `
-Start 22:00 `

Где:
- Name — имя процесса, который мы хотим изменить;
- Type — тип процесса. В нашем случае это сборка мусора (GarbageCollection);
- Enabled — будет ли включен этот процесс;
- StopWhenSystemBusy — остановится ли процесс, если сервер будет сильно нагружен другой задачей (затем попробует запустится снова);
- Days — дни, в которые этот процесс должен запускаться;
- Start — время запуска.
Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
- DurationHours — продолжительность работы задачи в часах, после которого он будет корректно завершен. По умолчанию равен 0, что означает работу до полного завершения без ограничения во времени.
- Full — параметр со значениями $True и $False. Зависит от того что указано в Type. Если мы выполняем сборку мусора, то этот параметр будет удалять все устаревшие данные сразу, а не до достижения определенного порога. При выполнении очистки (Scrubbing), если указан параметр Full, происходит проверка всех данных, а не только критически важных. В обоих случаях этот параметр стоит использовать раз в месяц.
- ReadOnly — при работе очистки не исправляет ошибки, а только уведомляет
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
- Cores — число с количеством ядер (в процентном соотношении), которые будут участвовать в процессе;
- Memory — количество памяти от общего значения (в процентном соотношении);
- StopWhenSystemBusy — останавливает задачу, если сервер, в данный момент, сильно нагружен (возобновляет ее позже);
- Priority — указывает тип нагрузки на процессор (ввод, вывод) со значениями: Low, Normal, High;
- InputOutputThrottle — ограничения работы ввода вывода при троттлинге в значениях от 0 до 100,;
- InputOutputThrottleLevel — ограничения работы ввода вывода при троттлинге со следующими значениями: None, Low, Medium, High. InputOutputThrottle имеет более высокий приоритет и при установке двух аргументов — InputOutputThrottleLevel может не работать.
- ThrottleLimit — указывает предел троттлинга. Если указан 0, то расчет будет выполнен автоматически.
На примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
New-DedupSchedule `
-Name 'Оптимизация по будням' `
-Cores 80 `
-Days Monday,Tuesday,Wednesday,Thursday,Friday `
-DurationHours 8 `
-InputOutputThrottleLevel Medium `
-Priority Normal `
-Memory 80 `
-Start 21:00 `
-Type 'Optimization' `
-StopWhenSystemBusy `

Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
Get-DedupSchedule -Name '*Scrub*' | New-DedupSchedule `
-Name 'Полная проверка целостности раз в месяц' `
-Full `
-Disable `
Так же можно и удалять задачи:
Get-DedupSchedule -Name '*Полная*' | Remove-DedupSchedule
# или
Remove-DedupSchedule -Name '*Полная*'
Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
New-DedupSchedule -Type UnoptimizationУчитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Запуск отдельных задач
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:
Start-DedupJob `
-Full `
-Volume 'E:' `
-Type 'Scrubbing'
Вернуть состояние задачи можно так:
Get-DedupJob
Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
- Exception calling «EndProcessing» with «0» argument(s)
- Start-DedupJob : MSFT_DedupVolume.Volume=’
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:
Get-DedupSchedule -Name '*полная проверка*' | Start-DedupJob -InputOutputThrottleLevel Low -Volume 'E:'
Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
- Cores
- Full
- InputOutputThrottle
- InputOutputThrottleLevel
- Memory
- Priority
- ReadOnly
- StopWhenSystemBusy
- ThrottleLimit
- Type
А эти параметры есть только у Start-DedupSchedule:
- Preempt — форсированный запуск задачи, отменяющий иные;
- Timestamp — работает только с задачами типа ‘Unoptimization’ и принимает значения типа данных DateTime. Отменяет оптимизацию файлов оптимизированных с указанной даты;
- Volume — можно указать один или несколько томов. Можно указывать буквы формата ‘E:’, ID и GUID;
- Wait — в фоне будет отображаться процесс задачи и ее результат. Пример ниже.

Пример отмены задач:
Get-DedupJob -Type Scrubbing | Stop-DedupJob
# или
Stop-DedupJob -Volume 'E:','C:'Отмену дедупликации вы так же можете запустить задачей:
Start-DedupJob -Type UnoptimizationСтатус дедупликации
Следующая команда вернет текущий статус дедупликации:
# Сокращенный вариант
Get-DedupStatus
# Полный отчет
Get-DedupStatus | select *
Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
# Для всех томов
Update-DedupStatus
# Для одного тома
Update-DedupStatus -Volume 'E:'
# Возвращение полной актуальной информации по тому
Update-DedupStatus -Volume 'E:' | SELECT *
Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:
Get-DedupStatus -Volume 'E:' | select -Property "*time*" | fl
Эта команда вернет информацию по работе с файлами:
Get-DedupStatus -Volume 'E:' | select -Property "*file*",'s*rate*' | fl
Где:
- InPolicyFilesCount — количество файлов, которые подходят для оптимизации;
- InPolicyFilesSize — общий размер файлов, которые подходят для оптимизации;
- OptimizedFilesCount — количество файлов, которые были оптимизированы;
- OptimizedFilesSavingRate — процент оптимизированных файлов относительно всех файлов которые подходят под установленные параметры;
- OptimizedFilesSize — общий размер оптимизированных файлов.
Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
Get-DedupMetadata -Volume 'E:'
Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
- DataChunkCount — количество чанков, размером 32-128 Кб на одном томе;
- DataContainerCount — количество контейнеров;
- DataChunkAverageSize — средний размер одного чанка (размер контейнера поделенный на количество чанков);
- TotalChunkStoreSize — размер хранилища;
- CorruptionLogEntryCount — количество ошибок на томе.
Свойства типа «Stream*» скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Measure-DedupFileMetadata -Path 'E:New folder'
Где:
- FilesCount — количество файлов на всем томе;
- OptimizedFilesCount — количество оптимизированных файлов на всем томе;
- Size — суммарный размер всех файлов;
- DedupSize — итоговый размер дедуплицированных файлов в этой папке;
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Expand-DedupFile -Path 'E:New folderOtchet2020.doc','E:New folder3285.wav'Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку:
Expand-DedupFile : MSFT_DedupVolume.Path=’E:file1′ — HRESULT 0x80070057, The parameter is incorrect.
…
Теги:
#powershell
#дедупликация
#windows server
Возможность дедупликации данных впервые появилась еще в Windows Server 2012. В Windows Server 2016 представлена уже третья версия компонента дедупликации, значительно переработанная и улучшенная. В этой статье мы поговорим о новых функциях дедупликации, ее настройках и отличиях от предыдущих реализаций.
- Новые возможности дедупликации данных в Windows Server 2016
- Установка компонента дедупликации в Windows Server 2016
- Включение и настройка дедупликации
- Ручной запуск дедупликации
- Просмотр состояния дедупликации
- Как отключить дедупликацию
Содержание:
Новые возможности дедупликации данных в Windows Server 2016
-
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Обновленный движок дудупликации в Windows Server 2016 выполнять задания дедупликации в многопоточном режиме, причем каждый том использует несколько вычислительных потоков и очередей ввода-вывода. Введение многопоточности и других изменений в компоненте сказалось на ограничениях на размер файлов и томов. Поскольку многопоточная дедупликация повышает производительность и устраняет необходимость разбиения диска на несколько томов в Windows Server 2016, вы можете использовать дедупликацию для тома до 64 ТБ. Также увеличен максимальный размер файла, теперь поддерживается дедупликация файлов до 1 Тб. - Поддержка виртуализированных приложений резервного копирования. В Windows Server 2012 был только один тип дедупликации, предназначенный в основном для обычных файловых серверов. Дедупликация непрерывно работающей ВМ не поддерживается, поскольку дедупликации не знает, как работать с открытыми файлами.
Дедупликация в Windows Server 2012 R2 начала использовать VSS, соответственно, стала поддерживаться дедупликация виртуальных машин. Для таких задач использовался отдельный тип дедупликации.В Windows Server 2016 добавлен еще третий тип дедупликации, предназначенный специально для виртуализированных серверов резервного копирования (например, DPM). - Поддержка Nano Server. Nano Server – эта технология позволяет развертывать операционную систему Windows Server 2016 с минимальным количеством установленных компонентов. Nano Server полностью поддерживает дедупликацию.
- Поддержка последовательного обновления кластера (Cluster OS Rolling Upgrade). Cluster OS Rolling Upgrade – это новая функция Windows Server 2016, которая может использоваться для обновления операционной системы на каждом узле кластера с Windows Server 2012 R2 до Windows Server 2016 без остановки кластера. Это возможно благодаря специальной смешанной работе кластера, когда узлы кластера одновременно могут работать под управлением Windows Server 2012 R2 и Windows Server 2016.Смешанный режим означает, что одни и те же данные могут быть расположены на узлах с разными версиями компонента дедупликации. Дедупликация в Windows Server 2016 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в процессе обновления кластера.
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Установка компонента дедупликации в Windows Server 2016
Первое, что нужно сделать, чтобы включить дедупликацию — это установить соответствующую роль сервера. Запустите Server Role wizard и добавьте роль файлового сервера с компонентом «Data Deduplication».
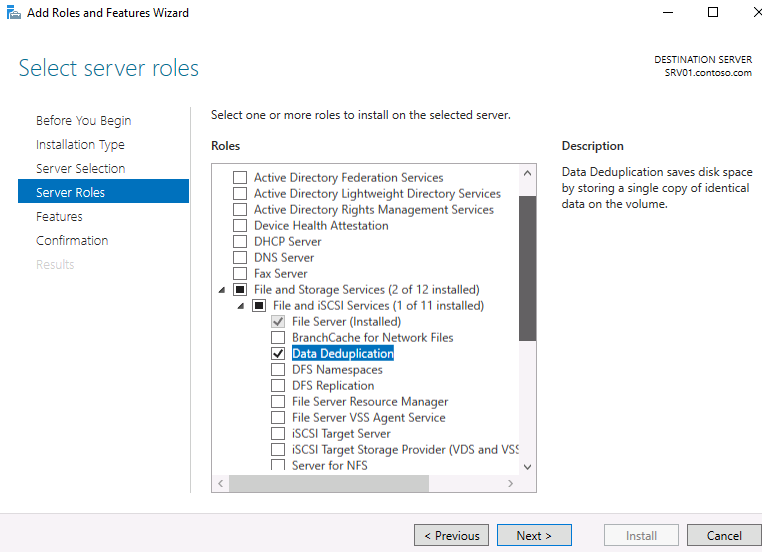
Или выполните следующую команду PowerShell:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Включение и настройка дедупликации
После установки компонентов вам необходимо включить дедупликацию для определенного тома (или нескольких томов). Это можно сделать двумя способами: с помощью графического интерфейса или с помощью PowerShell.
Чтобы настроить компонент из GUI, откройте Server Manager, перейдите в File and storage services -> Volumes, выберите нужный том, щелкните правой кнопкой мыши и в меню выберите «Configure Data Deduplication».
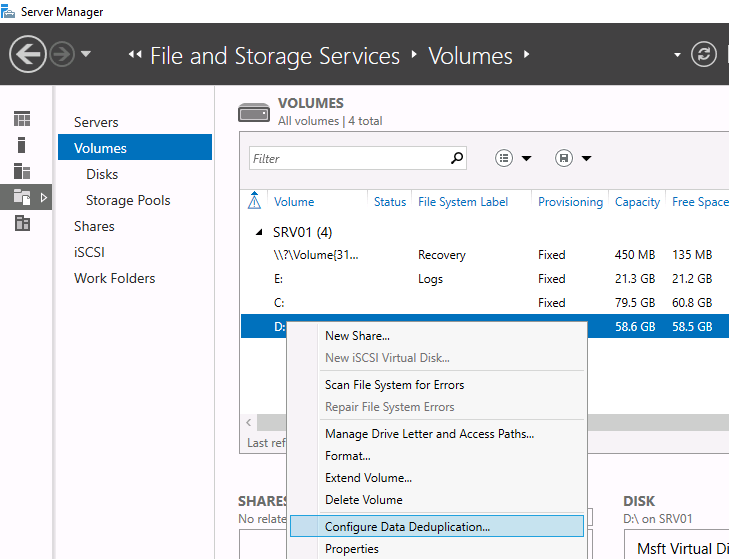
Затем выберите нужный тип дедупликации (например, General puprose file server) и нажмите «Применить». Кроме того, вы можете указать типы файлов, которые не должны подвергаться дедупликации, а также создать исключения для определенных каталогов (каталоги с мультимедиа файйлами, базами и т.д.).
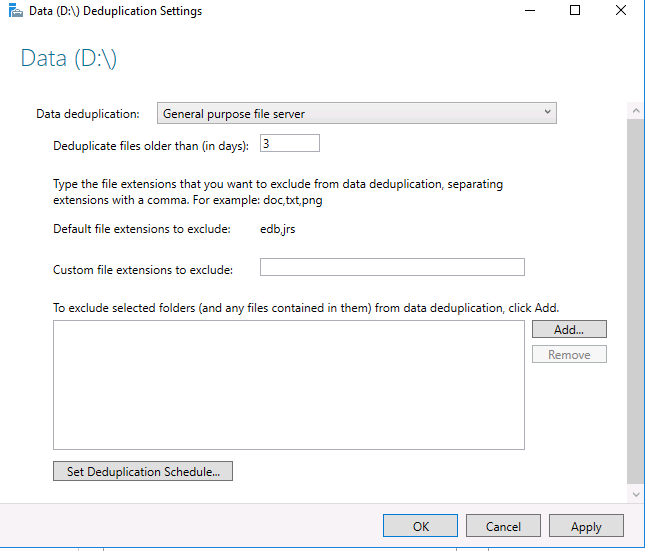
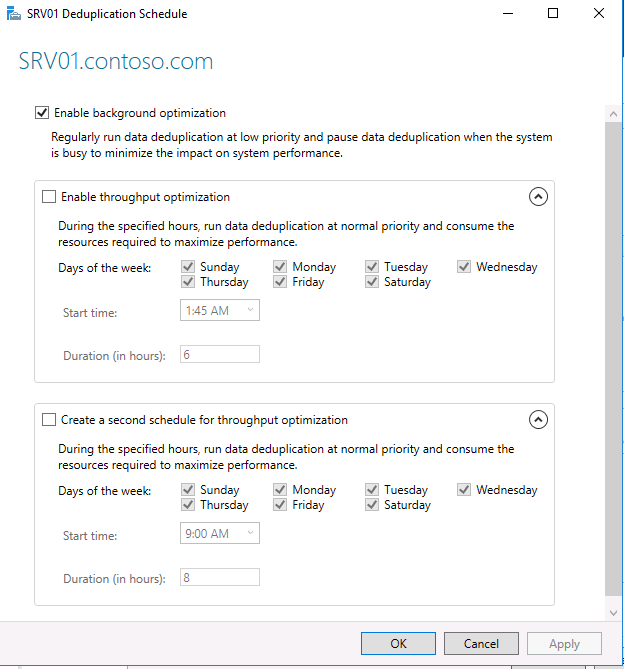
Затем вам необходимо настроить расписание, по которому будет работать задание дедупликации. Нажмите кнопку Set Deduplication Schedule.
По умолчанию включена фоновая оптимизация (background optimization), и вы можете настроить две дополнительные задачи принудительной оптимизации (throughput optimization). Здесь есть несколько настроек — вы можете выбрать дни недели, время начала и продолжительность работы.
Еще больше возможностей для настройки дедупликации предоставляет PowerShell. Чтобы включить дедупликацию, используйте следующую команду:
Enable-DedupVolume -Name D: -UsageType HyperV
Список текущих заданий дедупликации:
Get-DedupSchedule
Как вы видите, в дополнении к фоновой задачи оптимизации есть задача приоритетной оптимизации (PriorityOptimization), а также задания по сбору мусора (GarbageCollection) и очистке (Scrubbing). Все эти задачи нельзя увидеть в графическом интерфейсе.
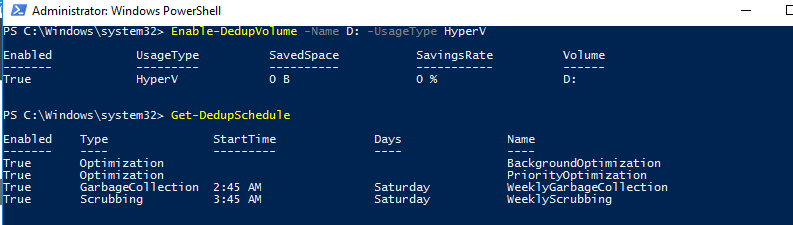
PowerShell позволяет вам точно настроить параметры заданий дедупликации. Например, создадим такую задачу оптимизации: задача должна запускаться в 9 утра с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, используя не более 20% ОЗУ и 20% CPU:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 11 -Start (Get-Date ″20/05/2017 9:00 PM″) -Memory 20 -Cores 20 -Priority Normal
Отключим приоритетную оптимизацию:
Set-DedupSchedule -Name PriorityOptimization -Enabled $false
Ручной запуск дедупликации
При необходимости вы можете запустить задание дедупликации вручную. Например, запустим полную оптимизацию тома D: с наивысшим приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -Full

Отслеживать выполнение заданий дедупликации можно с помощью команды Get-DedupJob. Заметим, что одновременно может выполняться только одна такая задача, остальные при этом находятся в очереди и ждут ее завершения.
Просмотр состояния дедупликации
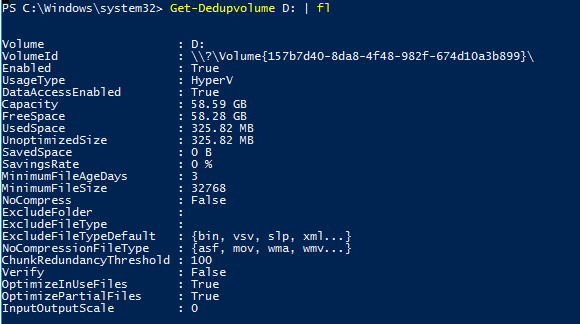
Состояние дедупликации данных для тома можно просмотреть, используя команду:
Get-DedupVolume -Volume D: | fl
Таким образом, вы можете видеть основные параметры тома — общий размер тома, использованный и сохраненный объем, уровень сжатия и т.д.
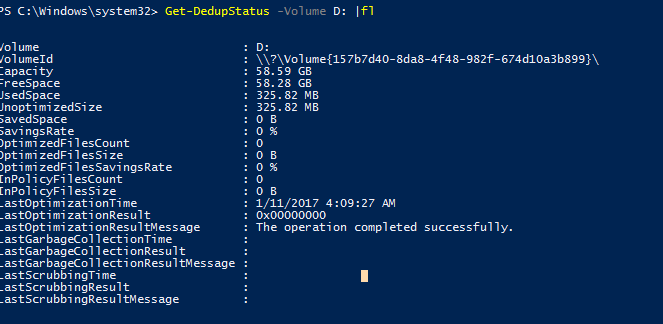
Чтобы проверить статус задания дедупликации, используйте команду:
Get-DedupStatus -Volume D: | fl
Как отключить дедупликацию
Вы можете отключить дедупликацию на диске из графического интерфейса или с помощью PowerShell. Например:
Disable-DedupVolume -Name D:

Отключение дедупликации для тома отменяет все запланированные задачи, а также предотвращает выполнение любых задач дедупликации, кроме операций на чтение (таких команд, как Get и unoptimization). Данные при этом остаются в неизменном состоянии, останавливается лишь дедупликация новых файлов.
Чтобы вернуть данные в исходное состояние, используйте процедуру обратной дедупликации. Например, выполните следующую команду для выполнения дедупликации данных на диске D с максимально возможной скоростью:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full

Обратите внимание, что для выполнения раздедупликации потребуется дополнительное пространство. Если свободного места на томе недостаточно, процедура не будет выполнена.

Data Deduplication (дедупликация данных) — это возможность уменьшать пространства за счет удаления одной части дублирующих данных. Впервые Microsoft выпустила такую возможность в Windows Server 2012 и технически она менялась вплоть до самой последней версии сервера 2019. Технология дедупликации реализована у множества брендов в том числе: HP, CISCO, IBM и VmWare.
Содержание
- Для чего нужна и как работает дедупликация
- Изменения в версиях
- Где и когда применять
- Где нельзя применять
- Установка
- Оценка потенциального освобождающегося места с DDPEval.exe
- Настройка роли
- Расширенные настройки с Powershell
- Включение и настройка дедупликации для томов
- Изменение расписаний
- Мгновенный запуск дедупликации
- Статус дедупликации
- Восстановление дедуплицированных файлов
- Отключение Deduplication
- Где найти логи Deduplication
- Восстановление данных с HDD после дедупликации Windows Server
- Дедуплицированные папки весят 0 байт
- Дудуплицированные файлы весят 0 байт
Для чего нужна и как работает дедупликация
Если взять обычный файловый или бэкап сервер, то мы увидим большой объем полностью или частично дублирующих файлов. На файловых серверах это полные копии данных, которые хранят разные пользователи, а на бэкап серверах — это минимум файлы с ОС. С определенным интервалом происходит процесс сканирования блоков с данными в 32-128 Кб и проверка уникальности. Такие блоки так же называются чанками (chunk/куски) и это важно запомнить, так как это название вы будете видеть в Powershell. При нахождении одинаковых чанков они оба будут удалены и заменен ссылкой на уникальный чанк помещенный в специальное место. Такие ссылки будут помещены в папку System Volume Information, а блоки, с уникальными данными, в контейнеры. Все такие данные, в Windows Server, имеют возможность восстановления в случае критических повреждений.
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
- Оптимизированные файлы, состоящие из ссылок на уникальные чанки;
- Чанки, организованные в контейнеры, которые сжимаются и помещаются в хранилище;
- Не оптимизированные файлы.
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:


Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
- файловая система только NTFS;
- поддержка томов до 10 Тб;
- не рекомендуется использовать с файлами объем которых достигает 1 Тб;
- 2012 не поддерживает VSS (не может работать с открытыми файлами) с 2012 r2 эта поддержка появилась;
- один режим работы.
Windows Server 2016
- файловая система только NTFS;
- поддержка томов до 64 Тб;
- дедупликация работает с первым 1 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- возможность доступна в Nano Server.
Windows Server 2019
- файловая система NTFS или ReFS;
- поддержка томов до 64 Тб;
- работа с первыми 4 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- интеграция с BranchCache;
- возможность доступна в Nano Server.

Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом ( Не рекомендую)
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная — вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные — все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет — они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Где нельзя применять
Дедупликация была создана для томов данных NTFS, она не поддерживает загрузочные или системные диски и не может использоваться с общими томами кластера (CSV). Не поддерживает дедупликацию работающих виртуальных машин или раюотающих баз данных SQL , также на диске не должен находится файл подкачки
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:

Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):

На этапе выбора ролей сервера, во вкладе «Файловые службы и службы хранилища» и «Файловые службы и службы iSCSI» выбираем «Дедупликация данных»:

Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:

Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:

Или выполните следующую команду PowerShell:Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:
- Документы пользователей — экономия 30-50%
- Установочные файлы — экономия 70-80%
- Файлы виртуализации — экономия 80-95%
- Файловые хранилища — экономия 50-60%

Если вы сомневаетесь стоит ли вам настраивать дедупликацию на вашем сервере, но хотите узнать сколько дискового пространства вы можете сэкономить за счет ее активации, то можно использовать ddpeval.exe
Диск не должен быть включен в дедупликацию , иначе будет ошибка
ERROR: Evaluation not supported on system, boot or Data Deduplication enabled volumes.
ddpeval.exe вы можете найти в папке WindowsSystem32 после установки роли Data Deduplication.
Предположим, у нас есть папка в которой лежит 3 Full бэкапа, сделанные средствами wbadmin, общим объемом 2.18 tb.
Нас интересует сколько мы сэкономим места за счет использования дедупликации.
Открываем CMD. Переходим в папку где находится ddpeval.exe и выполняем несложную команду
ddpeval E:backup1msk-exch01 /V /O:C:TempDedupEval.txt
где:
‘E:backup1msk-exch01’ — папку которую мы анализируем,
/V — как обычно, ключ расширенной обратной связи,
/O: — путь к файлу в который будет записан отчет по анализу экономии дискового пространств.
Известно что самый большой процент экономии места от дедупликации достигается на резервных копиях(если это не инкриментальные копии), за счет того что основная часть РК остается неизменной.

В таблице видно что самый большой коэффициент имеют образы виртуальных машин, а wbadmin как раз и создает файлы виртуальных дисков в формате vhdx.
Результат анализа папки с бэкапами

Нам предлагают ознакомиться с двумя вариантами анализа: с сжатием и без.
Мы можем видеть что экономия места после проведения дедупликации будет достаточно значительной — не менее 700 гигабайт.
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:

Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:

Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:

По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:

Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации (Те файлы которые больше 3 дней лежат на файловом сервере). Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) — включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) — расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) — расписание аналогично предыдущему. Можно настроить на вечернее время.

На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Install-WindowsFeature -Name "FS-Data-Deduplication" -ComputerName "Имя компьютера" -IncludeAllSubFeature -IncludeManagementTools
Следующим способом мы увидим все команды модуля дедупликации:
Get-Command -Module Deduplication

Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
- HyperV;
- Backup;
- Default (файловый сервер, устанавливается по умолчанию).
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:
Enable-DedupVolume -Volume 'E:','D:' -UsageType 'Default'

В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить ‘E:’ на ‘E:’:
No MSFT_DedupVolume objects found with property ‘Volume’ equal to ‘E:’
Так мы узнаем на каких томах настроена дедупликация:
Get-DedupVolume

Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
- ExcludeFolder — ограничения на папки, например ‘E:Folder1’,’E:Folder2»
- ExcludeFileType — ограничения по расширениям, например ‘txt’,’jpg’;
- MinimumFileAgeDays — минимальный возраст файла в днях, который будет оптимизироваться.
Следующий пример установит эти настройки и вернет их:
Set-DedupVolume `
-Volume 'E:' `
-ExcludeFolder 'E:folder_exclude' `
-ExcludeFileType 'txt','rar' `
-MinimumFileAgeDays 15
Get-DedupVolume | Select *
По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Set-DedupVolume `
-Volume 'E:' `
-MinimumFileSize 1GB
Get-DedupVolume | Select *
Есть еще несколько параметров, которые устанавливаются:
- ChunkRedundancyThreshold — устанавливает порог ссылок после которого будет создан еще один идентичный чанк. По умолчанию равен 100. С помощью этого параметра увеличивается избыточность. Проявляется она в более быстром и гарантированном (в случае повреждения) доступе файла. Не рекомендуется менять;
- InputOutputScale — установка значения I/O для распараллеливания процесса от 0 до 36. По умолчанию значение рассчитывается само;
- NoCompress — значению в $True или $False устанавливающая будет ли происходить сжатие;
- NoCompressionFileType — расширение файлов к которым не будет применяться сжатие;
- OptimizeInUseFiles — будут ли оптимизированы открытые файлы, например подключенные файлы VHDx;
- OptimizePartialFiles — если $True — будет работать блочная дедупликация. В ином случае будет работать файловая дедупликация;
- Verify — добавляет еще одну проверку идентичности чанков. Они будут сравниваться побайтно. Не могу сказать о ситуациях, где это могло бы пригодиться.
Для отключения используется следующая команда:
Disable-DedupVolume -Volume 'E:'

Отключенная дедупликация не конвертирует файлы в их исходное состояние. В примере выше у нас просто не будут оптимизироваться новые файлы и выполнятся задачи. Если к команде добавить параметр -DataAccess, то мы отключим доступ к файлам прошедшим через процесс дедупликации. О том как отменить дедупликацию полностью — будет рассказано далее.
Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
- Оптимизация (Optimization) — разбиение данных на блоки, их сравнение, сжатие и помещение в хранилище System Volume Information. По умолчанию происходит раз в час;
- Сбор мусора (GarbageCollection) — удаление устаревших фрагментов (например восстановление тех данных у которых нет дубликатов). По умолчанию происходит каждую субботу;
- Проверка целостности (Scrubbing) — обнаружение повреждений в хранилище блоков и их восстановление. По умолчанию происходит каждую субботу;
- Отмена оптимизации (Unoptimization)— отмена или отключение оптимизации на томе. Выполняется по требованию.
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:

Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:
Get-DedupSchedule

Задания никогда не выполняются одновременно — только в процессе очереди.
Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:
Set-DedupSchedule `
-Name 'WeeklyGarbageCollection' `
-Type 'GarbageCollection' `
-Enabled $True `
-StopWhenSystemBusy $True `
-Days 'Friday' `
-Start 22:00 `
Где:
- Name — имя процесса, который мы хотим изменить;
- Type — тип процесса. В нашем случае это сборка мусора (GarbageCollection);
- Enabled — будет ли включен этот процесс;
- StopWhenSystemBusy — остановится ли процесс, если сервер будет сильно нагружен другой задачей (затем попробует запустится снова);
- Days — дни, в которые этот процесс должен запускаться;
- Start — время запуска.
Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
- DurationHours — продолжительность работы задачи в часах, после которого он будет корректно завершен. По умолчанию равен 0, что означает работу до полного завершения без ограничения во времени.
- Full — параметр со значениями $True и $False. Зависит от того что указано в Type. Если мы выполняем сборку мусора, то этот параметр будет удалять все устаревшие данные сразу, а не до достижения определенного порога. При выполнении очистки (Scrubbing), если указан параметр Full, происходит проверка всех данных, а не только критически важных. В обоих случаях этот параметр стоит использовать раз в месяц.
- ReadOnly — при работе очистки не исправляет ошибки, а только уведомляет
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
- Cores — число с количеством ядер (в процентном соотношении), которые будут участвовать в процессе;
- Memory — количество памяти от общего значения (в процентном соотношении);
- StopWhenSystemBusy — останавливает задачу, если сервер, в данный момент, сильно нагружен (возобновляет ее позже);
- Priority — указывает тип нагрузки на процессор (ввод, вывод) со значениями: Low, Normal, High;
- InputOutputThrottle — ограничения работы ввода вывода при троттлинге в значениях от 0 до 100,;
- InputOutputThrottleLevel — ограничения работы ввода вывода при троттлинге со следующими значениями: None, Low, Medium, High. InputOutputThrottle имеет более высокий приоритет и при установке двух аргументов — InputOutputThrottleLevel может не работать.
- ThrottleLimit — указывает предел троттлинга. Если указан 0, то расчет будет выполнен автоматически.
Аналогия команды с другими ключами которая описана ниже
Задание должно запускаться в 9:00 с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, использовать не более 20% ОЗУ и 20% ЦП:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 11 -Start (Get-Date ″12/8/2016 9:00 PM″) -Memory 20 -Cores 20 -Priority NormalНа примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
New-DedupSchedule `
-Name 'Оптимизация по будням' `
-Cores 80 `
-Days Monday,Tuesday,Wednesday,Thursday,Friday `
-DurationHours 8 `
-InputOutputThrottleLevel Medium `
-Priority Normal `
-Memory 80 `
-Start 21:00 `
-Type 'Optimization' `
-StopWhenSystemBusy `
Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
Get-DedupSchedule -Name '*Scrub*' | New-DedupSchedule `
-Name 'Полная проверка целостности раз в месяц' `
-Full `
-Disable `
Так же можно и удалять задачи:
Get-DedupSchedule -Name '*Полная*' | Remove-DedupSchedule
# или
Remove-DedupSchedule -Name '*Полная*'
Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
New-DedupSchedule -Type Unoptimization
Учитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Мгновенный запуск дедупликации
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:
Аналогия команды
Например, запустите полную оптимизацию тома D с наивысшим приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -FullНиже комманда что предлагаю в тесте
Start-DedupJob `
-Full `
-Volume 'E:' `
-Type 'Scrubbing'
Вернуть состояние задачи можно так:
Get-DedupJob

Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
- Exception calling «EndProcessing» with «0» argument(s)
- Start-DedupJob : MSFT_DedupVolume.Volume=’
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:
Get-DedupSchedule -Name 'полная проверка' | Start-DedupJob -InputOutputThrottleLevel Low -Volume 'E:'

Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
- Cores
- Full
- InputOutputThrottle
- InputOutputThrottleLevel
- Memory
- Priority
- ReadOnly
- StopWhenSystemBusy
- ThrottleLimit
- Type
А эти параметры есть только у Start-DedupSchedule:
- Preempt — форсированный запуск задачи, отменяющий иные;
- Timestamp — работает только с задачами типа ‘Unoptimization’ и принимает значения типа данных DateTime. Отменяет оптимизацию файлов оптимизированных с указанной даты;
- Volume — можно указать один или несколько томов. Можно указывать буквы формата ‘E:’, ID и GUID;
- Wait — в фоне будет отображаться процесс задачи и ее результат. Пример ниже.

Пример отмены задач:
Get-DedupJob -Type Scrubbing | Stop-DedupJob # или Stop-DedupJob -Volume 'E:','C:'
Отмену дедупликации вы так же можете запустить задачей:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full
Статус дедупликации
Следующая команда вернет текущий статус дедупликации:
# Сокращенный вариант
Get-DedupStatus
# Полный отчет
Get-DedupStatus | select *
Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
# Для всех томов
Update-DedupStatus
# Для одного тома
Update-DedupStatus -Volume 'E:'
# Возвращение полной актуальной информации по тому
Update-DedupStatus -Volume 'E:' | SELECT *
Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:
Get-DedupStatus -Volume 'E:' | select -Property "time" | fl

Эта команда вернет информацию по работе с файлами:
Get-DedupStatus -Volume 'E:' | select -Property "file",'srate' | fl

Где:
- InPolicyFilesCount — количество файлов, которые подходят для оптимизации;
- InPolicyFilesSize — общий размер файлов, которые подходят для оптимизации;
- OptimizedFilesCount — количество файлов, которые были оптимизированы;
- OptimizedFilesSavingRate — процент оптимизированных файлов относительно всех файлов которые подходят под установленные параметры;
- OptimizedFilesSize — общий размер оптимизированных файлов.
Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
Get-DedupMetadata -Volume 'E:'

Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
- DataChunkCount — количество чанков, размером 32-128 Кб на одном томе;
- DataContainerCount — количество контейнеров;
- DataChunkAverageSize — средний размер одного чанка (размер контейнера поделенный на количество чанков);
- TotalChunkStoreSize — размер хранилища;
- CorruptionLogEntryCount — количество ошибок на томе.
Свойства типа «Stream*» скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Measure-DedupFileMetadata -Path 'E:New folder'

Где:
- FilesCount — количество файлов на всем томе;
- OptimizedFilesCount — количество оптимизированных файлов на всем томе;
- Size — суммарный размер всех файлов;
- DedupSize — итоговый размер дедуплицированных файлов в этой папке;
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Expand-DedupFile -Path 'E:New folderOtchet2020.doc','E:New folder3285.wav'
Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку:
Expand-DedupFile : MSFT_DedupVolume.Path='E:file1' - HRESULT 0x80070057, The parameter is incorrect.
При ошибке целого тома
PS C:Windowssystem32> Expand-DedupFile -Path F:
Expand-DedupFile : MSFT_DedupVolume.Path='F:' - HRESULT 0x80070005, Access is denied.
At line:1 char:2
+ Expand-DedupFile -Path F:Можно выполнить команду которая рекурсивно пройдет по всему тому и восстановит дедуплицированные файлыGet-ChildItem F: -Recurse -Attributes !D | Expand-DedupFile

После выполнения данной команды , доступ к файлам через проводник зависнет на самом сервере, но для других файлы будут доступны!!!
Процент данных , также будет уменьшатся

После делаем командуUpdate-DedupStatus
Отключение Deduplication
На томе отключаем дедупликацию

Восстанавливаем файлыGet-ChildItem F: -Recurse -Attributes !D | Expand-DedupFile
Обновляем статус
Update-DedupStatus
Где найти логи Deduplication
Applications and services — logsMicrosoftWindowsDedupliation
Восстановление данных с HDD после дедупликации Windows Server
К примеру, если вышла из строя система Windows Server в которой, выполнялась дедупликация одного из жестких дисков. Возможно, ли подключить этот диск к другому компьютеру и считать , восстановить эти данные?
Вся информация о дедупликации хранится на самом диске. Поэтому будет достаточно подключить диск/диски к другому ПК/Серверу с Windows Server , включить на нём дедупликацию и получить доступ к вашему старому диску.
Дедуплицированные папки весят 0 байт
Это означаем что по указанному пути файлы дедуплицированы
Дудуплицированные файлы весят 0 байт
Восстановите файл из бэкапа
For that matter, I’ll create a file server of two types: “File server for general use” and Scale-Out File Server. For the latter, I’ll have two scenarios: VMs running and off. After that, I’m gonna evaluate the deduplication ratio using a free tool – StarWind Deduplication Analyzer. And finally, run data deduplication using the Windows Server 2016 Data Deduplication feature. We also need our storage shared, so for this purpose, I’ve decided on StarWind Virtual SAN Free.
Here is the environment configuration:
Host 1:
- Intel Xeon E5-2660 v2
- 128GB RAM DDR3
- 1x HDD Seagate 1TB
- 1x HDD WD Black 1TB
- 1x Intel gigabit 4p i350-t rndc 1Gbsec
- Mellanox ConnectX-3 network adapter 10Gbsec
Host 2:
- Intel Xeon E5-2660 v2
- 128GB RAM DDR3
- 1x HDD Seagate 1TB
- 1x HDD WD Black 1TB
- 1xIntel gigabit 4p i350-t rndc 1Gbsec
- Mellanox ConnectX-3 network adapter 10Gbsec
For management, I’ve used the network: 172.16.0.0/24.
Network adapter – 1Gb/sec Intel gigabit qp i350-t rndc.
For StarWind VSAN Free synchronization, I’ve used an additional network: 10.0.0.0/24.
Network adapter – 10Gb/sec Mellanox ConnectX-3.
OS: Windows Server 2016 Version 1607 (OS Build 14393.0).
For working with file servers, I’ve joined the hosts into a domain under Active Directory administration.
Here is the network interconnection diagram:

Toolkit used
StarWind VSAN Free. Basically, it’s a Software-Defined Storage solution that mirrors internal server resources between the participating cluster nodes, thus delivering a highly available shared storage. Why StarWind VSAN Free? Well, obviously it costs nothing and simply gets the job done. The version used is v8.0.0.11818. You can find more info about the software on the company’s official website: https://www.starwindsoftware.com/starwind-virtual-san-free
Data Deduplication. Data Deduplication is a feature of Windows Server 2016 allowing to optimize free space on a volume by investigating the data for duplicates. When a duplicated element is found, it gets replaced with a pointer to a unique copy of that chunk, thus freeing storage space. Data Deduplication optimizes redundancies without compromising data fidelity or integrity. For additional information, please visit the Microsoft official website: https://docs.microsoft.com/en-us/windows-server/storage/data-deduplication/overview
StarWind Deduplication Analyzer. Another free tool from StarWind, which analyzes the data on your storage and estimates the savings you get when running deduplication on the data volume. Again, it’s free of charge and it can come in handy when you’re planning on deduplication but not sure of the benefits you’ll get with it. The used version is v2.0.0.2. In case you need more info on this tool, follow this link: https://www.starwindsoftware.com/starwind-deduplication-analyzer
File Server types
File server for general use. This type of clustered file server allows providing shared access to files in a failover cluster. It sometimes is referred to as active-passive or dual-active. This type of failover server is recommended for sharing data between the employees.
Scale-Out File Server (SOFS). This clustered file server has made its first appearance in Windows Server 2012. It allows storing server applications’ data such as Hyper-V VM’s files. All file resources are simultaneously online on all nodes. The shared file resources connected with that type of clustered file server are called scale-out file shares. Such configuration is sometimes called active-active. This file server type is recommended for storing Hyper-V or Microsoft SQL Server data.
You can find more info on file server types at the Microsoft official website:
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2012-R2-and-2012/hh831349(v=ws.11)
Now, let’s switch from theory to practice and do some real work.
Installing the required services
I’ll need to install the following services: File server, Data Deduplication, and Hyper-V.
Also, I’ll need Multipath I/O and Failover Clustering features deployed.

Enabling MPIO
Now, I need to enable the support for iSCSI devices in the Discover Multi-Paths tab.

Creating Device
First, I’ve installed StarWind VSAN Free on Host 1 and Host 2. Next, on Host 1, in StarWind Management Console, I’ve added both Hosts.

Next, create the device and set its size.

Now, I need to create a synchronized partner in Replication Manager.

Create a replication partner.

Next, configure the networks and specify the partner device initialization mode.

Now, by clicking “Extend Size of HA”, I’m increasing the total capacity of the HA device on a fly.


Configuring iSCSI Initiator
In this part, I’m going to discover the partner IPs on both nodes.
Configuring iSCSI Initiator on Host 1.

Now, connect the iSCSI target in the Targets tab.

The connected disk was formatted as NTFS via Disk Management console.

Creating a cluster in Failover Cluster Manager
OK, open Failover Cluster Manager and click Create Cluster in the Action tab. After that, specify the hosts to be added.

Now, specify the name and confirm the cluster creation.

Go to the Disks tab and add the cluster disk.

Creating “File server for general use”
For that matter, navigate to the Role tab and choose Configure Role.

Select the role and the file server type.

Select the name and storage for “File server for general use”.

All is ready, you can see the summary in the screenshot below.

Finally, “File server for general use” is good to go.

Now, let’s add a File Share to the File server.

Select the profile and the file share location.

Specify the share name and confirm the settings.

You can see the result in the screenshot below.

Finally, connect to the “File server for general use” the network.

Now that we’re done with “File server for general use”, we can go on and proceed with deduplication. I’ll configure the Scale-Out File Server later step-by-step not mix things.
Deduplication
Prior to enabling deduplication on the File server, I’ve copied Fonts files from “С:WindowsFonts” folder several times to give some work for Data Deduplication.
So, I’ve run deduplication analysis using the StarWind Deduplication Analyzer tool.

As you can see from the screenshot above, StarWind Deduplication Analyzer estimated the deduplication ratio of 6,69GB as 94,52%.
Prior to running deduplication, I need to configure the Data Deduplication feature.
Open Server Manager => File and Storage Services => Volumes, right-click on the “File server for general use” volume and choose Configure Data Deduplication.

Select “General purpose file server”.

Deduplication was run automatically according to the schedule set.
OK, let’s compare the storage size before and after deduplication.

The same comparison but this time in PowerShell.

So, StarWind Deduplication Analyzer estimated deduplication ratio of 6.69 GB as 94.52%.
But after first optimization, the deduplication ratio was 91%, thus freeing 6.41GB of disk space. 3% difference? Quite precise if you ask me.
Now let’s go on to the second part and create a Scale-Out File Server
For that purpose, we need at least three disks.
I’ve created 3 HA devices In StarWind Management Console.

After that, I need to connect iSCSI targets in iSCSI Initiator.

Next, initialize the disks as MBR in Disk Management.

In the Role tab, configure the file server role with Scale-Out File Server type.

Select the role and the File Server type.

Select the name and confirm the file server creation.

Here is the result.

Now, right-click the Pools tab and choose “New Storage Pool”.

Select the disks and confirm the storage pool configuration.

After creating the cluster pool, add the virtual disk.

Next, set the size and confirm the virtual disk settings.

Now, let’s create the volume.

Select the server, disk and confirm the volume settings.

After that, add a file share.

The next step is to select the profile and the file share location.

Select the share name and confirm the settings.

Here is what we get the result.

Now, connect to Scale-Out File Server over the network.

Deduplication
Prior to enabling deduplication on the File server, I’ve placed two VMs (created in Hyper-V Manager) in the shared folder.

The deduplication test was held under two scenarios:
- VMs running
- VMs turned off
Configuring Data Deduplication
For VMs deduplication, I’ve used Virtual Desktop Infrastructure (VDI) server mode. Data Deduplication is configured in Server Manager: Server Manager => File and Storage Services => Volumes.

Scenario 1 (VMs running)
First, let’s analyze the deduplication outcome with StarWind Deduplication Analyzer.

As you can see from the screenshot above, the tool calculated the deduplication ratio of 31.4 GB as 74.13%.
Once again, let’s take a look at how the storage size has changed after deduplication in Server Manager.

That’s how it looks in PowerShell.

The deduplication ratio 58% so we’ve managed to free up 18.7GB of disk space.
Scenario 2. VMs turned off
As usual, I first measure the deduplication ratio with StarWind Deduplication Analyzer.

As you can see, StarWind Dedup Analyzer estimated the deduplication ratio for 23.4 GB as 65.68%.
Let’s compare how storage size has changed after deduplication in Server Manager…

…and PowerShell.

So, we’ve managed to free up 78% – 18.6GB of disk space thanks to deduplication.
Conclusion
So, let’s take a look at the numbers once again. I’ve created two types of a file server: “File server for general use” and Scale-Out File Server. I’ve analyzed the deduplication ratio with StarWind Deduplication Analyzer tool and performed data deduplication.
Under the “File server for general use” scenario, StarWind Dedup Analyzer estimated the deduplication ratio as 94.52% while the actual result was 91% which allowed us to gain 6.41GB of free disk space.
Under the Scale-Out File Server scenario, we’ve investigated two options: VMs running and turned off.
When VMs were running, the StarWind tool showed the dedup ratio as 74.13% and the actual result was 58% – 18.7GB of free disk space.
With VMs off, StarWind Deduplication Analyzer gave 65.68% prediction for dedup ratio and the real deduplication result was 78% – 18.6GB disk space acquired.
Well, we can see that the VMs state does not affect the deduplication outcome as in both cases, the amount of storage space gained was practically identical. Overall, the smallest deduplication ratio was 58% (18.7GB) so it’s still a profit. To conclude, deduplication really helps to free some disk space for your file server, so if you still have any doubts considering its benefits, leave them behind.
| ms.assetid | title | ms.topic | author | manager | ms.author | ms.date | description |
|---|---|---|---|---|---|---|---|
|
07d6b251-c492-4d9f-bcc4-031023695b24 |
Installing and enabling Data Deduplication |
article |
wmgries |
klaasl |
wgries |
02/18/2022 |
How to install Data Deduplication on Windows Server, determine whether a workload is a good candidate for deduplication, and enable deduplication on volumes. |
Install and enable Data Deduplication
Applies to: Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, versions 21H2 and 20H2
This topic explains how to install Data Deduplication, evaluate workloads for deduplication, and enable Data Deduplication on specific volumes.
[!Note]
If you’re planning to run Data Deduplication in a Failover Cluster, every node in the cluster must have the Data Deduplication server role installed.
Install Data Deduplication
[!Important]
KB4025334 contains a roll up of fixes for Data Deduplication, including important reliability fixes, and we strongly recommend installing it when using Data Deduplication with Windows Server 2016.
Install Data Deduplication by using Server Manager
- In the Add Roles and Feature wizard, select Server Roles, and then select Data Deduplication.

- Click Next until the Install button is active, and then click Install.


Install Data Deduplication by using PowerShell
To install Data Deduplication, run the following PowerShell command as an administrator:
Install-WindowsFeature -Name FS-Data-Deduplication
To install Data Deduplication:
-
From a server running Windows Server 2016 or later, or from a Windows PC with the Remote Server Administration Tools (RSAT) installed, install Data Deduplication with an explicit reference to the server name (replace ‘MyServer’ with the real name of the server instance):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-Deduplication
Or
-
Connect remotely to the server instance with PowerShell remoting and install Data Deduplication by using DISM:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Enable Data Deduplication
Determine which workloads are candidates for Data Deduplication
Data Deduplication can effectively minimize the costs of a server application’s data consumption by reducing the amount of disk space consumed by redundant data. Before enabling deduplication, it is important that you understand the characteristics of your workload to ensure that you get the maximum performance out of your storage. There are two classes of workloads to consider:
- Recommended workloads that have been proven to have both datasets that benefit highly from deduplication and have resource consumption patterns that are compatible with Data Deduplication’s post-processing model. We recommend that you always enable Data Deduplication on these workloads:
- General purpose file servers (GPFS) serving shares such as team shares, user home folders, work folders, and software development shares.
- Virtualized desktop infrastructure (VDI) servers.
- Virtualized backup applications, such as Microsoft Data Protection Manager (DPM).
- Workloads that might benefit from deduplication, but aren’t always good candidates for deduplication. For example, the following workloads could work well with deduplication, but you should evaluate the benefits of deduplication first:
- General purpose Hyper-V hosts
- SQL servers
- Line-of-business (LOB) servers
Evaluate workloads for Data Deduplication
[!Important]
If you are running a recommended workload, you can skip this section and go to Enable Data Deduplication for your workload.
To determine whether a workload works well with deduplication, answer the following questions. If you’re unsure about a workload, consider doing a pilot deployment of Data Deduplication on a test dataset for your workload to see how it performs.
-
Does my workload’s dataset have enough duplication to benefit from enabling deduplication?
Before enabling Data Deduplication for a workload, investigate how much duplication your workload’s dataset has by using the Data Deduplication Savings Evaluation tool, or DDPEval. After installing Data Deduplication, you can find this tool atC:WindowsSystem32DDPEval.exe. DDPEval can evaluate the potential for optimization against directly connected volumes (including local drives or Cluster Shared Volumes) and mapped or unmapped network shares.Running DDPEval.exe will return an output similar to the following:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0 -
What do my workload’s I/O patterns to its dataset look like? What performance do I have for my workload?
Data Deduplication optimizes files as a periodic job, rather than when the file is written to disk. As a result, it is important to examine is a workload’s expected read patterns to the deduplicated volume. Because Data Deduplication moves file content into the Chunk Store and attempts to organize the Chunk Store by file as much as possible, read operations perform best when they are applied to sequential ranges of a file.Database-like workloads typically have more random read patterns than sequential read patterns because databases do not typically guarantee that the database layout will be optimal for all possible queries that may be run. Because the sections of the Chunk Store may exist all over the volume, accessing data ranges in the Chunk Store for database queries may introduce additional latency. High performance workloads are particularly sensitive to this extra latency, but other database-like workloads might not be.
[!Note]
These concerns primarily apply to storage workloads on volumes made up of traditional rotational storage media (also known as Hard Disk drives, or HDDs). All-flash storage infrastructure (also known as Solid State Disk drives, or SSDs), is less affected by random I/O patterns because one of the properties of flash media is equal access time to all locations on the media. Therefore, deduplication will not introduce the same amount of latency for reads to a workload’s datasets stored on all-flash media as it would on traditional rotational storage media. -
What are the resource requirements of my workload on the server?
Because Data Deduplication uses a post-processing model, Data Deduplication periodically needs to have sufficient system resources to complete its optimization and other jobs. This means that workloads that have idle time, such as in the evening or on weekends, are excellent candidates for deduplication, and workloads that run all day, every day may not be. Workloads that have no idle time may still be good candidates for deduplication if the workload does not have high resource requirements on the server.
Enable Data Deduplication
Before enabling Data Deduplication, you must choose the Usage Type that most closely resembles your workload. There are three Usage Types included with Data Deduplication.
- Default — tuned specifically for general purpose file servers
- Hyper-V — tuned specifically for VDI servers
- Backup — tuned specifically for virtualized backup applications, such as Microsoft DPM
Enable Data Deduplication by using Server Manager
- Select File and Storage Services in Server Manager.
- Select Volumes from File and Storage Services.
- Right-click the desired volume and select Configure Data Deduplication.
- Select the desired Usage Type from the drop-down box and select OK.
- If you are running a recommended workload, you’re done. For other workloads, see Other considerations.




[!Note]
You can find more information on excluding file extensions or folders and selecting the deduplication schedule, including why you would want to do this, in Configuring Data Deduplication.
Enable Data Deduplication by using PowerShell
-
With an administrator context, run the following PowerShell command:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>
-
If you are running a recommended workload, you’re done. For other workloads, see Other considerations.
[!Note]
The Data Deduplication PowerShell cmdlets, includingEnable-DedupVolume, can be run remotely by appending the-CimSessionparameter with a CIM Session. This is particularly useful for running the Data Deduplication PowerShell cmdlets remotely against a server instance. To create a new CIM Session runNew-CimSession.
Other considerations
[!Important]
If you are running a recommended workload, you can skip this section.
- Data Deduplication’s Usage Types give sensible defaults for recommended workloads, but they also provide a good starting point for all workloads. For workloads other than the recommended workloads, it is possible to modify Data Deduplication’s advanced settings to improve deduplication performance.
- If your workload has high resource requirements on your server, the Data Deduplication jobs should be scheduled to run during the expected idle times for that workload. This is particularly important when running deduplication on a hyper-converged host, because running Data Deduplication during expected working hours can starve VMs.
- If your workload does not have high resource requirements, or if it is more important that optimization jobs complete than workload requests be served, the memory, CPU, and priority of the Data Deduplication jobs can be adjusted.
Frequently asked questions (FAQ)
I want to run Data Deduplication on the dataset for X workload. Is this supported?
Aside from workloads that are known not to interoperate with Data Deduplication, we fully support the data integrity of Data Deduplication with any workload. Recommended workloads are supported by Microsoft for performance as well. The performance of other workloads depends greatly on what they are doing on your server. You must determine what performance impacts Data Deduplication has on your workload, and if this is acceptable for this workload.
What are the volume sizing requirements for deduplicated volumes?
In Windows Server 2012 and Windows Server 2012 R2, volumes had to be carefully sized to ensure that Data Deduplication could keep up with the churn on the volume. This typically meant that the average maximum size of a deduplicated volume for a high-churn workload was 1-2 TB, and the absolute maximum recommended size was 10 TB. In Windows Server 2016, these limitations were removed. For more information, see What’s new in Data Deduplication.
Do I need to modify the schedule or other Data Deduplication settings for recommended workloads?
No, the provided Usage Types were created to provide reasonable defaults for recommended workloads.
What are the memory requirements for Data Deduplication?
At a minimum, Data Deduplication should have 300 MB + 50 MB for each TB of logical data. For instance, if you are optimizing a 10 TB volume, you would need a minimum of 800 MB of memory allocated for deduplication (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). While Data Deduplication can optimize a volume with this low amount of memory, having such constrained resources will slow down Data Deduplication’s jobs.
Optimally, Data Deduplication should have 1 GB of memory for every 1 TB of logical data. For instance, if you are optimizing a 10 TB volume, you would optimally need 10 GB of memory allocated for Data Deduplication (1 GB * 10). This ratio will ensure the maximum performance for Data Deduplication jobs.
What are the storage requirements for Data Deduplication?
In Windows Server 2016, Data Deduplication can support volume sizes up to 64 TB. For more information, view What’s new in Data Deduplication.
| ms.assetid | title | ms.topic | author | manager | ms.author | ms.date | description |
|---|---|---|---|---|---|---|---|
|
07d6b251-c492-4d9f-bcc4-031023695b24 |
Installing and enabling Data Deduplication |
article |
wmgries |
klaasl |
wgries |
02/18/2022 |
How to install Data Deduplication on Windows Server, determine whether a workload is a good candidate for deduplication, and enable deduplication on volumes. |
Install and enable Data Deduplication
Applies to: Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, versions 21H2 and 20H2
This topic explains how to install Data Deduplication, evaluate workloads for deduplication, and enable Data Deduplication on specific volumes.
[!Note]
If you’re planning to run Data Deduplication in a Failover Cluster, every node in the cluster must have the Data Deduplication server role installed.
Install Data Deduplication
[!Important]
KB4025334 contains a roll up of fixes for Data Deduplication, including important reliability fixes, and we strongly recommend installing it when using Data Deduplication with Windows Server 2016.
Install Data Deduplication by using Server Manager
- In the Add Roles and Feature wizard, select Server Roles, and then select Data Deduplication.
- Click Next until the Install button is active, and then click Install.
Install Data Deduplication by using PowerShell
To install Data Deduplication, run the following PowerShell command as an administrator:
Install-WindowsFeature -Name FS-Data-Deduplication
To install Data Deduplication:
-
From a server running Windows Server 2016 or later, or from a Windows PC with the Remote Server Administration Tools (RSAT) installed, install Data Deduplication with an explicit reference to the server name (replace ‘MyServer’ with the real name of the server instance):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-Deduplication
Or
-
Connect remotely to the server instance with PowerShell remoting and install Data Deduplication by using DISM:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Enable Data Deduplication
Determine which workloads are candidates for Data Deduplication
Data Deduplication can effectively minimize the costs of a server application’s data consumption by reducing the amount of disk space consumed by redundant data. Before enabling deduplication, it is important that you understand the characteristics of your workload to ensure that you get the maximum performance out of your storage. There are two classes of workloads to consider:
- Recommended workloads that have been proven to have both datasets that benefit highly from deduplication and have resource consumption patterns that are compatible with Data Deduplication’s post-processing model. We recommend that you always enable Data Deduplication on these workloads:
- General purpose file servers (GPFS) serving shares such as team shares, user home folders, work folders, and software development shares.
- Virtualized desktop infrastructure (VDI) servers.
- Virtualized backup applications, such as Microsoft Data Protection Manager (DPM).
- Workloads that might benefit from deduplication, but aren’t always good candidates for deduplication. For example, the following workloads could work well with deduplication, but you should evaluate the benefits of deduplication first:
- General purpose Hyper-V hosts
- SQL servers
- Line-of-business (LOB) servers
Evaluate workloads for Data Deduplication
[!Important]
If you are running a recommended workload, you can skip this section and go to Enable Data Deduplication for your workload.
To determine whether a workload works well with deduplication, answer the following questions. If you’re unsure about a workload, consider doing a pilot deployment of Data Deduplication on a test dataset for your workload to see how it performs.
-
Does my workload’s dataset have enough duplication to benefit from enabling deduplication?
Before enabling Data Deduplication for a workload, investigate how much duplication your workload’s dataset has by using the Data Deduplication Savings Evaluation tool, or DDPEval. After installing Data Deduplication, you can find this tool atC:WindowsSystem32DDPEval.exe. DDPEval can evaluate the potential for optimization against directly connected volumes (including local drives or Cluster Shared Volumes) and mapped or unmapped network shares.Running DDPEval.exe will return an output similar to the following:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0 -
What do my workload’s I/O patterns to its dataset look like? What performance do I have for my workload?
Data Deduplication optimizes files as a periodic job, rather than when the file is written to disk. As a result, it is important to examine is a workload’s expected read patterns to the deduplicated volume. Because Data Deduplication moves file content into the Chunk Store and attempts to organize the Chunk Store by file as much as possible, read operations perform best when they are applied to sequential ranges of a file.Database-like workloads typically have more random read patterns than sequential read patterns because databases do not typically guarantee that the database layout will be optimal for all possible queries that may be run. Because the sections of the Chunk Store may exist all over the volume, accessing data ranges in the Chunk Store for database queries may introduce additional latency. High performance workloads are particularly sensitive to this extra latency, but other database-like workloads might not be.
[!Note]
These concerns primarily apply to storage workloads on volumes made up of traditional rotational storage media (also known as Hard Disk drives, or HDDs). All-flash storage infrastructure (also known as Solid State Disk drives, or SSDs), is less affected by random I/O patterns because one of the properties of flash media is equal access time to all locations on the media. Therefore, deduplication will not introduce the same amount of latency for reads to a workload’s datasets stored on all-flash media as it would on traditional rotational storage media. -
What are the resource requirements of my workload on the server?
Because Data Deduplication uses a post-processing model, Data Deduplication periodically needs to have sufficient system resources to complete its optimization and other jobs. This means that workloads that have idle time, such as in the evening or on weekends, are excellent candidates for deduplication, and workloads that run all day, every day may not be. Workloads that have no idle time may still be good candidates for deduplication if the workload does not have high resource requirements on the server.
Enable Data Deduplication
Before enabling Data Deduplication, you must choose the Usage Type that most closely resembles your workload. There are three Usage Types included with Data Deduplication.
- Default — tuned specifically for general purpose file servers
- Hyper-V — tuned specifically for VDI servers
- Backup — tuned specifically for virtualized backup applications, such as Microsoft DPM
Enable Data Deduplication by using Server Manager
- Select File and Storage Services in Server Manager.
- Select Volumes from File and Storage Services.
- Right-click the desired volume and select Configure Data Deduplication.
- Select the desired Usage Type from the drop-down box and select OK.
- If you are running a recommended workload, you’re done. For other workloads, see Other considerations.
[!Note]
You can find more information on excluding file extensions or folders and selecting the deduplication schedule, including why you would want to do this, in Configuring Data Deduplication.
Enable Data Deduplication by using PowerShell
-
With an administrator context, run the following PowerShell command:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>
-
If you are running a recommended workload, you’re done. For other workloads, see Other considerations.
[!Note]
The Data Deduplication PowerShell cmdlets, includingEnable-DedupVolume, can be run remotely by appending the-CimSessionparameter with a CIM Session. This is particularly useful for running the Data Deduplication PowerShell cmdlets remotely against a server instance. To create a new CIM Session runNew-CimSession.
Other considerations
[!Important]
If you are running a recommended workload, you can skip this section.
- Data Deduplication’s Usage Types give sensible defaults for recommended workloads, but they also provide a good starting point for all workloads. For workloads other than the recommended workloads, it is possible to modify Data Deduplication’s advanced settings to improve deduplication performance.
- If your workload has high resource requirements on your server, the Data Deduplication jobs should be scheduled to run during the expected idle times for that workload. This is particularly important when running deduplication on a hyper-converged host, because running Data Deduplication during expected working hours can starve VMs.
- If your workload does not have high resource requirements, or if it is more important that optimization jobs complete than workload requests be served, the memory, CPU, and priority of the Data Deduplication jobs can be adjusted.
Frequently asked questions (FAQ)
I want to run Data Deduplication on the dataset for X workload. Is this supported?
Aside from workloads that are known not to interoperate with Data Deduplication, we fully support the data integrity of Data Deduplication with any workload. Recommended workloads are supported by Microsoft for performance as well. The performance of other workloads depends greatly on what they are doing on your server. You must determine what performance impacts Data Deduplication has on your workload, and if this is acceptable for this workload.
What are the volume sizing requirements for deduplicated volumes?
In Windows Server 2012 and Windows Server 2012 R2, volumes had to be carefully sized to ensure that Data Deduplication could keep up with the churn on the volume. This typically meant that the average maximum size of a deduplicated volume for a high-churn workload was 1-2 TB, and the absolute maximum recommended size was 10 TB. In Windows Server 2016, these limitations were removed. For more information, see What’s new in Data Deduplication.
Do I need to modify the schedule or other Data Deduplication settings for recommended workloads?
No, the provided Usage Types were created to provide reasonable defaults for recommended workloads.
What are the memory requirements for Data Deduplication?
At a minimum, Data Deduplication should have 300 MB + 50 MB for each TB of logical data. For instance, if you are optimizing a 10 TB volume, you would need a minimum of 800 MB of memory allocated for deduplication (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). While Data Deduplication can optimize a volume with this low amount of memory, having such constrained resources will slow down Data Deduplication’s jobs.
Optimally, Data Deduplication should have 1 GB of memory for every 1 TB of logical data. For instance, if you are optimizing a 10 TB volume, you would optimally need 10 GB of memory allocated for Data Deduplication (1 GB * 10). This ratio will ensure the maximum performance for Data Deduplication jobs.
What are the storage requirements for Data Deduplication?
In Windows Server 2016, Data Deduplication can support volume sizes up to 64 TB. For more information, view What’s new in Data Deduplication.
Windows Server 2016 will also have a new deduplication engine. In this post, we will have a look on how to setup data deduplication in Windows Server 2016 and also what’s changes compared to 2012 R2. While 2012R2 the recommended size of volumes suitable for deduplication were limited to 10 Tb, with the upcoming Windows Server 2016 and multi-threaded processing, volumes with sizes up to 64 Tb can be used for deduplication.
Data deduplication is not supported for certain volumes, such as any volume that is not a NTFS file system or any volume that is smaller than 2 GB. This post is based on latest Windows Server 2016 TP5 available for download here.
But first, let me explain in few words for folks which do not know what is deduplication. The deduplication can be defined like this:
By using deduplication, you can store more data in less space by segmenting files into small variable-sized chunks (32–128 KB), identifying duplicate chunks, and maintaining a single copy of each chunk. Redundant copies of the chunk are replaced by a reference to the single copy. The chunks are compressed and then organized into special container files in the System Volume Information folder.
How to configure data deduplication in Windows Server 2016?
Step 1: Open Server manager and Add the Server Role (it’s not installed after a fresh server installation even if the Storage services are).
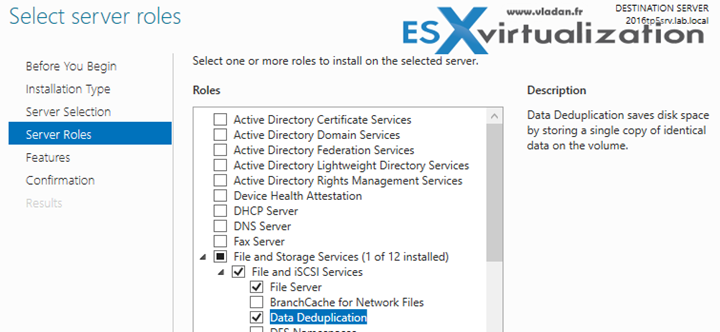
Step 2: Go to File and Storage Services to find a disk (or better say volume) suitable for deduplication.
First click on a disk and format it with NTSF file system.
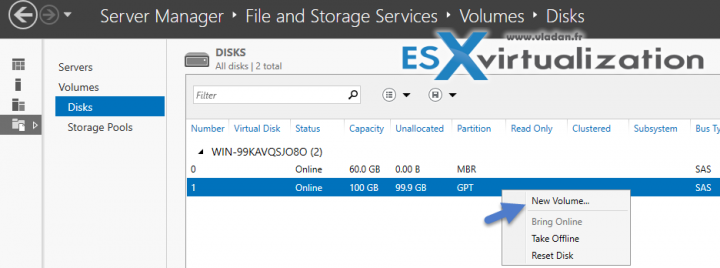
Usual operation. Nothing unusual here. Previous versions of Windows server systems were pretty much the same…
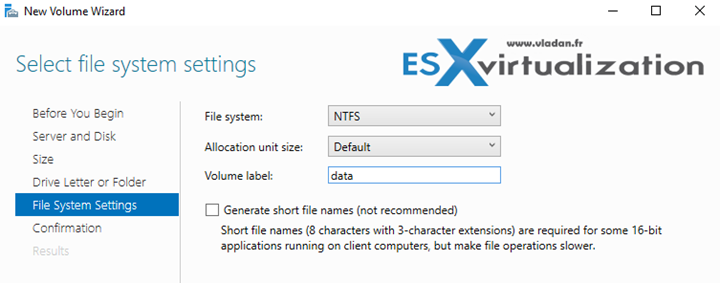
Note that during the volume creation wizard you actually get a page where you can activate deduplication, but in this guide I’m showing how to configure deduplication on a volume which does not have the deduplication activated yet, but it’s already formatted with an NTFS file system.
Step 3: Click on Volumes and select a volume where you want to setup the data deduplication.
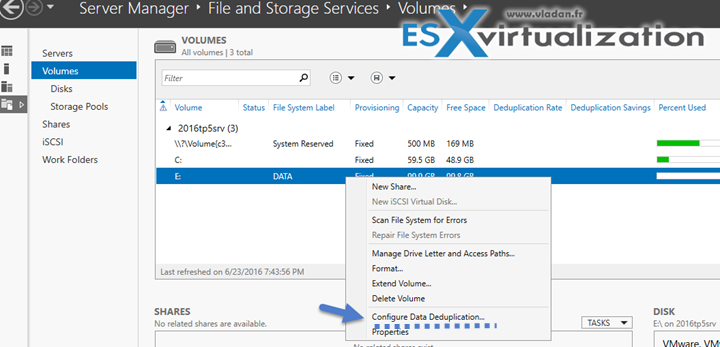
Then from the drop-down menu > select the purpose of the volume and the deduplication type….
You can also add custom file extensions you want to exclude there.
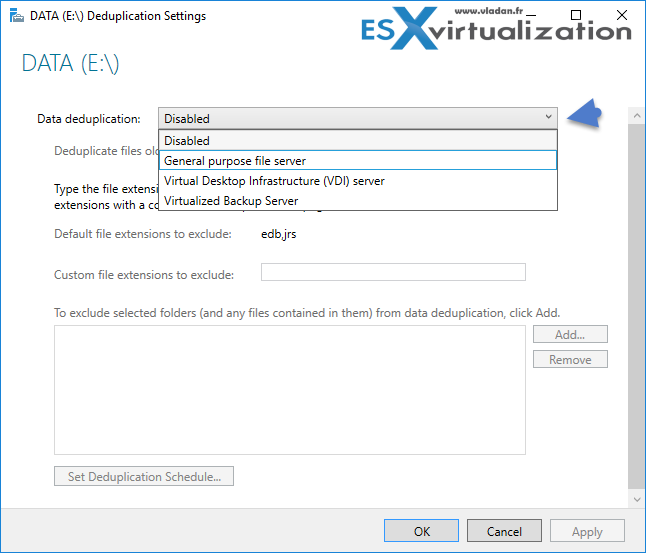
By clicking the Set Deduplication Schedule button you’ll be able to:
- Enable Background Optimization
- 1st and 2nd deduplication runs. Bear in mind that those two schedules will use CPU cycles and consume ressources so it’s preferable to set those outside of business hours and outside of backup window too…
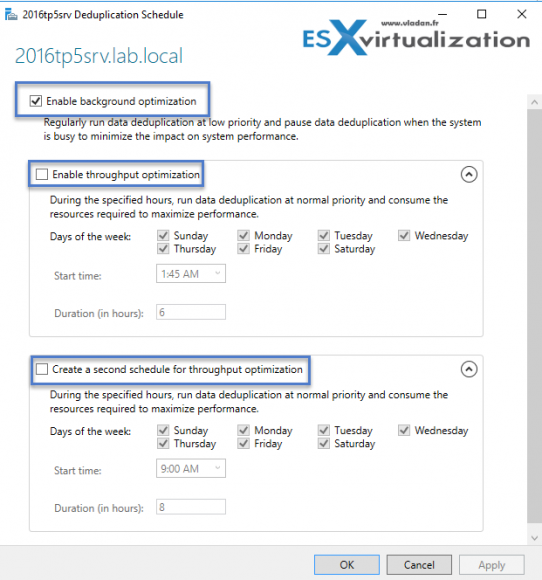
Data deduplication uses subfile variable-size chunking and compression, which deliver optimization ratios of 2:1 for general file servers and up to 20:1 for virtualization data.
Compared to Windows Server 2012 R2, it uses single threaded jobs and I/O queues. That all changes in Windows Server 2016 with a full redesign of deduplication and optimization processing. It does runs multiple threads in parallel using multiple I/O queues on a single volume, resulting in performance that was only possible before by dividing up your data into multiple, smaller volumes. (10Tb recommended).
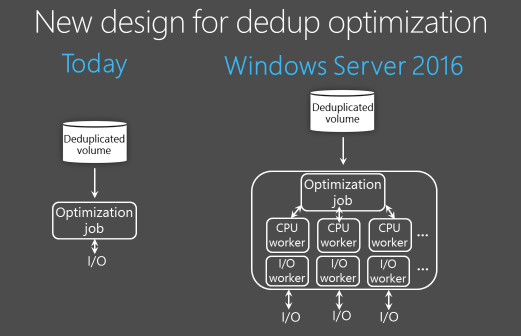
Wrap-up
I just scratched a surface with this post. I know. There are other options, with PowerShell. There is also a PowerShell cmdlet which allows activating the deduplication via PowerShell. It is certainly a very good improvement over the 2012R2 server but only for customers needed to use this technique on really big volumes.
Stay tuned for more…
Source: Technet