Curl (client URL) — это инструмент командной строки на основе библиотеки libcurl для передачи данных с сервера и на сервер при помощи различных протоколов, в том числе HTTP, HTTPS, FTP, FTPS, IMAP, IMAPS, POP3, POP3S, SMTP и SMTPS. Он очень популярен в сфере автоматизации и скриптов благодаря широкому диапазону функций и поддерживаемых протоколов. В этой статье мы расскажем, как использовать curl в Windows на различных примерах.
▍ Установка в Windows
Во всех современных версиях Windows, начиная с Windows 10 (версия 1803) и Server 2019, исполняемый файл curl поставляется в комплекте, поэтому ручная установка не требуется. Чтобы определить местоположение curl и его версию в системе, можно использовать следующие команды:
where curl
curl --version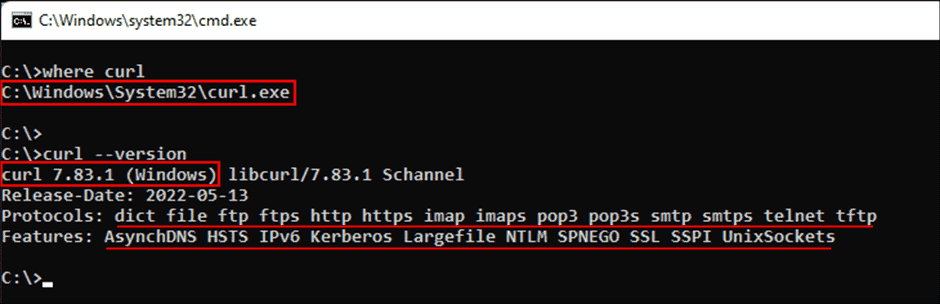
Определение местоположения и версии curl в Windows
Команда curl —version также выводит список протоколов и функций, поддерживаемых текущей версией curl. Как видно из показанного выше скриншота, к использованию встроенной утилиты curl всё готово. Если вместо этого отображается сообщение об ошибке, curl может быть недоступен потому, что вы используете более раннюю версию Windows (например, Windows 8.1 или Server 2016). В таком случае вам потребуется установить curl в Windows вручную.
▍ Синтаксис curl
Команда curl использует следующий синтаксис:
curl [options...] [url]Инструмент поддерживает различные опции, которые мы рассмотрим ниже. Как и в любом инструменте командной строки, вы можете использовать для получения справки команду curl —help.
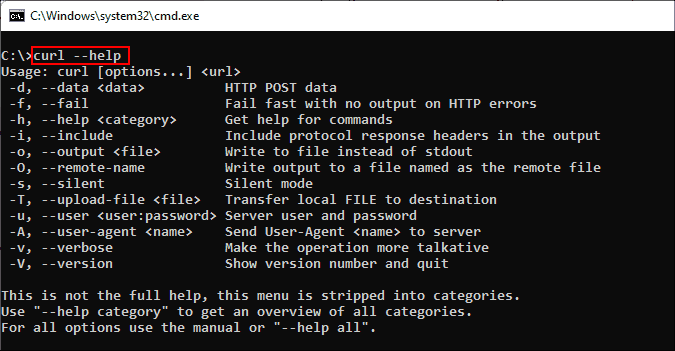
Получение справки при помощи команды curl
Для получения подробной справки можно использовать команду curl —help all. Справка разделена на категории, поэтому при помощи curl —help category можно просмотреть все темы.
Ознакомившись с синтаксисом curl, давайте рассмотрим различные способы применения этого инструмента на примерах.
▍ HTTP-запрос GET
При использовании curl с URL и без указания опций запрос по умолчанию использует метод GET протокола HTTP. Попробуйте выполнить такую команду:
curl https://4sysops.comПриведённая выше команда по сути эквивалентна curl —request GET 4sysops.com, отправляющей запрос GET к 4sysops.com по протоколу HTTPS. Чтобы указать версию протокола HTTP (например, http/2), используйте опцию —http2:
curl --http2 https://4sysops.comВ случае URL, начинающихся с HTTPS, curl сначала пытается установить соединение http/2 и автоматически откатывается к http/1.1, если это не удаётся. Также он поддерживает другие методы, например, HEAD, POST, PUT и DELETE. Для использования этих методов вместе с командой curl нужно указать опцию —request (или -X), за которой следует указание метода. Стоит заметить, что список доступных методов зависит от используемого протокола.
▍ Получение информации об удалённом файле
Если вы администратор, то иногда вам могут быть интересны только заголовки HTTP. Их можно получить при помощи опции —head (или -I). Иногда URL может перенаправлять пользователя в другую точку. В таком случае опция —location (или -L) позволяет curl выполнять перенаправления. Также можно использовать —insecure (или -k), чтобы разрешить незащищённые подключения и избежать ошибок с сертификатом TLS в случае, если целевой URL использует самоподписанный сертификат. Пользуйтесь этой опцией только при абсолютной необходимости. Все эти три опции можно скомбинировать в одну краткую запись, как показано в следующей команде:
curl -kIL 4sysops.com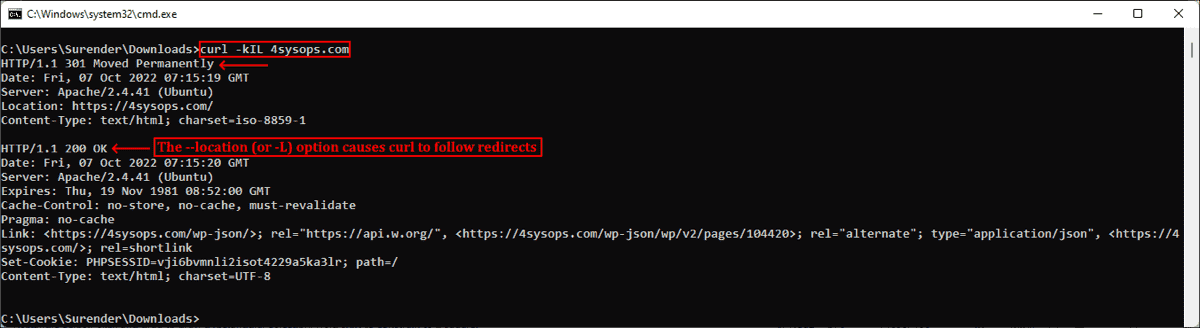
Опции просмотра заголовков запросов, включения незащищённого соединения и использования перенаправлений
Как можно заметить, такая краткая запись особенно полезна для комбинирования нескольких опций. Приведённая выше команда по сути эквивалентна команде curl —insecure —head —location 4sysops.com.
Опция —head (или -I) также даёт основную информацию об удалённом файле без его скачивания. Как показано на скриншоте ниже, при использовании curl с URL удалённого файла он отображает различные заголовки, дающие информацию об удалённом файле.
curl -IL https://curl.se/windows/dl-7.85.0_5/curl-7.85.0_5-win64-mingw.zip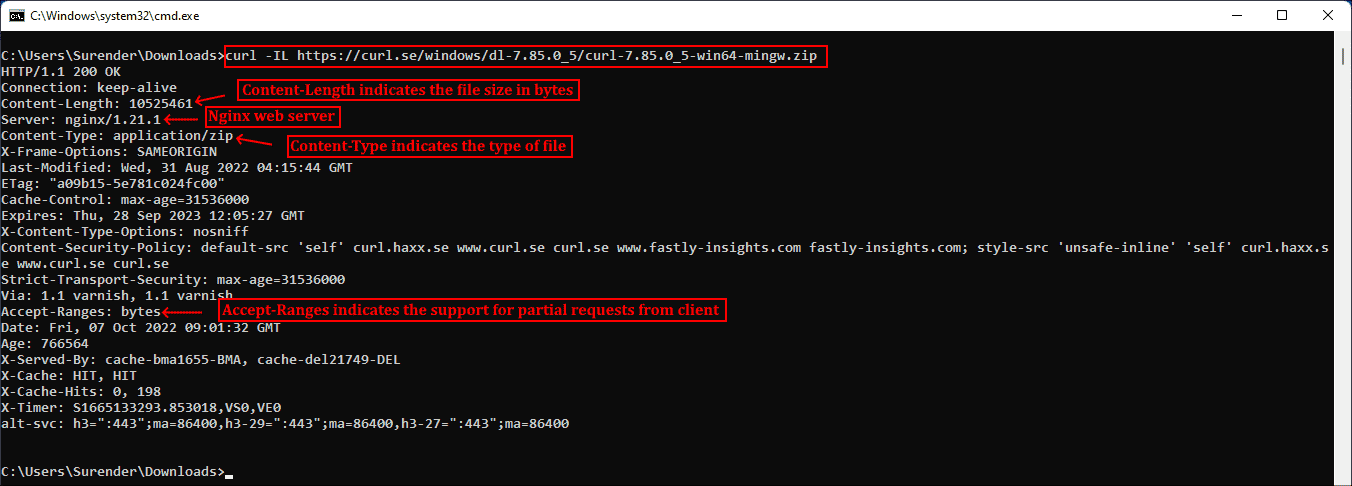
Использование curl для просмотра основной информации удалённых файлов
Заголовок Content-Length обозначает размер файла (в байтах), Content-Type сообщает о типе медиафайла (например, image/png, text/html), Server обозначает тип серверного приложения (Apache, Gunicorn и так далее), Last-Modified показывает дату последнего изменения файла на сервере, а заголовок Accept-Ranges обозначает поддержку частичных запросов для скачивания от клиента, что по сути определяет возможность продолжения прерванной загрузки.
▍ Скачивание файла
Для скачивания файла и сохранения с тем же именем, что и на сервере, можно использовать curl с опцией —remote-name (или -O). Показанная ниже команда скачивает последнюю версию curl для Windows с официального сайта:
curl -OL https://curl.se/windows/latest.cgi?p=win64-mingw.zip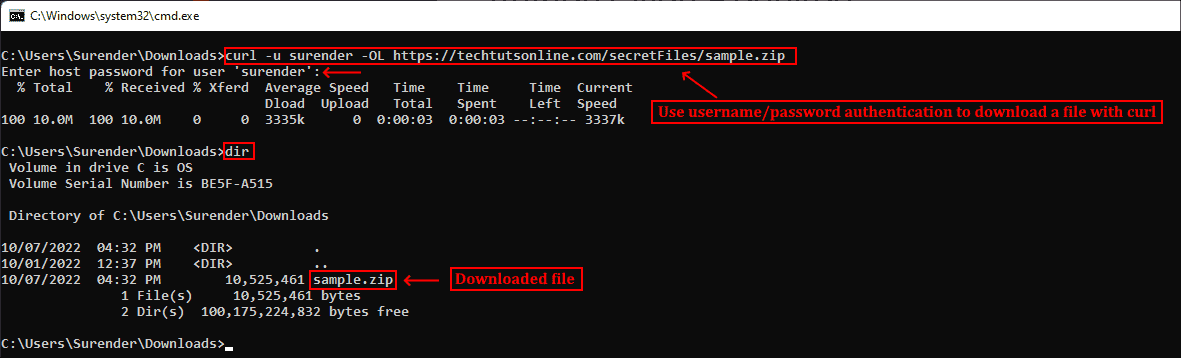
Скачивание файла с именем по умолчанию и индикатором прогресса
При необходимости для нахождения ресурса добавляется опция -L, разрешающая перенаправления. Если нужно сохранить файл с новым именем, используйте опцию —output (или -o). Кроме того, при использовании команды curl в скрипте может понадобиться отключить индикатор прогресса, что можно сделать при помощи опции —silent (или -s). Эти две опции можно скомбинировать:
curl -sLo curl.zip https://curl.se/windows/latest.cgi?p=win64-mingw.zip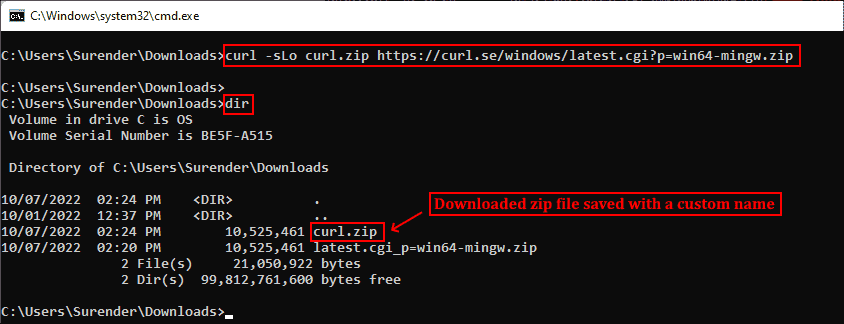
Скачивание файла без индикатора и сохранение под произвольным именем
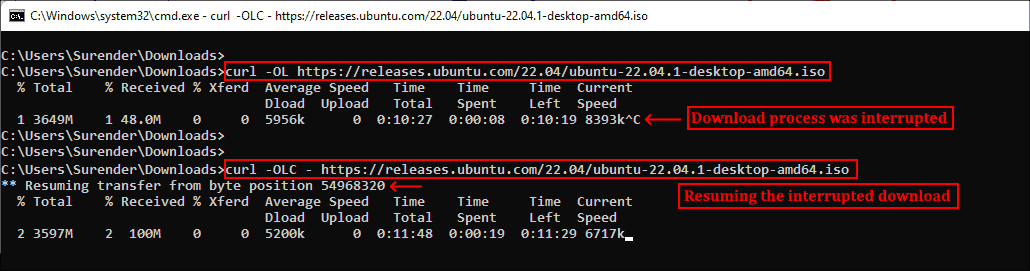
▍ Продолжение прерванного скачивания
Наличие Accept-Ranges: bytes в заголовке ответа в буквальном смысле обозначает, что сервер поддерживает скачивания с возможностью продолжения. Чтобы продолжить прерванное скачивание, можно использовать опцию —continue-at (или -C), получающую смещение (в байтах). Обычно указывать смещение непросто, поэтому curl предоставляет простой способ продолжения прерванной загрузки:
curl -OLC - https://releases.ubuntu.com/22.04/ubuntu-22.04.1-desktop-amd64.iso
Продолжение прерванного скачивания
Как видно из скриншота, я скачивал iso-файл Ubuntu, но скачивание было прервано. Затем я снова запустил команду curl с опцией -C, и передача продолжилась с того диапазона байтов, на котором была прервана. Знак минус (—) рядом с -C позволяет curl автоматически определить, как и где продолжить прерванное скачивание.
▍ Аутентификация с Curl
Также Curl поддерживает аутентификацию, что позволяет скачать защищённый файл, предоставив учётные данные при помощи опции —user (or -u), принимающей имя пользователя и пароль в формате username:password. Если не вводить пароль, curl попросит ввести его в режиме no-echo.
curl -u surender -OL https://techtutsonline.com/secretFiles/sample.zip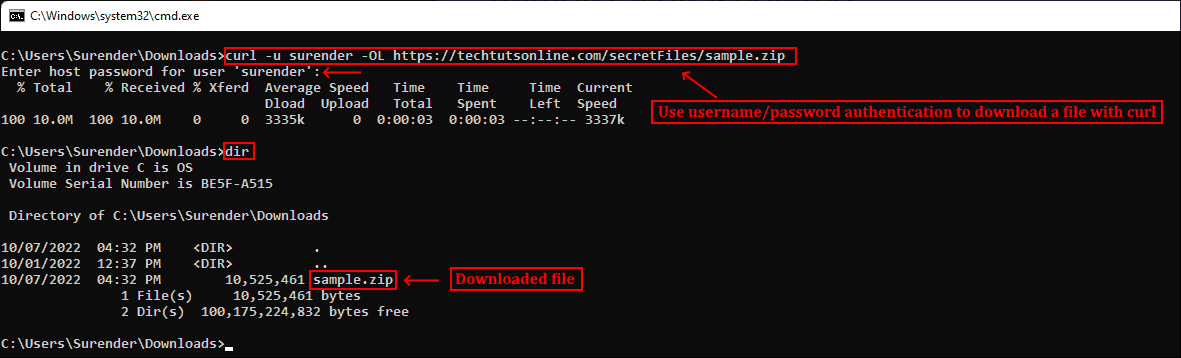
Скачивание файла с аутентификацией по имени пользователя и паролю
Если вы используете Basic authentication, то необходимо передать имя пользователя и пароль, а значит, воспользоваться защищённым протоколом наподобие HTTPS (вместо HTTP) или FTPS (вместо FTP). Если по каким-то причинам приходится использовать протокол без шифрования, то убедитесь, что вы используете способ аутентификации, не передающий учётные данные в виде простого текста (например, аутентификацию Digest, NTLM или Negotiate).
Также curl поддерживает использование файлов конфигурации .curlrc, _curlrc и .netrc, позволяющих задавать различные опции curl в файле, а затем добавлять файл в команду при помощи опции curl —config (или curl -K), что особенно полезно при написании скриптов.
▍ Выгрузка файла
Опция —upload-file (или -T) позволяет выгружать локальный файл на удалённый сервер. Показанная ниже команда выгружает файл из локальной системы на удалённый веб-сервер по протоколу FTPS:
curl -kT C:UsersSurenderDownloadssample1.zip -u testlabsurender ftps://192.168.0.80/awesomewebsite.com/files/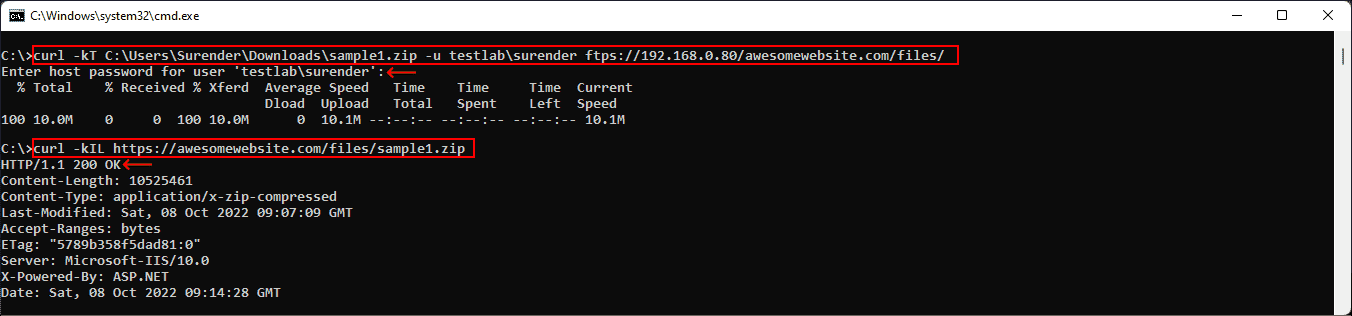
Выгрузка файла на удалённый сервер
Опция -k добавляется для устранения проблем с сертификатами на случай, если веб-сервер использует самоподписанный сертификат. Наклонная черта в конце URL сообщает curl, что конечная точка является папкой. Можно указать несколько имён файлов, например «{sample1.zip,sample2.zip}». Ниже показано, как с помощью одной команды curl можно выгрузить на сервер несколько файлов:
curl -kT sample[1-5].zip -u testlabsurender ftps://192.168.0.80/awesomewebsite.com/files/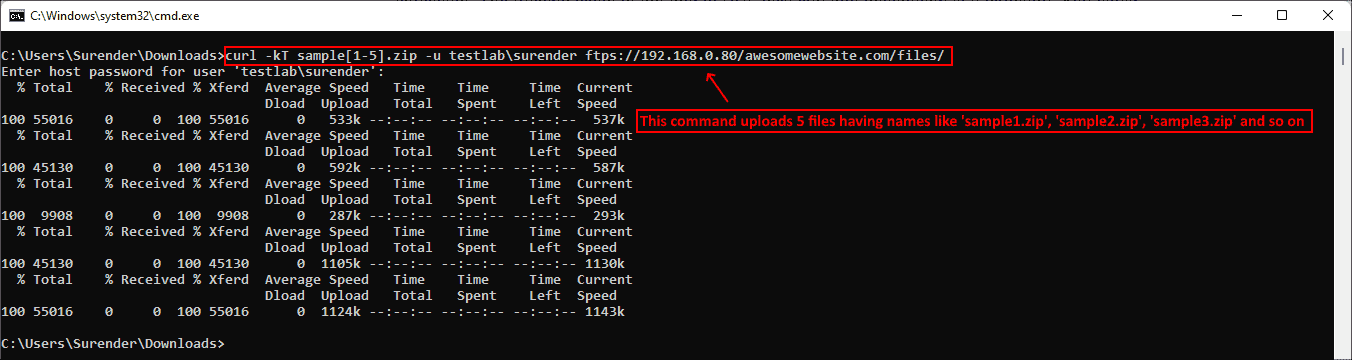
Выгрузка нескольких файлов на сервер
▍ Последовательность команд
Как говорилось ранее, curl поддерживает различные методы в зависимости от используемого протокола. Дополнительные команды можно отправлять при помощи —quote (или -Q) для выполнения операции до или после обычной операции curl. Например, можно скачать файл с удалённого сервера по протоколу FTPS и удалить файл с сервера после успешного скачивания. Для этого нужно выполнить следующую команду:
curl -u testlabsurender -kO "ftps://192.168.0.80/awesomewebsite.com/files/sample1.zip" -Q "-DELE sample1.zip"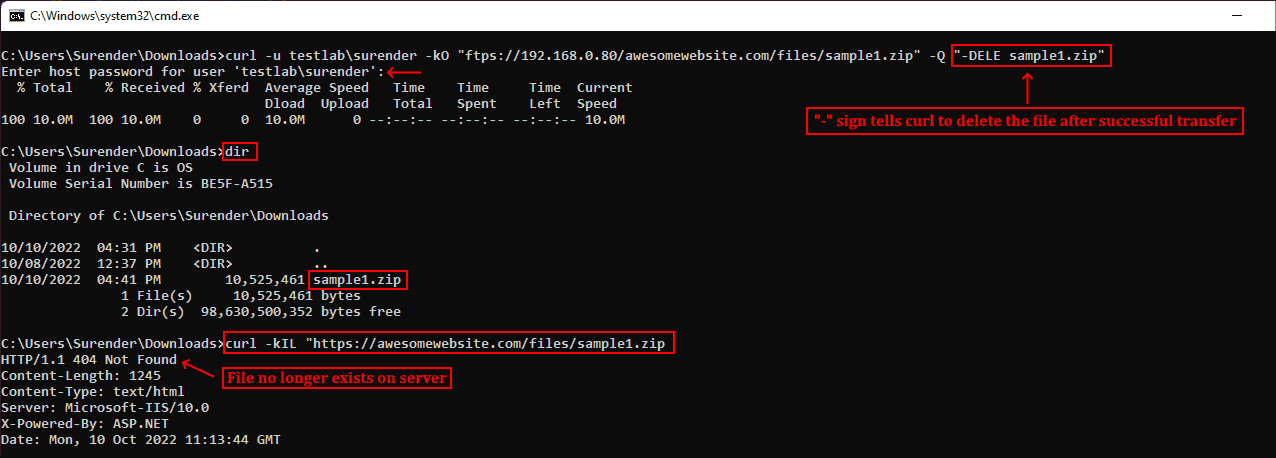
Удаление файла после успешного скачивания
В показанном выше примере я скачал файл sample1.zip с FTPS-сервера при помощи опции -O. После опции -Q я добавил минус (-) перед командой DELE, что заставляет curl отправить команду DELE sample1.zip сразу после успешного скачивания файла. Аналогично, если вы хотите отправить команду на сервер до выполнения операции curl, используйте плюс (+) вместо минуса.
▍ Изменение user-agent
Информация user-agent сообщает серверу тип клиента, отправляющего запрос. При отправке запроса curl на сервер по умолчанию используется user-agent curl/<version>. Если сервер настроен так, чтобы блокировать запросы curl, можно задать собственный user-agent при помощи опции —user-agent (или -A). Показанная ниже команда отправляет стандартный user-agent Google Chrome:
curl -kIA "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0" https://awesomewebsite.com/files/secretFile.zip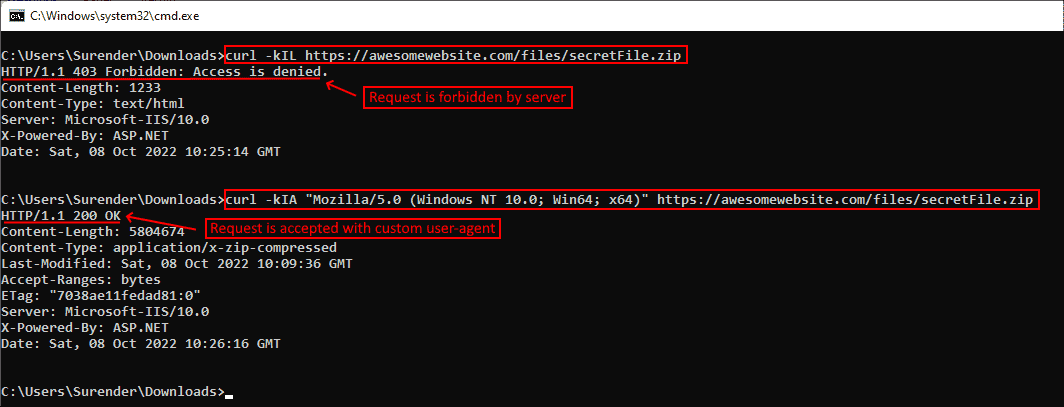
Использование собственного user-agent с командой curl, чтобы избежать блокировки сервером
На показанном выше скриншоте видно, что обычный запрос curl был отклонён веб-сервером (с ответом 403 Forbidden), но при передаче другого user-agent запрос выполняется успешно, возвращая ответ 200 OK.
▍ Отправка куки
По умолчанию запрос curl не отправляет и не сохраняет куки. Для записи куки можно использовать опцию —cookie-jar (или -c), а отправить куки можно опцией —cookie (or -b):
curl -c /path/cookie_file https://awesomewebsite.com/
curl -b /path/cookie_file https://awesomewebsite.com/Первая команда записывает файл куки, а вторая отправляет куки с запросом curl. Также можно отправить куки в формате ‘name = value’:
curl -b 'session=abcxyz' -b 'loggedin=true' http://echo.hoppscotch.io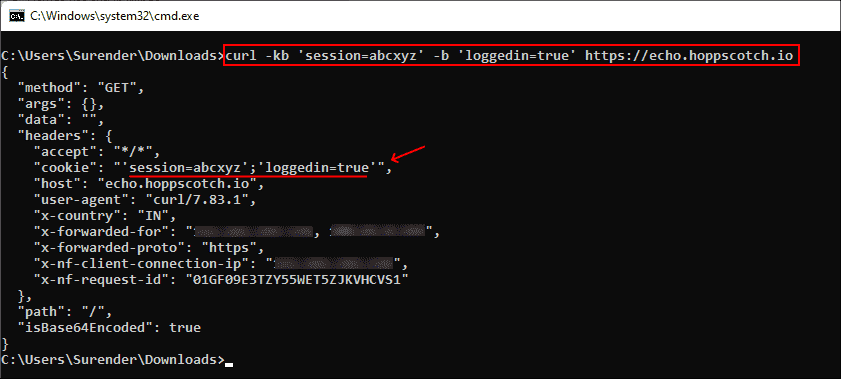
Отправка нескольких куки командой curl
Я воспользовался веб-сайтом echo.hoppscotch.io для демонстрации заголовков HTTP-запросов, которые обычно невидимы клиентам, отправляющим запрос. Если вы не хотите пользоваться этим веб-сайтом, то можете применить опцию –verbose (или -v) для отображения запроса в сыром виде (который отображает и заголовки запросов).
▍ Использование прокси-сервера
Если вы пользуетесь прокси-сервером для подключения к интернету, в curl можно указать прокси опцией —proxy (или -x). Если прокси-сервер требует аутентификации, то добавьте —proxy-user (или -U):
curl -x 192.168.0.250:8088 -U username:password https://awesomewebsite.com/Прокси-сервер указывается в формате server:port, а пользователь прокси — в формате username:password. Можно не вводить пароль пользователя прокси, тогда curl попросит ввести его в режиме no-echo.

Использование прокси-сервера и аутентификации
▍ Дополнительные заголовки запросов
Иногда вместе с запросом к серверу необходимо отправить дополнительную информацию. В curl это можно сделать при помощи —header (или -H), как показано в следующей команде:
curl -vkIH "x-client-os: Windows 11 Enterprise (x64)" https://awesomewebsite.com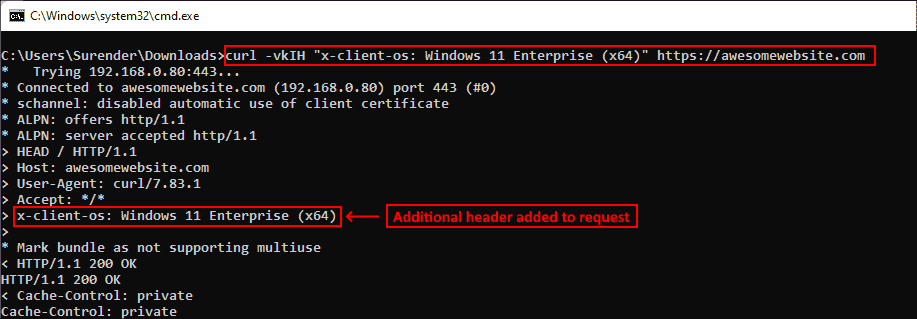
Указание дополнительных заголовков для запроса curl
Можно отправлять любую информацию, недоступную через стандартные заголовки HTTP-запросов. В этом примере я отправил название своей операционной системы. Также я добавил опцию -v для включения verbose-вывода, отображающего дополнительный заголовок, отправляемый вместе с каждым моим запросом curl.
▍ Отправка электронного письма
Так как curl поддерживает протокол SMTP, его можно использовать для отправки электронного письма. Показанная ниже команда позволяет отправить электронное письмо при помощи curl:
curl --insecure --ssl-reqd smtps://mail.yourdomain.com –-mail-from sender@yourdomain.com –-mail-rcpt receiver@company.com --user sender@yourdomain.com --upload-file email_msg.txt
Отправка электронного письма командой curl
Давайте вкратце перечислим использованные здесь опции:
- Опция —insecure (или -k) используется, чтобы избежать ошибки сертификата SSL. Мы уже применяли её ранее.
- Опция —ssl-reql используется для апгрейда соединения передачи простого текста до зашифрованного соединения, если оно поддерживается SMTP-сервером. Если вы уверены, что ваш SMTP-сервер поддерживает SSL, то можно использовать непосредственно имя сервера smtps (например, smtps://smtp.yourdomain.com), как показано на скриншоте.
- Опция —mail-from используется для указания адреса электронной почты отправителя.
- Опция mail-rcpt указывает адрес электронной почты получателя.
- Опция —user (или -u) отправляет имя пользователя для аутентификации, оно должно совпадать с адресом mail-from, потому что в противном случае письмо может быть отклонено или помечено как спам.
- Опция —upload-file (или -T) используется для указания файла, в котором находится отправляемое письмо.
На скриншоте ниже показано письмо, полученное мной во входящие:
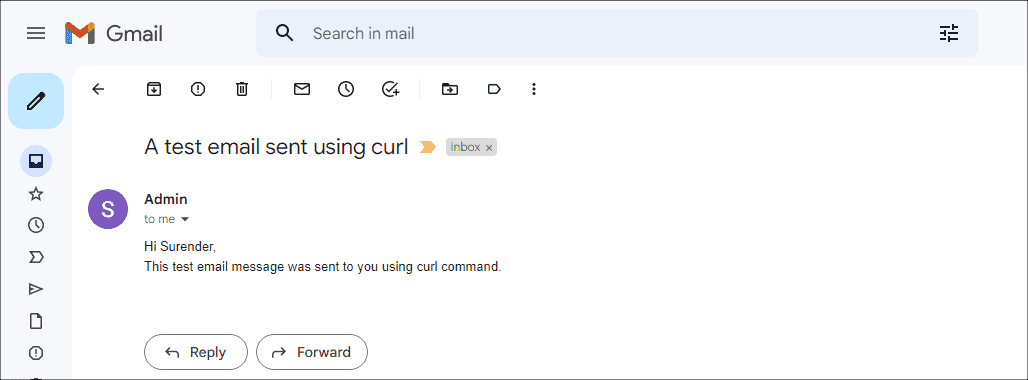
Просмотр письма, отправленного с помощью curl
Это всего лишь несколько примеров использования curl — на самом деле их гораздо больше. Я настоятельно рекомендую проверить справку по curl и поэкспериментировать с ней.
А вы используете curl? И если да, то для чего?
Telegram-канал с полезностями и уютный чат

curl tutorial
Simple Usage
Get the main page from a web-server:
curl https://www.example.com/
Get a README file from an FTP server:
curl ftp://ftp.funet.fi/README
Get a web page from a server using port 8000:
curl http://www.weirdserver.com:8000/
Get a directory listing of an FTP site:
Get the definition of curl from a dictionary:
curl dict://dict.org/m:curl
Fetch two documents at once:
curl ftp://ftp.funet.fi/ http://www.weirdserver.com:8000/
Get a file off an FTPS server:
curl ftps://files.are.secure.com/secrets.txt
or use the more appropriate FTPS way to get the same file:
curl --ftp-ssl ftp://files.are.secure.com/secrets.txt
Get a file from an SSH server using SFTP:
curl -u username sftp://example.com/etc/issue
Get a file from an SSH server using SCP using a private key (not
password-protected) to authenticate:
curl -u username: --key ~/.ssh/id_rsa scp://example.com/~/file.txt
Get a file from an SSH server using SCP using a private key
(password-protected) to authenticate:
curl -u username: --key ~/.ssh/id_rsa --pass private_key_password
scp://example.com/~/file.txt
Get the main page from an IPv6 web server:
curl "http://[2001:1890:1112:1::20]/"
Get a file from an SMB server:
curl -u "domainusername:passwd" smb://server.example.com/share/file.txt
Download to a File
Get a web page and store in a local file with a specific name:
curl -o thatpage.html http://www.example.com/
Get a web page and store in a local file, make the local file get the name of
the remote document (if no file name part is specified in the URL, this will
fail):
curl -O http://www.example.com/index.html
Fetch two files and store them with their remote names:
curl -O www.haxx.se/index.html -O curl.se/download.html
Using Passwords
FTP
To ftp files using name and password, include them in the URL like:
curl ftp://name:passwd@machine.domain:port/full/path/to/file
or specify them with the -u flag like
curl -u name:passwd ftp://machine.domain:port/full/path/to/file
FTPS
It is just like for FTP, but you may also want to specify and use SSL-specific
options for certificates etc.
Note that using FTPS:// as prefix is the implicit way as described in the
standards while the recommended explicit way is done by using FTP:// and
the --ssl-reqd option.
SFTP / SCP
This is similar to FTP, but you can use the --key option to specify a
private key to use instead of a password. Note that the private key may itself
be protected by a password that is unrelated to the login password of the
remote system; this password is specified using the --pass option.
Typically, curl will automatically extract the public key from the private key
file, but in cases where curl does not have the proper library support, a
matching public key file must be specified using the --pubkey option.
HTTP
Curl also supports user and password in HTTP URLs, thus you can pick a file
like:
curl http://name:passwd@machine.domain/full/path/to/file
or specify user and password separately like in
curl -u name:passwd http://machine.domain/full/path/to/file
HTTP offers many different methods of authentication and curl supports
several: Basic, Digest, NTLM and Negotiate (SPNEGO). Without telling which
method to use, curl defaults to Basic. You can also ask curl to pick the most
secure ones out of the ones that the server accepts for the given URL, by
using --anyauth.
Note! According to the URL specification, HTTP URLs can not contain a user
and password, so that style will not work when using curl via a proxy, even
though curl allows it at other times. When using a proxy, you must use the
-u style for user and password.
HTTPS
Probably most commonly used with private certificates, as explained below.
Proxy
curl supports both HTTP and SOCKS proxy servers, with optional authentication.
It does not have special support for FTP proxy servers since there are no
standards for those, but it can still be made to work with many of them. You
can also use both HTTP and SOCKS proxies to transfer files to and from FTP
servers.
Get an ftp file using an HTTP proxy named my-proxy that uses port 888:
curl -x my-proxy:888 ftp://ftp.leachsite.com/README
Get a file from an HTTP server that requires user and password, using the
same proxy as above:
curl -u user:passwd -x my-proxy:888 http://www.get.this/
Some proxies require special authentication. Specify by using -U as above:
curl -U user:passwd -x my-proxy:888 http://www.get.this/
A comma-separated list of hosts and domains which do not use the proxy can be
specified as:
curl --noproxy localhost,get.this -x my-proxy:888 http://www.get.this/
If the proxy is specified with --proxy1.0 instead of --proxy or -x, then
curl will use HTTP/1.0 instead of HTTP/1.1 for any CONNECT attempts.
curl also supports SOCKS4 and SOCKS5 proxies with --socks4 and --socks5.
See also the environment variables Curl supports that offer further proxy
control.
Most FTP proxy servers are set up to appear as a normal FTP server from the
client’s perspective, with special commands to select the remote FTP server.
curl supports the -u, -Q and --ftp-account options that can be used to
set up transfers through many FTP proxies. For example, a file can be uploaded
to a remote FTP server using a Blue Coat FTP proxy with the options:
curl -u "username@ftp.server Proxy-Username:Remote-Pass"
--ftp-account Proxy-Password --upload-file local-file
ftp://my-ftp.proxy.server:21/remote/upload/path/
See the manual for your FTP proxy to determine the form it expects to set up
transfers, and curl’s -v option to see exactly what curl is sending.
Piping
Get a key file and add it with apt-key (when on a system that uses apt for
package management):
curl -L https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add -
The ‘|’ pipes the output to STDIN. - tells apt-key that the key file
should be read from STDIN.
Ranges
HTTP 1.1 introduced byte-ranges. Using this, a client can request to get only
one or more sub-parts of a specified document. Curl supports this with the
-r flag.
Get the first 100 bytes of a document:
curl -r 0-99 http://www.get.this/
Get the last 500 bytes of a document:
curl -r -500 http://www.get.this/
Curl also supports simple ranges for FTP files as well. Then you can only
specify start and stop position.
Get the first 100 bytes of a document using FTP:
curl -r 0-99 ftp://www.get.this/README
Uploading
FTP / FTPS / SFTP / SCP
Upload all data on stdin to a specified server:
curl -T - ftp://ftp.upload.com/myfile
Upload data from a specified file, login with user and password:
curl -T uploadfile -u user:passwd ftp://ftp.upload.com/myfile
Upload a local file to the remote site, and use the local file name at the
remote site too:
curl -T uploadfile -u user:passwd ftp://ftp.upload.com/
Upload a local file to get appended to the remote file:
curl -T localfile -a ftp://ftp.upload.com/remotefile
Curl also supports ftp upload through a proxy, but only if the proxy is
configured to allow that kind of tunneling. If it does, you can run curl in a
fashion similar to:
curl --proxytunnel -x proxy:port -T localfile ftp.upload.com
SMB / SMBS
curl -T file.txt -u "domainusername:passwd"
smb://server.example.com/share/
HTTP
Upload all data on stdin to a specified HTTP site:
curl -T - http://www.upload.com/myfile
Note that the HTTP server must have been configured to accept PUT before this
can be done successfully.
For other ways to do HTTP data upload, see the POST section below.
Verbose / Debug
If curl fails where it is not supposed to, if the servers do not let you in, if
you cannot understand the responses: use the -v flag to get verbose
fetching. Curl will output lots of info and what it sends and receives in
order to let the user see all client-server interaction (but it will not show you
the actual data).
curl -v ftp://ftp.upload.com/
To get even more details and information on what curl does, try using the
--trace or --trace-ascii options with a given file name to log to, like
this:
curl --trace trace.txt www.haxx.se
Detailed Information
Different protocols provide different ways of getting detailed information
about specific files/documents. To get curl to show detailed information about
a single file, you should use -I/--head option. It displays all available
info on a single file for HTTP and FTP. The HTTP information is a lot more
extensive.
For HTTP, you can get the header information (the same as -I would show)
shown before the data by using -i/--include. Curl understands the
-D/--dump-header option when getting files from both FTP and HTTP, and it
will then store the headers in the specified file.
Store the HTTP headers in a separate file (headers.txt in the example):
curl --dump-header headers.txt curl.se
Note that headers stored in a separate file can be useful at a later time if
you want curl to use cookies sent by the server. More about that in the
cookies section.
POST (HTTP)
It is easy to post data using curl. This is done using the -d <data> option.
The post data must be urlencoded.
Post a simple name and phone guestbook.
curl -d "name=Rafael%20Sagula&phone=3320780" http://www.where.com/guest.cgi
How to post a form with curl, lesson #1:
Dig out all the <input> tags in the form that you want to fill in.
If there is a normal post, you use -d to post. -d takes a full post
string, which is in the format
<variable1>=<data1>&<variable2>=<data2>&...
The variable names are the names set with "name=" in the <input> tags, and
the data is the contents you want to fill in for the inputs. The data must
be properly URL encoded. That means you replace space with + and that you
replace weird letters with %XX where XX is the hexadecimal representation
of the letter’s ASCII code.
Example:
(page located at http://www.formpost.com/getthis/)
<form action="post.cgi" method="post"> <input name=user size=10> <input name=pass type=password size=10> <input name=id type=hidden value="blablabla"> <input name=ding value="submit"> </form>
We want to enter user foobar with password 12345.
To post to this, you enter a curl command line like:
curl -d "user=foobar&pass=12345&id=blablabla&ding=submit"
http://www.formpost.com/getthis/post.cgi
While -d uses the application/x-www-form-urlencoded mime-type, generally
understood by CGI’s and similar, curl also supports the more capable
multipart/form-data type. This latter type supports things like file upload.
-F accepts parameters like -F "name=contents". If you want the contents to
be read from a file, use @filename as contents. When specifying a file, you
can also specify the file content type by appending ;type=<mime type> to the
file name. You can also post the contents of several files in one field. For
example, the field name coolfiles is used to send three files, with
different content types using the following syntax:
curl -F "coolfiles=@fil1.gif;type=image/gif,fil2.txt,fil3.html"
http://www.post.com/postit.cgi
If the content-type is not specified, curl will try to guess from the file
extension (it only knows a few), or use the previously specified type (from an
earlier file if several files are specified in a list) or else it will use the
default type application/octet-stream.
Emulate a fill-in form with -F. Let’s say you fill in three fields in a
form. One field is a file name which to post, one field is your name and one
field is a file description. We want to post the file we have written named
cooltext.txt. To let curl do the posting of this data instead of your
favorite browser, you have to read the HTML source of the form page and find
the names of the input fields. In our example, the input field names are
file, yourname and filedescription.
curl -F "file=@cooltext.txt" -F "yourname=Daniel"
-F "filedescription=Cool text file with cool text inside"
http://www.post.com/postit.cgi
To send two files in one post you can do it in two ways:
Send multiple files in a single field with a single field name:
curl -F "pictures=@dog.gif,cat.gif" $URL
Send two fields with two field names
curl -F "docpicture=@dog.gif" -F "catpicture=@cat.gif" $URL
To send a field value literally without interpreting a leading @ or <, or
an embedded ;type=, use --form-string instead of -F. This is recommended
when the value is obtained from a user or some other unpredictable
source. Under these circumstances, using -F instead of --form-string could
allow a user to trick curl into uploading a file.
Referrer
An HTTP request has the option to include information about which address
referred it to the actual page. curl allows you to specify the referrer to be
used on the command line. It is especially useful to fool or trick stupid
servers or CGI scripts that rely on that information being available or
contain certain data.
curl -e www.coolsite.com http://www.showme.com/
User Agent
An HTTP request has the option to include information about the browser that
generated the request. Curl allows it to be specified on the command line. It
is especially useful to fool or trick stupid servers or CGI scripts that only
accept certain browsers.
Example:
curl -A 'Mozilla/3.0 (Win95; I)' http://www.nationsbank.com/
Other common strings:
Mozilla/3.0 (Win95; I)— Netscape Version 3 for Windows 95Mozilla/3.04 (Win95; U)— Netscape Version 3 for Windows 95Mozilla/2.02 (OS/2; U)— Netscape Version 2 for OS/2Mozilla/4.04 [en] (X11; U; AIX 4.2; Nav)— Netscape for AIXMozilla/4.05 [en] (X11; U; Linux 2.0.32 i586)— Netscape for Linux
Note that Internet Explorer tries hard to be compatible in every way:
Mozilla/4.0 (compatible; MSIE 4.01; Windows 95)— MSIE for W95
Mozilla is not the only possible User-Agent name:
Konqueror/1.0— KDE File Manager desktop clientLynx/2.7.1 libwww-FM/2.14— Lynx command line browser
Cookies
Cookies are generally used by web servers to keep state information at the
client’s side. The server sets cookies by sending a response line in the
headers that looks like Set-Cookie: <data> where the data part then
typically contains a set of NAME=VALUE pairs (separated by semicolons ;
like NAME1=VALUE1; NAME2=VALUE2;). The server can also specify for what path
the cookie should be used for (by specifying path=value), when the cookie
should expire (expire=DATE), for what domain to use it (domain=NAME) and
if it should be used on secure connections only (secure).
If you have received a page from a server that contains a header like:
Set-Cookie: sessionid=boo123; path="/foo";
it means the server wants that first pair passed on when we get anything in a
path beginning with /foo.
Example, get a page that wants my name passed in a cookie:
curl -b "name=Daniel" www.sillypage.com
Curl also has the ability to use previously received cookies in following
sessions. If you get cookies from a server and store them in a file in a
manner similar to:
curl --dump-header headers www.example.com
… you can then in a second connect to that (or another) site, use the
cookies from the headers.txt file like:
curl -b headers.txt www.example.com
While saving headers to a file is a working way to store cookies, it is
however error-prone and not the preferred way to do this. Instead, make curl
save the incoming cookies using the well-known Netscape cookie format like
this:
curl -c cookies.txt www.example.com
Note that by specifying -b you enable the cookie engine and with -L you
can make curl follow a location: (which often is used in combination with
cookies). If a site sends cookies and a location field, you can use a
non-existing file to trigger the cookie awareness like:
curl -L -b empty.txt www.example.com
The file to read cookies from must be formatted using plain HTTP headers OR as
Netscape’s cookie file. Curl will determine what kind it is based on the file
contents. In the above command, curl will parse the header and store the
cookies received from www.example.com. curl will send to the server the stored
cookies which match the request as it follows the location. The file
empty.txt may be a nonexistent file.
To read and write cookies from a Netscape cookie file, you can set both -b
and -c to use the same file:
curl -b cookies.txt -c cookies.txt www.example.com
Progress Meter
The progress meter exists to show a user that something actually is
happening. The different fields in the output have the following meaning:
% Total % Received % Xferd Average Speed Time Curr.
Dload Upload Total Current Left Speed
0 151M 0 38608 0 0 9406 0 4:41:43 0:00:04 4:41:39 9287
From left-to-right:
%— percentage completed of the whole transferTotal— total size of the whole expected transfer%— percentage completed of the downloadReceived— currently downloaded amount of bytes%— percentage completed of the uploadXferd— currently uploaded amount of bytesAverage Speed Dload— the average transfer speed of the downloadAverage Speed Upload— the average transfer speed of the uploadTime Total— expected time to complete the operationTime Current— time passed since the invokeTime Left— expected time left to completionCurr.Speed— the average transfer speed the last 5 seconds (the first
5 seconds of a transfer is based on less time of course.)
The -# option will display a totally different progress bar that does not
need much explanation!
Speed Limit
Curl allows the user to set the transfer speed conditions that must be met to
let the transfer keep going. By using the switch -y and -Y you can make
curl abort transfers if the transfer speed is below the specified lowest limit
for a specified time.
To have curl abort the download if the speed is slower than 3000 bytes per
second for 1 minute, run:
curl -Y 3000 -y 60 www.far-away-site.com
This can be used in combination with the overall time limit, so that the above
operation must be completed in whole within 30 minutes:
curl -m 1800 -Y 3000 -y 60 www.far-away-site.com
Forcing curl not to transfer data faster than a given rate is also possible,
which might be useful if you are using a limited bandwidth connection and you
do not want your transfer to use all of it (sometimes referred to as
bandwidth throttle).
Make curl transfer data no faster than 10 kilobytes per second:
curl --limit-rate 10K www.far-away-site.com
or
curl --limit-rate 10240 www.far-away-site.com
Or prevent curl from uploading data faster than 1 megabyte per second:
curl -T upload --limit-rate 1M ftp://uploadshereplease.com
When using the --limit-rate option, the transfer rate is regulated on a
per-second basis, which will cause the total transfer speed to become lower
than the given number. Sometimes of course substantially lower, if your
transfer stalls during periods.
Config File
Curl automatically tries to read the .curlrc file (or _curlrc file on
Microsoft Windows systems) from the user’s home dir on startup.
The config file could be made up with normal command line switches, but you
can also specify the long options without the dashes to make it more
readable. You can separate the options and the parameter with spaces, or with
= or :. Comments can be used within the file. If the first letter on a
line is a #-symbol the rest of the line is treated as a comment.
If you want the parameter to contain spaces, you must enclose the entire
parameter within double quotes ("). Within those quotes, you specify a quote
as ".
NOTE: You must specify options and their arguments on the same line.
Example, set default time out and proxy in a config file:
# We want a 30 minute timeout:
-m 1800
# ... and we use a proxy for all accesses:
proxy = proxy.our.domain.com:8080
Whitespaces ARE significant at the end of lines, but all whitespace leading
up to the first characters of each line are ignored.
Prevent curl from reading the default file by using -q as the first command
line parameter, like:
Force curl to get and display a local help page in case it is invoked without
URL by making a config file similar to:
# default url to get
url = "http://help.with.curl.com/curlhelp.html"
You can specify another config file to be read by using the -K/--config
flag. If you set config file name to - it will read the config from stdin,
which can be handy if you want to hide options from being visible in process
tables etc:
echo "user = user:passwd" | curl -K - http://that.secret.site.com
Extra Headers
When using curl in your own programs, you may end up needing to pass on your
own custom headers when getting a web page. You can do this by using the -H
flag.
Example, send the header X-you-and-me: yes to the server when getting a
page:
curl -H "X-you-and-me: yes" www.love.com
This can also be useful in case you want curl to send a different text in a
header than it normally does. The -H header you specify then replaces the
header curl would normally send. If you replace an internal header with an
empty one, you prevent that header from being sent. To prevent the Host:
header from being used:
curl -H "Host:" www.server.com
FTP and Path Names
Do note that when getting files with a ftp:// URL, the given path is
relative to the directory you enter. To get the file README from your home
directory at your ftp site, do:
curl ftp://user:passwd@my.site.com/README
If you want the README file from the root directory of that same site, you
need to specify the absolute file name:
curl ftp://user:passwd@my.site.com//README
(I.e with an extra slash in front of the file name.)
SFTP and SCP and Path Names
With sftp: and scp: URLs, the path name given is the absolute name on the
server. To access a file relative to the remote user’s home directory, prefix
the file with /~/ , such as:
curl -u $USER sftp://home.example.com/~/.bashrc
FTP and Firewalls
The FTP protocol requires one of the involved parties to open a second
connection as soon as data is about to get transferred. There are two ways to
do this.
The default way for curl is to issue the PASV command which causes the server
to open another port and await another connection performed by the
client. This is good if the client is behind a firewall that does not allow
incoming connections.
If the server, for example, is behind a firewall that does not allow
connections on ports other than 21 (or if it just does not support the PASV
command), the other way to do it is to use the PORT command and instruct the
server to connect to the client on the given IP number and port (as parameters
to the PORT command).
The -P flag to curl supports a few different options. Your machine may have
several IP-addresses and/or network interfaces and curl allows you to select
which of them to use. Default address can also be used:
curl -P - ftp.download.com
Download with PORT but use the IP address of our le0 interface (this does
not work on Windows):
curl -P le0 ftp.download.com
Download with PORT but use 192.168.0.10 as our IP address to use:
curl -P 192.168.0.10 ftp.download.com
Network Interface
Get a web page from a server using a specified port for the interface:
curl --interface eth0:1 http://www.example.com/
or
curl --interface 192.168.1.10 http://www.example.com/
HTTPS
Secure HTTP requires a TLS library to be installed and used when curl is
built. If that is done, curl is capable of retrieving and posting documents
using the HTTPS protocol.
Example:
curl https://www.secure-site.com
curl is also capable of using client certificates to get/post files from sites
that require valid certificates. The only drawback is that the certificate
needs to be in PEM-format. PEM is a standard and open format to store
certificates with, but it is not used by the most commonly used browsers. If
you want curl to use the certificates you use with your favorite browser, you
may need to download/compile a converter that can convert your browser’s
formatted certificates to PEM formatted ones.
Example on how to automatically retrieve a document using a certificate with a
personal password:
curl -E /path/to/cert.pem:password https://secure.site.com/
If you neglect to specify the password on the command line, you will be
prompted for the correct password before any data can be received.
Many older HTTPS servers have problems with specific SSL or TLS versions,
which newer versions of OpenSSL etc use, therefore it is sometimes useful to
specify what TLS version curl should use.:
curl --tlv1.0 https://secure.site.com/
Otherwise, curl will attempt to use a sensible TLS default version.
Resuming File Transfers
To continue a file transfer where it was previously aborted, curl supports
resume on HTTP(S) downloads as well as FTP uploads and downloads.
Continue downloading a document:
curl -C - -o file ftp://ftp.server.com/path/file
Continue uploading a document:
curl -C - -T file ftp://ftp.server.com/path/file
Continue downloading a document from a web server
curl -C - -o file http://www.server.com/
Time Conditions
HTTP allows a client to specify a time condition for the document it requests.
It is If-Modified-Since or If-Unmodified-Since. curl allows you to specify
them with the -z/--time-cond flag.
For example, you can easily make a download that only gets performed if the
remote file is newer than a local copy. It would be made like:
curl -z local.html http://remote.server.com/remote.html
Or you can download a file only if the local file is newer than the remote
one. Do this by prepending the date string with a -, as in:
curl -z -local.html http://remote.server.com/remote.html
You can specify a plain text date as condition. Tell curl to only download the
file if it was updated since January 12, 2012:
curl -z "Jan 12 2012" http://remote.server.com/remote.html
curl accepts a wide range of date formats. You always make the date check the
other way around by prepending it with a dash (-).
DICT
For fun try
curl dict://dict.org/m:curl
curl dict://dict.org/d:heisenbug:jargon
curl dict://dict.org/d:daniel:gcide
Aliases for m are match and find, and aliases for d are define and
lookup. For example,
curl dict://dict.org/find:curl
Commands that break the URL description of the RFC (but not the DICT
protocol) are
curl dict://dict.org/show:db
curl dict://dict.org/show:strat
Authentication support is still missing
LDAP
If you have installed the OpenLDAP library, curl can take advantage of it and
offer ldap:// support. On Windows, curl will use WinLDAP from Platform SDK
by default.
Default protocol version used by curl is LDAP version 3. Version 2 will be
used as a fallback mechanism in case version 3 fails to connect.
LDAP is a complex thing and writing an LDAP query is not an easy task. I do
advise you to dig up the syntax description for that elsewhere. One such place
might be: RFC 2255, The LDAP URL Format
To show you an example, this is how I can get all people from my local LDAP
server that has a certain sub-domain in their email address:
curl -B "ldap://ldap.frontec.se/o=frontec??sub?mail=*sth.frontec.se"
If I want the same info in HTML format, I can get it by not using the -B
(enforce ASCII) flag.
You also can use authentication when accessing LDAP catalog:
curl -u user:passwd "ldap://ldap.frontec.se/o=frontec??sub?mail=*"
curl "ldap://user:passwd@ldap.frontec.se/o=frontec??sub?mail=*"
By default, if user and password are provided, OpenLDAP/WinLDAP will use basic
authentication. On Windows you can control this behavior by providing one of
--basic, --ntlm or --digest option in curl command line
curl --ntlm "ldap://user:passwd@ldap.frontec.se/o=frontec??sub?mail=*"
On Windows, if no user/password specified, auto-negotiation mechanism will be
used with current logon credentials (SSPI/SPNEGO).
Environment Variables
Curl reads and understands the following environment variables:
http_proxy, HTTPS_PROXY, FTP_PROXY
They should be set for protocol-specific proxies. General proxy should be set
with
A comma-separated list of host names that should not go through any proxy is
set in (only an asterisk, * matches all hosts)
If the host name matches one of these strings, or the host is within the
domain of one of these strings, transactions with that node will not be done
over proxy. When a domain is used, it needs to start with a period. A user can
specify that both www.example.com and foo.example.com should not use a proxy
by setting NO_PROXY to .example.com. By including the full name you can
exclude specific host names, so to make www.example.com not use a proxy but
still have foo.example.com do it, set NO_PROXY to www.example.com.
The usage of the -x/--proxy flag overrides the environment variables.
Netrc
Unix introduced the .netrc concept a long time ago. It is a way for a user
to specify name and password for commonly visited FTP sites in a file so that
you do not have to type them in each time you visit those sites. You realize
this is a big security risk if someone else gets hold of your passwords,
therefore most Unix programs will not read this file unless it is only readable
by yourself (curl does not care though).
Curl supports .netrc files if told to (using the -n/--netrc and
--netrc-optional options). This is not restricted to just FTP, so curl can
use it for all protocols where authentication is used.
A simple .netrc file could look something like:
machine curl.se login iamdaniel password mysecret
Custom Output
To better allow script programmers to get to know about the progress of curl,
the -w/--write-out option was introduced. Using this, you can specify what
information from the previous transfer you want to extract.
To display the amount of bytes downloaded together with some text and an
ending newline:
curl -w 'We downloaded %{size_download} bytesn' www.download.com
Kerberos FTP Transfer
Curl supports kerberos4 and kerberos5/GSSAPI for FTP transfers. You need the
kerberos package installed and used at curl build time for it to be available.
First, get the krb-ticket the normal way, like with the kinit/kauth tool.
Then use curl in way similar to:
curl --krb private ftp://krb4site.com -u username:fakepwd
There is no use for a password on the -u switch, but a blank one will make
curl ask for one and you already entered the real password to kinit/kauth.
TELNET
The curl telnet support is basic and easy to use. Curl passes all data passed
to it on stdin to the remote server. Connect to a remote telnet server using a
command line similar to:
curl telnet://remote.server.com
And enter the data to pass to the server on stdin. The result will be sent to
stdout or to the file you specify with -o.
You might want the -N/--no-buffer option to switch off the buffered output
for slow connections or similar.
Pass options to the telnet protocol negotiation, by using the -t option. To
tell the server we use a vt100 terminal, try something like:
curl -tTTYPE=vt100 telnet://remote.server.com
Other interesting options for it -t include:
XDISPLOC=<X display>Sets the X display location.NEW_ENV=<var,val>Sets an environment variable.
NOTE: The telnet protocol does not specify any way to login with a specified
user and password so curl cannot do that automatically. To do that, you need to
track when the login prompt is received and send the username and password
accordingly.
Persistent Connections
Specifying multiple files on a single command line will make curl transfer all
of them, one after the other in the specified order.
libcurl will attempt to use persistent connections for the transfers so that
the second transfer to the same host can use the same connection that was
already initiated and was left open in the previous transfer. This greatly
decreases connection time for all but the first transfer and it makes a far
better use of the network.
Note that curl cannot use persistent connections for transfers that are used
in subsequent curl invokes. Try to stuff as many URLs as possible on the same
command line if they are using the same host, as that will make the transfers
faster. If you use an HTTP proxy for file transfers, practically all transfers
will be persistent.
Multiple Transfers With A Single Command Line
As is mentioned above, you can download multiple files with one command line
by simply adding more URLs. If you want those to get saved to a local file
instead of just printed to stdout, you need to add one save option for each
URL you specify. Note that this also goes for the -O option (but not
--remote-name-all).
For example: get two files and use -O for the first and a custom file
name for the second:
curl -O http://url.com/file.txt ftp://ftp.com/moo.exe -o moo.jpg
You can also upload multiple files in a similar fashion:
curl -T local1 ftp://ftp.com/moo.exe -T local2 ftp://ftp.com/moo2.txt
IPv6
curl will connect to a server with IPv6 when a host lookup returns an IPv6
address and fall back to IPv4 if the connection fails. The --ipv4 and
--ipv6 options can specify which address to use when both are
available. IPv6 addresses can also be specified directly in URLs using the
syntax:
http://[2001:1890:1112:1::20]/overview.html
When this style is used, the -g option must be given to stop curl from
interpreting the square brackets as special globbing characters. Link local
and site local addresses including a scope identifier, such as fe80::1234%1,
may also be used, but the scope portion must be numeric or match an existing
network interface on Linux and the percent character must be URL escaped. The
previous example in an SFTP URL might look like:
IPv6 addresses provided other than in URLs (e.g. to the --proxy,
--interface or --ftp-port options) should not be URL encoded.
Mailing Lists
For your convenience, we have several open mailing lists to discuss curl, its
development and things relevant to this. Get all info at
https://curl.se/mail/.
Please direct curl questions, feature requests and trouble reports to one of
these mailing lists instead of mailing any individual.
Available lists include:
curl-users
Users of the command line tool. How to use it, what does not work, new
features, related tools, questions, news, installations, compilations,
running, porting etc.
curl-library
Developers using or developing libcurl. Bugs, extensions, improvements.
curl-announce
Low-traffic. Only receives announcements of new public versions. At worst,
that makes something like one or two mails per month, but usually only one
mail every second month.
curl-and-php
Using the curl functions in PHP. Everything curl with a PHP angle. Or PHP with
a curl angle.
curl-and-python
Python hackers using curl with or without the python binding pycurl.
CURL — утилита командной строки для Linux или Windows, поддерживает работу с протоколами: FTP, FTPS, HTTP, HTTPS, TFTP, SCP, SFTP, Telnet, DICT, LDAP, POP3, IMAP и SMTP. Она отлично подходит для имитации действий пользователя на страницах сайтов и других операций с URL адресами. Поддержка CURL добавлена в множество различных языков программирования и платформ.
Для начала скачаем саму утилиту, для этого переходим на официальный сайт утилиты, в раздел Download. После скачивания архива для своей платформы (у меня это Windows 64 bit), распаковываем архив. Чтобы иметь возможность работать с HTTPS и FTPS, устанавливаем сертификат безопасности url-ca-bundle.crt, который находится в папке curl/bin.

Запускаем командную строку, переходим в директорию curl/bin и пытаемся скачать главную страницу Google:
> cd C:/curl/bin > curl google.com <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="http://www.google.com/">here</A>. </BODY></HTML>
Опция -X позволяет задать тип HTTP-запроса вместо используемого по умолчанию GET. Дополнительные запросы могут быть POST, PUT и DELETE или связанные с WebDAV — PROPFIND, COPY, MOVE и т.п.
Следовать за редиректами
Сервер Google сообщил нам, что страница google.com перемещена (301 Moved Permanently), и теперь надо запрашивать страницу www.google.com. С помощью опции -L укажем CURL следовать редиректам:
> curl -L google.com <!doctype html> <html itemscope="" itemtype="http://schema.org/WebPage" lang="ru"> <head> <meta content="Поиск информации в интернете: веб страницы, картинки, видео и многое другое." name="description"> <meta content="noodp" name="robots"> <meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"> <meta content="origin" name="referrer"> <title>Google</title> ..........
Сохранить вывод в файл
Чтобы сохранить вывод в файл, надо использовать опции -o или -O:
-o(oнижнего регистра) — результат будет сохранён в файле, заданном в командной строке;-O(Oверхнего регистра) — имя файла будет взято из URL и будет использовано для сохранения полученных данных.
Сохраняем страницу Google в файл google.html:
> curl -L -o google.html google.com % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 219 100 219 0 0 2329 0 --:--:-- --:--:-- --:--:-- 2329 100 14206 0 14206 0 0 69980 0 --:--:-- --:--:-- --:--:-- 69980
Сохраняем документ gettext.html в файл gettext.html:
> curl -O http://www.gnu.org/software/gettext/manual/gettext.html % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 1375k 100 1375k 0 0 800k 0 0:00:01 0:00:01 --:--:-- 800k
Загрузить файл, только если он изменён
Опция -z позволяет получить файлы, только если они были изменены после определённого времени. Это будет работать и для FTP и для HTTP. Например, файл archive.zip будет получен, если он изменялся после 20 августа 2018 года:
> curl -z 20-Aug-18 http://www.example.com/archive.zip
Команда ниже загрузит файл archive.zip, если он изменялся до 20 августа 2018 года:
> curl -z -20-Aug-18 http://www.example.com/archive.zip
Прохождение аутентификации HTTP
Опция -u позволяет указать данные пользователя (имя и пароль) для прохождения базовой аутентификаци (Basic HTTP Authentication):
> curl -u evgeniy:qwerty -O http://www.example.com/archive.zip
Получение и отправка cookie
Cookie используются сайтами для хранения некой информации на стороне пользователя. Сервер сохраняет cookie на стороне клиента (т.е. в браузере), отправляя заголовки:
Set-Cookie: PHPSESSID=svn7eb593i8d2gv471rs94og58; path=/ Set-Cookie: visitor=fa867bd917ad0d715830a6a88c816033; expires=Mon, 16-Sep-2019 08:20:53 GMT; Max-Age=31536000; path=/ Set-Cookie: lastvisit=1537086053; path=/
А браузер, в свою очередь, отправляет полученные cookie обратно на сервер при каждом запросе. Разумеется, тоже в заголовках:
Cookie: PHPSESSID=svn7eb593i8d2gv471rs94og58; visitor=fa867bd917ad0d715830a6a88c816033; lastvisit=1537086053
Передать cookie на сервер, как будто они были ранее получены от сервера:
> curl -b lastvisit=1537086053 http://www.example.com/
Чтобы сохранить полученные сookie в файл:
> curl -c cookie.txt http://www.example.com/
Затем можно отправить сохраненные в файле cookie обратно:
> curl -b cookie.txt http://www.example.com/catalog/
Файл cookie.txt имеет вид:
# Netscape HTTP Cookie File # https://curl.haxx.se/docs/http-cookies.html # This file was generated by libcurl! Edit at your own risk. www.example.com FALSE / FALSE 0 lastvisit 1537085301 www.example.com FALSE / FALSE 1568621304 visitor 60f7c17ba4b5d77975dfd020f06ac8ca www.example.com FALSE / FALSE 0 PHPSESSID p23cr2d14rlgj5kls58kd7l6a6
Получение и отправка заголовков
По умолчанию, заголовки ответа сервера не показываются. Но это можно исправить:
> curl -i google.com HTTP/1.1 301 Moved Permanently Location: http://www.google.com/ Content-Type: text/html; charset=UTF-8 Date: Sun, 16 Sep 2018 08:28:18 GMT Expires: Tue, 16 Oct 2018 08:28:18 GMT Cache-Control: public, max-age=2592000 Server: gws Content-Length: 219 X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="http://www.google.com/">here</A>. </BODY></HTML>
Если содержимое страницы не нужно, а интересны только заголовки (будет отправлен HEAD запрос):
> curl -I http://www.example.com/ HTTP/1.1 200 OK Date: Sun, 16 Sep 2018 08:20:52 GMT Server: Apache/2.4.34 (Win64) mod_fcgid/2.3.9 X-Powered-By: PHP/7.1.10 Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate Pragma: no-cache Set-Cookie: PHPSESSID=svn7eb593i8d2gv471rs94og58; path=/ Set-Cookie: visitor=fa867bd917ad0d715830a6a88c816033; expires=Mon, 16-Sep-2019 08:20:53 GMT; Max-Age=31536000; path=/ Set-Cookie: lastvisit=1537086053; path=/ Content-Length: 132217 Content-Type: text/html; charset=utf-8
Посмотреть, какие заголовки отправляет CURL при запросе, можно с помощью опции -v, которая выводит более подробную информацию:
> curl -v google.com
- Строка, начинающаяся с
>означает заголовок, отправленный серверу - Строка, начинающаяся с
<означает заголовок, полученный от сервера - Строка, начинающаяся с
*означает дополнительные данные от CURL
* Rebuilt URL to: http://google.com/ * Trying 173.194.32.206... * TCP_NODELAY set * Connected to google.com (173.194.32.206) port 80 (#0)
> GET / HTTP/1.1 > Host: google.com > User-Agent: curl/7.61.1 > Accept: */* > < HTTP/1.1 301 Moved Permanently < Location: http://www.google.com/ < Content-Type: text/html; charset=UTF-8 < Date: Mon, 17 Sep 2018 15:11:49 GMT < Expires: Wed, 17 Oct 2018 15:11:49 GMT < Cache-Control: public, max-age=2592000 < Server: gws < Content-Length: 219 < X-XSS-Protection: 1; mode=block < X-Frame-Options: SAMEORIGIN < <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="http://www.google.com/">here</A>. </BODY></HTML>
* Connection #0 to host google.com left intact
Если этой информации недостаточно, можно использовать опции --trace или --trace-ascii.
А вот так можно отправить свой заголовок:
> curl -H "User-Agent: Mozilla/5.0" http://www.example.com/
Отправка данных методом POST
Команда ниже отправляет POST запрос на сервер аналогично тому, как пользователь, заполнив HTML форму, нажал бы кнопку «Отправить». Данные будут отправлены в формате application/x-www-form-urlencoded.
> curl -d "key1=value1&key2=value2" http://www.example.com
> curl --data "key1=value1&key2=value2" http://www.example.com
Параметр --data аналогичен --data-ascii, для отправки двоичных данных необходимо использовать параметр --data-binary. Для URL-кодирования полей формы нужно использовать --data-urlencode.
> curl --data-urlencode "name=Василий" --data-urlencode "surname=Пупкин" http://www.example.com
Если значение опции --data начинается с @, то после него должно быть имя файла с данными (или дефис — тогда будут использованы данные из стандартного ввода). Пример получения данных из файла для отправки POST-запроса:
> curl --data @data.txt http://www.example.com
Содержимое файла data.txt:
key1=value1&key2=value2
Массив $_POST, который будет содержать данные этого запроса:
Array
(
[key1] => value1
[key2] => value2
)
Пример URL-кодирования данных из файла перед отправкой POST-запроса:
> curl --data-urlencode name@username.txt http://www.example.com
Содержимое файла username.txt:
Иванов Иван Иванович
Массив $_POST, который будет содержать данные этого запроса:
Array
(
[name] = Иванов Иван Иванович
)
Загрузка файлов методом POST
Для HTTP запроса типа POST существует два варианта передачи полей из HTML форм, а именно, используя алгоритм application/x-www-form-urlencoded и multipart/form-data. Алгоритм первого типа создавался давным-давно, когда в языке HTML еще не предусматривали возможность передачи файлов через HTML формы.
Со временем возникла необходимость через формы отсылать еще и файлы. Тогда консорциум W3C взялся за доработку формата POST запроса, в результате чего появился документ RFC 1867. Форма, которая позволяет пользователю загрузить файл, используя алгоритм multipart/form-data, выглядит примерно так:
<form action="/upload.php" method="POST" enctype="multipart/form-data"> <input type="file" name="upload"> <input type="submit" name="submit" value="OK"> </form>
Чтобы отправить на сервер данные такой формы:
> curl -F upload=@image.jpg -F submit=OK http://www.example.com/upload.php
Скрипт upload.php, который принимает данные формы:
<?php print_r($_POST); print_r($_FILES); move_uploaded_file($_FILES['upload']['tmp_name'], 'image.jpg');
Ответ сервера:
Array
(
[submit] => OK
)
Array
(
[upload] => Array
(
[name] => image.jpg
[type] => image/jpeg
[tmp_name] => D:worktempphpB02F.tmp
[error] => 0
[size] => 2897
)
)
Работа по протоколу FTP
Скачать файл с FTP-сервера:
> curl -u username:password -O ftp://example.com/file.zip
Если заданный FTP путь является директорией, то по умолчанию будет выведен список файлов в ней:
> curl -u username:password -O ftp://example.com/public_html/
Выгрузить файл на FTP-сервер
> curl -u username:password -T file.zip ftp://example.com/
Получить вывод из стандартного ввода и сохранить содержимое на сервере под именем data.txt:
> curl -u username:password -T - ftp://example.com/data.txt
Дополнительно:
- Утилита curl. Обмен данными с сервером
- Пользуемся curl для отладки HTTP
Поиск:
CLI • CURL • Cookie • FTP • GET • HTTP • Linux • POST • URL • Web-разработка • Windows • Форма
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Edit me
Хотя Postman удобен, его трудно использовать для представления в документации, как совершать запросы с его помощью. Кроме того, разные пользователи, вероятно, используют разные клиенты с графическим интерфейсом или вообще не используют их (предпочитая командную строку)
Вместо того, чтобы описывать, как выполнять REST-запросы с использованием GUI-клиента, такого как Postman, наиболее традиционный метод документирования синтаксиса запроса — использовать curl.
curl — это утилита командной строки, которая позволяет выполнять HTTP-запросы с различными параметрами и методами. Вместо того, чтобы переходить к веб-ресурсам в адресной строке браузера, можно использовать командную строку, чтобы получить те же ресурсы, извлеченные в виде текста.
Установка curl
curl доступен на MacOS по умолчанию, для Windows требуется установка. Ниже представлены инструкции по установке curl.
Установка на MacOS
Проверить установлен ли curl на MacOS можно так:
- Открываем Терминал (нажимаем
Cmd+spacebarдля открытия Спотлайт и вводим Terminal). - В терминале пишем
curl -V. Ответ должен быть примерно таким:
curl 7.54.0 (x86_64-apple-darwin16.0) libcurl/7.54.0 SecureTransport zlib/1.2.8
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp smb smbs smtp smtps telnet tftp Features: AsynchDNS IPv6 Largefile GSS-API Kerberos SPNEGO NTLM NTLM_WB SSL libz UnixSockets
Если такого ответа нет, то curl необходимо скачать и установить
Установка на Windows
Установка curl в Windows включает другие шаги. Сначала определяем версию windows: 32-разрядная или 64-разрядная версия Windows, щелкнув правой кнопкой мыши Компьютер и выбрав Свойства. Затем следуем инструкциям на этой странице. Нужно выбрать одну из бесплатных версий с правами Администратора.
После установки проверяем версию установленной curl;
- Открываем командную строку нажав кнопку
Пуски введяcmd - В строке пишем
curl -V
Ответ должен быть примерно таким:
curl 7.54.0 (x86_64-apple-darwin14.0) libcurl/7.37.1 SecureTransport zlib/1.2.5
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp smtp smtps telnet tftp
Features: AsynchDNS GSS-Negotiate IPv6 Largefile NTLM NTLM_WB SSL libz
Создание тестового вызова API
После установки curl делаем тестовый вызов API
curl -X GET "https://api.openweathermap.org/data/2.5/weather?zip=95050&appid=fd4698c940c6d1da602a70ac34f0b147&units=imperial"
В ответ должен вернуться минимизированный JSON:
{"coord":{"lon":-121.96,"lat":37.35},"weather":[{"id":701,"main":"Mist","description":"mist","icon":"50d"}],"base":"stations","main":{"temp":66.92,"pressure":1017,"humidity":50,"temp_min":53.6,"temp_max":75.2},"visibility":16093,"wind":{"speed":10.29,"deg":300},"clouds":{"all":75},"dt":1522526400,"sys":{"type":1,"id":479,"message":0.0051,"country":"US","sunrise":1522504404,"sunset":1522549829},"id":420006397,"name":"Santa Clara","cod":200}
curl и Windows
Если вы используете Windows, обратите внимание на следующие требования к форматированию при использовании curl:
- Используйте двойные кавычки в командной строке Windows. (Windows не поддерживает одинарные кавычки.);
- Не используйте обратную косую черту
для разделения строк. (Это только для удобства чтения и не влияет на вызов на Mac.) - Добавив -k в команду curl, вы можете обойти сертификат безопасности curl, который может быть необходимым.
🔙
Go next ➡

cURL is a command line tool and a library which can be used to receive and send data between a client and a server or any two machines connected over the internet. It supports a wide range of protocols like HTTP, FTP, IMAP, LDAP, POP3, SMTP and many more.
Due to its versatile nature, cURL is used in many applications and for many use cases. For example, the command line tool can be used to download files, testing APIs and debugging network problems. In this article, we shall look at how you can use the cURL command line tool to perform various tasks.
Contents
- 1 Install cURL
- 1.1 Linux
- 1.2 MacOS
- 1.3 Windows
- 2 cURL basic usage
- 3 Downloading Files with cURL
- 4 Anatomy of a HTTP request/response
- 5 Following redirects with cURL
- 6 Viewing response headers with cURL
- 7 Viewing request headers and connection details
- 8 Silencing errors
- 9 Setting HTTP request headers with cURL
- 10 Making POST requests with cURL
- 11 Submitting JSON data with cURL
- 12 Changing the request method
- 13 Replicating browser requests with cURL
- 14 Making cURL fail on HTTP errors
- 15 Making authenticated requests with cURL
- 16 Testing protocol support with cURL
- 17 Setting the Host header and cURL’s —resolve option
- 18 Resolve domains to IPv4 and IPv6 addresses
- 19 Disabling cURL’s certificate checks
- 20 Troubleshooting website issues with “cURL timing breakdown”
- 21 cURL configuration files
- 22 Conclusion
Install cURL
Linux
Most Linux distributions have cURL installed by default. To check whether it is installed on your system or not, type curl in your terminal window and press enter. If it isn’t installed, it will show a “command not found” error. Use the commands below to install it on your system.
For Ubuntu/Debian based systems use:
sudo apt update sudo apt install curl
For CentOS/RHEL systems, use:
sudo yum install curl
On the other hand, for Fedora systems, you can use the command:
sudo dnf install curl
MacOS
MacOS comes with cURL preinstalled, and it receives updates whenever Apple releases updates for the OS. However, in case you want to install the most recent version of cURL, you can install the curl Homebrew package. Once you install Homebrew, you can install it with:
brew install curl
Windows
For Windows 10 version 1803 and above, cURL now ships by default in the Command Prompt, so you can use it directly from there. For older versions of Windows, the cURL project has Windows binaries. Once you download the ZIP file and extract it, you will find a folder named curl-<version number>-mingw. Move this folder into a directory of your choice. In this article, we will assume our folder is named curl-7.62.0-win64-mingw, and we have moved it under C:.
Next, you should add cURL’s bin directory to the Windows PATH environment variable, so that Windows can find it when you type curl in the command prompt. For this to work, you need to follow these steps:
- Open the “Advanced System Properties” dialog by running
systempropertiesadvancedfrom the Windows Run dialog (Windows key + R). - Click on the “Environment Variables” button.
- Double-click on “Path” from the “System variables” section, and add the path
C:curl-7.62.0-win64-mingwbin. For Windows 10, you can do this with the “New” button on the right. On older versions of Windows, you can type in;C:curl-7.62.0-win64-mingwbin(notice the semicolon at the beginning) at the end of the “Value” text box.
Once you complete the above steps, you can type curl to check if this is working. If everything went well, you should see the following output:
C:UsersAdministrator>curl curl: try 'curl --help' or 'curl --manual' for more information
cURL basic usage
The basic syntax of using cURL is simply:
curl <url>
This fetches the content available at the given URL, and prints it onto the terminal. For example, if you run curl example.com, you should be able to see the HTML page printed, as shown below:
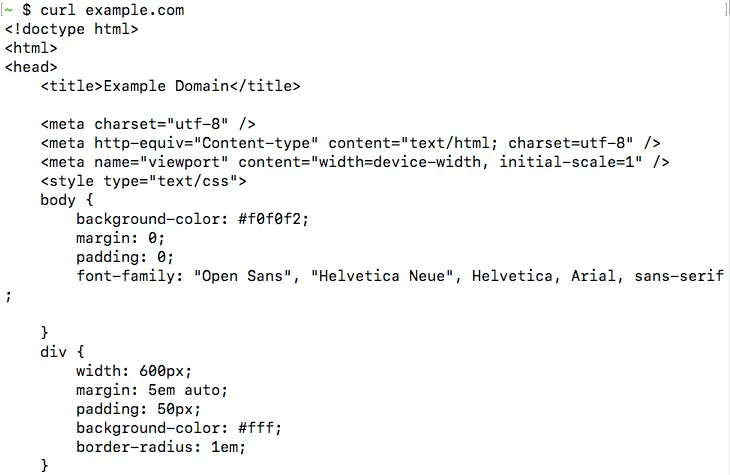
This is the most basic operation cURL can perform. In the next few sections, we will look into the various command line options accepted by cURL.
Downloading Files with cURL
As we saw, cURL directly downloads the URL content and prints it to the terminal. However, if you want to save the output as a file, you can specify a filename with the -o option, like so:
curl -o vlc.dmg http://ftp.belnet.be/mirror/videolan/vlc/3.0.4/macosx/vlc-3.0.4.dmg
In addition to saving the contents, cURL switches to displaying a nice progress bar with download statistics, such as the speed and the time taken:

Instead of providing a file name manually, you can let cURL figure out the filename with the -O option. So, if you want to save the above URL to the file vlc-3.0.4.dmg, you can simply use:
curl -O http://ftp.belnet.be/mirror/videolan/vlc/3.0.4/macosx/vlc-3.0.4.dmg
Bear in mind that when you use the -o or the -O options and a file of the same name exists, cURL will overwrite it.
If you have a partially downloaded file, you can resume the file download with the -C - option, as shown below:
curl -O -C - http://ftp.belnet.be/mirror/videolan/vlc/3.0.4/macosx/vlc-3.0.4.dmg

Like most other command line tools, you can combine different options together. For example, in the above command, you could combine -O -C - and write it as -OC - .
Anatomy of a HTTP request/response
Before we dig deeper into the features supported by cURL, we will discuss a little bit about HTTP requests and responses. If you are familiar with these concepts, you directly skip to the other sections.
To request a resource such as a webpage, or to submit some data to a server, a HTTP client (such as a browser or cURL) makes a HTTP request to the server The server responds back with a HTTP response, which contains the “contents” of that page.
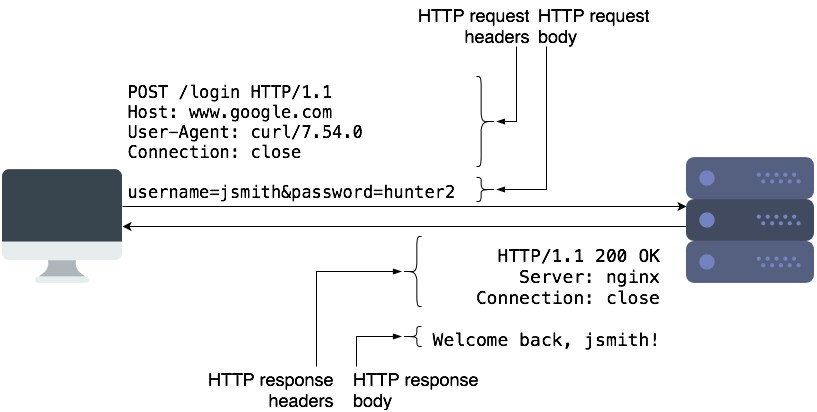
HTTP requests contain the request method, URL, some headers, and some optional data as part of the “request body”. The request method controls how a certain request should be processed. The most common types of request methods are “GET” and “POST”. Typically, we use “GET” requests to retrieve a resource from the server, and “POST” to submit data to the server for processing. “POST” requests typically contain some data in the request body, which the server can use.
HTTP responses are similar and contain the status code, some headers, and a body. The body contains the actual data that clients can display or save to a file. The status code is a 3-digit code which tells the client if the request succeeded or failed, and how it should proceed further. Common status codes are 2xx (success), 3xx (redirect to another page), and 4xx/5xx (for errors).
HTTP is an “application layer protocol”, and it runs over another protocol called TCP. It takes care of retransmitting any lost data, and ensures that the client and server transmit data at an optimal rate. When you use HTTPS, another protocol called SSL/TLS runs between TCP and HTTP to secure the data.
Most often, we use domain names such as google.com to access websites. Mapping the domain name to an IP address occurs through another protocol called DNS.
You should now have enough background to understand the rest of this article.
Following redirects with cURL
By default, when cURL receives a redirect after making a request, it doesn’t automatically make a request to the new URL. As an example of this, consider the URL http://www.facebook.com. When you make a request using to this URL, the server sends a HTTP 3XX redirect to https://www.facebook.com/. However, the response body is otherwise empty. So, if you try this out, you will get an empty output:
![]()
If you want cURL to follow these redirects, you should use the -L option. If you repeat make a request for http://www.facebook.com/ with the -L flag, like so:
curl -L http://www.facebook.com/
Now, you will be able to see the HTML content of the page, similar to the screenshot below. In the next section, we will see how we can verify that there is a HTTP 3XX redirect.
Please bear in mind that cURL can only follow redirects if the server replied with a “HTTP redirect”, which means that the server used a 3XX status code, and it used the “Location” header to indicate the new URL. cURL cannot process Javascript or HTML-based redirection methods, or the “Refresh header“.
If there is a chain of redirects, the -L option will only follow the redirects up to 500 times. You can control the number of maximum redirects that it will follow with the --max-redirs flag.
curl -L --max-redirs 700 example.com
If you set this flag to -1, it will follow the redirects endlessly.
curl -L --max-redirs -1 example.com
When debugging issues with a website, you may want to view the HTTP response headers sent by the server. To enable this feature, you can use the -i option.
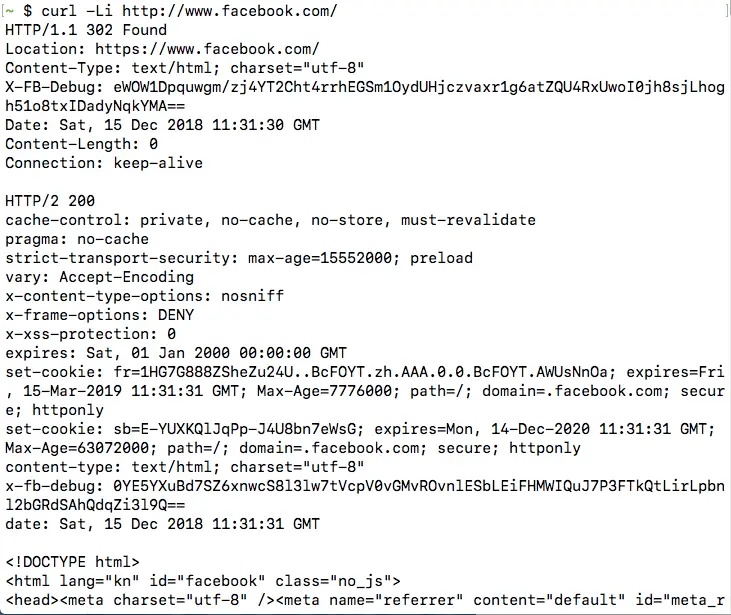
Let us continue with our previous example, and confirm that there is indeed a HTTP 3XX redirect when you make a HTTP request to http://www.facebook.com/, by running:
curl -L -i http://www.facebook.com/
Notice that we have also used -L so that cURL can follow redirects. It is also possible to combine these two options and write them as -iL or -Li instead of -L -i.
Once you run the command, you will be able to see the HTTP 3XX redirect, as well as the page HTTP 200 OK response after following the redirect:
If you use the -o/-O option in combination with -i, the response headers and body will be saved into a single file.
Viewing request headers and connection details
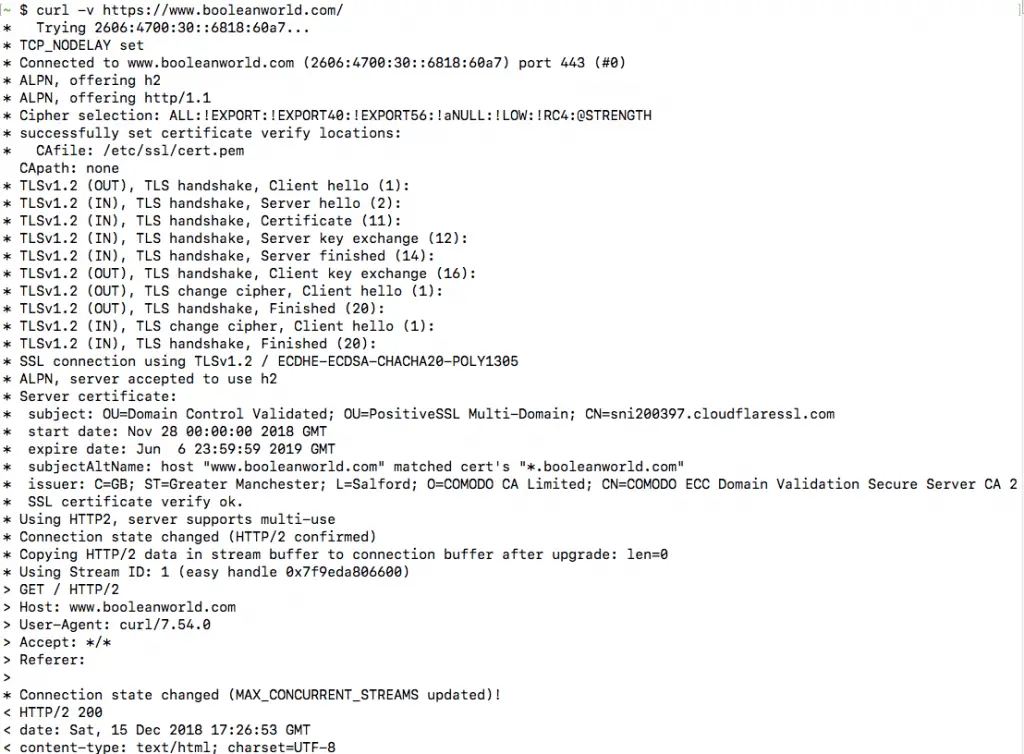
In the previous section, we have seen how you can view HTTP response headers using cURL. However, sometimes you may want to view more details about a request, such as the request headers sent and the connection process. cURL offers the -v flag (called “verbose mode”) for this purpose, and it can be used as follows:
curl -v https://www.booleanworld.com/
The output contains request data (marked with >), response headers (marked with <) and other details about the request, such as the IP used and the SSL handshake process (marked with *). The response body is also available below this information. (However, this is not visible in the screenshot below).
Most often, we aren’t interested in the response body. You can simply hide it by “saving” the output to the null device, which is /dev/null on Linux and MacOS and NUL on Windows:
curl -vo /dev/null https://www.booleanworld.com/ # Linux/MacOS curl -vo NUL https://www.booleanworld.com/ # Windows
Silencing errors
Previously, we have seen that cURL displays a progress bar when you save the output to a file. Unfortunately, the progress bar might not be useful in all circumstances. As an example, if you hide the output with -vo /dev/null, a progress bar appears which is not at all useful.
You can hide all these extra outputs by using the -s header. If we continue with our previous example but hide the progress bar, then the commands would be:
curl -svo /dev/null https://www.booleanworld.com/ # Linux/MacOS curl -svo NUL https://www.booleanworld.com/ # Windows
The -s option is a bit aggressive, though, since it even hides error messages. For your use case, if you want to hide the progress bar, but still view any errors, you can combine the -S option.
So, if you are trying to save cURL output to a file but simply want to hide the progress bar, you can use:
curl -sSvo file.html https://www.booleanworld.com/
When testing APIs, you may need to set custom headers on the HTTP request. cURL has the -H option which you can use for this purpose. If you want to send the custom header X-My-Custom-Header with the value of 123 to https://httpbin.org/get, you should run:
curl -H 'X-My-Custom-Header: 123' https://httpbin.org/get
(httpbin.org is a very useful website that allows you to view details of the HTTP request that you sent to it.)
The data returned by the URL shows that this header was indeed set:
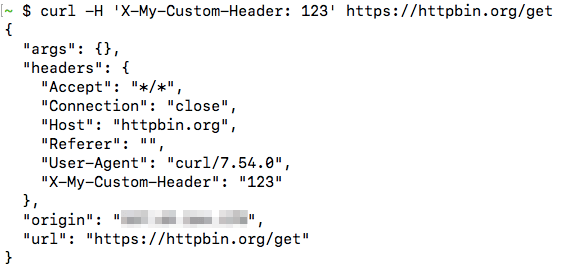
You can also override any default headers sent by cURL such as the “User-Agent” or “Host” headers. The HTTP client (in our case, cURL) sends the “User-Agent” header to tell the server about the type and version of the client used. Also, the client uses the “Host” header to tell the server about the site it should serve. This header is needed because a web server can host multiple websites at a single IP address.
Also, if you want to set multiple headers, you can simply repeat the -H option as required.
curl -H 'User-Agent: Mozilla/5.0' -H 'Host: www.google.com' ...
However, cURL does have certain shortcuts for frequently used flags. You can set the “User-Agent” header with the -A option:
curl -A Mozilla/5.0 http://httpbin.org/get
The “Referer” header is used to tell the server the location from which they were referred to by the previous site. It is typically sent by browsers when requesting Javascript or images linked to a page, or when following redirects. If you want to set a “Referer” header, you can use the -e flag:
curl -e http://www.google.com/ http://httpbin.org/get
Otherwise, if you are following a set of redirects, you can simply use -e ';auto' and cURL will take care of setting the redirects by itself.
Making POST requests with cURL
By default, cURL sends GET requests, but you can also use it to send POST requests with the -d or --data option. All the fields must be given as key=value pairs separated by the ampersand (&) character. As an example, you can make a POST request to httpbin.org with some parameters:
curl --data "firstname=boolean&lastname=world" https://httpbin.org/post
From the output, you can easily tell that we posted two parameters (this appears under the “form” key):
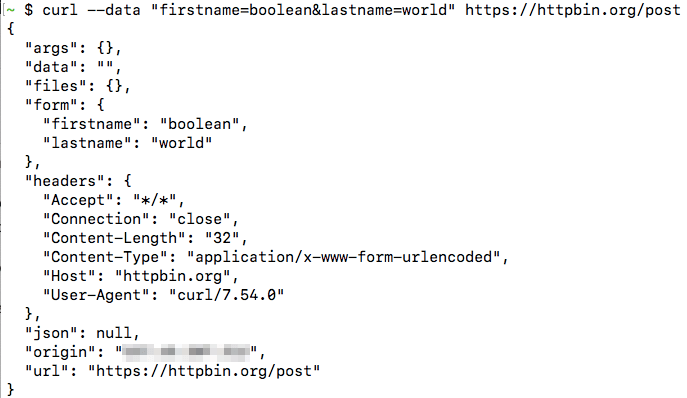
Any special characters such as @, %, = or spaces in the value should be URL-encoded manually. So, if you wanted to submit a parameter “email” with the value “[email protected]”, you would use:
curl --data "email=test%40example.com" https://httpbin.org/post
Alternatively, you can just use --data-urlencode to handle this for you. If you wanted to submit two parameters, email and name, this is how you should use the option:
curl --data-urlencode "[email protected]" --data-urlencode "name=Boolean World" https://httpbin.org/post
If the --data parameter is too big to type on the terminal, you can save it to a file and then submit it using @, like so:
curl --data @params.txt example.com
So far, we have seen how you can make POST requests using cURL. If you want to upload files using a POST request, you can use the -F (“form”) option. Here, we will submit the file test.c, under the parameter name file:
curl -F [email protected] https://httpbin.org/post
This shows the content of the file, showing that it was submitted successfully:
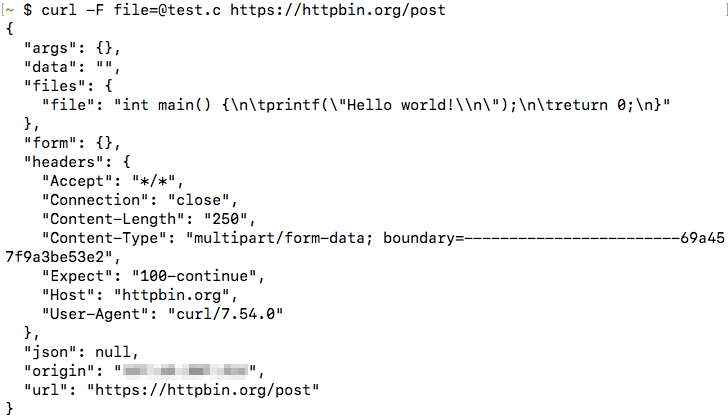
Submitting JSON data with cURL
In the previous section, we have seen how can submit POST requests using cURL. You can also submit JSON data using the --data option. However, most servers expect to receive a POST request with key-value pairs, similar to the ones we have discussed previously. So, you need to add an additional header called ‘Content-Type: application/json’ so that the server understands it’s dealing with JSON data and handles it appropriately. Also, you don’t need to URL-encode data when submitting JSON.
So if you had the following JSON data and want to make a POST request to https://httpbin.org/post:
{
"email": "[email protected]",
"name": ["Boolean", "World"]
}
Then, you can submit the data with:
curl --data '{"email":"[email protected]", "name": ["Boolean", "World"]}' -H 'Content-Type: application/json' https://httpbin.org/post
In this case, you can see the data appear under the json value in the httpbin.org output:
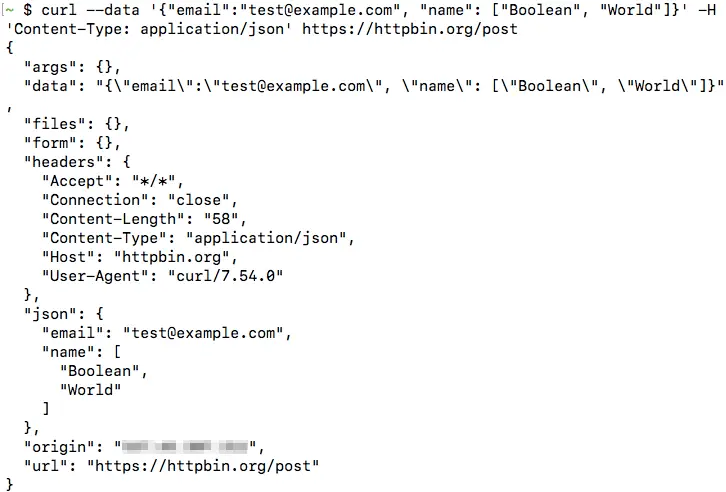
You can also save the JSON file, and submit it in the same way as we did previously:
curl --data @data.json https://httpbin.org/post
Changing the request method
Previously, we have seen how you can send POST requests with cURL. Sometimes, you may need to send a POST request with no data at all. In that case, you can simply change the request method to POST with the -X option, like so:
curl -X POST https://httpbin.org/post
You can also change the request method to anything else, such as PUT, DELETE or PATCH. One notable exception is the HEAD method, which cannot be set with the -X option. The HEAD method is used to check if a document is present on the server, but without downloading the document. To use the HEAD method, use the -I option:
curl -I https://www.booleanworld.com/
When you make a HEAD request, cURL displays all the request headers by default. Servers do not send any content when they receive a HEAD request, so there is nothing after the headers:
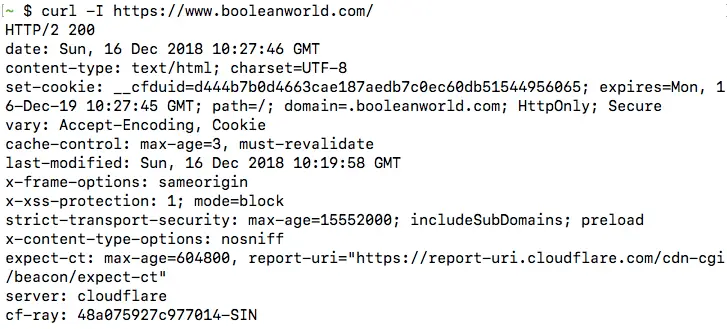
Replicating browser requests with cURL
If you want to replicate a request made through your browser through cURL, you can use the Chrome, Firefox and Safari developer tools to get a cURL command to do so.
The steps involved are the same for all platforms and browsers:
- Open developer tools in Firefox/Chrome (typically F12 on Windows/Linux and Cmd+Shift+I on a Mac)
- Go to the network tab
- Select the request from the list, right click it and select “Copy as cURL”
The copied command contains all the headers, request methods, cookies etc. needed to replicate the exact same request. You can paste the command in your terminal to run it.
Making cURL fail on HTTP errors
Interestingly, cURL doesn’t differentiate between a successful HTTP request (2xx) and a failed HTTP request (4xx/5xx). So, it always returns an exit status of 0 as long as there was no problem connecting to the site. This makes it difficult to write shell scripts because there is no way to check if the file could be downloaded successfully.
You can check this by making a request manually:
curl https://www.booleanworld.com/404 -sSo file.txt
You can see that curl doesn’t print any errors, and the exit status is also zero:

If you want to consider these HTTP errors as well, you can use the -f option, like so:
curl https://www.booleanworld.com/404 -fsSo file.txt
Now, you can see that cURL prints an error and also sets the status code to 22 to inform that an error occured:

Making authenticated requests with cURL
Some webpages and APIs require authentication with an username and password. There are two ways to do this. You can mention the username and password with the -u option:
curl -u boolean:world https://example.com/
Alternatively, you can simply add it to the URL itself, with the <username>:<password>@<host> syntax, as shown:
curl https://boolean:[email protected]/
In both of these methods, curl makes a “Basic” authentication with the server.
Testing protocol support with cURL
Due to the wide range of protocols supported by cURL, you can even use it to test protocol support. If you want to check if a site supports a certain version of SSL, you can use the --sslv<version> or --tlsv<version> flags. For example, if you want to check if a site supports TLS v1.2, you can use:
curl -v --tlsv1.2 https://www.booleanworld.com/
The request takes place normally, which means that the site supports TLSv1.2. Now, let us check if the site supports SSL v3:
curl -v --sslv3 https://www.booleanworld.com/
This command throws a handshake_failed error, because the server doesn’t support this version of SSL.
Please note that, depending on your system and the library version/configuration, some of these version options may not work. The above output was taken from Ubuntu 16.04’s cURL. However, if you try this with cURL in MacOS 10.14, it gives an error:

You can also test for HTTP protocol versions in the same way, by using the flags --http1.0, --http1.1 or --http2.
Setting the Host header and cURL’s --resolve option
Previously, we have discussed about how a web server chooses to serve different websites to visitors depending upon the “Host” header. This can be very useful to check if your website has virtual hosting configured correctly, by changing the “Host” header. As an example, say you have a local server at 192.168.0.1 with two websites configured, namely example1.com and example2.com. Now, you can test if everything is configured correctly by setting the Host header and checking if the correct contents are served:
curl -H 'Host: example1.com' http://192.168.0.1/ curl -H 'Host: example1.com' http://192.168.0.1/
Unfortunately, this doesn’t work so well for websites using HTTPS. A single website may be configured to serve multiple websites, with each website using its own SSL/TLS certificate. Since SSL/TLS takes place at a lower level than HTTP, this means clients such as cURL have to tell the server which website we’re trying to access at the SSL/TLS level, so that the server can pick the right certificate. By default, cURL always tells this to the server.
However, if you want to send a request to a specific IP like the above example, the server may pick a wrong certificate and that will cause the SSL/TLS verification to fail. The Host header only works at the HTTP level and not the SSL/TLS level.
To avoid the problem described above, you can use the --resolve flag. The resolve flag will send the request to the port and IP of your choice but will send the website name at both SSL/TLS and HTTP levels correctly.
Let us consider the previous example. If you were using HTTPS and wanted to send it to the local server 192.168.0.1, you can use:
curl https://example1.com/ --resolve example1.com:192.168.0.1:443
It also works well for HTTP. Suppose, if your HTTP server was serving on port 8080, you can use either the --resolve flag or set the Host header and the port manually, like so:
curl http://192.168.0.1:8080/ -H 'Host: example1.com:8080' curl http://example.com/ --resolve example1.com:192.168.0.1:8080
The two commands mentioned above are equivalent.
Resolve domains to IPv4 and IPv6 addresses
Sometimes, you may want to check if a site is reachable over both IPv4 or IPv6. You can force cURL to connect to either the IPv4 or over IPv6 version of your site by using the -4 or -6 flags.
Please bear in mind that a website can be reached over IPv4 and IPv6 only if:
- There are appropriate DNS records for the website that links it to IPv4 and IPv6 addresses.
- You have IPv4 and IPv6 connectivity on your system.
For example, if you want to check if you can reach the website icanhazip.com over IPv6, you can use:
curl -6 https://icanhazip.com/
If the site is reachable over HTTPS, you should get your own IPv6 address in the output. This website returns the public IP address of any client that connects to it. So, depending on the protocol used, it displays an IPv4 or IPv6 address.
You can also use the -v option along with -4 and -6 to get more details.
Disabling cURL’s certificate checks
By default, cURL checks certificates when it connects over HTTPS. However, it is often useful to disable the certificate checking, when you are trying to make requests to sites using self-signed certificates, or if you need to test a site that has a misconfigured certificate.
To disable certificate checks, use the -k certificate. We will test this by making a request to expired.badssl.com, which is a website using an expired SSL certificate.
curl -k https://expired.badssl.com/
With the -k option, the certificate checks are ignored. So, cURL downloads the page and displays the request body successfully. On the other hand, if you didn’t use the -k option, you will get an error, similar to the one below:
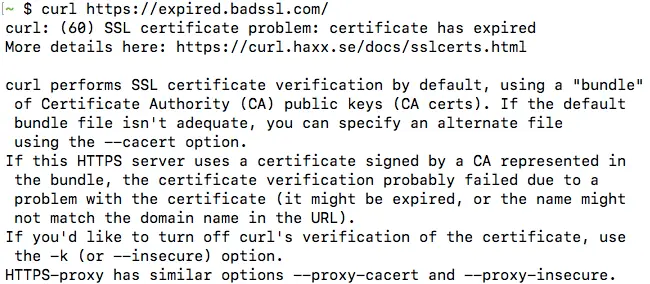
Troubleshooting website issues with “cURL timing breakdown”
You may run into situations where a website is very slow for you, and you would like to dig deeper into the issue. You can make cURL display details of the request, such as the time taken for DNS resolution, establishing a connection etc. with the -w option. This is often called as a cURL “timing breakdown”.
As an example, if you want to see these details for connecting to https://www.booleanworld.com/, run:
curl https://www.booleanworld.com/ -sSo /dev/null -w 'namelookup:t%{time_namelookup}nconnect:t%{time_connect}nappconnect:t%{time_appconnect}npretransfer:t%{time_pretransfer}nredirect:t%{time_redirect}nstarttransfer:t%{time_starttransfer}ntotal:tt%{time_total}n'
(If you are running this from a Windows system, change the /dev/null to NUL).
You will get some output similar to this:
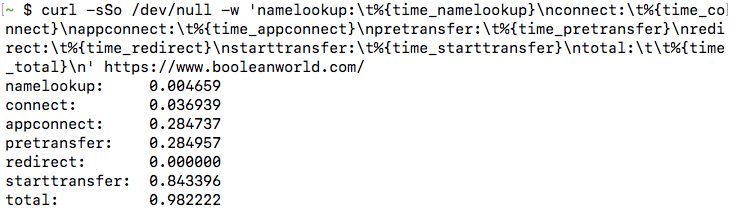
Each of these values is in seconds, and here is what each value represents:
- namelookup — The time required for DNS resolution.
- connect — The time required to establish the TCP connection.
- appconnect — This is the time taken to establish connections for any layers between TCP and the application layer, such as SSL/TLS. In our case, the application layer is HTTP. Also, if there is no such intermediate layer (such as when there is a direct HTTP request), this time will always be 0.
- pretransfer — This is the time taken from the start to when the transfer of the file is just about to begin.
- redirect — This is the total time taken to process any redirects.
- starttransfer — Time it took from the start to when the first byte is about to be transferred.
- total — The total time taken for cURL to complete the entire process.
As an example, say, you are facing delays connecting to a website and you notice the “namelookup” value was too high. As this indicates a problem with your ISP’s DNS server, you may start looking into why the DNS lookup is so slow, and switch to another DNS server if needed.
cURL configuration files
Sometimes, you may want to make all cURL requests use the same options. Passing these options by hand isn’t a feasible solution, so cURL allows you to specify options in a configuration file.
The default configuration file is located in ~/.curlrc in Linux/MacOS and %appdata%_curlrc in Windows. Inside this file, you can specify any options that you need, such as:
# Always use IPv4 -4 # Always show verbose output -v # When following a redirect, automatically set the previous URL as referer. referer = ";auto" # Wait 60 seconds before timing out. connect-timeout = 60
After creating the above file, try making a request with curl example.com. You will find that these options have taken effect.
If you want to use a custom configuration file instead of the default one, then you can use -K option to point curl to your configuration file. As an example, if you have a configuration file called config.txt, then you can use it with:
curl -K config.txt example.com
Conclusion
In this article, we have covered the most common uses of the cURL command. Of course, this article only scratches the surface and cURL can do a whole lot of other things. You can type man curl in your terminal or just visit this page to see the man page which lists all the options.

Осваиваем быстрый, маленький и простой инструмент тестирования API
- Настройка
- Базовые опции
- GET-метод
- POST-метод
- Отправка простого текста
- Параметры строки запроса
- Отправка JSON-объекта
- Эмуляция отправки значений формы
- Отправка файла
- Другие методы
- Аутентификация
- Платный тариф
“Когда я начал изучать HTTP-протокол и надо было работать с URL-ами и передаваемыми в них данными, в каждом найденном инструменте не хватало хорошей документации, или она была, но в виде избыточно сложных инструкций для простых вещей, типа отправки простого HTTP-запроса. Однажды обратил внимание на curl, которым раньше скачивал файлы, и это оказался лучший инструмент для изучения веб-API.
Этот материал требует базового знакомства с HTTP-протоколом, понимания что такое веб-API, а также умения работать с командной строкой в Windows, надеемся ты это умеешь.
Итак, поехали.
Настройка
Как всякий серьезный софт, curl требует установки в операционной системе. Хорошая новость: скорее всего, он уже установлен! Точнее, встроен в операционку. Уважающий себя тестировщик, разумеется, работает в Linux, а почти каждый дистрибутив Linux уже идет с curl. Более того, даже Windows 10 (начиная с версии 1803) поставляется с curl.
Проверим, есть ли в системе curl.
В Linux набираем в терминале:
curl --version
Если все-таки работаешь в Windows, то запускаешь cmd или, лучше, PowerShell:
curl.exe --version
Команда покажет версию curl, прикрепленные библиотеки, дату релиза, поддерживаемые протоколы и поддерживаемые функции. В Linux увидим следующее:
curl 7.68.0 (x86_64-pc-linux-gnu) libcurl/7.68.0 OpenSSL/1.1.1f zlib/1.2.11 brotli/1.0.7 libidn2/2.2.0 libpsl/0.21.0 (+libidn2/2.2.0) libssh/0.9.3/openssl/zlib nghttp2/1.40.0 librtmp/2.3 Release-Date: 2020-01-08 Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtmp rtsp scp sftp smb smbs smtp smtps telnet tftp Features: AsynchDNS brotli GSS-API HTTP2 HTTPS-proxy IDN IPv6 Kerberos Largefile libz NTLM NTLM_WB PSL SPNEGO SSL TLS-SRP UnixSockets
Если введенная команда выдала ошибку, то curl не установлен, значит его надо скачать и поставить. Еще одна хорошая новость: он бесплатный (но есть нюансы, о которых в конце). Есть версии для практически всех операционных систем, размер ехе-шника не превышает 5 Мб.
Если понадобилось ознакомиться с curl, а опыта с API нет, ситуацию облегчит тестовый httpbin-сервис, примеры с которым приведены далее в этом посте.
Примечание. С этого момента, будут приводиться исключительно «линуксовые» bash-команды, для ясности и читабельности. Если ты сидишь в Windows и примеры почему-то не работают, попробуй добавлять «.exe» после команды curl, или удалять (возможные) лишние пробелы в строках (line breaks).
Базовые опции
Несмотря на то, что Curl очень простой инструмент, он имеет множество различных функций. Начнем с ними знакомиться:
--requestили-X: Указывает нужный http-метод (здесь подробнее — желательно хорошо разобраться). Если опции нет, запрос по умолчанию обрабатывается как GET. Например:curl -X POST ...
--headerили-H: В HTTP-запрос добавляется дополнительный заголовок, их может быть сколько угодно. Например:curl -H "X-First-Name: John" -H "X-Last-Name: Doe" ...
--dataили-d: В запрос включаются какие-то данные. Они могут добавляться в той же строке, или указывать на текстовый файл, откуда считываются. Пример:curl -d "тут текстовые данные" ...
- —
-formили-F: curl эмулирует заполненную форму, с нажатием кнопки отправки. Допускается отправка бинарных файлов. Пример:curl -F name=John -F shoesize=11 ...
--user <user:password>или-u <user:password>: Логин и пароль для аутентификации на сервере.
curl показывает логи HTTP-транзакций в терминале. Если нужно еще больше подробностей, то curl сохраняет все в файлы для проверки при необходимости. Для это есть функции:
--dump-headerили-D: Сохраняет в указанный дамп-файл полученные заголовки. Пример:curl -D result.header ...--outputили-O: Выводит в указанный дамп-файл, минуя stdout. Пример:curl -o result.json ...
GET-метод
Мы познакомились с основами, пора перейти к более серьезным вещам.
Во первых, меняем текущую папку в командной оболочке, на домашнюю папку или на рабочий стол (desktop), чтобы легче было найти выведенные из curl файлы.
Делаем первые запросы:
curl -X GET "https://httpbin.org/get" -H "accept: application/json" -D result.headers -o result.json
В первой строке указываем curl выполнить HTTP-запрос GET-методом, по такому-то URL. Во второй строке добавляем заголовок, чтобы сервер знал, что нам отправить в ответе. В третьей строке прописываем вывод полученных заголовков в файл дампа, который мы назовем result.headers. В последней строчке даем указание вывести результат запроса в файл result.json.
Если все пошло как надо, после запуска команды в прописанной на первом этапе домашней папке появятся нужные файлы. В данном случае будет выглядеть так.
файл result.headers
HTTP/2 200 date: Thu, 02 Sep 2021 05:47:14 GMT content-type: application/json content-length: 169
В файле result.headers видим, что запрос успешно выполнен, с кодом ответа 200 (все ОК), от сервера получен таймкод ответа (timestamp), и все заголовки.
Файл result.json
{
"args": {},
"headers": {
"Accept": "application/json",
"Host": "httpbin.org",
"User-Agent": "curl/7.68.0"
},
"url": "https://httpbin.org/get"
}
В этом файле result.json находится тело ответа. Это данные, возвращенные сервером, в красивом JSON-формате (об особенностях формата читаем здесь).
POST-метод
Отправка простого текста
Сейчас попробуем отправить обычный текст (plaintext) на сервер, с помощью метода POST.
curl -X POST "https://httpbin.org/post" -H "accept: application/json" -H "Content-Type: text/plain" -H "Custom-Header: Testing" -d "I love hashnode" -D result.headers -o result.json
Как видим, в запрос включен кастомный заголовок "Custom-Header: Testing". Он должен отображаться в теле ответа.
Смотрим теперь в файл result.headers
HTTP/2 200 date: Fri, 03 Sep 2021 03:16:20 GMT content-type: application/json content-length: 182
и файл result.json
{
"data": "I love hashnode",
"headers": {
"Accept": "application/json",
"Content-Length": "15",
"Content-Type": "text/plain",
"Custom-Header": "Testing"
}
}
Видим, что сервер получил plaintext-сообщение с тестовым заголовком и вернул его обратно без изменений.
Параметры строки запроса
В curl поддерживается не только простой текст, но и достаточно сложные параметры типа:
curl -X POST "https://httpbin.org/post?name=Carlos&last=Jasso" -H "accept: application/json" -D result.headers -o result.json
файл result.headers
HTTP/2 200 date: Fri, 03 Sep 2021 03:30:47 GMT content-type: application/json content-length: 120
файл result.json
{
"args": {
"lastname": "Jasso",
"name": "Carlos"
},
"headers": {
"Accept": "application/json"
}
}
Сервер, как и предыдущем примере, правильно «зеркалит» параметры, которые curl отправил.
Отправка JSON-объекта
Поставим curl-у задачу посложнее, попытаемся отправить на сервер json-файл и посмотрим что получится:
curl -X POST "https://httpbin.org/post" -H "Content-Type: application/json; charset=utf-8" -d @data.json -o result.json
Тут мы добавили специальный заголовок Content-Type, сообщающий серверу, что ему посылается json-файл. Путь к файлу с данными указывается флагом -d с собачкой @, и далее путь к файлу (в нашем случае это будет текущая папка).
Вот содержимое файла data.json, который надо создать:
{
"name": "Jane",
"last": "Doe"
}
И файл result.json:
{
"data": "{ "name": "Jane", "last": "Doe"}",
"headers": {
"Accept": "*/*",
"Content-Length": "38",
"Content-Type": "application/json; charset=utf-8"
},
"json": {
"last": "Doe",
"name": "Jane"
}
}
И снова видим, как curl умеет корректно отправлять контент JSON-файлов на сервер.
Эмуляция отправки значений формы
Иногда может понадобиться имитировать отправку формы. Curl умеет и это:
curl -X POST "https://httpbin.org/post" -H "Content-Type: multipart/form-data" -F "FavoriteFood=Pizza" -F "FavoriteBeverage=Beer" -o result.json
Чтобы обозначить для сервера, что посылаются данные формы, добавляется заголовок с соответствующим MIME-типом (как показано выше), плюс параметр -F в каждом из полей и значений.
result.json:
{
"form": {
"FavoriteBeverage": "Beer",
"FavoriteFood": "Pizza"
},
"headers": {
"Accept": "*/*",
"Content-Length": "261",
"Content-Type": "multipart/form-data;"
}
}
Видим, что сервер получил форму и правильно обработал все поля.
Отправка файла
Выше мы демонстрировали достаточно простые действия. А как насчет передачи файла? Файлы передаются таким же образом, как формы выше. Отправим изображение из текущей папки:
curl -X POST "https://httpbin.org/post" -H "Content-Type: multipart/form-data" -F "FileComment=This is a JPG file" -F "image=@image.jpg" -o result.json
result.json:
{
"files": {
"image": "data:image/jpeg;base64,/9j/4AAQSkZJ..."
},
"form": {
"FileComment": "This is a JPG file"
},
"headers": {
"Accept": "*/*",
"Content-Length": "78592",
"Content-Type": "multipart/form-data;"
}
}
curl может потребоваться некоторое время чтобы отправить большой файл, а потом сервер вернет этот файл (причем закодированный в Base64). Curl должен правильно обработать такой запрос.
Другие методы
Можно попробовать «погонять» любые запросы, чтобы убедиться, как полезен бывает curl при тестировании API. В целом, обработка запросов зависит от типа API и имплементации метода.
Аутентификация
curl умеет проводить аутентификацию на сервере, когда по URL-адресу нужен ввод пользовательских имени-пароля. В этом случае httpbin получает ожидаемые имя и пароль в формате /basic-auth/{user}/{passwd} и сопоставляет значения с введенными. Если эти данные не введены, получается следующее:
curl -X GET "https://httpbin.org/basic-auth/carlos/secret" -H "accept: application/json" -D result.headers
result.headers:
HTTP/2 401 date: Fri, 03 Sep 2021 04:08:44 GMT content-length: 0
То есть код 401 (не прошла авторизация).
Добавим в запрос логин и пароль:
curl -X GET "https://httpbin.org/basic-auth/carlos/secret" -u carlos:secret -H "accept: application/json" -D result.headers
result.headers:
HTTP/2 200 date: Fri, 03 Sep 2021 04:14:19 GMT content-type: application/json content-length: 48
result.json:
{
"authenticated": true,
"user": "carlos"
}
Все хорошо, авторизация прошла успешно.
Curl позволяет авторизоваться и другими методами — например, с помощью токена. Токен просто отправляется в соответствующем заголовке.
Платный тариф
Уже должно быть понятно, что curl — полезная вещь для тестировщика. Чтобы в этом мнении укрепиться, рассмотрим еще некоторые нюансы.
Распространенные инструменты тестирования API — бесплатные, но в них чаще всего бывают платными функции командной работы. Или например, запросы к социальным сетям (Вконтакте и Facebook) блокированы в бесплатном тарифе, и это один из немногих минусов в столь приятном продукте.
В других похожих инструментах бывает слишком сложный интерфейс, но это не об curl. Для простоты, рекомендую работать в VSCode. Связка VSCode c curl — идеальная.

На скрине слева отрендеренный markdown-документ, справа полученные result.headers и result.json, и терминал внизу, куда тестировщику приходится глядеть чаще всего.
Вопреки убеждению, бытующему в определенных кругах, curl хорошо работает не только в REST-архитектуре, но и в SOAP.
Конечно, раскрыть все нюансы в одной статье невозможно, и чтобы продолжить знакомство с такой полезной вещью как curl, не обойтись без чтения официальной документации на их сайте. Там же и примеры использования.”
cURL (client URL) is a command line tool that can be used to transfer data from a server. It is often used by developers to test web applications. cURL can be used to download files, submit form data, and even to login to websites.
The curl command is one of the most used commands to automate the process of sending and receiving data to or from a server, and it provides a simple, easy-to-use command-line interface that can be used to do this.
The curl command supports many protocols such as – HTTP, HTTPS, FTP, SFTP, TELNET, etc. It is a cross-platform tool available in Windows, Unix, and macOS.
cURL has a very broad usage – a quick way to see how broad of a usage, you can run curl -h in your command line and see all of the options it offers.
Objectives
This tutorial will explain the basics of the cURL command and how to use it to transfer data to or from a server, along with some of it’s most frequently used options.
We’ll also explain the basics of HTTP requests and how to perform them with the cURL command, along with some useful things you can do.
Table of Contents
- Objectives
- Installing cURL on Your System
- Installing cURL on Debian-based Distros
- Installing cURL on RPM-based Distros
- Installing cURL on Windows
- Installing cURL on Mac OS X
- Basics of the cURL command
- Redirects with the cURL Command
- Use the -L Flag to Follow Redirects
- Save Outputs to A File with the cURL Command
- Downloading Multiple files
- Resuming Downloads
- Redirects with the cURL Command
- Basics of HTTP Requests & Responses
- HTTP Requests
- HTTP Responses
- HTTP Requests with The cURL Command
- GET Request With the cURL Command
- HEAD Request With the cURL Command
- Extract the HTTP Header
- Debugging with the HTTP Headers
- HTTP Header With the Redirect Option
- POST Requests With the cURL Command
- Sending Data Using POST Method
- Uploading Files with cURL
- Modify the HTTP Header
- PUT Requests With the cURL Command
- DELETE Requests With the cURL Command
- Conclusion
Installing cURL on Your System
If you’re using Linux, Mac OS X, or Windows 10 version 1803 or later, chances are cURL is already installed in your machine. You can check if you have cURL simply by typing the following in your command line:
curl -V
This will output the version of cURL, if it is installed:
Output
curl 7.68.0 (x86_64-pc-linux-gnu) libcurl/7.68.0 OpenSSL/1.1.1f zlib/1.2.11 brotli/1.0.7 libidn2/2.2.0 libpsl/0.21.0 (+libidn2/2.2.0) libssh/0.9.3/openssl/zlib nghttp2/1.40.0 librtmp/2.3 Release-Date: 2020-01-08 Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtmp rtsp scp sftp smb smbs smtp smtps telnet tftp Features: AsynchDNS brotli GSS-API HTTP2 HTTPS-proxy IDN IPv6 Kerberos Largefile libz NTLM NTLM_WB PSL SPNEGO SSL TLS-SRP UnixSockets
You can also see the list of the supported protocols and the features. If you did not have cURL installed, you would’ve got something like this:
cURL not installed on Ubuntu 20.04
Command 'curl' not found, but can be installed with: sudo snap install curl # version 7.76.1, or sudo apt install curl # version 7.68.0-1ubuntu2.5 See 'snap info curl' for additional versions.
cURL not installed on Windows
'curl' is not recognized as an internal or external command, operable program or batch file.
If you don’t have cURL installed, next we’ll cover how to install it on your system.
Installing cURL on Debian-based Distros
To install cURL on Debian-based distros (Debian, Ubuntu etc.) run:
sudo apt-get update sudo apt-get install curl
Installing cURL on RPM-based Distros
To install cURL on RPM-based distros (CentOS, Fedora etc.) run:
sudo yum update sudo yum install curl
Installing cURL on Windows
There are multiple ways you can install cURL on Windows. We’ll focus on just one quick and clean way (in my opinion), which I hope works for most using Windows. If you encounter any issues please leave a comment and we’ll get back to you as soon as we can.
- Go to download page: Go to the curl Windows (https://curl.se/windows/)
- Download zip file: Click on curl for 64 bit or curl for 32 bit, to download the package, depending on which version you have. (Here is an article on Microsoft.com with a FAQ on 32-bit and 64-bit Windows, in case you need to check which one you have, along with a bit more info on the topic)

- Extract necessary files: It’s a a .zip archive. Double click to see the contents and go inside the
binfolder. We wantcurl.exeandcurl-ca-bundle.crt. We’ll need to place them in some folder on our computer. You can create the folder anywhere and name it anything you want – I prefer to createC:Program Filescurland extract the two files in there. - Add cURL to
PATH: We need to do this to be able to run the cURL command from anywhere in the command line. If we don’t do this, we’ll have to always navigate to wherecurl.exeis located when we try to run it in the command line.What is thisPATH? It’s an environment variable that specifies directories in which executables are located on the machine without knowing and typing the whole path to the file on the command line. To do this we need to find the Environment Variables section.

Installing cURL on Mac OS X
Mac OS X should come with the cURL command, but if it isn’t, we recommend installing it via Homebrew, a very popular package manager for Mac.
To install Homebrew open up the command line and run:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
The script should explain what it’s doing in the output.
When it’s finished, just run the following command to install cURL:
brew install curl
Basics of the cURL command
Now let’s move on to some basic usages of the cURL command.
The general structure of the curl command looks like:
curl [options...] <url>
Let’s try the curl command without any options:
curl https://example.com
This command will display the source code of example.com on your command line.
curl example.com
Let’s try another:
curl bytexd.com
curl bytexd.com
You may be surprised that there is no output. We’ll discuss this in the next section.
Redirects with the cURL Command
The curl command without any options will use HTTP protocol by default. So, it will not perform any HTTPS redirects. As our website bytexd.com uses HTTPS redirect, cURL cannot fetch the data over the HTTP protocol.
Now let’s try running the command again but this time we add https://:
curl https://bytexd.com
Now you should get the expected result.
curl https://bytexd.com
Use the -L Flag to Follow Redirects
This is a good time to learn about the redirect option with the curl command:
curl -L bytexd.com
Notice how we didn’t have to specify https:// like we did previously.
The -L flag or --location option follows the redirects. Use this to display the contents of any website you want. By default, the curl command with the -L flag will follow up to 50 redirects.
curl -L bytexd.com
Save Outputs to A File with the cURL Command
Now that you know how to display website content in your terminal, you may be wondering why anybody would want to do this. A bunch of HTML is indeed difficult to read when you’re looking at it in the command line.
But that’s where outputting them to a file becomes super helpful. You can save the file in different formats that’ll make them easier to read.
What can be even more useful is some cURL script pulling up content from the website and performing some tasks with the content automatically.
For now, let’s see how to save the output of the curl command into a file:
curl -L -o file bytexd.com
The flag -o or --output will save the content of bytexd.com to the file.
You can open this file with your browser, and you’ll see the homepage of bytexd.com.
Now if the URL you used has some page with a name or some file you can use the -O or --remote-name flag to save the page/file with its original name. Let’s see this in action –
curl -O https://github.com/pbatard/rufus/releases/download/v3.14/rufus-3.14p.exe
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 619 100 619 0 0 3942 0 --:--:-- --:--:-- --:--:-- 3917
Here, I downloaded an executable file which is the Rufus tool. The file name will be rufus-3.14p.exe.
So, the main difference between the -o and -O flag is that the -o (lowercase) lets you save the file with a custom name.
Let’s understand this a bit more:
curl -L -O bytexd.com
curl -L -O bytexd.com
curl: Remote file name has no length! curl: try 'curl --help' or 'curl --manual' for more information
Now it’s clear that the -O flag cannot be used where there is no page/filename. Whereas:
curl -L -O php.net/manual/en/tutorial.firstpage.php
This will generate the file tutorial.firstpage.php which you can read.
Downloading Multiple files
You can download multiple files together using multiple -O flags. Here’s an example where we download both of the files we used as examples previously:
curl -L -O https://github.com/pbatard/rufus/releases/download/v3.14/rufus-3.14p.exe -O php.net/manual/en/tutorial.firstpage.php
curl -L -O ..rufus-3.14p.exe -O ..tutorial.firstpage.php
Resuming Downloads
If you cancel some downloads midway, you can resume them by using the -C - option:
curl -C - -O example.com/somefile.ext
With this, we’ve covered the basic cURL commands. Now we’ll move on to HTTP requests with cURL.
Basics of HTTP Requests & Responses
We need to learn some basics of the HTTP Requests & Responses before we can perform them with the cURL command efficiently.
Notice: Even though we’re starting the basics of HTTP requests, you’ve already done some HTTP requests with the curl command in previous sections. You’ll understand better to perform more commands after this section.
 Whenever your browser is loading a page from any website, it performs HTTP requests. It is a client-server model.
Whenever your browser is loading a page from any website, it performs HTTP requests. It is a client-server model.
- Your browser is the client here, and it requests the server to send back its content.
- The server provides the requested resources with the response.
The request your browser sent is called an HTTP request.
The response from the server is the HTTP response.
HTTP Requests
In the HTTP request-response model, the request is sent first.
These requests can be of different types which are called HTTP request methods.
The HTTP protocol establishes a group of methods that signals what action is required for the specific resources.
Let’s look at some of the HTTP request methods:
- GET Method: This request method does exactly as its name implies. It fetches the requested resources from the server. When a webpage is shown, the browser requests the server with this method.
- HEAD Method: This method is used when the client requests only for the HTTP Header. It does not retrieve other resources along with the header.
- POST Method: This method sends data and requests the server to accept it. The server might store it and use the data. Some common examples for this request method would be when you fill out a form and submit the data. This method would also be used when you’re uploading a photo, possibly a profile picture.
- PUT Method: This method is similar to the POST method, but it only affects the URI specified. It requests the server to create or replace the existing data. One key difference between this method and the post is that the PUT method always produces the same result when performed multiple times. The user decides the URI of the resource.
- DELETE Method: This method requests the server to delete the specified resources.
Now that you know some of the HTTP request methods, can you tell which request did you perform with the curl command in the previous sections? The GET requests. We only requested the server to send the specified data and retrieved it.
We’ll shortly go through the ways to perform other requests with the cURL command. Let’s quickly go over the HTTP responses before that.
HTTP Responses
The server responds to the HTTP requests by sending back some responses.
The structure of the HTTP response is as follows:
- Status code: This is the first line of an HTTP response. See all the codes here. (Another way to remember status codes is by seeing each code associated with a picture of silly cats – https://http.cat)
- Response Header: The response will have a header section revealing some more information about the request and the server.
- Message Body: The response might have an additional message-body attached to it. It is optional. The message body is just below the Response Header, separated by an empty line.
Let’s take a look at an example HTTP response. We’ll use the cURL command to generate a GET request and see what response the server sends back:
curl -i example.com
Don’t worry about the -i flag. It just tells the cURL command to show the response including the header.
Here is the response:
curl -i example.com
HTTP/1.1 200 OK
Age: 525920
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Sun, 16 May 2021 17:07:42 GMT
Etag: "3147526947+ident"
Expires: Sun, 23 May 2021 17:07:42 GMT
Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
Server: ECS (dcb/7F81)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 1256
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Can you break down the response?
The first line, which is highlighted, is the Status code. It means the request was successful, and we get a standard response.
Lines 2 to 12 represent the HTTP header. You can see some information like content type, date, etc.
The header ends before the empty line. Below the empty line, the message body is received.
Now you know extensive details about how the HTTP request and response work.
Let’s move on to learning how to perform some requests with the curl command.
From this section, you’ll see different HTTP requests made by the cURL command. We’ll show you some example commands and explain them along the way.
GET Request With the cURL Command
By default, the cURL command performs the GET requests when no other methods are specified.
We saw some basic commands with cURL at the beginning of the article. All of those commands sent GET requests to the server, retrieved the data, and showed them in your terminal.
Here are some examples in the context of the GET requests:
curl example.com
As we mentioned before, the -L flag enables the cURL command to follow redirects.
curl -L bytexd.com
Both will send GET requests to the servers specified.
HEAD Request With the cURL Command
We can extract the HTTP headers from the response of the server.
Why? Because sometimes you might want to take a look at the headers for some debugging or monitoring purposes.
The header is not shown when you perform GET requests with the cURL command.
For example, this command will only output the message body without the HTTP header.
curl example.com
To see only the header, we use the -I flag or the --head option.
curl -I example.com
It will output only the header section of the HTTP response.
Output
HTTP/1.1 200 OK Content-Encoding: gzip Accept-Ranges: bytes Age: 390829 Cache-Control: max-age=604800 Content-Type: text/html; charset=UTF-8 Date: Mon, 17 May 2021 19:33:52 GMT Etag: "3147526947" Expires: Mon, 24 May 2021 19:33:52 GMT Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT Server: ECS (dcb/7EEB) X-Cache: HIT Content-Length: 648
If you wanted to see the whole HTTP response, you’d use the -i flag or --include option as we mentioned earlier:
curl -i example.com
Now let’s find out why you might want to look at the headers. We’ll run the following command:
curl -I bytexd.com
Remember we couldn’t redirect to bytexd.com without the -L flag? If you didn’t include the -I flag there would’ve been no outputs.
With the -I flag you’ll get the header of the response, which offers us some information:
HTTP/1.1 301 Moved Permanently
Date: Thu, 13 May 2021 07:06:05 GMT
Connection: keep-alive
Cache-Control: max-age=3600
Expires: Thu, 13 May 2021 08:06:05 GMT
Location: https://bytexd.com/
cf-request-id: 0a062512d2000001c88dbb2000000001
Report-To: {"endpoints":[{"url":"https://a.nel.cloudflare.com/report?s=U8B0HJ%2BLZ9xb%2FodQtDu1E0YCDElQ9%2FHpFJ0kuLX6tJRdY%2F4t9rAr9e2sdeEpTtnz%2FuBnOpyJj%2BjIm74ffdfhDExFFVkAKHoJDgu3"}],"group":"cf-nel","max_age":604800}
NEL: {"report_to":"cf-nel","max_age":604800}
Server: cloudflare
CF-RAY: 64ea0acaeed601c8-SIN
alt-svc: h3-27=":443"; ma=86400, h3-28=":443"; ma=86400, h3-29=":443"; ma=86400
Look at the first line and you’ll see something interesting. It is the status code of your response. The code is 301 which indicates a redirect is necessary. As we mentioned before you can check HTTP status codes and their meanings here (Wikipedia) or here (status codes associated with silly cat pictures)
If you want to see the communication between cURL and the server then turn on the verbose option with the -v flag:
curl -v bytexd.com
Output
* Trying 104.21.37.46:80...
* TCP_NODELAY set
* Connected to bytexd.com (104.21.37.46) port 80 (#0)
> GET / HTTP/1.1
> Host: bytexd.com
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 301 Moved Permanently
< Date: Mon, 17 May 2021 19:40:57 GMT
< Transfer-Encoding: chunked
< Connection: keep-alive
< Cache-Control: max-age=3600
< Expires: Mon, 17 May 2021 20:40:57 GMT
< Location: https://bytexd.com/
< cf-request-id: 0a1d71998f00004108c090c000000001
< Report-To: {"endpoints":[{"url":"https://a.nel.cloudflare.com/report?s=y8EgEvrQ5VQuErysespUqCcmICva4jHOAap0Z1UKkT450FC4jcBLmAGOkyMcm2BhBnK7rRezgRwOOqffOIcCEJFH3zNQnO5vxy%2FO"}],"group":"cf-nel","max_age":604800}
< NEL: {"report_to":"cf-nel","max_age":604800}
< Server: cloudflare
< CF-RAY: 650f5208ee5e4108-PRG
< alt-svc: h3-27=":443"; ma=86400, h3-28=":443"; ma=86400, h3-29=":443"; ma=86400
<
* Connection #0 to host bytexd.com left intact
You can trace the whole request and response and save it to a file with the --trace option:
curl --trace-ascii file.log bytexd.com
This is important for debugging and looking under the hood.
Now you might wonder what will happen if we use the redirect option -L with the Header only -I option. Let’s try it out:
curl -L -I bytexd.com
This will show the headers for all the HTTP responses for all the redirects. Previously we saw that without the -L flag, the response only had one header. Now you’ll see two response headers.
The second one will have the status code of 200 OK which means Standard Response.
HTTP/1.1 301 Moved Permanently
Date: Thu, 13 May 2021 07:26:16 GMT
Connection: keep-alive
Cache-Control: max-age=3600
Expires: Thu, 13 May 2021 08:26:16 GMT
Location: https://bytexd.com/
cf-request-id: 0a06378cf60000ddbbac1c5000000001
Report-To: {"endpoints":[{"url":"https://a.nel.cloudflare.com/report?s=sBhAuyICvY79ULS0CZk3tMjz1y%2F%2BUiegyUCtTD7bojs1SXcXlGf26py8vLGXg%2Ba%2F%2FJAWgY2997sTMk4VS1qguJ3I%2F9IvKMe2TW7y"}],"group":"cf-nel","max_age":604800}
NEL: {"report_to":"cf-nel","max_age":604800}
Server: cloudflare
CF-RAY: 64ea285b28c7ddbb-SIN
alt-svc: h3-27=":443"; ma=86400, h3-28=":443"; ma=86400, h3-29=":443"; ma=86400
HTTP/1.1 200 OK
Date: Thu, 13 May 2021 07:26:19 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
Vary: Accept-Encoding
cf-edge-cache: cache,platform=wordpress
Link: <https://bytexd.com/wp-json/>; rel="https://api.w.org/"
X-Powered-By: WordOps
X-Frame-Options: SAMEORIGIN
X-Xss-Protection: 1; mode=block
X-Content-Type-Options: nosniff
Referrer-Policy: no-referrer, strict-origin-when-cross-origin
X-Download-Options: noopen
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
X-fastcgi-cache: HIT
CF-Cache-Status: DYNAMIC
cf-request-id: 0a063793f1000001f6efa4e000000001
Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
Report-To: {"endpoints":[{"url":"https://a.nel.cloudflare.com/report?s=vQ1vk%2BhP027gW2my981tBWMOTbmfpXYDwiJS%2BZExFsjw95qlyzHkFI2I1i3SdhuloGfDglCZRevbkdR8YdSNaD9C46KTz92qHqNd"}],"group":"cf-nel","max_age":604800}
NEL: {"report_to":"cf-nel","max_age":604800}
Server: cloudflare
CF-RAY: 64ea28664e4b01f6-SIN
alt-svc: h3-27=":443"; ma=86400, h3-28=":443"; ma=86400, h3-29=":443"; ma=86400
Now let’s move on to the POST requests.
POST Requests With the cURL Command
We already mentioned that the cURL command performs the GET request method by default. For using other request methods need to use the -X or --request flag followed by the request method.
Let’s see an example:
curl -X [method] [more options] [URI]
For using the POST method we’ll use:
curl -X POST [more options] [URI]
Sending Data Using POST Method
You can use the -d or --data option with the curl command to specify the data you want to send to the server.
This flag sends data with the content type of application/x-www-form-urlencoded.
We’ll use httpbin.org/post to send POST requests to. httpbin.org is free service HTTP request & response service and httpbin.org/post accepts POST requests and will help us better understand how requests are made.
Here’s an example with the -d flag:
curl -X POST -d "p1=value1" https://httpbin.org/post
This command will request the server to post the data p1=value1. The p1 could be any parameter having any value. The URI is used just as an example here.
Multiple data can be sent like below:
curl -X POST -d 'p1=value1' -d 'p2=value1' https://httpbin.org/post
..or..
curl -X POST -d 'p1=value1&p2=value2' https://httpbin.org/post
Uploading Files with cURL
Multipart data can be sent with the -F or --form flag which uses the multipart/form-data or form content type.
You can also send files using this flag, and you’ll also need to attach the @ prefix to attach a whole file.
Replace /root/Desktop/file with the path to any file on your computer that you want to test this command with.
curl -X POST -F '[email protected]/root/Desktop/file' https://httpbin.org/post
Upload multiple files by joining the strings representing the files to upload, joined by ;:
curl -X POST -F '[email protected]/root/Desktop/file1;fil[email protected]/root/Desktop/file2' https://httpbin.org/post
..or by using multiple -F flags:
curl -X POST -F '[email protected]/root/Desktop/file1' -F '[email protected]/root/Desktop/file2' https://httpbin.org/post
You can use the -H or --header flag to change the header content when sending data to a server. This will allow us to send custom-made requests to the server.
Specify the content type in the Header
We can specify the content type using this header.
Let’s send a JSON object with the application/json content type:
curl -H 'Content-Type: application/json' -X POST -d '{"date": "18-May-2021", "name": "Ed"}' https://httpbin.org/post
PUT Requests With the cURL Command
The PUT request will update or replace the specified content.
We’ll use httpbin.org/put for testing.
Perform the PUT request by using the -X flag:
curl -X PUT -d 'arg1=val1' -d 'arg2=val2' https://httpbin.org/put
We’ll show another example with the PUT method sending raw JSON data:
curl -X PUT -H "Content-Type: application/json" -d '{"name":"bytexd"}' https://httpbin.org/put
DELETE Requests With the cURL Command
You can request the server to delete some content with the DELETE request method.
We’ll use httpbin.org/delete for testing.
Here is the syntax for this request:
curl -X DELETE https://httpbin.org/delete
Let’s see what actually happens when we send a request like this. We can look at the status code by extracting the header:
curl -I -X DELETE https://httpbin.org/delete
HTTP/2 200 date: Mon, 17 May 2021 21:40:03 GMT content-type: application/json content-length: 319 server: gunicorn/19.9.0 access-control-allow-origin: * access-control-allow-credentials: true
Here we can see the status code is 200 which means the request was successful.
Conclusion
In this tutorial, we covered how to perform HTTP requests with the cURL command from the basics. You can learn more about the cURL command by typing man curl in the terminal.
If you have any issues, questions or feedback, then feel free to contact us or leave a comment below, and we’ll get back to you as soon as possible.