Все курсы > Программирование на Питоне > Занятие 14

Программа Jupyter Notebook — это локальная программа, которая открывается в браузере и позволяет интерактивно исполнять код на Питоне, записанный в последовательности ячеек.

Облачной версией Jupyter Notobook является программа Google Colab, которой мы уже давно пользуемся на курсах машинного обучения. Если вы проходили мои занятия, то в работе с этой программой для вас не будет почти ничего нового.
Способ 1. Если на вашем компьютере уже установлен Питон, то установить Jupyter Notebook можно через менеджер пакетов pip.
Способ 2 (рекомендуется). Кроме того, Jupyter Notebook входит в дистрибутив Питона под названием Anaconda.
На сегодняшнем занятии мы рассмотрим именно второй вариант установки.
Anaconda
Anaconda — это дистрибутив Питона и репозиторий пакетов, специально предназначенных для анализа данных и машинного обучения.
![]()
Основу дистрибутива Anaconda составляет система управления пакетами и окружениями conda.
Conda можно управлять двумя способами, а именно через Anaconda Prompt — программу, аналогичную командной строке Windows, или через Anaconda Navigator — понятный графический интерфейс.
Кроме того, в дистрибутив Anaconda входит несколько полезных программ:
- Jupyter Notebook и JupyterLab — это программы, позволяющие исполнять код на Питоне (и, как мы увидим, на других языках) и обрабатывать данные.
- Spyder и PyCharm представляют собой так называемую интегрированную среду разработки (Integrated Development Environment, IDE). IDE — это редактор кода наподобие программы Atom или Sublime Text с дополнительными возможностями автодополнения, компиляции и интерпретации, анализа ошибок, отладки (debugging), подключения к базам данных и др.
- RStudio — интегрированная среда разработки для программирования на R.
На схеме структура Anaconda выглядит следующим образом:

Установка дистрибутива Anaconda на Windows
Шаг 1. Скачайте Anaconda⧉ с официального сайта.
Шаг 2. Запустите установщик.
На одном из шагов установки вам предложат поставить две галочки, в частности (1) добавить Anaconda в переменную path и (2) сделать дистрибутив Anaconda версией, которую Windows обнаруживает по умолчанию.
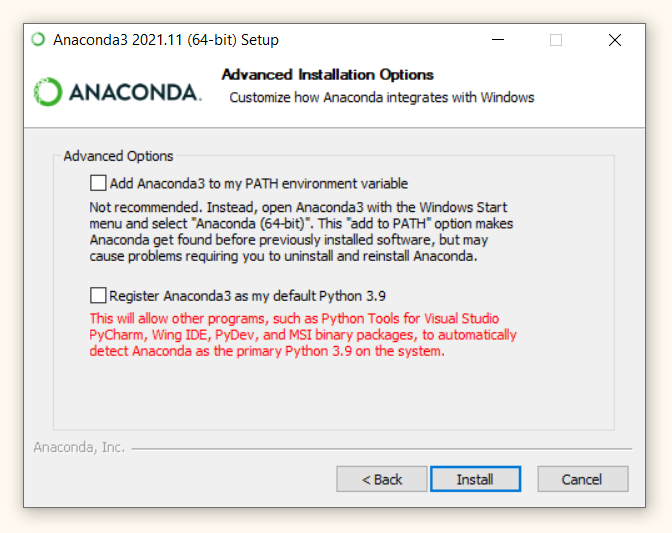
Не отмечайте ни один из пунктов!
Так вы сможете использовать два дистрибутива Питона, первый дистрибутив мы установили на прошлом занятии, второй — сейчас.
Как запустить Jupyter Notebook
После того как вы скачали и установили Anaconda, можно переходить к запуску ноутбука.
Шаг 1. Откройте Anaconda Navidator
Открыть Anaconda Navigator можно двумя способами.
Способ 1. Запуск из меню «Пуск». Просто перейдите в меню «Пуск» и выберите Anaconda Navigator.

Способ 2. Запуск через Anaconda Prompt. Также из меню «Пуск» откройте терминал Anaconda Prompt.

Введите команду
anaconda-navigator.
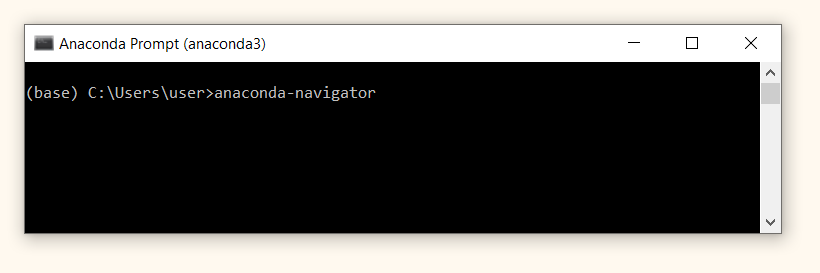
В результате должно появиться вот такое окно.

Шаг 2. Откройте Jupyter Notebook
Теперь выберите Jupyter Notebook и нажмите Launch («Запустить»).

Замечу, что Jupyter Notebook можно открыть не только из Anaconda Navigator, но и через меню «Пуск», а также введя в терминале Anaconda Prompt команду
jupyter-notebook.
В результате должен запуститься локальный сервер, и в браузере откроется перечень папок вашего компьютера.

Шаг 3. Выберите папку и создайте ноутбук
Выберите папку, в которой хотите создать ноутбук. В моем случае я выберу Рабочий стол (Desktop).
Теперь в правом верхнем углу нажмите New → Python 3.

Мы готовы писать и исполнять код точно также, как мы это делаем в Google Colab.
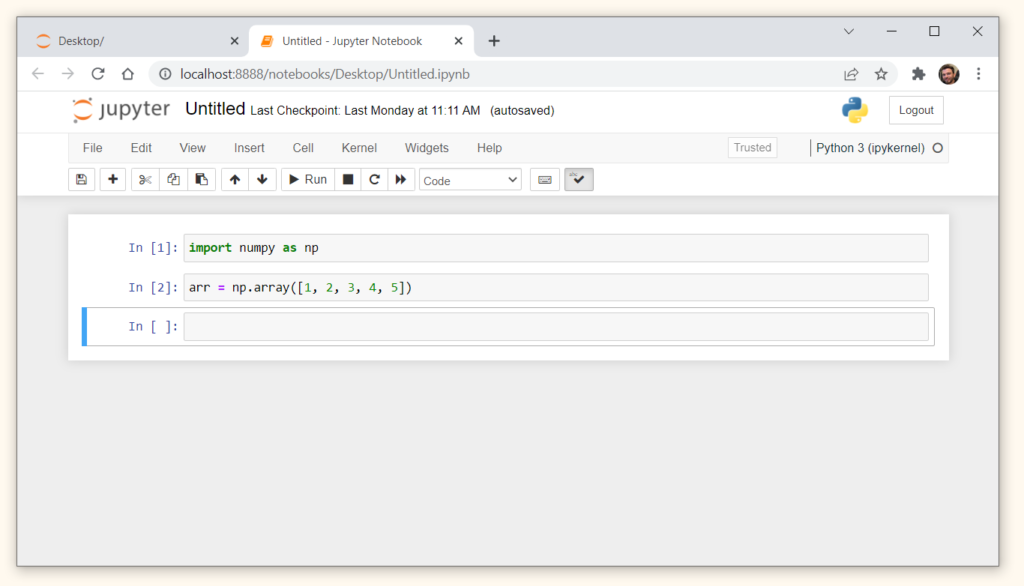
Импортируем библиотеку Numpy и создадим массив.
Шаг 4. Сохраните ноутбук и закройте Jupyter Notebook
Переименуйте ноутбук в mynotebook (для этого, как и в Google Colab, отредактируйте само название непосредственно в окне ноутбука). Сохранить файл можно через File → Save and Checkpoint.

Обратите внимание, помимо файла mynotebook.ipynb, Jupyter Notebook создал скрытую папку .ipynb_checkpoints. В ней хранятся файлы, которые позволяют вернуться к предыдущей сохраненной версии ноутбука (предыдущему check point). Сделать это можно, нажав File → Revert to Checkpoint и выбрав дату и время предыдущей сохраненной версии кода.
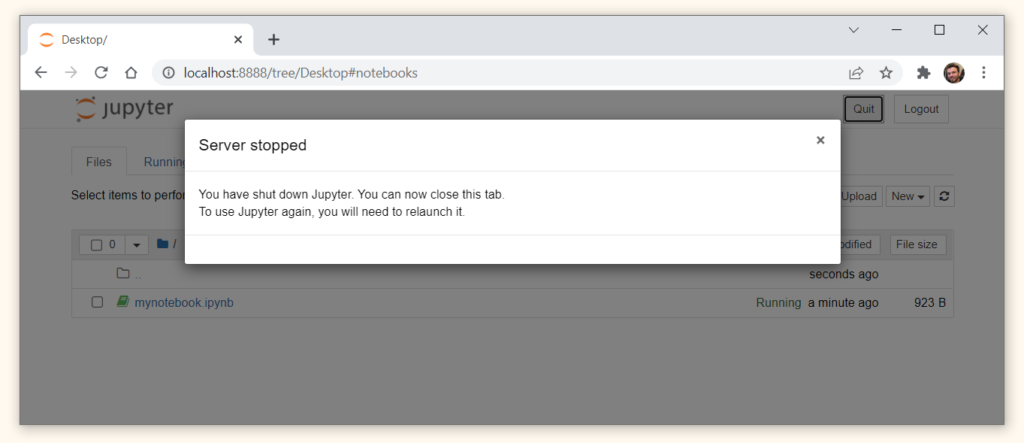
Когда вы закончили работу, закройте вкладку с ноутбуком. Остается прервать работу локального сервера, нажав Quit в правом верхнем углу.
Особенности работы
Давайте подробнее поговорим про возможности Jupyter Notebook. Снова запустим только что созданный ноутбук любым удобным способом.
Код на Python
В целом мы пишем обычный код на Питоне.
Вкладка Cell
Для управления запуском или исполнением ячеек можно использовать вкладку Cell.

Здесь мы можем, в частности:
- Запускать ячейку и оставаться в ней же через Run Cells
- Исполнять все ячейки в ноутбуке, выбрав Run All
- Исполнять все ячейки выше (Run All Above) или ниже текущей (Run All Below)
- Очистить вывод ячеек, нажав All Output → Clear
Вкладка Kernel
Командами вкладки Kernel мы управляем ядром (kernel) или вычислительным «движком» ноутбука.
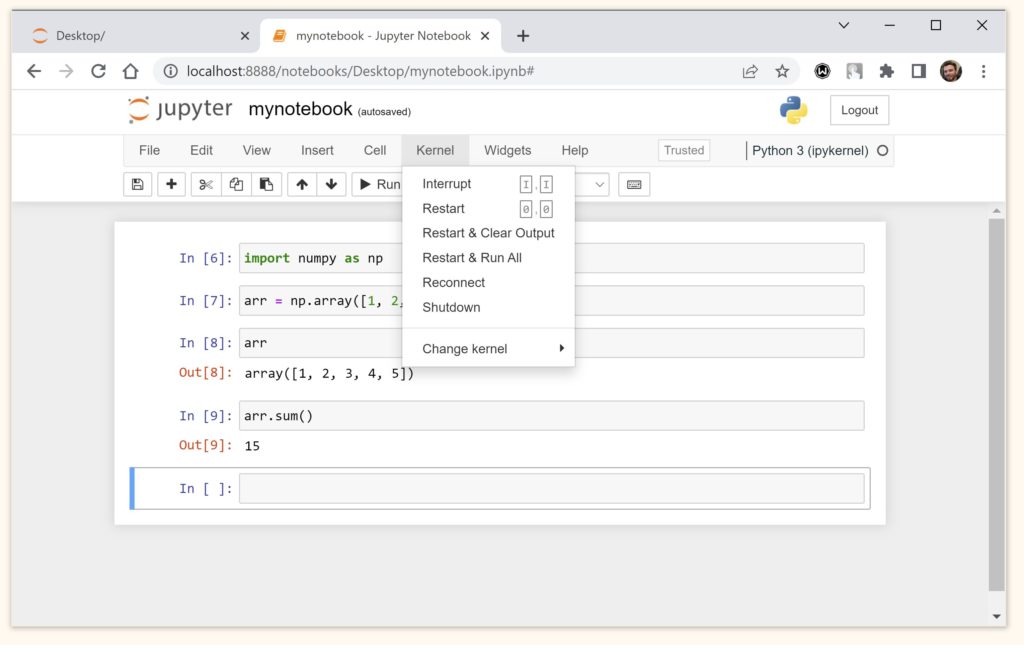
В этой вкладке мы можем, в частности:
- Прервать исполнение ячейки командой Interrupt. Это бывает полезно, если, например, исполнение кода занимает слишком много времени или в коде есть ошибка и исполнение кода не прервется самостоятельно.
- Перезапустить kernel можно командой Restart. Кроме того, можно
- очистить вывод (Restart & Clear Output) и
- заново запустить все ячейки (Restart & Run All)
Несколько слов про то, что такое ядро и как в целом функционирует Jupyter Notebook.

Пользователь взаимодействует с ноутбуком через браузер. Браузер в свою очередь отправляет запросы на сервер. Функция сервера заключается в том, чтобы загружать ноутбук и сохранять внесенные изменения в формате JSON с расширением .ipynb. Одновременно, сервер обращается к ядру в тот момент, когда необходимо обработать код на каком-либо языке (например, на Питоне).
Такое «разделение труда» между браузером, сервером и ядром позволяет во-первых, запускать Jupyter Notebook в любой операционной системе, во-вторых, в одной программе исполнять код на нескольких языках, и в-третьих, сохранять результат в файлах одного и того же формата.
Возможность программирования на нескольких языках (а значит использование нескольких ядер) мы изучим чуть позже, а пока посмотрим как устанавливать новые пакеты для Питона внутри Jupyter Notebook.
Установка новых пакетов
Установить новые пакеты в Anaconda можно непосредственно в ячейке, введя
!pip install <package_name>. Например, попробуем установить Numpy.

Система сообщила нам, что такой пакет уже установлен. Более того, мы видим путь к папке внутри дистрибутива Anaconda, в которой Jupyter «нашел» Numpy.
При подготовке этого занятия я использовал два компьютера, поэтому имя пользователя на скриншотах указано как user или dmvma. На вашем компьютере при указании пути к файлу используйте ваше имя пользователя.
В последующих разделах мы рассмотрим дополнительные возможности по установке пакетов через Anaconda Prompt и Anaconda Navigator.
По ссылке ниже вы можете скачать код, который мы создали в Jupyter Notebook.
Два Питона на одном компьютере
Обращу ваше внимание, что на данный момент на моем компьютере (как и у вас, если вы проделали шаги прошлого занятия) установлено два Питона, один с сайта www.python.org⧉, второй — в составе дистрибутива Anaconda.
Посмотреть на установленные на компьютеры «Питоны» можно, набрав команду
where python в Anaconda Prompt.

Указав полный или абсолютный путь (absolute path) к каждому из файлов python.exe, мы можем в интерактивном режиме исполнять код на версии 3.8 (установили с www.python.org) и на версии 3.10 (установили в составе Anaconda). При запуске файла python.exe из папки WindowsApps система предложит установить Питон из Microsoft Store.
В этом смысле нужно быть аккуратным и понимать, какой именно Питон вы используете и куда устанавливаете очередной пакет.
В нашем случае мы настроили работу так, чтобы устанавливать библиотеки для Питона с www.python.org через командную строку Windows, и устанавливать пакеты в Анаконду через Anaconda Prompt.
Убедиться в этом можно, проверив версии Питона через
python —version в обеих программах.

Теперь попробуйте ввести в них команду
pip list и сравнить установленные библиотеки.
Markdown в Jupyter Notebook
Вернемся к Jupyter Notebook. Помимо ячеек с кодом, можно использовать текстовые ячейки, в которых поддерживается язык разметки Markdown. Мы уже коротко рассмотрели этот язык на прошлом занятии, когда создавали пакет на Питоне.
По большому счету, с помощью несложных команд Markdown, вы говорите Jupyter как отформатировать ту или иную часть текста.
Рассмотрим несколько основных возможностей форматирования (для удобстства и в силу практически полного совпадения два последующих раздела приведены в ноутбуке Google Colab).
Откроем ноутбук к этому занятию⧉
Заголовки
Заголовки создаются с помощью символа решетки.
|
# Заголовок 1 ## Заголовок 2 ### Заголовок 3 #### Заголовок 4 ##### Заголовок 5 ###### Заголовок 6 |

Если перед первым символом решетки поставить знак , Markdown просто выведет символы решетки.

Абзацы
Абзацы отделяются друг от друга пробелами.

Мы также можем разделять абзацы прямой линией.
![]()
Выделение текста
|
**Полужирный стиль** *Курсив* ~~Перечеркнутый стиль~~ |

Форматирование кода и выделенные абзацы
Мы можем выделять код внутри строки или отдельным абзацем.
|
Отформатируем код `print(‘Hello world!’)` внутри строки и отдельным абзацем «` print(‘Hello world!’) «` |

Возможно выделение и текстовых абзацев ( так называемые blockquotes).
|
> Markdown позволяет форматировать текст без использования тэгов. > > Он был создан в 2004 году Джоном Грубером и Аароном Шварцем. |

Списки
Посмотрим на создание упорядоченных и неупорядоченных списков.
|
**Упорядоченный список** 1. Пункт 1 1. Пункт 2 (нумерация ведется автоматически) **Неупорядоченный список** * Пункт 1.1 * Пункт 2.1 * Пункт 2.2 * Пункт 3.1 * Пункт 3.2 * Пункт 1.2 |

Ссылки и изображения
Текст ссылки заключается в квадратные скобки, сама ссылка — в круглые.
|
[сайт проекта Jupyter](https://jupyter.org/) |
![]()
Изображение форматируется похожим образом.
|
 |
![]()
Таблицы
|
| id | item | price | |— |———-| ——| | 01 | pen | 200 | | 02 | pencil | 150 | | 03 | notebook | 300 | |
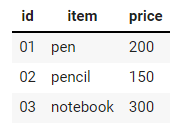
Таблицы для Markdown бывает удобно создавать с помощью специального инструмента⧉.
Формулы на LaTeX
В текстовых полях можно вставлять формулы и математические символы с помощью системы верстки, которая называется LaTeX (произносится «латэк»). Они заключаются в одинарные или двойные символы $.
Если использовать одинарный символ $, то расположенная внутри формула останется в пределах того же абзаца. Например, запись
$ y = x^2 $ даст $ y = x^2 $.
В то время как
$$ y = x^2 $$ поместит формулу в новый абзац.
$$ y = x^2 $$
Одинарный символ добавляет пробел. Двойной символ \ переводит текст на новую строку.
|
$$ hat{y} = theta_0 + theta_1 x_1 + theta_2 x_2 + ... + theta_n x_n $$ |

Рассмотрим некоторые элементы синтаксиса LaTeX.
Форматирование текста
|
$ text{just text} $ $ textbf{bold} $ $ textit{italic} $ $ underline{undeline} $ |

Надстрочные и подстрочные знаки
|
hat $ hat{x} $ bar $ bar{x} $ vector $ vec{x} $ tilde $ tilde{x} $ superscript $ e^{ax + b} $ subscript $ A_{i, j} $ degree $ 90^{circ} $ |

Скобки
Вначале рассмотрим код для скобок в пределах высоты строки.
|
$$ (a+b) [a+b] {a+b} langle x+y rangle |x+y| |x+y| $$ |
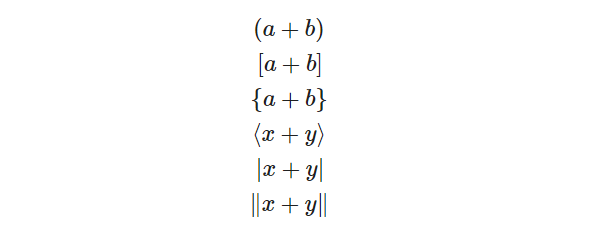
Кроме того, с помощью
left(,
right), а также
left[,
right] и так далее можно увеличить высоту скобки. Сравните.
|
$$ left(frac{1}{2}right) qquad (frac{1}{2}) $$ |

Также можно использовать отдельные команды для скобок различного размера.
|
$$ big( Big( bigg( Bigg( big] Big] bigg] Bigg] big{ Big{ bigg{ Bigg{ $$ |

Дробь и квадратный корень
|
fraction $$ frac{1}{1+e^{—z}} $$ square root $ sqrt{sigma^2} $ |
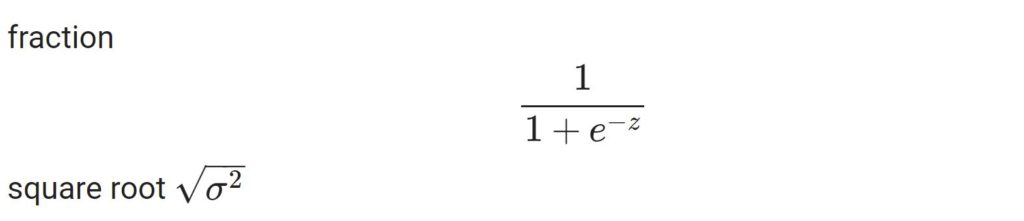
Греческие буквы
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|Uppercase | LaTeX |Lowercase | LaTeX | RU | |————— |———— |————— |———— |———— | |————— |———— |$alpha$ |alpha | альфа | |————— |———— |$beta$ |beta | бета | |$Gamma$ |Gamma |$gamma$ |gamma | гамма | |$Delta$ |Delta |$delta$ |delta | дельта | |————— |———— |$epsilon$ |epsilon | эпсилон | |————— |———— |$varepsilon$ |varepsilon | ———— | |————— |———— |$zeta$ |zeta | дзета | |————— |———— |$eta$ |eta | эта | |$Theta$ |Theta |$theta$ |theta | тета | |————— |———— |$vartheta$ |vartheta | ———— | |————— |———— |$iota$ |iota | йота | |————— |———— |$kappa$ |kappa | каппа | |$Lambda$ |Lambda |$lambda$ |lambda | лямбда | |————— |———— |$mu$ |mu | мю | |————— |———— |$nu$ |nu | ню | |$Xi$ |Xi |$xi$ |xi | кси | |————— |———— |$omicron$ |omicron | омикрон | |$Pi$ |Pi |$pi$ |pi | пи | |————— |———— |$varpi$ |varpi | ———— | |————— |———— |$rho$ |rho | ро | |————— |———— |$varrho$ |varrho | ———— | |$Sigma$ |Sigma |$sigma$ |sigma | сигма | |————— |———— |$varsigma$ |varsigma | ———— | |————— |———— |$tau$ |tau | тау | |$Upsilon$ |Upsilon |$upsilon$ |upsilon | ипсилон | |$Phi$ |Phi |$phi$ |phi | фи | |————— |———— |$varphi$ |varphi | ———— | |————— |———— |$chi$ |chi | хи | |$Psi$ |Psi |$psi$ |psi | пси | |$Omega$ |Omega |$omega$ |omega | омега | |


Латинские обозначения
|
$$ sin(—alpha) = —sin(alpha) cos(theta)=sin left( frac{pi}{2}—theta right) tan(x) = frac{sin(x)}{cos(x)} log_b(1) = 0 $$ |
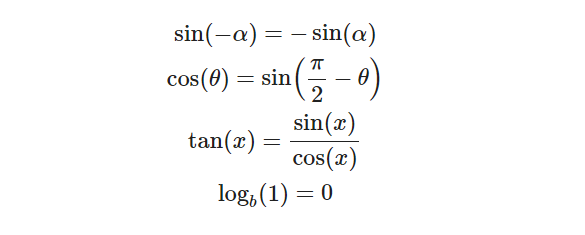
Логические символы и символы множества
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
| LaTeX | symbol | | ——————————— | ————————————— | |Rightarrow | $ Rightarrow $ | |rightarrow | $ rightarrow $ | |longleftrightarrow | $ Leftrightarrow $ | |cap | $ cap $ | |cup | $ cup $ | |subset | $ subset $ | |in | $ in $ | |notin | $ notin $ | |varnothing | $ varnothing $ | |neg | $ neg $ | |forall | $ forall $ | |exists | $ exists $ | |mathbb{N} | $ mathbb{N} $ | |mathbb{Z} | $ mathbb{Z} $ | |mathbb{Q} | $ mathbb{Q} $ | |mathbb{R} | $ mathbb{R} $ | |mathbb{C} | $ mathbb{C} $ | |

Другие символы
|
| LaTeX | symbol | | ——————————— | ————————————— | | < | $ < $ | | leq | $ leq $ | | > | $ geq $ | | neq | $ neq $ | | approx | $ approx $ | | angle | $ angle $ | | parallel | $ parallel $ | | pm | $ pm $ | | mp | $ mp $ | | cdot | $ cdot $ | | times | $ times $ | | div | $ div $ | |

Кусочная функция и система уравнений
Посмотрим на запись функции sgn (sign function) средствами LaTeX.
|
$$ sgn(x) = left{ begin{array} 1 & mbox{if } x in mathbf{N}^* 0 & mbox{if } x = 0 —1 & mbox{else.} end{array} right. $$ |

Схожим образом записывается система линейных уравнений.
|
$$ left{ begin{matrix} 4x + 3y = 20 —5x + 9y = 26 end{matrix} right. $$ |

Горизонтальная фигурная скобка
|
$$ overbrace{ underbrace{a}_{real} + underbrace{b}_{imaginary} i} ^{textit{complex number}} $$ |
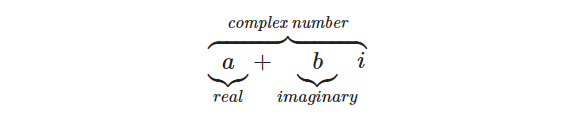
Предел, производная, интеграл
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Пределы: $$ lim_{x to +infty} f(x) $$ $$ lim_{x to —infty} f(x) $$ $$ lim_{x to с} f(x) $$ Производная (нотация Лагранжа): $$ f‘(x) $$ Частная производная (нотация Лейбница): $$ frac{partial f}{partial x} $$ Градиент: $$ nabla f(x_1, x_2) = begin{bmatrix} frac{partial f}{partial x_1} frac{partial f}{partial x_2} end{bmatrix} $$ Интеграл: $$int_{a}^b f(x)dx$$ |

Сумма и произведение
|
Сумма: $$ sumlimits_{i=1}^n a_{i} $$ $$sum_{i=1}^n a_{i} $$ Произведение: $$prod_{j=1}^m a_{j}$$ |

Матрица
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
Без скобок (plain): $$ begin{matrix} 1 & 2 & 3 a & b & c end{matrix} $$ Круглые скобки (parentheses, round brackets): $$ begin{pmatrix} 1 & 2 & 3 a & b & c end{pmatrix} $$ Квадратные скобки (square brackets): $$ begin{bmatrix} 1 & 2 & 3 a & b & c end{bmatrix} $$ Фигурные скобки (curly brackets, braces): $$ begin{Bmatrix} 1 & 2 & 3 a & b & c end{Bmatrix} $$ Прямые скобки (pipes): $$ begin{vmatrix} 1 & 2 & 3 a & b & c end{vmatrix} $$ Двойные прямые скобки (double pipes): $$ begin{Vmatrix} 1 & 2 & 3 a & b & c end{Vmatrix} $$ |

Программирование на R
Jupyter Notebook позволяет писать код на других языках программирования, не только на Питоне. Попробуем написать и исполнить код на R, языке, который специально разрабатывался для data science.
Вначале нам понадобится установить kernel для R. Откроем Anaconda Prompt и введем следующую команду
conda install -c r r-irkernel. В процессе установки система спросит продолжать или нет (Proceed ([y]/n)?). Нажмите y + Enter.
Откройте Jupyter Notebook. В списке файлов создайте ноутбук на R. Назовем его rprogramming.

После установки нового ядра и создания еще одного файла .ipynb схема работы нашего Jupyter Notebook немного изменилась.
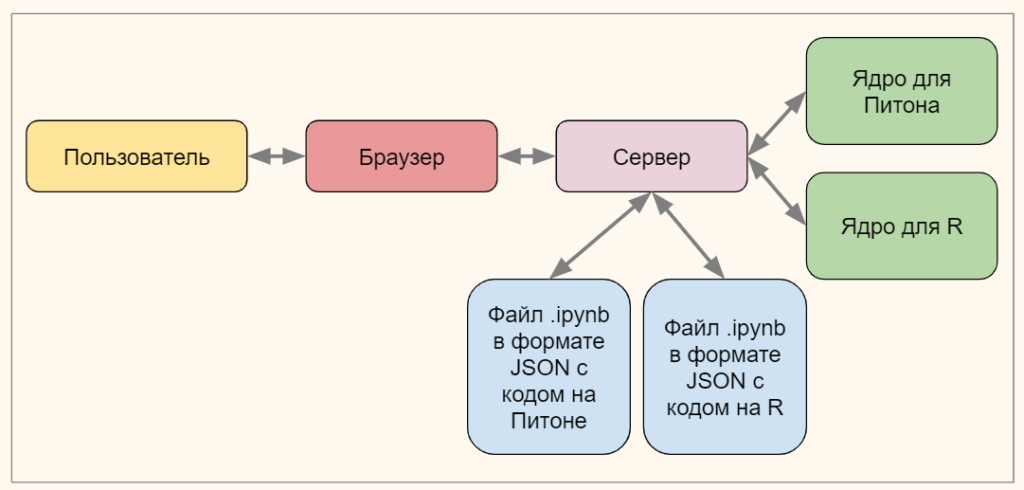
Теперь мы готовы писать код на R. Мы уже начали знакомиться с этим языком, когда изучали парадигмы программирования. Сегодня мы рассмотрим основные типы данных и особенности синтаксиса.
Переменные в R
Числовые, строковые и логические переменные
Как и в Питоне, в R мы можем создавать числовые (numeric), строковые (character) и логические (logical) переменные.
|
# поместим число 42 в переменную numeric_var numeric_var = 42 # строку поместим в переменную text_var text_var <— ‘Hello world!’ # наконец присвоим значение TRUE переменной logical_var TRUE -> logical_var |
Для присвоения значений можно использовать как оператор
=, так и операторы присваивания
<— и
->. Обратите внимание, используя
-> мы можем поместить значение слева, а переменную справа.
Посмотрим на результат (в Jupyter Notebook можно обойтись без функции print()).
Выведем класс созданных нами объектов с помощью функции class().
|
class(numeric_var) class(text_var) class(logical_var) |
|
‘numeric’ ‘character’ ‘logical’ |
Тип данных можно посмотреть с помощью функции typeof().
|
typeof(numeric_var) typeof(text_var) typeof(logical_var) |
|
‘double’ ‘character’ ‘logical’ |
Хотя вывод этих функций очень похож, мы, тем не менее, видим, что классу numeric соответствует тип данных double (число с плавающей точкой с двумя знаками после запятой).
Числовые переменные: numeric, double, integer
По умолчанию, в R и целые числа, и дроби хранятся в формате double.
|
# еще раз поместим число 42 в переменную numeric_var numeric_var <— 42 # выведем тип данных typeof(numeric_var) |
Принудительно перевести 42 в целочисленное значение можно с помощью функции as.integer().
|
int_var <— as.integer(numeric_var) typeof(int_var) |
Кроме того, если после числа поставить L, это число автоматически превратится в integer.
Превратить integer обратно в double можно с помощью функций as.double() и as.numeric().
|
typeof(as.double(int_var)) typeof(as.numeric(42L)) |
Если число хранится в формате строки, его можно перевести обратно в число (integer или double).
|
text_var <— ’42’ typeof(text_var) |
|
typeof(as.numeric(text_var)) # можно также использовать as.double() typeof(as.integer(text_var)) |
Вектор
Вектор (vector) — это одномерная структура, которая может содержать множество элементов одного типа. Вектор можно создать с помощью функции c().
|
# создадим вектор с информацией о продажах товара в магазине за неделю (в тыс. рублей) sales <— c(24, 28, 32, 25, 30, 31, 29) sales |
С помощью функций length() и typeof() мы можем посмотреть соответственно общее количество элементов и тип данных каждого из них.
|
# посмотрим на общее количество элементов и тип данных каждого из них length(sales) typeof(sales) |
У вектора есть индекс, который (в отличие, например, от списков в Питоне), начинается с единицы.
При указании диапазона выводятся и первый, и последний его элементы.
Отрицательный индекс убирает элементы из вектора.
Именованный вектор (named vector) создается с помощью функции names().
|
# создадим еще один вектор с названиями дней недели days_vector <— c(‘Понедельник’, ‘Вторник’, ‘Среда’, ‘Четверг’, ‘Пятница’, ‘Суббота’, ‘Воскресенье’) days_vector |
|
‘Понедельник’ ‘Вторник’ ‘Среда’ ‘Четверг’ ‘Пятница’ ‘Суббота’ ‘Воскресенье’ |
|
# создадим именованный вектор с помощью функции names() names(sales) <— days_vector sales |
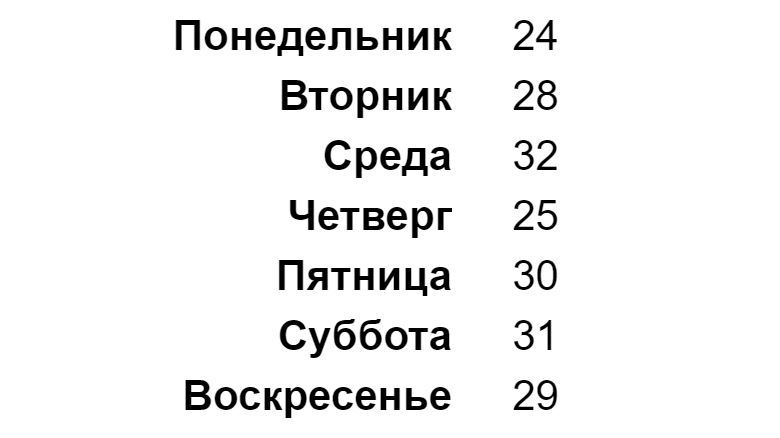
Выводить элементы именованного вектора можно не только по числовому индексу, но и по их названиям.
Список
В отличие от вектора, список (list) может содержать множество элементов различных типов.
|
# список создается с помощью функции list() list(‘DS’, ‘ML’, c(21, 24), c(TRUE, FALSE), 42.0) |
|
[[1]] [1] «DS» [[2]] [1] «ML» [[3]] [1] 21 24 [[4]] [1] TRUE FALSE [[5]] [1] 42 |
Матрица
Матрица (matrix) в R — это двумерная структура, содержащая одинаковый тип данных (чаще всего числовой). Матрица создается с помощью функции matrix() с параметрами data, nrow, ncol и byrow.
- data — данные для создания матрицы
- nrow и ncol — количество строк и столбцов
- byrow — параметр, указывающий заполнять ли элементы матрицы построчно (TRUE) или по столбцам (FALSE)
Рассмотрим несколько примеров. Cоздадим последовательность целых чисел (по сути, тоже вектор).
|
# для этого подойдет функция seq() sqn <— seq(1:9) sqn typeof(sqn) |
|
1 2 3 4 5 6 7 8 9 ‘integer’ |
Используем эту последовательность для создания двух матриц.
|
# создадим матрицу, заполняя значения построчно mtx <— matrix(sqn, nrow = 3, ncol = 3, byrow = TRUE) mtx |

|
# теперь создадим матрицу, заполняя значения по столбцам mtx <— matrix(sqn, nrow = 3, ncol = 3, byrow = FALSE) mtx |

Зададим названия для строк и столбцов второй матрицы.
|
# создадим два вектора с названиями строк и столбцов rows <— c(‘Row 1’, ‘Row 2’, ‘Row 3’) cols <— c(‘Col 1’, ‘Col 2’, ‘Col 3’) # используем функции rownames() и colnames(), # чтобы передать эти названия нашей матрице rownames(mtx) <— rows colnames(mtx) <— cols # посмотрим на результат mtx |
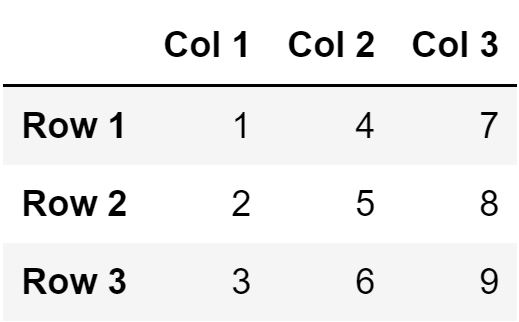
Посмотрим на размерность этой матрицы с помощью функции dim().
Массив
В отличие от матрицы, массив (array) — это многомерная структура. Создадим трехмерный массив размерностью 3 х 2 х 3. Вначале создадим три матрицы размером 3 х 2.
|
# создадим три матрицы размером 3 х 2, # заполненные пятерками, шестерками и семерками a <— matrix(5, 3, 2) b <— matrix(6, 3, 2) c <— matrix(7, 3, 2) |
Теперь соединим их с помощью функции array(). Передадим этой функции два параметра в форме векторов: данные (data) и размерность (dim).
|
arr <— array(data = c(a, b, c), # вектор с матрицами dim = c(3, 2, 3)) # вектор размерности print(arr) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
, , 1 [,1] [,2] [1,] 5 5 [2,] 5 5 [3,] 5 5 , , 2 [,1] [,2] [1,] 6 6 [2,] 6 6 [3,] 6 6 , , 3 [,1] [,2] [1,] 7 7 [2,] 7 7 [3,] 7 7 |
Факторная переменная
Факторная переменная или фактор (factor) — специальная структура для хранения категориальных данных. Вначале немного теории.
Как мы узнаем на курсе анализа данных, категориальные данные бывают номинальными и порядковыми. Номинальные категориальные (nominal categorical) данные представлены категориями, в которых нет естественного внутреннего порядка. Например, пол или цвет волос человека, марка автомобиля могут быть отнесены к определенным категориям, но не могут быть упорядочены.
Порядковые категориальные (ordinal categorical) данные наоборот обладают внутренним, свойственным им порядком. К таким данным относятся шкала удовлетворенности потребителей, класс железнодорожного билета, должность или звание, а также любая количественная переменная, разбитая на категории (например, низкий, средний и высокий уровень зарплат).
Посмотрим, как учесть такие данные с помощью R. Начнем с номинальных данных.
|
# предположим, что мы собрали данные о цветах нескольких автомобилей и поместили их в вектор color_vector <— c(‘blue’, ‘blue’, ‘white’, ‘black’, ‘yellow’, ‘white’, ‘white’) # преобразуем этот вектор в фактор с помощью функции factor() factor_color <— factor(color_vector) factor_color |

Как вы видите, функция factor() разбила данные на категории, при этом эти категории остались неупорядоченными. Посмотрим на класс созданного объекта.
Теперь поработаем с порядковыми данными.
|
# возьмем данные измерений температуры, выраженные категориями temperature_vector <— c(‘High’, ‘Low’, ‘High’,‘Low’, ‘Medium’, ‘High’, ‘Low’) # создадим фактор factor_temperature <— factor(temperature_vector, # указав параметр order = TRUE order = TRUE, # а также вектор упорядоченных категорий levels = c(‘Low’, ‘Medium’, ‘High’)) # посмотрим на результат factor_temperature |

Выведем класс созданного объекта.
|
class(factor_temperature) |
Добавлю, что количество элементов в каждой из категорий можно посмотреть с помощью функции summary().
|
summary(factor_temperature) |

Датафрейм
Датафрейм в R выполняет примерно ту же функцию, что и в Питоне. С помощью функции data.frame() создадим простой датафрейм, гда параметрами будут названия столбцов, а аргументами — векторы их значений.
|
df <— data.frame(city = c(‘Москва’, ‘Париж’, ‘Лондон’), population = c(12.7, 2.1, 8.9), country = c(‘Россия’, ‘Франция’, ‘Великобритания’)) df |
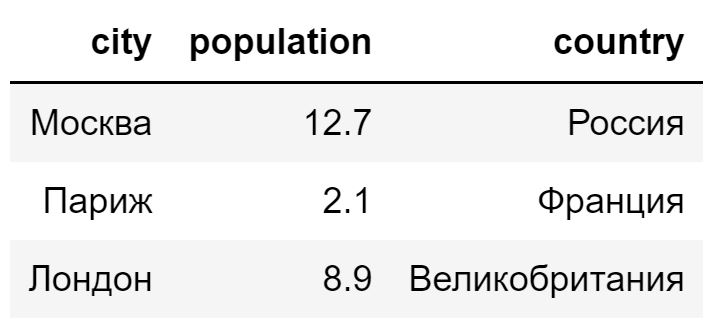
Доступ к элементам датафрейма можно получить по индексам строк и столбцов, которые также начинаются с единицы.
|
# выведем значения первой строки и первого столбца df[1, 1] |

|
# выведем всю первую строку df[1,] |

|
# выведем второй столбец df[,2] |
Получить доступ к столбцам можно и так.
Дополнительные пакеты
Как и в Питоне, в R мы можем установить дополнительные пакеты через Anaconda Prompt. Например, установим пакет ggplot2 для визуализации данных. Для этого введем команду
conda install r-ggplot2.
В целом команда установки пакетов для R следующая:
conda install r-<package_name>.
Продемонстрируем работу с этим пакетом с помощью несложного датасета mtcars.
|
# импортируем библиотеку datasets library(datasets) # загрузим датасет mtcars data(mtcars) # выведем его на экран mtcars |

Теперь импортируем установленную ранее библиотеку ggplot2.
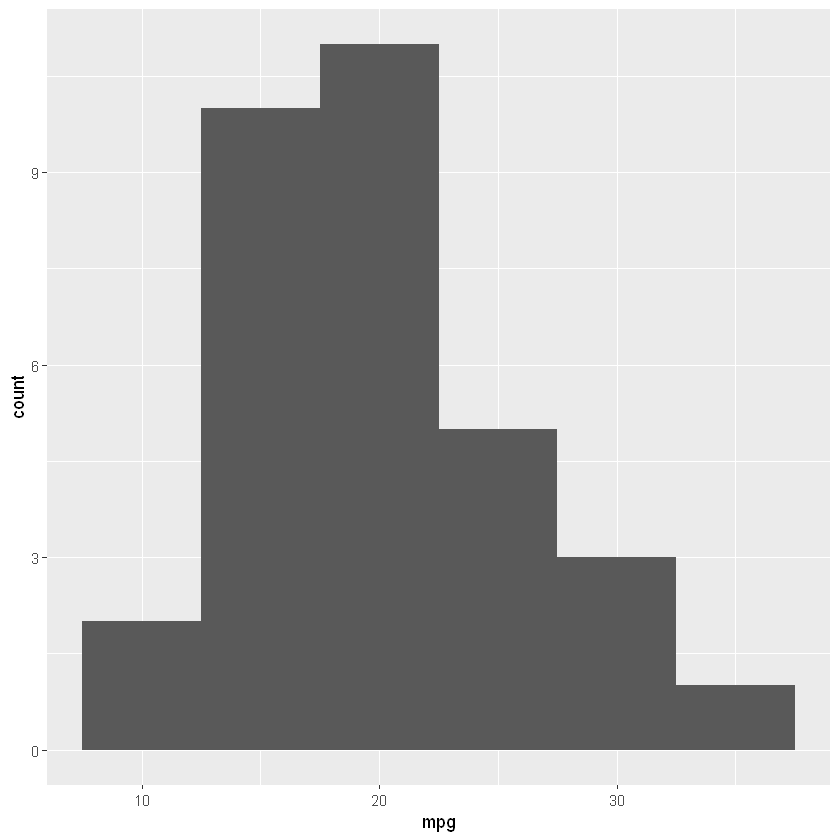
Построим гистограмму по столбцу mpg (miles per galon, расход в милях на галлон топлива). Для построения гистограммы нам потребуется через «+» объединить две функции:
- функцию ggplot(), которой мы передадим наши данные и еще одну функцию aes(), от англ. aesthetics, которая свяжет ось x нашего графика и столбец данных mpg, а также
- функцию geom_histogram() с параметрами bins (количество интервалов) и binwidth (их ширина), которая и будет отвечать за создание гистограммы
|
# данными будет датасет mtcars, столбцом по оси x — mpg ggplot(data = mtcars, aes(x = mpg)) + # типом графика будет гистограмма с 10 интервалами шириной 5 миль на галлон каждый geom_histogram(bins = 10, binwidth = 5) |
Примерно также мы можем построить график плотности распределения (density plot). Только теперь мы передадим функции aes() еще один параметр
fill = as.factor(vs), который (предварительно превратив столбец в фактор через as.factor()) позволит разбить данные на две категории по столбцу vs. В этом датасете признак vs указывает на конфигурацию двигателя (расположение цилиндров), v-образное, v-shaped (vs == 0) или рядное, straight (vs == 1).
Кроме того, для непосредственного построения графика мы будем использовать новую функцию geom_density() с параметром alpha, отвечающим за прозрачность заполнения пространства под кривыми.
|
ggplot(data = mtcars, aes(x = mpg, fill = as.factor(vs))) + geom_density(alpha = 0.3) |

Дополнительно замечу, что к столбцам датафрейма можно применять множество различных функций, например, рассчитать среднее арифметическое или медиану с помощью несложных для запоминания mean() и median().
|
mean(mtcars$mpg) median(mtcars$mpg) |
Кроме того, мы можем применить уже знакомую нам функцию summary(), которая для количественного столбца выдаст минимальное и максимальное значения, первый (Q1) и третий (Q2) квартили, а также медиану и среднее значение.
|
Min. 1st Qu. Median Mean 3rd Qu. Max. 10.40 15.43 19.20 20.09 22.80 33.90 |
В файле ниже содержится созданный нами код на R.
Вернемся к основной теме занятия.
Подробнее про Anaconda
Conda
Программа conda, как уже было сказано, объединяет в себе систему управления пакетами (как pip) и, кроме того, позволяет создавать окружения.
Идея виртуального окружения (virtual environment) заключается в том, что если в рамках вашего проекта вы, например, используете определенную версию библиотеки Numpy и установка более ранней или более поздней версии приведет к сбоям в работе вашего кода, хорошим решением была бы изоляция нужной версии Numpy, а также всех остальных используемых вами библиотек. Именно для этого и нужно виртуальное окружение.
Рассмотрим, как мы можем устанавливать пакеты и создавать окружения через Anaconda Prompt и через Anaconda Navigator.
Anaconda Prompt
Про пакеты. По аналогии с pip, установленные (в текущем окружении) пакеты можно посмотреть с помощью команды
conda list.
Установить пакет можно с помощью команды
conda install <package_name>. Обновить пакет можно через
conda update <package_name>. Например, снова попробуем установить Numpy. о

Про окружения. По умолчанию мы работаем в базовом окружении (base environment). Посмотреть, какие в целом установлены окружения можно с помощью команды
conda info —envs.

Как вы видите, пока у нас есть только одно окружение. Давайте создадим еще одно виртуальное окружение и назовем его, например, waterfall.
Введите команду
conda create —name waterfall.
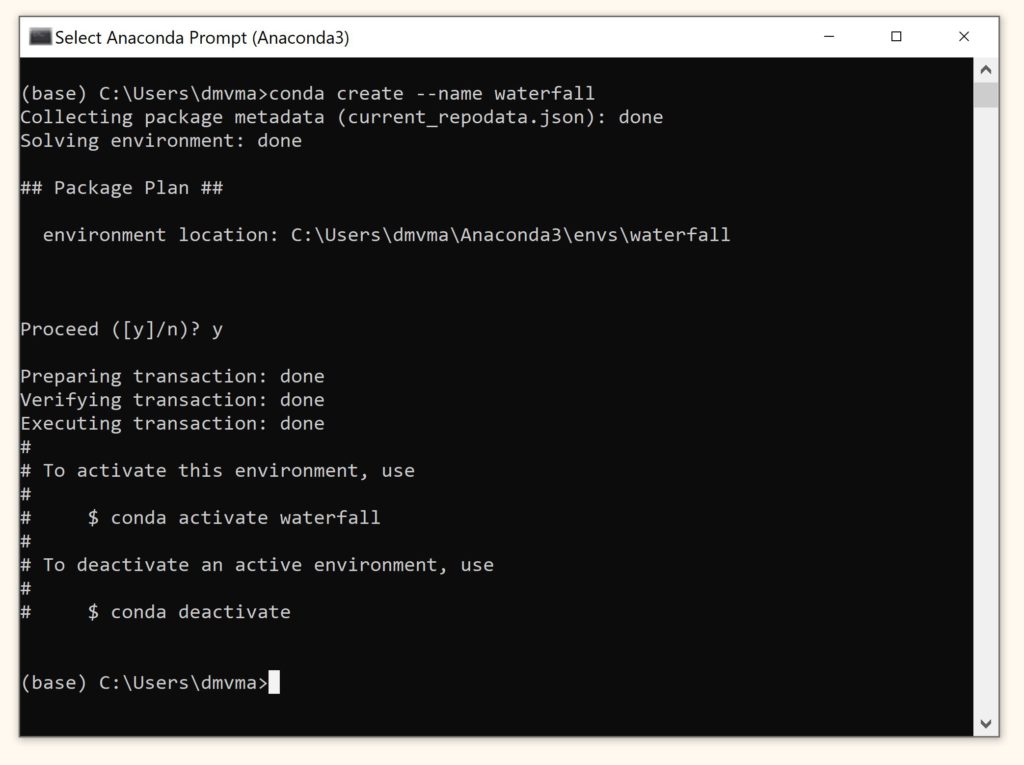
Введем две команды
- conda activate waterfall для активации нового окружения
- conda list для того, чтобы посмотреть установленные в нем пакеты

Как вы видите, в новом окружении нет ни одного пакета. Введем
conda search seaborn, чтобы посмотреть какие версии этого пакета доступны для скачивания.
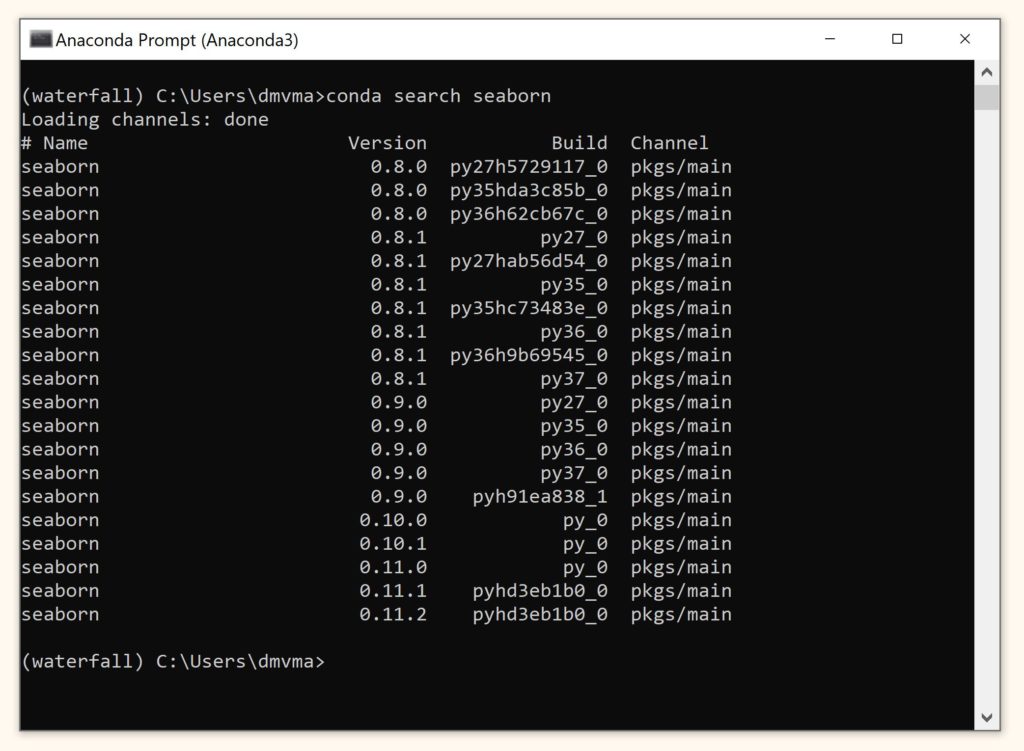
Скачаем этот пакет через
conda install seaborn. Проверим установку с помощью
conda list.
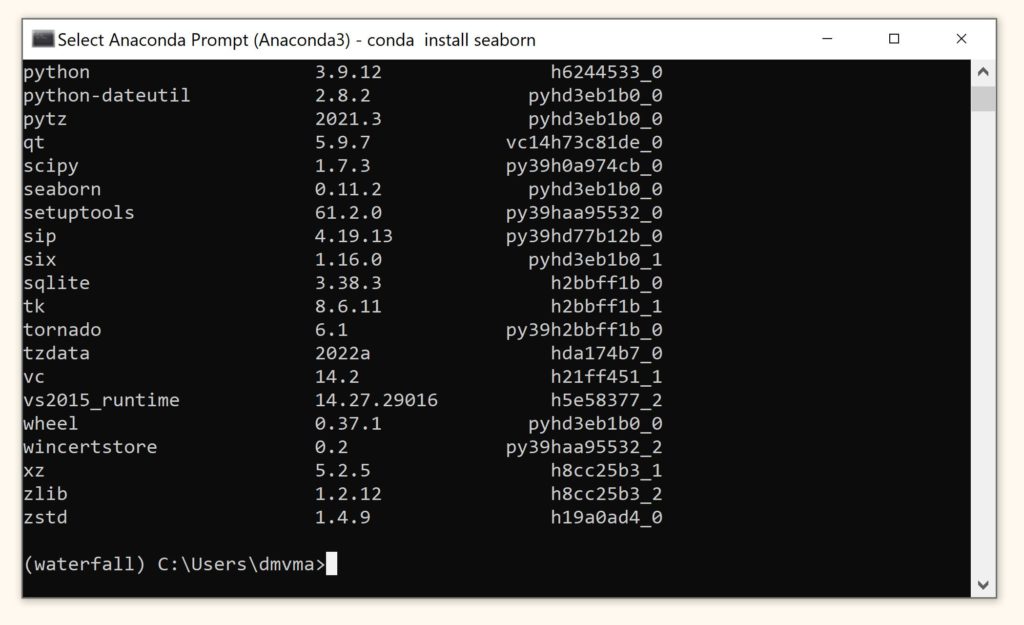
Как вы видите, помимо seaborn было установлено множество других необходимых для работы пакета библиотек. Вернуться в базовое окружение можно с помощью команд
conda activate base или
conda deactivate.
Импорт модулей и переменная path
На прошлом занятии мы научились импортировать собственный модуль в командной строке Windows (cmd).
Посмотрим, отличается ли содержимое списка path для двух установленных версий Питона. Для этого в командной строке Windows и в Anaconda Prompt перейдем в интерактивный режим с помощью
python. Затем введем

Как мы видим, пути в переменной path будут отличаться и это нужно учитывать, если мы хотим локально запускать собственные модули.
Anaconda Navigator
Запускать программы, управлять окружениями и устанавливать необходимые библиотеки можно также через Anaconda Nagivator. На вкладке Home вы видите программы, которые можно открыть (launch) или установить (install) для текущего окружения.

На вкладке Environments отображаются созданные нами окружения (в частности, окружение waterfall, которое мы создали ранее) и содержащиеся в них пакеты.
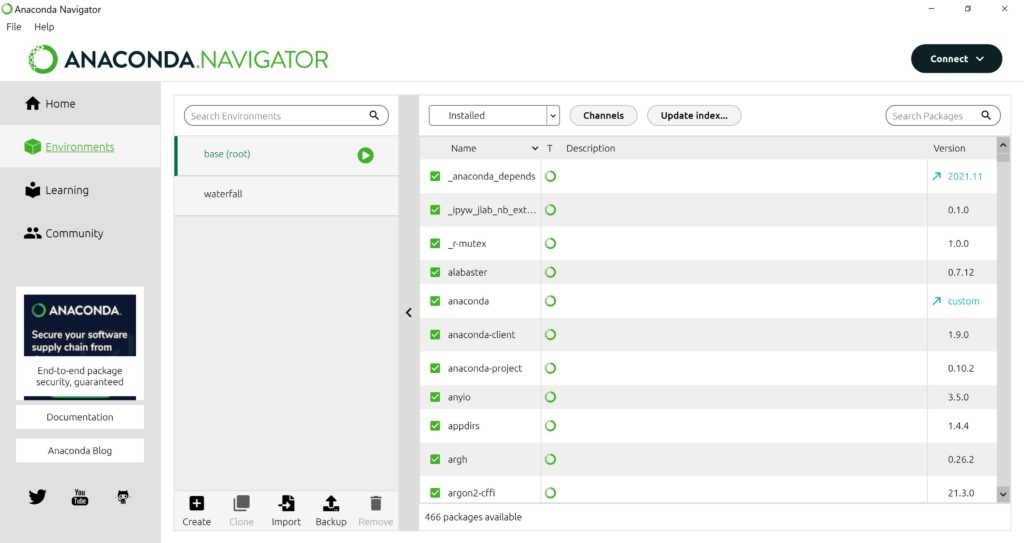
В целом интерфейс интуитивно понятен, и так как мы уже познакомились с принципом создания окружений и установки в них дополнительных пакетов, уверен, работа с Anaconda Navigator сложностей не вызовет.
Прежде чем завершить, обратимся к еще одной программе для интерактивного программирования JupyterLab.
JupyterLab
JupyterLab — расширенная версия Jupyter Notebook, которая также входит в дистрибутив Anaconda. Запустить эту программу можно через Anaconda Navigator или введя команду
jupyter lab в Anaconda Prompt.
После запуска вы увидите вкладку Launcher, в которой можно создать новый ноутбук (Notebook) на Питоне или R, открыть консоль (Console) на этих языках, а также создать файлы в различных форматах (Other). Слева вы видите список папок компьютера.
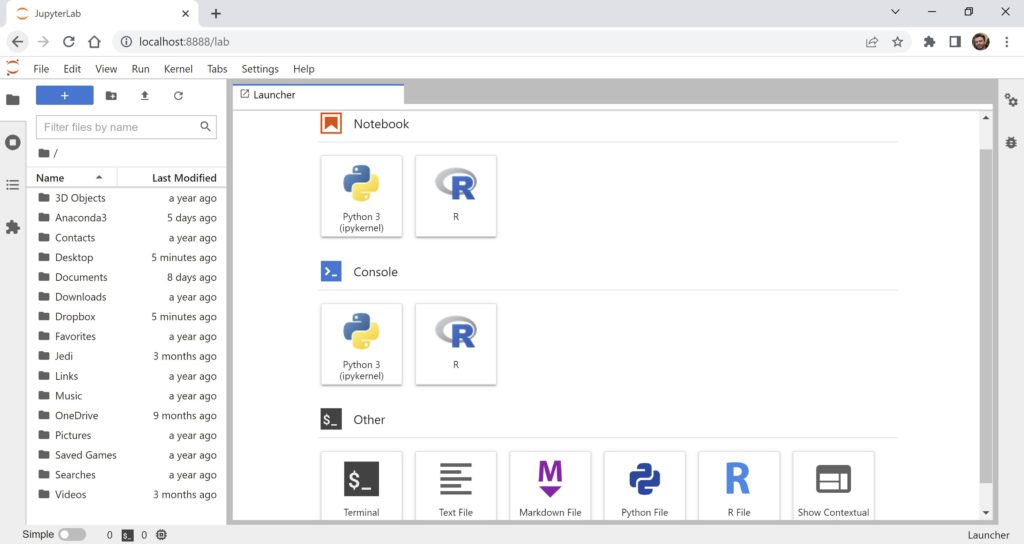
В разделе Console нажмем на Python 3 (ipykernel). Введем несложный код (см. ниже) и исполним его, нажимая Shift + Enter.
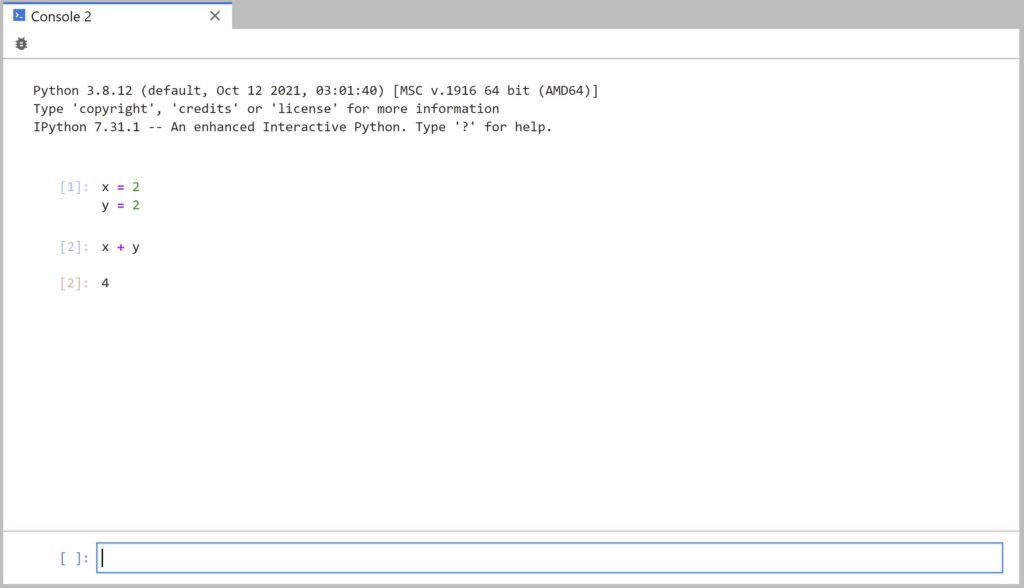
Как вы видите, здесь мы можем писать код на Питоне так же, как мы это делали в командной строке Windows на прошлом занятии. Закроем консоль.
В файловой системе слева мы можем открывать уже созданные ноутбуки. Например, откроем ноутбук на R rprogramming.ipynb.
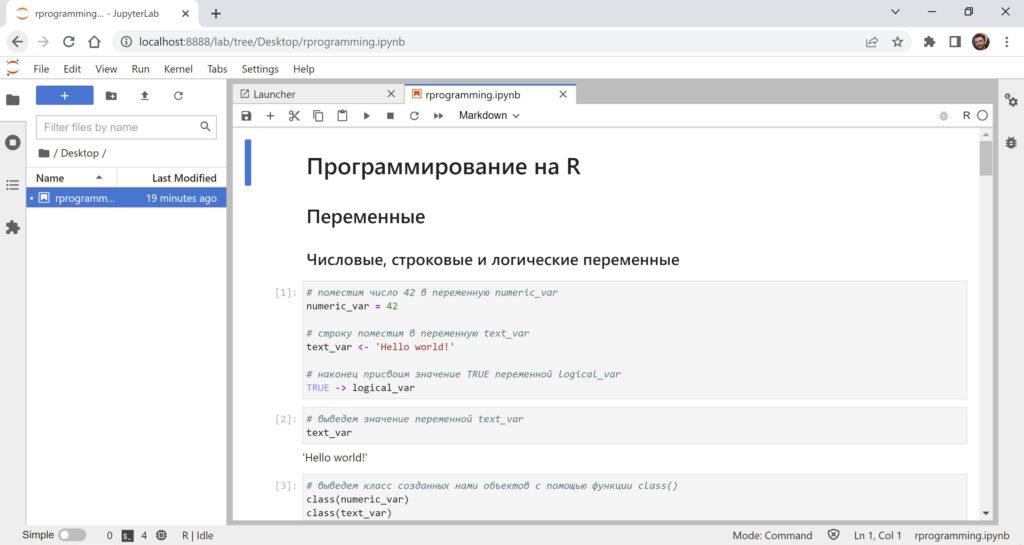
В левом меню на второй сверху вкладке мы видим открытые горизонтальные вкладки (Launcher и rprogramming.ipynb), а также запущенные ядра (kernels).
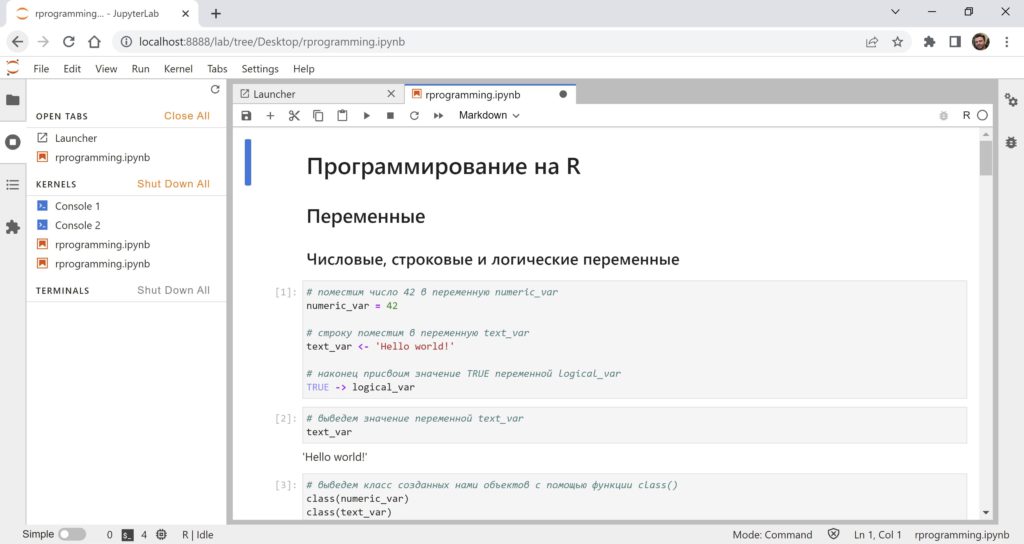
Консольные ядра (Console 1 и Console 2) можно открыть (по сути, мы снова запустим консоль).

Две оставшиеся вертикальные вкладки открывают доступ к автоматическому оглавлению (content) и расширениям (extensions).

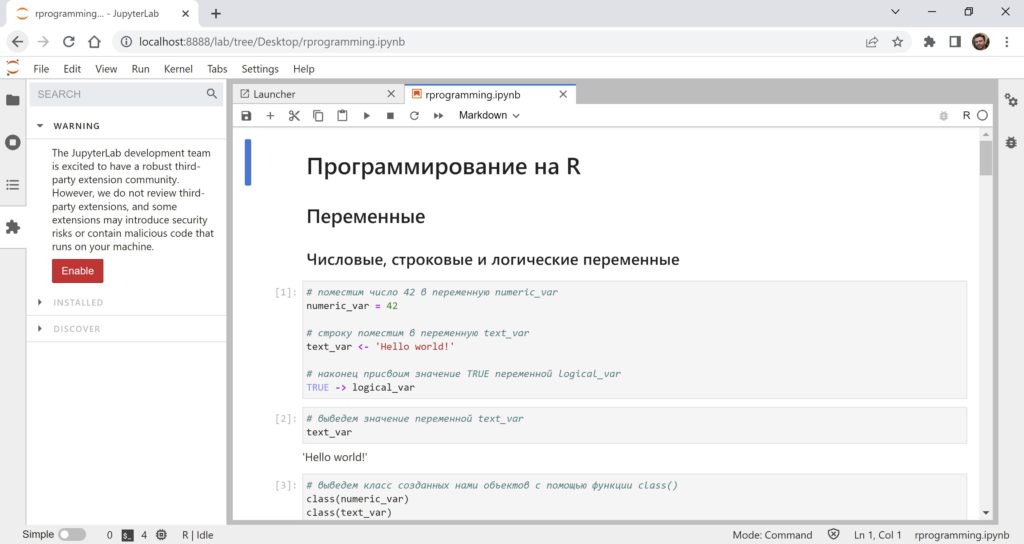
Вкладки Run и Kernel в верхнем меню JupyterLab в целом аналогичны вкладкам Cell и Kernel в JupyterNotebook.
Подведем итог
На сегодняшнем занятии мы познакомились с программой Jupyter Notebook, а также изучили дистрибутив Anaconda, в состав которого входит эта программа.
Говоря о программе Jupyter Notebook, мы узнали про возможности работы с ячейками и ядром программы. Кроме того, мы познакомились с языком разметки Markdown и написанием формул с помощью языка верстки LaTeX.
После этого мы установили ядро для программирования на R и рассмотрели основы этого языка.
При изучении дистрибутива Anaconda мы позникомились с системой conda и попрактиковались в установке библиотек и создании окружений через Anaconda Prompt и Anaconda Navigator.
Наконец мы узнали про особенности программы JupyterLab.
Вопросы для закрепления
Вопрос. Что такое Anaconda?
Посмотреть правильный ответ
Ответ: Anaconda — это дистрибутив Питона (с репозиторием пакетов) и отдельной программой управления окружениями и пакетами conda. Пользователь может взаимодействовать с этой программой через терминал (Anaconda Prompt) и графический интерфейс (Anaconda Navigator).
Помимо этого, в дистрибутив Anaconda входят, среди прочих, программы Jupyter Notebook и JupyterLab.
Вопрос. Какой тип ячеек доступен в Jupyter Notebook?
Посмотреть правильный ответ
Ответ: в Jupyter Notebook есть два основных типа ячеек — ячейки для написания кода (в частности, на Питоне и R) и текстовые ячейки, поддерживающие Markdown и LaTeX.
Вопрос. Для чего нужно виртуальное окружение?
Посмотреть правильный ответ
Ответ: виртуальное окружение (virtual environment) позволяет установить и изолировать определенные версии Питона и его пакетов. Таким образом код, написанный с учетом конкретной версии Питона и дополнительных библиотек, исполнится без ошибок.
Ответы на вопросы
Вопрос. Можно ли исполнить код на R в Google Colab?
Ответ. Да, это возможно. Причем двумя способами.
Способ 1. Откройте ноутбук. Введите и исполните команду
%load_ext rpy2.ipython. В последующих ячейках введите
%R, чтобы в этой же строке написать код на R или
%%R, если хотите, чтобы вся ячейка исполнилась как код на R (так называемые магические команды).
В этом случае мы можем исполнять код на двух языках внутри одного ноутбука.
|
# введем магическую команду, которая позволит программировать на R %load_ext rpy2.ipython |
|
# команда %%R позволит Colab распознать ячейку как код на R %%R # кстати, числовой вектор можно создать просто с помощью двоеточия x <— 1:10 x |
|
# при этом ничто не мешает нам продолжать писать код на Питоне import numpy as np np.mean([1, 2, 3]) |
Приведенный выше код можно найти в дополнительных материалах⧉ к занятию.
Способ 2. Если вы хотите, чтобы весь код исполнялся на R (как мы это делали в Jupyter Notebook), создайте новый ноутбук используя одну из ссылок ниже:
- https://colab.research.google.com/#create=true&language=r⧉
- https://colab.to/r⧉
Теперь, если вы зайдете на вкладку Runtime → Change runtime type, то увидите, что можете выбирать между Python и R.

Выведем версию R в Google Colab.
|
‘R version 4.2.0 (2022-04-22)’ |
Посмотреть на установленные пакеты можно с помощью
installed.packages(). Созданный ноутбук Google Colab на R доступен по ссылке⧉.
Вопрос. Очень медленно загружается Anaconda. Можно ли что-то сделать?
Ответ. Можно работать через Anaconda Prompt, эта программа быстрее графического интерфейса Anaconda Navigator.
Кроме того, можно использовать дистрибутив Miniconda⧉, в который входит conda, Питон и несколько ключевых пакетов. Остальные пакеты устанавливаются вручную по мере необходимости.
Вопрос. Разве Jupyter не должен писаться через i, как Jupiter?
Ответ. Вы правы в том плане, что название Jupyter Notebook происходит не от планеты Юпитер, которая по-английски как раз пишется через i (Jupiter), а представляет собой акроним от названий языков программирования Julia, Python и R.
При этом, как утверждают разработчики⧉, слово Jupyter также отсылает к тетрадям (notebooks) Галилея, в которых он, в частности, документировал наблюдение за лунами Юпитера.
Вопрос. В каких еще программах можно писать код на Питоне и R?
Ответ. Таких программ несколько. Довольно удобно пользоваться облачным решением Kaggle. Там можно создавать как скрипты (scripts, в том числе RMarkdown Scripts), так и ноутбуки на Питоне и R. Подробнее можно почитать в документации⧉ на их сайте.
Вопрос. Можно ли создать виртуальное окружение каким-либо другим способом помимо программы conda?
Ответ. Да, можно. Вот здесь⧉ есть хорошая видео-инструкция.
Вот коротко какие шаги нужно выполнить.
Вначале убедитесь, что у вас уже установлен Питон. В нем по умолчанию содержится модуль venv, который как раз предназначен для создания виртуального окружения.
Шаг 1. Создайте папку с вашим проектом, например, пусть это будет папка webapp для веб-приложения на популярном фреймворке для Питона Django.
Шаг 2. В командной строке перейдите в папку webapp.
Затем введите команду для создания виртуального окружения.
По сути мы говорим Питону создать окружение djenv (название может быть любым) с помощью модуля venv. Переключатель (flag или switch)
-m подсказывает питону, что venv — это модуль, а не файл.
После выполнения этой команды создается папка djenv виртуального окружения.

Шаг 3. Активируем это виртуальное окружение следующей командой.

Здесь мы обращаемся к файлу activate внутри папки Scripts. Как вы видите, название окружения появилось слева от пути к папке.
Теперь через pip можно устанавливать пакеты, которые будут «видны» только внутри виртуального окружения djenv.
Шаг 4. Выйти из этого виртуального окружения можно с помощью команды deactivate. Если вам нужно удалить окружение, сначала деактивируйте его, а затем вручную удалите соответствующую папку.
На следующем занятии мы поговорим про такую важную тему, как регулярные выражения.
Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations, and narrative text. Uses include data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
Jupyter has support for over 40 different programming languages and Python is one of them. Python is a requirement (Python 3.3 or greater, or Python 2.7) for installing the Jupyter Notebook itself.
Jupyter Notebook can be installed by using either of the two ways described below:
- Using Anaconda:
Install Python and Jupyter using the Anaconda Distribution, which includes Python, the Jupyter Notebook, and other commonly used packages for scientific computing and data science. To install Anaconda, go through How to install Anaconda on windows? and follow the instructions provided. -
Using PIP:
Install Jupyter using the PIP package manager used to install and manage software packages/libraries written in Python. To install pip, go through How to install PIP on Windows? and follow the instructions provided.
Installing Jupyter Notebook using Anaconda:
Anaconda is an open-source software that contains Jupyter, spyder, etc that are used for large data processing, data analytics, heavy scientific computing. Anaconda works for R and python programming language. Spyder(sub-application of Anaconda) is used for python. Opencv for python will work in spyder. Package versions are managed by the package management system called conda.
To install Jupyter using Anaconda, just go through the following instructions:
Launching Jupyter:
Installing Jupyter Notebook using pip:
PIP is a package management system used to install and manage software packages/libraries written in Python. These files are stored in a large “on-line repository” termed as Python Package Index (PyPI).
pip uses PyPI as the default source for packages and their dependencies.
To install Jupyter using pip, we need to first check if pip is updated in our system. Use the following command to update pip:
python -m pip install --upgrade pip

After updating the pip version, follow the instructions provided below to install Jupyter:
- Command to install Jupyter:
python -m pip install jupyter
- Beginning Installation:

- Downloading Files and Data:

- Installing Packages:

- Finished Installation:




Launching Jupyter:
Use the following command to launch Jupyter using command-line:
jupyter notebook

Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations, and narrative text. Uses include data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
Jupyter has support for over 40 different programming languages and Python is one of them. Python is a requirement (Python 3.3 or greater, or Python 2.7) for installing the Jupyter Notebook itself.
Jupyter Notebook can be installed by using either of the two ways described below:
- Using Anaconda:
Install Python and Jupyter using the Anaconda Distribution, which includes Python, the Jupyter Notebook, and other commonly used packages for scientific computing and data science. To install Anaconda, go through How to install Anaconda on windows? and follow the instructions provided. -
Using PIP:
Install Jupyter using the PIP package manager used to install and manage software packages/libraries written in Python. To install pip, go through How to install PIP on Windows? and follow the instructions provided.
Installing Jupyter Notebook using Anaconda:
Anaconda is an open-source software that contains Jupyter, spyder, etc that are used for large data processing, data analytics, heavy scientific computing. Anaconda works for R and python programming language. Spyder(sub-application of Anaconda) is used for python. Opencv for python will work in spyder. Package versions are managed by the package management system called conda.
To install Jupyter using Anaconda, just go through the following instructions:
Launching Jupyter:
Installing Jupyter Notebook using pip:
PIP is a package management system used to install and manage software packages/libraries written in Python. These files are stored in a large “on-line repository” termed as Python Package Index (PyPI).
pip uses PyPI as the default source for packages and their dependencies.
To install Jupyter using pip, we need to first check if pip is updated in our system. Use the following command to update pip:
python -m pip install --upgrade pip
After updating the pip version, follow the instructions provided below to install Jupyter:
- Command to install Jupyter:
python -m pip install jupyter
- Beginning Installation:
- Downloading Files and Data:
- Installing Packages:
- Finished Installation:
Launching Jupyter:
Use the following command to launch Jupyter using command-line:
jupyter notebook
IPython представляет собой мощный инструмент для работы с языком Python. Базовые компоненты IPython – это интерактивная оболочка для с широким набором возможностей и ядро для Jupyter. Jupyter notebook является графической веб-оболочкой для IPython, которая расширяет идею консольного подхода к интерактивным вычислениям.
Основные отличительные особенности данной платформы – это комплексная интроспекция объектов, сохранение истории ввода на протяжении всех сеансов, кэширование выходных результатов, расширяемая система “магических” команд, логирование сессии, дополнительный командный синтаксис, подсветка кода, доступ к системной оболочке, стыковка с pdb отладчиком и Python профайлером.
IPython позволяет подключаться множеству клиентов к одному вычислительному ядру и, благодаря своей архитектуре, может работать в параллельном кластере.
В Jupyter notebook вы можете разрабатывать, документировать и выполнять приложения на языке Python, он состоит из двух компонентов: веб-приложение, запускаемое в браузере, и ноутбуки – файлы, в которых можно работать с исходным кодом программы, запускать его, вводить и выводить данные и т.п.
Веб приложение позволяет:
- редактировать Python код в браузере, с подсветкой синтаксиса, автоотступами и автодополнением;
- запускать код в браузере;
- отображать результаты вычислений с медиа представлением (схемы, графики);
- работать с языком разметки Markdown и LaTeX.
Ноутбуки – это файлы, в которых сохраняются исходный код, входные и выходные данные, полученные в рамках сессии. Фактически, он является записью вашей работы, но при этом позволяет заново выполнить код, присутствующий на нем. Ноутбуки можно экспортировать в форматы PDF, HTML.
Установка и запуск
Jupyter Notebook входит в состав Anaconda. Описание процесса установки можно найти в первом уроке. Для запуска Jupyter Notebook перейдите в папку Scripts (она находится внутри каталога, в котором установлена Anaconda) и в командной строке наберите:
> ipython notebook
В результате будет запущена оболочка в браузере.

Примеры работы
Будем следовать правилу: лучше один раз увидеть… Рассмотрим несколько примеров, выполнив которые, вы сразу поймете принцип работы с Jupyter notebook.
Запустите Jupyter notebook и создайте папку для наших примеров, для этого нажмите на New в правой части экрана и выберите в выпадающем списке Folder.

По умолчанию папке присваивается имя “Untitled folder”, переименуем ее в “notebooks”: поставьте галочку напротив имени папки и нажмите на кнопку “Rename”.

Зайдите в эту папку и создайте в ней ноутбук, воспользовавшись той же кнопкой New, только на этот раз нужно выбрать “Python [Root]”.

В результате будет создан ноутбук.
 .
.
Код на языке Python или текст в нотации Markdown нужно вводить в ячейки:
![]()
Если это код Python, то на панели инструментов нужно выставить свойство “Code”.

Если это Markdown текст – выставить “Markdown”.

Для начал решим простую арифметическую задачу: выставите свойство “Code”, введите в ячейке “2 + 3” без кавычек и нажмите Ctrl+Enter или Shift+Enter, в первом случае введенный вами код будет выполнен интерпретатором Python, во втором – будет выполнен код и создана новая ячейка, которая расположится уровнем ниже так, как показано на рисунке.

Если у вас получилось это сделать, выполните еще несколько примеров.

У каждого ноутбука есть имя, оно отображается в верхней части экрана. Для изменения имени нажмите на его текущее имя и введите новое.

Из элементов интерфейса можно выделить, панель меню:
![]()
панель инструментов:
![]()
и рабочее поле с ячейками:

Ноутбук может находиться в одном из двух режимов – это режим правки (Edit mode) и командный режим (Command mode). Текущий режим отображается на панели меню в правой части, в режиме правки появляется изображение карандаша, отсутствие этой иконки значит, что ноутбук находится в командном режиме.

Для открытия справки по сочетаниям клавиш нажмите “Help->Keyboard Shortcuts”

В самой правой части панели меню находится индикатор загруженности ядра Python. Если ядро находится в режиме ожидания, то индикатор представляет собой окружность.

Если оно выполняет какую-то задачу, то изображение измениться на закрашенный круг.
![]()
Запуск и прерывание выполнения кода
Если ваша программа зависла, то можно прервать ее выполнение выбрав на панели меню пункт Kernel -> Interrupt.
Для добавления новой ячейки используйте Insert->Insert Cell Above и Insert->Insert Cell Below.
Для запуска ячейки используете команды из меню Cell, либо следующие сочетания клавиш:
Ctrl+Enter – выполнить содержимое ячейки.
Shift+Enter – выполнить содержимое ячейки и перейти на ячейку ниже.
Alt+Enter – выполнить содержимое ячейки и вставить новую ячейку ниже.
Как сделать ноутбук доступным для других людей?
Существует несколько способов поделиться своим ноутбуком с другими людьми, причем так, чтобы им было удобно с ним работать:
- передать непосредственно файл ноутбука, имеющий расширение “.ipynb”, при этом открыть его можно только с помощью Jupyter Notebook;
- сконвертировать ноутбук в html;
- использовать https://gist.github.com/;
- использовать http://nbviewer.jupyter.org/.
Вывод изображений в ноутбуке
Печать изображений может пригодиться в том случае, если вы используете библиотеку matplotlib для построения графиков. По умолчанию, графики не выводятся в рабочее поле ноутбука. Для того, чтобы графики отображались, необходимо ввести и выполнить следующую команду:
%matplotlib inline
Пример вывода графика представлен на рисунке ниже.

Магия
Важной частью функционала Jupyter Notebook является поддержка магии. Под магией в IPython понимаются дополнительные команды, выполняемые в рамках оболочки, которые облегчают процесс разработки и расширяют ваши возможности. Список доступных магических команд можно получить с помощью команды
%lsmagic

Для работы с переменными окружения используется команда %env.

Запуск Python кода из “.py” файлов, а также из других ноутбуков – файлов с расширением “.ipynb”, осуществляется с помощью команды %run.

Для измерения времени работы кода используйте %%time и %timeit.
%%time позволяет получить информацию о времени работы кода в рамках одной ячейки.

%timeit запускает переданный ей код 100000 раз (по умолчанию) и выводит информацию среднем значении трех наиболее быстрых прогонах.

Информацию по остальным магическим командам можете найти здесь:
https://ipython.org/ipython-doc/3/interactive/magics.html
https://www.dataquest.io/blog/jupyter-notebook-tips-tricks-shortcuts/
Интересные примеры ноутбуков, в которых довольно полно раскрыты возможности Jupyter Notebook можно найти в ресурсах, перечисленных ниже.
http://nb.bianp.net/sort/views/
https://github.com/jupyter/jupyter/wiki/A-gallery-of-interesting-Jupyter-and-IPython-Notebooks
https://blog.dominodatalab.com/interactive-dashboards-in-jupyter/
http://www.clawpack.org/notebooks.html
P.S.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. На нашем сайте вы можете найти вводные уроки по этой теме. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.

<<< Python. Урок 5. Условные операторы и циклы Python. Урок 7. Работа со списками (list) >>>
I had the exact same problem and it was driving me crazy. Other answers provide a solution, but they don’t explain why you and I are having this problem.
I will try to explain why this is happening and then provide some solutions.
You can go to the end to see the TL;DR.
1)What’s going on? Why is this error happening?
I’ll try to make a step-by-step answer so everything is explained clearly.
If you think it’s too basic at the beginning, go to the end of this «article».
I’ll first start with common things like running the python shell from the terminal or running pip. You’ll see why you can do that from the terminal and we’ll end up on why and how you can run the jupyter notebook from the terminal as well.
Ready? Let’s start!
Have you ever wondered why you can type python in the terminal (command prompt) and suddenly start the Python interpreter?
Microsoft Windows [Version 10.0.18363.1440]
(c) 2019 Microsoft Corporation. All rights reserved.
C:UsersYOUR-USERNAME>python
Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
You probably already know (but maybe don’t) that this is because Python was added to the Windows PATH environment variable. You probably did it at installation time or afterwards.
But, what is this PATH environment variable?
It basically allows you to run any executables, that are located inside
the paths specified in the variable, at the command prompt without
having to give the full path to the executable.
You can check the content of that PATH variable with:
>>> import sys
>>> for path in sys.path:
print(path)
C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39python39.zip
C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39DLLs
C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39lib
C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39
C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39libsite-packages
... (some other paths were taken out for clarity)
You can see this folder: C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39. This is the place where Python version 3.9 is installed. Let’s check its content:
<DIR> DLLs
<DIR> Doc
<DIR> etc
<DIR> include
<DIR> Lib
<DIR> libs
<DIR> Scripts
<DIR> share
<DIR> tcl
<DIR> Tools
LICENSE.txt
NEWS.txt
python.exe
python3.dll
python39.dll
pythonw.exe
vcruntime140.dll
vcruntime140_1.dll
Voilà! We have the python.exe file (an executable). We have a Python executable file in the PATH, that’s why you can start the Python interpreter from the terminal with just typing python. If this wasn’t the case you would have to type the full path to the executable file in the terminal:
C:UsersYOUR-USERNAME> C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39python)
Instead of just:
C:UsersYOUR-USERNAME> python
And what about when you use pip?
It’s the same principle. You can run pip from the terminal because there is a pip executable file in the PATH variable.
If you go to C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39Scripts (which is in the PATH showed above) you’ll see many executables files. One of them is pip. Actually I have three versions: pip, pip3.9 and pip3.
The Scripts folder allows exectuable files to be run from the terminal. Like pip or other libraries that you intend to run directly from the terminal. The Scripts folder:
…is not intended for you, it’s for scripts that are installed as
components of modules that you install. For example, pip is a module,
but it also has a wrapper script by the same name, pip, which will be
installed in that directory.If you put something there and it is properly in your PATH, then it
should be executable
That wrapper script would be the pip executable file. When this executable file is run, it locates the pip folder in the Python installation folder and runs pip.
But you could also run pip directly from the installation folder (C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39Libsite-packages), without needing the executable pip file.
But, how can you do it?
I’m glad you ask. There is a Python way to run modules as the main module (without the need to import it).
python -m pip
When you run a module directly its name becomes __main__. What -m does is:
Search
sys.pathfor the named module and execute its contents as the__main__module.
What is __main__?
'__main__'is the name of the scope in which top-level code executes.A module’s
__name__is set equal to'__main__'when read from standard
input, a script, or from an interactive prompt.
…
I guess that the pip executable does something similar, or at least, has the same effect: to start pip.
2)What does this have to do with the Jupyter Notebook?!
Think of the Jupyter Notebook as the same as pip. If you want to run jupyter in the terminal, you need an executable that it’s on the PATH.
We have already seen that the executables of modules like pip or jupyter are located here C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39Scripts.
If I check the content of the folder I see this:
easy_install-3.9.exe
easy_install.exe
f2py.exe
jsonschema.exe
jupyter-bundlerextension.exe
jupyter-console.exe
jupyter-nbconvert.exe
jupyter-nbextension.exe
jupyter-notebook.exe
jupyter-qtconsole.exe
jupyter-serverextension.exe
jupyter-trust.exe
pip.exe
pip3.9.exe
pip3.exe
I see the already mentioned pip, pip3.9 and pip3. But I don’t see jupyter (the word «jupyter» alone).
If I type jupyter in the terminal I get the error that started all:
'jupyter' is not recognized as an internal or external command, operable program or batch file.
Finally we’ve reached an answer to your question!!!
‘jupyter’ is not recognized as a command because there is no executable file in the Scripts folder called jupyter.
So, let’s try a different executable. What about jupyter-notebook?
BINGO! The notebook is running!
Serving notebooks from local directory:
C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39Scripts
Jupyter Notebook 6.3.0 is running at:
http://localhost:8888/?token=... (edited)
or http://127.0.0.1:8888/?token=... (edited)
Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
I don’t know why I don’t have a jupyter executable called ‘jupyter’. The official documentation says to use jupyter notebook on the terminal, but it seems that in some cases it doesn’t work. And I think it has to do with what I mentioned above: there is no jupyter exectuable in the Scripts folder.
If you remember, I told you that you can run pip as the main module using python -m pip.
It happens that you can do the same with jupyter.We just need to know how to call it. As in with pip, we have to check the folder where 3rd party libraries are installed: C:UsersYOUR-USERNAMEAppDataLocalProgramsPythonPython39Libsite-packages.
You’ll see jupyter_console, but this just creates an interactive notebook in the terminal, not exactly what you were looking for. You’re also going to find folders ending with .dist.info, like jupyter_console-6.4.0.dist-info. This is just metadata of the Wheel Binary Package builder. You’ll also see a folder like jupyterlab_pygments, but that’s for JupyterLab. We want to use the classic Jupyter notebook.
What we want is to run notebook. How do we know this?
You’ll see in the folder site-packages the folder (package) notebook. Inside there is a file called __main__.py:
#__main__.py
if __name__ == '__main__':
from notebook import notebookapp as app
app.launch_new_instance()
It’s calling notebookapp.py which is a «A tornado based Jupyter notebook server.» Yes, this is what we need.
We can see that launch_new_instance in the notebookapp calls launch_instance(), which «launches an instance of a Jupyter Application«.
Perfect! We are in the correct folder. To run the jupyter notebook from the Python interactive shell we have to run the notebook package with:
python -m notebook
3)*** SUMMARY: SOLUTION ***
tl;dr:
I have explained and showed why this error is happening.
Now let’s summarize the solutions:
-
To know the name of the
jupyterexecutable (in theScriptsfolder), so you can run directly from the terminal (Command Prompt) as:jupyter notebook
or as:
jupyter-notebook
Or whatever name you have.
-
Run the notebook as the main module from Python:
python -m notebook
I hope this helps you as much as it helped me. I’m open to your comments and suggestions.