Pairwise тестирование (Парное тестирование) — это метод позволяет обнаруживать дефекты с использованием комбинационного метода двух тестовых случаев. Он основан на наблюдении, что большинство дефектов вызвано взаимодействием не более двух факторов. Следовательно, выбирается пара из двух тестовых параметров, и все возможные пары этих двух параметров отправляются в качестве входных параметров для целей тестирования.
Этот метод используется, когда количество входных параметров велико. Например, мы хотим протестировать разделы системного диска с параметрами:
Type: Primary, Logical, Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: quick, slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: on, off
В Итоге получается 4 704 комбинацией случаев. Метод парного тестирования позволяет существенного сократить количество комбинаций.
Для удобства получения выходного множества тестов существует программа от Microsoft PICT. Установите ее себе на компьютер. Программа работает из командной строки.
Например, сохраним описанные ранее параметры в текстовый файл:
В командной строке вводим входной и выходной файл:
pict model.txt > model_out.xls
Входной файл model.txt, в выходном файле model_out.xls будет содержаться таблица всех возможных тестов по методу парного тестирования:
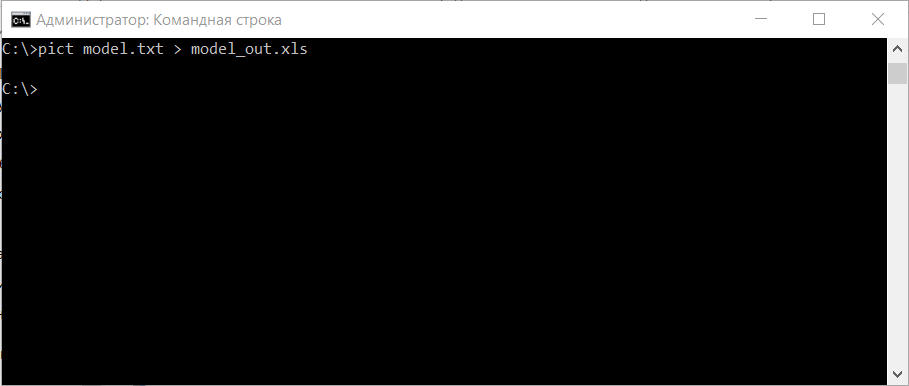
В данном случае количество тест кейсов уменьшилось с 4 704 до 60. Это существенно сократит время и ресурсы на тестирование.
Выходной файл model_out.xls будет содержать 60 тестовых случаев:
| мType | Size | Format method | File system | Cluster size | Compression |
| Mirror | 10 | quick | FAT | 32768 | off |
| RAID-5 | 10 | slow | FAT32 | 512 | on |
| Stripe | 500 | quick | NTFS | 512 | off |
| Span | 1000 | slow | NTFS | 1024 | on |
| Primary | 100 | quick | FAT32 | 16384 | off |
| Single | 1000 | slow | FAT | 8192 | off |
| Primary | 5000 | slow | FAT | 2048 | on |
| RAID-5 | 40000 | quick | NTFS | 8192 | on |
| Logical | 10 | slow | NTFS | 65536 | on |
| Span | 100 | quick | FAT | 65536 | off |
| Mirror | 10000 | slow | FAT32 | 65536 | on |
| Logical | 1000 | quick | FAT32 | 512 | off |
| Logical | 40000 | slow | FAT | 4096 | off |
| Single | 1000 | quick | NTFS | 4096 | on |
| Stripe | 500 | slow | FAT32 | 32768 | on |
| Mirror | 100 | quick | NTFS | 2048 | off |
| Span | 10 | slow | FAT32 | 4096 | off |
| Single | 40000 | quick | FAT32 | 65536 | off |
| RAID-5 | 5000 | quick | FAT | 65536 | off |
| Stripe | 1000 | slow | FAT32 | 2048 | on |
| Primary | 10000 | quick | NTFS | 8192 | off |
| Span | 10000 | slow | FAT | 16384 | on |
| Primary | 1000 | slow | FAT32 | 65536 | on |
| Single | 5000 | quick | FAT32 | 1024 | off |
| RAID-5 | 100 | slow | FAT | 1024 | on |
| Single | 500 | slow | NTFS | 2048 | off |
| Mirror | 500 | quick | FAT | 1024 | on |
| Stripe | 100 | quick | FAT | 4096 | on |
| Primary | 40000 | quick | FAT32 | 1024 | off |
| Single | 10 | quick | NTFS | 16384 | on |
| Logical | 5000 | slow | NTFS | 32768 | off |
| Stripe | 10 | slow | FAT | 1024 | off |
| Primary | 500 | slow | NTFS | 4096 | off |
| Mirror | 1000 | quick | FAT | 16384 | on |
| Stripe | 40000 | quick | FAT | 16384 | off |
| Mirror | 10 | slow | FAT32 | 8192 | on |
| Span | 40000 | quick | NTFS | 32768 | off |
| Logical | 10000 | slow | NTFS | 1024 | off |
| Span | 5000 | quick | FAT | 512 | on |
| Logical | 100 | slow | FAT32 | 8192 | on |
| RAID-5 | 500 | quick | NTFS | 16384 | on |
| Stripe | 5000 | slow | NTFS | 8192 | off |
| Mirror | 5000 | slow | NTFS | 4096 | off |
| Span | 500 | quick | FAT | 65536 | off |
| Span | 10000 | slow | NTFS | 2048 | on |
| Stripe | 10000 | quick | FAT32 | 65536 | off |
| Primary | 10 | quick | FAT | 2048 | off |
| RAID-5 | 10000 | slow | NTFS | 4096 | on |
| Primary | 10000 | quick | NTFS | 32768 | on |
| RAID-5 | 1000 | quick | FAT32 | 32768 | on |
| Primary | 10000 | quick | FAT | 512 | off |
| Mirror | 40000 | slow | FAT32 | 512 | on |
| Single | 100 | slow | NTFS | 512 | off |
| Logical | 500 | quick | FAT32 | 16384 | off |
| Single | 100 | slow | NTFS | 32768 | on |
| Mirror | 5000 | quick | FAT32 | 16384 | off |
| Span | 500 | slow | FAT | 8192 | on |
| RAID-5 | 40000 | slow | FAT | 2048 | off |
| Logical | 10 | quick | FAT | 2048 | off |
| Single | 10000 | slow | FAT32 | 65536 | on |
PICT
Pairwise Independent Combinatorial Testing tool
jacekcz@microsoft.com
PICT generates test cases and test configurations. With PICT, you can generate tests that are more effective than manually generated tests and in a fraction of the time required by hands-on test case design.
PICT runs as a command line tool. Prepare a model file detailing the parameters of the interface (or set of configurations, or data) you want to test. PICT generates a compact set of parameter value choices that represent the test cases you should use to get comprehensive combinatorial coverage of your parameters.
For instance, to create a test suite for disk partition creation, the domain can be described by the following parameters: Type, Size, File system, Format method, Cluster size, and Compression. Each parameter consists of a finite number of possible values. For example, Compression naturally can only be On or Off, other parameters are made finite with help of equivalence partitioning (e.g. Size).
Type: Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: Quick, Slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: On, Off
For such a model, thousands of possible test cases can be generated. It would be difficult to test all of them in a reasonable amount of time. Instead of attempting to cover all possible combinations, we settle on testing all possible pairs of values. For example, {Single, FAT} is one pair, {10, Slow} is another. Consequently, one test case can cover many pairs. Research shows that testing all pairs is an effective alternative to exhaustive testing and much less costly. It will provide very good coverage and the number of test cases will remain manageable.
Usage
PICT is a command-line tool that accepts a plain-text model file as an input and produces a set of test cases.
Usage: pict model [options]
Options:
/o:N|max - Order of combinations (default: 2)
/d:C - Separator for values (default: ,)
/a:C - Separator for aliases (default: |)
/n:C - Negative value prefix (default: ~)
/e:file - File with seeding rows
/r[:N] - Randomize generation, N - seed
/c - Case-sensitive model evaluation
/s - Show model statistics
Model File
A model consists of the following sections:
parameter definitions
[sub-model definitions]
[constraint definitions]
Model sections should always be specified in the order shown above and cannot overlap. All parameters should be defined first, then sub-models, and then constraints. The sub-models definition section is optional, as well as the constraints. Sections do not require any special separators between them. Empty lines can appear anywhere. Comments are also permitted and they should be prefixed with # character.
To produce a basic model file, list the parameters—each in a separate line—with the respective values delimited by commas:
<ParamName> : <Value1>, <Value2>, <Value3>, ...
Example:
#
# This is a sample model for testing volume create/delete functions
#
Type: Primary, Logical, Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: quick, slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: on, off
A comma is the default separator but you can specify a different one using /d option.
By default, PICT generates a pair-wise test suite (all pairs covered), but the order can be set by option /o to a value larger than two. For example, if /o:3 is specified, the test suite will cover all triplets of values thereby producing a larger number of tests but potentially making the test suite even more effective. The maximum order for a simple model is equal to the number of parameters, which will result in an exhaustive test suite. Following the same principle, specifying /o:1 will produce a test suite that merely covers all values (combinations of 1).
Output Format
All errors, warning messages, and the randomization seed are printed to the error stream. The test cases are printed to the standard output stream. The first line of the output contains names of the parameters. Each of the following lines represents one generated test case. Values in each line are separated by a tab. This way redirecting the output to a file creates a tab-separated value format.
If a model and options given to the tool do not change, every run will result in the same output. However, the output can be randomized if /r option is used. A randomized generation prints out the seed used for that particular execution to the error output stream. Consequently, that seed can be fed into the tool with /r:seed option to replay a particular generation.
Constraints
Constraints allow you to specify limitations on the domain. In the example with partitions, one of the pairs that will occur in at least one test case is {FAT, 5000}. In reality, the FAT file system cannot be applied on volumes larger than 4,096 MB. Note that you cannot simply remove those violating test cases from the result because an offending test case may cover other, possibly valid, pairs that would not otherwise be tested. Instead of losing valid pairs, it is better to eliminate disallowed combinations during the generation process. In PICT, this can be done by specifying constraints, for example:
Type: Primary, Logical, Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: quick, slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: on, off
IF [File system] = "FAT" THEN [Size] <= 4096;
IF [File system] = "FAT32" THEN [Size] <= 32000;
Conditional Constraints
A term [parameter] relation value is an atomic part of a constraint expression. The following relations can be used: =, <>, >, >=, <, <=, and LIKE. LIKE is a wildcard-matching operator (* — any character, ? – one character).
[Size] < 10000
[Compression] = "OFF"
[File system] like "FAT*"
Operator IN allows specifying a set of values that satisfy the relation explicitly:
IF [Cluster size] in {512, 1024, 2048} THEN [Compression] = "Off";
IF [File system] in {"FAT", "FAT32"} THEN [Compression] = "Off";
The IF, THEN, and ELSE parts of an expression may contain multiple terms joined by logical operators: NOT, AND, and OR. Parentheses are also allowed in order to change the default operator priority:
IF [File system] <> "NTFS" OR
( [File system] = "NTFS" AND [Cluster size] > 4096 )
THEN [Compression] = "Off";
IF NOT ( [File system] = "NTFS" OR
( [File system] = "NTFS" AND NOT [Cluster size] <= 4096 ))
THEN [Compression] = "Off";
Parameters can also be compared to other parameters, like in this example:
#
# Machine 1
#
OS_1: Win7, Win8, Win10
SKU_1: Home, Pro
LANG_1: English, Spanish, Chinese
#
# Machine 2
#
OS_2: Win7, Win8, Win10
SKU_2: Home, Pro
LANG_2: English, Spanish, Chinese, Hindi
IF [LANG_1] = [LANG_2]
THEN [OS_1] <> [OS_2] AND [SKU_1] <> [SKU_2];
Unconditional Constraints (Invariants)
An invariant declares an always valid limitation of a domain:
#
# At least one parameter must be different to be a meaningful test case
#
[OS_1] <> [OS_2] or [SKU_1] <> [SKU_2] or [LANG_1] <> [LANG_2];
#
# All parameters must be different (we use AND operator)
#
[OS_1] <> [OS_2] and [SKU_1] <> [SKU_2] and [LANG_1] <> [LANG_2];
Types
PICT uses the concept of a parameter type. There are two types of parameters: string and numeric. A parameter is considered numeric only when all its values are numeric. If a value has multiple names, only the first one counts. Types are only important when evaluating constraints. A numeric parameter is only comparable to a number, and a string parameter is only comparable to another string. For example:
Size: 1, 2, 3, 4, 5
Value: a, b, c, d
IF [Size] > 3 THEN [Value] > "b";
String comparison is lexicographical and case-insensitive by default. Numerical values are compared as numbers.
Case Sensitiveness
By default, PICT does all its comparisons and checks case-insensitively. For instance, if there are two parameters defined: OS and os, a duplication of names will be detected (parameter names must be unique). Constraints are also resolved case-insensitively by default:
IF [OS] = "Win10" THEN ...
will match both Win10 and win10 values (values of a parameter are not required to be unique). Option /c however, makes the model evaluation fully case-sensitive.
Advanced Modelling Features
Re-using Parameter Definitions
Once a parameter is defined, it can help in defining other parameters.
#
# Machine 1
#
OS_1: Win7, Win8, Win10
SKU_1: Home, Pro
LANG_1: English, Spanish, Chinese
#
# Machine 2
#
OS_2: <OS_1>
SKU_2: <SKU_1>
LANG_2: <LANG_1>, Hindi
Less typing and better maintainability.
Sub-Models
Sub-models allow the bundling of certain parameters into groups that get their own combinatory orders. This can be useful if combinations of certain parameters need to be tested more thoroughly or must be combined in separation from the other parameters in the model. The sub-model definition has the following format:
{ <ParamName1>, <ParamName2>, <ParamName3>, ... } @ <Order>
For example, sub-modeling is useful when hardware and software parameters are combined together. Without sub-models, each test case would produce a new, unique hardware configuration. Placing all hardware parameters into one sub-model produces fewer distinct hardware configurations and potentially lowers the cost of testing. The order of combinations that can be assigned to each sub-model allows for additional flexibility.
PLATFORM: x86, x64, arm
CPUS: 1, 2, 4
RAM: 1GB, 4GB, 64GB
HDD: SCSI, IDE
OS: Win7, Win8, Win10
Browser: Edge, Opera, Chrome, Firefox
APP: Word, Excel, Powerpoint
{ PLATFORM, CPUS, RAM, HDD } @ 3
{ OS, Browser } @ 2
The test generation for the above model would proceed as follows:
$
|
| order = 2 (defined by /o)
|
+------------------------------+-----------------------------+
| | |
| order = 3 | order = 2 |
| | |
{ PLATFORM, CPUS, RAM, HDD } { OS, Browser } APP
Notes:
- You can define as many sub-models as you want; any parameter can belong to any number of sub-models. Model hierarchy can be just one level deep.
- The combinatory order of a sub-model cannot exceed the number of its parameters. In the example above, an order of the first sub-model can be any value between one and four.
- If you do not specify the order for a sub-model, the default order, as specified by /o option, will be used.
Aliasing
Aliasing is a way of specifying multiple names for a single value. Multiple names do not change the combinatorial complexity of the model. No matter how many names a value has, it is treated as one entity. The only difference will be in the output; any test case that would normally have that one value will have one of its names instead. Names are rotated among the test cases. Specifying one value with two names will result in having them both show up in the output without additional test cases.
By default, names should be separated by | character but this can be changed with option /a.
OS_1: Win2008, Win2012, Win2016
SKU_1: Professional, Server | Datacenter
Note:
When evaluating constraints, only the first name counts. For instance, [SKU_1] = «Server» will result in a match but [SKU_1] = «Datacenter» will not. Also, only the first name is used to determine whether a value is negative or a numeric type.
Negative Testing
In addition to testing valid combinations, referred to as “positive testing,” it is often desirable to test using values outside the allowable range to make sure the program handles errors properly. This “negative testing” should be conducted such that only one invalid value is present in any test case. This is due to the way in which typical applications are written: namely, to take some failure action upon the first error detected. For this reason, a problem known as input masking—in which one invalid input prevents another invalid input from being tested—can occur with negative testing.
Consider the following routine, which takes two arguments:
float SumSquareRoots( float a, float b )
{
if ( a < 0 ) throw error; // [1]
if ( b < 0 ) throw error; // [2]
return ( sqrt( a ) + sqrt( b ));
};
Although the routine can be called with any numbers a or b, it only makes sense to do the calculation on non-negative numbers. For that reason by the way, the routine does verifications [1] and [2] on the arguments. Now, assume a test ( a= -1, b = -1 ) was used to test a negative case. Here, a = -1 actually masks b = -1 because check [2] never gets executed and it would go unnoticed if it didn’t exist.
To prevent input masking, it is important that two invalid values (of two different parameters) are not in the same test case. Prefixing any value with ~ (tilde) marks it invalid. Option /n allows for specifying a different prefix.
#
# Trivial model for SumSquareRoots
#
A: ~-1, 0, 1, 2
B: ~-1, 0, 1, 2
The tool guarantees that all possible pairs of valid values will be covered and all possible combinations of any invalid value will be paired with all positive values at least once.
A B
2 0
2 2
0 0
0 1
1 0
2 1
0 2
1 2
1 1
~-1 2
1 ~-1
0 ~-1
~-1 1
2 ~-1
~-1 0
Notes:
- A prefix is not a part of a value when it comes to comparisons therefore in constraints it should appear without it. A valid constraint (although quite artificial in this example) would be: if [A] = -1 then [B] = 0;. Also checking for the type of a value is not affected by the prefix. For example, both parameters in the above example are numeric despite having non-numeric “~” in one of their values. The prefix however will show up in the output.
- If a value has multiple names, only prefixing the first name will make the value negative.
Excluding other parameters
Sometimes we may want to ignore other parameters for certain values. A negative test is a typical scenario, as a failure may make any other parameters meaningless if it stops the application. In these cases we do not want to ‘use up’ any testable values for other parameters. A technique to handle this is be to add a dummy value to the parameters to be excluded. Since it is a dummy value, it must in turn be excluded from the other tests, which can be accomplished using the ELSE clause.
Consider the following example where a P1 value of -1 is a negative test where we expect the application to fail.
P1: -1, 0, 1
P2: A, B, C
P3: X, Y, Z
We want to test this independently and not associate any P2 and P3 values with it, as it would needlessly increase the amount of tests and use up P2/P3 combinations. So we add a dummy value NA to the P2 and P3 sets and exclude them from other cases with the ELSE clause:
P1: -1, 0, 1
P2: A, B, C, NA
P3: X, Y, Z, NA
IF [P1] = -1
THEN [P2] = "NA" AND [P3] = "NA"
ELSE [P2] <> "NA" AND [P3] <> "NA";
This will result in a single test for P1 = -1 and no NA‘s anywhere else; and no P2 and P3 combinations are used up for the -1 test:
P1 P2 P3
0 C Z
1 B Z
1 C Y
0 A X
1 C X
0 B X
0 A Y
-1 NA NA
0 B Y
1 A Z
However it will get progressively more complex if multiple layers of exclusions are needed. For example let’s extend the above with an additional negative test where P2 is Null:
P1: -1, 0, 1
P2: A, B, C, Null, NA
P3: X, Y, Z, NA
IF [P1] = -1
THEN [P2] = "NA" AND [P3] = "NA"
ELSE [P2] <> "NA" AND
( [P3] <> "NA" OR [P2] = "Null" );
IF [P2] = "Null" OR [P2] = "NA"
THEN [P3] = "NA";
Two additional tests will be added (not all output shown):
P1 P2 P3
0 Null NA
1 Null NA
Weighting
The generation mechanism can be forced to prefer certain values. This is done by means of weights. A weight can be any positive integer. If it is not specified explicitly it is assumed to be 1:
#
# Let’s focus on primary partitions formatted with NTFS
#
Type: Primary (10), Logical, Single, Span, Stripe, Mirror, RAID-5
Format method: quick, slow
File system: FAT, FAT32, NTFS (10)
Note:
Weight values have no intuitive meaning. For example, when a parameter is defined like this:
File system: FAT, FAT32, NTFS (10)
it does not mean that NTFS will appear in the output ten times more often than FAT or FAT32. Moreover, you cannot be sure that the weights you specified will be honored at all.
The reason for this is that we deal with two contradictory requirements:
- To cover all combinations in the smallest number of test cases.
- To choose values proportionally to their weights.
(1) will always take precedence over (2) and weights will only be honored when the choice of a value is not determined by a need of satisfying (1). More specifically, during the test case production, candidate values are evaluated and one that covers most of the still unused combinations is always picked. Sometimes there is a tie among candidate values and really no choice is better than another. In those cases, weights will be used to determine the final choice.
The bottom-line is that you can use weights to attempt to shift the bias towards some values but whether or not to honor that and to what extent is determined by multiple factors, not weights alone.
Seeding
Seeding makes two scenarios possible:
- Allows for specifying important e.g. regression-inducing combinations that should end up in any generated test suite. In this case, PICT will initialize the output with combinations you provide and will build up the rest of the suite on top of them, still making sure all n-order combinations get covered.
- Let’s you minimize changes to the output when your model is modified. Provide PICT with results of some previous generation and expect the tool to reuse the old test cases as much as possible.
Seeding rows must be defined in a separate file (a seeding file). Use new option /e to provide the tool with the file location:
pict.exe model.txt /e:seedrows.txt
Seeding files have the same format as any PICT output. First line contains parameter names separated by tab characters and each following line contains one seeding row with values also separated by tabs. This format can easily be prepared from scratch (scenario 1) either in Notepad or in Excel and also allows for quick and direct reuse of any prior results (scenario 2).
Ver SKU Lang Arch
Win7 Pro EN x86
Win7 FR x86
Win10 Pro EN x64
Any seeding row may be complete i.e. with values specified for all parameters, or partial, like the second seeding row above which does not have a value for the SKU parameter. In this case, the generation process will take care of choosing the best value for SKU.
Important notes:
There are a few rules of matching seeding rows with the current model:
- If a seeding file contains a parameter that is not in the current model, the entire column representing the parameter in the seeding file will be discarded.
- If a seeding row contains a value that is not in the current model, the value will be removed from the seeding row. The rest of the row however, if valid, will still be used. As a result of that, a complete row may become partial.
- If a seeding row violates any of the current constraints, it will be skipped entirely.
PICT will issue warnings if (1) or (2) occurs.
In addition, there are a few things that are normally allowed in PICT models but may lead to ambiguities when seeding is used:
- Blank parameter and value names.
- Parameter and value names containing tab characters.
- Values and all their aliases not unique within a parameter.
When seeding is used, you will be warned if any of the above problems are detected in your model.
Constraints Grammar
Constraints :: =
Constraint
| Constraint Constraints
Constraint :: =
IF Predicate THEN Predicate ELSE Predicate;
| Predicate;
Predicate :: =
Clause
| Clause LogicalOperator Predicate
Clause :: =
Term
| ( Predicate )
| NOT Predicate
Term :: =
ParameterName Relation Value
| ParameterName LIKE PatternString
| ParameterName IN { ValueSet }
| ParameterName Relation ParameterName
ValueSet :: =
Value
| Value, ValueSet
LogicalOperator ::=
AND
| OR
Relation :: =
=
| <>
| >
| >=
| <
| <=
ParameterName ::= [String]
Value :: =
"String"
| Number
String :: = whatever is typically regarded as a string of characters
Number :: = whatever is typically regarded as a number
PatternString ::= string with embedded special characters (wildcards):
* a series of characters of any length (can be zero)
? any one character
Автор: Алексей Федорко
Оригинальная публикация
Если в качестве инструмента у вас имеется лишь молоток, каждая проблема начинает напоминать гвоздь. Абрахам Маслоу
В этой небольшой заметке я бы хотел рассмотреть инструмент для попарного тестирования от Microsoft – PICT (Pairwise Independent Combinatorial Testing). Уже несколько раз я применял его в своей работе и был доволен теми гибкими опциями, которые он имеет.
Для начала неплохо вспомнить, что такое Pairwise Testing. Есть интересная статья про парное тестирование на MSDN. Также про это можно почитать тут. Вкратце, Pairwise testing – это техника формирования наборов тестовых данных. Заключается она в следующем: формируются такие наборы данных, в которых каждое тестируемое значение каждого из проверяемых параметров хотя бы единожды сочетается с каждым тестируемым значением всех остальных проверяемых параметров. Предыдущее предложение может быть не совсем понятным, но принцип можно легко проиллюстрировать на следующем примере. Представим, что у нас есть параметры A, B и C принимающие значения Yes или No. Максимальное количество комбинаций значений этих параметров – 8. Но при использовании попарного тестирования достаточно четырех комбинаций, так как учитываются все возможные пары параметров (пара A и B, пара B и C, пара A и C):
Эту технику полезно применять тогда, когда нам не нужны все возможные сочетания значений параметров (особенно когда параметров много), а мы хотим только убедиться, что мы проверим все уникальные пары значений параметров.
Так что же PICT? PICT позволяет генерировать компактный набор значений тестовых параметров, который представляет собой все тестовые сценарии для всестороннего комбинаторного покрытия ваших параметров. К примеру представим, что у нас есть следующие параметры для тестирования (параметры относятся к тестированию создания разделов на жестком диске и взят из мануала к PICT):
Type: Primary, Logical, Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: quick, slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: on, off
Существует больше 4700 комбинаций этих значений. Будет очень сложно протестировать из за разумное время. Исследования показывают, что тестирование всех пар возможных значений обеспечивает очень хорошее покрытие и количество тест кейсов остается в пределах разумного. К примеру, {Primary, FAT} это одна пара и {10, slow} другая; один тест кейс может покрывать много пар. Для набора приведенных выше параметров PICT создаст всего 60 тест кейсов (сравните с цифрой 4700!).
Рассмотрим работу с программой. Запускается PICT из командной строки.
На вход программа принимает простой текстовый файл с параметрами и их значениями, называемый Моделью, а на выход выдает сгенерированные тестовые сценарии.
Рассмотрим работу программы на примере из приведенной выше статьи из блога. Имеем следующие параметры и их значения: пол – мужской или женский; возраст – до 25, от 25 до 60, более 60; наличие детей – да или нет. Если перебирать все возможные значения, то количество сценариев будет 12. Составим модель и посмотрим какой результат нам выдаст программа.
Модель:
SEX: Male, Female
Age: Under 25, 25-60, Older than 60
Children: Yes, No
Используем модель и получим 7 тестовых сценариев (вместо 12):
Разница не такая ощутимая, но она будет становится все более и более заметной при увеличении количества параметров или их значений.
Можно использовать прямой вывод и сохранение тест кейсов в Excel.
В результате будет создан Excel файл со следующим содержанием:
Но самое интересное это те возможности, которые предоставляет PICT для подобной генерации сценариев. Все они тщательно рассмотрены в мануале. Вот некоторые из них:
- Можно указывать порядок группировки значений. По умолчанию используется порядок 2 и создаются комбинации пар значений (что и составляет попарное тестирование). Но можно указать к примеру 3 и тогда будут использоваться триплеты, а не пары. Максимальный порядок для простой модели равен количеству параметров, что создаст набор всевозможных вариантов.
- Можно группировать параметры в под-модели и указывать им отдельный порядок для комбинаций. Это необходимо если комбинации определенных параметров должны быть протестированы более тщательно или должны быть объединены по отдельности от других параметров.
- Можно создавать условия и ограничения. К примеру, можно указать, что один из параметров будет принимать определенное значение только тогда, когда несколько других параметров примут нужные значения. Это позволяет отсечь создание ненужных проверок.
- Можно обозначать не-валидные значения для параметров для создания комбинации для негативных тест кейсов.
- Используя весовые коэффициенты можно указать программе отдавать предпочтения определенным значениям при генерации комбинаций.
- Можно использовать опцию минимизации (запускать программу несколько раз с этой опцией), чтобы получить минимальное количество тест кейсов.
В заключение хочется сказать, что PICT достаточно удобный инструмент для быстрого создания набора комбинаций тестовых данных, особенно при наличии большого количества не сильно связанных между собой параметров (что позволяет не проводить тестирование всех возможных вариантов). Однако нужно тщательно создать необходимую вам Модель, чтобы тестовое покрытие было удовлетворительным. Use it wise and be happy. ![]()
Скачать PICT можно тут
Обсудить в форуме
Pairwise Independent Combinatorial Testing
PICT generates test cases and test configurations. With PICT, you can generate tests that are more effective than manually generated tests and in a fraction of the time required by hands-on test case design.
PICT runs as a command line tool. Prepare a model file detailing the parameters of the interface (or set of configurations, or data) you want to test. PICT generates a compact set of parameter value choices that represent the test cases you should use to get comprehensive combinatorial coverage of your parameters.
For instance, if you wish to create a test suite for partition and volume creation, the domain can be described by the following parameters: Type, Size, File system, Format method, Cluster size, and Compression. Each parameter has a limited number of possible values, each of which is determined by its nature (for example, Compression can only be On or Off) or by the equivalence partitioning (such as Size).
Type: Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: Quick, Slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: On, Off
There are thousands of possible combinations of these values. It would be difficult to test all of them in a reasonable amount of time. Instead, we settle on testing all possible pairs of values. For example, {Single, FAT} is one pair, {10, Slow} is another; one test case can cover many pairs. Research shows that testing all pairs is an effective alternative to exhaustive testing and much less costly. It will provide very good coverage and the number of test cases will remain manageable.
More information
See doc/pict.md for detailed documentation on PICT and http://pairwise.org has details on this testing methododology.
The most recent pict.exe is available at https://github.com/microsoft/pict/releases/.
Contributing
PICT consists of the following projects:
- api: The core combinatorial engine,
- cli: PICT.EXE command-line tool,
- clidll: PICT.EXE client repackaged as a Windows DLL to be used in-proc,
- api-usage: A sample of how the engine API can be used,
- clidll-usage: A sample of how the PICT DLL is to be used.
Building and testing on Windows with MsBuild
Use pict.sln to open the solution in Visual Studio 2019. You will need VC++ build tools installed. See https://www.visualstudio.com/downloads/ for details.
PICT uses MsBuild for building. _build.cmd script in the root directory will build both Debug and Release from the command-line.
The test folder contains all that is necessary to test PICT. You need Perl to run the tests. _test.cmd is the script that does it all.
The test script produces a log: dbg.log or rel.log for the Debug and Release bits respectively. Compare them with their committed baselines and make sure all the differences can be explained.
There are tests which randomize output which typically make it different on each run. These results should be masked in the baseline but currently aren’t.
Building on Linux, OS/X, *BSD, etc.
PICT uses CMake to build on Linux.
Assuming installation of CMake and C++ toolchain, following set of commands will build and run tests in the directory build
> cmake -DCMAKE_BUILD_TYPE=Release -S . -B build
> cmake --build build
> pushd build && ctest -v && popd
Debugging
Most commonly, you will want to debug the command-line tool. Start in the pictcli project, cli/pict.cpp file. You’ll find wmain routine there which would be a convenient place to put the very first breakpoint.
Pairwise Independent Combinatorial Testing
PICT generates test cases and test configurations. With PICT, you can generate tests that are more effective than manually generated tests and in a fraction of the time required by hands-on test case design.
PICT runs as a command line tool. Prepare a model file detailing the parameters of the interface (or set of configurations, or data) you want to test. PICT generates a compact set of parameter value choices that represent the test cases you should use to get comprehensive combinatorial coverage of your parameters.
For instance, if you wish to create a test suite for partition and volume creation, the domain can be described by the following parameters: Type, Size, File system, Format method, Cluster size, and Compression. Each parameter has a limited number of possible values, each of which is determined by its nature (for example, Compression can only be On or Off) or by the equivalence partitioning (such as Size).
Type: Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: Quick, Slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: On, Off
There are thousands of possible combinations of these values. It would be difficult to test all of them in a reasonable amount of time. Instead, we settle on testing all possible pairs of values. For example, {Single, FAT} is one pair, {10, Slow} is another; one test case can cover many pairs. Research shows that testing all pairs is an effective alternative to exhaustive testing and much less costly. It will provide very good coverage and the number of test cases will remain manageable.
More information
See doc/pict.md for detailed documentation on PICT and http://pairwise.org has details on this testing methododology.
The most recent pict.exe is available at https://github.com/microsoft/pict/releases/.
Contributing
PICT consists of the following projects:
- api: The core combinatorial engine,
- cli: PICT.EXE command-line tool,
- clidll: PICT.EXE client repackaged as a Windows DLL to be used in-proc,
- api-usage: A sample of how the engine API can be used,
- clidll-usage: A sample of how the PICT DLL is to be used.
Building and testing on Windows with MsBuild
Use pict.sln to open the solution in Visual Studio 2019. You will need VC++ build tools installed. See https://www.visualstudio.com/downloads/ for details.
PICT uses MsBuild for building. _build.cmd script in the root directory will build both Debug and Release from the command-line.
The test folder contains all that is necessary to test PICT. You need Perl to run the tests. _test.cmd is the script that does it all.
The test script produces a log: dbg.log or rel.log for the Debug and Release bits respectively. Compare them with their committed baselines and make sure all the differences can be explained.
There are tests which randomize output which typically make it different on each run. These results should be masked in the baseline but currently aren’t.
Building on Linux, OS/X, *BSD, etc.
PICT uses CMake to build on Linux.
Assuming installation of CMake and C++ toolchain, following set of commands will build and run tests in the directory build
> cmake -DCMAKE_BUILD_TYPE=Release -S . -B build
> cmake --build build
> pushd build && ctest -v && popd
Debugging
Most commonly, you will want to debug the command-line tool. Start in the pictcli project, cli/pict.cpp file. You’ll find wmain routine there which would be a convenient place to put the very first breakpoint.
Содержание
- Использование PICT для парного тестирования (pairwise)
- Как установить pict на windows
- Как установить pict на windows
- Что пишут в блогах
- Онлайн-тренинги
- Что пишут в блогах (EN)
- Разделы портала
- Про инструменты
- PICT и Pairwise тестирование
- Pairwise testing: проблематика
- Пример, где pairwise тестирование будет, как нельзя кстати
- Суть проблемы тестирования программного обеспечения с большим количеством параметров и пути ее решения
- Pairwise testing
- Возможные варианты решения проблемы помимо pairwise тестирования
- Идея и реализация метода pairwise testing
- PICT pairwise testing
- PICT, как пользоваться?
- Недостатки PICT
- Как установить pict на windows
- Available on
- Description
Использование PICT для парного тестирования (pairwise)
Pairwise тестирование (Парное тестирование) — это метод позволяет обнаруживать дефекты с использованием комбинационного метода двух тестовых случаев. Он основан на наблюдении, что большинство дефектов вызвано взаимодействием не более двух факторов. Следовательно, выбирается пара из двух тестовых параметров, и все возможные пары этих двух параметров отправляются в качестве входных параметров для целей тестирования.
Этот метод используется, когда количество входных параметров велико. Например, мы хотим протестировать разделы системного диска с параметрами:
Type: Primary, Logical, Single, Span, Stripe, Mirror, RAID-5
Size: 10, 100, 500, 1000, 5000, 10000, 40000
Format method: quick, slow
File system: FAT, FAT32, NTFS
Cluster size: 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536
Compression: on, off
В Итоге получается 4 704 комбинацией случаев. Метод парного тестирования позволяет существенного сократить количество комбинаций.
Для удобства получения выходного множества тестов существует программа от Microsoft PICT. Установите ее себе на компьютер. Программа работает из командной строки.
Например, сохраним описанные ранее параметры в текстовый файл:
В командной строке вводим входной и выходной файл:
Входной файл model.txt, в выходном файле model_out.xls будет содержаться таблица всех возможных тестов по методу парного тестирования:
В данном случае количество тест кейсов уменьшилось с 4 704 до 60. Это существенно сократит время и ресурсы на тестирование.
Источник
Как установить pict на windows
Pairwise Independent Combinatorial Testing
PICT generates test cases and test configurations. With PICT, you can generate tests that are more effective than manually generated tests and in a fraction of the time required by hands-on test case design.
PICT runs as a command line tool. Prepare a model file detailing the parameters of the interface (or set of configurations, or data) you want to test. PICT generates a compact set of parameter value choices that represent the test cases you should use to get comprehensive combinatorial coverage of your parameters.
For instance, if you wish to create a test suite for partition and volume creation, the domain can be described by the following parameters: Type, Size, File system, Format method, Cluster size, and Compression. Each parameter has a limited number of possible values, each of which is determined by its nature (for example, Compression can only be On or Off) or by the equivalence partitioning (such as Size).
There are thousands of possible combinations of these values. It would be difficult to test all of them in a reasonable amount of time. Instead, we settle on testing all possible pairs of values. For example, is one pair, is another; one test case can cover many pairs. Research shows that testing all pairs is an effective alternative to exhaustive testing and much less costly. It will provide very good coverage and the number of test cases will remain manageable.
See doc/pict.md for detailed documentation on PICT and http://pairwise.org has details on this testing methododology.
PICT consists of the following projects:
Building and testing on Windows with MsBuild
Use pict.sln to open the solution in Visual Studio 2019. You will need VC++ build tools installed. See https://www.visualstudio.com/downloads/ for details.
PICT uses MsBuild for building. _build.cmd script in the root directory will build both Debug and Release from the command-line.
The test folder contains all that is necessary to test PICT. You need Perl to run the tests. _test.cmd is the script that does it all.
The test script produces a log: dbg.log or rel.log for the Debug and Release bits respectively. Compare them with their committed baselines and make sure all the differences can be explained.
There are tests which randomize output which typically make it different on each run. These results should be masked in the baseline but currently aren’t.
Building with clang++ on Linux, OS/X, *BSD, etc.
Install clang through your package manager (most systems), Xcode (OS/X), or from the LLVM website. On Linux, you also need to install recent GNU’s «libstdc++» or LLVM’s «libc++».
Run make to build the pict binary.
Run make test to run the tests as described above (requires Perl).
Источник
Как установить pict на windows








Что пишут в блогах

Онлайн-тренинги
Что пишут в блогах (EN)
Разделы портала
Про инструменты
Если в качестве инструмента у вас имеется лишь молоток, каждая проблема начинает напоминать гвоздь. Абрахам Маслоу
В этой небольшой заметке я бы хотел рассмотреть инструмент для попарного тестирования от Microsoft – PICT (Pairwise Independent Combinatorial Testing). Уже несколько раз я применял его в своей работе и был доволен теми гибкими опциями, которые он имеет.
Для начала неплохо вспомнить, что такое Pairwise Testing. Есть интересная статья про парное тестирование на MSDN. Также про это можно почитать тут. Вкратце, Pairwise testing – это техника формирования наборов тестовых данных. Заключается она в следующем: формируются такие наборы данных, в которых каждое тестируемое значение каждого из проверяемых параметров хотя бы единожды сочетается с каждым тестируемым значением всех остальных проверяемых параметров. Предыдущее предложение может быть не совсем понятным, но принцип можно легко проиллюстрировать на следующем примере. Представим, что у нас есть параметры A, B и C принимающие значения Yes или No. Максимальное количество комбинаций значений этих параметров – 8. Но при использовании попарного тестирования достаточно четырех комбинаций, так как учитываются все возможные пары параметров (пара A и B, пара B и C, пара A и C):
Эту технику полезно применять тогда, когда нам не нужны все возможные сочетания значений параметров (особенно когда параметров много), а мы хотим только убедиться, что мы проверим все уникальные пары значений параметров.
Так что же PICT? PICT позволяет генерировать компактный набор значений тестовых параметров, который представляет собой все тестовые сценарии для всестороннего комбинаторного покрытия ваших параметров. К примеру представим, что у нас есть следующие параметры для тестирования (параметры относятся к тестированию создания разделов на жестком диске и взят из мануала к PICT):
Существует больше 4700 комбинаций этих значений. Будет очень сложно протестировать из за разумное время. Исследования показывают, что тестирование всех пар возможных значений обеспечивает очень хорошее покрытие и количество тест кейсов остается в пределах разумного. К примеру, это одна пара и другая; один тест кейс может покрывать много пар. Для набора приведенных выше параметров PICT создаст всего 60 тест кейсов (сравните с цифрой 4700!).
Рассмотрим работу с программой. Запускается PICT из командной строки.
На вход программа принимает простой текстовый файл с параметрами и их значениями, называемый Моделью, а на выход выдает сгенерированные тестовые сценарии.
Рассмотрим работу программы на примере из приведенной выше статьи из блога. Имеем следующие параметры и их значения: пол – мужской или женский; возраст – до 25, от 25 до 60, более 60; наличие детей – да или нет. Если перебирать все возможные значения, то количество сценариев будет 12. Составим модель и посмотрим какой результат нам выдаст программа.
Используем модель и получим 7 тестовых сценариев (вместо 12):
Разница не такая ощутимая, но она будет становится все более и более заметной при увеличении количества параметров или их значений.
Можно использовать прямой вывод и сохранение тест кейсов в Excel.
В результате будет создан Excel файл со следующим содержанием:
Но самое интересное это те возможности, которые предоставляет PICT для подобной генерации сценариев. Все они тщательно рассмотрены в мануале. Вот некоторые из них:
Источник
PICT и Pairwise тестирование
Pairwise тестирование (Парное тестирование), также известное как all pairs testing (тестирование «всех пар»), — это метод обнаружения дефектов с использованием комбинационного метода двух тестовых случаев. Он основан на наблюдении, что большинство дефектов вызвано взаимодействием не более двух факторов. Следовательно, выбирается пара из двух тестовых параметров, и все возможные пары этих двух параметров отправляются в качестве входных параметров для целей тестирования. Для облегчения генерации тестов для pairwise testing есть специальный инструментарий — PICT программа от Microsoft, о которой мы также поговорим в данной статье.
Pairwise testing приводит к сокращению количества тестовых случаев и, следовательно, к более быстрым и простым возможностям тестирования. Комбинационное тестирование более высокого порядка имеет большее количество тест кейсов, что делает тест более исчерпывающим, но также более дорогим и громоздким. Кроме того, большинство ошибок вызвано единственными входными параметрами или вызвано взаимодействием между двумя параметрами. Все эти ошибки могут быть устранены путем тестирования пар (test pair). Ошибки, вызванные взаимодействием трех или более параметров, обычно очень редки и дают меньше оснований для больших инвестиций в их поиск.
Давайте ниже рассмотрим суть проблематики, плюсы и минусы подхода а также посмотрим pairwise пример, который приложен в файле для скачивания.
Pairwise testing: проблематика

90% случаев команда тестирования должна работать в сжатые сроки. Таким образом, методы разработки тестов должны быть очень эффективными для максимального охвата и высокой вероятности обнаружения дефектов.
Примечание: Прежде чем переходить к примеру определимся с терминологией.
На экранах вы можете встретить следующие контролы – чек-боксы, листы, поля, радио-батоны и т.д.
Давайте будем их называть параметрами, а значения которые они принимают, например для дроп-даун листа это Option1, Option 2 и т.д. – это значения параметров.
Вполне возможно, что в литературе вы можете увидеть несколько другие термины, но такой русскоязычный вариант нам все же ближе…

Пример, где pairwise тестирование будет, как нельзя кстати
Предположим, что у нас есть тестируемое программное обеспечение, которое имеет набор контроллов (параметров), в свою очередь, каждый параметр может принимать значения (значения параметров), например:


Примечание: Давайте ради интереса посчитаем, какое кол-во комбинаций у нас получится…
Ради интереса, возьмем 2 шрифта (самых распространенных)*4 стиля * 3 размера(самых распространенных)*3 цвета*2 (учитываем эффекты) в 11 степени (11 переменных по 2 параметра) = 147 456
Таким образом мы подошли к сути проблемы, которая встает перед тестировщиком.
Суть проблемы тестирования программного обеспечения с большим количеством параметров и пути ее решения
Много параметров и много значений, которые принимают эти параметры, предполагают создание большого количества тестов, чтобы покрыть ими все возможные комбинации. Также абсолютно очевидно, что, сочетания этих переменных, могут вызывать ошибки. Баги из-за комбинации параметров, достаточно распространенное явление.

Закономерный вопрос тестировщика, что с этим делать? Ответ напрашивается сам собой, надо перебирать комбинации, но какие и в каком количестве? Таким образом, баги из-за «взаимодействия параметров» встречаются достаточно часто, но тестеры, порой, эти взаимодействия игнорируют из-за большого количества тестов (особенно этого пугаются новички). Тем не менее, не смотря на кажущуюся сложность вышеобозначенной задачи выход имеется и это pairwise тестирование, о котором подробнее поговорим дальше
Pairwise testing
Как мы отмечали в начале статьи, методика All Pairs testing очень полезна для разработки тестов для приложений с несколькими параметрами. Тесты составлены таким образом, что для каждой пары входных параметров системы существуют все возможные комбинации этих значений параметров. Тестовый набор охватывает все комбинации, поэтому он не является исчерпывающим, но очень эффективным в поиске ошибок.
Возможные варианты решения проблемы помимо pairwise тестирования
Прежде чем говорить о достоинствах, недостатках Pairwise тестирования а также инструментах, помогающих его реализовать, перечислим еще некоторые варианты решения вышеочерченной проблемы:

Monkey Testing
Полный перебор:
И если говорить непосредственно о pairwise testing, то данный метод базируется на исследовании, которое говорит, что 90% ошибок кроются в комбинациях пар и только 10 % ошибок дает сочетание троек, четверки. И если в кратце охарактеризоват данный метот, то это будет выглядеть следующим образом.
Метод «Всех пар» (all pairs testing)
Теперь давайте разберемся в чем заключается идея метода.
Идея и реализация метода pairwise testing
Вернемся к нашему примеру со страничкой из Word. В чем тут суть метода. Этот метод гарантирует, что мы каждый параметр протестируем в ПАРЕ со всеми другими параметрами.
Например, Arial со всеми стилями (обычный, курсив, жирный, маленький размер, белый цвет, и т.д. ) а именно со всеми значениями параметров других переменных. Тем самым мы обеспечим парное покрытие параметров, у каждого параметра будет своя пара с другим параметром из другой переменной. И так для всех. Для успешной реализации надо пройти через 3 шага:
Пример реализации этапов
| Этап | Реализация pairwise тестирования |
|---|---|
| Определение параметров | 
Итак, определяем переменные: |
| Определение значений | 
Каждый параметр имеет ряд значений: Примечание: обратите внимание на сокращения |
| Построение таблицы | 
И только на 6-ом символе у нас произошло бы переполнение и мы дописывали бы строчки. В итоге у нас количество тестов для этой таблицы сократилось с 96 до 8 (по кол-ву строк). 4-ая, 5-ая, 6-ая колонки фэйковые, чтобы ощутить размер пользы. Так как если бы мы оставили наши 3 колонки, то получилось бы 3*2*2 = 12 против 6 тестов (не очень внушающие цифры). PICT pairwise testingВозвращаясь к многострадальному примеру с Word. Как построить таблицу all pairs testing?
Выход очевиден – использовать спец фриварный инструментарий, например PICT. Инструмент pairwise тестирования (PICT) может помочь вам эффективно проектировать тестовые случаи для программных систем. С помощью PICT вы можете создавать тесты более эффективно, чем тесты, созданные вручную, и создавать их за короткий промежуток времени. PICT генерирует компактный набор вариантов значений параметров, представляющих тестовые наборы, которые вы должны использовать. Это позволяет получить всесторонний комбинаторный охват ваших параметров. Если кратко охарактеризовать преимущества PICT, то можно назвать: Примечание: Плюс ко всему PICT позволяет покрывать не только пары, но и тройки (используя спец синтаксис). Теперь давайте рассмотрим, ка работать с PICT. PICT, как пользоваться?
PICT работает как инструмент командной строки. Вы готовите файл модели, детализирующий параметры интерфейса (или набора конфигураций, или данных), которые вы хотите протестировать. PICT генерирует компактный набор вариантов значений параметров, которые представляют собой тестовые случаи. Процесс установки, после скачивания и разархивации: Для генерации тестовых случаев необходимо проделать несколько шагов: После чего PICT обработает txt файл и в папке появиться xls документ с набором комбинаций (пример сформированного PICT файла cases_pict.xls можно скачать ниже). Более полный набор возможностей PICT можно найти в мануале PICTHelp.htm, который находится в папке с установленным PICT. Недостатки PICT
При имеющихся недостатках, во многих ситуациях, пользу от использования PICT pairwise testing сложно переоценить. Ведь как показал пример с Word вместо 147456 комбинаций было сгенерировано 15 тестов. В итоге от применения pict и pairwise все счастливы! Так как эти тест сеты можно и заказчику показывать с обоснованием целесообразности сокращения количества тестов и сэкономить время на рутинной работе тестировщика. Скачать PICT и pairwise пример файла Источник Как установить pict на windowsPict lets your to organize your media library. Browse and view your photos and videos stored in any folder. View your images in fullscreen. Use the pinch-to-zoom gesture for more detailed view. Import photos from any USB device and group them by creation date. This feature helps you quickly take and organize photos from your camera after holidays. Create beautiful slideshows and display high resolution photos to your friends. Organize your photos in folders. Easily manage your folders: add, delete, rename, copy or move photos and videos between folders. Share the best photos with your friends. Publish photos from the Pict to the all popular social networks. Add comments to the photos. With Pict you can write about the place where the photo was taken, as well as those who are in the photo next to you. Available onDescriptionPict lets your to organize your media library. Browse and view your photos and videos stored in any folder. View your images in fullscreen. Use the pinch-to-zoom gesture for more detailed view. Import photos from any USB device and group them by creation date. This feature helps you quickly take and organize photos from your camera after holidays. Create beautiful slideshows and display high resolution photos to your friends. Organize your photos in folders. Easily manage your folders: add, delete, rename, copy or move photos and videos between folders. Share the best photos with your friends. Publish photos from the Pict to the all popular social networks. Add comments to the photos. With Pict you can write about the place where the photo was taken, as well as those who are in the photo next to you. Источник Adblock |





 В общем мы рассмотрели, как пользоваться pict, но несмотря на очевидные преимущества данного метода, все же с ним есть реальные проблемы. К ним относятся:
В общем мы рассмотрели, как пользоваться pict, но несмотря на очевидные преимущества данного метода, все же с ним есть реальные проблемы. К ним относятся:Резюме
PICT (Инструмент парного независимого комбинаторного тестирования) — это инструмент для разработки тестовых случаев, используемый внутри Microsoft. В процессе фактического использования вам необходимо ввести соответствующие параметры тестового примера, после чего PICT сможет эффективно создать и спроектировать тестовый пример в соответствии с принципом попарного тестирования, чтобы получить исчерпывающую комбинацию параметров.
О комбинированном тесте два на два:
При тестировании «черного ящика» значения нескольких входных параметров часто комбинируются друг с другом. Практика и исследования показали, что около 70% сбоев программного обеспечения вызваны одним или двумя параметрами. Вызвано совместными действиями. Следовательно, комбинированное тестирование, особенно попарное комбинированное тестирование, признано очень эффективным методом тестирования программного обеспечения в реальной инженерии.
Однако в реальном рабочем процессе слишком много пар комбинаций, и PICT очень хорошо решает эту проблему.
установка
Нажмите на официальный сайт, чтобы скачать, Может использоваться после установки.

Программа установки PICT добавит путь PICT к системным переменным, чтобы мы могли запускать его с любого пути в системе.
Простой пример
PICT — это инструмент командной строки. Перед выполнением необходимо подготовить файл модели в виде обычного текста, чтобы подробно описать параметры (или набор конфигурации, набор данных и т. Д.) Тестируемого интерфейса. Следует пояснить один момент: PICT используется очень широко и не ограничивается тестированием интерфейса, функциональным тестированием и т. Д.
PICT создает набор кратких вариантов значений параметров для формирования комбинированного тестового примера покрытия. Чтобы дать простой пример, теперь есть интерфейс, и его поддерживаемые параметры:

Сначала создайте файл test.txt как файл модели, а затем введите набор параметров в текстовом инструменте. Обратите внимание, что все знаки препинания должны быть английскими:
page:int,string,
rows:int,string,
sekContract:string,int,
sekPm:string,int,После сохранения нажмите и удерживайте shift в каталоге документа и щелкните правой кнопкой мыши, выберите «Открыть окно команд здесь», чтобы выполнитьpict test.txt,следующее:

В этот момент pict напечатает произвольную комбинацию параметров на экране; для удобства просмотра мы также можем перенаправить вывод:



Файл модели
Разделы модели
Стандартный формат определения файла модели следующий, [разделы] означает необязательный:
# Определение параметра
parameter definitions
# Определение подмодуля
[sub-model definitions]
# Определение ограничения
[constraint definitions]Элементы модели всегда следует указывать в указанном выше порядке и не могут перекрываться. Сначала появляется часть определения параметра, за которой следуют необязательные подмодели и определения ограничений. Если вы их используете, вам не нужны специальные разделители между параметрами. Пустые строки могут появляться где угодно. Мы можем идентифицировать комментарии по префиксу «#».
Определение ограничения
Доступны следующие операторы: =, <>,>,> =, <, <= и подстановочный знак нечеткого соответствия LIKE. В выражении нечеткого сопоставления «*» соответствует любому количеству символов, а «?» Соответствует одному символу. Для изменения приоритета оператора по умолчанию также разрешены скобки; логические операторы поддерживают IN, IF, THEN, ELSE, NOT, AND, OR;
Пример:
[Size] < 10000
[Compression] = "OFF"
[File system] like "FAT*"IF [Cluster size] in {512, 1024, 2048} THEN [Compression] = "Off";
IF [File system] in {"FAT", "FAT32"} THEN [Compression] = "Off";IF [File system] <> "NTFS" OR
( [File system] = "NTFS" AND [Cluster size] > 4096 )
THEN [Compression] = "Off";
IF NOT ( [File system] = "NTFS" OR
( [File system] = "NTFS" AND NOT [Cluster size] <= 4096 ))
THEN [Compression] = "Off";