From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This led to much confusion subsequently. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but now additionally supports and recommends using UTF-8 (aka CP_UTF8). UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder). Since Windows 10 version 1803, Windows machines can be configured to allow UTF-8 as the «ANSI» and OEM codepage.[5]
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This led to much confusion subsequently. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but now additionally supports and recommends using UTF-8 (aka CP_UTF8). UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder). Since Windows 10 version 1803, Windows machines can be configured to allow UTF-8 as the «ANSI» and OEM codepage.[5]
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
Кодовые страницы Windows представляют собой наборы символов или кодовые страницы (известные как символ кодировки в других операционных системах), используемые в Microsoft Windows с 1980-х и 1990-х годов. Кодовые страницы Windows были постепенно заменены, когда Unicode был реализован в Windows, хотя они по-прежнему поддерживаются как в Windows, так и на других платформах, и по-прежнему применяются при использовании ярлыков Alt code.
В системах Windows есть две группы кодовых страниц: OEM и собственные кодовые страницы Windows («ANSI»). Кодовые страницы в обеих этих группах являются кодовыми страницами расширенного ASCII.
Содержание
- 1 Кодовая страница ANSI
- 2 Кодовая страница OEM
- 3 История
- 3.1 UTF-8, UTF-16
- 4 Список
- 4.1 Windows-125x series
- 4.2 Кодовые страницы DOS
- 4.3 Восточноазиатские многобайтовые кодовые страницы
- 4.4 Кодовые страницы EBCDIC
- 4.5 Кодовые страницы, связанные с Unicode
- 4.6 Кодовые страницы совместимости с Macintosh
- 4.7 Кодовые страницы ISO 8859
- 4.8 Кодовые страницы ITU-T
- 4.9 Кодовые страницы KOI8
- 4.10 Другие кодовые страницы
- 5 Проблемы, возникающие при использовании кодовых страниц
- 6 См. Также
- 7 Ссылки
- 8 Внешние ссылки
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неправильное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяет | US -ASCII |
| Преемник | ISO 8859 |
| Преемник | Unicode. UTF-16 (в Win32 API) |
|
кодовые страницы ANSI (официально называемые «Windows code» страницы «после того, как Microsoft приняла первый термин как неправильное) используются для приложений, не поддерживающих Unicode (например, ориентированных на байт ), использующих графический пользовательский интерфейс в системе Windows tems. «ANSI» — неправильное название, потому что поведение не совсем соответствует стандарту ANSI и потому что в эти 8-битные кодовые страницы включены некоторые кодировки, отличные от стандарта ANSI.
Большинство устаревших ANSI «кодовые страницы имеют номера кодовых страниц в шаблоне 125x. Однако 874 (тайский) и многобайтовые кодовые страницы ANSI Восточной Азии (932, 936, 949, 950 ), все из которых также используются как кодовые страницы OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодировкам IBM. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера для вариантов Microsoft, они приведены для справки в списках ниже, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как «Windows-number», хотя «Windows-936» рассматривается как синоним «GBK «. Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница 1252, были так называемыми, поскольку они якобы были основаны на представленных черновиках или предназначен для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 vs. ISO-8859- 1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 vs. ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows- 1257 vs. ISO-8859-4 ; ISO-8859-13 был представлен намного позже). Кроме того, Windows-1251 не следует ISO -стандартизированный ISO-8859-5, ни преобладающий в то время KOI-8.
Microsoft присвоила около двенадцати из типографики и деловых символов (включая, в частности, знак евро, €) в CP1252 до кодовых точек 0x80–0x9F, которые в ISO 8859 присвоены контрольным кодам C1. Эти присвоения также присутствуют во многих другие кодовые страницы ANSI / Windows с теми же кодовыми точками. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Тем не менее, если эта информация была включена в файл, переданный на совместимую со стандартами платформу, такую как Unix или MacOS, она была невидимой и потенциально опасной.
Кодовая страница OEM
Кодовые страницы OEM (производитель оригинального оборудования ) используются приложениями консоли Win32 и с помощью виртуальной DOS и может считаться пережитком от DOS и исходной архитектуры IBM PC. Отдельный набор кодовых страниц был реализован не только из-за совместимости, но и потому, что шрифты аппаратного обеспечения VGA (и потомков) предлагают кодировку символов рисования линий для совместимости с кодовая страница 437. Большинство кодовых страниц OEM имеют много общих кодовых точек, особенно для небуквенных символов, со второй (не ASCII) половиной CP437.
Типичная кодовая страница OEM во второй половине даже приблизительно не похожа ни на одну кодовую страницу ANSI / Windows. Тем не менее, две однобайтовые кодовые страницы с фиксированной шириной (874 для тайского и 1258 для вьетнамского ) и четыре многобайтовых кодовых страницы CJK (932, 936, 949, 950 ) используются как кодовые страницы OEM и ANSI. В кодовой странице 1258 используется комбинация диакритических знаков, поскольку вьетнамский требует более 128 буквенно-диакритических комбинаций. Это отличается от VISCII, который заменяет некоторые из управляющих кодов C0 (то есть ASCII).
История
Первоначально компьютерные системы и языки системного программирования не делали различия между символами и байтами : для сегментарных скриптов используется в большинстве стран Африки, Америки, Южной и Юго-Восточной Азии, Ближнего Востока и Европы, для символа требуется всего один байт, но для используемых идеографических наборов требуется два или более байта в остальном мире. Впоследствии это привело к большой путанице. Программное обеспечение и системы Microsoft, предшествующие строке Windows NT, являются примерами этого, поскольку они используют кодовые страницы OEM и ANSI, которые не делают различия.
С конца 1990-х годов программное обеспечение и системы приняли Unicode в качестве предпочтительного формата хранения; эта тенденция была улучшена за счет повсеместного принятия XML, который обеспечивает более адекватный механизм для маркировки используемой кодировки. Последние продукты Microsoft и программные интерфейсы приложений внутренне используют Unicode, но многие приложения и API-интерфейсы продолжают использовать кодировку по умолчанию «локали» компьютера при чтении и записи текстовых данных в файлы или стандартный вывод. Таким образом, файлы могут быть разборчивыми и разборчивыми в одной части мира, но неразборчивыми моджибаке в другой.
UTF-8, UTF-16
Microsoft решила принять 16-битную (двухбайтовую) систему UTF-16 для всех своих операционных систем. начиная с Windows NT. Этот метод уникальным образом кодирует все символы Юникода в базовой многоязычной плоскости и 32-битный (четырехбайтовый) код для других, но остальная часть отрасли выбрала UTF-8 (который использует один байт для 7-битного набора символов ASCII, два или три байта для других символов в BMP и четыре байта для остатка). Начиная с Windows 10 версии 1803, компьютеры Windows могут быть настроены так, чтобы разрешить UTF-8 в качестве кодовой страницы «ANSI» и OEM.
Список
Существуют следующие кодовые страницы Windows :
Windows-125x series
Все эти девять кодовых страниц являются расширенными кодировками ASCII 8-битными SBCS и были разработаны Microsoft для использования в качестве кодовых страниц ANSI в Windows. Обычно они известны под своими зарегистрированными в IANA именами как windows-, но иногда их также называют cp, «cp» для «кодовой страницы». Все они используются как кодовые страницы ANSI; Windows-1258 также используется как кодовая страница OEM.
| ID | Описание | Отношение к ISO 8859 или другим установленным кодировкам |
|---|---|---|
| 1250 | Latin 2 / Центральноевропейская | Аналогично ISO-8859-2, но перемещает несколько символов, включая несколько букв. |
| 1251 | Кириллица | Несовместима как с ISO-8859-5, так и с KOI-8. |
| 1252 | Latin 1 / Western European | Расширенный набор ISO-8859-1 (без элементов управления C1). Буквенный репертуар, соответственно, аналогичен CP850. |
| 1253 | Греческий | Аналогичен ISO 8859-7, но перемещает несколько символов, включая букву. |
| 1254 | Турецкий | Расширенный набор ISO 8859-9 (без элементов управления C1). |
| 1255 | Иврит | Практически расширенный набор ISO 8859-8, но с двумя несовместимыми изменениями пунктуации. |
| 1256 | арабский | Несовместимо с ISO 8859-6 ; скорее OEM Кодовая страница 708 является расширенным набором ISO 8859-6 (ASMO 708). |
| 1257 | Балтийский | Не ISO 8859-4 ; более поздний ISO 8859-13 тесно связан, но с некоторыми отличиями в доступной пунктуации. |
| 1258 | Вьетнамский (также OEM) | Не относится к VSCII или VISCII, использует меньшее количество базовых символов с комбинированными диакритическими знаками. |
Кодовые страницы DOS
Они также основаны на ASCII. Большинство из них включены для использования в качестве кодовых страниц OEM; кодовая страница 874 также используется как кодовая страница ANSI.
- 437 — IBM PC US, 8-битный SBCS расширенный ASCII. Известная как OEM-US, кодировка основного встроенного шрифта видеокарт VGA.
- 708 — арабский, расширенный ISO 8859-6 (ASMO 708)
- 720 — арабский, символы рисования прямоугольников остаются на их обычном месте
- 737 — «MS-DOS Greek». Сохраняет все символы рисования прямоугольников. Популярнее, чем 869.
- 775 — «MS-DOS Baltic Rim»
- 850 — «MS-DOS Latin 1». Полный (реорганизованный) репертуар ISO 8859-1.
- 852 — «MS-DOS Latin 2»
- 855 — «MS-DOS Cyrillic». В основном используется для южнославянских языков. Включает (реорганизованный) репертуар ISO-8859-5. Не путать с cp866.
- 857 — «MS-DOS Turkish»
- 858 — Западноевропейский со знаком евро
- 860 — «MS-DOS Portuguese»
- 861 — «MS-DOS исландский»
- 862 — «MS-DOS Hebrew»
- 863 — «MS-DOS French Canada»
- 864 — арабский
- 865 — «MS-DOS Nordic»
- 866 — «MS-DOS Cyrillic Russian», cp866. Единственная кодовая страница исключительно OEM (а не ANSI или оба), включенная в качестве устаревшей кодировки в WHATWG Encoding Standard для HTML5.
- 869 — «MS-DOS Greek 2», IBM869. Полный (реорганизованный) репертуар ISO 8859-7.
- 874 — Тайский, также используемый в качестве кодовой страницы ANSI, расширяет ISO 8859-11 (и, следовательно, TIS-620 ) с несколькими дополнительными символами из Windows-1252. Соответствует кодовой странице IBM 1162 (IBM-874 аналогична, но имеет другие расширения).
Многобайтовые кодовые страницы восточноазиатских стран
Часто они лишь частично совпадают с кодовыми страницами IBM с тем же номером: кодовые страницы 932, 936 и 949 отличаются от кодовых страниц IBM с тем же номером, тогда как Windows-951, как часть кладжа, не связана с IBM-951. Эквивалентные кодовые страницы IBM приведены во втором столбце. Кодовые страницы 932, 936, 949 и 950/951 используются в качестве кодовых страниц как ANSI, так и OEM в рассматриваемых регионах.
| ID | IBM Equivalent | Язык | Кодировка | Используйте |
|---|---|---|---|---|
| 932 | 943 | Японский | Shift JIS (вариант Microsoft) | ANSI / OEM (Япония) |
| 936 | 1386 | Китайский (упрощенный) | GBK | ANSI / OEM (КНР, Сингапур) |
| 949 | 1363 | Корейский | Унифицированный код хангыль | ANSI / OEM (Республика Корея) |
| 950 | 1370, 1373 | Китайский (традиционный) | Big5 (вариант Microsoft) | ANSI / OEM (Тайвань, Гонконг) |
| 951 | 5471 | Китайский (традиционный) | Big5-HKSCS (изд. 2001 г.) | ANSI / OEM (Гонконг, 98 / NT4 / 2000 / XP с патчем HKSCS) |
Несколько дополнительных многобайтовых кодовых страниц поддерживаются для декодирования или кодирования с использованием библиотек операционной системы, но не используются в качестве системного кодирования в любом локаль.
| ID | IBM Equivalent | Язык | Кодировка | Используйте |
|---|---|---|---|---|
| — | корейский | Johab (KS C 5601-1992, приложение 3) | Преобразование | |
| 964 | Китайский (традиционный) | CNS 11643 | Преобразование | |
| — | Китайский (традиционный) | TCA | Преобразование | |
| — | Китайский (традиционный) | Big5 (вариант ETEN) | Преобразование | |
| ? | Китайский (традиционный) | Преобразование | ||
| — | Китайский (традиционный) | Телетекст | Преобразование | |
| — | Китайский (традиционный) | Ван | Преобразование | |
| 20932 | 954 (примерно) | Японский | EUC-JP | Преобразование |
кодовые страницы EBCDIC
- 37 — IBM EBCDIC США-Канада, 8-битный SBCS
- 500 — Latin 1
- 870 — IBM870
- 875 — cp875
- 1026 — EBCDIC Turkish
- 1047 — IBM01047 — Latin 1
- 1140 — IBM01141
- 1141 — IBM01141
- 1142 — IBM01142
- 1143 — IBM01143
- 1144 — IBM01144
- 1145 — IBM01145
- 1146 — IBM01146
- 1147 — IBM01147
- 1148 — IBM01148
- 1149 — IBM01149
- — EBCDIC Германия
- — EBCDIC Дания / Норвегия
- — EBCDIC Финляндия / Швеция
- — EBCDIC Италия
- — EBCDIC Латинская Америка / Испания
- — EBCDIC Соединенное Королевство
- — EBCDIC японский
- — EBCDIC Франция
- — EBCDIC арабский
- — EBCDIC Греческий
- — x-EBCDIC-KoreanExtended
- — Корейский
- — EBCDIC Тайский
- — EBCDIC Кириллица
- — EBCDIC Исландский
- — EBCDIC Кириллица
- — EBCDIC Турецкий
- — Японский EBCDIC (неполный, устаревший)
Кодовые страницы, связанные с Unicode
- 1200 — Unicode (BMP по ISO 10646, UTF-16LE ). Доступно только для управляемых приложений
- 1201 — Unicode (UTF-16BE ). Доступно только для управляемых приложений
- 12000 — utf-32. Доступно только для управляемых приложений
- 12001 — utf-32 Big Endian. Доступно только для управляемых приложений
- 65000 — Unicode (UTF-7 )
- 65001 — Unicode (UTF-8 )
Кодовые страницы совместимости Macintosh
- 10000 — Apple Macintosh Roman
- 10001 — Apple Macintosh Японский
- — Apple Macintosh китайский (традиционный) (BIG-5)
- — Apple Macintosh корейский
- 10004 — Apple Macintosh арабский
- — Apple Macintosh иврит
- 10006 — Apple Macintosh греческий
- 10007 — Apple Macintosh кириллица
- — Apple Macintosh китайский (упрощенный) (GB 2312)
- 10010 — Apple Macintosh Румынский
- 10017 — Apple Macintosh украинский
- — Apple Macintosh Thai
- 10029 — Apple Macintosh Roman II / Центральная Европа
- 10079 — Apple Macintosh Icelandic
- 10081 — Apple Macintosh Turkish
- 10082 — Apple Macintosh хорватский
ISO 8859 кодовых страниц
- 28591 — ISO-8859-1 — Latin-1 (эквивалент IBM: 819)
- 28592 — ISO-8859-2 — Latin-2
- 28593 — ISO-8859-3 — Latin-3 или южноевропейский
- 28594 — ISO-8859-4 — Latin-4 или североевропейский
- 28595 — ISO-8859-5 — латиница / кириллица
- 28596 — ISO-8859-6 — латиница / арабский
- 28597 — ISO- 8859-7 — Латинский / греческий
- 28598 — ISO-8859-8 — Латинский / иврит
- 28599 — ISO-8859-9 — Latin-5 или турецкий
- 28600 — ISO-8859-10 — Latin-6
- 28601 — ISO-8859-11 — Latin / Thai
- 28602 — ISO-8859-12 — зарезервировано для Latin / Devanagari, но не поддерживается (не поддерживается)
- 28603 — ISO-8859- 13 — Latin-7 или Baltic Rim
- 28604 — ISO-8859-14 — Latin-8 или Celtic
- 28605 — ISO-8859 -15 — Latin-9
- 28606 — ISO-8859-16 — Latin-10 или Юго-Восточная Европа
- 38596 — ISO- 8859-6-I — латинский / арабский (логический двунаправленный порядок)
- 38598 — ISO-8859-8-I — латинский / иврит (логический двунаправленный порядок)
Кодовые страницы ITU-T
- 20105 — 7-битный IA5 IRV (западноевропейский)
- 20106 — 7-битный IA5 немецкий (DIN 66003)
- — 7-битный IA5 шведский (SEN 850200 C)
- — 7-битный IA5 норвежский (NS 4551-2)
- 20127 — 7-битный US-ASCII
- 20261 — T.61 (T.61-8bit)
- 20269 — ISO-6937
кодовые страницы KOI8
- 20866 — Русский — KOI8-R
- 21866 — Украинский — KOI8-U (или KOI8-RU в некоторых версиях)
Другие кодовые страницы
- — IBM00924 — IBM EBCDIC Latin 1 / Open System (1047 + символ евро)
- — x-cp20936 — упрощенный китайский (GB2312); Упрощенный китайский (GB2312-80)
- — x-cp20949 — Korean Wansung
Проблемы, связанные с использованием кодовых страниц
Microsoft настоятельно рекомендует использовать Unicode в современных приложениях, но многие приложения или файлы данных по-прежнему зависят от устаревших кодовых страниц.
- Программы должны знать, какую кодовую страницу использовать, чтобы правильно отображать содержимое (до Unicode) файлов. Если программа использует неправильную кодовую страницу, она может отображать текст как mojibake.
- Используемая кодовая страница может отличаться на разных машинах, поэтому файлы (до Unicode), созданные на одной машине, могут быть нечитаемыми на другой.
- Данные часто неправильно помечены кодовой страницей или не помечены вообще, что затрудняет определение правильной кодовой страницы для чтения данных.
- Эти кодовые страницы Microsoft в разной степени отличаются от некоторых из стандарты и реализации других поставщиков. Это не проблема Microsoft как таковая, как это происходит со всеми поставщиками, но отсутствие согласованности делает взаимодействие с другими системами ненадежным в некоторых случаях.
- Использование кодовых страниц ограничивает набор символов, которые могут
- Символы, выраженные в неподдерживаемой кодовой странице, могут быть преобразованы в вопросительные знаки (?) или другие заменяющие символы, или в более простую версию (например, удаление диакритических знаков из буквы). В любом случае исходный символ может быть утерян.
См. Также
- AppLocale — утилита для запуска приложений, не поддерживающих Юникод (на основе кодовых страниц), в языковом стандарте по выбору пользователя.
Ссылки
- ^Кодовые страницы, MSDN
- ^ MSDN: Глоссарий терминов
- ^Список IANA из наборов символов
- ^«Расширяемый язык разметки (XML) 1.1 (второе издание): кодировки символов». W3C. 29 сентября 2006 г. Дата обращения 5 октября 2020 г.
- ^hylom (2017-11-14). «Windows 10 の Insider Preview シ ス テ ム ー ル を UTF-8 に す る プ シ ョ ン が 追加 さ れ る» [возможность сделать UTF-8 системным языковым стандартом, добавленным в Windows 10 Insider Preview].ス ラ ド (на японском). Проверено 10 мая 2018 г.
- ^«Наборы символов». IANA.
- ^Microsoft. «Windows 1250». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01250». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1251». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01251». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1252». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01252». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1253». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01253». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1254». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01254». Проверено 6 июля 2014.
- ^Microsoft. «Windows 1255». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01255». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1256». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01256». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1257». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01257». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1258». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01258». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS — CPGID 00437». Проверено 4 июля 2014 г.
- ^«IBM-943 и IBM-932». Центр знаний IBM. IBM.
- ^»Информационный документ CCSID 1370″. Архивировано из оригинального 27 марта 2016 года.
- ^»Converter Explorer: ibm-1373_P100-2002″. Демонстрация интенсивной терапии. Международные компоненты для Unicode.
- ^«Идентификаторы кодированного набора символов — CCSID 5471». IBM Globalization. IBM. Архивировано с оригинального 29.11.2014.
- ^IBM. «Информационный документ кодовой страницы SBCS — CPGID 00037». Проверено 4 июля 2014 г.
- ^Стил, Шон (12 сентября 2005 г.). «Кодовая страница 21027» Расширенный / расширенный алфавитный нижний регистр «». MSDN.
- ^Идентификаторы кодовой страницы
- ^ Список идентификаторов кодовой страницы
- ^ «Идентификаторы кодовой страницы». Сеть разработчиков Microsoft. Microsoft. 2014. Архивировано из оригинала 19.06.2016. Проверено 19 июня 2016 г.
- ^ «Веб-кодировки — Internet Explorer — Кодировки». WHATWG Wiki. 2012-10-23. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Западноевропейская (IA5) кодировка — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Кодировка немецкого (IA5) — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Шведская (IA5) кодировка — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Норвежская (IA5) кодировка — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Кодировка US-ASCII — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Нечаев, Валентин (2013) [2001]. «Обзор вселенной 8-битных кодировок кириллицы». Архивировано из оригинала на 2016-12-05. Проверено 5 декабря 2016 г.
Внешние ссылки
- Справочник по API поддержки национальных языков (NLS). Таблица, показывающая кодовые страницы ANSI и OEM для каждого языка (из веб-архива, поскольку Microsoft удалила исходную страницу)
- Регистрации имен кодировки IANA
- Таблица сопоставления Unicode для кодовых страниц Windows
- Сопоставление Unicode кодовых страниц Windows с «наилучшим соответствием» »

Анастасия Николаевна Королева
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Определение 1
Кодирование информации на ПК в среде операционной системы Windows — это представление информационных данных в формате последовательно расположенных битов, находящихся в одном из возможных состояний.
Операционная система Windows производит выборку команд программы и информационных данных, подлежащих обработке, из памяти персонального компьютера. Память представляет собой электронный модуль, состоящий из набора микросхем, которые также имеют в своём составе тысячи микроэлементов. Такие микроэлементы способны находиться лишь в двух устойчивых состояниях, условно говоря, «включено» или «выключено». Эти состояния имеют соответствие с бинарной (двоичной) системой счисления, где один бит может быть или нулём, или единицей. То есть, вся информация, расположенная в компьютерной памяти, является последовательностью битов, находящихся в одном из возможных состояний.
IT Профессия «Разработчик ПО»
Получишь знания, необходимые в работе, соберешь портфолио из собственных проектов и начнешь получать $$
Узнать подробнее
Кодирование текстовой информации
Когда текстовая информация вводится в память компьютера, то текстовые символы (буквенные, цифровые, знаковые) подвергаются кодированию при помощи разных систем кодирования, состоящих из разнообразных кодовых таблиц, которые размещены на определённых страницах стандартов кодировки информации в текстовом формате. В данных таблицах все символы имеют некоторый числовой код в шестнадцатеричной или десятичной системе счисления, то есть таблицы кодировки отображают соответствие начертания символов и численными кодами и предназначаются для кодировки и декодирования информации, представленной в текстовом формате.
Когда пользователь вводит текстовую информацию при посредстве компьютерной клавиатуры, то каждый заносимый символ проходит процедуру кодирования, то есть преобразования в численный код. А когда текстовая информация выводится на какое-либо периферийное устройство, к примеру, экран монитора, принтер или МФУ (многофункциональное устройство), то согласно символьному числовому коду осуществляется формирование его изображения. Назначение символу конкретного числового значения получается в результате совместного решения соответствующих организаций различных государств. На сегодняшний день не существует единообразной универсальной кодовой таблицы, которая бы удовлетворяла национальные алфавиты всех государств. Нынешние кодовые таблицы состоят из международной и национальной частей, то есть они включают в себя символы латинского и национального алфавитов, цифровые обозначения, знаки препинания и арифметических операций, управляющие и математические символы, псевдографику. Международный раздел кодовых таблиц, основанный на стандарте ASCII (American Standard Code for Information Interchange), определяет коды первой половины символов кодовой таблицы и занимает числовое пространство от нуля до 127 (7F в шестнадцатеричной системе). Следует заметить, что числа от нуля до 32 (то есть 20 в шестнадцатеричной системе) отводятся под кодирование функциональных клавиш (F1, F2, F3 и так далее) на клавиатуре компьютера. На рисунке ниже представлена кодовая таблица международной части, базирующаяся на стандарте ASCII, в десятичной системе счисления:
«Кодирование информации на ПК в среде операционной системы Windows» 👇

Рисунок 1. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
И та же таблица, но в шестнадцатеричной системе счисления:

Рисунок 2. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
Национальный раздел кодовых таблиц состоит из кодов национальных алфавитов, который именую также таблицей символьных наборов. На сегодняшний день есть несколько кодовых таблиц, поддерживающих символы русского алфавита (кириллица), используемых разными операционными системами. Это безусловно считается определённым недостатков и иногда может вызывать проблемы, которые сопряжены с процедурами декодирования численных величин символов. В таблице на рисунке ниже показаны наименования кодовых страниц, где имеются кириллические кодировки:

Рисунок 3. Наименования кодовых страниц, где имеются кириллические кодировки. Автор24 — интернет-биржа студенческих работ
Первым компьютерным стандартом, где была кодировка кириллицы, стал стандарт КОИ8-Р. На рисунке ниже изображена национальная часть кодовой таблицы данного стандарта:

Рисунок 4. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
Сегодня для кодирования кириллического алфавита чаще всего используется кодовая таблица, входящая в страницу стандарта СР1251, которая применяется в семействе операционных систем Windows корпорации Microsoft. Данная таблица изображена на рисунке ниже:

Рисунок 5. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
Все представленные кодовые таблицы, в отличие от стандарта Unicode, используют восьми битную систему кодировки одного символа. Стандарт Unicode был разработан в конце двадцатого века и в нём была применена система кодирования одного символа двумя байтами. Использование данного стандарта явилось продолжением проектирования универсального мирового стандарта, который позволяет разрешить проблему совместимости национальных кодовых таблиц символов. При помощи этого стандарта появилась возможность кодирования $2^{16} = 65536$ разных символьных знаков.
Кодирование графической информации
Информация в графическом формате, то есть это рисунки, фотографии, слайды, видео и так далее, может формироваться и подвергаться корректированию при помощи компьютера, но при этом она должна быть соответственно закодирована. Сегодня разработано много прикладных программ, работающих под управлением операционной системы Windows разных модификаций, способных выполнять обработку графических объектов, но все эти приложения базируются на трёх типах компьютерной графики, а именно это:
- Растровый тип графики.
- Векторный графический тип.
- Фрактальный тип графики.
При пристальном рассмотрении графического изображения на экране дисплея компьютера, можно заметить огромное число точек разных цветов, то есть пикселей (от английского pixel, являющего сокращением от picture element, то есть элемент изображения), которые и формируют все вместе видимую графическую картинку.
Отсюда проистекает следующий вывод, что все графические компьютерные изображения кодируются заданным методом и могут быть представлены в формате графического файла. Файл считается главной структурной составляющей организации и хранения информационных данных в памяти компьютера.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)

Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.
Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.
Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.

Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.
Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.

- Перейдите по ветке HKEY_CURRENT_USERConsole и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).

- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.


Отличного Вам дня!
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»).
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Имеет два недостатка:
- строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же
-1, в дополнительном коде длиной 8 бит представляющееся числом255, часто используется в программировании как специальное значение, например, индикатор конца файла EOF часто представляется значением-1). - отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Содержание
- 1 Таблицы
- 1.1 Кодировка Windows-1251 (синоним CP1251)
- 1.2 Другие варианты
- 1.2.1 Кодировка CP1251-k (KazWin, казахская кодировка)
- 1.2.2 Кодировка Windows-1251 (чувашский вариант)
- 1.2.3 Татарский вариант
- 2 Ссылки
Таблицы
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают 16-ричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
| C. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
| D. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
| E. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
| F. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
-

Таблица основного кода ASCII
-

Таблица расширенного кода ASCII

Другие варианты
(Показаны только отличающиеся строки, поскольку всё остальное совпадает)
Кодировка CP1251-k (KazWin, казахская кодировка)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ұ 4B0 |
Ғ 492 |
‚ 201A |
ғ 493 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ң 4A2 |
Қ 49A |
Һ 4BA |
Ү 4AE |
| 9. |
ұ 4B1 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ң 4A3 |
қ 49B |
һ 4BB |
ү 4AF |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Җ 496 |
¤ A4 |
Ҳ 4B2 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ҳ 4B3 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
җ 497 |
Ә 4D8 |
ә 4D9 |
ї 457 |
Кодировка Windows-1251 (чувашский вариант)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Татарский вариант
Эта кодировка была официально принята в Татарстане в 1996 г.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ә 4D8 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ү 4AE |
Җ 496 |
Ң 4A2 |
Һ 4BA |
| 9. |
ә 4D9 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ү 4AF |
җ 497 |
ң 4A3 |
һ 4BB |
Ссылки
- Информация о кодировке на Microsoft GlobalDev
- История создании кодировки в сообщении Игоря Семенюка в эхоконференции SU.LAN от 14 января 1996
- Юникод-коды символов на unicode.org
| Кодировки символов | |||
|---|---|---|---|
| Основы → | алфавит • текст ( файл • данные ) • набор символов • конверсия | ||
| Исторические кодировки → | Докомп.: семафорная (Макарова) • Морзе • Бодо • МТК-2 | Комп.: 6 бит • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| совре- менное 8-битное представ- ление |
символы → | ASCII ( управляющие • печатные ) | не-ASCII ( псевдографика ) |
| 8бит. код.стр. | Разные → Кириллица: КОИ-8 • ГОСТ 19768-87 • MacCyrillic | ||
| ISO 8859 → | 1(лат.) 2 3 4 5(кир.) 6 7 8 9 10 11 12 13 14 15(€) 16 | ||
| Windows → | 1250 1251(кир.) 1252 1253 1254 1255 1256 1257 1258 | WGL4 | ||
| IBM&DOS → | 437 • 850 • 852 • 855 • 866 «альт.» • ( МИК ) • ( НИИ ЭВМ ) | ||
| Много- байтные |
Традиционные → | DBCS ( GB2312 ) • HTML | |
| Unicode → | UTF-16 • UTF-8 • список символов ( кириллица ) | ||
| Связанные темы → |
интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • шрифт • кракозябры • транслит • нестандартные шрифты • текст как изображение | Утилиты: iconv • recode |
определенные перспективы. Она наиболее удобна для технических операций с текстовыми данными (поиск, преобразование и т.п.).
Схема кодирования CP 866
В 1974 г. Государственный комитет по стандартизации утвердил стандарт двоичного кодирования ГОСТ 19768-74, согласно которому внедрялись сразу две схемы кодирования. Одна из них получила название ГОСТ-альтернативной. Срок действия стандарта предусматривался до 1980 г.
Когда в начале 80-х годов XX в. началась поставка в СССР IBM-совместимых компьютеров, эта схема кодирования была принята для них в качестве основной. Впоследствии корпорация IBM опубликовала эту схему в своём корпоративном стандарте, и схема получила наименование CP 866 (Code page 866).
В настоящее время данной кодировкой пользуются только устаревшие программы, работающие под управлением операционной системы MS-DOS, поэтому эту кодировку называют также кодировкой MS-DOS. Таким образом, сегодня мы имеем три разных наименования для одной и той же устаревшей схемы кодирования.
Схема кодирования Windows-1251
Схема кодирования Windows-1251 представляет наглядный пример корпоративного стандарта. Ввела её в действие корпорация Microsoft, производитель операционных систем и программных продуктов, предназначенных для автоматизации работы с документами. Никакими государственными или международными стандартами данная схема кодирования не поддержана, но, тем не менее, является самой распространённой на компьютерах платформы IBM PC. Она считается основной для документов, созданных в таких программах, как Microsoft Word, Excel, Access и многих других. Большинстве русскоязычных веб-страниц в Интернете имеют именно эту кодировку.
Схема кодирования КОИ-8Р
Схема кодирования КОИ-8 была одной из двух, утверждённых Госстандартом СССР в 1974 г., и в те годы называлась ДКОИ (двоичный код обмена информацией). Она стала основной для сетевых ЭВМ, работающих под управлением операционной системы UNIX. Важную область использования этой схемы представлял международный документооборот социалистических стран, объединённых Советом Экономической Взаимопомощи (СЭВ).
На персональных компьютерных платформах эту схему стали применять только после внедрения электронной почты Интернета. Это связано с тем, что первое время работа электронной почты обслуживалась ЭВМ под управлением операционной системы UNIX. Сегодня данная схема кодирования называется КОИ-8 (код обмена информацией, восьмиразрядный). После распада СССР различают отдельные схемы кодирования для России и Украины: КОИ-8Р и КОИ-8У.
Использование 8-разрядных таблиц кодирования заметно сдерживает возможности международного информационного обмена. Даже в одной стране могут одновременно действовать несколько стандартов, что затрудняет информационный обмен. Приходится создавать программы, способные работать с разными таблицами кодирования, а это нерациональные затраты средств.
78
Для разработки универсальной системы кодирования в конце 80-х годов XX века был создан международный консорциум Unicode, который классифицировал национальные письменные системы и изучил их особенности. По результатам этой работы был разработан международный стандарт кодирования. В его основе лежат три положения.
1.Каждый символ имеет уникальное имя. Символы могут совпадать по начертанию, но не по имени. Так, латинская, русская и греческая буквы «А» выглядят совершенно одинаково, но это разные символы с разными именами и кодами.
2.Каждый символ имеет уникальный номер, определяющий его позицию в таблице кодирования.
3.Каждый символ можно представить его позицией, выраженной 16-разрядным двоичным кодом.
Теоретически, 16 битами можно закодировать 65536 различных символов. Однако на самом деле напрямую кодируется на 2048 символов меньше. Последние 2048 кодов разделены пополам и образуют дополнительную таблицу размером . В ячейках этой таблицы можно разместить ещё более миллиона символов. Эти символы кодируются парами 16-разрядных значений, одно из которых выражает номер строки, а другое — номер столбца. Числовые коды этих символов называются суррогатными парами. Суррогатные пары представляют собой технологию 32разрядного кодирования.
Значение стандарта Unicode
Считается, что современные потребности информационного обмена человечества требуют более 200 тысяч различных символов. Несколько десятков тысяч символов уже каталогизировано и зарегистрировано в основной таблице Unicode. Они в значительной степени охватывают символы алфавитов европейских языков, арабских, индийских и других слоговых систем, а также знаки иероглифических систем Японии, Китая и Кореи. На очереди кодирование знаков «мёртвых» письменных систем, что будет осуществлено с помощью механизма образования суррогатных пар.
Познакомиться с тем, как закодированы первые десятки тысяч символов, можно на компьютере, работающем в операционной системе Windows XP. Это первая операционная система, полностью поддерживающая стандарт Unicode. Запустите стандартную программу Таблица символов И откройте в ней какой-либо символьный набор, имеющий формат Open Туре. Рекомендуется использовать шрифт Arial Unicode MS. Сегодня это наиболее полный символьный набор из существующих в мире.
Механизмы трансформации Unicode
Наиболее распространённым заблуждением, касающимся схемы кодирования Unicode, является мнение о том, что «согласно этой схеме один символ кодируется двумя байтами». На самом деле стандарт ни слова не говорит о байтах, да и не может этого делать, потому что информационное содержание байта зависит от конкретных программ, которые записывают или воспроизводят данные. Стандарт обходит эту проблему, вообще избегая упоминаний о байтах.
В то же время, для практических целей надо как-то представлять данные байтами — этого ждут программы и устройства. Однако оказывается, что преобразовать 16 бит данных в байты можно далеко не единственным способом. Принципы этого преобразования называются механизмами
79
Содержание
- Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
- Таблица ASCII
- Таблица CP1251 (windows-1251)
- Таблица IS0-8859-5
- Кодировка UTF-8 (Unicode Transformation Format)
- Кодировки в Windows
- Таблицы кодировки
- Содержание
- Windows-1251
- cp866
- Юникод (Unicode)
Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
Таблица ASCII
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
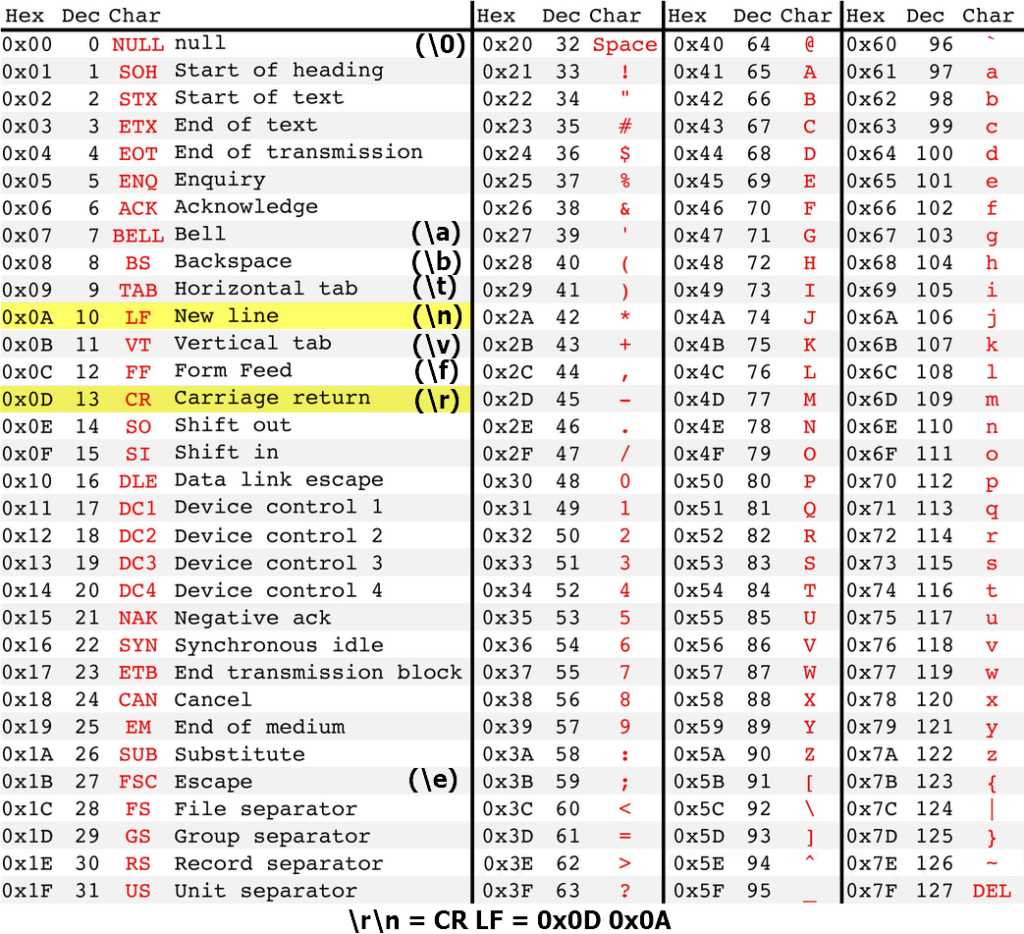
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.
Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.
Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Кодировки в Windows
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет. Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:

А тут было написано:
Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
Первый способ устранения проблемы, это Notepad++. Для этого Вам нужно открыть Ваш батник таким способом:

Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:

Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программ
Нередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad++, но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
Второй способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C++).
Если же не сработает:
3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
Теперь у Нас будет нормальный вывод в консоль. На других языках (С++):
4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
- Разрабатывать приложения на Windows ниже 10
- Спасти мир от данной проблемы
- Думать о других людях
- Разрабатывать десктопные приложения, так как Вам жизнь покажется мёдом
- Сменить Windows на версию ниже 10
- Ну и понимать людей, у которых Windows ниже 10
Установить Windows 10. Там кодировка консоли специально подходит для языка страны, и Вам больше не нужно будет беспокоиться об этой проблеме. Но у Вас появится ещё 6 проблем, и вернуться к предыдущей лицензионной версии Windows Вы не сможете.
Данная статья не подлежит комментированию, поскольку её автор ещё не является полноправным участником сообщества. Вы сможете связаться с автором только после того, как он получит приглашение от кого-либо из участников сообщества. До этого момента его username будет скрыт псевдонимом.
Таблицы кодировки
Содержание
Исторически так сложилось, что кириллическая кодировка существует в нескольких видах.
Windows-1251
Кодировка Windows-1251 (cp1251) является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. У неё существуют разновидности: казахская, чувашская и т.д. Первая часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Вторая часть (под символами указаны шестнадцатеричные коды Unicode) приводится ниже:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | Ђ 0402 |
Ѓ 0403 |
‚ 201A |
ѓ 0453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 0409 |
‹ 2039 |
Њ 040A |
Ќ 040C |
Ћ 040B |
Џ 040F |
| 9 | ђ 0452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 0459 |
› 203A |
њ 045A |
ќ 045C |
ћ 045B |
џ 045F |
|
| A | 00A0 | Ў 040E |
ў 045E |
Ј 0408 |
¤ 00A4 |
Ґ 0490 |
¦ 00A6 |
§ 00A7 |
Ё 0401 |
© 00A9 |
Є 0404 |
« 00AB |
¬ 00AC |
00AD |
® 00AE |
Ї 0407 |
| B | ° 00B0 |
± 00B1 |
І 0406 |
і 0456 |
ґ 0491 |
µ 00B5 |
¶ 00B6 |
· 00B7 |
ё 0451 |
№ 2116 |
є 0454 |
» 00BB |
ј 0458 |
Ѕ 0405 |
ѕ 0455 |
ї 0457 |
| C | А 0410 |
Б 0411 |
В 0412 |
Г 0413 |
Д 0414 |
Е 0415 |
Ж 0416 |
З 0417 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
П 041F |
| D | Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ф 0424 |
Х 0425 |
Ц 0426 |
Ч 0427 |
Ш 0428 |
Щ 0429 |
Ъ 042A |
Ы 042B |
Ь 042C |
Э 042D |
Ю 042E |
Я 042F |
| E | а 0430 |
б 0431 |
в 0432 |
г 0433 |
д 0434 |
е 0435 |
ж 0436 |
з 0437 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
п 043F |
| F | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
cp866
В консоли русифицированных систем семейства Windows NT используется кодировка cp866. Первая часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Вторая часть (под символами указаны шестнадцатеричные коды Unicode):
Для кодировки cp866 существуют разновидности (чувашская, ГОСТ 19768-87 и т.д.).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | А 0410 |
Б 0411 |
В 0412 |
Г 0413 |
Д 0414 |
Е 0415 |
Ж 0416 |
З 0417 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
П 041F |
| 9 | Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ф 0424 |
Х 0425 |
Ц 0426 |
Ч 0427 |
Ш 0428 |
Щ 0429 |
Ъ 042A |
Ы 042B |
Ь 042C |
Э 042D |
Ю 042E |
Я 042F |
| A | а 0430 |
б 0431 |
в 0432 |
г 0433 |
д 0434 |
е 0435 |
ж 0436 |
з 0437 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
п 043F |
| B | ░ 2591 |
▒ 2592 |
▓ 2593 |
│ 2502 |
┤ 2524 |
╡ 2561 |
╢ 2562 |
╖ 2556 |
╕ 2555 |
╣ 2563 |
║ 2551 |
╗ 2557 |
╝ 255D |
╜ 255C |
╛ 255B |
┐ 2510 |
| C | └ 2514 |
┴ 2534 |
┬ 252C |
├ 251C |
─ 2500 |
┼ 253C |
╞ 255E |
╟ 255F |
╚ 255A |
╔ 2554 |
╩ 2569 |
╦ 2566 |
╠ 2560 |
═ 2550 |
╬ 256C |
╧ 2567 |
| D | ╨ 2568 |
╤ 2564 |
╥ 2565 |
╙ 2559 |
╘ 2558 |
╒ 2552 |
╓ 2553 |
╫ 256B |
╪ 256A |
┘ 2518 |
┌ 250C |
█ 2588 |
▄ 2584 |
▌ 258C |
▐ 2590 |
▀ 2580 |
| E | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| F | Ё 0401 |
ё 0451 |
Є 0404 |
є 0454 |
Ї 0407 |
ї 0457 |
Ў 040E |
ў 045E |
° 00B0 |
∙ 2219 |
· 00B7 |
√ 221A |
№ 2116 |
¤ 00A4 |
■ 25A0 |
00A0 |
Стандартом для русской кириллицы в юникс-подобных операционных системах является кодировка КОИ-8 (код обмена информацией, 8 битов), или KOI8. Существует несколько вариантов кодировки КОИ-8 для различных кириллических алфавитов. Русский алфавит описывается в кодировке KOI8-R, украинский — в KOI8-U, существуют также кодировки KOI8-RU (русско-белорусско-украинская), KOI8-T (таджикская) и т.д.
Разработчики КОИ-8 разместили символы русского алфавита таким образом, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читабельный» текст, хотя он и написан латинскими символами.
Вторая часть кодировки KOI8-R (русская), под символами указаны шестнадцатеричные коды Unicode:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | ─ 2500 |
│ 2502 |
┌ 250C |
┐ 2510 |
└ 2514 |
┘ 2518 |
├ 251C |
┤ 2524 |
┬ 252C |
┴ 2534 |
┼ 253C |
▀ 2580 |
▄ 2584 |
█ 2588 |
▌ 258C |
▐ 2590 |
| 9 | ░ 2591 |
▒ 2592 |
▓ 2593 |
⌠23 20 |
■ 25A0 |
∙ 2219 |
√ 221A |
≈ 2248 |
≤ 2264 |
≥ 2265 |
00A0 | ⌡ 2321 |
° 00B0 |
² 00B2 |
· 00B7 |
÷ 00F7 |
| A | ═ 2550 |
║ 2551 |
╒ 2552 |
ё 0451 |
╓ 2553 |
╔ 2554 |
╕ 2555 |
╖ 2556 |
╗ 2557 |
╘ 2558 |
╙ 2559 |
╚ 255A |
╛ 255B |
╜ 255C |
╝ 255D |
╞ 255E |
| B | ╟ 255F |
╠ 2560 |
╡ 2561 |
Ё 0401 |
╢ 2562 |
╣ 2563 |
╤ 2564 |
╥ 2565 |
╦ 2566 |
╧ 2567 |
╨ 2568 |
╩ 2569 |
╪ 256A |
╫ 256B |
╬ 256C |
© 00A9 |
| C | ю 044E |
а 0430 |
б 0431 |
ц 0446 |
д 0434 |
е 0435 |
ф 0444 |
г 0433 |
х 0445 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
| D | п 043F |
я 044F |
р 0440 |
с 0441 |
т 0442 |
у 0443 |
ж 0436 |
в 0432 |
ь 044C |
ы 044B |
з 0437 |
ш 0448 |
э 044D |
щ 0449 |
ч 0447 |
ъ 044A |
| C | Ю 042E |
А 0410 |
Б 0411 |
Ц 0426 |
Д 0414 |
Е 0415 |
Ф 0424 |
Г 0413 |
Х 0425 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
| D | П 041F |
Я 042F |
Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ж 0416 |
В 0412 |
Ь 042C |
Ы 042B |
З 0417 |
Ш 0428 |
Э 042D |
Щ 0429 |
Ч 0427 |
Ъ 042A |
Юникод (Unicode)
В Юникоде нет русских букв с ударением, поэтому приходится их делать составными, добавляя символ U+0301 («combining acute accent») после ударной гласной (например, ы́ э́ ю́ я́).
Информатика. 10 класса. Босова Л.Л. Оглавление
§14. Кодирование текстовой информации
Компьютеры третьего поколения «научились» работать с текстовой информацией.
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
Для компьютерного представления текстовой информации достаточно:
1) определить множество всех символов (алфавит), требуемых для представления текстовой информации;
2) выстроить все символы используемого алфавита в некоторой последовательности (присвоить каждому символу алфавита свой номер);
3) получить для каждого символа n-разрядный двоичный код (n ? 2n), переведя номер этого символа в двоичную систему счисления.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 27 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
14.2. Стандарт Unicode
Ограниченность 8-битной кодировки, не позволяющей одновременно пользоваться несколькими языками, а также трудности, связанные с необходимостью преобразования одной кодировки в другую, привели к разработке нового кода. В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира.
Unicode — это «уникальный код для любого символа, независимо от платформы, независимо от программы, независимо от языка» (www.unicode.org).
В Unicode на кодирование символов отводится 31 бит. Первые 128 символов (коды 0-127) совпадают с таблицей ASCII. Далее размещены основные алфавиты современных языков: они полностью умещаются в первой части таблицы, их коды не превосходят 65 536 = 216.
Стандарт Unicode описывает алфавиты всех известных, в том числе и «мёртвых», языков. Для языков, имеющих несколько алфавитов или вариантов написания (например, японского и индийского), закодированы все варианты. В кодировку Unicode внесены все математические и иные научные символьные обозначения и даже некоторые придуманные языки (например, язык эльфов из трилогии Дж. Р. Р. Толкина «Властелин колец»).
Всего современная версия Unicode позволяет закодировать более миллиона различных знаков, но реально используется чуть менее 110 000 кодовых позиций.
Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок.
В операционных системах семейства Windows используется кодировка UTF-16. В ней все наиболее важные символы кодируются с помощью 2 байт (16 бит), а редко используемые — с помощью 4 байт.
В операционной системе Linux применяется кодировка UTF-8, в которой символы могут занимать от 1 (символы, входящие в таблицу ASCII) до 4 байт. Если значительную часть текста составляют цифры и латинские буквы, то это позволяет в несколько раз уменьшить размер файла по сравнению с кодировкой UTF-16.
Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
14.3. Информационный объём текстового сообщения
Мы уже касались этого вопроса, рассматривая алфавитный подход к измерению информации.
Информационным объёмом текстового сообщения называется количество бит (байт, килобайт, мегабайт и т. д.), необходимых для записи этого сообщения путём заранее оговоренного способа двоичного кодирования.
Оценим в байтах объём текстовой информации в современном словаре иностранных слов из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы).
Будем считать, что при записи используется кодировка «один символ — один байт». Количество символов во всем словаре равно:
80 • 60 • 740 = 3 552 000.
Следовательно, объём равен
3 552 000 байт = 3 468,75 Кбайт ? 3,39 Мбайт.
Если же использовать кодировку UTF-16, то объём этой же текстовой информации в байтах возрастёт в 2 раза и составит 6,78 Мбайт.
САМОЕ ГЛАВНОЕ
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил код ASCII, рассчитанный на передачу только английского текста. Расширения ASCII — кодировки, в которых первые 128 символов кодовой таблицы совпадают с кодировкой ASCII, а остальные (со 128-го по 255-й) используются для кодирования букв национального алфавита, символов национальной валюты и т. п.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира. Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Вопросы и задания
1. Какова основная идея представления текстовой информации в компьютере?
2. Что представляет собой кодировка ASCII? Сколько символов она включает? Какие это символы?
3. Как известно, кодовые таблицы каждому символу алфавита ставят в соответствие его двоичный код. Как, в таком случае, вы можете объяснить вид таблицы 3.8 «Кодировка ASCII»?
4. С помощью таблицы 3.8: 1) декодируйте сообщение 64 65 73 6В 74 6F 70; 2) запишите в двоичном коде сообщение TOWER; 3) декодируйте сообщение 01101100 01100001 01110000 01110100 01101111 01110000
5. Что представляют собой расширения ASCII-кодировки? Назовите основные расширения ASCII-кодировки, содержащие русские буквы.
6. Сравните подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8.
7. Представьте в кодировке Windows-1251 текст «Знание — сила!»:
8. Представьте в кодировке КОИ-8 текст «Дело в шляпе!»: 1) шестнадцатеричным кодом; 2) двоичным кодом; 3) десятичным кодом.
9. Что является содержимым файла, созданного в современном текстовом процессоре?
10. В кодировке Unicode на каждый символ отводится 2 байта. Определите в этой кодировке информационный объём следующей строки: Где родился, там и сгодился.
11. Набранный на компьютере текст содержит 2 страницы. На каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём текста в кодировке Unicode, в которой каждый символ кодируется 16 битами.
12. Текст на русском языке, первоначально записанный в 8-битовом коде Windows, был перекодирован в 16-битную кодировку Unicode. Известно, что этот текст был распечатан на 128 страницах, каждая из которых содержала 32 строки по 64 символа в каждой строке. Каков информационный объём этого текста?
13. В текстовом процессоре MS Word откройте таблицу символов (вкладка Вставка ? Символ ? Другие символы): В поле Шрифт установите Times New Roman, в поле из — кириллица (дес.). Вводя в поле Код знака десятичные коды символов, декодируйте сообщение
§ 13. Представление чисел в компьютере
§ 14. Кодирование текстовой информации
§ 15. Кодирование графической информации