Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
-
Общие сведения о кодировке текста
-
Выбор кодировки при открытии файла
-
Выбор кодировки при сохранении файла
-
Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
К началу страницы
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.
-
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
-
Закройте, а затем снова откройте файл.
-
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
Выполните одно из указанных ниже действий.
В Windows 7
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
-
На панели управления щелкните элемент Установка и удаление программ.
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
К началу страницы
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
-
Откройте вкладку Файл.
-
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
-
В поле Имя файла введите имя нового файла.
-
В поле Тип файла выберите Обычный текст.
-
Нажмите кнопку Сохранить.
-
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
-
В диалоговом окне Преобразование файла выберите подходящую кодировку.
-
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
-
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
-
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
-
-
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
-
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
К началу страницы
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
Courier New |
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Греческая |
Windows 1253 |
Courier New |
|
Иврит |
Windows 1255 |
Courier New |
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Тайская |
Windows 874 |
Tahoma |
|
Вьетнамская |
Windows 1258 |
Courier New |
|
Индийские: тамильская |
ISCII 57004 |
Latha |
|
Индийские: непальская |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: конкани |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: хинди |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: ассамская |
ISCII 57006 |
|
|
Индийские: бенгальская |
ISCII 57003 |
|
|
Индийские: гуджарати |
ISCII 57010 |
|
|
Индийские: каннада |
ISCII 57008 |
|
|
Индийские: малаялам |
ISCII 57009 |
|
|
Индийские: ория |
ISCII 57007 |
|
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
ISCII 57011 |
|
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
ISCII 57005 |
-
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
-
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
К началу страницы
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This led to much confusion subsequently. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but now additionally supports and recommends using UTF-8 (aka CP_UTF8). UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder). Since Windows 10 version 1803, Windows machines can be configured to allow UTF-8 as the «ANSI» and OEM codepage.[5]
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This led to much confusion subsequently. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but now additionally supports and recommends using UTF-8 (aka CP_UTF8). UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder). Since Windows 10 version 1803, Windows machines can be configured to allow UTF-8 as the «ANSI» and OEM codepage.[5]
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
Содержание
- Кодировки в Windows
- Выбор кодировки текста при открытии и сохранении файлов
- В этой статье
- Общие сведения о кодировке текста
- Различные кодировки для разных алфавитов
- Юникод: единая кодировка для разных алфавитов
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Выбор кодировки
- Поиск кодировок, доступных в Word
- О кодировках и кодовых страницах
- Гарантированная локализация/русификация консоли Windows
- Введение
- Виды консолей
- Конфликт кодировок
- Проблемы консолей Visual Studio
- Локализация отладочной консоли Visual Studio
- Стратегия локализации приложения в консоли
- Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
- Предпосылки Unicode
- Небольшой практикум ASCII
- Unicode
- Немного отступлю от темы, надо написать про совместимость ASCII и UTF
- UTF-16
Кодировки в Windows
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет. Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:

А тут было написано:
Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
Первый способ устранения проблемы, это Notepad++. Для этого Вам нужно открыть Ваш батник таким способом:
Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:
Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программ
Нередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad++, но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
Второй способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C++).
Если же не сработает:
3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
Теперь у Нас будет нормальный вывод в консоль. На других языках (С++):
4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
Источник
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Источник
О кодировках и кодовых страницах
Вряд ли это сейчас сильно актуально, но может кому-то покажется интересным (или просто вспомнит былые годы).
Начну с небольшого экскурса в историю компьютера. Поскольку компьютер использовался для обработки информации, то он просто обязан представлять эту информацию в «человеческом» виде. Компьютер хранит информацию в виде чисел (байтов), а человек воспринимает символы (буквы, цифры, различные знаки). Значит, надо сделать сопоставление число символ и задача будет решена. Сначала посчитаем, сколько символов нам надо (не забудем, что «мы» — американцы, использующие латинский алфавит). Нам надо 10 цифр + 26 заглавных букв английского алфавита + 26 строчных букв + математические знаки (хотя бы +-/*=> + можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.
Интересно, что примерно год назад проблема кодировок ненадолго всплыла при «наезде» ФАС на сотовых операторов, мол те дискриминируют русскоязычных пользователей, поскольку за передачу кириллицы берут больше. Это объясняется техническим решением, выбранным разработчиком протокола SMS связи. Если бы его россияне разработали, они бы, возможно, отдали приоритет кириллице. В указанной статье «начальник управления контроля транспорта и связи Дмитрий Рутенберг отметил, что существуют и восьмибитные кодировки для кириллицы, которые могли бы использовать операторы.» Во как — на улице 21-й век, Unicode шагает по миру, а господин Рутенберг тянет нас в начало 90-х, когда шла «война кодировок» и проблема перекодировок стояла во весь рост. Интересно, в какой кодировке должен получить СМС Вася Пупкин, пользующийся финским телефоном, находящийся в Турции на отдыхе, от жены с корейским телефоном, отправляющей СМС из Казахстана? А от своего французского компаньона (с японским телефоном), находящегося в Испании? Думаю, никакой начальник ответа на этот вопрос дать не сможет. К счастью, это «экономное» предложение не воплотилось в жизнь.
Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).
Источник
Гарантированная локализация/русификация консоли Windows
Введение
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Виды консолей
В общем случае функции консоли таковы:
управление операционной системой и системным окружением приложений на основе применения стандартных системных устройств ввода-вывода (экран и клавиатура), использования команд операционной системы и/или собственно консоли;
запуск приложений и обеспечение их доступа к стандартным потокам ввода-вывода системы, также с помощью стандартных системных устройств ввода-вывода.
Отдельным видом консоли можно считать консоль отладки Visual Studio (CMD-D ).
Конфликт кодировок
Совет 1. Выполнять разработку текстовых файлов (программных кодов, текстовых данных и др.) исключительно в кодировке UTF-8. Мир любит Юникод, а кроссплатформенность без него вообще невозможна.
Совет 2. Периодически проверять кодировку, например в текстовом редакторе Notepad++. Visual Studio может сбивать кодировку, особенно при редактировании за пределами VS.
Поскольку в консоли постоянно происходит передача управления от приложений к собственно командному процессору и обратно, регулярно возникает «конфликт кодировок», наглядно иллюстрируемый таблица 1 и 2, сформированных следующим образом:
Команды и код приложения под катом
> Echo ffffff фффффф // в командной строке
PS> Echo ffffff фффффф // в PowerShell
код тестового приложения:
Командную часть задания все консоли локализовали практически без сбоев во всех кодировках, за исключением: в WPS неверно отображена русскоязычная часть команды во всех кодировках.
 Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Вывод тестового приложения локализован лишь в 50% испытаний, как показано в табл.2.
 Табл. 2. Результат запуска приложения LoggingConsole.Test
Табл. 2. Результат запуска приложения LoggingConsole.Test
Сoвет 3. Про PowerShell забываем раз и навсегда. Ну может не навсегда, а до следующей мажорной версии.
По умолчанию Windows устанавливает для консоли кодовые страницы DOS. Чаще всего CP437, иногда CP866. Актуальные версии командной строки cmd.exe способны локализовать приложения на основе русифицированной кодовой страницы 866, но не 437, отсюда и изначальный конфликт кодировок консоли и приложения. Поэтому
Проблемы консолей Visual Studio
Отдельной опцией Visual Studio является встроенная односеансная консоль отладки, которая перехватывает команду Visual Studio на запуск приложения, запускается сама, ожидает компиляцию приложения, запускает его и отдает ему управление. Таким образом, отладочная консоль в течение всего рабочего сеанса находится под управлением приложения и возможность использования команд Windows или самой консоли, включая команду CHCP, не предусмотрена. Более того, отладочная консоль не воспринимает кодовую страницу по умолчанию, определенную в реестре, и всегда запускается в кодировке 437 или 866.
Совет 6. Тестирование приложения целесообразно выполнять во внешних консолях, более дружелюбных к локализации.
Локализация отладочной консоли Visual Studio
Ниже приведен пример вывода тестового приложения в консоль, иллюстрирующий изложенное. Метод Write получает номера текущих страниц, устанавливает новые кодовые страницы вводного и выводного потоков, выполняет чтение с консоли и записывает выводную строку, содержащий русский текст, в том числе считанный с консоли, обратно в консоль. Операция повторяется несколько раз для всех основных кодовых страниц, упомянутых ранее.
приложение запущено в консоли с кодовыми страницами 1251 (строка 2);
приложение меняет кодовые страницы консоли (current, setted);
приложение остановлено в консоли с кодовыми страницами 1252 (строка 11, setted);
Приложение адекватно локализовано только в случае совпадения текущих кодовых страниц консоли (setted 1251:1251) с начальными кодовыми страницами (строки 8 и 10).
Код тестового приложения под катом
Совет 7. Обязательный и повторный! Функции SetConsoleCP должны размещаться в коде до первого оператора ввода-вывода в консоль.
Стратегия локализации приложения в консоли
Удалить приложение PowerShell (если установлено), сохранив Windows PowerShell;
Установить в качестве кодовую страницу консоли по умолчанию CP65001 (utf-8 Unicode) или CP1251 (Windows-1251-Cyr), см. совет 5;
Разработку приложений выполнять в кодировке utf-8 Unicode;
Контролировать кодировку файлов исходных кодов, текстовых файлов данных, например с помощью Notepad++;
Реализовать программное управление локализацией приложения в консоли, пример ниже под катом:
Пример программной установки кодовой страницы и локализации приложения в консоли
Источник
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 2 8 =256).
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
Источник
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет. Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:
А тут было написано:
Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
Первый способ устранения проблемы, это Notepad++. Для этого Вам нужно открыть Ваш батник таким способом:
Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:
Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программ
Нередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad++, но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
Второй способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C++).
Если же не сработает:
3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
Теперь у Нас будет нормальный вывод в консоль. На других языках (С++):
4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
Источник
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Источник
Отличие utf-8 и windows 1251
О разнице между двумя кодировками utf-8 и windows 1251
О кодировках utf-8 и windows 1251
Чем отличаются utf-8 и windows 1251
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн!  , то и смысла особого вам читать дальше нет.
, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим.
Чем отличается текст в кодировках utf-8 и windows 1251
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И. нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя.
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
И выведем прямо здесь вот такую конструкцию :
И что мы здесь видим!?
Что количество элементов в строке 10. Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается.
Поэтому, и возникают проблемы с текстов в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример. как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций.
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’); :
string(5) «Marat»
Результат var_dump(‘Марат’); :
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
Пусть это будет функция str_split и её аналог mb_str_split
Источник
Кодировки, используемые шрифтами
Все шрифты используют кодировку. Кодировка содержит знаки препинания, цифры, прописные и строчные буквы и все остальные печатные символы. Каждый элемент кодировки определяется числом.
Большинство используемых наборов символов — это наборы символов ASCII США, которые определяют символы для 96 числовых значений от 32 до 127. Существует пять основных групп наборов символов:
Windows Кодировка
набор символов Windows является наиболее часто используемым набором символов. По сути, это эквивалентно кодировке ANSI. пустой символ — это первый символ в Windows кодировке. Он имеет шестнадцатеричное значение 0x20 (десятичное число 32). последний символ в Windows кодировке имеет шестнадцатеричное значение 0xff (десятичное число 255).
Многие шрифты задают символ по умолчанию. Каждый раз, когда запрос выполняется для символа, который отсутствует в шрифте, система предоставляет этот символ по умолчанию. многие шрифты, использующие Windows кодировку, задают точку (.) в качестве символа по умолчанию. Шрифты TrueType и OpenType обычно используют открытое поле в качестве символа по умолчанию.
Шрифты используют символ разрыва, именуемый четырьмя, для разделения слов и выравнивания текста. большинство шрифтов, использующих Windows кодировку, указывают, что пустой символ будет выступать в качестве символа разрыва.
Набор символов Юникода
в Windows кодировке для представления каждого символа используется 8 бит. Таким образом, максимальное число символов, которое можно выразить с помощью 8 битов, равно 256 (2 ^ 8). Обычно это достаточно для западных языков, включая диакритические знаки, используемые на французском, немецком, испанском и других языках. Однако в Восточно-языках используются тысячи отдельных символов, которые не могут быть закодированы с помощью однобайтовой схемы кодирования. Благодаря росту компьютерной торговли были разработаны двухбайтовые схемы кодирования, чтобы символы могли быть представлены в виде 8-разрядных, 16-разрядных, 24-разрядных или 32-разрядных последовательностей. Для этого требуются сложные алгоритмы передачи; Несмотря на это, использование разных наборов кодов может привести к совершенно разным результатам на двух разных компьютерах.
Для решения проблемы с несколькими схемами программирования был разработан стандарт Юникод для представления данных. 16-разрядная схема кодирования символов, Unicode может представлять 65 536 (2 ^ 16) символов, что достаточно для включения в сегодняшний день всех языков в компьютерной коммерции, а также знаков препинания, математических символов и помещения для расширения. Юникод устанавливает уникальный код для каждого символа, чтобы гарантировать, что преобразование символов всегда будет точным.
Набор символов OEM
Кодировка OEM обычно используется в сеансах MS-DOS в полноэкранном режиме для отображения на экране. символы от 32 до 127 обычно совпадают в наборах символов OEM, сша и Windows. Другие символы в наборе символов OEM (от 0 до 31 и от 128 до 255) соответствуют символам, которые могут отображаться в полноэкранном сеансе MS-DOS. обычно эти символы отличаются от Windows символов.
Кодировка символов
Кодировка символов содержит специальные символы, которые обычно используются для представления математических и научных формул.
Наборы символов, зависящие от поставщика
многие принтеры и другие устройства вывода предоставляют шрифты на основе наборов символов, которые отличаются от Windows и OEM сетсфор example, расширенной кодировки кода обмена десятичной кодировкой (EBCDIC). чтобы использовать один из этих наборов символов, драйвер принтера преобразуется из Windows символов в набор символов, зависящий от поставщика.
Источник
Что такое windows-1251 кодировка и как ее применять – подробное руководство
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.

Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему Windows для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.

Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
Для профессиональных программистов и технических специалистов, знание кодировки 1251 является обязательным условием для осуществления полноценной работы.
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:

Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:


Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
Существуют и другие аргументы, активно выступающие «ЗА» использование данной системы:
Важно отметить, что изначально многие разработчики стали использовать 1251.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей.
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием.
Источник
Содержание
- Что такое кодировка
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Вопросы и ответы

MS Word заслужено является самым популярным текстовым редактором. Следовательно, чаще всего можно столкнуться с документами в формате именно этой программы. Все, что может в них отличаться, это лишь версия Ворда и формат файла (DOC или DOCX). Однако, не смотря на общность, с открытием некоторых документов могут возникнуть проблемы.
Урок: Почему не открывается документ Word
Одно дело, если вордовский файл не открывается вовсе или запускается в режиме ограниченной функциональности, и совсем другое, когда он открывается, но большинство, а то и все символы в документе являются нечитабельными. То есть, вместо привычной и понятной кириллицы или латиницы, отображаются какие-то непонятные знаки (квадраты, точки, вопросительные знаки).
Урок: Как убрать режим ограниченной функциональности в Ворде
Если и вы столкнулись с аналогичной проблемой, вероятнее всего, виною тому неправильная кодировка файла, точнее, его текстового содержимого. В этой статье мы расскажем о том, как изменить кодировку текста в Word, тем самым сделав его пригодным для чтения. К слову, изменение кодировки может понадобиться еще и для того, чтобы сделать документ нечитабельным или, так сказать, чтобы “конвертировать” кодировку для дальнейшего использования текстового содержимого документа Ворд в других программах.
Примечание: Общепринятые стандарты кодировки текста в разных странах могут отличаться. Вполне возможно, что документ, созданный, к примеру, пользователем, проживающим в Азии, и сохраненный в местной кодировке, не будет корректно отображаться у пользователя в России, использующего на ПК и в Word стандартную кириллицу.
Что такое кодировка
Вся информация, которая отображается на экране компьютера в текстовом виде, на самом деле хранится в файле Ворд в виде числовых значений. Эти значения преобразовываются программой в отображаемые знаки, для чего и используется кодировка.
Кодировка — схема нумерации, в которой каждому текстовому символу из набора соответствует числовое значение. Сама же кодировка может содержать буквы, цифры, а также другие знаки и символы. Отдельно стоит сказать о том, что в разных языках довольно часто используются различные наборы символов, именно поэтому многие кодировки предназначены исключительно для отображения символов конкретных языков.
Выбор кодировки при открытии файла
Если текстовое содержимое файла отображается некорректно, например, с квадратами, вопросительными знаками и другими символами, значит, MS Word не удалось определить его кодировку. Для устранения этой проблемы необходимо указать правильную (подходящую) кодировку для декодирования (отображения) текста.
1. Откройте меню “Файл” (кнопка “MS Office” ранее).
2. Откройте раздел “Параметры” и выберите в нем пункт “Дополнительно”.
3. Прокрутите содержимое окна вниз, пока не найдете раздел “Общие”. Установите галочку напротив пункта “Подтверждать преобразование формата файла при открытии”. Нажмите “ОК” для закрытия окна.

Примечание: После того, как вы установите галочку напротив этого параметра, при каждом открытии в Ворде файла в формате, отличном от DOC, DOCX, DOCM, DOT, DOTM, DOTX, будет отображаться диалоговое окно “Преобразование файла”. Если же вам часто приходится работать с документами других форматов, но при этом не требуется менять их кодировку, снимите эту галочку в параметрах программы.
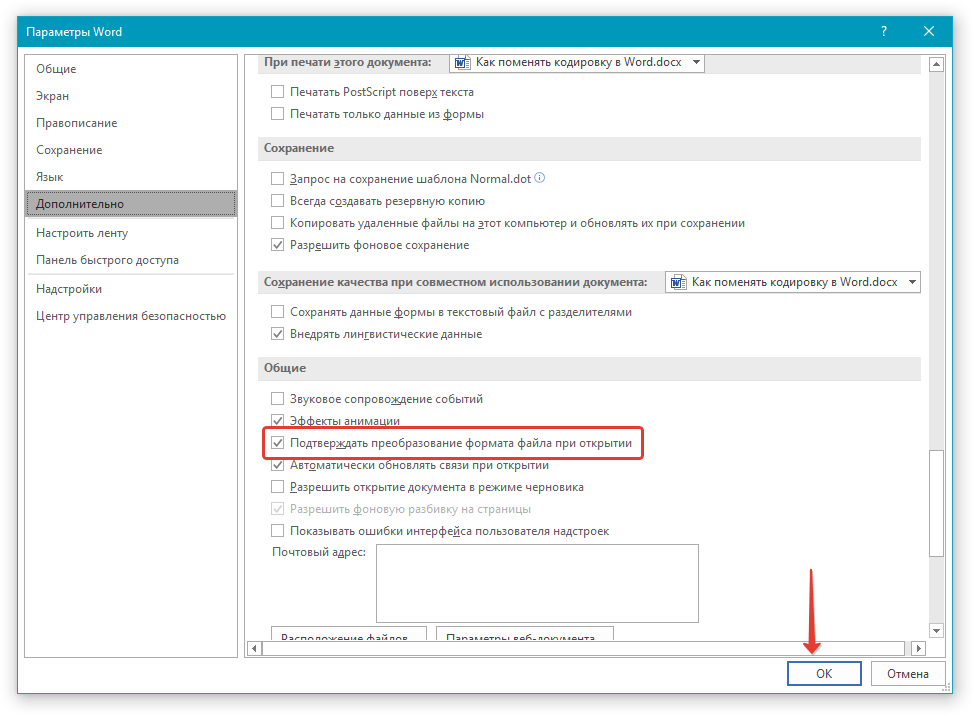
4. Закройте файл, а затем снова откройте его.
5. В разделе “Преобразование файла” выберите пункт “Кодированный текст”.
6. В открывшемся диалоговом окне “Преобразование файла” установите маркер напротив параметра “Другая”. Выберите необходимую кодировку из списка.
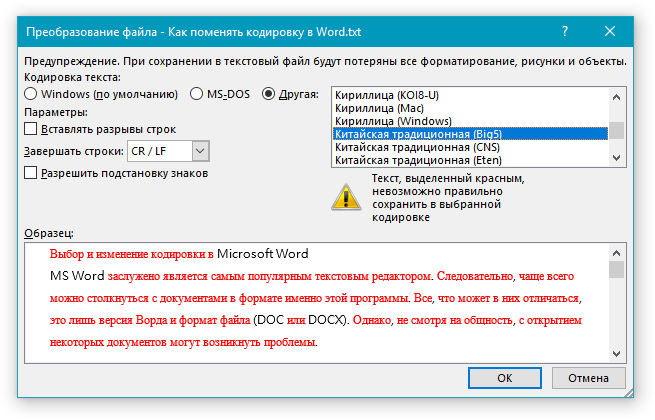
- Совет: В окне “Образец” вы можете увидеть, как будет выглядеть текст в той или иной кодировке.
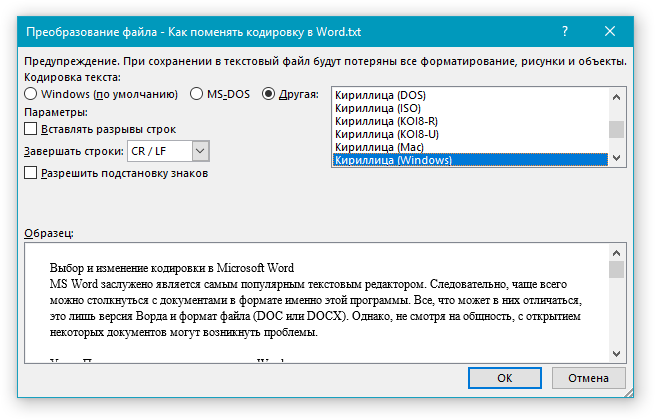
7. Выбрав подходящую кодировку, примените ее. Теперь текстовое содержимое документа будет корректно отображаться.
В случае, если весь текст, кодировку для которого вы выбираете, выглядит практически одинаков (например, в виде квадратов, точек, знаков вопроса), вероятнее всего, на вашем компьютере не установлен шрифт, используемый в документе, который вы пытаетесь открыть. О том, как установить сторонний шрифт в MS Word, вы можете прочесть в нашей статье.
Урок: Как в Ворде установить шрифт
Выбор кодировки при сохранении файла
Если вы не указываете (не выбираете) кодировку файла MS Word при сохранении, он автоматически сохраняется в кодировке Юникод, чего в большинстве случаев предостаточно. Данный тип кодировки поддерживает большую часть знаков и большинство языков.
В случае, если созданный в Ворде документ вы (или кто-то другой) планируете открывать в другой программе, не поддерживающей Юникод, вы всегда можете выбрать необходимую кодировку и сохранить файл именно в ней. Так, к примеру, на компьютере с русифицированной операционной системой вполне можно создать документ на традиционном китайском с применением Юникода.
Проблема лишь в том, что в случае, если данный документ будет открываться в программе, поддерживающей китайский, но не поддерживающей Юникод, куда правильнее будет сохранить файл в другой кодировке, например, “Китайская традиционная (Big5)”. В таком случае текстовое содержимое документа при открытии его в любой программе с поддержкой китайского языка, будет отображаться корректно.
Примечание: Так как Юникод является самым популярным, да и просто обширным стандартном среди кодировок, при сохранении текста в других кодировках возможно некорректное, неполное, а то и вовсе отсутствующее отображение некоторых файлов. На этапе выбора кодировки для сохранения файла знаки и символы, которые не поддерживаются, отображаются красным цветом, дополнительно высвечивается уведомление с информацией о причине.
1. Откройте файл, кодировку которого вам необходимо изменить.
2. Откройте меню “Файл” (кнопка “MS Office” ранее) и выберите пункт “Сохранить как”. Если это необходимо, задайте имя файла.

3. В разделе “Тип файла” выберите параметр “Обычный текст”.
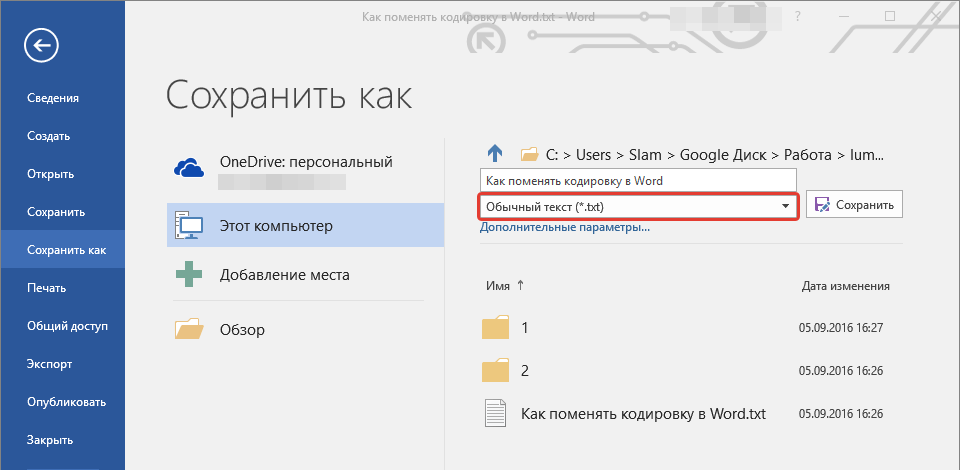
4. Нажмите кнопку “Сохранить”. Перед вами появится окно “Преобразование файла».
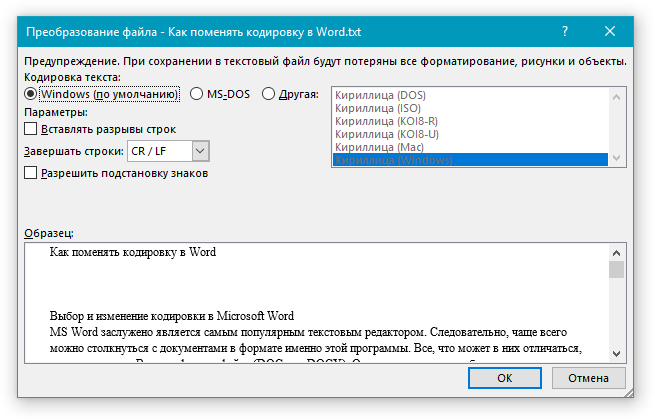
5. Выполните одно из следующих действий:
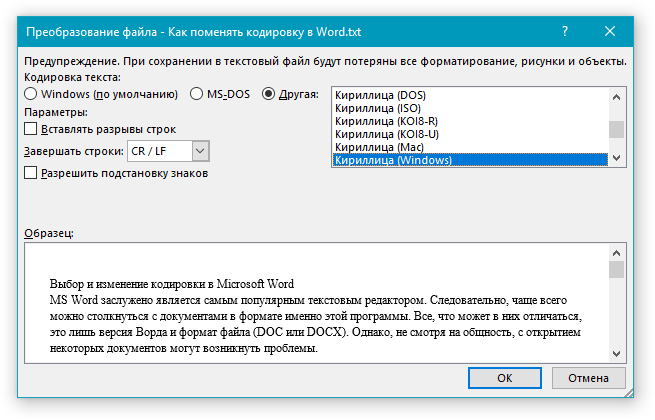
Примечание: Если при выборе той или иной (“Другой”) кодировки вы видите сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, выберите другую кодировку (иначе содержимое файла будет отображаться некорректно) или же установите галочку напротив параметра “разрешить подстановку знаков”.
Если подстановка знаков разрешена, все те знаки, которые отобразить в выбранной кодировке невозможно, будут автоматически заменены на эквивалентные им символы. Например, многоточие может быть заменено на три точки, а угловые кавычки — на прямые.
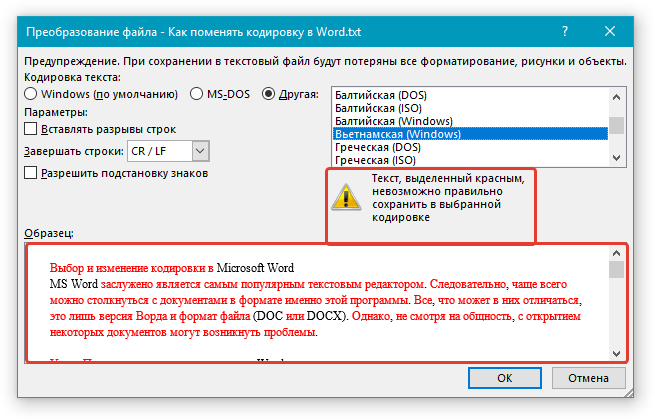
6. Файл будет сохранен в выбранной вами кодировке в виде обычного текста (формат “TXT”).
На этом, собственно, и все, теперь вы знаете, как в Word сменить кодировку, а также знаете о том, как ее подобрать, если содержимое документа отображается некорректно.
Кодовые страницы Windows представляют собой наборы символов или кодовые страницы (известные как символ кодировки в других операционных системах), используемые в Microsoft Windows с 1980-х и 1990-х годов. Кодовые страницы Windows были постепенно заменены, когда Unicode был реализован в Windows, хотя они по-прежнему поддерживаются как в Windows, так и на других платформах, и по-прежнему применяются при использовании ярлыков Alt code.
В системах Windows есть две группы кодовых страниц: OEM и собственные кодовые страницы Windows («ANSI»). Кодовые страницы в обеих этих группах являются кодовыми страницами расширенного ASCII.
Содержание
- 1 Кодовая страница ANSI
- 2 Кодовая страница OEM
- 3 История
- 3.1 UTF-8, UTF-16
- 4 Список
- 4.1 Windows-125x series
- 4.2 Кодовые страницы DOS
- 4.3 Восточноазиатские многобайтовые кодовые страницы
- 4.4 Кодовые страницы EBCDIC
- 4.5 Кодовые страницы, связанные с Unicode
- 4.6 Кодовые страницы совместимости с Macintosh
- 4.7 Кодовые страницы ISO 8859
- 4.8 Кодовые страницы ITU-T
- 4.9 Кодовые страницы KOI8
- 4.10 Другие кодовые страницы
- 5 Проблемы, возникающие при использовании кодовых страниц
- 6 См. Также
- 7 Ссылки
- 8 Внешние ссылки
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неправильное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяет | US -ASCII |
| Преемник | ISO 8859 |
| Преемник | Unicode. UTF-16 (в Win32 API) |
|
кодовые страницы ANSI (официально называемые «Windows code» страницы «после того, как Microsoft приняла первый термин как неправильное) используются для приложений, не поддерживающих Unicode (например, ориентированных на байт ), использующих графический пользовательский интерфейс в системе Windows tems. «ANSI» — неправильное название, потому что поведение не совсем соответствует стандарту ANSI и потому что в эти 8-битные кодовые страницы включены некоторые кодировки, отличные от стандарта ANSI.
Большинство устаревших ANSI «кодовые страницы имеют номера кодовых страниц в шаблоне 125x. Однако 874 (тайский) и многобайтовые кодовые страницы ANSI Восточной Азии (932, 936, 949, 950 ), все из которых также используются как кодовые страницы OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодировкам IBM. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера для вариантов Microsoft, они приведены для справки в списках ниже, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как «Windows-number», хотя «Windows-936» рассматривается как синоним «GBK «. Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница 1252, были так называемыми, поскольку они якобы были основаны на представленных черновиках или предназначен для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 vs. ISO-8859- 1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 vs. ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows- 1257 vs. ISO-8859-4 ; ISO-8859-13 был представлен намного позже). Кроме того, Windows-1251 не следует ISO -стандартизированный ISO-8859-5, ни преобладающий в то время KOI-8.
Microsoft присвоила около двенадцати из типографики и деловых символов (включая, в частности, знак евро, €) в CP1252 до кодовых точек 0x80–0x9F, которые в ISO 8859 присвоены контрольным кодам C1. Эти присвоения также присутствуют во многих другие кодовые страницы ANSI / Windows с теми же кодовыми точками. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Тем не менее, если эта информация была включена в файл, переданный на совместимую со стандартами платформу, такую как Unix или MacOS, она была невидимой и потенциально опасной.
Кодовая страница OEM
Кодовые страницы OEM (производитель оригинального оборудования ) используются приложениями консоли Win32 и с помощью виртуальной DOS и может считаться пережитком от DOS и исходной архитектуры IBM PC. Отдельный набор кодовых страниц был реализован не только из-за совместимости, но и потому, что шрифты аппаратного обеспечения VGA (и потомков) предлагают кодировку символов рисования линий для совместимости с кодовая страница 437. Большинство кодовых страниц OEM имеют много общих кодовых точек, особенно для небуквенных символов, со второй (не ASCII) половиной CP437.
Типичная кодовая страница OEM во второй половине даже приблизительно не похожа ни на одну кодовую страницу ANSI / Windows. Тем не менее, две однобайтовые кодовые страницы с фиксированной шириной (874 для тайского и 1258 для вьетнамского ) и четыре многобайтовых кодовых страницы CJK (932, 936, 949, 950 ) используются как кодовые страницы OEM и ANSI. В кодовой странице 1258 используется комбинация диакритических знаков, поскольку вьетнамский требует более 128 буквенно-диакритических комбинаций. Это отличается от VISCII, который заменяет некоторые из управляющих кодов C0 (то есть ASCII).
История
Первоначально компьютерные системы и языки системного программирования не делали различия между символами и байтами : для сегментарных скриптов используется в большинстве стран Африки, Америки, Южной и Юго-Восточной Азии, Ближнего Востока и Европы, для символа требуется всего один байт, но для используемых идеографических наборов требуется два или более байта в остальном мире. Впоследствии это привело к большой путанице. Программное обеспечение и системы Microsoft, предшествующие строке Windows NT, являются примерами этого, поскольку они используют кодовые страницы OEM и ANSI, которые не делают различия.
С конца 1990-х годов программное обеспечение и системы приняли Unicode в качестве предпочтительного формата хранения; эта тенденция была улучшена за счет повсеместного принятия XML, который обеспечивает более адекватный механизм для маркировки используемой кодировки. Последние продукты Microsoft и программные интерфейсы приложений внутренне используют Unicode, но многие приложения и API-интерфейсы продолжают использовать кодировку по умолчанию «локали» компьютера при чтении и записи текстовых данных в файлы или стандартный вывод. Таким образом, файлы могут быть разборчивыми и разборчивыми в одной части мира, но неразборчивыми моджибаке в другой.
UTF-8, UTF-16
Microsoft решила принять 16-битную (двухбайтовую) систему UTF-16 для всех своих операционных систем. начиная с Windows NT. Этот метод уникальным образом кодирует все символы Юникода в базовой многоязычной плоскости и 32-битный (четырехбайтовый) код для других, но остальная часть отрасли выбрала UTF-8 (который использует один байт для 7-битного набора символов ASCII, два или три байта для других символов в BMP и четыре байта для остатка). Начиная с Windows 10 версии 1803, компьютеры Windows могут быть настроены так, чтобы разрешить UTF-8 в качестве кодовой страницы «ANSI» и OEM.
Список
Существуют следующие кодовые страницы Windows :
Windows-125x series
Все эти девять кодовых страниц являются расширенными кодировками ASCII 8-битными SBCS и были разработаны Microsoft для использования в качестве кодовых страниц ANSI в Windows. Обычно они известны под своими зарегистрированными в IANA именами как windows-, но иногда их также называют cp, «cp» для «кодовой страницы». Все они используются как кодовые страницы ANSI; Windows-1258 также используется как кодовая страница OEM.
| ID | Описание | Отношение к ISO 8859 или другим установленным кодировкам |
|---|---|---|
| 1250 | Latin 2 / Центральноевропейская | Аналогично ISO-8859-2, но перемещает несколько символов, включая несколько букв. |
| 1251 | Кириллица | Несовместима как с ISO-8859-5, так и с KOI-8. |
| 1252 | Latin 1 / Western European | Расширенный набор ISO-8859-1 (без элементов управления C1). Буквенный репертуар, соответственно, аналогичен CP850. |
| 1253 | Греческий | Аналогичен ISO 8859-7, но перемещает несколько символов, включая букву. |
| 1254 | Турецкий | Расширенный набор ISO 8859-9 (без элементов управления C1). |
| 1255 | Иврит | Практически расширенный набор ISO 8859-8, но с двумя несовместимыми изменениями пунктуации. |
| 1256 | арабский | Несовместимо с ISO 8859-6 ; скорее OEM Кодовая страница 708 является расширенным набором ISO 8859-6 (ASMO 708). |
| 1257 | Балтийский | Не ISO 8859-4 ; более поздний ISO 8859-13 тесно связан, но с некоторыми отличиями в доступной пунктуации. |
| 1258 | Вьетнамский (также OEM) | Не относится к VSCII или VISCII, использует меньшее количество базовых символов с комбинированными диакритическими знаками. |
Кодовые страницы DOS
Они также основаны на ASCII. Большинство из них включены для использования в качестве кодовых страниц OEM; кодовая страница 874 также используется как кодовая страница ANSI.
- 437 — IBM PC US, 8-битный SBCS расширенный ASCII. Известная как OEM-US, кодировка основного встроенного шрифта видеокарт VGA.
- 708 — арабский, расширенный ISO 8859-6 (ASMO 708)
- 720 — арабский, символы рисования прямоугольников остаются на их обычном месте
- 737 — «MS-DOS Greek». Сохраняет все символы рисования прямоугольников. Популярнее, чем 869.
- 775 — «MS-DOS Baltic Rim»
- 850 — «MS-DOS Latin 1». Полный (реорганизованный) репертуар ISO 8859-1.
- 852 — «MS-DOS Latin 2»
- 855 — «MS-DOS Cyrillic». В основном используется для южнославянских языков. Включает (реорганизованный) репертуар ISO-8859-5. Не путать с cp866.
- 857 — «MS-DOS Turkish»
- 858 — Западноевропейский со знаком евро
- 860 — «MS-DOS Portuguese»
- 861 — «MS-DOS исландский»
- 862 — «MS-DOS Hebrew»
- 863 — «MS-DOS French Canada»
- 864 — арабский
- 865 — «MS-DOS Nordic»
- 866 — «MS-DOS Cyrillic Russian», cp866. Единственная кодовая страница исключительно OEM (а не ANSI или оба), включенная в качестве устаревшей кодировки в WHATWG Encoding Standard для HTML5.
- 869 — «MS-DOS Greek 2», IBM869. Полный (реорганизованный) репертуар ISO 8859-7.
- 874 — Тайский, также используемый в качестве кодовой страницы ANSI, расширяет ISO 8859-11 (и, следовательно, TIS-620 ) с несколькими дополнительными символами из Windows-1252. Соответствует кодовой странице IBM 1162 (IBM-874 аналогична, но имеет другие расширения).
Многобайтовые кодовые страницы восточноазиатских стран
Часто они лишь частично совпадают с кодовыми страницами IBM с тем же номером: кодовые страницы 932, 936 и 949 отличаются от кодовых страниц IBM с тем же номером, тогда как Windows-951, как часть кладжа, не связана с IBM-951. Эквивалентные кодовые страницы IBM приведены во втором столбце. Кодовые страницы 932, 936, 949 и 950/951 используются в качестве кодовых страниц как ANSI, так и OEM в рассматриваемых регионах.
| ID | IBM Equivalent | Язык | Кодировка | Используйте |
|---|---|---|---|---|
| 932 | 943 | Японский | Shift JIS (вариант Microsoft) | ANSI / OEM (Япония) |
| 936 | 1386 | Китайский (упрощенный) | GBK | ANSI / OEM (КНР, Сингапур) |
| 949 | 1363 | Корейский | Унифицированный код хангыль | ANSI / OEM (Республика Корея) |
| 950 | 1370, 1373 | Китайский (традиционный) | Big5 (вариант Microsoft) | ANSI / OEM (Тайвань, Гонконг) |
| 951 | 5471 | Китайский (традиционный) | Big5-HKSCS (изд. 2001 г.) | ANSI / OEM (Гонконг, 98 / NT4 / 2000 / XP с патчем HKSCS) |
Несколько дополнительных многобайтовых кодовых страниц поддерживаются для декодирования или кодирования с использованием библиотек операционной системы, но не используются в качестве системного кодирования в любом локаль.
| ID | IBM Equivalent | Язык | Кодировка | Используйте |
|---|---|---|---|---|
| — | корейский | Johab (KS C 5601-1992, приложение 3) | Преобразование | |
| 964 | Китайский (традиционный) | CNS 11643 | Преобразование | |
| — | Китайский (традиционный) | TCA | Преобразование | |
| — | Китайский (традиционный) | Big5 (вариант ETEN) | Преобразование | |
| ? | Китайский (традиционный) | Преобразование | ||
| — | Китайский (традиционный) | Телетекст | Преобразование | |
| — | Китайский (традиционный) | Ван | Преобразование | |
| 20932 | 954 (примерно) | Японский | EUC-JP | Преобразование |
кодовые страницы EBCDIC
- 37 — IBM EBCDIC США-Канада, 8-битный SBCS
- 500 — Latin 1
- 870 — IBM870
- 875 — cp875
- 1026 — EBCDIC Turkish
- 1047 — IBM01047 — Latin 1
- 1140 — IBM01141
- 1141 — IBM01141
- 1142 — IBM01142
- 1143 — IBM01143
- 1144 — IBM01144
- 1145 — IBM01145
- 1146 — IBM01146
- 1147 — IBM01147
- 1148 — IBM01148
- 1149 — IBM01149
- — EBCDIC Германия
- — EBCDIC Дания / Норвегия
- — EBCDIC Финляндия / Швеция
- — EBCDIC Италия
- — EBCDIC Латинская Америка / Испания
- — EBCDIC Соединенное Королевство
- — EBCDIC японский
- — EBCDIC Франция
- — EBCDIC арабский
- — EBCDIC Греческий
- — x-EBCDIC-KoreanExtended
- — Корейский
- — EBCDIC Тайский
- — EBCDIC Кириллица
- — EBCDIC Исландский
- — EBCDIC Кириллица
- — EBCDIC Турецкий
- — Японский EBCDIC (неполный, устаревший)
Кодовые страницы, связанные с Unicode
- 1200 — Unicode (BMP по ISO 10646, UTF-16LE ). Доступно только для управляемых приложений
- 1201 — Unicode (UTF-16BE ). Доступно только для управляемых приложений
- 12000 — utf-32. Доступно только для управляемых приложений
- 12001 — utf-32 Big Endian. Доступно только для управляемых приложений
- 65000 — Unicode (UTF-7 )
- 65001 — Unicode (UTF-8 )
Кодовые страницы совместимости Macintosh
- 10000 — Apple Macintosh Roman
- 10001 — Apple Macintosh Японский
- — Apple Macintosh китайский (традиционный) (BIG-5)
- — Apple Macintosh корейский
- 10004 — Apple Macintosh арабский
- — Apple Macintosh иврит
- 10006 — Apple Macintosh греческий
- 10007 — Apple Macintosh кириллица
- — Apple Macintosh китайский (упрощенный) (GB 2312)
- 10010 — Apple Macintosh Румынский
- 10017 — Apple Macintosh украинский
- — Apple Macintosh Thai
- 10029 — Apple Macintosh Roman II / Центральная Европа
- 10079 — Apple Macintosh Icelandic
- 10081 — Apple Macintosh Turkish
- 10082 — Apple Macintosh хорватский
ISO 8859 кодовых страниц
- 28591 — ISO-8859-1 — Latin-1 (эквивалент IBM: 819)
- 28592 — ISO-8859-2 — Latin-2
- 28593 — ISO-8859-3 — Latin-3 или южноевропейский
- 28594 — ISO-8859-4 — Latin-4 или североевропейский
- 28595 — ISO-8859-5 — латиница / кириллица
- 28596 — ISO-8859-6 — латиница / арабский
- 28597 — ISO- 8859-7 — Латинский / греческий
- 28598 — ISO-8859-8 — Латинский / иврит
- 28599 — ISO-8859-9 — Latin-5 или турецкий
- 28600 — ISO-8859-10 — Latin-6
- 28601 — ISO-8859-11 — Latin / Thai
- 28602 — ISO-8859-12 — зарезервировано для Latin / Devanagari, но не поддерживается (не поддерживается)
- 28603 — ISO-8859- 13 — Latin-7 или Baltic Rim
- 28604 — ISO-8859-14 — Latin-8 или Celtic
- 28605 — ISO-8859 -15 — Latin-9
- 28606 — ISO-8859-16 — Latin-10 или Юго-Восточная Европа
- 38596 — ISO- 8859-6-I — латинский / арабский (логический двунаправленный порядок)
- 38598 — ISO-8859-8-I — латинский / иврит (логический двунаправленный порядок)
Кодовые страницы ITU-T
- 20105 — 7-битный IA5 IRV (западноевропейский)
- 20106 — 7-битный IA5 немецкий (DIN 66003)
- — 7-битный IA5 шведский (SEN 850200 C)
- — 7-битный IA5 норвежский (NS 4551-2)
- 20127 — 7-битный US-ASCII
- 20261 — T.61 (T.61-8bit)
- 20269 — ISO-6937
кодовые страницы KOI8
- 20866 — Русский — KOI8-R
- 21866 — Украинский — KOI8-U (или KOI8-RU в некоторых версиях)
Другие кодовые страницы
- — IBM00924 — IBM EBCDIC Latin 1 / Open System (1047 + символ евро)
- — x-cp20936 — упрощенный китайский (GB2312); Упрощенный китайский (GB2312-80)
- — x-cp20949 — Korean Wansung
Проблемы, связанные с использованием кодовых страниц
Microsoft настоятельно рекомендует использовать Unicode в современных приложениях, но многие приложения или файлы данных по-прежнему зависят от устаревших кодовых страниц.
- Программы должны знать, какую кодовую страницу использовать, чтобы правильно отображать содержимое (до Unicode) файлов. Если программа использует неправильную кодовую страницу, она может отображать текст как mojibake.
- Используемая кодовая страница может отличаться на разных машинах, поэтому файлы (до Unicode), созданные на одной машине, могут быть нечитаемыми на другой.
- Данные часто неправильно помечены кодовой страницей или не помечены вообще, что затрудняет определение правильной кодовой страницы для чтения данных.
- Эти кодовые страницы Microsoft в разной степени отличаются от некоторых из стандарты и реализации других поставщиков. Это не проблема Microsoft как таковая, как это происходит со всеми поставщиками, но отсутствие согласованности делает взаимодействие с другими системами ненадежным в некоторых случаях.
- Использование кодовых страниц ограничивает набор символов, которые могут
- Символы, выраженные в неподдерживаемой кодовой странице, могут быть преобразованы в вопросительные знаки (?) или другие заменяющие символы, или в более простую версию (например, удаление диакритических знаков из буквы). В любом случае исходный символ может быть утерян.
См. Также
- AppLocale — утилита для запуска приложений, не поддерживающих Юникод (на основе кодовых страниц), в языковом стандарте по выбору пользователя.
Ссылки
- ^Кодовые страницы, MSDN
- ^ MSDN: Глоссарий терминов
- ^Список IANA из наборов символов
- ^«Расширяемый язык разметки (XML) 1.1 (второе издание): кодировки символов». W3C. 29 сентября 2006 г. Дата обращения 5 октября 2020 г.
- ^hylom (2017-11-14). «Windows 10 の Insider Preview シ ス テ ム ー ル を UTF-8 に す る プ シ ョ ン が 追加 さ れ る» [возможность сделать UTF-8 системным языковым стандартом, добавленным в Windows 10 Insider Preview].ス ラ ド (на японском). Проверено 10 мая 2018 г.
- ^«Наборы символов». IANA.
- ^Microsoft. «Windows 1250». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01250». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1251». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01251». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1252». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01252». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1253». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01253». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1254». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01254». Проверено 6 июля 2014.
- ^Microsoft. «Windows 1255». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01255». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1256». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01256». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1257». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01257». Проверено 6 июля 2014 г.
- ^Microsoft. «Windows 1258». Проверено 6 июля 2014.
- ^IBM. «Информационный документ кодовой страницы SBCS CPGID 01258». Проверено 6 июля 2014 г.
- ^IBM. «Информационный документ кодовой страницы SBCS — CPGID 00437». Проверено 4 июля 2014 г.
- ^«IBM-943 и IBM-932». Центр знаний IBM. IBM.
- ^»Информационный документ CCSID 1370″. Архивировано из оригинального 27 марта 2016 года.
- ^»Converter Explorer: ibm-1373_P100-2002″. Демонстрация интенсивной терапии. Международные компоненты для Unicode.
- ^«Идентификаторы кодированного набора символов — CCSID 5471». IBM Globalization. IBM. Архивировано с оригинального 29.11.2014.
- ^IBM. «Информационный документ кодовой страницы SBCS — CPGID 00037». Проверено 4 июля 2014 г.
- ^Стил, Шон (12 сентября 2005 г.). «Кодовая страница 21027» Расширенный / расширенный алфавитный нижний регистр «». MSDN.
- ^Идентификаторы кодовой страницы
- ^ Список идентификаторов кодовой страницы
- ^ «Идентификаторы кодовой страницы». Сеть разработчиков Microsoft. Microsoft. 2014. Архивировано из оригинала 19.06.2016. Проверено 19 июня 2016 г.
- ^ «Веб-кодировки — Internet Explorer — Кодировки». WHATWG Wiki. 2012-10-23. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Западноевропейская (IA5) кодировка — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Кодировка немецкого (IA5) — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Шведская (IA5) кодировка — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Норвежская (IA5) кодировка — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Фоллер, Антонин (2014) [2011]. «Кодировка US-ASCII — кодировки Windows». WUtils.com — онлайн-утилита и справка. Программное обеспечение Motobit. Архивировано из оригинала 20.06.2016. Проверено 20 июня 2016 г.
- ^Нечаев, Валентин (2013) [2001]. «Обзор вселенной 8-битных кодировок кириллицы». Архивировано из оригинала на 2016-12-05. Проверено 5 декабря 2016 г.
Внешние ссылки
- Справочник по API поддержки национальных языков (NLS). Таблица, показывающая кодовые страницы ANSI и OEM для каждого языка (из веб-архива, поскольку Microsoft удалила исходную страницу)
- Регистрации имен кодировки IANA
- Таблица сопоставления Unicode для кодовых страниц Windows
- Сопоставление Unicode кодовых страниц Windows с «наилучшим соответствием» »
Кодовые страницы Windows — это наборы символов или кодовых страниц (известные как кодировки символов в других операционных системах), используемые в Microsoft Windows с 1980-х и 1990-х годов. Кодовые страницы Windows , постепенно вытесняется , когда Unicode была реализована в ОС Windows , [ править ] , хотя они по — прежнему поддерживается как в Windows , и других платформ, и до сих пор применяется , когда код Alt используются ярлыки.
В системах Windows существует две группы системных кодовых страниц: OEM-кодовые страницы и собственные кодовые страницы Windows («ANSI»). Кодовые страницы в обеих этих группах являются расширенными кодовыми страницами ASCII . Дополнительные кодовые страницы поддерживаются стандартными процедурами преобразования Windows, но не используются ни в одном из типов системных кодовых страниц.
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неправильное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяется | US-ASCII |
| Предшествует | ISO 8859 |
| Преемник | Юникод UTF-16 (в Win32 API) |
|
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» [1] после того, как Microsoft приняла неправильный термин [2] ), используются для нативных не-Unicode (скажем, ориентированных на байты ) приложений, использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI ; кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , [2]который добавляет еще 32 управляющих кода и место для 96 печатных символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц «ANSI» имеют номера кодовых страниц в шаблоне 125x. Однако 874 (тайский) и восточноазиатские многобайтовые кодовые страницы «ANSI» ( 932 , 936 , 949 , 950 ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы в соответствии с кодировками IBM, ни одна из которых не является идентичны кодировкам Windows (хотя большинство из них похожи). Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все 125x кодовые страницы Windows, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как «Windows- номер », хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J». [3]
Кодовые страницы ANSI Windows, и особенно кодовая страница 1252 , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо: [2]
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной. [ необходима цитата ]
Кодовая страница OEM
В кодовые страницы OEM ( Original Equipment Manufacturer ) используются консольных Win32 приложений и виртуальной DOS , и может рассматриваться как пережиток от DOS и оригинальной IBM PC архитектуры. Отдельный набор кодовых страниц был реализован не только из-за совместимости, но и потому, что шрифты аппаратного обеспечения VGA (и потомков) предлагают кодирование символов рисования линий для совместимости с кодовой страницей 437 . Большинство кодовых страниц OEM имеют много общих кодовых точек, особенно для небуквенных символов, со второй (не ASCII) половиной CP437.
Типичная кодовая страница OEM во второй половине даже приблизительно не похожа ни на одну кодовую страницу ANSI / Windows. Тем не менее, две однобайтовые кодовые страницы фиксированной ширины (874 для тайского языка и 1258 для вьетнамского ) и четыре многобайтовых кодовых страницы CJK ( 932 , 936 , 949 , 950 ) используются как кодовые страницы OEM и ANSI. Кодовая страница 1258 использует комбинированные диакритические знаки , поскольку вьетнамский требует более 128 буквенно-диакритических комбинаций. Это отличается от VISCII , который заменяет некоторые управляющие коды C0 (т.е. ASCII).
История
Первоначально компьютерные системы и языки системного программирования не делали различия между символами и байтами : для сегментных сценариев, используемых в большей части Африки, Америки, Южной и Юго-Восточной Азии, Ближнего Востока и Европы, для символа требуется всего один байт. , но два или более байта необходимы для идеографических наборов, используемых в остальном мире. Впоследствии это привело к большой путанице. Программное обеспечение и системы Microsoft, предшествующие линейке Windows NT, являются примерами этого, потому что они используют кодовые страницы OEM и ANSI, которые не делают различий.
С конца 1990-х годов программное обеспечение и системы приняли Юникод в качестве предпочтительного формата хранения; эта тенденция была улучшена благодаря широкому распространению XML , который обеспечивает более адекватный механизм для маркировки используемой кодировки. [4] Последние продукты Microsoft и интерфейсы прикладных программ внутренне используют Unicode, [ необходима цитата ], но многие приложения и API-интерфейсы продолжают использовать кодировку по умолчанию «языкового стандарта» компьютера при чтении и записи текстовых данных в файлы или стандартный вывод. [ необходима цитата ] Таким образом, файлы могут все еще встречаться, которые являются разборчивыми и разборчивыми в одной части мира, но неразборчивымимоджибаке в другом.
UTF-8, UTF-16
Microsoft решила использовать 16-битную (двухбайтовую) систему UTF-16 для всех своих операционных систем, начиная с Windows NT. Этот метод однозначно кодирует все символы Unicode в базовой многоязычной плоскости и 32-битный (четырехбайтовый) код для других, но остальная часть отрасли ( Unix-подобные системы и Интернет) выбрали UTF-8 (который использует один байт для 7-битный набор символов ASCII , два или три байта для других символов в BMP и четыре байта для остатка). Начиная с Windows 10 версии 1803 , компьютеры с Windows можно настроить так, чтобы разрешить UTF-8 в качестве кодовой страницы «ANSI» и OEM. [5]
Список
Существуют следующие кодовые страницы Windows:
Серия Windows-125x
Все эти девять кодовых страниц представляют собой расширенные 8-битные кодировки SBCS ASCII и были разработаны Microsoft для использования в качестве кодовых страниц ANSI в Windows. Они широко известны по своим зарегистрированным в IANA [6] именам windows-<number>, но иногда их также называют cp<number>«cp» для «кодовой страницы». Все они используются как кодовые страницы ANSI; Windows-1258 также используется как кодовая страница OEM.
Серия Windows-125x включает девять кодовых страниц ANSI и в основном охватывает сценарии из Европы и Западной Азии с добавлением Вьетнама . Системные кодировки для тайского и восточноазиатских языков были пронумерованы для соответствия аналогичным кодовым страницам IBM и используются как кодовые страницы как ANSI, так и OEM; они описаны в следующих разделах.
| Я БЫ | Описание | Связь с ISO 8859 или другими установленными кодировками |
|---|---|---|
| 1250 [7] [8] | Latin 2 / Центральноевропейская | Аналогичен ISO-8859-2, но перемещает несколько символов, включая несколько букв. |
| 1251 [9] [10] | Кириллица | Несовместим как с ISO-8859-5, так и с KOI-8 . |
| 1252 [11] [12] | Латиница 1 / Западноевропейская | Расширенный набор ISO-8859-1 (без элементов управления C1). Буквенный репертуар соответственно аналогичен CP850 . |
| 1253 [13] [14] | Греческий | Аналогичен ISO 8859-7, но перемещает несколько символов, включая букву. |
| 1254 [15] [16] | турецкий | Расширенный стандарт ISO 8859-9 (без элементов управления C1). |
| 1255 [17] [18] | иврит | Практически надмножество ISO 8859-8 , но с двумя несовместимыми изменениями пунктуации. |
| 1256 [19] [20] | арабский | Несовместимо с ISO 8859-6 ; кодовая страница OEM 708 скорее является расширенным набором ISO 8859-6 (ASMO 708). |
| 1257 [21] [22] | Балтийский | Не ISO 8859-4 ; более поздний ISO 8859-13 тесно связан, но с некоторыми отличиями в доступной пунктуации. |
| 1258 [23] [24] | Вьетнамский (также OEM) | Не связано с VSCII или VISCII , использует меньшее количество базовых символов с диакритическими знаками , сочетающих. |
Кодовые страницы DOS
Они также основаны на ASCII. Большинство из них включены для использования в качестве кодовых страниц OEM; кодовая страница 874 также используется как кодовая страница ANSI.
- 437 — IBM PC US, 8-битный расширенный ASCII SBCS . [25] Известная как OEM-US, кодировка основного встроенного шрифта видеокарт VGA.
- 708 — арабский, расширенный ISO 8859-6 (ASMO 708)
- 720 — арабский, сохраняя символы рисования прямоугольников на их обычных местах
- 737 — «MS-DOS греческий». Сохраняет все символы рисования прямоугольников. Популярнее, чем 869.
- 775 — «MS-DOS Балтийский край»
- 850 — «MS-DOS Latin 1». Полный (переработанный) репертуар ISO 8859-1 .
- 852 — «MS-DOS Latin 2»
- 855 — «Кириллица MS-DOS». В основном используется для южнославянских языков . Включает (переработанный) репертуар ISO-8859-5 . Не путать с cp866.
- 857 — «MS-DOS Турецкий»
- 858 — Западноевропейский со знаком евро
- 860 — «Португальский MS-DOS»
- 861 — «Исландский MS-DOS»
- 862 — «Еврейский MS-DOS»
- 863 — «MS-DOS Французская Канада»
- 864 — арабский
- 865 — «MS-DOS Nordic»
- 866 — «MS-DOS Кириллица русская», cp866. Единственная кодовая страница исключительно OEM (а не ANSI или оба), включенная в качестве устаревшей кодировки в WHATWG Encoding Standard для HTML5 .
- 869 — «MS-DOS Greek 2», IBM869. Полный (переработанный) репертуар ISO 8859-7 .
- 874 — Тайский язык , также используемый в качестве кодовой страницы ANSI, расширяет ISO 8859-11 (и, следовательно, TIS-620 ) несколькими дополнительными символами из Windows-1252. Соответствует кодовой странице IBM 1162 (IBM-874 аналогична, но имеет другие расширения).
Многобайтовые кодовые страницы Восточной Азии
Они часто отличаются от кодовых страниц IBM с тем же номером: кодовые страницы 932, 949 и 950 лишь частично соответствуют кодовым страницам IBM с тем же номером, в то время как номер 936 использовался IBM для другой кодировки упрощенного китайского, которая теперь устарела и Windows-951, как часть кладжа , не имеет отношения к IBM-951. Эквивалентные кодовые страницы IBM приведены во втором столбце. Кодовые страницы 932, 936, 949 и 950/951 используются в качестве кодовых страниц как ANSI, так и OEM для рассматриваемых локалей.
| Я БЫ | Язык | Кодирование | Эквивалент IBM | Отличие от IBM CCSID того же номера | Использовать |
|---|---|---|---|---|---|
| 932 | Японский | Shift JIS (вариант Microsoft) | 943 [26] | IBM-932 также является Shift JIS, имеет меньше расширений (но некоторые общие расширения) и меняет местами некоторые itaiji для взаимодействия с более ранними версиями JIS C 6226 . | ANSI / OEM (Япония) |
| 936 | Упрощенный китайский) | ГБК | 1386 | IBM-936 — это другая кодировка упрощенного китайского с другим методом кодирования, которая устарела с 1993 года. | ANSI / OEM (КНР, Сингапур) |
| 949 | корейский язык | Единый код хангыль | 1363 | IBM-949 также является расширенным набором EUC-KR , но с другими (конфликтующими) расширениями. | ANSI / OEM (Республика Корея) |
| 950 | Китайский традиционный) | Big5 (вариант Microsoft) | 1373 [27] | IBM-950 также относится к категории Big5, но включает другое подмножество расширений ETEN и не имеет евро. | ANSI / OEM (Тайвань, Гонконг) |
| 951 | Китайский (традиционный), включая кантонский диалект | Big5-HKSCS (изд. 2001 г.) | 5471 [28] | IBM-951 — это двухбайтовая плоскость от IBM-949 (см. Выше), не имеющая отношения к внутреннему использованию числа 951 в Microsoft. | ANSI / OEM (Гонконг, 98 / NT4 / 2000 / XP с патчем HKSCS) |
Еще несколько многобайтовых кодовых страниц поддерживаются для декодирования или кодирования с использованием библиотек операционной системы, но не используются в качестве системного кодирования ни в одной локали.
| Я БЫ | Эквивалент IBM | Язык | Кодирование | Использовать |
|---|---|---|---|---|
| 1361 | — | корейский язык | Джохаб (KS C 5601-1992, приложение 3) | Преобразование |
| 20000 | — | Китайский традиционный) | Кодировка CNS 11643 | Преобразование |
| 20001 | — | Китайский традиционный) | TCA | Преобразование |
| 20002 | — | Китайский традиционный) | Big5 (вариант ETEN) | Преобразование |
| 20003 | 938 | Китайский традиционный) | IBM 5550 | Преобразование |
| 20004 | — | Китайский традиционный) | Телетекст | Преобразование |
| 20005 | — | Китайский традиционный) | Ван | Преобразование |
| 20932 , 51932 | 954 (примерно) | Японский | EUC-JP | Преобразование |
| 20936 , 51936 | 5479 | Упрощенный китайский) | GB2312 | Преобразование |
| 20949 , 51949 | 970 | корейский язык | Wansung (8-битный с ASCII, т.е. EUC-KR ) [29] | Преобразование |
Кодовые страницы EBCDIC
- 37 — IBM EBCDIC США-Канада, 8-битный SBCS [30]
- 500 — латиница 1
- 870 — IBM870
- 875 — cp875
- 1026 — EBCDIC Турецкий
- 1047 — IBM01047 — Латиница 1
- 1140 — IBM01141
- 1141 — IBM01141
- 1142 — IBM01142
- 1143 — IBM01143
- 1144 — IBM01144
- 1145 — IBM01145
- 1146 — IBM01146
- 1147 — IBM01147
- 1148 — IBM01148
- 1149 — IBM01149
- 20273 — EBCDIC Германия
- 20277 — EBCDIC Дания / Норвегия
- 20278 — EBCDIC Финляндия / Швеция
- 20280 — EBCDIC Италия
- 20284 — EBCDIC Латинская Америка / Испания
- 20285 — EBCDIC Соединенное Королевство
- 20290 — EBCDIC японский
- 20297 — EBCDIC Франция
- 20420 — EBCDIC арабский
- 20423 — EBCDIC Греческий
- 20424 — x-EBCDIC-KoreanExtended
- 20833 — корейский
- 20838 — EBCDIC тайский
- 20924 — IBM00924 — IBM EBCDIC Latin 1 / Открытая система (1047 + символ евро)
- 20871 — исландский EBCDIC
- 20880 — EBCDIC кириллица
- 20905 — EBCDIC Турецкий
- 21025 — EBCDIC кириллица
- 21027 — японский EBCDIC (неполный, [31] устаревший) [32]
- 1200 — Юникод (BMP по ISO 10646, UTF-16LE ). Доступно только для управляемых приложений [32]
- 1201 — Юникод ( UTF-16BE ). Доступно только для управляемых приложений [32]
- 12000 — UTF-32 . Доступно только для управляемых приложений [32]
- 12001 — UTF-32 . С прямым порядком байтов. Доступно только для управляемых приложений [32]
- 65000 — Юникод ( UTF-7 )
- 65001 — Юникод ( UTF-8 )
Кодовые страницы совместимости с Macintosh
- 10000 — Apple Macintosh Роман
- 10001 — Apple Macintosh на японском языке
- 10002 — Apple Macintosh Chinese (традиционный) (BIG-5)
- 10003 — Apple Macintosh корейский
- 10004 — Apple Macintosh на арабском языке
- 10005 — Apple Macintosh на иврите
- 10006 — Apple Macintosh греческий
- 10007 — кириллица Apple Macintosh
- 10008 — Apple Macintosh китайский (упрощенный) (ГБ 2312)
- 10010 — Apple Macintosh на румынском языке
- 10017 — Apple Macintosh украинский
- 10021 — Apple Macintosh Thai
- 10029 — Apple Macintosh Roman II / Центральная Европа
- 10079 — Исландский Apple Macintosh
- 10081 — Apple Macintosh Турецкий
- 10082 — Apple Macintosh хорватский
Кодовые страницы ISO 8859
- 28591 — ISO-8859-1 — Latin-1 (эквивалент IBM: 819)
- 28592 — ISO-8859-2 — Latin-2
- 28593 — ISO-8859-3 — Latin-3 или южноевропейский
- 28594 — ISO-8859-4 — Latin-4 или североевропейский
- 28595 — ISO-8859-5 — Латиница / кириллица
- 28596 — ISO-8859-6 — Латинский / арабский
- 28597 — ISO-8859-7 — Латинский / греческий
- 28598 — ISO-8859-8 — Латинский / Иврит
- 28599 — ISO-8859-9 — Latin-5 или турецкий
- 28600 — ISO-8859-10 — Latin-6
- 28601 — ISO-8859-11 — Латинский / тайский
- 28602 — ISO-8859-12 — зарезервировано для латиницы / деванагари, но заброшено (не поддерживается)
- 28603 — ISO-8859-13 — Latin-7 или Baltic Rim
- 28604 — ISO-8859-14 — Latin-8 или кельтский
- 28605 — ISO-8859-15 — Latin-9
- 28606 — ISO-8859-16 — Latin-10 или Юго-Восточная Европа
- 38596 — ISO-8859-6- I — Латинский / арабский (логический двунаправленный порядок)
- 38598 — ISO-8859-8- I — Латинский / иврит (логический двунаправленный порядок)
Кодовые страницы ITU-T
- 20105 — 7-битный IA5 IRV (западноевропейский) [33] [34] [35]
- 20106 — 7-битный IA5 немецкий (DIN 66003) [33] [34] [36]
- 20107 — 7-битный IA5 шведский (SEN 850200 C) [33] [34] [37]
- 20108 — 7-битный норвежский язык IA5 (NS 4551-2) [33] [34] [38]
- 20127 — 7-битный US-ASCII [33] [34] [39]
- 20261 — T.61 (T.61-8bit)
- 20269 — ISO-6937
Кодовые страницы KOI8
- 20866 — Русский — КОИ8-Р
- 21866 — украинский — КОИ8-У (или КОИ8-РУ в некоторых вариантах) [40]
Проблемы, возникающие при использовании кодовых страниц
Microsoft настоятельно рекомендует использовать Unicode в современных приложениях, но многие приложения или файлы данных по-прежнему зависят от устаревших кодовых страниц.
- Программы должны знать, какую кодовую страницу использовать, чтобы правильно отображать содержимое файлов (до Unicode). Если программа использует неправильную кодовую страницу, она может отображать текст как моджибаке .
- Используемая кодовая страница может отличаться на разных машинах, поэтому файлы (до Unicode), созданные на одной машине, могут быть нечитаемыми на другой.
- Данные часто неправильно помечены кодовой страницей или не помечены вообще, что затрудняет определение правильной кодовой страницы для чтения данных.
- Эти кодовые страницы Microsoft в разной степени отличаются от некоторых стандартов и реализаций других поставщиков. Это не проблема Microsoft как таковая , как это происходит со всеми поставщиками, но отсутствие согласованности делает взаимодействие с другими системами в некоторых случаях ненадежным.
- Использование кодовых страниц ограничивает набор символов, которые могут использоваться.
- Символы, выраженные в неподдерживаемой кодовой странице, могут быть преобразованы в вопросительные знаки (?) Или другие заменяющие символы или в более простую версию (например, удаление диакритических знаков из буквы). В любом случае исходный персонаж может быть утерян.
См. Также
- AppLocale — утилита для запуска приложений, не поддерживающих Юникод (на основе кодовых страниц), в языковом стандарте по выбору пользователя.
Ссылки
- ^ «Кодовые страницы» . 2016-03-07. Архивировано из оригинала на 2016-03-07 . Проверено 26 мая 2021 .
- ^ a b c «Глоссарий терминов, используемых на этом сайте» . 8 декабря, 2018. Архивировано из оригинала на 2018-12-08.
Термин «ANSI», используемый для обозначения кодовых страниц Windows, является исторической справкой, но в настоящее время это неправильное название, которое продолжает сохраняться в сообществе Windows. Источником этого является тот факт, что кодовая страница Windows 1252 изначально была основана на проекте ANSI, который стал стандартом Международной организации по стандартизации (ISO) 8859-1. «Приложения ANSI» обычно относятся к приложениям, не основанным на Unicode или кодовых страницах.
- ^ «Наборы символов» . www.iana.org . Архивировано 25 мая 2021 года . Проверено 26 мая 2021 .
- ^ «Расширяемый язык разметки (XML) 1.1 (второе издание): кодировки символов» . W3C . 29 сентября 2006 года архивация с оригинала на 19 апреля 2021 года . Дата обращения 5 октября 2020 .
- ^ хилом (2017-11-14). «Windows 10 の Insider Preview で シ ス テ ム ロ ケ ー ル を UTF-8 に す る シ ョ ン が 追加 さ れ» [возможность сделать UTF-8 системной локалью, добавленной в Windows 10 Insider Preview].ス ラ ド(на японском языке). Архивировано 11 мая 2018 года . Проверено 10 мая 2018 .
- ^ «Наборы символов» . IANA. Архивировано 3 декабря 2016 года . Проверено 7 апреля 2019 .
- ^ Microsoft. «Windows 1250» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01250» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1251» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01251» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1252» . Архивировано 4 мая 2013 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01252» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1253» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01253» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1254» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01254» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Windows 1255» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01255» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1256» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01256» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1257» . Архивировано 16 марта 2013 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01257» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ Microsoft. «Окна 1258» . Архивировано 25 октября 2013 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS CPGID 01258» . Архивировано 14 июля 2014 года . Проверено 6 июля 2014 .
- ^ IBM. «Информационный документ кодовой страницы SBCS — CPGID 00437» . Архивировано 9 июня 2016 года . Проверено 4 июля 2014 .
- ^ «IBM-943 и IBM-932» . Центр знаний IBM . IBM. Архивировано 18 августа 2018 года . Проверено 8 июля 2020 .
- ^ «Converter Explorer: ibm-1373_P100-2002» . Демонстрация интенсивной терапии . Международные компоненты для Unicode . Архивировано 26 мая 2021 года . Проверено 27 июня 2020 .
- ^ «Идентификаторы кодированного набора символов — CCSID 5471» . IBM Globalization . IBM . Архивировано из оригинала на 2014-11-29.
- ^ Джульярд, Александр. «dump_krwansung_codepage: построить корейскую таблицу Wansung из файла KSX1001» . make_unicode: создание файлов .c кодовой страницы из описаний ftp.unicode.org . Винный проект . Архивировано 26 мая 2021 года . Проверено 14 марта 2021 .
- ^ IBM. «Информационный документ кодовой страницы SBCS — CPGID 00037» . Архивировано 14 июля 2014 года . Проверено 4 июля 2014 .
- ↑ Стил, Шон (12 сентября 2005 г.). «Кодовая страница 21027« Расширенный / Расширенный алфавитный нижний регистр » » . MSDN . Архивировано 6 апреля 2019 года . Проверено 6 апреля 2019 .
- ^ a b c d e «Идентификаторы кодовой страницы» . docs.microsoft.com . Архивировано 07 апреля 2019 года . Проверено 7 апреля 2019 .
- ^ a b c d e «Идентификаторы кодовой страницы» . Сеть разработчиков Microsoft . Microsoft . 2014. Архивировано 19 июня 2016 года . Проверено 19 июня 2016 .
- ^ a b c d e «Веб-кодировки — Internet Explorer — Кодировки» . WHATWG Wiki . 2012-10-23. Архивировано 20 июня 2016 года . Проверено 20 июня 2016 .
- ^ Фоллер, Антонин (2014) [2011]. «Западноевропейская (IA5) кодировка — кодировки Windows» . WUtils.com — онлайн-утилита и справка . Программное обеспечение Motobit. Архивировано 20 июня 2016 года . Проверено 20 июня 2016 .
- ^ Фоллер, Антонин (2014) [2011]. «Немецкая (IA5) кодировка — кодировки Windows» . WUtils.com — онлайн-утилита и справка . Программное обеспечение Motobit. Архивировано 20 июня 2016 года . Проверено 20 июня 2016 .
- ^ Фоллер, Антонин (2014) [2011]. «Шведская (IA5) кодировка — кодировки Windows» . WUtils.com — онлайн-утилита и справка . Программное обеспечение Motobit. Архивировано 20 июня 2016 года . Проверено 20 июня 2016 .
- ^ Фоллер, Антонин (2014) [2011]. «Норвежская (IA5) кодировка — кодировки Windows» . WUtils.com — онлайн-утилита и справка . Программное обеспечение Motobit. Архивировано 20 июня 2016 года . Проверено 20 июня 2016 .
- ^ Фоллер, Антонин (2014) [2011]. «Кодировка US-ASCII — кодировки Windows» . WUtils.com — онлайн-утилита и справка . Программное обеспечение Motobit. Архивировано 20 июня 2016 года . Проверено 20 июня 2016 .
- ↑ Нечаев, Валентин (2013) [2001]. «Обзор вселенной 8-битных кодировок кириллицы» . Архивировано 5 декабря 2016 года . Проверено 5 декабря 2016 .
Внешние ссылки
- Справочник по API поддержки национальных языков (NLS) . Таблица, показывающая кодовые страницы ANSI и OEM для каждого языка (из веб-архива, поскольку Microsoft удалила исходную страницу)
- Регистрация имен с кодировкой IANA
- Таблица сопоставления Unicode для кодовых страниц Windows
- Отображение кодовых страниц Windows в Юникоде с «наилучшим соответствием»
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа! 
смайлы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн!
смайлы, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «�����»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить… 
смайлы
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 14 лет(число динамическое) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!