Концепция и характеристики операционных систем Windows.
Современные ОС Windows — высокопроизводительные, многозадачные и многопотоковые 64-разрядные операционные системы с графическим интерфейсом и расширенными сетевыми возможностями, работающие в защищенном режиме, поддерживающие 16-разрядные приложения без всякой их модификации.
ОС Windows — это интегрированная среда, обеспечивающая обмен текстовой, графической, звуковой и видеоинформацией между отдельными программами.
Основными характеристиками ОС Windows являются:
· вытесняющая многозадачность и многопоточность;
· графический пользовательский интерфейс;
· подключение новых периферийных устройств по технологии Plug and Play$
· наличие коммуникационных программных средств (поддержки компьютерных сетей);
· наличие средств мультимедиа;
· интеграция с глобальной сетью Интернет;
2.1.1.1 Базовая архитектура системы. 32-разрядная архитектура.
Windows NT – второй представитель нового поколения мощных 32-битовых многопотоковых операционных систем. Первой такой ОС была Windows – 95. 32-разрядная ОС способна непосредственно обрабатывать 32-разрядные числа (а не 16-разрядные, как ее предшественники DOS, Windows 3.1, 3.11 и другие) и, что более важно оперировать с 32-разрядными адресами.
Сравнение с пропускной способностью дороги, у которой 8, 16, 32, 64 полосы.
Микропроцессоры ПК, начиная с Intel-386 (далее Intel-486, Intel Pro) стали 32-разрядными, т.е. способными управляться с 32-разрядными кодами, в том числе с 32-разрядными адресами. Так как Windows-3.1,11 не могли работать с 32 разрядами, то возможности этих микропроцессоров использовались неполностью.
Начиная с Windows – 95, отпадает необходимость в сегментной модели памяти. Windows NT также поддерживает плоскую (flat) модель памяти, в рамках которой память никак не структурируется. Ее придется структурировать, только если программные продукты превысят размер 4 Гбайта, так как именно такое адресное пространство обеспечивается 32-разрядным адресом.
Итак, Windows – 95 и Windows NT преодолевают 2 основных ограничения прежних ОС (DOS, Windows 3.1):
1) выполнение операций только над 16-разрядными двоичными числами;
2) использование сегментной модели памяти.
Комментарий.
Непосредственная поддержка операций только над 16-разрядными числами не означает невозможность обработки чисел большей разрядности, скажем 32-разрядных. Но работа с ними требует их дробления на части, выполнения необходимых действий над отдельными частями и последующего объединения частичных результатов в окончательный. Такая техника существенно замедляет обработку данных. При этом на времени исполнения программ сказывается не только необходимость обрабатывать длинные коды чисел по частям, но и потребность в многократном считывании таких кодов из памяти.
Суть сегментной модели памяти заключается в том, что основная память на логическом уровне представлена в видесовокупности сегментов различного, но не превосходящего некоторую величину размера. 16-разрядным кодом можно адресовать только 64 Кбайта памяти, а этого явно недостаточно.
Windows NT – интегрированная среда.
Интегрированная ОС – операционная система, ядро которой загружается в момент включения ПК, и активизируется графический интерфейс.
Вытесняющая многозадачность и многопоточность.
Вытесняющая многозадачность – свойство ОС, самостоятельно в зависимости от внутренней ситуации передавать или забирать управление у того или иного приложения.
Многозадачность увеличивает загрузку микоропроцессора. Даже если работает 1 пользователь, то при выполнении медленных операций ввода-вывода, например, микропроцессор вынужден простаивать. В такие отрезки времени он может выполнять другие задачи.
В Windows 3.х приложения работали в режиме кооперативной многозадачности, т.е. последовательно. Каждое приложение периодически самостоятельно проверяет очередь сообщений, чтобы при необходимости передать управление другому приложению. ОС при этом пассивно наблюдает за этим процессом, не вмешиваясь в него. Приложения, редко проверяющие очередь сообщений, забирают себе практически все процессорное время.
Комментарий. В Windows NT для 32-битовых приложений используется механизм вытесняющей многозадачности, основанный на многопоточности.
Многопоточность – свойство ОС выполнять операции одновременно над потоками нескольких 32-битовых приложений, называемых процессами.
Процесс состоит из потоков.
Поток – это некоторая часть процесса, которой может быть выделено процессорное время для одновременного выполнения наряду с другими потоками того или иного процесса.
32-битовые приложения Windows NT способны порождать или инициировать несколько потоков внутри данного процесса. Каждый процесс состоит как минимум из одного потока. Многопоточное приложение значительно эффективнее в работе, быстрее реагирует на действия пользователя и выполняет многие операции в фоновом режиме.
Распределение времени между приложениями в Windows NT осуществляет ядро операционной системы, а поддержка вытесняющей многозадачности обеспечивает плавное переключение между одновременно выполняемыми процессами и не позволяет одному приложению занять все системные ресурсы.
Технология Plug and Play (включи и работай).
Начиная с Windows 95, в ОС этого семейства широко используется технология Plug and Play,обеспечивающая новые возможности интеграции программных продуктов и аппаратных средств. Они ориентированы на поддержку любого типа устройств, включая мониторы, видеоплаты, принтеры, звуковые карты, модемы, приводы CD-ROM/
Кроме того настройка и конфигурирование ОС, которые можно определить как изменение и уточнение режимов ее работы, а также порядка ее работы для:
1) обеспечения функционирования ОС на ПК с конкретным набором аппаратных средств;
2) адаптации ОС к потребностям пользователя и приложений;
3) повышения эффективности функционирования ОС и производительности ПК в целом.
К радости неквалифицированных пользователей настраивать Windows, начиная с 95-ой версии гораздо проще. Здесь нет необходимости вручную готовить какие-либо файлы конфигурации (CONFIG.SYS и AUTOEXEC.BAT не нужны). Некоторые функции унифицированы и вынесены в одно место
НастройкаПанель управленияСвойства системыОбщие …Быстродействие
НастройкаПанель управленияУстройства
В функциях настройки Windows, начиная с 95-ой, впечатляет, прежде всего то, что она способна распознать конкретное технические средства ПК, после чего учесть в работе их особенности и произвести автонастройку самих устройств. Это и есть результат технологии Plug and Play.
Комментарий.
Технология Plug and Play –это набор спецификаций, предложенных хорошо известными фирмамиMicrosoft, Compaq, Intel,иPhoenix Technologies с целью автоматизации процесса настройки подключаемых к ПК периферийных устройств. Начиная с Windows 95, пользователю для подключения нового устройства, поддерживающего технологию Plug and Play,достаточно его просто вставить в систему. Перераспределение и настройка системных ресурсов далее происходит автоматически. Например, ПК легко превращается в мультимедийную систему, простым присоединением звуковой платы и привода CD-ROM и последующим запуском Windows 95, 98 или NT.
Раньше этот процесс был очень трудоемким, требовал сложных манипуляций с коммутационными перемычками с целью бесконфликтного задания адресов портов ввода-вывода, номеров линий запроса прерывания, каналов прямого доступа к памяти (DMA) и зон адресного пространства. Теперь же все это не требуется – система справляется с настройкой устройств самостоятельно, одновременно подстраивая и себя – в частности, обеспечивая загрузку требуемых драйверов.
Категория: драйвер = драйвер устройства (device driver) + драйвер ресурсов (например, драйвер расширенной памяти HIMEM.SYS).
Windows 95, 98, NT и последующие версии также поддерживают динамическое реконфигурирование – замену периферийных устройств, выполняемых на платах PC Card,непосредственно в процессе работы без выключения питания (“горячее подключение”). Другой пример динамического изменения конфигурации системы: если в процессе работы от станции отключился портативный компьютер, Windows в этом компьютере автоматически изменяет конфигурацию, настраиваясь на монитор низкого рарешения, отсутствие сетевой платы и большого жесткого диска.
Технология Plug and Play,позволяет также работать с устройствами, не подчиняющимися спецификацииPlug and Play,упрощая их настройку и управление оборудованием.
Для корректного обращения с системными ресурсами ОС Windows отслеживает все устройства и выделяемые им ресурсы. Диспетчер устройств Windows позволяет пользователю получать информацию обо всех найденных системой устройствах, изменять при необходимости их конфигурацию. Кроме этого
Источник
Интеграция информационных систем
Ни для кого не секрет, что «уже все сделано до нас». Осталась всего-то малость «собрать фрагменты» для решения поставленной задачи. И тут оказывается, что интегрировать разобщенные части не редко сложнее, чем их написать. Почему же так происходит? Что можно с этим сделать?
Все программисты любят делать системы с нуля, когда мысль может свободно себе изобретать любые формы и средства, когда можно принимать решения без оглядки на легаси. Конечно, сконструированная цельно система, при условии, что ее делал специалист, всегда выглядит монолитно и радует глаз. Но ведь реальность у нас текучая и со временем, любая концептуальная идиллия нарушается в ходе развития бизнеса, изменения процессов, поглощения или слияния предприятий, внедрения новых систем, смены аппаратных или программных платформ и даже законодательства.
Кто поддерживал и внедрял системы, а уж тем более, занимался доработкой, реинженерингом и интеграцией, тот знает, что более двух третей всех усилий в ИТ (внимания, времени и денег) уходит на «склейку» несовместимого и попытки «подружить» модули, написанные разными людьми, в разное время, на разных языках и технологиях, под разные платформы.
Давайте перечислим и проанализируем факторы, влияющие на интеграцию:
- Ускорение процессов. Развитие организации требует все чаще и чаще менять структуры данных, бизнес-процессы, не говоря уже о дизайне и пользовательском интерфейсе, который просто постоянно находится в изменении. Вот, как раз в таких динамичных областях, где “изменчивость” является самой сутью и природой системы, задача интеграции усугубляется и превращается в серьезную проблему.
- Распределенность. Организации становятся все более крупными, а решаемые задачи все более комплексными, появляется логическая, организационная и географическая рассредоточенность.
- Гетерогенность. В крупном проекте, почти никогда нет возможности придерживаться платформ и инструментов от одного производителя, поэтому приходится учитывать и поддерживать особенности нескольких платформ.
- Наследственность. Невозможность полностью отказаться от легаси систем, морально устаревших технологий, старого аппаратного обеспечения, корторые, кстати, иногда дают вполне хорошие показатели по надежности и производительности но уж ни как не способствуют интеграции.
- Хаотичность. Не всегда есть возможность полностью формализовать, специфицировать и структурировать данные, и часть модели остается “слабо-связанной”, не поддающейся или слабо поддающейся машинной обработке, анализу, индексации, обсчету.
- Обусловленность. К сожалению, информационные системы ограничены не только техническими рамками, но и привычками людей (которых сложно переучивать), особенностями законодательства (которое просто не готово к появлению таких систем), множеством других факторов, не зависящих от разработчиков.
- Интерактивность. Потребитель информации постоянно повышает свои ожидания о скорости реакции системы, быстродействии и оперативности доставки информации. Большинство процессов стремятся к выполнению в реальном времени.
- Мобильность. Пользователь систем стал передвигаться быстрее, а взаимодействие с ним ведется через каналы связи общего пользования в транспорте, дома и на улице, в общественных местах и повсеместно.
- Безопасность. Пока данные хранились на носителе внутри охраняемого помещения, то особо ни кто не беспокоился о шифровании, но теперь сетевые пакеты летают в воздухе и это нельзя оставлять без внимания.
- Высоконагруженность. На сложность интеграции влияют: количество пользователей в системе, интенсивность потока обработки данных, объемы данных и ресурсоемкость вычислений.
- Непрерывность цикла работы. Интеграция и апгрейд систем почти всегда должны проводиться без остановки их функционирования, плавно, постепенно и незаметно для организации и ее клиентов.
- Межсистемная интеграция. Задачи стыковки не ограничены рамками организации, все чаще нужно интегрироваться с партнерами, клиентами, поставщиками, подрядчиками и даже государственными структурами.
Вот такие реалии, я даже готов утверждать, что нет в ИТ более сложной задачи, чем интеграция систем. Давайте проанализируем теперь задачу с другого ракурса, выделим параметры, отвечающие за сложность интеграции и предложим варианты минимизации негативного влияния этих параметров:
- Концептуальная разница — основывается та том, что разработчики разных систем изначально приняли разные решения, предположения и допущения, которые концептуально не стыкуются между собой. Решается введением еще одного слоя абстракции, который концептуально не противоречит обоим подходам. При этом, есть два варианта реализации: (а) когда получившаяся система становится централизованной, а две и более интегрируемых системы превращаются в подсистемы и (б) когда мы используем архитектуру брокера (посредника, не являющегося центром), при этом системы остаются независимыми, а брокер обеспечивает прослойку между ними.
- Технологическая разница — когда мы имеем несовместимые форматы обмена данными, протоколы взаимодействия и интерфейсы. Решается написанием конвертов, прослоек, брокеров и других примочек, не вполне красивых, но достаточно надежных.
- Несовместимость лицензий. Подробнее останавливаться на этом не буду, так как не специалист я в этом вопросе, а решение может быть в каждом случае индивидуальное, на организационном уровне.
Общая задача у нас теперь выглядит так: необходимо интегрировать N информационных систем, характеризуемых описанными выше факторами, с минимизацией количества прослоек, конвертеров, брокеров и интерфейсов между ними. Если решать задачу в лоб, то между N системами будет N(N-1)/2 связей, то есть, при двухстороннем взаимодействии N(N-1) интерфейсов. Если учесть, что под интерфейсом мы тут можем понимать все что угодно, от веб-сервиса до оффлайнового процесса, запускаемого, например раз в сутки и делающего целый ряд сложных операций по синхронизации баз (запросы, обработку, экспорт, закачку по FTP, передачу сигнала другой части системы, чтобы та приняла переданные данные и выполнила свою часть работы, а потом уведомила о результатах и передала необходимые данных обратно). В общем от таких вариантов никогда не удастся избавиться полностью, вопрос только в грамотной их реализации.
Но приведу весь арсенал средств по решению поставленной задачи, из тех, которым научился от других, использовал сам и наблюдал на практике:
- Стандартизация — нужно и важно использовать как можно больше международных, государственных и отраслевых стандартов, а если каких-то не хватает, а они явно просятся, то нужно вводить корпоративные стандарты, а часто имеет смысл и продвигать их в соответствующих организациях для скорейшего распространения и популяризации.
- Интеграция на уровне брокеров. Преимущества: универсальность — практически всегда можно создать дополнительный программный модуль, который будут обращаться в обе системы, еще и разными способами (например, в одну через базу данных, а в другую через RPC). Недостатки: сложность, трудоемкость, а следовательно высокая стоимость разработки, внедрения и владения.
- Интеграция на уровне данных — то есть несколько приложений могут обращаться в одну базу данных или в несколько баз данных, связанных репликациями. Преимущества: низкая стоимость интеграции, а при использовании одной СУБД это становится очень заманчивым решением. Недостатки: если база данных не экранирована хранимыми процедурами и не имеет необходимых ограничений целостности (в виде указания каскадных операций и триггеров), то разные приложения могут приводить данные в противоречивые состояния. Если же база экранирована и целостность обеспечивается, то и в этом случае, в параллельно работающих с одной БД приложениях, будут дублирующиеся части кода, выполняющие одинаковые или похожие операции. Кроме того, при изменениях структуры базы мы будем отдельно переписывать код всех приложений, с ней работающих.
- Интеграция на уровне сервисов — это красивая интеграция, основанная на фиксации интерфейсов и форматов данных с двух сторон и позволяющая наладить быструю отработку межкорпоративной бизнес-логики. Есть и недостатки: все же, присутствует фиксация, а если структуры или процессы изменяются, то образуются проблемы и узко специализированные, частные решения.
- Интеграция на уровне пользователя — это крайний случай, не автоматизированная интеграция, когда пользователи перемещают данные между системами через копипаст, файлы, почту и другие безобразия. Мы такие методы не рассматриваем, но они, к сожалению, часто применяются в тот период, пока программные системы не готовы, а развитие компании не позволяет ждать.
- Динамическая интерпретация метаинформации — об этом мы поговорим в отдельной статье.
Это почти исчерпывающий обзор классических методов, прошу дополнять, если я что-то упустил. А вот по не классическим методам интеграции я готовлю еще одну публикацию. Спасибо за внимание.
Источник
Синерги́я (греч. συνεργία — сотрудничество, содействие, помощь, соучастие, сообщничество; от греч. σύν — вместе, греч. ἔργον — дело, труд, работа, (воз)действие) — суммирующий эффект взаимодействия двух или более факторов, характеризующийся тем, что их действие существенно превосходит эффект каждого отдельного компонента в виде их простой суммы[1], эмерджентность.
Википедия.
В процессе работы бизнес консультантом, для увеличения эффективности работы систем предприятия, я почти всегда предлагаю провести интеграцию между различным ПО заказчика. Потому что интегрировав различные системы возможно добиться эффекта синергии.
Мне постоянно приходится сталкиваться с одними и теми же проблемами и решениями многие из которых приходится пояснять в каждом новом проекте заказчикам, некоторые – программистам. А потому я считаю, что о процессе интеграции стоит поговорить подробно. В большинстве примеров я выбрал различные случаи интеграции 1С и CRM, так как сегодня именно этот вопрос, как показывает моя практика, наиболее актуален. Хотя данная статья подойдет при интеграции практически любого программного обеспечения. Итак начнем.
Интеграция – это очень важная часть работы по автоматизации бизнес-процессов, так как требуется она постоянно. В разных ситуациях возникает потребность оперативно обмениваться данными между различными конфигурациями 1С, между программными продуктами 1С и сайтом, между 1С и CAD системами, а также системами биллинга и т.д. Также достаточно часто требуется интегрировать между собой различные веб сервисы, например, интернет-магазин и CRM-систему. В общем, объединить работу различных подразделений компании и автоматизировать рабочий процесс без использования интеграции в большинстве случаев невозможно.
Что такое интеграция?
Википедия дает нам такое определение:
Интегра́ция (от лат. integratio — «соединение») — процесс объединения частей в целое. В зависимости от контекста может подразумеваться:
- Веб-интеграция — объединение разнородных веб-приложений и систем в единую среду на базе веб.
- Интеграция данных — объединение данных, находящихся в различных источниках и предоставление данных пользователям в унифицированном виде
.
Я считаю, что в данном случае Вики абсолютно права. И дополнить ее можно только одним определением:
Интеграция программных систем и продуктов — это обмен данными между системами с возможной последующей их обработкой.
Смысл интеграции заключается в том, чтобы данные, которые пользователь вводит в одну систему, автоматически переносились в другую. Продукт, в который пользователь вводит данные, называется источник. А получатель данных, соответственно, приемник.
Достаточно часто данные переносят в обе стороны, например, после преобразования в системе-приемнике результаты отправляются обратно в источник. А потому интеграция бывает как односторонней, так и двухсторонней.
Например, если вы объединяете конфигурацию 1С: Торговля с 1С: Бухгалтерией, вам может потребоваться передать данные по всем продажам в бухгалтерию, а обратно получить сведения об оплате по этим продажам.
Лично я делю процесс интеграции на такие этапы:
- Определяем, какой продукт является источником, какой – приемником.
- Сопоставляем объекты между источником и приемником.
- Выбираем протокол для интеграции
- Проводим постобработку данных (после переноса в одну из сторон)
Я всегда придерживаюсь этой последовательности при планировании работ по интеграции. Это помогает работать системно, не упустить ни одного важного момента и провести интеграцию таким образом, чтобы клиенту было удобно работать в объединенной системе.
Важно: при интеграции различных программных решений нужно хорошо понимать их функционал.
Когда-то я и сам совершал такую ошибку, и брался за интеграцию программных продуктов, которые я недостаточно хорошо знал. А потому могу сказать точно: изучать программный продукт в процессе интеграции – это не совсем корректно. При таком подходе чаще всего возникает множество ошибок и проблем, например, перенос не тех данных или сбои в работе. Рекомендую сначала хорошо изучить программный продукт, понять, что он может, каким образом в нем реализованы те или иные функции, и только потом заниматься интеграцией.
В принципе, в процессе интеграции вам может потребоваться и более сложный обмен, и придется вводить, например, трех- или четырехстороннюю интеграцию. Но, по сути, эти процессы ничем не отличаются от обычного одно- или двухстороннего процесса. А потому я буду говорить об интеграции односторонней. А в конце скажу пару слов об особенностях двухсторонней. Все остальные направления вы всегда сможете выстроить по аналогии.
Выбираем источник и приемник
Для каждого случая интеграции данных важно четко определить, какая система будет источником, а какая – приемником.
Например, у вас есть система CRM и программа 1С: Торговля. В обеих системах существует такое понятие, как контактное лицо. В принципе, вводить его вы можете и с одной, и с другой стороны. В данном случае, очевидно, что источником стоит назначить CRM, так как этого требует логика работы с любой CRM-системой.
Аналогично и в других случаях. Нужно понимать, в какой системе пользователь будет вводить данные, а какая станет получателем этих данных через интеграцию. Это обязательно согласовывается с клиентом (пользователем), кроме случаев, когда источник очевиден. при этом обязательно нужно поставить в известность клиента, что данные определенного типа следует вводить именно через систему-источник.
Сопоставление объектов (данных)
Каждый раз при работе с данными нужно очень хорошо понимать, что именно вы выгружаете, в каком виде, а также, куда вы будете выгружать эти данные. В некоторых случаях в источнике у вас будет строковая переменная, а в приемнике – два или более объектов. В других важно просто правильно выбрать объект-приемник.
Например, практически в любой CRM контактное лицо и клиент – это одно и то же. С другой стороны в 1С контактное лицо может быть клиентом, партнером, поставщиком. И очень важно понимать, куда именно записывать данные этого контактного лица. Также важно сопоставлять все данные до того, как начнется работа непосредственно с кодом. Для этого прекрасно подойдут таблицы или блок-схемы.
Когда-то я так же, как и многие, пренебрегал этим этапом работы. Сейчас я знаю, что эти действия позволят избежать огромного количества ошибок. На какой бы стороне ни работал программист – на стороне программы-источника или приемника, такая табличка очень помогает в работе. Программист должен четко понимать, какие данные будут брать из источника, куда их нужно переносить, и как они будут обрабатываться.
Например, при выгрузке контактного лица из CRM нужно четко сопоставить этот контакт партнеру или покупателю.
Также очень важно понимать, какие преобразования потребуются для выгружаемых данных. Например, нужные для интеграции данные в источнике хранятся в качестве перечисления в виде текста. А в приемнике (пусть это будет 1С) аналогичное перечисление имеет ссылочный тип. Следовательно, вам потребуется преобразовать текст в ссылку, и уже ссылку передать в документ.
И здесь возникает проблема: требуются правила сопоставления.
Вы должны четко продумать и прописать правила сопоставления. Более того, об этих правилах необходимо оповестить ваших клиентов. Важно понимать, что клиент не видит логику работы обмена данными, он не понимает особенностей интеграции.
Конечно, вы обязательно введете ограничение прав доступа, добавите другие варианты защиты. Но, как показывает практика, это не гарантирует от того, что пользователь совершит ошибку, из-за которой интеграция перестанет работать или будет работать не корректно. Это может быть кто-то из сотрудников, обладающий правами администратора, или приглашенный специалист, который дорабатывает, например, печатную форму документа, но при этом не осведомлен об особенностях интеграции.
В результате возникают самые разные казусы. Например, вы используете в качестве ключевого слова для поиска при сопоставлении слово «дилер». Клиент по каким-то причинам меняет его в программе-источнике на слово «дилеры». Казалось бы, мелочь! Но эта мелочь приведет к тому, что поиск в 1С перестанет работать.
Я решил эту проблему таким образом:
- Обязательно оставляю клиенту подробно описанные правила сопоставления и пояснения, какие параметры и данные менять недопустимо.
- Предусматриваю варианты оповещения об ошибке. Т.е. не только фиксирую проблему в логе ошибок, но и оповещаю пользователя о сбое каким-то образом: при помощи SMS, письмом на email, всплывающими уведомлениями в 1С. А иногда всеми этими способами сразу.
Почему я пришел к такому варианту работы?
Интеграция – процесс сложный, и проблемы из-за человеческого фактора возникают достаточно часто, защититься от них практически не реально. Также бывают и программные сбои, особенно это касается таких сложных систем с большим числом багов, как программные продукты 1С. А для бизнеса очень важно, чтобы обмен данными проходил своевременно, а если возникла проблема также важно ее оперативно устранить.
Например, в моей практике была ситуация, когда я провел интеграцию 1С и Oracle, причем, последний являлся программой-источником. Далее на стороне Oracle изменили одно из полей. В результате заказы перестали загружаться в 1С вообще, при этом сервер не выдавал уведомление об ошибке. Обнаружили проблему через неделю.
С одной стороны, это явная недоработка отдела продаж моего клиента, так как неделю не получать ни одного заказа и не волноваться по этому поводу, мягко говоря, странно. С другой – отсутствие уведомления об ошибке я считаю собственной недоработкой. Конечно, в результате ошибки были исправлены, система дальше работала без сбоев, но теперь я всегда добавляю несколько вариантов уведомления об ошибке при передаче данных.
Самые распространенные решения:
- При помощи смс, электронного письма, всплывающих уведомлений в 1С информацию о сбое должен получить человек, который занимается обработкой заказов.
- Для контроля аналогичное уведомление (чаще всего на email) отправляется руководителю отдела или директору компании.
- Обязательно ведется лог-файл ошибок для того, чтобы специалист смог просмотреть все подробности.
В некоторых случаях также стоит добавлять уведомление о сбое другим лицам, этот вопрос решается с заказчиком индивидуально.
Также стоит лог-файл ошибок вести максимально подробно и как можно дольше хранить историю. Не забывайте, что вы имеете дело с данными, которые имеются в одной базе данных, но отсутствуют в другой. И без подробного отчета вам будет очень сложно понять, что именно произошло в процессе передачи данных.
Обмен данными: писать самому или применять типовое решение?
Лично я предпочитаю всегда разрабатывать решение под заказчика. Здесь можно спорить, можно обсуждать различные варианты, но есть факт: типовые обмены данными всегда сильно перегружены возможностями, которые вашему клиенту не нужны. В результате процесс обмена значительно замедляется, а число возможных ошибок вырастает в разы.
Кроме того, при выборе типового программного решения вы очень сильно зависите от поставщика программного обеспечения. Для любого исправления бага вам придется ждать выпуск очередной версии программы. Также придется подстраиваться при обновлениях под все изменения в работе, который внес разработчик.
А потому при выборе между самостоятельным написанием обмена данными и типовым решением, которое не на 100% подходит для данной ситуации, лучше писать обмен самому.
В некоторых случаях, когда типовое решение действительно на 100% удовлетворяет потребности клиента, а скорость работы для него не критична, я также применяю готовые продукты. Например, при выгрузке номенклатуры и фотографий на сайт я не редко использую готовый обмен данными от Битрикс. Но только для выгрузки. Для работы с заказами я применяю самописный обмен.
Метод подключения: REST API, SOAP или прямое подключение к базе приемника
Выбор протокола обмена данными в большинстве случаев напрямую зависит от системы, которую вы интегрируете. В большинстве случаев программисту приходится учитывать требования обеих систем, а потому выбора как такового не существует. В тех случаях, когда система может работать с несколькими протоколами, выбирайте тот, который вам удобнее. По моему опыту, для малых и средних предприятий этот вопрос не принципиален.
Вопросы клиентского доступа: почему не работает обмен?
Я считаю, что обо всех возможных ограничениях в доступе нужно узнать на начальном этапе интеграции. Таким образом, вы гарантированно избежите очень распространенной проблемы:
Вы внедрили интеграцию, все проверили, протестировали, убедились, что система работает. После чего пользователь обнаруживает, что обмен данными не происходит.
Самые распространенные ситуации:
- Ограничение доступа по IP.
- Ограничение прав пользователя.
- Ограничение по количеству обращений к источнику или приемнику
.
В первых двух случаях ограничения обычно связаны с политикой информационной безопасности предприятия, и решаются они на административном уровне. Для пользователей, которым потребуется работа с обменом данных, системный администратор настроит перечисленные вами права. Аналогично для ограничения по IP.
В случае работы с CRM-системой ограничения обычно обусловлены оплаченным пакетом услуг. Здесь достаточно оповестить клиента о наличии такого ограничения, и, при необходимости, помочь оплатить и настроить расширенный пакет.
1С идентификаторы и ошибки, связанные с ними
При интеграции с 1С очень часто ошибки обмена данных возникают из-за неверного выбора УИ (уникального идентификатора). Суть проблемы заключается в том, что объекты в 1С имеют два типа УИ: один уникален внутри выбранного типа объектов. Второй используется для работы со всей базой данных.
Если вы будете проводить поиск по всему справочнику с использованием идентификатора, который предназначен для работы внутри определенного типа данных, возникнет ошибка. Объект может быть вообще не найдет, либо система найдет сразу несколько разных объектов. К этой особенности 1С нужно относиться очень внимательно.
Еще одна проблема: нет возможности привязаться к уникальному идентификатору.
Например, системой-источником является сайт, и на нем не предусмотрено отдельное поле для информации о клиенте, она идет в общем тексте заказа. В этом случае придется выбрать какой-то другой вариант идентификации, например, по email.
При интеграции очень важно выбрать в источнике одно из полей, которое и станет уникальным идентификатором.
Я считаю хорошим тоном дублирование этого идентификатора в двух системах. Например, если я делаю выгрузку информации из CRM в 1С, то поле-идентификатор из CRM я копирую в систему 1С. В дальнейшем весь поиск и интеграция производится по этому полю быстро и просто.
В принципе, это не обязательное действие. Более того, вы будете хранить даже избыточные данные, так как у вас есть нужная информация в одной из систем, но такое дублирование повышает надежность работы обеих программ и является удобным решением для интеграции и последующей обработки данных.
Например, по идентификатору, который идентичен источнику, поиск будет производиться проще и быстрее, так как он не будет требовать дополнительной обработки. Кроме того, если что-то случится с базой данных одной из систем, благодаря дублирующимся идентификаторам сопоставить данные будет намного проще.
Формат выгрузки
Для обмена данными используются самые разные форматы. Это может быть JSON, XML, CSV, TXT, прямой доступ к базе и т.д. У меня в этом вопросе нет каких-то определенных предпочтений. Я считаю, что здесь нужно исходить из рациональных требований проекта.
Постобработка
Итак, обмен данными прошел успешно. Что дальше? Я считаю, что это еще не финал интеграции, так как пользователю мало того, что данные появились в системе. Обычно ему требуется, чтобы с этими данными выполнялись какие-то действия. Что именно нужно клиенту, следует уточнить у него. Но всегда надо помнить о том, что вы работаете для пользователя, для того, чтобы ему было удобно.
Для интернет магазинов при интеграции чаще всего требуются:
- Оповещение менеджера о поступлении заказа, например, при помощи sms
- Уведомление пользователей о поступлении новых заказов или другой актуальной информации по email
- Звуковой сигнал и/или всплывающее окно в 1С с напоминанием о том, что появились новые запросы или заявки
Постобработка требуется, прежде всего, для того, чтобы полученные данные прошли полный жизненный цикл, а, следовательно, приняли участие в каких-то последующих бизнес-процессах. А потому после загрузки должны запускаться оповещения или какие-то определенные процессы, например, обработка заказа.
Кроме действий, которые нужно выполнить в приемнике, также часто требуется после завершения успешной передачи данных выполнить определенные действия в источнике. Что именно потребуется, вам также расскажет пользователь.
Например, это может быть уведомление клиента о том, что его заказ успешно прошел выгрузку и отправлен в обработку. И здесь также может быть использовано sms, электронное письмо или просто изменение статуса заказа в системе.
Тестирование интеграции
С моей точки зрения интеграция – это часть (иногда частный случай) внедрения программного обеспечения. И здесь, как и для любой другой работы по внедрению ПО, потребуется тестирование программистом, потом – лично консультантом, а также различные варианты тестирования вместе с пользователями. Об этом я подробно писал в статье Внедрение программного продукта. Особенности работы бизнес-консультанта. Часть III. Финальная.
Отличие односторонней и двусторонней интеграции
На самом деле, принципиальных отличий у односторонней, двусторонней или многосторонней интеграции не существует. Суть процесса остается прежней, просто в разные моменты времени приемник и источник меняются ролями. Единственное важное правило, которое я ввел для себя и вам также советую: при двухстороннем обмене необходимо хранить уникальный идентификатор для всех систем, которые участвуют в интеграции. И я считаю, что его также стоит дублировать в обеих системах.
Сегодня
1. Основные понятия
информатики: информация, информатизация,
информационная система.
Информация
Информация
— это совокупность сведений (данных),
которая воспринимается из окружающей
среды (входная информация), выдается в
окружающую среду (исходная информация)
или сохраняется внутри определенной
системы.
Информация
– это знания или сведения о ком-либо
или о чем-либо.
Информация
– это сведения, которые можно собирать,
хранить, передавать, обрабатывать,
использовать.
Информатика
– наука об информации
или
– это
наука о структуре и свойствах информации,
способах сбора, обработки и передачи
информации
или
– информатика,
изучает технологию сбора, хранения и
переработки информации, а компьютер
основной инструмент в этой технологии.
Термин
информация происходит от латинского
слова informatio, что означает сведения,
разъяснения, изложение. В настоящее
время наука пытается найти общие свойства
и закономерности, присущие многогранному
понятию информация, но пока это понятие
во многом остается интуитивным и получает
различные смысловые наполнения в
различных отраслях человеческой
деятельности:
-
в
быту информацией называют любые данные,
сведения, знания, которые кого-либо
интересуют. Например, сообщение о
каких-либо событиях, о чьей-либо
деятельности и т.п.; -
в
технике под информацией понимают
сообщения, передаваемые в форме знаков
или сигналов (в этом случае есть источник
сообщений, получатель (приемник)
сообщений, канал связи); -
в
кибернетике под информацией понимают
ту часть знаний, которая используется
для ориентирования, активного действия,
управления, т.е. в целях сохранения,
совершенствования, развития системы; -
в
теории информации под информацией
понимают сведения об объектах и явлениях
окружающей среды, их параметрах,
свойствах и состоянии, которые уменьшают
имеющуюся о них степень неопределенности,
неполноты знаний.
Информация
– это отражение внешнего мира с помощью
знаков или сигналов.
Понятие
информации является основополагающим
понятием информатики. Любая деятельность
человека представляет собой процесс
сбора и переработки информации, принятия
на ее основе решении и их выполнения. С
появлением современных средств
вычислительной техники информация
стала выступать в качестве одного из
важнейших ресурсов научно-технического
прогресса.
Информатизация
Информатизация
общества – организованный
социально-экономический и научно-технический
процесс создания оптимальных условий
для удовлетворения информационных
потребностей граждан и организаций на
основе формирования и использования
информационных ресурсов.
Цель
информатизации — улучшение качества
жизни людей за счет увеличения
производительности и облегчения условий
их труда. Процесс информатизации включает
в себя три взаимосвязанных процесса:
—
медиатизацию — процесс совершенствования
средств сбора, хранения и распространения
информации;
—
компьютеризацию – процесс совершенствования
средств поиска и обработки информации;
—
интеллектуализацию — процесс развития
способности восприятия и порождения
информации, т.е. повышения интеллектуального
потенциала общества, включая использование
средств искусственного интеллекта.
Информационная
система
Информационная
система — упорядоченная совокупность
документированной информации, отвечающая
определенным принципам (достоверность,
точность, структурированность). Типичным
примером информационной системы является
база данных. Также в состав информационной
системы входят: локальные сети, базы
данных, глобальные сети и т.д.
2. Понятия информации,
данных, знаний.
Данные
— это
совокупность сведений, зафиксированных
на определенном носителе в форме,
пригодной для постоянного хранения,
передачи и обработки. Преобразование
и обработка данных позволяет получить
информацию.
Информация
— это результат преобразования и анализа
данных. Отличие информации от данных
состоит в том, что данные — это фиксированные
сведения о событиях и явлениях, которые
хранятся на определенных носителях, а
информация появляется в результате
обработки данных при решении конкретных
задач. Например, в базах данных хранятся
различные данные, а по определенному
запросу система управления базой данных
выдает требуемую информацию.
Существуют
и другие определения информации,
например, информация – это сведения об
объектах и явлениях окружающей среды,
их параметрах, свойствах и состоянии,
которые уменьшают имеющуюся о них
степень неопределенности, неполноты
знаний.
Знания
– это
зафиксированная и проверенная практикой
обработанная информация, которая
использовалась и может многократно
использоваться для принятия решений.
Знания
– это вид информации, которая хранится
в базе знаний и отображает знания
специалиста в конкретной предметной
области. Знания – это интеллектуальный
капитал.
Формальные
знания могут быть в виде документов
(стандартов, нормативов), регламентирующих
принятие решений или учебников,
инструкций с описанием решения задач.
Неформальные знания – это знания и опыт
специалистов в определенной предметной
области.
3. Свойства
информации
Информация
Информация
— это совокупность сведений (данных),
которая воспринимается из окружающей
среды (входная информация), выдается в
окружающую среду (исходная информация)
или сохраняется внутри определенной
системы.
Информация
– это знания или сведения о ком-либо
или о чем-либо.
Информация
– это сведения, которые можно собирать,
хранить, передавать, обрабатывать,
использовать.
Свойства
информации:
• полнота
— свойство информации исчерпывающе
(для данного потребителя) характеризовать
отображаемый объект или процесс;
• актуальность—
способность информации соответствовать
нуждам потребителя в нужный момент
времени;
• достоверность
— свойство информации не иметь скрытых
ошибок. Достоверная информация со
временем может стать недостоверной,
если устареет и перестанет отражать
истинное положение дел;
• доступность
— свойство информации, характеризующее
возможность ее получения данным
потребителем;
• релевантность
— способность информации соответствовать
нуждам (запросам) потребителя;
• защищенность
— свойство, характеризующее невозможность
несанкционированного использования
или изменения информации;
• эргономичность
— свойство, характеризующее удобство
формы или объема информации с точки
зрения данного потребителя.
Информацию
следует считать особым видом ресурса,
при этом имеется в виду толкование
«ресурса» как запаса неких знаний
материальных предметов или энергетических,
структурных или каких-либо других
характеристик предмета. В отличие от
ресурсов, связанных с материальными
предметами, информационные ресурсы
являются неистощимыми и предполагают
существенно иные методы воспроизведения
и обновления, чем материальные ресурсы.
С
этой точки зрения можно рассмотреть
такие свойства информации:
• запоминаемость;
• передаваемость;
• воспроизводимость;
• преобразуемость;
• стираемость.
Запоминаемость
— одно из самых важных свойств.
Запоминаемую информацию будем называть
макроскопической (имея в виду
пространственные масштабы запоминающей
ячейки и время запоминания). Именно с
макроскопической информацией мы имеем
дело в реальной практике.
Передаваемость
информации с помощью каналов связи (в
том числе с помехами) хорошо исследована
в рамках теории информации К.Шеннона.
В данном случае имеется в виду несколько
иной аспект — способность информации
к копированию, т.е. к тому, что она может
быть “запомнена” другой макроскопической
системой и при этом останется тождественной
самой себе. Очевидно, что количество
информации не должно возрастать при
копировании.
воспроизводимость
характеризует неиссякаемость и
неистощимость информации, т.е. что при
копировании информация остается
тождественной самой себе.
Фундаментальное
свойство информации — преобразуемость.
Оно означает, что информация может
менять способ и форму своего существования.
Копируемость есть разновидность
преобразования информации, при котором
ее количество не меняется. В общем случае
количество информации в процессах
преобразования меняется, но возрастать
не может.
Свойство
стираемости информации также не является
независимым. Оно связано с таким
преобразованием информации (передачей),
при котором ее количество уменьшается
и становится равным нулю.
4.Процессы сбора,
передачи и накопления информации.
Сбор
информации
Эта
фаза имеет место в цикле обращения,
когда отображение информации от источника
выполняет человек. Тогда источник
информации называют предметной областью.
Сбор
информации – это процесс целенаправленного
извлечения и анализа информации о
предметной области, в роли которой может
выступать тот или иной процесс, объект
и т.д. Цель сбора — обеспечение готовности
информации к дальнейшему продвижению
в информационном процессе. Поскольку
эта фаза начинает цикл обращения
информации, она очень важна, от качества
ее исполнения во многом зависит качество
информации, которая будет использоваться
потребителем при решении целевых задач
информационной технологии.
Данная
фаза содержит этапы:
-
первичное
восприятие информации. Здесь осуществляется
определение качественных и количественных
характеристик предметной области,
важных для решаемых потребителем
информации задач; -
разработка
системы классификации и кодирования
информации, кодирование классов; -
распознавание
и кодирование объектов; -
регистрация
результатов.
Передача
информации
Передача
информации — физический процесс,
посредством которого осуществляется
перемещение информации в пространстве.
Записали информацию на диск и перенесли
в другую комнату. Данный процесс
характеризуется наличием следующих
компонентов:
-
Источник
информации. -
Приёмник
информации. -
Носитель
информации. -
Среда
передачи.
5.История развития
и место информатики среди других наук.
История
развития информатики
Информатика
– молодая научная дисциплина, изучающая
вопросы, связанные с поиском, сбором,
хранением, преобразованием и использованием
информации в самых различных сферах
человеческой деятельности. Генетически
информатика связана с вычислительной
техникой, компьютерными системами и
сетями, так как именно компьютеры
позволяют порождать, хранить и
автоматически перерабатывать информацию
в таких количествах, что научный подход
к информационным процессам становится
одновременно необходимым и возможным.
До
настоящего времени толкование термина
“информатика” (в том смысле как он
используется в современной научной и
методической литературе) еще не является
установившимся и общепринятым. Обратимся
к истории вопроса, восходящей ко времени
появления электронных вычислительных
машин.
После
второй мировой войны возникла и начала
бурно развиваться кибернетика как наука
об общих закономерностях в управлении
и связи в различных системах: искусственных,
биологических, социальных. Рождение
кибернетики принято связывать с
опубликованием в 1948 г. американским
математиком Норбертом Винером, ставшей
знаменитой, книги “Кибернетика или
управление и связь в животном и машине”.
В этой работе были показаны пути создания
общей теории управления и заложены
основы методов рассмотрения проблем
управления и связи для различных систем
с единой точки зрения. Развиваясь
одновременно с развитием
электронно-вычислительных машин,
кибернетика со временем превращалась
в более общую науку о преобразовании
информации. Под информацией в кибернетике
понимается любая совокупность сигналов,
воздействий или сведений, которые
некоторой системой воспринимаются от
окружающей среды (входная информация
X), выдаются в окружающую среду (выходная
информация У), а также хранятся в себе
(внутренняя, внутрисистемная информация
Z), рис. 1.
Развитие
кибернетики в нашей стране встретило
идеологические препятствия. Как писал
академик А.И.Берг, “… в 1955-57 гг. и даже
позже в нашей литературе были допущены
грубые ошибки в оценке значения и
возможностей кибернетики. Это нанесло
серьезный ущерб развитию науки в нашей
стране, привело к задержке в разработке
многих теоретических положений и даже
самих электронных машин”. Достаточно
сказать, что еще в философском словаре
1959 года издания кибернетика характеризовалась
как “буржуазная лженаука”. Причиной
этому послужили, с одной стороны,
недооценка новой бурно развивающейся
науки отдельными учеными “классического”
направления, с другой – неумеренное
пустословие тех, кто вместо активной
разработки конкретных проблем кибернетики
в различных областях спекулировал на
полуфантастических прогнозах о
безграничных возможностях кибернетики,
дискредитируя тем самым эту науку.
Дело
к тому же осложнялось тем, что развитие
отечественной кибернетики на протяжении
многих лет сопровождалось серьезными
трудностями в реализации крупных
государственных проектов, например,
создания автоматизированных систем
управления (АСУ). Однако за это время
удалось накопить значительный опыт
создания информационных систем и систем
управления технико-экономическими
объектами. Требовалось выделить из
кибернетики здоровее научное и техническое
ядро и консолидировать силы для развития
нового движения к давно уже стоящим
глобальным целям.
Подойдем
сейчас к этому вопросу с терминологической
точки зрения. Вскоре вслед за появлением
термина “кибернетика” в мировой науке
стало использоваться англоязычное
“Computer Science”, а чуть позже, на рубеже
шестидесятых и семидесятых годов,
французы ввели получивший сейчас широкое
распространение термин “Informatique”. В
русском языке раннее употребление
термина “информатика” связано с
узко-конкретной областью изучения
структуры и общих свойств научной
информации, передаваемой посредством
научной литературы. Эта
информационно-аналитическая деятельность,
совершенно необходимая и сегодня в
библиотечном деле, книгоиздании и т.д.,
уже давно не отражает современного
понимания информатики. Как отмечал
академик А.П. Ершов, в современных
условиях термин информатика “вводится
в русский язык в новом и куда более
широком значении – как название
фундаментальной естественной науки,
изучающей процессы передачи и обработки
информации. При таком толковании
информатика оказывается более
непосредственно связанной с философскими
и общенаучными категориями, проясняется
и ее место в кругу “традиционных”
академических научных дисциплин”.
Попытку
определить, что же такое современная
информатика, сделал в 1978 г. Международный
конгресс по информатике: “Понятие
информатики охватывает области, связанные
с разработкой, созданием, использованием
и материально-техническим обслуживанием
систем обработки информации, включая
машины, оборудование, математическое
обеспечение, организационные аспекты,
а также комплекс промышленного,
коммерческого, административного и
социального воздействия”.
Место
информатики в системе наук
Рассмотрим
место науки информатики в традиционно
сложившейся системе наук (технических,
естественных, гуманитарных и т.д.). В
частности, это позволило бы найти место
общеобразовательного курса информатики
в ряду других учебных предметов.
Напомним,
что по определению А.П.Ершова информатика-
“фундаментальная естественная наука”.
Академик Б.Н.Наумов определял информатику
“как естественную науку, изучающую
общие свойства информации, процессы,
методы и средства ее обработки (сбор,
хранение, преобразование, перемещение,
выдача)”.
Уточним,
что такое фундаментальная наука и что
такое естественная наука. К фундаментальным
принято относить те науки, основные
понятия которых носят общенаучный
характер, используются во многих других
науках и видах деятельности. Нет,
например, сомнений в фундаментальности
столь разных наук как математика и
философия. В этом же ряду и информатика,
так как понятия “информация”, “процессы
обработки информации” несомненно имеют
общенаучную значимость.
Естественные
науки – физика, химия, биология и другие
– имеют дело с объективными сущностями
мира, существующими независимо от нашего
сознания. Отнесение к ним информатики
отражает единство законов обработки
информации в системах самой разной
природы – искусственных, биологических,
общественных.
Однако,
многие ученые подчеркивают, что
информатика имеет характерные черты и
других групп наук – технических и
гуманитарных (или общественных).
Черты
технической науки придают информатике
ее аспекты, связанные с созданием и
функционированием машинных систем
обработки информации. Науке информатике
присущи и некоторые черты гуманитарной
(общественной) науки, что обусловлено
ее вкладом в развитие и совершенствование
социальной сферы. Таким образом,
информатика является комплексной,
междисциплинарной отраслью научного
знания.
6. Информационные
ресурсы общества как экономическая
категория.
Информационный
ресурс- симбиоз знания и информации.
ИР
как экономическая категория выражает
совокупность экономических отношений
по поводу формирования и использования
запаса в виде совокупных данных
природного, правового, научного,
социально-экономического и иного
свойства, применяемых в хозяйственном
процессе для повышения его эффективности
вовлечения информационных ресурсов в
процесс общественного воспроизводства.
Информация
в экономике проявляется во множестве
аспектов:
o во-первых,
производство информации как таковой —
это производственная отрасль, т.е. вид
экономической деятельности;
o во-вторых,
информация является фактором производства,
один из фундаментальных ресурсов любой
экономической системы;
o в-третьих,
информация является объектом купли-продажи,
т.е. выступает в качестве товара;
o в-четвертых,
некоторая часть информации является
общественным благом, потребляемым всеми
членами общества;
o в-пятых,
информация — это элемент рыночного
механизма, который наряду с ценой и
полезностью влияет на определение
оптимального и равновесного состояний
экономической системы;
o в-шестых,
информация в современных условиях
становится одним из наиболее важных
факторов в конкурентной борьбе;
o в-седьмых,
информация становится резервом деловых
и правительственных кругов, используемым
при принятии решений и формировании
общественного мнения.
7. История
информационных революций
В
истории развития цивилизации произошло
несколько информационных революций —
преобразований общественных отношений
из-за кардинальных изменений в сфере
обработки информации. Следствием
подобных преобразований являлось
приобретение человеческим обществом
нового качества.
Первая
революция
связана с изобретением письменности,
что привело к гигантскому качественному
и количественному скачку. Появилась
возможность передачи знаний от поколения
к поколению.
Вторая
(середина XVI в.)
вызвана изобретением книгопечатания,
которое радикально изменило индустриальное
общество, культуру, организацию
деятельности.
Третья
(конец XIX в.)
обусловлена изобретением электричества,
благодаря которому появились телеграф,
телефон, радио, позволяющие оперативно
передавать и накапливать информацию в
любом объеме.
Четвертая
(70-е гг. XX в.)
связана с изобретением микропроцессорной
технологии и появлением персонального
компьютера. На микропроцессорах и
интегральных схемах создаются компьютеры,
компьютерные сети, системы передачи
данных (информационные коммуникации).
Этот период характеризуют три
фундаментальные инновации:
• переход
от механических и электрических средств
преобразования информации к
электронным;
•
миниатюризация
всех узлов, устройств, приборов, машин;
• создание
программно-управляемых устройств и
процессов.
Сегодня
мы переживаем пятую
информационную революцию,
связанную с формированием и развитием
трансграничных глобальных
информационно-телекоммуникационных
сетей, охватывающих все страны и
континенты, проникающих в каждый дом и
воздействующих одновременно и на каждого
человека в отдельности, и на огромные
массы людей.
Наиболее
яркий пример такого явления и результат
пятой революции — Интернет. Суть этой
революции заключается в интеграции в
едином информационном пространстве по
всему миру программно-технических
средств, средств связи и телекоммуникаций,
информационных запасов или запасов
знаний как единой информационной
телекоммуникационной инфраструктуры,
в которой активно действуют юридические
и физические лица, органы государственной
власти и местного самоуправления. В
итоге неимоверно возрастают скорости
и объемы обрабатываемой информации,
появляются новые уникальные возможности
производства, передачи и распространения
информации, поиска и получения информации,
новые виды традиционной деятельности
в этих сетях.
8. Кодирование
информации, аналоговая и цифровая
обработка, компьютерная обработка.
3.Кодирование
информации.
Для
автоматизации работы с данными,
относящимися к различным типам, очень
важно унифицировать их форму представления
— для этого обычно используется прием
кодирования, то есть выражение данных
одного типа через данные другого типа.
Естественные человеческие языки — это
не что иное, как системы кодирования
понятий для выражения мыслей посредством
речи. К языкам близко примыкают азбуки
(системы кодирования компонентов языка
с помощью графических символов). Своя
система существует и в вычислительной
технике — она называется двоичным
кодированием и основана на представлении
данных последовательностью всего двух
знаков: 0 и 1. Эти знаки называются
двоичными цифрами, по-английски — binary
digit или сокращенно bit (бит). Одним битом
могут быть выражены два понятия: 0 или
1 (да или нет, черное или белое, истина
или ложь и т. п.). Если количество битов
увеличить до двух, то уже можно выразить
четыре различных понятия:
00
01 10 11
Тремя
битами можно закодировать восемь
различных значений:
000
001 010 011 100 101 110 111
Увеличивая
на единицу количество разрядов в системе
двоичного кодирования, мы увеличиваем
в два раза количество значений, которое
может быть выражено в данной системе,
то есть общая формула имеет вид:
N=2m,
где
N— количество независимых кодируемых
значений;
т
— разрядность двоичного кодирования,
принятая в данной системе.
4.Представление
и обработка данных.
Для
того, чтобы использовать ЭВМ для обработки
данных, необходимо располагать некоторым
способом представления данных. Способ
представления данных будет зависеть
от того, для кого эти данные предназначены:
для человека (внешнее представление)
или для ЭВМ (внутреннее представление).
Во
внутреннем представлении данные могут
быть описаны в аналоговой (непрерывной)
или цифровой (дискретной) формах. В
соответствии с этим различают аналоговые
(в прошлом) и цифровые (сейчас) ЭВМ.
Любые
виды данных, обрабатываемых на ЭВМ,
могут быть сведены к совокупности
простейших форм: набор символов (текст),
звук (мелодия), изображение (фотографии,
рисунки, схемы), вещественные и целые
числа (числовая информация).
Каждый
такой вид данных должен быть некоторым
универсальным образом представлен в
виде набора целых чисел, т.к. ЭВМ цифровые!
Правила такого представления
разрабатываются научными институтами
и оформляются в виде стандартов.
Во
внешнем представлении все данные
хранятся в виде файлов. Во многих случаях
требуется ещё более высокий уровень
организации данных на внешнем уровне,
тогда данные группируются в базы данных.
Задачи
по обработке данных предполагают также
способы описания процесса самой
обработки. Процедуры обработки данных
также представляются на внешнем и
внутреннем уровне. На внутреннем уровне
каждая такая процедура представляет
собой последовательность логических
операций с целыми числами, и называется
программой. Сами логические операции
кодируются с помощью средств машинного
языка.
На
внешнем уровне процедуры представляются
в виде алгоритма. Конкретный вид алгоритма
зависит от используемого алгоритмического
языка
Таким
образом, решение любых задач с помощью
ЭВМ, в конечном счете, сводится к двум
взаимосвязанным проблемам: цифровому
представлению данных и алгоритмическому
представлению способов обработки
данных.
9. Понятие
о системах счисления, применяемых в
информатике.
Система
счисления — это знаковая система, в
которой числа записываются по определенным
правилам с помощью цифр — символов
некоторого алфавита. Например, в
десятичной системе для записи числа
существует десять всем хорошо известных
цифр: О, 1, 2 и т. д.
Все
системы счисления делятся на позиционные
и непозиционные. В позиционных системах
счисления значение цифры зависит от ее
положения в записи числа, а в непозиционных
— не зависит. Позиция цифры в числе
называется разрядом. Разряд числа
возрастает справа налево, от младших
разрядов к старшим.
Каждая
позиционная система использует
определенный алфавит цифр и основание.
В позиционных системах счисления
основание системы равно количеству
цифр (знаков в ее алфавите) и определяет,
во сколько раз различаются значения
цифр соседних разрядов числа.
Рассмотрим
в качестве примера десятичное число
555. Цифра 5 встречается трижды, причем
самая правая обозначает пять единиц,
вторая справа — пять десятков и, наконец,
третья — пять сотен.
Пример
непозиционной системы счисления-
римская, к позиционным системам счисления
относится двоичная, десятичная,
восьмеричная, шестнадцатеричная. Здесь
любое число записывается последовательностью
цифр соответствующего алфавита, причем
значение каждой цифры зависит от места
(позиции), которое она занимает в этой
последовательности.
10. Двоичная
система счисления.
Двоичная
система счисления — это
позиционная система счисления с
основанием 2. В этой системе счисления,
числа записываются с помощью двух
символов (0 и 1).
В
компьютерной технике очень часто
используется двоичная система счисления.
Такую систему очень легко реализовать
в электронике (кремнии, транзисторах,
микросхемах), так как для неё требуется
всего два устойчивых состояния (0 и 1).
Достоинства
двоичной системы счисления
-
Достоинства
двоичной системы счисления заключаются
в простоте реализации процессов
хранения, передачи и обработки информации
на компьютере. -
Для
ее реализации нужны элементы с двумя
возможными состояниями, а не с десятью. -
Представление
информации посредством только двух
состояний надежно и помехоустойчиво. -
Возможность
применения алгебры логики для выполнения
логических преобразований. -
Двоичная
арифметика проще десятичной.
Недостатки
двоичной системы счисления
-
Итак,
код числа, записанного в двоичной
системе счисления представляет собой
последовательность из 0 и 1. Большие
числа занимают достаточно большое
число разрядов. -
Быстрый
рост числа разрядов — самый существенный
недостаток двоичной системы счисления.
11. Перевод
из двоичной системы счисления в
десятичную, и перевод из десятичной
системы счисления в двоичную.
1.
Для перевода двоичного числа в десятичное
необходимо его записать в виде многочлена,
состоящего из произведений цифр числа
и соответствующей степени числа 2, и
вычислить по правилам десятичной
арифметики:
![]()
Например.
![]()
Для
перевода десятичного числа в двоичную
систему его необходимо последовательно
делить на 2 до тех пор, пока не останется
остаток, меньший или равный 1. Число в
двоичной системе записывается как
последовательность последнего результата
деления и остатков от деления в обратном
порядке.
Пример.
Число перевести в двоичную систему
счисления.

12. Подходы
к оценке количества информации. Единицы
измерения информации.
Для
определения количества информации
используется единица измерения –бит
(от англ. Bit, образовано от сочетания
binary digit—двоичная цифра). Один бит –
количество информации, содержащееся в
сообщении «да» или «нет» (в двоичном
коде «1» и «0»).
Так
как бит – это наименьшее количество
информации, то для измерения больших
объемов применяются более крупные
единицы измерения. Отношение между
единицами следующее.
1байт-
8 бит
1килобайт
(КБайт)- 2610бита==1024 байта
1мегабайт
(Мбайт)- 1024 КБайт
1гигабайт
(Гбайт)- 1024 Мбайт
«кило»
с системе измерений (система СИ) обозначает
число 1000, но в вычислительной технике
это 1024 байта. Поэтому, если говорят, «64
Кбайта», то это означает 64*1024 или 65536
байтов. Мегабайт, в свою очередь,
обозначает 1024*1024 или 1048576 байтов. В этих
же единицах (а именно, байт, КБайт, Мбайт,
Гбайт) измеряются и объемы памяти в
компьютере.
Подходы
к определению количества информации:
-
Прагматический
подход к
информации базируется на анализе ее
ценности, с точки зрения потребителя.
Например, информация, имеющая несомненную
ценность для биолога, будет иметь
ценность, близкую к нулевой, для
программиста. Ценность информации
связывают со временем, поскольку с
течением времени она стареет и ценность
ее, а, следовательно, и «количество»
уменьшается. Таким образом, прагматический
подход оценивает содержательный аспект
информации. Он имеет особое значение
при использовании информации для
управления, поскольку ее количество
тесно связано с эффективностью управления
в системе. -
На
синтаксическом
уровне для
оценки количества информации используют
вероятностные методы, которые принимают
во внимание только вероятностные
свойства информации и не учитывают
другие (смысловое содержание, полезность,
актуальность и т. д.). Разработанные в
середине XX в. математические и, в
частности, вероятностные методы
позволили сформировать подход к оценке
количества информации как к мере
уменьшения неопределенности знаний.
А)
В 1928 г. американский инженер Р. Хартли
предложил научный подход к оценке
сообщений. Предложенная им формула
имела следующий вид:
I
= log2 K ,
Где
К — количество равновероятных событий;
I — количество бит в сообщении, такое,
что любое из К событий произошло.
формула
Хартли позволяет определить количество
информации в сообщении только для
случая, когда появление символов
равновероятно и они статистически
независимы. На практике эти условия
выполняются редко.
Б)
Формулу для определения количества
информации для событий с различными
вероятностями предложил американский
ученый К. Шеннон
в 1948 г.
Согласно этой формуле количество
информации может быть определено
следующим образом:
![]()
-
На
семантическом
уровне
информация рассматривается по ее
содержанию, отражающему состояние
отдельного объекта или системы в целом.
При этом не учитывается ее полезность
для получателя информации. Поскольку
смысловое содержание информации
передается с помощью сообщения, , то
широкое распространение для измерения
смыслового содержания информации
получил подход, основанный на использовании
тезаурусной
меры. При
этом под тезаурусом понимается
совокупность информации (сведений),
которой располагает приемник информации.
Таким
образом, если принять знания о данном
объекте или явлении за тезаурус, то
количество информации, содержащееся в
новом сообщении о данном предмете, можно
оценить по изменению индивидуального
тезауруса под воздействием данного
сообщения. В зависимости от соотношений
между смысловым содержанием сообщения
и тезаурусом пользователя изменяется
количество семантической информации,
при этом характер такой зависимости не
поддается строгому математическому
описанию и сводится к рассмотрению трех
основных условий, при которых тезаурус
пользователя:
• стремится
к нулю, т. е. пользователь не воспринимает
поступившее сообщение;
• стремится
к бесконечности, т. е. пользователь
досконально знает все об объекте или
явлении и поступившее сообщение его не
интересует;
• согласован
со смысловым содержанием сообщения, т.
е. поступившее сообщение понятно
пользователю и несет новые сведения.
13. История
развития вычислительной техники.
Поколения вычислительной техники.
Ещё
1500 лет назад для облегчения вычислений
стали использовать счёты. В 1642 г. Блез
Паскаль изобрёл устройство, механически
выполняющее сложение чисел, а в 1694 г.
Готфрид Лейбниц сконструировал
арифмометр, позволяющий механически
производить четыре арифметических
действия.
Первая
счетная машина, использующая электрическое
реле, была сконструирована в 1888 г.
американцем немецкого происхождения
Германом Холлеритом и уже в 1890 г.
применялась при переписи населения. В
качестве носителя информации применялись
перфокарты. Они были настолько удачными,
что без изменений просуществовала до
наших дней.
Первой
электронной вычислительной машиной
принято считать машину ENIAC (Electronic
Numerical Integrator and Computer — электронный числовой
интегратор и вычислитель), разработанную
под руководством Джона Моучли и Джона
Экера в Пенсильванском университете в
США. ENIAC содержал 17000 электронных ламп,
7200 кристаллических диодов, 4100 магнитных
элементов и занимал площадь в 300 кв.
метром. Он в 1000 раз превосходил по
быстродействию релейные вычислительные
машины и был построен в 1945 г.
Первой
отечественной ЭВМ была МЭСМ (малая
электронная счетная машина), выпущенная
в 1951 г. под руководством Сергея
Александровича Лебедева. Её номинальное
быстродействие—50 операций в секунду.
Компьютеры
40-х и 50-х годов были доступны только
крупным компаниям и учреждениям, так
как они стоили очень дорого и занимали
несколько больших залов. Первый шаг к
уменьшению размеров и цены компьютеров
стал возможен с изобретением в 1948 г.
транзисторов. Через 10 лет, в 1958 г. Джек
Килби придумал, как на одной пластине
полупроводника получить несколько
транзисторов. В 1959 г. Роберт Нойс (будущий
основатель фирмы Intel) изобрел более
совершенный метод, позволивший создать
на одной пластинке и транзисторы, и все
необходимые соединения между ними.
Полученные электронные схемы стали
называться интегральными схемами, или
чипами. В 1968 г. фирма Burroughs выпустила
первый компьютер на интегральных схемах,
а в 1970 г. фирма Intel начала продавать
интегральные схемы памяти.
В
1971 г. был сделан ещё один важный шаг на
пути к персональному компьютеру—фирма
Intel выпустила интегральную схему,
аналогичную по своим функциям процессору
большой ЭВМ. Так появился первый
микропроцессор Intel-4004. Уже через год был
выпущен процессор Intel-8008, который работал
в два раза быстрее своего предшественника.
Вначале
эти микропроцессоры использовались
только электронщиками-любителями и в
различных специализированных устройствах.
Первый коммерчески распространяемый
персональный компьютер Altair был сделан
на базе процессора Intel-8080, выпущенного
в 1974 г. Разработчик Altair—крохотная
компания MIPS из Альбукерка (шт.
Нью-Мексико)—продавала машину в виде
комплекта деталей за 397 долл., а полностью
собранной—за 498 долл. У компьютера была
память объёмом 256 байт, клавиатура и
дисплей отсутствовали. Можно было только
щёлкать переключателями и смотреть,
как мигают лампочки. Вскоре у Altair
появились и дисплей, и клавиатура, и
добавочная оперативная память, и
устройство долговременного хранения
информации (сначала на бумажной ленте,
а затем на гибких дисках).
А
в 1976 г. был выпущен первый компьютер
фирмы Apple, который представлял собой
деревянный ящик с электронными
компонентами. Если сравнить его с
выпускаемым сейчас iMac, то становится
ясным, что со временем изменялась не
только производительность, но и улучшался
дизайн ПК.
Вскоре
к производству ПК присоединилась и
фирма IBM. В 1981 г. она выпустила первый
компьютер IBM PC. Благодаря принципу
открытой архитектуры этот компьютер
можно было самостоятельно модернизировать
и добавлять в него дополнительные
устройства, разработанные независимыми
производителями. За каких-то полгода
IBM продала 50 тыс. машин, а через два года
обогнала Apple по объёму продаж.
Производительность
современных ПК больше, чем у суперкомпьютеров,
сделанных десять лет назад. Поэтому
через несколько лет обыкновенные
персоналки будут работать со скоростью,
которой обладают современные суперЭВМ.
Кстати, в январе 1999 г. самым быстрым был
компьютер SGI ASCI Blue Mountain. По результатам
тестов Linpack parallel его быстродействие
равнялось 1,6 TFLOPS (триллионов операций
с плавающей точкой в секунду).
Так
как ЭВМ представляет собой систему,
состоящую из технических и программных
средств, то под поколением естественно
понимать модели ЭВМ, характеризуемые
одинаковыми технологическими и
программными решениями (элементная
база, логическая архитектура, программное
обеспечение). Между тем, в ряде случаев
оказывается весьма сложным провести
классификацию ВТ по поколениям, ибо
грань между ними от поколения к поколению
становиться все более размытой.
Первое
поколение.
Элементная
база- электронные лампы и реле; оперативная
память выполнялась на триггерах, позднее
на ферритовых сердечниках. Надежность
— невысокая, требовалась система
охлаждения; ЭВМ имели значительные
габариты. Быстродействие- 5 — 30 тыс.
арифметических оп/с; Программирование
— в кодах ЭВМ (машинный код), позднее
появились автокоды и ассемблеры.
Программированием занимался узкий круг
математиков, физиков, инженеров —
электронщиков. ЭВМ первого поколения
использовались в основном для
научно-технических расчетов.
Второе
поколение.
Полупроводниковая
элементная база. Значительно повышается
надежность и производительность,
снижаются габариты и потребляемая
мощность. Развитие средств ввода/вывода,
внешней памяти. Ряд прогрессивных
архитектурных решений и дальнейшее
развитие технологии программирования-
режим разделения времени и режим
мультипрограммирования (совмещение
работы центрального процессора по
обработке данных и каналов ввода/вывода,
а также распараллеливания операций
выборки команд и данных из памяти)
В
рамках второго поколения четко стала
проявляться дифференциация ЭВМ на
малые, средние и большие. Существенно
расширилась сфера применения ЭВМ на
решение задач — планово — экономических,
управления производственными процессами
и др.
Создаются
автоматизированные системы управления
(АСУ) предприятиями, целыми отраслями
и технологическими процессами (АСУТП).
Конец 50-х годов характеризуется появлением
целого ряда проблемно-ориентированных
языков программирования высокого уровня
(ЯВУ): FORTRAN, ALGOL-60 и др. Развитие ПО получило
в создании библиотек стандартных
программ на различных языках
программирования и различного назначения,
мониторов и диспетчеров для управления
режимами работы ЭВМ, планированием ее
ресурсов, заложивших концепции
операционных систем следующего поколения.
Третье
поколение.
Элементная
база на интегральных схемах (ИС).
Появляются серии моделей ЭВМ программно
совместимых снизу вверх и обладающих
возрастающими от модели к модели
возможностями. Усложнилась логическая
архитектура ЭВМ и их периферийное
оборудование, что существенно расширило
функциональные и вычислительные
возможности. Частью ЭВМ становятся
операционные системы (ОС). Многие задачи
управления памятью, устройствами
ввода/вывода и другими ресурсами стали
брать на себя ОС или же непосредственно
аппаратная часть ЭВМ. Мощным становиться
программное обеспечение: появляются
системы управления базами данных (СУБД),
системы автоматизирования проектных
работ (САПРы) различного назначения,
совершенствуются АСУ, АСУТП. Большое
внимание уделяется созданию пакетов
прикладных программ (ППП) различного
назначения.
Развиваются
языки и системы программирования
Примеры: -серия моделей IBM/360, США, серийный
выпуск -с 1964г; -ЕС ЭВМ, СССР и страны СЭВ
с 1972г.
Четвертое
поколение.
Элементной
базой становятся большие (БИС) и
сверхбольшие (СБИС) интегральные схемы.
ЭВМ проектировались уже на эффективное
использование программного обеспечения
(например, UNIX-подобные ЭВМ, наилучшим
образом погружаемые в программную
UNIX-среду; Prolog-машины, ориентированные
на задачи искусственного интеллекта);
современных ЯВУ. Получает мощное развитие
телекоммуникационная обработка
информации за счет повышения качества
каналов связи, использующих спутниковую
связь. Создаются национальные и
транснациональные информационно-вычислительные
сети, которые позволяют говорить о
начале компьютеризации человеческого
общества в целом.
Дальнейшая
интеллектуализация ВТ определяется
созданием более развитых интерфейсов
«человек-ЭВМ», баз знаний, экспертных
систем, систем параллельного
программирования и др.
Элементная
база позволила достичь больших успехов
в минитюаризации, повышении надежности
и производительности ЭВМ. Появились
микро- и мини-ЭВМ, превосходящие по
возможностям средние и большие ЭВМ
предыдущего поколения при значительно
меньшей стоимости. Технология производства
процессоров на базе СБИС ускорила темпы
выпуска ЭВМ и позволила внедрить
компьютеры в широкие массы общества. С
появление универсального процессора
на одном кристалле (микропроцессор
Intel-4004,1971г) началась эра ПК.
Первым
ПК можно считать Altair-8800, созданным на
базе Intel-8080, в 1974г. Э.Робертсом. П.Аллен
и У.Гейтс создали транслятор с популярного
языка Basic, существенно увеличив
интеллектуальность первого ПК
(впоследствии основали знаменитую
компанию Microsoft Inc). Лицо 4-го поколения в
значительной мере определяется и
созданием супер-ЭВМ, характеризующихся
высокой производительностью (среднее
быстродействие 50 — 130 мегафлопсов . 1
мегафлопс= 1млн. операций в секунду с
плавающей точкой) и нетрадиционной
архитектурой (принцип распараллеливания
на основе конвейерной обработки команд).
Супер-ЭВМ используются при решении
задач математической физики, космологии
и астрономии, моделировании сложных
систем и др. Так как важную коммутирующую
роль в сетях играют и будут играть мощные
ЭВМ, то сетевая проблематика часто
обсуждается совместно с вопросами по
супер-ЭВМ Среди отечественных разработок
супер-ЭВМ можно назвать машины серии
Эльбрус, вычислительные системы пс-2000
и ПС-3000, содержащие до 64 процессоров,
управляемых общим потоком команд,
быстродействие на ряде задач достигалось
порядка 200 мегафлопсов. Вместе с тем,
учитывая сложность разработки и
реализации проектов современных
супер-ЭВМ, требующих интенсивных
фундаментальных исследований в области
вычислительных наук, электронных
технологий, высокой культуры производства,
серьезных финансовых затрат, представляется
весьма маловероятным создание в обозримом
будущем отечественных супер-ЭВМ, по
основным характеристикам не уступающим
лучшим зарубежным моделям.
Следует
заметить, при переходе на ИС-технологию
производства ЭВМ определяющий акцент
поколений все более смещается с элементной
базы на другие показатели: логическая
архитектура, программное обеспечение,
интерфейс с пользователем, сферы
приложения и т.д.
Пятое
поколение.
Зарождается
в недрах четвертого поколения и в
значительной мере определяется
результатами работы японского Комитета
научных исследований в области ЭВМ,
опубликованными в 1981г. Согласно этому
проекту ЭВМ и вычислительные системы
пятого поколения кроме высокой
производительности и надежности при
более низкой стоимости, вполне
обеспечиваемые СБИС и др. новейшими
технологиями, должны удовлетворять
следующим качественно новым функциональным
требованиям:
-
обеспечить
простоту применения ЭВМ путем реализации
систем ввода/вывода информации голосом;
диалоговой обработки информации с
использованием естественных языков;
возможности обучаемости, ассоциативных
построений и логических выводов; -
упростить
процесс создания программных средств
путем автоматизации синтеза программ
по спецификациям исходных требований
на естественных языках -
улучшить
основные характеристики и эксплуатационные
качества ВТ для удовлетворения различных
социальных задач, улучшить соотношения
затрат и результатов, быстродействия,
легкости, компактности ЭВМ; обеспечить
их разнообразие, высокую адаптируемость
к приложениям и надежность в эксплуатации.
Учитывая
сложность реализации поставленных
перед пятым поколением задач, вполне
возможно разбиение его на более обозримые
и лучше ощущаемые этапы, первый из
которых во многом реализован в рамках
настоящего четвертого поколения.
14. Понятие
архитектуры. Архитектура ЭВМ по
Фон-Нейману.
С
середины 60-х годов существенно изменился
подход к созданию вычислительных машин.
Вместо независимой разработки аппаратуры
и некоторых средств математического
обеспечения стала проектироваться
система, состоящая из совокупности
аппаратных (hardware) и программных (software)
средств. При этом на первый план
выдвинулась концепция их взаимодействия.
Так возникло принципиально новое понятие
— архитектура ЭВМ.
Под
архитектурой ЭВМ понимается совокупность
общих принципов организации
аппаратно-программных средств и их
характеристик, определяющая функциональные
возможности ЭВМ при решении соответствующих
классов задач.
Архитектура
ЭВМ охватывает широкий круг проблем,
связанных с построением комплекса
аппаратных и программных средств и
учитывающих множество факторов. Среди
этих факторов важнейшими являются:
стоимость, сфера применения, функциональные
возможности, удобство эксплуатации, а
одним из главных компонентов архитектуры
являются аппаратные средства. Основные
компоненты архитектуры ЭВМ можно
представить в виде схемы, показанной
на рисунке.
Архитектуру
вычислительного средства следует
отличать от его структуры. Структура
вычислительного средства определяет
его конкретный состав на некотором
уровне детализации (устройства, блоки
узлы и т. д.) и описывает связи внутри
средства во всей их полноте. Архитектура
же определяет правила взаимодействия
составных частей вычислительного
средства, описание которых выполняется
в той мере, в какой это необходимо для
формирования правил их взаимодействия.
Она регламентирует не все связи, а
наиболее важные, которые должны быть
известны для более грамотного использования
данного средства.
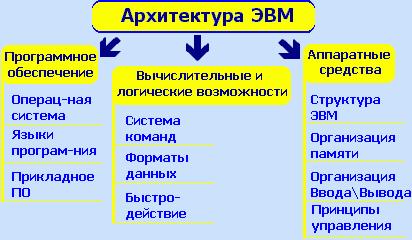
В
1946 году трое учёных — Артур Бёркс, Герман
Голдстайн и Джон фон Нейман — опубликовали
статью «Предварительное рассмотрение
логического конструирования электронного
вычислительного устройства». В статье
обосновывалось использование двоичной
системы для представления данных в ЭВМ
(преимущественно для технической
реализации, простота выполнения
арифметических и логических операций
— до этого машины хранили данные в
десятичном виде), выдвигалась идея
использования общей памяти для программы
и данных. Имя фон Неймана было достаточно
широко известно в науке того времени,
что отодвинуло на второй план его
соавторов, и данные идеи получили
название «принципы фон Неймана».
1.
Принцип двоичного кодирования. Согласно
этому принципу, вся информация, поступающая
в ЭВМ, кодируется с помощью двоичных
сигналов (двоичных цифр, битов) и
разделяется на единицы, называемые
словами.
2.
Принцип однородности памяти. Программы
и данные хранятся в одной и той же памяти.
Поэтому ЭВМ не различает, что хранится
в данной ячейке памяти — число, текст
или команда. Над командами можно выполнять
такие же действия, как и над данными.
3.
Принцип адресуемости памяти. Структурно
основная память состоит из пронумерованных
ячеек; процессору в произвольный момент
времени доступна любая ячейка. Отсюда
следует возможность давать имена
областям памяти, так, чтобы к запомненным
в них значениям можно было бы впоследствии
обращаться или менять их в процессе
выполнения программы с использованием
присвоенных имен.
4.
Принцип последовательного программного
управления. Предполагает, что программа
состоит из набора команд, которые
выполняются процессором автоматически
друг за другом в определенной
последовательности.
5
Принцип жесткости архитектуры.
Неизменяемость в процессе работы
топологии, архитектуры, списка команд.
Фон
Нейман не только выдвинул основополагающие
принципы логического устройства ЭВМ,
но и предложил ее структуру, которая
воспроизводилась в течение первых двух
поколений ЭВМ. Основными блоками по
Нейману являются устройство управления
(УУ) и арифметико-логическое устройство
(АЛУ) (обычно объединяемые в центральный
процессор), память, внешняя память,
устройства ввода и вывода. Схема
устройства такой ЭВМ представлена на
рис. 1. Следует отметить, что внешняя
память отличается от устройств ввода
и вывода тем, что данные в нее заносятся
в виде, удобном компьютеру, но недоступном
для непосредственного восприятия
человеком. Так, накопитель на магнитных
дисках относится к внешней памяти, а
клавиатура – устройство ввода, дисплей
и печать – устройства вывода.
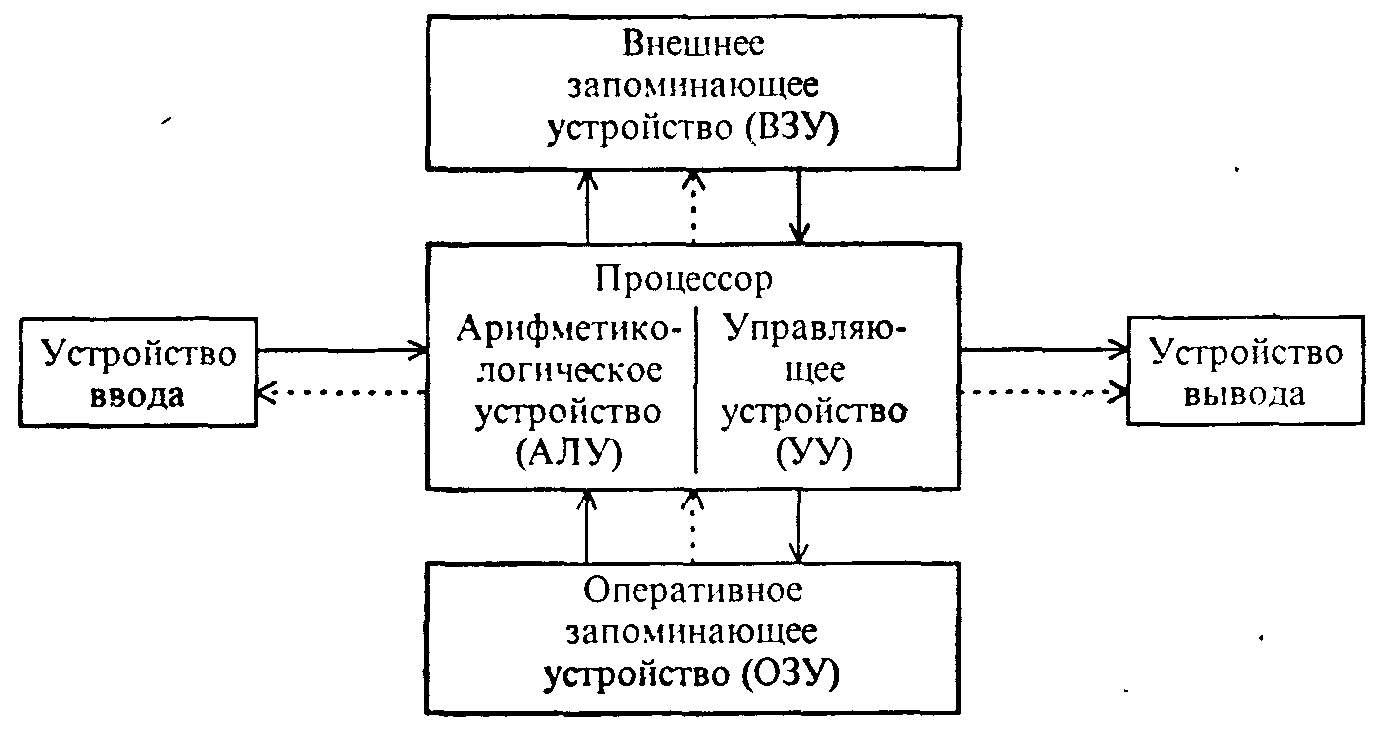
Рис.
1. Архитектура ЭВМ, построенной на
принципах фон Неймана. Сплошные линии
со стрелками указывают направление
потоков информации, пунктирные –
управляющих сигналов от процессора к
остальными узлам ЭВМ
15. Классификация
ЭВМ. Современный компьютер как совокупность
аппаратных и программных средств.
Рассмотрим
некоторые из наиболее популярных
классификаций:
по
принципу действия. Критерием
деления вычислительных машин здесь
является форма представления информации,
с которой они работают
1.
аналоговые (АВМ) — вычислительные машины
непрерывного действия, работают с
информацией, представленной в непрерывной
(аналоговой) форме, т.е. в виде непрерывного
ряда значений какой-либо физической
величины (чаще всего электрического
напряжения).
Аналоговые
вычислительные машины весьма просты и
удобны в эксплуатации; программирование
задач для решения на них, как правило,
нетрудоемкое; скорость решения задач
изменяется по желанию оператора и может
быть сделана сколь угодно большой
(больше ,чем у ЦВМ), но точность решения
задач очень низкая (относительная
погрешность 2-5%).На АВМ наиболее эффективно
решать математические задачи, содержащие
дифференциальные уравнения, не требующие
сложной логики.
2.
цифровые (ЦВМ) — вычислительные машины
дискретного действия, работают с
информацией, представленной в дискретной,
а точнее, в цифровой форме.
3.
гибридные (ГВМ) — вычислительные машины
комбинированного действия, работают с
информацией, представленной и в цифровой,
и в аналоговой форме; они совмещают в
себе достоинства АВМ и ЦВМ. ГВМ
целесообразно использовать для решения
задач управления сложными быстродействующими
техническими комплексами.
Наиболее
широкое применение получили ЦВМ с
электрическим представлением дискретной
информации — электронные цифровые
вычислительные машины, обычно называемые
просто электронными вычислительными
машинами (ЭВМ), без упоминания об их
цифровом характере.
по
назначению
1.
универсальные (общего назначения) —
предназначены для решения самых различных
технических задач: экономических,
математических, информационных и других
задач, отличающихся сложностью алгоритмов
и большим объемом обрабатываемых данных.
Они широко используются в вычислительных
центрах коллективного пользования и в
других мощных вычислительных комплексах.
2.
проблемно-ориентированные — служат для
решения более узкого круга задач,
связанных, как правило, с управлением
технологическими объектами; регистрацией,
накоплением и обработкой относительно
небольших объемов данных; выполнением
расчетов по относительно несложным
алгоритмам; они обладают ограниченными
по сравнению с универсальными ЭВМ
аппаратными и программными ресурсами.
К проблемно-ориентированным ЭВМ можно
отнести, в частности, всевозможные
управляющие вычислительные комплексы
3.
специализированные — используются для
решения узкого крута задач или реализации
строго определенной группы функций.
Такая узкая ориентация ЭВМ позволяет
четко специализировать их структуру,
существенно снизить их сложность и
стоимость при сохранении высокой
производительности и надежности их
работы. К специализированным ЭВМ можно
отнести, например, программируемые
микропроцессоры специального назначения;
адаптеры и контроллеры, выполняющие
логические функции управления отдельными
несложными техническими устройствами,
агрегатами и процессами; устройства
согласования и сопряжения работы узлов
вычислительных систем.
по
размерам и функциональным возможностям
1.
сверхбольшие (суперЭВМ)
2.
большие
3.
малые
4.
мини
5.
сверхмалые (микроЭВМ)
К
суперЭВМ относятся мощные многопроцессорные
вычислительные машины с быстродействием
сотни миллионов — десятки миллиардов
операций в секунду. Супер-компьютеры
используются для решения сложных и
больших научных задач (метеорология,
гидродинамика и т. п.), в управлении,
разведке, в качестве централизованных
хранилищ информации и т.д.
Малые
ЭВМ (мини ЭВМ) — надежные, недорогие и
удобные в эксплуатации компьютеры,
обладающие несколько более низкими по
сравнению с мэйнфреймами возможностями
Мини
— ЭВМ (и наиболее мощные из них супермини
— ЭВМ) обладают следующими характеристиками:
·
производительность — до 100
МIPS;
·
емкость основной памяти —
4-512 Мбайт;
·
емкость дисковой памяти —
2-100 Гбайт;
·
число поддерживаемых
пользователей-16-512.
Микрокомпьютеры
— это компьютеры, в которых центральный
процессор выполнен в виде мик Персональные
компьютеры (ПК) — это микрокомпьютеры
универсального назначения, рассчитанные
на одного пользователя и управляемые
одним человеком.
16. Структура
и принципы функционирования ЭВМ.
Перспективы развития вычислительных
средств. Понятие нейрокомпьютеров.
Любая
ЭВМ неймановской архитектуры содержит
следующие основные устройства:
-
арифметико-логическое
устройство (АЛУ); -
устройство
управления (УУ) -
запоминающее
устройство (ЗУ); -
устройства
ввода-вывода (УВВ); -
пульт
управления (ПУ).
В
современных ЭВМ АЛУ и УУ объединены в
общее устройство, называемое центральным
процессором. Обобщенная логическая
структура ЭВМ представлена на рис. 1.3.
Рис.
1.3. Обобщённая логическая структура ЭВМ
Процессор,
или микропроцессор, является основным
устройством ЭВМ. Он предназначен для
выполнения вычислении по хранящейся в
запоминающем устройстве программе и
обеспечения общего управления ЭВМ.
Быстродействие ЭВМ в значительной мере
определяется скоростью работы процессора.
Для ее увеличения процессор использует
собственную намять небольшого объема,
именуемую местной или сверхоперативной,
что в некоторых случаях исключает
необходимость обращения к запоминающему
устройству ЭВМ.
Вычислительный
процесс должен быть предварительно
представлен для ЭВМ в виде программы —
последовательности инструкций (команд),
записанных в порядке выполнения. В
процессе выполнения программы ЭВМ
выбирает очередную команду, расшифровывает
ее, определяет, какие действия и над
какими операндами следует выполнить.
Эту функцию осуществляет УУ. Оно же
помещает выбранные из ЗУ операнды в
АЛУ, где они и обрабатываются. Само АЛУ
работает под управлением УУ.
Обрабатываемые
данные и выполняемая программа должны
находиться в запоминающем устройстве
— памяти ЭВМ, куда они вводятся через
устройство ввода. Емкость памяти
измеряется в величинах, кратных байту.
Память представляет собой сложную
структуру, построенную по иерархическому
принципу, и включает в себя запоминающие
устройства различных типов. Функционально
она делится на две части: внутреннюю и
внешнюю.
Внутренняя,
или основная память — это запоминающее
устройство, напрямую связанное с
процессором и предназначенное для
хранения выполняемых программ и данных,
непосредственно участвующих в вычислениях.
Обращение к внутренней памяти ЭВМ
осуществляется с высоким быстродействием,
но она имеет ограниченный объем,
определяемый системой адресации машины.
Внутренняя
память, в свою очередь, делится на
оперативную (ОЗУ) и постоянную (ПЗУ)
память. Оперативная память, по объему
составляющая» большую часть внутренней
памяти, служит для приема, хранения и
выдачи информации. При выключении
питания ЭВМ содержимое оперативной
памяти в большинстве случаев теряется.
Постоянная память обеспечивает хранение
и выдачу информации. В отличие от
содержимого оперативной памяти,
содержимое постоянной заполняется при
изготовлении ЭВМ и не может быть изменено
в обычных условиях эксплуатации. В
постоянной памяти хранятся часто
используемые (универсальные) программы,
и данные, к примеру, некоторые программы
операционной системы, программы
тестирования оборудования ЭВМ и др. При
выключении питания содержимое постоянной
памяти сохраняется.
Внешняя
память (ВЗУ) предназначена для размещения
больших объемов информации и обмена ею
с оперативной памятью. Для построения
внешней памяти используют энергонезависимые
носители информации (диски и ленты),
которые к тому же являются переносимыми.
Емкость этой памяти практически не
имеет ограничений, а для обращения к
ней требуется больше времени, чем ко
внутренней.
Устройства
ввода-вывода служат соответственно для
ввода информации в ЭВМ и вывода из нее,
а также для обеспечения общения
пользователя с машиной. Процессы
ввода-вывода протекают с использованием
внутренней памяти ЭВМ. Иногда устройства
ввода-вывода называют периферийными
или внешними устройствами ЭВМ. К ним
относятся, в частности, дисплеи (мониторы),
клавиатура, манипуляторы типа «мышь»,
алфавитно-цифровые печатающие устройства
(принтеры), графопостроители, сканеры
и др. Для управления внешними устройствами
(в том числе и ВЗУ) и согласования их с
системным интерфейсом служат групповые
устройства управления внешними
устройствами, адаптеры или контроллеры.
Системный
интерфейс — это конструктивная часть
ЭВМ, предназначенная для взаимодействия
ее устройств и обмена информацией между
ними.
Пульт
управления служит для выполнения
оператором ЭВМ или системным программистом
системных операций в ходе управления
вычислительным процессом. Кроме того,
при техническом обслуживании ЭВМ за
пультом управления работает
инженерно-технический персонал. Пульт
управления конструктивно часто
выполняется вместе с центральным
процессором.
Перспективы
развития вычислительных средств
Появление
новых поколений ЭВМ обусловлено
расширением сферы их применения,
требующей более производительной,
дешевой и надежной вычислительной
техники. В настоящее время стремление
к реализации новых потребительских
свойств ЭВМ стимулирует работы по
созданию машин пятого и последующего
поколений. Вычислительные средства
пятого поколения, кроме более высокой
производительности и надежности при
более низкой стоимости, обеспечиваемых
новейшими электронными технологиями,
должны удовлетворять качественно новым
функциональным требованиям:
-
работать
с базами знаний в различных предметных
областях и организовывать на их основе
системы искусственного интеллекта; -
обеспечивать
простоту применения ЭВМ путем реализации
эффективных систем ввода-вывода
информации голосом, диалоговой обработки
информации с использованием естественных
языков, устройств распознавания речи
и изображения; -
упрощать
процесс создания программных средств
путем автоматизации синтеза программ.
В
настоящее время ведутся интенсивные
работы как по созданию ЭВМ пятого
поколения традиционной (неймановской)
архитектуры, так и по созданию и апробации
перспективных архитектур и схемотехнических
решений. На формальном и прикладном
уровнях исследуются архитектуры на
основе параллельных абстрактных
вычислителей (матричные и клеточные
процессоры, систолические структуры,
однородные вычислительные структуры,
нейронные сети и др.) Развитие вычислительной
техники с высоким параллелизмом во
многом определяется элементной базой,
степенью развития параллельного
программного обеспечения и методологией
распараллеливания алгоритмов решаемых
задач.
Наряду
с развитием архитектурных и
системотехнических решений ведутся
работы по совершенствованию технологий
производства интегральных схем и по
созданию принципиально новых элементных
баз, основанных на оптоэлектронных и
оптических принципах.
В
плане создания принципиально новых
архитектур вычислительных средств
большое внимание уделяется проектам
нейрокомпьютеров, базирующихся на
понятии нейронной сети (структуры на
формальных нейронах), моделирующей
основные свойства реальных нейронов.
В случае применения био- или оптоэлементов
могут быть созданы соответственно
биологические или оптические
нейрокомпьютеры. Многие исследователи
считают, что в следующем веке нейрокомпьютеры
в значительной степени вытеснят
современные ЭВМ, используемые для
решения трудно формализуемых задач.
Последние достижения в микроэлектронике
и разработка элементной базы на основе
биотехнологий дают возможность
прогнозировать создание биокомпьютеров.
Важным
направлением развития вычислительных
средств пятого и последующих поколений
является интеллектуализация ЭВМ,
связанная с наделением ее элементами
интеллекта, интеллектуализацией
интерфейса с пользователем и др. Работа
в данном направлении, затрагивая, в
первую очередь, программное обеспечение,
потребует и создания ЭВМ определенной
архитектуры, используемых в системах
управления базами знаний, — компьютеров
баз знаний, а так же других подклассов
ЭВМ. При этом ЭВМ должна обладать
способностью к обучению, производить
ассоциативную обработку информации и
вести интеллектуальный диалог при
решении конкретных задач.
В
заключение отметим, что ряд названных
вопросов реализован в перспективных
ЭВМ пятого поколения либо находится в
стадии технической проработки, другие
— в стадии теоретических исследований
и поисков.
Понятие
нейрокомпьютеров
Нейрокомпьютер
— это ЭВМ нового поколения, в которой
аналогом программирования является
перестройка структуры в ходе обучения.
Эффективность его работы достигается
специфической архитектурой, где элементы
работают параллельно. Создание
нейрокомпьютера базируется на основе
изучения организации нейронных структур
мозга.
Основные
особенности нейрокомпьютеров заключаются
в их способности к самоорганизации и
обучению на примерах (самопрограммирование
и самоорганизация). Наиболее перспективной
областью применения является робототехника
— создание роботов с элементами
искусственного интеллекта. Для создания
нейрокомпьютера необходимо решить
вопрос об отдельных элементах, топологии
связей между элементами и правилах
изменения весов связей между элементами.
В
качестве отдельных элементов
нейрокомпьютера были представлены:
предетекторы, детекторы новизны и
тождества, модуляторы, мнемонические
элементы, семантические элементы и
командные нейроподобные элементы.
17. Основные
устройства ЭВМ: процессор и основная
память.
Процессор
(Микропроцессор, chip-кристалл) – это
основной рабочий компонент компьютера,
который:
—
выполняет арифметические и логические
операции;
—
управляет вычислительным процессом;
—
координирует работу всех устройств
компьютера.
В
общем случае центральный процессор
содержит:
1)
Арифметико-логическое устройство —
часть процессора, выполняющая машинные
команды
2)
Устройство управления – часть процессора,
выполняющая функции управления
устройствами компьютера
3)
Шины данных и шины адресов (на физическом
уровне) – много проводные линии с
гнездами для подключения электронных
схем.
4)
Регистры — ячейки памяти, которые служат
для кратковременного хранения и
преобразования данных и команд. На
физическом уровне регистр – совокупность
триггеров, способных хранить один
двоичный разряд и связанных между собой
общей системой управления
5)
Счетчик команд – регистр управляющего
устройства компьютера содержимое,
которого соответствует адресу очередной
выполняемой команды. Счетчик команд
служит для автоматической выборки
программы из последовательных ячеек
памяти
6)
Кэш память — очень быстрая память малого
объема служит для увеличения
производительности компьютера,
согласования работы устройств различной
скорости. Кэш-память может быть встроена
сразу в процессор или размещаться на
материнской плате
7)
Сопроцессор – вспомогательный процессор,
предназначенный для выполнения
математических и логических действий.
Использование сопроцессора позволяет
ускорить процесс обработки информации
компьютером
Основная
память — это устройство для хранения
информации. Она состоит из оперативного
запоминающего устройства (ОЗУ) и
постоянного запоминающего устройства
(ПЗУ).
18. Понятие
ОЗУ, ПЗУ и КЭШ. Их назначение, основные
параметры, принципы действия.
Компактная
микроэлектронная «память» широко
применяется в современной электронной
аппаратуре самого различного значения.
Память определяют как функциональную
часть ЭВМ, предназначенную для записи,
хранения и выдачи команд и обрабатываемых
данных.
Комплекс технических средств, реализующих
функцию памяти, называют запоминающим
устройством
(ЗУ).
Для
обеспечения работы процессора
(микропроцессора) необходимы программа,
т.е. последовательность команд и данные,
над которыми процессор производит
предписываемые командами операции.
Команда и данные поступают в основную
память ЭВМ через устройство ввода, на
выходе которого они получают цифровую
форму представления, т.е. форму кодовых
комбинаций (0 и 1). Основная память, как
правило, состоит из ЗУ двух видов –
оперативного (ОЗУ) и постоянного (ПЗУ).
ОЗУ
предназначено для хранения переменной
информации, оно допускает изменение
своего содержимого в ходе выполнения
процессором вычислительных операций
с данными. Это значит, что процессор
может выбрать (режим считывания) из ОЗУ
код команды и данные и после обработки
поместить в ОЗУ (режим записи) полученный
результат. Причём возможно размещение
в ОЗУ новых данных на местах прежних,
которые этом случае перестают существовать.
Таким образом, ОЗУ может работать в
режимах записи, считывания и хранения
информации.
ПЗУ
содержит информацию, которая не должна
изменятся в ходе выполнения процессором
программы. Такую информацию составляют
стандартные подпрограммы, табличные
данные, коды физических констант и
постоянных коэффициентов и т.п. И эта
информация заносится в ПЗУ предварительно,
например, путём пережигания легкоплавких
перемычек в структуре ПЗУ, и в ходе
работы процессора может только
считываться. Таким образом, ПЗУ работает
только в режимах хранения и считывания.
Функциональные
возможности ОЗУ шире, чем ПЗУ: ОЗУ может
работать в качестве ПЗУ, т.е. в режиме
многократного считывания однократно
записанной информации, а ПЗУ в качестве
ОЗУ работать не может, т.к. не позволяет
изменить однократно записанную в ней
информацию. Далее коснёмся разновидности
ПЗУ, которая допускает перепрограммирование,
однако, и это ПЗУ не может заменить ОЗУ.
В
свою очередь, ПЗУ обладает преимуществом
перед ОЗУ в свойстве сохранять информацию
при сбоях и отключении питания. Это
свойство получило название энергозависимость.
ОЗУ является энергозависимым, т.к.
информация, записанная в ОЗУ, утрачивается
при сбоях питания.
Для
обеспечения надёжной работы ЭВМ при
отказах питания нередко ПЗУ используют
и в качестве памяти программ. В таком
случае программа заносится в ПЗУ
предварительно и уже не может быть
заменена в данном ПЗУ другой программы.
Очевидно, в использовании ПЗУ таким
образом целесообразно прежде всего в
специализированных автоматических
устройствах, работающих по постоянной
программе.
Запоминающее
устройство, реализующее функции основной
памяти, размещают рядом с процессором
на одной плате, в одном блоке в зависимости
от типа ЭВМ и такое ЗУ в этом смысле
является внутренним. Быстродействие
внутреннего ЗУ должно быть соизмеримо
с быстродействием процессора. Практически
это требование не всегда удаётся
выполнить: по временным параметрам ОЗУ
и ПЗУ отстают от процессора. По этому
внутри ЭВМ размещают ещё и вспомогательную
(буферную) память на быстродействующих
регистрах, которые используются в
качестве сверхоперативного ЗУ (СОЗУ) с
небольшой информационной ёмкостью.
КЭШ
память располагают между основной
памятью и процессором для улучшения
эффективной скорости взаимодействия
с памятью и увеличения быстродействия
процессора. Обычно КЭШ память реализуют
на полупроводниковых устройствах,
быстродействие которых сравнимо с
быстродействием процессора, тогда как
основная память использует более дешёвые
и медленно действующие устройства. Все
данные хранятся в основной памяти. С
помощью системы с КЭШ – памятью некоторые
из этих данных копируются в неё. Когда
процессору нужно считать или записать
данные в память, то сначала он проверят
их наличие в КЭШ – памяти. Если необходимые
данные находятся там (КЭШ — попадание),
то процессор может легко и быстро их
использовать. В противном случае (КЭШ
— промах) эти данные извлекаются из
основной памяти и переписываются в КЭШ
– память.
Для
увеличения процента КЭШ 0 попаданий
процессор использует блочную выборку.
КЭШ – контроллер разбивает основную
память на блоки (известные также как
длина строки) длиной обычно в 2, 4, 8, или
16 байт. Размер блока является одним из
наиболее важных параметров при
проектировании системы с КЭШ – памятью.
Если блок слишком мал, то уменьшается
эффективность выборки из основной
памяти и процент КЭШ – попаданий. Слишком
большой блок уменьшает количество
блоков, помещающихся в КЭШ – памяти.
Работая
с КЭШ – памятью, необходимо помнить,
что одновременно могут существовать
две копии одних и тех же данных: одна в
КЭШ — , а другая в основной памяти. Если
изменяется только одна из этих копий,
то по одном и тому же адресу будет
существовать два набора информации.
19. Системная
шина, внешняя память (винчестер, накопители
на гибких магнитных дисках и CD-ROM).
Системная
шина — это «паутина», соединяющая между
собой все устройства и отвечающая за
передачу информации между ними.
Расположена она на материнской плате
и внешне не видна. Системная шина — это
набор проводников (металлизированных
дорожек на материнской плате), по которым
передается информация в виде электрических
сигналов.
Чем
выше тактовая частота системной шины,
тем быстрее будет осуществляться
передача информации между устройствами
и, как следствие, увеличится общая
производительность компьютера, т. е.
повысится скорость компьютера.
Сегодня
самой распространенной является шина
PCI.
Все
стандарты различаются как по числу и
использованию сигналов, так и по
протоколам их обслуживания.
Шина
входит в состав материнской платы, на
которой располагаются ее проводники и
разъемы (слоты) для подключения плат
адаптеров устройств (видеокарты, звуковые
карты, внутренние модемы, накопители
информации, устройства ввода/вывода и
т. д.) и расширений базовой конфигурации
(дополнительные пустующие разъемы).
Существуют
16- и 32-разрядные, высокопроизводительные
(VESA, VLB, AGP и PCI с тактовой частотой более
16 МГц) и низкопроизводительные (ISA и EISA
с тактовой частотой 8 и 16 МГц) системные
шины. Также шины, разработанные по
современным стандартам (VESA, VLB и PCI),
допускают подключение нескольких
одинаковых устройств, например нескольких
жестких дисков, а шина PCI обеспечивает
самоконфигурируемость периферийного
(дополнительного) оборудования —
поддержку стандарта Plug and Play, исключающего
ручную конфигурацию аппаратных параметров
периферийного оборудования при его
изменении или наращивании. Операционная
система, поддерживающая этот стандарт,
сама настраивает оборудование,
подключенное по шине PCI, без вмешательства
пользователя.
Имеются
как 64-разрядные расширения шины PCI, так
и 32-разрядные, работающие на частоте 66
МГц.
Внешняя
память
Внешняя
память — это память, предназначенная
для длительного хранения программ и
данных. Целостность содержимого ВЗУ не
зависит от того, включен или выключен
компьютер
В
состав внешней памяти входят: 1) накопители
на жестких магнитных дисках (НЖМД); 2)
накопители на гибких магнитных дисках
(НГМД); 3) накопители на магнитооптических
компакт дисках; 4) накопители на оптических
дисках (CD-ROM); 5) накопители на магнитной
ленте и др.
НЖМД
— это основное устройство для долговременного
хранения больших объемов данных и
программ. Другие названия: жесткий диск,
винчестер, HDD (Hard Disk Drive). Внешне, винчестер
представляет собой плоскую, герметически
закрытую коробку, внутри которой
находятся на общей оси несколько жестких
алюминиевых или стеклянных пластинок
круглой формы. Поверхность любого из
дисков покрыта тонким ферромагнитным
слоем (вещество, которое реагирует на
внешнее магнитное поле), собственно на
нем хранятся записанные данные. При
этом запись проводится на обе поверхности
каждой пластины (кроме крайних) с помощью
блока специальных магнитных головок.
Каждая головка находится над рабочей
поверхностью диска на расстоянии
0,5-0,13 мкм. Пакет дисков вращается
непрерывно и с большой частотой
(4500-10000 об/мин), поэтому механический
контакт головок и дисков недопустим.
Работой
винчестера руководит специальное
аппаратно-логическое устройство —
контроллер жесткого диска. В прошлом
это была отдельная дочерняя плата,
которую подсоединяли через слоты к
материнской плате. В современных
компьютерах функции контроллера жесткого
диска выполняют специальные микросхемы,
расположенные в чипсете.
В
накопителе может быть до десяти дисков.
Их поверхность разбивается на круги,
которые называются дорожками (track).
Каждая дорожка имеет свой номер. Дорожки
с одинаковыми номерами, расположенные
одна над другой на разных дисках образуют
цилиндр. Дорожки на диске разбиты на
секторы (нумерация начинается с единицы).
Секторы и дорожки образуются во время
форматирования диска. Форматирование
выполняет пользователь с помощью
специальных программ. На неформатированный
диск не может быть записана никакая
информация. Жесткий диск можно разбить
на логические диски. Это удобно, поскольку
наличие нескольких логических дисков
упрощает структуризацию данных,
хранящихся на жестком диске.
Накопители
на гибких магнитных дисках
Гибкий
диск, дискета (англ. floppy disk) — устройство
для хранения небольших объёмов информации,
представляющее собой гибкий пластиковый
диск в защитной оболочке. Используется
для переноса данных с одного компьютера
на другой и для распространения
программного обеспечения.
Дискета
состоит из круглой полимерной подложки,
покрытой с обеих сторон магнитным
окислом и помещенной в пластиковую
упаковку, на внутреннюю поверхность
которой нанесено очищающее покрытие.
В упаковке сделаны с двух сторон
радиальные прорези, через которые
головки считывания/записи накопителя
получают доступ к диску.
Способ
записи двоичной информации на магнитной
среде называется магнитным кодированием.
Он заключается в том, что магнитные
домены в среде выстраиваются вдоль
дорожек в направлении приложенного
магнитного поля своими северными и
южными полюсами. Обычно устанавливается
однозначное соответствие между двоичной
информацией и ориентацией магнитных
доменов.
Информация
записывается по концентрическим дорожкам
(трекам), которые делятся на секторы.
Количество дорожек и секторов зависит
от типа и формата дискеты. Сектор хранит
минимальную порцию информации, которая
может быть записана на диск или считана.
Ёмкость сектора постоянна и составляет
512 байтов.

Рис.
2.7. Поверхность магнитного диска
На
дискете можно хранить от 360 Килобайт до
2,88 Мегабайт информации.
Дискета
устанавливается в накопитель на гибких
магнитных дисках (англ. floppy-disk drive),
автоматически в нем фиксируется, после
чего механизм накопителя раскручивается.
В накопителе вращается сама дискета,
магнитные головки остаются неподвижными.
Дискета вращается только при обращении
к ней.
Накопитель
связан с процессором через контроллер
гибких дисков.
CD_ROM
CD-ROM
состоит из прозрачной полимерной основы
диаметром 12 см и толщиной 1,2 мм. Одна
сторона покрыта тонким алюминиевым
слоем, защищенным от повреждений слоем
лака
На
одном дюйме (2,54 см) по радиусу диска
размещается 16 тысяч дорожек с информацией.
Для сравнения — на дюйме по радиусу
дискеты всего лишь 96 дорожек. Ёмкость
CD до 780 Мбайт. Информация заносится на
диск на заводе и не может быть изменена.
Достоинства
CD-ROM:
-
При
малых физических размерах CD-ROM обладают
высокой информационной ёмкостью, что
позволяет использовать их в справочных
системах и в учебных комплексах с
богатым иллюстративным материалом;
один CD, имея размеры примерно дискеты,
по информационному объёму равен почти
500 таким дискетам; -
Считывание
информации с CD происходит с высокой
скоростью, сравнимой со скоростью
работы винчестера; -
CD
просты и удобны в работе, практически
не изнашиваются; -
CD
не могут быть поражены вирусами; -
На
CD-ROM невозможно случайно стереть
информацию; -
Стоимость
хранения данных (в расчете на 1 Мбайт)
низкая.
В
отличие от магнитных дисков, компакт-диски
имеют не множество кольцевых дорожек,
а одну — спиральную, как у грампластинок.
В связи с этим, угловая скорость вращения
диска не постоянна. Она линейно уменьшается
в процессе продвижения читающей магнитной
головки к центру диска.
Для
работы с CD ROM нужно подключить к компьютеру
накопитель CD-ROM (CD-ROM Drive), в котором
компакт-диски сменяются как в обычном
проигрывателе. Накопители CD-ROM часто
называют проигрывателями CD-ROM или
приводами CD-ROM.
20. Устройства
ввода/вывода и мультимедиа. Принципы
устройства мониторов и принтеров.
Компьютер
обменивается информацией с внешним
миром с помощью периферийных устройств.
Периферийные устройства делятся на
устройства ввода и устройства вывода.
Устройства ввода преобразуют информацию
в форму понятную машине, после чего
компьютер может ее обрабатывать и
запоминать. Устройства вывода переводят
информацию из машинного представления
в образы, понятные человеку.
Ниже
приведена классификация устройств
ввода:
Самым
известным устройством ввода информации
является клавиатура
(keyboard) – это
стандартное устройство, предназначенное
для ручного ввода информации. Работой
клавиатуры управляет контроллер
клавиатуры, расположенный на материнской
плате и подключаемый к ней через разъем
на задней панели компьютера. При нажатии
пользователем клавиши на клавиатуре,
контроллер клавиатуры преобразует код
нажатой клавиши в соответствующую
последовательность битов и передает
их компьютеру. Отображение символов,
набранных на клавиатуре, на экране
компьютера называется эхом. Обычная
современная клавиатура имеет, как
правило, 101-104 клавиши, среди которых
выделяют алфавитно-цифровые клавиши,
необходимые для ввода текста, клавиши
управления курсором и ряд специальных
и управляющих клавиш. Существуют
беспроводные модели клавиатуры, в них
связь клавиатуры с компьютером
осуществляется посредством инфракрасных
лучей.
Наиболее
важными характеристиками клавиатуры
являются чувствительность ее клавиш к
нажатию, мягкость хода клавиш и расстояние
между клавишами. На долговечность
клавиатуры определяется количеством
нажатий, которые она рассчитана выдержать.
Клавиатура проектируется таким образом,
чтобы каждая клавиша выдерживала 30-50
миллионов нажатий.
К
манипуляторам
относят
устройства, преобразующие движения
руки пользователя в управляющую
информацию для компьютера. Среди
манипуляторов выделяют мыши, трекболы,
джойстики.
Мышь
предназначена
для выбора и перемещения графических
объектов экрана монитора компьютера.
Для этого используется указатель,
перемещением которого по экрану управляет
мышь. Мышь позволяет существенно
сократить работу человека с клавиатурой
при управлении курсором и вводе команд.
Особенно эффективно мышь используется
при работе графическими редакторами,
издательскими системами, играми.
Современные операционные системы также
активно используют мышь для управляющих
команд.
У
мыши могут быть одна, две или три клавиши.
Между двумя крайними клавишами современных
мышей часто располагают скрол. Это
дополнительное устройство в виде
колесика, которое позволяет осуществлять
прокрутку документов вверх-вниз и другие
дополнительные функции.
Трекбол
по функциям близок мыши, но шарик в нем
больших размеров, и перемещение указателя
осуществляется вращением этого шарика
руками. Трекбол удобен тем, что его не
требуется перемещать по поверхности
стола, которого может не быть в наличии.
Поэтому, по сравнению с мышью, он занимает
на столе меньше места. Большинство
переносных компьютеров оснащаются
встроенным трекболом.
Джойстик
представляет собой основание с подвижной
рукояткой, которая может наклоняться
в продольном и поперечном направлениях.
Рукоятка и основание снабжаются кнопками.
Внутри джойстика расположены датчики,
преобразующие угол и направление наклона
рукоятки в соответствующие сигналы,
передаваемые операционной системе. В
соответствии с этими сигналами
осуществляется перемещение и управление
графических объектов на экране.
Дигитайзер
– это устройство для ввода графических
данных, таких как чертежи, схемы, планы
и т. п. Он состоит из планшета, соединенного
с ним визира или специального карандаша.
Перемещая карандаш по планшету,
пользователь рисует изображение, которое
выводится на экран.
Сканер
– устройство
ввода графических изображений в
компьютер. В сканер закладывается лист
бумаги с изображением. Устройство
считывает его и пересылает компьютеру
в цифровом виде
После
ввода пользователем исходных данных
компьютер должен их обработать в
соответствии с заданной программой и
вывести результаты в форме, удобной для
восприятия пользователем или для
использования другими автоматическими
устройствам посредством устройств
вывода.
Выводимая
информация может отображаться в
графическом виде, для этого используются
мониторы,
принтеры или плоттеры.
Информация может также воспроизводиться
в виде звуков с помощью акустических
колонок или
головных
телефонов,
регистрироваться в виде тактильных
ощущений в технологии виртуальной
реальности, распространяться в виде
управляющих сигналов устройства
автоматики, передаваться в виде
электрических сигналов по сети.
Мультимедиа
Мультимедиа
— это взаимодействие визуальных и
аудиоэффектов под управлением
интерактивного программного обеспечения
с использованием современных технических
и программных средств, они объединяют
текст, звук, графику, фото, видео в одном
цифровом представлении.
Например,
в одном объекте-контейнере может
содержаться текстовая, аудиальная,
графическая и видео информация, а также,
возможно, способ интерактивного
взаимодействия с ней.
Термин
мультимедиа также, зачастую, используется
для обозначения носителей информации,
позволяющих хранить значительные объемы
данных и обеспечивать достаточно быстрый
доступ к ним (первыми носителями такого
типа были CD — compact disk). В таком случае
термин мультимедиа означает, что
компьютер может использовать такие
носители и предоставлять информацию
пользователю через все возможные виды
данных, такие как аудио, видео, анимация,
изображение и другие в дополнение к
традиционным способам предоставления
информации, таким как текст.
Принципы
устройства мониторов и принтеров
Монитор
(дисплей) является основным устройством
вывода графической информации. По
размеру диагонали экрана выделяют
мониторы 14-дюймовые, 15-дюймовые,
17-дюймовые, 19-дюймовые, 21-дюймовые. Чем
больше диагональ монитора, тем он дороже.
По цветности мониторы бывают монохромные
и цветные. Любое изображение на экране
монитора образуется из светящихся
разными цветами точек, называемых
пикселями (это название происходит от
PICture CELL — элемент картинки). Пиксель –
это самый мелкий элемент, который может
быть отображен на экране. Чем качественнее
монитор, тем меньше размер пикселей,
тем четче и контрастнее изображение,
тем легче прочесть самый мелкий текст,
а значит, и меньше напряжение глаз. По
принципу действия мониторы подразделяются
на мониторы с электронно-лучевой трубкой
(Catode Ray Tube — CRT) и жидкокристаллические —
(Liquid Crystal Display — LCD).
В
мониторах с электронно-лучевой трубкой
изображение формируется с помощью зерен
люминофора – вещества, которое светится
под воздействием электронного луча.
Современные
мониторы с электронно-лучевой трубкой
имеют специальное антибликовое покрытие,
уменьшающее отраженный свет окон и
осветительных приборов. Кроме того,
монитор покрывают антистатическим
покрытием и пленкой, защищающей от
электромагнитного излучения. Дополнительно
на монитор можно установить защитный
экран, который необходимо подсоединить
к заземляющему проводу, что также защитит
от электромагнитного излучения и бликов.
Жидкокристаллические
мониторы имеют меньшие размеры, потребляют
меньше электроэнергии, обеспечивают
более четкое статическое изображение.
В них отсутствуют типичные для мониторов
с электронно-лучевой трубкой искажения.
Принцип отображения на жидкокристаллических
мониторах основан на поляризации света.
Источником излучения здесь служат лампы
подсветки, расположенные по краям
жидкокристаллической матрицы. Свет от
источника света однородным потоком
проходит через слой жидких кристаллов.
В зависимости от того, в каком состоянии
находится кристалл, проходящий луч
света либо поляризуется, либо не
поляризуется. Далее свет проходит через
специальное покрытие, которое пропускает
свет только определенной поляризации.
Там же происходит окраска лучей в нужную
цветовую палитру. Жидкокристаллические
мониторы практически не производят
вредного для человека излучения.
Для
получения копий изображения на бумаге
применяют принтеры, которые классифицируются:
-
по
способу получения изображения: литерные,
матричные, струйные, лазерные и
термические; -
по
способу формирования изображения:
последовательные, строчные, страничные; -
по
способу печати: ударные, безударные; -
по
цветности: чёрно-белые, цветные.
Наиболее
распространены принтеры матричные,
лазерные и струйные принтеры. Матричные
принтеры схожи по принципу действия с
печатной машинкой. Печатающая головка
перемещается в поперечном направлении
и формирует изображение из множества
точек, ударяя иголками по красящей
ленте. Красящая лента перемещается
через печатающую головку с помощью
микроэлектродвигателя. Соответствующие
точки в месте удара иголок отпечатываются
на бумаге, расположенной под красящей
лентой. Бумага перемещается в продольном
направлении после формирования каждой
строчки изображения. Полиграфическое
качество изображения, получаемого с
помощью матричных принтеров низкое и
они шумны во время работы. Основное
достоинство матричных принтеров — низкая
цена расходных материалов и невысокие
требования к качеству бумаги.
Струйный
принтер относится к безударным принтерам.
Изображение в нем формируется с помощью
чернил, которые распыляются через
капилляры печатающей головки.
Лазерный
принтер также относится к безударным
принтерам. Он формирует изображение
постранично. Первоначально изображение
создается на фотобарабане, который
предварительно электризуется статическим
электричеством. Луч лазера в соответствии
с изображением снимает статический
заряд на белых участках рисунка. Затем
на барабан наносится специальное
красящее вещество – тонер, который
прилипает к фотобарабану на участках
с неснятым статическим зарядом. Затем
тонер переносится на бумагу и нагревается.
Частицы тонера плавятся и прилипают к
бумаге.
Для
ускорения работы, принтеры имеют
собственную память, в которой они хранят
образ информации, подготовленной к
печати.
К
основным характеристикам принтеров
относятся:
—
ширина каретки, которая обычно соответствую
бумажному формату А3 или А4;
—
скорость печати, измеряемая количеством
листов, печатаемых в минуту
—
качество печати, определяемое разрешающей
способностью принтера — количеством
точек на дюйм линейного изображения.
Чем разрешение выше, тем лучше качество
печати.
—
расход материалов: лазерным принтером
— порошка, струйным принтером — чернил,
матричным принтером — красящих лент.
21. Понятие
программного обеспечения, его виды и
назначение
Программное
обеспечение (ПО) — это совокупность всех
программ и соответствующей документации,
обеспечивающая использование ЭВМ в
интересах каждого ее пользователя.
Различают
системное и прикладное ПО. Схематически
программное обеспечение можно представить
так:
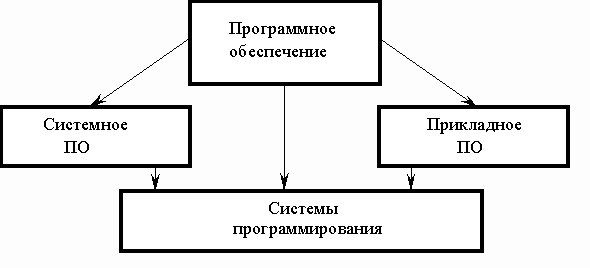
Системное
ПО – это совокупность программ для
обеспечения работы компьютера. Системное
ПО подразделяется на базовое и сервисное.
Системные программы предназначены для
управления работой вычислительной
системы, выполняют различные вспомогательные
функции (копирования, выдачи справок,
тестирования, форматирования и т. д).
Базовое
ПО включает в себя:
-
операционные
системы; -
оболочки;
-
сетевые
операционные системы.
Сервисное
ПО включает в себя программы (утилиты):
-
диагностики;
-
антивирусные;
-
обслуживания
носителей; -
архивирования;
-
обслуживания
сети.
Прикладное
ПО – это комплекс программ для решения
задач определённого класса конкретной
предметной области. Прикладное ПО
работает только при наличии системного
ПО.
Прикладные
программы называют приложениями. Они
включает в себя:
-
текстовые
процессоры; -
табличные
процессоры; -
базы
данных; -
интегрированные
пакеты; -
системы
иллюстративной и деловой графики
(графические процессоры); -
экспертные
системы; -
обучающие
программы; -
программы
математических расчетов, моделирования
и анализа; -
игры;
-
коммуникационные
программы.
Особую
группу составляют системы программирования
(инструментальные системы), которые
являются частью системного ПО, но носят
прикладной характер. Системы
программирования – это совокупность
программ для разработки, отладки и
внедрения новых программных продуктов.
Системы программирования обычно
содержат:
-
трансляторы;
-
среду
разработки программ; -
библиотеки
справочных программ (функций, процедур); -
отладчики;
-
редакторы
связей и др.
22. Операционная
система и ее функции
-
Операционная
система (ОС)
— система программ, предназначенная
для управления устройствами ЭВМ,
управления обработкой и хранением
данных, обеспечения пользовательского
интерфейса.
Операционная
система обычно хранится во внешней
памяти компьютера — на диске. При
включении компьютера она считывается
с дисковой памяти и размещается в ОЗУ.
Этот
процесс называется загрузкой операционной
системы.
Функции
ОС:
—
осуществление диалога с пользователем;
—
ввод-вывод и управление данными;
—
планирование и организация процесса
обработки программ;
—
распределение ресурсов (оперативной
памяти, процессора, внешних устройств);
—
запуск программ на выполнение;
—
всевозможные вспомогательные
операции обслуживания;
—
передача информации между различными
внутренними устройствами;
—
программная поддержка работы
периферийных устройств (дисплея,
клавиатуры, принтера и др
23. Принципы
хранения информации в ЭВМ. Понятие
файла и файловой системы. Имя файла,
расширение файла. Таблица размещения
файлов — FAT-таблица. Понятие сектора и
кластера.
Вся
информация, предназначенная для
долговременного использования, хранится
в файлах.
Все
современные дисковые операционные
системы обеспечивают создание файловой
системы, предназначенной для хранения
данных на дисках и обеспечения доступа
к ним. Принцип организации файловой
системы – табличный.
Файл
– это определенное количество информации,
хранящееся на диске и имеющее имя.
Файловая
система представляет собой систему
хранения файлов на запоминающем
устройстве, например, диске. Файлы
организованы в каталоги (иногда называемые
директориями или папками). Любой каталог
может содержать произвольное число
подкаталогов, в каждом из которых могут
храниться файлы и другие каталоги.
Имя
файла — строка символов, однозначно
определяющая файл в некотором пространстве
имён файловой системы.
Имя
файла состоит из двух частей, разделенных
точкой:
-
Название
(до точки, часто также называют именем); -
Расширение.
Расширение
файла-указывает тип файла и возможно
приложение в котором этот файл создан
и с помощью которого файл можно
просматривать и изменять:
Doc
– файл созданный в word
Exe-
выполняемый файл
Txt-
текстовый файл в формате ASCII
Имя
файла состоит из двух частей: собственно
имени и расширения имени (т. е. Типа
файла). Нельзя употреблять знаки
арифметических операций, пробела,
отношений, пунктуации. В качестве имен
файлов запрещены имена, являющиеся в
MS-DOS именами устройств, например con, ipt1,
ipt2. Расширение имени может состоять не
более чем из трех символов, в том числе
может отсутствовать. Если расширения
есть, то от основного имени оно отделяется
точкой, например ris. Bmp, mart. Txt, doc.doc. По
имени файла можно судить о его назначении,
так как для расширений установилось
некоторое соглашение, фиксирующее для
ОС тип обработки файлов.
Таблица
размещения файлов — FAT-таблица
FAT
(File
Allocation
Table
– таблица размещения файлов) — этот
термин относится к одному из способов
организации файловой системы на диске.
Эта таблица хранит информацию о файлах
на жестком диске в виде последовательности
чисел, определяющих, где находится
каждая часть каждого файла. С ее помощью
операционная система выясняет, какие
кластеры занимает нужный файл. FAT
— является самой распространенной
файловой системой и поддерживается
подавляющим большинством операционных
систем. Сначала FAT
была 12-разрядной и позволяла работать
с дискетами и логическими дисками
объемом не более 16 Мбайт. В MS-DOS
версии 3.0 таблица FAT
стала 16-разрядной для поддержки дисков
большей емкости, а для дисков объемом
до 2 047 Гбайт используется 32-разрядная
таблица FAT.

Структура
диска:
(A)
дорожка
(B)
геометрический сектор
(C)
сектор дорожки
(D)
кластер
Се́ктор
диска — минимальная адресуемая единица
хранения информации на дисковых
запоминающих устройствах (НЖМД, дискета,
CD). Является частью дорожки диска. Каждый
сектор имеет размер 512 байт.
Кластер
— логическая единица хранения данных в
таблице размещения файлов, объединяющая
группу секторов.
Как
правило, это наименьшее место на диске,
которое может быть выделено для хранения
файла.
Понятие
кластер используется в файловых системах
FAT, NTFS, a так же HFS Plus.
24. Архитектура
WINDOWS.
Операционная
система Windows NT обладает модульной
архитектурой.
Первый
модуль — режим пользователя – дает
возможность пользователю взаимодействовать
с системой. Этот уровень включает в себя
подсистемы среды и подсистему безопасности.
Набор инструментальных подсистем,
поддерживающих разнотипные пользовательские
программы, называют подсистемой среды.
Второй
модуль – режим ядра – обеспечивает
безопасное выполнение приложений
пользователя. На данном уровне выделяются
три укрупненных модуля: исполняющие
службы, ядро, уровень аппаратных
абстракций.
Взаимодействие
между ядром подсистемы и подсистемами
среды осуществляют исполняющие службы,
состоящие из системного сервиса и службы
режима ядра. Системный сервис является
интерфейсом между подсистемами среды
приложений и службами режима ядра.
Службу режима ядра составляют следующие
программные модули:
• диспетчер
ввода-вывода, позволяющий управлять
процессами ввода-вывода информации;
• диспетчер
объектов, управляющий системными
операциями, которые производятся над
объектами (использование, переименование,
удаление, защита объекта);
• диспетчер
контроля безопасности, гарантирующий
безопасность системы;
• диспетчер
виртуальной памяти;
• диспетчер
процессов, регулирующий действия
процессов (создание, удаление,
протоколирование); распределяющий
адресное пространство и другие ресурсы
между процессами.
Часть
системы, которая обеспечивает независимость
верхних уровней ОС от специфик и различий
конкретной аппаратуры, называют уровнем
аппаратных абстракций. В этом модуле
находится вся аппаратно-зависимая
информация.
Графический
пользовательский интерфейс предназначен
для создания пользователю комфортных
условий при работе с ОС Windows NT Графический
многооконный пользовательский интерфейс.
225. Свойства
WINDOWS: разрядность, многозадачность,
многопоточность, пользовательский
интерфейс, технология Plug and Play, поддержка
длинных имен файлов, сетевые возможности.
-
32
и 64 разрядная (Разрядность – способность
одновременно обрабатывать какое-то
количество битов.); -
Имеет
графический интерфейс (Графический
интерфейс Windows 95 стал значительно более
мощным и простым в использовании.); -
Многозадачность
предоставляет возможность одновременной
(параллельной) работы с несколькими
приложениями.; -
Многопроцессовая;
-
Многопользовательская;
-
Plug
and
Play(«включи-и-работай»)
— технология, предназначенная для
быстрого определения и конфигурирования
устройств в компьютере и других
технических устройствах. Функции:
идетенфикация установленных устройств;
автоматическое обновление системной
конфигурации и обнаружение конфликтов;
загрузка и выгрузка драйверов; -
Имеет
ряд встроенных прикладных компонентов
Paint,
Notepad
и др; -
Имеет
встроенные компоненты организации
сетей (Простое подключение и управление
работой модема; Электронная почта и
клиент Microsoft Exchange; Microsoft Fax; Доступ в
Internet); -
Многопоточность
означает способность Windows организовывать
одновременную обработку нескольких
потоков, конкурирующих за процессорное
время. При этом допускается параллельное
выполнение нескольких приложений, а
также нескольких фрагментов (подзадач)
одного или нескольких приложений. -
Поддержка
длинных имен файлов. Было снято
ограничение на длину имён файлов 8.3 и
появилась поддержка Unicode в именах. -
Графический
пользовательский интерфейс предназначен
для создания пользователю комфортных
условий при работе с ОС Windows NT Графический
многооконный пользовательский интерфейс.
26. Обмен
данными между приложениями Windows. Буфер
обмена. Технология OLE
-
Современные
операционные системы позволяют
производить обмен данными как внутри
одной программы, так и между различными
программами. При этом процесс копирования
или переноса осуществляется через
Буфер обмена.
Буфер
обмена –
это область оперативной памяти, которая
служит для временного хранения данных.
Данные
в Буфер обмена можно поместить только
один раз, а извлекать (вставлять)
неограниченное число раз. В Буфере
обмена могут храниться только данные,
помещенные в него последней операцией
Копировать (Вырезать). Каждая новая
операция Копировать (Вырезать) удаляет
старые данные из Буфера обмена и помещает
в него новые.
Технология
OLE (Object Linking and Embedding)
— это технология встраивания и связывания
объектов. Технология OLE включает следующие
возможности:
-
Возможность
совмещать в одном документе объекты с
различными форматами данных (текст,
рисунки, таблицы, базы данных и т.д.). -
Приложение,
содержащее встроенный или связанный
объект, хранит сведения о формате данных
этого объекта и приложениях работающих
с ним. -
Приложение,
содержащее объект, осуществляет функции
по отображению, перемещению и копированию
объекта внутри документа и между
приложениями. При этом поддерживается
целостность объекта. -
Возможность
автоматически вызывать приложения для
редактирования объектов или импортировать
функции редактирования из этого
приложения.
Технология
OLE может быть использована в двух
вариантах:
-
установление
связи с объектом; -
внедрение
объекта.
227. Математическая
логика: история. Понятия логического
выражения и логической переменной.
Количество логических операций от n
переменных.
-
Математическая
логика – это
раздел математики, изучающий высказывания,
рассматриваемые со стороны их логических
значений (истинности или ложности) и
логических операций над ними.
История:
В
XIX в. — начале XX в. в логике произошла
научная революция и на смену традиционной
логике пришла современная логика,
называемая также математической или
символической логикой. Развитие
математики выявило недостаточность
Аристотелевой логики и поставило задачу
о ее дальнейшем построении на математической
основе. Впервые в истории идеи о таком
построении логики были высказаны
немецким математиком Готфридом Лейбницем
(1646 — 1716) в конце XVII века. Он считал, что
основные понятия логики должны быть
обозначены символами, которые соединяются
по определенным правилам, и это позволяет
всякие рассуждения заменить вычислением.
Джордж Буль (1815 — 1864) в своей работе
«Исследование законов мысли» (1854 г.)
истолковывал умозаключения как результат
решения логических равенств, в результате
чего логическая теория приняла вид
обычной алгебры и получила название
алгебры высказываний. Буль рассматривал
свою алгебру как инструмент изучения
законов человеческого мышления.
Логическое
выражение
— это символическая запись, состоящая
из логических величин (констант или
переменных), объединенных логическими
операциями (связками).
В
булевой алгебре простым высказываниям
ставятся в соответствие логические
переменные,
значение которых равно 1, если высказывание
истинно, и 0, если высказывание ложно.
Обозначаются логические переменные
буквами латинского алфавита.
228. Логические
операции: логическое умножение, логическое
сложение, отрицание, импликация,
эквивалентность. Их таблицы истинности.
Формульные выражения для импликации и
эквивалентности.
Логические
операции:
Библиографическое описание:
Думченков, И. А. Обзор методов интеграции информационных систем, их преимуществ и недостатков / И. А. Думченков. — Текст : непосредственный // Молодой ученый. — 2018. — № 23 (209). — С. 176-177. — URL: https://moluch.ru/archive/209/51296/ (дата обращения: 07.02.2023).
Развитие информационной сферы повлекло за собой информатизацию общества. В настоящее время активно происходит автоматизация процессов в различных видах деятельности. Яркими примерами являются такие проекты, как «Портал ГосУслуг», «ЕМИАС», «Электронный дневник», которые позволяют выполнять различные действия, такие как оплата коммунальных услуг, запись к врачу, отслеживание успеваемости школьника, не выходя из дома. В связи с этим необходимо понимать, какие из методов интеграции информационных систем являются оптимальными для каждого конкретного случая.
В данной статье будут рассмотрены наиболее популярные и используемые методы интеграции.
‒ Интеграция на уровне брокеров. Преимуществом данного метода является универсальность: как правило, в любой ситуации можно реализовать дополнительный программный модуль, который может обращаться в другие системы различными способами. Например, такой модуль может обращаться к одной системе через базу данных (БД), а к другой с помощью RPC (англ. Remote Procedure Call — Удалённый вызов процедур). Недостатками такого подхода интеграции является трудоёмкость и сложность реализации, и, как следствие, высокая стоимость разработки, внедрения и поддержки.
‒ Интеграция на уровне интерфейсов (физических, программных и пользовательских). Данный вид интеграции разрабатывался как один из видов «лоскутной интеграции», целью которой являлось объединение распределённых программных приложений, реализованных разными разработчиками в разное время, в подобие единой системы. Приложения связывались по принципу «каждый с каждым», что, в конечном итоге, затрудняло их взаимодействие и создавало ряд проблем и ошибок. Также осложнялось использование унаследованных (Legacy Software) и встроенных (Embedded System) систем. Описанный подход интеграции удобен для небольшого количества программных приложений. Для большого числа приложений он является малоэффективным и не обеспечивает построение качественно новых запросов к объединяемым данным. Таким образом, агрегирование данных не принесёт выигрыш. На настоящий момент, проблема интеграции на уровне интерфейсов решается на базе внедрения информационных подсистем, которые реализуются стандартными приложениями с открытыми программными интерфейсами (англ. Open Application Programming Interface, OAPI — Открытый программный интерфейс приложения, Открытый интерфейс прикладного программирования).
‒ Интеграция на функционально-прикладном и организационном уровнях. Данный вид интеграции построен на объединении нескольких однотипных или похожих функций в макрофункции, в которых перераспределяются ресурсы, потоки данных, управление и механизмы исполнения. Как следствие, это влечёт за собой реорганизацию информационных структур, бизнес-процессов и, соответственно, перестройку схем их информационного и документационного обеспечения. Преимущества данного вида интеграции:
- прозрачность и управляемость процессов;
- процессы становятся менее затратными;
- сокращается количество обслуживающего персонала;
- сокращается число ошибок.
Недостатком интеграции такого вида является значительная трансформация или комплексный реинжиниринг всей сети процессов, что может повлечь за собой определённые риски. Целесообразно проводить данную интеграцию в случае, если организация готовится к внедрению корпоративной информационной системы (КИС) на платформе популярного решения. Это, в свою очередь, требует унификации и приведения бизнес-процессов к определённому стандарту. Или если организация перестраивает свою деятельность в связи со сменой приоритетов, расширением и освоением новых сегментов рынка.
‒ Интеграция на уровне корпоративных программных приложений. Данный вид интеграции предполагает совместное использование исполняемого кода, а не только внутренних данных интегрируемых приложений. Программы делятся на компоненты, которые затем интегрируются при помощи стандартизованных программных интерфейсов (API) и специализированного связующего программного обеспечения (ПО). Такой подход позволяет создать из этих компонентов универсальную программную платформу (ядро), которая может быть использовано всеми приложениями. Каждое приложение будет иметь только один интерфейс для взаимодействия с этим ядром, что значительно облегчает задачу интеграции. Систему, построенную на таком интеграционном подходе, легче администрировать, поддерживать и масштабировать. Возможность повторного использования функций в рамках имеющейся среды позволяет существенно сократить сроки и стоимость разработки приложений. Обязательным этапом оценки возможности интеграции приложений, которые предполагается связывать в рамках определённого проекта, является анализ внутренней архитектуры приложений. Этот анализ может быть осложнён тем, что, как правило, разработчик приложений, являющихся готовыми программными продуктами, не раскрывает всех деталей внутренней структуры приложений.
‒ Интеграция при помощи Web-сервисов. Данный вид интеграции является передовым и стремительно развивающимся подходом к интеграции приложений. Он базируется на предоставлении стандартного для Web-служб интерфейса доступа к приложениям и их данным. Примером может являться стандартный протокол доступа к объектам — SOAP (англ. Simple Object Access Protocol — простой протокол доступа к объектам). Так, при помощи SOAP, браузер пользователя может одновременно сравнить данные на нескольких выбранных веб-сайтах и представить клиенту сравнительный отчет. Другой пример: сотрудники одного географически распределенного предприятия могут единовременно использовать корпоративные приложения, доступ к которым осуществляется через соответствующие Web-сервисы (портальное решение). Web-сервисы похожи на подход EAI, но с одним главным отличием — EAI-решения, в своём множестве, выпускаются как частные случаи для связи определённых продуктов. Соответственно, подключить к уже используемому EAI-решению еще одну стороннюю систему будет довольно трудной и длительной задачей. По своей природе Web-сервисы существенно более унифицированы и стандартизованы. Поскольку Web-сервисы базируются на общих и единых для Консорциума Всемирной паутины (англ. World Wide Web Consortium, W3C-консорциум) стандартах, они могут работать везде, где используется сеть Интернет.
‒ Интеграция на уровне данных. Данный вид интеграции подразумевает, что несколько программных приложений могут обращаться к одной базе данных или в несколько баз данных, связанных репликациями. Преимуществом такого вида является низкая стоимость интеграции. К недостаткам можно отнести следующее: если база данных не экранирована хранимыми процедурами и не имеет необходимых ограничений и защиты целостности (например, в виде указания каскадных операций и триггеров), то взаимодействие различных приложений с данной БД может явиться причиной ошибок и приводить данные в противоречивые состояния. В случае если БД экранирована и поддерживается целостность хранимых данных, то в одновременно взаимодействующих с одной БД приложениях будут дублироваться части программного кода, выполняющие одинаковые или схожие операции. Кроме того, при внесении изменений в структуру базы, необходимо отдельно переписывать программный код всех приложений, работающих с такой БД.
‒ Интеграция на уровне сервисов. Данный вид интеграции основан на фиксации интерфейсов и форматов данных с обеих сторон. Преимуществом является организация стремительной отработки межкорпоративной бизнес-логики. Такой подход интеграции имеет и недостаток: поскольку изначально он базируется на «запоминании» или фиксации, то при изменении данных, структур или процессов образуются проблемы и ошибки, что приводит к разработке узконаправленных, частных решений.
‒ Интеграция на уровне пользователя. Данный вид относится к неавтоматизированной интеграции, и основан на взаимодействии пользователей друг с другом: обмен данными и файлами между системами через ручное копирование, оправку почты и т. д. Является наиболее простыми видомподходом, и часто применяются в тот момент, когда происходит подготовка внедрения программных систем, а деятельность компании не может прерываться.
Основные термины (генерируются автоматически): вид интеграции, приложение, SOAP, баз данных, Интеграция, API, EAI, OAPI, RPC, программный код.