Одной из важных составляющих современных операционных систем являются дисковые файловые системы. В общем случае каждая из них разработана с учетом специфики применения. Ярким примером может служить файловая система XFS от Silicon Graphics.
Одной из важных составляющих современных операционных систем являются дисковые файловые системы. В общем случае каждая из них разработана с учетом специфики применения. Ярким примером может служить файловая система XFS от Silicon Graphics. Однако, за некоторыми исключениями в виде той же XFS, большинство файловых систем общего назначения стремятся обеспечить не только быстродействие. Немаловажным показателем является устойчивость файловой системы к сбоям. В этом контексте имеется в виду обеспечение согласованности данных в случае непредвиденных сбоев в работе аппаратного обеспечения, например в результате сбоя питания.
Для того чтобы обеспечить подобную устойчивость, разработчики файловых систем обратились к механизмам, применяющимся в современных системах управления базами данных. Основные идеи улучшений были почерпнуты именно из этой области и в той или иной мере применены к существующим файловым системам с учетом того, что файловая система — все-таки не база данных. Справедливости ради стоит заметить, что это не первое удачное заимствование механизмов управления базой данных в файловые системы. К примеру, механизмы, применяемые при построении индексов базы данных, сегодня с успехом применяются и в файловых системах для организации деревьев каталогов и быстрой навигации по ним.
Одним из первых заимствований из области баз данных в область обеспечения отказоустойчивости стали журналы транзакций. Здесь стоит оговориться. То, что называется транзакциями почти во всех современных файловых системах общего назначения, не стоит считать транзакциями в полной мере. Они не соответствуют общим требованиям к транзакциям. Например, их нельзя отменить. Однако, с другой стороны, транзакции файловых систем работают аналогично транзакциям базы данных. Иначе говоря, если происходят какие-то изменения в файловой системе, то сначала они фиксируются в журнале транзакций в синхронном режиме. Если между фиксацией транзакции в журнале и записью в файловую систему произойдет сбой, состояние файловой системы можно будет восстановить по содержимому журнала.
Основными свойствами транзакции являются:
-
атомарность (Atomicity): изменения, производимые в рамках транзакции, являются одним целым. Они либо происходят все, либо не происходит ни одно из них, и данные остаются в том состоянии, в котором были до начала транзакции;
-
непротиворечивость (Consistency): данные по окончании транзакции должны подчиняться правилам, заданным для набора данных, к которым эта транзакция применяется. Например, не может появиться два одинаковых значения для поля, содержимое которого должно быть уникально;
-
изоляция (Isolation): транзакции не должны влиять друг на друга в процессе выполнения;
-
долговечность (Durability): независимо от внешних факторов, выполненная транзакция сохраняется, и ничто не может вернуть систему в состояние до начала транзакции.
Журналирующие файловые системы
Почти все файловые системы современных операционных систем общего назначения, таких как Windows или Linux, имеют журналирующую файловую систему в качестве основной. Их можно условно разделить на две категории:
-
журналирование метаданных — в журнале сохраняется информация о факте произошедших изменений;
-
полное журналирование — журнал содержит не только факт изменений, а еще и данные, с которыми были произведены изменения.
В первом случае журналирование не обеспечивает отказоустойчивости данных. Его основной задачей является обеспечение непротиворечивости метаданных файловой системы, а также повышение скорости проверки структуры файловой системы при старте операционной системы. К примеру, если вы переносите файл из каталога в каталог и происходит сбой, может случиться так, что файловая система будет иметь записи о новом и старом файлах. Мало того, если при этом должно было пройти копирование содержимого исходного файла в новый файл, но оно не произошло, попытка обратиться к новому файлу может привести к неожиданным последствиям. Кроме того, в NTFS журналирование может использоваться для быстрого отслеживания изменений в файлах для тех или иных целей. Такой метод мониторинга изменений используется для работы распределенной файловой системы DFS, репликации политик каталога Active Directory и работы различных приложений резервного копирования. Кроме того, метаданные можно использовать в качестве истории произошедших изменений, например для того, чтобы выявить различные санкционированные и несанкционированные действия с вашими файлами. Как же все-таки выглядят такого вида журналы в разных операционных системах?
В операционной системе Windows начиная с Windows 2000 используется файловая система NTFS версии 5, которая поддерживает журналирование метаданных. В клиентских версиях операционных систем ведение журнала по умолчанию отключено.
Если журнал активен, то каждый раз, когда на томе происходят изменения, файловая система добавляет запись в журнал изменений NTFS. Журнал представляет собой специальный системный файл метаданных$Extend$UsnJrnl. Данные журнала хранятся в потоке $J. Этот файл является разреженным файлом NTFS, поэтому он никогда не переполняется. Он имеется на каждом разделе диска, на котором активен журнал. Каждая запись идентифицируется значением номера последовательных изменений Update Sequence Number (USN) и добавляется в конец журнала. Записи не хранятся вечно. Система удаляет устаревшие записи журнала в случае, если его размер в два раза превышает заданный максимальный размер. Кроме того, NTFS поддерживает значение LastUSN для каждой записи в таблице MFT. Таким образом, даже в том случае, когда записи об изменении файла или папки были удалены из журнала, по наличию этого значения можно судить о том, что файл или папка были изменены. Однако необходимо помнить, что при отключении журналирования файл журнала удаляется вместе со всеми записями. Cистема при этом сбрасывает значение LastUSN каждой записи в MFT в ноль, т. е. операция удаления журнала — сравнительно продолжительная по времени.
Журнал изменений
Рассмотрим вкратце, как устроен этот журнал Windows. Структура записи журнала представлена в листинге 1. Наиболее важными, с точки зрения администратора, полями являются:

-
FileName. Это имя файла или каталога, с которым произошли изменения. К сожалению, это только имя. Путь в этом поле не хранится. Кроме того, в дополнение к этому полю в структуре предусмотрены еще вспомогательные поля FileNameLength и FileNameOffset, которые определяют длину имени и смещение поля с именем относительно начала структуры. Microsoft рекомендует работать с именами файлов в этой структуре, не рассчитывая на то, что имя оканчивается нулем, но используя значения смещения и длины строки. Таким образом обеспечивается совместимость с последующими версиями.
-
FileReferenceNumber. Поле, в котором содержится уникальное значение, идентифицирующее файл. Каждый файл или папка в системе имеют такой идентификатор. Идентификатор раздела и идентификатор файла уникально идентифицируют любой файл на компьютере. По открытым файловым описателям можно узнать, указывают ли они на один и тот же файл. Для этого нужно просто получить эти значения из описателя при помощи функции GetFileInformationByHandle и сравнить соответствующие значения. Если они равны, значит, описатели указывают на один и тот же файл.
-
ParentFileReferenceNumber. В этом поле содержится идентификатор контейнера записи, т. е. если запись описывает файл, то в этом поле будет содержаться идентификатор каталога, в котором он лежит. Это же верно и для папки. Для того чтобы получить полный путь до этого файла, необходимо пройти по дереву идентификаторов до самого корня, которым является идентификатор раздела, и получить имена каждого узла в этом пути.
-
Reason. Здесь хранится флаг, описывающий действие, которое происходит с объектом. Все возможные флаги причин указаны в табл. 1. Необходимо обратить внимание на одну особенность. При изменении файла система не проставляет один и тот же флаг дважды. В случае если выполняется несколько операций записи в файл, система создаст только одну запись в файл журнала с флагом USN_REASON_DATA_OVERWRITE после первой операции. Все последующие операции с этим флагом не отобразятся в журнале. Рассмотрим пример, в котором происходит следующая последовательность операций с файлом:
-
Запись в файл.
-
Установка времени изменения.
-
Запись в файл.
-
Урезание файла.
-
Запись в файл.
-
Закрытие файла.
В этом случае записи журнала будут производиться, как показано в табл. 2.
-
TimeStamp. Штамп времени этой записи в формате UTC.
-
USN. Номер последовательности изменений данной записи журнала. Значение USN является смещением записи относительно начала журнала. Оно постоянно возрастает, а значит, чем новее запись, тем это значение больше.
А как дела в Linux?
Наиболее распространенными файловыми системами в Linux являются reiserfs, ext2, ext3. Первая из этих файловых систем поддерживает журналирование как метаданных, так и данных. Но поддержка журналирования данных основана на особенностях функционирования самой файловой системы и является, так сказать, ее побочным эффектом и фактически не используется. Рассмотрим механизм журналирования в этой файловой системе подробней.
Файловая система reiserfs в качестве единицы манипуляции и хранения использует так называемые блоки фиксированной длины. Журнал в reiserfs — это последовательный набор блоков файловой системы. Каждый раз, когда какие-либо изменения вносятся в файловую систему, открывается своего рода транзакция, содержащая все изменения, атомарность которых необходимо обеспечить. Когда эта транзакция завершается, данные копируются на свое место, и транзакция соответствующим образом помечается. Журнал работает как циклический буфер: когда он достигает конца, данные начинают записываться в начало. Значение размера журнала по умолчанию может быть разным в разных ядрах. Он задается количеством блоков. Размер блока задается при создании файловой системы.
Общая структура журнала имеет вид, представленный на рис. 1. Journal Header — это описатель журнала, в котором содержится информация о последней оконченной (flushed) транзакции, а также о местоположении следующей неоконченной транзакции в журнале. Его структура представлена в табл. 3.
Транзакции, хранящиеся в журнале этой файловой системы, имеют вид, показанный на рис. 2. Все транзакции, попадающие в журнал, имеют заголовок, описывающий транзакцию и ее содержимое — description block, за которым следуют непосредственно блоки, которые и являются изменениями, применяемыми к файловой системе (см. табл. 4).
Наиболее важным полем в этом блоке является поле Real blocks, в котором блокам, следующим за description block, ставятся в соответствие реальные блоки файловой системы, которые и будут изменены по завершении транзакции. Иными словами, в этом поле содержится номер блока, в который попадет соответствующий блок из журнала. Например, представим это поле как массив четырехбайтных значений от К [1] до К [n]. Тогда если К [1]=8840, то в блок реальной файловой системы с номером 8840 попадет блок, идущий первым за description block, в блок с номером К [2] — второй и т. д. Окончание транзакции отмечается при помощи commit block, его описание дано в табл. 5.
Стоит отметить, что если блоки транзакции не умещаются в description block, то не уместившиеся блоки будут перенесены в это же поле в commit block. Таким образом, получается, что размер блока файловой системы влияет на объем сохраняемых данных в журнале транзакций. Чем меньше размер блока, тем меньше данных попадет в транзакцию, поскольку число соответствий ограничено значением 2* (размер блока — 24). Однако для журналирования в этой файловой системе этого более чем достаточно.
В файловой системе reiserfs имеется понятие ключ (key). Это запись, уникально идентифицирующая объект файловой системы: файл, каталог и ссылки на объект. Записи эти также хранятся в блоках специального типа.
Таким образом, механизм журналирования данной файловой системы сравнительно прост. Он сохраняет в журнал измененные блоки, включая блоки, содержащие управляющие структуры файловой системы, так называемые суперблоки, блоки битовых карт занятости и блоки, содержащие ключи. При этом не делается различия между измененными и неизмененными данными. Например, если происходит изменение управляющих структур, хранящих ключ, то сохраняется весь блок, включая как измененные, так и неизмененные ключи. Это верно и в случае внесения изменений в блоки на уровне листьев — самого нижнего уровня, на котором и хранятся собственно данные. Он устроен так, что небольшая часть данных содержится именно в блоке листьев. А если весь файл не помещается в блок, то этот блок содержит ссылки на другие блоки файловой системы. Побочный эффект такого механизма заключается в том, что в файл журнала попадают и небольшие файлы, которые умещаются в блок листьев целиком. Содержимое таких файлов можно восстановить, используя журнал.
Основной целью этого механизма является журналирование метаданных, при помощи которых значительно ускоряется процедура проверки целостности структур и метаданных файловой системы при ее старте, а также их восстановления после аварийного отказа.
Теперь о файловой системе ext3
Перейдем к рассмотрению устройства файловой системы ext3. Она является расширением файловой системы ext2, в которую добавлена возможность журналирования. В зависимости от вариантов монтирования файловой системы, на ней создается скрытый или видимый файл журнала. Кроме того, этот файл можно создавать на отдельном носителе, т. е. не на том, в котором происходят сами изменения. Такой подход призван обеспечить ускорение записи данных на диск за счет того, что время ожидания окончания записи в журнал будет меньше, чем если бы это происходило на одном диске. Сам механизм журналирования вынесен в отдельный логический уровень файловой системы, который занимается управлением и диспетчеризацией транзакций. Формат самого файла журнала сходен с применяемым в ReiserFS, как показано на рис. 3.
В начале журнала расположен заголовок, или суперблок. В нем описаны параметры журнала. Он предваряется структурой стандартного заголовка блока (см. листинг 2). Стандартный заголовок является общим для всех типов блоков, которые могут использоваться в журнале. Сам суперблок ext3 версии 2 представлен в листинге 3. Как мы видим, его структура несколько сложнее, чем в ReiserFS. Это обусловлено более развитыми механизмами журналирования и большей функциональностью.
В журнале присутствует несколько типов блоков:
-
#define JFS_DESCRIPTOR_BLOCK 1
-
#define JFS_COMMIT_BLOCK 2
-
#define JFS_SUPERBLOCK_V1 3
-
#define JFS_SUPERBLOCK_V2 4
-
#define JFS_REVOKE_BLOCK 5
На типах суперблока мы подробно останавливаться не будем. Коснемся только блоков, описывающих транзакции. Первый блок — DESCRIPTOR_BLOCK. Он описывает начало транзакции. Его структура, а также флаги, которые могут быть в нем выставлены, представлена в листинге 4. Говоря просто, при записи в журнал этим блоком открывается транзакция. Номер этой транзакции записывается в соответствующее поле стандартного заголовка. Следом за заголовком идут записи типа journal_block_tag_t из листинга 4. Каждая из этих записей определяет, какому блоку файловой системы соответствует данный блок журнала. Например, первый блок журнала после блока дескрипторов соответствует блоку файловой системы, описанному первой записью дескриптора. Этот механизм описания соответствия блоков журнала с блоками файловой системы схож с механизмом, применяемым в ReiserFS. При записи изменений на диск транзакция закрывается блоком COMMIT_BLOCK. Закрытие означает удачное завершение транзакции и тот факт, что данные будут непротиворечивы. Он содержит только стандартный заголовок, в котором указан номер закрываемой транзакции. В случае сбоя системы данные и метаданные файловой системы могут быть восстановлены в соответствии с блоками закрытой транзакции. Блок файловой системы, включенный в журнал, может быть отменен, чтобы хранящиеся в нем изменения не применялись в процессе восстановления. Для этой цели используется блок отмены (отзыва; см. листинг 5), который содержит порядковый номер и список отменяемых блоков. Во время восстановления все блоки, указанные в блоке отмены, порядковые номера которых меньше порядкового номера блока отмены, восстанавливаться не будут. Механизм отмены используется с целью избежать повторного применения журналированных данных. Например, вы удаляете каталог. Затем создаете некий файл, а файловая система выделят под него те же блоки, что были выделены под каталог. Обе эти транзакции зафиксированы. Происходит сбой. После перезагрузки начинается восстановление данных по журналу. Процедура восстановления начинает повторять транзакции, при этом берет измененные блоки из журнала. В итоге блоки нового файла, если данные не журналировались, могут оказаться затертыми метаданными каталога, т. е. в файловой системе появится удаленный ранее каталог и испортит ваш файл. Для того чтобы избежать такого поведения, во время процедуры фиксации транзакции в журнал записываются блоки отмены для операций удаления метаданных.
Таким образом, можно сказать, что в случае с ext3 мы имеем систему журналирования, сходную по своему принципу с ReiserFS. Тут также журналируется содержимое целых блоков. Однако, в отличие от ReiserFS и NTFS, существуют дополнительные режимы, позволяющие журналировать не только метаданные, но и сами данные файлов. Это может несколько уменьшить производительность, однако значительно повышает устойчивость файловой системы к различного рода сбоям. Кроме того, журналирование данных и знание устройства журнала может помочь вам побороть последствия хакерской атаки.
Подведем итог
Наиболее отказоустойчивой файловой системой, исходя из функциональности журналов, является файловая система ext3 в режиме полного журналирования. ReiserFS и NTFS в этом вопросе уступают. Кроме того, в NTFS процедура восстановления по журналу несколько сложнее логически, нежели в ReiserFS или ext3. Однако тут стоит отметить, что журнал NTFS предоставляет больше возможностей с точки зрения удобства отслеживания изменений в файловой системе в целях безопасности. Об этих возможностях и методах отслеживания речь пойдет в следующей статье.
Андрей Вернигора — администратор баз данных и системный администратор на одном из предприятий компании «Укртранснафта». Имеет сертификат MCP. eosfor@gmail.com
Журналируемая файловая система
Журналируемые
файловые системы — это класс файловых
систем, характерная черта которых —
ведение журнала, хранящего список
изменений, в той или иной степени
помогающего сохранить целостность
файловой системы.
Запуск
проверки системы (например, fsck) на больших
файловых системах может занять много
времени, что очень плохо для сегодняшних
высокоскоростных систем. Причиной
отсутствия целостности в файловой
системе может быть некорректное
размонтирование, например, если в момент
прекращения работы на диск велась
запись. Приложения могли обновлять
данные, содержащиеся в файлах, и система
могла обновлять метаданные файловой
системы, которые являются «данными о
данных файловой системы», иными словами,
информация о том, какие блоки связаны
с какими файлами, какие файлы размещены
в каких директориях и тому подобное.
Ошибки (отсутствие целостности) в файлах
данных — это плохо, но куда хуже ошибки
в метаданных файловой системы, что может
привести к потерям файлов и другим
серьезным проблемам.
Для
минимизации проблем, связанных с
целостностью, и минимизации времени
перезапуска системы, журналируемая
файловая система хранит список изменений,
которые она будет проводить с файловой
системой перед фактической записью
изменений. Эти записи хранятся в отдельной
части файловой системы, называемой
«журналом», или «логом». Как только
изменения файловой системы безопасно
внесены в журнал, журналируемая файловая
система применяет эти изменения к файлам
или метаданным, а затем удаляет эти
записи из журнала. Записи журнала
организованы в наборы связанных изменений
файловой системы, что очень похоже на
то, как изменения добавляемые в базу
данных организованы в транзакции.
Наличие
журнала повышает вероятность сохранения
целостности файловой системы, потому
что записи в лог-файл ведутся до проведения
фактических изменений, и эти записи
хранятся до тех пор, пока они не будут
целиком и безопасно применены. При
перезагрузке компьютера программа
монтирования может гарантировать
целостность журналируемой файловой
системы простой проверкой лог-файла на
наличие ожидаемых, но не произведенных
изменений и последующей записью их в
файловую систему. Т.о. при наличии журнала
в большинстве случаев системе не нужно
проводить проверку целостности файловой
системы, а это означает, что компьютер
будет доступен для работы практически
сразу после перезагрузки. Соответственно,
шансы потери данных в связи с проблемами
в файловой системе значительно снижаются.
Существует
несколько журналируемых файловых
систем, доступных в Linux. Наиболее известные
из них:
-
XFS,
журналируемая файловая система
разработанная Silicon Graphics, но сейчас
выпущенная открытым кодом (open source); -
ReiserFS,
журналируемая файловая система
разработанная специально для Linux; -
JFS,
журналируемая файловая система
первоначально разработанная IBM, но
сейчас выпущенная как открытый код; -
xt3
— журналируемое расширение файловой
системы ext2, используемой на большинстве
версий GNU/Linux. Уникальная особенность
системы ext3 — возможность перехода на
неё с ext2 без переформатирования диска.
Разработана доктором Стефаном Твиди
(Stephan Tweedie). -
В
семействе ОС Microsoft Windows к журналируемым
относится файловая система NTFS. В Mac OS X
— HFS+.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Данный материал является продолжением статьи «Файловая система NTFS». В этом обзоре будут подробно рассмотрены вопросы, рассмотрение которых в прошлой статье было поверхностным или отсутствовало вообще. Хотелось бы сразу сказать, что дисковая система NT настолько сложна, что говорить о ней можно еще достаточно долго — и эта статья не опишет всего, что можно было бы рассказать. Так что это лишь попытка координировано и подробно ответить на все вопросы, которые вызвала предыдущая публикация.
Часть 4. Журналирование NTFS
Описание того простого факта, что NTFS является журналируемой системой, повергло многочисленных поклонников других файловых и операционных систем в искреннее возмущение. В многочисленных письмах, адресованных мне, NTFS называли системой с квази-журналированием или даже без журналирования вообще, ставя в противовес многочисленные файловые системы Unix. Мне пришло также много писем, указывающих на фатальные сбои NTFS, восстановится от которых не удалось — данные были потеряны. В данной части я попытаюсь, в меру своих сил и понимания, объяснить философию журналирования и средств защиты от сбоев NTFS, а также пояснить причины появления фатальных сбоев. Я постараюсь оправдать подход корпорации Microsoft, которая сделала всё именно так, как сделала — по крайней мере, я изложу причины реализованных технологических решений и те компромиссы, на которые пришлось пойти коллективу разработчиков NTFS.
Журналируемые операции
Прежде всего, хотелось бы рассказать о том, какие именно операции журналируются. Совершенно очевидно, что полный undo-файл, способный откатить абсолютно все операции, абсолютно невозможен как с точки зрения быстродействия, так и с точки зрения здравого смысла. Да, такое журналирование дало бы возможность восстановить большее число данных — например, при осуществлении перезаписи трех мегабайт в середине файла мы могли бы сначала сохранить новые данные в логе, затем переписать туда же предыдущие три мегабайта файла, и уж только затем осуществлять операции с реальными данными. Такой подход гарантировал бы полную определенность с судьбой информации — мы всегда смогли бы понять, какая часть данных уже записалась на диск, а какая находится в исходном, не обновленном состоянии. Он имеет всего один скромный недостаток — небольшая накладочка по быстродействию: для записи на диск трех мегабайт мы вынуждены будем осуществить разнообразные дисковые операции на объем в три раза больший — девять мегабайт. Да, полное журналирование также применяется — но в основном при работе с базами данных. Если вы желаете обеспечить полное журналирование каких-либо данных, вы можете поставить MS SQL или даже Oracle, который вообще не будет пользоваться средствами какой либо файловой системы и обеспечит сохранность ваших данных в любых разумных условиях. Сторонникам же полного журналирования файловой системы я могу ответить одно: решение сократить быстродействие операций записи в три раза, на мой взгляд, является слишком смелым для обязательного применения — и на домашних компьютерах, и на серверах.
Подход разработчиков NTFS был принципиально иным. Главный девиз был, видимо, не «надежность любой ценой», а «неизменность быстродействия». Журналирование просто не должно было помешать работе файловой системы. Первый логичный шаг — отменить полное журналирование как абсолютно неприемлемое с точки зрения быстродействия. В NTFS применяется журналирование логических структур, а не данных пользователя — отсюда и идет фраза, что сохранность данных не гарантируется, но, тем не менее, корректное состояние самой системы будет поддерживаться. То, что NTFS не журналирует данные файлов, приводит на практике к одному варианту потери данных — в том же гипотетическом случае записи трех мегабайт, в случае сбоя в процессе записи никогда уже не удастся установить, какая часть данных записалась, а какая осталась неизменна. Операции, которые, тем не менее, журналируются системой — это операции со структурами самой системы, то есть с файлами и каталогами: добавление файлов, переименование, перенос, создание и удаление (освобождение свободного места). Журналируются также и операции дефрагментации — то есть перемещения фрагментов файлов. Одним словом, все логические операции журналированы.
Отложенная запись и контрольные точки журналирования
Известно, что любая современная система для ускорения файловых операций вынуждена использовать кэширование, в том числе — кэширование операций записи. Так называемая отложенная запись — принцип кэширования, при котором данные, предназначенные для записи на диск, некоторое время сохраняются в кэше и лишь в свободное от других занятий время сохраняются физически. Отложенная запись существенно повышает эффективность дисковых операций, так как такое кэширование группирует множество операций в одну — это особенно эффективно, если запись производится в компактные участки диска. Еще один плюс отложенной записи — не мешать более нужным операциям чтения, и осуществлять запись только тогда, когда система свободна и ей не требуется доступ к диску для других нужд. Как согласовать отложенную запись с журналированием? Это довольно сложный вопрос, так как откладывание записи делает возможным потерю тех данных, которые находились в очереди на физическую запись и не успели записаться на диск до сбоя. Самое неприятное здесь даже не потеря данных, а то, что происходит рассогласование времени записи: какие-то служебные области могут быть обновлены, а какие-то смежные по смыслу — еще нет, так как их обновление могло отложится еще на пару секунд и не состоятся из-за сбоя.
NTFS справляется с этими проблемами с помощью смысловой интеграции операций отложенной записи и ведения журнала. При попытке начать журналируемую операцию в лог тут же записывается намерение — например, стереть файл. Это случается без задержек — на этом этапе отложенная запись не работает: это плата за присутствие журналирования, которой нельзя избежать. Но вот все остальные операции уже идут в задержанном режиме — то есть они могут состояться частично (могут еще в придачу и не в том порядке) или не состоятся вообще. Единственная задержанная операция, работа которой несколько отличается от простой записи — запись в лог об удачном завершении предыдущих транзакций, так называемая контрольная точка. Через определенные промежутки времени — обычно через каждые несколько секунд — система в обязательном порядке сбрасывает абсолютно все задержанные операции на диск. После произведения этой операции в журнал записывается простейшая запись — контрольная точка — которая говорит о том, что все предыдущие операции выполнены корректно на всех уровнях — как на логическом, так и на физическом.
Такой режим работы — с помощью записей и контрольных точек — с одной стороны, по прежнему гарантирует полностью корректную работу журналирования, а с другой стороны практически совершенно не приводит к замедлению работы: простановка контрольных точек производится, считай, мгновенно, а запись в журнал о начале операции соответствует по трудозатратам записи самих данных без отложенного кэширования. Реальная же запись, осуществляемая позже, в подавляющем числе случаев не мешает никаким операциям и не идет в ущерб производительности системы.
Проблемы отложенного журналирования: концепция дублирования информации
Вся вышеописанная теория достаточно хороша, но способна, тем не менее, вызвать очень неприятные последствия, если не учесть еще нескольких вещей, о которых и пойдет речь.
Рассмотрим такой случай: мы стираем файл. Журнал получил запись — «файл N стирается». Затем запаздывающему кэшу стало угодно осуществить сначала физическую пометку о том, что место, занимаемое файлом, освободилось, а уж только затем удалить файл из физических структур MFT и каталога. Допустим, диск находится в активной работе, и на освободившееся место тут же записывается другой файл. В этот момент происходит сбой. Система, загружаясь, исследует журнал и видит незавершенную операцию «файл N стирается» — вернее, как я уже описал выше, не незавершенную, а просто операцию, контрольная точка после которой отсутствует, что автоматически говорит о её незавершенности. Следующая фаза была бы «откат операции» — то есть восстановление файла. Одна незадача — место, физически занимаемое файлом, содержит уже другие данные.
Для недопущения таких ситуаций система, желающая ограничиться логическим журналированием, вынуждена применять принцип «временно занятого места». Место, освобожденное каким-либо объектом или записью о нем, не объявляется свободным до тех пор, пока физически не завершились все операции с логическими структурами. Данный механизм в NTFS, по видимому, не синхронизирован даже с проставлением контрольных точек, так как типичное время освобождения временно занятого места — около 30 секунд, точки же идут чаще.
Данный механизм применяется не только при стирании файла, но и при самых разных операциях: принцип журналирования — объект, убранный или перемещенный на новое место, должен иметь возможность корректно откатить своё «отбытие» — то есть данные, на которые ссылаются логические структуры удаляемого или перемещаемого объекта, необходимо еще на некоторое время зарезервировать как занятое место (диска/каталога). Это еще один шаг NTFS к полному журналированию, где специфическим журналом файловой информации служат сами данные освобождаемых областей, не уничтожаемые физически.
Допущения, обеспечивающие надежность
Ну хорошо, скажете вы, всё так замечательно — но почему же тогда разделы NTFS всё же летят?.. Сейчас я постараюсь объяснить принципы, которые приводит к тому, что вышеописанная модель сможет обеспечить полную восстанавливаемость логических структур.
- Жесткий диск, в штатном режиме, должен записать именно то и именно туда, что и куда ему сказано было записать операционной системой. Данный принцип нарушается в случае, если система имеет ненадежный шлейф, процессор, память или контроллер — и это самая распространенная причина сбоев NTFS. Вам поможет: неразогнанный процессор, дорогая (качественная) память, хорошая материнская плата и протокол UDMA, обеспечивающий контроль и восстановление ошибок на участке контроллер-диск.
- Жесткий диск, в случае аварии, отключения питания или получения от контроллера сигнала «сброс» (в случае внезапной перезагрузки материнской платы) обязан корректно завершить запись данных текущего физического сектора, если таковая производилась на момент аварии. Промежуточное состояние сектора не допускается. Вам помогут современные винчестеры, которые могут осуществить данную операцию даже в случае полного пропадания питания — у них хватит буферизированной в конденсаторах энергии, и их логика рассчитана на корректное поведение в случае отказа питания при записи.
- Диск обязан мгновенно осуществить запись данных, отправленных с флагом «не кэшировать». Дело в том, что многие современные диски или контроллеры обеспечивают задержанную запись. Метафайлы NTFS обновляются в режиме «писать сразу», и контроллер/диск обязан выполнять это требование.
- Жесткий диск обязан обеспечить чтение именно тех данных, которые были записаны. В случае невозможности прочесть данные выдается сигнал «ошибка». Диск не имеет права возвращать ошибочные данные (возможно, лишь частично некорректные) без сигнала об ошибке. Все современные жесткие диски имеют контрольные суммы секторов и жестко следуют этой логике поведения.
Четкое выполнение этих требований полностью гарантирует надежную работу NTFS. Структура файловой системы не будет содержать существенных ошибок даже после сбоя. Некоторые несущественные ошибки всё же появляются из-за того, что логика журналирования часто пытается завершить недоделанные операции — например, то же удаление файла — тогда как полную надежность обеспечивал бы только безусловный откат всего, что находится после последней контрольной точки. Малые несоответствия, рождающиеся из этих попыток, относятся к избыточной информации системы безопасности, не представляют никакой реальной опасности для данных — они действительно незначительны. Суть этих несоответствий чаще всего заключается в том, что на диске остаются «лишние» данные о тех режимах доступов, которые уже не понадобятся системе. Их прочистка — дело сугубо повышения производительности, как, например, дефрагментация, поэтому их наличие не является на самом деле ошибкой. В случае же обнаружения серьезных, реальных, проблем драйвер сам установит флажок тома «грязный», что проинструктирует систему проверить том при следующем его монтировании.
Я с большим сожалением должен сказать, что подавляющее большинство фатальных ошибок NTFS происходит по вине аппаратуры, не выполняющей эти элементарные требования. Да, я понимаю, абсолютной надежности не бывает. Но Microsoft пошел по пути разделения труда — за надежность вашей аппаратуры корпорация ответственности не несет. Мой компьютер на 70% не попадает в список совместимого с Windows 2000 оборудования, и то же самое можно сказать про почти любую реальную машину, функционирующую на просторах бывшего СССР. Особенно это относится к любителям разгонять компьютеры. Запомните раз и навсегда: вы с огромной степенью вероятности угробите NTFS в первый же год работы, если ваш процессор — 333, разогнанный на 415. И даже не раз… Мне очень жаль, но это действительно так. От любых сбоев корректного компьютера NTFS защитит, но вот от записи случайных данных в бут-сектор (копия которого, кстати, хранится в самом конце раздела) и в MFT система просто не страхуется. Извините.Часть 5. Программный RAID
Журналирование NTFS, как уже указывалось ранее, ни в коей мере не гарантирует от сбоев с потерей пользовательской информации. Между тем, NT предлагает несколько вариантов создания систем, где, в разумных условиях, гарантируется абсолютно всё. Можно также использовать большее число дисков для обеспечения не повышенной надежности, а, наоборот, повышенной скорости — или того и другого одновременно. О таких конфигурациях и пойдет речь в этой части статьи.
RAID (Redundant Array of Inexpensive Disks) — избыточный массив недорогих дисков. Технология, заключающаяся в одновременном использовании нескольких дисковых устройств для обеспечения характеристик надежности или скорости, отсутствующих у накопителей в отдельности.
Windows NT поддерживает на программном уровне три уровня RAID (так называются стратегии работы дисковых массивов), краткие характеристики которых сведены в следующую таблицу.
| Быстродействие, по сравнению с обычными дисками | Надежность | Общее дисковое пространство | |
| RAID 0 Параллельные диски Существенное повышение производительности за счет дублирования дисков. |
Теоретически, в условиях некоторых (например, линейных) операций скорость чтения/записи, повышается во столько раз, сколько дисков задействовано в системе. Реально увеличение быстродействия меньше — процентов 50%-90% от этого числа, что всё равно очень существенно. |
Понижается — фатальный сбой одного из дисков вызовет потерю данных. | Равно сумме объемов составляющих массив дисков |
| RAID 1 Зеркальные диски Повышение надежности за счет дублирования информации. |
Скорость чтения теоретически повышается в число раз, соответствующее числу дисков. Реализованный в NT алгоритм не оптимален и приводит к гораздо более скромному увеличению быстродействия. Скорость записи снижается, особенно в случае не до конца многозадачных дисковых контроллеров. |
Потеря данных возможна лишь в случае отказа сразу всех дисков или повреждения одного и того же участка информации на всех дисках. | Остается неизменным (увеличение доступного дискового пространства за счет добавочных дисков не происходит). |
| RAID 5 Параллельные диски с четностью Комбинация RAID 1 и RAID 0 — более эффективное использование дополнительных дисков. |
Скорость чтения повышается аналогичным RAID 0 образом, но число дисков, влияющих на быстродействие, следует уменьшить на один. Т.е. три диска RAID 5 обладают примерно такой же скоростью чтения, как и два диска RAID 0. Скорость записи больше, чем у каждого диска в отдельности, но в целом невысока. |
Потеря данных возможна при выходе из строя двух дисков набора. Выход из строя одного из дисков существенно снижает скорость работы всего массива и является, по сути, аварийной ситуацией, хоть и без потери данных. | Увеличивается. Потеря от суммарного дискового объема составляет объем одного диска. Например, пять дисков по 10 Гб дают RAID 5 объемом 40 Гб. |
Остановимся подробнее на каждом из типов RAID-а.
RAID 0 (параллельные диски)
Данная стратегия направлена исключительно на повышение производительности. Несколько дисков хранят части дисковой структуры, которые собираются в один том лишь при наличии всех дисков массива.
Простейшая реализация RAID 0 из двух, например, дисков — указание на то, что каждый первый сектор тома (или любой другой объем информации) расположен на физическом диске A, а каждый второй — на диске B. Такая жесткая стратегия дает возможность избежать каких-либо дополнительных структур для хранения информации о том, где находятся какие данные. Скорость чтения, как и записи равны и зависят от числа дисков:
- Быстродействие операции по работе со случайно расположенными данными подчиняются следующей схеме: всё зависит от вероятности того, что диск, на который мы хотим записать очередную порцию информации, свободен и готов мгновенно выполнить наш запрос. Например, RAID 0 из двух дисков: при осуществлении операции одним из дисков и поступлении дополнительной команды на работу с дисковой системой вероятность того, что для выполнения команды нам придется тревожить свободный в данный момент диск составляет 50% — это соответствует общему увеличению производительности случайных операций в полтора раза. Если же используется, к примеру, массив из десяти дисков, то вероятность какой-либо операции попасть на уже занятый накопитель составляет всего 10% — то есть производительность повышается в девять раз. Любителям строгой теории вероятности хочу заметить, что при таких подсчетах не учитываются некоторые факторы реальной работы систем, но цифры, тем не менее, имеют именно такой порядок.
- Последовательные операции — чтение или запись последовательных участков — проходят практически всегда в n раз быстрее, чем на отдельном физическом диске, где n — число дисков в наборе. Это происходит потому, что вероятность в следующей операции попасть на свободный диск составляет 100% — ведь операции осуществляются последовательными блоками, которые равномерно раскидываются по дискам.
В качестве некоторого вывода — RAID 0 в любом случае существенно повышает быстродействие линейных операций, а с увеличением количества дисков, входящих в набор, существенно повышается скорость работы и со случайными данными. Для эффективной работы с дисковой системой в режиме RAID 0 просто необходим многозадачный режим работы контроллера, а желательно даже разных контроллеров, обеспечивающих доступ к разным дискам. Обязательным условием такой работы на интерфейсах IDE являются Bus-Mastering драйвера. Windows 2000 имеет встроенные драйвера, автоматически включающие этот режим для всех распространенных IDE контроллеров, для NT4 же могут понадобится дополнительные драйвера или изменения ключей реестра.
Надежность RAID 0 низка — отказ каждого диска является фатальным сбоем, точно так же, как и отказ накопителя в случае работы с обычными разделами.
Вероятность сбоя системы в целом только повышается — чем больше дисков вы используете, тем выше вероятность отказа хоть одного из них и, соответственно, потери какой-то части данных тома.
RAID 1 (зеркальные диски)
Самый простой способ обеспечения безопасности данных — создать копию двух дисков. Запись осуществляется на оба диска сразу, что приводит к замедлению этого процесса, тогда как чтение — с того диска, который в данный момент свободен — если, конечно, система способна эффективно осуществить такое чтение (необходимо наличие Bus-Mastering). Реализованный в NT алгоритм, к сожалению, не совсем оптимален и приводит к гораздо более скромному увеличению быстродействия чтения.
Некоторая сложность работы RAID 1 в программном режиме заключается в том, что часто система не может быть до конца уверена в идентичности данных двух дисков. Операция сверки двух физических дисков после серьезного сбоя может затянутся на часы и быть очень некстати, поэтому использовать программный RAID 1 следует очень осмотрительно. Если вы решаетесь на увеличение дисковых массивов в несколько раз только ради надежности, возможно, вам стоит приобрести аппаратный RAID контроллер, который, к тому же, обеспечит замену вышедших из строя дисков прямо на ходу и будет следить за синхронностью данных сам.
В любом случае, даже полный отказ одного из дисков не приводит к потере данных, так как диски полностью зеркальны.
RAID 5 (параллельные диски с четностью)
Данная стратегия представляется в настоящее время наиболее удачной и эффективной схемой работы RAID, состоящих из трех и более дисков. Информация дополняется так называемыми данными четности (parity), которые размещаются на другом физическом диске, нежели реальные данные, контролируемые этой информацией.
Концепцию четности можно понять, например, так: допустим, у нас есть пять бит — например, набор {0, 1, 1, 0, 1}. Мы формируем еще бит — бит четности, шестой, по такому правилу — если число единиц в предыдущих пяти битах четно, он будет равен 1, если нет — 0. В нашем случае число единиц равняется трем, т. е. нечетному числу — наш набор дополнился числом 0 и превратился в {0, 1, 1, 0, 1, <0>}.
Допустим, набору данных причинен урон — {0, X, 1, 0, 1, <0>}. С помощью правила, гласящего нам, что число единиц должно быть нечетно (последний бит), мы можем догадаться, что на месте X стояла единичка. Наш получившийся набор из шести бит (5 бит данных и 1 бит четности) избыточен и может грамотно скорректировать потерю любого из своих шести бит.
Операции четности могут осуществляться не только с битами, но и с любыми объемами данных, что применяется в простейших алгоритмах восстановления данных.
Возвращаемся к устройству RAID 5: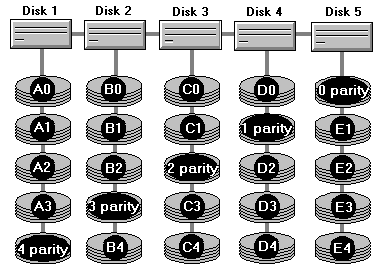
На рисунке изображен массив из пяти дисков. Видно, что каждый диск хранит четыре (условные) части реальных данных и один блок данных четности. Блок четности — скажем, 0 parity — способен восстановить потерю одного из фрагментов — любого, но одного — среди A0, B0, C0 и D0. Все вместе они, в свою очередь, способны восстановить блок 0 parity. Из изображенной структуры RAID видно, что данные, необходимые для полного восстановления всего столбика — то есть информации любого диска в случае сбоя — находятся на других дисках. В этом и заключается восстановление — при записи данных на любой из дисков обновляется также блок четности другого диска, соответствующего текущему блоку (например, при записи в A2 обновляется еще и блок 2 parity). Чтение данных с исправного диска происходит без использования блоков четности, т. е. почти в том же режиме, в каком работает RAID 0. Быстродействие RAID 5 в том виде, в каком это реализовано в NT, даже немного выше, чем у RAID 0.
Единственная накладка — в случае сбоя производительность массива снижается в огромное количество раз, так как при невозможности напрямую считать, например, D4, нужно будет восстанавливать данные этого блока с использованием всех других дисков одновременно — в нашем случае это будут блоки 4 parity, B4, C4 и E4.
Как видно, выход из строя одного из дисков RAID 5 является хоть и не фатальной, но резко аварийной ситуацией — хотя бы из соображений быстродействия чтения с массива. Нетрудно догадаться также, откуда исходит требования как минимум трех дисков — в случае двух накопителей RAID 5 просто вырождается в RAID 1, так как единственный способ создать информацию четности списка из одного элемента — это тем или иным образом дублировать этот элемент.
Допущения, обеспечивающие надежность
Как, опять? Да, опять — RAID также не является панацеей от абсолютно всех бед аппаратуры. Я должен сказать очень неожиданную для некоторых людей вещь: на ненадежном (некорректном) компьютере RAID грохнуть почти так же легко, как и однодисковую систему. RAID совершенно не спасет в следующих случаях:
- Корректная запись некорректных данных, а также запись данных мимо ожидаемой области. К этому приводят, как и ранее, сбойная память, процессор, шлейф, контроллер, питание привода.
- Если диск не способен сообщить об ошибке чтения.
RAID предназначен для минимизации ущерба всего в одном случае — при физическом отказе жесткого диска или, возможно, контроллера (в случае многоконтроллерного RAID). Отказы памяти, операционной системы, да и вообще всего остального RAID-ом не предусмотрены — точно так же, как и стратегией работы одиночной NTFS.
И, напоследок, аксиома работы вышеописанных уровней RAID-а — любой сбой одного из дисков системы считается аварией, которую необходимо как можно быстрее ликвидировать. Особенно это относится к RAID 0 и RAID 5, штатная работа которых в условиях аварии одного из дисков практически невозможна.
Более подробно с системой программных RAID Windows NT можно ознакомится в справке к программе (или модулю — в Windows 2000) Disk Administrator, где, собственно, и создаются эти типы дисков. Обращаю ваше внимание, что способности рабочих станций в создании и использовании RAID-ов сильно ограничены — рабочая станция NT4, к примеру, поддерживает только RAID 0 (параллельные диски), тогда как все описанные варианты работают лишь на серверных вариантах операционных систем.Часть 6. Стратегия восстановления томов NTFS
Компьютер с NTFS не загружается. Что делать в этом случае? Как восстановить данные? Возможны два случая, действия в которых несколько отличаются друг от друга. К сожалению, простых стратегий восстановления NT и, соответственно, NTFS не существует — система достаточно сложна и не имеет простейших загрузочных средств, как, например, DOS или Windows95/98.
1. Первый вариант — система находилась на том же NTFS диске. Система просто-напросто перестала загружаться. Что же, тогда нам в 90% случаев предстоит поднимать не NTFS, а просто-напросто саму NT. Данная операция выходит далеко за рамки данной статьи, поэтому описываю лишь способ поставить рядом (на тот же NTFS раздел) еще одну систему NT, на которой можно будет в дальнейшем работать (и которая сможет считать ваши данные).
Пользователи NT4 смогут поставить систему прямо на NTFS, каким-либо образом загрузившись в программу установки.
Вам понадобится CD диск, который представляет собой корректный дистрибутив NT4. Такими свойствами, скорее всего, обладают диски, на которых NT4 находится в каталоге под именем i386, расположенном в корневом каталоге. Команда winnt /?, запущенная в этом каталоге, поможет вам выбрать ключи для создания трех загрузочных дискет, с которых можно будет запустить установку NT4 прямо на диск NTFS. Можно выбрать другой каталог установки — например, winnt2, чтобы затем попытаться реанимировать вашу собственную инсталляцию NT4, если вы видите подходы к этой специфической проблеме, которая под силу только специалистам. Устанавливаемая заново операционная система корректно впишет себя в список загрузи и нисколько не помешает вашему старому NT4.
В случае отсутствия CD в соответствующем формате (симптомы — надпись «вставьте диск с дистрибутивом NT4», не реагирующая на наличие вашего CD) — вам остается только поставить NT на какой-нибудь другой раздел, так как диск с NTFS недоступен из систем, отличных от NT.
Стоит учесть, что NT4 нельзя поставить на NTFS, прошедшую преобразование в новый формат от Windows2000. NT4 всё же читает такой NTFS, но только при наличии пакета обновления SP4 или выше.
Пользователи Windows2000 будут вынуждены найти загрузочный CD диск с Windows2000 (таким является официальный дистрибутив), который сам предложит вам либо поставить систему с нуля, или попытаться восстановить старую инсталляцию. Считать диск NTFS, с которым работал Windows2000, можно только самим Windows2000 или NT4 с пакетом обновления SP4 или выше.
Имейте в виду: восстановить какую-либо NT, не обладая либо диском аварийного восстановления (создается в NT4 командой rdisk /s, в Windows2000 — программой резервного копирования), практически невозможно — это работа для специалиста. К слову говоря, даже при наличии диска восстановления, вам скорее всего очень не понравится работа «восстановленной» системы, поэтому переустановка всей системы практически неизбежна. Если вы не являетесь опытным специалистом по NT, советую вам не пытаться пользоваться починяющими опциями установщика NT, т.к. результат вас, скорее всего, крайне не удовлетворит. Попытка, конечно, не пытка, но комплекс операций по полноценной реанимации системы очень велик и мало где описан, поэтому вы останетесь в каком-то промежуточном, хотя, наверное, и загружабельном, состоянии.
2. Система сама по себе работает, но доступа к диску (не загрузочному, а какому-то другому) нет. Disk Administrator показывает для вашего раздела тип unknown (неизвестный). В подавляющем большинстве случаев это означает, что каким-то образом была осуществлена перезапись загрузочной области (boot sector-а) раздела, и NT действительно не догадывается, что это вообще NTFS. Операционная система NT на всякий случай хранит копию загрузочного сектора в конце раздела — если его скопировать обратно в надлежащее место, в подавляющем большинстве случаев диск опознается как NTFS и починится самостоятельно.
Процесс вычисления правильных адресов достаточно сложен, поэтому я не буду его описывать. Для получения исчерпывающих инструкций для данного случая вам придется пойти на сайт MSDN и найти там статью Knowledge Base под номером Q153973 (скорее всего, вы сможете сделать это простым поиском) — после корректного следования этим инструкциям система по крайней мере опознается как NTFS, и дальнейшая судьба раздела зависит от внутренних средств восстановления NT, которые в таком случае возьмут его в оборот. Вам также поможет скромная на вид команда chkdsk, являющаяся неким ярлычком к системе внутреннего восстановления дисковых систем NT.
Журналируемая файловая система — файловая система (ФС), в которой осуществляется ведение журнала, хранящего список изменений и, в той или иной степени, помогающего сохранить целостность файловой системы при сбоях.
Принцип работы
Журналируемая файловая система сохраняет список изменений, которые она будет проводить с файловой системой, перед фактическим их осуществлением. Эти записи хранятся в отдельной части файловой системы, называемой журналом (англ. journal) или логом (англ. log). Как только изменения файловой системы внесены в журнал, она применяет эти изменения к файлам или метаданным, а затем удаляет эти записи из журнала. Записи журнала организованы в наборы связанных изменений файловой системы.
При перезагрузке компьютера программа монтирования может гарантировать целостность журналируемой файловой системы простой проверкой лог-файла на наличие ожидаемых, но не произведённых изменений и последующей записью их в файловую систему. То есть, при наличии журнала в большинстве случаев системе не нужно проводить проверку целостности файловой системы. Соответственно, шансы потери данных в связи с проблемами в файловой системе значительно снижаются.
По типу внесения в журнал журналируемые ФС подразделяются на:[1]
- в режиме обратной связи (журналируются только метаданные): XFS, ext3fs;
- упорядоченные (журналируются только метаданные синхронно относительно данных): JFS2, ext3fs (по умолчанию), ReiserFS (основной);
- в режиме данных (журналируются как метаданные, так и данные): ext3fs;
Примеры
В семействе ОС Microsoft Windows к журналируемым относится файловая система NTFS.
В Mac OS X — HFS+.
В FreeBSD журналирование транзакций файловой системы UFS может осуществляться на уровне GEOM модулем gjournal.
В Linux существует несколько доступных журналируемых файловых систем. Наиболее известные из них:
- XFS — журналируемая файловая система, разработанная Silicon Graphics, но сейчас выпущенная с открытым исходным кодом;
- ReiserFS (Reiser4) — журналируемая файловая система разработанная специально для Linux;
- JFS (JFS1 и JFS2) (Smart File System) — журналируемая файловая система, первоначально разработанная IBM, но сейчас выпущенная с открытым исходным кодом;
- ext3fs (extended file system) — журналируемое расширение (можно подключать и отключать (
tune2fs), а также выбирать режим журналирования) файловой системы ext2, используемой на большинстве версий GNU/Linux; - ext4fs — логическое продолжение ext3;
- btrfs — разрабатываемая (альфа-версия) ФС, возможна прямая и обратная конвертация с ext3fs.[2]
Примечания
- ↑ М. Тим Джонс Анатомия журналируемых файловых систем Linux (рус.). Архивировано из первоисточника 26 августа 2011.
- ↑ Алексей Федорчук. Файловая система btrfs: Linux-ответ ZFS? (28 сентября 2009 г.). Архивировано из первоисточника 26 августа 2011. Проверено 4 августа 2010.
Литература
- Робачевский А. Н., Немнюгин С. А., Стесик О. Л. Журнальные файловые системы / Глава 4. Файловая система // Операционная система UNIX. — 2-е изд. — СПб.: БХВ-Петербург, 2008. — С. 351 — 353. — 656 с. — ISBN 978-5-94157-538-1
Рядовому пользователю компьютерных электронных устройств редко, но приходится сталкиваться с таким понятием, как «выбор файловой системы». Чаще всего это происходит при необходимости форматирования внешних накопителей (флешек, microSD), установке операционных систем, восстановлении данных на проблемных носителях, в том числе жестких дисках. Пользователям Windows предлагается выбрать тип файловой системы, FAT32 или NTFS, и способ форматирования (быстрое/глубокое). Дополнительно можно установить размер кластера. При использовании ОС Linux и macOS названия файловых систем могут отличаться.
Возникает логичный вопрос: что такое файловая система и в чем ее предназначение? В данной статье дадим ответы на основные вопросы касательно наиболее распространенных ФС.
Что такое файловая система
Обычно вся информация записывается, хранится и обрабатывается на различных цифровых носителях в виде файлов. Далее, в зависимости от типа файла, кодируется в виде знакомых расширений – *exe, *doc, *pdf и т.д., происходит их открытие и обработка в соответствующем программном обеспечении. Мало кто задумывается, каким образом происходит хранение и обработка цифрового массива в целом на соответствующем носителе.
Операционная система воспринимает физический диск хранения информации как набор кластеров размером 512 байт и больше. Драйверы файловой системы организуют кластеры в файлы и каталоги, которые также являются файлами, содержащими список других файлов в этом каталоге. Эти же драйверы отслеживают, какие из кластеров в настоящее время используются, какие свободны, какие помечены как неисправные.
Запись файлов большого объема приводит к необходимости фрагментации, когда файлы не сохраняются как целые единицы, а делятся на фрагменты. Каждый фрагмент записывается в отдельные кластеры, состоящие из ячеек (размер ячейки составляет один байт). Информация о всех фрагментах, как части одного файла, хранится в файловой системе.
Файловая система связывает носитель информации (хранилище) с прикладным программным обеспечением, организуя доступ к конкретным файлам при помощи функционала взаимодействия программ API. Программа, при обращении к файлу, располагает данными только о его имени, размере и атрибутах. Всю остальную информацию, касающуюся типа носителя, на котором записан файл, и структуры хранения данных, она получает от драйвера файловой системы.
На физическом уровне драйверы ФС оптимизируют запись и считывание отдельных частей файлов для ускоренной обработки запросов, фрагментации и «склеивания» хранящейся в ячейках информации. Данный алгоритм получил распространение в большинстве популярных файловых систем на концептуальном уровне в виде иерархической структуры представления метаданных (B-trees). Технология снижает количество самых длительных дисковых операций – позиционирования головок при чтении произвольных блоков. Это позволяет не только ускорить обработку запросов, но и продлить срок службы HDD. В случае с твердотельными накопителями, где принцип записи, хранения и считывания информации отличается от применяемого в жестких дисках, ситуация с выбором оптимальной файловой системы имеет свои нюансы.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Основные функции файловых систем
Файловая система отвечает за оптимальное логическое распределение информационных данных на конкретном физическом носителе. Драйвер ФС организует взаимодействие между хранилищем, операционной системой и прикладным программным обеспечением. Правильный выбор файловой системы для конкретных пользовательских задач влияет на скорость обработки данных, принципы распределения и другие функциональные возможности, необходимые для стабильной работы любых компьютерных систем. Иными словами, это совокупность условий и правил, определяющих способ организации файлов на носителях информации.
Основными функциями файловой системы являются:
- размещение и упорядочивание на носителе данных в виде файлов;
- определение максимально поддерживаемого объема данных на носителе информации;
- создание, чтение и удаление файлов;
- назначение и изменение атрибутов файлов (размер, время создания и изменения, владелец и создатель файла, доступен только для чтения, скрытый файл, временный файл, архивный, исполняемый, максимальная длина имени файла и т.п.);
- определение структуры файла;
- поиск файлов;
- организация каталогов для логической организации файлов;
- защита файлов при системном сбое;
- защита файлов от несанкционированного доступа и изменения их содержимого.

Задачи файловой системы
Функционал файловой системы нацелен на решение следующих задач:
- присвоение имен файлам;
- программный интерфейс работы с файлами для приложений;
- отображение логической модели файловой системы на физическую организацию хранилища данных;
- поддержка устойчивости файловой системы к сбоям питания, ошибкам аппаратных и программных средств;
- содержание параметров файла, необходимых для правильного взаимодействия с другими объектами системы (ядро, приложения и пр.).
В многопользовательских системах реализуется задача защиты файлов от несанкционированного доступа, обеспечение совместной работы. При открытии файла одним из пользователей для других этот же файл временно будет доступен в режиме «только чтение».
Вся информация о файлах хранится в особых областях раздела (томах). Структура справочников зависит от типа файловой системы. Справочник файлов позволяет ассоциировать числовые идентификаторы уникальных файлов и дополнительную информацию о них с непосредственным содержимым файла, хранящимся в другой области раздела.
Операционные системы и типы файловых систем
Существует три основных вида операционных систем, используемых для управления любыми информационными устройствами: Windows компании Microsoft, macOS разработки Apple и операционные системы с открытым исходным кодом на базе Linux. Все они, для взаимодействия с физическими носителями, используют различные типы файловых систем, многие из которых дружат только со «своей» операционкой. В большинстве случаев они являются предустановленными, рядовые пользователи редко создают новые дисковые разделы и еще реже задумываются об их настройках.
В случае с Windows все выглядит достаточно просто: NTFS на всех дисковых разделах и FAT32 (или NTFS) на флешках. Если установлен NAS (сервер для хранения данных на файловом уровне), и в нем используется какая-то другая файловая система, то практически никто не обращает на это внимания. К нему просто подключаются по сети и качают файлы.
На мобильных гаджетах с ОС Android чаще всего установлена ФС версии ext4 во внутренней памяти и FAT32 на карточках microSD. Владельцы продукции Apple зачастую вообще не имеют представления, какая файловая система используется на их устройствах – HFS+, HFSX, APFS, WTFS или другая. Для них существуют лишь красивые значки папок и файлов в графическом интерфейсе.
Более богатый выбор у линуксоидов. Но здесь настройка и использование определенного типа файловой системы требует хотя бы минимальных навыков программирования. Тем более, мало кто задумывается, можно ли использовать в определенной ОС «неродную» файловую систему. И зачем вообще это нужно.
Рассмотрим более подробно виды файловых систем в зависимости от их предпочтительного использования с определенной операционной системой.
Файловые системы Windows
Исходный код файловой системы, получившей название FAT, был разработан по личной договоренности владельца Microsoft Билла Гейтса с первым наемным сотрудником компании Марком Макдональдом в 1977 году. Основной задачей FAT была работа с данными в операционной системе Microsoft 8080/Z80 на базе платформы MDOS/MIDAS. Файловая система FAT претерпела несколько модификаций – FAT12, FAT16 и, наконец, FAT32, которая используется сейчас в большинстве внешних накопителей. Основным отличием каждой версии является преодоление ограниченного объема доступной для хранения информации. В дальнейшем были разработаны еще две более совершенные системы обработки и хранения данных – NTFS и ReFS.
FAT (таблица распределения файлов)
Числа в FAT12, FAT16 и FAT32 обозначают количество бит, используемых для перечисления блока файловой системы. FAT32 является фактическим стандартом и устанавливается на большинстве видов сменных носителей по умолчанию. Одной из особенностей этой версии ФС является возможность применения не только на современных моделях компьютеров, но и в устаревших устройствах и консолях, снабженных разъемом USB.
Пространство FAT32 логически разделено на три сопредельные области:
- зарезервированный сектор для служебных структур;
- табличная форма указателей;
- непосредственная зона записи содержимого файлов.
К недостатком стандарта FAT32 относится ограничение размера файлов на диске до 4 Гб и всего раздела в пределах 8 Тб. По этой причине данная файловая система чаще всего используется в USB-накопителях и других внешних носителях информации. Для установки последней версии ОС Microsoft Windows 10 на внутреннем носителе потребуется более продвинутая файловая система.
С целью устранения ограничений, присущих FAT32, корпорация Microsoft разработала обновленную версию файловой системы exFAT (расширенная таблица размещения файлов). Новая ФС очень схожа со своим предшественником, но позволяет пользователям хранить файлы намного большего размера, чем четыре гигабайта. В exFAT значительно снижено число перезаписей секторов, ответственных за непосредственное хранение информации. Функция очень важна для твердотельных накопителей ввиду необратимого изнашивания ячеек после определенного количества операций записи. Продукт exFAT совместим с операционными системами Mac, Android и Windows. Для Linux понадобится вспомогательное программное обеспечение.
NTFS (файловая система новой технологии)
Стандарт NTFS разработан с целью устранения недостатков, присущих более ранним версиям ФС. Впервые он был реализован в Windows NT в 1995 году, и в настоящее время является основной файловой системой для Windows. Система NTFS расширила допустимый предел размера файлов до шестнадцати гигабайт, поддерживает разделы диска до 16 Эб (эксабайт, 1018 байт). Использование системы шифрования Encryption File System (метод «прозрачного шифрования») осуществляет разграничение доступа к данным для различных пользователей, предотвращает несанкционированный доступ к содержимому файла. Файловая система позволяет использовать расширенные имена файлов, включая поддержку многоязычности в стандарте юникода UTF, в том числе в формате кириллицы. Встроенное приложение проверки жесткого диска или внешнего накопителя на ошибки файловой системы chkdsk повышает надежность работы харда, но отрицательно влияет на производительность.
ReFS (Resilient File System)
Последняя разработка Microsoft, доступная для серверов Windows 8 и 10. Архитектура файловой системы в основном организована в виде B + -tree. Файловая система ReFS обладает высокой отказоустойчивостью благодаря реализации новых функций:
- Copy-on-Write (CoW) – никакие метаданные не изменяются без копирования;
- данные записываются на новое дисковое пространство, а не поверх существующих файлов;
- при модификации метаданных новая копия хранится в свободном дисковом пространстве, затем система создает ссылку из старых метаданных на новую версию.
Все это позволяет повысить надежность хранения файлов, обеспечивает быстрое и легкое восстановление данных.
Файловые системы macOS
Для операционной системы macOS компания Apple использует собственные разработки файловых систем:
- HFS+, которая является усовершенствованной версией HFS, ранее применяемой на компьютерах Macintosh, и ее более соверешенный аналог APFS. Стандарт HFS+ используется во всех устройствах под управлением продуктов Apple, включая компьютеры Mac, iPod, а также Apple X Server.

- Кластерная файловая система Apple Xsan, созданная из файловых систем StorNext и CentraVision, используется в расширенных серверных продуктах. Эта файловая система хранит файлы и папки, информацию Finder о просмотре каталогов, положениях окна и т.д.
.png "Файловые системы macOS")
Файловые системы Linux
В отличие от ОС Windows и macOS, ограничивающих выбор файловой системы предустановленными вариантами, Linux предоставляет возможность использования нескольких ФС, каждая из которых оптимизирована для решения определенных задач. Файловые системы в Linux используются не только для работы с файлами на диске, но и для хранения данных в оперативной памяти или доступа к конфигурации ядра во время работы системы. Все они включены в ядро и могут использоваться в качестве корневой файловой системы.
Основные файловые системы, используемые в дистрибутивах Linux:
- Ext2;
- Ext3;
- Ext4;
- JFS;
- ReiserFS;
- XFS;
- Btrfs;
- ZFS.
Ext2, Ext3, Ext4 или Extended Filesystem – стандартная файловая система, первоначально разработанная еще для Minix. Содержит максимальное количество функций и является наиболее стабильной в связи с редкими изменениями кодовой базы. Начиная с ext3 в системе используется функция журналирования. Сегодня версия ext4 присутствует во всех дистрибутивах Linux.
JFS или Journaled File System разработана в IBM в качестве альтернативы для файловых систем ext. Сейчас она используется там, где необходима высокая стабильность и минимальное потребление ресурсов (в первую очередь в многопроцессорных компьютерах). В журнале хранятся только метаданные, что позволяет восстанавливать старые версии файлов после сбоев.
ReiserFS также разработана в качестве альтернативы ext3, поддерживает только Linux. Динамический размер блока позволяет упаковывать несколько небольших файлов в один блок, что предотвращает фрагментацию и улучшает работу с небольшими файлами. Недостатком является риск потери данных при отключении энергии.
XFS рассчитана на файлы большого размера, поддерживает диски до 2 терабайт. Преимуществом системы является высокая скорость работы с большими файлами, отложенное выделение места, увеличение разделов на лету, незначительный размер служебной информации. К недостаткам относится невозможность уменьшения размера, сложность восстановления данных и риск потери файлов при аварийном отключении питания.
Btrfs или B-Tree File System легко администрируется, обладает высокой отказоустойчивостью и производительностью. Используется как файловая система по умолчанию в OpenSUSE и SUSE Linux.
Другие ФС, такие как NTFS, FAT, HFS, могут использоваться в Linux, но корневая файловая система на них не устанавливается, поскольку они для этого не предназначены.
Дополнительные файловые системы
В операционных системах семейства Unix BSD (созданы на базе Linux) и Sun Solaris чаще всего используются различные версии ФС UFS (Unix File System), известной также под названием FFS (Fast File System). В современных компьютерных технологиях данные файловые системы могут быть заменены на альтернативные: ZFS для Solaris, JFS и ее производные для Unix.
Кластерные файловые системы включают поддержку распределенных хранилищ, расширяемость и модульность. К ним относятся:
- ZFS – «Zettabyte File System» разработана для распределенных хранилищ Sun Solaris OS;
- Apple Xsan – эволюция компании Apple в CentraVision и более поздних разработках StorNext;
- VMFS (Файловая система виртуальных машин) разработана компанией VMware для VMware ESX Server;
- GFS – Red Hat Linux именуется как «глобальная файловая система» для Linux;
- JFS1 – оригинальный (устаревший) дизайн файловой системы IBM JFS, используемой в старых системах хранения AIX.
Практический пример использования файловых систем
Владельцы мобильных гаджетов для хранения большого объема информации используют дополнительные твердотельные накопители microSD (HC), по умолчанию отформатированные в стандарте FAT32. Это является основным препятствием для установки на них приложений и переноса данных из внутренней памяти. Чтобы решить эту проблему, необходимо создать на карточке раздел с ext3 или ext4. На него можно перенести все файловые атрибуты (включая владельца и права доступа), чтобы любое приложение могло работать так, словно запустилось из внутренней памяти.
Операционная система Windows не умеет делать на флешках больше одного раздела. С этой задачей легко справится Linux, который можно запустить, например, в виртуальной среде. Второй вариант — использование специальной утилиты для работы с логической разметкой, такой как MiniTool Partition Wizard Free. Обнаружив на карточке дополнительный первичный раздел с ext3/ext4, приложение Андроид Link2SD и аналогичные ему предложат куда больше вариантов.
.png "Файловая система для microSD")
Флешки и карты памяти быстро умирают как раз из-за того, что любое изменение в FAT32 вызывает перезапись одних и тех же секторов. Гораздо лучше использовать на флеш-картах NTFS с ее устойчивой к сбоям таблицей $MFT. Небольшие файлы могут храниться прямо в главной файловой таблице, а расширения и копии записываются в разные области флеш-памяти. Благодаря индексации на NTFS поиск выполняется быстрее. Аналогичных примеров оптимизации работы с различными накопителями за счет правильного использования возможностей файловых систем существует множество.
Надеюсь, краткий обзор основных ФС поможет решить практические задачи в части правильного выбора и настройки ваших компьютерных устройств в повседневной практике.
Основной используемой операционной системой Linux FS является EXT4. Как и NTFS, EXT4 относится к группе журналируемых файловых систем, то есть ведущих учет изменений всех дисковых операций в специальном логе. Благодаря функции журналирования, вы можете восстановить файловую систему после сбоя, с другой стороны, в определенных сценариях работающая функция может нагружать жесткий диск.
В таких случаях журналирование можно временно отключить до выяснения причин проблемы.
Примечание: степень подробности ведения логов и отказоустойчивость у разных файловых систем может существенно отличаться.
Отключение журналирования EXT4 в Linux
По умолчанию журналирование должно быть включено для всех разделов диска.
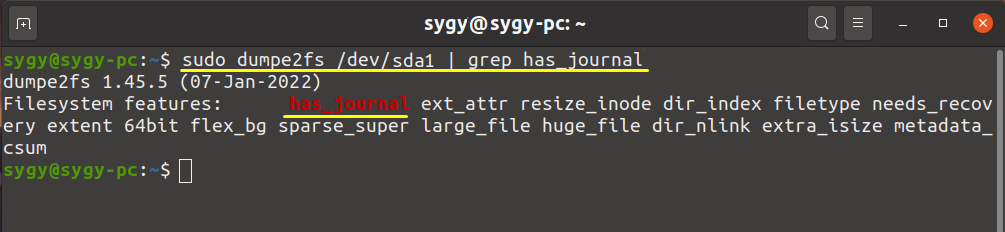
Чтобы просмотреть статус раздела, откройте Терминал и выполните в нём команду:
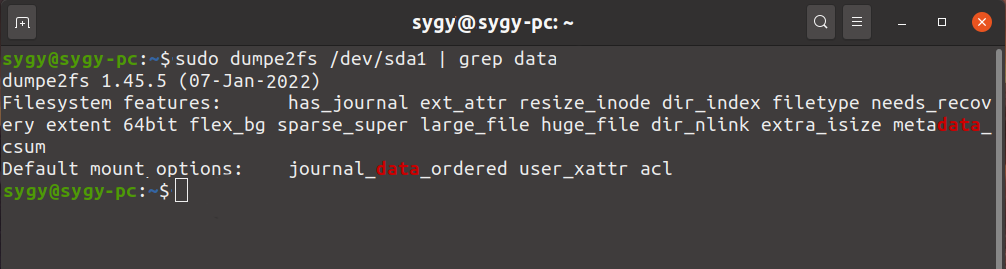
sudo dumpe2fs /dev/sda1 | grep has_journal
Где sda1 – это название проверяемого раздела.
Напоминаем, что вывести список имеющихся в Linux разделов можно командой:
ls -l /dev/ | grep sd
В результате команда вернет строку-описание Filesystem Features, если в нем будет элемент has_journal, значит журналирование включено.
Чтобы его полностью отключить, выполните команду:
sudo tune2fs -O ^has_journal /dev/sda1
Как вариант, можно отключить только запись основных данных, разрешив системе заносить в журнал только метаданные, что также повысит производительность диска.
Для этого выполните команду:
sudo tune2fs -o journal_data_writeback /dev/sda1
Чтобы восстановить функционал по умолчанию, выполните команду:
sudo tune2fs -o journal_data_ordered /dev/sda1
Отключение журналирования NTFS в Windows
Для отключения журналирования в файловой системе NTFS можно использовать встроенную в Windows консольную утилиту fsutil.exe.
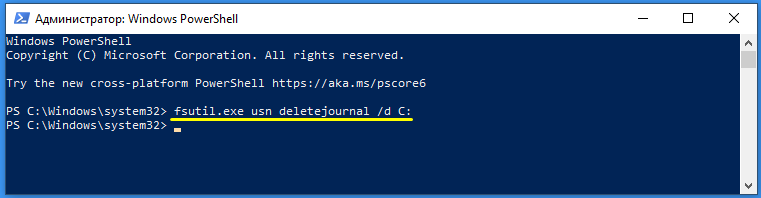
Запустите от имени администратора консоль PowerShell или командную строку и выполните команду:
fsutil usn deletejournal /D C:
Если хотите отключить запись лога дисковых операций для раздела C.
Если нужно отключить журналирование для другого тома, соответственно, вместо C: нужно указать его букву.
Для повторного включения функции используем команду:
fsutil usn createjournal m=1000 a=100 C:

Отключение журналирования может не только существенно снизить загрузку диска, оно также снижает объем записей, что актуально для SSD, тем не менее, мы настоятельно не рекомендуем отключать эту функцию без крайней на то необходимости.
![]() Загрузка…
Загрузка…