Содержание
- Каталог папок windows относится к типу баз данных
- Что такое База Данных (БД)
- Содержание
- Что такое база данных
- Как она выглядит
- Как получить информацию из базы
- Как связать данные между собой
- Базы данных и их разновидности
- Основные классификации баз данных
- SQL
- СУБД
- Типы данных в SQL
- Иерархические БД
- Урок 27. Информатика и ИКТ 11 класс (к учебнику Н. Д. Угриновича)
- В данный момент вы не можете посмотреть или раздать видеоурок ученикам
- Получите невероятные возможности
- Конспект урока «Иерархические БД»
Каталог папок windows относится к типу баз данных
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект, более близкий к корню) к потомку (объект более низкого уровня), при этом объект-предок может не иметь потомков или иметь их несколько, тогда как объект-потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
 |
| Рис. 3.1 Иерархическая база данных Каталог папок Windows |
Иерархической базой данных является Реестр Windows, в котором хранится вся информация, необходимая для нормального функционирования компьютерной системы (данные о конфигурации компьютера и установленных драйверах, сведения об установленных программах, настройки графического интерфейса и др.).
Содержание реестра автоматически обновляется при установке нового оборудования, инсталляции программ и т. п. Для просмотра и редактирования реестра Windows в ручном режиме можно использовать специальную программу rege-dit.exe, которая хранится в папке Windows. Однако редактирование реестра можно проводить только в случае крайней необходимости и при условии понимания выполняемых действий. Неквалифицированное редактирование реестра может привести компьютер в неработоспособное состояние.
 |
| Рис. 3.2 Иерархическая база данных Реестр Windows |
На втором уровне находятся табличные базы данных, содержащие перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне могут находиться табличные базы данных, содержащие перечень доменов третьего уровня для каждого домена второго уровня, и таблицы, содержащие IP-адреса компьютеров, находящихся в домене второго уровня (рис. 3.3).
 |
| Рис. 3.3. Иерархическая база данных Доменная система имен |
База данных Доменная система имен должна содержать записи обо всех компьютерах, подключенных к Интернету, то есть более 150 миллионов записей. Размещение такой огромной базы данных на одном компьютере сделало бы поиск информации очень медленным и неэффективным. Решение этой проблемы было найдено путем размещения отдельных составных частей базы данных на различных DNS-серверах. Таким образом, иерархическая база данных Доменная система имен является распределенной базой данных.
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Например, мы хотим ознакомиться с содержанием WWW-сервера фирмы Microsoft.
Сначала наш запрос, содержащий доменное имя сервера www.microsoft..com, будет оправлен на DNS-сервер нашего провайдера, который переадресует его на DNS-сервер самого верхнего уровня базы данных. В таблице первого уровня будет найден интересующий нас домен com и запрос будет адресован на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене com.
В таблице второго уровня будет найден домен microsoft и запрос будет переадресован на DNS-сервер третьего уровня. В таблице третьего уровня будет найдена запись, соответствующая доменному имени, содержавшемуся в запросе. Поиск информации в базе данных Доменная система имен будет завершен и начнется поиск компьютера в сети по его IP-адресу.
Сетевые базы данных. Сетевая база данных является обобщением иерархической за счет допущения объектов, имеющих более одного предка. Вообще, на связи между объектами в сетевых моделях не накладывается никаких ограничений.
Сетевой базой данных фактически является Всемирная паутина глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую распределенную сетевую базу данных.
1. Чем различаются между собой табличные, иерархические и сетевые базы данных? Приведите примеры.
2. Чем различаются между собой сетевые и распределенные базы данных?
Источник
Что такое База Данных (БД)
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов. Вы делаете заказ, а система сохраняет ваши данные в базе.

В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работу.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Содержание
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.
Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!
Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.
Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги.
Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
Тоже самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Пример базы Oracle
Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
заходишь в папку в винде → видишь файлики только из этой папки
заходишь в пространство → видишь только те таблицы, которые в нем есть
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки.
from — из такой-то таблицы базы.
where — такую-то информацию.
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
В дословном переводе:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. Тоже самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order
order (таблица order)
fio (таблица client)
phone (таблица contacts)
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name
first_name
birthdate
В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order
addr
date
time
Роллы «Филадельфия» и «Канада»
Пицца 35 см, роллы комбо 1
Пицца с сосиками по краям
Комбо набор 3, обед №4
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам. В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку. А если у нас два клиента Ивана? Или три Маши? Десять Саш. Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.
А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Здесь ключ — «id_order»
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Источник
Базы данных и их разновидности
База данных (БД) –это совокупность массивов и файлов данных, организованная по определённым правилам, предусматривающим стандартные принципы описания, хранения и обработки данных независимо от их вида.
Основные классификации баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Основные из них:
Центральным понятием в области баз данных является понятие модели.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Виды:
1) Иерархическая база данных – каждый объект, при таком хранение информации, представляется в виде определенной сущности, то есть у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть документ в формате XML или файловая система компьютера.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть базы данных, имеющие иерархическую структуру умеют очень быстро выбирать запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию. Здесь можно привести первый пример из жизни: компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути, являются объектами иерархической структуры), но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
На изображении Вы можете увидеть структуру иерархической базы данных. В самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы находящиеся на одном уровне называются братьями или соседними элементами. Соответственно, чем ниже уровень элемента, тем вложенность этого элемента больше.
Объектные базы данных — это модель работы с объектными данными.
Такая модель баз данных, несмотря на то, что она существует уже много лет, считается новой. И её создание открывает большие перспективы, в связи с тем, что использование объектной модели баз данных легко воспринимается пользователем, так как создается высокий уровень абстракции. Объектная модель идеально подходит для трактовки такого рода объектных данных как изображение, музыка, видео, разного вида текст.
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные моделируются в виде объектов, их атрибутов, методов и классов.
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
2) Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет ли осуществляться текстовый поиск?
3) Реляционная(или табличная) БД содержит перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.
Такую базу удобно представлять в виде двумерной таблицы (или, чаще всего, нескольких связанных между собой таблиц).
Примером такой таблицы может служить БД «Учащиеся», представляющая собой перечень объектов (учеников), каждый из которых имеет фамилию, имя, отчество, дату рождения, класс, номер личного дела и др.
Столбцы такой таблицы называют полями; каждое поле характеризуется своим именем (названием соответствующего свойства объекта) и типом данных, которые это поле может хранить. Каждое поле обладает определенным набором свойств (размер, формат и т. п.). Т. о., поле БД — это столбец таблицы, содержащий значения определенного свойства объектов.
Строки таблицы являются записями. Записи разбиты на поля. Каждая строка таблицы содержит запись об одном единственном объекте, включая все его свойства.
В каждой таблице должно быть хотя бы одно ключевое поле, содержимое которого уникально для любой записи в этой таблице. Значения ключевого поля однозначно определяют каждую запись в таблице. В приведенном выше примере ключевым полем может являться поле «Номер личного дела». Очень часто в качестве ключевого поля используется поле, содержащее данные типа счетчик.
4) Сетевые базы данных являются своеобразной модификацией иерархических баз данных. Если Вы внимательно смотрели на изображение выше, то наверняка обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на изображение:
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но сейчас нас не особо интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML.
5) Функциональные базы данных используются для решения аналитических задач: финансовое моделирование и управление производительностью. Функциональная база данных или функциональная модель отличается от реляционной модели. Функциональная модель также отличается от других аналогично названных концепций, включая модель функциональной базы данных DAPLEX и базы данных функциональных языков.
Функциональная модель является частью категории оперативной аналитической обработки (OLAP электронной таблице,), поскольку она включает многомерное иерархическое объединение. Но она выходит за рамки OLAP, требуя ориентирования ячейки, подобно тому, где ячейки могут быть введены или рассчитаны как функции других ячеек. Также, как и в электронных таблицах, данная модель поддерживает интерактивные вычисления, в которых значения всех зависимых ячеек автоматически обновляются каждый раз, когда изменяется значение ячейки.
SQL
SQL — язык структурированных запросов, основной задачей которого является предоставление простого способа считывания и записи информации в базу данных.
Функции языка SQL:
СУБД
Большинство современных СУБД построено на реляционной модели данных. Для получения информации из отношений (таблиц) базы данных в качестве языка манипулирования данными в теоретическом плане используется язык SQL
СУБД — система управления базами данных, совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных
Основные функции СУБД:
Типы данных в SQL
Каждый столбец в таблице базы данных должен иметь имя и тип данных.
SQL разработчики должны решить, какие типы данных будут храниться внутри каждого столбца таблицы при создании таблицы SQL. Тип данных представляет собой метку и ориентир для SQL, чтобы понять, какой тип данных, как ожидается, внутри каждого столбца, а также определяет, как SQL будут взаимодействовать с хранимыми данными.
В следующей таблице перечислены общие типы данных в SQL:
SQL Data Type — Краткий справочник в разрезе БД
Тем не менее, различные базы данных предлагают различные варианты для определения типа данных.
В следующей таблице приведены некоторые из общих названий типов данных между различными платформами баз данных:
Источник
Иерархические БД
Урок 27. Информатика и ИКТ 11 класс (к учебнику Н. Д. Угриновича)


В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока «Иерархические БД»
На этом уроке мы с вами вспомним, что такое иерархическая структура и из каких элементов она состоит. Также рассмотрим несколько примеров иерархической базы данных.
Начнём мы с вами с рассмотрения иерархической структуры базы данных.
Иерархическая структура – это многоуровневая форма организации объектов со строгой соотнесённостью объектов нижнего уровня определённому объекту верхнего уровня. Т. е. можно сказать, что иерархическая структура напоминает собой пирамиду, в которой объекты более низкого уровня подчиняются объектам более высокого уровня.

Из этого можно сделать вывод, что в иерархической структуре существуют отношения между её объектами (элементами).
Ещё иерархическую структуру называют древовидной. К примерам можно отнести содержание учебника.

А сейчас рассмотрим иерархическую структуру более подробно на примере.
Давайте построим иерархическую структуру школы.
Во главе всегда находится директор школы. Далее будут идти завуч старших классов, завуч младших классов, заведующий хозяйственной деятельностью. После завучей идут учителя, которые, соответственно, делятся на преподавателей младших и старших классов. Не будем расписывать всех учителей, а возьмём по три учителя каждых классов. Заведующему по хозяйственной деятельности будет подчиняться весь технический персонал. Его мы расписывать не будем. Далее у каждого учителя есть свой класс, в котором он является классным руководителем, а в каждом классе – ученики. В свою очередь, учителя старших классов ведут уроки и в других классах. Давайте отобразим несколько таких классов в нашей структуре. Если же всю эту структуру расписывать более подробно, то нам понадобится очень много места, так как объектов в этой системе очень большое количество.

Итак, во главе любой иерархической структуры всегда находится один элемент (объект). В нашем случае – это директор школы. Он является корнем вершины и находится на верхнем (первом) уровне.

Далее идёт второй уровень, на котором находятся заместители.

На третьем уровне находятся учителя и технический персонал, на четвёртом – классы и на пятом – ученики.
Как говорилось ранее, между всеми объектами существуют связи. Каждый объект более высокого уровня может включать в себя несколько объектов более низкого уровня. Давайте снова обратимся к нашему примеру. Так, завуч старшей школы включает в себя всех учителей, которые ведут уроки в старших классах. А заведующий хозяйственной деятельностью управляет всем техническим персоналом школы. Такие объекты находятся в отношении предка (объект более высокого уровня) к потомку (объект более низкого уровня). То есть завуч старшей школы и заведующий хозяйственной деятельностью являются предками, а учителя и технический персонал – потомками.

Также мы можем видеть, что у объекта-предка может быть несколько потомков. Но в то же время у объекта-потомка может быть только один предок. Объекты, которые находятся на одном уровне и у которых один общий предок, называются близнецами.

Рассмотрим ещё один пример. Построить иерархическую структуру, исходя из следующего условия: на кафедре иностранных языков работают три преподавателя. Иванова Инна Сергеевна преподаёт английский язык, Кулибина Анна Васильевна преподаёт немецкий язык, а Рудков Игорь Сергеевич преподаёт французский язык.

Корневой вершиной в этой структуре будет являться кафедра. Изобразим её в виде круга. Она включает в себя трёх преподавателей. Также изобразим их схематично, а от кафедры к каждому преподавателю проведём стрелки.

Далее у каждого преподавателя есть свои предметы, которые он ведёт. Также изобразим их схематично и проведём стрелки.

Таким образом мы получили графическое отображение иерархической структуры кафедры.
Корневой вершиной является кафедра.

Учителя являются потомками по отношению к кафедре и предками по отношению к предметам, которые они преподают. Также они между собой являются близнецами, так как находятся на одном уровне структуры и имеют одного предка – кафедру.

У нас получилось несколько определений.
Корень – это единственный объект, который стоит на вершине иерархической системы и является её первым уровнем.
Предок – это объект, который стоит более близко к корню системы и у него может быть несколько потомков.
Потомок – это объект, который стоит на более низком уровне по отношению к предку и у него может быть только один предок.
Близнецы – это объекты, которые имеют одного предка и находятся на одном уровне.
А сейчас рассмотрим ещё несколько примеров.
Начнём с иерархической базы данных папки Windows.

Иерархической базой данных является каталог папок Windows. Перед вами рисунок системного диска. Для того, чтобы увидеть древовидную структуру в проводнике в Windows 7, необходимо выбрать кнопку «Упорядочить», далее из появившегося списка – «Представления», а затем «Область переходов». Это в том случае, если данная область не отображается.



А вот, например, в Windows 10 необходимо в проводнике, во вкладке «Вид», выбрать «Область навигации» и из списка снова «Область навигации».



На рисунке представлен проводник операционной системы Windows 10.

Итак, корневой является папка «Этот компьютер».

Далее, на втором уровне на представленном рисунке находится локальный диск С, который включает в себя несколько папок третьего уровня.

В нашем случае выбрана папка «Program Files». Она в себя включает несколько папок-потомков.

Исходя из этого можно сказать, что корнем является – «Этот компьютер». Далее и предком, и потомком является локальный диск С. Папка «Program Files» также является и потомком (по отношению к локальному диску С), и предком (по отношению к остальным папкам, которые она в себя включает). Файл «Rar.txt» является потомком папки «WinRAR». В свою очередь, мы можем видеть, что у файла «Rar.txt» нет своих потомков. Также, например, файлы «Rar.txt» и «Rar.exe» являются близнецами, так как находятся на одном уровне и у них один общий предок – папка «WinRAR».
Ещё одним примером иерархической базы данных является файловая система Linux.

Мы ранее её рассматривали. В ней существует одна корневая папка, все остальные папки являются потомками. В корневой папке содержатся все системные файлы. А вот, например, каталоги логических томов и запоминающих устройств содержатся в составе других каталогов. Директории томов жёсткого диска содержатся в папке «mnt». Другие запоминающие устройства находятся в папке «media». В свою очередь, папки «mnt» и «media» содержатся в одном системном корневом каталоге. Таким образом, папки «mnt» и «media» являются и потомками (по отношению к основному корневому каталогу), и предками (по отношению к каталогам логических томов и запоминающих устройств). Помимо этого, эти две папки являются близнецами, так как они находятся на одном уровне и имеют одного предка.
А сейчас давайте рассмотрим такую иерархическую базу данных, как «Системный реестр Windows».

В этой иерархической базе данных хранится вся информация, которая нужна для нормального функционирования компьютерной системы. То есть в этой базе данных содержится информация о настройках компьютера, установленных драйверах, настройках графического интерфейса, сведения о программах, которые установлены на компьютере, и многое другое.
Вся эта информация автоматически обновляется при установке нового оборудования, удалении или установке программ и так далее.
Давайте рассмотрим рисунок.

Корневым объектом является сам компьютер. Папка «Adobe» является потомком по отношению к папке «SOFTWARE» и предком для всех остальных папок, которые она в себя включает. Папки «7-Zip» и «Adobe» являются близнецами, так как они находятся на одном уровне и у них один предок – папка «SOFTWARE». Файл «UserID» является потомком папки «IAC». В свою очередь, мы можем видеть, что у файла «UserID» нет своих потомков.
В операционной же системе Linux как такового реестра нет. Вместо этого в ней существует папка «etc».
А сейчас мы с вами рассмотрим иерархическую базу данных «Доменная система имён». Эта система получила название DNS.
DNS – это распределённая база данных, которая поддерживает иерархическую систему имён для идентификации узлов сети Интернет.
Эта служба предназначена для автоматического поиска IP-адреса по известному символьному имени узла. То есть в этой базе данных содержится информация о всех компьютерах, подключённых к сети Интернет.
Корневой вершиной в этой системе является табличная база данных, которая содержит перечень доменов верхнего уровня.

Сам же корень управляется центром Internet Network Information Center. Домены верхнего уровня назначаются для каждой страны, а также на организационной основе. Для обозначения стран используются трёхбуквенные и двухбуквенные аббревиатуры.

Так, например, для русскоязычных сайтов доменом верхнего уровня является «.ru», для Казахстана – «.kz» и т. д. Для различных типов организаций также есть свои аббревиатуры.
На втором уровне находятся также табличные базы данных, но они уже в себя включают перечень доменов второго уровня для каждого домена первого уровня.

На третьем уровне содержатся табличные базы данных и таблицы. Табличные базы данных содержат перечень доменов третьего уровня для каждого домена второго уровня. Таблицы, в свою очередь, содержат IP-адреса компьютеров, которые находятся в домене второго уровня.

А теперь представьте, какой большой будет база данных, которая должна включать в себя информацию о всех компьютерах, подключенных к Интернету. Как вы думаете, много ли места она будет занимать?
Такая база данных огромна по своим размерам и соответственно она не будет умещаться в памяти одного компьютера, а если бы и можно было загрузить такую базу данных в один компьютер, то работа в Интернете была бы очень медленной. Представьте себе количество запросов, которые поступают от пользователей всего мира в течение, например, 1 минуты. Их количество огромно. А теперь представьте, что все эти запросы должен принять и обработать один компьютер. Это просто невозможно, так как приведёт не только к медленной работе компьютера, но также и к зависанию, если не к поломке. Таким образом, размещение базы данных доменной системы имён на одном компьютере неэффективно. Но решение этой проблемы было найдено. Вся база данных была разделена на части и размещена на различных DNS-серверах, которые связаны между собой. Такая иерархическая база данных является распределённой базой данных.

А сейчас давайте рассмотрим, как происходит поиск информации в такой огромной иерархической распределённой базе данных.
Например, вам нужно зайти на свою почту в Яндексе. Для этого вы вводите в адресную строку запрос.

На этом сервере, в таблице первого уровня, произойдёт поиск интересующего нас домена «ru», после чего запрос будет перенаправлен на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене «ru».

На втором уровне будет происходить поиск среди доменов второго уровня. После того, как был найден интересующий нас домен «yandex», произойдёт перенаправление на DNS-сервер третьего уровня, на котором находится перечень доменов третьего уровня, зарегистрированных в домене «yandex».

В таблице третьего уровня будет найден домен «mail», и запрос будет переадресован на DNS-сервер четвёртого уровня.

В таблице четвёртого уровня будет найдена запись, которая соответствует доменному имени, содержащемуся в запросе. После этого поиск в самой базе данных «Доменная система имён» будет завершён и начнётся поиск компьютера в сети по его IP-адресу.

Пришла пора подвести итоги урока.
Сегодня мы с вами узнали, что такое иерархическая структура и построили такую структуру на примере. Более подробно познакомились с элементами иерархической базы данных: корнем, предком, потомком, близнецами.
Рассмотрели несколько иерархических баз данных на примере Windows и Linux, а также реестра Windows.
Узнали, как составлена и работает иерархическая база данных «Доменная система имён».
Источник
Иерархическая модель базы данных
Иерархические базы данных — самая
ранняя модель представления сложной
структуры данных. Информация в
иерархической базе организована по
принципу древовидной структуры, в виде
отношений «предок-потомок». Каждая
запись может иметь не более одной
родительской записи и несколько
подчиненных. Связи записей реализуются
в виде физических указателей с одной
записи на другую. Основной недостаток
иерархической структуры базы данных —
невозможность реализовать отношения
«много-ко-многим», а также ситуации,
когда запись имеет несколько предков.
Иерархические базы данных.
Иерархические базы данных графически
могут быть представлены как перевернутое
дерево, состоящее из объектов различных
уровней. Верхний уровень (корень дерева)
занимает один объект, второй — объекты
второго уровня и так далее.
Между объектами существуют
связи, каждый объект может включать в
себя несколько объектов
более низкого уровня. Такие объекты
находятся в отношении предка (объект,
более близкий к корню) к потомку (объект
более низкого уровня), при этом
объект-предок может не иметь потомков
или иметь их несколько, тогда как
объект-потомок обязательно имеет только
одного предка. Объекты, имеющие общего
предка, называются
близнецами.
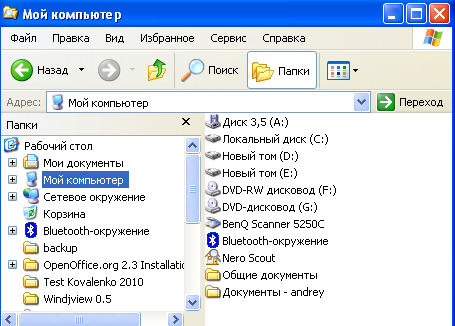
Иерархической базой данных
является Каталог папок Windows, с которым
можно работать, запустив Проводник.
Верхний уровень занимает папка Рабочий
стол. На втором уровне находятся папки
Мой компьютер, Мои документы, Сетевое
окружение и Корзина, которые являются
потомками папки Рабочий стол, а между
собой является близнецами. В свою
очередь, папка Мой компьютер является
предком по отношению к папкам третьего
уровня -папкам дисков (Диск 3,5(А:), (С:),
(D:), (Е:), (F:)) и системным папкам (сканер,
bluetooth
и.т.д.) — рис. 4.1.
Организация данных в СУБД
иерархического типа определяется в
терминах: элемент,
агрегат, запись (группа), групповое
отношение, база данных.
-
А

Рисунок 4.1
Иерархическая база данных Каталог
папок Windowsтрибут (элемент
данных) — наименьшая единица структуры
данных. Обычно каждому элементу при
описании базы данных присваивается
уникальное имя. По этому имени к нему
обращаются при обработке. Элемент
данных также часто называют полем. -
Запись —
именованная совокупность атрибутов.
Использование записей позволяет за
одно обращение к базе получить некоторую
логически связанную совокупность
данных. Именно записи изменяются,
добавляются и удаляются. Тип записи
определяется составом ее атрибутов.
Экземпляр
записи — конкретная
запись с конкретным значением элементов -
Групповое отношение
— иерархическое отношение между записями
двух типов. Родительская запись (владелец
группового отношения) называется
исходной записью, а дочерние записи
(члены группового отношения) — подчиненными.
Иерархическая база данных может хранить
только такие древовидные структуры.
Корневая запись
каждого дерева обязательно должна
содержать ключ с уникальным значением.
Ключи некорневых записей должны иметь
уникальное значение только в рамках
группового отношения. Каждая запись
идентифицируется полным сцепленным
ключом, под которым понимается совокупность
ключей всех записей от корневой по
иерархическому пути.
При графическом изображении групповые
отношения изображают дугами ориентированного
графа, а типы записей — вершинами
(диаграмма Бахмана).
Для групповых отношений в иерархической
модели обеспечивается автоматический
режим включения и фиксированное членство.
Это означает, что для запоминания любой
некорневой записи в БД должна существовать
ее родительская запись.
Пример:
Рассмотрим следующую модель данных
предприятия (см. рис.4.2): предприятие
состоит из отделов, в которых работают
сотрудники. В каждом отделе может
работать несколько сотрудников, но
сотрудник не может работать более чем
в одном отделе.
Поэтому, для информационной системы
управления персоналом необходимо
создать групповое отношение, состоящее
из родительской записи ОТДЕЛ
(НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ)
и дочерней записи СОТРУДНИК (ФАМИЛИЯ,
ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано
на рис. 4.2 (а) (Для простоты полагается,
что имеются только две дочерние записи).
Для автоматизации учета контрактов с
заказчиками необходимо создание еще
одной иерархической структуры: заказчик
— контракты с ним — сотрудники,
задействованные в работе над контрактом.
Это дерево будет включать записи ЗАКАЗЧИК
(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС),
КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ
(ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА)
(рис. 4.2 b).
Из этого примера видны недостатки
иерархических БД:
Ч

Рисунок 4.2. Пример
иерархической базы данных
астично дублируется
информация между записями СОТРУДНИК и
ИСПОЛНИТЕЛЬ (такие записи называют
парными), причем в иерархической модели
данных не предусмотрена поддержка
соответствия между парными записями.
Иерархическая модель реализует отношение
между исходной и дочерней записью по
схеме 1:N, то есть одной родительской
записи может соответствовать любое
число дочерних.
Допустим теперь, что исполнитель может
принимать участие более чем в одном
контракте (т.е. возникает связь типа
M:N). В этом случае в базу данных необходимо
ввести еще одно групповое отношение, в
котором ИСПОЛНИТЕЛЬ будет являться
исходной записью, а КОНТРАКТ – дочерней
(рис. 4.2 c). Таким образом, мы опять вынуждены
дублировать информацию.
Операции над данными, определенные в
иерархической модели:
-
ДОБАВИТЬ
в базу данных новую запись. Для корневой
записи обязательно формирование
значения ключа. -
ИЗМЕНИТЬ
значение данных предварительно
извлеченной записи. Ключевые данные
не должны подвергаться изменениям. -
УДАЛИТЬ
некоторую запись и все подчиненные ей
записи. -
ИЗВЛЕЧЬ:
извлечь корневую запись по ключевому
значению, допускается также последовательный
просмотр корневых записей
извлечь следующую запись (следующая
запись извлекается в порядке левостороннего
обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание
условий выборки (например, извлечь
сотрудников с окладом более 10 тысяч
руб.)
Как видим, все операции изменения
применяются только к одной «текущей»
записи (которая предварительно извлечена
из базы данных). Такой подход к
манипулированию данных получил название
«навигационного».
Ограничения целостности.
Поддерживается только целостность
связей между владельцами и членами
группового отношения (никакой потомок
не может существовать без предка). Как
уже отмечалось, не обеспечивается
автоматическое поддержание соответствия
парных записей, входящих в разные
иерархии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
поделиться знаниями или
запомнить страничку
- Все категории
-
экономические
43,612 -
гуманитарные
33,643 -
юридические
17,916 -
школьный раздел
611,384 -
разное
16,895
Популярное на сайте:
Как быстро выучить стихотворение наизусть? Запоминание стихов является стандартным заданием во многих школах.
Как научится читать по диагонали? Скорость чтения зависит от скорости восприятия каждого отдельного слова в тексте.
Как быстро и эффективно исправить почерк? Люди часто предполагают, что каллиграфия и почерк являются синонимами, но это не так.
Как научится говорить грамотно и правильно? Общение на хорошем, уверенном и естественном русском языке является достижимой целью.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект, более близкий к корню) к потомку (объект более низкого уровня), при этом объект-предок может не иметь потомков или иметь их несколько, тогда как объект-потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
| |
| Рис. 3.1 Иерархическая база данных Каталог папок Windows |
Иерархической базой данных является Реестр Windows, в котором хранится вся информация, необходимая для нормального функционирования компьютерной системы (данные о конфигурации компьютера и установленных драйверах, сведения об установленных программах, настройки графического интерфейса и др.).
Содержание реестра автоматически обновляется при установке нового оборудования, инсталляции программ и т. п. Для просмотра и редактирования реестра Windows в ручном режиме можно использовать специальную программу rege-dit.exe, которая хранится в папке Windows. Однако редактирование реестра можно проводить только в случае крайней необходимости и при условии понимания выполняемых действий. Неквалифицированное редактирование реестра может привести компьютер в неработоспособное состояние.
| |
| Рис. 3.2 Иерархическая база данных Реестр Windows |
На втором уровне находятся табличные базы данных, содержащие перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне могут находиться табличные базы данных, содержащие перечень доменов третьего уровня для каждого домена второго уровня, и таблицы, содержащие IP-адреса компьютеров, находящихся в домене второго уровня (рис. 3.3).
| |
| Рис. 3.3. Иерархическая база данных Доменная система имен |
База данных Доменная система имен должна содержать записи обо всех компьютерах, подключенных к Интернету, то есть более 150 миллионов записей. Размещение такой огромной базы данных на одном компьютере сделало бы поиск информации очень медленным и неэффективным. Решение этой проблемы было найдено путем размещения отдельных составных частей базы данных на различных DNS-серверах. Таким образом, иерархическая база данных Доменная система имен является распределенной базой данных.
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Например, мы хотим ознакомиться с содержанием WWW-сервера фирмы Microsoft.
Сначала наш запрос, содержащий доменное имя сервера www.microsoft..com, будет оправлен на DNS-сервер нашего провайдера, который переадресует его на DNS-сервер самого верхнего уровня базы данных. В таблице первого уровня будет найден интересующий нас домен com и запрос будет адресован на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене com.
В таблице второго уровня будет найден домен microsoft и запрос будет переадресован на DNS-сервер третьего уровня. В таблице третьего уровня будет найдена запись, соответствующая доменному имени, содержавшемуся в запросе. Поиск информации в базе данных Доменная система имен будет завершен и начнется поиск компьютера в сети по его IP-адресу.
Сетевые базы данных. Сетевая база данных является обобщением иерархической за счет допущения объектов, имеющих более одного предка. Вообще, на связи между объектами в сетевых моделях не накладывается никаких ограничений.
Сетевой базой данных фактически является Всемирная паутина глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую распределенную сетевую базу данных.
1. Чем различаются между собой табличные, иерархические и сетевые базы данных? Приведите примеры.
2. Чем различаются между собой сетевые и распределенные базы данных?
Источник
Какие бывают базы данных
Объясняем на картинках.
Базы данных — это способ упорядочить информацию так, чтобы компьютер мог с ней легко работать, а человек мог пользоваться этими данными как ему удобно. Мы уже писали о базах данных в общем, теперь углубимся.
👉 Это знания скорее из области информатики, чем прикладного программирования. Если вы просто делаете сайты или обслуживаете интернет-магазин, вероятнее всего, вам из этого понадобятся только реляционные базы данных. Но когда вы захотите сделать более сложные приложения — например рекомендации товаров, — вам потребуются знания о других типах баз.
Считайте, что эта статья для расширения кругозора.
Три основных типа
В зависимости от того, какие данные нужно в ней хранить и как с ними работать, базы делятся на реляционные и нереляционные:

Реляционные
Реляционные базы данных ещё называют табличными, потому что все данные в них можно представить в виде разных таблиц. Одни таблицы связаны с другими, а другие — с третьими. Например, база данных покупок в магазине может выглядеть так:

Смотрите, у магазина есть две таблицы — с товарами и покупателями. Но когда один из них что-то покупает, то данные попадают в третью таблицу. В ней есть своя информация (количество купленных товаров) и ссылки на покупателя и сам товар. Если нужно, можно по этим связям попасть в нужную таблицу и узнать подробности о той или другой записи.
Если у покупателя поменяется номер телефона, то нам достаточно будет поменять это в одной таблице «Клиенты». Благодаря тому, что в «Покупки» записывается только код покупателя, нам не нужно менять имя больше нигде — данные сами обновятся автоматически, когда мы захотим посмотреть, кто именно купил табурет.
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:

Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:

Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Главное о базах данных
Источник
Базы данных и их разновидности
База данных (БД) –это совокупность массивов и файлов данных, организованная по определённым правилам, предусматривающим стандартные принципы описания, хранения и обработки данных независимо от их вида.
Основные классификации баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Основные из них:
Центральным понятием в области баз данных является понятие модели.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Виды:
1) Иерархическая база данных – каждый объект, при таком хранение информации, представляется в виде определенной сущности, то есть у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть документ в формате XML или файловая система компьютера.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть базы данных, имеющие иерархическую структуру умеют очень быстро выбирать запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию. Здесь можно привести первый пример из жизни: компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути, являются объектами иерархической структуры), но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
На изображении Вы можете увидеть структуру иерархической базы данных. В самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы находящиеся на одном уровне называются братьями или соседними элементами. Соответственно, чем ниже уровень элемента, тем вложенность этого элемента больше.
Объектные базы данных — это модель работы с объектными данными.
Такая модель баз данных, несмотря на то, что она существует уже много лет, считается новой. И её создание открывает большие перспективы, в связи с тем, что использование объектной модели баз данных легко воспринимается пользователем, так как создается высокий уровень абстракции. Объектная модель идеально подходит для трактовки такого рода объектных данных как изображение, музыка, видео, разного вида текст.
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные моделируются в виде объектов, их атрибутов, методов и классов.
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
2) Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет ли осуществляться текстовый поиск?
3) Реляционная(или табличная) БД содержит перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.
Такую базу удобно представлять в виде двумерной таблицы (или, чаще всего, нескольких связанных между собой таблиц).
Примером такой таблицы может служить БД «Учащиеся», представляющая собой перечень объектов (учеников), каждый из которых имеет фамилию, имя, отчество, дату рождения, класс, номер личного дела и др.
Столбцы такой таблицы называют полями; каждое поле характеризуется своим именем (названием соответствующего свойства объекта) и типом данных, которые это поле может хранить. Каждое поле обладает определенным набором свойств (размер, формат и т. п.). Т. о., поле БД — это столбец таблицы, содержащий значения определенного свойства объектов.
Строки таблицы являются записями. Записи разбиты на поля. Каждая строка таблицы содержит запись об одном единственном объекте, включая все его свойства.
В каждой таблице должно быть хотя бы одно ключевое поле, содержимое которого уникально для любой записи в этой таблице. Значения ключевого поля однозначно определяют каждую запись в таблице. В приведенном выше примере ключевым полем может являться поле «Номер личного дела». Очень часто в качестве ключевого поля используется поле, содержащее данные типа счетчик.
4) Сетевые базы данных являются своеобразной модификацией иерархических баз данных. Если Вы внимательно смотрели на изображение выше, то наверняка обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на изображение:
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но сейчас нас не особо интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML.
5) Функциональные базы данных используются для решения аналитических задач: финансовое моделирование и управление производительностью. Функциональная база данных или функциональная модель отличается от реляционной модели. Функциональная модель также отличается от других аналогично названных концепций, включая модель функциональной базы данных DAPLEX и базы данных функциональных языков.
Функциональная модель является частью категории оперативной аналитической обработки (OLAP электронной таблице,), поскольку она включает многомерное иерархическое объединение. Но она выходит за рамки OLAP, требуя ориентирования ячейки, подобно тому, где ячейки могут быть введены или рассчитаны как функции других ячеек. Также, как и в электронных таблицах, данная модель поддерживает интерактивные вычисления, в которых значения всех зависимых ячеек автоматически обновляются каждый раз, когда изменяется значение ячейки.
SQL
SQL — язык структурированных запросов, основной задачей которого является предоставление простого способа считывания и записи информации в базу данных.
Функции языка SQL:
СУБД
Большинство современных СУБД построено на реляционной модели данных. Для получения информации из отношений (таблиц) базы данных в качестве языка манипулирования данными в теоретическом плане используется язык SQL
СУБД — система управления базами данных, совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных
Основные функции СУБД:
Типы данных в SQL
Каждый столбец в таблице базы данных должен иметь имя и тип данных.
SQL разработчики должны решить, какие типы данных будут храниться внутри каждого столбца таблицы при создании таблицы SQL. Тип данных представляет собой метку и ориентир для SQL, чтобы понять, какой тип данных, как ожидается, внутри каждого столбца, а также определяет, как SQL будут взаимодействовать с хранимыми данными.
В следующей таблице перечислены общие типы данных в SQL:
SQL Data Type — Краткий справочник в разрезе БД
Тем не менее, различные базы данных предлагают различные варианты для определения типа данных.
В следующей таблице приведены некоторые из общих названий типов данных между различными платформами баз данных:
Источник
Иерархические БД
Урок 27. Информатика и ИКТ 11 класс (к учебнику Н. Д. Угриновича)

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока «Иерархические БД»
На этом уроке мы с вами вспомним, что такое иерархическая структура и из каких элементов она состоит. Также рассмотрим несколько примеров иерархической базы данных.
Начнём мы с вами с рассмотрения иерархической структуры базы данных.
Иерархическая структура – это многоуровневая форма организации объектов со строгой соотнесённостью объектов нижнего уровня определённому объекту верхнего уровня. Т. е. можно сказать, что иерархическая структура напоминает собой пирамиду, в которой объекты более низкого уровня подчиняются объектам более высокого уровня.
Из этого можно сделать вывод, что в иерархической структуре существуют отношения между её объектами (элементами).
Ещё иерархическую структуру называют древовидной. К примерам можно отнести содержание учебника.
А сейчас рассмотрим иерархическую структуру более подробно на примере.
Давайте построим иерархическую структуру школы.
Во главе всегда находится директор школы. Далее будут идти завуч старших классов, завуч младших классов, заведующий хозяйственной деятельностью. После завучей идут учителя, которые, соответственно, делятся на преподавателей младших и старших классов. Не будем расписывать всех учителей, а возьмём по три учителя каждых классов. Заведующему по хозяйственной деятельности будет подчиняться весь технический персонал. Его мы расписывать не будем. Далее у каждого учителя есть свой класс, в котором он является классным руководителем, а в каждом классе – ученики. В свою очередь, учителя старших классов ведут уроки и в других классах. Давайте отобразим несколько таких классов в нашей структуре. Если же всю эту структуру расписывать более подробно, то нам понадобится очень много места, так как объектов в этой системе очень большое количество.
Итак, во главе любой иерархической структуры всегда находится один элемент (объект). В нашем случае – это директор школы. Он является корнем вершины и находится на верхнем (первом) уровне.
Далее идёт второй уровень, на котором находятся заместители.
На третьем уровне находятся учителя и технический персонал, на четвёртом – классы и на пятом – ученики.
Как говорилось ранее, между всеми объектами существуют связи. Каждый объект более высокого уровня может включать в себя несколько объектов более низкого уровня. Давайте снова обратимся к нашему примеру. Так, завуч старшей школы включает в себя всех учителей, которые ведут уроки в старших классах. А заведующий хозяйственной деятельностью управляет всем техническим персоналом школы. Такие объекты находятся в отношении предка (объект более высокого уровня) к потомку (объект более низкого уровня). То есть завуч старшей школы и заведующий хозяйственной деятельностью являются предками, а учителя и технический персонал – потомками.
Также мы можем видеть, что у объекта-предка может быть несколько потомков. Но в то же время у объекта-потомка может быть только один предок. Объекты, которые находятся на одном уровне и у которых один общий предок, называются близнецами.
Рассмотрим ещё один пример. Построить иерархическую структуру, исходя из следующего условия: на кафедре иностранных языков работают три преподавателя. Иванова Инна Сергеевна преподаёт английский язык, Кулибина Анна Васильевна преподаёт немецкий язык, а Рудков Игорь Сергеевич преподаёт французский язык.
Корневой вершиной в этой структуре будет являться кафедра. Изобразим её в виде круга. Она включает в себя трёх преподавателей. Также изобразим их схематично, а от кафедры к каждому преподавателю проведём стрелки.
Далее у каждого преподавателя есть свои предметы, которые он ведёт. Также изобразим их схематично и проведём стрелки.
Таким образом мы получили графическое отображение иерархической структуры кафедры.
Корневой вершиной является кафедра.
Учителя являются потомками по отношению к кафедре и предками по отношению к предметам, которые они преподают. Также они между собой являются близнецами, так как находятся на одном уровне структуры и имеют одного предка – кафедру.
У нас получилось несколько определений.
Корень – это единственный объект, который стоит на вершине иерархической системы и является её первым уровнем.
Предок – это объект, который стоит более близко к корню системы и у него может быть несколько потомков.
Потомок – это объект, который стоит на более низком уровне по отношению к предку и у него может быть только один предок.
Близнецы – это объекты, которые имеют одного предка и находятся на одном уровне.
А сейчас рассмотрим ещё несколько примеров.
Начнём с иерархической базы данных папки Windows.
Иерархической базой данных является каталог папок Windows. Перед вами рисунок системного диска. Для того, чтобы увидеть древовидную структуру в проводнике в Windows 7, необходимо выбрать кнопку «Упорядочить», далее из появившегося списка – «Представления», а затем «Область переходов». Это в том случае, если данная область не отображается.
А вот, например, в Windows 10 необходимо в проводнике, во вкладке «Вид», выбрать «Область навигации» и из списка снова «Область навигации».
На рисунке представлен проводник операционной системы Windows 10.
Итак, корневой является папка «Этот компьютер».
Далее, на втором уровне на представленном рисунке находится локальный диск С, который включает в себя несколько папок третьего уровня.
В нашем случае выбрана папка «Program Files». Она в себя включает несколько папок-потомков.
Исходя из этого можно сказать, что корнем является – «Этот компьютер». Далее и предком, и потомком является локальный диск С. Папка «Program Files» также является и потомком (по отношению к локальному диску С), и предком (по отношению к остальным папкам, которые она в себя включает). Файл «Rar.txt» является потомком папки «WinRAR». В свою очередь, мы можем видеть, что у файла «Rar.txt» нет своих потомков. Также, например, файлы «Rar.txt» и «Rar.exe» являются близнецами, так как находятся на одном уровне и у них один общий предок – папка «WinRAR».
Ещё одним примером иерархической базы данных является файловая система Linux.
Мы ранее её рассматривали. В ней существует одна корневая папка, все остальные папки являются потомками. В корневой папке содержатся все системные файлы. А вот, например, каталоги логических томов и запоминающих устройств содержатся в составе других каталогов. Директории томов жёсткого диска содержатся в папке «mnt». Другие запоминающие устройства находятся в папке «media». В свою очередь, папки «mnt» и «media» содержатся в одном системном корневом каталоге. Таким образом, папки «mnt» и «media» являются и потомками (по отношению к основному корневому каталогу), и предками (по отношению к каталогам логических томов и запоминающих устройств). Помимо этого, эти две папки являются близнецами, так как они находятся на одном уровне и имеют одного предка.
А сейчас давайте рассмотрим такую иерархическую базу данных, как «Системный реестр Windows».
В этой иерархической базе данных хранится вся информация, которая нужна для нормального функционирования компьютерной системы. То есть в этой базе данных содержится информация о настройках компьютера, установленных драйверах, настройках графического интерфейса, сведения о программах, которые установлены на компьютере, и многое другое.
Вся эта информация автоматически обновляется при установке нового оборудования, удалении или установке программ и так далее.
Давайте рассмотрим рисунок.
Корневым объектом является сам компьютер. Папка «Adobe» является потомком по отношению к папке «SOFTWARE» и предком для всех остальных папок, которые она в себя включает. Папки «7-Zip» и «Adobe» являются близнецами, так как они находятся на одном уровне и у них один предок – папка «SOFTWARE». Файл «UserID» является потомком папки «IAC». В свою очередь, мы можем видеть, что у файла «UserID» нет своих потомков.
В операционной же системе Linux как такового реестра нет. Вместо этого в ней существует папка «etc».
А сейчас мы с вами рассмотрим иерархическую базу данных «Доменная система имён». Эта система получила название DNS.
DNS – это распределённая база данных, которая поддерживает иерархическую систему имён для идентификации узлов сети Интернет.
Эта служба предназначена для автоматического поиска IP-адреса по известному символьному имени узла. То есть в этой базе данных содержится информация о всех компьютерах, подключённых к сети Интернет.
Корневой вершиной в этой системе является табличная база данных, которая содержит перечень доменов верхнего уровня.
Сам же корень управляется центром Internet Network Information Center. Домены верхнего уровня назначаются для каждой страны, а также на организационной основе. Для обозначения стран используются трёхбуквенные и двухбуквенные аббревиатуры.
Так, например, для русскоязычных сайтов доменом верхнего уровня является «.ru», для Казахстана – «.kz» и т. д. Для различных типов организаций также есть свои аббревиатуры.
На втором уровне находятся также табличные базы данных, но они уже в себя включают перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне содержатся табличные базы данных и таблицы. Табличные базы данных содержат перечень доменов третьего уровня для каждого домена второго уровня. Таблицы, в свою очередь, содержат IP-адреса компьютеров, которые находятся в домене второго уровня.
А теперь представьте, какой большой будет база данных, которая должна включать в себя информацию о всех компьютерах, подключенных к Интернету. Как вы думаете, много ли места она будет занимать?
Такая база данных огромна по своим размерам и соответственно она не будет умещаться в памяти одного компьютера, а если бы и можно было загрузить такую базу данных в один компьютер, то работа в Интернете была бы очень медленной. Представьте себе количество запросов, которые поступают от пользователей всего мира в течение, например, 1 минуты. Их количество огромно. А теперь представьте, что все эти запросы должен принять и обработать один компьютер. Это просто невозможно, так как приведёт не только к медленной работе компьютера, но также и к зависанию, если не к поломке. Таким образом, размещение базы данных доменной системы имён на одном компьютере неэффективно. Но решение этой проблемы было найдено. Вся база данных была разделена на части и размещена на различных DNS-серверах, которые связаны между собой. Такая иерархическая база данных является распределённой базой данных.
А сейчас давайте рассмотрим, как происходит поиск информации в такой огромной иерархической распределённой базе данных.
Например, вам нужно зайти на свою почту в Яндексе. Для этого вы вводите в адресную строку запрос.
На этом сервере, в таблице первого уровня, произойдёт поиск интересующего нас домена «ru», после чего запрос будет перенаправлен на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене «ru».
На втором уровне будет происходить поиск среди доменов второго уровня. После того, как был найден интересующий нас домен «yandex», произойдёт перенаправление на DNS-сервер третьего уровня, на котором находится перечень доменов третьего уровня, зарегистрированных в домене «yandex».
В таблице третьего уровня будет найден домен «mail», и запрос будет переадресован на DNS-сервер четвёртого уровня.
В таблице четвёртого уровня будет найдена запись, которая соответствует доменному имени, содержащемуся в запросе. После этого поиск в самой базе данных «Доменная система имён» будет завершён и начнётся поиск компьютера в сети по его IP-адресу.
Пришла пора подвести итоги урока.
Сегодня мы с вами узнали, что такое иерархическая структура и построили такую структуру на примере. Более подробно познакомились с элементами иерархической базы данных: корнем, предком, потомком, близнецами.
Рассмотрели несколько иерархических баз данных на примере Windows и Linux, а также реестра Windows.
Узнали, как составлена и работает иерархическая база данных «Доменная система имён».
Источник
Аннотация: В лекции рассматриваются модели организации баз данных, дается характеристика каждой модели. Описываются достоинства и недостатки существующих моделей баз данных. Даются определения атрибута, записи и отношений в различных моделях БД.
Цель лекции: Уяснить разницу между моделями организации БД. Ознакомиться с их достоинствами и недостатками. Понять, как организовываются связи в этих моделях, как применяются операции изменения в той или иной модели.
Различают три основные модели базы данных — это иерархическая, сетевая и реляционная. Эти модели отличаются между собой по способу установления связей между данными.
1. Иерархический подход к организации баз данных. Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными — одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Во-первых, все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель — единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково — таблицами. Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элемент модели — реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления (полнота последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL.
Третий элемент реляционной модели требует от реляционной модели поддержания некоторых ограничений целостности. Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор, называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель. Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты — текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных, не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности.
Несмотря на преимущества объектно-ориентированных систем — реализация сложных типов данных, связь с языками программирования и т.п. — на ближайшее время превосходство реляционных СУБД гарантировано.
Рассмотрим более подробно эти модели данных далее.
Иерархическая модель базы данных
Иерархические базы данных — самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок-потомок«. Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных — невозможность реализовать отношения «многие-ко-многим«, а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных. Иерархические базы данных графически могут быть представлены как перевернутое дерево, состоящее из объектов различных уровней. Верхний уровень (корень дерева) занимает один объект, второй — объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект, более близкий к корню) к потомку (объект более низкого уровня), при этом объект-предок может не иметь потомков или иметь их несколько, тогда как объект—потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
Иерархической базой данных является Каталог папок Windows, с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол. На втором уровне находятся папки Мой компьютер, Мои документы, Сетевое окружение и Корзина, которые являются потомками папки Рабочий стол, а между собой является близнецами. В свою очередь, папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков (Диск 3,5(А:), (С:), (D:), (Е:), (F:)) и системным папкам (сканер, bluetooth и.т.д.) — на
рис.
4.1.
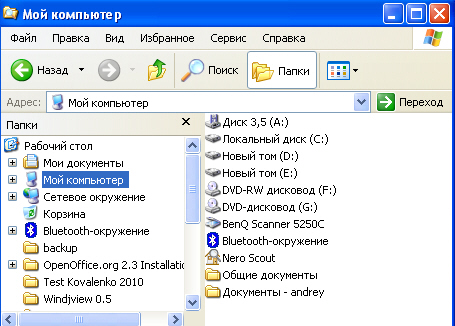
Рис.
4.1.
Иерархическая база данных Каталог папок Windows
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
| Атрибут (элемент данных) | — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. |
| Запись | — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов. |
| Групповое отношение | — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры. |
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей — вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись.
Пример
Рассмотрим следующую модель данных предприятия (см.
рис.
4.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на
рис.
4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (
рис.
4.2 b).
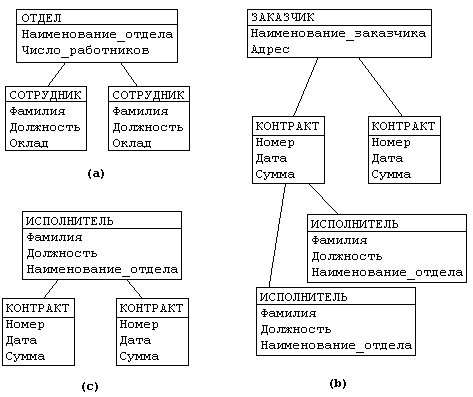
Рис.
4.2.
Пример иерархической базы данных
Из этого примера видны недостатки иерархических БД:
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних.
Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ — дочерней (
рис.
4.2 c). Таким образом, мы опять вынуждены дублировать информацию.
Операции над данными, определенные в иерархической модели:
- Добавить в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- Изменить значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- Удалить некоторую запись и все подчиненные ей записи.
- Извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей.
- Извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева).
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 10 тысяч руб.)
Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название «навигационного».
Ограничения целостности
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разные иерархии.
На этом уроке мы с вами
вспомним, что такое иерархическая структура и из каких элементов она состоит.
Также рассмотрим несколько примеров иерархической базы данных.
Начнём мы с вами с
рассмотрения иерархической структуры базы данных.
Иерархическая структура
– это многоуровневая форма организации объектов со строгой соотнесённостью
объектов нижнего уровня определённому объекту верхнего уровня. Т. е. можно
сказать, что иерархическая структура напоминает собой пирамиду, в которой
объекты более низкого уровня подчиняются объектам более высокого уровня.
Из этого можно сделать
вывод, что в иерархической структуре существуют отношения между её объектами
(элементами).
Ещё иерархическую
структуру называют древовидной. К примерам можно отнести содержание
учебника.
А сейчас рассмотрим
иерархическую структуру более подробно на примере.
Давайте построим
иерархическую структуру школы.
Во главе всегда находится
директор школы. Далее будут идти завуч старших классов, завуч младших классов,
заведующий хозяйственной деятельностью. После завучей идут учителя, которые,
соответственно, делятся на преподавателей младших и старших классов. Не будем
расписывать всех учителей, а возьмём по три учителя каждых классов. Заведующему
по хозяйственной деятельности будет подчиняться весь технический персонал. Его
мы расписывать не будем. Далее у каждого учителя есть свой класс, в котором он
является классным руководителем, а в каждом классе – ученики. В свою очередь,
учителя старших классов ведут уроки и в других классах. Давайте отобразим
несколько таких классов в нашей структуре. Если же всю эту структуру
расписывать более подробно, то нам понадобится очень много места, так как
объектов в этой системе очень большое количество.
Итак, во главе любой
иерархической структуры всегда находится один элемент (объект). В нашем случае
– это директор школы. Он является корнем вершины и находится на верхнем
(первом) уровне.
Далее идёт второй
уровень, на котором находятся заместители.
На третьем уровне
находятся учителя и технический персонал, на четвёртом – классы и на пятом –
ученики.
Как говорилось ранее,
между всеми объектами существуют связи. Каждый объект более высокого уровня
может включать в себя несколько объектов более низкого уровня. Давайте снова
обратимся к нашему примеру. Так, завуч старшей школы включает в себя всех
учителей, которые ведут уроки в старших классах. А заведующий хозяйственной
деятельностью управляет всем техническим персоналом школы. Такие объекты
находятся в отношении предка (объект более высокого уровня) к потомку
(объект более низкого уровня). То есть завуч старшей школы и заведующий
хозяйственной деятельностью являются предками, а учителя и технический персонал
– потомками.
Также мы можем видеть,
что у объекта-предка может быть несколько потомков. Но в то же время у
объекта-потомка может быть только один предок. Объекты, которые находятся на
одном уровне и у которых один общий предок, называются близнецами.
Рассмотрим ещё один
пример. Построить иерархическую структуру, исходя из следующего условия: на кафедре
иностранных языков работают три преподавателя. Иванова Инна Сергеевна преподаёт
английский язык, Кулибина Анна Васильевна преподаёт немецкий язык, а Рудков
Игорь Сергеевич преподаёт французский язык.
Корневой вершиной в этой
структуре будет являться кафедра. Изобразим её в виде круга. Она включает в
себя трёх преподавателей. Также изобразим их схематично, а от кафедры к каждому
преподавателю проведём стрелки.
Далее у каждого
преподавателя есть свои предметы, которые он ведёт. Также изобразим их
схематично и проведём стрелки.
Таким образом мы получили
графическое отображение иерархической структуры кафедры.
Корневой вершиной
является кафедра.
Учителя являются потомками
по отношению к кафедре и предками по отношению к предметам, которые они
преподают. Также они между собой являются близнецами, так как находятся на
одном уровне структуры и имеют одного предка – кафедру.
У нас получилось
несколько определений.
Корень
– это единственный объект, который стоит на вершине иерархической системы и
является её первым уровнем.
Предок
– это объект, который стоит более близко к корню системы и у него может быть
несколько потомков.
Потомок
– это объект, который стоит на более низком уровне по отношению к предку и у
него может быть только один предок.
Близнецы –
это объекты, которые имеют одного предка и находятся на одном уровне.
А сейчас рассмотрим ещё
несколько примеров.
Начнём с иерархической
базы данных папки Windows.
Иерархической базой
данных является каталог папок Windows. Перед вами
рисунок системного диска. Для того, чтобы увидеть древовидную структуру в
проводнике в Windows 7, необходимо выбрать кнопку
«Упорядочить», далее из появившегося списка – «Представления», а затем «Область
переходов». Это в том случае, если данная область не отображается.
А вот, например, в Windows 10 необходимо в проводнике, во вкладке «Вид»,
выбрать «Область навигации» и из списка снова «Область навигации».
На рисунке представлен
проводник операционной системы Windows 10.
Итак, корневой является
папка «Этот компьютер».
Далее, на втором уровне
на представленном рисунке находится локальный диск С, который включает в себя
несколько папок третьего уровня.
В нашем случае выбрана
папка «Program Files». Она
в себя включает несколько папок-потомков.
Исходя из этого можно
сказать, что корнем является – «Этот компьютер». Далее и предком, и потомком
является локальный диск С. Папка «Program Files» также является и потомком (по отношению к локальному
диску С), и предком (по отношению к остальным папкам, которые она в себя
включает). Файл «Rar.txt» является потомком папки «WinRAR».
В свою очередь, мы можем видеть, что у файла «Rar.txt» нет своих потомков. Также,
например, файлы «Rar.txt» и «Rar.exe» являются близнецами, так как
находятся на одном уровне и у них один общий предок – папка «WinRAR».
Ещё одним примером
иерархической базы данных является файловая система Linux.
Мы ранее её
рассматривали. В ней существует одна корневая папка, все остальные папки являются
потомками. В корневой папке содержатся все системные файлы. А вот, например,
каталоги логических томов и запоминающих устройств содержатся в составе других
каталогов. Директории томов жёсткого диска содержатся в папке «mnt».
Другие запоминающие устройства находятся в папке «media».
В свою очередь, папки «mnt» и «media»
содержатся в одном системном корневом каталоге. Таким образом, папки «mnt»
и «media» являются и потомками (по отношению к
основному корневому каталогу), и предками (по отношению к каталогам логических
томов и запоминающих устройств). Помимо этого, эти две папки являются
близнецами, так как они находятся на одном уровне и имеют одного предка.
А сейчас давайте
рассмотрим такую иерархическую базу данных, как «Системный реестр Windows».
В этой иерархической базе
данных хранится вся информация, которая нужна для нормального функционирования
компьютерной системы. То есть в этой базе данных содержится информация о
настройках компьютера, установленных драйверах, настройках графического
интерфейса, сведения о программах, которые установлены на компьютере, и многое
другое.
Вся эта информация
автоматически обновляется при установке нового оборудования, удалении или
установке программ и так далее.
Давайте рассмотрим
рисунок.
Корневым объектом
является сам компьютер. Папка «Adobe»
является потомком по отношению к папке «SOFTWARE» и предком для всех
остальных папок, которые она в себя включает. Папки «7-Zip» и «Adobe» являются близнецами, так как они
находятся на одном уровне и у них один предок – папка «SOFTWARE». Файл «UserID»
является потомком папки «IAC».
В свою очередь, мы можем видеть, что у файла «UserID» нет своих потомков.
В операционной же системе
Linux
как такового реестра нет. Вместо этого в ней существует папка «etc».
А сейчас мы с вами
рассмотрим иерархическую базу данных «Доменная система имён». Эта система
получила название DNS.
DNS – это распределённая
база данных, которая поддерживает иерархическую систему имён для идентификации
узлов сети Интернет.
Эта служба предназначена
для автоматического поиска IP-адреса
по известному символьному имени узла. То есть в этой базе данных содержится
информация о всех компьютерах, подключённых к сети Интернет.
Корневой вершиной в этой
системе является табличная база данных, которая содержит перечень доменов
верхнего уровня.
Сам же корень управляется
центром Internet Network Information Center. Домены
верхнего уровня назначаются для каждой страны, а также на организационной
основе. Для обозначения стран используются трёхбуквенные и двухбуквенные
аббревиатуры.
Так, например, для
русскоязычных сайтов доменом верхнего уровня является «.ru»,
для Казахстана – «.kz» и т. д. Для различных типов организаций
также есть свои аббревиатуры.
На втором уровне
находятся также табличные базы данных, но они уже в себя включают перечень
доменов второго уровня для каждого домена первого уровня.
На третьем уровне
содержатся табличные базы данных и таблицы. Табличные базы данных содержат
перечень доменов третьего уровня для каждого домена второго уровня. Таблицы, в
свою очередь, содержат IP-адреса
компьютеров, которые находятся в домене второго уровня.
А теперь представьте,
какой большой будет база данных, которая должна включать в себя информацию о
всех компьютерах, подключенных к Интернету. Как вы
думаете, много ли места она будет занимать?
Такая база данных огромна
по своим размерам и соответственно она не будет умещаться в памяти одного
компьютера, а если бы и можно было загрузить такую базу данных в один
компьютер, то работа в Интернете была бы очень медленной. Представьте себе
количество запросов, которые поступают от пользователей всего мира в течение,
например, 1 минуты. Их количество огромно. А теперь представьте, что все эти
запросы должен принять и обработать один компьютер. Это просто невозможно, так
как приведёт не только к медленной работе компьютера, но также и к зависанию,
если не к поломке. Таким образом, размещение базы данных доменной системы имён
на одном компьютере неэффективно. Но решение этой проблемы было найдено. Вся
база данных была разделена на части и размещена на различных DNS-серверах, которые связаны между
собой. Такая иерархическая база данных является распределённой базой данных.
А сейчас давайте
рассмотрим, как происходит поиск информации в такой огромной иерархической
распределённой базе данных.
Например, вам нужно зайти
на свою почту в Яндексе. Для этого вы вводите в адресную строку запрос.
Ваш запрос сначала
отправляется на DNS-сервер вашего провайдера, с которого он переадресуется
на DNS -сервер верхнего уровня базы данных.
На этом сервере, в
таблице первого уровня, произойдёт поиск интересующего нас домена «ru»,
после чего запрос будет перенаправлен на DNS-сервер второго уровня, который
содержит перечень доменов второго уровня, зарегистрированных в домене «ru».
На втором уровне будет
происходить поиск среди доменов второго уровня. После того, как был найден
интересующий нас домен «yandex», произойдёт
перенаправление на DNS-сервер
третьего уровня, на котором находится перечень доменов третьего уровня,
зарегистрированных в домене «yandex».
В таблице третьего уровня
будет найден домен «mail», и запрос будет
переадресован на DNS-сервер
четвёртого уровня.
В таблице четвёртого
уровня будет найдена запись, которая соответствует доменному имени,
содержащемуся в запросе. После этого поиск в самой базе данных «Доменная
система имён» будет завершён и начнётся поиск компьютера в сети по его IP-адресу.
Пришла пора подвести
итоги урока.
Сегодня мы с вами узнали,
что такое иерархическая структура и построили такую структуру на примере. Более
подробно познакомились с элементами иерархической базы данных: корнем, предком,
потомком, близнецами.
Рассмотрели несколько
иерархических баз данных на примере Windows и Linux,
а также реестра Windows.
Узнали, как составлена и
работает иерархическая база данных «Доменная система имён».

БАЗЫ ДАННЫХ И ИХ ИСПОЛЬЗОВАНИЕ В ТУРИЗМЕ Выполнила Широкова Мария Туризм; 2 курс
 – совокупность организованной информации, относящейся к определённой предметной области, предназначенная длительного")
База данных (БД) – совокупность организованной информации, относящейся к определённой предметной области, предназначенная длительного хранения во внешней памяти компьютера и постоянного применения.

Типы баз данных табличные иерархические сетевые

Для создания баз данных, а также выполнения операции поиска и сортировки данных предназначены специальные программы — системы управления базами данных (СУБД).
 включают язык определения данных, с помощью которого можно")
Современные СУБД имеют следующие возможности: 1) включают язык определения данных, с помощью которого можно определить базу данных, ее структуру, типы данных, а также средства задания ограничения для хранимой информации; 2) позволяют вставлять, удалять, обновлять и извлекать информацию из базы данных посредством языка запросов (SQL); 3) большинство СУБД могут работать на компьютерах с разной архитектурой и под разными операционными системами; 4) многопользовательские СУБД имеют развитые средства администрирования баз данных.


ПОПУЛЯРНЫЕ БАЗЫ ДАННЫХ В ТУРИСТИЧЕСКОМ БИЗНЕСЕ 1. Amadeus – система бронирования авиаперелетов, гостиниц, автомобилей, железнодорожных перевозок, паромов, круизов.

Amadeus Air — это система, обеспечивающая доступ в режиме реального времени к расписаниям полетов огромного количества авиакомпаний, гарантирующая совершенно точную, до последней минуты скорректированную информацию о рейсах до любого пункта назначения, стыковках рейсов и наличии свободных мест.

Amadeus Fare Quote — крупнейшая и тем не менее простая в использовании база данных по тарифам авиалиний. Вся нужная информация доступна с помощью одного запроса, поэтому нет необходимости просматривать на дисплее результаты дополнительных запросов. Имеется механизм быстрого и простого получения комбинированных цен для сложных маршрутов с учетом возможных скидок.

Amadeus Hotel предлагает точную информацию о размещении более чем в 51 тысяче отелей и гостиниц во всем мире. Дополнительно эта система предоставляет сведения о местонахождении гостиницы, наличии в ней свободных мест, дополнительных услугах и специальных расценках.

Amadeus Cars реализует возможность бронирования автомобилей в режиме реального времени в основных компаниях проката в тысячах населенных пунктов многих стран мира. Можно получить информацию о специальных расценках и предложениях, квотах и тарифах в местной валюте.

База данных GALILEO — это целый комплекс встроенных подсистем, каждая из которых предназначена для выполнения задачи получения полной информации и обеспечения простого доступа к ресурсам 527 авиакомпаний, 202 гостиничных цепочек, прокату автомобилей в 14500 городах, а также для бронирования круизов, туров, билетов в театры и просмотра сведений о тарифах, погоде, визах, прививках, кредитных картах и многое другое.



VEDI Quick Book – единая система бронирования различных туристических услуг в режиме реального времени, которая позволяет без труда найти нужный отель в любой точке мира, забронировать авиабилет по выгодному тарифу, добавить к заказу необходимые трансферы и подобрать экскурсии на месте пребывания. Также вы можете с комфортом путешествовать между европейскими городами на поездах.


SYSTUR — Cистема бронирования туров — Шерегеш, Алтай, вся Сибирь.

На сегодняшний день система бронирования туров “SYSTUR” предлагает следующие виды услуг: • Организация активных туров; • Корпоративный отдых и корпоративные туры; • Транспортные услуги; • Бронирование гостиниц; • Организация туров на европейские горнолыжные курорты.


ЗАКЛЮЧЕНИЕ Базы данных играют важную роль в работе туристических компаний. Они находят свое применение в турфмирмах для учета персонала, ведения бухгалтерии, партнеров в гостиничном и ресторанном бизнесе, клиентов, для бронирования авиа и ЖД билетов, гостиниц и дополнительных услуг, а также ведения электронного документооборота.

1. Какой тип баз данных содержит перечень объектов одного типа, то есть объектов, имеющих одинаковый набор свойств? а) иерархические БД; б) сетевые БД; в) табличные БД. 2. К какому виду баз данных относится каталог папок Windows, с которым можно работать, запустив проводник. : а) сетевые БД; б) иерархические БД; в) табличные БД.
 для ведения")
3. Для чего используются БД в туристской деятельности в первую очередь? а) для ведения электронного документооборота; б) для бронирования различных услуг; в) для ведения бухгалтерии. 4. Какая система бронирования предлагает своим клиентам доступ более чем к 25300 офисов 50 компаний по прокату автомобилей во всем мире? а) Amadeus; б) Galileo; в) Sabre.
")
5. Какая из систем бронирования получила максимальное распространение на территории государств Северной Америки? а) Sabre; б) Galileo; в) Worldspan.
Базы данных — это способ упорядочить информацию так, чтобы компьютер мог с ней легко работать, а человек мог пользоваться этими данными как ему удобно. Мы уже писали о базах данных в общем, теперь углубимся.
👉 Это знания скорее из области информатики, чем прикладного программирования. Если вы просто делаете сайты или обслуживаете интернет-магазин, вероятнее всего, вам из этого понадобятся только реляционные базы данных. Но когда вы захотите сделать более сложные приложения — например рекомендации товаров, — вам потребуются знания о других типах баз.
Считайте, что эта статья для расширения кругозора.
Три основных типа
В зависимости от того, какие данные нужно в ней хранить и как с ними работать, базы делятся на реляционные и нереляционные:
Реляционные
Реляционные базы данных ещё называют табличными, потому что все данные в них можно представить в виде разных таблиц. Одни таблицы связаны с другими, а другие — с третьими. Например, база данных покупок в магазине может выглядеть так:
Смотрите, у магазина есть две таблицы — с товарами и покупателями. Но когда один из них что-то покупает, то данные попадают в третью таблицу. В ней есть своя информация (количество купленных товаров) и ссылки на покупателя и сам товар. Если нужно, можно по этим связям попасть в нужную таблицу и узнать подробности о той или другой записи.
Если у покупателя поменяется номер телефона, то нам достаточно будет поменять это в одной таблице «Клиенты». Благодаря тому, что в «Покупки» записывается только код покупателя, нам не нужно менять имя больше нигде — данные сами обновятся автоматически, когда мы захотим посмотреть, кто именно купил табурет.
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:
Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:
Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Главное о базах данных
- Чаще всего базы данных напоминают таблицы: в них одному параметру соответствует один набор данных. Например, один клиент — одно имя, один телефон, один адрес.
- Такие «табличные» базы данных называются реляционными.
- Чтобы строить сложные связи, разные таблицы в реляционных базах можно связывать между собой: ставить ссылки.
- Реляционная база — не единственный способ хранения данных. Есть ситуации, когда нам нужна большая гибкость в хранении.
- Бывают сетевые базы данных: когда нужно хранить много связей между множеством объектов. Например, каталог фильмов: в одном фильме может участвовать много человек, а каждый из них может участвовать во множестве фильмов.
- Бывают иерархические базы, или «деревья». Пример — наша файловая система.
- Какую выбрать базу — зависит от задачи. Одна база не лучше другой, но они могут быть более или менее подходящими для определённых задач.
Иллюстратор
Даня Берковский
Что-то делает руками
Паша Федоров