(PHP 4 >= 4.0.5, PHP 5, PHP 7, PHP 
iconv — Convert a string from one character encoding to another
Description
iconv(string $from_encoding, string $to_encoding, string $string): string|false
Parameters
-
from_encoding -
The current encoding used to interpret
string. -
to_encoding -
The desired encoding of the result.
If the string
//TRANSLITis appended to
to_encoding, then transliteration is activated. This
means that when a character can’t be represented in the target charset,
it may be approximated through one or several similarly looking
characters. If the string//IGNOREis appended,
characters that cannot be represented in the target charset are silently
discarded. Otherwise,E_NOTICEis generated and the function
will returnfalse.Caution
If and how
//TRANSLITworks exactly depends on the
system’s iconv() implementation (cf.ICONV_IMPL).
Some implementations are known to ignore//TRANSLIT,
so the conversion is likely to fail for characters which are illegal for
theto_encoding. -
string -
The string to be converted.
Return Values
Returns the converted string, or false on failure.
Examples
Example #1 iconv() example
<?php
$text = "This is the Euro symbol '€'.";
echo
'Original : ', $text, PHP_EOL;
echo 'TRANSLIT : ', iconv("UTF-8", "ISO-8859-1//TRANSLIT", $text), PHP_EOL;
echo 'IGNORE : ', iconv("UTF-8", "ISO-8859-1//IGNORE", $text), PHP_EOL;
echo 'Plain : ', iconv("UTF-8", "ISO-8859-1", $text), PHP_EOL;?>
The above example will output
something similar to:
Original : This is the Euro symbol '€'. TRANSLIT : This is the Euro symbol 'EUR'. IGNORE : This is the Euro symbol ''. Plain : Notice: iconv(): Detected an illegal character in input string in .iconv-example.php on line 7
Notes
Note:
The character encodings and options available depend on the installed implementation
of iconv. If the argument tofrom_encoding
orto_encodingis not supported on the current system,false
will be returned.
See Also
- mb_convert_encoding() — Convert a string from one character encoding to another
- UConverter::transcode() — Convert a string from one character encoding to another
orrd101 at gmail dot com ¶
10 years ago
The "//ignore" option doesn't work with recent versions of the iconv library. So if you're having trouble with that option, you aren't alone.
That means you can't currently use this function to filter invalid characters. Instead it silently fails and returns an empty string (or you'll get a notice but only if you have E_NOTICE enabled).
This has been a known bug with a known solution for at least since 2009 years but no one seems to be willing to fix it (PHP must pass the -c option to iconv). It's still broken as of the latest release 5.4.3.
https://bugs.php.net/bug.php?id=48147
https://bugs.php.net/bug.php?id=52211
https://bugs.php.net/bug.php?id=61484
[UPDATE 15-JUN-2012]
Here's a workaround...
ini_set('mbstring.substitute_character', "none");
$text= mb_convert_encoding($text, 'UTF-8', 'UTF-8');
That will strip invalid characters from UTF-8 strings (so that you can insert it into a database, etc.). Instead of "none" you can also use the value 32 if you want it to insert spaces in place of the invalid characters.
Ritchie ¶
15 years ago
Please note that iconv('UTF-8', 'ASCII//TRANSLIT', ...) doesn't work properly when locale category LC_CTYPE is set to C or POSIX. You must choose another locale otherwise all non-ASCII characters will be replaced with question marks. This is at least true with glibc 2.5.
Example:
<?php
setlocale(LC_CTYPE, 'POSIX');
echo iconv('UTF-8', 'ASCII//TRANSLIT', "Žluťoučký kůňn");
// ?lu?ou?k? k??setlocale(LC_CTYPE, 'cs_CZ');
echo iconv('UTF-8', 'ASCII//TRANSLIT', "Žluťoučký kůňn");
// Zlutoucky kun
?>
daniel dot rhodes at warpasylum dot co dot uk ¶
11 years ago
Interestingly, setting different target locales results in different, yet appropriate, transliterations. For example:
<?php
//some German
$utf8_sentence = 'Weiß, Goldmann, Göbel, Weiss, Göthe, Goethe und Götz';//UK
setlocale(LC_ALL, 'en_GB');//transliterate
$trans_sentence = iconv('UTF-8', 'ASCII//TRANSLIT', $utf8_sentence);//gives [Weiss, Goldmann, Gobel, Weiss, Gothe, Goethe und Gotz]
//which is our original string flattened into 7-bit ASCII as
//an English speaker would do it (ie. simply remove the umlauts)
echo $trans_sentence . PHP_EOL;//Germany
setlocale(LC_ALL, 'de_DE');$trans_sentence = iconv('UTF-8', 'ASCII//TRANSLIT', $utf8_sentence);//gives [Weiss, Goldmann, Goebel, Weiss, Goethe, Goethe und Goetz]
//which is exactly how a German would transliterate those
//umlauted characters if forced to use 7-bit ASCII!
//(because really ä = ae, ö = oe and ü = ue)
echo $trans_sentence . PHP_EOL;?>
annuaireehtp at gmail dot com ¶
13 years ago
to test different combinations of convertions between charsets (when we don't know the source charset and what is the convenient destination charset) this is an example :
<?php
$tab = array("UTF-8", "ASCII", "Windows-1252", "ISO-8859-15", "ISO-8859-1", "ISO-8859-6", "CP1256");
$chain = "";
foreach ($tab as $i)
{
foreach ($tab as $j)
{
$chain .= " $i$j ".iconv($i, $j, "$my_string");
}
}
echo
$chain;
?>
then after displaying, you use the $i$j that shows good displaying.
NB: you can add other charsets to $tab to test other cases.
manuel at kiessling dot net ¶
13 years ago
Like many other people, I have encountered massive problems when using iconv() to convert between encodings (from UTF-8 to ISO-8859-15 in my case), especially on large strings.
The main problem here is that when your string contains illegal UTF-8 characters, there is no really straight forward way to handle those. iconv() simply (and silently!) terminates the string when encountering the problematic characters (also if using //IGNORE), returning a clipped string. The
<?php
$newstring
= html_entity_decode(htmlentities($oldstring, ENT_QUOTES, 'UTF-8'), ENT_QUOTES , 'ISO-8859-15');?>
workaround suggested here and elsewhere will also break when encountering illegal characters, at least dropping a useful note ("htmlentities(): Invalid multibyte sequence in argument in...")
I have found a lot of hints, suggestions and alternative methods (it's scary and in my opinion no good sign how many ways PHP natively provides to convert the encoding of strings), but none of them really worked, except for this one:
<?php
$newstring
= mb_convert_encoding($oldstring, 'ISO-8859-15', 'UTF-8');?>
Leigh Morresi ¶
14 years ago
If you are getting question-marks in your iconv output when transliterating, be sure to 'setlocale' to something your system supports.
Some PHP CMS's will default setlocale to 'C', this can be a problem.
use the "locale" command to find out a list..
$ locale -a
C
en_AU.utf8
POSIX
<?php
setlocale(LC_CTYPE, 'en_AU.utf8');
$str = iconv('UTF-8', 'ASCII//TRANSLIT', "Côte d'Ivoire");
?>
zhawari at hotmail dot com ¶
18 years ago
Here is how to convert UCS-2 numbers to UTF-8 numbers in hex:
<?php
function ucs2toutf8($str)
{
for ($i=0;$i<strlen($str);$i+=4)
{
$substring1 = $str[$i].$str[$i+1];
$substring2 = $str[$i+2].$str[$i+3];
if (
$substring1 == "00")
{
$byte1 = "";
$byte2 = $substring2;
}
else
{
$substring = $substring1.$substring2;
$byte1 = dechex(192+(hexdec($substring)/64));
$byte2 = dechex(128+(hexdec($substring)%64));
}
$utf8 .= $byte1.$byte2;
}
return $utf8;
}
echo
strtoupper(ucs2toutf8("06450631062D0020"));
?>
Input:
06450631062D
Output:
D985D8B1D8AD
regards,
Ziyad
Nopius ¶
7 years ago
As orrd101 said, there is a bug with //IGNORE in recent PHP versions (we use 5.6.5) where we couldn't convert some strings (i.e. "∙" from UTF8 to CP1251 with //IGNORE).
But we have found a workaround and now we use both //TRANSLIT and //IGNORE flags:
$text="∙";
iconv("UTF8", "CP1251//TRANSLIT//IGNORE", $text);
Daniel Klein ¶
6 years ago
I just found out today that the Windows and *NIX versions of PHP use different iconv libraries and are not very consistent with each other.
Here is a repost of my earlier code that now works on more systems. It converts as much as possible and replaces the rest with question marks:
<?php
if (!function_exists('utf8_to_ascii')) {
setlocale(LC_CTYPE, 'en_AU.utf8');
if (@iconv("UTF-8", "ASCII//IGNORE//TRANSLIT", 'é') === false) {
// PHP is probably using the glibc library (*NIX)
function utf8_to_ascii($text) {
return iconv("UTF-8", "ASCII//TRANSLIT", $text);
}
}
else {
// PHP is probably using the libiconv library (Windows)
function utf8_to_ascii($text) {
if (is_string($text)) {
// Includes combinations of characters that present as a single glyph
$text = preg_replace_callback('/X/u', __FUNCTION__, $text);
}
elseif (is_array($text) && count($text) == 1 && is_string($text[0])) {
// IGNORE characters that can't be TRANSLITerated to ASCII
$text = iconv("UTF-8", "ASCII//IGNORE//TRANSLIT", $text[0]);
// The documentation says that iconv() returns false on failure but it returns ''
if ($text === '' || !is_string($text)) {
$text = '?';
}
elseif (preg_match('/w/', $text)) { // If the text contains any letters...
$text = preg_replace('/W+/', '', $text); // ...then remove all non-letters
}
}
else { // $text was not a string
$text = '';
}
return $text;
}
}
}
jessiedeer at hotmail dot com ¶
9 years ago
iconv with //IGNORE works as expected: it will skip the character if this one does not exist in the $out_charset encoding.
If a character is missing from the $in_charset encoding (eg byte x81 from CP1252 encoding), then iconv will return an error, whether with //IGNORE or not.
atelier at degoy dot com ¶
8 years ago
There may be situations when a new version of a web site, all in UTF-8, has to display some old data remaining in the database with ISO-8859-1 accents. The problem is iconv("ISO-8859-1", "UTF-8", $string) should not be applied if $string is already UTF-8 encoded.
I use this function that does'nt need any extension :
function convert_utf8( $string ) {
if ( strlen(utf8_decode($string)) == strlen($string) ) {
// $string is not UTF-8
return iconv("ISO-8859-1", "UTF-8", $string);
} else {
// already UTF-8
return $string;
}
}
I have not tested it extensively, hope it may help.
Daniel Klein ¶
3 years ago
If you want to convert to a Unicode encoding without the byte order mark (BOM), add the endianness to the encoding, e.g. instead of "UTF-16" which will add a BOM to the start of the string, use "UTF-16BE" which will convert the string without adding a BOM.
i.e.
<?php
iconv('CP1252', 'UTF-16', $text); // with BOM
iconv('CP1252', 'UTF-16BE', $text); // without BOM
nikolai-dot-zujev-at-gmail-dot-com ¶
18 years ago
Here is an example how to convert windows-1251 (windows) or cp1251(Linux/Unix) encoded string to UTF-8 encoding.
<?php
function cp1251_utf8( $sInput )
{
$sOutput = "";
for (
$i = 0; $i < strlen( $sInput ); $i++ )
{
$iAscii = ord( $sInput[$i] );
if (
$iAscii >= 192 && $iAscii <= 255 )
$sOutput .= "&#".( 1040 + ( $iAscii - 192 ) ).";";
else if ( $iAscii == 168 )
$sOutput .= "&#".( 1025 ).";";
else if ( $iAscii == 184 )
$sOutput .= "&#".( 1105 ).";";
else
$sOutput .= $sInput[$i];
}
return
$sOutput;
}
?>
vitek at 4rome dot ru ¶
18 years ago
On some systems there may be no such function as iconv(); this is due to the following reason: a constant is defined named `iconv` with the value `libiconv`. So, the string PHP_FUNCTION(iconv) transforms to PHP_FUNCTION(libiconv), and you have to call libiconv() function instead of iconv().
I had seen this on FreeBSD, but I am sure that was a rather special build.
If you'd want not to be dependent on this behaviour, add the following to your script:
<?php
if (!function_exists('iconv') && function_exists('libiconv')) {
function iconv($input_encoding, $output_encoding, $string) {
return libiconv($input_encoding, $output_encoding, $string);
}
}
?>
Thanks to tony2001 at phpclub.net for explaining this behaviour.
gree:.. (gree 4T grees D0T net) ¶
15 years ago
In my case, I had to change:
<?php
setlocale(LC_CTYPE, 'cs_CZ');
?>
to
<?php
setlocale(LC_CTYPE, 'cs_CZ.UTF-8');
?>
Otherwise it returns question marks.
When I asked my linux for locale (by locale command) it returns "cs_CZ.UTF-8", so there is maybe correlation between it.
iconv (GNU libc) 2.6.1
glibc 2.3.6
nilcolor at gmail dot coom ¶
17 years ago
Didn't know its a feature or not but its works for me (PHP 5.0.4)
iconv('', 'UTF-8', $str)
test it to convert from windows-1251 (stored in DB) to UTF-8 (which i use for web pages).
BTW i convert each array i fetch from DB with array_walk_recursive...
jorortega at gmail dot com ¶
9 years ago
Be aware that iconv in PHP uses system implementations of locales and languages, what works under linux, normally doesn't in windows.
Also, you may notice that recent versions of linux (debian, ubuntu, centos, etc) the //TRANSLIT option doesn't work. since most distros doesn't include the intl packages (example: php5-intl and icuxx (where xx is a number) in debian) by default. And this because the intl package conflicts with another package needed for international DNS resolution.
Problem is that configuration is dependent of the sysadmin of the machine where you're hosted, so iconv is pretty much useless by default, depending on what configuration is used by your distro or the machine's admin.
ameten ¶
12 years ago
I have used iconv to convert from cp1251 into UTF-8. I spent a day to investigate why a string with Russian capital 'Р' (sounds similar to 'r') at the end cannot be inserted into a database.
The problem is not in iconv. But 'Р' in cp1251 is chr(208) and 'Р' in UTF-8 is chr(208).chr(106). chr(106) is one of the space symbol which match 's' in regex. So, it can be taken by a greedy '+' or '*' operator. In that case, you loose 'Р' in your string.
For example, 'ГР ' (Russian, UTF-8). Function preg_match. Regex is '(.+?)[s]*'. Then '(.+?)' matches 'Г'.chr(208) and '[s]*' matches chr(106).' '.
Although, it is not a bug of iconv, but it looks like it very much. That's why I put this comment here.
zhawari at hotmail dot com ¶
18 years ago
Here is how to convert UTF-8 numbers to UCS-2 numbers in hex:
<?phpfunction utf8toucs2($str)
{
for ($i=0;$i<strlen($str);$i+=2)
{
$substring1 = $str[$i].$str[$i+1];
$substring2 = $str[$i+2].$str[$i+3];
if (
hexdec($substring1) < 127)
$results = "00".$str[$i].$str[$i+1];
else
{
$results = dechex((hexdec($substring1)-192)*64 + (hexdec($substring2)-128));
if ($results < 1000) $results = "0".$results;
$i+=2;
}
$ucs2 .= $results;
}
return $ucs2;
}
echo
strtoupper(utf8toucs2("D985D8B1D8AD"))."n";
echo strtoupper(utf8toucs2("456725"))."n";?>
Input:
D985D8B1D8AD
Output:
06450631062D
Input:
456725
Output:
004500670025
ng4rrjanbiah at rediffmail dot com ¶
18 years ago
Here is a code to convert ISO 8859-1 to UTF-8 and vice versa without using iconv.
<?php
//Logic from http://twiki.org/cgi-bin/view/Codev/InternationalisationUTF8
$str_iso8859_1 = 'foo in ISO 8859-1';
//ISO 8859-1 to UTF-8
$str_utf8 = preg_replace("/([x80-xFF])/e",
"chr(0xC0|ord('\1')>>6).chr(0x80|ord('\1')&0x3F)",
$str_iso8859_1);
//UTF-8 to ISO 8859-1
$str_iso8859_1 = preg_replace("/([xC2xC3])([x80-xBF])/e",
"chr(ord('\1')<<6&0xC0|ord('\2')&0x3F)",
$str_utf8);
?>
HTH,
R. Rajesh Jeba Anbiah
anyean at gmail dot com ¶
17 years ago
<?php
//script from http://zizi.kxup.com/
//javascript unesape
function unescape($str) {
$str = rawurldecode($str);
preg_match_all("/(?:%u.{4})|&#x.{4};|&#d+;|.+/U",$str,$r);
$ar = $r[0];
print_r($ar);
foreach($ar as $k=>$v) {
if(substr($v,0,2) == "%u")
$ar[$k] = iconv("UCS-2","UTF-8",pack("H4",substr($v,-4)));
elseif(substr($v,0,3) == "&#x")
$ar[$k] = iconv("UCS-2","UTF-8",pack("H4",substr($v,3,-1)));
elseif(substr($v,0,2) == "&#") {
echo substr($v,2,-1)."<br>";
$ar[$k] = iconv("UCS-2","UTF-8",pack("n",substr($v,2,-1)));
}
}
return join("",$ar);
}
?>
kikke ¶
13 years ago
You can use native iconv in Linux via passthru if all else failed.
Use the -c parameter to suppress error messages.
Daniel Klein ¶
9 years ago
You can use 'CP1252' instead of 'Windows-1252':
<?php
// These two lines are equivalent
$result = iconv('Windows-1252', 'UTF-8', $string);
$result = iconv('CP1252', 'UTF-8', $string);
?>
Note: The following code points are not valid in CP1252 and will cause errors.
129 (0x81)
141 (0x8D)
143 (0x8F)
144 (0x90)
157 (0x9D)
Use the following instead:
<?php
// Remove invalid code points, convert everything else
$result = iconv('CP1252', 'UTF-8//IGNORE', $string);
?>
berserk220 at mail dot ru ¶
14 years ago
So, as iconv() does not always work correctly, in most cases, much easier to use htmlentities().
Example: <?php $content=htmlentities(file_get_contents("incoming.txt"), ENT_QUOTES, "Windows-1252"); file_put_contents("outbound.txt", html_entity_decode($content, ENT_QUOTES , "utf-8")); ?>
anton dot vakulchik at gmail dot com ¶
15 years ago
function detectUTF8($string)
{
return preg_match('%(?:
[xC2-xDF][x80-xBF] # non-overlong 2-byte
|xE0[xA0-xBF][x80-xBF] # excluding overlongs
|[xE1-xECxEExEF][x80-xBF]{2} # straight 3-byte
|xED[x80-x9F][x80-xBF] # excluding surrogates
|xF0[x90-xBF][x80-xBF]{2} # planes 1-3
|[xF1-xF3][x80-xBF]{3} # planes 4-15
|xF4[x80-x8F][x80-xBF]{2} # plane 16
)+%xs', $string);
}
function cp1251_utf8( $sInput )
{
$sOutput = "";
for ( $i = 0; $i < strlen( $sInput ); $i++ )
{
$iAscii = ord( $sInput[$i] );
if ( $iAscii >= 192 && $iAscii <= 255 )
$sOutput .= "&#".( 1040 + ( $iAscii - 192 ) ).";";
else if ( $iAscii == 168 )
$sOutput .= "&#".( 1025 ).";";
else if ( $iAscii == 184 )
$sOutput .= "&#".( 1105 ).";";
else
$sOutput .= $sInput[$i];
}
return $sOutput;
}
function encoding($string){
if (function_exists('iconv')) {
if (@!iconv('utf-8', 'cp1251', $string)) {
$string = iconv('cp1251', 'utf-8', $string);
}
return $string;
} else {
if (detectUTF8($string)) {
return $string;
} else {
return cp1251_utf8($string);
}
}
}
echo encoding($string);
phpmanualspam at netebb dot com ¶
13 years ago
mirek code, dated 16-May-2008 10:17, added the characters `^~'" to the output.
This function will strip out these extra characters:
<?php
setlocale(LC_ALL, 'en_US.UTF8');
function clearUTF($s)
{
$r = '';
$s1 = @iconv('UTF-8', 'ASCII//TRANSLIT', $s);
$j = 0;
for ($i = 0; $i < strlen($s1); $i++) {
$ch1 = $s1[$i];
$ch2 = @mb_substr($s, $j++, 1, 'UTF-8');
if (strstr('`^~'"', $ch1) !== false) {
if ($ch1 <> $ch2) {
--$j;
continue;
}
}
$r .= ($ch1=='?') ? $ch2 : $ch1;
}
return $r;
}
?>
mightye at gmail dot com ¶
15 years ago
To strip bogus characters from your input (such as data from an unsanitized or other source which you can't trust to necessarily give you strings encoded according to their advertised encoding set), use the same character set as both the input and the output, with //IGNORE on the output charcter set.
<?php
// assuming '†' is actually UTF8, htmlentities will assume it's iso-8859
// since we did not specify in the 3rd argument of htmlentities.
// This generates "â[bad utf-8 character]"
// If passed to any libxml, it will generate a fatal error.
$badUTF8 = htmlentities('†');// iconv() can ignore characters which cannot be encoded in the target character set
$goodUTF8 = iconv("utf-8", "utf-8//IGNORE", $badUTF8);
?>
The result of the example does not give you back the dagger character which was the original input (it got lost when htmlentities was misused to encode it incorrectly, though this is common from people not accustomed to dealing with extended character sets), but it does at least give you data which is sane in your target character set.
phpnet at dariosulser dot ch ¶
3 years ago
ANSI = Windows-1252 = CP1252
So UTF-8 -> ANSI:
<?php
$string = "Winkel γ=200 für 1€"; //"γ"=HTML:γ
$result = iconv('UTF-8', 'CP1252//IGNORE', $string);
echo $result;
?>
Note1
<?php
$string = "Winkel γ=200 für 1€";
$result = iconv('UTF-8', 'CP1252', $string);
echo $result; //"conv(): Detected an illegal character in input string"
?>
Note2 (ANSI is better than decode in ISO 8859-1 (ISO-8859-1==Latin-1)
<?php
$string = "Winkel γ=200 für 1€";
$result = utf8_decode($string);
echo $result; //"Winkel ?=200 für 1?"
?>
Note3 of used languages on Websites:
93.0% = UTF-8;
3.5% = Latin-1;
0.6% = ANSI <----- you shoud use (or utf-8 if your page is in Chinese or has Maths)
rasmus at mindplay dot dk ¶
8 years ago
Note an important difference between iconv() and mb_convert_encoding() - if you're working with strings, as opposed to files, you most likely want mb_convert_encoding() and not iconv(), because iconv() will add a byte-order marker to the beginning of (for example) a UTF-32 string when converting from e.g. ISO-8859-1, which can throw off all your subsequent calculations and operations on the resulting string.
In other words, iconv() appears to be intended for use when converting the contents of files - whereas mb_convert_encoding() is intended for use when juggling strings internally, e.g. strings that aren't being read/written to/from files, but exchanged with some other media.
martin at front of mind dot co dot uk ¶
13 years ago
For transcoding values in an Excel generated CSV the following seems to work:
<?php
$value = iconv('Windows-1252', 'UTF-8//TRANSLIT', $value);
?>
Locoluis ¶
16 years ago
The following are Microsoft encodings that are based on ISO-8859 but with the addition of those stupid control characters.
CP1250 is Eastern European (not ISO-8859-2)
CP1251 is Cyrillic (not ISO-8859-5)
CP1252 is Western European (not ISO-8859-1)
CP1253 is Greek (not ISO-8859-7)
CP1254 is Turkish (not ISO-8859-9)
CP1255 is Hebrew (not ISO-8859-8)
CP1256 is Arabic (not ISO-8859-6)
CP1257 is Baltic (not ISO-8859-4)
If you know you're getting input from a Windows machine with those encodings, use one of these as a parameter to iconv.
chicopeste at gmail dot com ¶
9 years ago
iconv also support CP850.
I used iconv("CP850", "UTF-8//TRANSLIT", $var);
to convert from SQL_Latin1_General_CP850_CI_AI to UTF-8.
jessie at hotmail dot com ¶
9 years ago
Provided that there is no invalid code point in the character chain for the input encoding, the //IGNORE option works as expected. No bug here.
vb (at) bertola.eu ¶
12 years ago
On my system, according to tests, and also as reported by other people elsewhere, you can combine TRANSLIT and IGNORE only by appending
//IGNORE//TRANSLIT
strictly in that order, but NOT by appending //TRANSLIT//IGNORE, which would lead to //IGNORE being ignored ( :) ).
Anyway, it's hard to understand how one could devise a system of passing options that does not allow to couple both options in a neat manner, and also to understand why the default behaviour should be the less useful and most dangerous one (throwing away most of your data at the first unexpected character). Software design FAIL :-/
admin at iecw dot net ¶
9 years ago
aissam at yahoo dot com ¶
18 years ago
For those who have troubles in displaying UCS-2 data on browser, here's a simple function that convert ucs2 to html unicode entities :
<?phpfunction ucs2html($str) {
$str=trim($str); // if you are reading from file
$len=strlen($str);
$html='';
for($i=0;$i<$len;$i+=2)
$html.='&#'.hexdec(dechex(ord($str[$i+1])).
sprintf("%02s",dechex(ord($str[$i])))).';';
return($html);
}
?>
Anonymous ¶
13 years ago
For text with special characters such as (é) é which appears at 0xE9 in the ISO-8859-1 and at 0x82 in IBM-850. The correct output character set is 'IBM850' as:
('ISO-8859-1', 'IBM850', 'Québec')
Andries Seutens ¶
13 years ago
When doing transliteration, you have to make sure that your LC_COLLATE is properly set, otherwise the default POSIX will be used.
To transform "rené" into "rene" we could use the following code snippet:
<?php
setlocale
(LC_CTYPE, 'nl_BE.utf8');$string = 'rené';
$string = iconv('UTF-8', 'ASCII//TRANSLIT', $string);
echo
$string; // outputs rene?>
mirek at burkon dot org ¶
14 years ago
If you need to strip as many national characters from UTF-8 as possible and keep the rest of input unchanged (i.e. convert whatever can be converted to ASCII and leave the rest), you can do it like this:
<?php
setlocale(LC_ALL, 'en_US.UTF8');
function
clearUTF($s)
{
$r = '';
$s1 = iconv('UTF-8', 'ASCII//TRANSLIT', $s);
for ($i = 0; $i < strlen($s1); $i++)
{
$ch1 = $s1[$i];
$ch2 = mb_substr($s, $i, 1);$r .= $ch1=='?'?$ch2:$ch1;
}
return $r;
}
echo
clearUTF('Šíleně žluťoučký Vašek úpěl olol! This will remain untranslated: ᾡᾧῘઍિ૮');
//outputs Silene zlutoucky Vasek upel olol! This will remain untranslated: ᾡᾧῘઍિ૮
?>
Just remember you HAVE TO set locale to some unicode encoding to make iconv handle //TRANSLIT correctly!
Проблема кодировок часто возникает при написании парсеров, чтении данных из xml и CSV файлов. Ниже представлены способы эту проблему решить.
1
windows-1251 в UTF-8
$text = iconv('windows-1251//IGNORE', 'UTF-8//IGNORE', $text);
echo $text;PHP
$text = mb_convert_encoding($text, 'UTF-8', 'windows-1251');
echo $text;PHP
2
UTF-8 в windows-1251
$text = iconv('utf-8//IGNORE', 'windows-1251//IGNORE', $text);
echo $text;PHP
$text = mb_convert_encoding($text, 'windows-1251', 'utf-8');
echo $text;PHP
3
Когда ни что не помогает
$text = iconv('utf-8//IGNORE', 'cp1252//IGNORE', $text);
$text = iconv('cp1251//IGNORE', 'utf-8//IGNORE', $text);
echo $text;PHP
Иногда доходит до бреда, но работает:
$text = iconv('utf-8//IGNORE', 'windows-1251//IGNORE', $text);
$text = iconv('windows-1251//IGNORE', 'utf-8//IGNORE', $text);
echo $text;PHP
4
File_get_contents / CURL
Бывают случаи когда file_get_contents() или CURL возвращают иероглифы (ÐлмазнÑе боÑÑ) – причина тут не в кодировке, а в отсутствии BOM-метки.
$text = file_get_contents('https://example.com');
$text = "xEFxBBxBF" . $text;
echo $text;PHP
Ещё бывают случаи, когда file_get_contents() возвращает текст в виде:
�mw�Ƒ0�����&IkAI��f��j4/{�</�&�h�� ��({�o�����:/��<g���g��(�=�9�Paɭ
Это сжатый текст в GZIP, т.к. функция не отправляет правильные заголовки. Решение проблемы через CURL:
function getcontents($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
echo getcontents('https://example.com');PHP
12.01.2017, обновлено 02.11.2021
Другие публикации

Отправка e-mail в кодировке UTF-8 с вложенными файлами и возможные проблемы.

JSON (JavaScript Object Notation) – текстовый формат обмена данными, основанный на JavaScript, который представляет собой набор пар {ключ: значение}. Значение может быть массивом, числом, строкой и…

Описание значений глобального массива $_SERVER с примерами.

Так как Instagram и Fasebook ограничили доступ к API, а фото с открытого аккаунта всё же нужно периодически получать и…

В статье представлены различные PHP-расширения для чтения файлов XLS, XLSX, описаны их плюсы и минусы, а также примеры…

Примеры как зарегистрировать бота в Телеграм, описание и взаимодействие с основными методами API.
-
Доступные статьи
-
PHP
-
Локали и кодировки
Локали и кодировки
- Введение
-
Работа с локалями в PHP
- Windows
- UNIX (FreeBSD)
- Кодировки в MySQL
- Кодировка HTML-страниц
- Заключение
Введение
При разработке веб-приложений есть три важных момента, связанных с кодировками: информация в файлах-сценариях, информация в базе данных и браузер пользователя. Если выставить хотя бы одну кодировку неверно, то, в лучшем случае, данные отобразятся неверно, в худшем, безвозвратно потеряются. Чтобы этого не произошло, а приложение работало корректно при любых настройках сервера, нужно правильно выставить кодировки.
Работа с локалями в PHP
Работа с локалями в PHP выглядит одинаково и в UNIX, и в Windows, и в любой другой платформе. Для установки значений локали служит всего одна функция setlocale(). Чтобы выставить локаль, нужно передать функции первым аргументом категорию, на которую эта локаль распространяется, последующими список возможных локалей. Результатом будет название первой подходящей локали, которая и была установлена.
Пример - установка и использование локали
|
<?php // Установка локали echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'); // Выведет ru_RU.CP1251 для FreeBSD // Выведет rus_RUS.CP1251 для линукса // Выведет Russian_Russia.1251 для Windows // ... // Вывод локализованных сообщений, например, даты echo '<br />', strftime('Число: %d, месяц: %B, день недели: %A'); ?> ru_RU.CP1251 Число: 10, месяц: октября, день недели: пятница или Russian_Russia.1251 Число: 10, месяц: Октябрь, день недели: пятница |
Локали в Windows
Для того, чтобы узнать, какие локали доступны в Windows, нужно зайти в панель управления, «Язык и региональные стандарты».
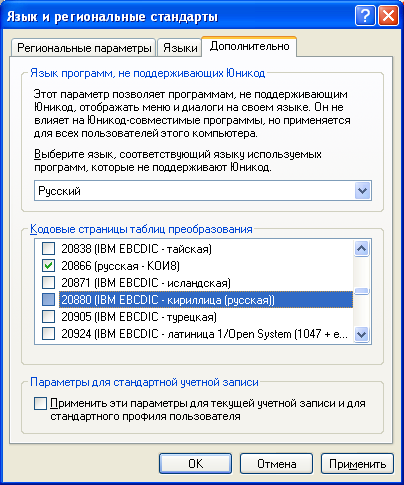
На вкладке «Дополнительно», в разделе «Кодовые страницы таблиц преобразования» показан список всех возможных локалей для Windows, которые можно использовать в PHP.
Кодовые страницы, которые отмечены в списке, из PHP могут быть использованы по их номеру.
В общем случае, использование выглядит по следующей схеме: Язык_Регион.Номер_кодовой_страницы
Для России это может выглядеть как Russian_Russia.1251 (cp1251) или Russian_Russia.20866 (KOI8-R).
Для Украины — Ukrainian_Ukraine.1251 (cp1251).
Вместо длинных названий можно использовать сокращённые russian, american, ukrainian и так далее. При этом кодовая страница выставится с учётом региональных настроек, для России и Украины — 1251, для Америки — 1252.
Единственная кодировка, с которой у меня возникли проблемы, как ни странно, оказалась UTF-8. При попытке выставить эту кодировку, выставляются все категории локалей, кроме основной. Вывод локализованных сообщений при этом идёт в cp1251.
Пример - установка локали UTF-8 на Windows
|
<? // Кодировка страницы windows-1251 header('Content-Type: text/html; charset=windows-1251'); echo '<pre>'; // Локаль устанавливаем UTF-8 echo setlocale(LC_ALL, 'Russian_Russia.65001'), PHP_EOL; // Но данные будут выводиться всё равно в cp1251 :((( echo strftime('%A'), PHP_EOL; ?> LC_COLLATE=Russian_Russia.65001;LC_CTYPE=Russian_Russia.1251; LC_MONETARY=Russian_Russia.65001;LC_NUMERIC=Russian_Russia.65001; LC_TIME=Russian_Russia.65001 пятница |
Пока это можно списать на внутренний механизм PHP работы со строками. С шестой версии PHP вся обработка строк должна будет вестись в UTF-8, но до тех пор надо просто знать об этом и делать поправку.
Ещё одной странностью при работе с локалями в PHP на Windows является неправильная работа с категориями локалей. Так, например, я выставляю локаль на функции времени KOI8-R, setlocale(LC_TIME, 'Russian_Russia.20866'), но почему-то выставляется cp1251 на все категории. Суть проблемы я так и не понял, возможно, это просто баг (проверялось на PHP 5.2.3), а возможно, что внутренний механизм Windows просто не позволяет этого делать. Хотя по мне, так это чистой воды баг.
В общем-то, на этом можно и закончить разговор о локалях на Windows. Главное, запомнить, что локали, которые портированы из UNIX, под WIndows работают только для «галочки». Шаг влево, шаг вправо и результат будет непредсказуемым. Безопасно можно использовать только cp1251 (windows-1251) и KOI8-R, и только для LC_ALL.
Код - установка локали на Windows
|
<?php // Устновка локалей для Windows // Кодировка Windows-1251 setlocale(LC_ALL, 'Russian_Russia.1251'); // Кодировка KOI8-R setlocale(LC_ALL, 'Russian_Russia.20866'); // Кодировка UTF-8 (использовать осторожно) setlocale(LC_ALL, 'Russian_Russia.65001'); ?> |
Локали в UNIX
Выше я описал работу с локалями в Windows, теперь можно заострить внимание на UNIX-like системах. Для простоты, я буду их называть UNIX, а подразумевать FreeBSD :). В контексте данной статьи это не особо важно.
Итак, дистрибутивы UNIX поставляются в одном виде для всех, и работа рассчитана на многопользовательский режим, поэтому о правильной настройке локали должен заботиться сам пользователь, например:
zg# locale LANG= LC_CTYPE="ru_RU.KOI8-R" LC_COLLATE="ru_RU.KOI8-R" LC_TIME="ru_RU.KOI8-R" LC_NUMERIC="ru_RU.KOI8-R" LC_MONETARY="ru_RU.KOI8-R" LC_MESSAGES="ru_RU.KOI8-R" LC_ALL=ru_RU.KOI8-R zg#
Так может выглядеть работа системной команды locale, которая выводит текущие настройки локали для пользователя. А так, обычно, выглядят настройки локали для пользователя, под которым работает PHP:
passthru('locale'); ================ LANG= LC_CTYPE="C" LC_COLLATE="C" LC_TIME="C" LC_NUMERIC="C" LC_MONETARY="C" LC_MESSAGES="C" LC_ALL=
Функция ucwords() должна была сделать заглавными первые буквы всех слов. А перед этим strtolower() должна была предварительно все заглавные буквы сделать строчными. Но ничего не произошло. Так же не будет работать следующий код:
echo ucwords(strtolower('привет, МИР!')); ================ привет, МИР!
Хотя w является множеством знаков, из которых может состоять слово (алфавит, цифры и _), регулярное выражение не срабатывает. Причина как раз в том, что, работая с cp1251, мы не сказали об этом php. Чтобы исправить положение, достаточно воспользоваться функцией setlocale() и указать правильную локаль, например, так:
setlocale(LC_ALL, 'ru_RU.CP1251');
Здесь первый аргумент — это категория, на которую будет распространяться локаль (константа LC_*), второй — название локали. Начиная с версии 4.3.0 можно указывать несколько имён локалей в виде массива или в качестве дополнительных аргументов. После вызова функция установит первую подходящую локаль и вернёт её имя:
echo setlocale(LC_ALL, 'cp1251', 'koi8-r', 'ru_RU.KOI8-R'); ================ ru_RU.KOI8-R
С помощью команды grep я отобрал локали, которые поддерживают русский язык. Любую из них можно использовать, однако следует понимать, что данные должны быть в кодировке, на которую рассчитана локаль. Если же это правило не будет соблюдено, то результат может оказаться весьма неожиданным:
echo setlocale(LC_ALL, 'ru_RU.KOI8-R'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')); =============== ru_RU.KOI8-R пРИВЕТ, мИР!
Если учесть, что koi8-r достаточно популярная кодировка для UNIX-севреров, а windows-1251 для русскоязычных сайтов, то подобное «необычное» поведение не такая уж и редкость. Когда-то я и сам столкнулся с этой проблемой при портировании проекта на реальный хостинг.
После установки правильной локали все примеры, которые не работали выше, будут работать как нужно!
echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')), PHP_EOL; echo preg_match('/^w+$/', 'привет') ? 'нашёл' : 'не работает', PHP_EOL; echo strftime('Сегодня: %A, %d %B, %Y года'); =============== ru_RU.CP1251 Привет, Мир! нашёл Сегодня: суббота, 12 июля, 2008 года
По-русски заговорит и функция strftime(), которая корректно работает с локалями, а также и всё остальное, что зависит от локали.
Кодировки в MySQL
Напомню, что возможность задавать кодировки появилась только в MySQL 4.1.11 и выше.
В отличие от php, проблемы с кодировками базы данных проявляют себя гораздо быстрее, чем проблемы с локалью. И связано это прежде всего с хранением и выборкой данных, поскольку от этого зависит информация на сайте. Я не буду подробно расписывать все тонкости, поскольку есть отдельная статья, остановлюсь на самых важных моментах.
Первое, чему необходимо научиться, смотреть текущие настройки соединения с mysql:
mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | cp1251 | | character_set_database | cp1251 | | character_set_filesystem | binary | | character_set_results | cp1251 | | character_set_server | cp1251 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.00 sec)
Критичными для пользователя являются character_set_client и character_set_results, которые отвечают за кодировку, в которой данные поступают в базу, и кодировку, в которой данные поступают из базы к пользователю. Если эти две кодировки отличаются от той, в которой работает клиент, в нашем случае php-скрипты, то неминуемо будут «странности», например, при сортировке выборки или внесении данных в базу.
Второе, что необходимо знать, как правильно сообщить mysql о кодировках. Самый простой и правильный способ, это использовать запрос set names:
mysql> set names 'cp1251'; Query OK, 0 rows affected (0.00 sec)
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение cp1251. Это будет означать — клиент работает в кодировке windows-1251 (cp1251).
Помимо этого можно устанавливать непосредственно серверные переменные:
mysql> set character_set_client='UTF8'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | utf8 | | character_set_connection | cp1251 | .....
Теперь данные поступают и извлекаются в разных кодировках.
Список доступных кодировок можно просмотреть так:
mysql> show charset; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | +----------+-----------------------------+---------------------+--------+ 26 rows in set (0.00 sec)
И третье, что необходимо знать, — правила создания таблиц для хранения данных в нужной кодировке. К слову, данные можно хранить в любой кодировке, а работать с ними в кодировке клиента. Однако, важно понимать, что кодировки носят национальный характер и должны соответствовать вносимым данным. Иначе будут потери. Для русского языка есть три национальных кодировки koi8r, cp866, cp1251, которые могут конвертироваться друг в друга без потерь. Также можно использовать интернациональную кодировку UTF8.
Кодировку можно выставить на базу данных, таблицу и поле таблицы. Так, например, можно создать базу данных в кодировке koi8r:
CREATE DATABASE `test` DEFAULT CHARACTER SET koi8r;
Следует отметить, что кодировка базы данных влияет только на дефолтные значения кодировок при создании таблиц. Это значит, что неважно в какой кодировке была создана база, если кодировка таблицы была задана явно. Это же правило относится и к полям таблицы.
Следующим шагом я создам таблицу в cp1251 и одним полем в utf8:
CREATE TABLE `t` ( `id` VARCHAR( 60 ) NOT NULL , `data` TEXT CHARACTER SET utf8 NOT NULL , PRIMARY KEY ( `id` ) ) TYPE = MYISAM CHARACTER SET cp1251;
После того, как таблица создана с нужными параметрами кодировки, mysql автоматически начинает переводить данные при внесении и выборке.
mysql> select * from t; +--------+-------------+ | id | data | +--------+-------------+ | привет | привет мир! | +--------+-------------+ 1 row in set (0.00 sec)
Данные хранятся в разном виде, но поступают к пользователю именно так, как надо!
Подробнее с кодировками и проблемами их использования можно ознакомиться на http://dev.mysql.com/doc/refman/5.1/en/charset.html.
Кодировка HTML-страниц
Объявить кодировку html-страницы можно двумя способами: через заголовки и мета-тег в самой странице. Мета-тег используется только в статичных страницах.
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Я не буду его разбирать, это проблемы html. Во всех остальных случаях предпочтительней использовать HTTP-заголовок Content-Type.
PHP позволяет работать с HTTP-заголовками посредством функции header():
// Объявление типа содержимого и его кодировки header('Content-Type: text/html; charset=windows-1251');
Но браузер отобразит страницу корректно только в том случае, когда php-файлы сами были созданы в кодировке cp1251. Также нужно понимать, что заголовки должны быть отправлены до любого вывода на экран.
При необходимости перекодировать страницы «на лету», достаточно воспользоваться буферизацией и iconv:
Код - динамическая перекодировка
|
|
1 |
<?php iconv_set_encoding('internal_encoding', 'WINDOWS-1251'); // Исходная кодировка файлов iconv_set_encoding('output_encoding' , 'UTF-8'); // Конечная кодировка ob_start('ob_iconv_handler'); // буферизация header('Content-Type: text/html; charset=UTF8'); ?> Привет, мир! |
Надпись «Привет, мир!» будет выведена в юникоде, при этом браузер получит информацию о кодировке через заголовки и правильно отобразит страницу. Но важно понимать, что внутри скрипта и при соединении с базой данных надо использовать windows-1251 (cp1251), поскольку страница должна быть сформирована в одной кодировке.
Важно помнить, что функции iconv доступны не всегда, и проверка на доступность этих функций не будет лишней.
Заключение
Для безопасной разработки русскоязычных веб-проектов необходимо включать в файл с общими настройками следующие команды:
Код - файл общих настроек
|
|
1 |
<?php // Файл общих настроек ... // Вывод заголовка с данными о кодировке страницы header('Content-Type: text/html; charset=windows-1251'); // Настройка локали setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251', 'russian'); // Настройка подключения к базе данных mysql_query('SET names "cp1251"'); ?> |
Как ни странно, но эти три строчки кода значительно повышают портируемость веб-проектов.
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft:

Кодировка является 8-битной и включает в себя символы славянской группы языков, в которую входят русский, белорусский, украинский, болгарский, македонский, сербский – это дает преимущество перед остальными кириллическими кодировками (ISO 8859-5, KOI8-R, CP866). Однако у 1251-кодировки имеются и весомые недостатки:
- Кодировка windows 1251 в html
- Кодировка windows 1251 в PHP
- Кодировка windows 1251 в htaccess
- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8, CP866.
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 (числа под символами являются кодом в шестнадцатеричной системе такого же символа в Юникоде):

Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина «кодировка страницы».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:

Для того чтобы html-документ корректно отобразился в браузере, необходимо указать используемую кодировку. Делается это следующим образом:
— между тегом <head> и закрывающим его </head> нужно прописать <meta http-equiv=»Content-Type» content=»text/html; charset=windows-1251″> — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP, чаще всего это mysql:

Нередко при смене хостинга возникает проблема: различные кодировки информации в базе данных и в шаблонах страниц. Из-за этого одна сгенерированная страница может одновременно содержать несколько кодировок. Если информация на сайте представлена в кодировке виндовс 1251, то и чтение из базы данных должно осуществляться с помощью таблицы, в которой представлена win 1251 кодировка.
Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251.
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251, необходимо найти (или создать) файл .htaccess. Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка. Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов.
Только для читателей Lifeexample возможно открыть интернет-магазин на Moguta.CMS со скидкой в 15%

Здравствуй уважаемый читатель блога LifeExample, кодировка веб страницы это очень интересный зверь, и за частую хищный для начинающих веб мастеров. Я уверен в том, что все новички сталкиваются с проблемой правильного отображения текста на страницах своего сайта. Ты дорогой читатель, наверное встречал в сети интернета ресурсы, на страницах которых отображался не читаемый текст, а кракозябры.
Кракозябрами в среде программирования веб сайтов принято называть символы не соответствующие тем, которые должны быть выведены на страницу. Например, на созданной вами странице должно отображаться приветствие: «Здравствуй читатель моего блога!», а на деле получаете непонятный набор закорючек «Р—РґСЂР°РІСЃС‚РІСѓР№ читатеРСЊ моего Р±РРѕРіР°!» – вот такие закорючки и есть злые КРАКОЗЯБРЫ.
В данной статье мы разберем эту проблему с ног до головы, чтобы больше не возвращаться к танцам с бубном вокруг нечитаемого текста.
И так, чтобы понять откуда появляются подобного рода иероглифы, нам нужно познакомиться с понятием кодировка страницы. Любой текст на компьютере представляется в виде набора байтов, в каждом из этих байтов определенным кодом — закодирован только один единственный символ. Так вот для того чтобы правильно расшифровать или раскодировать набор байтов и представить его в понятном человеку виде, браузеру нужно провести соответствие с одной из кодовых таблиц. Базовой кодировкой является ASCII кодировка, она содержит в себе коды 128 символов латинского алфавита и спец символов вроде скобок и решеток. Именно из ASCII появились первые русскосимвольные кодировки CP866 и KOI8-R, а из них вышла известная сегодняшним вебмастерам кодировка windows-1251. Не смотря на то, что все эти кодировки призваны для отображения русского текста, они все отличаются друг от друга кодами для одинаковых символов. Если текст писался в кодировке CP866, а браузер пытается раскодировать ее с помощью таблицы кодов windows-1251, то в результате мы получим не читаемые слова. Такое часто происходит при отправке сообщений через почтовый сервер.
Приведенные здесь названия кодировок далеко не все что существуют и используются в разных случаях, их намного больше чем вы думаете. С таким обилием кодовых таблиц образовалась проблема совместимости кодировок, и веб мастерам пришлось вставть на борьду с универсализацией кода, что занимало много времени и нервов. На сегодняшний день изобретена панацея для данной проблемы в виде универсальной кодировки utf-8, со временем она вытесняет используемые ранее кодовые таблицы символов, и сейчас уже не для кого не встает вопрос о том в какой кодировке лучше сохранять данные.
Много было сказано относительно эволюции кодировок, и постановке самой задачи, пришло время поговорить о практических моментах.
Существует четыре места на кухне программирования сайта, которые требуют соблюдения единого стандатра кодирования текста.
- Кодировки скриптов.
- Кодировка таблиц MySQL.
- Кодировка самой HTML страницы.
- Локаль используемая браузером пользователя.
Во всех этих составляющих сайта, должна использоваться единая кодировка, какая – решать вам, но я рекомендую utf-8, всетаки она универсальная)
И так теперь подробнее рассмотрим, что нужно сделать для того, чтобы привести к одной кодировке всеперечисленые составляющие.
Кодировки скриптов (шаг 1)
Для того чтобы все скрипты имели одну кодировку, нужно при создании нового скрипта указать желаемую кодировку в настройках вашего редактора. Приведу пример данной процедуры в NotePad++ . При создании нового PHP файла сразу идем в раздел Encoding, он находится в меню, и выбираем Convert to UTF-8 without BOM.

Выбираем именно Convert to UTF-8 without BOM, а не просто Convert to UTF‑8. Приставка without BOM означает то что в первых двух байтах файла будет зашифрована специальная информация о параметре кодировки, в скриптах нам не нужна никакая лишняя информация. В большенстве случаев сохранение с BOM не окажется криминальным, но когданить один из скриптов откажется правильно работать и одной из причин может отазаться именно информация заключенная в первых байтах файла.
Кодировка таблиц MySQL. (шаг 2)
Для того, чтобы узнать какие кодировки используются в ваше MySQL базе, воспользуемся интерфейсом phpMyAdmin. В разделе SQL напишем запрос:
|
1 |
SHOW VARIABLES LIKE ‘char%’; |
Выглядеть это должно вот так:

Жмем ОК и получаем информацию о кодировках таблицы

Значения на против character_set_client и character_set_results должны совпадать, так как эти параметры отвечают за кодировку, в которой данные поступают в базу и за кодировку в которой данные берутся из базы.
Если они у вас различаются, то нужно в PHP коде в ручную установить нужную кодировку. Делается это вот такой строчкой:
|
1 |
mysql_query(‘SET names «utf8″‘); |
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение utf8.
Подробнее о том как с помощью PHP работать с базой данных можно прочесть в статье PHP работа с базой данных (Часть 1-3).
Кодировка самой HTML страницы. (Шаг 3)
Теперь данные взятые с базы и данные обрабатываемые в php скрипте, будут совпадать по кодировке, и выводиться в понятном для человека тексте. Но это еще не все, нужно указать кодировку в разделе для мета тегов:
|
1 |
<meta http-equiv=«Content-Type» content=«text/html; charset=utf-8»> |
Либо в cкрипте настроек php командой:
|
1 |
header(‘Content-Type: text/html; charset= utf-8’); |
Если кодировка HTML будет задана сразу двумя способами, то приоритетным будет задание кодировки из php скрипта.
Также можно глобально задать правило кодировки HTML в файле .htaccess добавив в него строку:
|
1 |
AddDefaultCharset UTF—8 |
Локаль используемая браузером пользователя. (Шаг 4)
Еще одна важная деталь при корректном отображении текста это установка локали:
|
1 |
// Кодировка UTF-8 |
При установки такой локали, пердставители других стран использующие другую кодовую страницу в своей операционной системе, будут видеть русский текст.
Мы рассмотрели основные моменты возникновения противоречий в кодировках веб страницы, подведем итоги. Для того чтобы ваш рускоязычный сайт был всегда доступен для чтения, необходимо прописать в PHP скрипте настроек такие строки:
|
1 |
<?php |
Если у тебя дорогой читатель остались вопросы по данной статье о PHP кодировке страниц, то смело задавай их в комментариях.
Читайте также похожие статьи:

Чтобы не пропустить публикацию следующей статьи подписывайтесь на рассылку по E-mail или RSS ленту блога.
Иногда требуется сменить полностью кодировку файла, например с utf-8 в windows-1251. Зачастую это делается с помощью редактора кода. Но что если это необходимо сделать программно, в этом поможет функции php — iconv().
Для того чтобы не перекодировать каждую строку файла с помощью iconv(string $input_charset, string $output_charset, string $string) — мы можем преобразовать лишь одну строку. Этой строкой будет наш файл, полностью, полученный с помощью функции file_get_contents($path).
Для примера полностью перекодируем файл из UTF-8 в WINDOWS-1251.
В итоге это будет выглядеть вот так:
$file_string = file_get_contents ("tmp/test_file.csv");
$file_string = iconv("UTF-8", "WINDOWS-1251", $file_string);
file_put_contents ("tmp/test_file.csv", $file_string);
Также, если вы хотите сменить окончания строк, например с Mac ( r ) формата на Windows ( rn ) / Unix ( n ) формат:
// Windows CRLF
$string = preg_replace('~(*BSR_ANYCRLF)R~', "rn", $string);
// Unix CR
$string = preg_replace('~(*BSR_ANYCRLF)R~', "n", $string);
// Mac LF
$string = preg_replace('~(*BSR_ANYCRLF)R~', "r", $string);
При помощи функции php iconv (строго говоря, это не совсем функция PHP, она использует стороннюю библиотеку (есть iconv.dll и php_iconv.dll или iconv.so), которой может не быть на хостинге) легко преобразовать кодировку (например, из windows-1251 в utf-8 и наоборот:
$s = iconv( "cp1251","UTF-8", $s);
$s = iconv("UTF-8", "windows-1251", $s);
Однако, если не работает iconv на хостинге, а преобразовать текст из одной кодировки в другую необходимо, можно воспользоваться сторонними функциями (на самом деле, встречал несколько вариантов — какой из них лучше.. или точнее “более рабочий” — не скажу).
Про преобразование UFT-8 сущностей я уже писал ранее , однако иногда требуется наоборот перевести текст из cp1251 в utf-8 — например.
Если не работает iconv
function iconv ($in_charset, $out_charset, $str) string — для преобразования из Windows в UTF-8 выполняем один из вызовов
iconv( "cp1251","UTF-8", $s);
iconv( "windows-1251","UTF-8", $s);
выдаёт пустую строку (если в $s нет английских символов — они в любой кодировке отображаются одинаково) на некоторых хостингах можно попробовать использовать функцию mb_convert_encoding — у неё другой порядок аргументов!
function mb_convert_encoding ($str, $to_encoding, $from_encoding = null) string
Т.е. чтобы преобразовать текст из кодировки windows-1251 в UTF-8 следует выполнить:
mb_convert_encoding($s,"UTF-8","windows-1251");
iconv array для массива
В некоторых ситуациях преобразовать одномерный или многомерный массив из одной кодировки в другую (например, из utf8 в windows-1251) с сохранением ключей массива. Для решения, можно использовать несколько способов.
// если не требуется сохранять предыдущий массив, для экономии
// передаем его по ссылке, происходит замена внутри
function utf8to1251(&$text) {
$text = iconv("utf-8", "windows-1251", $text); //without return
}
array_walk_recursive($array, "utf8to1251");
Или, если требуется оставить исходный массив без изменений — можно воспользоваться:
$newArray = array_map(create_function('$v', 'return iconv("utf-8", "windows-1251", $v);'), $oldArray);
Метки: iconv
Опубликовано
Пятница, Октябрь 21, 2011 в 15:02 в следующих категориях: Без рубрики.
Вы можете подписаться на комментарии к этому сообщению через RSS 2.0.
Вы можете оставить комментарий. Пинг отключен.
Автор будет признателен, если Вы поделитесь ссылкой на статью, которая Вам помогла:
BB-код (для вставки на форум)
html-код (для вставки в ЖЖ, WP, blogger и на страницы сайта)
ссылка (для отправки по почте)
Некорректное отображение текста сайтов на PHP версии 5.6 и выше
07 сентября 2016
С введением новых серверов с версией PHP по умолчанию 5.6, к нам стали обращаться клиенты с проблемой отображения сайтов в кодировке WINDOWS-1251. Решение проблемы достаточно простое.
Несмотря на добавление в файл .htaccess кодировки по умолчанию для Apache и указанием кодировки в мета-тегах HTML, проблема не решалась. В заголовках от сервера приходил ответ с UTF-8 и браузер выбирал его.
|
# Кодировка по умолчанию в файле .htaccess AddDefaultCharset windows—1251 |
|
# Мета-тег в HTML коде страницы <meta http—equiv=«Content-Type» content=«text/html; charset=windows-1251»/> |
|
# Заголовок приходящий от сервера Content—Type:text/html; charset=utf—8 |
Проблема появилась из-за изменения кодировки по умолчанию в PHP, начиная с версии 5.6: http://php.net/manual/ru/ini.core.php#ini.default-charset, теперь она жестко задана в UTF-8, а в более ранних версиях просто не задавалась и её можно было легко устанавливать через мета-тег или файл .htaccess
Решением проблемы является добавление строчки в файл .htaccess, которая меняет кодировку на windows-1251:
|
# Установка кодировки для PHP php_value default_charset windows—1251 |
Данной проблеме подвержены все сайты, кодировка которых отличается от UTF-8 и скрипт в процессе работы не устанавливает параметр default_charset. К нам в основном обращаются с проблемой после установки сайтов на DLE (данная CMS работает в windows-1251).
Если Вы ищете тестовый хостинг для сайта wordpress, то LITE.HOST это то, что Вам нужно. Мы также оказываем услуги по хостингу php и не только. Переходите в раздел «Хостинг» и выбирайте удобный для Вас тариф.