Список из 256 символов и их коды в ASCII.
1
Управляющие символы
| DEC | OCT | HEX | BIN | Символ | Escape послед. | HTML код | Описание |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL | � | Нулевой байт | |
| 1 | 001 | 0x01 | 00000001 | SOH |  | Начало заголовка | |
| 2 | 002 | 0x02 | 00000010 | STX |  | Начало текста | |
| 3 | 003 | 0x03 | 00000011 | ETX |  | Конец «текста» | |
| 4 | 004 | 0x04 | 00000100 | EOT |  | конец передачи | |
| 5 | 005 | 0x05 | 00000101 | ENQ |  | «Прошу подтверждения!» | |
| 6 | 006 | 0x06 | 00000110 | ACK |  | «Подтверждаю!» | |
| 7 | 007 | 0x07 | 00000111 | BEL | a |  | Звуковой сигнал – звонок |
| 8 | 010 | 0x08 | 00001000 | BS | b |  | Возврат на один символ (BACKSPACE) |
| 9 | 011 | 0x09 | 00001001 | TAB | t | Табуляция | |
| 10 | 012 | 0x0A | 00001010 | LF | n | Перевод строки | |
| 11 | 013 | 0x0B | 00001011 | VT | v |  | Вертикальная табуляция |
| 12 | 014 | 0x0C | 00001100 | FF | f |  | Прогон страницы, новая страница |
| 13 | 015 | 0x0D | 00001101 | CR | r | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO |  | Переключиться на другую ленту (кодировку) | |
| 15 | 017 | 0x0F | 00001111 | SI |  | Переключиться на исходную ленту (кодировку) | |
| 16 | 020 | 0x10 | 00010000 | DLE |  | Экранирование канала данных | |
| 17 | 021 | 0x11 | 00010001 | DC1 |  | 1-й символ управления устройством | |
| 18 | 022 | 0x12 | 00010010 | DC2 |  | 2-й символ управления устройством | |
| 19 | 023 | 0x13 | 00010011 | DC3 |  | 3-й символ управления устройством | |
| 20 | 024 | 0x14 | 00010100 | DC4 |  | 4-й символ управления устройством | |
| 21 | 025 | 0x15 | 00010101 | NAK |  | «Не подтверждаю!» | |
| 22 | 026 | 0x16 | 00010110 | SYN |  | Символ для синхронизации | |
| 23 | 027 | 0x17 | 00010111 | ETB |  | Конец текстового блока | |
| 24 | 030 | 0x18 | 00011000 | CAN |  | Отмена | |
| 25 | 031 | 0x19 | 00011001 | EM |  | Конец носителя | |
| 26 | 032 | 0x1A | 00011010 | SUB |  | Подставить | |
| 27 | 033 | 0x1B | 00011011 | ESC | e |  | Escape (Расширение) |
| 28 | 034 | 0x1C | 00011100 | FS |  | Разделитель файлов | |
| 29 | 035 | 0x1D | 00011101 | GS |  | Разделитель групп | |
| 30 | 036 | 0x1E | 00011110 | RS |  | Разделитель записей | |
| 31 | 037 | 0x1F | 00011111 | US |  | Разделитель юнитов | |
| 127 | 177 | 0x7F | 01111111 | Delete | | Символ для удаления (на перфолентах) |
2
Печатные символы
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | Пробел | ||
| 33 | 041 | 0x21 | 00100001 | ! | ! | |
| 34 | 042 | 0x22 | 00100010 | « | " | " |
| 35 | 043 | 0x23 | 00100011 | # | # | |
| 36 | 044 | 0x24 | 00100100 | $ | $ | |
| 37 | 045 | 0x25 | 00100101 | % | % | |
| 38 | 046 | 0x26 | 00100110 | & | & | & |
| 39 | 047 | 0x27 | 00100111 | ‘ | ' | ' |
| 40 | 050 | 0x28 | 00101000 | ( | ( | |
| 41 | 051 | 0x29 | 00101001 | ) | ) | |
| 42 | 052 | 0x2A | 00101010 | * | * | |
| 43 | 053 | 0x2B | 00101011 | + | + | |
| 44 | 054 | 0x2C | 00101100 | , | , | |
| 45 | 055 | 0x2D | 00101101 | — | - | |
| 46 | 056 | 0x2E | 00101110 | . | . | |
| 47 | 057 | 0x2F | 00101111 | / | / | |
| 48 | 060 | 0x30 | 00110000 | 0 | 0 | |
| 49 | 061 | 0x31 | 00110001 | 1 | 1 | |
| 50 | 062 | 0x32 | 00110010 | 2 | 2 | |
| 51 | 063 | 0x33 | 00110011 | 3 | 3 | |
| 52 | 064 | 0x34 | 00110100 | 4 | 4 | |
| 53 | 065 | 0x35 | 00110101 | 5 | 5 | |
| 54 | 066 | 0x36 | 00110110 | 6 | 6 | |
| 55 | 067 | 0x37 | 00110111 | 7 | 7 | |
| 56 | 070 | 0x38 | 00111000 | 8 | 8 | |
| 57 | 071 | 0x39 | 00111001 | 9 | 9 | |
| 58 | 072 | 0x3A | 00111010 | : | : | |
| 59 | 073 | 0x3B | 00111011 | ; | ; | |
| 60 | 074 | 0x3C | 00111100 | < | < | < |
| 61 | 075 | 0x3D | 00111101 | = | = | |
| 62 | 076 | 0x3E | 00111110 | > | > | > |
| 63 | 077 | 0x3F | 00111111 | ? | ? | |
| 64 | 100 | 0x40 | 01000000 | @ | @ | |
| 65 | 101 | 0x41 | 01000001 | A | A | |
| 66 | 102 | 0x42 | 01000010 | B | B | |
| 67 | 103 | 0x43 | 01000011 | C | C | |
| 68 | 104 | 0x44 | 01000100 | D | D | |
| 69 | 105 | 0x45 | 01000101 | E | E | |
| 70 | 106 | 0x46 | 01000110 | F | F | |
| 71 | 107 | 0x47 | 01000111 | G | G | |
| 72 | 110 | 0x48 | 01001000 | H | H | |
| 73 | 111 | 0x49 | 01001001 | I | I | |
| 74 | 112 | 0x4A | 01001010 | J | J | |
| 75 | 113 | 0x4B | 01001011 | K | K | |
| 76 | 114 | 0x4C | 01001100 | L | L | |
| 77 | 115 | 0x4D | 01001101 | M | M | |
| 78 | 116 | 0x4E | 01001110 | N | N | |
| 79 | 117 | 0x4F | 01001111 | O | O | |
| 80 | 120 | 0x50 | 01010000 | P | P | |
| 81 | 121 | 0x51 | 01010001 | Q | Q | |
| 82 | 122 | 0x52 | 01010010 | R | R | |
| 83 | 123 | 0x53 | 01010011 | S | S | |
| 84 | 124 | 0x54 | 01010100 | T | T | |
| 85 | 125 | 0x55 | 01010101 | U | U | |
| 86 | 126 | 0x56 | 01010110 | V | V | |
| 87 | 127 | 0x57 | 01010111 | W | W | |
| 88 | 130 | 0x58 | 01011000 | X | X | |
| 89 | 131 | 0x59 | 01011001 | Y | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | [ | |
| 92 | 134 | 0x5C | 01011100 | \ | ||
| 93 | 135 | 0x5D | 01011101 | ] | ] | |
| 94 | 136 | 0x5E | 01011110 | ^ | ^ | |
| 95 | 137 | 0x5F | 01011111 | _ | _ | |
| 96 | 140 | 0x60 | 01100000 | ` | ` | |
| 97 | 141 | 0x61 | 01100001 | a | a | |
| 98 | 142 | 0x62 | 01100010 | b | b | |
| 99 | 143 | 0x63 | 01100011 | c | c | |
| 100 | 144 | 0x64 | 01100100 | d | d | |
| 101 | 145 | 0x65 | 01100101 | e | e | |
| 102 | 146 | 0x66 | 01100110 | f | f | |
| 103 | 147 | 0x67 | 01100111 | g | g | |
| 104 | 150 | 0x68 | 01101000 | h | h | |
| 105 | 151 | 0x69 | 01101001 | i | i | |
| 106 | 152 | 0x6A | 01101010 | j | j | |
| 107 | 153 | 0x6B | 01101011 | k | k | |
| 108 | 154 | 0x6C | 01101100 | l | l | |
| 109 | 155 | 0x6D | 01101101 | m | m | |
| 110 | 156 | 0x6E | 01101110 | n | n | |
| 111 | 157 | 0x6F | 01101111 | o | o | |
| 112 | 160 | 0x70 | 01110000 | p | p | |
| 113 | 161 | 0x71 | 01110001 | q | q | |
| 114 | 162 | 0x72 | 01110010 | r | r | |
| 115 | 163 | 0x73 | 01110011 | s | s | |
| 116 | 164 | 0x74 | 01110100 | t | t | |
| 117 | 165 | 0x75 | 01110101 | u | u | |
| 118 | 166 | 0x76 | 01110110 | v | v | |
| 119 | 167 | 0x77 | 01110111 | w | w | |
| 120 | 170 | 0x78 | 01111000 | x | x | |
| 121 | 171 | 0x79 | 01111001 | y | y | |
| 122 | 172 | 0x7A | 01111010 | z | z | |
| 123 | 173 | 0x7B | 01111011 | { | { | |
| 124 | 174 | 0x7C | 01111100 | | | | | |
| 125 | 175 | 0x7D | 01111101 | } | } | |
| 126 | 176 | 0x7E | 01111110 | ~ | ~ |
3
Расширенные символы ASCII Win-1251 кириллица
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ | € | |
| 129 | 201 | 0x81 | 10000001 | Ѓ | | |
| 130 | 202 | 0x82 | 10000010 | ‚ | ‚ | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ | ƒ | |
| 132 | 204 | 0x84 | 10000100 | „ | „ | „ |
| 133 | 205 | 0x85 | 10000101 | … | … | … |
| 134 | 206 | 0x86 | 10000110 | † | † | † |
| 135 | 207 | 0x87 | 10000111 | ‡ | ‡ | ‡ |
| 136 | 210 | 0x88 | 10001000 | € | ˆ | € |
| 137 | 211 | 0x89 | 10001001 | ‰ | ‰ | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ | Š | |
| 139 | 213 | 0x8B | 10001011 | ‹ | ‹ | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ | Œ | |
| 141 | 215 | 0x8D | 10001101 | Ќ | | |
| 142 | 216 | 0x8E | 10001110 | Ћ | Ž | |
| 143 | 217 | 0x8F | 10001111 | Џ | | |
| 144 | 220 | 0x90 | 10010000 | Ђ | | |
| 145 | 221 | 0x91 | 10010001 | ‘ | ‘ | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ | ’ | ’ |
| 147 | 223 | 0x93 | 10010011 | “ | “ | “ |
| 148 | 224 | 0x94 | 10010100 | ” | ” | ” |
| 149 | 225 | 0x95 | 10010101 | • | • | • |
| 150 | 226 | 0x96 | 10010110 | – | – | – |
| 151 | 227 | 0x97 | 10010111 | — | — | — |
| 152 | 230 | 0x98 | 10011000 | Начало строки | ˜ | |
| 153 | 231 | 0x99 | 10011001 | ™ | ™ | ™ |
| 154 | 232 | 0x9A | 10011010 | љ | š | |
| 155 | 233 | 0x9B | 10011011 | › | › | › |
| 156 | 234 | 0x9C | 10011100 | њ | œ | |
| 157 | 235 | 0x9D | 10011101 | ќ | | |
| 158 | 236 | 0x9E | 10011110 | ћ | ž | |
| 159 | 237 | 0x9F | 10011111 | џ | Ÿ | |
| 160 | 240 | 0xA0 | 10100000 | Неразрывный пробел | | |
| 161 | 241 | 0xA1 | 10100001 | Ў | ¡ | |
| 162 | 242 | 0xA2 | 10100010 | ў | ¢ | |
| 163 | 243 | 0xA3 | 10100011 | Ј | £ | |
| 164 | 244 | 0xA4 | 10100100 | ¤ | ¤ | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ | ¥ | |
| 166 | 246 | 0xA6 | 10100110 | ¦ | ¦ | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § | § | § |
| 168 | 250 | 0xA8 | 10101000 | Ё | ¨ | |
| 169 | 251 | 0xA9 | 10101001 | © | © | © |
| 170 | 252 | 0xAA | 10101010 | Є | ª | |
| 171 | 253 | 0xAB | 10101011 | « | « | « |
| 172 | 254 | 0xAC | 10101100 | ¬ | ¬ | ¬ |
| 173 | 255 | 0xAD | 10101101 | Мягкий перенос | | ­ |
| 174 | 256 | 0xAE | 10101110 | ® | ® | ® |
| 175 | 257 | 0xAF | 10101111 | Ї | ¯ | |
| 176 | 260 | 0xB0 | 10110000 | ° | ° | ° |
| 177 | 261 | 0xB1 | 10110001 | ± | ± | ± |
| 178 | 262 | 0xB2 | 10110010 | І | ² | |
| 179 | 263 | 0xB3 | 10110011 | і | ³ | |
| 180 | 264 | 0xB4 | 10110100 | ґ | ´ | |
| 181 | 265 | 0xB5 | 10110101 | µ | µ | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ | ¶ | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · | · | · |
| 184 | 270 | 0xB8 | 10111000 | ё | ¸ | |
| 185 | 271 | 0xB9 | 10111001 | № | ¹ | |
| 186 | 272 | 0xBA | 10111010 | є | º | |
| 187 | 273 | 0xBB | 10111011 | » | » | » |
| 188 | 274 | 0xBC | 10111100 | ј | ¼ | |
| 189 | 275 | 0xBD | 10111101 | Ѕ | ½ | |
| 190 | 276 | 0xBE | 10111110 | ѕ | ¾ | |
| 191 | 277 | 0xBF | 10111111 | ї | ¿ | |
| 192 | 300 | 0xC0 | 11000000 | А | À | |
| 193 | 301 | 0xC1 | 11000001 | Б | Á | |
| 194 | 302 | 0xC2 | 11000010 | В | Â | |
| 195 | 303 | 0xC3 | 11000011 | Г | Ã | |
| 196 | 304 | 0xC4 | 11000100 | Д | Ä | |
| 197 | 305 | 0xC5 | 11000101 | Е | Å | |
| 198 | 306 | 0xC6 | 11000110 | Ж | Æ | |
| 199 | 307 | 0xC7 | 11000111 | З | Ç | |
| 200 | 310 | 0xC8 | 11001000 | И | È | |
| 201 | 311 | 0xC9 | 11001001 | Й | É | |
| 202 | 312 | 0xCA | 11001010 | К | Ê | |
| 203 | 313 | 0xCB | 11001011 | Л | Ë | |
| 204 | 314 | 0xCC | 11001100 | М | Ì | |
| 205 | 315 | 0xCD | 11001101 | Н | Í | |
| 206 | 316 | 0xCE | 11001110 | О | Î | |
| 207 | 317 | 0xCF | 11001111 | П | Ï | |
| 208 | 320 | 0xD0 | 11010000 | Р | Ð | |
| 209 | 321 | 0xD1 | 11010001 | С | Ñ | |
| 210 | 322 | 0xD2 | 11010010 | Т | Ò | |
| 211 | 323 | 0xD3 | 11010011 | У | Ó | |
| 212 | 324 | 0xD4 | 11010100 | Ф | Ô | |
| 213 | 325 | 0xD5 | 11010101 | Х | Õ | |
| 214 | 326 | 0xD6 | 11010110 | Ц | Ö | |
| 215 | 327 | 0xD7 | 11010111 | Ч | × | |
| 216 | 330 | 0xD8 | 11011000 | Ш | Ø | |
| 217 | 331 | 0xD9 | 11011001 | Щ | Ù | |
| 218 | 332 | 0xDA | 11011010 | Ъ | Ú | |
| 219 | 333 | 0xDB | 11011011 | Ы | Û | |
| 220 | 334 | 0xDC | 11011100 | Ь | Ü | |
| 221 | 335 | 0xDD | 11011101 | Э | Ý | |
| 222 | 336 | 0xDE | 11011110 | Ю | Þ | |
| 223 | 337 | 0xDF | 11011111 | Я | ß | |
| 224 | 340 | 0xE0 | 11100000 | а | à | |
| 225 | 341 | 0xE1 | 11100001 | б | á | |
| 226 | 342 | 0xE2 | 11100010 | в | â | |
| 227 | 343 | 0xE3 | 11100011 | г | ã | |
| 228 | 344 | 0xE4 | 11100100 | д | ä | |
| 229 | 345 | 0xE5 | 11100101 | е | å | |
| 230 | 346 | 0xE6 | 11100110 | ж | æ | |
| 231 | 347 | 0xE7 | 11100111 | з | ç | |
| 232 | 350 | 0xE8 | 11101000 | и | è | |
| 233 | 351 | 0xE9 | 11101001 | й | é | |
| 234 | 352 | 0xEA | 11101010 | к | ê | |
| 235 | 353 | 0xEB | 11101011 | л | ë | |
| 236 | 354 | 0xEC | 11101100 | м | ì | |
| 237 | 355 | 0xED | 11101101 | н | í | |
| 238 | 356 | 0xEE | 11101110 | о | î | |
| 239 | 357 | 0xEF | 11101111 | п | ï | |
| 240 | 360 | 0xF0 | 11110000 | р | ð | |
| 241 | 361 | 0xF1 | 11110001 | с | ñ | |
| 242 | 362 | 0xF2 | 11110010 | т | ò | |
| 243 | 363 | 0xF3 | 11110011 | у | ó | |
| 244 | 364 | 0xF4 | 11110100 | ф | ô | |
| 245 | 365 | 0xF5 | 11110101 | х | õ | |
| 246 | 366 | 0xF6 | 11110110 | ц | ö | |
| 247 | 367 | 0xF7 | 11110111 | ч | ÷ | |
| 248 | 370 | 0xF8 | 11111000 | ш | ø | |
| 249 | 371 | 0xF9 | 11111001 | щ | ù | |
| 250 | 372 | 0xFA | 11111010 | ъ | ú | |
| 251 | 373 | 0xFB | 11111011 | ы | û | |
| 252 | 374 | 0xFC | 11111100 | ь | ü | |
| 253 | 375 | 0xFD | 11111101 | э | ý | |
| 254 | 376 | 0xFE | 11111110 | ю | þ | |
| 255 | 377 | 0xFF | 11111111 | я | ÿ |
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
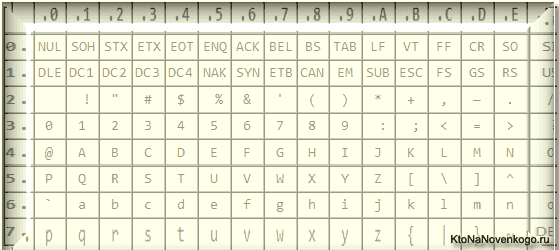
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
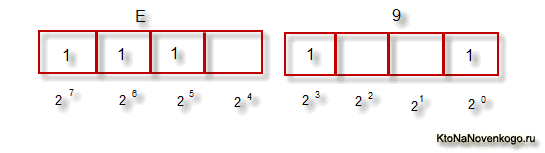
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
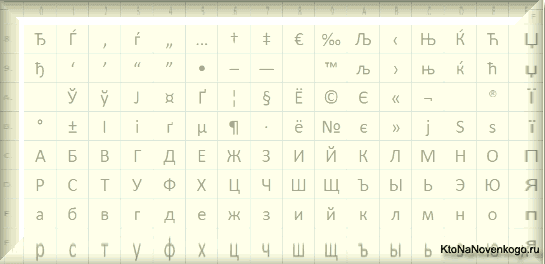
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
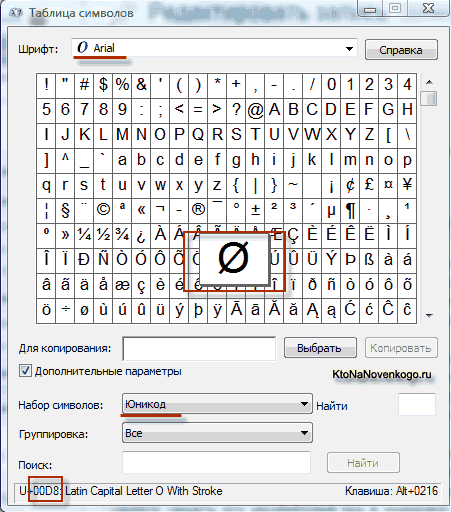
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
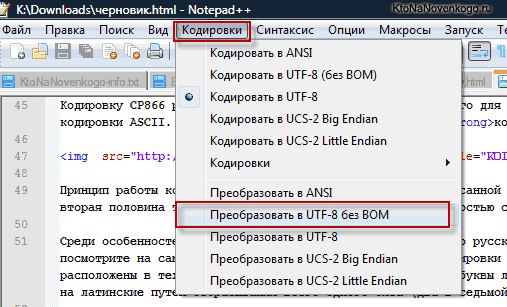
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.

Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах. Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| Dec | Hex | Символ | Dec | Hex | Символ | |
|---|---|---|---|---|---|---|
| 000 | 00 | NOP | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | BS | 136 | 88 | € | |
| 009 | 09 | TAB | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | VT | 139 | 8B | ‹ | |
| 012 | 0C | FF | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | SO | 142 | 8E | Ћ | |
| 015 | 0F | SI | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | NAK | 149 | 95 | • | |
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | CAN | 152 | 98 | ||
| 025 | 19 | EM | 153 | 99 | ™ | |
| 026 | 1A | SUB | 154 | 9A | љ | |
| 027 | 1B | ESC | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | GS | 157 | 9D | ќ | |
| 030 | 1E | RS | 158 | 9E | ћ | |
| 031 | 1F | US | 159 | 9F | џ | |
| 032 | 20 | SP | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | « | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | ‘ | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Ё | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | AA | Є | |
| 043 | 2B | + | 171 | AB | « | |
| 044 | 2C | , | 172 | AC | ¬ | |
| 045 | 2D | — | 173 | AD | | |
| 046 | 2E | . | 174 | AE | ® | |
| 047 | 2F | / | 175 | AF | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | ё | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | BC | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї | |
| 064 | 40 | @ | 192 | C0 | А | |
| 065 | 41 | A | 193 | C1 | Б | |
| 066 | 42 | B | 194 | C2 | В | |
| 067 | 43 | C | 195 | C3 | Г | |
| 068 | 44 | D | 196 | C4 | Д | |
| 069 | 45 | E | 197 | C5 | Е | |
| 070 | 46 | F | 198 | C6 | Ж | |
| 071 | 47 | G | 199 | C7 | З | |
| 072 | 48 | H | 200 | C8 | И | |
| 073 | 49 | I | 201 | C9 | Й | |
| 074 | 4A | J | 202 | CA | К | |
| 075 | 4B | K | 203 | CB | Л | |
| 076 | 4C | L | 204 | CC | М | |
| 077 | 4D | M | 205 | CD | Н | |
| 078 | 4E | N | 206 | CE | О | |
| 079 | 4F | O | 207 | CF | П | |
| 080 | 50 | P | 208 | D0 | Р | |
| 081 | 51 | Q | 209 | D1 | С | |
| 082 | 52 | R | 210 | D2 | Т | |
| 083 | 53 | S | 211 | D3 | У | |
| 084 | 54 | T | 212 | D4 | Ф | |
| 085 | 55 | U | 213 | D5 | Х | |
| 086 | 56 | V | 214 | D6 | Ц | |
| 087 | 57 | W | 215 | D7 | Ч | |
| 088 | 58 | X | 216 | D8 | Ш | |
| 089 | 59 | Y | 217 | D9 | Щ | |
| 090 | 5A | Z | 218 | DA | Ъ | |
| 091 | 5B | [ | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | ||
| 093 | 5D | ] | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю | |
| 095 | 5F | _ | 223 | DF | Я | |
| 096 | 60 | ` | 224 | E0 | а | |
| 097 | 61 | a | 225 | E1 | б | |
| 098 | 62 | b | 226 | E2 | в | |
| 099 | 63 | c | 227 | E3 | г | |
| 100 | 64 | d | 228 | E4 | д | |
| 101 | 65 | e | 229 | E5 | е | |
| 102 | 66 | f | 230 | E6 | ж | |
| 103 | 67 | g | 231 | E7 | з | |
| 104 | 68 | h | 232 | E8 | и | |
| 105 | 69 | i | 233 | E9 | й | |
| 106 | 6A | j | 234 | EA | к | |
| 107 | 6B | k | 235 | EB | л | |
| 108 | 6C | l | 236 | EC | м | |
| 109 | 6D | m | 237 | ED | н | |
| 110 | 6E | n | 238 | EE | о | |
| 111 | 6F | o | 239 | EF | п | |
| 112 | 70 | p | 240 | F0 | р | |
| 113 | 71 | q | 241 | F1 | с | |
| 114 | 72 | r | 242 | F2 | т | |
| 115 | 73 | s | 243 | F3 | у | |
| 116 | 74 | t | 244 | F4 | ф | |
| 117 | 75 | u | 245 | F5 | х | |
| 118 | 76 | v | 246 | F6 | ц | |
| 119 | 77 | w | 247 | F7 | ч | |
| 120 | 78 | x | 248 | F8 | ш | |
| 121 | 79 | y | 249 | F9 | щ | |
| 122 | 7A | z | 250 | FA | ъ | |
| 123 | 7B | { | 251 | FB | ы | |
| 124 | 7C | | | 252 | FC | ь | |
| 125 | 7D | } | 253 | FD | э | |
| 126 | 7E | ~ | 254 | FE | ю | |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.
Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
| Код | Описание |
|---|---|
| NUL, 00 | Null, пустой |
| SOH, 01 | Start Of Heading, начало заголовка |
| STX, 02 | Start of TeXt, начало текста |
| ETX, 03 | End of TeXt, конец текста |
| EOT, 04 | End of Transmission, конец передачи |
| ENQ, 05 | Enquire. Прошу подтверждения |
| ACK, 06 | Acknowledgement. Подтверждаю |
| BEL, 07 | Bell, звонок |
| BS, 08 | Backspace, возврат на один символ назад |
| TAB, 09 | Tab, горизонтальная табуляция |
| LF, 0A | Line Feed, перевод строки Сейчас в большинстве языков программирования обозначается как n |
| VT, 0B | Vertical Tab, вертикальная табуляция |
| FF, 0C | Form Feed, прогон страницы, новая страница |
| CR, 0D | Carriage Return, возврат каретки Сейчас в большинстве языков программирования обозначается как r |
| SO, 0E | Shift Out, изменить цвет красящей ленты в печатающем устройстве |
| SI, 0F | Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно |
| DLE, 10 | Data Link Escape, переключение канала на передачу данных |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 |
Device Control, символы управления устройствами |
| NAK, 15 | Negative Acknowledgment, не подтверждаю |
| SYN, 16 | Synchronization. Символ синхронизации |
| ETB, 17 | End of Text Block, конец текстового блока |
| CAN, 18 | Cancel, отмена переданного ранее |
| EM, 19 | End of Medium, конец носителя данных |
| SUB, 1A | Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче |
| ESC, 1B | Escape Управляющая последовательность |
| FS, 1C | File Separator, разделитель файлов |
| GS, 1D | Group Separator, разделитель групп |
| RS, 1E | Record Separator, разделитель записей |
| US, 1F | Unit Separator, разделитель юнитов |
| DEL, 7F | Delete, стереть последний символ. |
Смотрите также:
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
Таблица кодов символов кирилицы UTF-8

ASCII — A
merican
S
tandard
C
ode for
I
nformation
I
nterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL | & #000; | Null char | |
| 1 | 001 | 0x01 | 00000001 | SOH | & #001; | Start of Heading | |
| 2 | 002 | 0x02 | 00000010 | STX | & #002; | Start of Text | |
| 3 | 003 | 0x03 | 00000011 | ETX | & #003; | End of Text | |
| 4 | 004 | 0x04 | 00000100 | EOT | & #004; | End of Transmission | |
| 5 | 005 | 0x05 | 00000101 | ENQ | & #005; | Enquiry | |
| 6 | 006 | 0x06 | 00000110 | ACK | & #006; | Acknowledgment | |
| 7 | 007 | 0x07 | 00000111 | BEL | & #007; | Bell | |
| 8 | 010 | 0x08 | 00001000 | BS | & #008; | Back Space | |
| 9 | 011 | 0x09 | 00001001 | HT t | & #009; | Tab | |
| 10 | 012 | 0x0A | 00001010 | LF n | & #010; | Новая строка | |
| 11 | 013 | 0x0B | 00001011 | VT | & #011; | Vertical Tab | |
| 12 | 014 | 0x0C | 00001100 | FF | & #012; | Form Feed | |
| 13 | 015 | 0x0D | 00001101 | CR r | & #013; | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO | & #014; | Shift Out / X-On | |
| 15 | 017 | 0x0F | 00001111 | SI | & #015; | Shift In / X-Off | |
| 16 | 020 | 0x10 | 00010000 | DLE | & #016; | Data Line Escape | |
| 17 | 021 | 0x11 | 00010001 | DC1 | & #017; | Device Control 1 (oft. XON) | |
| 18 | 022 | 0x12 | 00010010 | DC2 | & #018; | Device Control 2 | |
| 19 | 023 | 0x13 | 00010011 | DC3 | & #019; | Device Control 3 (oft. XOFF) | |
| 20 | 024 | 0x14 | 00010100 | DC4 | & #020; | Device Control 4 | |
| 21 | 025 | 0x15 | 00010101 | NAK | & #021; | Negative Acknowledgement | |
| 22 | 026 | 0x16 | 00010110 | SYN | & #022; | Synchronous Idle | |
| 23 | 027 | 0x17 | 00010111 | ETB | & #023; | End of Transmit Block | |
| 24 | 030 | 0x18 | 00011000 | CAN | & #024; | Cancel | |
| 25 | 031 | 0x19 | 00011001 | EM | & #025; | End of Medium | |
| 26 | 032 | 0x1A | 00011010 | SUB | & #026; | Substitute | |
| 27 | 033 | 0x1B | 00011011 | ESC | & #027; | Escape | |
| 28 | 034 | 0x1C | 00011100 | FS | & #028; | File Separator | |
| 29 | 035 | 0x1D | 00011101 | GS | & #029; | Group Separator | |
| 30 | 036 | 0x1E | 00011110 | RS | & #030; | Record Separator | |
| 31 | 037 | 0x1F | 00011111 | US | & #031; | Unit Separator | |
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Печатные символы ASCII (код символа 32-127)
Буквы, цифры, знаки препинания и другие символы расположенные на клавиатуре (англ.).
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | & #32; | Space | ||
| 33 | 041 | 0x21 | 00100001 | ! | & #33; | Exclamation mark | |
| 34 | 042 | 0x22 | 00100010 | « | & #34; | & quot; | Double quotes (or speech marks) |
| 35 | 043 | 0x23 | 00100011 | # | & #35; | Number | |
| 36 | 044 | 0x24 | 00100100 | $ | & #36; | Dollar | |
| 37 | 045 | 0x25 | 00100101 | % | & #37; | Procenttecken | |
| 38 | 046 | 0x26 | 00100110 | & | & #38; | & amp; | Ampersand |
| 39 | 047 | 0x27 | 00100111 | ‘ | & #39; | Single quote | |
| 40 | 050 | 0x28 | 00101000 | ( | & #40; | Open parenthesis (or open bracket) | |
| 41 | 051 | 0x29 | 00101001 | ) | & #41; | Close parenthesis (or close bracket) | |
| 42 | 052 | 0x2A | 00101010 | * | & #42; | Asterisk | |
| 43 | 053 | 0x2B | 00101011 | + | & #43; | Plus | |
| 44 | 054 | 0x2C | 00101100 | , | & #44; | Comma | |
| 45 | 055 | 0x2D | 00101101 | — | & #45; | Hyphen | |
| 46 | 056 | 0x2E | 00101110 | . | & #46; | Period, dot or full stop | |
| 47 | 057 | 0x2F | 00101111 | / | & #47; | Slash or divide | |
| 48 | 060 | 0x30 | 00110000 | 0 | & #48; | Zero | |
| 49 | 061 | 0x31 | 00110001 | 1 | & #49; | One | |
| 50 | 062 | 0x32 | 00110010 | 2 | & #50; | Two | |
| 51 | 063 | 0x33 | 00110011 | 3 | & #51; | Three | |
| 52 | 064 | 0x34 | 00110100 | 4 | & #52; | Four | |
| 53 | 065 | 0x35 | 00110101 | 5 | & #53; | Five | |
| 54 | 066 | 0x36 | 00110110 | 6 | & #54; | Six | |
| 55 | 067 | 0x37 | 00110111 | 7 | & #55; | Seven | |
| 56 | 070 | 0x38 | 00111000 | 8 | & #56; | Eight | |
| 57 | 071 | 0x39 | 00111001 | 9 | & #57; | Nine | |
| 58 | 072 | 0x3A | 00111010 | : | & #58; | Colon | |
| 59 | 073 | 0x3B | 00111011 | ; | & #59; | Semicolon | |
| 60 | 074 | 0x3C | 00111100 | < | & #60; | & lt; | Less than (or open angled bracket) |
| 61 | 075 | 0x3D | 00111101 | = | & #61; | Equals | |
| 62 | 076 | 0x3E | 00111110 | > | & #62; | & gt; | Greater than (or close angled bracket) |
| 63 | 077 | 0x3F | 00111111 | ? | & #63; | Question mark | |
| 64 | 100 | 0x40 | 01000000 | @ | & #64; | At symbol | |
| 65 | 101 | 0x41 | 01000001 | A | & #65; | A | |
| 66 | 102 | 0x42 | 01000010 | B | & #66; | B | |
| 67 | 103 | 0x43 | 01000011 | C | & #67; | C | |
| 68 | 104 | 0x44 | 01000100 | D | & #68; | D | |
| 69 | 105 | 0x45 | 01000101 | E | & #69; | E | |
| 70 | 106 | 0x46 | 01000110 | F | & #70; | F | |
| 71 | 107 | 0x47 | 01000111 | G | & #71; | G | |
| 72 | 110 | 0x48 | 01001000 | H | & #72; | H | |
| 73 | 111 | 0x49 | 01001001 | I | & #73; | I | |
| 74 | 112 | 0x4A | 01001010 | J | & #74; | J | |
| 75 | 113 | 0x4B | 01001011 | K | & #75; | K | |
| 76 | 114 | 0x4C | 01001100 | L | & #76; | L | |
| 77 | 115 | 0x4D | 01001101 | M | & #77; | M | |
| 78 | 116 | 0x4E | 01001110 | N | & #78; | N | |
| 79 | 117 | 0x4F | 01001111 | O | & #79; | O | |
| 80 | 120 | 0x50 | 01010000 | P | & #80; | P | |
| 81 | 121 | 0x51 | 01010001 | Q | & #81; | Q | |
| 82 | 122 | 0x52 | 01010010 | R | & #82; | R | |
| 83 | 123 | 0x53 | 01010011 | S | & #83; | S | |
| 84 | 124 | 0x54 | 01010100 | T | & #84; | T | |
| 85 | 125 | 0x55 | 01010101 | U | & #85; | U | |
| 86 | 126 | 0x56 | 01010110 | V | & #86; | V | |
| 87 | 127 | 0x57 | 01010111 | W | & #87; | W | |
| 88 | 130 | 0x58 | 01011000 | X | & #88; | X | |
| 89 | 131 | 0x59 | 01011001 | Y | & #89; | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | & #90; | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | & #91; | Opening bracket | |
| 92 | 134 | 0x5C | 01011100 | & #92; | Backslash | ||
| 93 | 135 | 0x5D | 01011101 | ] | & #93; | Closing bracket | |
| 94 | 136 | 0x5E | 01011110 | ^ | & #94; | Caret — circumflex | |
| 95 | 137 | 0x5F | 01011111 | _ | & #95; | Underscore | |
| 96 | 140 | 0x60 | 01100000 | ` | & #96; | Grave accent | |
| 97 | 141 | 0x61 | 01100001 | a | & #97; | a | |
| 98 | 142 | 0x62 | 01100010 | b | & #98; | b | |
| 99 | 143 | 0x63 | 01100011 | c | & #99; | c | |
| 100 | 144 | 0x64 | 01100100 | d | & #100; | d | |
| 101 | 145 | 0x65 | 01100101 | e | & #101; | e | |
| 102 | 146 | 0x66 | 01100110 | f | & #102; | f | |
| 103 | 147 | 0x67 | 01100111 | g | & #103; | g | |
| 104 | 150 | 0x68 | 01101000 | h | & #104; | h | |
| 105 | 151 | 0x69 | 01101001 | i | & #105; | i | |
| 106 | 152 | 0x6A | 01101010 | j | & #106; | j | |
| 107 | 153 | 0x6B | 01101011 | k | & #107; | k | |
| 108 | 154 | 0x6C | 01101100 | l | & #108; | l | |
| 109 | 155 | 0x6D | 01101101 | m | & #109; | m | |
| 110 | 156 | 0x6E | 01101110 | n | & #110; | n | |
| 111 | 157 | 0x6F | 01101111 | o | & #111; | o | |
| 112 | 160 | 0x70 | 01110000 | p | & #112; | p | |
| 113 | 161 | 0x71 | 01110001 | q | & #113; | q | |
| 114 | 162 | 0x72 | 01110010 | r | & #114; | r | |
| 115 | 163 | 0x73 | 01110011 | s | & #115; | s | |
| 116 | 164 | 0x74 | 01110100 | t | & #116; | t | |
| 117 | 165 | 0x75 | 01110101 | u | & #117; | u | |
| 118 | 166 | 0x76 | 01110110 | v | & #118; | v | |
| 119 | 167 | 0x77 | 01110111 | w | & #119; | w | |
| 120 | 170 | 0x78 | 01111000 | x | & #120; | x | |
| 121 | 171 | 0x79 | 01111001 | y | & #121; | y | |
| 122 | 172 | 0x7A | 01111010 | z | & #122; | z | |
| 123 | 173 | 0x7B | 01111011 | { | & #123; | Opening brace | |
| 124 | 174 | 0x7C | 01111100 | | | & #124; | Vertical bar | |
| 125 | 175 | 0x7D | 01111101 | } | & #125; | Closing brace | |
| 126 | 176 | 0x7E | 01111110 | ~ | & #126; | Equivalency sign — tilde | |
| 127 | 177 | 0x7F | 01111111 | & #127; | Delete | ||
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Расширенные символы ASCII Win-1251 кириллица (код символа 128-255)
| DEC | OCT | HEX | BIN | Symbol |
|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ |
| 129 | 201 | 0x81 | 10000001 | Ѓ |
| 130 | 202 | 0x82 | 10000010 | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ |
| 132 | 204 | 0x84 | 10000100 | „ |
| 133 | 205 | 0x85 | 10000101 | … |
| 134 | 206 | 0x86 | 10000110 | † |
| 135 | 207 | 0x87 | 10000111 | ‡ |
| 136 | 210 | 0x88 | 10001000 | € |
| 137 | 211 | 0x89 | 10001001 | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ |
| 139 | 213 | 0x8B | 10001011 | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ |
| 141 | 215 | 0x8D | 10001101 | Ќ |
| 142 | 216 | 0x8E | 10001110 | Ћ |
| 143 | 217 | 0x8F | 10001111 | Џ |
| 144 | 220 | 0x90 | 10010000 | Ђ |
| 145 | 221 | 0x91 | 10010001 | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ |
| 147 | 223 | 0x93 | 10010011 | “ |
| 148 | 224 | 0x94 | 10010100 | ” |
| 149 | 225 | 0x95 | 10010101 | • |
| 150 | 226 | 0x96 | 10010110 | – |
| 151 | 227 | 0x97 | 10010111 | — |
| 152 | 230 | 0x98 | 10011000 | |
| 153 | 231 | 0x99 | 10011001 | ™ |
| 154 | 232 | 0x9A | 10011010 | љ |
| 155 | 233 | 0x9B | 10011011 | › |
| 156 | 234 | 0x9C | 10011100 | њ |
| 157 | 235 | 0x9D | 10011101 | ќ |
| 158 | 236 | 0x9E | 10011110 | ћ |
| 159 | 237 | 0x9F | 10011111 | џ |
| 160 | 240 | 0xA0 | 10100000 | |
| 161 | 241 | 0xA1 | 10100001 | Ў |
| 162 | 242 | 0xA2 | 10100010 | ў |
| 163 | 243 | 0xA3 | 10100011 | Ј |
| 164 | 244 | 0xA4 | 10100100 | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ |
| 166 | 246 | 0xA6 | 10100110 | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § |
| 168 | 250 | 0xA8 | 10101000 | Ё |
| 169 | 251 | 0xA9 | 10101001 | © |
| 170 | 252 | 0xAA | 10101010 | Є |
| 171 | 253 | 0xAB | 10101011 | « |
| 172 | 254 | 0xAC | 10101100 | ¬ |
| 173 | 255 | 0xAD | 10101101 | |
| 174 | 256 | 0xAE | 10101110 | ® |
| 175 | 257 | 0xAF | 10101111 | Ї |
| 176 | 260 | 0xB0 | 10110000 | ° |
| 177 | 261 | 0xB1 | 10110001 | ± |
| 178 | 262 | 0xB2 | 10110010 | І |
| 179 | 263 | 0xB3 | 10110011 | і |
| 180 | 264 | 0xB4 | 10110100 | ґ |
| 181 | 265 | 0xB5 | 10110101 | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · |
| 184 | 270 | 0xB8 | 10111000 | ё |
| 185 | 271 | 0xB9 | 10111001 | № |
| 186 | 272 | 0xBA | 10111010 | є |
| 187 | 273 | 0xBB | 10111011 | » |
| 188 | 274 | 0xBC | 10111100 | ј |
| 189 | 275 | 0xBD | 10111101 | Ѕ |
| 190 | 276 | 0xBE | 10111110 | ѕ |
| 191 | 277 | 0xBF | 10111111 | ї |
| 192 | 300 | 0xC0 | 11000000 | А |
| 193 | 301 | 0xC1 | 11000001 | Б |
| 194 | 302 | 0xC2 | 11000010 | В |
| 195 | 303 | 0xC3 | 11000011 | Г |
| 196 | 304 | 0xC4 | 11000100 | Д |
| 197 | 305 | 0xC5 | 11000101 | Е |
| 198 | 306 | 0xC6 | 11000110 | Ж |
| 199 | 307 | 0xC7 | 11000111 | З |
| 200 | 310 | 0xC8 | 11001000 | И |
| 201 | 311 | 0xC9 | 11001001 | Й |
| 202 | 312 | 0xCA | 11001010 | К |
| 203 | 313 | 0xCB | 11001011 | Л |
| 204 | 314 | 0xCC | 11001100 | М |
| 205 | 315 | 0xCD | 11001101 | Н |
| 206 | 316 | 0xCE | 11001110 | О |
| 207 | 317 | 0xCF | 11001111 | П |
| 208 | 320 | 0xD0 | 11010000 | Р |
| 209 | 321 | 0xD1 | 11010001 | С |
| 210 | 322 | 0xD2 | 11010010 | Т |
| 211 | 323 | 0xD3 | 11010011 | У |
| 212 | 324 | 0xD4 | 11010100 | Ф |
| 213 | 325 | 0xD5 | 11010101 | Х |
| 214 | 326 | 0xD6 | 11010110 | Ц |
| 215 | 327 | 0xD7 | 11010111 | Ч |
| 216 | 330 | 0xD8 | 11011000 | Ш |
| 217 | 331 | 0xD9 | 11011001 | Щ |
| 218 | 332 | 0xDA | 11011010 | Ъ |
| 219 | 333 | 0xDB | 11011011 | Ы |
| 220 | 334 | 0xDC | 11011100 | Ь |
| 221 | 335 | 0xDD | 11011101 | Э |
| 222 | 336 | 0xDE | 11011110 | Ю |
| 223 | 337 | 0xDF | 11011111 | Я |
| 224 | 340 | 0xE0 | 11100000 | а |
| 225 | 341 | 0xE1 | 11100001 | б |
| 226 | 342 | 0xE2 | 11100010 | в |
| 227 | 343 | 0xE3 | 11100011 | г |
| 228 | 344 | 0xE4 | 11100100 | д |
| 229 | 345 | 0xE5 | 11100101 | е |
| 230 | 346 | 0xE6 | 11100110 | ж |
| 231 | 347 | 0xE7 | 11100111 | з |
| 232 | 350 | 0xE8 | 11101000 | и |
| 233 | 351 | 0xE9 | 11101001 | й |
| 234 | 352 | 0xEA | 11101010 | к |
| 235 | 353 | 0xEB | 11101011 | л |
| 236 | 354 | 0xEC | 11101100 | м |
| 237 | 355 | 0xED | 11101101 | н |
| 238 | 356 | 0xEE | 11101110 | о |
| 239 | 357 | 0xEF | 11101111 | п |
| 240 | 360 | 0xF0 | 11110000 | р |
| 241 | 361 | 0xF1 | 11110001 | с |
| 242 | 362 | 0xF2 | 11110010 | т |
| 243 | 363 | 0xF3 | 11110011 | у |
| 244 | 364 | 0xF4 | 11110100 | ф |
| 245 | 365 | 0xF5 | 11110101 | х |
| 246 | 366 | 0xF6 | 11110110 | ц |
| 247 | 367 | 0xF7 | 11110111 | ч |
| 248 | 370 | 0xF8 | 11111000 | ш |
| 249 | 371 | 0xF9 | 11111001 | щ |
| 250 | 372 | 0xFA | 11111010 | ъ |
| 251 | 373 | 0xFB | 11111011 | ы |
| 252 | 374 | 0xFC | 11111100 | ь |
| 253 | 375 | 0xFD | 11111101 | э |
| 254 | 376 | 0xFE | 11111110 | ю |
| 255 | 377 | 0xFF | 11111111 | я |
| DEC | OCT | HEX | BIN | Symbol |
Расширенные символы ASCII Win-1252 (код символа 128-255)
| DEC | OCT | HEX | BIN | Symbol |
|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | € |
| 129 | 201 | 0x81 | 10000001 | |
| 130 | 202 | 0x82 | 10000010 | ‚ |
| 131 | 203 | 0x83 | 10000011 | ƒ |
| 132 | 204 | 0x84 | 10000100 | „ |
| 133 | 205 | 0x85 | 10000101 | … |
| 134 | 206 | 0x86 | 10000110 | † |
| 135 | 207 | 0x87 | 10000111 | ‡ |
| 136 | 210 | 0x88 | 10001000 | ˆ |
| 137 | 211 | 0x89 | 10001001 | ‰ |
| 138 | 212 | 0x8A | 10001010 | Š |
| 139 | 213 | 0x8B | 10001011 | ‹ |
| 140 | 214 | 0x8C | 10001100 | Π|
| 141 | 215 | 0x8D | 10001101 | |
| 142 | 216 | 0x8E | 10001110 | Ž |
| 143 | 217 | 0x8F | 10001111 | |
| 144 | 220 | 0x90 | 10010000 | |
| 145 | 221 | 0x91 | 10010001 | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ |
| 147 | 223 | 0x93 | 10010011 | “ |
| 148 | 224 | 0x94 | 10010100 | ” |
| 149 | 225 | 0x95 | 10010101 | • |
| 150 | 226 | 0x96 | 10010110 | – |
| 151 | 227 | 0x97 | 10010111 | — |
| 152 | 230 | 0x98 | 10011000 | ˜ |
| 153 | 231 | 0x99 | 10011001 | ™ |
| 154 | 232 | 0x9A | 10011010 | š |
| 155 | 233 | 0x9B | 10011011 | › |
| 156 | 234 | 0x9C | 10011100 | œ |
| 157 | 235 | 0x9D | 10011101 | |
| 158 | 236 | 0x9E | 10011110 | ž |
| 159 | 237 | 0x9F | 10011111 | Ÿ |
| 160 | 240 | 0xA0 | 10100000 | |
| 161 | 241 | 0xA1 | 10100001 | ¡ |
| 162 | 242 | 0xA2 | 10100010 | ¢ |
| 163 | 243 | 0xA3 | 10100011 | £ |
| 164 | 244 | 0xA4 | 10100100 | ¤ |
| 165 | 245 | 0xA5 | 10100101 | ¥ |
| 166 | 246 | 0xA6 | 10100110 | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § |
| 168 | 250 | 0xA8 | 10101000 | ¨ |
| 169 | 251 | 0xA9 | 10101001 | © |
| 170 | 252 | 0xAA | 10101010 | ª |
| 171 | 253 | 0xAB | 10101011 | « |
| 172 | 254 | 0xAC | 10101100 | ¬ |
| 173 | 255 | 0xAD | 10101101 | � |
| 174 | 256 | 0xAE | 10101110 | ® |
| 175 | 257 | 0xAF | 10101111 | ¯ |
| 176 | 260 | 0xB0 | 10110000 | ° |
| 177 | 261 | 0xB1 | 10110001 | ± |
| 178 | 262 | 0xB2 | 10110010 | ² |
| 179 | 263 | 0xB3 | 10110011 | ³ |
| 180 | 264 | 0xB4 | 10110100 | ´ |
| 181 | 265 | 0xB5 | 10110101 | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · |
| 184 | 270 | 0xB8 | 10111000 | ¸ |
| 185 | 271 | 0xB9 | 10111001 | ¹ |
| 186 | 272 | 0xBA | 10111010 | º |
| 187 | 273 | 0xBB | 10111011 | » |
| 188 | 274 | 0xBC | 10111100 | ¼ |
| 189 | 275 | 0xBD | 10111101 | ½ |
| 190 | 276 | 0xBE | 10111110 | ¾ |
| 191 | 277 | 0xBF | 10111111 | ¿ |
| 192 | 300 | 0xC0 | 11000000 | À |
| 193 | 301 | 0xC1 | 11000001 | Á |
| 194 | 302 | 0xC2 | 11000010 | Â |
| 195 | 303 | 0xC3 | 11000011 | Ã |
| 196 | 304 | 0xC4 | 11000100 | Ä |
| 197 | 305 | 0xC5 | 11000101 | Å |
| 198 | 306 | 0xC6 | 11000110 | Æ |
| 199 | 307 | 0xC7 | 11000111 | Ç |
| 200 | 310 | 0xC8 | 11001000 | È |
| 201 | 311 | 0xC9 | 11001001 | É |
| 202 | 312 | 0xCA | 11001010 | Ê |
| 203 | 313 | 0xCB | 11001011 | Ë |
| 204 | 314 | 0xCC | 11001100 | Ì |
| 205 | 315 | 0xCD | 11001101 | Í |
| 206 | 316 | 0xCE | 11001110 | Î |
| 207 | 317 | 0xCF | 11001111 | Ï |
| 208 | 320 | 0xD0 | 11010000 | Ð |
| 209 | 321 | 0xD1 | 11010001 | Ñ |
| 210 | 322 | 0xD2 | 11010010 | Ò |
| 211 | 323 | 0xD3 | 11010011 | Ó |
| 212 | 324 | 0xD4 | 11010100 | Ô |
| 213 | 325 | 0xD5 | 11010101 | Õ |
| 214 | 326 | 0xD6 | 11010110 | Ö |
| 215 | 327 | 0xD7 | 11010111 | × |
| 216 | 330 | 0xD8 | 11011000 | Ø |
| 217 | 331 | 0xD9 | 11011001 | Ù |
| 218 | 332 | 0xDA | 11011010 | Ú |
| 219 | 333 | 0xDB | 11011011 | Û |
| 220 | 334 | 0xDC | 11011100 | Ü |
| 221 | 335 | 0xDD | 11011101 | Ý |
| 222 | 336 | 0xDE | 11011110 | Þ |
| 223 | 337 | 0xDF | 11011111 | ß |
| 224 | 340 | 0xE0 | 11100000 | à |
| 225 | 341 | 0xE1 | 11100001 | á |
| 226 | 342 | 0xE2 | 11100010 | â |
| 227 | 343 | 0xE3 | 11100011 | ã |
| 228 | 344 | 0xE4 | 11100100 | ä |
| 229 | 345 | 0xE5 | 11100101 | å |
| 230 | 346 | 0xE6 | 11100110 | æ |
| 231 | 347 | 0xE7 | 11100111 | ç |
| 232 | 350 | 0xE8 | 11101000 | è |
| 233 | 351 | 0xE9 | 11101001 | é |
| 234 | 352 | 0xEA | 11101010 | ê |
| 235 | 353 | 0xEB | 11101011 | ë |
| 236 | 354 | 0xEC | 11101100 | ì |
| 237 | 355 | 0xED | 11101101 | í |
| 238 | 356 | 0xEE | 11101110 | î |
| 239 | 357 | 0xEF | 11101111 | ï |
| 240 | 360 | 0xF0 | 11110000 | ð |
| 241 | 361 | 0xF1 | 11110001 | ñ |
| 242 | 362 | 0xF2 | 11110010 | ò |
| 243 | 363 | 0xF3 | 11110011 | ó |
| 244 | 364 | 0xF4 | 11110100 | ô |
| 245 | 365 | 0xF5 | 11110101 | õ |
| 246 | 366 | 0xF6 | 11110110 | ö |
| 247 | 367 | 0xF7 | 11110111 | ÷ |
| 248 | 370 | 0xF8 | 11111000 | ø |
| 249 | 371 | 0xF9 | 11111001 | ù |
| 250 | 372 | 0xFA | 11111010 | ú |
| 251 | 373 | 0xFB | 11111011 | û |
| 252 | 374 | 0xFC | 11111100 | ü |
| 253 | 375 | 0xFD | 11111101 | ý |
| 254 | 376 | 0xFE | 11111110 | þ |
| 255 | 377 | 0xFF | 11111111 | ÿ |
| DEC | OCT | HEX | BIN | Symbol |

From Wikipedia, the free encyclopedia
| MIME / IANA | windows-1251 |
|---|---|
| Alias(es) | cp1251 (Code page 1251) |
| Language(s) | Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Bosnian Cyrillic, Macedonian, Rotokas, Rusyn, English |
| Created by | Microsoft |
| Standard | WHATWG Encoding Standard |
| Classification | extended ASCII, Windows-125x |
| Other related encoding(s) | Amiga-1251, KZ-1048, RFC 1345’s «ECMA-Cyrillic» |
|
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
On the web, it is the second most-used single-byte character encoding (or third most-used character encoding overall), and most used of the single-byte encodings supporting Cyrillic. As of November 2022, 0.4% of all websites use Windows-1251.[1][2] It’s by far mostly used for Russian, while a small minority of Russian websites use it, with 93.7% of Russian (.ru) websites using UTF-8,[3][4][5] and the legacy 8-bit encoding is distant second. In Linux, the encoding is known as cp1251.[6] IBM uses code page 1251 (CCSID 1251 and euro sign extended CCSID 5347) for Windows-1251.[7][8][9][10][11][12][13]
Windows-1251 and KOI8-R (or its Ukrainian variant KOI8-U) are much more commonly used than ISO 8859-5 (which is used by less than 0.0004% of websites).[14] In contrast to Windows-1252 and ISO 8859-1, Windows-1251 is not closely related to ISO 8859-5.
Unicode (e.g. UTF-8) is preferred to Windows-1251 or other Cyrillic encodings in modern applications, especially on the Internet, making UTF-8 the dominant encoding for web pages. (For further discussion of Unicode’s complete coverage, of 436 Cyrillic letters/code points, including for Old Cyrillic, and how single-byte character encodings, such as Windows-1251 and KOI8-R, cannot provide this, see Cyrillic script in Unicode.)
Character set[edit]
The following table shows Windows-1251. Each character is shown with its Unicode equivalent and its Alt code.
| Windows-1251[15] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Ќ | Ћ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | ќ | ћ | џ | |
| Ax | NBSP | Ў | ў | Ј | ¤ | Ґ | ¦ | § | Ё | © | Є | « | ¬ | SHY | ® | Ї |
| Bx | ° | ± | І | і | ґ | µ | ¶ | · | ё | № | є | » | ј | Ѕ | ѕ | ї |
| Cx | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Dx | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| Ex | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Fx | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Kazakh variant[edit]
An altered version of Windows-1251 was standardised in Kazakhstan as Kazakh standard STRK1048, and is known by the label KZ-1048. It differs in the rows shown below:
| KZ-1048 (STRK1048-2002)[16] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Қ | Һ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | қ | һ | џ | |
| Ax | NBSP | Ұ | ұ | Ә | ¤ | Ө | ¦ | § | Ё | © | Ғ | « | ¬ | SHY | ® | Ү |
| Bx | ° | ± | І | і | ө | µ | ¶ | · | ё | № | ғ | » | ә | Ң | ң | ү |
Differences from Windows-1251
Amiga variant[edit]
| MIME / IANA | Amiga-1251 |
|---|---|
| Alias(es) | Ami1251 |
| Language(s) | English, Russian |
| Classification | extended ASCII |
| Based on | Windows-1251, ISO-8859-1, ISO-8859-15 |
|
Russian Amiga OS systems used a version of code page 1251 which matches Windows-1251 for the Russian subset of the Cyrillic letters, but otherwise mostly follows ISO-8859-1. This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
| Amiga-1251[17] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | XXX | XXX | BPH | NBH | IND | NEL | SSA | ESA | HTS | HTJ | VTS | PLD | PLU | RI | SS2 | SS3 |
| 9x | DCS | PU1 | PU2 | STS | CCH | MW | SPA | EPA | SOS | XXX | SCI | CSI | ST | OSC | PM | APC |
| Ax | NBSP | ¡ | ¢ | £ | €[a] | ¥ | ¦ | § | Ё | © | №[b] | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ё | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
Different from Windows-1251 to match ISO-8859-1
Different from both Windows-1251 and ISO-8859-1
- ^ Matching ISO-8859-15; at a different location than in Windows-1251
- ^ Present in Windows-1251, but in a different location (absent from ISO-8859-1/15)
See also[edit]
- Latin script in Unicode
- Unicode
- Universal Character Set
- European Unicode subset (DIN 91379)
- UTF-8
References[edit]
- ^ «Historical trends in the usage of character encodings, November 2022». Retrieved 2022-11-28.
- ^ «Frequently Asked Questions».
- ^ «Distribution of Character Encodings among websites that use .ru». w3techs.com. Retrieved 2022-11-28.
- ^ «Distribution of Character Encodings among websites that use Russian». w3techs.com. Retrieved 2023-01-16.
- ^ «Distribution of Character Encodings among websites that use Russian Federation». w3techs.com. Retrieved 2021-11-05.
- ^ «cp1251(7) — Linux manual page». man7.org. Retrieved 2018-07-01.
- ^ «Code page 1251 information document». Archived from the original on 2016-03-03.
- ^ «CCSID 1251 information document». Archived from the original on 2014-11-29.
- ^ «CCSID 5347 information document». Archived from the original on 2014-11-29.
- ^ Code Page CPGID 01251 (pdf) (PDF), IBM
- ^ Code Page CPGID 01251 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1251_P100-1995.ucm, 2002-12-03
- ^ International Components for Unicode (ICU), ibm-5347_P100-1998.ucm, 2002-12-03
- ^ «Usage Statistics of Character Encodings for Websites». w3techs.com. Archived from the original on 2012-05-30.
- ^ Steele, Shawn (1998). CP1251 to Unicode table. Unicode Consortium. CP1251.TXT.
- ^ Whistler, Ken (2007). KZ-1048 to Unicode. Unicode Consortium. KZ1048.TXT.
- ^ a b Malyshev, Michael (2003). «Amiga-1251 to Unicode table». Registration of new charset [Amiga-1251]. IANA.
- ^ «Character Sets». IANA.
Further reading[edit]
- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). «CYRILLIC ENCODING FAQ Version 1.3». Retrieved 2020-06-24.
External links[edit]
- Windows 1251 reference chart
- IANA Charset Name Registration
- Unicode mappings of windows 1251 with «best fit»
- Universal Cyrillic decoder, an online program that may help recovering unreadable Cyrillic texts with broken Windows-1251 or other character encodings.
From Wikipedia, the free encyclopedia
| MIME / IANA | windows-1251 |
|---|---|
| Alias(es) | cp1251 (Code page 1251) |
| Language(s) | Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Bosnian Cyrillic, Macedonian, Rotokas, Rusyn, English |
| Created by | Microsoft |
| Standard | WHATWG Encoding Standard |
| Classification | extended ASCII, Windows-125x |
| Other related encoding(s) | Amiga-1251, KZ-1048, RFC 1345’s «ECMA-Cyrillic» |
|
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
On the web, it is the second most-used single-byte character encoding (or third most-used character encoding overall), and most used of the single-byte encodings supporting Cyrillic. As of November 2022, 0.4% of all websites use Windows-1251.[1][2] It’s by far mostly used for Russian, while a small minority of Russian websites use it, with 93.7% of Russian (.ru) websites using UTF-8,[3][4][5] and the legacy 8-bit encoding is distant second. In Linux, the encoding is known as cp1251.[6] IBM uses code page 1251 (CCSID 1251 and euro sign extended CCSID 5347) for Windows-1251.[7][8][9][10][11][12][13]
Windows-1251 and KOI8-R (or its Ukrainian variant KOI8-U) are much more commonly used than ISO 8859-5 (which is used by less than 0.0004% of websites).[14] In contrast to Windows-1252 and ISO 8859-1, Windows-1251 is not closely related to ISO 8859-5.
Unicode (e.g. UTF-8) is preferred to Windows-1251 or other Cyrillic encodings in modern applications, especially on the Internet, making UTF-8 the dominant encoding for web pages. (For further discussion of Unicode’s complete coverage, of 436 Cyrillic letters/code points, including for Old Cyrillic, and how single-byte character encodings, such as Windows-1251 and KOI8-R, cannot provide this, see Cyrillic script in Unicode.)
Character set[edit]
The following table shows Windows-1251. Each character is shown with its Unicode equivalent and its Alt code.
| Windows-1251[15] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Ќ | Ћ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | ќ | ћ | џ | |
| Ax | NBSP | Ў | ў | Ј | ¤ | Ґ | ¦ | § | Ё | © | Є | « | ¬ | SHY | ® | Ї |
| Bx | ° | ± | І | і | ґ | µ | ¶ | · | ё | № | є | » | ј | Ѕ | ѕ | ї |
| Cx | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Dx | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| Ex | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Fx | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Kazakh variant[edit]
An altered version of Windows-1251 was standardised in Kazakhstan as Kazakh standard STRK1048, and is known by the label KZ-1048. It differs in the rows shown below:
| KZ-1048 (STRK1048-2002)[16] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Қ | Һ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | қ | һ | џ | |
| Ax | NBSP | Ұ | ұ | Ә | ¤ | Ө | ¦ | § | Ё | © | Ғ | « | ¬ | SHY | ® | Ү |
| Bx | ° | ± | І | і | ө | µ | ¶ | · | ё | № | ғ | » | ә | Ң | ң | ү |
Differences from Windows-1251
Amiga variant[edit]
| MIME / IANA | Amiga-1251 |
|---|---|
| Alias(es) | Ami1251 |
| Language(s) | English, Russian |
| Classification | extended ASCII |
| Based on | Windows-1251, ISO-8859-1, ISO-8859-15 |
|
Russian Amiga OS systems used a version of code page 1251 which matches Windows-1251 for the Russian subset of the Cyrillic letters, but otherwise mostly follows ISO-8859-1. This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
| Amiga-1251[17] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | XXX | XXX | BPH | NBH | IND | NEL | SSA | ESA | HTS | HTJ | VTS | PLD | PLU | RI | SS2 | SS3 |
| 9x | DCS | PU1 | PU2 | STS | CCH | MW | SPA | EPA | SOS | XXX | SCI | CSI | ST | OSC | PM | APC |
| Ax | NBSP | ¡ | ¢ | £ | €[a] | ¥ | ¦ | § | Ё | © | №[b] | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ё | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
Different from Windows-1251 to match ISO-8859-1
Different from both Windows-1251 and ISO-8859-1
- ^ Matching ISO-8859-15; at a different location than in Windows-1251
- ^ Present in Windows-1251, but in a different location (absent from ISO-8859-1/15)
See also[edit]
- Latin script in Unicode
- Unicode
- Universal Character Set
- European Unicode subset (DIN 91379)
- UTF-8
References[edit]
- ^ «Historical trends in the usage of character encodings, November 2022». Retrieved 2022-11-28.
- ^ «Frequently Asked Questions».
- ^ «Distribution of Character Encodings among websites that use .ru». w3techs.com. Retrieved 2022-11-28.
- ^ «Distribution of Character Encodings among websites that use Russian». w3techs.com. Retrieved 2023-01-16.
- ^ «Distribution of Character Encodings among websites that use Russian Federation». w3techs.com. Retrieved 2021-11-05.
- ^ «cp1251(7) — Linux manual page». man7.org. Retrieved 2018-07-01.
- ^ «Code page 1251 information document». Archived from the original on 2016-03-03.
- ^ «CCSID 1251 information document». Archived from the original on 2014-11-29.
- ^ «CCSID 5347 information document». Archived from the original on 2014-11-29.
- ^ Code Page CPGID 01251 (pdf) (PDF), IBM
- ^ Code Page CPGID 01251 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1251_P100-1995.ucm, 2002-12-03
- ^ International Components for Unicode (ICU), ibm-5347_P100-1998.ucm, 2002-12-03
- ^ «Usage Statistics of Character Encodings for Websites». w3techs.com. Archived from the original on 2012-05-30.
- ^ Steele, Shawn (1998). CP1251 to Unicode table. Unicode Consortium. CP1251.TXT.
- ^ Whistler, Ken (2007). KZ-1048 to Unicode. Unicode Consortium. KZ1048.TXT.
- ^ a b Malyshev, Michael (2003). «Amiga-1251 to Unicode table». Registration of new charset [Amiga-1251]. IANA.
- ^ «Character Sets». IANA.
Further reading[edit]
- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). «CYRILLIC ENCODING FAQ Version 1.3». Retrieved 2020-06-24.
External links[edit]
- Windows 1251 reference chart
- IANA Charset Name Registration
- Unicode mappings of windows 1251 with «best fit»
- Universal Cyrillic decoder, an online program that may help recovering unreadable Cyrillic texts with broken Windows-1251 or other character encodings.
Содержание
- Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
- Таблица ASCII
- Таблица CP1251 (windows-1251)
- Таблица IS0-8859-5
- Кодировка UTF-8 (Unicode Transformation Format)
- ASCII таблица
- HTML кодировки
- Кодировка ISO
- Кодировки серии ISO 8859
- Для HTML4:
- Для HTML5:
- Кодировка Windows-1251 (CP1251)
- Кодировки стандарта UNICODE
- Windows 1251
- Содержание
- Таблицы
- Кодировка Windows-1251 (синоним CP1251)
- Другие варианты
- Кодировка CP1251-k (KazWin, казахская кодировка)
- Кодировка Windows-1251 (чувашский вариант)
- Татарский вариант
- Внешние ссылки
- Полезное
- Смотреть что такое «Windows 1251» в других словарях:
Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
Таблица ASCII
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.

Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.
Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.
Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Источник
ASCII таблица
ASCII — A merican S tandard C ode for I nformation I nterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 000 | 0x00 | 00000000 | NUL | & #000; | Null char | ||
| 1 | 001 | 0x01 | 00000001 | SOH | & #001; | Start of Heading | |
| 2 | 002 | 0x02 | 00000010 | STX | & #002; | Start of Text | |
| 3 | 003 | 0x03 | 00000011 | ETX | & #003; | End of Text | |
| 4 | 004 | 0x04 | 00000100 | EOT | & #004; | End of Transmission | |
| 5 | 005 | 0x05 | 00000101 | ENQ | & #005; | Enquiry | |
| 6 | 006 | 0x06 | 00000110 | ACK | & #006; | Acknowledgment | |
| 7 | 007 | 0x07 | 00000111 | BEL | & #007; | Bell | |
| 8 | 010 | 0x08 | 00001000 | BS | & #008; | Back Space | |
| 9 | 011 | 0x09 | 00001001 | HT t | & #009; | Tab | |
| 10 | 012 | 0x0A | 00001010 | LF n | & #010; | Новая строка | |
| 11 | 013 | 0x0B | 00001011 | VT | & #011; | Vertical Tab | |
| 12 | 014 | 0x0C | 00001100 | FF | & #012; | Form Feed | |
| 13 | 015 | 0x0D | 00001101 | CR r | & #013; | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO | & #014; | Shift Out / X-On | |
| 15 | 017 | 0x0F | 00001111 | SI | & #015; | Shift In / X-Off | |
| 16 | 020 | 0x10 | 00010000 | DLE | & #016; | Data Line Escape | |
| 17 | 021 | 0x11 | 00010001 | DC1 | & #017; | Device Control 1 (oft. XON) | |
| 18 | 022 | 0x12 | 00010010 | DC2 | & #018; | Device Control 2 | |
| 19 | 023 | 0x13 | 00010011 | DC3 | & #019; | Device Control 3 (oft. XOFF) | |
| 20 | 024 | 0x14 | 00010100 | DC4 | & #020; | Device Control 4 | |
| 21 | 025 | 0x15 | 00010101 | NAK | & #021; | Negative Acknowledgement | |
| 22 | 026 | 0x16 | 00010110 | SYN | & #022; | Synchronous Idle | |
| 23 | 027 | 0x17 | 00010111 | ETB | & #023; | End of Transmit Block | |
| 24 | 030 | 0x18 | 00011000 | CAN | & #024; | Cancel | |
| 25 | 031 | 0x19 | 00011001 | EM | & #025; | End of Medium | |
| 26 | 032 | 0x1A | 00011010 | SUB | & #026; | Substitute | |
| 27 | 033 | 0x1B | 00011011 | ESC | & #027; | Escape | |
| 28 | 034 | 0x1C | 00011100 | FS | & #028; | File Separator | |
| 29 | 035 | 0x1D | 00011101 | GS | & #029; | Group Separator | |
| 30 | 036 | 0x1E | 00011110 | RS | & #030; | Record Separator | |
| 31 | 037 | 0x1F | 00011111 | US | & #031; | Unit Separator | |
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Печатные символы ASCII (код символа 32-127)
Буквы, цифры, знаки препинания и другие символы расположенные на клавиатуре (англ.).
Источник
HTML кодировки
Чтобы правильно отобразить html-документ, браузер должен знать какая кодировка символов использовалась при создании документа.
ASCII — одна из самых старых компьютерных кодировок, в которой каждому символу соответствует строго определенное число. Например, символу «a» соответствует число 97, а символу «A» — число 65.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
ASCII — это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Вы можете посмотреть на полный комплект Печатаемых символов ASCII.
Позже ASCII была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в кодировку ASCII символы национальных языков разных стран, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8 (Код Обмена Информацией, 8 бит) — это тоже расширенная кодировка ASCII. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.
Кодировка ISO
Организация Международных стандартов (International Standards Organization) создала диапазон кодировок для различных алфавитов/языков.
Кодировки серии ISO 8859
Кодировка Описание ISO 8859-1 (Latin-1) Расширенная латиница, включающая символы большинства западноевропейских языков (английский, датский, ирландский, исландский, испанский, итальянский, немецкий, норвежский, португальский, ретороманский, фарерский, шведский, шотландский (гэльский) и частично голландский, финский, французский), а также некоторых восточноевропейских (албанский) и африканских языков (африкаанс, суахили). В Latin-1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для HTML-документов и сообщений электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода. ISO 8859-2 (Latin-2) Расширенная латиница, включающая символы центральноевропейских и восточноевропейских языков (боснийский, венгерский, польский, словацкий, словенский, хорватский, чешский). В Latin-2, как и в Latin-1, отсутствуют знак евро. ISO 8859-3 (Latin-3) Расширенная латиница, включающая символы южноевропейских языков (мальтийский, турецкий и эсперанто). ISO 8859-4 (Latin-4) Расширенная латиница, включающая символы североевропейских языков (гренландский, эстонский, латышский, литовский и саамские языки). ISO 8859-5 (Latin/Cyrillic) Кириллица, включающая символы славянских языков (белорусский, болгарский, македонский, русский, сербский и частично украинский). ISO 8859-6 (Latin/Arabic) Символы, используемые в арабском языке. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO 8859-6 требуется поддержка двунаправленного письма и контекстно-зависимых форм символов. ISO 8859-7 (Latin/Greek) Символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии. ISO 8859-8 (Latin/Hebrew) Символы современного иврита. Используется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов. ISO 8859-9 (Latin-5) Вариант Latin-1, в котором редко используемые символы исландского языка заменены на турецкие. Используется для турецкого и курдского языков. ISO 8859-10 (Latin-6) Вариант Latin-4, более удобный для скандинавских языков. ISO 8859-11 (Latin/Thai) Символы тайского языка. ISO 8859-13 (Latin-7) Вариант Latin-4, более удобный для балтийских языков. ISO 8859-14 (Latin-8) Расширенная латиница, включающая символы кельтских языков, таких как шотландский (гэльский) и бретонский. ISO 8859-15 (Latin-9) Вариант Latin-1, в котором редко используемые символы заменены на необходимые для полной поддержки финского, французского и эстонского языков. Кроме того, в Latin-9 был добавлен знак евро. ISO 8859-16 (Latin-10) Расширенная латиница, включающая символы южноевропейских и восточноевропейских (албанский, венгерский, итальянский, польский, румынский, словенский, хорватский), а также некоторых западноевропейских языков (ирландский в новой орфографии, немецкий, финский, французский). Как и в Latin-9, в Latin-10 был добавлен знак евро.
Для документов на английском и большинстве других западноевропейских языков, широко поддерживается кодирование ISO-8859-1.
Для HTML4:
Для HTML5:
Примером ANSI-кодировки является всем известная Windows-1251.
Windows-1251 выгодно отличается от других 8 битных кириллических кодировок (таких как CP866 и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения). Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Ниже приведены десятичные значения символов кодировки Windows-1251.
Для отображения символов таблицы в HTML-документе воспользуйтесь следующим синтаксисом:
Кодировка Windows-1251 (CP1251)
. .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E .F 8. Ђ
402 Ѓ
403 ‚
201A ѓ
453 „
201E …
2026 †
2020 ‡
2022 €
20AC ‰
2030 Љ
409 ‹
2039 Њ
40A Ќ
40C Ћ
40B Џ
40F 9. ђ
452 ‘
2018 ’
2019 “
201C ”
201D •
2022 –
2013 —
2014 ™
2122 љ
459 ›
203A њ
45A ќ
45C ћ
45B џ
45F A. A0 Ў
40E ў
45E Ј
408 ¤
A4 Ґ
490 ¦
A6 §
A7 Ё
401 ©
A9 Є
404 «
AB ¬
AC
AD ®
AE Ї
407 B. °
B0 ±
B1 І
406 і
456 ґ
491 µ
B5 ¶
B6 ·
B7 ё
451 №
2116 є
454 »
BB ј
458 Ѕ
405 ѕ
455 ї
457 C. А
410 Б
411 В
412 Г
413 Д
414 Е
415 Ж
416 З
417 И
418 Й
419 К
41A Л
41B М
41C Н
41D О
41E П
41F D. Р
420 С
421 Т
422 У
423 Ф
424 Х
425 Ц
426 Ч
427 Ш
428 Щ
429 Ъ
42A Ы
42B Ь
42C Э
42D Ю
42E Я
42F E. а
430 б
431 в
432 г
433 д
434 е
435 ж
436 з
437 и
438 й
439 к
43A л
43B м
43C н
43D о
43E п
43F F. р
440 с
441 т
442 у
443 ф
444 х
445 ц
446 ч
447 ш
448 щ
449 ъ
44A ы
44B ь
44C э
44D ю
44E я
44F
Кодировки стандарта UNICODE
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
Источник
Windows 1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO-8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Имеет два недостатка:
Содержание
Таблицы
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке Юникоде.
Кодировка Windows-1251 (синоним CP1251)
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2022 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
| 9. | ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
|
| A. | A0 | Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. | ° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
| C. | А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
| D. | Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
| E. | а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
| F. | р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
Другие варианты
(Показаны только отличающиеся строки, поскольку всё остальное совпадает)
Кодировка CP1251-k (KazWin, казахская кодировка)
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ұ 4B0 |
Ғ 492 |
‚ 201A |
ғ 493 |
„ 201E |
… 2026 |
† 2020 |
‡ 2022 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ң 4A2 |
Қ 49A |
Һ 4BA |
Ү 4AE |
| 9. | ұ 4B1 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ң 4A3 |
қ 49B |
һ 4BB |
ү 4AF |
|
| A. | A0 | Ў 40E |
ў 45E |
Җ 496 |
¤ A4 |
Ҳ 4B2 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. | ° B0 |
± B1 |
І 406 |
і 456 |
ҳ 4B3 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
җ 497 |
Ә 4D8 |
ә 4D9 |
ї 457 |
Кодировка Windows-1251 (чувашский вариант)
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2022 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. | ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Татарский вариант
Эта кодировка была официально принята в Татарстане в 1996 г.
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ә 4D8 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2022 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ү 4AE |
Җ 496 |
Ң 4A2 |
Һ 4BA |
| 9. | ә 4D9 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ү 4AF |
җ 497 |
ң 4A3 |
һ 4BB |
Внешние ссылки
Полезное
Смотреть что такое «Windows 1251» в других словарях:
Windows-1251 — (a.k.a. code page CP1251) is a popular 8 bit character encoding, designed to cover languages that use the Cyrillic alphabet such as Russian, Bulgarian, Serbian Cyrillic and other languages. It is the most widely used for encoding the Bulgarian,… … Wikipedia
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8 битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах… … Википедия
Windows-1251 — (a.k.a. CP1251) es un popular juego de caracteres de 8 bits, diseñado para cubrir lenguajes que usan el alfabeto cirilico como son el lenguaje Ruso y otros lenguajes. Este es la codifiación más ampliamente usada para codificar Búlgaro, Serbio y… … Wikipedia Español
Windows-1251 — Windows Codepages 874 Thai 932 Japanisch 936 Vereinfachtes Chinesisch 949 Koreanisch 950 Traditionelles Chinesisch 1250 Mitteleuropäisch 1251 Kyrillisch 1252 … Deutsch Wikipedia
Windows (значения) — Windows: Microsoft Windows семейство проприетарных операционных систем корпорации Microsoft, ориентированных на применение графического интерфейса при управлении. Windows (клавиша) клавиша на клавиатурах ПК совместимых компьютеров,… … Википедия
Windows-1252 — ISO 8859 1 Latin 1, Westeuropäisch 2 Latin 2, Mitteleuropäisch 3 Latin 3, Südeuropäisch 4 Latin 4, Baltisch 5 Kyrillisch 6 Arabisch 7 Griechisch 8 … Deutsch Wikipedia
Windows-1252 — ISO/IEC 8859 1 (также известная как ISO 8859 1 и Latin 1) кодовая страница, предназначенная для западноевропейских языков; она базируется на символьном наборе популярных в прошлом терминалов ISO 8859. ISO 8859 1 кодировка, зарегистрированная… … Википедия
Windows code page — Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in… … Wikipedia
Windows Glyph List 4 — (сокр. WGL4, также известен как Общеевропейский набор символов англ. Pan European character set) определённый компанией Майкрософт набор из 652 типографических символов Юникода, призванный помочь разработчикам шрифтов в обеспечении… … Википедия
Windows-1254 — Windows 1254 кодовая страница, используемая Microsoft Windows для представления турецкого языка. Символы с кодами от A0 до FF совместимы с ISO 8859 9. Для современных приложений UTF 8 предпочтительней windows 1254. Таблица кодов Символы с… … Википедия
Источник
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.

Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.
Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.

Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Вряд ли это сейчас сильно актуально, но может кому-то покажется интересным (или просто вспомнит былые годы).
Начну с небольшого экскурса в историю компьютера. Поскольку компьютер использовался для обработки информации, то он просто обязан представлять эту информацию в «человеческом» виде. Компьютер хранит информацию в виде чисел (байтов), а человек воспринимает символы (буквы, цифры, различные знаки). Значит, надо сделать сопоставление число <-> символ и задача будет решена. Сначала посчитаем, сколько символов нам надо (не забудем, что «мы» — американцы, использующие латинский алфавит). Нам надо 10 цифр + 26 заглавных букв английского алфавита + 26 строчных букв + математические знаки (хотя бы +-/*=><%) + знаки препинания (.,!?:;’” ) + различные скобки + служебные символы (_^%$@|) + 32 непечатных управляющих символов для работы с устройствами (в первую очередь, с телетайпом). В общем, 128 символов хватает «впритык» и этот стандартный набор символов «мы» назвали ASCII, т.е. «American Standard Code for Information Interchange»
Отлично, для 128 символов достаточно 7 бит. С другой стороны, в байте 8 бит и каналы связи 8-битные (забудем про «доисторические» времена, когда в байте и каналах бит было меньше). По 8-ми битному каналу будем передавать 7 бит кода символа и 1 бит контрольный (для повышения надежности и распознавания ошибок). И все было замечательно, пока компьютеры не стали использоваться в других странах (где латиница содержит больше 26 символов или вообще используется не латинский алфавит). Вместо того, чтобы всем поголовно освоить английский, жители СССР, Франции, Германии, Грузии и десятков других стран захотели, чтобы компьютер общался с ними на их родном языке. Пути были разные (в зависимости от остроты проблемы): одно дело, если к 26 символам латиницы надо добавить 2-3 национальных символа (можно пожертвовать какими-то специальными) и другое дело, когда надо «вклинить» кириллицу. Теперь «мы» — русские, стремящиеся «русифицировать» технику. Первыми были решения на основе замены строчных английских букв прописными русскими. Однако проблема в том, что русских букв (33) и они не влезают на 26 мест. Надо «уплотнить» и первой жертвой этого уплотнения пала буква Ё (еe просто повсеместно заменили на Е). Другой прием – вместо «русских» A,E,K,M,H,O,P,C,T стали использовать похожие английские (таких букв даже больше чем надо, но в некоторых парах прописные похожие, а строчные — не очень: Hh Tt Bb Kk Mm). Но все же «вклинили » и в результате весь вывод шел ПРОПИСНЫМИ БУКВАМИ, что неудобно и некрасиво, однако со временем привыкли. Второй прием – «переключение языка». Код русского символа совпадал с кодом английского символа, но устройство помнило, что сейчас оно в русском режиме и выводило символ кириллицы (а в английском режиме – латиницы). Режим переключался двумя служебными символами: Shift Out (SO, код 14) на русский и Shift IN (SI, код 15) на английский (интересно, что когда-то в печатных машинках использовалась двухцветная лента и SO приводил к физическому подъему ленты и в результате печать шла красным, а SI ставил ленту на место и печать снова шла черным). Текст с большими и маленькими буквами стал выглядеть вполне прилично. Все эти варианты более-менее работали на больших компьютерах, но после выпуска IBM PC началось массовое распространение персональных компьютеров по всему миру и надо было что-то решать централизовано.
Решением стала разработанная фирмой IBM технология кодовых страниц. К этому времени «контрольный символ» при передаче потерял свою актуальность и все 8-бит можно было использовать для кода символа. Вместо диапазона кодов 0-127 стал доступен диапазон 0-255. Кодовая страница (или кодировка)– это сопоставление кода из диапазона 0-255 некоему графическому образу (например, букве «Я» кириллицы или букве «омега» греческого). Нельзя сказать «символ с кодом 211 выглядит так», но можно сказать «символ с кодом 211 в кодовой странице CP1251 выглядит так: У, а в CP1253(греческая) выглядит так: Σ ». Во всех (или почти всех) кодовых таблица первые 128 кодов соответствуют таблице ASCII, только для первых 32 непечатных кодов IBM «назначила» свои картинки (которые показывается при выводе на экран монитора). В верхней части IBM разместила символы псевдографики (для рисования различных рамок), дополнительные символы латиницы, используемые в странах Западной Европы, некоторые математические символы и отдельные символы греческого алфавита. Эта кодовая страница получила название CP437 (IBM разработала и множество других кодовых страниц) и по умолчанию использовалась в видеоадаптерах. Кроме того, различные центры стандартизации (мировые и национальные) создали кодовые страницы для отображения национальных символов. Наши компьютерные «умы» предложили 2 варианта: основная кодировка ДОС и альтернативная кодировка ДОС. Основная предназначалась для работы везде, а альтернативная — в особых случаях, когда использование основной неудобно. Оказалось, что таких особых случаев большинство и основной (не по названию, а по использованию) стала именно «альтернативная» кодировка. Думаю, такой исход был ясен с самого начала для большинства специалистов (кроме «ученых мужей», оторванных от жизни). Дело в том, что в большинстве случаев использовались английские программы, которые «для красоты» активно использовали псевдографику для рисования различных рамок и тп. Типичные пример — суперпопулярный Нортон коммандер, стоящий тогда на большинстве компьютеров. Основная кодировка на местах псевдографики разместила русские символы и панели нортона выглядели просто ужасно (равно как и любой другой псевдографический вывод). А альтернативная кодировка бережно сохранила символы пседографики, использую для русских букв другие места. В результате и с Нортон коммандером и с другими программами вполне можно было работать. Андрей Чернов (широко известная личность в то время) разработал кодировку KOI8-R (КОИ8), пришедшую с «больших» компьютеров, где господствовал UNIX. Ее особенностью было то, что если у русского символа пропадал 8-й бит, то получившийся в результате «обрезания» английский символ будет созвучен исходному русскому. И вместо «Привет» получался «pRIVET», что не совсем то, но хотя бы читаемо. В результате в СССР на компьютерах использовали 3 различных кодовых страницы (основную, альтернативную и KOI8). И это не считая различных «вариаций», когда в альтернативной кодировке, скажем, отдельные символы (а то и строки) изменялись. От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.
Тем не менее в целом кодовые страницы позволили решить проблему вывода национальных символов (устройство просто должно уметь работать с соответствующей кодовой страницей), но породили проблему множественности кодировок, когда почтовая программа отправляет данные в одной кодировке, а принимающая программа показывает их в другой. В результате пользователь видит так называемые «кракозябры» (вместо «привет» написано «ЏаЁўҐв» или «оПХБЕР»). Потребовались программы-перекодировщики, переводящие данные из одной кодировки в другую. Увы, порой письма при прохождении через почтовые серверы неоднократно автоматически перекодировались (или даже «обрезался» 8-й бит) и нужно было найти и выполнить всю цепочку обратных преобразований.
После массового перехода на Windows к трем кодовым страницам добавилась четвертая (Windows-1251 она же CP1251 она же ANSI ) и пятая (CP866 она же OEM или DOS). Не удивляйтесь — Windows для работы с кириллицей в консоли по-умолчанию использует кодировку CP866 (русские символы такие же как в «альтернативной кодировке», только некоторые спецсимволы отличаются), для других целей — кодировку CP1251. Почему Windows понадобилось две кодировки, неужели нельзя было обойтись одной? Увы, не получается: DOS-кодировка используется в именах файлов (тяжелое наследие DOS) и консольные команды типа dir, copy должны правильно показывать и правильно обрабатывать досовские имена файлов. С другой стороны, в этой кодировке много кодов отведено символам псевдографики (различным рамкам и т.п.), а Windows работает в графическом режиме и ей (а точнее, windows-приложениям) не нужны символы псевдографики (но нужны занятые ими коды, которые в CP1251 использованы для других полезных символов). Пять кириллических кодировок поначалу еще больше усугубили ситуацию, но со временем наиболее популярными стали Windows-1251 и KOI8, а досовскими просто стали меньше пользоваться. Еще при использовании Windows стало неважно, какая кодировка в видеоадаптере (только изредка, до загрузки Windows в диагностических сообщениях можно видеть «кракозябры»).
Решение проблемы кодировок пришло, когда повсеместно стала внедряться система Unicode (и для персональных ОС и для серверов). Unicode каждому национальному символу ставит в соответствие раз и навсегда закрепленное за ним 20-ти битовое число («точку» в кодовом пространстве Unicode, причем чаще всего хватает 16 бит, поскольку 20-битные коды используются для редких символов и иероглифов), поэтому нет необходимости перекодировать (подробнее об Unicode см следующую запись в журнале). Теперь для любой пары <код байта>+<кодовая страница> можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.
Интересно, что примерно год назад проблема кодировок ненадолго всплыла при «наезде» ФАС на сотовых операторов, мол те дискриминируют русскоязычных пользователей, поскольку за передачу кириллицы берут больше. Это объясняется техническим решением, выбранным разработчиком протокола SMS связи. Если бы его россияне разработали, они бы, возможно, отдали приоритет кириллице. В указанной статье «начальник управления контроля транспорта и связи Дмитрий Рутенберг отметил, что существуют и восьмибитные кодировки для кириллицы, которые могли бы использовать операторы.» Во как — на улице 21-й век, Unicode шагает по миру, а господин Рутенберг тянет нас в начало 90-х, когда шла «война кодировок» и проблема перекодировок стояла во весь рост. Интересно, в какой кодировке должен получить СМС Вася Пупкин, пользующийся финским телефоном, находящийся в Турции на отдыхе, от жены с корейским телефоном, отправляющей СМС из Казахстана? А от своего французского компаньона (с японским телефоном), находящегося в Испании? Думаю, никакой начальник ответа на этот вопрос дать не сможет. К счастью, это «экономное» предложение не воплотилось в жизнь.
Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).
- ASCII — базовая кодировка текста для латиницы
- Расширенные версии Аски — кодировки CP866 и KOI8-R
- Windows 1251 — почему вылезают кракозябры
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Кракозябры вместо русских букв — как исправить
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
Читать дальше…
Copyright © 2017, KtoNaNovenkogo.ru — блог для начинающих вебмастеров.
Все права защищены. |
Постоянная ссылка |
Комментарии: 34
Вы также можете ознакомиться с другими материалами рубрики Вебмастеру.

![]()
Источник: http://feedproxy.google.com/~r/Ktonanovenkogoru/~3/H2BRSfcfSoI/kodirovka-teksta-krakozyabry-ascii-yunikod-utf-8-rasshirennaya-ascii-windows-1251-cp866-koi8-r-problemy-s-kodirovkoj.html
Данный материал является частной записью члена сообщества Club.CNews.
Редакция CNews не несет ответственности за его содержание.