Русские Блоги
Сколько строк в исходном коде Win 10? Какой язык программирования использовался?
(дайте Те вещи о программистах Помечено )
Оригинальная отделка: те штучки о программистах (id: iProgrammer)
В октябре 2013 года мы разместили на Weibo картинку (@ programmer’s things) инфограмма » Сравнение кодовых баз известных программных систем.
В инфографике упоминается, что объем кода для операционных систем Windows XP и Windows 7 составляет около 40 миллионов строк.

( инфограмма Несколько скриншотов, полная версия здесь: http: //t.cn/EXMs07e )
Windows Объем исходного кода Vista составляет около 50 миллионов строк.

Следовательно, объем исходного кода Windows 10 составляет не менее 50 миллионов строк.
Какой язык программирования использовался при разработке операционной системы Windows?
Windows операционная система Кому-то должно быть интересно, какой язык программирования используется для такой масштабной кодовой базы.
Это правда? Кто-то написал на Quora с вопросом: «Разработка W ind ows 10 Какой язык программирования используется? 》
В марте 2019 года инженер ядра Microsoft Аксель Ритчин ответил на этот пост на Quora.

«Вот что о программистах»:
Axel Говорят, что Windows 10 и Windows 8.x, 7, Vista, XP, 2000 и NT имеют одинаковую кодовую базу. Каждое поколение операционных систем претерпело серьезный рефакторинг, добавив большое количество новых функций, улучшив производительность и поддержку оборудования. И безопасность при сохранении очень высокой обратной совместимости.
Ядро (ntoskrnl.exe) Большинство из них написано на языке Си . Вы можете найти просочившуюся версию Windows Research Kernel на Github.

Детскую обувь, кому интересно, могут посмотреть: github.com/markjandrews/wrk-v1.2
Axel Сказал, что, хотя код WRK устарел и в основном неполный, он должен дать вам некоторое представление.
Например: каталог wrk-v1.2 / base / ntos / config — это исходный код известного реестра (Registry) .Этот компонент ядра является диспетчером конфигурации (CM).
Большинство программ, работающих в режиме ядра, также написаны на языке C. (Большинство файловых систем, сетей, большинство драйверов . ) и немного C ++.
Что касается языка программирования, на котором написано Window 10, Аксель считает, что это C и C ++, причем C составляет большинство.
.NET BCL И другие управляемые библиотеки и фреймворки обычно используют C # Написано, Из разных отделов ( Отдел разработчиков) И не принадлежит Windows Исходное дерево 。 По сравнению с океаном кода C, разбросанным по островам C ++, код, написанный на C #, — просто капля в море. 。
Windows действительно правда В самом деле В самом деле В самом деле Очень большой
Axel Я напоминаю всем, что большинство людей не осознают огромных размеров системы Windows, огромного проекта с эпическим масштабом.
Размер полного дерева исходного кода Windows (включая все коды, тестовые коды и т. Д.) Превышает 0,5 ТБ, что включает Более 56 миллионов папок, 400 Более десяти тысяч файлов 。

Вы можете потратить год, копаясь в дереве исходных текстов и копаясь в этих файлах. Они включают в себя все компоненты рабочей станции и серверных продуктов ОС, а также все их версии, инструменты и соответствующие комплекты разработки.
Затем вы снова читаете имя файла, чтобы увидеть, что в нем и для чего они используются. Хочу закончить эти дела , Персона (Или два человека ) Боюсь закончить жизнь 。
один раз Axel Покинув ветку Git на несколько недель, он вернулся и обнаружил, что за ним почти 60 000 коммитов. Axel Я думаю, кто-то сказал бы, что никто не может читать весь код, добавленный в Windows каждый день, не говоря уже о том, чтобы читать код, написанный за последние 30 лет!
Рекомендуемая литература
(Щелкните заголовок, чтобы перейти к прочтению)
Обратите внимание на звезду «вещи программиста» и не пропустите кружок.

Короткие байты: Многие крупнейшие технологии работают на программном обеспечении, которое создано с использованием языков программирования. Иллюстрация показывает, сколько строк кода было написано для создания программного обеспечения и сервисов. Google возглавляет список с ошеломляющим 2 000 000 000 строк кода.
Приложения и сервисы, которые являются важной частью нашей цифровой жизни, написаны на разных языках программирования. Например, приложения для iOS написаны с использованием Swift, а для Android разработчики могут использовать Java или более простой Lua с использованием Corona. Microsoft Windows разработана с использованием C и C ++. Ядро Linux, которое является сердцем всех дистрибутивов Linux, написано на C. Интернет-сайты созданы с использованием JavaScript, HTML, CSS для внешнего интерфейса и Python, Go, C ++, ASP.NET и т. Д. Для внутреннего интерфейса.
Помимо многих функций, одна вещь, которая отличает эти языки, — это количество строк кода. Например, люди, которые используют Python, имеют преимущество ввода меньшего числа строк, чем те, которые используют Java или C.
Вот иллюстрация, которая показывает количество строк кода, использованных для создания некоторых из самых больших творений в истории технологии. Он включает в себя программное обеспечение, которое запускает первый в мире космический челнок, марсоход Curiosity НАСА, живущий в одиночестве на Марсе, ОС Android от Google и т. Д.

Идея этой иллюстрации возникла в нашем мозгу, когда мы натолкнулись на инфографику «Миллион строк кода», разработанную компанией Information Is Beautiful. Наша гистограмма — это уменьшенная версия более крупной картинки, изображенной на миллионах строк кода.

Сравнивая строки кода для двух наиболее часто используемых веб-сайтов в Интернете, Google (включая все интернет-сервисы Google) явно выделяется своими 2 миллиардами строк, оставляя позади Facebook с 61 000 000 строк кода. Хотя Facebook является всего лишь социальной сетью по сравнению с Google, чьи продукты охватывают множество услуг.
Интересный факт: Первоначальному космическому шаттлу требовалось в 5000 раз меньше строк кода, чем Google.
Данные были собраны Information Is Beautiful. Вы можете увидеть оригинальную инфографику здесь.
Система STEPS: двадцать тысяч строк кода, которые изменят программирование, операционные системы и интернет
У программистов есть заветная мечта: взять и переделать заново всё — операционную систему, языки программирования, библиотеки и приложения. Упразднить ненужное дублирование функций и написать всё красиво и по-новому — словом, сделать всё как надо, а не как получилось в результате многих лет нагромождения разных стилей и технологий. При этом все обычно понимают, что мечтам никогда не сбыться и что никому не под силу заново проделать такой объём работы. Над смельчаками принято посмеиваться, а их попытки — обзывать переизобретением колеса. Но когда за работу берётся человек, который уже однажды изобрёл немалую часть технологий, которые мы ассоциируем с персональными компьютерами, все шутки становятся неуместными.
Алан Кей — живая легенда компьютерной индустрии. В середине шестидесятых он работал с Айвеном Сазерлендом, создавшим первый графический редактор и систему автоматизированного проектирования, а в 1970 году присоединился к исследовательской лаборатории Xerox PARC, где придумал объектно-ориентированное программирование, создав язык Smalltalk, и первый компьютер с оконным графическим интерфейсом. Позднее его работа вдохновит Стива Джобса и команду, сделавшую Macintosh, а прототип Macintosh убедит Билла Гейтса в том, что MS-DOS срочно нуждается в графической оболочке с оконным интерфейсом, известной нам как Windows.
После PARC Кей работал в самых разных исследовательских центрах: Atari, Apple, Disney и HP, а также в Калифорнийском университете в Лос-Анджелесе и Киотском университете. Видимым результатом его исследований стали Squeak — более современная и дружественная версия Smalltalk, а также Etoys — вариант Squeak для детей (на его основе был создан более известный сегодня Scratch). В 2005 году Кей основал исследовательский институт Viewpoints, финансируемый Национальным научным фондом США, а также рядом крупных компаний: Intel, Motorola, HP и Nokia. То, чем Кей и десяток сотрудников Viewpoints заняты сейчас, может ещё перевернуть наш взгляд на программирование.
Двадцати тысяч строк хватит на всё
Изначальное предложение Кея, представленное Национальному научному фонду США, звучало не просто смело, а почти фантастически. Кей пообещал создать среду (мы не будем называть её операционной системой, так как Кей настаивает на том, что это не ОС в привычном понимании), которая позволит функционировать современному компьютеру и будет включать в себя графический пользовательский интерфейс и набор прикладных программ. Главное отличие этой среды от всех уже существующих решений: длина кода этой системы не будет превышать двадцати тысяч строк.
Сказать, что двадцать тысяч строк — это немного, значит не сказать ничего. Если верить «Википедии», то исходные коды Windows NT 3.1 занимали 4-5 миллионов строк кода, ядро Linux 2.6.0 − 5,2 миллиона, а современные ОС с набором стандартных приложений могут содержать сотни миллионов строк кода.
Объём сопоставим с Эмпайр стейт билдинг и равен примерно 17,5 тысячам книг. «Кто из вас прочёл семнадцать тысяч книг? — вопрошает Кей собравшихся на лекции. — А кто из вас прочёл хотя бы одну?» Объёма одной книги, то есть примерно двадцати тысяч строк, по его мнению достаточно для того, чтобы создать систему, напоминающую по функциям те ОС и приложения, с которыми мы сейчас работаем. Просто строить нужно умело.
Современный софт Кей сравнивает с египетскими пирамидами. Их строители ещё ничего толком не знали об архитектуре и сооружали конструкции, которые почти полностью состояли из материала и практически не имели свободного пространства внутри. С изобретением колонн и арок стало возможно возводить куда более изящные и практичные сооружения. Нельзя ли изобрести аналог арок для написания программ?
Сейчас программист при всём желании не способен свободно ориентироваться в миллионах строк кода. Зато если уместить всю систему в объём книги и разделить на логические части по 100-1000 строк, это даст возможность легко понимать логику её строения и вносить изменения. Проблемы вроде багов, которые на протяжении многих лет преследуют крупные проекты, просто уйдут в прошлое.
You may say I’m a dreamer
Главный вопрос: возможно ли такое в принципе? За пять лет работы команда Кея доказала, что ответ на этот вопрос может быть положительным. Систему методов, которые позволят это сделать, авторы называют STEPS. Это рекурсивный акроним, расшифровывающийся как STEPS Toward Expressive Programming Systems — «Шаги к выразительным системам программирования».
Руководствуясь принципами STEPS, в институте Кея создали прототип системы. Он называется Frank, а если полностью — «Франкенштейн». Такое имя выбрано не зря: система составлена из кусочков, каждый из которых ещё может быть заменён или переписан заново.
Что может делать пользователь Frank? Всё то же, что мы обычно делаем за компьютером: создаём и редактируем текстовые документы, графику, видео, презентации и электронные таблицы, а также обмениваемся ими через сеть. Вся разница в том, что исследователи попытались полностью избавились от дублирования функций разными программами и максимально сократить исходный код.
Frank — это не операционная система, в которой работают приложения, а скорее, подобие Smalltalk или Squeak — большое приложение, которое можно расширять и дополнять, пока оно не станет делать всё, что нам нужно. Вместо приложений, в которых реализованы собственный интерфейс и функции, здесь присутствуют компоненты, имеющие сложные взаимосвязи.
Во Frank есть единое понятие «документ», в который могут быть включены и на месте изменены любые объекты, будь то изображения, таблицы или созданные пользователем скрипты. Презентация, например, — это документ, включающий в себя сценарий перехода вперёд и назад по страницам (или, если угодно, кадрам), а не файл, для открытия которого требуется специальная программа. Такая программа просто не нужна, потому что интерфейс для работы с изображениями и текстом идентичен тому, что используется для подготовки других документов.
То же и с электронной почтой: письмом во Frank считается любой документ, который был передан по Сети. Список писем — это результат поиска документов, полученных от других пользователей.
Ещё одно ценное качество системы Кея — универсальная отмена. Здесь может быть отменено действительно любое действие, а не как в сегодняшних программах — лишь некоторые, да и то не всегда. Для этого используется механизм «миров»: каждый раз, когда мы что-то меняем, система может запомнить, чем нынешний «мир» отличается от предыдущего, и в случае надобности вернуть всё, как было.
Интереснее всего то, как Кей предлагает переделать веб. Во Frank нет браузера, зато есть поддержка протокола TCP/IP (его код занимает 160 строк, и это, по словам Кея, не предел краткости). Вместо веб-страниц предлагается использовать те же самые документы, добавив в них объект нового типа — гиперссылку.
Поскольку код, содержащийся в документах, по сути, работает в виртуальной машине, это делает их загрузку извне не менее безопасной, чем исполнение JavaScript браузером. Получается, что объекты-страницы просто подгружаются через Сеть по мере необходимости. Кстати, делать такие «сайты» намного проще, чем обычные: можно пользоваться уже имеющимися в системе средствами — теми же самыми, при помощи которых редактируются текстовые документы, презентации и всё остальное.
Сила мысли и никакого мошенничества
Внешняя сторона Frank интересна уже хотя бы в качестве примера унифицированной среды, в которой нет ни разделения на приложения, ни традиционной файловой системы. Но настоящая чёрная программисткая магия скрыта внутри.
Сколько занимают разные части STEPS?
| TCP/IP | 160 строк |
| Алгоритм сглаживания на Nile | 45 строк |
| Весь код Gezira на Nile | 457 строк |
| Парсер Nile на OMeta | 130 строк |
| Транслятор Nile AST в Си на OMeta | 1110 строк |
Как Frank уместился в двадцать тысяч строк кода? Ответ кроется за двумя терминами: метапрограммирование и предметно-ориентированные языки (DSL). Главная идея заключается в том, чтобы создавать языки под конкретные задачи и, хитроумно комбинируя их, писать элегантные и короткие программы. Эта идея не нова: на ней основан язык Forth, и она используется в написании программ на языке Lisp, которым Кей в своё время вдохновлялся при создании Smalltalk. Более современный пример — фреймворк Ruby on Rails, применяемый в качестве DSL для разработки бэкэндов веб-приложений. Но STEPS — это нечто куда большее, чем один язык, — это набор методов и языков, при помощи которых можно создавать сложные системы, используя минимум кода.
Один из самых интересных компонентов STEPS — это объектно-ориентированный язык OMeta (pdf). Он предназначен для описания синтаксиса других языков. К примеру, на OMeta можно в несколько строк описать синтаксис калькулятора, а потом при помощи наследования расширить его и сделать научный калькулятор. Синтаксис OMeta при этом описан на самом OMeta.
Второй важный язык — это Nile (названный в честь реки Нил). Авторы STEPS называют его «языком исполняемой математики». Nile позволяет компактно описывать математические выражения и сделан таким образом, чтобы максимально облегчить параллельные вычисления. На нём написана графическая подсистема Frank, называемая Gezira. Gezira умещается в несколько сотен строк на Nile и умеет выводить растровую и векторную графику, поддерживает сглаживание и различные фильтры.
Самый низкий уровень во всей этой сложной системе — язык Nothing (переводится с английского как «Ничто»), «высокоуровневый язык с низкоуровневой семантикой». Nothing — это промежуточное звено между всеми языками в STEPS и машинными кодами. На Nothing не предполагается писать вручную, и нужен он лишь для возможности смотреть, что получается на выходе. Nothing, по словам исследователей, вдохновлён BCPL, использовавшимся в шестидесятые годы и вдохновившим авторов Си. На данный момент код на Nothing можно транслировать в Си для дальнейшего перевода в машинные коды или в JavaScript — чтобы система исполнялась в браузере. Предполагается, что в будущем из Nothing можно будет получать машинные коды напрямую.
В качестве промежуточного слоя, на котором написан пользовательский интерфейс, одно время использовался NotSqueak — упрощённый диалект Squeak. Но в последнем отчёте упоминаний о NotSqueak уже нет, зато появился новый объектно-ориентированный язык — Maru. Как и OMeta, он написан сам на себе и может использоваться как для описания высокоуровневого представления, так и для связи с низкоуровневыми функциями. На Maru может быть реализован парсер грамматики, и в 2011 году команда Кея была занята переносом Nile на Maru.
Бесконечный эксперимент
К сожалению, отчёты Кея и его команды (pdf) — это не пособие для программистов-суперменов и не справочник. Оно и понятно — STEPS пока что не готов, и каждый год во Viewpoints ставят разнообразные эксперименты, цель которых — не столько в создании законченной системы, сколько в том, чтобы отточить методы. «Франкенштейн» как цельная система здесь нужен лишь в качестве подопытного тела.
Если посмотреть отчёты Viewpoints за разные годы, то заметно, что здесь снова и снова изобретают языки программирования, делают их всё более самодостаточными (пока что кое-где ещё остаётся код на Си, но от него постепенно избавляются) и ставят смелые эксперименты.
Время от времени команда Кея пробует пробрасывать мостики в реальный мир, создавая, к примеру, виртуальную машину Squeak для Google Native Client или делая метаязык Tamacola на основе Tamarin VM, входящей во Flash. Эти методы могут позволить всей системе не просто работать в браузере, но исполняться быстрее, чем при трансляции в JavaScript.
Скорость, впрочем, не является целью Кея: по его оценке, в нынешнем виде Frank работает примерно на 30 процентов медленнее, чем если бы был написан традиционными методами. Оптимизацией исследователи занимаются лишь тогда, когда это не вредит компактности кода.
Понятно, что Frank не станет конкурентом современных ОС и вряд ли вообще будет доделан до необходимого для этого уровня. Тем не менее те методы, которые разрабатывает Алан Кей, могут повлиять на подход к программированию не меньше, чем в своё время повлиял Smalltalk.
(дайтеТе вещи о программистахПомечено)
Оригинальная отделка: те штучки о программистах (id: iProgrammer)
В октябре 2013 года мы разместили на Weibo картинку (@ programmer’s things)инфограмма «Сравнение кодовых баз известных программных систем.
В инфографике упоминается, что объем кода для операционных систем Windows XP и Windows 7 составляет около 40 миллионов строк.
(инфограммаНесколько скриншотов, полная версия здесь:http://t.cn/EXMs07e )
WindowsОбъем исходного кода Vista составляет около 50 миллионов строк.
Следовательно, объем исходного кода Windows 10 составляет не менее 50 миллионов строк.
Какой язык программирования использовался при разработке операционной системы Windows?
Windows операционная системаКому-то должно быть интересно, какой язык программирования используется для такой масштабной кодовой базы.
Это правда? Кто-то написал на Quora с вопросом: «РазработкаWindows 10 Какой язык программирования используется?》
В марте 2019 года инженер ядра Microsoft Аксель Ритчин ответил на этот пост на Quora.
«Вот что о программистах»:
AxelГоворят, что Windows 10 и Windows 8.x, 7, Vista, XP, 2000 и NT имеют одинаковую кодовую базу. Каждое поколение операционных систем претерпело серьезный рефакторинг, добавив большое количество новых функций, улучшив производительность и поддержку оборудования. И безопасность при сохранении очень высокой обратной совместимости.
Ядро (ntoskrnl.exe)Большинство из них написано на языке Си. Вы можете найти просочившуюся версию Windows Research Kernel на Github.
Детскую обувь, кому интересно, могут посмотреть:github.com/markjandrews/wrk-v1.2
AxelСказал, что, хотя код WRK устарел и в основном неполный, он должен дать вам некоторое представление.
Например: каталог wrk-v1.2 / base / ntos / config — это исходный код известного реестра (Registry) .Этот компонент ядра является диспетчером конфигурации (CM).
Большинство программ, работающих в режиме ядра, также написаны на языке C.(Большинство файловых систем, сетей, большинство драйверов …) и немного C ++.
Что касается языка программирования, на котором написано Window 10, Аксель считает, что это C и C ++, причем C составляет большинство.
.NET BCL И другие управляемые библиотеки и фреймворки обычно используют C #Написано,Из разных отделов (Отдел разработчиков)И не принадлежитWindows Исходное дерево。По сравнению с океаном кода C, разбросанным по островам C ++, код, написанный на C #, — просто капля в море.。
Windows действительно правдаВ самом делеВ самом делеВ самом делеОчень большой
AxelЯ напоминаю всем, что большинство людей не осознают огромных размеров системы Windows, огромного проекта с эпическим масштабом.
Размер полного дерева исходного кода Windows (включая все коды, тестовые коды и т. Д.) Превышает 0,5 ТБ, что включаетБолее 56 миллионов папок,400 Более десяти тысяч файлов。
Вы можете потратить год, копаясь в дереве исходных текстов и копаясь в этих файлах. Они включают в себя все компоненты рабочей станции и серверных продуктов ОС, а также все их версии, инструменты и соответствующие комплекты разработки.
Затем вы снова читаете имя файла, чтобы увидеть, что в нем и для чего они используются.Хочу закончить эти дела,Персона(Или два человека) Боюсь закончить жизнь。
один раз AxelПокинув ветку Git на несколько недель, он вернулся и обнаружил, что за ним почти 60 000 коммитов.AxelЯ думаю, кто-то сказал бы, что никто не может читать весь код, добавленный в Windows каждый день, не говоря уже о том, чтобы читать код, написанный за последние 30 лет!
Рекомендуемая литература
(Щелкните заголовок, чтобы перейти к прочтению)
В Microsoft Windows 10 есть ошибки. В чем корень проблемы?
Microsoft изменилась!Полностью изменен процесс набора программистов.
Windows 3.1 исполнилось 25 лет. Какую версию Windows вы использовали первой?
Обратите внимание на звезду «вещи программиста» и не пропустите кружок.

Если хотите, просто нажмите «Я смотрю» ~
Содержание
- Насколько сложный программный код у Windows?
- Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
- Насколько сложна Windows в программном коде?
- Кен Грегг (Ken Gregg)
- Как менялся программный код Windows?
- Как база кода Windows NT развивалась с 1993 года
- Кен Грегг (Ken Gregg)
- Несколько слов про ядро Windows NT
- В современном автомобиле строк кода больше чем…
- Количество строк кода меньше миллиона
- > миллиона
- О компании ИТЭЛМА
- Google — это 2 миллиарда строчек кода
- Система STEPS: двадцать тысяч строк кода, которые изменят программирование, операционные системы и интернет
- Двадцати тысяч строк хватит на всё
- You may say I’m a dreamer
- Сила мысли и никакого мошенничества
- Бесконечный эксперимент
Насколько сложный программный код у Windows?

Чтобы разобраться вопросе, насколько может быть сложным программный код «Виндовс» мы обратились к одному из разработчиков команды Windows NT в компании Microsoft — Кену Греггу (Ken Gregg).
Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
«Могу сказать вам, что у меня был доступ к исходному коду, когда я был в команде Windows NT (NT является основой для всех настольных версий Windows начиная с XP), во время проектов разработки NT 3.1 и NT 3.5. Всё было в рамках стандартов кодирования NT Workbook — эдакой «библии» для всей проектной команды.
. Хотя я и не читал каждую строку кода, но то, с чем мне пришлось работать, было очень:
Нужно исходить из того, что именно понимается под сложностью кода. Это понимание сугубо субъективное, ведь так? Благо существует множество различных метрик, используемых и комбинируемых для измерения сложности программного обеспечения в тех или иных ситуациях (та же самая модульность, многоуровневость и обслуживаемость).

Насколько сложна Windows в программном коде?
Конечно, чтобы прочитать и понять код, вам нужно было бы иметь представление об общей архитектуре Windows NT.
Вероятно, лучшим источником информации о внутренностях Windows сегодня являются книги Windows Internals 6th Edition (в двух томах).
Некоторые люди просто приравнивают сложность кода к размеру. У этого сравнения тоже есть метрика — строки кода (LOC).
Измерение LOC зависит от используемых инструментов и критериев. Их выбирают для точного определения строк кода на каждом языке программирования.

Кен Грегг (Ken Gregg)
«Существует много споров о методах, используемых для подсчета строк кода (LOC). Если использовать одни и те же критерии от одного выпуска к следующему, то получится относительное изменение размера базы кода.
Сравнивать эти числа с цифрами другой ОС, которая использовала другой метод подсчета строк кода, всё равно что сравнивать яблоки с апельсинами. То есть это некорректный подход».

Как менялся программный код Windows?
Как база кода Windows NT развивалась с 1993 года
MLOC — это количество миллионов строк исходного кода. По ним можно определить относительную сложность операционной системы, если опираться на размеры кода (LOC-методика).
Исходный код Windows состоит в основном из C и C++, а также небольшого количества кода на ассемблере.
Некоторые из утилит пользовательского режима и другие подобные службы пишутся на Си Шарп, но это относительно небольшой процент от общей базы кода.
Кен Грегг (Ken Gregg)
«Я намеренно не включил в список 16-битные версии ОС, выпущенные с 1985 по 2000 годы. Windows NT была основой для всех современных 32-бит и 64-бит версий Windows. Количество строк кода в серверных версиях было таким же, как и в несерверных версиях, выпущенных в том же году (то есть они имели одинаковую базу исходного кода)».

Несколько слов про ядро Windows NT
По словам Кена, работа над ядром NT началась в 1988 году. Ядро было создано с нуля в качестве 32-разрядной упреждающей многозадачной ОС.
Ядро NT впервые загрузилось в июле 1989 года на процессоре Intel i860 RISC. С самого начала был сильный толчок к тому, чтобы новая ОС была совместимой с различными архитектурами центральных процессоров и не была привязана только к архитектуре Intel x86 (IA-32).
NT в конечном итоге работал на MIPS, DEC Alpha, PowerPC, Itanium и, конечно, Intel x86 и x64.
Некоторая сложность была добавлена в базу кода на уровне абстрагирования оборудования (HAL). Это было нужно для поддержки неинтеловских архитектур.
А как вы оцениваете перспективы Windows в плане кода? Узнайте, какие версии Windows актуальны сейчас и какие ОС можно рассмотреть в качестве альтернативы.
Есть проблемы при использовании Windows и непонятен программный код для внедрения новых бизнес-инструментов в ОС от Microsoft? Проконсультируйтесь с экспертами по ИТ-аутсорсингу и получите поддержку по любым техническим вопросам и задачам.
Источник
В современном автомобиле строк кода больше чем…
Подписывайтесь на каналы:
@AutomotiveRu — новости автоиндустрии, железо и психология вождения
@TeslaHackers — сообщество российских Tesla-хакеров, прокат и обучение дрифту на Tesla

Количество строк кода в современном автомобиле в 200 раз больше чем в Шаттле, в 60 раз больше, чем в истребителе F-22 Raptor, в 50 раз больше, чем в телескопе Хаббл, в 20 раз больше чем в марсоходе Curiosity, в 4 раза больше чем в истребителях пятого поколения, в 2 раза больше, чем в большом адронном коллайдере или Facebook, если распечатать весь код на бумаге, то стопка будет высотой 200 метров. (по данным на 2009-2012 год)
Данные по количеству строк кода в современном автомобиле вызвали бурные споры на Reddit. Вопросы на темы от «В каком месте эти строчки прячутся, если у микроконтроллеров ограничена память?» до «Разве количество строк кода хоть что-то значит?»
Сравнительные данные по количеству строк кода (SLOC) в различных проектах довольно интересные.
Маргарет Гамильтон и её исходники кода для посадки Апполон-11
Количество строк кода меньше миллиона
10.000 — Unix v 1.0 (1971) [пруф]
10.000 — простая игра для iOS app [пруф]
14.000 — Win32/Simile virus [пруф]
39.000 — iOS app — photo editing [пруф]
80.000 — электрокардиостимуятор [пруф]
120.000 — первая версия Photoshop v1 (1990) [пруф]
200.000 — браузер Camino [пруф]
310.000 — движок Quake 3 [пруф]
400.000 — Space Shuttle [пруф]
> миллиона
Билл Гейтс в 1994 году демонстрирует, что на компакт-диск вмещается больше информации, чем на высоченные стопки бумаги.
1.000.000 строк кода помещается на 18.000 страницах, 2 метра высотой (в 14 раз больше чем «Война и мир», в 25 раз больше чем «Улисс», в 63 раза больше чем «Над пропастью во ржи»)
1.000.000 — игра Crysis [пруф]
1.140.000 — геном бактерии, вызывающей сифилис [пруф]
1.200.000 — Age of Empires Online [пруф]
1.200.000 — модель климата планеты CESM [пруф]
1.700.000 — истребитель F-22 Raptor [пруф]
1.800.000 — Linux Kernel 2.2.0 (1999) [пруф]
2.000.000 — Космический телескоп «Хаббл» [пруф]
2.000.000 — движок Unreal Engine 3 [пруф]
2.500.000 — Windows 3.1 (1992) [пруф]
3.500.000 — управляющий софт в дронах [пруф]
3.500.000 — софт для управления петабайтами данных с адронного коллайдера ROOT [пруф]
4.500.000 — Photoshop CS 6 (2012) [пруф]
4.500.000 — Windows NT 3.1 (1993) [пруф]
4.700.000 — HD DVD Players on XBox [пруф]
5.000.000 — марсоход Curiosity [пруф]
5.200.000 — Linux kernel 2.6.0 (2003) [пруф]
5.500.000 — сервер World of WarCraft [пруф]
6.100.000 — Windows XP Service Pack 1
6.500.000 — авионика и online support systems на Boeing 787 [пруф]
6.700.000 — Google Chrome [пруф]
7.500.000 — Windows NT 3.5 (1994) [пруф]
9.000.000 — LibreOffice [пруф]
9.500.000 — Windows NT 3.51 (1995) [пруф]
9.700.000 — Firefox [пруф]
10.000.000 — электроавтомобиль Chevy Volt [пруф]
10.000.000 — бухгалтерский программный пакет Intuit Quickbooks [пруф]
11.300.000 — OpenOffice [пруф]
11.500.000 — Windows NT 4.0 (1996) [пруф]
12.000.000 — Android (включая 3 миллиона строк на XML, 2.8 миллиона строк на C, 2.1 миллиона строк на Java и 1.75 миллиона строк на C++) [пруф]
12.500.000 — библитотеки Mozilla Core [пруф]
12.500.000 — MySQL [пруф]
14.000.000 — весь софт Boeing 787 [пруф]
15.000.000 — Android (верхняя оценка)
15.000.000 — Linux 3.1 (2013) [пруф]
20.000.000 — Linux kernel pre-4.2 (2015) [пруф]
23.000.000 — Apache Open Office [пруф]
24.000.000 — истребитель-бомбардировщик пятого поколения F-35 Fighter [пруф]
25.000.000 — Microsoft Office (2001) [пруф]
29.000.000 — Windows 2000 (2000) [пруф]
30.000.000 — Microsoft Office for Mac (2006) [пруф]
37.600.000 — Symbian [пруф]
40.000.000 — Windows 7 [пруф]
40.000.000 — Windows XP (2001) [пруф]
45.000.000 — Microsoft Office (2013) [пруф]
50.000.000 — Large Hadron Collider [пруф]
50.000.000 — Microsoft Visual Studio 2012 [пруф]
50.000.000 — Windows Vista (2007) [пруф]
62.000.000 — Facebook (without backend code) [пруф]
68.000.000 — Debian 5.0 codebase [пруф]
86.000.000 — Mac OS X 10.4 [пруф]
100.000.000 — софт в типичном новом автомобиле 2013 года [пруф]
324.000.000 — Debian 5.0 (all software in package) [пруф]
2.000.000.000 — Google [пруф] стопка распечатанных страниц высотой 3.6 км
Мы копнули первоисточники и выяснили, что первыми про 100 миллионов строк кода заявили в журнале IEEE Spectrum, сославшись на почетного профессора Мюнхенского технического университета Манфред Брой, который заслужил медаль Конрада Цузе (почти нобелевка в области computer science) в публикации 2009 «This Car Runs on Code»:
These are impressive amounts of software, yet if you bought a premium-class automobile recently, ”it probably contains close to 100 million lines of software code,” says Manfred Broy, a professor of informatics at Technical University, Munich, and a leading expert on software in cars. All that software executes on 70 to 100 microprocessor-based electronic control units (ECUs) networked throughout the body of your car.
Подписывайтесь на каналы:
@AutomotiveRu — новости автоиндустрии, железо и психология вождения
@TeslaHackers — сообщество российских Tesla-хакеров, прокат и обучение дрифту на Tesla
О компании ИТЭЛМА
Мы большая компания-разработчик automotive компонентов. В компании трудится около 2500 сотрудников, в том числе 650 инженеров.
Мы, пожалуй, самый сильный в России центр компетенций по разработке автомобильной электроники. Сейчас активно растем и открыли много вакансий (порядка 30, в том числе в регионах), таких как инженер-программист, инженер-конструктор, ведущий инженер-разработчик (DSP-программист) и др.
У нас много интересных задач от автопроизводителей и концернов, двигающих индустрию. Если хотите расти, как специалист, и учиться у лучших, будем рады видеть вас в нашей команде. Также мы готовы делиться экспертизой, самым важным что происходит в automotive. Задавайте нам любые вопросы, ответим, пообсуждаем.
Источник
Google — это 2 миллиарда строчек кода
Издание Wired обратило внимание на выступление сотрудницы Google Рейчел Потвин «The Motivation for a Monolithic Codebase», которое состоялось в рамках конференции в Кремниевой долине. В своём докладе она оценила число строк кода, который отвечает за работу всех интернет-сервисов Google: выяснилось, что число равно примерно 2 миллиардам. Если провести некорректное сравнение и учесть, что Windows содержит примерно 50 миллионов строк кода, то получается, что с 1998 года в Google успели написать 40 операционных систем от Microsoft, которая разрабатывается с 1985 года. Мало того, весь этот «Google-код» находится в едином репозитории, которым ежедневно пользуются 25 000 сотрудников поискового гиганта.
Рейчел заметила, что такой принцип хранения исходников позволяет разработчикам Google «… чувствовать необычную свободу в использовании и комбинировании кода других проектов». Единственное существующее ограничение — это доступ к коду, реализующему алгоритмы ранжирования Google’s PageRank, которые являются основой бизнеса, критичного для поискового гиганта. К этим файлам имеют доступ только специально выделенные сотрудники. В целом для управления кодом в Google используется собственная VCS, которая называется Piper и которая в свою очередь опирается на серьёзную инфраструктуру, состоящую из 10 дата-центров.
Любопытна статистика, приведённая Рейчел. По её словам, Piper управляет 85 терабайтами данных «Google-кода», в который ежедневно 25 000 разработчиков делают примерно 40 000 коммитов. Таким образом за каждую неделю модифицируются 250 000 файлов и 15 миллионов строк кода. В сравнении с Linux, которая вся насчитывает примерно 40 000 файлов, работа программистов Google выглядит фантастической.Также Рейчел отметила, что сейчас Google и Facebook вместе работают над новой open source VCS, которую можно будет использовать на проектах любого масштаба, сравнимого даже с самой Google. Интересно, что основой будущей VCS является не модная среди разработчиков git, а Mercurial, которую пытаются масштабировать до уровня, с которым приходится иметь дело обоим интернет-гигантам.
Источник
Система STEPS: двадцать тысяч строк кода, которые изменят программирование, операционные системы и интернет
У программистов есть заветная мечта: взять и переделать заново всё — операционную систему, языки программирования, библиотеки и приложения. Упразднить ненужное дублирование функций и написать всё красиво и по-новому — словом, сделать всё как надо, а не как получилось в результате многих лет нагромождения разных стилей и технологий. При этом все обычно понимают, что мечтам никогда не сбыться и что никому не под силу заново проделать такой объём работы. Над смельчаками принято посмеиваться, а их попытки — обзывать переизобретением колеса. Но когда за работу берётся человек, который уже однажды изобрёл немалую часть технологий, которые мы ассоциируем с персональными компьютерами, все шутки становятся неуместными.
Алан Кей — живая легенда компьютерной индустрии. В середине шестидесятых он работал с Айвеном Сазерлендом, создавшим первый графический редактор и систему автоматизированного проектирования, а в 1970 году присоединился к исследовательской лаборатории Xerox PARC, где придумал объектно-ориентированное программирование, создав язык Smalltalk, и первый компьютер с оконным графическим интерфейсом. Позднее его работа вдохновит Стива Джобса и команду, сделавшую Macintosh, а прототип Macintosh убедит Билла Гейтса в том, что MS-DOS срочно нуждается в графической оболочке с оконным интерфейсом, известной нам как Windows.
После PARC Кей работал в самых разных исследовательских центрах: Atari, Apple, Disney и HP, а также в Калифорнийском университете в Лос-Анджелесе и Киотском университете. Видимым результатом его исследований стали Squeak — более современная и дружественная версия Smalltalk, а также Etoys — вариант Squeak для детей (на его основе был создан более известный сегодня Scratch). В 2005 году Кей основал исследовательский институт Viewpoints, финансируемый Национальным научным фондом США, а также рядом крупных компаний: Intel, Motorola, HP и Nokia. То, чем Кей и десяток сотрудников Viewpoints заняты сейчас, может ещё перевернуть наш взгляд на программирование.
Двадцати тысяч строк хватит на всё
Изначальное предложение Кея, представленное Национальному научному фонду США, звучало не просто смело, а почти фантастически. Кей пообещал создать среду (мы не будем называть её операционной системой, так как Кей настаивает на том, что это не ОС в привычном понимании), которая позволит функционировать современному компьютеру и будет включать в себя графический пользовательский интерфейс и набор прикладных программ. Главное отличие этой среды от всех уже существующих решений: длина кода этой системы не будет превышать двадцати тысяч строк.
Сказать, что двадцать тысяч строк — это немного, значит не сказать ничего. Если верить «Википедии», то исходные коды Windows NT 3.1 занимали 4-5 миллионов строк кода, ядро Linux 2.6.0 − 5,2 миллиона, а современные ОС с набором стандартных приложений могут содержать сотни миллионов строк кода.
Объём сопоставим с Эмпайр стейт билдинг и равен примерно 17,5 тысячам книг. «Кто из вас прочёл семнадцать тысяч книг? — вопрошает Кей собравшихся на лекции. — А кто из вас прочёл хотя бы одну?» Объёма одной книги, то есть примерно двадцати тысяч строк, по его мнению достаточно для того, чтобы создать систему, напоминающую по функциям те ОС и приложения, с которыми мы сейчас работаем. Просто строить нужно умело.
Современный софт Кей сравнивает с египетскими пирамидами. Их строители ещё ничего толком не знали об архитектуре и сооружали конструкции, которые почти полностью состояли из материала и практически не имели свободного пространства внутри. С изобретением колонн и арок стало возможно возводить куда более изящные и практичные сооружения. Нельзя ли изобрести аналог арок для написания программ?
Сейчас программист при всём желании не способен свободно ориентироваться в миллионах строк кода. Зато если уместить всю систему в объём книги и разделить на логические части по 100-1000 строк, это даст возможность легко понимать логику её строения и вносить изменения. Проблемы вроде багов, которые на протяжении многих лет преследуют крупные проекты, просто уйдут в прошлое.
You may say I’m a dreamer
Главный вопрос: возможно ли такое в принципе? За пять лет работы команда Кея доказала, что ответ на этот вопрос может быть положительным. Систему методов, которые позволят это сделать, авторы называют STEPS. Это рекурсивный акроним, расшифровывающийся как STEPS Toward Expressive Programming Systems — «Шаги к выразительным системам программирования».
Руководствуясь принципами STEPS, в институте Кея создали прототип системы. Он называется Frank, а если полностью — «Франкенштейн». Такое имя выбрано не зря: система составлена из кусочков, каждый из которых ещё может быть заменён или переписан заново.
Что может делать пользователь Frank? Всё то же, что мы обычно делаем за компьютером: создаём и редактируем текстовые документы, графику, видео, презентации и электронные таблицы, а также обмениваемся ими через сеть. Вся разница в том, что исследователи попытались полностью избавились от дублирования функций разными программами и максимально сократить исходный код.
Frank — это не операционная система, в которой работают приложения, а скорее, подобие Smalltalk или Squeak — большое приложение, которое можно расширять и дополнять, пока оно не станет делать всё, что нам нужно. Вместо приложений, в которых реализованы собственный интерфейс и функции, здесь присутствуют компоненты, имеющие сложные взаимосвязи.
Во Frank есть единое понятие «документ», в который могут быть включены и на месте изменены любые объекты, будь то изображения, таблицы или созданные пользователем скрипты. Презентация, например, — это документ, включающий в себя сценарий перехода вперёд и назад по страницам (или, если угодно, кадрам), а не файл, для открытия которого требуется специальная программа. Такая программа просто не нужна, потому что интерфейс для работы с изображениями и текстом идентичен тому, что используется для подготовки других документов.
То же и с электронной почтой: письмом во Frank считается любой документ, который был передан по Сети. Список писем — это результат поиска документов, полученных от других пользователей.
Ещё одно ценное качество системы Кея — универсальная отмена. Здесь может быть отменено действительно любое действие, а не как в сегодняшних программах — лишь некоторые, да и то не всегда. Для этого используется механизм «миров»: каждый раз, когда мы что-то меняем, система может запомнить, чем нынешний «мир» отличается от предыдущего, и в случае надобности вернуть всё, как было.
Интереснее всего то, как Кей предлагает переделать веб. Во Frank нет браузера, зато есть поддержка протокола TCP/IP (его код занимает 160 строк, и это, по словам Кея, не предел краткости). Вместо веб-страниц предлагается использовать те же самые документы, добавив в них объект нового типа — гиперссылку.
Поскольку код, содержащийся в документах, по сути, работает в виртуальной машине, это делает их загрузку извне не менее безопасной, чем исполнение JavaScript браузером. Получается, что объекты-страницы просто подгружаются через Сеть по мере необходимости. Кстати, делать такие «сайты» намного проще, чем обычные: можно пользоваться уже имеющимися в системе средствами — теми же самыми, при помощи которых редактируются текстовые документы, презентации и всё остальное.
Сила мысли и никакого мошенничества
Внешняя сторона Frank интересна уже хотя бы в качестве примера унифицированной среды, в которой нет ни разделения на приложения, ни традиционной файловой системы. Но настоящая чёрная программисткая магия скрыта внутри.
Сколько занимают разные части STEPS?
| TCP/IP | 160 строк |
| Алгоритм сглаживания на Nile | 45 строк |
| Весь код Gezira на Nile | 457 строк |
| Парсер Nile на OMeta | 130 строк |
| Транслятор Nile AST в Си на OMeta | 1110 строк |
Как Frank уместился в двадцать тысяч строк кода? Ответ кроется за двумя терминами: метапрограммирование и предметно-ориентированные языки (DSL). Главная идея заключается в том, чтобы создавать языки под конкретные задачи и, хитроумно комбинируя их, писать элегантные и короткие программы. Эта идея не нова: на ней основан язык Forth, и она используется в написании программ на языке Lisp, которым Кей в своё время вдохновлялся при создании Smalltalk. Более современный пример — фреймворк Ruby on Rails, применяемый в качестве DSL для разработки бэкэндов веб-приложений. Но STEPS — это нечто куда большее, чем один язык, — это набор методов и языков, при помощи которых можно создавать сложные системы, используя минимум кода.
Один из самых интересных компонентов STEPS — это объектно-ориентированный язык OMeta (pdf). Он предназначен для описания синтаксиса других языков. К примеру, на OMeta можно в несколько строк описать синтаксис калькулятора, а потом при помощи наследования расширить его и сделать научный калькулятор. Синтаксис OMeta при этом описан на самом OMeta.
Второй важный язык — это Nile (названный в честь реки Нил). Авторы STEPS называют его «языком исполняемой математики». Nile позволяет компактно описывать математические выражения и сделан таким образом, чтобы максимально облегчить параллельные вычисления. На нём написана графическая подсистема Frank, называемая Gezira. Gezira умещается в несколько сотен строк на Nile и умеет выводить растровую и векторную графику, поддерживает сглаживание и различные фильтры.
Самый низкий уровень во всей этой сложной системе — язык Nothing (переводится с английского как «Ничто»), «высокоуровневый язык с низкоуровневой семантикой». Nothing — это промежуточное звено между всеми языками в STEPS и машинными кодами. На Nothing не предполагается писать вручную, и нужен он лишь для возможности смотреть, что получается на выходе. Nothing, по словам исследователей, вдохновлён BCPL, использовавшимся в шестидесятые годы и вдохновившим авторов Си. На данный момент код на Nothing можно транслировать в Си для дальнейшего перевода в машинные коды или в JavaScript — чтобы система исполнялась в браузере. Предполагается, что в будущем из Nothing можно будет получать машинные коды напрямую.
В качестве промежуточного слоя, на котором написан пользовательский интерфейс, одно время использовался NotSqueak — упрощённый диалект Squeak. Но в последнем отчёте упоминаний о NotSqueak уже нет, зато появился новый объектно-ориентированный язык — Maru. Как и OMeta, он написан сам на себе и может использоваться как для описания высокоуровневого представления, так и для связи с низкоуровневыми функциями. На Maru может быть реализован парсер грамматики, и в 2011 году команда Кея была занята переносом Nile на Maru.
Бесконечный эксперимент
К сожалению, отчёты Кея и его команды (pdf) — это не пособие для программистов-суперменов и не справочник. Оно и понятно — STEPS пока что не готов, и каждый год во Viewpoints ставят разнообразные эксперименты, цель которых — не столько в создании законченной системы, сколько в том, чтобы отточить методы. «Франкенштейн» как цельная система здесь нужен лишь в качестве подопытного тела.
Если посмотреть отчёты Viewpoints за разные годы, то заметно, что здесь снова и снова изобретают языки программирования, делают их всё более самодостаточными (пока что кое-где ещё остаётся код на Си, но от него постепенно избавляются) и ставят смелые эксперименты.
Время от времени команда Кея пробует пробрасывать мостики в реальный мир, создавая, к примеру, виртуальную машину Squeak для Google Native Client или делая метаязык Tamacola на основе Tamarin VM, входящей во Flash. Эти методы могут позволить всей системе не просто работать в браузере, но исполняться быстрее, чем при трансляции в JavaScript.
Скорость, впрочем, не является целью Кея: по его оценке, в нынешнем виде Frank работает примерно на 30 процентов медленнее, чем если бы был написан традиционными методами. Оптимизацией исследователи занимаются лишь тогда, когда это не вредит компактности кода.
Понятно, что Frank не станет конкурентом современных ОС и вряд ли вообще будет доделан до необходимого для этого уровня. Тем не менее те методы, которые разрабатывает Алан Кей, могут повлиять на подход к программированию не меньше, чем в своё время повлиял Smalltalk.
Источник
ZEL-Услуги
»Пресс-центр
»Статьи
»Насколько сложный программный код у Windows?
16.01.2020

Чтобы разобраться вопросе, насколько может быть сложным программный код «Виндовс» мы обратились к одному из разработчиков команды Windows NT в компании Microsoft — Кену Греггу (Ken Gregg).
Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
«Могу сказать вам, что у меня был доступ к исходному коду, когда я был в команде Windows NT (NT является основой для всех настольных версий Windows начиная с XP), во время проектов разработки NT 3.1 и NT 3.5. Всё было в рамках стандартов кодирования NT Workbook — эдакой «библии» для всей проектной команды…
…Хотя я и не читал каждую строку кода, но то, с чем мне пришлось работать, было очень:
- чётким,
- модульным,
- многоуровневым,
- обслуживаемым».
Нужно исходить из того, что именно понимается под сложностью кода. Это понимание сугубо субъективное, ведь так? Благо существует множество различных метрик, используемых и комбинируемых для измерения сложности программного обеспечения в тех или иных ситуациях (та же самая модульность, многоуровневость и обслуживаемость).

Насколько сложна Windows в программном коде?
Конечно, чтобы прочитать и понять код, вам нужно было бы иметь представление об общей архитектуре Windows NT.
Вероятно, лучшим источником информации о внутренностях Windows сегодня являются книги Windows Internals 6th Edition (в двух томах).
Некоторые люди просто приравнивают сложность кода к размеру. У этого сравнения тоже есть метрика — строки кода (LOC).
Измерение LOC зависит от используемых инструментов и критериев. Их выбирают для точного определения строк кода на каждом языке программирования.

Кен Грегг (Ken Gregg)
«Существует много споров о методах, используемых для подсчета строк кода (LOC). Если использовать одни и те же критерии от одного выпуска к следующему, то получится относительное изменение размера базы кода.
Сравнивать эти числа с цифрами другой ОС, которая использовала другой метод подсчета строк кода, всё равно что сравнивать яблоки с апельсинами. То есть это некорректный подход».

Как менялся программный код Windows?
Здесь приводятся некоторые лакомые кусочки, дающие представление о размерах современной кодовой базы Windows. Строки кода здесь являются приблизительными и неофициальными, но основаны на достаточно надёжных источниках, о которых говорит Кен Грегг.
Как база кода Windows NT развивалась с 1993 года
MLOC — это количество миллионов строк исходного кода. По ним можно определить относительную сложность операционной системы, если опираться на размеры кода (LOC-методика).
- Windows NT 3.1 (1993) — 5,6 MLOC
- Windows NT 3.5 (1994) — 8,4 MLOC
- Windows NT 3.51 (1995) — 10,2 MLOC
- Windows NT 4.0 (1996) — 16 MLOC
- Windows 2000 (2000) — 29 MLOC
- Windows XP (2001) — 35 MLOC
- Windows Vista (2007) — 45 MLOC
- Windows 7 (2009) — 42 MLOC
- Windows 8 (2012) — 50 MLOC
- Windows 10 (2015) — 55 MLOC
Исходный код Windows состоит в основном из C и C++, а также небольшого количества кода на ассемблере.
Некоторые из утилит пользовательского режима и другие подобные службы пишутся на Си Шарп, но это относительно небольшой процент от общей базы кода.
Кен Грегг (Ken Gregg)
«Я намеренно не включил в список 16-битные версии ОС, выпущенные с 1985 по 2000 годы. Windows NT была основой для всех современных 32-бит и 64-бит версий Windows. Количество строк кода в серверных версиях было таким же, как и в несерверных версиях, выпущенных в том же году (то есть они имели одинаковую базу исходного кода)».

Несколько слов про ядро Windows NT
По словам Кена, работа над ядром NT началась в 1988 году. Ядро было создано с нуля в качестве 32-разрядной упреждающей многозадачной ОС.
Ядро NT впервые загрузилось в июле 1989 года на процессоре Intel i860 RISC. С самого начала был сильный толчок к тому, чтобы новая ОС была совместимой с различными архитектурами центральных процессоров и не была привязана только к архитектуре Intel x86 (IA-32).
NT в конечном итоге работал на MIPS, DEC Alpha, PowerPC, Itanium и, конечно, Intel x86 и x64.
Некоторая сложность была добавлена в базу кода на уровне абстрагирования оборудования (HAL). Это было нужно для поддержки неинтеловских архитектур.
А как вы оцениваете перспективы Windows в плане кода? Узнайте, какие версии Windows актуальны сейчас и какие ОС можно рассмотреть в качестве альтернативы.
![]() Компания ZEL-Услуги
Компания ZEL-Услуги
Есть проблемы при использовании Windows и непонятен программный код для внедрения новых бизнес-инструментов в ОС от Microsoft? Проконсультируйтесь с экспертами по ИТ-аутсорсингу и получите поддержку по любым техническим вопросам и задачам.
Читайте также
- Мал бизнес, да удал: какие технологии сейчас помогают автоматизировать повторяющиеся задачи?
- Перестройка бизнес-коммуникаций: технологии, которые влияют на бизнес и приносят пользу прямо сейчас!
- Интернет-технологии в малом бизнесе — страх начинающих предпринимателей
- Интернет в оборот: 5 инсайдерских техносекретов в запуске малого бизнеса [2023]
- Азбука малого бизнеса: кибербезопасность, защита от фишинга, обучение сотрудников
Может быть интересно
- Онлайн конструктор тарифов
- Цены и тарифы на ИТ-аутсорсинг
- Абонентское обслуживание компьютеров
- ИТ-директор
- Настройка и обслуживание серверов
Windows 10
| Версия операционной системы Windows NT | |
| Снимок экрана Windows 10 версии 20H2, показывающий меню «Пуск» и Центр действий в светлой теме | |
| разработчик | Microsoft |
| Написано в | С, С ++, С # |
| Статус поддержки |
|---|
На каком языке программирования написана Windows?
Windows / Написано на
Написана ли Windows 10 на C #?
Мы почти полностью используем C, C ++ и C # для Windows. Некоторые области кода настроены вручную / написаны вручную.
Python написан на C или C ++?
Python написан на C (на самом деле реализация по умолчанию называется CPython). Python написан на английском языке. Но есть несколько реализаций: PyPy (написано на Python)
C ++ лучше Python?
Производительность C ++ и Python также заканчивается этим выводом: C ++ намного быстрее Python. В конце концов, Python — это интерпретируемый язык, и он не может совпадать с компилируемым языком, таким как C ++. Хорошая новость заключается в том, что вы можете получить лучшее из обоих миров, комбинируя код C ++ и Python.
Подходит ли Windows 10 для программирования?
Не знаю, как вы, но мой опыт работы с Windows был лучше, чем с Linux. Работать с Windows 10 проще, чем с любым дистрибутивом Linux, не говоря уже о том, что Visual Studio выполняет код как ничто другое… На медленной машине Windows 10 зависает меньше…
C все еще используется в 2020 году?
Наконец, статистика GitHub показывает, что и C, и C ++ являются лучшими языками программирования для использования в 2020 году, поскольку они по-прежнему входят в первую десятку списка. Так что ответ — НЕТ. C ++ по-прежнему остается одним из самых популярных языков программирования.
Написана ли Java на C?
Самый первый компилятор Java был разработан Sun Microsystems и был написан на C с использованием некоторых библиотек из C ++. Сегодня компилятор Java написан на Java, а JRE — на C.
Почему до сих пор используется C?
Программисты на C. У языка программирования C, похоже, нет срока годности. Его близость к оборудованию, отличная портативность и детерминированное использование ресурсов делают его идеальным для разработки на низком уровне таких вещей, как ядра операционных систем и встроенное программное обеспечение.
Почему C — язык среднего уровня?
C называется языком среднего уровня, потому что он фактически устраняет разрыв между языком машинного уровня и языками высокого уровня. Пользователь может использовать язык c для системного программирования (для написания операционной системы), а также прикладного программирования (для создания системы выставления счетов для клиентов на основе меню).
Сколько строк кода в Windows 10?
Есть ок. 50 миллионов строк кода в Windows 10. . . Власть разработчику!
Какой код использует Mac?
Objective-C — это язык, наиболее часто используемый в программировании Mac OS. Objective-C вошел в Mac OS X и имеет предки в NeXT.
Может ли Python заменить Java?
Python продолжает расти в списке популярных языков программирования в мире. По мнению аналитиков TIOBE, с такими темпами Python может обогнать C и Java и стать самым популярным языком программирования. …
Python проще, чем Java?
Здесь больше экспериментов, чем производственного кода. Java — это статически типизированный и компилируемый язык, а Python — динамически типизированный и интерпретируемый язык. Это единственное отличие делает Java быстрее во время выполнения и упрощает отладку, но Python проще в использовании и легче читается.
Python проще, чем C ++?
Python — это простой в использовании язык программирования по сравнению с C ++. Python медленнее C ++. … Написать код на C ++ не так просто, как на python, из-за его сложного синтаксиса. Python проще в использовании и написании кода благодаря удобному синтаксису.
Короткие байты: Многие крупнейшие технологии работают на программном обеспечении, которое создано с использованием языков программирования. Иллюстрация показывает, сколько строк кода было написано для создания программного обеспечения и сервисов. Google возглавляет список с ошеломляющим 2 000 000 000 строк кода.
Приложения и сервисы, которые являются важной частью нашей цифровой жизни, написаны на разных языках программирования. Например, приложения для iOS написаны с использованием Swift, а для Android разработчики могут использовать Java или более простой Lua с использованием Corona. Microsoft Windows разработана с использованием C и C ++. Ядро Linux, которое является сердцем всех дистрибутивов Linux, написано на C. Интернет-сайты созданы с использованием JavaScript, HTML, CSS для внешнего интерфейса и Python, Go, C ++, ASP.NET и т. Д. Для внутреннего интерфейса.
Помимо многих функций, одна вещь, которая отличает эти языки, — это количество строк кода. Например, люди, которые используют Python, имеют преимущество ввода меньшего числа строк, чем те, которые используют Java или C.
Вот иллюстрация, которая показывает количество строк кода, использованных для создания некоторых из самых больших творений в истории технологии. Он включает в себя программное обеспечение, которое запускает первый в мире космический челнок, марсоход Curiosity НАСА, живущий в одиночестве на Марсе, ОС Android от Google и т. Д.
Идея этой иллюстрации возникла в нашем мозгу, когда мы натолкнулись на инфографику «Миллион строк кода», разработанную компанией Information Is Beautiful. Наша гистограмма — это уменьшенная версия более крупной картинки, изображенной на миллионах строк кода.
Сравнивая строки кода для двух наиболее часто используемых веб-сайтов в Интернете, Google (включая все интернет-сервисы Google) явно выделяется своими 2 миллиардами строк, оставляя позади Facebook с 61 000 000 строк кода. Хотя Facebook является всего лишь социальной сетью по сравнению с Google, чьи продукты охватывают множество услуг.
Интересный факт: Первоначальному космическому шаттлу требовалось в 5000 раз меньше строк кода, чем Google.
Данные были собраны Information Is Beautiful. Вы можете увидеть оригинальную инфографику здесь.
Если вам есть что добавить, сообщите нам в комментариях ниже.
Русские Блоги
Сколько строк в исходном коде Win 10? Какой язык программирования использовался?
(дайте Те вещи о программистах Помечено )
Оригинальная отделка: те штучки о программистах (id: iProgrammer)
В октябре 2013 года мы разместили на Weibo картинку (@ programmer’s things) инфограмма » Сравнение кодовых баз известных программных систем.
В инфографике упоминается, что объем кода для операционных систем Windows XP и Windows 7 составляет около 40 миллионов строк.
( инфограмма Несколько скриншотов, полная версия здесь: http: //t.cn/EXMs07e )
Windows Объем исходного кода Vista составляет около 50 миллионов строк.
Следовательно, объем исходного кода Windows 10 составляет не менее 50 миллионов строк.
Какой язык программирования использовался при разработке операционной системы Windows?
Windows операционная система Кому-то должно быть интересно, какой язык программирования используется для такой масштабной кодовой базы.
Это правда? Кто-то написал на Quora с вопросом: «Разработка W ind ows 10 Какой язык программирования используется? 》
В марте 2019 года инженер ядра Microsoft Аксель Ритчин ответил на этот пост на Quora.
«Вот что о программистах»:
Axel Говорят, что Windows 10 и Windows 8.x, 7, Vista, XP, 2000 и NT имеют одинаковую кодовую базу. Каждое поколение операционных систем претерпело серьезный рефакторинг, добавив большое количество новых функций, улучшив производительность и поддержку оборудования. И безопасность при сохранении очень высокой обратной совместимости.
Ядро (ntoskrnl.exe) Большинство из них написано на языке Си . Вы можете найти просочившуюся версию Windows Research Kernel на Github.
Детскую обувь, кому интересно, могут посмотреть: github.com/markjandrews/wrk-v1.2
Axel Сказал, что, хотя код WRK устарел и в основном неполный, он должен дать вам некоторое представление.
Например: каталог wrk-v1.2 / base / ntos / config — это исходный код известного реестра (Registry) .Этот компонент ядра является диспетчером конфигурации (CM).
Большинство программ, работающих в режиме ядра, также написаны на языке C. (Большинство файловых систем, сетей, большинство драйверов . ) и немного C ++.
Что касается языка программирования, на котором написано Window 10, Аксель считает, что это C и C ++, причем C составляет большинство.
.NET BCL И другие управляемые библиотеки и фреймворки обычно используют C # Написано, Из разных отделов ( Отдел разработчиков) И не принадлежит Windows Исходное дерево 。 По сравнению с океаном кода C, разбросанным по островам C ++, код, написанный на C #, — просто капля в море. 。
Windows действительно правда В самом деле В самом деле В самом деле Очень большой
Axel Я напоминаю всем, что большинство людей не осознают огромных размеров системы Windows, огромного проекта с эпическим масштабом.
Размер полного дерева исходного кода Windows (включая все коды, тестовые коды и т. Д.) Превышает 0,5 ТБ, что включает Более 56 миллионов папок, 400 Более десяти тысяч файлов 。
Вы можете потратить год, копаясь в дереве исходных текстов и копаясь в этих файлах. Они включают в себя все компоненты рабочей станции и серверных продуктов ОС, а также все их версии, инструменты и соответствующие комплекты разработки.
Затем вы снова читаете имя файла, чтобы увидеть, что в нем и для чего они используются. Хочу закончить эти дела , Персона (Или два человека ) Боюсь закончить жизнь 。
один раз Axel Покинув ветку Git на несколько недель, он вернулся и обнаружил, что за ним почти 60 000 коммитов. Axel Я думаю, кто-то сказал бы, что никто не может читать весь код, добавленный в Windows каждый день, не говоря уже о том, чтобы читать код, написанный за последние 30 лет!
Рекомендуемая литература
(Щелкните заголовок, чтобы перейти к прочтению)
Обратите внимание на звезду «вещи программиста» и не пропустите кружок.
Система STEPS: двадцать тысяч строк кода, которые изменят программирование, операционные системы и интернет
У программистов есть заветная мечта: взять и переделать заново всё — операционную систему, языки программирования, библиотеки и приложения. Упразднить ненужное дублирование функций и написать всё красиво и по-новому — словом, сделать всё как надо, а не как получилось в результате многих лет нагромождения разных стилей и технологий. При этом все обычно понимают, что мечтам никогда не сбыться и что никому не под силу заново проделать такой объём работы. Над смельчаками принято посмеиваться, а их попытки — обзывать переизобретением колеса. Но когда за работу берётся человек, который уже однажды изобрёл немалую часть технологий, которые мы ассоциируем с персональными компьютерами, все шутки становятся неуместными.
Алан Кей — живая легенда компьютерной индустрии. В середине шестидесятых он работал с Айвеном Сазерлендом, создавшим первый графический редактор и систему автоматизированного проектирования, а в 1970 году присоединился к исследовательской лаборатории Xerox PARC, где придумал объектно-ориентированное программирование, создав язык Smalltalk, и первый компьютер с оконным графическим интерфейсом. Позднее его работа вдохновит Стива Джобса и команду, сделавшую Macintosh, а прототип Macintosh убедит Билла Гейтса в том, что MS-DOS срочно нуждается в графической оболочке с оконным интерфейсом, известной нам как Windows.
После PARC Кей работал в самых разных исследовательских центрах: Atari, Apple, Disney и HP, а также в Калифорнийском университете в Лос-Анджелесе и Киотском университете. Видимым результатом его исследований стали Squeak — более современная и дружественная версия Smalltalk, а также Etoys — вариант Squeak для детей (на его основе был создан более известный сегодня Scratch). В 2005 году Кей основал исследовательский институт Viewpoints, финансируемый Национальным научным фондом США, а также рядом крупных компаний: Intel, Motorola, HP и Nokia. То, чем Кей и десяток сотрудников Viewpoints заняты сейчас, может ещё перевернуть наш взгляд на программирование.
Двадцати тысяч строк хватит на всё
Изначальное предложение Кея, представленное Национальному научному фонду США, звучало не просто смело, а почти фантастически. Кей пообещал создать среду (мы не будем называть её операционной системой, так как Кей настаивает на том, что это не ОС в привычном понимании), которая позволит функционировать современному компьютеру и будет включать в себя графический пользовательский интерфейс и набор прикладных программ. Главное отличие этой среды от всех уже существующих решений: длина кода этой системы не будет превышать двадцати тысяч строк.
Сказать, что двадцать тысяч строк — это немного, значит не сказать ничего. Если верить «Википедии», то исходные коды Windows NT 3.1 занимали 4-5 миллионов строк кода, ядро Linux 2.6.0 − 5,2 миллиона, а современные ОС с набором стандартных приложений могут содержать сотни миллионов строк кода.
Объём сопоставим с Эмпайр стейт билдинг и равен примерно 17,5 тысячам книг. «Кто из вас прочёл семнадцать тысяч книг? — вопрошает Кей собравшихся на лекции. — А кто из вас прочёл хотя бы одну?» Объёма одной книги, то есть примерно двадцати тысяч строк, по его мнению достаточно для того, чтобы создать систему, напоминающую по функциям те ОС и приложения, с которыми мы сейчас работаем. Просто строить нужно умело.
Современный софт Кей сравнивает с египетскими пирамидами. Их строители ещё ничего толком не знали об архитектуре и сооружали конструкции, которые почти полностью состояли из материала и практически не имели свободного пространства внутри. С изобретением колонн и арок стало возможно возводить куда более изящные и практичные сооружения. Нельзя ли изобрести аналог арок для написания программ?
Сейчас программист при всём желании не способен свободно ориентироваться в миллионах строк кода. Зато если уместить всю систему в объём книги и разделить на логические части по 100-1000 строк, это даст возможность легко понимать логику её строения и вносить изменения. Проблемы вроде багов, которые на протяжении многих лет преследуют крупные проекты, просто уйдут в прошлое.
You may say I’m a dreamer
Главный вопрос: возможно ли такое в принципе? За пять лет работы команда Кея доказала, что ответ на этот вопрос может быть положительным. Систему методов, которые позволят это сделать, авторы называют STEPS. Это рекурсивный акроним, расшифровывающийся как STEPS Toward Expressive Programming Systems — «Шаги к выразительным системам программирования».
Руководствуясь принципами STEPS, в институте Кея создали прототип системы. Он называется Frank, а если полностью — «Франкенштейн». Такое имя выбрано не зря: система составлена из кусочков, каждый из которых ещё может быть заменён или переписан заново.
Что может делать пользователь Frank? Всё то же, что мы обычно делаем за компьютером: создаём и редактируем текстовые документы, графику, видео, презентации и электронные таблицы, а также обмениваемся ими через сеть. Вся разница в том, что исследователи попытались полностью избавились от дублирования функций разными программами и максимально сократить исходный код.
Frank — это не операционная система, в которой работают приложения, а скорее, подобие Smalltalk или Squeak — большое приложение, которое можно расширять и дополнять, пока оно не станет делать всё, что нам нужно. Вместо приложений, в которых реализованы собственный интерфейс и функции, здесь присутствуют компоненты, имеющие сложные взаимосвязи.
Во Frank есть единое понятие «документ», в который могут быть включены и на месте изменены любые объекты, будь то изображения, таблицы или созданные пользователем скрипты. Презентация, например, — это документ, включающий в себя сценарий перехода вперёд и назад по страницам (или, если угодно, кадрам), а не файл, для открытия которого требуется специальная программа. Такая программа просто не нужна, потому что интерфейс для работы с изображениями и текстом идентичен тому, что используется для подготовки других документов.
То же и с электронной почтой: письмом во Frank считается любой документ, который был передан по Сети. Список писем — это результат поиска документов, полученных от других пользователей.
Ещё одно ценное качество системы Кея — универсальная отмена. Здесь может быть отменено действительно любое действие, а не как в сегодняшних программах — лишь некоторые, да и то не всегда. Для этого используется механизм «миров»: каждый раз, когда мы что-то меняем, система может запомнить, чем нынешний «мир» отличается от предыдущего, и в случае надобности вернуть всё, как было.
Интереснее всего то, как Кей предлагает переделать веб. Во Frank нет браузера, зато есть поддержка протокола TCP/IP (его код занимает 160 строк, и это, по словам Кея, не предел краткости). Вместо веб-страниц предлагается использовать те же самые документы, добавив в них объект нового типа — гиперссылку.
Поскольку код, содержащийся в документах, по сути, работает в виртуальной машине, это делает их загрузку извне не менее безопасной, чем исполнение JavaScript браузером. Получается, что объекты-страницы просто подгружаются через Сеть по мере необходимости. Кстати, делать такие «сайты» намного проще, чем обычные: можно пользоваться уже имеющимися в системе средствами — теми же самыми, при помощи которых редактируются текстовые документы, презентации и всё остальное.
Сила мысли и никакого мошенничества
Внешняя сторона Frank интересна уже хотя бы в качестве примера унифицированной среды, в которой нет ни разделения на приложения, ни традиционной файловой системы. Но настоящая чёрная программисткая магия скрыта внутри.
Сколько занимают разные части STEPS?
| TCP/IP | 160 строк |
| Алгоритм сглаживания на Nile | 45 строк |
| Весь код Gezira на Nile | 457 строк |
| Парсер Nile на OMeta | 130 строк |
| Транслятор Nile AST в Си на OMeta | 1110 строк |
Как Frank уместился в двадцать тысяч строк кода? Ответ кроется за двумя терминами: метапрограммирование и предметно-ориентированные языки (DSL). Главная идея заключается в том, чтобы создавать языки под конкретные задачи и, хитроумно комбинируя их, писать элегантные и короткие программы. Эта идея не нова: на ней основан язык Forth, и она используется в написании программ на языке Lisp, которым Кей в своё время вдохновлялся при создании Smalltalk. Более современный пример — фреймворк Ruby on Rails, применяемый в качестве DSL для разработки бэкэндов веб-приложений. Но STEPS — это нечто куда большее, чем один язык, — это набор методов и языков, при помощи которых можно создавать сложные системы, используя минимум кода.
Один из самых интересных компонентов STEPS — это объектно-ориентированный язык OMeta (pdf). Он предназначен для описания синтаксиса других языков. К примеру, на OMeta можно в несколько строк описать синтаксис калькулятора, а потом при помощи наследования расширить его и сделать научный калькулятор. Синтаксис OMeta при этом описан на самом OMeta.
Второй важный язык — это Nile (названный в честь реки Нил). Авторы STEPS называют его «языком исполняемой математики». Nile позволяет компактно описывать математические выражения и сделан таким образом, чтобы максимально облегчить параллельные вычисления. На нём написана графическая подсистема Frank, называемая Gezira. Gezira умещается в несколько сотен строк на Nile и умеет выводить растровую и векторную графику, поддерживает сглаживание и различные фильтры.
Самый низкий уровень во всей этой сложной системе — язык Nothing (переводится с английского как «Ничто»), «высокоуровневый язык с низкоуровневой семантикой». Nothing — это промежуточное звено между всеми языками в STEPS и машинными кодами. На Nothing не предполагается писать вручную, и нужен он лишь для возможности смотреть, что получается на выходе. Nothing, по словам исследователей, вдохновлён BCPL, использовавшимся в шестидесятые годы и вдохновившим авторов Си. На данный момент код на Nothing можно транслировать в Си для дальнейшего перевода в машинные коды или в JavaScript — чтобы система исполнялась в браузере. Предполагается, что в будущем из Nothing можно будет получать машинные коды напрямую.
В качестве промежуточного слоя, на котором написан пользовательский интерфейс, одно время использовался NotSqueak — упрощённый диалект Squeak. Но в последнем отчёте упоминаний о NotSqueak уже нет, зато появился новый объектно-ориентированный язык — Maru. Как и OMeta, он написан сам на себе и может использоваться как для описания высокоуровневого представления, так и для связи с низкоуровневыми функциями. На Maru может быть реализован парсер грамматики, и в 2011 году команда Кея была занята переносом Nile на Maru.
Бесконечный эксперимент
К сожалению, отчёты Кея и его команды (pdf) — это не пособие для программистов-суперменов и не справочник. Оно и понятно — STEPS пока что не готов, и каждый год во Viewpoints ставят разнообразные эксперименты, цель которых — не столько в создании законченной системы, сколько в том, чтобы отточить методы. «Франкенштейн» как цельная система здесь нужен лишь в качестве подопытного тела.
Если посмотреть отчёты Viewpoints за разные годы, то заметно, что здесь снова и снова изобретают языки программирования, делают их всё более самодостаточными (пока что кое-где ещё остаётся код на Си, но от него постепенно избавляются) и ставят смелые эксперименты.
Время от времени команда Кея пробует пробрасывать мостики в реальный мир, создавая, к примеру, виртуальную машину Squeak для Google Native Client или делая метаязык Tamacola на основе Tamarin VM, входящей во Flash. Эти методы могут позволить всей системе не просто работать в браузере, но исполняться быстрее, чем при трансляции в JavaScript.
Скорость, впрочем, не является целью Кея: по его оценке, в нынешнем виде Frank работает примерно на 30 процентов медленнее, чем если бы был написан традиционными методами. Оптимизацией исследователи занимаются лишь тогда, когда это не вредит компактности кода.
Понятно, что Frank не станет конкурентом современных ОС и вряд ли вообще будет доделан до необходимого для этого уровня. Тем не менее те методы, которые разрабатывает Алан Кей, могут повлиять на подход к программированию не меньше, чем в своё время повлиял Smalltalk.
Количество строк кода в разных приложениях, системах
А вы задумывались из чего состоят системы которыми вы пользуетесь? Ответ на этот вопрос с вашей стороны меня не волнует (извините за возможную грубость). Сегодня, именно сегодня, я в любом случае расскажу вам о количестве строчек кода в разных проектах.
Начинаем с разных «операционок» — без них никуда.
1. Windows NT 3.1 — появилась на свет в далеком 1993, уже тогда содержала в себе больше 4 млн. строчек на С и С++.
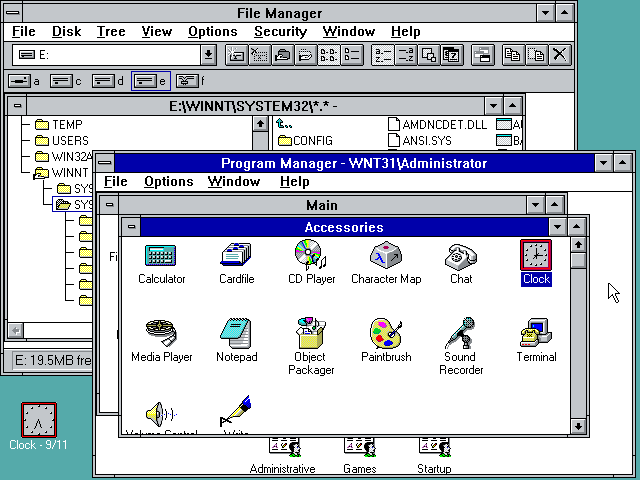
2. Windows NT 3.5 — родилась на год позже своего брата на С++ о котором мы говорили ранее.
Количество строк кода достигало 8 млн. Умный читатель может вычесть из этого количества 4 млн. — получить число на которое выросло число строчек кода за год.
3. А теперь вышедшая в 1996 году Windows NT 4.0, содержащая в себе 11-12 млн. строк.
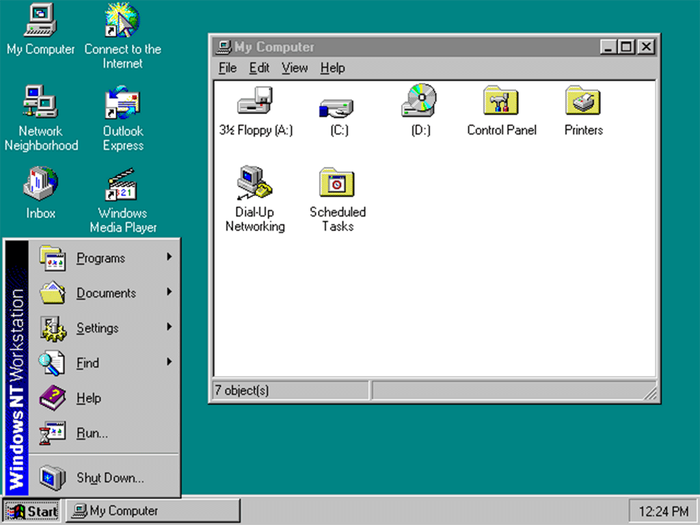
4. Windows 2000. Просто молчу. целых 30 млн строк.
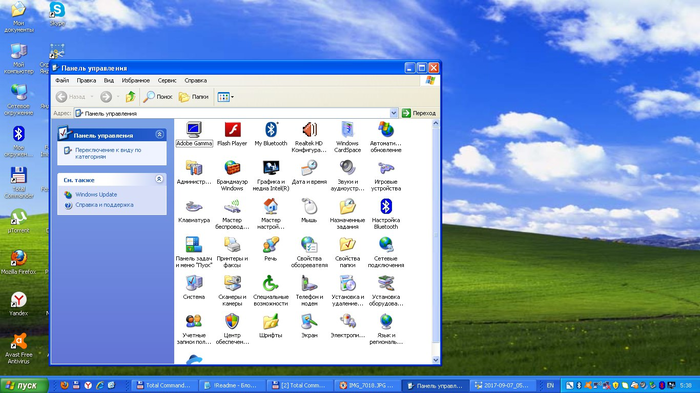
Стоит признать, это не предел, ведь дальше у нас Windows XP.
5. Windows XP — около 45 млн. строчек. Если я сказал, что предыдущие ОС содержали в себе много кода — прошу простить.
6. Windows 10 — более 60 млн. строк. По настоящему сложная сборка.
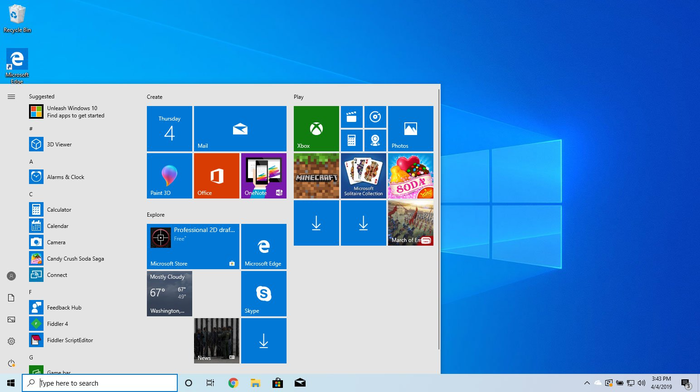
Что-то мы застряли на «Винде». Давайте перейдем к Linux.
1. Linux 0.1 — 10 239 строчек. Не стоит забывать, что выпуск этой версии состоялся в 1991 году.
2. Linux 1.0.0 вышедший спустя 3 года состоял из более чем 170к строк.
3. Linux 1.2.0 появившийся на свет в 1995 был создан при помощь 300к строчек.
4. Linux 2.0.0 — 777 956 строк.
5. Linux 2.2.0 — 1 800 847 строк.
6. 2001 год — рождается Linux 2.4.0 состоящий из 3 377 902 строк кода.
7. Linux 2.6.0 — 5 929 913 строк.
8. Linux 2.6.32 — 12 606 910 строк.
9. 2017 год на дворе — выходит Linux 4.11.7 основанный на 18 млн. строчках.

Android? 12 млн. строк.

Переходим к браузерам.
1. Google Chrome — 7 млн. строчек кода на C++.

2. Firefox — 18 млн. строк. В создании Firefox замешаны C++, C, Javascript, Rust, HTML, CSS, XUL.

Переход к обсуждению приложений, программ, фреймворков.
1. Photoshop CS 6 — 10 млн. строк кода. Величайшее изобретение, ежедневно помогающее дизайнерам, верстальщикам, разработчикам, блогерам.
2. 1C — 3 млн. строк.
3. MySql — 12 млн. строчек кода.
4. Unreal Engine 3 — около 2 млн. строк на C++. Движок для создания игр.
5. Bootstrap — популярный фреймворк для создания сайтов и веб-приложений. Состоит из 70к строчек.

6. React — популярный фреймворк от Facebook. Чуть меньше 160к строк.

7. Vue.js — популярный фреймворк для создания пользовательских интерфейсов.

Надеюсь вам понравилось!
На счет линукса — некорректно.
Когда вы приводилиипримеры винды, вы брали операционную систему. А линукс — это не операционная система — это ядро операционной системы. А операционная система с ядром линукс будет, например: linux mint, ubuntu, cent os, debian, fedora и много других. Поэтому количество строк в линукс-дистрибубутивах будет больше. Например в линукс минте браузером по умолчанию является фаерфокс, а это значит, что там в ядре линукса 18млн. строк + в фаерфоксе тоже 18млн. строк и еще много всякой хрени.
Для unreal engine взяли скриншот окна cinema 4d. Автор «потрудился» над статьёй как надо.
Игра «Посадка на Луну» на калькуляторе МК60: 1 (одна) строка кода.
Полный бред полного чайника.
Почти все сравнения некорректны типа кода в ЯДРЕ LINUX коим явлется Linux и ПОЛНОЙ СИСТЕМЕ где в 10 раз больше в GNU окружении даже уровня IceWM, а в полноценном DE ещё процентов 20 накинет как в ядре. А винда это полная система, ядро у неё к слову, достаточно простое и рядом с NET не стояло, так же начиная с 2000/xp винды не особо росло.
И каков, интересно, процент строк, состоящих из одной только фигурной скобочки?
Умный читатель может вычесть из этого количества 4 млн. — получить число на которое выросло число строчек кода за год.
Люблю, когда мне льстят.
Винда это количество строк во всем проекте или только в ядре ? Тогда как то глупо сравнивать с сухим ядром линя.
Какой-то бред написан.
Про линукс — особенно.
Приводится количество строк кода. чего? Ядра и модулей?
Вспоминается количество матерных слов в комментариях к коду разных версий Linux
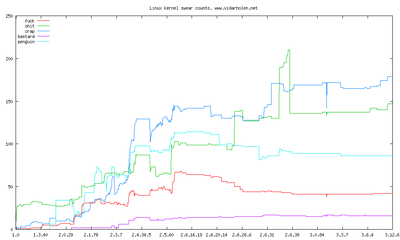
Некоторые кодят так, как Маяковский стихи писал, так что количество строк имхо далеко не показатель

Ответ на пост «Когда под капотом ещё куча фреймворков»

Когда под капотом ещё куча фреймворков


Обзор книги «Начинаем программировать на Python», лучшая книга для начинающих с нуля

Всем доброго времени суток!
Публикую обзор книги подписчика нашего телеграмм-канала IT-старт t.me/it_begin на книгу «Начинаем программировать на Python» от автора Тони Гэддиса.
Стоит читать? Да! Почему? Опишу в статье.
Python — хороший первый язык программирования, а это лучшая книга для его изучения.
Кто целевая аудитория книги?
Книга отлично подойдет для тех, кто только начал изучать Python с полного нуля, так как каждая тема рассматривается автором крайне подробно, что просто не оставляет шансов на то, что после прочтения у вас останутся какие-либо вопросы по рассмотренным в книге темам.
Также книга подойдет тем, кто уже до полугода пишет на Python, но всё же имеет пробелы в фундаментальных вещах и эта книга отлично их закроет своим подробным разбором синтаксиса Python.
Что в книге?
Для начала, чтобы было понимание, что представлено в книге, ознакомимся с её кратким оглавлением.

Рис.1.1 Краткое оглавление

Рис.1.2 Краткое оглавление

Рис.1.3 Краткое оглавление и начала обзора глав
Далее, после краткого оглавления, автором описана каждая глава, о чем она и что в ней будет рассмотрено

Рис.2.1 Краткий обзор глав

Рис.2.2 Краткий обзор глав
Перейдем к содержанию и особенностям книги.
В первой главе автор начинает с фундаментальных вещей и описывает роли языков программирования и то, как устроен компьютер.
По мне, это можно отнести к положительной стороне книги. Одно дело, когда, не особо вникая, человек покупает много оперативной памяти, мощную видеокарту и процессор с целью, чтобы компьютер «не тормозил» и «тянул» игры. Другое дело, когда вы имеете понимание о том, каким образом данные компоненты взаимодействуют между друг другом.
Всё зависит от ваших целей. Но, раз вы видите себя программистом, то понимание того как работает компьютер — необходимо!
Автор описывает функционал центрального процессора, для чего необходимы компьютеру жесткий диск и оперативная память и в каких случаях они задействуются им.
В следующей главе автор переходит непосредственно к началу описания синтаксиса Python и начинает он это с описания простых программ на нём.
Отличительной и одновременно положительной особенностью книги является крайне подробные объяснения того, что в ней написано.
Автор не ленится и разбирается каждую строчку коду, что и как работает, какой оператор выполняет какую задачу — всё это подробно разжевывается Тони Гэддисом.
Также, что не может не радовать, помимо разбора кода, автор уделяет много внимание программированию как дисциплине, как прикладной области.
Гэддис в подробных деталях рассматривает цикл создания программы, начиная описания проектирования и постепенно переходя непосредственно к написаю кода, тестированию и собственно исправлению найденных ошибок.
Процесс проектирования в книге сопровождается соответствующими блок-схемами
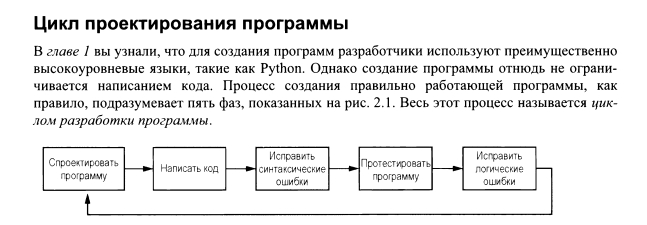
Рис.3 Цикл разработки программы
Теперь поговорим о практической составляющей книге, то , что нас интересует не в последнюю очередь.
Практические задания в книге
Практике в данной книге уделено огромное внимание, что очень радует.
Что по своему также мне понравилось, примеры не просто имеют абстрактные условия, а привязаны к настоящим задачам бизнеса. Рассмотрим, как описаны в книге такие задачи как вычисление розничной цены товара и вычисление зарплаты сотрудника.

Рис.4.1 Пример практической задачи — программа вычисления розничных цен
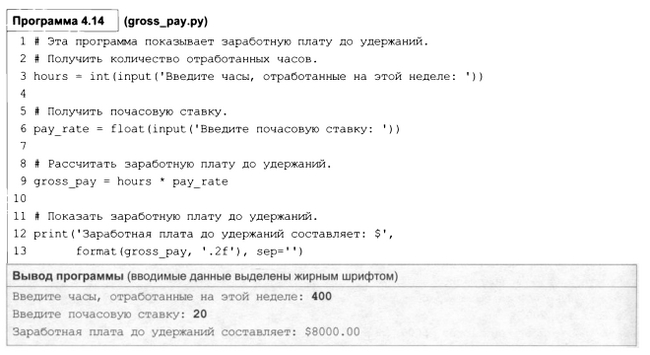
Рис.4.2 Пример практической задачи — программа вычисления заработной платы
Также радует, что Тони Гэддис не забыл о модуле turtle для рисования простейших фигур.
Отработка подобных задач отлично улучшает навыки алгоритмирования, что позволяет прекрасно набить руку в алгоритмах и элементарных операциях.

Рис.4.3 Модуль turtle — черепашья графика
Автор рассматривает те основные возможности Python, что нужны новичку как воздух и компетенция в которых будет его прекрасно отличать от орды тех, кто желает выучить Python по видео «Выучим Python за 1 час»
Рассматриваются в книге типы данных, условия и циклы, функции, работа с файлами, исключения и объектно-ориентированное программирование
Также Гэддис в целой главе описывает рекурсию
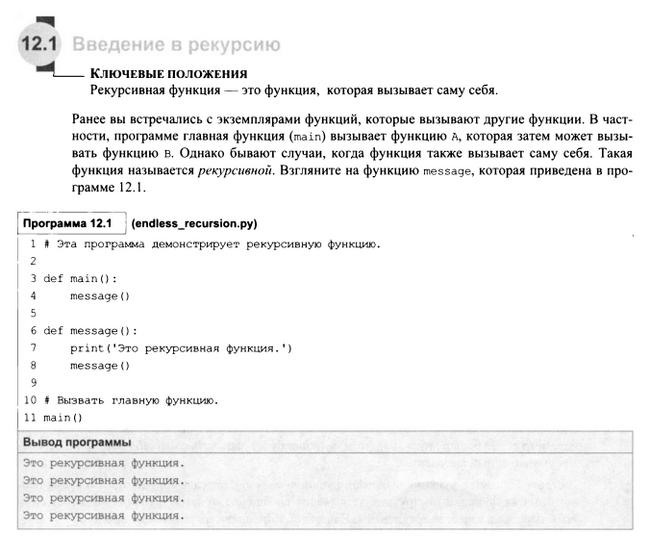
Рис.5 Введение в рекурсию
Отличительной особенностью является русский перевод книги. В оригинале главы об ООП нет, следует инициатива её появления лежит на локализаторах, спасибо вам ребята!
Тезисно по преимуществам и недостаткам книги:
Преимущества книги:
1. Подробные объяснения кода, для тех, кто учит с нуля
Автор не ленится и разбирается каждую строчку коду, что и как работает, какой оператор выполняет какую задачу — всё это подробно разжевывается
2. Автор уделяет много внимание программированию как дисциплине, как прикладной области.
Гэддис в подробных деталях рассматривает цикл создания программы, начиная описания проектирования и постепенно переходя непосредственно к написаю кода, тестированию и собственно исправлению найденных ошибок.
Процесс проектирования в книге сопровождается соответствующими блок-схемами
3. Отработка алгоритмической подготовки
Тони Гэддис не забыл о модуле turtle для рисования простейших фигур.
Отработка подобных задач отлично улучшает навыки алгоритмирования, что позволяет прекрасно набить руку в алгоритмах и элементарных операциях.
Недостатки книги:
1. Качество бумажной книги
Электронную версию книги выложил на канале, скачать её можете здесь
Если же предпочитаете бумажные книги и решите её заказать — внимательно проверяйте то, в каком состоянии придет вам книга.
Мне повезло и мой экземпляр в достаточно добротном состоянии.
Предлагаю оценить то, в каком состоянии пришла книга моему товарищу.

Рис.6.1 Брак обложки

Рис.6.2 Плохая склейка страниц
Данная «особенность» есть и в моем экземпляре к сожалению.
Минус данного издания — плохая склейка. После интенсивной работы книга стала разваливаться по листочку, склеивать бесполезно, книга буквально рассыпается. Может быть, я немного неаккуратно с ней работал, но когда занимаешься с книгой, а не читаешь ее как художественный роман, приходится много ее вертеть, расправлять (так как она толстая), что-то подчеркивать, и переплет должен быть качественным.

Рис.6.3 Разрезаны страницы

Рис.6.4 Разрезаны страницы
Даже не знаю, что происходит на складе, где хранятся партии этой книги. Но чувствую, люди там не скучают)
2. Вторым достаточно существенным недостатком являются опечатки

Изредка встречаются опечатки, но они очень явные и их достаточно легко увидеть.
3. Последним достаточно существенным недостатком является цена
Этим недостатком обладает практически вся техническая и профессиональная литература. Но всё же надеюсь, что в светлом будущем книги станут доступней, а не стоить, как в случае с данной книгой, 15% от среднего МРОТ по стране. Ниже предлагаю ознакомиться с ценной на Wildberries
На OZON эту книгу нашем 4-м издании не смог найти, там нашел только 5-е, но у меня на руках 4-е и о 5-м к сожалению ничего не могу сказать. В буквоеде, читай-городе и лабиринте на сайте также цена не указана
Рис.8 Цена книги на Wildberries
Итог по книге:
На данный момент, наилучшая книга из тех, что я ранее читал тематики «изучить Python с нуля»
Книга для тех, кто желает изучить Python с полного нуля или же кто имеет минимальный опыт работ с ним.
Начинается книга с с самых азов, постепенно углубляясь в каждую из тем. Код разбирается подробно и с более чем понятными объяснениями. Если будете не просто читать, а параллельно писать код и решать все те практические задачи, что представлены в книге — получите максимальную пользу от книги.
Повторюсь, не рассматривайте подобную литературу, как почитать по часу каждый вечер, не вникая и ждать, что вы станете крутым программистом. Только желание вникать в описанные в книге детали и постоянная практика написания кода — даст вам максимальный эффект от книги.
Мой канал в телеграмм
Если статья показалась вам интересной, то буду благодарен за подписку на мой
где я также публикую обзоры технической литературы и полезную информацию как для действующих, так и для начинающих программистов
Строки исходного кода ( SLOC ), также известные как строки кода ( LOC ), представляют собой программную метрику, используемую для измерения размера компьютерной программы путем подсчета количества строк в тексте исходного кода программы . SLOC обычно используется для прогнозирования количества усилий, которые потребуются для разработки программы, а также для оценки производительности программирования или ремонтопригодности после создания программного обеспечения.
Методы измерения
Многие полезные сравнения включают в себя только порядок строк кода в проекте. Использование строк кода для сравнения проекта из 10 000 строк и проекта из 100 000 строк гораздо полезнее, чем при сравнении проекта из 20 000 строк и проекта из 21 000 строк. Хотя вопрос о том, как именно измерять строки кода, является спорным, расхождения на порядок величины могут быть четкими индикаторами сложности программного обеспечения или человеко-часов .
Существует два основных типа показателей SLOC: физический SLOC (LOC) и логический SLOC (LLOC). Конкретные определения этих двух показателей различаются, но наиболее распространенное определение физического SLOC — это количество строк в тексте исходного кода программы, исключая строки комментариев. [1]
Логический SLOC пытается измерить количество исполняемых «операторов», но их конкретные определения привязаны к конкретным компьютерным языкам (одна простая логическая мера SLOC для C- подобных языков программирования — это количество точек с запятой в конце оператора). Намного проще создавать инструменты для измерения физического SLOC, а определения физического SLOC легче объяснить. Однако физические показатели SLOC чувствительны к логически нерелевантным соглашениям о форматировании и стилях, в то время как логический SLOC менее чувствителен к соглашениям о форматировании и стилях. Однако меры SLOC часто указываются без их определения, и логический SLOC часто может значительно отличаться от физического SLOC.
Рассмотрим этот фрагмент кода C как пример неоднозначности, возникающей при определении SLOC:
для ( я = 0 ; я < 100 ; я ++ ) printf ( "привет" ); / * Сколько это строк кода? * /
В этом примере мы имеем:
- 1 физическая строка кода (LOC),
- 2 логические строки кода (LLOC) ( для оператора и оператора printf ),
- 1 строка комментария.
В зависимости от программиста и стандартов кодирования указанная выше «строка» кода может быть записана на многих отдельных строках:
/ * Сколько это строк кода? * / для ( я = 0 ; я < 100 ; я ++ ) { printf ( "привет" ); }
В этом примере мы имеем:
- 4 физических строки кода (LOC): нужно ли оценивать работу расстановки скобок?
- Две логические строки кода (LLOC): как насчет всей работы по написанию строк без инструкций?
- 1 строка комментария: инструменты должны учитывать весь код и комментарии независимо от размещения комментариев.
Даже «логические» и «физические» значения SLOC могут иметь большое количество различных определений. Роберт Э. Парк (в то время как в Институте программной инженерии ) и другие разработали структуру для определения значений SLOC, чтобы люди могли тщательно объяснять и определять меру SLOC, используемую в проекте. Например, большинство программных систем повторно используют код, и определение того, какой (если есть) повторно используемый код включить, важно при составлении отчета о показателе.
Истоки
В то время, когда люди начали использовать SLOC в качестве метрики, наиболее часто используемые языки, такие как FORTRAN и язык ассемблера , были строчно-ориентированными языками. Эти языки были разработаны в то время, когда перфокарты были основной формой ввода данных для программирования. Одна перфокарта обычно представляет собой одну строку кода. Это был один дискретный объект, который легко пересчитать. Это был видимый результат работы программиста, поэтому менеджеры имели смысл считать строки кода мерой производительности программиста, даже имея в виду такие, как « изображения карточек».«. Сегодня наиболее часто используемые компьютерные языки предоставляют гораздо больше возможностей для форматирования. Текстовые строки больше не ограничены 80 или 96 столбцами, и одна строка текста больше не обязательно соответствует одной строке кода.
Использование мер SLOC
Меры SLOC несколько противоречивы, особенно в том смысле, что они иногда используются не по назначению. Эксперименты неоднократно подтверждали, что усилия сильно коррелируют с SLOC [ необходима цитата ]то есть программы с более высокими значениями SLOC требуют больше времени для разработки. Таким образом, SLOC может быть эффективным при оценке усилий. Однако функциональность хуже коррелирует с SLOC: опытные разработчики могут разработать ту же функциональность с гораздо меньшим количеством кода, поэтому одна программа с меньшим количеством SLOC может демонстрировать больше функциональности, чем другая аналогичная программа. Подсчет SLOC как показателя производительности имеет свои недостатки, поскольку разработчик может разработать только несколько строк и при этом быть гораздо более продуктивным с точки зрения функциональности, чем разработчик, который в итоге создает больше строк (и обычно затрачивает больше усилий). Хорошие разработчики могут объединить несколько модулей кода в один модуль, улучшая систему, но при этом снижая производительность, поскольку они удаляют код. Кроме того, неопытные разработчики часто прибегают к дублированию кода., который крайне не рекомендуется, поскольку он более подвержен ошибкам и требует больших затрат в обслуживании, но приводит к более высокому SLOC.
Подсчет SLOC вызывает дополнительные проблемы с точностью при сравнении программ, написанных на разных языках, если для нормализации языков не применяются поправочные коэффициенты. Различные компьютерные языки по-разному уравновешивают краткость и ясность; В качестве крайнего примера, большинству языков ассемблера потребуются сотни строк кода для выполнения той же задачи, что и несколько символов в APL . В следующем примере показано сравнение программы «hello world», написанной на C , и той же программы, написанной на COBOL — языке, который известен своей особенно многословностью.
| C | КОБОЛ |
|---|---|
#include <stdio.h> int main () { printf ( " n Привет, мир n " ); } |
идентификационное подразделение . идентификатор программы . привет . процедурное деление . показать "привет, мир" вернуться . конец программы привет . |
| Строки кода: 4 (без пробелов) |
Строк кода: 6 (без пробелов) |
Другой все более распространенной проблемой при сравнении показателей SLOC является разница между автоматически сгенерированным и написанным вручную кодом. Современные программные инструменты часто имеют возможность автоматически генерировать огромные объемы кода с помощью нескольких щелчков мыши. Например, построители графического пользовательского интерфейса автоматически генерируют весь исходный код для графических элементов управления, просто перетаскивая значок в рабочее пространство. Работа, связанная с созданием этого кода, не может разумно сравниваться с работой, необходимой, например, для написания драйвера устройства. Точно так же, созданный вручную пользовательский класс GUI может быть более требовательным, чем простой драйвер устройства; отсюда и недостаток этой метрики.
Существует несколько моделей оценки затрат, графика и усилий, которые используют SLOC в качестве входного параметра, включая широко используемую серию моделей конструктивной модели затрат ( COCOMO ) Барри Боэма и др., PRICE Systems True S и SEER-SEM от Galorath . Хотя эти модели показали хорошую предсказательную силу, их качество зависит от предоставленных им оценок (особенно оценок SLOC). Многие [2] выступали за использование функциональных точек вместо SLOC в качестве меры функциональности, но поскольку функциональные точки сильно коррелированы с SLOC (и не могут быть измерены автоматически), это не универсальная точка зрения.
Пример
По словам Винсента Maraia, [3] значения SLOC для различных операционных систем в Microsoft «s Windows NT линейки продуктов заключаются в следующем:
| Год | Операционная система | SLOC (млн.) |
|---|---|---|
| 1993 г. | Windows NT 3.1 | 4–5 [3] |
| 1994 г. | Windows NT 3.5 | 7–8 [3] |
| 1996 г. | Windows NT 4.0 | 11–12 [3] |
| 2000 г. | Windows 2000 | более 29 [3] |
| 2001 г. | Windows XP | 45 [4] [5] |
| 2003 г. | Windows Server 2003 | 50 [3] |
Дэвид А. Уиллер изучил дистрибутив Red Hat операционной системы Linux и сообщил, что Red Hat Linux версии 7.1 [6] (выпущенной в апреле 2001 г.) содержит более 30 миллионов физических SLOC. Он также экстраполировал, что, если бы он был разработан обычными собственными средствами, он потребовал бы около 8000 человеко-лет разработки и стоил бы более 1 миллиарда долларов (в долларах США 2000 года).
Позже аналогичное исследование было проведено для Debian GNU / Linux версии 2.2 (также известного как «Potato»); эта операционная система была первоначально выпущена в августе 2000 года. Это исследование показало, что Debian GNU / Linux 2.2 включает более 55 миллионов SLOC, и, если бы разработка производилась обычным частным способом, потребовалось бы 14 005 человеко-лет и 1,9 миллиарда долларов США на разработку. Более поздние прогоны использованных инструментов сообщают, что в следующем выпуске Debian было 104 миллиона SLOC, а по состоянию на 2005 год последний выпуск будет включать более 213 миллионов SLOC.
| Год | Операционная система | SLOC (млн.) |
|---|---|---|
| 2000 г. | Debian 2.2 | 55–59 [7] [8] |
| 2002 г. | Debian 3.0 | 104 [8] |
| 2005 г. | Debian 3.1 | 215 [8] |
| 2007 г. | Debian 4.0 | 283 [8] |
| 2009 г. | Debian 5.0 | 324 [8] |
| 2012 г. | Debian 7.0 | 419 [9] |
| 2009 г. | OpenSolaris | 9,7 |
| FreeBSD | 8,8 |
|
| 2005 г. | Mac OS X 10.4 | 86 [10] [n 1] |
| 1991 г. | Ядро Linux 0.01 | 0,010239 |
| 2001 г. | Ядро Linux 2.4.2 | 2,4 [6] |
| 2003 г. | Ядро Linux 2.6.0 | 5.2 |
| 2009 г. | Ядро Linux 2.6.29 | 11.0 |
| 2009 г. | Ядро Linux 2.6.32 | 12,6 [11] |
| 2010 г. | Ядро Linux 2.6.35 | 13,5 [12] |
| 2012 г. | Ядро Linux 3.6 | 15,9 [13] |
| 2015-06-30 | Ядро Linux до 4.2 | 20,2 [14] |
Утилита
Преимущества
- Возможности автоматизации подсчета: поскольку строка кода является физическим объектом, ручные подсчеты можно легко исключить, автоматизируя процесс подсчета. Для подсчета LOC в программе могут быть разработаны небольшие утилиты. Однако утилита подсчета логического кода, разработанная для определенного языка, не может использоваться для других языков из-за синтаксических и структурных различий между языками. Однако были произведены физические счетчики LOC, которые учитывают десятки языков.
- Интуитивная метрика: строка кода служит интуитивной метрикой для измерения размера программного обеспечения, потому что ее можно увидеть, а эффект от нее можно визуализировать. Функциональные точки считаются скорее объективной метрикой, которую нельзя представить как физическую сущность, она существует только в логическом пространстве. Таким образом, LOC пригодится, чтобы выразить размер программного обеспечения среди программистов с низким уровнем опыта.
- Повсеместная мера: меры LOC используются с первых дней появления программного обеспечения. [15] Таким образом, можно утверждать, что доступно больше данных LOC, чем любой другой показатель размера.
Недостатки
- Отсутствие подотчетности: мера по строкам кода страдает некоторыми фундаментальными проблемами. Некоторые [ кто? ] считают, что бесполезно измерять продуктивность проекта, используя только результаты этапа кодирования, на который обычно приходится от 30% до 35% общих усилий. [ необходима цитата ]
- Отсутствие согласованности с функциональностью: хоть эксперименты [ кем? ] неоднократно подтверждали, что, хотя усилия сильно коррелируют с LOC, функциональность хуже коррелирует с LOC. То есть опытные разработчики могут разработать ту же функциональность с гораздо меньшим количеством кода, поэтому одна программа с меньшим LOC может демонстрировать больше функциональности, чем другая аналогичная программа. В частности, LOC — плохой показатель продуктивности людей, потому что разработчик, который разрабатывает только несколько строк, может быть более продуктивным, чем разработчик, создающий больше строк кода — даже больше: некоторый хороший рефакторинг, такой как «метод извлечения», чтобы избавиться от него. избыточный код и его чистота в основном уменьшают количество строк кода.
- Неблагоприятное влияние на оценку: из-за факта, представленного в пункте № 1, оценки, основанные на строчках кода, при любой возможности могут оказаться неверными.
- Опыт разработчика: реализация определенной логики зависит от уровня опыта разработчика. Следовательно, количество строк кода отличается от человека к человеку. Опытный разработчик может реализовать определенные функции в меньшем количестве строк кода, чем другой разработчик с относительно меньшим опытом, хотя они используют тот же язык.
- Разница в языках: рассмотрим два приложения, которые предоставляют одинаковые функции (экраны, отчеты, базы данных). Одно из приложений написано на C ++, а другое — на таком языке, как COBOL. Количество функциональных точек будет точно таким же, но аспекты приложения будут другими. Строки кода, необходимые для разработки приложения, определенно не будут такими же. Как следствие, количество усилий, необходимых для разработки приложения, будет другим (часов на функциональную точку). В отличие от строк кода, количество функциональных точек останется постоянным.
- Появление инструментов с графическим интерфейсом : с появлением языков программирования и инструментов на основе графического интерфейса пользователя, таких как Visual Basic , программисты могут писать относительно небольшой код и достигать высоких уровней функциональности. Например, вместо того, чтобы писать программу для создания окна и рисования кнопки, пользователь с графическим интерфейсом пользователя может использовать перетаскивание и другие операции с мышью для размещения компонентов в рабочей области. Код, который автоматически генерируется инструментом GUI, обычно не принимается во внимание при использовании методов измерения LOC. Это приводит к различиям между языками; та же задача, которая может быть выполнена в одной строке кода (или вообще без кода) на одном языке, может потребовать нескольких строк кода на другом.
- Проблемы с несколькими языками: в сегодняшнем сценарии программного обеспечения программное обеспечение часто разрабатывается на нескольких языках. Очень часто используется несколько языков в зависимости от сложности и требований. Отслеживание и отчетность о производительности и дефектах представляет собой серьезную проблему в этом случае, поскольку дефекты не могут быть отнесены к конкретному языку после интеграции системы. Функциональная точка в этом случае является лучшим средством измерения размера.
- Отсутствие стандартов подсчета: нет стандартного определения того, что такое строка кода. Учитываются ли комментарии? Включены ли декларации данных? Что произойдет, если оператор растянется на несколько строк? — Это вопросы, которые часто возникают. Хотя такие организации, как SEI и IEEE, опубликовали некоторые руководящие принципы в попытке стандартизировать подсчет, их трудно применить на практике, особенно в связи с тем, что с каждым годом вводятся все новые и новые языки.
- Психология: программист, продуктивность которого измеряется строками кода, будет иметь стимул писать излишне подробный код. Чем больше руководство сосредотачивается на строках кода, тем больше у программиста стимула расширять свой код ненужной сложностью. Это нежелательно, поскольку повышенная сложность может привести к увеличению затрат на обслуживание и увеличению усилий, необходимых для исправления ошибок.
В документальном фильме PBS « Триумф ботаников» исполнительный директор Microsoft Стив Баллмер раскритиковал использование подсчета строк кода:
В IBM есть религия в программном обеспечении, которая гласит, что нужно считать K-LOC, а K-LOC — это тысяча строк кода. Насколько велик это проект? О, это своего рода проект 10K-LOC. Это 20K-LOCer. А это 50K-LOC. И IBM хотела сделать религию в отношении того, как нам платят. Сколько денег мы заработали на OS / 2 , сколько они сделали. Сколько K-LOC вы сделали? И мы продолжали убеждать их — эй, если у нас есть — у разработчика есть хорошая идея, и он может что-то сделать в 4K-LOC вместо 20K-LOC, должны ли мы зарабатывать меньше денег? Потому что он сделал что-то меньшее и быстрое, без K-LOC. K-LOCs, K-LOCs, это методология. Фу! В любом случае, от этой мысли у меня всегда морщится спина.
По данным Музея компьютерной истории, разработчик Apple Билл Аткинсон в 1982 году обнаружил проблемы с этой практикой:
Когда в 1982 году команда Lisa настаивала на доработке своего программного обеспечения, менеджеры проектов начали требовать от программистов еженедельно сдавать формы с отчетом о количестве написанных ими строк кода. Билл Аткинсон подумал, что это глупо. За неделю, в течение которой он переписал процедуры вычисления области QuickDraw, чтобы они были в шесть раз быстрее и на 2000 строк короче, он поставил в форму «-2000». Еще через несколько недель менеджеры перестали просить его заполнять форму, и он с радостью выполнил. [16] [17]
- KLOC KAY -lok : 1000 строк кода
- KDLOC: 1000 доставленных строк кода
- KSLOC: 1000 строк исходного кода
- MLOC: 1000000 строк кода
- GLOC: 1 000 000 000 строк кода
См. Также
- Оценка усилий по разработке программного обеспечения
- Оценка (управление проектом)
- Оценка затрат в программной инженерии
Заметки
- ^ Возможно, включая весь пакет iLife, а не только операционную систему и обычно связанные приложения.
Ссылки
- ^ Ву Нгуен; София Дидс-Рубин; Томас Тан; Барри Бём (2007), Стандарт подсчета SLOC (PDF) , Центр системной и программной инженерии, Университет Южной Калифорнии
- ^ IFPUG «Количественная оценка преимуществ использования функциональных точек»
- ^ a b c d e f «Сколько строк кода в Windows?» ( Научный поиск ) . Зная .NET. 6 декабря 2005 . Проверено 30 августа 2010 .
Это, в свою очередь, цитирует « Мастера сборки» Винсента Марайи в качестве источника информации. - ^ «Сколько строк кода в Windows XP?» . Microsoft. 11 января 2011 г.
- ^ «История Windows — Microsoft Windows» . 2012-09-21. Архивировано из оригинала на 2012-09-21 . Проверено 26 марта 2021 .
- ^ a b Дэвид А. Уиллер (30 июня 2001 г.). «Больше, чем гигабак: оценка размера GNU / Linux» .
- ^ Гонсалес-Бараона, Хесус М .; Мигель А. Ортуньо Перес; Педро де лас Эрас Кирос; Хосе Сентено Гонсалес; Висенте Мателлан Оливера. «Подсчет картошки: размер Debian 2.2» . debian.org . Архивировано из оригинала на 2008-05-03 . Проверено 12 августа 2003 .
- ^ a b c d e Роблес, Грегорио. «Подсчет Debian» . Архивировано из оригинала на 2013-03-14 . Проверено 16 февраля 2007 .
- ^ Debian 7.0 был выпущен в мае 2013 года. Это приблизительное число, опубликованное 13 февраля 2012 года с использованием базы кода, которая впоследствии станет Debian 7.0, с использованием того же программного метода, что и для данных, опубликованных Дэвидом А. Уилером. Джеймс Бромбергер. «Debian Wheezy: 19 миллиардов долларов. Ваша цена … БЕСПЛАТНО!» . Архивировано из оригинала на 2014-02-23 . Проверено 7 февраля 2014 .
- ↑ Джобс, Стив (август 2006 г.). «Прямой эфир с WWDC 2006: основной доклад Стива Джобса» . Проверено 16 февраля 2007 .
86 миллионов строк исходного кода, который был перенесен на совершенно новую архитектуру без сбоев.
- ^ Торстен Leemhuis (2009-12-03). «Что нового в Linux 2.6.32» . Архивировано 19 декабря 2013 года . Проверено 24 декабря 2009 .
- ^ Greg Kroah-Хартман; Джонатан Корбет; Аманда Макферсон (апрель 2012 г.). «Разработка ядра Linux: насколько быстро она идет, кто это делает, что они делают и кто это спонсирует» . Фонд Linux . Проверено 10 апреля 2012 .
- ^ Торстен Leemhuis (2012-10-01). «Резюме, прогноз, статистика — The H Open: новости и возможности» . Архивировано 19 декабря 2013 года.
- ^ http://heise.de/-2730780
- ^ IFPUG «Краткая история метрик строк кода (loc)»
- ^ «Исходный код MacPaint и QuickDraw» . CHM . 2010-07-18 . Проверено 15 апреля 2021 .
- ^ «Folklore.org: -2000 строк кода» . www.folklore.org . Проверено 15 апреля 2021 .
Дальнейшее чтение
- Ли, Ло; Хербслеб, Джим; Шоу, Мэри (май 2005). Прогнозирование количества дефектов в полевых условиях с использованием комбинированного подхода, основанного на времени и показателях, на примере OpenBSD (CMU-ISRI-05-125) . Университет Карнеги Меллон.
- МакГроу, Гэри (март – апрель 2003 г.). «С нуля: семинар по безопасности программного обеспечения DIMACS» . Безопасность и конфиденциальность IEEE . 1 (2): 59–66. DOI : 10.1109 / MSECP.2003.1193213 .
- Парк, Роберт Э .; и другие. «Измерение размера программного обеспечения: основа для подсчета исходных утверждений» . Технический отчет CMU / SEI-92-TR-20 .
Внешние ссылки
- Определения практических исходных строк стандартных метрик ресурсов кода (RSM) определяет «эффективные строки кода» как реалистичную метрику кода, независимую от стиля программирования.
- Эффективные строки кода Метрики eLOC для популярного программного обеспечения с открытым исходным кодом Linux Kernel 2.6.17, Firefox, Apache HTTPD, MySQL, PHP с использованием RSM.
- Уиллер, Дэвид А. «SLOCCount» . Проверено 12 августа 2003 .
- Уилер, Дэвид А. (июнь 2001 г.). «Подсчет исходных строк кода (SLOC)» . Проверено 12 августа 2003 .
- Таненбаум, Эндрю С. Современные операционные системы (2-е изд.). Прентис Холл. ISBN 0-13-092641-8 .
- Ховард Дахда (24 января 2007 г.). «Таненбаум излагает свое видение ОС, защищенной от бабушек» . Архивировано из оригинала на 2007-01-27 . Проверено 29 января 2007 .
- CM Lott: инструменты сбора метрик для исходного кода C и C ++
- Folklore.org: Истории о Macintosh: 2000 строк кода