В Windows по умочанию используется кодировка символов CP1251, чем иногда доставляет проблем пользователям других, нормальных ОС, которые давно перешли на юникод и забыли о проблемах с кодировками как страшный сон. Но пользователи Windows как американцы, не знают, что существуют другие страны ОС и сохраняют субтитры в CP1251 что делает их нечитабельными для других.
Для решения этой проблемы есть iconv который как раз и служит для перекодировки текстовых файлов из одной кодировки в другую. Во всех почти дистрибутивах данный пакет устанавливается по умолчанию, но если его вдруг не оказалось — установите его с помощью вашего пакетного менеджера.
Для перекодировки достаточно ввести всего одну команду в терминале, а именно:
iconv -f cp1251 -t utf8 /Video/somefile.srt -o /Video/subtitles.srt
Поясню: ключ «f» задает исходную кодировку в которой файл находится сейчас, ключ «t» указывает целевую кодировку, ключ «o» задает путь для сохранения перекодированного файла.
Вот, все очень просто. Так же вы можете таким образом кодировать любые текстовые файлы. Часто и тексты песен попадаются с такой неприятной особенностью.
Недавно узнал более простой и понятный способ перекодировки текстовых файлов — с помощью enconv.
Не буду приводить полного синтаксиса и описания всех ключей. Для перекодировки достаточно одного, например:
enconv -x UTF-8 somefile.txt
С помощью данной команды мы перегнали текст в UTF-8. Да, именно, просто перегнали без необходимости указания исходной кодировки. Все просто, указываем лишь ту которую хотим получить. Желательно сделать резервную копию файла, так как насколько я понял enconv’у нельзя задать выходной файл и изменяться кодировка будет прямо в исходном файле.
Если у кого то есть еще какие то методы перекодировки текстовых файлов — прошу в каменты.
The Linux administrators that work with web hosting know how is it important to keep correct character encoding of the html documents.
From the following article you’ll learn how to check a file’s encoding from the command-line in Linux.
You will also find the best solution to convert text files between different charsets.
I’ll also show the most common examples of how to convert a file’s encoding between CP1251 (Windows-1251, Cyrillic), UTF-8, ISO-8859-1 and ASCII charsets.
Cool Tip: Want see your native language in the Linux terminal? Simply change locale! Read more →
Use the following command to check what encoding is used in a file:
$ file -bi [filename]
| Option | Description |
|---|---|
-b, --brief |
Don’t print filename (brief mode) |
-i, --mime |
Print filetype and encoding |
Check the encoding of the file in.txt:
$ file -bi in.txt text/plain; charset=utf-8
Change a File’s Encoding
Use the following command to change the encoding of a file:
$ iconv -f [encoding] -t [encoding] -o [newfilename] [filename]
| Option | Description |
|---|---|
-f, --from-code |
Convert a file’s encoding from charset |
-t, --to-code |
Convert a file’s encoding to charset |
-o, --output |
Specify output file (instead of stdout) |
Change a file’s encoding from CP1251 (Windows-1251, Cyrillic) charset to UTF-8:
$ iconv -f cp1251 -t utf-8 in.txt
Change a file’s encoding from ISO-8859-1 charset to and save it to out.txt:
$ iconv -f iso-8859-1 -t utf-8 -o out.txt in.txt
Change a file’s encoding from ASCII to UTF-8:
$ iconv -f utf-8 -t ascii -o out.txt in.txt
Change a file’s encoding from UTF-8 charset to ASCII:
Illegal input sequence at position: As UTF-8 can contain characters that can’t be encoded with ASCII, the iconv will generate the error message “illegal input sequence at position” unless you tell it to strip all non-ASCII characters using the -c option.
$ iconv -c -f utf-8 -t ascii -o out.txt in.txt
| Option | Description |
|---|---|
-c |
Omit invalid characters from the output |
You can lose characters: Note that if you use the iconv with the -c option, nonconvertible characters will be lost.
Very common situation for ones who work inside the both Windows and Linux machines.
This concerns in particular Windows machines with Cyrillic.
You have copied some file from Windows to Linux, but when you open it in Linux, you see “Êàêèå-òî êðàêîçÿáðû” – WTF!?
Don’t panic – such strings can be easily converted from CP1251 (Windows-1251, Cyrillic) charset to UTF-8 with:
$ echo "Êàêèå-òî êðàêîçÿáðû" | iconv -t latin1 | iconv -f cp1251 -t utf-8 Какие-то кракозябры
List All Charsets
List all the known charsets in your Linux system:
$ iconv -l
| Option | Description |
|---|---|
-l, --list |
List known charsets |
13 Nov 2016 | Автор: dd |
Перевозил тут пачку сайтов с LAMP на LNAMP, где фронтэндом выступает NGINX. И все бы ничего, если бы не пачка статических сателлитов в кодировке Windows-1251 (cp1251).
Как тут прикололся девака – при анализе сайта, надо сначала чекать кодировку и в случае обнаружения кодировки сайта cp1251 – проверку возраста можно не осуществлять. Но, тем не менее, в инетах до сих пор встречаются такие мастадонты, которые клепают сайты в кодировке CP1251.
Под апачем, при добавлении сайта в ISP Panel это даже не заметишь, а вот при попытке добавить этот же сайт в Vesta CP, получаешь гемор на задницу с крикозябрами. Поэтому надо редактировать конфиг Nginx, предварительно прикрутив туда виндовую кодировку. Но, насколько я помню, у меня этот танец с бубнами не задался и в тот раз, я просто повесил саты на LAMP.
Так что оставалось либо плясать с бубнами вокруг прикручивания виндовой кодировки к NGINX, либо перекодивать файлы в родную для нжинкса UTF-8. Сделать это можно средствами текстового редактора Notepad++ путем перевода кодировки документа и последующего сохранения; либо же в самом линухе. Как я выше заметил, саты статические, то есть на файлах, без использования базы данных. Поэтому перекодировать надо было именно файлы. С базой данных все происходило бы несколько иначе.
Перекодировка файла из CP1251 в UTF-8 производится в консоли через команду iconv
# iconv -f cp1251 -t utf8 FILE-CP1251 -o FILE-UTF8
либо же можно переписать файл в самого себя
# iconv -f cp1251 -t utf8 file.txt -o file.txt
Но поскольку мне надо было перекодировать большое число файлов php, содержащихся в разных папках, то мне пришлось составить небольшое предложение:
# find /path-to-files/ -type f -name *php -exec iconv -f cp1251 -t utf-8 '{}' -o '{}' ;
Конвертит все в лет.
Для конвертации кодировок есть еще утилита enconv, входящая в состав пакета enca – вот он как раз конвертит сам в себя по умолчанию, перезаписывая файл выходной кодировкой:
# enconv -c file.txt
но, к сожалению, я его не смог подружить с русским языком, т.к даже при указании языка через ключик -L russian скрипт матерился на ошибки. Но с другой стороны, все нормально решилось и через iconv
Rating: 4.4/10 (21 votes cast)
Rating: +1 (from 3 votes)
Смена кодировки сайта из CP1251 на UTF-8, 4.4 out of 10 based on 21 ratings
Теги: centos, сайты
Перекодировка текста в Linux. Синтаксис программы iconv
Время создания: 27.04.2019 09:19
Текстовые метки: linux, iconv, bash, кодировка, перекодировка, конвертирование, кракозябры, cp1251, koi8-r, UTF-8
Раздел: Компьютер — Linux — Bash — Кодировки и локализация
Запись: xintrea/mytetra_syncro/master/base/0000001210/text.html на raw.github.com
Программа iconv служит для переконвертирования файлов из одной кодировки в другую.
Узнать, какие кодировки доступны, можно командой
iconv —list
Наиболее часто используемые кодировки — CP1251, KOI8-R, UTF-8, UTF-16.
Синтаксис команды следующий
iconv -f KOI8-R -t CP1251 file.txt
— эта команда будет перекодировать файл file.txt из KOI8-R в CP1251, и результат будет выводить в консоль.
iconv -f KOI8-R -t CP1251 file.txt -o outfile.txt
— эта команда будет перекодировать файл file.txt в файл outfile.txt.
Внимание! В качестве выходного файла нельзя указывать исходный файл, так как в этом случае исходный файл будет обнулен. Для того чтобы переконвертировать файл, не создавая новый файл, можно использовать команду вида
iconv -f KOI8-R -t CP1251 file -o tmpfile && mv tmpfile file
Пример скрипта, который переконвертирует файлы в директории и её поддиректориях:
f=`find . -name *.cpp -or -name *.c -or -name *.h`
for file in $f
do
iconv -f KOI8-R -t UTF8 $file -o tmpfile && mv tmpfile $file
done
На чтение 6 мин. Просмотров 1.2k. Опубликовано 15.12.2019
Давно в категории «Ubuntu» у меня не было материалов. Сегодня я исправлюсь и выпущу сразу две статьи. Итак, начнём. вам приходилось менять кодировку текстовых файлов в linux’e? А что если объем такого файла больше 10 Gb?!
Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку, а в этом нам поможет команда:
Ну а далее вот такие действия:
iconv -f WINDOWS-1251 -t UTF-8 -o output_file.txt original_file.txt
- -f WINDOWS-1251 — исходная кодировка,
- -t UTF-8 — конечная
- -o output_file.txt — куда выводить результат
- original_file.txt — исходный файл
Остальные ключики как обычно в man iconv.
Содержание
- iconv и большие файлы
- Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
iconv и большие файлы
Для быстрого выполнения процесса кодировки, iconv загружает файл в оперативную память и в swap. Но это работает только для небольших файлов. Если файл уж совсем большой, а ОЗУ не особо, то вы прост получите ошибку, мол «слишком большой файл», звиняйте хлопцы. Где взять такой файл? К примеру это может быть выборка из БД ( игры для ipad, PC, PSP или другие данные)
Вот здесь предлагают различные решения данного вопроса: и скриптами, и разбивка на части, вывод в потоки, а потом обратно сборка в файл. Лично мне понравилось весьма простое решение: команда split — она позволяет разбить текстовый файл на более мелкие, а дальше с ними работать как угодно можно.
В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить:
Это самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла.
К сожалению ни в gEdit, ни в Leafpad я не нашёл функции, которая бы могла сказать в какой кодировке находится файл. Но на выручку, как всегда приходить консоль:
file -i file.txt
Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
�� Тоже недавно наткнулся на этот совет.. Обязательно поможет кому нибудь…
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
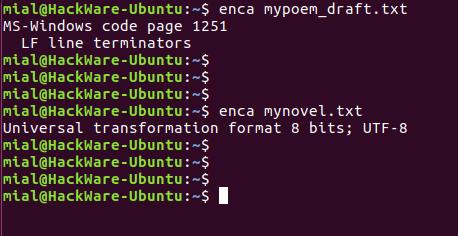
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
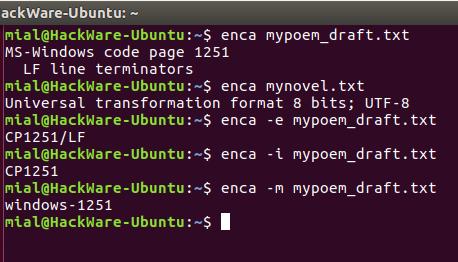
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
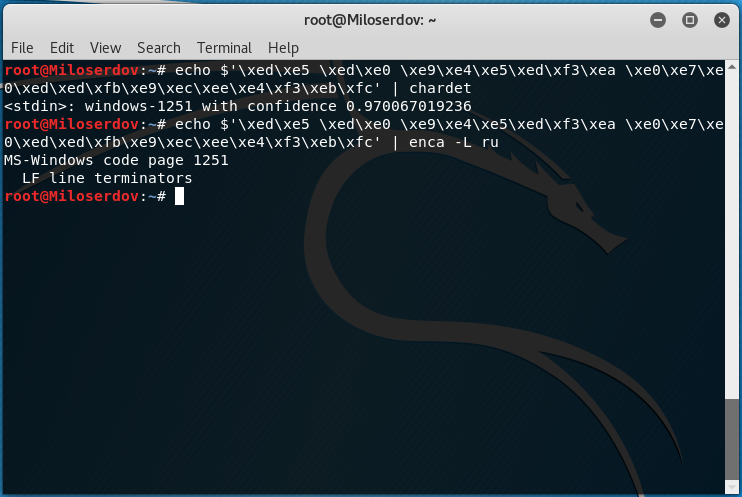
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
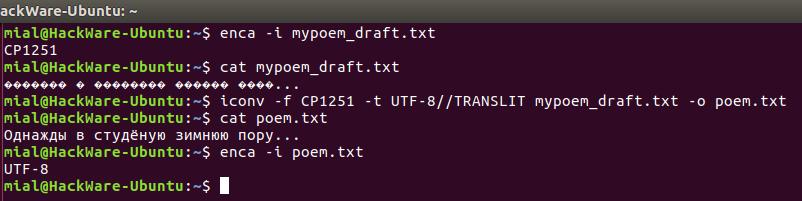
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
 Иногда, я бы даже сказал достаточно часто приходится заниматься перекодировкой файлов или названий файлов в ОС Unix. Хорошо когда у вас есть графический интерфейс и редактор типа kate, который позволяет без проблем конвертировать кодировки файлов. А если надо перекодировать название файлов? Или перекодировать само содержание файлов без графического интерфейса? Тут уже в помощь приходят команды Unix. И поверьте, набрать команду в консоле намного быстрее чем запускать какие-то редакторы кодировок и графические перекодировщики. А если для наиболее популярных перекодировок файлов написать исполняемые файлы с названием типа win2utf, то жизнь за консолью вам покажется очень простой 🙂
Иногда, я бы даже сказал достаточно часто приходится заниматься перекодировкой файлов или названий файлов в ОС Unix. Хорошо когда у вас есть графический интерфейс и редактор типа kate, который позволяет без проблем конвертировать кодировки файлов. А если надо перекодировать название файлов? Или перекодировать само содержание файлов без графического интерфейса? Тут уже в помощь приходят команды Unix. И поверьте, набрать команду в консоле намного быстрее чем запускать какие-то редакторы кодировок и графические перекодировщики. А если для наиболее популярных перекодировок файлов написать исполняемые файлы с названием типа win2utf, то жизнь за консолью вам покажется очень простой 🙂
Перекодировка названий файлов
В данном примере приведу перекодировку из UTF8 в KOI8-R.
Скачиваем и устанавливаем программу convmv. Если в вашем репозитории данного пакета не обнаружилось, то скачать исходники можно отсюда.
Переходим в каталог, где нам надо изменить название файлов и вводим команду
convmv -t KOI8-R -f UTF-8 *Смотрим что получилось:
./downloads/Сборник песен - Братушки подводники# ./convmv -t KOI8-R -f UTF-8 *
Starting a dry run without changes...
mv "./п═п╣п╩п╦пЁп╦я▐ п©п╬п╢п╡п╬п╢п╫п╦п╨п╟.mp3" "./Религия подводника.mp3"
mv "./п▓ п╠п╟п╥я┐.mp3" "./В базу.mp3"
Если после выполнения команды можно прочесть название файлов, тогда делаем окончательную перекодировку, добавляя в конец команды “–notest”. Сделано это для того чтобы пользователь еще больше не закодировал итак непонятные символы. А вдруг вы ошиблись в исходной или конечной кодировке?
Теперь команда будет выглядеть
convmv -t KOI8-R -f UTF-8 *--notestЕсли надо перекодировать рекурсивно каталоги, то добавляем в строку ключик -r и тогда можно за один проход перекодировать всю директорию с вложенными папками и подпапками. Остальные ключи программы можно посмотреть через команду
convmv --helpПерекодировка содержимого файлов
Чтобы не использовать графические редакторы можно использовать консольную программу перекодировщик, например такую как recode. Я считаю, что данная программа имеет очень логичный интерфейс и достаточно хорошо справляется с возложенной на нее задачей. Сначала установим программу recode, т.к. данная программа не входит в обязательный набор программ многих дистрибутивов.
Вот пример перекодировки файла из кодировки windows 1251 в utf8.
recode windows1251..utf8 <имя файла>Опасность действий с recode поджидает тех, кто невнимателен, т.к. содержимое файла изменяется сразу же после команды. Заранее делайте копию перекодируемого файла, или делайте обратную перекодировку в том случае если ошиблись.
Также для перекодировки содержимого файла можно использовать команду iconv. Синтаксис данной команды немного посложнее. Пример перекодировки из windows 1251 в utf8.
iconv -c -f windows-1251 -t UTF-8 имя_исходного_файла > имя_нового_файлаОбратите внимание на то, что в команде recode надо использовалась указание кодировки windows1251 слитно, а в iconv надо писать через дефис.
Преимущество команды iconv в том, что она есть почти в каждом дистрибутиве unix и возможность создать новый выходной файл.
Ну и напоследок приведу пример скрипта, с помощью которого можно перекодировать название файлов из koi8r в utf8 с помощью recode.
#!/bin/sh
IFS=$'n'
for x in `ls`
do
echo $x
mv "$x" `echo $x | recode koi8r..u8`
done
Перекодировка содержимого файла в транслит
Инсталлируем пакет yudit. Из всего пакета нам потребуется только утилита uniconv. Данная утилита имеет не совсем привычный синтаксис, но вполне подойдет для наших целей если задействовать вокруг неё команды unix
cat ./readme_koi8r | uniconv -decode koi8-r -encode Russian-Translit > ./readme_translitНа выходе получаем файл с латиницей, а входной файл был в кодировке KOI8-R.
Многие действия команд convmv, recode, iconv и uniconv имеют много общего и фактически делают одно и то же. Так что используйте их в зависимости от вашего настроения и ситуации. И не забывайте про составление скриптов из этих команд.
Похожие статьи:
 Однажды банально возникла задача поменять кодировку файла с Windows CP-1251 на UTF-8 посредством консоли. Как правило, задача возникает при работе с двумя системами windows и linux. Объяснение этому простое, windows предпочитает работать с текстовыми файлами в кодировке CP-1251, а linux в свою очередь использует кодировку UTF-8. Способов смены кодировки файла оказалось множество, опишу тот, который приглянулся мне.
Однажды банально возникла задача поменять кодировку файла с Windows CP-1251 на UTF-8 посредством консоли. Как правило, задача возникает при работе с двумя системами windows и linux. Объяснение этому простое, windows предпочитает работать с текстовыми файлами в кодировке CP-1251, а linux в свою очередь использует кодировку UTF-8. Способов смены кодировки файла оказалось множество, опишу тот, который приглянулся мне.
Существует такая утилита как enconv, она входит в состав пакета enca, который в свою очередь упрощает работу с кодировками файлов.
Итак, для начала неплохо бы узнать, в какой кодировке файл:
# file -i file.txt
Или так
# enca file.txt
Узнав исходную кодировку файла, меняем её с помощью команды:
# iconv -f cp1251 -t utf8 исходный.txt -o конечный.txt
Есть способ, при котором программа сама определит кодировку файла, и преобразует её к кодировке текущей локали:
# enconv file.txt
Преобразовать файл, в кодировку отличную от текущей локали, можно добавив параметр -x:
# enconv -x CP1251 file.txt
Итак, полагаю эта заметка пригодиться в работе, в частности лицам, которым приходиться работать с консолью linux.
Возникла задача поменять кодировку файла с Windows
CP-1251 на UTF-8 посредством консоли.
Как правило, задача возникает при
работе с двумя системами windows и linux. Объяснение этому простое,
windows предпочитает работать с текстовыми файлами в кодировке CP-1251, а
linux в свою очередь использует кодировку UTF-8. Способов смены
кодировки файла оказалось множество, опишу тот, который быстрый и простой.
Существует такая утилита как enconv, она входит в состав пакета enca, который в свою очередь упрощает работу с кодировками файлов.
Итак, для начала неплохо бы узнать, в какой кодировке файл:
~$ file -i file.txt
или так
~$ enca file.txt
Узнав исходную кодировку файла, меняем её с помощью команды:
~$ iconv -f cp1251 -t utf8 file.txt -o newfile.txt
Есть способ, при котором программа сама определит кодировку файла, и преобразует её к кодировке текущей локали:
~$ enconv file.txt
Преобразовать файл, в кодировку отличную от текущей локали, можно добавив параметр -x:
~$ enconv -x CP1251 file.txt
=====
Удачи.
$ file -i file.txt
file.txt: text/plain; charset=us-asciiДавно в категории «Ubuntu» у меня не было материалов. Сегодня я исправлюсь и выпущу сразу две статьи. Итак, начнём. вам приходилось менять кодировку текстовых файлов в linux’e? А что если объем такого файла больше 10 Gb?!
Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку
Как узнать кодировку файла в Linux
В этом нам поможет команда file:
$ file file.txt
file.txt: ASCII text, with no line terminators
Но лучше сразу с ключом -i.
$ file -i file.txt
file.txt: text/plain; charset=us-asciiНу а далее вот такие действия:
iconv -f WINDOWS-1251 -t UTF-8 -o output_file.txt original_file.txtгде
-f WINDOWS-1251- исходная кодировка, список исходных кодировок iconv -l, в команде работает tab, чтобы не опечататься-t UTF-8 - конечная-o output_file.txt - куда выводить результатoriginal_file.txt - исходный файл
Остальные ключики как обычно в man iconv.
iconv и большие файлы
Для быстрого выполнения процесса кодировки, iconv загружает файл в оперативную память и в swap. Но это работает только для небольших файлов. Если файл уж совсем большой, а ОЗУ не особо, то вы прост получите ошибку, мол «слишком большой файл», звиняйте хлопцы. Где взять такой файл? К примеру это может быть выборка из БД (игры для ipad, PC, PSP или другие данные)
Вот здесь предлагают различные решения данного вопроса: и скриптами, и разбивка на части, вывод в потоки, а потом обратно сборка в файл. Лично мне понравилось весьма простое решение: команда split — она позволяет разбить текстовый файл на более мелкие, а дальше с ними работать как угодно можно.
В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить:
split -b 1000000000 file.txtЭто самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла.