
Ранее в статьях, посвященных Zabbix, мы рассказали про особенности мониторинга SAAS-сервиса интернет-магазинов, а также про установку сервера и агента Zabbix.
Новая статья поможет вам настроить мониторинг дисков и программных RAID-массивов, созданных с помощью mdadm. Без преувеличения можно сказать, что мониторинг этих устройств сервера представляет собой одну из важнейших задач.
Если не контролировать постоянно состояние дисков и массивов, рано или поздно сервер прекратит свою работу. А если вдобавок еще и не делать резервное копирование данных, то в худшем случае при аварии с дисками можно потерять бизнес.
Объекты мониторинга дисковой системы
Перечислим объекты и свойства дисковых систем серверов, которые необходимо контролировать в любой системе:
-
состояние программных и аппаратных RAID-массивов;
-
исправность дисков SATA, SAS, SSD и SSD NVMe;
-
свободное пространство на дисках;
-
использование дисковых квот
Сейчас мы займемся решением только первых двух задач — настроим мониторинг программных RAID-массивов и контроль исправности дисков с помощью анализа данных S.M.A.R.T., а остальное оставим на потом.
На серверах SAAS-сервиса интернет-магазинов используются зеркальные аппаратные и программные массивы RAID-1. При выходе из строя одного из дисков массива сервер продолжает работать. Неисправный диск можно заменить в горячем режиме, не останавливая работу сервера и размещенных на нем интернет-магазинов.
Контроль программных RAID-массивов mdadm
Относительно недорогие серверы обычно не комплектуются аппаратными контроллерами дисков. В этом случае имеет смысл объединять диски в программные зеркальные массивы RAID-1 с помощью программы mdadm.
Если вы берете сервер в аренду, то можете заказать установку нужной вам ОС, а также объединение дисков в зеркало. Когда вы размещаете в дата-центре свой собственный сервер, то установку ОС и создание дисковых массивов придется делать самостоятельно.
В любом случае для размещения ОС и сайтов можно использовать два быстрых диска SSD, объединенных в зеркало RAID-1, а для создания и локального хранения резервных копий — массив RAID-1 из двух дисков SATA. Здесь предполагается, что резервные копии вначале создаются локально, а потом копируются на выделенные серверы для бэкапов.
Контроль программного массива вручную
Получив сервер в аренду, первым делом проверьте количество процессоров и ядер, объем памяти, объем доступного дискового пространства, а также состояние дисковых массивов.
Что касается количества процессоров, ядер и объема оперативной памяти, то для ручного контроля можно использовать утилиты lscpu и free. Команда «df -h» поможет вам узнать объем дискового пространства, занимаемого смонтированными файловыми системами, объем использованного и доступного дискового пространства.
Также запустите команду lsblk, которая выводит на консоль информацию обо всех доступных блочных устройствах в виде дерева:
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 894.3G 0 disk
├─sda1 8:1 0 953M 0 part
│ └─md0 9:0 0 952M 0 raid1 /boot
└─sda2 8:2 0 893.3G 0 part
└─md1 9:1 0 893.2G 0 raid1
├─vg00-swap 253:0 0 15.3G 0 lvm [SWAP]
└─vg00-root 253:1 0 877.9G 0 lvm /
sdb 8:16 0 894.3G 0 disk
├─sdb1 8:17 0 953M 0 part
│ └─md0 9:0 0 952M 0 raid1 /boot
└─sdb2 8:18 0 893.3G 0 part
└─md1 9:1 0 893.2G 0 raid1
├─vg00-swap 253:0 0 15.3G 0 lvm [SWAP]
└─vg00-root 253:1 0 877.9G 0 lvm /
sdc 8:32 0 1.8T 0 disk
└─sdc1 8:33 0 1.8T 0 part
└─md2 9:2 0 1.8T 0 raid1 /mnt/raid
sdd 8:48 0 1.8T 0 disk
└─sdd1 8:49 0 1.8T 0 part
└─md2 9:2 0 1.8T 0 raid1 /mnt/raidКак видите, на сервере установлены диски sda, sdbs sdcs и sdd. Создано три дисковых массива md0, md1 и md2.
Для ручной проверки состояния дисковых массивов введите команду:
# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sdc1[1] sdd1[0]
1953381376 blocks super 1.2 [2/2] [UU]
bitmap: 0/15 pages [0KB], 65536KB chunk
md1 : active raid1 sda2[0] sdb2[1]
936583168 blocks super 1.2 [2/2] [UU]
bitmap: 5/7 pages [20KB], 65536KB chunk
md0 : active raid1 sda1[0] sdb1[1]
974848 blocks super 1.2 [2/2] [UU]
unused devices: <none>Если в блоке параметров всех массивов есть строка [UU], значит с ними все хорошо. Если же вместо U в этой строке имеются символы подчеркивания «_», то соответствующие диски находятся в отключенном состоянии, а массив — в состоянии деградации или восстановления.
Когда массив находится в состоянии восстановления, вы увидите строки такого вида:
md2 : active raid1 sdc4[2] sda4[0]
1919763264 blocks super 1.2 [2/1] [U_]
[>....................] recovery = 1.7% (33233600/1919763264) finish=770.0min speed=40832K/secЕсли вы только что получили доступ к арендованному серверу и занимаетесь его проверкой, возможно, что еще не все дисковые массивы окончательно синхронизировались. Перед подключением мониторинга нужно дождаться завершения синхронизации.
Установка шаблона zabbix_mdraid
В составе Zabbix уже имеются шаблоны, предназначенных для мониторинга различных устройств и сервисов. Дополнительно на сайте https://www.zabbix.com/integrations можно найти очень много шаблонов, добавленных сторонними разработчиками.
В комплекте с этими шаблонами идут скрипты, которые нужно подключить к агенту Zabbix через файл конфигурации, а также инструкции по установке.
Что касается мониторинга программных массивов, созданных с помощью mdadm, то в составе встроенных шаблонов Zabbix 6.2 его нет. Поэтому мы воспользуемся готовым шаблоном Template MD RAID, доступным в Github:https://github.com/linuxsquad/zabbix_mdraid.
Импорт шаблона zabbix_mdraid
Скачайте файл zbx_export_templates.xml по ссылке https://github.com/linuxsquad/zabbix_mdraid/blob/master/zbx_export_templates.xml и добавьте его в шаблоны сервера Zabbix.
Для добавления на странице веб-интерфейса Zabbix выберите из меню Configuration строку Templates. Вы попадете на страницу с полным списком шаблонов. Щелкните кнопку Import, расположенную в верхнем правом углу страницы Templates. Далее в появившемся на экране всплывающем окне нажмите кнопку Import.
Если шаблон импортировался успешно, он появится в общем списке шаблонов под именем Template MD RAID.
Установка скрипта zabbix_mdraid.sh
Чтобы импортированный шаблон включился в работу, скачайте скрипт zabbix_mdraid.sh, доступный по адресу https://github.com/linuxsquad/zabbix_mdraid/blob/master/zabbix_mdraid.sh, и запишите его в каталог /usr/local/bin/.
Далее установите для файла скрипта разрешение на запуск, а затем назначьте владельцем пользователя zabbix:
chmod +x /usr/local/bin/zabbix_mdraid.sh
chown zabbix:zabbix /usr/local/bin/zabbix_mdraid.shСкрипт /usr/local/bin/zabbix_mdraid.sh будет запускаться агентом Zabbix с помощью sudo. Добавьте командой visudo разрешение на запуск скрипта через sudo (укажите полный путь к скрипту):
zabbix ALL= (ALL) NOPASSWD: /usr/local/bin/zabbix_mdraid.shПроверьте, что скрипт запускается от пользователя zabbix без ошибок:
sudo -u zabbix '/usr/local/bin/zabbix_mdraid.sh'Если посмотреть исходный текст скрипта, то видно, что для получения списке программных дисковых массивов используется команда:
# cat /proc/mdstat | grep ^md
md2 : active raid1 sdc1[1] sdd1[0]
md1 : active raid1 sda2[0] sdb2[1]
md0 : active raid1 sda1[0] sdb1[1]Результат работы этой команды записывается в файл /tmp/zabbix_mdraid_discovery.json примерно в таком виде:
{
"data":[
{ "{#MD_DEVICE}":"/dev/md2" },
{ "{#MD_DEVICE}":"/dev/md1" },
{ "{#MD_DEVICE}":"/dev/md0" }, ]
}Этот файл используется для низкоуровневого обнаружения LLD (Low-level discovery), описанного в документации: https://www.zabbix.com/documentation/current/en/manual/discovery/low_level_discovery.
Далее для получения состояния каждого массива используется команда «mdadm —query —detail», которой в качестве параметра передается путь к массиву:
# mdadm --query --detail /dev/md/0
/dev/md/0:
Version : 1.2
Creation Time : Tue May 17 22:43:58 2022
Raid Level : raid1
Array Size : 974848 (952.00 MiB 998.24 MB)
Used Dev Size : 974848 (952.00 MiB 998.24 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Mon Jul 11 00:38:06 2022
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : debian:0
UUID : e4932f3c:dd178f82:d972c9fe:71de1c90
Events : 88
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1Скрипт zabbix_mdraid.sh извлекает отсюда параметры состояния массива и передает их серверу Zabbix.
Редактирование файла конфигурации агента Zabbix
Для запуска скрипта zabbix_mdraid.sh добавьте в файл конфигурации агента /etc/zabbix/zabbix_agentd.conf следующие строки:
#### MDRAID
UserParameter=mdraid[*], sudo /usr/local/bin/zabbix_mdraid.sh -m'$1' -$2'$3'
UserParameter=mdraid.discovery, sudo /usr/local/bin/zabbix_mdraid.sh -DЗатем перезапустите агент:
systemctl restart zabbix-agentДля zabbix-agent2 используется файл конфигурации /etc/zabbix/zabbix_agent2.conf.
На этом установка шаблона закончена, и можно отслеживать получение данных о программных массивах.
Просмотр данных о программных массивах
Выберите в меню Monitoring строку Latest Data. Далее с помощью меню Host group и Hosts выберите нужный сервер, где вы только что отредактировали файл конфигурации агента Zabbix, а затем щелкните кнопку Apply.
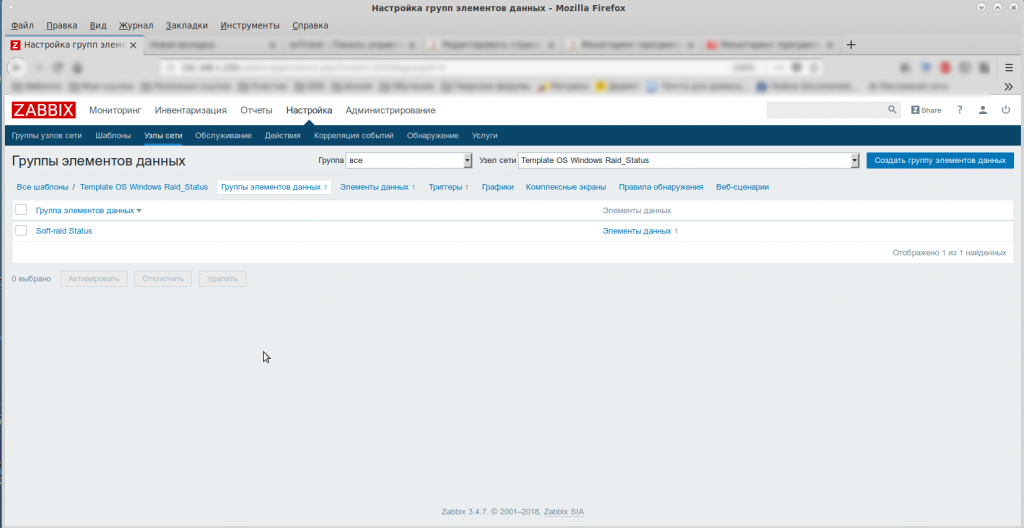
Вы увидите очень большую таблицу данных, полученных от агента. Щелкните в поле TAG Values строку MD_RAID, чтобы на странице остались только данные, полученные с помощью шаблона zabbix_mdraid (рис. 1).

Чтобы посмотреть график изменений данных, щелкните в соответствующей строке кнопку Graph. На рис. 2 показано изменение скорости записи данных для массива /dev/md1.

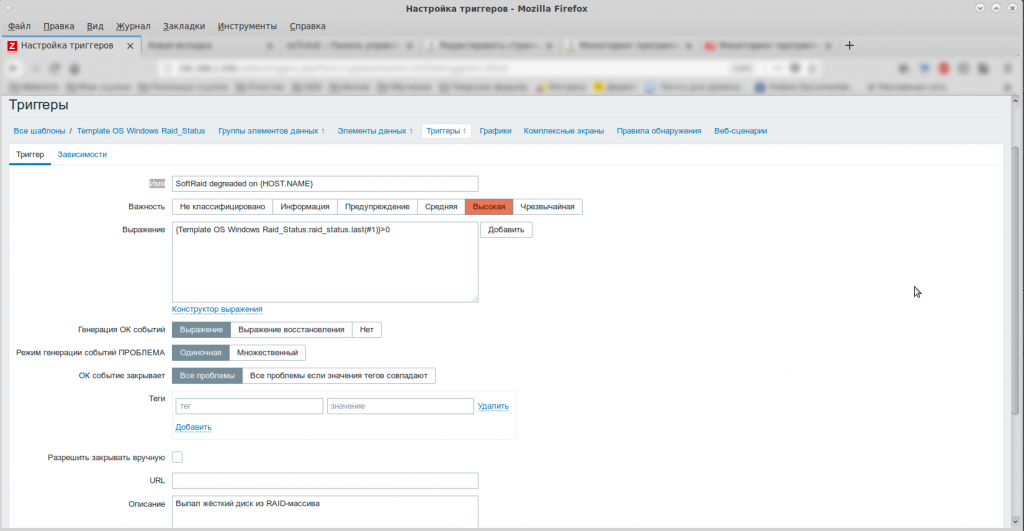
Триггеры контроля состояния программных дисковых массивов
Чтобы проверять, находятся ли отслеживаемые данные в допустимых пределах, а также имеют ли они допустимые значения, в Zabbix используются триггеры.
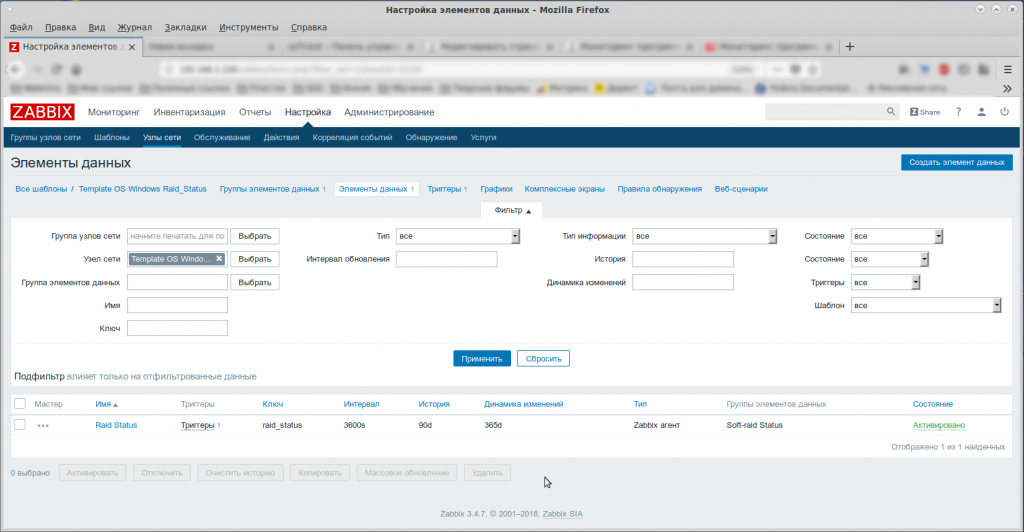
Вы можете посмотреть, какие триггеры созданы для контролируемого сервера и в каком они находятся состоянии. Для этого откройте список контролируемых узлов, выбрав из меню Configuration строку Hosts. В таблице щелкните ссылку Triggers в строке нужно хоста, в результате чего в окне браузера появится довольно большая таблица триггеров, определенная для хоста.
На рис. 3 показаны строки таблицы, имеющие отношение к шаблону zabbix_mdraid.

Эти триггеры были добавлены в процессе низкоуровневого обнаружения LLD.
Обратите внимание: если состояние массива, взятое из элемента данных с именем State, содержит строки degraded, resyncing, recovering или Not Started, триггер сработает. При правильной настройке системы оповещений, о которой мы расскажем в отдельной статье, системный администратор получит оповещение по электронной почте, через SMS или другим способом.
О создании триггеров можно прочитать в документации Zabbix: https://www.zabbix.com/documentation/current/en/manual/quickstart/trigger. Для версии 6.0 есть версия на русском языке: https://www.zabbix.com/documentation/6.0/ru/manual/quickstart/trigger.
Мониторинг S.M.A.R.T. дисковых устройств
В 1995 году производители жестких дисков создали технологию самотестирования, анализа состояния и накопления статистических данных об ухудшении характеристик дисков с названием S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology).
С помощью программы smartctl, входящей в пакет smartmontools, вы можете контролировать значение параметров S.M.A.R.T. дисковых устройств вашего сервера как вручную, так и средствами Zabbix.
Контроль параметров S.M.A.R.T. вручную
Для начала установите пакет smartmontools. В ОС Debian это можно сделать следующей командой:
# apt-get install smartmontoolsПосле установки вы сможете запускать программу smartctl для получения значений параметров.
Убедитесь, что будет установлена версия программы smartctl не ниже 7.1, это будет нужно для мониторинга параметров S.M.A.R.T. с помощью встроенного шаблона SMART by Zabbix agent 2. Проверить версию smartctl можно так:
/usr/sbin/smartctl -V
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-14-amd64] (local build)Давайте посмотрим параметры S.M.A.R.T. для устройства /dev/sda:
# smartctl -a /dev/sdaКоманда выведет на консоль довольно подробную информацию о диске, включая название модели Device Model, серийный номер Serial Number, объем User Capacity и другие параметры:
=== START OF INFORMATION SECTION ===
Device Model: INTEL SSDSC2KB480G8
Serial Number: BTYF83160CQ04878ER82
LU WWN Device Id: 5 5cd2e4 14fd79e98
Firmware Version: XCV10100
User Capacity: 480,103,981,056 bytes [480 GB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.2, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Thu Jul 21 18:44:31 2022 MSK
SMART support is: Available - device has SMART capability.
SMART support is: EnabledОбратите внимание на таблицу значений параметров, где есть идентификатор параметра ID, название параметра NAME, так называемое нормализованное значение VALUE, пороговое значение THRESH и другие данные:
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0032 100 100 000 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 31311
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 8
170 Unknown_Attribute 0x0033 100 100 010 Pre-fail Always - 0
171 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 0
172 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 0
174 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 8
175 Program_Fail_Count_Chip 0x0033 100 100 010 Pre-fail Always - 38654642595
183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0
184 End-to-End_Error 0x0033 100 100 090 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0022 071 062 000 Old_age Always - 29 (Min/Max 12/38)
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 8
194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 29
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
225 Unknown_SSD_Attribute 0x0032 100 100 000 Old_age Always - 1762160
226 Unknown_SSD_Attribute 0x0032 100 100 000 Old_age Always - 3389
227 Unknown_SSD_Attribute 0x0032 100 100 000 Old_age Always - 78
228 Power-off_Retract_Count 0x0032 100 100 000 Old_age Always - 1878671
232 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always - 0
233 Media_Wearout_Indicator 0x0032 097 097 000 Old_age Always - 0
234 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 0
235 Unknown_Attribute 0x0033 100 100 010 Pre-fail Always - 38654642595
241 Total_LBAs_Written 0x0032 100 100 000 Old_age Always - 1762160
242 Total_LBAs_Read 0x0032 100 100 000 Old_age Always - 6319391
243 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 5924573В интернете нетрудно найти описание этих параметров по названию. Заметим, что для дисков SSD разных производителей параметры могут различаться, и не все они документированы. Для дисков SSD компании Intel хорошее описание приведено здесь: https://www.thomas-krenn.com/en/wiki/SMART_attributes_of_Intel_SSDs, а для Kingston — здесь: https://media.kingston.com/support/downloads/MKP_306_SMART_attribute.pdf.
Также довольно полное описание параметров можно найти на этой странице: https://wiki5.ru/wiki/S.M.A.R.T.
Когда вы контролируете состояние дисков Intel SSD, обратите внимание на следующие параметры:
-
232 Available Reserved Space — доступный объем зарезервированного пространства;
-
233 Media Wearout Indicator — индикатор износа диска
Если первый из них достигает порогового значение 10, то ресурс диска подходит к концу. Второй представляет собой индикатор износа накопителя, и при достижении порогового значения диск подлежит замене.
Для дисков SSD Kingston интересен параметр 231 SSD Life Left, значение которого зависит от выполненный циклов стирания.
Что касается жестких дисков, то для них важен контроль следующих параметров:
-
1 Raw_Read_Error_Rate — частота ошибок чтения;
-
5 Reallocated_Sector_Ct — количество неисправных переназначенных секторов;
-
7 Seek_Error_Rate — частота ошибок поиска;
-
9 Power_On_Hours — время работы диска, «сырое» значение RAW_VALUE может задавать общее количество часов, минут или секунд (в зависимости от производителя) работы диска;
-
10 Spin_Retry_Count — количество повторных попыток раскрутки, увеличивается по мере износа механики диска;
-
194 Temperature_Celsius — температура диска в градусах Цельсия
Температуру имеет смысл контролировать для дисков любых типов.
Еще раз напомним, что диски разных производителей могут использовать разные параметры, поэтому точную информацию лучше искать на сайте производителя для ваших моделей.
В любом случае при ручном контроле нужно следить, чтобы значения VALUE не были равны или ниже соответствующих пороговых значений THRESH.
Контроль параметров S.M.A.R.T. с помощью шаблона SMART by Zabbix agent 2
В Zabbix версии 6.2 имеется шаблон SMART by Zabbix agent 2, контролирующий состояние дисков исходя из значений параметров S.M.A.R.T. Для работы этого шаблона вам нужно будет установить на сервер агент zabbix-agent2, о чем мы рассказывали в предыдущей статье.
Описание шаблона SMART by Zabbix agent 2 есть на этой странице: https://www.zabbix.com/integrations/smart.
Если у вас Zabbix версии 6.2, то для включения мониторинга S.M.A.R.T. на контролируемом сервере просто добавьте шаблон SMART by Zabbix agent 2 к шаблонам сервера.
Чтобы это сделать, выберите из меню Configuration строку Hosts, а затем щелкните название сервера. Откроется окно, где вам нужно щелкнуть кнопку Select в блоке Templates, а затем отыскать шаблон с названием SMART by Zabbix agent 2, отметить флажок возле него и щелкнуть кнопку Select.
В результате шаблон SMART by Zabbix agent 2 будет добавлен к серверу (рис. 4).

Шаблон SMART by Zabbix agent 2 устроен так, что ему не нужны дополнительные скрипты. Он обращается за данными к пакету smartmontools с помощью агента zabbix-agent2.
Через некоторое время после установки шаблона с помощью LLD к контролируемому серверу будут добавлены элементы данных и триггеры.
Для просмотра созданных элементов данных и триггеров выберите из меню Configuration строку Hosts. В строке вашего сервера для просмотра данных щелкните ссылку Items, а для просмотра триггеров — ссылку Triggers.
Вы увидите, что для сервера всего было создано очень много элементов данных. С помощью фильтра оставьте только те элементы, которые были получены с помощью LLD с именем sda (рис. 5).

В результате получаем вполне обозримый список элементов данных, имеющий отношение к S.M.A.R.T. (рис. 6).

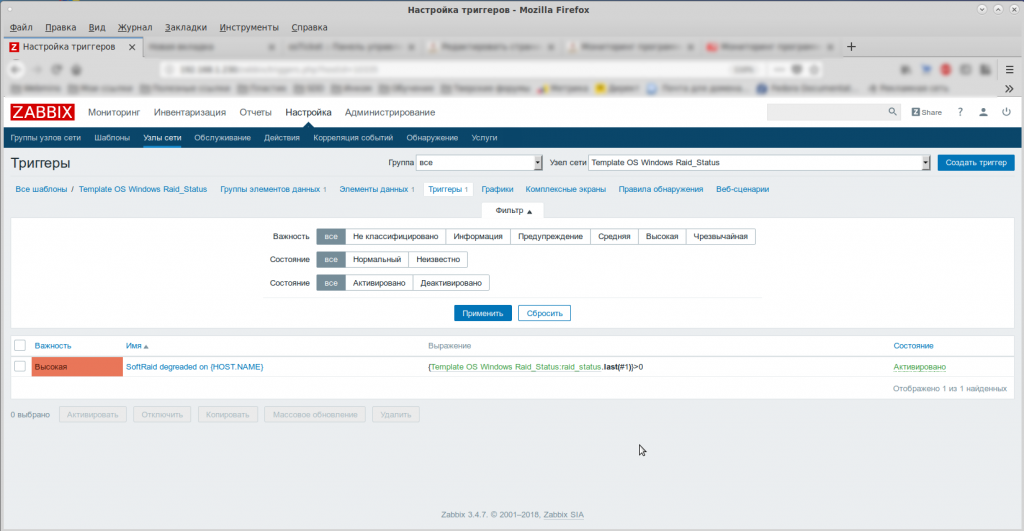
Аналогичным способом вы можете посмотреть список триггеров контролируемого сервера. Триггеры, созданные для диска /dev/sda, показаны на рис. 7.

Обратите внимание на триггер SMART [sda sat]: Some Attributes have been <= threshold. Он срабатывает, если какое-либо значение параметра S.M.A.R.T. достигает порогового значения или опускается еще ниже. В результате создается событие высокой степени важности High, и при правильной настройке оповещения такое событие попадает к системному администратору по приоритетному каналу.
Аналогичные события создаются и при обнаружении каких-либо других существенных проблем с диском.
Текущие значения параметров S.M.A.R.T. (как и других отслеживаемых параметров) и графики их изменения можно увидеть, если из меню Monitoring веб-интерфейса Zabbix выбрать строку Latest Data.
Мониторинг S.M.A.R.T.S с помощью своего шаблона Zabbix
Если по каким-то причинам вы не можете использовать новую версию Zabbix, или если вам нужно настроить мониторинг параметров S.M.A.R.T. своим особым способом, то такая возможность также имеется.
В любом случае сначала нужно установить пакет smartmontools, как это было описано ранее.
После этого создайте несложный шаблон для отслеживания параметра «здоровья» 233 Media_Wearout_Indicator дисков SSD.
Вы можете получить значение этого параметра для диска /dev/sda через консоль следующим образом:
# smartctl -a /dev/sda | grep Media_Wearout_Indicator
233 Media_Wearout_Indicator 0x0032 097 097 000 Old_age Always - 0Как видите, здесь значение этого параметра равно 97, что очень даже неплохо.
Настройка мониторинга
Добавьте в конец файла /etc/zabbix/zabbix_agentd.conf такие строки:
###### MY S.M.A.R.T.
UserParameter=smartd.value[*],sudo smartctl -A -f hex,id $1 | grep $2 | awk '{print $ 4+0}'
UserParameter=smartd.trash[*],sudo smartctl -A -f hex,id $1 | grep $2 | awk '{print $ 6+0}'
UserParameter=smartd.raw[*],sudo smartctl -A -f hex,id $1 | grep $2 | awk '{print $ 10+0}'Затем перезапустите агент Zabbix:
# systemctl restart zabbix-agentНе забудьте установить sudo (если эта программа у вас еще не установлена), и разрешить запуск через sudo программы /usr/sbin/smartctl.
Для разрешения запуска с помощью visudo добавьте в файл /etc/sudoers строку:
zabbix ALL= (ALL) NOPASSWD: /usr/sbin/smartctlПроверка получения параметра с сервера Zabbix
Проверьте, что сервер Zabbix получает данные добавленного вами мониторинга S.M.A.R.T. от агента. Установите на сервере Zabbix программу zabbix_get:
apt install zabbix-getТеперь на сервере Zabbix проверьте получение нужного вам параметра от агента Zabbix, запущенного на контролируемом сервере:
# zabbix_get -s xxx.xxx.xxx.xxx -k "smartd.value[/dev/sda,0xe9]"
97Здесь вместо xxx.xxx.xxx.xxx в параметре -s укажите адрес IP контролируемого сервера. Идентификатор атрибута S.M.A.R.T. следует указывать в шестнадцатеричной системе счисления с префиксом 0x.
В результате команда должна вывести на консоль значение атрибута 0xe9 или 233 (в десятичной системе счисления).
Результатом выполнения команда должно быть значение 100 при новом диске. У нас диск не совсем новый, поэтому мы получили значение 97.
Создание шаблона для Zabbix
Вы можете создать шаблон для мониторинга самостоятельно. Для этого зайдите на страницу Templates, доступную в меню Configuration, и щелкните кнопку Create Template.
Задайте имя шаблона, скажем, с именем MY SMART SSD и добавьте его в группу шаблонов Templates (если вы еще не создали группу для своих шаблонов).
Далее найдите этот шаблон в общем списке и добавьте в него элемент Items с помощью кнопки Create Items. Укажите такие параметры:
Name: 233 Media_Wearout_Indicator /dev/sda
Type: Zabbix Agent
Key: smartd.value[/dev/sda,0xe9]
Создайте аналогичный шаблон для диска /dev/sdb/.
Добавление триггера
Теперь откройте пока пустой список триггеров и щелкните кнопку Add Trigger. Для нового триггера задайте такие параметры:
Name: Life time SSD /dev/sda/ on {HOST.NAME}
Expression: last(/MY SMART SSD/smartd.value[/dev/sda,0xe9])<10
Аналогичный триггер создайте и для диска /dev/sdb.
Теперь, когда вы создали шаблон, подключите его к контролируемому серверу и наблюдайте получение данных через страницу Latest Data.
При необходимости подобным образом вы можете добавить в свой шаблон другие элементы данных и триггеры для отслеживания нужных вам параметров S.M.A.R.T.
В следующей статье мы займемся мониторингом аппаратных дисковых массивов, созданных с применением контроллера LSI.
Автор: Александр Фролов.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.


Делюсь полезным шаблоном для мониторинга программных RAID контроллеров Intel RST (Rapid Storage Technology), Intel RSTe (Intel Rapid Enterprise), Intel VROC (Virtual RAID on CPU).
Скачать шаблон для Zabbix 5.0: zabbix_intel_rst_vroc.zip
Мониторим с помощью утилит CLI. В пакете есть следующие утилиты:
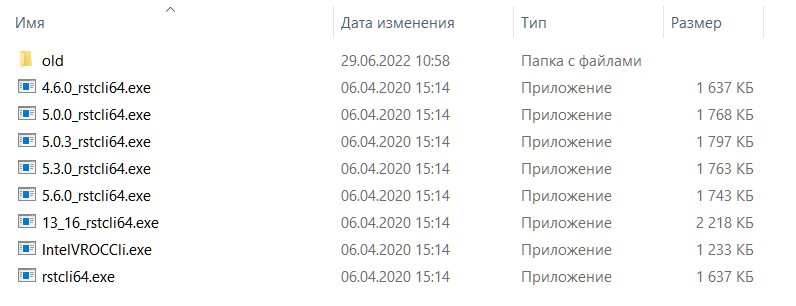
В зависимости от установленного в системе драйвера для RAID контроллера используется подходящая утилита CLI:
- 13_16_rstcli64.exe — для драйвера версии ниже 1.7.0.
- 4.6.0_rstcli64.exe — для драйвера версии ниже 5.0.0.
- 5.0.0_rstcli64.exe — для драйвера версии ниже 5.0.3.
- 5.0.3_rstcli64.exe — для драйвера версии ниже 5.3.0.
- 5.3.0_rstcli64.exe — для драйвера версии ниже 5.6.0.
- 5.6.0_rstcli64.exe — для драйвера версии ниже 6.1.0.
- IntelVROCCli.exe — для драйвера версии ниже 6.2.0.
- rstcli64.exe — для остальных случаев.
Не уверен в точности соответствия версий и утилит, возможно, в дальнейшем потребуется корректировка в BAT файле и препроцессинге элемента данных «RST cli path».
В папке old есть более старая утилита IntelVROCCli.exe, вдруг, кому-то пригодится.
Шаблон получает все данные от CLI, затем, используя javascript и регулярные выражения, с помощью низкоуровневого обнаружения LLD находит:
- Контроллеры
- Массивы
- Логические диски
- Физические диски
Можно было бы не заморачиваться с регулярными выражениями, если бы работало опция —xml, которая имеется в описании CLI IntelVROCCli.exe. Однако, вывод в XML не работает, о чём я нашёл подтверждение в документации к CLI.
Благодарности
Мой шаблон основан вот на этом шаблоне (автор Николай Куликов):
https://github.com/mykolq/zabbix_intel_rst_template
Изначально предполагалось создание локального пользователя, который в автоматическом режиме прописывал в макрос путь к CLI. Мне это не понравилось, я сделал автоматическое определение CLI по версии драйвера в файле BAT, который при первом запуске определяет драйвер и записывает путь CLI в текстовый файл. Если драйвер изменится, то нужно на сервере вручную удалить файл RST.txt. Можно избавиться от этого текстового файла и модифицировать скрипт, но тогда каждый раз при запросе будет определяться версия драйвера, а эта процедура отрабатывает секунд пять, не очень быстро. Ещё можно сделать полную автоматизацию, как у Николая, написав скрипт для обновления RST.txt в планировщике. Но, поскольку, я не собираюсь обновлять версию драйвера RST без особых причин, то не буду делать автоматизацию. Для защиты от дурака сделал триггер, который сравнивает текущий путь CLI и определённый по версии драйвера в системе. Вдруг, кто-то полезет на сервер и начнёт всё бездумно обновлять.
Добавил к исходному шаблону функционал определения контроллеров и массивов. Ну и добавил все элементы данных, которые возвращает мой RST контроллер.
А за набор CLI утилит спасибо Николаю. Я там только заменил IntelVROCCli.exe на более новый.
Установка шаблона в Linux
Отдельный мониторинг Intel RST в Linux не требуется. Для мониторинга Intel RST, Intel RSTe, Intel VROC в Linux необходимо использовать утилиту mdadm:
Zabbix — мониторинг программных RAID массивов в Linux
Установка шаблона в Windows
Качаем архив zabbix_intel_rst_vroc.zip
Импортируем шаблон zbx5_intel_rst_vroc.xml.
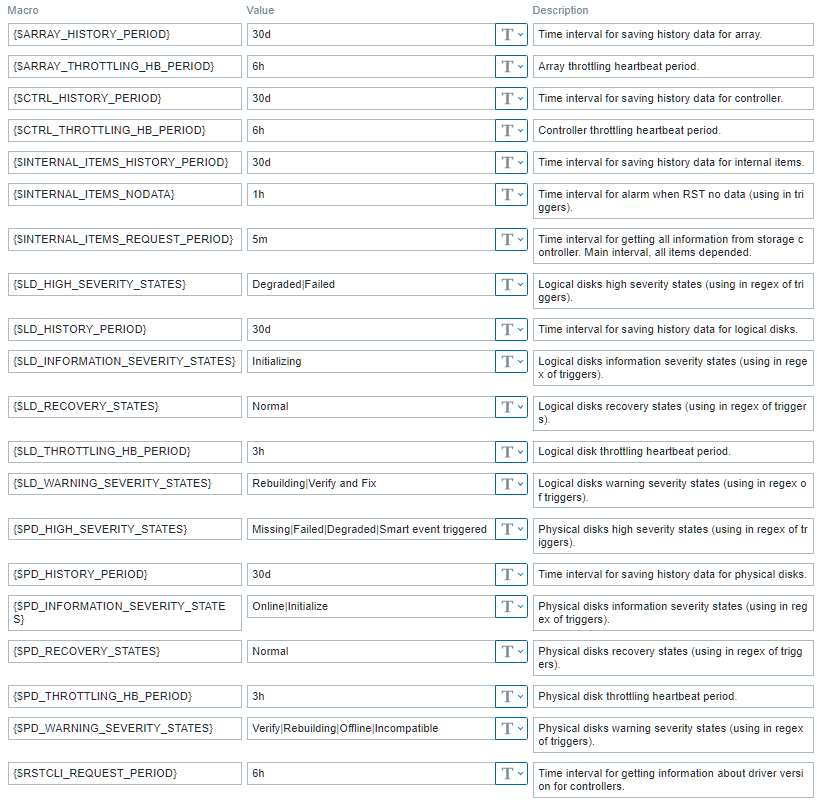
В макросах шаблона можно отредактировать параметры:
- {$ARRAY_HISTORY_PERIOD} — 30d. Срок хранения истории массивов.
- {$ARRAY_THROTTLING_HB_PERIOD} — 6h. Срок тротлинга массивов.
- {$CTRL_HISTORY_PERIOD} — 30d. Срок хранения истории контроллеров.
- {$CTRL_THROTTLING_HB_PERIOD} — 6h. Срок тротлинга контроллеров.
- {$INTERNAL_ITEMS_HISTORY_PERIOD} — 30d. Срок хранения истории внутренних элементов.
- {$INTERNAL_ITEMS_NODATA} — 1h. Для триггеров. Интервал, в течение которого допускается отсутствие данных от RST.
- {$INTERNAL_ITEMS_REQUEST_PERIOD} — 5m. Периодичность опроса RST. Основной интервал.
- {$LD_HIGH_SEVERITY_STATES} — Degraded|Failed. Для триггеров. Критичные статусы локальных дисков.
- {$LD_HISTORY_PERIOD} — 30d. Срок хранения истории локальных дисков.
- {$LD_INFORMATION_SEVERITY_STATES} — Initializing. Для триггеров. Информационные статусы локальных дисков.
- {$LD_RECOVERY_STATES} — Normal. Для триггеров. Нормальные статусы локальных дисков.
- {$LD_THROTTLING_HB_PERIOD} — 3h. Срок тротлинга локальных дисков.
- {$LD_WARNING_SEVERITY_STATES} — Rebuilding|Verify and Fix. Для триггеров. Предупреждающие статусы локальных дисков.
- {$PD_HIGH_SEVERITY_STATES} — Missing|Failed|Degraded|Smart event triggered. Для триггеров. Критичные статусы физических дисков.
- {$PD_HISTORY_PERIOD} — 30d. Срок хранения истории физических дисков.
- {$PD_INFORMATION_SEVERITY_STATES} — Online|Initialize. Для триггеров. Информационные статусы физических дисков.
- {$PD_RECOVERY_STATES} — Normal. Для триггеров. Нормальные статусы физических дисков.
- {$PD_THROTTLING_HB_PERIOD} — 3h. Срок тротлинга физических дисков.
- {$PD_WARNING_SEVERITY_STATES} — Verify|Rebuilding|Offline|Incompatible. Для триггеров. Предупреждающие статусы физических дисков.
- {$RSTCLI_REQUEST_PERIOD} — 6h. Периодичность опроса версий драйвера RST.
Копируем rst.conf в папку с пользовательскими переменными, у меня это C:zabbixzabbix_agent.conf.drst.conf. В конфигурации агента этот файл должен быть подключен.
Копируем папку со скриптами в C:zabbixscripts. В ней у нас:
- rst — папка с утилитами RST
- rst.bat — скрипт для получения данных RST
- rstcurrent.bat — скрипт для получения текущей утилиты RST CLI
Перезапускаем агент:
net stop "Zabbix Agent" && net start "Zabbix Agent"Версии
v.1 от 03.07.2022
Начальная версия
v.2 от 05.12.2022
Упрощено регулярное выражение для LLD контроллеров. В некоторых случаях обработка регулярки уходила в бесконечный цикл, непонятно почему. И нагрузку на сервер снизили.
Картинки
Содержание
- Мониторинг raid массивов в Windows Core
- Мониторинг Intel raid с помощью raidcfg и Zabbix
- Цели статьи
- Введение
- Скрипт для внешних проверок raid массивов
- Шаблон для мониторинга за intel raid
- Заключение
- Состояние raid массива windows
- Аппаратный RAID: особенности использования
- Внешний вид
- Технические характеристики
- Температура
- Скорость работы
- С программным RAID
- С аппаратным RAID
- Управление контроллером
- Настройка кэширования
- Настройка мониторинга
- Прошивка
- Заключение
- Как создать и настроить программный RAID 0, 1 массив в Windows
- Содержание:
- Создание программного RAID с помощью встроенных инструментов Windows 8 или Windows 10
- Как добавить или удалить диск в уже существующем массиве RAID
- Как добавить диск в RAID
- Как удалить диск из RAID-массива
- Создайте программный RAID с помощью командной строки
- RAID 0
- RAID 1
- Программное создание RAID в Windows 7
- Что делать, если вы потеряли важные данные на RAID-массиве
- Часто задаваемые вопросы
Мониторинг raid массивов в Windows Core

За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:

UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Мониторинг Intel raid с помощью raidcfg и Zabbix
У меня есть группа серверов с настроенным intel raid и установленными поверх Windows Hyper-V Server. Возникло больше желание с помощью zabbix наблюдать за состоянием массивов и предупреждать в случае проблем. Готового решения нигде не нашел, поэтому пораскинул мозгами и придумал свое, чем и хочу поделиться с вами.
Цели статьи
Введение
На серверах уже настроен мониторинг состояния SMART дисков. При использовании встроенного intel raid, состояние дисков с целевой системы нормально наблюдается. В принципе, мне этого хватало, но подумал, почему бы и состояние массивов не замониторить, ведь массив может развалиться и при нормальных показателях смарта дисков.
В первую очередь погуглил и не нашел практически ничего, что помогло бы настроить мониторинг интел рейдов в zabbix. На целевых системах установлена интеловская утилита raidcfg, с помощью которой можно посмотреть на состояние массивов и дисков. Например, с ключом /st получается вот такой вывод.

Красиво и наглядно, но для автоматизации не очень подходит. Лучше подойдет ключ /stv.

В этот раз мне не захотелось такие костыли городить на каждом сервере. Я в итоге решил поступить по-другому. На zabbix сервере сделать скрипт для внешних проверок. Этот скрипт будет на целевом сервере с помощью zabbix_get забирать вывод команды raidcfg.exe /stv, запущенной через system.run. Дальше вывод команды в исходном виде поступает на zabbix сервер. Его можно парсить каким-то образом, но я решил этого не делать. Вывод и так короткий, много места не занимает. Проверка на наличие тревожных слов будет уже в триггере с помощью regexp.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Скрипт для внешних проверок raid массивов
В директорию на zabbix сервере /usr/lib/zabbix/externalscripts кладем скрипт intelraid.sh для внешних проверок.
Скрипт, как вы видите, очень простой. Для того, чтобы он работал, вам обязательно нужно на каждом агенте разрешить выполнение внешних команд. По-умолчанию они отключены. Добавляем в агенте параметр:
И перезапускаем агент. Это все, что надо делать на целевых серверах. Теперь можно проверить работу скрипта. Для этого выбираете любой сервер и передаем его ip адрес в качестве параметра скрипту.
Если получаете результат работы утилиты raidcfg, значит все в порядке. Можно переходить в web интерфейс сервера мониторинга.
Шаблон для мониторинга за intel raid

А вот триггер к нему.

Если в строке будет найдено одно из слов Failed|Disabled|Degraded|Rebuild|Updating|Critical, то он сработает. Я на практике не проверял работу триггера, так как не хотелось рейд ломать. А потестил следующим образом. Добавил в проверочную строку название одного из массивов, к примеру, Storage, который встречается не на всех серверах. В итоге, триггер сработал только там, где было такое название. Так что в теории, проверка должна работать корректно.
Теперь можно добавлять шаблон к необходимым хостам и ждать поступление данных. В Latest Data должны увидеть следующее содержимое итема.

Вот и все. Теперь все intel raid массивы подключены к мониторингу.
Заключение
Так быстро и просто решается прикладная задача по мониторингу с помощью Zabbix. Сел, прикинул и сразу сделал. Вариантов решения обычно несколько, выбирай на свой вкус. Можно было на клиенте распарсить вывод и передавать в Zabbix сразу состояние массива в одно слово. А можно было просто True/False или 1/0.
Источник
Состояние raid массива windows

Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.
Читайте также: как запустить античит faceit на windows 7
Сообщения: 60
Благодарности:

Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Аппаратный RAID: особенности использования
Организация единого дискового пространства — задача, легко решаемая с помощью аппаратного RAID-контроллера. Однако следует вначале ознакомиться с особенностями использования и управления таким контроллером. Об этом сегодня расскажем в нашей статье.
Надежность и скорость работы дисковых накопителей — вопрос, волнующий каждого системного администратора. Несмотря на заверения производителей о качестве собственных устройств — HDD и SSD продолжают выходить из строя в самое неподходящее время, теряя драгоценные данные. Технология S.M.A.R.T. в большинстве случаев дает возможность оценить «здоровье» накопителя, но это не гарантирует того, что диск будет продолжать беспроблемно работать.
Предсказать выход диска из строя со 100%-ой точностью невозможно, поэтому следует предусмотреть вариант, при котором это не станет проблемой или причиной остановки сервисов. Использование RAID-массивов решает эту задачу. Рассмотрим три основных подхода, применяющихся для этой задачи:
Внешний вид
Мы выбрали решения Adaptec от компании Microsemi. Это RAID-контроллеры, зарекомендовавшие себя удобством использования и высокой производительностью. Их мы устанавливаем, если наш клиент решил заказать сервер произвольной или фиксированной конфигурации.
Для подключения дисков используются специальные интерфейсные кабели. Со стороны контроллера используются разъемы SFF8643. Каждый кабель позволяет подключить до 4-х дисков SAS или SATA (в зависимости от модели). Помимо этого интерфейсный кабель еще имеет восьмипиновый разъем SFF-8485 для шины SGPIO, о назначении которой поговорим чуть позже.
Помимо самого RAID-контроллера существует еще два дополнительных устройства, позволяющих увеличить надежность:
После того, как электропитание сервера восстановлено, содержимое кэша автоматически будет записано на диски. Именно такие модули устанавливаются в наши серверы с аппаратным RAID-контроллером и Cache Protection.
Это особенно важно, когда включен режим отложенной записи кэша (Writeback). При пропадании электропитания содержимое кэша не будет сброшено на диски, что приведет к потере данных и, как следствие, штатная работа дискового массива будет нарушена.
Технические характеристики
Температура
Вначале хотелось бы затронуть такую важную вещь, как температурный режим аппаратных RAID-контроллеров Adaptec. Все они оснащены небольшими пассивными радиаторами, что может вызвать ложное представление о небольшом тепловыделении.
Производитель контроллера приводит в качестве рекомендуемого значения воздушного потока — 200 LFM (linear feet per minute), что соответствует показателю 8,24 литра в секунду (или 1,02 метра в секунду). Рассчитаны такие контроллеры исключительно на установку в rackmount-корпусы, где такой воздушный поток создается скоростными штатными кулерами.
От 0°C до 40-55°C — рабочая температура большинства RAID-контроллеров Adaptec (в зависимости от наличия установленных модулей), рекомендованная производителем. Максимальная рабочая температура чипа составляет 100°C. Функционирование контроллера при повышенной температуре (более 85°C) может вывести его из строя. Удобства ради приводим под спойлером табличку рекомендуемых температур для разных серий контроллеров Adaptec.
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
| Series 2 (2405, 2045, 2805) and 2405Q | 55°C без модулей |
| Series 5 (5405, 5445, 5085, 5805, 51245, 51645, 52445) | 55°C без батарейного модуля, 40°C с батарейным модулем ABM-800 |
| Series 5Z (5405Z, 5445Z, 5805Z, 5805ZQ) | 50°C с модулем ZMCP |
| Series 5Q (5805Q) | 55°C без батарейного модуля, 40°C с батарейным модулем ABM-800 |
| Series 6E (6405E, 6805E) | 55°C без модулей |
| Series 6/6T (6405, 6445, 6805, 6405T, 6805T) | 55°C без ZMCP модуля, 50°C с ZMCP модулем AFM-600 |
| Series 6Q (6805Q, 6805TQ) | 50°C с ZMCP модулем AFM-600 |
| Series 7E (71605E) | 55°C без модулей |
| Series 7 (7805, 71605, 71685, 78165, 72405) | 55°C без ZMCP модуля, 50°C с ZMCP модулем AFM-700 |
| Series 7Q (7805Q, 71605Q) | 50°C с ZMCP модулем AFM-700 |
| Series 8E (8405E, 8805E) | 55°C без модулей |
| Series 8 (8405, 8805, 8885) | 55°C без ZMCP модуля, 50°C с ZMCP модулем AFM-700 |
| Series 8Q (8885Q, 81605Z, 81605ZQ) | 50°C с ZMCP модулем AFM-700 |
Нашим клиентам не приходится беспокоиться о перегреве контроллеров, поскольку в наших дата-центрах поддерживается постоянный температурный режим, а сборка серверов произвольной конфигурации происходит с учетом особенностей таких комплектующих (о чем мы упоминали в нашей предыдущей статье).
Скорость работы
Для того чтобы продемонстрировать, как наличие аппаратного RAID-контроллера способствует увеличению скорости работы сервера, мы решили собрать тестовый стенд со следующей конфигурацией:
Затем в этот же стенд поставим RAID-контроллер Adaptec ASR 7805 с модулем защиты кэша AFM-700, подключим к нему эти же жесткие диски и выполним точно такое же тестирование.
С программным RAID
Несомненное преимущество программного RAID — простота использования. Массив в ОС Linux создается с помощью штатной утилиты mdadm. При установке операционной системы чаще всего создание массива предусмотрено непосредственно из установщика. В случае, когда такой возможности установщик не предоставляет, достаточно всего лишь перейти в соседнюю консоль с помощью сочетания клавиш Ctrl+Alt+F2 (где номер функциональной клавиши — это номер вызываемой tty).
Проверяем, чтобы на дисках не было метаданных, например, от предыдущего массива:
На всех 4-х дисках должно быть сообщение:
В случае, если на одном или нескольких дисках будут метаданные, удалить их можно следующим образом (где sdX — требуемый диск):
Создадим на каждом диске разделы для будущего массива c помощью fdisk. В качестве типа раздела следует указать fd (Linux RAID autodetect).
Собираем массив RAID 10 из созданных разделов с помощью команды:
Сразу после этого будет создан массив /dev/md0 и будет запущен процесс перестроения данных на дисках. Для отслеживания текущего статуса процесса введите:
Пока процесс перестроения данных не будет завершен, скорость работы дискового массива будет снижена.
После установки операционной системы и Bitrix24 на созданный массив мы запустили стандартный тест и получили следующие результаты:
С аппаратным RAID
Прежде чем сервер сможет использовать единое дисковое пространство RAID-массива, необходимо выполнить базовую настройку контроллера и логических дисков. Сделать это можно двумя способами:
Утилита позволяет не только управлять настройками контроллера, но и логическими устройствами. Инициализируем физические диски (вся информация на дисках при инициализации будет уничтожена) и создадим массив RAID-10 с помощью раздела Create Array. При создании система запросит желаемый размер страйпа, то есть размер блока данных за одну I/O-операцию:
Важно — размер страйпа задается только один раз (при создании массива) и это значение в дальнейшем изменить нельзя.
Сразу после того, как контроллеру отдана команда создания массива, также, как и с программным RAID, начинается процесс перестроения данных на дисках. Этот процесс работает в фоновом режиме, при этом логический диск становится сразу доступен для BIOS. Производительность дисковой подсистемы будет также снижена до завершения процесса. В случае, если было создано несколько массивов, то необходимо определить загрузочный массив с помощью сочетания клавиш Ctrl + B.
После того как статус массива изменился на Optimal, мы установили Bitrix24 и провели точно такой же тест. Результат теста:
Сразу становится понятно, что аппаратный RAID-контроллер ускоряет операции чтения и записи на дисковый носитель за счет использования кэша, что позволяет быстрее обрабатывать массовые обращения пользователей.
Управление контроллером
Непосредственно из операционной системы управление контроллером производится с помощью программного обеспечения, доступного для скачивания с сайта производителя. Доступны варианты для большинства операционных систем и гипервизоров:
С помощью указанных утилит можно, не прерывая работу сервера, легко управлять логическими и физическими дисками. Также можно задействовать такой полезный функционал, как «подсветка диска». Мы уже упоминали про пятый кабель для подключения SGPIO — этот кабель подключается напрямую в бэкплейн (от англ. backplane — соединительная плата для накопителей сервера) и позволяет RAID-контроллеру полностью управлять световой индикацей каждого диска.
Следует помнить, что бэкплэйны поддерживают не только SGPIO, но и I2C. Переключение между этими режимами осуществляется чаще всего с помощью джамперов на самом бэкплэйне.
Каждому устройству, подключенному к аппаратному RAID-контроллеру Adaptec, присваивается идентификатор, состоящий из номера канала и номера физического диска. Номера каналов соответствуют номерам портов на контроллере.
Замена диска — штатная операция, впрочем, требующая однозначной идентификации. Если допустить ошибку при этой операции, можно потерять данные и прервать работу сервера. С аппаратным RAID-контроллером такая ошибка является редкостью.
Делается это очень просто:
Контроллер даст соответствующую команду на бэкплэйн, и светодиод нужного диска начнет равномерно моргать цветом, отличающимся от стандартного рабочего.
Например, на платформах Supermicro штатная работа диска — зеленый или синий цвет, а «подсвеченный» диск будет моргать красным. Перепутать диски в этом случае невозможно, что позволит избежать ошибки из-за человеческого фактора.
Настройка кэширования
Теперь пару слов о вариантах работы кэша на запись. Вариант Write Through означает, что контроллер сообщает операционной системе об успешном выполнении операции записи только после того, как данные будут фактически записаны на диски. Это повышает надежность сохранности данных, но никак не увеличивает производительность.
Чтобы достичь максимальной скорости работы, необходимо использовать вариант Write Back. При такой схеме работы контроллер будет сообщать операционной системе об успешной IO-операции сразу после того, как данные поступят в кэш.
Важно — при использовании Write Back настоятельно рекомендуется использовать BBU или ZMCP-модуль, поскольку без него при внезапном отключении электричества часть данных может быть утеряна.
Настройка мониторинга
Вопрос мониторинга статуса работы оборудования и возможности оповещения стоит достаточно остро для любого системного администратора. Для того чтобы настроить «связку» из Zabbix и RAID-контроллера Adaptec рекомендуем воспользоваться перечисленными решениями.
Зачастую требуется отслеживать состояние контроллера напрямую из гипервизора, например, VMware ESXi. Задача решается с помощью установки CIM-провайдера с помощью инструкции Microsemi.
Прошивка
Необходимость прошивки RAID-контроллера возникает чаще всего для исправления выявленных производителем проблем с работой устройства. Несмотря на то, что прошивки доступны для самостоятельного обновления, к этой операции следует подойти очень ответственно, особенно если процедура выполняется на «боевой» системе.
Если нашему клиенту требуется сменить версию прошивки контроллера, то ему достаточно создать тикет в нашей панели управления. Системные инженеры выполнят перепрошивку RAID-контроллера до требуемой версии в указанное время и сделают это максимально корректно.
Важно — не следует выполнять перепрошивку самостоятельно, поскольку любая ошибка может привести к потере данных!
Заключение
Использование аппаратного RAID-контроллера оправдано в большинстве случаев, когда требуется высокая скорость и надежность работы дисковой подсистемы.
Системные инженеры Selectel бесплатно выполнят базовую настройку дискового массива на аппаратном RAID-контроллере при заказе сервера произвольной конфигурации. В случае, если потребуется дополнительная помощь с настройкой, мы будем рады помочь в рамках нашей услуги администрирования. Также мы подготовили для наших читателей небольшую памятку по командам утилиты arcconf.
Используете ли вы аппаратные RAID-контроллеры? Ждем вас в комментариях.
Источник
Как создать и настроить программный RAID 0, 1 массив в Windows
Каким бы мощным ни был ваш компьютер, у него все же есть одно слабое место: жесткий диск. Он отвечает за целостность и безопасность ваших данных и оказывает значительное влияние на производительность вашего ПК. При этом жесткий диск – единственное устройство в системном блоке, внутри которого есть движущиеся механические части, что и делает его слабым звеном, способным полностью вывести из строя ваш компьютер.

Сегодня есть два способа ускорить работу вашего компьютера: первый – купить дорогой SSD, а второй – по максимуму использовать материнскую плату, то есть настроить массив RAID 0 из двух жестких дисков. Тем более RAID-массив можно использовать и для повышения безопасности ваших важных данных.
В этой статье мы рассмотрим, как создать программный RAID с помощью встроенных инструментов Windows.
Содержание:
Современные материнские платы позволяют создавать дисковые RAID-массивы без необходимости докупать оборудование. Это позволяет значительно сэкономить на сборке массива в целях повышения безопасности данных или ускорения работы компьютера.
Создание программного RAID с помощью встроенных инструментов Windows 8 или Windows 10
Windows 10 имеет встроенную функцию «Дисковые пространства», которая позволяет объединять жесткие диски или твердотельные накопители в один дисковый массив, называемый RAID. Эта функция была впервые представлена в Windows 8 и значительно улучшена в Windows 10, что упростило создание многодисковых массивов.
Чтобы создать массив RAID, вы можете использовать как функцию «Дисковые пространства», так и командную строку или «Windows PowerShell».
Перед созданием программного RAID необходимо определить его тип и для чего он будет использоваться. Сегодня Windows 10 поддерживает три типа программных массивов: RAID 0, RAID 1, RAID 5 (Windows Server).
Вы можете прочитать о том, какие типы RAID существуют и какой RAID в каких целях лучше использовать, в статье «Типы RAID и какой RAID лучше всего использовать».
Итак, мы определились с типом RAID. Затем для создания дискового массива мы подключаем все диски к компьютеру и загружаем операционную систему.
Стоит отметить, что все диски будущего RAID должны быть одинаковыми не только по объему памяти, но желательно и по всем другим параметрам. Это поможет избежать многих неприятностей в будущем.
Далее, чтобы создать программный RAID-массив, выполните следующие действия:
Шаг 1. Откройте «Панель управления», щелкнув правой кнопкой мыши «Пуск» и выбрав «Панель управления» («Control Panel»).

Шаг 2: В открывшемся окне выберите «Дисковые пространства» («Storage Spaces»)

Шаг 3. Затем выберите «Создать новый пул и дисковое пространство» («Create a new pool and storage space»).

Шаг 4: Выберите диски, которые вы хотите добавить в массив RAID, и нажмите «Создание пула носителей» («Create pool»).

Важно: все данные на дисках, из которых создается RAID-массив, будут удалены. Поэтому заранее сохраните все важные файлы на другой диск или внешний носитель.
После того, как вы настроили массив, вы должны дать ему имя и правильно настроить.
Шаг 5: В поле «Имя» введите имя нашего RAID-массива.

Шаг 6: Затем выберите букву и файловую систему для будущего RAID

Именно с этим именем и буквой массив будет отображаться в системе Windows.
Шаг 7: Теперь вы должны выбрать тип устойчивости.
В зависимости от выбранного типа RAID мастер автоматически установит максимально доступную емкость дискового массива.

Обычно это значение немного ниже, чем фактический объем доступных данных, и вы также можете установить больший размер дискового пространства. Однако имейте в виду, что это сделано для того, чтобы вы могли установить дополнительные жесткие диски, когда массив будет заполнен, без необходимости перестраивать его.
Шаг 8. Нажмите «Create storage space».
После того, как мастер настроит ваш новый RAID, он будет доступен как отдельный диск в окне «Этот компьютер».

Новый диск не будет отличаться от обычного жесткого диска, и вы можете выполнять с ним любые операции, даже зашифровать его с помощью BitLocker.
Об использовании BitLocker вы можете прочитать в статье «Как зашифровать данные на жестком диске с помощью BitLocker».
Вы можете создать еще один программный RAID. Только количество жестких дисков, подключенных к ПК, ограничивает количество создаваемых RAID-массивов.
Как добавить или удалить диск в уже существующем массиве RAID
Как добавить диск в RAID
Предположим, у вас уже есть программный RAID-массив, и вы его используете. Однажды может возникнуть ситуация, когда вам станет не хватать места на диске. К счастью, Windows 10 позволяет добавить еще один диск в уже существующий массив с помощью встроенных инструментов.
Чтобы добавить диск, вы должны открыть утилиту «Дисковые пространства», используя метод, описанный выше, и выбрать «Добавить диски».

В открывшемся меню выберите диск, который хотите добавить, и нажмите «Добавить диск». Жесткий диск будет добавлен к уже существующему массиву RAID.
Как удалить диск из RAID-массива
Чтобы удалить диск из RAID-массива, следуйте алгоритму:
Шаг 1: Откройте утилиту «Дисковые пространства», как описано выше, и нажмите кнопку «Изменить параметры».
Шаг 2. Откройте существующий массив RAID и выберите «Физические диски».
Шаг 3. Во всплывающем списке выберите диск, который вы хотите удалить, и нажмите «Подготовить к удалению».

Windows автоматически перенесет данные на другие диски, а кнопка «Подготовить к удалению» изменится на «Удалить».
После нажатия кнопки «Удалить» система удалит диск из RAID. Для дальнейшей работы с этим накопителем вам потребуется создать на нем новый раздел. Для этого вы можете использовать встроенную утилиту diskpart или утилиту Disk Management.
Создайте программный RAID с помощью командной строки
Другой способ создать программный RAID – использовать командную строку или Windows PowerShell.
Чтобы создать программный RAID с помощью командной строки:
Шаг 1. Щелкните правой кнопкой мыши «Пуск» и выберите «Командная строка (Администратор)» или «Windows PowerShell (Admin)».

Шаг 2: В открывшемся окне введите команду «diskpart» и нажмите «Enter».

Шаг 3: Чтобы отобразить список дисков, введите «list disk».
Утилита Diskpart отобразит все диски, подключенные к вашему ПК.

Шаг 4: Выберите диски, которые вы хотите добавить в массив RAID, один за другим, и превратите их в динамические диски с помощью команд:
Теперь, когда мы преобразовали наши диски, мы можем создать том RAID, введя следующие команды:
После этого следует убедиться, что массив создан.
Для этого введите команду «list disk».
Все диски будут объединены в один диск.

Шаг 5: Теперь все, что вам нужно сделать, это отформатировать диск и присвоить ему букву. Для этого введите следующие команды:
Шаг 6. Введите «exit» и нажмите Enter.
После этого выбранные диски будут объединены в RAID-массив.
Отметим, что с помощью этого метода будет создан RAID 5.
RAID 0
Если вы хотите создать RAID 0, в утилите Diskpart введите:
RAID 1
Чтобы создать RAID 1, вам необходимо ввести следующие команды одну за другой:
Внимание! Иногда появляется сообщение «Вам следует перезагрузить компьютер, чтобы завершить эту операцию». Если оно появилось – перезагрузите компьютер. Если есть только сообщение об успешной конвертации – продолжайте работу и введите:
После этого будет создан массив RAID 1.
Программное создание RAID в Windows 7
В Windows 7 вы можете использовать утилиту «Управление дисками» для создания программного RAID. Следует отметить, что диск, с которого загружается система, нельзя использовать в RAID, так как он будет преобразован в динамический. Вы можете использовать любые диски, кроме системных.
Шаг 1. Откройте «Пуск», щелкните правой кнопкой мыши «Компьютер» и выберите «Управление».

Шаг 2: В появившемся мастере нажмите «Далее».

Шаг 3. В открывшемся меню вы должны выбрать диски, которые вы хотите объединить в массив RAID, и нажать «Далее».

Шаг 4: Выберите букву для созданного RAID-массива и нажмите «Далее».

Шаг 5: В следующем окне выберите тип файловой системы (NTFS), укажите размер блока и укажите имя тома. После этого нажмите «Далее».

Шаг 6: После того, как система создаст новый массив RAID, нажмите кнопку «Готово».

После нажатия кнопки «Готово» появится окно с предупреждением о том, что будет выполнено преобразование базового диска в динамический и загрузка ОС с динамического диска будет невозможна. Просто нажмите «ОК».
После этого созданный RAID-массив отобразится в окне «Мой компьютер» как обычный жесткий диск, с которым можно выполнять любые операции.
Что делать, если вы потеряли важные данные на RAID-массиве
Использование RAID-массивов может значительно повысить безопасность данных, что очень важно в современном мире. Однако нельзя исключать человеческий фактор.
Потеря важных файлов возможна из-за случайного удаления, форматирования, изменения логической структуры файловой системы и многих других причин. Кроме того, не исключен сбой RAID.
В этой ситуации лучше не принимать поспешных решений. Оптимальный вариант — обратиться к специалистам или воспользоваться специализированным ПО для восстановления данных.
RS RAID Retrieve способен восстановить любой тип RAID-массива, поддерживает все файловые системы, используемые в современных операционных системах.
Восстановление данных с любых RAID массивов

Часто задаваемые вопросы
Это сильно зависит от емкости вашего жесткого диска и производительности вашего компьютера. В основном, большинство операций восстановления жесткого диска можно выполнить примерно за 3-12 часов для жесткого диска объемом 1 ТБ в обычных условиях.
Если файл не открывается, это означает, что файл был поврежден или испорчен до восстановления.
Используйте функцию «Предварительного просмотра» для оценки качества восстанавливаемого файла.
Когда вы пытаетесь получить доступ к диску, то получаете сообщение диск «X: не доступен». или «Вам нужно отформатировать раздел на диске X:», структура каталога вашего диска может быть повреждена. В большинстве случаев данные, вероятно, все еще остаются доступными. Просто запустите программу для восстановления данных и отсканируйте нужный раздел, чтобы вернуть их.
Пожалуйста, используйте бесплатные версии программ, с которыми вы можете проанализировать носитель и просмотреть файлы, доступные для восстановления.
Сохранить их можно после регистрации программы – повторное сканирование для этого не потребуется.
Источник
Содержание
- Как посмотреть состояние raid windows
- Как посмотреть текущее состояние дисков, подключенных к модулю Intel® Integrated RAID, без перезагрузки сервера
- Мониторинг raid массивов в Windows Core
Как посмотреть состояние raid windows
Сообщения: 26926
Благодарности: 3917
на сервере стоит аппаратный raid1 »
как проверить состояние дисков? »
——-
ВНИМАНИЕ ознакомьтесь, прежде чем создать тему! Процессор — мозг компьютера, блок питания — сердце и печень.
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.
Сообщения: 8628
Благодарности: 2126
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
какой контролер не знаю, надо перезагружать »
А посмотреть в Диспетчере Устройств?
как проверить состояние дисков? »
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
Это сообщение посчитали полезным следующие участники:
Сообщения: 8628
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
По поводу утилит – посмотреть Поиском, например запросом (скопировал в запрос вашу информацию без изменений, лишь добавив «utility»): Inte 631xESB/6321ESB — SATA RAID Controller utility. Я знаю, что такая обязана быть – но не знаю, как она звучит конкретно; скорее всего Raid Web Console – и она уже должна бы стоять на вашем сервере, ежели там фабричная установка.
Последний раз редактировалось mwz, 12-09-2014 в 19:06 .
Как посмотреть текущее состояние дисков, подключенных к модулю Intel® Integrated RAID, без перезагрузки сервера
Проверено. Это решение проверено нашими клиентами с целью устранения ошибки, связанной с этими переменными среды
Тип материала Обслуживание и производительность
Идентификатор статьи 000057913
Последняя редакция 19.11.2020
Как узнать текущее состояние дисков, подключенных к модулю Intel® Integrated RAID, без перезагрузки сервера?
Интегрированные контроллеры Intel® RAID на базе RAID (IR):
- Интегрированный RAID-модуль Intel® RMS3JC080
- Intel® RAID Controller RS3UC080
- Intel® RAID Controller RS3FC044
Как это исправить:
Вы можете использовать любой из приведенных далее методов для отображения состояния накопителей, подключенных к упомянутым выше контроллерам Intel® RAID на базе ИК-связи:
- Веб Консоль Intel® RAID 3 (RWC3)
RWC3 поддерживается на Окон И Управлением Это может контролировать и контролировать продукты Intel RAID. См. в Руководство пользователя RWC3 для получения информации об установке и использовании.
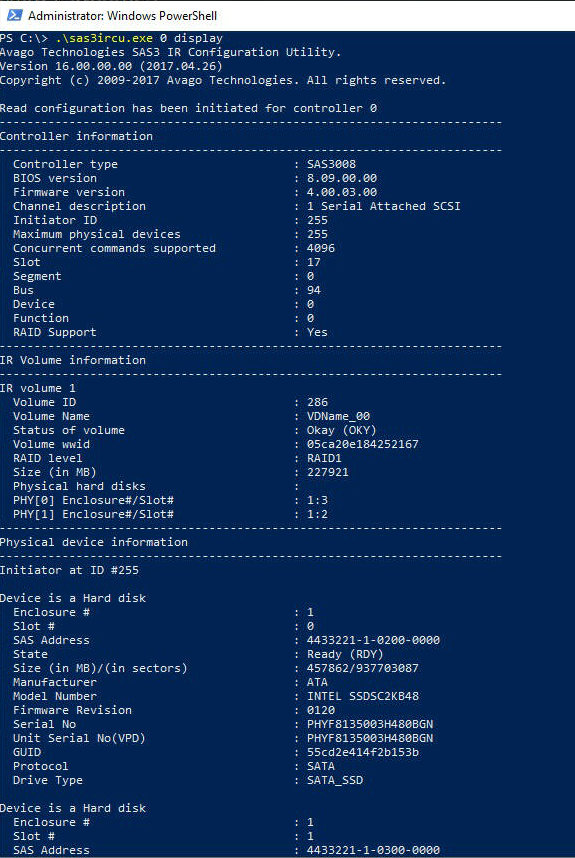
SAS3IRCU
SAS3IRCU — это приложение на базе командной строки, которое можно найти в страница встроенного по. См. в Руководство пользователя по(Приложение A. Использование встроенного по конфигурации RAID SAS-3) для получения дополнительной информации о параметрах и синтаксисе команд.
Для отображения состояния накопителей может использоваться следующая синтаксическая конструкция:
sas3ircu.exe 0 display
Привести к & получения дополнительной информации:
См. также см. раздел
ИНФОРМАЦИЯ, ПРЕДСТАВЛЕННАЯ В ЭТОЙ СТАТЬЕ, ИСПОЛЬЗОВАЛАСЬ НАШИМИ КЛИЕНТАМИ, НО НЕ ТЕСТИРОВАЛАСЬ, ПОЛНОСТЬЮ НЕ ПРОШЛА РЕПЛИКАЦИЯ ИЛИ НЕ ПРОВЕРЯЛАСЬ КОРПОРАЦИЕЙ INTEL. ОТДЕЛЬНЫЕ РЕЗУЛЬТАТЫ МОГУТ РАЗЛИЧАТЬСЯ. ВСЕ публикации и использование материалов на данном сайте задаются в соответствии с положениями и условиями использования веб-узла.
Мониторинг raid массивов в Windows Core

За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
- Powershell
- EventLog
- Raidcfg32.exe
- Вспомогательные:
- WinRM
- Rsyslog
- LogAnalyzer
Первым делом нужно установить драйвер для raid контроллера:
cmd.exe pnputil.exe -i -a [путь до *.inf]
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Подключаем содержимое файла EntryType.txt и удаляем в нем False, тем самым выводим корректный -EntryType что в свою очередь и является «Уровнем» сообщения.
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:
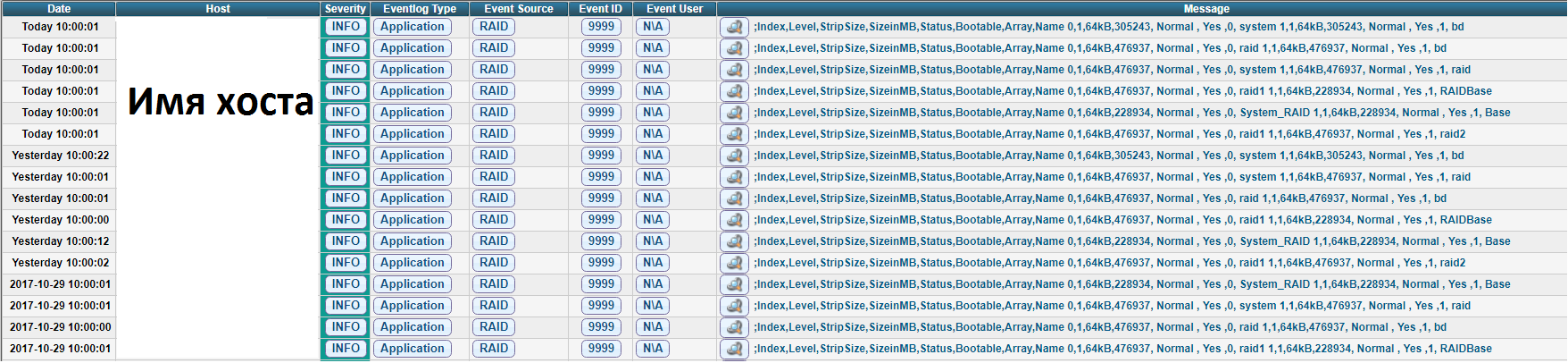
UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Adblock
detector
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>

Всем привет!
За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
- Powershell
- EventLog
- Raidcfg32.exe
- Вспомогательные:
- WinRM
- Rsyslog
- LogAnalyzer
Первым делом нужно установить драйвер для raid контроллера:
cmd.exe pnputil.exe -i -a [путь до *.inf]
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
New-EventLog -Source "RAID" -LogName "Application"
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
c:RAIDCFG32RAIDCFG32.exe /stv > c:RAIDCFG32raidcfgStatus.txt
Get-Content "c:RAIDCFG32raidcfgStatus.txt" | ForEach-Object {$_ -replace ('"'),' '} > c:RAIDCFG32raidstatus.txt
$1 = Get-Content c:RAIDCFG32raidstatus.txt
$2 = "$1"
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
$2 -match "failed" > c:RAIDCFG32errorRAID.txt
$2 -match "disabled" >> c:RAIDCFG32errorRAID.txt
$2 -match "degraded" >> c:RAIDCFG32errorRAID.txt
$2 -match "rebuild" >> c:RAIDCFG32errorRAID.txt
$2 -match "updating" >> c:RAIDCFG32errorRAID.txt
$2 -match "critical" >> c:RAIDCFG32errorRAID.txt
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
$3 = Get-Content c:RAIDCFG32errorRAID.txt
$4 = "$3"
$5 = $4 -match "true"
$6 = "$5"
$7 = $6 -replace "true", "Error" > c:RAIDCFG32EntryType.txt
$8 = $6 -replace "false", "Information" >> c:RAIDCFG32EntryType.txt
Подключаем содержимое файла EntryType.txt и удаляем в нем False, тем самым выводим корректный -EntryType что в свою очередь и является «Уровнем» сообщения.
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
$9 = Get-Content c:RAIDCFG32EntryType.txt
$10 = "$9"
$11 = $10 -replace "False"
Write-EventLog -LogName Application -Source "RAID" -EventID 9999 -EntryType "$11" -Message "$1"
exit
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:

Скрипт без комментариев
c:RAIDCFG32RAIDCFG32.exe /stv > c:RAIDCFG32raidcfgStatus.txt
Get-Content "c:RAIDCFG32raidcfgStatus.txt" | ForEach-Object {$_ -replace ('"'),' '} > c:RAIDCFG32raidstatus.txt
$1 = Get-Content c:RAIDCFG32raidstatus.txt
$2 = "$1"
$2 -match "failed" > c:RAIDCFG32errorRAID.txt
$2 -match "disabled" >> c:RAIDCFG32errorRAID.txt
$2 -match "degraded" >> c:RAIDCFG32errorRAID.txt
$2 -match "rebuild" >> c:RAIDCFG32errorRAID.txt
$2 -match "updating" >> c:RAIDCFG32errorRAID.txt
$2 -match "critical" >> c:RAIDCFG32errorRAID.txt
$3 = Get-Content c:RAIDCFG32errorRAID.txt
$4 = "$3"
$5 = $4 -match "true"
$6 = "$5"
$7 = $6 -replace "true", "Error" > c:RAIDCFG32EntryType.txt
$8 = $6 -replace "false", "Information" >> c:RAIDCFG32EntryType.txt
$9 = Get-Content c:RAIDCFG32EntryType.txt
$10 = "$9"
$11 = $10 -replace "False"
Write-EventLog -LogName Application -Source "RAID" -EventID 9999 -EntryType "$11" -Message "$1"Автор: den_scs
Источник
Достаточно часто использую программные RAID-массивы на Windows-серверах: удобно, дёшево, сердито. 🙂
Однако, за программным RAID-массивом, как и за любым другим, нужно следить. Хотя бы чуть-чуть.
Есть отличная статья, которая описывает, как следить за программным RAID-массивом в Linux: https://serveradmin.ru/monitoring-programmnogo-reyda-mdadm-v-zabbix/
И тут я подумал: “А чем Windows хуже?”. Сказано, – сделано. 🙂
Шаг 1. Настройка Zabbix-client на наблюдаемом сервере
Вояем простенький скрипт, который выводит “0”, если с массивом всё хорошо, и “1”, если есть проблемы. Сразу замечу, что скрипт писался с расчётом на то, что Windows Server у вас использует по умолчанию русский язык. Если же у вас используется другой язык, рекомендую от имени администратора выполнить команду “echo list volume | diskpart” и посмотреть, что выводится в том случае, если какой-то RAID-массив имеет проблемы.
Текст скрипта
@echo off
echo list volume | diskpart | findstr /i ошибка > %TEMP%mdadm.txt
set /p a=< %TEMP%mdadm.txt
echo %a% >nul
If %Errorlevel%==0 (echo 1) else (echo 0)
Открываем “блокнот”, в новый документ вставляем указанный выше текст и записываем всё это в bat-файл. У меня Zabbix-Client на серверах обычно установлен в папку с именем “C:zabbix”, поэтому полный путь до файла со скриптом будет таким: “C:zabbixraid_status.bat”
Теперь открываем файл с конфигурацией Zabbix-клиента, который у меня расположен по адресу “C:zabbixzabbix_agentd.win.conf”, и в самый конец файла дописываем новую строку
UserParameter=raid_status, C:zabbixraid_status.bat
После того, как сохранили конфигурацию, перезапускаем службу агента. Я обычно это делаю при помощи оснастки “Управление компьютером”.
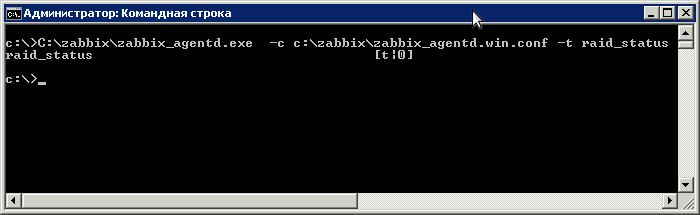
Теперь нужно проверить, всё ли правильно мы сделали. Открываем “От имени администратора” консоль (CMD) и подаём команду
C:zabbixzabbix_agentd.exe -c c:zabbixzabbix_agentd.win.conf -t raid_status
Если будет выведено “raid_status [t|0]”, значит вы всё настроили правильно.
Шаг 2. Настройка Zabbix-Server
Сервер настраиваем по аналогии с указанной выше статьёй: https://serveradmin.ru/monitoring-programmnogo-reyda-mdadm-v-zabbix/
Только всегда нужно делать “поправку на ветер”. Ну, например, я использую элемента данных “raid_status”, а в статье используется “mdadm.status”.
В статье написано всё очень подробно. Я просто приведу свои скриншоты. 🙂
Используемая вами версия браузера не рекомендована для просмотра этого сайта.
Установите последнюю версию браузера, перейдя по одной из следующих ссылок.
- Safari
- Chrome
- Edge
- Firefox
Веб Консоль Intel® RAID 3 (RWC3) для Windows*
Введение
Устанавливает веб-приложение для мониторинга и управления Intel RAID продукцией для Windows*.
Файлы, доступные для скачивания
-
Windows Server 2022 family*, Windows Server 2019 family*
-
Размер: 54.1 MB
-
SHA1: 6AAEAD4B8E82203907B01C2B7642A541E487A972
Подробное описание
Цель
Установите Веб Консоль Intel® RAID 3 (RWC3) — веб-приложение, которое выполняет мониторинг, обслуживание, поиск и устранение неисправностей, а также функции конфигурации для следующей Intel RAID продукции.
Модули и адаптеры трехре режимов
Intel® RAID Adapter RS3P4TF160F, RS3P4MF088F, RSP3DD080F, RSP3MD088F, RSP3TD160F, RSP3WD080E
Intel® RAID Module RMSP3AD160F, RMSP3CD080F RMSP3HD080E
Intel® Storage Adapter RS3P4QF160J¹, RS3P4GF016J¹, RSP3QD160J¹, RSP3GD016J¹
Intel® Storage Module RMSP3JD160J¹
Модули и адаптеры со скоростью 12 Гбит/с
Intel® Integrated RAID Module RMS3AC160, RMS3CC040, RMS3CC080, RMS3HC080, RMS3JC080¹, RMS3VC160¹
Intel® RAID Controller RS3DC040, RS3DC080, RS3FC044¹, RS3GC008¹, RS3MC044, RS3SC008, RS3UC080¹, RS3UC080J¹, RS3WC080
Платы моста со скоростью 12 Гбит/с и встроенные контроллеры
Интегрированный RAID-контроллер Intel® RS3YC (интегрированный контроллер на Intel Server Board S2600CW2SR / S2600CWTSR / S2600CW2S / S2600CWTS)
Интегрированный RAID-контроллер Intel® RMSP3LD060 (интегрированный контроллер на базе AHWBPBGB24R)
Intel RAID Controller RS3LC5 (встроенный контроллер AHWBP12GBGBR5 / AHWKPTP12GBGBR5)
Intel RAID Controller RS3LC (интегрированный контроллер на AHWBP12GBGB / AHWKPTP12GBGBR)
Intel RAID Controller RS3KC¹ (интегрированный контроллер на AHWBP12GBGBIT / AHWKPTP12GBGBIT)
Intel RAID Controller RS3PC¹ (интегрированный контроллер на AHWBPBGB24 для / FHWKPTPBGB24)
Intel® Embedded Server RAID Technology 2
Ограниченные поддерживаемые контроллеры:
Модули и адаптеры 6 Гбит/с
Intel® Integrated RAID Module RMS25PB080(N), RMS25PB040, RMS25CB080(N), RMS25CB040, RMS25JB040¹, RMS25JB080¹, RMS25KB040¹, RMS25KB080¹, RMS25LB080
Intel® RAID Controller RS25AB080, RS25SB008, RS25DB080, RS25NB008, RS25FB044¹, RS25GB008¹
¹RWC3 ограничивается отображением истории энергонезависимых событий только для этих контроллеров.
Другие темы
Веб Консоль Intel® RAID 3 Руководство по установке
Этот скачиваемый файл подходит для нижеуказанных видов продукции.
Отказ от ответственности1
Информация о продукте и производительности
Корпорация Intel находится в процессе удаления неинклюзивных формулировок из нашей текущей документации, пользовательских интерфейсов и кода. Обратите внимание, что обратные изменения не всегда возможны, и некоторые неинклюзивные формулировки могут остаться в старой документации, пользовательских интерфейсах и коде.
Содержание данной страницы представляет собой сочетание выполненного человеком и компьютерного перевода оригинального содержания на английском языке. Данная информация предоставляется для вашего удобства и в ознакомительных целях и не должна расцениваться как исключительная, либо безошибочная. При обнаружении каких-либо противоречий между версией данной страницы на английском языке и переводом, версия на английском языке будет иметь приоритет и контроль.
Посмотреть английскую версию этой страницы.
Введение
Есть у меня в парке серверов множество различных рейд-контроллеров, в том числе софтовых(mdadm). У каждого из них имеются различные средства мониторинга, но хотелось бы все это отслеживать централизовано, например через zabbix, а в случае изменения состояния любого из массивов — получать уведомления, например по почте. Данная статья не является пошаговым руководством, а представляет из себя набор заметок на память для различных контроллеров. В каждом подразделе описана техника получения информации о состоянии массивов zabbix-агентом.
mdadm
В Linux mdadm есть файл /proc/mdstat, в котором содержится информаци о всех массивах и их состоянии. У каждого массива есть вот такое текстовое обозначение: [UU] (кол-во букв U зависит от кол-ва дисков в массиве). Если один или более дисков выходит из строя, то вместо буквы U появляется знак подчеркивания: _ Соответственно ищем подобные массивы и подсчитываем их кол-во, если их больше 0, то поднимаем панику. В конфиге агента добавляем такой пользовательский параметр:
|
UserParameter=custom.softraid.status,egrep —c «[.*_.*]» /proc/mdstat |
И тестируем:
|
# zabbix_agentd -t custom.softraid.status custom.softraid.status[egrep —c «[.*_.*]» /proc/mdstat] [t|0] |
Как видно, параметр вернул ноль( [t|0] ), все нормально.
3Ware
Для мониторинга контроллеров 3ware (теперь уже LSI) понадобится утилита 3w_cli, скачать ее можно с оф. сайта производителя контроллера, либо поставить из стороннего репозитория(в случае с debian): hwraid.
Утилита 3w_cli работает только из под рута, поэтому нужно установить sudo и в конфиге разрешить забиксу без пароля запуск утилиты, добавляем в конец /etc/sudoers:
|
zabbix ALL=(ALL) NOPASSWD:/opt/3ware/CLI/tw_cli |
Теперь добавляем в конфиг забикса пользовательский параметр:
|
UserParameter=custom.3ware.status,sudo /opt/3ware/CLI/tw_cli /c0 show allunitstatus | grep «Not Optimal» | awk ‘{print $6}’ |
Этот параметр аналогичным образом подсчитывает кол-во массивов(на первом контроллере), которое имеет статус «Not Optimal». Если в сервере установлено несколько контроллеров, то можно будет сделать скрипт с несколькими подобными командами и в конце сумировать результат.
Проверяем работоспособность:
|
# zabbix_agentd -t custom.3ware.status custom.3ware.status[sudo /opt/3ware/CLI/tw_cli /c0 show allunitstatus | grep «Not Optimal» | awk ‘{print $6}’] [t|0] |
Все массивы в норме ([t|0]).
Adaptec
Для мониторинга контроллеров Adaptec понадобится утилита arcconf, скачать ее можно с оф. сайта производителя контроллера, либо поставить из стороннего репозитория(в случае с debian): hwraid.
В конфиг zabbix-агента добавляем следующий пользовательский параметр:
|
UserParameter=custom.adaptec.status,/opt/adaptec/arcconf GETCONFIG 1 | grep «Status of logical device» | grep —cv Optimal |
Этот параметр производит подсчет кол-ва массивов первого контроллера, статус которых отличается от «Optimal». Если в системе более одного контроллера, то нужно создать скрипт, который будет выполнять подобную команду для каждого контроллера и суммировать результат.
Проверяем:
|
# zabbix_agentd -t custom.adaptec.status custom.adaptec.status[/opt/adaptec/arcconf GETCONFIG 1 | grep «Status of logical device» | grep —cv Optimal] [t|0] |
Все нормально, кол-во отказавших массивов ноль ([t|0]).
LSI(IBM)
В серверах IBM серии X, например x3650 ставят контроллеры LSI, которые управляются утилитой megacli, скачать ее можно с сайта IBM(например ibm_utl_sraidmr_megacli-8.04.10_linux_32-64.zip). Есть пакеты только для redhat и suse, но не составляет труда конвертировать их в deb с поомщью alien. Делается это командой:
|
# alien —scripts _pakage_name_.rpm |
После конвертирования устанавливаем пакеты и добавляем пользовательский параметр в zabbix-агент:
|
UserParameter=custom.lsi.status,megacli —LDInfo —Lall —aAll | grep State | grep —vc Optimal |
Этот параметр выполняет подсчет всех массивов со статусом отличным от «Optimal».
Проверяем:
|
# zabbix_agentd -t custom.lsi.status custom.lsi.status[megacli —LDInfo —Lall —aAll | grep State | grep —vc Optimal] [t|0] |
LSI(Intel)
В некоторых сервера с мат. платами intel устанавливали интегрированные контроллеры axx4sasmod. Управлять и мониторить их можно с помощью RAID Web Console 2(не понятно, почему она называется Web, когда работает не через браузер, а требует установки на клиенте), либо с помощью snmp. Команднострочная утилита CmdTool2 почему-то контроллер не обнаружила. Корректно настроить работу через snmp на Debian мне не удалось, как это сделать на редхат-подобных описано в статье, ссылка на которую дана ниже.
Пример создания тригера
Создадим тригер отслеживания состояния массивов на примере mdadm.
Создаем шаблон Configuration → Templates → Create template, задаем имя и добавляем в группу Templates:

В шаблоне открываем вкладку Items и создаем элемент.

Указываем ключ(имя пользовательского параметра в zabbix-агенте) и уменьшаем кол-во дней хранения значений:

Дальше переходим во вкладку Triggers и создаем тригер,

в поле Expression (Выражение) нажимаем на конпке Add и в появившемся окне в поле Item нажимаем Select, в появившемся окне выбираем группу Templates и только что созданый шаблон,
там у нас один единственный элемент(Item), выбираем его.

В выпадающем меню Function выбираем «Last (most recent) T value is NOT N» и проверяем, что в поле N стоит ноль, таким образом трегер будет проверять, что полученное значение от zabbix-клиента(кол-во отказавших массивов) равняется нолю, если это не так — он сработает. Вот что должно получиться(если все нормально, нажимаем Insert):

Ну и в заключении задаем имя тригера и уровень серъезности произшествия, я оценил его как Hight:

Нажимаем сохранить(Save).