← →
HF-Trade ©
(2011-09-18 19:04)
[0]
Файл —
<?xml version=»1.0″ encoding=»windows-1251″?>
<m_list>
<movi>
<id>21</id>
<title><![CDATA[One]]></title>
……..
Код —
XMLDocument1.LoadFromFile(«1.xml»);
XMLDocument1.Active := true;
XMLDocument1.SaveToFile(«2.xml»);
XMLDocument1.Active := false;
При сохранении выдает сообщение из сабжа.
В файле есть вот такие теги —
<solution><«Bræin»></solution>
Открыл файл 2.xml
Он сохранен не полностью, до символов — æ
Собсно вопрос —
Документ и так в кодировке 1251, почему выскакивает данная ошибка, и как от нее избавится?
![]()
![]()
← →
HF-Trade ©
(2011-09-18 19:06)
[1]
P.S.
Символ æ
В файле отображен как —
&
#
230;
Слитно.
![]()
![]()
← →
Игорь Шевченко ©
(2011-09-18 19:30)
[2]
& # 230 — это «ц» в Win-1251, а вовсе не æ
![]()
![]()
← →
Anatoly Podgoretsky ©
(2011-09-18 20:25)
[3]
В кодировке 1251 нет символа æ
![]()
![]()
← →
Dimka Maslov ©
(2011-09-18 21:03)
[4]
давно уже пора забыть про всякие там 1251 и пользоваться юникодом.
![]()
![]()
Такое сообщение выдается на нестандартные символы, например, «&», ‘ скрытые пробелы, некоторые тире и т.п.
Уберите из текста нестандартные символы.
Если не находите нестандартных символов, то рекомендуем текст сначала скопировать в блокнот Windows, сохранять текстовый файл в кодировке ANSI, и копировать в Excel-таблицу текст блокнота. Для большей верности, вставляйте текст в строку формул ячейки.
- Методическая поддержка
- 01 Платные образовательные услуги (ПОУ)
- 1.1 Расчет стоимости платных образовательных услуг
- 1.2. Договор об оказании платных образовательных услуг
- 1.3 Мониторинг стоимости платных образовательных услуг
- 02 Отчетность о результатах деятельности и об использовании имущества
- 2.1 Отчет о результатах деятельности
- 03 Бюджетирование и планирование ФХД
- 3.01 Цели, задачи и принципы финансового планирования
- 3.02 Управленческая учетная политика
- 3.03 Состав показателей доходов и расходов
- 3.04 Виды и формы бюджетов
- 3.05 Нормативно-методические основы формирования плана ФХД
- 3.06 Формирование первичного плана ФХД
- 3.07 Внесение изменений в план ФХД
- 3.08 Соблюдение сроков формирования и размещения плана ФХД
- 3.09 Составление сведений об операциях с целевыми субсидиями
- 3.10 Дополнительные сведения о деятельности учреждения в плане ФХД
- 3.11 Формирование и корректировка доходной части бюджета учреждения
- 3.12 Формирование и корректировка расходной части бюджета
- 3.13 Балансировка бюджета
- 3.14 Расширенная аналитика
- 3.15 Расчетные формы в привязке к показателям
- 3.16 Распределение косвенных затрат
- 3.17 Закупки (Способы настройки процессов)
- 3.18. Связь с бухгалтерским учетом (Способы настройки процессов)
- 3.19 Получение фактических данных (способы настройки процессов)
- 3.20 Оценка финансовой устойчивости учреждения
- 3.21 Оценка рисков финансового состояния учреждения
- 3.22 Формирование ПФХД на 2020 и плановый период 2021 и 2022 годов
- 3.23 Расходы на оказание образовательных услуг по программам высшего образования
- 3.24 Иные вопросы
- 04 Программа повышения квалификации «Тьюторы»
- 4.1 Стратегическое планирование
- 4.2 Управление финансами в образовательной организации высшего образования
- 4.3 Управленческая учетная политика
- 4.4 Система учета как инструмент реализации стратегии развития образовательной организации
- 4.5 АСУ ПФХД
- 4.6 Внутренний финансовый контроль
- 05 Перечень государственных услуг
- 5.1 Перечень государственных и муниципальных услуг
- 5.2 Ведомственный перечень государственных услуг и работ Минобрнауки России
- 06 Государственное задание и отчет о его выполнении
- 6.1 Методические рекомендации о выполнении ГЗ
- 6.2 Методика расчета среднегодового контингента
- 6.3 Формирование и предоставление отчета о выполнении государственного задания
- 07 Расчет субсидии на выполнение ГЗ
- 7.1 Общие вопросы
- 7.2 Применение корректирующих коэффициентов
- 7.3 Содержание составляющих затрат
- 7.4 Реорганизация (ликвидация) подведомственных учреждений
- 7.5 Финансовое обеспечение услуг, не входящих в сферу деятельности Минобрнауки России
- 08 Нормативные затраты
- 8.1 Нормативное регулирование формирования объемов финансового обеспечения выполнения ГЗ
- 8.2 Базовые нормативы затрат (БНЗ)
- 8.3 Корректирующие коэффициенты
- 8.4 Определение нормативных затрат на выполнение государственных работ
- 09 Стипендиальный фонд
- 9.1 Академическая стипендия
- 9.2 Социальная стипендия
- 9.3 Президентские и прочие виды стипендии
- 10 Иные цели и публичные обязательства
- 10.1 Общие вопросы
- 10.2 Материальное обеспечение детей-сирот
- 11 АСУ ПФХД
- 11.1 План закупок
- 11.2 План доходов
- 11.3 Лимиты
- 11.4 План функциональных расходов
- 11.5 Планы ФХД, сводные планы ФХД
- 11.6 Перечень дополнительных показателей
- 11.7 Внутренние расчеты
- 12 Рейтинг качества финансового менеджмента
- 12.1 Методика расчета рейтинга качества финансового менеджмента
- 13 Текущее финансирование подведомственных организаций
- 14.1 Для негосударственных и субъектовых образовательных организаций
- 14.2 Для федеральных государственных образовательных организаций ВО подведомственных Минобрнауки РФ
- 14 Мониторинг численности и оплаты труда работников учреждений
- 15 Сбор информации по выплатам руководителю
- 16 Затраты на повышение заработной платы до МРОТ
- 17 Предоставление субсидий на основные средства
- 18 Формирование финансового обеспечения государственного задания на НИР
- 19 Отчет о публикационной активности
- 20 Отчетность по НИР
- 21 Отчет о принятых и исполненных в отчетном финансовом году и подлежащих принятию в текущем финансовом году обязательствах за счет средств целевых субсидий
- 22 Информационный портал «Поступай правильно»
- 23 Форма Согласия налогоплательщика (плательщика страховых взносов) на признание сведений, составляющих налоговую тайну, общедоступными
- 24 Мониторинг коммунальных услуг
- 01 Платные образовательные услуги (ПОУ)
- Техническая поддержка
- 01 Аналитический компонент комплексной системы управления финансами (АК КСУФ)
- 1.1 Вопросы администрирования системы
- 1.2 Вопросы функционирования системы
- 02 АСУ ПФХД
- 2.1 Вопросы администрирования системы
- 2.2 Вопросы функционирования системы
- 03 ИС сбора и обработки экономических показателей
- 3.01 Работа в разделе «Мониторинг численности и оплаты труда работников учреждений»
- 3.02 Работа в разделе «Сбор информации для формирования проекта бюджета, расчета объемов субсидий на финансовое обеспечение выполнения государственного задания»
- 3.03 Работа в разделе «Оценка финансовой устойчивости учреждений в текущей ситуации»
- 3.04 Работа в разделе «Отчет о результатах деятельности федеральных государственных учреждений»
- 3.05 Работа в разделе «Мониторинг налогообложения»
- 3.06 Работа в разделе «Отчет о принятых и исполненных в отчетном финансовом году и подлежащих принятию в текущем финансовом году обязательствах»
- 3.07 Работа в разделе «Плановые и отчетные показатели для расчета субсидий на 2021 год»
- 3.08 Работа в разделе «Расчетные объемы поставки газа»
- 3.09 Работа в разделе «Оценка рисков финансового состояния организаций»
- 3.10 Работа в разделе «Расходы на обучение по укрупненным группам специальностей и направлений подготовки»
- 3.11 Работа в разделах «Сбор бухгалтерской отчетности учреждений, подведомственных Минобрнауки России»
- 3.12 Работа в разделе «Сведения для расчета коэффициента платной деятельности»
- 3.13 Работа в разделе «Сведения о реализации органами государственной власти субъектов РФ мер, направленных на финансовое обеспечение мероприятий, реализуемых федеральными организациями»
- 3.14 Работа в разделе «Обеспечение организациями выполнения Методических рекомендаций по профилактике коронавирусной инфекции (COVID-19) №МР 3.1/2.1.0205-20»
- 3.15 Работа в разделе «Расчет потребности материального обеспечения детей-сирот в 2020 году»
- 3.16 Работа в разделе «Мониторинг стоимости коммунальных услуг»
- 04 ИС формирования ГЗ и сбора отчетов о выполнении ГЗ
- 4.1 Вопросы доступа к системе
- 4.2 Работа в разделе «Отчет о выполнении ГЗ. Форма №1»
- 4.3 Работа в разделах «Отчет о выполнении ГЗ. Форма №2», «Отчет о выполнении ГЗ. Форма №3»
- 4.4 Общие вопросы по работе с ИС
- 05 ИС по платным образовательным услугам
- 5.1 Регистрация в системе
- 5.2 Общие вопросы по работе ИС
- 5.3 Мониторинг ПОУ
- 06 ИС сбора, обработки и аналитической оценки заявки на получение субсидий
- 07 Система управления НИР
- 08 Формирование ПФХД на 2020 год и плановый период 2021 и 2022 годов
- 09 Информационный портал «Поступай правильно»
- 10 Система формирования и ведения паспортов выполнения работ
- 11 Информационная система «Судебный мониторинг»
- 01 Аналитический компонент комплексной системы управления финансами (АК КСУФ)
Содержание
- Работа с кодировкой текста
- Способ 1: изменение кодировки с помощью Notepad++
- Способ 2: применение Мастера текстов
- Способ 3: сохранение файла в определенной кодировке
- Вопросы и ответы

С потребностью менять кодировку текста часто сталкиваются пользователи, работающие браузерах, текстовых редакторах и процессорах. Тем не менее, и при работе в табличном процессоре Excel такая необходимость тоже может возникнуть, ведь эта программа обрабатывает не только цифры, но и текст. Давайте разберемся, как изменить кодировку в Экселе.
Урок: Кодировка в Microsoft Word
Работа с кодировкой текста
Кодировка текста – эта набор электронных цифровых выражений, которые преобразуются в понятные для пользователя символы. Существует много видов кодировки, у каждого из которых имеются свои правила и язык. Умение программы распознавать конкретный язык и переводить его на понятные для обычного человека знаки (буквы, цифры, другие символы) определяет, сможет ли приложение работать с конкретным текстом или нет. Среди популярных текстовых кодировок следует выделить такие:
- Windows-1251;
- KOI-8;
- ASCII;
- ANSI;
- UKS-2;
- UTF-8 (Юникод).
Последнее наименование является самым распространенным среди кодировок в мире, так как считается своего рода универсальным стандартом.
Чаще всего, программа сама распознаёт кодировку и автоматически переключается на неё, но в отдельных случаях пользователю нужно указать приложению её вид. Только тогда оно сможет корректно работать с кодированными символами.
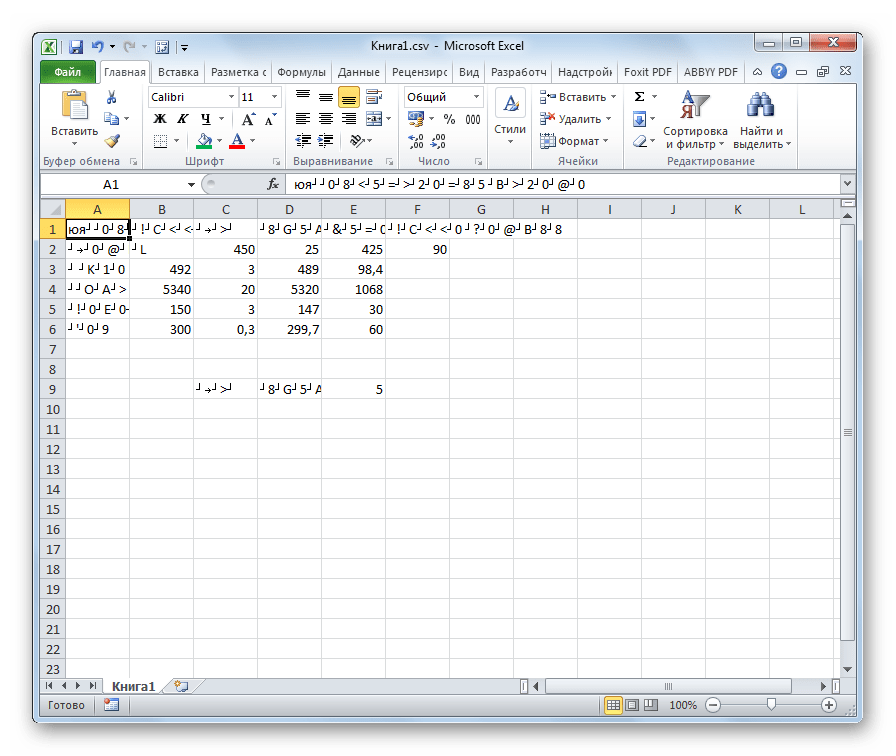
Наибольшее количество проблем с расшифровкой кодировки у программы Excel встречается при попытке открытия файлов CSV или экспорте файлов txt. Часто, вместо обычных букв при открытии этих файлов через Эксель, мы можем наблюдать непонятные символы, так называемые «кракозябры». В этих случаях пользователю нужно совершить определенные манипуляции для того, чтобы программа начала корректно отображать данные. Существует несколько способов решения данной проблемы.
Способ 1: изменение кодировки с помощью Notepad++
К сожалению, полноценного инструмента, который позволял бы быстро изменять кодировку в любом типе текстов у Эксель нет. Поэтому приходится в этих целях использовать многошаговые решения или прибегать к помощи сторонних приложений. Одним из самых надежных способов является использование текстового редактора Notepad++.
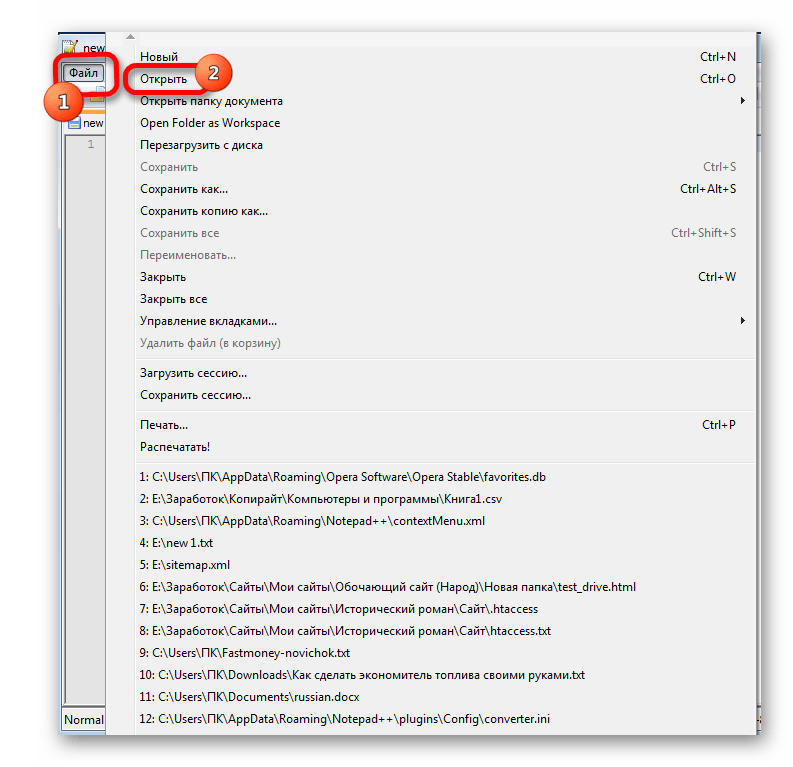
- Запускаем приложение Notepad++. Кликаем по пункту «Файл». Из открывшегося списка выбираем пункт «Открыть». Как альтернативный вариант, можно набрать на клавиатуре сочетание клавиш Ctrl+O.
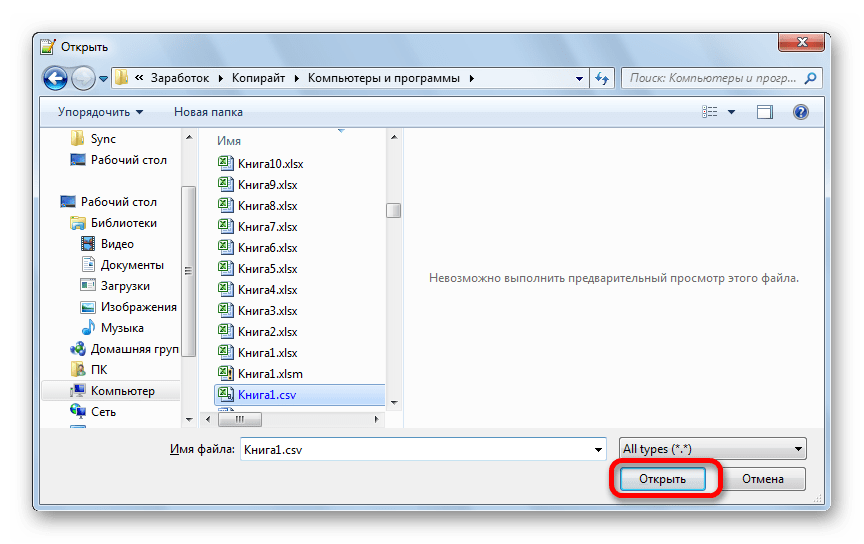
- Запускается окно открытия файла. Переходим в директорию, где расположен документ, который некорректно отобразился в Экселе. Выделяем его и жмем на кнопку «Открыть» в нижней части окна.
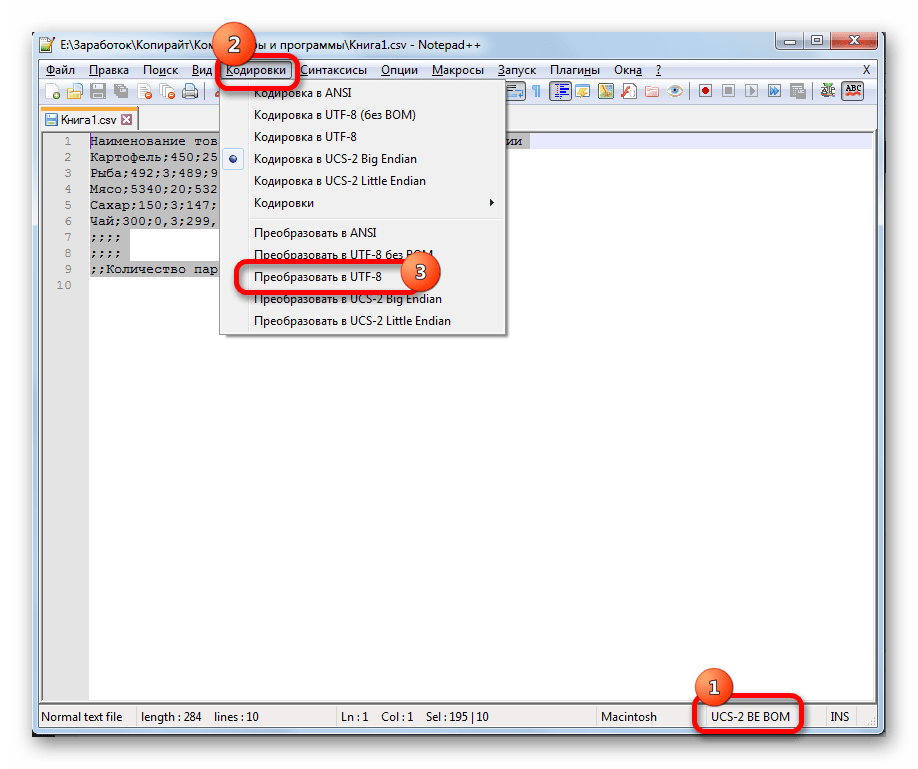
- Файл открывается в окне редактора Notepad++. Внизу окна в правой части строки состояния указана текущая кодировка документа. Так как Excel отображает её некорректно, требуется произвести изменения. Набираем комбинацию клавиш Ctrl+A на клавиатуре, чтобы выделить весь текст. Кликаем по пункту меню «Кодировки». В открывшемся списке выбираем пункт «Преобразовать в UTF-8». Это кодировка Юникода и с ней Эксель работает максимально корректно.
- После этого, чтобы сохранить изменения в файле жмем на кнопку на панели инструментов в виде дискеты. Закрываем Notepad++, нажав на кнопку в виде белого крестика в красном квадрате в верхнем правом углу окна.
- Открываем файл стандартным способом через проводник или с помощью любого другого варианта в программе Excel. Как видим, все символы теперь отображаются корректно.
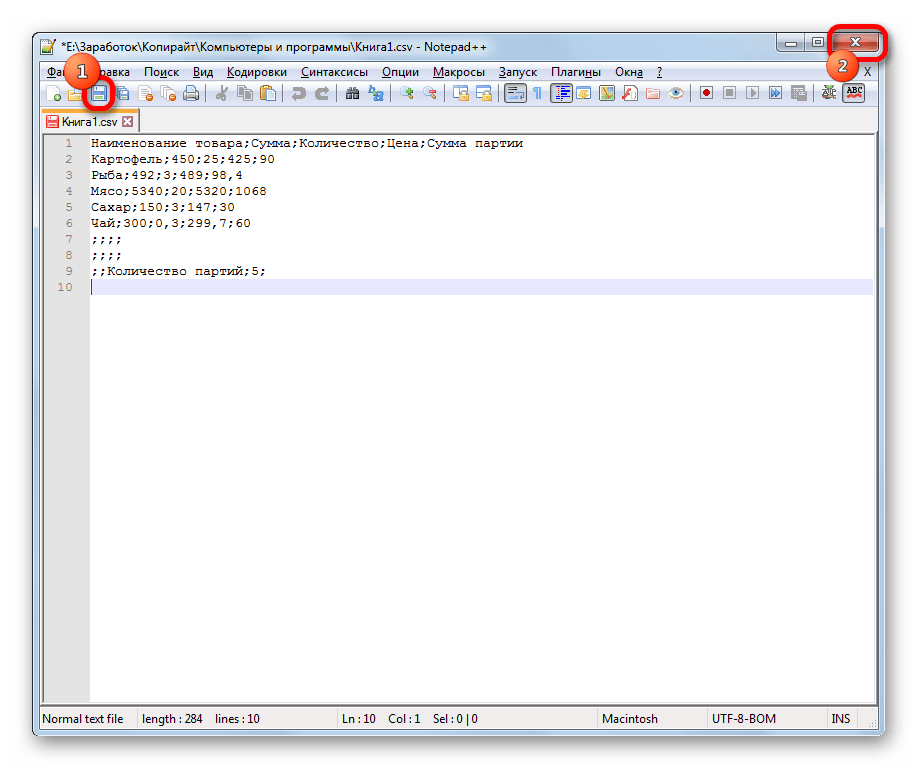
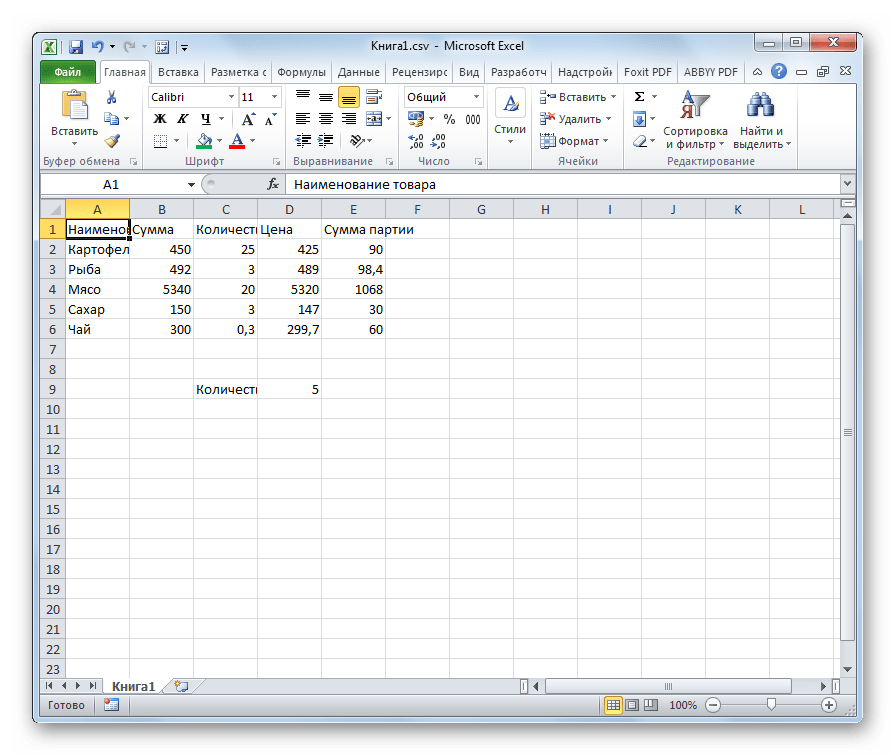
Несмотря на то, что данный способ основан на использовании стороннего программного обеспечения, он является одним из самых простых вариантов для перекодировки содержимого файлов под Эксель.

Способ 2: применение Мастера текстов
Кроме того, совершить преобразование можно и с помощью встроенных инструментов программы, а именно Мастера текстов. Как ни странно, использование данного инструмента несколько сложнее, чем применение сторонней программы, описанной в предыдущем методе.
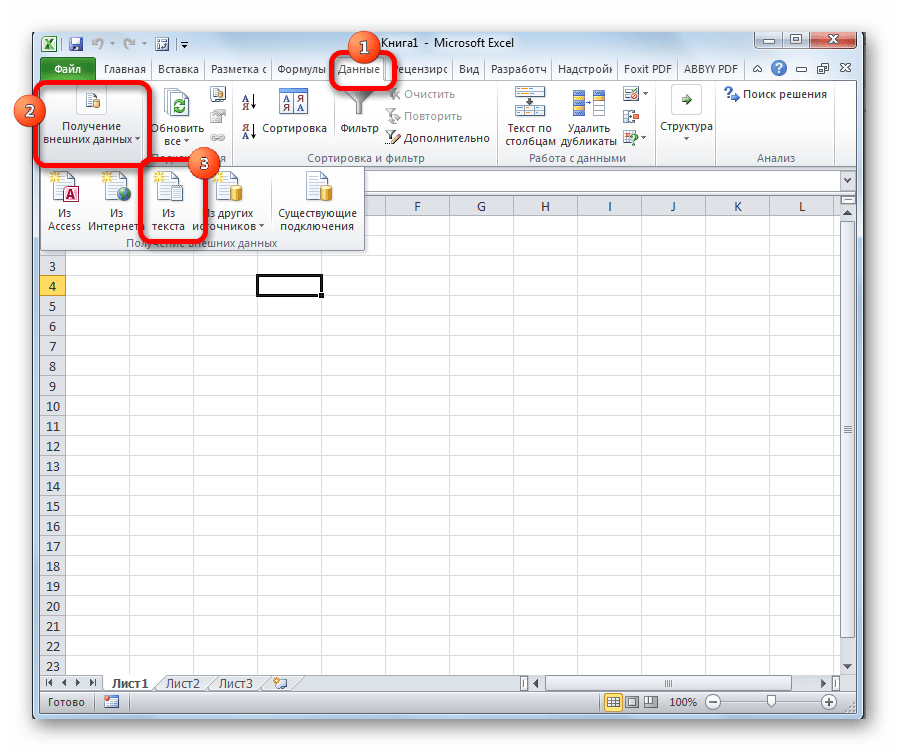
- Запускаем программу Excel. Нужно активировать именно само приложение, а не открыть с его помощью документ. То есть, перед вами должен предстать чистый лист. Переходим во вкладку «Данные». Кликаем на кнопку на ленте «Из текста», размещенную в блоке инструментов «Получение внешних данных».
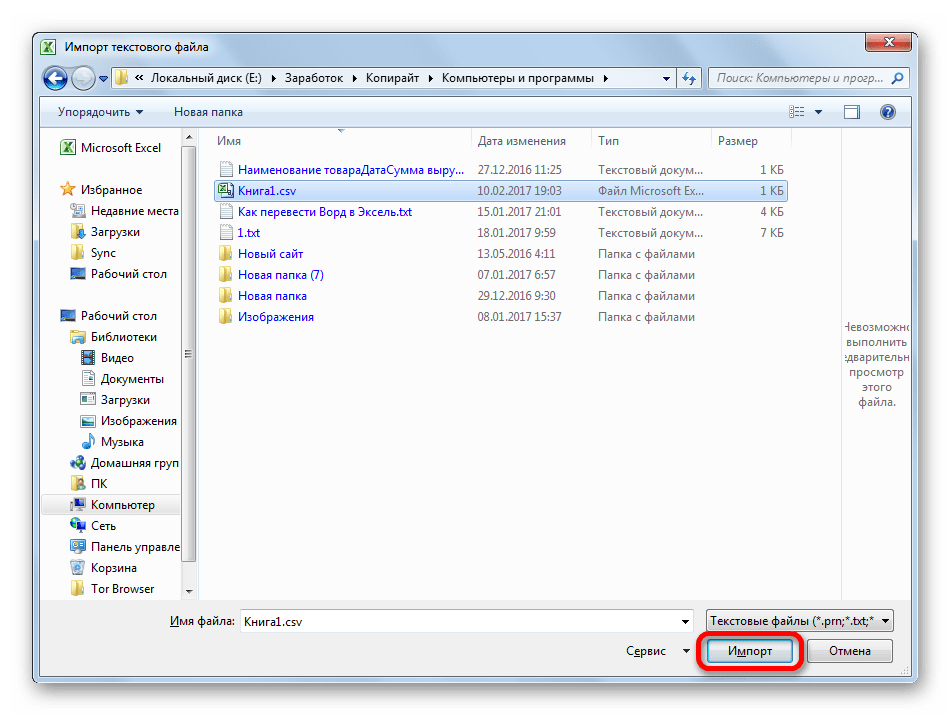
- Открывается окно импорта текстового файла. В нем поддерживается открытие следующих форматов:
- TXT;
- CSV;
- PRN.
Переходим в директорию размещения импортируемого файла, выделяем его и кликаем по кнопке «Импорт».
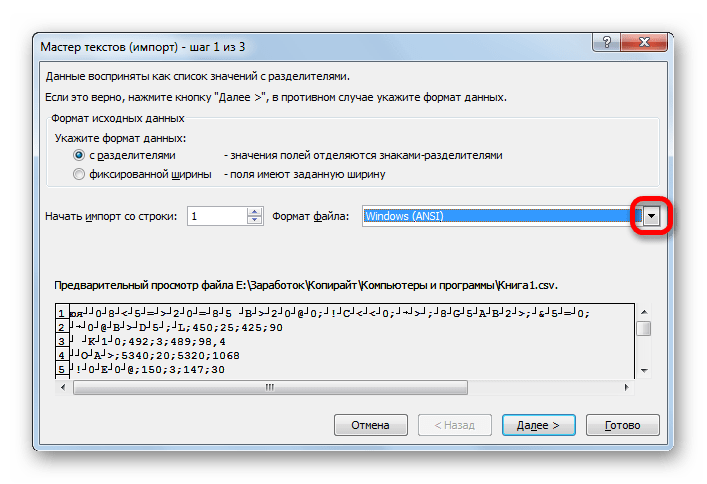
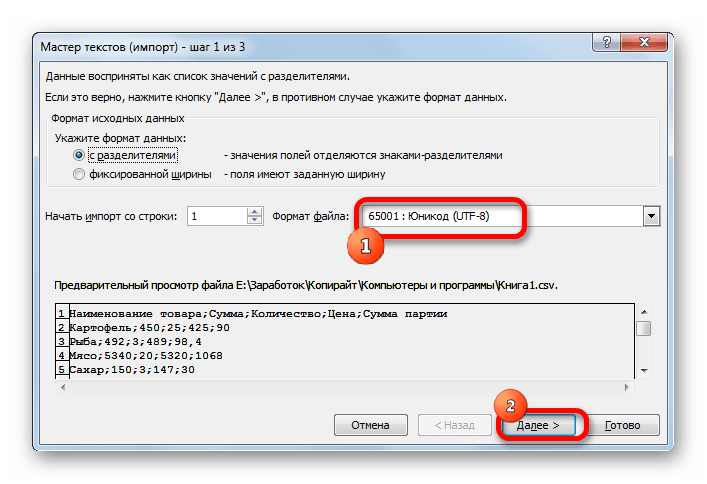
- Открывается окно Мастера текстов. Как видим, в поле предварительного просмотра символы отображаются некорректно. В поле «Формат файла» раскрываем выпадающий список и меняем в нем кодировку на «Юникод (UTF-8)».

Если данные отображаются все равно некорректно, то пытаемся экспериментировать с применением других кодировок, пока текст в поле для предпросмотра не станет читаемым. После того, как результат удовлетворит вас, жмите на кнопку «Далее».
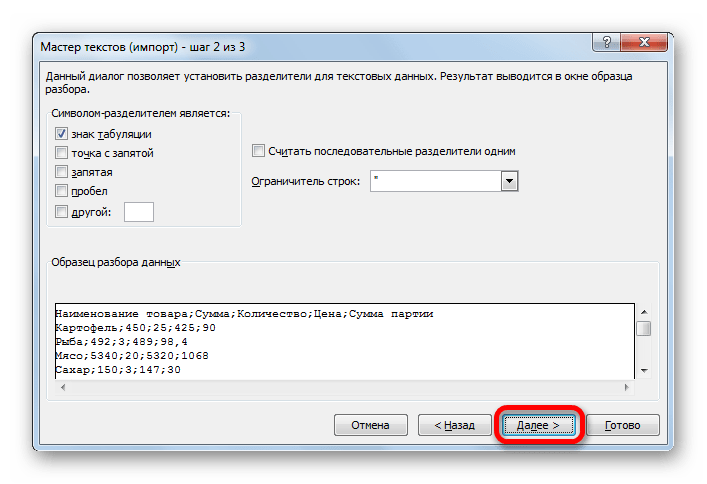
- Открывается следующее окно Мастера текста. Тут можно изменить знак разделителя, но рекомендуется оставить настройки по умолчанию (знак табуляции). Жмем на кнопку «Далее».
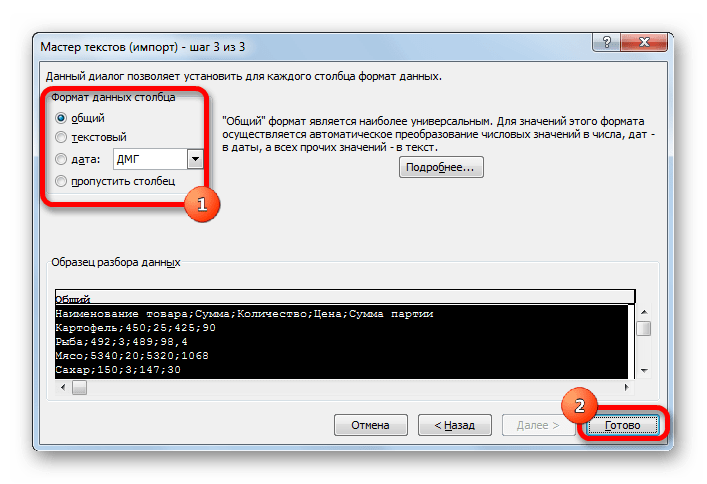
- В последнем окне имеется возможность изменить формат данных столбца:
- Общий;
- Текстовый;
- Дата;
- Пропустить столбец.
Тут настройки следует выставить, учитывая характер обрабатываемого контента. После этого жмем на кнопку «Готово».
- В следующем окне указываем координаты левой верхней ячейки диапазона на листе, куда будут вставлены данные. Это можно сделать, вбив адрес вручную в соответствующее поле или просто выделив нужную ячейку на листе. После того, как координаты добавлены, в поле окна жмем кнопку «OK».
- После этого текст отобразится на листе в нужной нам кодировке. Остается его отформатировать или восстановить структуру таблицы, если это были табличные данные, так как при переформатировании она разрушается.
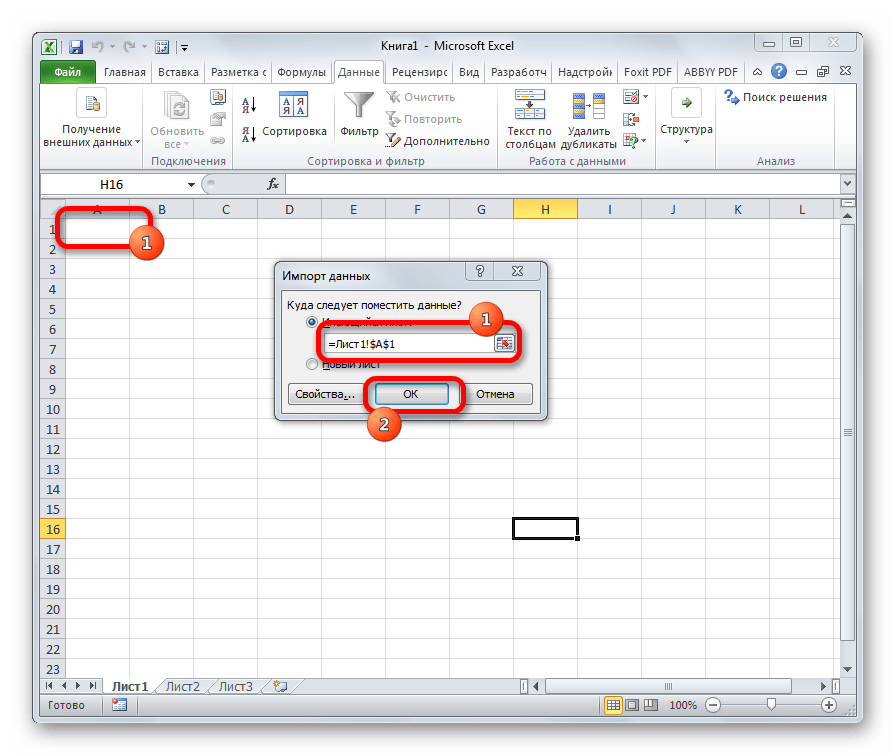
Способ 3: сохранение файла в определенной кодировке
Бывает и обратная ситуация, когда файл нужно не открыть с корректным отображением данных, а сохранить в установленной кодировке. В Экселе можно выполнить и эту задачу.
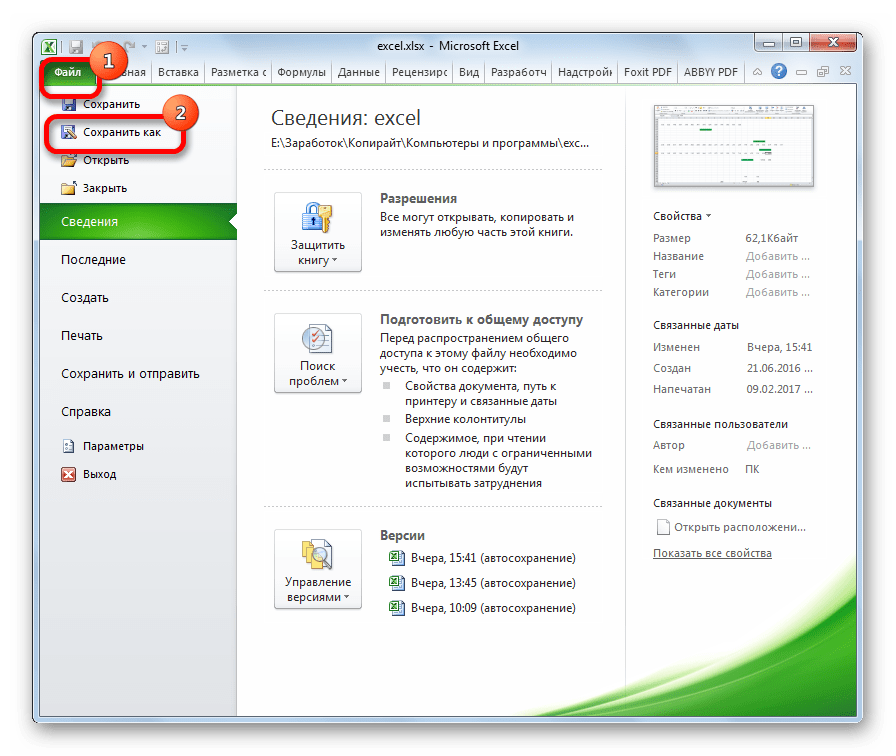
- Переходим во вкладку «Файл». Кликаем по пункту «Сохранить как».
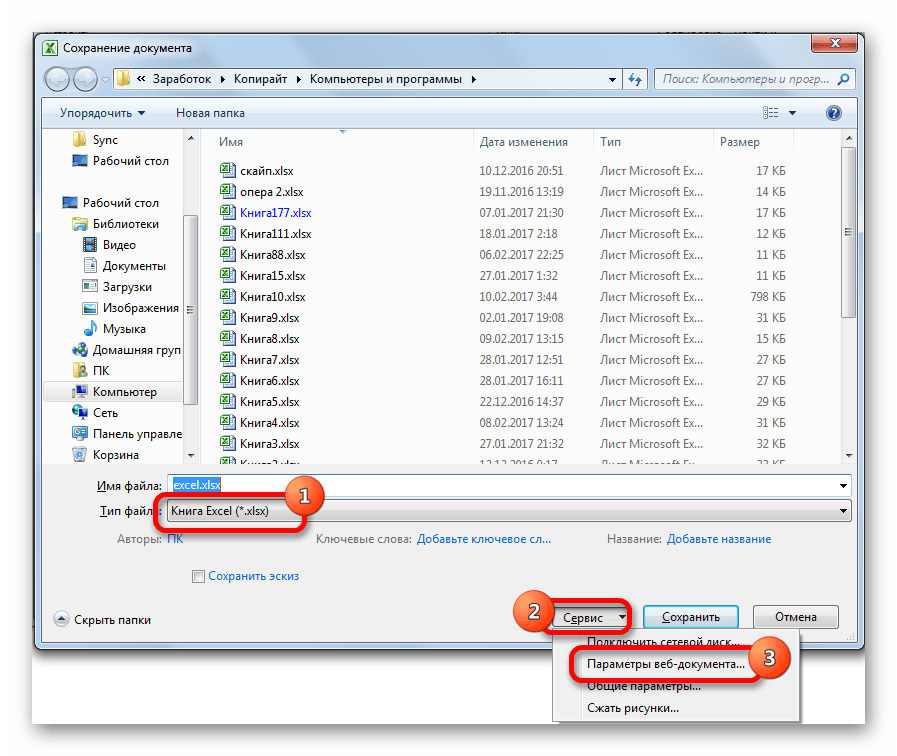
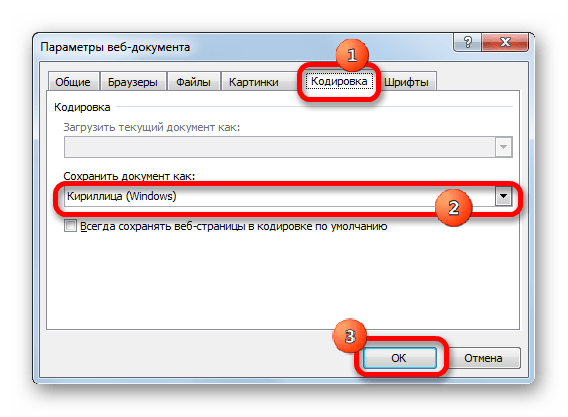
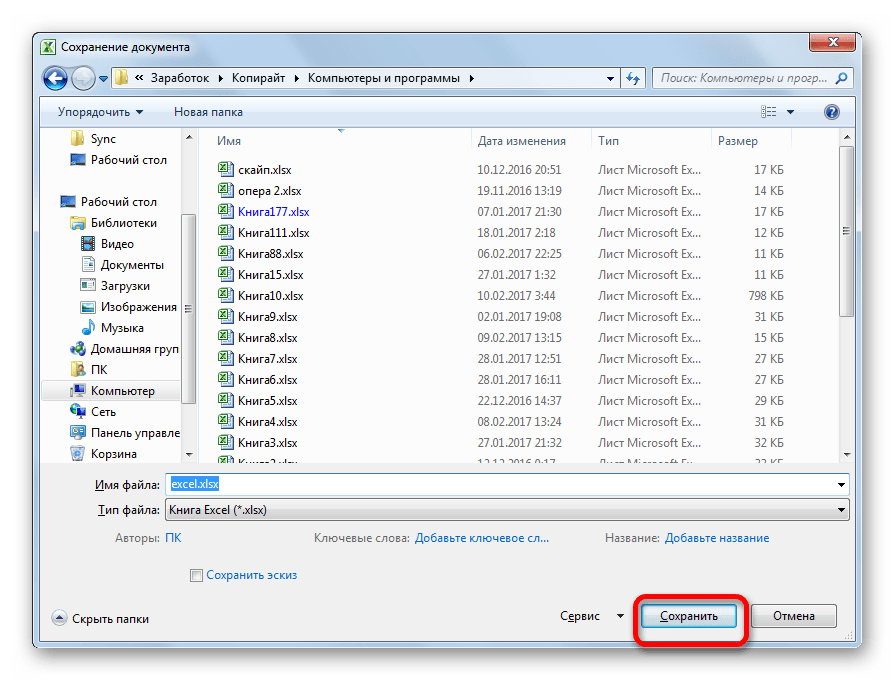
- Открывается окно сохранения документа. С помощью интерфейса Проводника определяем директорию, где файл будет храниться. Затем выставляем тип файла, если хотим сохранить книгу в формате отличном от стандартного формата Excel (xlsx). Потом кликаем по параметру «Сервис» и в открывшемся списке выбираем пункт «Параметры веб-документа».
- В открывшемся окне переходим во вкладку «Кодировка». В поле «Сохранить документ как» открываем выпадающий список и устанавливаем из перечня тот тип кодировки, который считаем нужным. После этого жмем на кнопку «OK».
- Возвращаемся в окно «Сохранения документа» и тут жмем на кнопку «Сохранить».
Документ сохранится на жестком диске или съемном носителе в той кодировке, которую вы определили сами. Но нужно учесть, что теперь всегда документы, сохраненные в Excel, будут сохраняться в данной кодировке. Для того, чтобы изменить это, придется опять заходить в окно «Параметры веб-документа» и менять настройки.
Существует и другой путь к изменению настроек кодировки сохраненного текста.
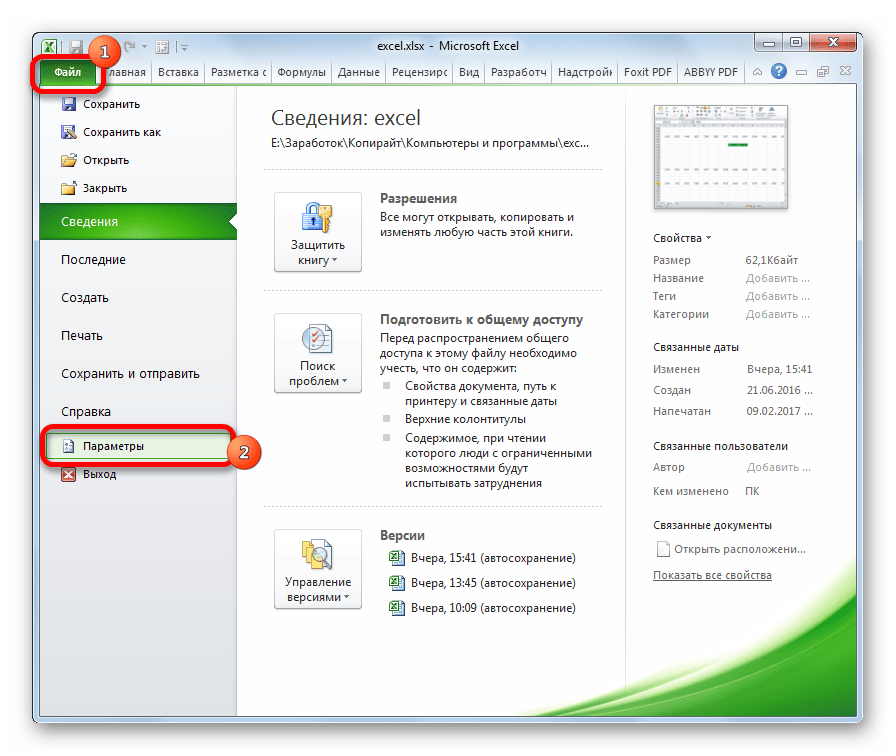
- Находясь во вкладке «Файл», кликаем по пункту «Параметры».
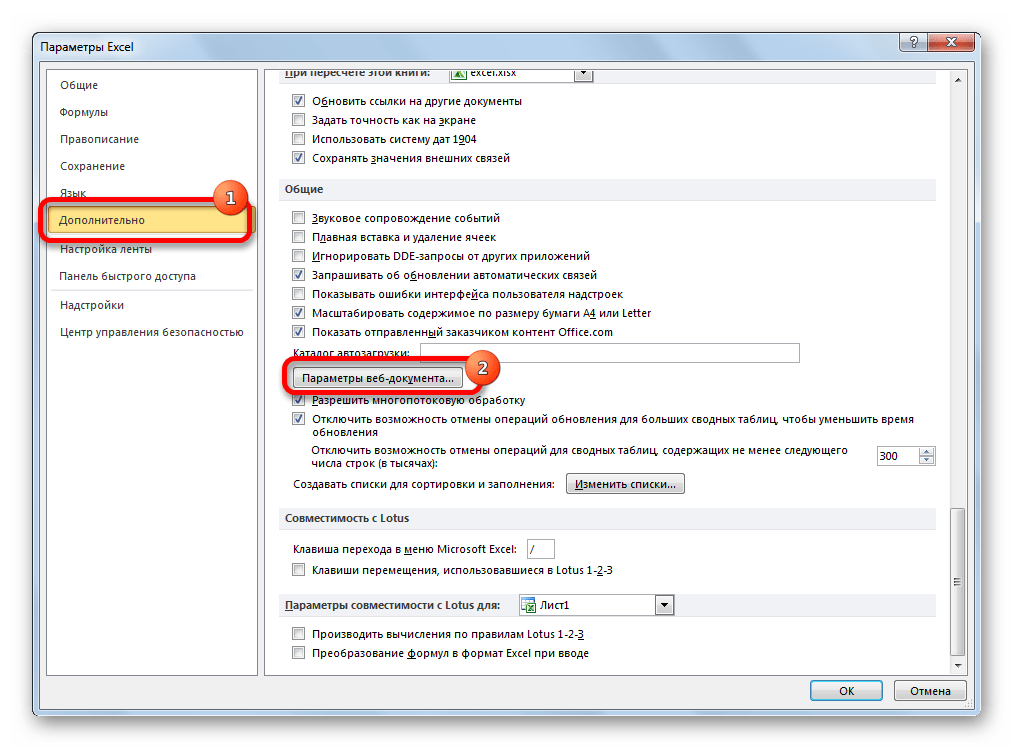
- Открывается окно параметров Эксель. Выбираем подпункт «Дополнительно» из перечня расположенного в левой части окна. Центральную часть окна прокручиваем вниз до блока настроек «Общие». Тут кликаем по кнопке «Параметры веб-страницы».
- Открывается уже знакомое нам окно «Параметры веб-документа», где мы проделываем все те же действия, о которых говорили ранее.
Теперь любой документ, сохраненный в Excel, будет иметь именно ту кодировку, которая была вами установлена.
Как видим, у Эксель нет инструмента, который позволил бы быстро и удобно конвертировать текст из одной кодировки в другую. Мастер текста имеет слишком громоздкий функционал и обладает множеством не нужных для подобной процедуры возможностей. Используя его, вам придется проходить несколько шагов, которые непосредственно на данный процесс не влияют, а служат для других целей. Даже конвертация через сторонний текстовый редактор Notepad++ в этом случае выглядит несколько проще. Сохранение файлов в заданной кодировке в приложении Excel тоже усложнено тем фактом, что каждый раз при желании сменить данный параметр, вам придется изменять глобальные настройки программы.
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню «Файл – Сохранить как».

В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку «Сохранить».

К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню «Кодировки – Кириллица» и выбрать нужный вариант.

После открытия текста можно изменить его кодировку. Для этого нужно открыть меню «Кодировки» и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.

После преобразования файл нужно сохранить с помощью меню «Файл – Сохранить» или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню «Файл – Открыть».

В открывшемся окне нужно выделить текстовый файл, снять отметку «Автовыбор» и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.

Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню «Файл – Сохранить как» и сохранить документ с указанием новой схемы кодирования.

В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Посмотрите также:
- Чем открыть PDF файл в Windows 7 или Windows 10
- Как перевернуть страницу в Word
- Как копировать текст с помощью клавиатуры
- Как сделать рамку в Word
- Как сделать буклет в Word
Автор
Александр Степушин
Создатель сайта comp-security.net, автор более 2000 статей о ремонте компьютеров, работе с программами, настройке операционных систем.
Остались вопросы?
Задайте вопрос в комментариях под статьей или на странице
«Задать вопрос»
и вы обязательно получите ответ.
Содержание
- Как изменить кодировку текстового файла на UTF-8 или Windows 1251
- Блокнот Windows
- Notepad++
- Akelpad
- Txt кодировка
- Подробно о кодировке txt файлов
- Неправильная кодировка файла txt пример:
- Какая кодировка в txt файле
- Поменять кодировку txt файла
- Поисковые запросы : «кодировка txt файла»
- хорошая кодировка txt файла
- Сообщение системы комментирования :
- Выбор кодировки текста при открытии и сохранении файлов
- В этой статье
- Общие сведения о кодировке текста
- Различные кодировки для разных алфавитов
- Юникод: единая кодировка для разных алфавитов
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Выбор кодировки
- Поиск кодировок, доступных в Word
- Как сменить кодировку в Блокноте по умолчанию с ANSI на другую
- Очень кратко:
- Немного лирики о том, почему всё так, а не иначе:
- Что делать, чтобы сменить кодировку в Блокноте по умолчанию с ANSI на другую:
- Кодировка в bat файлах
Как изменить кодировку текстового файла на UTF-8 или Windows 1251
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню « Файл – Сохранить как ».
В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку « Сохранить ».
К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню « Кодировки – Кириллица » и выбрать нужный вариант.
После открытия текста можно изменить его кодировку. Для этого нужно открыть меню « Кодировки » и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.
После преобразования файл нужно сохранить с помощью меню « Файл – Сохранить » или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню « Файл – Открыть ».
В открывшемся окне нужно выделить текстовый файл, снять отметку « Автовыбор » и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.
Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню « Файл – Сохранить как » и сохранить документ с указанием новой схемы кодирования.
В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Источник
Txt кодировка
Я очень часто использую txt файлы и периодически получается так, что кодировка txt файла не та. Которая требуется!
Но как я определил, что кодировка неправильная!? Тут мы собрались написать новую статью и там, для иллюстрации работы придется использовать txt файла и фот что он выводит, если применить javascript include
Подробно о кодировке txt файлов
Неправильная кодировка файла txt пример:
Хотел показать результат неправильной кодировки, которая периодически встречается при работе с txt файлами.
Какая кодировка в txt файле
Самое простое, как определить кодировку txt файла открыть файл в блокноте(простой текстовый блокнот! Либо в любой другой программе), который есть в любой операционной системе. Давайте сразу узнаем и изменим кодировку файла txt
 Какая кодировка в txt файле
Какая кодировка в txt файле
Поменять кодировку txt файла
 Поменять кодировку txt файла
Поменять кодировку txt файла
Поисковые запросы : «кодировка txt файла»
Интересный поисковый запрос:
хорошая кодировка txt файла
В смысле хорошая!? Ты чЁ на рынке!?
— Покажите мне вон ту хорошую кодировку. Не. это плохая кодировка, протухла совсем. вон ту рядом. У вас кодировка свежая!? Только свежая может быть хорошей кодировкой!
Сообщение системы комментирования :
Форма пока доступна только админу. скоро все заработает. надеюсь.
Источник
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Источник
Как сменить кодировку в Блокноте по умолчанию с ANSI на другую

Рано или поздно любой пользователь Windows сталкивается с проблемой кодировки текста. «Кракозяблики» настигают всех, кто более-менее часто пользуется компьютером. Особенно остро эта задача стоит перед теми, кто не просто пользуется компьютером, а создаёт какой-то осмысленный контекст, например у себя на сайте. Сайт может находиться на удалённом сервере, где кодировка может отличаться от той, которую предлагает Windows по умолчанию.
Очень кратко:
Немного лирики о том, почему всё так, а не иначе:
Но и для пользователей, остающихся обычными «пользователями ПК» проблема с кодировками кириллистических символов иногда встаёт довольно остро. «Кракозяблики» — наследие предыдущей эпохи, когда каждый программист писал собственную таблицу кодировок. Например, скачал и хочешь почитать интересную книжку, а тут такое >=O
И так продолжалось до тех пор, пока не начали вводиться стандарты. Но и стандартов на текущее время уже немало. Например, есть кодировка Unicode, есть UTF-8, есть UTF-16 и так далее.
Я так и не нашёл, как сменить кодировку по умолчанию при открытии Блокнота и создания нового документа уже из открытой сессии Блокнота.
Зато нашёл, как сменить кодировку по умолчанию, когда текстовый документ сначала создаётся (из контекстного меню) и только потому открывается Блокнотом. Тогда кодировка файла будет та, которая будет прописана по умолчанию. Об этом и пойдёт ниже речь.
Итак, для того, чтобы поменять кодировку создаваемых текстовых документов по умолчанию, нам понадобиться внести изменения в Реестр Windows.
Ну и хватит лирики. К делу!

Что делать, чтобы сменить кодировку в Блокноте по умолчанию с ANSI на другую:

Если в файле-образце набрать какой-то текст, то он будет во всех новых файлах, создаваемых с помощью контекстного меню.
Источник
Кодировка в bat файлах
В этой статье я хочу поговорить о кодировке русского текста в bat файлах. Имеются различные способы правильного отображения кирилицы в bat файлах. Некоторые из достаточно запутанные и сложные. Так как я сторонник простоты и эфффективности, то в этой статье я разберу два самых простых способа, которых вам будет достаточно в самых различных ситуациях.
Создадим какой-нибудь bat файл, так называемый батник. Будет он называться test.bat. Ранее с помощью обычного блокнота, в нём были набраны строки:

При запуске его как bat файла, выводятся две строки. Одна на латинице, другая на кирилице.

Итак, что мы видим, строка на латинице выводится без изменений, строка на кирилице в виде каких-то скрякозябров. Это то, что случается в случае не правильной кодировки. Теперь давайте разберёмся, почему так получилось, и как это поправить.
Первое, документ test.bat обработал и вывел интерпритатор командной строки(cmd). Cmd кодирует програмный код в своей кодировке. Это, так называемая, DOS кодировка. Как подробнее узнать, какая это кодировка?
Откройте test.bat в любом текстовом редакторе(я воспользуюсь Notepad++). Наберите команду chcp.

Это команда покажет, в какой кодировке выполняет cmd bat файл. Сохраните документ и запустите его.

Итак, мы видим строку: Текущая кодовая страница: 866. Это говорит о том, что cmd кодирует bat файл в кодировке 866. Теперь выясним, в какой кодировке закодирован наш bat файл. Для этого можно открыть его в том текстовом редакторе, который показывает кодировку документа. Я воспользуюсь для этого редактором Notepad++. Открыв в нём test.bat в нижней правой части мы видим кодировку Windows-1251.

Теперь мы видим несоответствие в кодировках. Что нужно сделать? Нужно перекодировать документ test.bat в ту кодировку, в которую кодирует документ интерпритатор командной строки. Как это сделать? Открыв документ test.bat в текстовом редакторе Notepad++, в верхнем горизонтальном меню выберите: Кодировки > Кодировки > Кирилица > ОЕМ866.

Теперь в Notepad++ там, где была кодировка Windows-1251, стала ОЕМ866. Не забывайте сохранять документ после различных манипуляций с ним. Теперь можно опять запустить уже перекодированный файл test.bat.

Мы видим, что и кирилица и латиница стали корректно отображаться после работы команды вывода echo в test.bat.
Что если у вас на компьютере нет редактора Notepad++, и вы принципиально не хотите его устанавливать. Или текст вы не набирали сами, а где-то скачали его, и он в DOS кодировке.
К примеру, вы хотит скачать в текстовый файл справочник команд CMD. Создайте в папке С файл Help.txt. Запустите на выполнение bat файл со следующим кодом.

Вот текст записанный в файл Help.txt.

Теперь добавьте в bat файл следующую строку: «chcp 1251 >nul». Она аннулирует действующую кодировку 1251, которая мешает нам читать кирилицу.

И запустите его на выполнение.

Мы разобрали два простых способа, как в bat файлах настроить кодировку для правильного отображения русского текста. Надеюсь моя статья была вам полезна.
Источник
|
23 / 22 / 17 Регистрация: 06.05.2016 Сообщений: 260 |
|
|
1 |
|
|
10.03.2017, 18:52. Показов 7539. Ответов 9
Добрый день уважаемые, подскажите пожалуйста, почему у меня не получаться запустить фаил с кодировкой «windows-1251» ? Пример в архиве. Что я не так прописываю? Миниатюры
__________________
0 |


|
2960 / 2578 / 1068 Регистрация: 15.12.2012 Сообщений: 9,733 Записей в блоге: 11 |
|
|
10.03.2017, 18:59 |
2 |
|
Black_Star, неверная кодировка самого файла… В кириллице надо сохранять… fullForm.rar
1 |
")
|
23 / 22 / 17 Регистрация: 06.05.2016 Сообщений: 260 |
|
|
10.03.2017, 19:08 [ТС] |
3 |
|
Не могу понять, что именно надо сохранять в Криллице,(и html и css ?) а главное как?
0 |
|
2960 / 2578 / 1068 Регистрация: 15.12.2012 Сообщений: 9,733 Записей в блоге: 11 |
|
|
10.03.2017, 19:18 |
4 |
|
Решение
Не могу понять, что именно надо сохранять в Криллице,(и html и css ?) а главное как? HTML…
Смысл в том, чтобы создать новый файл, сохранить его в кодировке windows-1251 и перенести в него содержимое Вашего файла… Тупо преобразование приведёт к появлению крякозябров…
1 |
 Сообщение было отмечено Black_Star как решение
Сообщение было отмечено Black_Star как решение

|
23 / 22 / 17 Регистрация: 06.05.2016 Сообщений: 260 |
|
|
10.03.2017, 20:48 [ТС] |
5 |
|
Спасибо, за пояснения. (Я вообще то на phpStorm верстаю, думал там будет что-то подобное) Миниатюры
0 |
|
Fedor92
2960 / 2578 / 1068 Регистрация: 15.12.2012 Сообщений: 9,733 Записей в блоге: 11 |
||||
|
10.03.2017, 20:59 |
6 |
|||
|
Прислали проект с кодировкой windows-1251 а когда я повесил его на локальный сервер (OpenServer) показывает одну кракозябру. Про настройку сервера в принципе я уже говорил… Сначала сервер настраиваем на работу с нужной кодировкой, затем проверяем кодировку файла и все метатеги… Судя по скрину информация поднимается из БД, тогда дополнительно надо проверять кодировку данных в БД и кодировку в запросах к БД, если конечно я прав… А вообще можно попробовать задать кодировку для проекта жёстко, запилив в корень проекта файл .htaccess со строкой:
При таком методе надо быть внимательным, внося правки, неверная кодировка может вылезти где угодно…
0 |
|
23 / 22 / 17 Регистрация: 06.05.2016 Сообщений: 260 |
|
|
10.03.2017, 21:17 [ТС] |
7 |
|
Спасибо, за совет. Что-то из этого помогло Миниатюры
0 |
|
2960 / 2578 / 1068 Регистрация: 15.12.2012 Сообщений: 9,733 Записей в блоге: 11 |
|
|
10.03.2017, 21:28 |
8 |
|
Black_Star, где знаки вопроса данные либо из БД?
0 |
|
23 / 22 / 17 Регистрация: 06.05.2016 Сообщений: 260 |
|
|
11.03.2017, 09:42 [ТС] |
9 |
|
Black_Star, где знаки вопроса данные либо из БД? Данные из БД подтягиваются
0 |
|
2960 / 2578 / 1068 Регистрация: 15.12.2012 Сообщений: 9,733 Записей в блоге: 11 |
|
|
11.03.2017, 10:30 |
10 |
|
Данные из БД подтягиваются Этот момент я уже комментировал надо проверять кодировку БД, подключение к БД и запросы на выборку… Вы уверены вообще, что Вам проект прислали именно для работы с кодировкой windoes-1251? Складывается впечатление, что это гибрид…
1 |
31.01.15 — 15:07
через XDTO создаю текст XML
потом пишу его в файл и проверяю на соответствие схеме
ЗаписьXML = Новый ЗаписьXML;
ЗаписьXML.УстановитьСтроку();
ЗаписьXML.ЗаписатьОбъявлениеXML();
ФабрикаXDTO.ЗаписатьXML(ЗаписьXML, КорневойРаздел);
Возврат ЗаписьXML.Закрыть();
это возвращает получившийся текст ХМЛ в реквизит документа типа Строка(0)
потом:
ВыводитьВсеОшибки = Истина;
ИмяФайла = ПолучитьИмяВременногоФайла(«xml»);
ИмяФайлаСхемы = ПолучитьИмяВременногоФайла(«xsd»);
ФайлРеестра = Новый ТекстовыйДокумент;
ФайлРеестра.УстановитьТекст(Объект.ТекстВыгрузки);
ФайлРеестра.Записать(ИмяФайла,»windows-1251″);
ФайлСхемы = Новый ТекстовыйДокумент;
ФайлСхемы.УстановитьТекст(Объект.ТекстСхемыДокумента);
ФайлСхемы.Записать(ИмяФайлаСхемы,»windows-1251″);
Попытка
Схема=Новый COMОбъект(«MSXML2.XMLSchemaCache.6.0»);
Исключение
Сообщить(«Не удалось создать объект XMLSchemaCache (возможно, не установлен MSXML 6)»);
Возврат;
КонецПопытки;
Попытка
Схема.add(«»,ИмяФайлаСхемы);
Исключение
Сообщить(«Не удалось подключить схему: «+ИмяФайлаСхемы);
Схема=Неопределено;
Возврат;
КонецПопытки;
Попытка
ДОМ=Новый COMОбъект(«MSXML2.DOMDocument.6.0»);
Исключение
Сообщить(«Не удалось создать объект DOMDocument (возможно, не установлен MSXML 6)»);
Схема=Неопределено;
Возврат;
КонецПопытки;
ДОМ.schemas=Схема;
ДОМ.async=Ложь;
ДОМ.validateOnParse=Истина;
ДОМ.resolveExternals=Истина;
Если ВыводитьВсеОшибки Тогда
ДОМ.SetProperty(«MultipleErrorMessages»,Истина);
КонецЕсли;
ДОМ.load(ИмяФайла);
Если (ДОМ.parseError.errorCode<>0) Тогда
// ошибки при проверке правильности
Сообщить(«При проверке по схеме выявлены ошибки!»);
Если ВыводитьВсеОшибки Тогда
Для каждого parseError из ДОМ.parseError.AllErrors Цикл
Сообщить(parseError.reason);
Сообщить(parseError.srcText);
КонецЦикла;
Иначе
Сообщить(ДОМ.parseError);
КонецЕсли;
Иначе
Сообщить(«Файл успешно прошёл проверку по схеме!»);
РезПроверки=Истина;
КонецЕсли;
получаю ошибку на первом же атрибуте где встречается кириллица:
В текстовом комментарии обнаружен недопустимый знак.
<patient patientcod=»44240″ surname=»
заголовок схемы:
<?xml version=»1.0″ encoding=»Windows-1251″?>
<!— edited with XMLSpy v2011 rel. 2 (http://www.altova.com) by TeaM DJiNN (TeaM DJiNN) —>
<!—W3C Schema generated by XMLSpy v2009 sp1 (http://www.altova.com)—>
<xs:schema xmlns:xs=»http://www.w3.org/2001/XMLSchema»>;
<xs:element name=»package»>
1 — 31.01.15 — 16:08
мб нужно пересохранить в другой кодировке?
2 — 31.01.15 — 16:29
(0) Писать через XDTO, но читать через «MSXML2.DOMDocument.6.0» — это такой особый вид сексуального извращения?
3 — 31.01.15 — 21:52
(2) ну на всякий случай
и в общем-то он себя оправдал — файлик-то не проходит проверку
(1) в смысле? — в какой другой? и как это «пересохранить?
4 — 31.01.15 — 21:54
(2) прикол в том, что XDTO выдает ошибку, например на запись текста в число, но в общем-то пишет просто атрибут отсутсвует
но в схеме этот атрибут обязателен
на выходе имею XML без обязательного атрибута, однако
5 — 31.01.15 — 23:21
(3) >> в смысле? — в какой другой?
ЗаписьXML.УстановитьСтроку(«windows-1251»);
6 — 01.02.15 — 00:09
(5) скорее ЗаписьXML.УстановитьСтроку(«utf<смотреть в сп>»);
7 — 01.02.15 — 19:46
(5)
ФайлРеестра = Новый ТекстовыйДокумент;
ФайлРеестра.УстановитьТекст(Объект.ТекстВыгрузки);
ФайлРеестра.Записать(ИмяФайла,»windows-1251″);
а это не подходит?
8 — 02.02.15 — 07:35
блин, делаю:
Запись = Новый ЗаписьXML;
Запись.ОткрытьФайл(ИмяФайла, «UTF-8»);
Запись.ЗаписатьБезОбработки(Объект.ТекстВыгрузки);
Запись.Закрыть();
но мне надо «windows-1251»
«Требование на оплату / ответ на требование представляет собой один XML-файл с именем bill.xml в кодировке Windows-1251 (стандартная русская кодировка), упакованный архиватором 7-zip в архивный файл с именем»
другой вариант:
создаю XML файл в Notepad ++ устанавливаю ему кодировку windows-1251
копирую в него текст получивщшийся в 1С
сохраняю — проверяю — все ок
как в 1С создать сразу файл с нужной кодировкой. что бы валидацию проходил?
9 — 02.02.15 — 07:45
+(8)
делаю:
Запись = Новый ЗаписьXML;
Запись.ОткрытьФайл(ИмяФайла, «UTF-8»);
Запись.ЗаписатьБезОбработки(Объект.ТекстВыгрузки);
Запись.Закрыть();
— проверка проходит
10 — 02.02.15 — 07:55
//———-Сериализация
Функция XML(Данные)
ЗаписьXML = Новый ЗаписьXML();
ЗаписьXML.УстановитьСтроку();
СериализаторXDTO.ЗаписатьXML(ЗаписьXML, Данные);
Возврат ЗаписьXML.Закрыть();
КонецФункции
//——Десериализация
Функция ДанныеИзXML(Стр)
ЧтениеXML = Новый ЧтениеXML();
ЧтениеXML.УстановитьСтроку(Стр);
Возврат СериализаторXDTO.ПрочитатьXML(ЧтениеXML);
КонецФункции
11 — 02.02.15 — 08:30
(10) и что мне в «данные» передать? готовый XML текст?
12 — 02.02.15 — 08:30
(10) и чем мне это поможет с кодировкой?
13 — 02.02.15 — 08:37
(12) После вот этого:
ФайлРеестра.Записать(ИмяФайла,»windows-1251″);
Файл в какой кодировке сохраняется? Просто из всего понаписанного не понял, в чём проблема — 1С неправильно сохраняет, или парсер MS пытается неверно читать.
14 — 02.02.15 — 08:38
еще раз:
имею текст XML сохраненный в реквизите документа типа строка(0)
задача — проверить его на валидность посхеме сохраненной в другом реквизите этого документа
делаю:
ИмяФайла = ПолучитьИмяВременногоФайла(«xml»);
ИмяФайлаСхемы = ПолучитьИмяВременногоФайла(«xsd»);
ФайлРеестра = Новый ТекстовыйДокумент;
ФайлРеестра.УстановитьТекст(Объект.ТекстВыгрузки);
ФайлРеестра.Записать(ИмяФайла,»windows-1251″);
ФайлСхемы = Новый ТекстовыйДокумент;
ФайлСхемы.УстановитьТекст(Объект.ТекстСхемыДокумента);
ФайлСхемы.Записать(ИмяФайлаСхемы,»windows-1251″);
Попытка
Схема=Новый COMОбъект(«MSXML2.XMLSchemaCache.6.0»);
Исключение
Сообщить(«Не удалось создать объект XMLSchemaCache (возможно, не установлен MSXML 6)»);
Возврат;
КонецПопытки;
Попытка
Схема.add(«»,ИмяФайлаСхемы);
Исключение
Сообщить(«Не удалось подключить схему: «+ИмяФайлаСхемы);
Схема=Неопределено;
Возврат;
КонецПопытки;
Попытка
ДОМ=Новый COMОбъект(«MSXML2.DOMDocument.6.0»);
Исключение
Сообщить(«Не удалось создать объект DOMDocument (возможно, не установлен MSXML 6)»);
Схема=Неопределено;
Возврат;
КонецПопытки;
ДОМ.schemas=Схема;
ДОМ.async=Ложь;
ДОМ.validateOnParse=Истина;
ДОМ.resolveExternals=Истина;
Если ВыводитьВсеОшибки Тогда
ДОМ.SetProperty(«MultipleErrorMessages»,Истина);
КонецЕсли;
ДОМ.load(ИмяФайла);
Если (ДОМ.parseError.errorCode<>0) Тогда
// ошибки при проверке правильности
Сообщить(«При проверке по схеме выявлены ошибки!»);
Если ВыводитьВсеОшибки Тогда
Для каждого parseError из ДОМ.parseError.AllErrors Цикл
Сообщить(parseError.reason);
Сообщить(parseError.srcText);
КонецЦикла;
Иначе
Сообщить(ДОМ.parseError);
КонецЕсли;
Иначе
Сообщить(«Файл успешно прошёл проверку по схеме!»);
РезПроверки=Истина;
КонецЕсли;
получаю в итоге:
В текстовом комментарии обнаружен недопустимый знак.
<patient patientcod=»44240″ surname=»
хотя если открываю проверяемый файл блокнотом — то кирилица нормально читается
15 — 02.02.15 — 08:42
(14) Блокнот автоматически определяет кодировку, и читает и то, и то.
Проблема у тебя, вероятно, в том, что в заголовке файла указана одна кодировка, а сам файл записан в другой. Вот я и пытаюсь понять, что и в какой именно.
Ты можешь не просто открыть блокнотом, а посмотреть, какую он при этом кодировку определяет?
16 — 02.02.15 — 08:43
(13) вопрос — а как посмотреть в какой он кодировке?
17 — 02.02.15 — 08:44
А в заголовке xml файла какая кодировка указана?
18 — 02.02.15 — 08:46
(16) При «Сохранить как…» что пишет вот тут:
https://yadi.sk/i/INAUlU5oeQ6Zi
19 — 02.02.15 — 08:46
Lister при открытии тоже ругается на кодировку
20 — 02.02.15 — 08:47
21 — 02.02.15 — 08:48
если никакой — это значит что по-умолчанию принят UTF-8
22 — 02.02.15 — 08:48
(18) ANSI
23 — 02.02.15 — 08:49
(20) Если никакая не указана, то парсер по умолчанию использует то ли UTF-8, то ли UTF-16. Вот и твоя ошибка — укажи кодировку в заголовке.
24 — 02.02.15 — 08:49
(21) где принят? достаточно заголовок добавить? какой?
25 — 02.02.15 — 08:49
(24) <?xml version=»1.0″ encoding=»Windows-1251″?>
26 — 02.02.15 — 08:50
27 — 02.02.15 — 08:52
(26) Там всё несколько сложнее  Но если дополнительной информации нет, и никакое определение не проканало — то UTF-8.
Но если дополнительной информации нет, и никакое определение не проканало — то UTF-8.
28 — 02.02.15 — 08:53
спасибо
mehfk
29 — 02.02.15 — 08:54
(27) Мне не надо объяснять.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
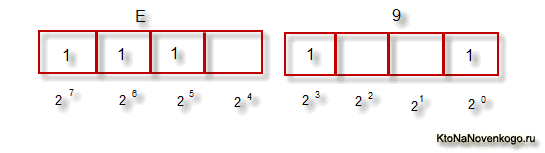
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
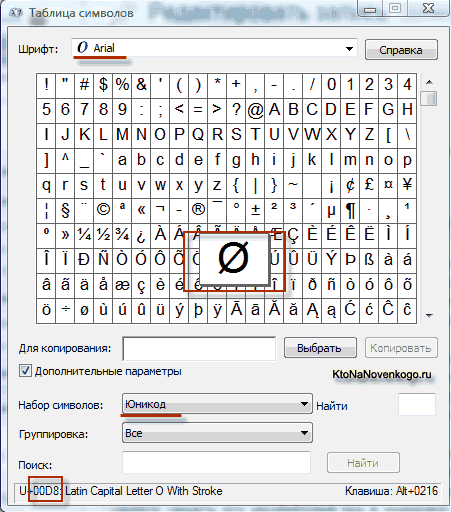
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
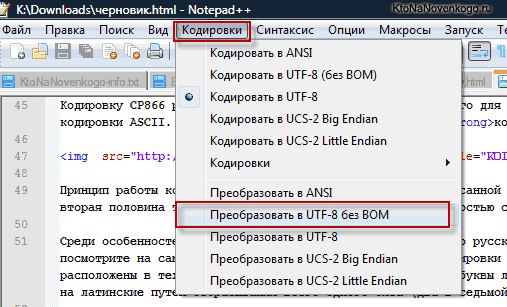
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.