Windows
- 09.06.2020
- 61 787
- 6
- 150
- 147
- 3

- Содержание статьи
- Исправляем проблему с кодировкой с помощью смены шрифта
- Исправляем проблему с кодировкой с помощью смены кодировки
- Комментарии к статье ( 6 шт )
- Добавить комментарий
В некоторых случаях, когда используется неверная кодировка, могут возникать так называемые кракозябры или иероглифы, т.е. не читаемые символы, которые невозможно разобрать при работе с командной строкой. Эти проблемы могут также возникать и при запуске различных BAT-файлов. В данной статье мы расскажем о том, как можно сменить шрифт или кодировку, чтобы избавиться от этой проблемы. Пример таких не читаемых символов можно видеть на картинке ниже:
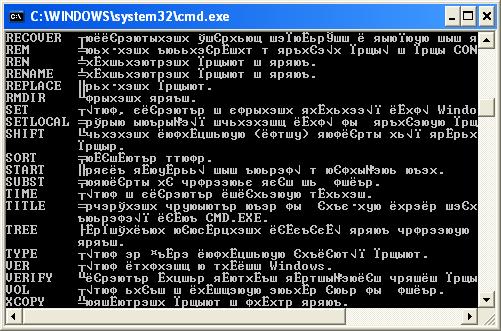
Исправляем проблему с кодировкой с помощью смены шрифта
Первым делом нужно зайти в свойства окна: Правой кнопкой щелкнуть по верхней части окна -> Свойства -> в открывшемся окне в поле Шрифт выбрать Lucida Console и нажать кнопку ОК.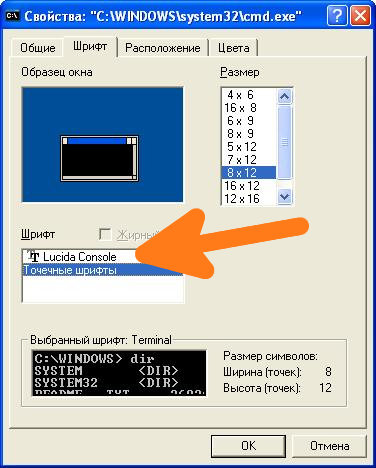
После этого не читаемые символы должны исчезнуть, а текст должен выводиться на русском языке.
Исправляем проблему с кодировкой с помощью смены кодировки
Вместо смены шрифта, можно сменить кодировку, которая используется при работе cmd.exe.
Узнать текущую кодировку можно введя в командной строке команду chcp, после ввода данной команды необходимо нажать Enter.
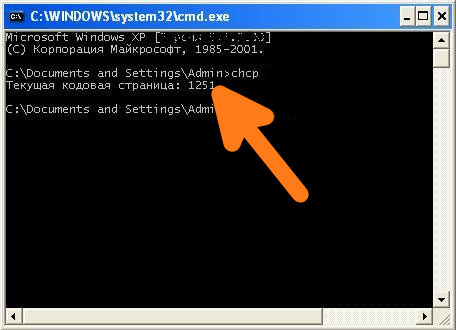
Как видно на скриншоте, текущая используемая кодировка Windows-1251
Для изменения кодировки нам необходимо воспользоваться командой chcp <код_новой_кодировки>, где <код_новой_кодировки> — это сам код кодировки, на которую мы хотим переключиться. Возможные значения:
- 1251 — Windows-кодировка (Кириллица);
- 866 — DOS-кодировка;
- 65001 — Кодировка UTF-8;
Т.е. для смены кодировки на DOS, команда примет следующий вид:
chcp 866Для смены кодировки на UTF-8, команда примет следующий вид:
chcp 65001Для смены кодировки на Windows-1251, команда примет следующий вид:
chcp 1251
Добавил(а) microsin
Иногда по неизвестным причинам некоторые команды русскоязычной версии Windows выводят русский текст в нечитаемой кодировке, кракозябрами.
Например, команда help выводит нормальный текст:

Но при этом подсказка telnet выводит в ответ кракозябры.

Так может происходить, к примеру, если текущая кодировка консоли 866, а утилита telnet.exe почему-то выводит текст в кодировке 1251. Вывести текст в нужной кодировке поможет команда chcp, которая устанавливает нужную кодировку.
Вот так можно посмотреть текущую кодировку консоли:
c:Documents and Settingsuser>chcp Текущая кодовая страница: 866 c:Documents and Settingsuser>
А вот так можно поменять кодировку на 1251, после чего вывод подсказки telnet будет отображаться нормально:
c:Documents and Settingsuser>chcp 1251 Текущая кодовая страница: 1251 c:Documents and Settingsuser>

К сожалению, заранее угадать, в какой кодировке выводится текст, невозможно, поэтому проще попробовать установить командой chcp разные кодировки, чтобы добиться правильного отображения русского текста. Обычно используются кодировки 866 (кодировка русского текста DOS), 1251 (кодировка русского текста Windows), 65001 (UTF-8).
[Шрифт cmd.exe]
Иногда кракозябры можно убрать, если выбрать в свойствах окна cmd.exe шрифт Lucida Console (по умолчанию там стоит «Точечные шрифты»).
[Ссылки]
1. Универсальный декодер — конвертер кириллицы.
Время чтение: 4 минуты
2014-01-19
Как корректно отобразить Русский текст в CMD. Проблемы с кодировкой могут возникнуть, например, при выполнении Bat файла, когда нужно вывести в консоль русский текст и при других обстоятельствах, о которых речь пойдёт далее.
Рассмотрим пример: когда нужно вывести в консоль Русский текст, скажем «Примет мир». Для этого создадим Bat файл с именем «1.bat». Используйте для этого обычный Блокнот Windows (Notepad.exe) Запишем в него следующие строки!
|
@Echo off echo. echo ПРИВЕТ МИР echo. Pause |
Для тех, кто не понял или не в курсе, строчки «echo.» я добавил специально, что бы были отступы, от строки «Примет мир»
Теперь запускаем файл 1.bat и результат будет такого вида.
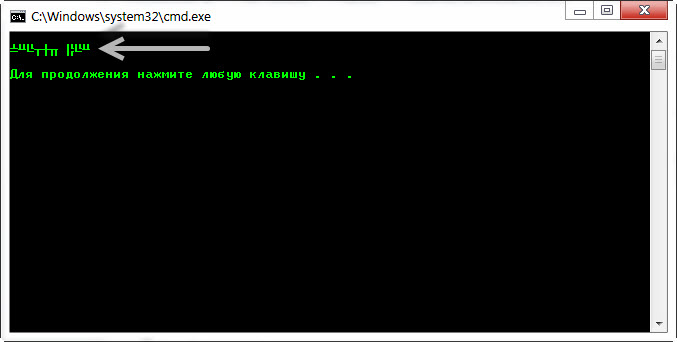
Как видим проблема с кодировкой в cmd на лицо. И произошло это по следующей причине.
Стандартный блокнот Windows сохранил Bat файл в кодировке «1251» а консоль вывела его в кодировки «866». Вот от сюда все проблемы!
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++».
После запуска «Notepad++» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
|
@Echo off echo. echo ПРИВЕТ МИР echo. Pause |
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки > Кодировки > Кириллица > OEM-866»
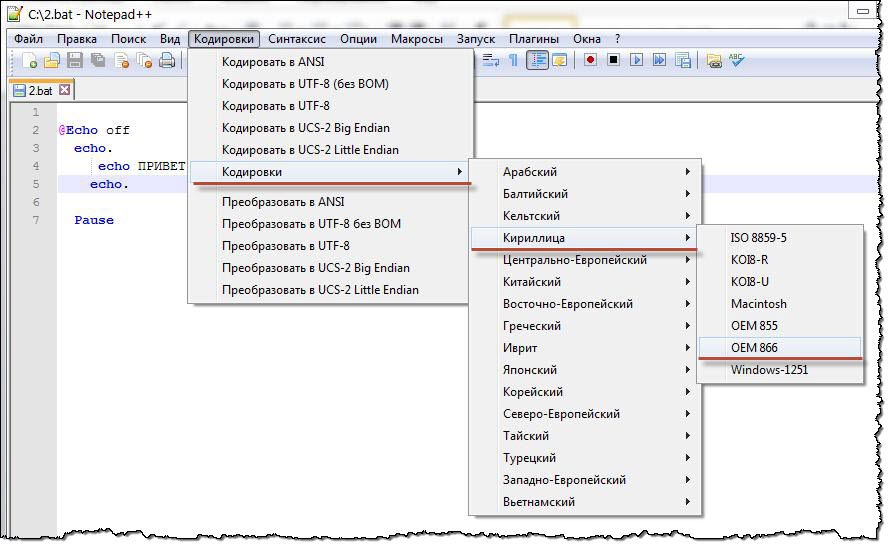
и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.
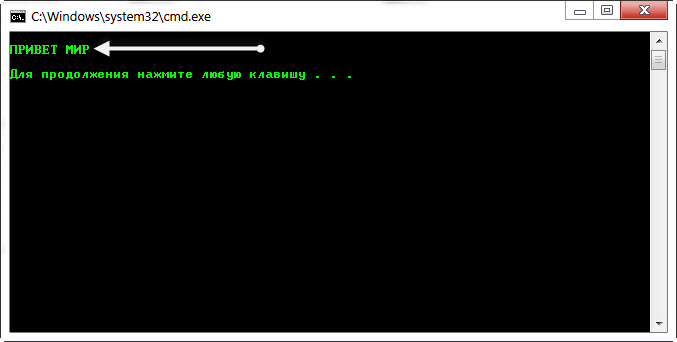
Как видим, текст на Русском в CMD отобразился, как положено.
Решения проблемы с кодировкой в CMD. 2 Способ.
Теперь рассмотрим ещё одну ситуацию, когда могут возникнуть проблемы с кодировкой в CMD.
Допустим, ситуация требует сохранить результат выполнения той или иной команды в обычный «TXT» файл. В приделах этого поста возьмём для примера команду «HELP».
Задача: Сохранить справку CMD в файл «HelpCMD.txt. Для этого создайте Bat файл и запишите в него следующие строки.
|
@Echo off Help > C:HelpCMD.txt Pause |
После выполнения Bat файла в корне диска «C:» появится файл «HelpCMD.txt» и вместо справки получится вот что:
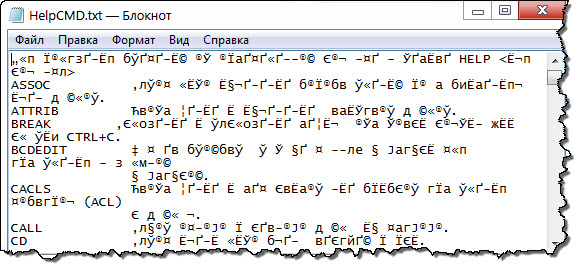
Естественно, такой вариант не кому не понравится и что бы сохранить справку в понятном для человека виде, допишите в Bat файл строку.
Теперь содержимое кода будет такое.
|
@Echo off chcp 1251 >nul Help > C:HelpCMD.txt Pause |
После выполнения «Батника» результат будет такой:
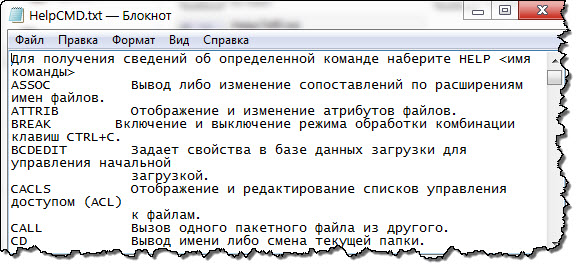
Вот так на много лучше, правда?
Пожалуй, на этом я закончу пост. Добавить больше нечего. Если у Вас имеются какие-то соображения по данной теме, буду рад Вашему комментарию к посту.
Дополнительно из комментариев то Garric
Автор очень хорошо описал принцип. ! Но это неудобно.
Нужно бы добавить. Если автор добавит это в статью то это будет Good.
Создаём файл .reg следующего содержания:
——
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT.batShellNew]
«FileName»=»BATНастроенная кодировка.bat»
——
Выполняем.
——
Топаем в %SystemRoot%SHELLNEW
Создаём там файл «BATНастроенная кодировка.bat»
Открываем в Notepad++
Вводим любой текст. (нужно!) Сохраняемся.
Удаляем текст. Меняем кодировку как сказано в статье. Сохраняемся.
———-
Щёлкаем правой кнопкой мыши по Рабочему столу. Нажимаем «Создать» — «Пакетный файл Windows».
Переименовываем. Открываем в Notepad++. Пишем батник.
В дальнейшем при работе с файлом не нажимаем ничего кроме как просто «Сохранить». Никаких «Сохранить как».
My background: I use Unicode input/output in a console for years (and do it a lot daily. Moreover, I develop support tools for exactly this task). There are very few problems, as far as you understand the following facts/limitations:
CMDand “console” are unrelated factors.CMD.exeis a just one of programs which are ready to “work inside” a console (“console applications”).- AFAIK,
CMDhas perfect support for Unicode; you can enter/output all Unicode chars when any codepage is active. - Windows’ console has A LOT of support for Unicode — but it is not perfect (just “good enough”; see below).
chcp 65001is very dangerous. Unless a program was specially designed to work around defects in the Windows’ API (or uses a C runtime library which has these workarounds), it would not work reliably. Win8 fixes ½ of these problems withcp65001, but the rest is still applicable to Win10.- I work in
cp1252. As I already said: To input/output Unicode in a console, one does not need to set the codepage.
The details
- To read/write Unicode to a console, an application (or its C runtime library) should be smart enough to use not
File-I/OAPI, butConsole-I/OAPI. (For an example, see how Python does it.) - Likewise, to read Unicode command-line arguments, an application (or its C runtime library) should be smart enough to use the corresponding API.
- Console font rendering supports only Unicode characters in BMP (in other words: below
U+10000). Only simple text rendering is supported (so European — and some East Asian — languages should work fine — as far as one uses precomposed forms). [There is a minor fine print here for East Asian and for characters U+0000, U+0001, U+30FB.]
Practical considerations
-
The defaults on Window are not very helpful. For best experience, one should tune up 3 pieces of configuration:
- For output: a comprehensive console font. For best results, I recommend my builds. (The installation instructions are present there — and also listed in other answers on this page.)
- For input: a capable keyboard layout. For best results, I recommend my layouts.
- For input: allow HEX input of Unicode.
-
One more gotcha with “Pasting” into a console application (very technical):
- HEX input delivers a character on
KeyUpofAlt; all the other ways to deliver a character happen onKeyDown; so many applications are not ready to see a character onKeyUp. (Only applicable to applications usingConsole-I/OAPI.) - Conclusion: many application would not react on HEX input events.
- Moreover, what happens with a “Pasted” character depends on the current keyboard layout: if the character can be typed without using prefix keys (but with arbitrary complicated combination of modifiers, as in
Ctrl-Alt-AltGr-Kana-Shift-Gray*) then it is delivered on an emulated keypress. This is what any application expects — so pasting anything which contains only such characters is fine. - However, the “other” characters are delivered by emulating HEX input.
Conclusion: unless your keyboard layout supports input of A LOT of characters without prefix keys, some buggy applications may skip characters when you
Pastevia Console’s UI:Alt-Space E P. (This is why I recommend using my keyboard layouts!) - HEX input delivers a character on
One should also keep in mind that the “alternative, ‘more capable’ consoles” for Windows are not consoles at all. They do not support Console-I/O APIs, so the programs which rely on these APIs to work would not function. (The programs which use only “File-I/O APIs to the console filehandles” would work fine, though.)
One example of such non-console is a part of MicroSoft’s Powershell. I do not use it; to experiment, press and release WinKey, then type powershell.
(On the other hand, there are programs such as ConEmu or ANSICON which try to do more: they “attempt” to intercept Console-I/O APIs to make “true console applications” work too. This definitely works for toy example programs; in real life, this may or may not solve your particular problems. Experiment.)
Summary
-
set font, keyboard layout (and optionally, allow HEX input).
-
use only programs which go through
Console-I/OAPIs, and accept Unicode command-line arguments. For example, anycygwin-compiled program should be fine. As I already said,CMDis fine too.
UPD: Initially, for a bug in cp65001, I was mixing up Kernel and CRTL layers (UPD²: and Windows user-mode API!). Also: Win8 fixes one half of this bug; I clarified the section about “better console” application, and added a reference to how Python does it.
Проблема: в консоли кириллические символы отображаются в неверной кодировке (в народе «кракозябры»):

При этом, если выполнить команду
chcp 866
кириллица становится читаемой только для текущего сеанса. А при перезапуске командной строки кодировка снова сбивается. Если у вас ситуация выглядит так же, то это означает, что неверные параметры кодовой страницы берутся из реестра и решать проблему нужно именно там.
Как установить правильную кодировку в консоли
Запустите редактор реестра:

Откройте раздел HKEY_CURRENT_USERConsole и проверьте значение параметра CodePage (должно быть 866).
В нашем примере на картинке мы видим, что в параметре по какой-то причине указана кодировка 1251, что бесспорно и является причиной появления абракадабры.
Если у вас значение этого параметра отличается от 866, нажмите два раза по параметру CodePage:

Установите переключатель в положение Десятичная.
В поле Значение введите 866.
Нажмите OK:

Перезапустите командную строку (закройте окно и запустите его заново — Win+R, cmd, enter). Вы должны увидеть корректное отображение кириллицы:

Приложение cmd.exe – это командная строка или программная оболочка с текстовым интерфейсом (во загнул 🙂 ).
Запустить командную строку можно следующим способом: Пуск →Выполнить → вводим в поле команду – cmd и жмем ОК. В итоге откроется рабочее окно программы – c:WINDOWSsystem32cmd.exe.

Если Вы занялись проблемой кодировки шрифтов в cmd.exe, то как запускать командную строку наверняка уже знаете 🙂
Перейдем собственно к проблеме: иногда вместо русских букв при выполнении команд выходит набор непонятных символов

Первым делом нужно зайти в свойства окна – правой кнопкой щелкнуть по верхней части окна → Свойства → выйдет окно рис.3, здесь в поле Шрифт выбираем Lucida Console и жмем ОК.

Теперь Вы получили нормальный текст на русском языке. Так же можно поменять текущую кодировку шрифта, для этого используется команда chcp. Набираем эту команду и жмем Enter, в результате получим текущую кодировку для командной строки

Для изменения кодировки так же применим chcp в следующем формате:
Chcp <код>
Где <код> – это цифровой параметр нужного шрифта, например,
1251 – Windows (кириллица);
866 – DOC-кодировка;
65001 – UTF-8;
Выбирайте на любой вкус. Т.е. что бы изменить кодировку на UTF-8 нужно выполнить команду chcp 65001.
- Remove From My Forums

Иероглифы в командной строке
-
Вопрос
-
Добрый день!
Может кто знает, есть решение проблемы «иероглифов» в командной строке?
Вот такое например: ╤хЁтхЁ
Использую Windows 7 Professional
Александр Щербаков
Ответы
-
Тогда второй, дополнительный вариант, сменить шрифт на Юникодовый, например на Lucuda Console, True Type
-
Помечено в качестве ответа
11 мая 2011 г. 4:57
-
Снята пометка об ответе
Александр Щербаков
11 мая 2011 г. 6:33 -
Помечено в качестве ответа
Александр Щербаков
11 мая 2011 г. 10:12
-
Помечено в качестве ответа