I’m attempting to upgrade a Postgres instance from version 12 to version 13, following the steps outlined at https://www.postgresql.org/docs/13/pgupgrade.html.
From an elevated command prompt, I’m running (under Windows 10):
SET PATH=%PATH%;C:Program FilesPostgreSQL13bin;
pg_upgrade.exe —old-datadir «E:ProgramsPostgreSQL12data»
—new-datadir «E:ProgramsPostgreSQL13data» —old-bindir «C:Program FilesPostgreSQL12bin» —new-bindir «C:Program
FilesPostgreSQL13bin» —old-port=5431 —new-port=5432 —jobs=5
The directories appear to be all correct, however the command returns:
Performing Consistency Checks ----------------------------- Checking cluster versions ok *failure* Consult the last few lines of "pg_upgrade_server_start.log" or "pg_upgrade_server.log" for the probable cause of the failure. connection to database failed: could not connect to server: Connection refused (0x0000274D/10061) Is the server running on host "localhost" (::1) and accepting TCP/IP connections on port 5431? could not connect to server: Connection refused (0x0000274D/10061) Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5431? could not connect to source postmaster started with the command: "C:/Program Files/PostgreSQL/12/bin/pg_ctl" -w -l "pg_upgrade_server.log" -D "E:/Programs/PostgreSQL/12/data" -o "-p 5431 -b " start Failure, exiting
pg_upgrade_server_start.log says:
command: «C:/Program Files/PostgreSQL/12/bin/pg_ctl» -w -l «pg_upgrade_server.log» -D «E:/Programs/PostgreSQL/12/data» -o «-p 5431 -b » start >> «pg_upgrade_server_start.log» 2>&1
The program «postgres» was found by «C:/Program Files/PostgreSQL/12/bin/pg_ctl»
but was not the same version as pg_ctl.
Check your installation.
I’m at a loss; what might be wrong, and how can I successfully perform this procedure?
I’m attempting to upgrade a Postgres instance from version 12 to version 13, following the steps outlined at https://www.postgresql.org/docs/13/pgupgrade.html.
From an elevated command prompt, I’m running (under Windows 10):
SET PATH=%PATH%;C:Program FilesPostgreSQL13bin;
pg_upgrade.exe —old-datadir «E:ProgramsPostgreSQL12data»
—new-datadir «E:ProgramsPostgreSQL13data» —old-bindir «C:Program FilesPostgreSQL12bin» —new-bindir «C:Program
FilesPostgreSQL13bin» —old-port=5431 —new-port=5432 —jobs=5
The directories appear to be all correct, however the command returns:
Performing Consistency Checks ----------------------------- Checking cluster versions ok *failure* Consult the last few lines of "pg_upgrade_server_start.log" or "pg_upgrade_server.log" for the probable cause of the failure. connection to database failed: could not connect to server: Connection refused (0x0000274D/10061) Is the server running on host "localhost" (::1) and accepting TCP/IP connections on port 5431? could not connect to server: Connection refused (0x0000274D/10061) Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5431? could not connect to source postmaster started with the command: "C:/Program Files/PostgreSQL/12/bin/pg_ctl" -w -l "pg_upgrade_server.log" -D "E:/Programs/PostgreSQL/12/data" -o "-p 5431 -b " start Failure, exiting
pg_upgrade_server_start.log says:
command: «C:/Program Files/PostgreSQL/12/bin/pg_ctl» -w -l «pg_upgrade_server.log» -D «E:/Programs/PostgreSQL/12/data» -o «-p 5431 -b » start >> «pg_upgrade_server_start.log» 2>&1
The program «postgres» was found by «C:/Program Files/PostgreSQL/12/bin/pg_ctl»
but was not the same version as pg_ctl.
Check your installation.
I’m at a loss; what might be wrong, and how can I successfully perform this procedure?
In a recent blog about what is new in PostgreSQL 13, we reviewed some of the new features of this version, but now, let’s see how to upgrade to be able to take advantage of all these mentioned functionalities.
Upgrading to PostgreSQL 13
If you want to upgrade your current PostgreSQL version to this new one, you have three main native options to perform this task.
-
Pg_dump/pg_dumpall: It is a logical backup tool that allows you to dump your data and restore it in the new PostgreSQL version. Here you will have a downtime period that will vary according to your data size. You need to stop the system or avoid new data in the primary node, run the pg_dump, move the generated dump to the new database node, and restore it. During this time, you can’t write into your primary PostgreSQL database to avoid data inconsistency.
-
Pg_upgrade: It is a PostgreSQL tool to upgrade your PostgreSQL version in-place. It could be dangerous in a production environment and we don’t recommend this method in that case. Using this method you will have downtime too, but probably it will be considerably less than using the previous pg_dump method.
-
Logical Replication: Since PostgreSQL 10, you can use this replication method which allows you to perform major version upgrades with zero (or almost zero) downtime. In this way, you can add a standby node in the last PostgreSQL version, and when the replication is up-to-date, you can perform a failover process to promote the new PostgreSQL node.
So, let’s see these methods one by one.
Using pg_dump/pg_dumpall
In case downtime is not a problem for you, this method is an easy way for upgrading.
To create the dump, you can run:
$ pg_dumpall > dump_pg12.outOr to create a dump of a single database:
$ pg_dump world > dump_world_pg12.outThen, you can copy this dump to the server with the new PostgreSQL version, and restore it:
$ psql -f dump_pg12.out postgresKeep in mind that you will need to stop your application or avoid writing in your database during this process, otherwise, you will have data inconsistency or a potential data loss.
Using pg_upgrade
First, you will need to have both the new and the old PostgreSQL versions installed on the server.
$ rpm -qa |grep postgres
postgresql13-contrib-13.3-2PGDG.rhel8.x86_64
postgresql13-server-13.3-2PGDG.rhel8.x86_64
postgresql13-libs-13.3-2PGDG.rhel8.x86_64
postgresql13-13.3-2PGDG.rhel8.x86_64
postgresql12-libs-12.7-2PGDG.rhel8.x86_64
postgresql12-server-12.7-2PGDG.rhel8.x86_64
postgresql12-12.7-2PGDG.rhel8.x86_64
postgresql12-contrib-12.7-2PGDG.rhel8.x86_64Then, first, you can run pg_upgrade for testing the upgrade by adding the -c flag:
$ /usr/pgsql-13/bin/pg_upgrade -b /usr/pgsql-12/bin -B /usr/pgsql-13/bin -d /var/lib/pgsql/12/data -D /var/lib/pgsql/13/data -c
Performing Consistency Checks on Old Live Server
------------------------------------------------
Checking cluster versions ok
Checking database user is the install user ok
Checking database connection settings ok
Checking for prepared transactions ok
Checking for system-defined composite types in user tables ok
Checking for reg* data types in user tables ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
*Clusters are compatible*The flags mean:
-
-b: The old PostgreSQL executable directory
-
-B: The new PostgreSQL executable directory
-
-d: The old database cluster configuration directory
-
-D: The new database cluster configuration directory
-
-c: Check clusters only. It doesn’t change any data
If everything looks fine, you can run the same command without the -c flag and it will upgrade your PostgreSQL server. For this, you need to stop your current version first and run the mentioned command.
$ systemctl stop postgresql-12
$ /usr/pgsql-13/bin/pg_upgrade -b /usr/pgsql-12/bin -B /usr/pgsql-13/bin -d /var/lib/pgsql/12/data -D /var/lib/pgsql/13/data
...
Upgrade Complete
----------------
Optimizer statistics are not transferred by pg_upgrade so, once you start the new server, consider running:
./analyze_new_cluster.sh
Running this script will delete the old cluster's data files:
./delete_old_cluster.shWhen it is completed, as the message suggests, you can use those scripts for analyzing the new PostgreSQL server and deleting the old one when it is safe.
Using Logical Replication
Logical replication is a method of replicating data objects and their changes, based upon their replication identity. It is based on a publish and subscribe mode, where one or more subscribers subscribe to one or more publications on a publisher node.
So based on this, let’s configure the publisher,in this case the PostgreSQL 12 server, as follows.
Edit the postgresql.conf configuration file:
listen_addresses = '*'
wal_level = logical
max_wal_senders = 8
max_replication_slots = 4Edit the pg_hba.conf configuration file:
# TYPE DATABASE USER ADDRESS METHOD
host all rep1 10.10.10.141/32 md5Use the subscriber IP address there.
Now, you must configure the subscriber, in this case the PostgreSQL 13 server, as follows.
Edit the postgresql.conf configuration file:
listen_addresses = '*'
max_replication_slots = 4
max_logical_replication_workers = 4
max_worker_processes = 8As this PostgreSQL 13 will be the new primary node soon, you should consider adding the wal_level and archive_mode parameters in this step, to avoid a new restart of the service later.
wal_level = logical
archive_mode = onThese parameters will be useful if you want to add a new replica or for using PITR backups.
Some of these changes require a server restart, so restart both publisher and subscriber.
Now, in the publisher, you must create the user to be used by the subscriber to access it. The role used for the replication connection must have the REPLICATION attribute and, in order to be able to copy the initial data, it also need the SELECT privilege on the published table:
world=# CREATE ROLE rep1 WITH LOGIN PASSWORD '********' REPLICATION;
CREATE ROLE
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep1;
GRANTLet’s create the pub1 publication in the publisher node, for all the tables:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONAs the schema is not replicated, you must take a backup in your PostgreSQL 12 and restore it in your PostgreSQL 13. The backup will only be taken for the schema since the information will be replicated in the initial transfer.
In PostgreSQL 12, run:
$ pg_dumpall -s > schema.sqlIn PostgreSQL 13, run:
$ psql -d postgres -f schema.sqlOnce you have your schema in PostgreSQL 13, you need to create the subscription, replacing the values of host, dbname, user, and password with those that correspond to your environment.
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=10.10.10.140 dbname=world user=rep1 password=********' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONThe above will start the replication process, which synchronizes the initial table contents of the tables in the publication and then starts replicating incremental changes to those tables.
To verify the created subscription you can use the pg_stat_subscription catalog. This view will contain one row per subscription for the main worker (with null PID if the worker is not running), and additional rows for workers handling the initial data copy of the subscribed tables.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16421
subname | sub1
pid | 464
relid |
received_lsn | 0/23A8490
last_msg_send_time | 2021-07-23 22:42:26.358605+00
last_msg_receipt_time | 2021-07-23 22:42:26.358842+00
latest_end_lsn | 0/23A8490
latest_end_time | 2021-07-23 22:42:26.358605+00To verify when the initial transfer is finished you can check the srsubstate variable on pg_subscription_rel catalog. This catalog contains the state for each replicated relation in each subscription.
world=# SELECT * FROM pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+-----------
16421 | 16408 | r | 0/23B1738
16421 | 16411 | r | 0/23B17A8
16421 | 16405 | r | 0/23B17E0
16421 | 16402 | r | 0/23B17E0
(4 rows)Column descriptions:
-
srsubid: Reference to subscription.
-
srrelid: Reference to relation.
-
srsubstate: State code: i = initialize, d = data is being copied, s = synchronized, r = ready (normal replication).
-
srsublsn: End LSN for s and r states.
When the initial transfer is finished, you have everything ready to point your application to your new PostgreSQL 13 server.
Conclusion
As you can see, PostgreSQL has different options to upgrade, depending on your requirements and downtime tolerance.
No matter what kind of technology you are using, keeping your database servers up to date by performing regular upgrades is a necessary but difficult task, as you need to make sure that you won’t have data loss or data inconsistency after upgrading. A detailed and tested plan is the key here, and of course, it must include a rollback option, just in case.
Subscribe to get our best and freshest content
Предлагаю ознакомиться с расшифровкой доклада 2018 года Андрея Сальникова «Практика обновления версий PostgreSQL»
В большинстве своем, системные администраторы и ДБА бояться как огня делать мажорные обновления версий баз данных (RDBMS), особенно если эта база данных в эксплуатации и имеет достаточно высокую нагрузку. Главной причиной тому некоторый даунтайм базы данных, который всегда подразумевается при планировании таких работ.
На практике, такого рода upgrade занимает довольно длительное время и зачастую администраторам с малым опытом подобных операций приходится откатываться на старую версию баз данных из-за достаточно банальных ошибок, которые можно было бы избежать еще на этапе подготовки.
В Data Egret мы накопили огромный опыт проведения мажорных апгрейдов PostgreSQL в проектах, где нет права на ошибку. Я поделюсь своим опытом и расскажу о следующих шагах процесса: как правильно подготовиться к upgrade-у PostgreSQL? что необходимо сделать на этапе подготовки? как запланировать последовательность действий на сам upgrade? как провести процедуру upgrade-а успешно, без возврата на предыдущую версию бд? как минимизировать или вообще избежать простоя всей системы во время upgrade-а? какие действия необходимо выполнить после успешного upgrade-а PostgreSQL? Я также расскажу про две наиболее популярные процедуры апгрейда PostgreSQL — pg_upgrade и pg_dump/pg_restore, плюсы и минусы каждого из методов и расскажу про все типичные проблемы на всех этапах этой процедуры, и как их избежать.
Доклад будет интересен как новичкам так и тем ДБА которые уже давно работают с PostgreSQL, но хотят побольше узнать о том как правильно планировать и проводить upgrade максимально безболезненно.

Здравствуйте! Я тружусь в компании Data Egret. Мы занимаемся тем, что поддерживаем сервера PostgreSQL и оказываем услуги консалтинга PostgreSQL. И практика показала, что очень мало людей обновляют базу данных. Они запустили проект, устанавливают версию актуальную на тот момент и работают до сих пор.
Доклад будет состоять из трех частей. Первая – вводная, чтобы к общей терминологии прийти. Вторая про минорные обновления. И третья про мажорные будет.

Цель доклада – дать ответ на вопросы.
- Зачем нужно обновляться? Обновления необходимы потому, что Postgres не стоит на месте. Там постоянно делают новые фичи, исправляют какие-то баги. И чтобы не прыгать все время на одних и тех же проблемах, лучше обновляться. И все быстрее будет у вас работать, и меньше проблем будет. Это основная цель обновления.
- Расскажу, какие методики обновления существуют в процессе доклада.
- Затрону темы, где у вас могут быть проблемы по той или иной методике и расскажу, как избежать их.
- Немало важный вопрос, который многих беспокоит: «Это возможно ли обновления без даунтайма и как их провернуть?». Про это поговорим.
- Если у вас нет никакого опыта в обновлении, опираясь на этот доклад вы сможете сами попробовать это сделать. Сможете сначала на кошках потренироваться, а потом уже и production базы данных обновлять.
В общем основная цель в том, чтобы люди старались поддерживать у себя актуальную версию Postgres.

Немного вводной информации о том, как нумеруются версии, чтобы общее понимание было. До 10 версии у нас нумерация бывает из трех цифр. Первые две цифры, разделенные точкой, отвечали за мажорную версию, последняя цифра – это минорная версия.
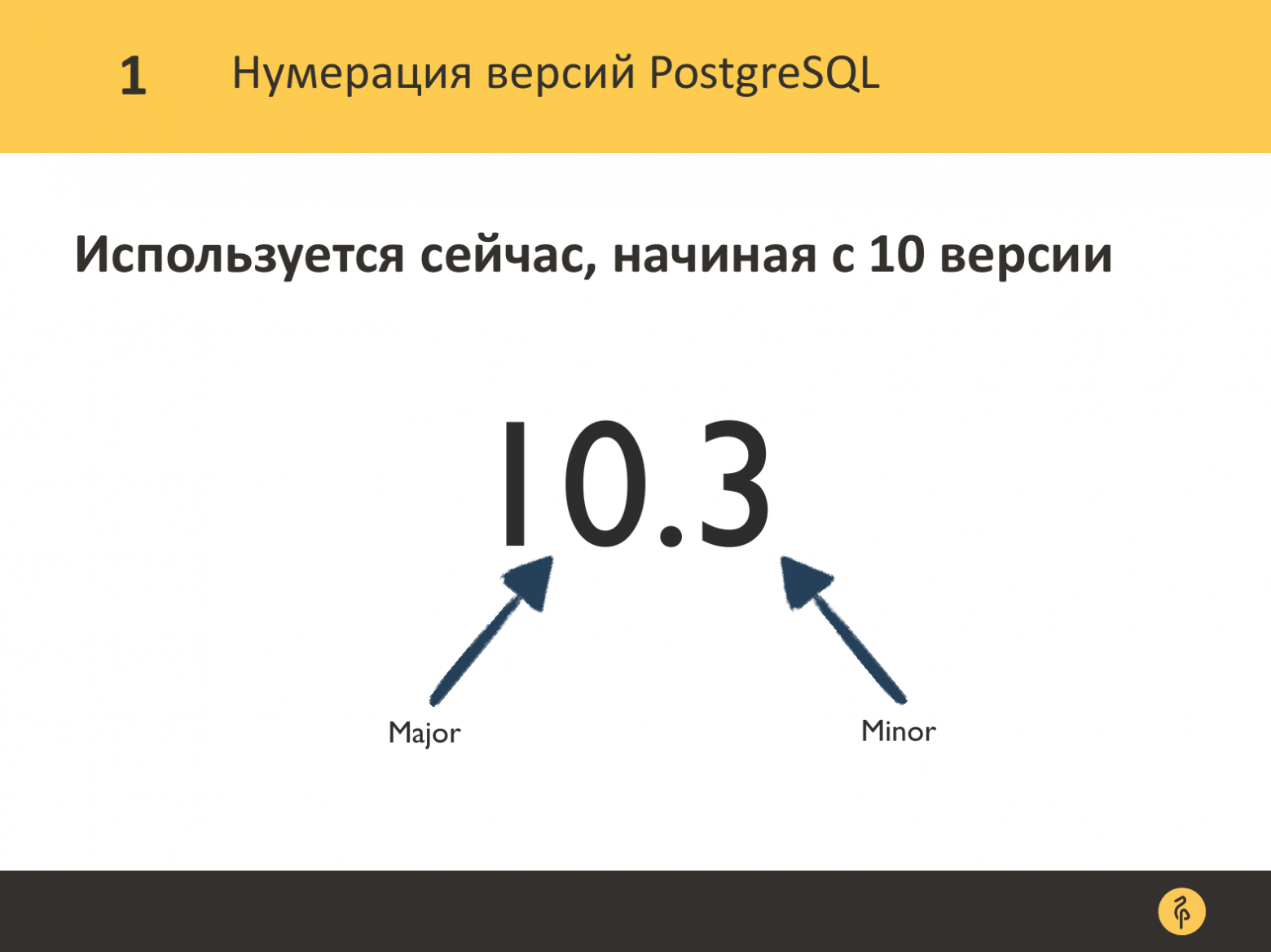
Начиная с 10-ой версии сообщество решило изменить стиль нумерации. Теперь у нас два числа, разделенные точкой. Первое число – это номер мажорной версии, последнее число – номер минорной версии.

Какие могут быть типы обновлений?
Минорные обновления. Тут важно понимать, что минорные обновления – это обновления в рамках одной мажорной версии. Если вы работаете с версией 9.6 и обновления между этими мелкими пачами, которые приходят, довольно важны, то будут обновления минорные. Это по последней цифре. Они самые легкие.
Для 10-ой версии начинается новый стиль нумерации. Ничего не изменяется, последнее число отвечает за минорную версию.
Мажорные обновления. Тут все достаточно интересно. В мажорных обновлениях мы прыгаем между версиями и стремимся за новыми фичами и возможностями баз данных, и всякими плюшками.
Тут уже минорные версии базы уже не играют роли. При мажорном обновлении мы будем стараться обновляться на самую последнюю доступную версию релиза.
Актуальные версии на сегодняшний день – это те, куда приехали патчи минорных обновлений. Их 6. Но одна помечена красным. И помечена по той причине, потому что эту версию сообщество уже перестало поддерживать. Т. е. они попатчили в 9.2. Это был последний патч, больше не будет, про 9.2 можно забыть. Если вы работаете на 9.2, то вам самое время обновляться.
Любая процедура обновления будет состоять из двух вещей: мы готовимся и делаем обновление.

Есть общие рекомендации. Перед любым обновлением, не зависимо от того минорная или мажорная эта версия, необходимо будет проделать перед обновлением на production следующее:
- Очень важно прочитать полностью release notes. Что под этим я подразумеваю? Обычно, если люди и читают release notes, то читают release notes по главной мажорной версии, потому что там много всего написано. Написано про вкусняшки, которые там разработчики сделали. А минорные как-то упускают. А минорные обновления несут серьезные багфиксы, потому что все мы люди и разработчики тоже люди и когда выкатывается новый релиз, он еще достаточно сырой и там приходят очень много патчей. К примеру, мы до сих пор не очень стремимся устанавливать 10-ку клиентам, потому что ожидаем второй патч-сет. Только после этого, скорее всего, займемся вплотную этим.
- Почему вам нужно будет обновиться на тестовом окружении? Причина простая. Нужно проверить, как ваша система будет работать с новой версией базы данных. Если вы не читали release notes, то для вас могут будут сюрпризы. Например, приложение не будет работать с какой-нибудь специфической фичей. В основном, Postgres обратно совместимый и проблемы возникают редко, но бывают, что возникают. Поэтому погонять свое приложение на тестовом окружении всегда полезно, не только с точки зрения обновления Postgres, но и разработки.
- Если вы столкнетесь с какими-то проблемами, то вам нужно будет подойти к своим разработчикам, которые писали приложение и рассказать, что необходимо поменять и как это необходимо поменять, иначе у вас потом сюрпризы в production полезут.
- И вещь, которая нужна всегда и везде и о чем мы не перестаем напоминать – это то, что бэкапирование нужно везде и всегда. И бэкапирование настоящее — это то, когда вы с бэкапа поднялись, подключили свое приложение к базе и у вас все заработало, и нет никаких проблем. Все данные консистентные и все хорошо.
Советы общие, но частенько ими, к сожалению, пренебрегают.

Теперь перейдем к самим обновлениям. И начнем от легкого к более тяжелому по количеству действий и пониманию.
Минорное обновление хорошо тем, что несет исправления в коде самой базы данных. У нас не происходят никаких изменений со структуры данных, с внутренним представлением системного каталога Postgres. Там багфиксы самого движка Postgres.
Как это происходит:
- Установите пакеты с новой версией PostgreSQL. Но тут важно понимать, что если вы пользуетесь какими-то стандартными репозиториями, то у вас, скорее всего, Postgres запущен как сервис. И установка пакетов перезапустит этот сервис. И вы себе установите небольшую аварию с установкой базы данных и своего приложения. Поэтому на этом акцентуируйте внимание и устанавливайте пакет так, чтобы не рестартовали. В Ubuntu, например, есть стандартный конфигурационный файл для каждого кластера, который создается. Называется он start.conf. И вы там можете поправить режим перезапуска сервисом конкретного кластера. Можете запретить сервису его рестартовать автоматически.
- Необходимо установить связанные с PostgreSQL другие пакеты. Если мы обновим только серверный пакет, то автоматически у вас по связям не подтянутся ни клиентская часть, не common-пакет и пакет расширения тоже может не подтянуться. Будьте внимательны тут.
- Следующий – checkpoint. Зачем нам нужен checkpoint? Когда у нас работает база данных, то все изменения происходят у нас в памяти. И когда мы начнем останавливать базу данных для перезапуска, то база данных начнет активно все, что наработала в памяти, скидывать на диск. И это нам устроит небольшой коллапс, потому что, если у нас очень огромная оперативная память, допустим, 250 GB, то моментально скинуть их на диск мы не сможем. Поэтому нужно предварительно об этом позаботиться и выполнить checkpoint, который произведет сброс всех данных из памяти на диск и облегчит нам дальнейшую жизнь при рестарте Postgres.
- Как избежать даунтайма? Если вы используете pgbouncer, то он в данном случае поможет приложениям прозрачно оставить соединение с базой данных, потому что он является прослойкой между базой данных и приложением. Приложение входит в pgbouncer, а pgbouncer входит в базу данных. И pgbouncer’у мы можем сказать – поставь на паузу приложение, а сами в это время по-тихому перезапустить базу данных с новой версией бинарника. Для приложения это будет как большой latency при ответе запросов. Т. е. они подвиснут на время рестарта, потом мы снимем с паузы pgbouncer, и приложение начнет работать снова. Если вы предварительно сделаете checkpoint, паузу в pgbouncer, то рестарт у вас займет в зависимости от активности в базе данных от секунды до полминуты.
- И перезапускаем базу данных, чтобы она заработала с новыми бинарниками. Никаких изменений в файловых данных у нас в это время не происходит. Мы просто запускаем новые бинарники, которые работают с теми же данными.
- Некоторые багфиксы, обновления могут повлиять на extensions, если вы используете какие-то специфические extensions. И поэтому рекомендую – не полениться пройтись по всем базам и обновить все extensions в каждой базе данных. Это очень полезно. Особенно это полезно будет при мажорных обновлениях. Там это совсем яркая проблема. На минорных я пока не сталкивался. Но я их обновляю всегда.
- И также минорные обновления (возвращаюсь к тому, что очень важно читать release notes) иногда требуют дополнительные процедуры из release notes. Каждый раз от каждого минора к следующему минору – это могут быть какие-то специфические вещи. Допустим, если вы обновляетесь с 9.6.1 на 9.6.6, которая сейчас актуальна, то вам нужно прочитать release notes для 9.6.2 – 9.6.6. И если вы сталкиваетесь с какими-то проблемами, то вычленить оттуда то, что вам нужно будет сделать после того, как вы перезапустите базу с новыми бинарниками.
- Если вы работаете со standby серверами, с потоковой репликацией, то реплики лучше и правильней обновлять до обновления Мастера сервера. Недавно у нас возникла ситуация, когда у клиента был Мастер 14-ой минорной версии, а реплика была 2.3 и у нас встала репликация. Он миграцию схем данных запустил. Перестроились синтаксисы и у репликации был баг, она встала и перестала работать. Крутилась в бесконечном цикле.
Это к важности того, что нужно читать release notes.
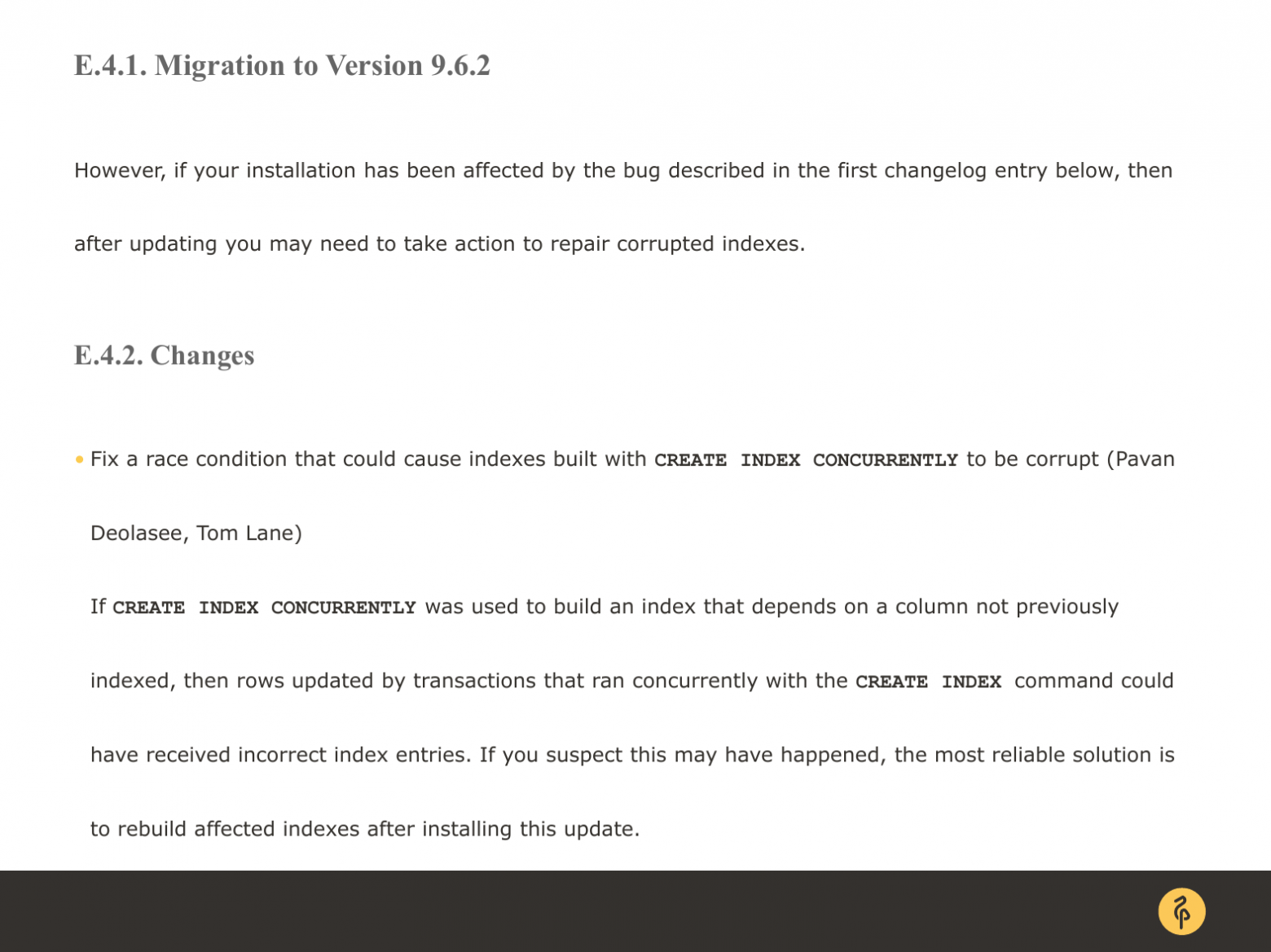
Вот эта конкретная вырезка из официального Postgres.org. Релиз для версии 9.6.2. И тут черным по белому написано, что в этом релизе пофиксили создание конкурентных индексов всех.
Суть бага в чем была? Если ранее вы создавали конкурентный индекс по полю, по которому никогда до этого не было индекса и не участвовало оно ни в каком другом индексе, то у вас мог оказаться битый индекс и вы об этом бы не узнали. Потому что в базе данных он у вас выглядел бы валидным, а по факту в индексе были бы пропущены значения или ссылки были бы не на те строки в таблице. Что в итоге приводит к неожиданным результатам выполнения запросов.
И вот таких интересных штук в каждой минорной версии много. Просто так минорные версии сообщество не выпускает. Будьте внимательны. Читайте, пожалуйста, release notes. Это очень важно.
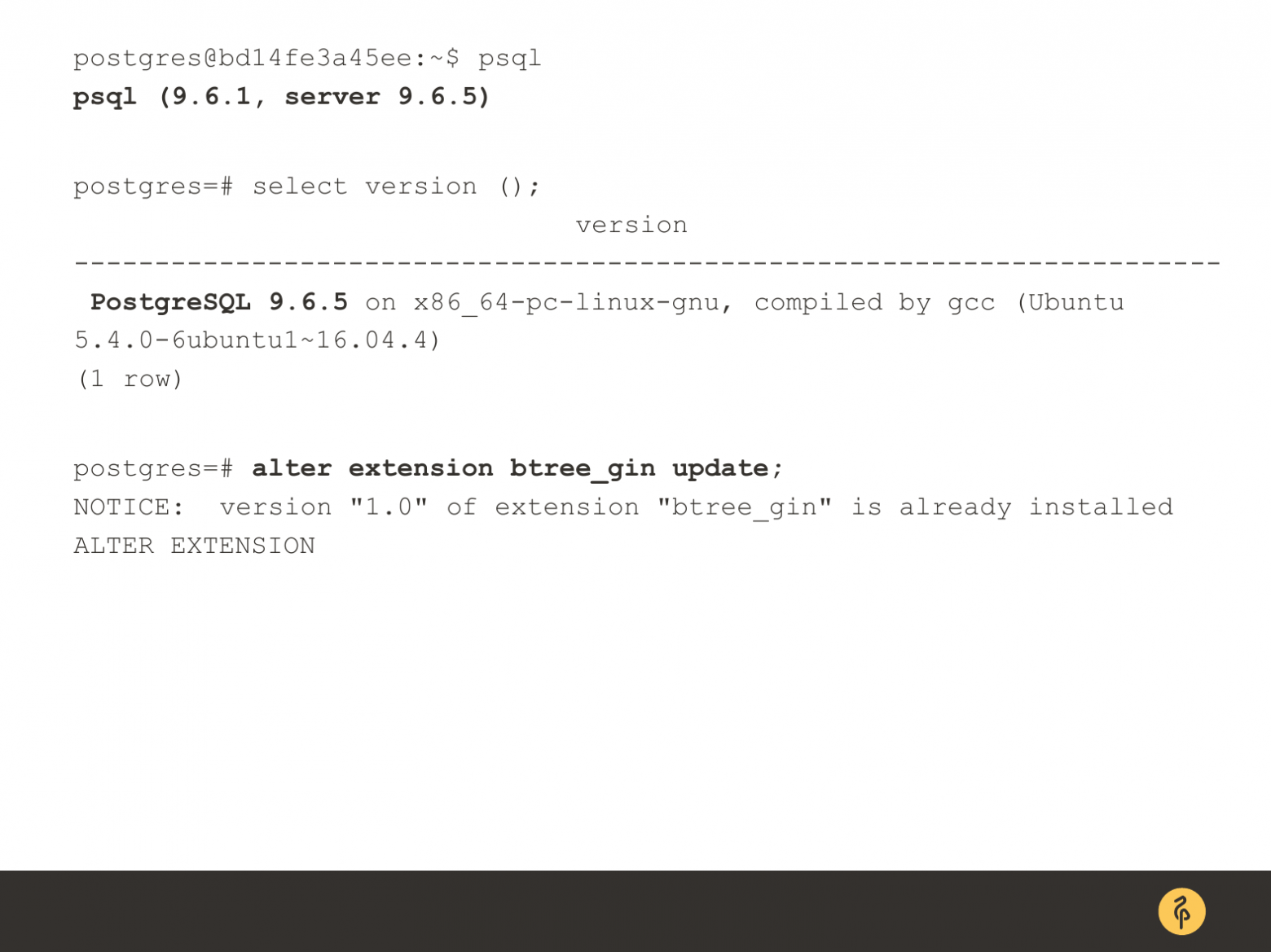
И вот иллюстрация о том, что пакеты по зависимостям не тянутся. В данном случае я обновлял серверную версию. Вы, как видите, что сервер у меня 9.6.5. А клиент по зависимостям у меня не подтянулся 9.6.1. Это тоже не очень хорошо, потому что не гарантируется обратная совместимость. И могут быть какие-то проблемы с клиентом. На минорной версии это мало вероятно, с мажорной – большая вероятность может быть. Поэтому обновили серверную часть – обновляйте другие пакеты.
И пример того, как нужно пройти по расширениям. Т. е. по каждой базе bash-скрипт напишите, который по каждой базе идет и тянет имя расширения. И просто нагенерируете себе alter extension, update и для душевного спокойствия запустите.

Какие итоги можно сделать?
- Делается просто. Мы просто устанавливаем новый пакет. Делаем несложные действия, чтобы произвести рестарт базы данных достаточно безопасный и прозрачный для приложения, чтобы его никак не задействовать и никак не повлиять на него.
- Каждое минорное обновление несет существенное исправление ошибок. Да, у вас может не возникнуть эта ситуация сейчас, но в следующем миноре может возникнуть такая проблема, поэтому читайте release notes.
- Как дополнительный эффект багфиксы несут улучшение производительности. Допустим, в параллельном сканировании есть какой-то баг, который пару лишних цифр добавляет. Ребята выкатили минорное обновление. Убрали лишние циклы. И у вас параллельное сканирование идет быстрее.
- И минимальный простой системы, т. е. у вас база не доступна ровно в рестарт. Вы ее остановили, если сделали правильно с checkpoint, то у вас рестарт базы от миллисекунды до 30 секунд максимум занимает.

Самая большая и интересная часть доклада – это мажорные обновления.
Есть несколько методик мажорных обновлений. Кому какая подходит, тот ту и выбирает. Моя цель рассказать о каждой и них.
- Pg_dump и restore – это самая старая и добрая методика. Мы ею до сих пор иногда пользуемся, потому что надежнее нее ничего нет. Но у нее есть куча-куча недостатков для современно мира.
- Pg_upgrade – это наша любимая утилита, которой мы пользуемся, наверное, в 95 % случаев, когда проводим мажорные обновления базы данных. А проводим мы их еженедельно точно.
- И также основанные на репликациях обновления.
И эти обновления тут стоят в порядке усложнения.

Как с помощью pg_dump будет выглядеть для вас процедура обновления?
- Устанавливаем пакет с новой мажорной версией. Тут нам не стоит переживать, потому что это разные пакеты. Один пакет 9.5, к примеру, другой пакет 10. В Ubuntu нужно быть внимательным, в RedHat ветке можно не париться – не рестартанет Postgres. Но помним, чтобы случайно не перезапустить текущую рабочую базу данных.
- Создаем пустой кластер в той же locale, в которой существует текущая работающая база данных.
- Пробегаемся по конфигам Postgres, потому что, если вы им пользуетесь, то вы, скорее всего, их крутили и дефолтные параметры некоторые вам не нужны.
- И дальше начинается та вещь, которая не удовлетворяет большинство людей в проведении апгрейда базы данных при pg_dumop. Нам необходимо остановить модификацию данных в PostgreSQL. Зачем нам это нужно сделать? Если мы pg_dump пользуемся для снятия дампа, то мы снимаем снапшот на момент, когда он стартанул, но база может продолжать писать в этот момент изменения в себя. Нам изменения не нужны, потому что мы хотим перенести весь объем данных из старой базы в новую, чтобы они были актуальные и самые свежие. И это можно сделать только одним способом. Остановив запись в PostgreSQL, т. е. остановив приложение, закрыв порт. Там путей много разных, выбирайте удобный для себя.
- С остановки модификации данных начинается даунтайм. И это главный недостаток pg_dump, потому что после этого мы создаем дамп базы данных. И тут время полностью прямо пропорционально размеру вашей базы. Чем больше база данных, тем дольше вы будете ждать создание дампа.
- А потом еще и восстановление дампа в новую версию. Но зато дамп вам гарантированно восстановит вашу базу данных в новую версию с некоторыми оговорками.
- И после того, как мы восстановили дамп на новой версии, запускаем приложение так, чтобы оно писало уже в новую версию PostgreSQL.
Сложная и нудная процедура, но есть случаи, когда без нее никак не обойтись, к сожалению.

Некоторые особенности pg_dump:
- Некоторые сложности с обновлением нагруженных баз данных. Сложность одна – даунтайм. Большой и неприемлемый в современном мире.
- Мы останавливаем приложение. Это тоже последствие даунтайма.
- Требует дополнительное дисковое пространство. Тут есть варианты: в два раза, в три раза, можно и больше. Все зависит от того, как вы снимаете дамп.
- Если вы снимаете дамп промежуточно на диск, то есть у утилитки хорошая опция, которая позволяет вам при снятии дампа сразу его архивировать и складывать упакованным на диск. Это позволит вам сохранить место.
- Также вы можете параллельно это снимать. Если вам дисковая система позволяет, то вы можете распараллелить снятие дампа. И это вам позволит быстрее обрабатывать данные. Но это касается SSD-систем, где SSD-диски используются хорошие. Но если вы хотите переливать дамп со старой базы в новую без промежуточного хранения на диске, то параллельно это не получится, к сожалению. И это тоже недостаток достаточно большого дампа.
- И эта вещь очень важная. Прежде чем делать апгрейд, мы всегда снимаем схему базы данных со старых версий и накатываем в новую версию. И эта процедура нам позволяет поймать большинство граблей, которые могут встретиться. Например, несовместимые версии расширений, пропали типы. И снятие только схемы восстановления, только схемы данных позволяет поймать все эти грабли до того, как вы реально запустите дамп с даунтаймом. Это позволит избежать многих проблем.

Теперь переходим к нашей любимой утилите, к pg_upgrade.
- Pg_upgrade намного сложнее с точки зрения подготовки проведения апгрейда. Но если вы с ним будете близки, т. е. потренируетесь, то вы его полюбите. Предварительная подготовка сложная.
- При определенных обстоятельствах вы можете запороть себе базу данных. Как это происходит я вам расскажу и, надеюсь, что вы так не сделаете.
- Это самый быстрый способ обновления PostgreSQL. И самый дешевый по ресурсам и по ресурсам человеко-часов, а это самый ценный ресурс в нашей жизни.
- Могут быть проблемы после обновления. О них я расскажу чуть попозже.
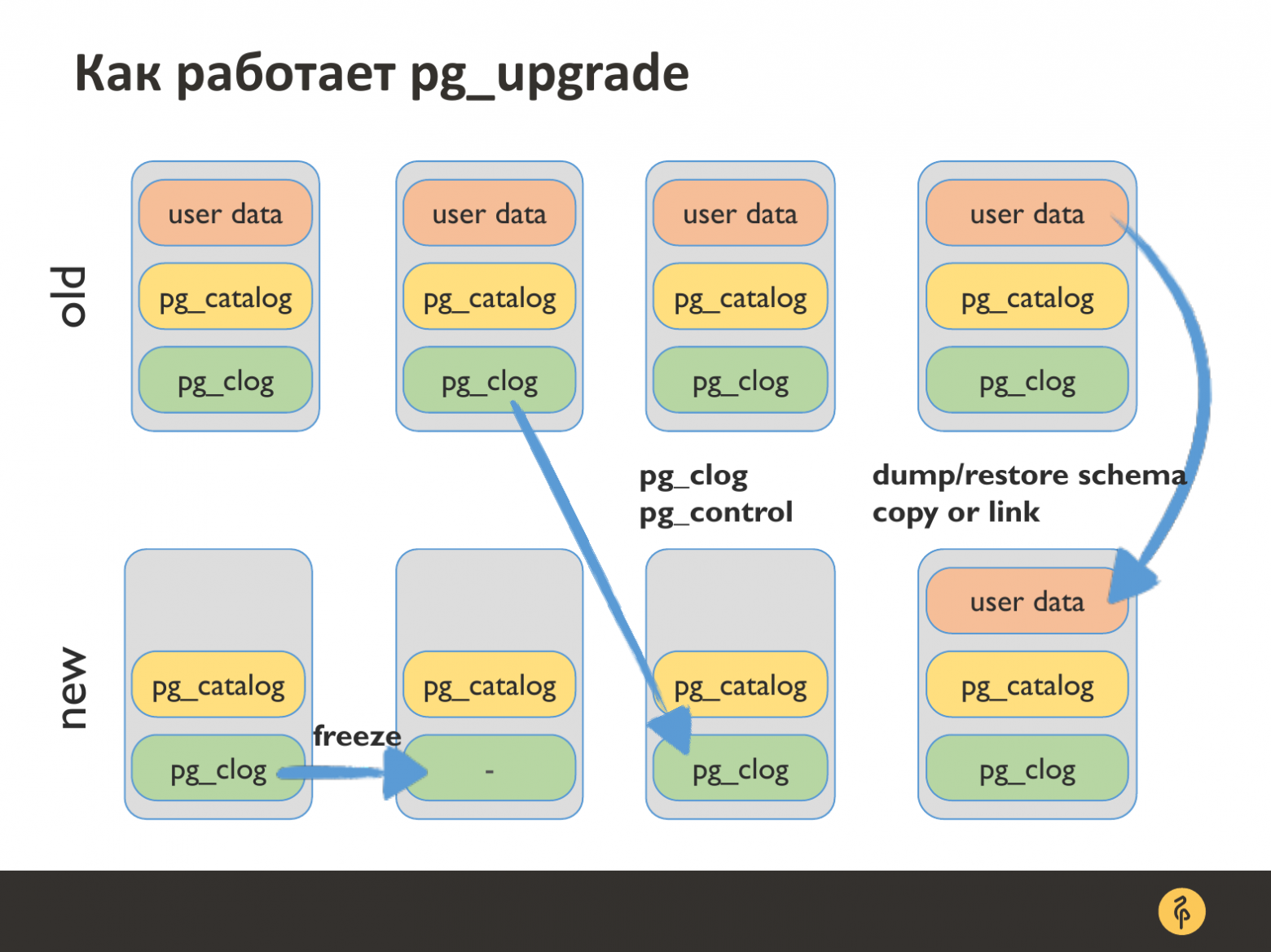
Небольшой ликбез, как работает pg_upgrade. На входе мы должны иметь две базы данных: старую, которая у нас с данными и новый кластер пустой, который мы создали.
Соответственно, когда мы запускаем pg_upgrade, и он начинает делать свое светлое дело, то в первую очередь он чистит информацию в новом кластере о счетчиках транзакции, потому что нам нужно перенести счетчик транзакции из старой базы в новую. И когда мы стартанем, начнем ровно с того места, на котором мы закончили в старой версии базы данных. Тут происходит перенос этого счетчика транзакции.
И последняя самая массивная, но самая веселая вещь – pg_upgrade делает dump и restore схемы, он запускает pg_dump, restore с некоторыми флажками для того, чтобы восстановить новой базе всю схему данных, которая была в старой базе данных, но не переносит при этом данные. Это именно схема.
А перенос данных может быть осуществлен двумя вещами. Мы можем скопировать файлы с данными, а можем сделать хардлинк на существующие данные, потому что блок данных у нас не меняется с версией 8.4. В Postgres и мы можем позволить себе такой финт ушами.
И когда мы делаем хардлинк, то у вас в этот момент смотрят две версии базы данных (допустим, 9.0 и 10) на одни и те же дата-файлы. И если вы одновременно обе их запустите, то ваша база данных превратиться в тыкву, с которой вы потом ничего не сделаете. Поэтому будьте очень осторожны с линком. Но мы делаем через линк всегда, у нас руки не дрожат.

Тут именно такая процедура подготовки, которую мы всегда делаем перед реальным апгрейдом на production. Т. е. прежде чем устроить даунтайм и коллапс, мы сначала проверяем – действительно ли мы это можем сделать.
- Ставим новые пакеты новой версии PostgreSQL.
- Создаем новую базу в правильной locace. Это общие шаги.
- Делаем pg_upgrade. Запускаем с ключом «check». Check делает почти все, что может апгрейд сделать в реальности. И при этом, если у вас есть какие-то несовместимости с типами данных, со схемой и это все вылезет, то он ругнется, отвалится, но при этом вы не попортили старую базу и не сделала никаких изменений в пустом кластере. И вы можете сразу прекратить процедуру апгрейда, запланированный даунтайм и общий кипеш. И вернуться к тесту и посмотреть, что у вас там не так и исправить это.
- Pg_dumpall — schema-only. К сожалению апгрейд с check не все показывает. И мы себя дополнительно проверяем через pg_dumpall – schema-only, и накатываем новую базу данных. Недостаток этой процедуры в том, что потом придется пересоздать кластер заново пустой. Но она того стоит, потому что бывали ситуации, когда check не поймал у нас проблему апгрейда, а dump поймал.
- Заодно с некоторыми extensions есть особые ситуации. Особый яркий пример – это PostGIS, потому что PostGIS обновляется до обновления Postgres. Этот extension всегда нужно обновлять до обновления Postgres, потом обновлять сам Postgres. Нужно почитать changelog и выяснить – можете ли вы вот так просто, пользуясь pg_upgrade обновить, потому что на старых версия этого сделать было нельзя. Там требовалось через dump restore делать.

Сама процедура обновления, после того, как вы подготовились, довольно простая.
-
Создаем базу в новой locale, если мы пользовались pg_dumpall only, restore.
-
Останавливаем старую базу данных. При этом не забываем о том, что pgbouncer нам поможет подвесить соединение к базе данных, т. е. приложение не потеряет соединение, а просто подвиснут.
-
Не забываем про checkpoints, которые нам помогают очистить память и скинуть ее на диск, чтобы побыстрее остановить базу данных.
-
И следующим шагом запускаем обновление pg_upgrade. Сама процедура переноса счетчика транзакции, схемы данных и линковки довольно быстрая. Время обновления зависит от размера вашей базы данных именно в количестве объектов в базе данных. Может занять от минуты до 45 минут. Был у меня один раз критичный момент, когда обновление шло 45 минут, но это отдельная история. Чаще всего обновление занимает от минуты до 15 минут, независимо от размера базы данных. Это зависит от количества объектов в базе данных созданных.

-
Если мы копируем файл, то будет зависимость от размеров базы данных. Мы делаем через hard links. И создание линков занимает секунды в нормальной ситуации.
-
И запускаем новую версию PostgreSQL. Но мы еще не разрешаем приложению туда ходить. Почему мы не разрешаем приложению ходить в новую версию PostgreSQL? Потому что там нет статистики. К сожалению, pg_upgrade теряет статистику при обновлении.
-
И нам нужно собрать эту статистику.
-
И после этого мы разрешаем соединения с базой данных. Даунтайм у нас в зависимости от ситуации составляет от одной до 10 минут. И еще зависит от опытности человека, который проводит этот даунтайм.

По сбору статистики есть следующие замечания:
-
Стандартно pg_upgrade генерирует скрипт по сбору статистики. Суть его в том, что запускается вакуум по всем базам данных в трех стадиях: по одной цели, по 10 целям и полный сбор статистики.
-
Если у вас база небольшая или в ней немного объектов, то можно запустить сразу полноценный сбор статистики, игнорировав автосгенерированный скрипт.
-
Начиная с версии 9.5 можно немного подредактировать этот скрипт. В зависимости от того, сколько у вас ядер и насколько у вас позволяют диски и можно распараллелить сбор в статистики.
-
Мы обычно используем стандартный скрипт. И делаем следующим образом. Без статистики у нас планировщик сойдет с ума, он не будет знать, как правильно ему строить планы. Поэтому мы ждем, пока у нас vacuumdb соберет статистику по 1, 10 целям. И когда он уже приступает к сбору полноценной статистики, мы разрешаем соединение к БД приложению. Уже более-менее адекватной становится работа с базой данных. Планировщик более-менее адекватен. Хотя выверты могут быть, но это не так страшно, нежели ждать полной сборки статистики.
-
Но тут есть один фактор. Если приложение активно начинает менять записи в базе данных, то у вас возникнет блокировка. У вас придет автовакуум в какой-то момент. И возникнет блокировка между вакуум, который мы запустили после апгрейда, и автовакуумом. В это время нужно посидеть и последить за блокировками, прибивая автовакуум, чтобы он не мешал полноценному сбору статистики после апгрейда.


Кратко о процедуре обновления на слайде.

- Pg_upgrade не обновляет extensions. Это такой же недостаток, как отсутствие статистики.
- Не забудьте почитать release notes для расширений.
- После того, как вы обновитесь, вам придется пройтись по всем extensions и обновить их вручную сказать – alter extension EXTENSION_NAME update. Это обязательно. Если вы используете pg_stat_statements, то в какой-то версии они изменили количество столбцов. Обновились вы через pg_upgrade, вы не увидите новые столбцы со статистикой от pg_stat_statements. То же самое касается других расширений. Обязательно по всем пройтись надо.

Очень часто задают вопрос – как обновлять реплики? Делается это просто:
- Сначала обновляем мастер-сервер по какой-нибудь процедуре.
- Далее мы смотрим, что у нас все хорошо, приложение работает с мастером, мы нигде не накосячили, все счастливы, все работает. И тогда реплика нам не нужна. Потому что, если мы накосячили, нам будет куда откатиться и сделать промоут старой реплики старой версии.
- Как мы это проверяем? Мы просто смотрим лог Postgres. И смотрим наличие ошибок и внештатных ситуаций. Разное время на это уходит. Бывает, сутки смотрим, бывает, 10 минут смотрим.
- После этого мы на серверах с репликами устанавливаем новую версию PostgreSQL.
- И pg_basebackup копируем базу данных с обновленного мастера на реплику. Старая версия реплики нам не нужна.
- Запускаем реплику на новой версии PostgreSQL.
- И если вы неопытной, то мы не рекомендуем вам использовать rsync, потому что это сложный и трудоемкий процесс. Можно обновить так, но, скорее всего, вы допустите ошибку и у вас реплика превратится в бесполезный набор файлов. Поэтому до rsync дойдите только тогда, когда наберетесь опыта.

Мы не очень это любим. Причин тут несколько:
- Во-первых, потоковая репликация не работает между разными версиями PostgreSQL.
- Работают только логические виды репликаций. Их несколько видов.
С версией 9.4 появилась встроенная логическая репликация. С каждой версией она развивается. И я думаю, что с версии 10 на версию 11 можно уже с ее помощью мигрировать довольно легко.
Есть также сторонние репликации, которые появились ранее. Это Slony-l, Londiste, Bucardo и т. д. Их можно использовать.

Как выглядит процедура обновления с помощью логических репликаций?
- Мы настраиваем новую версию PostgreSQL.
- Каким-то образом переносим основной объем данных из старой версии Postgres в новую версию Postgres.
- И настраиваем репликацию, чтобы изменения, которые у нас идут реплицировались в новую версию. Для каждой логической репликации будет свой путь.
- Потом убеждаемся, что мастер и реплика в достаточно консистентном состоянии. Там есть несколько путей. Или сразу переключаем приложение, чтобы оно работало с репликой в новой версии Postgres. Или поочередно переключаем, если у вас микросервисная структура, т. е. по одному приложению начинаем переводить. Это зависит от того, как у вас организовано.
- И после этого тушим старую версию Postgres, убедившись, что туда ничего не пишется.
- И делаем для себя промоут логической реплики новой версии Postgres, и работаем на ней. Даунтайма, в принципе, нет при переключении приложения. В любом случае нам что-то всегда останавливаться.

Какие проблемы будут при этом присутствовать?
- Вы замучаетесь настраивать логическую репликацию для сложных схем БД, когда у вас десятки тысяч таблиц. Есть какие-то автоматические инструменты.
- Как правило, логические репликации переносят данные. Это на текущий момент ситуация. Т. е. данные, которые хранятся в таблице.
- Но у нас есть еще sequences, которые нам нужно будет потом синхронизировать как-то.
- У нас может прийти DDL, который нам подпортит все. Потому что DDL логические репликации, как правило, не обрабатывают. И если вдруг девелопер решил задеплоить изменения в схемах данных, станет плохо.
- Нужны будут дополнительные объемы дискового пространства, потому что это у нас две работающие базы данных, как минимум.
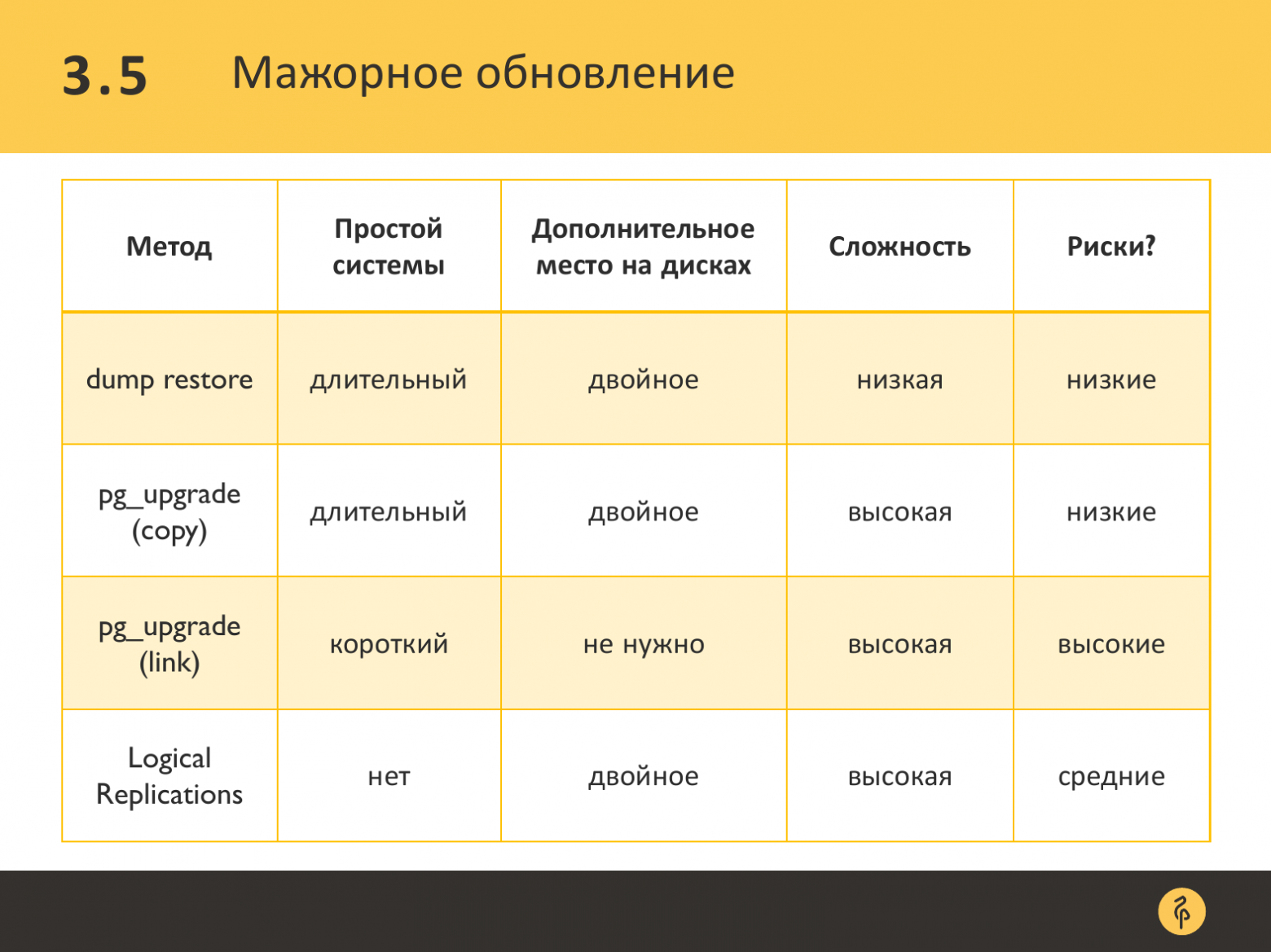
Тут небольшая сводная таблица, в которой приведены плюсы и минусы того или иного вида мажорного обновления. И довольно привлекательно выглядит pg_upgrade с линковкой файлов и логическая репликация, если вы действительно решите ее настраивать.
Почему мы используем апгрейд? Потому что, если у вас база 3 TB, то не все могут позволить себе 2 SSD RAID по 3 TB. Это достаточно дорогое удовольствие. А тут мы обновляемся ровно на те же файлы.
В случае с логической репликацией нам нужно больше дискового места. Это не всегда возможно.
Я посчитал, что Амазон дает гарантию, что у вас сервер работает 99 и сколько-то 9-ок после запятой. Это всегда больше 15 минут. Тут у вас даунтайм будет меньше 15 минут в общем случае. Я думаю. Что это позволительный даунтайм даже для очень онлайн-онлайн системы.

Тут приведены ссылки на полезную информацию, которую вы можете прочитать от разработчиков pg_upgrade. Также почитать об особенности сбора статистики. Там дополнительная и более детальная информация по этой теме.
На этом у меня все.
Вопросы
Добрый день! Когда мы ставим pgbouncer и потом включаем после рестарта, то если у нас идет большая нагрузка, то, соответственно, нам нужно еще дождаться, когда прогреются кэши. Как эта проблема у вас решается?
Нам в большинстве случаев кэши не приходится прогревать, потому что у нас большинство клиентов на SSD сидят хороших. И там разница чтения между операционной памятью и SSD не сильно большая, т. е. незаметно это время прогрева кэшей. Оно не сильно влияет на производительность систем. Но, конечно, просаживается, это да, надо подождать пока прогреются. И бывает, что если специально не прогревать, то может длиться часами прогрев кэшей. Это зависит от того, насколько активно идет общение с Postgres. Но специально мы обычно не прогреваем, только по просьбе.
К расширениям типа pg_worm и pg_hibernate, как относитесь для прогрева?
Я говорю, что мы в большинстве случаев не прогреваем, потому что оборудование у клиентов позволяет.
Спасибо за доклад! Можно ли реплики не перескачивать после обновлением pg_upgrade?
В принципе, можно. И те же ребята из Яндекса могут рассказать, как это делать. И смогут рассказать более подробно о граблях, на которых они попрыгали. Мы стараемся этого избегать, потому что довольно неизвестны последствия, если где-то пропустишь шаг, реплика может быть нерабочей. И когда нужно будет делать промоут на реплику, мы можем получить не базу, а просто набор файликов. И мы можем не знать об этом совсем, пока не сделаем промоут.
Там через rsync как-то?
А что rsync? Rsync можно с разными ключами запустить. Вы запустите, и он у вас не обновит файл, потому что даты, допустим, совпадают. Как это должно быть? Вы должны параллельно запустить сразу pg_upgrate мастер и реплики. Поднять мастер, собрать статистику. Потом на мастере сказать – pg_start_backup. И уже потом сделать rsync с мастера на реплику. Вот тогда вы можете более-менее себе гарантировать, что у вас rsync правильно сделает все, что вам нужно. Но не забывайте, что если у вас будет несколько дисков и вы забудете, допустим, про tablespace на HDD, сделаете rsync и запустите, то у вас сначала будет работать. А потом сделаете промоут – и все, реплики нет. Там очень много моментов, где вы можете ошибиться и просто испортить свою реплику. Лучше – надежный pg_basebackup.
Спасибо за доклад! Вы сначала сказали, что следует сначала обновить реплики…
Это касается минорного обновления.
Содержание
- Upgrading and updating PostgreSQL
- Updating PostgreSQL
- Upgrading PostgreSQL
- Preparing a sample database
- pg_upgrade in action
- “pg_upgrade –link” under the hood
- Finally …
- Database Migration from Version 10 or 12 to 13
- 1. Prepare to Upgrade
- 2. Upgrade PostgreSQL
- Upgrade PostgreSQL from 12 to 13 on Ubuntu 21.04
- Howto guide for upgrading PostgreSQL from version 12 to 13 on Ubuntu, after its upgrade from version 20.10 to 21.04 (Hirsute Hippo).
- TL ; DR ¶
- Upgrade PostgreSQL¶
- Disclaimer¶
- Upgrading to PostgreSQL13
- Upgrading to PostgreSQL 13
- Using pg_dump/pg_dumpall
- Using pg_upgrade
- Using Logical Replication
- Conclusion
Upgrading and updating PostgreSQL
Recently, PostgreSQL 13 was released. People are asking what are best ways upgrading and updating PostgreSQL 12 or some other version to PostgreSQL 13. This blog post covers how you can move to the latest release.
Before we get started, we have to make a distinction between two things:
- Updating PostgreSQL
- Upgrading PostgreSQL
Let’s take a look at both scenarios.
Updating PostgreSQL
The first scenario I want to shed some light on is updating within a major version of PostgreSQL: What does that mean? Suppose you want to move from PostgreSQL 13.0 to PostgreSQL 13.1. In that case, all you have to do is to install the new binaries and restart the database.
There is no need to reload the data. The downtime required is minimal. The binary format does not change; a quick restart is all you need. The same is true if you are running a HA (high availability cluster) solution such as Patroni. Simply restart all nodes in your PostgreSQL cluster and you are ready to go.
The following table contains a little summary:
| Tooling | Task | Reloading data | Downtime needed |
| pg_dump | Minor release update | Not needed | Close to zero |
Upgrading PostgreSQL
Now let’s take a look at upgrades: if you want to move from PostgreSQL 9.5, 9.6, 10, 11 or 12 to PostgreSQL 13, an upgrade is needed. To do that, you have various options:
- pg_dump: Dump / reload
- pg_upgrade: Copy data on a binary level
- pg_upgrade –link: In-place upgrades
If you dump and reload data, it might take a lot of time. The bigger your database is, the more time you will need to do the upgrade. It follows that pg_dump(all) and pg_restore are not the right tools to upgrade a large multi-terabyte database.
pg_upgrade is here to do a binary upgrade. It copies all the data files from the old directory to the new one. Depending on the amount of data, this can take quite a lot of time and cause serious downtime. However, if the new and the old data directory are on the same filesystem, there is a better option: “pg_upgrade –link”. Instead of copying all the files, pg_upgrade will create hardlinks for those data files. The amount of data is not a limiting factor anymore, because hardlinks can be created quickly. “pg_upgrade –link” therefore promises close-to-zero downtime.
| Tooling | Task | Reloading data | Downtime needed |
| pg_upgrade | Major release update | Copy is needed | Downtime is needed |
| pg_upgrade –link | Major release update | Only hardlinks | Close to zero |
What is important to note here is that pg_upgrade is never destructive. If things go wrong, you can always delete the new data directory and start from scratch.
Preparing a sample database
To show pg_upgrade in action, I have created a little sample database to demonstrate how things work in real life:
This is a fairly small database, but it is already large enough so that users can feel the difference when doing the upgrade:
7.4 GB are ready to be upgraded. Let’s see how it works.
pg_upgrade in action
To upgrade a database, two steps are needed:
Let us start with initdb:
Note that pg_upgrade is only going to work in case the encodings of the old and the new database instance match. Otherwise, it will fail.
Then we can run pg_upgrade: Basically, we need 4 pieces of information here: The old and the new data directory as well as the path of the old and the new binaries:
What is worth mentioning here is that the upgrade process takes over 4 minutes because all the data had to be copied to the new directory. My old Mac is not very fast and copying takes a very long time.
To reduce downtime, we can clean out the directory, run initdb again and add the –link option:
In this case, it took only 3.5 seconds to upgrade. We can start the database instance directly and keep working with the new instance.
“pg_upgrade –link” under the hood
The –link option can reduce the downtime to close to zero. The question is what happens under the hood? Let’s check out the data files:
What you see here is that the relevant data files have two entries: “2” means that the same piece of storage shows up as two files. pg_upgrade creates hardlinks and this is exactly what we see here.
That’s why it is super important to make sure that the mountpoint is /data and not /data/db12. Otherwise, hardlinks are not possible.
Finally …
pg_upgrade is an important tool. However, there are more ways to upgrade: Logical replication is an alternative method. Check out our blog post about this exciting technology.
Hans-Jürgen Schönig
Hans-Jürgen Schönig has experience with PostgreSQL since the 90s. He is CEO and technical lead of CYBERTEC, which is one of the market leaders in this field and has served countless customers around the globe since the year 2000.
Источник
Database Migration from Version 10 or 12 to 13
This section covers upgrading the PostgreSQL database from version 10 or version 12 to version 13. If you are already using PostgreSQLВ 13, you do not need to perform this migration. If you are using an older version, such as versionВ 9.6, see upgrade:db-migration-10.adoc.
If you want to upgrade to the latest SUSE ManagerВ version, you must be using PostgreSQL versionВ 12 orВ 13, depending on the underlying operating system:
If you are running SLES 15 SP3, use PostgreSQL 13.
If you are running Leap 15.2, use PostgreSQL 12.
1. Prepare to Upgrade
Before you begin the upgrade, prepare your existing SUSE Manager Server and create a database backup.
PostgreSQL stores data at /var/lib/pgsql/data/ .
Check the active PostgreSQL version:
If you are using PostgreSQL 10 or 12, you can upgrade to PostgreSQL 13. If you are already using PostgreSQL versionВ 13, you do not need to perform this migration.
Check the active smdba version:
PostgreSQL 13 requires smdba version 1.7.6 or later.
Perform a database backup. For more information on backing up, see administration:backup-restore.adoc.
2. Upgrade PostgreSQL
Always create a database backup before performing a migration.
PostgreSQL upgrades can be performed in two ways: a regular upgrade, or a fast upgrade:
A regular upgrade creates a complete copy of the database, so you need double the existing database size of space available. Regular upgrades can take a considerable amount of time, depending on the size of the database and the speed of the storage system.
A fast upgrade only takes a few minutes, and uses almost no additional disk space. However, if a fast upgrade fails, you must restore the database from the backup. A fast upgrade reduces the risk of running out of disk space, but increases the risk of data lose when a backup does not exist or cannot be replayed. A regular upgrade will copy the database files instead of creating hard links between the files.
PostgreSQL stores data at /var/lib/pgsql/data/ .
Perform a database backup. For more information on backing up, see administration:backup-restore.adoc.
Start the upgrade. If you have version 12, run:
Источник
Upgrade PostgreSQL from 12 to 13 on Ubuntu 21.04
Howto guide for upgrading PostgreSQL from version 12 to 13 on Ubuntu, after its upgrade from version 20.10 to 21.04 (Hirsute Hippo).
TL ; DR ¶
After upgrade Ubuntu from version 20.10 to 21.04:
This article is aimed at those like me who use Ubuntu and PostgreSQL to develop locally on their computer and after the last update to Ubuntu 21.04 they have two versions of PostgreSQL installed.
Upgrade PostgreSQL¶
During Ubuntu updgrade to 21.04 you receive this message “Configuring postgresql-common”:
The PostgreSQL version 12 is obsolete, but the server or client packages are still installed.
Please install the latest packages ( postgresql-13 and postgresql-client-13 ) and upgrade the existing clusters with pg_upgradecluster (see manpage).
Please be aware that the installation of postgresql-13 will automatically create a default cluster 13/main .
If you want to upgrade the 12/main cluster, you need to remove the already existing 13 cluster ( pg_dropcluster —stop 13 main , see manpage for details).
The old server and client packages are no longer supported.
After the existing clusters are upgraded, the postgresql-12 and postgresql-client-12 packages should be removed.
Please see /usr/share/doc/postgresql-common/README.Debian.gz for details.
Use dpkg -l | grep postgresql to check which versions of postgres are installed:
Run pg_lsclusters , your 12 and 13 main clusters should be “online”.
There already is a cluster “main” for 13 (since this is created by default on package installation). This is done so that a fresh installation works out of the box without the need to create a cluster first, but of course it clashes when you try to upgrade 12/main when 13/main also exists. The recommended procedure is to remove the 13 cluster with pg_dropcluster and then upgrade with pg_upgradecluster .
Stop the 13 cluster and drop it.
Upgrade the 12 cluster to the latest version.
Your 12 cluster should now be “down” and you can verifity running pg_lsclusters
Check that the upgraded cluster works, then remove the 12 cluster.
After all your data check you can remove your old packages.
Disclaimer¶
There is no warranty for the program, to the extent permitted by applicable law. Except when otherwise stated in writing the copyright holders and/or other parties provide the program “as is” without warranty of any kind, either expressed or implied, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. The entire risk as to the quality and performance of the program is with you. Should the program prove defective, you assume the cost of all necessary servicing, repair or correction.
Источник
Upgrading to PostgreSQL13
Published July 27, 2021

In a recent blog about what is new in PostgreSQL 13, we reviewed some of the new features of this version, but now, let’s see how to upgrade to be able to take advantage of all these mentioned functionalities.
Upgrading to PostgreSQL 13
If you want to upgrade your current PostgreSQL version to this new one, you have three main native options to perform this task.
Pg_dump/pg_dumpall : It is a logical backup tool that allows you to dump your data and restore it in the new PostgreSQL version. Here you will have a downtime period that will vary according to your data size. You need to stop the system or avoid new data in the primary node, run the pg_dump, move the generated dump to the new database node, and restore it. During this time, you can’t write into your primary PostgreSQL database to avoid data inconsistency.
Pg_upgrade : It is a PostgreSQL tool to upgrade your PostgreSQL version in-place. It could be dangerous in a production environment and we don’t recommend this method in that case. Using this method you will have downtime too, but probably it will be considerably less than using the previous pg_dump method.
Logical Replication: Since PostgreSQL 10, you can use this replication method which allows you to perform major version upgrades with zero (or almost zero) downtime. In this way, you can add a standby node in the last PostgreSQL version, and when the replication is up-to-date, you can perform a failover process to promote the new PostgreSQL node.
So, let’s see these methods one by one.
Using pg_dump/pg_dumpall
In case downtime is not a problem for you, this method is an easy way for upgrading.
To create the dump, you can run:
Or to create a dump of a single database:
Then, you can copy this dump to the server with the new PostgreSQL version, and restore it:
Keep in mind that you will need to stop your application or avoid writing in your database during this process, otherwise, you will have data inconsistency or a potential data loss.
Using pg_upgrade
First, you will need to have both the new and the old PostgreSQL versions installed on the server.
Then, first, you can run pg_upgrade for testing the upgrade by adding the -c flag:
-b : The old PostgreSQL executable directory
-B : The new PostgreSQL executable directory
-d : The old database cluster configuration directory
-D : The new database cluster configuration directory
-c : Check clusters only. It doesn’t change any data
If everything looks fine, you can run the same command without the -c flag and it will upgrade your PostgreSQL server. For this, you need to stop your current version first and run the mentioned command.
When it is completed, as the message suggests, you can use those scripts for analyzing the new PostgreSQL server and deleting the old one when it is safe.
Using Logical Replication
Logical replication is a method of replicating data objects and their changes, based upon their replication identity. It is based on a publish and subscribe mode, where one or more subscribers subscribe to one or more publications on a publisher node.
So based on this, let’s configure the publisher,in this case the PostgreSQL 12 server, as follows.
Edit the postgresql.conf configuration file:
Edit the pg_hba.conf configuration file:
Use the subscriber IP address there.
Now, you must configure the subscriber, in this case the PostgreSQL 13 server, as follows.
Edit the postgresql.conf configuration file:
As this PostgreSQL 13 will be the new primary node soon, you should consider adding the wal_level and archive_mode parameters in this step, to avoid a new restart of the service later.
These parameters will be useful if you want to add a new replica or for using PITR backups.
Some of these changes require a server restart, so restart both publisher and subscriber.
Now, in the publisher, you must create the user to be used by the subscriber to access it. The role used for the replication connection must have the REPLICATION attribute and, in order to be able to copy the initial data, it also need the SELECT privilege on the published table:
Let’s create the pub1 publication in the publisher node, for all the tables:
As the schema is not replicated, you must take a backup in your PostgreSQL 12 and restore it in your PostgreSQL 13. The backup will only be taken for the schema since the information will be replicated in the initial transfer.
In PostgreSQL 12, run:
In PostgreSQL 13, run:
Once you have your schema in PostgreSQL 13, you need to create the subscription, replacing the values of host, dbname, user, and password with those that correspond to your environment.
The above will start the replication process, which synchronizes the initial table contents of the tables in the publication and then starts replicating incremental changes to those tables.
To verify the created subscription you can use the pg_stat_subscription catalog. This view will contain one row per subscription for the main worker (with null PID if the worker is not running), and additional rows for workers handling the initial data copy of the subscribed tables.
To verify when the initial transfer is finished you can check the srsubstate variable on pg_subscription_rel catalog. This catalog contains the state for each replicated relation in each subscription.
srsubid : Reference to subscription.
srrelid : Reference to relation.
srsubstate : State code: i = initialize, d = data is being copied, s = synchronized, r = ready (normal replication).
srsublsn : End LSN for s and r states.
When the initial transfer is finished, you have everything ready to point your application to your new PostgreSQL 13 server.
Conclusion
As you can see, PostgreSQL has different options to upgrade, depending on your requirements and downtime tolerance.
No matter what kind of technology you are using, keeping your database servers up to date by performing regular upgrades is a necessary but difficult task, as you need to make sure that you won’t have data loss or data inconsistency after upgrading. A detailed and tested plan is the key here, and of course, it must include a rollback option, just in case.
Источник