Информатика. 10 класса. Босова Л.Л. Оглавление
§14. Кодирование текстовой информации
Компьютеры третьего поколения «научились» работать с текстовой информацией.
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
Для компьютерного представления текстовой информации достаточно:
1) определить множество всех символов (алфавит), требуемых для представления текстовой информации;
2) выстроить все символы используемого алфавита в некоторой последовательности (присвоить каждому символу алфавита свой номер);
3) получить для каждого символа n-разрядный двоичный код (n ? 2n), переведя номер этого символа в двоичную систему счисления.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
14.1. Кодировка ASCII и её расширения
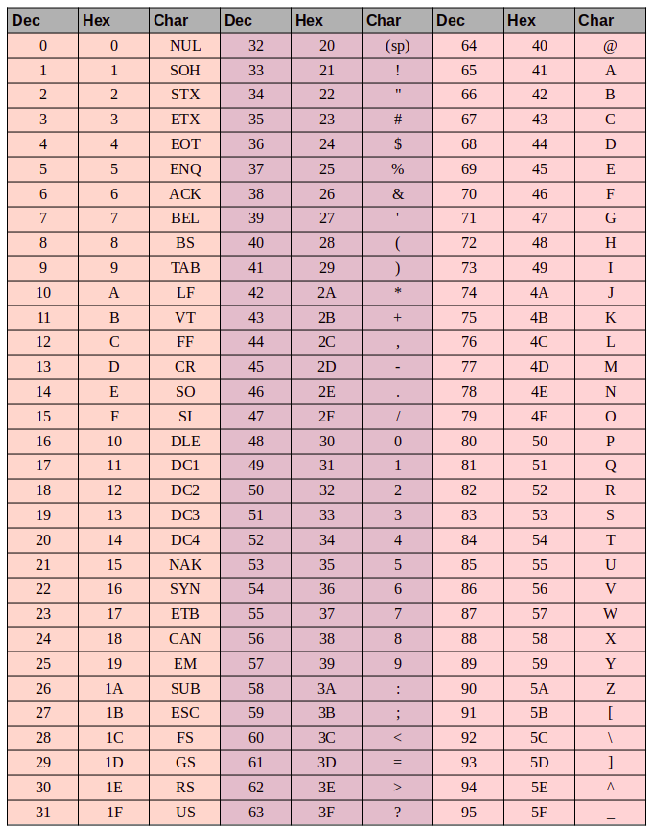
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 27 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
14.2. Стандарт Unicode
Ограниченность 8-битной кодировки, не позволяющей одновременно пользоваться несколькими языками, а также трудности, связанные с необходимостью преобразования одной кодировки в другую, привели к разработке нового кода. В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира.
Unicode — это «уникальный код для любого символа, независимо от платформы, независимо от программы, независимо от языка» (www.unicode.org).
В Unicode на кодирование символов отводится 31 бит. Первые 128 символов (коды 0-127) совпадают с таблицей ASCII. Далее размещены основные алфавиты современных языков: они полностью умещаются в первой части таблицы, их коды не превосходят 65 536 = 216.
Стандарт Unicode описывает алфавиты всех известных, в том числе и «мёртвых», языков. Для языков, имеющих несколько алфавитов или вариантов написания (например, японского и индийского), закодированы все варианты. В кодировку Unicode внесены все математические и иные научные символьные обозначения и даже некоторые придуманные языки (например, язык эльфов из трилогии Дж. Р. Р. Толкина «Властелин колец»).
Всего современная версия Unicode позволяет закодировать более миллиона различных знаков, но реально используется чуть менее 110 000 кодовых позиций.
Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок.
В операционных системах семейства Windows используется кодировка UTF-16. В ней все наиболее важные символы кодируются с помощью 2 байт (16 бит), а редко используемые — с помощью 4 байт.
В операционной системе Linux применяется кодировка UTF-8, в которой символы могут занимать от 1 (символы, входящие в таблицу ASCII) до 4 байт. Если значительную часть текста составляют цифры и латинские буквы, то это позволяет в несколько раз уменьшить размер файла по сравнению с кодировкой UTF-16.
Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
14.3. Информационный объём текстового сообщения
Мы уже касались этого вопроса, рассматривая алфавитный подход к измерению информации.
Информационным объёмом текстового сообщения называется количество бит (байт, килобайт, мегабайт и т. д.), необходимых для записи этого сообщения путём заранее оговоренного способа двоичного кодирования.
Оценим в байтах объём текстовой информации в современном словаре иностранных слов из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы).
Будем считать, что при записи используется кодировка «один символ — один байт». Количество символов во всем словаре равно:
80 • 60 • 740 = 3 552 000.
Следовательно, объём равен
3 552 000 байт = 3 468,75 Кбайт ? 3,39 Мбайт.
Если же использовать кодировку UTF-16, то объём этой же текстовой информации в байтах возрастёт в 2 раза и составит 6,78 Мбайт.
САМОЕ ГЛАВНОЕ
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил код ASCII, рассчитанный на передачу только английского текста. Расширения ASCII — кодировки, в которых первые 128 символов кодовой таблицы совпадают с кодировкой ASCII, а остальные (со 128-го по 255-й) используются для кодирования букв национального алфавита, символов национальной валюты и т. п.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира. Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Вопросы и задания
1. Какова основная идея представления текстовой информации в компьютере?
2. Что представляет собой кодировка ASCII? Сколько символов она включает? Какие это символы?
3. Как известно, кодовые таблицы каждому символу алфавита ставят в соответствие его двоичный код. Как, в таком случае, вы можете объяснить вид таблицы 3.8 «Кодировка ASCII»?
4. С помощью таблицы 3.8: 1) декодируйте сообщение 64 65 73 6В 74 6F 70; 2) запишите в двоичном коде сообщение TOWER; 3) декодируйте сообщение 01101100 01100001 01110000 01110100 01101111 01110000
5. Что представляют собой расширения ASCII-кодировки? Назовите основные расширения ASCII-кодировки, содержащие русские буквы.
6. Сравните подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8.
7. Представьте в кодировке Windows-1251 текст «Знание — сила!»:
8. Представьте в кодировке КОИ-8 текст «Дело в шляпе!»: 1) шестнадцатеричным кодом; 2) двоичным кодом; 3) десятичным кодом.
9. Что является содержимым файла, созданного в современном текстовом процессоре?
10. В кодировке Unicode на каждый символ отводится 2 байта. Определите в этой кодировке информационный объём следующей строки: Где родился, там и сгодился.
11. Набранный на компьютере текст содержит 2 страницы. На каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём текста в кодировке Unicode, в которой каждый символ кодируется 16 битами.
12. Текст на русском языке, первоначально записанный в 8-битовом коде Windows, был перекодирован в 16-битную кодировку Unicode. Известно, что этот текст был распечатан на 128 страницах, каждая из которых содержала 32 строки по 64 символа в каждой строке. Каков информационный объём этого текста?
13. В текстовом процессоре MS Word откройте таблицу символов (вкладка Вставка ? Символ ? Другие символы): В поле Шрифт установите Times New Roman, в поле из — кириллица (дес.). Вводя в поле Код знака десятичные коды символов, декодируйте сообщение
§ 13. Представление чисел в компьютере
§ 14. Кодирование текстовой информации
§ 15. Кодирование графической информации
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16

Charsets
Часто в веб-программировании и вёрстке html-страниц приходится думать о кодировке редактируемого файла — ведь если кодировка выбрана неверная, то есть вероятность, что браузер не сможет автоматически её определить и в результате пользователь увидит т.н. «кракозябры».
Возможно, вы сами видели на некоторых сайтах вместо нормального текста непонятные символы и знаки вопроса. Всё это возникает тогда, когда кодировка html-страницы и кодировка самого файла этой страницы не совпадают.
Вообще, что такое кодировка текста? Это просто набор символов, по-английски «charset » (character set). Нужна она для того, чтобы текстовую информацию преобразовывать в биты данных и передавать, например, через Интернет.
Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец.символов, в которые преобразуется каждый символ исходного текста.
Краткая история кодировок:
Одной из первых для передачи цифровой информации стало появление кодировки ASCII — American Standard Code for Information Interchange — Американская стандартная кодировочная таблица, принятая Американским национальным институтом стандартов — American National Standards Institute (ANSI).
В этих аббревиатурах можно запутаться ![]() Для практики же важно понимать, что исходная кодировка создаваемых текстовых файлов может не поддерживать все символы некоторых алфавитов (к примеру, иероглифы), потому идёт тенденция к переходу к т.н. стандарту Юникод (Unicode), который поддерживает универсальные кодировки — Utf-8, Utf-16, Utf-32 и др.
Для практики же важно понимать, что исходная кодировка создаваемых текстовых файлов может не поддерживать все символы некоторых алфавитов (к примеру, иероглифы), потому идёт тенденция к переходу к т.н. стандарту Юникод (Unicode), который поддерживает универсальные кодировки — Utf-8, Utf-16, Utf-32 и др.
Самая популярная из кодировок Юникода — кодировка Utf-8. Обычно в ней сейчас верстаются страницы сайтов и пишутся разные скрипты. Она позволяет без проблем отображать различные иероглифы, греческие буквы и прочие мыслимые и немыслимые символы (размер символа до 4-х байт). В частности, все файлы WordPress и Joomla пишутся именно в этой кодировке. А также некоторые веб-технологии (в частности, AJAX) способны нормально обрабатывать только символы utf-8.

Установка кодировок текстового файла при создании его обычным блокнотом. Кликабельно
В Рунете же ещё можно встретить сайты, написанные с расчётом на кодировку Windows-1251 (или cp-1251). Это специальная кодировка, предназначенная специально для кириллицы.
Почему вообще необходимо иметь представление о разных кодировках? Дело в том, что нередко на том же WordPress можно встретить, например, в Footer’е знаки вопроса вместо нормального текста. Это просто говорит о том, что php-файл Footer’а сохранён в одной кодировке, а в заголовке html-страницы указана совсем другая кодировка. Прочитайте — как сменить кодировку файла и что в этом поможет.
![]() Loading…
Loading…
Современный компьютер может обрабатывать
числовую, текстовую, графическую,
звуковую и видео информацию. Все эти
виды информации в компьютере представлены
в двоичном коде, т. е. используется
алфавит мощностью два (всего два символа
0 и 1). Связано это с тем, что удобно
представлять информацию в виде
последовательности электрических
импульсов: импульс отсутствует (0),
импульс есть (1). Такое кодирование
принято называть двоичным, а сами
логические последовательности нулей
и единиц — машинным языком. Каждая цифра
машинного двоичного кода несет количество
информации равное одному биту.
Кодовая таблица — таблица соответствий
символов и их компьютерных кодов. В РФ
распространены следующие кодировки:
WIN1251 (Windows), KOI-8 (Unix), СP866 (DOS), Macintosh, ISO-8859-5
(Unix).
Системы кодирования ASCII. Быстрое
развитие коммуникационных средств и
технологий для обработки данных в первой
половине XX-го века в США сделало очевидной
необходимость в создании стандартной
системы кодирования для обмена текстовой
информацией. Эта система должна была
обеспечивать представление всего того
набора символов, что имеется в англоязычной
пишущей машинке. Система кодирования,
в которой используется 7-битный метод
кодирования — когда для представления
каждого из символов используется
двоичная последовательность длиною в
7 бит, — устраняет необходимость в
«сдвиге», используемом в системе
кодирования Бодо. Поэтому использования
7-битного метода кодирования будет
достаточно для достижения поставленной
цели.
Система кодирования ASCII, в таблице
символов которой было 128 позиций — для
32-х управляющих двоичных последовательностей
и 96-ти печатаемых символов. Несмотря на
то, что система кодирования ASCII специально
разрабатывалась так, чтобы избежать
необходимости в «сдвиге», в её
таблицу символов были включены управляющие
двоичные последовательности для его
обеспечения.
Система кодирования ASCII была принята
всеми изготовителями компьютеров в США
за исключением корпорации IBM, которая
разработала собственную «фирменную»
систему кодирования символов для
использования в своих больших ЭВМ.
Система кодирования ASCII стала международным
стандартом. Это вызвало необходимость
адаптировать систему кодирования ASCII
для других языков, использующих латинский
алфавит. Эта работа была проделана
Международной организацией по
стандартизации (ISO), базирующейся в
Женеве, Швейцария. На данный момент
существует в общей сложности порядка
180 таблиц символов для различных языков.
Юнико́д (Unicode) — стандарт кодирования
символов, позволяющий представить знаки
практически всех письменных языков.
Применение этого стандарта позволяет
закодировать очень большое число
символов из разных письменностей: в
документах Unicode могут соседствовать
китайские иероглифы, математические
символы, буквы греческого алфавита,
латиницы и кириллицы, при этом становятся
ненужными кодовые страницы.
Стандарт состоит из двух основных
разделов: универсальный набор символов
и семейство кодировок. Универсальный
набор символов задаёт однозначное
соответствие символов кодам — элементам
кодового пространства, представляющим
неотрицательные целые числа. Семейство
кодировок определяет машинное
представление последовательности кодов
UCS.
Коды в стандарте Unicode разделены на
несколько областей. Область с кодами
от U+0000 до U+007F содержит символы набора
ASCII с соотв2етствующими кодами. Далее
расположены области знаков различных
письменностей, знаки пунктуации и
технические символы. Часть кодов
зарезервирована для использования в
будущем. Под символы кириллицы выделены
коды от U+0400 до U+052F.
Универсальная система кодирования
(Юникод) представляет собой набор
графических символов и способ их
кодирования для компьютерной обработки
текстовых данных.
Юникод — это система для линейного
представления текста. Символы, имеющие
дополнительные над- или подстрочные
элементы, могут быть представлены в
виде построенной по определённым
правилам последовательности кодов
(составной вариант) или в виде единого
символа (монолитный вариант).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This led to much confusion subsequently. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but now additionally supports and recommends using UTF-8 (aka CP_UTF8). UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder). Since Windows 10 version 1803, Windows machines can be configured to allow UTF-8 as the «ANSI» and OEM codepage.[5]
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This led to much confusion subsequently. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but now additionally supports and recommends using UTF-8 (aka CP_UTF8). UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder). Since Windows 10 version 1803, Windows machines can be configured to allow UTF-8 as the «ANSI» and OEM codepage.[5]
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
Содержание:

Введение
Поскольку текст изначально дискретен — он состоит из отдельных символов, — для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов, его составляющих. При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые таблицы символов, в которых каждому коду символа ставится в соответствие изображение символа.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
-
Кодировки ASCII, ANSI, КОI8 и др.
Существует много различных кодировок. В большинстве из них символы кодируются восьмибитовыми (или однобайтными) числами. В одном байте можно записать 256 различных целых чисел. Этого достаточно для кодирования всех букв русского и латинского алфавитов, арабских цифр, знаков препинания и некоторых других необходимых символов.
Для наглядности кодируемые символы располагаются в таблице. Таблица разбита на 16 строк и 16 столбцов. Каждая строка и каждый столбец имеют четырехразрядные двоичные номера от 0000 до 1111 (или шестнадцатеричные от 0 до F). Код символа составляется из номеров столбца и строки, на пересечении которых он находится. Этим двоичным числам соответствуют десятичные числа от 0 до 255.
До появления операционной системы Windows основной являлась кодовая таблица символов ASCII (American Standard Code for Information Interchange — американский стандартный код обмена информацией).
Разработана она была в 1960-х годах в США и применялась для любых видов передачи информации, в том числе и некомпьютерных (телеграф, факсимильная связь и т. д.).
Первая половина таблицы ASCII (коды от 0 до 127) содержит знаки препинания, цифры, символы латинского алфавита, математические знаки и является общепринятой. Коды от 128 до 255 называются расширенными и используются для национальных алфавитов и символов псевдографики.
В таблице ASCII отсутствуют символы кириллицы. Для представления кириллицы в DOS была разработана кодовая страница СР-866, построенная на основе ASCII. Символы с кодами от 0 до 127 в этой таблице такие же, как в кодировке ASCII, а символы кириллицы расположены на тех позициях, где в таблице ASCII находятся относительно редко используемые символы национальных алфавитов и греческие буквы. На рисунке 1 приведен фрагмент этой таблицы. Символам кириллицы здесь соответствуют десятичные коды от 128 до 175 и от 224 до 239.
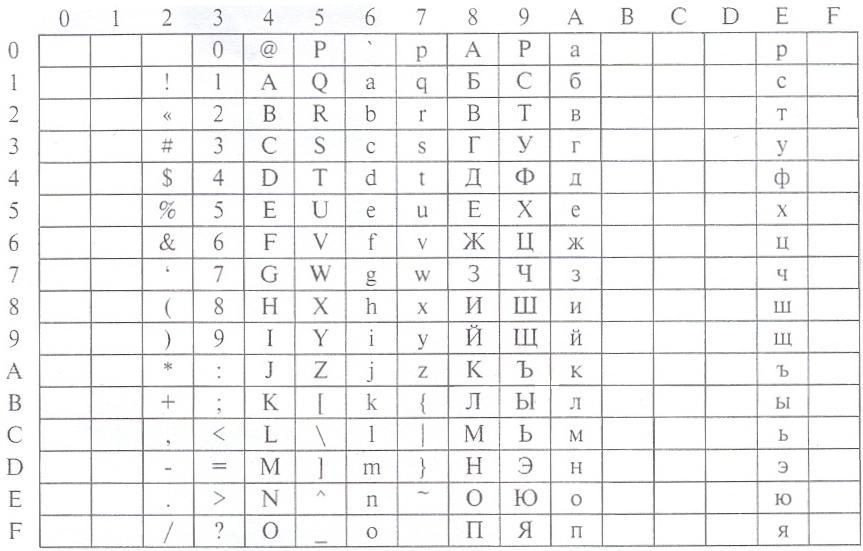
Рисунок 1. Таблица ASCII
С появлением графической среды Windows ASCII морально устарела, в частности, ненужными стали псевдографические символы. Фирмой Мiсrosоft была разработана новая кодовая таблица ANSI. Для представления кириллицы в Windows на основе кодировки ANSI построена кодовая страница СР-12565. Символам кириллицы здесь соответствуют шестнадцатеричные коды от С0 до FF, или в десятичной системе счисления от 192 до 255.
В середине семидесятых годов специалистами одного из советских НИИ был разработан новый стандарт, предназначенный для представления символов русского языка в электронной форме. Сейчас эта кодировка известна под наименованием КОI8 (код обмена информации восьмибитовый). Став базовой кодировкой для только что появившихся тогда в нашей стране русифицированных UNIХ — совместимых операционных систем, KOI8 была принята Госстандартом СССР в качестве базовой спецификации для обмена электронными документами на русском языке, в силу чего данной кодировке было присвоено соответствие стандарту ГОСТ 19768-74.
После ликвидации Советского Союза этот стандарт претерпел некоторые изменения, разделившись на две отдельные спецификации: KOI8-R применяется в настоящее время для представления символов русского языка, KOI8-U – украинского.
Кодировка КОI8 также используется в качестве принятого в Российском Интернете «формата по умолчанию» при пересылке сообщений электронной почты.
Стандарт MicroSoft/IBM code page 866 (альтернативная кодировка DOS) служит базовой кодировкой в операционных системах MS-DOS и OS/2, и потому в настоящее время медленно, но верно утрачивает свои позиции, ибо даже сам разработчик и производитель DOS компания Мiсrоsоft отказалась от дальнейшей поддержки этой линии операционных платформ. Тем не менее, кодировка жива и по сей день, прежде всего благодаря той части пользователей, которые не намерены пока расставаться с браузерами, работающими в среде MS – DOS.
Компания MicroSoft, создавая программное обеспечение для работы в Интернете, как водится, пошла своим путем, предложив стандарт Мiсrоsоft code page 1251 (Windows-1251), получивший чрезвычайно широкое распространение благодаря необыкновенной популярности операционной системы Мiсrоsоft Windows и http — сервера IIS (Internet 1nformation Server), входящего в комплект поставки Windows NT/2000. Именно поэтому и Windows – 1251, и KOI8 — R входят в тот минимально допустимый набор кодировок, которые должна обязательно поддерживать любая мало-мальски уважающая себя веб — страница.
Кодировка ISO – 8859-5 была разработана Международной организацией по стандартизации (International Standards Organization, ISO) с единственной целью: унифицировать представление символов национальных алфавитов в электронной форме. Именно поэтому ISO предложила целый набор кодировок серии 8859, каждая из которых описывала свой набор знаков: существует соответствующая кодировка ISO для арабского языка (ISO-8859-6), иврита (ISO-8859-8), латиницы (ISO-8859-1) и других языков мира. В силу различных причин русский вариант кодировки ISO не получил широкого распространения, однако все же изредка встречается в Интернете и потому поддерживается рядом русскоязычных серверов.
Кодировка Macintosh СР (МАС) ориентирована на персональные компьютеры Apple Macintosh, оснащенные операционной системой MacOS. Из-за высокой стоимости Аррlе — совместимые компьютеры не стали в России популярными, однако они весьма широко используются на Западе и иногда эксплуатируются на крупных отечественных предприятиях.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы любых языков мира. Этот стандарт используется в качестве основной кодировки в операционной системе Microsoft Windows ХР.
-
Стандарт кодирования символов Unicode.
Unicode (Юникод или Уникод, англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. «Unicode Consortium»), объединяющей крупнейшие IT-корпорации. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены коды от U+0400 до U+052F.
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах.
UNIX-образные операционные системы, в том числе, Linux, BSD, Mac OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от восьмибитного представления символов в пользу шестнадцатибитного. Сейчас большинство языков программирования поддерживают строки Unicode, хотя их представление может различаться в зависимости от реализации.
Стандарт Юникод поддерживает языки как с направлением написания слева — направо (англ. Left – to — right, LTR) так и с написанием справа — налево (англ. Right – to — eft, RTL), как иврит и арабский язык. Кроме того, Юникод поддерживает комбинированные тексты, содержащие одновременно RTL и LTR фразы. Данная возможность называется двунаправленность (англ. bidirectional, Bidir). Простые реализации Юникода могут не иметь поддержки двунаправленности.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов;
- цифры;
- знаки пунктуации;
- специальные знаки (математические, технические, идеограммы и пр.);
- разделители.
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные надстрочные или подстрочные элементы, представляются в виде последовательности кодов, составленной по определённым правилам (декомпозированный вариант) или единого символа (композированный вариант). На рисунке 2 предоставлен символа «Й» (U+0419) в виде базового символа «И» (U+0418) и комбинируемого символа « ̆ » (U+0306).
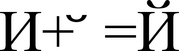
Рисунок 2. Комбинация символа Й
Графические символы в Юникод подразделяются на протяжённые и непротяжённые (бесширинные). Непротяженные символы при отображении не занимают места в строке. К ним относятся ударения, диакритические знаки и т. п. При кодировании в Юникоде, как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми, а непротяжённые — комбинируемыми, потому что они не могут встречаться самостоятельно. Например, символ «á» будет представлен как последовательность базового символа «a» (U+0061) и комбинируемого символа «´» (U+0301) или как отдельный символ «á» (U+00C1).
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит. В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
В Юникоде зарезервировано 1 114 112 (= 220 + 216) позиций символов, из которых сейчас используется около 90000. Первые 256 знакомест совпадают с кодовой таблицей ISO 8859-1 (Latin-1).
Хоть формы записи UTF-8 и UTF-32 позволяют кодировать до 231 (2 147 483 648) кодовых позиций, принято решение использовать лишь 220+216 (1 114 112) для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — на сегодняшний день используется чуть больше 96 000 кодовых позиций.
Кодовое пространство разделено на 17 «плоскостей» по 65536 (= 216) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей. Плоскости 16 и 17 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» или «U+yyyyyyyy», где xxxx и yyyyyyyy — шестнадцатеричная запись номера символа. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Базовая многоязыковая плоскость предоставлена на рисунке 2.
Рисунок 2. Базовая многоязыковая плоскость
Базовая плоскость UNICODE расшифрована в таблице 1.
|
Цвет |
Что зашифровано |
|---|---|
|
Чёрный |
Расширенный латинский алфавит |
|
Голубой |
Лингвистические символы международного фонетического алфавита IPA |
|
Синий |
Другие европейские алфавиты |
|
Оранжевый |
Письменности Ближнего Востока |
|
Светло-оранжевый |
Письменности Африки |
|
Зелёный |
Письменности Южной Азии |
|
Фиолетовый |
Письменности Юго-восточной Азии |
|
Красный |
Письменности Восточной Азии |
|
Розовый |
Унифицированные китайско-японско-корейские символы |
|
Жёлтый |
Письменности аборигенов Северной Америки |
|
Пурпурный |
Символы |
|
Тёмно-серый |
диакритики |
|
Светло-серый |
Суррогатные пары UTF-16 и области для частного использования |
|
Сине-зелёный |
Другие знаки |
|
Белый |
Не используется |
|
Чёрный |
Расширенный латинский алфавит |
Таблица 1.
Расшифровка базовой плоскости UNICODE
Плоскость 0 (Основная многоязыковая плоскость, англ. Basic Multilanguage Plane, BMP) содержит символы практически для всех современных письменностей и большое число специальных символов. Большая часть таблицы занята китайско – японско — корейскими иероглифами.
Плоскость 1 (дополнительная многоязыковая плоскость, англ. Supplementary Multilingual Plane, SMP) отведена, в первую очередь, для исторических письменностей, но также включает музыкальные и математические символы.
Некоторые регионы Unicode выделены для частного использования и экспериментов.
Частная область включает:
- Регион в Базовой плоскости U+E000…U+F8FF;
- Расширенные плоскости 15 (U+F0000…U+FFFFF) и 16 (U+100000…U+10FFFF).
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы — а эта работа ведётся постоянно, поскольку изначально система Юникод была представлена в ISO в недоработанном виде — выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
- 1.1 (соответствует стандарту ISO/IEC 10646—1:1993);
- 2.0, 2.1 (тот же стандарт ISO/IEC 10646—1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2);
- 3.0 (стандарт ISO/IEC 10646—1:2000);
- 3.2 (стандарт 2002 года);
- 4.0 (стандарт 2003);
- 4.01 (стандарт 2004);
- 4.1 (стандарт 2005);
- 5.0 (стандарт 2006).
Для примера можно рассмотреть символы, представленные в основной плоскости в версии Unicode 4.1.
В Unicode 4.1 в основной плоскости представлены следующие символы:
- Базовый латинский алфавит (0000—007F);
- Дополнительные символы Latin-1 (0080—00FF);
- Расширенный латинский алфавит-A (0100—017F);
- Расширенный латинский алфавит-B (0180—024F);
- Международный фонетический алфавит (IPA) Extensions (0250—02AF);
- Пробельные символы (02B0—02FF);
- диакритические символы (0300—036F);
- Греческий и коптский алфавиты (0370—03FF);
- Кириллица (0400—04FF);
- Дополнительные символы кириллицы (0500—052F);
- Армянский алфавит (0530—058F);
- Еврейский алфавит (0590—05FF);
- Арабский алфавит (0600—06FF);
- Сирийский алфавит (0700—074F);
- Дополнительные символы арабского алфавита (0750—077F);
- Thaana (0780—07BF);
- Индийские письменности:
- Деванагари (0900—097F);
- Бенгали (0980—09FF);
- Gurmukhi (0A00—0A7F);
- Gujarati (0A80—0AFF);
- Oriya (0B00—0B7F);
- Tamil (0B80—0BFF);
- Telugu (0C00—0C7F);
- Kannada (0C80—0CFF);
- Malayalam (0D00—0D7F);
- Sinhala (0D80—0DFF).
- Тайский алфавит (0E00—0E7F);
- Лаосская письменность (0E80—0EFF);
- Тибетская письменность (0F00—0FFF);
- Бирманский алфавит (1000—109F);
- Грузинский алфавит (10A0—10FF);
- Отдельные буквы (Jamo) хангыль (1100—11FF);
- Амхарский язык (1200—137F);
- Ethiopic Supplement (1380—139F);
- Язык чероки (13A0—13FF);
- Unified Canadian Aboriginal Syllabics (1400—167F);
- Ogham (1680—169F);
- Рунный алфавит (16A0—16FF);
- Филиппинские письменности:
- Tagalog (1700—171F);
- Hanunoo (1720—173F);
- Buhid (1740—175F);
- Tagbanwa (1760—177F).
- Кхмерский алфавит (1780—17FF);
- Монгольский алфавит (1800—18AF);
- Limbu (1900—194F);
- Tai Le (1950—197F);
- New Tai Lue (1980—19DF);
- Khmer Symbols (19E0—19FF);
- Buginese (1A00—1A1F);
- Фонетические расширения (1D00—1D7F);
- Дополнительные фонетичестие расширения (1D80—1DBF);
- Дополнительные диакритические знаки (1DC0—1DFF);
- Latin Extended Additional (1E00—1EFF);
- Расширенный греческий алфавит (1F00—1FFF);
- Символы:
- Пунктуация (2000—206F);
- Надстрочные и подстрочные знаки (2070—209F);
- Символы валют (20A0—20CF);
- Combining Diacritical Marks for Symbols (20D0—20FF);
- Letterlike Symbols (2100—214F);
- Number Forms (2150—218F);
- Стрелки (2190—21FF);
- Математические операторы (2200—22FF);
- Прочие технические символы (2300—23FF);
- Control Pictures (2400—243F);
- Optical Character Recognition (2440—245F);
- Enclosed Alphanumerics (2460—24FF);
- Символы для рисования рамок (2500—257F);
- Block Elements (2580—259F);
- Геометрические фигуры (25A0—25FF);
- Прочие символы (2600—26FF);
- Dingbats (2700—27BF);
- Miscellaneous Mathematical Symbols-A (27C0—27EF);
- Supplemental Arrows-A (27F0—27FF);
- Азбука Брайля (2800—28FF);
- Supplemental Arrows-B (2900—297F);
- Miscellaneous Mathematical Symbols-B (2980—29FF);
- Supplemental Mathematical Operators (2A00—2AFF);
- Miscellaneous Symbols and Arrows (2B00—2BFF).
- Глаголица (2C00—2C5F);
- Коптский алфавит (2C80—2CFF);
- Georgian Supplement (2D00—2D2F);
- Tifinagh (2D30—2D7F);
- Ethiopic Extended (2D80—2DDF);
- Supplemental Punctuation (2E00—2E7F);
- CJK Radicals Supplement (2E80—2EFF);
- Kangxi Radicals (2F00—2FDF);
- Ideographic Description Characters (2FF0—2FFF);
- CJK Symbols and Punctuation (3000—303F);
- Хирагана (3040—309F);
- Катакана (30A0—30FF);
- Чжуинь (Бопомофо) (3100—312F);
- Хангыль Compatibility Jamo (3130—318F);
- Kanbun (3190—319F);
- Расширение Бопомофо (31A0—31BF);
- CJK Strokes (31C0—31EF);
- Katakana Phonetic Extensions (31F0—31FF);
- Enclosed CJK Letters and Months (3200—32FF);
- CJK Compatibility (3300—33FF);
- CJK Unified Ideographs Extension A (3400—4DBF);
- Yijing Hexagram Symbols (4DC0—4DFF);
- CJK Unified Ideographs (4E00—9FFF);
- Yi Syllables (A000—A48F);
- Yi Radicals (A490—A4CF);
- Modifier Tone Letters (A700—A71F);
- Syloti Nagri (A800—A82F);
- Слоги хангыль (AC00—D7AF);
- Верхняя часть суррогатных пар (D800—DB7F);
- Верхняя часть суррогатных пар для частного использования (DB80—DBFF);
- Нижняя часть суррогатных пар (DC00—DFFF);
- Область для частного использования (E000—F8FF);
- CJK Compatibility Ideographs (F900—FAFF);
- Alphabetic Presentation Forms (FB00—FB4F);
- Arabic Presentation Forms-A (FB50—FDFF);
- Variation Selectors (FE00—FE0F);
- Vertical Forms (FE10—FE1F);
- Combining Half Marks (FE20—FE2F);
- CJK Compatibility Forms (FE30—FE4F);
- Small Form Variants (FE50—FE6F);
- Arabic Presentation Forms-B (FE70—FEFF);
- Halfwidth and Fullwidth Forms (FF00—FFEF);
- Специальные символы (FFF0—FFFF).
Некоторые письменности будут добавлены в следующей версии Unicode. Эти письменности и предложенные диапазоны перечислены далее:
- N’Ko ( Mandekan) (07C0—07FF);
- Balinese (1B00—1B7F);
- Lepcha ( Rong) (1C00—1C4F);
- Latin Extended-C (2C60—2C7F);
- Santali (Ol Cemet’ / Ol Chiki) (2DE0—2DFF);
- Vai (A500—A61F);
- Latin Extended-D (A720—A7FF);
- Phags-pa (A840—A87F);
- Saurashtra (AB00—AB5F).
Но, как ни грустно это признавать, как и любая изобретённая человеком система, Unicode тоже не свободен от недостатков.
-
Недостатки стандарта кодирования символов Unicode
Многие системы письма всё ещё не представлены в Юникоде. Например, письменность церковнославянского языка содержит много дополнительных графических элементов (такие как титлы и надстрочные буквы). Они не могут быть должным образом представлены в системе Юникод, хотя отдельные элементы для этого имеются. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, пока в принципе не предусмотрено.
Тексты на китайском, корейском и японском языке имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Данная возможность не отражена в Юникоде (впрочем, она и не должна быть отражена, поскольку это относится к форматированию текста, а не к кодированию символов).
В стандартах Юникода не было зафиксировано, когда вводится отдельная кодовая позиция для готового (Precomposed) символа, а когда его необходимо набирать из базового и диакритического. Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде отдельных символов, хотя могут быть представлены и набором базового символа плюс диакритика (Decomposed): Е+¨ (U+0415 U+0308), И+ (U+0418 U+0306). В то же время, множество символов из языков с алфавитами на основе кириллицы не имеют precomposed форм.

Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханджа), но при этом в Юникоде обозначаться одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды. Часто возникают накладки, когда, например, японский текст выглядит «по-китайски». Аналогично, русский и сербский языки используют разное начертание курсивных букв n и m (в сербском они выглядят как и и ш). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
Файлы с текстом в Юникоде занимают больше места в памяти, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков алфавит которых укладывается в ASCII). Однако с увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной.
Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки BOM и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
- ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO) началось в 1991 году. В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним, Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате, значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. Universal Multiple-Octet Coded Character Set). Как уже упоминалось, UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Вывод
В информатике большое число информационных процессов проходит с использованием кодирования данных. Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов, записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.
В данной работе рассматривались такие кодировки, как:
- ASCII;
- ANSI;
- КОI8;
- Unicode;
- ISO/IEC 10646.
Каждый из них имеет свои особенности, достоинства и недостатки кодирования, но без них не сможет работать современная электронная вычислительная машина.
Обычно каждый образ при кодировании представлении отдельным знаком. Знак — это элемент конечного множества отличных друг от друга элементов. Знак вместе с его смыслом называют символом. Длиной кода называется такое количество знаков, которое используется при кодировании.
Код может быть постоянной и непостоянной длины. Для представления информации в памяти ЭВМ используется двоичный способ кодирования.
Элементарная ячейка памяти ЭВМ имеет длину 8 бит. Каждый байт имеет свой номер. Наибольшую последовательность бит, которую ЭВМ может обрабатывать как единое целое, называют машинным словом. Длина машинного слова зависит от разрядности процессора и может быть равной 16, 32 битам и т.д. Другой способ представления целых чисел — дополнительный код. Диапазон значений величин зависит от количества бит памяти, отведенных для их хранения. Дополнительный код положительного числа совпадает с его прямым кодом.

- Русское искусство первой половины XIX века. Творчество Ореста Кипренского, Василия Тропинина, Алексея Венецианова, Карла Брюллова, Александра Иванова
- Петроглифы Северной России и территорий Балтии, Скандинавии, Кавказа (Петроглифы Северной России)
- Дефекты магнитных дисков
- Статус несовершеннолетних родителей
- Защита интересов ребенка при расторжении брака родителей
- Интернет и авторское право
- Система Е1-Евфрат.
- Судебный прецедент как источник международного гражданского процесса
- Анализ объекта промышленного дизайна. Стулья для отдыха «Веранда» для фирмы «Cassina»
- Разбор техник отображения персонажей в комиксах
- Искусство конца XIX – начала XX века. Импрессионизм в живописи и скульптуре. Творчество Огюста Ренуара, Клода Моне, Камиля Писарро, Огюста Родена
- Развитие унификации и стандартизации документов