Yes, Windows 1252 characters are a subset of Unicode.
Unicode, by design, implements lossless transformation back and forth from most (common) character encoding available in year 1993. CP-1252 is older then Unicode, and frequent used, so Unicode was designed to include all CP-1252.
This design was specified for your case: you may convert one layer at a time, without losing information, so without need a flag day. You just convert database, but and set the client [driver] to translate back to CP-1252. (Usually it is the default, clients know what coding you expect, and they know what database will deliver, so it will do transcoding). On a second step you can change the client part (and maybe later the front-end).
Just you should care about some problems: Unicode has various canonical form, and much more possible representation for the same character. From CP-1252 it is not a problem, but on the back way, you may have problems, depending on the library you use. If you need to convert back, just do some experiments.
Many code are the same in Unicode and in CP-1252, but the encoding UTF-8 requires two (or more) bytes for codes about 127, so these are not byte to byte compatible. But usually a simple lookup table (256 elements) is enough.
Non-printable characters are, in theory the same, but every system could change interpretation (e.g. new line, and form feed [new page or now often new section], or all escape sequences (starting with ^[). But this is not really relevant to you.
Yes, Windows 1252 characters are a subset of Unicode.
Unicode, by design, implements lossless transformation back and forth from most (common) character encoding available in year 1993. CP-1252 is older then Unicode, and frequent used, so Unicode was designed to include all CP-1252.
This design was specified for your case: you may convert one layer at a time, without losing information, so without need a flag day. You just convert database, but and set the client [driver] to translate back to CP-1252. (Usually it is the default, clients know what coding you expect, and they know what database will deliver, so it will do transcoding). On a second step you can change the client part (and maybe later the front-end).
Just you should care about some problems: Unicode has various canonical form, and much more possible representation for the same character. From CP-1252 it is not a problem, but on the back way, you may have problems, depending on the library you use. If you need to convert back, just do some experiments.
Many code are the same in Unicode and in CP-1252, but the encoding UTF-8 requires two (or more) bytes for codes about 127, so these are not byte to byte compatible. But usually a simple lookup table (256 elements) is enough.
Non-printable characters are, in theory the same, but every system could change interpretation (e.g. new line, and form feed [new page or now often new section], or all escape sequences (starting with ^[). But this is not really relevant to you.
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа! 
смайлы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн! 
смайлы, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «�����»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить… 
смайлы
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 14 лет(число динамическое) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!
Взял с сайта
Немного теории
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8… А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них:
“У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _);
“С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
The answer to your first question is yes. It is recommended that you should absolutely change all your character encoding Attributes for all your HTML 5 documents.
This is because it is the current HTML5 Standard according to W3C. I would change all of the pages in any given site based on this reason alone as a standardization of all markup rendering is inevitable.
This can easily be done on any editor that has a find/replace feature. Simply use the feature to find in every document the term
<meta charset="windows-1252">
and replace it with
<meta charset="utf-8"/>
The UTF-8 character encoding should be able to handle your math characters but if it doesn’t simply leave your original charset as is. And the rest of your pages with text only you will want to change to UTF-8. Here is W3Schools position on your char encoding.
The HTML5 specification encourages web developers to use the UTF-8
character set, which covers almost all of the characters and symbols
in the world!
—W3Schools.com
If size is an issue, again you will only leave those documents that have the special math character requirements with the original encoding if they don’t render correctly and I don’t think it will effect your browser load time enough to damage your SEO.
If you have many pages with math symbols then this could be a problem if your looking for a popular site or for business, if not the size is so small the problem with file size seems mute.
For the other documents you should still change the encoding for them as UTF-8 even if you have a BOM.
If you have a UTF-8 byte-order mark (BOM) at the start of your file
then recent browser versions other than Internet Explorer 10 or 11
will use that to determine that the encoding of your page is UTF-8. It
has a higher precedence than any other declaration, including the HTTP
header.You could skip the meta encoding declaration if you have a BOM, but we
recommend that you keep it, since it helps people looking at the
source code to ascertain what the encoding of the page is.
—w3.org
Good luck and happy coding! 
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
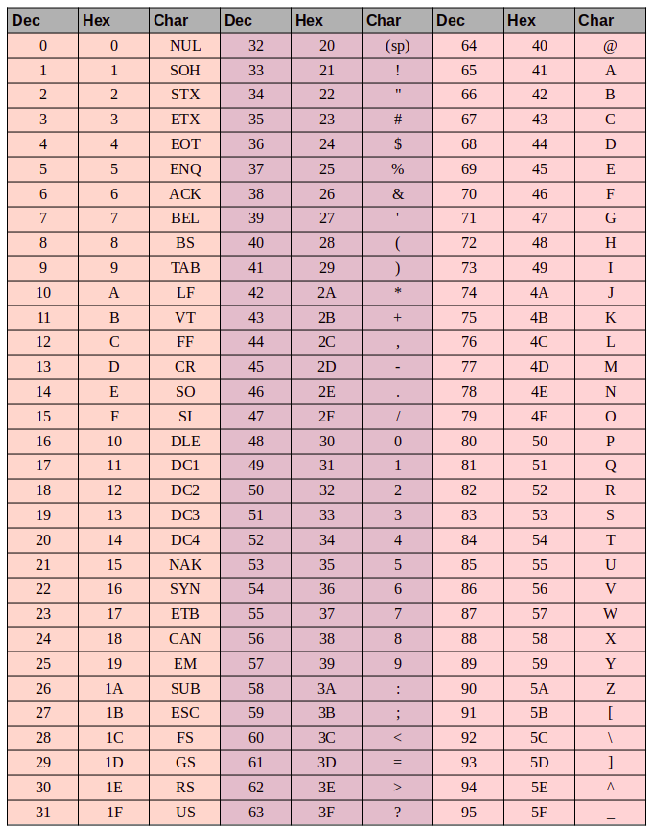
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Чтобы правильно отобразить HTML страницу, веб браузер должен знать, какой набор символов использовать.
Что такое кодировка символов?
ASCII была первая стандартная кодировка символов (также называется набор символов).
ASCII определенны 128 различных буквенно-цифровых символов, которые могут быть использованы в интернете: числа от (0-9),
английские буквы (A-Z), и некоторые специальные символы, такие как ! $ + — ( ) @ < > .
ANSI (Windows-1252) был оригинальным Windows набор символов, с поддержкой 256 различных кодов символов.
ISO-8859-1 была кодировка по умолчанию для HTML 4. Этот набор символов тоже поддерживается 256 различных кодов символов.
Потому что ANSI и ISO-8859-1 были настолько ограничены, что HTML 4 также поддерживает UTF-8.
UTF-8 (Юникод) охватывает практически все знаки и символы в мире.
Кодировка по умолчанию для HTML5 является UTF-8.
HTML Атрибут charset
Для корректного отображения HTML страницы веб браузер должен знать набор символов, используемый на этой странице.
Это указано в теге <meta>:
Если браузер обнаруживает ISO-8859-1 на веб странице, он по умолчанию использует ANSI.
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
| Число | ASCII | ANSI | 8859 | UTF-8 | Описание |
|---|---|---|---|---|---|
| 32 | Пространство | ||||
| 33 | ! | ! | ! | ! | Восклицательный знак |
| 34 | « | « | « | « | Кавычки двойные |
| 35 | # | # | # | # | Знак числа |
| 36 | $ | $ | $ | $ | Знак доллара |
| 37 | % | % | % | % | Знак процента |
| 38 | & | & | & | & | Амперсанд |
| 39 | ‘ | ‘ | ‘ | ‘ | Кавычки одинарные |
| 40 | ( | ( | ( | ( | Левая собка |
| 41 | ) | ) | ) | ) | Правая скобка |
| 42 | * | * | * | * | Звездочка |
| 43 | + | + | + | + | Плюс |
| 44 | , | , | , | , | Запятая |
| 45 | — | — | — | — | Дефис-минус |
| 46 | . | . | . | . | Точка |
| 47 | / | / | / | / | Косая черта |
| 48 | 0 | 0 | 0 | 0 | Число нуль |
| 49 | 1 | 1 | 1 | 1 | Число один |
| 50 | 2 | 2 | 2 | 2 | Число два |
| 51 | 3 | 3 | 3 | 3 | Число три |
| 52 | 4 | 4 | 4 | 4 | Число четыре |
| 53 | 5 | 5 | 5 | 5 | Число пять |
| 54 | 6 | 6 | 6 | 6 | Число шесть |
| 55 | 7 | 7 | 7 | 7 | Число семь |
| 56 | 8 | 8 | 8 | 8 | Число восемь |
| 57 | 9 | 9 | 9 | 9 | Число девять |
| 58 | : | : | : | : | Двоеточие |
| 59 | ; | ; | ; | ; | Точка с запятой |
| 60 | < | < | < | < | Знак меньше чем |
| 61 | = | = | = | = | Знак равенства |
| 62 | > | > | > | > | Знак больше чем |
| 63 | ? | ? | ? | ? | Знак вопроса |
| 64 | @ | @ | @ | @ | Коммерческая в |
| 65 | A | A | A | A | Латинская буква A |
| 66 | B | B | B | B | Латинская буква B |
| 67 | C | C | C | C | Латинская буква C |
| 68 | D | D | D | D | Латинская буква D |
| 69 | E | E | E | E | Латинская буква E |
| 70 | F | F | F | F | Латинская буква F |
| 71 | G | G | G | G | Латинская буква G |
| 72 | H | H | H | H | Латинская буква H |
| 73 | I | I | I | I | Латинская буква I |
| 74 | J | J | J | J | Латинская буква J |
| 75 | K | K | K | K | Латинская буква K |
| 76 | L | L | L | L | Латинская буква L |
| 77 | M | M | M | M | Латинская буква M |
| 78 | N | N | N | N | Латинская буква N |
| 79 | O | O | O | O | Латинская буква O |
| 80 | P | P | P | P | Латинская буква P |
| 81 | Q | Q | Q | Q | Латинская буква Q |
| 82 | R | R | R | R | Латинская буква R |
| 83 | S | S | S | S | Латинская буква S |
| 84 | T | T | T | T | Латинская буква T |
| 85 | U | U | U | U | Латинская буква U |
| 86 | V | V | V | V | Латинская буква V |
| 87 | W | W | W | W | Латинская буква W |
| 88 | X | X | X | X | Латинская буква X |
| 89 | Y | Y | Y | Y | Латинская буква Y |
| 90 | Z | Z | Z | Z | Латинская буква Z |
| 91 | [ | [ | [ | [ | Левая квадратная скобка |
| 92 | Обратный солидус | ||||
| 93 | ] | ] | ] | ] | Правая квадратная скобка |
| 94 | ^ | ^ | ^ | ^ | Циркумфлекс ударение |
| 95 | _ | _ | _ | _ | Низкая линия |
| 96 | ` | ` | ` | ` | Знак ударения |
| 97 | a | a | a | a | Латинская строчная буква a |
| 98 | b | b | b | b | Латинская строчная буква b |
| 99 | c | c | c | c | Латинская строчная буква c |
| 100 | d | d | d | d | Латинская строчная буква d |
| 101 | e | e | e | e | Латинская строчная буква e |
| 102 | f | f | f | f | Латинская строчная буква f |
| 103 | g | g | g | g | Латинская строчная буква g |
| 104 | h | h | h | h | Латинская строчная буква h |
| 105 | i | i | i | i | Латинская строчная буква i |
| 106 | j | j | j | j | Латинская строчная буква j |
| 107 | k | k | k | k | Латинская строчная буква k |
| 108 | l | l | l | l | Латинская строчная буква l |
| 109 | m | m | m | m | Латинская строчная буква m |
| 110 | n | n | n | n | Латинская строчная буква n |
| 111 | o | o | o | o | Латинская строчная буква o |
| 112 | p | p | p | p | Латинская строчная буква p |
| 113 | q | q | q | q | Латинская строчная буква q |
| 114 | r | r | r | r | Латинская строчная буква r |
| 115 | s | s | s | s | Латинская строчная буква s |
| 116 | t | t | t | t | Латинская строчная буква t |
| 117 | u | u | u | u | Латинская строчная буква u |
| 118 | v | v | v | v | Латинская строчная буква v |
| 119 | w | w | w | w | Латинская строчная буква w |
| 120 | x | x | x | x | Латинская строчная буква x |
| 121 | y | y | y | y | Латинская строчная буква y |
| 122 | z | z | z | z | Латинская строчная буква z |
| 123 | { | { | { | { | Левая фигурная скобка |
| 124 | | | | | | | | | Вертикальная линия |
| 125 | } | } | } | } | Правая фигурная скобка |
| 126 | ~ | ~ | ~ | ~ | Тильда |
| 127 | DEL | ||||
| 128 | € | Знак евро | |||
| 129 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 130 | ‚ | Одинарная 9 низкая кавычка | |||
| 131 | ƒ | Латинская строчная буква f с крючком | |||
| 132 | „ | Двойная 9 низкая кавычка | |||
| 133 | … | Горизонтальное многоточие | |||
| 134 | † | Кинжал | |||
| 135 | ‡ | Двойной кинжал | |||
| 136 | ˆ | Письмо модификатор облеченным ударением | |||
| 137 | ‰ | Знак промилле | |||
| 138 | Š | Латинская буква S с caron | |||
| 139 | ‹ | Одинарный угол влево низкая кавычка | |||
| 140 | Œ | Латинская заглавная лигатура OE | |||
| 141 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 142 | Ž | Латинская буква Z с caron | |||
| 143 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 144 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 145 | ‘ | Левая одинарная низкая кавычка | |||
| 146 | ’ | Правая одинарная низкая кавычка | |||
| 147 | “ | Левая двойная низкая кавычка | |||
| 148 | ” | Правая двойная низкая кавычка | |||
| 149 | • | Маркер | |||
| 150 | – | Тире | |||
| 151 | — | Длинное тире | |||
| 152 | ˜ | Маленькая тильда | |||
| 153 | ™ | Знак торговой марки | |||
| 154 | š | Латинская строчная буква s с caron | |||
| 155 | › | Одинарный угол вправо низкая кавычка | |||
| 156 | œ | Латинская строчная лигатура oe | |||
| 157 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 158 | ž | Латинская строчная буква z с caron | |||
| 159 | Ÿ | Латинская буква Y с diaeresis | |||
| 160 | Неразрывный пробел | ||||
| 161 | ¡ | ¡ | ¡ | Перевернутый восклицательный знак | |
| 162 | ¢ | ¢ | ¢ | Знак цента | |
| 163 | £ | £ | £ | Знак фунта | |
| 164 | ¤ | ¤ | ¤ | Знак валюты | |
| 165 | ¥ | ¥ | ¥ | Знак иены | |
| 166 | ¦ | ¦ | ¦ | Прерывистая полоса | |
| 167 | § | § | § | Знак раздела | |
| 168 | ¨ | ¨ | ¨ | Трема | |
| 169 | © | © | © | Знак авторского права | |
| 170 | ª | ª | ª | Женский порядковый индикатор | |
| 171 | « | « | « | Двойной угол влево | |
| 172 | ¬ | ¬ | ¬ | Знак нет | |
| 173 | | | | Мягкий дефис | |
| 174 | ® | ® | ® | Зарегистрированный знак | |
| 175 | ¯ | ¯ | ¯ | Макрон | |
| 176 | ° | ° | ° | Знак степени | |
| 177 | ± | ± | ± | Плюс-минус | |
| 178 | ² | ² | ² | Верхний индекс два | |
| 179 | ³ | ³ | ³ | Верхний индекс три | |
| 180 | ´ | ´ | ´ | Острый знак ударения | |
| 181 | µ | µ | µ | Микро знак | |
| 182 | ¶ | ¶ | ¶ | Знак абзаца | |
| 183 | · | · | · | Точка посередине | |
| 184 | ¸ | ¸ | ¸ | Седиль | |
| 185 | ¹ | ¹ | ¹ | Верхний индекс один | |
| 186 | º | º | º | Мужской порядковый индикатор | |
| 187 | » | » | » | Двойной угол вправо | |
| 188 | ¼ | ¼ | ¼ | Грубая дробь одна четвертая | |
| 189 | ½ | ½ | ½ | Грубая дробь одна вторая | |
| 190 | ¾ | ¾ | ¾ | Грубая дробь три четвертых | |
| 191 | ¿ | ¿ | ¿ | Перевернутый вопросительный знак | |
| 192 | À | À | À | Латинская буква A с grave | |
| 193 | Á | Á | Á | Латинская буква A с acute | |
| 194 | Â | Â | Â | Латинская буква A с circumflex | |
| 195 | Ã | Ã | Ã | Латинская буква A с tilde | |
| 196 | Ä | Ä | Ä | Латинская буква A с diaeresis | |
| 197 | Å | Å | Å | Латинская буква A с ring above | |
| 198 | Æ | Æ | Æ | Латинская буква AE | |
| 199 | Ç | Ç | Ç | Латинская буква C с cedilla | |
| 200 | È | È | È | Латинская буква E с grave | |
| 201 | É | É | É | Латинская буква E с acute | |
| 202 | Ê | Ê | Ê | Латинская буква E с circumflex | |
| 203 | Ë | Ë | Ë | Латинская буква E с diaeresis | |
| 204 | Ì | Ì | Ì | Латинская буква I с grave | |
| 205 | Í | Í | Í | Латинская буква I с acute | |
| 206 | Î | Î | Î | Латинская буква I с circumflex | |
| 207 | Ï | Ï | Ï | Латинская буква I с diaeresis | |
| 208 | Ð | Ð | Ð | Латинская буква Eth | |
| 209 | Ñ | Ñ | Ñ | Латинская буква N с tilde | |
| 210 | Ò | Ò | Ò | Латинская буква O с grave | |
| 211 | Ó | Ó | Ó | Латинская буква O с acute | |
| 212 | Ô | Ô | Ô | Латинская буква O с circumflex | |
| 213 | Õ | Õ | Õ | Латинская буква O с tilde | |
| 214 | Ö | Ö | Ö | Латинская буква O с diaeresis | |
| 215 | × | × | × | Знак умножения | |
| 216 | Ø | Ø | Ø | Латинская буква O с stroke | |
| 217 | Ù | Ù | Ù | Латинская буква U с grave | |
| 218 | Ú | Ú | Ú | Латинская буква U с acute | |
| 219 | Û | Û | Û | Латинская буква U с circumflex | |
| 220 | Ü | Ü | Ü | Латинская буква U с diaeresis | |
| 221 | Ý | Ý | Ý | Латинская буква Y с acute | |
| 222 | Þ | Þ | Þ | Латинская буква thorn | |
| 223 | ß | ß | ß | Латинская строчная буква sharp s | |
| 224 | à | à | à | Латинская строчная буква a с grave | |
| 225 | á | á | á | Латинская строчная буква a с acute | |
| 226 | â | â | â | Латинская строчная буква a с circumflex | |
| 227 | ã | ã | ã | Латинская строчная буква a с tilde | |
| 228 | ä | ä | ä | Латинская строчная буква a с diaeresis | |
| 229 | å | å | å | Латинская строчная буква a с ring above | |
| 230 | æ | æ | æ | Латинская строчная буква ae | |
| 231 | ç | ç | ç | Латинская строчная буква c с cedilla | |
| 232 | è | è | è | Латинская строчная буква e с grave | |
| 233 | é | é | é | Латинская строчная буква e с acute | |
| 234 | ê | ê | ê | Латинская строчная буква e с circumflex | |
| 235 | ë | ë | ë | Латинская строчная буква e с diaeresis | |
| 236 | ì | ì | ì | Латинская строчная буква i с grave | |
| 237 | í | í | í | Латинская строчная буква i с acute | |
| 238 | î | î | î | Латинская строчная буква i с circumflex | |
| 239 | ï | ï | ï | Латинская строчная буква i с diaeresis | |
| 240 | ð | ð | ð | Латинская строчная буква eth | |
| 241 | ñ | ñ | ñ | Латинская строчная буква n с tilde | |
| 242 | ò | ò | ò | Латинская строчная буква o с grave | |
| 243 | ó | ó | ó | Латинская строчная буква o с acute | |
| 244 | ô | ô | ô | Латинская строчная буква o с circumflex | |
| 245 | õ | õ | õ | Латинская строчная буква o с tilde | |
| 246 | ö | ö | ö | Латинская строчная буква o с diaeresis | |
| 247 | ÷ | ÷ | ÷ | division sign | |
| 248 | ø | ø | ø | Латинская строчная буква o с stroke | |
| 249 | ù | ù | ù | Латинская строчная буква u с grave | |
| 250 | ú | ú | ú | Латинская строчная буква u с acute | |
| 251 | û | û | û | Латинская строчная буква с circumflex | |
| 252 | ü | ü | ü | Латинская строчная буква u с diaeresis | |
| 253 | ý | ý | ý | Латинская строчная буква y с acute | |
| 254 | þ | þ | þ | Латинская строчная буква thorn | |
| 255 | ÿ | ÿ | ÿ | Латинская строчная буква y с тремой |
ASCII Набор символов
ASCII используются значения от 0 до 31 (и 127) для управляющих символов.
ASCII используются значения от 32 до 126 для букв, цифр и символов.
ASCII не используйте значения от 128 до 255.
ANSI Набор символов (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентична кодировке utf-8 для значений от 160 до 255.
ISO-8859-1 Набор символов
8859-1 идентичен ASCII для значений от 0 до 127.
8859-1 не используйте значения от 128 до 159.
8859-1 идентична кодировке utf-8 для значений от 160 до 255.
UTF-8 Набор символов
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не используйте значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжается от значение 256 с более чем 10 000 различных символов.
Для более близкого взгляда, изучите наш Полный набор символов HTML справочник.
Правило CSS @charset
Вы можете использовать CSS правило @charset для указания кодировки символов, используемой в таблице стилей:
Пример
Установите кодировку таблицы стилей в Юникод UTF-8:
@charset «UTF-8»;
Подробнее о компании читайте здесь CSS Правило @charset.
Письмо Число Пунктуация Условное обозначение Другой Неопределенный
История
Расширения OS / 2
Расширения MSDOS [редко]
Существует редко используемая, но полезная расширенная кодовая страница 1252 для графики, где коды от 0x00 до 0x1f позволяют рисовать блоки, как это используется в таких приложениях, как MSDOS Edit и Codeview. Одним из приложений, использующих эту кодовую страницу, была утилита установки / восстановления образа диска корпорации Intel, выпущенная в середине / конце 1995 года. Эти программы были написаны для компьютеров с пользовательской тестовой программой P6 (пример для США). Он использовался исключительно в тогдашнем регионе EMEA (Европа, Ближний Восток и Африка). Со временем программы были изменены, чтобы использовать кодовую страницу 850.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ | ○ 25CB |
■ 25A0 |
↑ 2191 |
↓ 2193 |
→ 2192 |
← 2190 |
║ 2551 |
= 2550 |
2554 ╔ |
╗ 2557 |
╚ 255A |
╝ 255D |
░ 2591 |
2592 ▒ |
► 25БА |
◄ 25C4 |
| 1_ 16 |
2502 │ |
─ 2500 |
┌ 250C |
┐ 2510 |
└ 2514 |
┘ 2518 |
├ 251C |
┤ 2524 |
┴ 2534 |
┬ 252C |
♦ 2666 |
┼ 253C |
█ 2588 г. |
▄ 2584 |
2580 ▀ |
▬ 25AC |
Графическая расширенная кодовая страница 1252
Вариант Palm OS
Этот вариант Windows-1252 используется в Palm OS 3.5. Python дает ему palmos ярлык.
Источник
Кодировка Windows-1252 в UTF-8
Я скопировал определенные файлы с машины Windows на машину Linux. Таким образом, все файлы с кодировкой Windows (windows-1252) должны быть преобразованы в UTF-8. Файлы, которые уже находятся в UTF-8 не должны быть изменены. Я планирую использовать recode утилита для этого. Как я могу указать, что recode утилита должна конвертировать только файлы в кодировке windows-1252, а не файлы UTF-8?
пример использования recode:
это будет конвертировать myfile.txt от windows-1252 для UTF-8. Прежде чем сделать это, я хотел бы знать, что myfile.txt на самом деле кодируется windows-1252, а не UTF-8. В противном случае, я считаю, что это повредит файл.
10 ответов
Как вы ожидаете, что recode узнает, что файл Windows-1252? Теоретически, я верю любой файл является допустимым файлом Windows-1252, поскольку он отображает каждый возможный байт на символ.
одним из вариантов было бы определить, действительно ли это полностью действительный файл UTF-8 во-первых, я полагаю. опять же, это только наводит на размышления.
Я не знаком с самим инструментом перекодирования, но вы можете захотеть увидеть, способен ли он перекодировать файл из и в же encoding-если вы сделаете это с недопустимым файлом (т. е. тем, который содержит недопустимые последовательности байтов UTF-8), он вполне может преобразовать недопустимые последовательности в вопросительные знаки или что-то подобное. В этот момент Вы можете обнаружить, что файл действителен UTF-8, перекодировав его в UTF-8 и проверка идентичности входных и выходных данных.
просто повторю: все это эвристика. Если вы действительно не знаете кодировку файла, ничто не скажет вам об этом со 100% точностью.
вы можете использовать функцию iconv:
нет общего способа узнать, закодирован ли файл с определенной кодировкой. Помните, что кодировка-это не что иное, как» соглашение » о том, как биты в файле должны быть сопоставлены с символами.
еще один счастливый случай для вас будет, если вы знаете, что файлы на самом деле содержат только символы, которые кодируются одинаково как в UTF-8, так и в windows-1252. В таком случае, конечно, вы уже закончили.
вот транскрипция другого ответа, который я дал на аналогичный вопрос:
если вы примените utf8_encode () к уже строке UTF8, он вернет искаженный вывод UTF8.
Я сделал функцию, которая решает все эти вопросы. Его называют кодировкой:: toUTF8 ().
вам не нужно знать, что кодировка строк. Это может быть Latin1 (iso 8859-1), Windows-1252 или UTF8, или строка может иметь их сочетание. Кодировка::toUTF8() преобразует все в utf8.
Я сделал это, потому что служба давала мне поток данных, все перепуталось, смешивая UTF8 и Latin1 в одной строке.
Я включил другую функцию, Encoding:: fixUFT8(), которая исправит каждую строку UTF8, которая выглядит искаженной.
Update: я преобразовал функцию (forceUTF8) в семейство статических функций в классе под названием Encoding. Новая функция-кодировка:: toUTF8 ().
чтобы убедиться, что файл находится в Windows-1252, откройте его в блокноте (под Windows) и нажмите кнопку Сохранить как. Блокнот предлагает текущую кодировку по умолчанию; если это Windows-1252 (или любая 1-байтовая кодовая страница, если на то пошло), он сказал бы «ANSI».
Если вы хотите переименовать несколько файлов в одной команде-предположим, вы хотите преобразовать все *.txt files-вот команда:
Если вы уверены, что ваши файлы UTF-8 или Windows 1252 (или Latin1), вы можете воспользоваться тем, что recode выйдет с ошибкой, если вы попытаетесь преобразовать недопустимый файл.
в то время как utf8 является допустимым Win-1252, обратное неверно: win-1252 не является допустимым UTF-8. Итак:
выплюнет ошибки для всех файлов cp1252, а затем продолжит их преобразование в UTF8.
Я бы обернул это в более чистый скрипт bash, сохраняя резервную копию каждого преобразованный файл.
прежде чем выполнять преобразование кодировок, вы можете сначала убедиться, что у вас есть согласованные окончания строк во всех файлах. В противном случае recode будет жаловаться из-за этого и может конвертировать файлы, которые уже были UTF8, но просто имели неправильные окончания строк.
вы можете изменить кодировку файла с помощью редактора, такого как notepad++. Просто перейдите к кодировке и выберите то, что вы хотите.
Я всегда предпочитаю Windows 1252
преобразование файла ASCII (Windows1252) в текстовый файл Unicode (UCS-2 le):
метод выше (на основе сценария Карлоса М.) сначала создает файл с меткой порядка байтов (BOM), а затем добавляет содержимое исходного файла. CHCP используется для обеспечения выполнения сеанса с кодовой страницей Windows1252, чтобы символы 0xFF и 0xFE (ÿþ) интерпретировались правильно.
UTF-8 не имеет спецификации, поскольку она является как излишней, так и недействительной. Где BOM полезен в UTF-16, который может быть заменен байтом, как в случае Microsoft. UTF-16 если для внутреннего представления в буфере памяти. Использовать UTF-8 для обмена. По умолчанию и UTF-8, и все остальное, производное от US-ASCII и UTF-16, являются естественным/сетевым порядком байтов. Microsoft UTF-16 требует спецификации, так как она заменяется байтами.
для covert Windows-1252 в ISO8859-15, сначала я конвертирую ISO8859-1 в US-ASCII для кодов с похожими символами. Затем я преобразую Windows-1252 до ISO8859-15, другие символы, отличные от ISO8859-15, в несколько символов US-ASCII.
Источник
В зависимости от страны использование может быть намного выше, чем в среднем в мире, например, для Германии, согласно использованию веб-сайта (включая ISO-8859-1) и составляет 5,7%.
СОДЕРЖАНИЕ
Подробности
Очень часто неправильно маркировать текст Windows-1252 меткой кодировки ISO-8859-1. Общим результатом было то, что все кавычки и апострофы (созданные с помощью «умных кавычек» в текстовых редакторах) были заменены вопросительными знаками или квадратами в операционных системах, отличных от Windows, что затрудняло чтение текста. Большинство современных веб-браузеров и клиентов электронной почты обрабатывают кодировку типа мультимедиа ISO-8859-1 как Windows-1252, чтобы учесть такую неправильную маркировку. Теперь это стандартное поведение в спецификации HTML5, которое требует, чтобы документы, рекламируемые как ISO-8859-1, фактически анализировались в кодировке Windows-1252.
В пакетах LaTeX CP-1252 упоминается как «ответный».
IBM использует кодовую страницу 1252 ( CCSID 1252 и расширенный CCSID 5348 для знака евро ) для Windows-1252.
Набор символов
В следующей таблице показан Windows-1252. Каждый символ отображается с его эквивалентом в Юникоде на основе сопоставления Unicode.org Windows-1252 с «наилучшим соответствием». Десятичные числа (в стиле 0123 ) представляют собой альтернативный код, который можно использовать для их ввода в системах Windows. Отличия от ISO-8859-1 показаны более темным оттенком поверх цветов легенды.
Adblock
detector
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | ||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ | NUL 0000 |
SOH 0001 01 |
STX 0002 02 |
ETX 0003 03 |
EOT 0004 04 |
ENQ 0005 05 |
ACK 0006 06 |
БЕЛ 0007 07 |
BS 0008 08 |
HT 0009 09 |
LF 000A 010 |
ВТ 000Б 011 |
FF 000C 012 |
CR 000D 013 |
SO 000E 014 |
SI 000F 015 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 1_ 16 |
DLE 0010 016 |
DC1 0011 017 |
DC2 0012 018 |
DC3 0013 019 |
DC4 0014 020 |
NAK 0015 021 |
SYN 0016 022 |
ETB 0017 023 |
CAN +0018 +024 |
EM 0019 025 |
SUB 001A 026 |
ESC 001B 027 |
FS 001C 028 |
GS 001D 029 |
RS 001E 030 |
США 001F 031 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 2_ 32 |
SP 0020 32 |
! 0021 33 |
» 0022 34 |
# 0023 35 |
$ 0024 36 |
% 0025 37 |
& 0026 38 |
‘ 0027 39 |
( 0028 40 |
) 0029 41 |
* 002A 42 |
+ 002B 43 |
, 002C 44 |
— 002D 45 |
. 002E 46 |
/ 002F 47 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 3_ 48 |
0 0030 48 |
1 0031 49 |
2 0032 50 |
3 0033 51 |
4 0034 52 |
5 0035 53 |
6 0036 54 |
7 0037 55 |
8 0038 56 |
9 0039 57 |
: 003A 58 |
; 003B 59 |
003C 60 |
= 003D 61 |
> 003E 62 |
? 003F 63 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 4_ 64 |
@ 0040 64 |
A 0041 65 |
В 0042 66 |
С 0043 67 |
D 0044 68 |
E 0045 69 |
F 0046 70 |
G 0047 71 |
В 0048 72 |
Я 0049 73 |
J 004A 74 |
К 004В 75 |
L 004C 76 |
M 004D 77 |
№ 004E 78 |
O 004F 79 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 5_ 80 |
П 0050 80 |
Q 0051 81 |
R 0052 82 |
С 0053 83 |
Т 0054 84 |
U 0055 85 |
V 0056 86 |
W 0057 87 |
X 0058 88 |
Y 0059 89 |
Z 005A 90 |
[ 005B 91 |
005C 92 |
] 005D 93 |
^ 005E 94 |
_ 005F 95 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 6_ 96 |
` 0060 96 |
а 0061 97 |
b 0062 98 |
c 0063 99 |
d 0064 100 |
e 0065 101 |
f 0066 102 |
г 0067 103 |
h 0068 104 |
я 0069 105 |
j 006A 106 |
k 006B 107 |
l 006C 108 |
м 006D 109 |
№ 006E 110 |
o 006F 111 |
|||||||||||||||||||||||||||||||||||||||||||||||||
| 7_ 112 |
п 0070 112 |
в 0071 113 |
р 0072 114 |
с 0073 115 |
т 0074 116 |
u 0075 117 |
v 0076 118 |
ж 0077 119 |
х 0078 120 |
г 0079 121 |
z 007A 122 |
< 007B 123 |
| 007C 124 |
> 007D 125 |
Письмо Число Пунктуация Условное обозначение Другой Неопределенный ИсторияРасширения OS / 2Расширения MSDOS [редко]Существует редко используемая, но полезная расширенная кодовая страница 1252 для графики, где коды от 0x00 до 0x1f позволяют рисовать блоки, как это используется в таких приложениях, как MSDOS Edit и Codeview. Одним из приложений, использующих эту кодовую страницу, была утилита установки / восстановления образа диска корпорации Intel, выпущенная в середине / конце 1995 года. Эти программы были написаны для компьютеров с пользовательской тестовой программой P6 (пример для США). Он использовался исключительно в тогдашнем регионе EMEA (Европа, Ближний Восток и Африка). Со временем программы были изменены, чтобы использовать кодовую страницу 850.
Графическая расширенная кодовая страница 1252 Вариант Palm OSЭтот вариант Windows-1252 используется в Palm OS 3.5. Python дает ему palmos ярлык. Источник |
Окна-1252 (CP1252)
I’m trying to convert UTF-8 to ANSI encoding through a tool.
But it shows Western European (Windows)-1252 instead of ANSI.
Are they both the same thing? Should I go ahead with this?
![]()
Henke
7071 gold badge4 silver badges17 bronze badges
asked Jan 8, 2017 at 14:55
![]()
What is the difference between Windows-1252 and ANSI encoding?
See below. In practice it probably won’t make much difference to your conversion.
If you keep a copy of the original file then you can always apply a different conversion if necessary.
Having said that there are ways of converting UTF-8 to ANSI.
Windows-1252
This character encoding is a superset of ISO 8859-1 in terms of printable characters, but differs from the IANA’s ISO-8859-1 by using displayable characters rather than control characters in the 80 to 9F (hex) range. Notable additional characters include curly quotation marks and all the printable characters that are in ISO 8859-15. It is known to Windows by the code page number 1252, and by the IANA-approved name «windows-1252».
…
Historically, the phrase «ANSI Code Page» (ACP) is used in Windows to refer to various code pages considered as native. The intention was that most of these would be ANSI standards such as ISO-8859-1. Even though Windows-1252 was the first and by far most popular code page named so in Microsoft Windows parlance, the code page has never been an ANSI standard. Microsoft explains, «The term ANSI as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community.
Source Windows-1252
Note that is spite of the above statement by Microsoft they still call Windows 1252 «ANSI»:

Source Code Page 1252 Windows Latin 1 (ANSI)
answered Jan 8, 2017 at 15:13
![]()
DavidPostill♦DavidPostill
149k77 gold badges344 silver badges383 bronze badges
4
Are [Windows-1252 and ANSI] the same thing?
– Yes, for all practical purposes, they are the same thing –
provided that the language of the text file is «Western European».
If the natural language is not Western European, try consulting
the following table.
1
| ANSI encoding | Language/Alphabet |
|---|---|
| Windows-1250 | Slavic languages – Latin alphabet: Bosnian, Croatian, Czech, Polish, Romanian, Slovak, … |
| Windows-1251 | Slavic languages – Cyrillic alphabet: Azeri, Bulgarian, Macedonian, Ukrainian, Uzbek, … |
| Windows-1252 | Western European languages: Albanian, Basque, Catalan, Dutch, Finnish, Irish, Spanish, … |
| Windows-1253 | Greek |
| Windows-1254 | Turkish, Latin Azeri, and Latin Uzbek |
| Windows-1255 | Hebrew |
| Windows-1256 | Arabic, Farsi, Urdu |
| Windows-1257 | Baltic languages: Estonian, Latvian, Lithuanian |
| Windows-1258 | Vietnamese |
For more details,
see this post on how to encode a text file to display characters
instead of question marks.
For charts displaying the Windows-1252 character set,
see this post, Section 4 about ASCII, ANSI, and UTF-8.
References
- Windows code pages | science.co.il
- Windows code pages | Wikipedia
- Display non-ASCII characters correctly instead of question marks
- Charts showing the Windows-1252 character set | Section 4
1
Sources :
- Israel Science and Technology Directory – Language Character Sets
- Wikipedia – Windows emulation code pages
answered Oct 20, 2022 at 11:53
![]()
HenkeHenke
7071 gold badge4 silver badges17 bronze badges