Version: 20220421
By the same author: Virtour.fr — visites virtuelles
Универсальный декодер — конвертер кириллицы
Результат
[Результат перекодировки появится здесь…]
|
Гостевая книга
Поставьте ссылку на наш сайт! <a href=»https://2cyr.com/decode/»>Универсальный декодер кириллицы</a> |
Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available). FAQ and contact information. |
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
- Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Декодер онлайн (decoder online)
Текст успешно скопирован!
Определить исходную кодировку
Декодировано
| Двоичная строка | |
|---|---|
| Строка Hex | |
| HTML Escape | |
| Кодирование URL | |
| Punycode IDN | |
| Base32 | |
| Base45 | |
| Base45/Zlib/COSE/CBOR | |
| Base64 | |
| Ascii85 | |
| QP-кодировка | |
| Unicode Escape | |
| Программная строка | |
| Азбука Морзе |
Вариант |
| Unicode NFD | |
| Unicode NFKD | |
| Число из десятичном | |
| Число из двоичн | |
| Число из восьме | |
| Число из десяти | |
| Число из Англ | |
| Число из Кандзи | |
| Цезарь |
Сдвиг |
| ROT13 (A-Z) | |
| ROT18 (A-Z, 0-9) | |
| ROT47 (!-~) | |
| Аффинный |
A B |
| Энигма |
Машина Роторы Кольцо Позиции Проводка коммутационная панель Uhr Проводка UKW-D |
| Скитейл |
Количество букв каждая |
| Ограждения рельсов |
Рельсы |
Закодировано
| Двоичная строка |
Разделитель |
|---|---|
| Строка Hex |
Разделитель A-F |
| HTML Escape (Basic) | |
| HTML Escape (Fully) | |
| Кодирование URL |
Пустой |
| Punycode IDN | |
| Base32 | |
| Base45 | |
| Base64 |
Разрыв строки |
| Ascii85 |
Вариант |
| QP-кодировка | |
| Unicode Escape |
Формат A-F |
| Программная строка |
Кавычки |
| Азбука Морзе |
Вариант |
| UpperCamelCase | |
| lowerCamelCase | |
| UPPER_SNAKE_CASE | |
| lower_snake_case | |
| UPPER-KEBAB-CASE | |
| lower-kebab-case | |
| Половина ширины | |
| Полная ширина | |
| Прописные | |
| Строчные | |
| Замена | |
| Заглавные | |
| Инициалы | |
| Обратный | |
| Unicode NFC | |
| Unicode NFKC | |
| Сортировка строк |
Приказ |
| Удалятор строк | |
| Число в десятичном | |
| Число в двоично | |
| Число в восьмер | |
| Число в десятич | |
| Число в Англ |
Обозначение дробной части Система |
| Число в Кандзи | |
| Число в Кандзи Дайджи | |
| UNIX-время [ms] | |
| Дата W3C-DTF | |
| Дата ISO8601 |
Дробная часть |
| Дата ISO8601 (расширенный) |
Дробная часть |
| Дата ISO8601 (Неделя) |
Дробная часть |
| Дата ISO8601 (Порядковый) |
Дробная часть |
| Дата RFC2822 | |
| Дата ctime | |
| Японская эра | |
| Название цвета | |
| Цвет RGB (Hex) | |
| Цвет RGB |
Обозначение |
| Цвет HSL | |
| Цвет HSV | |
| Цвет CMYK | |
| Цезарь |
Сдвиг |
| ROT13 (A-Z) | |
| ROT18 (A-Z, 0-9) | |
| ROT47 (!-~) | |
| Атбаш | |
| Аффинный |
A B |
| Энигма |
Машина Роторы Кольцо Позиции Проводка коммутационная панель Uhr Проводка UKW-D |
| JIS Клавиатура |
Режим |
| Скитейл |
Количество букв каждая |
| Ограждения рельсов |
Рельсы |
| MD2 | |
| MD5 | |
| SHA-1 | |
| SHA-256 | |
| SHA-384 | |
| SHA-512 | |
| CRC32 |
Содержание
- Сайты для перекодировки онлайн
- Способ 1: Универсальный декодер
- Способ 2: Студия Артемия Лебедева
- Способ 3: Fox Tools
- Вопросы и ответы

Если вам прислали текстовый документ, информация в котором отображается в виде странных и непонятных символов, можно предположить, что автор использовал кодировку, не распознаваемую вашим компьютером. Для изменения кодировки существуют специальные программы-декодеры, однако куда проще воспользоваться одним из онлайн-сервисов.
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
Перейти на сайт Универсальный декодер
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.

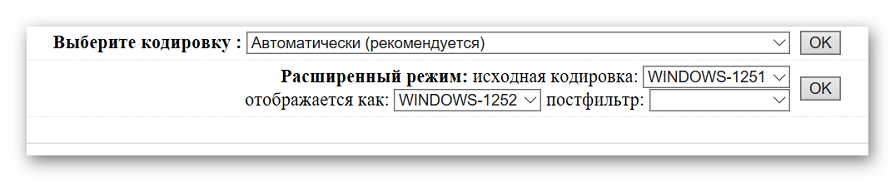
- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».

- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.

Обратите внимание на то, что если в отправленном вам документе вместо символов отображается «???? ?? ??????», преобразовать его вряд ли получится. Символы появляются из-за ошибок со стороны отправителя, поэтому просто попросите отправить вам текст повторно.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
Перейти на сайт Студия Артемия Лебедева
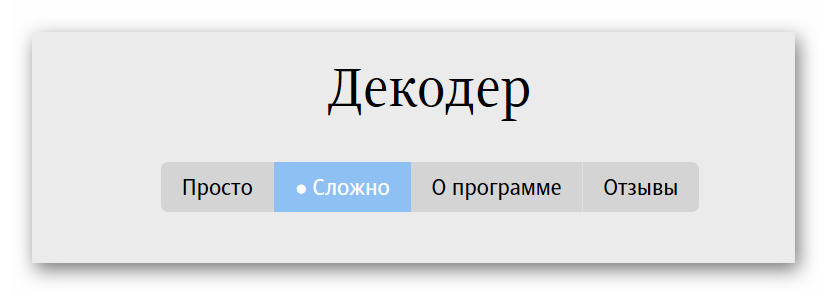
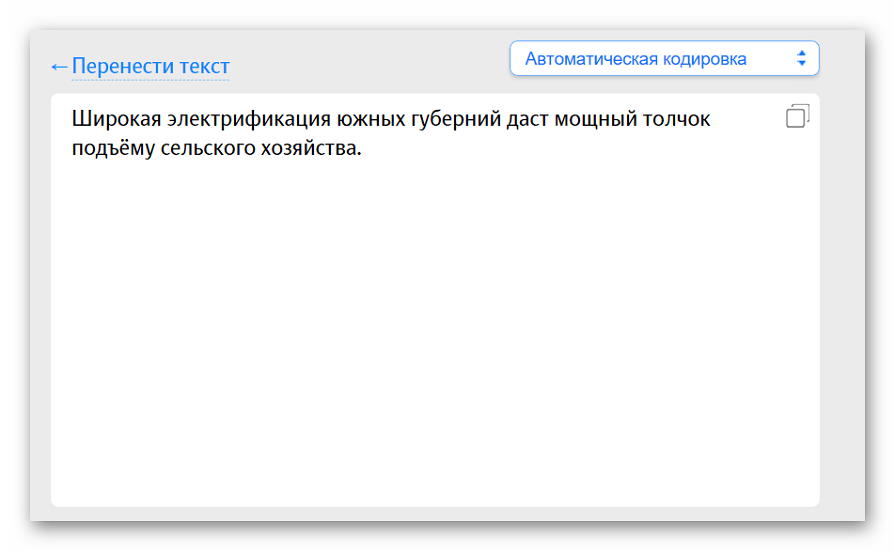
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.

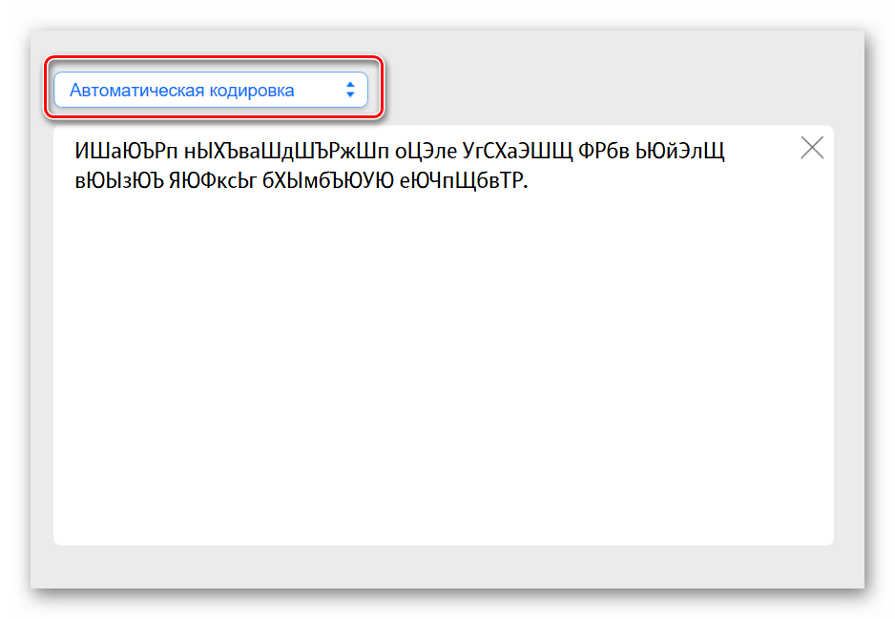
- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.

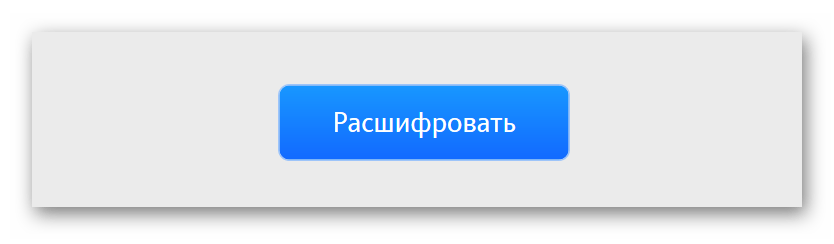
- Щелкаем на кнопку «Расшифровать».

- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.

С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
Перейти на сайт Fox Tools
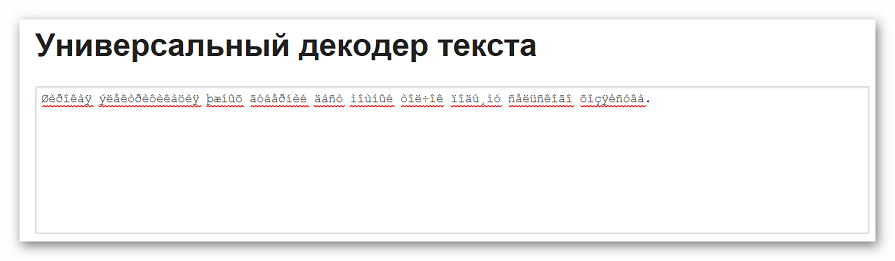
- Вводим исходный текст в верхнее поле.

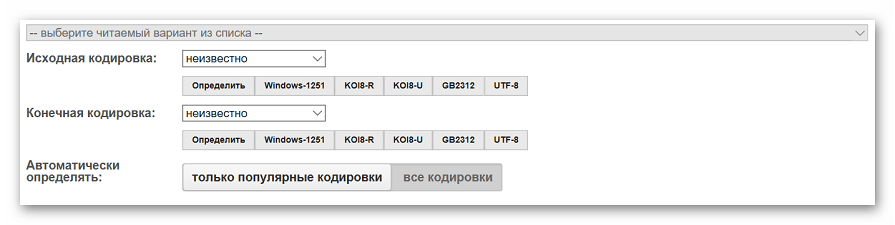
- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.

- После завершения настроек нажимаем на кнопку «Отправить».

- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.

- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».


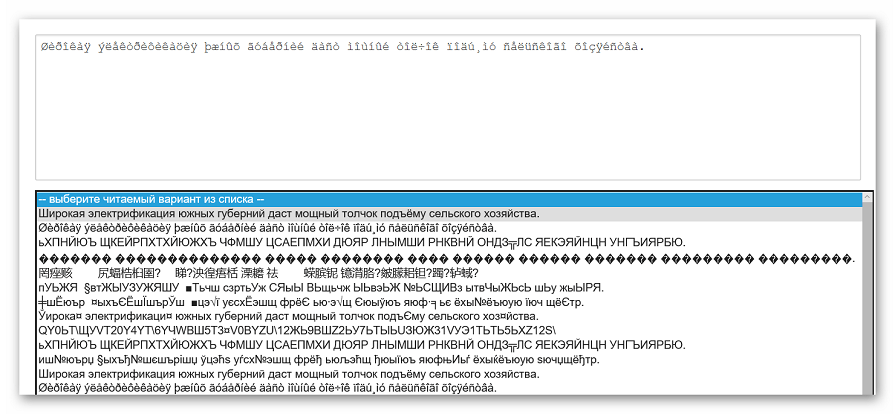
Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Читайте также: Выбор и изменение кодировки в Microsoft Word

Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
Еще статьи по данной теме:
Помогла ли Вам статья?
- Подробности
- Категория: вебмастер
- Автор: SEO & WEB — KELL4
Декодер текста — переводчик кодировок utf 8 и windows 1251 онлайн
UTF-8 (Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы в Unicode. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка нашла широкое применение в UNIX-подобных операционных системах и веб-пространстве. В качестве BOM использует последовательность байт EF16, BB16, BF16 (что является трёхбайтовой реализацией символа FEFF16). Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум). Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму в сравнении с UTF-16.
Windows-1251 (синоним CP1251) — является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак — ударение); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского, македонского и болгарского.
Универсальный онлайн декодер (переводчик кодировок)
Такой переводчик (сервис или программное обеспечение) еще называют как дешифратор, если Вам приходится работать с разными кодировками текста или возникли проблемы с кодировкой страниц в PHP (отображение в виде странной комбинации загадочных символов — «кракозябры»). Функциональный и универсальный сервис в режиме онлайн, автоматически поможет определить кодировку, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую и перевести текст из одной кодировки в другую. То есть универсальный декодер поможет перевести текст (предположим, что на кириллице) в другие международные форматы.
Чтобы воспользоваться переводчиком кодировок текста в режиме онлайн, просто перейдите по ссылке [ДЕКОДЕР] откроется в новом окне.
Данный декодер универсален, хотите закодировать текст для PHP или HTML страниц, а может быть в Java?
Все проблемы кодировок решаются раскодировкой (перекодировкой) путем декодера, но способ кодирования зависит от формата документа в котором тот был закодирован и для этого необходимо сменить формат самого документа, а не изобретать новые способы интерпритации. В случае с серверами используйте их конфигурацию — онлайн переводчик кодировок поможет узнать какая именно кодировка используется в вашем случае — вставьте скопированные символы в окно декодера.
Ссылки на сервисы по декодированию текста:
http://www.online-decoder.com/ru
https://2cyr.com/decode/
В предыдущей статье я уже затрагивал тему кодировок текста, более подробно описал Юникод и представление его в виде последовательности символов переменной длины UTF-8. Данный калькулятор позволяет преобразовать текст в другие исторические кодировки. Я называю их историческими, потому, что в современных решениях везде, где это можно следует использовать Юникод и его самое удобное представление UTF-8.
Однако старые кодировки также могут быть полезны, когда требуется компактно закодировать текст, например для последующего сжатия и передачи, в том случае, когда принимающая сторона гарантированно знает в какой кодировке передается текст. Например русский текст в в кодировке Windows-1251 будет занимать вдвое меньше места, чем текст в UTF-8.
Итак калькулятор ниже позволяет скачать файл в выбранной кодировке или просмотреть шестнадцатеричный дамп закодированного текста.
![]()
Скачать текст как файл с выбором кодировки
Просмотреть созданный файл можно при помощи калькулятора Прочитать файл в старой кодировке.
Калькулятор вернет ошибку, в том случае, если выбрана неверная кодировка. В случае с Юникодом, это невозможно — в нем представлены символы всех современных языков. А вот устаревшие 8-битные кодировки содержат ограниченный набор символов и для текста на нескольких языках может вполне не найтись нужной кодировки.
За годы до появления Юникода было придумано множество кодировок для разных языков и наборов символов, поэтому сама задача выбора правильной кодировки для вашего текста может быть непростой. Следующий калькулятор позволяет подобрать кодировки для введенного текста. В результирующей таблице будут выданы, только те кодировки, при помощи которых можно гарантированно закодировать заданный текст.
![]()
В какой кодировке можно представить текст?
Файл очень большой, при загрузке и создании может наблюдаться торможение браузера.
В калькуляторах поддерживаются 70 различных кодировок:
Кодировки IBM EBCDIC
EBCDIC — стандартный 8-битный код, разработанный корпорацией IBM для использования на мэйнфреймах IBM и совместимых с ними.
| Кодировка | Языки / Страны использования |
|---|---|
| EBCDIC 424 Hebrew | Иврит |
| EBCDIC 037 USA/Canada | США, Канада, Португалия, Бразилия, Австралия, Новой Зеландия и Южной Африка |
| EBCDIC 1026 Turkish | Турция |
| EBCDIC 500 International | Интернациональный |
| EBCDIC 875 Greek | Греческий |
Кодировки в стандарте ISO 8859
Семейство ASCII совместимых кодировок, разработанных международными организациями ISO и IEC
| Кодировка | Языки/Страны |
|---|---|
| ISO 8859-2 (Latin-2) | Восточноевропейские языки, использующие латиницу |
| ISO 8859-5 | Кириллица |
| ISO 8859-6 | Арабский |
| ISO 8859-7 | Современный греческий |
| ISO/IEC 8859-1 (Latin-1) | Западноевропейские языки |
| ISO/IEC 8859-10 (Latin-6) | Североевропейские языки |
| ISO/IEC 8859-11 | Тайский |
| ISO/IEC 8859-13 (Latin-7) | Эстонский, латышский, литовский |
| ISO/IEC 8859-14 | Кельтские языки |
| ISO/IEC 8859-15 (Latin-9) | Западноевропейские языки |
| ISO/IEC 8859-16 (Latin-10) | Восточноевропейские языки, использующие латиницу |
| ISO/IEC 8859-3 | Турецкий, мальтийский, эсперанто |
| ISO/IEC 8859-4 (Latin-4) | Эстонский, латышский, литовский, гренландский, саамский |
| ISO/IEC 8859-8 | Иврит |
| ISO/IEC 8859-9 | Турецкий |
Кодировки KOI8
KOI8 — 8-битовая кодировка совместимая с ASCII для представления букв кириллических алфавитов
| Кодировка | Языки |
|---|---|
| KOI8-R | Русский |
| KOI8-U | Украинский |
Кодировки Mac OS
| Кодировка | Языки/Страны |
|---|---|
| Mac OS Celtic | Кельтские языки |
| Mac OS Gaelic | Гэльский |
| Mac OS Central European | Языки Центральной Европы |
| Mac OS Croatian | Сербско/Хорватский |
| Mac OS Cyrillic | Кириллица |
| Mac OS Greek | Греческй |
| Mac OS Icelandic | Исландский |
| Mac OS Inuit | Инуктитут |
| Mac OS Roman | Западноевропейские языки |
| Mac OS Romanian | Румынский |
| Mac OS Turkish | Турецкий |
Кодировки DOS
Кодировки для MS-DOS и подобных ей операционных систем.
| Кодировка | Языки/Страны |
|---|---|
| DOS Latin US (CP437) | Восточноевропейские языки, использующие латиницу |
| DOS Greek (CP737) | Греческий |
| DOS Baltic Rim (CP775) | Эстонский, латышский, литовский |
| DOS Latin 1 (CP850) | Западноевропейские языки |
| DOS Latin 2 (CP852) | Восточноевропейские языки, использующие латиницу |
| DOS Cyrillic (CP855) | Кириллица |
| CP 856 Hebrew | Иврит |
| DOS Turkish (CP857) | Турецкий |
| DOS Portuguese (CP860) | Португальский |
| DOS Icelandic (CP861) | Исландский |
| DOS Hebrew (CP862) | Иврит |
| DOS French Canada (CP863) | Французский |
| DOS Arabic (CP864) | Арабский |
| DOS Nordic (CP865) | Норвежский |
| DOS Cyrillic Russian (CP866) | Русский |
| DOS Greek 2 (CP869) | Греческий |
Кодировки Windows
| Кодировка | Языки/Страны |
|---|---|
| Windows-1250 | Языки Центральной и Восточной Европы |
| Windows-1251 | Русский, украинский белорусский, сербский, македонский, болгарский |
| Windows-1252 | Западноевропейские языки |
| Windows-1253 | Современный греческий |
| Windows-1254 | Турецкий |
| Windows-1255 | Иврит |
| Windows-1256 | Арабский |
| Windows-1257 | Эстонский, латышский, литовский |
| Windows-1258 | Вьетнамский |
| Windows-874 | Тайский |
| Windows-932 | Японский |
| Windows-936 | Упрощенный китайский |
| Windows-949 | Корейский |
| Windows-950 | Традиционный китайский |
| KZ-1048 | Казахский |
Прочие кодировки
| Кодировка | Описание |
|---|---|
| Atari ST | Кодировка, использовалась в домашних персональных компьютерах фирмы Atari |
| GSM 03.38 | Кодировка использовалась в сетях GSM для SMS (коротких сообщений), CB (широковещательная передача коротких сообщений) and USSD (Сервис для организации интерактивных взаимодействий) |
| KPS 9566 | Кодировка, разработанная в Северной Корее для поддержки символов корейского языка Хангыль |
| ISO 8-bit Urdu (IBM CP1006) | Использовалась компанией IBM в операционной системе AIX в Пакистане для языка Урду |
| ISO-IR-68 | Кодировка для представления символов в языке программирования APL |
Правила преобразования исторических кодировок в Юникод были получены с сайта unicode.org1
Наш конвертер онлайн поможет вам кодировать и декодировать текст в кодировку (XX WIN-1251, XX UTF-16, uXXXX).
Данное приложение необходимо для преобразования вашего текста в шестнадцатеричные коды его символов и обратно.
Конвертер работает для текста в кодировках Windows-1251, UTF-16, и декодирует UTF-8 текст с кириллицей, который при кодировании в JSON переводится штатной php функцией json_encode() в uXXXX кодировку.
Шестнадцатеричная система счисления — это позиционная система счисления с основанием 16, и использует шестнадцать различных символов, чаще всего символы 0-9 для представления значений от нуля до девяти, и A, B, C, D, E, F (или альтернативно a, b, c, d, e, f) для представления значений от десяти до пятнадцати.
Шестнадцатеричные цифры часто используются разработчиками компьютерных систем и программистами, и поскольку каждая шестнадцатеричная цифра представляет собой четыре двоичные цифры (биты), она позволяет более удобное для человека представление двоичных кодированных значений.
Одна шестнадцатеричная цифра представляет собой кусочек в (4 бита), который составляет половину октета или байта (8 бит).
В свою очередь один байт может иметь значения в диапазоне от 00000000 до 11111111 в двоичном виде, но это может быть более удобно представлено как 00 до FF в шестнадцатеричном виде.
Кодирование информации — это процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Декодирование информации — это преобразование закодированной информации в понятный, пригодный для непосредственного использования и чтения вид.
Универсальный раскодировщик
Наверное Вы сталкивались с проблемой, что видите на экране какую-то аброкадабру и не знаете что с ней делать.
Наиболее распространенные ситуации это полученные письма с неправильной кодировкой,
URL — адреса.
Для того, чтобы раскодировать такую последовательность нужно знать чем она закодированна. А как быть если это неизвестно?
Для раскодирования аброкадабры я в одном месте собрал различные системы раскодирования:
UTF-8, windows-1251, KOI-8, Unicode, iso8859-1, base64_decode, UUE, urldecode, rawurldecode, gzinflate, str_rot13, punicode, json раскодировку / парсер online и другие.
А ещё система может переводить время из UNIX формата (FROM UNIX TIME STAMP), например:
1551423730 -> 01.03.2019 10:02:10
Вам достаточно ввести ваш текст и нажать кнопку раскодировать, система попытается всеми известными способами раскодировать ваш текст.
Вы увидите только те результаты, которые отличаются от исходной последовательности и могут быть раскодированны соответствующим методом.