(PHP 4 >= 4.0.5, PHP 5, PHP 7, PHP 
iconv — Преобразует строку из одной кодировки символов в другую
Описание
iconv(string $from_encoding, string $to_encoding, string $string): string|false
Список параметров
-
from_encoding -
Текущая кодировка, используемая для интерпретации параметра
string. -
to_encoding -
Требуемая на выходе кодировка.
Если к параметру
to_encodingдобавлена строка
//TRANSLIT, включается режим транслитерации.
Это значит, что в случае, если символ не может быть представлен в требуемой кодировке,
он может быть заменён одним или несколькими похожими символами.
Если добавлена строка//IGNORE, то символы,
которые не могут быть представлены в требуемой кодировке, будут
удалены.
В случае отсутствия вышеуказанных параметров
будет сгенерирована ошибка уровняE_NOTICE,
а функция вернётfalse.Предостережение
Как будет работать
//TRANSLITи будет ли вообще, зависит от
системной реализации iconv() (ICONV_IMPL).
Известны некоторые реализации, которые просто игнорируют
//TRANSLIT, так что конвертация для символов некорректных
дляto_encodingскорее всего закончится ошибкой. -
string -
Строка (string) для преобразования.
Возвращаемые значения
Возвращает преобразованную строку или false в случае возникновения ошибки.
Примеры
Пример #1 Пример использования iconv()
<?php
$text = "Это символ евро - '€'.";
echo
'Исходная строка : ', $text, PHP_EOL;
echo 'С добавлением TRANSLIT : ', iconv("UTF-8", "ISO-8859-1//TRANSLIT", $text), PHP_EOL;
echo 'С добавлением IGNORE : ', iconv("UTF-8", "ISO-8859-1//IGNORE", $text), PHP_EOL;
echo 'Обычное преобразование : ', iconv("UTF-8", "ISO-8859-1", $text), PHP_EOL;?>
Результатом выполнения данного примера
будет что-то подобное:
Исходная строка : Это символ евро - '€'. С добавлением TRANSLIT : Это символ евро - 'EUR'. С добавлением IGNORE :Это символ евро - ''. Обычное преобразование : Notice: iconv(): Detected an illegal character in input string in .iconv-example.php on line 7
Примечания
Замечание:
Доступные кодировки и опции зависят от установленной реализации iconv.
Если параметрfrom_encodingилиfrom_encoding
не поддерживается в текущей системе, будет возвращено значениеfalse.
Смотрите также
- mb_convert_encoding() — Преобразует строку из одной кодировки символов в другую
- UConverter::transcode() — Преобразует строку из одной кодировки символов в другую
orrd101 at gmail dot com ¶
10 years ago
The "//ignore" option doesn't work with recent versions of the iconv library. So if you're having trouble with that option, you aren't alone.
That means you can't currently use this function to filter invalid characters. Instead it silently fails and returns an empty string (or you'll get a notice but only if you have E_NOTICE enabled).
This has been a known bug with a known solution for at least since 2009 years but no one seems to be willing to fix it (PHP must pass the -c option to iconv). It's still broken as of the latest release 5.4.3.
https://bugs.php.net/bug.php?id=48147
https://bugs.php.net/bug.php?id=52211
https://bugs.php.net/bug.php?id=61484
[UPDATE 15-JUN-2012]
Here's a workaround...
ini_set('mbstring.substitute_character', "none");
$text= mb_convert_encoding($text, 'UTF-8', 'UTF-8');
That will strip invalid characters from UTF-8 strings (so that you can insert it into a database, etc.). Instead of "none" you can also use the value 32 if you want it to insert spaces in place of the invalid characters.
Ritchie ¶
15 years ago
Please note that iconv('UTF-8', 'ASCII//TRANSLIT', ...) doesn't work properly when locale category LC_CTYPE is set to C or POSIX. You must choose another locale otherwise all non-ASCII characters will be replaced with question marks. This is at least true with glibc 2.5.
Example:
<?php
setlocale(LC_CTYPE, 'POSIX');
echo iconv('UTF-8', 'ASCII//TRANSLIT', "Žluťoučký kůňn");
// ?lu?ou?k? k??setlocale(LC_CTYPE, 'cs_CZ');
echo iconv('UTF-8', 'ASCII//TRANSLIT', "Žluťoučký kůňn");
// Zlutoucky kun
?>
daniel dot rhodes at warpasylum dot co dot uk ¶
11 years ago
Interestingly, setting different target locales results in different, yet appropriate, transliterations. For example:
<?php
//some German
$utf8_sentence = 'Weiß, Goldmann, Göbel, Weiss, Göthe, Goethe und Götz';//UK
setlocale(LC_ALL, 'en_GB');//transliterate
$trans_sentence = iconv('UTF-8', 'ASCII//TRANSLIT', $utf8_sentence);//gives [Weiss, Goldmann, Gobel, Weiss, Gothe, Goethe und Gotz]
//which is our original string flattened into 7-bit ASCII as
//an English speaker would do it (ie. simply remove the umlauts)
echo $trans_sentence . PHP_EOL;//Germany
setlocale(LC_ALL, 'de_DE');$trans_sentence = iconv('UTF-8', 'ASCII//TRANSLIT', $utf8_sentence);//gives [Weiss, Goldmann, Goebel, Weiss, Goethe, Goethe und Goetz]
//which is exactly how a German would transliterate those
//umlauted characters if forced to use 7-bit ASCII!
//(because really ä = ae, ö = oe and ü = ue)
echo $trans_sentence . PHP_EOL;?>
annuaireehtp at gmail dot com ¶
13 years ago
to test different combinations of convertions between charsets (when we don't know the source charset and what is the convenient destination charset) this is an example :
<?php
$tab = array("UTF-8", "ASCII", "Windows-1252", "ISO-8859-15", "ISO-8859-1", "ISO-8859-6", "CP1256");
$chain = "";
foreach ($tab as $i)
{
foreach ($tab as $j)
{
$chain .= " $i$j ".iconv($i, $j, "$my_string");
}
}
echo
$chain;
?>
then after displaying, you use the $i$j that shows good displaying.
NB: you can add other charsets to $tab to test other cases.
manuel at kiessling dot net ¶
13 years ago
Like many other people, I have encountered massive problems when using iconv() to convert between encodings (from UTF-8 to ISO-8859-15 in my case), especially on large strings.
The main problem here is that when your string contains illegal UTF-8 characters, there is no really straight forward way to handle those. iconv() simply (and silently!) terminates the string when encountering the problematic characters (also if using //IGNORE), returning a clipped string. The
<?php
$newstring
= html_entity_decode(htmlentities($oldstring, ENT_QUOTES, 'UTF-8'), ENT_QUOTES , 'ISO-8859-15');?>
workaround suggested here and elsewhere will also break when encountering illegal characters, at least dropping a useful note ("htmlentities(): Invalid multibyte sequence in argument in...")
I have found a lot of hints, suggestions and alternative methods (it's scary and in my opinion no good sign how many ways PHP natively provides to convert the encoding of strings), but none of them really worked, except for this one:
<?php
$newstring
= mb_convert_encoding($oldstring, 'ISO-8859-15', 'UTF-8');?>
Leigh Morresi ¶
14 years ago
If you are getting question-marks in your iconv output when transliterating, be sure to 'setlocale' to something your system supports.
Some PHP CMS's will default setlocale to 'C', this can be a problem.
use the "locale" command to find out a list..
$ locale -a
C
en_AU.utf8
POSIX
<?php
setlocale(LC_CTYPE, 'en_AU.utf8');
$str = iconv('UTF-8', 'ASCII//TRANSLIT', "Côte d'Ivoire");
?>
zhawari at hotmail dot com ¶
18 years ago
Here is how to convert UCS-2 numbers to UTF-8 numbers in hex:
<?php
function ucs2toutf8($str)
{
for ($i=0;$i<strlen($str);$i+=4)
{
$substring1 = $str[$i].$str[$i+1];
$substring2 = $str[$i+2].$str[$i+3];
if (
$substring1 == "00")
{
$byte1 = "";
$byte2 = $substring2;
}
else
{
$substring = $substring1.$substring2;
$byte1 = dechex(192+(hexdec($substring)/64));
$byte2 = dechex(128+(hexdec($substring)%64));
}
$utf8 .= $byte1.$byte2;
}
return $utf8;
}
echo
strtoupper(ucs2toutf8("06450631062D0020"));
?>
Input:
06450631062D
Output:
D985D8B1D8AD
regards,
Ziyad
Nopius ¶
7 years ago
As orrd101 said, there is a bug with //IGNORE in recent PHP versions (we use 5.6.5) where we couldn't convert some strings (i.e. "∙" from UTF8 to CP1251 with //IGNORE).
But we have found a workaround and now we use both //TRANSLIT and //IGNORE flags:
$text="∙";
iconv("UTF8", "CP1251//TRANSLIT//IGNORE", $text);
Daniel Klein ¶
6 years ago
I just found out today that the Windows and *NIX versions of PHP use different iconv libraries and are not very consistent with each other.
Here is a repost of my earlier code that now works on more systems. It converts as much as possible and replaces the rest with question marks:
<?php
if (!function_exists('utf8_to_ascii')) {
setlocale(LC_CTYPE, 'en_AU.utf8');
if (@iconv("UTF-8", "ASCII//IGNORE//TRANSLIT", 'é') === false) {
// PHP is probably using the glibc library (*NIX)
function utf8_to_ascii($text) {
return iconv("UTF-8", "ASCII//TRANSLIT", $text);
}
}
else {
// PHP is probably using the libiconv library (Windows)
function utf8_to_ascii($text) {
if (is_string($text)) {
// Includes combinations of characters that present as a single glyph
$text = preg_replace_callback('/X/u', __FUNCTION__, $text);
}
elseif (is_array($text) && count($text) == 1 && is_string($text[0])) {
// IGNORE characters that can't be TRANSLITerated to ASCII
$text = iconv("UTF-8", "ASCII//IGNORE//TRANSLIT", $text[0]);
// The documentation says that iconv() returns false on failure but it returns ''
if ($text === '' || !is_string($text)) {
$text = '?';
}
elseif (preg_match('/w/', $text)) { // If the text contains any letters...
$text = preg_replace('/W+/', '', $text); // ...then remove all non-letters
}
}
else { // $text was not a string
$text = '';
}
return $text;
}
}
}
jessiedeer at hotmail dot com ¶
9 years ago
iconv with //IGNORE works as expected: it will skip the character if this one does not exist in the $out_charset encoding.
If a character is missing from the $in_charset encoding (eg byte x81 from CP1252 encoding), then iconv will return an error, whether with //IGNORE or not.
atelier at degoy dot com ¶
8 years ago
There may be situations when a new version of a web site, all in UTF-8, has to display some old data remaining in the database with ISO-8859-1 accents. The problem is iconv("ISO-8859-1", "UTF-8", $string) should not be applied if $string is already UTF-8 encoded.
I use this function that does'nt need any extension :
function convert_utf8( $string ) {
if ( strlen(utf8_decode($string)) == strlen($string) ) {
// $string is not UTF-8
return iconv("ISO-8859-1", "UTF-8", $string);
} else {
// already UTF-8
return $string;
}
}
I have not tested it extensively, hope it may help.
Daniel Klein ¶
3 years ago
If you want to convert to a Unicode encoding without the byte order mark (BOM), add the endianness to the encoding, e.g. instead of "UTF-16" which will add a BOM to the start of the string, use "UTF-16BE" which will convert the string without adding a BOM.
i.e.
<?php
iconv('CP1252', 'UTF-16', $text); // with BOM
iconv('CP1252', 'UTF-16BE', $text); // without BOM
nikolai-dot-zujev-at-gmail-dot-com ¶
18 years ago
Here is an example how to convert windows-1251 (windows) or cp1251(Linux/Unix) encoded string to UTF-8 encoding.
<?php
function cp1251_utf8( $sInput )
{
$sOutput = "";
for (
$i = 0; $i < strlen( $sInput ); $i++ )
{
$iAscii = ord( $sInput[$i] );
if (
$iAscii >= 192 && $iAscii <= 255 )
$sOutput .= "&#".( 1040 + ( $iAscii - 192 ) ).";";
else if ( $iAscii == 168 )
$sOutput .= "&#".( 1025 ).";";
else if ( $iAscii == 184 )
$sOutput .= "&#".( 1105 ).";";
else
$sOutput .= $sInput[$i];
}
return
$sOutput;
}
?>
vitek at 4rome dot ru ¶
18 years ago
On some systems there may be no such function as iconv(); this is due to the following reason: a constant is defined named `iconv` with the value `libiconv`. So, the string PHP_FUNCTION(iconv) transforms to PHP_FUNCTION(libiconv), and you have to call libiconv() function instead of iconv().
I had seen this on FreeBSD, but I am sure that was a rather special build.
If you'd want not to be dependent on this behaviour, add the following to your script:
<?php
if (!function_exists('iconv') && function_exists('libiconv')) {
function iconv($input_encoding, $output_encoding, $string) {
return libiconv($input_encoding, $output_encoding, $string);
}
}
?>
Thanks to tony2001 at phpclub.net for explaining this behaviour.
gree:.. (gree 4T grees D0T net) ¶
15 years ago
In my case, I had to change:
<?php
setlocale(LC_CTYPE, 'cs_CZ');
?>
to
<?php
setlocale(LC_CTYPE, 'cs_CZ.UTF-8');
?>
Otherwise it returns question marks.
When I asked my linux for locale (by locale command) it returns "cs_CZ.UTF-8", so there is maybe correlation between it.
iconv (GNU libc) 2.6.1
glibc 2.3.6
nilcolor at gmail dot coom ¶
17 years ago
Didn't know its a feature or not but its works for me (PHP 5.0.4)
iconv('', 'UTF-8', $str)
test it to convert from windows-1251 (stored in DB) to UTF-8 (which i use for web pages).
BTW i convert each array i fetch from DB with array_walk_recursive...
jorortega at gmail dot com ¶
9 years ago
Be aware that iconv in PHP uses system implementations of locales and languages, what works under linux, normally doesn't in windows.
Also, you may notice that recent versions of linux (debian, ubuntu, centos, etc) the //TRANSLIT option doesn't work. since most distros doesn't include the intl packages (example: php5-intl and icuxx (where xx is a number) in debian) by default. And this because the intl package conflicts with another package needed for international DNS resolution.
Problem is that configuration is dependent of the sysadmin of the machine where you're hosted, so iconv is pretty much useless by default, depending on what configuration is used by your distro or the machine's admin.
ameten ¶
12 years ago
I have used iconv to convert from cp1251 into UTF-8. I spent a day to investigate why a string with Russian capital 'Р' (sounds similar to 'r') at the end cannot be inserted into a database.
The problem is not in iconv. But 'Р' in cp1251 is chr(208) and 'Р' in UTF-8 is chr(208).chr(106). chr(106) is one of the space symbol which match 's' in regex. So, it can be taken by a greedy '+' or '*' operator. In that case, you loose 'Р' in your string.
For example, 'ГР ' (Russian, UTF-8). Function preg_match. Regex is '(.+?)[s]*'. Then '(.+?)' matches 'Г'.chr(208) and '[s]*' matches chr(106).' '.
Although, it is not a bug of iconv, but it looks like it very much. That's why I put this comment here.
zhawari at hotmail dot com ¶
18 years ago
Here is how to convert UTF-8 numbers to UCS-2 numbers in hex:
<?phpfunction utf8toucs2($str)
{
for ($i=0;$i<strlen($str);$i+=2)
{
$substring1 = $str[$i].$str[$i+1];
$substring2 = $str[$i+2].$str[$i+3];
if (
hexdec($substring1) < 127)
$results = "00".$str[$i].$str[$i+1];
else
{
$results = dechex((hexdec($substring1)-192)*64 + (hexdec($substring2)-128));
if ($results < 1000) $results = "0".$results;
$i+=2;
}
$ucs2 .= $results;
}
return $ucs2;
}
echo
strtoupper(utf8toucs2("D985D8B1D8AD"))."n";
echo strtoupper(utf8toucs2("456725"))."n";?>
Input:
D985D8B1D8AD
Output:
06450631062D
Input:
456725
Output:
004500670025
ng4rrjanbiah at rediffmail dot com ¶
18 years ago
Here is a code to convert ISO 8859-1 to UTF-8 and vice versa without using iconv.
<?php
//Logic from http://twiki.org/cgi-bin/view/Codev/InternationalisationUTF8
$str_iso8859_1 = 'foo in ISO 8859-1';
//ISO 8859-1 to UTF-8
$str_utf8 = preg_replace("/([x80-xFF])/e",
"chr(0xC0|ord('\1')>>6).chr(0x80|ord('\1')&0x3F)",
$str_iso8859_1);
//UTF-8 to ISO 8859-1
$str_iso8859_1 = preg_replace("/([xC2xC3])([x80-xBF])/e",
"chr(ord('\1')<<6&0xC0|ord('\2')&0x3F)",
$str_utf8);
?>
HTH,
R. Rajesh Jeba Anbiah
anyean at gmail dot com ¶
17 years ago
<?php
//script from http://zizi.kxup.com/
//javascript unesape
function unescape($str) {
$str = rawurldecode($str);
preg_match_all("/(?:%u.{4})|&#x.{4};|&#d+;|.+/U",$str,$r);
$ar = $r[0];
print_r($ar);
foreach($ar as $k=>$v) {
if(substr($v,0,2) == "%u")
$ar[$k] = iconv("UCS-2","UTF-8",pack("H4",substr($v,-4)));
elseif(substr($v,0,3) == "&#x")
$ar[$k] = iconv("UCS-2","UTF-8",pack("H4",substr($v,3,-1)));
elseif(substr($v,0,2) == "&#") {
echo substr($v,2,-1)."<br>";
$ar[$k] = iconv("UCS-2","UTF-8",pack("n",substr($v,2,-1)));
}
}
return join("",$ar);
}
?>
kikke ¶
13 years ago
You can use native iconv in Linux via passthru if all else failed.
Use the -c parameter to suppress error messages.
Daniel Klein ¶
9 years ago
You can use 'CP1252' instead of 'Windows-1252':
<?php
// These two lines are equivalent
$result = iconv('Windows-1252', 'UTF-8', $string);
$result = iconv('CP1252', 'UTF-8', $string);
?>
Note: The following code points are not valid in CP1252 and will cause errors.
129 (0x81)
141 (0x8D)
143 (0x8F)
144 (0x90)
157 (0x9D)
Use the following instead:
<?php
// Remove invalid code points, convert everything else
$result = iconv('CP1252', 'UTF-8//IGNORE', $string);
?>
berserk220 at mail dot ru ¶
14 years ago
So, as iconv() does not always work correctly, in most cases, much easier to use htmlentities().
Example: <?php $content=htmlentities(file_get_contents("incoming.txt"), ENT_QUOTES, "Windows-1252"); file_put_contents("outbound.txt", html_entity_decode($content, ENT_QUOTES , "utf-8")); ?>
anton dot vakulchik at gmail dot com ¶
15 years ago
function detectUTF8($string)
{
return preg_match('%(?:
[xC2-xDF][x80-xBF] # non-overlong 2-byte
|xE0[xA0-xBF][x80-xBF] # excluding overlongs
|[xE1-xECxEExEF][x80-xBF]{2} # straight 3-byte
|xED[x80-x9F][x80-xBF] # excluding surrogates
|xF0[x90-xBF][x80-xBF]{2} # planes 1-3
|[xF1-xF3][x80-xBF]{3} # planes 4-15
|xF4[x80-x8F][x80-xBF]{2} # plane 16
)+%xs', $string);
}
function cp1251_utf8( $sInput )
{
$sOutput = "";
for ( $i = 0; $i < strlen( $sInput ); $i++ )
{
$iAscii = ord( $sInput[$i] );
if ( $iAscii >= 192 && $iAscii <= 255 )
$sOutput .= "&#".( 1040 + ( $iAscii - 192 ) ).";";
else if ( $iAscii == 168 )
$sOutput .= "&#".( 1025 ).";";
else if ( $iAscii == 184 )
$sOutput .= "&#".( 1105 ).";";
else
$sOutput .= $sInput[$i];
}
return $sOutput;
}
function encoding($string){
if (function_exists('iconv')) {
if (@!iconv('utf-8', 'cp1251', $string)) {
$string = iconv('cp1251', 'utf-8', $string);
}
return $string;
} else {
if (detectUTF8($string)) {
return $string;
} else {
return cp1251_utf8($string);
}
}
}
echo encoding($string);
phpmanualspam at netebb dot com ¶
13 years ago
mirek code, dated 16-May-2008 10:17, added the characters `^~'" to the output.
This function will strip out these extra characters:
<?php
setlocale(LC_ALL, 'en_US.UTF8');
function clearUTF($s)
{
$r = '';
$s1 = @iconv('UTF-8', 'ASCII//TRANSLIT', $s);
$j = 0;
for ($i = 0; $i < strlen($s1); $i++) {
$ch1 = $s1[$i];
$ch2 = @mb_substr($s, $j++, 1, 'UTF-8');
if (strstr('`^~'"', $ch1) !== false) {
if ($ch1 <> $ch2) {
--$j;
continue;
}
}
$r .= ($ch1=='?') ? $ch2 : $ch1;
}
return $r;
}
?>
mightye at gmail dot com ¶
15 years ago
To strip bogus characters from your input (such as data from an unsanitized or other source which you can't trust to necessarily give you strings encoded according to their advertised encoding set), use the same character set as both the input and the output, with //IGNORE on the output charcter set.
<?php
// assuming '†' is actually UTF8, htmlentities will assume it's iso-8859
// since we did not specify in the 3rd argument of htmlentities.
// This generates "â[bad utf-8 character]"
// If passed to any libxml, it will generate a fatal error.
$badUTF8 = htmlentities('†');// iconv() can ignore characters which cannot be encoded in the target character set
$goodUTF8 = iconv("utf-8", "utf-8//IGNORE", $badUTF8);
?>
The result of the example does not give you back the dagger character which was the original input (it got lost when htmlentities was misused to encode it incorrectly, though this is common from people not accustomed to dealing with extended character sets), but it does at least give you data which is sane in your target character set.
phpnet at dariosulser dot ch ¶
3 years ago
ANSI = Windows-1252 = CP1252
So UTF-8 -> ANSI:
<?php
$string = "Winkel γ=200 für 1€"; //"γ"=HTML:γ
$result = iconv('UTF-8', 'CP1252//IGNORE', $string);
echo $result;
?>
Note1
<?php
$string = "Winkel γ=200 für 1€";
$result = iconv('UTF-8', 'CP1252', $string);
echo $result; //"conv(): Detected an illegal character in input string"
?>
Note2 (ANSI is better than decode in ISO 8859-1 (ISO-8859-1==Latin-1)
<?php
$string = "Winkel γ=200 für 1€";
$result = utf8_decode($string);
echo $result; //"Winkel ?=200 für 1?"
?>
Note3 of used languages on Websites:
93.0% = UTF-8;
3.5% = Latin-1;
0.6% = ANSI <----- you shoud use (or utf-8 if your page is in Chinese or has Maths)
rasmus at mindplay dot dk ¶
8 years ago
Note an important difference between iconv() and mb_convert_encoding() - if you're working with strings, as opposed to files, you most likely want mb_convert_encoding() and not iconv(), because iconv() will add a byte-order marker to the beginning of (for example) a UTF-32 string when converting from e.g. ISO-8859-1, which can throw off all your subsequent calculations and operations on the resulting string.
In other words, iconv() appears to be intended for use when converting the contents of files - whereas mb_convert_encoding() is intended for use when juggling strings internally, e.g. strings that aren't being read/written to/from files, but exchanged with some other media.
martin at front of mind dot co dot uk ¶
13 years ago
For transcoding values in an Excel generated CSV the following seems to work:
<?php
$value = iconv('Windows-1252', 'UTF-8//TRANSLIT', $value);
?>
Locoluis ¶
16 years ago
The following are Microsoft encodings that are based on ISO-8859 but with the addition of those stupid control characters.
CP1250 is Eastern European (not ISO-8859-2)
CP1251 is Cyrillic (not ISO-8859-5)
CP1252 is Western European (not ISO-8859-1)
CP1253 is Greek (not ISO-8859-7)
CP1254 is Turkish (not ISO-8859-9)
CP1255 is Hebrew (not ISO-8859-8)
CP1256 is Arabic (not ISO-8859-6)
CP1257 is Baltic (not ISO-8859-4)
If you know you're getting input from a Windows machine with those encodings, use one of these as a parameter to iconv.
chicopeste at gmail dot com ¶
9 years ago
iconv also support CP850.
I used iconv("CP850", "UTF-8//TRANSLIT", $var);
to convert from SQL_Latin1_General_CP850_CI_AI to UTF-8.
jessie at hotmail dot com ¶
9 years ago
Provided that there is no invalid code point in the character chain for the input encoding, the //IGNORE option works as expected. No bug here.
vb (at) bertola.eu ¶
12 years ago
On my system, according to tests, and also as reported by other people elsewhere, you can combine TRANSLIT and IGNORE only by appending
//IGNORE//TRANSLIT
strictly in that order, but NOT by appending //TRANSLIT//IGNORE, which would lead to //IGNORE being ignored ( :) ).
Anyway, it's hard to understand how one could devise a system of passing options that does not allow to couple both options in a neat manner, and also to understand why the default behaviour should be the less useful and most dangerous one (throwing away most of your data at the first unexpected character). Software design FAIL :-/
admin at iecw dot net ¶
9 years ago
aissam at yahoo dot com ¶
18 years ago
For those who have troubles in displaying UCS-2 data on browser, here's a simple function that convert ucs2 to html unicode entities :
<?phpfunction ucs2html($str) {
$str=trim($str); // if you are reading from file
$len=strlen($str);
$html='';
for($i=0;$i<$len;$i+=2)
$html.='&#'.hexdec(dechex(ord($str[$i+1])).
sprintf("%02s",dechex(ord($str[$i])))).';';
return($html);
}
?>
Anonymous ¶
13 years ago
For text with special characters such as (é) é which appears at 0xE9 in the ISO-8859-1 and at 0x82 in IBM-850. The correct output character set is 'IBM850' as:
('ISO-8859-1', 'IBM850', 'Québec')
Andries Seutens ¶
13 years ago
When doing transliteration, you have to make sure that your LC_COLLATE is properly set, otherwise the default POSIX will be used.
To transform "rené" into "rene" we could use the following code snippet:
<?php
setlocale
(LC_CTYPE, 'nl_BE.utf8');$string = 'rené';
$string = iconv('UTF-8', 'ASCII//TRANSLIT', $string);
echo
$string; // outputs rene?>
mirek at burkon dot org ¶
14 years ago
If you need to strip as many national characters from UTF-8 as possible and keep the rest of input unchanged (i.e. convert whatever can be converted to ASCII and leave the rest), you can do it like this:
<?php
setlocale(LC_ALL, 'en_US.UTF8');
function
clearUTF($s)
{
$r = '';
$s1 = iconv('UTF-8', 'ASCII//TRANSLIT', $s);
for ($i = 0; $i < strlen($s1); $i++)
{
$ch1 = $s1[$i];
$ch2 = mb_substr($s, $i, 1);$r .= $ch1=='?'?$ch2:$ch1;
}
return $r;
}
echo
clearUTF('Šíleně žluťoučký Vašek úpěl olol! This will remain untranslated: ᾡᾧῘઍિ૮');
//outputs Silene zlutoucky Vasek upel olol! This will remain untranslated: ᾡᾧῘઍિ૮
?>
Just remember you HAVE TO set locale to some unicode encoding to make iconv handle //TRANSLIT correctly!
Проблема кодировок часто возникает при написании парсеров, чтении данных из xml и CSV файлов. Ниже представлены способы эту проблему решить.
1
windows-1251 в UTF-8
$text = iconv('windows-1251//IGNORE', 'UTF-8//IGNORE', $text);
echo $text;PHP
$text = mb_convert_encoding($text, 'UTF-8', 'windows-1251');
echo $text;PHP
2
UTF-8 в windows-1251
$text = iconv('utf-8//IGNORE', 'windows-1251//IGNORE', $text);
echo $text;PHP
$text = mb_convert_encoding($text, 'windows-1251', 'utf-8');
echo $text;PHP
3
Когда ни что не помогает
$text = iconv('utf-8//IGNORE', 'cp1252//IGNORE', $text);
$text = iconv('cp1251//IGNORE', 'utf-8//IGNORE', $text);
echo $text;PHP
Иногда доходит до бреда, но работает:
$text = iconv('utf-8//IGNORE', 'windows-1251//IGNORE', $text);
$text = iconv('windows-1251//IGNORE', 'utf-8//IGNORE', $text);
echo $text;PHP
4
File_get_contents / CURL
Бывают случаи когда file_get_contents() или CURL возвращают иероглифы (ÐлмазнÑе боÑÑ) – причина тут не в кодировке, а в отсутствии BOM-метки.
$text = file_get_contents('https://example.com');
$text = "xEFxBBxBF" . $text;
echo $text;PHP
Ещё бывают случаи, когда file_get_contents() возвращает текст в виде:
�mw�Ƒ0�����&IkAI��f��j4/{�</�&�h�� ��({�o�����:/��<g���g��(�=�9�Paɭ
Это сжатый текст в GZIP, т.к. функция не отправляет правильные заголовки. Решение проблемы через CURL:
function getcontents($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
echo getcontents('https://example.com');PHP
12.01.2017, обновлено 02.11.2021
Другие публикации

Отправка e-mail в кодировке UTF-8 с вложенными файлами и возможные проблемы.

JSON (JavaScript Object Notation) – текстовый формат обмена данными, основанный на JavaScript, который представляет собой набор пар {ключ: значение}. Значение может быть массивом, числом, строкой и…

Описание значений глобального массива $_SERVER с примерами.

Так как Instagram и Fasebook ограничили доступ к API, а фото с открытого аккаунта всё же нужно периодически получать и…

В статье представлены различные PHP-расширения для чтения файлов XLS, XLSX, описаны их плюсы и минусы, а также примеры…

Примеры как зарегистрировать бота в Телеграм, описание и взаимодействие с основными методами API.
I need to convert uploaded filenames with an unknown encoding to Windows-1252 whilst also keeping UTF-8 compatibility.
As I pass on those files to a controller (on which I don’t have any influence), the files have to be Windows-1252 encoded. This controller then again generates a list of valid file(names) that are stored via MySQL into a database – therefore I need UTF-8 compatibility. Filenames passed to the controller and filenames written to the database MUST match. So far so good.
In some rare cases, when converting to «Windows-1252» (like with te character «ï»), the character is converted to something invalid in UTF-8. MySQL then drops those invalid characters – as a result filenames on disk and filenames stored to the database don’t match anymore. This conversion, which failes sometimes, is achieved with simple recoding:
$sEncoding = mb_detect_encoding($sOriginalFilename);
$sTargetFilename = iconv($sEncoding, "Windows-1252//IGNORE", $sOriginalFilename);
To prevent invalid characters being generated by the conversion, I then again can remove all invalid UTF-8 characters from the recoded string:
ini_set('mbstring.substitute_character', "none");
$sEncoding = mb_detect_encoding($sOriginalFilename);
$sTargetFilename = iconv($sEncoding, "Windows-1252//TRANSLIT", $sOriginalFilename);
$sTargetFilename = mb_convert_encoding($sTargetFilename, 'UTF-8', 'Windows-1252');
But this will completely remove / recode any special characters left in the string. For example I lose all «äöüÄÖÜ» etc., which are quite regular in german language.
If you know a cleaner and simpler way of encoding to Windows-1252 (without losing valid special characters), please let me know.
Any help is very appreciated. Thank you in advance!
Learn how to write a plain text file in PHP with the Western Windows 1252 encoding.
The fwrite function of PHP or file_put_content doesn’t care about metadata of the file, it just writes the given data to the storage and that’s it. This leads to a simply conjecture, the charset of the text file is defined by its data, so you need to convert the data that you will write into the file to a specific format.
In some enterprises, this process is necessary as the software of other big companies is out of date and doesn’t operate well with the UTF-8 default encoding, so you will need to change obligatorily the encoding of your generated files to the named «ANSI» codification. The term «ANSI» when applied to Microsoft’s 8-bit code pages is a misnomer. They were based on drafts submitted for ANSI standardization, but ANSI itself never standardized them. Windows-1252 (the code page most commonly referred to as «ANSI») is similar to ISO 8859-1 (Latin-1), except that Windows-1252 has printable characters in the range 0x80..0x9F, where ISO 8859-1 has control characters in that range. Unicode also has control characters in that range.
In PHP, you can achieve such thing using the iconv function, trying to detect the encoding of your data (usually UTF-8) and convert it into the new format namely Windows-1252 (CP1252):
<?php
// Store your original text in some variable
$data = "Los señores del pueblo de alli comen sopa con cucharas.";
// Change the encoding of the file using iconv
$string_encoded = iconv( mb_detect_encoding( $data ), 'Windows-1252//TRANSLIT', $data );
// Write File
$file = fopen("my_text_file.txt", "w+");
fwrite($file, $string_encoded);
fclose($file);The output file will be recognized automatically by your favorite text editor with the Windows-1252 encoding:
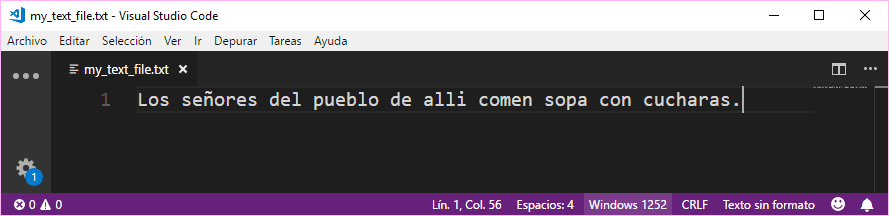
And that’s it, normally. If the content of your files doesn’t have special characters, the content may be recognized by the text editor as UTF-8, so your only option will be to use a CLI tool to convert the encoding of the file (read next paragraph).
If file still without correct encoding
If after using plain PHP to write the content manually on your file doesn’t use the desired encoding in the content of the file, you may need to use instead the system-level way to set the encoding of the file.
The preferred and easiest way to do it using the CLI is with iconv. This CLI tool converts the encoding of characters in inputfile from one coded character set to another. The result is written to standard output unless otherwise specified by the —output option or by a simply output redirect with the cli, for example:
iconv -t CP1252 -f UTF-8 "input_file.txt" > "encoded_output_file.txt"You can use the exec function of PHP to run the iconv program with the mentioned arguments, available on every UNIX based OS or in Windows (using Cygwin).
As mentioned, most of the text editors that use the automatic encoding detector decide which encoding to use according to the content, so normally although the strings stored in the file with PHP that have the Windows-1252 encoding (CP1252), the UTF-8 mode will be used. This means that the detection of the encoding based on the content is based just on heuristic, so doesn’t guarantee that the encoding used to open the file is correct.
However, the content doesn’t lie, so if you try to open the content of a Windows-1252 encoded file with the UTF-8 encoding, you will see weird characters in the text editor:
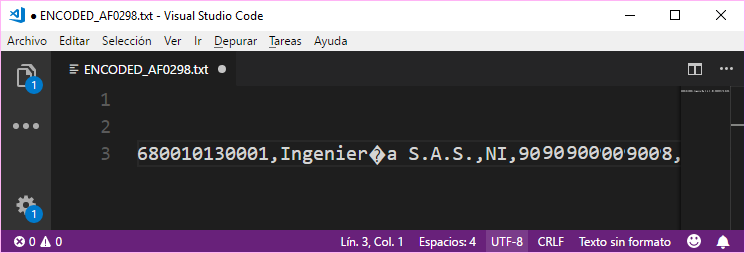
However if the text editor reads the content of the file with the Windows-1252 (CP1252) encoding, it will be read correctly:
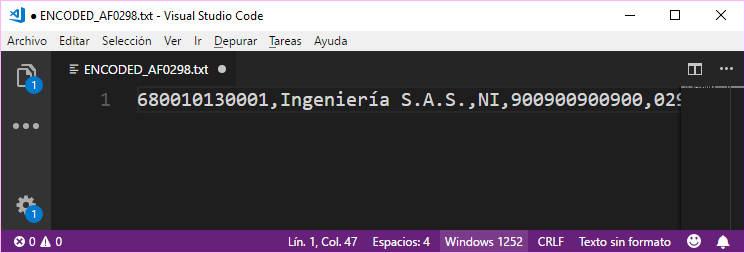
Happy coding !
-
php
-
utf-8
-
character-encoding
- 02-01-2020
|
Question
I’m needing to convert a UTF-8 character set to Windows-1252 using PHP and i’m not having much luck thus far. My aim is to transfer text to a 3rd party system and exclude any characters not in the Windows-1252 character set.
I’ve tried both iconv and mb_convert_encoding but both give unexpected results.
$text = 'KØBENHAVN Ø ô& üü þþ';
echo iconv("UTF-8", "WINDOWS-1252", $text);
echo mb_convert_encoding($text, "WINDOWS-1252");
Output for both is ‘K?BENHAVN ? ?& ?? ??’
I would not have expected the ?’s as these characters are in the WINDOWS-1252 character set.
Can anyone help cast some light on this for me please.
No correct solution
OTHER TIPS
I ended up running the text from UTF-8 to WINDOWS-1252 and then back from WINDOWS-1252 to UTF-8. This gave the desire output.
$text = "Ѭjanky";
$converted = iconv("UTF-8//IGNORE", "WINDOWS-1252//IGNORE", $text);
$converted = iconv("WINDOWS-1252//IGNORE", "UTF-8//IGNORE", $converted);
echo $text; // outputs "janky"
-
#1
трабл с utf-8 -> windows-1252
Сорри, если раньше обсуждалось — поиск по форуму ничего не дал.
Никогда ранее не сталкивался с кодировкой windows-1252 (cp1252 ), а тут пришлось. Надо скриптом преобразовать текст из utf-8 в windows-1252, попытался любимой [m]iconv[/m]
PHP:
iconv('utf-8', 'windows-1252', 'Русский текст')не помогло… как можно порешать?
-
#4
предлагаю поискать в windows-1252 русские символы 
-
#7
хорошо, без намеков: как ты собираешься преобразовать русский текст в кодировку, в которой он отсутствует?

-
#8
x-yuri
предлагаю с другой стороны зайти:
Страшный Злодей
объясни, какая перед тобой стоит задача.
-
#9
Автор оригинала: zerkms
предлагаю с другой стороны зайти:
Ну вы это… насчет другой стороны это как? не надо ")
А по существу — задача тупая до ужаса. Есть корпоративный сервер, на котором содержится инфа для структурных подразделений. Для каждого свой раздел. После авторизации народ ручками выбирает то, что нужно, тратя на это драго-время. Попросили помочь этот процесс автоматизировать, дабы по расписанию некий скрипт подключался и выбирал нужную инфу. ПО сервера перенастраивать не реально, центральный сервер в главке, там и слышать ничего не хотят про любые доработки, им это на фиг не нужно, а люди пользователи страдают… Так вот какая там бодяга обнаружилась, загадка прямо для меня. Через браузер все работает. Через сокеты только когда посылаешь в кодировке 1252 (русские слова в теле хидера boundary). Понимаю, что похоже на бред, но вы сами просили задачу описать…
ys
отодвинутый новичок
-
#10
Страшный Злодей
Вы не ответили на вопрос, где в данной кодировке закрались русские буквы.
-
#11
[telepat mode on]
У него центральный сервер принимает в 1251, но заголовки хочет для этого 1252
[telepat mode off]
Чтобы убедиться в этом, надо посмотреть заголовки, которые получает-посылает броузер.
Если я прав, то перекодировать надо в 1251.

-
#12
> Через браузер все работает
Что все?
> Через сокеты только когда посылаешь в кодировке 1252 (русские
> слова в теле хидера boundary).
Это что такое? я не въехал)
> У него центральный сервер принимает в 1251, но заголовки
> хочет для этого 1252
Что за план? Поделитесь)))
-~{}~ 14.01.09 02:06:
Русский слов в кодировке 1252 быть не может)) вообще не может, ни как не может…
Проблему нужно объяснять четко. А тут сопли…
-~{}~ 14.01.09 02:08:
dimagolov
> У него центральный сервер принимает в 1251, но заголовки
> хочет для этого 1252
Кажись наоборот. Хранит в 1252, а заголовки хочет 1251 ))
-~{}~ 14.01.09 02:10:
Коды та символов остаются прежними. Дело видать в заголовках да и только. В любом случае, отображаться может только в cp1251.
-
#14
dimagolov
Блин, ну я сам не пойму, что за беда.. фраза «Русский язык», обработается лишь тогда, когда будет послана в таком виде —

. Как браузер «догадывается» до того, каким образом кодировать эту фразу — не знаю.
Активист
Что значит твой вопрос — «Что все?» каким ты хочешь увидеть ответ на него?
>»Это что такое? я не въехал)» — Чего именно тебе не понятно,про то как послать в теле заголовка boundary, русскую фразу???
> «Русский слов в кодировке 1252 быть не может)) вообще не может, ни как не может…» — выше в этом же сообщении почитай
>»Проблему нужно объяснять четко. А тут сопли…» — На вопросы нужно либо не отвечать, либо отвечать по делу, а у тебя оффтоп, спам, флуд и какашки
-~{}~ 14.01.09 02:57:
x-yuri
Дя нет, не в БД, а в скрипте-клиенте дело — не получается браузер полноценно эмулировать.
-
#15
для чего используется boundary? ты файлы uploadишь?
как связаны сокеты с браузером? браузер может через сокеты коннектится к веб-серверу?
не получается браузер полноценно эмулировать.
эмулировать браузер? это как?
-~{}~ 14.01.09 02:00:
а по поводу того, что бразер сам определяет кодировку — есть наверное какие-то эмпирические методы
-~{}~ 14.01.09 02:03:
например, mbstring может автоматически выбирать кодировку исходной строки из заданного списка
-
#16
x-yuri
boundary использую, так как там разнородное содержимое бывает, чаще правда тексты большие и по кол-ву полей много.
-
#17
там это где? ты почту отсылаешь, файлы скачиваешь/закачиваешь?
и как связан браузер с сокетами?
-
#18
я все описал здесь Через браузер — это когда руками. Через сокеты — это автоматически скриптом. boundary юзаю для отправки POST данных. Не файлы, не почта, только текстовые данные (на описываемом этапе).
-
#20
Автор оригинала: x-yuri
и еще, русские символы в названии границы? или в тексте частей? для каждой части можно задавать Content-Type
Внутри частей, в тексте т.е.
За подсказочку по поводу Content-Type, спасибо. Теперь буду думать как применить, но в любом случае не сейчас так в дальнейшем пригодится — буду знать.
Обидно, что туплю не могу понять — каким образом браузеру удаётся сделать, то, что мне не удаётся через сокеты. Почему он русский текст загоняет в эту уродливую кодировку???
PHP utf8_to_windows1252 — 5 примеров найдено. Это лучшие примеры PHP кода для utf8_to_windows1252, полученные из open source проектов. Вы можете ставить оценку каждому примеру, чтобы помочь нам улучшить качество примеров.
Язык программирования: PHP
Метод/Функция: utf8_to_windows1252
Примеров на hotexamples.com: 5
function u2wi($string)
{
return utf8_to_windows1252($string, "//TRANSLIT");
}
function GetMessage($folderid, $id, $truncsize)
{
debugLog("IMAP-GetMessage: (fid: '{$folderid}' id: '{$id}' truncsize: {$truncsize})");
// Get flags, etc
$stat = $this->StatMessage($folderid, $id);
if ($stat) {
$this->imap_reopenFolder($folderid);
$mail = @imap_fetchheader($this->_mbox, $id, FT_PREFETCHTEXT | FT_UID) . @imap_body($this->_mbox, $id, FT_PEEK | FT_UID);
$mobj = new Mail_mimeDecode($mail);
$message = $mobj->decode(array('decode_headers' => true, 'decode_bodies' => true, 'include_bodies' => true, 'input' => $mail, 'crlf' => "n", 'charset' => 'utf-8'));
$output = new SyncMail();
// decode body to truncate it
$body = utf8_to_windows1252($this->getBody($message));
if (strlen($body) > $truncsize) {
$body = substr($body, 0, $truncsize);
$output->bodytruncated = 1;
} else {
$body = $body;
$output->bodytruncated = 0;
}
$body = str_replace("n", "rn", windows1252_to_utf8(str_replace("r", "", $body)));
$output->bodysize = strlen($body);
$output->body = $body;
$output->datereceived = isset($message->headers["date"]) ? strtotime($message->headers["date"]) : null;
$output->displayto = isset($message->headers["to"]) ? $message->headers["to"] : null;
$output->importance = isset($message->headers["x-priority"]) ? preg_replace("/\D+/", "", $message->headers["x-priority"]) : null;
$output->messageclass = "IPM.Note";
$output->subject = isset($message->headers["subject"]) ? $message->headers["subject"] : "";
$output->read = $stat["flags"];
$output->to = isset($message->headers["to"]) ? $message->headers["to"] : null;
$output->cc = isset($message->headers["cc"]) ? $message->headers["cc"] : null;
$output->from = isset($message->headers["from"]) ? $message->headers["from"] : null;
$output->reply_to = isset($message->headers["reply-to"]) ? $message->headers["reply-to"] : null;
// Attachments are only searched in the top-level part
$n = 0;
if (isset($message->parts)) {
foreach ($message->parts as $part) {
if (isset($part->disposition) && ($part->disposition == "attachment" || $part->disposition == "inline")) {
$attachment = new SyncAttachment();
if (isset($part->body)) {
$attachment->attsize = strlen($part->body);
}
if (isset($part->d_parameters['filename'])) {
$attname = $part->d_parameters['filename'];
} else {
if (isset($part->ctype_parameters['name'])) {
$attname = $part->ctype_parameters['name'];
} else {
if (isset($part->headers['content-description'])) {
$attname = $part->headers['content-description'];
} else {
$attname = "unknown attachment";
}
}
}
$attachment->displayname = $attname;
$attachment->attname = $folderid . ":" . $id . ":" . $n;
$attachment->attmethod = 1;
$attachment->attoid = isset($part->headers['content-id']) ? $part->headers['content-id'] : "";
array_push($output->attachments, $attachment);
}
$n++;
}
}
// unset mimedecoder & mail
unset($mobj);
unset($mail);
return $output;
}
return false;
}
function u2w($string)
{
return utf8_to_windows1252($string);
}
function GetMessage($folderid, $id, $truncsize)
{
debugLog("KOLAB-GetMessage: (fid: '{$folderid}' id: '{$id}' truncsize: {$truncsize})");
// Get flags, etc
$stat = $this->StatMessage($folderid, $id);
if ($stat) {
if ($this->kolabFolderType($folderid)) {
//get the imap_id
$imap_id = array_pop(explode("/", $stat['mod']));
//$imap_id=$stat['mod'];
if (substr($folderid, 0, 7) == "VIRTUAL") {
$folderid = $this->CacheIndexUid2FolderUid($id);
debugLog("GetMessage Flmode: {$id} - > {$folderid}");
$this->Log("NOTICE GetMessage Flmode: {$id} - > {$folderid}");
}
} else {
$imap_id = $id;
}
$this->imap_reopenFolder($folderid);
$mail = @imap_fetchheader($this->_mbox, $imap_id, FT_PREFETCHTEXT | FT_UID) . @imap_body($this->_mbox, $imap_id, FT_PEEK | FT_UID);
$mobj = new Mail_mimeDecode($mail);
$message = $mobj->decode(array('decode_headers' => true, 'decode_bodies' => true, 'include_bodies' => true, 'input' => $mail, 'crlf' => "n", 'charset' => 'utf-8'));
if ($this->kolabFolderType($folderid) == 1) {
$output = $this->KolabReadContact($message, 0);
$this->Log("Changed on Server C: {$folderid} /" . $id . "imap id : " . $imap_id);
$this->Log(" : " . u2w($output->fileas));
$this->CacheCreateIndex($folderid, $id, $imap_id);
return $output;
} elseif ($this->kolabFolderType($folderid) == 2) {
//bug #9 we must test if we want alarms or not
// for the moment disable it if namespace <> INBOX
$fa = $this->CacheReadFolderParam($folderid);
$fa->setFolder($folderid);
if ($fa->showAlarm($this->_devid)) {
$output = $this->KolabReadEvent($message, $id, false);
//alarm must be shown
} else {
$output = $this->KolabReadEvent($message, $id, true);
}
$this->Log("Changed on Server A: {$folderid}/" . $id);
$this->Log(" : " . u2w($output->subject));
$this->CacheCreateIndex($folderid, $id, $imap_id);
$this->CacheWriteSensitivity($id, $output->sensitivity);
return $output;
} elseif ($this->kolabFolderType($folderid) == 3) {
$output = $this->KolabReadTask($message, $id);
$this->Log("Changed on Server T: {$folderid} /" . $id);
$this->Log(" : " . u2w($output->subject));
$this->CacheCreateIndex($folderid, $id, $imap_id);
//rewrite completion
$this->CacheWriteTaskCompleted($id, $output->completed);
$this->CacheWriteSensitivity($id, $output->sensitivity);
return $output;
} else {
$output = new SyncMail();
// decode body to truncate it
$body = utf8_to_windows1252($this->getBody($message));
$truncsize = 2048;
if (strlen($body) > $truncsize) {
$body = substr($body, 0, $truncsize);
$output->bodytruncated = 1;
} else {
$body = $body;
$output->bodytruncated = 0;
}
$body = str_replace("n", "rn", windows1252_to_utf8(str_replace("r", "", $body)));
$output->bodysize = strlen($body);
$output->body = $body;
$output->datereceived = isset($message->headers["date"]) ? strtotime($message->headers["date"]) : null;
$output->displayto = isset($message->headers["to"]) ? $message->headers["to"] : null;
$output->importance = isset($message->headers["x-priority"]) ? preg_replace("/\D+/", "", $message->headers["x-priority"]) : null;
$output->messageclass = "IPM.Note";
$output->subject = isset($message->headers["subject"]) ? $message->headers["subject"] : "";
$output->read = $stat["flags"];
$output->to = isset($message->headers["to"]) ? $message->headers["to"] : null;
$output->cc = isset($message->headers["cc"]) ? $message->headers["cc"] : null;
$output->from = isset($message->headers["from"]) ? $message->headers["from"] : null;
$output->reply_to = isset($message->headers["reply-to"]) ? $message->headers["reply-to"] : null;
// Attachments are only searched in the top-level part
$n = 0;
if (isset($message->parts)) {
foreach ($message->parts as $part) {
if (isset($part->disposition) && ($part->disposition == "attachment" || $part->disposition == "inline")) {
$attachment = new SyncAttachment();
if (isset($part->body)) {
$attachment->attsize = strlen($part->body);
}
if (isset($part->d_parameters['filename'])) {
$attname = $part->d_parameters['filename'];
} else {
if (isset($part->ctype_parameters['name'])) {
$attname = $part->ctype_parameters['name'];
} else {
if (isset($part->headers['content-description'])) {
$attname = $part->headers['content-description'];
} else {
$attname = "unknown attachment";
}
}
}
$attachment->displayname = $attname;
$attachment->attname = $folderid . ":" . $id . ":" . $n;
$attachment->attmethod = 1;
$attachment->attoid = isset($part->headers['content-id']) ? $part->headers['content-id'] : "";
array_push($output->attachments, $attachment);
}
$n++;
}
}
// unset mimedecoder & mail
unset($mobj);
unset($mail);
return $output;
}
}
return false;
}
function setSettings($request, $devid)
{
if (isset($request["oof"])) {
if ($request["oof"]["oofstate"] == 1) {
foreach ($request["oof"]["oofmsgs"] as $oofmsg) {
switch ($oofmsg["appliesto"]) {
case SYNC_SETTINGS_APPLIESTOINTERNAL:
$result = mapi_setprops($this->_defaultstore, array(PR_EC_OUTOFOFFICE_MSG => utf8_to_windows1252(isset($oofmsg["replymessage"]) ? $oofmsg["replymessage"] : ""), PR_EC_OUTOFOFFICE_SUBJECT => utf8_to_windows1252(_("Out of office notification"))));
break;
}
}
$response["oof"]["status"] = mapi_setprops($this->_defaultstore, array(PR_EC_OUTOFOFFICE => $request["oof"]["oofstate"] == 1 ? true : false));
} else {
$response["oof"]["status"] = mapi_setprops($this->_defaultstore, array(PR_EC_OUTOFOFFICE => $request["oof"]["oofstate"] == 1 ? true : false));
}
}
if (isset($request["deviceinformation"])) {
if ($this->_defaultstore !== false) {
//get devices settings from store
$props = array();
$props[SYNC_SETTINGS_MODEL] = mapi_prop_tag(PT_MV_STRING8, 0x6890);
$props[SYNC_SETTINGS_IMEI] = mapi_prop_tag(PT_MV_STRING8, 0x6891);
$props[SYNC_SETTINGS_FRIENDLYNAME] = mapi_prop_tag(PT_MV_STRING8, 0x6892);
$props[SYNC_SETTINGS_OS] = mapi_prop_tag(PT_MV_STRING8, 0x6893);
$props[SYNC_SETTINGS_OSLANGUAGE] = mapi_prop_tag(PT_MV_STRING8, 0x6894);
$props[SYNC_SETTINGS_PHONENUMBER] = mapi_prop_tag(PT_MV_STRING8, 0x6895);
$props[SYNC_SETTINGS_USERAGENT] = mapi_prop_tag(PT_MV_STRING8, 0x6896);
$props[SYNC_SETTINGS_ENABLEOUTBOUNDSMS] = mapi_prop_tag(PT_MV_STRING8, 0x6897);
$props[SYNC_SETTINGS_MOBILEOPERATOR] = mapi_prop_tag(PT_MV_STRING8, 0x6898);
$sprops = mapi_getprops($this->_defaultstore, array(0x6881101e, $props[SYNC_SETTINGS_MODEL], $props[SYNC_SETTINGS_IMEI], $props[SYNC_SETTINGS_FRIENDLYNAME], $props[SYNC_SETTINGS_OS], $props[SYNC_SETTINGS_OSLANGUAGE], $props[SYNC_SETTINGS_PHONENUMBER], $props[SYNC_SETTINGS_USERAGENT], $props[SYNC_SETTINGS_ENABLEOUTBOUNDSMS], $props[SYNC_SETTINGS_MOBILEOPERATOR]));
//try to find index of current device
$ak = array_search($devid, $sprops[0x6881101e]);
// Set undefined properties to the amount of known device ids
foreach ($props as $key => $value) {
if (!isset($sprops[$value])) {
for ($i = 0; $i < sizeof($sprops[0x6881101e]); $i++) {
$sprops[$value][] = "undefined";
}
}
}
if ($ak !== false) {
//update settings (huh this could really occur?!?! - maybe in case of OS update)
foreach ($request["deviceinformation"] as $key => $value) {
if (trim($value) != "") {
$sprops[$props[$key]][$ak] = $value;
} else {
$sprops[$props[$key]][$ak] = "undefined";
}
}
} else {
//new device settings for the db
$devicesprops[0x6881101e][] = $devid;
foreach ($props as $key => $value) {
if (isset($request["deviceinformation"][$key]) && trim($request["deviceinformation"][$key]) != "") {
$sprops[$value][] = $request["deviceinformation"][$key];
} else {
$sprops[$value][] = "undefined";
}
}
}
// save them
$response["deviceinformation"]["status"] = mapi_setprops($this->_defaultstore, $sprops);
}
}
if (isset($request["devicepassword"])) {
if ($this->_defaultstore !== false) {
//get devices settings from store
$props = array();
$props[SYNC_SETTINGS_PASSWORD] = mapi_prop_tag(PT_MV_STRING8, 0x689f);
$pprops = mapi_getprops($this->_defaultstore, array(0x6881101e, $props[SYNC_SETTINGS_PASSWORD]));
//try to find index of current device
$ak = array_search($devid, $pprops[0x6881101e]);
// Set undefined properties to the amount of known device ids
foreach ($props as $key => $value) {
if (!isset($pprops[$value])) {
for ($i = 0; $i < sizeof($pprops[0x6881101e]); $i++) {
$pprops[$value][] = "undefined";
}
}
}
if ($ak !== false) {
//update password
if (trim($value) != "") {
$pprops[$props[$key]][$ak] = $request["devicepassword"];
} else {
$pprops[$props[$key]][$ak] = "undefined";
}
} else {
//new device password for the db
$devicesprops[0x6881101e][] = $devid;
foreach ($props as $key => $value) {
if (isset($request["devicepassword"]) && trim($request["devicepassword"]) != "") {
$pprops[$value][] = $request["devicepassword"];
} else {
$pprops[$value][] = "undefined";
}
}
}
// save them
$response["devicepassword"]["status"] = mapi_setprops($this->_defaultstore, $pprops);
}
}
return $response;
}
Мне нужно преобразовать загруженные имена файлов с неизвестной кодировкой в Windows-1252, сохраняя при этом совместимость с UTF-8.
Когда я передаю эти файлы контроллеру (на который я не имею никакого влияния), файлы должны быть закодированы в Windows-1252. Затем этот контроллер снова генерирует список допустимых файлов (имен), которые хранятся через MySQL в базе данных, поэтому мне нужна совместимость с UTF-8. Имена файлов, передаваемые контроллеру, и имена файлов, записываемых в базу данных, ДОЛЖНЫ совпадать. Все идет нормально.
В некоторых редких случаях при преобразовании в «Windows-1252» (например, с символом «ï») символ преобразуется во что-то недопустимое в UTF-8. Затем MySQL отбрасывает эти недопустимые символы — в результате имена файлов на диске и имена файлов, хранящиеся в базе данных, больше не совпадают. Это преобразование, которое иногда дает сбой, достигается простой перекодировкой:
$sEncoding = mb_detect_encoding($sOriginalFilename);
$sTargetFilename = iconv($sEncoding, "Windows-1252//IGNORE", $sOriginalFilename);
Чтобы предотвратить создание недопустимых символов при преобразовании, я снова могу удалить все недопустимые символы UTF-8 из перекодированной строки:
ini_set('mbstring.substitute_character', "none");
$sEncoding = mb_detect_encoding($sOriginalFilename);
$sTargetFilename = iconv($sEncoding, "Windows-1252//TRANSLIT", $sOriginalFilename);
$sTargetFilename = mb_convert_encoding($sTargetFilename, 'UTF-8', 'Windows-1252');
Но это полностью удалит/перекодирует любые специальные символы, оставшиеся в строке. Например, я теряю все «äöüÄÖÜ» и т. д., которые вполне регулярны в немецком языке.
Если вы знаете более чистый и простой способ кодирования в Windows-1252 (без потери допустимых специальных символов), сообщите мне об этом.
Любая помощь очень ценится. Заранее спасибо!