Привязки
Привязки, или атомарные утверждения нулевой ширины, приводят к успеху или сбою сопоставления, в зависимости от текущей позиции в строке, но не предписывают обработчику перемещаться по строке или обрабатывать символы. Метасимволы, приведенные в следующей таблице, являются привязками. Дополнительные сведения см. в разделе Привязки.
Конструкции группирования
Конструкции группирования отображают части выражений регулярных выражений и обычно захватывают части строки входной строки. Конструкции группирования состоят из языковых элементов, приведенных в следующей таблице. Для получения дополнительной информации см. Конструкции группирования.
Квантификаторы
Квантор указывает количество вхождений предшествующего элемента (знака, группы или класса знаков), которое должно присутствовать во входной строке, чтобы было зафиксировано соответствие. Кванторы состоят из языковых элементов, приведенных в следующей таблице. Для получения дополнительной информации см. Квантификаторы.
Конструкции обратных ссылок
| Конструкция обратных ссылок | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| число | Обратная ссылка. Соответствует значению нумерованной части выражения. | (w)1 | «ee» в «seek» |
| k имя > | Именованная обратная ссылка. Соответствует значению именованного выражения. | (? w)k | «ee» в «seek» |
Конструкции чередования
Конструкции изменения модифицируют регулярное выражение, включая сопоставление по принципу «либо-либо». Такие конструкции состоят из языковых элементов, приведенных в следующей таблице. Дополнительные сведения см. в разделе Конструкции чередования.
Подстановки
Подстановки — это языковые элементы регулярных выражений, которые поддерживаются в шаблонах замены. Для получения дополнительной информации см. Подстановки. Приведенные в следующей таблице метасимволы являются атомарными утверждениями нулевой ширины.
| Знак | Описание | Шаблон | Шаблон замены | Входная строка | Результирующая строка |
|---|---|---|---|---|---|
| $ число | Замещает часть строки, соответствующую группе число. | b(w+)(s)(w+)b | $3$2$1 | «one two» | «two one» |
| $< имя > | Замещает часть строки, соответствующую именованной группе имя. | b(? w+)(s)(? w+)b | $ $ | «one two» | «two one» |
| $$ | Подставляет литерал «$». | b(d+)s?USD | $$$1 | «103 USD» | «$103» |
| $& | Замещает копией полного соответствия. | $?d*.?d+ | **$&** | «$1.30» | «**$1.30**» |
| $` | Замещает весь текст входной строки до соответствия. | B+ | $` | «AABBCC» | «AAAACC» |
| $’ | Замещает весь текст входной строки после соответствия. | B+ | $’ | «AABBCC» | «AACCCC» |
| $+ | Замещает последнюю захваченную группу. | B+(C+) | $+ | «AABBCCDD» | «AACCDD» |
| $_ | Замещает всю входную строку. | B+ | $_ | «AABBCC» | «AAAABBCCCC» |
Параметры регулярных выражений
Можно определить параметры, управляющие интерпретацией шаблона регулярного выражения обработчиком регулярных выражений. Многие из этих параметров можно указать в шаблоне регулярного выражения либо в виде одной или нескольких констант RegexOptions. Этот краткий справочник перечисляет только встраиваемые параметры. Дополнительные сведения о встроенных параметрах и параметрах RegexOptions см. в статье Параметры регулярных выражений.
Встроенный параметр можно задать двумя способами:
Прочие конструкции
Источник
Регулярные выражения в C#
Регулярные выражения — это часть небольшой технологической области, невероятно широко используемой в огромном диапазоне программ. Регулярные выражения можно представить себе как мини-язык программирования, имеющий одно специфическое назначение: находить подстроки в больших строковых выражениях.
Введение в регулярные выражения
Язык регулярных выражений предназначен специально для обработки строк. Он включает два средства:
Набор управляющих кодов для идентификации специфических типов символов
Система для группирования частей подстрок и промежуточных результатов таких действий
С помощью регулярных выражений можно выполнять достаточно сложные и высокоуровневые действия над строками:
Идентифицировать (и возможно, помечать к удалению) все повторяющиеся слова в строке
Сделать заглавными первые буквы всех слов
Преобразовать первые буквы всех слов длиннее трех символов в заглавные
Обеспечить правильную капитализацию предложений
Выделить различные элементы в URI (например, имея http://www.professorweb.ru, выделить протокол, имя компьютера, имя файла и т.д.)
Главным преимуществом регулярных выражений является использование метасимволов — специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям C#. Это символы, предваренные знаком обратного слеша () и имеющие специальное назначение.
В следующей таблице специальные метасимволы регулярных выражений C# сгруппированы по смыслу:
Использование регулярных выражений в C#
Безуcловно, задачу поиска и замены подстроки в строке можно решить на C# с использованием различных методов System.String и System.Text.StringBuilder. Однако в некоторых случаях это потребует написания большого объема кода C#. Если вы используете регулярные выражения, то весь этот код сокращается буквально до нескольких строк. По сути, вы создаете экземпляр объекта RegEx, передаете ему строку для обработки, а также само регулярное выражение (строку, включающую инструкции на языке регулярных выражений) — и все готово.
В следующей таблице показана часть информации о перечислении RegexOptions, экземпляр которого можно передать конструктору класса RegEx:
После создания шаблона регулярного выражения с ним можно осуществить различные действия, в зависимости от того, что вам необходимо. Можно просто проверить, существует ли текст, соответствующий шаблону, в исходной строке. Для этого нужно использовать метод IsMatch(), который возвращает логическое значение:

Если нужно вернуть найденное соответствие из исходной строки, то можно воспользоваться методом Match(), который возвращает объект класса Match, содержащий сведения о первой подстроке, которая сопоставлена шаблону регулярного выражения. В этом классе имеется свойство Success, которое возвращает значение true, если найдено следующее совпадение, которое можно получить с помощью вызова метода Match.NextMatch(). Эти вызовы метода можно продолжать пока свойство Match.Success не вернет значение false. Например:

Извлечь все совпадения можно и более простым способом, используя метод Regex.Matches(), который возвращает объект класса MatchCollection, который, в свою очередь, содержит сведения обо всех совпадениях, которые обработчик регулярных выражений находит во входной строке. Например, предыдущий пример может быть переписан для вызова метода Matches вместо метода Match и метода NextMatch:
Наконец, можно не просто извлекать совпадения в исходной строке, но и заменять их на собственные значения. Для этого используется метод Regex.Replace(). В качестве замены методу Replace() можно передавать как строку, так и шаблон замены. В следующей таблице показано как формируются метасимволы для замены:
Давайте рассмотрим метод Regex.Replace() на примере:

Для закрепления темы давайте рассмотрим еще один пример использования регулярных выражений, где будем искать в исходном тексте слово «сериализация» и его однокоренные слова, при этом выделяя в консоли их другим цветом:
Результат работы данной программы:

Для проверки гибкости работы регулярных выражений, подставьте в исходный текст еще несколько слов «сериализация», вы увидите, что они будут автоматически выделены зеленым цветом в консоли.
Источник
Регулярные выражения для самых маленьких
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показать возможности этого инструмента.
Некоторые из них для наглядности будут показаны на примере языков программирования PHP или JavaScript, но в целом они работают независимо от ЯП.
Из названия понятно, что статья ориентирована на самый начальный уровень — тех, кто еще ни разу не использовал регулярные выражения в своих программах или делал это без должного понимания.
В конце статьи я в двух словах расскажу, какие задачи нельзя решить регулярными выражениями и какие инструменты для этого стоит использовать.

Вступление
Регулярные выражения — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:
Функции на match возвращают число найденных подстрок или false в случае ошибок. Функция на replace возвращает измененную строку/массив или null в случае ошибки. Результат можно привести к bool (false, если не было найдено значений и true, если было) и использовать вместе с if или assertTrue для обработки результата работы.
В JS чаще всего мне приходится использовать:
Пример использования функций
В PHP регулярное выражение — это строка, которая начинается и заканчивается символом-разделителем. Все, что находится между разделителями и есть регулярное выражение.
Часто используемыми разделителями являются косые черты “/”, знаки решетки “#” и тильды “
”. Ниже представлены примеры шаблонов с корректными разделителями:
Создать регулярное выражение можно так:
Или более короткий вариант:
Пример самого простого регулярного выражения для поиска:
В этом примере мы просто ищем все символы “o”.
В PHP разница между preg_match и preg_match_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.
Пример кода на PHP:
Пробуем то же самое для второй функции:
В последнем случае функция вернула все вхождения, которые есть в нашем тексте.
Тот же пример на JavaScript:
Модификаторы шаблонов
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска. Они обозначаются одиночной буквой латинского алфавита и ставятся в конце регулярного выражения, после закрывающего “/”.
О том, какие вообще бывают модификаторы, можно почитать тут.
Пример предыдущего регулярного выражения с модификатором на JavaScript:
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.
Первый пример, нам надо получить все числа из текста:
Чтобы выбрать любое число, надо собрать все числа, указав “[0123456789]”. Более коротко можно задать вот так: “3”. Для всех цифр существует метасимвол “d”. Он работает идентично.
Но если мы укажем регулярное выражение “/d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “”, где N — нужное количество. Или задать “от” и “до”, указав вот так: “”.
Сейчас будет пара примеров, чтобы это уложилось в голове:
Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:
Такое выражение выберет все слова, которые есть в предложении и написаны кириллицей. Нам нужно третье слово.
Помимо букв и цифр у нас могут быть еще важные символы, такие как:
Если мы точно знаем, что искомое слово последнее, мы ставим “$” и результатом работы будет только тот набор символов, после которого идет конец строки.
То же самое с началом строки:
Прежде, чем знакомиться с метасимволами дальше, надо отдельно обсудить символ “^”, потому что он у нас ходит на две работы сразу (это чтобы было интереснее). В некоторых случаях он обозначает начало строки, но в некоторых — отрицание.
Это нужно для тех случаев, когда проще указать символы, которые нас не устраивают, чем те, которые устраивают.
Допустим, мы собрали набор символов, которые нам подходят: “[a-z0-9]” (нас устроит любая маленькая латинская буква или цифра). А теперь предположим, что нас устроит любой символ, кроме этого. Это будет обозначаться вот так: “[^a-z0-9]”.
Выбираем все “не пробелы”.
Итак, вот список основных метасимволов:
Операторы [] и ()
По описанному выше можно было догадаться, что [] используется для группировки нескольких символов вместе. Так мы говорим, что нас устроит любой символ из набора.
Тут мы собрали в группу (между символами []) все латинские буквы и пробел. При помощи <> указали, что нас интересуют вхождения, где минимум 2 символа, чтобы исключить вхождения из пустых пробелов.
Аналогично мы могли бы получить все русские слова, сделав инверсию: “[^A-Za-zs]<2,>”.
В отличие от [], символы () собирают отмеченные выражения. Их иногда называют “захватом”.
Они нужны для того, чтобы передать выбранный кусок (который, возможно, состоит из нескольких вхождений [] в результат выдачи).
Существует много решений. Пример ниже — это приближенный вариант, который просто покажет возможности регулярных выражений. На самом деле есть RFC, который определяет правильность email. И есть “регулярки” по RFC — вот примеры.
Мы выбираем все, что не пробел (потому что первая часть email может содержать любой набор символов), далее должен идти символ @, далее что угодно, кроме точки и пробела, далее точка, далее любой символ латиницы в нижнем регистре…
Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:
В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.
В PHP можно именовать “захваты”, используя следующий синтаксис:
Тогда массив матча станет ассоциативным:
Это сразу +100 к читаемости и кода, и регулярки.
Примеры из реальной жизни
Парсим письмо в поисках нового пароля:
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. Текст может быть либо на английском, либо на русском:
Сначала мы говорим, что текст перед паролем может быть двух вариантов, использовав “или”.
Вариантов можно перечислять сколько угодно:
Далее у нас знак двоеточия и один пробел:
А дальше нас интересует все, что не символ “
Источник
Adblock
detector
Поиск файлов с использованием регyлярных выражений
Всем хорошо известно, что для поиска файлов и папок с помощью стандартных средств Windows в именах можно использовать подстановочные символы «?» (обозначает любой один символ) и «*» (обозначает любое число любых символов). Например, на рис. 5.12 представлен результат поиска файлов *.sys (все файлы с расширением sys) на диске С:.

Рис. 5.12. Использование подстановочных символов при поиске файлов
В сценариях WSH можно производить поиск файлов (как и любого другого текста) с помощью гораздо более сложных правил для определения соответствий. Для этого используются регулярные выражения, которые определяют образец текста для поиска. Для задания этого образца используются литералы и метасимволы. Каждый символ, который не имеет специального значения в регулярных выражениях, рассматривается как литерал и должен точно совпасть при поиске. Метасимволы — это символы со специальным значением в регулярных выражениях. Описание наиболее часто используемых метасимволов приведено в табл. 5.14.
Таблица 5.14. Некоторые метасимволы, использующиеся в регулярных выражениях
Символы
Описание
Следующий символ будет являться специальным символом или, наоборот, литералом. Например, n означает символ «n», а »
» означает символ новой строки. Последовательности соответствует символ «», а ( — символ «(»
^
Начало строки
$
Конец строки
*
Предыдущий символ повторяется любое число раз (в том числе ни разу). Например, выражению zo* соответствуют как «z», так и «zoo»
+
Предыдущий символ повторяется не менее одного раза. Например, выражению zo+ соответствует «zoo», но не «z»
?
Предыдущий символ повторяется не более одного раза
. (точка)
Любой символ, кроме перевода строки
х|у
Либо символ «х», либо символ «у». Например, выражению z|food соответствуют «z» или «food»
[xyz]
Множество символов. Означает любой один символ из набора символов, заключенных в квадратные скобки. Например, выражению [abc] соответствует символ «а» в слове «plain»
[a-z]
Диапазон символов. Означает любой один символ из заданного диапазона. Например, выражению [a-z] соответствует любая буква английского алфавита в нижнем регистре
[^m-z]
Означает любой символ, не входящий в заданный диапазон. Например, выражению [^m-z] соответствует любой символ, не попадающий в диапазон символов от «m» до «z»
Граница слова, т.е. позиция между словом и пробелом. Например, выражению er соответствует символ «er» в слове «never», но не в слове «verb»
В
Позиция внутри слова (не на границе). Например, выражению еа*rB соответствует подстрока «ear» в «never early»
d
Символ, обозначающий цифру. Эквивалентно [0-9]
D
Любой символ, кроме цифры. Эквивалентно [^0-9]
Метасимволы можно употреблять совместно, например, комбинация «.*» означает любое число любых символов.
Замечание
Более подробную информацию о регулярных выражениях можно найти, например, в документации Microsoft по языку VBScript.
В качестве примера использования регулярных выражений в листинге 5.18 приведен сценарий FindRegExp.js, в котором производится поиск в подкаталоге ForFind текущего каталога всех файлов, имена которых начинаются с символов «П», «А» или «И» и имеют расширение txt.
Для получения доступа к каталогу ForFind в сценарии используется метод GetFolder объекта FileSystemObject:
//Создаем объект WshShell
WshShell=WScript.CreateObject(«WScript.Shell»);
//Создаем объект FileSystemObject
FSO=WScript.CreateObject(«Scripting.FileSystemObject»);
//Создаем объект Folder для доступа к подкаталогу ForFind
//текущего каталога
Folder = FSO.GetFolder(WshShell.CurrentDirectory+»ForFind»);
Поиск нужных файлов будет выполняться с помощью следующего регулярного выражения:
//Создаем регулярное выражение (объект RegExp)
RegEx=new RegExp(«^[ПАИ].*.txt$», «i»);
Сам поиск и вывод имен найденный файлов производятся в функции FindFilesInFolder(Fold, RegEx). Здесь сначала инициализируются счетчик найденных файлов и переменная, в которой будут сохраняться имена найденных файлов, а также создается объект Enumerator (переменная Files) для доступа к файлам каталога Fold:
ColFind=0; //Счетчик найденных файлов
SFileNames=»»; //Строка с именами файлов
//Создаем коллекцию файлов в каталоге Fold
Files=new Enumerator(Fold.Files);
Элементы коллекции просматриваются в цикле while:
//Цикл по всем файлам в коллекции
while (!Files.atEnd()) {
Files.moveNext(); //Переходим к следующему файлу
}
Для текущего файла в коллекции выделяется его имя, которое затем с помощью метода test объекта RegExp проверяется на соответствие заданному регулярному выражению:
//Выделяем имя файла
SName=Files.item().Name;
//Проверяем, соответствует ли имя файла регулярному выражению
if (RegEx.test(SName)) {
ColFind++; //Увеличиваем счетчик найденных файлов
//Добавляем имя файла к переменной SFileNames
SFileNames+=SName+ »
«;
}
В конце функции FindFilesInFolder(Fold, RegEx) на экран выводятся имена найденных файлов и их общее количество:
SItog=»Найдено файлов: «+ColFind;
//Выводим на экран имена и количество найденных файлов
WScript.Echo(SFileNames+SItog);
Листинг 5.18. Поиск файлов, имена которых соответствуют регулярному выражению
/*******************************************************************/
/* Имя: FindRegExp.js */
/* Язык: JScript */
/* Описание: Поиск файлов, имена которых соответствуют заданному */
/* регулярному выражению */
/*******************************************************************/
//Объявляем переменные
var WshShell,FSO,Folder,ColFind,RegExp,SFileNames;
//Функция для поиска файлов в заданном каталоге
function FindFilesInFolder(Fold,RegEx) {
var Files,SName; //Объявляем переменные
ColFind=0; //Счетчик найденных файлов
SFileNames=»»; //Строка с именами файлов
//Создаем коллекцию файлов в каталоге Fold
Files=new Enumerator(Fold.Files);
//Цикл по всем файлам в коллекции
while (!Files.atEnd()) {
//Выделяем имя файла
SName=Files.item().Name;
//Проверяем, соответствует ли имя файла регулярному
//выражению
if (RegEx.test(SName)) {
ColFind++; //Увеличиваем счетчик найденных файлов
//Добавляем имя файла к переменной SFileNames
SFileNames+=SName+»
«;
}
Files.moveNext(); //Переходим к следующему файлу
}
SItog=»Найдено файлов: «+ColFind;
//Выводим на экран имена и количество найденных файлов
WScript.Echo(SFileNames+SItog);
}
/******************* Начало **********************************/
//Создаем объект WshShell
WshShell=WScript.CreateObject(«WScript.Shell»);
//Создаем объект FileSystemObject
FSO=WScript.CreateObject(«Scripting.FileSystemObject»);
//Создаем объект Folder для доступа к подкаталогу ForFind
//текущего каталога
Folder = FSO.GetFolder(WshShell.CurrentDirectory+»ForFind»);
//Создаем регулярное выражение (объект RegExp)
RegExp=new RegExp(«^[ПАИ].*.txt$»,»i»);
//Ищем файлы, имена которых соответствуют регулярному
//выражению RegExp в каталоге Folder
FindFilesInFolder(Folder,RegExp);
/************* Конец *********************************************/
Читайте также
Копирование файлов с использованием стандартной библиотеки С
Копирование файлов с использованием стандартной библиотеки С
Как видно из текста программы 1.1, стандартная библиотека С поддерживает объекты потоков ввода/вывода FILE, которые напоминают, несмотря на меньшую общность, объекты Windows HANDLE, представленные в программе
Копирование файлов с использованием Windows
Копирование файлов с использованием Windows
В программе 1.2 решается та же задача копирования файлов, но делается это с помощью Windows API, а базовые приемы, стиль и соглашения, иллюстрируемые этой программой, будут использоваться на протяжении всей этой книги.Программа 1.2. cpW:
Копирование файлов с использованием вспомогательной функции Windows
Копирование файлов с использованием вспомогательной функции Windows
Для повышения удобства работы в Windows предусмотрено множество вспомогательных функций (convenience functions), которые, объединяя в себе несколько других функций, обеспечивают выполнение часто встречающихся задач
Пример: последовательная обработка файлов с использованием метода отображения
Пример: последовательная обработка файлов с использованием метода отображения
Программа atou (программа 2.4) иллюстрирует последовательную обработку файлов на примере преобразования ASCII-файлов к кодировке Unicode, приводящего к удвоению размера файла. Этот случай является
Пример: преобразование файлов с использованием перекрывающегося ввода/вывода и множественной буферизации
Пример: преобразование файлов с использованием перекрывающегося ввода/вывода и множественной буферизации
Программа 2.4 (atou) осуществляла преобразование ASCII-файла к кодировке UNICODE путем последовательной обработки файла, а в главе 5 было показано, как выполнить такую же
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам»
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам»
Тема научного поиска не прошла мимо разработчиков персональных поисковиков. Подробному рассказу о возможностях таких поисковых систем посвящена отдельная глава нашей книги (см. главу 6).
Поиск файлов на FTP-серверах
Поиск файлов на FTP-серверах
FTP-серверы привлекательны тем, что обеспечивают возможность получать доступ непосредственно к файлам (без текстовой информации) и быстрее (чем по протоколу HTTP) загружать выбранные объекты на жесткий диск компьютера. Самое сложное в Интернете —
Поиск и закачка файлов
Поиск и закачка файлов
Теперь, когда мы познакомились с окном программы DC++, следует приступить к поиску и закачке понравившихся файлов.Как уже упоминалось ранее, загрузка файлов в сетях Direct Connect происходит напрямую с компьютера пользователя. Хаб является только
10.1.34. Поиск файлов и каталогов
10.1.34. Поиск файлов и каталогов
Ниже мы воспользовались стандартной библиотекой find.rb для написания метода, который находит один или более файлов и возвращает их список в виде массива. Первый параметр — это начальный каталог, второй — либо имя файла (строка), либо
Поиск с использованием подзапроса
Поиск с использованием подзапроса
Использование существующих предикатов в подзапросах- особенно предиката EXISTS О- обсуждалось в главе 21. Подзапросы могут также быть использованы другими способами в предикатах условий поиска в предложениях WHERE и
Поиск в содержимом файлов
Поиск в содержимом файлов
По умолчанию операционная система Windows Vista поддерживает возможность выполнения поиска в содержимом файлов со следующими расширениями: ASM, BAT, C, CMD, CPP, DIC, H, INF, INI, JAVA, LOG, M3U, MDB, RC, REG, SQL, TXT, VBS, WRI и т. д.Однако вы можете самостоятельно определить расширения
7.7. Поиск файлов
7.7. Поиск файлов
Для поиска файлов выполните команду главного меню Windows Пуск, Найти, Файлы и папки или нажмите Win+F — так будет быстрее. Вы увидите окно поиска (рис. 64). Помощник поиска предложит вам выбрать категории файлов, которые вы хотите найти. Если вы не собираетесь
4.4. Поиск файлов и папок
4.4. Поиск файлов и папок
Для поиска файлов нажмите <Win>+<F> и введите имя файла или папки. Вместо имени можно ввести маску (см. ранее). Второй способ: нажмите кнопку Пуск и в поле Найти программы и файлы введите имя файла (папки) или маску. Вы увидите результаты поиска. На
2.4.8. Поиск файлов и папок
2.4.8. Поиск файлов и папок
Иногда случается пренеприятная ситуация — предположим, писали вы что-то, или рисовали, или еще чего делали, сохранили ваши достижения на жесткий диск и… начисто забыли, в какой папке результаты ваших трудов лежат-покоятся. Диск большой, папок
I’m doing a little string validation with findstr and its /r flag to allow for regular expressions. In particular I’d like to validate integers.
The regex
^[0-9][0-9]*$
worked fine for non-negative numbers but since I now support negative numbers as well I tried
^([1-9][0-9]*|0|-[1-9][0-9]*)$
for either positive or negative integers or zero.
The regex works fine theoretically. I tested it in PowerShell and it matches what I want. However, with
findstr /r /c:"^([1-9][0-9]*|0|-[1-9][0-9]*)$"
it doesn’t.
While I know that findstr doesn’t have the most advanced regex support (even below Notepad++ which is probably quite an achievement), I would have expected such simple expressions to work.
Any ideas what I’m doing wrong here?
![]()
jfs
390k188 gold badges966 silver badges1647 bronze badges
asked Apr 10, 2010 at 15:10
![]()
4
This works for me:
findstr /r "^[1-9][0-9]*$ ^-[1-9][0-9]*$ ^0$"
If you don’t use the /c option, the <Strings> argument is treated as a space-separated list of search strings, which makes the space a sort of crude replacement for the | construct. (As long as your regexes don’t contain spaces, that is.)
answered Apr 11, 2010 at 0:29
![]()
Alan MooreAlan Moore
73k12 gold badges98 silver badges155 bronze badges
2
Argh, I should have read the documentation better. findstr apparently doesn’t support alternations (|).
So I’m probably back to multiple invocations or replacing the whole thing with a custom parser eventually.
This is what I do for now:
set ERROR=1
rem Test for zero
echo %1|findstr /r /c:"^0$">nul 2>&1
if not errorlevel 1 set ERROR=
rem Test for positive numbers
echo %1|findstr /r /c:"^[1-9][0-9]*$">nul 2>&1
if not errorlevel 1 set ERROR=
rem Test for negative numbers
echo %1|findstr /r /c:"^-[1-9][0-9]*$">nul 2>&1
if not errorlevel 1 set ERROR=
answered Apr 10, 2010 at 15:13
![]()
JoeyJoey
339k83 gold badges681 silver badges680 bronze badges
2
Or if you can, download grep for windows.. Many more features than findstr provides.
answered Apr 10, 2010 at 15:19
![]()
ghostdog74ghostdog74
320k56 gold badges255 silver badges342 bronze badges
2
A simpler regex that achieves the same thing is possible, just add an optional minus to the start of your original expression:
^-?[0-9][0-9]*$
![]()
answered Apr 8, 2016 at 10:40
![]()
martskimartski
3441 silver badge5 bronze badges
Support for regex in findstr is quite limited. I suggest using Notepad++. The find in files option supports Perl Compatible Regular Expressions; results showing filename, line number and matching text can be easily copied to a text file.
answered Jun 13, 2019 at 13:14
![]()
Paulo MersonPaulo Merson
12.6k7 gold badges77 silver badges72 bronze badges
1
Поиск образцов текста в файлах с использованием регулярных выражений.
Синтаксис
findstr [/b] [/e] [/l] [ /r] [/s] [/i] [/x] [/v] [ /n] [/m] [/o] [/p] [/offline] [ /g:файл] [/f:файл] [/c:строка] [ /d:СписокКаталогов] [/a:АтрибутЦвета] [строки] [[ диск:][путь] ИмяФайла […]]
Параметры
- /b
- Сравнивает шаблон с началом строки.
- /e
- Сравнивает шаблон с концом строки.
- /l
- Использует заданную строку буквально.
- /r
- Использует строку поиска как регулярное выражение. Команда Findstrинтерпретирует все метасимволы как регулярные выражения, если не используется ключ /l.
- /s
- Задает поиск файлов в текущем каталоге и его подкаталогах.
- /i
- Задает поиск без различия строчных и заглавных букв.
- /x
- Печатает точно совпавшие строки.
- /v
- Печатает строки, не содержащие совпадений.
- /n
- Печатает в начале совпавшей строки ее номер.
- /m
- Печатает только имя файла при обнаружении совпадения.
- /o
- Печатает смещение перед выводом строки с совпадением.
- /p
- Пропускает файлы с непечатаемыми символами.
- /offline
- Обработка файлов с автономным атрибутом.
- /f:файл
- Читает список из заданного файла.
- /c:строка
- Использует заданный текст как литеральную строку поиска.
- /g:файл
- Получает строки поиска из заданного файла.
- /d:СписокКаталогов
- Ищет в списке каталогов, разделенном запятыми.
- /a:АтрибутЦвета
- Задает атрибуты цвета двумя шестнадцатеричными цифрами.
- строки
- Текст, поиск которого производится в файле, заданном параметромИмяФайла.
- [диск:][путь] ИмяФайла […]
- Файл или несколько файлов для поиска.
- /?
- Отображение справки в командной строке.
Заметки
- Использование регулярных выражений с командой findstr
Команда findstr способна выполнять точный поиск текста в любом текстовом файле или файлах формата ASCII. Однако иногда имеется только часть информации, которая должна быть найдена, или требуется найти информацию в широком диапазоне. В таких случаях команда findstr предоставляет мощную возможность поиска с использованием регулярных выражений.
В противоположность точному заданию строки символов для поиска, регулярные выражения позволяют задать образец текста. Для задания образца используются литералы и метасимволы. Каждый символ, который не имеет специального значения в регулярных выражениях, рассматривается как литерал и должен точно совпасть при поиске. Например, буквы и цифры являются литеральными символами. Метасимволы это символы со специальным значением (оператор или разделитель) в регулярных выражениях.
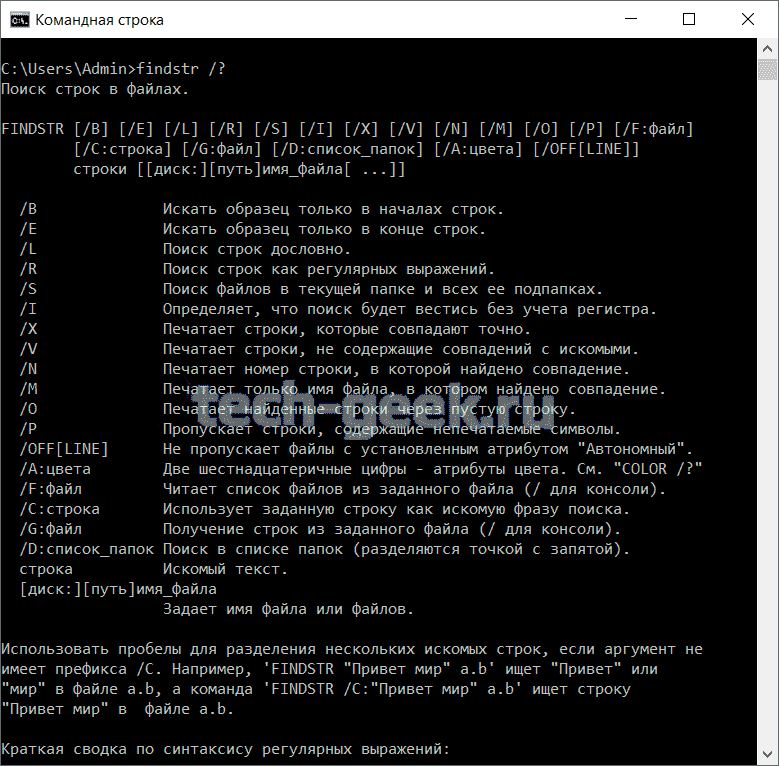
В приведенной ниже таблице перечислены метасимволы, допустимые для команды findstr.
Символ Значение . Подстановочный знак: любой символ * Повтор: ноль или более предшествующих символов или классов символов. ^ Позиция строки: начало строки $ Позиция строки: конец строки [класс] Класс символа: любой символ из множества [^класс] Инвертированный класс: любой символ из множества [x—y] Диапазон: любой символ из диапазона x Исключение: использование метасимвола x в качестве литерала <xyz Позиция слова: начало слова xyz> Позиция слова: конец слова Специальные символы в регулярных выражениях дают наилучший результат при совместном использовании. Например, при комбинации символа подстановки (.) и повторителя (*) совпадает любая строка символов:
.*
Используйте следующее выражение как часть более объемного выражения, которое совпадает со строкой, начинающейся с «b» и оканчивающейся на «ing»:
b.*ing
Примеры
Для отделения строк поиска друг от друга следует использовать пробелы, кроме тех случаев, когда задан ключ /c. Для поиска слова «hello» или «there» в файле x.y введите следующую каманду:
findstr «hello there» x.y
Для поиска словосочетания «hello there» в файле x.y введите следующую каманду:
findstr /c:»hello there» x.y
Для поиска всех слов «Windows» (с первой заглавной буквой W) в файле Proposal.txt может быть использована следующая команда:
findstr Windows proposal.txt
Для поиска в каждом файле текущего каталога и в файлах всех подкаталогов слова «Windows» без учета строчных и заглавных букв может быть использована следующая команда:
findstr /s /i Windows *.*
Для поиска всех строк, содержащих слово «FOR», перед которым идет несколько пробелов (чтобы найти в программе оператор цикла), с выводом номера каждой строки можно использовать команду:
findstr /b /n /c:» *FOR» *.bas
Если требуется найти несколько разных наборов символов в нескольких файлах, можно создать текстовый файл, каждая строка которого содержит образец для поиска. Также можно задать точный список файлов, если поиск будет производиться в текстовых файлах. Для использования файла Finddata.txt, содержащего образцы для поиска, файла Filelist.txt, содержащего список файлов, в которых будет производиться поиск, и записи результатов работы программы в файл Results.out служит следующая команда:
findstr /g:finddata.txt /f:filelist.txt > results.out
Предположим, необходимо найти каждый файл в текущем каталоге и его подкаталогах, содержащий слово «computer» без различия строчных и заглавных букв. Для вывода списка таких файлов можно использовать следующую команду:
findstr /s /i /m «<computer>» *.*
Теперь, предположим, требуется найти не только само слово «computer», но и все другие слова, начинающиеся с тех же букв, таких как «compliment» и «compete». Введите следующую команду:
findstr /s /i /m «<comp.*» *.*
Вы когда-нибудь слышали о FINDSTR и Select-String ? Select-String-это командлет, который используется для поиска текста и шаблонов во входных строках и файлах. Он похож на grep в Linux и FINDSTR в Windows. В этом руководстве мы увидим, что и как использовать команды FINDSTR и Select-String в Windows 11/10.
FINDSTR-это команда, используемая для поиска определенного текста в файлах в Windows. Строка Find при кратком превращении стала FINDSTR. Он также используется для поиска файлов с определенным текстом. Существуют различные команды FINDSTR для выполнения различных функций. Впервые он был выпущен вместе с Windows 2000 Resource Kit под названием qgrep . Это встроенный инструмент в Windows, и его файл доступен в формате.exe. FINDSTR не выполняет поиск нулевых байтов, таких как пробелы, в формате Unicode.
Существуют некоторые основные правила использования команды findstr в командной строке или других интерпретаторах командной строки, разработанные Microsoft . Это:
Каждая команда FINDSTR должна содержать строку, за которой следует имя файла. Вы можете использовать буквальные символы и метасимволы в командах FINDSTR. Буквенные символы не имеют особого значения в синтаксисе. Буквы и цифры называются буквальными символами. Мета-символы-это символы, каждый из которых имеет определенное значение. Ниже приведены допустимые метасимволы в синтаксисе и их значения.
Метасимвол
Значение
.
Подстановочный знак -любой символ
*
Повтор -ноль или более вхождений предыдущего символа или класса.
^
Позиция начала строки -начало строки.
$
Позиция конечной строки -конец строка.
[class]
Класс символа -любой символ в наборе.
[^ class]
Обратный класс -любой символ, не входящий в набор.
[xy]
Диапазон -любой символов в указанном диапазоне.
x
Escape -буквальное использование метасимвола.
Позиция начала слова -начало слова.
string >
Позиция конечного слова -Конец слова.
Вы должны создать текстовый файл с поиском c riteria в отдельной строке, если вы хотите найти несколько строк. Используйте пробелы между строками для поиска нескольких строк в одной команде, за исключением синтаксиса с/c.
Параметры и их значения в синтаксисе findstr
Параметр
Описание
/b
Соответствует текстовому шаблону, если он находится в начале строки.
/e
Соответствует текстовому шаблону, если он находится в конце строки.
/l
Обрабатывает строки поиска буквально.
/r
Обрабатывает строки поиска как регулярные выражения. Это настройка по умолчанию.
/s
Выполняет поиск в текущем каталоге и во всех подкаталогах.
/i
Игнорирует регистр символы при поиске строки.
/x
Печатает строки, которые точно соответствуют.
/v
Печатает только те строки, которые не содержат совпадений.
/n
Печатает номер каждой строки, которая соответствует.
/m
Печатает только имя файла, если файл содержит совпадение.
/o
Печатает смещение символа перед каждой совпадающей строкой.
/p
Пропускает файлы с непечатаемыми символами.
/off [line]
Не пропускает файлы с установленным атрибутом offline.
/f:
Получает список файлов из указанного файла.
/c:
Использует указанный текст как буквальную строку поиска.
/g:
Получает строки поиска из указанного файла.
/d:
Выполняет поиск в указанном списке каталогов. Каждый каталог должен быть разделен точкой с запятой (;), например dir1; dir2; dir3.
/a:
Задает атрибуты цвета с двумя шестнадцатеричными цифрами. Цвет шрифта
/? для получения дополнительной информации.
Задает текст для поиска в имени файла. Обязательно.
[ :] [] […]
Указывает расположение и файл или файлы для поиска. Требуется хотя бы одно имя файла.
/?
Отображает справку в командной строке.
Использование команд findstr
1] Для поиска слова microsoft или windows в файле xy вы должны использовать:
findstr microsoft windows xy
2] Для поиска для слова microsoft windows в файле xy вы должны использовать:
findstr/c:”microsoft windows”xy
В приведенной выше команде/c используется для поиска указанного текста «Microsoft Windows» в файле.
3] Если вы хотите найти в текстовом файле twc.txt вхождения слова Microsoft с большой буквы, вы должны использовать:
findstr Microsoft twc.txt
4] Если вы хотите найти определенное слово Microsoft в каталоге и его подкаталогах, не придавая значения регистрам, используйте:
findstr/s/i Microsoft *. *
В приведенном выше синтаксисе/s используется для поиска в текущем каталоге и его подкаталогах./i используется для игнорирования регистра типа (заглавная M) в строке Microsoft.
5] Если вы хотите найти строки, начинающиеся с To с несколькими пробелами перед словом, и хотите отобразить номер строки, где строки встречаются, используйте:
findstr/b/n/r/c: ^ * To *.bas
6] Если вы хотите искать несколько строк в нескольких файлах с критерии поиска в stringlist.txt и список файлов в filelist.txt, и вы хотите увидеть результаты, хранящиеся в файле result.out, используйте:
findstr/g:stringlist.txt/f:filelist.txt > results.out
7] Если вы хотите найти файлы, содержащие слово thewindowsclub в определенном каталоге и его подкаталогах, используйте:
findstr/s/i/m *. *
8] Если вы хотите найти файлы, содержащие thewindowsclub и другие слова, начинающиеся с подобных тезисов, термометра и т. д., используйте:
findstr/s/i/m
Это способы использования команд findstr в интерпретаторах командной строки, таких как командная строка и т. д. должны понимать каждый параметр и его функцию, а также метасимволы и их значение, чтобы писать синтаксис и регулярно использовать команду findstr.
Что такое Select-String и его параметры
Представьте себе вы пишете фрагменты кода в PowerShell и потеряли из виду определенные строки и текст в этом файле PowerShell. Вам нужно найти это во многих тысячах строк кода в тысячах строк и слов. Появляется команда Select-String, которая позволяет вам искать строки и текст в этих входных файлах PowerShell. Он похож на grep в Linux.
Select-String-это командлет, который используется для поиска текста и шаблонов во входных строках и файлах. Он похож на grep в Linux и FINDSTR в Windows. При использовании Select-String для поиска некоторого текста он находит первое совпадение в каждой строке и отображает имя файла, номер строки и всю строку, в которой произошло совпадение. Его можно использовать для поиска нескольких совпадений в строке или для отображения текста до или после совпадения или для получения результатов в логических выражениях, таких как True или False. Вы также можете использовать его для отображения всего текста, кроме совпадения с выражением, которое вы используете в команде. Подстановочные знаки, которые вы используете в FINDSTR, также можно использовать в Select-String. Кроме того, Select-String работает с различными кодировками файлов, такими как ASCII, Unicode и т. Д. Он использует Byte-Order-Mark (BOM) для определения кодировки файла. Если спецификация отсутствует в файле, Select-String примет файл как UTF8.
Параметры Select-String
Microsoft предусмотрела и разработала следующие параметры, которые будут использоваться в синтаксисе..
-AllMatches
Он используется для поиска всех совпадений в строке, в отличие от первого совпадения в строке, которое обычно выполняет Select-Sting.
-CaseSensitive
Он означает, что совпадение чувствительно к регистру. По умолчанию Select-String не чувствителен к регистру.
-Context
Он используется для захвата указанного количества строк, которые вы вводите до и после строки соответствия. Если вы введете 1, он захватит одну строку до и после совпадения.
-Culture
В кодировании есть определенные культуры, такие как порядковый, инвариантный и т. Д. Этот параметр используется для указания культуры в синтаксисе.
-Encoding
Он используется для указания формата кодировки текста в таких файлах, как ASCII, UTF8, UTF7, Unicode, и т. д.
-Exclude
Этот параметр используется для исключения определенного текста из файла.
-Include
Этот параметр используется для включения определенного текста в файл.
-InputObject
Используется для указания текста для поиска.
-List
Он используется для получения списка файлов, соответствующих тексту.
-LiteralPath
Используется для указания пути для поиска.
-NoEmphasis
Как правило, Select-String выделяет совпадение в файле. Этот параметр используется, чтобы избежать выделения.
-NotMatch
Он используется для поиска текста, не соответствующего указанному шаблону.
-Path
Он используется для указания пути для поиска вместе с использованием подстановочных знаков.
-Pattern
Параметр используется для поиска совпадения в каждой строке в качестве шаблона.
-Quiet
Этот параметр используется для получения вывода в виде логических значений, таких как True или False.
-Raw
Он используется для просмотра только совпадающих объектов, а не для информации о совпадении.
-SimpleMatch
Параметр используется для указания простого совпадения, а не совпадения по регулярному выражению.
Разница между FINDSTR и Select-String
FINDSTR-это исполняемый файл, созданный до эпохи PowerShell, который используется для поиска текста и строк в файлах. Select-String-это командлет PowerShell, который используется для поиска текста и шаблонов в файлах. По сравнению с FINDSTR, Select-String является более мощным и сложным командлетом, который отображает много информации о совпадении.
Что такое PowerShell, эквивалент grep?
Select-String-это PowerShell-эквивалент grep, доступный в Windows. Он работает так же, как grep, и предоставляет подробную информацию о совпадении в соответствии с параметрами, которые мы используем в синтаксисе.
Работает ли FINDSTR с файлами Word?
Да, FINDSTR работает в файлах Word. Но он не может показать найденные совпадения, даже если введенные вами строки присутствуют в файле. Он может давать результаты в двоичных файлах в форматах.doc, но не в форматах.docx по неизвестным техническим причинам.
Связанное чтение : Как проверить версию PowerShell в Windows.
Если вы хотите найти определенный текст в файлах из командной строки, вы можете использовать нативную команду Windows findstr.
Findstr — это встроенный инструмент операционной системы Windows, который вы можете запускать из командной строки для поиска текста в файлах или в выводах командной строки.
Вы можете использовать приложение для фильтрации выходов командной строки, поиска отдельных файлов или целых структур каталогов для файлов с соответствующим текстом.
Вам может быть интересно: Как открыть большой текстовый файл
Вы можете запустить findstr из командной строки или командных файлов. Откройте командную строку, нажав на клавишу Windows, и наберите в ней cmd.exe.
Полезные параметры для поиска текста в файлах из командной строки с findstr:
- /? — отобразить текст справки
- / S — ищет каталог и все подкаталоги
- / I — поиск не чувствителен к регистру
- / R — использовать строки поиска в качестве регулярных выражений
- / B — соответствует шаблонам в начале строк
- / P — пропускать файлы с непечатаемыми символами
- / V — печатать только строки, содержащие совпадение
- / N — распечатать номер строки
Список примеров, которые могут оказаться полезными:
- ipconfig | findstr «192.168» — команда запускает ipconfig и возвращает любой результат, соответствующий 192.168. Любой другой результат игнорируется.
- netstat | findstr «123.123.123.13» — запускает команду netstat и возвращает любой результат, соответствующий строке (в данном случае IP-адрес).
- findstr / c: «windows 10» windows.txt — Ищет документ windows.txt для строки «windows 10»
- findstr «windows 10» windows txt — Ищет слова «windows» или «10» в файле.
- findstr «windows» c:documents *. * — Ищет любой файл под c:documents для строки «windows».
- findstr / s / i Windows *. * — Поиск каждого файла в текущем каталоге и всех подкаталогах для слова Windows, игнорирующего регистр букв.
- findstr / b / n / r / c: «^ * FOR» * .bas— Возвращает любую строку, начинающуюся с FOR, которой предшествует ноль или больше пробелов. Также печатает номер строки.
Findstr — мощная команда, которую вы можете использовать для поиска текста в файлах из командной строки. Вы можете использовать его для сканирования целых структур каталогов или дисков, которые соответствуют выбранной строке или ее части, и быстро найти указанный текст не закрывая командную строку.
Запустите findstr /? из командной строки для отображения всех параметров и опций, поддерживаемых «Find String».
Дополнительные параметры включают возврат содержимого, которое находится в начале или конце строк, с использованием регулярных выражений или с использованием подстановочных знаков.
Заключение
Главное преимущество Findstr в том, что это встроенный инструмент, который можно запускать на любой машине Windows. Уметь быстро находить текст в файлах — полезно. Findstr также служит инструментом для фильтрации вывода инструментов командной строки.
Если же вам необходим поиск текста в файлах без привязки к командной строке, то вам помогут сторонние инструменты, такие как Notepad ++, GGRep или Everything.


 (3 оценок, среднее: 3,67 из 5)
(3 оценок, среднее: 3,67 из 5)
![]() Загрузка…
Загрузка…