Все приложения взаимодействуют с данными, чаще всего через систему управления базами данных (СУБД). Одни языки программирования поставляются с модулями для работы с СУБД, другие требуют использования сторонних пакетов. Из этого подробного руководства вы узнаете о различных библиотеках Python для работы с SQL-базами данных. Мы разработаем простое приложение для взаимодействия с БД SQLite, MySQL и PostgreSQL.
Примечание. Если вы не разбираетесь в базах данных, советуем обратить внимание на следующие публикации Библиотеки программиста: 11 типов современных баз данных, SQL за 20 минут, Подборка материалов для изучения баз данных и SQL.
Из этого пособия вы узнаете:
- как подключиться к различным СУБД с помощью библиотек Python для работы с SQL базами данных;
- как управлять базами данных SQLite, MySQL и PostgreSQL;
- как выполнять запросы к базе данных внутри приложения Python;
- как разрабатывать приложения для разных баз данных.
Чтобы получить максимальную отдачу от этого учебного пособия, необходимо знать основы Python, SQL и работы с СУБД. Вы также должны иметь возможность загружать и импортировать пакеты в Python и знать, как устанавливать и запускать серверы БД локально или удаленно.
Содержание статьи:
- Схема базы данных
- Подключение к базам данных
- Создание таблиц
- Вставка записей
- Извлечение записей
- Обновление содержания
- Удаление записей таблицы
В каждом разделе по три подраздела: SQLite, MySQL и PostgreSQL.
1. Схема базы данных для обучения
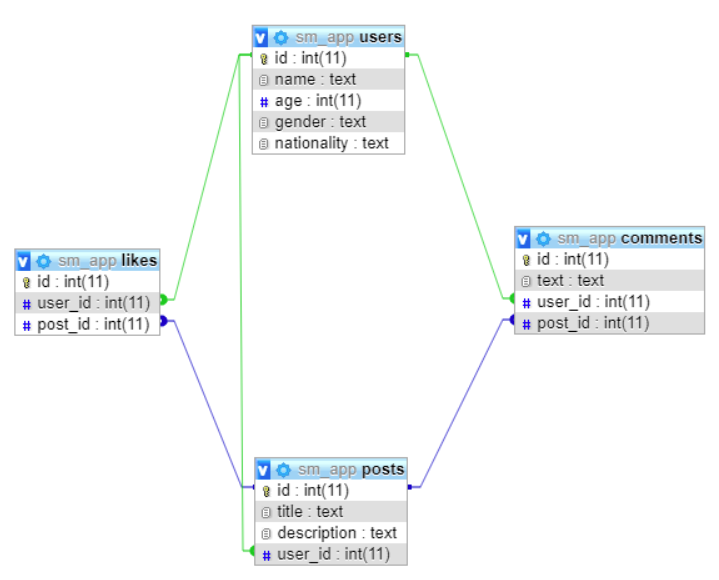
В этом уроке мы разработаем очень маленькую базу данных приложения для социальных сетей. База данных будет состоять из четырех таблиц:
userspostscommentslikes
Схема базы данных показана на рисунке ниже.
Пользователи (users) и публикации (posts) будут находиться иметь тип связи один-ко-многим: одному читателю может понравиться несколько постов. Точно так же один и тот же юзер может оставлять много комментариев (comments), а один пост может иметь несколько комментариев. Таким образом, и users, и posts по отношению к comments имеют тот же тип связи. А лайки (likes) в этом плане идентичны комментариям.
2. Подключение к базам данных
Прежде чем взаимодействовать с любой базой данных через SQL-библиотеку, с ней необходимо связаться. В этом разделе мы рассмотрим, как подключиться из приложения Python к базам данных SQLite , MySQL и PostgreSQL. Рекомендуем сделать собственный .py файл для каждой из трёх баз данных.
Примечание. Для выполнения разделов о MySQL и PostgreSQL необходимо самостоятельно запустить соответствующие серверы. Для быстрого ознакомления с тем, как запустить сервер MySQL, ознакомьтесь с разделом MySQL в публикации Запуск проекта Django (англ.). Чтобы узнать, как создать базу данных в PostgreSQL, перейдите к разделу Setting Up a Database в публикации Предотвращение атак SQL-инъекций с помощью Python (англ.).
SQLite
SQLite, вероятно, является самой простой базой данных, к которой можно подключиться с помощью Python, поскольку для этого не требуется устанавливать какие-либо внешние модули. По умолчанию стандартная библиотека Python уже содержит модуль sqlite3.
Более того, SQLite база данных не требует сервера и самодостаточна, то есть просто читает и записывает данные в файл. Подключимся с помощью sqlite3 к базе данных:
import sqlite3
from sqlite3 import Error
def create_connection(path):
connection = None
try:
connection = sqlite3.connect(path)
print("Connection to SQLite DB successful")
except Error as e:
print(f"The error '{e}' occurred")
return connection
Вот как работает этот код:
- Строки 1 и 2 – импорт
sqlite3и классаError. - Строка 4 определяет функцию
create_connection(), которая принимает путь к базе данных SQLite. - Строка 7 использует метод
connect()и принимает в качестве параметра путь к базе данных SQLite. Если база данных в указанном месте существует, будет установлено соединение. В противном случае по указанному пути будет создана новая база данных и так же установлено соединение. - В строке 8 выводится состояние успешного подключения к базе данных.
- Строка 9 перехватывает любое исключение, которое может быть получено, если методу
.connect()не удастся установить соединение. - В строке 10 отображается сообщение об ошибке в консоли.
sqlite3.connect(path) возвращает объект connection. Этот объект может использоваться для выполнения запросов к базе данных SQLite. Следующий скрипт формирует соединение с базой данных SQLite:
connection = create_connection("E:\sm_app.sqlite")
Выполнив вышеуказанный скрипт, вы увидите, как в корневом каталоге диска E появится файл базы данных sm_app.sqlite. Конечно, вы можете изменить местоположение в соответствии с вашими интересами.
MySQL
В отличие от SQLite, в Python по умолчанию нет модуля, который можно использовать для подключения к базе данных MySQL. Для этого вам нужно установить драйвер Python для MySQL. Одним из таких драйверов является mysql-connector-python. Вы можете скачать этот модуль Python SQL с помощью pip:
pip install mysql-connector-python
Обратите внимание, что MySQL – это серверная система управления базами данных. Один сервер MySQL может хранить несколько баз данных. В отличие от SQLite, где соединение равносильно порождению БД, формирование базы данных MySQL состоит из двух этапов:
- Установка соединения с сервером MySQL.
- Выполнение запроса для создания БД.
Определим функцию, которая будет подключаться к серверу MySQL и возвращать объект подключения:
import mysql.connector
from mysql.connector import Error
def create_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("Connection to MySQL DB successful")
except Error as e:
print(f"The error '{e}' occurred")
return connection
connection = create_connection("localhost", "root", "")
В приведенном выше коде мы определили новую функцию create_connection(), которая принимает три параметра:
host_nameuser_nameuser_password
Модуль mysql.connector определяет метод connect(), используемый в седьмой строке для подключения к серверу MySQL. Как только соединение установлено, объект connection возвращается вызывающей функции. В последней строке функция create_connection() вызывается с именем хоста, именем пользователя и паролем.
Пока мы только установили соединение. Самой базы ещё нет. Для этого мы определим другую функцию – create_database(), которая принимает два параметра:
- Объект
connection; query– строковый запрос о создании базу данных.
Вот как выглядит эта функция:
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as e:
print(f"The error '{e}' occurred")
Для выполнения запросов используется объект cursor.
Создадим базу данных sm_app для нашего приложения на сервере MySQL:
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Теперь у нас есть база данных на сервере. Однако объект connection, возвращаемый функцией create_connection() подключен к серверу MySQL. А нам необходимо подключиться к базе данных sm_app. Для этого нужно изменить create_connection() следующим образом:
def create_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("Connection to MySQL DB successful")
except Error as e:
print(f"The error '{e}' occurred")
return connection
Функция create_connection() теперь принимает дополнительный параметр с именем db_name. Этот параметр указывает имя БД, к которой мы хотим подключиться. Имя теперь можно передать при вызове функции:
connection = create_connection("localhost", "root", "", "sm_app")
Скрипт успешно вызывает create_connection() и подключается к базе данных sm_app.
PostgreSQL
Как и в случае MySQL, для PostgreSQL в стандартной библиотеке Python нет модуля для взаимодействия с базой данных. Но и для этой задачи есть решение – модуль psycopg2:
pip install psycopg2
Определим функцию create_connection() для подключения к базе данных PostgreSQL:
from psycopg2 import OperationalError
def create_connection(db_name, db_user, db_password, db_host, db_port):
connection = None
try:
connection = psycopg2.connect(
database=db_name,
user=db_user,
password=db_password,
host=db_host,
port=db_port,
)
print("Connection to PostgreSQL DB successful")
except OperationalError as e:
print(f"The error '{e}' occurred")
return connection
Подключение осуществляется через интерфейс psycopg2.connect(). Далее используем написанную нами функцию:
connection = create_connection(
"postgres", "postgres", "abc123", "127.0.0.1", "5432"
)
Теперь внутри дефолтной БД postgres нужно создать базу данных sm_app. Ниже определена соответствующая функция create_database():
def create_database(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Запустив вышеприведенный скрипт, мы увидим базу данных sm_app на своем сервере PostgreSQL. Подключимся к ней:
connection = create_connection(
"sm_app", "postgres", "abc123", "127.0.0.1", "5432"
)
Здесь 127.0.0.1 и 5432 это соответственно IP-адресу и порт хоста сервера.
3. Создание таблиц
В предыдущем разделе мы увидели, как подключаться к серверам баз данных SQLite, MySQL и PostgreSQL, используя разные библиотеки Python. Мы создали базу данных sm_app на всех трех серверах БД. В данном разделе мы рассмотрим, как формировать таблицы внутри этих трех баз данных.
Как обсуждалось ранее, нам нужно получить и связать четыре таблицы:
userspostscommentslikes
SQLite
Для выполнения запросов в SQLite используется метод cursor.execute(). В этом разделе мы определим функцию execute_query(), которая использует этот метод. Функция будет принимать объект connection и строку запроса. Далее строка запроса будет передаваться методу execute( ). В этом разделе он будет использоваться для формирования таблиц, а в следующих – мы применим его для выполнения запросов на обновление и удаление.
Примечание. Описываемый далее скрипт – часть того же файла, в котором мы описали соединение с базой данных SQLite.
Итак, начнем с определения функции execute_query():
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query executed successfully")
except Error as e:
print(f"The error '{e}' occurred")
Теперь напишем передаваемый запрос (query):
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
);
"""
В запросе говорится, что нужно создать таблицу users со следующими пятью столбцами:
idnameagegendernationality
Наконец, чтобы появилась таблица, вызываем execute_query(). Передаём объект connection, который мы описали в предыдущем разделе, вместе с только что подготовленной строкой запроса create_users_table:
execute_query(connection, create_users_table)
Следующий запрос используется для создания таблицы posts:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id)
);
"""
Поскольку между users и posts имеет место отношение один-ко-многим, в таблице появляется ключ user_id, который ссылается на столбец id в таблице users. Выполняем следующий скрипт для построения таблицы posts:
execute_query(connection, create_posts_table)
Наконец, формируем следующим скриптом таблицы comments и likes:
create_comments_table = """
CREATE TABLE IF NOT EXISTS comments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
user_id INTEGER NOT NULL,
post_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
create_likes_table = """
CREATE TABLE IF NOT EXISTS likes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL,
post_id integer NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
execute_query(connection, create_comments_table)
execute_query(connection, create_likes_table)
Вы могли заметить, что создание таблиц в SQLite очень похоже на использование чистого SQL. Все, что вам нужно сделать, это сохранить запрос в строковой переменной и затем передать эту переменную cursor.execute().
MySQL
Так же, как с SQLite, чтобы создать таблицу в MySQL, нужно передать запрос в cursor.execute(). Создадим новый вариант функции execute_query():
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query executed successfully")
except Error as e:
print(f"The error '{e}' occurred")
Описываем таблицу users:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT,
name TEXT NOT NULL,
age INT,
gender TEXT,
nationality TEXT,
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_users_table)
Запрос для реализации отношения внешнего ключа в MySQL немного отличается от SQLite. Более того, MySQL использует ключевое слово AUTO_INCREMENT для указания столбцов, значения которых автоматически увеличиваются при вставке новых записей.
Следующий скрипт составит таблицу posts, содержащую внешний ключ user_id, который ссылается на id столбца таблицы users:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id INT AUTO_INCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY fk_user_id (user_id) REFERENCES users(id),
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_posts_table)
Аналогично для создания таблиц comments и likes, передаём соответствующие CREATE-запросы функции execute_query().
PostgreSQL
Применение библиотеки psycopg2 в execute_query() также подразумевает работу с cursor:
def execute_query(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
Мы можем использовать эту функцию для организации таблиц, вставки, изменения и удаления записей в вашей базе данных PostgreSQL.
Создадим внутри базы данных sm_app таблицу users :
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
)
"""
execute_query(connection, create_users_table)
Запрос на создание таблицы users в PostgreSQL немного отличается от SQLite и MySQL. Здесь для указания столбцов с автоматическим инкрементом используется ключевое слово SERIAL. Кроме того, отличается способ указания ссылок на внешние ключи:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER REFERENCES users(id)
)
"""
execute_query(connection, create_posts_table)
4. Вставка записей
В предыдущем разделе мы разобрали, как развертывать таблицы в базах данных SQLite, MySQL и PostgreSQL с использованием различных модулей Python. В этом разделе узнаем, как вставлять записи.
SQLite
Чтобы вставить записи в базу данных SQLite, мы можем использовать ту же execute_query() функцию, что и для создания таблиц. Для этого сначала нужно сохранить в виде строки запрос INSERT INTO. Затем нужно передать объект connection и строковый запрос в execute_query(). Вставим для примера пять записей в таблицу users:
create_users = """
INSERT INTO
users (name, age, gender, nationality)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Поскольку мы установили автоинкремент для столбца id, нам не нужно указывать его дополнительно. Таблица users будет автоматически заполнена пятью записями со значениями id от 1 до 5.
Вставим в таблицу posts шесть записей:
create_posts = """
INSERT INTO
posts (title, description, user_id)
VALUES
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3);
"""
execute_query(connection, create_posts)
Важно отметить, что столбец user_id таблицы posts является внешним ключом, который ссылается на столбец таблицы users. Это означает, что столбец user_id должен содержать значение, которое уже существует в столбце id таблицы users. Если его не существует, мы получим сообщение об ошибке.
Следующий скрипт вставляет записи в таблицы comments и likes:
create_comments = """
INSERT INTO
comments (text, user_id, post_id)
VALUES
('Count me in', 1, 6),
('What sort of help?', 5, 3),
('Congrats buddy', 2, 4),
('I was rooting for Nadal though', 4, 5),
('Help with your thesis?', 2, 3),
('Many congratulations', 5, 4);
"""
create_likes = """
INSERT INTO
likes (user_id, post_id)
VALUES
(1, 6),
(2, 3),
(1, 5),
(5, 4),
(2, 4),
(4, 2),
(3, 6);
"""
execute_query(connection, create_comments)
execute_query(connection, create_likes)
MySQL
Есть два способа вставить записи в базы данных MySQL из приложения Python. Первый подход похож на SQLite. Можно сохранить запрос INSERT INTO в строке, а затем использовать для вставки записей cursor.execute().
Ранее мы определили функцию-оболочку execute_query(), которую использовали для вставки записей. Мы можем использовать ту же функцию:
create_users = """
INSERT INTO
`users` (`name`, `age`, `gender`, `nationality`)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Второй подход использует метод cursor.executemany(), который принимает два параметра:
- Строка
query, содержащая заполнители для вставляемых записей. - Список записей, которые мы хотим вставить.
Посмотрите на следующий пример, который вставляет две записи в таблицу likes:
sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )"
val = [(4, 5), (3, 4)]
cursor = connection.cursor()
cursor.executemany(sql, val)
connection.commit()
Какой подход выбрать – зависит от вас. Если вы не очень хорошо знакомы с SQL, проще использовать метод курсора executemany().
PostgreSQL
В предыдущем подразделе мы познакомились с двумя подходами для вставки записей в таблицы баз данных MySQL. В psycopg2 используется второй подход: мы передаем SQL-запрос с заполнителями и списком записей методу execute(). Каждая запись в списке должна являться кортежем, значения которого соответствуют значениям столбца в таблице БД. Вот как мы можем вставить пользовательские записи в таблицу users:
users = [
("James", 25, "male", "USA"),
("Leila", 32, "female", "France"),
("Brigitte", 35, "female", "England"),
("Mike", 40, "male", "Denmark"),
("Elizabeth", 21, "female", "Canada"),
]
user_records = ", ".join(["%s"] * len(users))
insert_query = (
f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, users)
Список users содержит пять пользовательских записей в виде кортежей. Затем мы создаём строку с пятью элементами-заполнителями (%s), соответствующими пяти пользовательским записям. Строка-заполнитель объединяется с запросом, который вставляет записи в таблицу users. Наконец, строка запроса и пользовательские записи передаются в метод execute().
Следующий скрипт вставляет записи в таблицу posts:
posts = [
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3),
]
post_records = ", ".join(["%s"] * len(posts))
insert_query = (
f"INSERT INTO posts (title, description, user_id) VALUES {post_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, posts)
По той же методике можно вставить записи в таблицы comments и likes.
5. Извлечение данных из записей
SQLite
Чтобы выбрать записи в SQLite, можно снова использовать cursor.execute(). Однако после этого потребуется вызвать метод курсора fetchall(). Этот метод возвращает список кортежей, где каждый кортеж сопоставлен с соответствующей строкой в извлеченных записях. Чтобы упростить процесс, напишем функцию execute_read_query():
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Эта функция принимает объект connection и SELECT-запрос, а возвращает выбранную запись.
SELECT
Давайте выберем все записи из таблицы users:
select_users = "SELECT * from users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
В приведенном выше скрипте запрос SELECT забирает всех пользователей из таблицы users. Результат передается в написанную нами функцию execute_read_query(), возвращающую все записи из таблицы users.
Примечание. Не рекомендуется использовать SELECT * для больших таблиц, так как это может привести к большому числу операций ввода-вывода, которые увеличивают сетевой трафик.
Результат вышеприведенного запроса выглядит следующим образом:
(1, 'James', 25, 'male', 'USA')
(2, 'Leila', 32, 'female', 'France')
(3, 'Brigitte', 35, 'female', 'England')
(4, 'Mike', 40, 'male', 'Denmark')
(5, 'Elizabeth', 21, 'female', 'Canada')
Таким же образом вы можете извлечь все записи из таблицы posts:
select_posts = "SELECT * FROM posts"
posts = execute_read_query(connection, select_posts)
for post in posts:
print(post)
Вывод выглядит так:
(1, 'Happy', 'I am feeling very happy today', 1)
(2, 'Hot Weather', 'The weather is very hot today', 2)
(3, 'Help', 'I need some help with my work', 2)
(4, 'Great News', 'I am getting married', 1)
(5, 'Interesting Game', 'It was a fantastic game of tennis', 5)
(6, 'Party', 'Anyone up for a late-night party today?', 3)
JOIN
Вы также можете выполнять более сложные запросы, включающие операции типа JOIN для извлечения данных из двух связанных таблиц. Например, следующий скрипт возвращает идентификаторы и имена пользователей, а также описание сообщений, опубликованных этими пользователями:
select_users_posts = """
SELECT
users.id,
users.name,
posts.description
FROM
posts
INNER JOIN users ON users.id = posts.user_id
"""
users_posts = execute_read_query(connection, select_users_posts)
for users_post in users_posts:
print(users_post)
Вывод данных:
(1, 'James', 'I am feeling very happy today')
(2, 'Leila', 'The weather is very hot today')
(2, 'Leila', 'I need some help with my work')
(1, 'James', 'I am getting married')
(5, 'Elizabeth', 'It was a fantastic game of tennis')
(3, 'Brigitte', 'Anyone up for a late night party today?')
Следующий скрипт возвращает все сообщения вместе с комментариями к сообщениям и именами пользователей, которые разместили комментарии:
select_posts_comments_users = """
SELECT
posts.description as post,
text as comment,
name
FROM
posts
INNER JOIN comments ON posts.id = comments.post_id
INNER JOIN users ON users.id = comments.user_id
"""
posts_comments_users = execute_read_query(
connection, select_posts_comments_users
)
for posts_comments_user in posts_comments_users:
print(posts_comments_user)
Вывод выглядит так:
('Anyone up for a late night party today?', 'Count me in', 'James')
('I need some help with my work', 'What sort of help?', 'Elizabeth')
('I am getting married', 'Congrats buddy', 'Leila')
('It was a fantastic game of tennis', 'I was rooting for Nadal though', 'Mike')
('I need some help with my work', 'Help with your thesis?', 'Leila')
('I am getting married', 'Many congratulations', 'Elizabeth')
Из вывода понятно, что имена столбцов не были возвращены методом fetchall(). Чтобы вернуть имена столбцов, нужно забрать атрибут description объекта cursor. Например, следующий список возвращает все имена столбцов для вышеуказанного запроса:
cursor = connection.cursor()
cursor.execute(select_posts_comments_users)
cursor.fetchall()
column_names = [description[0] for description in cursor.description]
print(column_names)
Вывод выглядит так:
['post', 'comment', 'name']
WHERE
Теперь мы выполним SELECT-запрос, который возвращает текст поста и общее количество лайков, им полученных:
select_post_likes = """
SELECT
description as Post,
COUNT(likes.id) as Likes
FROM
likes,
posts
WHERE
posts.id = likes.post_id
GROUP BY
likes.post_id
"""
post_likes = execute_read_query(connection, select_post_likes)
for post_like in post_likes:
print(post_like)
Вывод следующий:
('The weather is very hot today', 1)
('I need some help with my work', 1)
('I am getting married', 2)
('It was a fantastic game of tennis', 1)
('Anyone up for a late night party today?', 2)
То есть используя запрос WHERE, вы можете возвращать более конкретные результаты.
MySQL
Процесс выбора записей в MySQL абсолютно идентичен процессу выбора записей в SQLite:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Теперь выберем все записи из таблицы users:
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Вывод будет похож на то, что мы видели с SQLite.
PostgreSQL
Процесс выбора записей из таблицы PostgreSQL с помощью модуля psycopg2 тоже похож на SQLite и MySQL. Снова используем cursor.execute(), затем метод fetchall() для выбора записей из таблицы. Следующий скрипт выбирает все записи из таблицы users:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except OperationalError as e:
print(f"The error '{e}' occurred")
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Опять же, результат будет похож на то, что мы видели раньше.
6. Обновление записей таблицы
SQLite
Обновление записей в SQLite выглядит довольно просто. Снова можно применить execute_query(). В качестве примера обновим текст поста с id равным 2. Сначала создадим описание для SELECT:
select_post_description = "SELECT description FROM posts WHERE id = 2"
post_description = execute_read_query(connection, select_post_description)
for description in post_description:
print(description)
Увидим следующий вывод:
('The weather is very hot today',)
Следующий скрипт обновит описание:
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Теперь, если мы выполним SELECT-запрос еще раз, увидим следующий результат:
('The weather has become pleasant now',)
То есть запись была обновлена.
MySQL
Процесс обновления записей в MySQL с помощью модуля mysql-connector-python является точной копией модуля sqlite3:
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
PostgreSQL
Запрос на обновление PostgreSQL аналогичен SQLite и MySQL.
7. Удаление записей таблицы
SQLite
В качестве примера удалим комментарий с id равным 5:
delete_comment = "DELETE FROM comments WHERE id = 5"
execute_query(connection, delete_comment)
Теперь, если мы извлечем все записи из таблицы comments, то увидим, что пятый комментарий был удален. Процесс удаления в MySQL и PostgreSQL идентичен SQLite:
Заключение
В этом руководстве мы разобрались, как применять три распространенные библиотеки Python для работы с реляционными базами данных. Научившись работать с одним из модулей sqlite3, mysql-connector-python и psycopg2, вы легко сможете перенести свои знания на другие модули и оперировать любой из баз данных SQLite, MySQL и PostgreSQL.
Однако это лишь вершина айсберга! Существуют также библиотеки для работы с SQL и объектно-реляционными отображениями, такие как SQLAlchemy и Django ORM, которые автоматизируют задачи взаимодействия Python с базами данных.
Если вам интересна тематика работы с базами данных с помощью Python, напишите об этом в комментариях – мы подготовим дополнительные материалы.
Время прочтения
6 мин
Просмотры 469K
Python DB-API – это не конкретная библиотека, а набор правил, которым подчиняются отдельные модули, реализующие работу с конкретными базами данных. Отдельные нюансы реализации для разных баз могут отличаться, но общие принципы позволяют использовать один и тот же подход при работе с разными базами данных.
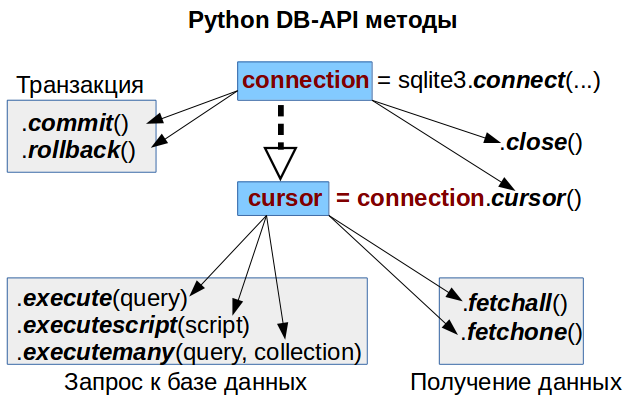
В статье рассмотрены основные методы DB-API, позволяющие полноценно работать с базой данных. Полный список можете найти по ссылкам в конец статьи.
Требуемый уровень подготовки: базовое понимание синтаксиса SQL и Python.
Готовим инвентарь для дальнейшей комфортной работы
- Python имеет встроенную поддержку SQLite базы данных, для этого вам не надо ничего дополнительно устанавливать, достаточно в скрипте указать импорт стандартной библиотеки
import sqlite3 - Скачаем тестовую базу данных, с которой будем работать. В данной статье будет использоваться открытая (MIT лицензия) тестовая база данных “Chinook”. Скачать ее можно с репозитория:
github.com/lerocha/chinook-database
Нам нужен для работы только бинарный файл “Chinook_Sqlite.sqlite”:
github.com/lerocha/chinook-database/blob/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite - Для удобства работы с базой (просмотр, редактирование) нам нужна программа браузер баз данных, поддерживающая SQLite. В статье работа с браузером не рассматривается, но он поможет Вам наглядно видеть что происходит с базой в процессе наших экспериментов.
Примечание: внося изменения в базу не забудьте их применить, так как база с непримененными изменениями остается залоченной.
Вы можете использовать (последние два варианта кросс-платформенные и бесплатные):
- Привычную вам утилиту для работы с базой в составе вашей IDE;
- SQLite Database Browser
- SQLiteStudio
Python DB-API модули в зависимости от базы данных
Соединение с базой, получение курсора
Для начала рассмотрим самый базовый шаблон DB-API, который будем использовать во всех дальнейших примерах:
# Импортируем библиотеку, соответствующую типу нашей базы данных
import sqlite3
# Создаем соединение с нашей базой данных
# В нашем примере у нас это просто файл базы
conn = sqlite3.connect('Chinook_Sqlite.sqlite')
# Создаем курсор - это специальный объект который делает запросы и получает их результаты
cursor = conn.cursor()
# ТУТ БУДЕТ НАШ КОД РАБОТЫ С БАЗОЙ ДАННЫХ
# КОД ДАЛЬНЕЙШИХ ПРИМЕРОВ ВСТАВЛЯТЬ В ЭТО МЕСТО
# Не забываем закрыть соединение с базой данных
conn.close()При работе с другими базами данных, используются дополнительные параметры соединения, например для PostrgeSQL:
conn = psycopg2.connect( host=hostname, user=username, password=password, dbname=database)Чтение из базы
# Делаем SELECT запрос к базе данных, используя обычный SQL-синтаксис
cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT 3")
# Получаем результат сделанного запроса
results = cursor.fetchall()
results2 = cursor.fetchall()
print(results) # [('A Cor Do Som',), ('Aaron Copland & London Symphony Orchestra',), ('Aaron Goldberg',)]
print(results2) # []Обратите внимание: После получения результата из курсора, второй раз без повторения самого запроса его получить нельзя — вернется пустой результат!
Запись в базу
# Делаем INSERT запрос к базе данных, используя обычный SQL-синтаксис
cursor.execute("insert into Artist values (Null, 'A Aagrh!') ")
# Если мы не просто читаем, но и вносим изменения в базу данных - необходимо сохранить транзакцию
conn.commit()
# Проверяем результат
cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT 3")
results = cursor.fetchall()
print(results) # [('A Aagrh!',), ('A Cor Do Som',), ('Aaron Copland & London Symphony Orchestra',)]Примечание: Если к базе установлено несколько соединений и одно из них осуществляет модификацю базы, то база SQLite залочивается до завершения (метод соединения .commit()) или отмены (метод соединения .rollback()) транзакции.
Разбиваем запрос на несколько строк в тройных кавычках
Длинные запросы можно разбивать на несколько строк в произвольном порядке, если они заключены в тройные кавычки — одинарные (»’…»’) или двойные («»»…»»»)
cursor.execute("""
SELECT name
FROM Artist
ORDER BY Name LIMIT 3
""")Конечно в таком простом примере разбивка не имеет смысла, но на сложных длинных запросах она может кардинально повышать читаемость кода.
Объединяем запросы к базе данных в один вызов метода
Метод курсора .execute() позволяет делать только один запрос за раз, при попытке сделать несколько через точку с запятой будет ошибка.
Для тех кто не верит на слово:
cursor.execute("""
insert into Artist values (Null, 'A Aagrh!');
insert into Artist values (Null, 'A Aagrh-2!');
""")
# sqlite3.Warning: You can only execute one statement at a time.
Для решения такой задачи можно либо несколько раз вызывать метод курсора .execute()
cursor.execute("""insert into Artist values (Null, 'A Aagrh!');""")
cursor.execute("""insert into Artist values (Null, 'A Aagrh-2!');""")Либо использовать метод курсора .executescript()
cursor.executescript("""
insert into Artist values (Null, 'A Aagrh!');
insert into Artist values (Null, 'A Aagrh-2!');
""")Данный метод также удобен, когда у нас запросы сохранены в отдельной переменной или даже в файле и нам его надо применить такой запрос к базе.
Делаем подстановку значения в запрос
Важно! Никогда, ни при каких условиях, не используйте конкатенацию строк (+) или интерполяцию параметра в строке (%) для передачи переменных в SQL запрос. Такое формирование запроса, при возможности попадания в него пользовательских данных – это ворота для SQL-инъекций!
Правильный способ – использование второго аргумента метода .execute()
Возможны два варианта:
# C подставновкой по порядку на места знаков вопросов:
cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT ?", ('2'))
# И с использованием именнованных замен:
cursor.execute("SELECT Name from Artist ORDER BY Name LIMIT :limit", {"limit": 3})Примечание 1: В PostgreSQL (UPD: и в MySQL) вместо знака ‘?’ для подстановки используется: %s
Примечание 2: Таким способом не получится заменять имена таблиц, одно из возможных решений в таком случае рассматривается тут: stackoverflow.com/questions/3247183/variable-table-name-in-sqlite/3247553#3247553
UPD: Примечание 3: Благодарю Igelko за упоминание параметра paramstyle — он определяет какой именно стиль используется для подстановки переменных в данном модуле.
Вот ссылка с полезным приемом для работы с разными стилями подстановок.
Делаем множественную вставку строк проходя по коллекции с помощью метода курсора .executemany()
# Обратите внимание, даже передавая одно значение - его нужно передавать кортежем!
# Именно по этому тут используется запятая в скобках!
new_artists = [
('A Aagrh!',),
('A Aagrh!-2',),
('A Aagrh!-3',),
]
cursor.executemany("insert into Artist values (Null, ?);", new_artists)Получаем результаты по одному, используя метод курсора .fetchone()
Он всегда возвращает кортеж или None. если запрос пустой.
cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT 3")
print(cursor.fetchone()) # ('A Cor Do Som',)
print(cursor.fetchone()) # ('Aaron Copland & London Symphony Orchestra',)
print(cursor.fetchone()) # ('Aaron Goldberg',)
print(cursor.fetchone()) # NoneВажно! Стандартный курсор забирает все данные с сервера сразу, не зависимо от того, используем мы .fetchall() или .fetchone()
Курсор как итератор
# Использование курсора как итератора
for row in cursor.execute('SELECT Name from Artist ORDER BY Name LIMIT 3'):
print(row)
# ('A Cor Do Som',)
# ('Aaron Copland & London Symphony Orchestra',)
# ('Aaron Goldberg',)UPD: Повышаем устойчивость кода
Благодарю paratagas за ценное дополнение:
Для большей устойчивости программы (особенно при операциях записи) можно оборачивать инструкции обращения к БД в блоки «try-except-else» и использовать встроенный в sqlite3 «родной» объект ошибок, например, так:
try:
cursor.execute(sql_statement)
result = cursor.fetchall()
except sqlite3.DatabaseError as err:
print("Error: ", err)
else:
conn.commit()UPD: Использование with в psycopg2
Благодарю KurtRotzke за ценное дополнение:
Последние версии psycopg2 позволяют делать так:
with psycopg2.connect("dbname='habr'") as conn:
with conn.cursor() as cur:Некоторые объекты в Python имеют __enter__ и __exit__ методы, что позволяет «чисто» взаимодействовать с ними, как в примере выше.
UPD: Ипользование row_factory
Благодарю remzalp за ценное дополнение:
Использование row_factory позволяет брать метаданные из запроса и обращаться в итоге к результату, например по имени столбца.
По сути — callback для обработки данных при возврате строки. Да еще и полезнейший cursor.description, где есть всё необходимое.
Пример из документации:
import sqlite3
def dict_factory(cursor, row):
d = {}
for idx, col in enumerate(cursor.description):
d[col[0]] = row[idx]
return d
con = sqlite3.connect(":memory:")
con.row_factory = dict_factory
cur = con.cursor()
cur.execute("select 1 as a")
print(cur.fetchone()["a"])Дополнительные материалы (на английском)
- Краткий бесплатный он-лайн курс — Udacity — Intro to Relational Databases — Рассматриваются синтаксис и принципы работы SQL, Python DB-API – и теория и практика в одном флаконе. Очень рекомендую для начинающих!
- Advanced SQLite Usage in Python
- SQLite Python Tutorial на tutorialspoint.com
- A thorough guide to SQLite database operations in Python
- UPD: The Novice’s Guide to the Python 3 DB-API
- Справочные руководства по SQLite он-лайн:
- www.tutorialspoint.com/sql/index.htm
- www.tutorialspoint.com/sqlite
- www.sqlitetutorial.net
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
В прошлой статье мы рассказали про SQLite — простую базу данных, которая может работать почти на любой платформе. Теперь проверим теорию на практике: напишем простой код на Python, который сделает нам простую базу и наполнит её данными и связями.
Предыстория
Если это первая статья про базы данных, которую вы читаете, то лучше сделать так, а потом вернуться сюда:
- Почитать про виды баз данных и посмотреть на схему связей в реляционной базе данных. Там простая схема про магазин — в ней связаны товары, клиенты и покупки.
- Посмотреть, как работают SQL-запросы: что это такое, как база на них реагирует и что получается в итоге. В статье мы с помощью SQL-запросов сделали базу данных по магазинной схеме.

Что будем делать
Сегодня мы сделаем то же самое, что и в SQL-запросах, но на Python, используя стандартную библиотеку sqlite3:
- создадим базу и таблицы в ней;
- наполним их данными;
- создадим связи;
- проверим, как это работает.
После этого мы сможем использовать такой же подход в других проектах и хранить все данные не в текстовых файлах, а в полноценной базе данных.
Подключаем и создаём базу данных
За работу с SQLite в Python отвечает стандартная библиотека sqlite3:
# подключаем SQLite
import sqlite3 as sl
Теперь нам нужно указать файл базы данных, с которым мы будем дальше работать. Удобство библиотеки в том, что нам достаточно указать имя файла, а дальше будет такое:
- если этого файла нет, то программа создаст пустую базу данных с таким именем;
- если указанный файл есть, то программа подключится к нему и будет с ним работать.
Получается, нам неважно, есть файл с базой или нет — мы в любом случае после запуска получим то, что нам нужно. Для этого пишем команду:
# открываем файл с базой данных
con = sl.connect('thecode.db')
Мы указали, что файл называется thecode.db, без указания папок и дисков. Это значит, что файл с базой появится в той же папке, что и наш скрипт — можно в этом убедиться после запуска программы.
Создаём таблицу с товарами
У нас есть база, в которой можно создавать таблицы для хранения данных. Создадим первую таблицу для товаров:
with con:
con.execute("""
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INTEGER,
price INTEGER
);
""")Если посмотреть внимательно на код, можно заметить, что текст внутри кавычек полностью повторяет обычный SQL-запрос, который мы уже использовали в прошлой статье. Единственное отличие — в SQLite используется INTEGER вместо INT:
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INT,
price INT
);Теперь соберём код вместе и запустим его ещё раз:
# подключаем SQLite
import sqlite3 as sl
# открываем файл с базой данных
con = sl.connect('thecode.db')
# создаём таблицу для товаров
with con:
con.execute("""
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INTEGER,
price INTEGER
);
""")Но после второго запуска компьютер почему-то выдаёт ошибку:
❌ sqlite3.OperationalError: table goods already exists
Дело в том, что при повторном запуске программа пытается создать таблицу с товарами, которая уже есть в базе. Так как имена таблиц совпадают, а двух одинаковых имён быть не может, отсюда и возникает ошибка.
Чтобы не попадать в такую ситуацию, добавим проверку: посмотрим, есть ли в базе нужная нам таблица или нет. Если нет — создаём, если есть — двигаемся дальше:
# открываем базу
with con:
# получаем количество таблиц с нужным нам именем
data = con.execute("select count(*) from sqlite_master where type='table' and name='goods'")
for row in data:
# если таких таблиц нет
if row[0] == 0:
# создаём таблицу для товаров
with con:
con.execute("""
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INTEGER,
price INTEGER
);
""")Точно так же мы потом сделаем и с остальными таблицами — сразу встроим проверку, и если нужных таблиц не будет, то программа создаст их автоматически.
Теперь наполняем нашу таблицу товарами, используя стандартный SQL-запрос. Например, можно добавить два стола, которые стоят по 3000 ₽:
INSERT INTO goods SET
product = 'стол',
count = 2,
price = 3000;
Но добавлять записи по одному товару за раз — это долго и неэффективно. Проще сразу в одном запросе добавить все нужные товары: стол, стул и табурет:
# подготавливаем множественный запрос
sql = 'INSERT INTO goods (product, count, price) values(?, ?, ?)'
# указываем данные для запроса
data = [
('стол', 2, 3000),
('стул', 5, 1000),
('табурет', 1, 500)
]
# добавляем с помощью множественного запроса все данные сразу
with con:
con.executemany(sql, data)
# выводим содержимое таблицы на экран
with con:
data = con.execute("SELECT * FROM goods")
for row in data:
print(row)В конце мы добавили вывод таблицы — так можно убедиться, что запрос сработал и данные отправились в базу в нужное место.

Создаём и заполняем таблицу с товарами
Заведём таблицу clients для клиентов и заполним её точно так же, как мы это сделали с клиентской таблицей. Для этого просто копируем предыдущий код, меняем название таблицы и указываем правильные названия полей.Ещё посмотрите на отличие от обычного SQL в последней строке объявления полей таблицы: вместо id INT AUTO_INCREMENT PRIMARY KEY надо указать id INTEGER PRIMARY KEY. Без этого не будет работать автоувеличение счётчика.
# --- создаём таблицу с клиентами ---
# открываем базу
with con:
# получаем количество таблиц с нужным нам именем — clients
data = con.execute("select count(*) from sqlite_master where type='table' and name='clients'")
for row in data:
# если таких таблиц нет
if row[0] == 0:
# создаём таблицу для клиентов
with con:
con.execute("""
CREATE TABLE clients (
name VARCHAR(40),
phone VARCHAR(10) UNIQUE,
id INTEGER PRIMARY KEY
);
""")
# подготавливаем множественный запрос
sql = 'INSERT INTO clients (name, phone) values(?, ?)'
# указываем данные для запроса
data = [
('Миша', 9208381096),
('Наташа', 9307265198),
('Саша', 9307281096)
]
# добавляем с помощью множественного запроса все данные сразу
with con:
con.executemany(sql, data)
# выводим содержимое таблицы с клиентами на экран
with con:
data = con.execute("SELECT * FROM clients")
for row in data:
print(row)Cоздаём таблицу с покупками и связываем всё вместе
У нас всё готово для того, чтобы на основе первых двух таблиц создать третью — в ней будут данные сразу и о покупках, и о том, кто это купил. Если интересно, как это работает в деталях, — почитайте статью про связи в базе данных.
# --- создаём таблицу с покупками ---
# открываем базу
with con:
# получаем количество таблиц с нужным нам именем — orders
data = con.execute("select count(*) from sqlite_master where type='table' and name='orders'")
for row in data:
# если таких таблиц нет
if row[0] == 0:
# создаём таблицу для покупок
with con:
con.execute("""
CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
product VARCHAR,
amount INTEGER,
client_id INTEGER,
FOREIGN KEY (product) REFERENCES goods(product),
FOREIGN KEY (client_id) REFERENCES clients(id)
);
""")Проверим, что связь работает: добавим в таблицу с заказами запись о том, что Миша купил 2 табурета:
# подготавливаем запрос
sql = 'INSERT INTO orders (product, amount, client_id) values(?, ?, ?)'
# указываем данные для запроса
data = [
('табурет', 2, 1)
]
# добавляем запись в таблицу
with con:
con.executemany(sql, data)
# выводим содержимое таблицы с покупками на экран
with con:
data = con.execute("SELECT * FROM orders")
for row in data:
print(row)Компьютер выдал строку (1, ‘табурет’, 2, 1), значит, таблицы связались правильно.
Что дальше
Теперь, когда мы знаем, как работать с SQLite в Python, можно использовать эту базу данных в более серьёзных проектах:
- хранить результаты парсинга;
- запоминать отсортированные датасеты;
- вести учёт пользователей и их действий в системе.
Подпишитесь, чтобы не пропустить продолжение про SQLite. А если вам интересна аналитика и работа с данными, приходите на курс «SQL для работы с данными и аналитики».
Вёрстка:
Кирилл Климентьев
5 апреля 2022
3 518
0
Время чтения ≈ 37 минут

Содержание:
- Логическая структура БД
- Подключение к базам данных SQL из Python
- Создание таблиц
- Добавление записей
- Выборка записей
- Обновление табличных записей
- Удаление записей
Многие программы взаимодействуют с данными с помощью систем управления базами данных (СУБД). В одних языках программирования предусмотрены встроенные модули для работы с СУБД, другие же требуют использования библиотек, предоставляемых сторонними пакетами.
В этой статье рассмотрены различные SQL-библиотеки Python, а также процесс создания простого приложения для работы с базами данных SQLite, MySQL и PostgreSQL.
Благодаря этому руководству можно научиться:
- Подключаться к различным СУБД с помощью SQL-библиотек Python.
- Работать с базами SQLite, MySQL и PostgreSQL.
- Выполнять из приложения Python типичные запросы к базам данных.
- Разрабатывать приложения для различных баз данных, используя скрипты Python.
Для получения максимальной пользы от руководства нужно знать основы Python, SQL и работы с СУБД. Вы должны уметь скачивать и импортировать пакеты в Python. Знать, как устанавливать и запускать разные серверы баз данных, локально или удалённо.
Логическая структура базы данных
В этом руководстве мы создадим небольшую базу данных для приложения социальной сети. База будет состоять из четырёх таблиц:
- users (пользователи).
- posts (публикации).
- comments (комментарии).
- likes (лайки).
Логическая структура нашей базы данных показана ниже:
У таблиц «users» и «posts» будут связи типа «один ко многим», поскольку один пользователь может поставить лайк нескольким постам. Точно так же один пользователь может оставить много комментариев или сделано много комментариев к одной и той же публикации.
Поэтому таблицы «users» и «posts» имеют связь типа «один ко многим» с таблицей «comments». То же самое с таблицей «likes» — таблицы «users» и «posts» будут иметь связь типа «один ко многим» и с ней.
Прежде чем работать с любой базой при помощи SQL-библиотек Python, к ней необходимо подключиться. В этом разделе вы увидите, как подключиться к PostgreSQL, SQLite и MySQL из приложения Python.
Примечание. Для выполнения скриптов из подразделов MySQL и PostgreSQL вам понадобятся их запущенные серверы.
Рекомендуется создать для каждой из трёх СУБД по отдельному файлу Python. Так вы сможете запускать скрипт для каждой базы из нужного файла.
SQLite

SQLite — это, пожалуй, самая простая база данных SQL для Python, поскольку не требует установки внешних SQL модулей. По умолчанию в установленной системе Python уже есть SQL библиотека «sqlite3», которая позволяет подключаться к базе SQLite.
Более того, базы SQLite не нуждаются в сервере и самодостаточны, поскольку просто считывают и записывают данные в файл. В отличие от MySQL и PostgreSQL, для выполнения операций с базами данных даже не нужно устанавливать и запускать серверное приложение.
Подключение к базе SQLite в Python с помощью «sqlite3» происходит следующим образом:
1 import sqlite3
2 from sqlite3 import Error
3
4 def create_connection(path):
5 connection = None
6 try:
7 connection = sqlite3.connect(path)
8 print("Подключение к базе данных SQLite прошло успешно")
9 except Error as e:
10 print(f"Произошла ошибка '{e}'")
11
12 return connection
Как работает этот код:
- Строки 1 и 2 импортируют библиотеку «sqlite3» и класс «Error» этого модуля.
- Строка 4 определяет функцию «.create_connection()», которая принимает в качестве входного параметра путь к базе данных SQLite (path).
- В строке 7 используется функция «.connect()» из модуля «sqlite3», которой передаётся этот путь. Если база данных находится в указанном месте, с ней устанавливается соединение. В противном случае там создаётся новая база и подключение осуществляется уже к ней.
- Строка 8 выводит статус успешного подключения к базе.
- Строка 9 перехватывает исключение, которое может возникнуть, если по методу «.connect()» подключиться к базе SQL не удалось.
- Строка 10 выводит на терминал сообщение об ошибке.
Метод «sqlite3.connect(path)» возвращает объект «(connection)». Его же, в свою очередь, возвращает и наша функция «create_connection()».
Объект «connection» можно использовать для выполнения запросов к базе SQLite. Следующий скрипт устанавливает подключение к SQLite:
connection = create_connection("E:\sm_app.sqlite")
Когда вы запустите скрипт базы данных SQL, то увидите, что в корневом каталоге создан файл базы данных «sm_app.sqlite». Путь к файлу можно изменить.
MySQL

В отличие от SQLite, в Python нет встроенного модуля для подключения к базам MySQL. Чтобы подключиться к базе MySQL из Python, нужно установить подходящий SQL-драйвер. Один из таких — «mysql-connector-python».
Скачать этот SQL модуль можно с помощью менеджера пакетов «pip»:
$ pip install mysql-connector-python
Учтите, что MySQL — серверная СУБД. Поэтому на одном сервере может быть много баз. В отличие от SQLite, где подключение к базе равносильно её созданию, в MySQL для создания базы нужны два шага:
- Подключение к серверу MySQL.
- Выполнение запроса на создание базы данных SQL.
Подключение к серверу MySQL
Определим функцию, которая подключается к серверу MySQL и возвращает объект «connection»:
1 import mysql.connector
2 from mysql.connector import Error
3
4 def create_connection(host_name, user_name, user_password):
5 connection = None
6 try:
7 connection = mysql.connector.connect(
8 host=host_name,
9 user=user_name,
10 passwd=user_password
11 )
12 print("Подключение к базе данных MySQL прошло успешно")
13 except Error as e:
14 print(f"Произошла ошибка '{e}'")
15
16 return connection
17
18 connection = create_connection("localhost", "root", "")
В приведенном выше скрипте определяется функция «create_connection()». Она принимает три параметра:
- host_name (имя сервера)
- user_name (имя пользователя)
- user_password (пароль пользователя)
В строке 7 для подключения к серверу MySQL используется метод «.connect()» из модуля «mysql.connector». После установки соединения объект «connection» возвращается вызывающей функции.
Наконец, в строке 18 вызывается функция «create_connection()». Её аргументами служат имя сервера, пользователь и пароль.
Выполнение запроса на создание базы данных
Пока мы только установили подключение MySQL к Python, но база данных ещё не создана. Чтобы это сделать, мы определим ещё функцию «create_database()». Она будет принимать два параметра:
- connection — объект подключения к серверу баз данных.
- query — запрос, который создаёт новую базу.
Функция выглядит так:
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("База данных создана успешно")
except Error as e:
print(f"Произошла ошибка '{e}'")
Для выполнения SQL запросов используется объект «cursor». Запрос «query» передаётся методу «cursor.execute()» в формате строки.
Создадим на сервере MySQL базу данных под названием «sm_app» для нашего приложения соцсети:
create_database_query = "CREATE DATABASE sm_app" create_database(connection, create_database_query)
Теперь на сервере баз данных создана база «sm_app». Однако, объект «connection», возвращённый функцией «create_connection()», всё ещё указывает на сам сервер баз данных MySQL. А нам нужно подключиться к базе «sm_app». Чтобы сделать это, изменим функцию «create_connection()» так:
1 def create_connection(host_name, user_name, user_password, db_name):
2 connection = None
3 try:
4 connection = mysql.connector.connect(
5 host=host_name,
6 user=user_name,
7 passwd=user_password,
8 database=db_name
9 )
10 print("Подключение к базе данных MySQL прошло успешно")
11 except Error as e:
12 print(f"Произошла ошибка '{e}'")
13
14 return connection
Как видно из приведенного кода, на строке 8 теперь функция «create_connection()» принимает дополнительный параметр «db_name». Он указывает имя базы данных для подключения. Теперь имя базы, к которой вы хотите подключиться, можно передать при вызове функции:
connection = create_connection("localhost", "root", "", "sm_app")
Этот скрипт успешно вызывает функцию «create_connection()» и подключается к базе «sm_app».
PostgreSQL

Как и в случае с MySQL, в PostgreSQL нет встроенной в Python SQL библиотеки. Для подключения к PostgreSQL из Python можно использовать сторонний драйвер баз данных. Примером может послужить модуль «psycopg2».
Для установки в Python SQL-модуля «psycopg2» выполним в терминале следующую команду:
$ pip install psycopg2
Как и в случае с MySQL и SQLite, для подключения к базе PostgreSQL определим функцию «create_connection()»:
import psycopg2
from psycopg2 import OperationalError
def create_connection(db_name, db_user, db_password, db_host, db_port):
connection = None
try:
connection = psycopg2.connect(
database=db_name,
user=db_user,
password=db_password,
host=db_host,
port=db_port,
)
print("Подключение к базе данных PostgreSQL прошло успешно")
except OperationalError as e:
print(f"Произошла ошибка '{e}'")
return connection
Для подключения из нашего приложения Python к серверу PostgreSQL используется метод «psycopg2.connect()».
После этого для подключения к самой базе можно использовать функцию «create_connection()». Сперва подключимся к «postgres», базе по умолчанию:
connection = create_connection( "postgres", "postgres", "abc123", "127.0.0.1", "5432" )
Затем нужно создать внутри базы «postgres» уже нашу базу «sm_app». Можно определить функции для выполнения в PostgreSQL любых SQL-запросов. Ниже определим функцию «create_database()», которая создаст новую базу данных на сервере PostgreSQL.
def create_database(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Запрос выполнен успешно")
except OperationalError as e:
print(f"Произошла ошибка '{e}'")
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
После запуска скрипта мы увидим, что на сервере PostgreSQL создана база «sm_app».
Прежде чем выполнять SQL запросы к базе «sm_app», к ней нужно подключиться:
connection = create_connection( "sm_app", "postgres", "abc123", "127.0.0.1", "5432" )
При выполнении скрипта установится соединение с базой «sm_app» на сервере баз данных «postgres». Параметр «127.0.0.1» задаёт IP-адрес сервера баз данных, а «5432» — это номер порта сервера баз данных.
Создание таблиц
В предыдущем разделе вы узнали, как подключиться к базам данных SQLite, MySQL и PostgreSQL, используя SQL-библиотеки Python. На всех трёх СУБД мы создали базу «sm_app». В этом разделе расскажем, как создать таблицы баз данных SQL внутри этих трёх баз.
Как уже говорилось, мы будем создавать четыре таблицы:
- users;
- posts;
- comments;
- likes.
SQLite
Для выполнения запросов в SQLite используется метод «cursor.execute()». В этом разделе мы определим для его использования функцию «execute_query()». Она будет принимать объект «connection» и строку запроса. Эти аргументы она передаст методу «cursor.execute()».
Метод «.execute()» может выполнять любой запрос, переданный в форме строки. В этом разделе мы используем его для создания таблиц. В остальных разделах также прибегнем к нему уже для выполнения запросов на обновление или удаление.
Примечание. Этот фрагмент кода должен выполняться из того же файла, в котором создаётся подключение к нашей базе SQLite .
Вот определение функции:
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Запрос выполнен успешно")
except Error as e:
print(f"Произошла ошибка '{e}'")
Этот код пытается выполнить запрос «query», при необходимости выводя сообщение об ошибке.
Теперь напишем наш запрос «query»:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, age INTEGER, gender TEXT, nationality TEXT ); """
Это позволяет создать таблицу «users» с пятью столбцами:
- id (идентификатор);
- name (имя);
- age (возраст);
- gender (пол)
- nationality (гражданство).
Наконец, для создания этой таблицы выполняем «execute_query()». Мы передаём созданный в предыдущем сеансе объект «connection» вместе со строкой «create_users_table», которая содержит запрос на создание таблицы.
execute_query(connection, create_users_table)
Следующий запрос создаст таблицу «posts»:
create_posts_table = """ CREATE TABLE IF NOT EXISTS posts( id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) ); """
Как уже говорилось, таблицы «users» и «posts» связаны по типу «один ко многим». Поэтому в таблице «posts» есть внешний ключ «user_id», отсылающий к столбцу «id» таблицы «users». Выполним скрипт для создания таблицы «posts»:
execute_query(connection, create_posts_table)
Наконец, таблицы «comments» и «likes» можно создать таким скриптом:
create_comments_table = """ CREATE TABLE IF NOT EXISTS comments ( id INTEGER PRIMARY KEY AUTOINCREMENT, text TEXT NOT NULL, user_id INTEGER NOT NULL, post_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id) ); """ create_likes_table = """ CREATE TABLE IF NOT EXISTS likes ( id INTEGER PRIMARY KEY AUTOINCREMENT, user_id INTEGER NOT NULL, post_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id) ); """ execute_query(connection, create_comments_table) execute_query(connection, create_likes_table)
Как видно из примера, создание таблиц в SQLite очень похоже на использование языка SQL напрямую. Нужно лишь поместить запрос в строковую переменную и передать её методу «cursor.execute()».
MySQL
Для создания таблиц в MySQL воспользуемся драйвером «mysql-connector-python». Точно так же, как и с SQLite, нам нужно передать методу «cursor.execute()» запрос, который возвращается функцией «.cursor()» по объекту «connection».
Мы можем создать свою функцию «execute_query()». Её аргументами также будут объект подключения «connection» и строка запроса «query»:
1 def execute_query(connection, query):
2 cursor = connection.cursor()
3 try:
4 cursor.execute(query)
5 connection.commit()
6 print("Запрос выполнен успешно")
7 except Error as e:
8 print(f"Произошла ошибка '{e}'")
На строке 4 запрос «query» передаётся методу «cursor.execute()».
Теперь с помощью этой функции можно создать таблицу «users»:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id INT AUTO_INCREMENT, name TEXT NOT NULL, age INT, gender TEXT, nationality TEXT, PRIMARY KEY (id) ) ENGINE = InnoDB """ execute_query(connection, create_users_table)
По сравнению с SQLite, запрос на создание отношения по внешнему ключу для MySQL немного отличается. Кроме того, для создания столбцов, значение которых при добавлении новых записей автоматически возрастает на единицу, MySQL использует ключевое слово «AUTO_INCREMENT», а не «AUTOINCREMENT», как SQLite.
Этот скрипт создаёт таблицу «posts» с внешним ключом «user_id», связанным со столбцом «id» таблицы «users»:
create_posts_table = """ CREATE TABLE IF NOT EXISTS posts ( id INT AUTO_INCREMENT, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER NOT NULL, FOREIGN KEY fk_user_id (user_id) REFERENCES users(id), PRIMARY KEY (id) ) ENGINE = InnoDB """ execute_query(connection, create_posts_table)
Аналогично можно создать таблицы «comments» и «likes», передав методу «execute_query()» запросы «CREATE».
PostgreSQL
Как и в случае с MySQL и SQLite, возвращаемый функцией «psycopg2.connect()» объект «connection» содержит в себе объект «cursor». Для выполнения SQL-запросов к базам данных PostgreSQL в Python воспользуемся методом «cursor.execute()».
Определим функцию «execute_query()»:
def execute_query(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Запрос выполнен успешно")
except OperationalError as e:
print(f"Произошла ошибка '{e}'")
С помощью этой функции в базе PostgreSQL можно создавать таблицы, а также добавлять, изменять и удалять записи.
Теперь создадим внутри базы «sm_app» таблицу «users»:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id SERIAL PRIMARY KEY, name TEXT NOT NULL, age INTEGER, gender TEXT, nationality TEXT ) """ execute_query(connection, create_users_table)
Как видно, в PostgreSQL запрос на создание таблицы «users» немного отличается от аналогичных для SQLite и MySQL. Здесь для автоинкремента столбца используется ключевое слово «SERIAL». Вспомним, что в MySQL использовалось «AUTO_INCREMENT».
Связь по внешнему ключу также задаётся иначе, что видно по скрипту, создающему таблицу «posts»:
create_posts_table = """ CREATE TABLE IF NOT EXISTS posts ( id SERIAL PRIMARY KEY, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER REFERENCES users(id) ) """ execute_query(connection, create_posts_table)
Для создания таблицы «comments» нужно написать для неё запрос «CREATE» и передать функции «execute_query()». Процесс создания для таблицы «likes» тот же. Нужно лишь изменить запрос «CREATE» так, чтобы вместо таблицы «comments» создалась «likes».
Добавление записей
В предыдущем разделе вы узнали, как создавать таблицы в базах SQLite, MySQL и PostgreSQL с помощью разных модулей Python. В этом разделе вы узнаете, как добавлять данные в ваши таблицы.
SQLite
Чтобы добавить записи в нашу базу SQLite, можно использовать ту же функцию «execute_query()», что мы использовали для создания таблиц. Сперва нужно задать строку с запросом «INSERT INTO». Затем можно передать объект «connection» и строковой запрос «query» на вход функции «execute_query()».
Внесём в таблицу «users» пять записей:
create_users = """
INSERT INTO
users (name, age, gender, nationality)
VALUES
('Джеймс', 25, 'мужской', 'США'),
('Лейла', 32, 'женский', 'Франция'),
('Бриджит', 35, 'женский', 'Англия'),
('Майк', 40, 'мужской', 'Дания'),
('Элизабет', 21, 'женский', 'Канада');
"""
execute_query(connection, create_users)
Так как мы задали для столбца «id» автоинкремент, указывать его значение для таблицы «users» незачем. Она сама заполнит значения «id» для этих пяти записей числами от 1 до 5.
Теперь внесём шесть записей в таблицу «posts»:
create_posts = """
INSERT INTO
posts (title, description, user_id)
VALUES
("Счастлив", "Сегодня я очень счастлив", 1),
("Жара", "Погода сегодня очень жаркая", 2),
("Помогите", "Мне надо немного помочь с работой", 2),
("Отличная новость", "Я женюсь", 1),
("Интересная игра", "Это был потрясающий теннисный матч", 5),
("Вечеринка", "Кто готов сегодня ночью тусить?", 3);
"""
execute_query(connection, create_posts)
Важно отметить, что столбец «user_id» таблицы «posts» связан по внешнему ключу со столбцом «id» таблицы «users». Это означает, что столбец «user_id» должен содержать значение, которое уже есть в столбце «id» таблицы «users». Если такового нет, вы получите ошибку.
Аналогично внесёт записи в таблицы «comments» и «likes» такой скрипт:
create_comments = """
INSERT INTO
comments (text, user_id, post_id)
VALUES
('Я с вами', 1, 6),
('А с чем помочь?', 5, 3),
('Поздравляю, чувак', 2, 4),
('А я за Надаля болел', 4, 5),
('Помочь тебе с дипломом?', 2, 3),
('Мои поздравления', 5, 4);
"""
create_likes = """
INSERT INTO
likes (user_id, post_id)
VALUES
(1, 6),
(2, 3),
(1, 5),
(5, 4),
(2, 4),
(4, 2),
(3, 6);
"""
execute_query(connection, create_comments)
execute_query(connection, create_likes)
В обоих случаях вы задаёте запрос «INSERT INTO» в виде строки и выполняете его с помощью функции «execute_query()».
MySQL
Есть два способа добавлять записи в базы MySQL из Python-приложения. Первый подход аналогичен действиям с SQLite. Можно создать строку-запрос «INSERT INTO», а затем для добавления записей в таблицу SQL вызвать функцию «cursor.execute()».
Ранее мы уже определили функцию-обёртку «execute_query()», с помощью которой добавляли записи. Ту же самую функцию можно использовать для внесения записей в таблицу MySQL. Следующий скрипт вносит записи в таблицу «users» с помощью функции «execute_query()»:
create_users = """
INSERT INTO
`users` (`name`, `age`, `gender`, `nationality`)
VALUES
('Джеймс', 25, 'мужской', 'США'),
('Лейла', 32, 'женский', 'Франция'),
('Бриджит', 35, 'женский', 'Англия'),
('Майк', 40, 'мужской', 'Дания'),
('Элизабет', 21, 'женский', 'Канада');
"""
execute_query(connection, create_users)
Второй подход использует метод «cursor.executemany()», принимающий два входных параметра:
- Строку запроса, которая содержит заполнители для вносимых записей.
- Список записей для добавления.
Посмотрим на случай, в котором в таблицу «likes» вносят две записи:
sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )" val = [(4, 5), (3, 4)] cursor = connection.cursor() cursor.executemany(sql, val) connection.commit()
Для внесения записей в таблицу MySQL можно использовать любой подход. Если вы хорошо разбираетесь в SQL, можете использовать метод «.execute()».
Если вы мало с ним знакомы, проще будет обратиться к методу «.executemany()». Успешно добавить записи в таблицы «posts», «comments» и «likes» позволят оба подхода.
PostgreSQL
В предыдущем разделе мы рассмотрели два подхода, которые позволяют добавлять записи в таблицы базы MySQL. Первый использует строку с SQL-запросом, а второй — метод «.executemany()».
Модуль «psycopg2» следует второму подходу c использованием заполнителей «%s», хотя его метод и назван просто «.execute()». Поэтому мы передаём этому методу SQL запрос на добавление записей с заполнителями и список записей.
Каждая запись в списке представляет собой кортеж, значения которого соотносятся со столбцами в таблице базы. Добавить пользователей в таблицу «users» базы PostgreSQL можно так:
users = [
("Джеймс", 25, "мужской", "США"),
("Лейла", 32, "женский", "Франция"),
("Бриджит", 35, "женский", "Англия"),
("Майк", 40, "мужской", "Дания"),
("Элизабет", 21, "женский", "Канада"),
]
user_records = ", ".join(["%s"] * len(users))
insert_query = (
f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, users)
Этот скрипт создаёт список «users», который содержит пять пользовательских записей в формате кортежа. Теперь для пяти пользовательских записей создадим строку с пятью заполнителями «%s». Строка с заполнителями связана с запросом, который добавляет записи в таблицу «users». Наконец, пользовательские записи и строка с запросом передаются методу «.execute()». Скрипт успешно добавляет пять записей в таблицу users.
Посмотрим на ещё один пример добавления записей в таблицу PostgreSQL. Этот скрипт вносит записи в таблицу «posts»:
posts = [
("Счастлив", "Сегодня я очень счастлив", 1),
("Жара", "Погода сегодня очень жаркая", 2),
("Помогите", "Мне надо немного помочь с работой", 2),
("Отличная новость", "Я женюсь", 1),
("Интересная игра", "Это был потрясающий теннисный матч", 5),
("Вечеринка", "Кто готов сегодня ночью тусить?", 3),
]
post_records = ", ".join(["%s"] * len(posts))
insert_query = (
f"INSERT INTO posts (title, description, user_id) VALUES {post_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, posts)
Добавить записи в таблицы «comments» и «likes» можно точно так же.
Выборка записей
В этом разделе вы узнаете, как делать из таблиц выборки записей с помощью SQL модулей Python. В частности, выполнять запросы «SELECT» для наших баз SQLite, MySQL и PostgreSQL.
SQLite
Чтобы получить выборку записей из SQLite, можно снова обратиться к функции «cursor.execute()». Однако после этого понадобится ещё вызов метода «.fetchall()». Он возвращает полученные записи в виде списка кортежей, каждый из которых соответствует определенной строке таблицы.
Процесс можно упростить, создав функцию «execute_read_query()»:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"Произошла ошибка '{e}'")
Эта функция принимает объект «connection» и запрос «SELECT», возвращая выбранную запись.
SELECT
Сделаем выборку всех записей таблицы «users».
select_users = "SELECT * from users" users = execute_read_query(connection, select_users) for user in users: print(user)
В этом скрипте запрос «SELECT» выбирает всех пользователей из таблицы «users». Он передаётся функции «execute_read_query()», которая возвращает все записи из таблицы «users». После получения записей они выводятся на терминал.
Примечание. Использование запроса «SELECT *» не рекомендуется для больших таблиц. Это может привести к большому числу операций ввода-вывода и увеличить объём передаваемого сетевого трафика.
Результат запроса выглядит примерно так:
(1, 'Джеймс, 25, 'мужской', 'США') (2, 'Лейла', 32, 'женский', 'Франция') (3, 'Бриджит', 35, 'женский', 'Англия') (4, 'Майк', 40, 'мужской', 'Дания') (5, 'Элизабет', 21, 'женский', 'Канада')
Точно так же можно извлечь все записи из таблицы «posts»:
select_posts = "SELECT * FROM posts" posts = execute_read_query(connection, select_posts) for post in posts: print(post)
Результат выглядит примерно так:
(1, 'Счастлив', 'Сегодня я очень счастлив', 1) (2, 'Жара', 'Погода сегодня очень жаркая', 2) (3, 'Помогите', 'Мне надо немного помочь с работой', 2) (4, 'Отличная новость', 'Я женюсь', 1) (5, 'Интересная игра', 'Это был потрясающий теннисный матч', 5) (6, 'Вечеринка', 'Кто готов сегодня ночью тусить?', 3)
Здесь показаны все записи таблицы «posts».
JOIN
Извлекать данные из двух связанных таблиц можно также при помощи комплексных запросов с оператором «JOIN». Например такой скрипт вернёт идентификаторы и имена пользователей, связав это с описаниями публикаций:
select_users_posts = """ SELECT users.id, users.name, posts.description FROM posts INNER JOIN users ON users.id = posts.user_id """ users_posts = execute_read_query(connection, select_users_posts) for users_post in users_posts: print(users_post)
Вот результат:
(1, 'Джеймс', 'Сегодня я очень счастлив') (2, 'Лейла', 'Погода сегодня очень жаркая') (2, 'Лейла', 'Мне надо немного помочь с работой') (1, 'Джеймс', 'Я женюсь') (5, 'Элизабет', 'Это был потрясающий теннисный матч') (3, 'Бриджит', 'Кто готов сегодня ночью тусить?')
Используя несколько операторов «JOIN» можно сделать выборку сразу из трёх таблиц. Этот скрипт выводит все публикации с комментариями под ними и имена оставивших их пользователей:
select_posts_comments_users = """ SELECT posts.description as post, text as comment, name FROM posts INNER JOIN comments ON posts.id = comments.post_id INNER JOIN users ON users.id = comments.user_id """ posts_comments_users = execute_read_query( connection, select_posts_comments_users ) for posts_comments_user in posts_comments_users: print(posts_comments_user)
Результат выглядит примерно так:
('Кто готов сегодня ночью тусить?', 'Я с вами, 'Джеймс')
('Мне надо немного помочь с работой', 'А с чем помочь?', 'Элизабет')
('Я женюсь', 'Поздравляю, приятель', 'Лейла')
('Это был потрясающий теннисный матч', 'А я за Надаля болел', 'Майк')
('Мне надо немного помочь с работой', 'Помочь тебе с дипломом?', ''Бриджит')
('Я женюсь', 'Мои поздравления', 'Элизабет')
Как видно, метод «.fetchall()» не возвращает названия столбцов. Чтобы их получить, можно использовать атрибут «.description» объекта «cursor». Например следующий список возвращает все имена столбцов из предыдущего запроса:
cursor = connection.cursor() cursor.execute(select_posts_comments_users) cursor.fetchall() column_names = [description[0] for description in cursor.description] print(column_names) Результат выглядит примерно так: Командная строка ['post', 'comment', 'name']
Здесь содержатся имена столбцов для данного запроса.
WHERE
Теперь выполним запрос «SELECT», который возвращает публикации вместе с числом набранных лайков:
select_post_likes = """ SELECT description as Post, COUNT(likes.id) as Likes FROM likes, posts WHERE posts.id = likes.post_id GROUP BY likes.post_id """ post_likes = execute_read_query(connection, select_post_likes) for post_like in post_likes: print(post_like)
Результат таков:
('Погода сегодня очень жаркая', 1)
('Мне надо немного помочь с работой', 1)
('Я женюсь', 2)
('Это был потрясающий теннисный матч', 1)
('Кто готов сегодня ночью тусить?', 2)
Так, с помощью оператора «WHERE» можно получить более конкретные результаты.
MySQL
Выборка записей из MySQL происходит точно так же, как и из SQLite. Можно воспользоваться методом «cursor.execute()», а затем «.fetchall()». Этот скрипт создаёт функцию-обёртку «execute_read_query()», которая позволяет делать выборки записей:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"Произошла ошибка '{e}'")
Сделаем выборку всех записей из таблицы «users»:
select_users = "SELECT * from users" users = execute_read_query(connection, select_users) for user in users: print(user)
Результат выполнения похож на то, что мы видели у SQLite.
PostgreSQL
Процесс выборки записей из таблиц PostgreSQL с помощью SQL-модуля «psycopg2» напоминает то, что мы делали с SQLite и MySQL.
Для получения записей из таблицы PostgreSQL мы снова используем сначала метод «cursor.execute()», а затем «.fetchall()». Этот скрипт получает все записи из таблицы «users» и выводит их на терминал:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except OperationalError as e:
print(f"Произошла ошибка '{e}'")
select_users = "SELECT * from users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Результат аналогичен тому, что мы уже видели.
Обновление табличных записей
В прошлом разделе вы узнали, как получать записи из баз SQLite, MySQL и PostgreSQL. В этом разделе мы рассмотрим, как обновлять записи, используя SQL-библиотеки Python: SQLite, PostgreSQL и MySQL.
SQLite
Обновление записей в SQLite происходит довольно просто. Можно вновь воспользоваться методом «execute_query()».
Для примера обновим текст публикации (поле «description») с идентификатором («id») 2. Используем оператор «SELECT» для извлечения текста публикации:
select_post_description = "SELECT description FROM posts WHERE id = 2" post_description = execute_read_query(connection, select_post_description) for description in post_description: print(description)
Мы должны получить такой результат:
('Погода сегодня очень жаркая',)
Этот скрипт изменит текст:
update_post_description = """ UPDATE posts SET description = "Установилась приятная погода" WHERE id = 2 """ execute_query(connection, update_post_description)
Если теперь снова выполнить запрос «SELECT», вывод команды будет иным:
('Установилась приятная погода',)
Как видно, результат изменился.
MySQL
При использовании драйвера «mysql-connector-python» процесс обновления записей в MySQL ничем не отличается от «sqlite3». Нужно лишь передать строку запроса методу «cursor.execute()».
К примеру такой скрипт обновит текст публикации с идентификатором («id») 2:
update_post_description = """ UPDATE posts SET description = "Установилась приятная погода" WHERE id = 2 """ execute_query(connection, update_post_description)
Здесь для обновления текста публикации мы вновь использовали нашу функцию-обёртку «execute_query()».
PostgreSQL
В PostgreSQL запрос на изменение записи похож на те, что мы видели в SQLite и MySQL. Для обновления записей в таблице PostgreSQL можно использовать те же скрипты.
Удаление табличных записей
В этом разделе вы узнаете, как удалить запись в таблице, используя модули Python для баз данных SQLite, MySQL и PostgreSQL.
Процесс удаления записей для всех трёх СУБД в Python одинаков, поскольку использование оператора «DELETE» в них идентично.
SQLite
Для удаления записей из нашей базы SQLite можно вновь прибегнуть к функции «execute_query()». Нужно лишь передать ей объект «connection» и строку запроса с указанием записи, которую мы хотим удалить.
Затем функция «execute_query()» создаст на основе объекта «connection» объект «cursor» и передаст строку запроса методу «cursor.execute()», который и удалит записи.
Для примера попробуем удалить комментарий с идентификатором («id») 5:
delete_comment = "DELETE FROM comments WHERE id = 5" execute_query(connection, delete_comment)
Если теперь сделать выборку всех записей таблицы «comments», будет видно, что пятый комментарий удалён.
MySQL
В MySQL удаление аналогично тому же действию в SQLite:
delete_comment = "DELETE FROM comments WHERE id = 2" execute_query(connection, delete_comment)
Здесь мы удаляем второй комментарий из таблицы «comments» в базе данных «sm_app» на сервере MySQL.
PostgreSQL
Запрос на удаление в PostgreSQL выполняется аналогично подобным запросам в SQLite и MySQL.
Можно написать строку с запросом на удаление, в которой будет использоваться оператор «DELETE». Затем передать эту строку вместе с объектом «connection» функции «execute_query()». Это удалит указанные записи из нашей базы PostgreSQL.
Заключение
Из этого руководства вы узнали, как использовать три основные SQL-библиотеки Python. Модули «sqlite3», «mysql-connector-python» и «psycopg2» позволяют подключиться из приложений Python к базам SQLite, MySQL и PostgreSQL соответственно.
Теперь вы умеете:
- Применять Python для работы с MySQL, SQLite и PostgreSQL.
- Использовать три различных SQL модуля Python.
- Выполнять из приложений Python SQL запросы для различных баз данных.
Но всё это только вершина айсберга. В Python есть и SQL-библиотеки для объектно-реляционного отображения (ORM). Например SQLAlchemy или Django ORM, которые автоматизируют работу с SQL базами данных из Python.
Нужна надёжная база для разработки программных продуктов? Выбирайте виртуальные серверы от Eternalhost с технической поддержкой 24/7 и бесплатной защитой от DDoS!
Автор оригинала: Usman Malik
Оцените материал:
[Всего голосов: 0 Средний: 0/5]

Python and SQL are two of the most important languages for Data Analysts.
In this article I will walk you through everything you need to know to connect Python and SQL.
You’ll learn how to pull data from relational databases straight into your machine learning pipelines, store data from your Python application in a database of your own, or whatever other use case you might come up with.
Together we will cover:
- Why learn how to use Python and SQL together?
- How to set up your Python environment and MySQL Server
- Connecting to MySQL Server in Python
- Creating a new Database
- Creating Tables and Table Relationships
- Populating Tables with Data
- Reading Data
- Updating Records
- Deleting Records
- Creating Records from Python Lists
- Creating re-usable functions to do all of this for us in the future
That is a lot of very useful and very cool stuff. Let’s get into it!
A quick note before we start: there is a Jupyter Notebook containing all the code used in this tutorial available in this GitHub repository. Coding along is highly recommended!
The database and SQL code used here is all from my previous Introduction to SQL series posted on Towards Data Science (contact me if you have any problems viewing the articles and I can send you a link to see them for free).
If you are not familiar with SQL and the concepts behind relational databases, I would point you towards that series (plus there is of course a huge amount of great stuff available here on freeCodeCamp!)
For Data Analysts and Data Scientists, Python has many advantages. A huge range of open-source libraries make it an incredibly useful tool for any Data Analyst.
We have pandas, NumPy and Vaex for data analysis, Matplotlib, seaborn and Bokeh for visualisation, and TensorFlow, scikit-learn and PyTorch for machine learning applications (plus many, many more).
With its (relatively) easy learning curve and versatility, it’s no wonder that Python is one of the fastest-growing programming languages out there.
So if we’re using Python for data analysis, it’s worth asking — where does all this data come from?
While there is a massive variety of sources for datasets, in many cases — particularly in enterprise businesses — data is going to be stored in a relational database. Relational databases are an extremely efficient, powerful and widely-used way to create, read, update and delete data of all kinds.
The most widely used relational database management systems (RDBMSs) — Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 — all use the Structured Query Language (SQL) to access and make changes to the data.
Note that each RDBMS uses a slightly different flavour of SQL, so SQL code written for one will usually not work in another without (normally fairly minor) modifications. But the concepts, structures and operations are largely identical.
This means for a working Data Analyst, a strong understanding of SQL is hugely important. Knowing how to use Python and SQL together will give you even more of an advantage when it comes to working with your data.
The rest of this article will be devoted to showing you exactly how we can do that.
Getting Started
Requirements & Installation
To code along with this tutorial, you will need your own Python environment set up.
I use Anaconda, but there are lots of ways to do this. Just google «how to install Python» if you need further help. You can also use Binder to code along with the associated Jupyter Notebook.
We will be using MySQL Community Server as it is free and widely used in the industry. If you are using Windows, this guide will help you get set up. Here are guides for Mac and Linux users too (although it may vary by Linux distribution).
Once you have those set up, we will need to get them to communicate with each other.
For that, we need to install the MySQL Connector Python library. To do this, follow the instructions, or just use pip:
pip install mysql-connector-pythonWe are also going to be using pandas, so make sure that you have that installed as well.
pip install pandasImporting Libraries
As with every project in Python, the very first thing we want to do is import our libraries.
It is best practice to import all the libraries we are going to use at the beginning of the project, so people reading or reviewing our code know roughly what is coming up so there are no surprises.
For this tutorial, we are only going to use two libraries — MySQL Connector and pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdWe import the Error function separately so that we have easy access to it for our functions.
Connecting to MySQL Server
By this point we should have MySQL Community Server set up on our system. Now we need to write some code in Python that lets us establish a connection to that server.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionCreating a re-usable function for code like this is best practice, so that we can use this again and again with minimum effort. Once this is written once you can re-use it in all of your projects in the future too, so future-you will be grateful!
Let’s go through this line by line so we understand what’s happening here:
The first line is us naming the function (create_server_connection) and naming the arguments that that function will take (host_name, user_name and user_password).
The next line closes any existing connections so that the server doesn’t become confused with multiple open connections.
Next we use a Python try-except block to handle any potential errors. The first part tries to create a connection to the server using the mysql.connector.connect() method using the details specified by the user in the arguments. If this works, the function prints a happy little success message.
The except part of the block prints the error which MySQL Server returns, in the unfortunate circumstance that there is an error.
Finally, if the connection is successful, the function returns a connection object.
We use this in practice by assigning the output of the function to a variable, which then becomes our connection object. We can then apply other methods (such as cursor) to it and create other useful objects.
connection = create_server_connection("localhost", "root", pw)This should produce a success message:

Creating a New Database
Now that we have established a connection, our next step is to create a new database on our server.
In this tutorial we will do this only once, but again we will write this as a re-usable function so we have a nice useful function we can re-use for future projects.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")This function takes two arguments, connection (our connection object) and query (a SQL query which we will write in the next step). It executes the query in the server via the connection.
We use the cursor method on our connection object to create a cursor object (MySQL Connector uses an object-oriented programming paradigm, so there are lots of objects inheriting properties from parent objects).
This cursor object has methods such as execute, executemany (which we will use in this tutorial) along with several other useful methods.
If it helps, we can think of the cursor object as providing us access to the blinking cursor in a MySQL Server terminal window.
![]()
Next we define a query to create the database and call the function:

All the SQL queries used in this tutorial are explained in my Introduction to SQL tutorial series, and the full code can be found in the associated Jupyter Notebook in this GitHub repository, so I will not be providing explanations of what the SQL code does in this tutorial.
This is perhaps the simplest SQL query possible, though. If you can read English you can probably work out what it does!
Running the create_database function with the arguments as above results in a database called ‘school’ being created in our server.
Why is our database called ‘school’? Perhaps now would be a good time to look in more detail at exactly what we are going to implement in this tutorial.
Our Database
Following the example in my previous series, we are going to be implementing the database for the International Language School — a fictional language training school which provides professional language lessons to corporate clients.
This Entity Relationship Diagram (ERD) lays out our entities (Teacher, Client, Course and Participant) and defines the relationships between them.
All the information regarding what an ERD is and what to consider when creating one and designing a database can be found in this article.
The raw SQL code, database requirements, and data to go into the database is all contained in this GitHub repository, but you’ll see it all as we go through this tutorial too.
Connecting to the Database
Now that we have created a database in MySQL Server, we can modify our create_server_connection function to connect directly to this database.
Note that it’s possible — common, in fact — to have multiple databases on one MySQL Server, so we want to always and automatically connect to the database we’re interested in.
We can do this like so:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionThis is the exact same function, but now we take one more argument — the database name — and pass that as an argument to the connect() method.
Creating a Query Execution Function
The final function we’re going to create (for now) is an extremely vital one — a query execution function. This is going to take our SQL queries, stored in Python as strings, and pass them to the cursor.execute() method to execute them on the server.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")This function is exactly the same as our create_database function from earlier, except that it uses the connection.commit() method to make sure that the commands detailed in our SQL queries are implemented.
This is going to be our workhorse function, which we will use (alongside create_db_connection) to create tables, establish relationships between those tables, populate the tables with data, and update and delete records in our database.
If you’re a SQL expert, this function will let you execute any and all of the complex commands and queries you might have lying around, directly from a Python script. This can be a very powerful tool for managing your data.
Creating Tables
Now we’re all set to start running SQL commands into our Server and to start building our database. The first thing we want to do is to create the necessary tables.
Let’s start with our Teacher table:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryFirst of all we assign our SQL command (explained in detail here) to a variable with an appropriate name.
In this case we use Python’s triple quote notation for multi-line strings to store our SQL query, then we feed it into our execute_query function to implement it.
Note that this multi-line formatting is purely for the benefit of humans reading our code. Neither SQL nor Python ‘care’ if the SQL command is spread out like this. So long as the syntax is correct, both languages will accept it.
For the benefit of humans who will read your code, however, (even if that will only be future-you!) it is very useful to do this to make the code more readable and understandable.
The same is true for the CAPITALISATION of operators in SQL. This is a widely-used convention that is strongly recommended, but the actual software that runs the code is case-insensitive and will treat ‘CREATE TABLE teacher’ and ‘create table teacher’ as identical commands.

Running this code gives us our success messages. We can also verify this in the MySQL Server Command Line Client:

Great! Now let’s create the remaining tables.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)This creates the four tables necessary for our four entities.
Now we want to define the relationships between them and create one more table to handle the many-to-many relationship between the participant and course tables (see here for more details).
We do this in exactly the same way:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Now our tables are created, along with the appropriate constraints, primary key, and foreign key relations.
Populating the Tables
The next step is to add some records to the tables. Again we use execute_query to feed our existing SQL commands into the Server. Let’s again start with the Teacher table.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Does this work? We can check again in our MySQL Command Line Client:

Now to populate the remaining tables.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Amazing! Now we have created a database complete with relations, constraints and records in MySQL, using nothing but Python commands.
We have gone through this step by step to keep it understandable. But by this point you can see that this could all very easily be written into one Python script and executed in one command in the terminal. Powerful stuff.
Reading Data
Now we have a functional database to work with. As a Data Analyst, you are likely to come into contact with existing databases in the organisations where you work. It will be very useful to know how to pull data out of those databases so it can then be fed into your python data pipeline. This is what we are going to work on next.
For this, we will need one more function, this time using cursor.fetchall() instead of cursor.commit(). With this function, we are reading data from the database and will not be making any changes.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Again, we are going to implement this in a very similar way to execute_query. Let’s try it out with a simple query to see how it works.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)
Exactly what we are expecting. The function also works with more complex queries, such as this one involving a JOIN on the course and client tables.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)
Very nice.
For our data pipelines and workflows in Python, we might want to get these results in different formats to make them more useful or ready for us to manipulate.
Let’s go through a couple of examples to see how we can do that.
Formatting Output into a List
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formatting Output into a List of Lists
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatting Output into a pandas DataFrame
For Data Analysts using Python, pandas is our beautiful and trusted old friend. It’s very simple to convert the output from our database into a DataFrame, and from there the possibilities are endless!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)
Hopefully you can see the possibilities unfolding in front of you here. With just a few lines of code, we can easily extract all the data we can handle from the relational databases where it lives, and pull it into our state-of-the-art data analytics pipelines. This is really helpful stuff.
Updating Records
When we are maintaining a database, we will sometimes need to make changes to existing records. In this section we are going to look at how to do that.
Let’s say the ILS is notified that one of its existing clients, the Big Business Federation, is moving offices to 23 Fingiertweg, 14534 Berlin. In this case, the database administrator (that’s us!) will need to make some changes.
Thankfully, we can do this with our execute_query function alongside the SQL UPDATE statement.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Note that the WHERE clause is very important here. If we run this query without the WHERE clause, then all addresses for all records in our Client table would be updated to 23 Fingiertweg. That is very much not what we are looking to do.
Also note that we used «WHERE client_id = 101» in the UPDATE query. It would also have been possible to use «WHERE client_name = ‘Big Business Federation'» or «WHERE address = ‘123 Falschungstraße, 10999 Berlin'» or even «WHERE address LIKE ‘%Falschung%'».
The important thing is that the WHERE clause allows us to uniquely identify the record (or records) we want to update.
Deleting Records
It is also possible use our execute_query function to delete records, by using DELETE.
When using SQL with relational databases, we need to be careful using the DELETE operator. This isn’t Windows, there is no ‘Are you sure you want to delete this?’ warning pop-up, and there is no recycling bin. Once we delete something, it’s really gone.
With that said, we do really need to delete things sometimes. So let’s take a look at that by deleting a course from our Course table.
First of all let’s remind ourselves what courses we have.
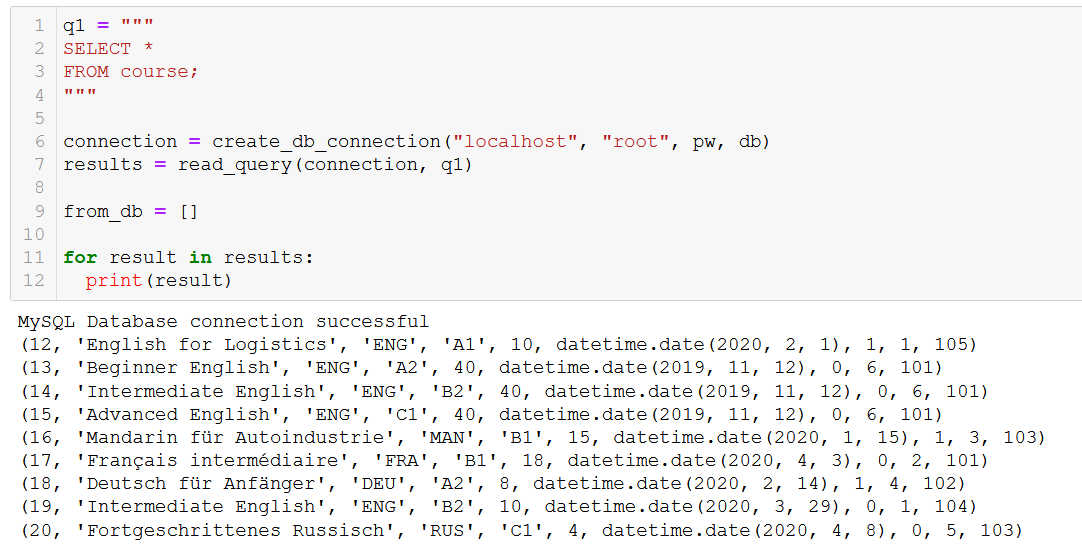
Let’s say course 20, ‘Fortgeschrittenes Russisch’ (that’s ‘Advanced Russian’ to you and me), is coming to an end, so we need to remove it from our database.
By this stage, you will not be at all surprised with how we do this — save the SQL command as a string, then feed it into our workhorse execute_query function.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Let’s check to confirm that had the intended effect:
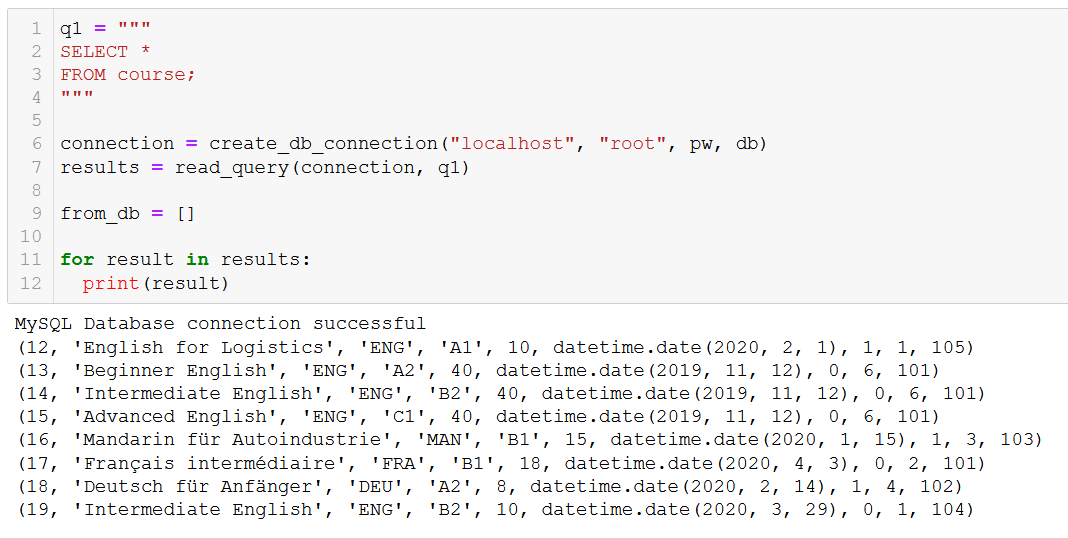
‘Advanced Russian’ is gone, as we expected.
This also works with deleting entire columns using DROP COLUMN and whole tables using DROP TABLE commands, but we will not cover those in this tutorial.
Go ahead and experiment with them, however — it doesn’t matter if you delete a column or table from a database for a fictional school, and it’s a good idea to become comfortable with these commands before moving into a production environment.
Oh CRUD
By this point, we are now able to complete the four major operations for persistent data storage.
We have learned how to:
- Create — entirely new databases, tables and records
- Read — extract data from a database, and store that data in multiple formats
- Update — make changes to existing records in the database
- Delete — remove records which are no longer needed
These are fantastically useful things to be able to do.
Before we finish things up here, we have one more very handy skill to learn.
Creating Records from Lists
We saw when populating our tables that we can use the SQL INSERT command in our execute_query function to insert records into our database.
Given that we’re using Python to manipulate our SQL database, it would be useful to be able to take a Python data structure (such as a list) and insert that directly into our database.
This could be useful when we want to store logs of user activity on a social media app we have written in Python, or input from users into a Wiki we have built, for example. There are as many possible uses for this as you can think of.
This method is also more secure if our database is open to our users at any point, as it helps to prevent against SQL Injection attacks, which can damage or even destroy our whole database.
To do this, we will write a function using the executemany() method, instead of the simpler execute() method we have been using thus far.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Now we have the function, we need to define an SQL command (‘sql’) and a list containing the values we wish to enter into the database (‘val’). The values must be stored as a list of tuples, which is a fairly common way to store data in Python.
To add two new teachers to the database, we can write some code like this:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Notice here that in the ‘sql’ code we use the ‘%s’ as a placeholder for our value. The resemblance to the ‘%s’ placeholder for a string in python is just coincidental (and frankly, very confusing), we want to use ‘%s’ for all data types (strings, ints, dates, etc) with the MySQL Python Connector.
You can see a number of questions on Stackoverflow where someone has become confused and tried to use ‘%d’ placeholders for integers because they’re used to doing this in Python. This won’t work here — we need to use a ‘%s’ for each column we want to add a value to.
The executemany function then takes each tuple in our ‘val’ list and inserts the relevant value for that column in place of the placeholder and executes the SQL command for each tuple contained in the list.
This can be performed for multiple rows of data, so long as they are formatted correctly. In our example we will just add two new teachers, for illustrative purposes, but in principle we can add as many as we would like.
Let’s go ahead and execute this query and add the teachers to our database.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)
Welcome to the ILS, Hank and Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you’d like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly — all feedback is warmly received!
![]()
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Python and SQL are two of the most important languages for Data Analysts.
In this article I will walk you through everything you need to know to connect Python and SQL.
You’ll learn how to pull data from relational databases straight into your machine learning pipelines, store data from your Python application in a database of your own, or whatever other use case you might come up with.
Together we will cover:
- Why learn how to use Python and SQL together?
- How to set up your Python environment and MySQL Server
- Connecting to MySQL Server in Python
- Creating a new Database
- Creating Tables and Table Relationships
- Populating Tables with Data
- Reading Data
- Updating Records
- Deleting Records
- Creating Records from Python Lists
- Creating re-usable functions to do all of this for us in the future
That is a lot of very useful and very cool stuff. Let’s get into it!
A quick note before we start: there is a Jupyter Notebook containing all the code used in this tutorial available in this GitHub repository. Coding along is highly recommended!
The database and SQL code used here is all from my previous Introduction to SQL series posted on Towards Data Science (contact me if you have any problems viewing the articles and I can send you a link to see them for free).
If you are not familiar with SQL and the concepts behind relational databases, I would point you towards that series (plus there is of course a huge amount of great stuff available here on freeCodeCamp!)
For Data Analysts and Data Scientists, Python has many advantages. A huge range of open-source libraries make it an incredibly useful tool for any Data Analyst.
We have pandas, NumPy and Vaex for data analysis, Matplotlib, seaborn and Bokeh for visualisation, and TensorFlow, scikit-learn and PyTorch for machine learning applications (plus many, many more).
With its (relatively) easy learning curve and versatility, it’s no wonder that Python is one of the fastest-growing programming languages out there.
So if we’re using Python for data analysis, it’s worth asking — where does all this data come from?
While there is a massive variety of sources for datasets, in many cases — particularly in enterprise businesses — data is going to be stored in a relational database. Relational databases are an extremely efficient, powerful and widely-used way to create, read, update and delete data of all kinds.
The most widely used relational database management systems (RDBMSs) — Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 — all use the Structured Query Language (SQL) to access and make changes to the data.
Note that each RDBMS uses a slightly different flavour of SQL, so SQL code written for one will usually not work in another without (normally fairly minor) modifications. But the concepts, structures and operations are largely identical.
This means for a working Data Analyst, a strong understanding of SQL is hugely important. Knowing how to use Python and SQL together will give you even more of an advantage when it comes to working with your data.
The rest of this article will be devoted to showing you exactly how we can do that.
Getting Started
Requirements & Installation
To code along with this tutorial, you will need your own Python environment set up.
I use Anaconda, but there are lots of ways to do this. Just google «how to install Python» if you need further help. You can also use Binder to code along with the associated Jupyter Notebook.
We will be using MySQL Community Server as it is free and widely used in the industry. If you are using Windows, this guide will help you get set up. Here are guides for Mac and Linux users too (although it may vary by Linux distribution).
Once you have those set up, we will need to get them to communicate with each other.
For that, we need to install the MySQL Connector Python library. To do this, follow the instructions, or just use pip:
pip install mysql-connector-pythonWe are also going to be using pandas, so make sure that you have that installed as well.
pip install pandasImporting Libraries
As with every project in Python, the very first thing we want to do is import our libraries.
It is best practice to import all the libraries we are going to use at the beginning of the project, so people reading or reviewing our code know roughly what is coming up so there are no surprises.
For this tutorial, we are only going to use two libraries — MySQL Connector and pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdWe import the Error function separately so that we have easy access to it for our functions.
Connecting to MySQL Server
By this point we should have MySQL Community Server set up on our system. Now we need to write some code in Python that lets us establish a connection to that server.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionCreating a re-usable function for code like this is best practice, so that we can use this again and again with minimum effort. Once this is written once you can re-use it in all of your projects in the future too, so future-you will be grateful!
Let’s go through this line by line so we understand what’s happening here:
The first line is us naming the function (create_server_connection) and naming the arguments that that function will take (host_name, user_name and user_password).
The next line closes any existing connections so that the server doesn’t become confused with multiple open connections.
Next we use a Python try-except block to handle any potential errors. The first part tries to create a connection to the server using the mysql.connector.connect() method using the details specified by the user in the arguments. If this works, the function prints a happy little success message.
The except part of the block prints the error which MySQL Server returns, in the unfortunate circumstance that there is an error.
Finally, if the connection is successful, the function returns a connection object.
We use this in practice by assigning the output of the function to a variable, which then becomes our connection object. We can then apply other methods (such as cursor) to it and create other useful objects.
connection = create_server_connection("localhost", "root", pw)This should produce a success message:
Creating a New Database
Now that we have established a connection, our next step is to create a new database on our server.
In this tutorial we will do this only once, but again we will write this as a re-usable function so we have a nice useful function we can re-use for future projects.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")This function takes two arguments, connection (our connection object) and query (a SQL query which we will write in the next step). It executes the query in the server via the connection.
We use the cursor method on our connection object to create a cursor object (MySQL Connector uses an object-oriented programming paradigm, so there are lots of objects inheriting properties from parent objects).
This cursor object has methods such as execute, executemany (which we will use in this tutorial) along with several other useful methods.
If it helps, we can think of the cursor object as providing us access to the blinking cursor in a MySQL Server terminal window.
![]()
Next we define a query to create the database and call the function:
All the SQL queries used in this tutorial are explained in my Introduction to SQL tutorial series, and the full code can be found in the associated Jupyter Notebook in this GitHub repository, so I will not be providing explanations of what the SQL code does in this tutorial.
This is perhaps the simplest SQL query possible, though. If you can read English you can probably work out what it does!
Running the create_database function with the arguments as above results in a database called ‘school’ being created in our server.
Why is our database called ‘school’? Perhaps now would be a good time to look in more detail at exactly what we are going to implement in this tutorial.
Our Database
Following the example in my previous series, we are going to be implementing the database for the International Language School — a fictional language training school which provides professional language lessons to corporate clients.
This Entity Relationship Diagram (ERD) lays out our entities (Teacher, Client, Course and Participant) and defines the relationships between them.
All the information regarding what an ERD is and what to consider when creating one and designing a database can be found in this article.
The raw SQL code, database requirements, and data to go into the database is all contained in this GitHub repository, but you’ll see it all as we go through this tutorial too.
Connecting to the Database
Now that we have created a database in MySQL Server, we can modify our create_server_connection function to connect directly to this database.
Note that it’s possible — common, in fact — to have multiple databases on one MySQL Server, so we want to always and automatically connect to the database we’re interested in.
We can do this like so:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionThis is the exact same function, but now we take one more argument — the database name — and pass that as an argument to the connect() method.
Creating a Query Execution Function
The final function we’re going to create (for now) is an extremely vital one — a query execution function. This is going to take our SQL queries, stored in Python as strings, and pass them to the cursor.execute() method to execute them on the server.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")This function is exactly the same as our create_database function from earlier, except that it uses the connection.commit() method to make sure that the commands detailed in our SQL queries are implemented.
This is going to be our workhorse function, which we will use (alongside create_db_connection) to create tables, establish relationships between those tables, populate the tables with data, and update and delete records in our database.
If you’re a SQL expert, this function will let you execute any and all of the complex commands and queries you might have lying around, directly from a Python script. This can be a very powerful tool for managing your data.
Creating Tables
Now we’re all set to start running SQL commands into our Server and to start building our database. The first thing we want to do is to create the necessary tables.
Let’s start with our Teacher table:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryFirst of all we assign our SQL command (explained in detail here) to a variable with an appropriate name.
In this case we use Python’s triple quote notation for multi-line strings to store our SQL query, then we feed it into our execute_query function to implement it.
Note that this multi-line formatting is purely for the benefit of humans reading our code. Neither SQL nor Python ‘care’ if the SQL command is spread out like this. So long as the syntax is correct, both languages will accept it.
For the benefit of humans who will read your code, however, (even if that will only be future-you!) it is very useful to do this to make the code more readable and understandable.
The same is true for the CAPITALISATION of operators in SQL. This is a widely-used convention that is strongly recommended, but the actual software that runs the code is case-insensitive and will treat ‘CREATE TABLE teacher’ and ‘create table teacher’ as identical commands.
Running this code gives us our success messages. We can also verify this in the MySQL Server Command Line Client:
Great! Now let’s create the remaining tables.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)This creates the four tables necessary for our four entities.
Now we want to define the relationships between them and create one more table to handle the many-to-many relationship between the participant and course tables (see here for more details).
We do this in exactly the same way:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Now our tables are created, along with the appropriate constraints, primary key, and foreign key relations.
Populating the Tables
The next step is to add some records to the tables. Again we use execute_query to feed our existing SQL commands into the Server. Let’s again start with the Teacher table.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Does this work? We can check again in our MySQL Command Line Client:
Now to populate the remaining tables.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Amazing! Now we have created a database complete with relations, constraints and records in MySQL, using nothing but Python commands.
We have gone through this step by step to keep it understandable. But by this point you can see that this could all very easily be written into one Python script and executed in one command in the terminal. Powerful stuff.
Reading Data
Now we have a functional database to work with. As a Data Analyst, you are likely to come into contact with existing databases in the organisations where you work. It will be very useful to know how to pull data out of those databases so it can then be fed into your python data pipeline. This is what we are going to work on next.
For this, we will need one more function, this time using cursor.fetchall() instead of cursor.commit(). With this function, we are reading data from the database and will not be making any changes.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Again, we are going to implement this in a very similar way to execute_query. Let’s try it out with a simple query to see how it works.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)
Exactly what we are expecting. The function also works with more complex queries, such as this one involving a JOIN on the course and client tables.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)
Very nice.
For our data pipelines and workflows in Python, we might want to get these results in different formats to make them more useful or ready for us to manipulate.
Let’s go through a couple of examples to see how we can do that.
Formatting Output into a List
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formatting Output into a List of Lists
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatting Output into a pandas DataFrame
For Data Analysts using Python, pandas is our beautiful and trusted old friend. It’s very simple to convert the output from our database into a DataFrame, and from there the possibilities are endless!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)
Hopefully you can see the possibilities unfolding in front of you here. With just a few lines of code, we can easily extract all the data we can handle from the relational databases where it lives, and pull it into our state-of-the-art data analytics pipelines. This is really helpful stuff.
Updating Records
When we are maintaining a database, we will sometimes need to make changes to existing records. In this section we are going to look at how to do that.
Let’s say the ILS is notified that one of its existing clients, the Big Business Federation, is moving offices to 23 Fingiertweg, 14534 Berlin. In this case, the database administrator (that’s us!) will need to make some changes.
Thankfully, we can do this with our execute_query function alongside the SQL UPDATE statement.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Note that the WHERE clause is very important here. If we run this query without the WHERE clause, then all addresses for all records in our Client table would be updated to 23 Fingiertweg. That is very much not what we are looking to do.
Also note that we used «WHERE client_id = 101» in the UPDATE query. It would also have been possible to use «WHERE client_name = ‘Big Business Federation'» or «WHERE address = ‘123 Falschungstraße, 10999 Berlin'» or even «WHERE address LIKE ‘%Falschung%'».
The important thing is that the WHERE clause allows us to uniquely identify the record (or records) we want to update.
Deleting Records
It is also possible use our execute_query function to delete records, by using DELETE.
When using SQL with relational databases, we need to be careful using the DELETE operator. This isn’t Windows, there is no ‘Are you sure you want to delete this?’ warning pop-up, and there is no recycling bin. Once we delete something, it’s really gone.
With that said, we do really need to delete things sometimes. So let’s take a look at that by deleting a course from our Course table.
First of all let’s remind ourselves what courses we have.
Let’s say course 20, ‘Fortgeschrittenes Russisch’ (that’s ‘Advanced Russian’ to you and me), is coming to an end, so we need to remove it from our database.
By this stage, you will not be at all surprised with how we do this — save the SQL command as a string, then feed it into our workhorse execute_query function.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Let’s check to confirm that had the intended effect:
‘Advanced Russian’ is gone, as we expected.
This also works with deleting entire columns using DROP COLUMN and whole tables using DROP TABLE commands, but we will not cover those in this tutorial.
Go ahead and experiment with them, however — it doesn’t matter if you delete a column or table from a database for a fictional school, and it’s a good idea to become comfortable with these commands before moving into a production environment.
Oh CRUD
By this point, we are now able to complete the four major operations for persistent data storage.
We have learned how to:
- Create — entirely new databases, tables and records
- Read — extract data from a database, and store that data in multiple formats
- Update — make changes to existing records in the database
- Delete — remove records which are no longer needed
These are fantastically useful things to be able to do.
Before we finish things up here, we have one more very handy skill to learn.
Creating Records from Lists
We saw when populating our tables that we can use the SQL INSERT command in our execute_query function to insert records into our database.
Given that we’re using Python to manipulate our SQL database, it would be useful to be able to take a Python data structure (such as a list) and insert that directly into our database.
This could be useful when we want to store logs of user activity on a social media app we have written in Python, or input from users into a Wiki we have built, for example. There are as many possible uses for this as you can think of.
This method is also more secure if our database is open to our users at any point, as it helps to prevent against SQL Injection attacks, which can damage or even destroy our whole database.
To do this, we will write a function using the executemany() method, instead of the simpler execute() method we have been using thus far.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Now we have the function, we need to define an SQL command (‘sql’) and a list containing the values we wish to enter into the database (‘val’). The values must be stored as a list of tuples, which is a fairly common way to store data in Python.
To add two new teachers to the database, we can write some code like this:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Notice here that in the ‘sql’ code we use the ‘%s’ as a placeholder for our value. The resemblance to the ‘%s’ placeholder for a string in python is just coincidental (and frankly, very confusing), we want to use ‘%s’ for all data types (strings, ints, dates, etc) with the MySQL Python Connector.
You can see a number of questions on Stackoverflow where someone has become confused and tried to use ‘%d’ placeholders for integers because they’re used to doing this in Python. This won’t work here — we need to use a ‘%s’ for each column we want to add a value to.
The executemany function then takes each tuple in our ‘val’ list and inserts the relevant value for that column in place of the placeholder and executes the SQL command for each tuple contained in the list.
This can be performed for multiple rows of data, so long as they are formatted correctly. In our example we will just add two new teachers, for illustrative purposes, but in principle we can add as many as we would like.
Let’s go ahead and execute this query and add the teachers to our database.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)
Welcome to the ILS, Hank and Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you’d like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly — all feedback is warmly received!
![]()
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Эта статья о том, как работать с базами данных в Python. Эта статья носит, скорее, вступительный характер. Вы не изучите весь язык SQL, вместо этого, я дам вам развернутое представление о командах SQL и затем мы научимся подключаться к нескольким популярным базам данных в Python. Большая часть баз данных использует базовые команды SQL одинаково, но они также могут использовать специальные команды для бекенда той или иной базы данных, или просто работают с некоторыми отличиями. Рекомендую ознакомиться с документацией к базам данных, если у вас возникнут проблемы. Мы начнем статью с изучения базового синтаксиса SQL.
Базовый синтаксис SQL
SQL расшифровывается как Structured Query Language (язык структурированных запросов). Это, в сущности, де-факто язык для взаимодействия с базами данных и является примитивным языком программирования. В данном разделе мы рассмотрим основы CRUD (Create, Read, Update и Delete). Это самые важные функции, которые вам нужно освоить, перед тем как использовать базы данных в Python. Конечно, вам также понадобится узнать как создавать запросы, но мы рассмотрим это по ходу дела, когда нужно будет выполнять запрос для чтения, обновления или удаления.
Создание таблицы
Первое что вам нужно для базы данных – это таблица. Это место, где ваши данные будут организованы и храниться. Большую часть времени вам будут нужны несколько таблиц, в каждой из которых будут храниться поднастройки ваших данных. Создание таблицы в SQL это просто. Все что вам нужно сделать, это следующее:
|
CREATE TABLE table_name ( id INTEGER, name VARCHAR, make VARCHAR model VARCHAR, year DATE, PRIMARY KEY (id) ); |
Это довольно обобщенный код, но он работает в большей части случаев. Первое, на что стоит обратить внимание – куча слов прописанных заглавными буквами. Это команды SQL. Их не всегда нужно вписывать через капс, но мы сделали это, чтобы помочь вам увидеть их. Я также хочу обратить внимание на то, что каждая база данных поддерживает слегка отличающиеся команды. Большинство будет содержать CREATE TABLE, но типы столбцов баз данных могут быть разными. Обратите внимание на то, что в этом примере у нас есть базы данных INTEGER, VARCHAR и DATE.
DATE может вызывать много разных штук, как и VARCHAR. Проконсультируйтесь с документацией на тему того, что вам нужно делать. В любом случае, в этом примере мы создаем базу данных с пятью столбцами. Первый – это id, который мы настраиваем в качестве нашего основного ключа. Он не должен быть NULL, но мы и не указываем, что в нем, так как еще раз, каждый бекенд базы данных выполняет работу по-разному, или делает это автоматически для нас. Остальные столбцы говорят сами за себя
Введение данных
Сейчас наша база данных пустая. Это не очень полезно в использовании, так что в этом разделе мы научимся добавлять данные в базу. Вот общая идея:
|
INSERT INTO table_name (id, name, make, model, year) VALUES (1, ‘Marly’, ‘Ford’, ‘Explorer’, ‘2000’); |
SQL использует команды INSERT INTO для добавления данных в определенную базу данных. Вы также указываете, в какие столбцы вы добавляете данные. Когда мы создаем таблицу, мы можем определить необходимый столбец, который может вызвать ошибку, если мы не добавим в него необходимые данные. Однако, мы не делали этого в нашем определении таблицы ранее. Это просто на заметку. Вы также получите ошибку, если передадите неправильный тип данных, от этой вредной привычки я не мог отвыкнуть целый год. Я передавал строку или varchar, вместо данных. Конечно, каждая база данных требует определенный формат этих самых данных, так что вам может понадобиться разобраться с тем, что именно значит DATE для вашей базы данных.
Обновление данных
Представим, что мы сделали опечатку в нашем INSERT. Чтобы это исправить, нам нужно использовать команду SQL под названием UPDATE:
|
UPDATE table_name SET name=‘Chevrolet’ WHERE id=1; |
Команда UPDATE говорит нам, какая таблица нуждается в обновлении. Далее мы используем SET в одном или более столбцах для вставки нового значения. Наконец, на нужно указать базе данных ту строку, которую мы хотим обновить. Мы можем использовать команду WHERE, чтобы указать базе данных, что мы хотим изменить строчку, Id которой является 1.
Чтение данных
Чтение данных нашей базы данных осуществляется при помощи оператора SQL под названием SELECT:
|
SELECT name, make, model FROM table_name; |
Так мы возвращаем все строчки из нашей базы данных, но результат будет содержать только три части данных: название, создание и модель. Если вы хотите охватить все данные в базе данных, вы можете выполнить следующее:
|
SELECT * FROM table_name; |
Звездочка в данном случае это подстановка, которая говорит SQL, что вы хотите охватить все столбцы. Если вы хотите ограничить выбранный вами охват, вы можете добавить команду WHERE в вашем запросе:
|
SELECT name, make, model FROM table_name WHERE year >= ‘2000-01-01’ AND year <= ‘2006-01-01’; |
Так мы получим информацию о названии, создании и модели для 2000-2006 годов. Существует ряд других команд SQL, которые помогут вам в работе с запросами. Убедитесь, что ознакомитесь с такими командами как BETWEEN, LIKE, ORDER BY, DISTINCT и JOIN.
Удаление данных
Возможно, вам понадобиться удалить данные из вашей базы данных. Как это сделать:
|
DELETE FROM table_name WHERE name=‘Ford’; |
Этот код удалит все строчки, в поле названия которых указано «Ford» из нашей таблицы. Если вы хотите удалить всю таблицу, вы можете воспользоваться оператором DROP:
Используйте DROP и DELETE осторожно, так как вы легко можете потерять все данные, если вызовете оператор неправильно. Всегда держите хороший, годный, проверенный бекап вашей базы данных.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
adodbapi
В версиях Python2.4 и 2.5, мне нужно было подключаться к серверу SQL 2005 и Microsoft Access, и один из них или оба были настроены только для использования методологии подключения Microsoft к ADO. На то время решением было использовать пакет adodbapi. Этот пакет следует использовать тогда, когда вам нужно получить доступ к базе данных через Microsoft ADO. Я заметил, что этот пакет не обновлялся с 2014 года, так что помните об этом. К счастью, вам не нужно использовать этот пакет, так как Microsoft также предоставляет драйвер связи ODBC, но если по какой-то причине вам нужно поддерживать только ADO, то этот пакет – то, что вам нужно!
Запомните: adodbapi зависит от наличия установленного пакета PyWin32.
Для установки adodbapi, вам нужно сделать следующее:
Давайте посмотрим на простой пример, который я использую для связи с Microsoft Access на протяжении длительного времени:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import adodbapi database = «db1.mdb» constr = ‘Provider=Microsoft.Jet.OLEDB.4.0; Data Source=%s’ tablename = «address» # Подключаемся к базе данных. conn = adodbapi.connect(constr) # Создаем курсор. cur = conn.cursor() # Получаем все данные. sql = «select * from %s» % tablename cur.execute(sql) # Показываем результат. result = cur.fetchall() for item in result: print item # Завершаем подключение. cur.close() conn.close() |
Сначала мы создаем строку соединения. Эти строки определяют, как связаться с Microsoft Access или сервером SQL. В данном случае, мы подключаемся к Access. Для непосредственной связи с базой данных, вы вызываете метод connect и передаете ему вашу строку связи. Теперь у вас есть объект соединения, но для взаимодействия с базой данных вам нужен курсор. Его мы и создаем. Следующая часть – написание запроса SQL. В данном случае мы используем всю базу данных, так что мы выделяем * и передаем этот оператор SQL методу execute нашего курсора. Для получения результата мы вызываем fetchall, который возвращает весь результат. Наконец, мы закрываем cursor и connection. Если вы используете пакет adodbapi, я настоятельно рекомендую пройтись по справочному документу. Это очень полезно для понимания пакета, так как он не слишком хорошо документирован.
pyodbc
ODBC (Open Database Connectivity) – это стандартный API для доступа к базам данных. Большая часть баз данных продукции включает драйвер ODBC, который вы можете установить для связи с базой данных. Один из самых популярных методов связи с Python через ODBC – это пакет pyodbc. В соответствии с его страницей на Python Packaging Index, вы можете использовать его как на Windows, так и Linux. Пакет pyodbc реализует спецификацию DB API 2.0. Вы можете установить pyodbc при помощи pip:
Давайте взглянем на довольно обобщенный способ подключения к серверу SQL при помощи pyodbc и выберем какие-нибудь данные, как мы делали это в разделе adodbapi:
|
import pyodbc driver = ‘DRIVER={SQL Server}’ server = ‘SERVER=localhost’ port = ‘PORT=1433’ db = ‘DATABASE=testdb’ user = ‘UID=me’ pw = ‘PWD=pass’ conn_str = ‘;’.join([driver, server, port, db, user, pw]) conn = pyodbc.connect(conn_str) cursor = conn.cursor() cursor.execute(‘select * from table_name’) row = cursor.fetchone() rest_of_rows = cursor.fetchall() |
В данном коде мы создаем очень длинную строку связи. У нее много частей. Драйвер, сервер, номер порта, название базы данных, пользователь и пароль. Возможно, вам захочется сохранить большую часть этой информации в какой-нибудь файл конфигурации, так что вам не нужно будет вводить эту строку каждый раз. Желательно не перемудрить с именем пользователя и паролем. После получения нашей строки связи, мы попытаемся соединиться с базой данных, вызвав функцию connection. Если подключение прошло удачно, то мы получаем объект подключения, который мы можем использовать для создания объекта курсора. Теперь у нас есть курсор, мы можем запросить базу данных и запустить любые команды, которые нам нужны, в зависимости от того, какой доступ у базы данных. В этом примере, мы запускаем SELECT * для извлечения всех строчек. Далее мы демонстрируем нашу возможность брать по одной строчке за раз и вытягивать их через fetchone и fetchall соответственно. Также у нас в распоряжении имеется функция fetchmany, которую вы можете использовать для определения того, как много строчек вам нужно вернуть. Если вы имеете дело с базой данных, которая работает с ODBC, вы также можете использовать данный пакет. Обратите внимание на то, что базы данных Microsoft не единственные поддерживают данный метод соединения.
pypyodbc
Пакет pypyodbc, по сути, чистый скрипт Python. Это, в целом, переопределенный pyodbc чисто под Python. Это значит, что pyodbc – это Python, обернутый в бекенд C++, в то время как pypyodbc это чистый код Python. Он поддерживает тот же API, как и предыдущий модуль, так что эти модули взаимозаменяемые в большинстве случаев. В связи с этим, я не буду показывать никаких примеров в данном разделе, так как единственная разница между ними – это импорт.
MySQL в Python
MySQL – это очень популярный бекенд баз данных с открытым кодом. Вы можете подключить его к Python несколькими различными путями. Например, вы можете подключить его, используя один из методов ODBC, которые я упоминал в последних двух разделах. Один из наиболее популярных способов подключения MySQL к Python это пакет MySQLdb. Существует несколько вариантов того пакета:
- MySQLdb1
- MySQLdb2
- moist
Первый – это привычный способ подключения MySQL к Python. Однако, в основном он используется только в разработке и на данный момент не получает никаких новых функций. Разработчики переключились на MySQLdb2, и преобразовали его в проект moist. В MySQL произошел раскол после того, как их купили Oracle, что привело к разветвлению на проект, который называется Maria. Так что мы имеем дело с проектами MariaDB, MySQL и еще одной веткой, под названием Drizzle, каждая из которых, в той или иной мере основана на исходном коде MySQL. Проект moist направлен на создание моста, который мы можем использовать для соединения со всеми этими бекендами, к тому же, он все еще находится на этапах альфа или бета с момента публикации. Путаницу также создает тот факт, что MySQLdb завернут в _mysql, который вы можете использовать напрямую, если это нужно. В любом случае, вы быстро заметите, что MySQLdb не совместим с Python 3, вообще. Совместимость с проектом moist скоро будет, но пока её нет. Итак, как же работать с Python 3? У вас есть несколько вариантов:
- mysql-connector-python
- pymysql
- CyMySQL
- mysqlclient
mysqlclient – это ответвление MySQL-Python (другими словами, MySQLdb), который обеспечивает поддержку Python 3. Это метод, который проект Django рекомендует для подключения к MySQL. Так что мы сфокусируемся на этом пакете в данном разделе. Обратите внимание на то, что вам понадобится установленный MySQL или MySQL Client для успешной установки пакета mysqlclient. Если вы уже сделали это ранее, то вам остается только использовать pip для установки:
Давайте посмотрим на простой пример:
|
import MySQLdb conn = MySQLdb.connect(‘localhost’, ‘username’, ‘password’, ‘table_name’) cursor = conn.cursor() cursor.execute(«SELECT * FROM table_name») # Получаем данные. row = cursor.fetchone() print(row) # Разрываем подключение. conn.close() |
Этот код должен выглядеть знакомым. Большая часть качественных пакетов, ориентированных на базы данных следуют одному и тому же API. Так что в нашем случае мы импортируем наш пакет и создаем соединение. Обратите внимание на то, что нам нужно знать название сервера, к которому мы подключаемся в том числе (localhost, IP, и т.д.), имя пользователя и пароль для соединения, а также таблица, с которой мы хотим взаимодействовать. Далее, мы создаем объект курсора, так что мы можем выполнять команды SQL, что мы и делаем в следующей строке кода. Наконец, мы извлекаем одну строчку из полученного результата, выводим её и закрываем связь базы данных. Я хочу притормозить здесь и обратить внимание на то, что документация на этот счет достаточно вялая. В ней, по большому счету, указан только код, так что вам придется положиться только на это и на несколько находящихся в документации инструкций.
PostgreSQL в Python
PostgreSQL – это еще одна популярная база данных с открытым исходным кодом, которой пользуется очень много программистов. Python содержит несколько различных пакетов, которые поддерживают такой бекенд, но самый популярный это Psycopg. Пакет Psycopg поддерживает Python 2.5-2.7 и Python 3.1-3.4. Он также может работать с Python 3.5, если вы построите его лично.
Установка:
Если у вас получилось установить его, вы можете попробовать использовать следующий код:
|
import psycopg2 conn = psycopg2.connect(dbname=‘my_database’, user=‘username’) cursor = conn.cursor() # Выполняем запрос. cursor.execute(«SELECT * FROM table_name») row = cursor.fetchone() # Закрываем подключение. cursor.close() conn.close() |
Как и ожидалось, пакет Psycopg следует стандартному API, который мы видели ранее. Здесь мы просто импортируем пакет и подключаемся к нашей базе данных. Далее, мы создаем курсор и запускаем наш любимый оператор SELECT *. Наконец, мы берем первую строчку данных из выдачи при помощи fetchone. Наконец, мы закрываем наш курсор и подключение.
Объектно-реляционное отображение (ORM)
Если вы работаете с большим количеством баз данных, то вам определенно захочется познакомиться с объектно-реляционными мапперами (ORM). ORM позволяет вам работать с базой данных, без непосредственного использования SQL. Некоторые разработчики называют его более питонным, так как это ORM не является смесью SQL и Python. Самый популярный ORM в Python – это SQLAlchemy. Основное преимущество в использовании SQLAlchemy это то, что вы можете вписать код вашей базы данных один раз, и затем, если бекенд меняется, вам не нужно менять ваши запросы. Единственное, что вам нужно будет изменить – это строку соединения. Я использовал SQLAlchemy для перемещения таблиц из одного бекенда в другой, сохраняя возможность использовать тот же код в обоих концах. Также существуют другие представители ORM, например SQLObject и peewee. Сначала я попробовал использовать SQLObject, но он не поддерживает композитные ключи (на то время, по крайней мере), так что я переключился на SQLAlchemy. В принципе, я об этом ни разу не пожалел. Пакет peewee это маленький, легкий ORM, но все еще не такой гибкий как SQLAlchemy. Я настоятельно рекомендую ознакомиться с различными способами реализации данных ORM, потому, что то только так вы поймете, какой из них подойдет вам лучше.
Вы можете прямо сейчас заказать офферов для своего сообщества в ВК на сайте Doctor SMM по очень дешевым ценам. Кроме того, у Вас есть возможность выбрать наиболее оптимальный скоростной режим поступления страниц. Также на сайте действуют привлекательные оптовые скидки. Поэтому торопитесь сделать свое самое выгодное приобретение!
Подведем итоги
В данной статье мы рассмотрели ряд различных тем. Вы освоили основы использования SQL. Также вы узнали кое-что о различных способах подключения к базам данных, используя Python. Это был не исчерпывающий список способов, и тем не менее. Существует ряд других пакетов, которые вы можете использовать для подключения к различным базам данных.
К примеру, мы даже не затронули вопрос использования MongoDb, как и других баз данных NoSQL, несмотря на то, что они так же поддерживаются Python. Если база данных не так популярна, по сравнению с остальными, скорее всего, есть способ подключиться к ней с помощью Python. Вам определенно следует потратить время на то, чтобы проверить эти пакеты лично и найти тот самый!

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
Перед началом статьи хочу сказать, что еще больше полезной и нужной информации вы найдете в нашем Telegram-канале. Подпишитесь, мне будет очень приятно.
Если вы разработчик программного обеспечения, то, скорее всего, вы знакомы с невероятно легкой базой данных SQLite или даже уже использовали ее. Она содержит практически все функции реляционной базы данных и представлена всего одним файлом. На официальном сайте можно найти несколько сценариев применения SQLite:
- встроенные устройства и интернет вещей;
- анализ данных;
- передача данных;
- архив файлов и/или контейнер данных;
- внутренние или временные базы данных;
- замена корпоративной базы данных в период демо-версий или тестирования;
- обучение и тестирование;
- экспериментальные расширения языка SQL.
Если вам нужна SQLite для каких-либо других целей, то обратитесь к документации.
Но самое главное — SQLite встроена в библиотеку Python. То есть вам не нужно устанавливать серверное или клиентское ПО и поддерживать работу какого-либо сервиса. Если вы импортировали библиотеку в Python и приступили к работе, значит вы уже используете систему управления реляционными базами данных!
Импортирование и использование
«Встроенность» предполагает, что вам не нужно запускать pip install для получения библиотеки. Просто импортируйте ее с помощью:
import sqlite3 as sl
Создание соединения с БД
Не беспокойтесь о драйверах, строках подключения и т.д. Вы можете создать базу данных SQLite и задать такой простой объект подключения, как:
con = sl.connect(‘my-test.db’)
После запуска этой строки кода происходит создание с БД и активируется подключение к ней. Дело в том, что базы данных, к которой мы просим подключиться Python, не существует, поэтому он автоматически создает пустую. Также мы можем ввести точно такой же код для подключения к уже существующей базе данных.
Создание таблицы
Теперь создадим таблицу:
with con:
con.execute(«»»
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
«»»)
Мы добавили три столбца в таблицу USER. Как видите, SQLite действительно легка и при этом поддерживает все основные функции обычной реляционной СУБД, такие как тип данных, обнуляемый тип, первичный ключ и автоинкремент.
После запуска этого кода создается таблица, но она ничего не выводит.
Включение записей
Вставим несколько записей в только что созданную таблицу USER, чтобы доказать, что она действительно создана.
Предположим, мы хотим вставить сразу несколько записей. Выполним:
sql = ‘INSERT INTO USER (id, name, age) values(?, ?, ?)’
data = [
(1, ‘Alice’, 21),
(2, ‘Bob’, 22),
(3, ‘Chris’, 23)
]
Определяем оператор SQL с вопросительными знаками ? в качестве заполнителя. Теперь создадим образцы данных для вставки, а затем вставим их с помощью объекта подключения:
with con:
con.executemany(sql, data)
После запуска кода не появилось никаких предупреждений, значит все прошло успешно.
Запрос к таблице
Пришло время удостовериться, что все сделано правильно. Выполним запрос к таблице на возврат образцов строк.
with con:
data = con.execute(«SELECT * FROM USER WHERE age <= 22»)
for row in data:
print(row)
Как видите, все очень просто!
Более того, несмотря на свою легкость SQLite является широко используемой базой данных, и большинство программного обеспечения клиентов SQL ее поддерживает.
Чаще всего я использую инструмент DBeaver. Рассмотрим его на примере.
Подключение к базе данных SQLite из клиента SQL (DBeaver)
Поскольку я использую Google Colab, я буду загружать файл my-test.db на свой компьютер. При запуске Python на локальном компьютере можно использовать клиент SQL для прямого подключения к файлу баз данных.
Создаем новое соединение в DBeaver и выбираем SQLite в качестве типа БД:
Затем переходим к файлу БД:
Теперь к базе данных можно выполнить любой SQL-запрос, как и в любых других реляционных БД:
Непрерывная интеграция с Pandas
Но это еще не все. Дело в том, что, являясь встроенной функцией Python, SQLite может легко интегрироваться с фреймом данных Pandas.
Определяем фрейм данных:
df_skill = pd.DataFrame({
‘user_id’: [1,1,2,2,3,3,3],
‘skill’: [‘Network Security’, ‘Algorithm Development’, ‘Network Security’, ‘Java’, ‘Python’, ‘Data Science’, ‘Machine Learning’]
})
Затем просто вызываем метод фрейма данных to_sql(), чтобы сохранить его в базе данных:
df_skill.to_sql(‘SKILL’, con)
И это все, что нужно сделать! Вам даже не придется создавать таблицу заранее — типы данных и длина столбцов будут определены автоматически. Конечно, при желании вы также можете определить ее заранее.
Допустим, мы хотим объединить таблицу USER и SKILL и прочитать результат во фрейме данных Pandas. Это тоже можно выполнить без проблем.
df = pd.read_sql(»’
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
»’, con)
Результаты запишем в новую таблицу под названием USER_SKILL:
df.to_sql(‘USER_SKILL’, con)
Теперь мы также можем использовать клиент SQL для получения таблицы:
Выводы
В Python есть множество скрытых сюрпризов. Но скрыты они не специально: дело лишь в том, что в Python настолько много функций «из коробки», что невозможно раскрыть их все сразу.
В этой статье мы узнали, как использовать встроенную библиотеку Python sqlite3 для создания таблиц и манипулирования ими в базе данных SQLite. Конечно, она также поддерживает обновление и удаление, которые вы можете попробовать самостоятельно.
Но самое главное, мы можем легко прочитать таблицу из базы данных SQLite во фрейме данных Pandas и наоборот. Такая возможность еще больше упрощает взаимодействие с этой легкой реляционной базой данных.
Возможно, вы заметили, что в SQLite нет аутентификации. С ней бы данная библиотека перестала быть такой легкой.
Открывайте для себя еще больше удивительных возможностей Python!
SQL и Python — обязательные инструменты для любого специалиста в сфере анализа данных. Это руководство — все, что вам нужно для первоначальной настройки и освоения основ работы с SQLite в Python. Оно включает следующие пункты:
- Загрузка библиотеки
- Создание и соединение с базой данных
- Создание таблиц базы данных
- Добавление данных
- Запросы на получение данных
- Удаление данных
- И многое другое!
SQLite3 (часто говорят просто SQLite) — это часть стандартного пакета Python 3, поэтому ничего дополнительно устанавливать не придется.
Что будем создавать
В процессе этого руководства создадим базу данных в SQLite с помощью Python, несколько таблиц и настроим отношения:

Типы данных SQLite в Python
SQLite для Python предлагает меньше типов данных, чем есть в других реализациях SQL. С одной стороны, это накладывает ограничения, но, с другой стороны, в SQLite многое сделано проще. Вот основные типы:
NULL— значениеNULLINTEGER— целое числоREAL— число с плавающей точкойTEXT— текстBLOB— бинарное представление крупных объектов, хранящееся в точности с тем, как его ввели
К сожалению, других привычных для SQL типов данных в SQLite нет.
Первые шаги с SQLite в Python
Начнем руководство с загрузки библиотеки. Для этого нужно использовать следующую команду:
import sqlite3
Следующий шаг — создание базы данных.
Создание базы данных SQLite в Python
Есть несколько способов создания базы данных в Python с помощью SQLite. Для этого используется объект Connection, который и представляет собой базу. Он создается с помощью функции connect().
Создадим файл .db, поскольку это стандартный способ управления базой SQLite. Файл будет называться orders.db. За соединение будет отвечать переменная conn.
conn = sqlite3.connect('orders.db')
Эта строка создает объект connection, а также новый файл orders.db в рабочей директории. Если нужно использовать другую, ее нужно обозначить явно:
conn = sqlite3.connect(r'ПУТЬ-К-ПАПКИ/orders.db')
Если файл уже существует, то функция connect осуществит подключение к нему.
перед строкой с путем стоит символ «r». Это дает понять Python, что речь идет о «сырой» строке, где символы «/» не отвечают за экранирование.
Функция connect создает соединение с базой данных SQLite и возвращает объект, представляющий ее.
Резидентная база данных
Еще один способ создания баз данных с помощью SQLite в Python — создание их в памяти. Это отличный вариант для тестирования, ведь такие базы существуют только в оперативной памяти.
conn = sqlite3.connect(:memory:)
Однако в большинстве случаев (и в этом руководстве) будет использоваться описанный до этого способ.
Создание объекта cursor
После создания объекта соединения с базой данных нужно создать объект cursor. Он позволяет делать SQL-запросы к базе. Используем переменную cur для хранения объекта:
cur = conn.cursor()
Теперь выполнять запросы можно следующим образом:
cur.execute("ВАШ-SQL-ЗАПРОС-ЗДЕСЬ;")
Обратите внимание на то, что сами запросы должны быть помещены в кавычки — это важно. Это могут быть одинарные, двойные или тройные кавычки. Последние используются в случае особенно длинных запросов, которые часто пишутся на нескольких строках.
Создание таблиц в SQLite в Python
Пришло время создать первую таблицу в базе данных. С объектами соединения (conn) и cursor (cur) это можно сделать. Будем следовать этой схеме.
Начнем с таблицы users.
cur.execute("""CREATE TABLE IF NOT EXISTS users(
userid INT PRIMARY KEY,
fname TEXT,
lname TEXT,
gender TEXT);
""")
conn.commit()
В коде выше выполняются следующие операции:
- Функция
executeотвечает за SQL-запрос - SQL генерирует таблицу
users IF NOT EXISTSпоможет при попытке повторного подключения к базе данных. Запрос проверит, существует ли таблица. Если да — проверит, ничего ли не поменялось.- Создаем первые четыре колонки:
userid,fname,lnameиgender.Userid— это основной ключ. - Сохраняем изменения с помощью функции
commitдля объекта соединения.
Для создания второй таблицы просто повторим последовательность действий, используя следующие команды:
cur.execute("""CREATE TABLE IF NOT EXISTS orders(
orderid INT PRIMARY KEY,
date TEXT,
userid TEXT,
total TEXT);
""")
conn.commit()
После исполнения этих двух скриптов база данных будет включать две таблицы. Теперь можно добавлять данные.
Добавление данных с SQLite в Python
По аналогии с запросом для создания таблиц для добавления данных также нужно использовать объект cursor.
cur.execute("""INSERT INTO users(userid, fname, lname, gender)
VALUES('00001', 'Alex', 'Smith', 'male');""")
conn.commit()
В Python часто приходится иметь дело с переменными, в которых хранятся значения. Например, это может быть кортеж с информацией о пользователе.
user = ('00002', 'Lois', 'Lane', 'Female')
Если его нужно загрузить в базу данных, тогда подойдет следующий формат:
cur.execute("INSERT INTO users VALUES(?, ?, ?, ?);", user)
conn.commit()
В данном случае все значения заменены на знаки вопроса и добавлен параметр, содержащий значения, которые нужно добавить.
Важно заметить, что SQLite ожидает получить значения в формате кортежа. Однако в переменной может быть и список с набором кортежей. Таким образом можно добавить несколько пользователей:
more_users = [('00003', 'Peter', 'Parker', 'Male'), ('00004', 'Bruce', 'Wayne', 'male')]
Но нужно использовать функцию executemany вместо обычной execute:
cur.executemany("INSERT INTO users VALUES(?, ?, ?, ?);", more_users)
conn.commit()
Если применить execute, то функция подумает, то пользователь хочет передать в таблицу два объекта (два кортежа), а не два кортежа, каждый из которых содержит по 4 значения для каждого пользователя. Хотя в первую очередь вообще должна была возникнуть ошибка.
SQLite и предотвращение SQL-инъекций
Использование способа с вопросительными знаками (?, ?, …) также помогает противостоять SQL-инъекциям. Поэтому рекомендуется использовать его, а не упомянутый до этого.
Скрипты для загрузки данных
Следующие скрипты можно скопировать и вставить для добавления данных в обе таблицы:
customers = [
('00005', 'Stephanie', 'Stewart', 'female'), ('00006', 'Sincere', 'Sherman', 'female'), ('00007', 'Sidney', 'Horn', 'male'),
('00008', 'Litzy', 'Yates', 'female'), ('00009', 'Jaxon', 'Mills', 'male'), ('00010', 'Paul', 'Richard', 'male'),
('00011', 'Kamari', 'Holden', 'female'), ('00012', 'Gaige', 'Summers', 'female'), ('00013', 'Andrea', 'Snow', 'female'),
('00014', 'Angelica', 'Barnes', 'female'), ('00015', 'Leah', 'Pitts', 'female'), ('00016', 'Dillan', 'Olsen', 'male'),
('00017', 'Joe', 'Walsh', 'male'), ('00018', 'Reagan', 'Cooper', 'male'), ('00019', 'Aubree', 'Hogan', 'female'),
('00020', 'Avery', 'Floyd', 'male'), ('00021', 'Elianna', 'Simmons', 'female'), ('00022', 'Rodney', 'Stout', 'male'),
('00023', 'Elaine', 'Mcintosh', 'female'), ('00024', 'Myla', 'Mckenzie', 'female'), ('00025', 'Alijah', 'Horn', 'female'),
('00026', 'Rohan', 'Peterson', 'male'), ('00027', 'Irene', 'Walters', 'female'), ('00028', 'Lilia', 'Sellers', 'female'),
('00029', 'Perla', 'Jefferson', 'female'), ('00030', 'Ashley', 'Klein', 'female')
]
orders = [
('00001', '2020-01-01', '00025', '178'), ('00002', '2020-01-03', '00025', '39'), ('00003', '2020-01-07', '00016', '153'),
('00004', '2020-01-10', '00015', '110'), ('00005', '2020-01-11', '00024', '219'), ('00006', '2020-01-12', '00029', '37'),
('00007', '2020-01-14', '00028', '227'), ('00008', '2020-01-18', '00010', '232'), ('00009', '2020-01-22', '00016', '236'),
('00010', '2020-01-26', '00017', '116'), ('00011', '2020-01-28', '00028', '221'), ('00012', '2020-01-31', '00021', '238'),
('00013', '2020-02-02', '00015', '177'), ('00014', '2020-02-05', '00025', '76'), ('00015', '2020-02-08', '00022', '245'),
('00016', '2020-02-12', '00008', '180'), ('00017', '2020-02-14', '00020', '190'), ('00018', '2020-02-18', '00030', '166'),
('00019', '2020-02-22', '00002', '168'), ('00020', '2020-02-26', '00021', '174'), ('00021', '2020-02-29', '00017', '126'),
('00022', '2020-03-02', '00019', '211'), ('00023', '2020-03-05', '00030', '144'), ('00024', '2020-03-09', '00012', '112'),
('00025', '2020-03-10', '00006', '45'), ('00026', '2020-03-11', '00004', '200'), ('00027', '2020-03-14', '00015', '226'),
('00028', '2020-03-17', '00030', '189'), ('00029', '2020-03-20', '00004', '152'), ('00030', '2020-03-22', '00026', '239'),
('00031', '2020-03-23', '00012', '135'), ('00032', '2020-03-24', '00013', '211'), ('00033', '2020-03-27', '00030', '226'),
('00034', '2020-03-28', '00007', '173'), ('00035', '2020-03-30', '00010', '144'), ('00036', '2020-04-01', '00017', '185'),
('00037', '2020-04-03', '00009', '95'), ('00038', '2020-04-06', '00009', '138'), ('00039', '2020-04-10', '00025', '223'),
('00040', '2020-04-12', '00019', '118'), ('00041', '2020-04-15', '00024', '132'), ('00042', '2020-04-18', '00008', '238'),
('00043', '2020-04-21', '00003', '50'), ('00044', '2020-04-25', '00019', '98'), ('00045', '2020-04-26', '00017', '167'),
('00046', '2020-04-28', '00009', '215'), ('00047', '2020-05-01', '00014', '142'), ('00048', '2020-05-05', '00022', '173'),
('00049', '2020-05-06', '00015', '80'), ('00050', '2020-05-07', '00017', '37'), ('00051', '2020-05-08', '00002', '36'),
('00052', '2020-05-10', '00022', '65'), ('00053', '2020-05-14', '00019', '110'), ('00054', '2020-05-18', '00017', '36'),
('00055', '2020-05-21', '00008', '163'), ('00056', '2020-05-24', '00024', '91'), ('00057', '2020-05-26', '00028', '154'),
('00058', '2020-05-30', '00022', '130'), ('00059', '2020-05-31', '00017', '119'), ('00060', '2020-06-01', '00024', '137'),
('00061', '2020-06-03', '00017', '206'), ('00062', '2020-06-04', '00013', '100'), ('00063', '2020-06-05', '00021', '187'),
('00064', '2020-06-09', '00025', '170'), ('00065', '2020-06-11', '00011', '149'), ('00066', '2020-06-12', '00007', '195'),
('00067', '2020-06-14', '00015', '30'), ('00068', '2020-06-16', '00002', '246'), ('00069', '2020-06-20', '00028', '163'),
('00070', '2020-06-22', '00005', '184'), ('00071', '2020-06-23', '00022', '68'), ('00072', '2020-06-27', '00013', '92'),
('00073', '2020-06-30', '00022', '149'), ('00074', '2020-07-04', '00002', '65'), ('00075', '2020-07-05', '00017', '88'),
('00076', '2020-07-09', '00007', '156'), ('00077', '2020-07-13', '00010', '26'), ('00078', '2020-07-16', '00008', '55'),
('00079', '2020-07-20', '00019', '81'), ('00080', '2020-07-22', '00011', '78'), ('00081', '2020-07-23', '00026', '166'),
('00082', '2020-07-27', '00014', '65'), ('00083', '2020-07-30', '00021', '205'), ('00084', '2020-08-01', '00026', '140'),
('00085', '2020-08-05', '00006', '236'), ('00086', '2020-08-06', '00021', '208'), ('00087', '2020-08-07', '00021', '169'),
('00088', '2020-08-08', '00004', '157'), ('00089', '2020-08-11', '00017', '71'), ('00090', '2020-08-13', '00025', '89'),
('00091', '2020-08-16', '00014', '249'), ('00092', '2020-08-18', '00012', '59'), ('00093', '2020-08-19', '00013', '121'),
('00094', '2020-08-20', '00025', '179'), ('00095', '2020-08-22', '00017', '208'), ('00096', '2020-08-26', '00024', '217'),
('00097', '2020-08-28', '00004', '206'), ('00098', '2020-08-30', '00017', '114'), ('00099', '2020-08-31', '00017', '169'),
('00100', '2020-09-02', '00022', '226')
]
Используйте следующие запросы:
cur.executemany("INSERT INTO users VALUES(?, ?, ?, ?);", customers)
cur.executemany("INSERT INTO orders VALUES(?, ?, ?, ?);", orders)
conn.commit()
Получение данных с SQLite в Python
Следующий момент касательно SQLite в Python — выбор данных. Структура формирования запроса та же, но к ней будет добавлен еще один элемент.
Использование fetchone() в SQLite в Python
Начнем с использования функции fetchone(). Создадим переменную one_result для получения только одного результата:
cur.execute("SELECT * FROM users;")
one_result = cur.fetchone()
print(one_result)
Она вернет следующее:
[(1, 'Alex', 'Smith', 'male')]
Использование fetchmany() в SQLite в Python
Если же нужно получить много данных, то используется функция fetchmany(). Выполним другой скрипт для генерации 3 результатов:
cur.execute("SELECT * FROM users;")
three_results = cur.fetchmany(3)
print(three_results)
Он вернет следующее:
[(1, 'Alex', 'Smith', 'male'), (2, 'Lois', 'Lane', 'Female'), (3, 'Peter', 'Parker', 'Male')]
Использование fetchall() в SQLite в Python
Функцию fetchall() можно использовать для получения всех результатов. Вот что будет, если запустить скрипт:
cur.execute("SELECT * FROM users;")
all_results = cur.fetchall()
print(all_results)
Удаление данных в SQLite в Python
Теперь рассмотрим процесс удаления данных с SQLite в Python. Здесь та же структура. Предположим, нужно удалить любого пользователя с фамилией «Parker». Напишем следующее:
cur.execute("DELETE FROM users WHERE lname='Parker';")
conn.commit()
Если затем сделать следующей запрос:
cur.execute("select * from users where lname='Parker'")
print(cur.fetchall())
Будет выведен пустой список, подтверждающий, что запись удалена.
Объединение таблиц в SQLite в Python
Наконец, посмотрим, как использовать объединение данных для более сложных запросов. Предположим, нужно сгенерировать запрос, включающий имя и фамилию каждого покупателя заказа.
Для этого напишем следующее:
cur.execute("""SELECT *, users.fname, users.lname FROM orders
LEFT JOIN users ON users.userid=orders.userid;""")
print(cur.fetchall())
Тот же подход работает с другими SQL-операциями.
Выводы
В этом материале вы узнали все, что требуется для работы с SQLite в Python: загрузка библиотеки, создание баз и таблиц, добавление, запрос и удаление данных.