From Wikipedia, the free encyclopedia
(Redirected from Win1251)
| MIME / IANA | windows-1251 |
|---|---|
| Alias(es) | cp1251 (Code page 1251) |
| Language(s) | Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Bosnian Cyrillic, Macedonian, Rotokas, Rusyn, English |
| Created by | Microsoft |
| Standard | WHATWG Encoding Standard |
| Classification | extended ASCII, Windows-125x |
| Other related encoding(s) | Amiga-1251, KZ-1048, RFC 1345’s «ECMA-Cyrillic» |
|
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
On the web, it is the second most-used single-byte character encoding (or third most-used character encoding overall), and most used of the single-byte encodings supporting Cyrillic. As of November 2022, 0.4% of all websites use Windows-1251.[1][2] It’s by far mostly used for Russian, while a small minority of Russian websites use it, with 93.7% of Russian (.ru) websites using UTF-8,[3][4][5] and the legacy 8-bit encoding is distant second. In Linux, the encoding is known as cp1251.[6] IBM uses code page 1251 (CCSID 1251 and euro sign extended CCSID 5347) for Windows-1251.[7][8][9][10][11][12][13]
Windows-1251 and KOI8-R (or its Ukrainian variant KOI8-U) are much more commonly used than ISO 8859-5 (which is used by less than 0.0004% of websites).[14] In contrast to Windows-1252 and ISO 8859-1, Windows-1251 is not closely related to ISO 8859-5.
Unicode (e.g. UTF-8) is preferred to Windows-1251 or other Cyrillic encodings in modern applications, especially on the Internet, making UTF-8 the dominant encoding for web pages. (For further discussion of Unicode’s complete coverage, of 436 Cyrillic letters/code points, including for Old Cyrillic, and how single-byte character encodings, such as Windows-1251 and KOI8-R, cannot provide this, see Cyrillic script in Unicode.)
Character set[edit]
The following table shows Windows-1251. Each character is shown with its Unicode equivalent and its Alt code.
| Windows-1251[15] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Ќ | Ћ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | ќ | ћ | џ | |
| Ax | NBSP | Ў | ў | Ј | ¤ | Ґ | ¦ | § | Ё | © | Є | « | ¬ | SHY | ® | Ї |
| Bx | ° | ± | І | і | ґ | µ | ¶ | · | ё | № | є | » | ј | Ѕ | ѕ | ї |
| Cx | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Dx | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| Ex | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Fx | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Kazakh variant[edit]
An altered version of Windows-1251 was standardised in Kazakhstan as Kazakh standard STRK1048, and is known by the label KZ-1048. It differs in the rows shown below:
| KZ-1048 (STRK1048-2002)[16] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Қ | Һ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | қ | һ | џ | |
| Ax | NBSP | Ұ | ұ | Ә | ¤ | Ө | ¦ | § | Ё | © | Ғ | « | ¬ | SHY | ® | Ү |
| Bx | ° | ± | І | і | ө | µ | ¶ | · | ё | № | ғ | » | ә | Ң | ң | ү |
Differences from Windows-1251
Amiga variant[edit]
| MIME / IANA | Amiga-1251 |
|---|---|
| Alias(es) | Ami1251 |
| Language(s) | English, Russian |
| Classification | extended ASCII |
| Based on | Windows-1251, ISO-8859-1, ISO-8859-15 |
|
Russian Amiga OS systems used a version of code page 1251 which matches Windows-1251 for the Russian subset of the Cyrillic letters, but otherwise mostly follows ISO-8859-1. This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
| Amiga-1251[17] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | XXX | XXX | BPH | NBH | IND | NEL | SSA | ESA | HTS | HTJ | VTS | PLD | PLU | RI | SS2 | SS3 |
| 9x | DCS | PU1 | PU2 | STS | CCH | MW | SPA | EPA | SOS | XXX | SCI | CSI | ST | OSC | PM | APC |
| Ax | NBSP | ¡ | ¢ | £ | €[a] | ¥ | ¦ | § | Ё | © | №[b] | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ё | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
Different from Windows-1251 to match ISO-8859-1
Different from both Windows-1251 and ISO-8859-1
- ^ Matching ISO-8859-15; at a different location than in Windows-1251
- ^ Present in Windows-1251, but in a different location (absent from ISO-8859-1/15)
See also[edit]
- Latin script in Unicode
- Unicode
- Universal Character Set
- European Unicode subset (DIN 91379)
- UTF-8
References[edit]
- ^ «Historical trends in the usage of character encodings, November 2022». Retrieved 2022-11-28.
- ^ «Frequently Asked Questions».
- ^ «Distribution of Character Encodings among websites that use .ru». w3techs.com. Retrieved 2022-11-28.
- ^ «Distribution of Character Encodings among websites that use Russian». w3techs.com. Retrieved 2023-01-16.
- ^ «Distribution of Character Encodings among websites that use Russian Federation». w3techs.com. Retrieved 2021-11-05.
- ^ «cp1251(7) — Linux manual page». man7.org. Retrieved 2018-07-01.
- ^ «Code page 1251 information document». Archived from the original on 2016-03-03.
- ^ «CCSID 1251 information document». Archived from the original on 2014-11-29.
- ^ «CCSID 5347 information document». Archived from the original on 2014-11-29.
- ^ Code Page CPGID 01251 (pdf) (PDF), IBM
- ^ Code Page CPGID 01251 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1251_P100-1995.ucm, 2002-12-03
- ^ International Components for Unicode (ICU), ibm-5347_P100-1998.ucm, 2002-12-03
- ^ «Usage Statistics of Character Encodings for Websites». w3techs.com. Archived from the original on 2012-05-30.
- ^ Steele, Shawn (1998). CP1251 to Unicode table. Unicode Consortium. CP1251.TXT.
- ^ Whistler, Ken (2007). KZ-1048 to Unicode. Unicode Consortium. KZ1048.TXT.
- ^ a b Malyshev, Michael (2003). «Amiga-1251 to Unicode table». Registration of new charset [Amiga-1251]. IANA.
- ^ «Character Sets». IANA.
Further reading[edit]
- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). «CYRILLIC ENCODING FAQ Version 1.3». Retrieved 2020-06-24.
External links[edit]
- Windows 1251 reference chart
- IANA Charset Name Registration
- Unicode mappings of windows 1251 with «best fit»
- Universal Cyrillic decoder, an online program that may help recovering unreadable Cyrillic texts with broken Windows-1251 or other character encodings.
From Wikipedia, the free encyclopedia
(Redirected from Win1251)
| MIME / IANA | windows-1251 |
|---|---|
| Alias(es) | cp1251 (Code page 1251) |
| Language(s) | Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Bosnian Cyrillic, Macedonian, Rotokas, Rusyn, English |
| Created by | Microsoft |
| Standard | WHATWG Encoding Standard |
| Classification | extended ASCII, Windows-125x |
| Other related encoding(s) | Amiga-1251, KZ-1048, RFC 1345’s «ECMA-Cyrillic» |
|
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
On the web, it is the second most-used single-byte character encoding (or third most-used character encoding overall), and most used of the single-byte encodings supporting Cyrillic. As of November 2022, 0.4% of all websites use Windows-1251.[1][2] It’s by far mostly used for Russian, while a small minority of Russian websites use it, with 93.7% of Russian (.ru) websites using UTF-8,[3][4][5] and the legacy 8-bit encoding is distant second. In Linux, the encoding is known as cp1251.[6] IBM uses code page 1251 (CCSID 1251 and euro sign extended CCSID 5347) for Windows-1251.[7][8][9][10][11][12][13]
Windows-1251 and KOI8-R (or its Ukrainian variant KOI8-U) are much more commonly used than ISO 8859-5 (which is used by less than 0.0004% of websites).[14] In contrast to Windows-1252 and ISO 8859-1, Windows-1251 is not closely related to ISO 8859-5.
Unicode (e.g. UTF-8) is preferred to Windows-1251 or other Cyrillic encodings in modern applications, especially on the Internet, making UTF-8 the dominant encoding for web pages. (For further discussion of Unicode’s complete coverage, of 436 Cyrillic letters/code points, including for Old Cyrillic, and how single-byte character encodings, such as Windows-1251 and KOI8-R, cannot provide this, see Cyrillic script in Unicode.)
Character set[edit]
The following table shows Windows-1251. Each character is shown with its Unicode equivalent and its Alt code.
| Windows-1251[15] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Ќ | Ћ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | ќ | ћ | џ | |
| Ax | NBSP | Ў | ў | Ј | ¤ | Ґ | ¦ | § | Ё | © | Є | « | ¬ | SHY | ® | Ї |
| Bx | ° | ± | І | і | ґ | µ | ¶ | · | ё | № | є | » | ј | Ѕ | ѕ | ї |
| Cx | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Dx | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| Ex | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Fx | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Kazakh variant[edit]
An altered version of Windows-1251 was standardised in Kazakhstan as Kazakh standard STRK1048, and is known by the label KZ-1048. It differs in the rows shown below:
| KZ-1048 (STRK1048-2002)[16] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Қ | Һ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | қ | һ | џ | |
| Ax | NBSP | Ұ | ұ | Ә | ¤ | Ө | ¦ | § | Ё | © | Ғ | « | ¬ | SHY | ® | Ү |
| Bx | ° | ± | І | і | ө | µ | ¶ | · | ё | № | ғ | » | ә | Ң | ң | ү |
Differences from Windows-1251
Amiga variant[edit]
| MIME / IANA | Amiga-1251 |
|---|---|
| Alias(es) | Ami1251 |
| Language(s) | English, Russian |
| Classification | extended ASCII |
| Based on | Windows-1251, ISO-8859-1, ISO-8859-15 |
|
Russian Amiga OS systems used a version of code page 1251 which matches Windows-1251 for the Russian subset of the Cyrillic letters, but otherwise mostly follows ISO-8859-1. This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
| Amiga-1251[17] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | XXX | XXX | BPH | NBH | IND | NEL | SSA | ESA | HTS | HTJ | VTS | PLD | PLU | RI | SS2 | SS3 |
| 9x | DCS | PU1 | PU2 | STS | CCH | MW | SPA | EPA | SOS | XXX | SCI | CSI | ST | OSC | PM | APC |
| Ax | NBSP | ¡ | ¢ | £ | €[a] | ¥ | ¦ | § | Ё | © | №[b] | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ё | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
Different from Windows-1251 to match ISO-8859-1
Different from both Windows-1251 and ISO-8859-1
- ^ Matching ISO-8859-15; at a different location than in Windows-1251
- ^ Present in Windows-1251, but in a different location (absent from ISO-8859-1/15)
See also[edit]
- Latin script in Unicode
- Unicode
- Universal Character Set
- European Unicode subset (DIN 91379)
- UTF-8
References[edit]
- ^ «Historical trends in the usage of character encodings, November 2022». Retrieved 2022-11-28.
- ^ «Frequently Asked Questions».
- ^ «Distribution of Character Encodings among websites that use .ru». w3techs.com. Retrieved 2022-11-28.
- ^ «Distribution of Character Encodings among websites that use Russian». w3techs.com. Retrieved 2023-01-16.
- ^ «Distribution of Character Encodings among websites that use Russian Federation». w3techs.com. Retrieved 2021-11-05.
- ^ «cp1251(7) — Linux manual page». man7.org. Retrieved 2018-07-01.
- ^ «Code page 1251 information document». Archived from the original on 2016-03-03.
- ^ «CCSID 1251 information document». Archived from the original on 2014-11-29.
- ^ «CCSID 5347 information document». Archived from the original on 2014-11-29.
- ^ Code Page CPGID 01251 (pdf) (PDF), IBM
- ^ Code Page CPGID 01251 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1251_P100-1995.ucm, 2002-12-03
- ^ International Components for Unicode (ICU), ibm-5347_P100-1998.ucm, 2002-12-03
- ^ «Usage Statistics of Character Encodings for Websites». w3techs.com. Archived from the original on 2012-05-30.
- ^ Steele, Shawn (1998). CP1251 to Unicode table. Unicode Consortium. CP1251.TXT.
- ^ Whistler, Ken (2007). KZ-1048 to Unicode. Unicode Consortium. KZ1048.TXT.
- ^ a b Malyshev, Michael (2003). «Amiga-1251 to Unicode table». Registration of new charset [Amiga-1251]. IANA.
- ^ «Character Sets». IANA.
Further reading[edit]
- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). «CYRILLIC ENCODING FAQ Version 1.3». Retrieved 2020-06-24.
External links[edit]
- Windows 1251 reference chart
- IANA Charset Name Registration
- Unicode mappings of windows 1251 with «best fit»
- Universal Cyrillic decoder, an online program that may help recovering unreadable Cyrillic texts with broken Windows-1251 or other character encodings.

Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах. Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| Dec | Hex | Символ | Dec | Hex | Символ | |
|---|---|---|---|---|---|---|
| 000 | 00 | NOP | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | BS | 136 | 88 | € | |
| 009 | 09 | TAB | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | VT | 139 | 8B | ‹ | |
| 012 | 0C | FF | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | SO | 142 | 8E | Ћ | |
| 015 | 0F | SI | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | NAK | 149 | 95 | • | |
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | CAN | 152 | 98 | ||
| 025 | 19 | EM | 153 | 99 | ™ | |
| 026 | 1A | SUB | 154 | 9A | љ | |
| 027 | 1B | ESC | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | GS | 157 | 9D | ќ | |
| 030 | 1E | RS | 158 | 9E | ћ | |
| 031 | 1F | US | 159 | 9F | џ | |
| 032 | 20 | SP | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | « | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | ‘ | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Ё | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | AA | Є | |
| 043 | 2B | + | 171 | AB | « | |
| 044 | 2C | , | 172 | AC | ¬ | |
| 045 | 2D | — | 173 | AD | | |
| 046 | 2E | . | 174 | AE | ® | |
| 047 | 2F | / | 175 | AF | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | ё | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | BC | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї | |
| 064 | 40 | @ | 192 | C0 | А | |
| 065 | 41 | A | 193 | C1 | Б | |
| 066 | 42 | B | 194 | C2 | В | |
| 067 | 43 | C | 195 | C3 | Г | |
| 068 | 44 | D | 196 | C4 | Д | |
| 069 | 45 | E | 197 | C5 | Е | |
| 070 | 46 | F | 198 | C6 | Ж | |
| 071 | 47 | G | 199 | C7 | З | |
| 072 | 48 | H | 200 | C8 | И | |
| 073 | 49 | I | 201 | C9 | Й | |
| 074 | 4A | J | 202 | CA | К | |
| 075 | 4B | K | 203 | CB | Л | |
| 076 | 4C | L | 204 | CC | М | |
| 077 | 4D | M | 205 | CD | Н | |
| 078 | 4E | N | 206 | CE | О | |
| 079 | 4F | O | 207 | CF | П | |
| 080 | 50 | P | 208 | D0 | Р | |
| 081 | 51 | Q | 209 | D1 | С | |
| 082 | 52 | R | 210 | D2 | Т | |
| 083 | 53 | S | 211 | D3 | У | |
| 084 | 54 | T | 212 | D4 | Ф | |
| 085 | 55 | U | 213 | D5 | Х | |
| 086 | 56 | V | 214 | D6 | Ц | |
| 087 | 57 | W | 215 | D7 | Ч | |
| 088 | 58 | X | 216 | D8 | Ш | |
| 089 | 59 | Y | 217 | D9 | Щ | |
| 090 | 5A | Z | 218 | DA | Ъ | |
| 091 | 5B | [ | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | ||
| 093 | 5D | ] | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю | |
| 095 | 5F | _ | 223 | DF | Я | |
| 096 | 60 | ` | 224 | E0 | а | |
| 097 | 61 | a | 225 | E1 | б | |
| 098 | 62 | b | 226 | E2 | в | |
| 099 | 63 | c | 227 | E3 | г | |
| 100 | 64 | d | 228 | E4 | д | |
| 101 | 65 | e | 229 | E5 | е | |
| 102 | 66 | f | 230 | E6 | ж | |
| 103 | 67 | g | 231 | E7 | з | |
| 104 | 68 | h | 232 | E8 | и | |
| 105 | 69 | i | 233 | E9 | й | |
| 106 | 6A | j | 234 | EA | к | |
| 107 | 6B | k | 235 | EB | л | |
| 108 | 6C | l | 236 | EC | м | |
| 109 | 6D | m | 237 | ED | н | |
| 110 | 6E | n | 238 | EE | о | |
| 111 | 6F | o | 239 | EF | п | |
| 112 | 70 | p | 240 | F0 | р | |
| 113 | 71 | q | 241 | F1 | с | |
| 114 | 72 | r | 242 | F2 | т | |
| 115 | 73 | s | 243 | F3 | у | |
| 116 | 74 | t | 244 | F4 | ф | |
| 117 | 75 | u | 245 | F5 | х | |
| 118 | 76 | v | 246 | F6 | ц | |
| 119 | 77 | w | 247 | F7 | ч | |
| 120 | 78 | x | 248 | F8 | ш | |
| 121 | 79 | y | 249 | F9 | щ | |
| 122 | 7A | z | 250 | FA | ъ | |
| 123 | 7B | { | 251 | FB | ы | |
| 124 | 7C | | | 252 | FC | ь | |
| 125 | 7D | } | 253 | FD | э | |
| 126 | 7E | ~ | 254 | FE | ю | |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.
Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
| Код | Описание |
|---|---|
| NUL, 00 | Null, пустой |
| SOH, 01 | Start Of Heading, начало заголовка |
| STX, 02 | Start of TeXt, начало текста |
| ETX, 03 | End of TeXt, конец текста |
| EOT, 04 | End of Transmission, конец передачи |
| ENQ, 05 | Enquire. Прошу подтверждения |
| ACK, 06 | Acknowledgement. Подтверждаю |
| BEL, 07 | Bell, звонок |
| BS, 08 | Backspace, возврат на один символ назад |
| TAB, 09 | Tab, горизонтальная табуляция |
| LF, 0A | Line Feed, перевод строки Сейчас в большинстве языков программирования обозначается как n |
| VT, 0B | Vertical Tab, вертикальная табуляция |
| FF, 0C | Form Feed, прогон страницы, новая страница |
| CR, 0D | Carriage Return, возврат каретки Сейчас в большинстве языков программирования обозначается как r |
| SO, 0E | Shift Out, изменить цвет красящей ленты в печатающем устройстве |
| SI, 0F | Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно |
| DLE, 10 | Data Link Escape, переключение канала на передачу данных |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 |
Device Control, символы управления устройствами |
| NAK, 15 | Negative Acknowledgment, не подтверждаю |
| SYN, 16 | Synchronization. Символ синхронизации |
| ETB, 17 | End of Text Block, конец текстового блока |
| CAN, 18 | Cancel, отмена переданного ранее |
| EM, 19 | End of Medium, конец носителя данных |
| SUB, 1A | Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче |
| ESC, 1B | Escape Управляющая последовательность |
| FS, 1C | File Separator, разделитель файлов |
| GS, 1D | Group Separator, разделитель групп |
| RS, 1E | Record Separator, разделитель записей |
| US, 1F | Unit Separator, разделитель юнитов |
| DEL, 7F | Delete, стереть последний символ. |
Смотрите также:
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
Таблица кодов символов кирилицы UTF-8
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)

Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.
Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.
Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.

Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.
Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.

- Перейдите по ветке HKEY_CURRENT_USERConsole и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).

- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.


Отличного Вам дня!
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа! 
смайлы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн! 
смайлы, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «�����»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить… 
смайлы
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 14 лет(число динамическое) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!
Содержание
- 1 Представление символов в вычислительных машинах
- 2 Таблицы кодировок
- 3 Кодировки стандарта ASCII
- 3.1 Структурные свойства таблицы
- 4 Кодировки стандарта UNICODE
- 4.1 Кодовое пространство
- 4.2 Модифицирующие символы
- 4.3 Способы представления
- 4.4 UTF-8
- 4.4.1 Принцип кодирования
- 4.4.1.1 Правила записи кода одного символа в UTF-8
- 4.4.1.2 Определение длины кода в UTF-8
- 4.4.1 Принцип кодирования
- 4.5 UTF-16
- 4.5.1 UTF-16LE и UTF-16BE
- 4.6 UTF-32
- 4.7 Порядок байт
- 4.7.1 Варианты записи
- 4.7.1.1 Порядок от старшего к младшему
- 4.7.1.2 Порядок от младшего к старшему
- 4.7.1.3 Переключаемый порядок
- 4.7.1.4 Смешанный порядок
- 4.7.1.5 Различия
- 4.7.2 Маркер последовательности байт
- 4.7.1 Варианты записи
- 4.8 Проблемы Юникода
- 5 Примеры
- 5.1 Код на python
- 5.2 hex-дамп файла exampleBOM
- 6 См. также
- 7 Источники информации
Представление символов в вычислительных машинах
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины , задается простой формулой . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до кодовых позиций, было принято решение использовать лишь для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее кодовых позиций ( графических и прочих символов).
Кодовое пространство разбито на плоскостей (англ. planes) по символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости и выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов ) или «U+xxxxx» (для кодов ) или «U+xxxxxx» (для кодов ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
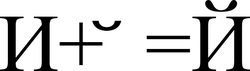
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими -битные символы. Текст, состоящий только из символов с номером меньше , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид , а остальные — .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
111111xx |
служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = байт
- Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 байт (то есть от до ):
- 2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
- 2.2 «0» — бит терминатор, означающий завершение кода размера
- 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
В общем случае количество значащих бит , кодируемых байтами UTF-8, определяется по формуле:
при
при
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством ), причем -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от до ). При этом можно кодировать символы Unicode в диапазонах и . Исключенный отсюда диапазон используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя -битными словами. Символы Unicode до включительно (исключая диапазон для суррогатов) записываются как есть -битным словом. Символы же в диапазоне (больше бит) уже кодируются парой -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число ). В результате получится значение от нуля до , которое занимает до бит. Старшие бит этого значения идут в лидирующее (первое) слово, а младшие бит — в последующее (второе). При этом в обоих словах старшие бит используются для обозначения суррогата. Биты с по имеют значения , а -й бит содержит у лидирующего слова и — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа , большего (здесь — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число записывается в позиционной системе счисления по основанию :
Набор целых чисел , каждое из которых лежит в интервале от до , является последовательностью байт, составляющих . При этом называется младшим байтом, а — старшим байтом числа .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление -байтных целых чисел на -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число , то прочитав его как int16 (два байта) мы получим число , прочитав один байт — число . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
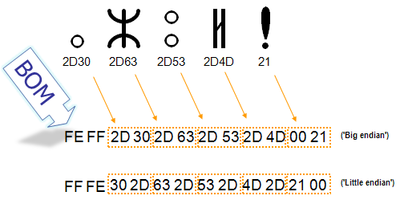
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF
|
| UTF-16 (BE) | FE FF
|
| UTF-16 (LE) | FF FE
|
| UTF-32 (BE) | 00 00 FE FF
|
| UTF-32 (LE) | FF FE 00 00
|
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его или байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.

Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.

Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
| Эта статья в настоящее время активно дополняется.Не вносите сюда изменений до тех пор, пока это объявление не будет убрано. |
Windows-1251 — цифровая (компьютерная) кодировка, расширяющая ASCII для представления букв кириллицы и других символов. Самая популярная в Интернете однобайтовая (чисто 8-битная) кодировка кириллицы и вторая по используемости однобайтовая кодировка символов вообще после Windows-1252. Является одной из кодовых страниц для операционной системы Windows; под тем же номером внесена в каталог корпорации IBM.[1] На UNIX-системах называется «CP1251»; исторически называлась «кириллицей Windows» или «кириллицей Microsoft».
Содержание
- 1 Набор и расположение символов
- 2 Использование
- 2.1 В Интернете
- 2.2 В Microsoft Windows
- 2.3 В прочих контекстах
- 3 История создания, варианты и модификации
- 4 Интересные факты
- 5 Ссылки
Набор и расположение символов[править]
Основой для Windows-1251 служит кодовая страница западной латиницы Windows-1252, вторая половина кодовой таблицы которой освобождена от специфичных для латиницы букв и ряда подобных им знаков, а также нескольких таких (малоиспользуемых в кириллической типографике) символов, как простые двоичные дроби. Однако, свои места сохраняют символы «©», «®» и «™». Остаются нетронутыми не только все ASCII-символы, но и несколько (уточнить) позиций типографики. Это обеспечивает некоторую меру совместимости страницы 1251 с Windows-1252 и ею подобными: хотя при чтении записанного в Windows-1251 текста при установленной странице 1252 (или наоборот) и будут испорчены буквы, то хотя бы сохранят свой вид тире, кавычки-ёлочки, кривые апострофы и т.п. Знак евро «€», являющийся позднейшим добавлением в Windows, находится в Windows-1251 на 0x88 (136, 210) в отличие от 0x80 (128, 200) в 1252 и большинстве других страниц Windows.
Использование[править]
В Интернете[править]
Наличие в кодовой странице множества символов типографики (что не имеет места ни в «альтернативной» кодировке, ни в KOI8, ни тем более в ISO 8859-5) сделало весьма удобным представление свёрстанного кириллического текста в Windows-1251 независимо от операционной системы потребителя. Это обеспечило уверенное доминирование Windows-1251 в кириллическом секторе WWW на протяжение примерно двенадцати лет. При этом в электронной почте и сообщениях NNTP преобладала KOI8-R (и её модификации) ввиду особенностей передачи данных по некоторым каналам.
С конца 2000-х годов главной кодировкой Интернета становится UTF-8, в том числе для кириллической письменности.
По тем же причинам, что и вышеназванные, Windows-1251 имела широкое использование в IRC и используется (в русскоязычной среде) до сих пор. Ограничения протокола делают нежелательным полный переход на UTF-8 (или какую-либо многобайтную кодировку вообще).
В Microsoft Windows[править]
Служила локализацией для использующих кириллицу славянских языков и некоторых других (перечислить) как до введения в Windows Юникода, так и после — ради поддержания приложений, работающих через старый 8-битный API. Информацию о кодовой странице можно найти в реестре в разделе «HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage», ключах «1251» и (при наличии локали) «ACP».
В прочих контекстах[править]
Кроме использования кода 0xFF (255, 377) для строчной буквы «я», нет противопоказаний для использования Windows-1251 в системах UNIX. Современные системы (большинство разновидностей GNU/Linux, FreeBSD и т.д.) позволяют без установки стороннего ПО собрать локаль с кодировкой CP1251.
История создания, варианты и модификации[править]
Ни CP866 (разновидность «альтернативной» кодировки), уже поддерживаемая ПО от Microsoft, ни KOI8-R разработчиков Windows не удовлетворили ввиду отсутствия многих полезных символов типографики. Их место во второй половине кодовых таблиц CP866 и KOI8-R занимает псевдографика, бесполезная в графической среде Windows. Как указано выше, расположение символов Windows-1251 обусловлено частичной совместимостью с Windows-1252, разработанной ранее.
В течение 1990-х годов и до 2002 года были разработаны несколько модификаций кодировки для поддержки алфавитов, не полностью покрываемых исходной кодовой страницей Windows-1251.
Интересные факты[править]
- Номера кодовых страниц Windows назначаются не в порядке создания. Кодировка из страницы 1252 присутствовала в ПО Windows изначально, а 1250 (центральноевропейская латиница) и 1251 появились позже — во время Windows 3.1.
Ссылки[править]
- ↑ ftp://ftp.software.ibm.com/software/globalization/gcoc/attachments/CP01251.txt
- http://dibr.nnov.ru/use012.html — версия истории создания Windows-1251, опубликованная в фидоэхе SU.LAN неким Igor V. Semenyuk.
- http://web.archive.org/web/20140606085903/http://msdn.microsoft.com/ru-RU/goglobal/cc305144.aspx
| Кодировки символов | ||
|---|---|---|
| Основы | Алфавит • текст • набор символов • конверсия | |
| Исторические кодировки | Докомп.: | семафорная (Макарова) • Морзе • Бодо • МТК-2 |
| Комп.: | 6-битная • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| современное 8-битное представление |
символы | ASCII ( управляющие • печатные ) |
| 8-битные код.стр. | ISO 8859 • кириллица (КОИ-8 • ГОСТ 19768-87 • MacCyrillic) | |
| Windows | 1250 • 1251 (кир.) • 1252 • 1253 • 1254 • 1255 • 1256 • 1257 • 1258 • WGL4 | |
| IBM & DOS | 437 • 850 • 852 • 855 • 866 «альт.» • МИК • НИИ ЭВМ | |
| Многобайтные | Традиционные | DBCS ( GB 2312 ) • HTML |
| Unicode | UTF • список символов (кириллица • латиница) | |
| Связанные темы | интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • кракозябры • транслит • нестандартные шрифты |