Определить объём текста
Онлайн калькулятор легко и непринужденно вычислит объем текста в битах, байтах и килобайтах. Для перевода в другие единицы измерения данных воспользуйтесь онлайн конвертером.
Информационный вес (объем) символа текста определяется для следующих кодировок:
Unicode UTF-8
Unicode UTF-16
ASCII, ANSI, Windows-1251
| Текст |
|
Символов 0 Символов без учета пробелов 0 Уникальных символов 0 Слов 0 Слов (буквенных) 0 Уникальных слов 0 Строк 0 Абзацев 0 Предложений 0 Средняя длина слова 0 Время чтения 0 сек Букв 0 Русских букв 0 Латинских букв 0 Гласных букв 0 Согласных букв 0 Слогов 0 Цифр 0 Чисел 0 Пробелов 0 Остальных знаков 0 Знаков препинания 0 Объем текста (Unicode UTF-8) бит 0 Объем текста (Unicode UTF-8) байт 0 Объем текста (Unicode UTF-8) килобайт 0 Объем текста (Unicode UTF-16) бит 0 Объем текста (Unicode UTF-16) байт 0 Объем текста (Unicode UTF-16) килобайт 0 Объем текста (ASCII, ANSI, Windows-1251) бит 0 Объем текста (ASCII, ANSI, Windows-1251) байт 0 Объем текста (ASCII, ANSI, Windows-1251) килобайт 0 |
|
|
Почему на windows сохраняя текст блокноте перенос строки занимает — 4 байта в юникоде или 2 байта в анси?
Это историческое явление, которое берёт начало с дос, последовательность OD OA (nr ) в виндовс используются чтоб был единообразный вывод на терминал независимо консоль это или принтер. Но для вывода просто на консоль достаточно только n.
В юникоде есть символы которые весят 4 байта, например эмоджи: 🙃
×
Для установки калькулятора на iPhone — просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android — просто добавьте страницу
«На главный экран»

В таблице ASCII символ весит 8 бит, это 1 байт.
В UTF-8 от 1 од 6 байт
Отмена

Олеся Точемкина
Отвечено 1 октября 2019
-
Комментариев (0)
Добавить
Отмена
Объем памяти (биты, байты, килобайты,…)
Так вот 1 символ двоичной системы (0 или 1) занимает в памяти компьютера 1 бит.
А 8 бит составляют 1 байт (легко запомнить, что байт больше, ведь в нем даже больше букв, чем в слове «бит»)
Итак, даже одна буква или цифра в компьютере будет занимать пространство в 1 байт на жестком диске (ведь для её кодировки нужно восемь нулей и единиц).
В этом легко убедиться, создайте в текстовом блокноте файл (не в Word, а именно в блокноте). Файл должен иметь расширение (то, что в названии после последней точки) .txt и может иметь любое название.
Если расширения файлов у вас не отображаются, то включите их.
1. Для этого зайдите в любую папке на компьютере.
2. Выберите в меню Сервис — Параметры папок.
3. Перейдите во вкладку Вид.
4. И уберите последнюю галочку напротив фразы «Скрывать расширения для зарегистрированных типов файлов».
Теперь все файлы будут показываться у вас с расширением. Не меняйте их, чтобы не потерять доступ к файлам. После упражнения можете вернуть галочку на место.
Итак, файл создан. Посмотрите сколько он «весит». Для этого нажмите на файл правой кнопкой мыши и выберете последний пункт «Свойства».
Его размер должен составлять 0 байт. Т.е. он пуст и ничего не весит.
Теперь откройте его и впишите любую цифру от 0 до 9. Сохраните файл и снова посмотрите в свойствах его вес. Теперь он должен весить 1 байт (8 бит). Это именно вес вписанной в него информации.
На диске файл будет занимать больше места, что связано с заполнением диска служебной информацией о расположении файла, его имени и т.д. Но конкретно наша цифра занимает всего 1 байт. Если мы впишем еще одну цифру, размер станет в 2 раза больше и т.д.
Теперь попробуем с буквами английского алфавита. Любая буква строчная или прописная тоже будет занимать 1 байт.
Русский же алфавит не умещается в кодировку в 256 символов, поэтому для него выделяется целых 2 байта другой кодировки 16-битной или 16-разрядной (из 16 единиц и нулей). Попробуйте русские буквы и убедитесь в этом.
Добавить интересную новость
Добавить анкету репетитора и получать бесплатно заявки на обучение от учеников
user->isGuest) »]) . ‘ или ‘ . Html::a(‘зарегистрируйтесь’, [‘/user/registration/register’], [‘class’ => »]) . ‘ , чтобы получать деньги $$$ за каждый набранный балл!’); > else user->identity->profile->first_name) || !empty(Yii::$app->user->identity->profile->surname))user->identity->profile->first_name . ‘ ‘ . Yii::$app->user->identity->profile->surname; > else echo ‘Получайте деньги за каждый набранный балл!’; > ?>—>
При правильном ответе Вы получите 1 балл
Сколько байт занимает одна буква латинского алфавита?
Выберите всего один правильный ответ.
Добавление комментариев доступно только зарегистрированным пользователям
Lorem iorLorem ipsum dolor sit amet, sed do eiusmod tempbore et dolore maLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempborgna aliquoLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempbore et dLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempborlore m mollit anim id est laborum.
28.01.17 / 22:14, Иван Иванович Ответить +5
Lorem ipsum dolor sit amet, consectetu sed do eiusmod qui officia deserunt mollit anim id est laborum.
28.01.17 / 22:14, Иван ИвановичОтветить -2
Lorem ipsum dolor sit amet, consectetur adipisicing sed do eiusmod tempboLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod temLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempborpborrum.
Измерение информации. Алфавитный подход к измерению информации. Мощность алфавита. Информационный объем текста
Алфавитный подход к измерению информации Вам хорошо известно, что для измерения таких величин, как, например, расстояние, масса, время, существуют эталонные единицы. Для расстояния — это метр, для массы — килограмм, для времени — секунда. Измерение происходит путем сопоставления измеряемой величины с эталонной единицей. Сколько раз эталонная единица укладывается в измеряемой величине, таков и результат измерения. Следовательно, и для измерения информации должна быть введена своя эталонная единица. Алфавитный подход позволяет измерять информационный объем текста на некотором языке (естественном или формальном), не связанный с содержанием этого текста.
Алфавит. Мощность алфавита
Под алфавитом мы будем понимать набор букв, знаков препинания, цифр, скобок и др. символов, используемых в тексте. В алфавит также следует включить и пробел, т. е. пропуск между словами.
Полное число символов в алфавите принято называть мощностью алфавита. Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54:33 буквы + 10 цифр + 11 знаков препинания, скобки, пробел.
Информационный вес символа
При алфавитном подходе считается, что каждый символ текста имеет определенный информационный вес. Информационный вес символа зависит от мощности алфавита. А каким может быть наименьшее число символов в алфавите? Оно равно двум! Скоро вы узнаете, что такой алфавит используется в компьютере. Он содержит всего 2 символа, которые обозначаются цифрами «0» и «1». Его называют двоичным алфавитом. Изучая устройство и работу компьютера, вы узнаете, как с помощью всего двух символов можно представить любую информацию.
Информационный вес символа двоичного алфавита принят за единицу информации и называется 1 бит.
Биты, байты, кодировки
Почти полтора месяца писала данную статью, но надеюсь оно того стоило. Данная статья может выглядеть холиварной, поэтому не спешите писать комментарии пока не прочитаете полностью. Статья главным образом о методологии.
Дело в том, что я твёрдо уверена, что в учебных заведениях по информационной специальности, школьникам и студентам забивают голову историей древнего мира вместо актуальных знаний. Все методички преподают дамы бальзаковского возраста, а пишут эти методички профессора возраста Карла Маркса. В результате от соискателей на работу, и от стажёров, я слышала такие забавные заблуждения, относительно фундаментальных основ, как:
- в байте 1024 бита
- в байте 8 бит потому что 8 — степень двойки
- бит принимает всякие разные значения от 0 до 1
В числе прочих забавных случаев: для выбора десяти случайных чисел из бд, соискатели десять раз делают запрос; для открытия файла на чтение используют в PHP флаг ‘a+’; не умеют работать со строками, кодировками и указателями. Написать функцию, которая возвращает строку задом наперёд, не используя переменную-буфер — вообще непосильная задача.
В этой статье, я хочу коснуться проблемы заблуждений с битами и байтами, и написать свою методику обучения этим фундаментальным знаниям.
Итак… сперва я хочу написать определения из википедии методичек, которые являются догмой в умах профессоров из мин.образования.
- Бит — это двоичный логарифм вероятности равновероятных событий или сумма произведений вероятности на двоичный логарифм вероятности при равновероятных событиях; (или другими словами) бит — это единица информации, равная результату эксперимента, имеющему два исхода
- Бит — минимальная единица информации.
- Байт — минимальная адресуемая единица информации.
Из-за этих определений, в умах будущих программистов ЭВМ, больше каши, чем из-за каких-либо других определений! Они совершенно истинны, но совершенно бесполезны для обучения. Я превращаюсь в Халка, когда слышу их.
Про биты
Итак, дети, садитесь, урок первый, представьте себе выключатель. Нет, не двоичный логарифм вероятности… А обычный такой выключатель, тумблер, рычажок, что угодно, включающее например лампочку, когда находится в одном положении и выключающее в другом. На некоторых рычажках даже подписывают буковки I/O, как указатели положений ручки. Нет, выключатель не несёт в себе информацию. Он выключает свет.
У выключателя есть два положения — вкл/выкл. Если мы поставим рядом два выключателя, то количество комбинаций позиций, которое могут занимать их ручки — четыре. (Когда оба выключены, когда оба включены, и две комбинации когда включен только один из них). Если мы возьмём систему из трёх выключателей — они смогут занимать восемь комбинаций. И так далее, N выключателей имеют 2^N комбинаций. Выключатель который имеет только два положения (вкл/выкл) мы можем назвать битом. Если мы представим, что положениям вкл/выкл соответствуют числа 1 и 0, то можно легко записать какое-нибудь целое число в двоичной системе счисления, используя только последовательный набор выключателей, так чтобы каждый выключатель отвечал за свой двоичный разряд.
Безусловно выключатели мы можем применить к магнитной дорожке, или оптическому диску, так, чтобы при помощи специального устройства можно было «включать» или «выключать» их маленькие участки. Теперь мы наконец подошли к тому, что все компьютерные запоминающие устройства состоят из «ноликов и единичек».
Однако, в этих ноликах и единичках нам надо хранить информацию. Какую же информацию нам можно хранить? Давайте рассмотрим один бит. Мы можем условно договориться, что он может хранить информацию, и два его состояния вкл/выкл содержат значения «баклажан» и «не баклажан» соответственно. Это отлично подходит, когда нам надо произвести учёт баклажанов! Однако в реальном мире компьютеры, которые умеют только считать баклажаны — не пользуются спросом. Выходит выключатель (бит) не может нести в себе информацию. Чтобы записывать ноликами и единичками какую-то информацию, было решено группировать их по несколько штук, и такую группу называть байтом.
На заре компьютеров байты составляли 4, потом 5, потом 6 бит… Группа из 6 бит может принимать целых 64 значений. Вполне неплохо, так как можно создать некую таблицу соответствий этих значений определённым символам — кодировку. Такая кодировка уже может содержать цифры и заглавные буквы латинского алфавита, а также некоторые арифметические знаки. «Шестибитные-кодировки» — применялись на компьютерах в 1950-х — 1960-х годах.
Для человека который только начинает изучать информатику, будет понятно и легко запомнить что байт — является минимальной единицей информации. В байт можно записать какое-нибудь число, либо например какой-нибудь символ из таблицы символов (англ. charset, буквально «набор символов») — кодировки (codepage, encoding).
С развитием компьютеров, появилась потребность в большем количестве значений для байта. В 1963-м году появилась первая редакция семибитной кодировки ASCII. Поэтому байты стали занимать 7 бит. 7 бит, требующиеся для одного символа данной кодировки позволяют использовать 128 значений. В этой кодировке уже были включены строчные латинские символы, и больший набор управляющих и арифметических символов.
Всемирное распространение компьютеров подтолкнуло дальнейшее расширение границ занимаемых байтом. Для различных языков требовалось чтобы таблица символов также могла хранить алфавит того языка, где используется данная ЭВМ. На текущий момент восемь — это последнее и видимо окончательное количество бит составляющих байт. Соответственно байт может принимать 256 значений. По сравнению с таблицей ASCII в. новых таблицах символов — организовалось 128 вакантных мест. Теперь я думаю можно рассказать как значения хранятся в различных кириллических кодировках.
Кодировки
Итак, чтобы хранить символы не входящие в ASCII, необходимо было придумать новые кодировки. Поскольку до этого таблица ASCII была наиболее подходящей (были и другие), то она и пошла в основу новых кодировок. Поэтому следующие кодировки отличаются только значениями начиная с 80 (hex). Для наглядности оставлю только кириллические символы.

Так выглядела наиболее популярная кодировка под DOS. Примечательно что файлы в этой кодировке до сих пор встречаются. Как правило среди устаревшей архивной информации, в программах WinRar, Блокнот и WordPad, до сих пор есть опции «открыть как текст DOS», впрочем последними двумя мало кто пользуется =).
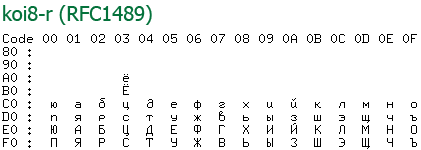
Кодировка koi8 была примечательна тем, что русские буквы там располагались на позициях английских звуков из нижней половины (т. е. ASCII). Это когда-то давно позволяло смягчить переход со старых серверов понимающие только ascii на новые, что было актуально среди почтовых серверов. Смысл был в том что если отправленное вами письмо приходило на старый сервер, то пользователю оно показывалось как транслит, что позволяло хоть как-то понять текст письма.

Самая популярная у нас в России однобайтная кодировка, на сегодняшний день, это именно «windows-1251». Разумеется популярность её целиком обусловлена популярностью Windows среди других операционных систем. Возможностей кодировки вполне хватает для использования её в широком круге задач. Например движок моего блога, по-умолчанию, использует для работы именно данную кодировку.

Я не могу не упомянуть о кодировке ISO, Удивительно, но несмотря на то что её никто никогда не использовал, эта кодировка является единственной кодировкой имеющей статус стандарта.
На примере данных кодировок видно, как один байт может хранить какое угодно символьное значение русского и английского языков, а также цифр и знаков пунктуации.
Но что делать когда этого не достаточно?
Многобайтные кодировки
Если вам хочется создать кодировку которая бы имела коды одновременно для русского и греческого алфавита? Одним байтом тут не отделаться. Появилась задача разработать кодировку один знак которой может занимать больше чем один байт, так как два байта могут принимать уже 2^16 = 65536 значений, а четыре байта аж 4294967296. Поэтому сначала придумали стандарт кодирования символов — Юникод, который включал бы в себя максимально полный перечень символов которые может принимать один знак.
Первая версия Юникода (Unicode 1991 г.) представляла собой 16-битную кодировку с фиксированной шириной символа; общее число разных символов было 2 16 (65 536).
Вторая версия Юникода (UCS-2), стала называться UTF-16, она позволяла гораздо расширить количество возможных значений, также используя для символов 16-битные последовательности (т. е. по 2 или по 4 байта на символ).
Символы с кодами 0×0000.0xD7FF и 0xE000.0xFFFF представляются одним 16-битным словом, а символы с кодами 0×10000–0×10FFFF — в виде последовательности двух 16-битных слов. Количество символов, представляемых двумя 16-битными словами равно (2 20 ). Для представления символов с кодами 0×10000–0×10FFFF используется матрица перекодировки. Первое слово из двух переданных лежит в диапазоне 0xD800-0xDBFF, а второе — 0xDC00-0xDFFF. Именно этот диапазон значений не может встречаться среди символов, передаваемых с помощью одного 16-битного слова, так что расшифровка кодировки всегда однозначна. Ясно, что имеется как раз 2 10 * 2 10 = 2 20 таких комбинаций.
Википедия — UTS-2
Кодировка UTF-32 (UCS-4) использует по 32 бита, или 4 байта на хранение одного символа. Строго говоря, стандарт Unicode не описывает символы со значениями выше 2^21, так что хватило бы и трёх байт, на символ, вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум, или для того чтобы в сектор диска попадало кратное количество символов. Так или иначе это единственная из многобайтных кодировок с постоянной длиной. Помимо недостатка — использования четырёх байт на символ, у неё есть и очевидное преимущество — возможность прямой адресации к N-ному символу. В других кодировках требуется последовательное вычисление позиции каждого символа. Поэтому текстовые редакторы, внутри себя хранят всю информацию в виде UCS-4.
В 1992 году Кеном Томпсоном и Робом Пайком был изобретён формат UTF-8. Он отличается тем, что он ASCII совместим, и значения из таблицы Юникода могут занимать от 1 до 4х символов.
Символы UTF-8 получаются из Unicode следующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0×00000000 — 0×0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0×00000080 — 0×000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания |
| 0×00000800 — 0×0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0×00010000 — 0×001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
Символы, в кодировке UTF-8, могут занимать до шести байт, но Unicode не определяет символов выше 0×10ffff , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Заключение
Вот собственно и всё что я хотела рассказать. Я считаю что очень интересно разбираться в том как работает компьютер, знать как хранятся в нём символы которые я набираю на клавиатуре, представлять насколько однобайтная кодировка например win-1251 (или utf-32 с фикс. длиной) работает быстрее со строковыми функциями и почему и т. п. Надеюсь статья вам понравилась.
Большое спасибо Википедии за возможность скопировать цитаты и таблицы, а то бы писала статью ещё месяц.
Все кто хочет узнать больше, также могут почитать про то в каком порядке записываются байты в кодировках UTF-16 и UTF-32 — в википедии тут и тут. А также что такое порядок байтов тут: Порядок_байтов. Также интересна будет статья Юникод в операционных системах Microsoft.
На чтение 5 мин. Просмотров 1.1k. Опубликовано 15.12.2019
Я просто смущен. сколько символов в одном бите?
Это зависит от характера и того, в каком кодировании он находится:
Символ ASCII в 8-разрядной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит.
Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт).
Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Символ Юникода в кодировке UTF-16 находится между 16 (2 байтами) и 32 битами (4 байта), хотя большинство общих символов принимают 16 бит. Это кодировка, используемая Windows внутренне.
Символ Unicode в кодировке UTF-32 всегда 32 бита (4 байта).
Символ ASCII в UTF-8 — 8 бит (1 байт), а в UTF-16 — 16 бит.
Дополнительные символы (не ASCII) в ISO-8895-1 (0xA0-0xFF) будут принимать 16 бит в UTF-8 и UTF-16.
Это означало бы, что между 0.03125 и 0.125 символами.
Один бит это 1/8 (одна восьмая или 0.125 символа). Из учебника информатики мы знаем что для того чтобы записать один символ нам нужен 1 байт, который состоит из 8 бит, отсюда 1 бит это 1/8 символа или 0.125 символа. Почему 1 символ это байт? Все дело в том что машина (компьютер) не понимает наши буквы и символы, она понимает только значения «верно» и «ложь» которые записаны в двоичном коде (то есть при помощи двух символов 1 и 0). Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования текста, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах [1] . Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9 [2] . Идентификатор кодировки в Windows – 65001 [3] .
Сравнивая UTF-8 и UTF-16, можно отметить, что наибольший выигрыш в компактности UTF-8 даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII. [4] [5]
Содержание
- Содержание
- Алгоритм кодирования [ править | править код ]
- Примеры кодирования [ править | править код ]
- Маркер UTF-8 [ править | править код ]
- Пятый и шестой байты [ править | править код ]
Содержание
Алгоритм кодирования [ править | править код ]
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникод.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
| 00000000-0000007F | 1 |
| 00000080-000007FF | 2 |
| 00000800-0000FFFF | 3 |
| 00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
- 0xxxxxxx — если для кодирования потребуется один октет;
- 110xxxxx — если для кодирования потребуется два октета;
- 1110xxxx — если для кодирования потребуется три октета;
- 11110xxx — если для кодирования потребуется четыре октета.
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования [ править | править код ]
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 100100 | 0 0100100 | 24 |
| ¢ | U+00A2 | 10 100010 | 110 00010 10 100010 | C2 A2 |
| € | U+20AC | 10 0000 10 101100 | 1110 0010 10 000010 10 101100 | E2 82 AC |
| �� | U+10348 | 1 0000 0011 01 001000 | 11110 000 10 010000 10 001101 10 001000 | F0 90 8D 88 |
Маркер UTF-8 [ править | править код ]
Для указания, что файл или поток содержит символы Юникода, в начале файла или потока может быть вставлен маркер последовательности байтов (англ. Byte order mark, BOM ), который в случае кодирования в UTF-8 принимает форму трёх байтов: EF BB BF16 .
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код | 1110 1111 | 1011 1011 | 1011 1111 |
| Шестнадцатеричный код | EF | BB | BF |
Пятый и шестой байты [ править | править код ]
Изначально кодировка UTF-8 допускала использование до шести байтов для кодирования одного символа, однако в ноябре 2003 года стандарт RFC 3629 запретил использование пятого и шестого байтов, а диапазон кодируемых символов был ограничен символом U+10FFFF . Это было сделано для обеспечения совместимости с UTF-16.
Plan
- 1 Как напечатать +-?
- 2 Как открыть дополнительные символы на клавиатуре?
- 3 Для чего нужна таблица ascii?
- 4 Для чего нужна кодировка?
- 5 Сколько весит один символ в UTF-8?
- 6 Сколько байт занимает один символ в кодировке UTF-8?
- 7 Сколько весит 1 мб?
- 8 Сколько бит в двоичном коде?
- 9 Какое количество информации позволяют закодировать два разряда двоичного кода?
Как напечатать +-?
Для того чтобы вставить +-, нужно использовать «Alt+0177». Зажмите «Alt» на клавиатуре, и, не отпуская кнопки, наберите на цифровой клавиатуре (цифры справа) «0177».
Как открыть таблицу символов?
Используем горячие клавиши, то есть:
- нажимаем одновременно две клавиши «Win+R».
- Появится окно “Выполнить”, в котором набираем без кавычек «charmap.exe».
- После чего щелкаем “ОК”, и откроется «Таблица символов».
Как открыть таблицу символов в Word?
Чтобы открыть таблицу символов перейдите на вкладку Символы, специальные символы находятся на вкладке Специальные знаки этого же окна. Для вставки символа в документ выберите его из набора символов и щелкните на кнопке Вставить (см.
Как открыть дополнительные символы на клавиатуре?
– нажмите и удерживайте клавишу Alt; – на дополнительной цифровой клавиатуре (цифровой блок расположен в правой части клавиатуры) наберите код символа; – когда вы отпустите клавишу Alt, в текст будет вставлен нужный символ.
Для чего нужна таблица символов?
Таблица символов это стандартная программа Windows, предназначенная для досмотра, поиска и копирования символов, входящих в состав любого шрифта, установленного в Windows.
Что такое символ в компьютере?
Символ — это некоторый значок, изображение. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа “=”, “(”, “&” и т.
Для чего нужна таблица ascii?
ASCII представляет собой кодировочную таблицу печатных символов (см. скриншот №1), набираемых на компьютерной клавиатуре, для передачи информации и некоторых кодов. Иными словами происходит кодирование алфавита и десятичных цифр в соответствующие символы, представляющие и несущие в себе необходимую информацию.
Для чего нужно кодирование Юникод?
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных. Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Как ввести символы юникода?
Вставка символов Юникода Чтобы вставить символ Юникода, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X.
Для чего нужна кодировка?
Нужна она для того, чтобы текстовую информацию преобразовывать в биты данных и передавать, например, через Интернет. Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец. символов, в которые преобразуется каждый символ исходного текста.
Сколько байт занимает символ юникода?
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.
Сколько байтов отводится на кодирование одного символа в кодировке Unicode?
Поэтому быстрый ответ таков: он занимает от 1 до 4 байт, в зависимости от первого, который укажет, сколько байт он займет. Вы не увидите простого ответа, потому что его нет. Во-первых, Unicode не содержит «каждый символ из каждого языка», хотя он, конечно, пытается.
Сколько весит один символ в UTF-8?
2 либо 4 байта, смотря какой юникод. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом.
Сколько байт занимает один символ?
Так вот 1 символ двоичной системы (0 или 1) занимает в памяти компьютера 1 бит. Итак, даже одна буква или цифра в компьютере будет занимать пространство в 1 байт на жестком диске (ведь для её кодировки нужно восемь нулей и единиц).
Сколько байт весит пробел?
Принцип кодирования текстовой информации несложен: каждый символ (включая буквы, цифры, пробел, знаки препинания и другие символы) занимает 1 байт (в классических кодировках КОИ-8r, Windows-1251, CP866); 2 байта (современная кодировка Unicode-16) или переменное количество от 1 до 4 байт (UTF-8, где английские буквы.
Сколько байт занимает один символ в кодировке UTF-8?
Замечание: Символы, закодированные в UTF-8, могут быть длиной до шести байт, однако стандарт Unicode не определяет символов выше 0x10ffff , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Сколько байт в одной букве?
1 байт = 8 бит. Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Сколько символов байтов и битов в слове информатика?
В слове «информатика» 11 букв. Каждую букву мы можем закодировать одним байтом. В одном байте 8 бит, поэтому ответ 11х8=88.
Сколько весит 1 мб?
Почему жесткий диск на терабайт имеет размер в 900 гигабайт?
| Единица | Аббревиатура | Сколько |
|---|---|---|
| бит | б | 0 или 1бит |
| килобайт | КБайт (KБ) | 1024 байта |
| мегабит | мбит (мб) | 1 000 килобит |
| мегабайт | МБайт (МБ) | 1024 килобайта |
Сколько бит в одной цифре?
Бит — это двоичная цифра . Вы можете преобразовать десятичное число 10 в двоичное число 1010 (8 + 2), поэтому вам потребуется 4 бита для выражения десятичного значения 10.
Сколько бит в десятичном числе?
Сколько бит в двоичном коде?
И поэтому основание двоичной системы равно 2. Аналогично, основание десятичной системы равно 10, так как там используются 10 цифр. Каждая цифра в двоичном числе называется бит (или разряд). Четыре бита – это полубайт (или тетрада), 8 бит – байт, 16 бит – слово, 32 бита – двойное слово.
Сколько двоичных разрядов необходимо для кодирования 1 символа?
Двоичное кодирование кодирование информации i = log2 256 = 8 бит = 1 байт. Для двоичного кодирования 1 символа требуется 1 байт, или 8 двоичных разрядов. Двоичный код каждого конкретного символа определяется кодовой таблицей.
Сколько двоичных разрядов используется для записи символа в таблице Unicode?
Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т. е. 16 бит.
Какое количество информации позволяют закодировать два разряда двоичного кода?
Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111.
Сколько цветов можно закодировать при использовании 16 разрядного двоичного кода?
Кроме режима истинного цвета используется также 16-битное кодирование (англ. High Color – «высокий» цвет), когда на красную и синюю составляющую отводится по 5 бит, а на зеленую, к которой человеческий глаз более чувствителен – 6 бит. В режиме High Color можно закодировать 216 = 65 536 различных цветов.