Определить объём текста
Онлайн калькулятор легко и непринужденно вычислит объем текста в битах, байтах и килобайтах. Для перевода в другие единицы измерения данных воспользуйтесь онлайн конвертером.
Информационный вес (объем) символа текста определяется для следующих кодировок:
Unicode UTF-8
Unicode UTF-16
ASCII, ANSI, Windows-1251
| Текст |
|
Символов 0 Символов без учета пробелов 0 Уникальных символов 0 Слов 0 Слов (буквенных) 0 Уникальных слов 0 Строк 0 Абзацев 0 Предложений 0 Средняя длина слова 0 Время чтения 0 сек Букв 0 Русских букв 0 Латинских букв 0 Гласных букв 0 Согласных букв 0 Слогов 0 Цифр 0 Чисел 0 Пробелов 0 Остальных знаков 0 Знаков препинания 0 Объем текста (Unicode UTF-8) бит 0 Объем текста (Unicode UTF-8) байт 0 Объем текста (Unicode UTF-8) килобайт 0 Объем текста (Unicode UTF-16) бит 0 Объем текста (Unicode UTF-16) байт 0 Объем текста (Unicode UTF-16) килобайт 0 Объем текста (ASCII, ANSI, Windows-1251) бит 0 Объем текста (ASCII, ANSI, Windows-1251) байт 0 Объем текста (ASCII, ANSI, Windows-1251) килобайт 0 |
|
|
Почему на windows сохраняя текст блокноте перенос строки занимает — 4 байта в юникоде или 2 байта в анси?
Это историческое явление, которое берёт начало с дос, последовательность OD OA (nr ) в виндовс используются чтоб был единообразный вывод на терминал независимо консоль это или принтер. Но для вывода просто на консоль достаточно только n.
В юникоде есть символы которые весят 4 байта, например эмоджи: 🙃
×
Для установки калькулятора на iPhone — просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android — просто добавьте страницу
«На главный экран»

I am a bit confused about encodings. As far as I know old ASCII characters took one byte per character. How many bytes does a Unicode character require?
I assume that one Unicode character can contain every possible character from any language — am I correct? So how many bytes does it need per character?
And what do UTF-7, UTF-6, UTF-16 etc. mean? Are they different versions of Unicode?
I read the Wikipedia article about Unicode but it is quite difficult for me. I am looking forward to seeing a simple answer.
![]()
asked Mar 13, 2011 at 15:02
![]()
8
Strangely enough, nobody pointed out how to calculate how many bytes is taking one Unicode char. Here is the rule for UTF-8 encoded strings:
Binary Hex Comments
0xxxxxxx 0x00..0x7F Only byte of a 1-byte character encoding
10xxxxxx 0x80..0xBF Continuation byte: one of 1-3 bytes following the first
110xxxxx 0xC0..0xDF First byte of a 2-byte character encoding
1110xxxx 0xE0..0xEF First byte of a 3-byte character encoding
11110xxx 0xF0..0xF7 First byte of a 4-byte character encoding
So the quick answer is: it takes 1 to 4 bytes, depending on the first one which will indicate how many bytes it’ll take up.
![]()
tambre
4,4844 gold badges45 silver badges55 bronze badges
answered Oct 26, 2015 at 15:38
![]()
paul.agopaul.ago
3,8251 gold badge21 silver badges15 bronze badges
5
You won’t see a simple answer because there isn’t one.
First, Unicode doesn’t contain «every character from every language», although it sure does try.
Unicode itself is a mapping, it defines codepoints and a codepoint is a number, associated with usually a character. I say usually because there are concepts like combining characters. You may be familiar with things like accents, or umlauts. Those can be used with another character, such as an a or a u to create a new logical character. A character therefore can consist of 1 or more codepoints.
To be useful in computing systems we need to choose a representation for this information. Those are the various unicode encodings, such as utf-8, utf-16le, utf-32 etc. They are distinguished largely by the size of of their codeunits. UTF-32 is the simplest encoding, it has a codeunit that is 32bits, which means an individual codepoint fits comfortably into a codeunit. The other encodings will have situations where a codepoint will need multiple codeunits, or that particular codepoint can’t be represented in the encoding at all (this is a problem for instance with UCS-2).
Because of the flexibility of combining characters, even within a given encoding the number of bytes per character can vary depending on the character and the normalization form. This is a protocol for dealing with characters which have more than one representation (you can say "an 'a' with an accent" which is 2 codepoints, one of which is a combining char or "accented 'a'" which is one codepoint).
![]()
Mazdak
103k18 gold badges158 silver badges186 bronze badges
answered Mar 13, 2011 at 15:19
![]()
Logan CapaldoLogan Capaldo
39.2k5 gold badges63 silver badges78 bronze badges
3
I know this question is old and already has an accepted answer, but I want to offer a few examples (hoping it’ll be useful to someone).
As far as I know old ASCII characters took one byte per character.
Right. Actually, since ASCII is a 7-bit encoding, it supports 128 codes (95 of which are printable), so it only uses half a byte (if that makes any sense).
How many bytes does a Unicode character require?
Unicode just maps characters to codepoints. It doesn’t define how to encode them. A text file does not contain Unicode characters, but bytes/octets that may represent Unicode characters.
I assume that one Unicode character can contain every possible
character from any language — am I correct?
No. But almost. So basically yes. But still no.
So how many bytes does it need per character?
Same as your 2nd question.
And what do UTF-7, UTF-6, UTF-16 etc mean? Are they some kind Unicode
versions?
No, those are encodings. They define how bytes/octets should represent Unicode characters.
A couple of examples. If some of those cannot be displayed in your browser (probably because the font doesn’t support them), go to http://codepoints.net/U+1F6AA (replace 1F6AA with the codepoint in hex) to see an image.
-
- U+0061 LATIN SMALL LETTER A:
a- Nº: 97
- UTF-8: 61
- UTF-16: 00 61
- U+0061 LATIN SMALL LETTER A:
-
- U+00A9 COPYRIGHT SIGN:
©- Nº: 169
- UTF-8: C2 A9
- UTF-16: 00 A9
- U+00AE REGISTERED SIGN:
®- Nº: 174
- UTF-8: C2 AE
- UTF-16: 00 AE
- U+00A9 COPYRIGHT SIGN:
-
- U+1337 ETHIOPIC SYLLABLE PHWA:
ጷ- Nº: 4919
- UTF-8: E1 8C B7
- UTF-16: 13 37
- U+2014 EM DASH:
—- Nº: 8212
- UTF-8: E2 80 94
- UTF-16: 20 14
- U+2030 PER MILLE SIGN:
‰- Nº: 8240
- UTF-8: E2 80 B0
- UTF-16: 20 30
- U+20AC EURO SIGN:
€- Nº: 8364
- UTF-8: E2 82 AC
- UTF-16: 20 AC
- U+2122 TRADE MARK SIGN:
™- Nº: 8482
- UTF-8: E2 84 A2
- UTF-16: 21 22
- U+2603 SNOWMAN:
☃- Nº: 9731
- UTF-8: E2 98 83
- UTF-16: 26 03
- U+260E BLACK TELEPHONE:
☎- Nº: 9742
- UTF-8: E2 98 8E
- UTF-16: 26 0E
- U+2614 UMBRELLA WITH RAIN DROPS:
☔- Nº: 9748
- UTF-8: E2 98 94
- UTF-16: 26 14
- U+263A WHITE SMILING FACE:
☺- Nº: 9786
- UTF-8: E2 98 BA
- UTF-16: 26 3A
- U+2691 BLACK FLAG:
⚑- Nº: 9873
- UTF-8: E2 9A 91
- UTF-16: 26 91
- U+269B ATOM SYMBOL:
⚛- Nº: 9883
- UTF-8: E2 9A 9B
- UTF-16: 26 9B
- U+2708 AIRPLANE:
✈- Nº: 9992
- UTF-8: E2 9C 88
- UTF-16: 27 08
- U+271E SHADOWED WHITE LATIN CROSS:
✞- Nº: 10014
- UTF-8: E2 9C 9E
- UTF-16: 27 1E
- U+3020 POSTAL MARK FACE:
〠- Nº: 12320
- UTF-8: E3 80 A0
- UTF-16: 30 20
- U+8089 CJK UNIFIED IDEOGRAPH-8089:
肉- Nº: 32905
- UTF-8: E8 82 89
- UTF-16: 80 89
- U+1337 ETHIOPIC SYLLABLE PHWA:
-
- U+1F4A9 PILE OF POO:
💩- Nº: 128169
- UTF-8: F0 9F 92 A9
- UTF-16: D8 3D DC A9
- U+1F680 ROCKET:
🚀- Nº: 128640
- UTF-8: F0 9F 9A 80
- UTF-16: D8 3D DE 80
- U+1F4A9 PILE OF POO:
Okay I’m getting carried away…
Fun facts:
- If you’re looking for a specific character, you can copy&paste it on http://codepoints.net/.
- I wasted a lot of time on this useless list (but it’s sorted!).
- MySQL has a charset called «utf8» which actually does not support characters longer than 3 bytes. So you can’t insert a pile of poo, the field will be silently truncated. Use «utf8mb4» instead.
- There’s a snowman test page (unicodesnowmanforyou.com).
answered May 1, 2014 at 15:17
![]()
basic6basic6
3,5031 gold badge39 silver badges47 bronze badges
6
Simply speaking Unicode is a standard which assigned one number (called code point) to all characters of the world (Its still work in progress).
Now you need to represent this code points using bytes, thats called character encoding. UTF-8, UTF-16, UTF-6 are ways of representing those characters.
UTF-8 is multibyte character encoding. Characters can have 1 to 6 bytes (some of them may be not required right now).
UTF-32 each characters have 4 bytes a characters.
UTF-16 uses 16 bits for each character and it represents only part of Unicode characters called BMP (for all practical purposes its enough). Java uses this encoding in its strings.
answered Mar 13, 2011 at 15:15
![]()
ZimbabaoZimbabao
8,1242 gold badges29 silver badges36 bronze badges
5
In UTF-8:
1 byte: 0 - 7F (ASCII)
2 bytes: 80 - 7FF (all European plus some Middle Eastern)
3 bytes: 800 - FFFF (multilingual plane incl. the top 1792 and private-use)
4 bytes: 10000 - 10FFFF
In UTF-16:
2 bytes: 0 - D7FF (multilingual plane except the top 1792 and private-use )
4 bytes: D800 - 10FFFF
In UTF-32:
4 bytes: 0 - 10FFFF
10FFFF is the last unicode codepoint by definition, and it’s defined that way because it’s UTF-16’s technical limit.
It is also the largest codepoint UTF-8 can encode in 4 byte, but the idea behind UTF-8’s encoding also works for 5 and 6 byte encodings to cover codepoints until 7FFFFFFF, ie. half of what UTF-32 can.
answered Aug 27, 2016 at 12:18
![]()
JohnJohn
6,4003 gold badges48 silver badges89 bronze badges
In Unicode the answer is not easily given. The problem, as you already pointed out, are the encodings.
Given any English sentence without diacritic characters, the answer for UTF-8 would be as many bytes as characters and for UTF-16 it would be number of characters times two.
The only encoding where (as of now) we can make the statement about the size is UTF-32. There it’s always 32bit per character, even though I imagine that code points are prepared for a future UTF-64 
What makes it so difficult are at least two things:
- composed characters, where instead of using the character entity that is already accented/diacritic (À), a user decided to combine the accent and the base character (`A).
- code points. Code points are the method by which the UTF-encodings allow to encode more than the number of bits that gives them their name would usually allow. E.g. UTF-8 designates certain bytes which on their own are invalid, but when followed by a valid continuation byte will allow to describe a character beyond the 8-bit range of 0..255. See the Examples and Overlong Encodings below in the Wikipedia article on UTF-8.
- The excellent example given there is that the € character (code point
U+20ACcan be represented either as three-byte sequenceE2 82 ACor four-byte sequenceF0 82 82 AC. Both are valid, and this shows how complicated the answer is when talking about «Unicode» and not about a specific encoding of Unicode, such as UTF-8 or UTF-16.Strictly speaking, as pointed out in a comment, this doesn’t seem to be the case any longer or was even based on a misunderstanding on my part. The quote from the updated Wikipedia article reads: Longer encodings are called overlong and are not valid UTF-8 representations of the code point.
- The excellent example given there is that the € character (code point
answered Mar 13, 2011 at 15:10
![]()
0xC0000022L0xC0000022L
20.2k9 gold badges82 silver badges149 bronze badges
2
Well I just pulled up the Wikipedia page on it too, and in the intro portion I saw «Unicode can be implemented by different character encodings. The most commonly used encodings are UTF-8 (which uses one byte for any ASCII characters, which have the same code values in both UTF-8 and ASCII encoding, and up to four bytes for other characters), the now-obsolete UCS-2 (which uses two bytes for each character but cannot encode every character in the current Unicode standard)»
As this quote demonstrates, your problem is that you are assuming Unicode is a single way of encoding characters. There are actually multiple forms of Unicode, and, again in that quote, one of them even has 1 byte per character just like what you are used to.
So your simple answer that you want is that it varies.
answered Mar 13, 2011 at 15:09
![]()
LoduwijkLoduwijk
1,9201 gold badge16 silver badges27 bronze badges
Unicode is a standard which provides a unique number for every character. These unique numbers are called code points (which is just unique code) to all characters existing in the world (some’s are still to be added).
For different purposes, you might need to represent this code points in bytes (most programming languages do so), and here’s where Character Encoding kicks in.
UTF-8, UTF-16, UTF-32 and so on are all Character Encodings, and Unicode’s code points are represented in these encodings, in different ways.
UTF-8 encoding has a variable-width length, and characters, encoded in it, can occupy 1 to 4 bytes inclusive;
UTF-16 has a variable length and characters, encoded in it, can take either 1 or 2 bytes (which is 8 or 16 bits). This represents only part of all Unicode characters called BMP (Basic Multilingual Plane) and it’s enough for almost all the cases. Java uses UTF-16 encoding for its strings and characters;
UTF-32 has fixed length and each character takes exactly 4 bytes (32 bits).
answered Jun 17, 2020 at 14:15
![]()
Giorgi TsiklauriGiorgi Tsiklauri
9,0478 gold badges40 silver badges62 bronze badges
For UTF-16, the character needs four bytes (two code units) if it starts with 0xD800 or greater; such a character is called a «surrogate pair.» More specifically, a surrogate pair has the form:
[0xD800 - 0xDBFF] [0xDC00 - 0xDFF]
where […] indicates a two-byte code unit with the given range. Anything <= 0xD7FF is one code unit (two bytes). Anything >= 0xE000 is invalid (except BOM markers, arguably).
See http://unicodebook.readthedocs.io/unicode_encodings.html, section 7.5.
answered Jul 12, 2016 at 20:45
![]()
prewettprewett
1,55714 silver badges19 bronze badges
Check out this Unicode code converter. For example, enter 0x2009, where 2009 is the Unicode number for thin space, in the «0x… notation» field, and click Convert. The hexadecimal number E2 80 89 (3 bytes) appears in the «UTF-8 code units» field.
![]()
Yash
8,9802 gold badges67 silver badges72 bronze badges
answered Oct 9, 2013 at 16:14
![]()
ma11hew28ma11hew28
118k116 gold badges447 silver badges645 bronze badges
From Wiki:
UTF-8, an 8-bit variable-width encoding which maximizes compatibility with ASCII;
UTF-16, a 16-bit, variable-width encoding;
UTF-32, a 32-bit, fixed-width encoding.
These are the three most popular different encoding.
- In UTF-8 each character is encoded into 1 to 4 bytes ( the dominant encoding )
- In UTF16 each character is encoded into 1 to two 16-bit words and
- in UTF-32 every character is encoded as a single 32-bit word.
![]()
answered Nov 24, 2019 at 21:20
![]()
chikitinchikitin
7336 silver badges24 bronze badges
I am a bit confused about encodings. As far as I know old ASCII characters took one byte per character. How many bytes does a Unicode character require?
I assume that one Unicode character can contain every possible character from any language — am I correct? So how many bytes does it need per character?
And what do UTF-7, UTF-6, UTF-16 etc. mean? Are they different versions of Unicode?
I read the Wikipedia article about Unicode but it is quite difficult for me. I am looking forward to seeing a simple answer.
![]()
asked Mar 13, 2011 at 15:02
![]()
8
Strangely enough, nobody pointed out how to calculate how many bytes is taking one Unicode char. Here is the rule for UTF-8 encoded strings:
Binary Hex Comments
0xxxxxxx 0x00..0x7F Only byte of a 1-byte character encoding
10xxxxxx 0x80..0xBF Continuation byte: one of 1-3 bytes following the first
110xxxxx 0xC0..0xDF First byte of a 2-byte character encoding
1110xxxx 0xE0..0xEF First byte of a 3-byte character encoding
11110xxx 0xF0..0xF7 First byte of a 4-byte character encoding
So the quick answer is: it takes 1 to 4 bytes, depending on the first one which will indicate how many bytes it’ll take up.
![]()
tambre
4,4844 gold badges45 silver badges55 bronze badges
answered Oct 26, 2015 at 15:38
![]()
paul.agopaul.ago
3,8251 gold badge21 silver badges15 bronze badges
5
You won’t see a simple answer because there isn’t one.
First, Unicode doesn’t contain «every character from every language», although it sure does try.
Unicode itself is a mapping, it defines codepoints and a codepoint is a number, associated with usually a character. I say usually because there are concepts like combining characters. You may be familiar with things like accents, or umlauts. Those can be used with another character, such as an a or a u to create a new logical character. A character therefore can consist of 1 or more codepoints.
To be useful in computing systems we need to choose a representation for this information. Those are the various unicode encodings, such as utf-8, utf-16le, utf-32 etc. They are distinguished largely by the size of of their codeunits. UTF-32 is the simplest encoding, it has a codeunit that is 32bits, which means an individual codepoint fits comfortably into a codeunit. The other encodings will have situations where a codepoint will need multiple codeunits, or that particular codepoint can’t be represented in the encoding at all (this is a problem for instance with UCS-2).
Because of the flexibility of combining characters, even within a given encoding the number of bytes per character can vary depending on the character and the normalization form. This is a protocol for dealing with characters which have more than one representation (you can say "an 'a' with an accent" which is 2 codepoints, one of which is a combining char or "accented 'a'" which is one codepoint).
![]()
Mazdak
103k18 gold badges158 silver badges186 bronze badges
answered Mar 13, 2011 at 15:19
![]()
Logan CapaldoLogan Capaldo
39.2k5 gold badges63 silver badges78 bronze badges
3
I know this question is old and already has an accepted answer, but I want to offer a few examples (hoping it’ll be useful to someone).
As far as I know old ASCII characters took one byte per character.
Right. Actually, since ASCII is a 7-bit encoding, it supports 128 codes (95 of which are printable), so it only uses half a byte (if that makes any sense).
How many bytes does a Unicode character require?
Unicode just maps characters to codepoints. It doesn’t define how to encode them. A text file does not contain Unicode characters, but bytes/octets that may represent Unicode characters.
I assume that one Unicode character can contain every possible
character from any language — am I correct?
No. But almost. So basically yes. But still no.
So how many bytes does it need per character?
Same as your 2nd question.
And what do UTF-7, UTF-6, UTF-16 etc mean? Are they some kind Unicode
versions?
No, those are encodings. They define how bytes/octets should represent Unicode characters.
A couple of examples. If some of those cannot be displayed in your browser (probably because the font doesn’t support them), go to http://codepoints.net/U+1F6AA (replace 1F6AA with the codepoint in hex) to see an image.
-
- U+0061 LATIN SMALL LETTER A:
a- Nº: 97
- UTF-8: 61
- UTF-16: 00 61
- U+0061 LATIN SMALL LETTER A:
-
- U+00A9 COPYRIGHT SIGN:
©- Nº: 169
- UTF-8: C2 A9
- UTF-16: 00 A9
- U+00AE REGISTERED SIGN:
®- Nº: 174
- UTF-8: C2 AE
- UTF-16: 00 AE
- U+00A9 COPYRIGHT SIGN:
-
- U+1337 ETHIOPIC SYLLABLE PHWA:
ጷ- Nº: 4919
- UTF-8: E1 8C B7
- UTF-16: 13 37
- U+2014 EM DASH:
—- Nº: 8212
- UTF-8: E2 80 94
- UTF-16: 20 14
- U+2030 PER MILLE SIGN:
‰- Nº: 8240
- UTF-8: E2 80 B0
- UTF-16: 20 30
- U+20AC EURO SIGN:
€- Nº: 8364
- UTF-8: E2 82 AC
- UTF-16: 20 AC
- U+2122 TRADE MARK SIGN:
™- Nº: 8482
- UTF-8: E2 84 A2
- UTF-16: 21 22
- U+2603 SNOWMAN:
☃- Nº: 9731
- UTF-8: E2 98 83
- UTF-16: 26 03
- U+260E BLACK TELEPHONE:
☎- Nº: 9742
- UTF-8: E2 98 8E
- UTF-16: 26 0E
- U+2614 UMBRELLA WITH RAIN DROPS:
☔- Nº: 9748
- UTF-8: E2 98 94
- UTF-16: 26 14
- U+263A WHITE SMILING FACE:
☺- Nº: 9786
- UTF-8: E2 98 BA
- UTF-16: 26 3A
- U+2691 BLACK FLAG:
⚑- Nº: 9873
- UTF-8: E2 9A 91
- UTF-16: 26 91
- U+269B ATOM SYMBOL:
⚛- Nº: 9883
- UTF-8: E2 9A 9B
- UTF-16: 26 9B
- U+2708 AIRPLANE:
✈- Nº: 9992
- UTF-8: E2 9C 88
- UTF-16: 27 08
- U+271E SHADOWED WHITE LATIN CROSS:
✞- Nº: 10014
- UTF-8: E2 9C 9E
- UTF-16: 27 1E
- U+3020 POSTAL MARK FACE:
〠- Nº: 12320
- UTF-8: E3 80 A0
- UTF-16: 30 20
- U+8089 CJK UNIFIED IDEOGRAPH-8089:
肉- Nº: 32905
- UTF-8: E8 82 89
- UTF-16: 80 89
- U+1337 ETHIOPIC SYLLABLE PHWA:
-
- U+1F4A9 PILE OF POO:
💩- Nº: 128169
- UTF-8: F0 9F 92 A9
- UTF-16: D8 3D DC A9
- U+1F680 ROCKET:
🚀- Nº: 128640
- UTF-8: F0 9F 9A 80
- UTF-16: D8 3D DE 80
- U+1F4A9 PILE OF POO:
Okay I’m getting carried away…
Fun facts:
- If you’re looking for a specific character, you can copy&paste it on http://codepoints.net/.
- I wasted a lot of time on this useless list (but it’s sorted!).
- MySQL has a charset called «utf8» which actually does not support characters longer than 3 bytes. So you can’t insert a pile of poo, the field will be silently truncated. Use «utf8mb4» instead.
- There’s a snowman test page (unicodesnowmanforyou.com).
answered May 1, 2014 at 15:17
![]()
basic6basic6
3,5031 gold badge39 silver badges47 bronze badges
6
Simply speaking Unicode is a standard which assigned one number (called code point) to all characters of the world (Its still work in progress).
Now you need to represent this code points using bytes, thats called character encoding. UTF-8, UTF-16, UTF-6 are ways of representing those characters.
UTF-8 is multibyte character encoding. Characters can have 1 to 6 bytes (some of them may be not required right now).
UTF-32 each characters have 4 bytes a characters.
UTF-16 uses 16 bits for each character and it represents only part of Unicode characters called BMP (for all practical purposes its enough). Java uses this encoding in its strings.
answered Mar 13, 2011 at 15:15
![]()
ZimbabaoZimbabao
8,1242 gold badges29 silver badges36 bronze badges
5
In UTF-8:
1 byte: 0 - 7F (ASCII)
2 bytes: 80 - 7FF (all European plus some Middle Eastern)
3 bytes: 800 - FFFF (multilingual plane incl. the top 1792 and private-use)
4 bytes: 10000 - 10FFFF
In UTF-16:
2 bytes: 0 - D7FF (multilingual plane except the top 1792 and private-use )
4 bytes: D800 - 10FFFF
In UTF-32:
4 bytes: 0 - 10FFFF
10FFFF is the last unicode codepoint by definition, and it’s defined that way because it’s UTF-16’s technical limit.
It is also the largest codepoint UTF-8 can encode in 4 byte, but the idea behind UTF-8’s encoding also works for 5 and 6 byte encodings to cover codepoints until 7FFFFFFF, ie. half of what UTF-32 can.
answered Aug 27, 2016 at 12:18
![]()
JohnJohn
6,4003 gold badges48 silver badges89 bronze badges
In Unicode the answer is not easily given. The problem, as you already pointed out, are the encodings.
Given any English sentence without diacritic characters, the answer for UTF-8 would be as many bytes as characters and for UTF-16 it would be number of characters times two.
The only encoding where (as of now) we can make the statement about the size is UTF-32. There it’s always 32bit per character, even though I imagine that code points are prepared for a future UTF-64
What makes it so difficult are at least two things:
- composed characters, where instead of using the character entity that is already accented/diacritic (À), a user decided to combine the accent and the base character (`A).
- code points. Code points are the method by which the UTF-encodings allow to encode more than the number of bits that gives them their name would usually allow. E.g. UTF-8 designates certain bytes which on their own are invalid, but when followed by a valid continuation byte will allow to describe a character beyond the 8-bit range of 0..255. See the Examples and Overlong Encodings below in the Wikipedia article on UTF-8.
- The excellent example given there is that the € character (code point
U+20ACcan be represented either as three-byte sequenceE2 82 ACor four-byte sequenceF0 82 82 AC. Both are valid, and this shows how complicated the answer is when talking about «Unicode» and not about a specific encoding of Unicode, such as UTF-8 or UTF-16.Strictly speaking, as pointed out in a comment, this doesn’t seem to be the case any longer or was even based on a misunderstanding on my part. The quote from the updated Wikipedia article reads: Longer encodings are called overlong and are not valid UTF-8 representations of the code point.
- The excellent example given there is that the € character (code point
answered Mar 13, 2011 at 15:10
![]()
0xC0000022L0xC0000022L
20.2k9 gold badges82 silver badges149 bronze badges
2
Well I just pulled up the Wikipedia page on it too, and in the intro portion I saw «Unicode can be implemented by different character encodings. The most commonly used encodings are UTF-8 (which uses one byte for any ASCII characters, which have the same code values in both UTF-8 and ASCII encoding, and up to four bytes for other characters), the now-obsolete UCS-2 (which uses two bytes for each character but cannot encode every character in the current Unicode standard)»
As this quote demonstrates, your problem is that you are assuming Unicode is a single way of encoding characters. There are actually multiple forms of Unicode, and, again in that quote, one of them even has 1 byte per character just like what you are used to.
So your simple answer that you want is that it varies.
answered Mar 13, 2011 at 15:09
![]()
LoduwijkLoduwijk
1,9201 gold badge16 silver badges27 bronze badges
Unicode is a standard which provides a unique number for every character. These unique numbers are called code points (which is just unique code) to all characters existing in the world (some’s are still to be added).
For different purposes, you might need to represent this code points in bytes (most programming languages do so), and here’s where Character Encoding kicks in.
UTF-8, UTF-16, UTF-32 and so on are all Character Encodings, and Unicode’s code points are represented in these encodings, in different ways.
UTF-8 encoding has a variable-width length, and characters, encoded in it, can occupy 1 to 4 bytes inclusive;
UTF-16 has a variable length and characters, encoded in it, can take either 1 or 2 bytes (which is 8 or 16 bits). This represents only part of all Unicode characters called BMP (Basic Multilingual Plane) and it’s enough for almost all the cases. Java uses UTF-16 encoding for its strings and characters;
UTF-32 has fixed length and each character takes exactly 4 bytes (32 bits).
answered Jun 17, 2020 at 14:15
![]()
Giorgi TsiklauriGiorgi Tsiklauri
9,0478 gold badges40 silver badges62 bronze badges
For UTF-16, the character needs four bytes (two code units) if it starts with 0xD800 or greater; such a character is called a «surrogate pair.» More specifically, a surrogate pair has the form:
[0xD800 - 0xDBFF] [0xDC00 - 0xDFF]
where […] indicates a two-byte code unit with the given range. Anything <= 0xD7FF is one code unit (two bytes). Anything >= 0xE000 is invalid (except BOM markers, arguably).
See http://unicodebook.readthedocs.io/unicode_encodings.html, section 7.5.
answered Jul 12, 2016 at 20:45
![]()
prewettprewett
1,55714 silver badges19 bronze badges
Check out this Unicode code converter. For example, enter 0x2009, where 2009 is the Unicode number for thin space, in the «0x… notation» field, and click Convert. The hexadecimal number E2 80 89 (3 bytes) appears in the «UTF-8 code units» field.
![]()
Yash
8,9802 gold badges67 silver badges72 bronze badges
answered Oct 9, 2013 at 16:14
![]()
ma11hew28ma11hew28
118k116 gold badges447 silver badges645 bronze badges
From Wiki:
UTF-8, an 8-bit variable-width encoding which maximizes compatibility with ASCII;
UTF-16, a 16-bit, variable-width encoding;
UTF-32, a 32-bit, fixed-width encoding.
These are the three most popular different encoding.
- In UTF-8 each character is encoded into 1 to 4 bytes ( the dominant encoding )
- In UTF16 each character is encoded into 1 to two 16-bit words and
- in UTF-32 every character is encoded as a single 32-bit word.
![]()
answered Nov 24, 2019 at 21:20
![]()
chikitinchikitin
7336 silver badges24 bronze badges
Объем памяти (биты, байты, килобайты,…)
Так вот 1 символ двоичной системы (0 или 1) занимает в памяти компьютера 1 бит.
А 8 бит составляют 1 байт (легко запомнить, что байт больше, ведь в нем даже больше букв, чем в слове «бит»)
Итак, даже одна буква или цифра в компьютере будет занимать пространство в 1 байт на жестком диске (ведь для её кодировки нужно восемь нулей и единиц).
В этом легко убедиться, создайте в текстовом блокноте файл (не в Word, а именно в блокноте). Файл должен иметь расширение (то, что в названии после последней точки) .txt и может иметь любое название.
Если расширения файлов у вас не отображаются, то включите их.
1. Для этого зайдите в любую папке на компьютере.
2. Выберите в меню Сервис — Параметры папок.
3. Перейдите во вкладку Вид.
4. И уберите последнюю галочку напротив фразы «Скрывать расширения для зарегистрированных типов файлов».
Теперь все файлы будут показываться у вас с расширением. Не меняйте их, чтобы не потерять доступ к файлам. После упражнения можете вернуть галочку на место.
Итак, файл создан. Посмотрите сколько он «весит». Для этого нажмите на файл правой кнопкой мыши и выберете последний пункт «Свойства».
Его размер должен составлять 0 байт. Т.е. он пуст и ничего не весит.
Теперь откройте его и впишите любую цифру от 0 до 9. Сохраните файл и снова посмотрите в свойствах его вес. Теперь он должен весить 1 байт (8 бит). Это именно вес вписанной в него информации.
На диске файл будет занимать больше места, что связано с заполнением диска служебной информацией о расположении файла, его имени и т.д. Но конкретно наша цифра занимает всего 1 байт. Если мы впишем еще одну цифру, размер станет в 2 раза больше и т.д.
Теперь попробуем с буквами английского алфавита. Любая буква строчная или прописная тоже будет занимать 1 байт.
Русский же алфавит не умещается в кодировку в 256 символов, поэтому для него выделяется целых 2 байта другой кодировки 16-битной или 16-разрядной (из 16 единиц и нулей). Попробуйте русские буквы и убедитесь в этом.
Добавить интересную новость
Добавить анкету репетитора и получать бесплатно заявки на обучение от учеников
user->isGuest) »]) . ‘ или ‘ . Html::a(‘зарегистрируйтесь’, [‘/user/registration/register’], [‘class’ => »]) . ‘ , чтобы получать деньги $$$ за каждый набранный балл!’); > else user->identity->profile->first_name) || !empty(Yii::$app->user->identity->profile->surname))user->identity->profile->first_name . ‘ ‘ . Yii::$app->user->identity->profile->surname; > else echo ‘Получайте деньги за каждый набранный балл!’; > ?>—>
При правильном ответе Вы получите 1 балл
Сколько байт занимает одна буква латинского алфавита?
Выберите всего один правильный ответ.
Добавление комментариев доступно только зарегистрированным пользователям
Lorem iorLorem ipsum dolor sit amet, sed do eiusmod tempbore et dolore maLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempborgna aliquoLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempbore et dLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempborlore m mollit anim id est laborum.
28.01.17 / 22:14, Иван Иванович Ответить +5
Lorem ipsum dolor sit amet, consectetu sed do eiusmod qui officia deserunt mollit anim id est laborum.
28.01.17 / 22:14, Иван ИвановичОтветить -2
Lorem ipsum dolor sit amet, consectetur adipisicing sed do eiusmod tempboLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod temLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempborpborrum.
Измерение информации. Алфавитный подход к измерению информации. Мощность алфавита. Информационный объем текста
Алфавитный подход к измерению информации Вам хорошо известно, что для измерения таких величин, как, например, расстояние, масса, время, существуют эталонные единицы. Для расстояния — это метр, для массы — килограмм, для времени — секунда. Измерение происходит путем сопоставления измеряемой величины с эталонной единицей. Сколько раз эталонная единица укладывается в измеряемой величине, таков и результат измерения. Следовательно, и для измерения информации должна быть введена своя эталонная единица. Алфавитный подход позволяет измерять информационный объем текста на некотором языке (естественном или формальном), не связанный с содержанием этого текста.
Алфавит. Мощность алфавита
Под алфавитом мы будем понимать набор букв, знаков препинания, цифр, скобок и др. символов, используемых в тексте. В алфавит также следует включить и пробел, т. е. пропуск между словами.
Полное число символов в алфавите принято называть мощностью алфавита. Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54:33 буквы + 10 цифр + 11 знаков препинания, скобки, пробел.
Информационный вес символа
При алфавитном подходе считается, что каждый символ текста имеет определенный информационный вес. Информационный вес символа зависит от мощности алфавита. А каким может быть наименьшее число символов в алфавите? Оно равно двум! Скоро вы узнаете, что такой алфавит используется в компьютере. Он содержит всего 2 символа, которые обозначаются цифрами «0» и «1». Его называют двоичным алфавитом. Изучая устройство и работу компьютера, вы узнаете, как с помощью всего двух символов можно представить любую информацию.
Информационный вес символа двоичного алфавита принят за единицу информации и называется 1 бит.
Биты, байты, кодировки
Почти полтора месяца писала данную статью, но надеюсь оно того стоило. Данная статья может выглядеть холиварной, поэтому не спешите писать комментарии пока не прочитаете полностью. Статья главным образом о методологии.
Дело в том, что я твёрдо уверена, что в учебных заведениях по информационной специальности, школьникам и студентам забивают голову историей древнего мира вместо актуальных знаний. Все методички преподают дамы бальзаковского возраста, а пишут эти методички профессора возраста Карла Маркса. В результате от соискателей на работу, и от стажёров, я слышала такие забавные заблуждения, относительно фундаментальных основ, как:
- в байте 1024 бита
- в байте 8 бит потому что 8 — степень двойки
- бит принимает всякие разные значения от 0 до 1
В числе прочих забавных случаев: для выбора десяти случайных чисел из бд, соискатели десять раз делают запрос; для открытия файла на чтение используют в PHP флаг ‘a+’; не умеют работать со строками, кодировками и указателями. Написать функцию, которая возвращает строку задом наперёд, не используя переменную-буфер — вообще непосильная задача.
В этой статье, я хочу коснуться проблемы заблуждений с битами и байтами, и написать свою методику обучения этим фундаментальным знаниям.
Итак… сперва я хочу написать определения из википедии методичек, которые являются догмой в умах профессоров из мин.образования.
- Бит — это двоичный логарифм вероятности равновероятных событий или сумма произведений вероятности на двоичный логарифм вероятности при равновероятных событиях; (или другими словами) бит — это единица информации, равная результату эксперимента, имеющему два исхода
- Бит — минимальная единица информации.
- Байт — минимальная адресуемая единица информации.
Из-за этих определений, в умах будущих программистов ЭВМ, больше каши, чем из-за каких-либо других определений! Они совершенно истинны, но совершенно бесполезны для обучения. Я превращаюсь в Халка, когда слышу их.
Про биты
Итак, дети, садитесь, урок первый, представьте себе выключатель. Нет, не двоичный логарифм вероятности… А обычный такой выключатель, тумблер, рычажок, что угодно, включающее например лампочку, когда находится в одном положении и выключающее в другом. На некоторых рычажках даже подписывают буковки I/O, как указатели положений ручки. Нет, выключатель не несёт в себе информацию. Он выключает свет.
У выключателя есть два положения — вкл/выкл. Если мы поставим рядом два выключателя, то количество комбинаций позиций, которое могут занимать их ручки — четыре. (Когда оба выключены, когда оба включены, и две комбинации когда включен только один из них). Если мы возьмём систему из трёх выключателей — они смогут занимать восемь комбинаций. И так далее, N выключателей имеют 2^N комбинаций. Выключатель который имеет только два положения (вкл/выкл) мы можем назвать битом. Если мы представим, что положениям вкл/выкл соответствуют числа 1 и 0, то можно легко записать какое-нибудь целое число в двоичной системе счисления, используя только последовательный набор выключателей, так чтобы каждый выключатель отвечал за свой двоичный разряд.
Безусловно выключатели мы можем применить к магнитной дорожке, или оптическому диску, так, чтобы при помощи специального устройства можно было «включать» или «выключать» их маленькие участки. Теперь мы наконец подошли к тому, что все компьютерные запоминающие устройства состоят из «ноликов и единичек».
Однако, в этих ноликах и единичках нам надо хранить информацию. Какую же информацию нам можно хранить? Давайте рассмотрим один бит. Мы можем условно договориться, что он может хранить информацию, и два его состояния вкл/выкл содержат значения «баклажан» и «не баклажан» соответственно. Это отлично подходит, когда нам надо произвести учёт баклажанов! Однако в реальном мире компьютеры, которые умеют только считать баклажаны — не пользуются спросом. Выходит выключатель (бит) не может нести в себе информацию. Чтобы записывать ноликами и единичками какую-то информацию, было решено группировать их по несколько штук, и такую группу называть байтом.
На заре компьютеров байты составляли 4, потом 5, потом 6 бит… Группа из 6 бит может принимать целых 64 значений. Вполне неплохо, так как можно создать некую таблицу соответствий этих значений определённым символам — кодировку. Такая кодировка уже может содержать цифры и заглавные буквы латинского алфавита, а также некоторые арифметические знаки. «Шестибитные-кодировки» — применялись на компьютерах в 1950-х — 1960-х годах.
Для человека который только начинает изучать информатику, будет понятно и легко запомнить что байт — является минимальной единицей информации. В байт можно записать какое-нибудь число, либо например какой-нибудь символ из таблицы символов (англ. charset, буквально «набор символов») — кодировки (codepage, encoding).
С развитием компьютеров, появилась потребность в большем количестве значений для байта. В 1963-м году появилась первая редакция семибитной кодировки ASCII. Поэтому байты стали занимать 7 бит. 7 бит, требующиеся для одного символа данной кодировки позволяют использовать 128 значений. В этой кодировке уже были включены строчные латинские символы, и больший набор управляющих и арифметических символов.
Всемирное распространение компьютеров подтолкнуло дальнейшее расширение границ занимаемых байтом. Для различных языков требовалось чтобы таблица символов также могла хранить алфавит того языка, где используется данная ЭВМ. На текущий момент восемь — это последнее и видимо окончательное количество бит составляющих байт. Соответственно байт может принимать 256 значений. По сравнению с таблицей ASCII в. новых таблицах символов — организовалось 128 вакантных мест. Теперь я думаю можно рассказать как значения хранятся в различных кириллических кодировках.
Кодировки
Итак, чтобы хранить символы не входящие в ASCII, необходимо было придумать новые кодировки. Поскольку до этого таблица ASCII была наиболее подходящей (были и другие), то она и пошла в основу новых кодировок. Поэтому следующие кодировки отличаются только значениями начиная с 80 (hex). Для наглядности оставлю только кириллические символы.

Так выглядела наиболее популярная кодировка под DOS. Примечательно что файлы в этой кодировке до сих пор встречаются. Как правило среди устаревшей архивной информации, в программах WinRar, Блокнот и WordPad, до сих пор есть опции «открыть как текст DOS», впрочем последними двумя мало кто пользуется =).
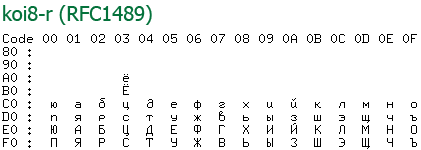
Кодировка koi8 была примечательна тем, что русские буквы там располагались на позициях английских звуков из нижней половины (т. е. ASCII). Это когда-то давно позволяло смягчить переход со старых серверов понимающие только ascii на новые, что было актуально среди почтовых серверов. Смысл был в том что если отправленное вами письмо приходило на старый сервер, то пользователю оно показывалось как транслит, что позволяло хоть как-то понять текст письма.

Самая популярная у нас в России однобайтная кодировка, на сегодняшний день, это именно «windows-1251». Разумеется популярность её целиком обусловлена популярностью Windows среди других операционных систем. Возможностей кодировки вполне хватает для использования её в широком круге задач. Например движок моего блога, по-умолчанию, использует для работы именно данную кодировку.

Я не могу не упомянуть о кодировке ISO, Удивительно, но несмотря на то что её никто никогда не использовал, эта кодировка является единственной кодировкой имеющей статус стандарта.
На примере данных кодировок видно, как один байт может хранить какое угодно символьное значение русского и английского языков, а также цифр и знаков пунктуации.
Но что делать когда этого не достаточно?
Многобайтные кодировки
Если вам хочется создать кодировку которая бы имела коды одновременно для русского и греческого алфавита? Одним байтом тут не отделаться. Появилась задача разработать кодировку один знак которой может занимать больше чем один байт, так как два байта могут принимать уже 2^16 = 65536 значений, а четыре байта аж 4294967296. Поэтому сначала придумали стандарт кодирования символов — Юникод, который включал бы в себя максимально полный перечень символов которые может принимать один знак.
Первая версия Юникода (Unicode 1991 г.) представляла собой 16-битную кодировку с фиксированной шириной символа; общее число разных символов было 2 16 (65 536).
Вторая версия Юникода (UCS-2), стала называться UTF-16, она позволяла гораздо расширить количество возможных значений, также используя для символов 16-битные последовательности (т. е. по 2 или по 4 байта на символ).
Символы с кодами 0×0000.0xD7FF и 0xE000.0xFFFF представляются одним 16-битным словом, а символы с кодами 0×10000–0×10FFFF — в виде последовательности двух 16-битных слов. Количество символов, представляемых двумя 16-битными словами равно (2 20 ). Для представления символов с кодами 0×10000–0×10FFFF используется матрица перекодировки. Первое слово из двух переданных лежит в диапазоне 0xD800-0xDBFF, а второе — 0xDC00-0xDFFF. Именно этот диапазон значений не может встречаться среди символов, передаваемых с помощью одного 16-битного слова, так что расшифровка кодировки всегда однозначна. Ясно, что имеется как раз 2 10 * 2 10 = 2 20 таких комбинаций.
Википедия — UTS-2
Кодировка UTF-32 (UCS-4) использует по 32 бита, или 4 байта на хранение одного символа. Строго говоря, стандарт Unicode не описывает символы со значениями выше 2^21, так что хватило бы и трёх байт, на символ, вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум, или для того чтобы в сектор диска попадало кратное количество символов. Так или иначе это единственная из многобайтных кодировок с постоянной длиной. Помимо недостатка — использования четырёх байт на символ, у неё есть и очевидное преимущество — возможность прямой адресации к N-ному символу. В других кодировках требуется последовательное вычисление позиции каждого символа. Поэтому текстовые редакторы, внутри себя хранят всю информацию в виде UCS-4.
В 1992 году Кеном Томпсоном и Робом Пайком был изобретён формат UTF-8. Он отличается тем, что он ASCII совместим, и значения из таблицы Юникода могут занимать от 1 до 4х символов.
Символы UTF-8 получаются из Unicode следующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0×00000000 — 0×0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0×00000080 — 0×000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания |
| 0×00000800 — 0×0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0×00010000 — 0×001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
Символы, в кодировке UTF-8, могут занимать до шести байт, но Unicode не определяет символов выше 0×10ffff , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Заключение
Вот собственно и всё что я хотела рассказать. Я считаю что очень интересно разбираться в том как работает компьютер, знать как хранятся в нём символы которые я набираю на клавиатуре, представлять насколько однобайтная кодировка например win-1251 (или utf-32 с фикс. длиной) работает быстрее со строковыми функциями и почему и т. п. Надеюсь статья вам понравилась.
Большое спасибо Википедии за возможность скопировать цитаты и таблицы, а то бы писала статью ещё месяц.
Все кто хочет узнать больше, также могут почитать про то в каком порядке записываются байты в кодировках UTF-16 и UTF-32 — в википедии тут и тут. А также что такое порядок байтов тут: Порядок_байтов. Также интересна будет статья Юникод в операционных системах Microsoft.
На чтение 5 мин. Просмотров 1.1k. Опубликовано 15.12.2019
Я просто смущен. сколько символов в одном бите?
Это зависит от характера и того, в каком кодировании он находится:
Символ ASCII в 8-разрядной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит.
Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт).
Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Символ Юникода в кодировке UTF-16 находится между 16 (2 байтами) и 32 битами (4 байта), хотя большинство общих символов принимают 16 бит. Это кодировка, используемая Windows внутренне.
Символ Unicode в кодировке UTF-32 всегда 32 бита (4 байта).
Символ ASCII в UTF-8 — 8 бит (1 байт), а в UTF-16 — 16 бит.
Дополнительные символы (не ASCII) в ISO-8895-1 (0xA0-0xFF) будут принимать 16 бит в UTF-8 и UTF-16.
Это означало бы, что между 0.03125 и 0.125 символами.
Один бит это 1/8 (одна восьмая или 0.125 символа). Из учебника информатики мы знаем что для того чтобы записать один символ нам нужен 1 байт, который состоит из 8 бит, отсюда 1 бит это 1/8 символа или 0.125 символа. Почему 1 символ это байт? Все дело в том что машина (компьютер) не понимает наши буквы и символы, она понимает только значения «верно» и «ложь» которые записаны в двоичном коде (то есть при помощи двух символов 1 и 0). Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования текста, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах [1] . Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9 [2] . Идентификатор кодировки в Windows – 65001 [3] .
Сравнивая UTF-8 и UTF-16, можно отметить, что наибольший выигрыш в компактности UTF-8 даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII. [4] [5]
Содержание
- Содержание
- Алгоритм кодирования [ править | править код ]
- Примеры кодирования [ править | править код ]
- Маркер UTF-8 [ править | править код ]
- Пятый и шестой байты [ править | править код ]
Содержание
Алгоритм кодирования [ править | править код ]
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникод.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
| 00000000-0000007F | 1 |
| 00000080-000007FF | 2 |
| 00000800-0000FFFF | 3 |
| 00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
- 0xxxxxxx — если для кодирования потребуется один октет;
- 110xxxxx — если для кодирования потребуется два октета;
- 1110xxxx — если для кодирования потребуется три октета;
- 11110xxx — если для кодирования потребуется четыре октета.
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования [ править | править код ]
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 100100 | 0 0100100 | 24 |
| ¢ | U+00A2 | 10 100010 | 110 00010 10 100010 | C2 A2 |
| € | U+20AC | 10 0000 10 101100 | 1110 0010 10 000010 10 101100 | E2 82 AC |
| �� | U+10348 | 1 0000 0011 01 001000 | 11110 000 10 010000 10 001101 10 001000 | F0 90 8D 88 |
Маркер UTF-8 [ править | править код ]
Для указания, что файл или поток содержит символы Юникода, в начале файла или потока может быть вставлен маркер последовательности байтов (англ. Byte order mark, BOM ), который в случае кодирования в UTF-8 принимает форму трёх байтов: EF BB BF16 .
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код | 1110 1111 | 1011 1011 | 1011 1111 |
| Шестнадцатеричный код | EF | BB | BF |
Пятый и шестой байты [ править | править код ]
Изначально кодировка UTF-8 допускала использование до шести байтов для кодирования одного символа, однако в ноябре 2003 года стандарт RFC 3629 запретил использование пятого и шестого байтов, а диапазон кодируемых символов был ограничен символом U+10FFFF . Это было сделано для обеспечения совместимости с UTF-16.
Содержание
- 1 символ это сколько бит
- Содержание
- Алгоритм кодирования [ править | править код ]
- Примеры кодирования [ править | править код ]
- Маркер UTF-8 [ править | править код ]
- Пятый и шестой байты [ править | править код ]
- Сколько требуется бит памяти для кодирования кода одного символа в кодировке windows
- Сколькими битами кодируется 1 символ в unicode. Кодирование текста
- Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
- Компьютерная грамотность с Надеждой
- Заполняем пробелы — расширяем горизонты!
- Двоичное кодирование текстовой информации и таблица кодов ASCII
- Сколько значений можно закодировать с помощью нуля и единицы
- Как происходит кодирование текстовой информации
- Таблица ASCII
- Коды из международной таблицы ASCII
- Кодировка слова МИР
- Неужели нужно знать все коды?
1 символ это сколько бит
Я просто смущен. сколько символов в одном бите?
Это зависит от характера и того, в каком кодировании он находится:
Символ ASCII в 8-разрядной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит.
Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт).
Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Символ Юникода в кодировке UTF-16 находится между 16 (2 байтами) и 32 битами (4 байта), хотя большинство общих символов принимают 16 бит. Это кодировка, используемая Windows внутренне.
Символ Unicode в кодировке UTF-32 всегда 32 бита (4 байта).
Символ ASCII в UTF-8 — 8 бит (1 байт), а в UTF-16 — 16 бит.
Дополнительные символы (не ASCII) в ISO-8895-1 (0xA0-0xFF) будут принимать 16 бит в UTF-8 и UTF-16.
Это означало бы, что между 0.03125 и 0.125 символами.
Один бит это 1/8 (одна восьмая или 0.125 символа). Из учебника информатики мы знаем что для того чтобы записать один символ нам нужен 1 байт, который состоит из 8 бит, отсюда 1 бит это 1/8 символа или 0.125 символа. Почему 1 символ это байт? Все дело в том что машина (компьютер) не понимает наши буквы и символы, она понимает только значения «верно» и «ложь» которые записаны в двоичном коде (то есть при помощи двух символов 1 и 0). Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
Сравнивая UTF-8 и UTF-16, можно отметить, что наибольший выигрыш в компактности UTF-8 даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII. [4] [5]
Содержание
Алгоритм кодирования [ править | править код ]
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникод.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
| 00000000-0000007F | 1 |
| 00000080-000007FF | 2 |
| 00000800-0000FFFF | 3 |
| 00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования [ править | править код ]
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 100100 | 0 0100100 | 24 |
| ¢ | U+00A2 | 10 100010 | 110 00010 10 100010 | C2 A2 |
| € | U+20AC | 10 0000 10 101100 | 1110 0010 10 000010 10 101100 | E2 82 AC |
| �� | U+10348 | 1 0000 0011 01 001000 | 11110 000 10 010000 10 001101 10 001000 | F0 90 8D 88 |
Маркер UTF-8 [ править | править код ]
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код | 1110 1111 | 1011 1011 | 1011 1111 |
| Шестнадцатеричный код | EF | BB | BF |
Пятый и шестой байты [ править | править код ]
Источник
Сколько требуется бит памяти для кодирования кода одного символа в кодировке windows
Кодирование текстовой информации
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.

В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Все остальные отражаются определенными знаками.
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.

Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.

К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-е годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.

От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).

Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.

Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.

Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.

С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.

Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII

Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Н апример, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ» (Рис. 10), тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
Источник
Сколькими битами кодируется 1 символ в unicode. Кодирование текста
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
Для кодирования одного символа требуется 1 байт информации. Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N = 216 = 65536 различных
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:

Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “10 3 ”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”.
1 байт = 2 3 =8 бит, 1 килобайт = 2 10 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
Источник
Компьютерная грамотность с Надеждой
Заполняем пробелы — расширяем горизонты!
Двоичное кодирование текстовой информации и таблица кодов ASCII
Минимальные единицы измерения информации – это бит и байт.
Один бит позволяет закодировать 2 значения (0 или 1).
Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11.
Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111.
Сколько значений можно закодировать с помощью нуля и единицы
Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать:
1 бит кодирует —> 2 разных значения (2 1 = 2),
2 бита кодируют —> 4 разных значения (2 2 = 4),
3 бита кодируют —> 8 разных значений (2 3 = 8),
4 бита кодируют —> 16 разных значений (2 4 = 16),
5 бит кодируют —> 32 разных значения (2 5 = 32),
6 бит кодируют —> 64 разных значения (2 6 = 64),
7 бит кодируют —> 128 разных значения (2 7 = 128),
8 бит кодируют —> 256 разных значений (2 8 = 256),
9 бит кодируют —> 512 разных значений (2 9 = 512),
10 бит кодируют —> 1024 разных значений (2 10 = 1024).
Мы помним, что в одном байте не 9 и не 10 бит, а всего 8. Следовательно, с помощью одного байта можно закодировать 256 разных символов. Как Вы думаете, много это или мало? Давайте посмотрим на примере кодирования текстовой информации.
Как происходит кодирование текстовой информации
В русском языке 33 буквы и, значит, для их кодирования надо 33 байта. Компьютер различает большие (заглавные) и маленькие (строчные) буквы, только если они кодируются различными кодами. Значит, чтобы закодировать большие и маленькие буквы русского алфавита, потребуется 66 байт.
А дальше дело осталось за малым. Надо сделать так, чтобы все люди на Земле договорились между собой о том, какие именно коды (с 0 до 255, т.е. всего 256) присвоить символам. Допустим, все люди договорились, что код 33 означает восклицательный знак (!), а код 63 – вопросительный знак (?). И так же – для всех применяемых символов. Тогда это будет означать, что текст, набранный одним человеком на своем компьютере, всегда можно будет прочитать и распечатать другому человеку на другом компьютере.
Таблица ASCII
Такая всеобщая договоренность об одинаковом использовании чего-либо называется стандартом. В нашем случае стандарт должен представлять из себя таблицу, в которой зафиксировано соответствие кодов (с 0 до 255) и символов. Подобная таблица называется таблицей кодировки.
Но не всё так просто. Ведь символы, которые хороши, например, для Греции, не подойдут для Турции потому, что там используются другие буквы. Аналогично то, что хорошо для США, не подойдет для России, а то, что подойдет для России, не годится для Германии.
Поэтому приняли решение разделить таблицу кодов пополам.
Первые 128 кодов (с 0 до 127) должны быть стандартными и обязательными для всех стран и для всех компьютеров, это – международный стандарт.
А со второй половиной таблицы кодов (с 128 до 255) каждая страна может делать все, что угодно, и создавать в этой половине свой стандарт – национальный.
Первую (международную) половину таблицы кодов называют таблицей ASCII, которую создали в США и приняли во всем мире.
За вторую половину кодовой таблицы (с 128 до 255) стандарт ASCII не отвечает. Разные страны создают здесь свои национальные таблицы кодов.
Может быть и так, что в пределах одной страны действуют разные стандарты, предназначенные для различных компьютерных систем, но только в пределах второй половины таблицы кодов.
Коды из международной таблицы ASCII
0-31 – Особые символы, которые не распечатываются на экране или на принтере. Они служат для выполнения специальных действий, например, для «перевода каретки» – перехода текста на новую строку, или для «табуляции» – установки курсора на специальные позиции в строке текста и т.п.
32 – Пробел, который является разделителем между словами. Это тоже символ, подлежащий кодировке, хоть он и отображается в виде «пустого места» между словами и символами.
33-47 – Специальные символы (круглые скобки и пр.) и знаки препинания (точка, запятая и пр.).
48-57 – Цифры от 0 до 9.
58-64 – Математические символы: плюс (+), минус (-), умножить (*), разделить (/) и пр., а также знаки препинания: двоеточие, точка с запятой и пр.
65-90 – Заглавные (прописные) английские буквы.
91-96 – Специальные символы (квадратные скобки и пр.).
97-122 – Маленькие (строчные) английские буквы.
123-127 – Специальные символы (фигурные скобки и пр.).
За пределами таблицы ASCII, начиная с цифры 128 по 159, идут заглавные (прописные) русские буквы. А с цифры 160 по 170 и с 224 по 239 – маленькие (строчные) русские буквы.
Кодировка слова МИР
Пользуясь показанной кодировкой, мы можем представить себе, как компьютер кодирует и затем воспроизводит. Например, рассмотрим слово МИР (заглавными буквами). Это слово представляется тремя кодами:
букве М соответствует код 140 (по национальной российской системе кодировки),
для буквы И – это код 136 и
буква Р – это 144.
Но как уже говорилось ранее, компьютер воспринимает информацию только в двоичном виде, т.е. в виде последовательности нулей и единиц. Каждый байт, соответствующий каждой букве слова МИР, содержит последовательность из восьми нулей и единиц. Используя правила перевода десятичной информации в двоичную, можно заменить десятичные значения кодов букв на их двоичные аналоги.
Десятичной цифре 140 соответствует двоичное число 10001100. Это можно проверить, если сделать следующие вычисления: 2 7 + 2 3 +2 2 = 140. Степень, в которую возводится каждая «двойка» – это номер позиции двоичного числа 10001100, в которой стоит «1». Причем позиции нумеруются справа налево, начиная с нулевого номера позиции: 0, 1, 2 и т.д.
Более подробно о переводе чисел из одной системы счисления в другую можно узнать, например, из учебников по информатике или через Интернет.
Аналогичным образом можно убедиться, что цифре 136 соответствует двоичное число 10001000 (проверка: 2 7 + 2 3 = 136). А цифре 144 соответствует двоичное число 10010000 (проверка: 2 7 + 2 4 = 144).
Таким образом, в компьютере слово МИР будет храниться в виде следующей последовательности нулей и единиц (бит): 10001100 10001000 10010000.
Разумеется, что все показанные выше преобразования данных производятся с помощью компьютерных программ, и они не видны пользователям. Они лишь наблюдают результаты работы этих программ, как при вводе информации с помощью клавиатуры, так и при ее выводе на экран монитора или на принтер.
Неужели нужно знать все коды?
Следует отметить, что на уровне изучения компьютерной грамотности пользователям компьютеров не обязательно знать двоичную систему счисления. Достаточно иметь представление о десятичных кодах символов.
Только системные программисты на практике используют двоичную, шестнадцатеричную, восьмеричную и иные системы счисления. Особенно это важно для них, когда компьютеры выводят сообщения об ошибках в программном обеспечении, в которых указываются ошибочные значения без преобразования в десятичную систему.
Упражнения по компьютерной грамотности, позволяющие самостоятельно увидеть и почувствовать описанные системы кодировок, приведены в статье «Проверяем, кодирует ли компьютер текст?»
Источник
В таблице ASCII символ весит 8 бит, это 1 байт.
В UTF-8 от 1 од 6 байт
Отмена

Олеся Точемкина
Отвечено 1 октября 2019
-
Комментариев (0)
Добавить
Отмена
Plan
- 1 Как напечатать +-?
- 2 Как открыть дополнительные символы на клавиатуре?
- 3 Для чего нужна таблица ascii?
- 4 Для чего нужна кодировка?
- 5 Сколько весит один символ в UTF-8?
- 6 Сколько байт занимает один символ в кодировке UTF-8?
- 7 Сколько весит 1 мб?
- 8 Сколько бит в двоичном коде?
- 9 Какое количество информации позволяют закодировать два разряда двоичного кода?
Как напечатать +-?
Для того чтобы вставить +-, нужно использовать «Alt+0177». Зажмите «Alt» на клавиатуре, и, не отпуская кнопки, наберите на цифровой клавиатуре (цифры справа) «0177».
Как открыть таблицу символов?
Используем горячие клавиши, то есть:
- нажимаем одновременно две клавиши «Win+R».
- Появится окно “Выполнить”, в котором набираем без кавычек «charmap.exe».
- После чего щелкаем “ОК”, и откроется «Таблица символов».
Как открыть таблицу символов в Word?
Чтобы открыть таблицу символов перейдите на вкладку Символы, специальные символы находятся на вкладке Специальные знаки этого же окна. Для вставки символа в документ выберите его из набора символов и щелкните на кнопке Вставить (см.
Как открыть дополнительные символы на клавиатуре?
– нажмите и удерживайте клавишу Alt; – на дополнительной цифровой клавиатуре (цифровой блок расположен в правой части клавиатуры) наберите код символа; – когда вы отпустите клавишу Alt, в текст будет вставлен нужный символ.
Для чего нужна таблица символов?
Таблица символов это стандартная программа Windows, предназначенная для досмотра, поиска и копирования символов, входящих в состав любого шрифта, установленного в Windows.
Что такое символ в компьютере?
Символ — это некоторый значок, изображение. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа “=”, “(”, “&” и т.
Для чего нужна таблица ascii?
ASCII представляет собой кодировочную таблицу печатных символов (см. скриншот №1), набираемых на компьютерной клавиатуре, для передачи информации и некоторых кодов. Иными словами происходит кодирование алфавита и десятичных цифр в соответствующие символы, представляющие и несущие в себе необходимую информацию.
Для чего нужно кодирование Юникод?
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных. Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Как ввести символы юникода?
Вставка символов Юникода Чтобы вставить символ Юникода, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X.
Для чего нужна кодировка?
Нужна она для того, чтобы текстовую информацию преобразовывать в биты данных и передавать, например, через Интернет. Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец. символов, в которые преобразуется каждый символ исходного текста.
Сколько байт занимает символ юникода?
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.
Сколько байтов отводится на кодирование одного символа в кодировке Unicode?
Поэтому быстрый ответ таков: он занимает от 1 до 4 байт, в зависимости от первого, который укажет, сколько байт он займет. Вы не увидите простого ответа, потому что его нет. Во-первых, Unicode не содержит «каждый символ из каждого языка», хотя он, конечно, пытается.
Сколько весит один символ в UTF-8?
2 либо 4 байта, смотря какой юникод. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом.
Сколько байт занимает один символ?
Так вот 1 символ двоичной системы (0 или 1) занимает в памяти компьютера 1 бит. Итак, даже одна буква или цифра в компьютере будет занимать пространство в 1 байт на жестком диске (ведь для её кодировки нужно восемь нулей и единиц).
Сколько байт весит пробел?
Принцип кодирования текстовой информации несложен: каждый символ (включая буквы, цифры, пробел, знаки препинания и другие символы) занимает 1 байт (в классических кодировках КОИ-8r, Windows-1251, CP866); 2 байта (современная кодировка Unicode-16) или переменное количество от 1 до 4 байт (UTF-8, где английские буквы.
Сколько байт занимает один символ в кодировке UTF-8?
Замечание: Символы, закодированные в UTF-8, могут быть длиной до шести байт, однако стандарт Unicode не определяет символов выше 0x10ffff , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Сколько байт в одной букве?
1 байт = 8 бит. Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Сколько символов байтов и битов в слове информатика?
В слове «информатика» 11 букв. Каждую букву мы можем закодировать одним байтом. В одном байте 8 бит, поэтому ответ 11х8=88.
Сколько весит 1 мб?
Почему жесткий диск на терабайт имеет размер в 900 гигабайт?
| Единица | Аббревиатура | Сколько |
|---|---|---|
| бит | б | 0 или 1бит |
| килобайт | КБайт (KБ) | 1024 байта |
| мегабит | мбит (мб) | 1 000 килобит |
| мегабайт | МБайт (МБ) | 1024 килобайта |
Сколько бит в одной цифре?
Бит — это двоичная цифра . Вы можете преобразовать десятичное число 10 в двоичное число 1010 (8 + 2), поэтому вам потребуется 4 бита для выражения десятичного значения 10.
Сколько бит в десятичном числе?
Сколько бит в двоичном коде?
И поэтому основание двоичной системы равно 2. Аналогично, основание десятичной системы равно 10, так как там используются 10 цифр. Каждая цифра в двоичном числе называется бит (или разряд). Четыре бита – это полубайт (или тетрада), 8 бит – байт, 16 бит – слово, 32 бита – двойное слово.
Сколько двоичных разрядов необходимо для кодирования 1 символа?
Двоичное кодирование кодирование информации i = log2 256 = 8 бит = 1 байт. Для двоичного кодирования 1 символа требуется 1 байт, или 8 двоичных разрядов. Двоичный код каждого конкретного символа определяется кодовой таблицей.
Сколько двоичных разрядов используется для записи символа в таблице Unicode?
Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т. е. 16 бит.
Какое количество информации позволяют закодировать два разряда двоичного кода?
Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111.
Сколько цветов можно закодировать при использовании 16 разрядного двоичного кода?
Кроме режима истинного цвета используется также 16-битное кодирование (англ. High Color – «высокий» цвет), когда на красную и синюю составляющую отводится по 5 бит, а на зеленую, к которой человеческий глаз более чувствителен – 6 бит. В режиме High Color можно закодировать 216 = 65 536 различных цветов.
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)

Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.
Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.
Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.

Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.
Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.

- Перейдите по ветке HKEY_CURRENT_USERConsole и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).

- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.


Отличного Вам дня!
Время прочтения
7 мин
Просмотры 30K
Введение
С появлением первых устройств цифровой передачи информации и электронно-вычислительных машин возникла задача кодирования текстовых символов с помощью последовательностей единиц и нулей. Минимальная единица представления информации – байт. Исходя их этого в 1963 году в США разработана, стандартизована, а впоследствии расширена кодовая таблица ASCII (American standard code for information interchange), использовавшая 8 битную кодировку. В первую очередь с помощью этой таблицы предполагалось кодирование цифр и букв английского языка. Первые 128 символов таблицы представлены на рис.1:

Номер ячейки в таблице (рис.1) является кодом символа. В качестве примера рассмотрим кодирование слова Hello. Номера ячеек таблицы ASCII, в которых размещены буквы: 72 (H), 101 (e), 108 (l), 111 (o). Код слова в бинарном представлении выглядит следующим образом:
00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o) (старший бит справа).
Выделенные подчеркиванием и жирным коды в двоичном представлении соответствуют номерам ячеек в таблице (рис.1). Алгоритм формирования кода следующий:
1. Выделены жирным – биты управления кодированием (префикс). 010 – кодируется заглавная буква алфавита, 011 – строчная.
2. Выделены подчеркиванием – порядковые номера букв в английском алфавите.
Таким образом, с помощью первых 128 ячеек таблицы ASCII могли быть закодированы основные символы, цифры и буквы английского языка. Остальные 128 ячеек (8 битная кодировка позволяет закодировать 256 символов) могли использоваться для кодирования других языков. Однако, учитывая разнообразие символов и языков, 8 бит недостаточно.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.
Стандарт кодирования UTF-8
Стандарт закреплен в RFC (Request For Comments) 3629. Алгоритм кодирования согласно RFC:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xx 10xxxxxx 10xxxxxx 10xxxxxx
Старший бит слева. Началом кода является управляющий символ (выделен жирным):
0 – используется 8-битная кодировка,
110 – используется 16-битная кодировка,
1110 – используется 24-битная кодировка,
11110 – используется 32 битная кодировка.
В начале каждого последующего байта – биты 10 – управляющий символ (выделен подчеркиванием), означающий продолжение кодирования.
Первые 128 ячеек таблицы Юникод повторяют таблицу ASCII. Для кодирования заглавных и строчных букв русского алфавита используются ячейки с номерами 1040-1103.
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
00001011 11111001 (П) 00001011 00001101 (а) 00001011 11111101 (п) 00001011 00001101 (а) 00000100 (пробел) 00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o).
Букве П русского алфавита согласно таблицы Юникод соответствует номер 1055, в бинарном представлении 10000011111 – 11 бит. Соответственно данный символ может быть закодирован двумя байтами с использованием префикса 110 – для первого байта и 10 – для второго байта. Английские буквы слова Hello кодируются 1 байтом, а коды совпадают с кодами в таблице ASCII.
Основными преимуществами способа кодирования UTF-8 являются многообразие символов, которые могут быть закодированы, а также возможность кодирования переменным количеством бит, что позволяет сэкономить количество информации, передаваемое в канале связи.
Стандарт кодирования UTF-16
В феврале 2000 года опубликован документ RFC 2781, в котором закреплен стандарт UTF-16, позволяющий кодировать символы таблицы Юникод с помощью 16 или 32 битных значений. Символы с номерами 0-55295 и 57344-65535 кодируются с помощью 16 бит без изменений (без использования префиксов), а остальные символы, номера которых в двоичном представлении формируются количеством бит больше 16, кодируются 32 битами с использованием специального алгоритма. Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
11111000 00100000 (П) 00001100 001000000 (а) 11111100 00100000 (п) 00001100 001000000 (а) 00000100 00000000 (пробел) 00010010 00000000 (H) 10100110 00000000 (e) 00110110 00000000 (l) 00110110 00000000 (l) 111110110 00000000 (o).
Номера букв русского и английского алфавитов таблицы Юникод передаются без изменений при помощи 16 бит, старшие незначащие биты принимают нулевое значение.
Рассмотрим подробнее алгоритм кодирования символов, номера которых превышают значение 65535. Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:

Номер предложенного символа в таблице Юникод – 68620 (0х10COC).
Алгоритм преобразования номера символа в код UTF-16 состоит из нескольких шагов:
-
Из значения номера символа вычесть число 0х10000. Данная операция позволяет привести размерность бинарного представления номера символа к 20 битам. Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
-
Для полученного значения выделить старшие 10 бит и младшие 10 бит. В примере число 0хС0С в бинарном виде представляется, как 00000000110000001100, где жирным выделены 10 старших бит, а подчеркиванием – 10 младших.
-
К шестнадцатеричному значению 0xD800 (11011000 00000000) прибавить значение 0х03 (00000000 00000011), сформированное 10 старшими битами, полученными на предыдущем шаге. 0xD800 + 0х03 = 0хD803 (11011000 00000011) – 16 старших бит кодового слова UTF-16.
-
К шестнадцатеричному значению 0xDC00 (11011000 00000000) прибавить значение 0х0C (00000000 00001100), сформированное 10 младшими битами, полученными на шаге №2. 0xDС00 + 0х0С = DС0С (11011100 00001100) – 16 младших бит кодового слова UTF-16.
-
Кодовое слово UTF-16, соответствующее символу в примере, формируется из бит, полученных на шагах 3 и 4: 0хD803DC0C (11011000 00000011 11011100 00001100).
Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
Результаты сравнения стандартов представлены в таблице 1.
Таблица 1. Результаты сравнения стандартов.
|
Диапазон номеров |
0-127 |
128 — 2047 |
2048-32767 |
32768-65535 |
65535- 1048575 |
1048575-… |
|
UTF-8 |
8 |
16 |
24 |
32 |
32 |
_ |
|
UTF-16 |
16 |
16 |
16 |
16 |
32 |
32 |
В ячейках таблицы 1 содержится количество бит, требуемое для кодирования одного символа из таблицы Юникод. Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
В предыдущих главах приведены примеры кодирования фразы «Папа Hello» стандартами UTF-8 и UTF-16. Кодировкой UTF-8 используются 14 байт, кодировкой UTF-16 20 байт, что связано с избыточностью кодирования англоязычных символов во втором случае из-за использования дополнительного байта 0х00. Можно сделать вывод, что для кодирования текста содержащего набор букв русского и английского алфавитов, предпочтительно использование кодировки UTF-8.
Вывод: в зависимости от языка алфавита может быть выбрана как кодировка UTF-8, так и кодировка UTF-16. Для английского алфавита однозначно более выгодно использование кодировки UTF-8, для русского алфавита буквы представляются одинаковым количеством бит при использовании как одной, так и другой кодировки.
Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе. Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776. Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.