Содержание
- Как настроить и запустить Microsoft SQL Server
- MS SQL Server
- Обзор возможностей MS SQL Server
- Эволюция SQL Server
- Запуск Microsoft SQL Server
- Основы администрирования SQL Server
- Что такое MS SQL Server и чем она отличается от других СУБД
- Что такое MS SQL Server
- Что такое СУБД
- Расширения языка SQL
- Инсталляция MS SQL Server
- Зачем нужен SQL Server Management Studio
- Национальная библиотека им. Н. Э. Баумана Bauman National Library
- Персональные инструменты
- Microsoft SQL Server
- Содержание
- История
- Версии
- Используемые технологии
- Хранение данных
- Работа с данными
- Когда использовать собственный клиент SQL Server
- Стандартные технологии отказоустойчивости для MS SQL Server 2017
- AlwaysOn
- Кластеризация
- Репликация
- Зеркалирование
- Доставка журналов транзакций
- Общие сведения об обслуживании установки SQL Server
- Установка
- Создание базы данных
- Создание тестовых таблиц с использованием ISQL
- Создание тестовых таблиц с использованием провайдера данных
- Удаление SQL Server
Как настроить и запустить Microsoft SQL Server
Порой так хочется привести свои мысли в порядок, разложить их по полочкам. А еще лучше в алфавитной и тематической последовательности, чтобы, наконец, наступила ясность мышления. Теперь представьте, какой бы хаос творился в « электронных мозгах » любого компьютера без четкой структуризации всех данных и Microsoft SQL Server :

MS SQL Server

Реляционные базы данных построены на взаимосвязи всех структурных элементов, в том числе и за счет их вложенности. Реляционные базы данных имеют встроенную поддержку наиболее распространенных типов данных. Благодаря этому в SQL Server интегрирована поддержка программного структурирования данных с помощью триггеров и хранимых процедур.
Обзор возможностей MS SQL Server

СУБД является частью длинной цепочки специализированного программного обеспечения, которое корпорация Microsoft создала для разработчиков. А это значит, что все звенья этой цепи ( приложения ) глубоко интегрированы между собой.
Конечно, это не единственная популярная СУБД на мировом рынке. Но именно она является более приемлемой для компьютеров, работающих под управлением Windows, за счет своей направленности именно на эту операционную систему. И не только из-за этого.
Преимущества MS SQL Server :
Клиентская часть системы поддерживает создание пользовательских запросов и их отправку для обработки на сервер.
Эволюция SQL Server
Особенности этой популярной СУБД легче всего прослеживаются при рассмотрении истории эволюции всех ее версий. Более подробно мы остановимся лишь на тех выпусках, в которые разработчики вносили весомые и кардинальные изменения:

Диспетчер конфигурации. Позволяет управлять всеми сетевыми настройками и службами сервера базы данных. Используется для настройки SQL Server внутри сети.


Запуск Microsoft SQL Server
Для примера будет использована версия сервера баз данных выпуска 2005 года. Запуск сервера можно произвести несколькими способами:

Для запуска сервера баз данных запускаем приложение. В диалоговом окне « Соединение с сервером » в поле « Имя сервера » выбираем нужный нам экземпляр. В поле « Проверка подлинности » оставляем значение « Проверка подлинности Windows ». И нажимаем на кнопку « Соединить »:

Основы администрирования SQL Server

Основные настройки можно осуществить через « Обозреватель объектов », отображающий слева в окне приложения все основные элементы сервера в виде древовидного списка. Самой важной является вкладка « Безопасность ». Через нее можно настроить права и роли пользователей и администраторов для основного сервера, или отдельно для каждой базы данных:

Основная часть настроек сервера баз данных доступна в окне « Свойства сервера »:

Источник
Что такое MS SQL Server и чем она отличается от других СУБД

Веб-ресурсы содержат огромное количество данных – от учетных записей пользователей до контента, опубликованного на страницах. То же относится к «облачным» приложениям вроде CRM, программ для бухучета, складского учета и пр. Везде используется один способ хранения информации – база данных. И этой базой необходимо как-то управлять.
Сегодня мы поговорим об одной из самых популярных систем управления реляционными базами данных – MS SQL Server.
Что такое MS SQL Server
Чтобы упростить работу с такими хранилищами данных и повысить эффективность их применения, создаются специализированные системы управления. Одной из наиболее популярных является разработка от Microsoft – SQL Server. Первый релиз платформы опубликован еще в 1989 году, а последняя версия выпущена в 2019 году (проект продолжает развиваться).
Каждый выпуск включает в себя несколько специализированных редакций. Это снижает сложность внедрения и затраты на процесс разработки собственных решений, адаптированных для «узких» задач. При написании программного кода активно используется интеграция с продуктами Microsoft, например, с платформой Visual Studio.
Прямые конкуренты на рынке – Oracle Database, PostgreSQL. Первый проект коммерческий, он создан для поддержки крупных компаний, поэтому сопоставим по возможностям с MS SQL Server. Второй же распространяется на бесплатной основе и не «блещет» функциональностью, хотя весьма популярен среди многих разработчиков (аналог от Oracle MySQL).
Что такое СУБД
Появление таких продуктов позволило объединить разное понимание БД (баз данных) со стороны пользователей и системных администраторов. Неискушенные в технических деталях люди «видят» таблицы как некий перечень данных с колонками и строками. Системный подход включает файлы с табличными данными, связанными друг с другом согласно определенному алгоритму.

Функции базы данных:
Клиентами БД являются прикладные программы, их интерфейс, различные интерактивные модули сайтов вроде калькуляторов и онлайн-редакторов. Но есть еще один компонент системы – СУБД. Он предназначен для ручного доступа к информации и позволяет извлекать данные на диск, работать с ними в памяти сервера, в том числе с применением структурированного языка SQL.
Всего различают три типа БД – клиент-серверные, файл-серверные и встраиваемые. MS SQL Server относится к первой категории. Плюс система является реляционной, т.е. адаптированной для хранения данных без избыточности, с минимальными рисками появления аномалий и нарушения целостности внутренних таблиц.
Расширения языка SQL
Язык SQL представляет собой стандарт, унифицирующий обработку данных всеми реляционными базами данных. Такой подход упрощает перекрестные обращения, дает возможность переходить на «иную платформу» без серьезных переделок проекта. Но здесь нужно учитывать, что в каждой БД имеется собственный язык, который называется диалектом (расширением).
Обычно от выбранной СУБД зависит, какой язык предстоит использовать (или от навыков человека, который будет администрировать систему). Синтаксис конструкций у них сильно различается, как и формат обращения ко встроенным функциям, поэтому чаще всего тип БД для проекта выбирается раз и навсегда.
Инсталляция MS SQL Server
Подготовительный шаг – скачать установочный пакет SQL Server Enterprise с официальной страницы сайта Microsoft. После нажатия на кнопку «Бесплатная пробная версия» будет предложено выбрать вариант EXE или Azure («облако») и внести свои анкетные данные, при сохранении которых начнется загрузка инсталляционного файла.

Перед запуском установщика нужно создать учетную запись пользователя. Она пригодится для авторизации на сервере при запросе доступа с клиентских компьютеров (даже при условии, что ПК будет один и тот же).
Рекомендуется в имени и пароле использовать только буквы латиницы и цифры, кириллица будет привносить риски локальных сбоев из-за особенностей обработки. Теперь можно запускать файл с дистрибутивом MS SQL Server. Программа предложит 3 варианта действий: базовая инсталляция с настройками «по умолчанию», выборочный режим или скачивание файлов «на потом».

В большинстве случаев выбирается первый пункт, при нажатии на который предлагается прочитать и подтвердить лицензионное соглашение. На следующем шаге система позволяет вручную выбрать каталог для установки или согласиться с предложенным значением. Остается нажать на кнопку «Установить» и дождаться завершения процесса.

Файлы в основном скачиваются с официального сервера, поэтому понадобится стабильный доступ к интернету. Такой подход обеспечивает установку последнего релиза и проверку легитимности всех модулей (отсутствие вредоносного ПО). Последнее окно сообщает об успешном завершении, после которого можно сразу подключаться к серверу.

Зачем нужен SQL Server Management Studio
Для удобства администрирования также понадобится SQL Server Management Studio (SSMS). Он представляет собой интегрированную среду для управления инфраструктурой БД и поддерживает любые ее варианты – от локальной до Azure. В него встроены инструменты настройки, наблюдения и редактирования экземпляров баз данных.

Программные пакеты приложения также загружаются напрямую из интернета, поэтому требуется стабильный доступ к сети. После завершения установки будет запрошена перезагрузка компьютера. Все, система полностью готова к эксплуатации и созданию первой базы данных.
Хостинг-провайдеры обычно предлагают предустановленный комплект поддержки баз данных на SQL Server. Он не всегда последней версии, зато наверняка работоспособен в рамках как панели управления, так и публикуемых веб-ресурсов. Пользователю фактически предлагается сразу начать с создания БД – запрашивается всего лишь ее название, имя пользователя и пароль.
Источник
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная корпорацией Microsoft. Написана на C, С++, C#. Использует язык Transact-SQL, который является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями.
Содержание
История
Исходный код MS SQL Server (до версии 7.0) основывался на коде Sybase SQL Server, и это позволило Microsoft выйти на рынок баз данных для предприятий, где конкурировали Oracle, IBM, и, позже, сама Sybase. Microsoft, Sybase и Ashton-Tate первоначально объединились для создания и выпуска на рынок первой версии программы, получившей название SQL Server 1.0 для OS/2 (около 1989 года), которая фактически была эквивалентом Sybase SQL Server 3.0 для Unix, VMS и др. Microsoft SQL Server 4.2 был выпущен в 1992 году и входил в состав операционной системы Microsoft OS/2 версии 1.3. Официальный релиз Microsoft SQL Server версии 4.21 для ОС Windows NT состоялся одновременно с релизом самой Windows NT (версии 3.1). Microsoft SQL Server 6.0 был первой версией SQL Server, созданной исключительно для архитектуры NT и без участия в процессе разработки Sybase.
К тому времени, как вышла на рынок ОС Windows NT, Sybase и Microsoft разошлись и следовали собственным моделям программного продукта и маркетинговым схемам. Microsoft добивалась исключительных прав на все версии SQL Server для Windows. Позже Sybase изменила название своего продукта на Adaptive Server Enterprise во избежание путаницы с Microsoft SQL Server. До 1994 года Microsoft получила от Sybase три уведомления об авторских правах как намёк на происхождение Microsoft SQL Server.
После разделения компании сделали несколько самостоятельных релизов программ. SQL Server 7.0 был первым сервером баз данных с настоящим пользовательским графическим интерфейсом администрирования. Для устранения претензий со стороны Sybase в нарушении авторских прав, весь наследуемый код в седьмой версии был переписан.
Версия SQL Server 2005 — была представлена в ноябре 2005 года. Запуск версии происходил параллельно запуску Visual Studio 2005. Существует также «урезанная» версия Microsoft SQL Server — Microsoft SQL Server Express; она доступна для скачивания и может бесплатно распространяться вместе с использующим её программным обеспечением.
С момента выпуска предыдущей версии SQL Server (SQL Server 2000) было осуществлено развитие интегрированной среды разработки и ряда дополнительных подсистем, входящих в состав SQL Server 2005. Изменения коснулись реализации технологии ETL (извлечение, преобразование и загрузка данных), входящей в состав компонента SQL Server Integration Services (SSIS), сервера оповещения, средств аналитической обработки многомерных моделей данных (OLAP) и сбора релевантной информации (обе службы входят в состав Microsoft Analysis Services), а также нескольких служб сообщений, а именно Service Broker и Notification Services. Помимо этого, были произведены улучшения в производительности.
7 августа 2008 года компания Microsoft объявила о выходе новой версии СУБД SQL Server 2008. Именно с этого момента английская версия SQL Server 2008 стала доступна пользователям по различным программам корпоративного лицензирования, таким как Microsoft Enterprise Agreement, Microsoft Enterprise Agreement Subscription, Microsoft Open Value, Microsoft Open Value Subscription, Microsoft Open License.
21 апреля 2010 года корпорация Microsoft объявила о выпуске финальной версии SQL Server 2008 R2.
Версии
История выпусков SQL Server
| Версия | Год | Название | Кодовое имя |
|---|---|---|---|
| 1.0 (OS/2) | 1989 | SQL Server 1.0 (16 bit) | Ashton-Tate / MS SQL Server |
| 1.1 (OS/2) | 1991 | SQL Server 1.1 (16 bit) | — |
| WinNT | 1993 | SQL Server 4.21 | SQLNT |
| 6.0 | 1995 | SQL Server 6.0 | SQL95 |
| 6.5 | 1996 | SQL Server 6.5 | Hydra |
| 7.0 | 1998 | SQL Server 7.0 | Sphinx |
| — | 1999 | SQL Server 7.0 OLAP Tools | Palato mania |
| 8.0 | 2000 | SQL Server 2000 | Shiloh |
| 8.0 | 2003 | SQL Server 2000 64-bit | Liberty |
| 9.0 | 2005 | SQL Server 2005 | Yukon |
| 10.0 | 2008 | SQL Server 2008 | Katmai |
| 10.25 | 2010 | Azure SQL DB | Cloud Database or CloudDB |
| 10.50 | 2010 | SQL Server 2008 R2 | Kilimanjaro (aka KJ) |
| 11.0 | 2012 | SQL Server 2012 | Denali |
| 12.0 | 2014 | SQL Server In-Memory OLTP | Hekaton |
| 14 | 2016 | SQL Server 2016 |
Используемые технологии
Database Engine
Компонент Database Engine [Источник 1] представляет собой основную службу для хранения, обработки и обеспечения безопасности данных. Этот компонент обеспечивает управляемый доступ к ресурсам и быструю обработку транзакций, что позволяет использовать его даже в самых требовательных корпоративных приложениях обработки данных. Кроме того, компонент Database Engine предоставляет разносторонние средства поддержания высокого уровня доступности.
Службы Data Quality Services
Службы SQL Server Data Quality Services (DQS) [Источник 2] являются решением для очистки данных на основе знаний. Службы DQS позволяют создать базу знаний, а затем выполнить в ней исправление данных и удаление дубликатов с помощью как автоматизированных, так и интерактивных средств. Можно использовать службы справочных данных на основе облачных вычислений, а также создавать решения по управлению данными, где службы DQS будут интегрированы со службами SQL Server Integration Services и Master Data Services.
Службы Analysis Services
Службы Analysis Services [Источник 3] — это платформа аналитических данных и набор средств для бизнес-аналитики на личном уровне, уровне рабочей группы и организации. Серверный и клиентский конструкторы поддерживают стандартные решения OLAP, новые решения для создания табличных моделей, а также самостоятельную аналитику и совместную работу с помощью PowerPivot, Excel и среды SharePoint Server. Службы Службы Analysis Services также включают интеллектуальный анализ данных, который позволяет выявлять закономерности и связи на основе больших объемов данных.
Службы Integration Services
Службы Integration Services [Источник 4] представляют собой платформу для создания высокопроизводительных решений по интеграции данных, в том числе пакетов для хранения данных, обеспечивающих извлечение, преобразование и загрузку данных.
Master Data Services
Master Data Services [Источник 5] — это решение SQL Server для управления основными данными. Решение, построенное на основе Master Data Services, позволяет обеспечить правильность информации, используемой для построения отчетов и выполнения анализа. С помощью Master Data Services можно создать центральный репозиторий основных данных и поддерживать запись этих данных по мере их изменения, защищенную и доступную для аудита.
Репликация
Репликация представляет собой набор технологий копирования и распространения данных и объектов баз данных между базами данных, а также синхронизации баз данных для поддержания согласованности. Благодаря репликации данные можно размещать в различных местах, обеспечивая возможность доступа к ним удаленных и мобильных пользователей по локальным или глобальным сетям, посредством коммутируемых и беспроводных соединений, а также через Интернет.
Службы Reporting Services
Службы Reporting Services [Источник 6] предлагают средства создания корпоративных отчетов с поддержкой веб-интерфейса, которые позволяют включать в отчеты данные из различных источников, публиковать отчеты в разнообразных форматах, а также централизованно управлять безопасностью и подписками.
Хранение данных
Хранилище данных представляет собой базу данных, которая представляет собой набор таблиц из типизированных столбцов. SQL Server поддерживает различные типы данных, включая основные, такие как Integer, Float, Decimal, Сhar, Varchar, двоичный, Text и другие.
Дисковое пространство базы данных делится на последовательно пронумерованные страницы, каждая по 8 КБ. Страница является основной единицей ввода / вывода для операций SQL Server. Страница отмечена 96-байтный заголовком, который хранит метаданные о странице, включая номер страницы, тип страницы, свободное пространство на странице и идентификатор объекта, которому они принадлежат. Тип страницы определяет данные, содержащиеся на странице: данные, хранящиеся в базе данных, индекс, карту распределения, карту изменения, которая содержит информацию об изменениях, внесенных в другие страницы с момента последнего резервного копирования или протоколирования, или содержат большие типы данных, такие как изображение или текст.
Для физического хранения таблицы, ее строки разделены на ряд разделов (пронумерованных от 1 до N). Размер раздела определяется пользователем; по умолчанию все строки находятся в одном разделе. Таблица разделена на несколько разделов, чтобы распределить базу данных по кластерам. Строки в каждом разделе хранятся в виде B-дерева или кучи.
Работа с данными
Когда использовать собственный клиент SQL Server
Стандартные технологии отказоустойчивости для MS SQL Server 2017
AlwaysOn
Распределение нагрузки среди всех участников, все участники должны быть по своим характеристикам максимально похожи между собой. В синхронном режиме обеспечивается максимальная надежность передачи данных, однако скорость работы будет равняться скорости работы самого медленного участника. В асинхронном режиме обеспечивается максимальное быстродействие, однако могут возникать рассогласованности данных между участниками, что ведет к более сложной поддержке и вероятности потерять последние изменения в случае сбоя основного участника.
Быстрота переключения в синхронном режиме-практически мгновенно и не требует вмешательства системного администратора и DBA, в асинхронном-зависит от текущего состояния БД-дублей, но обычно в среднем до 5 минут (также можно автоматизировать переключение силами одного DBA без привлечения системного администратора).
Признана Microsoft рекомендуемой технологией для БД. Доступна с лицензией Enterprise от 2012 версии и выше. Доступна с ограничениями с лицензией Standard
Кластеризация
Несмотря на простоту настройки, данное решение ненадежно в виду узкого места в виде единого для всех хранилища данных. В случае выхода из строя хранилища данных, восстановление займет достаточно длительный промежуток времени-более 1 часа. Доступна с лицензией Standard до 2008 версии и выше
Репликация
Любая репликация подразумевает создание системных триггеров на каждую таблицу-участницу, а репликация моментальных снимков будет достаточно сильно нагружать основную БД. Поэтому репликацию моментальных снимков можно делать только в минимальные часы нагрузки БД (например, ночью), что неприемлемо, т к необходим горячий резерв. Репликация слиянием сложна в сопровождении для некоторых системы (например, CRM, NAV), также она не подходит для 1С в виду частого изменения структур БД.
Зеркалирование
Возможна в любом режиме, однако как и при AlwaysOn, синхронный режим обеспечивает максимальную надежность и быстрое переключение, а асинхронный режим дает максимальную скорость работы с основной БД, но возможны рассогласованности данных между всеми участниками, а также переключение не будет мгновенным. Здесь переключение на уровне БД обеспечивает следящий сервер автоматически (при например, нагрузке ЦП более, чем в 50% на основном сервере) или средствами DBA. Подключение же к другому серверу обеспечивается силами системного администратора. Резервная БД при любом типе зеркалирования находится в режиме постоянного восстановления, в следствие чего к ней невозможно обратиться. Режим восстановления БД-полный.
Доставка журналов транзакций
Есть 2 режима-постоянное восстановление на резервном сервере или восстановление с отсрочкой.
Первый режим переводит резервную БД (как и при зеркалировании) в режим постоянного восстанавления и к ней невозможно обратиться.
Второй же режим переводит резервную БД в режим восстановления периодически в момент накатывания обновлений (между накатываниями обновлений резервная БД доступна, но это возможно при условии, что экземпляры MS SQL Server одной версии).
Принцип работы прост:
Переключение можно автоматизировать на уровне БД-силами DBA, а на уровне подключений к серверу-на уровне системного администратора.
Общие сведения об обслуживании установки SQL Server
Установка
Создание базы данных
В составе Microsoft Visual Studio 2008 [Источник 7] находится сервер баз данных Microsoft SQL Server 2005 Express Edition. От полнофункционального сервера данных он отличается только ограничением размера базы данных в 2 гигабайта, что позволяет производить разработку и тестирование приложений баз данных.
Для работы по созданию базы данных и таблиц будем использовать Microsoft SQL Server Management Studio Express. Данный программный продукт является свободнораспространяемым и доступен для скачивания в Интернет.
Создание тестовых таблиц с использованием ISQL
Создание тестовых таблиц с использованием провайдера данных
Удаление SQL Server
Перед удалением SQL Server удалите локальные группы безопасности для компонентов SQL Server. Перед удалением компонентов SQL Server рекомендуется остановить все службы SQL Server. Наличие активных соединений может помешать удалению компонентов. Выполните вход на сервер с учетной записью службы SQL Server или с учетной записью, обладающей аналогичным набором разрешений. Например, можно войти на сервер с учетной записью, входящей в локальную группу администраторов.
Источник
| Developer(s) | Microsoft |
|---|---|
| Initial release | April 24, 1989; 33 years ago, as SQL Server 1.0 |
| Stable release |
SQL Server 2022[1] |
| Written in | C, C++[2] |
| Operating system | Linux, Microsoft Windows Server, Microsoft Windows |
| Available in | English, Chinese, French, German, Italian, Japanese, Korean, Portuguese (Brazil), Russian, Spanish and Indonesian[3] |
| Type | Relational database management system |
| License | Proprietary software |
| Website | www.microsoft.com/sql-server |
Microsoft SQL Server is a relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications—which may run either on the same computer or on another computer across a network (including the Internet). Microsoft markets at least a dozen different editions of Microsoft SQL Server, aimed at different audiences and for workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users.
History[edit]
The history of Microsoft SQL Server begins with the first Microsoft SQL Server product—SQL Server 1.0, a 16-bit server for the OS/2 operating system in 1989—and extends to the current day. Its name is entirely descriptive, it being server software that responds to queries in the SQL language.
Milestones[edit]
- MS SQL Server for OS/2 began as a project to port Sybase SQL Server onto OS/2 in 1989, by Sybase, Ashton-Tate, and Microsoft.
- SQL Server 4.2 for NT is released in 1993, marking the entry onto Windows NT.
- SQL Server 6.0 is released in 1995, marking the end of collaboration with Sybase; Sybase would continue developing their own variant of SQL Server, Sybase Adaptive Server Enterprise, independently of Microsoft.
- SQL Server 7.0 is released in 1998, marking the conversion of the source code from C to C++.
- SQL Server 2005, released in 2005, finishes the complete revision of the old Sybase code into Microsoft code.
- SQL Server 2012, released in 2012, adds columnar in-memory storage aka xVelocity.
- SQL Server 2017, released in 2017, adds Linux support for these Linux platforms: Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu & Docker Engine.[4]
- SQL Server 2019, released in 2019, adds Big Data Clusters, enhancements to the «Intelligent Database», enhanced monitoring features, updated developer experience, and updates/enhancements for Linux based installations.[5]
- SQL Server 2022, released in 2022, adds improved analytics, disaster recovery (to Azure) the «Purview» unified data governance and management service, and plumbing improvements that make the database faster and more resilient.
Currently[edit]
|
|
This section’s factual accuracy may be compromised due to out-of-date information. Relevant discussion may be found on the talk page. Please help update this article to reflect recent events or newly available information. (January 2023) |
As of July 2022, the following versions are supported by Microsoft:
- SQL Server 2008 (with ESU program until July 12, 2022, With Azure installed since that date)
- SQL Server 2012 (Until July 12, 2022, with ESU program since that date)
- SQL Server 2014
- SQL Server 2016
- SQL Server 2017
- SQL Server 2019
- SQL Server 2022 (Azure-enabled)
From SQL Server 2016 onward, the product is supported on x64 processors only and must have 1.4 GHz processor as a minimum, 2.0 GHz or faster is recommended.[6]
The current version is Microsoft SQL Server 2019, released November 4, 2019. The RTM version is 15.0.2000.5.[7]
Editions[edit]
Microsoft makes SQL Server available in multiple editions, with different feature sets and targeting different users. These editions are:[8][9]
Mainstream editions[edit]
- Enterprise
- SQL Server Enterprise Edition includes both the core database engine and add-on services, with a range of tools for creating and managing a SQL Server cluster. It can manage databases as large as 524 petabytes and address 12 terabytes of memory and supports 640 logical processors (CPU cores).[10]
- Standard
- SQL Server Standard edition includes the core database engine, along with the stand-alone services. It differs from Enterprise edition in that it supports fewer active instances (number of nodes in a cluster) and does not include some high-availability functions such as hot-add memory (allowing memory to be added while the server is still running), and parallel indexes.
- Web
- SQL Server Web Edition is a low-TCO option for Web hosting.
- Business intelligence
- Introduced in SQL Server 2012 and focusing on Self Service and Corporate Business Intelligence. It includes the Standard Edition capabilities and Business Intelligence tools: Power Pivot, Power View, the BI Semantic Model, Master Data Services, Data Quality Services and xVelocity in-memory analytics.[11]
- Workgroup
- SQL Server Workgroup Edition includes the core database functionality but does not include the additional services. Note that this edition has been retired in SQL Server 2012.[12]
- Express
- SQL Server Express Edition is a scaled down, free edition of SQL Server, which includes the core database engine. While there are no limitations on the number of databases or users supported, it is limited to using one processor, 1 GB memory and 10 GB database files (4 GB database files prior to SQL Server Express 2008 R2).[13] It is intended as a replacement for MSDE. Two additional editions provide a superset of features not in the original Express Edition. The first is SQL Server Express with Tools, which includes SQL Server Management Studio Basic. SQL Server Express with Advanced Services adds full-text search capability and reporting services.[14]
Specialized editions[edit]
- Azure
- Microsoft Azure SQL Database is the cloud-based version of Microsoft SQL Server, presented as a platform as a service offering on Microsoft Azure.
- Azure MPP
- Azure SQL Data Warehouse is the cloud-based version of Microsoft SQL Server in a MPP (massively parallel processing) architecture for analytics workloads, presented as a platform as a service offering on Microsoft Azure.
- Compact (SQL CE)
- The compact edition is an embedded database engine. Unlike the other editions of SQL Server, the SQL CE engine is based on SQL Mobile (initially designed for use with hand-held devices) and does not share the same binaries. Due to its small size (1 MB DLL footprint), it has a markedly reduced feature set compared to the other editions. For example, it supports a subset of the standard data types, does not support stored procedures or Views or multiple-statement batches (among other limitations). It is limited to 4 GB maximum database size and cannot be run as a Windows service, Compact Edition must be hosted by the application using it. The 3.5 version includes support for ADO.NET Synchronization Services. SQL CE does not support ODBC connectivity, unlike SQL Server proper.
- Developer
- SQL Server Developer Edition includes the same features as SQL Server Enterprise Edition, but is limited by the license to be only used as a development and test system, and not as production server. Starting early 2016, Microsoft made this edition free of charge to the public.[15]
- Embedded (SSEE)
- SQL Server 2005 Embedded Edition is a specially configured named instance of the SQL Server Express database engine which can be accessed only by certain Windows Services.
- Evaluation
- SQL Server Evaluation Edition, also known as the Trial Edition, has all the features of the Enterprise Edition, but is limited to 180 days, after which the tools will continue to run, but the server services will stop.[16]
- Fast Track
- SQL Server Fast Track is specifically for enterprise-scale data warehousing storage and business intelligence processing, and runs on reference-architecture hardware that is optimized for Fast Track.[17]
- LocalDB
- Introduced in SQL Server Express 2012, LocalDB is a minimal, on-demand, version of SQL Server that is designed for application developers.[18] It can also be used as an embedded database.[19]
- Analytics Platform System (APS)
- Formerly Parallel Data Warehouse (PDW) A massively parallel processing (MPP) SQL Server appliance optimized for large-scale data warehousing such as hundreds of terabytes.[20]
- Datawarehouse Appliance Edition
- Pre-installed and configured as part of an appliance in partnership with Dell & HP base on the Fast Track architecture. This edition does not include SQL Server Integration Services, Analysis Services, or Reporting Services.sqlcmd
Discontinued editions[edit]
- Microsoft Data Engine
- Version 1.0 is based on SQL Server version 7.0.[21] Afterwards, it was replaced by Microsoft SQL Server Data Engine.
- Microsoft SQL Server Data Engine
- Also called Desktop Engine, Desktop Edition, it is based on SQL Server 2000. Intended for use as an application component, it did not include GUI management tools. Later, Microsoft also made available a web admin tool. Included with some versions of Microsoft Access, Microsoft development tools, and other editions of SQL Server.[22] After SQL Server 2000, it was replaced by SQL Server 2005 Express Edition.
- Personal Edition
- SQL Server 2000. Had workload or connection limits like MSDE, but no database size limit. Includes standard management tools. Intended for use as a mobile / disconnected proxy, licensed for use with SQL Server 2000 Standard edition.[22] Similar to Standard Edition in SQL Server 2000, but Full-Text Search not working in Windows 98, transactional replication limited to subscriber.[23]
- Datacenter
- SQL Server 2008 R2 Datacenter is a full-featured edition of SQL Server and is designed for datacenters that need high levels of application support and scalability. It supports 256 logical processors and virtually unlimited memory and comes with StreamInsight Premium edition.[24] The Datacenter edition has been retired in SQL Server 2012; all of its features are available in SQL Server 2012 Enterprise Edition.[12]
- Windows CE Edition
- Introduced in SQL Server 2000,[25] and was replaced by SQL Server 2005 Mobile Edition.
- SQL Server 2005 Mobile Edition
- Replaced by SQL Server 2005 Compact Edition after 1 release.
- SQL Server 2005 Compact Edition
- Replaced by SQL Server Compact 3.5 after 1 release.
[edit]
Tools published Microsoft include:
- SQL Server 2000:
-
- Samples:[26] Northwind and pubs Sample Databases, Updated Samples for SQL Server 2000.
- Tools: Stress Testing and Performance Analysis tools (Read80Trace and OSTRESS), PSSDIAG Data Collection Utility, Notification services (up to service pack 1), Security Tools, Best Practices Analyzer 1.0, Reporting Services (up to Service Pack 2), Reporting Services Report Packs, SQL Server 2000 Driver for JDBC (up to service pack 3), SQLXML 3.0 (up to service pack 3).
- Documentation:[27] SQL Server 2000 Books Online, SQL Server 2000 System Table Map, Resource Kit, SQL Server 2000 — Getting Started Guide.
Architecture[edit]
The protocol layer implements the external interface to SQL Server. All operations that can be invoked on SQL Server are communicated to it via a Microsoft-defined format, called Tabular Data Stream (TDS). TDS is an application layer protocol, used to transfer data between a database server and a client. Initially designed and developed by Sybase Inc. for their Sybase SQL Server relational database engine in 1984, and later by Microsoft in Microsoft SQL Server, TDS packets can be encased in other physical transport dependent protocols, including TCP/IP, named pipes, and shared memory. Consequently, access to SQL Server is available over these protocols. In addition, the SQL Server API is also exposed over web services.[9]
Data storage[edit]
Data storage is a database, which is a collection of tables with typed columns. SQL Server supports different data types, including primitive types such as Integer, Float, Decimal, Char (including character strings), Varchar (variable length character strings), binary (for unstructured blobs of data), Text (for textual data) among others. The rounding of floats to integers uses either Symmetric Arithmetic Rounding or Symmetric Round Down (fix) depending on arguments: SELECT Round(2.5, 0) gives 3.
Microsoft SQL Server also allows user-defined composite types (UDTs) to be defined and used. It also makes server statistics available as virtual tables and views (called Dynamic Management Views or DMVs). In addition to tables, a database can also contain other objects including views, stored procedures, indexes and constraints, along with a transaction log. A SQL Server database can contain a maximum of 231 objects, and can span multiple OS-level files with a maximum file size of 260 bytes (1 exabyte).[9] The data in the database are stored in primary data files with an extension .mdf. Secondary data files, identified with a .ndf extension, are used to allow the data of a single database to be spread across more than one file, and optionally across more than one file system. Log files are identified with the .ldf extension.[9]
Storage space allocated to a database is divided into sequentially numbered pages, each 8 KB in size. A page is the basic unit of I/O for SQL Server operations. A page is marked with a 96-byte header which stores metadata about the page including the page number, page type, free space on the page and the ID of the object that owns it. The page type defines the data contained in the page. This data includes: data stored in the database, an index, an allocation map, which holds information about how pages are allocated to tables and indexes; and a change map which holds information about the changes made to other pages since last backup or logging, or contain large data types such as image or text. While a page is the basic unit of an I/O operation, space is actually managed in terms of an extent which consists of 8 pages. A database object can either span all 8 pages in an extent («uniform extent») or share an extent with up to 7 more objects («mixed extent»). A row in a database table cannot span more than one page, so is limited to 8 KB in size. However, if the data exceeds 8 KB and the row contains varchar or varbinary data, the data in those columns are moved to a new page (or possibly a sequence of pages, called an allocation unit) and replaced with a pointer to the data.[28]
For physical storage of a table, its rows are divided into a series of partitions (numbered 1 to n). The partition size is user defined; by default all rows are in a single partition. A table is split into multiple partitions in order to spread a database over a computer cluster. Rows in each partition are stored in either B-tree or heap structure. If the table has an associated, clustered index to allow fast retrieval of rows, the rows are stored in-order according to their index values, with a B-tree providing the index. The data is in the leaf node of the leaves, and other nodes storing the index values for the leaf data reachable from the respective nodes. If the index is non-clustered, the rows are not sorted according to the index keys. An indexed view has the same storage structure as an indexed table. A table without a clustered index is stored in an unordered heap structure. However, the table may have non-clustered indices to allow fast retrieval of rows. In some situations the heap structure has performance advantages over the clustered structure. Both heaps and B-trees can span multiple allocation units.[29]
Buffer management[edit]
SQL Server buffers pages in RAM to minimize disk I/O. Any 8 KB page can be buffered in-memory, and the set of all pages currently buffered is called the buffer cache. The amount of memory available to SQL Server decides how many pages will be cached in memory. The buffer cache is managed by the Buffer Manager. Either reading from or writing to any page copies it to the buffer cache. Subsequent reads or writes are redirected to the in-memory copy, rather than the on-disc version. The page is updated on the disc by the Buffer Manager only if the in-memory cache has not been referenced for some time. While writing pages back to disc, asynchronous I/O is used whereby the I/O operation is done in a background thread so that other operations do not have to wait for the I/O operation to complete. Each page is written along with its checksum when it is written. When reading the page back, its checksum is computed again and matched with the stored version to ensure the page has not been damaged or tampered with in the meantime.[30]
Concurrency and locking[edit]
SQL Server allows multiple clients to use the same database concurrently. As such, it needs to control concurrent access to shared data, to ensure data integrity—when multiple clients update the same data, or clients attempt to read data that is in the process of being changed by another client. SQL Server provides two modes of concurrency control: pessimistic concurrency and optimistic concurrency. When pessimistic concurrency control is being used, SQL Server controls concurrent access by using locks. Locks can be either shared or exclusive. Exclusive lock grants the user exclusive access to the data—no other user can access the data as long as the lock is held. Shared locks are used when some data is being read—multiple users can read from data locked with a shared lock, but not acquire an exclusive lock. The latter would have to wait for all shared locks to be released.
Locks can be applied on different levels of granularity—on entire tables, pages, or even on a per-row basis on tables. For indexes, it can either be on the entire index or on index leaves. The level of granularity to be used is defined on a per-database basis by the database administrator. While a fine-grained locking system allows more users to use the table or index simultaneously, it requires more resources, so it does not automatically yield higher performance. SQL Server also includes two more lightweight mutual exclusion solutions—latches and spinlocks—which are less robust than locks but are less resource intensive. SQL Server uses them for DMVs and other resources that are usually not busy. SQL Server also monitors all worker threads that acquire locks to ensure that they do not end up in deadlocks—in case they do, SQL Server takes remedial measures, which in many cases are to kill one of the threads entangled in a deadlock and roll back the transaction it started.[9] To implement locking, SQL Server contains the Lock Manager. The Lock Manager maintains an in-memory table that manages the database objects and locks, if any, on them along with other metadata about the lock. Access to any shared object is mediated by the lock manager, which either grants access to the resource or blocks it.
SQL Server also provides the optimistic concurrency control mechanism, which is similar to the multiversion concurrency control used in other databases. The mechanism allows a new version of a row to be created whenever the row is updated, as opposed to overwriting the row, i.e., a row is additionally identified by the ID of the transaction that created the version of the row. Both the old as well as the new versions of the row are stored and maintained, though the old versions are moved out of the database into a system database identified as Tempdb. When a row is in the process of being updated, any other requests are not blocked (unlike locking) but are executed on the older version of the row. If the other request is an update statement, it will result in two different versions of the rows—both of them will be stored by the database, identified by their respective transaction IDs.[9]
Data retrieval and programmability[edit]
The main mode of retrieving data from a SQL Server database is querying for it. The query is expressed using a variant of SQL called T-SQL, a dialect Microsoft SQL Server shares with Sybase SQL Server due to its legacy. The query declaratively specifies what is to be retrieved. It is processed by the query processor, which figures out the sequence of steps that will be necessary to retrieve the requested data. The sequence of actions necessary to execute a query is called a query plan. There might be multiple ways to process the same query. For example, for a query that contains a join statement and a select statement, executing join on both the tables and then executing select on the results would give the same result as selecting from each table and then executing the join, but result in different execution plans. In such case, SQL Server chooses the plan that is expected to yield the results in the shortest possible time. This is called query optimization and is performed by the query processor itself.[9]
SQL Server includes a cost-based query optimizer which tries to optimize on the cost, in terms of the resources it will take to execute the query. Given a query, then the query optimizer looks at the database schema, the database statistics and the system load at that time. It then decides which sequence to access the tables referred in the query, which sequence to execute the operations and what access method to be used to access the tables. For example, if the table has an associated index, whether the index should be used or not: if the index is on a column which is not unique for most of the columns (low «selectivity»), it might not be worthwhile to use the index to access the data. Finally, it decides whether to execute the query concurrently or not. While a concurrent execution is more costly in terms of total processor time, because the execution is actually split to different processors might mean it will execute faster. Once a query plan is generated for a query, it is temporarily cached. For further invocations of the same query, the cached plan is used. Unused plans are discarded after some time.[9][31]
SQL Server also allows stored procedures to be defined. Stored procedures are parameterized T-SQL queries, that are stored in the server itself (and not issued by the client application as is the case with general queries). Stored procedures can accept values sent by the client as input parameters, and send back results as output parameters. They can call defined functions, and other stored procedures, including the same stored procedure (up to a set number of times). They can be selectively provided access to. Unlike other queries, stored procedures have an associated name, which is used at runtime to resolve into the actual queries. Also because the code need not be sent from the client every time (as it can be accessed by name), it reduces network traffic and somewhat improves performance.[32] Execution plans for stored procedures are also cached as necessary.
T-SQL[edit]
T-SQL (Transact-SQL) is Microsoft’s proprietary procedural language extension for SQL Server. It provides REPL (Read-Eval-Print-Loop) instructions that extend standard SQL’s instruction set for Data Manipulation (DML) and Data Definition (DDL) instructions, including SQL Server-specific settings, security and database statistics management.
It exposes keywords for the operations that can be performed on SQL Server, including creating and altering database schemas, entering and editing data in the database as well as monitoring and managing the server itself. Client applications that consume data or manage the server will leverage SQL Server functionality by sending T-SQL queries and statements which are then processed by the server and results (or errors) returned to the client application. For this it exposes read-only tables from which server statistics can be read. Management functionality is exposed via system-defined stored procedures which can be invoked from T-SQL queries to perform the management operation. It is also possible to create linked Servers using T-SQL. Linked servers allow a single query to process operations performed on multiple servers.[33]
SQL Server Native Client (a.k.a. SNAC)[edit]
SQL Server Native Client is the native client side data access library for Microsoft SQL Server, version 2005 onwards. It natively implements support for the SQL Server features including the Tabular Data Stream implementation, support for mirrored SQL Server databases, full support for all data types supported by SQL Server, asynchronous operations, query notifications, encryption support, as well as receiving multiple result sets in a single database session. SQL Server Native Client is used under the hood by SQL Server plug-ins for other data access technologies, including ADO or OLE DB. The SQL Server Native Client can also be directly used, bypassing the generic data access layers.[34]
On November 28, 2011, a preview release of the SQL Server ODBC driver for Linux was released.[35]
SQL CLR[edit]
Microsoft SQL Server 2005 includes a component named SQL CLR («Common Language Runtime») via which it integrates with .NET Framework. Unlike most other applications that use .NET Framework, SQL Server itself hosts the .NET Framework runtime, i.e., memory, threading and resource management requirements of .NET Framework are satisfied by SQLOS itself, rather than the underlying Windows operating system. SQLOS provides deadlock detection and resolution services for .NET code as well. With SQL CLR, stored procedures and triggers can be written in any managed .NET language, including C# and VB.NET. Managed code can also be used to define UDT’s (user defined types), which can persist in the database. Managed code is compiled to CLI assemblies and after being verified for type safety, registered at the database. After that, they can be invoked like any other procedure.[36] However, only a subset of the Base Class Library is available, when running code under SQL CLR. Most APIs relating to user interface functionality are not available.[36]
When writing code for SQL CLR, data stored in SQL Server databases can be accessed using the ADO.NET APIs like any other managed application that accesses SQL Server data. However, doing that creates a new database session, different from the one in which the code is executing. To avoid this, SQL Server provides some enhancements to the ADO.NET provider that allows the connection to be redirected to the same session which already hosts the running code. Such connections are called context connections and are set by setting context connection parameter to true in the connection string. SQL Server also provides several other enhancements to the ADO.NET API, including classes to work with tabular data or a single row of data as well as classes to work with internal metadata about the data stored in the database. It also provides access to the XML features in SQL Server, including XQuery support. These enhancements are also available in T-SQL Procedures in consequence of the introduction of the new XML Datatype (query, value, nodes functions).[37]
Services[edit]
SQL Server also includes an assortment of add-on services. While these are not essential for the operation of the database system, they provide value added services on top of the core database management system. These services either run as a part of some SQL Server component or out-of-process as Windows Service and presents their own API to control and interact with them.
Machine Learning Services[edit]
The SQL Server Machine Learning services operates within the SQL server instance, allowing people to do machine learning and data analytics without having to send data across the network or be limited by the memory of their own computers. The services come with Microsoft’s R and Python distributions that contain commonly used packages for data science, along with some proprietary packages (e.g. revoscalepy, RevoScaleR, microsoftml) that can be used to create machine models at scale.
Analysts can either configure their client machine to connect to a remote SQL server and push the script executions to it, or they can run a R or Python scripts as an external script inside a T-SQL query. The trained machine learning model can be stored inside a database and used for scoring.[38]
Service Broker[edit]
Used inside an instance, programming environment. For cross-instance applications, Service Broker communicates over TCP/IP and allows the different components to be synchronized, via exchange of messages. The Service Broker, which runs as a part of the database engine, provides a reliable messaging and message queuing platform for SQL Server applications.[39]
Service broker services consists of the following parts:[40]
- message types
- contracts
- queues
- service programs
- routes
The message type defines the data format used for the message. This can be an XML object, plain text or binary data, as well as a null message body for notifications. The contract defines which messages are used in an conversation between services and who can put messages in the queue. The queue acts as storage provider for the messages. They are internally implemented as tables by SQL Server, but don’t support insert, update, or delete functionality. The service program receives and processes service broker messages. Usually the service program is implemented as stored procedure or CLR application. Routes are network addresses where the service broker is located on the network.[40]
Also, service broker supports security features like network authentication (using NTLM, Kerberos, or authorization certificates), integrity checking, and message encryption.[40]
Replication Services[edit]
SQL Server Replication Services are used by SQL Server to replicate and synchronize database objects, either in entirety or a subset of the objects present, across replication agents, which might be other database servers across the network, or database caches on the client side. Replication Services follows a publisher/subscriber model, i.e., the changes are sent out by one database server («publisher») and are received by others («subscribers»). SQL Server supports three different types of replication:[41]
- Transaction replication
- Each transaction made to the publisher database (master database) is synced out to subscribers, who update their databases with the transaction. Transactional replication synchronizes databases in near real time.[42]
- Merge replication
- Changes made at both the publisher and subscriber databases are tracked, and periodically the changes are synchronized bi-directionally between the publisher and the subscribers. If the same data has been modified differently in both the publisher and the subscriber databases, synchronization will result in a conflict which has to be resolved, either manually or by using pre-defined policies. rowguid needs to be configured on a column if merge replication is configured.[43]
- Snapshot replication
- Snapshot replication publishes a copy of the entire database (the then-snapshot of the data) and replicates out to the subscribers. Further changes to the snapshot are not tracked.[44]
Analysis Services[edit]
SQL Server Analysis Services (SSAS) adds OLAP and data mining capabilities for SQL Server databases. The OLAP engine supports MOLAP, ROLAP and HOLAP storage modes for data. Analysis Services supports the XML for Analysis standard as the underlying communication protocol. The cube data can be accessed using MDX and LINQ[45] queries.[46]
Data mining specific functionality is exposed via the DMX query language. Analysis Services includes various algorithms—Decision trees, clustering algorithm, Naive Bayes algorithm, time series analysis, sequence clustering algorithm, linear and logistic regression analysis, and neural networks—for use in data mining.[47]
Reporting Services[edit]
SQL Server Reporting Services (SSRS) is a report generation environment for data gathered from SQL Server databases. It is administered via a web interface. Reporting services features a web services interface to support the development of custom reporting applications. Reports are created as RDL files.[48]
Reports can be designed using recent versions of Microsoft Visual Studio (Visual Studio.NET 2003, 2005, and 2008)[49] with Business Intelligence Development Studio, installed or with the included Report Builder. Once created, RDL files can be rendered in a variety of formats,[50][51] including Excel, PDF, CSV, XML, BMP, EMF, GIF, JPEG, PNG, and TIFF,[52] and HTML Web Archive.
Notification Services[edit]
Originally introduced as a post-release add-on for SQL Server 2000,[53] Notification Services was bundled as part of the Microsoft SQL Server platform for the first and only time with SQL Server 2005.[54][55] SQL Server Notification Services is a mechanism for generating data-driven notifications, which are sent to Notification Services subscribers. A subscriber registers for a specific event or transaction (which is registered on the database server as a trigger); when the event occurs, Notification Services can use one of three methods to send a message to the subscriber informing about the occurrence of the event. These methods include SMTP, SOAP, or by writing to a file in the filesystem.[56] Notification Services was discontinued by Microsoft with the release of SQL Server 2008 in August 2008, and is no longer an officially supported component of the SQL Server database platform.
Integration Services[edit]
SQL Server Integration Services (SSIS) provides ETL capabilities for SQL Server for data import, data integration and data warehousing needs. Integration Services includes GUI tools to build workflows such as extracting data from various sources, querying data, transforming data—including aggregation, de-duplication, de-/normalization and merging of data—and then exporting the transformed data into destination databases or files.[57]
Full Text Search Service[edit]

The SQL Server Full Text Search service architecture
SQL Server Full Text Search service is a specialized indexing and querying service for unstructured text stored in SQL Server databases. The full text search index can be created on any column with character based text data. It allows for words to be searched for in the text columns. While it can be performed with the SQL LIKE operator, using SQL Server Full Text Search service can be more efficient. Full allows for inexact matching of the source string, indicated by a Rank value which can range from 0 to 1000—a higher rank means a more accurate match. It also allows linguistic matching («inflectional search»), i.e., linguistic variants of a word (such as a verb in a different tense) will also be a match for a given word (but with a lower rank than an exact match). Proximity searches are also supported, i.e., if the words searched for do not occur in the sequence they are specified in the query but are near each other, they are also considered a match. T-SQL exposes special operators that can be used to access the FTS capabilities.[58][59]
The Full Text Search engine is divided into two processes: the Filter Daemon process (msftefd.exe) and the Search process (msftesql.exe). These processes interact with the SQL Server. The Search process includes the indexer (that creates the full text indexes) and the full text query processor. The indexer scans through text columns in the database. It can also index through binary columns, and use iFilters to extract meaningful text from the binary blob (for example, when a Microsoft Word document is stored as an unstructured binary file in a database). The iFilters are hosted by the Filter Daemon process. Once the text is extracted, the Filter Daemon process breaks it up into a sequence of words and hands it over to the indexer. The indexer filters out noise words, i.e., words like A, And, etc., which occur frequently and are not useful for search. With the remaining words, an inverted index is created, associating each word with the columns they were found in. SQL Server itself includes a Gatherer component that monitors changes to tables and invokes the indexer in case of updates.[60]
When a full text query is received by the SQL Server query processor, it is handed over to the FTS query processor in the Search process. The FTS query processor breaks up the query into the constituent words, filters out the noise words, and uses an inbuilt thesaurus to find out the linguistic variants for each word. The words are then queried against the inverted index and a rank of their accurateness is computed. The results are returned to the client via the SQL Server process.[60]
SQLCMD[edit]
SQLCMD is a command line application that comes with Microsoft SQL Server, and exposes the management features of SQL Server. It allows SQL queries to be written and executed from the command prompt. It can also act as a scripting language to create and run a set of SQL statements as a script. Such scripts are stored as a .sql file, and are used either for management of databases or to create the database schema during the deployment of a database.
SQLCMD was introduced with SQL Server 2005 and has continued through SQL Server versions 2008, 2008 R2, 2012, 2014, 2016 and 2019. Its predecessor for earlier versions was OSQL and ISQL, which were functionally equivalent as it pertains to T-SQL execution, and many of the command line parameters are identical, although SQLCMD adds extra versatility.
Visual Studio[edit]
Microsoft Visual Studio includes native support for data programming with Microsoft SQL Server. It can be used to write and debug code to be executed by SQL CLR. It also includes a data designer that can be used to graphically create, view or edit database schemas. Queries can be created either visually or using code. SSMS 2008 onwards, provides intellisense for SQL queries as well.
SQL Server Management Studio[edit]
SQL Server Management Studio is a GUI tool included with SQL Server 2005 and later for configuring, managing, and administering all components within Microsoft SQL Server. The tool includes both script editors and graphical tools that work with objects and features of the server.[61] SQL Server Management Studio replaces Enterprise Manager as the primary management interface for Microsoft SQL Server since SQL Server 2005. A version of SQL Server Management Studio is also available for SQL Server Express Edition, for which it is known as SQL Server Management Studio Express (SSMSE).[62]
A central feature of SQL Server Management Studio is the Object Explorer, which allows the user to browse, select, and act upon any of the objects within the server.[63] It can be used to visually observe and analyze query plans and optimize the database performance, among others.[64] SQL Server Management Studio can also be used to create a new database, alter any existing database schema by adding or modifying tables and indexes, or analyze performance. It includes the query windows which provide a GUI based interface to write and execute queries.[9]
Azure Data Studio[edit]
Azure Data Studio is a cross platform query editor available as an optional download. The tool allows users to write queries; export query results; commit SQL scripts to Git repositories and perform basic server diagnostics. Azure Data Studio supports Windows, Mac and Linux systems.[65]
It was released to General Availability in September 2018. Prior to release the preview version of the application was known as SQL Server Operations Studio.
Business Intelligence Development Studio[edit]
Business Intelligence Development Studio (BIDS) is the IDE from Microsoft used for developing data analysis and Business Intelligence solutions utilizing the Microsoft SQL Server Analysis Services, Reporting Services and Integration Services. It is based on the Microsoft Visual Studio development environment but is customized with the SQL Server services-specific extensions and project types, including tools, controls and projects for reports (using Reporting Services), Cubes and data mining structures (using Analysis Services).[66] For SQL Server 2012 and later, this IDE has been renamed SQL Server Data Tools (SSDT).
See also[edit]
- Comparison of relational database management systems
- Comparison of object-relational database management systems
- Comparison of data modeling tools
- List of relational database management systems
- XLeratorDB
References[edit]
- ^ «Explore SQL Server 2022 capabilities». Retrieved January 6, 2023.
- ^ «Download Microsoft SQL Server 2008 R2». Microsoft Evaluation Center. Microsoft Corporation. Retrieved July 18, 2011.
- ^ «Installation guidance for SQL Server on Linux». microsoft.com. December 21, 2017. Retrieved February 1, 2018.
- ^ «What’s new in SQL Server 2019 (15.x)». microsoft.com/. April 6, 2022. Retrieved May 11, 2022.
- ^ «Requirements for Installing SQL Server 2016». docs.microsoft.com. msdn.microsoft.com. May 2, 2016. Retrieved July 28, 2016.
- ^ «KB4518398 — SQL Server 2019 build versions». support.microsoft.com. Retrieved March 4, 2022.
- ^ «Compare Editions». SQL Server homepage. Microsoft Corporation. Retrieved December 3, 2007.
- ^ a b c d e f g h i Kalen Delaney (2007). Inside Microsoft SQL Server 2005: The Storage Engine. Microsoft Press. ISBN 978-0-7356-2105-3.
- ^ «SQL Server 2008: Editions». Microsoft. Retrieved July 21, 2011.
- ^ «Database System | Performance & Scalability | SQL Server 2012 Business Intelligence Editions». Microsoft.com. Retrieved June 15, 2013.
- ^ a b SQL Server 2012 Licensing Datasheet and FAQ (March 2012)
- ^ «SQL Server 2008 R2 Express Database Size Limit Increased to 10GB». Retrieved April 23, 2010.
- ^ «What’s up with SQL Server 2008 Express editions». Retrieved August 15, 2008.
- ^ «Developer Edition». SQL Server home. Microsoft Corporation. Retrieved July 18, 2011.
- ^ «SQL Server 2008 Trial Software». Microsoft. Retrieved March 26, 2009.
- ^ «Microsoft SQL Server 2008: Fast Track Data Warehouse». Microsoft. Retrieved March 26, 2009.
- ^ «SQL Server Express LocalDB». SQL Server. Microsoft Docs. Retrieved August 2, 2021.
- ^ «Introducing LocalDB, an improved SQL Express». SQL Server Express WebLog. Microsoft Docs. July 12, 2011. Retrieved August 2, 2021.
- ^ «Microsoft Analytics Platform System». Microsoft. Retrieved April 29, 2015.
- ^ Choosing an Edition of SQL Server 2000
- ^ a b «IT Pro».
- ^ Features Supported by the Editions of SQL Server 2000
- ^ «Choosing a StreamInsight Edition». MSDN. Microsoft Corporation. Retrieved July 18, 2011.
- ^ «Chapter 3 — Choosing an Edition of SQL Server 2000». November 1, 2010. Archived from the original on November 1, 2010. Retrieved November 4, 2022.
- ^ SQL Server 2000 — Downloads
- ^ SQL Server 2000 Product Documentation
- ^ «Pages and Extents». Retrieved December 2, 2007.
- ^ «Table and Index Organization». Retrieved December 2, 2007.
- ^ «Buffer Management». Retrieved December 2, 2007.
- ^ «Single SQL Statement Processing». Retrieved December 3, 2007.
- ^ «Stored Procedure Basics». Retrieved December 3, 2007.
- ^ «Transact-SQL Reference». Retrieved December 3, 2007.
- ^ «Features of SQL Server Native Client». Retrieved December 3, 2007.
- ^ «Available Today: Preview Release of the SQL Server ODBC Driver for Linux». SQL Server Team Blog. November 28, 2011. Retrieved June 15, 2013.
- ^ a b «Overview of CLR integration». Retrieved December 3, 2007.
- ^ «XML Support in SQL Server». Retrieved September 5, 2008.
- ^ «What is SQL Server Machine Learning Services». SQL Server homepage. Microsoft Corporation. Retrieved April 10, 2018.
- ^ «Introducing Service Broker». Retrieved December 3, 2007.
- ^ a b c Klaus Aschenbrenner (2011). «Introducing Service Broker». Pro SQL Server 2008 Service Broker (1st ed.). Vienna: Apress. pp. 17–31. ISBN 978-1-4302-0865-5. Retrieved December 15, 2019.
- ^ «Types of Replication Overview». Retrieved December 3, 2007.
- ^ «Transactional Replication Overview». Retrieved December 3, 2007.
- ^ «Merge Replication Overview». Retrieved December 3, 2007.
- ^ «Snapshot replication Overview». Retrieved December 3, 2007.
- ^ «SSAS Entity Framework Provider». Retrieved September 29, 2011.
- ^ «Analysis Services Architecture». Retrieved December 3, 2007.
- ^ «Data Mining Concepts». Retrieved December 3, 2007.
- ^ «SQL Server Reporting Services». Retrieved December 3, 2007.
- ^ «Cannot open a SQL Reporting Services .rptproj file | Microsoft Connect». Connect.microsoft.com. Archived from the original on February 3, 2012. Retrieved September 4, 2011.
- ^ MSDN Library: Reporting Services Render Method
- ^ Device Information Settings
- ^ Image Device Information Settings
- ^ «An Introduction to SQL Server Notification Services». September 3, 2002. Retrieved November 14, 2008.
- ^ «SQL Server Notification Services Removed from SQL Server 2008». Archived from the original on October 16, 2008. Retrieved September 17, 2008.
- ^ «Discontinued Functionality in SQL Server 2008 Reporting Services». Retrieved September 17, 2008.
- ^ «Introducing SQL Server Notification Services». Retrieved December 3, 2007.
- ^ «Integration Services Overview». Retrieved December 3, 2007.
- ^ «Introduction to Full-Text Search». Retrieved December 3, 2007.
- ^ «Querying SQL Server using Full-Text Search». Retrieved December 3, 2007.
- ^ a b «Full-Text Search Architecture». Retrieved December 3, 2007.
- ^ «MSDN: Introducing SQL Server Management Studio». Msdn.microsoft.com. Retrieved September 4, 2011.
- ^ «SQL Server Management Studio Express». Microsoft.com. April 18, 2006. Retrieved September 4, 2011.
- ^ «MSDN: Using Object Explorer». Msdn.microsoft.com. Retrieved September 4, 2011.
- ^ «SQL Server 2005 Management Tools». Sqlmag.com. July 19, 2005. Retrieved September 4, 2011.
- ^ «What is Microsoft SQL Operations Studio (preview)?». docs.microsoft.com. Retrieved January 19, 2018.
- ^ «Introducing Business Intelligence Development Studio». Retrieved December 3, 2007.
Further reading[edit]
- Lance Delano, Rajesh George et al. (2005). Wrox’s SQL Server 2005 Express Edition Starter Kit (Programmer to Programmer). Microsoft Press. ISBN 0-7645-8923-7.
- Delaney, Kalen, et al. (2007). Inside SQL Server 2005: Query Tuning and Optimization. Microsoft Press. ISBN 0-7356-2196-9.
- Ben-Gan, Itzik, et al. (2006). Inside Microsoft SQL Server 2005: T-SQL Programming. Microsoft Press. ISBN 0-7356-2197-7.
- Klaus Elk (2018). SQL Server with C#. ISBN 1-7203-5867-2.
External links[edit]
- Official website
- 2nd official website at Microsoft TechNet
| Developer(s) | Microsoft |
|---|---|
| Initial release | April 24, 1989; 33 years ago, as SQL Server 1.0 |
| Stable release |
SQL Server 2022[1] |
| Written in | C, C++[2] |
| Operating system | Linux, Microsoft Windows Server, Microsoft Windows |
| Available in | English, Chinese, French, German, Italian, Japanese, Korean, Portuguese (Brazil), Russian, Spanish and Indonesian[3] |
| Type | Relational database management system |
| License | Proprietary software |
| Website | www.microsoft.com/sql-server |
Microsoft SQL Server is a relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications—which may run either on the same computer or on another computer across a network (including the Internet). Microsoft markets at least a dozen different editions of Microsoft SQL Server, aimed at different audiences and for workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users.
History[edit]
The history of Microsoft SQL Server begins with the first Microsoft SQL Server product—SQL Server 1.0, a 16-bit server for the OS/2 operating system in 1989—and extends to the current day. Its name is entirely descriptive, it being server software that responds to queries in the SQL language.
Milestones[edit]
- MS SQL Server for OS/2 began as a project to port Sybase SQL Server onto OS/2 in 1989, by Sybase, Ashton-Tate, and Microsoft.
- SQL Server 4.2 for NT is released in 1993, marking the entry onto Windows NT.
- SQL Server 6.0 is released in 1995, marking the end of collaboration with Sybase; Sybase would continue developing their own variant of SQL Server, Sybase Adaptive Server Enterprise, independently of Microsoft.
- SQL Server 7.0 is released in 1998, marking the conversion of the source code from C to C++.
- SQL Server 2005, released in 2005, finishes the complete revision of the old Sybase code into Microsoft code.
- SQL Server 2012, released in 2012, adds columnar in-memory storage aka xVelocity.
- SQL Server 2017, released in 2017, adds Linux support for these Linux platforms: Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu & Docker Engine.[4]
- SQL Server 2019, released in 2019, adds Big Data Clusters, enhancements to the «Intelligent Database», enhanced monitoring features, updated developer experience, and updates/enhancements for Linux based installations.[5]
- SQL Server 2022, released in 2022, adds improved analytics, disaster recovery (to Azure) the «Purview» unified data governance and management service, and plumbing improvements that make the database faster and more resilient.
Currently[edit]
|
|
This section’s factual accuracy may be compromised due to out-of-date information. Relevant discussion may be found on the talk page. Please help update this article to reflect recent events or newly available information. (January 2023) |
As of July 2022, the following versions are supported by Microsoft:
- SQL Server 2008 (with ESU program until July 12, 2022, With Azure installed since that date)
- SQL Server 2012 (Until July 12, 2022, with ESU program since that date)
- SQL Server 2014
- SQL Server 2016
- SQL Server 2017
- SQL Server 2019
- SQL Server 2022 (Azure-enabled)
From SQL Server 2016 onward, the product is supported on x64 processors only and must have 1.4 GHz processor as a minimum, 2.0 GHz or faster is recommended.[6]
The current version is Microsoft SQL Server 2019, released November 4, 2019. The RTM version is 15.0.2000.5.[7]
Editions[edit]
Microsoft makes SQL Server available in multiple editions, with different feature sets and targeting different users. These editions are:[8][9]
Mainstream editions[edit]
- Enterprise
- SQL Server Enterprise Edition includes both the core database engine and add-on services, with a range of tools for creating and managing a SQL Server cluster. It can manage databases as large as 524 petabytes and address 12 terabytes of memory and supports 640 logical processors (CPU cores).[10]
- Standard
- SQL Server Standard edition includes the core database engine, along with the stand-alone services. It differs from Enterprise edition in that it supports fewer active instances (number of nodes in a cluster) and does not include some high-availability functions such as hot-add memory (allowing memory to be added while the server is still running), and parallel indexes.
- Web
- SQL Server Web Edition is a low-TCO option for Web hosting.
- Business intelligence
- Introduced in SQL Server 2012 and focusing on Self Service and Corporate Business Intelligence. It includes the Standard Edition capabilities and Business Intelligence tools: Power Pivot, Power View, the BI Semantic Model, Master Data Services, Data Quality Services and xVelocity in-memory analytics.[11]
- Workgroup
- SQL Server Workgroup Edition includes the core database functionality but does not include the additional services. Note that this edition has been retired in SQL Server 2012.[12]
- Express
- SQL Server Express Edition is a scaled down, free edition of SQL Server, which includes the core database engine. While there are no limitations on the number of databases or users supported, it is limited to using one processor, 1 GB memory and 10 GB database files (4 GB database files prior to SQL Server Express 2008 R2).[13] It is intended as a replacement for MSDE. Two additional editions provide a superset of features not in the original Express Edition. The first is SQL Server Express with Tools, which includes SQL Server Management Studio Basic. SQL Server Express with Advanced Services adds full-text search capability and reporting services.[14]
Specialized editions[edit]
- Azure
- Microsoft Azure SQL Database is the cloud-based version of Microsoft SQL Server, presented as a platform as a service offering on Microsoft Azure.
- Azure MPP
- Azure SQL Data Warehouse is the cloud-based version of Microsoft SQL Server in a MPP (massively parallel processing) architecture for analytics workloads, presented as a platform as a service offering on Microsoft Azure.
- Compact (SQL CE)
- The compact edition is an embedded database engine. Unlike the other editions of SQL Server, the SQL CE engine is based on SQL Mobile (initially designed for use with hand-held devices) and does not share the same binaries. Due to its small size (1 MB DLL footprint), it has a markedly reduced feature set compared to the other editions. For example, it supports a subset of the standard data types, does not support stored procedures or Views or multiple-statement batches (among other limitations). It is limited to 4 GB maximum database size and cannot be run as a Windows service, Compact Edition must be hosted by the application using it. The 3.5 version includes support for ADO.NET Synchronization Services. SQL CE does not support ODBC connectivity, unlike SQL Server proper.
- Developer
- SQL Server Developer Edition includes the same features as SQL Server Enterprise Edition, but is limited by the license to be only used as a development and test system, and not as production server. Starting early 2016, Microsoft made this edition free of charge to the public.[15]
- Embedded (SSEE)
- SQL Server 2005 Embedded Edition is a specially configured named instance of the SQL Server Express database engine which can be accessed only by certain Windows Services.
- Evaluation
- SQL Server Evaluation Edition, also known as the Trial Edition, has all the features of the Enterprise Edition, but is limited to 180 days, after which the tools will continue to run, but the server services will stop.[16]
- Fast Track
- SQL Server Fast Track is specifically for enterprise-scale data warehousing storage and business intelligence processing, and runs on reference-architecture hardware that is optimized for Fast Track.[17]
- LocalDB
- Introduced in SQL Server Express 2012, LocalDB is a minimal, on-demand, version of SQL Server that is designed for application developers.[18] It can also be used as an embedded database.[19]
- Analytics Platform System (APS)
- Formerly Parallel Data Warehouse (PDW) A massively parallel processing (MPP) SQL Server appliance optimized for large-scale data warehousing such as hundreds of terabytes.[20]
- Datawarehouse Appliance Edition
- Pre-installed and configured as part of an appliance in partnership with Dell & HP base on the Fast Track architecture. This edition does not include SQL Server Integration Services, Analysis Services, or Reporting Services.sqlcmd
Discontinued editions[edit]
- Microsoft Data Engine
- Version 1.0 is based on SQL Server version 7.0.[21] Afterwards, it was replaced by Microsoft SQL Server Data Engine.
- Microsoft SQL Server Data Engine
- Also called Desktop Engine, Desktop Edition, it is based on SQL Server 2000. Intended for use as an application component, it did not include GUI management tools. Later, Microsoft also made available a web admin tool. Included with some versions of Microsoft Access, Microsoft development tools, and other editions of SQL Server.[22] After SQL Server 2000, it was replaced by SQL Server 2005 Express Edition.
- Personal Edition
- SQL Server 2000. Had workload or connection limits like MSDE, but no database size limit. Includes standard management tools. Intended for use as a mobile / disconnected proxy, licensed for use with SQL Server 2000 Standard edition.[22] Similar to Standard Edition in SQL Server 2000, but Full-Text Search not working in Windows 98, transactional replication limited to subscriber.[23]
- Datacenter
- SQL Server 2008 R2 Datacenter is a full-featured edition of SQL Server and is designed for datacenters that need high levels of application support and scalability. It supports 256 logical processors and virtually unlimited memory and comes with StreamInsight Premium edition.[24] The Datacenter edition has been retired in SQL Server 2012; all of its features are available in SQL Server 2012 Enterprise Edition.[12]
- Windows CE Edition
- Introduced in SQL Server 2000,[25] and was replaced by SQL Server 2005 Mobile Edition.
- SQL Server 2005 Mobile Edition
- Replaced by SQL Server 2005 Compact Edition after 1 release.
- SQL Server 2005 Compact Edition
- Replaced by SQL Server Compact 3.5 after 1 release.
[edit]
Tools published Microsoft include:
- SQL Server 2000:
-
- Samples:[26] Northwind and pubs Sample Databases, Updated Samples for SQL Server 2000.
- Tools: Stress Testing and Performance Analysis tools (Read80Trace and OSTRESS), PSSDIAG Data Collection Utility, Notification services (up to service pack 1), Security Tools, Best Practices Analyzer 1.0, Reporting Services (up to Service Pack 2), Reporting Services Report Packs, SQL Server 2000 Driver for JDBC (up to service pack 3), SQLXML 3.0 (up to service pack 3).
- Documentation:[27] SQL Server 2000 Books Online, SQL Server 2000 System Table Map, Resource Kit, SQL Server 2000 — Getting Started Guide.
Architecture[edit]
The protocol layer implements the external interface to SQL Server. All operations that can be invoked on SQL Server are communicated to it via a Microsoft-defined format, called Tabular Data Stream (TDS). TDS is an application layer protocol, used to transfer data between a database server and a client. Initially designed and developed by Sybase Inc. for their Sybase SQL Server relational database engine in 1984, and later by Microsoft in Microsoft SQL Server, TDS packets can be encased in other physical transport dependent protocols, including TCP/IP, named pipes, and shared memory. Consequently, access to SQL Server is available over these protocols. In addition, the SQL Server API is also exposed over web services.[9]
Data storage[edit]
Data storage is a database, which is a collection of tables with typed columns. SQL Server supports different data types, including primitive types such as Integer, Float, Decimal, Char (including character strings), Varchar (variable length character strings), binary (for unstructured blobs of data), Text (for textual data) among others. The rounding of floats to integers uses either Symmetric Arithmetic Rounding or Symmetric Round Down (fix) depending on arguments: SELECT Round(2.5, 0) gives 3.
Microsoft SQL Server also allows user-defined composite types (UDTs) to be defined and used. It also makes server statistics available as virtual tables and views (called Dynamic Management Views or DMVs). In addition to tables, a database can also contain other objects including views, stored procedures, indexes and constraints, along with a transaction log. A SQL Server database can contain a maximum of 231 objects, and can span multiple OS-level files with a maximum file size of 260 bytes (1 exabyte).[9] The data in the database are stored in primary data files with an extension .mdf. Secondary data files, identified with a .ndf extension, are used to allow the data of a single database to be spread across more than one file, and optionally across more than one file system. Log files are identified with the .ldf extension.[9]
Storage space allocated to a database is divided into sequentially numbered pages, each 8 KB in size. A page is the basic unit of I/O for SQL Server operations. A page is marked with a 96-byte header which stores metadata about the page including the page number, page type, free space on the page and the ID of the object that owns it. The page type defines the data contained in the page. This data includes: data stored in the database, an index, an allocation map, which holds information about how pages are allocated to tables and indexes; and a change map which holds information about the changes made to other pages since last backup or logging, or contain large data types such as image or text. While a page is the basic unit of an I/O operation, space is actually managed in terms of an extent which consists of 8 pages. A database object can either span all 8 pages in an extent («uniform extent») or share an extent with up to 7 more objects («mixed extent»). A row in a database table cannot span more than one page, so is limited to 8 KB in size. However, if the data exceeds 8 KB and the row contains varchar or varbinary data, the data in those columns are moved to a new page (or possibly a sequence of pages, called an allocation unit) and replaced with a pointer to the data.[28]
For physical storage of a table, its rows are divided into a series of partitions (numbered 1 to n). The partition size is user defined; by default all rows are in a single partition. A table is split into multiple partitions in order to spread a database over a computer cluster. Rows in each partition are stored in either B-tree or heap structure. If the table has an associated, clustered index to allow fast retrieval of rows, the rows are stored in-order according to their index values, with a B-tree providing the index. The data is in the leaf node of the leaves, and other nodes storing the index values for the leaf data reachable from the respective nodes. If the index is non-clustered, the rows are not sorted according to the index keys. An indexed view has the same storage structure as an indexed table. A table without a clustered index is stored in an unordered heap structure. However, the table may have non-clustered indices to allow fast retrieval of rows. In some situations the heap structure has performance advantages over the clustered structure. Both heaps and B-trees can span multiple allocation units.[29]
Buffer management[edit]
SQL Server buffers pages in RAM to minimize disk I/O. Any 8 KB page can be buffered in-memory, and the set of all pages currently buffered is called the buffer cache. The amount of memory available to SQL Server decides how many pages will be cached in memory. The buffer cache is managed by the Buffer Manager. Either reading from or writing to any page copies it to the buffer cache. Subsequent reads or writes are redirected to the in-memory copy, rather than the on-disc version. The page is updated on the disc by the Buffer Manager only if the in-memory cache has not been referenced for some time. While writing pages back to disc, asynchronous I/O is used whereby the I/O operation is done in a background thread so that other operations do not have to wait for the I/O operation to complete. Each page is written along with its checksum when it is written. When reading the page back, its checksum is computed again and matched with the stored version to ensure the page has not been damaged or tampered with in the meantime.[30]
Concurrency and locking[edit]
SQL Server allows multiple clients to use the same database concurrently. As such, it needs to control concurrent access to shared data, to ensure data integrity—when multiple clients update the same data, or clients attempt to read data that is in the process of being changed by another client. SQL Server provides two modes of concurrency control: pessimistic concurrency and optimistic concurrency. When pessimistic concurrency control is being used, SQL Server controls concurrent access by using locks. Locks can be either shared or exclusive. Exclusive lock grants the user exclusive access to the data—no other user can access the data as long as the lock is held. Shared locks are used when some data is being read—multiple users can read from data locked with a shared lock, but not acquire an exclusive lock. The latter would have to wait for all shared locks to be released.
Locks can be applied on different levels of granularity—on entire tables, pages, or even on a per-row basis on tables. For indexes, it can either be on the entire index or on index leaves. The level of granularity to be used is defined on a per-database basis by the database administrator. While a fine-grained locking system allows more users to use the table or index simultaneously, it requires more resources, so it does not automatically yield higher performance. SQL Server also includes two more lightweight mutual exclusion solutions—latches and spinlocks—which are less robust than locks but are less resource intensive. SQL Server uses them for DMVs and other resources that are usually not busy. SQL Server also monitors all worker threads that acquire locks to ensure that they do not end up in deadlocks—in case they do, SQL Server takes remedial measures, which in many cases are to kill one of the threads entangled in a deadlock and roll back the transaction it started.[9] To implement locking, SQL Server contains the Lock Manager. The Lock Manager maintains an in-memory table that manages the database objects and locks, if any, on them along with other metadata about the lock. Access to any shared object is mediated by the lock manager, which either grants access to the resource or blocks it.
SQL Server also provides the optimistic concurrency control mechanism, which is similar to the multiversion concurrency control used in other databases. The mechanism allows a new version of a row to be created whenever the row is updated, as opposed to overwriting the row, i.e., a row is additionally identified by the ID of the transaction that created the version of the row. Both the old as well as the new versions of the row are stored and maintained, though the old versions are moved out of the database into a system database identified as Tempdb. When a row is in the process of being updated, any other requests are not blocked (unlike locking) but are executed on the older version of the row. If the other request is an update statement, it will result in two different versions of the rows—both of them will be stored by the database, identified by their respective transaction IDs.[9]
Data retrieval and programmability[edit]
The main mode of retrieving data from a SQL Server database is querying for it. The query is expressed using a variant of SQL called T-SQL, a dialect Microsoft SQL Server shares with Sybase SQL Server due to its legacy. The query declaratively specifies what is to be retrieved. It is processed by the query processor, which figures out the sequence of steps that will be necessary to retrieve the requested data. The sequence of actions necessary to execute a query is called a query plan. There might be multiple ways to process the same query. For example, for a query that contains a join statement and a select statement, executing join on both the tables and then executing select on the results would give the same result as selecting from each table and then executing the join, but result in different execution plans. In such case, SQL Server chooses the plan that is expected to yield the results in the shortest possible time. This is called query optimization and is performed by the query processor itself.[9]
SQL Server includes a cost-based query optimizer which tries to optimize on the cost, in terms of the resources it will take to execute the query. Given a query, then the query optimizer looks at the database schema, the database statistics and the system load at that time. It then decides which sequence to access the tables referred in the query, which sequence to execute the operations and what access method to be used to access the tables. For example, if the table has an associated index, whether the index should be used or not: if the index is on a column which is not unique for most of the columns (low «selectivity»), it might not be worthwhile to use the index to access the data. Finally, it decides whether to execute the query concurrently or not. While a concurrent execution is more costly in terms of total processor time, because the execution is actually split to different processors might mean it will execute faster. Once a query plan is generated for a query, it is temporarily cached. For further invocations of the same query, the cached plan is used. Unused plans are discarded after some time.[9][31]
SQL Server also allows stored procedures to be defined. Stored procedures are parameterized T-SQL queries, that are stored in the server itself (and not issued by the client application as is the case with general queries). Stored procedures can accept values sent by the client as input parameters, and send back results as output parameters. They can call defined functions, and other stored procedures, including the same stored procedure (up to a set number of times). They can be selectively provided access to. Unlike other queries, stored procedures have an associated name, which is used at runtime to resolve into the actual queries. Also because the code need not be sent from the client every time (as it can be accessed by name), it reduces network traffic and somewhat improves performance.[32] Execution plans for stored procedures are also cached as necessary.
T-SQL[edit]
T-SQL (Transact-SQL) is Microsoft’s proprietary procedural language extension for SQL Server. It provides REPL (Read-Eval-Print-Loop) instructions that extend standard SQL’s instruction set for Data Manipulation (DML) and Data Definition (DDL) instructions, including SQL Server-specific settings, security and database statistics management.
It exposes keywords for the operations that can be performed on SQL Server, including creating and altering database schemas, entering and editing data in the database as well as monitoring and managing the server itself. Client applications that consume data or manage the server will leverage SQL Server functionality by sending T-SQL queries and statements which are then processed by the server and results (or errors) returned to the client application. For this it exposes read-only tables from which server statistics can be read. Management functionality is exposed via system-defined stored procedures which can be invoked from T-SQL queries to perform the management operation. It is also possible to create linked Servers using T-SQL. Linked servers allow a single query to process operations performed on multiple servers.[33]
SQL Server Native Client (a.k.a. SNAC)[edit]
SQL Server Native Client is the native client side data access library for Microsoft SQL Server, version 2005 onwards. It natively implements support for the SQL Server features including the Tabular Data Stream implementation, support for mirrored SQL Server databases, full support for all data types supported by SQL Server, asynchronous operations, query notifications, encryption support, as well as receiving multiple result sets in a single database session. SQL Server Native Client is used under the hood by SQL Server plug-ins for other data access technologies, including ADO or OLE DB. The SQL Server Native Client can also be directly used, bypassing the generic data access layers.[34]
On November 28, 2011, a preview release of the SQL Server ODBC driver for Linux was released.[35]
SQL CLR[edit]
Microsoft SQL Server 2005 includes a component named SQL CLR («Common Language Runtime») via which it integrates with .NET Framework. Unlike most other applications that use .NET Framework, SQL Server itself hosts the .NET Framework runtime, i.e., memory, threading and resource management requirements of .NET Framework are satisfied by SQLOS itself, rather than the underlying Windows operating system. SQLOS provides deadlock detection and resolution services for .NET code as well. With SQL CLR, stored procedures and triggers can be written in any managed .NET language, including C# and VB.NET. Managed code can also be used to define UDT’s (user defined types), which can persist in the database. Managed code is compiled to CLI assemblies and after being verified for type safety, registered at the database. After that, they can be invoked like any other procedure.[36] However, only a subset of the Base Class Library is available, when running code under SQL CLR. Most APIs relating to user interface functionality are not available.[36]
When writing code for SQL CLR, data stored in SQL Server databases can be accessed using the ADO.NET APIs like any other managed application that accesses SQL Server data. However, doing that creates a new database session, different from the one in which the code is executing. To avoid this, SQL Server provides some enhancements to the ADO.NET provider that allows the connection to be redirected to the same session which already hosts the running code. Such connections are called context connections and are set by setting context connection parameter to true in the connection string. SQL Server also provides several other enhancements to the ADO.NET API, including classes to work with tabular data or a single row of data as well as classes to work with internal metadata about the data stored in the database. It also provides access to the XML features in SQL Server, including XQuery support. These enhancements are also available in T-SQL Procedures in consequence of the introduction of the new XML Datatype (query, value, nodes functions).[37]
Services[edit]
SQL Server also includes an assortment of add-on services. While these are not essential for the operation of the database system, they provide value added services on top of the core database management system. These services either run as a part of some SQL Server component or out-of-process as Windows Service and presents their own API to control and interact with them.
Machine Learning Services[edit]
The SQL Server Machine Learning services operates within the SQL server instance, allowing people to do machine learning and data analytics without having to send data across the network or be limited by the memory of their own computers. The services come with Microsoft’s R and Python distributions that contain commonly used packages for data science, along with some proprietary packages (e.g. revoscalepy, RevoScaleR, microsoftml) that can be used to create machine models at scale.
Analysts can either configure their client machine to connect to a remote SQL server and push the script executions to it, or they can run a R or Python scripts as an external script inside a T-SQL query. The trained machine learning model can be stored inside a database and used for scoring.[38]
Service Broker[edit]
Used inside an instance, programming environment. For cross-instance applications, Service Broker communicates over TCP/IP and allows the different components to be synchronized, via exchange of messages. The Service Broker, which runs as a part of the database engine, provides a reliable messaging and message queuing platform for SQL Server applications.[39]
Service broker services consists of the following parts:[40]
- message types
- contracts
- queues
- service programs
- routes
The message type defines the data format used for the message. This can be an XML object, plain text or binary data, as well as a null message body for notifications. The contract defines which messages are used in an conversation between services and who can put messages in the queue. The queue acts as storage provider for the messages. They are internally implemented as tables by SQL Server, but don’t support insert, update, or delete functionality. The service program receives and processes service broker messages. Usually the service program is implemented as stored procedure or CLR application. Routes are network addresses where the service broker is located on the network.[40]
Also, service broker supports security features like network authentication (using NTLM, Kerberos, or authorization certificates), integrity checking, and message encryption.[40]
Replication Services[edit]
SQL Server Replication Services are used by SQL Server to replicate and synchronize database objects, either in entirety or a subset of the objects present, across replication agents, which might be other database servers across the network, or database caches on the client side. Replication Services follows a publisher/subscriber model, i.e., the changes are sent out by one database server («publisher») and are received by others («subscribers»). SQL Server supports three different types of replication:[41]
- Transaction replication
- Each transaction made to the publisher database (master database) is synced out to subscribers, who update their databases with the transaction. Transactional replication synchronizes databases in near real time.[42]
- Merge replication
- Changes made at both the publisher and subscriber databases are tracked, and periodically the changes are synchronized bi-directionally between the publisher and the subscribers. If the same data has been modified differently in both the publisher and the subscriber databases, synchronization will result in a conflict which has to be resolved, either manually or by using pre-defined policies. rowguid needs to be configured on a column if merge replication is configured.[43]
- Snapshot replication
- Snapshot replication publishes a copy of the entire database (the then-snapshot of the data) and replicates out to the subscribers. Further changes to the snapshot are not tracked.[44]
Analysis Services[edit]
SQL Server Analysis Services (SSAS) adds OLAP and data mining capabilities for SQL Server databases. The OLAP engine supports MOLAP, ROLAP and HOLAP storage modes for data. Analysis Services supports the XML for Analysis standard as the underlying communication protocol. The cube data can be accessed using MDX and LINQ[45] queries.[46]
Data mining specific functionality is exposed via the DMX query language. Analysis Services includes various algorithms—Decision trees, clustering algorithm, Naive Bayes algorithm, time series analysis, sequence clustering algorithm, linear and logistic regression analysis, and neural networks—for use in data mining.[47]
Reporting Services[edit]
SQL Server Reporting Services (SSRS) is a report generation environment for data gathered from SQL Server databases. It is administered via a web interface. Reporting services features a web services interface to support the development of custom reporting applications. Reports are created as RDL files.[48]
Reports can be designed using recent versions of Microsoft Visual Studio (Visual Studio.NET 2003, 2005, and 2008)[49] with Business Intelligence Development Studio, installed or with the included Report Builder. Once created, RDL files can be rendered in a variety of formats,[50][51] including Excel, PDF, CSV, XML, BMP, EMF, GIF, JPEG, PNG, and TIFF,[52] and HTML Web Archive.
Notification Services[edit]
Originally introduced as a post-release add-on for SQL Server 2000,[53] Notification Services was bundled as part of the Microsoft SQL Server platform for the first and only time with SQL Server 2005.[54][55] SQL Server Notification Services is a mechanism for generating data-driven notifications, which are sent to Notification Services subscribers. A subscriber registers for a specific event or transaction (which is registered on the database server as a trigger); when the event occurs, Notification Services can use one of three methods to send a message to the subscriber informing about the occurrence of the event. These methods include SMTP, SOAP, or by writing to a file in the filesystem.[56] Notification Services was discontinued by Microsoft with the release of SQL Server 2008 in August 2008, and is no longer an officially supported component of the SQL Server database platform.
Integration Services[edit]
SQL Server Integration Services (SSIS) provides ETL capabilities for SQL Server for data import, data integration and data warehousing needs. Integration Services includes GUI tools to build workflows such as extracting data from various sources, querying data, transforming data—including aggregation, de-duplication, de-/normalization and merging of data—and then exporting the transformed data into destination databases or files.[57]
Full Text Search Service[edit]
The SQL Server Full Text Search service architecture
SQL Server Full Text Search service is a specialized indexing and querying service for unstructured text stored in SQL Server databases. The full text search index can be created on any column with character based text data. It allows for words to be searched for in the text columns. While it can be performed with the SQL LIKE operator, using SQL Server Full Text Search service can be more efficient. Full allows for inexact matching of the source string, indicated by a Rank value which can range from 0 to 1000—a higher rank means a more accurate match. It also allows linguistic matching («inflectional search»), i.e., linguistic variants of a word (such as a verb in a different tense) will also be a match for a given word (but with a lower rank than an exact match). Proximity searches are also supported, i.e., if the words searched for do not occur in the sequence they are specified in the query but are near each other, they are also considered a match. T-SQL exposes special operators that can be used to access the FTS capabilities.[58][59]
The Full Text Search engine is divided into two processes: the Filter Daemon process (msftefd.exe) and the Search process (msftesql.exe). These processes interact with the SQL Server. The Search process includes the indexer (that creates the full text indexes) and the full text query processor. The indexer scans through text columns in the database. It can also index through binary columns, and use iFilters to extract meaningful text from the binary blob (for example, when a Microsoft Word document is stored as an unstructured binary file in a database). The iFilters are hosted by the Filter Daemon process. Once the text is extracted, the Filter Daemon process breaks it up into a sequence of words and hands it over to the indexer. The indexer filters out noise words, i.e., words like A, And, etc., which occur frequently and are not useful for search. With the remaining words, an inverted index is created, associating each word with the columns they were found in. SQL Server itself includes a Gatherer component that monitors changes to tables and invokes the indexer in case of updates.[60]
When a full text query is received by the SQL Server query processor, it is handed over to the FTS query processor in the Search process. The FTS query processor breaks up the query into the constituent words, filters out the noise words, and uses an inbuilt thesaurus to find out the linguistic variants for each word. The words are then queried against the inverted index and a rank of their accurateness is computed. The results are returned to the client via the SQL Server process.[60]
SQLCMD[edit]
SQLCMD is a command line application that comes with Microsoft SQL Server, and exposes the management features of SQL Server. It allows SQL queries to be written and executed from the command prompt. It can also act as a scripting language to create and run a set of SQL statements as a script. Such scripts are stored as a .sql file, and are used either for management of databases or to create the database schema during the deployment of a database.
SQLCMD was introduced with SQL Server 2005 and has continued through SQL Server versions 2008, 2008 R2, 2012, 2014, 2016 and 2019. Its predecessor for earlier versions was OSQL and ISQL, which were functionally equivalent as it pertains to T-SQL execution, and many of the command line parameters are identical, although SQLCMD adds extra versatility.
Visual Studio[edit]
Microsoft Visual Studio includes native support for data programming with Microsoft SQL Server. It can be used to write and debug code to be executed by SQL CLR. It also includes a data designer that can be used to graphically create, view or edit database schemas. Queries can be created either visually or using code. SSMS 2008 onwards, provides intellisense for SQL queries as well.
SQL Server Management Studio[edit]
SQL Server Management Studio is a GUI tool included with SQL Server 2005 and later for configuring, managing, and administering all components within Microsoft SQL Server. The tool includes both script editors and graphical tools that work with objects and features of the server.[61] SQL Server Management Studio replaces Enterprise Manager as the primary management interface for Microsoft SQL Server since SQL Server 2005. A version of SQL Server Management Studio is also available for SQL Server Express Edition, for which it is known as SQL Server Management Studio Express (SSMSE).[62]
A central feature of SQL Server Management Studio is the Object Explorer, which allows the user to browse, select, and act upon any of the objects within the server.[63] It can be used to visually observe and analyze query plans and optimize the database performance, among others.[64] SQL Server Management Studio can also be used to create a new database, alter any existing database schema by adding or modifying tables and indexes, or analyze performance. It includes the query windows which provide a GUI based interface to write and execute queries.[9]
Azure Data Studio[edit]
Azure Data Studio is a cross platform query editor available as an optional download. The tool allows users to write queries; export query results; commit SQL scripts to Git repositories and perform basic server diagnostics. Azure Data Studio supports Windows, Mac and Linux systems.[65]
It was released to General Availability in September 2018. Prior to release the preview version of the application was known as SQL Server Operations Studio.
Business Intelligence Development Studio[edit]
Business Intelligence Development Studio (BIDS) is the IDE from Microsoft used for developing data analysis and Business Intelligence solutions utilizing the Microsoft SQL Server Analysis Services, Reporting Services and Integration Services. It is based on the Microsoft Visual Studio development environment but is customized with the SQL Server services-specific extensions and project types, including tools, controls and projects for reports (using Reporting Services), Cubes and data mining structures (using Analysis Services).[66] For SQL Server 2012 and later, this IDE has been renamed SQL Server Data Tools (SSDT).
See also[edit]
- Comparison of relational database management systems
- Comparison of object-relational database management systems
- Comparison of data modeling tools
- List of relational database management systems
- XLeratorDB
References[edit]
- ^ «Explore SQL Server 2022 capabilities». Retrieved January 6, 2023.
- ^ «Download Microsoft SQL Server 2008 R2». Microsoft Evaluation Center. Microsoft Corporation. Retrieved July 18, 2011.
- ^ «Installation guidance for SQL Server on Linux». microsoft.com. December 21, 2017. Retrieved February 1, 2018.
- ^ «What’s new in SQL Server 2019 (15.x)». microsoft.com/. April 6, 2022. Retrieved May 11, 2022.
- ^ «Requirements for Installing SQL Server 2016». docs.microsoft.com. msdn.microsoft.com. May 2, 2016. Retrieved July 28, 2016.
- ^ «KB4518398 — SQL Server 2019 build versions». support.microsoft.com. Retrieved March 4, 2022.
- ^ «Compare Editions». SQL Server homepage. Microsoft Corporation. Retrieved December 3, 2007.
- ^ a b c d e f g h i Kalen Delaney (2007). Inside Microsoft SQL Server 2005: The Storage Engine. Microsoft Press. ISBN 978-0-7356-2105-3.
- ^ «SQL Server 2008: Editions». Microsoft. Retrieved July 21, 2011.
- ^ «Database System | Performance & Scalability | SQL Server 2012 Business Intelligence Editions». Microsoft.com. Retrieved June 15, 2013.
- ^ a b SQL Server 2012 Licensing Datasheet and FAQ (March 2012)
- ^ «SQL Server 2008 R2 Express Database Size Limit Increased to 10GB». Retrieved April 23, 2010.
- ^ «What’s up with SQL Server 2008 Express editions». Retrieved August 15, 2008.
- ^ «Developer Edition». SQL Server home. Microsoft Corporation. Retrieved July 18, 2011.
- ^ «SQL Server 2008 Trial Software». Microsoft. Retrieved March 26, 2009.
- ^ «Microsoft SQL Server 2008: Fast Track Data Warehouse». Microsoft. Retrieved March 26, 2009.
- ^ «SQL Server Express LocalDB». SQL Server. Microsoft Docs. Retrieved August 2, 2021.
- ^ «Introducing LocalDB, an improved SQL Express». SQL Server Express WebLog. Microsoft Docs. July 12, 2011. Retrieved August 2, 2021.
- ^ «Microsoft Analytics Platform System». Microsoft. Retrieved April 29, 2015.
- ^ Choosing an Edition of SQL Server 2000
- ^ a b «IT Pro».
- ^ Features Supported by the Editions of SQL Server 2000
- ^ «Choosing a StreamInsight Edition». MSDN. Microsoft Corporation. Retrieved July 18, 2011.
- ^ «Chapter 3 — Choosing an Edition of SQL Server 2000». November 1, 2010. Archived from the original on November 1, 2010. Retrieved November 4, 2022.
- ^ SQL Server 2000 — Downloads
- ^ SQL Server 2000 Product Documentation
- ^ «Pages and Extents». Retrieved December 2, 2007.
- ^ «Table and Index Organization». Retrieved December 2, 2007.
- ^ «Buffer Management». Retrieved December 2, 2007.
- ^ «Single SQL Statement Processing». Retrieved December 3, 2007.
- ^ «Stored Procedure Basics». Retrieved December 3, 2007.
- ^ «Transact-SQL Reference». Retrieved December 3, 2007.
- ^ «Features of SQL Server Native Client». Retrieved December 3, 2007.
- ^ «Available Today: Preview Release of the SQL Server ODBC Driver for Linux». SQL Server Team Blog. November 28, 2011. Retrieved June 15, 2013.
- ^ a b «Overview of CLR integration». Retrieved December 3, 2007.
- ^ «XML Support in SQL Server». Retrieved September 5, 2008.
- ^ «What is SQL Server Machine Learning Services». SQL Server homepage. Microsoft Corporation. Retrieved April 10, 2018.
- ^ «Introducing Service Broker». Retrieved December 3, 2007.
- ^ a b c Klaus Aschenbrenner (2011). «Introducing Service Broker». Pro SQL Server 2008 Service Broker (1st ed.). Vienna: Apress. pp. 17–31. ISBN 978-1-4302-0865-5. Retrieved December 15, 2019.
- ^ «Types of Replication Overview». Retrieved December 3, 2007.
- ^ «Transactional Replication Overview». Retrieved December 3, 2007.
- ^ «Merge Replication Overview». Retrieved December 3, 2007.
- ^ «Snapshot replication Overview». Retrieved December 3, 2007.
- ^ «SSAS Entity Framework Provider». Retrieved September 29, 2011.
- ^ «Analysis Services Architecture». Retrieved December 3, 2007.
- ^ «Data Mining Concepts». Retrieved December 3, 2007.
- ^ «SQL Server Reporting Services». Retrieved December 3, 2007.
- ^ «Cannot open a SQL Reporting Services .rptproj file | Microsoft Connect». Connect.microsoft.com. Archived from the original on February 3, 2012. Retrieved September 4, 2011.
- ^ MSDN Library: Reporting Services Render Method
- ^ Device Information Settings
- ^ Image Device Information Settings
- ^ «An Introduction to SQL Server Notification Services». September 3, 2002. Retrieved November 14, 2008.
- ^ «SQL Server Notification Services Removed from SQL Server 2008». Archived from the original on October 16, 2008. Retrieved September 17, 2008.
- ^ «Discontinued Functionality in SQL Server 2008 Reporting Services». Retrieved September 17, 2008.
- ^ «Introducing SQL Server Notification Services». Retrieved December 3, 2007.
- ^ «Integration Services Overview». Retrieved December 3, 2007.
- ^ «Introduction to Full-Text Search». Retrieved December 3, 2007.
- ^ «Querying SQL Server using Full-Text Search». Retrieved December 3, 2007.
- ^ a b «Full-Text Search Architecture». Retrieved December 3, 2007.
- ^ «MSDN: Introducing SQL Server Management Studio». Msdn.microsoft.com. Retrieved September 4, 2011.
- ^ «SQL Server Management Studio Express». Microsoft.com. April 18, 2006. Retrieved September 4, 2011.
- ^ «MSDN: Using Object Explorer». Msdn.microsoft.com. Retrieved September 4, 2011.
- ^ «SQL Server 2005 Management Tools». Sqlmag.com. July 19, 2005. Retrieved September 4, 2011.
- ^ «What is Microsoft SQL Operations Studio (preview)?». docs.microsoft.com. Retrieved January 19, 2018.
- ^ «Introducing Business Intelligence Development Studio». Retrieved December 3, 2007.
Further reading[edit]
- Lance Delano, Rajesh George et al. (2005). Wrox’s SQL Server 2005 Express Edition Starter Kit (Programmer to Programmer). Microsoft Press. ISBN 0-7645-8923-7.
- Delaney, Kalen, et al. (2007). Inside SQL Server 2005: Query Tuning and Optimization. Microsoft Press. ISBN 0-7356-2196-9.
- Ben-Gan, Itzik, et al. (2006). Inside Microsoft SQL Server 2005: T-SQL Programming. Microsoft Press. ISBN 0-7356-2197-7.
- Klaus Elk (2018). SQL Server with C#. ISBN 1-7203-5867-2.
External links[edit]
- Official website
- 2nd official website at Microsoft TechNet
Содержание
- 1 Данные
- 2 Как используется SQL и в чём его польза?
- 3 Теперь про базы
- 4 Вернёмся к SQL
- 5 Области применения и где используется SQL:
- 5.1 DDL
- 5.2 DML
- 5.3 DCL
- 5.4 TCL
- 6 Виды СУБД
- 7 Сервер базы данных
- 7.1 2.1. Технология и модели «клиент-сервер».
- 7.2 2.2. Эволюция серверов баз данных
- 7.3 2.3. Активный сервер
- 7.3.1 2.3.1. Актуальные задачи
- 7.3.2 2.3.2. Традиционные подходы
- 7.3.3 2.3.3. Современные решения
- 8 Оперативная память сервера баз данных
- 8.1 Дисковая подсистема сервера баз данных
- 8.2 Вычислительная мощность сервера баз данных
- 9 Microsoft SQL Server
- 10 История
- 11 Функциональность
- 11.1 Microsoft разработала конкурента Oracle Exadata и SAP HANA
- 12 Разработка приложений
- 13 SQL Server Express Edition
- 14 Особенности линейки B
- 14.1 От B1 до B3
- 14.2 От B4 до B6
- 14.3 B7
- 14.4 От B8 до B12
- 14.5 B13
- 14.6 B14 и B15
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
- название производителя;
- название модели;
- высота;
- длина;
- цвет;
- количество дверей.
Составим таблицу и вобьём в неё выдуманные данные.
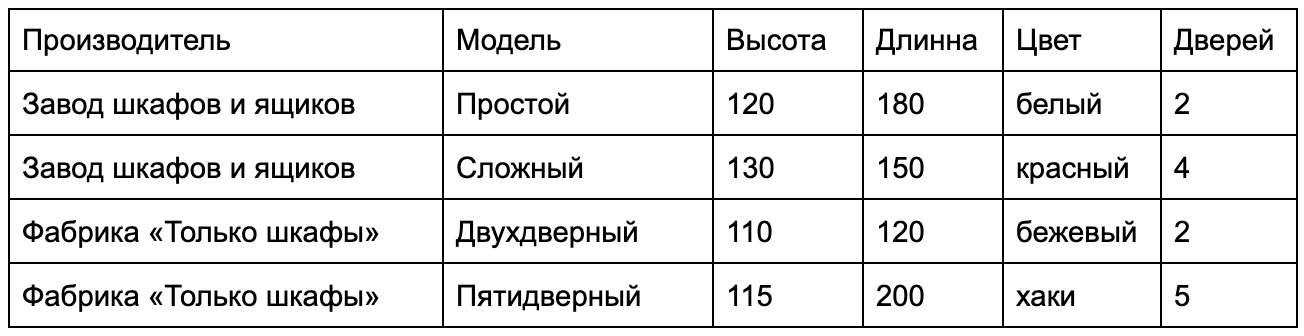
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Как используется SQL и в чём его польза?
С 1974 года, когда язык структурированных запросов только появился, он обеспечивает взаимодейтсвие с системами управления базами данных (СУБД) во всём мире.
SQL, как простой и лёгкий в изучении язык из области свободного программного обеспечения, сегодня активно применяется:
- разработчиками баз данных (обеспечивают функциональность приложений),
- тестировщиками (в ручном и автоматическом режиме),
- администраторами (выполняют поддержание работоспособности среды).
Язык универсален и обладает чётко определённой структурой за счёт устоявшихся стандартов. Взаимодействие с базами данных происходит быстро даже в ситуациях, когда объёмы данных велики (Big Data). Кроме того, эффективное управление возможно даже без особых познаний кода.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Таблица «Производитель»:

Теперь таблицу «Каталог» можно оформить в другом виде:
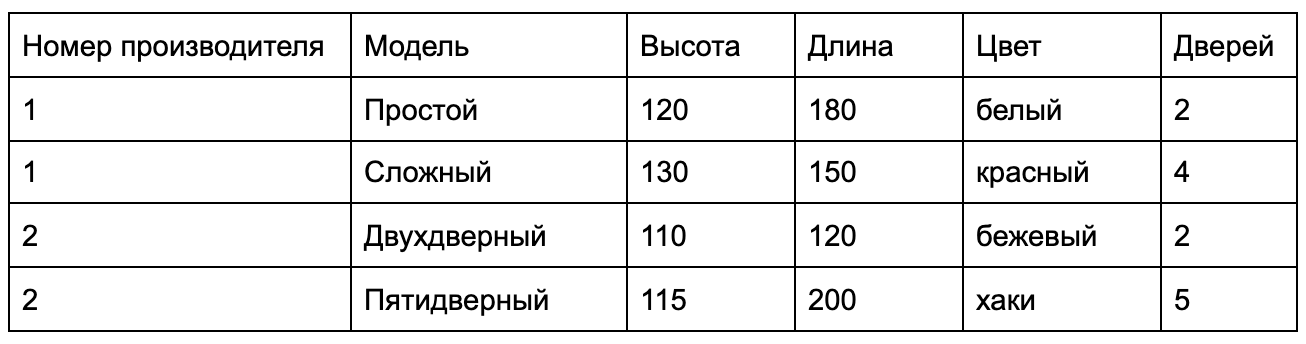
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
- Избавились от избыточных данных. Каталог стал занимать меньше места. Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
- Снизили вероятность ошибиться. При смене названия производителя нам достаточно отредактировать строку в таблице «Производитель», «Каталог» останется без изменений.
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
Области применения и где используется SQL:
DDL
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
- Создание объектов базы данных (таблиц, схем). Оператор: CREATE.
- Удаление объектов базы данных. Оператор: DROP.
- Изменение объектов базы данных. Оператор: ALTER.
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
- Оператор SELECT позволяет выбрать данные.
- Оператор INSERT — добавить новые.
- Оператор UPDATE — изменить существующие.
- Оператор DELETE — удалить.
DCL
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
- GRANT — оператор предоставления пользователю или группе набор каких-либо разрешений;
- REVOKE — оператор отзыва разрешений;
- DENY — задаёт запрет. Приоритет оператора DENY выше, чем у разрешения, выданного оператором GRANT.
TCL
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
- BEGIN TRANSACTION — необходим для обозначения начала транзакции;
- COMMIT TRANSACTION — применяет изменения команд внутри транзакции;
- ROLLBACK TRANSACTION — откатывает транзакцию;
- SAVE TRANSACTION — указывает промежуточную точку сохранения внутри транзакции.
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
Сервер базы данных
Современная СУБД должна удовлетворять ряду требований, важнейшее из которых — высокопроизводительный интеллектуальный сервер базы данных. Далее мы рассмотрим основные тенденции его развития и обсудим конкретные механизмы, в которых они находят свое воплощение.
Процесс технического совершенствования сервера базы данных пока остается невидимым для большинства пользователей современных СУБД. Поэтому при выборе той или иной системы они, как правило, не учитывают ни технический уровень решений, заложенных в механизм его функционирования, ни влияние этих решений на общую производительность СУБД. Между тем ее качество определяется отнюдь не богатством интерфейсов с пользователем, не разнообразием средств поддержки разработок, а в первую очередь зависит от особенностей архитектуры сервера базы данных. Далее будут рассмотрены модели технологии «клиент-сервер», определено место сервера БД в этих моделях и кратко описаны важнейшие механизмы сервера БД — процедуры, правила (триггеры), события. Последние будут проиллюстрированы примерами, в которых использован диалект SQL, принятый в СУБД Ingres.
2.1. Технология и модели «клиент-сервер».
«Клиент-сервер» — это модель взаимодействия компьютеров в сети. Как правило, компьютеры не являются равноправными. Каждый из них имеет свое, отличное от других, назначение, играет свою роль. Некоторые компьютеры в сети владеют и распоряжается информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных. Другие же компьютеры имеют возможность обращаться к этим службам, пользуясь услугами первых. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться — клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого — обслуживать запросы клиентов, связанные с обработкой данных; если ресурс — это файловая система, то говорят о файловом сервере, или файл-сервере, и т. д.
В сети один и тот же компьютер может выполнять роль как клиента, так и сервера. Например, в информационной системе, включающей персональные компьютеры, большую ЭВМ и мини-компьютер под управлением UNIX, последний может выступать как в качестве сервера базы данных, обслуживая запросы от клиентов — персональных компьютеров, так и в качестве клиента, направляя запросы большой ЭВМ.
Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа выступает в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами. Так, ядро реляционной SQL-ориентированной СУБД часто называют сервером базы данных, или SQL-сервером, а программу, обращающуюся к нему за услугами по обработке данных — SQL-клиентом.
Первоначально СУБД имели централизованную архитектуру (рис.1). В ней сама СУБД и прикладные программы, которые работали с базами данных, функционировали на центральном компьютере (большая ЭВМ или мини-компьютер). Там же располагались базы данных. К центральному компьютеру были подключены терминалы, выступавшие в качестве рабочих мест пользователей. Все процессы, связанные с обработкой данных, как то: поддержка ввода, осуществляемого пользователем, формирование, оптимизация и выполнение запросов, обмен с устройствами внешней памяти и т.д., выполнялись на центральном компьютере, что предъявляло жесткие требования к его производительности. Особенности СУБД первого поколения напрямую связаны с архитектурой систем больших ЭВМ и мини-компьютеров и и адекватно отражают все их преимущества и недостатки. Однако нас больше интересует современное состояние многопользовательских СУБД, для которых архитектура «клиент-сервер» стала фактическим стандартом.
Для более четкого представления об ее особенностях необходимо рассмотреть несколько моделей технологии «клиент-сервер», что и будет сделано.
Если предполагается, что проектируемая информационная система (ИС) будет иметь технологию «клиент-сервер», то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер. Иными словами, часть функций прикладной программы (или, проще, приложения) будет реализована в программе-клиенте, другая — в программе-сервере, причем для их взаимодействия будет определен некоторый протокол.
Основной принцип технологии «клиент-сервер» заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу. Первая группа — это функции ввода и отображения данных. Вторая группа объединяет чисто прикладные функции, характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета на другой и т.д.). К третьей группе относятся фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.). Наконец, функции четвертой группы — это служебные функции (играющие роль связок между функциями первых трех групп.
В соответствии с этим в любом приложении выделяются следующие логические компоненты:
· компонент представления, реализующий функции первой группы;
· прикладной компонент, поддерживающий функции второй группы;
· компонент доступа к информационным ресурсам, поддерживающий функции третьей групп, а также вводятся и уточняются соглашения о способах их взаимодействия (протокол взаимодействия).
Различия в реализациях технологии «клиент-сервер» определяются четырьмя факторами. Во-первых, тем, в какие виды программного обеспечения интегрированы каждый из этих компонентов. Во-вторых, тем, какие механизмы программного обеспечения используются для реализации функций всех трех групп. Во-третьих, как логические компоненты распределяются между компьютерами в сети. В-четвертых, какие механизмы используются для связи компонентов между собой.
Выделяются четыре подхода, реализованные в моделях:
· модель файлового сервера (File Server — FS);
· модель доступа к удаленным данным (Remote Data Access — RDA);
· модель севера базы данных (DataBase Server — DBS);
· модель сервера приложений (Application Server — AS).
FS-модель является базовой для локальных сетей персональных компьютеров. Не так давно она была исключительно популярной среди отечественных разработчиков, использовавших такие системы, как FoxPRO, Clipper, Clarion, Paradox и т.д. Суть модели проста и всем известна. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (то есть к файлам). На других компьютерах в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент (рис.2). Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере. Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипуляции с данными («данные — это файлы»), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д. Собственно, перечисленное не есть недостатки, но — следствие внутренне присущих FS-модели ограничений, определяемых ее характером. Недоразумения возникают, когда FS-модель используют не по назначению, например, пытаются интерпретировать как модель сервера базы данных. Место FS-модели в иерархии моделей «клиент-сервер» — это место модели файлового сервера, и ничего более. Именно поэтому обречены на провал попытки создания на основе FS-модели крупных корпоративных систем — попытки, которые предпринимались в недавнем прошлом и нередко предпринимаются сейчас.
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, например, если речь идет о базах данных), либо вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования — API).
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия, и возвращает клиенту результат, оформленный как блок данных (рис.3). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль — обслуживание запросов и обработка данных. В Разделе 2 будет показано, что такое распределение обязанностей между клиентами и сервером базы данных не догма — сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Прежде всего перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД, сводя к минимуму общее число процессов операционной системы. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на ввод-вывод (как в системах с файловым сервером), а запросы на языке SQL, их объем существенно меньше.
Основное достоинство RDA-модели — унификация интерфейса «клиент-сервер» в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обоим. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором уже шла речь . Поэтому целесообразно использовать его не только в качестве средства доступа к данным, но и стандарта общения клиента и сервера.
Такое общение можно сравнить с беседой нескольких человек, когда один отвечает на вопросы остальных (вопросы задаются одновременно). Причем делает это он так быстро, что время ожидания ответа приближается к нулю. Высокая скорость общения достигается прежде всего благодаря четкой формулировке вопроса, когда спрашивающему и отвечающему не нужно дополнительных консультаций по сути вопроса. Беседующие обмениваются несколькими короткими однозначными фразами, им ничего не нужно уточнять.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные). Более подробно о недостатках RDA-модели сказано в п. 2.3.1.
Наряду с RDA-моделью все большую популярность приобретает перспективная DBS-модель (рис. 4). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур — средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД. Более подробно о хранимых процедурах рассказано в п. 2.3.3.
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, то есть ядро СУБД. Достоинства DBS-модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам модели можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими как C или Pascal. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель). Так или иначе современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей либо их разумное сочетание.
В AS-модели (рис.5) процесс, выполняющийся на компьютере-клиенте, отвечает, как обычно, за интерфейс с пользователем (то есть осуществляет функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client — AC). Прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения (Application Server — AS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов — базы данных, очереди, почтовые службы и др.
RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во-втором — интегрируется в компонент доступа к информационным ресурсам. В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. AS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitors — TPM), или, проще, мониторов транзакций, которые выделяются как особый вид программного обеспечения. Мониторы транзакций — предмет Раздела 4.
В заключение отметим, что, часто, говоря о сервере базы данных, подразумевают как компьютер, так и программное обеспечение — ядро СУБД. При описании архитектуры «Клиент-сервер» под сервером базы данных мы имели в виду компьютер. Далее сервер базы данных будет пониматься как программное обеспечение — ядро СУБД.
2.2. Эволюция серверов баз данных
В период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия такого типа, в современных же системах он жизненно необходим.
Чтобы понять суть проблемы, рассмотрим эволюцию серверов баз данных. Первое время доминировала модель, когда управление данными (функция Сервера) и взаимодействие с пользователем были совмещены в одной программе (рис.6a). Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один-к-одному» (рис.6б), то есть сервер обслуживал запросы ровно одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу — революционный шаг, позволяющий, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети (рис.7). Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Проблемы, возникающие в модели «один-к-одному», решаются в архитектуре систем с выделенным сервером, способным обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис.8). Логически каждый клиент связан с сервером отдельной нитью (thread) или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой (multi-threaded).
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей (trashing). С другой стороны, возможность взаимодействия с одним сервером многих клиентов позволяет в полной степени использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один-к-одному» будет создано 50 копий процессов СУБД для 50 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один сервер.
Однако такое решение привносит новую проблему. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается заменой выделенного сервера на диспетчер или виртуальный сервер (virtual server) (рис.9), который теряет право монопольно распоряжаться данными, выполняя только функции диспетчеризации запросов к актуальным серверам. Таким образом, в архитектуру системы добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки (load balancing) и ограничивает возможности управления взаимодействием «клиент-сервер». Во-первых, становиться невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов.
Подобная организация взаимодействия «клиент-сервер» является аналогом банка, где имеется несколько окон кассиров, и банковский служащий (диспетчер), направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако, стоит лишь появиться посетителям с высшим приоритетом (которые должны обслуживаться в специальном окне), как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основание говорить о многопотоковой архитектуре с несколькими серверами (multi-threaded, multi-server architecture)
2.3. Активный сервер
Действительно профессиональные СУБД обладают мощным активным сервером базы данных. Это не просто технические новшество. Идея активного сервера коренным образом изменяет представление о роли, масштабах и принципах использования СУБД, а в чисто практическом плане позволяет выбрать современные, эффективные методы построения глобальных информационных систем.
Идея активного интеллектуального сервера БД возникла не сама по себе — она стала ответом на задачи реальной жизни. В Разделе 1 было сформулировано общее представление о базе данных. Однако вдумчивый читатель может его расширить. Действительно, объекты реального мира, помимо непосредственных, прямых связей, имеют друг с другом более сложные причинно-следственные связи; они динамичны, находятся в постоянном изменении. Эти связи и процессы должны каким-то образом отражаться и в базе данных, если мы имеем в виду не статичное хранилище данных, а информационную модель маленькой части реального мира. Иными словами, в базе данных, помимо собственно данных и непосредственных связей между ними, должны хранится знания о данных, а сама база должна адекватно отражать процессы, происходящие в реальном мире. Значит, необходимо иметь средства хранения и управления такой информацией.
2.3.1. Актуальные задачи
Указанные требования выливаются в решение следующих задач.
Во-первых, необходимо, чтобы база данных в любой момент правильно отражала состояние предметной области — данные должны быть взаимно непротиворечивыми. Пусть, например, база данных Кадры хранит сведения о рядовых сотрудниках, отделах, в которых они работают, и их руководителях. Нужно учесть следующие правила: каждый сотрудник должен быть подчинен реальному руководителю; если руководитель уволился, то все его сотрудники переходят в подчинение другому, а отдел реорганизуется; во главе каждого отдела должен стоять реальный руководитель; если отдел сокращен, то его руководитель переводится в резерв на выдвижение и т.д.
Во-вторых, база данных должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rule). Завод может нормально работать, только в том случае, если на складе имеется достаточный запас деталей определенной номенклатуры. Следовательно, как только количество деталей некоторого типа станет меньше минимально допустимого, завод должен докупить эти детали в нужном количестве.
В-третьих, необходим постоянный контроль за состоянием базы данных, отслеживание всех изменений, и адекватная реакция на них. Например, в автоматизированной системе управления производством датчики контролируют температуру инструмента; она периодически передается в базу данных и там сохраняется; как только температура инструмента превышает максимально возможное значение, он отключается.
В-четвертых, необходимо, чтобы возникновение некоторой ситуации в базе данных четко и оперативно влияло на ход выполнения прикладной программы. Многие программы требуют оперативного оповещения о всех происходящих в базе данных изменениях. Так, в системах автоматизированного управления производством необходимо моментально уведомлять программы о любых изменениях параметров технологических процессов, когда последние хранятся в базе данных. Почтовая служба требует оперативного уведомления получателя, как только получено новое сообщение. Брокер на бирже СУБД должен немедленно получать сообщение об изменении цены акций, поскольку промедление в несколько секунд грозит большими потерями.
Оповещение о возникновении определенного состояния базы данных и изменениях в ней может потребоваться в любом учреждении для контроля прохождения документов. Если документ, который должен быть просмотрен и последовательно завизирован несколькими руководителями, хранится в базе данных, то каждый из них в свою очередь будет оперативно уведомлен о поступлении документа ему на подпись.
Важная проблема СУБД — контроль типов данных. В Разделе 1 уже говорилось о том, что в базе данных каждый столбец в любой таблице содержит данные некоторых типов. Тип данных определяется при создании таблицы. Каждому столбцу присваивается один из стандартных типов данных, разрешенных в СУБД. Стало быть, в базе данных можно хранить только данные стандартных типов — числа, целые и вещественные, строки символов, данные типа «дата», «время» и «денежная единица» — репертуар реальной СУБД ограничен именно этими типами данных. Как же быть с нестандартными данными? Ведь в реальной жизни требуется хранить и обрабатывать данные в значительно более широком диапазоне — плоскостные и пространственные координаты, единицы различных метрик, пятидневные недели (рабочая неделя, в которой сразу после пятницы следует понедельник), дроби, не говоря уже о графических изображениях.
2.3.2. Традиционные подходы
До недавнего времени функции управления знаниями оставались за границами возможностей реляционных СУБД или были очень ограниченны.
Знания о предметной области традиционно включались непосредственно в прикладные программы, для чего использовались возможности процедурных языков программирования. Этот подход в подавляющем большинстве случаев преобладает и сейчас.
Рассмотрим, например, базу данных Склад, хранящую информацию о наличии деталей на заводском складе. Прикладная программа Складской Учет обеспечивает учет имеющихся и вновь поступающих деталей. В ее функции входит просмотр содержимого базы данных, добавление информации о новых деталях, замена снятых с производства деталей на новые и т.д. В программе реализованы некоторые правила, например «В любой момент времени количество деталей типа «втулка» не должно быть меньше 1000″ (ситуация со втулками на производстве всегда напряженная). Нетрудно понять, что оно должно применяться только в том случае, когда количество втулок уменьшается. Значит, нужно проверить: а не уменьшилось ли оно настолько, что стало меньше 1000. Если это произошло, то нужно срочно направить на завод-изготовитель письмо с просьбой отгрузить нужное количество втулок, если, конечно, такое письмо не было направлено до этого.
А чтобы это правило применялось, программа должна периодически, через определенные интервалы времени опрашивать значение в столбце Количество таблицы Деталь для всех строк, которые удовлетворяют условию Деталь. Название =»Втулка». Если это значение становится меньше 1000, программа должна послать письмо на завод-изготовитель.
Фрагмент программы указан в Примере 1.
… SELECT Количество, Номер_поставщика FROM Деталь WHERE Название = «Втулка»; IF (Количество < 1000) THEN BEGIN SELECT Адрес_поставщика FROM Поставщик WHERE Номер = Номер_поставщика; Послать письмо(Адрес_поставщика, 1000-Количество); END ELSE Ничего не делать … { … ВЫБРАТЬ Количество, Номер_поставщика ИЗ Деталь ГДЕ Название = «Втулка»; ЕСЛИ (Количество < 1000) ТО НАЧАТЬ ВЫБРАТЬ Адрес_поставщика ИЗ Поставщик ГДЕ Номер = Номер_поставщика; Послать письмо(Адрес_поставщика, 1000-Количество); ЗАКОНЧИТЬ ИНАЧЕ Ничего не делать … }
Пример 1.
В чем недостатки такого подхода?
Во-первых, реализация правил перегружает прикладную программу и усложняет ее написание и понимание. Во-вторых, и это более существенный недостаток, когда изменяется само правило, изменения должны быть отражены в тексте программы. Когда же правила изменяются кардинальным образом, разработчику приходится пересматривать логику выполнения программы и практически переписывать ее заново.
Удобнее оставить за прикладными программами только базовые алгоритмы управления данными, а часто меняющиеся правила, которые действуют во внешнем мире, вынести за рамки программ и оформить как-то иначе. В противном случае разработчиков ждут неприятные сюрпризы.
Рассмотрим для примера прикладную банковскую систему. При ее создании разработчики в алгоритмах управления данными учли те правила финансовой деятельности, которые диктовались действующим законодательством. Предположим теперь, что законы претерпели некоторые изменения (что в наше время происходит слишком часто!). Естественно, эти изменения должны быть немедленно отражены и в алгоритмах управления данными, что повлечет за собой необходимость модификации всех прикладных программ, составляющих информационную систему.
Это огромная работа — нужно исправить и отладить программы, откомпилировать и собрать их, внести изменения в документацию и переобучить персонал.
С другой стороны, правила, о которых идет речь, не должны противоречить друг другу. Когда их реализует группа разработчиков, нет никаких гарантий взаимной непротиворечивости правил. Фактически правила должен формулировать и контролировать один человек — администратор базы данных. При традиционном подходе практически невозможно обеспечить централизованный контроль за взаимным соответствием правил, если они разбросаны по многим программам, и, что более важно для коммерческих организаций, практически невозможно проконтролировать преднамеренное искажение правил программистами.
Таким образом, включение правил в прикладные программы, когда серверу отводится пассивная роль поставщика и хранителя данных, а вся интеллектуальная часть реализуется в программе, представляет собой устаревшую технологию. Она чревата большими накладными расходами при изменении правил и не обеспечивает централизованного контроля за их непротиворечивостью. Ясно, что эта технология имеет в своей основе столь популярную ныне RDA-модель (о ней речь шла выше).
Традиционное решение задач контроля за состоянием базы данных и уведомления прикладных программ о всех происходящих в ней событиях опирается на механизмы опроса (polling) прикладными программами базы данных, которому присущи следующие недостатки.
Прикладная программа не может непрерывно опрашивать базу данных, так как это приведет к перегрузке сервера бесполезными запросами. Опрос производится через интервалы времени, которые определяет программист. Следовательно, если в базе данных происходят какие-либо изменения, то они выявляются не сразу, а через какое-то время. Именно поэтому традиционное решение не обеспечивает оперативного оповещения, в прикладных же программах, работающих в реальном времени (см. примеры выше), это требование является ключевым. Постоянный опрос базы данных сильно сказывается на производительности системы — программы, опрашивающие базу данных, перегружают своими запросами сервер и сеть. Громоздкие конструкции в тексте программ, реализующие опрос, серьезно затрудняют ее написание и понимание.
Другое важное требование реальной жизни — синхронизация работы нескольких программ, обращающихся к базе данных. Рассмотрим пример. Финансовая система завода должна отслеживать поступление платежей за продукцию на некоторый счет. Как только деньги поступили (все знают, насколько это важное событие — «пришли деньги!»), все прикладные программы, включенные в финансовую систему, должны быть оповещены об этом. После этого каждая из них может предпринять некоторые действия. Так, программа Отгрузка Продукции должна найти в базе данных соответствующий заказ, определить номенклатуру заказанной продукции, ее количество, сроки поставки, сформировать и послать на склад готовой продукции заказ на отгрузку, распечатать сопроводительные документы — иными словами подготовить продукцию к отправке. Программа Бухгалтерия, в частности, должна по дате поступления денег определить, просрочен ли платеж, и, если это так, начислить штраф. Все эти действия активизируются событием в базе данных — поступлением денег на счет (в терминах реляционной СУБД это означает добавление новой строки в таблицу Платежи). Работа всех программ синхронизируется этим событием.
Традиционное решение проблемы синхронизации программ обеспечивается стандартными средствами многозадачной операционной системы. Однако такая синхронизация может быть связана с изменениями, происходящими в базе данных, только посредством постоянного опроса таблицы Платежи. Недостатки такого подхода очевидны — в нем взаимосвязь программ обеспечивается на уровне операционной системы, тогда как эту функцию, безусловно, должна выполнять СУБД. Кроме того, приходится привлекать программы опроса, недостатки которого мы уже обсуждали.
Общепринятый способ преодоления ограничения на типы данных в СУБД — приведение данных новых типов к стандартным. Как правило, данные новых типов рассматриваются как целые или вещественные числа, или как строки символов.
Рассмотрим пример. В ряде стран, в том числе и в США, для измерения длины наряду с привычными мерами метрической системоы используются также футы и дюймы. Правила выполнения арифметических операций в этой системе отличны от десятичной. Так, три фута одиннадцать дюймов плюс один дюйм равно четырем футам ( 3″11″ + 1″ = 4″). Стандартный набор типов данных не позволяет определить данные в этой системе и оперировать с ними. Они должны быть преобразованы в вещественные числа с плавающей точкой, то есть представлены соответственно, как 3.91666 (три фута одиннадцать дюймов) и 0.08333 (один дюйм). Выполнив операцию сложения (3.91666+0.08333=3.99999), мы убедимся, что такое представление приводит к потере точности (ведь результат должен быть равен четырем!).
Следовательно, прямое приведение новых типов данных к стандартным чревато ошибками — необходимо их преобразование в данные стандартных типов. Функции преобразования данных должны взять на себя прикладные программы (больше некому). В результате получается довольно громоздкая схема. Программа извлекает из базы данных данные новых типов, представленные как стандартные, преобразует и обрабатывает их, затем вновь преобразует и передает серверу для хранения. Сервер в обработке данных новых типов при такой схеме участия не принимает — ведь он рассматривает их как стандартные и будет обрабатывать как стандартные (и тогда возникнут ошибки!).
Сегодня, например, для отечественных банков актуальна проблема больших чисел. Масштаб расчетов настолько возрос, что в некоторых итоговых операциях фигурируют суммы, которые превосходят разрядную сетку для целых чисел. Поэтому в программах приходится преобразовывать целые числа в строки и наоборот, что не упрощает их логику. Хранение и обработка больших целых как вещественных приводит к потере точности, что в финансовой системе недопустимо.
Далее мы увидим, что решение проблемы заключается в определении нового типа данных «большие целые». Как только это сделано, сервер базы данных начинает «понимать» новый тип данных и выполнять над ним все операции, характерные для целых чисел.
Другое важнейшее требование к современным СУБД — возможность хранения неструктурированных объектов большого объема (Binary Large OBjects — BLOB). Отвечая на это требование, разработчики СУБД предусматривают такую возможность. Однако сервер лишь хранит такие объекты, не обладая возможностями их обработки. Например, работая с графическим объектами, сервер не делает различий между изображением автомобиля BMW и структурой ДНК. Сервер вынужден передавать их для интерпретации прикладной программе, которая сможет разобраться, кто есть кто.
Не следует забывать и о проблеме целостности. Если одна программа интерпретирует данные некоторого типа, преобразуя его в собственный формат, то ничто не мешает делать то же самое другой программе с той только разницей, что формат представления тех же данных будет уже другим. Это делает принципиально невозможным контроль целостности данных хотя бы потому, что различные программы интерпретируют их по-разному.
Отметим, что отсутствие в СУБД нестандартных типов данных заметно сказывается на их производительности, так как нормальное взаимодействие клиента и сервера возможно только тогда, когда и тот и другой адекватно воспринимают типы данных, с которыми ведется работа. Если используются типы данных, не известные серверу, то он вынужден передавать клиенту для обработки практически всю базу данных, что перегружает сеть и приводит к потере производительности. Фактически в такой схеме появление нестандартных типов данных приводит к деградации архитектуры системы к архитектуре с файловым сервером. Не понимая нового типа данных, сервер способен лишь послушно сохранять его, не умея сравнивать, сортировать, выполнять какие бы то ни было операции над данными.
С другой стороны, это ограничение приводит к тому, что основная тяжесть обработки данных нестандартных типов ложится на прикладные программы. При этом вопрос о целостности данных остается открытым, поскольку не поддерживается централизованный контроль типов данных, несомненно являющейся функцией сервера базы данных.
Итак, в традиционной технологии решение задач, о которых шла речь выше, ложится целиком на прикладные программы. Недостатки традиционной технологии — следствие того, что традиционно в СУБД в модели взаимодействия «клиент-сервер» последнему отводится в основном пассивная роль. Во-первых, сервер базы данных лишен функций хранения и обработки знаний о предметной области. Во-вторых, за границами возможностей сервера остается контроль за состоянием базы данных и программирование реакции на ее изменения. В-третьих, пассивный сервер не имеет средств отслеживания событий в базе данных, а также средств воздействия на работу прикладных программ и возможностей их синхронизации.
2.3.3. Современные решения
Идеи, реализованные в СУБД третьего поколения (пока, к сожалению, не во всех), заключаются в том, что знания выносятся за рамки прикладных программ и оформляются как объекты базы данных. Функции применения знаний начинает выполнять непосредственно сервер базы данных.
Такая архитектура суть воплощение концепции активного сервера. Она опирается на четыре «столпа»:
- процедуры базы данных
- правила (триггеры)
- события в базе данных
- типы данных, определяемые пользователем
Оперативная память сервера баз данных
Большой объем оперативной памяти, в идеале такой, чтобы закэшировать всю базу данных целиком. Работа с оперативной памятью на порядки быстрее, чем работа с жесткими дисками, поэтому чем бОльшим объемом памяти будет распологать сервер, тем лучше, при условии, что операционная система и само приложение сервера СУБД способны адресовать и работать с таким количеством памяти. Современные операционные системы и приложения фактически не имеют данных ограничений, т.к. способны адресовать до 64Гб и более. Двухпроцессорные серверы способны оснащаться 128Гб оперативной памяти, а четырех- и восьмипроцессорные — до 256Гб.
Дисковая подсистема сервера баз данных
Для получения максимальной производительности дисковой подсистемы на транзакционных задачах ее строят следующим образом: несколько жестких дисков объединяются в RAID-массив, т. к. в RAID-массиве операции чтения-записи происходят одновременно на нескольких дисках, то рост производительности (количества операций ввода-вывода в секунду, IOPS) растет пропорционально количеству жестких дисков в массиве. В качестве жестких дисков рекомендуется использовать диски SAS (Serial Attached SCSI)на 10000 об/мин или 15000 об/мин. Данные диски оптимизированы для работы на транзакционных нагрузках и по этому показателю имеют вдвое-втрое более высокую производительность, чем диски SATA. Кроме того, диски SAS изначально проектировались под работу в RAID-массивах и показывают практически линейный рост производительности массива при увеличении количества дисков в нем.
Вычислительная мощность сервера баз данных
Современные процессоры стали значительно производительнее, чем 2-3 года назад благодаря внедрению технологии многоядерности. Сейчас сервер с 8-ю ядрами (фактически процессорами) доступен практически каждой организации. Благодаря этому, появилась возможность обрабатывать существенные объемы информации на относительно недорогом оборудовании. Для «тяжелых» систем постепенно отпадает необходимость в приобретении дорогостоящих многопроцессорных RISC-систем, стоящих при равной производительности на порядки дороже. В настоящий момент существуют четырех- и восьмипроцессорные серверы стандартной архитектуры x86 с поддержкой четырех и даже шестиядерных процессоров, что позволяет иметь в одной системе до 32-х ядер.
Компания STSS рада предложить своим закачикам широкий спектр серверов для СУБД самого различного уровня. Начиная от небольших баз данных на 10-20 пользователей, и заканчивая системами корпоративного уровня с числом пользователей, превышающем 1000 человек.
Нами разработано уникальное решение — четырехпроцессорный сервер с большим количеством отсеков для жестких дисков. Уникальное сочетание высокой вычислительной мощности и высокопроизводительной дисковой подсистемы в одном конструктиве позволяет сэкономить до 50% по сравнению с традиционным решением — сервер + внешний RAID-массив
На нашем сайте серверы баз данных представлены в следующих разделах:
- Серверы 2 CPU
- Cерверы 4-8 CPU
Microsoft SQL Server
Продукт
| Разработчики: | Microsoft |
| Дата последнего релиза: | 2010/04/21 |
| Отрасли: | Информационные технологии |
| Технологии: | СУБД |
История
Исходный код MS SQL Server (до версии 7.0) основывался на коде Sybase SQL Server, и это позволило Microsoft выйти на рынок баз данных для предприятий, где конкурировали Oracle, IBM, и, позже, сама Sybase. Microsoft, Sybase и Ashton-Tate первоначально объединились для создания и выпуска на рынок первой версии программы, получившей название SQL Server 1.0 для OS/2 (около 1989 года), которая фактически была эквивалентом Sybase SQL Server 3.0 для Unix, VMS и др. Microsoft SQL Server 4.2 был выпущен в 1992 году и входил в состав операционной системы Microsoft OS/2 версии 1.3. Официальный релиз Microsoft SQL Server версии 4.21 для ОС Windows NT состоялся одновременно с релизом самой Windows NT (версии 3.1). Microsoft SQL Server 6.0 был первой версией SQL Server, созданной исключительно для архитектуры NT и без участия в процессе разработки Sybase.
К тому времени, как вышла на рынок ОС Windows NT, Sybase и Microsoft разошлись и следовали собственным моделям программного продукта и маркетинговым схемам. Microsoft добивалась исключительных прав на все версии SQL Server для Windows. Позже Sybase изменила название своего продукта на Adaptive Server Enterprise во избежание путаницы с Microsoft SQL Server. До 1994 года Microsoft получила от Sybase три уведомления об авторских правах как намёк на происхождение Microsoft SQL Server.
После разделения компании сделали несколько самостоятельных релизов программ. SQL Server 7.0 был первым сервером баз данных с настоящим пользовательским графическим интерфейсом администрирования. Для устранения претензий со стороны Sybase в нарушении авторских прав, весь наследуемый код в седьмой версии был переписан.
Версия SQL Server 2005 — была представлена в ноябре 2005 года. Запуск версии происходил параллельно запуску Visual Studio 2005. Существует также «урезанная» версия Microsoft SQL Server — Microsoft SQL Server Express; она доступна для скачивания и может бесплатно распространяться вместе с использующим её программным обеспечением.
С момента выпуска предыдущей версии SQL Server (SQL Server 2000) было осуществлено развитие интегрированной среды разработки и ряда дополнительных подсистем, входящих в состав SQL Server 2005. Изменения коснулись реализации технологии ETL (извлечение, преобразование и загрузка данных), входящей в состав компонента SQL Server Integration Services (SSIS), сервера оповещения, средств аналитической обработки многомерных моделей данных (OLAP) и сбора релевантной информации (обе службы входят в состав Microsoft Analysis Services), а также нескольких служб сообщений, а именно Service Broker и Notification Services. Помимо этого, были произведены улучшения в производительности.
Функциональность
Microsoft SQL Server в качестве языка запросов использует версию SQL, получившую название Transact-SQL (сокращённо T-SQL), являющуюся реализацией SQL-92 (стандарт ISO для SQL) с множественными расширениями. T-SQL позволяет использовать дополнительный синтаксис для хранимых процедур и обеспечивает поддержку транзакций (взаимодействие базы данных с управляющим приложением). Microsoft SQL Server и Sybase ASE для взаимодействия с сетью используют протокол уровня приложения под названием Tabular Data Stream (TDS, протокол передачи табличных данных). Протокол TDS также был реализован в проекте FreeTDS с целью обеспечить различным приложениям возможность взаимодействия с базами данных Microsoft SQL Server и Sybase.
Microsoft SQL Server также поддерживает Open Database Connectivity (ODBC) — интерфейс взаимодействия приложений с СУБД. Версия SQL Server 2005 обеспечивает возможность подключения пользователей через веб-сервисы, использующие протокол SOAP. Это позволяет клиентским программам, не предназначенным для Windows, кроссплатформенно соединяться с SQL Server. Microsoft также выпустила сертифицированный драйвер JDBC, позволяющий приложениям под управлением Java (таким как BEA и IBM WebSphere) соединяться с Microsoft SQL Server 2000 и 2005.
SQL Server поддерживает зеркалирование и кластеризацию баз данных. Кластер сервера SQL — это совокупность одинаково конфигурированных серверов; такая схема помогает распределить рабочую нагрузку между несколькими серверами. Все сервера имеют одно виртуальное имя, и данные распределяются по IP-адресам машин кластера в течение рабочего цикла. Также в случае отказа или сбоя на одном из серверов кластера доступен автоматический перенос нагрузки на другой сервер.
SQL Server поддерживает избыточное дублирование данных по трем сценариям:
- Снимок: Производится «снимок» базы данных, который сервер отправляет получателям.
- История изменений: Все изменения базы данных непрерывно передаются пользователям.
- Синхронизация с другими серверами: Базы данных нескольких серверов синхронизируются между собой. Изменения всех баз данных происходят независимо друг от друга на каждом сервере, а при синхронизации происходит сверка данных. Данный тип дублирования предусматривает возможность разрешения противоречий между БД.
В SQL Server 2005 встроена поддержка .NET Framework. Благодаря этому, хранимые процедуры БД могут быть написаны на любом языке платформы .NET, используя полный набор библиотек, доступных для .NET Framework, включая Common Type System (система обращения с типами данных в Microsoft .NET Framework). Однако, в отличие от других процессов, .NET Framework, будучи базисной системой для SQL Server 2005, выделяет дополнительную память и выстраивает средства управления SQL Server вместо того, чтобы использовать встроенные средства Windows. Это повышает производительность в сравнении с общими алгоритмами Windows, так как алгоритмы распределения ресурсов специально настроены для использования в структурах SQL Server.
Microsoft разработала конкурента Oracle Exadata и SAP HANA
Microsoft разработал новую технологию in-memory, которая будет в скором времени добавлена в SQL Server. Технология получила название Hekaton. Об этом 7 ноября 2012 года сообщил ComputerWorld.
Microsoft в стремлении ускорить процессы оперативной обработки транзакций (OLTP) добавил в SQL Server возможность использовать реляционные системы управления базами данных.
Планируется, что уже в следующей версии SQL Server будет включена возможность размещения части таблиц баз данных или даже все базы данных в памяти сервера. Так же будут добавлены дополнительные инструменты для упрощенного запуска технологии.
По словам генерального менеджера Microsoft Дуга Леланда, технология Hekaton сейчас тестируется некоторыми заказчиками. Но о более точных сроках ее запуска пока не сообщает.
Microsoft утверждает, что сервер будет быстрее выполнять операции,если необходимые таблицы и базы данных будут в памяти, а не записаны на диск, к которому необходимо будет обращаться. Гигант уверен, что технология позволит увеличить скорость обработки данных до 50 раз по сравнению с аналогичными системами для SQL Server.
Основными направлениями для использования Hekaton являются банковские онлайн системы, ERP, и другие транзакционные системы, которым необходимо оперативно связываться и использовать базы данных. Технология может быть установлена на одном сервере и далее масштабирована на остальные сервера, т.к. она не имеет жестких ограничений по используемой памяти.
Выход Hekaton может стать серьезной головной болью для таких компаний как Oracle с ее продуктом Oracle Exadata и для SAP, в частности SAP HANA. Это обусловлено тем, что технология значительно упрощает ИТ-архитектуру и снимает необходимость докупать компоненты для обработки данных, как это реализовано у конкурентов.
Дуг Леланд утверждает, что Hekaton — не первый опыт Microsoft в работе с технологиями in-memory. Так в офисном приложении Microsoft Excel используются технологии PowerPivot и Power View, позволяющие оперативно манипулировать большим объемом данных.
Microsoft также объявила о скором выходе следующей версии Data Warehouse Appliance, SQL Server 2012 Parallel Data Warehouse (PDW). А для SQL Server 2012 выпущен пакет обновлений, который в частности включает возможность пользователям Exel 2013 работать с данными, хранящимися на SQL Server.
Разработка приложений
Microsoft и другие компании производят большое число программных средств разработки, позволяющих разрабатывать бизнес-приложения с использованием баз данных Microsoft SQL Server. Microsoft SQL Server 2005 включает в себя также Common Language Runtime (CLR) Microsoft .NET, позволяющий реализовывать хранимые процедуры и различные функции приложениям, разработанным на языках платформы .NET (например, VB.NET или C#). Предыдущие версии средств разработки Microsoft использовали только API для получения функционального доступа к Microsoft SQL Server.
SQL Server Express Edition
Microsoft SQL Server Express является бесплатно распространяемой версией SQL Server, развитием системы MSDE. Данная версия имеет некоторые технические ограничения. Такие ограничения делают её непригодной для развертывания больших баз данных, но она вполне годится для ведения программных комплексов в масштабах небольшой компании. Содержит полноценную поддержку новых типов данных, в том числе XML-спецификации. Фактически, это полноценный MS SQL Server, включая все его компоненты программирования, поддержку национальных алфавитов и Unicode. Поэтому используется в приложениях, при проектировании или для самостоятельного изучения. Нет никаких препятствий для дальнейшего развёртывания накопленной базы данных на MS SQL Server неэкспрессной версии. В 2007 году Microsoft выпустила отдельную утилиту с графическим интерфейсом для администрирования данной версии, которая также доступна для бесплатного скачивания с сайта корпорации.
Особенности линейки B
Все серверы этой линейки — рэковые: они изначально предназначены для установки в стойку или шкаф. Размер всех моделей линейки B — 1U.
Во всех моделях используется оперативная память DIMM DDR4 и диски SATA III (6Gb/s) 2.5″ SSD.
Все серверы поддерживают замену дисков в горячем режиме и не содержат оптического привода. Функция горячей замены чрезвычайно важна: она позволяет заменить неисправный блок, не останавливая работу сервера.
От B1 до B3
Первые три модели данной линейки.
Какие у них параметры?
— платформа Supermicro 5019S-M SYS-5019S-M;
— поддержка одного процессора;
— 32 Гб оперативной памяти;
— блок питания мощностью 350 Вт;
— контроллер дисков Software RAID.
Чем можно дополнить? В оба сервера можно установить:
— один процессор с разъемом LGA 1151 серий Intel Xeon E3 1200v5/1200v6 и Intel Core i3-6000/7000, Pentium G4000, Celeron G3000;
— четыре модуля памяти и четыре диска 3,5”.
Серверы B1 и B2 работают на базе процессора Intel Pentium G4620, но отличаются объемом SSD:
ANDPRO-B1 — два диска по 240 Гб.
ANDPRO-B2 — два диска по 480 Гб.
ANDPRO-B3 отличается от двух предыдущих моделей процессором Intel Xeon E3 1230v6 и объемом SSD два диска по 480 Гб.
От B4 до B6
Еще три, более продвинутые модели данной линейки.
Какие у них параметры?
— платформа Supermicro 5019S-MN4 SYS-5019S-MN4;
— поддержка одного процессора (Intel Xeon E3 1275v6);
— 64 Гб оперативной памяти;
— блок питания мощностью 350 Вт;
— контроллер дисков Software RAID.
Чем можно дополнить? В оба сервера можно установить:
— один процессор с разъемом LGA 1151 серий Intel Xeon E3 1200v5/1200v6 и Intel Core i3-6000/7000, Pentium G4000, Celeron G3000;
— четыре модуля памяти и четыре диска формата 3.5”.
Серверы отличаются друг от друга объемом SSD:
ANDPRO-B4 — два диска по 480 Гб.
ANDPRO-B5 — два диска по 240 Гб и два диска по 200 Гб.
ANDPRO-B6 — два диска по 240 Гб и два диска по 480 Гб.
B7
ANDPRO-B7 — это следующая модель линейки B.
Какие у него параметры?
— платформа Intel Silver Pass R1304SPOSHORR;
— поддержка одного процессора (Intel Xeon E3 1270v6);
— 64 Гб оперативной памяти;
— четыре SSD-накопителя формата 3,5» по 480 Гб;
— два блока питания мощностью 450 Вт;
— контроллер дисков RMS3CC040.
Чем можно дополнить? В оба сервера можно установить:
— один процессор с разъемом LGA 1151 серии Intel Xeon E3 1200v5;
— четыре модуля памяти и четыре диска формата 3.5”.
От B8 до B12
Эти четыре модели, в отличие от предыдущих, являются серверами энтерпрайз-уровня.
Какие у них параметры?
— платформа Intel Silver Pass R1304SPOSHORR;
— поддержка двух процессоров (Intel Xeon E5 2620v4);
— 128 Гб оперативной памяти (кроме модели B10 с 256 Гб);
— один блок питания мощностью 1100 Вт;
— контроллер дисков Software RAID.
Чем можно дополнить? В оба сервера можно установить:
— два процессора с разъемом LGA 2011v3 серии Intel Xeon E5 2600v3;
— 24 модуля памяти и восемь диска формата 2.5”;
— один блок питания мощностью 750 Вт.
Между собой они отличаются объемом SSD-накопителей:
ANDPRO-B8 — два диска по 240 Гб и два диска по 400 Гб.
ANDPRO-B9 — два диска по 240 Гб и четыре диска по 480 Гб.
ANDPRO-B10 — два диска по 240 Гб и четыре диска по 480 Гб (а также 256 Гб оперативной памяти вместо 128 Гб).
ANDPRO-B12 — два диска по 480 Гб, а также два HDD-накопителя SAS 3.0 (12Gb/s) по 2 Тб и один SSD PCI-E 3.0×4 PCI-E.
B13
Как в и предыдущей модели, в ANDPRO-B13 установлены не только SATA III (6Gb/s) 2.5″ SSD.
Какие у него параметры?
— платформа Intel Wildcat Pass R1208WT2GSR;
— поддержка двух процессоров (Intel Xeon E5 2680v4);
— 128 Гб оперативной памяти;
— два SSD-накопителя формата 2,5” по 240 Гб, а также два HDD-накопителя SAS 3.0 (12Gb/s) формата 2,5” по 2 Тб и один SSD PCI-E 3.0×4 PCI-E объемом 2 Тб;
— один блок питания мощностью 1100 Вт;
— контроллер дисков RMS3CC080.
Чем можно дополнить? В оба сервера можно установить:
— два процессора с разъемом LGA 2011v3 серии Intel Xeon E5 2600v3;
— 24 модуля памяти и восемь диска формата 2.5”;
— один блок питания мощностью 750 Вт.
B14 и B15
Последние и самые мощные модели энтерпрайз-уровня в линейке B.
Какие у них параметры?
— платформа Intel Wolf Pass R1208WFTYSR;
— поддержка двух процессоров (предустановлен Intel Xeon Gold 6138: один в B14 и два в B15);
— два блока питания мощностью 1100 Вт;
— два SSD формата 2,5» по 240 Гб, а также один SSD PCIe NVMe 3.0 x4 PCI-E объемом 375 Гб и один SSD PCIe NVMe 3.0 x4 PCI-E объемом 2Тб;
— контроллер дисков RMS3CC080.
Чем можно дополнить? В оба сервера можно установить:
— два процессора с разъемом LGA 3647;
— 24 модуля памяти и восемь диска формата 2.5”.
Между собой они отличаются объемом оперативной памяти: 192 Гб в ANDPRO-B14 и 384 Гб в ANDPRO-B15.
Источники
- https://gb.ru/posts/chto-takoe-sql-i-kak-on-rabotaet
- https://www.zeluslugi.ru/info-czentr/it-glossary/term-sql
- https://www.osp.ru/dbms/1995/02/13031414
- http://www.STSS.ru/solutions/database_server.html
- https://www.tadviser.ru/index.php/%D0%9F%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82:Microsoft_SQL_Server
- https://zen.yandex.ru/media/andpro/kak-vybrat-server-baz-dannyh-5d6fbf9b32335400ad58c28b
Слайд %{start} из %{total}. %{slideTitle}
Пропустить Карусель
Знакомство с SQL Server 2022
SQL Server 2022 с поддержкой Azure и постоянными инновациями в области производительности и безопасности предоставляет современную платформу данных, которая поможет вам преобразовать бизнес.
Окончание — Карусель раздел
Переосмыслите свой бизнес
Быстрее внедряйте инновации в локальной среде
Microsoft SQL Server 2019 обладает встроенными интеллектуальными функциями и средствами обеспечения безопасности. Вы получаете бесплатный доступ к дополнительным возможностям, а также лучшие в своем классе средства для обеспечения производительности и гибкости при выполнении задач в локальной среде.
Ускорьте переход в облако
Воспользуйтесь эффективностью и гибкостью облачных решений — легко и быстро перенесите свои базы данных в облако, не меняя код. Получите доступ к аналитике и быстрее формируйте прогнозы благодаря Azure.
Создавайте интеллектуальные приложения
Применяйте для разработки технологии, которые вас устраивают, в том числе возможности открытого кода, расширенные за счет инноваций Майкрософт. Легко интегрируйте данные в свои приложения и используйте широкий набор когнитивных служб, чтобы создавать интеллектуальные решения, действующие подобно человеку и способные обрабатывать данные в любом масштабе.
Пользуйтесь аналитикой для преобразований
Искусственный интеллект является естественным элементом платформы для работы с данными — вы сможете быстрее извлекать полезные сведения из своих данных, как локальных, так и хранящихся в облаке. Дополните уникальную информацию, накопленную вашим предприятием, данными, собранными по всему миру, и обеспечьте осознанное принятие решений в организации.
Преимущества платформы данных Майкрософт
Скорость и гибкость
Используя гибкую платформу данных, обеспечивающую согласованность между архитектурами и ускоряющую вывод инноваций на рынок, вы сможете разрабатывать приложения и развертывать их в любых структурах.

Встроенные интеллектуальные возможности
Платформа данных Майкрософт обеспечивает интеллектуальный анализ данных, что позволяет как никогда полно и всесторонне изучить особенности вашего бизнеса и хозяйственной деятельности клиентов. Только корпорация Майкрософт предлагает ядра СУБД и пограничные службы со встроенными функциями машинного обучения, обеспечивающими улучшенную безопасность и быстрое построение прогнозов.

Решение, проверенное в корпоративных средах
Масштабируйте бизнес, не беспокоясь о безопасности, производительности и доступности, и обеспечьте себе лучшую в отрасли совокупную стоимость владения.
Цифры говорят сами за себя
98
компаний из списка Fortune 100 используют SQL Server
1 млн
прогнозов в секунду выполняется за счет Служб машинного обучения
100 трлн
транзакций в день осуществляется с помощью Azure Cosmos DB
№1
в тестах производительности TPC-E и TPC-H
Узнайте, как компании используют платформу данных Майкрософт для расширения своих возможностей
Узнайте, почему компании выбирают платформу Майкрософт для обработки своих данных
Отчет Magic Quadrant от компании Gartner по системам управления облачными базами данных
Отчет Magic Quadrant от компании Gartner по средствам бизнес-аналитики и аналитическим платформам
Следите за новостями
 |
|
| Тип | Реляционная СУБД |
|---|---|
| Разработчик | Sybase,
Ashton-Tate, Microsoft |
| Написана на | C, C++, C# |
| Операционная система | UNIX,
OS/2, Windows |
| Последняя версия | SQL Server 2014 (22 мая 2014 год) |
| Лицензия | Microsoft EULA |
| Сайт | microsoft.com/sqlserver/en/us/default.aspx |
Microsoft SQL Server — система управления реляционными базами данных (РСУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов — Transact-SQL, создан совместно Microsoft и Sybase. Transact-SQL является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями. Используется для работы с базами данных размером от персональных до крупных баз данных масштаба предприятия; конкурирует с другими СУБД в этом сегменте рынка.
| Версия | Год | Название | Кодовое имя | Внутренняя версия |
|---|---|---|---|---|
| 1.0 (OS/2) | 1989 | SQL Server 1.0 (16 bit) | Ashton-Tate / MS SQL Server | — |
| 1.1 (OS/2) | 1991 | SQL Server 1.1 (16 bit) | — | — |
| 4.21 (WinNT) | 1993 | SQL Server 4.21 | SQLNT | — |
| 6.0 | 1995 | SQL Server 6.0 | SQL95 | — |
| 6.5 | 1996 | SQL Server 6.5 | Hydra | — |
| 7.0 | 1998 | SQL Server 7.0 | Sphinx | 515 |
| — | 1999 | SQL Server 7.0 OLAP Tools | Palato mania | — |
| 8.0 | 2000 | SQL Server 2000 | Shiloh | 539 |
| 8.0 | 2003 | SQL Server 2000 64-bit | Liberty | 539 |
| 9.0 | 2005 | SQL Server 2005 | Yukon | 611 и 612 |
| 10.0 | 2008 | SQL Server 2008 | Katmai | 661 |
| 10.25 | 2010 | Azure SQL DB | Cloud Database or CloudDB | — |
| 10.50 | 2010 | SQL Server 2008 R2 | Kilimanjaro (aka KJ) | 665 |
| 11.0 | 2012 | SQL Server 2012 | Denali | 706 |
| 12.0 | 2014 | SQL Server 2014 | SQL14 | 782 |
| 13.0 | 2016 | SQL Server 2016 |
Предыстория (по 1986)[]
Развитие клиент-серверных технологий во второй половине 80-х было обусловлено развитием двух ключевых направлений, активно разрабатываемых с конца 70-х годов: персональных компьютеров с одной стороны, и компьютерных сетей — с другой. Долгое время СУБД были доступны лишь для мэйнфреймов, и лишь благодаря росту производительности процессоров для домашних компьютеров и мини-ЭВМ разработчики СУБД (как, например,Oracle) начали создавать соответствующие версии своих продуктов. Одной из первых СУРБД для ПК стала Oracle v3, выпущенная в 1983 году. На тот момент немногочисленные владельцы ПК использовали их в основном для разработки приложений и тестирования[1].
Одним из ключевых этапов в развитии СУБД стал 1986 год. К этому времени появилось еще несколько компаний-разработчиков СУБД, одной из самых заметных из них стала компания Sybase, основанная двумя годами ранее. К 1986 году Sybase начала комплектовать интеллектуальные рабочие станции (как правило, разработки Sun Microsystems или Apollo Computer) с серверами базы данных (разработанных, например, Oracle). При этом сама клиент-серверная технология сделала возможным отделение модулей обработки информации (т. н. back end) от модулей интерфейса (т. н. front end). Учтя постоянный рост проникновения компьютерных сетей, поставщики решений перешли к задачам распределения остальных задач (например, форматирование отчётов, проверка данных и т. д.) среди рабочих станций сети, оставив серверу выполнять лишь задачи, требующие централизованного решения (хранение и защита данных, оптимизация потока выполнения запросов и т. д.)[1].
Существенную роль в переходе от иерархических БД к реляционным сыграли и сами разработчики СУБД. Так, IBM к этому времени уже постепенно переводила своих клиентов с иерархических СУБД (как, например, IMS) на СУРДБ DB2 и SQL/DS. Новые СУБД хотя и уступали в скорости IMS, но превосходили её в легкости программирования и обслуживания. Поставки DB2 быстро превзошли ожидания, захватив значительную долю рынка в первый же год продаж. В сентябре 1986 года Gupta Technologies представила свою разработку SQL Base, заключающую в себе концепт сервера базы данных для ПК, объединённых в сеть. Также Gupta одной из первых реализовала прозрачный доступ к мэйнфреймам IBM с запущенными на них DB2, предоставив прямой доступ к хранившимся там данным без необходимости скачивания файлов или таблиц на рабочую станцию пользователя[1].
К концу 1986 года использование языка SQL в качестве основного для работы с данными в СУБД стало практически повсеместным. IBM, Oracle, Sybase и Gupta использовали схожий синтаксис языка SQL для отправки сообщений от клиентской части СУБД (front end) к серверной (back end), что позволяло сочетать клиентские и серверные части разных производителей. В том же году Американский национальный институт стандартов утвердил версию языка SQL в качестве международного стандарта обработки данных, что поставило под угрозу благополучие СУБД, не обладавших поддержкой языка SQL. Так, например, компания Cullinet хотя и анонсировала поддержку языка SQL в своих СУБД для миникомпьютеров, но из-за задержки в её реализации потеряла свою долю рынка СУБД, уступив IBM и её продукту DB2[1].
Первые шаги (1985—1987)[]
К этому моменту все имевшиеся у Microsoft разработки были ориентированы исключительно на домашние компьютеры, а её самым прибыльным продуктом являлась операционная система MS-DOS. Клиент-серверная обработка данных на персональных компьютерах к 1986 году только набрала популярность и по этой причине лежала вне интересов компании [источник не указан 1339 дней]. Годом ранее, в июне 1985 года, IBM и Microsoft подписали соглашение о совместной разработке (англ. Joint Development Agreement, сокр. JDA), содержащее лишь общие положения о будущей кооперации. В августе 1985 года JDA был дополнен документом под кодовым обозначением «Этап II» (англ. Phase II), содержавшим в себе планы по разработке OS/2. На тот момент продукт указывался как CP/DOS (англ. Control Program/DOS в соответствии с политикой именования продуктов IBM для мэйнфреймов, Microsoft же указывала продукт как DOS 5. В конце 1986 — начале 1987 года проект был официально переименован в OS/2 для придания схожести названия с линейкой компьютеров IBM PS/2[2].
2 апреля 1987 года OS/2 была анонсирована (версия 1.0 согласно пресс-релизу должна была выйти в первом квартале 1988 года, но в конечном итоге была выпущена в декабре 1987 года)[2]. Согласно заявленным в апреле 1987 года планам, IBM планировала добавить функциональность СУБД в OS/2, причём с использованием концепции, разработанной компанией Gupta Technologies, и заключающуюся в отправке персональным компьютером SQL-запросов к хосту через сетевые маршрутизаторы и возврате в качестве ответа лишь результатов выполнения запроса. Несмотря на то, что на протяжении уже нескольких лет разработчики ОС включали некоторые функции СУБД в свои продукты, идея IBM о реализации полноценной СУБД, встроенной в ОС, заставила многих менеджеров пересмотреть свою точку зрения на ПК как подходящую платформу для реализации многопользовательских приложений и концепции клиент-серверной технологии[1].
Вскоре после объявления, IBM анонсировало ещё и специальную, усовершенствованную версию этой ОС — OS/2 Extended Edition. Эта версия должна была комплектоваться с СУБД OS/2 Database Manager и несколькими другими сетевыми и серверными решениями. И хотя Database Manager был более ориентирован на мейнфреймы, а не на персональные компьютеры, тем не менее, на базе их общей разработки IBM могла предложить покупателям более выгодный продукт, нежели конкуренты. Необходимость в собственных разработках в области управления базами данных стала для Microsoft очевидной и весьма актуальной.
Для решения этой проблемы Microsoft обратилась к Sybase, которая на тот момент ещё не выпустила коммерческую версию своего продукта DataServer (это произошло чуть позже, в мае 1987 года и только для рабочих станций Sun под управлением UNIX). Причиной обращения было то, что предрелизная версия DataServer хоть и не была продуктом, рассчитанным на широкое применение, тем не менее за счёт реализации новых идей (клиент-серверной архитектуры, в частности) новая СУБД получила весьма неплохие отзывы. В результате подобного соглашения Microsoft получила бы эксклюзивные права на версию DataServer для OS/2 и всех ОС, разработанных самой Microsoft, а Sybase помимо роялти от Microsoft получила бы доступ к части рынка, занимаемого продуктами Microsoft (в том числе и новой OS/2). Поскольку производительность домашних ПК невысока, то Sybase рассматривала данный сегмент рынка как основу для последующих продаж своего продукта для более производительных систем на базе ОС UNIX, тем более, что Microsoft благодаря своей налаженной сети дистрибьюции могла обеспечить значительно более высокие продажи DataServer, чем сама Sybase. 27 марта 1987 года президент Microsoft Джон Ширли (англ.) и один из основателей Sybase Марк Хофманн (англ.) (являвшийся на тот момент и президентом компании) подписали договор.
На тот момент львиную долю рынка СУБД для ПК занимала компания Ashton-Tate со своей dBASE. Поскольку DataServer обладал несколько иными возможностями по сравнению с dBASE, то данные продукты в качестве потенциальных конкурентов не рассматривались. Это позволило Microsoft заключить сделку с Ashton-Tate, согласно которой последняя должна была заняться продвижением DataServer среди сообщества пользователей её dBASE.
SQL Server 1.0 (1988—1989)[]
Разработка[]
13 января 1988 года в Нью-Йорке состоялась пресс-конференция, на которой было объявлено о союзе Ashton-Tate и Microsoft для разработки нового продукта, получившего название Ashton-Tate/Microsoft SQL Server. В этот же день был выпущен совместный пресс-релиз с анонсом нового продукта, основанного на разработках Sybase. Предварительной датой выхода продукта указывалась вторая половина 1988 года[3]. Что касается ролей компаний в разработке и продвижении продукта, то согласно пресс-релизу Ashton-Tate должна была отвечать за контроль разработки в области баз данных (а также предоставить собственные разработки в этой области), а Microsoft же была отведена аналогичная роль в области технологий для работы в локальных сетях. После выхода SQL Server Ashton-Tate должна была получить лицензию на продукт у Microsoft и заняться розничными продажами по всему миру (как в виде отдельного продукта, так и в комплекте с будущими версиями dBASE), а Microsoft — поставлять продукт для OEM-производителей аппаратного обеспечения[4].
SQL Server уже сразу позиционировался как реляционная СУБД с поддержкой языка SQL и возможностью работы по локальной сети. Кроме того, была заявлена поддержка совместной работы SQL Server с dBASE или любым другим ПО для рабочей станции. Большой упор делался на клиент-серверную архитектуру продукта, благодаря которой должны были разделиться функции клиента (англ. front-end), в котором пользователи будет видеть нужные ему данные, и сервера (англ. back-end), который эти данные будет хранить. Также Ashton-Tate и Microsoft заявляли о «трёх главных новшествах в области технологий реляционных баз данных»: поддержка хранимых процедур, компилируемых SQL Server и благодаря которым будет «значительно ускорена» выборка данных, а также поддерживаться целостность данных при работе в многопользовательской среде. Вторым новшеством была заявлена постоянная доступность ядра (не прерывая действий пользователей) для административных задач, таких как создание резервных копий данных (бэкап) и их восстановлений. Третьим новшеством была заявлена поддержка технологии, выполняющей роль моста между системами обработки онлайн-транзакций и базами данных на ПК. Сам же SQL Server должен был быть основан на архитектуре «открытой платформы», что дало бы возможность сторонним разработчикам ПО создавать прикладные программы, использующие сетевые и многопользовательские возможности SQL Server. При этом Билл Гейтс, на тот момент являвшийся председателем совета директоров Microsoft, назвал сеть «самой важной вычислительной платформой для новых и инновационных прикладных программ». Запускаться SQL Server должен был на любых сетевых серверах на базе OS/2, включая Microsoft OS/2 LAN Manaqer и IBM LAN Server, а взаимодействовать должен был с рабочими станциями под управлением OS/2, PC-DOS или MS-DOS[4].
Ashton-Tate рассматривала SQL Server как возможность завоевания рынка СУБД для домашних компьютеров, не отказываясь при этом от дальнейшего развития dBASE. При этом оба продукта должны были предлагаться и корпоративным заказчикам. Microsoft рассчитывала на продвижение SQL Server как основу транзакционно-ориентированных систем, включая различные системы учёта, библиотеки документов, системы управления исследованиями и другие. Для продвижения нового продукта обеими компаниями был намечен ряд различных семинаров и конференций, первой из которых стала конференция Microsoft Advanced Network Development Conference, назначенная на 30 марта-1 апреля в Сан-Франциско и 13-15 апреля в Нью-Йорке[4].
Sybase же, несмотря на то, что её название в наименовании нового продукта не фигурировало, являлась по сути главным разработчиком из всей троицы компаний. Вклад же Microsoft, напротив, был весьма невелик. В Sybase уже была сформирована небольшая команда, задачей которой было портирование движка DataServer на OS/2, а также перенос клиентского интерфейса DB-Library на MS-DOS и OS/2. Microsoft же отвечала за тестирование и проект-менеджмент, а также разработала несколько дополнительных утилит, облегчавших установку и администрирование SQL Server 1.0.
Новый продукт задумывался как порт Sybase DataServer на OS/2, продажами которого должны были заняться как Microsoft, так и Ashton-Tate. Параллельно разрабатываемая Ashton-Tate новая версия dBASE IV также должны была быть доступной в серверном варианте, что позволило бы использовать язык и средства разработки dBASE IV для создания клиентских приложений, способных работать с новым SQL Server. Новая клиент-серверная модель должна была дать возможность dBASE выйти на новый уровень производительности, предоставив возможность работать с данными гораздо большему количеству пользователей, чем это могла позволить распространённая на тот момент модель работы с общими файлами.
Бета-версии[]
Бета-версия Ashton-Tate/Microsoft SQL Server была выпущена 31 октября 1988 года в составе набора инструментов для сетевой разработки SQL Server Network Developer’s Kit (сокр. MDK). Данный набор содержал предрелизную версию SQL Server, документацию, программные библиотеки прикладного интерфейса для SQL Server, а также Microsoft OS/2 LAN Manager. Программные библиотеки были предназначены для компиляции (компилятором языкаСи от самой Microsoft) MS-DOS-, Windows- или OS/2-приложений, предназначенных для работы с SQL Server по локальной сети. Набор продавался исключительно для разработки ПО, но при этом к нему прилагался специальный купон, позволявший покупателям обновить версию SQL Server до полноценной после её выхода[5].
MDK продавался напрямую Ashton-Tate на территории США и Канады (а также Microsoft на территории США) по сниженной цене. Microsoft при этом предлагала существенную скидку разработчикам, которые уже приобрели набор инструментов Microsoft OS/2 Software Developer’s Kit или посетили одну из конференций Microsoft Advanced Network Development Conference. В свою очередь, Ashton-Tate также предлагала аналогичную скидку разработчикам, посетившим в 1988 году конференцию Ashton-Tate Developer’s Conference[5].
MDK обладал большим количеством ошибок и недостатков, тем не менее он работал на домашних компьютерах (с процессором, например, Intel 80286 с частотой 10МГц, 6 Мб оперативной памяти и жёстким диском объёмом 50 Мб).
Выход[]
29 апреля 1989 года началась официальная продажа Ashton-Tate/Microsoft SQL Server 1.0. Члены команды, занимавшейся SQL Server, на специальном мероприятии по сертификации команд, проходившем в Торрансе, надели майки с надписью «Ashton-Tate SQL Server: сделал вовремя и горжусь этим» (англ. Ashton-Tate SQL Server: On-Time and Proud of it)[3].
Тесты журнала Infoworld показывали, что Ashton-Tate/Microsoft SQL Server 1.0 даже при работе в сети с 24 рабочими станциями справлялся с нагрузкой быстрее, чем обычная база данных с многопользовательским режимом (наиболее распространённый тип БД на тот момент), а при использованиихранимых процедур удавалось достичь скорости отклика менее двух секунд. Также журналисты отмечали лёгкость и удобство написания тестового кода[источник не указан 1342 дня].
Профильная пресса отзывалась достаточно положительно о новом продукте, тем не менее продажи были весьма невысокими. Кроме того, разочаровывали и продажи OS/2, поскольку многие пользователи не пожелали переходить с MS-DOS на OS/2. Картину довершала возможность создавать приложения для SQL Server лишь на языке Си, поскольку выход обещанного dBASE IV Server Edition от Ashton-Tate был отложен, и аналогичная ситуация была и со сторонними разработчиками инструментов для SQL Server[источник не указан 1362 дня]. Кроме того, свою роль сыграла и конкуренция: на рынке СУБД для ПК-платформ к этому времени уже существовали XDB от компании XDB, SQLBase от Gupta Technologies и OS/2 Extended Edition (в однопользовательском режиме) от IBM[3].
К 1990 году ситуация лучше не стала. Планы по совместному продвижению продукта, в результате чего SQL Server должен был завоевать позиции в большом сообществе dBASE-разработчиков, провалились. Несмотря на перенос сроков выхода десктопной версии dBASE IV (вышла в 1989 году), она всё же содержала большое количество ошибок, благодаря чему заслужила дурную репутацию. Серверная версия (Server Edition), которая должна была упростить разработку высокопроизводительных приложений для SQL Server так и не вышла. Разработка приложений в dBASE для SQL Server стала представлять собой проблему, поскольку разработка однопользовательского запись-ориентированного приложения кардинально отличалась от разработки многопользовательских приложений, для которых нужно ещё было решать возникающие проблемы с параллельным выполнением задач, корректной параллельной работой с данными, а также невысокой пропускной способностью тогдашних локальных сетей. Первые попытки соединить инструменты dBASE с SQL Server приводили к неэффективной совместной работе этих продуктов (так, например, построчный запрос данных превращался в проблему, а курсоров с произвольным переходом по строкам тогда ещё не существовало).
В результате, Ashton-Tate, двумя годами ранее занимавшая лидирующие позиции на рынке СУБД для домашних ПК, ныне была вынуждена бороться за своё существование, что в свою очередь вынудило её вновь переключиться на свой основной продукт dBASE. Microsoft же тем временем запустила в продажу OS/2 LAN Manager под собственной торговой маркой (тогда как изначально планировалось лишь поставлять OEM-версии), и ей необходимо было, чтобы SQL Server помог заложить фундамент для разработки клиент-серверных инструментов, способных работать с Microsoft LAN Manager и Microsoft OS/2. Всё это привело к принятию решения о прекращении совместного продвижения SQL Server, после чего данный продукт был немного изменён и представлен уже как Microsoft SQL Server.
SQL Server 1.1 (1990)[]
Ещё до выхода версии 1.1 официальные представители Microsoft (в отличие от независимых аналитиков) предсказывали резкий рост продаж новой версии продукта, однако их надежды не оправдались. Microsoft SQL Server 1.1 вышел в августе 1990 года как обновление и замена для Ashton-Tate/Microsoft SQL Server 1.0, продававшегося в 1989 году[6]. На момент выхода версии 1.1 Microsoft всё ещё не рассматривала SQL Server как продукт, способный приносить прибыль сам по себе — именно поэтому он являлся лишь одним из приложений к LAN Manager (Microsoft даже начала создавать для партнёров каналы продаж обоих продуктов, хотя ранее никогда не занималась продажами в розницу решений для ЛВС). Положительную роль должен был сыграть скорый выход клиентских приложений (англ. front ends) от Borland и DataEase International (англ.), тем более, что в течение года ожидалась ещё несколько подобных решений (на тот момент их условно называли «вторым поколением»). Но при этом, не менее важная часть SQL Server — пакет устанавливаемых протоколов — всё ещё находился в разработке. TCP/IP-версия библиотеки Net-Library, первая из данного пакета, всё ещё находилась на этапе альфа-тестирования, а её DEC-NET- и SPX-версии вообще находились на этапе разработке без каких-либо объявленных сроков выхода. Кроме того, очевидная сложность клиент-серверных вычислений и ещё продолжающаяся эволюция серверных и клиентских приложений привели к тому, что первые продажи SQL Server 1.1 были весьма невысокими[7].
Возможности SQL Server 1.1, в целом, были аналогичны возможностям версии 1.0, но при этом новая версия содержала множество исправлений ошибок, проявлявшихся в версии 1.0. Кроме того, SQL Server 1.1 поддерживал обмен информацией ещё и с новой клиентской платформой — Microsoft Windows 3.0, поставки которой начались в мае 1990 года и вызывали ощутимую реакцию в компьютерной индустрии. SQL Server 1.1 теперь можно было значительно удобнее настраивать для совместной работы с LAN Manager, кроме того была усовершенствована установка продукта для работы с сетями Novell и в качестве отдельной системы разработки ПО. В комплект была включена библиотека Basic Library for SQL Server, представлявшая собой интерфейс между SQL Server и Microsoft Basic Professional Development System. Благодаря этой библиотеке была впервые добавлена поддержка этого языка[6].
Клиентская часть SQL Server 1.1 могла работать с новой версией DB-Library, интерфейса между клиентской частью и SQL Server, которая рассылалась некоторым разработчикам за месяц до выхода новой версии самого SQL Server. Новая версия DB-Library представляла собой практически полностью переписанный вариант предыдущей версии, благодаря чему она стала занимать лишь 40 Кбайт вместо прежних 80 Кб, оставляя больше памяти для DOS-приложений на клиентских системах (теперь разработчик получал 250 Кбайт для своего приложения вместо прежних 50 Кбайт, получаемых при использовании статических библиотек DB-Library, шедших в комплекте с SQL Server 1.0). Архитектура устанавливаемого протокола соединения в DB-Library теперь могла взаимодействовать с клиентами на DOS, Windows и OS/2, а также поддерживала доступ к Sybase SQL Server на других платформах. Впрочем, согласно информации от самих Microsoft и Sybase, эти драйверы всё ещё находились в стадии активной разработки[6].
Лицензирование SQL Server 1.1 предусматривало следующие варианты[6]:
- полнофункциональная версия для 5 пользователей (с возможностью дополнительного увеличения числа пользователей до 10);
- полнофункциональная версия для неограниченного количества пользователей;
- обновление версии для 5 пользователей до версии для неограниченного количества пользователей;
- обновление для версии SQL Server 1.0.
Возможность работы с SQL Server 1.1 клиентских систем разных производителей позволило последним продавать Microsoft SQL Server 1.1 наряду с собственными разработками. Первыми членами партнёрской программы SQL Business Partner Program стали Ashton-Tate, Blyth Software, Dataease International, Revelation Technologies и Sybase. Эти компании могли совершать продажи через незадолго до этого сформированную специальную сеть сбыта (англ. Microsoft Network Specialist channel), главной задачей которой до этого была продажа Microsoft LAN Manager, либо продавать конечным пользователям напрямую. Из этих пяти партнёров на момент выхода новой версии лишь Ashton-Tate могла предложить пользователям клиентскую часть для SQL Server — SQL Link for Framework III (всего же на рынке на тот момент было доступно около 40 подобных решений). Dataease International заявляла, что её решение Dataease SQL 1.0 станет доступным для покупки с 14 сентября того же года. По информации от Microsoft, оставшиеся два партнёра планировали выпустить свои решения (MS-SQL Server Bond for Advanced Revelation от Revelation Technologies и Omnis 5 от Blyth Software) в третьем квартале того же года. Выпуск Dbase IV 1.1 Server Edition производства Ashton-Tate, который должен был поддерживать и SQL Server, ожидался до конца 1990 года. В первой четверти 1991 года должны были выйти и серверные интерфейсы для поддержки прочих клиентских систем Dbase, а именно Arago Dbxl и Arago Quicksilver производства Wordtech Systems[6].
В третьей четверти 1990 года состоялся выход Access SQL (производства Software Products International) и Q+E (производства Pioneer Software), предназначенные для организации прямой связи между Microsoft Excel и SQL Server[6]. В частности, Q+E предоставлял возможность по сути всем Windows-приложениям (в том числе для версии Windows 3.0), способным работать с соединениями по технологии Dynamic Data Exchange, взаимодействовать и с SQL Server. С точки зрения пользователя, Q+E 2.5 позволял пользователям просматривать, объединять и сортировать информацию в базах данных без написания соответствующих SQL-запросов. А поскольку DDE-вызовы были встроены в само приложение Q+E, то пользователи, например, Excel могли выполнять последующую обработку данных[8].
К началу 1991 года уже несколько десятков сторонних программных продуктов могли работать с SQL Server. Значительную роль в этом сыграла поддержка со стороны SQL Server динамических библиотек, реализованных в Windows 3.0, причём в SQL Server была реализована эта поддержка практически с самого начала продаж Windows 3.0. Благодаря этому Microsoft SQL Server планомерно начал завоевывать позиции лидера среди СУБД, ориентированных на Windows-платформу. Тем не менее, несмотря на улучшение ситуации, всё ещё актуальной оставалась проблема с наличием инструментов, поддерживающих разработку на языках, отличных от Си.
В целом, политика ранней и полной поддержки приложений для Windows 3.0 обусловила и успех Microsoft SQL Server, а кроме того очевидный успех Windows как платформы также потребовал изменений как в SQL Server, так и в самой Microsoft. В частности, команда в Microsoft, занимавшаяся портированием чужого продукта, постепенно перешла к полноценному тестированию и проект-менеджменту, а затем — и к разработке собственных инструментов для облегчения установки и администрирования SQL Server. Но несмотря на то, что вместе с SQL Server 1.1 Microsoft поставляла собственное клиентское ПО и утилиты, программные библиотеки, а также инструменты для администрирования, движок SQL Server по-прежнему писался компанией Sybase, тогда как у Microsoft не было даже доступа к исходному коду. Подобная модель предусматривала, что для выполнения каких-либо запросов на изменение в функционале SQL Server (в том числе и для исправления ошибок) Microsoft должна была направлять эти запросы Sybase, которая и вносила соответствующие изменения. Microsoft же стремилась к созданию полноценной и самостоятельной команды поддержки SQL Server, для чего нанимала на работу инженеров, имевших опыт работы с базами данных. Но, не имея доступа к исходному коду, команда столкнулась с невозможностью решать критичные для клиентов вопросы поддержки продукта. Кроме этого, существовала проблема с зависимостью Microsoft от Sybase в вопросах исправления ошибок в продукте, следствием чего являлась недостаточная скорость исправления Sybase критичных ошибок, заявленных Microsoft.
В начале 1991 года Microsoft и Sybase достигли соглашения, согласно которому первая получала доступ к исходному коду SQL Server, но исключительно в режиме чтения (то есть без возможности вносить изменения). Это соглашение дало возможность команде, занимавшейся поддержкой продукта (т. н.англ. SQL Server group), читать код для лучшего понимания логики работы продукта в каких-либо неочевидных ситуациях. Помимо этого, Microsoft, воспользовавшись удобным случаем, собрала небольшую команду разработчиков, которые занялись изучением исходного кода SQL Server. Эта группа занималась построчным исследованием кода в тех частях программы, где было подозрение на наличие ошибки, и делала «виртуальные исправления ошибок» (поскольку возможности вносить изменения в код SQL Server у них по-прежнему не было). Однако, когда подобные отчеты с разбором исходного кода стали направляться в Sybase, то исправление критичных для Microsoft ошибок, стало происходить существенно быстрее. Спустя несколько месяцев в подобном режиме работы, в середине 1991 года Microsoft наконец-то получила возможность исправлять ошибки напрямую в коде. Но поскольку исходный код продукта по-прежнему контролировала Sybase, то все изменения в коде предварительно отправлялись ей на проверку. В итоге, разработчики Microsoft стали экспертами по коду SQL Server, что позволило с одной стороны улучшить его поддержку, а с другой — больше внимания уделять его качеству.
SQL Server 1.11 (1991)[]
Схема работы Microsoft SQL Server 1.11 в локальной сети Netware при помощи Microsoft Named Pipes API и стека протоколов Netware IPX/SPX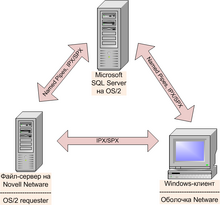
В 1991 году Microsoft выпустила промежуточную версию — SQL Server 1.11. Данный выпуск был обусловлен тем, что список пользователей к тому моменту уже значительно расширился. Несмотря на то, что клиент-серверная архитектура по-прежнему не была широко распространенной, клиенты всё же постепенно переходили на неё. Но, несмотря на положительную критику от профильной прессы, продажи SQL Server по-прежнему оставляли желать лучшего. По большей части это было связано с провалом OS/2. Пользователи домашних ПК вместо ожидаемого перехода с MS-DOS на OS/2 предпочитали переходить на Windows 3.0. Как следствие, продажи Windows 3.0 были весьма высоки. Чтобы подстегнуть продажи SQL Server и LAN Manager Microsoft объявила о начале специальной программы поддержки независимых производителей ПО, в рамках которой каждый разработчик, удовлетворяющий определённым требованиям, мог лицензировать урезанные версии этих продуктов (эти версии позволяли лишь функционировать стороннему ПО, т. н. англ. run-time versions) с 40 % скидкой и при этом получить полгода бесплатной поддержки, а также некоторые другие преимущества[9].
Как писал журнал InfoWorld в конце июля 1991 года, Microsoft при анонсе новой версии SQL Server делала упор на улучшенную работу с сетью и новое Windows-приложение для администрирования БД. В частности, Microsoft обещала в течение года предоставить копию утилиты SQL Commander для зарегистрированных пользователей SQL Server для OS/2. Инструмент под названием SQL Commander был представлен ранее, в мае 1990 года компанией Datura Corp. (ранее известной как Strategic Technologies Group). Данная утилита упрощала администраторам БД управление аккаунтами пользователей, индексами таблиц, триггерами и сложными запросами. Однако, как отмечали критики, данный инструмент практически полностью совпадал по функциональности с другой утилитой от Microsoft — Server Administration Facility tool, поставлявшейся в комплекте с SQL Server. Кроме того, в SQL Server 1.11 была добавлена поддержка инструментов для администрирования сетей Novell, новейший на тот момент инструмент OS/2 Requester 1.3 и детальная техническая документация для пользователей продукции Novell. Улучшение работы с сетью включало в себя улучшение работы с сетями фирмы Novell, добавленную поддержку протоколов Banyan VINES 4.10, а также клиентское взаимодействие с Sybase SQL Server на UNIX- или VMS-машинах. Изменения затронули и лицензионную политику: версия для 5 пользователей была заменена на десятипользовательскую версию, а пользователи SQL Server 1.1 с неограниченным количеством пользователей могли получить версию 1.11 бесплатно[10].
Но с другой стороны, SQL Server 1.11 обладал весьма ощутимыми ограничениями, в том числе и масштабируемости. Это был 16-битный продукт, поскольку OS/2 поддерживала лишь 16-битное адресное пространство для приложений, а его производительность была ограничена отсутствием механизмов высокой производительности в самой OS/2, как например, асинхроного ввода-вывода. Несмотря на то, что SQL Server на OS/2 на тот момент мог справиться с большинством задач, тем не менее существовал некий предел, после которого сервер просто начинал «захлёбываться». Чётко установленной границы не существовало, но SQL Server на OS/2 использовался для рабочих групп, численностью до 50 человек. Для более крупных групп существовала версия Sybase SQL Server для высокопроизводительных систем на базе ОС UNIX или VMS. И вот здесь как раз и проходила граница продаж между Microsoft и Sybase. Клиенты, выбирающие продукт от Microsoft хотели быть уверены, что их запросы не «перерастут» его. Большое число программных инструментов, разработанных для Microsoft SQL Server, работали без серьёзных доработок с Sybase SQL Server, а приложения, запросы которых уже не могли быть удовлетворены OS/2, легко могли быть перенесены на более мощную UNIX-систему. Подобная взаимосвязь была выгодна обеим компаниям, поскольку большое число программных инструментов для Microsoft SQL Server как правило без проблем работало и с Sybase SQL Server, а приложения, которым производительности OS/2 уже было недостаточно, легко работали и с UNIX-серверами.
SQL Server 4.2 (1991—1992)[]
Тем временем конкуренция на рынке СУБД постепенно росла, равно как и требования клиентов к выбираемому ими ПО, результатом чего при разработке следующей версии SQL Server для Microsoft на первый план вышли вопросы совместимости и взаимодействия, а также необходимость реализации новой функциональности, дабы удовлетворить запросы клиентов. Поскольку новая версия продукта нужна была как можно быстрее, то Microsoft вскоре после выхода версии SQL Server 1.11 приступила к разработке следующей версии.
Однако возник вопрос о следующем номере новой версии. Дело в том, что параллельно с продажами Microsoft SQL Server 1.0 велись продажи и Sybase SQL Server 3.0, который привнес некоторые весьма используемые механизмы на рынок СУБД для ПК, как например, типы данных text и image, а также режим просмотра данных (англ. browse mode). И следующей версией Sybase SQL Server стала версия 4.0 для наиболее распространённых платформ, и версия 4.2 — для менее распространённых. Таким образом, разработка новой версии Microsoft SQL Server фактически велась на базе исходного кода Sybase SQL Server 4.2. Соответственно, для маркетинговых целей новая версия Microsoft SQL Server также получила номер 4.2.
Однако, ещё в мае 1991 года Microsoft и IBM объявили о прекращении совместной разработки OS/2, поскольку к тому времени уже стало очевидным, что пользователи предпочитали Windows, а не OS/2. Таким образом, Microsoft решила сосредоточиться на дальнейшем развитии Windows, равно как и на ПО для них. К этому времени Microsoft уже вела разработку новой версии ОС на базе микроядра под кодовым названием NT (сокр. от англ. new technology — «новая технология»). Изначально предполагалось, что это будет новая версия OS/2 (иногда даже упоминалась как OS/2 3.0). После прекращения совместной разработки проект было решено переориентировать на Windows, то есть добавить пользовательский интерфейс в стиле Windows и программный интерфейс Win32 API, в результате чего проект получил новое название — Microsoft Windows NT.
Согласно имевшимся на тот момент планам, первая версия Windows NT должна была выйти не ранее чем через 2 года, а Microsoft SQL Server в конечном счёте должен был быть перенесён на Windows NT, что выглядело как не самый разумный ход. Однако, при всём при этом Microsoft приходилось поддерживать и разработку SQL Server для OS/2, при том, что OS/2 теперь была по сути конкурентным продуктом для самой же Microsoft. Microsoft же пошла на это, поскольку альтернативы у неё на тот момент не было.
Microsoft разрабатывала SQL Server 4.2 для грядущей OS/2 2.0, первой 32-битной версии OS/2. Поскольку SQL Server 4.2 должен был стать 32-битным, то его портирование с линейки для UNIX представлялось более простым, поскольку в этом случае проблема с сегментацией памяти не была насущной. Теоретически, 32-битный SQL Server должен был стать и более производительным. В прессе появлялось множество статей, посвящённых сравнению производительности на 16- и 32-битных платформах, и практически все авторы были уверены, что переход на 32-битность даст существенный прирост производительности (хотя в некоторых статьях и приводилось уточнение, при каких условиях это будет (или не будет) именно так). В качестве главного источника прироста производительности рассматривалась адресация памяти. Для её выполнения в 16-битном сегментированном адресном пространстве OS/2 линейки 1.x требовались как минимум 2 инструкции: первая инструкция загружала нужный сегмент памяти, вторая — загружала нужный адрес в данном сегменте. При 32-битной адресации отпадала необходимость в инструкции для загрузки сегмента, и таким образом память могла адресоваться лишь одной инструкцией. Согласно некоторым расчётам, благодаря этому потенциальный общий прирост производительности мог составить до 20 %.
На тот момент множество людей ошибочно полагало, что SQL Server должен быть запущен на полноценной 32-битной платформе, чтобы иметь возможность адресовать более 16 Мб памяти. Будучи запущенным на OS/2 1.x, приложение получало доступ лишь к 16 Мб реальной памяти. И хотя там была возможность получить более 16 Мб виртуальной памяти, но тогда начинала оказывать свое негативное влияние подкачка страниц. В OS/2 2.0 приложение могло адресовать более 16 Мб памяти и при этом избежать её подкачки. В свою очередь, это позволяло SQL Server иметь большой кэш и получать все необходимые данные из памяти быстрее, чем с диска, что очень положительно влияло на прирост производительности. Однако, с точки зрения приложений, вся память в OS/2 была виртуальной (как в версии 1.х, так и в 2.х), поэтому даже 16-битная версия SQL Server могла воспользоваться преимуществами OS/2 2.0 для получения доступа к большему пространству реальной памяти. С этой точки зрения 32-битная версия была просто не нужна.
Однако, как оказалось, первые бета-версии OS/2 2.0 были значительно медленнее OS/2 1.x, сводя на нет все преимущества нового подхода к адресации памяти. В результате, пользователи вместо ожидаемого прироста производительности наблюдали её серьёзное падение при запуске первых сборок 32-битного SQL Server 4.2 на OS/2 2.0 (по сравнению с SQL Server 1.1).
Неожиданно, планы по выходу OS/2 2.0 к концу 1991 года подверглись пересмотру. Фактически, стало непонятно, будет ли IBM вообще заниматься выпуском версии 2.0. То есть, выхода OS/2 2.0 ранее конца 1992 года ждать не приходилось. В виду этой ситуации, Microsoft вынуждена была вернуться к 16-битной реализации SQL Server и перенацелить её на OS/2 1.3. На возврат обратно к 16-битной реализации разработчикам из Microsoft потребовалось около трёх месяцев, но тут возникла другая проблема: поставляемая IBM версия OS/2 1.3 работала только на её лицензионных компьютерах. Теоретически, сторонние производители ПК могли лицензировать OS/2 у Microsoft и поставлять её как часть OEM-соглашения. Однако спрос на OS/2 упал настолько, что большинство OEM-производителей предпочли не связываться с ней, в результате чего покупка OS/2 для сторонних ПК превратилась в проблему. В качестве временного решения проблемы Microsoft создала урезанную версию OS/2 версии 1.3 (кодовое название Tiger), которая поставлялась в одной коробке с Microsoft SQL Server и Microsoft LAN Manager. При этом всё очевиднее становился тот факт, что OS/2 — это уже «мёртвая» ОС.
Бета-тест Microsoft SQL Server 4.2 начался осенью 1991 года, а в январе 1992 года на Сан-Францисской конференции для разработчиков ПО, использующих Microsoft SQL Server, Билл Гейтс, тогдашний глава (CEO) Microsoft, и Боб Эпстейн, основатель и руководитель Sybase, официально анонсировали продукт. Версия 4.2 стала первой поистине совместно разработанной версией. Движок, работающий с БД, был портирован из исходного кода версии 4.2 для UNIX, причём над портированием и исправлением ошибок инженеры Microsoft и Sybase работали совместно. Более того, Microsoft создала библиотеки клиентского интерфейса для MS-DOS, Windows и OS/2, а также впервые в комплект поставки вошёл инструмент с графическим интерфейсом Windows для упрощения администрирования. Исходный код объединялся в штаб-квартире Sybase, а файлы исходного кода пересылались туда по модемной связи или через копирование и отправку магнитных лент.
Поставки Microsoft SQL Server 4.2 начались в марте 1992 года. Критика в профильной прессе была довольно благосклонной, равно как и отзывы покупателей продукта. Тем не менее, после начала поставок в 1992 году многие задавались вопросом о сроках выхода 32-битной версии SQL Server. Как показали дальнейшие события, данная версия движка стала последней версией, полученной Microsoft от Sybase (не считая нескольких исправлений ошибок, которыми компании ещё некоторое время продолжали обмениваться).
SQL Server for Windows NT (1992—1993)[]
В начале 1992 года команда разработчиков SQL Server оказалась на распутье. С одной стороны, уже имелась клиентская база SQL Server, у которых СУБД была установлена на OS/2. Эти клиенты уже ждали 32-битную версию SQL Server, причём версию для OS/2 2.0 и желательно сразу после её выпуска OS/2 2.0 корпорацией IBM, то есть они желали оставаться на OS/2 в обозримом будущем. Но проблема была в том, что не было точно известно, когда же выйдет OS/2 2.0. Представители IBM заявляли, что выпуск новой версии состоится осенью 1992 года. Многие воспринимали эти слова со скепсисом. Так например, Стив Баллмер, старший вице-президент Microsoft, публично поклялся, что он съест флоппи-диск, если IBM выпустит свой продукт в 1992 году.
С другой стороны, от разработчиков SQL Server требовали скорейшего переноса их продукта на Windows NT, причём желательно так, чтобы бета-версии обоих продуктов вышли примерно в одно время. Windows NT на тот момент рассматривалась как продукт Microsoft верхнего ценового диапазона, а с точки зрения разработчиков эта ОС обладала ещё и несколькими техническими преимуществами по сравнению с OS/2: асинхронный ввод-вывод, симметричная многопоточность, переносимость на RISC-архитектуру.
Кроме того, хотя Microsoft и решила в 1991 году вернуться к 16-битной версии SQL Server, но при этом работа над 32-битной версией не прекращалась. К марту 1992 года, когда только вышла версия 4.2, тесты показывали, что обе версии (и 16-битная и 32-битная) на бета-версиях OS/2 2.0 работают медленнее по сравнению с 16-битной версией, запущенной на OS/2 1.3. Возможно, после официального выхода OS/2 2.0 ситуация и изменилась бы, но имевшиеся на тот момент бета-версии указывали скорее на обратное. По факту работа получалась менее производительной и менее стабильной.
Поскольку ресурсы для разработки были ограниченными, то в текущей ситуации Microsoft не могла позволить себе заниматься разработкой под обе платформы сразу. В противном случае разработчики столкнулись бы еще с дополнительным ворохом проблем, а именно им пришлось бы добавлять в продукт абстрактный слой, который скрыл бы различия между операционными системами либо вести параллельную разработку двух версий продукта. Таким образом, разработчики в Microsoft приняли решение прекратить работу над 32-битной версией SQL Server для OS/2 2.0, вместо этого они вплотную занялись разработкой продукта для Windows NT. При разработке новой версии внимания переносимости SQL Server на OS/2 или другие ОС не уделялось, вместо этого решено было воспользоваться всеми преимуществами Windows NT. Соответственно, подобный подход фактически положил конец разработке SQL Server для OS/2 вообще, за исключением поддержки уже выпущенных версий и исправления в них ошибок. Microsoft же начала информировать своих клиентов о том, что появление будущих версии (в том числе 32-битной версии) SQL Server для OS/2 2.0 будет зависеть от наличия и объёма спроса покупателей, тогда как она сама переориентировалась на Windows NT. Восприятие клиентами подобной новости было различным: некоторые отнеслись с пониманием к подобной позиции, другим, чей бизнес напрямую зависел от OS/2, такая новость не понравилась.
Тем временем, Sybase так же работала над новой версией своей СУБД, которая должна была получить название System 10. В данной ситуации, как и в случае с разработкой версии 4.2, разработчикам нужно было чтобы новая версия Microsoft SQL Server была совместима с System 10 и имела тот же порядковый номер, что и продукт Sybase, выпущенный для UNIX. Таким образом, сложилась ситуация когда для Microsoft главной целью стала победа Windows NT над OS/2, а для Sybase — успех её System 10.
Несмотря на то, что System 10 еще не была даже переведена на этап бета-тестирования, уже имелись расхождения в планировании обеими компаниями выпуска новых версий продукта. Так, например, Microsoft желала как можно скорее портировать Microsoft SQL Server на Windows NT, равно как и получить версию System 10 для Windows NT, OS/2 2.0 или обеих сразу. В результате было достигнуто соглашение о том, что Microsoft портирует SQL Server 4.2 для OS/2 на Windows NT, причём начнёт это незамедлительно, а Sybase включит Windows NT в список приоритетных ОС для System 10. Таким образом, Windows NT станет одной из первых ОС, для которых будет выпущена соответствующая версия System 10. В свою очередь, Microsoft возобновит поддержку OS/2 для Sybase, так чтобы клиенты, желающие остаться на OS/2 вполне могли это сделать. Хотя Microsoft и надеялась, что большинство клиентов мигрирует на Windows NT, но было ясно, что на все 100 % этого не произойдёт. Поэтому в этом отношении подобная договорённость была даже выгодна Microsoft.
Кроме того, подобный план действий имел дополнительные преимущества с точки зрения разработки. Команда разработчиков Microsoft должна была работать над стабильной и проверенной версией 4.2, в которой они к тому времени уже превосходно разбирались, что сильно облегчало задачу её переноса на новую ОС. Sybase же в свою очередь могла полностью сконцентрироваться на разработке новой версии, не беспокоясь о проблемах, связанных с предварительными версиями ОС. В итоге, согласно имевшемуся на тот момент (1992 год) плану должны были выйти обе версии (System 10 и SQL Server для Windows NT), а компании продолжить совместную разработку продукта.
Команда в Microsoft, занимавшаяся разработкой SQL Server, приступила к ускоренной разработке первой версии SQL Server для Windows NT, поскольку команда должна была выпустить продукт в течение 90 дней после выхода Windows NT, но согласно поставленным планам они должны были уложиться в 30 дней. Тут расчёт был на то, что Windows NT теперь фактически являлась единственной платформой для SQL Server, а значит разработчикам не было нужды беспокоиться о проблемах, связанных с портированием, и в частности не нужно было заниматься разработкой абстрактного слоя для сокрытия различий операционных систем. Роль абстрактного слоя должна была сыграть сама Windows NT, которая изначально планировалась как портируемая ОС, то есть предполагалось выпустить её версии для различных машинных архитектур.
Как следствие, разработчики сделали плотную привязку функциональности SQL Server к функциональности Windows NT, например, обработку событий в едином месте, установку SQL Server в качестве службы Windows NT, экспорт статистики производительности СУБД в Windows NT Performance Monitor и т. д. Так как Windows NT предусматривала возможность запуска приложениями динамического кода (при помощи динамических библиотек), то для SQL Server была предусмотрена возможность создавать сторонними разработчиками собственные динамические библиотеки. В результате подобных изменений Microsoft SQL Server для Windows NT сильно стал отличаться от исходной версии 4.2 для OS/2, так как оказалось, что Microsoft фактически переписала ядро SQL Server (часть программы, отвечающей за взаимодействие с ОС) для работы с Win32 API напрямую.
Ещё одной задачей при разработке SQL Server для Windows NT было облегчение перехода с имеющихся установок на OS/2 на новую версию SQL Server и ОС. Разработчики желали, чтобы все приложения, написанные для SQL Server 4.2 для OS/2 смогли работать без изменений на SQL Server для Windows NT. Поскольку для Windows NT планировалась возможность двойной загрузки с MS-DOS или OS/2, то команда решила, что SQL Server для Windows NT должен обладать способностью напрямую читать и писать в базы данных, созданные в SQL Server для OS/2. Для достижения поставленных целей разработчики переработали внутреннюю архитектуру SQL Server, добавив при этом множество функций для администрирования, работы по сети и расширяемости, тогда как от добавления внешних функций в ядро движка пришлось отказаться. Также задачей стала совместимость диалектов языка SQL и возможностей версий СУБД для Windows NT и OS/2, тогда как новые возможности предполгалось добавить в версию, которая была бы разработана на основе System 10. Для разграничения совместимости с версией 4.2 для OS/2 и новыми разработками Sybase, Microsoft приняла решение назвать свою новую версию SQL Server для Windows NT 4.2 (то есть добавив номер версии), при этом маркетинговое название продукта должно было выглядеть как Microsoft SQL Server for Windows NT, а внутреннее обозначение — SQL NT.
В июле 1992 года Microsoft провела конференцию для разработчиков ПО для платформы Windows NT и раздала альфа-версии Windows NT участникам конференции. Несмотря на то, что новая версия SQL Server не имела статсу даже «беты-версии», Microsoft всё же незамедлительно обнародовала через CompuServe 32-битные программные библиотеки, необходимые разработчикам для портирования своих приложений с OS/2 и 16-битных версий Windows на Windows NT. Сделано это было с учётом успеха распространения NDK среди разработчиков ПО для Windows 3.0 в 1990 году, Microsoft же надеялась повторить тот успех, снабдив разработчиков всеми необходимыми инструментами для разработки ПО под Windows NT.
В октябре 1992 года Microsoft выпустила первую бета-версию SQL Server для Windows NT. Данная версия обладала всем основным (из заявленного) функционалом, а все его компоненты обладали полной поддержкой Win32. Данная версия распространялась при помощи более ста сайтов. Для СУБД подобное количество сайтов являлось беспрецедентным, поскольку типичное количество сайтов, выделяемых для распространения этого типа ПО, как правило не превышало 10.
Параллельно с рассылкой NDK всё ещё продолжались поставки версии SQL Server для OS/2 (они продолжились и в следующем году). К марту 1993 года Microsoft выпустила бета-версию продукта. Данную версию (SQL Server Client/Server Development Kit (CSDK)) можно было свободно купить за небольшую плату. Для его поддержки MIcrosoft организовала открытый форум на CompuServe и не требовала с тех, кто к ней обращался, подписания соглашения о неразглашении сообщаемых сведений. Таким образом удалось реализовать более трёх тысяч комплектов CSDK. К маю 1993 года количество обращений за поддержкой предварительной версии продукта превысило количество обращений по поводу версии для OS/2. Несмотря на количество заявок, общая реакция на предварительную версию продукта была довольно положительной.
В июле 1993 года Microsoft выпустила Windows NT 3.1. В течение 30 дней после её выхода команда разработчиков SQL Server выпустила первую версию Microsoft SQL Server для Windows NT. Выход был весьма успешен: росли продажи как самой СУБД, так и ОС для неё.
К началу декабря 1993 года значительная доля клиентов мигрировала с OS/2-версии на SQL Server для Windows NT. Опросы свидетельствовали о том, что те, кто ещё не перешёл на новую версию для Windows NT, планировали это сделать даже невзирая на объявление Sybase о намерении разрабатывать System 10 для OS/2. Переход с версии SQL Server для OS/2 на версию для Windows NT для приложений происходил довольно безболезненно, а кроме того при переходе на новую версию наблюдался рост производительности. Как следствие, через 9 месяцев продажи SQL Server уже в два раза превосходили продажи на начало этого периода. При этом 90 % продаж приходилось на новую версию для Windows NT, тогда как на старую версию для OS/2 — оставшиеся 10 %.
Внутренние тесты Microsoft показывали, что ориентация на единственную платформу (Windows NT) дала свои плоды: SQL Server для Windows NT (запущенный на более дешёвом оборудовании) превосходил по производительности СУБД, работавших на UNIX и более дорогом оборудовании. В сентябре 1993 года Compaq Computer Corporation опубликовала первые результаты проведённого теста Transaction Processing Council (TPC). На тот момент, согласно тестам TPC-B, наиболее распространённым показателем являлся $1000/TPS (англ. transactions per second, транзакций в секунду). SQL Server, запущенный на машине с двумя процессорами Pentium с частотой 66 МГц, показал результат в 226 TPS при показателе $440 на транзакцию, что стало вполовину дешевле по сравнению с ранее опубликованными тестами. При этом большинство файл-серверов, работавших на миникомпьютерах под управлением UNIX, демонстрировали результаты, не превосходящие 100 TPS. И хотя были такие СУБД, которые демонстрировали значительно более высокие показатели, но и их ценовой эквивалент значительно превышал показатель в $440/TPS. Для сравнения, 18 месяцами ранее показатель производительности в 226 TPS являлся самым высоким из когда-либо достигнутых мэйнфреймами или миникомпьютерами.
SQL Server 6.0 (1993—1995)[]
Основная статья: Microsoft SQL Server 6.0
Успех Microsoft вызвал рост напряжённости в отношениях с Sybase. Ситуация на рынке СУБД в конце 1993 года уже сильно отличалась от ситуации 1987 года, когда Microsoft и Sybase подписывали контракт. В 1993 году Sybase уже являлась успешной софтверной компанией, на рынке СУБД уступая лишь корпорации Oracle. Аналогично, за прошедшее время с 1987 года значительно выросла и Microsoft. Вместе с ней выросла и команда разработчиков SQL Server (в 1990 году их было около дюжины человек, а в 1993 году — уже более 50), не считая тех, кто занимался маркетингом и поддержкой продукта. Эти разработчики уже вполне хорошо знали внутренние механизмы SQL Server, а также обладали большим опытом по разработке аналогичной версии для Windows NT. Таким образом, Microsoft уже обладала всеми необходимыми ресурсами для самостоятельной разработки SQL Server, но соглашение с Sybase 1987 года связывало её, поскольку контракт подразумевал лишь лицензирование ею разработок у Sybase. Согласно действовавшим ограничеиям этого контракта, Microsoft не могла добавлять новую функциональность или вносить любые другие изменения в код, не согласовав их предварительно с Sybase.
Ещё одним поводом для взаимного недовольства стало окончательное расхождение в потребностях при разработке SQL Server. Например, разработчики Microsoft желали интегрировать в SQL Server поддержку MAPI (Messaging API), но поскольку данная возможность была специфичной для Windows, то разработчики Sybase не спешили давать добро на её внедрение, поскольку в сфере интересов Sybase была разработка продукта для UNIX, а не для Windows NT. Поскольку Sybase с портирования своего продукта под прочие ОС не получала никакой выгоды, то инициативы Microsoft начали встречать у неё всё большее сопротивление. Фактически, перенос версии 4.2 на Windows NT уже был предметом разногласий, поскольку добавление специфичной для Windows NT функциональности версии 4.2 существенно тормозило разработку System 10 для прочих платформ. Sybase разрабатывала свою System 10 уже с прицелом на упрощение дальнейшего портирования на различные ОС (в том числе и Windows NT), но с точки зрения Microsoft это означало отказ от максимально возможного использования средств Windows NT, поскольку System 10 не могла и не смогла бы при подобном подходе работать на Windows NT также эффективно, как если бы она изначально именно для неё и разрабатывалась.
Всё это привело к тому, что теперь уже обе компании не особо нуждались друг в друге, а их соглашение 1987 года уже фактически перестало действовать. Microsoft SQL Server для Windows NT уже был вполне жизнеспособной альтернативой Sybase SQL Server, работавшему на UNIX, Novell NetWare и VMS. Теперь клиенты могли приобрести Microsoft SQL Server по стоимости, равной части стоимости подобного решения для UNIX, причём MS SQL Server можно было запустить на менее мощном (а значит и более дешёвом оборудовании) и для его администрирования требовался менее квалифицированный специалист. Роялти же от Microsoft составили бы лишь небольшую долю доходов Sybase от продаж её продуктов для UNIX. Так что обе компании уже боролись фактически за одних и тех же клиентов, но при этом уже обе понимали, что пришло время менять характер их отношений.
12 апреля 1994 года Microsoft и Sybase объявили об окончании совместной разработки SQL Server. Каждая компания решила продолжить работу над собственной версией SQL Server. Microsoft получила возможность самостоятельно, без оглядки на Sybase, разрабатывать Microsoft SQL Server. Sybase теперь без помех могла заняться портированием System 10 на Windows NT (впервые SQL Server с логотипом Sybase стал бы доступен на платформе Windows NT, поскольку их соглашение подразумевало исключительно права Microsoft на разработку под свою платформу). При этом оба продукта должны были поддерживать обратную совместимость с существовавшими на тот момент приложениями для SQL Server, однако в дальнейшем эта идея никак не поддерживалась из-за слишком различающихся целей. Sybase разрабатывала свой продукт ориентируясь в первую очередь на его совместимость с версиями для UNIX, а Microsoft — совместимость с Windows NT. Вскоре, обе линейки SQL Server стали напрямую конкурировать друг с другом, причём Microsoft вновь попала в двойственную ситуацию: ей пришлось заниматься поддержкой конкурирующего продукта (System 10) на платформе Windows NT, поскольку доступность различных продуктов позитивно влияла на продажи ОС.
В начале 1994 года команда разработчиков SQL Server для новой версии планировала взять исходный код Sybase System 10, но разрыв соглашения полностью изменил эти планы. Если не считать пары исправлений, то последние исходники от Sybase были получены в начале 1992 года (версия 4.2 для OS/2). С учётом того, что Sybase собиралась выпустить System 10 для Windows NT к концу этого года, то с точки зрения пользователей это стало бы неплохим поводом обновить свою версию СУБД, перейдя с версии Microsoft SQL Server 4.2 на Sybase System 10. В свою очередь, для Microsoft это означало потерю клиентской базы, а следовательно нужно было быстро готовить ответный шаг.
В Microsoft был быстро запланирован амбициозный релиз, содержащий множество улучшений производительности и функциональности. Будущий релиз получил кодовое обозначение SQL95, намекая на запланированный к выходу релиз Windows 95. В 1994 году был актуален вопрос репликации данных средствами СУБД, поэтому репликация стала краеугольным камнем будущего релиза. То же касалось и позиционируемых курсоров — механизм, по мнению разработчиков, просто необходимый для преодоления разрыва между приложениями, ориентированными на работу со множеством записей, и реляционной БД. Ни одна из распространённых СУБД на тот момент ещё не обладала полнофункциональной реализацией позиционируемых курсоров для клиент-серверной архитектуры, и команда разработчиков SQL Server считала, что данный механизм положительно скажется на репутации их продукта. Кроме того, шла работа над абсолютно новым набором инструментов управления под кодовым названием Starfighter (впоследствии получивший название SQL Server Enterprise Manager), который планировалось включить в следующую версию. Список новых возможностей постпенно всё более расширялся.
Общая реакция клиентов на новость о планах Microsoft самостоятельно разрабатывать SQL Server была довольно негативной. 14 июня 1994 года в Сан-Франциско Microsoft провела общую конференцию для клиентов, аналитиков и журналистов. Джим Алчин, на тот момент занимавший должность старшего вице-президента Microsoft, рассказал о планах на будущее и о планируемом выпуске SQL95. Представленные планы и проекты были восприняты с одобрением, но многие открыто высказывали скепсис в отношении сроков выхода, сомневаясь в том, что Microsoft сможет выпустить обещанный продукт к концу 1995 года. В прессе новый релиз даже саркастически именовали SQL97 и даже SQL2000. Согласно же внутренним планам, разработчики готовились представить релиз в первой половине 1995 года. Первую бета-версию выпустили в октябре 1994 года. На этот момент Starfighter ещё не был закончен, но сам сервер был уже завершён, а поскольку именно при скачивании сервера создаётся наибольшая нагрузка на сайты с бета-версиями, то было решено выпустить его бета-версию в первую очередь. После выпуска последовала череда обновлений, продолжавшаяся несколько месяцев, параллельно с увеличением количества сайтов, достигшим показателя в 2000 сайтов.
Кроме того, ещё в 1993 году Microsoft приняла решение, что базы данных будут ключевой технологией в полной продуктовой линейке, и в конце 1994 года Microsoft начала заказывать экспертные консультации со стороны DEC и других ключевых вендоров рынка для команд разработчиков, работавших над проектами Microsoft Jet and SQL Server. Целью данных консультаций являлось планирование компонентов для нового поколения продуктов для работы с базами данных. В течение 1995 года пареллельно с выпусками основной командой SQL Server 6.0 и SQL Server 6.5, вторая команда разработала новый процессор запросов как часть компонента, который впоследствии превратился в Microsoft Data Engine (MSDE). Параллельно с разработкой MSDE велась работа и над OLE DB, набором интерфейсов, который позволил бы разрабатывать элементы основного продукта SQL Server как независимые компоненты. Такие компоненты обладали бы возможностью взаимодействовать друг с другом, используя слой OLE DB.
Примерно в течение девяти месяцев работа над SQL Server велась и по ночам. 14 июня 1995 года продукт был выпущен под названием Microsoft SQL Server 6.0, таким образом уложившись во внутрикорпоративные сроки. Вслед за выпуском версии последовало множество положительных публикаций в профильной прессе. Журнал InfoWorld по результатам второго ежегодного опроса о 100 компаниях с самыми инновационными приложениями в области клиент-серверных технологий поместил Microsoft SQL Server на второе место в рейтинге среди СУБД. При этом SQL Server увеличил свою долю с 15 % до 18 % среди опрошенных, указавших данную СУБД в качестве своего выбора, тогда как доля СУБД Oracle снизилась с 24 % до 19 %, соответственно. Доля Sybase также выросла с 12 % до 14 %. Три из десяти лучших приложений, отмеченных InfoWorld, были созданы с использованием Microsoft SQL Server.
SQL Server 6.5 (1995—1996)[]
Основная статья: Microsoft SQL Server 6.5
Однако были данные и о том, что доля Microsoft SQL Server на рынке значительно меньше, чем показывали подобные опросы. Одной из проблем оставалось то, что Microsoft всё ещё оставалась новичком в секторе СУБД. На тот момент явным лидером являлась Oracle, и серьёзные позиции были у Sybase, Informix и IBM. На рынке фактически сложилась весьма тревожная ситуация для Microsoft поскольку все эти компании начали выстраивать свои тактики продаж, нацеливая их против Microsoft SQL Server. При этом Sybase, Informix и Oracle планировали выпуск новых версий своих продуктов. В рамках стратегии развития SQL Server Microsoft продолжила активное усиление команды разработчиков SQL Server, история которой на тот момент уже насчитывала более четырёх лет. Были наняты как уже известные профессионалы на тот момент как, например, Джим Грей, Дейв Ломет и Фил Бернштейн, так и менее известные разработчики, в том числе бывшие работники DEC, работавшие над Rdb.
После выхода версии 6.0 началась работа над версией 6.5. В рамках новой версии планировалось реализовать те возможности, которые были отложены при выпуске версии 6.0, тем более, что за 18 месяцев её разработки требования к СУБД существенно подросли. Например, в 1995 году большую роль уже играли Интернет и передача данных. Выпуск версии 6.5 должен был удовлетворить данные запросы. Полнофункциональная бета-версия версии 6.5 была выпущена 15 декабря 1995 года при помощи 150 бета-сайтов. Официальные поставки новой версии начались в апреле 1996, то есть примерно через 10 месяцев после выхода версии 6.0.
В функциональность также были добавлены инструменты для упрощения использования продукта пользователями, расширенная поддержка распределённых транзакций и другие возможности. Также был получен сертификат соответствия стандарту языка ANSI SQL.
Позднее, в декабре 1997 года, параллельно с выходом второй бета-версии SQL Server 7.0 была выпущена и версия SQL Server 6.5 EE, обладавшая поддержкой двухузловых отказоустойчивых кластеров Microsoft Cluster Server, 8 процессоров и адресного пространства 3 Гбайт.
SQL Server 7.0 (1996—1998)[]
Основная статья: Microsoft SQL Server 7.0
Разработка[]
В конце 1995 года началась разработка следующей версии SQL Server, получившей кодовое название Сфинкс (англ. Sphinx). Уже на первом этапе в код SQL Server был добавлен код будущего MSDE, а команда разработчиков, работавшая над ним, присоединилась к основной команде разработчиков SQL Server. Разработка нового поколения SQL Server преследовала одну главную цель: перепроектировать весь движок сервера баз данных таким образом, чтобы позволить пользователям масштабировать SQL Server согласно их желаниям. Это подразумевало собой последовательное наращивание возможностей для максимально эффективного использования более быстрых процессоров (а также увеличения их количества) и объёма памяти, доступного операционной системе. Кроме того, такое наращивание не должно было ограничивать возможность добавления новой функциональности в любой из компонентов, то есть, например, в код обработчика запросов можно было также легко добавить новый алгоритм как подключить новый жёсткий диск к компьютеру. Кроме подобного наращивания возможностей, SQL Server должен был поддерживать новые классы приложений для баз данных, а это в свою очередь означало процесс, обратный наращиванию возможностей, а именно урезание требований к аппаратному обеспечению, чтобы продукт смог работать и значительно более слабых системах, как например, домашние ПК или ноутбуки.
В ближайшей перспективе благодаря подобному перепроектированию планировалось достичь двух целей:
- реализовать полноценную блокировку на уровне строк с наличием интеллектуального менеджера блокировок;
- создать новый обработчик запросов, поддерживающий такие механизмы, как распределённые гетерогенные запросы, и эффективно обрабатывающий произвольные запросы.
Одной из областей, вызвавшей повышенное внимание при разработке, было улучшение качества работы высокоуровневых приложений, таких как программное обеспечение планирования корпоративных ресурсов. Здесь как раз и требовались масштабируемость и удобство использования вкупе с высокой надежностью ядра базы данных. Также было разработано несколько алгоритмов, которые автоматизировали большую часть процесса конфигурации базы данных и позволяли системе самостоятельно решать некоторые вопросы настройки, которые вставали перед администратором базы данных. По данным алгоритмам впоследствии Microsoft получила несколько патентов. Также велась работа и над обеспечением механизма блокировки на уровне записи. Данный механизм позволил бы приложениям обращаться к конкретной строке в таблице, а не к целой странице, что привело бы к значительному уменьшению числа конфликтов при нескольких одновременных изменениях данных в одной таблице. В версии 6.5 данный механизм имел весьма ограниченную реализацию, поэтому в новой версии предполагалась уже реализация полной блокировки на уровне записи[11].
В октябре 1996 года Microsoft приобрела технологию Plato у израильской компании Panorama Software Systems. Данная технология представляла собой одну из реализаций технологий OLAP для СУБД. На тот момент (равно как и к моменту выхода SQL Server 7.0 в 1998 году) технология OLAP считалась весьма сложной в использовании и потому была малоиспользуемой. Тем не менее было принято решение встроить Plato в код SQL Server 7.0, но с учётом требований масштабирования, предъявляемых к новой версии SQL Server, в результате потребовалась переделка Plato для соответствия аналогичным требованиям. Перед разработчиками была поставлена задача превратить её в продукт, который по масштабируемости, удобству использования и интеграции с ПО корпорации не отличался бы от любого продукта Microsoft. В дальнейшем, сервер OLAP, ставший одним из ключевых дополнений SQL Server 7.0, получил название OLAP Services[11].
В декабре 1996 года был выпущен Microsoft Transaction Server 1.0 (кодовое название — Viper), сочетающий функциональность монитора транзакций и брокера объектных запросов.
Бета-версии[]
В июне 1997 года состоялся ограниченный выпуск первой бета-версии нового SQL Server 7.0. В декабре того же года нескольким сотням пользователей была разослана для тестирования вторая бета-версия продукта. Из-за перехода к новой архитектуре при обновлении версии SQL Server пользователям требовалось полное изменение баз данных и их структур. Для поддержки перехода клиентов на новую версию была объявлена специальная программа 1K Challenge, в рамках которой 1000 клиентов могли прислать разработчикам SQL Server копии своих баз данных для портирования их на версию 7.0. Спецлаборатория для проверки результатов портирования была создана в том же редмондском кампусе, где размещалась команда разработчиков SQL Server. Еженедельно с февраля по август 1998 года четверо или пятеро сторонних компаний-разработчиков ПО на неделю присылали свои группы разработчиков в Microsoft, в течение которой они в лаборатории проверяли, что их продукты будут без каких-либо проблем работать с SQL Server 7.0. При обнаружении каких-либо проблем ведущие разработчики SQL Server сразу занимались их решением, предварительно обсудив варианты решений с гостями.
В июне 1998 года была выложена версия Beta 3 на специально выделенном для этого веб-сайте. Вместе с бета-версией было опубликовано и несколько примеров решений задач, демонстрируюших новые возможности продукта. Кроме того, был запущен специальный новостной сервер, чтобы любой пользователь версии Beta 3 мог сообщить о найденных ошибках или задать вопрос разработчикам о новых возможностях продукта. Всего более 120 тысяч тестировщиков получили SQL Server 7.0 Beta 3. В это число вошли компании, напрямую заказавшие версию через веб-сайт Microsoft, подписчики MSDN, а также участники официальной программы по бета-тестированию Microsoft Beta Program (которые получают бета-версии всех продуктов Microsoft по мере их выхода).
Перед выходом SQL Server 7.0 появились слухи о намерении Microsoft заменить Access упрощенной версией своей реляционной базой данных SQL Server. Корпорация опровергла их, заявляя о том, что в новой версии Access для Office 2000 будет два альтернативных ядра базы данных: Jet, — уже выпускаемая, «родная» среда хранения для Access, и новое MSDE. Согласно представленной тогда информации, MSDE должен был стать не встроенной версией SQL Server, а представлять собой технологию хранения данных, совместимую с SQL Server, имеющим ту же компонентную архитектуру, что в свою очередь позволило бы разработчикам, используя Access в качестве интерфейсного модуля к SQL Server, применять MSDE для создания приложений, которые могли бы масштабироваться от настольной базы данных в реляционного «старшего брата» для SQL Server или SQL Server Enterprise[11].
Выход[]
16 ноября 1998 года на конференции COMDEX в Лас-Вегасе SQL Server 7.0 был публично представлен. Представлял новую версию лично Стив Балмер. Основной упор в своём выступлении он сделал на повышении производительность SQL Server 7.0 относительно предыдущей версии. Также он отметил и вопросы, связанные с масштабируемостью и готовностью работы с приложениями. По его словам, «такие производители ERP-систем, как Baan, PeopleSoft и SAP, смогут использовать эту СУБД практически во всех своих проектах, за исключением, может быть, самых крупных». По его прогнозам в течение ближайших полутора лет независимыми производителями должно было быть создано около 3 тыс. приложений для SQL Server 7.0. К моменту же выхода данной версии было более дюжины успешных её внедрений, в том числе в таких крупных компаниях как HarperCollins, CBS Sportsline, Comcast Cellular и Southwest Securities[источник не указан 1371 день]. Причём 10 из них уже перешли на новую версию, а Pennzoil, Barnes & Noble и HarperCollins Publishers к тому моменту тестировали её уже несколько месяцев. Представители Pennzoil, News America (подразделение HarperCollins) и Barnes & Noble подтвердили возросшую производительность новой версии. Помимо самого продукта SQL Server 7.0 на COMDEX был представлен и специальный сервер для бесперебойной работы SQL Server 7.0, а производитель ERP-систем корпорация Baan представила комплект приложений BaanSeries ’99, предназначенный исключительно для SQL Server 7.0[11].
Весь цикл разработки, по словам Дуга Леланда, менеджера по маркетингу SQL Server корпорации Microsoft, длился 3,5 года. Им же новая версия позиционировалась как «первая реляционная СУБД Microsoft, которая поддерживает все её 32-разрядные операционные системы семейства Windows», причём планов по выпуску версий SQL Server для других ОС у Microsoft не было[11].
Выход же версии 7.0 состоялся 2 декабря 1998 года как билд 7.00.623.07, при этом заморозка кода состоялась 27 ноября 1998 года. Для свободного заказа продукт стал доступен в январе 1999 года.
Многие аналитики рассматривали выпуск версии 7.0 как «значительный шаг к завоеванию рынка корпоративных вычислительных систем». По их мнению, Microsoft рассчитывала на то, что благодаря переработанной функциональности SQL Server 7.0 станет корпоративным стандартом на базы данных. Добавление оперативной аналитической обработки в SQL Server 7.0 аналитиками рассматривалось как событие, которое «может стать самым важным событием, произошедшим на рынке OLAP с момента его возникновения». Причиной этого было то, что системы OLAP на тот момент были рассчитаны исключительно на корпоративный сегмент, а поскольку стратегия Microsoft предполагала создание версий и для домашних ПК в том числе, то благодаря этому технологии OLAP становятся доступными и для небольших компаний, что само по себе подразумевает значительную популяризацию OLAP[11].
Ещё одним доводом в пользу «стандартизации SQL Server 7.0» была способность SQL Server интегрироваться с остальными корпоративными системами, что было критически важно в условиях гетерогенных многоуровневых сред и наличии разнородных платформ и хранилищ данных. Для продвижения в этой области Microsoft разработала внутренние стандарты на интеграцию данных, такие как OLE DB и ADO, а также вела работу со сторонними производителями ПО. Однако, конкуренты критиковали подобные стандарты, заявляя, что «некоторые из этих стандартов — сугубо внутренние», что резко ограничивает возможность их применения сторонними заказчиками. Значительной критике подвергся в том числе и стандарт OLE DB for OLAP, который Microsoft предлагала в качестве отраслевого стандарта и вместе с тем как часть своей оболочки для создания хранилищ данных. Так, например, Джефф Джонс, менеджер программы по маркетингу систем управления данными корпорации IBM, в качестве основного недостатка называл то, что данный стандарт разрабатывался Microsoft, а не каким-либо консорциумом по стандартизации, как это широко практиковалось. На подобную критику представители Microsoft отвечали, что стандарт разрабатывался с участием более 60 производителей хранилищ данных[11].
Аналитики отмечали, что у Microsoft были все шансы добиться поставленной цели. В пользу этого говорило и активное стимулирование сторонних производителей создавать программное обеспечение для SQL Server 7.0, и модель распространения выглядела лучше чем у конкурирующих Oracle и IBM, способная в перспективе позволить продавать оптовые партии по более низкой цене и за счет этого стать серьезным игроком на рынке корпоративных баз данных[11].
Продавать новую версию планировалось по всему миру через реселлеров, сначала — оригинальную англоязычную версию, а в течение следующих двух месяцев должны были появиться и версии на французском, немецком, испанском и японском языках. К концу февраля 1999 года Microsoft планировала выпустить также и китайскую версию. С точки зрения версий продукта планировался выпуск стандартной и корпоративной версий в трёх конфигурациях каждая (в зависимости от количества допускаемых пользователй). Кроме того, было объявлено о специальном предложении, благодаря которому пользователи в течение 99 дней с момента объявления могли модернизировать свою систему до SQL Server или перейти на нее с конкурирующих СУБД, заплатив за SQL Server 7.0 всего 99 долларов на пользователя[11].
Аналитики высказывали предположения о том, что эти расценки могут вынудить конкурентов Microsoft в области баз данных снизить традиционно высокую стоимость своих продуктов (тем не менее, Oracle, например, официально отказалась пойти на такой шаг). Также аналитики довольно скептически восприняли новую версию, посчитав, что SQL Server 7.0 был предназначен в первую очередь для систем младшего класса рынка баз данных для Windows NT, тем более, что несколько участников бета-тестирования подтвердили, что новая версия полностью удовлетворяет их требованиям. Так, Херб Эдельштейн, аналитик компании Two Crows, заявил о том, что «низкие цены, установленные Microsoft, направлены на устранение конкуренции на этом рынке», при этом «даже с учётом всех новых возможностей SQL Server 7.0 сможет решить лишь часть задач, стоящих перед пользователями крупных корпораций». Бетси Бартон, аналитик компании Gartner Group, считал, что хотя и дополнения, представленные в новой версии, «заслуживают внимания», тем не менее «общая надежность и масштабируемость системы пока остается под вопросом». Однако, представители компаний, в которых тестировалась новая версия, продолжали положительно характеризовать продукт. Помимо ранее упомянутых компаний, положительно о продукте отозвались и Марк Митчел, системный консультант компании Applied Automation, и Джо Мисяжек, менеджер по поддержке приложений для системы, используемой в Colorado Community College. Они отметили доступную стоимость продукта, хорошую производительность и относительную простоту освоения[11].
Подобные шаги Microsoft вызвала ответную реакцию конкурентов. Так, например, корпорация Oracle вынуждена была изменить свою стратегию продаж. Согласно распростраённому заявлению, корпорация должна была начать продавать свою СУБД, установленную на предварительно сконфигурированных «серверных устройствах», которые используют упрощенную операционную систему, разработанную с участием самой Oracle. Согласно словам главы Oracle Ларри Эллисона, подобные нововведения должны были «снизить стоимость владения СУБД Oracle и в то же время усилить конкурентоспособность продукта в противостоянии с SQL Server компании Microsoft». В середине ноября 1998 года Oracle подписала соглашение с компаниями Dell, Compaq, Hewlett-Packard и Sun Microsystems, в соответствии с которым продажа серверов должна была начаться к концу первого квартала 1999 года. Операционная система, устанавливаемая на новых серверах, содержала компоненты Solaris (в дальнейшем предполагалось использовать компоненты Linux) и была настолько простой, что данная инициатива получила название Raw Iron («Голое железо»). Партнёры Oracle собирались предложить три типа серверов («небольшие, средние и крупные», как назвал их Эллисон), предварительно сконфигурированных для решения конкретных задач, таких как электронная почта и IFS (файловая система Internet). Таким образом, должен был состояться переход от продаж коробочной версии СУБД к продажам серверов, стоимость владения которых намного ниже. Эта стратегия, по мнению Эллисона, должна была помочь переманить часть покупателей SQL Server[11].
SQL Server 2000 (1998—2000)[]
Как и в предыдущие разы, работа над SQL Server после выхода седьмой версии не остановилась. В версию 7.0 была включена далеко не вся изначально запланированная функциональность, а кроме того имелось ещё несколько разработок, находившихся на финальных этапах, предназначенных для включения в следующий крупный релиз. Таким образом началась разработка двух версий: Шило (англ. Shiloh) — «младший» релиз версии 7.0 (условно говоря 7.5 по аналогии с предыдущим релизом), и Юкон (англ. Yukon) — следующий крупный релиз.
Изначально продукт-менеджеры SQL Server неохотно прогнозировали популярность SQL Server 7.0. Причина этого заключалась в том, что данный релиз основывался на полностью переписанном коде движка сервера, из-за чего многие клиенты рассматривали его лишь как первый релиз и было очевидно, что многие из потенциальных клиентов седьмой версии предпочтут подождать какой-нибудь «исправленной версии» либо хотя бы первого сервис-пака (пакета обновления). Так что Shiloh изначально был запланирован как некий суперсервис-пак, причём в него планировалось включить и функциональность, не вошедшую в версию 7.0 из-за сжатых сроков разработки, а также и исправление всех найденных на тот момент ошибок, что было слишком объёмно для обычной «ненумерованной» версии. Соответственно, планировалось выпустить Shiloh не позже чем через год после выхода SQL Server 7.0.
Однако сразу несколько факторов повлияли на изменение первоначальной концепции Shiloh. Во-первых, вопреки ожиданиям лишь небольшая часть клиентов сомневалась в необходимости перехода на версию 7.0, причём показатели продаж новым клиентам превосходили самые смелые ожидания. Отзывы клиентов также были вполне благожелательными. Даже после выхода SQL Server 7.0 Microsoft продолжала держать лабораторию для разработчиков стороннего ПО, благодаря чему разработчики постоянно получали отзывы и замечания клиентов. Замечания и обнаруженные ошибки легко правились в обычном порядке и пакет исправлений для SQL Server 7.0 был выпущен в мае 1999 года. Второй пакет исправлений вышел в марте 2000 года. Таким образом, необходимость в суперсервис-паке, каким изначально выглядел Shiloh, отпала.
Вторым фактором стали запросы функциональности от клиентов. Так, например, запланированная изначально реализация контроля ссылочной целостности при каскадных обновлениях и удалениях в конечном итоге в состав SQL Server 7.0 не вошла. Клиенты же высказывали чрезвычайную заинтересованность в подобном механизме и требовали реализовать его как можно скорее. Помимо этого, высказывались многочисленные пожелания относительно реализации поддержки секционированных представлений и оптимизации поддержки звездообразной схемы проектирования, широко используемой в приложениях для учёта товаров на складах.
Ещё одним фактором была конкуренция между производителями СУБД, требовавшая, чтобы следующий релиз был больше и лучше, чем это изначально планировалось. Большое влияние оказала и «задача на миллион долларов», заданная Ларри Эллисоном из Oracle Corporation, наглядно выявившей ту часть функциональности, что была уже реализована в СУБД Oracle, но всё ещё отсутствовала в SQL Server. Добавление подобной функциональности далеко выходило за рамки простого исправления.
В итоге, было принято решение сделать Shiloh полноценным крупным релизом с 18-месячным циклом разработки, но с сохранением официального номера версии 7.5. Количество изменений на тот момент прогнозировалось с трудом, и единственным изменением, о котором на тот момент было точно известно, это усовершенствование каскадных обновлений и удалений. Вскоре стало ясно, что релиз уже вырастает за рамки первоначальных планов. Параллельно росла и команда разработчиков, переселившаяся из главного кампуса Microsoft в часть офисов сдвоенного здания. Увеличение числа разработчиков позволяло добавить в продукт большое количество средних и мелких доработок без какого-либо существенного сдвига сроков выпуска продукта.
Также разработчики помимо задач улучшения и увеличения функциональности поставили перед собой т. н. «гибкие задачи». Например, он объявили о необходимости добиться 20%-го прироста производительности для всех типов приложений, но для конкретизации задачи производилось сравнение с определёнными приложениями. Так, например, одной из главных целей было улучшение показателей производительности в тесте производительностиSAP R/3 Sales and Distribution как минимум на 40 %. Для достижения поставленной задачи разработчиками были сделаны специальные изменения в оптимизаторе, напрямую влияющие на запросы от SAP, но при этом улучшающие и запросы от других приложений. 17 февраля 2000 года на мероприятии в честь выхода Windows 2000 в Сан-Фрациско были объявлены результаты измерения производительности в тесте Sales and Distribution, показавшие допустимую нагрузку в 6700 пользователей, что значительно превзошло показатели SQL Server 7.0 (4500 пользователей) на том же самом тесте и оборудовании (использовалась восьмипроцессорная машина с Pentium III-550). Таким образом, прирост производительности составил 48 %, и значит данная задача была выполнена.
После принятия решения о продлении срока разработки до 18 месяцев было принято ещё одно решение о добавлении новой функциональности. Данное решение содержалось в строжайшем секрете и не обсуждалось даже со многими руководителями в Microsoft. Новая функциональность не упоминалась даже после выхода первой бета-версии в ноябре 1999 года, и была публично прдставлена лишь в феврале на мероприятии в честь выхода Windows 2000. Этот тайный проект под кодовым именем Койот (англ. Coyote) был нацелен на добавление в SQL Server 2000 поддержки распределённых секционированных представлений, что позволило бы достичь высокой масштабируемости при работе с данными. Именно эта функциональность и позволила поставить мировой рекорд, о котором было объявлено в Сан-Франциско в феврале 2000 года. Изначально данные изменения масштабируемости были задуманы для версии, следующей за Shiloh, но поскольку большинство из необходимых компонентов уже фактически были готовы, то данную функциональность было решено добавить в SQL Server 2000. К этим изменениям относилось и расширение оптимизации объединяющих представлений, а также возможность обновлять такие представления.
Первая бета-версия Shiloh была выпущена для первых испытаний и тестирования бета-тестировщиками в сентябре 1999 года, а вскоре Microsoft объявила, что официальным названием новой версии продукта станет SQL Server 2000. Для подобной смены названий было две основные причины. Во-первых, в виду многочисленных и серьёзных изменений в новой версии было невыгодно выпускать её как промежуточную (7.5), а значит нужен был новый номер. Но во-вторых, если выпустить новую версию как 8.0, то получится, что из всего семейства Microsoft BackOffice это будет единственный продукт, не имеющий приставки 2000 в названии. Чтобы соблюсти единство названий продуктов было решено назвать продукт SQL Server 2000 (при этом внутренний номер версии всё равно выглядел как 8.00.194).
С точки зрения пользователя, SQL Server 2000 предоставлял ему гораздо больше возможностей чем предыдущая версия. SQL Server 7.0 обладал полностью переписанным движком, поддержкой новых хранимых структур, методов доступа к данным, технологий блокировки записей, алгоритмов восстановления, новой архитектурой логирования транзакций, новой архитектурой памяти и оптимизатором. Но несмотря на всё это, с точки зрения разработчика или администратора БД изменения и улучшения языка в SQL Server 7 были минимальными. SQL Server 2000 обладал многочисленными языковыми улучшениями, равно как и серьёзными изменениями в представленных ранее объектах, таких как например, табличные ограничения, представления и триггеры, в которых нуждались все разаботчики и большинство администраторов БД.
Поскольку внутренние изменения в движке были минимальны, то запланированы были лишь две бета-версии. Вторая бета-версия, вышедшая в апреле 2000 года, стала публичной бета-версией и была разослана тысячам заинтересованных пользователей, участникам специализированных конференций, сторонним разработчикам ПО и консультантам. Команда разработчиков заморозила код 6 августа 2000 года на версии 8.00.194.01, и 9 августа продукт был выпущен.
SQL Server 2005 (2000—2005)[]
Разработка следующей версии SQL Server, получившей кодовое обозначение Yukon, началась параллельно с подготовкой 64-битной версии SQL Server 2000 под кодовым названием Liberty. Liberty по функциональности представляла собой по сути ту же самую 32-битную версию, но отличие заключалось в значительно больших возможностях масштабирования. Новая же функциональность должен был быть реализован в составе Yukon.
В июле 2002 года Microsoft в рамках официальной презентации своей новой платформы .NET Framework объявила о том, что следующая версия SQL Server под кодовым названием Yukon сможет использовать возможности платформы .NET. В частности, было заявлено, что в Yukon будет проще управлять распределёнными данными[12].
24 апреля 2003 года на конференции в Сан-Франциско, посвящённой выходу Windows Server 2003, Microsoft объявила о выходе 64-битной версии SQL Server 2000 (ранее известной как Liberty). Согласно опубликованному пресс-релизу новая версия SQL Server 2000 была рассчитана на работу совместно с 64-битной версией Windows Server 2003. Третьим продуктом, представленным вместе с Windows Server 2003 и новой версией SQL Server 2000 стал Visual Studio .NET 2003. Данное трио продуктов, согласно замыслу Microsoft, представляло собой следующую ступень взаимосвязанности ОС, SQL-сервера и среды разработки, тем самым вплотную подойдя к переходу на единую платформу .NET Framework, что было в гораздо более полной мере реализовано в следующей версии SQL Server. В рамках презентации Стив Баллмер и Пол Отеллини (en) заявили, что сервер с установленной новой версией SQL Server 2000 поставил два новых рекорда согласно результатам тестов некоммерческой организации Transaction Processing Performance Council (en). Как и в предыдущих случаях, новая версия была заранее установлена для тестирования крупным партнёрам Microsoft, среди которых называлисьКорнелльский университет, Information Resources, Inc (en), JetBlue Airways, Liberty Medical Supply (en) и Университет Джонса Хопкинса, в ответ на что официальные представители этих организаций дали положительную характеристику новому продукту[13].
Целью выпуска 64-битной версии было желание начать занимать ту часть рынка, которая раньше полностью принадлежала высокопроизводительным решениям на базе систем под управлением ОС UNIX. Несмотря на то, что функциональность по сути осталась неизменным относительно 32-битной версии, 64-битная версия могла работать со значительно большим объёмом памяти, доступ к которой реализовывала 64-битная система Windows Server 2003, за счёт чего новая версия SQL Server 2000 могла масштабироваться до уровня высокопроизводительных систем, с которыми конкурировать 32-битная версия не могла в силу своих ограничений. Покупателям 32-битной версии переход на новую версию предлагался без дополнительной платы[13].
В ноябре 2003 года на конференции PASS в Сиэттле руководители Microsoft рассказали о новых механизмах ETL, реализуемых в Yukon, при помощи которых реализовывался перенос ранее накопленной информации из существующих приложений в хранилища данных. С точки зрения Microsoft эти механизмы должны были стать одним из аргументов для привлечения корпоративных пользователей. Архитектура SQL Server ETL, реализуемая в Yukon, получила название Data Transformation Services (DTS). Как отметил Гордон Манжионе, вице-президент Microsoft и глава подразделения SQL Server Team, в DTS планировалось реализовать поддержку параллелизма, благодаря чему пользователи смогут одновременно выполнять несколько сложных задач, как например, трансляция данных, их чтение и перезапись в одном потоке[14].
Помимо ETL упор делался и на упрощение конфигурирования и управления СУБД, а также улучшение масштабируемости. В частности, представители Microsoft заявляли, что, к примеру, процесс, охватывающий миллионы колонок данных, благодаря увеличению масштабируемости сможет выполняться в течение нескольких секунд, а не минут. Кроме того, в новую версию SQL Server планировалось включить функции, упрощающие создание хранилищ данных и управление ими, а также выполнение операций, связанных с интеллектуальной поддержкой бизнеса. Разработчикам Microsoft обещала новыйAPI, поддерживающий платформу .NET (и язык Visual Basic в частности), избавляя тем самым от необходимости использовать специфический код DTS[14].
Также во время конференции Манжионе объявил о завершении работ по созданию продукта Best Practices Analyzer для SQL Server 2000, поддерживающий список из 70 правил, составленный совместно разработчиками Microsoft и пользователями SQL Server. Такой список должен был упростить процесс конфигурирования СУБД администраторами баз данных и помочь им избежать самых распространенных ошибок. При этом поддерживались функции резервного копирования и восстановления после сбоев, а также управления СУБД и контроля производительности. Манжионе пообещал, что корпорация будет обновлять этот инструментарий ежеквартально[14].
SQL Server 2008 (2005—2008)[]
Версия SQL Server, которая должна была заменить SQL Server 2005, получила кодовое имя Katmai. В период активной разработки Microsoft крайне неохотно делилась информацией о новой версии. На презентации SQL Server 2005 Пол Флесснер (на тот момент занимавший пост вице-президента подразделения Microsoft, занимавшегося разработкой SQL Server), уверенно заявил, что выход новой версии состоится не позднее, чем через два года после выхода SQL Server 2005. Однако в апреле 2007 года ещё не было никакой информации о скором выходе продукта, или хотя бы о начале его бета-тестирования. Тем не менее, в австрийском блоге на TechNet была опубликована информация о программе Katmai Technology Adoption Program (сокр. TAP), начало которой было якобы запланировано на июнь 2007 года. Также были упомянуты слухи о том, что новая версия выйдет в 2008 году, но Microsoft на тот момент ни подтверждала, ни отрицала эту информацию. Некоторые источники привязывали выход Katmai к выходу Longhorn Server and Visual Studio Orcas, из-за чего согласно этой информации новая версия должна была выйти в первой половине 2008 года. Microsoft также отказывалась комментировать эту информацию[15].
Тем не менее, некоторые журналисты, общавшиеся с представителями корпорации, заявляли о том, что слухи о выходе Katmai в 2008 году вполне соответствуют внутренним планам самой Microsoft. А отказ корпорации разглашать какую-либо информацию о новой версии связывался с переходом на новую модель разработки, причём именно из-за этого Katmai вряд ли должен был выйти в начале 2008 года. Также упоминалось о том, что Katmai не получит этапа официального бета-тестирования, а вместо этого публичное тестирование пройдёт в рамках программы Community Technology Preview (сокр. CTP). При этом утверждалось, что некоторые клиенты Microsoft уже в апреле 2007 года имели на тестировании некоторые части Katmai, не имея при этом на руках релиза целиком. Что касается функциональности новой версии, то журналисты писали о том, что Katmai будет представлять собой лишь развитие SQL Server 2005, а не новое поколение продукта, которым в своё время как раз и стал SQL Server 2005[15].
SQL Server 2008 R2 (2008—2010)[]
Основная статья: Microsoft SQL Server 2008 R2
Разработка[]
После выпуска Microsoft SQL Server 2008.
Бета-версии[]
Бета-версия Microsoft SQL Server 2008 R2 выпущена в 2009 году.
Выход[]
SQL Server 2008 R2 официально стала доступна для покупки 21 апреля 2010 года.
В конце 2010 года вице-президент подразделения Microsoft Business Platform Division Тед Каммерт сообщил, что новая версия «внедряется весьма быстро», в частности, за два месяца после выхода продукта «он был загружен по каналам Интернета около 700 тысяч раз», что, по его словам, стало «самым высоким показателем для новой версии SQL Server»[16].
SQL Server 2012 (2010—2012)[]
Основная статья: Microsoft SQL Server 2012
См. также: Microsoft SQL Server Compact 4.0
Разработка[]
Параллельно с этим, 30 июня 2010 года Скотт Гатри в своём блоге анонсировал выход новой мобильной версии SQL Server — SQL Server Compact 4.0, ориентированной в первую очередь на веб-приложения, созданные на основе технологии ASP.NET 4. В качестве достоинств новой версии Гатри выделил отсутствие необходимости в установке программы, а также совместимость с API .NET Framework (поддержка технологий ADO.NET, Entity Framework,NHibernate и др., возможность работы с Visual Studio 2010 и Visual Web Developer 2010 Express) и последними на тот момент версиями SQL Server и SQL Azure[17].
7 июля 2010 года Амбриш Мишра, менеджер проекта SQL Server Compact, в официальном блоге команды разработчиков SQL Server CE представил версию CTP1 нового SQL Server Compact 4.0. В качестве нововведений (помимо указанных Скоттом Гатри) указывались повышенная надёжность, улучшение алгоритма шифрования SHA 2, совместимость с файлами БД версии Compact 3.5, упрощение установки (в том числе и поддержка режимов WOW64 и 64-битных естественных приложений), снижение использования виртуальной памяти, технология делегирования полномочий Allow Partially Trusted Caller’s Attribute (APTCA), поддержка WebMatrix Beta и Visual Studio 2010, поддержка Paging Queries в языке T-SQL. При этом версия CTP1 обладала определёнными проблемами (некорректная работа деинсталляции через командную строку, проблемы с совместимостью с актуальной на тот момент версией ADO.NET Entity Framework CTP3 и др.)[18].
Бета-версии[]
Во время конференции PASS Summit, проходившей с 8 по 11 ноября 2010 года в Сиэттле, её участникам (а также подписчикам MSDN и TechNet) раздавались копии CTP-варианта Denali (через некоторое время эта версия была выложена на официальном сайте Microsoft). На самой конференции Тед Каммерт и Квентин Кларк, генеральный менеджер подразделения Microsoft Database Systems Group, представляя новую версию, рассказали о новой функции AlwaysOn и технологии VertiPac (входящей в состав служб аналитики SQL Server и хранилищ данных). Также упор был сделан на развитие инструментов бизнес-аналитики в новой версии, интерактивных средств виртуализации на базе Web (проект Crescent), а также инструментов для разработчиков под кодовым названием Juneau[16].
22 декабря 2010 года Амбриш Мишра в официальном блоге команды разработчиков объявил о выходе версии SQL Server Compact 4.0 CTP2 и наборе инструментов Visual Studio 2010 для работы с этой версией SQL Sever CE[19].
Финальная версия SQL Server Compact 4.0 официально была выложена на сайте Microsoft 12 января 2011 года, завершив таким образом этап разработки длиной примерно год[20].
11 июля 2011 года команда разработчиков SQL Server в своём официальном блоге объявила о выходе версии Community Technology Preview 3 (сокр. CTP3) и первом сервис-паке для SQL Server 2008 R2[21]. В качестве самых существенных нововведений (относительно SQL Server 2008 R2), реализованных в CTP3-версии нового продукта, аналитики отмечали компонент SQL Server AlwaysOn для создания резервных копий БД, возможность устанавливать SQL Server в среде Windows Server Core, столбцовую организацию хранения данных для ускорения выполнения запросов, усовершенствования языка T-SQL (введение объектов Sequence и оконных функций), возможность отслеживать изменение данных (CDC) для СУБД Oracle, возможность определения пользователем ролей сервера (ранее они были жёстко закреплены), службы управления качеством данных Data Quality Services (базы знаний, определяющие правила метаданных), новый инструмент визуализации данных под названием «Проект Crescent», поддержку автономных баз данных (для перемещения между локальными экземплярами SQL Server и SQL Azure) и новую среду разработки SQL Server Developer Tools под кодовым названием Juneau[22].
SQL Server 2008 R2 SP1 содержал исправления ошибок, на которые Microsoft получила жалобы от клиентов через службу Windows Error Reporting, а также некоторые улучшения функциональности (динамические административные представления (англ. Dynamic Management Views), повышение скорости выполнения запросов при помощи технологии ForceSeek, технология Data-tier Application Component Framework (сокр. DAC Fx) для упрощения обновления БД, контроль доступного места на жёстком диске для PowerPivot)[21].
Выход[]
Вышла в 2012 году.
SQL Server 2014[]
В конце 2010 года (то есть до выхода SQL Server 2012) вице-президент подразделения Microsoft Business Platform Division Тед Каммерт в интервью рассказал о планах по дальнейшему развитию продукта (как версии SQL Server 2012, так и будущих версий). В частности, Каммерт рассказал о том, что работа над SQL Server идёт в контексте идей Information Platform Vision, представляющей собой набор разнообразных возможностей, который ложится в основу платформы. SQL Server будет по-прежнему представлять собой единый продукт, реализуемый в настольных системах, в центрах обработки данных и в «облаке» (как в 32-битном, так и 64-битном варианте). Одним из приоритетных направлений по-прежнему останется бизнес-аналитика (англ. business intelligence, BI). С точки зрения Microsoft приоритетом в области бизнес-аналитики останется разработка средств BI, реализующих принципсамообслуживания, а также развитие экосистемы «облачных» вычислений. Кроме того, Microsoft при переносе средств бизнес-аналитики в «облака» по-прежнему работает над реализацией принципа согласованности относительно реализуемых моделей программирования и инструментальных средств (это подразумевает, в частности, наращивание возможностей работы SQL Server Management Studio со средой SQL Azure). Также большое внимание уделено вопросам масштабирования СУБД (при этом лимит системы SQL Server должен быть увеличен до порога в несколько сот терабайтов), виртуализации приложений в среде баз данных, а также пространственному представлению данных[16].
Релиз SQL Server 2014 стал доступен 1 апреля 2014 года.
SQL Server 2016[]
В настоящее время разрабатывается SQL Server 2016[23], доступен Community Technology Preview 3.1 для него[24].
В нашей базе содержится 1261 разных файлов с именем sqlservr.exe . You can also check most distributed file variants with name sqlservr.exe. Чаще всего эти файлы принадлежат продукту Microsoft SQL Server. Наиболее частый разработчик — компания Microsoft Corporation. Самое частое описание этих файлов — SQL Server Windows NT. Совокупная оценка — 5(5) (комментариев: 5).Это исполняемый файл. Вы можете найти его выполняющимся в диспетчере задач как процесс sqlservr.exe.

Подробности о наиболее часто используемом файле с именем «sqlservr.exe»
- Продукт:
- Microsoft SQL Server
- Компания:
- Microsoft Corporation
- Описание:
- SQL Server Windows NT
- Версия:
- 2005.90.5000.0
- MD5:
- 837608240884733792ddae81e50b802a
- SHA1:
- 53678782b418c509940492ba2174b0b868beb373
- SHA256:
- 51f8096091a450b8bc7bb2b16bd3429df52e2b997df23d4370627ea557badcd2
- Размер:
- 29293408
- Папка:
- %PROGRAMFILES%Microsoft SQL ServerMSSQL.1MSSQLBinn
- ОС:
- Windows XP
- Частота:
- Высокая

- Цифровая подпись:
- Microsoft Corporation
Процесс «sqlservr.exe» безопасный или опасный?
100% файлов помечены как безопасные .
Последний новый вариант файла «sqlservr.exe» был обнаружен 3587 дн. назад. В нашей базе содержится 105 шт. вариантов файла «sqlservr.exe» с окончательной оценкой Безопасный и ноль вариантов с окончательной оценкой Опасный . Окончательные оценки основаны на комментариях, дате обнаружения, частоте инцидентов и результатах антивирусных проверок.
Комментарии пользователей для «sqlservr.exe»
Текущим параметрам фильтрации удовлетворяют несколько файлов. Будут показаны комментарии ко всем файлам.
Комментарии ко всем файлам с именем «sqlservr.exe»
Добавить комментарий для «sqlservr.exe»
Для добавления комментария требуется дополнительная информация об этом файле. Если вам известны размер, контрольные суммы md5/sha1/sha256 или другие атрибуты файла, который вы хотите прокомментировать, то вы можете воспользоваться расширенным поиском на главной странице .
Если подробности о файле вам неизвестны, вы можете быстро проверить этот файл с помощью нашей бесплатной утилиты. Загрузить System Explorer.
Проверьте свой ПК с помощью нашей бесплатной программы
System Explorer это наша бесплатная, удостоенная наград программа для быстрой проверки всех работающих процессов с помощью нашей базы данных. Эта программа поможет вам держать систему под контролем. Программа действительно бесплатная, без рекламы и дополнительных включений, она доступна в виде установщика и как переносное приложение. Её рекомендуют много пользователей.