И есть ли в этом смысл?

Для тех, кто задумался и сомневается, я решил описать кое-что из своего опыта.
Мониторинг вообще штука полезная, бесспорно. У меня лично в какой-то период возникло сразу несколько задач:
-
Круглосуточно и непрерывно мониторить одну специфическую железку по ряду параметров;
-
Мониторить у рабочих станций информацию о температурах, ЦП в первую очередь;
-
Всякие мелочи в связи с широким внедрением удалёнки: количество подключений по VPN, общее состояние дополнительных виртуальных машин.
Подробнее про локальные задачи:
-
Надо было оценить и наглядно представить данные об интернет-канале. Канал на тот момент представлял собой 4G-роутер Huawei. Это устройство было последним, но далеко не первым в огромном количестве плясок с бубном в попытках избавиться от разного рода нестабильностей. Забегая вперёд: забирать с него данные напрямую о качестве сигнала более-менее стандартными средствами оказалось невозможно, и даже добраться до этих данных — отдельный квест. Пришлось городить дендрофекальную конструкцию, которая, на удивление стабильно, и стала в итоге поставлять данные. Данные в динамике и в графическом представлении оказались настолько неутешительными, что позволили убедить всех причастных таки поменять канал, даже и на более дорогой;
-
Данные о температуре процессора дают сразу несколько линий: можно обнаружить шифровальщик в процессе работы, наглядно сделать вывод о недостаточной мощности рабочей станции, найти повод провести плановую чистку, узнать о нарушении условий эксплуатации. Последний пункт особенно хорош: множество отказов оборудования и BSOD’ов в итоге нашли причину в «я ставлю обогреватель под стол, ну и свой баул, ну да, прям к этой решётке. А что? А я канпуктер развернула, а то неудобно»;
-
Интерфейс того же OpenVPN… ну, он в общем даже и не интерфейс и оставляет желать любого другого. Отдельная история.
Как большой любитель велосипедить всё подряд, сначала я решил свелосипедить и это. Уже валялись под рукой всякие скрипты по сбору статистки, и html проекты с графиками на js, и какие-то тестовые БД… Но тут сработала жадность (и лень, чоужтам). А чего это, подумал я, самому опять корячиться, если в том же Zabbix уже куча всяких шаблонов, и помимо задач из списка можно будет видеть много чего ещё? Да и он бесплатный к тому же. Всего-то делов, виртуалку поднять да клиенты централизованно расставить. Потренируюсь с ним, опять же, он много где используется.
Итак, нам понадобятся:
-
Виртуальная машина или физический хост. Zabbix нетребователен к ресурсам при небольшом количестве хостов на мониторинге: мне хватило одного виртуального процессора на 2ГГц и 4 Гб RAM за глаза;
-
Любой инструмент для автоматического раскидывания zabbix-agent. При некотором скилле это можно делать даже через оригинальный WSUS, или просто батником с psexec, вариантов много. Также желательно запилить предварительно сконфигурированный инсталлятор агента — об этом ниже;
-
Много желания пилить напильником. Скажу честно и сразу: из первоначального списка 3 из 3 реализовывалось руками на местности. Zabbix стандартной комплектации в такое не может.
У Zabbix много вариантов установки. В моём случае (я начинал с 4 LTS) сработала только установка руками в чистую, из собственного образа, OC в виртуальной машине на Hyper-V. Так что, коли не получится с первого раза, — не сдавайтесь, пробуйте. Саму процедуру подробнее описывать не буду, есть куча статей и хороший официальный мануал.

Про формирование инсталлятора агента: один из самых простых способов — использовать утилиты наподобие 7zfx Builder . Нужно будет подготовить:
-
файл zabbix_agentd.conf ;
-
файлы сторонних приложений и скриптов, используемых в userParameters (об этом ниже) ;
-
скрипт инсталлятора с кодом наподобие этого:
SETLOCAL ENABLEDELAYEDEXPANSION
SET INSTDR=C:ZabbixAgent
SET IP=192.168.100.10
set ip_address_string="IPv4-адрес"
for /f "usebackq tokens=2 delims=:" %%F in (ipconfig ^| findstr /c:%ip_address_string%) do SET IP=%%F
SET IP=%IP: =%
ECHO SourceIP=%IP%>> "%INSTDR%confzabbix_agentd.conf"
ECHO ListenIP=%IP%>> "%INSTDR%confzabbix_agentd.conf"
ECHO Hostname=%COMPUTERNAME%>> "%INSTDR%confzabbix_agentd.conf"
"%INSTDR%binzabbix_agentd.exe" -c "%INSTDR%confzabbix_agentd.conf" -i
net start "Zabbix Agent"
ENDLOCALКстати, об IP. Адрес в Zabbix является уникальным идентификатором, так что при «свободном» DHCP нужно будет настроить привязки. Впрочем, это и так хорошая практика.
Также могу порекомендовать добавить в инсталлятор следующий код:
sc failure "Zabbix Agent" reset= 30 actions= restart/60000Как и многие сервисы, Zabbix agent под Windows при загрузке ОС стартует раньше, чем некоторые сетевые адаптеры. Из-за этого агент не может увидеть IP, к которому должен быть привязан, и останавливает службу. В оригинальном дистрибутиве при установке настроек перезапуска нет.
После этого добавляем хосты. Не забудьте выбрать Template – OS Windows. Если сервер не видит клиента — проверяем:
-
IP-адрес;
-
файрвол на клиенте;
-
работу службы на клиенте — смотрим zabbix_agentd.log, он вполне информативный.
По моему опыту, сервер и агенты Zabbix очень стабильны. На сервере, возможно, придётся расширить пул памяти по active checks (уведомление о необходимости такого действия появляется в дашборде), на клиентах донастроить упомянутые выше нюансы с запуском службы, а также, при наличии UserParameters, донастроить параметр timeout (пример будет ниже).
Что видно сразу, без настроек?
Сразу видно, что Zabbix заточен под другое  Но и об обычных рабочих станциях в конфигурации «из коробки» можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о «необычном» поведении. Практически из коробки (со скачиванием доп. template’ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
Но и об обычных рабочих станциях в конфигурации «из коробки» можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о «необычном» поведении. Практически из коробки (со скачиванием доп. template’ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
В общем-то, очень неплохо, но…
Что доделывать?
Оооо. Ну, хотел повелосипедить, так это всегда пожалуйста. Прежде всего, нет алертов на события типа «критические» из системного лога Windows, при том, что механизм доступа к логам Windows встроенный, а не внешний, как Zabbix agent active. Странно, ну штош. Всё придётся добавлять руками.
Например
для записи и оповещения по событию «Система перезагрузилась, завершив работу с ошибками» (Microsoft-Windows-Kernel-Power, коды 41, 1001) нужно создать Item c типом Zabbix agent (active) и кодом в поле Key:
eventlog[System,,,,1001]По этому же принципу создаём оповещения на другие коды. Странно, но готового template я не нашёл.
Cистема автоматизированной генерации по службам генерирует целую тучу спама. Часть служб в Windows предполагает в качестве нормального поведения тип запуска «авто» и остановку впоследствии. Zabbix в такое не может и будет с упорством пьяного сообщать «а BITS-то остановился!». Есть широко рекомендуемый способ избавления от такого поведения — добавление набора служб в фильтр-лист: нужно добавить в Template «Module Windows services by Zabbix agent», в разделе Macros, в фильтре {$SERVICE.NAME.NOT_MATCHES} имя службы в формате RegExp. Получается список наподобие:
^RemoteRegistry|MMCSS|gupdate|SysmonLog|
clr_optimization_v.+|clr_optimization_v.+|
sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|
MapsBroker|IntelAudioService|Intel(R) TPM Provisioning Service|
dbupdate|DoSvc|BITS.*|ShellHWDetection.*$И он не работает работает с задержкой в 30 дней.

Про службы, автоматически генерируемые в Windows 10, я вообще промолчу.
Нет никаких температур (но это, если подумать, ладно уж), нет SMART и его алертов (тоже отдельная история, конечно). Нет моих любимых UPS.
Некоторые устройства генерируют данные и алерты, работу с которыми надо выстраивать. В частности, например, управляемый свитч Tp-Link генерирует интересный алерт «скорость на порту понизилась». Почти всегда это означает, что рабочая станция просто выключена в штатном режиме (ушла в S3), но сама постановка вопроса заставляет задуматься: сведения, вообще, полезные — м.б. и драйвер глючит, железо дохнет, время странное…
Некоторые встроенные алерты требуют переработки и перенастройки. Часть из них не закрывается в «ручном» режиме по принципу «знаю, не ори, так надо» и создаёт нагромождение информации на дашборде.
Короче говоря, многое требует допиливания напильником под местные реалии и задачи.

О локальных задачах
Всё, что не встроено в Zabbix agent, реализуется через механизм Zabbix agent (active). Суть проста: пишем скрипт, который будет выдавать нужные нам данные. Прописываем наш скрипт в conf:
UserParameter=имя.параметра,путькскрипту Нюансы:
-
если хотите получать в Zabbix строку на кириллице из cmd — не надо. Только powershell;
-
если параметр специфический – для имени нужно будет придумать и сформулировать дерево параметров, наподобие «hardware.huawei.modem.link.speed» ;
-
отладка и стабильность таких параметров — вопрос и скрипта, и самого Zabbix. Об этом дальше.
Хотелка №1: температуры процессоров рабочих станций
В качестве примера реализуем хотелку «темература ЦП рабочей станции». Вам может встретиться вариант наподобие:
wmic /namespace:rootwmi PATH MSAcpi_ThermalZoneTemperature get CurrentTemperatureно это не работает (вернее, работает не всегда и не везде).
Самый простой способ, что я нашёл — воспользоваться проектом OpenHardwareMonitor. Он свои результаты выгружает прямо в тот же WMI, так что температуру получим так:
@echo OFF
SETLOCAL ENABLEDELAYEDEXPANSION
SET TMPTMP=0
for /f "tokens=* skip=1 delims=" %%I in ('wmic /namespace:rootOpenHardwareMonitor PATH Sensor WHERE Identifier^="/intelcpu/0/temperature/1" get Value') DO (
SET TMPTMP=%%I && GOTO :NXT
)
:NXT
ECHO %TMPTMP%
ENDLOCAL
GOTO :EOFКонечно, при условии, что OHM запущен. В текущем релизе OHM не умеет работать в качестве Windows service. Так что придётся либо смущать пользователей очередной иконкой в трее, либо снова городить свой инсталлятор и запихивать OHM в сервисы принудительно. Я выбрал поcледнее, создав инсталляционный cmd для всё того же 7zfx Builder наподобие:
nssm install OHMservice "%programfiles%OHMOpenHardwareMonitor.exe"
timeout 3
net start "OHMservice"
del nssm.exe /QДва момента:
-
NSSM — простая и достаточно надёжная утилита с многолетней историей. Применяется как раз в случаях, когда ПО не имеет режима работы «сервис», а надо. Во вредоносности утилита не замечена;
-
Обратите внимание на «intelcpu» в скрипте получения температуры от OHM. Т.к. речь идёт о внедрении в малом офисе, можно рассчитывать на единообразие парка техники. Более того, таким образом лично у меня получилось извлечь и температуру ЦП от AMD. Но тем не менее этот пункт требует особого внимания. Возможно, придётся модифицировать и усложнять инсталлятор для большей универсальности.
Работает более чем надёжно, проблем не замечено.
Хотелка № 2: получаем и мониторим температуру чего угодно
Понадобятся нам две вещи:
-
Штука от братского китайского народа: стандартный цифровой термометр DS18B20, совмещённый с USB-UART контроллером. Стоит не сказать что бюджетно, но приемлемо;
-
powershell cкрипт:
param($cPort='COM3')
$port= new-Object System.IO.Ports.SerialPort $cPort,9600,None,8,one
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
if (([int]$tmp -lt 1) -or ([int]$tmp -gt 55)){
#echo ("trigg "+$tmp)
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
}
echo ($tmp)Связка работает достаточно надёжно, но есть интересный момент: иногда, бессистемно, появляются провалы или пики на графиках:
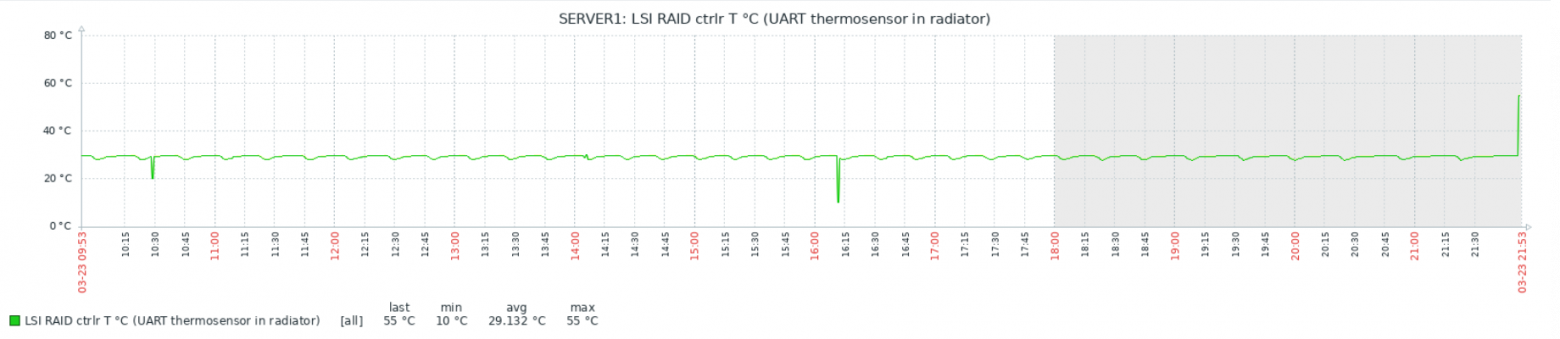
Тесты показали, что проблема в самом Zabbix, а данные с китайских датчиков приходят верные. Детальное рассмотрение пиков и провалов выявило неожиданный факт: похоже Zabbix иногда получает и/или записывает в БД не полное значение, а «хвост». Т.е., например, 1.50 от значения 21.50. При этом положение точки не важно — может получить и 1.50, и 50, и даже 0. Как так происходит, мне выяснить пока не удалось. Изменение timeout на поведение не влияет никак, ни в большую, ни в меньшую сторону.
Наверное, стоило бы написать багрепорт. Но уже вышел 6.0 LTS (у меня 5) и обновляться в текущей ситуации, пожалуй, не буду.
Хотелка № 3: OpenVPN подключения
Template’ов для OpenVPN и Zabbix существует довольно много, но все они реализованы на том или ином sh под *nix’ы . В свою очередь, «dashboard» OpenVPN-сервера представляет из себя, по сути, вывод утилиты в консоль, который пишется в файл по событиям. Мне лень было считать трафик по отдельным пользователям и вообще делать их discover, т.к. подключений и пользователей немного. Ограничился текущим количеством подключений:
$openvpnLogPath = "C:OpenVPNconfig"
$openvpnLogName = "openvpn-status.log"
try {
$logData = Get-Content $openvpnLogPath$openvpnLogName -ErrorAction Stop
}
catch{
Write-Host("Missing log file")
exit 1
}
$logHeader = "OpenVPN CLIENT LIST"
$logHeader2 = "Common Name,Real Address,Bytes Received,Bytes Sent,Connected Since"
$logMark1 = "ROUTING TABLE"
if ($logData[0] -ne $logHeader -or $logData[2] -ne $logHeader2 ){
Write-Host("Bad log file")
exit 1
}
$i = 0
foreach ($tmpStr in ($logData | select -skip 3)) {
if ($tmpStr -eq $logMark1) {break}
$i++
}
Write-Host($i)
exit 0Хотелка № 4: спецжелезка 1
Для большого количества специфического оборудования существуют написанные энтузиастами Template’ы. Обычно они используют и реализуют функционал, уже имеющийся в утилитах к этим железкам.
Боли лирическое отступление
установив один из таких темплейтов, я узнал, что «нормальная рабочая» температура чипа RAID-контроллера в серваке — 65+ градусов. Это, в свою очередь, побудило внимательнее посмотреть и на контроллер, и на сервер в целом. Были найдены косяки и выражены «фи»:
-
Apaptec’у – за игольчатый радиатор из неизвестного крашеного силумина высотой чуть более чем нихрена, поток воздуха к которому закрыт резервной батарейкой с высотой больше, чем радиатор. Особенно мне понравилось потом читать у Adaptec того же «ну, это его нормальная рабочая температура. Не волнуйтесь». Ответственно заявляю: при такой «нормальной рабочей температуре» контроллер безбожно и непредсказуемо-предсказуемо глючил;
-
Одному отечественному сборщику серверов. «Берём толстый жгут проводов. Скрепляем его, чтобы он был толстым, плотным, надёжным. Вешаем это прямо перед забором воздуха вентиляторами продува серверного корпуса. Идеально!». На «полу» сервера было дофига места, длины кабелей тоже хватало, но сделали почему-то так.
Также был замечен интересный нюанс поведения, связанный с Zabbix. Со старым RAID контроллером при наличии в системном логе специфичных репортов, отваливался мониторинг температуры контроллера в Zabbix, но! при запуске руками в консоли скрипта или спец. утилиты температура выводилась корректно и без задержек.
Но полный функционал реализован далеко не всегда. В частности, мне понадобились температуры жёстких дисков с нового RAID-контроллера (ну люблю я температуры, что поделать ), которых в оригинальном темплейте не было. Пришлось самому реализовывать температуры и заодно autodiscover физических дисков: https://github.com/automatize-it/zabbix-lsi-raid/commit/1d3a8b3a0e289b8c2df637028475177a2b940689

Оригинальный репозиторий, вероятно, заброшен, как это довольно часто бывает.
Хотелка № 5, на десерт: спецжелезка 2
Как и обещал, делюсь опытом вырывания данных из беспроводной железки Huawei. Речь о 4G роутере серии B*. Внутри себя железка имеет ПО на ASP, а данные о качестве сигнала — RSSI, SINR и прочее — в пользовательском пространстве показывать не хочет совсем. Смотри, мол, картинку с уровнем сигнала и всё, остальное не твоего юзерского ума дело. К счастью, в ПО остались какие-то хвосты, выводящие нужное в plain JSON. К сожалению, взять да скачать это wget-ом не получается никак: мало того, что авторизация, так ещё и перед генерацией plain json требуется исполнение JS на клиенте. К счастью, существует проект phantomjs. Кроме того, нам понадобится перенесённая руками кука из браузера, где мы единожды авторизовались в веб-интерфейсе, вручную. Кука живёт около полугода, можно было и скрипт написать, но я поленился.
Алгоритм действий и примеры кода:
вызываем phantomjs с кукой и сценарием:
phantomjs.exe --cookies-file=cookie.txt C:cmdyota_signalscenery.jsПримеры сценариев:
//получаем общий уровень сигнала
var url = "http://192.168.2.1/html/home.html";
var page = require('webpage').create();
page.open(url, function(status) {
//console.log("Status: " + status);
if(status === "success") {
var sgnl = page.evaluate(function() {
return document.getElementById("status_img").innerHTML; //
});
var stt = page.evaluate(function() {
return document.getElementById("index_connection_status").innerText; //
});
var sttlclzd = "dis";
var sgnlfnd = "NA";
if (stt.indexOf("Подключено") != -1) {sttlclzd = "conn";}
if (sgnl.indexOf("icon_signal_01") != -1) {sgnlfnd = "1";}
else {
var tmpndx = sgnl.indexOf("icon_signal_0");
sgnlfnd = sgnl.substring(tmpndx+13,tmpndx+14);
}
console.log(sttlclzd+","+sgnlfnd);
var fs = require('fs');
try {
fs.write("C:\cmd\siglvl.txt", sgnlfnd, 'w');
} catch(e) {
console.log(e);
}
}
phantom.exit();
});
//получаем технические параметры сигнала через какбэ предназначенный для этого "API"
var url = "http://192.168.2.1/api/device/signal";
var page = require('webpage').create();
page.onLoadFinished = function() {
//console.log("page load finished");
//page.render('export.png');
console.log(page.content);
parser = new DOMParser();
xmlDoc = parser.parseFromString(page.content,"text/xml");
var rsrq = xmlDoc.getElementsByTagName("rsrq")[0].childNodes[0].nodeValue.replace("dB","");
var rsrp = xmlDoc.getElementsByTagName("rsrp")[0].childNodes[0].nodeValue.replace("dBm","");
var rssi = xmlDoc.getElementsByTagName("rssi")[0].childNodes[0].nodeValue.replace("dBm","").replace(">=","");
var sinr = xmlDoc.getElementsByTagName("sinr")[0].childNodes[0].nodeValue.replace("dB","");
var fs = require('fs');
try {
fs.write("C:\cmd\rsrq.txt", rsrq, 'w');
fs.write("C:\cmd\rsrp.txt", rsrp, 'w');
fs.write("C:\cmd\rssi.txt", rssi, 'w');
fs.write("C:\cmd\sinr.txt", sinr, 'w');
} catch(e) {
console.log(e);
}
phantom.exit();
};
page.open(url, function() {
page.evaluate(function() {
});
});
Конструкция запускается из планировщика задач. В Zabbix-агенте производится лишь чтение соответствующих файлов:
UserParameter=internet.devices.huawei1.signal.level,type C:cmdsiglvl.txt 
Требует постоянного присмотра, ручных прибиваний и перезапусков процессов, обновления кук. Но для такого шаткого нагромождения фекалий и палок работает достаточно стабильно.
Итого
Стоит ли заморачиваться на Zabbix, если у вас 20 машин и 1-2 сервера, да ещё и инфраструктура Windows?
Как можно понять из вышеизложенного, работы будет много. Я даже рискну предположить, что объёмы работ и уровень квалификации для них сравнимы с решением «свелосипедить своё с нуля по-быстрому на коленке».
Не стоит рассматривать Zabbix как панацею или серебряную пулю.
Тем не менее, использование уже готового и популярного продукта имеет свои преимущества — в первую очередь, это релевантный опыт для интересных работодателей.
А красивые графики дают усладу глазам и часто — новое видение процессов в динамике.
Если захочется внедрить, то могу пообещать, как минимум — скучно не будет! 
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Мониторите малые офисы?
59.42%
Мониторю, Заббиксом
41
2.9%
Мониторю, не Заббиксом
2
2.9%
Мониторю, самописной системой
2
24.64%
Не мониторю, но вообще надо бы
17
10.14%
Не мониторю и не надо
7
Проголосовали 69 пользователей.
Воздержались 25 пользователей.
Шаблоны Windows в ZABBIX отличаются главным образом использованием специфическими для этой ОС счетчиками производительности. Счетчики представляют из себя встроенное средство анализа основных показателей операционной системы, некоторого программного обеспечения, а также аппаратных ресурсов. Подавляющее большинство серьезных систем мониторинга умеют использовать эти счетчики, вот и ZABBIX не исключение. В этой статье я постараюсь рассказать об основных «подводных камнях», встретившихся мне при работе с этим инструментом.
Вводная статья по шаблонам мониторинга ZABBIX — Шаблоны ZABBIX.
Если вам интересна тематика ZABBIX, рекомендую обратиться к основной статье — Система мониторинга ZABBIX, в ней вы найдете дополнительную информацию.
Прочитав документацию ZABBIX касательно настройки счетчиков (кому интересно, глава «6 Счетчики производительности Windows«), я поразился насколько все просто и был удивлен столь богатой функциональностью, но не тут то было… Поначалу я пользовался встроенными в систему шаблонами, но в итоге на некоторых узлах сети счетчики у меня работали, а на некоторых данные просто не приходили не по одному ключу. В конечном счете я решил пройти процесс создания ключа данных с использованием счетчика Windoows с самого начала и до момента пока не увижу красивые графики с необходимой мне информацией.
В руководстве все просто:
Вы можете эффективно мониторить счетчики производительности Windows используя ключ perf_counter[].
Например:
perf_counter[«Processor(0)Interrupts/sec»]
или
perf_counter[«Processor(0)Interrupts/sec», 10]
Но почему счетчики работают не на каждом узле сети? Ответ тоже прост:
В зависимости от настроек местоположения, именования счетчиков производительности могут быть разными на разных серверах Windows. Это может ввести определенные проблемы при создании шаблонов для Windows, имеющих разные настройки местоположения.
Каждый счетчик производительности может быть переведен в цифровую форму, которая является уникальной и независимой от языковых настроек, так что вы можете использовать числовое представление, а не строковое.
Для того чтобы найти цифровые эквиваленты, выполните regedit, а затем найдите HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionPerflib09.
Напрашивается следующий вывод: буквенное представление счетчиков работает только на системе с языком, который аналогичен языку счетчиков в вашем шаблоне. В итоге я решил использовать только цифровое представление и перевести все необходимые мне данные на эту форму.
С переводом все элементарно: просто ищем необходимый ключ реестра (см. выше), выгружаем данные в любой текстовый файл и ищем необходимые ключи:
Здесь вы можете найти соответствующие числа для каждой части строки счетчика производительности, как для ‘System% Processor Time’:
System -> 2
% Processor Time -> 6
Затем используйте эти числа для преобразования пути в числа:
26
UPD: 2016.05.19: есть некоторые неприятные нюансы, подробнее см. в Изменения счетчиков производительности CPU
Но тут меня ждал сюрприз: на некоторых серверах с использованием большого количества ролей я находил в этом файле несколько ключей данных! Какой из них выбрать, какой будет правильным? Я определил для себя следующие правила: поскольку счетчик состоит из двух параметров, надо найти сначала первый (ваш Кэп), запомнить примерное месторасположение в файле, а потом найти второй и если он будет выше первого по месторасположению, то игнорировать его; если же сразу после месторасположения первого мы найдем ниже него несколько одинаковых вторых ключей, то нам будет нужен ближайший к первому второй ключ. Подобная логика должна вам помочь выбрать правильный ключ данных. В противном случае получаемая информация будет некорректная или в ней не будет смысла, либо вы вообще не получите никаких данных. Нигде в интернете этого я почему-то не нашел, видимо авторы статей не слишком сильно углублялись в мониторинг счетчиков.
Далее. Следующий неприятный момент в этой системе мониторинга — это типы данных элементов мониторинга. В принципе все просто, но вы должны помнить, что тип данных автоматически не определяется и вы должны определить его самостоятельно и, что самое главное, при неправильном выборе вы останетесь без данных, они просто не будут приниматься. В случае со счетчиками производительности вам будет нужен исключительно «Числовой (с плавающей точкой)» как показано на скриншоте ниже:
Чтобы уяснить это простое правило, несколько лет назад у меня ушла куча времени и я дошел почти до отчаяния, ведь не знал ни основные проблемы при настройке, ни методики «траблшутинга». В таких случаях есть одно проверенное средство — zabbix_get, рекомендую использовать его всякий раз. когда вы находитесь в тупике.
В принципе это все, что я и хотел сказать. В интернете куча статей на тему «zabbix счетчики производительности» и копировать я их не намерен, я лишь хочу поделиться основным опытом в решении ранее казалось бы тупиковых проблем. Мало кто ставит целью не изобретение велосипеда, а описание рассуждений и логики мышления при решении обыденных для них задач, но ведь информации в интернете сейчас масса, а вырабатыванию подхода не учит почти никто.
comments powered by HyperComments
После создания элемента мониторинга создайте новый триггер, вы можете проверить, полезен ли триггер в конструкторе выражений
Выражение: {Загрузка ЦП Windows в шаблоне: perf_counter [ Processor (_Total) % времени процессора] .avg (5m)}> 80
После создания триггера добавьте график для просмотра графика использования процессора
После того, как добавление прошло успешно, вы можете просмотреть графическую таблицу CPU, и данные указывают на успешный мониторинг!
▼Примечание. Этот шаблон ввода-вывода собирает данные ввода-вывода всех физических жестких дисков всего сервера.
Например: сервер имеет твердотельный жесткий диск, механический жесткий диск, он твердотельный жесткий диск и данные механического жесткого диска отображаются вместе
При мониторинге сервера базы данных лучше всего рассматривать твердотельный диск и механический жесткий диск отдельно, используя разные пороги срабатывания.
Поскольку все жесткие диски на машине сложены вместе, очень трудно отличить триггер от твердотельного диска и механического жесткого диска
Адрес загрузки шаблона: https://files.cnblogs.com/files/Sungeek/Windows%E7%9B%91%E6%8E%A7%E7%A3%81%E7%9B%98IO.xml

4. Мониторинг Windows — изменение порога срабатывания диска
Выберите Конфигурация —> Шаблон —> (Шаблон ОС Linux / Шаблон ОС Windows)
Я здесь для мониторинга Windows, поэтому измените шаблон Windows, если вы отслеживаете Linux, вы можете изменить шаблон Linux
По умолчанию обновляется один раз в час, и изменяется до 600 секунд, то есть обновляется каждые 10 минут. Через 10 минут вы можете видеть значения мониторинга сетевой карты и диска!


Выберите конфигурацию —> шаблон —> (Шаблон ОС Linux / Шаблон ОС Windows) —> Обнаружение подключенной файловой системы —> Тип триггера
Я уже модифицировал его здесь. Если нет изменений или нет элемента триггера, вы можете нажать в правом верхнем углу (создать прототип триггера)
Имя: на диске {#FSNAME} свободное место на диске менее 50 ГБ.
Выражение: {Шаблон ОС Windows: vfs.fs.size [{# FSNAME}, бесплатно] .last (0)} <50000000000


Выберите конфигурацию —> шаблон —> (Шаблон ОС Linux / Шаблон ОС Windows) —> Обнаружение подключенной файловой системы —> Тип элемента мониторинга
Моя сторона была изменена. Если нет изменений или этот элемент мониторинга недоступен, вы можете нажать в правом верхнем углу (создать прототип элемента мониторинга)
Название: Свободное место на диске на $ 1
Выражение: vfs.fs.size [{# FSNAME}, бесплатно]
Единица измерения: B
Интервал обновления: 1 м или 60 с

5. Мониторинг правил автоматического обнаружения Windows-сетевой карты
Описание проблемы: Это шаблон Windows по умолчанию, который содержит сетевую карту сервера автообнаружения, но он автоматически найдет много других сетевых карт и другую графику.
Решение: Бесполезно удалять соответствующий графический объект напрямую, поскольку правило автоматического обнаружения будет снова автоматически обнаружено, поэтому вам необходимо изменить правило
1. Внутри правил автообнаружения —-> Обнаружение службы Windows (это можно отключить)
2. Управление —> Общее —> Регулярные выражения —> Сетевые интерфейсы для обнаружения (добавьте параметры ниже, чтобы сетевая карта не была автоматически обнаружена с этими параметрами)
1 »Microsoft [Результат неверный] 2 »Тередо [Результат ложный] 3 »Qos [результат ложный] 4 »ВПП [Результат неверный] 5 »RAS [Результат ложный] 6 »WAN [результат ложный] 7 » ^Nu[0-9.]*$ [Результат ложный] 8 » ^[Ss] ystem $ [Результат ложный] 9 » ^[Ll]o[0-9.]*$ [Результат ложный] 10 » ^NULL[0-9.]*$ [Результат ложный] 11 » ^(In)?[Ll]oop[Bb]ack[0-9._]*$ [Результат ложный] 12 » ^Программный интерфейс Loopback [результат ложный] 13 »Сетевой трафик в Broadcom NetXtreme Gigabit Ethernet [Результат неверен]


6. Настройте функцию почтовой тревоги на сервере
Я использую корпоративную электронную почту Tencent
Как показано на рисунке ниже, Management —> Alarm Media Type —> Email
Следует отметить, что в качестве имени пользователя следует указать свою служебную электронную почту, пароль ввести пароль
Сначала я подумал, что это имя электронной почты, поэтому я не мог его отправить, я мог использовать свой почтовый ящик QQ
SMTP-сервер: smtp.exmail.qq.com
Порт: 465
SMTP электронная почта: [email protected]
Имя пользователя: [email protected]

Конфигурация —> Действие —> Триггер
Создать триггер для отправки оповещений по электронной почте

Операция:
Заголовок по умолчанию: сбой {TRIGGER.STATUS}, сервер: {HOSTNAME1}: сбой {TRIGGER.NAME}!
Содержание сообщения:
Хост тревоги: {HOSTNAME1}
Время будильника: {EVENT.DATE} {EVENT.TIME}
Уровень тревоги: {TRIGGER.NAME}
Элемент тревоги: {TRIGGER.KEY1}
Подробности вопроса: {ITEM.NAME}: {ITEM.VALUE}
Текущий статус: {TRIGGER.STATUS}: {ITEM.VALUE1}
Идентификатор события: {ENET.ID}
Операция восстановления:
Заголовок по умолчанию: Восстановить {TRIGGER.STATUS}, Сервер: {HOSTNAME1}: {TRIGGER.NAME} восстановлен!
Содержание сообщения:
Хост тревоги: {HOSTNAME1}
Время будильника: {EVENT.DATE} {EVENT.TIME}
Уровень тревоги: {TRIGGER.NAME}
Элемент тревоги: {TRIGGER.KEY1}
Подробности вопроса: {ITEM.NAME}: {ITEM.VALUE}
Текущий статус: {TRIGGER.STATUS}: {ITEM.VALUE1}
Идентификатор события: {ENET.ID}
Подтвердите операцию:
Название по умолчанию: Подтверждено: {TRIGGER.NAME}
Содержание сообщения:
{USER.FULLNAME} подтвердил проблему {ACK.DATE} {ACK.TIME} следующее сообщение:
{ACK.MESSAGE}
Текущее состояние проблемы: {EVENT.STATUS}

Наконец, настройте среду тревоги, то есть, чтобы активировать условие тревоги, вам нужно отправить электронное письмо, чтобы узнать, какой почтовый ящик
Нажмите на маленький аватар, затем введите основную информацию пользователя, выберите медиа-сигнал тревоги, чтобы установить
Вы можете выбрать уровень серьезности самостоятельно. После того, как настройка включена, функция будильника установлена!


Приведу пример мониторинга использования каждого ядра процессора используя Zabbix.
Допустим на высоконагруженном NAT сервере основная нагрузка от softirq, присутствует один процессор с 8 ядрами, а также на сервере установлен Zabbix агент.
И чтобы увидеть равномерно ли распределены прерывания сетевого адаптера по ядрам процессора, создадим элементы данных на Zabbix сервере, в которых укажем:
Тип: Zabbix агент
Тип информации: Числовой (с плавающей точкой)
Единица измерения: %
А также ключ:
system.cpu.util[0,softirq,avg5]
Где 0 — номер процессора, softirq — тип нагрузки, avg5 — средняя нагрузка за 5 минут. Аналогично создадим элементы данных для других ядер процессора с ключами, а также добавим их на один график:
system.cpu.util[1,softirq,avg5] system.cpu.util[2,softirq,avg5] system.cpu.util[3,softirq,avg5] ...
Вместо softirq можно указать idle, nice, user (по умолчанию для Linux), system (по умолчанию для Windows), iowait, interrupt, softirq, steal, guest, guest_nice.
А вместо avg5 можно указать: avg1 (среднее за одну минуту, по умолчанию) или avg15 (среднее за 15 минут).

Чтобы не указывать ядра процессоров вручную, можно создать правило обнаружения:
И указать в нем элемент данных, например:
system.cpu.util[{#CPU.NUMBER},softirq,avg5]
Также можно создать триггер, чтобы узнать когда значение будет больше 90:
({ixnfo.com cpu template:system.cpu.util[0,softirq,avg5].last(0)}>90)
Ниже приведу примеры элементов данных, которые отображают различную информацию о CPU, кстати эти элементы данных по умолчанию присутствуют в шаблоне «Template OS Linux».
Processor load (1 min average per core):
system.cpu.load[percpu,avg1]
Processor load (5 min average per core):
system.cpu.load[percpu,avg5]
Processor load (15 min average per core):
system.cpu.load[percpu,avg15]
Interrupts per second:
Context switches per second:
CPU idle time:
CPU interrupt time:
system.cpu.util[,interrupt]
CPU iowait time:
CPU nice time:
CPU softirq time:
system.cpu.util[,softirq]
CPU steal time:
CPU system time:
CPU user time:
Смотрите другие мои статьи в категории Zabbix.
Как создать универсальный Zabbix шаблон для мониторинга Linux процесса, указанного по имени.
Идем в Configuration -> Templates -> Create template и добавляем имя, группу и описание шаблона.
2. Добавление макроса
Мы хотим мониторить 3 параметра:
- количество процессов, с уведомлением о том, что процессов стало меньше (упали)
- использование памяти, с уведомлением о превышении
- использование процессора, с уведомлением о превышении
Давайте тут же определим значения по умолчанию. Для этого мы будем использовать макросы шаблона (вкладка Macros), чтобы потом была возможность заменить их для каждого хоста.
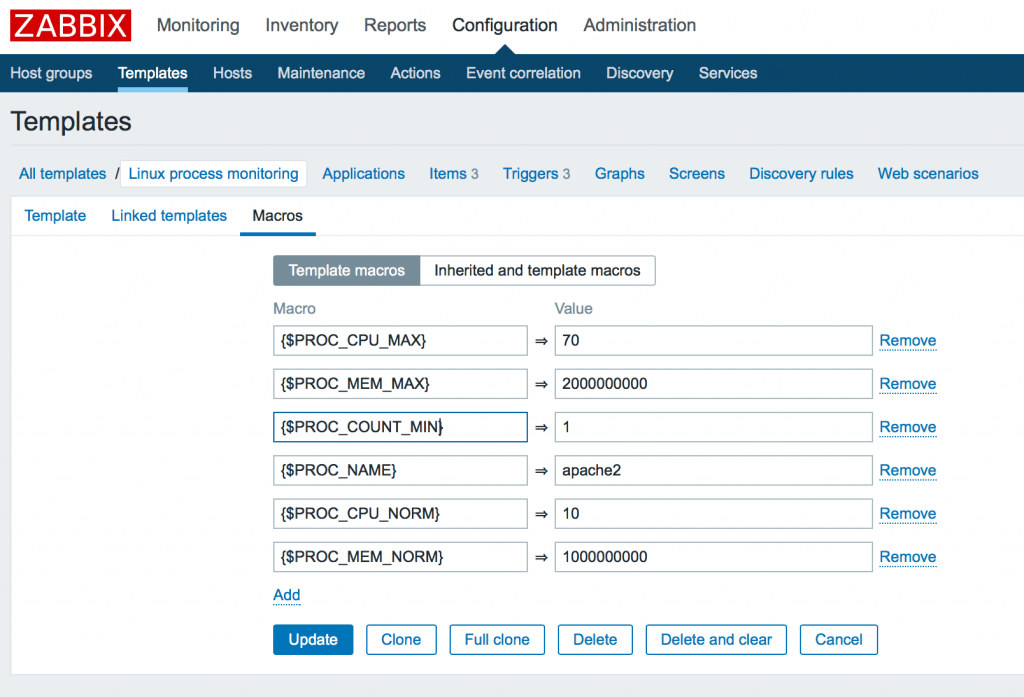
В этом примере мы создали 6 макросов.
{$PROC_CPU_MAX} => 70 {$PROC_MEM_MAX} => 2000000000 {$PROC_COUNT_MIN} => 1 {$PROC_NAME} => apache2 {$PROC_CPU_NORM} => 10 {$PROC_MEM_NORM} => 1000000000
Тут вы можете увидеть максимально использование cpu 70%, использование памяти 2G, минимально 1 запущенный процесс, а так же имя процесса для примера: apache2. Так же мы должны задать нормальные значения наших параметров для построения гистерезиса в целях защиты от ложных срабатываний (описано ниже). По этому мы так же указываем {$PROC_CPU_NORM} как 10% и {$PROC_MEM_NORM} как 1G.
3. Добавление элементов данных
Теперь мы должны добавить элементы входных данных (items). Переходим в меню Items нашего шаблона и кликаем кнопку: Create item. Затем создаем 3 элемента:
- количество процессов
- использование cpu
- использование памяти
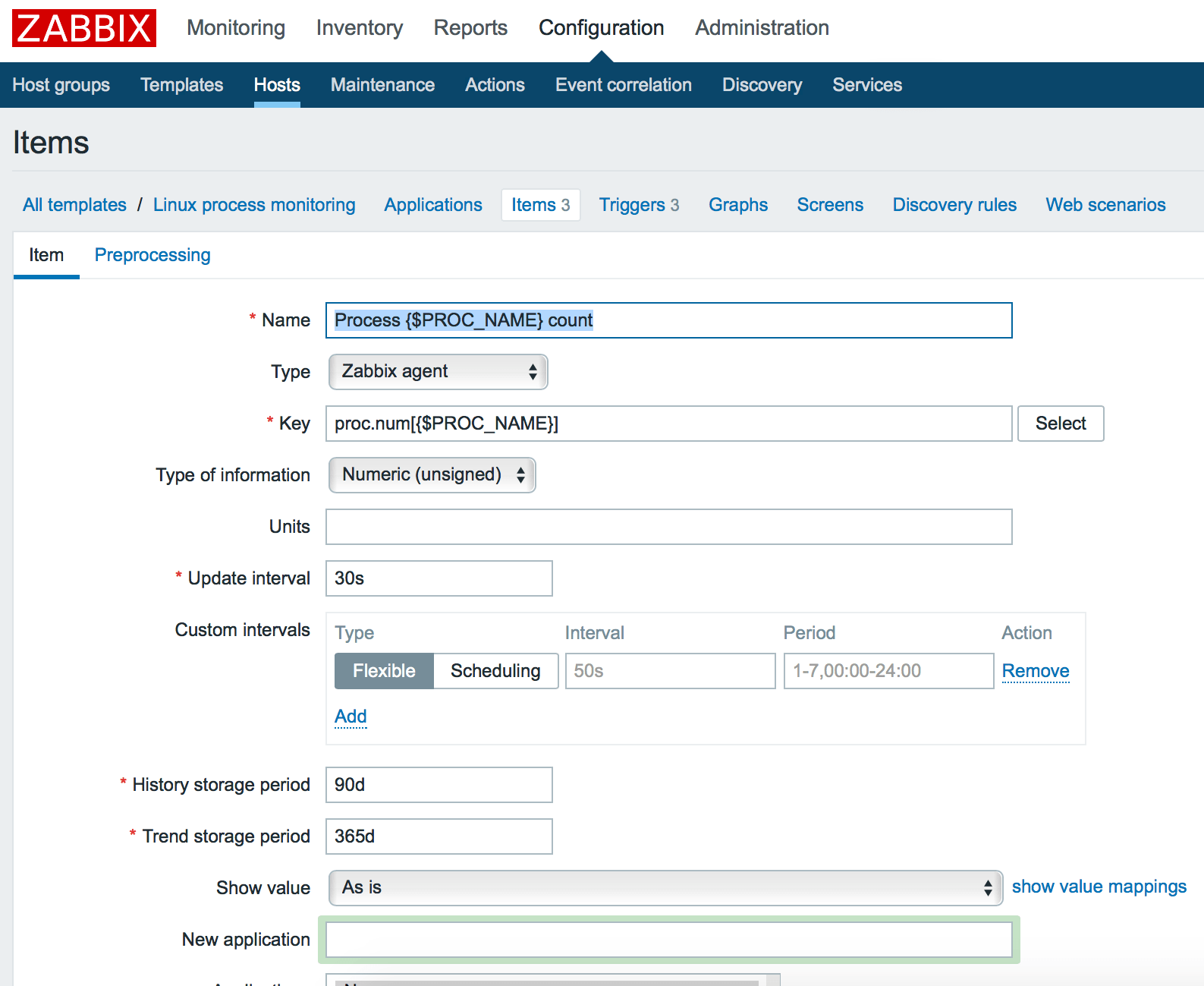
Мы можем использовать {$PROC_NAME} как макрос для задания конкретного имени процесса позже внутри конечной конфигурации хоста. Итак, добавляем 3 элемента с 3 ключами:
proc.num[{$PROC_NAME}] proc.cpu.util[{$PROC_NAME}] proc.mem[{$PROC_NAME}]
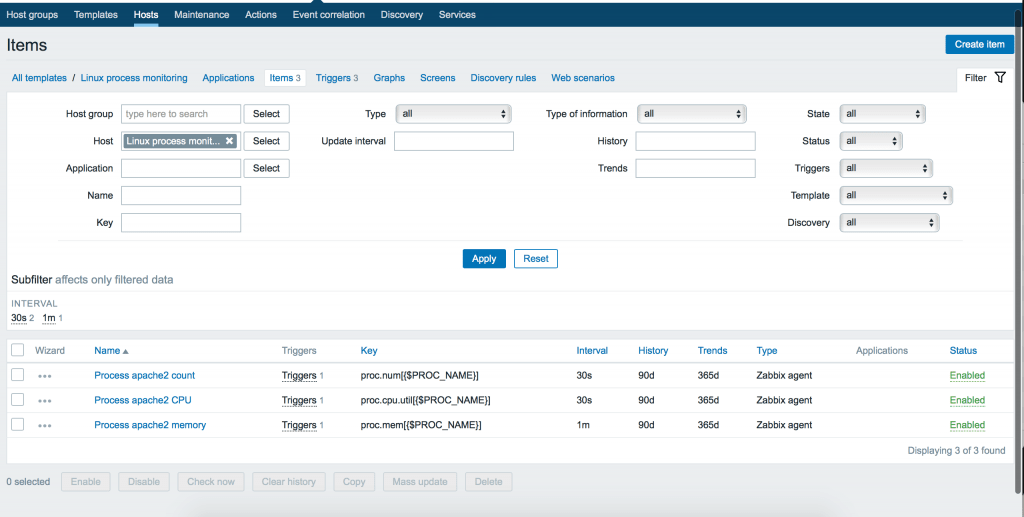
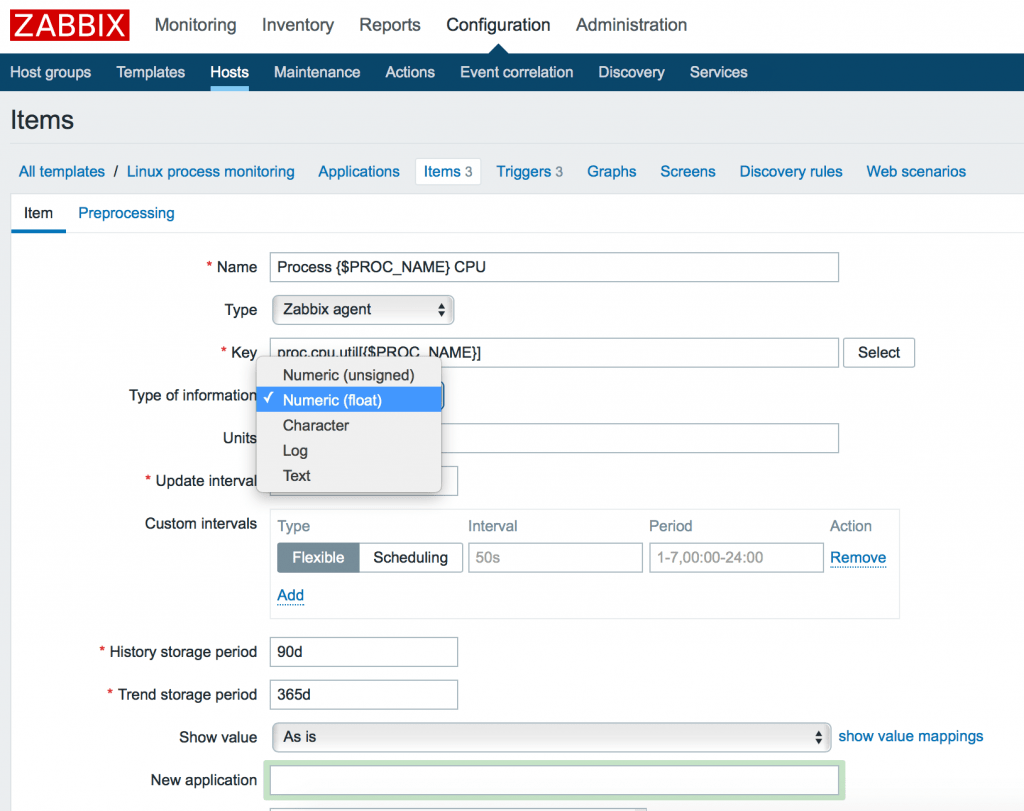
Заметим, что параметры могут иметь различные типы данных. Так к примеру proc.num, proc.mem имеет тип данных: Numeric (int), а proc.cpu.util – Numeric (float). Вы можете удостовериться в правильности указания типа данных в меню Key -> Select или официальной документации Zabbix.
4. Триггеры с гистерезисом
Пришло время создать тригеры. Переходим в закладку Triggers нашего шаблона. Вы можете использовать встроенный конструктор выражений, нажав Problem expression -> Add, затем выбрав item и function. К примеру last (most recent) T value. Но это только одно последнее значение. Оно будет меняться каждый раз, что вызовет нестабильность в определении статуса. Чтобы определить жесткое (установившееся) значение статуса, это значение должно повториться несколько раз подряд. Для такого подсчета лучше использовать функцию count. Болле подробную информацию о функциях вы можете получить в официальной документации Zabbix.
Итак, создаем триггер, который будет срабатывать при привышении потребления памяти больше чем {$PROC_MEM_MAX} 3 раза подряд.
{Linux process monitoring:proc.mem[{$PROC_NAME}].count(#3,{$PROC_MEM_MAX},gt)}>=3
Мы можем прочитать его так: “Количество (count) последних 3 значений (#3), которые были больше (gt) чем {$PROC_MEM_MAX} равно >= 3″. Что означает, что все последние 3 значения были были больше чем PROC_MEM_MAX. Это хороший способ определения устоявшегося значения.
Но что делать с возвратом в нормальное состояние? Если мы просто оставим так как есть, мы рискуем получить что-то на подобие этого:
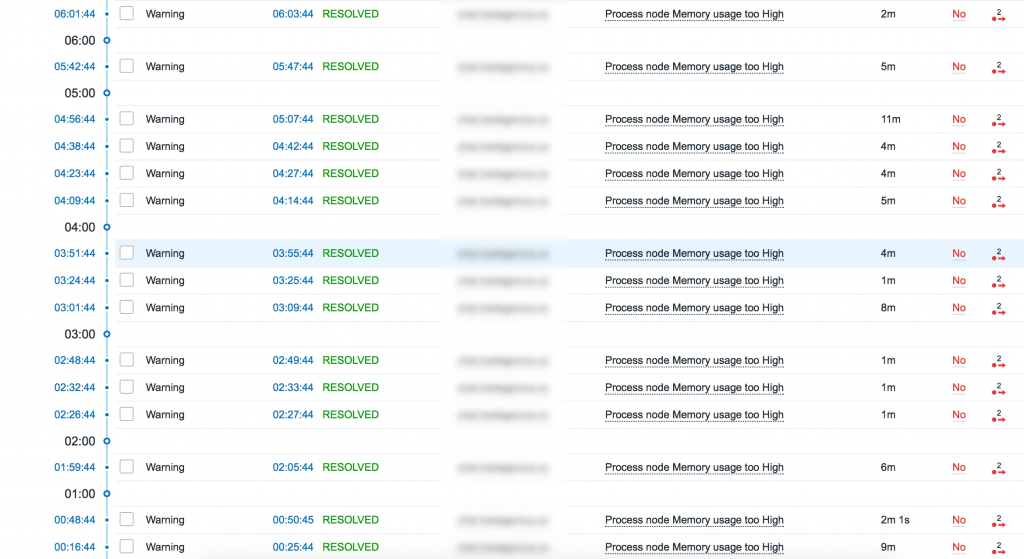
Каждые 5-10 минут статус меняет значение, колеблясь то выше, то ниже указанного порога. Он получает 3 подряд превышающих значения и триггер срабатывает, после чего он получает 3 нормальных значения и помечает проблему как RESOLVED (решена)! Что же делать? Нам поможет гистерезис с указанием не только максимального, но и нормального значения. Триггер будет в состоянии PROBLEM (проблема) до тех пор, пока значение нашего элемента не опустится до ${PROC_MEM_NORM}.
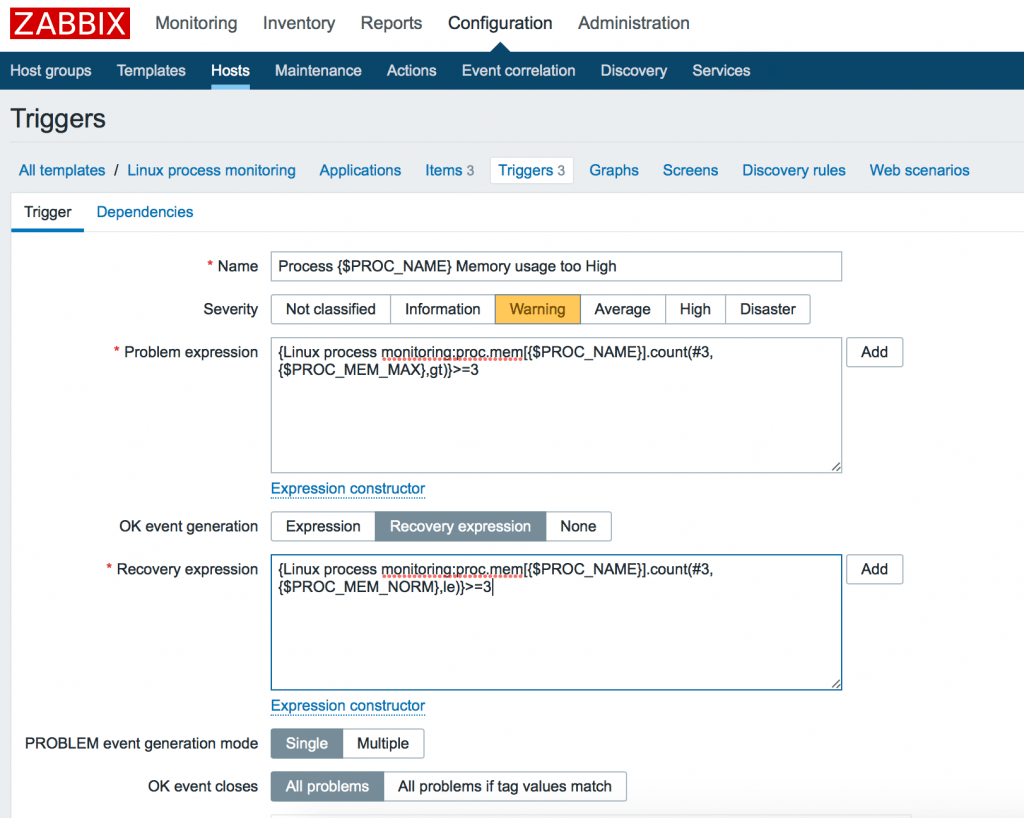
Итак, нажимаем OK event generation -> Recovery expression и добавляем выражение:
{Linux process monitoring:proc.mem[{$PROC_NAME}].count(#3,{$PROC_MEM_NORM},le)}>=3
Его можно прочитать как: “Количество (count) последних трех (#3) значений элемента, которые были меньше или равны (le) числу {$PROC_MEM_NORM} было >= 3 раз. То есть установившееся в нормальном положении значение.
Подобным образом добавляем остальные тригеры (для использования процессора и количества процессов):
{Linux process monitoring:proc.mem[{$PROC_NAME}].count(#3,{$PROC_MEM_MAX},gt)}>=3 {Linux process monitoring:proc.mem[{$PROC_NAME}].count(#3,{$PROC_MEM_NORM},le)}>=3 {Linux process monitoring:proc.cpu.util[{$PROC_NAME}].count(#3,{$PROC_CPU_MAX},gt)}>=3 {Linux process monitoring:proc.cpu.util[{$PROC_NAME}].count(#3,{$PROC_CPU_NORM},le)}>=3 {Linux process monitoring:proc.num[{$PROC_NAME}].count(#3,{$PROC_COUNT_MIN},lt)}>=3 {Linux process monitoring:proc.num[{$PROC_NAME}].count(#3,{$PROC_COUNT_MIN},ge)}>=3
5. Конфигурация хоста
Теперь мы можем добавить наш шаблон к хосту. Идем в Configuration -> Hosts -> ваш сервер -> Templates. И добавляем только что созданный шаблон к серверу. Далее мы должны переопределись макросы.
Для примера на нашем сервере необходимо мониторить процесс node (node.js). Давайте посмотрим один из моих графиков данного процесса:
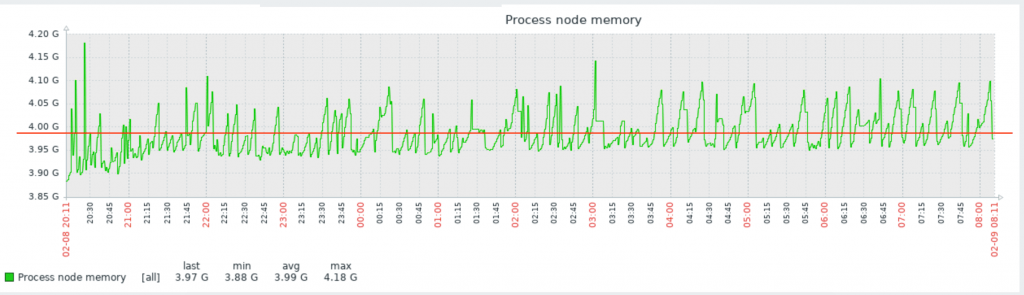
Вы видите, что у меня он потребляет порядка 4Gb RAM. Это нормальное состояние для моего сервиса. Так же вы видите колебание в районе красной линии. Без гистерезиса Zabbix нас просто заспамил бы сообщениями об изменении статуса в районе этой линии. В моем примере нормальное значение потребления памяти для указания в гистерезисе это 4G, а максимальное – больше чем 4.20G, пусть будет 4,5G. Добавим эти значения, а так же имя нашего процесса как макросы для данного хоста:
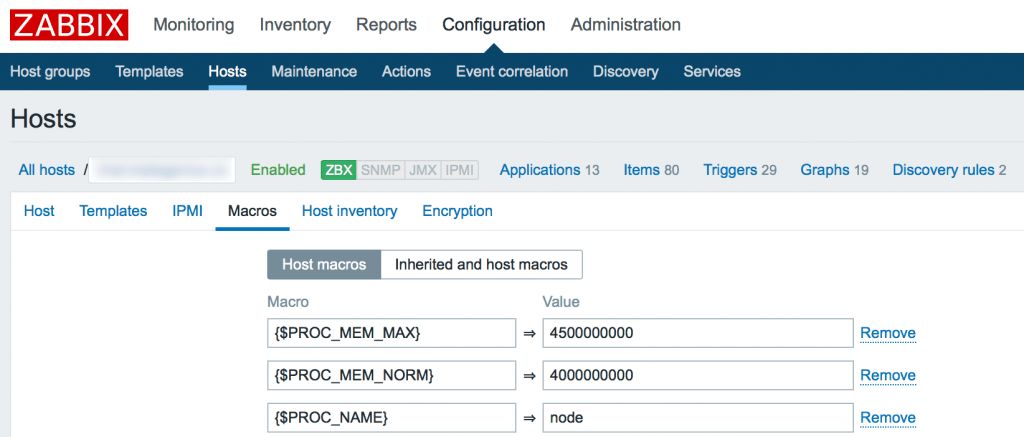
Итак, мой триггер перейдет в состоянии PROBLEM только когда значение потребляемой памяти будет больше чем 4,5Gb 3 раза подряд. А вернется он в нормальное состояние только тогда, когда потребление снизится ниже 4Г 3 раза подряд.
Готово! Позравляю! Теперь можно проверить последние данные в разделе Monitoring -> Latest data.
Вы можете скачать представленный в данной статье шаблон для вашего использования : linux-process.zip
источник
Прочитано:
4 452
Всегда хотел знать об обслуживаемой системе чуточку больше – это как хобби которое нравится, стараешься узнать максимум всей информации. А в моем случае хобби совпадает с работой и я собственно рад этому. Цель данной заметки практически воспроизвести все действия которые нужно сделать чтобы снимать показатель температуры процессора, но если Вам не известно, то штатных средств для этой простой задачи в системе Windows 7 к сожалению нет. Что же мне даст в конечном итоге данный съем показателей температуры, а вот что, если температуры держится всегда на достаточно высоком уровне, то возможно не лишним будет произвести чистку системного блога, от пыли, заменить термопасту, сделать тщательный осмотр системного блога. И вот я перехожу к самому главному, раз нет встроенных средств, то буду использовать сторонние, а именно консольную утилиту для решения данной задачи – OpenHardwareMonitor, состоит она из двух файлов, exe-исполняемого файла и dll-библиотеки.
- OpenHardwareMonitorReport.exe
- OpenHardwareMonitorLib.dll
Настраиваю сервер по мониторингу Zabbix если не настроен по своей заметке:
Первым делом ставлю агент Zabbix по своей заметке:
Где брать данные мы поняли, теперь нужно наладить поставки значений показателей Zabbix серверу.
Для этих целей создам новый Template и в нем создам новый элемент данных (Item), захожу на Zabbix сервер:
http://IP&DNS – Configuration – Templates – Create template
Template Name: Template Hardware
Groups: OFFICE (это мои системы в обслуживаемой сети)
Save
Перехожу в созданный Template и в нем создаю приложение и элемент данных:
Configuration – Templates – Template Hardware – Applications – Create Applications
Name: CPU
Configuration – Templates – Template Hardware – Items – Create Item
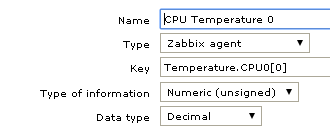
Привожу к виду:
Name: CPU Template
Type: Zabbix agent
Key: Temperature.CPU[0]
Type of information: Numeric (unsigned)
Data type: Decimal
History storage period (in days): 90
Trend storage period (in days): 365
Application: CPU
Enabled: Yes
Save
Теперь нужно связать данный Template с хостом рабочей станции под управлением Windows 7:
Http://IP&DNS – Configuration – Hosts – выбираю хост (Name = aollo) – вкладка Templates – select (Group: Office, Template Hardware), нажимаю Select – после Add – после Save (для сохранения изменений)
Настройки серверного описания завершены, теперь перейдем собственно к клиенту, потребуется в конфигурационный файл Zabbix агента (zabbix_agentd.win.conf) на клиентской станции под управлением Windows 7 добавить пользовательский параметр: — UserParameters следующего вида:
Синтаксис: UserParameter=ключ[*],команда
Как этот синтаксис работает:
Команда, через которую мы получим значение, обрабатывается на стороне клиента. Zabbix сервер будет получать ключ с присвоенным ему значением. В статье имеется в виду, что агент у вас уже установлен в виде службы и дружит с сервером.
Открываем текстовым редактором Notepad++ конфигурационный файл (zabbix_agentd.win.conf) и добавляем следующую строчку:
UserParameter=Temperature.CPU[*],c:scripttemperature.bat
Теперь пояснения:
temperature.bat – это скрипт который задействует консольную утилиту OpenHardwareMonitorReport и некоторые дополнения по обработке получаемых результатов в системе Windows 7 текущей станции.
Для всех дополнений, снимаемых с рабочей станции я в системе создал каталог: c:script и в него поместил следующие файлы:
- OpenHardwareMonitorReport.exe
- OpenHardwareMonitorLib.dll
- temperature.bat
Теперь продемонстрирую содержимое bat—файла для извлечения значения температуры из системы:
@echo off
for /F "usebackq tokens=7-10" %%a in (C:scriptOpenHardwareMonitorReport.exe) do echo %%b %%c %%d| find "/intelcpu/0/temperature/0">nul && set temper0=%%a
echo %temper0%
Скрипт возвращает значение в виде десятичного числа.
Можно также проверить, что параметр по ключу успешно извлекается:
c:Program Files (x86)zabbix>zabbix_agentd.exe --config zabbix_agentd.win.conf
--print | findstr Temperature
Temperature.CPU [t|52]
Видите, значения извлекаются, все работает.
После этого изменения конфиг файла и размещения всех файлов и скриптов, перезагружаем службу zabbix agent.
c:Program Files (x86)zabbix>net stop «Zabbix Agent» && net start «Zabbix Agent»
Служба «Zabbix Agent» останавливается.
Служба «Zabbix Agent» успешно остановлена.
Служба «Zabbix Agent» успешно запущена.
Теперь нужно связать хост
Начинаем получать значения на сервер:
http://IP&DNS – Monitoring – Latest data – Group (OFFICE):Host(aollo) – опускаемся в самый низ и видим новую категорию: -other – развернув которую можно наблюдать извлекаемые значения:
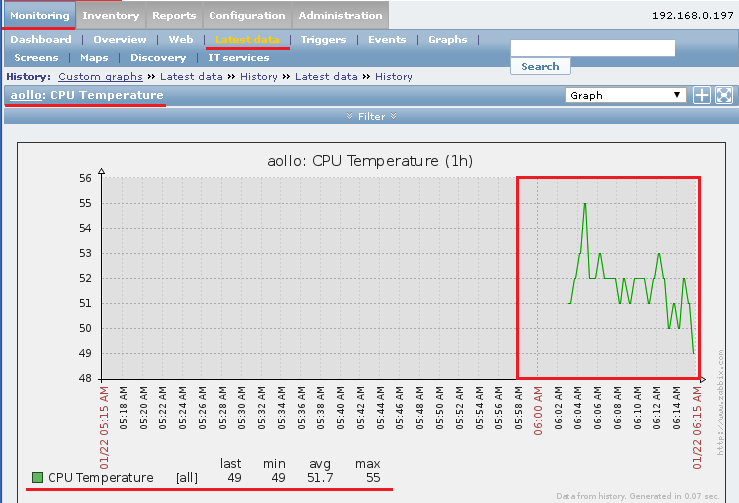
CPU Temperature Jan 22nd, 2015 06:14:56 AM 52 +2 Graph
Нажимаю Graph и получаю уже сейчас собранную статистику:
Работает, но это для одного CPU[0], а если из два CPU[1], то нужно:
Изменяем на клиенте конфигурационный файл:
LogFile=c:zabbix_agentd.log
LogFileSize=10
Server=192.168.0.197
ListenPort=10050
Hostname=aollo
UserParameter=windows.services,"%ProgramFiles%zabbixservices.exe"
UserParameter=Temperature.CPU0[*],c:scripttemperature0.bat
UserParameter=Temperature.CPU1[*],c:scripttemperature1.bat
c:Program Files (x86)zabbix>zabbix_agentd.exe —config zabbix_agentd.win.conf
—print | findstr Temperature
Temperature.CPU0 [t|51]
Temperature.CPU1 [t|60]
И также изменяем/дополняем элемент данных на сервере:
Теперь последние снимаемые данные с рабочей станции график уже пишутся и строятся отдельно.
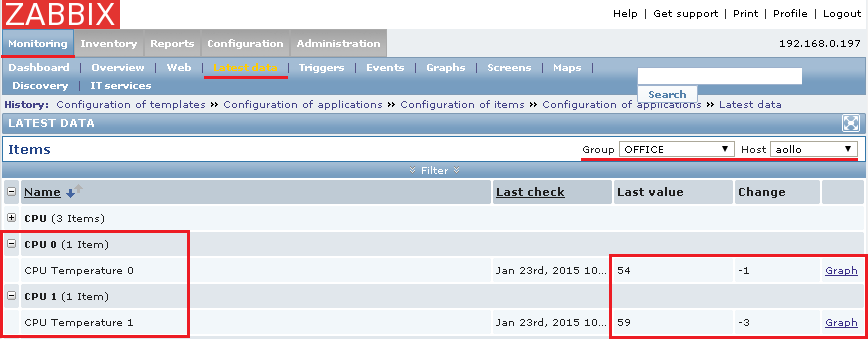
Работает съем данных, проверил, что данные идут с клиентских рабочих станций различных материнок и в довесок с моего ноутбука Lenovo G700, а вот с серверной материнки (ProLiant DL180G6) данные с помощью данной утилиты вообще не снимаются, так что в отсутствие стандартизированных компонентов в малой компании подбор различных параметров которые нужно мониторить работа системного администратора превращается в отличное подобие квеста. Но я не отказываюсь от такого, а собираю статистику. Посмотрим, что еще можно с помощью данной консольной утилиты извлечь из системы чтобы мониторить:
c:script>OpenHardwareMonitorReport.exe | findstr temperature
| +- CPU Core #1 : 53 52 53 (/intelcpu/0/temperature/0)
| +- CPU Core #2 : 59 59 59 (/intelcpu/0/temperature/1)
| +- GPU Core : 38 38 38 (/nvidiagpu/0/temperature/0)
Вот еще можно GPU мониторить, т.е. температуру графического процессора.
Возможно, если найти более функциональную утилиту консольного вида то съем различных параметров можно расширить, но не стоит стараться охватить все, следует остановиться, только на самом нужном и значимом в практическом применении, не тратьте время попусту. А вот и график за период в шесть дней, как меняется температура на моем рабочем ноутбуке с течением выполняемых задач (наверное, как-то так), и конечно же удовольствие от проделанной и визуализированной работы.
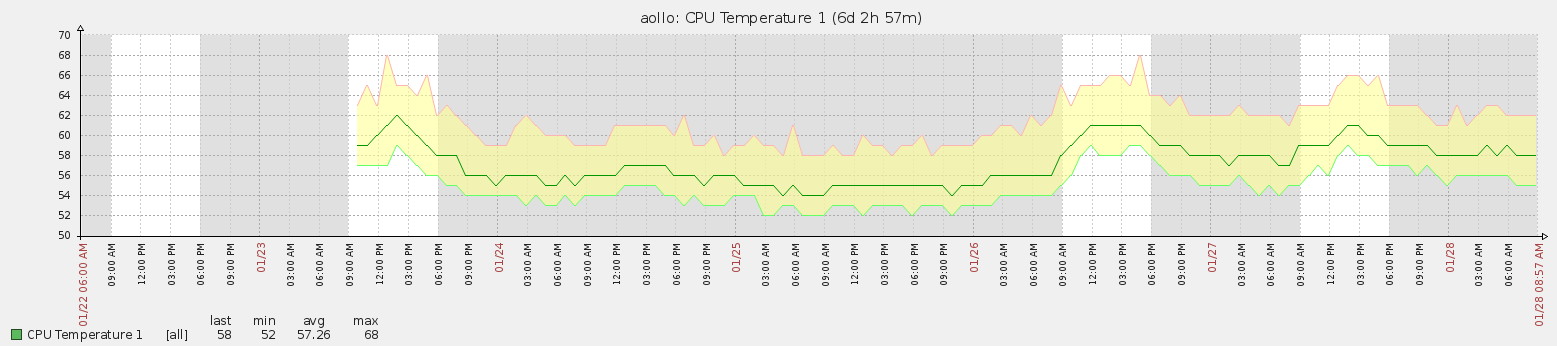
А так заметка полностью работоспособна, теперь буду прощаться. До встречи, с уважением – автор блога ekzorchik.
1
2
Доброго времени суток!
Развернули Zabbix, и почти сразу столкнулись с довольно весомой проблемой.
С машин пользователей в логи (и на почту) валится целая куча мусора, которая не является важной или существенной. К примеру: «Problem started at 16:20:06 on 2020.08.04 Problem name: «sppsvc» (Защита программного обеспечения) is not running (startup type automatic delayed)»
Понятно, что это все можно настроить, вот только как раз с этим проблема и возникла.
За сбор информации сервисов винды отвечает шаблон Template OS Windows by Zabbix agent. Пытаюсь отсечь неугодные мне службы следующим образом:
Макрос: {$SERVICE.NAME.MATCHES}
Значение: ^.*$
Макрос:{$SERVICE.NAME.NOT_MATCHES}
Значение: ^RemoteRegistry|MMCSS|gupdate|SysmonLog|clr_optimization_v.+|clr_optimization_v.+|sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|MapsBroker|IntelAudioService|Intel(R) TPM Provisioning Service|dbupdate|DoSvc$ (те самые неважные службы)
Макрос: {$SERVICE.STARTUPNAME.MATCHES}
Значение:^automatic$
Макрос: {$SERVICE.STARTUPNAME.NOT_MATCHES}
Значение: ^manual|disabled$
Но как раз это и не срабатывает. Мусор как валился, так и валится.
Подскажите, что сделано не так? В какую сторону еще копать?
Заранее спасибо.