Your graphics card does not support CUDA 9.0.
Since I’ve seen a lot of questions that refer to issues like this I’m writing a broad answer on how to check if your system is compatible with CUDA, specifically targeted at using PyTorch with CUDA support. Various circumstance-dependent options for resolving issues are described in the last section of this answer.
The system requirements to use PyTorch with CUDA are as follows:
- Your graphics card must support the required version of CUDA
- Your graphics card driver must support the required version of CUDA
- The PyTorch binaries must be built with support for the compute capability of your graphics card
Note: If you install pre-built binaries (using either pip or conda) then you do not need to install the CUDA toolkit or runtime on your system before installing PyTorch with CUDA support. This is because PyTorch, unless compiled from source, is always delivered with a copy of the CUDA library.
1. How to check if your GPU/graphics card supports a particular CUDA version
First, identify the model of your graphics card.
Before moving forward ensure that you’ve got an NVIDIA graphics card. AMD and Intel graphics cards do not support CUDA.
NVIDIA doesn’t do a great job of providing CUDA compatibility information in a single location. The best resource is probably this section on the CUDA Wikipedia page. To determine which versions of CUDA are supported
- Locate your graphics card model in the big table and take note of the compute capability version. For example, the GeForce 820M compute capability is 2.1.
- In the bullet list preceding the table check to see if the required CUDA version is supported by the compute capability of your graphics card. For example, CUDA 9.2 is not supported for compute compatibility 2.1.
If your card doesn’t support the required CUDA version then see the options in section 4 of this answer.
Note: Compute capability refers to the computational features supported by your graphics card. Newer versions of the CUDA library rely on newer hardware features, which is why we need to determine the compute capability in order to determine the supported versions of CUDA.
2. How to check if your GPU/graphics driver supports a particular CUDA version
The graphics driver is the software that allows your operating system to communicate with your graphics card. Since CUDA relies on low-level communication with the graphics card you need to have an up-to-date driver in order use the latest versions of CUDA.
First, make sure you have an NVIDIA graphics driver installed on your system. You can acquire the newest driver for your system from NVIDIA’s website.
If you’ve installed the latest driver version then your graphics driver probably supports every CUDA version compatible with your graphics card (see section 1). To verify, you can check Table 3 in the CUDA release notes. In rare cases I’ve heard of the latest recommended graphics drivers not supporting the latest CUDA releases. You should be able to get around this by installing the CUDA toolkit for the required CUDA version and selecting the option to install compatible drivers, though this usually isn’t required.
If you can’t, or don’t want to upgrade the graphics driver then you can check to see if your current driver supports the specific CUDA version as follows:
On Windows
- Determine your current graphics driver version (Source https://www.nvidia.com/en-gb/drivers/drivers-faq/)
Right-click on your desktop and select NVIDIA Control Panel. From the
NVIDIA Control Panel menu, select Help > System Information. The
driver version is listed at the top of the Details window. For more
advanced users, you can also get the driver version number from the
Windows Device Manager. Right-click on your graphics device under
display adapters and then select Properties. Select the Driver tab and
read the Driver version. The last 5 digits are the NVIDIA driver
version number.
- Visit the CUDA release notes and scroll down to Table 3. Use this table to verify your graphics driver is new enough to support the required version of CUDA.
On Linux/OS X
Run the following command in a terminal window
nvidia-smi
This should result in something like the following
Sat Apr 4 15:31:57 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 435.21 Driver Version: 435.21 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 206... Off | 00000000:01:00.0 On | N/A |
| 0% 35C P8 16W / 175W | 502MiB / 7974MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1138 G /usr/lib/xorg/Xorg 300MiB |
| 0 2550 G /usr/bin/compiz 189MiB |
| 0 5735 G /usr/lib/firefox/firefox 5MiB |
| 0 7073 G /usr/lib/firefox/firefox 5MiB |
+-----------------------------------------------------------------------------+
Driver Version: ###.## is your graphic driver version. In the example above the driver version is 435.21.
CUDA Version: ##.# is the latest version of CUDA supported by your graphics driver. In the example above the graphics driver supports CUDA 10.1 as well as all compatible CUDA versions before 10.1.
Note: The CUDA Version displayed in this table does not indicate that the CUDA toolkit or runtime are actually installed on your system. This just indicates the latest version of CUDA your graphics driver is compatible with.
To be extra sure that your driver supports the desired CUDA version you can visit Table 3 on the CUDA release notes page.
3. How to check if a particular version of PyTorch is compatible with your GPU/graphics card compute capability
Even if your graphics card supports the required version of CUDA then it’s possible that the pre-compiled PyTorch binaries were not compiled with support for your compute capability. For example, in PyTorch 0.3.1 support for compute capability <= 5.0 was dropped.
First, verify that your graphics card and driver both support the required CUDA version (see Sections 1 and 2 above), the information in this section assumes that this is the case.
The easiest way to check if PyTorch supports your compute capability is to install the desired version of PyTorch with CUDA support and run the following from a python interpreter
>>> import torch
>>> torch.zeros(1).cuda()
If you get an error message that reads
Found GPU0 XXXXX which is of cuda capability #.#.
PyTorch no longer supports this GPU because it is too old.
then that means PyTorch was not compiled with support for your compute capability. If this runs without issue then you should be good to go.
Update If you’re installing an old version of PyTorch on a system with a newer GPU then it’s possible that the old PyTorch release wasn’t compiled with support for your compute capability. Assuming your GPU supports the version of CUDA used by PyTorch, then you should be able to rebuild PyTorch from source with the desired CUDA version or upgrade to a more recent version of PyTorch that was compiled with support for the newer compute capabilities.
4. Conclusion
If your graphics card and driver support the required version of CUDA (section 1 and 2) but the PyTorch binaries don’t support your compute capability (section 3) then your options are
- Compile PyTorch from source with support for your compute capability (see here)
- Install PyTorch without CUDA support (CPU-only)
- Install an older version of the PyTorch binaries that support your compute capability (not recommended as PyTorch 0.3.1 is very outdated at this point). AFAIK compute capability older than 3.X has never been supported in the pre-built binaries
- Upgrade your graphics card
If your graphics card doesn’t support the required version of CUDA (section 1) then your options are
- Install PyTorch without CUDA support (CPU-only)
- Install an older version of PyTorch that supports a CUDA version supported by your graphics card (still may require compiling from source if the binaries don’t support your compute capability)
- Upgrade your graphics card
@SimplyLucKey Please run
python -m torch.utils.collect_envand post its output here.
Oops sorry I think I uninstalled pytorch so I reinstalled it again and it worked this time.
However I have been running into an error with memory allocation and they’re only a few MB big (I have 8 GB RAM).
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<timed exec> in <module>
<ipython-input-19-334bcbb678d7> in train_epoch(model, data_loader, loss_fn, optimizer, device, scheduler, n_examples)
10 targets = i['targets'].to(device)
11
---> 12 outputs = model(input_ids=input_ids, attention_mask=attention_mask)
13 _, preds = torch.max(outputs, dim=1) # process with the highest probability
14 loss = loss_fn(outputs, targets)
~anaconda3libsite-packagestorchnnmodulesmodule.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
<ipython-input-16-80e63a2794b9> in forward(self, input_ids, attention_mask)
7
8 def forward(self, input_ids, attention_mask):
----> 9 _, pooled_output = self.bert(input_ids=input_ids, attention_mask=attention_mask, return_dict=False)
10 output = self.drop(pooled_output)
11 return self.out(output)
~anaconda3libsite-packagestorchnnmodulesmodule.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
~anaconda3libsite-packagestransformersmodelsbertmodeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
956 past_key_values_length=past_key_values_length,
957 )
--> 958 encoder_outputs = self.encoder(
959 embedding_output,
960 attention_mask=extended_attention_mask,
~anaconda3libsite-packagestorchnnmodulesmodule.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
~anaconda3libsite-packagestransformersmodelsbertmodeling_bert.py in forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
557 )
558 else:
--> 559 layer_outputs = layer_module(
560 hidden_states,
561 attention_mask,
~anaconda3libsite-packagestorchnnmodulesmodule.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
~anaconda3libsite-packagestransformersmodelsbertmodeling_bert.py in forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions)
493 present_key_value = present_key_value + cross_attn_present_key_value
494
--> 495 layer_output = apply_chunking_to_forward(
496 self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
497 )
~anaconda3libsite-packagestransformersmodeling_utils.py in apply_chunking_to_forward(forward_fn, chunk_size, chunk_dim, *input_tensors)
1785 return torch.cat(output_chunks, dim=chunk_dim)
1786
-> 1787 return forward_fn(*input_tensors)
~anaconda3libsite-packagestransformersmodelsbertmodeling_bert.py in feed_forward_chunk(self, attention_output)
505
506 def feed_forward_chunk(self, attention_output):
--> 507 intermediate_output = self.intermediate(attention_output)
508 layer_output = self.output(intermediate_output, attention_output)
509 return layer_output
~anaconda3libsite-packagestorchnnmodulesmodule.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
~anaconda3libsite-packagestransformersmodelsbertmodeling_bert.py in forward(self, hidden_states)
408
409 def forward(self, hidden_states):
--> 410 hidden_states = self.dense(hidden_states)
411 hidden_states = self.intermediate_act_fn(hidden_states)
412 return hidden_states
~anaconda3libsite-packagestorchnnmodulesmodule.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
~anaconda3libsite-packagestorchnnmoduleslinear.py in forward(self, input)
91
92 def forward(self, input: Tensor) -> Tensor:
---> 93 return F.linear(input, self.weight, self.bias)
94
95 def extra_repr(self) -> str:
~anaconda3libsite-packagestorchnnfunctional.py in linear(input, weight, bias)
1690 ret = torch.addmm(bias, input, weight.t())
1691 else:
-> 1692 output = input.matmul(weight.t())
1693 if bias is not None:
1694 output += bias
RuntimeError: CUDA out of memory. Tried to allocate 30.00 MiB (GPU 0; 4.00 GiB total capacity; 2.66 GiB already allocated; 27.74 MiB free; 2.88 GiB reserved in total by PyTorch)
CUDA(or Computer Unified Device Architecture) is a proprietary parallel computing platform and programming model from NVIDIA. Using the CUDA SDK, developers can utilize their NVIDIA GPUs(Graphics Processing Units), thus enabling them to bring in the power of GPU-based parallel processing instead of the usual CPU-based sequential processing in their usual programming workflow.
With deep learning on the rise in recent years, it’s seen that various operations involved in model training, like matrix multiplication, inversion, etc., can be parallelized to a great extent for better learning performance and faster training cycles. Thus, many deep learning libraries like Pytorch enable their users to take advantage of their GPUs using a set of interfaces and utility functions. This article will cover setting up a CUDA environment in any system containing CUDA-enabled GPU(s) and a brief introduction to the various CUDA operations available in the Pytorch library using Python.
Installation
First, you should ensure that their GPU is CUDA enabled or not by checking their system’s GPU through the official Nvidia CUDA compatibility list. Pytorch makes the CUDA installation process very simple by providing a nice user-friendly interface that lets you choose your operating system and other requirements, as given in the figure below. According to our computing machine, we’ll be installing according to the specifications given in the figure below.
Refer to Pytorch’s official link and choose the specifications according to their computer specifications. We also suggest a complete restart of the system after installation to ensure the proper working of the toolkit.
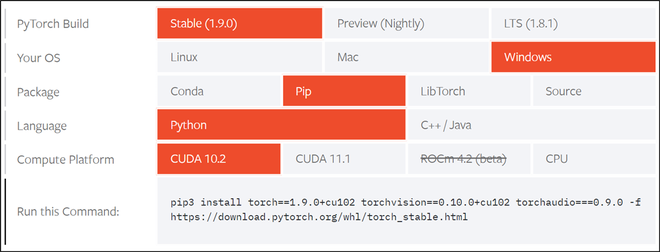
Screenshot from Pytorch’s installation page
pip3 install torch==1.9.0+cu102 torchvision==0.10.0+cu102 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
Getting started with CUDA in Pytorch
Once installed, we can use the torch.cuda interface to interact with CUDA using Pytorch. We’ll use the following functions:
Syntax:
- torch.version.cuda(): Returns CUDA version of the currently installed packages
- torch.cuda.is_available(): Returns True if CUDA is supported by your system, else False
- torch.cuda.current_device(): Returns ID of current device
- torch.cuda.get_device_name(device_ID): Returns name of the CUDA device with ID = ‘device_ID’
Code:
Python3
import torch
print(f"Is CUDA supported by this system?
{torch.cuda.is_available()}")
print(f"CUDA version: {torch.version.cuda}")
cuda_id = torch.cuda.current_device()
print(f"ID of current CUDA device:
{torch.cuda.current_device()}")
print(f"Name of current CUDA device:
{torch.cuda.get_device_name(cuda_id)}")
Output:

CUDA version
Handling Tensors with CUDA
For interacting Pytorch tensors through CUDA, we can use the following utility functions:
Syntax:
- Tensor.device: Returns the device name of ‘Tensor’
- Tensor.to(device_name): Returns new instance of ‘Tensor’ on the device specified by ‘device_name’: ‘cpu’ for CPU and ‘cuda’ for CUDA enabled GPU
- Tensor.cpu(): Transfers ‘Tensor’ to CPU from it’s current device
To demonstrate the above functions, we’ll be creating a test tensor and do the following operations:
Checking the current device of the tensor and applying a tensor operation(squaring), transferring the tensor to GPU and applying the same tensor operation(squaring) and comparing the results of the 2 devices.
Code:
Python3
import torch
x = torch.randint(1, 100, (100, 100))
print(x.device)
res_cpu = x ** 2
x = x.to(torch.device('cuda'))
print(x.device)
res_gpu = x ** 2
assert torch.equal(res_cpu, res_gpu.cpu())
Output:
cpu cuda : 0
Handling Machine Learning models with CUDA
A good Pytorch practice is to produce device-agnostic code because some systems might not have access to a GPU and have to rely on the CPU only or vice versa. Once that’s done the following function can be used to transfer any machine learning model onto the selected device
Syntax: Model.to(device_name):
Returns: New instance of Machine Learning ‘Model’ on the device specified by ‘device_name’: ‘cpu’ for CPU and ‘cuda’ for CUDA enabled GPU
In this example, we are importing the pre-trained Resnet-18 model from the torchvision.models utility, the reader can use the same steps for transferring models to their selected device.
Code:
Python3
import torch
import torchvision.models as models
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = models.resnet18(pretrained=True)
model = model.to(device)
Output:

ML with CUDA
#pytorch #torch
#pytorch #torch
Вопрос:
Я попробовал несколько решений, которые намекали на то, что делать, когда графический процессор CUDA доступен и CUDA установлен, но Torch.cuda.is_available() возвращается False . Они помогли, но только временно, что означает torch.cuda-is_available() сообщение True, но через некоторое время оно снова переключилось на False. Я использую CUDA 9.0.176 и GTX 1080. Что я должен сделать, чтобы получить постоянный эффект?
Я попробовал следующие методы:
https://forums.fast.ai/t/torch-cuda-is-available-returns-false/16721/5
https://github.com/pytorch/pytorch/issues/15612
Примечание: Когда torch.cuda.is_available() работает нормально, но затем в какой-то момент переключается на False , тогда мне нужно перезагрузить компьютер, а затем он снова работает (в течение некоторого времени).
Комментарии:
1. Я сталкиваюсь с той же проблемой, но внутри docker. Это так раздражает, что мне нужно время от времени перезапускать docker. Вы нашли решение?
Ответ №1:
Также с torch.cuda.is_available () had false .
Но при установке драйвера Nvidia до самой последней версии 436.48 отображается значение True. Ранее я обновил Pytorch до 1.2.0. У меня Windows 10 и Anaconda.

Ответ №2:
Причиной torch.cuda.is_available() False этого является несовместимость между версиями pytorch и cudatoolkit .
По состоянию на июнь 2022 года текущая версия pytorch совместима с cudatoolkit = 11.3, тогда как текущая версия cuda toolkit = 11.7. Источник
Решение:
- Удалите Pytorch для новой установки. Вы не можете установить старую версию поверх новой версии без принудительной установки (с помощью
pip install --upgrade --force-reinstall <package_name>. - Запустите
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorchдля установки pytorch. - Установите версию CUDA 11.3 из https://developer.nvidia.com/cuda-11.3.0-download-archive .
Все готово.
1. 1 Это решило мою проблему. Я попробовал это с помощью CUDA 11.6, и он отлично работает. (в этом случае cuda-11.6.0-download-archive следует использовать вместе с conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge )
Ответ №3:
Ответ №4:
Я тоже видел эту проблему. Причиной была несинхронизация версии CUDA, используемой Pytorch, с установленным драйвером Nvidia. Как и в ответе Джо, решением было обновление драйверов Nvidia. Некоторая другая важная справочная информация, о которой следует знать:
- Для каждого выпуска CUDA требуется минимальная версия драйвера Nvidia (см. Таблицу совместимости здесь).
- Вы можете проверить версию драйвера Nvidia с
nvidia-smiпомощью . - Pytorch поставляется в комплекте с версией CUDA, которая может отличаться от версии, установленной на вашем компьютере.
- Версия CUDA, которую вы установили вручную, отображается при запуске
nvidia-smi. Даже если ваша версия драйвера совместима с этой версией CUDA, она может быть несовместима с версией Pytorch CUDA. - Вы можете получить версию Pytorch CUDA, напечатав
torch.version.cudaпеременную в ipython или в программе Python. Это версия, которая определяет необходимую версию драйвера Nvidia.
Комментарии:
1.
AttributeError: module 'torch.cuda' has no attribute 'version'2. спасибо — должно быть
torch.version.cuda. Я отредактировал сообщение
This package adds support for CUDA tensor types, that implement the same
function as CPU tensors, but they utilize GPUs for computation.
It is lazily initialized, so you can always import it, and use
is_available() to determine if your system supports CUDA.
CUDA semantics has more details about working with CUDA.
-
torch.cuda.current_blas_handle()[source]¶ -
Returns cublasHandle_t pointer to current cuBLAS handle
-
torch.cuda.current_device() → int[source]¶ -
Returns the index of a currently selected device.
-
torch.cuda.current_stream(device: Union[torch.device, str, int, None] = None) → torch.cuda.streams.Stream[source]¶ -
Returns the currently selected
Streamfor a given device.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
the currently selectedStreamfor the current device, given
bycurrent_device(), ifdeviceisNone
(default).
-
torch.cuda.default_stream(device: Union[torch.device, str, int, None] = None) → torch.cuda.streams.Stream[source]¶ -
Returns the default
Streamfor a given device.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
the defaultStreamfor the current device, given by
current_device(), ifdeviceisNone
(default).
-
class
torch.cuda.device(device)[source]¶ -
Context-manager that changes the selected device.
- Parameters
-
device (torch.device or int) – device index to select. It’s a no-op if
this argument is a negative integer orNone.
-
torch.cuda.device_count() → int[source]¶ -
Returns the number of GPUs available.
-
class
torch.cuda.device_of(obj)[source]¶ -
Context-manager that changes the current device to that of given object.
You can use both tensors and storages as arguments. If a given object is
not allocated on a GPU, this is a no-op.- Parameters
-
obj (Tensor or Storage) – object allocated on the selected device.
-
torch.cuda.get_device_capability(device: Union[torch.device, str, int, None] = None) → Tuple[int, int][source]¶ -
Gets the cuda capability of a device.
- Parameters
-
device (torch.device or int, optional) – device for which to return the
device capability. This function is a no-op if this argument is
a negative integer. It uses the current device, given by
current_device(), ifdeviceisNone
(default). - Returns
-
the major and minor cuda capability of the device
- Return type
-
tuple(int, int)
-
torch.cuda.get_device_name(device: Union[torch.device, str, int, None] = None) → str[source]¶ -
Gets the name of a device.
- Parameters
-
device (torch.device or int, optional) – device for which to return the
name. This function is a no-op if this argument is a negative
integer. It uses the current device, given bycurrent_device(),
ifdeviceisNone(default).
-
torch.cuda.init()[source]¶ -
Initialize PyTorch’s CUDA state. You may need to call
this explicitly if you are interacting with PyTorch via
its C API, as Python bindings for CUDA functionality will not
be until this initialization takes place. Ordinary users
should not need this, as all of PyTorch’s CUDA methods
automatically initialize CUDA state on-demand.Does nothing if the CUDA state is already initialized.
-
torch.cuda.ipc_collect()[source]¶ -
Force collects GPU memory after it has been released by CUDA IPC.
Note
Checks if any sent CUDA tensors could be cleaned from the memory. Force
closes shared memory file used for reference counting if there is no
active counters. Useful when the producer process stopped actively sending
tensors and want to release unused memory.
-
torch.cuda.is_available() → bool[source]¶ -
Returns a bool indicating if CUDA is currently available.
-
torch.cuda.is_initialized()[source]¶ -
Returns whether PyTorch’s CUDA state has been initialized.
-
torch.cuda.set_device(device: Union[torch.device, str, int]) → None[source]¶ -
Sets the current device.
Usage of this function is discouraged in favor of
device. In most
cases it’s better to useCUDA_VISIBLE_DEVICESenvironmental variable.- Parameters
-
device (torch.device or int) – selected device. This function is a no-op
if this argument is negative.
-
torch.cuda.stream(stream)[source]¶ -
Context-manager that selects a given stream.
All CUDA kernels queued within its context will be enqueued on a selected
stream.- Parameters
-
stream (Stream) – selected stream. This manager is a no-op if it’s
None.
Note
Streams are per-device. If the selected stream is not on the
current device, this function will also change the current device to
match the stream.
-
torch.cuda.synchronize(device: Union[torch.device, str, int] = None) → None[source]¶ -
Waits for all kernels in all streams on a CUDA device to complete.
- Parameters
-
device (torch.device or int, optional) – device for which to synchronize.
It uses the current device, given bycurrent_device(),
ifdeviceisNone(default).
Random Number Generator¶
-
torch.cuda.get_rng_state(device: Union[int, str, torch.device] = ‘cuda’) → torch.Tensor[source]¶ -
Returns the random number generator state of the specified GPU as a ByteTensor.
- Parameters
-
device (torch.device or int, optional) – The device to return the RNG state of.
Default:'cuda'(i.e.,torch.device('cuda'), the current CUDA device).
Warning
This function eagerly initializes CUDA.
-
torch.cuda.get_rng_state_all() → List[torch.Tensor][source]¶ -
Returns a list of ByteTensor representing the random number states of all devices.
-
torch.cuda.set_rng_state(new_state: torch.Tensor, device: Union[int, str, torch.device] = ‘cuda’) → None[source]¶ -
Sets the random number generator state of the specified GPU.
- Parameters
-
-
new_state (torch.ByteTensor) – The desired state
-
device (torch.device or int, optional) – The device to set the RNG state.
Default:'cuda'(i.e.,torch.device('cuda'), the current CUDA device).
-
-
torch.cuda.set_rng_state_all(new_states: Iterable[torch.Tensor]) → None[source]¶ -
Sets the random number generator state of all devices.
- Parameters
-
new_states (Iterable of torch.ByteTensor) – The desired state for each device
-
torch.cuda.manual_seed(seed: int) → None[source]¶ -
Sets the seed for generating random numbers for the current GPU.
It’s safe to call this function if CUDA is not available; in that
case, it is silently ignored.- Parameters
-
seed (int) – The desired seed.
Warning
If you are working with a multi-GPU model, this function is insufficient
to get determinism. To seed all GPUs, usemanual_seed_all().
-
torch.cuda.manual_seed_all(seed: int) → None[source]¶ -
Sets the seed for generating random numbers on all GPUs.
It’s safe to call this function if CUDA is not available; in that
case, it is silently ignored.- Parameters
-
seed (int) – The desired seed.
-
torch.cuda.seed() → None[source]¶ -
Sets the seed for generating random numbers to a random number for the current GPU.
It’s safe to call this function if CUDA is not available; in that
case, it is silently ignored.Warning
If you are working with a multi-GPU model, this function will only initialize
the seed on one GPU. To initialize all GPUs, useseed_all().
-
torch.cuda.seed_all() → None[source]¶ -
Sets the seed for generating random numbers to a random number on all GPUs.
It’s safe to call this function if CUDA is not available; in that
case, it is silently ignored.
-
torch.cuda.initial_seed() → int[source]¶ -
Returns the current random seed of the current GPU.
Warning
This function eagerly initializes CUDA.
Communication collectives¶
-
torch.cuda.comm.broadcast(tensor, devices=None, *, out=None)[source]¶ -
Broadcasts a tensor to specified GPU devices.
- Parameters
-
-
tensor (Tensor) – tensor to broadcast. Can be on CPU or GPU.
-
devices (Iterable[torch.device, str or int], optional) – an iterable of
GPU devices, among which to broadcast. -
out (Sequence[Tensor], optional, keyword-only) – the GPU tensors to
store output results.
-
Note
Exactly one of
devicesandoutmust be specified.- Returns
-
-
- If
devicesis specified, -
a tuple containing copies of
tensor, placed on
devices.
- If
-
- If
outis specified, -
a tuple containing
outtensors, each containing a copy of
tensor.
- If
-
-
torch.cuda.comm.broadcast_coalesced(tensors, devices, buffer_size=10485760)[source]¶ -
Broadcasts a sequence tensors to the specified GPUs.
Small tensors are first coalesced into a buffer to reduce the number
of synchronizations.- Parameters
-
-
tensors (sequence) – tensors to broadcast. Must be on the same device,
either CPU or GPU. -
devices (Iterable[torch.device, str or int]) – an iterable of GPU
devices, among which to broadcast. -
buffer_size (int) – maximum size of the buffer used for coalescing
-
- Returns
-
A tuple containing copies of
tensor, placed ondevices.
-
torch.cuda.comm.reduce_add(inputs, destination=None)[source]¶ -
Sums tensors from multiple GPUs.
All inputs should have matching shapes, dtype, and layout. The output tensor
will be of the same shape, dtype, and layout.- Parameters
-
-
inputs (Iterable[Tensor]) – an iterable of tensors to add.
-
destination (int, optional) – a device on which the output will be
placed (default: current device).
-
- Returns
-
A tensor containing an elementwise sum of all inputs, placed on the
destinationdevice.
-
torch.cuda.comm.scatter(tensor, devices=None, chunk_sizes=None, dim=0, streams=None, *, out=None)[source]¶ -
Scatters tensor across multiple GPUs.
- Parameters
-
-
tensor (Tensor) – tensor to scatter. Can be on CPU or GPU.
-
devices (Iterable[torch.device, str or int], optional) – an iterable of
GPU devices, among which to scatter. -
chunk_sizes (Iterable[int], optional) – sizes of chunks to be placed on
each device. It should matchdevicesin length and sums to
tensor.size(dim). If not specified,tensorwill be divided
into equal chunks. -
dim (int, optional) – A dimension along which to chunk
tensor.
Default:0. -
out (Sequence[Tensor], optional, keyword-only) – the GPU tensors to
store output results. Sizes of these tensors must match that of
tensor, except fordim, where the total size must
sum totensor.size(dim).
-
Note
Exactly one of
devicesandoutmust be specified. When
outis specified,chunk_sizesmust not be specified and
will be inferred from sizes ofout.- Returns
-
-
- If
devicesis specified, -
a tuple containing chunks of
tensor, placed on
devices.
- If
-
- If
outis specified, -
a tuple containing
outtensors, each containing a chunk of
tensor.
- If
-
-
torch.cuda.comm.gather(tensors, dim=0, destination=None, *, out=None)[source]¶ -
Gathers tensors from multiple GPU devices.
- Parameters
-
-
tensors (Iterable[Tensor]) – an iterable of tensors to gather.
Tensor sizes in all dimensions other thandimhave to match. -
dim (int, optional) – a dimension along which the tensors will be
concatenated. Default:0. -
destination (torch.device, str, or int, optional) – the output device.
Can be CPU or CUDA. Default: the current CUDA device. -
out (Tensor, optional, keyword-only) – the tensor to store gather result.
Its sizes must match those oftensors, except fordim,
where the size must equalsum(tensor.size(dim) for tensor in tensors).
Can be on CPU or CUDA.
-
Note
destinationmust not be specified whenoutis specified.- Returns
-
-
- If
destinationis specified, -
a tensor located on
destinationdevice, that is a result of
concatenatingtensorsalongdim.
- If
-
- If
outis specified, -
the
outtensor, now containing results of concatenating
tensorsalongdim.
- If
-
Streams and events¶
-
class
torch.cuda.Stream[source]¶ -
Wrapper around a CUDA stream.
A CUDA stream is a linear sequence of execution that belongs to a specific
device, independent from other streams. See CUDA semantics for
details.- Parameters
-
-
device (torch.device or int, optional) – a device on which to allocate
the stream. IfdeviceisNone(default) or a negative
integer, this will use the current device. -
priority (int, optional) – priority of the stream. Lower numbers
represent higher priorities.
-
-
query()[source]¶ -
Checks if all the work submitted has been completed.
- Returns
-
A boolean indicating if all kernels in this stream are completed.
-
record_event(event=None)[source]¶ -
Records an event.
- Parameters
-
event (Event, optional) – event to record. If not given, a new one
will be allocated. - Returns
-
Recorded event.
-
synchronize()[source]¶ -
Wait for all the kernels in this stream to complete.
-
wait_event(event)[source]¶ -
Makes all future work submitted to the stream wait for an event.
- Parameters
-
event (Event) – an event to wait for.
Note
This is a wrapper around
cudaStreamWaitEvent(): see
CUDA Stream documentation for more info.This function returns without waiting for
event: only future
operations are affected.
-
wait_stream(stream)[source]¶ -
Synchronizes with another stream.
All future work submitted to this stream will wait until all kernels
submitted to a given stream at the time of call complete.- Parameters
-
stream (Stream) – a stream to synchronize.
Note
This function returns without waiting for currently enqueued
kernels instream: only future operations are affected.
-
class
torch.cuda.Event[source]¶ -
Wrapper around a CUDA event.
CUDA events are synchronization markers that can be used to monitor the
device’s progress, to accurately measure timing, and to synchronize CUDA
streams.The underlying CUDA events are lazily initialized when the event is first
recorded or exported to another process. After creation, only streams on the
same device may record the event. However, streams on any device can wait on
the event.- Parameters
-
-
enable_timing (bool, optional) – indicates if the event should measure time
(default:False) -
blocking (bool, optional) – if
True,wait()will be blocking (default:False) -
interprocess (bool) – if
True, the event can be shared between processes
(default:False)
-
-
elapsed_time(end_event)[source]¶ -
Returns the time elapsed in milliseconds after the event was
recorded and before the end_event was recorded.
-
classmethod
from_ipc_handle(device, handle)[source]¶ -
Reconstruct an event from an IPC handle on the given device.
-
ipc_handle()[source]¶ -
Returns an IPC handle of this event. If not recorded yet, the event
will use the current device.
-
query()[source]¶ -
Checks if all work currently captured by event has completed.
- Returns
-
A boolean indicating if all work currently captured by event has
completed.
-
record(stream=None)[source]¶ -
Records the event in a given stream.
Uses
torch.cuda.current_stream()if no stream is specified. The
stream’s device must match the event’s device.
-
synchronize()[source]¶ -
Waits for the event to complete.
Waits until the completion of all work currently captured in this event.
This prevents the CPU thread from proceeding until the event completes.
-
wait(stream=None)[source]¶ -
Makes all future work submitted to the given stream wait for this
event.Use
torch.cuda.current_stream()if no stream is specified.
Memory management¶
-
torch.cuda.empty_cache() → None[source]¶ -
Releases all unoccupied cached memory currently held by the caching
allocator so that those can be used in other GPU application and visible in
nvidia-smi.Note
empty_cache()doesn’t increase the amount of GPU
memory available for PyTorch. However, it may help reduce fragmentation
of GPU memory in certain cases. See Memory management for
more details about GPU memory management.
-
torch.cuda.memory_stats(device: Union[torch.device, str, None, int] = None) → Dict[str, Any][source]¶ -
Returns a dictionary of CUDA memory allocator statistics for a
given device.The return value of this function is a dictionary of statistics, each of
which is a non-negative integer.Core statistics:
-
"allocated.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
number of allocation requests received by the memory allocator. -
"allocated_bytes.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
amount of allocated memory. -
"segment.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
number of reserved segments fromcudaMalloc(). -
"reserved_bytes.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
amount of reserved memory. -
"active.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
number of active memory blocks. -
"active_bytes.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
amount of active memory. -
"inactive_split.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
number of inactive, non-releasable memory blocks. -
"inactive_split_bytes.{all,large_pool,small_pool}.{current,peak,allocated,freed}":
amount of inactive, non-releasable memory.
For these core statistics, values are broken down as follows.
Pool type:
-
all: combined statistics across all memory pools. -
large_pool: statistics for the large allocation pool
(as of October 2019, for size >= 1MB allocations). -
small_pool: statistics for the small allocation pool
(as of October 2019, for size < 1MB allocations).
Metric type:
-
current: current value of this metric. -
peak: maximum value of this metric. -
allocated: historical total increase in this metric. -
freed: historical total decrease in this metric.
In addition to the core statistics, we also provide some simple event
counters:-
"num_alloc_retries": number of failedcudaMalloccalls that
result in a cache flush and retry. -
"num_ooms": number of out-of-memory errors thrown.
- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistics for the current device, given bycurrent_device(),
ifdeviceisNone(default).
-
-
torch.cuda.memory_summary(device: Union[torch.device, str, None, int] = None, abbreviated: bool = False) → str[source]¶ -
Returns a human-readable printout of the current memory allocator
statistics for a given device.This can be useful to display periodically during training, or when
handling out-of-memory exceptions.- Parameters
-
-
device (torch.device or int, optional) – selected device. Returns
printout for the current device, given bycurrent_device(),
ifdeviceisNone(default). -
abbreviated (bool, optional) – whether to return an abbreviated summary
(default: False).
-
-
torch.cuda.memory_snapshot()[source]¶ -
Returns a snapshot of the CUDA memory allocator state across all devices.
Interpreting the output of this function requires familiarity with the
memory allocator internals.
-
torch.cuda.memory_allocated(device: Union[torch.device, str, None, int] = None) → int[source]¶ -
Returns the current GPU memory occupied by tensors in bytes for a given
device.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistic for the current device, given bycurrent_device(),
ifdeviceisNone(default).
Note
This is likely less than the amount shown in nvidia-smi since some
unused memory can be held by the caching allocator and some context
needs to be created on GPU. See Memory management for more
details about GPU memory management.
-
torch.cuda.max_memory_allocated(device: Union[torch.device, str, None, int] = None) → int[source]¶ -
Returns the maximum GPU memory occupied by tensors in bytes for a given
device.By default, this returns the peak allocated memory since the beginning of
this program.reset_peak_stats()can be used to
reset the starting point in tracking this metric. For example, these two
functions can measure the peak allocated memory usage of each iteration in a
training loop.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistic for the current device, given bycurrent_device(),
ifdeviceisNone(default).
-
torch.cuda.reset_max_memory_allocated(device: Union[torch.device, str, None, int] = None) → None[source]¶ -
Resets the starting point in tracking maximum GPU memory occupied by
tensors for a given device.See
max_memory_allocated()for details.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistic for the current device, given bycurrent_device(),
ifdeviceisNone(default).
Warning
This function now calls
reset_peak_memory_stats(), which resets
/all/ peak memory stats.
-
torch.cuda.memory_reserved(device: Union[torch.device, str, None, int] = None) → int[source]¶ -
Returns the current GPU memory managed by the caching allocator in bytes
for a given device.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistic for the current device, given bycurrent_device(),
ifdeviceisNone(default).
-
torch.cuda.max_memory_reserved(device: Union[torch.device, str, None, int] = None) → int[source]¶ -
Returns the maximum GPU memory managed by the caching allocator in bytes
for a given device.By default, this returns the peak cached memory since the beginning of this
program.reset_peak_stats()can be used to reset
the starting point in tracking this metric. For example, these two functions
can measure the peak cached memory amount of each iteration in a training
loop.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistic for the current device, given bycurrent_device(),
ifdeviceisNone(default).
-
torch.cuda.memory_cached(device: Union[torch.device, str, None, int] = None) → int[source]¶ -
Deprecated; see
memory_reserved().
-
torch.cuda.max_memory_cached(device: Union[torch.device, str, None, int] = None) → int[source]¶ -
Deprecated; see
max_memory_reserved().
-
torch.cuda.reset_max_memory_cached(device: Union[torch.device, str, None, int] = None) → None[source]¶ -
Resets the starting point in tracking maximum GPU memory managed by the
caching allocator for a given device.See
max_memory_cached()for details.- Parameters
-
device (torch.device or int, optional) – selected device. Returns
statistic for the current device, given bycurrent_device(),
ifdeviceisNone(default).
Warning
This function now calls
reset_peak_memory_stats(), which resets
/all/ peak memory stats.
You can accelerate the training of your model by making use of hardware accelerators such as Graphics Processing Units(GPUs). You can make use of GPU hardware accelerators for training your Pytorch models if you have NVIDIA GPU(s) by making use of Compute Unified Device Architecture(CUDA) API. In this chapter of the Pytorch tutorial, you will learn how you can make use of CUDA/GPU to accelerate the training process.
Checking CUDA Availability
Before you start using CUDA, you need to check if you have CUDA available in your environment. You can check it by using the torch.cuda.is_available() function.
# Checking if CUDA is available
torch.cuda.is_available()The function returns True if CUDA is available, else it will return False.
Moving to CUDA
If you have CUDA available in your environment, you can move your tensor to GPU. You can do this by calling the to() method on the variable(tensors and models) and specifying the device parameter.
Example
In this example, we are moving a tensor from CPU to GPU by creating a copy of the tensor in the GPU with the same variable name, therefore, effectively moving the tensor to GPU.
# Create a tensor
tensor_1 = torch.tensor([1, 2, 3, 4])
# Copy the tensor to GPU with same variable name
tensor_1 = tensor_1.to(device='cuda')Similarly, you can also move your Neural Network model to GPU.
Example
In this example, we are moving our Neural Network model mynet to GPU. We don’t need to create another variable, you can just make use of the to() method.
mynet.to(device='cuda')You can check the device on which your variable exists.
Example
For a tensor, this can be achieved by checking the device attribute of your tensor.
tensor_2 = torch.tensor([5, 6, 7, 8])
# Print the device on which tensor is present
print(tensor_2.device)
# Outputs- device(type='cpu')
# Moving the tensor to GPU
tensor_2 = tensor_2.to(device='cuda')
# Print the device on which tensor is present
print(tensor_2.device)
# Outputs- device(type='cuda', index=0)Example
A model consists of many layers, each of which has its own set of parameters. Therefore you need to check the device on which the parameters of the models exist. In this example, we will see how to check the device on which our Neural Network model mynet exists by checking the device on which its parameters exist.
# Print the device on which mynet exists
print(next(mynet.parameters()).device)
# Outputs- device(type='cpu')
# Moving the model to GPU
mynet.to(device='cuda')
# Print the device on which mynet exists
print(next(mynet.parameters()).device)
# Outputs- device(type='cuda', index=0)Notice how Pytorch by default makes use of CPU for storing tensors and models. If you have to make use of GPU to store your tensors and models, you will have to explicitly move them to a GPU. However, it can be quite challenging to check if CUDA is available in your environment and moving your Pytorch tensors and models to a GPU if it’s available. This step can be simplified a bit, take a look at the example below.
Example
In this example, we are setting the value of device to 'cuda' if CUDA is available, else we are setting it to 'cpu'. Next, we can move all the tensors and models to device. Therefore, if CUDA is available, then all the models and tensors will be moved to GPU else they will be in CPU.
# Assigning the value of device
if torch.cuda.is_available():
device = 'cuda'
else:
device = 'cpu'
# Moving the Neural Network model to the available device
mynet.to(device=device)
# Moving the tensor to the available device
tensor_3 = tensor_3.to(device=device)Now you can move all your models and parameters to device before training without having to worry about if CUDA will be available or not in the environment in which your code will be running. This way you will be able to take advantage of GPU for training if it’s available.
runtimeerror: attempting to deserialize object on a cuda device but torch.cuda.is_available() is false. if you are running on a cpu-only machine, please use torch.load with map_location=torch.device(‘cpu’) to map your storages to the cpu, How to solve the error presented here with Pytorch in python in the context of deeplearning?
Introduction
First of all, usually this error is encountered when trying to run your model code on the machine’s CPU instead of the GPU.
lib/python3.6/site-packages/torch/serialization.py", ... in validate_cuda_device
raise RuntimeError('Attempting to deserialize object on a CUDA '
RuntimeError: Attempting to deserialize object on a CUDA device but
torch.cuda.is_available() is False. If you are running on a CPU-only machine,
please use torch.load with map_location='cpu' to map your storages to the CPU.
In this case you encounter an error which is a raised RuntimeError exception.
This means that you are looking to deserialize an object using code that runs with the GPU while the GPU is disabled.
Then, The error then occurs when you try to load the pytorch model using the torch.load instruction (see https://pytorch.org/docs/stable/generated/torch.load.html)
Example :
torch.load('mymodel.pt')
So when the reloading is done with the wrong configuration you get the error:
lib/python3.6/site-packages/torch/serialization.py", ... in validate_cuda_device
raise RuntimeError('Attempting to deserialize object on a CUDA '
RuntimeError: Attempting to deserialize object on a CUDA device but
torch.cuda.is_available() is False. If you are running on a CPU-only machine,
please use torch.load with map_location='cpu' to map your storages to the CPU.
Solution
Also, As you can see in the Pytorch documentation (see https://pytorch.org/docs/stable/generated/torch.load.html) there is a map_location parameter – (a function, torch.device, string or a dict specifying how to remap storage locations).
This is where we must force the parameter to specify the location to use.
Note that if your model is registered and saved as using the GPU you will have to specify GPU otherwise you will have to put CPU. The objective here is to put a consistent parameter between what has been saved and what is reloaded.
And If you want to force CPU usage :
torch.load('mymodel.pt',map_location='cpu')
For CPU usage you can also use :
torch.load('mymodel.pt', map_location=torch.device('cpu'))
# Load on first GPU
torch.load('mymodel.pt', map_location=lambda storage, loc: storage.cuda(1))
# Lord on GPU 0 and 1
torch.load('mymodel.pt', map_location={'cuda:1':'cuda:0'})
External links :
https://pytorch.org/tutorials/beginner/saving_loading_models.html
https://pytorch.org/tutorials/recipes/recipes/save_load_across_devices.html
https://discuss.pytorch.org/t/saving-and-loading-a-model-in-pytorch/2610
Internal links – runtimeerror: attempting to deserialize object on a cuda device but torch.cuda.is_available() is false :
https://128mots.com/index.php/en/category/non-classe-en/
I installed CUDA and NVIDIA driver using the following two commands.
$ sudo ubuntu-drivers install
$ sudo apt install nvidia-cuda-toolkit
However, now cuda is not available from within torch. Do you know how I could fix it?
$ python
Python 3.7.6 (default, Jan 8 2020, 19:59:22)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'1.6.0'
>>> torch.version.cuda
'10.1'
>>> torch.cuda.is_available()
False
I am also not sure why after installing the drivers still nvidia-smi is not working:
$ nvidia-smi
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.1 LTS
Release: 20.04
Codename: focal
$ lspci | grep -i nvidia
01:00.0 VGA compatible controller: NVIDIA Corporation TU106M [GeForce RTX 2070 Mobile] (rev a1)
01:00.1 Audio device: NVIDIA Corporation TU106 High Definition Audio Controller (rev a1)
01:00.2 USB controller: NVIDIA Corporation TU106 USB 3.1 Host Controller (rev a1)
01:00.3 Serial bus controller [0c80]: NVIDIA Corporation TU106 USB Type-C UCSI Controller (rev a1)
asked Sep 24, 2020 at 6:45
![]()
The problem was fixed after I did a reboot:
(base) mona@mona:~$ nvidia-smi
Thu Sep 24 13:04:12 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 2070 Off | 00000000:01:00.0 Off | N/A |
| N/A 54C P8 8W / N/A | 428MiB / 7982MiB | 3% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1256 G /usr/lib/xorg/Xorg 275MiB |
| 0 N/A N/A 2422 G /usr/bin/gnome-shell 151MiB |
+-----------------------------------------------------------------------------+
(base) mona@mona:~$ python
Python 3.7.6 (default, Jan 8 2020, 19:59:22)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'1.6.0'
>>> torch.version.cuda
'10.1'
>>> torch.cuda.is_
torch.cuda.is_available( torch.cuda.is_initialized(
>>> torch.cuda.is_available()
True
answered Sep 24, 2020 at 17:05
![]()
Mona JalalMona Jalal
4,00919 gold badges59 silver badges93 bronze badges