I’m a Java developer and I’m using Ubuntu to develop. The project was created in Windows with Eclipse and it’s using the Windows-1252 encoding.
To convert to UTF-8 I’ve used the recode program:
find Web -iname *.java | xargs recode CP1252...UTF-8
This command gives this error:
recode: Web/src/br/cits/projeto/geral/presentation/GravacaoMessageHelper.java failed: Ambiguous output in step `CR-LF..data
I’ve searched about it and get the solution in Bash and Windows, Recode: Ambiguous output in step `data..CR-LF’ and it says:
Convert line endings from CR/LF to a
single LF: Edit the file with Vim,
give the command:set ff=unixand save
the file. Recode now should run
without errors.
Nice, but I’ve many files to remove the CR/LF character from, and I can’t open each to do it. Vi doesn’t provide any option to command line for Bash operations.
Can sed be used to do this? How?
![]()
asked Oct 8, 2010 at 13:37
![]()
4
There should be a program called dos2unix that will fix line endings for you. If it’s not already on your Linux box, it should be available via the package manager.
![]()
Tomas
56.5k48 gold badges232 silver badges368 bronze badges
answered Oct 8, 2010 at 13:40
![]()
cHaocHao
84k20 gold badges146 silver badges172 bronze badges
6
sed cannot match n because the trailing newline is removed before the line is put into the pattern space, but it can match r, so you can convert rn (DOS) to n (Unix) by removing r:
sed -i 's/r//g' file
Warning: this will change the original file
However, you cannot change from Unix EOL to DOS or old Mac (r) by this. More readings here:
How can I replace a newline (n) using sed?
![]()
answered Oct 9, 2013 at 21:51
![]()
JichaoJichao
1,7031 gold badge14 silver badges10 bronze badges
4
Actually, Vim does allow what you’re looking for. Enter Vim, and type the following commands:
:args **/*.java
:argdo set ff=unix | update | next
The first of these commands sets the argument list to every file matching **/*.java, which is all Java files, recursively. The second of these commands does the following to each file in the argument list, in turn:
- Sets the line-endings to Unix style (you already know this)
- Writes the file out iff it’s been changed
- Proceeds to the next file
![]()
answered Aug 19, 2014 at 13:59
![]()
ArandurArandur
7276 silver badges19 bronze badges
2
I’ll take a little exception to jichao’s answer. You can actually do everything he just talked about fairly easily. Instead of looking for a n, just look for carriage return at the end of the line.
sed -i 's/r$//' "${FILE_NAME}"
To change from Unix back to DOS, simply look for the last character on the line and add a form feed to it. (I’ll add -r to make this easier with grep regular expressions.)
sed -ri 's/(.)$/1r/' "${FILE_NAME}"
Theoretically, the file could be changed to Mac style by adding code to the last example that also appends the next line of input to the first line until all lines have been processed. I won’t try to make that example here, though.
Warning: -i changes the actual file. If you want a backup to be made, add a string of characters after -i. This will move the existing file to a file with the same name with your characters added to the end.
Update: The Unix to DOS conversion can be simplified and made more efficient by not bothering to look for the last character. This also allows us to not require using -r for it to work:
sed -i 's/$/r/' "${FILE_NAME}"
answered May 26, 2017 at 20:51
![]()
5
The tr command can also do this:
tr -d '1532' < winfile.txt > unixfile.txt
and should be available to you.
You’ll need to run tr from within a script, since it cannot work with file names. For example, create a file myscript.sh:
#!/bin/bash
for f in `find -iname *.java`; do
echo "$f"
tr -d '1532' < "$f" > "$f.tr"
mv "$f.tr" "$f"
recode CP1252...UTF-8 "$f"
done
Running myscript.sh would process all the java files in the current directory and its subdirectories.
![]()
tripleee
170k31 gold badges261 silver badges305 bronze badges
answered Oct 8, 2010 at 13:44
![]()
KeithLKeithL
1,13010 silver badges12 bronze badges
3
In order to overcome
Ambiguous output in step `CR-LF..data'
the simple solution might be to add the -f flag to force the conversion.
answered May 16, 2012 at 13:29
![]()
V_VV_V
5858 silver badges22 bronze badges
1
Try the Python script by Bryan Maupin found here (I’ve modified it a little bit to be more generic):
#!/usr/bin/env python
import sys
input_file_name = sys.argv[1]
output_file_name = sys.argv[2]
input_file = open(input_file_name)
output_file = open(output_file_name, 'w')
line_number = 0
for input_line in input_file:
line_number += 1
try: # first try to decode it using cp1252 (Windows, Western Europe)
output_line = input_line.decode('cp1252').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):t%sn' % (line_number, error)) # write to stderr
try: # then if that fails, try to decode using latin1 (ISO 8859-1)
output_line = input_line.decode('latin1').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):t%sn' % (line_number, error)) # write to stderr
sys.exit(1) # and just keep going
output_file.write(output_line)
input_file.close()
output_file.close()
You can use that script with
$ ./cp1252_utf8.py file_cp1252.sql file_utf8.sql
![]()
answered Dec 8, 2010 at 15:49
![]()
Anthony O.Anthony O.
20.7k15 gold badges102 silver badges159 bronze badges
Go back to Windows, tell Eclipse to change the encoding to UTF-8, then back to Unix and run d2u on the files.
answered Oct 8, 2010 at 14:10
![]()
JonathanJonathan
13.2k4 gold badges35 silver badges32 bronze badges
3
Иногда бывает такая ситуация – получаешь от заказчика движок для его дальнейшего «допиливания». Пытаешься положить его в репозиторий Git – и получаешь кучу варнингов типа:
LF will be replaced by CRLF in index.php
Это понятно — файлы в исходнике писались/правились до меня разными людьми и на разных операционных системах. Поэтому в файлах наблюдается полная мешанина в вопросе формата окончания строк.
Небольшая справка для тех, кто не в курсе. В разных операционных системах принят разный формат символов, обозначающий перевод строк:
- Windows — rn или CRLF (код 0D0A)
- Unix — n или LF (код 0A)
- Mac — r или CR (код 0D).
Такую разносортицу в своем проекте мне держать не хочется, поэтому я предпочитаю перед началом работ приводить все окончания строк к единому виду — n, он же LF. Почему так? Большинство серверов работают под управлением систем на базе Unix, поэтому, на мой взгляд, логично использовать nix’овые окончания строк и для файлов движка сайта.
Теперь опишу свой способ приведения конца строк к единому виду. Описывать работу буду на примере графической оболочки Git – Git GUI. Так проще и нагляднее.
- Кладу все файлы движка в папку – например, Original.
- Удаляю всякие временные файлы и прочий мусор.
- В пустые папки, которые тем не менее необходимы для работы сайта, кладу файл readme.txt. Это надо по той причине, что Git отслеживает только файлы, а не папки. Поэтому если закоммитить в Git движок с пустыми папками, то потом при выгрузке движка этих пустых, но нужных папок мы не увидим.
- Открываю пункт меню «Редактировать» -> «Настройки» и указываю имя пользователя, email и кодировку файлов проекта.
- В файлах настроек Git – gitconfig — для параметра core прописываю:
- autocrlf = input
- safecrlf = warn
- $ git config —global core.autocrlf input
- $ git config —global core.safecrlf warn
- Теперь записываю все файлы движка в репозиторий. В итоге в репозитории все файлы будут иметь концы строк LF или CR (т.к. Git сконвертировал только CRLF в LF, преобразование CR->LF от не выполняет).
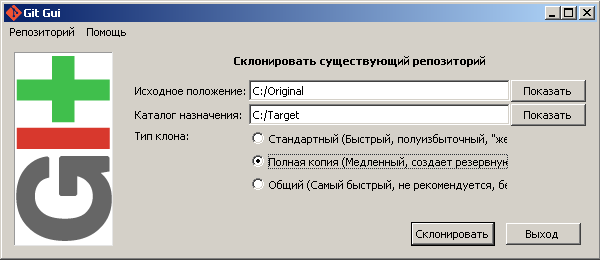
- Запускаю Git GUI, выбираю «Склонировать существующий репозиторий».
- В строке «Исходное положение» указываю папку Original.
- В строке «Каталог назначения» указываю полный пусть к папке, в которую я хочу скопировать репозиторий из папки Original. В данном случае я указал папку Target. Важно: папки с таким именем на диске быть не должно. Git GUI создаст ее сам.
- Выбираю «Полная копия».
- Жму «Склонировать».
или выполнить команды:
Первый параметр дает команду Git заменить все окончания строк с CRLF в LF при записи в репозиторий.
Второй – выдает предупреждения о конвертации специфических бинарников, если вдруг такие окажутся в движке.
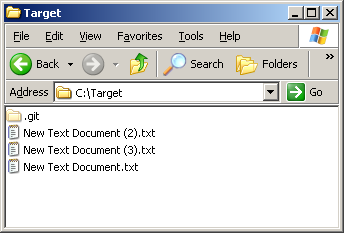
- В результате этой манипуляции у нас на диске C появилась папка Target, в которой лежат файлы из репозитория папки Original. Т.е. в папке Target все концы строк приведены к формату LF или CR.
- Заходим в папку Target, видим в ней папку .git – удаляем эту папку.
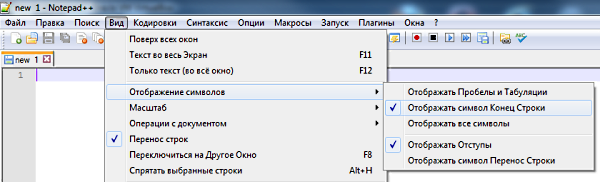
- Открываем редактор Notepad++, выбираем пункт меню «Вид» -> «Отображение символов» -> отмечаем «Отображать символ Конец строки». Теперь редактор будет нам показывать символы конца строк.
- Выбираем пункт меню «Поиск» -> «Искать в файлах». В настройках поиска выбираем:
- Режим поиска – Расширенный
- Папка – C:Target
- Найти — r
Жмем «Найти все»

- В итоге мы найдем все файлы, которые имеют концы строк в формате Mac, т.е.r или CR. Вряд ли их будет много, но иногда встречаются. Открываем каждый файл по очереди в том же редакторе Notepad++. Мы сможем визуально увидеть, что у файла концы строк в формате Mac:
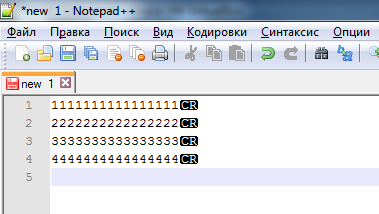
- Преобразуем его в Unix формат. Выбираем «Правка» -> «Формат Конца Строк» -> «Преобразовать в UNIX-формат»
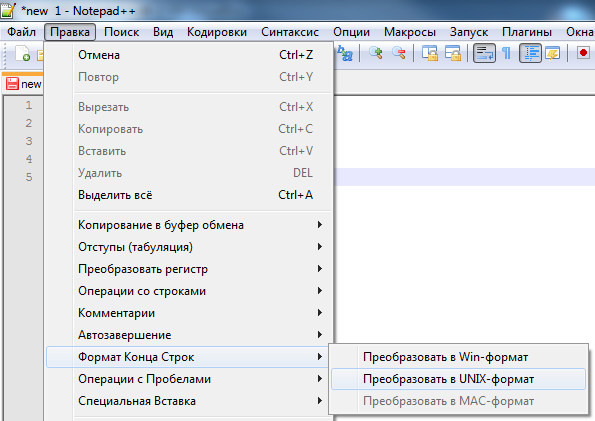
- В итоге файл преобразуется в UNIX-формат.
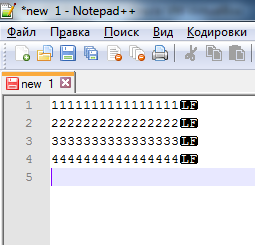
- Сохраняем файл и выполняем аналогичное преобразование для всех оставшихся файлов в формате Mac. В итоге в папке Target мы будем иметь движок, все файлы которого будут иметь конец строк Unix-формата LF.
Теперь движок можно класть в репозиторий Git. И не забудьте в редакторе, которым выпотом будете править файлы, выставить по умолчанию концовку строк LF, чтобы опять не возникла мешанина.
I’m a Java developer and I’m using Ubuntu to develop. The project was created in Windows with Eclipse and it’s using the Windows-1252 encoding.
To convert to UTF-8 I’ve used the recode program:
find Web -iname *.java | xargs recode CP1252...UTF-8
This command gives this error:
recode: Web/src/br/cits/projeto/geral/presentation/GravacaoMessageHelper.java failed: Ambiguous output in step `CR-LF..data
I’ve searched about it and get the solution in Bash and Windows, Recode: Ambiguous output in step `data..CR-LF’ and it says:
Convert line endings from CR/LF to a
single LF: Edit the file with Vim,
give the command:set ff=unixand save
the file. Recode now should run
without errors.
Nice, but I’ve many files to remove the CR/LF character from, and I can’t open each to do it. Vi doesn’t provide any option to command line for Bash operations.
Can sed be used to do this? How?
![]()
asked Oct 8, 2010 at 13:37
![]()
4
There should be a program called dos2unix that will fix line endings for you. If it’s not already on your Linux box, it should be available via the package manager.
![]()
Tomas
56.5k48 gold badges232 silver badges368 bronze badges
answered Oct 8, 2010 at 13:40
![]()
cHaocHao
84k20 gold badges146 silver badges172 bronze badges
6
sed cannot match n because the trailing newline is removed before the line is put into the pattern space, but it can match r, so you can convert rn (DOS) to n (Unix) by removing r:
sed -i 's/r//g' file
Warning: this will change the original file
However, you cannot change from Unix EOL to DOS or old Mac (r) by this. More readings here:
How can I replace a newline (n) using sed?
![]()
answered Oct 9, 2013 at 21:51
![]()
JichaoJichao
1,7031 gold badge14 silver badges10 bronze badges
4
Actually, Vim does allow what you’re looking for. Enter Vim, and type the following commands:
:args **/*.java
:argdo set ff=unix | update | next
The first of these commands sets the argument list to every file matching **/*.java, which is all Java files, recursively. The second of these commands does the following to each file in the argument list, in turn:
- Sets the line-endings to Unix style (you already know this)
- Writes the file out iff it’s been changed
- Proceeds to the next file
![]()
answered Aug 19, 2014 at 13:59
![]()
ArandurArandur
7276 silver badges19 bronze badges
2
I’ll take a little exception to jichao’s answer. You can actually do everything he just talked about fairly easily. Instead of looking for a n, just look for carriage return at the end of the line.
sed -i 's/r$//' "${FILE_NAME}"
To change from Unix back to DOS, simply look for the last character on the line and add a form feed to it. (I’ll add -r to make this easier with grep regular expressions.)
sed -ri 's/(.)$/1r/' "${FILE_NAME}"
Theoretically, the file could be changed to Mac style by adding code to the last example that also appends the next line of input to the first line until all lines have been processed. I won’t try to make that example here, though.
Warning: -i changes the actual file. If you want a backup to be made, add a string of characters after -i. This will move the existing file to a file with the same name with your characters added to the end.
Update: The Unix to DOS conversion can be simplified and made more efficient by not bothering to look for the last character. This also allows us to not require using -r for it to work:
sed -i 's/$/r/' "${FILE_NAME}"
answered May 26, 2017 at 20:51
![]()
5
The tr command can also do this:
tr -d '1532' < winfile.txt > unixfile.txt
and should be available to you.
You’ll need to run tr from within a script, since it cannot work with file names. For example, create a file myscript.sh:
#!/bin/bash
for f in `find -iname *.java`; do
echo "$f"
tr -d '1532' < "$f" > "$f.tr"
mv "$f.tr" "$f"
recode CP1252...UTF-8 "$f"
done
Running myscript.sh would process all the java files in the current directory and its subdirectories.
![]()
tripleee
170k31 gold badges261 silver badges305 bronze badges
answered Oct 8, 2010 at 13:44
![]()
KeithLKeithL
1,13010 silver badges12 bronze badges
3
In order to overcome
Ambiguous output in step `CR-LF..data'
the simple solution might be to add the -f flag to force the conversion.
answered May 16, 2012 at 13:29
![]()
V_VV_V
5858 silver badges22 bronze badges
1
Try the Python script by Bryan Maupin found here (I’ve modified it a little bit to be more generic):
#!/usr/bin/env python
import sys
input_file_name = sys.argv[1]
output_file_name = sys.argv[2]
input_file = open(input_file_name)
output_file = open(output_file_name, 'w')
line_number = 0
for input_line in input_file:
line_number += 1
try: # first try to decode it using cp1252 (Windows, Western Europe)
output_line = input_line.decode('cp1252').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):t%sn' % (line_number, error)) # write to stderr
try: # then if that fails, try to decode using latin1 (ISO 8859-1)
output_line = input_line.decode('latin1').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):t%sn' % (line_number, error)) # write to stderr
sys.exit(1) # and just keep going
output_file.write(output_line)
input_file.close()
output_file.close()
You can use that script with
$ ./cp1252_utf8.py file_cp1252.sql file_utf8.sql
![]()
answered Dec 8, 2010 at 15:49
![]()
Anthony O.Anthony O.
20.7k15 gold badges102 silver badges159 bronze badges
Go back to Windows, tell Eclipse to change the encoding to UTF-8, then back to Unix and run d2u on the files.
answered Oct 8, 2010 at 14:10
![]()
JonathanJonathan
13.2k4 gold badges35 silver badges32 bronze badges
3
I’m a Java developer and I’m using Ubuntu to develop. The project was created in Windows with Eclipse and it’s using the Windows-1252 encoding.
To convert to UTF-8 I’ve used the recode program:
find Web -iname *.java | xargs recode CP1252...UTF-8
This command gives this error:
recode: Web/src/br/cits/projeto/geral/presentation/GravacaoMessageHelper.java failed: Ambiguous output in step `CR-LF..data
I’ve searched about it and get the solution in Bash and Windows, Recode: Ambiguous output in step `data..CR-LF’ and it says:
Convert line endings from CR/LF to a
single LF: Edit the file with Vim,
give the command:set ff=unixand save
the file. Recode now should run
without errors.
Nice, but I’ve many files to remove the CR/LF character from, and I can’t open each to do it. Vi doesn’t provide any option to command line for Bash operations.
Can sed be used to do this? How?
![]()
asked Oct 8, 2010 at 13:37
![]()
4
There should be a program called dos2unix that will fix line endings for you. If it’s not already on your Linux box, it should be available via the package manager.
![]()
Tomas
56.5k48 gold badges232 silver badges368 bronze badges
answered Oct 8, 2010 at 13:40
![]()
cHaocHao
84k20 gold badges146 silver badges172 bronze badges
6
sed cannot match n because the trailing newline is removed before the line is put into the pattern space, but it can match r, so you can convert rn (DOS) to n (Unix) by removing r:
sed -i 's/r//g' file
Warning: this will change the original file
However, you cannot change from Unix EOL to DOS or old Mac (r) by this. More readings here:
How can I replace a newline (n) using sed?
![]()
answered Oct 9, 2013 at 21:51
![]()
JichaoJichao
1,7031 gold badge14 silver badges10 bronze badges
4
Actually, Vim does allow what you’re looking for. Enter Vim, and type the following commands:
:args **/*.java
:argdo set ff=unix | update | next
The first of these commands sets the argument list to every file matching **/*.java, which is all Java files, recursively. The second of these commands does the following to each file in the argument list, in turn:
- Sets the line-endings to Unix style (you already know this)
- Writes the file out iff it’s been changed
- Proceeds to the next file
![]()
answered Aug 19, 2014 at 13:59
![]()
ArandurArandur
7276 silver badges19 bronze badges
2
I’ll take a little exception to jichao’s answer. You can actually do everything he just talked about fairly easily. Instead of looking for a n, just look for carriage return at the end of the line.
sed -i 's/r$//' "${FILE_NAME}"
To change from Unix back to DOS, simply look for the last character on the line and add a form feed to it. (I’ll add -r to make this easier with grep regular expressions.)
sed -ri 's/(.)$/1r/' "${FILE_NAME}"
Theoretically, the file could be changed to Mac style by adding code to the last example that also appends the next line of input to the first line until all lines have been processed. I won’t try to make that example here, though.
Warning: -i changes the actual file. If you want a backup to be made, add a string of characters after -i. This will move the existing file to a file with the same name with your characters added to the end.
Update: The Unix to DOS conversion can be simplified and made more efficient by not bothering to look for the last character. This also allows us to not require using -r for it to work:
sed -i 's/$/r/' "${FILE_NAME}"
answered May 26, 2017 at 20:51
![]()
5
The tr command can also do this:
tr -d '1532' < winfile.txt > unixfile.txt
and should be available to you.
You’ll need to run tr from within a script, since it cannot work with file names. For example, create a file myscript.sh:
#!/bin/bash
for f in `find -iname *.java`; do
echo "$f"
tr -d '1532' < "$f" > "$f.tr"
mv "$f.tr" "$f"
recode CP1252...UTF-8 "$f"
done
Running myscript.sh would process all the java files in the current directory and its subdirectories.
![]()
tripleee
170k31 gold badges261 silver badges305 bronze badges
answered Oct 8, 2010 at 13:44
![]()
KeithLKeithL
1,13010 silver badges12 bronze badges
3
In order to overcome
Ambiguous output in step `CR-LF..data'
the simple solution might be to add the -f flag to force the conversion.
answered May 16, 2012 at 13:29
![]()
V_VV_V
5858 silver badges22 bronze badges
1
Try the Python script by Bryan Maupin found here (I’ve modified it a little bit to be more generic):
#!/usr/bin/env python
import sys
input_file_name = sys.argv[1]
output_file_name = sys.argv[2]
input_file = open(input_file_name)
output_file = open(output_file_name, 'w')
line_number = 0
for input_line in input_file:
line_number += 1
try: # first try to decode it using cp1252 (Windows, Western Europe)
output_line = input_line.decode('cp1252').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):t%sn' % (line_number, error)) # write to stderr
try: # then if that fails, try to decode using latin1 (ISO 8859-1)
output_line = input_line.decode('latin1').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):t%sn' % (line_number, error)) # write to stderr
sys.exit(1) # and just keep going
output_file.write(output_line)
input_file.close()
output_file.close()
You can use that script with
$ ./cp1252_utf8.py file_cp1252.sql file_utf8.sql
![]()
answered Dec 8, 2010 at 15:49
![]()
Anthony O.Anthony O.
20.7k15 gold badges102 silver badges159 bronze badges
Go back to Windows, tell Eclipse to change the encoding to UTF-8, then back to Unix and run d2u on the files.
answered Oct 8, 2010 at 14:10
![]()
JonathanJonathan
13.2k4 gold badges35 silver badges32 bronze badges
3
I’m going to throw this solution out there. Git will do this. See this post about it
So theoretically you could do this to convert an entire tree
cd root/of/tree
git init .
git add .
git commit -m "initial commit"
echo "* text eol=crlf" > .gitattributes
git rm --cached -r .
git reset --hard
Change crlf to lf if you want to go the other way. NOTE: you’re not done yet, keep reading
Type git status to see which files will be affected. You might have to add lines like
*.jpg binary
*.png binary
*.gif binary
etc to .gitattributes to avoid converting certain files. You can also explicit mark certain files as text
*.md text
*.css text
Then just repeat these 2 lines after you’ve edited .gitattributes
git rm --cached -r .
git reset --hard
Then use git status again to see which files will be changed. When you’re sure all the files you want affected are listed by git status then commit
git add .
git commit -m "normalize line endings"
now check all the files out again
git rm --cached -r .
git reset --hard
They should now have whatever your desired line endings are
** NOTE: If you were already using git skip the first 3 commands git commands. If you were not using git you can now delete the .gitattributes file and the .git folder.
** Back up your files: the git rm --cached -r deletes them all (although they are theoretically in your git repo (the .git folder) which is how they get restored by the last command git reset --hard. It’s just since files are getting deleted it’s probably best to back them up.
Заключение. Самый простой способ преобразовать файл из формата UNIX в Windows (и наоборот) — использовать программу FTP. Команды преобразования — ваш следующий лучший выбор. Если вам нужны дополнительные команды, которые выполняют ту же задачу, вы можете искать команды perl и sed.
Как изменить окончания строк в Unix?
Чтобы записать файл таким способом, пока файл открыт, перейдите в меню «Правка», выберите подменю «Преобразование EOL» и из появившихся опций выберите «Формат UNIX / OSX». В следующий раз, когда вы сохраните файл, его окончания строк будут сохранены с окончаниями строк в стиле UNIX.
Почему Windows и Unix используют разные окончания строк в текстовых файлах?
DOS против окончаний строк в Unix. … DOS использует возврат каретки и перевод строки («rn») в качестве окончания строки, а Unix использует только перевод строки («n»). Вы должны быть осторожны при передаче файлов между машинами Windows и Unix, чтобы убедиться, что концы строк переводятся правильно.
Как изменить LF на CRLF?
- Открыть файл с помощью блокнота ++
- Нажмите Edit -> EOL Conversion -> Windows Format (это добавит замену LF на CRLF)
- Сохраните файл.
Как открыть файл Unix в Windows?
Чтобы установить и использовать PuTTY:
- Загрузите PuTTY отсюда.
- Установите с использованием настроек по умолчанию на вашем компьютере.
- Дважды щелкните значок PuTTY.
- Введите имя хоста сервера UNIX / Linux в поле «Имя хоста» и нажмите кнопку «Открыть» в нижней части диалогового окна.
- При появлении запроса введите свое имя пользователя и пароль.
Как сохранить файл в формате Unix?
После того, как вы изменили файл, нажмите [Esc], перейдите в командный режим и нажмите: w и нажмите [Enter], как показано ниже. Чтобы сохранить файл и выйти одновременно, вы можете использовать ESC и и нажмите [Enter]. При желании нажмите [Esc] и введите Shift + ZZ, чтобы сохранить файл и выйти из него.
Что такое символ конца строки в UNIX?
Конец строки
Символ конца строки (EOL) на самом деле представляет собой два символа ASCII — комбинацию символов CR и LF. … Символ EOL используется в качестве символа новой строки в большинстве других операционных систем, отличных от Unix, включая Microsoft Windows и Symbian OS.
Как мне найти конец символа строки в UNIX?
Попробуйте файл, затем файл -k, затем dos2unix -ih
- Он будет выводить с окончанием строки CRLF для окончания строки DOS / Windows.
- Он будет выводиться с окончанием строки LF для окончания строки MAC.
- А для Linux / Unix строка «CR» будет просто выводить текст.
20 колода 2015 г.
Как вы заканчиваете строчку в Linux?
Escape-символ () может использоваться для выхода из конца строки, например
Почему Windows до сих пор использует Crlf?
Возврат каретки означал «вернуть набранный вами бит в начало строки». Windows использует CR + LF, потому что это использовала MS-DOS, потому что использовала CP / M, потому что это имело смысл для последовательных линий. Unix скопировал свое соглашение n, потому что это сделал Multics.
Как найти окончания строк в Windows?
используйте текстовый редактор, например notepad ++, который поможет вам разобраться в окончании строки. Он покажет вам форматы конца строки, используемые как Unix (LF), Macintosh (CR) или Windows (CR LF) на панели задач инструмента. вы также можете перейти к View-> Show Symbol-> Show End Of Line, чтобы отобразить концы строки как LF / CR LF / CR.
Что такое LF и CRLF?
Описание. Термин CRLF означает возврат каретки (ASCII 13, r), перевод строки (ASCII 10, n). … Например: в Windows и CR, и LF требуются для обозначения конца строки, тогда как в Linux / UNIX требуется только LF. В протоколе HTTP для завершения строки всегда используется последовательность CR-LF.
Что мне следует использовать — LF или CRLF?
основной. eol = crlf Когда Git нужно изменить окончание строки для записи файла в ваш рабочий каталог, он всегда будет использовать CRLF для обозначения конца строки. основной. eol = lf Когда Git нужно изменить окончание строки для записи файла в ваш рабочий каталог, он всегда будет использовать LF для обозначения конца строки.
Что это LF будет заменено на Crlf?
В системах Unix конец строки представлен переводом строки (LF). В окнах строка представлена возвратом каретки (CR) и переводом строки (LF), таким образом (CRLF). когда вы получаете код от git, который был загружен из системы unix, у них будет только LF.
Как мне найти и заменить CR LF в Notepad ++?
Использование Notepad ++ для изменения символов конца строки (CRLF на LF)
- Щелкните Поиск> Заменить (или Ctrl + H).
- Найди то, что: рН.
- Заменить на: n.
- Режим поиска: выберите Расширенный.
- Заменить все.
19 центов 2017 г.
Question
How to convert a UNIX LF to a CR/LF? (SCI57956)
Answer
Connect:Direct alone does not do this. Please use other utilities to accomplish this. See examples below:
1) Use a freeware utility or create a simple script which uses cat and/or sed to add the CR to the LF: Example follows showing how to accomplish the same funtcions using a script which contains cat and sed:
Write dos2unix and unix2dos as scripts, see examples below:
The equivalent scripts look like:
====== dos2unix ======
cat file | sed «s/^M{1,}$//» | sed «$ s/^Z//» > file.new
====== unix2dos ======
cat file | sed «s/$/^M/» | sed «$ s/$/^Z/» > file.new
2) On Windows or UNIX, gzip and gunzip has a -a switch that tells Windows gunzip to uncompress a file and change all LF’s to CRLF.
3) If this is a PGP file, UNIX and Linux has several different utilities that change «UNIX» text files to «Windows» text files. One of these utilities can be run by inserting into a exiisting or new C:Direct UNIX process, an extra runtask step ( or extending a current runtask and pipe «|» the output straight into the PGP command they’re already running on the box). Probably the fastest is the stream editor, «sed».
Assuming Step01 is the mainframe to Linux transfer, then step02 could be something like
Step02 (if step01 <=4 then)</font></font></p>
runtask (sed command to convert LF to CRLF)
Step03 (if step02 = 0 then)
runtask (PGP-encrypt the new file as before)
Step04 (if step03 = 0 then)
continue processing as before. Send file on to next UNIX machine.
In this scenario the customer would not have change anything. This will add a very small resource impact to that Linux box.
Here are some sed examples to use under Linux. At the end, the output is piped straight into another text file. However, the output could also be piped straight into the current PGP runtask with the «|» symbol.
# command line under ksh
cat mainframe.txt | sed «s/$/`echo -e \r`/» > windows.txt
# command line under bash
cat mainframe.txt | sed ‘s/$'»/`echo \r`/» > windows.txt
[{«Product»:{«code»:»SSKTYY»,»label»:»IBM Sterling Connect:Direct for UNIX»},»Business Unit»:{«code»:»BU059″,»label»:»IBM Software w/o TPS»},»Component»:»Not Applicable»,»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Version»:»All»,»Edition»:»»,»Line of Business»:{«code»:»LOB59″,»label»:»Sustainability Software»}}]
Один из самых частых вопросов о Гите — почему так сложно работать с окончаниями строк. В этой статье мы попробуем ответить на этот вопрос и рассказать о множестве опций и настроек для контроля над окончаниями строк в Гите.
Гит имеет дело с двумя системами для работы с концами строк в репозиториях. Корень проблемы в том, что популярные операционные системы по-разному обозначают конец строки: Unix, Linux и Mac OS X используют LF, а Windows CRLF.
В этой статье мы не будем брать во внимание, что в предыдущих версиях Mac OS X использовался CR.
Ничего из этого не было бы проблемой, если бы каждый из нас жил в своём маленьком, изолированном мире и никогда не обменивался кодом между разными операционными системами. Под обменом кодом, в данном случае, будем понимать всё — от работы над кросс-платформенным проектом до копирования кода из браузера. Всякий раз, когда вы скачиваете архив проекта с Гитхаба, копируете код из чьего-то блога или гиста или используете код из файла на облачном хранилище, вы работаете с текстом, а значит имеете дело с невидимыми символами окончаний строк.
Все эти действия с кодом потенциально могут привнести разные настройки окончаний строк в вашу кодовую базу. Это может привести к беспорядочным диффам и сделать работу с Гитом в целом неприятной.
Основное решение, которое принял Гит для этой проблемы — указать, что лучший способ хранить окончания строк в репозитории для текстовых файлов — использование LF. Это правило ни к чему вас не принуждает, но большинство разработчиков, использующих Гит и Гитхаб, приняли его как соглашение и мы тоже рекомендуем так настроить ваш конфиг.
Основы
Перед тем, как мы опишем настройки для управления окончаниями строк, нам надо узнать несколько вещей о core.eol и разобраться с тем, что значит записать что-либо в базу данных Гит.
Конец строки
core.eol — первый параметр, о котором нужно знать.
Почти всегда, кроме самых редких случаев, нам не стоит менять дефолтное значение этого параметра. Хотя сам по себе core.eol мало что делает, нам нужно знать его значение каждый раз, когда мы хотим, чтобы Гит изменил окончания строк. Так как этот параметр будет использоваться во всём, о чём пойдёт речь дальше, хорошо бы знать о его существовании и о том, что его значение, вероятно, менять не придётся.
core.eol = native— значение по умолчанию. При записи файла в рабочую папку, Гит изменит окончания строк на соответствующие вашей платформе по умолчанию. Для Windows это будетCRLF, для Unix, Linux и Mac OS X —LF;core.eol = crlf— если установлено такое значение, Гит всегда будет использовать для обозначения конца строкиCRLFпри записи файла в вашу рабочую директорию;core.eol = lf— это значение скажет Гиту всегда использоватьLFдля обозначения конца строки при записи файла в вашу рабочую папку.
Чтобы узнать, какое значение core.eol установлено в вашей системе, нужно запустить в консоли команду git config --global core.eol. Если команда ничего не вернёт, значит, в вашей системе используется значение по умолчанию, native.
Запись и вывод объектов из базы данных
Прежде чем двигаться дальше, мы поговорим о двух важных операциях: записи в объектную базу и выводе данных из неё в рабочую директорию.
Возможно, вы уже знаете, что Гит хранит свою базу данных в папке .git. Он создаёт эту директорию и несколько файлов в ней, после запуска команды git init. Файлы в папке .git определяют все конфигурации Гита, в них хранится история проекта. Это обычные файлы и мы можем их читать и редактировать так же, как файлы самого проекта.
Каждый раз, когда мы делаем команду типа git commit, мы записываем объекты в эту базу данных. Запись в базу данных включает в себя:
- сохранение всего содержимого файла;
- добавление его в список со всеми файлами, которые отслеживает Гит;
- создание блоб-файла;
- вычисление SHA-ключа — хэш-кода, в котором хранится информация о содержимом файла.
Во время записи в базу данных **Гит может запустить фильтры и преобразовать окончания строк.
Есть ещё один случай, когда у Гита появляется возможность преобразовать окончания строк — это запись файлов из базы данных в нашу рабочую папку. Это то, что мы подразумеваем под выводом из базы данных. Такой процесс можно запустить множеством команд, но самая очевидная и простая для понимания — git checkout. Вывод из объектной базы данных также происходит после запуска команд, которые делают изменения в нашей рабочей папке, например, git clone или git reset.
Старая система
Теперь давайте поговорим о старой системе — оригинальном наборе функций в Гите, предназначенном для решения конкретной проблемы с окончаниями строк. Есть большая вероятность, что вы прямо сейчас пользуетесь старой системой и даже не подозреваете об этом.
Вот как это работает: у Гита есть настройка конфигураций core.autocrlf, которая специально создана для того, чтобы все окончания строк в текстовом файле преобразовывались в LF при записи в объектную базу данных репозитория. Вот список разных настроек для core.autocrlf и их значений:
core.autocrlf = false— это значение по умолчанию, которое большинству людей следует сменить. Результатом использования этого значения станет то, что Гит не будет связываться с окончаниями строк в ваших файлах. Там могут быть разные окончаниями строк:LF,CRLF,CRили микс из всех них, но Гиту это будет безразлично. Такое значение может привести к тому, что диффы станут менее читаемыми и появятся сложности при слиянии веток. У большинства пользователей Unix/Linux установлено именно это значение, потому что у них нет проблем сCRLFи им не нужно, чтобы Гит делал дополнительную работу каждый раз при записи файлов в базу данных или в рабочую папку.core.autocrlf = true— значит, что Гит обработает все текстовые файлы и убедится, что всеCRLFзаменены наLFперед записью в базу данных. При обратном процессе он преобразует всеLFвCRLF.
Такая установка гарантирует, что ваш репозиторий можно будет использовать на других платформах, сохраняяCRLFв вашем рабочей папке. Поэтому параметрtrueдляcore.autocrlfрекомендован для Windows.core.autocrlf = input— значит, что Гит обработает все текстовые файлы и убедится, что всеCRLFизменены наLFпри записи файлов в базу данных. Однако обратной замены не произойдёт. При записи файлов в рабочую папку из базы данных, для обозначения конца строки останутсяLF.
Этот параметр обычно используется в Unix / Linux / OS X для предотвращения записиCRLFв репозиторий. Идея заключается в том, что если вы вставили код из браузера и случайно записалиCRLFв один из ваших файлов, Гит удостоверится, что произойдёт замена наLFпри записи в базу данных.
Чтобы увидеть, какое значение для core.autocrlf установлено в вашей системе, нужно запустить в командной строке git config --global core.autocrlf .
Если команда ничего не вернёт, то вы используете значение по умолчанию, false.
Как же Гит определяет, что файл текстовый? Хороший вопрос. У Гита есть внутренний эвристический метод, который проверяет, двоичный ли файл. Если файл не двоичный, то Гит считает его текстовым. Но Гит иногда может ошибаться, и это будет причиной для знакомства со следующей настройкой.
Параметр core.safecrlf был создан на тот случай, если Гит ошибётся и изменит окончания строк там, где лучше было бы оставить их в покое.
core.safecrlf = true— перед записью в базу данных при подготовке к заменеCRLFнаLF, Гит убедится, что сможет успешно прервать операцию. Он проверит, что можно откатить изменения (изLFвCRLF), а если нет, то отменит операцию.core.safecrlf = warn— сделает то же, что и предыдущий параметр, но вместо того, чтобы прервать операцию, Гит просто предупредит вас о том, что может случиться что-то нехорошее.
Наконец, вы можете создать в корне своего репозитория файл .gitattributes и указать в нём настройки для конкретных файлов. Это позволит вам управлять такими настройками, как autocrlf для каждого типа файлов.
-
Например, для того, чтобы Гит заменил
CRLFнаLFво всех текстовых файлах, можно написать в.gitattributesтакую строку:*.txt crlf. -
Или можно сделать, чтобы Гит никогда не заменял
CRLFнаLFв текстовых файлах с помощью такой строки:*.txt -crlf -
Чтобы Гит заменял
CRLFнаLFв текстовых файлах только при записи в базу данных, но возвращалLFпри записи в рабочий каталог, нужно написать:*.txt crlf=input
Хорошо, видите, какой беспорядок мы тут учинили? И он становится ещё больше, если мы начинаем работать над проектами, которые подталкивают нас к другим глобальным настройкам.
Введём в дело новую систему, доступную начиная с версии Гит 1.7.2.
Новая система
Новая система определяет все настройки для окончаний строк в файле .gitattributes вашего репозитория, инкапсулируя их внутри и делая независимыми от глобальных настроек.
В новой системе за то, чтобы указать Гиту, в каких файлах надо заменить CRLF на LF, отвечаете вы, сообщая об этом с помощью атрибута text в файле .gitattributes. В этом случае будет полезен мануал для .gitattributes, а ниже вы найдёте несколько примеров использования атрибута text.
*.txt text— устанавливает атрибутtextдля всех текстовых файлов. Это значит, что Гит будет запускать процесс заменыCRLFнаLFкаждый раз при записи в БД и делать обратную замену при выводе из базы данных в рабочий репозиторий.*.txt -text— снимет со всех текстовых файлов этот фильтр. Это значит, что в указанных файлах не будет заменыCRLFнаLF.*.txt text=auto— установит для всех, подходящих под условие файлов, заменуCRLFнаLF, если Гит с помощью своего эвристического метода определит эти файлы как текстовые, а не бинарные.
Если файл не определён, Гит вернётся к старой системе и настройке core.autocrlf.
Именно так работает обратная совместимость, но я рекомендую, особенно тем, кто использует Windows для разработки, явно создавать файл .gitattributes.
Ниже пример файла .gitattributes с общими настройками, который можно использовать для своего проекта. Пример взят отсюда.
# Общие настройки, которые всегда должны быть использованы для настроек вашего языка.
# Автоматическое определение текстовых файлов и выполнение нормализации LF
# http://davidlaing.com/2012/09/19/customise-your-gitattributes-to-become-a-git-ninja/
* text=auto
#
# Строка выше будет обрабатывать все файлы, которых нет в списке ниже.
#
# Documents
*.doc diff=astextplain
*.DOC diff=astextplain
*.docx diff=astextplain
*.DOCX diff=astextplain
*.dot diff=astextplain
*.DOT diff=astextplain
*.pdf diff=astextplain
*.PDF diff=astextplain
*.rtf diff=astextplain
*.RTF diff=astextplain
*.md text
*.tex text
*.adoc text
*.textile text
*.mustache text
*.csv text
*.tab text
*.tsv text
*.sql text
# Graphics
*.png binary
*.jpg binary
*.jpeg binary
*.gif binary
*.tif binary
*.tiff binary
*.ico binary
# SVG по дефолту рассматривается как бинарный. Если вы хотите, чтобы он распознавался как текст, закомментируйте следующую строку и раскомментируйте следующую за ней.
*.svg binary
#*.svg text
*.eps binary
#
# Исключить файлы из экспорта
#
.gitattributes export-ignore
.gitignore export-ignore
Как вы могли заметить, с помощью следующей команды можно сказать Гиту обнаруживать все текстовые файлы и автоматически конвертировать в них CRLF в LF:
* text=autoЭто, конечно, лучше, чем требовать от всех одной глобальной настройки для core.autocrlf, но и означает, что вы полностью доверяете Гиту в определении бинарности файлов. На наш взгляд, лучше явно указать текстовые файлы, которым требуется нормализация. Если вы собираетесь использовать этот параметр, не забудьте, что он должен быть указан на первой строке файла .gitattributes, чтобы последующие строки могли его переопределить.
22 ответа
Вы можете использовать tr для преобразования из DOS в Unix; однако вы можете сделать это только безопасно, если CR появляется в вашем файле только как первый байт пары байтов CRLF. Это обычно так. Затем вы используете:
tr -d '15' <DOS-file >UNIX-file
Обратите внимание, что имя DOS-file отличается от имени UNIX-file; если вы попытаетесь использовать одно и то же имя дважды, вы не получите никаких данных в файле.
Вы не можете сделать это наоборот (со стандартным «tr» ).
Если вы знаете, как ввести возврат каретки в script (control-V, control-M, чтобы ввести control-M), тогда:
sed 's/^M$//' # DOS to Unix
sed 's/$/^M/' # Unix to DOS
где ‘^ M’ является символом control-M. Вы также можете использовать механизм bash dos2unix и unix2dos, или, возможно, dtou и utod) и используйте их.
Jonathan Leffler
10 апр. 2010, в 17:00
Поделиться
tr -d "r" < file
посмотрите здесь для примеров, используя sed:
# IN UNIX ENVIRONMENT: convert DOS newlines (CR/LF) to Unix format.
sed 's/.$//' # assumes that all lines end with CR/LF
sed 's/^M$//' # in bash/tcsh, press Ctrl-V then Ctrl-M
sed 's/x0D$//' # works on ssed, gsed 3.02.80 or higher
# IN UNIX ENVIRONMENT: convert Unix newlines (LF) to DOS format.
sed "s/$/`echo -e \r`/" # command line under ksh
sed 's/$'"/`echo \r`/" # command line under bash
sed "s/$/`echo \r`/" # command line under zsh
sed 's/$/r/' # gsed 3.02.80 or higher
Используйте sed -i для преобразования на месте, например. sed -i 's/..../' file.
ghostdog74
10 апр. 2010, в 17:19
Поделиться
Выполнение этого с помощью POSIX сложно:
-
POSIX Sed не поддерживает
rили15. Даже если бы это было так, то на месте
опция-iне POSIX -
POSIX Awk поддерживает
rи15, однако опция-i inplace
не POSIX -
d2u и dos2unix не утилиты POSIX, но ex
-
POSIX ex не поддерживает
r,15,nили12
Чтобы удалить возврат каретки:
ex -bsc '%!awk "{sub(/r/,"")}1"' -cx file
Чтобы добавить возврат каретки:
ex -bsc '%!awk "{sub(/$/,"r")}1"' -cx file
Steven Penny
30 апр. 2014, в 11:35
Поделиться
Эта проблема может быть решена с помощью стандартных инструментов, но для неосторожных есть достаточно много ловушек, которые я рекомендую вам установить flip, который был написан более 20 лет назад Рахулом Деси, автором zoo.
Он отлично работает, конвертируя форматы файлов, в то время как, например, избегая случайного уничтожения двоичных файлов, что слишком легко, если вы просто участвуете в изменении каждого CRLF, который вы видите…
Norman Ramsey
11 апр. 2010, в 00:25
Поделиться
Используя AWK, вы можете:
awk '{ sub("r$", ""); print }' dos.txt > unix.txt
Используя Perl, вы можете:
perl -pe 's/r$//' < dos.txt > unix.txt
codaddict
10 апр. 2010, в 16:54
Поделиться
Решения, опубликованные до сих пор, касаются только части проблемы, конвертируя DOS/Windows CRLF в Unix LF; часть, которую им не хватает, заключается в том, что DOS использует CRLF в качестве разделителя строк, а Unix использует LF в качестве терминатора линии. Разница в том, что файл DOS (обычно) не будет иметь ничего после последней строки в файле, в то время как Unix будет. Чтобы правильно выполнить преобразование, вам нужно добавить этот финальный LF (если только файл не имеет нулевой длины, то есть вообще не имеет линий). Мое любимое заклинание для этого (с небольшой добавленной логикой для обработки файлов в формате CR, разделенных в стиле Mac, а не для файлов досье, которые уже есть в unix-формате) немного Perl:
perl -pe 'if ( s/rn?/n/g ) { $f=1 }; if ( $f || ! $m ) { s/([^n])z/$1n/ }; $m=1' PCfile.txt
Обратите внимание, что это отправляет Unixified версию файла в stdout. Если вы хотите заменить файл Unixified, добавьте флаг perl -i.
Gordon Davisson
10 апр. 2010, в 18:07
Поделиться
Если у вас нет доступа к dos2unix, но вы можете прочитать эту страницу, вы можете скопировать/вставить dos2unix.py отсюда.
#!/usr/bin/env python
"""
convert dos linefeeds (crlf) to unix (lf)
usage: dos2unix.py <input> <output>
"""
import sys
if len(sys.argv[1:]) != 2:
sys.exit(__doc__)
content = ''
outsize = 0
with open(sys.argv[1], 'rb') as infile:
content = infile.read()
with open(sys.argv[2], 'wb') as output:
for line in content.splitlines():
outsize += len(line) + 1
output.write(line + 'n')
print("Done. Saved %s bytes." % (len(content)-outsize))
Отправлено через superuser.
anatoly techtonik
31 окт. 2013, в 10:20
Поделиться
Супер пупер с PCRE;
Как script или замените [email protected] вашими файлами.
#!/usr/bin/env bash
perl -pi -e 's/rn/n/g' -- [email protected]
Это перезапишет ваши файлы на месте!
Я рекомендую делать это только с помощью резервного копирования (контроль версий или иначе)
ThorSummoner
30 июль 2015, в 17:59
Поделиться
Еще более простое awk-решение без программы:
awk -v ORS='rn' '1' unix.txt > dos.txt
Технически «1» — это ваша программа, b/c awk требует один, если задана опция.
UPDATE:
После повторного просмотра этой страницы в первый раз за долгое время я понял, что никто еще не опубликовал внутреннее решение, так что вот один из них:
while IFS= read -r line;
do printf '%sn' "${line%$'r'}";
done < dos.txt > unix.txt
nawK
04 сен. 2014, в 00:57
Поделиться
Чтобы преобразовать файл на место, выполните
dos2unix <filename>
Для вывода преобразованного текста в другой файл выполните
dos2unix -n <input-file> <output-file>
Он уже установлен на Ubuntu и доступен на homebrew с brew install dos2unix
Я знаю, что вопрос явно запрашивает альтернативы этой утилите, но это первый результат поиска google для «convert dos to unix line endings».
Boris
18 июль 2018, в 01:43
Поделиться
Интересно, что в моем git — bash на окнах sed "" уже сделал трюк:
$ echo -e "abcr" >tst.txt
$ file tst.txt
tst.txt: ASCII text, with CRLF line terminators
$ sed -i "" tst.txt
$ file tst.txt
tst.txt: ASCII text
Моя догадка заключается в том, что sed игнорирует их при чтении строк с ввода и всегда записывает окончание строк unix на выходе.
user829755
21 июль 2017, в 10:25
Поделиться
Вы можете использовать vim программно с опцией -c {команда}:
Дос для Unix:
vim file.txt -c "set ff=unix" -c ":wq"
Unix для dos:
vim file.txt -c "set ff=dos" -c ":wq"
Johan Zicola
31 авг. 2018, в 11:55
Поделиться
Это сработало для меня
tr "r" "n" < sampledata.csv > sampledata2.csv
Santosh
13 март 2015, в 00:27
Поделиться
TIMTOWTDI!
perl -pe 's/rn/n/; s/([^n])z/$1n/ if eof' PCfile.txt
Основываясь на @GordonDavisson
Необходимо рассмотреть возможность [noeol]…
lzc
31 май 2016, в 17:47
Поделиться
Было бы просто подумать об этом же вопросе (на стороне Windows, но в равной степени применимом к Linux).
Удивительно, что никто не упомянул очень автоматизированный способ преобразования CRLF ↔ LF для текстовых файлов с использованием старой старой опции zip -ll (Info-ZIP):
zip -ll textfiles-lf.zip files-with-crlf-eol.*
unzip textfiles-lf.zip
ПРИМЕЧАНИЕ. Это создало бы zip файл, сохраняющий исходные имена файлов, но преобразовывая окончания строки в LF. Затем unzip будет извлекать файлы как zip’ed, то есть с их исходными именами (но с LF-окончаниями), тем самым предлагая перезаписать локальные исходные файлы, если они есть.
Соответствующая выдержка из zip --help:
zip --help
...
-l convert LF to CR LF (-ll CR LF to LF)
vmsnomad
23 июнь 2017, в 20:30
Поделиться
Вы можете использовать awk. Установите разделитель записей (RS) в регулярное выражение, которое соответствует всем возможным символам новой строки или символам. И установите разделитель выходной записи (ORS) в символ новой строки в стиле unix.
awk 'BEGIN{RS="r|n|rn|nr";ORS="n"}{print}' windows_or_macos.txt > unix.txt
kazmer
06 нояб. 2016, в 23:32
Поделиться
Для Mac OSX, если у вас установлен доморощенный [http:// brew.sh/] [1]
brew install dos2unix
for csv in *.csv; do dos2unix -c mac ${csv}; done;
Убедитесь, что вы сделали копии файлов, так как эта команда будет изменять файлы на месте.
Параметр -c mac делает коммутатор совместимым с osx.
Ashley Raiteri
20 май 2014, в 00:02
Поделиться
sed --expression='s/rn/n/g'
Поскольку в вопросе упоминается sed, это самый простой способ использовать sed для достижения этой цели. В выражении говорится, что все возвраты каретки и перевод строки заменяются только переводом строки. Это то, что вам нужно, когда вы переходите с Windows на Unix. Я проверил, что это работает.
John Paul
18 окт. 2018, в 16:43
Поделиться
В Linux легко преобразовать ^ M (ctrl-M) в * nix newlines (^ J) с sed.
В CLI будет что-то вроде этого, в тексте будет разрыв строки. Тем не менее,передает, что ^ J для sed:
sed 's/^M/
/g' < ffmpeg.log > new.log
Вы получаете это, используя ^ V (ctrl-V), ^ M (ctrl-M) и(обратная косая черта) по мере ввода:
sed 's/^V^M/^V^J/g' < ffmpeg.log > new.log
jet
13 июль 2018, в 14:46
Поделиться
В качестве расширения для решения Jonathan Leffler Unix для DOS, чтобы безопасно конвертировать в DOS, когда вы не уверены в текущем окончании строки файла:
sed '/^M$/! s/$/^M/'
Это проверяет, что линия еще не заканчивается в CRLF перед преобразованием в CRLF.
Gannet
24 янв. 2017, в 09:09
Поделиться
Есть много ответов awk/sed/etc, так как дополнение (поскольку это один из лучших результатов поиска для этой проблемы):
У вас может не быть dos2unix, но у вас есть iconv?
iconv -f UTF-16LE -t UTF-8 [filename.txt]
-f from format type
-t to format type
Или все файлы в каталоге:
find . -name "*.sql" -exec iconv -f UTF-16LE -t UTF-8 {} -o ./{} ;
Выполняет ту же самую команду для всех файлов .sql в текущей папке. -o — это выходной каталог, поэтому вы можете заменить его текущими файлами или, по соображениям безопасности/резервного копирования, выводить в отдельный каталог.
Katastic Voyage
13 окт. 2017, в 01:45
Поделиться
Ещё вопросы
- 0Повторите порядок по данным php json_encode
- 0UnknownHostException: при подключении к серверу базы данных
- 0отправка свойства объекта в качестве параметра функции возвращает неопределенное
- 1Внутренние классы унылого класса
- 1Добавьте две таблицы данных в один лист Excel в c #
- 1WordNetLemmatizer: различная обработка wn.ADJ и wn.ADJ_SAT?
- 1Pandas создает новый столбец каждый раз, когда я сохраняю фрейм данных как csv в Python
- 1Как изменить содержимое определенного столбца в таблице?
- 1Используя Beautifulsoup, как извлечь информацию, которая не встроена в теги
- 0Затем jQuery .before () найдите его содержимое и примените цикл for. Что я делаю неправильно
- 1CA Rally — Как получить детали дочернего объекта, например, из ProjectPermission получить детали проекта
- 1Как отобразить заголовки сгруппированной гистограммы в Python Pandas?
- 0Safari 7 jQuery не работает
- 0Как передать две разные переменные в директиву ng, используя angular?
- 0проблемы с получением позиции элемента в массиве
- 1Нажмите вопрос в Android
- 0Как получить обновленный идентификатор строки в Java
- 0Angularjs — скрыть div с помощью «если» и «еще»
- 1Реализация меню навигации в Консольном приложении
- 1Производительность JToken.FromObject против поведения по умолчанию в Json.net
- 0скользящий цикл меню со следующими и предыдущими кнопками
- 0почему эта угловая директива не обновляется
- 1какие сервлеты не являются частью веб-приложения
- 0Как я могу сделать собственный маркер легенды для круговой диаграммы Google пончик?
- 1Невозможно вызвать getApplicationContext () внутри потока
- 0Удалить строку из XML в PHP
- 1GeckoFX — альтернатива для элемента управления WebBrowser «RaiseEvent» или «InvokeMember»
- 0Тестовый выход () с буст-тестами
- 1реагировать родной — Как использовать состояние в конструкторе
- 0Разница между пустыми и не пустыми функциями в C ++
- 0Установка выбранной опции из контроллера в Angularjs
- 0скопировать все таблицы из базы данных в другую базу данных в MySQL
- 0JS Установка атрибута onclick разными способами
- 0boost :: multi_index_container — равные значения
- 1невозможно загрузить ресурсный javascript с относительным путем $ {pageContext.request.contextPath}
- 1Анимация полноэкранного оверлея SVG
- 0Как исправить изображение в правом нижнем углу с изменением размера окна?
- 0Ошибка обновления при добавлении двузначного целого числа mysql
- 0Как перенаправить после самостоятельной публикации форму с атрибутами фильтра?
- 0Работа с couchdb и push to git repo в проекте angularjs
- 1Более эффективный способ извлечения данных из строки в JavaScript?
- 1Python разница между оператором и функцией
- 0JavaScript-DHTML: доступ к значениям объекта
- 0Форма выпадающего списка (счетчик) и попытка изменить значение на значение выбранного элемента
- 0Проверка достоверности: уникальный параметр, 4-й параметр
- 0html показывает результат до того, как ng-if вычислит регулярное выражение в angularjs
- 0Добавление диапазона с определенным именем класса JQuery
- 1лучший способ сохранить список в Python?
- 1Местные сервисы Android: они полезны?
- 0получить изображение из базы данных, но ничего не показывает