Состояния потока
ОС выполняет планирование потоков,
принимая во внимание их состояние. В
мультипрограммной системе поток может
находиться в одном из трех основных
состояний:
-
выполнение —
активное состояние потока, во время
которого поток обладает всеми необходимыми
ресурсами и непосредственно выполняется
процессором; -
ожидание –
пассивное состояние потока, находясь
в котором, поток заблокирован по своим
внутренним причинам (ждет осуществления
некоторого события, например, завершения
операции ввода-вывода, получения
сообщения от другого потока или
освобождения какого-либо необходимого
ему ресурса); -
готовность –
также пассивное состояние потока,
но в этом случае поток заблокирован в
связи с внешним по отношению к нему
обстоятельством (имеет все требуемые
для него ресурсы, готов выполняться,
однако процессор занят выполнением
другого потока).
Состояния выполнения и ожидания могут
быть отнесены и к задачам, выполняющимся
в однопрограммном режиме, а вот состояние
готовности характерно только для режима
мультипрограммирования.
В течение своей жизни каждый поток
переходит из одного состояния в другое
в соответствии с алгоритмом планирования
потоков, принятым в данной операционной
системе.
Рассмотрим типичный граф состояния
потока (рис.5.3). Только что созданный
поток находится в состоянии готовности,
он готов к выполнению и стоит в очереди
к процессору. Когда в результате
планирования подсистема управления
потоками принимает решение об активизации
данного потока, он переходит в состояние
выполнения и находится в нем до тех пор,
пока либо он сам освободит процессор,
перейдя в состояние ожидания какого-нибудь
события, либо будет принудительно
вытеснен из процессора, например,
вследствие исчерпания отведенного
данному потоку кванта процессорного
времени. В последнем случае поток
возвращается в состояние готовности.
В это же состояние поток переходит из
состояния ожидания, после того как
ожидаемое событие произойдет.
В состоянии выполнения в однопроцессорной
системе может находиться не более одного
потока, а в каждом из состояний ожидания
и готовности – несколько потоков. Эти
потоки образуют очереди соответственно
ожидающих и готовых потоков. Очереди
потоков организуются путем объединения
в списки описателей отдельных потоков.
Таким образом, каждый описатель потока,
кроме всего прочего, содержит по крайней
мере, один указатель на другой описатель,
соседствующий с ним в очереди. Такая
организация очередей позволяет легко
их переупорядочивать, включать и
исключать потоки, переводить потоки из
одного состояния в другое. Если
предположить, что на рис. 5.4 показана
очередь готовых потоков, то запланированный
порядок выполнения выглядит так: А, В,
D, С.
Вытесняющие и невытесняющие алгоритмы планирования
С самых общих позиций все множество
алгоритмов планирования можно разделить
на два класса: вытесняющие и не вытесняющие
алгоритмы планирования.
-
Невытесняющие
(non-preemptive) алгоритмы основаны на том,
что активному потоку позволяется
выполняться, пока он сам, по собственной
инициативе, не отдаст управление
операционной системе для того, чтобы
та выбрала из очереди другой готовый
к выполнению поток. -

Вытесняющие
(preemptive) алгоритмы – это такие способы
планирования потоков, в которых решение
о переключении процессора с выполнения
одного потока на выполнение другого
потока принимается операционной
системой, а не активной задачей.

Основным различием между вытесняющими
и невытесняющими алгоритмами является
степень централизации механизма
планирования потоков. При вытесняющем
мультипрограммировании функции
планирования потоков целиком сосредоточены
в операционной системе, и программист
пишет свое приложение, не заботясь о
том, что оно будет выполняться одновременно
с другими задачами. При этом операционная
система выполняет следующие функции:
-
определяет момент
снятия с выполнения активного потока; -
запоминает его
контекст; -
выбирает из очереди
готовых потоков следующий; -
запускает новый
поток на выполнение, загружая его
контекст.
При не вытесняющем мультипрограммировании
механизм планирования распределен
между операционной системой и прикладными
программами. Прикладная программа,
получив управление от операционной
системы, сама определяет момент завершения
очередного цикла своего выполнения и
только затем передает управление ОС с
помощью какого-либо системного вызова.
ОС формирует очереди потоков и выбирает
в соответствии с некоторым правилом
(например, с учетом приоритетов) следующий
поток на выполнение. Такой механизм
создает проблемы как для пользователей,
так и для разработчиков приложений.
Для пользователей это означает, что
управление системой теряется на
произвольный период времени, который
определяется приложением (а не
пользователем). Если приложение тратит
слишком много времени на выполнение
какой-либо работы, например, на
форматирование диска, пользователь не
может переключиться с этой задачи на
другую задачу, например, на текстовый
редактор, в то время как форматирование
продолжалось бы в фоновом режиме.
Поэтому разработчики приложений для
операционной среды с невытесняющей
многозадачностью вынуждены, возлагая
на себя часть функций планировщика,
создавать приложения так, чтобы они
выполняли свои задачи небольшими
частями. Например, программа форматирования
может отформатировать одну дорожку
дискеты и вернуть управление системе.
После выполнения других задач система
возвратит управление программе
форматирования, чтобы та отформатировала
следующую дорожку. Подобный метод
разделения времени между задачами
работает, но он существенно затрудняет
разработку программ и предъявляет
повышенные требования к квалификации
программиста. Программист должен
обеспечить «дружественное» отношение
своей программы к другим выполняемым
одновременно с ней программам. Для этого
в программе должны быть предусмотрены
частые передачи управления операционной
системе. Крайним проявлением
«недружественности» приложения является
его зависание, которое приводит к общему
краху системы. В системах с вытесняющей
многозадачностью такие ситуации, как
правило, исключены, так как центральный
планирующий механизм имеет возможность
снять зависшую задачу с выполнения.
Однако распределение функций планирования
потоков между системой и приложениями
не всегда является недостатком, а при
определенных условиях может быть и
преимуществом, потому что дает возможность
разработчику приложений самому
проектировать алгоритм планирования,
наиболее подходящий для данного
фиксированного набора задач. Так как
разработчик сам определяет в программе
момент возвращения управления, то при
этом исключаются нерациональные
прерывания программ в «неудобные» для
них моменты времени. Кроме того, легко
разрешаются проблемы совместного
использования данных: задача во время
каждого цикла выполнения использует
их монопольно и уверена, что на протяжении
этого периода никто другой не изменит
данные. Существенным преимуществом
невытесняющего планирования является
более высокая скорость переключения с
потока на поток.
Примечание. Понятия вытесняющих
и невытесняющих алгоритмов планирования
иногда отождествляют с понятиями
приоритетных и бесприоритетных дисциплин,
что, возможно, связано со звучанием
соответствующих англоязычных терминов
«preemptive» и «non-preemptive».
Однако это совершенно неверно, так
как приоритеты в том и другом случаях
могут как использоваться, так и не
использоваться.
Почти во всех современных операционных
системах, ориентированных на
высокопроизводительное выполнение
приложений (UNIX, Windows
NT/2000, OS/2 и
др.), реализованы вытесняющие алгоритмы
планирования потоков (процессов). В
последнее время дошла очередь и до ОС
класса настольных систем, например,
OS/2 Warp и
Windows 95/98.
Примером эффективного использования
невытесняющего планирования являются
ОС Netware З.х и 4.х, в которых
в значительной степени благодаря такому
планированию достигнута высокая скорость
выполнения файловых операций. В
соответствии с концепцией невытесняющего
планирования, чтобы не занимать процессор
слишком долго, поток в Netware
сам отдает управление планировщику ОС,
используя следующие системные вызовы:
-
ThreadSwitch — поток,
вызвавший эту функцию, считает себя
готовым к немедленному выполнению, но
отдает управление для того, чтобы могли
выполняться и другие потоки; -
ThreadSwitchWithDelay —
функция аналогична предыдущей, но
поток считает, что будет готов к
выполнению только через определенное
количество переключений с потока на
поток; -
Delay — функция
аналогична предыдущей, но задержка
дана в миллисекундах; -
T
hreadSwitchLowPriority
— функция отдачи управления, отличается
от ThreadSwitch тем, что поток просит
поместить его в очередь готовых к
выполнению, но низкоприоритетных
потоков.

Планировщик NetWare использует
несколько очередей готовых потоков
(рис. 5.5). Только что созданный поток
попадает в конец очереди RunList,
которая содержит готовые к выполнению
потоки. После отказа от процессора поток
попадает в ту или иную очередь в
зависимости от того, какой из системных
вызовов был использован при передаче
управления. Поток поступает:
-
в конец очереди
RunList при вызове ThreadSwitch; -
в конец очереди
DelayedWorkToDoList при вызовах ThreadSwitchWithDelay или
Delay; -
в конец очереди
LowPriorityRunList при вызове
ThreadSwitchLowPriority.
После того как выполнявшийся процессором
поток завершит свой очередной цикл
выполнения, отдав управление с помощью
одного из вызовов передачи управления,
планировщик выбирает для выполнения
стоящий первым в очереди RunList
поток и запускает его.
Потоки, находящиеся в очереди
LowPriorityRunList, запускаются на выполнение
только в том случае, если очередь RunList
пуста. Обычно в эту очередь назначаются
потоки, выполняющие несрочную фоновую
работу.
Очередь WorkToDoList
является в системе самой приоритетной.
В эту очередь попадают так называемые
рабочие потоки. В NetWare,
как и в некоторых других ОС, вместо
создания нового потока для выполнения
определенной работы может быть использован
уже существующий системный поток. Пул
рабочих потоков создается при старте
системы для системных целей и выполнения
срочных работ.
Описанный невытесняющий механизм
организации многопоточной работы в ОС
Netware3.x и
Netware 4.х потенциально очень
производителен, так как отличается
небольшими накладными расходами ОС на
диспетчеризацию потоков за счет простых
алгоритмов планирования и иерархии
контекстов. Но для достижения высокой
производительности к разработчикам
приложений для ОС Netware
предъявляются высокие требования, так
как распределение процессорного времени
между различными приложениями зависит
в конечном счете от искусства программиста.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Рассмотрим, как в системе Windows осуществляется планирование потоков для их выполнения на центральном процессоре. Также посмотрим на приоритеты процессов и потоков.
Планирование потоков в системе
В Windows всегда выполняется хотя бы один поток с самым высоким приоритетом. Если в системе много ядер, то Windows делит все ядра на группы по 64 ядра. Каждому процессу даётся доступ к определённой группе ядер. Следовательно потоки этих процессов могут видеть только свою группу ядер.
Поток выполняется на процессоре определённое время, затем уступает место другому потоку. Кстати, максимальное время на которое поток может занять процессор называется квантом. Причем время кванта можно настроить, выбрав короткие или длинные кванты. Как это сделать, я покажу ниже в этой статье, так что читайте дальше.
Поток может не отработать весь свой квант, так как если другой поток готов к выполнению и имеет более высокий приоритет, то он вытеснит первый поток.
В системе существует планировщик, который и занимается управлением потоками. Именно он решает какой поток будет выполняться на процессоре следующим. Причем планировщик работает в режиме ядра.
Так как процессор постоянно обрабатывает разные, несвязанные между собой потоки, то он должен запоминать на каком результате он остановился выполняя определённый поток. Такое запоминание предыдущего потока и переключение на новый называют – переключением контекста.
Планирование осуществляется на уровне потоков, а не процессов. Например, Процесс_А имеет 10 потоков, а Процесс_Б – 2 потока. Тогда процессорное время распределился между этими 12 потоками равномерно.
Приоритеты потоков
Планирование потоков полагается на их приоритеты. Windows использует 32 уровня приоритета для потоков от 0 до 31:
- 16 — 31 — уровни реального времени;
- 1 — 15 — обычные динамические приоритеты;
- 0 — зарезервирован для потока обнуления страниц.
Вначале поток получает свой Базовый приоритет, который наследуется от приоритета процесса:
- реального времени (24),
- высокий (13),
- выше среднего (10),
- обычный (8),
- ниже среднего (6),
- низкий (4).
Дальше назначается относительный приоритет который увеличивает или уменьшает приоритет потока:
- критический по времени (+15),
- наивысший (+2),
- выше среднего(+1),
- обычный (0),
- ниже среднего (-1),
- самый низкий (-2),
- уровень простоя (-15).
После получения базового приоритета и корректировки относительным приоритетом получается динамический приоритет:
| Базовый приоритет ⇨
Относительный приоритет ⇩ |
Реального времени (24) |
Высокий (13) |
Выше среднего (10) |
Обычный (8) |
Ниже среднего (6) |
Низкий (4) |
| Критический по времени (+15 но не выше 15 если это не поток реального времени и не выше 31 если поток реального времени) |
31 | 15 | 15 | 15 | 15 | 15 |
| Наивысший (+2) | 26 | 15 | 12 | 10 | 8 | 6 |
| Выше среднего (+1) | 25 | 14 | 11 | 9 | 7 | 5 |
| Обычный (0) | 24 | 13 | 10 | 8 | 6 | 4 |
| Ниже среднего (-1) | 23 | 12 | 9 | 7 | 5 | 3 |
| Самый низкий (-2) | 22 | 11 | 8 | 6 | 4 | 2 |
| Уровень простоя (-15 но не ниже 1 если это не поток реального времени и не ниже 16 если это поток реального времени) |
16 | 1 | 1 | 1 | 1 | 1 |
Изменить базовый приоритет процесса можно из “Диспетчера задач” на вкладке “Подробности“, или в “Process Explorer“. Однако, это не поменяет относительный приоритет потока.

Приоритеты отдельных потоков можно посмотреть в программе “Process Explorer“. Но изменять их нет смысла, так как только разработчик данной программы понимает как лучше расставить приоритеты потокам.
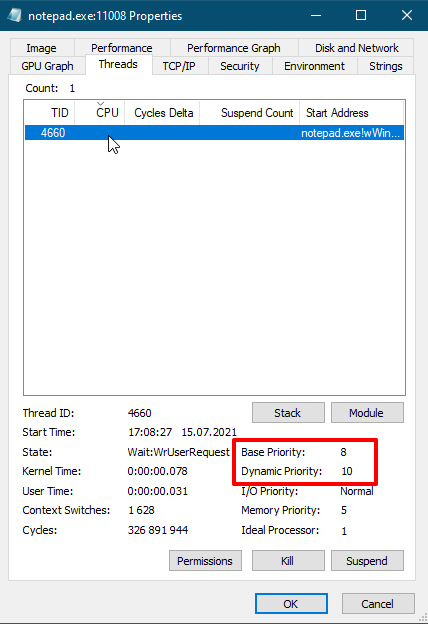
Получается что относительный приоритет у потока Notepad.exe равен 2, так как динамический приоритет больше базового на 2.
Состояния потоков
Поток может находиться в следующих состояниях:
- Готов (Ready) — поток готов к выполнению и ожидает процессор.
- Готов с отложенным выполнением (Deferred ready) — поток выбран для выполнения на конкретном ядре и ожидает именно это ядро.
- В повышенной готовности (Standby) — поток выбран следующим для выполнения на конкретном ядре. Как только сможет процессор выполнит переключение контекста на этот поток.
- Выполнение (Running) — выполняется на процессоре пока не истечет его квант времени, или пока его не вытеснит поток с большем приоритетом.
- Ожидание (Waiting) — поток ждет каких-то ресурсов.
- Переходное состояние (Transition) — готов к выполнению, но стек ядра выгружен из памяти, как только стек загрузится в память поток перейдет в состояние Готов.
- Завершение (Terminated) — поток выполнил свою работу и завершился сам, или его завершили принудительно.
- Инициализация (Initializated) — состояние при создании потока.
Кванты времени
Как я уже говорил квант времени выполнения потока может быть длинным или коротким. В настольных системах по умолчанию квант времени короткий, чтобы различные приложения быстро уступали друг другу место. В серверных системах по умолчанию длинный квант времени, чтобы серверные службы реже переключали контекст процессора.
Итак, теперь я вам покажу как переключить систему на работу с длинным или коротким квантом. Длительность кванта времени настраивается тут: “Свойства системы” / “Дополнительные параметры системы” / “Дополнительно” / “Быстродействие” / “Параметры” / “Дополнительно”:

- Программ – короткий квант времени;
- Служб – длинный квант времени.
На серверной системе можно выбрать “программ” если это сервер терминалов или просто настольный компьютер с установленной серверной системой.
На десктопной системе можно выбрать “служб” если вы запускаете какую-то длительную компиляцию или рендерите видео, а потом вернуть обратно в состояние “программ“.
Изменение приоритета планировщиком
Планировщик Windows периодически меняет текущий приоритет потоков. Делается это например для:
- повышения приоритета, если поток слишком долго ожидает выполнение (предотвращает зависание программы);
- повышения приоритета, если происходит ввод из пользовательского интерфейса (сокращение времени отклика);
- повышения приоритета, после завершения операции ввода/вывода (чтобы потоки ждущие ввод/вывод быстрее выполнялись). При ждать могут:
- диск, cd-rom, параллельный порт, видео — повышение на 1 пункт;
- сеть, почтовый слот, именованный канал, последовательный порт — повышение на 2 пункта;
- клавиатура или мышь — повышение на 6 пунктов;
- звуковая карта — повышение на 8 пунктов.
- когда поток ожидает ресурс, который занят другим потоком, то система может повысить приоритет потока который занял нужный ресурс, чтобы он быстрее выполнил свою работу и освободил этот ресурс;
- повышается приоритет у потоков которые на первом плане, а свёрнутые приложения работают с низким приоритетом.
Эксперимент
Позвольте продемонстрировать следующий эксперимент, который покажет как посмотреть за повышением и понижением динамического приоритета:
- Запустите программу «Блокнот».
- Запустите «Системный монитор».
- Щелкните на кнопке панели инструментов «Добавить» (Add Counter).
- Выберите объект «Поток» (Thread), а затем выберите счетчик «Текущий приоритет» (Priority Current).
- В поле со списком введите «Notepad», а затем щелкните на кнопке «Поиск» (Search).
- Найдите строку «Notepad/0». Выберите ее, щелкните на кнопке «Добавить» (Add), а затем щелкните на кнопке «ОК».
- Как только вы щелкните мышкой по блокноту, то заметите в Системном мониторе, что приоритет у потока «Блокнот» поднялся до 12, если свернуть блокнот то приоритет вновь упадет до 10.
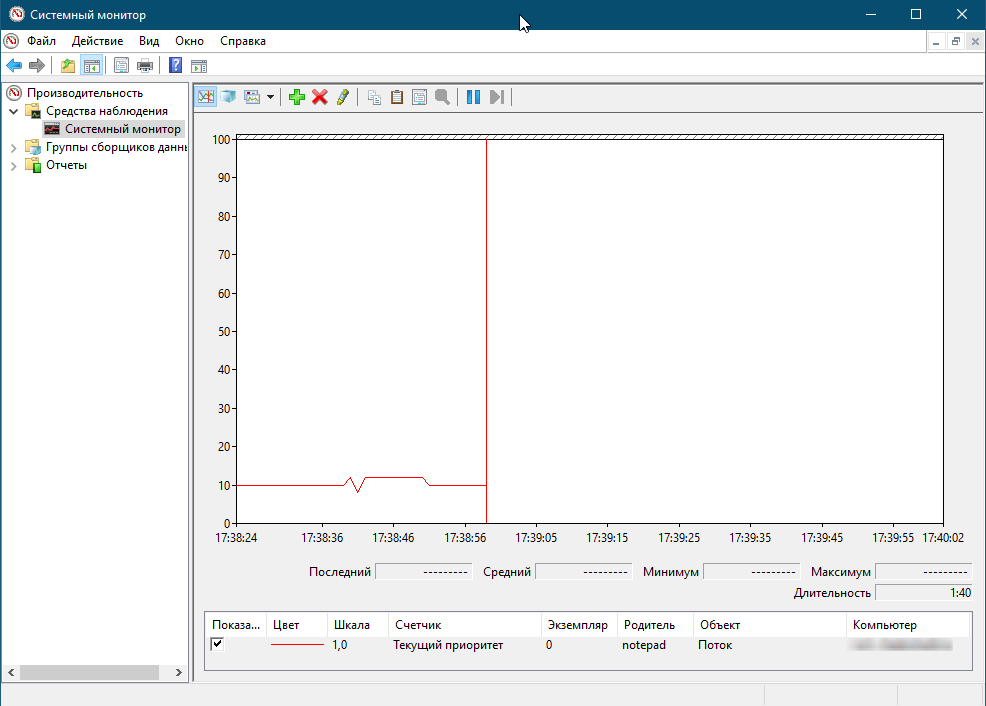
Поток простоя — idle
К вашему сведению процессор всегда обрабатывает какой-нибудь поток. Когда кажется что процессор ничем не занят, на самом деле запускается специальный поток idle (поток простоя). Притом, на каждое ядро процессора существует свой собственный поток простоя. В общем-то все потоки простоя принадлежат процессу простоя. Поток простоя имеет самый низкий приоритет (1), поэтому выполняется только тогда — когда полезных потоков нет.
Групповое планирование
Планирование потоков на базе потоков отлично работает, но не способно решить задачу равномерного распределения процессорного времени между несколькими пользователями на терминальном сервере. Потому в Windows Server 2012 появился механизм группового планирования.
Термины группового планирования:
- поколение — период времени, в течении которого отслеживается использование процессора;
- квота — процессорное время, разрешенное группе на поколение (исчерпание квоты означает, что группа израсходовала весь свой бюджет);
- вес — относительная важность группы от 1 до 9 (по умолчанию 5);
- справедливое долевое планирование — вид планирования, при котором потокам исчерпавшим квоту могут выделяться циклы простоя;
- ранг — приоритет групповой политики, 0 — наивысший, чем больше процессорного времени истратила группа, тем больше будет ранг, и с меньшей вероятностью получит процессорное время (ранг всегда превосходит приоритет) (0 ранг у потоков которые: не входят ни в одну группу, не израсходовали квоту, потоки с приоритетами реального времени).
Где же применяется групповое планирование? Например его использует механизм DFSS для справедливого распределения процессорного времени между сеансами на машине. Этот механизм включается по умолчанию при установке роли служб терминалов.
Помимо DFSS групповое планирование применяется в объектах Jobs (Задания), так мы можем ограничить Задание по % потребления CPU, например задание будет потреблять не больше 20% процессорного времени.
Вернуться к оглавлению
Сводка

Имя статьи
Планирование потоков Windows
Описание
Рассмотрим, как в Windows осуществляется планирование потоков для их выполнения на центральном процессоре. Также посмотрим на приоритеты процессов и потоков
ВикиЧтение
Системное программирование в среде Windows
Харт Джонсон М
Состояния потоков
Состояния потоков
На рис. 7.4, взятом из [9] (см. также [38], версию, обновленную Соломоном (Solomon) и Руссиновичем (Russinovych)), представлена схема планирования потоков и показаны их возможные состояния. Кроме того, этот рисунок иллюстрирует результаты работы программы. Такие диаграммы состояния являются общими для всех многозадачных ОС и помогают выяснить, каким образом планируется выполнение потоков и как они переходят из одного состояния в другое.
Рис. 7.4. Состояния потоков и переходы между состояниями (Источник: Inside Windows NT, Copyright © 1993, by Helen Custer. Copyright Microsoft Press. Воспроизводится с разрешения Microsoft Press. Все права сохранены.)
Ниже приводится краткая сводка основных положений. Для получения более подробной информации по этому вопросу обратитесь в [38] или к руководству по ОС.
• Поток находится в состоянии выполнения (running state), если она фактически выполняется процессором. В SMP-системах в состоянии выполнения могут находиться одновременно несколько потоков.
• Планировщик переводит поток в состояние ожидания (wait state), если он выполняет функцию ожидания несигнализирующих объектов, например, потоков или процессов, или перехода в сигнальное состояние объектов синхронизации, о чем говорится в главе 8. Операции ввода/вывода также будут ожидать завершения передачи дисковых или иных данных, но ожидание может быть вызвано и другими многочисленными функциями. О потоках, находящихся в состоянии ожидания, нередко говорят как о блокированных (blocked) или спящих (sleeping).
• Поток находится в состоянии готовности (ready state), если она может выполняться. Планировщик в любой момент может перевести такой поток в состояние выполнения. Когда процессор станет доступным, планировщик запустит тот из потоков, находящихся в состоянии готовности, который обладает наивысшим приоритетом, а при наличии нескольких потоков с одинаковым высшим приоритетом запущен будет та, который пребывал в состоянии готовности дольше всех. При этом поток проходит через состояние простоя (standby state), или резервное состояние.
• Обычно, в соответствии с приведенным описанием, планировщик помещает поток, находящийся в состоянии готовности, на любой доступный процессор. Программист может указать маску родства процессоров (processor affinity mask) для потока (см. главу 9), предоставляя потоку процессоры, на которых он может выполняться. Используя этот способ, программист может распределять процессоры между потоками. Соответствующими функциями являются SetProcessorAffinityMask и GetProcessorAffinityMask. Функция SetThreadIdealProcessor позволяет указать предпочтительный процессор, подлежащий использованию планировщиком при первой же возможности.
• После истечения кванта времени, отведенного выполняющемуся потоку, планировщик без ожидания переводит его в состояние готовности. В результате выполнения функции Sleep(0) поток также будет переведен из состояния выполнения в состояние готовности.
• Планировщик переводит ожидающий поток в состояние готовности сразу же, как только соответствующие дескрипторы оказываются в сигнальном состоянии, хотя при этом поток фактически проходит через промежуточное переходное состояние (transition state). В подобных случаях принято говорить о том, что поток пробуждается (wakes).
• Не существует способа, позволяющего программе определить состояние другого потока (разумеется, если поток выполняется, то он находится в состоянии выполнения, и поэтому ему нет никакого смысла определять свое состояние). Даже если бы такой способ и существовал, то состояние потока может измениться еще до того, как опрашивающий поток успеет предпринять какие-либо действия в ответ на полученную информацию.
• Поток, независимо от его состояния, может быть приостановлен (suspended), и приостановленный поток не будет запущен, даже если он находится в состоянии готовности. В случае приостановки выполняющегося потока, независимо от того, по собственной ли инициативе или по инициативе потока, выполняющегося на другом процессоре, он переводится в состояние готовности.
• Поток переходит в состояние завершения (terminated state) тогда, когда его выполнение завершается, и остается в этом состоянии до тех пор, пока остается открытым хотя бы один из ее дескрипторов. Это позволяет другим потокам запрашивать состояние данного потока и его код завершения.
Читайте также
Стеки потоков и допустимые количества потоков
Стеки потоков и допустимые количества потоков
Следует сделать еще два предостережения. Во-первых, подумайте о размере стека, который по умолчанию составляет 1 Мбайт. В большинстве случаев этого будет вполне достаточно, но если существуют какие-либо сомнения на сей счет,
Состояния потоков
Состояния потоков
Несколько раз небрежно упомянув о «выполнении», «готовности» и «блокировке», давайте теперь формализуем эти состояния потока.Выполнение (RUNNING)Состояние выполнения (RUNNING) в QNX/Neutrino означает, что поток активно использует ресурсы процессора. В системе SMP
Динамический пул потоков
Динамический пул потоков
Динамический пул потоков не является каким-то специфическим механизмом, продиктованным именно микроядерной архитектурой QNX. Это удачная искусственная конструкция, все определения которой размещены в файле <sys/dispatch.h>. Удивительно не то, что в
Имя состояния
Имя состояния
Имя состояния представляет собой строку текста, которая раскрывает содержательный смысл данного состояния. Имя всегда записывается с заглавной буквы. Поскольку состояние системы является составной частью процесса ее функционирования, рекомендуется в
10.4.2 Анализ потоков
10.4.2 Анализ потоков
Ричи упоминает о том, что им была предпринята попытка создания потоков только с процедурами «вывода» или только с процедурами обслуживания. Однако, процедура обслуживания необходима для управления потоками данных, так как модули должны иногда ставить
10.17 Состояния TCP
10.17 Состояния TCP
Соединение TCP проходит несколько стадий: устанавливается соединение посредством обмена сообщениями, затем пересылаются данные, а далее соединение закрывается с помощью обмена специальными сообщениями. Каждый шаг в работе соединения соответствует
Создание потоков
Создание потоков
Обеспечить многопоточную обработку в приложении Qt достаточно просто: мы только создаем подкласс QThread и переопределяем его функцию run(). Чтобы показать, как это работает, мы начнем с рассмотрения программного кода очень простого подкласса QThread, который
Синхронизация потоков
Синхронизация потоков
Обычным требованием для многопоточных приложений является синхронизация работы нескольких потоков. Для этого в Qt предусмотрены следующие классы: QMutex, QReadWriteLock, QSemaphore и QWaitCondition.Класс QMutex обеспечивает такую защиту переменной или участка
13.1.1. Создание потоков
13.1.1. Создание потоков
Создать поток просто: достаточно вызвать метод new и присоединить блок, который будет исполняться в потоке.thread = Thread.new do # Предложения, исполняемые в потоке…endВозвращаемое значение — объект типа Thread. Главный поток программы может использовать его для
13.2. Синхронизация потоков
13.2. Синхронизация потоков
Почему необходима синхронизация? Потому что из-за «чередования» операций доступ к переменным и другим сущностям может осуществляться в порядке, который не удается установить путем чтения исходного текста отдельных потоков. Два и более потоков,
Пул потоков CLR
Пул потоков CLR
Заключительной темой нашего обсуждения в этой плаве, посвященной потокам, будет пул потоков CLR. При асинхронном вызове типов с помощью делегатов (посредством метода BeginInvoke()) нельзя сказать, что среда CLR буквально создает совершенно новый поток. В целях
2.2.1.3 Планирование потоков
2.2.1.3 Планирование потоков
Сервер осведомлен о степени значимости различных потоков и в соответствии с этим назначает для них приоритеты. Например, потоки ввода-вывода получают приоритеты следующим образом: 1. ввод-вывод логической журнализации — наивысший приоритет;2.
ИТЕРАТОРЫ ПОТОКОВ
ИТЕРАТОРЫ ПОТОКОВ
Чтобы шаблоны алгоритмов могли работать непосредственно с потоками ввода-вывода, предусмотрены соответствующие шаблонные классы, подобные итераторам. Например,partial_sum_copy(istream_iterator‹double›(cin), istream_iterator‹double›(), ostream_iterator‹double›(cout, »
«));читает файл,
4.1.5. Атрибуты потоков
4.1.5. Атрибуты потоков
Потоковые атрибуты — это механизм настройки поведения отдельных потоков. Вспомните, что функция pthread_create() принимает аргумент, являющийся указателем на объект атрибутов потока. Если этот указатель равен NULL, поток конфигурируется на основании
Закрытие потоков
Закрытие потоков
Функции fclose и fcloseall закрывают поток или потоки. Функция fclose закрывает один заданный поток, fcloseall — все потоки, кроме потоков stdin, stdout, stderr, stdaux, stdprn.Если программа не выполняет закрытия потоков, потоки автоматически закрываются, когда программа завершается
5.3 Мониторинг состояния системы, устранение ошибок, восстановление утерянных файлов и защита данных Анализ состояния аппаратной части системы
Введение
Как и всякая техника, персональный компьютер нуждается в техническом обслуживании, настройке и наладке. Небрежное отношение к своей машине приводит к тому, что работа компьютера становится нестабильной и не эффективной. А потом происходит сбой, и компьютер
Ниже представлена не простая расшифровка доклада с семинара CLRium, а переработанная версия для книги .NET Platform Architecture. Той её части, что относится к потокам.
Потоки и планирование потоков
Что такое поток? Давайте дадим краткое определение. По своей сути поток это:
- Средство параллельного относительно других потоков исполнения кода;
- Имеющего общий доступ ко всем ресурсам процесса.
Очень часто часто слышишь такое мнение, что потоки в .NET — они какие-то абсолютно свои. И наши .NET потоки являются чем-то более облегчённым чем есть в Windows. Но на самом деле потоки в .NET являются самыми обычными потоками Windows (хоть Windows thread id и скрыто так, что сложно достать). И если Вас удивляет, почему я буду рассказывать не-.NET вещи в хабе .NET, скажу вам так: если нет понимания этого уровня, можно забыть о хорошем понимании того, как и почему именно так работает код. Почему мы должны ставить volatile, использовать Interlocked и SpinWait. Дальше обычного lock дело не уйдёт. И очень даже зря.
Давайте посмотрим из чего они состоят и как они рождаются. По сути поток — это средство эмуляции параллельного исполнения относительно других потоков. Почему эмуляция? Потому, что поток как бы странно и смело это ни звучало — это чисто программная вещь, которая идёт из операционной системы. А операционная система создаёт этот слой эмуляции для нас. Процессор при этом о потоках ничего не знает вообще.
Задача процессора — просто исполнять код. Поэтому с точки зрения процессора есть только один поток: последовательное исполнение команд. А задача операционной системы каким-либо образом менять поток т.о. чтобы эмулировать несколько потоков.
Поток в физическом понимании
«Но как же так?», — скажите вы, — «во многих магазинах и на различных сайтах я вижу запись «Intel Xeon 8 ядер 16 потоков». Говоря по-правде это — либо скудность в терминологии либо — чисто маркетинговый ход. На самом деле внутри одного большого процессора есть в данном случае 8 ядер и каждое ядро состоит из двух логических процессоров. Такое доступно при наличии в процессоре технологии Hyper-Threading, когда каждое ядро эмулирует поведение двух процессоров (но не потоков). Делается это для повышения производительности, да. Но по большому счёту если нет понимания, на каких потоках идут расчёты, можно получить очень не приятный сценарий, когда код выполняется со скоростью, ниже чем если бы расчёты шли на одном ядре. Именно поэтому раздача ядер идёт +=2 в случае Hyper-Threading. Т.е. пропуская парные ядра.
Технология эта — достаточно спорная: если вы работаете на двух таких псевдо-ядрах (логических процессорах, которые эмулируются технологией Hyper-Threading), которые при этом находятся на одном физическом ядре и работают с одной и той-же памятью, то вы будете постоянно попадать в ситуацию, когда второй логический процессор так же пытается обратиться к данной памяти, создавая блокировку либо попадая в блокировку, т.к. поток, находящийся на первом ядре работает с той же памятью.
Возникает блокировка совместного доступа: хоть и идёт эмуляция двух ядер, на самом-то деле оно одно. Поэтому в наихудшем сценарии эти потоки исполняются по очереди, а не параллельно.
Так если процессор ничего не знает о потоках, как же достигается параллельное исполнение потоков на каждом из его ядер? Как было сказано, поток — средство операционной системы выполнять на одном процессоре несколько задач одновременно. Достигается параллелизм очень быстрым переключением между потоками в течение очень короткого промежутка времени. Последовательно запуская на выполнение код каждого из потоков и делая это достаточно часто, операционная система достигает цели: делает их исполнение псевдопараллельным, но параллельным с точки зрения восприятия человека. Второе обоснование существования потоков — это утверждение, что программа не так часто срывается в математические расчёты. Чаще всего она взаимодействует с окружающим её миром: различным оборудованием. Это и работа с жёстким диском и вывод на экран и работа с клавиатурой и мышью. Поэтому чтобы процессор не простаивал, пока оборудование сделает то, чего хочет от него программа, поток можно на это время установить в состояние блокировки: ожидания сигнала от операционной системы, что оборудование сделало то, что от него просили. Простейший пример этого — вызов метода Console.ReadKey().
Если заглянуть в диспетчер задач Windows 10, то можно заметить, что в данный момент в вашей системе существует около 1,5 тысячи потоков. И если учесть, что квант на десктопе равен 20 мс, а ядер, например, 4, то можно сделать вывод, что каждый поток получает 20 мс работы 1 раз в 7,5 сек… Ну конечно же, нет. Просто почти все потоки чего-то ждут. То ввода пользователя, то изменения ключей реестра… В операционной системе существует очень много причин, чтобы что-либо ждать.
Так что пока одни потоки в блокировке, другие — что-то делают.
Создание потоков
Простейшая функция создания потоков в пользовательском режиме операционной системы — CreateThread. Эта функция создаёт поток в текущем процессе. Вариантов параметризации CreateThread очень много и когда мы вызываем new Thread(), то из нашего .NET кода вызывается данная функция операционной системы.
В эту функцию передаются следующие атрибуты:
1) Необязательная структура с атрибутами безопасности:
- Дескриптор безопасности (SECURITY_ATTRIBUTES) + признак наследуемости дескриптора.
В .NET его нет, но можно создать поток через вызов функции операционной системы;
2) Необязательный размер стека:
- Начальный размер стека, в байтах (система округляет это значение до размера страницы памяти)
Т.к. за нас размер стека передаёт .NET, нам это делать не нужно. Это необходимо для вызовов методов и поддержки памяти.
3) Указатель на функцию — точка входа нового потоками
4) Необязательный аргумент для передачи данных функции потока.
Из того, что мы не имеем в .NET явно — это структура безопасности с атрибутами безопасности и размер стэка. Размер стэка нас мало интересует, но атрибуты безопасности нас могут заинтересовать, т.к. сталкиваемся мы с ними впервые. Сейчас мы рассмотривать их не будем. Скажу только, что они влияют на возможность изменения информации о потоке средствами операционной системы.
Если мы создаём любым способом: из .NET или же вручную, средствами ОС, мы как итог имеем и ManageThreadId и экземпляр класса Thread.
Также у этой функции есть необязательный флаг: CREATE_SUSPENDED — поток после создания не стартует. Для .NET это поведение по умолчанию.
Помимо всего прочего существует дополнительный метод CreateRemoteThread, который создаёт поток в чужом процессе. Он часто используется для мониторинга состояния чужого процесса (например программа Snoop). Этот метод создаёт в другом процессе поток и там наш поток начинает исполнение. Приложения .NET так же могут заливать свои потоки в чужие процессы, однако тут могут возникнуть проблемы. Первая и самая главная — это отсутствие в целевом потоке .NET runtime. Это значит, что ни одного метод фреймворка там не будет: только WinAPI и то, что вы написали сами. Однако, если там .NET есть, то возникает вторая проблема (которой не было раньше). Это — версия runtime. Необходимо: понять, что там запущено (для этого необходимо импортировать не-.NET методы runtime, которые написаны на C/C++ и разобраться, с чем мы имеем дело). На основании полученной информации подгрузить необходимые версии наших .NET библиотек и каким-то образом передать им управление.
Я бы рекомендовал вам поиграться с задачкой такого рода: вжиться в код любого .NET процесса и вывести куда-либо сообщение об удаче внедрения (например, в файл лога)
Планирование потоков
Для того чтобы понимать, в каком порядке исполнять код различных потоков, необходима организация планирования тих потоков. Ведь система может иметь как одно ядро, так и несколько. Как иметь эмуляцию двух ядер на одном так и не иметь такой эмуляции. На каждом из ядер: железных или же эмулированных необходимо исполнять как один поток, так и несколько. В конце концов система может работать в режиме виртуализации: в облаке, в виртуальной машине, песочнице в рамках другой операционной системы. Поэтому мы в обязательном порядке рассмотрим планирование потоков Windows. Это — настолько важная часть материала по многопоточке, что без его понимания многопоточка не встанет на своё место в нашей голове никоим образом.
Итак, начнём. Организация планирования в операционной системе Windows является: гибридной. С одной стороны моделируются условия вытесняющей многозадачности, когда операционная система сама решает, когда и на основе каких условия вытеснить потоки. С другой стороны — кооперативной многозадачности, когда потоки сами решают, когда они всё сделали и можно переключаться на следующий (UMS планировщик). Режим вытесняющей многозадачности является приоритетным, т.к. решает, что будет исполняться на основе приоритетов. Почему так? Потому что у каждого потока есть свой приоритет и операционная система планирует к исполнению более приоритетные потоки. А вытесняющей потому, что если возникает более приоритетный поток, он вытесняет тот, который сейчас исполнялся. Однако во многих случаях это бы означало, что часть потоков никогда не доберется до исполнения. Поэтому в операционной системе есть много механик, позволяющих потокам, которым необходимо время на исполнение его получить несмотря на свой более низкий по сравнению с остальными, приоритет.
Уровни приоритета
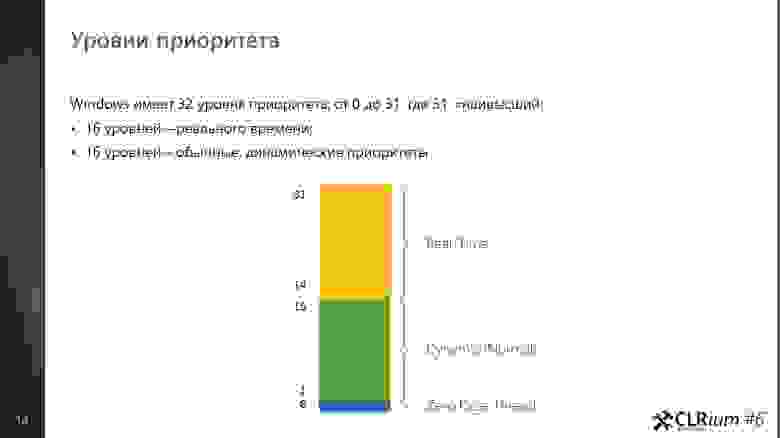
Windows имеет 32 уровня приоритета (0-31)
- 1 уровень (00 — 00) — это Zero Page Thread;
- 15 уровней (01 — 15) — обычные динамические приоритеты;
- 16 уровней (16 — 31) — реального времени.
Самый низкий приоритет имеет Zero Page Thread. Это — специальный поток операционной системы, который обнуляет страницы оперативной памяти, вычищая тем самым данные, которые там находились, но более не нужны, т.к. страница была освобождена. Необходимо это по одной простой причине: когда приложение освобождает память, оно может ненароком отдать кому-то чувствительные данные. Личные данные, пароли, что-то ещё. Поэтому как операционная система так и runtime языков программирования (а у нас — .NET CLR) обнуляют получаемые участки памяти. Если операционная система понимает, что заняться особо нечем: потоки либо стоят в блокировке в ожидании чего-либо либо нет потоков, которые исполняются, то она запускает самый низко приоритетный поток: поток обнуления памяти. Если она не доберется этим потоком до каких-либо участков, не страшно: их обнулят по требованию. Когда их запросят. Но если есть время, почему бы это не сделать заранее?
Продолжая говорить о том, что к нам не относится, стоит отметить приоритеты реального времени, которые когда-то давным-давно таковыми являлись, но быстро потеряли свой статус приоритетов реального времени и от этого статуса осталось лишь название. Другими словами, Real Time приоритеты на самом деле не являются таковыми. Они являются приоритетами с исключительно высоким значением приоритета. Т.е. если операционная система будет по какой-то причине повышать приоритет потока с приоритетом из динамической группы (об этом — позже, но, например, потому, что потоку освободили блокировку) и при этом значение до повышения было равно 15, то повысить приоритет операционная система не сможет: следующее значение равно 16, а оно — из диапазона реального времени. Туда повышать такими вот «твиками» нельзя.
Уровень приоритетов процессов с позиции Windows API.
Приоритеты — штука относительная. И чтобы нам всем было проще в них ориентироваться, были введены некие правила относительности расчетов: во-первых все потоки вообще (от всех приложений) равны для планировщика: планировщик не различает потоки это различных приложений или же одного и того же приложения. Далее, когда программист пишет свою программу, он задаёт приоритет для различных потоков, создавая тем самым модель многопоточности внутри своего приложения. Он прекрасно знает, почему там был выбран пониженный приоритет, а тут — обычный. Внутри приложения всё настроено. Далее, поскольку есть пользователь системы, он также может выстраивать приоритеты для приложений, которые запускаются на этой системе. Например, он может выбрать повышенный приоритет для какого-то расчетного сервиса, отдавая ему тем самым максимум ресурсов. Т.е. уровень приоритета можно задать и у процесса.
Однако, изменение уровня приоритета процесса не меняет относительных приоритетов внутри приложения: их значения сдвигаются, но не меняется внутренняя модель приоритетов: внутри по-прежнему будет поток с пониженным приоритетом и поток — с обычным. Так, как этого хотел разработчик приложения. Как же это работает?
Существует 6 классов приоритетов процессов. Класс приоритетов процессов — это то, относительно чего будут создаваться приоритеты потоков. Все эти классы приоритетов можно увидеть в «Диспетчере задач», при изменении приоритета какого-либо процесса.
Другими словами класс приоритета — это то, относительно чего будут задаваться приоритеты потоков внутри приложения. Чтобы задать точку отсчёта, было введено понятие базового приоритета. Базовый приоритет — это то значение, чем будет являться приоритет потока с типом приоритета Normal:
- Если процесс создаётся с классом Normal и внутри этого процесса создаётся поток с приоритетом Normal, то его реальный приоритет Normal будет равен 8 (строка №4 в таблице);
- Если Вы создаёте процесс и у него класс приоритета Above Normal, то базовый приоритет будет равен 10. Это значит, что потоки внутри этого процесса будут создаваться с более повышенным приоритетом: Normal будет равен 10.
Для чего это необходимо? Вы как программисты знаете модель многопоточности, которая у вас присутствует.
Потоков может быть много и вы решаете, что один поток должен быть фоновым, так как он производит вычисления и вам
не столь важно, когда данные станут доступны: важно чтобы поток завершил вычисления (например поток обхода и анализа дерева). Поэтому, вы устанавливаете пониженный приоритет данного потока. Аналогично может сложится ситуация когда необходимо запустить поток с повышенным приоритетом.
Представим, что ваше приложение запускает пользователь и он решает, что ваше приложение потребляет слишком много процессорных ресурсов. Пользователь считает, что ваше приложение не столь важное в системе, как какие-нибудь другие приложения и понижает приоритет вашего приложения до Below Normal. Это означает, что он задаёт базовый приоритет 6 относительно которого будут рассчитываться приоритеты потоков внутри вашего приложения. Но в системе общий приоритет упадёт. Как при этом меняются приоритеты потоков внутри приложения?
Таблица 3
Normal остаётся на уровне +0 относительно уровня базового приоритета процесса. Below normal — это (-1) относительно уровня базового. Т.е. в нашем примере с понижением уровня приоритета процесса до класса Below Normal приоритет потока ‘Below Normal’ пересчитается и будет не 8 - 1 = 7 (каким он был при классе Normal), а 6 - 1 = 5. Lowest (-2) станет равным 4.
Idle и Time Critical — это уровни насыщения (-15 и +15). Почему Normal — это 0 и относительно него всего два шага: -2, -1, +1 и +2? Легко провести параллель с обучением. Мы ходим в школу, получаем оценки наших знаний (5,4,3,2,1) и нам понятно, что это за оценки: 5 — молодец, 4 — хорошо, 3 — вообще не постарался, 2 — это не делал ни чего, а 1 — это то, что можно исправить потом на 4. Но если у нас вводится 10-ти бальная система оценок (или что вообще ужас — 100-бальная), то возникает неясность: что такое 9 баллов или 7? Как понять, что вам поставили 3 или 4?
Тоже самое и с приоритетами. У нас есть Normal. Дальше, относительно Normal у нас есть чуть повыше
Normal (Normal above), чуть пониже Normal (Normal below). Также есть шаг на два вверх
или на два вниз (Higest и Lowest). Нам, поверьте, нет никакой необходимости в более подробной градации. Единственное, очень редко, может раз в жизни, нам понадобится сказать: выше чем любой приоритет в системе. Тогда мы выставляем уровень Time Critical. Либо наоборот: это надо делать, когда во всей системе делать нечего. Тогда мы выставляем уровень Idle. Это значения — так называемые уровни насыщения.
Как рассчитываются уровни приоритета?

У нас бал класс приоритета процесса Normal (Таблица 3) и приоритет потоков Normal — это 8. Если процесс Above Normal то поток Normal получается равен 9. Если же процесс выставлен в Higest, то поток Normal получается равен 10.
Поскольку для планировщика потоков Windows все потоки процессов равнозначны, то:
- Для процесса класса Normal и потока Above-Normal
- Для процесса класса Higest и потока Normal
конечные приоритеты будут одинаковыми и равны 10.
Если мы имеем два процесса: один с приоритетом Normal, а второй — с приоритетом Higest, но при этом
первый имел поток Higest а второй Normal, то система их приоритеты будет рассматривать как одинаковые.
Как уже обсуждалось, группа приоритетов Real-Time на самом деле не является таковой, поскольку настоящий Real-Time — это гарантированная доставка сообщения за определённое время либо обработка его получения. Т.е., другими словами, если на конкретном ядре есть такой поток, других там быть не должно. Однако это ведь не так: система может решить, что низко приоритетный поток давно не работал и дать ему время, отключив real-time. Вернее его назвать классом приоритетов который работает над обычными приоритетами и куда обычные приоритеты не могут уйти, попав под ситуации, когда Windows временно повышает им приоритет.
Но так как поток повышенным приоритетом исполняется только один на группе ядер, то получается,
что если у вас даже Real-Time потоки, не факт, что им будет выделено время.
Если перевести в графический вид, то можно заметить, что классы приоритетов пересекаются. Например, существует пересечение Above-Normal Normal Below-Normal (столбик с квадратиками):

Это значит, что для этих трех классов приоритетов процессов существуют такие приоритеты потоков внутри этих классов, что реальный приоритет будет равен. При этом, когда вы задаёте приоритет процессу вы просто повышаете или понижаете все его внутренние приоритеты потоков на определённое значение (см. Таблица 3).
Поэтому, когда процессу выдаётся более высокий класс приоритета, это повышает приоритет потоков процесса относительно обычных – с классом Normal.
Кстати говоря, мы стартовали продажи на CLRium #7, в котором мы с огромным удовольствием будем говорить про практику работы с многопоточным кодом. Будут и домашние задания и даже возможность работы с личным ментором.
Загляните к нам на сайт: мы сильно постарались, чтобы его было интересно изучить.
Introduction
In today’s programming world, multi-threading has become an imperative part of any programming language whether it’s .NET, Java or C++. To write highly responsive and scalable applications, you must avail the power of multi threading programming. While working on .NET Framework, I came across various Framework Class Libraries (FCL) for parallel task processing like Task Parallel Library (TPL), Parallel LINQ (PLINQ), Task Factories, Thread Pool, Asynchronous programming modal, etc., all of which behind the scene use power of Windows threads to achieve parallelism. Understanding the basic structure of Windows thread always help developer in implementing and understanding these advanced features like TPL, PLINQ, etc. in a better way and help in visualizing how multiple threads work in a system together, specially when you are trouble shooting multithreaded applications. In this article, I would like to share some of the basics about Windows thread which may help you in understanding how operating system implements threads.
What Windows Thread Consists Of
Let’s start with looking at the basic components of a thread. There are three basic components of Windows thread:
- Thread Kernel Object
- Stack
- TEB

Windows Thread Components
All of these three components together create Windows thread. I tried to explain all of them one by one below but before looking into these three components, let’s have a brief introduction about Windows kernel and kernel objects as these are the most important part of Windows operating system.
What Is Operating System Kernel
Kernel is the main component of any operating system. It is a bridge between applications and hardware. Kernel provides layer of abstraction through which application can interact with hardware.
Kernel is the part of the operating system that loads first, and it remains in physical memory. The kernel’s primary function is to manage the computer’s hardware and resources and allow other programs to run and use these resources. To know more about kernel, visit this link.
What Are Kernel Objects
Kernel needs to maintain lots of data about numerous resources such as processes, threads, files, etc., for that kernel use “kernel data structures” which are known as kernel objects. Each kernel object is simply a memory block allocated by the kernel and is accessible only to the kernel. This memory block is a data structure whose members maintain information about the object. Some members (security descriptor, usage count, and so on) are same across all object types, but most data members are specific to the type of kernel object. Kernel creates and manipulates several types of kernel objects, such as process objects, thread objects, event objects, file objects, file-mapping objects, I/O completion port objects, job objects, mutex objects, pipe objects, semaphore objects, etc.
Winobj Screenshot
If you are curious to see the list of all the kernel object types, then you can use free WinObj tool from Sysinternals located here.
Thread Kernel Object
First and very basic component of Windows thread is thread kernel object. For every thread in system, operating system create one thread kernel object. Operating systems use these thread kernel objects for managing and executing threads across the system. The kernel object is also where the system keeps all the statistical information about the thread. Below are some of the important properties of thread kernel object.
Thread Context
Each thread kernel object contains set of CPU registers, called the thread’s context. The context reflects state of the CPU registers when the thread last executed. The set of CPU registers for the thread is saved in a CONTEXT structure. The instruction pointer and stack pointer registers are the two most important registers in the threads context. A stack pointer is a register that stores the starting memory address of the stack frame of the current function executing inside the thread. Instruction pointer points to the current instruction that need to be executed by the CPU. Operating system use kernel object context information while performing thread context switching. Context switch is the process of storing and restoring the state (context) of a thread so that execution can be resumed from the same point at a later time.
Below mentioned table displays some of other important information held in thread kernel object about the thread.
| Property Name | Description |
CreateTime |
This field contains the time when the Thread was created. |
ThreadsProcess |
This field contains a pointer to the EPROCESS Structure of the Process that owns this Thread. |
StackBase |
This field contains the Base Address of this Thread’s Stack. |
StackLimit |
This field contains the end of the Kernel-Mode Stack of the Thread. |
TEB |
This field contains a pointer to the Thread’s Environment Block. |
State |
This field contains the Thread’s current state. |
Priority |
This field contains the Thread’s current priority. |
ContextSwitches |
This field counts the number of Context Switches that the Thread has gone through (switching Contexts/Threads). |
WaitTime |
This field contains the time until a Wait will expire. |
Queue |
This field contains a Queue for this Thread. |
Preempted |
This field specifies if the Thread will be preempted or not. |
Affinity |
This field contains the Thread’s Kernel Affinity. |
KernelTime |
This field contains the time that the Thread has spent in Kernel Mode. |
UserTime |
This field contains the time that the Thread has spent in User Mode. |
ImpersonationInfo |
This field contains a pointer to a structure used when the Thread is impersonating another one. |
SuspendCount |
This field contains a count on how many times the Thread has been suspended. |
Stack
The second basic component of a thread is stack. Once the thread kernel object has been created, the system allocates memory, which is used for the thread’s stack. Every thread got its own stack which is used for maintaining local variables of functions and for passing arguments to functions executing inside a thread. When a function executes, it may add some of its state data to the top of the stack like arguments and local variables, when the function exits it is responsible for removing that data from the stack. Apart from that, a thread’s stack is used to store the location of function calls in order to allow return statements to return to the correct location.
Operating system allocates two types of stack for every thread, one is user-mode stack and other is kernel-mode stack.
User-mode stack
The user-mode stack is used for local variables and arguments passed to methods. It also contains the address indicating what the thread should execute next when the current method returns. By default, Windows allocates 1 MB of memory for each thread’s user-mode stack
Kernel-mode stack
The kernel-mode stack is used when application code passes arguments to a kernel function in the operating system. For security reasons, Windows copies any arguments passed from user-mode code to the kernel from the thread’s user-mode stack to the thread’s kernel-mode stack. Once copied, the kernel can verify the arguments’ values, and since the application code can’t access the kernel mode stack, the application can’t modify the arguments’ values after they have been validated and the OS kernel code begins to operate on them. In addition, the kernel calls methods within itself and uses the kernel-mode stack to pass its own arguments, to store a function’s local variables, and to store return addresses. The kernel-mode stack is 12 KB when running on a 32-bit Windows system and 24 KB when running on a 64-bit Windows system.
You can learn more about thread stack at the following links:
- http://www.linfo.org/kernel_space.html
- http://en.wikipedia.org/wiki/Stack-based_memory_allocation
- http://en.wikipedia.org/wiki/Call_stack
Thread Environment Block (TEB)
Another important data structure used by every thread is Thread environment Block (TEB). TEB is a block of memory allocated and initialized in user mode (user mode address space is directly accessible to the application code where else kernel mode address space is not accessible to the application code directly). The TEB consumes 1 page of memory (4 KB on x86 and x64 CPUs).
On of the important information TEB contains is information about exception handling which is used by SEH (Microsoft Structured Exception Handling). The TEB contains the head of the thread’s exception-handling chain. Each try block that the thread enters inserts a node in the head of this chain.The node is removed from the chain when the thread exit the try block. You can learn more about SEH
here.
In addition, TEB contains the thread-local storage data. In multi-threaded applications, there often arises the need to maintain data that is unique to a thread. The place where this thread specific data get stored called thread-local storage. You can learn more about thread-local storage here.
Below mentioned table displays few important properties of TEB:
| Property Name | Description |
ThreadLocalStorage |
This field contains the thread specific data. |
ExceptionList |
This field contains the Exception Handlers List used by SEH |
ExceptionCode |
This field contains the last exception code generated by the Thread. |
LastErrorValue |
This field contains the last DLL Error Value for the Thread. |
CountOwnedCriticalSections |
This field counts the number of Critical Sections (a Synchronization mechanism) that the Thread owns. |
IsImpersonating |
This field is a flag on whether the Thread is doing any impersonation. |
ImpersonationLocale |
This field contains the locale ID that the Thread is impersonating. |
Thread kernel object as thread handle
System keeps all information required for thread execution/ scheduling inside thread kernel object. Apart from that, the operating system stores address of thread stack and thread TEB in thread kernel object as shown in the below figure:
Thread kernel object mapping
Thread kernel object is the only handle through which operating system access all the information about the thread and is use it for thread execution/ scheduling.
Thread State
Each thread exists in a particular execution state at any given time. Operating system stores the state of thread inside thread kernel object field «state». Operating system uses these states that are relevant to performance; these are:
- Running — thread is using CPU
- Blocked — thread is waiting for input
- Ready — thread is ready to run (not Blocked or Running)
- Exited — thread has exited but not been destroyed

Thread State Diagram
Thread Scheduler Queues
Operating system thread scheduler maintains thread kernel objects in different queues based on the state of a thread
- Ready queue — Scheduler maintains list containing threads in Ready state and can be scheduled on CPU. Often list is sorted, generally one queue per CPU.
- Waiting queues — A thread in Blocked state is put in a wait queue. Below are few examples which cause thread block.
- Thread kernel object might have a suspend count greater than 0. This means that the thread is suspended
- Thread is waiting on some lock to get release
- Thread is waiting for reply from E.g., disk, console, network, etc.
- Exited queue — A thread in Exited state is put in this queue
Thread scheduler use doubly linked list data structure for maintaining these queues where in a list head points to a collection of list elements or entries and each item points to the next and previous items in the list.
Thread kernel object doubly link list
Scheduler moves threads across queues on thread state change — E.g., thread moves from a wait queue to ready queue on wake up.
How OS Run Threads
As we already know that thread context structure is maintained inside the thread’s kernel object. This context structure reflects the state of the thread’s CPU registers when the thread was last executing. Every 20 milliseconds or so, operating system thread scheduler looks at all the thread kernel objects currently inside Ready Queue (doubly linked list). Thread scheduler selects one of the thread kernel objects and loads the CPU’s registers with the values that were last saved in the thread’s context. This action is called a context switch. At this point, the thread is executing code and manipulating data in its process’ address space. After another 20 milliseconds or so, scheduler saves the CPU’s registers back into the thread’s context. The scheduler again examines the remaining thread kernel objects in Ready Queue, selects another thread’s kernel object, loads this thread’s context into the CPU’s registers, and continues.
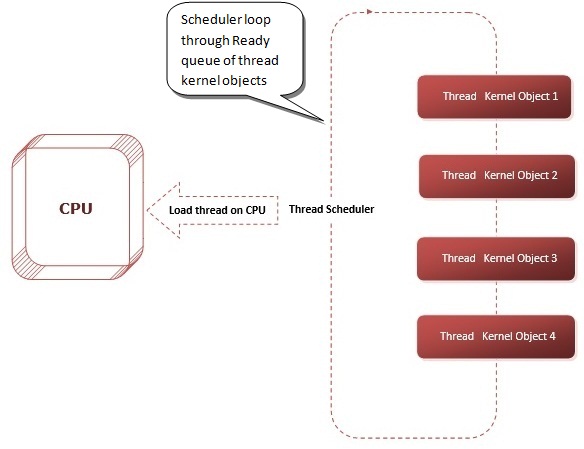
Thread Scheduler Diagram
This operation of loading a thread’s context, letting the thread run, saving the context, and repeating the operation begins when the system boots and continues until the system is shut down.
Processes and Threads
One more thing I would like to share is the relationship between thread and process. Every process requires at least one thread. A process never executes anything, it is simply a container for threads. Threads are always created in the context of some process and live their entire life within that process. What this really means is that the thread executes code and manipulates data within its process’ address space. So if you have two or more threads running in the context of a single process, the threads share a single address space. The threads can execute the same code and manipulate the same data.
Process gives structural information to the in-memory copy of your executable program, such as which memory is currently allocated, which program is running, how much memory it is using, etc. The Process however, does not execute any code on its own. It simply allows the OS (and the user) to know to which executable program a certain Thread belongs to. It also contains all the handles and security rights and privileges that threads create. Therefore, code actually runs in Threads.
For understanding, you can make analogy for processes and threads using a regular, everyday object — a house. A house is really a container, with certain attributes (such as the amount of floor space, the number of bedrooms, and so on). If you look at it that way, the house really doesn’t actively do anything on its own — it’s a passive object. This is effectively what a process is.
The people living in the house are the active objects — they’re the ones using the various rooms, watching TV, cooking, taking showers, and so on. We’ll soon see that’s how threads behave. Just as a house occupies an area of real estate, a process occupies memory. And just as a house’s occupants are free to go into any room they want, a processes’ threads all have common access to that memory.
A process, just like a house, has some well-defined «borders.» A person in a house has a pretty good idea when they’re in the house, and when they’re not. A thread has a very good idea — if it’s accessing memory within the process, it can live. If it steps out of the bounds of the process’s address space, it gets killed. This means that two threads, running in different processes, are effectively isolated from each other.
If you want to learn more about process and thread, please read Processes and Threads.
Summary
Three basic components of thread are:
- Thread Kernel Object is the primary data structure through which OS manages thread.
- Thread stack is used for maintaining local variables of functions and for passing arguments to functions executing inside a thread. Operating system allocates two types of stack for every thread, one is user-mode stack and other is kernel-mode stack.
- Thread Environment Block is a block of memory allocated and initialized in user mode primarily used for exception handling and thread-local storage data.
Thread State
Each thread exists in a particular execution state at any given time which are below:
- Running — thread is using CPU
- Blocked — thread is waiting for input
- Ready — thread is ready to run (not Blocked or Running)
- Exited — thread has exited but not been destroyed
Thread Scheduler Queues
Operating system thread scheduler maintains thread kernel objects in different queues based on the state of a thread:
- Ready queue
- Waiting
- Exited queue
How OS Run Threads
Every 20 milliseconds or so, operating system thread scheduler looks at all the thread kernel objects currently inside Ready Queue. Thread scheduler selects one of the thread kernel objects and loads the CPU’s registers with the values in the thread’s context and execute thread.
Processes and Threads
Every process requires at least one thread. A process never executes anything, it is simply a container for threads. Threads are always created in the context of some process and live their entire life within that process.
References
- CLR via C#, Third Edition (February 10, 2010) By Jeffrey Richter
- Windows via C/C++ Fifth Edition (December 2007) by Jeffrey Richter and Christophe Nasarre
- Introduction to NT Internals — Alex Ionescu’s Blog
- Processes and Threads
Introduction
In today’s programming world, multi-threading has become an imperative part of any programming language whether it’s .NET, Java or C++. To write highly responsive and scalable applications, you must avail the power of multi threading programming. While working on .NET Framework, I came across various Framework Class Libraries (FCL) for parallel task processing like Task Parallel Library (TPL), Parallel LINQ (PLINQ), Task Factories, Thread Pool, Asynchronous programming modal, etc., all of which behind the scene use power of Windows threads to achieve parallelism. Understanding the basic structure of Windows thread always help developer in implementing and understanding these advanced features like TPL, PLINQ, etc. in a better way and help in visualizing how multiple threads work in a system together, specially when you are trouble shooting multithreaded applications. In this article, I would like to share some of the basics about Windows thread which may help you in understanding how operating system implements threads.
What Windows Thread Consists Of
Let’s start with looking at the basic components of a thread. There are three basic components of Windows thread:
- Thread Kernel Object
- Stack
- TEB
Windows Thread Components
All of these three components together create Windows thread. I tried to explain all of them one by one below but before looking into these three components, let’s have a brief introduction about Windows kernel and kernel objects as these are the most important part of Windows operating system.
What Is Operating System Kernel
Kernel is the main component of any operating system. It is a bridge between applications and hardware. Kernel provides layer of abstraction through which application can interact with hardware.
Kernel is the part of the operating system that loads first, and it remains in physical memory. The kernel’s primary function is to manage the computer’s hardware and resources and allow other programs to run and use these resources. To know more about kernel, visit this link.
What Are Kernel Objects
Kernel needs to maintain lots of data about numerous resources such as processes, threads, files, etc., for that kernel use “kernel data structures” which are known as kernel objects. Each kernel object is simply a memory block allocated by the kernel and is accessible only to the kernel. This memory block is a data structure whose members maintain information about the object. Some members (security descriptor, usage count, and so on) are same across all object types, but most data members are specific to the type of kernel object. Kernel creates and manipulates several types of kernel objects, such as process objects, thread objects, event objects, file objects, file-mapping objects, I/O completion port objects, job objects, mutex objects, pipe objects, semaphore objects, etc.
Winobj Screenshot
If you are curious to see the list of all the kernel object types, then you can use free WinObj tool from Sysinternals located here.
Thread Kernel Object
First and very basic component of Windows thread is thread kernel object. For every thread in system, operating system create one thread kernel object. Operating systems use these thread kernel objects for managing and executing threads across the system. The kernel object is also where the system keeps all the statistical information about the thread. Below are some of the important properties of thread kernel object.
Thread Context
Each thread kernel object contains set of CPU registers, called the thread’s context. The context reflects state of the CPU registers when the thread last executed. The set of CPU registers for the thread is saved in a CONTEXT structure. The instruction pointer and stack pointer registers are the two most important registers in the threads context. A stack pointer is a register that stores the starting memory address of the stack frame of the current function executing inside the thread. Instruction pointer points to the current instruction that need to be executed by the CPU. Operating system use kernel object context information while performing thread context switching. Context switch is the process of storing and restoring the state (context) of a thread so that execution can be resumed from the same point at a later time.
Below mentioned table displays some of other important information held in thread kernel object about the thread.
| Property Name | Description |
CreateTime |
This field contains the time when the Thread was created. |
ThreadsProcess |
This field contains a pointer to the EPROCESS Structure of the Process that owns this Thread. |
StackBase |
This field contains the Base Address of this Thread’s Stack. |
StackLimit |
This field contains the end of the Kernel-Mode Stack of the Thread. |
TEB |
This field contains a pointer to the Thread’s Environment Block. |
State |
This field contains the Thread’s current state. |
Priority |
This field contains the Thread’s current priority. |
ContextSwitches |
This field counts the number of Context Switches that the Thread has gone through (switching Contexts/Threads). |
WaitTime |
This field contains the time until a Wait will expire. |
Queue |
This field contains a Queue for this Thread. |
Preempted |
This field specifies if the Thread will be preempted or not. |
Affinity |
This field contains the Thread’s Kernel Affinity. |
KernelTime |
This field contains the time that the Thread has spent in Kernel Mode. |
UserTime |
This field contains the time that the Thread has spent in User Mode. |
ImpersonationInfo |
This field contains a pointer to a structure used when the Thread is impersonating another one. |
SuspendCount |
This field contains a count on how many times the Thread has been suspended. |
Stack
The second basic component of a thread is stack. Once the thread kernel object has been created, the system allocates memory, which is used for the thread’s stack. Every thread got its own stack which is used for maintaining local variables of functions and for passing arguments to functions executing inside a thread. When a function executes, it may add some of its state data to the top of the stack like arguments and local variables, when the function exits it is responsible for removing that data from the stack. Apart from that, a thread’s stack is used to store the location of function calls in order to allow return statements to return to the correct location.
Operating system allocates two types of stack for every thread, one is user-mode stack and other is kernel-mode stack.
User-mode stack
The user-mode stack is used for local variables and arguments passed to methods. It also contains the address indicating what the thread should execute next when the current method returns. By default, Windows allocates 1 MB of memory for each thread’s user-mode stack
Kernel-mode stack
The kernel-mode stack is used when application code passes arguments to a kernel function in the operating system. For security reasons, Windows copies any arguments passed from user-mode code to the kernel from the thread’s user-mode stack to the thread’s kernel-mode stack. Once copied, the kernel can verify the arguments’ values, and since the application code can’t access the kernel mode stack, the application can’t modify the arguments’ values after they have been validated and the OS kernel code begins to operate on them. In addition, the kernel calls methods within itself and uses the kernel-mode stack to pass its own arguments, to store a function’s local variables, and to store return addresses. The kernel-mode stack is 12 KB when running on a 32-bit Windows system and 24 KB when running on a 64-bit Windows system.
You can learn more about thread stack at the following links:
- http://www.linfo.org/kernel_space.html
- http://en.wikipedia.org/wiki/Stack-based_memory_allocation
- http://en.wikipedia.org/wiki/Call_stack
Thread Environment Block (TEB)
Another important data structure used by every thread is Thread environment Block (TEB). TEB is a block of memory allocated and initialized in user mode (user mode address space is directly accessible to the application code where else kernel mode address space is not accessible to the application code directly). The TEB consumes 1 page of memory (4 KB on x86 and x64 CPUs).
On of the important information TEB contains is information about exception handling which is used by SEH (Microsoft Structured Exception Handling). The TEB contains the head of the thread’s exception-handling chain. Each try block that the thread enters inserts a node in the head of this chain.The node is removed from the chain when the thread exit the try block. You can learn more about SEH
here.
In addition, TEB contains the thread-local storage data. In multi-threaded applications, there often arises the need to maintain data that is unique to a thread. The place where this thread specific data get stored called thread-local storage. You can learn more about thread-local storage here.
Below mentioned table displays few important properties of TEB:
| Property Name | Description |
ThreadLocalStorage |
This field contains the thread specific data. |
ExceptionList |
This field contains the Exception Handlers List used by SEH |
ExceptionCode |
This field contains the last exception code generated by the Thread. |
LastErrorValue |
This field contains the last DLL Error Value for the Thread. |
CountOwnedCriticalSections |
This field counts the number of Critical Sections (a Synchronization mechanism) that the Thread owns. |
IsImpersonating |
This field is a flag on whether the Thread is doing any impersonation. |
ImpersonationLocale |
This field contains the locale ID that the Thread is impersonating. |
Thread kernel object as thread handle
System keeps all information required for thread execution/ scheduling inside thread kernel object. Apart from that, the operating system stores address of thread stack and thread TEB in thread kernel object as shown in the below figure:
Thread kernel object mapping
Thread kernel object is the only handle through which operating system access all the information about the thread and is use it for thread execution/ scheduling.
Thread State
Each thread exists in a particular execution state at any given time. Operating system stores the state of thread inside thread kernel object field «state». Operating system uses these states that are relevant to performance; these are:
- Running — thread is using CPU
- Blocked — thread is waiting for input
- Ready — thread is ready to run (not Blocked or Running)
- Exited — thread has exited but not been destroyed
Thread State Diagram
Thread Scheduler Queues
Operating system thread scheduler maintains thread kernel objects in different queues based on the state of a thread
- Ready queue — Scheduler maintains list containing threads in Ready state and can be scheduled on CPU. Often list is sorted, generally one queue per CPU.
- Waiting queues — A thread in Blocked state is put in a wait queue. Below are few examples which cause thread block.
- Thread kernel object might have a suspend count greater than 0. This means that the thread is suspended
- Thread is waiting on some lock to get release
- Thread is waiting for reply from E.g., disk, console, network, etc.
- Exited queue — A thread in Exited state is put in this queue
Thread scheduler use doubly linked list data structure for maintaining these queues where in a list head points to a collection of list elements or entries and each item points to the next and previous items in the list.
Thread kernel object doubly link list
Scheduler moves threads across queues on thread state change — E.g., thread moves from a wait queue to ready queue on wake up.
How OS Run Threads
As we already know that thread context structure is maintained inside the thread’s kernel object. This context structure reflects the state of the thread’s CPU registers when the thread was last executing. Every 20 milliseconds or so, operating system thread scheduler looks at all the thread kernel objects currently inside Ready Queue (doubly linked list). Thread scheduler selects one of the thread kernel objects and loads the CPU’s registers with the values that were last saved in the thread’s context. This action is called a context switch. At this point, the thread is executing code and manipulating data in its process’ address space. After another 20 milliseconds or so, scheduler saves the CPU’s registers back into the thread’s context. The scheduler again examines the remaining thread kernel objects in Ready Queue, selects another thread’s kernel object, loads this thread’s context into the CPU’s registers, and continues.
Thread Scheduler Diagram
This operation of loading a thread’s context, letting the thread run, saving the context, and repeating the operation begins when the system boots and continues until the system is shut down.
Processes and Threads
One more thing I would like to share is the relationship between thread and process. Every process requires at least one thread. A process never executes anything, it is simply a container for threads. Threads are always created in the context of some process and live their entire life within that process. What this really means is that the thread executes code and manipulates data within its process’ address space. So if you have two or more threads running in the context of a single process, the threads share a single address space. The threads can execute the same code and manipulate the same data.
Process gives structural information to the in-memory copy of your executable program, such as which memory is currently allocated, which program is running, how much memory it is using, etc. The Process however, does not execute any code on its own. It simply allows the OS (and the user) to know to which executable program a certain Thread belongs to. It also contains all the handles and security rights and privileges that threads create. Therefore, code actually runs in Threads.
For understanding, you can make analogy for processes and threads using a regular, everyday object — a house. A house is really a container, with certain attributes (such as the amount of floor space, the number of bedrooms, and so on). If you look at it that way, the house really doesn’t actively do anything on its own — it’s a passive object. This is effectively what a process is.
The people living in the house are the active objects — they’re the ones using the various rooms, watching TV, cooking, taking showers, and so on. We’ll soon see that’s how threads behave. Just as a house occupies an area of real estate, a process occupies memory. And just as a house’s occupants are free to go into any room they want, a processes’ threads all have common access to that memory.
A process, just like a house, has some well-defined «borders.» A person in a house has a pretty good idea when they’re in the house, and when they’re not. A thread has a very good idea — if it’s accessing memory within the process, it can live. If it steps out of the bounds of the process’s address space, it gets killed. This means that two threads, running in different processes, are effectively isolated from each other.
If you want to learn more about process and thread, please read Processes and Threads.
Summary
Three basic components of thread are:
- Thread Kernel Object is the primary data structure through which OS manages thread.
- Thread stack is used for maintaining local variables of functions and for passing arguments to functions executing inside a thread. Operating system allocates two types of stack for every thread, one is user-mode stack and other is kernel-mode stack.
- Thread Environment Block is a block of memory allocated and initialized in user mode primarily used for exception handling and thread-local storage data.
Thread State
Each thread exists in a particular execution state at any given time which are below:
- Running — thread is using CPU
- Blocked — thread is waiting for input
- Ready — thread is ready to run (not Blocked or Running)
- Exited — thread has exited but not been destroyed
Thread Scheduler Queues
Operating system thread scheduler maintains thread kernel objects in different queues based on the state of a thread:
- Ready queue
- Waiting
- Exited queue
How OS Run Threads
Every 20 milliseconds or so, operating system thread scheduler looks at all the thread kernel objects currently inside Ready Queue. Thread scheduler selects one of the thread kernel objects and loads the CPU’s registers with the values in the thread’s context and execute thread.
Processes and Threads
Every process requires at least one thread. A process never executes anything, it is simply a container for threads. Threads are always created in the context of some process and live their entire life within that process.
References
- CLR via C#, Third Edition (February 10, 2010) By Jeffrey Richter
- Windows via C/C++ Fifth Edition (December 2007) by Jeffrey Richter and Christophe Nasarre
- Introduction to NT Internals — Alex Ionescu’s Blog
- Processes and Threads
Состояния потоков и планирование их выполнения
Для каждого созданного потока в системе предусматриваются три возможных его состояния:
- состояние выполнения, когда код потока выполняется процессором; на однопроцессорных платформах в этом состоянии в каждый момент времени может находиться только один поток;
- состояние готовности к выполнению, когда поток готов продолжать свою работу и ждет освобождения ЦП;
- состояние ожидания наступления некоторого события; в этом случае поток не претендует на время ЦП, пока не наступит определенное событие (завершение операции ввода/вывода, освобождение необходимого потоку занятого ресурса, сигнала от другого потока); часто такие потоки называют блокированными.
Изменение состояния потока происходит в результате соответствующих действий. Удобно для этих целей использовать следующую диаграмму состояний и переходов.
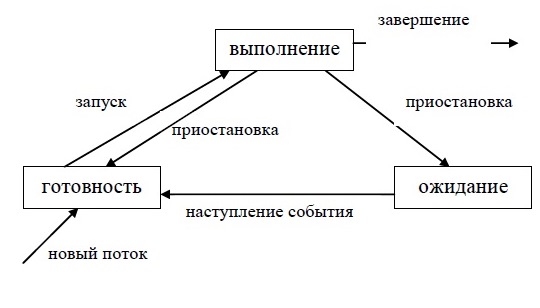
Переходы между состояниями можно описать следующим образом:
- «готовность» → «выполнение»: система в соответствии с алгоритмом планирования выбирает для выполнения текущий поток, предоставляя ему ЦП
- «выполнение» → «готовность»: поток готов продолжать свою работу, но система принимает решение прервать его выполнение; чаще всего это происходит по следующим двум причинам:
- завершается выделенное потоку время владения процессором;
- в числе готовых к выполнению появляется более приоритетный поток по сравнению с текущим;
- «выполнение» → «ожидание»: дальнейшее исполнение кода текущего активного потока невозможно без наступления некоторого события, и поэтому активный поток прерывает свое выполнение и переводится системой в состояние ожидания (блокируется);
- «ожиданием» → «готовность»: в системе происходит некоторое событие, наступление которого ожидает один из блокированных потоков, и поэтому система переводит этот поток в состояние готовности (разблокирует), после чего он будет учитываться системой при планировании порядка предоставления ЦП;
- наконец, поток может нормально или аварийно завершить свое выполнение, после чего система удаляет его дескриптор из своей внутренней структуры, и тем самым поток перестает существовать.
В состояниях готовности и ожидания может находиться несколько потоков, поэтому система создает для хранения их дескрипторов отдельные списковые структуры. Организация этих списков зависит от тех принципов, которые положены в основу планирования потоков для данной ОС.
Цель планирования потоков вполне очевидна — определение порядка выполнения потоков в условиях внешней или внутренней многозадачности. Однако способы достижения этой цели существенно зависят от типа ОС. Рассмотрим сначала принципы планирования для универсальных ОС. Для таких ОС нельзя заранее предсказать, сколько и какие потоки будут запущены в каждый момент времени и в каких состояниях они будут находиться. Поэтому планирование должно выполняться динамически на
основе сбора и анализа информации о текущем состоянии вычислительной системы.
Для этого в состав ОС включается модуль-планировщик, реализующий выбранные алгоритмы планирования. Поскольку этот модуль представляет собой программный код, то для решения своих задач планировщик должен на некоторое время забирать ЦП. Отсюда следует, что алгоритмы планирования должны быть максимально простыми, иначе возникает опасность, что система будет тратить недопустимо большое время на решение своих внутренних задач, а на выполнение прикладных программ времени не останется.
Кроме вычислительной простоты, алгоритмы планирования должны обладать следующими общими свойствами:
- обеспечение максимально возможной загрузки ЦП;
- обеспечение равномерной загрузки ресурсов вычислительной системы;
- обеспечение справедливого обслуживания всех процессов и потоков;
- минимизация времени отклика для интерактивных процессов.
За время существования ОС было предложено и реализовано несколько принципов управления потоками. В настоящее время большинство универсальных ОС используют метод вытесняющей многозадачности (preemptive multitasking), который тоже имеет несколько разновидностей. В основе метода лежат два важнейших и достаточно понятных принципа: квантование времени ЦП и приоритеты потоков.
Квантование означает, что каждому потоку система выделяет определенный интервал времени (квант), в течение которого процессор потенциально может выполнять код этого потока. По завершении выделенного кванта планировщик принудительно переключает процессор на выполнение другого готового потока (если, конечно, такой есть), переводя старый активный поток в состояние готовности. Это гарантирует, что ни один поток не захватит ЦП на непозволительно большое время (как было в более ранних системах с так называемой невытесняющей или кооперативной многозадачностью). Конечно, выделенный квант поток может и не использовать до конца, если в процессе своего выполнения он нормально или аварийно завершится, или потребует наступления некоторого события, или будет прерван системой.
Для эффективной работы ОС большое значение имеет выбор величины кванта. Очень маленькие значения кванта приводят к частым переключениям ЦП, что повышает непроизводительные расходы из-за необходимости постоянного сохранения контекста прерываемого потока и загрузки контекста активизируемого потока. Наоборот, большие значения кванта уменьшают иллюзию одновременного выполнения нескольких приложений. Некоторые планировщики умеют изменять кванты в определенных пределах, увеличивая их для тех потоков, которые не используют до конца выделенное время, например, из-за частых обращений к операциям ввода/вывода. Типичный диапазон изменения кванта – от 10 до 50 миллисекунд. При этом необходимо учитывать все возрастающие скорости работы современных процессоров: за 10 миллисекунд (т.е. за 1/100 секунды) процессор успеет выполнить около 10 млн. элементарных команд.
Можно связать величину кванта с приоритетом потока. Приоритет определяет важность потока и влияет на частоту запуска потока и, возможно, на величину выделяемого кванта. Интуитивно понятно, что потоки могут иметь разную степень важности: системные – более высокую (иначе ОС не сможет решать свои задачи), прикладные – менее высокую. Многие ОС позволяют группировать потоки по их важности, выделяя три группы, или класса:
- потоки реального времени с максимально высоким уровнем приоритета;
- системные потоки с меньшим уровнем приоритета;
- прикладные потоки с самым низким приоритетом.
Внутри каждой группы выделяется свой диапазон возможных значений приоритетов, причем эти диапазоны между собой не пересекаются, т.е. максимально возможный приоритет прикладного потока всегда будет строго меньше минимально возможного приоритета для системных потоков. Внутри каждой группы могут использоваться разные алгоритмы управления приоритетами.
Если приоритет потока может меняться системой, то такие приоритеты называют динамическими, иначе – фиксированными. Конечно, реализация фиксированных приоритетов гораздо проще, тогда как динамические приоритеты позволяют реализовать более справедливое распределение процессорного времени. Например, потоки, интенсивно использующие внешние устройства, очень часто блокируются до завершения выделенного кванта времени, т.е. не используют эти кванты полностью. Справедливо при разблокировании таких потоков дать им более высокий приоритет для быстрой активации, что обеспечивает большую загрузку относительно медленных внешних устройств. С другой стороны, если поток полностью расходует выделенный квант, система может после его приостановки уменьшить приоритет. Тем самым, более высокие приоритеты получают более короткие потоки, быстро освобождающие процессор, и следовательно, достигается более равномерная загрузка вычислительной системы в целом.
Довольно интересной и часто используемой разновидностью приоритетов являются так называемые абсолютные приоритеты: как только среди готовых потоков появляется поток, приоритет которого выше, чем приоритет текущего активного потока, этот активный поток досрочно прерывается с передачей процессора более приоритетному потоку.
Для реализации приоритетного обслуживания ОС должна создавать и поддерживать набор приоритетных очередей. Для каждого возможного значения приоритета создается своя очередь, в которую потоки (в виде своих дескрипторов) помещаются строго в соответствии с очередностью. Планировщик просматривает эти очереди по порядку следования приоритетов и выбирает для выполнения первый поток в самой приоритетной непустой очереди. Отсюда следует, что потоки с меньшими приоритетами будут выполняться, только если пусты все более приоритетные очереди. Если допускается изменение приоритета, то планировщик должен уметь перемещать поток в другую очередь в соответствии с новым значением приоритета.
Схематично массив приоритетных очередей представлен на следующем рисунке, где для удобства более приоритетные потоки собраны в левой части массива, менее приоритетные – в правой, а сами приоритеты изменяются от 1 (максимум) до n (минимум). Условное обозначение «поток i.2» показывает, что данный поток имеет приоритет i и стоит вторым по порядку в своей очереди.
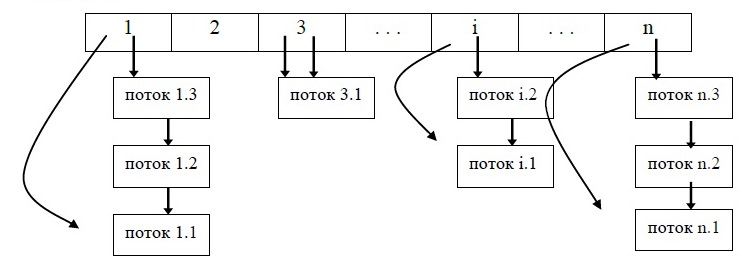
Для изменения приоритета и, возможно, кванта времени планировщику необходима следующая информация: базовая величина приоритета и кванта, время ожидания в очереди, накопленное время выполнения, интенсивность обращения к операциям ввода/вывода. Вся эта информация должна сохраняться в соответствующих структурах данных.
В итоге, планировщик включается в работу при возникновении одного из следующих событий:
- завершение кванта времени для текущего активного потока (сигнал от системного таймера);
- нормальное завершение кода текущего активного потока;
- аварийное завершение кода текущего активного потока;
- запрос активным потоком занятого системного ресурса;
- появление среди готовых потоков более приоритетного потока.
При этом запускается код планировщика, который просматривает приоритетные очереди и выбирает наиболее приоритетный поток. После этого происходит собственно само переключение потоков:
- формируется контекст прерываемого потока;
- поскольку в регистр-счетчик команд из контекста заносится адрес очередной подлежащей выполнению команды активизируемого потока, то процессор переходит к выполнению кода нового потока точно с того места, где оно было прервано.
с помощью контекста вновь активизируемого потока восстанавливается необходимое состояние вычислительной системы, в частности, загружаются необходимые значения во все регистры процессора;
Планирование потоков в системах реального времени строится на других принципах. Поскольку для подобных систем наиболее важным показателем является скорость работы, то планирование выполняется статически. Для этого заранее строится так называемая таблица переключений, с помощью которой в зависимости от текущего состояния вычислительного процесса быстро и однозначно определяется запускаемый в данный момент поток.

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
![]() статьи IT, теория программирования, операционные системы, потоки
статьи IT, теория программирования, операционные системы, потоки