
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах. Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| Dec | Hex | Символ | Dec | Hex | Символ | |
|---|---|---|---|---|---|---|
| 000 | 00 | NOP | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | BS | 136 | 88 | € | |
| 009 | 09 | TAB | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | VT | 139 | 8B | ‹ | |
| 012 | 0C | FF | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | SO | 142 | 8E | Ћ | |
| 015 | 0F | SI | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | NAK | 149 | 95 | • | |
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | CAN | 152 | 98 | ||
| 025 | 19 | EM | 153 | 99 | ™ | |
| 026 | 1A | SUB | 154 | 9A | љ | |
| 027 | 1B | ESC | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | GS | 157 | 9D | ќ | |
| 030 | 1E | RS | 158 | 9E | ћ | |
| 031 | 1F | US | 159 | 9F | џ | |
| 032 | 20 | SP | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | « | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | ‘ | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Ё | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | AA | Є | |
| 043 | 2B | + | 171 | AB | « | |
| 044 | 2C | , | 172 | AC | ¬ | |
| 045 | 2D | — | 173 | AD | | |
| 046 | 2E | . | 174 | AE | ® | |
| 047 | 2F | / | 175 | AF | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | ё | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | BC | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї | |
| 064 | 40 | @ | 192 | C0 | А | |
| 065 | 41 | A | 193 | C1 | Б | |
| 066 | 42 | B | 194 | C2 | В | |
| 067 | 43 | C | 195 | C3 | Г | |
| 068 | 44 | D | 196 | C4 | Д | |
| 069 | 45 | E | 197 | C5 | Е | |
| 070 | 46 | F | 198 | C6 | Ж | |
| 071 | 47 | G | 199 | C7 | З | |
| 072 | 48 | H | 200 | C8 | И | |
| 073 | 49 | I | 201 | C9 | Й | |
| 074 | 4A | J | 202 | CA | К | |
| 075 | 4B | K | 203 | CB | Л | |
| 076 | 4C | L | 204 | CC | М | |
| 077 | 4D | M | 205 | CD | Н | |
| 078 | 4E | N | 206 | CE | О | |
| 079 | 4F | O | 207 | CF | П | |
| 080 | 50 | P | 208 | D0 | Р | |
| 081 | 51 | Q | 209 | D1 | С | |
| 082 | 52 | R | 210 | D2 | Т | |
| 083 | 53 | S | 211 | D3 | У | |
| 084 | 54 | T | 212 | D4 | Ф | |
| 085 | 55 | U | 213 | D5 | Х | |
| 086 | 56 | V | 214 | D6 | Ц | |
| 087 | 57 | W | 215 | D7 | Ч | |
| 088 | 58 | X | 216 | D8 | Ш | |
| 089 | 59 | Y | 217 | D9 | Щ | |
| 090 | 5A | Z | 218 | DA | Ъ | |
| 091 | 5B | [ | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | ||
| 093 | 5D | ] | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю | |
| 095 | 5F | _ | 223 | DF | Я | |
| 096 | 60 | ` | 224 | E0 | а | |
| 097 | 61 | a | 225 | E1 | б | |
| 098 | 62 | b | 226 | E2 | в | |
| 099 | 63 | c | 227 | E3 | г | |
| 100 | 64 | d | 228 | E4 | д | |
| 101 | 65 | e | 229 | E5 | е | |
| 102 | 66 | f | 230 | E6 | ж | |
| 103 | 67 | g | 231 | E7 | з | |
| 104 | 68 | h | 232 | E8 | и | |
| 105 | 69 | i | 233 | E9 | й | |
| 106 | 6A | j | 234 | EA | к | |
| 107 | 6B | k | 235 | EB | л | |
| 108 | 6C | l | 236 | EC | м | |
| 109 | 6D | m | 237 | ED | н | |
| 110 | 6E | n | 238 | EE | о | |
| 111 | 6F | o | 239 | EF | п | |
| 112 | 70 | p | 240 | F0 | р | |
| 113 | 71 | q | 241 | F1 | с | |
| 114 | 72 | r | 242 | F2 | т | |
| 115 | 73 | s | 243 | F3 | у | |
| 116 | 74 | t | 244 | F4 | ф | |
| 117 | 75 | u | 245 | F5 | х | |
| 118 | 76 | v | 246 | F6 | ц | |
| 119 | 77 | w | 247 | F7 | ч | |
| 120 | 78 | x | 248 | F8 | ш | |
| 121 | 79 | y | 249 | F9 | щ | |
| 122 | 7A | z | 250 | FA | ъ | |
| 123 | 7B | { | 251 | FB | ы | |
| 124 | 7C | | | 252 | FC | ь | |
| 125 | 7D | } | 253 | FD | э | |
| 126 | 7E | ~ | 254 | FE | ю | |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.
Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
| Код | Описание |
|---|---|
| NUL, 00 | Null, пустой |
| SOH, 01 | Start Of Heading, начало заголовка |
| STX, 02 | Start of TeXt, начало текста |
| ETX, 03 | End of TeXt, конец текста |
| EOT, 04 | End of Transmission, конец передачи |
| ENQ, 05 | Enquire. Прошу подтверждения |
| ACK, 06 | Acknowledgement. Подтверждаю |
| BEL, 07 | Bell, звонок |
| BS, 08 | Backspace, возврат на один символ назад |
| TAB, 09 | Tab, горизонтальная табуляция |
| LF, 0A | Line Feed, перевод строки Сейчас в большинстве языков программирования обозначается как n |
| VT, 0B | Vertical Tab, вертикальная табуляция |
| FF, 0C | Form Feed, прогон страницы, новая страница |
| CR, 0D | Carriage Return, возврат каретки Сейчас в большинстве языков программирования обозначается как r |
| SO, 0E | Shift Out, изменить цвет красящей ленты в печатающем устройстве |
| SI, 0F | Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно |
| DLE, 10 | Data Link Escape, переключение канала на передачу данных |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 |
Device Control, символы управления устройствами |
| NAK, 15 | Negative Acknowledgment, не подтверждаю |
| SYN, 16 | Synchronization. Символ синхронизации |
| ETB, 17 | End of Text Block, конец текстового блока |
| CAN, 18 | Cancel, отмена переданного ранее |
| EM, 19 | End of Medium, конец носителя данных |
| SUB, 1A | Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче |
| ESC, 1B | Escape Управляющая последовательность |
| FS, 1C | File Separator, разделитель файлов |
| GS, 1D | Group Separator, разделитель групп |
| RS, 1E | Record Separator, разделитель записей |
| US, 1F | Unit Separator, разделитель юнитов |
| DEL, 7F | Delete, стереть последний символ. |
Смотрите также:
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
Таблица кодов символов кирилицы UTF-8
Лабораторная
работа 3 (4 часа)
Языки
программирования
Кодировки
ASCII,
Windows-1251,
UTF-8,
UTF-16
-
Используйте
при выполнении лабораторной работы
материал лекции 2 [Л2]. -
Исследуйте
таблицы кодировок US—ASCII
и Windows-1251
[Л2]. -
Создайте
проект консольного C++-приложения
с именем LP_Lab03. -
Запишите
в строках комментариев три строки:
1)
фамилия, имя, год рождения на английском
языке, например: IvanovAlex1998;
2)
фамилия, имя, год рождения на русском
языке, например: ИвановАлексей1998;
3)
фамилия (на русском), год рождения, имя
(на английском), например: Иванов1998Alex.
-
Используя
таблицы кодировок в [Л2] запишите в
комментариях шестнадцатеричное
представление 3х строк записанных ранее
в кодировке Windows-1251. -
Используя
таблицы кодировок в [Л2] запишите в
комментариях шестнадцатеричное
представление трех строк в кодировках
UTF-8
и
UTF-16. -
В
программе проекта LP_Lab03
объявите
6 строк: 3 записанные ранее в кодировке
Windows-1251
и
3 эти же строки в кодировке UTF-16.

-
Запустите
приложение и с помощью отладчика VS
просмотрите области памяти, соответствующие
шести объявленным строкам. -
Убедитесь,
что записанное в комментариях
шестнадцатеричное представление строк
в кодировках Windows-1251
и Unicode-16
(п.5, 6) идентично полученному с помощью
отладчика. -
Используя
HEX—Editor
(обратитесь
к преподавателю) определите, в какой
кодировке представлены входные файлы
(*.cpp
и
*.h)
транслятора C++. -
С
помощью VS
разработайте 3 XML-файла,
содержащих 3 строки (п.4):
1)
XML1251.xml
— в кодировке Windows-1251;
2)
XMLUTF8.xml
— в кодировке UTF-8;
3)
XMLUTF16.xml
в кодировке UTF-16.
-
Используя
HEX—Editor
проанализируйте
XML-файлы
(п.11)
XML1251.xml,
XMLUTF8.xml,
XMLUTF16.xml. -
Определите
символы BOM
(Byte
order
mark)
в файлах XML1251.xml,
XMLUTF8.xml,
XMLUTF16.xml. -
Определите
в какой кодировке представлены входные
файлы (*.cpp
и
*.h)
транслятора C++. -
Разработайте
XML-файл
XMLUTF16BE.xml,
применяющий
кодировку
UTF-16BE. -
Используя
HEX—Editor,
проанализируйте
XML-файлы
(п.15)
XMLUTF16BE.xml,
поясните отличие от файла XMLUTF16BE.xml. -
Определите
разницу значений кодов
Windows-1251
символов: F
и f,
S
и s,
L
и l,
Б
и б,
Г
и г,
Э
и э. -
В
рамках проекта LP_Lab03
разработайте функцию:
char*
UpperW1251(char* destination, char* source)
функция
принимает строку символов в кодировке
Windows-1251
(параметр
source),
формирует строку в кодировке Windows-1251
(параметр
destination),
содержащей буквы только верхнего
регистра и возвращает указатель на
строку destination.

Ответьте
на следующие вопросы:
-
что
такое таблица
кодировки?
Это
таблица,
где каждой букве алфавита (а также цифрам
и специальным знакам) присвоен уникальный
номер — код символа.
-
расшифруйте
аббревиатуру ASCII;
American
standard code for information interchange
-
поясните
структуру кодировки Windows-1251;

-
что
такое UNICODE?
Юникод
(англ. Unicode)
— это универсальный стандарт кодирования
символов, который позволяет предоставить
знаки всех языков мира.
-
поясните
структуру кодировки UNICODE; -
что
такое UTF-8
и UTF-16? -
в
каких случаях целесообразно применять
кодировку UTF-8? -
определите
разницу значений кодов
UTF-16
символов: F
и f,
S
и s,
L
и l,
Б
и б,
Г
и г,
Э
и э;
каким образом получить из кода буквы
нижнего регистра получить букву верхнего
регистра.
3
Краткие теоретические сведения
Лекция
Задание к работе
-
Исходный текст.
- Создайте свой каталог на учебном компьютере.
- В этом каталоге создайте текстовый файл и откройте его в редакторе.
- Переключите кодировку текста на «CP 866».
- Наберите в текстовом файле фразу «Hello, мир-25!» и сохраните его.
-
Шестнадцатеричное представление текста
- Откройте набранный файл в программе «Frhed».
- Допишите справа от текста цифры 0, 1 и 2. Чему равны шестнадцатеричные коды этих символов?
- Найдите в шестнадцатеричном представлении код запятой, дефиса и восклицательного знака. Чему они равны в десятичной системе счисления?
-
Кодировки символов
- Клинув в строке статуса в программе «Frhed» по надписи «OEM» измените кодировку. Как изменился текст в правой половине окна и почему? Верните исходную кодировку.
- В текстовом редакторе измените кодировку на «Windows 1251» (основная кодировка операционной системы windows) и сохраните файл. Какие варианты изменения кодировки поддерживаются в текстовом редакторе?
- Запустите еще один экземпляр программы «Frhed» и откройте в нем новую версию файла. Сравните шестнадцатеричные коды версий текстовых файлов в различных кодировках. Для каких символов коды совпадают?
- Проделайте аналогичные операции с текстом для кодировки «UTF-8». Определите, почему текст в этой кодировке занимает больше символов.
- Наберите текст из букв русского алфавита: «абвгдеёжзийклмнопрстуфхцчшщъыьэюя АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ». Посмотрите его шестнадцатеричное представление в трех рассмотренных кодировках. Какие кодировки можно использовать для сортировки русских слов по алфавиту и с какими ограничениями?
-
Специальные символы
- В меню «View» текстового редактора установите галочки «Render Whitespace» и «Render Control Characters». Установите расширение «code-eol». Вставьте в текстовый файл символ конца строки (нажмите «Enter») и табуляции (возьмите тут: « »). Как отображаются эти символы в vs code?
- Откройте текстовый файл в программе «Frhed». Какие коды имеют набранные символы?
- В правом нижнем углу, левее символов текущей кодировки, найдите обозначение текущего способа обозначение конца строки: «LF» (используется по умолчанию в Linux) или «CR LF» (Windows). Поменяйте способ обозначение конца строки и опишите, что произошло с текстом.
- Из List of Unicode characters возьмите символы длинного (—) и короткого тире (–) и символы принятых в русском языке кавычек елочек (как, например, в предыдущих предложениях). Составьте предложение, включающее эти символы. Определите коды этих символов.
- Откройте окно «Keyboard Shortcuts», в дополнительных операциях этого окна нажмите найдите команду «Open Keyboard Shortcuts(JSON)». По образцу для длинного тире создайте горячие клавиши для ввода символов из предыдущего параграфа (в параметре «key» указывается сочетание клавиш, в «text» — символ):
[ { "key": "alt+k m", "command": "type", "args": { "text": "—" } }, // Другие горячие клавиши ]
Содержание
- 1 Представление символов в вычислительных машинах
- 2 Таблицы кодировок
- 3 Кодировки стандарта ASCII
- 3.1 Структурные свойства таблицы
- 4 Кодировки стандарта UNICODE
- 4.1 Кодовое пространство
- 4.2 Модифицирующие символы
- 4.3 Способы представления
- 4.4 UTF-8
- 4.4.1 Принцип кодирования
- 4.4.1.1 Правила записи кода одного символа в UTF-8
- 4.4.1.2 Определение длины кода в UTF-8
- 4.4.1 Принцип кодирования
- 4.5 UTF-16
- 4.5.1 UTF-16LE и UTF-16BE
- 4.6 UTF-32
- 4.7 Порядок байт
- 4.7.1 Варианты записи
- 4.7.1.1 Порядок от старшего к младшему
- 4.7.1.2 Порядок от младшего к старшему
- 4.7.1.3 Переключаемый порядок
- 4.7.1.4 Смешанный порядок
- 4.7.1.5 Различия
- 4.7.2 Маркер последовательности байт
- 4.7.1 Варианты записи
- 4.8 Проблемы Юникода
- 5 Примеры
- 5.1 Код на python
- 5.2 hex-дамп файла exampleBOM
- 6 См. также
- 7 Источники информации
Представление символов в вычислительных машинах
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины , задается простой формулой . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до кодовых позиций, было принято решение использовать лишь для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее кодовых позиций ( графических и прочих символов).
Кодовое пространство разбито на плоскостей (англ. planes) по символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости и выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов ) или «U+xxxxx» (для кодов ) или «U+xxxxxx» (для кодов ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
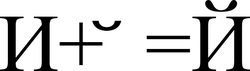
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими -битные символы. Текст, состоящий только из символов с номером меньше , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид , а остальные — .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
111111xx |
служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = байт
- Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 байт (то есть от до ):
- 2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
- 2.2 «0» — бит терминатор, означающий завершение кода размера
- 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
В общем случае количество значащих бит , кодируемых байтами UTF-8, определяется по формуле:
при
при
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством ), причем -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от до ). При этом можно кодировать символы Unicode в диапазонах и . Исключенный отсюда диапазон используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя -битными словами. Символы Unicode до включительно (исключая диапазон для суррогатов) записываются как есть -битным словом. Символы же в диапазоне (больше бит) уже кодируются парой -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число ). В результате получится значение от нуля до , которое занимает до бит. Старшие бит этого значения идут в лидирующее (первое) слово, а младшие бит — в последующее (второе). При этом в обоих словах старшие бит используются для обозначения суррогата. Биты с по имеют значения , а -й бит содержит у лидирующего слова и — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа , большего (здесь — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число записывается в позиционной системе счисления по основанию :
Набор целых чисел , каждое из которых лежит в интервале от до , является последовательностью байт, составляющих . При этом называется младшим байтом, а — старшим байтом числа .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление -байтных целых чисел на -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число , то прочитав его как int16 (два байта) мы получим число , прочитав один байт — число . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
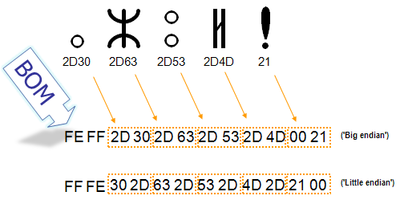
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF
|
| UTF-16 (BE) | FE FF
|
| UTF-16 (LE) | FF FE
|
| UTF-32 (BE) | 00 00 FE FF
|
| UTF-32 (LE) | FF FE 00 00
|
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его или байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32
|
Информатика для 10-го класса |
|
|
|
|
| Предмет: | Информатика |
| Класс: | 10 |
| Автор учебника: | Босова Л.Л. |
| Год издания: | 2016 |
| Издательство: | |
| Кол-во заданий: | 25 |
| Кол-во упражнений: | |
|
Мы в социальных сетях |
|
|
Телеграм • ВКонтакте |

Если есть вопросы, дополнения, правки, вопросы к тексту ответа, пишите на странице обсуждения.
Кодирование текстовой информации[править | править код]
Представление текстовой информации в компьютере[править | править код]
- Какова основная идея представления текстовой информации в компьютере?
Основная идея представления текстовой информации в компьютере заключается в преобразовании текста в цифровую форму, понятную компьютеру. Это делается путем назначения символов и символов для представления текста. После преобразования текста в цифровую форму он может обрабатываться, храниться и использоваться компьютером.
Кодировка ASCII[править | править код]
- Что представляет собой кодировка ASCII? Сколько символов она включает? Какие это символы?
Кодировка ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией) представляет собой систему представления символов (букв, цифр, символов и знаков препинания) в виде чисел. Он включает 128 символов и символов от 0 до 127. Эти символы в основном представляют собой буквы и цифры, а также некоторые распространенные символы, такие как !, @, #, $, %, ^, &, *, (, ), -, + , =, {, }, [, ], :, ;, » , ‘, <, >, ?, /, , | и ~.
- Как известно, кодовые таблицы каждому символу алфавита ставят в соответствие его двоичный код. Как, в таком случае, вы можете объяснить вид таблицы 3.8 «Кодировка ASCII»?
Таблица ASCII — это таблица кодов, которая соответствует каждому символу алфавита, а также другим неалфавитным символам, таким как знаки препинания, цифры и специальные символы. Это одна из наиболее широко используемых систем кодирования символов в мире, и она является основой для многих других систем кодирования символов. В таблице ASCII каждому символу присваивается уникальный номер, и этот номер используется для представления символа в двоичной форме. Это позволяет компьютерам интерпретировать символы и правильно отображать их на экране.
- С помощью таблицы 3.8 Кодировка ASCII:
- а) декодируйте сообщение 64 65 73 6B 74 6F 70; — Desktop;
- б) запишите в двоичном коде сообщение TOWER; — 01010100 01001111 01001111 01000101 01010010;
- в) декодируйте сообщение 01101100 01100001 01110000 01110100 01101111 01110000 — Laptop.
- Что представляют собой расширения ASCII-кодировки? Назовите основные расширения ASCII-кодировки, содержащие русские буквы.
ASCII (American Standard Code for Information Interchange) — это система кодирования символов, используемая для представления текста в компьютерах и других электронных устройствах. Расширения кодировки ASCII — это дополнительные наборы символов, которые были разработаны для включения символов неанглийских языков, например русского. Основные расширения кодировки ASCII, содержащие русские буквы:
- КОИ8-Р (русский)
- Windows-1251 (кириллица)
- ISO-8859-5 (кириллица)
- CP866 (кириллица-DOS)
- маккириллица
- IBM855 (кириллица)
Подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8[править | править код]
- Сравните подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8.
Кодировка Windows-1251 представляет собой одну из самых распространенных кодировок для отображения русских букв. Она использует для каждой буквы последовательность байтов из двух символов. Первый символ указывает на расположение буквы в кодовой таблице, а второй указывает на саму букву. Таким образом, русские буквы могут быть расположены в пределах одного байта и внутри двух байтов.
КОИ-8 является двухбайтной кодировкой, которая использует два байта для представления каждой русской буквы. Первый байт указывает на конкретную букву, а второй байт указывает на соседние буквы, которые могут быть использованы для построения слова. Таким образом, КОИ-8 позволяет располагать русские буквы внутри двух байтов, что делает ее более эффективной по сравнению с Windows-1251.
Расшифровка кодировок в разных системах кодировок[править | править код]
- Представьте в кодировке Windows-1251 текст «Знание — сила!»:
- а) шестнадцатеричным кодом — 8F D8 D2 EE E4 EA E2 20 E1 E2 E0 F2 E0 21;
- б) двоичным кодом — 10001111 11011000 11010010 11101110 11100100 11101010 11100010 00100000 11100001 1100010 11100000 11110010 11100000 00100001;
- в) десятичным кодом — 143 216 210 238 228 202 32 177 194 192 242 224 33.
- Представьте в кодировке КОИ-8 текст «Дело в шляпе!»:
- а) шестнадцатеричным кодом — 44 65 6C 6F 20 77 20 E8 6C 7A 61 70 65 21;
- б) двоичным кодом — 01000100 01100101 01101100 01101111 00100000 01110111 00100000 11101000 01101100 01111010 01100001 01110000 01100101 00100001;
- в) десятичным кодом — 68 101 108 111 32 119 111 232 108 122 97 112 101 33.
Содержание файла в современном текстовом процессоре[править | править код]
- Что является содержимым файла, созданного в современном текстовом процессоре?
Содержимое файла, созданного в современном текстовом процессоре, зависит от выбранного типа файла. Большинство текстовых процессоров поддерживают следующие типы файлов: текстовые документы, таблицы, базы данных, презентации, изображения, и прочее. В зависимости от типа файла в нем могут содержаться текстовые данные, изображения, данные базы данных, или мультимедиа.
Расчёты объёма памяти различных кодировок[править | править код]
- В кодировке Unicode на каждый символ отводится 2 байта. Определите в этой кодировке информационный объём следующей строки: Где родился, там и сгодился.
Строка состоит из 34 символов. Так как в кодировке Unicode на каждый символ отводится 2 байта, то общий информационный объём строки составит 68 байт.
- Набранный на компьютере текст содержит 2 страницы. На каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём текста в кодировке Unicode, в которой каждый символ кодируется 16 битами.
В данном случае информационный объем текста составит 2 страницы * 32 строки * 64 символа * 16 бит = 65536 бит, что в свою очередь равно 8192 байтам (1 байт = 8 бит).
Это обусловлено тем, что каждый символ в Unicode кодируется 16 битами. Следовательно, информационный объем текста в данной кодировке равен количеству символов в тексте, умноженному на 16 бит.
- Текст на русском языке, первоначально записанный в 8-битовом коде Windows, был перекодирован в 16-битную кодировку Unicode. Известно, что этот текст был распечатан на 128 страницах, каждая из которых содержала 32 строки по 64 символа в каждой строке. Каков информационный объём этого текста?
Информационный объем текста равен 128 страниц * 32 строки * 64 символам * 2 байта на символ, то есть 167772160 байт. Это примерно 16 мегабайт. Это означает, что он содержит приблизительно 16 мегабайт информации.
В кодировке Unicode используется 2 байта для кодирования каждого символа текста. Для более точного расчета необходимо учитывать и другие факторы, такие как количество пробелов и дефисов, количество различных символов и их повторений.
- В текстовом процессоре MS Word откройте таблицу символов (вкладка Вставка → Символ → Другие символы): (рисунок). В поле Шрифт установите Times New Roman, в поле из — кириллица (дес.). Вводя в поле Код знака десятичные коды символов, декодируйте сообщение:
| 196 | 238 | 240 | 238 | 227 | 243 | 32 |
|---|---|---|---|---|---|---|
| 238 | 241 | 232 | 235 | 232 | 242 | 32 |
| 232 | 228 | 243 | 249 | 232 | 233 | 46 |
|
|
Этот раздел требует полной доработки. Знаете ответ? Тогда Вы можете помочь проекту!
|
