В Windows Server 2012 появилась новая функция Data Deduplication (Дедупликация данных). Что же такое дедубликация? Дедупликация данных в общем случае – это процедура поиска и удаления дублирующих данных на носителе информации без ущерба для целостности информации. Цель дудупликации – хранить информацию в небольших блоках (32-128 Кб), выявлять одинаковые (дублирующие блоки) и сохранять только одну копию для каждого блока, а блоки-дубликаты заменять ссылками на единственную копию.
Ранее для организации дедупликации приходилось использовать сторонние продукты (существуют как аппаратные решение по дедупликации на уровне дисковых массивов, так и программные на уровне файлов). Стоимость подобных решений была достаточно высока, ведь они в первую очередь ориентированы на богатых корпоративных заказчиков. Теперь эта функция абсолютно бесплатно доступна всем пользователям a Windows Server 2012.
Есть небольшой хак, позволяющий включить дедупликацию и в клиентских ОС (Windows 8 и Windows 8.1).
В Windows Server 2012 функция дедупликация реализована в виде двух компонентов:
- Драйвера–фильтра, который контролирует функции ввода/вывода
- Службы дедупликации – контролирует три операции («Сборка мусора», «Оптимизация» и «Очистка»).
Указанные компоненты отвечают за поиск совпадающих данных, организации их хранения в единственном числе и корректное предоставление к ним доступа.
Ранее дедупликация в продуктах Microsoft встречалась в почтовом сервер Exchange 200/2003/2007 – в компоненте Single Instance Storage (на сервере в ящике одного из адресатов хранится только один экземпляр сообщения, а остальные адресаты получают просто ссылку на него).
Дедупликация данных в Windows Server 2012 выполняется в фоновом режиме и по-умолчанию запускается каждый час. Процесс запускается при низкой нагрузке на сервер и не снижает общую производительность сервера. Также по-умолчанию дедупликации подвергаются файлы, к которым не было доступа более 30 дней. Кроме того, процедура не осуществляется для следующих типов файлов:: aac, aif, aiff, asf, asx, au, avi, flac, jpeg, m3u, mid, midi, mov, mp1, mp2, mp3, mp4, mpa, mpe, mpeg, mpeg2, mpeg3, mpg, ogg, qt, qtw, ram, rm, rmi, rmvb, snd, swf, vob, wav, wax, wma, wmv, wvx, accdb, accde, accdr, accdt, docm, docx, dotm, dotx, pptm, potm, potx, ppam, ppsx, pptx, sldx, sldm, thmx, xlsx, xlsm, xltx, xltm, xlsb, xlam, xll, ace, arc, arj, bhx, b2, cab, gz, gzip, hpk, hqx, jar, lha, lzh, lzx, pak, pit, rar, sea, sit, sqz, tgz, uu, uue, z, zip, zoo.
Функционал управления дедупликацей доступен из графического интерфейса и через PowerShell. Рассмотрим оба варианта.
Windows Server 2012 Data Deduplication GUI
Чтобы включить дедупликацию данных нужно установить компонент Data Deduplicaion роли File and Storage Services. Сделать это можно из консоли Server Manahger.

После окончания установки компонента откройте консоль Server manager -> File and Storage Servcies -> Volumes –> и щелкните правой кнопкой по разделу, для которого хотите включить дедупликацию и выберите Configure Data Deduplication.

В следующем окне поставьте галочку на пункт “Enable data deduplication”. Здесь же можно указать каталоги, которые не нужно дедуплицировать и настройки планировщика дедупликации.
Текущий уровень дедупликации будет отображаться в столбце Deduplication Rate (обновится через несколько часов).
Для анализа использования дискового пространства и возможной экономии от включения дедупликаций для данного тома, разработана утилита DDPEVAL.exe. Оценить, сколько же дискового пространства получится сэкономить после включении Data deduplication, можно с помощью следующей команды (учтите, для больших томов она может создать существенную нагрузку на CPU)
c:windowssystem32ddpeval.exe e:
В моем случае экономия составила бы порядка 57%.
Дедупликация с Powershell
Процессом дедупликации можно управлять и из Powershell. Для этого нужно установить функцию Data-Deduplicationс помощью команд:
Import-Module ServerManager
Add-WindowsFeature -name FS-Data-Deduplication
Import-Module Deduplication
После того, как функция дедупликации включена, ее нужно сконфигурировать. Чтобы включить дедуплликацию для диска D:, выполним команду:
Enable-DedupVolume D:

По-умолчаию дедупликации подвергаются файлы, к которым не было доступа (Last Access)более 30 дней. Это значение можно изменить, например, на 2 дня, для этого выполните команду:
Set-DedupVolume D: -MinimumFileAgeDays 2
Обычно процесс дедупликации запускается планировщиком Windows, но его можно запустить и вручную:
Start-DedupJob D: –Type Optimization
Текущую статистику можно посмотреть с помощью команды:
Get-DedupStatus

Со списком текущих заданий можно познакомится с помощью команды:
Get-DedupJob
Все результаты работы для тома можно отобразить командой PoSH:
Get-DedupMetadata -Volume D:
И, наконец, полностью отменить дедупликацию для тома можно командой:
Start-DedupJob -Volume D: -Type Unoptimization
На скриншоте ниже видно, что после включения дедупликации на диске E: (для теста я сложил на него 4 одинаковых ISO с Windows 8), размер занятого места на диске уменьшился с 12 Гб до 3Гб. 
Служба дедупликации хранит свою базу и дедуплицированные чанки в каталоге System Volume Information. Поэтому ни в коем случае не стоит вручную вмешиваться в его структуру.
Рекомендации по использованию технологии Data Deduplication в Windows Server 2012
Microsoft опубликовала следующие результаты исследования эффективности при дудупликации различных типов данных.
| Типы данных | Возможная экономия места |
| Общие данные | 50-60% |
| Документы | 30-50% |
| Библиотека приложений | 70-80% |
| Библиотека VHD(X) | 80-95% |
Основные особенности Data Deduplication в Windows Server 2012:
- Работает только на NTFS томах и не подерживает файловую систему ReFS
- Не поддерживается для загрузочных и системных томов
- Не работает со сжатыми и шифрованными файлами NTFS
- Поддерживает кеширование и BITS
- Не поддерживает файлы меньше 32KB
- Не настраивается через групповые политики
- Не поддерживает Cluster Shared Volumes
- Дедупликация – процесс не мгновенный и требует определённого времени
Продолжаем раскапывать новые фичи Windows Server 2012. Сегодня речь пойдет о технологии дедупликации данных (data deduplication). В общем случае дедупликация — это поиск и удаление дублирующихся данных. Найденные копии данных удаляются и заменяются ссылками на оригинал, что позволяет хранить только уникальный контент и высвобождает дисковое пространство. Цель дедупликации заключается в том, чтобы разместить большее количество данных на меньшем пространстве.
Описание
Дедупликация бывает разная — на уровне файлов, блоков данных и даже на битовом уровне. В Windows Server 2012 используется блочная дедупликация. Файлы разбиваются на небольшие блоки различного размера (32–128 КБ), определяются дублирующие блоки и сохраняется одна копия каждого блока. Избыточные копии блока заменяются ссылками на эту единственную копию. Блоки организуются в файлы-контейнеры, которые могут сжиматься для дальнейшей оптимизации использования пространства, и помещаются в хранилище блоков.
Для примера предположим, у нас есть два файла — File1 и File2. В исходном состоянии они содержат метаданные (имя файла, аттрибуты и т.п.) и сами данные.

После дедупликации данные из File1 и File2 удаляются и заменяются заглушками, указывающими на соответствующие блоки данных, хранящиеся в общем хранилище блоков. Так как блоки A, B и C одинаковы для обоих файлов, они хранятся в единственной копии, что снижает объем дискового пространства, необходимый для хранения обоих файлов.
Во время доступа к одному из файлов соответствующие блоки собираются вместе. При этом пользователь или приложение работают с файлом как и раньше, не подозревая о том, что файл был подвергнут преобразованиям. Это позволяет применять дедупликацию, не беспокоясь о ее влиянии на поведение приложений или доступ пользователей к файлу.

Таким образом, после включения дедупликации тома и оптимизации данных том содержит:
• Оптимизированные файлы (файлы точек повторного анализа) которые содержат указатели на соответствующие блоки данных в хранилище блоков, необходимые для построения исходного файла;
• Хранилище блоков (данные оптимизированных файлов);
• Неоптимизированные файлы (т. е. пропущенные файлы, например файлы состояния системы, зашифрованные файлы, файлы с дополнительными атрибутами или файлы размером менее 32 КБ);
Планирование
Дедупликация может значительно снизить потребляемое дисковое пространство (на 50-90% и более), но только при правильном планировании. Поэтому при выборе объекта для дедупликации следует учитывать некоторые моменты.
Тип данных
Эффективность дедупликации очень сильно зависит от типа данных. Так мультимедийные файлы (фотографии, музыка, видео) практически не содержат повторяющихся данных, поэтому их дедупликация не даст большой экономии. В то же время файлы виртуальных машин (VHD) замечательно дедуплицируются и на них экономия может составлять до 95 %. По этой причине перед включением дедупликации рекомендуется выполнить предварительную оценку данных на предмет дедуплицируемости 🙂
Частота изменения файлов
Файлы, которые часто изменяются и к которым часто обращаются пользователи или приложения, не очень подходят для дедупликации. Постоянный доступ к данным и их изменение скорее всего сведут на нет все результаты дедупликации и могут просто не дать дедупликации возможности обработать файлы. Проще говоря, для дедупликации хорошо подойдут данные, которые часто читают, но редко изменяют.
Загруженность сервера
Во время дедупликации выполняется чтение, обработка и запись большого объема данных. Этот процесс потребляет ресурсы сервера, что необходимо учитывать при планировании развертывания. Как правило, сервера имеют периоды высокой и низкой активности. Большую часть дедупликации можно выполнить, когда ресурсы доступны. Постоянно высоконагруженные сервера не рекомендуется использовать для дедупликации.
Не рекомендуется выполнять дедупликацию файлов, которые открыты, постоянно изменяются в течение продолжительного периода времени либо имеют высокие требования ввода/вывода, например файлы работающих виртуальных машин, динамических баз данных SQL или активных сеансов VDI. Дело в том, что при дедупликации не выполняется обработка файлов, открытых постоянно в монопольном режиме для записи. Это значит, что дедупликация не будет проведена до тех пор, пока файл не будет закрыт. Только тогда задание оптимизации выполнит попытку обработать файл, отвечающий выбранным параметрам политики дедупликации.
В принципе дедупликацию можно настроить на обработку постоянно изменяющихся файлов. Но в этом случае возможна ситуация, когда процесс оптимизации не сможет получить доступ к этим файлам и пропустит их обработку. Не стоит тратить ресурсы сервера на дедупликацию файлов, в которые постоянно записываются новые данные.
Приведу рекомендации Microsoft. Для дедупликации:
Не рекомендуется
- Сервера Hyper-V;
- VHD-файлы запущенных виртуальных машин;
- Службы WSUS;
- Сервера SQL и Exchange;
- Любые файлы, размер которых равен или больше 1 Тб.
Рекомендуется:
- Файловые ресурсы общего доступа (общие папки, профили и домашние папки пользователей, прочие файлопомойки);
- Развертывание программных продуктов (бинарники, образа дисков и обновления ПО);
- Библиотеки виртуализации (VHD-диски);
- Тома архивов SQL и Exchange.
Надо сказать, что рекомендации Microsoft часто противоречат друг другу, поэтому не стоит их безоговорочно принимать на веру. В любом случае перед включением дедупликации необходим тщательный анализ.
Для определения ожидаемой экономии в результате включения дедупликации можно использовать средство оценки дедупликации Ddpeval.exe. После установки компонента дедупликации утилита Ddpeval.exe автоматически устанавливается в папку WindowsSystem32. Кстати, ее можно просто скопировать из любой установки Windows Server 2012 и запустить в системах Windows 7, Windows 8 или Windows Server 2008 R2.
Синтаксис у программы проще некуда, пишем Ddpeval.exe и указываем путь. В качестве пути можно указать локальный диск, папку или сетевую шару:
Ddpeval.exe E:
Ddpeval E:Test
Ddpeval.exe \ServerShare
Программа выдаст ожидаемый размер экономии дискового пространства, после чего уже можно принимать решение — включать дедупликацию или нет.

Системные требования
Дедупликация предъявляет к системе некоторые требования.
Тома
• Тома, предназначенные для дедупликации не должны быть системными или загрузочными. Дедупликация не поддерживается для томов операционной системы;
• Тома могут быть разбиты под MBR или GPT и отформатированы в NTFS. Новая отказоустойчивая файловая система ReFS не поддерживается;
• Тома могут находиться на локальных дисках либо в общедоступном хранилище (SAS, iSCSI или Fibre Channel);
• Windows должна видеть тома как несъемные диски. Сетевые диски и съемные носители не поддерживаются;
• Нельзя включать дедупликацию для общих томов кластера (Claster Shared Volume, CSV). Если дедуплицированный том преобразовать в CSV, то доступ к данным останется, но задания дедупликации не смогут отработать;
Аппаратные ресурсы
• Оборудование серверов должно отвечать минимальным требованиям Windows Server 2012. Функция дедупликации разработана для поддержки минимальных конфигураций, таких как система с одним процессором, 4 ГБ ОЗУ и одним жестким диском SATA;
• Сервер должен иметь одно процессорное ядро и 350 МБ свободной памяти для выполнения задания дедупликации на одном томе, при этом будет обрабатываться около 1,5 ТБ данных в день. Если планируется поддерживать дедупликацию в нескольких томах на одном сервере, необходимо соответствующим образом увеличить производительность системы, чтобы гарантировать, что она сможет обрабатывать данные.
• Функция дедупликации поддерживает одновременную обработку до 90 томов, однако при дедупликации одновременно может обрабатываться один том на физическое процессорное ядро плюс один. Применение технологии Hyper-Threading не влияет на этот процесс, поскольку для обработки тома можно использовать только физические ядра. К примеру сервер с 16 процессорными ядрами и 90 томами будет обрабатывать по 17 томов одновременно, пока не обработает все 90 томов;
• К виртуальным серверам применяются те же правила, что и к физическому оборудованию в отношении ресурсов сервера.
Общие требования
• Наличие свободного места на диске. При отсутствии дискового пространства на дедуплицированном томе некоторые приложения не смогут получить доступ к данным и будут завершены с ошибкой. Необходимо сохранять, по крайней мере, один гигабайт свободного места на дедуплицированном томе;
• Жесткие квоты. При использовании FSRM (File System Resource Managet) не поддерживается установка жестких квот на объем тома. Когда для тома установлены жесткие квоты, фактический объем свободного места на томе и ограниченное квотами пространство отличается, что может привести к неудаче процесса дедупликации. Все другие FSRM-квоты, в том числе мягкие квоты на объем тома и квоты на подпапки, будут нормально работать при дедупликации;
• Файлы с дополнительными атрибутами, зашифрованные файлы, файлы размером меньше 32 КБ и файлы точек повторного анализа при дедупликации не обрабатываются.
Установка и настройка
Для включения дедупликации можно воспользоваться диспетчером сервера (Server Manager). Запускаем его и открываем пункт «Add roles and features».

В ролях сервера отмечаем пункт «Data Deduplication», соглашаемся на установку необходимых компонентов и жмем Install.

Затем все в том же Server Manager идем в «File and Storage Services» -> «Volumes» и выбираем диск, который планируется оптимизировать. Напоминаю, что дедупликацию можно включить для логического диска, или тома (Volume). Кликаем на выбраном томе и в контекстном меню выбираем пункт «Configure Data Deduplication».

В открывшемся окне включаем дедупликацию для выбранного тома. Также можно произвести некоторые настройки:
• Указать количество дней, прошедших с последнего изменения файла, после которых файл можно оптимизировать. Как я уже говорил, для дедупликации лучше подходят редко изменяемые файлы, поэтому период по умолчанию составляет 5 дней. Для часто изменяющихся файлов период можно уменьшить до 1-2 дней, а если задать значение 0, дедупликация будет выполняться для всех файлов вне зависимости от их срока существования.
• Исключить из процесса дедупликации отдельные файлы (по расширениям) или целые папки. Кстати, Microsoft почему то не рекомендует этого делать.

Нажав на кнопку «Set Deduplication Shedule» мы попадаем в окно настройки расписания запуска оптимизации. По умолчанию файлы обрабатываются внутри активного тома один раз в час в режиме фоновой (background) оптимизации. Дополнительно можем включить производительную (throughput) оптимизацию и настроить для нее основное и дополнительное расписание. Например, можно запланировать производительную оптимизацию на часы минимальной активности сервера.

Из консоли PowerShel можно сделать все то же самое (и даже больше) гораздо быстрее. Установка фичи:
Install-WindowsFeature -Name FS-Data-Deduplication
Включение дедупликации c дефолтными настройками на выбраном томе:
Enable-DedupVolume -Volume E:

Для настройки есть командлет Set-DedupVolume. С его помощью можно настроить гораздо больше параметров, чем из графического интерфейса:
-MinimumFileSize — минимальный размер файла (в байтах) для дедупликации. По умолчанию составляет 32 КБ. Уменьшить это значение нельзя, но можно увеличить.
-NoCompress — указывает, надо ли сжимать данные после дедупликации ($True — не сжимать, $False — сжимать). Сжатие освобождает дисковое пространство, но задействует дополнительные ресурсы процессора. По умолчанию сжатие включено.
-NoCompressionFileType — указываем типы файлов, которые не надо сжимать. Это значит, что файлы будут дедуплицированы, но не сжаты, например потому что их формат уже предполагает сжатие. По умолчанию в эту группу включены все аудио, видео файлы, изображения, архивные файлы и файлы MS Office нового формата (.docx, .xlsx и т.д.).
-ChunkRedundancyThreshold — если я правильно понял, то он указывает количество ссылок на блок данных в активной зоне, при котором этот блок необходимо продублировать. По умолчанию этот параметр равен 100, при его уменьшении количество дублирующих блоков увеличиться и соответственно понизится эффективность дедупликации. В общем, лучше не трогать.
Для примера выставим минимальный возраст файлов 2 дня, минимальный размер 64КБ и отключим сжатие на диске E командой:
Set-DedupVolume -Volume E: -MinimumFileAgeDays 2 -MinimumFileSize 65536
-NoCompress $true

Задания дедупликации
Дедупликация включает в себя три функции, которые выполняются в виде запланированных заданий — оптимизация, очистка данных и сбор мусора.
Фоновая оптимизация (Background Optimization) — режим по умолчанию. В этом режиме процесс оптимизации файлов запускается в фоновом режиме с регулярностью раз в 1 час. Процесс работает с низким приоритетом, потребляя не более 25% системной памяти. Подобный режим запуска позволяет максимально экономить ресурсы сервера и выполнять оптимизацию только при отсутствии нагрузки. Если ресурсы для выполнения задания оптимизации окажутся недоступны без влияния на рабочую нагрузку сервера, то задание будет остановлено.
Производительная оптимизация (Throughput Optimization) — может использоваться дополнительно, вместе с фоновой. Производительная оптимизация запускается ежедневно в указанное время, с нормальным приоритетом и отрабатывает вне зависимости от того, есть ли у сервера свободные ресурсы или нет. Можно запланировать ее на часы низкой активности сервера для ускорения процесса оптимизации.

Очистка данных (Scrubbing) — встроенная функция целостности данных, выполняющая проверку контрольных сумм и согласованности метаданных. Также имеется встроенная избыточность для критических метаданных и наиболее популярных блоков данных. Когда выполняется доступ к данным или обработка данных в заданиях, эта функция обнаруживает повреждения и регистрирует их в журнале. Очистка используется для анализа повреждения хранилища блоков и, по возможности, для выполнения восстановления.

Для восстановления поврежденных данных можно использовать три источника:
1) Дедупликация создает резервные копии популярных блоков. Популярность определяется количеством ссылок на них в области, которую называют активной зоной. Если рабочая копия повреждена, средство дедупликации будет использовать резервную;
2) При использовании дисков в зеркальной конфигурации дедупликация может использовать зеркальный образ избыточного блока для обслуживания операций ввода-вывода и устранения повреждения;
3) Если обрабатывается файл с поврежденным блоком, то поврежденный блок исключается и для устранения повреждения используется новый входящий блок.
Очистка целостности данных проводится еженедельно, при этом инициируется задание, которое пытается выполнить восстановление всех повреждений, занесенных во внутренний журнал повреждений дедупликации во время операций ввода-вывода с файлами дедупликации. По необходимости очистку можно запустить вручную командой PowerShell:
Start-DedupJob E: –Type Scrubbing
Чтобы проверить целостность всех дедуплицированных данных в томе, используйте параметр -full. Этот параметр, называемый также глубокой очисткой, задает очистку всего набора дедуплицированных данных и поиск всех повреждений, приводящих к отказам в доступе к данным.
Сбор мусора (Garbage Collection) — обработка удаленных или измененных данных, т.е. удаление все блоков данных, на которые больше нет ссылок. Когда оптимизированный файл удаляется или переписывается новыми данными, старые данные в хранилище блоков не удаляются немедленно. Задания сбора мусора обрабатывают ранее удаленное или перезаписанное содержимое, чтобы освободить место на диске.

Операция сбора мусора также выполняется еженедельно. Она удаляет блоки, на которые нет ссылок, и сжимает контейнеры, содержащие более 5 % данных, на которые нет ссылок. Во время каждой десятой сборки мусора используется параметр /Full, который запускает задание по освобождению всего доступного пространства и максимально сжимает весь контейнер. Процесс сбора мусора связан с интенсивной обработкой данных, поэтому его надо либо запланировать на нерабочие часы, либо запускать вручную и отслеживать нагрузку. Сделать это можно командой:
Start-DedupJob E: –Type GarbageCollection
А если добавить ключ –full, то задание будет сжимать все контейнеры максимально возможным образом.
Задания дедупликации можно настроить в Server Manager (только оптимизацию), с помощью командлета Set-DedupShedule или в планировщике заданий, в разделе MicrosoftWindowsDeduplication. Кстати, дедупликация поддерживает только планирование недельных заданий. Если требуется создать расписание на любой другой временной период, то используйте планировщик заданий Windows. Имейте в виду, что вы не сможете просматривать расписания пользовательских заданий, созданных или измененных в планировщике заданий, с помощью командлета Get-DedupSchedule.

В принципе настройки расписания по умолчанию должны удовлетворять большинство конфигураций сервера. Однако в определенных ситуациях может потребоваться ускорение дедупликации. Например, при большом объеме входящих данных для ускорения процесса стоит добавить дополнительные задания оптимизации. Или если данные быстро удаляются и требуется возвращать свободный объем максимально оперативно, то необходимо добавить дополнительные задания сбора мусора.
Мониторинг результатов
Основные результаты дедупликации для конкретного тома можно увидеть, открыв его свойства в Server Manager. Здесь показано общее количество сэкономленного пространства и процент оптимизации. Как видите, в моем случае сжатие 76%, а экономия составила почти 32ГБ. Очень неплохо.

Несколько больше информации выдаст команда Get-DedupVolume E: | fl

Посмотреть, когда и с каким результатом прошла последняя оптимизация можно командой:
Get-DedupStatus -Volume E: | fl

Ну и подробные данные (размер хранилища блоков, средний размер блока и т.п.) покажет командлет Get-DedupMetadata.

На этом пожалуй закончу обзор. Все, что в него не уместилось можно посмотреть на Technet, лучше в оригинале (перевод ужасный). В качестве заключения скажу, что на мой взгляд дедупликация — фича интересная, но довольно неоднозначная и требующая правильного подхода и планирования.
Всем доброго времени суток!
Сегодня хотелось бы провести обзор такой интересной новой фичи в Windows Server 2012 как дедупликация данных (data deduplication). Фича крайне интересная, но все же сначала нужно разобраться насколько она нужна…

А нужна ли вообще деупликация?
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей вселенной и на нашей планете, то практически все в этом мире имеет свойство подчиняться 3-му закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространства постоянно растут и тем самым нивелируют увеличение объем и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.

И вот тут как раз вопрос о дедупликации данных очень сильно становится актуальным. Ведь данные, которые мы используем бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент, фича серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд так оно будет нагляднее.
1) Файловая дедупликация — как и любой механизм дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, где вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и кажется будет продолжать это делать. Как нетрудно догадаться — файловый уровень самый высокий (если вспомнить устройство систем хранения данных в общем) — а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном применяется данный тип дедупликации к архивным данным.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но на уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскроют свои таланты.
Очень интересным в этом плане выглядит доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
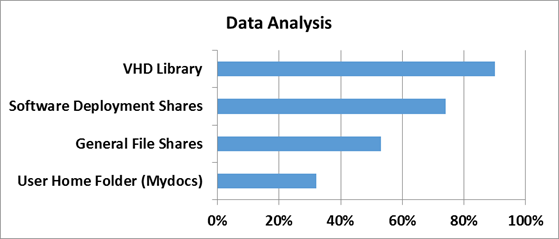
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:
1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно изменение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.

А теперь самое интересное — ниже приведен скриншот с томами в Windows Server 2012, на которых размещаются все эти данные.
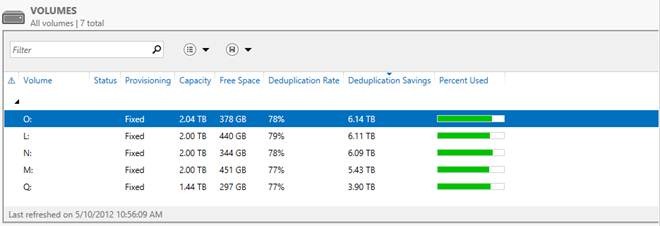
Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
1) Прозрачность и легкость в использовании — настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрывайте роль File and Storage Services, далее File and iSCSI Services — а у же там включаете опцию Data Deduplication.
После этого в Server Manager вы выбираете Fike and Storage Services, клик правой кнопкой мыши — и там вы выбираете пункт «Enable Volume Deduplication». Спешл линк для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы — то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома защищенные с помощью EFS (Encrypted Fike System). Также под дедупликацию не попадают фалы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).
2) Оптимизация под основные данные — стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен 5 дням, но никто не мешает вам изменить этот параметр — но будьте разумны в своих экспериментах!
3) Планирование процессов оптимизации — механизм который каждый час проверяет файлы на соответствия параметрам дедупликации и добавляет их в расписание.
4) Механизмы исключения объектов из области дедупликации — данный механизм позволяет исключит файлы из области дедупликации по их типу (JPG, MOV, AVI — как пример, это потоковые данны — то, что меньше всего поддается дедупликации — если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
5) Мобильность — дедуплицированный том — это целостный объект — его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Все что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
6) Оптимизация ресурсоемкости — данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом применять дедупликацию можно даже к очень массивным наборам данных.
Также алгоритм всегда проверяет достаточно ли ресурсов памяти для проведения процесса дедупликации — если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.
7) Интеграция с BranchCache — механизмы индексация для дедупликация являются общими также и для BranchCache — поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
1) Резервное копирование — Windows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома, с точки зрения процессов резервного копирования. Также доступно специальное API, которое позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
После установки дедупликации вы можете найти инструмент под названием DDPEval.exe, который находится в WindowsSystem32 — данная утиль может быть портирована на сменный носитель или другой том. Поддерживаются ОС Windows 7 и выше. Так что вы можете проанализировать ваши данный и понять стоимость овечье шкурки. (смайл).
На этом мой обзор завершен. Надеюсь вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях — ВКонтакте, Facebook — по имени и фамилии — и я постараюсь вам помочь.
Для тех, кто хочет узнать про новые возможности в Windows Server 2012, а также System Center 2012 SP1 — я всех приглашаю посетить IT Camp — 26 ноября, накануне TechEd Russia 2012 состоится данное мероприятие — проводить его будем я, Георгий Гаджиев и Саймон Перриман, который специально прилетает к нам из США.
До встречи на IT Camp и на TechEd!
С уважением,
человек-огонь
Георгий А. Гаджиев
Microsoft Corporation
Disk / Data Deduplication is a feature new to Windows in Server 2012 and has recently been improved in Server 2012 R2. Data Deduplication is based on the idea that if you have multiple copies of the same file you can only actually write one to disk and then just provide pointers to the copy.
Contents
- Install and enable Data Deduplication in GUI
- Enable Data Deduplication with Powershell
- Author
- Recent Posts

Jim Jones has been a SysAdmin for 15 years and is currently working as a Sr. Network Administrator in West Virginia, USA. Honored to be elected a vExpert and Veeam Vanguard, Jim can be found on Twitter @k00laidIT and at his personal site, koolaid.info.
Server 2012 takes that idea one step further to be able to recognize duplication down to the level of chunks of files (32–128 KB). Further with Windows Server 2012 R2 they have improved the performance of deduplicated volumes to allow them to be a repository for Hyper-V VHDs.
So where does this really help? The use case for this technology is obviously fileservers, specifically those that have large files that aren’t modified very often. In my case, my two biggest usages are for Veeam backup files of my virtual machines and the images within the document retention system. According to Microsoft you can expect to see space savings up to 95% on virtual hard drives, 80 on ISOs and other deployment software and 50% on basic user documents. If you have a mix of all of the above the process can save you between 50-60% of the actual data size.
Install and enable Data Deduplication in GUI
Getting started with Windows Server 2012 R2 disk deduplication is not hard but it does require a few steps. To make this easy here’s a quick run down.
- Enable the Data Deduplication Role under File and Storage Services> File and iSCSI Services.

- Enable Deduplication on a volume under Server Manager > Volumes by right clicking on the volume and choosing “Configure Data Deduplication…”

- Configure the basic settings for the volume in the window that pops up. You can mess with these depending on your particular need, but I recommend not setting the “Deduplicate files older than…” setting any lower than the default of three days. More than that can have a negative impact on your I/O load.

- Finally you can modify the schedule in which deduplication occurs. By default Windows will just allow it to run at low priority and pause when the server is busy. In our environment backups are typically done by midnight so I allow it to run at normal priority between 12 AM and 6 AM in addition to the default.





After you set Data Deduplication up you can easily monitor how it’s doing, although I would probably give it at least a day to process on a mature file server before expecting to see real results. Graphically you can look at the properties either of the volume or any folder contained with it to see how it’s doing by comparing Size versus Size on disk. Know that that will reflect not only deduplication but also any compression you may have turned on as well. As you can see from the screenshot, the results can be rather staggering.

Verfiy Data Deduplication
Further you run Get-DedupeStatus as Administrator from the PowerShell prompt to see the output of just what Data Deduplication is doing for you.
Enable Data Deduplication with Powershell
So you want to do this in a few places at once? The good news is all the configuration above can be done via PowerShell if you would like to script it. The commands below will enable the role, configure Data Deduplication on a mythical volume F:, and configure the Minimum File Age to 5 days. There are other settings possible but these should get you going for most uses.
Import-Module ServerManager Add-WindowsFeature -name FS-Data-Deduplication Import-Module Deduplication Enable-DedupVolume F: Set-Dedupvolume F: -MinimumFileAgeDays 5
For more information regarding when and where to use Data Deduplication Technet has a pretty good read on the subject.
 Новые версии серверных ОС от Microsoft, кроме спорного интерфейса, содержат большое количество новых возможностей, многие из которых раннее были доступны только крупным предприятиям и требовали значительных финансовых затрат. Одна из таких возможностей — дедупликация, технология позволяющая по новому посмотреть на использование уже существующих систем хранения для предприятий любого масштаба.
Новые версии серверных ОС от Microsoft, кроме спорного интерфейса, содержат большое количество новых возможностей, многие из которых раннее были доступны только крупным предприятиям и требовали значительных финансовых затрат. Одна из таких возможностей — дедупликация, технология позволяющая по новому посмотреть на использование уже существующих систем хранения для предприятий любого масштаба.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Основная проблема с которой сталкиваются сегодня администраторы систем хранения, это стремительный рост хранимых данных, который требует все нового и нового дискового пространства. А если добавить сюда необходимость хранения резервных копий, архивов и т.п., то проблема рационального использования дискового пространства встает в полный рост.
В тоже время очень многие файлы содержат дублирующуюся информацию, а то и являются практически полными дубликатами. Это характерно для файловых серверов общего назначения, где различные сотрудники могут хранить практически полные или незначительно различающиеся копии одного и того же файла. В хранилищах резервных копий и архивах дублирование информации также может достигать существенных объемов.
Дедупликация позволяет найти одинаковые части файлов и хранить их в единственном экземпляре, заменяя данные ссылкой на дублирующийся блок. Windows Server 2012 разбивает файлы на небольшие блоки (32-128 Кб), находит среди них одинаковые и помещает их в специальное хранилище, избыточные копии блоков заменяются ссылкой на единственный экземпляр в хранилище.
Схематично дедупликацию можно представить следующим образом (одинаковым цветом помечены одинаковые области данных):
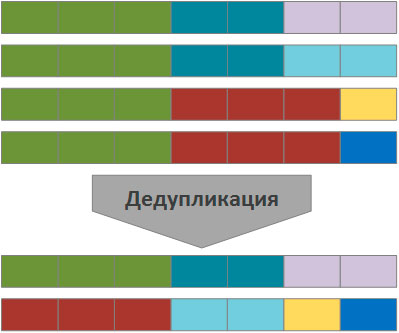 В зависимости от характера хранимой информации результат оптимизации может давать существенный выигрыш в дисковом пространстве, позволяя отложить увеличение емкости системы хранения, а, следовательно дополнительные материальные затраты.
В зависимости от характера хранимой информации результат оптимизации может давать существенный выигрыш в дисковом пространстве, позволяя отложить увеличение емкости системы хранения, а, следовательно дополнительные материальные затраты.
Но данная технология не является панацеей, как нетрудно заметить, наибольший выигрыш будет на больших массивах данных, которые имеют много общих блоков и редко изменяются, для часто меняющихся данных дедупликация не даст никакого эффекта.
Наиболее подходящие кандидаты на дедупликацию:
- Файловые сервера
- Хранилища резервных копий и архивы
- Хранилища инсталляционных файлов и иной информации использующейся преимущественно только для чтения
- Библиотеки образов виртуальных машин
Не рекомендуется использовать дедупликацию для:
- Узлов Hyper-V
- SQL и Exchange серверов
- Служб WSUS
В остальных случаях требуется предварительный анализ и взвешивание всех возможных плюсов и минусов. Из общих рекомендаций: не рекомендуется включать дефрагментацию на томах с интенсивным вводом-выводом.
Также не следует заполнять дедуплицированные тома «под завязку», всегда необходимо иметь резерв на случай одновременного изменения большого объема дедуплицированных данных, чтобы не столкнуться с проблемой нехватки дискового пространства.
В Windows Server 2012 дедупликация поддерживается на уровне тома, в том числе допускается использование томов, расположенных во внешних хранилищах и подключенных по iSCSI. Не допускается дедупликация для системных томов и общих томов кластера (CSV).
Перейдем от теории к практике. Для включения дедупликации откроем Диспетчер серверов — Управление — Добавить роли и компоненты.
 Затем выберем нужный сервер и, развернув роль Файловые службы и службы iSCSI, включим данную опцию. Закончим установку роли, перезагрузка сервера не потребуется.
Затем выберем нужный сервер и, развернув роль Файловые службы и службы iSCSI, включим данную опцию. Закончим установку роли, перезагрузка сервера не потребуется.
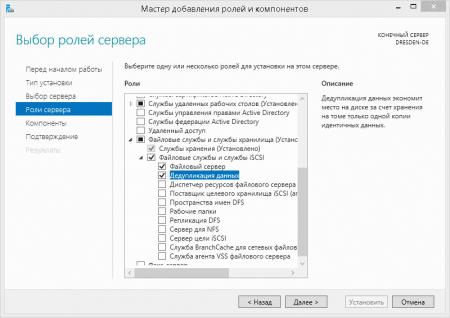 Снова вернемся в Диспетчер серверов, слева выберем Файловые службы и службы хранилища — Тома. Теперь щелкнув правой кнопкой мыши на выбранном томе мы увидим опцию Настройка дедупликации данных.
Снова вернемся в Диспетчер серверов, слева выберем Файловые службы и службы хранилища — Тома. Теперь щелкнув правой кнопкой мыши на выбранном томе мы увидим опцию Настройка дедупликации данных.
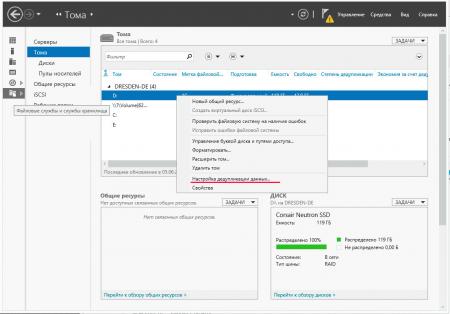 Настройки просты и понятны: выбираем профиль, срок хранения файла для включения его в дедупликацию и исключения, как по расширению, так и по местам хранения. Например, мы исключили из дедупликации временную папку.
Настройки просты и понятны: выбираем профиль, срок хранения файла для включения его в дедупликацию и исключения, как по расширению, так и по местам хранения. Например, мы исключили из дедупликации временную папку.
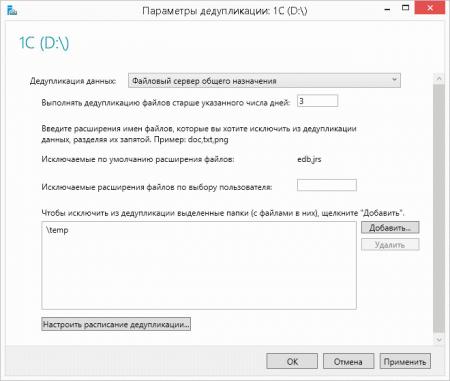 Отдельно стоит остановиться на возрасте файлов, выбирать этот параметр следует исходя из реальных условий, а именно интенсивности изменения данных и их объемов. После того как вы настроите дедупликацию, фоновая оптимизация будет производиться каждый час, поэтому если данные в течении этого времени будут активно изменяться, то система будет постоянно выполнять пустую работу. Слишком большие значения могут, наоборот, приводить к неэффективности процесса дедупликации, т.е. будут дублироваться довольно редко изменяемые данные.
Отдельно стоит остановиться на возрасте файлов, выбирать этот параметр следует исходя из реальных условий, а именно интенсивности изменения данных и их объемов. После того как вы настроите дедупликацию, фоновая оптимизация будет производиться каждый час, поэтому если данные в течении этого времени будут активно изменяться, то система будет постоянно выполнять пустую работу. Слишком большие значения могут, наоборот, приводить к неэффективности процесса дедупликации, т.е. будут дублироваться довольно редко изменяемые данные.
Также имеет смысл более детально настроить расписание, чтобы служба дедупликации могла использовать ресурсы системы полностью в нерабочее время или периоды с малой нагрузкой.
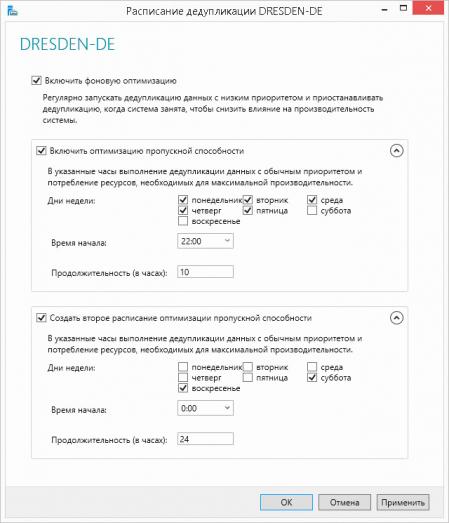 В нашем случае мы настроили два расписания, одно позволяет выделять максимум ресурсов каждую ночь, с 22:00 до 8:00, второе полностью снимает ограничения на выходные.
В нашем случае мы настроили два расписания, одно позволяет выделять максимум ресурсов каждую ночь, с 22:00 до 8:00, второе полностью снимает ограничения на выходные.
В принципе на этом можно закончить, система сама выполнит все необходимые действия и через некоторое время у вас появится возможность оценить эффективность данной технологии применительно к вашей системе хранения. Также можно инициировать процесс дедупликации вручную. При этом стоит учитывать, что дедупликация будет выполняться с обычным приоритетом и правильно оценить необходимое для этого время. Средняя скорость дедупликации — 20 МБ/с или 72 ГБ в час, поэтому на больших объемах данных данный процесс может занять весьма продолжительное время.
Если вы используете дедупликацию для томов во внешнем хранилище, то также следует принять во внимание загрузку сети. Ниже показана сетевая активность при дедупликации iSCSI диска:
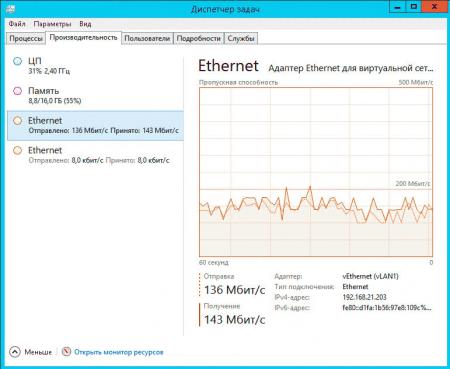 Если принять среднюю скорость за 150 Мбит/с, то получим скорость дедупликации 18,75 МБ/с, что соответствует заявленным Microsoft значениям.
Если принять среднюю скорость за 150 Мбит/с, то получим скорость дедупликации 18,75 МБ/с, что соответствует заявленным Microsoft значениям.
Для запуска процесса дедупликации откройте консоль PowerShell и выполните команду (указав букву необходимого тома, в нашем случае это D:):
Start-DedupJob -Volume D: -Type OptimizationКонтролировать ход выполнения задания можно командой:
Get-DedupStatus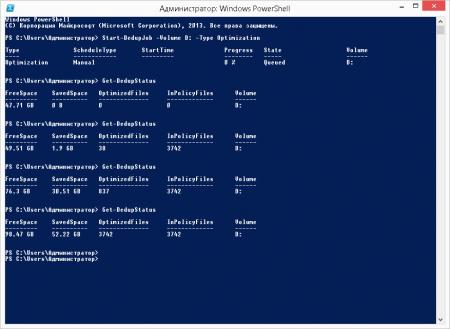 Теперь самое время оценить эффективность данной технологии. В нашем случае целью дедупликации был том на SSD диске терминального сервера, хранящий информационные базы 1С:Предприятия. Так как данная организация предоставляет аутсорсинговые услуги по ведению бухгалтерского учета для небольших фирм, то имеется большое количество однотипных баз (около 40 баз Бухгалтерии 3.0 и примерно столько же Камина). В тоже время работа с базами не отличается особой интенсивностью: единицы-десятки документов в день.
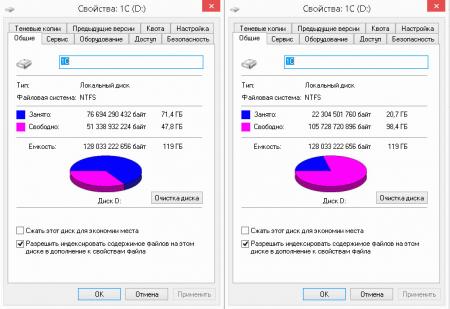
Теперь самое время оценить эффективность данной технологии. В нашем случае целью дедупликации был том на SSD диске терминального сервера, хранящий информационные базы 1С:Предприятия. Так как данная организация предоставляет аутсорсинговые услуги по ведению бухгалтерского учета для небольших фирм, то имеется большое количество однотипных баз (около 40 баз Бухгалтерии 3.0 и примерно столько же Камина). В тоже время работа с базами не отличается особой интенсивностью: единицы-десятки документов в день.
Взвесив все за и против, мы пришли к решению, что дедупликация существенно не повлияет на производительность, но в тоже время поможет более оптимально использовать дорогостоящую емкость SSD диска. И мы не ошиблись, результат говорит сам за себя:
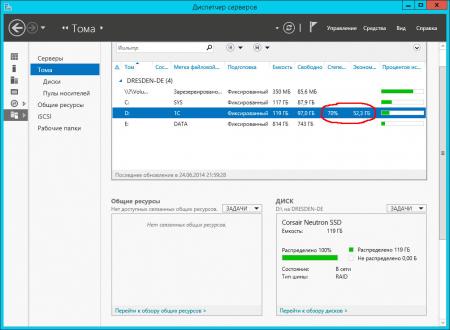
 Также эффективность дедупликации можно оценить открыв оснастку Тома в Диспетчере серверов.
Также эффективность дедупликации можно оценить открыв оснастку Тома в Диспетчере серверов.
 Степень дедупликации сильно зависит от характера данных, ниже показаны результаты для хранилища резервных копий виртуальных машин Hyper-V:
Степень дедупликации сильно зависит от характера данных, ниже показаны результаты для хранилища резервных копий виртуальных машин Hyper-V:
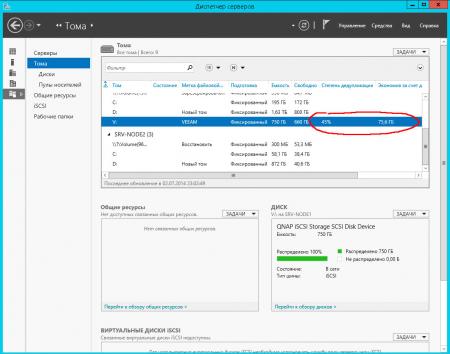 И файлового сервера общего назначения:
И файлового сервера общего назначения:
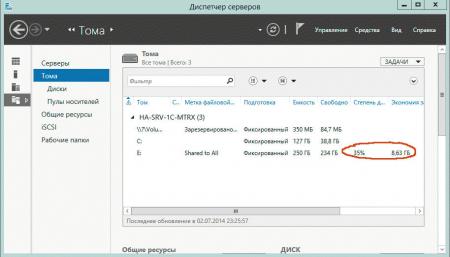 В любом случае результат можно назвать неплохим, так как даже 30-40% экономия в масштабах предприятия позволяет предотвратить вполне ощутимые затраты по наращиванию емкости системы хранения. Также дедупликацию можно рассматривать как серьезный аргумент к переходу на новое семейство серверных операционных систем от Microsoft.
В любом случае результат можно назвать неплохим, так как даже 30-40% экономия в масштабах предприятия позволяет предотвратить вполне ощутимые затраты по наращиванию емкости системы хранения. Также дедупликацию можно рассматривать как серьезный аргумент к переходу на новое семейство серверных операционных систем от Microsoft.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Дата: 03.06.2016 Автор Admin
В данной статье я расскажу как легко и быстро можно настроить дедупликацию через Powershell.
1) Устанавливаем роль дедупликации.
|
Import-Module ServerManager Add-WindowsFeature -name FS-Data-Deduplication Import-Module Deduplication |
2) Включаем дедупликацию. В данном случае на диске E
|
Enable-DedupVolume E: -UsageType Default |
Если вы планируете дедуплицировать хранилище дисков виртуальных машин Hyper-v, используйте следующую команду:
|
Enable-DedupVolume E: -UsageType HyperV |
3) Задаем минимальное количество дней, после которых выполняется дедупликация файлов
|
Set-Dedupvolume E: -MinimumFileAgeDays 20 |
Если необходимо дедупликацировать файлы сразу и вам необходима максимальная дедупликация установите значение 0
4) Добавляем каталог, который не нужно дедупликацировать (если необходимо)
|
Set-DedupVolume –Volume «E:» -ExcludeFolder «E:temp» |
5) Устанавливаем минимальный размер файла
|
Set-DedupVolume –Volume «E:» -MinimumFileSize «32768» |
6) Отключаем дедупликацию используемых файлов
|
Set-DedupVolume –Volume «E:» -OptimizeInUseFiles:$False Set-DedupVolume –Volume «E:» -OptimizePartialFiles:$False |
Для просмотра текущих запущенных заданий дедупликации выполните команду:
Для просмотра существующих заданий используйте команду:
Если вы хотите добавить новое задание используйте команду — New-DedupSchedule
Ниже пример как добавить задание оптимизации:
|
New-DedupSchedule –Name «ThroughputOptimization» –Type Optimization –Days on,Tues,Wed,Thurs,Fri,Sunday –Start 00:00 –DurationHours 8 -Priority Normal |
Теперь разберем этот пример
–Name — имя нового задания
–Type тип задания (Optimization/GarbageCollection/Scrubbing)
Scrubbing — восстановление поврежденных данных
GarbageCollection — сборка мусора (высвобождение места)
Optimization — дедупликация и сжатие данных
–Days дни в которые задание должно запускаться
—Start в какое время
–DurationHours сколько часов может выполняться задание
—Priority приоритет
Для просмотра текущего статуса дедупликации используйте команду:
Вывод будет таким:
Enabled UsageType SavedSpace SavingsRate Volume
——- ——— ———- ———— ——
True Default 76.94 GB 66 % E:
В моем случае дедупликация превратила 65 GB в 354MB.
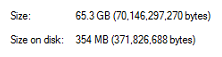
Это очень эффективно! Удачной настройки! =)
Related posts:
Data Deduplication is the best feature in Server 2012/2012 R2. For any shop, it provides a huge benefit for 5 minutes of work! When configured, data deduplication will analyze files for duplicate chunks, remove the duplicate portions, and reference files to a single specially stored copy. This can give you some amazing space savings!
Data deduplication is useful for three main scenarios:
- Folder Redirection/Home Folders/User Share: imagine all of the PDFs that are emailed out and saved into each user’s documents.
- Software Distribution/Application shares: a lot of software share the same components.
- VDI: If you have 100 VMs running the same OS, the disk space saved with data deduplication would be insane! Microsoft saved close to 90% in their environment!
In this guide, we will setup data deduplication and learn some best practices for integration.

Saving 31% on an SCCM distribution point!
How to Configure Data Deduplication in Server 2012/2012 R2
First, data deduplication can not be configured on a system or boot volume. With that out of the way, pick a machine running Server 2012 or higher. In Server Manager, launch the Add Roles and Features Wizard. Under Server Roles, expand File and Storage Services – select the Data Deduplication role and finish the wizard. This role does not require a reboot.

Side note – I love data deduplication so much that I enable this role on nearly every new server with role installations in my Task Sequence.
Select the File and Storage Services node in Server Manager and then select volumes. Right click on data volume and select Configure Data Deduplication…

Configure Data Deduplication on a new volume.
Change the type from disabled to General purpose file server (or check the enable box if you are on Server 2012). Leave the deduplicate files older than setting at the default value. You may want to exclude certain folders/files from deduplication. For example, SCCM 2012 requires a few folders to be excluded.

Excluding folders from Data Deduplication for SCCM 2012
Select Set Deduplication Schedule and check the Enable throughput optimization box. Adjust the duration so that the optimization is outside of your work hours – the server will be taxed while this optimization occurs. Use Server Manager Performance Counters to keep an eye on resources during optimization.
Depending on your server size, it may take a day or two for volumes to be completely optimized. If you are wanting to see results quickly, you have two options:
- Launch DDPEval.exe (ex: ddpeval.exe \Server-01Data). This tool in is the System32 folder on any server with data dedupe installed on it. You can copy this EXE to any 2008R2+ machine to evaluate potential savings.
- Start a dedup job with PowerShell. The following command will dedup volume D and consume up to 50% of the server’s RAM: Start-DedupJob D: -Type Optimization –Memory 50
That wraps up our data deduplication guide. If you wish to learn more, the links below will help:
- TechNet Data Deduplication Overview and Deployment Guides
- Introduction to Data Deduplication
- Hacking the Data Deduplication role into Windows 8.1
Windows Server How-To
How to Use Data Deduplication in Windows Server 2012 R2
Brien Posey shows you how to take advantage of one of Windows Server’s newest tricks.

One of the more useful features of Windows Server 2012 and Windows Server 2012 R2 is native data deduplication. Although deduplication features have existed in storage hardware for years, the release of Windows Server 2012 marks the first time that Microsoft has allowed deduplication to occur at the operating system level.
Before you can use the deduplication feature, you will have to install it. To do so, open Server Manager and then choose the Add Roles and Features command from the Manage menu. When the Add Roles and Features Wizard launches, navigate through the wizard until you reach the Add Roles screen. Expand the File and Storage Services role, and then expand the File and iSCSI Services container and select Data Deduplication, as shown in Figure 1. Click Next on the remaining screens and then click Install to install the necessary components. When the process completes, click Close.
Deduplication is performed on a per-volume basis. To do duplicate a volume, open the Server Manager and select the Volumes container. Next, right click on a volume and choose the Configure Data Deduplication command from the resulting shortcut menu, as shown in Figure 2.
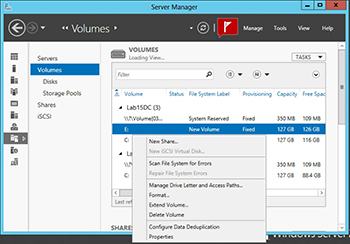
At this point the Deduplication Settings dialog box will appear, as shown in Figure 3. You can enable data deduplication by simply selecting the Enable Data Deduplication check box and clicking OK. However, there are a couple of other settings on this dialog box that are worth paying attention to.
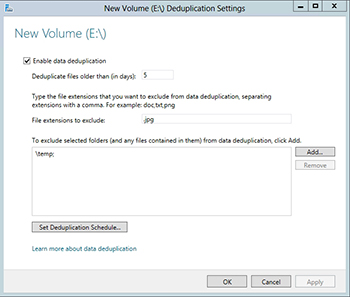
The first such setting is the Duplicate Files Older Than setting. The deduplication mechanism in Windows is post process. In other words, deduplication does not happen in real time. Instead, a scheduled process performs the deduplication at a later time. The reason why Microsoft gives you the option of waiting until a file is a few days old before it is be duplicated is because the deduplication process consumes system resources such as CPU cycles and disk I/O. You really don’t want to waste these resources on deduplicating temporary files. Making sure that a file is at least a few days old before it is deduplicated is a great way to avoid wasting system resources.
Another setting that is worth paying attention to is the File Extensions to Exclude setting. The basic idea behind this setting is that some types of files cannot be deduplicated because they are already compressed. This includes things like zip files, and compressed media files such as MP3 files. The File Extensions to Exclude setting lets you avoid wasting system resources by preventing Windows from trying to do duplicate files that most likely will not benefit from the deduplication process. Similarly, if you have folders containing compressed files you can exclude those folders from the deduplication process.
Finally, there is an option to set the deduplication schedule. You should configure the deduplication process to occur outside of peak hours of operation.
Of course this raises the question of the hardware resources that are required in order to perform data deduplication. The minimum supported configuration is a single processor system with 4 GB of RAM and a SATA hard disk. According to Microsoft, a deduplication job needs one CPU core and about 350 MB of RAM. Such a system could theoretically run a single deduplication job that would be capable of processing about 100 GB per hour. Higher-end systems can be duplicate multiple volumes simultaneously. The theoretical limit is that ninety volumes can be deduplicated simultaneously. In reality however, seventeen volumes at a time is a more realistic expectation from today’s hardware.
It is also worth noting that not every volume type can be deduplicated. Windows Server cannot deduplicate a system volume or a boot volume. Furthermore, the volume cannot reside on removable media and it must not be formatted as ReFS. Cluster shared volumes also cannot be deduplicated.
As I alluded to earlier, there are certain data types that can benefit from the deduplication process more than others. However, there are some types of data that should not be deduplicated. For example, you should not attempt to deduplicate a volume containing files that are constantly open or that change frequently. Similarly, Microsoft does not support deduplicating volumes containing Hyper-V virtual hard disks (for production VMs), although Windows Server 2012 R2 supports the deduplication of Hyper-V-based virtual desktops. You should also avoid deduplicating any volume containing files that are near 1 TB in size.
The biggest restriction with regard to data deduplication is that you cannot deduplicate volumes containing Exchange Server or SQL Server databases. If you attempt to do duplicate these volumes, there is a very real chance that you will corrupt the databases. Although not explicitly spelled out by Microsoft support policies, I recommend that you avoid deduplicating any volume containing a database. Many database applications expect to have control over the way the database pages are stored. Introducing deduplication when the database application expects to have full control over the underlying storage can result in corruption.
The Windows Server native deduplication feature does a great job of helping to conserve physical storage. Even so, it is important to properly plan for deduplication prior to implementing it because there are a number of situations in which the use of deduplication is not appropriate.
About the Author
Brien Posey is a 21-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country’s largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.
Last Update: 16.03.2018
What Data Deduplication Does
- Data deduplication optimizes the file data on the volume by performing the following steps:
- Segment the data in each file into small variable-sized chunks.
- Identify duplicate chunks.
- Maintain a single copy of each chunk.
- Compress the chunks.
- Replace redundant copies of each chunk with a reference to a single copy.
- Replace each file with a reparse point containing references to its data chunks.
PowerShell commands for Windows Server 2012 R2/Windows Server 2016 Data Deduplication
To install deduplication components on the server
Import-Module ServerManager
Add-WindowsFeature -name FS-Data-Deduplication
Import-Module Deduplication
To enable data deduplication on volume
Enable-DedupVolume E: -UsageType HyperV
or
Enable-DedupVolume E: -UsageType Default
Type HyperV – Select this if you are configuring deduplication for running virtual machines.
Type Default – Select this if you are configuring deduplication for general data files.
Set the minimum number of days that must pass before a file is deduplicated
Set-Dedupvolume E: -MinimumFileAgeDays 20
To return a list of the volumes that have been enabled for data deduplication
Get-DedupVolume
or
Get-DedupVolume | format-list
Start deduplication job manually
Optimization job:
Start-DedupJob –Volume E: –Type Optimization
Garbage collection job to process deleted or modified data on the volume so that any data chunks no longer referenced are cleaned up:
Start-DedupJob –Volume E: –Type GarbageCollection
Data integrity scrubbing job:
Start-DedupJob –Volume E: –Type Scrubbing
Get the status of deduplication jobs
Get-DedupJob
Query the key status statistics
Get-DedupStatus
or
Get-DedupStatus E: | fl
Get deduplication metadata information
Get-DedupMetadata
or
Get-DedupMetadata E:
Deduplication ratios and percentages
Table to understand space reduction percentage and space reduction rate.

Deduplication status for a volume from Windows Server 2012 R2

More information
Data Deduplication Overview
Install and Configure Data Deduplication
Deduplication Cmdlets in Windows PowerShell
Deploying Data Deduplication for VDI storage in Windows Server 2012 R2
What’s New in Data Deduplication for Windows Server 2016